
В C++ различают ошибки времени компиляции и ошибки времени выполнения. Ошибки первого типа обнаруживает компилятор до запуска программы. К ним относятся, например, синтаксические ошибки в коде. Ошибки второго типа проявляются при запуске программы. Примеры ошибок времени выполнения: ввод некорректных данных, некорректная работа с памятью, недостаток места на диске и т. д. Часто такие ошибки могут привести к неопределённому поведению программы.
Некоторые ошибки времени выполнения можно обнаружить заранее с помощью проверок в коде. Например, такими могут быть ошибки, нарушающие инвариант класса в конструкторе. Обычно, если ошибка обнаружена, то дальнейшее выполение функции не имеет смысла, и нужно сообщить об ошибке в то место кода, откуда эта функция была вызвана. Для этого предназначен механизм исключений.
Коды возврата и исключения
Рассмотрим функцию, которая считывает со стандартного потока возраст и возвращает его вызывающей стороне. Добавим в функцию проверку корректности возраста: он должен находиться в диапазоне от 0 до 128 лет. Предположим, что повторный ввод возраста в случае ошибки не предусмотрен.
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
// Что вернуть в этом случае?
}
return age;
}
Что вернуть в случае некорректного возраста? Можно было бы, например, договориться, что в этом случае функция возвращает ноль. Но тогда похожая проверка должна быть и в месте вызова функции:
int main() {
if (int age = ReadAge(); age == 0) {
// Произошла ошибка
} else {
// Работаем с возрастом age
}
}
Такая проверка неудобна. Более того, нет никакой гарантии, что в вызывающей функции программист вообще её напишет. Фактически мы тут выбрали некоторое значение функции (ноль), обозначающее ошибку. Это пример подхода к обработке ошибок через коды возврата. Другим примером такого подхода является хорошо знакомая нам функция main. Только она должна возвращать ноль при успешном завершении и что-либо ненулевое в случае ошибки.
Другим способом сообщить об обнаруженной ошибке являются исключения. С каждым сгенерированным исключением связан некоторый объект, который как-то описывает ошибку. Таким объектом может быть что угодно — даже целое число или строка. Но обычно для описания ошибки заводят специальный класс и генерируют объект этого класса:
#include <iostream>
struct WrongAgeException {
int age;
};
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Здесь в случае ошибки оператор throw генерирует исключение, которое представлено временным объектом типа WrongAgeException. В этом объекте сохранён для контекста текущий неправильный возраст age. Функция досрочно завершает работу: у неё нет возможности обработать эту ошибку, и она должна сообщить о ней наружу. Поток управления возвращается в то место, откуда функция была вызвана. Там исключение может быть перехвачено и обработано.
Перехват исключения
Мы вызывали нашу функцию ReadAge из функции main. Обработать ошибку в месте вызова можно с помощью блока try/catch:
int main() {
try {
age = ReadAge(); // может сгенерировать исключение
// Работаем с возрастом age
} catch (const WrongAgeException& ex) { // ловим объект исключения
std::cerr << "Age is not correct: " << ex.age << "n";
return 1; // выходим из функции main с ненулевым кодом возврата
}
// ...
}
Мы знаем заранее, что функция ReadAge может сгенерировать исключение типа WrongAgeException. Поэтому мы оборачиваем вызов этой функции в блок try. Если происходит исключение, для него подбирается подходящий catch-обработчик. Таких обработчиков может быть несколько. Можно смотреть на них как на набор перегруженных функций от одного аргумента — объекта исключения. Выбирается первый подходящий по типу обработчик и выполняется его код. Если же ни один обработчик не подходит по типу, то исключение считается необработанным. В этом случае оно пробрасывается дальше по стеку — туда, откуда была вызвана текущая функция. А если обработчик не найдётся даже в функции main, то программа аварийно завершается.
Усложним немного наш пример, чтобы из функции ReadAge могли вылетать исключения разных типов. Сейчас мы проверяем только значение возраста, считая, что на вход поступило число. Но предположим, что поток ввода досрочно оборвался, или на входе была строка вместо числа. В таком случае конструкция std::cin >> age никак не изменит переменную age, а лишь возведёт специальный флаг ошибки в объекте std::cin. Наша переменная age останется непроинициализированной: в ней будет лежать неопределённый мусор. Можно было бы явно проверить этот флаг в объекте std::cin, но мы вместо этого включим режим генерации исключений при таких ошибках ввода:
int ReadAge() {
std::cin.exceptions(std::istream::failbit);
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Теперь ошибка чтения в операторе >> у потока ввода будет приводить к исключению типа std::istream::failure. Функция ReadAge его не обрабатывает. Поэтому такое исключение покинет пределы этой функции. Поймаем его в функции main:
int main() {
try {
age = ReadAge(); // может сгенерировать исключения разных типов
// Работаем с возрастом age
} catch (const WrongAgeException& ex) {
std::cerr << "Age is not correct: " << ex.age << "n";
return 1;
} catch (const std::istream::failure& ex) {
std::cerr << "Failed to read age: " << ex.what() << "n";
return 1;
} catch (...) {
std::cerr << "Some other exceptionn";
return 1;
}
// ...
}
При обработке мы воспользовались функцией ex.what у исключения типа std::istream::failure. Такие функции есть у всех исключений стандартной библиотеки: они возвращают текстовое описание ошибки.
Обратите внимание на третий catch с многоточием. Такой блок, если он присутствует, будет перехватывать любые исключения, не перехваченные ранее.
Исключения стандартной библиотеки
Функции и классы стандартной библиотеки в некоторых ситуациях генерируют исключения особых типов. Все такие типы выстроены в иерархию наследования от базового класса std::exception. Иерархия классов позволяет писать обработчик catch сразу на группу ошибок, которые представлены базовым классом: std::logic_error, std::runtime_error и т. д.
Вот несколько примеров:
-
Функция
atу контейнеровstd::array,std::vectorиstd::dequeгенерирует исключениеstd::out_of_rangeпри некорректном индексе. -
Аналогично, функция
atуstd::map,std::unordered_mapи у соответствующих мультиконтейнеров генерирует исключениеstd::out_of_rangeпри отсутствующем ключе. -
Обращение к значению у пустого объекта
std::optionalприводит к исключениюstd::bad_optional_access. -
Потоки ввода-вывода могут генерировать исключение
std::ios_base::failure.
Исключения в конструкторах
В главе 3.1 мы написали класс Time. Этот класс должен был соблюдать инвариант на значение часов, минут и секунд: они должны были быть корректными. Если на вход конструктору класса Time передавались некорректные значения, мы приводили их к корректным, используя деление с остатком.
Более правильным было бы сгенерировать в конструкторе исключение. Таким образом мы бы явно передали сообщение об ошибке во внешнюю функцию, которая пыталась создать объект.
class Time {
private:
int hours, minutes, seconds;
public:
// Заведём класс для исключения и поместим его внутрь класса Time как в пространство имён
class IncorrectTimeException {
};
Time::Time(int h, int m, int s) {
if (s < 0 || s > 59 || m < 0 || m > 59 || h < 0 || h > 23) {
throw IncorrectTimeException();
}
hours = h;
minutes = m;
seconds = s;
}
// ...
};
Генерировать исключения в конструкторах — совершенно нормальная практика. Однако не следует допускать, чтобы исключения покидали пределы деструкторов. Чтобы понять причины, посмотрим подробнее, что происходит при генерации исключения.
Свёртка стека
Вспомним класс Logger из предыдущей главы. Посмотрим, как он ведёт себя при возникновении исключения. Воспользуемся в этом примере стандартным базовым классом std::exception, чтобы не писать свой класс исключения.
#include <exception>
#include <iostream>
void f() {
std::cout << "Welcome to f()!n";
Logger x;
// ...
throw std::exception(); // в какой-то момент происходит исключение
}
int main() {
try {
Logger y;
f();
} catch (const std::exception&) {
std::cout << "Something happened...n";
return 1;
}
}
Мы увидим такой вывод:
Logger(): 1 Welcome to f()! Logger(): 2 ~Logger(): 2 ~Logger(): 1 Something happened...
Сначала создаётся объект y в блоке try. Затем мы входим в функцию f. В ней создаётся объект x. После этого происходит исключение. Мы должны досрочно покинуть функцию. В этот момент начинается свёртка стека (stack unwinding): вызываются деструкторы для всех созданных объектов в самой функции и в блоке try, как если бы они вышли из своей области видимости. Поэтому перед обработчиком исключения мы видим вызов деструктора объекта x, а затем — объекта y.
Аналогично, свёртка стека происходит и при генерации исключения в конструкторе. Напишем класс с полем Logger и сгенерируем нарочно исключение в его конструкторе:
#include <exception>
#include <iostream>
class C {
private:
Logger x;
public:
C() {
std::cout << "C()n";
Logger y;
// ...
throw std::exception();
}
~C() {
std::cout << "~C()n";
}
};
int main() {
try {
C c;
} catch (const std::exception&) {
std::cout << "Something happened...n";
}
}
Вывод программы:
Logger(): 1 // конструктор поля x C() Logger(): 2 // конструктор локальной переменной y ~Logger(): 2 // свёртка стека: деструктор y ~Logger(): 1 // свёртка стека: деструктор поля x Something happened...
Заметим, что деструктор самого класса C не вызывается, так как объект в конструкторе не был создан.
Механизм свёртки стека гарантирует, что деструкторы для всех созданных автоматических объектов или полей класса в любом случае будут вызваны. Однако он полагается на важное свойство: деструкторы самих классов не должны генерировать исключений. Если исключение в деструкторе произойдёт в момент свёртки стека при обработке другого исключения, то программа аварийно завершится.
Пример с динамической памятью
Подчеркнём, что свёртка стека работает только с автоматическими объектами. В этом нет ничего удивительного: ведь за временем жизни объектов, созданных в динамической памяти, программист должен следить самостоятельно. Исключения вносят дополнительные сложности в ручное управление динамическими объектами:
void f() {
Logger* ptr = new Logger(); // конструируем объект класса Logger в динамической памяти
// ...
g(); // вызываем какую-то функцию
// ...
delete ptr; // вызываем деструктор и очищаем динамическую память
}
На первый взгляд кажется, что в этом коде нет ничего опасного: delete вызывается в конце функции. Однако функция g может сгенерировать исключение. Мы не перехватываем его в нашей функции f. Механизм свёртки уберёт со стека лишь сам указатель ptr, который является автоматической переменной примитивного типа. Однако он ничего не сможет сделать с объектом в памяти, на которую ссылается этот указатель. В логе мы увидим только вызов конструктора класса Logger, но не увидим вызова деструктора. Нам придётся обработать исключение вручную:
void f() {
Logger* ptr = new Logger();
// ...
try {
g();
} catch (...) { // ловим любое исключение
delete ptr; // вручную удаляем объект
throw; // перекидываем объект исключения дальше
}
// ...
delete ptr;
}
Здесь мы перехватываем любое исключение и частично обрабатываем его, удаляя объект в динамической памяти. Затем мы прокидываем текущий объект исключения дальше с помощью оператора throw без аргументов.
Согласитесь, этот код очень далёк от совершенства. При непосредственной работе с объектами в динамической памяти нам приходится оборачивать в try/catch любую конструкцию, из которой может вылететь исключение. Понятно, что такой код чреват ошибками. В главе 3.6 мы узнаем, как с точки зрения C++ следует работать с такими ресурсами, как память.
Гарантии безопасности исключений
Предположим, что мы пишем свой класс-контейнер, похожий на двусвязный список. Наш контейнер позволяет добавлять элементы в хранилище и отдельно хранит количество элементов в некотором поле elementsCount. Один из инвариантов этого класса такой: значение elementsCount равно реальному числу элементов в хранилище.
Не вдаваясь в детали, давайте посмотрим, как могла бы выглядеть функция добавления элемента.
template <typename T>
class List {
private:
struct Node { // узел двусвязного списка
T element;
Node* prev = nullptr; // предыдущий узел
Node* next = nullptr; // следующий узел
};
Node* first = nullptr; // первый узел списка
Node* last = nullptr; // последний узел списка
int elementsCount = 0;
public:
// ...
size_t Size() const {
return elementsCount;
}
void PushBack(const T& elem) {
++elementsCount;
// Конструируем в динамической памяти новой узел списка
Node* node = new Node(elem, last, nullptr);
// Связываем новый узел с остальными узлами
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
}
};
Не будем здесь рассматривать другие функции класса — конструкторы, деструктор, оператор присваивания… Рассмотрим функцию PushBack. В ней могут произойти такие исключения:
-
Выражение
newможет сгенерировать исключениеstd::bad_allocиз-за нехватки памяти. -
Конструктор копирования класса
Tможет сгенерировать произвольное исключение. Этот конструктор вызывается при инициализации поляelementсоздаваемого узла в конструкторе классаNode. В этом случаеnewведёт себя как транзакция: выделенная перед этим динамическая память корректно вернётся системе.
Эти исключения не перехватываются в функции PushBack. Их может перехватить код, из которого PushBack вызывался:
#include <iostream>
class C; // какой-то класс
int main() {
List<C> data;
C element;
try {
data.PushBack(element);
} catch (...) { // не получилось добавить элемент
std::cout << data.Size() << "n"; // внезапно 1, а не 0
}
// работаем дальше с data
}
Наша функция PushBack сначала увеличивает счётчик элементов, а затем выполняет опасные операции. Если происходит исключение, то в классе List нарушается инвариант: значение счётчика elementsCount перестаёт соответствовать реальности. Можно сказать, что функция PushBack не даёт гарантий безопасности.
Всего выделяют четыре уровня гарантий безопасности исключений (exception safety guarantees):
-
Гарантия отсутствия сбоев. Функции с такими гарантиями вообще не выбрасывают исключений. Примерами могут служить правильно написанные деструктор и конструктор перемещения, а также константные функции вида
Size. -
Строгая гарантия безопасности. Исключение может возникнуть, но от этого объект нашего класса не поменяет состояние: количество элементов останется прежним, итераторы и ссылки не будут инвалидированы и т. д.
-
Базовая гарантия безопасности. При исключении состояние объекта может поменяться, но оно останется внутренне согласованным, то есть, инварианты будут соблюдаться.
-
Отсутсвие гарантий. Это довольно опасная категория: при возникновении исключений могут нарушаться инварианты.
Всегда стоит разрабатывать классы, обеспечивающие хотя бы базовую гарантию безопасности. При этом не всегда возможно эффективно обеспечить строгую гарантию.
Переместим в нашей функции PushBack изменение счётчика в конец:
void PushBack(const T& elem) {
Node* node = new Node(elem, last, nullptr);
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
++elementsCount; // выполнится только если раньше не было исключений
}
Теперь такая функция соответствует строгой гарантии безопасности.
В документации функций из классов стандартной библиотеки обычно указано, какой уровень гарантии они обеспечивают. Рассмотрим, например, гарантии безопасности класса std::vector.
-
Деструктор, функции
empty,size,capacity, а такжеclearпредоставляют гарантию отсутствия сбоев. -
Функции
push_backиresizeпредоставляют строгую гарантию. -
Функция
insertпредоставляет лишь базовую гарантию. Можно было бы сделать так, чтобы она предоставляла строгую гарантию, но за это пришлось бы заплатить её эффективностью: при вставке в середину вектора пришлось бы делать реаллокацию.
Функции класса, которые гарантируют отсутсвие сбоев, следует помечать ключевым словом noexcept:
class C {
public:
void f() noexcept {
// ...
}
};
С одной стороны, эта подсказка позволяет компилятору генерировать более эффективный код. С другой — эффективно обрабатывать объекты таких классов в стандартных контейнерах. Например, std::vector<C> при реаллокации будет использовать конструктор перемещения класса C, если он помечен как noexcept. В противном случае будет использован конструктор копирования, который может быть менее эффективен, но зато позволит обеспечить строгую гарантию безопасности при реаллокации.
Типы исключений
Последнее обновление: 18.03.2023
Кроме типа exception в C++ есть еще несколько производных типов исключений, которые могут использоваться при различных ситуациях. Основные из них:
-
runtime_error: общий тип исключений, которые возникают во время выполнения
-
range_error: исключение, которое возникает, когда полученный результат превосходит допустимый диапазон
-
overflow_error: исключение, которое возникает, если полученный результат превышает допустимый диапазон
-
underflow_error: исключение, которое возникает, если полученный в вычислениях результат имеет недопустимое отрицательное значение (выход за нижнюю допустимую границу значений)
-
logic_error: исключение, которое возникает при наличии логических ошибок к коде программы
-
domain_error: исключение, которое возникает, если для некоторого значения, передаваемого в функцию, не определен результат
-
invalid_argument: исключение, которое возникает при передаче в функцию некорректного аргумента
-
length_error: исключение, которое возникает при попытке создать объект большего размера, чем допустим для данного типа
-
out_of_range: исключение, которое возникает при попытке доступа к элементам вне допустимого диапазона
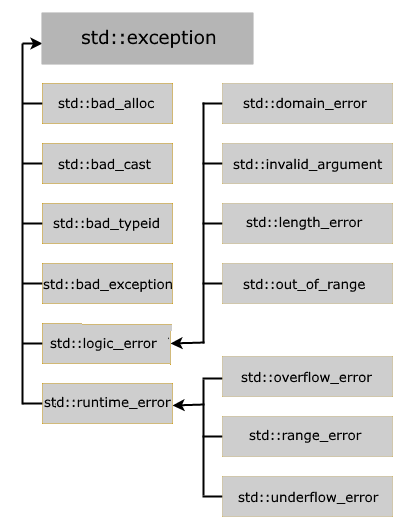
Многие стандартные типы исключений делятся на две группы в зависимости от базового класса — logic_error или runtime_error.
Большинство этих типов определено в заголовочном файле <stdexcept>
Типы, основанные на logic_error, предназначены для ошибок, которые могли быть обнаружены до выполнения программы и являются следствием неправильной логики программы. Например,
ввызов функции с одним или несколькими недопустимыми аргументами или вызов функции-члена для объекта, состояние которого не соответствует требованиям
для этой конкретной функции. Вместо обработки подобных исключений можно явно проверять допустимость аргументов или состояние объекта перед вызовом функции.
Другая группа, производная от runtime_error, предназначена для ошибок, которые могут быть обнаружены только во время выполнения.
Например, исключения, производные от system_error, обычно инкапсулируют ошибки, происходящие от вызовов базовой операционной системы,
таких как сбой ввода или вывода файла. Доступ к файлам, как и любое взаимодействие с оборудованием, всегда может дать сбой, который нельзя предсказать
(например, сбои диска, отсоединенные кабели, сбои сети и т. д.).
Конструкция try…catch может использовать несколько блоков catch для обработки различных типов исключений. При возникновении исключения
для его обработки будет выбран тот, который использует тип возникшего исключения.
При использовании нескольких блоков catch вначале помещаются блоки catch, которые обрабатывают более частные исключения, а только потом блоки catch с более
общими типами исключений:
#include <iostream>
class Person
{
public:
Person(std::string name, unsigned age)
{
if(name.length() > 11)
throw std::length_error("Name must be less than 10 chars");
if(!age || age > 110)
throw std::range_error("Age must be between 1 and 110");
this->name = name;
this->age = age;
}
void print() const
{
std::cout << "Name: " << name << "tAge: " << age << std::endl;
}
private:
std::string name;
unsigned age;
};
void testPerson(std::string name, unsigned age)
{
try
{
Person person{name, age}; // создаем один объект Person
person.print();
}
catch (const std::length_error& ex)
{
std::cout << "Length_error: " << ex.what() << std::endl;
}
catch (const std::range_error& ex)
{
std::cout << "Range_error: " << ex.what() << std::endl;
}
catch (const std::exception&)
{
std::cout << "Something wrong"<< std::endl;
}
}
int main()
{
testPerson("Tom", 38); // Name: Tom Age: 38
testPerson("Gai Yulii Cezar", 42); // Length_error: Name must be less than 10 chars
testPerson("Sam", 250); // Range_error: Age must be between 1 and 110
}
Здесь определен класс Person, в конструктор которого передаем строку-имя и число-возраст пользователя. Но передаваемые данные могут быть некорректными. Например, для допустимого возраста установим
пределельный диапазон 1-110, а имя не должно быть длинее 11 символов. И в конструкторе проверяем переданные значения и генерируем различные исключения:
Person(std::string name, unsigned age)
{
if(name.length() > 11)
throw std::length_error("Name must be less than 10 chars");
if(!age || age > 110)
throw std::range_error("Age must be between 1 and 110");
this->name = name;
this->age = age;
}
Для теста определена функция testPerson, в которой в блоке try создается объект Person. Конструкция try..catch использует три блока catch
для разных типов исключений. Причем последний блок представляет самый общий тип исключений exception. Второй блок
обрабатывает исключения типа range_error, производный от runtime_error. А первый блок обрабатывает исключения типа length_error, который является производным от
logic_error.
catch (const std::length_error& ex)
{
std::cout << "Length_error: " << ex.what() << std::endl;
}
catch (const std::range_error& ex)
{
std::cout << "Range_error: " << ex.what() << std::endl;
}
catch (const std::exception&)
{
std::cout << "Something wrong"<< std::endl;
}
С помощью функции what() в блоках catch возвращаем информацию об ошибке. И в данном случае программа выдаст следующий результат:
Name: Tom Age: 38 Length_error: Name must be less than 10 chars Range_error: Age must be between 1 and 110
Раздел: Статьи /
С/С++ /
Ошибки программирования в С++
|
|
Все способы изучить С++
Начинающие программисты даже не догадываются о том, какой огромный пласт в этой области скрыт от их глаз, и чего многие из новичков не увидят никогда, потому что это тёмная сторона программирования — чистый исходный код системного уровня… |

Даже простая программа может содержать ошибки. Эти ошибки надо уметь находить и устранять.
Как это делать? Какие средства использовать?
Этим темам посвящены целые книги. Я не буду говорить об отладке слишком долго. Однако общее понимание того, зачем это надо и как это работает, должен иметь даже начинающий программист.
Именно поэтому я и создал этот раздел.
Здесь будут статьи и видео об ошибках программирования в С++. Именно на этот язык сделан упор. И особое внимание уделяется тем ошибкам, которые совершают начинающие программисты, переходящие с Паскаля на С++.
Однако это не значит, что программистам на других языках этот раздел ничего не даст. Как правило, новички совершают одинаковые ошибки. Поэтому, хотя все примеры будут на языке С++, большинство из них будут типичными для всех языков.
Виды ошибок в программировании
Ошибки можно разделить на три вида:
- Синтаксические ошибки. Это самые простые ошибки, так как если в вашей программе есть такая ошибка, то программа просто не будет создана, а компилятор выдаст сообщение об ошибке с указанием строки в исходном коде, где была найдена ошибка.
- Семантические ошибки. Эти ошибки не подвластны компилятору. Такие ошибки обычно очень трудно найти и поэтому их называют труднонаходимыми.
- Ошибки времени выполнения. Это ошибки, которые могут произойти во время выполнения программы. Например, если пользователь введёт ноль в качестве делителя — тогда произойдёт ошибка, так как на ноль делить нельзя.
Статьи об ошибках в С++
Более подробно об ошибках как-нибудь в другой раз. А пока вот список статей с конкретными примерами ошибок в С++:
- Закон Мэрфи. Вступительное слово и немного юмора.
- Равно или не равно. Об ошибочном использовании оператора присваивания в С++.
- А ещё есть циклы. Продолжение предыдущей темы.
- Как неправильно вызвать функцию. Об особенностях вызова функций в С++ и типичных ошибках новичков.
- Проблемы с идентификаторами. Начинающие могут споткнуться даже здесь.
- Строки и символы в C++. О некоторых особенностях использования строк и символов в С++, и об ошибках, которые можно при этом совершить.
- Автоматическое преобразование типов. О неожиданностях, которые ждут новичков при автоматическом преобразовании типов в С++.
- Унарные операторы. Об особенностях использования операторов инкремента и декремента и ошибках, которые можно совершить при их использовании.
|
|
Как стать программистом 2.0
Эта книга для тех, кто хочет стать программистом. На самом деле хочет, а не просто мечтает. И хочет именно стать программистом с большой буквы, а не просто научиться кулебякать какие-то примитивные программки… |

Аннотация: Попытка классификации ошибок. Сообщение об ошибке с помощью возвращаемого значения. Исключительные ситуации. Обработка исключительных ситуаций, операторы try и catch.
Виды ошибок
Существенной частью любой программы является обработка ошибок.
Прежде чем перейти к описанию средств языка Си++, предназначенных
для обработки ошибок, остановимся немного на том,какие, собственно, ошибки
мы будем рассматривать.
Ошибки компиляции пропустим:пока все они не исправлены,
программа не готова, и запустить ее нельзя. Здесь мы будем рассматривать
только ошибки, происходящие во время выполнения программы.
Первый вид ошибок, который всегда приходит в голову – это ошибки
программирования. Сюда относятся ошибки в алгоритме, в логике
программы и чисто программистские ошибки. Ряд возможных ошибок
мы называли ранее (например, при работе с указателями), но гораздо
больше вы узнаете на собственном горьком опыте.
Теоретически возможно написать программу без таких ошибок. Во
многом язык Си++ помогает предотвратить ошибки во время выполнения
программы,осуществляя строгий контроль на стадии компиляции.
Вообще, чем строже контроль на стадии компиляции, тем меньше ошибок
остается при выполнении программы.
Перечислим некоторые средства языка, которые помогут избежать ошибок:
-
Контроль типов. Случаи использования недопустимых операций
и смешения несовместимых типов будут обнаружены компилятором. - Обязательное объявление имен до их использования. Невозможно
вызвать функцию с неверным числом аргументов. При изменении определения
переменной или функции легко обнаружить все места, где она
используется. - Ограничение видимости имен, контексты имен. Уменьшается возможность
конфликтов имен, неправильного переопределения имен.
Самым важным средством уменьшения вероятности ошибок является
объектно-ориентированный подход к программированию, который поддерживает
язык Си++. Наряду с преимуществами объектного программирования,
о которых мы говорили ранее, построение программы из классов позволяет
отлаживать классы по отдельности и строить программы из надежных
составных «кирпичиков», используя одни и те же классы многократно.
Несмотря на все эти положительные качества языка, остается «простор»
для написания ошибочных программ. По мере рассмотрения
свойств языка, мы стараемся давать рекомендации, какие возможности
использовать, чтобы уменьшить вероятность ошибки.
Лучше исходить из того, что идеальных программ не существует, это
помогает разрабатывать более надежные программы. Самое главное –
обеспечить контроль данных, а для этого необходимо проверять в программе
все, что может содержать ошибку. Если в программе предполагается
какое-то условие, желательно проверить его, хотя бы в начальной
версии программы, до того, как можно будет на опыте убедиться, что это
условие действительно выполняется. Важно также проверять указатели,
передаваемые в качестве аргументов, на равенство нулю; проверять, не
выходят ли индексы за границы массива и т.п.
Ну и решающими качествами, позволяющими уменьшить количество ошибок,
являются внимательность, аккуратность и опыт.
Второй вид ошибок – «предусмотренные», запланированные ошибки.
Если разрабатывается программа диалога с пользователем, такая
программа обязана адекватно реагировать и обрабатывать неправильные
нажатия клавиш. Программа чтения текста должна учитывать возможные
синтаксические ошибки. Программа передачи данных по телефонной линии
должна обрабатывать помехи и возможные сбои при передаче. Такие ошибки – это, вообще говоря, не ошибки с точки зрения программы, а
плановые ситуации, которые она обрабатывает.
Третий вид ошибок тоже в какой-то мере предусмотрен. Это исключительные
ситуации, которые могут иметь место, даже если в программе
нет ошибок . Например, нехватка памяти для создания нового объекта.
Или сбой диска при извлечении информации из базы данных.
Именно обработка двух последних видов ошибок и рассматривается в последующих
разделах. Граница между ними довольно условна. Например,
для большинства программ сбой диска – исключительная ситуация, но
для операционной системы сбой диска должен быть предусмотрен и должен
обрабатываться. Скорее два типа можно разграничить по тому, какая
реакция программы должна быть предусмотрена. Если после плановых ошибок программа должна продолжать работать, то после исключительных
ситуаций надо лишь сохранить уже вычисленные данные и завершить программу.
Возвращаемое значение как признак ошибки
Простейший способ сообщения об ошибках предполагает использование возвращаемого значения функции или метода. Функция сохранения
объекта в базе данных может возвращать логическое значение: true в
случае успешного сохранения, false – в случае ошибки.
class Database
{
public:
bool SaveObject(const Object& obj);
};
Соответственно, вызов метода должен выглядеть так:
if (database.SaveObject(my_obj) == false ){
//обработка ошибки
}
Обработка ошибки, разумеется, зависит от конкретной программы.
Типична ситуация, когда при многократно вложенных вызовах функций
обработка происходит на несколько уровней выше, чем уровень, где ошибка произошла. В таком случае результат, сигнализирующий об ошибке,
придется передавать во всех вложенных вызовах.
int main()
{
if (fun1()==false ) //обработка ошибки
return 1;
}
bool
fun1()
{
if (fun2()==false )
return false ;
return true ;
}
bool
fun2()
{
if (database.SaveObject(obj)==false )
return false ;
return true ;
}
Если функция или метод должны возвращать какую-то величину в качестве
результата, то особое, недопустимое, значение этой величины используется в
качестве признака ошибки. Если метод возвращает указатель,
выдача нулевого указателя применяется в качестве признака ошибки. Если
функция вычисляет положительное число, возврат — 1 можно использовать
в качестве признака ошибки.
Иногда невозможно вернуть признак ошибки в качестве возвращаемого значения.
Примером является конструктор объекта, который не может вернуть значение. Как же сообщить о том, что во время инициализации объекта что-то было не так?
Распространенным решением является дополнительный атрибут
объекта – флаг, отражающий состояние объекта. Предположим, конструктор
класса Database должен соединиться с сервером базы данных.
class Database
{
public :
Database(const char *serverName);
...
bool Ok(void) const {return okFlag;};
private :
bool okFlag;
};
Database::Database(const char*serverName)
{
if (connect(serverName)==true )
okFlag =true ;
else
okFlag =false ;
}
int main()
{
Database database("db-server");
if (!database.Ok()){
cerr <<"Ошибка соединения с базой данных"<<endl;
return 0;
}
return 1;
}
Лучше вместо метода Ok, возвращающего значение флага okFlag,
переопределить операцию ! (отрицание).
class Database
{
public :
bool operator !()const {return !okFlag;};
};
Тогда проверка успешности соединения с базой данных будет выглядеть так:
if (!database){
cerr <<"Ошибка соединения с базой
данных"<<endl;
}
Следует отметить, что лучше избегать такого построения классов,
при котором возможны ошибки в конструкторе. Из конструктора можно
выделить соединение с сервером базы данных в отдельный метод Open:
class Database
{
public :
Database();
bool Open(const char*serverName);
}
и тогда отпадает необходимость в операции ! или методе Ok().
Использование возвращаемого значения в качестве признака ошибки –
метод почти универсальный. Он применяется, прежде всего, для обработки
запланированных ошибочных ситуаций. Этот метод имеет ряд
недостатков. Во-первых, приходится передавать признак ошибки через
вложенные вызовы функций. Во-вторых, возникают неудобства, если
метод или функция уже возвращают значение, и приходится либо модифицировать
интерфейс, либо придумывать специальное » ошибочное »
значение. В-третьих, логика программы оказывается запутанной из-за
сплошных условных операторов if с проверкой на ошибочное значение.

Существует две фундаментальные стратегии: обработка исправимых ошибок (исключения, коды возврата по ошибке, функции-обработчики) и неисправимых (assert(), abort()). В каких случаях какую стратегию лучше использовать?
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
- Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
Программистские ошибки
Это худший вид ошибок. Для их обработки я стараюсь сделать так, чтобы мои ошибки были связаны только с вызовами функций, то есть с плохими параметрами. Прочие типы программистских ошибок могут быть пойманы только в runtime, с помощью отладочных макросов (assertion macros), раскиданных по коду.
При работе с плохими параметрами есть две стратегии: дать им определённое или неопределённое поведение.
Если исходное требование для функции — запрет на передачу ей плохих параметров, то, если их передать, это считается неопределённым поведением и должно проверяться не самой функцией, а оператором вызова (caller). Функция должна делать только отладочное подтверждение (debug assertion).
С другой стороны, если отсутствие плохих параметров не является частью исходных требований, а документация определяет, что функция будет бросать bad_parameter_exception при передаче ей плохого параметра, то передача — это хорошо определённое поведение (бросание исключения или любая другая стратегия обработки исправимых ошибок), и функция всегда должна это проверять.
В качестве примера рассмотрим получающие функции (accessor functions) std::vector<T>operator[] говорится, что индекс должен быть в пределах валидного диапазона, при этом at() сообщает нам, что функция кинет исключение, если индекс не попадает в диапазон. Более того, большинство реализаций стандартных библиотек обеспечивают режим отладки, в котором проверяется индекс operator[], но технически это неопределённое поведение, оно не обязано проверяться.
Примечание: необязательно бросать исключение, чтобы получилось определённое поведение. Пока это не упомянуто в исходных условиях для функции, это считается определённым. Всё, что прописано в исходных условиях, не должно проверяться функцией, это неопределённое поведение.
Когда нужно проверять только с помощью отладочных подтверждений, а когда — постоянно?
К сожалению, однозначного рецепта нет, решение зависит от конкретной ситуации. У меня есть лишь одно проверенное правило, которому я следую при разработке API. Оно основано на наблюдении, что проверять исходные условия должен вызывающий, а не вызываемый. А значит, условие должно быть «проверяемым» для вызывающего. Также условие «проверяемое», если можно легко выполнить операцию, при которой значение параметра всегда будет правильным. Если для параметра это возможно, то это получается исходное условие, а значит, проверяется только посредством отладочного подтверждения (а если слишком дорого, то вообще не проверяется).
Но конечное решение зависит от многих других факторов, так что очень трудно дать какой-то общий совет. По умолчанию я стараюсь свести к неопределённому поведению и использованию только подтверждений. Иногда бывает целесообразно обеспечить оба варианта, как это делает стандартная библиотека с operator[] и at().
Хотя в ряде случаев это может быть ошибкой.
Об иерархии std::exception
Если в качестве стратегии обработки исправимых ошибок вы выбрали исключения, то рекомендуется создать новый класс и наследовать его от одного из классов исключений стандартной библиотеки.
Я предлагаю наследовать только от одного из этих четырёх классов:
std::bad_alloc: для сбоев выделения памяти.std::runtime_error: для общих runtime-ошибок.std::system_error(производное отstd::runtime_error): для системных ошибок с кодами ошибок.std::logic_error: для программистских ошибок с определённым поведением.
Обратите внимание, что в стандартной библиотеке разделяются логические (то есть программистские) и runtime-ошибки. Runtime-ошибки — более широкое определение, чем «системные». Оно описывает «ошибки, обнаруживаемые только при выполнении программы». Такая формулировка не слишком информативна. Лично я использую её для плохих параметров, которые не являются исключительно программистскими ошибками, а могут возникнуть и по вине пользователей. Но это можно определить лишь глубоко в стеке вызовов. Например, плохое форматирование комментариев в standardese приводит к исключению при парсинге, проистекающему из std::runtime_error. Позднее оно ловится на соответствующем уровне и фиксируется в логе. Но я не стал бы использовать этот класс иначе, как и std::logic_error.
Подведём итоги
Есть два пути обработки ошибок:
- как исправимые: используются исключения или возвращаемые значения (в зависимости от ситуации/религии);
- как неисправимые: ошибки журналируются, а программа прерывается.
Подтверждения — это особый вид стратегии обработки неисправимых ошибок, только в режиме отладки.
Есть три основных источника ошибок, каждый требует особого подхода:
- Пользовательские ошибки не должны обрабатываться как ошибки на верхних уровнях программы. Всё, что вводит пользователь, должно проверяться соответствующим образом. Это может обрабатываться как ошибки только на нижних уровнях, которые не взаимодействуют с пользователями напрямую. Применяется стратегия обработки исправимых ошибок.
- Системные ошибки могут обрабатываться в рамках любой из двух стратегий, в зависимости от типа и тяжести. Библиотеки должны работать как можно гибче.
- Программистские ошибки, то есть плохие параметры, могут быть запрещены исходными условиями. В этом случае функция должна использовать только проверку с помощью отладочных подтверждений. Если же речь идёт о полностью определённом поведении, то функции следует предписанным образом сообщать об ошибке. Я стараюсь по умолчанию следовать сценарию с неопределённым поведением и определяю для функции проверку параметров лишь тогда, когда это слишком трудно сделать на стороне вызывающего.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Проблема
Я работаю над проектом foonathan/memory. Это решение предоставляет различные классы выделения памяти (allocator classes), так что в качестве примера рассмотрим структуру функции выделения.
Для простоты возьмём malloc(). Она возвращает указатель на выделяемую память. Если выделить память не получается, то возвращается nullptr, то есть NULL, то есть ошибочное значение.
У этого решения есть недостатки: вам нужно проверять каждый вызов malloc(). Если вы забудете это сделать, то выделите несуществующую память. Кроме того, по своей натуре коды ошибок транзитивны: если вызвать функцию, которая может вернуть код ошибки, и вы не можете его проигнорировать или обработать, то вы тоже должны вернуть код ошибки.
Это приводит нас к ситуации, когда чередуются нормальные и ошибочные ветви кода. Исключения в таком случае выглядят более подходящим решением. Благодаря им вы сможете обрабатывать ошибки только тогда, когда вам это нужно, а в противном случае — достаточно тихо передать их обратно вызывающему.
Это можно расценить как недостаток.
Но в подобных ситуациях исключения имеют также очень большое преимущество: функция выделения памяти либо возвращает валидную память, либо вообще ничего не возвращает. Это функция «всё или ничего», возвращаемое значение всегда будет валидным. Это полезное следствие согласно принципу Скотта Майера «Make interfaces hard to use incorrectly and easy to use correctly».
Учитывая вышесказанное, можно утверждать, что вам следует использовать исключения в качестве механизма обработки ошибок. Этого мнения придерживается большинство разработчиков на С++, включая и меня. Но проект, которым я занимаюсь, — это библиотека, предоставляющая средства выделения памяти, и предназначена она для приложений, работающих в реальном времени. Для большинства разработчиков подобных приложений (особенно для игроделов) само использование исключений — исключение.
Каламбур детектед.
Чтобы уважить эту группу разработчиков, моей библиотеке лучше обойтись без исключений. Но мне и многим другим они нравятся за элегантность и простоту обработки ошибок, так что ради других разработчиков моей библиотеке лучше использовать исключения.
Так что же делать?
Идеальное решение: возможность включать и отключать исключения по желанию. Но, учитывая природу исключений, нельзя просто менять их местами с кодами ошибок, поскольку у нас не будет внутреннего кода проверки на ошибки — весь внутренний код опирается на предположение о прозрачности исключений. И даже если бы внутри можно было использовать коды ошибок и преобразовывать их в исключения, это лишило бы нас большинства преимуществ последних.
К счастью, я могу определить, что вы делаете, когда обнаруживаете ошибку нехватки памяти: чаще всего вы журналируете это событие и прерываете программу, поскольку она не может корректно работать без памяти. В таких ситуациях исключения — просто способ передачи контроля другой части кода, которая журналирует и прерывает программу. Но есть старый и эффективный способ передачи контроля: указатель функции (function pointer), то есть функция-обработчик (handler function).
Если у вас включены исключения, то вы просто их бросаете. В противном случае вызываете функцию-обработчика и затем прерываете программу. Это предотвратит бесполезную работу функции-обработчика, та позволит программе продолжить выполняться в обычном режиме. Если не прервать, то произойдёт нарушение обязательного постусловия функции: всегда возвращать валидный указатель. Ведь на выполнении этого условия может быть построена работа другого кода, да и вообще это нормальное поведение.
Я называю такой подход обработкой исключений и придерживаюсь его при работе с памятью.
Решение 1: обработчик исключений
Если вам нужно обработать ошибку в условиях, когда наиболее распространённым поведением будет «журналировать и прервать», то можно использовать обработчика исключений. Это такая функция-обработчик, которая вызывается вместо бросания объекта-исключения. Её довольно легко реализовать даже в уже существующем коде. Для этого нужно поместить управление обработкой в класс исключений и обернуть в макрос выражение throw.
Сначала дополним класс и добавим функции для настройки и, возможно, запрашивания функции-обработчика. Я предлагаю делать это так же, как стандартная библиотека обрабатывает std::new_handler:
class my_fatal_error
{
public:
// тип обработчика, он должен брать те же параметры, что и конструктор,
// чтобы у них была одинаковая информация
using handler = void(*)( ... );
// меняет функцию-обработчика
handler set_handler(handler h);
// возвращает текущего обработчика
handler get_handler();
... // нормальное исключение
};Поскольку это входит в область видимости класса исключений, вам не нужно именовать каким-то особым образом. Отлично, нам же легче.
Если исключения включены, то для удаления обработчика можно использовать условное компилирование (conditional compilation). Если хотите, то также напишите обычный подмешанный класс (mixin class), дающий требуемую функциональность.
Конструктор исключений элегантен: он вызывает текущую функцию-обработчика, передавая ей требуемые аргументы из своих параметров. А затем комбинирует с последующим макросом throw:
If```cpp #if EXCEPTIONS #define THROW(Ex) throw (Ex) #else #define THROW(Ex) (Ex), std::abort() #endif> Такой макрос throw также предоставляется [foonathan/compatiblity](https://github.com/foonathan/compatibility).
Можно использовать его и так:
```cpp
THROW(my_fatal_error(...))
Если у вас включена поддержка исключений, то будет создан и брошен объект-исключение, всё как обычно. Но если поддержка выключена, то объект-исключение всё равно будет создан, и — это важно — только после этого произойдёт вызов std::abort(). А поскольку конструктор вызывает функцию-обработчика, то он и работает, как требуется: вы получаете точку настройки для журналирования ошибки. Благодаря же вызову std::abort() после конструктора пользователь не может нарушить постусловие.
Когда я работаю с памятью, то при включённых исключениях у меня также включён и обработчик, который вызывается при бросании исключения.
Так что при этой методике вам ещё будет доступна определённая степень кастомизации, даже если вы отключите исключения. Конечно, замена неполноценная, мы только журналируем и прерываем работу программы, без дальнейшего продолжения. Но в ряде случаев, в том числе при исчерпании памяти, это вполне пригодное решение.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);
При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
Решение 2: предоставить две перегрузки
Если недостаточно обработчика исключений, то нужно предоставить две перегрузки. Одна использует код возврата, а вторая бросает исключение.
Если рассматриваемая функция не имеет возвращаемого значения, то можете её использовать для кода ошибки. В противном случае вам придётся возвращать недопустимое значение для сигнализирования об ошибке — как nullptr в вышеприведённом примере, — а также установить выходной параметр для кода ошибки, если хотите предоставить вызывающему дополнительную информацию.
Пожалуйста, не используйте глобальную переменную errno или что-то типа GetLastError()!
Если возвращаемое значение не содержит недопустимое значение для обозначения сбоя, то по мере возможности используйте std::optional или что-то похожее.
Перегрузка исключения (exception overload) может — и должна — быть реализована в рамках версии с кодом ошибки, как это показано выше. Если компилируете без исключений, сотрите перегрузку с помощью условного компилирования.
std::system_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
std::expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected<void*, std::error_code> try_malloc(...);
В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Заключение
Если вы создаёте библиотеки, то иногда приходится обеспечивать максимальную гибкость использования. Под этим подразумевается и разнообразие средств обработки ошибок: иногда требуются коды возврата, иногда — исключения.
Одна из возможных стратегий — улаживание этих противоречий с помощью обработчика исключений. Просто удостоверьтесь, что когда нужно, то вызывается callback, а не бросается исключение. Это замена для критических ошибок, которая в любом случае будет журналироваться перед прерыванием работы программы. Как таковой этот способ не универсален, вы не можете переключаться в одной программе между двумя версиями. Это лишь обходное решение при отключённой поддержке исключений.
Более гибкий подход — просто предоставить две перегрузки, одну с исключениями, а вторую без. Это даст пользователям максимальную свободу, они смогут выбирать ту версию, что лучше подходит в их ситуации. Недостаток этого подхода: вам придётся больше потрудиться при создании библиотеки.