
Время на прочтение
5 мин
Количество просмотров 26K
Нам известны 7 принципов тестирования и сейчас мы их подробно разберём.
Итак, приступим:
-
Исчерпывающее тестирование невозможно
-
Тестирование демонстрирует наличие дефектов, а не их отсутствие
-
Заблуждение об отсутствии ошибок
-
Раннее тестирование сохраняет время и деньги
-
Принцип скопления или кластеризация дефектов
-
Тестирование зависит от контекста
-
Парадокс пестицида
Зачем вообще они нужны и как могут помочь в понимании процесса тестирования? Это хороший вопрос. И если тщательно разобраться и следовать этим принципам, то можно избежать многих ошибок, недоразумений и неожиданных ситуаций в будущем.
В переводе с латинского При́нцип — это основа, начало, первоначало, и можно сказать, что принципы тестирования — это основы тестирования.

1️. Исчерпывающее тестирование невозможно
Давайте начнём так. Допустим, есть некий сайт. На этом сайте присутствует форма с полем для ввода какого-либо значения.
Возникает вопрос: а сколько различных комбинаций, их общее количество нам доступно для использования? И если нет каких-то конкретных требований, то вводить туда мы можем всё что угодно: любые буквы разных алфавитов, числа, символы, эмоджи, соответственно текст любой длины…
И, конечно, ответ будет: ∞
Ну давайте предположим, что максимально в поле мы можем ввести только 3 символа. Даже и в этом случае количество комбинаций, если брать во внимание, что UTF-8 поддерживает 2,164,864 доступных символа, будет равно:
Х = 2,164,864³ =10 145 929 857 329 004 544
Сколько же комбинаций выйдет, если в поле для ввода текста мы можем ввести 100 символов? А 1000 или с N количеством нулей?
Насколько бы тщательным тестирование не было, нельзя учесть все возможные сценарии и предвидеть все возможные ошибки.

2️. Тестирование демонстрирует наличие дефектов, а не их отсутствие
Тестирование может выявить тот момент, что ошибки присутствуют, но не может доказать в полной мере, что дефектов нет.
Каким образом мы сможем утверждать, что багов в продукте нет? Этого, к сожалению, сделать нельзя, потому как, выявить любую проблему можно только сделав какие-то действия, произведя какую-либо проверку.
Это так же, как нельзя, например, по вешнему виду определить состояние автомобиля. Допустим, снаружи он выглядит хорошо, нет ни потертостей, ни царапин на кузове, – но это не означает, что у него нет каких-нибудь проблем внутри, в двигателе или в механике.
Констатировать о том, что ошибки отсутствуют, в данном случает, будет неверным. Даже сделав возможные проверки, и не найдя глобальных поломок, мы не можем сказать, что дефектов нет. Потому как, в автомобиле в незаметном месте может быть открутился винтик, не влияющий особо на функциональность, расхлябалась маленькая незначительная деталь и т.д.
А вот как раз наличие дефектов и может продемонстрировать тестирование. Начиная проверять систему, мы выявляем те или иные баги.

3️. Заблуждение об отсутствии ошибок
Можно сколько угодно находить ошибки, и даже, казалось бы, не обнаруживая их больше, нет гарантии того, что ошибки найдены все и продукт полностью качественный и готовый.
Надо помнить такую аксиому – не существует какого-либо продукта без багов или ошибок.

Даже готовый и хорошо протестированный продукт может оказаться не идеален, так как под каждого человека индивидуально его не подстроить. Например, одному человеку с его потребностями и возможностями будет подходить такое представление продукта, а другому, с его индивидуальными особенностями – это будет не совсем приемлемо. Будет эта ситуация багом, дефектом или нет? Точного ответа нет, но можно сказать с полной уверенностью, что для одного будет нормой, – то для другого — ошибкой в программе или продукте.
Дефекты однозначно будут. Но в тестировании и нет такой задачи, чтобы выявить 100% багов, т.к. мы уже знаем, что это невозможно, исходя из первых трёх принципов. Главное здесь – найти наиболее критичные ошибки.
Присутствует в тестировании и такой парадокс – не все ошибки нужно исправлять). Но это отдельная тема.
4. Раннее тестирование сохраняет время и деньги

Это принцип говорит о том, что чем раньше выявится та или иная проблема – тем меньше средств и трудозатрат потребуется для её устранения. Соответственно, если баг попадёт в «прод» или ещё хуже, если его найдёт пользователь – исправление такого дефекта обойдётся немалой кровью для всей команды. Помимо того, что удаление его будет стоить бо́льших денег, нежели на начальной стадии разработки, может получиться так, что этот дефект затронет другой функционал. И тогда проблемы начнут накапливаться как снежный ком. Сколько кода потребуется переписать разработчикам? Сколько времени уйдет на исправление и тестирование? Тут вам и сорванные сроки релизов, рассерженное руководство, потеря нервных клеток и т.д. Сюда же добавим недовольство или даже потерю клиентов, ну и все остальные вытекающие…
Принято считать, что тестирование необходимо начинать на самых ранних стадиях в жизненном цикле разработки, например, ещё на уровне написания требований или на этапе оформления дизайна.
5. Принцип скопления или кластеризация дефектов
Существует такое определение – наибо́льшее количество дефектов обычно содержится в небольшо́м количестве модулей.
Простыми словами кластеризация – это группировка (на кластеры) множества объектов, схожих между собой по каким-либо параметрам. Представим полки и витрины в магазине – товары подразделены на хлебобулочные, молочные, мясные, напитки и др. Это и есть кластеризация.

Давайте проведём параллель с багами. Ошибки скапливаются в определённых местах, например, там, где код наиболее сложный или некорректно написан. Любой продукт состоит из модулей – кластеров в нашем случае. Если в каком-то модуле нашлось несколько багов, — это сигнал к тому, чтобы ещё внимательнее протестировать или даже перелопатить его с особой тщательностью на наличие скрытых дефектов.
6. Тестирование зависит от контекста
Для разного софта будут применяться разные подходы к его тестированию. К примеру, способ тестирования мобильного приложения будет отличаться от того, которым тестируется коммерческий сайт.
По каким характеристикам различать контекст:
-
по типу продукта – web, desktop, мобильное приложение, сервис и др.;
-
по цели продукта – обеспечение безопасности, Game, продажа товаров и др.;
-
по проектной команде – специализация, количество человек, опыт и т.д.;
-
по доступным инструментам – что присутствует на проекте, для успешной реализации;
-
по срокам – как построен рабочий процесс, как часто выходят релизы, время между ними на подготовку;
-
по ожидаемому уровню качества – чем выше требования, тем тщательнее нужно тестировать.

Опытные QA-engineer знают, что перед любым тестированием нужно провести анализ и сформировать план и стратегию проверок. Ну и затем приступать к составлению тестовой документации.
7. Парадокс пестицида
Почему именно так назван этот принцип? Здесь всё просто. Википедия говорит нам, что Пестици́д (лат. pestis «зараза» + caedo «убивать») – ядовитое вещество, используемое для уничтожения вредителей и различных паразитов. Возьмём пример из жизни. Если использовать один и тот же пестицид на протяжении долгого времени, например, для истребления тараканов, то со временем его эффективность упадёт, так как у этих насекомых выработается устойчивость к одному и тому же препарату.

То же самое относится и к багам и процессу тестирования. Если к какому-либо функционалу применять постоянно повторяющийся набор тестов – то эти проверки в скором времени будут неэффективны в нахождении новых дефектов.
Поэтому тест-кейсы должны постоянно обновляться и видоизменяться. Важно пользоваться такими рекомендациями:
-
добавлять новые тесты;
-
просматривать и изменять существующие;
-
применять разные виды и техники тестирования;
-
осуществлять тестирование новыми сотрудниками и др.
В целом посмотреть на продукт под другим углом.
Можно отметить здесь ещё тот факт, что в наибольшей степени парадокс пестицида может проявляться в регрессе и автотестах.
Заключение
В этой статье мы разобрали 7 принципов тестирования. Понимание сути данных постулатов и умение применять их на практике отличает опытного QA-engineer от новичка. Однозначно, знание этих основ тестирования помогает формировать грамотную стратегию тестирования, совершать в итоге меньше ошибок в процессе работы с продуктом, сокращать время и упрощать некоторые процессы проводимых проверок.
Принцип 6. Тестирование зависит от контекста
Тестирование выполняется по-разному, в зависимости от контекста. Например, тестирование систем, критических с точки зрения безопасности, проводится иначе, чем тестирование сайта интернет-магазина.
Этот принцип тесно связан с понятием риска. Что такое риск? Риск — это потенциальная проблема. У риска есть вероятность (likelihood) — она всегда выше 0 и ниже 100% — и есть влияние (impact) — те негативные последствия, которых мы опасаемся. Анализируя риски, мы всегда взвешиваем эти два аспекта: вероятность и влияние.
То же можно сказать и о мире ПО: разные системы связаны с различными уровнями риска, влияние того или иного дефекта также сильно варьируется. Одни проблемы довольно тривиальны, другие могут дорого обойтись и привести к большим потерям денег, времени, деловой репутации, а в некоторых случаях даже привести к травмам и смерти.
Уровень риска влияет на выбор методологий, техник и типов тестирования.
Принцип 7. Заблуждение об отсутствии ошибок
Нахождение и исправление дефектов бесполезно, если построенная система неудобна для использования и не соответствует нуждам и ожиданиям пользователей.
Заказчики ПО — люди и организации, которые покупают и используют его, чтобы выполнять свои повседневные задачи — на самом деле совершенно не интересуются дефектами и их количеством, кроме тех случаев, когда они непосредственно сталкиваются с нестабильностью продукта. Им также неинтересно, насколько ПО соответствует формальным требованиям, которые были задокументированы. Пользователи ПО более заинтересованы в том, чтобы оно помогало им эффективно выполнять задачи. ПО должно отвечать их потребностям, и именно с этой точки зрения они его оценивают.
Даже если вы выполнили все тесты и ошибок не обнаружили, это еще не гарантия того, что ПО будет соответствовать нуждам и ожиданиям пользователей.
Иначе говоря, верификация не равна валидации.
Вместо пролога
Эта статья была начата ещё в апреле текущего (2020) года. И с тех пор я её несколько раз переписывал. Я никак не мог достичь того результата, который бы меня устроил. Я не хотел писать очередную статью про 7 принципов тестирования, куда бы просто скопипастились переводы этих принципов из ISTQB, а потом (как в лучших из статей) сопровождались разъяснениями на тему «Что это всё означает». Получилось бы очередное переписывание «священного писания» с его толкованием. Однако, поистине священное писание в толковании не нуждается.
Моя статья будет не про то, что же это за 7 столпов тестирования. Я специально опущу некоторые детали при объяснении принципов. Легким движением руки по клавиатуре вы сможете нагуглить всё это сами. Мы поговорим сразу о боли.
Принципы тестирования — это своеобразная конституция, манифест и договорённости нашей профессии. Но, как и в реальной жизни, как бы чётко ни был написан документ, какими бы благими намерениями не руководствовались авторы, конституцию можно трактовать по-разному, на манифест можно забить, о договорённостях можно забыть.
Вот об этом я бы хотел поговорить в этой статье. О том, как же мы живём с семью принципами тестирования на самом деле.
Это статья-рассуждение. Тут не будет слишком много полезностей, будьте к этому готовы. Скорее призыв к диалогу и попытка поделиться своим опытом и кое-где даже болью. Так что комментарии приветствуются.
Немного о себе, прежде чем начать (эту часть можно пропустить)
Меня зовут Кирилл, я в ИТ с 2009 года, тестированием занимаюсь уже почти 10 лет. Сейчас я работаю на руководящей должности в QA, а так же помогаю в обучении начинающих тестировщиков и параллельно этому всему веду свой телеграм-канал для джуниоров QA (ссылочка будет в конце статьи)
Я не всегда руководствовался в жизни 7ю принципами тестирования. Более того, я не всегда даже знал о них (как и многие тестировщики, я думаю). Но, чем больше сила, тем больше и ответственность, как говаривал дядя Бен. И со временем до меня начал доходить смысл каждого принципа, а после я начал замечать как эти принципы трактуются, искажаются и видоизменяются под тяжестью корпоративных культур каждой отдельной компании.
Собственно семь принципов тестирования
- Тестирование демонстрирует (только) наличие дефектов (Testing shows presence of defects)
- Исчерпывающее тестирование недостижимо (Exhaustive testing is impossible)
- Раннее тестирование (экономит время и деньги) (Early testing saves time and money)
- Принцип скопления дефектов (Defect clustering)
- Парадокс пестицида (Pesticide paradox)
- Тестирование зависит от контекста (Testing is context dependent)
- Заблуждение об отсутствии ошибок (Absence-of-errors fallacy)
Тестирование демонстрирует наличие дефектов
О чём принцип:
Тестирование может показать наличие дефектов в программе, но не доказать их отсутствие.
На этот принцип довольно часто плюют с высоты бизнеса и проджект менеджмента. Менеджменту иногда кажется, что если багов не нашли на этапе тестирования (не важно сколько у вас степеней фильтрации в жизненном цикле), то багов нет. И когда юзеры находят баги на проде, бизнес искренне удивляется и недоумевает: «Как же вы тестируете? Очевидно вы вообще ничего не делаете, ведь если бы тестировали — баг был бы найден».
Но, коллеги, не забывайте, что иногда бизнес спрашивает «почему этот баг попал на продакшн?». На этот вопрос вы обязаны ответить вполне конкретно. У каждого конкретного бага есть причины появления/пропуска. Но давая ответ на вопрос, так же давайте понять бизнесу, что отсутствие найденных дефектов в процессе тестирования не гарантирует отсутствия ошибок в системе.
Исчерпывающее тестирование невозможно
О чём принцип:
Сколь бы скрупулёзным тестирование не было, нельзя учесть все возможные сценарии, а значит и предвидеть все возможные ошибки.
Запомнили принцип выше? Отсутствие багов не гарантирует отсутствие ошибок, кажется, что второй принцип очевидно вытекает из первого, верно?
Некоторые недобросовестные тестировщики используют этот принцип, чтобы оправдывать свою некомпетентность. Ушёл критичный баг в продакшн — «ну что поделать, нельзя предусмотреть всё на свете. Вы вообще знаете, что исчерпывающее тестирование невозможно?». Но они забывают о том, что хотя предусмотреть всё невозможно, это не повод не предусматривать ничего.
В мире ограниченных ресурсов и возможностей нужно уметь оценивать риски и расставлять приоритеты. Тестируя, мы снижаем риски. Делая правильный тест-дизайн, мы ещё сильнее снижаем риски. Так и живём.
Раннее тестирование экономит время и деньги
О чём принцип:
Чем раньше начнутся активности тестирования, тем дешевле исправление выявленных ошибок. Грубо говоря, вычитка требований стоит пары часов обсуждений и времени аналитика, в то время, как тот же баг в боевой системе стоит потерянных клиентов, времени разработчиков и всего цикла релиза.
Это избитая истина, примерно такого же плана, как и «ПО надо тестировать, т.к. писать код без ошибок физически невозможно». Но многим руководителям кажется, что на самом деле тестирование отнимает время релизного цикла, т.к. задерживает доставку фич, а так же тратит время тестировщиков, на то, чтобы они читали «бумажки» вместо того, чтоб тестировать.
Я всю свою жизнь сталкиваюсь с этим удивительным противоречием; парадоксом, если угодно. Менеджеры говорят, что качество ПО превыше всего, недовольные клиенты — недопустимо, если надо тестировать, то мы выделим на это время. Но на деле почти всегда оказывается, что рук не хватает, бюджета нет и «давайте вы сейчас проверите, чтобы катнуть побыстрее, а потом уже будете свои тест-кейсы писать».
Кластеризация (или скопление) дефектов
О чём принцип:
Дефекты не размазаны равномерно по приложению, а сконцентрированы в больших количествах в некоторых модулях системы
Для начала хотелось бы заметить, что об этом принципе вообще не вспоминают. Наоборот, найдя пару ошибок в каком-то блоке функционала некоторые тестировщики успокаиваются, мол «ну мы там баги нашли, отлично, пойдем дальше».
Крайний случай (но справедливости ради замечу, что это не самый распространенный случай) — это «тест до первого бага». Причин тому может быть несколько: ленивый или некомпетентный тестировщик, или же метрики/kpi, которые поджимают тестировщика быстрее перекинуть мяч на сторону разработчиков.
Просто помните, если вы уже нашли несколько багов в каком-то модуле, стоит перелопатить его ещё тщательнее, скорее всего там есть ещё скрытые дефекты.
В то же время, отсутствие дефектов в других модулях не говорит, что дефектов там нет (помните первый принцип?)
Парадокс (эффект) пестицида
О чём принцип:
Это самый распиаренный принцип тестирования. Суть его в том, что если вы долго проводите одни и те же проверки, скорее всего новых багов вы не найдете. Именно поэтому периодически нужно «встряхивать» вашу тестовую базу, ревьюить её новыми сотрудниками и проводить исследовательское тестирование.
Некоторые коллеги во имя избегания этого эффекта «забивают» на классические подходы к тестированию и всё время проводят только исследовательское тестирование. Часто объясняют это тем, что «раз регрессионные прогоны одних и тех же тестов не помогают выявлять новые дефекты, проще полностью отказаться от этого подхода и каждый раз тестировать как на новенького». К сожалению в этом суждении забывается тот факт, что парадокс пестицида говорит лишь о том, что имеющиеся наборы больше не находят новые баги, а не о том, что формальные повторяющиеся из раза в раз проверки вообще не способны находить ошибки.
Тестирование зависит от контекста
О чём принцип:
Об этом я уже как-то упоминал в одной из предыдущих статей. Набор методологий и инструментов, а также подходов и ресурсов для тестирования зависит от того, что именно вы тестируете и на сколько объект тестирования важен
Иногда забывают о том, что каждой задаче своё решение и подход. Очень распространённая тактика, везде использовать старую методологию, если она себя показала хорошо. Однако этот принцип как раз напоминает нам о противоположном.
Тем не менее, многие прикрываются этим принципом со словами «Если у других методика работает — не значит, что и у нас будет». Это безусловно верно по-умолчанию. Но дело в том, что «чморение новой идеи» не доказывает, что выбранные сейчас подходы оптимальны для тестирования (так же как и доказательства вредности фаст-фуда не подтверждают полезность овощей).
Зачастую, говоря о контексте, тестировщики рассуждают о внешнем контексте: доменных областях и пользователях (которые не меняются длительное время в рамках одного продукта). Но они забывают внутренний контекст: новые разработчики, больше разработчиков, другие владельцы компании, нагрузка на сотрудников, внутриполитические силы в компании. Этот внутренний контекст и позволяет нам поднимать вопрос о смене методологии и процессов, которые раньше были неуместны.
Заблуждение об отсутствии ошибок
О чём принцип:
Тот факт, что тестирование не обнаружило дефектов, ещё не значит, что программа хорошая.
Ну вот снова! Хочется сорвать с себя шапку-ушанку и крикнуть: «Ай, да катись оно всё пропадом», раз никаких гарантий нет, то нафига вообще тестировать!? Ответ прост: чтобы снизить риски. Протестированный продукт с вероятностью 95% bug free, но не протестированный продукт с вероятностью 95% уйдет в продакшн с багами.
С учетом того, как этот принцип доносят на просторах интернета, легко спутать его с первым принципом. Многие забывают, что суть принципа: отсутствие дефектов — необходимое, но не достаточное условие хорошего ПО. Есть и другие факторы, влияющие на качество продукта. И вот о них-то как раз все забывают, считая, что лишь тестировщики и тестирование ответственны за качество.
Эпилог
Не могу сказать, что я всю свою сознательную QA жизнь только и вижу, как принципы тестирования нарушаются. Нет, ни в коем случае. Я просто подобрал для каждого принципа распространенные случаи игнорирования или иной трактовки. В том или ином виде, объёме, сознательно или нет, но часть принципов соблюдается почти всеми командами, в которых присутствует процесс тестирования ПО. Мне лишь хотелось подсветить некоторые моменты/признаки, по которым чуть легче пустить факт нарушения принципов в своё сознание.
И напоследок вопрос без ответа, который я задаю сам себе (а теперь задам и вам): можно ли поступиться принципами тестирования во имя каких-то благих целей, или принципы тестирования, как семь смертных грехов (ох, вот это аллюзия… только сейчас это понял), являются нерушимой догмой, нарушение которой есть зло?
Бонус
На просторах интернета я наткнулся ещё на парочку неофициальных доп.принципов, которые мне кажутся более понятными, приземленными и интуитивно полезными:
- тестирование должно производиться независимыми специалистами;
- тестируйте как позитивные, так и негативные сценарии;
- не допускайте изменений в ПО в процессе тестирования;
- указывайте ожидаемый результат выполнения тестов.
Но вот их я как раз разберу отдельным постом в своём телеграм-канале, так что если кому интересно — присоединяйтесь к @aboutqa
Существует 7 принципов тестирования:
- Тестирование демонстрирует наличие дефектов, а не их отсутствие
- Исчерпывающее тестирование недостижимо
- Раннее тестирование сохраняет время и деньги
- Кластеризация дефектов
- Парадокс пестицида
- Тестирование зависит от контекста
- Заблуждение об отсутствии ошибок
Именно принципы тестирования являются основой всех стандартов, книг, методов и техник тестирования.
Их понимание является фундаментом знаний тестировщика и позволяет работать быстрее, качественнее и эффективнее.
В статье подробно рассказываю и объясняю принципы тестирования программного обеспечения. В конце вы сможете пройти тест и увидеть как хорошо вы разобрались.
Начнем с определения понятия “принцип”.
Принцип или основа, начало, первоначало (лат. principium, греч. αρχή, дословно первейшее) — постулат, утверждение, на основе которого создают научные теории и законы, юридические документы, выбирают нормы поведения в обществе.
Исходя из этого определения, мы можем сказать, что:
Принципы тестирования — это основы тестирования
Их нельзя изменить, отменить, понимать “частично” или поверхностно.
Они всегда были, есть и будут, и без их понимания тестировщик никогда не станет высокооплачиваемым профессионалом.
Давайте разбираться! 🧐
1️⃣ Тестирование демонстрирует наличие дефектов, а не их отсутствие
Дефекты найдены!
Тестирование может показать, что дефекты присутствуют, но не может доказать, что их нет.
Тестирование снижает вероятность наличия дефектов, находящихся в программном обеспечении, но, даже если дефекты не были обнаружены, тестирование не доказывает корректность работы ПО.
Для лучшего понимания, разобьем первый принцип на 2 части:
- Тестирование может показать, что дефекты присутствуют
- Тестирование не может доказать, что дефектов нет
и посмотрим на каждую из них в отдельности.
Тестирование может показать, что дефекты присутствуют
Предположим, у нас есть сайт, который нужно проверить перед передачей заказчику.
Мы проводим тестирование и находим 20 багов.
В этом случае тестирование показало, что в изначальном варианте сайта было 20 дефектов.
Дальше, мы исправляем все ошибки и после следующего тестирования не находим ни одного бага. О чем это говорит?
Повторное тестирования показало, что мы исправили 20 багов и не нашли новых.
Это факт — мы нашли и исправили 20 дефектов в ПО.
Тестирование не может доказать, что дефектов нет
Предположим, что принцип не правильный.
Q: Тестирование МОЖЕТ доказать, что дефектов нет — что для этого необходимо?
A: Как минимум, знать все “места”, где находятся все дефекты, чтоб тестировщик смог их проверить после исправления ошибки.
Q: А можем ли мы каким-то образом узнать о всех “местах”?
A: Короткий ответ — нет!
Для нахождения всех дефектов нужно будет проделать очень большой объем работы:
- проверить каждую строку кода сайта на наличие ошибок (включая ВСЕ сторонние библиотеки)
- проверить сайт на ВСЕХ возможных версиях ВСЕХ возможных браузеров
- проверить сайт на всех возможных устройствах, системах, размерах экранов с шагом 1px
- проверить работу сайта во всех странах мира
- …
- …
- … (думаю, список можно продолжать практически до бесконечности)
И знаете что самое интересное?
Для ДОКАЗАТЕЛЬСТВА, что дефектов нет — эту проверку нужно будет делать КАЖДЫЙ раз после ЛЮБОЙ правки, внесенной в сайт, после ЛЮБОГО обновления ЛЮБОГО браузера, после выхода на рынок ЛЮБОГО телефона, часов, нового экрана и т.д. и т.п.
А учитывая количество и скорость изменений “систем”, окружающих сайт — нужно будет проводить десятки тысяч сложнейших тестов ежедневно, чтоб доказать, что дефектов нет, и надеяться, что вы учли все…
Именно из-за ОГРОМНОЙ сложности и ОБЪЕМА всей системы, в которой создается и работает сайт, мы не можем узнать ОБЩЕЕ КОЛИЧЕСТВО дефектов.
А не зная общего количества дефектов — мы никогда не докажем, что их нет.
Поэтому, запоминаем:
Тестирование демонстрирует наличие дефектов, но не доказывает их отсутствие.
2️⃣ Исчерпывающее тестирование недостижимо
Рост количества тестов в процессе анализа задачи
Полное тестирование с использованием всех комбинаций вводов и предусловий физически невыполнимо (за исключением тривиальных случаев).
Вместо попытки исчерпывающего тестирования должны использоваться анализ рисков, методы тестирования и расстановка приоритетов, что бы сосредоточить усилия по тестированию.
Предположим, у нас есть сайт.
На сайте есть форма, в которой есть поле для ввода возраста.
Q: Какое общее количество комбинаций вводов существует для этого поля?
A: ∞
Если это поле — без ограничений и валидации — мы можем писать туда что угодно: числа, символы, буквы любого алфавита, emoji 😇, да еще и текст любой длины.
Если предположить, что максимальная длина строки для этого поля должна быть 3 символа (вряд-ли кто-то живет больше 999 лет), то максимальное количество всех возможных комбинаций (учитывая, что UTF-8 поддерживает 2,164,864 доступных символов) будет равно:
Х = 2,164,864³ =10 145 929 857 329 004 544
Можете представить, сколько комбинаций будет у поля для ввода текста с ограничением по длине в 10,000 символов 😅
Именно для упрощения таких ситуаций существует тест-анализ, анализ рисков и приоритезация проверок, которые позволяют сократить количество тестов к минимуму не ухудшая качество продукта.
3️⃣ Раннее тестирование сохраняет время и деньги
Для нахождения дефектов на ранних стадиях разработки, статические и динамические активности по тестированию должны быть начаты как можно раньше в жизненном цикле разработки программного обеспечения.
Тестирование на ранних этапах жизненного цикла разработки программного обеспечения помогает сократить или исключить дорогостоящие изменения.
Для простоты примера можно рассмотреть процесс исправления дефекта, найденного в требованиях к ПО и дефекта, найденного клиентом.
Дефект, найденный в требованиях к ПО — исправляется очень быстро.
Например, кнопка “Оплатить” в требованиях называется “Sell” , а должна называться “Pay”. Это дефект. Исправление — замена текста “Sell” на “Pay”, занимает 2 секунды и стоит $0,05.
Теперь посчитаем стоимость исправления этого же дефекта, найденного клиентом.
Тут — сложнее.
Во первых, мы оцениваем стоимость технического исправления командой разработки.
Пусть это занимает 30 минут времени команды, которая стоит $100 / час (правка в дизайне, в коде, тестирование, создание релиза, заливка…) Итого — $50.
Дальше, мы оцениваем “ущерб” от потерь репутации.
- Сколько клиентов отказались покупать товар из-за недопонимания текста на кнопке?
- Сколько клиентов подумало, что “если наш сервис не может нормально называть кнопки, как он может качественно делать продаваемый товар?” и ушло с формы заказа.
- …
Грубо предположим, и будем сильно надеяться, это еще $50 😔
Таким образом, стоимость исправления ошибки, найденной клиентом — $100. Это в 2000 ❗️ раз больше, чем исправление ошибки в требованиях.
Если очень приблизительно, то стоимость исправления ошибки в зависимости от этапа разработки следующая:
- Требования — х1
- Дизайн — х5
- Разработка — х15
- Тестирование — х25
- Production — x100+
4️⃣ Кластеризация дефектов
Баги живут здесь
Обычно небольшое количество модулей содержит большинство дефектов, обнаруженных во время тестирования перед выпуском и отвечает за большинство эксплуатационных отказов.
Предсказанные кластеры дефектов и фактические наблюдаемые кластеры дефектов в ходе тестирования или эксплуатации являются важными входными данными для анализа риска, используемого для сосредоточения усилий по тестированию.
Код пишут люди. Люди ошибаются. Одни — ошибаются чаще, чем другие и это не исправить.
То же самое применимо и к системам. Одни — проще, другие — сложнее. Чем сложнее система— тем больше вероятность возникновения ошибки и так будет всегда.
Добавим сюда дедлайны. Чем ближе к дедлайну — тем больше нагрузка. Чем больше нагрузка — тем меньше времени разработчик уделяет “красоте” кода и перепроверке самого себя. Отсюда тоже берутся ошибки.
Все эти факторы приводят к одним и тем же последствиям — дефекты “собираются” в “кучки” в определенных частях системы.
Любой тестировщик, который занимался тестированием в команде разработки с более чем одним разработчиком на протяжении длительного отрезка времени “чувствует” это.
Он знает, что за Васей нужно проверять по 2 раза, а Саша — все делает хорошо, в большинстве случаев.
Также, он знает, что баги на сайте А — возникают очень редко, так как его делает команда опытных разработчиков. А вот с сайтом Б — не все так гладко, потому что там разработчики менее опытные.
Свойство дефектов к “группированию” нужно учитывать при планировании тестирования.
Это поможет вам, как тестировщику, лучше оптимизировать время на тестирование и помогать там, где это действительно необходимо.
5️⃣ Парадокс пестицида
Automation Test Run #428421 — ALL PASSED!
Если одни и те же тесты будут выполняться снова и снова, в конечном счете они перестанут находить новые дефекты.
Для обнаружения новых дефектов может потребоваться изменение существующих тестов / тестовых данных или написание новых.
Предположим, у нас есть набор тестов, которые проверяют некий функционал, в котором есть 3 дефекта.
Пройдя тесты, мы находим 2 дефекта и исправляем их, а один дефект останется “незамеченным”.
Проходя одни и те же тесты снова и снова — мы всегда будем видеть одну и ту же картину: PASS / Пройдено.
Но, по факту, один дефект будет оставаться в системе и текущие тесты НИКАК не смогут его найти.
Для определения дефекта придется:
- либо изменять существующие тесты
- либо изменять тестовые данные, которые “покажут” ошибку
Чаще всего парадокс пестицида проявляется в автоматизированном тестировании изменений (регрессионном тестировании).
Постоянно “зеленые” тесты создают иллюзию “все работает”, но, как мы уже знаем, на самом деле они перестают находить новые ошибки, а ошибки со временем начинают накапливаться…
Именно поэтому ручное тестирование НИКОГДА не исчезнет 🥳😎
Название принципа происходит от “эффекта пестицида”, так как пестициды через некоторое время больше не эффективны при борьбе с вредителями (как и тесты — с нахождением новых дефектов).
*я пытался найти информацию об этом “эффекте” в Google — и ничего не нашел 🙂 Не Fake ли это??? (Если у кого-то есть ссылка на описание этого эффекта в природе — поделитесь, пожалуйста, в комментариях)
6️⃣ Тестирование зависит от контекста
Тестирование выполняется по-разному в зависимости от контекста.
Например, программное обеспечение управления производством, в котором критически важна безопасность, тестируется иначе, чем мобильное приложение электронной коммерции.
Предположим, нам нужно проверить простой сайт, который состоит из 5 страниц.
Вы пишете некий простой чек-лист (функционала нет, тест-кейсы не нужны, не тратим время) и проверяете сайт.
Все супер, залили, ничего критического нет, вы молодец! 🥳🥳🥳
Дальше, вам отдают на проверку другой сайт.
Но в этот раз не из 5, а из 45,000 страниц, с сложным функционалом, админками и т.д. и т.п.
- Как вы думаете, сможете ли вы проверить этот сайт по уже готовому чек-листу?
- Как на счет “нагуглить” какой-то чек-лист в интернете — и проверить сайт по нему?
Надеюсь, что вы ответили — нет на оба вопроса! 😍
Тестирование всегда зависит от контекста!
- Для сайта из 5 страниц — подход один
- Для сайта из 45,000 — другой
- Для онлайн-магазина — третий
- Для посадочной страницы — четвертый
- Для мобильного приложения todo-list— пятый
- Для мобильного приложения банка — шестой
- …
Поэтому, перед тем как начинать что-то проверять, нужно сделать анализ и продумать стратегию и план тестирования.
И только после этого приступать к написанию тестовой документации и тестированию!
7️⃣ Заблуждение об отсутствии ошибок
Некоторые организации ожидают, что тестировщики смогут выполнить все возможные тесты и найти все возможные дефекты, но принципы 2 и 1, соответственно, говорят нам, что это невозможно.
Кроме того, ошибочно ожидать, что простое нахождение и исправление большого числа дефектов обеспечит успех системе.
Например, тщательное тестирование всех указанных требований и исправление всех обнаруженных дефектов может привести к созданию системы, которая будет трудной в использовании, не будет соответствовать потребностям и ожиданиям пользователей или будет хуже по сравнению с другими конкурирующими системами.
Сейчас мы уже знаем, что все ошибки найти невозможно, исходя из принципа 1 и 2. Ошибки есть всегда. Они были и будут, вы с этим ничего не сделаете и это нормально.
Важно не отсутствие ошибок, а критичность, скорость реакции и исправления!
Более того, не все ошибки нужно исправлять!
Если ошибка встречается на окружении, которым пользуется 0,002% ваших пользователей, которые приносят $5 прибыли в год и на ее исправление нужно будет потратить $50,000 и пол года разработки — вы будете ее исправлять? Сильно сомневаюсь 😏
Почитайте про Zero Bug Policy, лучший процесс работы с багами, по моему мнению.
Резюме
В статье мы подробно рассмотрели 7 принципов тестирования:
- Тестирование демонстрирует наличие дефектов, а не их отсутствие
- Исчерпывающее тестирование недостижимо
- Раннее тестирование сохраняет время и деньги
- Кластеризация дефектов
- Парадокс пестицида
- Тестирование зависит от контекста
- Заблуждение об отсутствии ошибок
Попробуйте пройти тест и узнайте, насколько хорошо вы разобрались.
Желаю удачи в ваших проектах и начинаниях!
Принципы тестирования являются одним из важных аспектов в области разработки программного обеспечения. Эти принципы определяют методы, процессы и стратегии, которые позволяют эффективно тестировать программное обеспечение, чтобы убедиться в его правильности и соответствии требованиям. Правильное тестирование программного обеспечения не только помогает предотвратить ошибки и дефекты, но и повышает качество и надежность продукта, что в свою очередь увеличивает удовлетворенность клиентов.
Нам известно, что тестирование является неотъемлемой частью процесса разработки программного обеспечения. Его основная цель заключается в проверке работоспособности и качества разрабатываемого продукта. Однако, эта цель достигается с помощью выполнения определенных принципов тестирования.
Принципы тестирования
7 принципов тестирования в деле
Исчерпывающее тестирование невозможно
Принцип «Исчерпывающее тестирование невозможно» гласит о том, что невозможно протестировать все возможные сценарии использования программного продукта и покрыть все возможные варианты входных данных, состояний и переходов.
Этот принцип основывается на том, что сложность современных программных продуктов не позволяет проводить тестирование на всех возможных комбинациях входных данных и состояний системы. Это может быть связано с ограниченным временем, бюджетом, ресурсами или просто с физическими ограничениями, связанными с количеством возможных вариантов.
Кроме того, даже если было бы возможно провести исчерпывающее тестирование, это не гарантирует отсутствие ошибок в программном продукте, так как новые ошибки могут возникнуть при изменении условий использования или окружения.
Однако, это не означает, что необходимо тестировать наугад или ограничивать количество тестов. Вместо этого, необходимо проводить тестирование наиболее критических и вероятных сценариев использования программного продукта, а также учитывать опыт пользователей и результаты предыдущих тестирований.
Примером может служить тестирование веб-приложения, которое может быть доступно с разных устройств, браузеров и разрешений экранов. Использованные Принципы тестирования тестирования и проведение его на всех возможных комбинациях может занять слишком много времени и ресурсов. Вместо этого, тестирование может быть сосредоточено на основных функциях, устройствах и браузерах, которые наиболее часто используются пользователями.
Критика данного принципа заключается в том, что некоторые компании и команды тестирования могут использовать его в качестве оправдания для проведения минимального количества тестов и недостаточного тестирования. Это может привести к появлению серьезных ошибок в программном продукте, которые могут нанести ущерб бизнесу или пользователям. Поэтому необходимо соблюдать баланс между количеством тестов и их качеством, учитывая особенности и контекст программного продукта.

Тестирование демонстрирует наличие дефектов
Принцип «Тестирование демонстрирует наличие дефектов» является одним из основополагающих принципов тестирования. Он гласит, что цель тестирования заключается не в доказательстве отсутствия дефектов в тестируемом продукте, а в нахождении дефектов, которые могут привести к отказу продукта в работе. Этот принцип является основой для оценки качества продукта, так как наличие дефектов может значительно снизить удовлетворенность пользователей и повредить репутацию компании. Принципы тестирования направлены на улучшение качества продукта и максимальное уменьшение вероятности наличия дефектов в работе продукта.
Критика этого принципа связана с тем, что тестирование не может покрыть все возможные сценарии использования продукта, поэтому даже при успешном прохождении тестов могут быть обнаружены дефекты в реальных условиях эксплуатации. Также существует риск недостаточного тестирования, когда некоторые дефекты могут остаться незамеченными.
Однако, данный принцип важен для того, чтобы обеспечить качество продукта и его соответствие требованиям заказчика. Ведь наличие дефектов может привести к утечке конфиденциальной информации, потере клиентов и репутации компании.
Примером может служить тестирование мобильного приложения для онлайн-банкинга. В ходе тестирования был обнаружен дефект, при котором приложение закрывается при попытке внести большую сумму на счёт. Это может привести к потере денег клиентов и негативному опыту использования приложения.
Таким образом, принцип «Тестирование демонстрирует наличие дефектов» важен для обеспечения качества продукта и выявления дефектов, которые могут привести к серьезным последствиям. Однако, необходимо учитывать, что полного отсутствия дефектов в продукте достичь невозможно, поэтому тестирование должно быть надлежащим и адекватным для обеспечения нужного уровня качества продукта.
Заблуждение об отсутствии ошибок
Принципы тестирования подчеркивают важность осознания того, что тестирование не может гарантировать полное отсутствие ошибок в продукте, а лишь демонстрирует наличие обнаруженных дефектов. Принцип «Заблуждение об отсутствии ошибок» говорит о том, что не все ошибки могут быть обнаружены в процессе тестирования, поэтому необходимо принимать во внимание этот факт и использовать другие методы обнаружения ошибок.
Критика данного принципа заключается в том, что он может привести к необоснованному увеличению объема тестирования. Если тестировщики будут искать ошибки до тех пор, пока не найдут ни одной, это может занять очень много времени и ресурсов. Кроме того, чрезмерная зацикленность на поиске ошибок может отвлекать от других важных аспектов тестирования, таких как оценка качества продукта в целом.
Например, представим, что есть программный продукт, который должен работать с файлами в формате PDF. Если тестировщики не обнаружили никаких ошибок при работе с файлами, это не означает, что все файлы будут обработаны корректно. Возможно, некоторые файлы могут содержать ошибки, которые не были предусмотрены в процессе тестирования.
Однако, принцип «Заблуждение об отсутствии ошибок» не означает, что тестирование не имеет смысла. Напротив, тестирование позволяет обнаружить множество ошибок и повысить качество программного продукта. Однако, необходимо понимать, что тестирование не является идеальным инструментом и не может гарантировать полную отсутствие ошибок.
Важно помнить, что тестирование должно рассматриваться как один из инструментов для обеспечения качества программного продукта, а не как единственный способ проверки. Разработчики также должны следить за качеством кода и придерживаться современных стандартов разработки.
Раннее тестирование сохраняет время и деньги
Принцип «Раннее тестирование сохраняет время и деньги» заключается в том, что чем раньше обнаружатся дефекты в процессе разработки, тем дешевле их исправление и тем меньше вероятность, что они окажутся критическими для продукта. Этот принцип утверждает, что инвестирование в тестирование в начале проекта позволяет обеспечить более высокое качество и ускорить разработку.
Примером раннего тестирования может быть использование метода тестирования черного ящика в начале проекта. Таким образом принципы тестирования используемые на проекте начинают приносить пользу на самых ранних этапах. В этом случае тестирование проводится без знания внутренней структуры программного продукта. Тестировщик проверяет, соответствует ли функциональность продукта требованиям, описанным в спецификации, и проверяет, как продукт взаимодействует с пользователем и другими системами. Раннее тестирование может также включать автоматизированные тесты, которые могут запускаться при каждой новой сборке продукта.
Критика принципа «Раннее тестирование сохраняет время и деньги» может состоять в том, что раннее тестирование может привести к перерасходу ресурсов на тестирование в начале проекта, когда функциональность продукта еще не полностью определена, а дизайн может меняться. Такое тестирование приводит к ненужным затратам на тестирование функциональности, которая позже могут изменить или удалить вовсе. Также раннее тестирование может привести к дополнительным затратам на поддержку тестов и обеспечение их работоспособности с каждым изменением продукта.
Принцип скопления или кластеризация дефектов
Принципы тестирования связаны с принципом скопления (или кластеризации) дефектов, который заключается в том, что дефекты в программном обеспечении склонны к сгруппированию в определенных областях или компонентах системы. Это означает, что для повышения эффективности тестирования необходимо уделять больше внимания тестируемым областям, где уже были найдены дефекты, так как вероятность обнаружения других дефектов в этих областях выше.
Примером принципа скопления дефектов может служить веб-сайт, на котором при поиске дефектов обнаружено, что все ошибки касаются только одного модуля веб-приложения. Это может указывать на проблемы с этим модулем, например, на его сложность, неправильный дизайн или наличие ошибок в его коде.
Один из подходов, используемых для реализации этого принципа, — это концентрация тестирования на областях, где ожидается больше всего дефектов. Это может помочь обнаружить большее количество дефектов за меньшее время и с меньшими затратами на тестирование.
Критика принципа скопления дефектов заключается в том, что он может привести к неполному тестированию, когда другие области системы могут содержать скрытые дефекты, которые могут привести к серьезным проблемам в будущем. Кроме того, принцип скопления дефектов не является универсальным и может не подходить для всех проектов и систем.
Например, в некоторых случаях дефекты могут быть равномерно распределены по всей системе, и в этом случае сконцентрированное тестирование на определенных областях может привести к пропуску других дефектов. Также важно учитывать, что принцип скопления дефектов не гарантирует полного тестирования системы и должен использоваться в сочетании с другими методами тестирования.

Тестирование зависит от контекста
Принцип «Тестирование зависит от контекста» подчеркивает, что каждый проект и продукт уникален и имеет свои собственные требования и особенности. Этот принцип говорит о том, что методы тестирования, которые подходят для одного проекта, могут не работать для другого. Тестирование должно быть контекстуальным, и тестировщикам нужно учитывать множество факторов, таких как:
- Бизнес-требования
- Требования к безопасности
- Требования к производительности
- Целевая аудитория
- Технические ограничения
Контекст зависит от множества факторов, которые могут влиять на принципы тестирования, методы и приоритет тестирования. Например, для медицинского приложения может быть важнее обеспечить безопасность данных и защиту персональной информации, чем проверять функциональность пользовательского интерфейса.
Еще одним примером контекстуального тестирования является тестирование игровых приложений. Контекст игры требует, чтобы тестировщик проверил не только функциональность, но и игровой процесс, пользовательский интерфейс, звук и графику. Тестирование игр также требует особенного подхода к тестированию уровней, искусственного интеллекта и многопользовательской игры.
Однако, принцип «Тестирование зависит от контекста» не должен стать оправданием для отсутствия методологии тестирования или необоснованных решений. Критики этого принципа считают, что в некоторых случаях тестировщики могут использовать его для оправдания недостаточного тестирования или несоблюдения методологии.
Также, не все факторы контекста могут быть учтены, поэтому тестирование всегда должно быть сбалансированным и ориентированным на риски. Тестирование не должно зависеть от контекста в ущерб безопасности или качество программного обеспечения. Вместо этого, контекст должен использоваться для определения приоритетов и выбора наиболее эффективных методов тестирования для достижения конечной цели — высококачественного продукта.
Парадокс пестицида
Принципы тестирования очень важны для обеспечения качества программного обеспечения. Они помогают определить подходящие методы тестирования и повысить эффективность процесса тестирования. Один из таких принципов — «Парадокс пестицида» — говорит о том, что повторное использование одних и тех же тестовых случаев может привести к их обесцвечиванию, то есть уменьшению эффективности в обнаружении дефектов.
Концепция парадокса пестицида была впервые сформулирована в 1970-х годах Борисом Бизертом, одним из основателей современного тестирования программного обеспечения. В своих исследованиях Бизерт пришел к выводу, что при использовании одних и тех же тестов на протяжении длительного периода времени тестирование может стать менее эффективным, поскольку в процессе тестирования программное обеспечение подвергается изменениям и модификациям.
Примером парадокса пестицида может служить тестирование программного обеспечения, которое выполняется с использованием одного и того же набора тестовых случаев на протяжении нескольких лет. Поначалу тесты могут быть эффективными и обнаруживать множество дефектов, однако со временем тестировщики могут начать игнорировать некоторые дефекты, которые ранее были найдены, так как они привыкли к тестам и уже знают, какие проблемы могут возникнуть.
Критика принципа парадокса пестицида связана с тем, что он может привести к ситуации, когда тестирование не выполняется достаточно часто из-за опасений по поводу обесцвечивания тестов. Это может привести к тому, что дефекты будут обнаружены позднее, когда их исправление будет более трудозатратным и дорогостоящим. Кроме того, если тесты не обновляются регулярно, то новые дефекты могут остаться незамеченными.
Тем не менее, принцип парадокса пестицида все еще остается важным аспектом при проектировании тестовых сценариев. Тесты должны периодически обновляться и модифицироваться, чтобы они оставались эффективными в обнаружении новых дефектов. Также важно убедиться, что тесты достаточно разнообразны и покрывают
• Дымовое тестирование (Smoke Testing)
• Регрессионное тестирование (Regression Testing)
• Повторное тестирование (Re-testing)
• Тестирование сборки (Build Verification Test)
• Санитарное тестирование или проверка согласованности/исправности (Sanity Testing)
Функциональное тестирование рассматривает заранее указанное поведение и основывается на анализе спецификаций функциональности компонента или системы в целом.
Тестирование безопасности— это стратегия тестирования, используемая для проверки безопасности системы, а также для анализа рисков, связанных с обеспечением целостного подхода к защите приложения, атак хакеров, вирусов, несанкционированного доступа к конфиденциальным данным.
Тестирование взаимодействия (Interoperability Testing)— это функциональное тестирование, проверяющее способность приложения взаимодействовать с одним и более компонентами или системами и включающее в себя тестирование совместимости (compatibility testing) и интеграционное тестирование
Нагрузочное тестирование — это автоматизированное тестирование, имитирующее работу определенного количества бизнес пользователей на каком-либо общем (разделяемом ими) ресурсе.
Стрессовое тестирование (Stress Testing) позволяет проверить насколько приложение и система в целом работоспособны в условиях стресса и также оценить способность системы к регенерации, т.е. к возвращению к нормальному состоянию после прекращения воздействия стресса. Стрессом в данном контексте может быть повышение интенсивности выполнения операций до очень высоких значений или аварийное изменение конфигурации сервера. Также одной из задач при стрессовом тестировании может быть оценка деградации производительности, таким образом цели стрессового тестирования могут пересекаться с целями тестирования производительности.
Объемное тестирование (Volume Testing). Задачей объемного тестирования является получение оценки производительности при увеличении объемов данных в базе данных приложения
Тестирование стабильности или надежности (Stability / Reliability Testing). Задачей тестирования стабильности (надежности) является проверка работоспособности приложения при длительном (многочасовом) тестировании со средним уровнем нагрузки.
Тестирование установки направленно на проверку успешной инсталляции и настройки, а также обновления или удаления программного обеспечения.
Тестирование удобства пользования — это метод тестирования, направленный на установление степени удобства использования, обучаемости, понятности и привлекательности для пользователей разрабатываемого продукта в контексте заданных условий. Сюда также входит:
Тестирование пользовательского интерфейса (англ. UI Testing) — это вид тестирования исследования, выполняемого с целью определения, удобен ли некоторый искусственный объект (такой как веб-страница, пользовательский интерфейс или устройство) для его предполагаемого применения.
User eXperience (UX) — ощущение, испытываемое пользователем во время использования цифрового продукта, в то время как User interface — это инструмент, позволяющий осуществлять интеракцию «пользователь — веб-ресурс».
Тестирование на отказ и восстановление (Failover and Recovery Testing)проверяет тестируемый продукт с точки зрения способности противостоять и успешно восстанавливаться после возможных сбоев, возникших в связи с ошибками программного обеспечения, отказами оборудования или проблемами связи (например, отказ сети). Целью данного вида тестирования является проверка систем восстановления (или дублирующих основной функционал систем), которые, в случае возникновения сбоев, обеспечат сохранность и целостность данных тестируемого продукта.
Конфигурационное тестирование (Configuration Testing)— специальный вид тестирования, направленный на проверку работы программного обеспечения при различных конфигурациях системы (заявленных платформах, поддерживаемых драйверах, при различных конфигурациях компьютеров и т.д.)
Дымовое (Smoke) тестирование рассматривается как короткий цикл тестов, выполняемый для подтверждения того, что после сборки кода (нового или исправленного) устанавливаемое приложение, стартует и выполняет основные функции.
Регрессионное тестирование— это вид тестирования направленный на проверку изменений, сделанных в приложении или окружающей среде (починка дефекта, слияние кода, миграция на другую операционную систему, базу данных, веб сервер или сервер приложения), для подтверждения того факта, что существующая ранее функциональность работает как и прежде. Регрессионными могут быть как функциональные, так и нефункциональные тесты.
Повторное тестирование — тестирование, во время которого исполняются тестовые сценарии, выявившие ошибки во время последнего запуска, для подтверждения успешности исправления этих ошибок.
В чем разница между regression testing и re-testing?
Re-testing — проверяется исправление багов
Regression testing — проверяется то, что исправление багов не повлияло на другие модули ПО и не вызвало новых багов.
Тестирование сборки или Build Verification Test — тестирование направленное на определение соответствия, выпущенной версии, критериям качества для начала тестирования. По своим целям является аналогом Дымового Тестирования, направленного на приемку новой версии в дальнейшее тестирование или эксплуатацию. Вглубь оно может проникать дальше, в зависимости от требований к качеству выпущенной версии.
Санитарное тестирование— это узконаправленное тестирование достаточное для доказательства того, что конкретная функция работает согласно заявленным в спецификации требованиям. Является подмножеством регрессионного тестирования. Используется для определения работоспособности определенной части приложения после изменений произведенных в ней или окружающей среде. Обычно выполняется вручную.
Предугадывание ошибки (Error Guessing — EG). Это когда тест аналитик использует свои знания системы и способность к интерпретации спецификации на предмет того, чтобы «предугадать» при каких входных условиях система может выдать ошибку. Например, спецификация говорит: «пользователь должен ввести код». Тест аналитик, будет думать: «Что, если я не введу код?», «Что, если я введу неправильный код? », и так далее. Это и есть предугадывание ошибки.

Подходы к интеграционному тестированию:
• Снизу вверх (Bottom Up Integration)
Все низкоуровневые модули, процедуры или функции собираются воедино и затем тестируются. После чего собирается следующий уровень модулей для проведения интеграционного тестирования. Данный подход считается полезным, если все или практически все модули, разрабатываемого уровня, готовы. Также данный подход помогает определить по результатам тестирования уровень готовности приложения.
• Сверху вниз (Top Down Integration)
Вначале тестируются все высокоуровневые модули, и постепенно один за другим добавляются низкоуровневые. Все модули более низкого уровня симулируются заглушками с аналогичной функциональностью, затем по мере готовности они заменяются реальными активными компонентами. Таким образом мы проводим тестирование сверху вниз.
• Большой взрыв («Big Bang» Integration)
Все или практически все разработанные модули собираются вместе в виде законченной системы или ее основной части, и затем проводится интеграционное тестирование. Такой подход очень хорош для сохранения времени. Однако если тест кейсы и их результаты записаны не верно, то сам процесс интеграции сильно осложнится, что станет преградой для команды тестирования при достижении основной цели интеграционного тестирования.
Принципы тестирования
Принцип 1 — Тестирование демонстрирует наличие дефектов (Testing shows presence of defects)
Тестирование может показать, что дефекты присутствуют, но не может доказать, что их нет. Тестирование снижает вероятность наличия дефектов, находящихся в программном обеспечении, но, даже если дефекты не были обнаружены, это не доказывает его корректности.
Принцип 2— Исчерпывающее тестирование недостижимо (Exhaustive testing is impossible)
Полное тестирование с использованием всех комбинаций вводов и предусловий физически невыполнимо, за исключением тривиальных случаев. Вместо исчерпывающего тестирования должны использоваться анализ рисков и расстановка приоритетов, чтобы более точно сфокусировать усилия по тестированию.
Принцип 3— Раннее тестирование (Early testing)
Чтобы найти дефекты как можно раньше, активности по тестированию должны быть начаты как можно раньше в жизненном цикле разработки программного обеспечения или системы, и должны быть сфокусированы на определенных целях.
Принцип 4 — Скопление дефектов (Defects clustering)
Усилия тестирования должны быть сосредоточены пропорционально ожидаемой, а позже реальной плотности дефектов по модулям. Как правило, большая часть дефектов, обнаруженных при тестировании или повлекших за собой основное количество сбоев системы, содержится в небольшом количестве модулей.
Принцип 5 — Парадокс пестицида (Pesticide paradox)
Если одни и те же тесты будут прогоняться много раз, в конечном счете этот набор тестовых сценариев больше не будет находить новых дефектов. Чтобы преодолеть этот «парадокс пестицида», тестовые сценарии должны регулярно рецензироваться и корректироваться, новые тесты должны быть разносторонними, чтобы охватить все компоненты программного обеспечения,
или системы, и найти как можно больше дефектов.
Принцип 6 — Тестирование зависит от контекста (Testing is concept depending)
Тестирование выполняется по-разному в зависимости от контекста. Например, программное обеспечение, в котором критически важна безопасность, тестируется иначе, чем сайт электронной коммерции.
Принцип 7 — Заблуждение об отсутствии ошибок (Absence-of-errors fallacy)
Обнаружение и исправление дефектов не помогут, если созданная система не подходит пользователю и не удовлетворяет его ожиданиям и потребностям.
Cтатическое и динамическое тестирование
Статическое тестирование отличается от динамического тем, что производится без запуска программного кода продукта. Тестирование осуществляется путем анализа программного кода (code review) или скомпилированного кода. Анализ может производиться как вручную, так и с помощью специальных инструментальных средств. Целью анализа является раннее выявление ошибок и потенциальных проблем в продукте. Также к статическому тестирвоанию относится тестирования спецификации и прочей документации.
Исследовательское / ad-hoc тестирование
Простейшее определение исследовательского тестирования — это разработка и выполнения тестов в одно и то же время. Что является противоположностью сценарного подхода (с его предопределенными процедурами тестирования, неважно ручными или автоматизированными). Исследовательские тесты, в отличие от сценарных тестов, не определены заранее и не выполняются в точном соответствии с планом.
Разница между ad hoc и exploratory testing в том, что теоретически, ad hoc может провести кто угодно, а для проведения exploratory необходимо мастерство и владение определенными техниками. Обратите внимание, что определенные техники это не только техники тестирования.
Требования — это спецификация (описание) того, что должно быть реализовано.
Требования описывают то, что необходимо реализовать, без детализации технической стороны решения. Что, а не как.
Требования к требованиям:
• Корректность
• Недвусмысленность
• Полнота набора требований
• Непротиворечивость набора требований
• Проверяемость (тестопригодность)
• Трассируемость
• Понимаемость
Жизненный цикл бага

Стадии разработки ПО — это этапы, которые проходят команды разработчиков ПО, прежде чем программа станет доступной для широко круга пользователей. Разработка ПО начинается с первоначального этапа разработки (стадия «пре-альфа») и продолжается стадиями, на которых продукт дорабатывается и модернизируется. Финальным этапом этого процесса становится выпуск на рынок окончательной версии программного обеспечения («общедоступного релиза»).
Программный продукт проходит следующие стадии:
• анализ требований к проекту;
• проектирование;
• реализация;
• тестирование продукта;
• внедрение и поддержка.
Каждой стадии разработки ПО присваивается определенный порядковый номер. Также каждый этап имеет свое собственное название, которое характеризует готовность продукта на этой стадии.
Жизненный цикл разработки ПО:
• Пре-альфа
• Альфа
• Бета
• Релиз-кандидат
• Релиз
• Пост-релиз
Таблица принятия решений (decision table) — великолепный инструмент для упорядочения сложных бизнес требований, которые должны быть реализованы в продукте. В таблицах решений представлен набор условий, одновременное выполнение которых должно привести к определенному действию.

QA/QC/Test Engineer

Таким образом, мы можем построить модель иерархии процессов обеспечения качества: Тестирование — часть QC. QC — часть QA.
Диаграмма связей — это инструмент управления качеством, основанный на определении логических взаимосвязей между различными данными. Применяется этот инструмент для сопоставления причин и следствий по исследуемой проблеме.

Источники: www.protesting.ru, bugscatcher.net, qalight.com.ua, thinkingintests.wordpress.com, книга ISTQB, www.quizful.net,bugsclock.blogspot.com, www.zeelabs.com, devopswiki.net, hvorostovoz.blogspot.com.

Автор: Джейми Джеп
14.08.2012
В нашу цифровую эпоху тестирование ПО перед выпуском является императивным требованием. Ведь отказ ПО способен повредить бизнесу и репутации компании. Если учесть, что сегодня лояльность бренду стала недолговечной, негативная реакция пользователей может привести к их переориентации на другого производителя.
Такие потенциальные последствия важнее технических неисправностей, утверждают обозреватели, которые единодушно подчеркивают необходимость тестирования ПО.
Принцип “тестируй как можно раньше и как можно чаще” большинством компаний, к сожалению, не соблюдается. Обычно тестирование откладывается до последней минуты, говорит Джефф Финдли, старший архитектор решений для Азиатско-Тихоокеанского региона и Японии в фирме Micro Focus. Разработчики стремятся отсрочить тестирование важнейших функций и транзакций вплоть до самого выпуска продукта.
Рей Ванг, главный аналитик и генеральный директор фирмы Constellation Research, добавляет, что даже если компании признают важность подготовки высококачественного ПО, то скорее в соответствии с принципом “быстрее, лучше, дешевле”. Это ограничивает вероятность отказа программ, но одновременно и возможности предвидения неожиданных трудностей, которые могут возникнуть в реальной жизни, и готовности к ним.
“Тестирование из искусства превратилось в науку”, — считает Ванг. Немногие компании сейчас достигают этого уровня в процессе интегрированной гибкой разработки. Они составляют планы тестирования параллельно с функциональными спецификациями. При этом больше времени уходит на планирование, зато остается меньше ошибок, сказал аналитик.
“Если вы пересчитали все деревья, это не значит, что вы видели лес”, — сказал Рамешвар Вьяс, генеральный директор компании Ranosys Technologies, предоставляющей услуги по тестированию ПО. Компаниям всегда следует помнить об этом при подготовке тестовых программ, считает он. Управление изменениями и рисками являются составными частями общего плана, который должен включать тестирование на предмет всего того, что ПО не должно делать.
Финдли подчеркивает, что всё тестируемое компаниями ПО должно соответствовать требованиям бизнеса. Эти требования следует четко сформулировать, согласовать с акционерами и хранить в центральном репозитарии. Зачастую составляются многочисленные документы, в которых многократно и различным образом описываются предъявляемые требования. В результате появляется множество интерпретаций, что в свою очередь ведет к сбоям в работе приложения и к его дорогостоящей переделке, поясняет он.
Эти комментарии были высказаны после 1 августа, когда американская трейдерская компания Knight Capital Group потеряла 440 млн. долл. из-за того, что небрежно обновленное ПО отдало несколько ошибочных распоряжений на Нью-Йоркской фондовой бирже. Ей пришлось выпутываться с помощью финансового спасательного круга. Всего неделю спустя в Азии произошел сбой системы резервного копирования на Токийской фондовой бирже. В результате торговля дериватами была приостановлена на 95 минут.
Достаточно — это сколько?
Как компаниям оценить, какой объем и продолжительность тестирования ПО позволит избежать подобных инцидентов? Это зависит от того, как они определяют риски, связанные с выполнением конкретных функций приложения, считает Финдли.
Важно понять влияние сбоя на бизнес, а затем двигаться в обратном направлении, тестируя каждый элемент как можно раньше, причём тесты должны соответствовать требованиям бизнеса, для проверки которых они проводятся, поясняет руководитель компании Micro Focus.
Когда транзакции имеют важнейшее значение для успеха всего предприятия, они должны быть тщательно протестированы как в функциональном, так и в нефункциональном отношении. Это необходимо, чтобы определить, корректно ли приложение выполняет транзакцию по времени для всех пользователей независимо от того, как они получают доступ к нему.
Тесты, касающиеся второстепенных функций приложения, не требуют такой же строгости. В данном случае можно обойтись тестированием по сокращенной программе, отказ не будет иметь серьезных последствий для бизнеса.

Даже после выпуска ПО важно проводить непрерывное и регулярное тестирование его важнейших транзакций. Для этого следует как можно раньше разработать автоматизированные тесты и регулярно прогонять их, убеждаясь, что усилия разработчиков не нарушают работу приложения. Такое автоматическое тестирование должно распространяться на программный код, функциональность ключевых транзакций и производительность приложения, рекомендует Финдли.
Понять влияние отказов ПО на бизнес очень важно при планировании и проведении тестирования. Но компании редко этим занимаются, откладывая такую работу до последней минуты.
Тестирование — способ обеспечения качества.Недостаточно выполнить проектирование и кодирование ПО, необходимо также обеспечить его соответствие требованиям и спецификациям.
С технической точки зрения тестирование заключается в выполнении ПО на некотором множестве исходных данных и сверке получаемых результатов с заранее известными (эталонными) с целью установить соответствие различных свойств и характеристик ПО заказанным свойствам.
В общем случае в программах ошибки выполнения могут быть следующих видов:
— системные;
— алгоритмические;
— программные;
— технологические.
СИСТЕМНЫЕ ошибки могут быть вызваны неполной информацией о предметной области, а также о реальных процессах, происходящих в источниках и потребителях информации. Допускаются на этапе проектирования ПО, а именно при системном анализе.
АЛГОРИТМИЧЕСКИЕ(ЛОГИЧЕСКИЕ) ошибки (30%) — ошибки, обусловленные некорректной постановкой задачи, неполным учетом всех условий решения задачи, ошибки связей модулей, просчеты в использовании доступных ресурсов ЗВМ и т.д. Эти ошибки очень сложно устраняются.
ПРОГРАММНЫЕ ошибки (30%) — деление на 0, обработка отсутствующих данных, использование индекса за пределами массива, корень квадратный из отрицательного числа и т.д.
Причинами таких ошибок могут быть ошибки в программе, допущенные при разработке, ошибки при вводе исходных данных и т.д. Они могут быть обнаружены только при выполнении программы, т.к. как правило приводят к прекращению ее выполнения.
ТЕХНОЛОГИЧЕСКИЕ ошибки(5-10%) — связаны с вводом программы, ее копированием, редактированием и т.д. Ошибки, возникающие при вводе в компьютер неверных данных.
В соответствии с этапом обработки, на котором проявляются ошибки, различают:
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы;
ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы (переполнение, защита памяти, несоответствие типов, зацикливание).
Программа не соответсвует спецификации
Спецификация не соответсвует требованиям
| Вид программной ошибки | Способ обнаружения |
| Синтаксические | Статический контроль и диагностика компилятором |
| Компоновки | Статический контроль и диагностика компоновщиком |
| Выполнения: — переполнение, защита памяти; — несоответствие типов; — зацикливание |
Динамический контроль: — аппаратурой процессора; — run-time системы программирования; — операционной системой – по превышению лимита времени |
| Программа не соответсвует спецификации |
Целенаправленное тестирование |
| Спецификация не соответсвует требованиям | Испытания, бета-тестирование |
ыполнерия
Многократно проводимые исследования показали, что чем раньше обнаруживаются те или иные несоответствия или ошибки, тем больше вероятность их правильного исправления (рис. 9.1, а) и ниже его стоимость (рис. 9.1, б) [7].
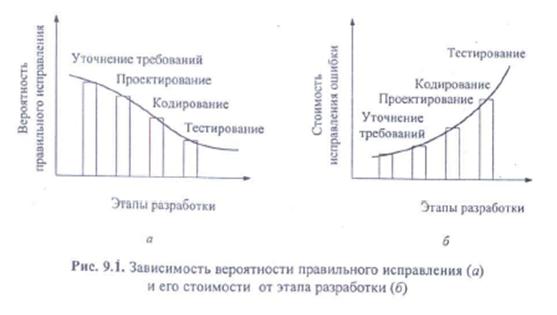
Если стоимость обнаружения и устранения ошибок кодирования принять за единицу, то стоимость выявления и исправления на следующих этапах ЖЦ ПО можно представить следующим образом
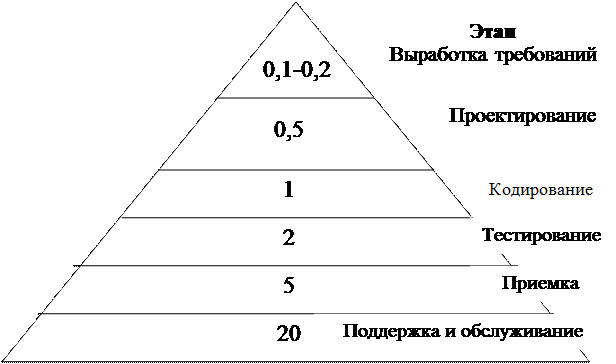
Оценка стоимости ошибок на разных этапах создания ПО
Откуда складывается такая высокая стоимость ошибки? Ко времени обнаружения ошибки, например, в требованиях группа разработчиков уже могла потратить время и усилия на создание проекта по этим ошибочным требоованиям. В результате проект, вероятно придется отбросить или пересмотреть.
Истиная природа ошибки может быть замаскирована; при проведении тестирования и проверок на данной стадии все думают, что имеют дело с ошибками проектирования, и значительное время и усилия могут быть потрачены впустую.
В зависимости от того, где и когда при работе над проектом разработки ПО был обнаружен дефект, цена его может разниться в 50-100 раз. Причина состоит в том, что для его исправления придется затратить средства на некоторые (или все) нижеперечисленные действия.
1. Повторная спецификация.
2. Повторное проектирование.
3. Повторное кодирование
4. Повторное тестирование
5. Замена заказа – сообщить клиентам и операторам в необходимости заменить дефектную версию исправленной
6. Внесение исправлений – выявить и устранить все неточности, вызванные неправильным функционированием ошибочно специфицированной системы, что может потребовать выплаты определенных сумм возмущенным клиентам, повторнрго выполнения определенных вычислительных задач на ЭВМ и т.д.
7. Списание той части работы (кода, части проектов и т.п.), которая выполнялась с наилучшими побуждениями, но оказалось ненужной, когда обнаружилось, что все это создавалось на основе неверных требований.
8. Отозвание дефектных версий встроенного ПО и соответсвующих руководств. Если приянть во внимание, что ПО сеголня встраивается в различные изделия – от наручных часов и микроволновых печей до автомобилий, — такая замена может коснуться как этих изделий, так встроенного в них ПО.
9. Выплаты по гарантийным обязательствам.
10. Ответсвенность за изделие, если клиент через суд требует возмещения убытка, причиненного некачественным ПП.
11. Затраты на обслуживание — представитель компании должен посетить клиента, чтобы установить новую версию ПО.
12. Создание документации.
В целом различают дефекты ПО и сбои. В случае сбоя программа ведет себя не так, как ожидает пользователь. Дефект – это ошибка/неточность, которая может быть (а может и не быть) следствием сбоя.
Современные технологии разработки ПО предусматривают раннее обнаружение ошибок за счет выполнения контроля результатов всех этапов и стадий разработки.
На начальных этапах такой контроль осуществляют в основном вручную или с использованием CASE-средств, на последних — он принимает форму тестирования.
Как правило, невисимой группой тестировщиков проводится тестирование ПО. Тестирование либо выполняется в виде отдельной фазы после окончания программирования и до передачи его заказчику, либо начинается вместе с началом проекта и пролжается паралельно созданию продукта до завершения проекта.
Тестирование — это процесс выполнения программы, целью которого является выявление ошибок.
Примечание. Обычно на вопрос о цели тестирования начинающие программисты отвечают, что целью тестирования является «доказательство правильности программы». Это абсолютно неверное мнение. Г. Майерс [47] предлагает очень удачную аналогию для пояснения этого положения.
Представьте себе, что вы пришли на прием к врачу и пожаловались на боль в боку. Врач выслушал вас и направил на обследование. Через некоторое время вы возвращаетесь к врачу с ворохом заключений и результатов анализов, и во всех этих бумагах написано, что все исследуемые
параметры у вас в норме. Но бок то болит, значит, что-то не в порядке, хотя анализы этого и не показывают… Так и сложное программное обеспечение, безошибочно работающее на всех тестовых наборах, может содержать и обычно содержит некоторое количество ошибок.
Процесс разработки современного программного обеспечения предполагает три стадии тестирования:
• автономное тестирование компонентов программного обеспечения (модульное тестирование);
• комплексное тестирование разрабатываемого программного обеспечения (интеграционное тестирование);
• системное или оценочное тестирование на соответствие основным критериям качества и исходным требованиям.
Уровни тестирования:
— альфа-тестирование – имитация реальной работы с системой штатными разработчиками либо реальная работа с системой потенциальными пользователями/заказчиком на стороне разработчика.
— бета-тестирование – выполняется в случаях, когда распространяется версия с ограничениями (по функциональности или времени работы) для некторой группы лиц с тем, чтобы убедиться что продукт содержит достаточно мало ошибок. Иногда бета-тестирование выполняется для того, чтобы получить обратную связь о продукте от его будущих пользователей.
Для повышения качества тестирования рекомендуется соблюдать следующие основные принципы:
• предполагаемые результаты должны быть известны до тестирования;
• следует избегать тестирования программы автором;
• необходимо досконально изучать результаты каждого теста;
• необходимо проверять действия программы на неверных данных;
• необходимо проверять программу на неожиданные побочные эффекты
на неверных данных.
Следует также иметь в виду, что вероятность наличия необнаруженных ошибок в части программы пропорциональны количеству ошибок уже найденных в этой части.
Сущность тестирования состоит в том, что пользователь готовит систему тестов, с помощью которых проверяется работа программы во всех возможных режимах. Тест – это набор контрольных входных данных совместно с ожидаемыми результатами и условиями для запуска программы. Т.е. каждый тест содержит набор исходных данных, для которых известен результат. Если в результате работы программы с данным тестом получаются результаты, отличные от ожидаемых, то это говорит о наличии ошибок.
Ключевой вопрос – полнота тестирования: какое количество какихтестов гарантирует, возможно, более полную проверку программы?
Пример. Программа, вычисляющая функцию двух переменных Y=F(X, Z). Если тип X, Y, Z real, то полное число тестов 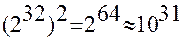
Если на каждый тест тратить 1мс, то 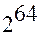 мс = 800 млн. лет.
мс = 800 млн. лет.
А чего не может тестирование?
Никакое тестирование не может доказать отсутствие ошибок в хоть сколько-нибудь сложном программном обеспечении (оно может показывать только присутствие дефектов). Важно помнить это (скорее печальное) утверждение при проведении тестирования.
Для такого программного обеспечения выполнение полного тестирования, т. е. задания всех возможных комбинаций исходных данных, становится невозможным, а, следовательно, всегда имеется вероятность того, что в программном обеспечении остались не выявленные ошибки. Однако соблюдение основных правил тестирования и научно обоснованный подбор тестов может уменьшить их количество.
Тестирование – технико-экономическая проблема, основанная на компромиссе время – полнота.Поэтому нужно стремиться к возможно меньшему количеству хороших тестов с желательными свойствами.
Формирование тестовых наборов.В соответствии с определением тестирования удачным следует считать тест, который обнаруживает хотя бы одну ошибку.
Так как о тестировании мы будем говорить все остальные томные вечера, то сейчас будем лаконичны, как спартанцы.
После того как проинтегрирован код, тестировщики проводят тест приемки (smoke test, sanity test или confidence test), в процессе которого проверяются основные функциональности.
Пример
Если мы не можем погнуться (log into) в наш эккаунт (account) на www.main.testshop.rs, то о каком дальнейшем тестировании можно говорить.
Если тест приемки не пройден, то программисты и релиз-инженеры совместно работают над поиском причины. Если проблема была в коде, то код ремонтируется, интегрируется и над ним снова производится тест приемки. И так по кругу, пока тест приемки не будет пройден.
Если же тест приемки пройден, то код замораживается и тестировщики начинают тестирование новых компонентов(new feature testing), т.е. исполнение своих тест-кейсов, написанных по спекам данного релиза (более подробно о значении термина feature поговорим в беседе о системе трэкинга багов).
После того как новые функциональности протестированы, наступает очередь исполнения «старых» тест-кейсов. Этот процесс называется регрессивным тестированием(regression testing), ко-
Цикл разработки ПО
105
торое проводится для того, чтобы удостовериться, что компоненты ПО, которые работали раньше, все еще работают.
Баги заносятся в систему трэкинга багов(Bug Tracking System, далее — СТБ,о ней у нас будет отдельный разговор), программисты их ремонтируют, и затем тестировщики проверяют, насколько качественным был ремонт.
Допустим, мы все, что хотели и как смогли, протестировали. Программисты залатали дыры в коде, что мы тоже протестировали, и у нас есть версия нашего проекта, готовая для релиза. Эту версию мы мурыжим еще пару деньков, проводя тест сдачи (Acceptance or Certification Test), и включаем зеленый свет релиз-инженерам, чтобы они передали плод наших терзаний кликам (от англ. click) пользователей.
Релиз
Release (англ.) — «выпуск, освобождение».
Пример
Герой романа Стивена Кинга — ботаник, чудик и домосед — подвергается постоянным унижениям от одноклассников, домочадцев и случайных прохожих. В один день он вдруг говорит себе «Хватит» и начинает колоть, резать и душить подлых обидчиков, а также в превентивных целях и всех остальных. Этот выпуск пара и есть «релиз» в его обыденном понимании.
До этого мы употребляли слово «релиз» в значении «основной релиз» (так будем поступать и дальше), но у нас есть и его «родственники».
Вот полная классификация «релизообразных»:
1. Релиз (он же основной релиз) (major release) — стадия в цикле разработки ПО, идущая за стадией тестирование и ремонт багов, т.е. передача пользователям кода новой версии нашего ПО. Как правило, обозначается целыми числами, например 7.0.
2. Дополнительный релиз (minor release) — ситуация, когда после основного релиза планово выпускается новая функциональность или изменяется/удаляется старая. Дополнительный релиз не связан в багами. Как правило, обозначается десятыми, например 7.1.
106
Тестирование Дот Ком. Часть 1
3. Заплаточный релиз (patch release), когда после обнаружения и ремонта бага выпускается исправленный код. Как правило, обозначается сотыми, например 7.11.
О чем говорит версия 12.46 нашего www.testshop.rs? А говорит она о трех вещах:
1) о том, что последний основной релиз является двенадцатым по счету;
2) о четырех дополнительных релизах, выпущенных ПОСЛЕ двенадцатого релиза;
3) о шести заплаточных релизах, выпущенных ПОСЛЕ двенадцатого релиза.
Кстати, о номерах релизов. Некоторые компании в желании пооригинальничать дают основным релизам не номера, а названия. Ну, например, имя поп-группы или отдельного исполнителя.
Звонит программисту дружок:
—Здорово, старик. Слушай, Ленка подружку приводит, так что бери шампанское и подъезжай к семи.
—Не, я пас. Я тут с «Бритни Спирс» завис. -О!..
Неудобство такого подхода заключается в том, что непонятно, какой релиз был раньше — «Пол Маккартни» или «Джон Леннон», и в идиотизме произнесения названий дополнительных или заплаточных релизов: звонит контрагент со своей проблемой, а ему говорят: «Да усе будет в порядке. Мы заутра патч номер 7 кДорз присобачим».
Идем дальше.
Любой из трех релизов для пользователя означает, что наш www.testshop.rs как-то изменился.
Возможные изменения:
1. Новые функциональности (основной и дополнительный релизы);
2. Изменение/удаление старых функциональностей (основной и дополнительный релизы);
3. Починка багов, пропущенных в одном из релизов любого типа (заплаточный релиз).
Организация упаковки кода в виртуальный мешок и его передача пользователю осуществляются релиз-инженерами.
Давайте представим, что ЗАО «Тест-шоп», предназначенное, кстати, для продажи книг, только начинает работу.
Цикл разработки ПО 107
Унас есть
• два программиста (Дима и Митя) и
• хозяин-барин (месье Кукушкин Илья Харитонович),
а также
• два компьютера с «Виндоуз» для программистов (здесь и далее я не буду давать версий не нашего ПО),
• клевый лэптоп Харитоныча (ОС значения не имеет) и
• машина с Линуксом (далее называемая тест-машина) для разработки и тестирования ПО.
Проект начинается:
1. Регистрируется домен www.testshop.rs.
2. У интернет-провайдера и по совместительству хостинг-провайдера покупается доступ в Интернет и арендуется сервер, чтобы весь мир мог зайти на огонек, увидеть и оценить.
3. Программистские компьютеры, лэптоп СЕО и тест-машина объединяются в локальную сеть с выходом в Интернет.
4. Программисты начинают работать над проектом.
Мы уже говорили о том, что классическая архитектура веб-проекта — это
• веб-сервер;
• сервер с приложением;
• база данных.
Так вот, так как мы — интернет-компания молодая, то у нас все будет по-простому: на тест-машине будут все три компонента.
Архитектура www.testshop.rs
1. Веб-сервер Apache («апачи», имя которого идет не от названия американского племени индейцев, издревле промышлявших подработками на интернет-проектах, а от patchy (залатанный), как память о неимоверном количестве заплаток, на него приклеенных, в результате чего он приобрел белизну и пушистость).
В директориях Apache мы храним:
• файлы, содержащие HTML-код с инкорпорированным
JavaScript-кодом. JavaScript-код, вставляется в HTML.-файлы и может служить, например, для проверки е-мейла при регистрации на наличие двух @. Достоинство использования JavaScript-кода, заключается в том, что проверка осуществ-
108 Тестирование Дот Ком. Часть 1
ляется на компьютере пользователя в отличие от варианта, когда мы посылаем непроверенную форму с регистрацией на сервер с приложением, нагружая этот сервер;
• файлы-картинки(images).
2. Приложение на Python иC++. Наше приложение состоит из:
• файлов с Python-скриптами,которые можно использовать, например, для «перевода» регистрационной формы, отправленной пользователем, на язык, понятный базе данных, и для создания новой строки в таблице для новых пользователей;
• файлов сC++ кодом.Например, нам нужно вставить новое значение в определенной колонке определенной таблицы базы данных для всех пользователей, зарегистрированных у нас более 1 года. Для этой цели мы можем написать программу на C++.
Кстати, C++ файлы — это единственные файлы в нашем проекте, которые мы компилируем перед использованием: каждый из наших C++ файлов — это простой текстовый файл с кодом, написанным на C++, и, чтобы он стал исполняемым, его нужно скормить C++ компайлеру, который проверит код на наличие багов синтаксиса и, если все О’к, переведет язык, понятный человеку (C++), на язык, понятный тест-машине (нули и единицы).
3. База данных MySQL («майсиквел»). Здесь мы будем хранить
данные
• о пользователях (например, день регистрации в системе, е-мейл, имя, фамилию и пароль);
• о транзакциях пользователя (например, когда и что купил);
• о наименованиях книг и их наличии.
Идем дальше.
Начинаются первые неудобства и проблемы, связанные с отсутствием релиз-инженерных знаний:
1. При каждом сохранении файла в той же директории нужно давать ему новое имя, чтобы не удалить старый вариант редакции.
2. При сохранении файла после редактирования нельзя прокомментировать, что было изменено.
3. Самое главное: постоянно присутствует риск, что один из программистов удалит свою работу или работу коллеги.
Цикл разработки ПО 109
Пример
а. После спецификации, пробормоченнои Харитонычем за рюмочкой
чая, программисты начинают писать код.
б. Частью кода является файл registration.py, который лежит в ди
ректории /usr/local/apache/cgi-bin/ и был написан Димой два дня
назад.
в. Дима копирует этот файл в свою директорию /home/dima и начи
нает его редактировать.
г. Одновременно с ним без всякого злого умысла этот же файл копи
рует и сохраняет в своей директории (/home/mitya) Митя и тоже на
чинает его редактировать.
д. Дима, дописав и протестировав registration.ру, переносит (move)
его обратно в /usr/local/apache/cgi-bin/.
е. Вслед за ним туда же переносит свою версию registration.ру и Митя,
в результате чего:
• в /usr/local/apache/cgi-bin/ лежит Митина редакция;
• Дима рвет на себе волосы, так как не сохранил у себя ни копии первоначального файла, ни файла с новым кодом;
• Митя рвет на себе волосы, так как в процессе разработки у него была работающая версия, но он ее не сохранил, а, решив, что другой алгоритм будет лучше, написал другую версию, которую, толком не протестировав, перенес в /usr/local/apache/cgi-bin/.
• первый релиз откладывается, так как Митина версия registration.ру абсолютно «не пашет».
осле разбора полетов принимается решение об установке CVS. VS устанавливается на тест-машину и это дает следующее:
Файлы хранятся в репозитарии (repository),
ОТКУДА
их можно взять для редактирования (checkout) и КУДА
их можно положить после редактирования (checkin).
При этом
а) каждый раз,когда мы кладем файл в репозитарии,
• не нужно менять имени файла;
• мы можем комментировать, что было изменено в этом файле;
• CVS автоматически присваивает файлу номер редакции (версии), уникальный для этого файла;
• CVS связывает номер версии файла, комментарий к изменениям, имя изменившего и время изменения в одну
110
Тестирование Дот Ком. Часть 1
запись (при желании можно увидеть всю историческую последовательность записей);
б) если Дима взял из репозитария файл, то Митя не может его оттуда взять, пока Дима не положит его обратно.
Итак, поставив старую добрую и бесплатную CVS, мы имеем:
• все версии файла, каждая из которых кроме уникального номера версии имеет еще и запись об изменениях;
• программистов, которые уже не могут случайно уничтожить код друг друга;
• возможность сравнить содержание файла в разных редакциях.
Теперь, когда наш код хранится в CVS, возникает другая задача — как сделать так, чтобы этот код стал доступным на веб-сайте для тестирования — www.main.testshop.rs? Для решения этой задачи нужно, чтобы файлы из CVS были интегрированы и отправлены по назначению в соответствующие директории тест-машины и чтобы у нас было отражение содержимого CVS
• по состоянию на данный момент и
• для данного релиза.
Каждоетакое отражение кода веб-сайта называется билдом(build). Иными словами, билд— это версия версии ПО.
Билды делаются или вручную, или путем запуска билд-скриптов
(build script), т.е. программ, написанных релиз-инженерами для автоматизации процесса. Как правило, билд-скрипты добавляются в сгоп (это расписание запуска программ в Линукс-системах), с тем чтобы создавать новые билды через определенные промежутки времени.
Цель создания новых билдов заключается в том, чтобы измененный код (сохраненный в CVS) стал доступным для тестиров-щиков:
а. После того как программист починил баг, найденный при
тестировании, он тестирует починку на своем плэйгра-
унде, после чего делает checkin отремонтированного кода
в CVS.
б. Отремонтированный код становится частью нового билда.
в. Новый билд замещает (replace) на тест-машине код преды
дущего билда.
Цикл разработки ПО
111
Пример
Допустим, что время на создание нового билда равно 15 минутам. Билд-скрипты создают новые билды каждые 3 часа в соответствии с расписанием билдов (build schedule): в 12:00, 15:00, 18:00 и т.д. Практическую ценность здесь имеют две вещи:
1. Нет смысла тестировать веб-сайт с 12:00 до 12:15, с 15:00 до 15:15, с 18:00 до 18:15 и т.д., так как билд находится в процессе создания и одна часть файлов может принадлежать старому билду, а другая — новому.
2. Если программист починил ваш баг и сделал checkln измененного кода в CVS, то вы сможете протестировать починку только после следующего билда, т.е. если checkin файла в CVS произошел в 16:00, то протестировать починку можно после билда, который начнется в 18:00.
Соответственно иногда в целях экономии времени имеет смысл попросить релиз-инженера, чтобы тот сделал внеочередной билд, причем о последнем должны быть оповещены все остальные тести-ровщики.
Итак, перед проверкой починки бага убедитесь не только в том, что вы тестируете нужную версию, но и в том, что тестируете нужный билд. Номер билда, содержащего отремонтированный код, включается программистом в запись о баге в СТБ
(подробнее об этом в разговоре о СТБ).
Кстати, номера билда для данной конкретной версии начинаются с единицы для первого билда (который мы проверяем во время теста приемки) и увеличиваются на единицу с каждым новым билдом.
Как узнать номер билда? Спросите об этом своего релиз-инженера. В веб-проектах номер билда часто включается в HTML-kojx каждой страницы веб-сайта и может быть найден, если посмотреть этот код, используя функциональность веб-браузера View source.
Итак, Дима написал билд-скрипт, добавил его в сгоп, и новый билд у нас создается каждые 3 часа.
С точки зрения конфигурации системы плэйграунд каждого из программистов находится на той же тест-машине.
Дело в том, что на одном веб-сервере могут находиться сразу несколько веб-сайтов. В нашем случае:
• www.mitya.testshop.rs — это адрес Митиного плэйграунда,
• www.dima.testshop.rs — это адрес Диминого плэйграунда, а
• www.main.testshop.rs — это веб-сайт, на который делается каждый из билдов.
112 Тестирование Дот Ком. Часть 1
Следовательно, тестировщики будут использовать именно www.main.testshop.rs для своего тестирования.
Соответствующие
• директория с ЯГЖ-файлами и картинками,
• директория с приложением (Python и C++ файлы) и
• база данных
слинкованы с каждым из сайтов, так что у нас есть три конфигурации, независимые друг от друга.
Кстати, важный нюанс о плэйграундах, билдах и CVS. Основное правило для checkin: сначала сделай быстрый юнит-тест и убедись, что твои файлы компилируются по крайней мере на твоем плэйграунде, и уже после этого делай их «публичными» через checkin в CVS.
Рациональное объяснение: билды строятся из кода, хранимого в CVS. Если же код не компилируется, то билд будет сломан (build is broken) и соответственно никакого тестирования не будет. Мы касались этого правила, говоря об идее постоянной интеграции кода.
Идем дальше.
Код написан, тестирование и ремонт багов закончены. Настало время первого релиза www.testshop.rs!!!
Первый релиз происходит так:
1. Подготовка машины у хостинг-провайдера(production server, просто production или live machine — машина для пользователей).
Когда говорили об аренде сервера хостинг-провайдера, то имелось в виду, что мы арендовали совершенно конкретный компьютер, который находится где-то у провайдера и имеет уникальное (в общемировом масштабе) сетевое ID, которое называется IP Address («ай-пи адрес»). Используя этот IP Address, мы подсоединяемся к этой машине и настраиваем
а) провайдерский Линукс (например, создаем директории,
редактируем разрешения и т.д.);
б) провайдерский Apache (например, вносим изменения в
файл конфигурации и т.д.);
в) провайдерскую MySQL (например, определяем максималь
ное количество соединений и т.д.).
Цикл разработки ПО
113
2. Подготовка релиз-скрипта(release script) — программы, которая автоматизирует процесс релиза на машину для пользователей.
3. Исполнение релиз-скрипта:
а) релиз-скрипт запускает билд-скрипт, чтобы на тест-маши
не создался новый билд;
б) релиз-скрипт берет файлы этого нового билда и по прото
колу FTP («эф-ти-пи» — File Transfer Protocol) пересылает
их в машину для пользователей;
в) релиз-скрипт:
• копирует из CVS на машину для пользователя скрипты для базы данных (DB-scripts) и
• запускает эти скрипты.
Скрипты для базы данных создают или модифицируют схему базы данных.Так как у нас первый релиз, то схема базы данных только создается, а именно создаются три таблицы:
• user_info (для данных о пользователях);
• user_transaction (для данных о транзакциях пользователя);
• book_vault (для данных о наименованиях книг и их наличии).
Кстати, нужно различать
• схему базы данных (database, или просто DB, schema) и
• сами данные.
Схема базы данных — это совокупность виртуальных контейнеров (над БД работают программисты и администраторы БД).
Данные — это начинка этих виртуальных контейнеров, которую своими действиями на www.testshop.rs, например регистрацией, создают/изменяют пользователи (user_info и user_transaction) или другие лица (например, Харитоныч, который через специальную программу, написанную Митей, может добавить новые названия книг и их количество в book_vault).
Небольшое отступление
По мере развития проекта машина для пользователей превратится в десятки связанных между собой веб-серверов, серверов с приложением и серверов с базами данных, образующих production pool, т.е. совокупность компьютеров, обслуживающих наших пользователей. Но это будет потом. А пока…
Welcome to www.testshop.rs!!! Наш первый релиз состоялся!!!
Книги продаются, к проекту примкнули кореша Харитоныча, в результате чего появились деньги, чтобы нанять новых людей и вообще начать активно расширяться.
114
Тестирование Дот Ком. Часть 1
Над проектом уже работают 2 продюсера, 7 программистов и 1 тестировщик. Долго ли, коротко ли, а уже и второй релиз (версия 2.0) состоялся.
На следующий день после выпуска версии 2.0 лавина жалоб от пользователей дает основания полагать, что версия 2.0 www.testshop.rs так же насыщена багами, как версия-2004 Государственной думы единороссами.
Компания превращается в форпост по борьбе с последствиями релиза версии 2.0:
• месье Кукушкинносится между столами программистов и тестировщика, давая ценные указания и оперируя словарным запасом, приобретенным на раннем (колымском) этапе своей карьеры;
• программисты,которые не чинят баги версии 2.0, не могут сохранить файлы для версии 3.0 в CVS, так как в CVS решением руководства можно сохранять только код с отремонтированными багами для релиза 2.0;
• программисты,которые чинят баги, естественно, не могут работать над версией 3.0;
• тестировщикпроверяет отремонтированный код для версии 2.0 вместо подготовки к тестированию версии 3.0;
• продюсерыотвечают на е-мейлы разгневанных пользователей, которые, несмотря на биографии менее яркие, чем биография Харитоныча, тем не менее с легкостью оперируют тем же словарным запасом.
Кстати, справедливости ради стоит отметить, что по идее к версии 1.0 вернуться можно, но это займет время и чревато ошибками, так как основной объем работы будет делаться вручную. Понадобится:
• найти версии файлов в CVS на день первого релиза*,
• изменить и протестировать билд- и релиз-скрипты,
• запустить релиз-скрипты и проверить, насколько правильно они сработали.
• Если в первом релизе у нас были десятки файлов, то с течением времени
их будут сотни!!!
В таком бедламе проходит двое безвылазных суток, и наконец баги придушены, билд протестирован на тест-машине и срочно организуется патч-релиз 2.01 на машину для пользователей.
После разбора полетов Митей, как одним из старожилов компании, вносится предложение о создании бранчей (branch — ветвь)
Цикл разработки ПО
115
в CVS. Предложение принимается единогласно (тем более что отвечать в случае провала будет инициатор), и Митя рассказывает, в чем суть этого подхода.
РАССКАЗ МИТИ
‘В общем так, други. Допустим, у нас есть ребенок и его фотографии нужно раз в месяц по е-мейлу посылать теще. Если присылается фотография ребенка в недовольном состоянии, то теща приезжает и устраивает дома такой шухер, как будто она попользовалась нашей версией 2.0. Соответственно нужно сохранить фотографию ребенка, когда он улыбается, и если новая фотография теще не нравится, то нужно просто послать ей старую фотографию с улыбкой и сказать, что ошибка вышла».
Харитоныч:
— Да вот я помню… (далее следует 30-минутный рассказ о его тещах с постепенным переходом к обобщениям и, наконец, декларативному изложению отношения ко всему прекрасному полу). Да-а-а, вот так-то. Что ты там говорил про версию 2.0?
ПРОДОЛЖЕНИЕ МИТИНОГО РАССКАЗА
«Да, вот. Как я и говорил о хорошем и улыбающемся билде. Вот мини-история нашего проекта со стороны релиз-инженера:
В один прекрасный день мы начали работать над кодом ПО, и по мере написания этого кода стали добавлять в CVS новые файлы ,и изменять файлы, уже существующие в ней. В определенный момент мы сказали «Стоп» и назвали совокупность файлов в CVS «версия 1.0». Затем мы продолжили работу над кодом и снова стали добавлять в CVS новые файлы и изменять файлы, существующие в ней. В определенный момент мы снова сказали «Стоп» и назвали совокупность файлов в CVS «версия 2.0». Основной проблемой, которую мы взрастили, стала мешанина, начавшаяся в тот момент, когда мы не разделили файлы версии 1.0 и версии 2.0.
Идем дальше.
Представьте себе дерево, т.е.
ствол, и
ветви, растущие из ствола.
116
Тестирование Дот Ком. Часть 1
Вот как мы должны были поступить с самого начала:
• файлы, созданные вплоть до момента релиза версии 1.0, были основой, т.е. виртуальным стволом (trunk), нашего ПО;

• из этого ствола мы могли создать виртуальную ветвь (или бранч, от англ. branch) под названием «версия 1.0», которая включала бы все файлы версии 1.0 в редакциях (версиях) на момент, когда мы сказали «Стоп » для версии 1.0. Мы говорим «Стоп» после того, как код написани готов для интеграции и тестирования;
• таким образом, у нас появились бы ствол и одна ветвь;

• программисты, пишущие код для версии 2.0, должны были модифицировать код ствола (нарисунке — пунктиром);
• и когда код версии 2.0 был бы дописан, мы создали бы еще одну ветвь и назвали ее «версия 2.0 «;
• таким образом, у нас был бы ствол, из которого сначала рос бы бранч версии 1.0 и затем бранч версии 2.0;

• начиная работать над кодом релиза версии 3.0, мы снова работаем со стволом (на рисунке — пунктиром);

• и т.д.
Цикл разработки ПО
117
Таким образом, код каждой версии живет в CVS в виде отдельного бранча или ствола.
Кстати, есть множество нюансов, например слияние бранча и ствола, и ситуации, когда бранч сам становится стволом с ветвями и прочее, но я не буду вас этим загружать. Сейчас мне нуж-<:но, чтобы вы поняли главное.
Теперь вернемся к нашим баранам. Что сделано — то сделано. Сейчас в CVS y нас есть
• весь код версии 1.0;
• весь код версии 2.0;
• часть кода версии 3.0.
Пусть все это содержимое CVS будет нашим стволом. Я берусь найти совокупность файлов с редакциями, которые были у нас на момент релиза 2.0, и обратным числом создать из них бранч 2.0, чтобы в случае фиаско с версией 3.0 мы могли быстро вернуться к коду версии 2.0 и вообще начали хорошую традицию создания бранчей».
Выслушав Митю и мысленно поаплодировав ему, разберемся, что даст реализация Митиного предложения:
Во-первых,мы всегда сможем вернуться к предыдущей версии, если новая версия окажется некачественной.
Во-вторых,программисты
• смогут работать одновременно над различными версиями, например ремонтировать баги для 2.0 (бранч 2.0) и писать код для 3.0 (ствол) и
• результаты их работынад каждой из версий будут в CVS отделены друг от друга.
Вэтом случае www.main.testshop.rs будет веб-сайтом с кодом для 3.0 и вообще площадкой для билдов каждого нового релиза, а, скажем, www.old.testshop.rs будет веб-сайтом с кодом для 2.0 и вообще площадкой с кодом каждого предыдущего релиза.
В-третьих,мы сможем руководить состоянием бранчей.
У бранча есть три состояния:
1) открытый,т.е. в нем можно сохранять файлы;
2) условно открытый,в нем можно сохранять файлы, НО при определенном условии, например, программист дол-
118 Тестирование Дот Ком. Часть 1
жен написать номер реального бага в комментарии при сохранении файла; 3) закрытый.В этом случае файл может быть сохранен в соответствии с процедурой о неотложном ремонте багов (о процедуре через минуту).
Кстати, когда мы говорили о замораживании спеков, используя CVS, нужно понимать, что бранчи, в которых сохраняются спеки, не имеют никакой связи с бранчами, в которых сохраняется код. Как правило, это даже две CVS, установленные на двух разных машинах, но если даже используется одна и та же CVS на одной и той же машине, то бранчи для спеков и бранчи для кода — это как два сына одной женщины (т.е. CVS), один из которых мочит одноклассников в сортирах, а другой в это время читает Артура Шопенгауэра.
Кстати, часто возникает ситуация, когда программист сохранил код в бранче для патч-релиза и забыл сохранить исправленный код в стволе, т.е. в коде, из которого будет сделан бранч для следующего релиза. Таким образом, может получиться ситуация, когда баг, патч для которого уже был выпущен на машину для пользователей в предыдущем релизе, вновь появляется в следующем релизе. Чтобы избежать таких казусов, тестировщики придерживаются железного правила: на каждый баг, для которого был произведен патч-релиз, должен быть написан тест-кейс приоритета 1. Этот тест-кейс добавляется к группе тест-кейсов для регрессивного тестирования соответствующей функциональности.
Совместим наш цикл разработки ПО с открытостью бранчей.
1. Во время стадии кодирование, например, для версии 3.0 бранч с версией 3.0 является открытым.
2. Во время стадии тестирование и ремонт багов бранч является условно закрытым — никакой код не может сохраняться в таком бранче, за исключением кода с починкой для конкретного бага, при сохранении кода в CVS программист обязануказать номер открытого бага в СТБ, иначе CVS не разрешит checkin. Именно такой статус у бранча после заморозки кода и передачи кода тестировщикам.
3. После того как произошел релиз на машину для пользователей и в этом релизе найден баг, у нас есть два варианта:
а) если баг некритический (например, отсутствует проверка
е-мейла пользователя на два «@»), то его можно отре
монтировать в следующем релизе, т.е. мы фиксируем код
только в стволе;
б) если баг критический (например, невозможно совершить
покупку), то нужно отремонтировать его и выпустить патч-
Цикл разработки ПО
119
релиз как можно быстрее. Для такого срочного ремонта нужен формальный документ: процедура о неотложном ремонте багов(Emergency Bug Fix Procedure).
Кстати, не хочу вас путать, но есть одна важная для понимания вещь: иногда нужно незамедлительно изменить код приложения на машине для пользователей, и это изменение не связано с багами. В таком случае тоже заносится запись в СТБ, но с типом «Feature Request» — запрос о новой функциональности (подробнее об этом в разговоре о СТБ), и релиз такого кода регулируется этой же процедурой.
Примером, в котором нужен быстрый, не связанный с багами релиз, может послужить ситуация, когда у нас есть решение суда (например, о нарушении патента), которое обязывает срочно изменить код.
Релиз такого кода также называется патч-релизом.
Вопрос:В чем отличие такого патч-релиза от дополнительного релиза?
Ответ:В том, что дополнительный релиз — это плановый релиз, когда было заранее решено, что такие-то функциональности увидят свет, но включены они будут не в основной, а в дополнительный релиз.
Процедура о неотложном ремонте баговдолжна содержать:
• приоритет багов, которые подлежат НРБ. Например, это могут быть только П1 баги;
• список лиц, имеющих право инициировать процесс НРБ;
• последовательность действий между лицами, участвующими в НРБ, например:
1) программист, извещенный о проблеме, фиксирует баг;
2) исправление кода заверяется одним из его коллег через рассмотрение кода (code review);
3) релиз-инженер делает билд для регрессивного тестирования;
4) тестировщик производит тестирование;
5) релиз-инженер делает патч-релиз на машину для пользователей;
• коммуникацию между лицами, участвующими в НРБ. На
пример, в начале и конце каждого из этапов ответственное
лицо отвечает всем на последний е-мейл этой цепочки.
Причем в начале этапа посылается е-мейл типа «Начал де
лать билд для регрессивного тестирования. Примерный
120
Тестирование Дот Ком. Часть 1
срок до завершения операции — 30 минут». В конце этапа посылается е-мейл типа «Билд для регрессивного тестирования завершен. Тестировщики. Ау!».
Во многих компаниях для быстрого и эффективного исправления проблем после основного релиза по примеру полицейских создаются SWAT-команды (Special Weapons and Tactics teams — подразделения оперативного реагирования), по минимуму состоящие из продюсера, программиста, релиз-инженера и тестировщика. Допустим, у нас есть четыре такие команды. Для каждой их них устанавливается расписание на каждый день (по шесть часов каждая) на 10 дней после релиза, так чтобы по звонку в любое время дня и ночи головорезы соответствующего подразделения были готовы сорваться, приехать в офис и сидеть до посинения, пока патч-релиз не вылетит на машину для пользователей.