
Время на прочтение
8 мин
Количество просмотров 18K
Наша компания уже более двух лет использует Kotlin в продакшене. Лично я с этим языком столкнулся около года назад. Тут есть много тем для разговора, но сегодня поговорим об обработке ошибок, в том числе в функциональном стиле. Расскажу, как это можно делать в Kotlin.

(Фото с митапа по этой теме, проходившего в офисе одной из компаний Таганрога. Выступал Алексей Шафранов — лидер рабочей группы (Java) в «Максилект»)
Как можно в принципе обрабатывать ошибки?
Я нашел несколько путей:
- можно использовать некое возвращаемое значение в качестве указателя на то, что есть ошибка;
- можно с той же целью использовать параметр-индикатор,
- ввести глобальную переменную,
- обрабатывать исключения,
- добавлять контракты (DbC).
Остановимся чуть подробнее на каждом из вариантов.
Возвращаемое значение
Некое “магическое” значение возвращается, если возникла ошибка. Если вы когда-либо использовали скриптовые языки, наверняка видели подобные конструкции.
Пример 1:
function sqrt(x) {
if(x < 0)
return -1;
else
return √x;
}
Пример 2:
function getUser(id) {
result = db.getUserById(id)
if (result)
return result as User
else
return “Can’t find user ” + id
}
Параметр-индикатор
Используется некий передаваемый в функцию параметр. После возвращения значения по параметру можно посмотреть, была ли внутри функции ошибка.
Пример:
function divide(x,y,out Success) {
if (y == 0)
Success = false
else
Success = true
return x/y
}
divide(10, 11, Success)
id (!Success) //handle error
Глобальная переменная
Примерно так же работает и глобальная переменная.
Пример:
global Success = true
function divide(x,y) {
if (y == 0)
Success = false
else
return x/y
}
divide(10, 11, Success)
id (!Success) //handle error
Исключения
К исключениям мы все привыкли. Они используются практически везде.
Пример:
function divide(x,y) {
if (y == 0)
throw Exception()
else
return x/y
}
try{ divide(10, 0)}
catch (e) {//handle exception}
Контракты (DbC)
Откровенно говоря, вживую я этого подхода никогда не видел. Путем долгого гугления я нашел, что в Kotlin 1.3 есть библиотека, фактически позволяющая использовать contracts. Т.е. вы можете ставить condition на переменные, которые передаются в функцию, condition на возвращаемое значение, количество вызовов, то, откуда она вызывается и т.д. И если все условия выполняются, считается, что функция сработала правильно.
Пример:
function sqrt (x)
pre-condition (x >= 0)
post-condition (return >= 0)
begin
calculate sqrt from x
end
Честно говоря, эта библиотека отличается ужасным синтаксисом. Возможно, поэтому я и не видел подобного вживую.
Исключения в Java
Перейдем к Java и к тому, как все это изначально работало.
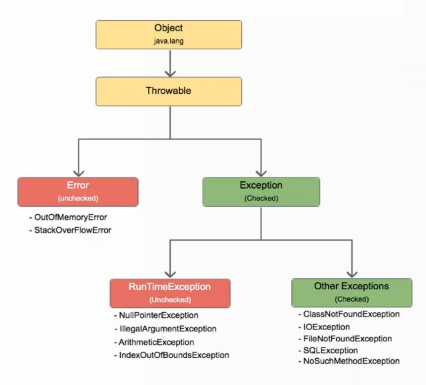
При проектировании языка заложили два типа исключений:
- checked – проверяемые;
- unchecked – непроверяемые.
Для чего нужны checked исключения? Теоретически они нужны, чтобы люди обязательно проверяли ошибки. Т.е. если возможно определенное checked исключение, в дальнейшем оно обязательно должно быть проверено. Теоретически такой подход должен был привести к отсутствию необработанных ошибок и повышению качества кода. Но на практике это не так. Думаю, каждый хотя бы раз в жизни видел пустой блок catch.
Почему это может быть плохо?
Вот классический пример прямо из документации по Kotlin – интерфейс из JDK, реализованный в StringBuilder:
Appendable append(CharSequence csq) throws IOException;
try {
log.append(message)
}
catch (IOException e) {
//Must be safe
}
Уверен, вы встречали достаточно много кода, обернутого в try-catch, где catch – пустой блок, поскольку такой ситуации просто не должно было произойти, по мнению разработчика. Во многих случаях обработка checked исключений реализуется следующим способом: просто бросают RuntimeException и где-то выше его ловят (или не ловят…).
try {
// do something
}
catch (IOException e) {
throw new RuntimeException(e); // там где-нибудь поймаю...
Что можно в Kotlin
С точки зрения исключений компилятор Kotlin отличается тем, что:
1. Не различает checked и unchecked исключения. Все исключения – только unchecked, и вы самостоятельно принимаете решение, стоит ли их отлавливать и обрабатывать.
2. Try можно использовать как выражение – можно запустить блок try и либо вернуть из него последнюю строчку, либо вернуть последнюю строчку из блока catch.
val value = try {Integer.parseInt(“lol”)}
catch(e: NumberFormanException) { 4 } //Рандомное число
3. А также можно использовать подобную конструкцию при обращении к какому-либо объекту, который может быть nullable:
val s = obj.money
?: throw IllegalArgumentException(“Где деньги, Лебовски”)
Совместимость с Java
Kotlin-код можно использовать в Java и наоборот. Как при этом обращаться с исключениями?
- Проверяемые исключения из Java в Kotlin можно не проверять и не объявлять (поскольку в Kotlin нет проверяемых исключений).
- Возможные проверяемые исключения из Kotlin (например, появившиеся изначально из Java) в Java проверять необязательно.
- Если проверить необходимо, исключение можно сделать проверяемым, используя в методе аннотацию @Throws (необходимо указать, какие исключения этот метод может выбрасывать). Упомянутая аннотация нужна только для совместимости с Java. Но на практике у нас ее многие используют, чтобы декларировать, что подобный метод в принципе может передавать какие-то исключения.
Альтернатива блоку try-catch
У блока try-catch есть существенный недостаток. При его появлении часть бизнес-логики переносится внутрь catch, причем это может происходить в одном из множества методов выше. Когда бизнес-логика размазана по блокам или всей цепочке вызова, понимать, как работает приложение, сложнее. Да и сами блоки читаемости коду не добавляют.
try {
HttpService.SendNotification(endpointUrl);
MarkNotificationAsSent();
} catch (e: UnableToConnectToServerException) {
MarkNotificationAsNotSent();
}
Какие есть альтернативы?
Один из вариантов нам предлагает функциональный подход к обработке исключений. Выглядит подобная реализация следующим образом:
val result: Try<Result> =
Try{HttpService.SendNotification(endpointUrl)}
when(result) {
is Success -> MarkNotificationAsSent()
is Failure -> MarkNotificationAsNotSent()
}
У нас есть возможность использовать монаду Try. По сути это контейнер, который хранит некоторое значение. flatMap – метод работы с этим контейнером, который вместе с текущим значением может принимать функцию и возвращать опять же монаду.
В данном случае вызов обернут в монаду Try (мы возвращаем Try). Обработать это можно в единственном месте – там, где нам нужно. Если на выходе есть значение, мы совершаем с ним последующие действия, если же у нас выброшено исключение, мы его обрабатываем в самом конце цепочки.
Функциональная обработка исключений
Откуда можно взять Try?
Во-первых, существует достаточно много реализаций классов Try и Either от сообщества. Можно взять их или даже написать реализацию самостоятельно. В одном из “боевых” проектов мы использовали самописную реализацию Try – обошлись одним классом и прекрасно справлялись.
Во-вторых, есть библиотека Arrow, которая в принципе добавляет много функциональщины в Kotlin. Естественно, там есть Try и Either.
Ну и кроме того, в Kotlin 1.3 появился класс Result, подробнее о котором я расскажу немного позже.
Try на примере библиотеки Arrow
Библиотека Arrow дает нам класс Try. Фактически он может быть в двух состояниях: Success или Failure:
- Success при успешном выводе сохранит наше значение,
- Failure хранит исключение, которое возникло в процессе выполнения блока кода.
Вызов выглядит следующим образом. Естественно, он обернут в обычный try – catch, но это будет происходить где-то внутри нашего кода.
sealed class Try<out A> {
data class Success<out A>(val value: A) : Try<A>()
data class Failure(val e: Throwable) : Try<Nothing>()
companion object {
operator fun <A> invoke(body: () -> A): Try<A> {
return try {
Success(body())
} catch (e: Exception) {
Failure(e)
}
}
}
Этот же класс должен реализовать метод flatMap, который позволяет передать функцию и вернуть нашу монаду try:
inline fun <B> map(f: (A) -> B): Try<B> =
flatMap { Success(f(it)) }
inline fun <B> flatMap(f: (A) -> TryOf<B>): Try<B> =
when (this) {
is Failure -> this
is Success -> f(value)
}
Для чего это нужно? Чтобы не обрабатывать ошибки на каждый из результатов, когда у нас их несколько. К примеру, мы получили несколько значений с разных сервисов и хотим их объединить. Фактически у нас может быть две ситуации: либо мы успешно их получили и объединили, либо что-то упало. Поэтому мы можем поступить следующим образом:
val result1: Try<Int> = Try { 11 }
val result2: Try<Int> = Try { 4 }
val sum = result1.flatMap { one ->
result2.map { two -> one + two }
}
println(sum) //Success(value=15)
Если оба вызова прошли успешно и мы получили значения, мы выполняем функцию. Если же они не успешны, то вернется Failure с исключением.
Вот как это выглядит, если что-то упало:
val result1: Try<Int> = Try { 11 }
val result2: Try<Int> = Try { throw RuntimeException(“Oh no!”) }
val sum = result1.flatMap { one ->
result2.map { two -> one + two }
}
println(sum) //Failure(exception=java.lang.RuntimeException: Oh no!
Мы использовали ту же функцию, но на выходе получается Failure от RuntimeException.
Также библиотека Arrow позволяет использовать конструкции, которые по факту являются синтаксическим сахаром, в частности binding. Все то же самое можно переписать через последовательный flatMap, но binding позволяет сделать это читабельным.
val result1: Try<Int> = Try { 11 }
val result2: Try<Int> = Try { 4 }
val result3: Try<Int> = Try { throw RuntimeException(“Oh no, again!”) }
val sum = binding {
val (one) = result1
val (two) = result2
val (three) = result3
one + two + three
}
println(sum) //Failure(exception=java.lang.RuntimeException: Oh no, again!
Учитывая, что у нас один из результатов упал, мы получаем на выходе ошибку.
Подобную монаду можно использовать для асинхронных вызовов. Вот, например, две функции, которые запускаются асинхронно. Мы точно так же объединяем их результаты, не проверяя отдельно их состояния:
fun funA(): Try<Int> {
return Try { 1 }
}
fun funB(): Try<Int> {
Thread.sleep(3000L)
return Try { 2 }
}
val a = GlobalScope.async { funA() }
val b = GlobalScope.async { funB() }
val sum = runBlocking {
a.await().flatMap { one ->
b.await().map {two -> one + two }
}
}
А вот более “боевой” пример. У нас есть запрос к серверу, мы его обрабатываем, получаем из него тело и пытаемся намапить его на наш класс, из которого уже возвращаем данные.
fun makeRequest(request: Request): Try<List<ResponseData>> =
Try { httpClient.newCall(request).execute() }
.map { it.body() }
.flatMap { Try { ObjectMapper().readValue(it, ParsedResponse::class.java) } }
.map { it.data }
fun main(args : Array<String>) {
val response = makeRequest(RequestBody(args))
when(response) {
is Try.Success -> response.data.toString()
is Try.Failure -> response.exception.message
}
}
Try-catch сделал бы этот блок гораздо менее читабельным. А в данном случае мы на выходе получаем response.data, который можем обработать в зависимости от результата.
Result из Kotlin 1.3
В Kotlin 1.3 ввели класс Result. По факту он представляет собой нечто похожее на Try, но с рядом ограничений. Его изначально предполагается использовать для различных асинхронных операций.
val result: Result<VeryImportantData> = Result.runCatching { makeRequest() }
.mapCatching { parseResponse(it) }
.mapCatching { prepareData(it) }
result.fold{
{ data -> println(“We have $data”) },
exception -> println(“There is no any data, but it’s your exception $exception”) }
)
Если не ошибаюсь, этот класс на данный момент экспериментальный. Разработчики языка могут поменять его сигнатуру, поведение или вообще убрать, поэтому на данный момент его запрещено использовать в качестве возвращаемого значения из методов или переменной. Однако его можно использовать как локальную (приватную) переменную. Т.е. по факту его можно применять как try из примера.
Выводы
Выводы, которые я сделал лично для себя:
- функциональная обработка ошибок в Kotlin – это просто и удобно;
- никто не мешает обрабатывать их через try-catch в классическом стиле (и то, и то имеет право на жизнь; и то, и то удобно);
- отсутствие проверяемых исключений не означает, что можно не обрабатывать ошибки;
- непойманные исключения на продакшене приводят к печальным последствиям.
Автор статьи: Алексей Шафранов, лидер рабочей группы (Java), компания Maxilect
P.S. Мы публикуем наши статьи на нескольких площадках Рунета. Подписывайтесь на наши страницы в VK, FB или Telegram-канал, чтобы узнавать обо всех наших публикациях и других новостях компании Maxilect.
Переменные
Для хранения данных в программе в Kotlin, как и в других языках программирования, применяются переменные.
Каждая переменная характеризуется определенным именем, типом данных и значением. Имя переменной представляет поизвольный идентификатор, который может содержать алфавитно-цифровые символы или символ подчеркивания и должен начинаться либо с алфавитного символа, либо со знака подчеркивания. Для определения переменной можно использовать либо ключевое слово val, либо ключевое слово var.
Например, определим переменную age:
Вначале идет слово val или var, затем имя переменной и через двоеточие тип переменной. То есть в данном случае объявлена переменная age, которая имеет тип Int. Тип Int говорит о том, что переменная будет содержать целочисленные значения.
После определения переменной ей можно присвоить значение:
val age: Int age = 23 println(age)
Для присвоения значения переменной используется знак равно. Затем мы можем производить с переменной различные операции. Например, в данном случае с помощью функции println значение переменной выводится на консоль. И при запуске этой программы на консоль будет выведено число 23.
Присвоение значения переменной должно производиться только после ее объявления. И также мы можем сразу присвоить переменной начальное значение при ее объявлении. Такой прием называется инициализацией. При инициализации можно опустить указание типа, тип переменной будет задан по типу присваимого значения:
val age: Int = 23 println(age)
Изменяемые и неизменяемые переменные
Выше было сказано, что переменные могут объявляться как с помощью слова val, так и с помощью слова var. В чем же разница между двумя этими способами?
С помощью ключевого слова val определяется неизменяемая переменная (immutable variable). То есть мы можем присвоить значение такой переменной только один раз, но изменить его после первого присвоения мы уже не сможем. Например, в следующем случае мы получим ошибку:
val age: Int age = 23 // здесь норм - первое присвоение age = 56 // здесь ошибка - переопределить значение переменной нельзя println(age)
В этом плане подобные переменные похожи на константы в других языках программирования.
А у переменной, которая определена с помощью ключевого слова var мы можем многократно менять значения (mutable variable):
var age: Int age = 23 println(age) age = 56 println(age)
Поэтому если не планируется изменять значение переменной в программе, то лучше определять ее с ключевым словом val.
Типы данных
В Kotlin каждая переменная имеет определенный тип. Тип данных определяет, какие операции можно производить с данными этого типа.
В отличие от языка Java и ряда других языков Kotlin не имеет встроенных примитивных типов. Все типы представляют определенные классы.
Числовые типы
- Byte: хранит целое число от -128 до 127 и занимает 1 байт
- Short: хранит целое число от -32768 до 32767 и занимает 2 байта
- Int: хранит целое число от -2147483648 до 2147483647 и занимает 4 байта
- Long: хранит целое число от –9 223 372 036 854 775 808 до 9 223 372 036 854 775 807 и занимает 8 байт
- Float: хранит число с плавающей точкой от -3.41038 до 3.41038 и занимает 4 байта
- Double: хранит число с плавающей точкой от ±5.010-324 до ±1.710308 и занимает 8 байта.
Литералы
Литералы представляют неизменяемые значения (иногда их еще называют константами). Литералы можно передавать переменным в качестве значения. Литералы бывают логическими, целочисленными, вещественными, символьными и строчными.
Любые литералы, которые представляют целые числа, воспринимаются как данные типа Int.
// переменная age будет иметь тип Int val age: Int = 45
Литерал 45 представляет целое число и является значением типа Int. Если же мы хотим явно указать, что число представляет значение типа Long, то следует использовать суффикс «L»:
// тут Котлин автоматически приведет к объявленному типу val age: Long = 45 // а вот тут мы используем суффикс, чтобы явно указать тип val age = 45L
Аналогично все числа с плавающей точкой (которые содержат точку в качестве разделителя целой и дробной части) рассматриваются как числа типа Double:
val weight: Double = 68.71
Если мы хотим указать, что данные будут представлять тип Float, то необходимо использовать суффикс F:
val weight: Float = 68.71F
Кроме чисел в десятичной системе мы можем определять числа в двоичной и шестнадцатеричной системах.
Шестнадцатеричная запись числа начинается с 0x, затем идет набор символов от 0 до F, которые представляют число:
val age: Int = 0x0A1 // 161
Двоичная запись числа предваряется символами 0b, после которых идет последовательность из нулей и единиц:
val a: Int = 0b0101 // 5 val b: Int = 0b1011 // 11
Нижние подчеркивания в числовых литералах (начиная с версии 1.1)
Вы можете использовать нижние подчеркивания, чтобы сделать числовые константы более читаемыми:
val oneMillion = 1_000_000 val creditCardNumber = 1234_5678_9012_3456L val socialSecurityNumber = 999_99_9999L val hexBytes = 0xFF_EC_DE_5E val bytes = 0b11010010_01101001_10010100_10010010
Выведение типа
Kotlin позволяет выводить тип переменной на основании данных, которыми переменная инициализируется. Поэтому при инициализации переменной тип можно опустить:
В данном случае компилятор увидит, что переменной присваивается значение типа Int, поэтому переменная age будет представлять тип Int.
Соответственно если мы присваиваем переменной строку, то такая переменная будет иметь тип String.
Однако при этом нам обязательно надо инициализировать переменную некоторым значением. То есть нельзя сначала объявить переменную, а потом где-то в программе присвоить ей какое-то значение:
val age // Ошибка, переменная не инициализирована age = 5
Логический тип Boolean
Тип Boolean может хранить одно из двух значений: true (истина) или false (ложь).
val a = true val b = false
Символы
Символьные данные представлены типом Char. Он представляет отдельный символ, который заключается в одинарные кавычки.
val a = 'A' val b = 'B' val c = 'T'
Также тип Char может представлять специальные последовательности, которые интерпретируются особым образом:
- t: табуляция
- n: перевод строки
- r: возврат каретки
- ‘: одинарная кавычка
- «: двойная кавычка
\: обратный слеш
Строки
Строки представлены типом String. Строка представляет последовательность символов, заключенную в двойные кавычки, либо в тройные двойные кавычки.
val name = "Eugene" println(name)
Строка может содержать специальные символы или эскейп-последовательности. Например, если необходимо вставить в текст перевод на другую строку, можно использовать эскейп-последовательность n:
val text: String = "SALT II was a series of talks between United States n and Soviet negotiators from 1972 to 1979"
Для большего удобства при создании многострочного текста можно использовать тройные двойные кавычки:
val text: String = """SALT II was a series of talks between United States and Soviet negotiators from 1972 to 1979. It was a continuation of the SALT I talks.""" println(text)
Строки состоят из символов, которые могут быть получены по порядковому номеру: s[i]. Проход по строке можно выполнить циклом for:
for (c in str) { println(c) }
Строковые шаблоны
Строки могут содержать шаблонные выражения, т.е. участки кода, которые выполняются, а полученный результат встраивается в строку. Шаблон начинается со знака доллара ($) и состоит либо из простого имени (например, переменной):
val i = 10 val s = "i = $i" // evaluates to "i = 10"
либо из произвольного выражения в фигурных скобках:
val s = "abc" val str = "$s.length is ${s.length}" // evaluates to "abc.length is 3"
Шаблоны поддерживаются как в обычных, так и в экранированных строках. При необходимости символ $ может быть представлен с помощью следующего синтаксиса:
Тип Any
Тип Any является базовым для всех остальных типов. Остальные базовые типы, такие как Int или Double, являются производными от Any. Соответственно мы можем присвоить переменной данного типа любое значение:
var name: Any = "Tom Smith" name = 6758
Операторы is и !is
Мы можем проверить принадлежит ли объект к какому-либо типу во время исполнения с помощью оператора is или его отрицания !is:
if (obj is String) { print(obj.length) } if (obj !is String) { // то же самое, что и !(obj is String) print("Not a String") } else { print(obj.length) }
Умные приведения
Во многих случаях в Kotlin вам не нужно использовать явные приведения, потому что компилятор следит за is-проверками для неизменяемых значений и вставляет приведения автоматически, там, где они нужны:
fun demo(x: Any) { if (x is String) { print(x.length) // x автоматически преобразовывается в String } }
Компилятор достаточно умён для того, чтобы делать автоматические приведения в случаях, когда проверка на несоответствие типу (!is) приводит к выходу из функции:
if (x !is String) return // x автоматически преобразовывается в String print(x.length)
или в случаях, когда приводимая переменная находится справа от оператора && или ||:
// x автоматически преобразовывается в String справа от || if (x !is String || x.length == 0) return // x автоматически преобразовывается в String справа от && if (x is String && x.length > 0) { print(x.length) // x автоматически преобразовывается в String }
Заметьте, что умные приведения не работают, когда компилятор не может гарантировать, что переменная не изменится между проверкой и использованием. Более конкретно, умные приведения будут работать:
- с локальными val переменными — всегда;
- с val свойствами — если поле имеет модификатор доступа private или internal, или проверка происходит в том же модуле, в котором объявлено это свойство. Умные приведения неприменимы к публичным свойствам или свойствам, которые имеют переопределённые getter’ы;
- с локальными var переменными — если переменная не изменяется между проверкой и использованием и не захватывается лямбдой, которая её модифицирует;
- с var свойствами — никогда (потому что переменная может быть изменена в любое время другим кодом).
Оператор «небезопасного» приведения
Этот оператор приведения выбрасывает исключение, если приведение невозможно, поэтому мы называем его небезопасным. Небезопасное приведение в Kotlin выполняется с помощью инфиксного оператора as:
val x: String = y as String
Заметьте, что null не может быть приведен к String, так как String не является nullable, т.е. если y — null, код выше выбросит исключение. Чтобы соответствовать семантике приведений в Java, нам нужно указать nullable тип в правой части приведения:
val x: String? = y as String?
Null безопасность
Nullable типы и Non-Null типы
Система типов в языке Kotlin нацелена на то, чтобы искоренить опасность обращения к null значениям.
Самым распространённым подводным камнем многих языков программирования, в том числе Java, является попытка произвести доступ к null значению. Это приводит к ошибке. В Java такая ошибка называется NullPointerException (сокр. «NPE»).
Kotlin призван исключить ошибки подобного рода из нашего кода. NPE могу возникать только в случае:
- Явного указания
throw NullPointerException() - Использования оператора
!!(описано ниже) - Эту ошибку вызвал внешний Java-код
- Есть какое-то несоответствие при инициализации данных (в конструкторе использована ссылка
thisна данные, которые не были ещё проинициализированы)
Система типов Kotlin различает ссылки на те, которые могут иметь значение null (nullable ссылки) и те, которые таковыми быть не могут (non-null ссылки). К примеру, переменная часто используемого типа String не может быть null:
var a: String = "abc" a = null // ошибка компиляции
Для того, чтобы разрешить null значение, мы можем объявить эту строковую переменную как String?:
var b: String? = "abc" b = null // ok
Теперь, при вызове метода с использованием переменной a, исключены какие-либо NPE. Вы спокойно можете писать:
Но в случае, если вы захотите получить доступ к значению b, это будет небезопасно. Компилятор предупредит об ошибке:
val l = b.length // ошибка: переменная `b` может быть null
Но нам по-прежнему надо получить доступ к этому свойству/значению, так? Есть несколько способов этого достичь.
Проверка на null
Первый способ. Вы можете явно проверить b на null значение и обработать два варианта по отдельности:
val l = if (b != null) b.length else -1
Компилятор отслеживает информацию о проведённой вами проверке и позволяет вызывать length внутри блока if. Также поддерживаются более сложные конструкции:
if (b != null && b.length > 0) { print("String of length ${b.length}") } else { print("Empty string") }
Обратите внимание: это работает только в том случае, если b является неизменной переменной (ориг.: immutable). Например, если это локальная переменная, значение которой не изменяется в период между его проверкой и использованием. Также такой переменной может служить val. В противном случае может так оказаться, что переменная b изменила своё значение на null после проверки.
Безопасные вызовы
Вторым способом является оператор безопасного вызова ?.:
Этот код возвращает b.length в том, случае, если b не имеет значение null. Иначе он возвращает null. Типом этого выражения будет Int?.
Такие безопасные вызовы полезны в цепочках. К примеру, если Bob, Employee (работник), может быть прикреплён (или нет) к отделу Department, и у отдела может быть управляющий, другой Employee. Для того, чтобы обратиться к имени этого управляющего (если такой есть), напишем:
bob?.department?.head?.name
Такая цепочка вернёт null в случае, если одно из свойств имеет значение null.
Для проведения каких-либо операций исключительно над non-null значениями вы можете использовать let оператор вместе с оператором безопасного вызова:
val listWithNulls: List<String?> = listOf("A", null) for (item in listWithNulls) { item?.let { println(it) } // выводит A и игнорирует null }
Элвис-оператор
Если у нас есть nullable ссылка r, мы можем либо провести проверку этой ссылки и использовать её, либо использовать non-null значение x:
val l: Int = if (b != null) b.length else -1
Аналогом такому if-выражению является элвис-оператор ?::
Если выражение, стоящее слева от Элвис-оператора, не является null, то элвис-оператор его вернёт. В противном случае, в качестве возвращаемого значения послужит то, что стоит справа. Обращаем ваше внимание на то, что часть кода, расположенная справа, выполняется ТОЛЬКО в случае, если слева получается null.
Так как throw и return тоже являются выражениями в Kotlin, их также можно использовать справа от Элвис-оператора. Это может быть крайне полезным для проверки аргументов функции:
fun foo(node: Node): String? { val parent = node.getParent() ?: return null val name = node.getName() ?: throw IllegalArgumentException("name expected") // ... }
Оператор !!
Для любителей NPE существует ещё один способ. Мы можем написать b!! и это вернёт нам либо non-null значение b (в нашем примере вернётся String), либо выкинет NPE:
В случае, если вам нужен NPE, вы можете заполучить её только путём явного указания.
Безопасные приведения типов
Обычное приведение типа может вызвать ClassCastException в случае, если объект имеет другой тип. Можно использовать безопасное приведение, которое вернёт null, если попытка не удалась:
val aInt: Int? = a as? Int
Коллекции nullable типов
Если у вас есть коллекция nullable элементов и вы хотите отфильтровать все non-null элементы, используйте функцию filterNotNull.
val nullableList: List<Int?> = listOf(1, 2, null, 4) val intList: List<Int> = nullableList.filterNotNull()
Операции с числами
Арифметические операции
Kotlin поддерживает базовые арифметические операции:
+ (сложение): возвращает сумму двух чисел.
val x = 5 val y = 6 val z = x + y println(z) // z = 11
— (вычитание): возвращает разность двух чисел.
val x = 5 val y = 6 val z = x - y // z = -1
***** (умножение): возвращает произведение двух чисел.
val x = 5 val y = 6 val z = x * y // z = 30
/ (деление): возвращает частное двух чисел.
val x = 60 val y = 10 val z = x / y // z = 6
%: возвращает остаток от целочисленного деления двух чисел.
val x = 65 val y = 10 val z = x % y // z = 5
++ (инкремент): увеличивает значение на единицу.
Префиксный инкремент возвращает увеличенное значение:
var x = 5
val y = ++x
println(x) // x = 6
println(y) // y = 6
Постфиксный инкремент возвращает значение до увеличения на единицу:
var x = 5 val y = x++ println(x) // x = 6 println(y) // y = 5
— (декремент): уменьшает значение на единицу.
Префиксный декремент возвращает уменьшенное значение:
var x = 5 val y = --x println(x) // x = 4 println(y) // y = 4
Постфиксный декремент возвращает значение до уменьшения на единицу:
var x = 5 val y = x-- println(x) // x = 4 println(y) // y = 5
Также есть ряд операций присвоения, которые сочетают арифметические операции и присвоение:
+=: присваивание после сложения. Присваивает левому операнду сумму левого и правого операндов: A += B эквивалентно A = A + B
-=: присваивание после вычитания. Присваивает левому операнду разность левого и правого операндов: A -= B эквивалентно A = A — B
*=: присваивание после умножения. Присваивает левому операнду произведение левого и правого операндов: A *= B эквивалентно A = A * B
/=: присваивание после деления. Присваивает левому операнду частное левого и правого операндов: A /= B эквивалентно A = A / B
%=: присваивание после деления по модулю. Присваивает левому операнду остаток от целочисленного деления левого операнда на правый: A %= B эквивалентно A = A % B
Побитовые операторы
Ряд операций выполняется над двоичными разрядми числа. Здесь важно понимать, как выглядит двоичное представление тех или иных чисел. В частности, число 4 в двоичном виде — 100, а число 15 — 1111.
Есть следующие побитовые операторы (они применяются только к данным типов Int и Long):
shl: сдвиг битов числа со знаком влево
val z = 3 shl 2 // z = 11 << 2 = 1100 println(z) // z = 12 val d = 0b11 shl 2 println(d) // d = 12
В данном случае число сдвигается на два разряда влево, поэтому справа число в двоичном виде дополняется двумя нулями. То есть в двоичном виде 3 представляет 11. Сдвигаем на два разряда влево (дополняем справа двумя нулями) и получаем 1100, то есть в десятичной системе число 12.
shr: сдвиг битов числа со знаком вправо
val z = 12 shr 2 // z = 1100 >> 2 = 11 println(z) // z = 3 val d = 0b1100 shr 2 println(d) // d = 3
Число 12 сдвигается на два разряда вправо, то есть два числа справа факически отбрасываем и получаем число 11, то есть 3 в десятичой системе.
ushr: сдвиг битов беззнакового числа вправо
val z = 12 ushr 2 // z = 1100 >> 2 = 11 println(z) // z = 3
and: побитовая операция AND (логическое умножение или конъюнкция). Эта операция сравнивает соответствующие разряды двух чисел и возвращает единицу, если эти разряды обоих чисел равны 1. Иначе возвращает 0.
val x = 5 // 101 val y = 6 // 110 val z = x and y // z = 101 & 110 = 100 println(z) // z = 4 val d = 0b101 and 0b110 println(d) // d = 4
or: побитовая операция OR (логическое сложение или дизъюнкция). Эта операция сравнивают два соответствуюших разряда обоих чисел и возвращает 1, если хотя бы один разряд равен 1. Если оба разряда равны 0, то возвращается 0.
val x = 5 // 101 val y = 6 // 110 val z = x or y // z = 101 | 110 = 111 println(z) // z = 7 val d = 0b101 or 0b110 println(d) // d = 7
xor: побитовая операция XOR. Сравнивает два разряда и возвращает 1, если один из разрядов равен 1, а другой равен 0. Если оба разряда равны, то возвращается 0.
val x = 5 // 101 val y = 6 // 110 val z = x xor y // z = 101 ^ 110 = 011 println(z) // z = 3 val d = 0b101 xor 0b110 println(d) // d = 3
inv: логическое отрицание или инверсия — инвертирует биты числа
val b = 11 // 1011 val c = b.inv() println(c) // -12
Условные выражения
Условные выражения представляют некоторое условие, которое возвращает значение типа Boolean: либо true (если условие истинно), либо false (если условие ложно).
Операции отношения
> (больше чем): возвращает true, если первый операнд больше второго. Иначе возвращает false
val a = 11 val b = 12 val c : Boolean = a > b println(c) // false - a меньше чем b val d = 35 > 12 println(d) // true - 35 больше чем 12
< (меньше чем): возвращает true, если первый операнд меньше второго. Иначе возвращает false
val a = 11 val b = 12 val c = a < b // true val d = 35 < 12 // false
>= (больше чем или равно): возвращает true, если первый операнд больше или равен второму
val a = 11 val b = 12 val c = a >= b // false val d = 11 >= a // true
<= (меньше чем или равно): возвращает true, если первый операнд меньше или равен второму.
val a = 11 val b = 12 val c = a <= b // true val d = 11 <= a // false
== (равно): возвращает true, если оба операнда равны. Иначе возвращает false
val a = 11 val b = 12 val c = a == b // false val d = b == 12 // true
!= (не равно): возвращает true, если оба операнда НЕ равны
val a = 11 val b = 12 val c = a != b // true val d = b != 12 // false
Логические операции
Операндами в логических операциях являются два значения типа Boolean. Нередко логические операции объединяют несколько операций отношения:
and: возвращает true, если оба операнда равны true.
val a = true val b = false val c = a and b // false val d = (11 >= 5) and (9 < 10) // true println(c) println(d)
or: возвращает true, если хотя бы один из операндов равен true.
val a = true val b = false val c = a or b // true val d = (11 < 5) or (9 > 10) // false
xor: возвращает true, если только один из операндов равен true. Если операнды равны возвращается false
val a = true val b = false val c = a xor b // true val d = a xor (90 > 10) // false
!: возвращает true, если операнд равен false. И, наоборот, если операнд равен false, возвращает true.
val a = true val b = !a // false val c = !b // true
В качестве альтернативы оператору ! можно использовать метод not():
val a = true val b = a.not() // false val c = b.not() // true
in: возвращает true, если операнд имеется в некоторой последовательности.
val a = 5 val b = a in 1..6 // true
Выражение 1..6 создает последовательность чисел от 1 до 6. И в данном случае оператор in проверяет, есть ли значение переменной a в этой последовательности. Поскольку значение переменной a имеется в данной последовательности, то возвращается true.
Условные конструкции
Условные конструкции позволяют направить выполнение программы по одному из путей в зависимости от условия.
if…else
Конструкция if принимает условие, и если это условие истинно, то выполняется последующий блок инструкций.
val a = 10 if(a == 10) { println("a равно 10") }
В данном случае в конструкции if проверяется истинность выражения a == 10, если оно истинно, то выполняется последующий блок кода в фигурных скобках, и на консоль выводится сообщение «a равно 10». Если же выражение ложно, тогда блок кода не выполняется.
Если необходимо задать альтернативный вариант, то можно добавить блок else:
val a = 10 if(a == 10) { println("a равно 10") } else{ println("a НЕ равно 10") }
Таким образом, если условное выражение после оператора if истинно, то выполняется блок после if, если ложно — выполняется блок после else.
Если блок кода состоит из одного выражения, то в принципе фигурные скобки можно опустить:
val a = 10 if(a == 10) println("a равно 10") else println("a НЕ равно 10")
Если необходимо проверить несколько альтернативных вариантов, то можно добавить выражения else if:
val a = 10 if(a == 10) { println("a равно 10") } else if(a == 9){ println("a равно 9") } else if(a == 8){ println("a равно 8") } else{ println("a имеет неопределенное значение") }
Стоит отметить, что конструкция if может возвращать значение. Например, найдем максимальное из двух чисел:
val a = 10 val b = 20 val c = if (a > b) a else b println(c) // 20
Если при определении возвращаемого значения надо выполнить еще какие-нибудь действия, то можно заключить эти действия в блоки кода:
val a = 10 val b = 20 val c = if (a > b){ println("a = $a") a } else { println("b = $b") b }
В конце каждого блока указывается возвращаемое значение.
Конструкция when
Конструкция when проверяет значение некоторого объекта и в зависимости от его значения выполняет тот или иной код. Конструкция when аналогична конструкции switch в других языках.
val a = 10 when(a){ 10 -> println("a = 10") 20 -> println("a = 20") else -> println("неопределенное значение") }
После ключевого слова when в скобках идет выражение. Затем идет блок кода, в котором определяются значения для сравнения. После каждого значения после стрелки -> идет последовательность выполняемых инструкций:
То есть в данном случае если переменная a равна 10, то на консоль будет выводиться сообщение «a = 10».
Если ни одно из значений в блоке when не соответствуют выражению, то выполняются инструкции из выражения else. Выражение else не обязательное, его можно не определять.
Если надо, чтобы при совпадении значений выполнялось несколько инструкций, то для каждого значения можно определить блок кода:
var a = 10 when(a){ 10 -> { println("a = 10") a *= 2 } 20 -> { println("a = 20") a *= 5 } else -> { println("неопределенное значение")} } println(a)
Можно определить одни и те же действия сразу для нескольких значений. В этом случае значения перечисляются через запятую:
val a = 10 when(a){ 10, 20 -> println("a = 10 или a = 20") else -> println("неопределенное значение") }
Также можно сравнивать с целым диапазоном значений с помощью оператора in:
val a = 10 when(a){ in 10..19 -> println("a в диапазоне от 10 до 19") in 20..29 -> println("a в диапазоне от 20 до 29") !in 10..20 -> println("a вне диапазона от 10 до 20") else -> println("неопределенное значение") }
Если оператор in позволяет узнать, есть ли значение в определенном диапазоне, то связка операторов !in позволяет проверить отсутствие значения в определенной последовательности.
Возвращение значения
Как и if конструкция when может возвращать значение:
val sum = 1000 val rate = when(sum){ in 100..999 -> 10 in 1000..9999 -> 15 else -> 20 } println(rate) // 15
Таким образом, если значение переменной sum располагается в определенном диапазоне, то возвращается то значение, которое идет после стрелки.
Также вместе с when-выражениями работают умные приведения (is, !is)
when (x) { is Int -> print(x + 1) is String -> print(x.length + 1) is IntArray -> print(x.sum()) }
when удобно использовать вместо цепочки условий вида if-else if. При отстутствии аргумента, условия работают как простые логические выражения, а тело ветки выполняется при его истинности:
when { x.isOdd() -> print("x is odd") x.isEven() -> print("x is even") else -> print("x is funny") }
Циклы
Циклы представляют вид управляющих конструкций, которые позволяют в зависимости от определенных условий выполнять некоторое действие множество раз.
For
Цикл for пробегается по всем элементам коллекции. В этом плане цикл for в Kotlin эквивалентен циклу for-each в ряде других языков программирования. Его формальная форма выглядит следующим образом:
for(переменная in поледовательность){ выполняемые инструкции }
Например, выведем все квадраты чисел от 1 до 9, используя цикл for:
for(n in 1..9){ print("${n * n} t") }
В данном случае перебирается последовательность чисел от 1 до 9. При каждом проходе цикла (итерации цикла) из этой последовательности будет извлекаться элемент и помещаться в переменную n. И через переменную n можно манипулировать значением элемента. То есть в данном случае мы получим следующий консольный вывод:
Циклы могут быть вложенными. Например, выведем таблицу умножения:
for(i in 1..9){ for(j in 1..9){ print("${i * j} t") } println() }
В итоге на консоль будет выведена следующая таблица умножения:
1 2 3 4 5 6 7 8 9
2 4 6 8 10 12 14 16 18
3 6 9 12 15 18 21 24 27
4 8 12 16 20 24 28 32 36
5 10 15 20 25 30 35 40 45
6 12 18 24 30 36 42 48 54
7 14 21 28 35 42 49 56 63
8 16 24 32 40 48 56 64 72
9 18 27 36 45 54 63 72 81
Цикл while
Цикл while повторяет определенные действия пока истинно некоторое условие:
var i = 10 while(i > 0){ println(i*i) i--; }
Здесь пока переменная i больше 0, будет выполняться цикл, в котором на консоль будет выводиться квадрат значения i.
В данном случае вначале проверяется условие (i > 0) и если оно истинно (то есть возвращает true), то выполняется цикл. И вполне может быть ситуация, когда к началу выполнения цикла условие не будет выполняться. Например, переменная i изначально меньше 0, тогда цикл вообще не будет выполняться.
Но есть и другая форма цикла while — do..while:
var i = -1 do{ println(i*i) i--; } while(i > 0)
В данном случае вначале выполняется блок кода после ключевого слова do, а потом оценивается условие после while. Если условие истинно, то повторяется выполнение блока после do. То есть несмотря на то, что в данном случае переменная i меньше 0 и она не соответствует условию, тем не менее блок do выполнится хотя бы один раз.
Операторы continue и break
Иногда при использовании цикла возникает необходимость при некоторых условиях не дожидаться выполнения всех инструкций в цикле, перейти к новой итерации. Для этого можно использовать оператор continue:
for(n in 1..8){ if(n == 5) continue; println(n * n) }
В данном случае когда n будет равно 5, сработает оператор continue. И последующая инструкция, которая выводит на консоль квадрат числа, не будет выполняться. Цикл перейдет к обработке следующего элемента в массиве
Бывает, что при некоторых условиях нам вовсе надо выйти из цикла, прекратить его выполнение. В этом случае применяется оператор break:
for(n in 1..5){ if(n == 5) break; println(n * n) }
В данном случае когда n окажется равен 5, то с помощью оператора break будет выполнен выход из цикла. Цикл полностью завершится.
Последовательности
Последовательность представляет набор значений или диапазон. Для создания последовательности применяется оператор ..:
var range = 1..5 // последовательность [1, 2, 3, 4, 5]
Этот оператор принимает два значения — границы последовательности, и все элементы между этими значениями (включая их самих) составляют последовательность.
Последовательность необязательно должна представлять числовые данные. Например, это могут быть строки:
Оператор .. позволяет создать последовательность по нарастающей, где каждый следующий элемент будет больше предыдущего. С помощью специальной функции downTo можно построить последовательность в обратном порядке:
var range1 = 1..5 // 1 2 3 4 5 var range2 = 5 downTo 1 // 5 4 3 2 1
Еще одна специальная функция step позволяет задать шаг, на который будут изменяться последующие элементы:
var range1 = 1..10 step 2 // 1 3 5 7 9 var range2 = 10 downTo 1 step 3 // 10 7 4 1
Еще одна функция until позволяет не включать верхнюю границу в саму последовательность:
var range1 = 1 until 9 // 1 2 3 4 5 6 7 8 var range2 = 1 until 9 step 2 // 1 3 5 7
С помощью специальных операторов можно проверить наличие или отсутствие элементов в последовательности:
in: возвращает true, если объект имеется в последовательности
!in: возвращает true, если объект отсутствует в последовательности
fun main(args: Array<String>) { var range = 1..5 var isInRange = 5 in range println(isInRange) // true isInRange = 86 in range println(isInRange) // false var isNotInRange = 6 !in range println(isNotInRange) // true isNotInRange = 3 !in range println(isNotInRange) // false }
С помощью цикла for можно перебирать последовательность:
var range1 = 5 downTo 1 for(c in range1) print(c) // 54321 println() for(c in 1..9) print(c) // 123456789 println() for(c in 1 until 9) print(c) // 12345678 println() for(c in 1..9 step 2) print(c) // 13579
Массивы
Массив представляет набор данных одного типа. В языке Kotlin массивы представлены типом Array.
При определении массива после типа Array в угловых скобках необходимо указать, объекты какого типа могут храниться в массиве. Например, определим массив целых чисел:
С помощью встроенной функции arrayOf() можно передать набор значений, которые будут составлять массив:
val numbers: Array<Int> = arrayOf(1, 2, 3, 4, 5)
То есть в данном случае в массиве 5 чисел от 1 до 5.
С помощью индексов мы можем обратиться к определенному элементу в массиве. Индексация начинается с нуля, то есть первый элемент буде иметь индекс 0. Индекс указывается в квадратных скобках:
val numbers: Array<Int> = arrayOf(1, 2, 3, 4, 5) val n = numbers[1] // получаем второй элемент n=2 numbers[2] = 7 // переустанавливаем третий элемент
Также инициализировать массив значениями можно следующим способом:
val numbers = Array(3, {5}) // [5, 5, 5]
Здесь применяется конструктор класса Array. В этот конструктор передаются два параметра. Первый параметр указывает, сколько элементов будет в массиве. В данном случае 3 элемента. Второй параметр представляет выражение, которое генерирует элементы массива. Оно заключается в фигурные скобки. В данном случае в фигурных скобках стоит число 5, то есть все элементы массива будут представлять число 5. Таким образом, массив будет состоять из трех пятерок.
Для упрощения создания массива в Kotlin определены дополнительные типы BooleanArray, ByteArray, ShortArray, IntArray, LongArray, CharArray, FloatArray и DoubleArray, которые позволяют создавать массивы для определенных типов. Например, тип IntArray позволяет определить массив объектов Int, а DoubleArray — массив объектов Double:
val numbers: IntArray = intArrayOf(1, 2, 3, 4, 5) val doubles: DoubleArray = doubleArrayOf(2.4, 4.5, 1.2)
Для определения данных для этих массивов можно применять функции, которые начинаются на название типа в нижнем регистре, например, int, и затем идет ArrayOf.
Аналогично для инициализации подобных массивов также можно применять конструктор соответствуюшего класса:
val numbers = IntArray(3, {5}) val doubles = DoubleArray(3, {1.5})
Как и в случае с последовательностью мы можем проверить наличие или отсутствие элементов в массиве с помощью операторов in и !in:
val numbers: Array<Int> = arrayOf(1, 2, 3, 4, 5) println(4 in numbers) // true println(2 !in numbers) // false
Двухмерные массивы
Выше рассматривались одномерные массивы, которые можно представить в виде ряда или строки значений. Но кроме того, мы можем использовать многомерные массивы. К примеру, возьмем двухмерный массив — то есть такой массив, каждый элемент которого в свою очередь сам является массивом. Двухмерный массив еще можно представить в виде таблицы, где каждая строка — это отдельный массив, а ячейки строки — это элементы вложенного массива.
Определение двухмерных массивов менее интуитивно понятно и может вызывать сложности. Например, двухмерный массив чисел:
val table: Array<Array<Int>> = Array(3, { Array(5, {0}) })
В данном случае двухмерный массив будет иметь три элемента — три строки. Каждая строка будет иметь по пять элементов, каждый из которых равен 0.
Используя индексы, можно обращаться к подмассивам в подобном массиве, в том числе переустанавливать их значения:
val table = Array(3, { Array(3, {0}) }) table[0] = arrayOf(1, 2, 3) table[1] = arrayOf(4, 5, 6) table[2] = arrayOf(7, 8, 9)
Для обращения к элементам подмассивов двухмерного массива необходимы два индекса. По первому индексу идет получение строки, а по второму индексу — столбца в рамках этой строки:
val table = Array(3, { Array(3, {0}) }) table[0][1] = 6 // второй элемент первой строки val n = table[0][1] // n = 6
Перебор массивов
Для перебора массивов применяется цикл for:
val phones: Array<String> = arrayOf("Galaxy S8", "iPhone X", "Motorola C350") for(phone in phones){ println(phone) }
В данном случае переменная phones представляет массив строк. При переборе этого массива в цикле каждый его элемент оказывается в переменной phone. Консольный вывод программы:
Galaxy S8
iPhone X
Motorola C350
Используя два цикла, можно перебирать двухмерные массивы:
fun main(args: Array<String>) { val table: Array<Array<Int>> = Array(3, { Array(3, {0}) }) table[0] = arrayOf(1, 2, 3) table[1] = arrayOf(4, 5, 6) table[2] = arrayOf(7, 8, 9) for(row in table){ for(cell in row){ print("$cell t") } println() } }
С помощью внешнего цикла for(row in table) пробегаемся по всем элементам двухмерного массива, то есть по строкам таблицы. Каждый из элементов двухмерного массива сам представляет массив, поэтому мы можем пробежаться по этому массиву и получить из него непосредственно те значения, которые в нем хранятся. В итоге на консоль будет выведено следующее:
Функции и их параметры
Одним из строительных блоков программы являются функции. Функция определяет некоторое действие. В Kotlin функция объявляется с помощью ключевого слова fun, после которого идет название функции. Затем после названия в скобках указывается список параметров. Если функция возвращает какое-либо значение, то после списка параметров через двоеточие можно указать тип возвращаемого значения. И далее в фигурных скобках идет тело функции.
fun имя_функции (параметры) : возвращаемый_тип
{
выполняемые инструкции
}
Параметры необязательны.
Например, определим и вызовем функцию, которая просто выводит некоторую строку на консоль:
fun main(args: Array<String>) { hello() // вызов функции hello hello() // вызов функции hello hello() // вызов функции hello } // определение функции hello fun hello(){ println("Hello") }
Функции можно определять в файле вне других функций или классов, сами по себе, как например, определяется функция main. Такие функции еще называют функциями верхнего уровня (top-level functions).
Здесь кроме главной функции main также определена функция hello, которая не принимает никаких параметров и ничего не возвращает. Она просто выводит строку на консоль.
Функция hello (и любая другая определенная функция, кроме main) сама по себе не выполняется. Чтобы ее выполнить, ее надо вызвать. Для вызова функции указывается ее имя (в данном случае «hello»), после которого идут пустые скобки.
Таким образом, если необходимо в разных частях программы выполнить одни и те же действия, то можно эти действия вынести в функцию, и затем вызывать эту функцию.
Предача параметров
Через параметры функция может получать некоторые значения извне. Параметры указываются после имени функции в скобках через запятую в формате имя_параметра : тип_параметра. Например, определим функцию, которая вычисляет факториал числа:
fun main(args: Array<String>) { factorial(4) factorial(5) factorial(6) } fun factorial(n: Int){ var result = 1; for(d in 1..n){ result *= d } println("Factorial of $n is equal to $result") }
Функция factorial принимает один параметр типа Int. Поэтому при вызове функции в скобках необходимо передать значение для этого параметра: factorial(4). Причем это значение должно представлять тип Int. Значения, которые передаются параметрам функции, еще назвают аргументами.
Консольный вывод программы:
Factorial of 4 is equal to 24
Factorial of 5 is equal to 120
Factorial of 6 is equal to 720
Другой пример — функция, которая выводит данные о пользователе на консоль:
fun main(args: Array<String>) { displayUser("Tom", 23) displayUser("Alice", 19) displayUser("Kate", 25) } fun displayUser(name: String, age: Int){ println("Name: $name Age: $age") }
Функция displayUser() принимает два параметра — name и age. При вызове функции в скобках ей передаются значения для этих параметров. При этом значения передаются параметрам по позиции и должны соответствовать параметрам по типу. Так как вначале идет параметр типа String, а потом параметр типа Int, то при вызове функции в скобках вначале передается строка, а потом число.
Аргументы по умолчанию
В примере выше при вызове функций factorial и displayUser мы обязательно должны предоставить для каждого их параметра какое-то определенное значение, которое соответствует типу параметра. Мы не можем, к примеру, вызвать функцию displayUser, не передав ей аргументы для параметров, это будет ошибка.
Однако мы можем определить какие-то параметры функции как необязательные и установить для них значения по умолчанию:
fun displayUser(name: String, age: Int = 18, position: String="unemployed"){ println("Name: $name Age: $age Position: $position") } fun main(args: Array<String>) { displayUser("Tom", 23, "Manager") displayUser("Alice", 21) displayUser("Kate") }
В данном случае функция displayUser имеет три параметра для передачи имени, возраста и должности. Для первого параметр name значение по умолчанию не установлено, поэтому для него по-прежнему обязательно передавать значение. Два последующих — age и position являются необязательными, и для них установлено значение по умолчанию. Если для этих параметров не передаются значения, тогда параметры используют значения по умолчанию. Поэтому для этих параметров в принципе нам необязательно передавать аргументы. Но если для какого-то параметра определено значение по умолчанию, то для всех последующих параметров тоже должно быть установлено значение по умолчанию.
Консольный вывод программы
Name: Tom Age: 23 Position: Manager
Name: Alice Age: 21 Position: unemployed
Name: Kate Age: 18 Position: unemployed
Именованные аргументы
По умолчанию значения передаются параметрам по позиции: первое значение — первому параметру, второе значение — второму параметру и так далее. Однако, используя именованные аргументы, мы можем переопределить порядок их передачи параметрам:
fun main(args: Array<String>) { displayUser(name="Tom", position="Manager", age=28) displayUser(age=21, name="Alice") displayUser("Kate", position="Middle Developer") }
При вызове функции в скобках мы можем указать название параметра и с помощью знака равно передать ему нужное значение.
При этом, как видно из последнего случае, необязательно все аргументы передавать по имени. Часть аргументов могут передаваться параметрам по позиции. Но если какой-то аргумент передан по имени, то остальные также должны передаваться по имени соответствующих параметров.
Переменное количество параметров. Vararg
Функция может принимать переменное количество параметров одного типа. Для определения таких параметров применяется ключевое слово vararg. Например, нам необходимо передать в функцию несколько строк, но сколько именно строк, мы точно не знаем. Их может быть пять, шесть, семь и т.д.:
fun printStrings(vararg strings: String){ for(str in strings) println(str) } fun main(args: Array<String>) { printStrings("Tom", "Bob", "Sam") printStrings("Kotlin", "JavaScript", "Java", "C#", "C++") }
Функция printStrings принимает неопределенное количество строк. В самой функции мы можем работать с параметром как с последовательностью строк, например, перебирать элементы последовательности в цикле и производить с ними некоторые действия.
При вызове функции мы можем ей передать любое количество строк.
Другой пример — подсчет суммы неопределенного количества чисел:
fun sum(vararg numbers: Int){ var result=0 for(n in numbers) result += n println("Сумма чисел равна $result") } fun main(args: Array<String>) { sum(1, 2, 3, 4, 5) sum(1, 2, 3, 4, 5, 6, 7, 8, 9) }
Если функция принимает несколько параметров, то обычно vararg-параметр является последним.
fun printUserGroup(count:Int, vararg users: String){ println("Count: $count") for(user in users) println(user) } fun main(args: Array<String>) { printUserGroup(3, "Tom", "Bob", "Alice") }
Однако это необязательно, и если после vararg-параметра идут еще какие-нибудь параметры, то при вызове функции значения этим параметрам передаются через именованные аргументы:
fun printUserGroup(group: String, vararg users: String, count:Int){ println("Group: $group") println("Count: $count") for(user in users) println(user) } fun main(args: Array<String>) { printUserGroup("KT-091", "Tom", "Bob", "Alice", count=3) }
Здесь функция printUserGroup принимает три параметра. Значения параметрам до vararg-параметра передаются по позициям. То есть в данном случае «KT-091» будет представлять значение для параметра group. Последующие значения интерпретируются как значения для vararg-параметра вплоть до именнованных аргументов.
Оператор *
Оператор ***** (spread operator) (не стоит путать со знаком умножения) позволяет передать параметру в качестве значения элементы из массива:
fun printUserGroup(group: String, vararg users: String, count:Int){ println("Count: $count") for(user in users) println(user) } fun main(args: Array<String>) { val users = arrayOf("Tom", "Bob", "Alice") printUserGroup("MO-011", *users, count=3) }
Обратите внимание на звездочку перед users при вызове функции: printUserGroup(«MO-011», *users, count=3). Без применения данного оператора мы столкнулись бы с ошибкой, поскольку параметры функции представляют не массив, а неопределенное количество строк.
Возвращение результата. Оператор return
Функция может возвращать некоторый результат. В этом случае после списка параметров через двоеточие указывается возвращаемый тип. А в теле функции применяется оператор return, после которого указывается возвращаемое значение.
Например, определим функцию, которая возвращает факториал числа:
// функция возвращает значение типа Int fun factorial(n: Int) : Int { var result = 1; for(d in 1..n){ result *= d } return result // возвращение значения } fun main(args: Array<String>) { val a = factorial(4) val b = factorial(5) val c = factorial(6) println("a=$a b=$b c=$c") }
В объявлении функции factorial после списка параметров через двоеточие указывается тип Int, который будет представлять тип возвращаемого значения.
Так как функция возвращает значение, то при ее вызове это значение можно присвоить переменной:
Тип Unit
Если функция не возвращает какого-либо результата, то фактически неявно она возвращает значение типа Unit. Этот тип аналогичен типу void в ряде языков программирования, которое указывает, что функция ничего не возвращает. Например, следующая функция
fun hello() { println("Hello") }
будет аналогична следующей:
fun hello() : Unit { println("Hello") }
Формально мы даже можем присвоить результат такой функции переменной:
val d = hello() val e = hello()
Однако практического смысла это не имеет, так как возвращаемое значение представляет объект Unit, который больше никак не применяется.
Если функция возвращает значение Unit, мы также можем использовать оператор return для возврата из функции:
fun factorial(n: Int){ if(n < 1){ println("Incorrect input parameter") return } var result = 1; for(d in 1..n){ result *= d } println("Factorial of $n is equal $result") }
В данном случае если значение параметра n меньше 1, то с помощью оператора return осуществляется выход из функции, и последующие инструкции не выполняются. При этом если функция возвращает значение Unit, то после оператора return можно не указывать никакого значения.
Однострочные функции
Однострочные функции (single expression function) используют сокращенный синтаксис определения функции в виде одного выражения. Эта форма позволяет опустить возвращаемый тип и оператор return.
fun имя_функции (параметры_функции) = тело_функции
Функция также определяется с помощью ключевого слова fun, после которого идет имя функции и список параметров. Но после списка параметров не указывается возвращаемый тип. Возвращаемый тип будет выводится компилятором. Далее через оператор присвоения = определяется тело функции в виде одного выражения.
Например, функция возведения числа в квадрат:
fun double(x: Int) = x * x fun main(args: Array<String>) { val a = double(5) // 25 val b = double(6) // 36 println("a=$a b=$b") }
В данном случае функция double возводит число в квадрат. Она состоит из одного выражения x * x. Значение этого выражения и будет возвращаться функцией. При этом оператор return не используется.
Такие функции более лаконичны, более читабельны, но также опционально можно и указывать возвращаемый тип явно:
fun double(x: Int) : Int = x * x
Область действия функций
В Kotlin функции могут быть объявлены в самом начале файла. Подразумевается, что вам не обязательно создавать объект какого-либо класса, чтобы воспользоваться его функцией (как в Java, C# или Scala). В дополнение к этому, функции в языке Kotlin могут быть объявлены локально, как функции-члены (ориг. «member functions») и функции-расширения («extension functions»).
Локальные функции
Одни функции могут быть определены внутри других функций. Внутренние или вложенные функции еще называют локальными.
Локальные функции могут определять действия, которые используются только в рамках какой-то конкретной функции и нигде больше не применяются.
Например, функция принимает на вход основание и высоту двух треугольников и должна вычислить, больше ли площадь первого треугольника, чем второго:
fun isFirstGreater(base1: Double, height1: Double, base2: Double, height2: Double): Boolean{ fun square(base: Double, height: Double) = base * height / 2 return square(base1, height1) > square(base2, height2) } fun main(args: Array<String>) { val a = isFirstGreater(10.0, 10.0, 20.0, 20.0) val b = isFirstGreater(20.0, 20.0, 10.0, 10.0) println("a=$a b=$b") }
Для промежуточных вычислений — вычисления площади каждого отдельного треугольника в функции isFirstGreater определена вспомогательная функция square. Больше в программе эта функция нигде не используется, поэтому ее можно сделать локальной.
При этом локальная может использоваться только в той функции, где она определена.
Перегрузка функций
Перегрузка функций (function overloading) представляет определение нескольких функций с одним и тем же именем, но с различными параметрами. Параметры перегруженных функций могут отличаться по количеству, типу или по порядку в списке параметров.
fun add(a: Int, b: Int) : Int{ return a + b } fun add(a: Double, b: Double) : Double{ return a + b } fun add(a: Int, b: Int, c: Int) : Int{ return a + b + c } fun add(a: Int, b: Double) : Double{ return a + b } fun add(a: Double, b: Int) : Double{ return a + b }
В данном случае для одной функции add определено пять перегруженных версий. Каждая из версий отличается либо по типу, либо количеству, либо по порядку параметров. При вызове функции add компилятор в зависимости от типа и количества параметров сможет выбрать для выполнения нужную версию:
fun main(args: Array<String>) { val a = add(1, 2) val b = add(1.5, 2.5) val c = add(1, 2, 3) val d = add(2, 1.5) val e = add(1.5, 2) }
При этом при перегрузке не учитывает возвращаемый результат функции. Например, пусть у нас будут две следующие версии функции add:
fun add(a: Double, b: Int) : Double{ return a + b } fun add(a: Double, b: Int) : String{ return "$a + $b" }
Они совпадают во всем за исключением возвращаемого типа. Однако в данном случае мы сталкивамся с ошибкой, так как перегруженные версии должны отличаться именно по типу, порядку или количеству параметров. Отличие в возвращаемом типе не имеют значения.
Лямбда-выражения
Лямбда-выражения представляют небольшие кусочки кода, которые выполняют некоторые действия. Фактически лямбды преставляют сокращенную запись функций. При этом лямбды могут передаваться в качестве параметра в функции.
Лямбда-выражения оборачиваются в фигурные скобки:
В данном случае лямбда-выражение выводит на консоль строку «hello».
Лямбда-выражение можно сохранить в обычную переменную и затем вызывать через имя этой переменной как обычную функцию.
fun main(args: Array<String>) { val hello = {println("hello")} hello() hello() }
В данном случае лямбда сохранена в переменную hello и через эту переменную вызывается два раза.
Также лямбда-выражение можно выполнить сразу при определении с помощью оператора run:
fun main(args: Array<String>) { run {println("hello")} }
Передача параметров
Лямбды как и функции могут принимать параметры. Для передачи параметров используется стрелка ->. Параметры указываются слева от стрелки, а тело лямбда-выражения, то есть сами выполняемые действия, справа от стрелки.
fun main(args: Array<String>) { val printer = {message: String -> println(message)} printer("Hello") printer("Good Bye") }
Здесь лямбда-выражение принимает один параметр типа String, значение которого выводится на консоль.
Если параметров несколько, то они передаются слева от стрелки через запятую:
fun main(args: Array<String>) { val sum = {x:Int, y:Int -> println(x + y)} sum(2, 3) // 5 sum(4, 5) // 9 }
Если в лямбда-выражении надо выполнить не одно, а несколько действий, то эти действия можно размещать на отдельных строках после стрелки:
val sum = {x:Int, y:Int -> val result = x + y println("$x + $y = $result") }
Возвращение результата
Выражение, стоящее после стрелки, определяет результат лямбда-выражения. И этот результат мы можем присвоить, например, переменной.
Если лямбда-выражение формально не возвращает никакого результата, то фактически, как и в функциях, возвращается значение типа Unit:
val hello = { println("Hello")} val h = hello() // h представляет тип Unit val printer = {message: String -> println(message)} val p = printer("Welcome") // p представляет тип Unit
В обоих случаях используется функция println, которая формально не возвращает никакого значения (точнее возвращает объект типа Unit).
Но также может возвращаться конкретное значение:
fun main(args: Array<String>) { val sum = {x:Int, y:Int -> x + y} val a = sum(2, 3) // 5 val b = sum(4, 5) // 9 println("a=$a b=$b") }
Здесь выражение справа от стрелки x + y продуцирует новое значение — сумму чисел, и при вызове лямбда-выражения это значение можно передать переменной.
Если лямбда-выражение многострочное, состоит из нескольких инструкций, то возвращается то значение, которое генерируется последней инструкцией:
val sum = {x:Int, y:Int -> val result = x + y println("$x + $y = $result") result }
Последнее выражение по сути представляет число — сумму чисел x и y и оно будет возвращаться в качестве результата лямбда-выражения.
Функции высокого порядка
Функции высокого порядка (high order function) — это функции, которые либо принимают функцию в качестве параметра, либо возвращают функцию, либо и то, и другое.
Тип функции
Для определения функций высокого порядка прежде всего необходимо представлять, что такое тип функции. Тип функции определяется следующим образом:
(типы_параметров) -> возвращаемый_тип
Например, возьмем следующее лямбда-выражение:
{mes:String-> println(mes)}
Это лямбда-выражение принимает в качестве параметра строку и формально ничего не возвращает (точнее возвращаемым типом является Unit). Поэтому тип этого выражения будет следующий:
Другой пример: лямбда-выражение принимает два числа и возвращает их сумму:
Это выражение будет иметь следующий тип:
Если лямбда-выражение не принимает никаких параметров, то указываются пустые скобки:
К примеру, этому типу будет соответствовать лямбда-выражение {println(«hello»)}
При определении лямбда-выражения и присвоении его переменной мы можем явным образом у этой переменной указать тип:
val sum: (Int, Int)-> Int = {x:Int, y: Int -> x+y} val printer: (String) -> Unit = {message: String -> println(message)}
Правда, в данном случае тип можно не указывать, так как компилятор может сам вывести тип переменной.
Передача лямбда-выражения в функцию
Для передачи лямбда-выражения в функцию, необходимо определить у функции параметр, тип которого соответствует типу лямбда-выражения:
fun main(args: Array<String>) { val add = {x:Int, y: Int -> x+y} val multiply = {x:Int, y: Int -> x*y} action(5, 3, add) action(5, 3, multiply) action(5, 3, {x: Int, y: Int -> x -y}) } fun action (n1: Int, n2: Int, operation: (Int, Int)-> Int){ val result = operation(n1, n2) println(result) }
В данном случае функция action определяет три параметра. Первый два параметра — числа, а третий параметр — некоторая операция, которая производится над этими числами. На момент определения функции можно не знать, что это будет за операция. Это может быть любое лямбда-выражение, которое принимает два объекта типа Int и возвращает также объект типа Int.
В самой функции action вызываем эту операцию, передавая ей два числа, и полученный результат выводим на консоль.
При вызове функции action мы можем передать для ее третьего параметра лямбда-выражение, которое соответствует этому параметру по типу:
action(5, 3, add) action(5, 3, multiply) action(5, 3, {x: Int, y: Int -> x -y})
Возвращение функции из функции
В более редких случаях может потребоваться возвратить функцию из другой функции. В этом случае для функции в качестве возвращаемого типа устанавливается тип другой функции. А в теле функции возвращается лямбда выражение. Например:
fun selectAction(key: Int): (Int, Int) -> Int{ // определение возвращаемого результата when(key){ 1 -> return {x:Int, y: Int -> x + y} 2 -> return {x:Int, y: Int -> x - y} 3 -> return {x:Int, y: Int -> x * y} else -> return {x:Int, y: Int -> 0} } }
Здесь функция selectAction принимает один параметр — key, который представляет тип Int. В качестве возвращаемого типа у функции указан тип (Int, Int) -> Int. То есть selectAction будет возвращать некую функцию, которая принимает два параметра типа Int и возвращает объект типа Int.
В теле функции selectAction в зависимости от значения параметра key возвращается определенное лямбда-выражение, которое соответствует типу (Int, Int) -> Int.
Используем данную функцию:
fun main(args: Array<String>) { var action = selectAction(1) println(action(8,5)) // 13 action = selectAction(2) println(action(8,5)) // 3 } fun selectAction(key: Int): (Int, Int) -> Int{ // определение возвращаемого результата when(key){ 1 -> return {x:Int, y: Int -> x + y} 2 -> return {x:Int, y: Int -> x - y} 3 -> return {x:Int, y: Int -> x * y} else -> return {x:Int, y: Int -> 0} } }
Здесь переменная action хранит результат функции selectAction. Так как selectAction возвращает лямбда-выражение, то и переменная action будет хранить определенное лямбда-выражение. Затем через переменную action можно вызвать это лямбда-выражение. Поскольку лямбда-выражение соответствует типу (Int, Int) -> Int, то при его вызове ему необходимо передать два числа и соответственно мы можем получить его результат и вывести его на консоль.
Анонимные функции
Анонимные функции выглядят как обычные за тем исключением, что они не имеют имени. Анонимная функция может иметь одно выражение:
fun(x: Int, y: Int): Int = x + y
Либо может представлять блок кода:
fun(x: Int, y: Int): Int{ return x + y }
Анонимные функции используется только в качестве аргументов в других функциях. Например:
fun main(args: Array<String>) { operation(9, 5, fun(x: Int, y: Int): Int { return x + y }) // 14 operation(9, 5, fun(x: Int, y: Int): Int = x - y) // 4 } fun operation(x: Int, y: Int, op: (Int, Int) ->Int){ val result = op(x, y) println(result) }
Функция operation принимает три параметра. Первые два параметра — числа, а третий параметр — функция, которая выполняет некоторые действия над этими числами.
При вызове функции operation для третьего параметра в качестве аргумента передается анонимная функция, которая соответствует этому параметру по типу: (Int, Int) ->Int. То есть анонимная функция должна принимать два парамтра типа Int и возвращать значение типа Int.
Передача анонимной функции в данном случае аналогична передачи лямбда-выражения, в то же время лямбда-выражения представляют более лаконичный синтаксис, поэтому, как правило, в этой роли применяются лямбда-выражения.
Исключения
В любой, особенно большой, программе могут возникать ошибки, приводящие к ее неработоспособности или к тому, что программа делает не то, что должна. Причин возникновения ошибок много.
Программист может сделать ошибку в употреблении самого языка программирования. Другими словами, выразиться так, как выражаться не положено. Например, начать имя переменной с цифры или забыть поставить двоеточие в заголовке сложной инструкции. Подобные ошибки называют синтаксическими, они нарушают синтаксис и пунктуацию языка. IDE, встретив ошибочное выражение, не знает как его интерпретировать. Поэтому выводит соответствующее сообщение, указав на место возникновения ошибки.
Но случаются ошибки, которые происходят во время выполнения программы, например, деление на 0 или попытка открыть несуществующий файл. В таких случаях JVM «выбрасывает» исключение.
На этот случай в языках программирования, в том числе Котлин, существует специальный оператор, позволяющий перехватывать возникающие исключения и обрабатывать их так, чтобы программа продолжала работать или корректно завершала свою работу.
Классы исключений
Все исключения в Kotlin являются наследниками класса Throwable. У каждого исключения есть сообщение, трассировка стека, а также причина, по которой это исключение вероятно было вызвано.
Обычно исключения вызываются системой (деление на 0, попытка открыть не существующий файл…), но можно и самому возбудить исключение явным образом, для этого используется оператор throw
throw MyException("Hi There!")
try
Оператор try позволяет перехватывать исключения
try { // при возникновении исключения в этом блоке кода выполнение программы перейдет в блок catch } catch (e: SomeException) { // handler } catch (e: AnotherException) { // handler } finally { // этот блок выполнится всегда }
В коде может быть любое количество блоков catch (такие блоки могут и вовсе отсутствовать). Блоки finally могут быть опущены. Однако, должен быть использован как минимум один блок catch или finally.
Try — это выражение
Ключевое слово try является выражением, то есть оно может иметь возвращаемое значение.
val a: Int? = try { parseInt(input) } catch (e: NumberFormatException) { null }
Возвращаемым значением будет либо последнее выражение в блоке try, либо последнее выражение в блоке catch (или блоках). Содержимое finally блока никак не повлияет на результат try-выражения.
Регулярные выражения в Котлине
Для описания регулярных выражений в Котлине используется тип Regex. Для создания регулярного выражения следует вызвать его конструктор, например Regex(«KotlinAsFirst»). Второй способ создания регулярного выражения — вызов функции toRegex() на строке-получателе, например «KotlinAsFirst».toRegex().
При создании регулярных выражений вместо обычных строк в двойных кавычках рекомендуется использовать так называемые raw string literals (необработанные строки). Перед и после такого литерала должны стоять три двойных кавычки. Внутри необработанных строк не применяется экранирование, что позволяет применять специфичные для регулярных выражений символы без дополнительных ухищрений. Например: Regex(«»»x|+|-|*|/|(|)|d+?| +?»»») — задаёт выражение x, или +, или -, или …, или число, или любое количество пробелов. Без тройных кавычек нам пришлось бы дважды записать каждый из .
fun main(args: Array<String>){ // регулярное выражение создано конструтором с одним флагом val regex = Regex("""(d+)""", RegexOption.IGNORE_CASE) val res = regex.find("найдет только число 99, а число 22 не найдет") if(res!=null) for (r in res.groupValues) println(r) }
Программа выдаст:
Во втором варианте создадим регулярное выражение через метод строки:
fun main(args: Array<String>){ val regex = """(d+)""".toRegex(setOf(RegexOption.IGNORE_CASE, RegexOption.MULTILINE)) val res = regex.findAll("найдет число 99, и число 22 тоже") if(res!=null) for (r in res) for(r2 in r.groupValues.drop(1)) println(r2) }
Программа выдаст:
Для анализа результата поиска применяется тип MatchResult, который можно получить, вызвав find на регулярном выражении-получатале: Regex(«»»…»»»).find(string, startIndex). find ищет первое вхождение регулярного выражения в строку string, начиная с индекса startIndex (по умолчанию — 0). Если вхождений регулярного выражения не найдено, результат find равен null.
Regex(«»»…»»»).findAll(string, startIndex) ищет ВСЕ вхождения регулярного выражения, которые после этого можно перебрать с помощью цикла for.
Тип MatchResult включает в себя следующие свойства:
- result.value — подстрока исходной строки, с которой совпало регулярное выражение (совпадение)
- result.range — интервал индексов символов, в котором было найдено совпадение
- result.groupValues — список строк, 0-й элемент которого содержит всё регулярное выражение, а последующие содержат значения групп поиска из регулярного выражения (то есть размер списка равен числу групп поиска в выражении + 1)
Некоторые другие полезные методы, связанные:
- Regex(«»»…»»»).replace(«MyString», «Replacement») — находит в данной строке все вхождения регулярного выражения и заменяет их на `»Replacement»
- «MyString».contains(Regex(«»»…»»»)) — есть ли в данной строке хоть одно вхождение регулярного выражения
- Regex(«»»…»»»).containsMatchIn(«MyString») — то же самое, но в другом порядке
- «MyString».matches(Regex(«»»…»»»)) — соответствует ли данная строка данному регулярному выражению
- Regex(«»»…»»»).matches(«MyString») — то же самое, но в другом порядке
- Regex(«»»…»»»).split(«MyString») — деление строки на части с использованием заданного регулярного выражения как разделителя
Мини-пример:
fun timeStrToSeconds(str: String): Int { val matchResult = Regex("""(dd):(dd):(dd)""").find(str) if (matchResult == null) return -1 return matchResult.groupValues.drop(1).map { it.toInt() }.fold(0) { previous, next -> previous * 60 + next } }
Здесь мы разбираем исходную строку вида «12:34:56» с целью найти в ней три одинаковых группы поиска (dd). Каждая из групп поиска включает в себя две цифры. Убедившись с помощью проверки на null, что регулярное выражение успешно найдено, мы отбрасываем первый элемент groupValues с помощью функции drop(1), оставляя, таким образом, в списке только значения трёх групп поиска. Далее каждая из пар цифр конвертируется в число. Результат сворачивается в число секунд, прошедших с начала дня, с помощью функции высшего порядка fold
Асинхронное выполнение кода (Корутины)
Создание слишком большого количества потоков может на самом деле сделать приложение неэффективным в некоторых ситуациях; потоки — это объекты, которые накладывают накладные расходы во время размещения объектов и сборки мусора.
Чтобы преодолеть эти проблемы, Kotlin представил новый способ написания асинхронного неблокирующего кода: Coroutine (сопрограммы).
Подобно потокам, сопрограммы могут работать одновременно, ожидать и общаться друг с другом, с той разницей, что их создание намного дешевле, чем потоков.
Сопрограммы обеспечивают возможность избежать блокировки исполняющегося потока путём использования более дешёвой и управляемой операции: приостановки (suspend) сопрограммы.
Сопрограммы упрощают асинхронное программирование, оставив все осложнения внутри библиотек. Логика программы может быть выражена последовательно в сопрограммах, а базовая библиотека будет её реализовывать асинхронно. Библиотека может обернуть соответствующие части кода пользователя в обратные вызовы (callbacks), подписывающиеся на соответствующие события, и диспетчировать исполнение на различные потоки (или даже на разные машины!). Код при этом останется столь же простой, как если бы исполнялся строго последовательно.
Kotlin, как язык, предоставляет только минимальные низкоуровневые API в своей стандартной библиотеке, чтобы позволить различным другим библиотекам использовать сопрограммы.
Для работы с корутинами сделана библиотека kotlinx.coroutines. Она содержит ряд высокоуровневых примитивов с поддержкой корутин, которые рассматриваются ниже, включая запуск, асинхронность и другие.
Для того, чтобы использовать библиотеку в своем проекте, необходимо добавить ее в зависимости:
//build.graddle dependencies { ... implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.3.3' }
дальше перевод официальной доки
Основы
Здесь рассмотрим основные концепции.
Наша первая корутина
Запустите следующий код:
import kotlinx.coroutines.* fun main(){ // запускает новую корутину в фоне и ПРОДОЛЖАЕТ выполнение GlobalScope.launch { // НЕ блокирующая задержака на 1 секунду delay(1_000L) println("World!") } // код в основном потоке продолжает выполняться println("Hello,") // БЛОКИРУЮЩАЯ задержка на 2 сек Thread.sleep(2_000L) }
Увидим следующий результат:
Hello,
World! //выведет через секунду
По существу, корутины — это легкие потоки. Они запускаются с помощью launch coroutine builder в контексте некоторой области видимости Coroutine. Здесь мы запускаем новую сопрограмму в глобальной области, что означает, что время жизни новой сопрограммы ограничено только временем жизни всего приложения.
Аналогичный результат можно получить заменив GlobalScope.launch { … } на thread { … } и delay(…) на Thread.sleep(…).
Если попробовать использовать delay(…) в обычных потоках, то система выбросит исключение: Error: Kotlin: Suspend functions are only allowed to be called from a coroutine or another suspend function.
Это происходит потому, что delay это специальная suspending function, которая не блокирует поток, но приостанавливает корутину.
Смешивание блокирующих и неблокирующих методов
В первом примере мы смешивали блокирующие и не-блокирующие задержки. Чтобы не запутаться какой вызов блокирующий, а какой нет, можно явно указать блокирующий вызов используя runBlocking:
import kotlinx.coroutines.* fun main(){ // запускает новую корутину в фоне и ПРОДОЛЖАЕТ выполнение GlobalScope.launch { // НЕ блокирующая задержака на 1 секунду delay(1_000L) println("World!") } // код в основном потоке продолжает выполняться println("Hello,") // это выражение блокирует основной поток runBlocking { delay(2_000L) } }
Этот пример можно переписать по-другому:
fun main() = runBlocking<Unit> { GlobalScope.launch { delay(1000L) println("World!") } println("Hello,") delay(2000L) }
Мы весь код функции пометили как блокирующий.
Ожидание выполнения работы
Жесткое задание времени ожидания корутины плохая практика (нас извиняет что других способов мы пока не знаем).
Можно явно дождаться (не блокируя) завершения фонового задания:
fun main() = runBlocking<Unit> { val job = GlobalScope.launch { delay(1000L) println("World!") } println("Hello,") // ждем, пока выполнится корутина job.join() }
Теперь функция завершится сразу, как только завершится корутина.
Structured concurrency (упорядоченный параллелизм?)
Как бы ни мало процессорного времени занимали корутины, но все-равно они потребляют ресурсы (основного потока!), особенно если их много, а тем более если какие-то корутины из-за внутренних ошибок работают неправильно. Хранить ссылки на все корутины муторно и может привести к ошибкам.
Есть лучшее решение. Мы можем использовать Structured concurrency в нашем коде. Вместо того чтобы запускать сопрограммы в глобальной области, как мы обычно делаем с потоками (потоки всегда глобальны), мы можем запускать сопрограммы в конкретной области выполняемой нами операции.
В этом примере мы запускаем функцию main в корутине используя runBlocking Coroutine Builder (хз как это правильно перевести, строитель сопрограмм звучит криво). Каждый билдер добавляет CoroutineScope в область блока кода. Мы можем выполнять корутину без вызова метода join, т.к. внешняя корутина (runBlocking в нашем случае) не завершится, пока полностью не выполнится корутина запущенная в области. Т.о. мы можем упростить код:
fun main() = runBlocking<Unit> {//this: CoroutineScope launch { delay(1000L) println("World!") } println("Hello,") // убрали join }
Scope builder
В дополниние к областям предоставленным разными билдерами, мы можем объявить свою область, используя билдер coroutineScope. Он создает область и не завершает ее, пока не завершатся все вложенные корутины (дети).
runBlocking и coroutineScope выглядят похоже, т.к. обе ждут, пока не выполнится блок кода и вложенных детей. Основное отличие между ними в том, что runBlocking блокирует текущий поток, тогда как coroutineScope просто ожидает…
fun main() = runBlocking<Unit> { launch { delay(200L) println("[${Thread.currentThread().name}] Task from runBlocking") } coroutineScope { // Creates a coroutine scope launch { delay(500L) println("[${Thread.currentThread().name}] Task from nested launch") } delay(100L) println("[${Thread.currentThread().name}] Task from coroutine scope") // This line will be printed before the nested launch } println("[${Thread.currentThread().name}] Coroutine scope is over") }
[main] Task from coroutine scope
[main] Task from runBlocking
[main] Task from nested launch
[main] Coroutine scope is over
Обратите внимание, что сразу после сообщения «Task from coroutine scope», в ожидании вложенного запуска, выполняется и печатается «Task from runBlocking», хотя coroutineScope еще не завершен.
Оформим код в функцию
Просто вынесем содержимое блока кода внутри launch {…} в отдельную функцию. Для этой функции указываем модификатор suspend. Suspending функция может быть использована внутри корутин как обычная функция, но в ней доступны дополнительные возможности, такие как вызов других suspend функций, например delay.
import kotlinx.coroutines.* fun main() = runBlocking { launch { doWorld() } println("Hello,") } // это наша первая suspending функция suspend fun doWorld() { delay(1000L) println("World!") }
Корутины ОЧЕНЬ легкие
Предлагается выполнить следующий код:
import kotlinx.coroutines.* fun main() = runBlocking { repeat(100_000) { // launch a lot of coroutines launch { delay(1000L) print(".") } } }
Выполнится за секунду. А если использовать обычные потоки, то скорее всего получим ошибку нехватки памяти.
Глобальные корутины похожи на «демонов»
GlobalScope.launch { repeat(1000) { i -> println("I'm sleeping $i ...") delay(500L) } } delay(1300L) // just quit after delay
На выходе мы получим только 3 строки.
I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Корутины запущенные в GlobalScope не препятсствуют завершению процесса. Этим они и похожи на «демонов».
Прерывание работы и таймауты
Прерывание работы корутины
Мы можем не дожидаться выполнения корутины и в любое время завершить ее вызвав методом cancel() (GlobalScope не указан, значит корутина не в режиме демона и не даст завершиться приложению, пока не доработает до конца)
fun main() = runBlocking<Unit> { val job = launch { repeat(1000) { i -> println("job: I'm sleeping $i ...") delay(500L) } } delay(1300L) // delay a bit println("main: I'm tired of waiting!") job.cancel() // cancels the job job.join() // waits for job's completion println("main: Now I can quit.") }
job: I'm sleeping 0 ...
job: I'm sleeping 1 ...
job: I'm sleeping 2 ...
main: I'm tired of waiting!
main: Now I can quit.
У класса Job есть еще метод cancelAndJoin
Прерывания кооперативны
Это означает что ЛЮБАЯ корутина может быть прервана, но для этого она должна проверять свое состояние. Ниже приведен пример корутины, которая несмотря на вызов cancelAndJoin прервана не будет:
val startTime = System.currentTimeMillis() val job = launch(Dispatchers.Default) { var nextPrintTime = startTime var i = 0 while (i < 5) { // computation loop, just wastes CPU // print a message twice a second if (System.currentTimeMillis() >= nextPrintTime) { println("job: I'm sleeping ${i++} ...") nextPrintTime += 500L } } } delay(1300L) // delay a bit println("main: I'm tired of waiting!") job.cancelAndJoin() // cancels the job and waits for its completion println("main: Now I can quit.")
Делаем корутину прерываемой
Существует два способа. Первый что-то с yield, но примера нет. Второй — периодически проверять состояние прерывания:
Заменим проверку счетчика на проверку состояния (вообще это не хорошо, лучше бы обе проверки оставить…):
val startTime = System.currentTimeMillis() val job = launch(Dispatchers.Default) { var nextPrintTime = startTime var i = 0 while (isActive) { // cancellable computation loop // print a message twice a second if (System.currentTimeMillis() >= nextPrintTime) { println("job: I'm sleeping ${i++} ...") nextPrintTime += 500L } } } delay(1300L) // delay a bit println("main: I'm tired of waiting!") job.cancelAndJoin() // cancels the job and waits for its completion println("main: Now I can quit.")
Свойство isAlive видно внутри корутины через объект CoroutineScope.
Освобождайте ресурсы с помощью try .. finally
При прерывании корутины возникает исключение CancellationException, поэтому если есть какие-то открытые ресурсы, то их нужно завернуть в блок try .. finally (в примере ниже открытых ресурсов нет)
val job = launch { try { repeat(1000) { i -> println("job: I'm sleeping $i ...") delay(500L) } } finally { println("job: I'm running finally") } } delay(1300L) // delay a bit println("main: I'm tired of waiting!") job.cancelAndJoin() // cancels the job and waits for its completion println("main: Now I can quit.")
И метод join и метод cancelAndJoin ждут завершения блока finally (в принципе это и так понятно — они ждут завершения ВСЕЙ корутины)
Выполнение не прерываемого блока
Любая попытка использовать suspending функцию в блоке finally предыдущего примера вызывает исключение CancellationException, поскольку корутина, выполняющая этот код, в состоянии отмены. Как правило, это не проблема, так как все хорошо работающие операции закрытия (закрытие файла, отмена задания или закрытие любого канала связи) обычно не блокируются и не включают в себя какие-либо функции приостановки. Однако в редких случаях, когда вам нужно приостановить работу в отмененной корутине, вы можете обернуть соответствующий код в withContext (Nonancellable) {…} используя withContext функции и NonCancellable контекст, как показано в следующем примере:
val job = launch { try { repeat(1000) { i -> println("job: I'm sleeping $i ...") delay(500L) } } finally { withContext(NonCancellable) { println("job: I'm running finally") delay(1000L) println("job: And I've just delayed for 1 sec because I'm non-cancellable") } } } delay(1300L) // delay a bit println("main: I'm tired of waiting!") job.cancelAndJoin() // cancels the job and waits for its completion println("main: Now I can quit.")
Таймаут
Наиболее очевидная практическая причина отмены выполнения корутины заключается в том, что время ее выполнения превысило некоторый тайм-аут. В то время как вы можете вручную отслеживать ссылку на соответствующее задание и запускать отдельную корутину для отмены отслеживаемого после задержки, есть готовая к использованию функция withTimeout, которая делает это. Рассмотрим следующий пример:
withTimeout(1300L) { repeat(1000) { i -> println("I'm sleeping $i ...") delay(500L) } }
Программа выдаст:
I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Exception in thread "main" kotlinx.coroutines.TimeoutCancellationException: Timed out waiting for 1300 ms
Исключение TimeoutCancellationException, создаваемое withTimeout, является подклассом исключения CancellationException. Внутри отмененной сопрограммы исключение CancellationException считается нормальной причиной завершения сопрограммы. Однако в этом примере мы использовали withTimeout прямо внутри основной функции.
Поскольку отмена — это всего лишь исключение, все ресурсы закрываются обычным способом. Вы можете обернуть код с таймаутом в try {…} catch (e: TimeoutCancellationException) {…} блок, если необходимо выполнить какое-либо дополнительное действие специально для любого вида таймаута или использовать функцию withTimeoutOrNull, которая аналогична функции withTimeout, но возвращает значение null при таймауте, а не создает исключение:
val result = withTimeoutOrNull(1300L) { repeat(1000) { i -> println("I'm sleeping $i ...") delay(500L) } "Done" // will get cancelled before it produces this result } println("Result is $result")
I'm sleeping 0 ...
I'm sleeping 1 ...
I'm sleeping 2 ...
Result is null
Составление Suspending функций
В этом разделе рассматриваются различные подходы к составлению Suspending функций.
Последовательность действий по-умолчанию
Предположим, что у нас есть две suspending функции, которые делают что-то полезное, например, какой-то удаленный вызов службы или вычисление (в нашем примере каждая из них просто задерживается на секунду для примера):
suspend fun doSomethingUsefulOne(): Int { delay(1000L) // pretend we are doing something useful here return 13 } suspend fun doSomethingUsefulTwo(): Int { delay(1000L) // pretend we are doing something useful here, too return 29 }
Мы используем обычный последовательный вызов, т.к. код в корутине, как и в обычном коде по умолчанию является последовательным. В следующем примере измеряется время, затраченное на работу корутин:
val time = measureTimeMillis { val one = doSomethingUsefulOne() val two = doSomethingUsefulTwo() println("The answer is ${one + two}") } println("Completed in $time ms")
Видно, что общее время работы примерно равно сумме времени работы каждой функции:
The answer is 42
Completed in 2017 ms
Одновременный асинхронный запуск
Если выполнение функций не зависит друг от друга, то можно выполнить работу быстрее, запустив их одновременно. В этом нам поможет async.
Концептуально async — это то же самое, что и launch. Он запускает отдельную корутину, работающей одновременно со всеми другими корутинами. Разница в том, что launch возвращает Job и не несет никакого результирующего значения, в то время как async возвращает Deffered — легкое неблокирующее будущее, которое представляет собой обещание предоставить результат позже. Вы можете использовать метод .await() на отложенное значение, чтобы получить его конечный результат, но Deffered также является Job, поэтому вы можете отменить его при необходимости.
val time = measureTimeMillis { val one = async { doSomethingUsefulOne() } val two = async { doSomethingUsefulTwo() } println("The answer is ${one.await() + two.await()}") } println("Completed in $time ms")
По затраченному времени видно, что функции выполнялись параллельно и вся работа выполнена в два раза быстрее:
The answer is 42
Completed in 1017 ms
Отложенный асинхронный запуск
При необходимости, мы можем создать асинхронный блок, но его реальный запуск отложить (задав параметр start = CoroutineStart.LAZY). В этом случае запуск производится методом start:
val time = measureTimeMillis { val one = async(start = CoroutineStart.LAZY) { doSomethingUsefulOne() } val two = async(start = CoroutineStart.LAZY) { doSomethingUsefulTwo() } // some computation one.start() // start the first one two.start() // start the second one println("The answer is ${one.await() + two.await()}") } println("Completed in $time ms")
Таким образом, здесь две корутины созданы, но не выполняются. Программист сам решает когда именно начать выполнение, вызывая start.
Обратите внимание, что если мы просто вызовем await в println без вызова start, это приведет к последовательному выполнению, так как await запускает выполнение корутины и ждет ее завершения.
Асинхронные функции
Мы можем определить функции как асинхронные, используя async coroutine builder с явной ссылкой на GlobalScope. Мы называем такие функции с суффиксом «… Async», чтобы подчеркнуть тот факт, что они начинают асинхронные вычисления и нужно использовать полученное отложенное значение, чтобы получить результат.
// The result type of somethingUsefulOneAsync is Deferred<Int> fun somethingUsefulOneAsync() = GlobalScope.async { doSomethingUsefulOne() } // The result type of somethingUsefulTwoAsync is Deferred<Int> fun somethingUsefulTwoAsync() = GlobalScope.async { doSomethingUsefulTwo() }
Обратите внимание, что эти функции xxxAsync не являются suspend функциями. Они могут быть использованы из любого места. Однако их использование всегда подразумевает асинхронное (здесь имеется в виду параллельное) выполнение с вызывающим кодом.
В следующем примере показано их использование за пределами корутин:
// note that we don't have `runBlocking` to the right of `main` in this example fun main() { val time = measureTimeMillis { // we can initiate async actions outside of a coroutine val one = somethingUsefulOneAsync() val two = somethingUsefulTwoAsync() // but waiting for a result must involve either suspending or blocking. // here we use `runBlocking { ... }` to block the main thread while waiting for the result runBlocking { println("The answer is ${one.await() + two.await()}") } } println("Completed in $time ms") }
Этот стиль программирования с асинхронными функциями приведен здесь только для иллюстрации, потому что это популярный стиль в других языках программирования. Использование этого стиля в Kotlin категорически не рекомендуется по причинам, описанным ниже.
Рассмотрим, что произойдет, если между строкой val one = somethingUsefulOneAsync() и выражением one.await() в коде возникает некоторая логическая ошибка, и программа выдает исключение, а операция, выполняемая программой, прерывается. Обычно глобальный обработчик ошибок может перехватывать это исключение, регистрировать и сообщать об ошибке разработчикам, но в противном случае программа может продолжать выполнять другие операции. Но здесь у нас есть somethingUsefulOneAsync, все еще работающее в фоновом режиме, хотя операция, которая его инициировала, была прервана. Эта проблема не возникает со структурированным параллелизмом, как показано в разделе ниже.
Асинхронный структурированный параллелизм
Возьмем пример из Одновременный асинхронный запуск и извлечем функцию, которая одновременно выполняет doSomethingUsefulOne и doSomethingUsefulTwo и возвращает сумму их результатов. Поскольку async coroutine builder определяется как расширение в CoroutineScope, нам необходимо иметь его в области видимости, и именно это обеспечивает функция coroutineScope:
suspend fun concurrentSum(): Int = coroutineScope { val one = async { doSomethingUsefulOne() } val two = async { doSomethingUsefulTwo() } one.await() + two.await() }
Таким образом, если что-то пойдет не так в коде параллельной функции Sum и она выдаст исключение, все сопрограммы, запущенные в ее области видимости, будут отменены.
val time = measureTimeMillis { println("The answer is ${concurrentSum()}") } println("Completed in $time ms")
Операции по прежнему выполняются асинхронно:
The answer is 42
Completed in 1017 ms
Отмена всегда распространяется через иерархию корутин:
import kotlinx.coroutines.* fun main() = runBlocking<Unit> { try { failedConcurrentSum() } catch(e: ArithmeticException) { println("Computation failed with ArithmeticException") } } suspend fun failedConcurrentSum(): Int = coroutineScope { val one = async<Int> { try { delay(Long.MAX_VALUE) // Emulates very long computation 42 } finally { println("First child was cancelled") } } val two = async<Int> { println("Second child throws an exception") throw ArithmeticException() } one.await() + two.await() }
Обратите внимание, что и первый async (one) и ожидающий родитель (failedConcurrentSum) отменяются при сбое второго потомка:
Second child throws an exception
First child was cancelled
Computation failed with ArithmeticException
Корутины: контекст и диспетчеры
Корутины всегда выполняются в некотором контексте, представленном значением типа CoroutineContext, определенного в стандартной библиотеке Kotlin.
Контекст корутины — это набор различных элементов. Основными элементами являются Job, которую мы видели ранее, и ее диспетчер, который рассматривается в этом разделе.
Деспетчеры и потоки
Контекст корутины включает в себя coroutine dispatcher, который определяет, какой поток или потоки использует соответствующая корутина для своего выполнения. Диспетчер может ограничить выполнение корутины определенным потоком, отправить его в пул потоков или позволить ему работать неограниченно.
Все конструкторы корутин (coroutine builders), такие как launch и async, принимают необязательный параметр контекста сопрограммы, который можно использовать для явного указания диспетчера для новой корутины и других элементов контекста.
Попробуйте выполнить следующий пример:
import kotlinx.coroutines.* fun main() = runBlocking<Unit> { launch { // контекст родителя, main runBlocking println("main runBlocking : I'm working in thread ${Thread.currentThread().name}") } launch(Dispatchers.Unconfined) { // not confined - будет запущен в основном потоке println("Unconfined : I'm working in thread ${Thread.currentThread().name}") } launch(Dispatchers.Default) { // будет запущен в потоке DefaultDispatcher println("Default : I'm working in thread ${Thread.currentThread().name}") } launch(newSingleThreadContext("MyOwnThread")) { // запустся в созданном потоке println("newSingleThreadContext: I'm working in thread ${Thread.currentThread().name}") } }
Получим примерно следующее (порядок может отличаться):
Unconfined : I'm working in thread main
Default : I'm working in thread DefaultDispatcher-worker-1
main runBlocking : I'm working in thread main
newSingleThreadContext: I'm working in thread MyOwnThread
При запуске корутины без параметров (launch { … }) наследуется текущий контекст (и его диспетчер) от CoroutineScope. В нашем случае она наследует контекст корутины main runBlocking, которая выполняется в главном потоке.
Dispatchers.Unconfined — это специальный диспетчер, который также работает в основном потоке, но на самом деле это другой механизм, который будет объяснен позже.
Диспетчер по умолчанию, используемый при запуске корутины в GlobalScope, представлен Dispatchers.Default и использует общий фоновый пул потоков, поэтому launch(Dispatchers.Default) { ... } использует тот же диспетчер, что и GlobalScope.launch { ... }.
newSingleThreadContext создает поток для запуска сопрограммы. Выделенный поток — это очень дорогой ресурс. В реальном приложении он должен быть либо освобожден, когда больше не нужен, с помощью функции close, либо сохранен в переменной верхнего уровня и повторно использован в приложении.
Неограниченный (Unconfined) и ограниченный (confined) деспетчер
Dispatchers.Unconfined запускает корутину в вызывающем потоке, но только до первой точки приостановки (suspend функции). После приостановки он возобновляет работу сопрограммы в потоке, который полностью определяется вызванной функцией приостановки. Неограниченный диспетчер подходит для корутин, которые не потребляют процессорное время и не обновляют общие данные (например, пользовательский интерфейс).
С другой стороны, диспетчер наследуется от CoroutineScope по умолчанию. Диспетчер по умолчанию для runBlocking, в частности, ограничен потоком вызова, поэтому его наследование приводит к ограничению выполнения этим потоком с предсказуемым расписанием FIFO.
launch(Dispatchers.Unconfined) { // not confined -- will work with main thread println("Unconfined : I'm working in thread ${Thread.currentThread().name}") delay(500) println("Unconfined : After delay in thread ${Thread.currentThread().name}") } launch { // context of the parent, main runBlocking coroutine println("main runBlocking: I'm working in thread ${Thread.currentThread().name}") delay(1000) println("main runBlocking: After delay in thread ${Thread.currentThread().name}") }
Выведет следующее:
Unconfined : I'm working in thread main
main runBlocking: I'm working in thread main
Unconfined : After delay in thread kotlinx.coroutines.DefaultExecutor
main runBlocking: After delay in thread main
Итак, корутина с контекстом, унаследованным от runBlocking {…} продолжает выполняться в основном потоке, в то время как неограниченная возобновляется в потоке по умолчанию, который использует функция delay.
Неограниченный диспетчер — это усовершенствованный механизм, который может быть полезен в некоторых случаях, … . Неограниченный диспетчер не должен использоваться в общем коде.
Отладка курутин и потоков
Корутины могут приостанавливаться в одном потоке и возобновляться в другом потоке. Даже с однопоточным диспетчером было бы трудно понять, что делает корутина, где и когда. Общий подход к отладке приложений с потоками заключается в печати имени потока в файле журнала для каждой записи. Эта функция повсеместно поддерживается фреймворками ведения журнала. При использовании корутин имя потока само по себе не дает большого контекста, поэтому kotlinx.coroutines включает средства отладки, чтобы сделать его проще.
Запустите следующий код с JVM опцией -Dkotlinx.coroutines.debug:
val a = async { log("I'm computing a piece of the answer") 6 } val b = async { log("I'm computing another piece of the answer") 7 } log("The answer is ${a.await() * b.await()}")
Здесь у нас три корутины. Основная корутина (#1) внутри runBlocking и две корутины, вычисляющие отложенные значения a (#2) и b (#3). Все они выполняются в контексте runBlocking и ограничены основным потоком.
[main @coroutine#2] I'm computing a piece of the answer
[main @coroutine#3] I'm computing another piece of the answer
[main @coroutine#1] The answer is 42
Функция log выводит имя потока в квадратных скобках, и вы можете видеть, что это основной поток с добавленным к нему идентификатором текущей выполняемой корутины. Этот идентификатор последовательно присваивается всем созданным корутинам, когда включен режим отладки.
Переключение между потоками
Выполните следующий код с опцией JVM -Dkotlinx.coroutines.debug
newSingleThreadContext("Ctx1").use { ctx1 -> newSingleThreadContext("Ctx2").use { ctx2 -> runBlocking(ctx1) { log("Started in ctx1") withContext(ctx2) { log("Working in ctx2") } log("Back to ctx1") } } }
Он демонстрирует несколько новых методов. Один из них использует runBlocking с явно заданным контекстом, а другой использует функцию withContext для изменения контекста корутины, оставаясь при этом в той же самой корутине, как вы можете видеть ниже:
[Ctx1 @coroutine#1] Started in ctx1
[Ctx2 @coroutine#1] Working in ctx2
[Ctx1 @coroutine#1] Back to ctx1
Обратите внимание, что в этом примере используется функция use из стандартной библиотеки Kotlin для освобождения потоков, созданных с помощью newSingleThreadContext.
Job в контексте
Объект job корутины является частью его контекста и может быть получен с помощью выражения coroutineContext[Job]:
println("My job is ${coroutineContext[Job]}")
В отладочном режиме получим что-то типа:
My job is "coroutine#1":BlockingCoroutine{Active}@6d311334
Потомки корутины
Когда корутина запускается в CoroutineScope другой корутины, она наследует свой контекст от CoroutineScope.coroutineContext и новая корутина становится дочерней по отношению к родительской корутине. Когда родительская корутина отменяется, все ее дочерние элементы также рекурсивно отменяются.
Однако если для запуска корутины используется GlobalScope, то для нее нет родителя. Поэтому корутина не привязана к области, из которой она была запущена, и работает независимо.
// launch a coroutine to process some kind of incoming request val request = launch { // эта корутина будет запущена в GlobalScope GlobalScope.launch { println("job1: I run in GlobalScope and execute independently!") delay(1000) println("job1: I am not affected by cancellation of the request") } // а эта в контексте родителя launch { delay(100) println("job2: I am a child of the request coroutine") delay(1000) println("job2: I will not execute this line if my parent request is cancelled") } } delay(500) request.cancel() // cancel processing of the request delay(1000) // delay a second to see what happens println("main: Who has survived request cancellation?")
На выходе получим:
job1: I run in GlobalScope and execute independently!
job2: I am a child of the request coroutine
job1: I am not affected by cancellation of the request
main: Who has survived request cancellation?
Родительская ответственность
Родительская корутина всегда ожидает завершения всех своих потомков. Родителю не нужно явно отслеживать всех детей, которых он запускает,и не нужно использовать Job.join, чтобы дождаться их завершения:
// launch a coroutine to process some kind of incoming request val request = launch { repeat(3) { i -> // launch a few children jobs launch { delay((i + 1) * 200L) // variable delay 200ms, 400ms, 600ms println("Coroutine $i is done") } } println("request: I'm done and I don't explicitly join my children that are still active") } request.join() // wait for completion of the request, including all its children println("Now processing of the request is complete")
На выходе получим:
request: I'm done and I don't explicitly join my children that are still active
Coroutine 0 is done
Coroutine 1 is done
Coroutine 2 is done
Now processing of the request is complete
Присвоение имен корутинам для отладки
Автоматически назначенные идентификаторы хороши, когда корутины часто регистрируются, и вам просто нужно сопоставить записи журнала, поступающие из одной и той же корутины. Однако, когда корутина связана с обработкой конкретного запроса или выполнением какой-то конкретной фоновой задачи, ее лучше называть явно для целей отладки. Элемент контекста CoroutineName служит той же цели, что и имя потока. Он включается в имя потока, выполняющего эту корутину, когда включен режим отладки.
log("Started main coroutine") // run two background value computations val v1 = async(CoroutineName("v1coroutine")) { delay(500) log("Computing v1") 252 } val v2 = async(CoroutineName("v2coroutine")) { delay(1000) log("Computing v2") 6 } log("The answer for v1 / v2 = ${v1.await() / v2.await()}")
При запуске с JVM ключем -Dkotlinx.coroutines.debug выведет:
[main @main#1] Started main coroutine
[main @v1coroutine#2] Computing v1
[main @v2coroutine#3] Computing v2
[main @main#1] The answer for v1 / v2 = 42
Комбинирование элементов контекста
Для определения нескольких элементов контекста мы можем использовать оператор «+». Например, мы можем запустить корутину с явно заданным диспетчером и явно заданным именем:
launch(Dispatchers.Default + CoroutineName("test")) { println("I'm working in thread ${Thread.currentThread().name}") }
Область видимости корутины
Давайте объединим наши знания о контекстах, детях и job. Предположим, что приложение имеет объект, и этот объект не является корутиной. Например, мы пишем приложение для Android и запускаем различные корутины в контексте Android activity для выполнения асинхронных операций по извлечению и обновлению данных, анимации и т. д. Все эти корутины должны быть отменены при уничтожении активности, чтобы избежать утечки памяти. Мы, конечно, можем манипулировать контекстами и job вручную, чтобы связать activity и ее корутины, но kotlinx.coroutines предоставляет абстракцию, инкапсулирующую это: CoroutineScope. Вы должны быть уже знакомы с областью действия coroutine, так как все конструкторы корутин объявляются в ней как расширения.
Мы управляем жизненными циклами наших корутин, создавая экземпляр CoroutineScope, привязанный к жизненному циклу нашей activity. Экземпляр CoroutineScope может быть создан с помощью фабричных функций CoroutineScope() или MainScope(). Первый создает область общего назначения, в то время как второй создает область для приложений пользовательского интерфейса и использует Dispatchers.Main диспетчером по умолчанию:
class Activity { private val mainScope = MainScope() fun destroy() { mainScope.cancel() } // to be continued ...
В качестве альтернативы мы можем реализовать интерфейс CoroutineScope в этом классе Activity. Лучший способ сделать это — использовать делегирование с фабричными функциями по умолчанию. Мы также можем объединить нужный диспетчер (мы использовали Dispatchers.Default в этом примере) с областью действия:
class Activity : CoroutineScope by CoroutineScope(Dispatchers.Default) { // to be continued ...
Теперь мы можем запускать корутины в рамках этой activity без необходимости явно указывать их контекст. Для демонстрации мы запускаем десять корутин, которые задерживаются на разное время:
// class Activity continues fun doSomething() { // launch ten coroutines for a demo, each working for a different time repeat(10) { i -> launch { delay((i + 1) * 200L) // variable delay 200ms, 400ms, ... etc println("Coroutine $i is done") } } } } // class Activity ends
В основной функции мы создаем activity, вызываем нашу тестовую функцию doSomething и через 500 мс уничтожаем activity. При уничтожении activity отменятся все корутины, которые были запущены из doSomething.
val activity = Activity() activity.doSomething() // run test function println("Launched coroutines") delay(500L) // delay for half a second println("Destroying activity!") activity.destroy() // cancels all coroutines delay(1000) // visually confirm that they don't work
Это видно по логам:
Launched coroutines
Coroutine 0 is done
Coroutine 1 is done
Destroying activity!
Видно, что только первые две корутины печатают сообщение, а остальные отменяются вызовом job.cancel() в Activity.destroy().
локальные данные потока (thread) — не понятно, переварить и переписать
Иногда удобно иметь возможность передавать некоторые локальные данные в корутины или между ними.
В этом нам поможет функция asContextElement из ThreadLocal. Она создает дополнительный элемент контекста, который сохраняет значение данного ThreadLocal и восстанавливает его каждый раз, когда корутина переключает свой контекст.
Легче показать на примере:
threadLocal.set("main") println("Pre-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'") val job = launch(Dispatchers.Default + threadLocal.asContextElement(value = "launch")) { println("Launch start, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'") yield() println("After yield, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'") } job.join() println("Post-main, current thread: ${Thread.currentThread()}, thread local value: '${threadLocal.get()}'")
В этом примере мы запускаем новую корутину в фоновом пуле потоков с помощью Dispatchers.Default, поэтому он может работает в потоке, отличном от текущего, но все равно имеет значение локальной переменной потока, заданной с помощью threadLocal.asContextElement (value = «launch»). Таким образом, вывод (с включенной отладкой) будет:
Pre-main, current thread: Thread[main @coroutine#1,5,main], thread local value: 'main'
Launch start, current thread: Thread[DefaultDispatcher-worker-1 @coroutine#2,5,main], thread local value: 'launch'
After yield, current thread: Thread[DefaultDispatcher-worker-2 @coroutine#2,5,main], thread local value: 'launch'
Post-main, current thread: Thread[main @coroutine#1,5,main], thread local value: 'main'
Легко забыть установить соответствующий элемент контекста. Локальная переменная потока, доступная из корутины, может иметь неожиданное значение, если поток, выполняющий корутину, отличается. Чтобы избежать таких ситуаций, рекомендуется использовать метод ensurePresent.
ThreadLocal может использоваться с любыми примитивами kotlinx.coroutines. Однако у него есть одно ключевое ограничение: при изменении локального потока новое значение не передается вызывающему объекту корутины (поскольку элемент контекста не может отслеживать все обращения к объекту ThreadLocal), и обновленное значение теряется при следующей приостановке. Используйте withContext для обновления значения threadlocal в корутине, см. asContextElement для получения более подробной информации.
Кроме того, значение может храниться в изменяемом поле типа class Counter(var i: Int), которое, в свою очередь, хранится в локальной переменной потока. Однако в этом случае вы несете полную ответственность за синхронизацию потенциально одновременных изменений переменной в этом изменяемом поле.
Для расширенного использования, например для интеграции с журналированием MDC, транзакционными контекстами или любыми другими библиотеками, которые внутренне используют локальные потоки для передачи данных, см. документацию интерфейса ThreadContextElement, который должен быть реализован.
Асинхронные потоки
Suspend функции асинхронно возвращают одно значение, но как мы можем вернуть несколько асинхронно вычисленных значений? Вот тут-то и появляются потоки Котлина.
Представление нескольких значений
Несколько значений могут быть представлены с помощью коллекций. Например, у нас может быть функция foo(), которая возвращает список из трех чисел:
fun foo(): List<Int> = listOf(1, 2, 3) fun main() { foo().forEach { value -> println(value) } }
Последовательности
Если мы вычисляем числа с некоторым блокирующим кодом, потребляющим процессор (каждое вычисление занимает 100 мс), то мы можем представить числа с помощью Sequence:
fun foo(): Sequence<Int> = sequence { // конструктор последовательностей for (i in 1..3) { Thread.sleep(100) // симулируем вычисления yield(i) // yield next value } } fun main() { foo().forEach { value -> println(value) } }
На выходе мы получим тот же результат, но перед выводом значений будет задержка 100 мс.
// TODO: включить в лекции sequences и yield
Функцию yield() мы раньше не рассматривали. Она возвращает значение итератора и приостанавливает (suspend) работу до тех пор, пока не будет запрошено следующее значение.
Приостановка (Suspending) функций
Однако это вычисление блокирует основной поток, который выполняет код. Когда эти значения вычисляются асинхронным кодом, мы можем пометить функцию foo модификатором suspend, чтобы она могла выполнять свою работу без блокировки и возвращать результат в виде списка:
suspend fun foo(): List<Int> { delay(1000) // pretend we are doing something asynchronous here return listOf(1, 2, 3) } fun main() = runBlocking<Unit> { foo().forEach { value -> println(value) } }
Потоки (Flows)
Использование типа результата List означает, что мы можем возвращать только все значения сразу. Для представления потока значений, которые вычисляются асинхронно, мы можем использовать тип Flow так же, как и тип Sequence для синхронно вычисляемых значений:
fun foo(): Flow<Int> = flow { // конструктор потоков for (i in 1..3) { delay(100) // pretend we are doing something useful here emit(i) // emit next value } } fun main() = runBlocking<Unit> { // Launch a concurrent coroutine to check if the main thread is blocked launch { for (k in 1..3) { println("I'm not blocked $k") delay(100) } } // Collect the flow foo().collect { value -> println(value) } }
Этот код ожидает 100 мс перед печатью каждого числа, не блокируя основной поток. Это подтверждается печатью «I’m not blocked» каждые 100 мс из отдельной корутины, которая выполняется в основном потоке:
I'm not blocked 1
1
I'm not blocked 2
2
I'm not blocked 3
3
Обратите внимание на следующие отличия кода с потоком от предыдущих примеров:
- Конструктор корутин для типа Flow называется flow.
- Код внутри блока flow { … } можно приостановить.
- Функция foo () больше не помечена модификатором suspend.
- Значения испускаются (emitted) из потока с помощью функции emit.
- Значения собираются из потока с помощью функции collect.
Потоки холодные (Flows are cold)
Flows — это холодные потоки, похожие на последовательности: код внутри конструктора потоков не запускается, пока поток не собран. Это становится ясно в следующем примере:
fun foo(): Flow<Int> = flow { println("Flow started") for (i in 1..3) { delay(100) emit(i) } } fun main() = runBlocking<Unit> { println("Calling foo...") val flow = foo() println("Calling collect...") flow.collect { value -> println(value) } println("Calling collect again...") flow.collect { value -> println(value) } }
Calling foo...
Calling collect...
Flow started
1
2
3
Calling collect again...
Flow started
1
2
3
Это ключевая причина, по которой функция foo () (которая возвращает поток) не помечена модификатором suspend. Сам по себе foo() возвращается быстро и ничего не ждет. Поток запускается каждый раз, когда он собирается, поэтому мы видим, что «поток запущен», когда мы снова вызываем collect.
Отмена потока
Поток придерживается общей кооперативной отмены корутин. Однако инфраструктура потока не вводит дополнительных точек отмены. Он полностью прозрачен для отмены. Обычно, сбор потока может быть отменен, когда поток приостановлен в suspend функции приостановки (например, delay), и не может быть отменен иначе.
В следующем примере показано, как поток отменяется по таймауту при выполнении в блоке withTimeoutOrNull:
fun foo(): Flow<Int> = flow { for (i in 1..3) { delay(100) println("Emitting $i") emit(i) } } fun main() = runBlocking<Unit> { withTimeoutOrNull(250) { // Timeout after 250ms foo().collect { value -> println(value) } } println("Done") }
Обратите внимание, что поток успел сгенерировать только два числа:
Emitting 1
1
Emitting 2
2
Done
Конструкторы потоков (Flow builders)
Конструктор flow { ... } из предыдущих примеров является самым базовым. Однако есть и другие конструкторы для облегчения декларирования потоков:
- конструктор flowOf, определяющий поток, генерирующий фиксированный набор значений.
- Различные коллекции и последовательности могут быть преобразованы в потоки с помощью функции asFlow().
Пример, который выводит числа от 1 до 3 из потока, может быть записан как:
// Convert an integer range to a flow (1..3).asFlow().collect { value -> println(value) }
Операторы промежуточного потока
Потоки могут быть преобразованы с помощью операторов, так же как и с помощью коллекций и последовательностей. Промежуточные операторы применяются к восходящему потоку и возвращают нисходящий поток. Эти операторы холодны, как и потоки. Вызов такого оператора сам по себе не является функцией приостановки. Он работает быстро, возвращая определение нового преобразованного потока.
Основные операторы имеют знакомые названия: map и filter. Важным отличием последовательностей является то, что блоки кода внутри этих операторов могут вызывать функции приостановки.
Например, поток входящих запросов может быть сопоставлен с результатами с помощью оператора map, даже если выполнение запроса является длительной операцией, которая реализуется suspend функцией:
suspend fun performRequest(request: Int): String { delay(1000) // imitate long-running asynchronous work return "response $request" } fun main() = runBlocking<Unit> { (1..3).asFlow() // a flow of requests .map { request -> performRequest(request) } .collect { response -> println(response) } }
Этот пример выведет три строки, каждая строка появляется с задержкой в секунду:
response 1 response 2 response 3
Оператор Transform
Среди операторов преобразования потока наиболее общим является так называемый transform. Он может использоваться для имитации простых преобразований, таких как map и filter, а также для реализации более сложных преобразований. Используя оператор transform, мы можем генерировать (emit) произвольные значения произвольное число раз.
Например, с помощью transform мы можем выдать строку перед выполнением длительного асинхронного запроса и следовать за ней с ответом:
(1..3).asFlow() // a flow of requests .transform { request -> emit("Making request $request") emit(performRequest(request)) } .collect { response -> println(response) }
Making request 1
response 1
Making request 2
response 2
Making request 3
response 3
Операторы ограничения размера
Промежуточные операторы ограничения размера, такие как take, отменяют выполнение потока при достижении соответствующего предела. Отмена в корутинах всегда выполняется путем создания исключения, поэтому нужно использовать функции управления ресурсами (например, try { … } finally { … }):
fun numbers(): Flow<Int> = flow { try { emit(1) emit(2) println("This line will not execute") emit(3) } finally { println("Finally in numbers") } } fun main() = runBlocking<Unit> { numbers() .take(2) // take only the first two .collect { value -> println(value) } }
В логах видно, что выполнение блока flow { … } в функции numbers() остановилось после генерации второго числа:
ООП
Класс и объект
// объявление класса с помощью ключевого слова class class Transformer(var x: Int){ // объявление метода run fun run(){ // обращение к собственному атрибуту x += 1 } } // а теперь клиентский код: // создаем новый экземпляр трансформера с начальной позицией 0 var optimus = Transformer(0) optimus.run() // приказываем Оптимусу бежать println( optimus.x ) // выведет 1 optimus.run() // приказывает Оптимусу еще раз бежать print( optimus.x ) // выведет 2
Что мы видим из кода?
-
Объект может обращаться из своих методов к собственным атрибутам (у нас аттрибут x). Обращаю внимание, что только к собственным, то бишь, когда трансформер вызывает свой метод, либо меняет собственное состояние. Если снаружи обращение будет выглядеть так: optimus.x, то изнутри, если Оптимус захочет сам обратиться к своему полю x, в его методе обращение будет звучать так: x, то есть «я (Оптимус) обращаюсь к своему атрибуту x». В большинстве языков для обращения к аттрибутам класса используются ключевые слова this или self, но в Котлине обходятся без них.
-
constructor — это специальный метод, который автоматически вызывается при создании объекта. Конструктор может принимать любые аргументы, как и любой другой метод. В каждом языке конструктор обозначается своим именем. Где-то это специально зарезервированные имена типа
__constructили__init__, а где-то имя конструктора должно совпадать с именем класса. Назначение конструкторов — произвести первоначальную инициализацию объекта, заполнить нужные поля. Про конструкторы мы подробнее поговорим ниже, а в нашем примере конструктор присутствует сразу при объявлении класса — это круглые скобки с параметром, который, в свою очередь является аттрибутом класса. -
В котлине для создания экземпляра класса нужно вызвать конструктор класса (как фкнкцию). В этот момент создается объект и вызывается конструктор. В нашем примере, конструктору передается 0 в качестве стартовой позиции трансформера (это и есть вышеупомянутая инициализация).
-
Методы constructor и run работают с внутренним состоянием, а во всем остальном не отличаются от обычных функций. Даже синтаксис объявления совпадает.
Основные принципы ООП.
Ортодоксальная ООП-церковь проповедует нам фундаментальную троицу — инкапсуляцию, полиморфизм и наследование, на которых зиждется весь объектно-ориентированный подход. Разберем их по порядку.
Наследование
Наследование — это механизм системы, который позволяет, как бы парадоксально это не звучало, наследовать одними классами свойства и поведение других классов для дальнейшего расширения или модификации.
class Transformer { // базовый класс fun run(){ // код, отвечающий за бег } fun fire(){ // код, отвечающий за стрельбу } } class Autobot : Transformer() { // дочерний класс, наследование от Transformer fun transform(){ // код, отвечающий за трансформацию в автомобиль } } class Decepticon : Transformer() { // дочерний класс, наследование от Transformer fun transform(){ // код, отвечающий за трансформацию в самолет } } optimus = new Autobot() megatron = new Decepticon()
Этот пример наглядно иллюстрирует, как наследование становится одним из способов избежать дублирования кода с помощью родительского класса, и одновременно предоставляет возможности для мутации в классах-потомках.
Перегрузка
Если же в классе-потомке переопределить уже существующий в классе-родителе метод, то сработает перегрузка. Это позволяет не дополнять поведение родительского класса, а модифицировать. В момент вызова метода или обращения к полю объекта, поиск атрибута происходит от потомка к самому корню — родителю. То есть, если у автобота вызвать метод fire(), сначала поиск метода производится в классе-потомке — Autobot, а поскольку его там нет, поиск поднимается на ступень выше — в класс Transformer, где и будет обнаружен и вызван.
Полиморфизм
Полиморфизм — свойство системы, позволяющее иметь множество реализаций одного интерфейса. Ничего непонятно. Обратимся к трансформерам.
Инкапсуляция
Инкапсуляция — это контроль доступа к полям и методам объекта. Под контролем доступа подразумевается не только можно/неможно, но и различные валидации, подгрузки, вычисления и прочее динамическое поведение.
Во многих языках частью инкапсуляции является сокрытие данных. Для этого существуют модификаторы доступа (опишем те, которые есть почти во всех ООП языках):
publiс — к атрибуту может получить доступ любой желающий
private — к атрибуту могут обращаться только методы данного класса
protected — то же, что и private, только доступ получают и наследники класса в том числе
class Transformer { public fun constructor(){ } protected fun setup(){ } private fun dance(){ } }
Как правильно выбрать модификатор доступа? В простейшем случае так: если метод должен быть доступен внешнему коду, выбираем public. В противном случае — private. Если есть наследование, то может потребоваться protected в случае, когда метод не должен вызываться снаружи, но должен вызываться потомками.
Абстрактные классы
Кроме обычных классов в некоторых языках существуют абстрактные классы. От обычных классов они отличаются тем, что нельзя создать объект такого класса. Зачем же нужен такой класс, спросит читатель? Он нужен для того, чтобы от него могли наследоваться потомки — обычные классы, объекты которых уже можно создавать.
Абстрактный класс наряду с обычными методами содержит в себе абстрактные методы без реализации (с названием, но без кода), которые обязан реализовать программист, задумавший создать класс-потомок. Абстрактные классы не обязательны, но они помогают установить контракт, обязующий реализовать определенный набор методов.
Интерфейсы
Задача интерфейса — снизить уровень зависимости сущностей друг от друга, добавив больше абстракции.
Выше мы рассматривали абстрактные классы, затрагивая тему контрактов, обязующих реализовать какие-то абстрактные методы. Так вот интерфейс очень смахивает на абстрактный класс, но является не классом, а просто пустышкой с перечислением абстрактных методов.
Интерфейсы в Kotlin, однако, могут содержать как абстрактные методы, тик и методы с реализацией. Главное отличие интерфейсов от абстрактных классов заключается в невозможности хранения переменных экземпляров. Они могут иметь свойства, но те должны быть либо абстрактными, либо предоставлять реализацию методов доступа.
Обычно в языках, в которых есть интерфейсы, нет множественного наследования классов, но есть множественное наследование интерфейсов. Это позволяет классу перечислить интерфейсы, которые он обязуется реализовать.
Классы с интерфейсами состоят в отношении «многие ко многим»: один класс может имплементировать множество интерфейсов, и каждый интерфейс, в свою очередь, может имплементироваться многими классами.
// описания интерфейсов:
interface Weapon { fun fire() // декларация метода без имплементации. Ниже аналогично } interface EnergyGenerator { // тут уже два метода, которые должны будут реализовать классы: fun generate_energy() // первый fun load_fuel() // второй } interface Scanner { fun scan() } // классы, реализующие интерфейсы: class RocketLauncher : Weapon { override fun fire(){ // имплементация запуска ракеты } } class LaserGun : Weapon { override fun fire(){ // имплементация выстрела лазером } } class NuclearReactor : EnergyGenerator { override fun generate_energy(){ // имплементация генерации энергии ядерным реактором } override fun load_fuel(){ // имплементация загрузки урановых стержней } } class RITEG : EnergyGenerator { override fun generate_energy(){ // имплементация генерации энергии РИТЭГ } override fun load_fuel(){ // имплементация загрузки РИТЭГ-пеллет } } class Radar : Scanner { override fun scan(){ // имплементация использования радиолокации } } class Lidar : Scanner { override fun scan(){ // имплементация использования оптической локации } } // класс - потребитель: class Transformer { // привет, композиция: // Интерфейсы указаны в качестве типов данных. // Они могут принимать любые объекты, // которые имплементируют указанный интерфейс private var slot_weapon: Weapon? = null private var slot_energy_generator: EnergyGenerator? = null private var slot_scanner: Scanner? = null /* в параметрах методов интерфейс тоже указан как тип данных, метод может принимать объект любого класса, имплементирующий данный интерфейс: */ fun install_weapon(weapon: Weapon){ slot_weapon = weapon } fun install_energy_generator(energy_generator: EnergyGenerator ){ slot_energy_generator = energy_generator } function install_scanner(scanner: Scanner){ slot_scanner = scanner } } // фабрика трансформеров class TransformerFactory { fun build_some_transformer { transformer = Transformer() laser_gun = LaserGun() nuclear_reactor = NuclearReactor() radar = Radar() transformer.install_weapon(laser_gun) transformer.install_energy_generator(nuclear_reactor) transformer.install_scanner(radar) return transformer } } // использование transformer_factory = TransformerFactory() oleg = transformer_factory.build_some_transformer()
От теории к практике
Классы в Kotlin объявляются с помощью использования ключевого слова class:
Объявление класса состоит из ключевого слова class, имени класса (помним, что в котлине названия типов данных начинаются с большой буквы), заголовка (указания типов его параметров, основного конструктора и т.п) и тела класса, заключённого в фигурные скобки. И заголовок, и тело класса являются необязательными составляющими: если у класса нет тела, фигурные скобки могут быть опущены.
Конструкторы
Конструктор — это метод, который будет выполнен при создании экземпляра класса. В нем, обычно, производится инициализация данных.
Класс в Kotlin может иметь основной конструктор (primary constructor) и дополнительные конструкторы (secondary constructors). Основной конструктор является частью заголовка класса, его объявление идёт сразу после имени класса (и необязательных параметров):
class Transformer constructor(firstName: String)
Если у конструктора нет аннотаций и модификаторов видимости, ключевое слово constructor может быть опущено:
class Transformer(firstName: String)
Основной конструктор не может содержать в себе исполняемого кода. Инициализирующий код может быть помещён в соответствующий блок (initializers blocks), который помечается словом init:
class Transformer(name: String) { init { logger.info("Transformer initialized with value ${name}") } }
Обратите внимание, что параметры основного конструктора фактически являются свойствами класса и могут быть использованы в его методах и других свойствах:
class Transformer(name: String) { val transformerAlias = name.toUpperCase() }
В действительности, для объявления и инициализации свойств основного конструктора в Kotlin есть лаконичное синтаксическое решение:
class Transformer(val firstName: String, val lastName: String, var age: Int) { // ... }
Дополнительные конструкторы
В классах также могут быть объявлены дополнительные конструкторы (secondary constructors), перед которыми используется ключевое слово constructor:
class Transformer { constructor(parent: Person) { parent.children.add(this) } }
Если у класса есть основной конструктор, каждый дополнительный конструктор должен прямо или косвенно ссылаться (через другой(ие) конструктор(ы)) на основной:
class Transformer(val name: String) { constructor(name: String, parent: Person) : this(name) { parent.children.add(this) } }
Создание экземпляров классов
Для создания экземпляра класса конструктор вызывается так, как если бы он был обычной функцией:
val transformer = Transformer() val Transformer2 = Transformer("Joe Smith")
Члены класса
Классы могут содержать в себе:
- Конструкторы и инициализирующие блоки
- Функции
- Свойства
- Вложенные классы
- Объявления объектов
Наследование
Для всех классов в языке Koltin родительским суперклассом является класс Any. Он также является родительским классом для любого класса, в котором не указан какой-либо другой родительский класс:
class Example // Неявно наследуется от Any
Класс Any не является аналогом java.lang.Object. В частности, у него нет никаких членов кроме методов: equals(), hashCode(), и toString().
Для явного объявления суперкласса (предка, от которого наследуемся) мы помещаем его имя за знаком двоеточия в оглавлении класса:
open class Transformer {...} class Autobot(p: Int) : Transformer()
Если у класса есть основной конструктор, базовый класс может (и должен) быть проинициализирован там же, с использованием параметров основного конструктора.
Если у класса нет основного конструктора, тогда каждый последующий дополнительный конструктор должен включать в себя инициализацию базового класса с помощью ключевого слова super или давать отсылку на другой конструктор, который это делает. Примечательно, что любые дополнительные конструкторы могут ссылаться на разные конструкторы базового класса:
class MyView : View { constructor(ctx: Context) : super(ctx) { } constructor(ctx: Context, attrs: AttributeSet) : super(ctx, attrs) { } }
Ключевое слово open является противоположностью слову final в Java: оно позволяет другим классам наследоваться от данного. По умолчанию, все классы в Kotlin имеют статус final.
Переопределение членов класса
Как упоминалось ранее, мы придерживаемся идеи определённости и ясности в языке Kotlin. И, в отличие от Java, Kotlin требует чёткой аннотации и для членов, которые могут быть переопределены, и для самого переопределения:
open class Base { open fun v() {} fun nv() {} } class Derived() : Base() { override fun v() {} }
Для метода Derived.v() необходима аннотация override. В случае её отсутствия компилятор выдаст ошибку. Если у метода Base.nv() нет аннотации open, объявление метода с такой же сигнатурой в производном классе невозможно, с override или без. В final классе (классе без аннотации open), запрещено использование аннотации open для его членов.
Метод класса, помеченный override, является сам по себе open, т.е. он может быть переопределён в производных классах. Если вы хотите запретить возможность переопределения такого члена, используйте final:
open class AnotherDerived() : Base() { final override fun v() {} }
Правила переопределения
В Kotlin правила наследования реализации определены следующим образом: если класс наследует многочисленные реализации одного и того метода от ближайших родительских классов, он должен переопределить этот член и обеспечить свою собственную реализацию (возможно, используя одну из унаследованных). Для того, чтобы отметить конкретный супертип (родительский класс), от которого мы наследуем данную реализацию, мы используем ключевое слово super. Для задания имени родительского супертипа используются треугольные скобки, например super:
open class A { open fun f() { print("A") } fun a() { print("a") } } interface B { fun f() { print("B") } // члены интерфейса открыты ('open') по умолчанию fun b() { print("b") } } class C() : A(), B { // Компилятор требует, чтобы f() была переопределена: override fun f() { super<A>.f() // вызов A.f() super<B>.f() // вызов B.f() } }
Для метода f() у нас есть две реализации, унаследованные классом C, поэтому необходимо переопределить метод f() в классе C и обеспечить нашу собственную реализацию этого метода для устранения получившейся неоднозначности.
Абстрактные классы
Класс и некоторые его члены могут быть объявлены как abstract. Абстрактный метод не имеет реализации в своём классе. Обратите внимание, что нам не надо аннотировать абстрактный класс или функцию словом open — это подразумевается и так.
Свойства и поля
Объявление свойств
Классы в Kotlin могут иметь свойства: изменяемые (mutable) и неизменяемые (read-only) — var и val соответственно (т.е. выглядят как обычные переменные).
public class Address { public var name: String = ... public var street: String = ... public var city: String = ... public var state: String? = ... public var zip: String = ... }
Для того, чтобы воспользоваться свойством, мы просто обращаемся к его имени:
fun copyAddress(address: Address): Address { val result = Address() // нет никакого слова `new` result.name = address.name // получаем свойство класса result.street = address.street // ... return result }
Свойства с поздней инициализацией
Обычно, свойства, объявленные non-null типом, должны быть проинициализированы в конструкторе. Однако, довольно часто это неосуществимо. К примеру, свойства могут быть инициализированы через внедрение зависимостей, в установочном методе (ориг.: «setup method») юнит-теста или в методе onCreate в Android. В таком случае вы не можете обеспечить non-null инициализацию в конструкторе, но всё равно хотите избежать проверок на null при обращении внутри тела класса к такому свойству.
Для того, чтобы справиться с такой задачей, вы можете пометить свойство модификатором lateinit:
public class MyTest { lateinit var subject: TestSubject @SetUp fun setup() { subject = TestSubject() } @Test fun test() { subject.method() // объект инициализирован, проверять на null не нужно } }
Такой модификатор может быть использован только с var свойствами, объявленными внутри тела класса (не в основном конструкторе, и только тогда, когда свойство не имеет пользовательских геттеров и сеттеров) и, начиная с Kotlin 1.2, со свойствами, расположенными на верхнем уровне, и локальными переменными. Тип такого свойства должен быть non-null и не должен быть примитивным.
Доступ к lateinit свойству до того, как оно проинициализировано, выбрасывает специальное исключение, которое чётко обозначает, что свойство не было определено.
Проверка инициализации lateinit var (начиная с версии 1.2)
Чтобы проверить, было ли проинициализировано lateinit var свойство, используйте .isInitialized метод ссылки на это свойство:
if (foo::bar.isInitialized) { println(foo.bar) }
Реализация интерфейсов
Класс или объект могут реализовать любое количество интерфейсов:
class Child : MyInterface { override fun bar() { // тело } }
Модификаторы доступа
Классы, объекты, интерфейсы, конструкторы, функции, свойства и их сеттеры могут иметь модификаторы доступа (у геттеров всегда такая же видимость, как у свойств, к которым они относятся). В Kotlin предусмотрено четыре модификатора доступа: private, protected, internal и public. Если явно не используется никакого модификатора доступа, то по умолчанию применяется public.
Пакеты
Функции, свойства, классы, объекты и интерфейсы могут быть объявлены на самом «высоком уровне» прямо внутри пакета:
// имя файла: example.kt package foo fun baz() {} class Bar {}
- Если вы не укажете никакого модификатора доступа, будет использован public. Это значит, что весь код данного объявления будет виден в глобальной области видимости;
- Если вы пометите объявление словом private, оно будет видно только внутри файла, где было объявлено;
- Если вы используете internal, видимость будет распространяться на весь модуль;
- protected запрещено использовать в объявлениях «высокого уровня».
Примеры:
// имя файла: example.kt package foo private fun foo() {} // имеет видимость внутри example.kt public var bar: Int = 5 // свойство видно со дна Марианской впадины private set // сеттер видно только внутри example.kt internal val baz = 6 // имеет видимость внутри модуля
Классы и интерфейсы
Для методов, объявленых в классе:
- private означает видимость только внутри этого класса;
- protected — то же самое, что и private + видимость в потомках;
- internal — любой клиент внутри модуля, который видит объявленный класс, видит и его internal члены;
- public — любой клиент, который видит объявленный класс, видит его public члены.
Примеры:
open class Outer { private val a = 1 protected open val b = 2 internal val c = 3 val d = 4 // public по умолчанию protected class Nested { public val e: Int = 5 } } class Subclass : Outer() { // a не видно // b, c и d видно // класс Nested и его свойство e видно override val b = 5 // 'b' - protected } class Unrelated(o: Outer) { // o.a, o.b не видно // o.c и o.d видно (тот же модуль) // Outer.Nested не видно, и Nested::e также не видно }
Конструкторы
Для указания видимости основного конструктора класса используется следующий синтаксис:
class C private constructor(a: Int) { ... }
В этом примере конструктор является private. По умолчанию все конструкторы имеют модификатор доступа public, то есть видны везде, где виден сам класс (а вот конструктор internal класса видно только в том же модуле).
Расширения (extensions)
Аналогично таким языкам программирования, как C# и Gosu, Kotlin позволяет расширять класс путём добавления нового функционала. Не наследуясь от такого класса и не используя паттерн «Декоратор». Это реализовано с помощью специальных выражений, называемых расширения. Kotlin поддерживает функции-расширения и свойства-расширения.
Функции-расширения
Для того, чтобы объявить функцию-расширение, нам нужно указать в качестве префикса расширяемый тип, то есть тип, который мы расширяем. Следующий пример добавляет функцию swap к MutableList:
fun MutableList<Int>.swap(index1: Int, index2: Int) { val tmp = this[index1] // 'this' даёт ссылку на список this[index1] = this[index2] this[index2] = tmp }
Ключевое слово this внутри функции-расширения соотносится с объектом расширяемого типа. Теперь мы можем вызывать такую функцию в любом MutableList:
val l = mutableListOf(1, 2, 3) l.swap(0, 2) // 'this' внутри 'swap()' будет содержать значение 'l'
Разумеется, эта функция имеет смысл для любого MutableList, и мы можем сделать её обобщённой:
fun <T> MutableList<T>.swap(index1: Int, index2: Int) { val tmp = this[index1] // 'this' относится к списку this[index1] = this[index2] this[index2] = tmp }
Расширение null-допустимых типов
Обратите внимание, что расширения могут быть объявлены для null-допустимых типов. Такие расширения могут ссылаться на переменные объекта, даже если значение переменной равно null. В таком случае есть возможность провести проверку this == null внутри тела функции. Благодаря этому метод toString() в языке Koltin вызывается без проверки на null: она проходит внутри функции-расширения.
fun Any?.toString(): String { if (this == null) return "null" // после проверки на null, `this` автоматически приводится к не-null типу, // поэтому toString() обращается (ориг.: resolves) к функции-члену класса Any return toString() }
Область видимости расширений
Чаще всего мы объявляем расширения на самом верхнем уровне, то есть сразу под пакетами:
package foo.bar fun Baz.goo() { ... }
Для того, чтобы использовать такое расширение вне пакета, в котором оно было объявлено, нам надо импортировать его на стороне вызова:
package com.example.usage import foo.bar.goo // импортировать все расширения за именем "goo" // или import foo.bar.* // импортировать все из "foo.bar" fun usage(baz: Baz) { baz.goo() )
Классы данных
Нередко мы создаём классы, единственным назначением которых является хранение данных. Функционал таких классов зависит от самих данных, которые в них хранятся. В Kotlin класс может быть отмечен словом data:
data class User(val name: String, val age: Int)
Такой класс называется классом данных. Компилятор автоматически формирует следующие члены данного класса из свойств, объявленных в основном конструкторе:
- пару функций equals()/hashCode(),
- функцию toString() в форме «User(name=John, age=42)»,
- компонентные функции componentN(), которые соответствуют свойствам, в соответствии с порядком их объявления,
- функцию copy() (см. ниже)
Если какая-либо из этих функций явно определена в теле класса (или унаследована от родительского класса), то генерироваться она не будет.
Для обеспечения согласованности и осмысленного поведения сгенерированного кода классы данных должны удовлетворять следующим требованиям:
- Основной конструктор должен иметь как минимум один параметр;
- Все параметры основного конструктора должны быть отмечены, как val или var;
- Классы данных не могут быть абстрактными, open, sealed или inner;
- (до версии 1.1) Классы данных не могут наследоваться от других классов (но могут реализовывать интерфейсы).
Дополнительно, генерация членов классов данных при наследовании подчиняется следующим правилам:
- Если существуют явные реализации equals(), hashCode() или toString() в теле класса данных или конечные (final) реализации в суперклассе, то эти функции не генерируются, а используются существующие реализации;
- Если суперкласс включает функции componentN(), которые являются открытыми и возвращают совместимые типы, соответствующие компонентные функции создаются для класса данных и переопределяют функции суперкласса. Если функции суперкласса не могут быть переопределены из-за несовместимости сигнатур или являются конечными (final), выдаётся сообщение об ошибке;
- Наследование класса данных от типа, который уже имеет функцию copy(…) с совпадающей сигнатурой не рекомендуется в Kotlin 1.2 и запрещена в Kotlin 1.3;
- Предоставление явных реализаций для функций componentN() и copy() не допускается.
Для того, чтобы у сгенерированного в JVM класса был конструктор без параметров, значения всех свойств должны быть заданы по умолчанию
data class User(val name: String = "", val age: Int = 0)
Свойства, объявленные в теле класса
Обратите внимание, что компилятор использует только свойства, определенные в основном конструкторе для автоматически созданных функций. Чтобы исключить свойство из автоматически созданной реализации, объявите его в теле класса:
data class Person(val name: String) { var age: Int = 0 }
Только свойство name будет учитываться в реализациях функций toString(), equals(), hashCode() и copy(), и будет создана только одна компонентная функция component1(). Даже если два объекта класса Person будут иметь разные значения свойств age, они будут считаться равными.
val person1 = Person("John") val person2 = Person("John") person1.age = 10 person2.age = 20 println("${person1 == person2}") // выведет "true"
Контрольные вопросы
Null safety
Нулевые типы и ненулевые типы
Система типов Kotlin направлена на устранение опасности нулевых ссылок, также известной как « Ошибка на миллиард долларов» .
Одна из наиболее распространенных ошибок во многих языках программирования, включая Java, заключается в том, что доступ к члену нулевой ссылки приведет к исключению нулевой ссылки. В Java это будет эквивалентно NullPointerException NullPointerException сокращенно NPE .
Единственными возможными причинами NPE в Kotlin являются:
-
Явный вызов
throw NullPointerException(). -
Использование
!!оператор, описанный ниже. -
Несогласованность данных при инициализации,например,когда:
-
Неинициализированное
this, доступное в конструкторе, передается и где-то используется («утечкаthis»). -
Конструктор суперкласса вызывает открытый член , реализация которого в производном классе использует неинициализированное состояние.
-
-
Java interoperation:
-
Попытки получить доступ к элементу
nullссылки типа платформы ; -
Проблемы с возможностью обнуления с универсальными типами, используемыми для взаимодействия с Java. Например, фрагмент кода Java может добавить
nullв KotlinMutableList<String>, поэтому для работы с ним требуетсяMutableList<String?>. -
Другие проблемы,вызванные внешним Java-кодом.
-
В Kotlin система типов различает ссылки, которые могут содержать null (ссылки, допускающие значение NULL), и ссылки, которые не могут (ссылки, отличные от NULL). Например, обычная переменная типа String не может содержать null :
fun main() { var a: String = "abc" a = null }
Чтобы разрешить значения NULL, вы можете объявить переменную как строку, допускающую значение NULL, написав String? :
fun main() { var b: String? = "abc" b = null print(b) }
Теперь, если вы вызываете метод или получаете доступ к свойству в a , это гарантированно не вызовет NPE, поэтому вы можете смело сказать:
val l = a.length
Но если вы хотите получить доступ к тому же свойству на b , это будет небезопасно, и компилятор сообщает об ошибке:
val l = b.length
Но вам все равно нужно получить доступ к этому имуществу,верно? Есть несколько способов сделать это.
Проверка наличия null в условиях
Во- первых, вы можете явно проверить b является null , и обрабатывать два варианта отдельно:
val l = if (b != null) b.length else -1
Компилятор отслеживает информацию о выполненной вами проверке и позволяет length вызова внутри if . Также поддерживаются более сложные условия:
fun main() { val b: String? = "Kotlin" if (b != null && b.length > 0) { print("String of length ${b.length}") } else { print("Empty string") } }
Обратите внимание, что это работает только там, где b является неизменным (это означает, что это локальная переменная, которая не изменяется между проверкой и ее использованием, или это член val , который имеет резервное поле и не может быть переопределен), потому что в противном случае это могло быть так что b меняется на null после проверки.
Safe calls
Второй вариант доступа к свойству переменной, допускающей значение NULL, — это использование оператора безопасного вызова ?. :
fun main() { val a = "Kotlin" val b: String? = null println(b?.length) println(a?.length) }
Это возвращает b.length , если b не равно нулю, и null в противном случае. Тип этого выражения — Int? .
Безопасные вызовы полезны в цепочках.Например,Боб-сотрудник,который может быть приписан к отделу (или нет).В этом отделе,в свою очередь,может быть другой сотрудник,являющийся начальником отдела.Чтобы узнать имя начальника отдела Боба (если он есть),вы напишете следующее:
bob?.department?.head?.name
Такая цепочка возвращает null если какое-либо из свойств в ней равно null .
Чтобы выполнить определенную операцию только для ненулевых значений, вы можете использовать оператор безопасного вызова вместе с let :
fun main() { val listWithNulls: List<String?> = listOf("Kotlin", null) for (item in listWithNulls) { item?.let { println(it) } } }
Безопасный вызов также можно разместить слева от задания. Затем, если один из получателей в цепочке безопасных вызовов имеет значение null , присвоение пропускается, а выражение справа вообще не оценивается:
// If either `person` or `person.department` is null, the function is not called: person?.department?.head = managersPool.getManager()
Elvis operator
Когда у вас есть ссылка b , допускающая значение NULL, вы можете сказать: «Если b не равно null , используйте его, в противном случае используйте какое-нибудь ненулевое значение»:
val l: Int = if (b != null) b.length else -1
Вместо того, чтобы писать полное выражение if , вы также можете выразить это с помощью оператора Элвиса ?: ::
val l = b?.length ?: -1
Если выражение слева от ?: Не равно null , оператор Элвиса возвращает его, в противном случае он возвращает выражение справа. Обратите внимание, что выражение в правой части оценивается только в том случае, если левая часть равна null .
Поскольку throw и return являются выражениями в Kotlin, их также можно использовать в правой части оператора Элвиса. Это может быть удобно, например, при проверке аргументов функции:
fun foo(node: Node): String? { val parent = node.getParent() ?: return null val name = node.getName() ?: throw IllegalArgumentException("name expected") }
Оператор !!!
Третий вариант предназначен для любителей NPE: оператор утверждения ненулевого значения ( !! ) преобразует любое значение в ненулевой тип и выдает исключение, если значение равно null . Можно написать b!! , и это вернет ненулевое значение b (например, String в нашем примере) или выдаст NPE, если b равно null :
val l = b!!.length
Таким образом, если вам нужен NPE, вы можете его получить, но вы должны запросить его явно, и он не появится на ровном месте.
Safe casts
Регулярное приведение типов может привести к ClassCastException если объект не относится к целевому типу. Другой вариант — использовать безопасные приведения, которые возвращают null , если попытка не удалась:
val aInt: Int? = a as? Int
Коллекции нулевого типа
Если у вас есть коллекция элементов обнуляемого типа и вы хотите отфильтровать ненулевые элементы, вы можете сделать это с помощью filterNotNull :
val nullableList: List<Int?> = listOf(1, 2, null, 4) val intList: List<Int> = nullableList.filterNotNull()
Последнее изменение: 06 сентября 2022 г.
Kotlin
1.8
-
Вложенные и внутренние классы
Классы могут быть вложены друг в друга. Также можно использовать интерфейсы с вложением.
-
плагин компилятора No-arg
Плагин компилятора без аргументов создает дополнительный конструктор без аргументов для классов с определенной аннотацией.
-
Numbers
Kotlin предоставляет набор встроенных типов,которые представляют числа.
-
Выражения и объявления объектов
Иногда вам нужно создать объект, который является небольшой модификацией класса, без явного объявления нового подкласса для выражений объекта, создающих объекты.
Nullable типы и Non-Null типы
Система типов в Kotlin нацелена на то, чтобы искоренить опасность обращения к null значениям, более известную как
«Ошибка на миллиард».
Самым распространённым подводным камнем многих языков программирования, в том числе Java, является попытка произвести
доступ к null значению. Это приводит к ошибке. В Java такая ошибка называется NullPointerException (сокр. NPE).
В Kotlin NPE могут возникать только в случае:
- Явного указания
throw NullPointerException(); - Использования оператора
!!(описано ниже); - Несоответствие данных в отношении инициализации, например, когда:
- Неинициализированное
this, доступное в конструкторе, передается и где-то используется («утечкаthis«); - Конструктор суперкласса вызывает open элемент, реализация которого в производном классе использует неинициализированное состояние.
- Неинициализированное
- Эту ошибку вызвал внешний Java-код:
- Попытка получить доступ к элементу
nullзначения платформенного типа; - Проблемы с обнуляемостью при использовании обобщённых типов для взаимодействия с Java. Например, фрагмент кода Java может добавить
nullв KotlinMutableList<String>, поэтому для работы с ним требуетсяMutableList<String?>; - Другие проблемы, вызванные внешним Java-кодом.
- Попытка получить доступ к элементу
Система типов Kotlin различает ссылки на те, которые могут иметь значение null (nullable ссылки) и те, которые
таковыми быть не могут (non-null ссылки). К примеру, переменная часто используемого типа String не может быть null.
var a: String = "abc" // Обычная инициализация означает non-null значение по умолчанию
a = null // ошибка компиляции
Для того чтобы разрешить null значение, вы можете объявить эту строковую переменную как String?.
var b: String? = "abc" // null-значения возможны
b = null // ok
Теперь, при вызове метода с использованием переменной a, исключены какие-либо NPE. Вы спокойно можете писать:
val l = a.length
Но в случае, если вы захотите получить доступ к значению b, это будет небезопасно. Компилятор предупредит об ошибке:
val l = b.length // ошибка: переменная `b` может быть null
Но вам по-прежнему нужен доступ к этому свойству/значению, верно? Есть несколько способов этого достичь.
Проверка на null
Первый способ: вы можете явно проверить b на null значение и обработать два варианта по отдельности.
val l = if (b != null) b.length else -1
Компилятор отслеживает информацию о проведённой вами проверке и позволяет вызывать length внутри блока if.
Также поддерживаются более сложные конструкции:
if (b != null && b.length > 0) {
print("Строка длиной ${b.length}")
} else {
print("Пустая строка")
}
Обратите внимание: это работает только в том случае, если b является неизменной переменной (ориг.: immutable).
Например, если это локальная переменная, значение которой не изменяется в период между его проверкой и использованием,
или переменная val, которая имеет теневое поле и не может быть переопределено. В противном случае может так оказаться,
что переменная b изменила своё значение на null после проверки.
Безопасные вызовы
Вторым способом доступа к свойству nullable переменной — это использование оператора безопасного вызова ?..
val a = "Kotlin"
val b: String? = null
println(b?.length)
println(a?.length) // Ненужный безопасный вызов
Этот код возвращает b.length в том, случае, если b не имеет значение null. Иначе он возвращает null. Типом этого
выражения будет Int?.
Такие безопасные вызовы полезны в цепочках. К примеру, если Bob (Боб), Employee (работник), может быть прикреплён (или
нет) к отделу Department, и у отдела может быть управляющий, другой Employee. Для того чтобы обратиться к имени этого
управляющего (если такой есть), напишем:
bob?.department?.head?.name
Такая цепочка вернёт null в случае, если одно из свойств имеет значение null.
Для проведения каких-либо операций исключительно над non-null значениями вы можете использовать
let оператор вместе с оператором безопасного вызова.
val listWithNulls: List<String?> = listOf("Kotlin", null)
for (item in listWithNulls) {
item?.let { println(it) } // выводит Kotlin и игнорирует null
}
Безопасный вызов также может быть размещен в левой части присвоения. Затем, если один из получателей в цепочке
безопасных вызовов равен null, присвоение пропускается, а выражение справа вообще не вычисляется.
// Если значение `person` или `person.department` равно null, функция не вызывается
person?.department?.head = managersPool.getManager()
Элвис-оператор
Если у вас есть nullable ссылка b, вы можете либо провести проверку этой ссылки и использовать её, либо использовать
non-null значение:
val l: Int = if (b != null) b.length else -1
Вместо того чтобы писать полное if-выражение, вы можете использовать элвис-оператор ?:.
val l = b?.length ?: -1
Если выражение, стоящее слева от Элвис-оператора, не является null, то элвис-оператор его вернёт. В противном случае
в качестве возвращаемого значения послужит то, что стоит справа. Обращаем ваше внимание на то, что часть кода,
расположенная справа, выполняется ТОЛЬКО в случае, если слева получается null.
Так как throw и return тоже являются выражениями в Kotlin, их также можно использовать справа от Элвис-оператора.
Это может быть крайне полезным для проверки аргументов функции.
fun foo(node: Node): String? {
val parent = node.getParent() ?: return null
val name = node.getName() ?: throw IllegalArgumentException("name expected")
// ...
}
Оператор !!
Для любителей NPE существует третий способ: оператор not-null (!!) преобразует любое значение в non-null тип и выдает
исключение, если значение равно null. Вы можете написать b!! и это вернёт нам либо non-null значение b
(в нашем примере вернётся String), либо выкинет NPE, если b равно null.
val l = b!!.length
В случае, если вам нужен NPE, вы можете заполучить её только путём явного указания.
Безопасные приведения типов
Обычное приведение типа может вызвать ClassCastException в случае, если объект имеет другой тип.
Можно использовать безопасное приведение, которое вернёт null, если попытка не удалась.
val aInt: Int? = a as? Int
Коллекции nullable типов
Если у вас есть коллекция nullable элементов и вы хотите отфильтровать все non-null элементы, используйте функцию filterNotNull.
val nullableList: List<Int?> = listOf(1, 2, null, 4)
val intList: List<Int> = nullableList.filterNotNull()
Последнее обновление: 30.05.2021
Ключевое слово null представляет специальный литерал, который указывает, что переменная не имеет как такового значения. То есть у нее по сути отсутствует значение.
val n = null println(n) // null
Подобное значение может быть полезно в ряде ситуациях, когда необходимо использовать данные, но при этом точно неизвестно, а есть ли в реальности
эти данные. Например, мы получаем данные по сети, данные могут прийти или не прийти. Либо может быть ситуация, когда нам надо явным образом указать, что
данные не установлены.
Однако переменным стандартных типов, например, типа Int или String или любых других классов, мы не можем просто взять и присвоить значение null:
val n : Int = null // ! Ошибка, переменная типа Int допускает только числа
Мы можем присвоить значение null только переменной, которая представляет тип Nullable. Чтобы превратить обычный тип в тип nullable, достаточно поставить после названия типа
вопросительный знак:
// val n : Int = null //! ошибка, Int не допускает значение null val d : Int? = null // норм, Int? допускает значение null
При этом мы можем передавать переменным nullable-типов как значение null, так и конкретные значения, которые укладываются в диапазон значений данного типа:
var age : Int? = null age = 34 // Int? допускает null и числа var name : String? = null name = "Tom" // String? допускает null и строки
Nullable-типы могут представлять и создаваемые разработчиком классы:
fun main() {
var bob: Person = Person("Bob")
// bob = null // ! Ошибка - bob представляет тип Person и не допускает null
var tom: Person? = Person("Tom")
tom = null // норм - tom представляет тип Person? и допускает null
}
class Person(val name: String)
В то же время надо понимать, что String? и Int? — это не то же самое, что и String и Int. Nullable типы имеют ряд ограничений:
-
Значения nullable-типов нельзя присвоить напрямую переменным, которые не допускают значения null
var message : String? = "Hello" val hello: String = message // ! Ошибка - hello не допускает значение null
-
У объектов nullable-типов нельзя вызвать напрямую те же функции и свойства, которые есть у обычных типов
var message : String? = "Hello" // у типа String свойство length возвращает длину строки println("Message length: ${message.length}") // ! Ошибка -
Нельзя передавать значения nullable-типов в качестве аргумента в функцию, где требуется конкретное значение, которое не может представлять null
Оператор ?:
Одним из преимуществ Kotlin состоит в том, что его система типов позволяет определять проблемы, связанные с использованием null, во время компиляции,
а не во время выполнения. Например, возьмем следующий код:
var name : String? = "Tom" val userName: String = name // ! Ошибка
Переменная name хранит строку «Tom». Переменная userName представляет тип String и тоже может хранить строки, но тем не менее напрямую
в данном случае мы не можем передать значение из переменной name в userName. В данном случае для компилятора неизвестно, каким значением
инициализирована переменная name. Ведь переменная name может содержать и значение null, которое недопустимо для типа String.
В этом случае мы можем использовать оператор ?:, который позволяет предоставить альтернативное значение, если присваиваемое
значение равно null:
var name : String? = "Tom" val userName: String = name ?: "Undefined" // если name = null, то присваивается "Undefined" var age: Int? = 23 val userAge: Int = age ?:0 // если age равно null, то присваивается число 0
Оператор ?: принимает два операнда. Если первый операнд не равен null, то возвращается значение первого операнда. Если
первый операнд равен null, то возвращается значение второго операнда.
То есть это все равно, если бы мы написали:
var name : String? = "Tom"
val userName: String
if(name!=null){
userName = name
}
Но оператор ?: позволяет сократить подобную конструкцию.
Оператор ?.
Оператор ?. позволяет объединить проверку значения объекта на null и обратиться к функциям или свойствам этого объекта.
Например, у строк есть свойство length, которое возвращает длину строки в символах. У объекта String? мы просто так не можем обратиться к свойству length,
так как если объект String? равен null, то и строки как таковой нет, и соответственно длину строки нельзя определить. И в этом случае мы можем применить оператор
?.:
var message : String? = "Hello" val length: Int? = message?.length
Если переменная message вдруг равна null, то переменная length получит значение null.
Если переменная name содержит строку, то возвращается длина этой строки.
По сути выражение val length: Int? = message?.length эквивалентно следующему коду:
val length: Int? if(message != null) length = message.length else length = null
С помощью оператора ?. подобным образом можно обращаться к любым свойствам и функциям объекта.
Также в данном случае мы могли совместить оба выше рассмотренных оператора:
val message : String? = "Hello" val length: Int = message?.length ?:0
Теперь переменная length не допускает значения null. И если переменная name не определена, то length получает число 0.
Используя этот оператор, можно создавать цепочки проверок на null:
fun main() {
var tom: Person? = Person("Tom")
val tomName: String? = tom?.name?.uppercase()
println(tomName) // TOM
var bob: Person? = null
val bobName: String? = bob?.name?.uppercase()
println(bobName) // null
var sam: Person? = Person(null)
val samName: String? = sam?.name?.uppercase()
println(samName) // null
}
class Person(val name: String?)
Здесь класс Person в первичном конструкторе принимает значение типа String?, то есть это можт быть строка, а может быть null.
Допустим, мы хотим получить переданное через конструктор имя пользователя в верхнем регистре (заглавными буквами). Для перевода текста в верхний регистр у
класса String есть функция uppercase(). Однако может сложиться ситуация, когда либо объект Person равен null, либо его свойство name (
которое представляет тип String?) равно null. И в этом случае перед вызовом функции uppercase() нам надо проверять на null все эти объекты. А оператор
?. позволяет сократить код проверки:
val tomName: String? = tom?.name?.uppercase()
То есть если tom не равен null, то обращаемся к его свойству name. Далее если name не равен null, то обращаемся
к ее функции uppercase(). Если какое-то звено в этой проверки возвратит null, переменная tomName тоже будет равна null.
Но здсь мы также можем избежать финального возвращения null и присвоить значение по умолчанию:
val tomName: String = tom?.name?.uppercase() ?: "Undefined"
Оператор !!
Оператор !! (not-null assertion operator) принимает один операнд. Если операнд равен null, то генерируется исключение.
Если операнд не равен null, то возвращается его значение.
fun main() {
try {
val name : String? = "Tom"
val id: String = name!!
println(id)
} catch (e: Exception) { println(e.message)}
}
Поскольку данный оператор возвращает объект, который не представляет nullable-тип, то после применения оператора мы можем обратиться к методам и свойствам этого
объекта:
val name : String? = null val length :Int = name!!.length