
Неисправный жёсткий диск — одно из самых неприятных явлений в работе компьютера. Мало того что мы легко можем потерять очень много важной информации и файлов, так и замена HDD неслабо бьёт по бюджету. Прибавим к этому потраченное время и нервы, которые, как известно, не восстанавливаются. Чтобы не дать проблеме застать нас врасплох и заранее диагностировать её, стоит знать, как проверить жёсткий диск на ошибки в ОС Ubuntu. Программных средств, предоставляющих такие услуги, предостаточно.

Как в Ubuntu протестировать жесткий диск на ошибки.
Проверка с помощью встроенного ПО
Совсем необязательно качать программы, чтобы выполнить проверку диска в Ubuntu. Операционная система уже обладает утилитой, которая предназначена для этой задачи. Называется она badblocks, управляется через терминал.
Открываем терминал и вводим:
sudo fdisk -l
Эта команда отображает информацию о всех HDD, которые используются системой.
После этого вводим:
sudo badblocks -sv /dev/sda
Команда служит уже для поиска повреждённых секторов. Вместо /dev/sda вводим имя своего накопителя. Ключи -s и -v служат для того, чтобы отображать в правильном порядке ход проверки блоков (s) и чтобы выдавать отчёт обо всех действиях (v).

Нажатием клавиш Ctrl + C мы останавливаем проверку жёсткого диска.
Для контроля за файловой системой можно также использовать две другие команды.
Для того чтобы размонтировать файловую систему, вводим:
umount /dev/sda
Для проверки и исправления ошибок:
sudo fsck -f -c /dev/sda
- «-f» делает процесс принудительным, то есть проводит его, даже если HDD помечен как работоспособный;
- «-c» находит и помечает бэд-блоки;
- «-y» — дополнительный вводимый аргумент, который сразу же отвечает Yes на все вопросы системы. Вместо него можно ввести «-p», он проведёт проверку в автоматическом режиме.
Программы
Дополнительное программное обеспечение также отлично справляется с этой функцией. А иногда даже лучше. Тем более что некоторым пользователям проще работать с графическим интерфейсом.
GParted
GParted как раз для тех, кому текстовый интерфейс не по душе. Утилита выполняет большое количество задач, связанных с работой HDD на Убунту. В их число входит и проверка диска на ошибки.

Для начала нам нужно скачать и установить GParted. Вводим следующую команду, чтобы выполнить загрузку из официальных репозиториев:
sudo apt-get install gparted
Установить программу легко и при помощи Центра загрузки приложений.
- Открываем приложение. На главном экране сразу же выводятся все носители. Если какой-то из них помечен восклицательным знаком, значит, с ним уже что-то не так.
- Щёлкаем по тому диску, который хотим проверить.
- Жмём на кнопку «Раздел», расположенную сверху.
- Выбираем «Проверка на ошибки».
Программа отсканирует диск. В зависимости от его объёма процесс может идти дольше или меньше. После сканирования мы будем оповещены о его результатах.
Smartmontools
Это уже более сложная утилита, которая выполняет более серьёзную проверку HDD по различным параметрам. Как следствие, управлять ей тоже сложнее. Графический интерфейс в Smartmontools не предусмотрен.

Качаем программу:
aptitude install smartmontools
Смотрим, какие накопители подключены к нашей системе. Обращать внимание нужно на строчки, оканчивающиеся буквой, а не цифрой. Именно в этих строках содержится информация о дисках.
ls -l /dev | grep -E ‘sd|hd’
Вбиваем команду для выведения подробной информации о носителе. Стоит посмотреть на параметр ATA. Дело в том, что при замене родного диска, лучше ставить устройство с тем же либо большим ATA. Так можно максимально раскрыть его возможности. А также посмотрите и запомните параметры SMART.
smartctl —info /dev/sde
Запускаем проверку. Если SMART поддерживается, то добавляем «-s». Если он не поддерживается или уже включён, то этот аргумент можно убрать.
smartctl -s on -a /dev/sde
После этого смотрим информацию под READ SMART DATA. Результат может принимать два значения: PASSED или FAILED. Если выпало последнее, можно начинать делать резервные копии и искать замену винчестеру.
Этим возможности программы не исчерпываются. Но для однократной проверки HDD этого будет вполне достаточно.
Safecopy
Это уже та программа, которую впору использовать на тонущем судне. Если мы осведомлены, что с нашим диском что-то не так, и нацелены спасти как можно больше выживших файлов, то Safecopy придёт на помощь. Её задача как раз заключается в копировании данных с повреждённых носителей. Причём она извлекает файлы даже из битых блоков.
Устанавливаем Safecopy:
sudo apt install safecopy
Переносим файлы из одной директории в другую. Выбрать можно любую другую. В данном случае мы переносим данные с диска sda в папку home.
sudo safecopy /dev/sda /home/
Бэд-блоки
У некоторых могут возникнуть вопросы: «что такое эти битые блоки и откуда они, вообще, взялись на моём HDD, если я его ни разу не трогал?» Bad blocks, или бэд-секторы — разделы HDD, которые больше не читаются. Во всяком случае так они по объективным причинам были помечены файловой системой. И скорее всего, с диском в этих местах действительно что-то не так. «Бэды» встречаются как на старых винчестерах, так и на самых современных, поскольку работают они практически по тем же самым технологиям.

Появляются же сбойные секторы по разным причинам.
- Прерывание записи из-за отключения питания. Вся информация, поступающая на жёсткий диск, разбивается в виде единиц и нулей на самые разные его части. Сбить этот процесс — значит сильно запутать винчестер. После такого сбоя может нарушиться загрузочный сектор и тогда система вообще не запускается.
- Некачественная сборка. Тут и говорить нечего. У дешёвого китайского устройства полететь может что угодно.
Теперь вы знаете, как сканировать HDD на ошибки. Проверка диска как на Ubuntu, так и на других системах довольно важная операция, которую стоит проводить хотя бы раз в год.
Throughout this answer I’ll assume, that a storage drive appears as a block device at the path /dev/sdc. To find the path of a storage drive in our current setup, use:
- Gnome Disks
 (formerly Gnome Disk Utility, a. k. a.
(formerly Gnome Disk Utility, a. k. a. palimpsest), if a GUI is available, or - on the terminal look at the output of
lsblkandls -l /dev/disk/by-idand try to find the right device by size, partitioning, manufacturer and model name.
Basic check
- only detects entirely unresponsive media
- almost instantaneous (unless medium is spun down or broken)
- safe
- works on read-only media (e. g. CD, DVD, BluRay)
Sometimes a storage medium simply refuses to work at all. It still appears as a block device to the kernel and in the disk manager, but its first sector holding the partition table is not readable. This can be verified easily with:
sudo dd if=/dev/sdc of=/dev/null count=1
If this command results in a message about an “Input/output error”, our drive is broken or otherwise fails to interact with the Linux kernel as expected. In the a former case, with a bit of luck, a data recovery specialist with an appropriately equipped lab can salvage its content. In the latter case, a different operating system is worth a try. (I’ve come across USB drives that work on Windows without special drivers, but not on Linux or OS X.)
S.M.A.R.T. self-test
- adjustable thoroughness
- instantaneous to slow or slower (depends on thoroughness of the test)
- safe
- warns about likely failure in the near future
Devices that support it, can be queried about their health through S.M.A.R.T. or instructed to perform integrity self-tests of different thoroughness. This is generally the best option, but usually only available on (non-ancient) hard disk and solid state drives. Most removable flash media don’t support it.
Further resources and instructions:
- Answer about S.M.A.R.T. on this question
- How can I check the SMART status of a drive on Ubuntu 14.04 through 16.10?
Read-only check
- only detects some flash media errors
- quite reliable for hard disks
- slow
- safe
- works on read-only media (e. g. CD, DVD, BluRay)
To test the read integrity of the whole device without writing to it, we can use badblocks(8) like this:
sudo badblocks -b 4096 -c 4096 -s /dev/sdc
This operation can take a lot of time, especially if the storage drive actually is damaged. If the error count rises above zero, we’ll know that there’s a bad block. We can safely abort the operation at any moment (even forcefully like during a power failure), if we’re not interested in the exact amount (and maybe location) of bad blocks. It’s possible to abort automatically on error with the option -e 1.
Note for advanced usage: if we want to reuse the output for e2fsck, we need to set the block size (-b) to that of the contained file system. We can also tweak the amount of data (-c, in blocks) tested at once to improve throughput; 16 MiB should be alright for most devices.
Non-destructive read-write check
- very thorough
- slowest
- quite safe (barring a power failure or intermittent kernel panic)
Sometimes – especially with flash media – an error only occurs when trying to write. (This will not reliably discover (flash) media, that advertise a larger size, than they actually have; use Fight Flash Fraud instead.)
-
NEVER use this on a drive with mounted file systems!
badblocksrefuses to operate on those anyway, unless you force it. -
Don’t interrupt this operation forcefully! Ctrl+C (SIGINT/SIGTERM) and waiting for graceful premature termination is ok, but
killall -9 badblocks(SIGKILL) isn’t. Upon forceful terminationbadblockscannot restore the original content of the currently tested block range and will leave it overwritten with junk data and possibly corrupt the file system.
To use non-destructive read-write checks, add the -n option to the above badblocks command.
Destructive read-write check
- very thorough
- slower
- ERASES ALL DATA ON THE DRIVE
As above, but without restoring the previous drive content after performing the write test, therefore it’s a little faster. Since data is erased anyway, forceful termination remains without (additional) negative consequence.
To use destructive read-write checks, add the -w option to the above badblocks command.
Из-за различных неполадок или неожиданного отключения компьютера файловая система может быть повреждена. При обычном выключении все файловые системы монтируются только для чтения, а все не сохраненные данные записываются на диск.
Но если питание выключается неожиданно, часть данных теряется, и могут быть потерянны важные данные, что приведет к повреждению самой файловой системы. В этой статье мы рассмотрим как восстановить файловую систему fsck, для нескольких популярных файловых систем, а также поговорим о том, как происходит восстановление ext4.
Немного теории
Как вы знаете файловая система содержит всю информацию обо всех хранимых на компьютере файлах. Это сами данные файлов и метаданные, которые управляют расположением и атрибутами файлов в файловой системе. Как я уже говорил, данные не сразу записываются на жесткий диск, а некоторое время находятся в оперативной памяти и при неожиданном выключении, за определенного стечения обстоятельств файловая система может быть повреждена.
Современные файловые системы делятся на два типа — журналируемые и нежурналируемые. Журналиуемые файловые системы записывают в лог все действия, которые собираются выполнить, а после выполнения стирают эти записи. Это позволяет очень быстро понять была ли файловая система повреждена. Но не сильно помогает при восстановлении. Чтобы восстановить файловую систему linux необходимо проверить каждый блок файловой системы и найти поврежденные сектора.
Для этих целей используется утилита fsck. По сути, это оболочка для других утилит, ориентированных на работу только с той или иной файловой системой, например, для fat одна утилита, а для ext4 совсем другая.
В большинстве систем для корневого раздела проверка fsck запускается автоматически, но это не касается других разделов, а также не сработает если вы отключили проверку.
В этой статье мы рассмотрим ручную работу с fsck. Возможно, вам понадобиться LiveCD носитель, чтобы запустить из него утилиту, если корневой раздел поврежден. Если же нет, то система сможет загрузиться в режим восстановления и вы будете использовать утилиту оттуда. Также вы можете запустить fsck в уже загруженной системе. Только для работы нужны права суперпользователя, поэтому выполняйте ее через sudo.
А теперь давайте рассмотрим сам синтаксис утилиты:
$ fsck [опции] [опции_файловой_системы] [раздел_диска]
Основные опции указывают способ поведения утилиты, оболочки fsck. Раздел диска — это файл устройства раздела в каталоге /dev, например, /dev/sda1 или /dev/sda2. Опции файловой системы специфичны для каждой отдельной утилиты проверки.
А теперь давайте рассмотрим самые полезные опции fsck:
- -l — не выполнять другой экземпляр fsck для этого жесткого диска, пока текущий не завершит работу. Для SSD параметр игнорируется;
- -t — задать типы файловых систем, которые нужно проверить. Необязательно указывать устройство, можно проверить несколько разделов одной командой, просто указав нужный тип файловой системы. Это может быть сама файловая система, например, ext4 или ее опции в формате opts=ro. Утилита просматривает все файловые системы, подключенные в fstab. Если задать еще и раздел то к нему будет применена проверка именно указанного типа, без автоопределения;
- -A — проверить все файловые системы из /etc/fstab. Вот тут применяются параметры проверки файловых систем, указанные в /etc/fstab, в том числе и приоритетность. В первую очередь проверяется корень. Обычно используется при старте системы;
- -C — показать прогресс проверки файловой системы;
- -M — не проверять, если файловая система смонтирована;
- -N — ничего не выполнять, показать, что проверка завершена успешно;
- -R — не проверять корневую файловую систему;
- -T — не показывать информацию об утилите;
- -V — максимально подробный вывод.
Это были глобальные опции утилиты. А теперь рассмотрим опции для работы с файловой системой, их меньше, но они будут более интересны:
- -a — во время проверки исправить все обнаруженные ошибки, без каких-либо вопросов. Опция устаревшая и ее использовать не рекомендуется;
- -n — выполнить только проверку файловой системы, ничего не исправлять;
- -r — спрашивать перед исправлением каждой ошибки, используется по умолчанию для файловых систем ext;
- -y — отвечает на все вопросы об исправлении ошибок утвердительно, можно сказать, что это эквивалент a.
- -c — найти и занести в черный список все битые блоки на жестком диске. Доступно только для ext3 и ext4;
- -f — принудительная проверка файловой системы, даже если по журналу она чистая;
- -b — задать адрес суперблока, если основной был поврежден;
- -p — еще один современный аналог опции -a, выполняет проверку и исправление автоматически. По сути, для этой цели можно использовать одну из трех опций: p, a, y.
Теперь мы все разобрали и вы готовы выполнять восстановление файловой системы linux. Перейдем к делу.
Как восстановить файловую систему в fsck
Допустим, вы уже загрузились в LiveCD систему или режим восстановления. Ну, одним словом, готовы к восстановлению ext4 или любой другой поврежденной ФС. Утилита уже установлена по умолчанию во всех дистрибутивах, так что устанавливать ничего не нужно.
Восстановление файловой системы
Если ваша файловая система находится на разделе с адресом /dev/sda1 выполните:
sudo fsck -y /dev/sda1
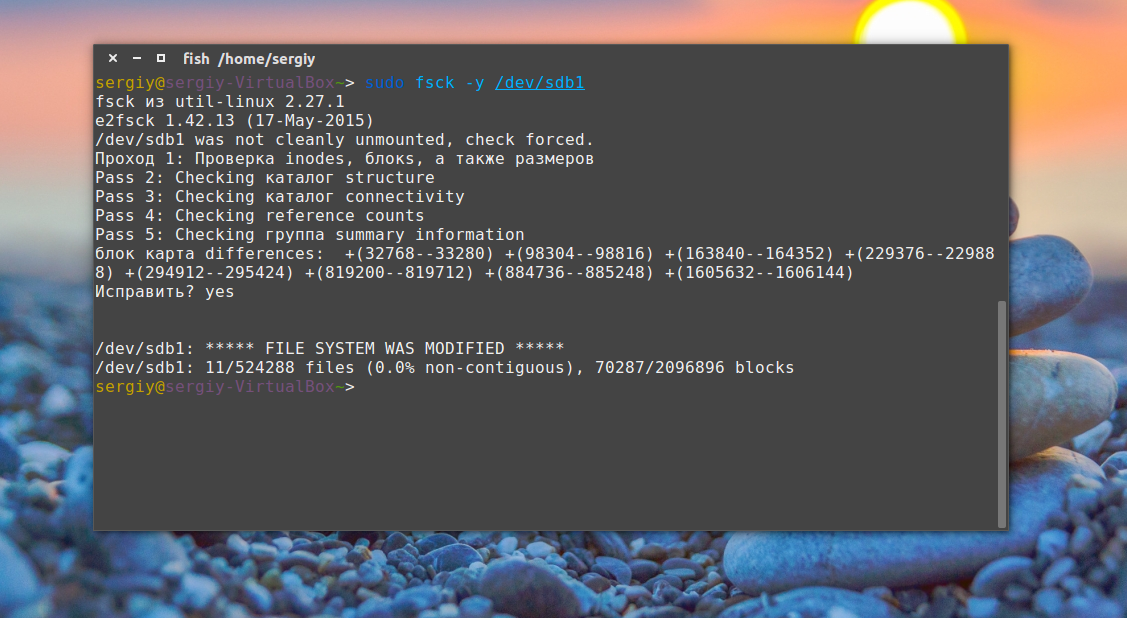
Опцию y указывать необязательно, но если этого не сделать утилита просто завалит вас вопросами, на которые нужно отвечать да.
Восстановление поврежденного суперблока
Обычно эта команда справляется со всеми повреждениями на ура. Но если вы сделали что-то серьезное и повредили суперблок, то тут fsck может не помочь. Суперблок — это начало файловой системы. Без него ничего работать не будет.
Но не спешите прощаться с вашими данными, все еще можно восстановить. С помощью такой команды смотрим куда были записаны резервные суперблоки:
sudo mkfs -t ext4 -n /dev/sda1
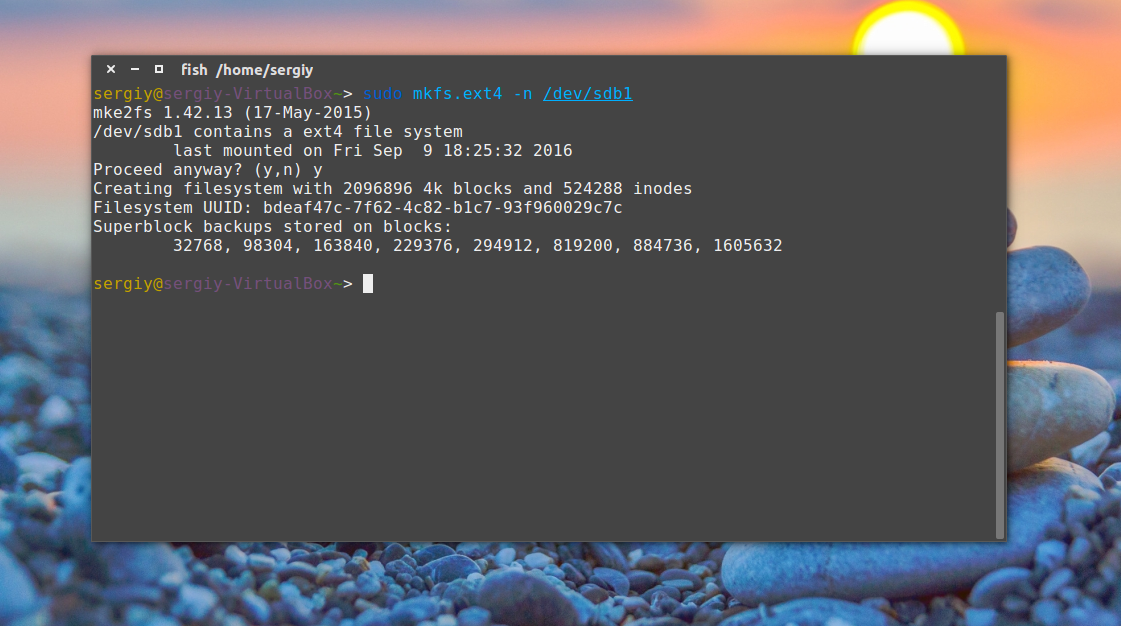
На самом деле эта команда создает новую файловую систему. Вместо ext4 подставьте ту файловую систему, в которую был отформатирован раздел, размер блока тоже должен совпадать иначе ничего не сработает. С опцией -n никаких изменений на диск не вноситься, а только выводится информация, в том числе о суперблоках.
Теперь у нас есть шесть резервных адресов суперблоков и мы можем попытаться восстановить файловую систему с помощью каждого из них, например:
sudo fsck -b 98304 /dev/sda1
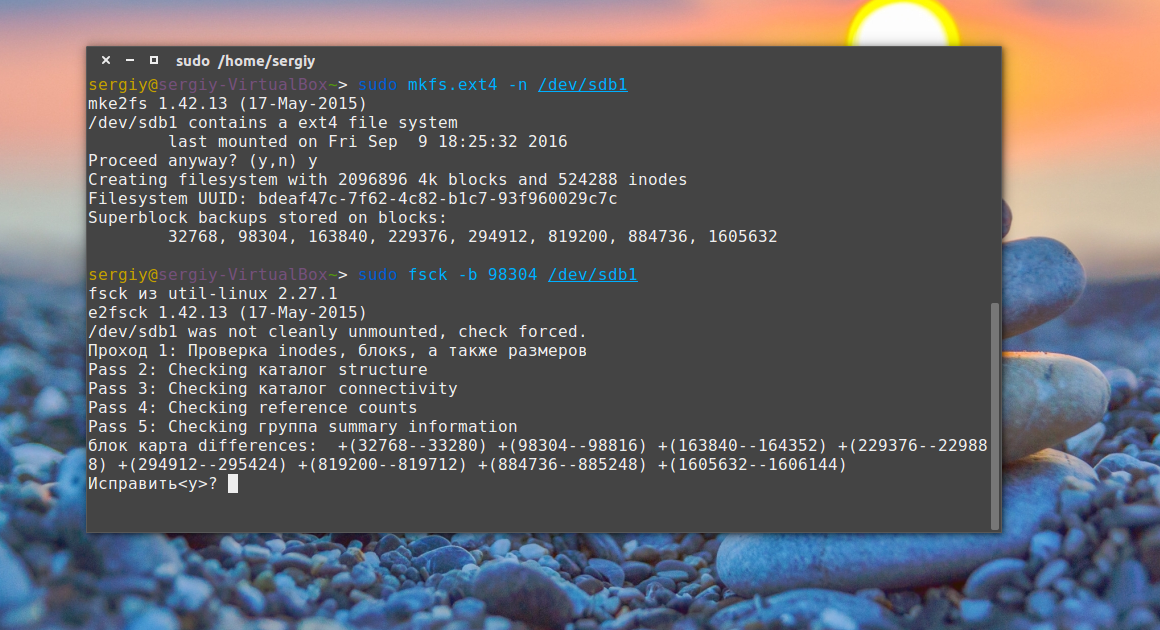
После этого, скорее всего, вам удастся восстановить вашу файловую систему. Но рассмотрим еще пару примеров.
Проверка чистой файловой системы
Проверим файловую систему, даже если она чистая:
sudo fsck -fy /dev/sda1
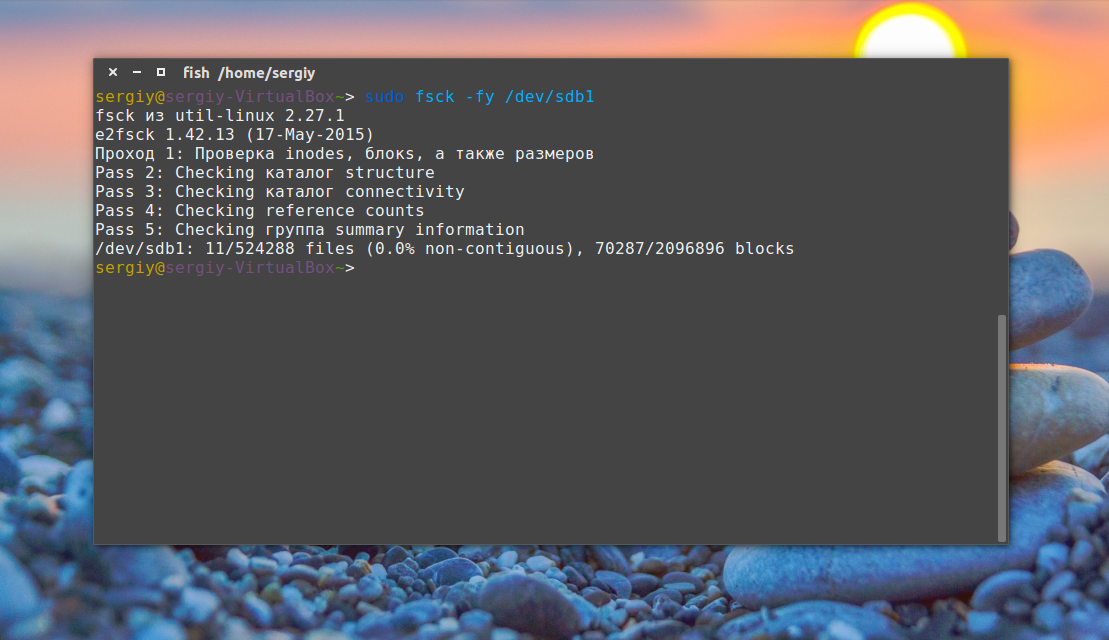
Битые сектора
Или еще мы можем найти битые сектора и больше в них ничего не писать:
sudo fsck -c /dev/sda1
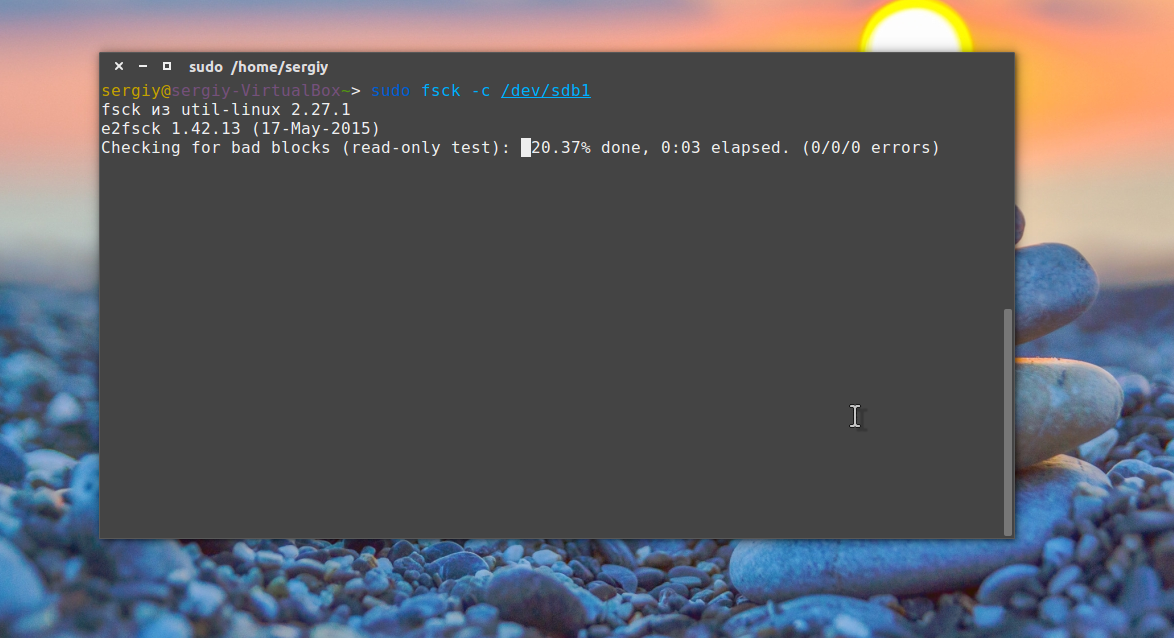
Установка файловой системы
Вы можете указать какую файловую систему нужно проверять на разделе, например:
sudo fsck -t ext4 /dev/sdb1
Проверка всех файловых систем
С помощью флага -A вы можете проверить все файловые системы, подключенные к компьютеру:
sudo fsck -A -y
Но такая команда сработает только в режиме восстановления, если корневой раздел и другие разделы уже примонтированы она выдаст ошибку. Но вы можете исключить корневой раздел из проверки добавив R:
sudo fsck -AR -y
Или исключить все примонтированные файловые системы:
sudo fsck -M -y
Также вы можете проверить не все файловые системы, а только ext4, для этого используйте такую комбинацию опций:
sudo fsck -A -t ext4 -y
Или можно также фильтровать по опциям монтирования в /etc/fstab, например, проверим файловые системы, которые монтируются только для чтения:
sudo fsck -A -t opts=ro
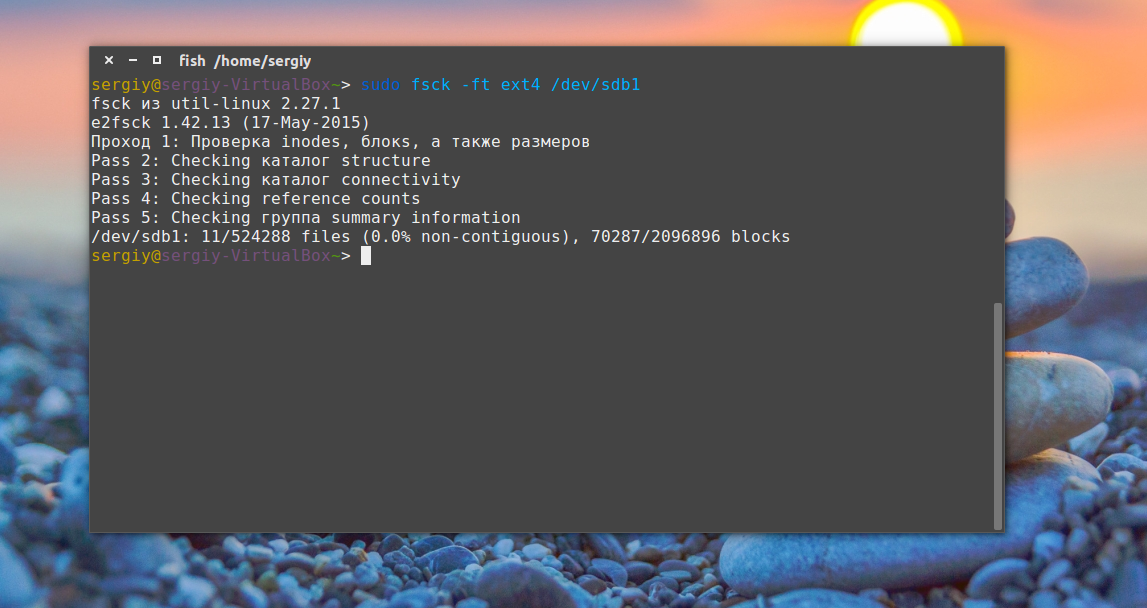
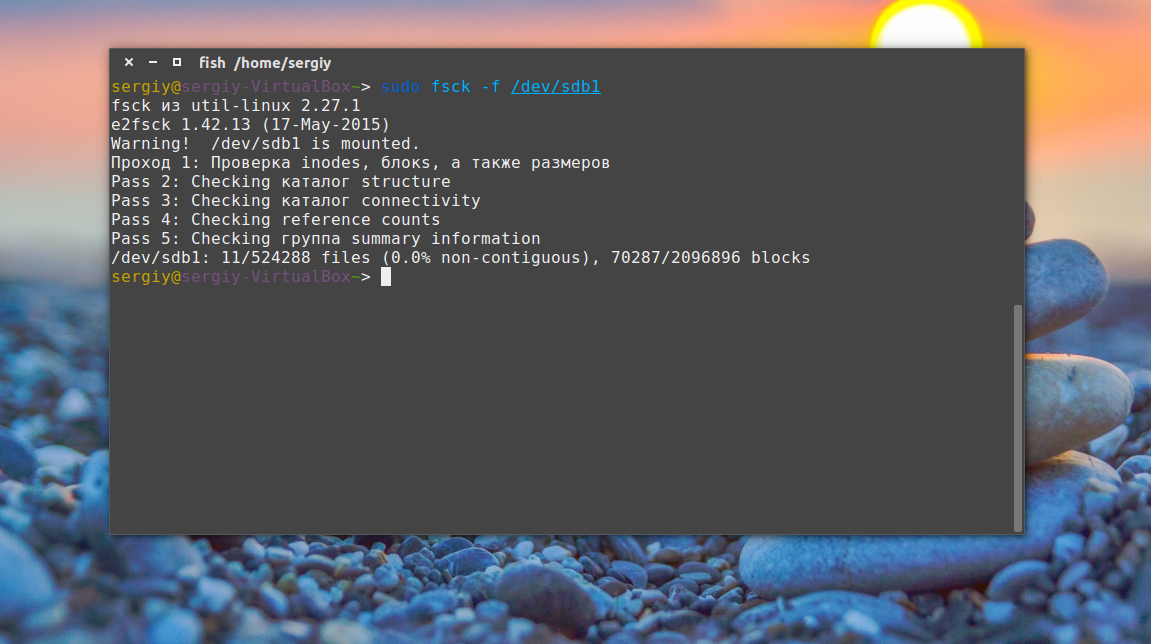
Проверка примонтированных файловых систем
Раньше я говорил что нельзя. Но если другого выхода нет, то можно, правда не рекомендуется. Для этого нужно сначала перемонтировать файловую систему в режим только для чтения. Например:
sudo mount -o remount,ro /dev/sdb1
А теперь проверка файловой системы fsck в принудительном режиме:
sudo fsck -fy /dev/sdb1
Просмотр информации
Если вы не хотите ничего исправлять, а только посмотреть информацию, используйте опцию -n:
sudo fsck -n /dev/sdb1
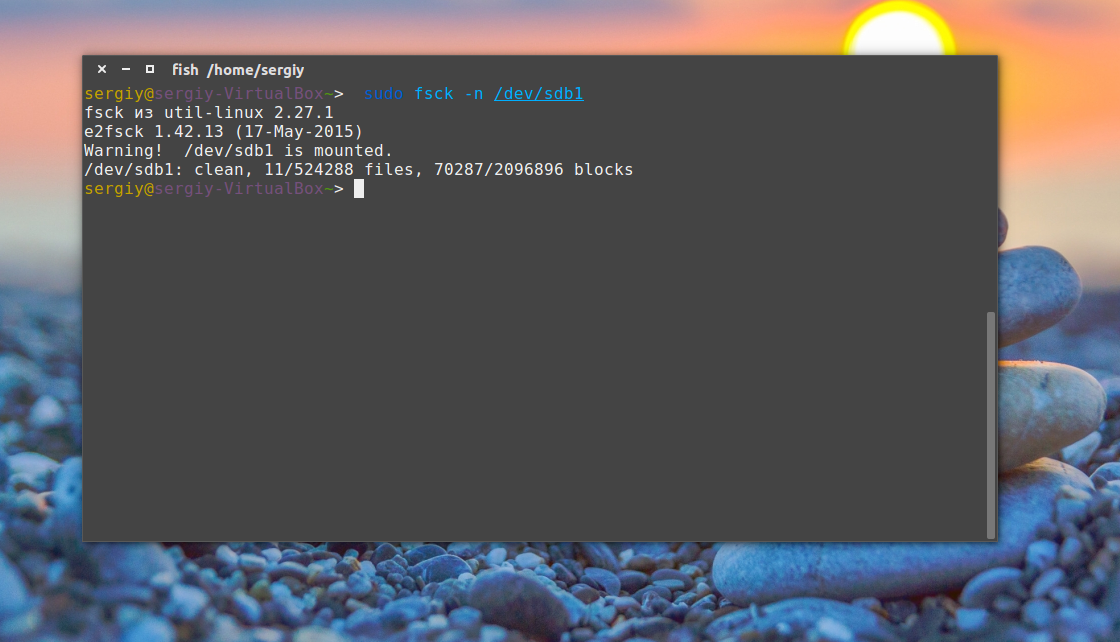
Выводы
Вот и все, теперь вы знаете как выполняется восстановление файловой системы ext4 или любой другой, поддерживаемой в linux fsck. Если у вас остались вопросы, спрашивайте в комментариях!
На десерт сегодня видео на английском про различия файловых систем ext4 и xfs, как обычно, есть титры:
https://www.youtube.com/watch?v=pECp066gGcY
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
|
|
Duplicate Article |

See: SystemAdministration/Fsck and TestingStorageMedia
Introduction
Contents
- Introduction
- Basic filesystem checks and repairs
- e2fsprogs — ext2, ext3, ext4 filesystems
- dosfstools — FAT12, FAT16 and FAT32 (vfat) filesystem
- ntfs-3g (previously also ntfsprogs) — NTFS filesystem
- reiserfstools — reiserfs
- xfsprogs — xfs
- Missing superblock
- Bad blocks
- Sources and further reading
This guide will help diagnose filesystem problems one may come across on a GNU/Linux system. New sections are still being added to this howto.
Basic filesystem checks and repairs
The most common method of checking filesystem’s health is by running what’s commonly known as the fsck utility. This tool should only be run against an unmounted filesystem to check for possible issues. Nearly all well established filesystem types have their fsck tool. e.g.: ext2/3/4 filesystems have the e2fsck tool. Most notable exception until very recently was btrfs. There are also filesystems that do not need a filesystem check tool i.e.: read-only filesystems like iso9660 and udf.
e2fsprogs — ext2, ext3, ext4 filesystems
Ext2/3/4 have the previously mentioned e2fsck tool for checking and repairing filesystem. This is a part of e2fsprogs package — the package needs to be installed to have the fsck tool available. Unless one removes it in aptitude during installation, it should already be installed.
There are 4 ways the fsck tool usually gets run (listed in order of frequency of occurrence):
- it runs automatically during computer bootup every X days or Y mounts (whichever comes first). This is determined during the creation of the filesystem and can later be adjusted using tune2fs.
- it runs automatically if a filesystem has not been cleanly unmounted (e.g.: powercut)
- user runs it against an unmounted filesystem
-
user makes it run at next bootup
case 1
When filesystem check is run automatically X days after the last check or after Y mounts, Ubuntu gives user the option to interrupt the check and continue bootup normally. It is recommended that user lets it finish the check.
case 2
If a filesystem has not been cleanly unmounted, the system detects a dirty bit on the filesystem during the next bootup and starts a check. It is strongly recommended that one lets it finish. It is almost certain there are errors on the filesystem that fsck will detect and attempt to fix. Nevertheless, one can still interrupt the check and let the system boot up on a possibly corrupted filesystem.
2 things can go wrong
-
fsck dies — If fsck dies for whatever reason, you have the option to press ^D (Ctrl + D) to continue with an unchecked filesystem or run fsck manually. See e2fsck cheatsheet for details how.
-
fsck fails to fix all errors with default settings — If fsck fails to fix all errors with default settings, it will ask to be run manually by the user. See e2fsck cheatsheet for details how.
case 3
User may run fsck against any filesystem that can be unmounted on a running system. e.g. if you can issue umount /dev/sda3 without an error, you can run fsck against /dev/sda3.
case 4
You can make your system run fsck by creating an empty ‘forcefsck’ file in the root of your root filesystem. i.e.: touch /forcefsck Filesystems that have 0 or nothing specified in the sixth column of your /etc/fstab, will not be checked
Till Ubuntu 6.06 you can also issue shutdown -rF now to reboot your filesystem and check all partitions with non-zero value in sixth column of your /etc/fstab. Later versions of Ubuntu use Upstart version of shutdown which does not support the -F option any more.
Refer to man fstab for what values are allowed.
e2fsck cheatsheet
e2fsck has softlinks in /sbin that one can use to keep the names of fsck tools more uniform. i.e. fsck.ext2, fsck.ext3 and fsck.ext4 (similarly, other filesystem types have e.g.: fsck.ntfs) This cheatsheet will make use of these softlinks and will use ext4 and /dev/sda1 as an example.
-
fsck.ext4 -p /dev/sda1 — will check filesystem on /dev/sda1 partition. It will also automatically fix all problems that can be fixed without human intervention. It will do nothing, if the partition is deemed clean (no dirty bit set).
-
fsck.ext4 -p -f /dev/sda1 — same as before, but fsck will ignore the fact that the filesystem is clean and check+fix it nevertheless.
-
fsck.ext4 -p -f -C0 /dev/sda1 — same as before, but with a progress bar.
-
fsck.ext4 -f -y /dev/sda1 — whereas previously fsck would ask for user input before fixing any nontrivial problems, -y means that it will simply assume you want to answer «YES» to all its suggestions, thus making the check completely non-interactive. This is potentially dangerous but sometimes unavoidable; especially when one has to go through thousands of errors. It is recommended that (if you can) you back up your partition before you have to run this kind of check. (see dd command for backing up filesystems/partitions/volumes)
-
fsck.ext4 -f -c -C0 /dev/sda1 — will attempt to find bad blocks on the device and make those blocks unusable by new files and directories.
-
fsck.ext4 -f -cc -C0 /dev/sda1 — a more thorough version of the bad blocks check.
-
fsck.ext4 -n -f -C0 /dev/sda1 — the -n option allows you to run fsck against a mounted filesystem in a read-only mode. This is almost completely pointless and will often result in false alarms. Do not use.
In order to create and check/repair these Microsoft(TM)’s filesystems, dosfstools package needs to be installed. Similarly to ext filesystems’ tools, dosfsck has softlinks too — fsck.msdos and fsck.vfat. Options, however, vary slightly.
dosfsck cheatsheet
These examples will use FAT32 and /dev/sdc1
-
fsck.vfat -n /dev/sdc1 — a simple non-interactive read-only check
-
fsck.vfat -a /dev/sdc1 — checks the file system and fixes non-interactively. Least destructive approach is always used.
-
fsck.vfat -r /dev/sdc1 — interactive repair. User is always prompted when there is more than a single approach to fixing a problem.
-
fsck.vfat -l -v -a -t /dev/sdc1 — a very verbose way of checking and repairing the filesystem non-interactively. The -t parameter will mark unreadable clusters as bad, thus making them unavailable to newly created files and directories.
Recovered data will be dumped in the root of the filesystem as fsck0000.rec, fsck0001.rec, etc. This is similar to CHK files created by scandisk and chkdisk on MS Windows.
ntfs-3g (previously also ntfsprogs) — NTFS filesystem
Due to the closed sourced nature of this filesystem and its complexity, there is no fsck.ntfs available on GNU/Linux (ntfsck isn’t being developed anymore). There is a simple tool called ntfsfix included in ntfs-3g package. Its focus isn’t on fixing NTFS volumes that have been seriously corrupted; its sole purpose seems to be making an NTFS volume mountable under GNU/Linux.
Normally, NTFS volumes are non-mountable if their dirty bit is set. ntfsfix can help with that by clearing trying to fix the most basic NTFS problems:
-
ntfsfix /dev/sda1 — will attempt to fix basic NTFS problems. e.g.: detects and fixes a Windows XP bug, leading to a corrupt MFT; clears bad cluster marks; fixes boot sector problems
-
ntfsfix -d /dev/sda1 — will clear the dirty bit on an NTFS volume.
-
ntfsfix -b /dev/sda1 — clears the list of bad sectors. This is useful after cloning an old disk with bad sectors to a new disk.
Windows 8 and GNU/Linux cohabitation problems This segment is taken from http://www.tuxera.com/community/ntfs-3g-advanced/ When Windows 8 is restarted using its fast restarting feature, part of the metadata of all mounted partitions are restored to the state they were at the previous closing down. As a consequence, changes made on Linux may be lost. This can happen on any partition of an internal disk when leaving Windows 8 by selecting “Shut down” or “Hibernate”. Leaving Windows 8 by selecting “Restart” is apparently safe.
To avoid any loss of data, be sure the fast restarting of Windows 8 is disabled. This can be achieved by issuing as an administrator the command : powercfg /h off
Install reiserfstools package to have reiserfsck and a softlink fsck.reiserfs available. Reiserfsck is a very talkative tool that will let you know what to do should it find errors.
-
fsck.reiserfs /dev/sda1 — a readonly check of the filesystem, no changes made (same as running with —check). This is what you should run before you include any other options.
-
fsck.reiserfs —fix-fixable /dev/sda1 — does basic fixes but will not rebuild filesystem tree
-
fsck.reiserfs —scan-whole-partition —rebuild-tree /dev/sda1 — if basic check recommends running with —rebuild-tree, run it with —scan-whole-partition and do NOT interrupt it! This will take a long time. On a non-empty 1TB partition, expect something in the range of 10-24 hours.
xfsprogs — xfs
If a check is necessary, it is performed automatically at mount time. Because of this, fsck.xfs is just a dummy shell script that does absolutely nothing. If you want to check the filesystem consistency and/or repair it, you can do so using the xfs_repair tool.
-
xfs_repair -n /dev/sda — will only scan the volume and report what fixes are needed. This is the no modify mode and you should run this first.
-
xfs_repair will exit with exit status 0 if it found no errors and with exit status 1 if it found some. (You can check exit status with echo $?)
-
-
xfs_repair /dev/sda — will scan the volume and perform all fixes necessary. Large volumes take long to process.
XFS filesystem has a feature called allocation groups (AG) that enable it to use more parallelism when allocating blocks and inodes. AGs are more or less self contained parts of the filesystem (separate free space and inode management). mkfs.xfs creates only a single AG by default.
xfs_repair checks and fixes your filesystems by going through 7 phases. Phase 3 (inode discovery and checks) and Phase 4 (extent discovery and checking) work sequentially through filesystem’s allocation groups (AG). With multiple AGs, this can be heavily parallelised. xfs_repair is clever enough to not process multiple AGs on same disks.
Do NOT bother with this if any of these is true for your system:
- you created your XFS filesystem with only a single AG.
-
your xfs_repair is older than version 2.9.4 or you will make the checks even slower on GNU/Linux. You can check your version with xfs_repair -V
- your filesystem does not span across multiple disks
otherwise:
-
xfs_repair -o ag_stride=8 -t 5 -v /dev/sda — same as previous example but reduces the check/fix time by utilising multiple threads, reports back on its progress every 5 minutes (default is 15) and its output is more verbose.
-
if your filesystem had 32 AGs, the -o ag_stride=8 would start 4 threads, one to process AGs 0-7, another for 8-15, etc… If ag_stride is not specified, it defaults to the number of AGs in the filesystem.
-
-
xfs_repair -o ag_stride=8 -t 5 -v -m 2048 /dev/sda — same as above but limits xfs_repair’s memory usage to a maximum of 2048 megabytes. By default, it would use up to 75% of available ram. Please note, -o bhash=xxx has been superseded by the -m option
== jfsutils — jfs == == btrfs ==
Missing superblock
Bad blocks
Sources and further reading
- man pages
-
<XFS user guide> — more details about XFS filesystem
Неисправный жёсткий диск — одно из самых неприятных явлений в работе компьютера. Мало того что мы легко можем потерять очень много важной информации и файлов, так и замена HDD неслабо бьёт по бюджету. Прибавим к этому потраченное время и нервы, которые, как известно, не восстанавливаются. Чтобы не дать проблеме застать нас врасплох и заранее диагностировать её, стоит знать, как проверить жёсткий диск на ошибки в ОС Ubuntu. Программных средств, предоставляющих такие услуги, предостаточно.
Как в Ubuntu протестировать жесткий диск на ошибки.
Проверка с помощью встроенного ПО
Совсем необязательно качать программы, чтобы выполнить проверку диска в Ubuntu. Операционная система уже обладает утилитой, которая предназначена для этой задачи. Называется она badblocks, управляется через терминал.
Открываем терминал и вводим:
sudo fdisk -l
Эта команда отображает информацию о всех HDD, которые используются системой.
После этого вводим:
sudo badblocks -sv /dev/sda
Команда служит уже для поиска повреждённых секторов. Вместо /dev/sda вводим имя своего накопителя. Ключи -s и -v служат для того, чтобы отображать в правильном порядке ход проверки блоков (s) и чтобы выдавать отчёт обо всех действиях (v).
Нажатием клавиш Ctrl + C мы останавливаем проверку жёсткого диска.
Для контроля за файловой системой можно также использовать две другие команды.
Для того чтобы размонтировать файловую систему, вводим:
umount /dev/sda
Для проверки и исправления ошибок:
sudo fsck -f -c /dev/sda
- «-f» делает процесс принудительным, то есть проводит его, даже если HDD помечен как работоспособный;
- «-c» находит и помечает бэд-блоки;
- «-y» — дополнительный вводимый аргумент, который сразу же отвечает Yes на все вопросы системы. Вместо него можно ввести «-p», он проведёт проверку в автоматическом режиме.
Программы
Дополнительное программное обеспечение также отлично справляется с этой функцией. А иногда даже лучше. Тем более что некоторым пользователям проще работать с графическим интерфейсом.
GParted
GParted как раз для тех, кому текстовый интерфейс не по душе. Утилита выполняет большое количество задач, связанных с работой HDD на Убунту. В их число входит и проверка диска на ошибки.
Для начала нам нужно скачать и установить GParted. Вводим следующую команду, чтобы выполнить загрузку из официальных репозиториев:
sudo apt-get install gparted
Установить программу легко и при помощи Центра загрузки приложений.
- Открываем приложение. На главном экране сразу же выводятся все носители. Если какой-то из них помечен восклицательным знаком, значит, с ним уже что-то не так.
- Щёлкаем по тому диску, который хотим проверить.
- Жмём на кнопку «Раздел», расположенную сверху.
- Выбираем «Проверка на ошибки».
Программа отсканирует диск. В зависимости от его объёма процесс может идти дольше или меньше. После сканирования мы будем оповещены о его результатах.
Smartmontools
Это уже более сложная утилита, которая выполняет более серьёзную проверку HDD по различным параметрам. Как следствие, управлять ей тоже сложнее. Графический интерфейс в Smartmontools не предусмотрен.
Качаем программу:
aptitude install smartmontools
Смотрим, какие накопители подключены к нашей системе. Обращать внимание нужно на строчки, оканчивающиеся буквой, а не цифрой. Именно в этих строках содержится информация о дисках.
ls -l /dev | grep -E ‘sd|hd’
Вбиваем команду для выведения подробной информации о носителе. Стоит посмотреть на параметр ATA. Дело в том, что при замене родного диска, лучше ставить устройство с тем же либо большим ATA. Так можно максимально раскрыть его возможности. А также посмотрите и запомните параметры SMART.
smartctl —info /dev/sde
Запускаем проверку. Если SMART поддерживается, то добавляем «-s». Если он не поддерживается или уже включён, то этот аргумент можно убрать.
smartctl -s on -a /dev/sde
После этого смотрим информацию под READ SMART DATA. Результат может принимать два значения: PASSED или FAILED. Если выпало последнее, можно начинать делать резервные копии и искать замену винчестеру.
Этим возможности программы не исчерпываются. Но для однократной проверки HDD этого будет вполне достаточно.
Safecopy
Это уже та программа, которую впору использовать на тонущем судне. Если мы осведомлены, что с нашим диском что-то не так, и нацелены спасти как можно больше выживших файлов, то Safecopy придёт на помощь. Её задача как раз заключается в копировании данных с повреждённых носителей. Причём она извлекает файлы даже из битых блоков.
Устанавливаем Safecopy:
sudo apt install safecopy
Переносим файлы из одной директории в другую. Выбрать можно любую другую. В данном случае мы переносим данные с диска sda в папку home.
sudo safecopy /dev/sda /home/
Бэд-блоки
У некоторых могут возникнуть вопросы: «что такое эти битые блоки и откуда они, вообще, взялись на моём HDD, если я его ни разу не трогал?» Bad blocks, или бэд-секторы — разделы HDD, которые больше не читаются. Во всяком случае так они по объективным причинам были помечены файловой системой. И скорее всего, с диском в этих местах действительно что-то не так. «Бэды» встречаются как на старых винчестерах, так и на самых современных, поскольку работают они практически по тем же самым технологиям.
Появляются же сбойные секторы по разным причинам.
- Прерывание записи из-за отключения питания. Вся информация, поступающая на жёсткий диск, разбивается в виде единиц и нулей на самые разные его части. Сбить этот процесс — значит сильно запутать винчестер. После такого сбоя может нарушиться загрузочный сектор и тогда система вообще не запускается.
- Некачественная сборка. Тут и говорить нечего. У дешёвого китайского устройства полететь может что угодно.
Теперь вы знаете, как сканировать HDD на ошибки. Проверка диска как на Ubuntu, так и на других системах довольно важная операция, которую стоит проводить хотя бы раз в год.
Throughout this answer I’ll assume, that a storage drive appears as a block device at the path /dev/sdc. To find the path of a storage drive in our current setup, use:
- Gnome Disks (formerly Gnome Disk Utility, a. k. a.
palimpsest), if a GUI is available, or - on the terminal look at the output of
lsblkandls -l /dev/disk/by-idand try to find the right device by size, partitioning, manufacturer and model name.
Basic check
- only detects entirely unresponsive media
- almost instantaneous (unless medium is spun down or broken)
- safe
- works on read-only media (e. g. CD, DVD, BluRay)
Sometimes a storage medium simply refuses to work at all. It still appears as a block device to the kernel and in the disk manager, but its first sector holding the partition table is not readable. This can be verified easily with:
sudo dd if=/dev/sdc of=/dev/null count=1
If this command results in a message about an “Input/output error”, our drive is broken or otherwise fails to interact with the Linux kernel as expected. In the a former case, with a bit of luck, a data recovery specialist with an appropriately equipped lab can salvage its content. In the latter case, a different operating system is worth a try. (I’ve come across USB drives that work on Windows without special drivers, but not on Linux or OS X.)
S.M.A.R.T. self-test
- adjustable thoroughness
- instantaneous to slow or slower (depends on thoroughness of the test)
- safe
- warns about likely failure in the near future
Devices that support it, can be queried about their health through S.M.A.R.T. or instructed to perform integrity self-tests of different thoroughness. This is generally the best option, but usually only available on (non-ancient) hard disk and solid state drives. Most removable flash media don’t support it.
Further resources and instructions:
- Answer about S.M.A.R.T. on this question
- How can I check the SMART status of a drive on Ubuntu 14.04 through 16.10?
Read-only check
- only detects some flash media errors
- quite reliable for hard disks
- slow
- safe
- works on read-only media (e. g. CD, DVD, BluRay)
To test the read integrity of the whole device without writing to it, we can use badblocks(8) like this:
sudo badblocks -b 4096 -c 4096 -s /dev/sdc
This operation can take a lot of time, especially if the storage drive actually is damaged. If the error count rises above zero, we’ll know that there’s a bad block. We can safely abort the operation at any moment (even forcefully like during a power failure), if we’re not interested in the exact amount (and maybe location) of bad blocks. It’s possible to abort automatically on error with the option -e 1.
Note for advanced usage: if we want to reuse the output for e2fsck, we need to set the block size (-b) to that of the contained file system. We can also tweak the amount of data (-c, in blocks) tested at once to improve throughput; 16 MiB should be alright for most devices.
Non-destructive read-write check
- very thorough
- slowest
- quite safe (barring a power failure or intermittent kernel panic)
Sometimes – especially with flash media – an error only occurs when trying to write. (This will not reliably discover (flash) media, that advertise a larger size, than they actually have; use Fight Flash Fraud instead.)
-
NEVER use this on a drive with mounted file systems!
badblocksrefuses to operate on those anyway, unless you force it. -
Don’t interrupt this operation forcefully! Ctrl+C (SIGINT/SIGTERM) and waiting for graceful premature termination is ok, but
killall -9 badblocks(SIGKILL) isn’t. Upon forceful terminationbadblockscannot restore the original content of the currently tested block range and will leave it overwritten with junk data and possibly corrupt the file system.
To use non-destructive read-write checks, add the -n option to the above badblocks command.
Destructive read-write check
- very thorough
- slower
- ERASES ALL DATA ON THE DRIVE
As above, but without restoring the previous drive content after performing the write test, therefore it’s a little faster. Since data is erased anyway, forceful termination remains without (additional) negative consequence.
To use destructive read-write checks, add the -w option to the above badblocks command.
Компьютер представляет собой устройство, работа которого основана на взаимодействии множества компонентов. Со временем они могут вызывать сбои в работе. Одной из частых причин неполноценной работы машины становятся битые сектора на диске, поэтому периодически его нужно тестировать. Linux предоставляет для этого все возможности.
Что такое битые блоки и почему они появляются
Блок (сектор) – это маленькая ячейка диска, на которой в виде битов (0 и 1) хранится информация. Когда системе не удается записать очередной бит в ячейку, говорят о битом секторе. Причин возникновения таких блоков может быть несколько:
- брак при производстве;
- отключение питания в процессе записи информации;
- физический износ диска.
Изначально практически на всех носителях имеются нарушения. Со временем их количество может увеличиваться, что говорит о скором выходе устройства из строя. В Linux тестировать диск на ошибки возможно несколькими способами.

На ядре Linux работает несколько ОС, среди которых Ubuntu и Debian. Процедура проверки диска универсальная и подходит для каждой из них. О том, что носитель пора тестировать, стоит задуматься, когда на дисковую систему оказывается большая нагрузка, скорость работы с носителем (запись/чтение) значительно уменьшилась, либо эти процедуры и вовсе вызывают ошибки.
Многие знакомы с программой на Windows – Victoria HDD. Разработчики позаботились о написании ее аналогов для Linux.
Badblocks
Badblocks – дисковая утилита, имеющаяся в Ubuntu и других дистрибутивах Linux по умолчанию. Программа позволяет тестировать как жесткий диск, так и внешние накопители.
Важно! Все приведенные в статье терминальные команды начинаются с параметра sudo, так как для выполнения требуются права суперпользователя.
Перед тем, как тестировать диск в Linux следует проверить, какие накопители подключены к системе, с помощью утилиты fdisk-l. Она также покажет имеющиеся на них разделы.

Теперь можно приступать к непосредственному тестированию на битые сектора. Работа Badblocks организовывается следующим образом:
badblocks -v /dev/sdk1 > bsector.txt
В записи используются следующие команды и операнды:·
- -v – выводит подробный отчет о проведенной проверке;·
- /dev/sdk1 – проверяемый раздел;·
- bsector.txt – запись результатов в текстовый файл.

Если при проверке диска нашлись битые блоки, нужно запустить утилиту fsck, либо e2fsck, в зависимости от используемой файловой системы. Они ограничат запись информации в нерабочие сектора. В случае файловых систем ext2, ext3 или ext4 выполняется следующая команда:
fsck -l bsector.txt /dev/sdk1
В противном случае:
fsck -l bsector.txt /dev/sdk1
Параметр -l указывает программе, что битые блоки перечислены в файле bsector.txt, и исключать нужно именно их.
GParted
Утилита проверяет файловую систему Linux, не прибегая к текстовому интерфейсу.
Инструмент изначально не содержится в дистрибутивах операционной системы, поэтому ее необходимо установить, выполнив команду:
apt-get install gparted
В главном окне приложения отображаются доступные диски. О том, что носитель пора тестировать, понятно по восклицательному знаку, расположенному рядом с его именем. Запуск проверки производится путем щелчка по пункту «Проверка на ошибки» в подменю «Раздел», расположенном на панели сверху. Предварительно выбирается нужный диск. По завершении сканирования утилита выведет результат.

Проверка HDD и других запоминающих устройств приложением GParted доступна для пользователей ОС Ubuntu, FreeBSD, Centos, Debian и других и других дистрибутивов, работающих на ядре Linux.
Smartmontools
Инструмент позволяет тестировать файловую систему с большей надежностью. В современных жестких дисках имеется встроенный модуль самоконтроля S. M. A. R. T., который анализирует данные накопителя и помогает определить неисправность на первоначальной стадии. Smartmontools предназначен для работы с этим модулем.
Запуск установки производится через терминал:
- apt install smartmontools – для Ubuntu/Debian;
- yum install smartmontools – для CentOS.
Для просмотра информации о состоянии жесткого диска, вводится строка:
smartctl –H /dev/sdk1

Проверка на ошибки занимает различное время, в зависимости от объема диска. По окончании программа выведет результат о наличии битых секторов, либо их отсутствии.
Утилита имеет и другие параметры: -a, —all, -x, —xall. Для получения дополнительной информации вызывается справка:
man smartctl –h

Safecopy
Когда возникает потребность тестировать винчестер в Linux, стоит быть готовым к любому результату.
Приложение Safecopy копирует данные с поврежденного устройства на рабочее. Источником могут быть как жесткие диски, так и съемные носители. Этот инструмент игнорирует ошибки ввода/вывода, чтения, битые блоки, продолжая беспрерывно работать. Скорость выполнения максимально возможная, которую обеспечивает компьютер.

Для установки Safecopy на Linux в терминал вводится строка:
apt install safecopy
Сканирование запускается командой:
safecopy /dev/sdk1 /home/files/
Здесь первый путь обозначает поврежденный диск, второй – директорию, куда сохранятся файлы.
Программа способна создать образ файловой системы нестабильно работающего запоминающего устройства.
Что делать, если обнаружена ошибка в системной программе Ubuntu
Установка нового программного обеспечения или изменения системных настроек могут вызвать сообщение «Обнаружена ошибка в системной программе». Многие его игнорируют, так как на общей работе оно не отражается.

С проблемой обычно сталкиваются пользователи Ubuntu версии 16.04. Тестировать HDD в этом случае нет необходимости, так как проблема скорее заключается именно в программном сбое. Сообщение оповещает о непредвиденном завершении работы программы и предлагает отправить отчет разработчикам. При согласии откроется окно браузера, где требуется заполнить форму из 4 шагов. Такой вариант вызывает сложности и не гарантирует исчезновения ошибки.
Второй способ поможет избежать появления сообщения лишь в том случае, если оно вызывается одной и той же программой. Для этого при очередном оповещении нужно установить галку на опцию «Не показывать больше для этой программы».
Третий метод – отключить утилиту Apport, которая отвечает в Linux за сбор информации и отправку отчетов. Такой подход полностью исключит всплывание окон с ошибками. Возможно отключение только показа уведомлений, оставляя службу сбора в рабочем состоянии. Для этого необходимо выполнить:
gsettings set com.ubuntu.update-notifier show-apport-crashes false

Данные продолжат собираться в папке /var/crash. Их периодически необходимо чистить, чтобы они не заполняли дисковое пространство:
rm /var/crash
Для полного отключения служб Apport, в терминал вводится запись:
gksu gedit /etc/default/apport
В появившемся тексте значение поля enable меняется с 1 на 0. В дальнейшем, чтобы снова включить службу, возвращаются настройки по умолчанию.
Заключение
Для предотвращения потери файлов жесткий диск и съемные носители рекомендуется периодически тестировать. Linux предлагает несколько подходов к решению задачи. На выбор предоставляется перечень утилит, которые выявляют поврежденные сектора и обеспечивают перенос информации на нормально функционирующее устройство.
Concerned that you have a failing hard drive? Make a backup. Then, use these Linux tools to check your disk/drive.
Not concerned that you have a failing drive? Back up anyway. It could be failing, and you don’t know it. Or it could get stolen. Or a meteorite could hit it.
Back. Up. Your. Files.
What is SMART?
S.M.A.R.T. (Self-Monitoring, Analysis, and Reporting Technology) is the system most hard disks use to report their health to the installed system.
This information can be queried to find out whether a drive is reporting any issues.
Using smartmontools/smartctl
The smartmontools contains the smartctl package, which can query the SMART status of a physical hard drive.
You can install it on Ubuntu and Debian based systems by running:
sudo apt install smartmontools
Once installed, you provide it with the path to the device name for your hard disk, and it queries the SMART status of the drive and outputs the results:
sudo smartctl -a /dev/sda
Above, the -a option is passed, telling smartctl to print all available SMART information for that disk.
/dev/sda is the path to the hard disk you want to check the health of. If you don’t know what this is, you can find a list of disks that can be queried by running:
sudo smartctl --scan
Most commands in this article are run using sudo as they require root/administrative privileges.
You can view the full user manual for smartmontools and smartctl by running:
man smartctl
Checking Using badblocks
The badblocks tools come pre-installed on many distributions, including Ubuntu. It will check for bad blocks on your disk.
A block (or sector) is an area of the physical storage device where data is stored. badblocks will scan your disk block by block; if a block is damaged, it is marked as bad -, and the system actively avoids storing data on that part of the hard disk. When it’s done, you’ll get a full report on how many bad blocks were found.
sudo badblocks -v /dev/sda
Above, the -v option is used, which tells badblocks to be verbose and output as much information as possible while it is running. Finally,/dev/sda is the path to the device to be checked.
Running badblocks may take quite a while, depending on the size of the disk. However, once completed, you will receive a report on how many bad blocks or sector was found – which can be a good indicator of whether your disk has been damaged.
You can view the full user manual for backblocks by running:
man badblocks
Viewing SMART Status in a GUI Using gsmartcontrol
If you want to view the information provided by smartctl, but want to view it in a graphical window, you can use gsmartcontrol. Install it by running:
sudo apt install gsmartcontrol
You will be presented with a window containing a list of devices you can select:

…each can be clicked on to reveal SMART data, which can be inspected and exported.
Conclusion
Don’t bet on any of these tools. Drives fail ungracefully. Mechanical drives can jam up after being bumped at just the right angle. Power surges can happen. Cars can fly off of roads, bounce off of trees and crash through your house and destroy your computers. Please make a backup, and keep it somewhere safe.
Если и есть то, с чем вы очень не хотите столкнуться в вашей операционной системе, то это неожиданный выход из строя жестких дисков. С помощью резервного копирования и технологии хранения RAID вы можете очень быстро вернуть все данные на место, но потеря аппаратного устройства может очень сильно сказаться на бюджете, особенно если вы такого не планировали.
Чтобы избежать таких проблем можно использовать пакет smartmontools. Это программный пакет для управления и мониторинга устройств хранения данных с помощью технологии Self-Monitoring Analysis and Reporting Technology или просто SMART.
Большинство современных ATA/SATA/SCSI/SAS накопителей информации предоставляют интерфейс SMART. Цель SMART — мониторинг надежности жесткого диска, для выявления различных ошибок и своевременного реагирования на их появление. Пакет smartmontools состоит из двух утилит — smartctl и smartd. Вместе они представляют мощную систему мониторинга и предупреждения о возможных поломках HDD в Linux. Дальше будет подробно рассмотрена проверка жесткого диска linux.
Установка Smartmontools
Пакет smartmontools есть в официальных репозиториях большинства дистрибутивов Linux, поэтому установка сводится к выполнению одной команды. В Debian и основанных на нем системах выполните:
sudo apt install smartmontools
А для RedHat:
sudo yum install smartmontools
Во время установки надо выбрать способ настройки почтового сервера. Можно его вовсе не настраивать, если вы не собираетесь отправлять уведомления о проблемах с диском на почту.
Отправлять почту получится только на веб-сервере, к которому привязан домен, на локальной машине можно выбрать пункт только для локального использования и тогда почта будет складываться в локальную папку и её можно будет посмотреть утилитой mail. Теперь можно переходить к диагностике жесткого диска Linux.
Проверка жесткого диска в smartctl
Сначала узнайте какие жесткие диски подключены к вашей системе:
ls -l /dev | grep -E 'sd|hd'
В выводе будет что-то подобное:
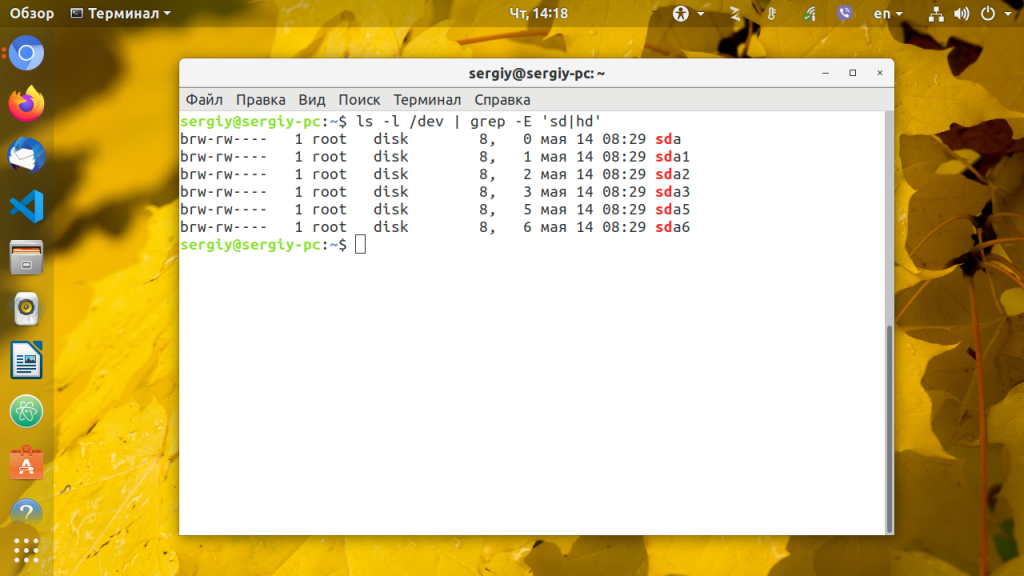
Здесь sdX это имя устройства HDD подключенного к компьютеру.
Для отображения информации о конкретном жестком диске (модель устройства, S/N, версия прошивки, версия ATA, доступность интерфейса SMART) Запустите smartctl с опцией info и именем жесткого диска. Например, для /dev/sda:
smartctl --info /dev/sda
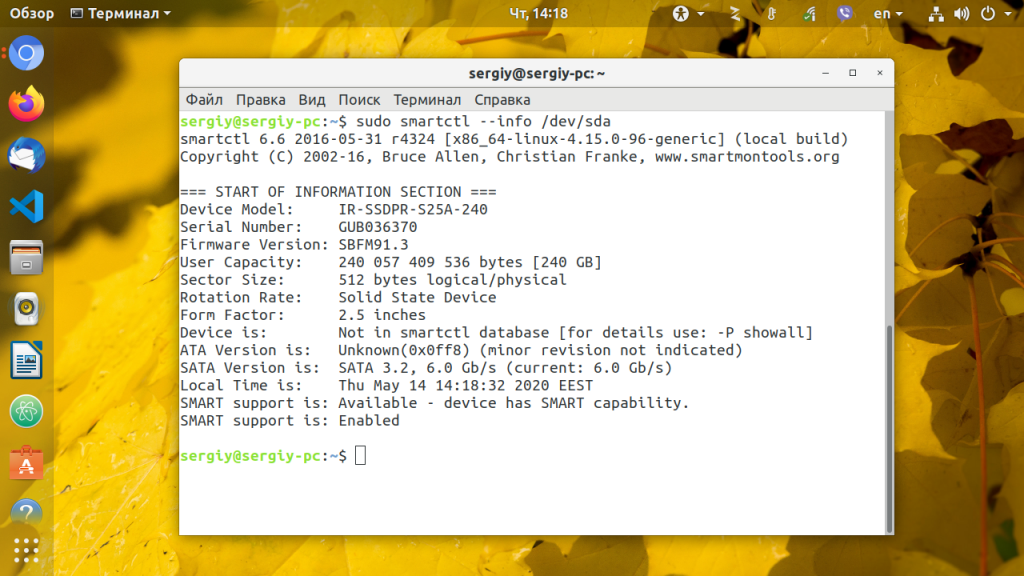
Хотя вы можете и не обратить внимания на версию SATA или ATA, это один из самых важных факторов при поиске замены устройству. Каждая новая версия ATA совместима с предыдущими. Например, старые устройства ATA-1 и ATA-2 прекрасно будут работать на ATA-6 и ATA-7 интерфейсах, но не наоборот. Когда версии ATA устройства и интерфейса не совпадают, возможности оборудования не будут полностью раскрыты. В данном случае для замены лучше всего выбрать жесткий диск SATA 3.2.
Запустить проверку жесткого диска ubuntu можно командой:
smartctl -s on -a /dev/sda
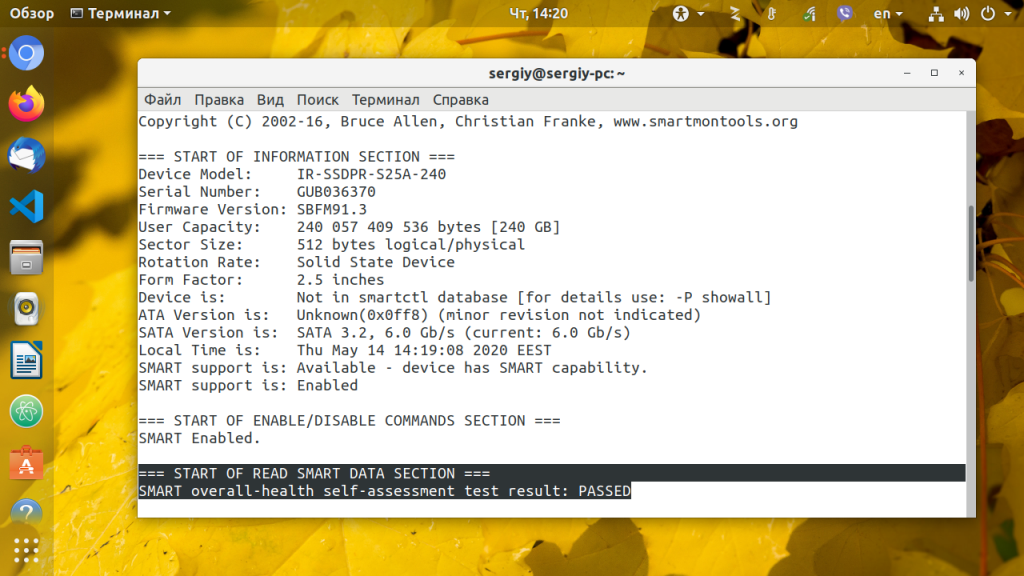
Здесь опция -s включает флаг SMART на указном устройстве. Вы можете его убрать если поддержка SMART уже включена. Информация о диске разделена на несколько разделов, В разделе READ SMART DATA находится общая информация о здоровье жесткого диска.
=== START OF READ SMART DATA SECTION ===
SMART overall-health self-assessment rest result: PASSED
Этот тест может быть пройден (PASSED) или нет (FAILED). В последнем случае сбой неизбежен, начинайте резервное копирование данных с этого диска.
Следующая вещь которую можно посмотреть, когда выполняется диагностика HDD в linux, это таблица SMART атрибутов.
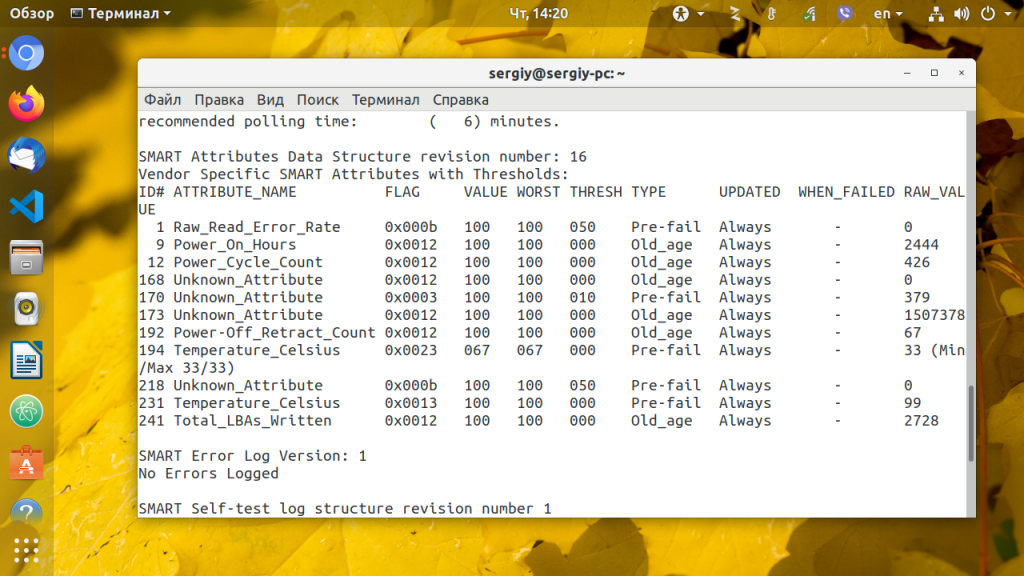
В SMART таблице записаны параметры, определенные для конкретного диска разработчиком, а также порог отказа для этих параметров. Таблица заполняется автоматически и обновляется на основе прошивки диска.
- ID # — идентификатор атрибута, как правило, десятичное число между 1 и 255;
- ATTRIBUTE_NAME — название атрибута;
- FLAG — флаг обработки атрибута;
- VALUE — это поле представляет нормальное значение для состояния данного атрибута в диапазоне от 1 до 253, 253 — лучшее состояние, 1 — худшее. В зависимости от свойств, начальное значение может быть от 100 до 200;
- WORST — худшее значение value за все время;
- THRESH — самое низкое значение value, после перехода за которое нужно сообщить что диск непригоден для эксплуатации;
- TYPE — тип атрибута, может быть Pre-fail или Old_age. Все атрибуты по умолчанию считаются критическими, то-есть если диск не прошел проверку по одному из атрибутов, то он уже считается не пригодным (FAILED) но атрибуты old_age не критичны;
- UPDATED — показывает частоту обновления атрибута;
- WHEN_FAILED — будет установлено в FAILING_NOW если значение атрибута меньше или равно THRESH, или в «—» если выше. В случае FAILING_NOW, лучше как можно скорее выполнить резервное копирование, особенно если тип атрибута pre-fail.
- RAW_VALUE — значение, определенное производителем.
Сейчас вы думаете, да smartctl хороший инструмент, но у меня нет возможности запускать его каждый раз вручную, было бы неплохо автоматизировать все это дело чтобы программа запускалась периодически и сообщала мне о результатах проверки. И это возможно, с помощью smartd.
Автоматическая диагностика в smartd
Автоматическая диагностика HDD в Linux настраивается очень просто. Сначала отредактируйте файл конфигурации smartd — /etc/smartd.conf. Добавьте следующую строку:
nano /etc/smartd.conf
/dev/sda -m myemail@mydomain.com -M test
Здесь:
- -m <email адрес> — адрес электронной почты для отправки результатов проверки. Это может быть адрес локального пользователя, суперпользователя или внешний адрес, если настроен сервер для отправки электронной почты;
- -M — частота отправки писем. once — отправлять только одно сообщение о проблемах с диском. daily — отправлять сообщения каждый день если была обнаружена проблема. diminishing — отправлять сообщения через день если была обнаружена проблема. test — отправлять тестовое сообщение при запуске smartd. exec — выполняет указанную программу в место отправки почты.
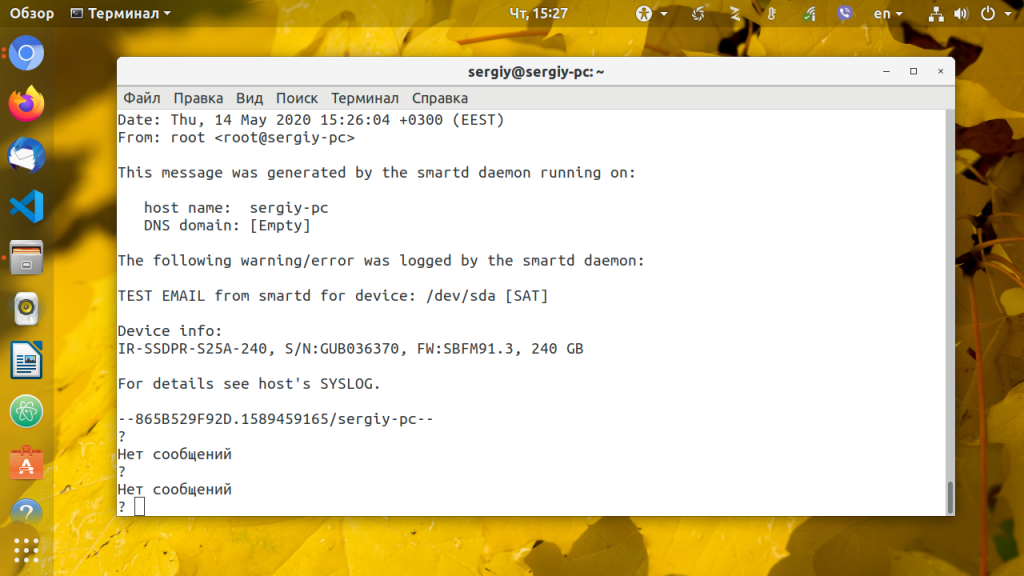
Сохраните изменения и перезапустите smartd:
sudo systemctl restart smartd
Вы должны получить на электронную почту письмо о том, что программа была запущена успешно. Это будет работать только если на компьютере настроен почтовый сервер.
Также можно запланировать тесты по своему графику, для этого используйте опцию -s и регулярное выражение типа T/MM/ДД/ДН/ЧЧ, где:
Здесь T — тип теста:
- L — длинный тест;
- S — короткий тест;
- C — тест перемещения (ATA);
- O — оффлайн тест.
Остальные символы определяют дату и время теста:
- ММ — месяц в году;
- ДД — день месяца;
- ЧЧ — час дня;
- ДН — день недели (от 1 — понедельник 7 — воскресенье;
- MM, ДД и ЧЧ — указываются с двух десятичных цифр.
Точка означает все возможные значения, выражение в скобках (A|B|C) — означает один из трех вариантов, выражение в квадратных скобках [1-5] означает диапазон (от 1 до 5).
Например, чтобы выполнять полную проверку жесткого диска linux каждый рабочий день в час дня добавьте опцию -s в строчку конфигурации вашего устройства:
/dev/sda -m myemail@mydomain.com -M once -s (L /../../[1-5]/13)
Если вы хотите чтобы утилита сканировала и проверяла все устройства, которые есть в системе используйте вместо имени устройства директиву DEVICESCAN:
DEVICESCAN -m myemail@mydomain.com -M once -s (L /../../[1-5]/13)
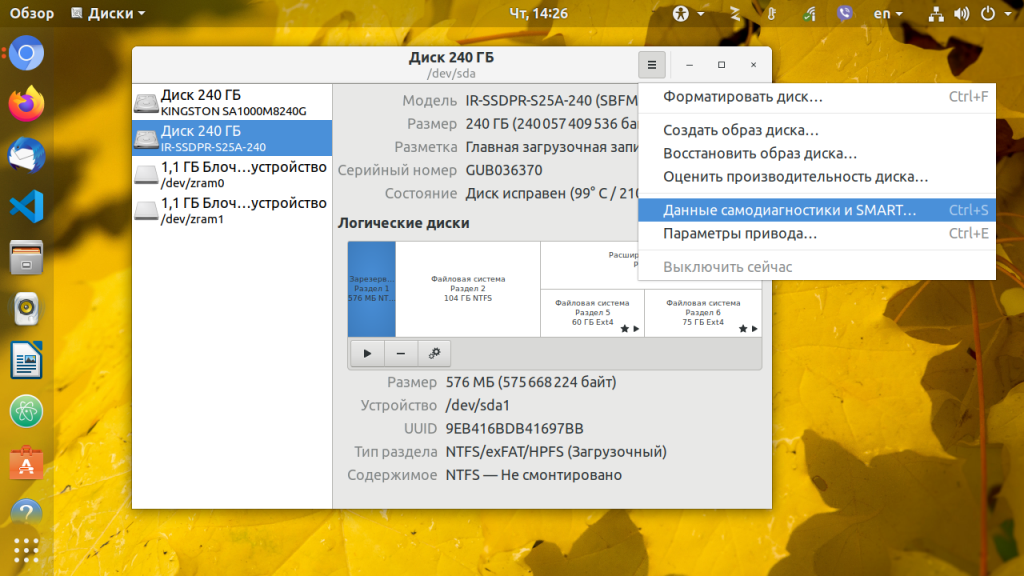
Проверка диска на ошибки в GUI
В графическом интерфейсе тоже можно посмотреть информацию из SMART. Для этого можно воспользоваться приложением Gnome Диски, откройте его из главного меню, выберите нужный диск, а затем кликните по пункту Данные самодиагностики и SMART в контекстном меню:
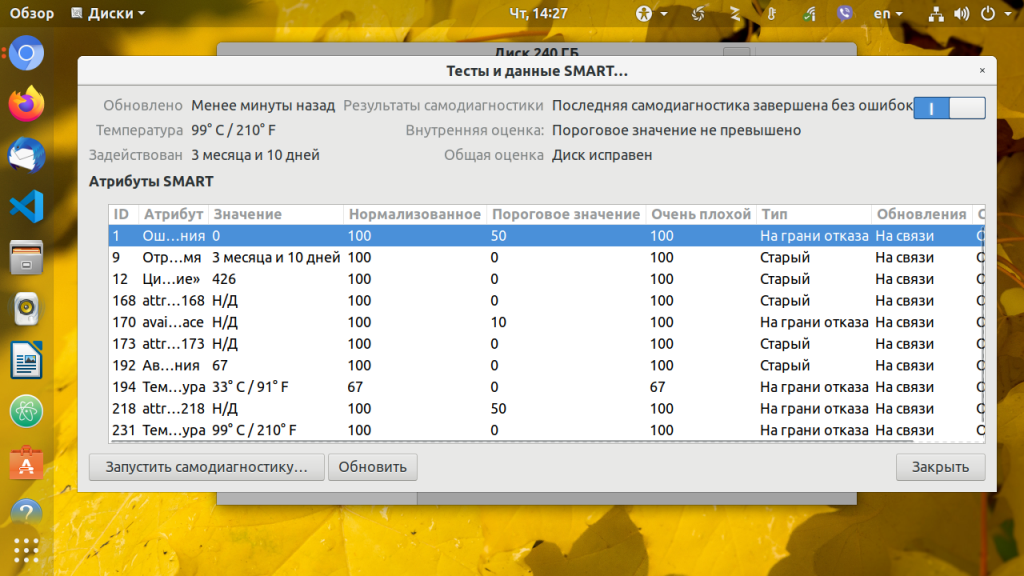
В открывшемся окне вы увидите те же данные диагностики SMART, а также все атрибуты SMART и их состояние:
Выводы
Если вы хотите быстро проверить механическую работу жесткого диска, посмотреть его физическое состояние или выполнить более-менее полное сканирование поверхности диска используйте smartmontools. Не забывайте выполнять регулярное сканирование, потом будете себя благодарить. Вы уже делали это раньше? Будете делать? Или используете другие методы? Напишите в комментариях!
Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Though laptops and desktops are very resilient, you should keep checking the health of the components to ensure the longevity. A data storage device is a core-component of any computer. The two main types are known as HDD aka Hard Disk Drive and SSD aka Solid-State Drive. The main differences between these two boils down to the price and the IO speeds, but that’s a discussion for another post. If you want to ensure that your computer performs optimally, it is crucial that your HDD/SSD performs well. In this post, we’ll outline the main ways how you can check the health of your HDD/SSD in Ubuntu 20.04.
Through the interface
With this method, you can perform the tests without much knowledge of terminal commands. You can start by opening up the “Disks” Application.
- You can either start by pressing the “window” key or by clicking on “Activities” in the upper left corner of the screen.
- When the text box for search pops up, type “Disks”, now click on the icon and launch the application.
Once the application opens up, it will list the data storage devices in your computer, as shown below. 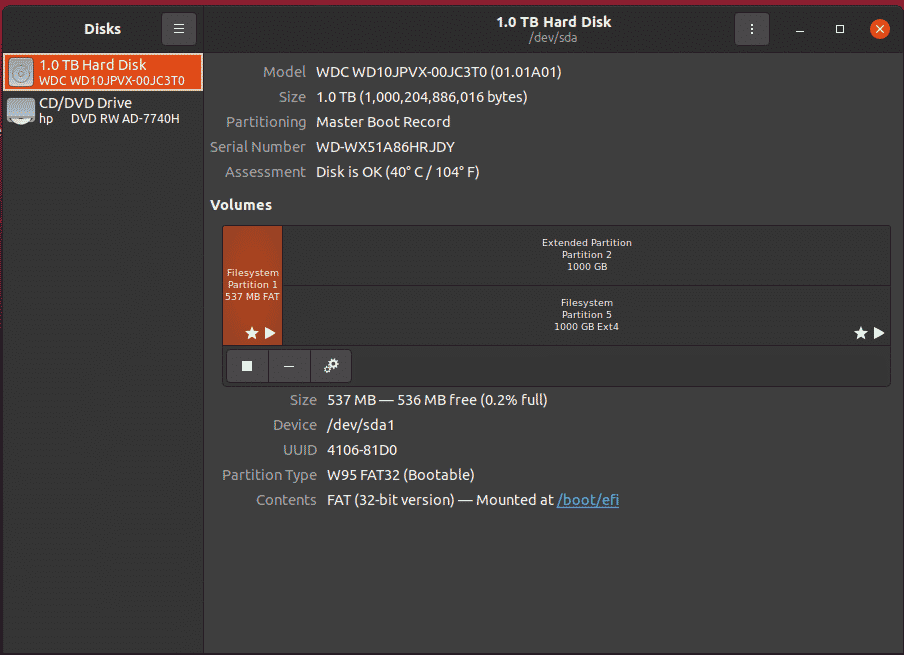
Select the HDD/SSD you want to test. Now:
- Open the options menu, it’s next to the minimize button.
- Select “SMART Data and Tests”
In the window that opens up, you’ll be able to see the status of your data storage device.
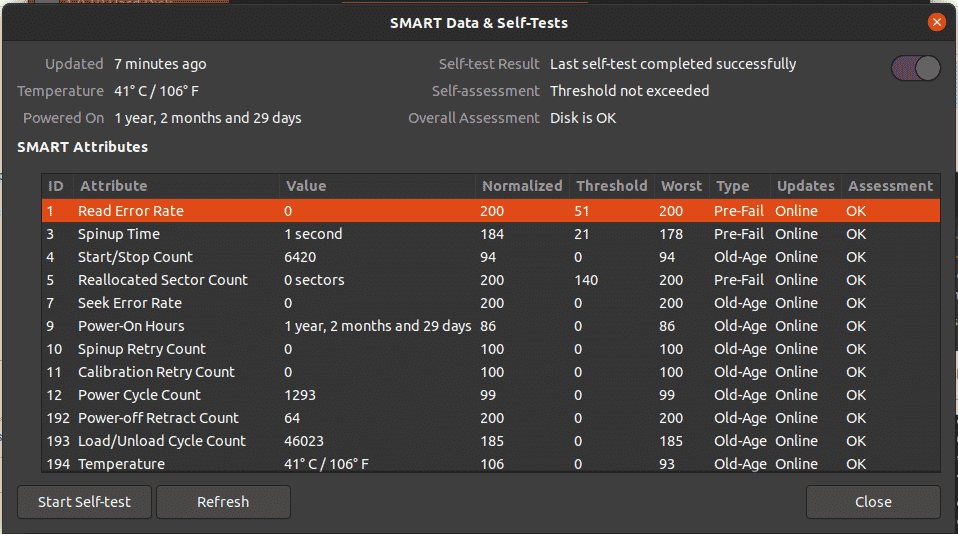
If there are multiple storage devices, you can go back to the previous window and select the other device to test it.
Through the terminal
Through the terminal, you’ll need to start by installing the SmartCtl package. In your terminal, type the following:
$sudo apt-get install smartmontools -y

Once done, you’ll need to start the service through the following command
$systemctl start smartd
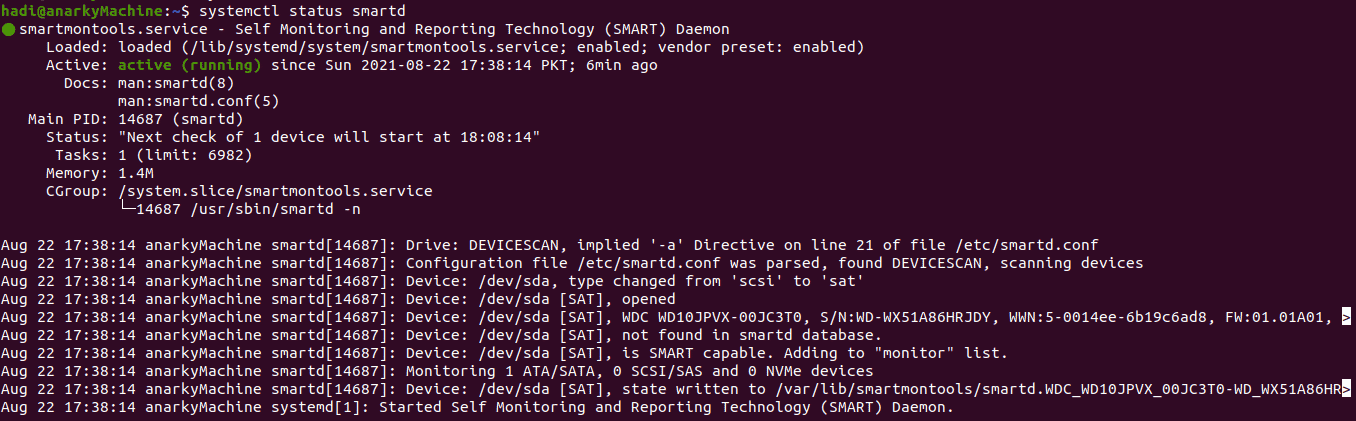
Since you need the service running, you need to check the status of the service before running any tests. Type this command to check the status:
$systemctl status smartd
You’ll get an output similar to the following:
 Testing the health of your HDD/SSD
Testing the health of your HDD/SSD
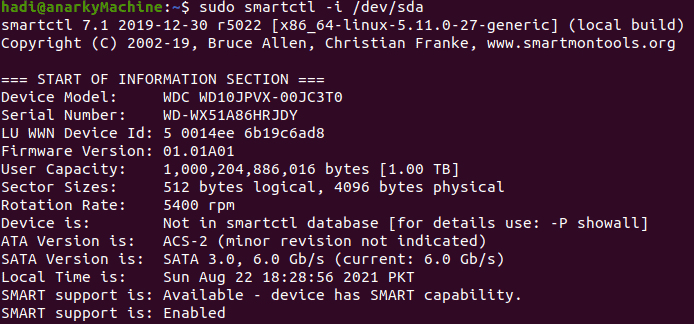
Once the service has been started, get the information of your hard drive through the following command:
$sudo smartctrl -i /dev/sda
Now you can launch a short test, using the following command:
$sudo smartctl -t short -a /dev/sda
Through this short test, you’ll test the electrical and mechanical properties along with read/verify. You’ll get the following output.
Following a short testing, you can run a long test, using the following command:
$sudo smartctl -t long -a /dev/sda
Through this long test, you’ll get everything included in the short test along with much more.
If you want to inspect the overall health of your data storage device, type and run the following:
$sudo smartctl -d ata -H /dev/sda
You’ll get the following short output, and rather than stats, you’ll see if the test passed or failed.

If you want to explore all the possible options you can use with the smartctl command, you can pull it up by using the following:
$smartctl --help
You’ll get all the arguments and parameters you can mix and match to customize the tests as extensive and comprehensive as possible.
Conclusion
Throughout this post, you got to know about the multiple ways you can check the health of your Hard Disk Drives and Solid-State Drives. If you want to discuss any third-party tools, drop a comment below and let us know.

Karim Buzdar holds a degree in telecommunication engineering and holds several sysadmin certifications including CCNA RS, SCP, and ACE. As an IT engineer and technical author, he writes for various websites.
FSCK – очень важная утилита для Linux / Unix, она используется для проверки и исправления ошибок в файловой системе.
Она похоже на утилиту «chkdsk» в операционных системах Windows.
Она также доступна для операционных систем Linux, MacOS, FreeBSD.
FSCK означает «File System Consistency Check», и в большинстве случаев он запускается во время загрузки, но может также запускаться суперпользователем вручную, если возникнет такая необходимость.
Может использоваться с 3 режимами работы,
1- Проверка наличия ошибок и позволить пользователю решить, что делать с каждой ошибкой,
2- Проверка на наличие ошибок и возможность сделать фикс автоматически, или,
3- Проверка наличия ошибок и возможность отобразить ошибку, но не выполнять фикс.
Содержание
- Синтаксис использования команды FSCK
- Команда Fsck с примерами
- Выполним проверку на ошибки в одном разделе
- Проверьте файловую систему на ошибки и исправьте их автоматически
- Проверьте файловую систему на наличие ошибок, но не исправляйте их
- Выполним проверку на ошибки на всех разделах
- Проверим раздел с указанной файловой системой
- Выполнять проверку только на несмонтированных дисках
Синтаксис использования команды FSCK
$ fsck options drives
Опции, которые можно использовать с командой fsck:
- -p Автоматический фикс (без вопросов)
- -n не вносить изменений в файловую систему
- -у принять «yes» на все вопросы
- -c Проверить наличие плохих блоков и добавить их в список.
- -f Принудительная проверка, даже если файловая система помечена как чистая
- -v подробный режим
- -b использование альтернативного суперблока
- -B blocksize Принудительный размер блоков при поиске суперблока
- -j external_journal Установить местоположение внешнего журнала
- -l bad_blocks_file Добавить в список плохих блоков
- -L bad_blocks_file Установить список плохих блоков
Мы можем использовать любую из этих опций, в зависимости от операции, которую нам нужно выполнить.
Давайте обсудим некоторые варианты команды fsck с примерами.
Команда Fsck с примерами
Примечание: – Прежде чем обсуждать какие-либо примеры, прочтите это. Мы не должны использовать FSCK на смонтированных дисках, так как высока вероятность того, что fsck на смонтированном диске повредит диск навсегда.
Поэтому перед выполнением fsck мы должны отмонтировать диск с помощью следующей команды:
$ umount drivename
Например:
$ umount /dev/sdb1
Вы можете проверить номер раздела с помощью следующей команды:
$ fdisk -l
Также при запуске fsck мы можем получить некоторые коды ошибок.
Ниже приведен список кодов ошибок, которые мы могли бы получить при выполнении команды вместе с их значениями:
- 0 – нет ошибок
- 1 – исправлены ошибки файловой системы
- 2 – система должна быть перезагружена
- 4 – Ошибки файловой системы оставлены без исправлений
- 8 – Операционная ошибка
- 16 – ошибка использования или синтаксиса
- 32 – Fsck отменен по запросу пользователя
- 128 – Ошибка общей библиотеки
Теперь давайте обсудим использование команды fsck с примерами в системах Linux.
Выполним проверку на ошибки в одном разделе
Чтобы выполнить проверку на одном разделе, выполните следующую команду из терминала:
$ umount /dev/sdb1 $ fsck /dev/sdb1
Проверьте файловую систему на ошибки и исправьте их автоматически
Запустите команду fsck с параметром «a» для проверки целостности и автоматического восстановления, выполните следующую команду.
Мы также можем использовать опцию «у» вместо опции «а».
$ fsck -a /dev/sdb1
Проверьте файловую систему на наличие ошибок, но не исправляйте их
В случае, если нам нужно только увидеть ошибки, которые происходят в нашей файловой системе, и не нужно их исправлять, тогда мы должны запустить fsck с опцией “n”,
$ fsck -n /dev/sdb1
Выполним проверку на ошибки на всех разделах
Чтобы выполнить проверку файловой системы для всех разделов за один раз, используйте fsck с опцией «A»
$ fsck -A
Чтобы отключить проверку корневой файловой системы, мы будем использовать опцию «R»
$ fsck -AR
Проверим раздел с указанной файловой системой
Чтобы запустить fsck на всех разделах с указанным типом файловой системы, например, «ext4», используйте fsck с опцией «t», а затем тип файловой системы,
$ fsck -t ext4 /dev/sdb1
или
$ fsck -t -A ext4
Выполнять проверку только на несмонтированных дисках
Чтобы убедиться, что fsck выполняется только на несмонтированных дисках, мы будем использовать опцию «M» при запуске fsck,
$ fsck -AM
Вот наше короткое руководство по команде fsck с примерами.
Пожалуйста, не стесняйтесь присылать нам свои вопросы, используя поле для комментариев ниже.
Hard disk failures are just a thing that’s bound to happen to every computer. But, time of complete failure is something that you should estimate based on the scan results. Presence of bad sectors is the beginning of the end of a hard disk drive. Bad sectors are hardware related and can’t be fixed. You can only monitor it and make your OS to not use the bad sectors for writing data.
You Might Be Interested In
- Linux PS command with examples
- Tmux takes your Linux terminal to a whole new level
- 25 basic Linux commands a beginner needs to know
- How to sync date and time from the command-line in Ubuntu
- How to capture the Tmux pane history
- How to use htop command to monitor system processes in real-time
In this session of Terminal Tuts, let’s learn how to find out the presence of bad sectors and errors in your computer’s hard disk. We had already published the GUI method of finding SMART status and errors using ‘Disks’ utility – just FYI.
Scan for Bad Sectors and Errors on the hard disk in Ubuntu, Linux Mint, and elementary OS
Note that if you want to scan your computer’s internal hard disk which is mounted, you should be using an Ubuntu Live USB drive and boot into it. Then launch ‘Terminal’ from the Live environment and follow these steps. If you are checking an external hard disk, you need to see that it is not mounted.
Step 1: First, let’s use the fdisk command to find out the hard disk partitions status.
sudo fdisk -l
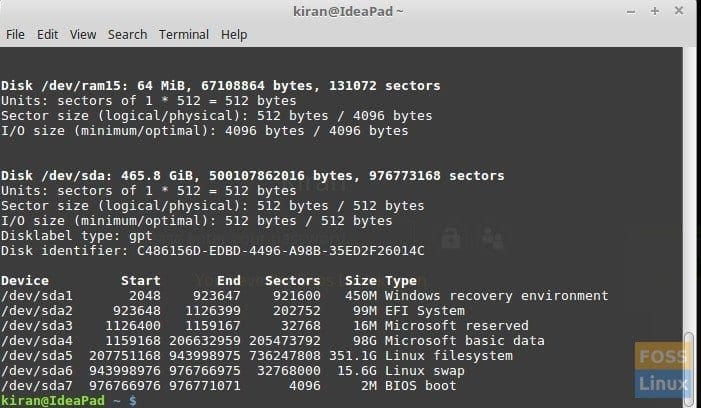
fdisk command output
You should see a few entries of RAM. For example, Disk /dev/ram15 seen in my test PC. You can ignore it as this is the RAM disk driver used by main system memory as a block device.
In the above screen-shot example, /dev/sda is the hard disk of size 465.8 GB that I’m interested in scanning.
Step 2: Next, let’s find if there are any Bad Sectors on the hard disk. We shall use badblocks command. Make sure to enter your hard disk info instead of /dev/sda in below command. My test PC has /dev/sda for the hard disk. This command will scan for bad blocks in the hard disk and then export the result to the file badsectors.txt in the ‘scan_result’ directory.
sudo badblocks -v /dev/sda > /scan_result/badsectors.txt
Step 3: Finally we shall use fsck command to tell Ubuntu not to use the bad sectors mentioned in the badsectors.txt file. That way life of the hard disk is increased a bit until you get a new one for replacement.
sudo fsck -l /scan_result/badsectors.txt /dev/sda
You Might Be Interested In
- How to search Wikipedia by command-line on Ubuntu
- How to download Torrents using the command-line in Terminal
- Creating, Deleting, and Managing Directories on Linux
- How to create and edit text files using command-line from Linux Terminal
- Apt vs. Aptitude Command: A Definitive Guide
- Top 6 commands to check the memory usage on Linux
18 comments

parity n
February 14, 2018 — 6:46 AM
how long did it take to scan your 465.8 GB drive? i.e.run step 2 from start to finish.
I started it on a 1.5Tb external drive and it ran for over 30 minutes (without any clue how long was left), so killed it. Can we run it with the ‘-s’ option (to show progress bar)?, if so, does it give a good indication of progress?
Reply

parity n
February 14, 2018 — 6:46 AM
how long did it take to scan your 465.8 GB drive? i.e.run step 2 from start to finish.
I started it on a 1.5Tb external drive and it ran for over 30 minutes (without any clue how long was left), so killed it. Can we run it with the ‘-s’ option (to show progress bar)?, if so, does it give a good indication of progress?
Reply
Kiran Kumar
February 17, 2018 — 9:15 PM
Sorry, I don’t remember how long it took, but generally badblocks command is not the fastest. It takes several days sometimes to even complete a 1TB hard disk. 30 minutes is too short in your case. You can use -s to show progress bar. The command format for it: badblocks -s device. All the best!
Reply
parity n
February 27, 2018 — 9:31 PM
I ran the badblocks test on my 1.5TB external usb drive with the -s switch. It gives % complete and time elapsed (in seconds). Once it hit 1% I looked at the time elapsed. It said 138 seconds, so I multiplied this by 100 = 138000, then divided by 60 (to get minutes), again divided by 60 (to get hours) = 3.8 hours.
Left it running this time. It actually took around 4 hours to complete. So with the -s switch you can get an idea/estimate (early on in the process) how long it will take to complete.
Here’s my output:
test@test:~$ sudo badblocks -v -s /dev/sdc > ~/testbadblocks-ext-hdd.txt
Checking blocks 0 to 1465105407
Checking for bad blocks (read-only test): 0.00% done, 0:00 elapsed. (0/0/0 errdone
Pass completed, 0 bad blocks found. (0/0/0 errors)
The process was pretty resource hungry. Don’t know if running it in the background/low priority will make it less resource intensive. (probably take longer to complete) Something to ponder.
Reply

QuikMaths
April 22, 2019 — 6:17 AM
138 seconds is just over 2 minutes… I don’t know what kind of maths you applied but if the elapsed time said 138 seconds that means that it took 2 minutes and 18 seconds to reach a progress of 1%.
Reply

QuikMaths
April 22, 2019 — 6:17 AM
138 seconds is just over 2 minutes… I don’t know what kind of maths you applied but if the elapsed time said 138 seconds that means that it took 2 minutes and 18 seconds to reach a progress of 1%.
Reply
marc
November 21, 2020 — 9:07 PM
True, but he said it was at 1%. He used normal maths. I don’t know what kind of reading you applied.

Rajarshi Paul
May 15, 2018 — 11:13 AM
Hello Sir,
I cannot access my hard drive partitions on my Ubuntu OS. I have a 500Gb Hard disk size which is not accessible or rather even visible with the Ubuntu OS. Any suggestions?
Reply

Rajarshi Paul
May 15, 2018 — 11:13 AM
Hello Sir,
I cannot access my hard drive partitions on my Ubuntu OS. I have a 500Gb Hard disk size which is not accessible or rather even visible with the Ubuntu OS. Any suggestions?
Reply
Ingo
May 24, 2018 — 3:43 PM
sudo fsck -l < /scan_result/badsectors.txt /dev/sda
Reply

Ali
July 5, 2018 — 3:24 AM
Dear Kiran, Thank you for this article. it’s really helpful. there’s only one problem (maybe 2) . When I run the fsck command, I receive the following error messages:
fsck: the -l option can be used with one device only — ignore
e2fsck: need terminal for interactive repairs
any idea what can be done about them?
Reply

Ali
July 5, 2018 — 3:24 AM
Dear Kiran, Thank you for this article. it’s really helpful. there’s only one problem (maybe 2) . When I run the fsck command, I receive the following error messages:
fsck: the -l option can be used with one device only — ignore
e2fsck: need terminal for interactive repairs
any idea what can be done about them?
Reply
Henrique Picelli
November 22, 2018 — 8:30 AM
Hi there, just a question. If my hard drive shows 0 bad sectors, should i tell Ubuntu the output file or it is not necessary?
Best regards,
Henrique
Reply

Mustafa
January 8, 2019 — 8:57 AM
Hello, I have a new laptop with a new SSD hard disk and I don’t have ‘SDA’ name for my hard disk partition. Since new SSDs are using NVMe drivers the name of partitions comes such as “nvme0n1p1”. I cannot use these kinds of names with smart or any other application so far. Disks program also does not give me anything because the “self-test” button is inactive.
Do you know how can I get information about the health of my hard disk with NVMe drivers?
Reply

Mustafa
January 8, 2019 — 8:57 AM
Hello, I have a new laptop with a new SSD hard disk and I don’t have ‘SDA’ name for my hard disk partition. Since new SSDs are using NVMe drivers the name of partitions comes such as “nvme0n1p1”. I cannot use these kinds of names with smart or any other application so far. Disks program also does not give me anything because the “self-test” button is inactive.
Do you know how can I get information about the health of my hard disk with NVMe drivers?
Reply
Kammua
July 26, 2020 — 12:54 PM
Dear Mustafa,
SSDs do not need to be checked for bad sectors. They are not mechanical drives. If they start to fail it is because of flash memory’s limited rewrite potential. A SSD that is failing has run it’s usable lifespan, and needs to be replaced immedeately. Perhaps SSDs of the future will use memory technologies with indefinite rewrites. But until then it’s best to replace them about every 5 years, before they show signs of failure.
Reply

John
August 5, 2019 — 3:57 PM
Dear Kiram,
Thank your for sharing this information. I would suggest you to use:
sudo badblocks -vs /dev/sda > /scan_result/badsectors.txt
because it takes some time to finish the task and “-vs” (specially the “s”) give you a update of the task completed.
Reply

John
August 5, 2019 — 3:57 PM
Dear Kiram,
Thank your for sharing this information. I would suggest you to use:
sudo badblocks -vs /dev/sda > /scan_result/badsectors.txt
because it takes some time to finish the task and “-vs” (specially the “s”) give you a update of the task completed.
Reply
Christophe NAUD
September 17, 2019 — 12:27 PM
christophe@christophe-ESPRIMO-E5731:~$ sudo badblocks -v /dev/sdb1 > /scan_result/badsectors.txt
bash: /scan_result/badsectors.txt: No such file or directory
Reply

Sanaul
October 25, 2021 — 3:27 AM
I have same problem
Reply

Sanaul
October 25, 2021 — 3:27 AM
I have same problem
Reply
UncleMonkeyPants
November 23, 2021 — 6:38 AM
the ‘ > /scan_result/badsectors.txt ‘ part means “write the results to this file”. You’re getting that error because the directory /scan_result does not exist, so use a different directory, like ~/Desktop/badsectors.txt or something
Reply

Andy
March 14, 2020 — 5:30 PM
If you get :
badblocks: Value too large for defined data type invalid end block (7814026240): must be 32-bit value
Then add -b 4096
e.g.
sudo badblocks -b 4096 -vs /dev/sdb > ~/Desktop/badsectors.txt
Andy
Reply

Andy
March 14, 2020 — 5:30 PM
If you get :
badblocks: Value too large for defined data type invalid end block (7814026240): must be 32-bit value
Then add -b 4096
e.g.
sudo badblocks -b 4096 -vs /dev/sdb > ~/Desktop/badsectors.txt
Andy
Reply
Vitalicsu
March 13, 2021 — 10:50 AM
fsck from util-linux 2.34
fsck: the -l option can be used with one device only — ignore
e2fsck: need terminal for interactive repairs
Reply
Leave a Comment
FSCK – очень важная утилита для Linux / Unix, она используется для проверки и исправления ошибок в файловой системе.
Она похоже на утилиту «chkdsk» в операционных системах Windows.
Она также доступна для операционных систем Linux, MacOS, FreeBSD.
FSCK означает «File System Consistency Check», и в большинстве случаев он запускается во время загрузки, но может также запускаться суперпользователем вручную, если возникнет такая необходимость.
Может использоваться с 3 режимами работы,
1- Проверка наличия ошибок и позволить пользователю решить, что делать с каждой ошибкой,
2- Проверка на наличие ошибок и возможность сделать фикс автоматически, или,
3- Проверка наличия ошибок и возможность отобразить ошибку, но не выполнять фикс.
Содержание
- Синтаксис использования команды FSCK
- Команда Fsck с примерами
- Выполним проверку на ошибки в одном разделе
- Проверьте файловую систему на ошибки и исправьте их автоматически
- Проверьте файловую систему на наличие ошибок, но не исправляйте их
- Выполним проверку на ошибки на всех разделах
- Проверим раздел с указанной файловой системой
- Выполнять проверку только на несмонтированных дисках
Синтаксис использования команды FSCK
$ fsck options drives
Опции, которые можно использовать с командой fsck:
- -p Автоматический фикс (без вопросов)
- -n не вносить изменений в файловую систему
- -у принять «yes» на все вопросы
- -c Проверить наличие плохих блоков и добавить их в список.
- -f Принудительная проверка, даже если файловая система помечена как чистая
- -v подробный режим
- -b использование альтернативного суперблока
- -B blocksize Принудительный размер блоков при поиске суперблока
- -j external_journal Установить местоположение внешнего журнала
- -l bad_blocks_file Добавить в список плохих блоков
- -L bad_blocks_file Установить список плохих блоков
Мы можем использовать любую из этих опций, в зависимости от операции, которую нам нужно выполнить.
Давайте обсудим некоторые варианты команды fsck с примерами.
Команда Fsck с примерами
Примечание: – Прежде чем обсуждать какие-либо примеры, прочтите это. Мы не должны использовать FSCK на смонтированных дисках, так как высока вероятность того, что fsck на смонтированном диске повредит диск навсегда.
Поэтому перед выполнением fsck мы должны отмонтировать диск с помощью следующей команды:
$ umount drivename
Например:
$ umount /dev/sdb1
Вы можете проверить номер раздела с помощью следующей команды:
$ fdisk -l
Также при запуске fsck мы можем получить некоторые коды ошибок.
Ниже приведен список кодов ошибок, которые мы могли бы получить при выполнении команды вместе с их значениями:
- 0 – нет ошибок
- 1 – исправлены ошибки файловой системы
- 2 – система должна быть перезагружена
- 4 – Ошибки файловой системы оставлены без исправлений
- 8 – Операционная ошибка
- 16 – ошибка использования или синтаксиса
- 32 – Fsck отменен по запросу пользователя
- 128 – Ошибка общей библиотеки
Теперь давайте обсудим использование команды fsck с примерами в системах Linux.
Выполним проверку на ошибки в одном разделе
Чтобы выполнить проверку на одном разделе, выполните следующую команду из терминала:
$ umount /dev/sdb1 $ fsck /dev/sdb1
Проверьте файловую систему на ошибки и исправьте их автоматически
Запустите команду fsck с параметром «a» для проверки целостности и автоматического восстановления, выполните следующую команду.
Мы также можем использовать опцию «у» вместо опции «а».
$ fsck -a /dev/sdb1
Проверьте файловую систему на наличие ошибок, но не исправляйте их
В случае, если нам нужно только увидеть ошибки, которые происходят в нашей файловой системе, и не нужно их исправлять, тогда мы должны запустить fsck с опцией “n”,
$ fsck -n /dev/sdb1
Выполним проверку на ошибки на всех разделах
Чтобы выполнить проверку файловой системы для всех разделов за один раз, используйте fsck с опцией «A»
$ fsck -A
Чтобы отключить проверку корневой файловой системы, мы будем использовать опцию «R»
$ fsck -AR
Проверим раздел с указанной файловой системой
Чтобы запустить fsck на всех разделах с указанным типом файловой системы, например, «ext4», используйте fsck с опцией «t», а затем тип файловой системы,
$ fsck -t ext4 /dev/sdb1
или
$ fsck -t -A ext4
Выполнять проверку только на несмонтированных дисках
Чтобы убедиться, что fsck выполняется только на несмонтированных дисках, мы будем использовать опцию «M» при запуске fsck,
$ fsck -AM
Вот наше короткое руководство по команде fsck с примерами.
Пожалуйста, не стесняйтесь присылать нам свои вопросы, используя поле для комментариев ниже.