
Области управления ошибками; конфигурацией; доступом; производительностью; безопасностью.
Любая сложная вычислительная сеть требует дополнительных специальных
средств управления помимо тех, которые имеются в стандартных сетевых ОС. Это
связано с большим количеством разнообразного коммуникационного оборудования,
работа которого критична для выполнения сетью своих основных функций.
Распределенный характер крупной корпоративной сети делает невозможным
поддержание ее работы без централизованной системы управления, которая в
автоматическом режиме собирает информацию о состоянии каждого концентратора,
коммутатора, мультиплексора и маршрутизатора и предоставляет эту информацию
оператору сети. Обычно система управления работает в автоматизированном режиме,
выполняя наиболее простые действия по управлению сетью автоматически, а сложные
решения предоставляя принимать человеку на основе подготовленной системой
информации. Система управления должна быть интегрированной. Это означает, что
функции управления разнородными устройствами должны служить общей цели
обслуживания конечных пользователей сети с заданным качеством.
Сами системы управления представляют собой сложные программно-аппаратные
комплексы, поэтому существует граница целесообразности применения системы
управления – она зависит от сложности сети, разнообразия применяемого
коммуникационного оборудования и степени его распределенности по территории. В
небольшой сети можно применять отдельные программы управления наиболее сложными
устройствами, например, коммутатором, поддерживающим технику VLAN. Обычно каждое устройство, которое требует достаточно
сложного конфигурирования, производитель сопровождает автономной программой
конфигурирования и управления. Однако при росте сети может возникнуть проблема
объединения разрозненных программ управления устройствами в единую систему
управления, и для решения этой проблемы придется, возможно, отказаться от этих
программ и заменить их интегрированной системой управления.
Функции и архитектура
систем управления сетями
Задачи управления
Системы управления корпоративными сетями существуют не очень давно. Одной
из первых систем такого назначения, получившей широкое распространения, был
программный продукт SunNet Manager, выпущенный в 1989 году компанией SunSoft.
SunNet Manager был ориентирован
на управление коммуникационным оборудованием и контроль трафика сети. Именно
эти функции имеют чаще всего в виду, когда говорят о системе управления сетью.
Кроме систем управления сетями существуют и системы управления другими
элементами корпоративной сети: системы управления ОС, СУБД, корпоративными
приложениями. Применяются также системы управления телекоммуникационными
сетями: телефонными, а также первичными сетями технологий PDHи SDH.
Независимо от объекта управления, желательно, чтобы система управления
выполняла ряд функций, которые определены международными стандартами,
обобщающими опыт применения систем управления в различных областях. Существуют
рекомендации ITU-T X.700 и близкий к
ним стандарт ISO 7498-4, которые
делят задачи системы управления на пять функциональных групп:
- управление конфигурацией сети и именованием;
- обработка ошибок;
- анализ производительности и надежности;
- управление безопасностью;
- учет работы сети.
Рассмотрим задачи этих функциональных областей управления применительно к
системам управления сетями.
Управление конфигурацией
сети и именованием (Configuration Management). Эти задачи заключаются в
конфигурировании параметров как элементов сети (Network Element, NE), так и сети в целом. Для элементов сети, таких как
маршрутизаторы, мультиплексоры и т.п., с помощью этой группы задач определяются
сетевые адреса, идентификаторы (имена), географическое положение и пр.
Для сети в целом управление конфигурацией обычно начинается с построения
карты сети, т.е. отображении реальных связей между элементами сети и изменении
связей между элементами сети – образование новых физических или логических
каналов, изменение таблиц коммутации и маршрутизации.
Управление конфигурацией (как и другие задачи системы управления) могут
выполняться в автоматическом, ручном или полуавтоматическом режимах. Например,
карта сети может составляться автоматически, на основании зондирования реальной
сети пакетами-исследователями, а может быть введена оператором системы
управления вручную. Чаще всего применяются полуавтоматические методы, когда
автоматически полученную карту оператор подправляет вручную. Методы
автоматического построения топологической карты, как правило, являются
фирменными разработками.
Более сложной задачей является настройка коммутаторов и маршрутизаторов на
поддержку маршрутов и виртуальных путей между пользователями сети.
Согласованная ручная настройка таблиц маршрутизации при полном или частичном
отказе от использования протокола маршрутизации (а в некоторых глобальных сетях,
например, Х.25, такого протокола просто не существует) представляет собой
сложную задачу. Многие системы управления сетью общего назначения ее не
выполняют, но существуют специализированные системы конкретных производителей,
например, система NetSys компании Cisco Systems, которая решает ее для
маршуртизаторов этой же компании.
Обработка ошибок (Fault Management). Эта группа задач
включает выявление, определение и устранение последствий сбоев и отказов в
работе сети. На этом уровне выполняется не только регистрация сообщений об
ошибках, но и их фильтрация, маршрутизация и анализ на основе некоторой
корреляционной модели. Фильтрация позволяет выделить из весьма интенсивного
потока сообщений об ошибках, который обычно наблюдается в большой сети, только
важные сообщения, маршрутизация обеспечивает их доставку нужному элементу
системы управления, а корреляционный анализ позволяет найти причину, породившую
поток взаимосвязанных сообщений (например, обрыв кабеля может быть причиной
большого количества сообщений о недоступности сетей и серверов).
Устранение ошибок может быть как автоматическим, так и полуавтоматическим.
В первом случае система непосредственно управляет оборудованием или
программными комплексами и обходит отказавший элемент за счет резервных каналов
и т.п. В полуавтоматическом режиме основные решения и действия по устранению
неисправности выполняют люди, а система управления только помогает в
организации этого процесса – оформляет квитанции на выполнение работ и
отслеживает их поэтапное выполнение (подобно системам групповой работы).
В этой группе задач иногда выделяют подгруппу задач управления проблемами,
подразумевая под проблемой сложную ситуацию, требующую для разрешения
обязательного привлечения специалистов по обслуживанию сети.
Анализ производительности
и надежности (Performance Management). Задачи этой группы
связаны с оценкой на основе накопленной статистической информации таких
параметров, как время реакции системы, пропускная способность реального или
виртуального канала связи между двумя конечным и абонентами сети, интенсивность
трафика в отдельных сегментах и каналах сети, вероятность искажения данных при
их передаче через сеть, а также коэффициент готовности сети или ее определенной
транспортной службы.
Функции анализа производительности и надежности сети нужны как для
оперативного управления сетью, так и для планирования развития сети.
Результаты анализа производительности и надежности позволяют
контролировать соглашение об уровне обслуживания (Service Level Agreement, SLA), заключаемое между пользователем сети и ее администраторами (или
компанией, продающей услуги). Обычно в SLA оговариваются такие параметры надежности, как коэффициент готовности
службы в течение года и месяца, максимальное время устранения отказа, а также
параметры производительности, например, средняя и максимальная пропускная
способности при соединении двух точек подключения пользовательского
оборудования, время реакции сети (если информационная служба, для которой
определяется время реакции, поддерживается внутри сети), максимальная задержка
пакетов при передаче через сеть (если сеть используется только как транзитный
транспорт). Без средств анализа производительности и надежности поставщик услуг
публичной сети или отдел информационных технологий предприятия не сможет ни
проконтролировать, ни тем более обеспечить нужный уровень обслуживания для
конечных пользователей сети.
Управление безопасностью (Security Management). Задачи этой группы
включают в себя контроль доступа к ресурсам сети (данным и оборудованию) и
сохранение целостности данных при их хранении и передчае через сеть. Базовыми
элементами управления безопасностью являются процедуры аутентификации пользователей,
назначение и проверка прав доступа к ресурсам сети, распределение и поддержка
ключей шифрования, управления полномочиями и т.п. Часто функции этой группы не
включаются в системы управления сетями, а реализуются либо в виде специальных
продуктов (например, системы аутентификации и авторизации Kerberos, различных защитных экранов, систем
шифрования данных), либо входят в состав операционных систем и системных
приложений.
Учет работы сети (Accounting Management). Задачи этой группы занимаются регистрацией
времени использования различных ресурсов сети – устройств, каналов и
транспортных служб. Эти задачи имеют дело с такими понятиями, как время
использования службы и плата за ресурсы – billing. Ввиду специфического характера оплаты услуг у различных поставщиков и
различными формами соглашения об уровне услуг, эта группа функций обычно не
включается в коммерческие системы и платформы управления типа HP Open View, а реализуется в заказных системах, разрабатываемых
для конкретного заказчика.
Модель управления OSI не делает различий
между управляемыми объектами – каналами, сегментами локальных сетей, мостами,
коммутаторами и маршрутизаторами, модемами и мультиплексорами, аппаратным и
программным обеспечением компьютеров, СУБД. Все эти объекты управления входят в
общее понятие “система”, и управляемая система взаимодействует с
управляющей системой по открытым протоколам OSI.
Однако на практике деление систем управления по типам управляемых
объектов широко распространено. Ставшими классическими системы управления
сетями, такие как SunNet Manager, HP Open View или Cabletron Spectrum, управляют только
коммуникационными объектами корпоративных сетей, т.е. концентраторами и
коммутаторами локальных сетей, а также маршрутизаторами и удаленными мостами,
как устройствами доступа к глобальным сетям. Оборудованием территориальных
сетей обычно управляют системы производителей телекоммуникационного
оборудования, такие как RADView компании RAD Data Communecations, MainStreetXpress 46020 компании Newbridge и т.п.
Рассмотрим, как описываются общие
функциональные задачи системы управления, определенные в стандартах X.700/ISO 7498-4, для такого
конкретного класса систем управления, как системы управления компьютерами и их
системным и прикладным программным обеспечением. Их называют системами
управления системой (System Management System).
Обычно система управления системой выполняет следующие функции.
- Учет используемых аппаратных и программных средств (Configuration Management). Система автоматически
собирает информацию об установленных в сети компьютерах и создает записи в
специальной базе данных об аппаратных и программных ресурсах. После этого
администратор может быстро выяснить, какими ресурсами он располагает и где тот
или иной ресурс находится, например, узнать о том, на каких компьютерах нужно
обновить драйверы принтеров, какие компьютеры обладают достаточным количеством
памяти, дискового пространства и т.п.
- Распределение и установка программного обеспечения (Configuration Management). После завершения обследования
администратор может создать пакеты рассылки нового ПО, которое нужно
инсталлировать на всех компьютерах сети или на какой-либо группе компьютеров. В
большой сети, где проявляются преимущества системы управления, такой способ
инсталляции может существенно уменьшить трудоемкость этой процедуры. Система
может также позволять централизованно устанавливать и администрировать
приложения, которые запускаются с файловых серверов, а также дать возможность
конечным пользователям запускать такие приложения с любой рабочей станции сети.
- Удаленный анализ производительности и возникающих
проблем (Fault Management and Performance Management). Эта группа функций позволяет удаленно
измерять наиболее важные параметры компьютера, операционной системы, СУБД и т.д.
(например, коэффициент использования процессора, интенсивность страничных
прерываний, коэффициент использования физической памяти, интенсивность
выполнения транзакций). Для разрешения проблем эта группа функций может давать
администратору возможность брать на себя удаленное управление компьютером в
режиме эмуляции графического интерфейса популярных операционных систем. База
данных системы управления обычно хранит детальную информацию о конфигурации
всех компьютеров в сети для того, чтобы можно было выполнять удаленный анализ
возникающих проблем.
Примерами систем управления системами являются Microsoft System Management Server (SMS), CA Unicenter, HP Operationscenter и многие другие.
Как видно из описания функций системы управления системами, они повторяют функции
системы управления сетью, но только для других объектов. Действительно, функция
учета используемых аппаратных и программных средств соответствует функции
построения карты сети, функция распределения и установки программного
обеспечения – функции управления конфигурацией коммутаторов и маршрутизаторов,
а функция анализа производительности и возникающих проблем – функции
производительности.
Эта близость функций систем управления сетями и систем управления системами
позволила разработчикам стандартов OSI не делать различия между ними и разрабатывать общие стандарты
управления.
На практике уже несколько лет также заметна отчетливая тенденция интеграции
систем управления сетями и системами в единые интегрированные продукты
управления корпоративными сетями, например, CA Unicenter TNG или TME-10 IBM/Tivoli. Наблюдается также интеграция систем управления
телекоммуникационными сетями с системами управления корпоративными сетями.
Многоуровневая модель
задач управления
Кроме описанного выше разделения задач управления на несколько
функциональных групп, полезно разделять задачи управления на уровни в
соответствии с иерархической организацией корпоративной сети. корпоративная
сеть строится иерархически, отражая иерархию самого предприятия и его задач.
Нижний уровень сети составляют элементы сети – отдельные компьютеры,
коммуникационные устройства, каналы передачи данных. На следующем уровне
иерархии эти элементы образуют сети разного масштаба – сеть рабочей группы,
сеть отдела, сеть отделения и, наконец, сеть предприятия в целом.
Для построения интегрированной системы управления разнородными элементами
сети естественно применить многоуровневый иерархический подход. Это, в
принципе, стандартный подход для построения большой системы любого типа и
назначения – от государства до автомобильного завода. Применительно к системам
управления сетями наиболее проработанным и эффективным для создания
многоуровневой иерархической системы является стандарт Telecommunication Management Network (TMN), разработанный совместными усилиями ITU-T, ISO, ANSI и ETSI. Хотя этот стандарт и предназначался изначально для
телекоммуникационных сетей, но ориентация на использование общих принципов
делает его полезным для построения любой крупной интегрированной системы
управления сетями. Стандарты TMN состоят из
большого количества рекомендаций ITU-T (и стандартов других организаций), но основные
принципы модели TMNописаны в рекомендации
М.3010.
На каждом уровне иерархии модели TMN решаются задачи одних и тех же пяти функциональных групп,
рассмотренных выше (т.е. управления конфигурацией, производительностью,
ошибками, безопасностью и учетом), однако на каждом уровне эти задачи имеют
свою специфику. Чем выше уровень управления, тем более общий и агрегированный
характер приобретает собираемая о сети информация, а сугубо технический
характер собираемых данных начинает по мере повышения уровня меняться на
производственный, финансовый и коммерческий.
Модель TMN упрощенно можно
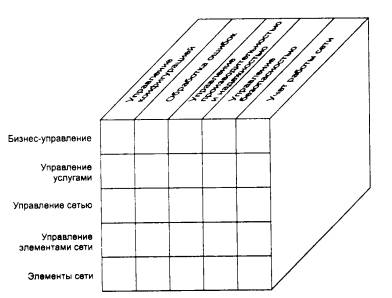
представить в виде следующей диаграммы (рис. 1).

Рис. 1. Многоуровневое представление задач управления сетью
Нижний уровень – уровень элементов сети (Network Element Layer, NE) – состоит из отдельных
устройств сети: каналов, усилителей, оконечной аппаратуры, мультиплексоров,
коммутаторов и т.п. Элементы могут содержать встроенные средства для поддержки
управления – датчики, интерфейсы управления, а могут и представлять вещь в
себе, требующую для связи с системой управления разработки специального
оборудования – устройств связи с объектом, УСО. Современные
технологии обычно имеют встроенные функции управления, которые позволяют
выполнять хотя бы минимальные операции по контролю за состоянием устройства и
за передаваемым устройством трафиком. Подобные функции встроены в
технологии FDDI, ISDN, Frame Relay, SDH. В этом случае
устройство всегда можно охватить системой вправления, даже если оно не имеет
специального блока управления, т.к. протокол технологии обязывает устройство
поддерживать некоторые функции управления. Устройства, которые работают по
протоколам, не имеющим встроенных функций контроля и управления, снабжаются
отдельным блоком управления, который поддерживает один из двух наиболее
распространенных протоколов управления – SNMP или CMIP. Эти протоколы
относятся к прикладному уровню модели OSI.
Следующий уровень – уровень управления элементами сети (Network Element Management Layer) – представляет
собой элементарные системы управления. Элементарные системы управления
автономно управляют отдельными элементами сети – контролируют канал связи SDH, управляют коммутатором или мультиплексором. Уровень
управления элементами изолирует верхние слои системы управления от деталей и
особенностей управления конкретным оборудованием. Этот уровень ответственен за
моделирование поведения оборудования и функциональных ресурсов нижележащей
сети. Атрибуты этих моделей позволяют управлять различными аспектами поведения
управляемых ресурсов. Обычно элементарные системы управления разрабатываются и
поставляются производителями оборудования. Примерами таких систем могут служить
системы управления Cisco View от Cisco Systems, Optivity от Bay Networks, RADView от RAD Data Communications и т.д.
Выше лежит уровень управления сетью (Network Management Layer). Этот уровень координирует работу элементарных
систем управления, позволяя контролировать конфигурацию составных каналов,
согласовывать работу транспортных подсетей разных технологий и т.п. С помощью
этого уровня сеть начинает работать как единое целое, передавая данные между
своими абонентами.
Следующий уровень – уровень управления услугами (Service Management Layer) – занимается контролем и управлением за
транспортными и информационными услугами, которые предоставляются конечным
пользователям сети. В задачу этого уровня входит подготовка сети к
предоставлению определенной услуги, ее активизация, обработка вызовов клиентов.
Формирование услуги (service provisioning) заключается в фиксации в базе данных
значений параметров услуги, например, требуемой средней пропускной способности,
максимальных величин задержек пакетов, коэффициента готовности и т.п. В функции
этого уровня входит также выдача уровню управления сетью задания на
конфигурирование виртуального или физического канала связи для поддержания
услуги. После формирования услуги данный уровень занимается контролем за качеством
ее реализации, т.е. за соблюдением сетью всех принятых на себя обязательств в
отношении производительности и надежности транспортных услуг. Результаты
контроля качества обслуживания нужны, в частности, для подсчета оплаты за
пользование услугами клиентами сети. Например, в сети Frame Relayуровень управления
услугами следит за заказанными пользователем значениями средней скорости и
согласованной пульсации, фиксируя нарушения со стороны пользователя и сети.
Уровень бизнес-управления (Business Management Layer) занимается вопросами
долговременного планирования сети с учетом финансовых аспектов деятельности
организации, владеющей сетью. На этом уровне помесячно и поквартально
подсчитываются доходы от эксплуатации сети и ее отдельных составляющих,
учитываются расходы на эксплуатацию и модернизацию сети, принимаются решения о
развитии сети с учетом финансовых возможностей. Уровень бизнес-управления
обеспечивает для пользователей и поставщиков услуг возможность предоставления
дополнительных услуг. Этот уровень является частным случаем уровня
автоматизированной системы управления предприятием (АСУП), в то время как все
нижележащие уровни соответствуют уровням автоматизированной системы управления
технологическими процессами (АСУТП), для такого специфического типа
предприятия, как телекоммуникационная или корпоративная сеть. Но если
телекоммуникационная сеть действительно чаще всего является основой
телекоммуникационной компании, то корпоративную сеть и обслуживающий ее
персонал обычно трудно назвать предприятием. Тем не менее, на некоторых
западных фирмах корпоративная сеть выделена в автономное производственное
подразделение со своим бюджетом и со своими финансовыми договорами на
обслуживание, которое данное подразделение заключает с основными
производственными подразделениями предприятия.
Области управления ошибками; конфигурацией; доступом; производительностью; безопасностью.
Любая сложная вычислительная сеть требует дополнительных специальных
средств управления помимо тех, которые имеются в стандартных сетевых ОС. Это
связано с большим количеством разнообразного коммуникационного оборудования,
работа которого критична для выполнения сетью своих основных функций.
Распределенный характер крупной корпоративной сети делает невозможным
поддержание ее работы без централизованной системы управления, которая в
автоматическом режиме собирает информацию о состоянии каждого концентратора,
коммутатора, мультиплексора и маршрутизатора и предоставляет эту информацию
оператору сети. Обычно система управления работает в автоматизированном режиме,
выполняя наиболее простые действия по управлению сетью автоматически, а сложные
решения предоставляя принимать человеку на основе подготовленной системой
информации. Система управления должна быть интегрированной. Это означает, что
функции управления разнородными устройствами должны служить общей цели
обслуживания конечных пользователей сети с заданным качеством.
Сами системы управления представляют собой сложные программно-аппаратные
комплексы, поэтому существует граница целесообразности применения системы
управления – она зависит от сложности сети, разнообразия применяемого
коммуникационного оборудования и степени его распределенности по территории. В
небольшой сети можно применять отдельные программы управления наиболее сложными
устройствами, например, коммутатором, поддерживающим технику VLAN. Обычно каждое устройство, которое требует достаточно
сложного конфигурирования, производитель сопровождает автономной программой
конфигурирования и управления. Однако при росте сети может возникнуть проблема
объединения разрозненных программ управления устройствами в единую систему
управления, и для решения этой проблемы придется, возможно, отказаться от этих
программ и заменить их интегрированной системой управления.
Функции и архитектура
систем управления сетями
Задачи управления
Системы управления корпоративными сетями существуют не очень давно. Одной
из первых систем такого назначения, получившей широкое распространения, был
программный продукт SunNet Manager, выпущенный в 1989 году компанией SunSoft.
SunNet Manager был ориентирован
на управление коммуникационным оборудованием и контроль трафика сети. Именно
эти функции имеют чаще всего в виду, когда говорят о системе управления сетью.
Кроме систем управления сетями существуют и системы управления другими
элементами корпоративной сети: системы управления ОС, СУБД, корпоративными
приложениями. Применяются также системы управления телекоммуникационными
сетями: телефонными, а также первичными сетями технологий PDHи SDH.
Независимо от объекта управления, желательно, чтобы система управления
выполняла ряд функций, которые определены международными стандартами,
обобщающими опыт применения систем управления в различных областях. Существуют
рекомендации ITU-T X.700 и близкий к
ним стандарт ISO 7498-4, которые
делят задачи системы управления на пять функциональных групп:
- управление конфигурацией сети и именованием;
- обработка ошибок;
- анализ производительности и надежности;
- управление безопасностью;
- учет работы сети.
Рассмотрим задачи этих функциональных областей управления применительно к
системам управления сетями.
Управление конфигурацией
сети и именованием (Configuration Management). Эти задачи заключаются в
конфигурировании параметров как элементов сети (Network Element, NE), так и сети в целом. Для элементов сети, таких как
маршрутизаторы, мультиплексоры и т.п., с помощью этой группы задач определяются
сетевые адреса, идентификаторы (имена), географическое положение и пр.
Для сети в целом управление конфигурацией обычно начинается с построения
карты сети, т.е. отображении реальных связей между элементами сети и изменении
связей между элементами сети – образование новых физических или логических
каналов, изменение таблиц коммутации и маршрутизации.
Управление конфигурацией (как и другие задачи системы управления) могут
выполняться в автоматическом, ручном или полуавтоматическом режимах. Например,
карта сети может составляться автоматически, на основании зондирования реальной
сети пакетами-исследователями, а может быть введена оператором системы
управления вручную. Чаще всего применяются полуавтоматические методы, когда
автоматически полученную карту оператор подправляет вручную. Методы
автоматического построения топологической карты, как правило, являются
фирменными разработками.
Более сложной задачей является настройка коммутаторов и маршрутизаторов на
поддержку маршрутов и виртуальных путей между пользователями сети.
Согласованная ручная настройка таблиц маршрутизации при полном или частичном
отказе от использования протокола маршрутизации (а в некоторых глобальных сетях,
например, Х.25, такого протокола просто не существует) представляет собой
сложную задачу. Многие системы управления сетью общего назначения ее не
выполняют, но существуют специализированные системы конкретных производителей,
например, система NetSys компании Cisco Systems, которая решает ее для
маршуртизаторов этой же компании.
Обработка ошибок (Fault Management). Эта группа задач
включает выявление, определение и устранение последствий сбоев и отказов в
работе сети. На этом уровне выполняется не только регистрация сообщений об
ошибках, но и их фильтрация, маршрутизация и анализ на основе некоторой
корреляционной модели. Фильтрация позволяет выделить из весьма интенсивного
потока сообщений об ошибках, который обычно наблюдается в большой сети, только
важные сообщения, маршрутизация обеспечивает их доставку нужному элементу
системы управления, а корреляционный анализ позволяет найти причину, породившую
поток взаимосвязанных сообщений (например, обрыв кабеля может быть причиной
большого количества сообщений о недоступности сетей и серверов).
Устранение ошибок может быть как автоматическим, так и полуавтоматическим.
В первом случае система непосредственно управляет оборудованием или
программными комплексами и обходит отказавший элемент за счет резервных каналов
и т.п. В полуавтоматическом режиме основные решения и действия по устранению
неисправности выполняют люди, а система управления только помогает в
организации этого процесса – оформляет квитанции на выполнение работ и
отслеживает их поэтапное выполнение (подобно системам групповой работы).
В этой группе задач иногда выделяют подгруппу задач управления проблемами,
подразумевая под проблемой сложную ситуацию, требующую для разрешения
обязательного привлечения специалистов по обслуживанию сети.
Анализ производительности
и надежности (Performance Management). Задачи этой группы
связаны с оценкой на основе накопленной статистической информации таких
параметров, как время реакции системы, пропускная способность реального или
виртуального канала связи между двумя конечным и абонентами сети, интенсивность
трафика в отдельных сегментах и каналах сети, вероятность искажения данных при
их передаче через сеть, а также коэффициент готовности сети или ее определенной
транспортной службы.
Функции анализа производительности и надежности сети нужны как для
оперативного управления сетью, так и для планирования развития сети.
Результаты анализа производительности и надежности позволяют
контролировать соглашение об уровне обслуживания (Service Level Agreement, SLA), заключаемое между пользователем сети и ее администраторами (или
компанией, продающей услуги). Обычно в SLA оговариваются такие параметры надежности, как коэффициент готовности
службы в течение года и месяца, максимальное время устранения отказа, а также
параметры производительности, например, средняя и максимальная пропускная
способности при соединении двух точек подключения пользовательского
оборудования, время реакции сети (если информационная служба, для которой
определяется время реакции, поддерживается внутри сети), максимальная задержка
пакетов при передаче через сеть (если сеть используется только как транзитный
транспорт). Без средств анализа производительности и надежности поставщик услуг
публичной сети или отдел информационных технологий предприятия не сможет ни
проконтролировать, ни тем более обеспечить нужный уровень обслуживания для
конечных пользователей сети.
Управление безопасностью (Security Management). Задачи этой группы
включают в себя контроль доступа к ресурсам сети (данным и оборудованию) и
сохранение целостности данных при их хранении и передчае через сеть. Базовыми
элементами управления безопасностью являются процедуры аутентификации пользователей,
назначение и проверка прав доступа к ресурсам сети, распределение и поддержка
ключей шифрования, управления полномочиями и т.п. Часто функции этой группы не
включаются в системы управления сетями, а реализуются либо в виде специальных
продуктов (например, системы аутентификации и авторизации Kerberos, различных защитных экранов, систем
шифрования данных), либо входят в состав операционных систем и системных
приложений.
Учет работы сети (Accounting Management). Задачи этой группы занимаются регистрацией
времени использования различных ресурсов сети – устройств, каналов и
транспортных служб. Эти задачи имеют дело с такими понятиями, как время
использования службы и плата за ресурсы – billing. Ввиду специфического характера оплаты услуг у различных поставщиков и
различными формами соглашения об уровне услуг, эта группа функций обычно не
включается в коммерческие системы и платформы управления типа HP Open View, а реализуется в заказных системах, разрабатываемых
для конкретного заказчика.
Модель управления OSI не делает различий
между управляемыми объектами – каналами, сегментами локальных сетей, мостами,
коммутаторами и маршрутизаторами, модемами и мультиплексорами, аппаратным и
программным обеспечением компьютеров, СУБД. Все эти объекты управления входят в
общее понятие “система”, и управляемая система взаимодействует с
управляющей системой по открытым протоколам OSI.
Однако на практике деление систем управления по типам управляемых
объектов широко распространено. Ставшими классическими системы управления
сетями, такие как SunNet Manager, HP Open View или Cabletron Spectrum, управляют только
коммуникационными объектами корпоративных сетей, т.е. концентраторами и
коммутаторами локальных сетей, а также маршрутизаторами и удаленными мостами,
как устройствами доступа к глобальным сетям. Оборудованием территориальных
сетей обычно управляют системы производителей телекоммуникационного
оборудования, такие как RADView компании RAD Data Communecations, MainStreetXpress 46020 компании Newbridge и т.п.
Рассмотрим, как описываются общие
функциональные задачи системы управления, определенные в стандартах X.700/ISO 7498-4, для такого
конкретного класса систем управления, как системы управления компьютерами и их
системным и прикладным программным обеспечением. Их называют системами
управления системой (System Management System).
Обычно система управления системой выполняет следующие функции.
- Учет используемых аппаратных и программных средств (Configuration Management). Система автоматически
собирает информацию об установленных в сети компьютерах и создает записи в
специальной базе данных об аппаратных и программных ресурсах. После этого
администратор может быстро выяснить, какими ресурсами он располагает и где тот
или иной ресурс находится, например, узнать о том, на каких компьютерах нужно
обновить драйверы принтеров, какие компьютеры обладают достаточным количеством
памяти, дискового пространства и т.п.
- Распределение и установка программного обеспечения (Configuration Management). После завершения обследования
администратор может создать пакеты рассылки нового ПО, которое нужно
инсталлировать на всех компьютерах сети или на какой-либо группе компьютеров. В
большой сети, где проявляются преимущества системы управления, такой способ
инсталляции может существенно уменьшить трудоемкость этой процедуры. Система
может также позволять централизованно устанавливать и администрировать
приложения, которые запускаются с файловых серверов, а также дать возможность
конечным пользователям запускать такие приложения с любой рабочей станции сети.
- Удаленный анализ производительности и возникающих
проблем (Fault Management and Performance Management). Эта группа функций позволяет удаленно
измерять наиболее важные параметры компьютера, операционной системы, СУБД и т.д.
(например, коэффициент использования процессора, интенсивность страничных
прерываний, коэффициент использования физической памяти, интенсивность
выполнения транзакций). Для разрешения проблем эта группа функций может давать
администратору возможность брать на себя удаленное управление компьютером в
режиме эмуляции графического интерфейса популярных операционных систем. База
данных системы управления обычно хранит детальную информацию о конфигурации
всех компьютеров в сети для того, чтобы можно было выполнять удаленный анализ
возникающих проблем.
Примерами систем управления системами являются Microsoft System Management Server (SMS), CA Unicenter, HP Operationscenter и многие другие.
Как видно из описания функций системы управления системами, они повторяют функции
системы управления сетью, но только для других объектов. Действительно, функция
учета используемых аппаратных и программных средств соответствует функции
построения карты сети, функция распределения и установки программного
обеспечения – функции управления конфигурацией коммутаторов и маршрутизаторов,
а функция анализа производительности и возникающих проблем – функции
производительности.
Эта близость функций систем управления сетями и систем управления системами
позволила разработчикам стандартов OSI не делать различия между ними и разрабатывать общие стандарты
управления.
На практике уже несколько лет также заметна отчетливая тенденция интеграции
систем управления сетями и системами в единые интегрированные продукты
управления корпоративными сетями, например, CA Unicenter TNG или TME-10 IBM/Tivoli. Наблюдается также интеграция систем управления
телекоммуникационными сетями с системами управления корпоративными сетями.
Многоуровневая модель
задач управления
Кроме описанного выше разделения задач управления на несколько
функциональных групп, полезно разделять задачи управления на уровни в
соответствии с иерархической организацией корпоративной сети. корпоративная
сеть строится иерархически, отражая иерархию самого предприятия и его задач.
Нижний уровень сети составляют элементы сети – отдельные компьютеры,
коммуникационные устройства, каналы передачи данных. На следующем уровне
иерархии эти элементы образуют сети разного масштаба – сеть рабочей группы,
сеть отдела, сеть отделения и, наконец, сеть предприятия в целом.
Для построения интегрированной системы управления разнородными элементами
сети естественно применить многоуровневый иерархический подход. Это, в
принципе, стандартный подход для построения большой системы любого типа и
назначения – от государства до автомобильного завода. Применительно к системам
управления сетями наиболее проработанным и эффективным для создания
многоуровневой иерархической системы является стандарт Telecommunication Management Network (TMN), разработанный совместными усилиями ITU-T, ISO, ANSI и ETSI. Хотя этот стандарт и предназначался изначально для
телекоммуникационных сетей, но ориентация на использование общих принципов
делает его полезным для построения любой крупной интегрированной системы
управления сетями. Стандарты TMN состоят из
большого количества рекомендаций ITU-T (и стандартов других организаций), но основные
принципы модели TMNописаны в рекомендации
М.3010.
На каждом уровне иерархии модели TMN решаются задачи одних и тех же пяти функциональных групп,
рассмотренных выше (т.е. управления конфигурацией, производительностью,
ошибками, безопасностью и учетом), однако на каждом уровне эти задачи имеют
свою специфику. Чем выше уровень управления, тем более общий и агрегированный
характер приобретает собираемая о сети информация, а сугубо технический
характер собираемых данных начинает по мере повышения уровня меняться на
производственный, финансовый и коммерческий.
Модель TMN упрощенно можно
представить в виде следующей диаграммы (рис. 1).
Рис. 1. Многоуровневое представление задач управления сетью
Нижний уровень – уровень элементов сети (Network Element Layer, NE) – состоит из отдельных
устройств сети: каналов, усилителей, оконечной аппаратуры, мультиплексоров,
коммутаторов и т.п. Элементы могут содержать встроенные средства для поддержки
управления – датчики, интерфейсы управления, а могут и представлять вещь в
себе, требующую для связи с системой управления разработки специального
оборудования – устройств связи с объектом, УСО. Современные
технологии обычно имеют встроенные функции управления, которые позволяют
выполнять хотя бы минимальные операции по контролю за состоянием устройства и
за передаваемым устройством трафиком. Подобные функции встроены в
технологии FDDI, ISDN, Frame Relay, SDH. В этом случае
устройство всегда можно охватить системой вправления, даже если оно не имеет
специального блока управления, т.к. протокол технологии обязывает устройство
поддерживать некоторые функции управления. Устройства, которые работают по
протоколам, не имеющим встроенных функций контроля и управления, снабжаются
отдельным блоком управления, который поддерживает один из двух наиболее
распространенных протоколов управления – SNMP или CMIP. Эти протоколы
относятся к прикладному уровню модели OSI.
Следующий уровень – уровень управления элементами сети (Network Element Management Layer) – представляет
собой элементарные системы управления. Элементарные системы управления
автономно управляют отдельными элементами сети – контролируют канал связи SDH, управляют коммутатором или мультиплексором. Уровень
управления элементами изолирует верхние слои системы управления от деталей и
особенностей управления конкретным оборудованием. Этот уровень ответственен за
моделирование поведения оборудования и функциональных ресурсов нижележащей
сети. Атрибуты этих моделей позволяют управлять различными аспектами поведения
управляемых ресурсов. Обычно элементарные системы управления разрабатываются и
поставляются производителями оборудования. Примерами таких систем могут служить
системы управления Cisco View от Cisco Systems, Optivity от Bay Networks, RADView от RAD Data Communications и т.д.
Выше лежит уровень управления сетью (Network Management Layer). Этот уровень координирует работу элементарных
систем управления, позволяя контролировать конфигурацию составных каналов,
согласовывать работу транспортных подсетей разных технологий и т.п. С помощью
этого уровня сеть начинает работать как единое целое, передавая данные между
своими абонентами.
Следующий уровень – уровень управления услугами (Service Management Layer) – занимается контролем и управлением за
транспортными и информационными услугами, которые предоставляются конечным
пользователям сети. В задачу этого уровня входит подготовка сети к
предоставлению определенной услуги, ее активизация, обработка вызовов клиентов.
Формирование услуги (service provisioning) заключается в фиксации в базе данных
значений параметров услуги, например, требуемой средней пропускной способности,
максимальных величин задержек пакетов, коэффициента готовности и т.п. В функции
этого уровня входит также выдача уровню управления сетью задания на
конфигурирование виртуального или физического канала связи для поддержания
услуги. После формирования услуги данный уровень занимается контролем за качеством
ее реализации, т.е. за соблюдением сетью всех принятых на себя обязательств в
отношении производительности и надежности транспортных услуг. Результаты
контроля качества обслуживания нужны, в частности, для подсчета оплаты за
пользование услугами клиентами сети. Например, в сети Frame Relayуровень управления
услугами следит за заказанными пользователем значениями средней скорости и
согласованной пульсации, фиксируя нарушения со стороны пользователя и сети.
Уровень бизнес-управления (Business Management Layer) занимается вопросами
долговременного планирования сети с учетом финансовых аспектов деятельности
организации, владеющей сетью. На этом уровне помесячно и поквартально
подсчитываются доходы от эксплуатации сети и ее отдельных составляющих,
учитываются расходы на эксплуатацию и модернизацию сети, принимаются решения о
развитии сети с учетом финансовых возможностей. Уровень бизнес-управления
обеспечивает для пользователей и поставщиков услуг возможность предоставления
дополнительных услуг. Этот уровень является частным случаем уровня
автоматизированной системы управления предприятием (АСУП), в то время как все
нижележащие уровни соответствуют уровням автоматизированной системы управления
технологическими процессами (АСУТП), для такого специфического типа
предприятия, как телекоммуникационная или корпоративная сеть. Но если
телекоммуникационная сеть действительно чаще всего является основой
телекоммуникационной компании, то корпоративную сеть и обслуживающий ее
персонал обычно трудно назвать предприятием. Тем не менее, на некоторых
западных фирмах корпоративная сеть выделена в автономное производственное
подразделение со своим бюджетом и со своими финансовыми договорами на
обслуживание, которое данное подразделение заключает с основными
производственными подразделениями предприятия.
Анализ производительности и надежности
Задачи анализа производительности и
надежности связаны с оценкой на
основе накопленной статистической
информации таких параметров, как время
реакции системы, пропускная способность
реального или виртуального канала связи
между двумя конечными абонентами сети,
интенсивность трафика в отдельных
сегментах и каналах сети, вероятность
искажения данных при их передаче через
сеть, а также коэффициент готовности
сети или ее определенной транспортной
службы. Функции анализа производительности
и надежности сети нужны как для
оперативного управления сетью, так и
для планирования развития сети.
Результаты
анализа производительности и надежности
позволяют контролироватьсоглашение
об уровне обслуживания (SLA),
заключаемое между пользователем сети
и ее администраторами (или компанией,
продающей услуги). Обычно вSLAоговариваются такие параметры надежности,
как коэффициент готовности службы в
течение года и месяца, максимальное
время устранения отказа, а также параметры
производительности, например средняя
и максимальная пропускная способности
при соединении двух точек подключения
пользовательского оборудования, время
реакции сети (если информационная
служба, для которой определяется время
реакции, поддерживается внутри сети),
максимальная задержка пакетов при
передаче через сеть (если сеть используется
только как транзитный транспорт).
Без средств анализа производительности
и надежности поставщик услуг публичной
сети или отдел информационных технологий
предприятия не сможет ни проконтролировать,
ни тем более обеспечить нужный уровень
обслуживания для конечных пользователей
сети.
Управление безопасностью
Задачи управления безопасностью
подразумевают контроль доступа к
ресурсам сети (данным и оборудованию)
и сохранение целостности данных при их
хранении и передаче через сеть. Базовыми
элементами управления безопасностью
являются процедуры аутентификации
пользователей, назначение и проверка
прав доступа к ресурсам сети, распределение
и поддержка ключей шифрования, управления
полномочиями и т. п. Часто функции этой
группы не включаются в системы управления
сетями, а реализуются либо в виде
специальных продуктов (например, систем
аутентификации и авторизацииKerberos,
различных защитных экранов, систем
шифрования данных), либо входят в состав
операционных систем и системныхприложений.
Учет работы сети
К задачам учета работы сети
относится регистрация времени
использования различных ресурсов сети
— устройств, каналов и транспортных
служб. Подобные задачи имеют дело с
такими понятиями, как время использования
службы и плата за ресурсы —billing.
Ввиду специфического характера оплаты
услуг у различных поставщиков и различными
формами соглашения об уровне услуг эта
группа функций обычно не включается в
коммерческие системы и платформы
управления типаHPOpenView, а реализуется в заказных
системах, разрабатываемых для конкретного
заказчика.
9. Коммуникационная сеть
Коммуникационной сетьюназывается
сеть, основной задачей которой является
передача данных. Коммуникационная сеть,
именуемая также сетью передачи данных,
является ядром информационной сети,
обеспечивающим передачу и некоторые
виды обработки данных. На базе одной
коммуникационной сети можно создать
несколько информационных сетей. Задачей
коммуникационной сети является доставка
адресатам блоков данных, которые при
этом не должны терять своей целостности,
доставляться без ошибок и искажения.
Важными в сети являются также операции
по предотвращению больших очередей и
переполнения буферов систем,
Коммуникационные сети делятся на три
класса: сети с маршрутизацией данных,
сети с селекцией данных и смешанные
сети.
Наряду с сетями, каждая из которых
функционирует в соответствии с принятым
протоколом, появились многопротокольные
сети. Их создание требует больших
капиталовложений. Однако затраченные
средства быстро окупаются гибкостью
работы этих сетей. Высокопроизводительные
коммуникационные сети стали именоваться
базовыми сетями. Примером такой сети
является сеть TWBNET. Высокие скорости
обеспечивают сети ретрансляции кадров.
Соответственно типам передаваемых
сигналов различают аналоговые сети и
дискретные сети.
Аналоговая сеть— коммуникационная
сеть, передающая и обрабатывающая
аналоговые сигналы. Необходимость
передачи звука, речи и изображений
привела к созданию аналоговых сетей, в
которых носителем данных является
аналоговый сигнал. Для передачи речи
были созданы телефонные сети.
Как и любая сеть с маршрутизацией данных,
телефонная состоит из узлов коммутации,
именуемых Автоматическими телефонными
станциями (АТС). АТС обеспечивают
коммутацию каналов, а в качестве
абонентских систем, в первую очередь,
используются телефонные аппараты. Чаще
всего, телефонная сеть опирается на
кабельную сеть. Вместе с этим, используются
и телефонные радиосети. Первоначально
телефонная сеть, обеспечивая
телекоммуникации, передавала аналоговые
сигналы и поэтому была аналоговой сетью.
Это было связано с тем, что акустический
сигнал имеет непрерывную форму.
Соответственно речи Человека частотный
диапазон в аналоговой телефонной сети
был выбран от 300 до 3400 Гц. Это позволяет
передавать понятную речь и даже узнавать
говорящего.
В настоящее время телефонная сеть быстро
переходит на дискретные сигналы. Это
дает возможность использовать
многопрофильные коммуникационные сети,
строить работу телефонных станций на
базе микропроцессоров, расширять виды
предоставляемых сетевых служб, повышать
качество передачи информации. Дискретная
телефонная сеть надежна в работе и
обеспечивает высокую помехоустойчивость
связи.
Передача движущихся изображений стала
осуществляться через телевизионные
сети. Телевизионная сеть — сеть,
предназначенная для обеспечения
функционирования телевидения. На первых
этапах своего развития телевизионные
сети создавались как аналоговые сети,
предназначенные только для передачи
движущихся изображений и звукового их
сопровождения. Сегодня наряду с этим,
телевизионные сети обеспечивают широкий
диапазон видов информационного сервиса
для многочисленных пользователей.
Например, телетекст. Характерной
особенностью всех телевизионных сетей
является их высокая пропускная
способность, достигающая сотен мегабит
в секунду. На первом этапе своего развития
телевизионные сети передавали информацию
только в одном направлении — от телецентра
к абонентам, имеющим телевизоры. Второй
этап характерен тем, что информация
стала передаваться в обе стороны — и от
ее многочисленных абонентов к телецентру.
Возникло интерактивное телевидение.
При этом телевизор превратился в
многоцелевой терминал.
Телевизионная сеть вначале базировалась
на использовании одного либо двух
древовидных моноканалов, построенных
на широкополосных каналах, создаваемых
на основе эфира. Теперь большое
распространение получают сети кабельного
телевидения; особенно с использованием
оптических кабелей. Из-за увеличения
числа абонентов, наращивания длины
магистралей древовидная структура в
кабельном телевидении стала неэффективной.
Ей на смену пришла гнездовая структура.
Здесь, подключение к центральной станции
более простых гнездовых станций позволило
существенно улучшить экономичность и
качество передачи информации в сети. В
гнездовой сети сокращается, длина
магистралей, повышается соотношение
сигнал-шум.
В телевизионных сетях широко используются
спутники связи. Особенно удобны
геостационарные спутники, неподвижно
расположенные относительно наземных
абонентов. Созданы и функционируют
системы прямого (непосредственного)
телевещания со спутников. Они, при
использовании терминалов VSAT, рассчитаны
на прием сигналов на малые телевизионные
антенны диаметром 0,6-0,9 м. Еще отсутствуют
общие для всех международные стандарты
на телевизионные сети. Эта стандартизация
начнется с телевидения высокого
разрешения HDTV. Готовится стандартизация
по основам обработки сигналов изображения
и звука, способам преобразования
сигналов, передающей аппаратуре, методам
кодирования, способам сжатия данных.
Ведутся работы, связанные с переходом
телевизионных сетей на передачу и
обработку дискретных сигналов.
Телевизионная сеть из сети широковещания
постепенно превращается в многоцелевую
коммуникационную сеть большой пропускной
способности.
Однако, вскоре стал ясен первый важный
недостаток аналоговых сетей — искажение
сигналов и трудности, связанные с
восстановлением их первоначальной
формы. С появлением компьютеров стал
ясен второй недостаток рассматриваемых
сетей трудности, связанные с обеспечением
взаимодействия компьютеров, которые
данные передают с помощью дискретных
сигналов. В результате, наряду с
аналоговыми появились дискретные сети.
Развитие коммуникационных сетей показало
необходимость интеграции звука,
изображений и других типов данных для
возможности их совместной передачи.
Так как дискретные сети надежней и
экономичней аналоговых, то за основу
были приняты именно они. В этой связи
число аналоговых сетей быстро сокращается
и они заменяются дискретными.
Дискретная сеть— коммуникационная
сеть, передающая и обрабатывающая
дискретные сигналы. Первоначально
дискретные принципы использовались в
системах обработки данных. В семидесятых
годах эти принципы стали применяться
и в коммуникационных сетях. Разработка
теории, массовое производство разнообразных
высокоскоростных Интегральных Схем
(ИС), создание дискретной аппаратуры
для каналов привели к тому, что обработка
и передача данных слились в единое
целое. Появились протоколы, определяющие
дискретные сети, именуемые также
цифровыми сетями. Использование в сетях
дискретных сигналов позволило обеспечить
различные виды коммутации на базе одних
и тех же узлов коммутации и каналов. Эта
задача решена международным союзом
электросвязи, который разработал модель
Цифровой Сети с Интегральным Обслуживанием
(ЦСИО или ISDN). Для дискретных сетей
созданы дискретные системы, обеспечивающие
скоростную передачу сигналов. Дискретные
сети по сравнению с прежними (аналоговыми
сетями) имеют достаточно много преимуществ.
К ним, в первую очередь, относятся:
высокая помехоустойчивость, широкое
использование микропроцессоров и
устройств памяти, простота каналообразующей
аппаратуры.
Число аналоговых сетей быстро сокращается
и они заменяются дискретными.
Коммуникационные подсети характеризуются
многими свойствами. Важнейшими из них
являются те, которые определяют способы
поставки информации конкретным адресатам.
В этом отношении коммуникационные
подсети делятся на два класса (см. рис.)
К первому из них относятся коммуникационные
подсети с селекцией информации. Они
характеризуются тем, что в них любой
блок данных передается от одной
абонентской системы-отправителя всем
абонентским системам. Системы, получив
очередной блок данных, проверяют адрес
его назначения. Система, которой адресован
блок, принимает его, остальные системы
отвергают этот блок. В результате
происходит селекция информации, которая
позволяет посылать блоки данных одной
группе, а также сразу всем абонентским
системам, подключенным к коммуникационной
подсети.
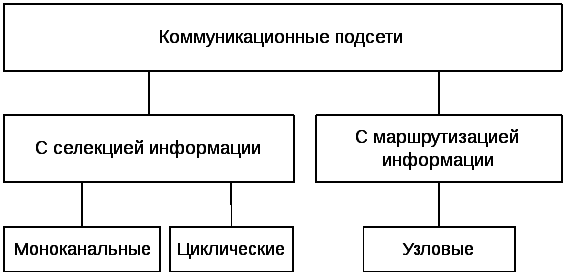
Рис. Классификация коммуникационных
подсетей
Подсети с селекцией информации делятся
на две группы: моноканальные ициклические. Они различаются тем,
что в подсети первой группы каждый
посланный блок данных попадает ко всем
абонентским системам практически
одновременно, а в подсети второй группы
каждый передаваемый блок доставляется
всем абонентским системам последовательно
(по очереди), проходя мимо каждой из них.
Моноканальная коммуникационная подсеть
далее для краткости именуется моноканалом.
Моноканал строится на основе общего
канала, к которому через специальные
устройства подключаются все абонентские
системы сети.
Циклическая коммуникационная подсеть,
часто именуемая циклическим кольцом,
— это канал, имеющий кольцевую форму. В
это кольцо врезаются абонентские
системы, деля его на сегменты.
Ко второму классу относятся коммуникационные
подсети с маршрутизацией информации.
В этих подсетях передача данных в отличие
от сетей предыдущего класса осуществляется
от одной абонентской системы-отправителя
к другой абонентской системе-получателю.
Для обеспечения такой доставки информации
в коммуникационной подсети используются
один либо более узлов коммутации. Поэтому
рассматриваемую подсеть далее будем
именовать узловой.
Каждый узел коммутации принимает блоки
данных и передает далее по различным
направлениям в зависимости от адресов
их назначения. Благодаря этому в подсети
осуществляется маршрутизация информации
— прокладка через коммуникационную
подсеть трактов, связывающих абонентские
системы. Моноканальные, циклические и
узловые подсети нередко конкурируют
друг с другом. При этом, правда, нужно
иметь в виду, что моноканальные и узловые
подсети могут быть как локальными, так
и территориальными. Что же касается
циклических подсетей, то они являются
только локальными.
Соседние файлы в папке Лекции по сетям ЭВМ4
- #
- #
Сетевое управление помогает администратору локализовать возникающие в сети ошибки и без промедления оценить ее состояние. Многие системы построены в соответствии с моделью FCAPS, т. е. разделены на управление ошибками, конфигурацией, статистикой, производительностью и безопасностью, причем не все решения охватывают полностью пять областей. Часто предприятиям попросту не нужна такая функциональность, им вполне хватает даже возможностей свободно распространяемого программного обеспечения или менеджеров элементов от производителей активных компонентов.

Администратор сети обычно отвечает за управление активными компонентами в локальных и глобальных сетях. В большинстве случаев к его обязанностям добавляется распространение программного обеспечения, а также управление системами и уровнем обслуживания. На крупных предприятиях некоторые предметные области переданы отдельным подразделениям, они занимаются мониторингом и конфигурацией своих компонентов, документируют их состояние в отчетах. Нередко для этой цели используется централизованное решение управления. Однако для различных компонентов и дисциплин могут применяться разные инструменты управления, работа с которыми в идеальном случае осуществляется тем не менее подразделением ИТ централизованно. Такой сценарий называется «зонтичное управление».
КОМПЕТЕНЦИИ
Говоря о сетевом управлении, как правило, имеют в виду управление и обслуживание коммутаторов и маршрутизаторов. Отсюда ясно, какие подразделения и лица должны быть вовлечены в соответствующие проекты. Однако система сетевого управления, охватывающая как локальную, так и глобальную сеть, обречена на провал, когда, к примеру, администраторы маршрутизаторов и глобальных сетей отказываются предоставлять доступ к собственным системам. Ни одно подразделение не захочет находиться под контролем у другого и добровольно никому не дает прав мониторинга своих компонентов. Чтобы провести внедрение новой системы управления с минимальным количеством препятствий, необходимо ответить на следующие вопросы:
- каких специалистов нужно привлечь к участию в проекте?
- кто принимает решение о выборе продукта?
- какие права для работы с системой управления будут предоставлены конкретным лицам?
Кроме того, с самого начала следует четко установить, каким требованиям должна отвечать система. Лишь когда все заинтересованные стороны — и руководство, и исполнители — привлечены к реализации проекта, можно понять, что является причиной проблем — например, нежелание некоторых подразделений работать совместно и предоставлять доступ к своим системам.
ФУНКЦИОНАЛЬНЫЙ ОХВАТ
Все системы обычно позволяют получить графическое представление сети, когда инфраструктура ИТ изображается на так называемых картах (см. Рисунок 1). Многие производители предлагают возможность получения важной информации через интерфейс Web, а некоторые решения полностью базируются на Web и потому не зависят от платформы.
|
|
Рисунок 1. Карта раскинувшейся на всю Германию сети предприятия с указанием имеющихся соединений маршрутизаторов. |
На карте, как правило, системы отображают сети IP — по одной или несколько подсетей IP. Однако это представление не учитывает зависимостей на втором уровне модели OSI. Так, например, оставшийся без ответа ping часто не позволяет определить, почему сервер недостижим. Поэтому производители систем сетевого управления дополнили свое программное обеспечение интеллектуальными элементами на втором уровне. Эти системы распознают, через какие порты или интерфейсы соединены между собой маршрутизаторы, коммутаторы и серверы, а по результатам опроса интерфейса сообщают, отчего нет доступа к серверу: из-за его отключения или по причине отсутствия соединения с магистралью.
Многие производители решений сетевого управления для описания различных возможностей своих инструментов используют модель управления сбоями, конфигурацией, статистикой, производительностью и безопасностью (Fault, Configuration, Accounting, Performance and Security, FCAPS). Эта модель была разработана Международным союзом телекоммуникаций (International Telecommunications Union, ITU) для провайдеров и операторов, поэтому для локальных сетей используются не все описанные в ней функции. Большинство систем предусматривает управление только такими категориями, как ошибки, конфигурация и производительность, причем на практике они часто перекрываются, и определить их границы невозможно. Часть из них, например статистика, реализуется в виде отдельных решений, которые рациональнее применять для специальных задач, поскольку многофункциональные универсальные продукты оказываются сложными и трудно поддаются управлению.
УПРАВЛЕНИЕ СБОЯМИ
Управление сбоями — основополагающая составная часть всех систем. Оно определяет поведение в случае тревоги, отвечает за обнаружение и исправление неисправностей, тестирование, а также за восстановление сети. Речь идет о том, чтобы после проявления ошибки как можно быстрее восстановить рабочее состояние. Путем опроса переменных SNMP в агентах сетевых компонентов и получения сообщений SNMP система распознает ошибки и анализирует их. Это может быть неготовность системы или превышение порогового значения, когда нагрузка на канал к серверу или между двумя коммутаторами превышает критическую. Система определяет причину ошибки: например, обнаруживает отсутствие соединения с магистралью. После выяснения причины система сопоставляет ее с различными сообщениями об ошибках и состоянии, подает сигнал тревоги, а управление конфигурацией устраняет ошибку — перезапускает системы или вызывает внешние программы для ликвидации проблемы.
Однако решающим фактором является то, что сообщения о тревоге в зависимости от времени суток и дня недели немедленно направляются ответственному сотруднику по электронной почте, SMS или пейджинговой связи. Слишком часто администраторы вычислительных центров узнают о случившемся лишь после звонка пользователя с жалобой на неработоспособность системы. Неправильно же сконфигурированные системы, постоянно выдающие тревожные сообщения, когда инфраструктуре ИТ ничего не угрожает, попросту игнорируются. Часто персонал не принимает всерьез работающую таким образом систему сетевого управления, поскольку она не предлагает никакой помощи. Тем не менее многие системы поддерживают возможность автоматического направления вызова в справочную техническую службу и именно этим интересны предприятиям, где бы хотели структурировать свои информационные технологии в соответствии с библиотекой инфраструктуры ИТ (IT Infrastructure Library, ITIL). В ней определены 12 ключевых процессов управления службами ИТ, а основная идея заключается в том, что правильно функционирующие процессы управления ведут к повышению качества услуг.
УПРАВЛЕНИЕ КОНФИГУРАЦИЕЙ
Управление конфигурацией позволяет контролировать, изменять и следить за компонентами при помощи соответствующих функций, к которым относятся сбор, представление, управление и актуализация параметров конфигурации. Управление конфигурацией должно автоматически обнаруживать все компоненты сети, распознавать их и классифицировать.
Автоматическое обнаружение наряду с данными об адресе сетевого узла (IP-адрес и MAC-адрес) должно позволять извлекать и другую информацию. Для топологий локальных и глобальных сетей недостаточно, когда из маршрутизатора или коммутатора третьего уровня считываются данные о маршрутизируемых сетях IP, поскольку все остальные сведения о топологии так же интересны и необходимы, например управляющая информация (Management Information Base, MIB) о мостах или исчерпывающие подробности о продвижении данных. В итоге может быть составлена точная топология сети, в частности способ физического соединения коммутаторов и маршрутизаторов между собой. Таким образом можно установить контроль за механизмами обеспечения избыточности, а в случае отказа сервера отследить цепочку соединений вплоть до соответствующего порта коммутатора.
С этой функциональностью связана и возможность документирования при условии, что предусмотрена функция экспорта, например в Visio. Более того, благодаря управлению конфигурацией должна появиться возможность устанавливать пороговые значения для самых различных параметров, к примеру нагрузки на сеть или широковещания. Само по себе конфигурирование компонентов проще всего осуществлять с помощью менеджеров элементов от соответствующих производителей компонентов.
УПРАВЛЕНИЕ ПРОИЗВОДИТЕЛЬНОСТЬЮ
В идеальном случае управление производительностью предоставляет данные обо всех коммуникационных процессах на предприятии. Сбор данных может происходить при помощи SNMP/удаленного мониторинга (т. е. путем опроса и сообщений SNMP от отдельных компонентов) или от внешних источников данных. Управление производительностью позволяет получить статистику о работе портов коммутаторов или маршрутизаторов в реальном времени. Кроме того, соответствующий инструментарий должен уметь также измерять время отклика компонентов и учитывать, например, нагрузку центрального процессора коммутатора или маршрутизатора. Отчеты позволяют сетевому администратору выдвигать предположения относительно производительности сети в будущем, поэтому хороший инструмент измерения производительности становится основой определения типовых характеристик и анализа тенденций для прогнозирования нормальной производительности сети и составления мнения о перспективах изменения объемов поступления данных. Анализ производительности позволяет предотвратить появление узких мест и тем самым повысить готовность сети (см. Рисунок 2).
|
|
Рисунок 2. Показания нагрузки и возникающих ошибок. |
СТАТИСТИКА
Создание отчетов об использовании сетевых услуг и передача их инициаторам, персонам и группам относится к управлению статистикой (см. Рисунок 3). Эта задача относительно сложна и в большинстве систем сетевого управления реализуется с большими затратами. Классическое управление на базе SNMP часто не в состоянии с ней справиться, поскольку требуется другой коллектор данных. Однако для растущего числа предприятий упорядочение затрат играет главную роль и потому должно быть хорошо продумано в рамках сетевого управления.
|
|
Рисунок 3. Отчет о готовности коммутатора. |
УПРАВЛЕНИЕ БЕЗОПАСНОСТЬЮ
Управление безопасностью при сетевом управлении играет второстепенную роль, поскольку состоит преимущественно в ограничении доступа и задании прав на использование сети. В эту категорию попадают идентификация, аутентификация и авторизация. Для указанных действий разработаны специальные решения.
ЗАКЛЮЧЕНИЕ
Не всегда необходима поддержка всех категорий модели FCAPS. Часто в небольших однородных сетях для сетевого управления достаточно менеджера элементов от производителя активных компонентов — к примеру, IronView от Foundry, Cisco Works или EpiCenter от Extreme. Система сетевого управления вовсе не обязательно должна быть дорогой. Если она применяется правильно, то быстро окупается благодаря сокращению времени на ликвидацию отказа, а в небольших сетях администратору даже не приходится применять такие сложные платформы, как Tivoli или HP OpenView. В этом случае можно предложить соответствующее свободно распространяемое решение Nagios или Whats Up Gold от IPswitsch.
Оливер Зюэс — консультант в компании Magellan. С ним можно связаться по адресу: db@lanline.awi.de.
? AWi Verlag
Скачать материал
Выберите документ из архива для просмотра:
lk12_mdk_03_01_Arkhitektura_i_oblasti_upravlenia_setyami.doc
lk13-14_mdk_03_01_Mnogourovnevaya_arkhitektura_upravlenia_TMN.doc
lk15_mdk_03_01_Protokoly_upravlenia.doc
lk16-17_mdk_03_01_Upravlenie_otkazami_v_rabote_seti.doc
lk18_mdk_03_01_Upravlenie_proizvoditelnostyu_i_bezopasnostyu_seti.doc
lk19_mdk_03_01_Obsluzhivanie_LVS.doc
lk1_03_01_PROFILAKTIKA_OB_EKTOV_SETEVOJ_INFRASTRUKTURY.docx
lk20_mdk_03_01_Iskusstvo_diagnostiki_lokalnykh_setey.doc
lk21_mdk_03_01_diagnosticheskie_programmy.doc
lk22_mdk_03_01_izmerenie_utilizatsii_seti.doc
lk23_mdk_03_01_Izmerenie_chisla_kolliziy_v_seti.doc
lk24_mdk_03_01_Tekhnicheskie_predlozhenia_i_proektnaya_dokumentatsia.doc
lk2_Monitoring_i_analiz_kompyuternykh_setey.docx
lk3_mdk_03_01.docx
lk4_mdk_03_01_Oborudovanie_dlya_diagnostiki_i_sertifikatsii_kabelnykh_sistem.docx
lk5_mdk_03_01_Expertnye_sistemy.docx
lk6_mdk_03_01_Vstroennye_sredstva_monitoringa_i_analiza_setey.docx
lk7_mdk_03_01_Autsorsing_setevoy_infrastruktury.docx
lk8-9-10-11_mdk_03_01_Proverka_i_profilaktika_setevykh_obektov.doc
Выбранный для просмотра документ lk12_mdk_03_01_Arkhitektura_i_oblasti_upravlenia_setyami.doc
ЭКСПЛУАТАЦИЯ СЕТЕВЫХ
КОНФИГУРАЦИЙ
Управление сетями
Архитектура и области
управления сетями
Системы управления сетями
представляют собой сложные программно-аппаратные комплексы, поэтому существует
граница целесообразности их применения, которая зависит от сложности сети. В
небольшой сети можно применять отдельные программы управления наиболее сложными
устройствами. Однако при росте сети встает проблема объединения разных программ
управления устройствами в единую систему управления, и для решения этой проблемы
придется, возможно, отказаться от этих программ и заменить их интегрированной
системой управления.
Первые системы управления
корпоративными сетями были ориентированы на управление коммуникационным
оборудованием и контроль трафика сети. Именно эти функции чаще всего имеют в
виду, когда говорят о системе управления сетью. Кроме систем управления сетями,
существуют и системы управления другими элементами корпоративной сети: системы
управления ОС; системы управления базами данных (СУБД), корпоративными приложениями
идр.
Типовая архитектура систем
управления сетями. Независимо от объекта управления желательно, чтобы система
управления выполняла ряд функций, которые определены международными
стандартами, обобщающими опыт применения систем управления в различных
областях. Стандарты X.700/ISO 7498-4 делят задачи системы
управления на пять функциональных групп [12]:
- 1) управление
конфигурацией сети; - 2) обработка
ошибок; - 3) анализ
производительности и надежности; - 4) управление
безопасностью; - 5) учет работы
сети.
Рассмотрим задачи этих
функциональных областей управления применительно к системам управления сетями.
Управление
конфигурацией сети заключаются в конфигурировании
параметров как элементов сети, так и сети в целом. Для элементов сети, таких
как маршрутизаторы, мультиплексоры и др., с помощью этой группы задач
определяются сетевые адреса, идентификаторы, географическое положение и пр. Для
сети в целом управление конфигурацией обычно начинается с построения карты
сети, т.е. отображения реальных связей между элементами сети и изменения связей
между элементами сети — образования новых физических или логических каналов,
изменения таблиц коммутации и маршрутизации.
Управление конфигурацией,
как и другие задачи системы управления, может выполняться в автоматическом, ручном
или полуавтоматическом режимах. Например, карта сети может составляться
автоматически, на основании зондирования реальной сети пакетами-
исследователями (программными агентами или просто агентами), либо
вводиться оператором системы управления вручную. Чаще всего применяются
полуавтоматические методы, когда автоматически полученную карту оператор
подправляет вручную. Одной из наиболее сложных задач управления конфигурацией
сети является настройка коммутаторов и маршрутизаторов на поддержку маршрутов и
виртуальных путей между пользователями сети. Согласованную ручную настройку
таблиц маршрутизации при полном или частичном отказе от использования протокола
маршрутизации (а в некоторых глобальных сетях, например Х.25, такого
протокола просто не существует) многие системы управления сетью общего
назначения просто не выполняют. Однако существуют специализированные системы
конкретных производителей, например система NetSys компании Cisco
Systems, которая решает ее для маршрутизаторов этой же компании.
Обработка
ошибок — выявление, определение и устранение последствий сбоев и
отказов в работе сети. На этом уровне выполняется регистрация сообщений об
ошибках, их фильтрация, маршрутизация и попытка устранения последствий их
возникновения. Фильтрация позволяет выделить из весьма
интенсивного потока сообщений об ошибках, который обычно наблюдается в большой
сети, только важные сообщения. Маршрутизация обеспечивает их
доставку нужному элементу системы управления, а корреляционный анализ позволяет
найти причину, породившую поток взаимосвязанных сообщений (например, обрыв
кабеля может быть причиной большого количества сообщений о недоступности сетей
и серверов).
Устранение ошибок может
быть как автоматическим, так и полуавтоматическим. В первом случае система
непосредственно управляет оборудованием или программными комплексами и обходит
отказавший элемент за счет резервных каналов. В полуавтоматическом режиме
основные решения и действия по устранению неисправности выполняют люди, а
система управления только помогает в организации этого процесса: оформляет
квитанции на выполнение работ и отслеживает их поэтапное выполнение (подобно
системам групповой работы).
Если при этом процесс
управления сбоями поддерживается процессом управления конфигурациями,
удаленным администрированием, то становится возможным архивировать
различные сетевые настройки на сервере и проводить регулярное обслуживание
сетевого оборудования. Кроме того, необходимо ежедневно проверять сетевые
настройки и сравнивать их с ожидаемыми, что позволяет быстро распознавать
возможные атаки на сетевые устройства. Вот почему так важно включать в число
областей управления сетью инструмент управления конфигурациями, который
может быть как простой системой, способной лишь распознавать устройства, так и
более сложной системой, способной проверять /og-файлы устройств, обнаруживать
ошибки конфигураций и составлять статистику использования устройств. В качестве
примера в табл. 3.1 приведен перечень типовых наблюдаемых параметров управления
сетью.
Анализ
производительности и надежности. Задачи этой группы связаны
с оценкой времени реакции системы, пропускной способности реального или
виртуального канала связи между двумя конечными абонентами сети, интенсивности
трафика в отдельных сегментах и каналах сети, вероятности искажения данных при
их передаче через сеть, а также коэффициента готовности сети или ее
определенной транспортной службы. Анализ производится после сбора необходимой
статистической информации. Функции анализа производительности и надежности сети
нужны как для оперативного управления сетью, так и для планирования развития
сети. Результаты анализа производительности и надежности позволяют
контролировать соглашение об уровне обслуживания, заключаемое
между пользователем сети и ее администраторами или компанией, продающей услуги.
Подобные соглашения в количественной форме оговаривают все перечисленные выше
функции управления безопасностью (например, максимальное время устранения
отказа, реальный коэффициент готовности службы в течение года и месяца и пр.).
Управление
безопасностью включает в себя контроль доступа и сохранение целостности
данных. В функции управления безопасноПеречень типовых наблюдаемых параметров
управления сетью
Таблица
3.1
|
Параметр |
Содержание параметра |
|
Скорость распространения |
Величина, обратная времени |
|
Задержка очереди |
Среднее время, которое |
|
Задержка |
Время, в течение |
|
Ширина:
|
Характеризует пропускную Показывает скорость |
|
Пропускная способность |
Показывает объем данных, |
|
Латентность |
Время движения пакета |
|
Потеря пакетов |
Процент пакетов, |
|
Неустойчивость |
Варьирование временной |
стью входит процедура
аутентификации, проверки привилегий, поддержка ключей шифрования, управления
полномочиями, а также механизмы управления паролями, внешним доступом и
соединения с другими сетями.
Учет
работы сети включает регистрацию и управление используемыми ресурсами
и устройствами. Эта функция оперирует понятиями время использования и плата
за ресурсы.
Из приведенного списка
видно, что системы управления выполняют не только функции мониторинга и анализа
работы сети, необходимые для получения исходных данных для настройки сети, но и
включают функции активного воздействия на сеть — управления конфигурацией и
безопасностью, которые нужны для отработки выработанного плана настройки и
оптимизации сети. Сам этап создания плана настройки сети обычно остается за
пределами функций системы управления, хотя некоторые системы управления имеют в
своем составе экспертные подсистемы, помогающие администратору или интегратору
определить необходимые меры по настройке сети.
На практике уже несколько
лет прослеживается отчетливая тенденция интеграции систем управления
сетями и систем управления системами в единые
интегрированные продукты управления корпоративными сетями. Наблюдается
также интеграция систем управления телекоммуникационными сетями с системами
управления корпоративными сетями. Целесообразно в этой связи рассмотреть, как
преломляются общие функциональные задачи системы управления, определенные в
стандартах Х700//50 7498-4, в задачи такого конкретного класса систем
управления, как системы управления компьютерами и их системным и прикладным ПО,
которые называют системами управления системой (System
Management System).
Обычно система управления
системой выполняет следующие функции.
- 1. Учет
используемых аппаратных и ПС. Система автоматически собирает
информацию об установленных в сети компьютерах и создает записи в
специальной базе данных об аппаратных и программных ресурсах. После этого
администратор может быстро выяснить, какими ресурсами он располагает и где
тот или иной ресурс находится, например узнать о том, на каких компьютерах
нужно обновить драйверы принтеров, какие компьютеры обладают достаточным
количеством памяти, дискового пространства и т.п. - 2. Распределение
и установка ПО. После завершения обследования администратор может
создать пакеты рассылки нового ПО, которое нужно инсталлировать на всех
компьютерах сети или на какой-либо группе компьютеров. В большой сети, где
проявляются преимущества системы управления, такой способ инсталляции
может существенно уменьшить трудоемкость этой процедуры. Система может
также позволять централизованно устанавливать и администрировать
приложения, которые запускаются с файловых серверов, а также дать
возможность конечным пользователям запускать такие приложения с любой
рабочей станции сети. - 3. Удаленный
анализ производительности и возникающих проблем. Эта группа
функций позволяет удаленно измерять наиболее важные параметры компьютера,
ОС, СУБД и т.д. (например, коэффициент использования процессора,
интенсивность страничных прерываний, коэффициент использования физической памяти,
интенсивность выполнения транзакций). Для разрешения проблем эта группа
функций может давать администратору возможность брать на себя удаленное
управление компьютером в режиме эмуляции графического интерфейса
популярных ОС. База данных системы управления обычно хранит детальную
информацию о конфигурации всех компьютеров в сети, для того чтобы можно
было выполнять удаленный анализ возникающих проблем.
Как видно из описания
функций системы управления системами, они повторяют функции системы управления
сетями, но только для других объектов. Действительно, функция учета
используемых аппаратных и ПС соответствует функции построения карты сети,
функция распределения и установки ПО — функции управления конфигурацией
коммутаторов и маршрутизаторов, а функция анализа производительности и
возникающих проблем — функции производительности.
Эта близость функций
систем управления сетями и систем управления системами позволила разработчикам
стандартов OSI не делать различия между ними и разрабатывать
общие стандарты управления.
Архитектура систем
управления сетями IBM. В отличие от рассмотренной архитектуры
системы управления сетью, которая отвечает стандартам Х.700/ISO 7498-4,
система управления сетями IBM имеет свою собственную
архитектуру сетевого управления, в основе которой лежат пять функциональных
групп, ориентированных на пользователя.
- 1. Управление
конфигурацией — идентифицирует ресурсы физических и логических систем и
обеспечивает управление их взаимоотношениями. - 2. Управление
производительностью и учетом использования ресурсов — обеспечивает
квалификацию, измерение, сообщение и управление реакцией, доступностью,
утилизацией и использованием компонентов сети. - 3. Управление
проблемами — обеспечивает обнаружение, диагностику, решение, а также
средства отслеживания и управления проблемой. - 4. Управление
операциями — обеспечивает средства для запроса и управления
распределенными сетевыми ресурсами из центрального пункта.
5. Управление изменениями
— обеспечивает планирование, управление и применение дополнений, исключений и
модификаций в аппаратном и ПО системы.
Сравнение функций сетевого
управления OSI и IBM дано в табл. 3.2.
Таблица
3.2
|
Области управления OSI |
Области управления IBM |
|
Управление конфигурацией |
Управление конфигурацией |
|
Анализ |
Управление |
|
Учет работы сети |
|
|
Обработка ошибок |
Управление проблемами |
|
Управление безопасностью |
— |
|
Управление операциями |
Управление
конфигурацией в архитектуре IBM затрагивает как
физические, так и логические ресурсы информационных систем и их взаимоотношение
друг с другом. Эта информация обычно состоит из названий ресурсов, адресов,
местоположений, контактов и телефонных номеров. Функция управления
конфигурацией IBM очень близко соответствует концепции OSI об
управлении конфигурацией. Так же как и в «стандартной» архитектуре,
пользователи с помощью средств управления конфигурацией могут поддерживать
ведомость сетевых ресурсов, а управление конфигурацией помогает гарантировать
быстроту и точность отражения изменений сетевой конфигурации в базе данных
конфигурационного управления и т.д.
Управление
производительностью и учетом сетевых ресурсов. Эта
функция позволяет пользователям определять, будут ли удовлетворены задачи
производительности сети. Функция включает в себя учет ресурсов, контролирование
времени реакции, доступности, утилизации и компонентной задержки, а также
регулировку, отслеживание и управление производительностью. Информация от
работы каждой из этих функций может привести к инициированию процедуры
определения проблемы, если уровни производительности не отвечают требуемым
условиям.
Управление
проблемами. Система определяют проблему как сбойную ситуацию, которая
приводит к потере пользователем всех функциональных свойств и ресурсов системы.
К задачам системы управления проблемами относятся:
- 1. Определение
проблемы. Выявляет проблему и выполняет шаги, необходимые для
начала диагностики проблемы. Назначение этой области — изолировать
проблему в конкретной подсистеме, например в каком-нибудь аппаратном
устройстве, программном изделии, компоненте микрокода или сегменте
носителя. - 2. Диагноз
проблемы. Определяет точную причину проблемы и воздействие,
необходимое для решения этой проблемы. Если диагноз проблемы выполняется
вручную, то он следует за определением проблемы. Если он выполняется
автоматически, то это обычно делается одновременно с определением
проблемы, чтобы можно было выдать результаты вместе. - 3. Обход
проблемы и восстановление. Выполняются попытки обойти проблему
либо частично, либо полностью. Обычно эта операция является временной,
причем подразумевается, что далее последует полное ее решение. - 4. Решение
проблемы. Включает усилия, необходимые для устранения проблемы.
Решение проблемы обычно начинается после установления ее диагноза и часто
включает в себя корректирующее воздействие, которое должно быть занесено в
график; например, это может быть замена отказавшего дисковода. - 5. Отслеживание
и управление проблемой до ее полного решения. В частности, если
для решения проблемы необходимо внешнее воздействие, то критическая для
системы информация, описывающая эту проблему, включается в запись
управления проблемой и вводится в БД этой проблемы.
Управление
операциями включает в себя управление распределенными сетевыми ресурсами
из центрального пункта. Оно предусматривает два набора функций: услуги общих
операций и услуги управления операциями. Услуги общих операций обеспечивают
управление ресурсами с помощью прикладных программ. Услуги управления
операциями обеспечивают возможность управления дистанционными ресурсами путем
активации и дезактивации ресурсов, отмены команды и установки часов сетевых
ресурсов.
Управление
изменениями помогает пользователям управлять сетевыми или системными
изменениями путем обеспечения отправки, извлечения, установки и удаления файлов
изменений в отдаленных узлах. Кроме того, управление изменениями обеспечивает
активацию узла. Изменения имеют место либо из-за изменений в требованиях
пользователя, либо из-за необходимости обойти проблему.
Скачать материал


- Сейчас обучается 365 человек из 68 регионов


- Сейчас обучается 29 человек из 22 регионов




Выбранный для просмотра документ lk13-14_mdk_03_01_Mnogourovnevaya_arkhitektura_upravlenia_TMN.doc
Многоуровневая архитектура
управления TMN
Кроме разделения задач
управления на пять функциональных групп, полезно разделять задачи управления на
уровни в соответствии с иерархической организацией корпоративной сети.
Корпоративная сеть строится иерархически, отражая иерархию самого предприятия и
его задач. Нижний уровень сети составляют элементы сети — отдельные компьютеры,
коммуникационные устройства, каналы передачи данных. На следующем уровне
иерархии эти элементы образуют сети разного масштаба — сеть рабочей группы,
отдела, отделения и, наконец, сеть предприятия в целом.
Для построения
интегрированной системы управления разнородными элементами сети обычно
применяется иерархический подход. Применительно к системам управления сетями
наиболее проработанным и эффективным для создания многоуровневой иерархической
системы является стандарт Telecommunication Management Network (TMN) [И12].
На каждом уровне иерархии
модели TMN решаются задачи одних и тех же пяти функциональных
групп, рассмотренных выше (управления конфигурацией, производительностью,
ошибками, безопасностью и учетом), однако на каждом уровне эти задачи имеют
свою специфику. Чем выше уровень управления, тем более общий характер
приобретает собираемая о сети информация, а сугубо технический характер собираемых
данных по мере повышения уровня меняется на производственный, финансовый и
коммерческий. Модель TMN упрощенно можно представить в виде
двухмерной диаграммы, показанной на рис. 3.1.

Рис. 3.1. Многоуровневое
представление задач управления сетью
Нижний уровень —
уровень элементов сети — состоит из отдельных устройств сети:
каналов, усилителей, оконечной аппаратуры, мультиплексоров, коммутаторов и т.п.
Элементы могут содержать встроенные средства для поддержки управления —
датчики, интерфейсы управления, а могут требовать для связи с системой
управления разработки специального оборудования — устройств связи с объектом.
Современные технологии обычно имеют встроенные функции управления, которые
позволяют выполнять хотя бы минимальные операции контроля за состоянием
устройства и передаваемым устройством трафиком.
Следующий уровень — уровень
управления элементами сети — представляет собой элементарные системы
управления, которые автономно управляют отдельными элементами сети, например
коммутатором или мультиплексором. Уровень управления элементами изолирует
верхние слои системы управления от деталей и особенностей управления конкретным
оборудованием. Этот уровень ответствен за моделирование поведения оборудования
и функциональных ресурсов нижележащей сети.
Выше лежит уровень
управления сетью. Этот уровень координирует работу элементарных систем
управления, позволяя контролировать конфигурацию составных каналов,
согласовывать работу транспортных подсетей разных технологий и т.п. С помощью
этого уровня сеть начинает работать как единое целое, передавая данные между
своими абонентами.
Следующий уровень — уровень
управления услугами — занимается контролем и управлением за транспортными
и информационными услугами, которые предоставляются конечным пользователям
сети. В задачу этого уровня входит подготовка сети к предоставлению
определенной услуги, ее активизация, обработка вызовов клиентов. Формирование
услуги заключается в фиксации в БД значений параметров услуги, например
требуемой средней пропускной способности, максимальной величины задержки
пакетов и т.п. В функции этого уровня входит выдача уровню управления сетью
задания на конфигурирование виртуального или физического канала связи для
поддержания услуги. После формирования услуги данный уровень занимается
контролем качества ее реализации, т.е. соблюдения сетью всех принятых на себя
обязательств в отношении производительности и надежности транспортных услуг.
Результаты контроля качества обслуживания нужны, в частности, для подсчета
оплаты за пользование услугами клиентами сети.
Уровень
бизнес-управления занимается вопросами долговременного
планирования сети с учетом финансовых аспектов деятельности организации,
владеющей сетью. На этом уровне помесячно и поквартально подсчитываются доходы
от эксплуатации сети и ее отдельных составляющих, учитываются расходы на
эксплуатацию и модернизацию сети, принимаются решения о развитии сети с учетом
финансовых возможностей.
Схема «Менеджер — Агент» — основа управления сетью.
Выделение в системах управления типовых групп функций и
разбиение этих функций на уровни еще не дают ответа на вопрос, каким же образом
устроены системы управления, из каких элементов они состоят и какие архитектуры
связей этих элементов используются на практике. Оказывается, в основе
построения любой системы управления сетью лежит концепция, именуемая как
«Менеджер — Агент». Примером агента может служить программа слежения за
действиями пользователей терминальных клиентов LanAgent, которая осуществляет
контроль и мониторинг всех действий пользователей, а именно:
- • перехватывает
все нажатия клавиш; - • делает снимки
экрана; - • отслеживает
установку, удаление, запуск и закрытие программ; - • следит за
изменением и содержимым буфера обмена данными; - • следит за
состоянием файлов, папок и списком посещенных сайтов; - • ведет учет
документов, распечатываемых на принтере, и логов запускаемых программ.
Подобные агенты позволяют выявлять деятельность пользователей,
не имеющую отношения к тематике отдела предприятия или офиса.
На основе схемы «Агент — Менеджер» могут быть построены системы
управления сетями практически любой сложности с большим количеством агентов и
менеджеров разного типа. Схема «Менеджер — Агент» представлена на рис. 3.2.
Агент здесь является посредником между основной управляющей
программой—менеджером и управляемым ресурсом (УР), в качестве которого может
выступать канал передачи данных, ОС и/или маршрутизатор. Чтобы один и тот же
менеджер мог управлять различными реальными ресурсами, создается модель
управляемого ресурса, которая отражает только те его характеристики,
которые нужны для контроля и управления ресурсом (УРП). Например, модель
маршрутизатора обычно включает такие характеристики, как количество портов, их
тип, таблица маршрутизации, количество кадров и пакетов протоколов канального,
сетевого и транспортного уровней, прошедших через эти порты.

Рис. 3.2. Взаимодействие
агента, менеджера и управляемого ресурса
Менеджер получает от агента только те данные, которые
описываются моделью ресурса. Агент же является некоторым
экраном, освобождающим менеджера от ненужной информации о деталях реализации
ресурса. Агент поставляет менеджеру обработанную и представленную в
нормализованном виде информацию. На основе этой информации менеджер принимает
решения по управлению, а также выполняет дальнейшее обобщение данных о
состоянии управляемого ресурса, например строит зависимость загрузки порта от
времени.
Для получения требуемых данных от объекта, а также для выдачи на
него управляющих воздействий агент взаимодействует с реальным ресурсом
нестандартным способом (вне протокола). Когда агенты встраиваются в
коммуникационное оборудование, то разработчик оборудования предусматривает
точки и способы взаимодействия внутренних узлов устройства с агентом. При
разработке агента для ОС разработчик агента пользуется теми интерфейсами,
которые существуют в этой ОС, например интерфейсами ядра, драйверов и приложений.
Агент может снабжаться специальными датчиками для получения информации,
например датчиками релейных контактов или датчиками температуры.
Менеджер и агент работают с одной и той же моделью управляемого
ресурса. Однако в использовании этой модели агентом и менеджером имеется
существенное различие. Агент наполняет модель управляемого ресурса текущими
значениями характеристик данного ресурса, и в связи с этим модель агента
называют базой данных управляющей информации, Management
Information Base (MIВ). Менеджер использует модель, чтобы знать о том,
чем характеризуется ресурс, какие характеристики он может запросить у агента и
какими параметрами можно управлять.
Менеджер взаимодействует с агентами по стандартному
протоколу. Этот протокол должен позволять менеджеру запрашивать
значения параметров, хранящихся в базе MIB, а также передавать
агенту управляющую информацию, на основе которой тот должен управлять
устройством. Различают управление inband, т.е. по тому же
каналу, по которому передаются пользовательские данные, и управление out-of-band, т.е.
вне канала, по которому передаются пользовательские данные. Например, если
менеджер взаимодействует с агентом, встроенным в маршрутизатор, по
протоколу SNMP, передаваемому по той же ЛВС, что и
пользовательские данные, то это будет управление inband. Если
же менеджер контролирует коммутатор первичной сети, работающий по технологии
частотного уплотнения FDM, с помощью отдельной сети Х.25, к
которой подключен агент, то это будет управление out-of-band. Управление inband более
экономично, так как не требует создания отдельной инфраструктуры передачи
управляющих данных. Однако способ out-of-band более надежен, так
как предоставляет возможность управлять оборудованием сети и тогда, когда
какие-то элементы вышли из строя и по основным каналам оборудование недоступно.
Стандарт многоуровневой системы управления TMN для управления
ТКС создает отдельную управляющую сеть, которая обеспечивает режим out-of-band.
Обычно менеджер работает с несколькими агентами, обрабатывая
получаемые от них данные и выдавая на них управляющие воздействия. Агенты могут
встраиваться в управляемое оборудование, а могут работать на отдельном компьютере,
связанном с управляемым оборудованием по какому-либо интерфейсу. Менеджер
обычно работает на отдельном компьютере, который выполняет также роль консоли
управления для оператора или администратора системы.
Модель «Менеджер — Агент» лежит в основе таких популярных
стандартов управления, как SNMP (стандартный интернет-протокол
для управления устройствами в IP-сетях на основе архитектур UDP/
TCP) и стандарты управления ISO/OSI на основе
протокола CMIP (выполняет специальные функции, не
предусмотренные протоколом SNMP).
Агенты могут отличаться различным уровнем интеллекта. Они могут
обладать как самым минимальным интеллектом, необходимым для подсчета проходящих
через оборудование кадров и пакетов, так и весьма высоким, достаточным для
выполнения самостоятельных действий по выполнению последовательности
управляющих действий в аварийных ситуациях, построению временных зависимостей,
фильтрации аварийных сообщений.
Платформенный подход.
При построении систем
управления крупными локальными и корпоративными сетями обычно используется
платформенный подход, когда индивидуальные программы управления разрабатываются
не «с нуля», а используют службы и примитивы, предоставляемые специально
разработанным для этих целей программным продуктом — платформой. Примерами платформ
для систем управления являются SunNet Manager, Cdbletron Spectrum, I МВ/Tivoli
TMN10.
Эти платформы создают
общую операционную среду для приложений системы управления точно так же, как
универсальные ОС, такие как Unix или Windows NT, создают
операционную среду для приложений любого типа. Платформа обычно включает
поддержку протоколов взаимодействия менеджера с агентами — SNMP, набор
базовых средств для построения менеджеров и агентов, а также средства
графического интерфейса для создания консоли управления. В набор базовых
средств обычно входят функции, необходимые для построения карты сети, средства
фильтрации сообщений от агентов, средства ведения базы данных. Набор
интерфейсных функций платформы образует интерфейс прикладного программирования {API) системы
управления. Пользуясь этим API, разработчики в ОС той или иной
платформы прямо создают законченные системы управления специфическим
оборудованием.
Обычно платформа
управления поставляется с каким-либо универсальным менеджером, который может
выполнять некоторые базовые функции управления без программирования. Чаще всего
к этим функциям относятся функции построения карты сети, функции отображения
состояния управляемых устройств и функции фильтрации сообщений об ошибках.
Например, одна из наиболее популярных платформ HP Open View поставляется
с менеджером Network Node Manager, который выполняет
перечисленные функции.
Компании, производящие
коммуникационное оборудование, разрабатывают добавочные менеджеры для
популярных платформ, которые выполняют функции управления оборудованием данного
производителя более полно.
Хорошая платформа системы
управления сетью позволяет отслеживать изменение параметров сети в реальном
времени и представлять их графически на мониторе администратора сети. Эти
платформы опираются на единые для всех протоколы архитектуры и содержат агенты,
базу данных управления MIB и рабочую станцию управления и
слежения.
Технология RMON. Эффективным
добавлением к функциональным возможностям SNMP является
спецификация RMON, которая обеспечивает удаленное
взаимодействие с базой MIB. До появления RMON протокол SNMP не
мог использоваться удаленным образом, он допускал только локальное управление
устройствами. База RMONMIB обладает улучшенным набором свойств
для удаленного управления, так как содержит агрегированную информацию об
устройстве, что не требует передачи по сети больших объемов информации.
Объекты RMONMIB включают дополнительные счетчики ошибок в
пакетах, более гибкие средства анализа графических трендов и статистики, более
мощные средства фильтрации для захвата и анализа отдельных пакетов, а также
более сложные условия установления сигналов предупреждения. Агенты RMONMIB более
интеллектуальны по сравнению с агентами MIB-1 или MIB-II
и выполняют значительную часть работы по обработке информации об устройстве,
которую раньше выполняли менеджеры. Эти агенты могут располагаться внутри
различных коммуникационных устройств, а также быть выполнены в виде отдельных
программных модулей, работающих на универсальных ПК и ноутбуках (примером может
служить LANalyzerNovell).
Объект RMON в
базе MIB объединяет 10 групп следующих объектов:
- • Statistics
— статистические данные о количестве пакетов, коллизий и т.п.; - • History
— статистические данные, сохраненные через определенные
промежутки времени для анализа тенденций их изменений; - • Alarms — пороговые
значения статистических показателей, при превышении которых агент RMON посылает
сообщение менеджеру; - • Host — данных
о хостах сети, включая их MAC-адреса; - • HostTopN
— таблица наиболее загруженных хостов сети; - • TrafficMatrix
— статистика об интенсивности трафика между каждой парой хостов
сети, упорядоченная в виде матрицы; - • Filter — условия
фильтрации пакетов; - • PacketCapture
— условия захвата пакетов; - • Event —
условия регистрации и генерации событий. Отличительной чертой
стандарта RMONMIB является его независимость от протокола
сетевого уровня (в отличие от стандартов MIB- I и MIB-II,
ориентированных на протоколы TCP/IP). Поэтому его удобно
использовать в сетях, применяющих различные протоколы сетевого уровня.
Скачать материал
Выбранный для просмотра документ lk15_mdk_03_01_Protokoly_upravlenia.doc
Протоколы управления:
SNMP, CMIP, TMN
Большая часть работы по
управлению компьютерными сетями состоит из слежения за работой устройств,
контроля производительности компьютерной сети, диагностики проблем и устранения
причин возникновения этих проблем. К настоящему моменту разработаны два четких
практически аналогичных протокола для управления ЛВС:
- 1) простой
протокол для управления вычислительной сетью (SNMP, Simple Network
Management Protocol) — для решения коммуникационных проблем TCP/IP; - 2) протокол общего
управления информацией CMIP (Common Management Information
Protocol) — продукт Международного комитета по стандартизации.
Каждый из этих протоколов
имеет свои преимущества, и производители сетевых систем разрабатывают средства
управления ЛВС с учетом требований обоих протоколов.
Протоколы SNMP и CMIP имеют
общую цель, состоящую в облегчении задач управления и диагностики при работе в
ЛВС. Оба протокола используют рассмотренную в предыдущем разделе базу М1В, состоящую
из набора переменных, тестовых точек и контрольных параметров, которые
поддерживаются всеми устройствами ЛВС и могут контролироваться администратором
ЛВС. Оба протокола поддерживают также расширения MIB, вводимые
различными производителями с целью сбора большого количества служебной
информации при запросах в ЛВС.
При разработке систем
управления компьютерными сетями производители сочетают возможности
протоколов SNMP и CMIP. Совместимость обоих
протоколов позволяет производителям создавать системы управления ЛВС, которые
смогут принимать информацию как от SNMP, так и от CMIP, а
хранить ее в общем формате. Различия SNMP и CMIP. Протоколы SNMP и CMIP различаются
способами, при помощи которых они извлекают и выдают данные о вычислительной
сети. Эти протоколы предлагают различные функции, требуют разных затрат
вычислительной мощности и используют разное количество памяти. Каждый из этих
протоколов использует собственный набор протоколов низкого уровня для
передачи и приема информации, необходимой для управления Л ВС, и каждый
протокол поддерживается различными комитетами по стандартизации.
Доступ к
данным. Протоколы SNMP и CMIP имеют
функции извлечения данных, но делают это разными способами. Протокол
SNMP предназначен
для получения сведений о конкретных устройствах, а протокол CMIP ориентирован
на извлечение наборов данных. При использовании SNMP необходима
точная формулировка запроса об интересующем вас предмете. В случае CM
IP вы имеете возможность сделать общий запрос и затем уточнять его,
определяя, какая информация вас не интересует.
Опрос/отчет. Протокол SNMP работает
через опросы, т.е. центральное устройство управления (возможно, ваша рабочая
станция) периодически опрашивает каждое устройство в ЛВС для определения его
статуса. В протоколе CMIP используются отчеты, в которых
устройства информируют центральную управляющую станцию об изменениях в своем
статусе.
При большом числе
устройств протокол SNMP может вызвать большой трафик ЛВС и
замедлить ее работу, но он может работать с любыми устройствами, включая самые
примитивные, которые не могут сами определить свою неисправность.
Размеры и
производительность. Система управления ЛВС на базе
протокола SNMP может быть меньших размеров, более
быстродействующей и менее дорогостоящей по сравнению с CMIP. Система CMIP требует
более быстродействующего компьютера и большей памяти.
Протоколы
транспортного уровня. Для передачи запросов или
ответов при управлении ЛВС в SNMP используются простые
датаграммы. При таком способе обмена связывающиеся стороны должны
предусматривать возможность неполучения данных адресатом. Это значит, что
отправитель должен повторить передачу несколько раз, прежде чем констатировать
факт неработоспособности адресата. В SNMP для маршрутизации
сообщений могут быть использованы простые коммуникационные протоколы
(например, IPX или IP и UDP).
Использование в
протоколе CMIP сеансового обмена информацией делает его более
удобным при необходимости получения большого количества данных. Однако это
может затруднить управление сетью при возникновении неполадок. Если ЛВС выйдет
из строя или практически перестанет функционировать, SNMP будет
продолжать посылать управляющие запросы до тех пор, пока один из них не
пройдет. Сеансовый обмен информацией, на котором базируется CMIP,
становится невозможным, как только пропадает связь в результате сбоя в работе ЛВС.
Стандарты
протоколов. Протокол CMIP является протоколом OSI и
потому контролируется Международной организацией по стандартизации ISO. Производители
систем, реализующих протокол CMIP, могут проверять свои
изделия в COS (Corporation of Open Systems, Корпорация
открытых систем), где производится тестирование на совместимость с
протоколами OSI.
В противоположность
этому SNMP не является международным стандартом. Однако,
подобно TCP/IP, SNMP контролируется организацией Internet
Activities Boar — Советом по архитектуре Интернета, осуществляющим
надзор за архитектурой Интернета, включая его протоколы и связанные с ними
процедуры, а также надзор за созданием новых стандартов Интернета.
На практике главным
преимуществом SNMP перед CM IP является то,
что изделий на базе SNMP гораздо больше. Несмотря на
определенные преимущества, CM IP был использован в небольшом
количестве сетевых устройств. Продукты же на базе SNMP — маршрутизаторы, EtherNet-разветвители, волоконно-оптические
и прочие устройства — широко распространены. Частично причиной этого является
разница в возрасте этих протоколов — SNMP гораздо старше. Но в
настоящее время многие компании разрабатывают системы управления
вычислительными сетями, использующие CMIP или комбинацию SNMP и CMIP.
Протокол SNMP больше
ориентирован на управление конкретными устройствами, в то время как CMIP лучше
подходит для коммуникаций между двумя или несколькими системами управления ЛВС.
С этих позиций SNMP и CMIP могут играть
взаимно дополняющую роль. В зависимости от размеров и сложности ЛВС может
оказаться, что лучшей является система управления, использующая как CMIP, так
и SNMP.
Рассмотрим, как происходит
управление сетью на базе протокола SNMP. Протокол SNMP создавался
специально для контроля удаленных сегментов сети без применения постоянного
мониторинга и необходимости непосредственного присутствия администратора. Он
позволяет выполнять статистическую оценку работы сети за длительные периоды и
осуществлять подробный анализ ее функционирования в течение коротких промежутков
времени.
Чтобы сеть, не дожидаясь
поступления запроса, могла проинформировать управляющую станцию о
проблеме, SNMP предусматривает возможность отправки
незапрашиваемого отклика, так называемое прерывание {trap). С
помощью функции отправки прерываний управляемое устройство — агент SNMP
— способно уведомить управляющую станцию, например, о достижении либо
превышении заранее указанных значений и, таким образом, привлечь к себе
внимание. При получении определенных или любых прерываний станция управления
сетью уведомит пользователя, например, путем отправки сообщения по электронной
почте или подачи сигнала на пейджер.
Для коммутаторов,
поддерживающих протокол SNMP, существует много различных баз
управляющей информации (MIB). По сути, эти базы представляют
собой словари-справочники, где перечислены разрешенные запросы с возможными
откликами на них и соответствующим описанием. Каждая поддерживаемая
производителем база MIB позволяет консоли управления получить
более или менее подробное описание текущего состояния сети поблизости от
устройства, за которым ведется наблюдение, включая само это устройство.
В отличие от частных MIB, обычно
предназначенных для поддержки определенного типа коммутатора и программного
кода, стандартные базы MIB, опирающиеся на документы RFC, позволяют
эффективно следить за всей коммутируемой сетью. Для обеспечения диагностики
наиболее полезны приведенные ниже базы MIB, перечисленные в
порядке возрастающей детализации данных: a) RFC 1213 — MIB II;
б) RFC 2021 — RMON 2; в) RFC 1643
— Ethernet-Like Interface MIB; r) RFC 2819 — RMON
Ethernet.
При использовании SNMP
для мониторинга сети необходимо обратить особое внимание на вопросы
безопасности. Если агенты SNMP не защищены от
несанкционированного доступа, то злоумышленник, находящийся где угодно, в
состоянии отследить работу вашей сети или даже поменять настройки коммутаторов.
Часто протокол SNMP включен по умолчанию и защищен несложным
паролем, одинаковым как для коммутаторов, так и для других агентов SNMP. Пароли SNMP называют
также общей строкой, поскольку в нее включаются и имя, и пароль, которые
вводятся с учетом регистра и знаков препинания. Пароль передается в виде
открытого текста, что само по себе создает дополнительную опасность. Чтобы
закрыть эту лазейку, в третьей версии SNMP предусмотрены
процедура аутентификации и шифрование передачи. Необходимо, как
минимум, сразу же изменить пароль, заданный по умолчанию. Агенты SNMP можно
настроить таким образом, чтобы разным пользователям предоставлялись разные
уровни доступа, они откликались бы на запросы от конкретной подсети и
игнорировали запросы от других подсетей, отвечали бы на запросы только
конкретных IP-адресов. Помимо перечисленных настроек, возможны и
другие. Маршрутизаторы, через которые пролегает путь к агентам SNMP, способны
накладывать на использование SNMP дополнительные ограничения.
Брандмауэры (firewall) могут полностью блокировать
работу SNMP.
Но получения доступа к
агенту с помощью SNMP недостаточно — агент должен поддерживать
базу MIB, к которой обращен ваш запрос. Большинство
производителей реализуют поддержку стандартных баз MIB в
нужном объеме, однако некоторые этого не делают. В отдельных случаях необходимо
обновить ОС коммутатора, чтобы он мог поддерживать желаемую общую или частную
базу MIB.
Если коммутатор не
отвечает на запрос SNMP, это может быть следствием отсутствия
в коммутаторе необходимой базы Ml В. С другой стороны, с
помощью протокола SNMP можно получить любую информацию о вашей
сети, если агент поддерживает соответствующую базу MIB.
Стек протоколов TNM. В
основе любой системы управления сетью, как было сказано выше, лежит схема
взаимодействия агента с менеджером, показанная на рис. 3.3. Агенты и менеджеры
представляют собой программно-аппаратные модули, устанавливаемые в
телекоммуникационное оборудование, либо программные модули, встроенные в ОС и
выполняющие функции диагностики и управления телекоммуникационным устройством.

Рис. 3.3. Общая
схема взаимодействия «Агент-Менеджер»
Подключение сетевого
элемента (СЭ) к архитектуре TMN также выполняется по принципу
«Агент — Менеджер», причем агент реализуется в сетевом элементе, а менеджер — в
центре управления (ЦУ). Агент и менеджер являются активными взаимодействующими
компонентами TMN, которые распределены по сети и общаются
путем обмена сообщениями. Сообщения со стороны менеджера переносят запросы на
выполнение операций (30), которые предусмотрены в информационных структурах
обслуживаемых агентом объектов. Агент может передавать уведомления (УВ),
генерируемые либо в ответ на запрос менеджера, либо автономно. В теле
уведомления могут передаваться атрибуты, характеризующие состояние объекта. Процесс
«Агент» является ключевым звеном любого сетевого элемента, совместимого с TMN,
— телефонной станции, маршрутизатора, центра эксплуатационного
управления и т.д.
Кроме того, подключение
сетевого элемента к архитектуре TMN предполагает наличие
иерархического стека протоколов, каждый из которых на каждом уровне стека
отвечает за обмен блоками данных этого уровня. Стек протоколов обеспечивает
последовательное преобразование информации, начиная от абстрактного описания
объектов и операций на некотором языке высокого уровня. Далее формируются
двоичные наборы данных сетевого уровня, которые с помощью протоколов
транспортного (и далее — пакетного и физического) уровня передаются в сеть для
отправки адресату. При получении адресатом предназначенного ему пакета происходит
обратное восстановление данных/операций.
Каждый элемент в сети
заменяется абстрактной информационной моделью (АИМ), которая рассматривает его
как сетевой ресурс. Параметры этого ресурса (объекта информационной модели)
передаются средствами используемого протокола (например, CM IP). Информационная
модель определяет основные параметры объекта, абстрагируясь от его физической
сущности и используя наборы атрибутов, уведомлений и действий.
Для создания
информационной модели объекта, который описывается как некоторый класс в
терминах объектно-ориентированного подхода, в стандартах TMN используются
шаблоны GDMO (Х.122), на смену которым в ближайшем будущем
придет язык IDL, используемый для описания данных в системах CORBA и JAVA.
В качестве информационной
базы данных, откуда менеджер и/ или агент получает информацию о структуре и
особенностях любого зарегистрированного в сети объекта, используется база
данных MIB, которая является ресурсом, разделяемым всеми объектами
сети. Все объекты, зарегистрированные в сети, представлены своими
информационными моделями (ИМО).
Интерфейс
(называемый Q-интерфейс или Q-adanmep), через
который агент взаимодействует с менеджером через сеть TMN, представляет
собой стек протоколов выхода в сеть CMIP/CORBA (ПВС/С),
показанный на рис. 3.4. В его основе лежат следующие принципы:
- 1) использование в
качестве транспортного средства для передачи сообщений между агентом и
менеджером полного 7-уровневого стека протоколов, соответствующего
модели OSI, в качестве которого могут применяться стеки ISO/OSI или TCP/IP; - 2) использование
для передачи сообщений на прикладном уровне протокола СМ1Р
3) применение поверх CMIP более
содержательных протоколов взаимодействия «Агент — Менеджер», конкретизирующих
отдельные функции эксплуатационного управления, например контроль ошибок,
измерение производительности и т.п.

Рис. 3.4. Взаимодействие
процессов «Агент — Менеджер» через сеть TMN
Так как менеджер
связывается с агентом при помощи полного транспортного стека, то при сборе
данных от встроенных агентов можно использовать промежуточную сеть передачи
данных произвольной сложности. Это обстоятельство является одним из важных
компонентов открытости архитектуры TMN. Оно дает возможность
объединять любые сети, в том числе и такие, которые не могут переносить в своих
основных информационных потоках данные, используемые системой эксплуатационного
управления.
Поддержка стандартов TMN и
Q-интерфейса декларируется практически всеми ведущими разработчиками платформ
эксплуатационного управления: Hewlett-Packard, Digital, Sun, Cabletron,
IBM, TTI. К тому же оборудование новых технологий SDH, ATM,
ADSL, WLL и др. сегодня выпускается со встроенной поддержкой
Q-интерфейса.
Скачать материал
Выбранный для просмотра документ lk16-17_mdk_03_01_Upravlenie_otkazami_v_rabote_seti.doc
Управление отказами в
работе сети
Управлением отказами в
сети называется такое управление сетью, которое имеет целью находить и
распознавать отказы в сети. Цель управления отказами — определить,
зарегистрировать, уведомить пользователей и, по мере возможности, автоматически
разрешить сетевые проблемы, для того чтобы обеспечить эффективное
функционирование сети. Поскольку неисправности могут привести к простою или
недопустимому снижению производительности, управление отказами в сетевом
управлении ISO является наиболее важным элементом. Управление
отказами включает следующие этапы:
• определение симптомов
проблемы;
- • изолирование и
устранение единичной проблемы; - • обнаружение и
устранение проблем во всех важных подсистемах; - • запись
информации об обнаружении и исправлении проблемы. Современные средства
управления отказами в ЛВС позволяют
прогнозировать,
обнаруживать и устранять некоторые виды отказов. Специальные датчики сбора
данных о параметрах сетевого оборудования постоянно информируют систему об
уходе этих параметров за установленные пределы. При обнаружении отказа в сети
система управления отказами производит соответствующую запись в журнале
фиксации отказов, после чего выполняется автоматический и/или ручной поиск в
базе данных решения возникшей проблемы. Таким образом, инструменты,
используемые системой в процессе управления отказами, информируют ее об
ошибочных ситуациях, анализируют и указывают причину ошибки, автоматически
устраняют ошибочные ситуации. Примером автоматического решения проблемы может служить
ПО маршрутизатора, которое способно восстановить прерванный в результате отказа
сетевой путь, выбрав альтернативный оптимальный маршрут для передачи пакета
и/или сообщения. Однако этого может и не произойти, если коммутируемая сеть
имеет топологию, показанную на рис. 3.5, в которой коммутаторы (К) соединены
единственным каналом.

Рис. 3.5. Простая
коммутируемая сеть
Сеть на рис. 3.6. выгодно
отличается от нее наличием параллельных связей между коммутаторами, позволяющих
им выбирать альтернативный маршрут для передачи пакетов при выходе из строя
любой одной линии связи между коммутаторами.

Рис. 3.6. Коммутируемая
сеть с резервными связями
Повышение уровня связности
сети, т.е. создание альтернативных маршрутов, — мощное масштабируемое средство
повышения эксплуатационных характеристик сети. Неизбежные дополнительные
затраты, как правило, оказываются меньше, чем при простом повышении
производительности (за счет применения более сложной технологии канала), а для
повышения надежности введение избыточных соединений чаще всего становится
единственным практически осуществимым способом достижения цели. При этом не
стоит опасаться возможного образования петель в графе топологии резервированной
сети, поскольку любой коммутатор и/или маршрутизатор поддерживает работу
специального алгоритма Spanning Tree, автоматически устраняющего
петли в ячеистой сетевой топологии путем отключения портов, через которые
проходит петля.
В настоящее время
разработчики ЛВС используют новую технологию резервирования каналов, получившую
название агрегирование портов. Различные производители
коммутаторов используют разные термины для реализации этой технологии.
Например, компания Cisco (мировой лидер в области сетевых
технологий, предназначенных для сети Интернет) использует термин Etherchannel, а
компания Brocade (лидер в индустрии производства надежных,
высокопроизводительных сетевых решений) использует термин Brocade LAG. Стандартное
решение для агрегирования портов реализовано в протоколе LACP (Link
Aggregation Control Protocol). Данный протокол не зависит от
производителя коммутационного оборудования и в настоящее время поддерживается
почти всеми коммутаторами.
Независимо от
производителя все реализации агрегирования портов выполняют одну и ту же задачу
по объединению двух и более портов в единый логический порт с повышенной
пропускной способностью, резервированием соединений и балансировкой
нагрузки между физическими соединениями. Технически коммутаторы
соединяются несколькими физическими соединениями для создания единого канала с
повышенной пропускной способностью. В качестве примера на рис. 3.7 показана
агрегация физических соединений между двумя коммутаторами. Если скорость одного
физического канала равна 10 кбит/с, то скорость агрегированного соединения
будет в 2 раза выше, т.е. 20 кбит/с.
Если просто включить
показанную на рис. 3.7 пару коммутаторов в действующую сеть, протокол Spanning
Tree, который поддерживает каждый из них, воспримет эти соединения как
петли и отключит одно дублирующее соединение, оставив активным другое. В этой
связи в паре коммутаторов, использующих агрегированные

Рис. 3.7. Агрегация
портов между двумя коммутаторами
порты, протокол Spanning
Tree должен быть отключен и заменен другим — протоколом LACP. Агрегирование
портов создает одно логическое соединение, которое может служить как
магистралью с удвоенной пропускной способностью, так и в качестве единого
соединения (для подключения серверов). Естественно при этом, что коммутаторы и
серверы, образующие агрегацию портов, должны использовать единый протокол LACP для
совместимости и стабильности работы. Как видим, агрегация портов позволяет
резервировать физические соединения: если одно из физических соединений из
агрегированного соединения обрывается, то данные могут продолжать передаваться
по оставшимся соединениям. Восстановление агрегированного соединения обычно
занимает несколько миллисекунд.
Поскольку агрегированное
соединение может содержать в общем случае А физических соединений, то
соединение между коммутаторами будет установлено, до тех пор пока все N физических
соединений не оборвутся. Обрывы физических соединений в агрегированном канале
обычно незаметны для пользователей. Однако чем меньше физических соединений в
агрегированном канале остается, тем большее количество информации требуется
передать через оставшиеся в агрегированном канале физические соединения. Также
чем больше физических соединений находится в агрегированном канале, тем лучше
нагрузка сбалансируется между физическими соединениями.
Резервирование как метод
управления сбоями в сети.
Системы управления
отказами часто используют методы, позволяющие уменьшить риск полной утраты
работоспособности системы. Основой подобных мероприятий является
резервирование. На практике применяют:
- • «холодное»
резервирование, при котором запасной модуль, находящийся постоянно на
складе, в случае выхода основного модуля монтируется вместо отказавшего
устройства; - • «теплое»
резервирование, при котором запасной агрегат подключен параллельно
основному, но находится в выключенном состоянии и включается
автоматически, как только откажет основной агрегат; - • «горячее»
резервирование: резервирующий и резервируемый элементы работают
параллельно.
С точки зрения времени,
требуемого на восстановление работоспособности системы, оптимален варианте
«горячим» резервированием, поскольку он включается практически мгновенно.
Однако с точки зрения времени наработки на отказ «горячее» резервирование
приводит к преждевременному износу запасных модулей.
Впрочем, для современных
систем (например, коммутаторов) среднее время наработки на отказ составляет
сотни тысяч часов непрерывной работы. Отказать может любой элемент сети: линия
передачи, образуемая кабелем (витая пара с разъемами 8Р8С, зачастую ошибочно
называемыми RJ45, оптоволокно с соответствующими разъемами), порт
коммутатора и/или коммутаторов, плата расширения коммутатора, контроллер плат
расширения, процессор коммутации, блок-вентилятор, сеть переменного тока.
Для того чтобы обезопасить
свою сеть от перебоев электропитания, следует предусматривать источники
бесперебойного питания, а если возможны долгосрочные перебои с электропитанием,
то и системы резервного энергообеспечения. Чтобы максимально обезопаситься от
поломок оборудования, следует резервировать все уязвимые узлы системы и
использовать надежное оборудование известных производителей, причем обе
рекомендации равнозначны.
Примером «горячего»
резервирования может служить отказоустойчивый сервер Gemini компании Themis
Computer, в котором продублирован каждый компонент. Для распределения
задач и процессов используется специализированное ПО и линии связи Ethernet. В
подобных системах с двойным резервированием все узлы продублированы сверху
донизу — все, от источников питания до питающих проводов, имеется в запасном
варианте в каждой половине общего блока. Каждая половина совершенно независима,
со своими собственными системами охлаждения, питания и диагностики, работающими
от любого из источников питания. Любая неисправность в какой-либо половине
интерпретируется как отказ системы. Это может быть как перегрев поступающего
охлаждающего либо вытяжного воздуха, так и выход напряжения питания за границы
допуска, невозможность обновить значение сторожевого таймера либо ошибка
программного протокола. Любое из этих событий может привести к запуску
процедуры отключения соответствующей половины, после чего другая половина берет
всю вычислительную нагрузку на себя.
Скачать материал
Выбранный для просмотра документ lk18_mdk_03_01_Upravlenie_proizvoditelnostyu_i_bezopasnostyu_seti.doc
Управление
производительностью и безопасностью сети
Управление
производительностью — это вид сетевого управления, которое позволяет следить за
нагрузкой сетевых узлов и устройств и, таким образом, находить узкие места в
сети. Процессу планирования производительности способствует проверка сетевых
устройств на соответствие предъявляемым к ним требованиям и корректность их
использования в инфраструктуре сети. Перечислим основные параметры, влияющие на
эффективное управление производительностью сети:
- • объем данных,
передаваемых по сети в единицу времени; - • время
реагирования устройств и сервисов в часы пик, равное сумме времени
запроса, обработки и ответа; - • процент
отклоненных запросов из-за перегрузки сети; - • среднее время
между двумя ошибками (доступность сети). Управление производительностью
включает следующие мероприятия: - • сбор статистики
использования устройств сети; - • определение
порога уведомления; - • тестирование
сети; - • составление
отчетности.
Задачу сбора
статистики использования устройств сети выполняет отдельная
подсистема, которая является частью общего программного комплекса по управления
сетью. Подсистема накапливает разнообразную информацию о параметрах работы ЛВС,
необходимую для решения задач управления сетью. Собственно сбор статистики
работы сети предполагает периодическое получение информации о состоянии
устройств сети. Данный процесс базируется на использовании протокола SNMP
— простого протокола управления сетью. Получаемая информация
ограничена управляющей базой, поддерживаемой SNMP-агентом. Все
устройства, входящие в состав современных ЛВС, как минимум, поддерживают
стандартную управляющую базу MIB2 и базу удаленного
мониторинга RMON, что необходимо для систем, построенных по
распределенному принципу, реализующих сбор статистики удаленно через сеть.
Использование
протокола SNMP в подсистеме сбора статистики работы сети
позволяет получить гибкий, универсальный и, главное, стандартизированный подход
к получению информации о состоянии устройств сети. Гибкость использования SNMP заключается
в расширяемости информационной базы, поддерживаемой устройствами, и в
использовании абстракции получения данных, которая позволяет использовать общий
подход получения данных, не опираясь на их конкретное значение и интерпретацию.
В более продвинутых системах наряду с протоколом SNMP используется
протокол управляющих сообщений ICMP, с помощью которого
производится сбор информации о доступности хостов на основе эхо-запросов и
данных о состоянии TCP- и UDP-портов, позволяющих
определить работу определенных служб.
Подсистема сбора
статистики позволяет производить периодический сбор данных о состоянии
информационно-вычислительной сети. Собираемые данные задаются в параметрах
работы подсистемы. При запуске исполняемого модуля программы производится
считывание начальных параметров опроса из конфигурационного файла. Обычно
изменение параметров опроса во время работы подсистемы выполняется без ее
останова.
Для обеспечения
универсальности взаимодействия с другими подсистемами передаваемые данные
преобразуются в ЛЖ?-доку- мент, передаваемый через сеть по протоколу передачи
гипертекста HTTP. Использование языка XML позволяет
существенно упростить протокол обмена данными между подсистемами, упрощается
взаимодействие модулей, написанных на разных языках программирования и под разные
платформы.
Как правило, подсистема
сбора статистики обеспечивает получение данных от некоторого количества
устройств сети одновременно. Получение данных от одного устройства может
потребовать несколько минут, что не должно препятствовать сбору данных с
другого устройства. Для решения этой проблемы используется идеология пула
потоков, позволяющая выполнять одновременно несколько запросов, не перегружая
систему.
Результаты сбора
информации о состоянии сети также передаются через сеть подсистеме обработки.
Если последняя по каким- либо причинам недоступна, обычно используется очередь,
кэширующая передаваемые данные. И только если наступает переполнение очереди,
непереданные данные отбрасываются. Предоставляемые данные используются для
решения других задач управления, перечисленных выше, таких как управление
конфигурациями, ошибками, производительностью, безопасностью, учет работы
пользователей [И 14].
Определение
порога уведомления — функция SNMP-менеджера,
которая обеспечивает постоянное тестирование состояния сети с целью определения
устройств, не отвечающих на управляющее воздействие. Не отвечающие на
запрос SNMP-менеджера устройства классифицируются им как
поврежденные в том случае, если превышен установленный заранее порог
уведомления, равный числу посланных к нему управляющих воздействий.
В задачи тестирования
ЛВС могут входить: построение карты сети; выявление узких мест и
возможных проблем, способных привести к неработоспособности сети или ее части;
выявление причин низкой производительности работы сети; анализ антивирусной
защиты сети и ее защищенности от несанкционированного доступа, а также общий
анализ топологии и масштабируемости ЛВС. Проведение тестирования позволяет
избежать неоправданных расходов на ее последующую модернизацию. В качестве
примера кратко перечислим возможные шаги тестирования типовой ЛВС и
используемые для этого программы: построение карты сети и определение скорости
каналов (программа 3COM Network Director); снятие статистики
загруженности портов с корневого коммутатора сети (программа MRTG);
анализ трафика (программа Sniffer Pro); сканирование
внешних IP-адресов на предмет поиска возможных уязвимостей
(программы XSpider).
В управлении
безопасностью применяются всевозможные средства и системы управления
сетью, позволяющие установить, предотвратить и противостоять возможным атакам и
другим угрозам безопасности.
Обеспечение безопасности
предполагает предварительный сбор информации, которая является критически
важной или касается приватности личных данных сотрудников. Далее требуется
идентифицировать все каналы доступа, такие как терминальные услуги, FTP,
HTTP-серверы, разделение сетей и все, что связано с предоставлением доступа
к ним, включая такие службы инфраструктуры, как DNS.
Обеспечение безопасности
данных осуществляется на разных уровнях:
- • на уровне канала
передачи данных (использование криптографии); - • уровне сети
(разрешается лишь избранный трафик); - • уровне
приложений посредством безопасной процедуры аутентификации.
Средства и методы
управления безопасностью сети должны распознавать атаки, направленные на
блокировку услуг, т.е. обеспечивать доступность самого персонала к необходимым
службам. Управление безопасностью должно предотвращать возможные атаки, попытки
кражи или изменения данных. Для этого система управления безопасностью должна
быть оснащена системами контроля и слежения, позволяющими быстро и эффективно
отображать использование информации. Системы контроля предупреждают
неавторизиро- ванный доступ, отслеживая его попытки или атаки и информируя об
этом администратора.
По типу механизма слежения
инструменты защиты можно разделить на активные и пассивные. Пассивные инструменты
позволяют контролировать текущее состояние сети через определенные интервалы
времени. Активные инструменты могут непрерывно измерять использование
услуг и устройств в реальном времени и реагировать на подозрительные действия
путем сообщений или изменения конфигураций.
В функции системы
управления безопасностью сети входит, кроме того, слежение за использованием
сетевых ресурсов отдельными пользователями. На основании этой информации можно
определить пользовательскую нагрузку сети и при необходимости отрегулировать
сетевой трафик, чтобы избежать заторов в сети. Например, следует выделить
приоритет VoIP-трафику (голосовой) и ограничить трафик, связанный с
загрузкой файлов.
Скачать материал
Выбранный для просмотра документ lk19_mdk_03_01_Obsluzhivanie_LVS.doc
Обслуживание ЛВС

Обслуживание ЛВС
Обслуживание
ЛВС в случае ее грамотной установки сводится к текущему подержанию
работоспособности сети, которое включает в себя следующие основные работы:
·
Плановую диагностику серверов и другого сетевого оборудования
·
Настройка и поддержка работоспособности компьютеров и периферии
·
Настройка рабочих мест
·
Установка и настройка ПО
·
Текущий ремонт и замена вышедших из строя комплектующих
·
Поддержание в рабочем состоянии компьютерной техники
·
Обеспечение взломостойкости сети
·
Плановый контроль антивирусной защиты
·
Резервное копирование и восстановление данных
·
Консультативная помощь пользователям
·
Обновление сети в случае изменения стандартов
·
Координация связи с поставщиками внешних услуг
Кроме
того, техническое обслуживание ЛВС может включать в себя предложения по
модернизации сети и замене устаревшего оборудования с целью повышения
производительности,надежности и сроков службы.
Остается
определить,кто будет осуществлять обслуживание ЛВС: штатный системный
администратор или специализированная компания-аутсосрсер?
SystemRescueCD —дистрибутив Linux,
основанный на Gentoo. Распространяется в виде
загрузочного LiveCD-образа.Предназначен для обслуживания и выполнения
административных задач. Содержит инструменты для работы с жестким диском:
разбивка на разделы, диагностика,сохранение и восстановление разделов. Умеет
монтировать разделы Windows Ntfs для чтения и записи. Содержит также средства
для настройки сети, сетевых сервисов, средства поиска руткитов и
антивирус. Может быть загружен с компакт-диска,USB-накопителя, или по сети по
протоколу PXE.
SystemRescueCD представляет
из себя обычный живой дистрибутив основанный на Gentoo linux. Его специализация
—работа с разделами жёсткого диска. Он включает в себя набор программ и утилит
как для реанимации убитых файловых систем, так и для повседневной работы с
дисками.В состав дистрибутива входят все основные команды GNU окружения,
PartImage и GParted. Для более комфортной работы в системе присутствуют
текстовые редакторы, инструмент для записи CD и DVD дисков, браузер и несколько
полезных скриптов.
Рассмотрим
имеющиеся инструменты подробнее.
GParted —
программа с графическим интерфейсом, при помощи которой можно работать с
разделами диска.
PartImage —
программа для создания образов раздела или клонирования разделов. При создании
образа диска программа берёт только данные и сжимает образ, что позволяет
создавать достаточно компактные файлы-образы. Хотя программа и работает в
консоли,управлять ей довольно легко. PartImage действительно создаёт хорошие
образы системы, однако её использование в рамках этого дистрибутива имеет ряд
неудобств:
1.
Перед созданием/восстановлением образа нужно монтировать диск,
где этот образ хранится;
2.
Сохранить можно только раздел, весь диск записать не получится;
3.
После развёртывания образа нужно отдельно восстанавливать MBR
(главную загрузочную запись);
Всё выше
сказанное не позволяет PartImage стать удобным инструментом клонирования
дисков. Так утилита dd в данном случае удобнее.
Отдельно хочется поговорить об программе TestDisk. Она позволяет восстанавливать удалённые с
диска файлы и целые разделы. Программа бесспорно замечательная, однако она
требует изучения документации перед применением, так как интерфейс у неё не
совсем логичен. В деле она показала себя молодцом, хотя восстанавливала далеко
не все удалённые файлы.
Кроме «высокоуровневых» программ в дистрибутиве так же присутствуют небольшие
утилиты для работы с дисками:
dd —
для побайтового копирования файла;
cfdisk —
для создания/удаления разделов на диске;
mkfs —
для форматирования разделов (нужно после создания разделов в cfdisk);
df —
статистика по занятому пространству на диске;
fsarchiver —
для резервного копирования содержимого файловых систем;
fsdisk —
сохранение и восстановление таблицы разделов;
fsck —
для проверки и исправления файловой системы;
SystemRescueCD
— это отличный инструмент, способный выручить в трудную минуту. Его стоит
всегда носить с собой.
Достоинства: очень
полезный набор инструментов для работы с дисками и ФС, наличие оперативной
справки, малый размер.
Недостатки:
как и любой Linux дистрибутив, требует от пользователя достаточно глубоких
знаний предмета.
Скачать материал
Выбранный для просмотра документ lk1_03_01_PROFILAKTIKA_OB_EKTOV_SETEVOJ_INFRASTRUKTURY.docx
ПРОФИЛАКТИКА ОБЪЕКТОВ
СЕТЕВОЙ ИНФРАСТРУКТУРЫ
Классификация регламентов
технических осмотров
Согласно
нормативно-технической документации техническое обслуживание (ТО)
есть комплекс технических и организационных мероприятий, осуществляемых в процессе
эксплуатации технических объектов с целью обеспечения требуемой эффективности
выполнения ими заданных функций. Правила организации ТО и ремонта оборудования
ОСИС установлены рядом нормативных документов (СО 34.04.181-2003 и др.). В
настоящее время в практике эксплуатации сетей используют три основных метода
ТО: а) профилактический; б) статистический; в) восстановительный.
Выбор системы ТО
обусловлен многими объективными факторами. Так, для уходящих в прошлое машинной
и декадно-шаговых систем автоматических телефонных станций был широко
распространен профилактический метод ТО оборудования.
Технологический процесс обслуживания оборудования при этом методе складывается
из следующих основных видов работ: а) профилактических проверок и измерений
оборудования станции; б) текущего обслуживания; в) планово-предупредительного
ремонта оборудования;
- г) статистического
учета технического состояния оборудования; - д) контроля за
качеством работы.
Каждая из указанных работ
имеет решающее значение для поддержания оборудования в нормальном рабочем
режиме. Так, текущее обслуживание заключается в круглосуточном
наблюдении технического персонала за работой оборудования и устройств
электросвязи, в выявлении и устранении повреждений, возникающих в процессе эксплуатации,
а также в наблюдении за содержанием и состоянием оборудования и помещения.
Профилактические
проверки проводятся для того, чтобы обнаружить неисправные детали и
отдельные элементы оборудования и сооружений (осмотр линий связи), а также
предупредить возникновение нарушений связи. Профилактические проверки
складываются: а) из электрической проверки действия устройств; б) внешнего
осмотра приборов и оборудования; в) чистки, регулировки и замены изношенных
деталей и т.д.
Профилактические проверки
проводятся по плану с определенной периодичностью в часы наименьшей нагрузки,
т.е. после 24.00 ночи до 6.00 утра. Планово-предупредительный ремонт включает
плановый ремонт аппаратуры, приборов, механизмов, аппаратов, линий и т.д. При
этом при необходимости снимают приборы с рабочих мест, разбирают их, чистят,
складывают, регулируют. Опыт применения профилактического метода проверок
показал, что он:
- • фактически не
улучшает состояние оборудования, а лишь выявляют часть имеющихся в данный
момент повреждений, причем отсутствует дифференцированный подход к
состоянию оборудования; - • при
удовлетворительном состоянии оборудования обнаруживает очень мало
повреждений, несмотря на большие эксплуатационные расходы; - • необоснованно
применяется ко всему оборудованию независимо от его состояния; - • приводит к новым
дополнительным повреждениям со стороны самого техперсонала; - • снижает качество
обслуживания абонентов из-за недостатка каналов, возникающих при
выключении части оборудования во время проверок.
В настоящее время надежность
элементной базы сетевых объектов выросла на 1—2 порядка и на смену
профилактическому методу ТО пришли более прогрессивные методы, поддерживающие
допустимый уровень качества обслуживания при меньших эксплуатационных расходах.
Одним из таких методов является статистический
метод ТО сетевых объектов, известный еще под названием контролъно-коррек-
тирующего метода (ККМ). Сущность метода заключается в сборе
статистических данных о работе сетевых объектов с последующим анализом
собранных данных и сопоставлением показателей качества с предельно допустимыми
нормативными величинами. На основании проведенного анализа принимаются решения
о проведении работ по обеспечению уровня качества, определенного нормативными
величинами.
Метод ККМ не исключает
полностью профилактических проверок и измерений, но ограничивает их объем. Для
сбора и обработки данных о состоянии оборудования применяются методы
математической статистики, что приводит к уменьшению объема необходимых
статистических данных и сокращению затрат рабочего времени на их сбор и
обработку.
Для анализа массовых сбоев
и отказов оборудования и/или кабельной системы сети метод ККМ использует выборочный
метод наблюдений, при котором обследованию подвергается только
некоторая часть оборудования. Это дает возможность: а) характеризовать
изучаемое явление на основе обследования части входящих в него единиц; б)
провести статистическое изучение с меньшими затратами сил и средств; в)
сократить сроки наблюдения и организовать его более тщательно. Основными
характеристиками служат средний размер признака и его удельный вес в изучаемом
явлении. Структура контрольно-корректирующего метода ТО представлена в табл.
2.1.
Таблица
2.1
|
Статистический метод |
||
|
Текущее обслуживание |
Контроль состояния оборудования |
Капитальный ремонт |
|
Накопление и анализ |
Другим прогрессивным
методом ТО, обеспечивающим допустимый уровень качества при меньших
эксплуатационных расходах, является восстановительный метод, при
котором профилактические проверки не проводятся, а исправляются лишь
повреждения, обнаруженные и выявленные согласно заявкам абонентов и/или с
помощью сигнализации.
Восстановительный метод ТО
требует значительно меньших затрат по сравнению с профилактическим и статистическим
методами. Этот метод предназначен для оборудования, которое работает
безотказно, с заранее заданными потерями в течение определенного времени до
предусмотренной планом его замены, что свойственно современной цифровой
технике.
При наличии аппаратуры
автоматического контроля сетевое оборудование находится под постоянным,
непрерывным наблюдением, а выявленные повреждения автоматически фиксируются и
выдаются на монитор оператора. Это позволяет своевременно восстанавливать
работоспособность устройств и/или корректировать их характеристики. Простой
связи при данном методе сведен до минимума, а ее качество улучшается при
сокращении расходов на техническую эксплуатацию. Кроме того, применение
автоматизированного — программированного контроля оборудовании средств
телекоммуникации повышает дисциплину обслуживания.
Техническое
обслуживание (ТО) – это комплекс организационно-технических мероприятий и
работ, производимых на объекте и направленных на поддержание в рабочем или
исправном состоянии оборудования (программного обеспечения (ПО)) технических
систем в процессе их использования по назначению с целью повышения надежности и
эффективности их работы.
Основными задачами Технического обслуживания систем являются:
• определение качественного состояния оборудования, кабельных сетей и проверка
их работоспособности (в том числе ПО);
• своевременное выявление и устранение недостатков, снижающих эффективность
работы систем и приводящих к возникновению отказов аппаратуры (ПО);
• предупреждение отказов оборудования (ПО), увеличение межремонтных сроков
эксплуатации и сроков службы оборудования;
• проверка и доведение до установленных норм параметров оборудования систем,
линейно-кабельных и распределительных устройств;
• ликвидация последствий воздействия на оборудование неблагоприятных
клима-тических и других условий эксплуатации;
• подготовка оборудования к сезонной эксплуатации;
• проверка укомплектованности механизмов, аппаратуры, наличия инструментов и
пополнение ЗИП;
• анализ и обобщение сведений результатов выполненных работ, разработка
мероприятий по совершенствованию форм и методов Технического обслуживания,
эксплуатации систем;
• техническая консультативная поддержка эксплуатирующего персонала и
руководителей по любым вопросам, связанным с эксплуатацией систем в целях
эффективного использования.
Порядок планирования и проведения мониторинга компьютерных сетей и порядок
организации работ по техническому сопровождению корпоративной компьютерной сети
1.
Мониторинг аппаратного обеспечения
2.
Мониторинг работоспособности аппаратных компонентов КС
осуществляется в процессе их обслуживания и при проведении работ по
техническому обслуживанию оборудования. Наиболее существенные компоненты
системы, имеющие встроенные средства контроля работоспособности (серверы,
активное сетевое оборудование), должны контролироваться постоянно.
3.
Мониторинг парольной защиты
4.
Мониторинг парольной защиты и контроль надежности
пользовательских паролей предусматривают:
—
установление сроков действия паролей;
—
периодическую (не реже 1 раза в месяц) проверку пользовательских паролей.
5.
Мониторинг попыток несанкционированного доступа
3.1. Предупреждение и своевременное выявление попыток несанкционированного
доступа осуществляется с использованием средств операционной системы,
специальных программных средств и предусматривает:
—
фиксацию неудачных попыток входа в систему в системном журнале;
—
протоколирование работы сетевых сервисов;
—
выявление фактов сканирования определенного диапазона сетевых портов в короткие
промежутки времени с целью обнаружения сетевых анализаторов, изучающих систему
и выявляющих ее уязвимости.
6.
Мониторинг производительности
4.1. Мониторинг производительности КС производится по обращениям пользователей
в ходе обслуживания систем и при проведении профилактических работ.
7.
Системный аудит
8.
Системный аудит производится администратором информационной
безопасности ежеквартально и в особых ситуациях. Он включает проведение обзоров
безопасности с занесением записей в Журнал обзоров безопасности, тестирование
системы, контроль внесения изменений в системное программное обеспечение.
9.
Активное тестирование надежности механизмов контроля доступа
производится путем осуществления попыток проникновения в систему (с помощью
автоматического инструментария или вручную).
10.
Пассивное тестирование механизмов контроля доступа
осуществляется путем анализа конфигурационных файлов системы.
11.
Внесение изменений в системное программное обеспечение
осуществляется с условием обязательного документирования изменений в соответствующем
журнале; уведомлением каждого сотрудника, которого касается изменение;
рассмотрением претензий в случае, если внесение изменений повлекло причинение
вреда; разработкой планов действий в аварийных ситуациях для восстановления
работоспособности системы, если внесенное в нее изменение вывело ее из строя.
12.
Антивирусный контроль
13.
Для защиты объектов вычислительной техники необходимо
использовать антивирусные программы:
• резидентные антивирусные мониторы, контролирующие подозрительные действия
программ;
• утилиты для обнаружения и анализа новых вирусов.
• К использованию допускаются только лицензионные средства защиты от
вредоносных программ и вирусов или сертифицированные свободно распространяемые
антивирусные средства.
• При подозрении на наличие не выявленных установленными средствами защиты
заражений следует использовать Live CD с другими антивирусными средствами.
• Запуск антивирусных программ должен осуществляться автоматически по заданию,
централизованно созданному с использованием планировщика задач (входящим в
поставку операционной системы либо поставляемым вместе с антивирусными
программами).
Устанавливаемое (изменяемое) на серверы программное обеспечение должно быть
предварительно проверено на отсутствие компьютерных вирусов и вредоносных программ.
Непосредственно после установки (изменения) программного обеспечения сервера
должна быть выполнена антивирусная проверка.
14.
Анализ попыток взлома инцидентов
15.
Если администратор информационной безопасности подозревает или
получил сообщение о том, что система подвергается атаке или уже была
скомпрометирована, то он должен установить:
—
факт попытки несанкционированного доступа (далее – НСД);
—
продолжается ли НСД в настоящий момент;
—
кто является источником НСД;
—
что является объектом НСД;
—
когда происходила попытка НСД;
—
как и при каких обстоятельствах была предпринята попытка НСД;
—
точка входа нарушителя в систему;
—
была ли попытка НСД успешной;
—
определить системные ресурсы, безопасность которых была нарушена;
—
какова мотивация попытки НСД.
16.
Порядок проведения резервного копирования
17.
Для предотвращения потери данных из-за сбоев оборудования,
уничтожения оборудования, программных ошибок, неправильных действий персонала и
других возможных причин утери информации предусмотрена система регулярного
резервного копирования данных. Такое резервное копирование позволяет в случае
возникновения ошибки и потери информации вернуться к ближайшей работоспособной
копии.
18.
Резервное копирование критически важной информации и информации,
размещенной на серверах, выполняется на предназначенные для этих целей сервера,
ленточные накопители и оптические носители.
19.
Резервное копирование проводится автоматически в установленные
промежутки времени (ночью, 1 раз в сутки).
20.
На объектах вычислительной техники пользователей не предусматривается
резервного копирования системной информации, но в целях сохранности важных
документов пользователю желательно проводить архивирование и хранение данных
документов на оптических дисках (CD-R).
Указания
по проведению профилактических работ
1.
Профилактические работы проводятся строго в соответствии с
установленным графиком. График проведения профилактических работ на серверах на
следующий месяц составляется администратором.
2.
Администратор ЛС обязан включить в график все периодические профилактические
работы, независимо от необходимости их проведения.
3.
Профилактика целостности операционной системы, сетевого
взаимодействия, проверка работы сервисов и служб проводятся в рабочем порядке,
поскольку в подавляющем большинстве случаев не требуют перезагрузки серверов.
4.
Профилактика баз данных, проверки на наличие вирусов, обновлений
системы и серверных приложений, проверка отказоустойчивости системы,
профилактика работоспособности дисковой и файловой подсистем, остановки сервера
для чистки и вентиляции проводятся в рабочее время с учетом времени минимальной
загрузки серверов.
5.
Профилактические работы на серверах, требующие длительного
(более 1 часа) отключения и способные повлиять на рабочие процессы в
организации, проводятся в выходные дни.
6.
Процедуры, необходимые для проведения профилактических работ,
включают в себя:
—
анализ журналов событий серверов: проводится ежедневно для выявления ошибок,
связанных с функционированием базовых компонентов серверного
аппаратно-программного комплекса;
—
анализ отчетов системы безопасности: проводится ежедневно с целью выявления
соответствия политик доступа к ресурсам локальной сети путем просмотра журналов
системы безопасности серверов и программ, отвечающих за безопасность
информационных потоков с оценкой соответствия доступа пользователей к ресурсам
организации;
—
проверка работоспособности почтовых служб и служб Интернет: проводится
ежедневно с целью поддержания возможности получения пользователями оперативной
информации из внешних источников;
—
анализ Интернет-трафика: проводится ежедневно с целью предотвращения нецелевого
использования Интернет-ресурсов;
—
анализ возможностей доступа пользователей к сетевым ресурсам: проводится
ежедневно с целью определения возможности совместного доступа к различным сетевым
ресурсам и выполнения пользователями их должностных обязанностей;
—
просмотр отчетов служебных программ: проводится с целью проверки
работоспособности пользовательских приложений, установленных на сервере;
—
проверка сетевого взаимодействия: производится еженедельно в начале рабочей
недели и включает в себя краткий анализ журналов событий и графиков загрузки
сети;
—
проверка работы служб: проводится еженедельно на каждом из работающих серверов,
находящихся в ЛС;
—
проверка наличия обновлений операционной системы и серверных приложений:
проводится еженедельно с целью поддержания работоспособности
аппаратно-программного комплекса на должном уровне и сохранения безопасности
использования внешних источников информации;
Перечень
профилактических работ
1.
Профилактические работы включают в себя:
—
анализ журналов событий серверов (ежедневно);
—
анализ отчетов системы безопасности (ежедневно);
—
анализ изменения состава групп безопасности в AD (Active Directory);
—
выявление попыток несанкционированного доступа к ресурсам;
—
выявление попыток несанкционированного изменения уровня доступа к ресурсам;
—
проверку работоспособности почтовых служб и служб Интернет (ежедневно);
—
анализ Интернет-трафика (ежедневно);
—
анализ возможностей доступа пользователей к сетевым ресурсам (ежедневно);
—
просмотр отчетов служебных программ (ежедневно);
—
проверку сетевого взаимодействия (1 раз в неделю);
—
проверку работы сервисов и служб (1 раз в неделю);
—
проверку наличия обновлений операционной системы и серверных приложений (1 раз
в неделю);
—
профилактику баз данных (1 раз в неделю);
—
антивирусную профилактику сервера (1 раз в неделю);
—
проверку целостности операционной системы (1 раз в 2 недели);
—
принудительную проверку отказоустойчивости системы (1 раз в 2 недели);
—
профилактику дисковой и файловой подсистем на сервере (1 раз в 2 недели);
—
профилактическую остановку сервера (1 раз в 2 недели);
—
составление отчета доступа к Интернет-ресурсам (1 раз в месяц);
—
профилактические работы на объектах вычислительной техники (выполняются
пользователем, по необходимости при помощи сотрудников ООВТ ЦСИТ).
К профилактическим работам на объектах вычислительной техники относятся:
—
проверка обновления клиентских приложений (по необходимости);
—
проверка времени последнего обновления антивирусных баз (1 раз в неделю);
—
выявление попыток несанкционированной установки приложений пользователем
(ежедневно);
—
удаление временных и устаревших копий файлов (по необходимости);
—
выполнение прочих работ, непосредственно связанных с работоспособностью
объектов вычислительной техники (по необходимости).
Скачать материал
Выбранный для просмотра документ lk20_mdk_03_01_Iskusstvo_diagnostiki_lokalnykh_setey.doc
Искусство диагностики локальных
сетей
Тема: Искусство диагностики локальных
сетей
При диагностировании локальных
сетей более длительным и трудоемким является процесс выявления скрытых дефектов
оборудования и программного обеспечения (далее – ПО), а также оценка качества
архитектурного решения сети.
Скрытые дефекты – это такие дефекты,которые проявляются нерегулярно. Они имеют
особенность проявляться в самые неподходящие моменты. Пока сеть невелика,
скрытые дефекты проявляются редко ина них не обращают особого внимания. При
расширении сети и увеличении ее загруженности вероятность проявления скрытых
дефектов растет.
Существуют
два основных подхода к выявлению скрытых дефектов и оценке качества архитектуры
локальной сети: пассивная диагностика и стрессовое тестирование.
Метод
пассивной диагностики состоит в постоянном наблюдении за состоянием сети и
регистрации изменений в ее поведении. Он основан на использовании специальных
средств пассивного наблюдения за работой сети: анализаторов протоколов или
программ на основе протокола SNMP. Этот метод получил очень широкое
распространение, и сегодня уже существуют диагностические средства, содержащие
встроенную экспертную систему, которая упрощает процесс диагностики.
Метод
стрессового тестирования состоит в создании в сетибольшой нагрузки и проверке
ее работоспособности в этих экстремальных условиях.Метод стрессового
тестирования дополняет метод пассивной диагностики. Он позволяет проверить сеть
в экстремальных условиях эксплуатации и построить”систему координат”,
облегчающую интерпретацию данных, полученных в результате пассивной
диагностики. Обычно метод стрессового тестирования используется на этапе
пуско-наладки сети и после существенных модификаций ее архитектуры или
топологии. Метод пассивной диагностики целесообразно использовать в процессе
эксплуатации сети после уже проведенного стрессового тестирования.
Организация процесса диагностики сети
На
качество работы сети значительное влияние оказывает состояние активного
оборудования (сетевых плат, концентраторов, коммутаторов),качество оборудования
сервера и настройки сетевой операционной системы. Кроме того, функционирование
сети существенно зависит от алгоритмов работы эксплуатируемого в ней
прикладного ПО (далее – ППО).
Именно
качество работы ППО в сети оказывается определяющим, с точки зрения
пользователей. Все прочие критерии, такие как число ошибок передачи данных,
степень загруженности сетевых ресурсов,производительность оборудования и т. п.,
являются вторичными.
Основных
причин неудовлетворительной работы ППО в сети может быть несколько: повреждения
кабельной системы, дефекты активного оборудования, перегруженность сетевых
ресурсов (канала связи и сервера), ошибки самого ППО.
Часто
одни дефекты сети маскируют другие. Таким образом, чтобы достоверно определить,
в чем причина неудовлетворительной работы прикладного ПО, локальную сеть
требуется подвергнуть комплексной диагностике.
Комплексная
диагностика предполагает выполнение следующих этапов (работ):
1.
выявление дефектов физического уровня сети: кабельной системы,
системы электропитания активного оборудования; наличия шума от внешних
источников;
2.
измерение текущей загруженности канала связи сети и определение
влияния величины загрузки канала связи на время реакции прикладного ПО;
3.
измерение числа коллизий в сети и выяснение причин их
возникновения;
4.
измерение числа ошибок передачи данных на уровне канала связи и
выяснение причин их возникновения;
5.
выявление дефектов архитектуры сети;
6.
измерение текущей загруженности сервера и определение влияния
степени его загрузки на время реакции ППО;
7.
выявление дефектов ППО, следствием которых является
неэффективное использование пропускной способности сервера и сети.
Измерение утилизации сети и установление корреляции между
замедлением работы сети и перегрузкой канала связи
Утилизация
канала связи сети – это процент времени, в течение которого канал связи
передает сигналы, или иначе – доля пропускной способности канала связи,
занимаемой кадрами, коллизиями и помехами.
Параметр
“Утилизация канала связи” характеризует величину загруженности сети.
Канал
связи сети является общим сетевым ресурсом,поэтому его загруженность влияет на
время реакции ППО. Первоочередная задача состоит в определении наличия
взаимозависимости между плохой работой ППО и утилизацией канала связи сети.
Чтобы
определить, какова же максимально допустимая утилизация канала связи в данном
конкретном случае, рекомендуется следовать приведенным ниже правилам:
Правило 1 Если
в сети Ethernet в любой момент времени обмен данными происходит не более чем
между двумя компьютерами, то любая сколь угодно высокая утилизация сети
является допустимой.
Правило 2 Высокая
утилизация канала связи сети только в том случае замедляет работу конкретного
ППО, когда именно канал связи является”узким местом” для работы данного
конкретного ПО.
Правило 3 Максимально
допустимая утилизация канала связи зависит от протяженности сети.
Программные средства диагностики
1 Команда NET DIAGS
Используется
для интерактивной загрузки утилиты диагностики сети.
NET DIAGS
Утилита
диагностики Personal NetWare (Network Diagnostics utility) позволяет
отслеживать операции сети.
Она
позволяет просматривать и отслеживать другие группы в сети, сравнивать трафик
клиентов и серверов, сравнивать использование серверов, информацию о диске
клиента, просматривать информацию о конфигурации,статистику по серверам и
клиентам, а также тестировать подключения сервера и клиента.
Утилита
сетевой диагностики имеет версии для DOS и MSWindows, которые имеют аналогичные
функции, однако некоторые средства уникальны и имеются только в версии для DOS.
2 ScanLink
Программа
ScanLink предназначена для обработки информации, накопленной прибором в
процессе тестирования кабельных сетей. Оно легко устанавливается на любую
рабочую станцию. Передача данных из прибора осуществляется через
последовательный порт, для чего он комплектуется соответствующим шнуром.Выбором
пункта “Upload” данные загружаются в компьютер и сортируются согласно дате
проведения тестов. После этого можно удалить информацию из прибора. Программа
способна печатать на принтер табличные отчеты, и отчеты для сертификации сетей.
Дополнительно ScanLink имеет возможность сохранять данные в стандарте CSV, для
обработки информации в таких программах, как Exel, Access и Word, и создавать
произвольные для них шаблоны.
Полезные инструменты диагностики
Ключевой
функцией инструмента диагностики является обеспечение визуального представления
реального состояния сети. Традиционно поставляемые производителями инструменты
визуализации приблизительно соответствуют уровням модели OSI.
Для
разрешения проблем на физическом уровне, а также в электрических или оптических
средах передачи данных предназначены кабельные тестеры и такие
специализированные инструменты, как временные рефлектометры (Time Domain
Reflectometers, TDRs). В кабельных тестерах реализовано множество функций,
например выполнение автоматизированных тестовых последовательностей с
возможностью печати сертификационных документов на основании результатов
тестирования.
В число
лидирующих поставщиков кабельных тестеров входят компании Fluke Networks,
Microtest, Agilent, Acterna (прежнее название WWG) и Datacom Textron.
Традиционным
инструментом решения проблем канального, сетевого и транспортного уровней
является анализатор протоколов.Недорогие анализаторы обычно создаются на основе
серийно выпускаемых портативных ПК с использованием стандартных сетевых карт с
поддержкой режима приема всех пакетов. В результате некоторые виды неполадок на
канальном уровне для таких систем остаются невидимыми. Кроме того, они не
позволяют выявить проблемы физического уровня в электрических или оптических
кабелях. Вместе стем, со временем в анализаторах протоколов появилась
возможность исследования неполадок прикладного уровня, включая транзакции баз
данных.
В число
лидирующих поставщиков анализаторов протоколов локальных сетей входят Network
Associates/SnifferTechnologies, Shomiti, Acterna (прежнее название WWG),
Agilent, GN Nettest,WildPackets и Network Instruments.
Третьим
основным диагностическим инструментом наряду с кабельными тестерами и
анализаторами протоколов является зонд или монитор. Эти устройства обычно
подключаются к сети на постоянной основе, а не только в случае возникновения
проблемы и функционируют в соответствии со спецификациями удаленного
мониторинга RMON и RMON II.
Лидирующими
поставщиками устройств RMONявляются NetScout, Agilent, 3Com и Nortel. Кроме
того, производители коммутаторов Ethernet встраивают поддержку основных функций
RMON в каждый порт.
Производители
диагностического оборудования объединили функции всех перечисленных
традиционных инструментов в портативных устройствах для обнаружения
распространенных неисправностей на нескольких уровнях OSI. Например, некоторые
из этих устройств осуществляют проверку основных параметров кабеля, отслеживают
количество ошибок на уровнеEthernet, обнаруживают дублированные IP-адреса, а
также отображают распределение в сегменте протоколов третьего уровня.
В число
лидирующих поставщиков интегрированных диагностических инструментов входят
Fluke Networks, DatacomTextron, Agilent и Microtest. Компания Fluke недавно
представила продукт OptiView Pro, в котором все компоненты для полномасштабной
семиуровневой диагностики объединены в едином портативном устройстве.
Фактически Optiview Pro представляет собой ПК под управлением ОС Windows с
разъемами под платы расширения, где в дополнение к встроенному анализатору
протоколов собственной разработки компании можно установить другой анализатор.
Скачать материал
Выбранный для просмотра документ lk21_mdk_03_01_diagnosticheskie_programmy.doc
Тема: Диагностические программы Advanced Sysinfo Tool and
Reporting Assistant , GoldMemory, SiSoft Sandra, 3d marc.
ASTRA32 – Advanced System Information Tool. Программа
определения конфигурации и диагностики компьютера. Позволяет получить подробную
информацию (в том числе недокументированную) об аппаратном обеспечении
компьютера и режимах его работы.Содержит уникальную функцию поиска устройств с
неустановленными драйверами и функцию быстрой проверки надежности винчестеров.
Позволяет получить сведения о процессоре, материнской плате, жестких дисках,
S.M.A.R.T., CD/DVD, SCSIустройствах, модулях памяти, чипсете, BIOS, PCI/AGP,
USB и ISA/PnP устройствах,мониторе, видеокарте, звуковой и сетевой карте,
принтере, установленных программах и обновлениях и многом другом. Создание
файла-отчета в текстовом,INI, HTML, XML и CSV форматах, возможность экспорта
данных в программы учета вычислительной техники. Возможность работы в режиме
командной строки. Версия без инсталлятора так же доступна. Возможности
программы
·
определение 704 типов процессоров и сопроцессоров фирм Intel,
AMD, Cyrix, VIA, Centaur/IDT, Rise, Transmeta,NexGen, UMC, IBM, Texas
Instruments, C&T, IIT, ULSI, NationalSemiconductor, SiS, DM&P, RDC,
Spreadtrum, Hygon
·
определение тактовой частоты процессора,коэффициента умножения и
частоты системной шины, определение оригинальной (без учета разгона) частоты
процессора, номера процессора, типа разъема (slot,socket) и типа упаковки
(Platform ID) процессора, определение поддерживаемых процессором возможностей
(MMX, SSE, SSE2, SSE3, Supplemental SSE3, SSE4, AVX,3DNow!, 3DNow! Extensions и
другое), размера и параметров кэша
·
уникальная функция поиска устройств с неустановленными
драйверами (Drivers Troubleshooter). Данная функция выводит список всех
физических устройств с неустановленными или неправильно установленными
драйверами
·
вычисление статуса надежности винчестеров с помощью уникального
алгоритма, а так же вычисление оставшегося ресурса SSDдисков
·
определение подробной информации о драйверах(имя драйвера,
поставщик, версия, дата, статус и другое) всех физических устройств
·
определение производителя материнской платы иURL сайта,
определение производителя, даты и версии BIOS, определение производителя и
модели чипсета
·
определение модели и емкости ATA/ATAPI устройств(винчестеры,
CD/DVD устройства, ZIP накопители). Определение типа интерфейса(Parallel
ATA, Serial ATA I, Serial ATA II). Определение PIO, DMA иUltraDMA
режимов (в том числе активных в данной конфигурации). Работа сATA/ATAPI
устройствами на внешних UDMA/SATA/RAID контроллерах. Определение скорости
чтения/записи CD/DVD приводов
·
чтение S.M.A.R.T. информации (в том числе дисков на внешних
UDMA/SATA/RAID контроллерах) и определение температуры винчестеров
·
определение SCSI устройств (винчестеры, CDприводы, сканеры,
стримеры) и их параметров (имя устройства, тип, размер,серийный номер,
·
температура, дата выпуска, размер буфера,скорость вращения
винчестеров и другое)
·
чтение SPD информации из модулей памяти (объем,тип,
производитель, скоростные характеристики и многое другое)
·
определение PCI/AGP/PCI-X/PCI-E/PCMCIA, ISA/PnPустройств и
используемых ими ресурсов. Программе известны более 18700 устройств
·
определение USB устройств (производитель,модель, серийный номер,
·
версия, скорость и другое). Программе известны более 36800
устройств
·
определение более 15600 моделей мониторов и их характеристик
·
поддержка стандарта DMI/SMBIOS, в т.ч.определение названия
системы, модели материнской платы, параметров BIOS,процессора, кэша, подсистемы
памяти, вывод информации о слотах и портах материнской платы
·
определение производителя и названия видеокарты,размера
видеопамяти
·
определение типа звуковой карты, модема, сетевой карты, LPT/PnP
устройств (принтеры, сканеры) и многое другое
·
информация о Windows, установленных программах и обновлениях
·
создание файла-отчета в текстовом (посмотреть пример отчета),
INI (посмотреть пример отчета), HTML (посмотреть пример отчета), XML
(посмотреть пример отчета) и CSV (посмотреть пример отчета) форматах
·
возможность работы в режиме командной строки
·
возможность запуска без инсталляции. Версия без инсталлятора так
же доступна
·
возможность импорта отчетов в программу учета компьютеров на
предприятии Hardware Inspector
·
возможность импорта отчетов в программу TuneSoft
Учет компьютеров
SiSoftware Sandra
(сокращение
от System ANalyser, Diagnostic
and Reporting Assistant) – то
системный анализатор для 32- и 64-битных версий Windows, включающий в себя
тестовые и информационный модули. Sandra объединяет возможности для сравнения
производительности как на высоком, так и на низком уровне
Sandra
предоставляет реальную информацию о комплектующих ПК и установленном на нем ПО,
объединяя в одной программе возможности для сравнения производительности как на
высоком, так и на низком уровне. Вы можете получить сведения о процессоре,
чипсете, видеоадаптере, портах, принтерах, звуковой карте, памяти, сети,
Windows, AGP, соединениях ODBC, USB2, Firewire, и т. д.Также вы можете
сохранять, распечатывать и отправлять по факсу и электронной почте, загружать
на сервер или вставлять в базу данных ADO/ODBC отчеты в текстовом, HTML, XML,
SMS/DMI или RPT форматах.
Программа
предназначена для анализа, тестирования и диагностики компьютеров,серверов,
КПК, смартфонов, небольших домашних и офисных сетей, а также корпоративных
сетей предприятий. Дистрибутив доступен в четырех различных вариантах:
Professional, Lite, Engineer и Enterprise. Все они отличаются количеством
модулей, бесплатная версия Lite урезана до 55, по сравнению сEnterprise (83),
однако все необходимые компоненты для оценки производительности и идентификации
присутствуют на месте. Другие версии различаются преимущественно сетевыми
возможностями: удаленным анализом, диагностикой и сетевыми инструментами.
Перечень
модулей программы Sandra:
– Сводная
информация
–
Информация о материнской плате/чипсете/системных мониторах
–
Информация о процессоре и BIOS
–
Информация об APM & ACPI (Advanced Power Management)
–
Информация об устройствах и шинах PCI(e), AGP, CardBus, PCMCIA
–
Информация о видеосистеме (монитор, видеокарта, видео BIOS, и т.д.)
– Информация о OpenGL
– Информация о DirectX
(DirectDraw, Direct3D, DirectSound (3D), DirectMusic, DirectPlay, DirectInput)
–
Информация о клавиатуре
–
Информация о мыши
–
Информация о звуковой карты (wave, midi, aux, mix)
–
Информация об устройствах MCI (mpeg, avi, seq, vcr, video-disc, wave)
–
Информация о джойстике
–
Информация о принтерах
–
Информация о памяти Windows
–
Информация о Windows
– Информация о шрифтах (Raster,
Vector, TrueType, OpenType)
–
Информация о модеме/ISDN TA
–
Информация о сети*
– Информация
об IP-сети*
–
Информация о WinSock & Интернет-безопасности
–
Информация о дисках (Съемные жесткие диски, CD-ROM/DVD, RamDrives, и т.д.)
–
Информация о портах (последовательный, параллельный)
–
Удаленные соединения (Dial-Up, Internet)*
–
Информация об объектах OLE*
–
Информация о процессах и потоках
–
Информация о модулях (DLL, DRV)
–
Информация о службах и драйверах*
–
Информация о SCSI*
–
Информация о ATA/ATAPI
–
Информация об источниках информации*
–
Информация о CMOS/RTC*
–
Информация о смарт- и СИМ-картах*
–
Арифметический тест процессора (с поддержкой MP/MT)
–
Мультимедийный тест процессора (включая MMX, MMX Enh, 3DNow!, 3DNow! Enh,
SSE(2)) (с поддержкой MP/MT)
– Тест
файловой системы (Съемные диски, жесткие диски, сетевые диски, RamDrives)
– Тест
съемных/флэш накопителей
– Тест
CD-ROM/DVD
– Тест
пропускной способности памяти (с поддержкой MP/MT)
– Тест
кэш и памяти (с поддержкой MP/MT)
– Тест
пропускной способности сети
– Тест
соединения с Интернет
– Тест
скорости Интернет
–
Использование аппаратных прерываний*
–
Использование каналов DMA*
–
Использование портов ввода/вывода*
–
Использование диапазона памяти*
–
Перечислитель Plug & Play*
–
Настройки аппаратного реестра
–
Настройки окружения
–
Зарегистрированные типы файлов
–
Ключевые приложения* (веб-браузер, e-mail, новости, антивирус, брандмауэр, и
т.д.)
–
Установленные приложения*
–
Установленные программы*
–
Приложения меню Пуск*
–
Программы и библиотеки на диске*
–
Установленные веб-пакеты* (ActiveX, классы Java)
– Журнал
событий*
– Мастер
стресс-тестирования* (тестирование стабильности компьютера)
– Мастер
соединений (соединение с удаленными компьютерами, КПК, смартфонами и другими
устройствами)
– Мастер
обобщенного индекса производительности (оценка общей производительности
компьютера)
– Мастер
создания отчетов (сохранение, печать, отправка по факсу или e-mail в форматах
CIM (SMS/DMI), HTML, XML, RPT или TEXT)
– Мастер
увеличения производительности (настройка компьютера)
– Мастер
мониторинга окружения (температуры, напряжения, скорости вентиляторов,
термостойкость системы охлаждения, и т.д.)
– Мастер
обновлений для автоматического обновления версий
– Совет
дня
–
Обширный файл помощи, содержащий более 500 подсказок
–
Подробная он-лайн документация (HTML) с базой вопросов и ответов
GoldMemory
Программа
GoldMemory- представляет собой комплексный тест для проверки оперативной памяти
на предмет наличии ошибок. Поддерживает практически любые типы модулей, а также
любые PC-совместимые платформы в различных конфигурациях. Позволяет
просканировать все доступные модули и определить наличие ошибок, которые, как
правило, сказываются на нестабильности работы системы в целом. Утилита
предназначена для работы в среде DOS-совместимых операционных систем, имеется
ряд командных параметров для пакетной работы и функции для создания отчетов по
итогам тестирования.
GoldMemory
– программа,позволяющая производить тестирование модулей памяти на предмет
ошибок функционирования. Написана на чистом ассемблере и работает без запуска
операционной системы.С
Проверка ОЗУ
Как уже
было сказано выше, софт запускается без ОС, с загрузочного диска или флешки. В
GoldMemory имеется несколько режимов тестирования:
·
Quick – «быстрый», при котором проверка осуществляется в один
проход и занимает меньше времени.
·
Normal – обычный тест ОЗУ.
·
Thorough – тщательная проверка.
·
User – режим, позволяющий выбрать определенные адреса для
тестирования.
![]() Рис.
Рис.
1 Режимы тестирования
Циклический тест
Программа
позволяет запустить проверку в режиме циклического теста, когда процедура
продолжается до тех пор, пока не будет прервана пользователем.
![]() Рис. 2 Тестирование
Рис. 2 Тестирование
Определение объема ОЗУ
Общий
объем определяется двумя методами – с помощью BIOS и автоматически
(программно). GoldMemory позволяет пользоваться двумя этими режимами.
![]() Рис. 3
Рис. 3
Определение объема ОЗУ
Тест производительности
Перед
началом проверки можно включить встроенный бенчмарк для определения
быстродействия модулей.
![]() Рис. 4
Рис. 4
Тест производительности
Сохранение истории проверок
Софт
умеет сохранять данные тестов в файл, который формируется в папке с программой.
![]() Рис.
Рис.
5 Сохранение истории проверок
Звуковые оповещения
Функция
звукового оповещения предупреждает пользователя о наличии ошибок в модулях
памяти.
![]() Рис. 6 Звуковые оповещения
Рис. 6 Звуковые оповещения
Остановка при обнаружении ошибки
Данная
опция позволяет остановить проверку и завершить работу программы при
обнаружении ошибки, что позволяет точно определить, в каком модуле произошел
сбой.
![]() Рис.
Рис.
7 Остановка при обнаружении ошибки
Ускоренная проверка
Функция «AcceleratedExecution» позволяет
сократить время проверки до 50%, при этом не снижая эффективности тестирования.
![]() Рис. 8 Ускоренная проверка
Рис. 8 Ускоренная проверка
Достоинства
·
Программа работает без запуска ОС, что позволяет получать более
точные результаты;
·
Имеет небольшой размер, а значит, может быть записана на
носитель малого объема.
Недостатки
·
Софт является платным;
·
Пробная версия может не работать с новым железом.
GoldMemory
– высокоточная программа для выявления ошибок в модулях памяти. Принцип ее
работы позволяет исключить различные факторы, мешающие нормальному поиску
сбойных адресов памяти.
3DMark
![]()
3DMark —
название серии популярнейших и широко известных компьютерных бенчмарков,
разработанных финской компанией Futuremark (ранее MadOnion.com).
Бенчмарки
данной серии ориентированы на тестирование прежде всего для графических
компонентов персонального компьютера с целью определения производительности
системы в компьютерных играх. Основное предназначение 3DMark — тестирование
производительности и стабильности графической платы (видеокарты) и оценка её
производительности в условных единицах. Последние версии 3DMark, кроме
видеокарты, тестируют также производительность центрального процессора в таких
задачах, как игровой искусственный интеллект и физический движок. 3DMark, по
сути, визуально представляет собой компьютерную игру, которая является не
интерактивной, так как пользователь не может воздействовать на
геймплей.Бенчмарки 3DMark являются проприетарными коммерческими программами,
однако все бенчмарки серии, за исключением 3DMark Vantage, имеют урезанные
бесплатные версии с ограниченной функциональностью.
3DMark
является одной из самых популярных и используемых программ в среде энтузиастов-оверклокеров
и геймеров, которые оценивают и сравнивают производительность своих систем с
помощью
Скачать материал
Выбранный для просмотра документ lk22_mdk_03_01_izmerenie_utilizatsii_seti.doc
Тема: Измерение утилизации сети и
установление корреляции между замедлением работы сети и перегрузкой канала
связи
Утилизация
канала связи сети – это процент времени, в течение которого канал связи
передает сигналы, или иначе – доля пропускной способности канала связи,
занимаемой кадрами, коллизиями и помехами.
Параметр
“Утилизация канала связи” характеризует величину загруженности сети.
Канал
связи сети является общим сетевым ресурсом, поэтому его загруженность влияет на
время реакции прикладного программного обеспечения.
Первоочередная
задача состоит в определении наличия взаимозависимости между плохой работой
прикладного программного обеспечения и утилизацией канала связи сети.
Предположим,
что анализатор протоколов установлен в том домене сети (collision domain), где
прикладное ПО работает медленно . Средняя утилизация канала связи составляет
19%, пиковая доходит до 82%. Можно ли на основании этих данных сделать
достоверный вывод о том, что причиной медленной работы программ в сети является
перегруженность канала связи? Вряд ли.
Часто
можно слышать о стандарте де-факто,в соответствии с которым для
удовлетворительной работы сети Ethernet утилизация канала связи “в тренде”
(усредненное значение за 15 минут) не должна превышать 20%, а “в пике”
(усредненное значение за 1 минуту) -35-40%.
Приведенные
значения объясняются тем, что в сети Ethernet при утилизации канала связи,
превышающей 40%, существенно возрастает число коллизий и, соответственно, время
реакции прикладного ПО.Несмотря на то что такие рассуждения в общем случае
верны, безусловное следование подобным рекомендациям может привести к
неправильному выводу о причинах медленной работы программ в сети. Они не
учитывают особенности конкретной сети, а именно: тип прикладного ПО,
протяженность домена сети, число одновременно работающих станций.
Чтобы
определить, какова же максимально допустимая утилизация канала связи в вашем
конкретном случае, рекомендуется следовать приведенным ниже правилам.
Правило
1. Если в сети Ethernet в любой момент времени обмен данными происходит не
более чем между двумя компьютерами,то любая сколь угодно высокая утилизация
сети является допустимой.
Сеть
Ethernet устроена таким образом, что если два компьютера одновременно
конкурируют друг с другом за захват канала связи,то через некоторое время они
синхронизируются друг с другом и начинают выходить в канал связи строго по
очереди. В таком случае коллизий между ними практически не возникает.
Если
рабочая станция и сервер обладают высокой производительностью, и между ними
идет обмен большими порциями данных,то утилизация в канале связи может
достигать 80-90% (особенно в пакетном режиме- burst mode). Это абсолютно не
замедляет работу сети, а, наоборот,свидетельствует об эффективном использовании
ее ресурсов прикладным ПО.
Таким
образом, если в вашей сети утилизация канала связи высока, постарайтесь
определить, сколько компьютеров одновременно ведут обмен данными.
Это можно
сделать, например, собрав и декодировав пакеты в интересующем канале в период
его высокой утилизации.
Правило
2. Высокая утилизация канала связи сети только в том случае замедляет работу
конкретного прикладного ПО, когда именно канал связи является “узким местом”
для работы данного конкретного ПО.
Кроме
канала связи узкие места в системе могут возникнуть из-за недостаточной
производительности или неправильных параметров настройки сервера, низкой
производительности рабочих станций, неэффективных алгоритмов работы самого
прикладного ПО.
В какой
мере канал связи ответственен за недостаточную производительность системы,
можно выяснить следующим образом.Выбрав наиболее массовую операцию данного
прикладного ПО (например, для банковского ПО такой операцией может быть ввод
платежного поручения), вам следует определить, как утилизация канала связи
влияет на время выполнения такой операции.
Проще
всего это сделать, воспользовавшись функцией генерации трафика, имеющейся в
ряде анализаторов протоколов (например,в Observer). С помощью этой функции
интенсивность генерируемой нагрузки следует наращивать постепенно, и на ее фоне
производить измерения времени выполнения операции.Фоновую нагрузку
целесообразно увеличивать от 0 до 50-60% с шагом не более 10%.
Если
время выполнения операции в широком интервале фоновых нагрузок не будет
существенно изменяться, то узким местом системы является не канал связи.
Если же
время выполнения операции будет существенно меняться в зависимости от величины
фоновой нагрузки (например, при 10% и 20% утилизации канала связи время
выполнения операции будет значительно различаться), то именно канал связи,
скорее всего, ответственен за низкую производительность системы, и величина его
загруженности критична для времени реакции прикладного ПО. Зная желаемое время
реакции ПО, вы легко сможете определить, какой утилизации канала связи
соответствует желаемое время реакции прикладного ПО.
В данном
эксперименте фоновую нагрузку не следует задавать более 60-70%. Даже если канал
связи не является узким местом,при таких нагрузках время выполнения операций
может возрасти вследствие уменьшения эффективной пропускной способности сети.
Правило
3. Максимально допустимая утилизация канала связи зависит от протяженности
сети.
При
увеличении протяженности домена сети допустимая утилизация уменьшается. Чем
больше протяженность домена сети, тем позже будут обнаруживаться коллизии.
Если
протяженность домена сети мала, то коллизии будут выявлены станциями еще в
начале кадра, в момент передачи преамбулы. Если протяженность сети велика, то
коллизии будут обнаружены позже -в момент передачи самого кадра. В результате
накладные расходы на передачу пакета (IP или IPX) возрастают.
Чем позже
выявлена коллизия, тем больше величина накладных расходов и большее время
тратится на передачу пакета. В результате время реакции прикладного ПО, хотя и
незначительно, но увеличивается.
Выводы.
Если в результате проведения диагностики сети вы определили, что причина
медленной работы прикладного ПО – в перегруженности канала связи, то
архитектуру сети необходимо изменить. Число станций в перегруженных доменах
сети следует уменьшить, а станции, создающие наибольшую нагрузку на сеть,
подключить к выделенным портам коммутатора.
Скачать материал
Выбранный для просмотра документ lk23_mdk_03_01_Izmerenie_chisla_kolliziy_v_seti.doc
Измерение числа коллизий в
сети. Измерение
числа ошибок на канальном уровне сети. Методика упреждающей диагностики
сети.
1.
Измерение числа
коллизий в сети
Если две
станции домена сети одновременно ведут передачу данных, то в домене возникает
коллизия. Коллизии бывают трех типов:местные, удаленные, поздние.
Местная коллизия (local collision) –
это коллизия, фиксируемая в домене, где подключено измерительное устройство, в
пределах передачи преамбулы или первых 64 байт кадра, когда источник передачи
находится в домене. Алгоритмы обнаружения местной коллизии для сети на основе
витой пары (10BaseT) и коаксиального кабеля (10Base2) отличны друг от друга.
В сети
10Base2 передающая кадр станция определяет, что произошла локальная коллизия по
изменению уровня напряжения в канале связи (по его удвоению). Обнаружив
коллизию, передающая станция посылает в канал связи серию сигналов о заторе
(jam), чтобы все остальные станции домена узнали, что произошла коллизия.
Результатом этой серии сигналов оказывается появление в сети коротких,
неправильно оформленных кадров длиной менее 64 байт с неверной контрольной
последовательностью CRC.
Такие
кадры называются фрагментами (collision fragment или runt).
В сети
10BaseT станция определяет, что произошла локальная коллизия, если во время
передачи кадра она обнаруживает активность на приемной паре (Rx).
Удаленная коллизия (remote collision) –
это коллизия, которая возникает в другом физическом сегменте сети (т. е. за
повторителем). Станция узнает, что произошла удаленная коллизия, если она
получает неправильно оформленный короткий кадр с неверной контрольной
последовательностью CRC, и при этом уровень напряжения в канале связи остается
в установленных пределах (для сетей 10Base2). Для сетей 10BaseT/100BaseT
показателем является отсутствие одновременной активности на приемной и
передающей парах (Tx и Rx).
Поздняя коллизия (late collision) – это
местная коллизия, которая фиксируется уже после того, как станция передала в
канал связи первые 64 байт кадра. В сетях 10BaseT поздние коллизии часто
фиксируются измерительными устройствами как ошибки CRC.
Если
выявление локальных и удаленных коллизий, как правило, еще не свидетельствует о
наличии в сети дефектов, то обнаружение поздних коллизий – это явное
подтверждение наличия дефекта в домене. Чаще всего это связано с чрезмерной
длиной линий связи или некачественным сетевым оборудованием.
Помимо
высокого уровня утилизации канала связи коллизии в сети Ethernet могут быть
вызваны дефектами кабельной системы и активного оборудования, а также наличием
шумов.
Даже если
канал связи не является узким местом системы, коллизии несущественно, но
замедляют работу прикладного ПО. Причем основное замедление вызывается не
столько самим фактом необходимости повторной передачи кадра, сколько тем, что
каждый компьютер сети после возникновения коллизии должен выполнять алгоритм
отката (backoff algorithm): до следующей попытки выхода в канал связи ему
придется ждать случайный промежуток времени, пропорциональный числу предыдущих
неудачных попыток.
В этой
связи важно выяснить, какова причина коллизий -высокая утилизация сети или
“скрытые” дефекты сети. Для выявления причин используются следующие правила.
Правило 1.
Не все
измерительные приборы правильно определяют общее число коллизий в сети.
Практически
все чисто программные анализаторы протоколов фиксируют наличие коллизии только
в том случае, если они обнаруживают в сети фрагмент, т. е. результат коллизии.
При этом наиболее распространенный тип коллизий – происходящие в момент
передачи преамбулы кадра (т. е. до начального ограничителя кадра (SFD)) –
программные измерительные средства не обнаруживают, так уж устроен набор
микросхем сетевых плат Ethernet. Наиболее точно коллизии обнаруживают
аппаратные измерительные приборы, например LANMeterкомпании Fluke.
Правило2.
Высокая
утилизация канала связи не всегда сопровождается высоким уровнем коллизий.
Уровень
коллизий будет низким, если в сети одновременно работает не более двух
станций или если небольшое число станций одновременно ведут обмен длинными
кадрами (что особенно характерно для пакетного режима). В этом случае до начала
передачи кадра станции “видят” несущую в канале связи, и коллизии редки.
Правило 3.
Признаком
наличия дефекта в сети служит такая ситуация, когда невысокая утилизация канала
(менее 30%) сопровождается высоким уровнем коллизий (более 5%).
Если
кабельная система предварительно была протестирована сканером, то наиболее
вероятной причиной повышенного уровня коллизий является шум в линии связи,
вызванный внешним источником, или дефектная сетевая плата, неправильно
реализующая алгоритм доступа к среде передачи(CSMA/CD).
Компания
Network Instruments в анализаторе протоколов Observer оригинально решила задачу
выявления коллизий, вызванных дефектами сети. Встроенный в программу тест
провоцирует возникновение коллизий: он посылает в канал связи серию пакетов с
интенсивностью 100 пакетов в секунду и анализирует число возникших коллизий.
При этом совмещенный график отображает зависимость числа коллизий в сети от
утилизации канала связи.
Долю
коллизий в общем числе кадров имеет смысл анализировать в момент активности
подозрительных (медленно работающих) станций и только в случае, когда
утилизация канала связи превышает 30%. Если из трех кадров один столкнулся с
коллизией, то это еще не означает, что в сети есть дефект.
Правило 4.
При
диагностике сети 10BaseT все коллизии должны фиксироваться как удаленные, если
анализатор протоколов не создает трафика.
Если вы
пассивно (без генерации трафика) наблюдаете за сетью 10BaseT и физический
сегмент в месте подключения анализатора (измерительного прибора) исправен, то
все коллизии должны фиксироваться как удаленные.
Если тем
не менее вы видите именно локальные коллизии,то это может означать одно из
трех: физический сегмент сети, куда подключен измерительный прибор, неисправен;
порт концентратора или коммутатора, куда подключен измерительный прибор, имеет
дефект, или измерительный прибор не умеет различать локальные и удаленные
коллизии.
Правило 5.
Коллизии
в сети могут быть следствием перегруженности входных буферов коммутатора.
Следует
помнить, что коммутаторы при перегруженности входных буферов эмулируют
коллизии, дабы “притормозить” рабочие станции сети. Этот механизм называется
“управление потоком” (flowcontrol).
Правило 6.
Причиной
большого числа коллизий (и ошибок) в сети может быть неправильная организация
заземления компьютеров, включенных в локальную сеть.
Если
компьютеры, включенные в сеть не имеют общей точки заземления (зануления), то
между корпусами компьютеров может возникать разность потенциалов. В
персональных компьютерах “защитная” земля объединена с “информационной” землей.
Поскольку компьютеры объединены каналом связи локальной сети, разность
потенциалов между ними приводит к возникновению тока по каналу связи. Этот ток
вызывает искажение информации и является причиной коллизий и ошибок в сети.
Такой эффект получил название ground loopили inter ground noise.
Аналогичный
эффект возникает в случае, когда сегмент коаксиального кабеля заземлен более
чем в одной точке. Это часто случается, если Т-соединитель сетевой платы
соприкасается с корпусом компьютера.
При
обнаружении большого числа коллизий и ошибок в сетях 10Base2 первое, что надо
сделать, – проверить разность потенциалов между оплеткой коаксиального кабеля и
корпусами компьютеров. Если ее величина для любого компьютера в сети составляет
более одного вольта по переменному току, то в сети не все в порядке с
топологией линий заземления компьютеров.
2 Измерение числа ошибок на
канальном уровне сети.
В сетях
Ethernet наиболее распространенными являются следующие типы ошибок.
Короткий
кадр – кадр длиной менее 64 байт (после 8-байтной преамбулы) с правильной
контрольной последовательностью. Наиболее вероятная причина появления коротких
кадров – неисправная сетевая плата или неправильно сконфигурированный или
испорченный сетевой драйвер.
Длинный
кадр (long frame) – кадр длиннее 1518 байт.Длинный кадр может иметь правильную
или неправильную контрольную последовательность.В последнем случае такие кадры
обычно называют jabber. Фиксация длинных кадров с правильной контрольной
последовательностью указывает чаще всего на некорректность работы сетевого
драйвера; фиксация ошибок типа jabber – на неисправность активного оборудования
или наличие внешних помех.
Ошибки
контрольной последовательности (CRC error) -правильно оформленный кадр
допустимой длины (от 64 до 1518 байт), но с неверной контрольной
последовательностью (ошибка в поле CRC).
Ошибка
выравнивания (alignment error) – кадр, содержащий число бит, не кратное числу
байт.
Блики
(ghosts) – последовательность сигналов, отличных по формату от кадров Ethernet,
не содержащая разделителя (SFD) и длиной более 72 байт. Впервые данный термин
был введен компанией Fluke с целью дифференциации различий между удаленными
коллизиями и шумами в канале связи.
Блики
являются наиболее коварной ошибкой, так как они не распознаются программными
анализаторами протоколов по той же причине, что и коллизии на этапе передачи
преамбулы. Выявить блики можно специальными приборами или с помощью метода
стрессового тестирования сети.
В
соответствии с общепринятым стандартом де-факточисло ошибок канального уровня
не должно превышать 1% от общего числа переданных по сети кадров.
Правило 1.
Прежде
чем анализировать ошибки в сети, выясните,какие типы ошибок могут быть
определены сетевой платой и драйвером платы на компьютере, где работает ваш
программный анализатор протоколов.
Работа
любого анализатора протоколов основана на том,что сетевая плата и драйвер
переводятся в режим приема всех кадров сети(promiscuous mode). В этом режиме
сетевая плата принимает все проходящие посети кадры, а не только
широковещательные и адресованные непосредственно к ней,как в обычном режиме.
Анализатор протоколов всю информацию о событиях в сети получает именно от
драйвера сетевой платы, работающей в режиме приема всех кадров.
Не все
сетевые платы и сетевые драйверы предоставляют анализатору протоколов
идентичную и полную информацию об ошибках в сети. Сетевые платы 3Com вообще
никакой информации об ошибках не выдают. Если вы установите анализатор
протоколов на такую плату, то значения на всех счетчиках ошибок будут нулевыми.
Правило 2.
Обращайте
внимание на “привязку” ошибок к конкретным MAC-адресам станций.
При
анализе локальной сети, ошибки обычно “привязаны” к определенным МАС-адресам
станций . Однако коллизии, произошедшие в адресной части кадра, блики,
нераспознанные ситуации типа короткого кадра с нулевой длиной данных не могут
быть “привязаны” к конкретным МАС-адресам.
Если в
сети наблюдается много ошибок, которые не связаны с конкретными МАС-адресами,
то их источником скорее всего является не активное оборудование. Вероятнее
всего, такие ошибки – результат коллизий, дефектов кабельной системы сети или
сильных внешних шумов. Они могут быть также вызваны низким качеством или
перебоями питающего активное оборудование напряжения.
Если
большинство ошибок привязаны к конкретнымMAC-адресам станций, то постарайтесь
выявить закономерность между местонахождением станций, передающих ошибочные
кадры, расположением измерительного прибора и топологией сети.
Правило 3.
В
пределах одного домена сети (collision domain) тип и число ошибок, фиксируемых
анализатором протоколов, зависят от места подключения измерительного прибора.
Другими
словами, в пределах сегмента коаксиального кабеля, концентратора или стека
концентраторов картина статистики по каналу может зависеть от места подключения
измерительного прибора.
Правило 4.
Для
выявления ошибок на канальном уровне сети измерения необходимо проводить на
фоне генерации анализатором протоколов собственного трафика.
Генерация
трафика позволяет обострить имеющиеся проблемы и создает условия для их
проявления. Трафик должен иметь невысокую интенсивность (не более 100 кадров/с)
и способствовать образованию коллизий в сети, т. е. содержать короткие (<100
байт) кадры.
Правило 5.
Если
наблюдаемая статистика зависит от места подключения измерительного прибора, то
источник ошибок, скорее всего, находится на физическом уровне данного домена
сети (причина – дефекты кабельной системы или шум внешнего источника). В
противном случае источник ошибок расположен на канальном уровне (или выше) или
в другом, смежном, домене сети.
Правило 6.
Если доля
ошибок CRC в общем числе ошибок велика, то следует определить длину кадров,
содержащих данный тип ошибок.
Ошибки
CRC могут возникать в результате коллизий,дефектов кабельной системы, внешнего
источника шума, неисправных трансиверов.Еще одной возможной причиной появления
ошибок CRC могут быть дефектные порты концентратора или коммутатора, которые
добавляют в конец кадра несколько”пустых” байтов.
При
большой доле ошибок CRC в общем числе ошибок целесообразно выяснить причину их
появления. Для этого ошибочные кадры из серии надо сравнить с аналогичными
хорошими кадрами из той же серии. Если ошибочные кадры будут существенно короче
хороших, то это, скорее всего, результаты коллизий. Если ошибочные кадры будут
практически такой же длины, то причиной искажения, вероятнее всего, является
внешняя помеха. Если же испорченные кадры длиннее хороших, то причина кроется,
вероятнее всего, в дефектном порту концентратора или коммутатора, которые
добавляют в конец кадра”пустые” байты.
Сравнить
длину ошибочных и правильных кадров проще всего посредством сбора в буфер
анализатора серии кадров с ошибкой CRC.
Правило 7.
Таблица 1
систематизирует причины ошибок и коллизий для этапов 2 и 3

Наиболее
надежным способом локализации дефектов является поочередное отключение
подозрительных станций, концентраторов и кабельных трасс, тщательная проверка
топологии линий заземления компьютеров (особенно для сетей 10Base2).
Правило 8.
Отсутствие
ошибок на канальном уровне еще не гарантирует того, что информация в вашей сети
не искажается.
Следствием
ошибок нижнего уровня является повторная передача кадров. Благодаря высокой
скорости сети Ethernet (особенно FastEthernet) и высокой производительности
современных компьютеров, ошибки нижнего уровня не оказывает существенного
влияния на время реакции прикладного ПО.
Значительно
большее влияние на работу прикладного ПО в сети оказывают такие ошибки, как
бесследное исчезновение или искажение информации в сетевых платах,
маршрутизаторах или коммутаторах при полном отсутствии информации об ошибках
нижних уровней.
Причина
таких дефектов в следующем. Информация искажается (или исчезает) “в недрах”
активного оборудования – сетевой платы, маршрутизатора или коммутатора. При
этом приемо-передающий блок этого оборудования вычисляет правильную контрольную
последовательность (CRC) уже искаженной ранее информации, и корректно оформленный
кадр передается по сети.Никаких ошибок в этом случае, естественно, не
фиксируется. SNMP-агенты,встроенные в активное оборудование, здесь ничем помочь
не могут.
Иногда
кроме искажения наблюдается исчезновение информации. Чаще всего оно происходит
на дешевых сетевых платах или на коммутаторахEthernet-FDDI. Механизм
исчезновения информации в последнем случае понятен. В ряде коммутаторов
Ethernet-FDDI обратная связь быстрого порта с медленным (или наоборот)
отсутствует, в результате другой порт не получает информации о перегруженности
входных/выходных буферов быстрого (медленного) порта. В этом случае при
интенсивном трафике информация на одном из портов может пропасть.
Опытный
администратор сети может возразить, что кроме защиты информации на канальном
уровне в протоколах IPX и TCP/IP возможна защита информации с помощью
контрольной суммы.
В полной
мере на защиту с помощью контрольной суммы можно полагаться, только если
прикладное ПО в качестве транспортного протокола задействует TCP или UDP.
Только при их использовании контрольной суммой защищается весь пакет. Если в
качестве “транспорта” применяетсяIPX/SPX или непосредственно IP, то контрольной
суммой защищается лишь заголовок пакета.
Даже при
наличии защиты с помощью контрольной суммы описанное искажение или исчезновение
информации вызывает существенное увеличение времени реакции прикладного ПО.
Если же
защита не установлена, то поведение прикладного ПО может быть непредсказуемым.
Помимо
замены (отключения) подозрительного оборудования выявить такие дефекты можно
двумя способами.
Первый
способ заключается в захвате, декодировании и анализе кадров от подозрительной
станции, маршрутизатора или коммутатора. Признаком описанного дефекта служит
повторная передача пакета IP или IPX, которой не предшествует ошибка нижнего
уровня сети. Некоторые анализаторы протоколов и экспертные системы упрощают
задачу, выполняя анализ трассы или самостоятельно вычисляя контрольную сумму
пакетов.
Вторым
способом является метод стрессового тестирования сети.
Выводы.
Основная задача диагностики канального уровня сети – выявить наличие
повышенного числа коллизий и ошибок в сети и найти взаимосвязь между числом
ошибок, степенью загруженности канала связи, топологией сети и местом
подключения измерительного прибора. Все измерения следует проводить на фоне
генерации анализатором протоколов собственного трафика.
Если
установлено, что повышенное число ошибок и коллизий не является следствием
перегруженности канала связи, то сетевое оборудование, при работе которого
наблюдается повышенное число ошибок, следует заменить.
Если не
удается выявить взаимосвязи между работой конкретного оборудования и появлением
ошибок, то проведите комплексное тестирование кабельной системы, проверьте
уровень шума в кабеле, топологию линий заземления компьютеров, качество
питающего напряжения.
3. Методика
упреждающей диагностики сети
Методика
упреждающей диагностики заключается в следующем. Администратор сети должен
непрерывно или в течение длительного времени наблюдать за работой сети. Такие
наблюдения желательно проводить с момента ее установки. На основании этих
наблюдений администратор должен определить,во-первых, как значения наблюдаемых
параметров влияют на работу пользователей сети и, во-вторых, как они изменяются
в течение длительного промежутка времени:рабочего дня, недели, месяца,
квартала, года и т. д.
Наблюдаемыми
параметрами обычно являются:
·
параметры работы канала связи сети – утилизация канала связи,
число принятых и переданных каждой станцией сети кадров, число ошибок в сети,
число широковещательных и многоадресных кадров и т. п.;
·
параметры работы сервера – утилизация процессора сервера, число
отложенных (ждущих) запросов к диску, общее число кэш-буферов,число “грязных”
кэш-буферов и т. п.
Зная
зависимость между временем реакции прикладного ПО и значениями наблюдаемых
параметров, администратор сети должен определить максимальные значения
параметров, допустимые для данной сети. Эти значения вводятся в виде порогов
(thresholds) в диагностическое средство. Если в процессе эксплуатации сети
значения наблюдаемых параметров превысят пороговые, то диагностическое средство
проинформирует об этом событии администратора сети.Такая ситуация
свидетельствует о наличии в сети проблемы.
Наблюдая
достаточно долго за работой канала связи и сервера, вы можете установить тенденцию
изменения значений различных параметров работы сети (утилизации ресурсов, числа
ошибок и т. п.). На основании таких наблюдений администратор может сделать
выводы о необходимости замены активного оборудования или изменения архитектуры
сети.
В случае
появления в сети проблемы, администратор в момент ее проявления должен записать
в специальный буфер или файл дамп канальной трассы и на основании анализа ее
содержимого сделать выводы о возможных причинах проблемы.
Скачать материал
Выбранный для просмотра документ lk24_mdk_03_01_Tekhnicheskie_predlozhenia_i_proektnaya_dokumentatsia.doc
Технические предложения и проектная
документация
Подготовка технического предложения
1.
Общие положения
Подготовка
технического предложения обычно осуществляется менеджером отдела
(сектора)кабельных систем или локальных вычислительных сетей. В крупных компаниях
эта функция часто исполняется техническим специалистом, работающим в
конструкторском бюро по заданию менеджера или продавца в соответствии с
полученными от этих сотрудников исходными данными.
Процесс
подготовки технического предложения имеет следующие основные особенности:
•
техническое предложение должно давать заказчику исчерпывающее представление
како технических решениях и параметрах создаваемой кабельной системы, так и о
стоимости СКС, порядке финансирования проекта и сроках реализации;
• от
технического предложения в большинстве случаев не требуется высокой точности
проведения расчетов; опыт показывает, что вполне допустима ошибка в
20%,поскольку оно достаточно часто рассматривается заказчиком как
предварительная оценка и используется главным образом для уточнения требований
к СКС и как основание для включения расходов на создание и модернизацию
кабельной системы в финансовый план своего предприятия;
•
составление технического предложения не должно отнимать у проектировщика и
менеджера много времени.
Достичь
достаточно хорошо сбалансированного сочетания полноты представления
материала,точности расчетов и времени подготовки технического предложения
можно, в частности, при выполнении следующих условий:
• наличие
стандартного вопросника, ответы на основные пункты которого позволяют
определить структуру кабельной системы и выполнить с приемлемой точностью
прикидочный расчет и обоснование как спецификации используемого
оборудования,так и перечня работ, выполняемых в процессе реализации СКС без
выезда на объект;
•
применение специалистом, разрабатывающим техническое предложение, заготовок или
шаблонов основных видов документов, передаваемых заказчику в процессе
выполнения процедуры формирования технического предложения;
•
привлечение для обработки запросов статистических закономерностей, в
обязательном порядке проявляющихся в любом проекте по реализации кабельной
проводки. В данной ситуации выполнение основной массы рутинных операций может
быть переложено на средства вычислительной техники, расчеты ведутся в автоматическом
режиме. Это существенно ускоряет работу, минимизирует количество ошибок,
вызываемых человеческим фактором, и позволяет провести быстрый первичный анализ
нескольких возможных вариантов построения кабельной системы непосредственно в
присутствии представителя заказчика.
Точность
расчета на этапе формирования технических предложений (эскизного
проектирования) существенно зависит от точности задания исходных данных и
глубины их детализации. Сбор исходной информации об объекте в полном объеме
является достаточно трудоемкой процедурой. На этапе эскизного проектирования и
формирования коммерческого предложения столь высокая степень детализации
исходных данных в подавляющем большинстве случаев является излишней, поэтому
пользуются краткой формой опросника, приведенного ниже:
• общее
количество рабочих мест, их распределение по кабинетам, залам и прочим рабочим
помещениям;
• состав
типовой ИР рабочего места;
•
габаритные размеры здания;
•
количество этажей и высота потолка;
• места
расположения технических помещений;
• наличие
фальшполов и фальшпотолков;
• наличие
и расположение стояков.
2. Формат представления и шаблоны
документов
Комплект
документов в минимальной форме должен включать в себя общее описание структуры
кабельной системы и ее функциональных возможностей, информацию о сроках и
этапах процесса монтажа, а также спецификацию поставляемого оборудования и
перечень выполняемых работ.
Техническое
предложение в общем случае включает в себя текстовую и табличную части, а также
приложения.
В
тестовую часть технического предложения (пояснительную записку) включаются:
•
описание структуры СКС и технические характеристики кабельной системы с
глубиной проработки этих вопросов на уровне эскизного проекта;
•
сведения об уровне гарантий и сервисной поддержки кабельной системы;
•
информация о времени реализации проекта;
•
различные дополнительные сведения, которые могут оказаться полезными заказчику
в процессе принятия решения о выборе исполнителя (например, условия и варианты
финансирования проекта, план-график поставки оборудования и выполнения работ
ит.д.).
Табличная
часть технического предложения обычно представляет собой предварительную
спецификацию оборудования и материалов вместе с перечнем выполняемых работ.
В
приложения иногда включаются подборки копий документов, показывающих уровень
профессиональной квалификации компании-разработчика и наличие у нее
опыта,достаточного для реализации предлагаемого технического решения.
Примерный
перечень этих документов включает в себя:
• общие
сведения о компании, разработавшей технические предложения (так называемый
профайл);
• список
проектов, реализованных разработчиком;
• отзывы
заказчиков о ранее выполненных проектах;
• копии
фирменных сертификатов сотрудников компании и лицензии на различные виды
деятельности, которыми обладает исполнитель как юридическое лицо.
3. Принципы ускорения и
средства
автоматизации процесса подготовки технических предложений
Несмотря
на индивидуальный характер процесса построения структурированной кабельной
проводки, практически в любом проекте можно выделить ряд общих этапов, работа в
расчетной и оформительской части которых выполняется по практически одинаковым
правилам и принципам.
С
учетом данного обстоятельства на практике находят широкое применение средства
ускорения формирования типовых документов,основанных на частичной или полной
автоматизации расчетных процедур и прочих рутинных операций. Основной целью
таких программных продуктов или даже их комплексов является подготовка
предварительной (эскизной) спецификации поставляемого оборудования и
выполняемых работ. Наличие этого документа позволяет конкретизировать как
состав поставляемого оборудования и объем необходимого финансирования, так и
время выполнения проекта.
4. Принципы и правила
оформления проектной документации
4.1 Общие положения
В
соответствии с положениями ГОСТ 21.101-97 проектную документацию комплектуют
втома с разбивкой, как правило, по отдельным разделам. Каждый том получает свой
уникальный идентификационный номер, который выполняется арабскими
цифрами,например том 1, том 2 и т.д. При большом объеме предоставляемого
материала или по иным соображениям тома делят на части. В этом случае тома
нумеруют по типу:том 1.1, том 1.2 и т.д. Текстовые и графические материалы,
включаемые в том,комплектуют в следующем порядке:
•
обложка;
•
титульный лист;
•
содержание;
• состав
проекта;
•
пояснительная записка;
•
основные чертежи.
4.2. Особенности оформления текстовой
части проектной документации
Подтекстовой
проектной документацией понимаются документы, содержащие в основном только
текст. В качестве примера таких документов можно указать ТУ,
расчеты,пояснительные записки, инструкции и т.д. Их оформление ведется в
соответствии с ГОСТ 2.105-95. Согласно этому межгосударственному стандарту
стран СНГ текстовые документы выполняются на формах, установленных
соответствующими стандартами ЕСКД и СПДС.
Текстовая часть проектной документации может выпускаться в виде подлинников и
копий. Подлинники текстовых документов выполняются одним из следующих способов:
•
машинописным;
•
рукописным;
• с
применением печатающих и графических устройств вывода ПК;
• на
внешних запоминающих устройствах.
Для
изготовления копий текстовых документов может быть использована одна из
следующих технологий:
•
типографский способ;
• ксерокопирование;
•
микрофильмирование;
•
копирование на съемные носители.
Документация,предназначенная
для микрофильмирования, должна соответствовать требованиям системы стандартов
«Репрография».
4.3. Особенности оформления
спецификации
В
качестве основного нормативного документа, регламентирующего правила оформления
спецификации, могут быть использованы как упомянутый в предыдущем разделе ГОСТ
2.105-95, так и ГОСТ 21.110-95. Последний стандарт входит в систему проектной
документации для строительства. Согласно этому межгосударственному стандарту
стран СНГ под спецификацией применительно к рассматриваемой области понимается
текстовый проектный документ, определяющий состав оборудования, изделий и
материалов, необходимых для реализации СКС.
В
спецификацию в обязательном порядке включаются все оборудование, изделия и
материалы, предусмотренные рабочей документацией. В спецификацию не включаются
отдельные виды изделий и материалы, номенклатуру и количество которых
определяет строительно-монтажная организация на основе действующих
технологических и производственных норм. Данный документ рекомендуется
составлять по разделам, наименование каждого раздела выносится в отдельную
строку в виде заголовка и подчеркивается.
4.4. Рабочие чертежи
Рабочие
чертежи, предназначенные для производства строительных и монтажных
работ,согласно ГОСТ 21.101-97, пункт 4.21 объединяются в так называемые
основные комплекты по маркам. Любой основной комплект рабочих чертежей из
соображений удобства использования может быть разделен на несколько основных
комплектов той же марки с добавлением к ней порядкового номера. Схема разбиения
на комплекты обычно осуществляется в соответствии с процессом организации
строительных и монтажных работ.
Скачать материал
Выбранный для просмотра документ lk2_Monitoring_i_analiz_kompyuternykh_setey.docx
Мониторинг
и анализ компьютерных сетей
1.
Классификация средств мониторинга и анализа
Постоянный
контроль за работой локальной сети, составляющей основу любой корпоративной
сети, необходим для поддержания ее в работоспособном состоянии.
Контроль
– это необходимый первый этап, который должен выполняться при управлении сетью.
Ввиду важности этой функции ее часто отделяют от других функций систем
управления и реализуют специальными средствами.
Такое
разделение функций контроля и собственно управления полезно для небольших и
средних сетей, для которых установка интегрированной системы управления
экономически нецелесообразна. Использование автономных средств контроля
помогает администратору сети выявить проблемные участки и устройства сети, а их
отключение или реконфигурацию он может выполнять в этом случае вручную.
Процесс
контроля работы сети обычно делят на два этапа – мониторинг и анализ.
На
этапе мониторинга выполняется более простая
процедура – процедура сбора первичных данных о работе сети: статистики о
количестве циркулирующих в сети кадров и пакетов различных протоколов,
состоянии портов концентраторов, коммутаторов и маршрутизаторов и т.п.
Далее
выполняется этап анализа,
под которым понимается более сложный и интеллектуальный процесс осмысления
собранной на этапе мониторинга информации, сопоставления ее с данными,
полученными ранее, и выработки предположений о возможных причинах замедленной
или ненадежной работы сети.
Задачи
мониторинга решаются программными и аппаратными измерителями, тестерами, сетевыми
анализаторами, встроенными средствами мониторинга коммуникационных устройств, а
также агентами систем управления.
Задача
анализа требует более активного участия человека и использования таких сложных
средств, как экспертные системы, аккумулирующие практический опыт многих
сетевых специалистов.
Все
многообразие средств, применяемых для анализа и диагностики вычислительных
сетей, можно разделить на несколько крупных классов.
Агенты
систем управления, поддерживающие функции одной из стандартных MIB и
поставляющие информацию по протоколу SNMP или CMIP. Для
получения данных от агентов обычно требуется наличие системы управления,
собирающей данные от агентов в автоматическом режиме.
Встроенные
системы диагностики и управления (Embedded systems)
Эти
системы выполняются в виде программно-аппаратных модулей, устанавливаемых в
коммуникационное оборудование, а также в виде программных модулей, встроенных в
операционные системы. Они выполняют функции диагностики и управления только
одним устройством, и в этом их основное отличие от централизованных систем
управления. Примером средств этого класса может служить модуль управления
многосегментным повторителем Ethernet, реализующий функции автосегментации
портов при обнаружении неисправностей, приписывания портов внутренним сегментам
повторителя и некоторые другие. Как правило, встроенные модули управления “по
совместительству” выполняют роль SNMP-агентов, поставляющих данные о
состоянии устройства для систем управления.
Анализаторы
протоколов (Protocol analyzers)
Представляют
собой программные или аппаратно-программные системы, которые ограничиваются в
отличие от систем управления лишь функциями мониторинга и анализа трафика в
сетях. Хороший анализатор протоколов может захватывать и декодировать пакеты
большого количества протоколов, применяемых в сетях, – обычно несколько
десятков. Анализаторы протоколов позволяют установить некоторые логические
условия для захвата отдельных пакетов и выполняют полное декодирование
захваченных пакетов, т.е. показывают в удобной для специалиста форме
вложенность пакетов протоколов разных уровней друг в друга с расшифровкой
содержания отдельных полей каждого пакета.
Экспертные
системы
Этот
вид систем аккумулирует знания технических специалистов о выявлении причин аномальной
работы сетей и возможных способах приведения сети в работоспособное состояние.
Экспертные системы часто реализуются в виде отдельных подсистем различных
средств мониторинга и анализа сетей: систем управления сетями, анализаторов
протоколов, сетевых анализаторов. Простейшим вариантом экспертной системы
является контекстно-зависимая система помощи. Более сложные экспертные системы
представляют собой т.н. базы знаний, обладающие элементами искусственного
интеллекта. Примерами таких систем являются экспертные системы, встроенные в
систему управления Spectrum компании Cabletron и
анализатора протоколов Sniffer компании Network General. Работа
экспертных систем состоит в анализе большого числа событий для выдачи пользователю
краткого диагноза о причине неисправности сети.
Оборудование
для диагностики и сертификации кабельных систем
Условно
это оборудование можно поделить на четыре основные группы: сетевые мониторы,
приборы для сертификации кабельных систем, кабельные сканеры и тестеры.
·
Сетевые мониторы(называемые также сетевыми
анализаторами) предназначены для тестирования кабелей различных категорий.
Сетевые мониторы собирают также данные о статистических показателях трафика –
средней интенсивности общего трафика сети, средней интенсивности потока пакетов
с определенным типом ошибки и т.п. Эти устройства являются наиболее
интеллектуальными устройствами из всех четырех групп устройств данного класса,
т.к. работают не только на физическом, но и на канальном, а иногда и на сетевом
уровнях.
·
Устройства для сертификации кабельных систем выполняют
сертификацию в соответствии с требованиями одного из международных стандартов
на кабельные системы.
·
Кабельные сканеры используются
для диагностики медных кабельных систем.
·
Тестеры предназначены для проверки
кабелей на отсутствие физического разрыва.
·
Многофункциональные портативные устройства анализа и диагностики.
В связи с развитием технологии больших интегральных схем появилась возможность
производства портативных приборов, которые совмещали бы функции нескольких
устройств: кабельных сканеров, сетевых мониторов и анализаторов протоколов.
Анализаторы
протоколов
Анализатор
протоколов представляет собой либо специализированное устройство, либо
персональный компьютер, обычно переносной, класса Notebook, оснащенный
специальной сетевой картой и соответствующим программным обеспечением.
Применяемые сетевая карта и программное обеспечение должны соответствовать
технологии сети (Ethernet, Token Ring, FDDI, Fast Ethernet). Анализатор
подключается к сети точно так же, как и обычный узел. Отличие состоит в том,
что анализатор может принимать все пакеты данных, передаваемые по сети, в то
время как обычная станция – только адресованные ей. Для этого сетевой адаптер
анализатора протоколов переводится в режим “беспорядочного”
захвата – promiscuous mode.
Программное
обеспечение анализатора состоит из ядра, поддерживающего работу сетевого
адаптера и программного обеспечения, декодирующего протокол канального уровня,
с которым работает сетевой адаптер, а также наиболее распространенные протоколы
верхних уровней, например IP, TCP, ftp, telnet, HTTP, IPX, NCP, NetBEUI,
DECnet и т.п. В состав некоторых анализаторов может входить также
экспертная система, которая позволяет выдавать пользователю рекомендации о том,
какие эксперименты следует проводить в данной ситуации, что могут означать те
или иные результаты измерений, как устранить некоторые виды неисправности сети.
Анализаторы
протоколов имеют некоторые общие свойства.
·
Возможность (кроме захвата пакетов) измерения среднестатистических
показателей трафика в сегменте локальной сети, в котором установлен сетевой
адаптер анализатора. Обычно измеряется коэффициент использования сегмента,
матрицы перекрестного трафика узлов, количество хороших и плохих кадров,
прошедших через сегмент.
·
Возможность работы с несколькими агентами, поставляющими
захваченные пакеты из разных сегментов локальной сети. Эти агенты чаще всего
взаимодействуют с анализатором протоколов по собственному протоколу прикладного
уровня, отличному от SNMP или CMIP.
·
Наличие развитого графического интерфейса, позволяющего
представить результаты декодирования пакетов с разной степенью детализации.
·
Фильтрация захватываемых и отображаемых пакетов. Условия
фильтрации задаются в зависимости от значения адресов назначения и источника,
типа протокола или значения определенных полей пакета. Пакет либо игнорируется,
либо записывается в буфер захвата. Использование фильтров значительно ускоряет
и упрощает анализ, т.к. исключает захват или просмотр ненужных в данный момент
пакетов.
·
Использование триггеров. Триггеры в данном случае – это
задаваемые администратором некоторые условия начала и прекращения процесса
захвата данных из сети. Такими условиями могут быть: время суток,
продолжительность процесса захвата, появление определенных значений в кадрах
данных. Триггеры могут использоваться совместно с фильтрами, позволяя более
детально и тонко проводить анализ, а также продуктивнее расходовать
ограниченный объем буфера захвата.
·
Многоканальность. Некоторые анализаторы протоколов позволяют
проводить одновременную запись пакетов от нескольких сетевых адаптеров, что
удобно для сопоставления процессов, происходящих в разных сегментах сети.
Возможности
анализа проблем сети на физическом уровне у анализаторов протоколов минимальные,
поскольку всю информацию они получают от стандартных сетевых адаптеров. Поэтому
они передают и обобщают информацию физического уровня, которую сообщает им
сетевой адаптер, а она во многом зависит от типа сетевого адаптера. Некоторые
сетевые адаптеры сообщают более детальные данные об ошибках кадров и
интенсивности коллизий в сегменте, а некоторые вообще не передают такую
информацию верхним уровням протоколов, на которых работает анализатор
протоколов.
Сетевые
анализаторы
Сетевые
анализаторы представляют собой эталонные измерительные приборы для диагностики
и сертификации кабелей и кабельных систем. Они могут с высокой точностью
измерить все электрические параметры кабельных систем, а также работают на
более высоких уровнях стека протоколов. Сетевые анализаторы генерируют
синусоидальные сигналы в широком диапазоне частот, что позволяет измерять на
приемной паре амплитудно-частотную характеристику и перекрестные наводки,
затухание и суммарное затухание. Сетевой анализатор представляет собой
лабораторный прибор больших размеров, достаточно сложный в обращении.
Кабельные
сканеры и тестеры
Основное
назначение кабельных сканеров – измерение электрических и механических
параметров кабелей: длины кабеля, параметра NEXT, затухания, импеданса,
схемы разводки пар проводников, уровня электрических шумов в кабеле. Точность
измерений, произведенный этими устройствами, ниже, чем у сетевых анализаторов,
но вполне достаточна для оценки соответствия кабеля стандарту.
Для
определения местоположения неисправности кабельной системы (обрыва, короткого
замыкания, неправильно установленного разъема и т.д.) используется метод
“отраженного импульса” (Time Domain Reflectometry, TDR). Суть этого метода
состоит в том, что сканер излучает в кабель короткий электрический импульс и
измеряет время задержки до прихода отраженного сигнала. По полярности
отраженного импульса определяется характер повреждения кабеля (короткое
замыкание или обрыв). В правильно установленном и подключенном кабеле
отраженный импульс почти отсутствует.
Точность
измерения расстояния зависит от того, насколько точно известна скорость
распространения электромагнитных волн в кабеле.
Кабельные
сканеры – это портативные приборы, которые обслуживающий персонал может
постоянно носить с собой.
Кабельные
тестеры – наиболее простые и дешевые приборы для диагностики кабеля. Они
позволяют определить непрерывность кабеля, однако, в отличие от кабельных
сканеров, не дают ответа на вопрос о том, в каком месте произошел сбой.
Многофункциональные
портативные приборы мониторинга
В
последнее время начали выпускаться многофункциональные портативные приборы,
которые объединяют в себе возможности кабельных сканеров, анализаторов
протоколов и даже некоторые функции систем управления, сохраняя в то же время
такое важное свойство, как портативность. Многофункциональные приборы
мониторинга имеют специализированный физический интерфейс, позволяющий выявлять
проблемы и тестировать кабели на физическом уровне, который дополняется
микропроцессором с программным обеспечением для выполнения высокоуровневых
функций.
Функции
проверки аппаратуры и кабелей
многофункциональные
приборы сочетают наиболее часто используемые на практике функции кабельных
сканеров с рядом новых возможностей тестирования.
● Сканирование кабеля
Функция позволяет измерять длину кабеля, расстояние до самого
серьезного дефекта и распределение импеданса по длине кабеля. При проверке
неэкранированной витой пары могут быть выявлены следующие ошибки: расщепленная
пара, обрывы, короткое замыкан е и другие виды нарушения соединения. Для
сетей Ethernet на коаксиальном кабеле эти проверки могут быть
осуществлены на работающей сети.
·
Функция определения распределения кабельных жил
Осуществляет проверку правильности подсоединения жил, наличие
промежуточных разрывов и перемычек на витых парах. На дисплей выводится
перечень связанных между собой контактных групп.
·
Функция определения карты кабелей
Используется
для составления карты основных кабелей и кабелей, ответвляющихся от
центрального помещения.
·
Автоматическая проверка кабеля
В
зависимости от конфигурации возможно определить длину, импеданс, схему
подключения жил, затухание и параметр NEXT на частоте до 100 МГц.
Автоматическая проверка выполняется для коаксиальных кабелей, экранированной
витой пары с импедансом 150 Ом, неэкранированной витой пары с сопротивлением
100 ОМ.
● Целостность цепи при проверке постоянным током
Эта
функция используется при проверке коаксиальных кабелей для верификации правильности
используемых терминаторов и их установки.
● Определение номинальной скорости распространения
Функция
вычисляет номинальную скорость распространения (Nominal Velocity of
Propagation, NVP) по кабелю известной длины и дополнительно сохраняет
полученные результаты в файле для определяемого пользователем типа кабеля (User
Defined Cable Type) или стандартного кабеля.
● Комплексная автоматическая проверка пары “сетевой
адаптер-концентратор”
Этот комплексный тест позволяет последовательно подключить прибор
между конечным узлом сети и концентратором. Тест дает возможность автоматически
определить местонахождение источника неисправности – кабель, концентратор,
сетевой адаптер или программное обеспечение станции.
● Автоматическая проверка сетевых адаптеров
Проверяет
правильность функционирования вновь установленных или “подозрительных” сетевых
адаптеров. Для сетей Ethernet по итогам проверки
сообщаются: MAC-адрес, уровень напряжения сигналов (а также присутствие и
полярность импульсов Link Test для 10Base-T). Если сигнал не
обнаружен на сетевом адаптере, то тест автоматически сканирует соединительный
разъем и кабель для их диагностики.
Функции
сбора статистики
Эти
функции позволяют в реальном масштабе времени проследить за изменением наиболее
важных параметров, характеризующих “здоровье” сегментов сети. Статистика обычно
собирается с разной степенью детализации по разным группам.
● Сетевая статистика
В этой группе собраны наиболее важные статистические показатели – коэффициент
использования сегмента (utilization), уровень коллизий, уровень ошибок и
уровень широковещательного трафика. Превышение этими показателями определенных
порогов в первую очередь говорят о проблемах в том сегменте сети, к которому
подключен многофункциональный прибор.
● Статистика ошибочных кадров
Эта
функция позволяет отслеживать все типы ошибочных кадров для определенной
технологии. Например, для технологии Ethernet характерны следующие
типы ошибочных кадров.
·
Укороченные кадры (Short Frames).Это кадры, имеющие длину,
меньше допустимой, т.е. меньше 64 байт. Иногда этот тип кадров дифференцируют
на два класса – просто короткие кадры (short), у которых имеется корректная
контрольная сумма, и “коротышки” (runts), не имеющие корректной контрольной
суммы. Наиболее вероятными причинами появления укороченных кадров являются
неисправные сетевые адаптеры и их драйверы.
Удлиненные кадры (Jabbers). Это кадры, имеющие длину, превышающую допустимое
значение в 1518 байт с хорошей или плохой контрольной суммой. Удлиненные кадры
являются следствием затянувшейся передачи, которая появляется из-за
неисправностей сетевых адаптеров.
·
Кадры нормальных размеров, но с плохой контрольной суммой (Bad
FCS) и кадры с ошибками выравнивания по границе байта. Кадры с неверной
контрольной суммой являются следствием множества причин – плохих адаптеров,
помех на кабелях, плохих контактов, некорректно работающих портов повторителей,
мостов, коммутаторов и маршрутизаторов. Ошибка выравнивания всегда
сопровождается ошибкой по контрольной сумме, поэтому некоторые средства анализа
трафика не делают между ними различий. Ошибка выравнивания может быть
следствием прекращения передачи кадра при распознавании коллизии передающим
адаптером.
Кадры-призраки (ghosts) являются результатом электромагнитных наводок на
кабеле. Они воспринимаются сетевыми адаптерами как кадры, не имеющие
нормального признака начала кадра – 10101011. Кадры-призраки имеют длину более
72 байт, в противном случае они классифицируются как удаленные коллизии.
Количество обнаруженных кадров-призраков в большой степени зависит от точки
подключения сетевого анализатора. Причинами их возникновения являются петли
заземления и другие проблемы с кабельной системой.
Знание
процентного распределения общего количества ошибочных кадров по их типам может
многое подсказать администратору о возможных причинах неполадок в сети. Даже
небольшой процент ошибочных кадров может привести к значительному снижению
полезной пропускной способности сети, если протоколы, восстанавливающие
искаженные кадры, работают с большими тайм-аутами ожидания квитанций.
Считается, что в нормально работающей сети процент ошибочных кадров не должен
превышать 0,01% , т.е. не более 1 ошибочного кадра из 10000.
● Статистика
по коллизиям
Эта группа характеристик дает информацию о количестве и видах
коллизий, отмеченных на сегменте сети, позволяет определить наличие и
местонахождение проблемы. Анализаторы протоколов обычно не могут дать
дифференцированной картины распределения общего числа коллизий по их отдельным
типам, в то же время знание преобладающего типа коллизий может помочь понять
причину плохой работы сети. Ниже приведены основные типы коллизий
сети Ethernet.
·
Локальная коллизия (Local Collision). Является
результатом одновременной передачи двух или более узлов, принадлежащих к тому
сегменту, в котором производятся измерения. Если многофункциональный прибор не
генерирует кадры, то в сети на витой паре или волоконно-оптическом кабеле
локальные коллизии не фиксируются. Слишком высокий уровень локальных коллизий
является следствием проблем с кабельной системой.
·
Удаленная коллизия (Remote Collision). Эти
коллизии происходят на другой стороне повторителя (по отношению к тому
сегменту, в котором установлен измерительный прибор). В сетях, построенных на
многопортовых повторителях (10Base-T, 10Base-FL/FB, 100Base-TX/FX/T4, Gigabit
Ethernet), все измеряемые коллизии являются удаленными (кроме тех случаев,
когда анализатор сам генерирует кадры и может быть виновником коллизии). Не все
анализаторы протоколов и средства мониторинга одинаковым образом фиксируют
удаленные коллизии. Это происходит из-за того, что некоторые измерительные
средства и системы не фиксируют коллизии, происходящие при передаче преамбулы.
·
Поздняя коллизия (Late Collision).
Это коллизия, которая происходит после передачи первых 64 байт кадра (по
протоколу Ethernetколлизия должна обнаруживаться при передаче первых 64
бай кадра). Результатом поздней коллизии будет кадр, который имеет длину более
64 байт и содержит неверное значение контрольной суммы. Чаще всего это
указывает на то, что сетевой адаптер, являющийся источником конфликта,
оказывается не в состоянии правильно прослушивать линию и поэтому не может
вовремя остановить передачу. Другой причиной поздней коллизии является слишком
большая длина кабельной системы или слишком большое количество промежуточных
повторителей, приводящее к превышению максимального значения времени двойного
оборота сигнала.Средняя интенсивность коллизий в нормально работающей сети
должна быть меньше 5%. Большие всплески (более 20%) могут быть индикатором
кабельных проблем.
·
Распределение используемых сетевых протоколов
Эта статистическая группа относится к протоколам сетевого
уровня. На дисплее отображается список основных протоколов в убывающем порядке
относительно процентного соотношения кадров, содержащих пакеты данного
протокола к общему числу кадров в сети.● Основные
отправители (Top Sendes)
Функция позволяет отслеживать наиболее активные передающие узлы
локальной сети. Прибор можно настроить на фильтрацию по единственному адресу и
выявить список основных отправителей кадров для данной станции. Данные
отражаются на дисплее в виде диаграммы вместе с перечнем основных отправителей
кадров.
● Основные получатели (Top Receivers)
Функция позволяет следить за наиболее активными
узлами-получателями сети. Информация отображается в виде, аналогичном
приведенному выше.
● Основные генераторы
широковещательного трафика (Top Broadcasters)
Функция выявляет станции сети, которые больше остальных
генерируют кадры с широковещательными и групповыми адресами.
● Генерирование
трафика (Traffic Generation)
Прибор может генерировать трафик для проверки работы сети при
повышенной нагрузке. Трафик может генерироваться параллельно с активизированными
функциями Сетевая статистика, Статистика
ошибочных кадрови Статистика
по коллизиям.
Пользователь может задать
параметры генерируемого трафика, такие как интенсивность и размер кадров. Для
тестирования мостов и маршрутизаторов прибор может автоматически создавать
заголовки IP- и IPX-пакетов, и все что требуется от оператора – это
внести адреса источника и назначения.
В ходе испытаний пользователь
может увеличить на ходу размер и частоту следования кадров с помощью клавиш
управления курсором. Это особенно ценно при поиске источника проблем
производительности сети и условий возникновения отказов.
Функции
анализа протоколов
Обычно
портативные многофункциональные приборы поддерживают декодирование и анализ
только основных протоколов локальных сетей, таких как протоколы стековTCP/IP,
Novell NetWare, NetBIOS и Banyan VINES.
В
некоторых многофункциональных приборах отсутствует возможность декодирования
захваченных пакетов, как в анализаторах протоколов, а вместо этого собирается
статистика о наиболее важных пакетах, свидетельствующих о наличии проблем в
сетях. Например, при анализе протоколов стека TCP/IP собирается
статистика по пакетам протокола ICMP, с помощью которого маршрутизаторы
сообщают конечным узлам о возникновении разного рода ошибок. Для ручной
проверки достижимости узлов сети в приборы включается поддержка утилиты IP
Ping, а также аналогичных по назначению утилит NetWare Ping и NetBIOS
Ping.
Мониторинг
локальных сетей на основе коммутаторов
Наблюдение
за трафиком
Так
как перегрузки процессоров портов и других обрабатывающих элементов коммутатора
могут приводить к потерям кадров, то функция наблюдения за распределением
трафика в сети, построенной на основе коммутаторов, очень важна.
Однако
если сам коммутатор не снабжен встроенным агентом SNMP для каждого
своего порта, то задача слежения за трафиком, традиционно решаемая в сетях с
разделяемыми средами с помощью установки в сеть внешнего анализатора протоколов,
очень усложняется.
Обычно
в традиционных сетях анализатор протоколов или многофункциональный прибор
подключался к свободному порту концентратора, что позволяло ему наблюдать за
всем трафиком, передаваемым между любыми узлами сети.
Если
же анализатор протокола подключить к свободному порту коммутатора, то он не
зафиксирует почти ничего, т.к. кадры ему передавать никто не будет, а чужие
кадры в его порт также направляться не будут. Единственный вид трафика, который
будет фиксировать анализатор, – это трафик широковещательных пакетов, которые
будут передаваться всем узлам сети, а также трафик кадров с неизвестными
коммутатору адресами назначения. В случае когда сеть разделена на виртуальные
сети, анализатор протоколов будет фиксировать только широковещательный трафик
своей виртуальной сети, чтобы анализаторами протоколов можно было по-прежнему
пользоваться и в коммутируемых сетях, производители коммутаторов снабжают свои
устройства функцией зеркального отображения трафика любого порта на специальный
порт. К специальному порту подключается анализатор протоколов, а затем на
коммутатор подается команда через его модульSNMP-управления для отображения
трафика какого-либо порта на специальный порт.
Наличие
функции зеркализации портов частично снимает проблему, но оставляет некоторые
вопросы. Например, как просматривать одновременно трафик двух портов или трафик
порта, работающего в полнодуплексном режиме.
Более
надежным способом слежения за трафиком, проходящим через порты коммутатора,
является замена анализатора протокола на агенты RMON MIB для каждого
порта коммутатора.
Агент RMON выполняет
все функции хорошего анализатора протокола для
протоколов Ethernet и Token Ring, собирая детальную информацию
об интенсивности трафика, различных типах плохих кадров, о потерянных кадрах,
причем самостоятельно строя временные ряды
для каждого фиксируемого параметра. Кроме того, агент RMON может
самостоятельно строить матрицы перекрестного трафика между узлами сети, которые
очень нужны для анализа эффективности применения коммутатора.
Так
как агент RMON, реализующий все 9 групп объектов Ethernet, стоит
весьма дорого, то производители для снижения стоимости коммутатора часто
реализуют только первые несколько групп объектов RMON MIB. Другим приемом
снижения стоимости коммутатора является использование одного
агента RMON для нескольких портов. Такой агент по очереди
подключается к нужному порту, позволяя снять с него требуемые статистические
данные.
Управление
виртуальными сетями
Виртуальные
локальные сети VLAN порождают проблемы для традиционных систем
управления на платформе SNMP как при их создании, так и при
наблюдении за их работой.
Как
правило, для создания виртуальных сетей требуется специальное программное
обеспечение компании-производителя, которое работает на платформе системы
управления, например, HP Open View. Сами платформы систем управления этот
процесс поддержать не могут в основном из-за долгого отсутствия стандарта на
виртуальные сети. Можно надеяться, что появление стандарта 802.1Q изменит
ситуацию в этой области.
Наблюдение
за работой виртуальных сетей также создает проблемы для традиционных систем
управления. При создании карты сети, включающей виртуальные сети, необходимо
отображать как физическую структуру сети, так и ее логическую структуру,
соответствующую связям отдельных узлов виртуальной сети. При этом по желанию
администратора система управления должна уметь отображать соответствие
логических и физических связей в сети, т.е. на одном физическом канале должны
отображаться все или отдельные пути виртуальных сетей.
К
сожалению, многие системы управления либо вообще не отображают виртуальные
сети, либо делают это очень неудобным для пользователя способом, что вынуждает
обращаться к менеджерам компаний-производителей для решения этой задачи.
Скачать материал
Выбранный для просмотра документ lk3_mdk_03_01.docx
Техническое обслуживание
(ТО) – это комплекс организационно-технических мероприятий и работ,
производимых на объекте и направленных на поддержание в рабочем или исправном
состоянии оборудования (программного обеспечения (ПО)) технических систем в процессе
их использования по назначению с целью повышения надежности и эффективности их
работы.
Основными задачами Технического обслуживания систем являются:
• определение качественного состояния оборудования, кабельных сетей и проверка
их работоспособности (в том числе ПО);
• своевременное выявление и устранение недостатков, снижающих эффективность
работы систем и приводящих к возникновению отказов аппаратуры (ПО);
• предупреждение отказов оборудования (ПО), увеличение межремонтных сроков
эксплуатации и сроков службы оборудования;
• проверка и доведение до установленных норм параметров оборудования систем,
линейно-кабельных и распределительных устройств;
• ликвидация последствий воздействия на оборудование неблагоприятных
клима-тических и других условий эксплуатации;
• подготовка оборудования к сезонной эксплуатации;
• проверка укомплектованности механизмов, аппаратуры, наличия инструментов и
пополнение ЗИП;
• анализ и обобщение сведений результатов выполненных работ, разработка
мероприятий по совершенствованию форм и методов Технического обслуживания,
эксплуатации систем;
• техническая консультативная поддержка эксплуатирующего персонала и
руководителей по любым вопросам, связанным с эксплуатацией систем в целях
эффективного использования.
Порядок планирования и проведения мониторинга компьютерных сетей и порядок
организации работ по техническому сопровождению корпоративной компьютерной сети
1. Мониторинг
аппаратного обеспечения
2. Мониторинг
работоспособности аппаратных компонентов КС осуществляется в процессе их обслуживания
и при проведении работ по техническому обслуживанию оборудования. Наиболее
существенные компоненты системы, имеющие встроенные средства контроля
работоспособности (серверы, активное сетевое оборудование), должны
контролироваться постоянно.
3. Мониторинг
парольной защиты
4. Мониторинг
парольной защиты и контроль надежности пользовательских паролей
предусматривают:
— установление
сроков действия паролей;
— периодическую (не
реже 1 раза в месяц) проверку пользовательских паролей.
5. Мониторинг попыток
несанкционированного доступа
3.1. Предупреждение и своевременное выявление попыток несанкционированного
доступа осуществляется с использованием средств операционной системы,
специальных программных средств и предусматривает:
— фиксацию
неудачных попыток входа в систему в системном журнале;
— протоколирование
работы сетевых сервисов;
— выявление фактов
сканирования определенного диапазона сетевых портов в короткие промежутки
времени с целью обнаружения сетевых анализаторов, изучающих систему и
выявляющих ее уязвимости.
6. Мониторинг
производительности
4.1. Мониторинг производительности КС производится по обращениям пользователей
в ходе обслуживания систем и при проведении профилактических работ.
7. Системный аудит
8. Системный аудит
производится администратором информационной безопасности ежеквартально и в
особых ситуациях. Он включает проведение обзоров безопасности с занесением
записей в Журнал обзоров безопасности, тестирование системы, контроль внесения
изменений в системное программное обеспечение.
9. Активное
тестирование надежности механизмов контроля доступа производится путем
осуществления попыток проникновения в систему (с помощью автоматического
инструментария или вручную).
10. Пассивное
тестирование механизмов контроля доступа осуществляется путем анализа
конфигурационных файлов системы.
11. Внесение изменений
в системное программное обеспечение осуществляется с условием обязательного
документирования изменений в соответствующем журнале; уведомлением каждого
сотрудника, которого касается изменение; рассмотрением претензий в случае, если
внесение изменений повлекло причинение вреда; разработкой планов действий в
аварийных ситуациях для восстановления работоспособности системы, если
внесенное в нее изменение вывело ее из строя.
12. Антивирусный
контроль
13. Для защиты
объектов вычислительной техники необходимо использовать антивирусные программы:
• резидентные антивирусные мониторы, контролирующие подозрительные действия
программ;
• утилиты для обнаружения и анализа новых вирусов.
• К использованию допускаются только лицензионные средства защиты от
вредоносных программ и вирусов или сертифицированные свободно распространяемые
антивирусные средства.
• При подозрении на наличие не выявленных установленными средствами защиты
заражений следует использовать Live CD с другими антивирусными средствами.
• Запуск антивирусных программ должен осуществляться автоматически по заданию,
централизованно созданному с использованием планировщика задач (входящим в
поставку операционной системы либо поставляемым вместе с антивирусными
программами).
Устанавливаемое (изменяемое) на серверы программное обеспечение должно быть
предварительно проверено на отсутствие компьютерных вирусов и вредоносных
программ. Непосредственно после установки (изменения) программного обеспечения
сервера должна быть выполнена антивирусная проверка.
14. Анализ попыток
взлома инцидентов
15. Если администратор
информационной безопасности подозревает или получил сообщение о том, что
система подвергается атаке или уже была скомпрометирована, то он должен
установить:
— факт попытки
несанкционированного доступа (далее – НСД);
— продолжается ли
НСД в настоящий момент;
— кто является
источником НСД;
— что является
объектом НСД;
— когда происходила
попытка НСД;
— как и при каких
обстоятельствах была предпринята попытка НСД;
— точка входа
нарушителя в систему;
— была ли попытка
НСД успешной;
— определить
системные ресурсы, безопасность которых была нарушена;
— какова мотивация
попытки НСД.
16. Порядок проведения
резервного копирования
17. Для предотвращения
потери данных из-за сбоев оборудования, уничтожения оборудования, программных
ошибок, неправильных действий персонала и других возможных причин утери
информации предусмотрена система регулярного резервного копирования данных.
Такое резервное копирование позволяет в случае возникновения ошибки и потери
информации вернуться к ближайшей работоспособной копии.
18. Резервное
копирование критически важной информации и информации, размещенной на серверах,
выполняется на предназначенные для этих целей сервера, ленточные накопители и
оптические носители.
19. Резервное копирование
проводится автоматически в установленные промежутки времени (ночью, 1 раз в
сутки).
20. На объектах
вычислительной техники пользователей не предусматривается резервного
копирования системной информации, но в целях сохранности важных документов
пользователю желательно проводить архивирование и хранение данных документов на
оптических дисках (CD-R).
Указания по проведению
профилактических работ
1. Профилактические
работы проводятся строго в соответствии с установленным графиком. График
проведения профилактических работ на серверах на следующий месяц составляется
администратором.
2. Администратор ЛС
обязан включить в график все периодические профилактические работы, независимо
от необходимости их проведения.
3. Профилактика
целостности операционной системы, сетевого взаимодействия, проверка работы
сервисов и служб проводятся в рабочем порядке, поскольку в подавляющем
большинстве случаев не требуют перезагрузки серверов.
4. Профилактика баз
данных, проверки на наличие вирусов, обновлений системы и серверных приложений,
проверка отказоустойчивости системы, профилактика работоспособности дисковой и
файловой подсистем, остановки сервера для чистки и вентиляции проводятся в
рабочее время с учетом времени минимальной загрузки серверов.
5. Профилактические
работы на серверах, требующие длительного (более 1 часа) отключения и способные
повлиять на рабочие процессы в организации, проводятся в выходные дни.
6. Процедуры,
необходимые для проведения профилактических работ, включают в себя:
— анализ журналов
событий серверов: проводится ежедневно для выявления ошибок, связанных с
функционированием базовых компонентов серверного аппаратно-программного
комплекса;
— анализ отчетов
системы безопасности: проводится ежедневно с целью выявления соответствия
политик доступа к ресурсам локальной сети путем просмотра журналов системы
безопасности серверов и программ, отвечающих за безопасность информационных
потоков с оценкой соответствия доступа пользователей к ресурсам организации;
— проверка
работоспособности почтовых служб и служб Интернет: проводится ежедневно с целью
поддержания возможности получения пользователями оперативной информации из
внешних источников;
— анализ
Интернет-трафика: проводится ежедневно с целью предотвращения нецелевого
использования Интернет-ресурсов;
— анализ возможностей
доступа пользователей к сетевым ресурсам: проводится ежедневно с целью
определения возможности совместного доступа к различным сетевым ресурсам и
выполнения пользователями их должностных обязанностей;
— просмотр отчетов
служебных программ: проводится с целью проверки работоспособности
пользовательских приложений, установленных на сервере;
— проверка сетевого
взаимодействия: производится еженедельно в начале рабочей недели и включает в
себя краткий анализ журналов событий и графиков загрузки сети;
— проверка работы
служб: проводится еженедельно на каждом из работающих серверов, находящихся в
ЛС;
— проверка наличия
обновлений операционной системы и серверных приложений: проводится еженедельно
с целью поддержания работоспособности аппаратно-программного комплекса на
должном уровне и сохранения безопасности использования внешних источников
информации;
Перечень профилактических
работ
1. Профилактические
работы включают в себя:
— анализ журналов
событий серверов (ежедневно);
— анализ отчетов
системы безопасности (ежедневно);
— анализ изменения
состава групп безопасности в AD (Active Directory);
— выявление попыток
несанкционированного доступа к ресурсам;
— выявление попыток
несанкционированного изменения уровня доступа к ресурсам;
— проверку
работоспособности почтовых служб и служб Интернет (ежедневно);
— анализ
Интернет-трафика (ежедневно);
— анализ
возможностей доступа пользователей к сетевым ресурсам (ежедневно);
— просмотр отчетов
служебных программ (ежедневно);
— проверку сетевого
взаимодействия (1 раз в неделю);
— проверку работы
сервисов и служб (1 раз в неделю);
— проверку наличия
обновлений операционной системы и серверных приложений (1 раз в неделю);
— профилактику баз
данных (1 раз в неделю);
— антивирусную
профилактику сервера (1 раз в неделю);
— проверку
целостности операционной системы (1 раз в 2 недели);
— принудительную
проверку отказоустойчивости системы (1 раз в 2 недели);
— профилактику
дисковой и файловой подсистем на сервере (1 раз в 2 недели);
— профилактическую
остановку сервера (1 раз в 2 недели);
— составление
отчета доступа к Интернет-ресурсам (1 раз в месяц);
— профилактические
работы на объектах вычислительной техники (выполняются пользователем, по
необходимости при помощи сотрудников ООВТ ЦСИТ).
К профилактическим работам на объектах вычислительной техники относятся:
— проверка
обновления клиентских приложений (по необходимости);
— проверка времени
последнего обновления антивирусных баз (1 раз в неделю);
— выявление попыток
несанкционированной установки приложений пользователем (ежедневно);
— удаление
временных и устаревших копий файлов (по необходимости);
— выполнение прочих
работ, непосредственно связанных с работоспособностью объектов вычислительной
техники (по необходимости).
Скачать материал
Выбранный для просмотра документ lk4_mdk_03_01_Oborudovanie_dlya_diagnostiki_i_sertifikatsii_kabelnykh_sistem.docx
Оборудование
для диагностики и сертификации кабельных систем
К
оборудованию данного класса относятся сетевые анализаторы, приборы для
сертификации кабелей, кабельные сканеры и тестеры.
1. Сетевые
анализаторы
Сетевые
анализаторы представляют собой эталонные измерительные инструменты для
диагностики и сертификации кабелей и кабельных систем. В качестве примера можно
привести сетевые анализаторы компании Hewlett Packard – HP 4195A и HP 8510C.
Сетевые
анализаторы содержат высокоточный частотный генератор и узкополосный приемник.
Передавая сигналы различных частот в передающую пару и измеряя сигнал в
приемной паре, можно измерить затухание и NEXT. Сетевые анализаторы – это
прецизионные крупногабаритные и дорогие (стоимостью более $20000) приборы,
предназначенные для использования в лабораторных условиях специально обученным
техническим персоналом.
2. Кабельные
сканеры
Данные
приборы позволяют определить длину кабеля, NEXT, затухание, импеданс, схему
разводки, уровень электрических шумов и провести оценку полученных результатов.
Цена на эти приборы варьируется от $1’000 до $3’000. Существует достаточно
много устройств данного класса, например, сканеры компаний MicrotestInc.,
FlukeCorp., Datacom TechnologiesInc., Scope CommunicationInc. В отличие от
сетевых анализаторов сканеры могут быть использованы не только специально
обученным техническим персоналом, но даже администраторами-новичками.
Для
определения местоположения неисправности кабельной системы (обрыва, короткого
замыкания, неправильно установленного разъема и т.д.) используется метод
“кабельного радара”, или Time Domain Reflectometry (TDR). Суть этого метода
состоит в том, что сканер излучает в кабель короткий электрический импульс и
измеряет время задержки до прихода отраженного сигнала. По полярности
отраженного импульса определяется характер повреждения кабеля (короткое
замыкание или обрыв). В правильно установленном и подключенном кабеле
отраженный импульс совсем отсутствует.
Точность
измерения расстояния зависит от того, насколько точно известна скорость
распространения электромагнитных волн в кабеле. В различных кабелях она будет
разной. Скорость распространения электромагнитных волн в кабеле (NVP – nominal
velocity of propagation) обычно задается в процентах к скорости света в
вакууме. Современные сканеры содержат в себе электронную таблицу данных о NVP
для всех основных типов кабелей и позволяют пользователю устанавливать эти
параметры самостоятельно после предварительной калибровки.
Наиболее
известными производителями компактных кабельных сканеров являются компании
MicrotestInc., WaveTekCorp., Scope Communication Inc.
3. Тестеры
кабельных систем
Тестеры
кабельных систем – наиболее простые и дешевые приборы для диагностики кабеля.
Они позволяют определить непрерывность кабеля, однако, в отличие от кабельных
сканеров, не дают ответа на вопрос о том, в каком месте произошел сбой.
Существуют
целые классы средств тестирования кабельных систем, появление которых стало
возможным благодаря наличию четких стандартов на характеристики компонентов
(TIA/EIA568), а также на процедуры и критерии тестирования кабельных линий СКС
(TSB-67).
Для
удобства кабельные линии разделены на категории в соответствии с их
параметрами. Многие из эксплуатируемых кабельных линий относятся к Категории 3
и предназначены для телефонии и передачи данных в диапазоне частот до 16 МГц
(например, 10BaseT Ethernet). Однако наибольшее распространение получили
кабельные линии Категории 5, гарантирующие передачу сигнала с частотой до 100
МГц. Комитетами стандартизации закончена работа над составлением перечня более
жестких требований к параметрам кабельных линий Категории 5 (улучшенная
Категория 5 или 5E), Категории 6 (200-250 МГц), Категории 7 (до 600 МГц) с
целью повышения надежности передачи.
Большое
количество моделей выпускаемых тестеров СКС предназначено для контроля
кабельных линий Категорий 3, 5 и 5E (улучшенная Категория 5). Уже появились
первые тестеры для проводки Категории 6 (например, LANcat System 6 компании
Datacom или OMNIScanner компании Microtest). Однако основной парк тестеров СКС
сегодня все же ориентирован на анализ характеристик линий в диапазоне частот до
100-155 МГц. За исключением анализируемого диапазона частот, другие параметры
этих тестеров отличаются друг от друга несущественно, так как тестирование
выполняется по одним и тем же методикам. Основные отличия заключаются в
характеристиках встроенных рефлектометров для проводных линий (максимальная
дальность, точность, разрешение, форма представления результата), в пользовательском
интерфейсе и удобстве работы, а также в наборе вспомогательных и сервисных
функций.
Среди
вспомогательных функций могут быть особенно, полезны следующие:
·
двустороннее измерение;
·
тестирование волоконно-оптических кабелей;
·
карта (схема соединения) жил кабеля;
·
обнаружение импульсных помех;
·
мониторинг трафика
ЛВС;
·
составление программ тестирования;
·
организация разговорного тракта между основным и удаленным
модулем;
·
встроенный тональный генератор для трассировки и идентификации и
др.
Приведенная
ниже информация позволит ознакомиться с измеряемыми параметрами кабельной линии
и облегчит выбор прибора для конкретных нужд.
Основными
электрическими параметрами, от которых зависит работоспособность кабельной
линии, являются:
·
целостность цепи (connectivity);
·
характеристический импеданс (characteristic impedance) и
обратные потери (return loss);
·
погонное затухание (attenuation);
·
переходное затухание (crosstalk);
·
задержка распространения сигнала (propagation delay) и длина
линии (cable length);
·
сопротивление линии по постоянному току (loop resistance);
·
емкость линии (capacitance);
·
электрическая симметричность (balance);
·
наличие шумов в линии
(electrical noise, electromagnetic interference).
Рассмотрим
эти характеристики подробнее
1)
Целостность цепи
Основная
задача этого теста – выявить ошибки монтажа соединителей или кроссировки
(замыкания, обрывы, перепутанные жилы). Поскольку ошибки подобного рода на
практике преобладают, то существует большое количество недорогих приборов,
единственной функцией которых является только контроль целостности цепи. Однако
полнофункциональные тестеры СКС,
как правило, предоставляют более полную информацию о характере ошибки, вплоть
до схемы соединения, по которой монтажник может точно идентифицировать дефект.

Рис.
1 – Тестеры СКС
2)
Характеристический импеданс (волновое сопротивление)
Поскольку
передача данных ведется на высоких частотах, то немаловажную роль имеет
импеданс линии, т. е. ее сопротивление переменному току заданной частоты. Роль
играет не только величина сопротивления, но и его постоянство по всей линии
(кабелю и соединителям) для всего диапазона рассматриваемых частот. Это
объясняется тем, что сигнал, отраженный от точек с аномальным импедансом, будет
накладываться на основной сигнал и искажать его.
Для
кабеля из витых пар импеданс обычно составляет 100 или 120 Ом. Для линий
Категории 5 импеданс нормируется для диапазона частот 1-100 МГц и должен
составлять 100 Ом v15%.
Основные
причины неоднородности импеданса следующие:
–
нарушение шага скрутки в местах разделки кабеля около соединителей
(максимальное расстояние, на которое жилы могут быть развиты при разделке, – 13
мм);
–
дефекты кабеля (повышенное сопротивление жил, пониженное сопротивление
изоляции, нарушение шага скрутки);
–
неправильная укладка кабеля (применение скоб и хомутов для крепления, малый
радиус изгиба, заломы и “барашки” из-за неправильной отмотки);
–
некачественная опрессовка соединителей или использование некачественных
соединителей.
Аналогичные
проблемы возникают на прошедших тестирование линиях при подключении к ее
розеткам некачественных (не соответствующих требованиям заданной категории)
коммутационных шнуров, переходников или расщепителей линии (сплиттеров).
Оценка
влияния, вносимого неоднородностями импеданса, выражается таким параметром, как
обратные потери (отношение амплитуды переданного сигнала к амплитуде
отраженного в дБ). Если дефект порождает в линии существенную неоднородность
импеданса, то обратные потери будут малы, так как большая часть энергии сигнала
будет отражена от неоднородности. Так, в случае обрыва или замыкания кабеля
обратные потери будут равны 0.
Все
полнофункциональные тестеры СКС имеют встроенный рефлектометр для проводных
линий с цифровым или графическим отображением результата, с помощью которого
место с аномальным импедансом может быть без труда локализовано. Некоторые
рефлектометры позволяют вычислять обратные потери для заданного участка линии,
что позволяет определить влияние имеющихся на нем неоднородностей на
результирующую характеристику линии.
3)
Погонное затухание (Attenuation)
Ослабление
сигнала при его распространении по линии оценивается затуханием (выраженное в
дБ отношение мощности сигнала, поступившего в нагрузку на конце линии, к
мощности сигнала, поданного в линию). Затухание сильно увеличивается с ростом
частоты, поэтому оно должно измеряться для всего диапазона используемых частот.
Для кабеля категории 5 при частоте 100 Мгц затухание не должно превышать 23.6
Дб на 100 м, а для кабеля категории 3, применяемого по стандарту IEEE 802.3
10BASE-T, допустимая величина затухания на сегменте длиной 100 м не должна
превышать 11,5 Дб при частоте переменного тока 10 МГц.
4)
Переходное затухание
Данный
параметр характеризует степень перекрестных наводок сигнала между парами одного
кабеля (отношение амплитуды поданного сигнала к амплитуде наведенного сигнала в
дБ). Эта характеристика имеет несколько разновидностей, каждая из которых
позволяет оценить разные свойства кабеля.
При
определении переходного затухания на ближнем конце линии (Near End Cross Talk,
NEXT; Power Sum NEXT, PS-NEXT) подача сигнала и измерение производятся с одной
стороны линии для всех частот заданного диапазона. В первом случае для
проведения измерения в одной паре сигнал подается поочередно на все остальные
пары. Именно это измерение и применяется для тестирования кабельных линий
Категории 5. Во втором случае тестирование производится по более жестким
правилам: сигнал подается сразу на все остальные пары и измеряется суммарное
затухание.
Очевидно,
что переходное затухание на ближнем конце линии необходимо измерять с обеих ее
сторон, так как влияние дефектов на этот параметр будет тем сильнее, чем ближе
они расположены к месту измерения. В новых стандартах предполагается проводить
и измерение затухания на разных концах линии одновременно.
Функционирование
линии будет надежным только тогда, когда переходное затухание велико, а
погонное – мало, поэтому оценку качества линии очень удобно производить на
основании комбинированного параметра – защищенности на дальнем конце линии
(Attenuation to Crosstalk Ratio, ACR; Power Sum ACR, PS-ACR), выраженного как
отношение величин погонного затухания и переходного затухания на ближнем конце
линии. Фактически этот параметр показывает, насколько амплитуда принимаемого
полезного сигнала выше амплитуды шумов для заданной частоты сигнала.
Однако
если передача ведется по нескольким парам одновременно (например, 100Base-T4 и
100VG-AnyLAN), то в таких сетях важное значение имеет и уровень переходного
затухания на дальнем конце линии (Far-End CrossTalk, FEXT). Поскольку на
приемник поступает суперпозиция полезного сигнала, передаваемого по данной
паре, и сигнала, наведенного на нее с другой пары, оценка качества линии
производится на основании отношения величин полезного сигнала на дальнем конце
линии (т. е. с учетом его затухания) и наведенного сигнала – приведенное
переходное затухание на дальнем конце линии (Equal-Level Far-End Cross Talk,
ELFEXT; Power Sum ELFEXT, PS-ELFEXT).
Удовлетворительное
значение переходного затухания косвенно свидетельствует о симметричности линии
и, следовательно, об отсутствии излучения витой парой электромагнитных и приема
электромагнитных и радиопомех.
5)
Задержка распространения сигнала и длина линии
Для
надежной работы на высоких скоростях необходимо, чтобы задержка распространения
сигнала не превышала заданную и была одинакова для всех пар кабельной линии.
Измерение длины кабеля осуществляется в соответствии с принципом
рефлектометрии.
Следует
отметить, что некоторые системы передачи (например, 100Base-T4 и 100VG-AnyLAN)
весьма чувствительны не только к абсолютному значению задержки распространения
сигнала, но и к ее разнице (propagation delay skew) для различных пар одной
кабельной линии. Такой перекос задержки и, как следствие, необходимость его
измерения возникли после того, как некоторые производители стали выпускать
кабели с различной изоляцией пар (известные как “2+2” и “3+1”).
6)
Уровень шумов в линии
Иногда
электромагнитные и радиопомехи делают невозможной устойчивую передачу сигнала в
линии. Большинство тестеров СКС позволяют измерить уровень шумов для
последующего анализа и устранения их причин.
Самые
распространенные шумы – это импульсные помехи от расположенного вдоль трассы
мощного электрооборудования (моторов, пускорегулирующей аппаратуры,
светильников дневного света и т. п.) или силовой проводки к ним. Очень часто
для устранения подобной проблемы кабель достаточно переместить на несколько
метров в сторону. Гораздо реже работе мешает расположенное поблизости
радиопередающее оборудование. Устранение помех в этом случае потребует
экранировки кабеля или его укладки в металлических каналах.
Как
видно из вышесказанного, подлежащих определению параметров кабельных линий
достаточно много, причем они имеют различное значение для тех или иных
приложений. Однако и разнообразие приборов для их измерения не менее велико.
Самый простой способ не ошибиться при выборе – исходить из потребностей вашей
организации и ее планов на ближайшее будущее.
Не
все рассмотренные параметры охватываются стандартами СКС. Например, TSB-67
требует для кабельных систем Категории 5 контроля четырех параметров:
правильности подключения линии, длины линии, затухания сигнала, переходного
затухания на ближнем конце линии. В то же время спецификации некоторых высокоскоростных
систем передачи предъявляют и ряд других, более жестких требований к параметрам
кабельных линий. Некоторые из них уже включены в новые стандарты, остальные
будут включены в ближайшем будущем.
Если
компания занимается монтажом, то лучше приобретать прибор с развитыми
сервисными функциями для быстрой локализации ошибок монтажа, с возможностью
сохранения результатов для последующей передачи на компьютер и формирования
протоколов приемочных испытаний. Кроме того, желательно, чтобы приобретенный прибор
обеспечивал возможность модернизации заложенной в нем программы в соответствии
с требованиями новых стандартов. Затраты на приобретение прибора такого уровня
могут оказаться высоки, но окупятся достаточно быстро.
Если
же прибор приобретается для обслуживания существующей СКС, то в целях экономии
можно ограничиться недорогим устройством для проверки линий СКС требованиям
конкретных приложений (10BaseT, 100BaseTX, ATM 155 и т. п.), которые
организация использует в настоящее время или собирается использовать в
ближайшем будущем.
Скачать материал
Выбранный для просмотра документ lk5_mdk_03_01_Expertnye_sistemy.docx
Экспертные
системы
Экспертные
системы. Этот вид систем аккумулирует знания технических специалистов о
выявлении причин аномальной работы сетей и
возможных способах приведения сети в работоспособное состояние.
Экспертные
системы часто реализуются в виде отдельных подсистем различных средств
мониторинга и анализа сетей : систем управления
сетями , анализаторов протоколов, сетевых анализаторов. Простейшим
вариантом экспертной системы является
контекстно-зависимая система помощи. Более сложные
экспертные системы представляют собой, так называемые базы
знаний, обладающие элементами искусственного интеллекта. Примерами таких
систем являются экспертные системы , встроенные в
систему управления Spectrum компании Cabletron и анализатора
протоколов Sniffer компании Network General. Работа
экспертных систем состоит в анализе большого
числа событий для выдачи пользователю краткого диагноза о причине
неисправности сети .
Спектроанализатор
радиоэфира Cisco Spectrum Expert
Программно-аппаратный
спектроанализатор Cisco Spectrum Expert – высокоточное решении,
предназначенное как для проведения предварительного радиообследования, так и
для мониторинга существующих беспроводных сетей.
Ключевыми
преимуществами решения Cisco Spectrum Expert являются:
1.
Возможность интеграции с системами WCS для real-time мониторинга
существующей сети;
2.
Запись лог-файлов, с возможностью просмотра их без аппаратного
комплекса;
3.
Наличие встроенной базы спектральных масок, позволяющей
определить тип источника сигнала;
4.
Возможность автономного режима работы с отсылкой статистики о
превышении заданных пороговых уровней;
5.
Единое решение для всех частотных Wi-Fi диапазонов;
Аппаратный
комплекс Cisco Spectrum Expert выполнен в виде PCMCIA радиомодуля, имеющего
встроенную антенну, и разъем для подключения внешней антенны.
Одной
из ключевых возможностей системы Cisco Spectrum Expert является анализ
источников помех, благодаря встроенной базе радиомасок наиболее
распространенного оборудования. Анализатор спектра работает в связке с
радиомодулем, как правило, уже встроенным в ноутбук. Сканируя эфир, система
выделяет из общего сигнала отдельные источники и классифицирует их по типам:
1.
Wi-Fi совместимое радиооборудование:
2.
Широкополосное радиооборудование, в том числе Wi-MAX и частные
решения;
3.
Оборудование, работающее по принципу частотных скачков: DECT,
Bluetooth;
4.
Узкополосные системы передачи данных: радиорелейные станции,
аналоговые радиотелефоны, беспроводные видеокамеры и видеосендеры, аналоговые
камеры;
5.
Промышленные источники электромагнитного излучения, радары,
микроволновые печи;
Еще
одной возможностью системы является запись лог файла. Лог файл представляет все
результаты замеров анализатора, представленные в виде анимированных графиков и
статистики с привязкой к времени записи. Для просмотра лог файла достаточно иметь
только программную часть анализатора, без аппаратного модуля.
Помимо
независимого мониторинга анализатор спектра Cisco Spectrum Expert может быть
интегрирован в систему управления беспроводной сетью Cisco WCS;
Интеграция осуществляется с централизованной системой управления
беспроводной сетью от Cisco (Wireless Control System) при помощи установки
дополнительной лицензии WCS-ADV-K9 (поддержка 1 модуля Spectrum Expert) или
WCS-ADV-SI-SE-10= (поддержка до 10 модулей Spectrum Expert)
Система
WCS с подключенными к ней Cisco Spectrum Expert позволяет администратору помимо
Wi-Fi устройств ,определяемых стандартными методами (мониторинг точками
доступа), видеть на карте источники помех не соответствующие стандарту Wi-Fi и,
таким образом, не определяемые точками доступа. Модули Cisco Spectrum Expert
непрерывно сканируют эфир и отправляют в WCS статистику по уровню,
местоположению и типу источников помех.
Благодаря
возможности Cisco Spectrum Expert обнаруживать источники сигнала с произвольной
маской, с его помощью можно найти и такие объекты как нелегально установленные
беспроводные средства аудио/видео наблюдения.
«SPECTRUM»
система управления сетями
Масштабируемое
решение для управления информационной системой
SPECTRUM
предназначен для распределенного управления сетями неограниченного размера
независимо от сетевого протокола и установленного сетевого оборудования.
SPECTRUM способен управлять любыми сетевыми устройствами и элементами сети,
выявлять, исправлять или корректировать проблемы, возникающие в сети, и
информировать сетевых администраторов об изменении их состояния.
Платформа
SPECTRUM и ее приложения предоставляют необходимые «строительные блоки» для
создания открытой и наращиваемой системы управления, от простого мониторинга устройств
до полностью распределенного управления предприятием с системами различных
поставщиков в сетевых и системных средах окружения любого типа.
На
основе индуктивного моделирования (IMT) – разновидность искусственного
интеллекта – SPECTRUM, обеспечивая активное управление сетью, реально
«вычисляет» проблемы, самостоятельно их решает или инициирует их устранение
администратором сети.
SPECTRUM
создает интеллектуальную модель для каждого элемента сети, даже если
представляемый ею элемент не интеллектуален, включая физические соединения,
сетевые устройства, серверы, топологии, настольные компьютеры и приложения, а
способность к выявлению связей между различными сетевыми объектами и
компонентами позволяет оператору непосредственно визуализировать структуру
всего предприятия.
Spectrum
позволяет с помощью дополнительного набора Level I Developer’s Toolkit (без
использования элементов программирования) создавать новые типы моделей хабов,
мостов, коммутаторов, маршрутизаторов, серверов и т. п. или же производить
модификации существующих типов.
Скачать материал
Выбранный для просмотра документ lk6_mdk_03_01_Vstroennye_sredstva_monitoringa_i_analiza_setey.docx
Встроенные средства мониторинга и анализа сетей

1. Агенты
SNMP
Первоначальная
спецификация MIB-Iопределяла только операции чтения значений переменных.
Операции изменения или установки значений объекта являются частью спецификаций
MIB-II.
На
сегодня существует несколько стандартов на базы данных управляющей информации.
Основными являются стандарты MIB-I иMIB-II, а также версия базы данных для
удаленного управления RMONMIB. Кроме этого, существуют стандарты для
специальных MIB устройств конкретного типа(например, MIB для концентраторов или
MIB для модемов), а также частные MIBконкретных фирм-производителей оборудования.
Версия
MIB-I (RFC 1156) определяет до 114 объектов, которые подразделяются на 8 групп:
·
System – общие данные об устройстве (например, идентификатор
поставщика, время последней инициализации системы).
·
Interfaces – описываются параметры сетевых интерфейсов
устройства (например, их количество, типы, скорости обмена, максимальный размер
пакета).
·
AddressTranslationTable – описывается соответствие между
сетевыми и физическими адресами (например, по протоколу ARP).
·
InternetProtocol – данные, относящиеся к протоколу IP (адреса
IP-шлюзов, хостов, статистика об IP-пакетах).
·
ICMP – данные, относящиеся к протоколу обмена управляющими
сообщениями ICMP.
·
TCP – данные, относящиеся к протоколу TCP (например, о
TCP-соединениях).
·
UDP – данные, относящиеся к протоколу UDP (число переданных,
принятых и ошибочных UPD-дейтаграмм).
·
EGP – данные, относящиеся к протоколу обмена маршрутной
информацией ExteriorGatewayProtocol, используемому в сети Internet (число
принятых с ошибками и без ошибок сообщений).
Из этого
перечня групп переменных видно, что стандарт MIB-I разрабатывался с жесткой
ориентацией на управление маршрутизаторами, поддерживающими протоколы стека
TCP/IP.
В версии
MIB-II (RFC 1213), принятой в 1992 году, был существенно (до 185) расширен набор
стандартных объектов, а число групп увеличилось до 10.
2. Агенты
RMON
Новейшим
добавлением к функциональным возможностям SNMP является спецификация RMON,
которая обеспечивает удаленное взаимодействие с базой MIB. До появления RMON
протокол SNMP не мог использоваться удаленным образом, он допускал только
локальное управление устройствами. База RMONMIB обладает улучшенным набором
свойств для удаленного управления, так как содержит агрегированную информацию
об устройстве, что не требует передачи по сети больших объемов информации.
Объекты RMONMIB включают дополнительные счетчики ошибок в пакетах, более гибкие
средства анализа графических трендов и статистики, более мощные средства
фильтрации для захвата и анализа отдельных пакетов, а также более сложные
условия установления сигналов предупреждения.
Агенты
RMONMIB более интеллектуальны по сравнению с агентами MIB-I или MIB-II и
выполняют значительную часть работы по обработке информации об устройстве,
которую раньше выполняли менеджеры. Эти агенты могут располагаться внутри
различных коммуникационных устройств, а также быть выполнены в виде отдельных
программных модулей, работающих на универсальных ПК и ноутбуках (примером может
служить LANalyzerNovell).
Объекту
RMON присвоен номер 16 в наборе объектов MIB, а сам объект RMON объединяет 10
групп следующих объектов:
·
Statistics – текущие накопленные статистические данные о
характеристиках пакетов, количестве коллизий и т.п.
·
History – статистические данные, сохраненные через определенные
промежутки времени для последующего анализа тенденций их изменений.
·
Alarms – пороговые значения статистических показателей, при
превышении которых агент RMON посылает сообщение менеджеру.
·
Host – данных о хостах сети, в том числе и об их MAC-адресах.
·
HostTopN – таблица наиболее загруженных хостов сети.
·
TrafficMatrix – статистика об интенсивности трафика между каждой
парой хостов сети, упорядоченная в виде матрицы.
·
Filter – условия фильтрации пакетов.
·
PacketCapture – условия захвата пакетов.
·
Event – условия регистрации и генерации событий.
Данные
группы пронумерованы в указанном порядке, поэтому, например, группа Hosts имеет
числовое имя 1.3.6.1.2.1.16.4.
Десятую
группу составляют специальные объекты протокола TokenRing.
Всего
стандарт RMONMIB определяет около 200 объектов в 10 группах, зафиксированных в
двух документах – RFC 1271 для сетей Ethernet и RFC 1513 для сетей TokenRing.
Отличительной
чертой стандарта RMONMIB является его независимость от протокола сетевого
уровня (в отличие от стандартов MIB-I и MIB-II, ориентированных на протоколы
TCP/IP). Поэтому, его удобно использовать в гетерогенных средах, использующих
различные протоколы сетевого уровня.
3.
Анализаторы протоколов
В ходе
проектирования новой или модернизации старой сети часто возникает необходимость
в количественном измерении некоторых характеристик сети таких, например, как
интенсивности потоков данных по сетевым линиям связи, задержки, возникающие на
различных этапах обработки пакетов, времена реакции на запросы того или иного
вида, частота возникновения определенных событий и других характеристик.
Для этих
целей могут быть использованы разные средства и прежде всего – средства
мониторинга в системах управления сетью, которые уже обсуждались в предыдущих
разделах. Некоторые измерения на сети могут быть выполнены и встроенными в
операционную систему программными измерителями, примером тому служит компонента
ОС WindowsNTPerformanceMonitor. Даже кабельные тестеры в их современном
исполнении способны вести захват пакетов и анализ их содержимого.
Но
наиболее совершенным средством исследования сети является анализатор
протоколов. Процесс анализа протоколов включает захват циркулирующих в сети
пакетов, реализующих тот или иной сетевой протокол, и изучение содержимого этих
пакетов. Основываясь на результатах анализа, можно осуществлять обоснованное и
взвешенное изменение каких-либо компонент сети, оптимизацию ее
производительности, поиск и устранение неполадок. Очевидно, что для того, чтобы
можно было сделать какие-либо выводы о влиянии некоторого изменения на сеть,
необходимо выполнить анализ протоколов и до, и после внесения изменения.
Анализатор
протоколов представляет собой либо самостоятельное специализированное
устройство, либо персональный компьютер, обычно переносной, класса Notebook,
оснащенный специальной сетевой картой и соответствующим программным
обеспечением. Применяемые сетевая карта и программное обеспечение должны
соответствовать топологии сети (кольцо, шина, звезда). Анализатор подключается
к сети точно также, как и обычный узел. Отличие состоит в том, что анализатор
может принимать все пакеты данных, передаваемые по сети, в то время как обычная
станция – только адресованные ей. Программное обеспечение анализатора состоит
из ядра, поддерживающего работу сетевого адаптера и декодирующего получаемые данные,
и дополнительного программного кода, зависящего от типа топологии исследуемой
сети. Кроме того, поставляется ряд процедур декодирования, ориентированных на
определенный протокол, например, IPX. В состав некоторых анализаторов может
входить также экспертная система, которая может выдавать пользователю
рекомендации о том, какие эксперименты следует проводить в данной ситуации, что
могут означать те или иные результаты измерений, как устранить некоторые виды
неисправности сети.
Несмотря
на относительное многообразие анализаторов протоколов, представленных на рынке,
можно назвать некоторые черты, в той или иной мере присущие всем им:
·
Пользовательский интерфейс. Большинство
анализаторов имеют развитый дружественный интерфейс, базирующийся, как правило,
на Windows или Motif. Этот интерфейс позволяет пользователю: выводить
результаты анализа интенсивности трафика; получать мгновенную и усредненную
статистическую оценку производительности сети; задавать определенные события и
критические ситуации для отслеживания их возникновения; производить
декодирование протоколов разного уровня и представлять в понятной форме
содержимое пакетов.
·
Буфер захвата. Буферы различных анализаторов
отличаются по объему. Буфер может располагаться на устанавливаемой сетевой
карте, либо для него может быть отведено место в оперативной памяти одного из
компьютеров сети. Если буфер расположен на сетевой карте, то управление им
осуществляется аппаратно, и за счет этого скорость ввода повышается. Однако это
приводит к удорожанию анализатора. В случае недостаточной производительности
процедуры захвата, часть информации будет теряться, и анализ будет невозможен.
Размер буфера определяет возможности анализа по более или менее
представительным выборкам захватываемых данных. Но каким бы большим ни был
буфер захвата, рано или поздно он заполнится. В этом случае либо прекращается
захват, либо заполнение начинается с начала буфера.
·
Фильтры. Фильтры позволяют управлять
процессом захвата данных, и, тем самым, позволяют экономить пространство
буфера. В зависимости от значения определенных полей пакета, заданных в виде
условия фильтрации, пакет либо игнорируется, либо записывается в буфер захвата.
Использование фильтров значительно ускоряет и упрощает анализ, так как
исключает просмотр ненужных в данный момент пакетов.
·
Переключатели – это задаваемые оператором
некоторые условия начала и прекращения процесса захвата данных из сети. Такими
условиями могут быть выполнение ручных команд запуска и остановки процесса
захвата, время суток, продолжительность процесса захвата, появление
определенных значений в кадрах данных. Переключатели могут использоваться
совместно с фильтрами, позволяя более детально и тонко проводить анализ, а
также продуктивнее использовать ограниченный объем буфера захвата.
·
Поиск. Некоторые анализаторы
протоколов позволяют автоматизировать просмотр информации, находящейся в
буфере, и находить в ней данные по заданным критериям. В то время, как фильтры
проверяют входной поток на предмет соответствия условиям фильтрации, функции
поиска применяются к уже накопленным в буфере данным.
Методология
проведения анализа может быть представлена в виде следующих шести этапов:
1.
Захват данных.
2.
Просмотр захваченных данных.
3.
Анализ данных.
4.
Поиск ошибок. (Большинство анализаторов облегчают эту работу, определяя
типы ошибок и идентифицируя станцию, от которой пришел пакет с ошибкой.)
5.
Исследование производительности. Рассчитывается коэффициент
использования пропускной способности сети или среднее время реакции на запрос.
6.
Подробное исследование отдельных участков сети. Содержание этого
этапа конкретизируется по мере того, как проводится анализ.
Обычно
процесс анализа протоколов занимает относительно немного времени – 1-2 рабочих
дня.
Скачать материал
Выбранный для просмотра документ lk7_mdk_03_01_Autsorsing_setevoy_infrastruktury.docx
Аутсорсинг
сетевой инфраструктуры
Аутсорсинг.
Многообразие
прикладных систем, оборудования, бизнес-приложений и IT-сервисов в современных
компаниях увеличивается с каждым днем. Организации понимают значимость
качественной работы IT-подразделений по предоставлению IT-услуг, поэтому
стремятся сохранить и застраховать инвестиции в IT.
Основные
причины для перехода компании на аутсорсинг:
Сокращение
издержек на сопровождение сетевой инфраструктуры. Передача
второстепенных функций поставщику услуг IT-аутсорсинга позволяет управляющему
персоналу сконцентрироваться на задачах, имеющих для компании первостепенное
значение, и за счет этого добиться конкурентных преимуществ.
Повышение
качества обслуживания. Передача всех функций
технической поддержки и сопровождения единому поставщику позволяет
стандартизировать обслуживание и гарантировать высокий уровень качества работ.
Снижение
рисков в проектах. При расширении или модернизации
IT-инфраструктуры, внедрении IT-сервисов и бизнес-приложений профессионалами
узкой специализации, занимающихся только конкретными направлениями, риски
гораздо ниже, нежели при использовании специалистов«широкого» профиля.
В рамках
аутсорсинга принимаются на обслуживание как отдельные элементы ЛВС, так и
вся сетевую инфраструктура компании.
Существует
типовой список работ в разных областях обслуживания сетевой инфраструктуры
компании (см. таблицу).
|
Область |
Типовой |
|
Комплексное |
Обнаружение |
|
Сопровождение |
Настройка |
|
Сопровождение |
Подключение |
|
Сопровождение |
Настройка |
|
Сопровождение |
Подключение |
|
Сопровождение |
Изменение |
|
Сопровождение |
Настройка |
Возможные
услуги по аутсорсингу:
Безлимитное
абонентское обслуживание
В
распоряжение заказчика предоставляются квалифицированные IT-специалисты,готовые
выполнить работы по согласованным направлениям. В зависимости от потребностей
заказчика, предлагаются следующие варианты организации службы поддержки:
·
Телефонные консультации, удаленное администрирование;
·
Выезд в офис заказчика по заявкам. Гарантированное время
прибытия специалистов на территорию заказчика (например, не позднее, чем через
4 часа после подачи заявки) предварительно оговаривается в договоре на
обслуживание;
·
Регулярный выезд специалистов по поддержке в офис заказчика с
целью выполнения профилактических работ.
Стоимость
услуг на безлимитное абонентское обслуживание рассчитывается исходя из объема
предоставляемых услуг, и зависит от количества оборудования, передаваемого на
сопровождение.
Преимущество
варианта заключается в том, что заказчик имеет неограниченное
количество обращений и вызововIT-специалистов.
Стандартное
абонентское обслуживание
В отличие
от безлимитного обслуживания, стандартное ограничено фиксированным количеством
обращений в месяц. Остальные условия сотрудничества сохраняются.
Стоимость
услуг на стандартное абонентское обслуживание рассчитывается исходя из
фиксированного количества обращений к инженерам. Дополнительно оплачиваются
обращения и вызовы IT-специалистов сверх установленного лимита.
Преимущество
варианта заключается в более низкой стоимости сравнительно с
безлимитным обслуживанием.
Скачать материал
Выбранный для просмотра документ lk8-9-10-11_mdk_03_01_Proverka_i_profilaktika_setevykh_obektov.doc
Проверка и профилактика
сетевых объектов
Проведение резервирования
и обслуживание сетей
Резервирование в технике
связи в общем случае применяется с целью увеличения надежности функционирования
сети. Наличие резервных трактов передачи информации дополнительно увеличивает
также гибкость кабельной системы. Резервирование всего комплекса технических
средств структурированной проводки предусмотрено на уровне основных нормативных
документов (стандарт ISO/ IEC 11801 : 2002).
Способы и системы
переключения на резерв. Разработаны различные системы переключения на резерв
для кабельных, волноводных и радиорелейных линий связи, отличающиеся
функциональными особенностями, скоростью переключения и т.п. Системы
переключения по способу резервирования могут быть разделены: а) на системы
переключения на резервный тракт; б) системы переключения на обходные пути. При
создании сетей в ряде случаев применяют оба способа одновременно.
Использование особенностей
обеих систем переключения, взаимно дополняющих одна другую, ведет к повышению
надежности сетей передачи. Переключение на обходные пути применяется
в том случае, когда возникает необходимость устранения повреждений нескольких
линейных трактов, например возникающих из-за полного повреждения всех пар
кабеля. При этом функции поврежденных ветвей сети и линейных трактов принимают
на себя другие ветви сети и другие линейные тракты. Если применять переключение
на обходные пути, то после завершения создания разветвленных сетей можно,
пользуясь переключением на обходные пути, осуществлять управление загрузкой
сети для усреднения трафика по обходным путям и по видам загрузки.
Эти функции управления
приближаются по характеру к функциям коммутации; их можно рассматривать также
как средство сопряжения передачи и коммутации. Для высокоскоростной
коаксиальной линии, скорость передачи которой ограничивается возможностями
современной элементной базы, т.е. когда надежность системы в большей степени
определяется надежностью оборудования, наиболее целесообразно обеспечение
автоматического переключения на резервный линейный тракт. Для
систем, в которых надежность при сравнительно низкой скорости передачи в
большей степени будет определяться уже надежностью кабеля, может быть
достаточно только переключения на обходные пути. При проектировании системы переключения
на резервный тракт необходимо обеспечивать независимость всех участков
переключения.
На практике применяют три
вида переключений: а) автоматическое — вышедший из строя
рабочий тракт автоматически переключается на резервный; б) ручное — выполняется
с пульта управления при выполнении технических проверок; в) экспериментальное
— выполняется при проверке резервных трактов. По результатам
проведения исследований и проверок резервных трактов могут быть сделаны
следующие выводы:
- 1) переключение на
резерв следует выполнять в следующем порядке: автоматическое, ручное,
экспериментальное; - 2) целесообразно
производить переключение на резерв одновременно трактов прямого и
обратного направления, даже если повреждение обнаружено только в одном из
них; - 3) с целью
уменьшения времени переключения собственно переключение необходимо
начинать с параллельной передачи информации по рабочему и резервному
трактам на передающем конце.
Сигналы о необходимости
автоматического переключения на резерв дублируются по нескольким рабочим
трактам, что повышает их достоверность. Одновременно с принятием решения о
переключении на резерв отказавшего тракта приостанавливается функционирование
переключающих элементов передающей станции, что предотвращает явление
распространения неисправности на последующие участки переключения.
Время переключения
трактов, в случаях когда в результате выхода из строя регенератора или
повреждения кабеля резко возрастает вероятность ошибок, определяется следующей
формулой:
![]()
где /он —
время обнаружения неисправности (несколько десятков микросекунд); — время
формирования сигнала о необходимости переключения (порядка 2 мс); /зап, tC4, /пер —
время записи, считывания и передачи (порядка 1 мс на 280 км) сигналов о
необходимости переключения; / /прм —
время срабатывания переключающих элементов на передающем и приемном концах
участка переключения.
В тех случаях, когда в
результате старения или по каким-либо другим причинам вероятность ошибок
возрастает постепенно, время переключения определяется как Гпер ~
/прм. Последний результат важен с
точки зрения организации высокоскоростных систем передачи данных по
широкополосным цифровым трактам, когда недопустима потеря (при переключении) какого-либо
одного информационного символа или массива данных.
Резервирование кабельных
систем.
Стандарт ISO/1ЕС 11801 :
2002 в явном виде допускает прокладку резервных кабелей в области магистральных
подсистем только между техническими помещениями одного уровня. Какие-либо
запреты на подключение к техническим помещениям более высокого уровня в этом и
других нормативных документах отсутствуют, поэтому задача увеличения надежности
кабельной системы и сети в целом может быть решена двумя способами, каждый из которых
может иметь два основных варианта, показанных на рис. 2.1.

Рис. 2.1. Варианты
организации резервных связей между двумя техническими помещениями различных
уровней
Первый способ
не предполагает прохождения линейных кабелей через другие технические помещения
(ТП). Это может быть как прямое увеличение емкости кабелей, соединяющих два
различных ТП, так и прокладка резервных кабелей по пространственно разнесенным
трассам, как показано на рис. 2.1, а, б. Характерным
отличительным признаком второго способа является ввод линейных
кабелей, образующих тракт передачи сигнала, в одно или несколько дополнительных
ТП. Варианты реализации в этом случае появляются из-за того, что резервный
тракт может организовываться через техническое помещение того же уровня, что и
один из связываемых узлов, или не заходить в него (рис. 2.1, в, г).
Резервирование систем
оптической связи
[И9]. Высокий уровень
надежности современных сетей оптической связи обеспечивается реализацией
комплекса различных мер, среди которых ключевыми являются средства полного или
частичного восстановления связи в аварийных ситуациях. Этим целям эффективно
служит резервирование — целенаправленное введение в систему определенной
избыточности с целью увеличения степени связности отдельных ее узлов, т.е.
количества независимых путей передачи информации.
Волоконная оптика и
оптоэлектроника находят широкое применение при построении всех уровней сетей
электросвязи: магистральных линий междугородной и городской связи; сетей
доступа и структурированных кабельных систем. Ввиду важности задач, решаемых с
их помощью, к надежности предъявляются очень высокие требования. При этом
под надежностью понимается способность поддерживать передачу
информации с заданной скоростью и с заданной достоверностью в течение
требуемого промежутка времени. Варианты повышения надежности сети с
привлечением резервирования неизбежно связаны с дополнительными материальными
затратами. Поэтому выбор наиболее эффективного варианта резервирования имеет
важное прикладное значение как с технической, так и с экономической точки
зрения.
Линейное резервирование.
Аварийные ситуации в линейной части сети в большинстве случаев возникают из-за
механических повреждений (обрывов) оптического волокна, поэтому очевидным
решением этой проблемы является увеличение количества доступных физических
трактов передачи, на которые будет осуществляться переключение при
возникновении неисправности. Технически это достигается наращиванием числа
световодов свыше минимально необходимого значения. Данный прием получил
название линейного резервирования.
В простейшем случае
резервные волокна выделяются в том же кабеле, что и основные. Общая надежность
сети, однако, существенно возрастает, если волокна основного и дополнительного
трактов находятся в различных кабелях, проложенных, кроме того, по различным
маршрутам для минимизации риска одновременного выхода из строя. Ясно, что
данный вид резервирования сети ведет к увеличению затрат на его реализацию.
Линейное резервирование
может быть организовано по схемам 1 + 1 и 1:1. При использовании схемы 1 +1
информация передается одновременно по основному и резервному трактам. На
принимающей стороне выбирается сигнал с наилучшими качественными показателями. Обычно
таковым считается тот из них, который имеет более высокий уровень, так как
выбор между двумя сигналами с различной мощностью не представляет каких-либо
технических проблем.
Использование схемы 1:1
показано на рис. 2.2. «Резервная линия» здесь при нормальном режиме работы не
передает трафик, но всегда готова взять на себя его передачу, т.е. находится в
режиме горячего резерва. Переключение на резерв осуществляется
по аварийному сигналу, который система управления подает при полной потере
связи или превышении предопределенного предела частоты появления битовых
ошибок. Длительность переключения имеет порядок десятков миллисекунд и
определяется стандартом для конкретного вида сети.

Рис. 2.2. Линейное
резервирование участка сети по схеме 1:1: а — нормальный
режим; б — режим использования резерва
После завершения ремонта
поврежденного участка обычно восстанавливается первоначальная конфигурация
сети. Кроме применения схемы 1:1 (100%-е резервирование), допустима организация
резервирования по схеме т : N, когда на iV
основных цепей передачи приходится т резервных. В случае т
< N резервирование уже не является 100%-м. В данной ситуации
резервируются только те оптические тракты, по которым осуществляется передача
сигналов наиболее значимых информационных сервисов.
Системное резервирование.
Организация системного резервирования в оптической сети предполагает
одновременное введение: а) дополнительных волокон в линейную часть; б) блоков в
активное приемо-передающее оборудование на узлах сети. Если на основном
направлении передачи повреждаются световоды или происходит отказ узловой
сетевой аппаратуры, то выполняется переключение на резервное направление.
Системное резервирование может быть организовано по схемам 1+1, 1:1 или т : N (1
: N — как частный случай).
При прочих равных условиях
наиболее предпочтительной представляется схема 1+1, поскольку она обеспечивает
практически непрерывную передачу сигнала даже в момент отказа. Схема работы
участка сети с системным резервированием по схеме 1:1 в нормальном режиме и при
выходе из строя основного тракта передачи показана на рис. 2.3. Участок сети
«приемо-передатчики Ли В + основной тракт», передающий в
нормальном режиме трафик между точками S и R сети,
резервируется трактом, «приемо-передатчики А + В1 + резервный
тракт», находящимся в состоянии «горячий резерв»
(рис. 2.3, а). При
отказе любого объекта основного тракта система практически мгновенно переходит
в режим использования резерва, показанный на рис. 2.3, б, передачу
трафика между точками S и R сети берет на
себя резервный участок сети, образованный приемопередатчиками А1
и В и световодом «Резервный тракт».
Системное резервирование
обеспечивает высокую надежность связи, однако этот вариант требует значительных
материальных затрат. В то же время возможность увеличения пропускной
способности сети за счет использования резервных ресурсов при отсутствии
отказов может оправдать необходимые вложения.

Рис. 2.3. Системное
резервирование участка S—R сети: а —
нормальный режим; б — режим использования резерва
Каждый из вышеописанных
вариантов резервирования обладает определенными преимуществами и недостатками,
от которых зависит его применение на различных участках сети связи. Как
правило, наибольшей эффективности резервирования позволяет добиться
использование различных комбинаций рассмотренных выше способов.
Наиболее требовательными к
надежности связи являются транспортные сети: нарушение их работоспособности
приводит к отсутствию или недопустимо низкому качеству связи для большого
количества абонентов. Поэтому резервирование должно быть организовано с
максимально возможной эффективностью. Обычно резервируются как линии связи, так
и приемо-передающее оборудование, т.е. используется системное резервирование.
В оптических кабельных
подсистемах, как правило, используется линейное резервирование. В простейшем
случае увеличивают количество волокон рабочих кабелей, предназначенных для
организации резервных каналов. Более эффективным, но и более дорогим способом
является прокладка нескольких пространственно разнесенных кабелей. На уровне
подсистемы внутренних магистралей они проходят по различным стоякам.
Системное резервирование
требует обращения к нескольким уровням информационной системы. Его практическая
реализация облегчается за счет того, что современное сетевое оборудование
обычно имеет два или более магистрального порта (up-link), а
также поддерживает автоматическое восстановление связи с привлечением
стандартного протокола Spanning Tree и его быстродействующего
варианта Rapid Spanning Tree. В необходимых случаях в
сетях Ethernet организуются кольцевые структуры с аппаратным
восстановлением нормальной связи в течение не более 20—50 мс.
Кроме того, в кабельных
сетях в случае трактов длиной не более 90 м, предназначенных для поддержки
функционирования сетевого оборудования, может применяться так называемое
неоднородное резервирование. Фактически это означает, что основные линии
оптической связи резервируются линиями из витых пар. Большинство видов
современных коммутаторов ЛВС поддерживают автоматический переход с одного типа
среды передачи на другой за счет привлечения протоколов Spanning Tree и Rapid
Spanning Tree. Именно поэтому данный вариант резервирования
встречается довольно часто.
Обслуживание технических
компонентов ЛВС предполагает проведение мероприятий: а) по организации
технического обслуживания технических компонентов ЛВС; б) обеспечению
надежности магистральных трактов передачи информации в сетях.
Комплекс мероприятий по
организации технического обслуживания компонентов ЛВС можно разделить на три
вида: а) индивидуальное ТО; б) групповое ТО; в) централизованное ТО.
При индивидуальном
обслуживании обеспечивается обслуживание одного технического ОСИС
(например, сервера) силами и средствами персонала отдела. При этом виде
обслуживания предполагается проведение регламентных работ, контроль
технического состояния, проведение ремонтно-восстановительных работ с помощью
аппаратуры и оборудования вычислительного центра.
Групповой
сервис служит для проведения технического обслуживания нескольких
ОСИС (серверов, кабельной системы и др.), сосредоточенных в едином
вычислительном центре, силами и средствами его персонала. Как при
индивидуальном, так и при групповом обслуживании используется следующий набор
оборудования [10]:
- • аппаратура
контроля элементной базы и электропитания; - •
контрольно-наладочная аппаратура для автономной проверки
ОСИС;
• комплект
радиоизмерительной аппаратуры;
- • комплект
программ с тестами; - • вспомогательное
оборудование, инструмент.
Централизованное
обслуживание представляется сетью региональных центров обслуживания и
их филиалов — пунктов технического обслуживания. Эти организации осуществляют:
- • наладочные
работы и ввод в эксплуатацию сетевых объектов; - • устранение
сложных отказов в процессе эксплуатации (например, централизованное
восстановление элементов и узлов сервера); - • оказание
технической помощи и обучение персонала; - • выполнение
профилактических работ.
При централизованном
обслуживании сокращаются расходы на технический персонал, но увеличивается
время на восстановление работоспособности. В настоящее время чаще всего
применяют сочетание всех трех типов обслуживания.
В процессе эксплуатации
сетевое оборудование подвергается следующим операциям ТО:
- • хранение,
установка, наладка, ввод в эксплуатацию; - • обслуживание при
нормальной работе; - •
планово-профилактические работы и устранение неисправностей; - • обслуживание
информационных баз и ПО.
Все мероприятия по ТО,
включая перечисленные операции, можно разделить на группы: а) контроль
технического состояния; б) профилактическое обслуживание; в) текущее
техническое обслуживание.
Контроль
технического состояния служит для оперативной
диагностики процессора, каналов связи и т.д. и осуществляется сервером сети при
пуске и в процессе функционирования при возникновении сбоя.
Профилактическое
ТО — это мероприятия, направленные на поддержание исправного
технического состояния машины в течение определенного промежутка времени и
продление ее технического ресурса. С точки зрения организации ТО наибольшее
распространение получило так называемое планово-предупредительное обслуживание,
основанное на календарном принципе. При этом составляется график проведения
регламентных работ, в котором указываются сроки и объемы профилактических
мероприятий. Во многих современных системах этот принцип заложен во
вспомогательном ПО системы.
Текущее
ТО — это комплекс настроечных и ремонтных работ, направленных
на устранение возникающих неполадок и восстановление работы сетевого
оборудования.
Рациональная организация
системы ТО является одним из главных средств обеспечения эффективного
использования сетевого оборудования.
Отдельно остановимся на
вопросе ТО существующей ЛВС. Эта задача является актуальной, если при переезде
в новый офис старый арендатор оставил после себя кабельную систему, которую
новый владелец собирается использовать в собственных целях без значительных
капиталовложений. Технический осмотр в этом случае должен включать следующие
этапы:
- • технический
осмотр телекоммуникационного оборудования; - • восстановление
схемы существующей ЛВС; - • проверка всех
элементов на пригодность к эксплуатации; - • проведение
комплексной проверки и тестирования оборудования и кабельной системы ЛВС.
Невыполнение работ хотя бы
по одному из перечисленных пунктов приведет к тому, что смонтированная сеть
будет неработоспособна частично или полностью, дефекты монтажа могут проявиться
во время эксплуатации и нарушить нормальную работу организации, причем затраты
на исправление дефектов могут достигать стоимости монтажа новой системы.
Перед тем как начать
использовать ЛВС в таком офисе, необходимо провести полный аудит компьютерной
сети, чтобы избежать возможных проблем при наладке и дальнейшей эксплуатации.
Генеральным подрядчикам аудит ЛВС необходим для того, чтобы была возможность
убедиться в качестве работ субподрядчика и иметь основание для приемки таких
работ.
Полный перечень работ по
аудиту ЛВС включает следующие этапы:
- • проведение
комплексного технического осмотра ЛВС; - • осмотр и
тестирование кабельных линий; - • маркировка
компонентов ЛВС; - • составление
технической документации; - • составление и
выдача технического заключения; - • устранение
неисправностей и модернизация.
Перечень работ по
техническому обслуживанию ЛВС:
- • проверка
работоспособности приборов и аппаратуры ЛВС; - • оценка
деградации волокон в волоконно-оптическом сегменте ЛВС; - • проверка
состояния гибких соединений (переходов); - • аудит основных и
резервных источников питания; - • проверка общей
работоспособности ЛВС и комплекса в целом;
- • выявление,
сокращение числа и устранение неисправностей в сети; - • ликвидация
последствий воздействия на сеть внешних условий. Обеспечение надежности
кабельных систем ЛВС. Фундаментальной основой любой ЛВС, обеспечивающей
передачу сигналов всех типов, является ее структурированная
кабельная система (СКС), под которой понимается физическая основа
инфраструктуры здания, объединяющая следующие информационные сервисы ЛВС
[И9]: - • электросиловая
сеть и освещение; - • компьютерная
сеть и /Р-телефония; - • система контроля
и управления доступом; - • система пожарной
сигнализации и пожаротушения; - • системы охранных
датчиков и видеонаблюдения; - • аудиосистема
(системы оповещения и радио).
ЛВС объединяет телефоны,
компьютеры и другое оборудование. Каждая точка подключения обеспечивает доступ
ко всем ресурсам сети, поэтому на каждом рабочем месте достаточно двух линий —
компьютерной и телефонной, которые могут быть взаимозаменяемы.
В основе построения СКС
лежат принципы структуризации, универсальности, избыточности, надежности,
гибкости, экономичности и долговечности. Рассмотрим их содержание.
Структуризация. Кабельная
проводка и ее составляющие разбиваются на отдельные подсистемы. Каждая
подсистема выполняет определенные функции и имеет связь с другими подсистемами
и другими ОСИС. Каждая подсистема должна иметь средства переключения,
позволяющие легко изменять конфигурацию системы. При построении системы могут
использоваться различные виды кабеля и коммутационного оборудования в
зависимости от условий конкретного проекта.
Универсальность. Кабельная
система строится по принципам открытой архитектуры с техническими
характеристиками, определенными в стандартах. Параметры электрических и
оптических кабельных трасс подсистем и их интерфейсов указываются в нормативной
документации. Таким образом, кабельная система может использоваться для
передачи сигналов различных приложений посредством кабелей всего двух типов —
витой пары и оптоволокна. Коммутация подсистем СКС друг с другом и с активным
сетевым оборудованием осуществляется определенным набором шнуров с
универсальными разъемами, что облегчает администрирование кабельной системы и
адаптацию ее к различным приложениям.
Избыточность. С
КС предусматривает возможность расширения — ее топология и оборудование
обеспечивают возможность увеличения количества подключаемого оборудования и
объема трафика. Все оборудование СКС выбирается с резервом по
производительности, возможности установки дополнительных модулей и расширению
функциональности.
Надежность. Производители
СКС гарантируют работоспособность и соответствие кабельной системы стандартам
на протяжении всего срока службы. В случае аварии в СКС быстро локализуется неисправный
участок, выполняется переход на резервную линию и проводятся ремонтные работы.
Восстановление работы СКС осуществляется без остановки работы сети только
силами ее администратора.
Гибкость. Функционирующая
СКС без изменения кабельной системы и без дополнительных затрат предоставляет
следующие возможности:
- • модификация
программно-аппаратного комплекса; - • управление
перемещением пользователей в здании; - • изменение
количества пользователей; - • разделение
пользователей на группы по различным признакам.
Экономичность. Крупные
первичные вложения в СКС обычно
быстро окупаются за счет
меньших затрат на модификацию и поддержку телекоммуникационной инфраструктуры.
Срок эксплуатации СКС значительно больше времени жизни других компонентов
информационной системы (активное сетевое оборудование, серверы и персональные
компьютеры, ПС, телефонные станции и коммуникационное оборудование и т.д.).
Долговечность. СКС
обеспечит постепенный переход к высокоскоростным протоколам, которые будут
работать на перспективу, простой заменой активного оборудования; при этом не
потребуется реконструкция кабельной системы. Технологический запас
характеристик и стандарты СКС гарантируют, что моральное устаревание кабельной
проводки случится не раньше срока, когда закончится ее системная гарантия (у
большинства производителей он составляет 20 лет).
В структурном плане СКС
представляет собой кабельную систему здания (группы зданий) иерархического
типа, которая состоит из структурных подсистем, показанных на рис. 2.4.
Структура СКС включает: этажный (ЭРП), главный (ГРП) и промежуточный (ПРП)
распределительные пункты, каждый из которых имеет определенную топологию и
состав компонентов. Для каждого типа подсистем в стандартах определены
требования, ограничения и правила. Кабельные подсистемы СКС:
- • магистральная
подсистема I уровня (МП-1); - • магистральная
подсистема II уровня (МП-2); - • горизонтальная
подсистема (Г П).

Рис. 2.4. Подсистемы
структурированной кабельной системы
Магистральная
подсистема I уровня располагается между главным и
промежуточным распределительными пунктами, а также между главным
распределительным пунктом и этажным распределительным пунктом. Данная
подсистема включает: а) магистральные кабели 1 -го уровня; б) распределительные
устройства, используемые для магистрального кабеля 1-го уровня; в)
коммутационные перемычки и шнуры, которые используются для коммутации в главном
распределительном пункте.
Магистральная
подсистема II уровня, отделяемая от магистральной
подсистемы I уровня промежуточным распределительным пунктом, включает: а)
магистральные кабели 2-го уровня; б) распределительные устройства, используемые
для магистрального кабеля 2-го уровня; в) коммутационные перемычки и шнуры, которые
используются для коммутации в промежуточной распределительной точке.
Горизонтальная
подсистема, находящаяся между распределительными устройствами этажного
распределительного пункта и телекоммуникационными розетками, включает: а)
горизонтальные кабели; б) распределительные устройства, используемые для
горизонтальных кабелей; в) коммутационные перемычки и шнуры, которые
используются для коммутации с этажным распределительным пунктом; г)
телекоммуникационные розетки и консолидационные точки.
СКС включает следующее
оборудование: телекоммуникационные и серверные шкафы; кабели и проволочные
лотки; патч-панели и кросс-панели; электрощетки; конвекторы; компьютерные и
телефонные розетки.
СКС создается во время
строительства здания или переоборудования помещений, и при этом гарантированный
срок эксплуатации составляет не менее 10 лет.
Организация удаленного
оповещения
Любая сложная
вычислительная сеть требует дополнительных специальных средств контроля
состояния аппаратного обеспечения помимо тех, которые имеются в стандартных
сетевых ОС. Это связано с большим количеством разнообразного коммуникационного
оборудования зачастую различных производителей, работа которого критична для
выполнения сетью своих основных функций. Распределенный характер крупной
корпоративной сети делает невозможным поддержание ее работы без централизованной
системы контроля и управления, которая в автоматическом режиме
собирает информацию о состоянии каждого концентратора, коммутатора,
мультиплексора и маршрутизатора и предоставляет эту информацию оператору сети.
Обычно система контроля
состояния аппаратного обеспечения работает в автоматизированном режиме,
выполняя наиболее простые действия по сбору данных о сетевом оборудовании
автоматически. Сложные решения принимает администратор сети на основе
подготовленной системой информации. Обычно система управления является интегрированной, в
которой функции управления разнородными устройствами служат общей цели
обслуживания конечных пользователей сети с заданным качеством [ИЮ].
Для целей контроля обычно
используется набор сетевых программных модулей (утилит), каждый из которых
«следит» за состоянием отдельного устройства и/или группы однотипных устройств.
Например, анализ технического состояния дисковых устройств можно производить с
помощью утилит, обращающихся к устройствам, используя технологию S.M.A.R.T (Self
Monitoring Analyzing and Reporting Technology). Данная
технология позволяет пользователю своевременно выявлять проблемы блока
магнитных головок, а также проблемы повреждения дисков. После инсталляции пакет
работает как фоновая задача, которая периодически проводит тесты оборудования и
высылает на почтовый ящик администратора уведомления о состоянии дисковых
устройств.
Известны отечественные
разработки в области анализа программного и аппаратного обеспечения сетевого
оборудования, известные как сетевые сканеры. Рассмотрим
функциональные возможности одной из таких систем — «Ревизор Сети» версии 2.0
[ИЮ]. Объектами ее исследования являются компьютеры, серверы, коммутационное
оборудование, межсетевые экраны и другие узлы сети, имеющие IP-адреса.
«Ревизор Сети» предназначен для использования администраторами и службами
информационной безопасности вычислительных сетей в целях обнаружения
уязвимостей установленного сетевого программного и аппаратного обеспечения,
использующего протоколы стека TCP/IP. В системе реализованы
различные категории проверок, функционально относящиеся к одному из двух
основных режимов работы ревизора: сбор информации о тестируемой сети и
сканирование уязвимостей сети. Наборы проверок позволяют проводить тестирование
наиболее распространенных сервисов {WEB, Mail, FTP, SNMP, RPC и
пр.), определение типов ОС, проверки типа «отказ в обслуживании», проверки
учетных записей и системного реестра Windows и др.
Наряду с необходимостью
оперативного управления сетевым оборудованием, часто возникают задачи
мониторинга и управления другими интеллектуальными системами —
электроснабжения, контроля доступа, пожаротушения и др., которые не имеют
собственных систем удаленного мониторинга и управления и требуют использования
выделенных линий. Выходом из такой ситуации может служить применение системы
удаленного управления наподобие 3-уровневой системы HPOpenView [И
11, И12] компании Hewlett-Packard, использующей стандартные
сетевые каналы и протоколы для управления указанными интеллектуальными
системами.
Более эффективным, но и
более дорогим способом организации контроля и удаленного оповещения о состояния
аппаратного обеспечения ОСИС является использование автоматизированной
системы диспетчеризации и управления в центрах обработки данных,
подобных [И 13], имеющих централизованное управление и применяющихся в крупных
организациях.
Центры обработки данных
отличают очень высокая надежность, управляемость и безопасность. Круглосуточный
мониторинг, комплексный анализ параметров сетевого оборудования, предупреждение
отказов и минимальное время реакции — важнейшие требования к диспетчерским
службам, контролирующим инженерные подсистемы центров обработки данных, для
чего привлекают специалистов из разных областей: электрики, вентиляции и
кондиционирования, обслуживания специального оборудования [11].
В структурном плане
автоматизированная система диспетчеризации и управления представляет целостную
платформу для управления всеми инженерными подсистемами и создается как
многоуровневая автоматическая система, обеспечивающая контроль состояния и
управление технологическим оборудованием центров обработки данных с выводом
данных на экраны рабочих мест операторов. Система ведет непрерывный мониторинг
инженерных систем с регистрацией основных параметров и обеспечивает контроль и
управление инженерным комплексом из единого диспетчерского центра.

Рис. 2.5.
Архитектура системы удаленного мониторинга
Современная система имеет
3-уровневую архитектуру, показанную на рис. 2.5. Первый уровень образуют
инженерное оборудование (ИО), контроллеры нижнего уровня (КНУ) и групповые
датчики (ГД), формирующие первичные данные. Второй уровень — сетевые контроллеры
(СК), принимающие и обрабатывающие информацию, и сеть передачи данных. Третий
(верхний) уровень — это аналитическое ПО, предоставляющее средства
визуализации, архивации и публикации поступающих данных. На автоматизированные
рабочие места диспетчеров (АРМ-Д) поступает структурированная информация о
рабочих параметрах системы. Аналитический модуль постоянно отслеживает рабочие
параметры систем на предмет отклонения от нормы и способен автоматически
запускать процедуры согласно заложенным инструкциям, например подать сигнал
тревоги или запустить аварийный источник питания. Важная задача аналитического
модуля — заблаговременные предупреждения о грядущих отказах.
Собранные данные можно: в)
передать операторам и представить их в легко читаемом виде; б) сохранить в базе
данных; в) проанализировать и представить в виде статистических отчетов; г)
использовать как управляющий сигнал при реакции на определенные события для
запуска систем в автоматическом режиме.
Инженерные системы центра
обработки данных состоят из множества взаимоувязанного оборудования, поэтому
при наступлении какого-либо тревожного события (например, проблема в контуре
питания, между распределительным щитом и активным сетевым оборудованием)
система автоматически локализует проблему, определяет уровень возможных
последствий и отображает информацию о конкретной системе в окне тревог. На
поиск и устранение подобных проблем «вручную» может потребоваться несколько
рабочих смен высококвалифицированного персонала. В автоматизированной же
системе экранная форма со схемой системы моментально показывает отношения между
взаимосвязанным оборудованием и возможными последствиями неполадок в отдельных
компонентах.
Выделение в системах
управления типовых групп функций и разбиение этих функций на уровни еще не дают
ответа на вопрос, каким же образом устроены системы управления, из каких
элементов они состоят и какие архитектуры связей этих элементов используются на
практике. Данный круг вопросов обсуждается в следующем разделе учебника.
Вопросы
для самоконтроля
- 1. Дайте
определение ТО. - 2. Перечислите
виды работ по техническому обслуживанию ОСИС. - 3. Актуальность и
цели профилактических проверок ОСИС. - 4. Назовите и
охарактеризуйте современные методы ТО сетей. - 5. Расскажите о
структуре статистического метода ТО. - 6. В чем суть
восстановительного метода ТО сетей? - 7. Для какой цели
применяется резервирование в технике связи? - 8. Назовите три
способа переключения на резерв. - 9. Из чего
складывается время переключения на резерв? - 10. Дайте
характеристику двум способам резервирования кабельных систем. - 11. Дайте
определение надежности ЛВС. - 12. Для какой цели
применяется резервирование магистралей ЛВС?
- 13. Дайте
характеристику способам линейного резервирования. - 14. Для какой цели
применяется системное резервирование в сетях? - 15. Дайте
характеристику трем видам ТО компонентов ЛВС. - 16. Назовите
операции ТО сетевого оборудования в процессе эксплуатации. - 17. Перечислите
мероприятия по ТО модернизируемой ЛВС. - 18. Мероприятия по
обеспечению надежности СКС. - 19. Расскажите о
централизованной системе управления сетью. - 20. Расскажите о
структуре автоматизированной системы диспетчеризации и управления ЛВС.
Скачать материал
Краткое описание документа:
Конспект лекций МДК 03.01 Эксплуатация объектов сетевой инфраструктуры для обучающихся специальности 09.02.02 Компьютерные сети 7 семестр
Найдите материал к любому уроку, указав свой предмет (категорию), класс, учебник и тему:
6 284 420 материалов в базе
- Выберите категорию:
- Выберите учебник и тему
- Выберите класс:
-
Тип материала:
-
Все материалы
-
Статьи
-
Научные работы
-
Видеоуроки
-
Презентации
-
Конспекты
-
Тесты
-
Рабочие программы
-
Другие методич. материалы
-
Найти материалы
Другие материалы
- 10.01.2021
- 494
- 24

- 10.01.2021
- 1572
- 84
- 10.01.2021
- 1273
- 20
- 10.01.2021
- 250
- 9

- 10.01.2021
- 450
- 28

- 10.01.2021
- 776
- 32

- 10.01.2021
- 434
- 11
- 10.01.2021
- 201
- 3
Вам будут интересны эти курсы:
-
Курс повышения квалификации «Облачные технологии в образовании»
-
Курс повышения квалификации «Сетевые и дистанционные (электронные) формы обучения в условиях реализации ФГОС по ТОП-50»
-
Курс повышения квалификации «Развитие информационно-коммуникационных компетенций учителя в процессе внедрения ФГОС: работа в Московской электронной школе»
-
Курс профессиональной переподготовки «Информационные технологии в профессиональной деятельности: теория и методика преподавания в образовательной организации»
-
Курс повышения квалификации «Специфика преподавания информатики в начальных классах с учетом ФГОС НОО»
-
Курс повышения квалификации «Применение MS Word, Excel в финансовых расчетах»
-
Курс повышения квалификации «Введение в программирование на языке С (СИ)»
-
Курс повышения квалификации «Специфика преподавания дисциплины «Информационные технологии» в условиях реализации ФГОС СПО по ТОП-50»
-
Курс повышения квалификации «Современные языки программирования интегрированной оболочки Microsoft Visual Studio C# NET., C++. NET, VB.NET. с использованием структурного и объектно-ориентированного методов разработки корпоративных систем»
-
Курс повышения квалификации «Применение интерактивных образовательных платформ на примере платформы Moodle»
Оставьте свой комментарий
Почему сетью необходимо управлять?
Сегодня крайне актуальным становится снижение издержек на содержание сети.
Корпорации строят разветвленные сети, но не в состоянии управлять сетью так,
как это требуется в отношении единой вычислительной среды предприятия. Исследования
показали, что затраты на добавление и перемещение оборудования и рабочих станций
в расчете на одно рабочее место в год в среднем составляют 500 долл., а потери
от простоев в расчете на одну сеть — 60 тыс. долл. в год. Установлено,
что 95% времени простоев — время, затраченное на нахождение повреждения (дефекта).
Простой сети уже сегодня грозит огромными потерями: некоторые американские компании
сообщают, что час простоя обоходится им в 0,5 млн. долл.
В области управления сетями еще очень много
вопросов. Необходимо отметить, что даже само
определение управления сетью — неконкретно.
Термин используется настолько широко, что может
трактоваться по-разному — как неискушенными
пользователями, изредка прибегающими к
файловому сервису Personal NetWare, так и
администраторами информационных систем,
развернутых на комплексе из нескольких
мэйнфреймов и использующих, например, IBM NetView. В
наиболее строгом смысле управление сетью —
это деятельность по поддержанию сети в
работоспособном состоянии. Она включает в себя
действия как с физическими компонентами сети
(начиная с кабеля), так и с программными.
В соответствии с трактовкой ISO можно выделить
пять функций управления сетью:
- Управление конфигурацией сети (configuration
management) включает в себя регистрацию
устройств, работающих в сети, их местоположение,
сетевые адреса и идентификаторы, управление
параметрами сетевых операционных систем,
поддержание схемы сети. - Управление ошибками (fault management) — это
выявление, определение и разрешение проблем в
работе сети. - Анализ эффективности (performance management)
помогает на основе накопленной статистической
информации оценивать время ответа системы и
величину трафика и планировать развитие сети. - Управление безопасностью (security management)
включает в себя контроль доступа и сохранение
целостности данных. В его функции входит
процедура аутентификации, проверка привилегий,
поддержка ключей шифрования, управление
полномочиями. К этой же группе можно отнести
важные механизмы управления паролями, внешним
доступом, соединения с другими сетями (именно
из-за недостатков в этих механизмах происходит
большинство вторжений в систему). - Учет работы сети (accounting management)
подразумевает регистрацию использования
ресурсов и устройств сети.
По материалам «Академии АйТи»
![]()
Подборка по базе: Законодательные механизмы обеспечения прав налогоплательщиков ко, Толпа. Психологические аспекты работы при большом скоплении люде, Курсовая. Правовые аспекты причинения вреда при вакцинопрофилакт, 1. Теоретические и прикладные аспекты методической работы учител, МЕТОДИЧЕСКИЕ АСПЕКТЫ РЕАЛИЗАЦИИ ЗАНЯТИЙ ПО 3D-МОДЕЛИРОВАНИЮ НА П, Теоретические аспекты делового общения.doc, Нормативно-правовые аспекты фитнес-услуг.pdf, Иконопись как специфический вид живописи. Основные эстетические , Содержание по эксплуатации.doc, ДОКЛАД Медико-социальные и психологические аспекты смерти 10_04_
- Логические (информационные) аспекты эксплуатации. Несанкционированное ПО, паразитная нагрузка.
Ответ: Логические аспекты работы ЛВС: Недопустимо использование несанкционированного ПО (непрошедшее надлежащих проверок по(возможно хранящая вирусы)) . Пользователи не должны использовать ЛВС для передачи другим компьютерам или оборудованию сети бессмысленной или бесполезной информации, создающей паразитную нагрузку на эти компьютеры или оборудование.
- Физические аспекты эксплуатации. Физическое вмешательство в инфраструктуру сети.
Ответ: физическое вмешательство в сетевую инфраструктуру обуславливается, самостоятельной проверкой со стороны сис. админа, всех элементов сети, чаще всего такого рода проверки производятся с использованием специальных инструментов мониторинга.
- Расширяемость сети. Масштабируемость сети. Добавление отдельных элементов сети (пользователей, компьютеров, приложений, служб);
Ответ: означает, что сеть позволяет наращивать количество узлов и протяженность связей в очень широких пределах, при этом производительность сети не ухудшается. Для обеспечения масштабируемости сети приходится применять дополнительное коммуникационное оборудование и специальным образом структурировать сеть.
- Техническая и проектная документация. Паспорт технических устройств; руководство по эксплуатации.
Ответ: Паспорт на техническое устройство — это документ, в котором имеется описание устройства и его технических характеристик, также в документе может присутствовать сведения о капитальном или текущих ремонтах, сроке службы. Руководство по эксплуатации технического устройства — это документ, в котором описан принцип работы устройства, его целевое применение, техническое обслуживание, текущий ремонт, хранение, порядок транспортировки, допустимые способы утилизации.
- Классификация регламентов технических осмотров, технические осмотры объектов сетевой инфраструктуры.
Ответ: а) профилактические проверки и измерения оборудования станции;
б) текущее обслуживание;
в) планово-предупредительный ремонт оборудования;
г) статистический учет технического состояния оборудования;
д) контроль за качеством работы.
6. Проверка объектов сетевой инфраструктуры и профилактические работы
Ответ: тоже что и в 5
- Проведение регулярного резервирования. Обслуживание физических компонентов.
Ответ: Резервирование в технике связи в общем случае применяется с целью увеличения надежности функционирования сети. Наличие резервных трактов передачи информации дополнительно увеличивает также гибкость кабельной системы.
- Эксплуатация технических средств сетевой инфраструктуры (принтеры, компьютеры, серверы, коммутационное оборудование)
Ответ: эксплуотация любых тех средств, включает в себя бережное обращение и соблюдение норм тех обслуживания
- Архитектура системы управления. Структура системы управления.
Ответ: Архитектура систем управления, представляет собой динамические методы изменяемые в зависимости от ситуации и необходимости, способные удовлетворить нужны различных предприятий Наиболее оптимальным подходом к созданию
системы управления предприятием микроэлектроники является интеграционный подход, построенный на статических и динамических моделях [46,47,50,58,96], позволяющих решать ряд задач, стоящих перед предприятиями отрасли.
- Удаленный доступ по телефонной линии; Авторизация подключений удаленного доступа.
Ответ: Для того чтобы получить доступ в Интернет или корпоративную сеть через телефонную сеть, модем пользователя должен выполнить вызов по одному из номеров, присвоенному модемам, находящимся на сервере удаленного доступа. После установления соединения между модемами в телефонной сети образуется канал с полосой пропускания около 4 кГц.
- Области управления ошибками; конфигурацией; доступом; производительностью; безопасностью.
Ответ: Управление производительностью — это вид сетевого управления, которое позволяет следить за нагрузкой сетевых узлов и устройств и, таким образом, находить узкие места в сети. Управление конфигурацией — доступ к редактируемой и настраиваемой
системе, позволяющей подогнать устройство под нужды пользователя. Управление доступом — программа позволяющая настраивать доступ к программам, файлам, данным и тд. Устройство безопасности — программа позволяющая обеспечить безопасность устройства от вредоносных программ хакеров и тд.
- Управление отказами. Выявление, определение и устранение последствий сбоев и отказов в работе сети.
Ответ: Для произведения управления отказами существует ряд программ, сканирующих и проверяющих систему. С помощью этих программ специалист может анализировать, вычислять и устранять возникающие ошибки, неполадки и отказы.
- Учет работы сети. Управление конфигурацией. Регистрация, управление используемыми ресурсами и устройствами.
Ответ: При создании любой сети, у нас есть возможность настройки ее конфигурации , таким образом мы задаем пароль, логин, лимитный трафик и тд, а так же можем ограничить доступ к этой сети для определенных пользователей.
- Оборудование для диагностики и сертификации кабельных систем Сетевые мониторы, приборы для сертификации кабельных систем, кабельные сканеры и тестеры.
Ответ: Существует огромный спектр устройств предназначенных для диагностики кабельных систем, такие устройства могут различаться по точности и качеству в зависимости от производителя. Кабельные сканеры — позволяют отследить непрерывность кабеля, и определить место сбоя. Кабельные тестеры – позволяют определить непрерывность кабеля, однако, в отличие от кабельных сканеров, не дают ответа на вопрос о том, в каком месте произошел сбой.
- Экспертные системы. Выявление причин аномальной работы сетей.
Ответ: экспертные системы, привлекаются для диагностики неисправностей на узлах ЛВС. Позволяют обнаружить причину возникновения неисправностей, если она связанна с программной или аппаратной частью.
- Хранилищ данных Принципы работы хранилищ данных. Принципы построения. Основные компоненты хранилища данных
Ответ: хранилища данных, это те же самые базы данных, слегка измененные и усовершенствованные.1 в отличие от бд, хд позволяют: не только изменять данные но и принимать решения.2 обычная бд подвержена постоянным изменениям,3 обычно бд, является источникомиз которого данные попадают в хд.