
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий: .
.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия .
.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Соседние файлы в папке Лекции 2 семестр
- #
- #
- #
- #
Ошибки, встроенные в систему: их роль в статистике
Время на прочтение
6 мин
Количество просмотров 13K
В прошлой статье я указал, как распространена проблема неправильного использования t-критерия в научных публикациях (и это возможно сделать только благодаря их открытости, а какой трэш творится при его использовании во всяких курсовых, отчетах, обучающих задачах и т.д. — неизвестно). Чтобы обсудить это, я рассказал об основах дисперсионного анализа и задаваемом самим исследователем уровне значимости α. Но для полного понимания всей картины статистического анализа необходимо подчеркнуть ряд важных вещей. И самая основная из них — понятие ошибки.
Ошибка и некорректное применение: в чем разница?
В любой физической системе содержится какая-либо ошибка, неточность. В самой разнообразной форме: так называемый допуск — отличие в размерах разных однотипных изделий; нелинейная характеристика — когда прибор или метод измеряют что-то по строго известному закону в определенных пределах, а дальше становятся неприменимыми; дискретность — когда мы чисто технически не можем обеспечить плавность выходной характеристики.
И в то же время существует чисто человеческая ошибка — некорректное использование устройств, приборов, математических законов. Между ошибкой, присущей системе, и ошибкой применения этой системы есть принципиальная разница. Важно различать и не путать между собой эти два понятия, называемые одним и тем же словом «ошибка». Я в данной статье предпочитаю использовать слово «ошибка» для обозначения свойства системы, а «некорректное применение» — для ошибочного ее использования.
То есть, ошибка линейки равна допуску оборудования, наносящего штрихи на ее полотно. А ошибкой в смысле некорректного применения было бы использовать ее при измерении деталей наручных часов. Ошибка безмена написана на нем и составляет что-то около 50 граммов, а неправильным использованием безмена было бы взвешивание на нем мешка в 25 кг, который растягивает пружину из области закона Гука в область пластических деформаций. Ошибка атомно-силового микроскопа происходит из его дискретности — нельзя «пощупать» его зондом предметы мельче, чем диаметром в один атом. Но способов неправильно использовать его или неправильно интерпретировать данные существует множество. И так далее.
Так, а что же за ошибка имеет место в статистических методах? А этой ошибкой как раз и является пресловутый уровень значимости α.
Ошибки первого и второго рода
Ошибкой в математическом аппарате статистики является сама ее Байесовская вероятностная сущность. В прошлой статье я уже упоминал, на чем стоят статистические методы: определение уровня значимости α как наибольшей допустимой вероятности неправомерно отвергнуть нулевую гипотезу, и самостоятельное задание исследователем этой величины перед исследователем.
Вы уже видите эту условность? На самом деле, в критериальных методах нету привычной математической строгости. Математика здесь оперирует вероятностными характеристиками.
И тут наступает еще один момент, где возможна неправильная трактовка одного слова в разном контексте. Необходимо различать само понятие вероятности и фактическую реализацию события, выражающуюся в распределении вероятности. Например, перед началом любого нашего эксперимента мы не знаем, какую именно величину мы получим в результате. Есть два возможных исхода: загадав некоторое значение результата, мы либо действительно его получим, либо не получим. Логично, что вероятность и того, и другого события равна 1/2. Но показанная в предыдущей статье Гауссова кривая показывает распределение вероятности того, что мы правильно угадаем совпадение.
Наглядно можно проиллюстрировать это примером. Пусть мы 600 раз бросаем два игральных кубика — обычный и шулерский. Получим следующие результаты:

До эксперимента для обоих кубиков выпадение любой грани будет равновероятно — 1/6. Однако после эксперимента проявляется сущность шулерского кубика, и мы можем сказать, что плотность вероятности выпадения на нем шестерки — 90%.
Другой пример, который знают химики, физики и все, кто интересуется квантовыми эффектами — атомные орбитали. Теоретически электрон может быть «размазан» в пространстве и находиться практически где угодно. Но на практике есть области, где он будет находиться в 90 и более процентах случаев. Эти области пространства, образованные поверхностью с плотностью вероятности нахождения там электрона 90%, и есть классические атомные орбитали, в виде сфер, гантелей и т.д.
Так вот, самостоятельно задавая уровень значимости, мы заведомо соглашаемся на описанную в его названии ошибку. Из-за этого ни один результат нельзя считать «стопроцентно достоверным» — всегда наши статистические выводы будут содержать некоторую вероятность сбоя.
Ошибка, формулируемая определением уровня значимости α, называется ошибкой первого рода. Ее можно определить, как «ложная тревога», или, более корректно, ложноположительный результат. В самом деле, что означают слова «ошибочно отвергнуть нулевую гипотезу»? Это значит, по ошибке принять наблюдаемые данные за значимые различия двух групп. Поставить ложный диагноз о наличии болезни, поспешить явить миру новое открытие, которого на самом деле нет — вот примеры ошибок первого рода.
Но ведь тогда должны быть и ложноотрицательные результаты? Совершенно верно, и они называются ошибками второго рода. Примеры — не поставленный вовремя диагноз или же разочарование в результате исследования, хотя на самом деле в нем есть важные данные. Ошибки второго рода обозначаются буквой, как ни странно, β. Но само это понятие не так важно для статистики, как число 1-β. Число 1-β называется мощностью критерия, и как нетрудно догадаться, оно характеризует способность критерия не упустить значимое событие.
Однако содержание в статистических методах ошибок первого и второго рода не является только лишь их ограничением. Само понятие этих ошибок может использоваться непосредственным образом в статистическом анализе. Как?
ROC-анализ
ROC-анализ (от receiver operating characteristic, рабочая характеристика приёмника) — это метод количественного определения применимости некоторого признака к бинарной классификации объектов. Говоря проще, мы можем придумать некоторый способ, как отличить больных людей от здоровых, кошек от собак, черное от белого, а затем проверить правомерность такого способа. Давайте снова обратимся к примеру.
Пусть вы — подающий надежды криминалист, и разрабатываете новый способ скрытно и однозначно определять, является ли человек преступником. Вы придумали количественный признак: оценивать преступные наклонности людей по частоте прослушивания ими Михаила Круга. Но будет ли давать адекватные результаты ваш признак? Давайте разбираться.
Вам понадобится две группы людей для валидации вашего критерия: обычные граждане и преступники. Положим, действительно, среднегодовое время прослушивания ими Михаила Круга различается (см. рисунок):

Здесь мы видим, что по количественному признаку времени прослушивания наши выборки пересекаются. Кто-то слушает Круга спонтанно по радио, не совершая преступлений, а кто-то нарушает закон, слушая другую музыку или даже будучи глухим. Какие у нас есть граничные условия? ROC-анализ вводит понятия селективности (чувствительности) и специфичности. Чувствительность определяется как способность выявлять все-все интересующие нас точки (в данном примере — преступников), а специфичность — не захватывать ничего ложноположительного (не ставить под подозрение простых обывателей). Мы можем задать некоторую критическую количественную черту, отделяющую одних от других (оранжевая), в пределах от максимальной чувствительности (зеленая) до максимальной специфичности (красная).
Посмотрим на следующую схему:
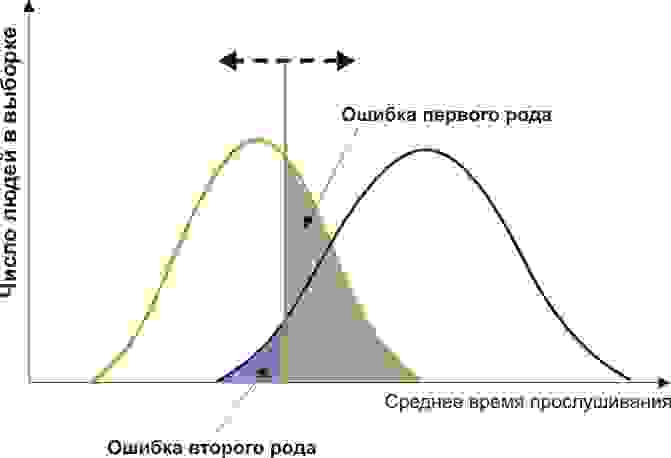
Смещая значение нашего признака, мы меняем соотношения ложноположительного и ложноотрицательного результатов (площади под кривыми). Точно так же мы можем дать определения Чувствительность = Полож. рез-т/(Полож. рез-т + ложноотриц. рез-т) и Специфичность = Отриц. рез-т/(Отриц. рез-т + ложноположит. рез-т).
Но главное, мы можем оценить соотношение положительных результатов к ложноположительным на всем отрезке значений нашего количественного признака, что и есть наша искомая ROC-кривая (см. рисунок):
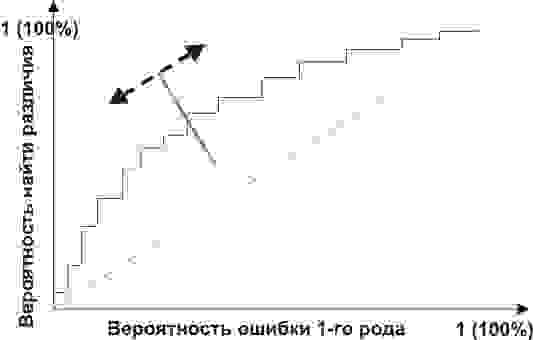
А как нам понять из этого графика, насколько хорош наш признак? Очень просто, посчитать площадь под кривой (AUC, area under curve). Пунктирная линия (0,0; 1,1) означает полное совпадение двух выборок и совершенно бессмысленный критерий (площадь под кривой равна 0,5 от всего квадрата). А вот выпуклость ROC кривой как раз и говорит о совершенстве критерия. Если же нам удастся найти такой критерий, что выборки вообще не будут пересекаться, то площадь под кривой займет весь график. В целом же признак считается хорошим, позволяющим надежно отделить одну выборку от другой, если AUC > 0,75-0,8.
С помощью такого анализа вы можете решать самые разные задачи. Решив, что слишком много домохозяек оказались под подозрением из-за Михаила Круга, а кроме того упущены опасные рецидивисты, слушающие Ноггано, вы можете отвергнуть этот критерий и разработать другой.
Возникнув, как способ обработки радиосигналов и идентификации «свой-чужой» после атаки на Перл-Харбор (отсюда и пошло такое странное название про характеристику приемника), ROC-анализ нашел широкое применение в биомедицинской статистике для анализа, валидации, создания и характеристики панелей биомаркеров и т.д. Он гибок в использовании, если оно основано на грамотной логике. Например, вы можете разработать показания для медицинской диспансеризации пенсионеров-сердечников, применив высокоспецифичный критерий, повысив эффективность выявления болезней сердца и не перегружая врачей лишними пациентами. А во время опасной эпидемии ранее неизвестного вируса вы наоборот, можете придумать высокоселективный критерий, чтобы от вакцинации в прямом смысле не ускользнул ни один чих.
С ошибками обоих родов и их наглядностью в описании валидируемых критериев мы познакомились. Теперь же, двигаясь от этих логических основ, можно разрушить ряд ложных стереотипных описаний результатов. Некоторые неправильные формулировки захватывают наши умы, часто путаясь своими схожими словами и понятиями, а также из-за очень малого внимания, уделяемого неверной интерпретации. Об этом, пожалуй, нужно будет написать отдельно.
5.3. Ошибки первого и второго рода
Ошибка первого рода состоит в том, что гипотеза ![]() будет отвергнута, хотя на самом деле она правильная. Вероятность
будет отвергнута, хотя на самом деле она правильная. Вероятность
допустить такую ошибку называют уровнем значимости и обозначают буквой ![]() («альфа»).
(«альфа»).
Ошибка второго рода состоит в том, что гипотеза ![]() будет принята, но на самом деле она неправильная. Вероятность
будет принята, но на самом деле она неправильная. Вероятность
совершить эту ошибку обозначают буквой ![]() («бета»). Значение
(«бета»). Значение ![]() называют мощностью критерия – это вероятность отвержения неправильной
называют мощностью критерия – это вероятность отвержения неправильной
гипотезы.
В практических задачах, как правило, задают уровень значимости, наиболее часто выбирают значения ![]() .
.
И тут возникает мысль, что чем меньше «альфа», тем вроде бы лучше. Но это только вроде: при уменьшении
вероятности ![]() —
—
отвергнуть правильную гипотезу растёт вероятность ![]() — принять неверную гипотезу (при прочих равных условиях).
— принять неверную гипотезу (при прочих равных условиях).
Поэтому перед исследователем стоит задача грамотно подобрать соотношение вероятностей ![]() и
и ![]() , при этом учитывается тяжесть последствий, которые
, при этом учитывается тяжесть последствий, которые
повлекут за собой та и другая ошибки.
Понятие ошибок 1-го и 2-го рода используется не только в статистике, и для лучшего понимания я приведу пару
нестатистических примеров.
Петя зарегистрировался в почтовике. По умолчанию, ![]() – он считается добропорядочным пользователем. Так считает антиспам
– он считается добропорядочным пользователем. Так считает антиспам
фильтр. И вот Петя отправляет письмо. В большинстве случаев всё произойдёт, как должно произойти – нормальное письмо дойдёт до
адресата (правильное принятие нулевой гипотезы), а спамное – попадёт в спам (правильное отвержение). Однако фильтр может
совершить ошибку двух типов:
1) с вероятностью ![]() ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
ошибочно отклонить нулевую гипотезу (счесть нормальное письмо
за спам и Петю за спаммера) или
2) с вероятностью ![]() ошибочно принять нулевую гипотезу (хотя Петя редиска).
ошибочно принять нулевую гипотезу (хотя Петя редиска).
Какая ошибка более «тяжелая»? Петино письмо может быть ОЧЕНЬ важным для адресата, и поэтому при настройке фильтра
целесообразно уменьшить уровень значимости ![]() , «пожертвовав» вероятностью
, «пожертвовав» вероятностью ![]() (увеличив её). В результате в основной ящик будут попадать все
(увеличив её). В результате в основной ящик будут попадать все
«подозрительные» письма, в том числе особо талантливых спаммеров. …Такое и почитать даже можно, ведь сделано с любовью 
Существует примеры, где наоборот – более тяжкие последствия влечёт ошибка 2-го рода, и вероятность ![]() следует увеличить (в пользу уменьшения
следует увеличить (в пользу уменьшения
вероятности ![]() ). Не хотел я
). Не хотел я
приводить подобные примеры, и даже отшутился на сайте, но по какой-то мистике через пару месяцев сам столкнулся с непростой
дилеммой. Видимо, таки, надо рассказать:
У человека появилась серьёзная болячка. В медицинской практике её принято лечить (основное «нулевое» решение). Лечение
достаточно эффективно, однако не гарантирует результата и более того опасно (иногда приводит к серьёзному пожизненному
увечью). С другой стороны, если не лечить, то возможны осложнения и долговременные функциональные нарушения.
Вопрос: что делать? И ответ не так-то прост – в разных ситуациях разные люди могут принять разные
решения (упаси вас).
Если болезнь не особо «мешает жить», то более тяжёлые последствия повлечёт ошибка 2-го рода – когда человек соглашается
на лечение, но получает фатальный результат (принимает, как оказалось, неверное «нулевое» решение). Если же…, нет, пожалуй,
достаточно, возвращаемся к теме:
 5.4. Процесс проверки статистической гипотезы
5.4. Процесс проверки статистической гипотезы
 5.2. Нулевая и альтернативная гипотезы
5.2. Нулевая и альтернативная гипотезы
| Оглавление |
8 июля 2021 г.
При проверке гипотез нулевая гипотеза — это гипотеза по умолчанию, которая утверждает, что между переменными нет статистической значимости. Исследователь проверяет нулевую гипотезу, чтобы увидеть, достаточно ли статистической значимости, чтобы опровергнуть ее, и это иногда приводит к ошибке типа 1 или типа 2. Если вы занимаетесь проверкой гипотез как частью своей работы, важно понимать, как ошибки типа 1 и типа 2 могут повлиять на ваши результаты.
В этой статье мы объясним, что такое ошибки типа 1 и типа 2, рассмотрим, как они могут возникнуть, обсудим их важность в исследованиях и приведем примеры, которые помогут вам понять эти концепции.
Ошибки типа 1 и типа 2 относятся к неправильным определениям нулевой гипотезы, но они различаются тем, что исследователь считает верным или ложным в отношении гипотезы. Ошибка 1-го типа, также называемая ложноположительной, возникает, когда исследователь отвергает нулевую гипотезу, которая является истинной, и решает, что существует статистически значимое различие, которого не существует. Ошибка типа 2 является обратной ошибкой типа 1. Также известная как ложный отрицательный результат, она возникает, когда исследователь не отвергает нулевую гипотезу, когда альтернативная гипотеза верна.
Например, в судебном деле нулевая гипотеза будет заключаться в том, что обвиняемый невиновен, пока его вина не будет доказана, а альтернативная гипотеза будет состоять в том, что он виновен. Есть четыре возможных исхода в отношении истинного характера дела:
-
Истинно отрицательный: признан невиновным в суде и невиновен на самом деле.
-
Ложное срабатывание: признан виновным в суде, но на самом деле невиновен.
-
Ложноотрицательный: признан невиновным в суде, но на самом деле виновен.
-
Истинно положительный: признан виновным в суде и фактически виновен
В приведенном выше примере второй и третий результаты являются ошибками типа 1 и типа 2 соответственно. В случае ложного срабатывания присяжные ошибочно отвергают нулевую гипотезу, утверждающую, что подсудимый невиновен. В случае ложноотрицательного результата они ошибочно не отвергают нулевую гипотезу.
Почему возникают ошибки первого рода?
Есть два фактора, которые обычно способствуют возникновению ошибок 1-го рода:
Шанс
Проверка гипотез никогда не бывает стопроцентной, поэтому всегда есть возможность сделать неверные выводы на основе имеющихся данных. Как правило, данные поступают из выборочной совокупности, относительно небольшой выборки лиц, предназначенных для обозначения более широкой демографической группы. Иногда данные, генерируемые выборочными совокупностями, искажают выводы, которые не обязательно отражают интересы всего населения. Это переменная, которую исследователи не могут контролировать, но они могут помочь смягчить ее, выбрав более крупные выборки.
Злоупотребление служебным положением
Иногда ошибки 1-го рода возникают из-за неправильной исследовательской практики. Например, исследователи могут неосознанно исказить результаты теста, завершив его слишком рано. Им может показаться, что у них достаточно данных, хотя стандартная практика рекомендует продолжить тест. В качестве альтернативы они могут сделать вывод, несмотря на то, что им не удалось достичь соответствующего уровня статистической значимости. Исследователи могут избежать выводов типа 1, связанных с злоупотреблением служебным положением, если будут следовать протоколам исследований и обеспечивать надежность своей практики.
Почему возникают ошибки второго рода?
Основным фактором, способствующим возникновению ошибок 2-го рода, является размер выборки. Чем больше размер выборки, тем больше вероятность обнаружения различий в статистическом тесте. Например, если вы хотите проверить, относятся ли студенты колледжа положительно или отрицательно к определенному продукту, группа из трех человек может выразить только два к одному разнообразию или вообще ничего не сказать. Для сравнения, выборка из 1000 человек с большей вероятностью вызовет широкий спектр мнений и, таким образом, более точно отразит большую часть населения.
Какова важность ошибок типа 1 по сравнению с ошибками типа 2?
Ошибки типа 1 и типа 2 являются значительными из-за последствий, которые они имеют в реальных приложениях. Ошибки типа 1 обычно приводят к ненужному использованию ресурсов без какой-либо выгоды. Например, если исследователь-медик совершает ошибку 1-го рода в отношении эффективности нового лечения, он может подтвердить ошибочность исследований и методов, что может привести к созданию лекарства, не приносящего облегчения.
Ошибки 2-го типа важны тем, что могут помешать выделению ресурсов и выполнению необходимых действий. Например, при скрининге пациента на наличие заболевания ложноотрицательный результат может свидетельствовать о том, что пациент здоров, хотя на самом деле он нуждается в медицинском вмешательстве.
Примеры ошибок типа 1 и типа 2
Рассмотрим эти примеры ошибок типа 1 и типа 2, чтобы помочь вам понять, что они из себя представляют:
Пример ошибки 1 рода
Медицинский исследователь проверяет эффективность домашнего средства от головной боли. Нулевая гипотеза состоит в том, что домашнее средство не влияет на головную боль, в то время как альтернативная гипотеза состоит в том, что оно лечит головную боль. Исследователь набирает выборку из 20 пациентов с хроническими головными болями и назначает лекарство половине из них в течение одного месяца. Половина, не получающая лекарство, продолжает страдать от хронических головных болей, в то время как у шести человек из оставшейся половины головные боли прекратились.
На основании вышеизложенного исследователь отвергает нулевую гипотезу. Однако, учитывая небольшое количество тех, кто испытал облегчение, могут возникнуть сомнения относительно того, было ли это лекарство или посторонний фактор, который улучшил состояние шести участников. Если эти шесть участников использовали другие средства от головной боли вместе с тестируемым средством, вполне вероятно, что исследователь совершил ошибку 1-го типа.
Пример ошибки 2 рода
Интернет-магазин хочет знать, могут ли изменения дизайна его веб-сайта помочь увеличить продажи. Нулевая гипотеза состоит в том, что изменения дизайна не влияют на продажи, а альтернативная гипотеза говорит об обратном. Продавец проводит A/B-тестирование, в ходе которого сравниваются две версии сайта, существующая версия и обновленная версия. Три дня мониторят продажи на основе существующей версии. Затем в течение следующих трех дней они представляют новую версию и смотрят, как она повлияет на продажи. По истечении шести дней они не видят значительных изменений в показателях продаж.
Однако возможно, что увеличение периодов наблюдения для каждой версии сайта привело бы к статистически значимой разнице. Если бы розничный продавец отслеживал продажи в течение одного месяца каждый и заметил увеличение продаж во втором месяце, он совершил бы ошибку второго рода, ошибочно приняв нулевую гипотезу.