
Выборочная оценка всегда ошибочна. Так, стандартная ошибка средней показывает разброс средней. Для бинарной переменной (с двумя возможными значениями) средней арифметической является доля «успехов». В этой статье показано, как рассчитать дисперсию и стандартную ошибку доли.
Долю используют в качестве выборочной оценки вероятности. Обозначим долю как p*, а истинную вероятность как p . При бесконечно большом количестве наблюдений доля p* стремится к теоретической вероятности p. Этот факт известен со времен Якоба Бернулли.
Дисперсия и стандартная ошибка доли
Обратимся вначале к дисперсии биномиальной переменной. Если истинная вероятность p не известна, то используют ее оценку p*.
![]()
где B – сумма «успехов» в выборке;
n – количество наблюдений;
p* – оценка вероятности, т.е. доля «успехов».
Нас интересует дисперсия величины B/n. Согласно одному из свойств дисперсии, постоянный множитель выносится за скобки и возводится в квадрат.
Получаем формулу дисперсию доли:
![]()
Почти полная аналогия со средней арифметической. В числителе дисперсия самой переменной (1 или 0), внизу – объем выборки.
Стандартная ошибка доли – корень из дисперсии:

Стандартная ошибка доли при увеличении выборки ведет себя так же, как и стандартная ошибка средней: чем больше выборка, тем меньше ошибка, но при этом уменьшение постоянно замедляется.
Как известно, максимально возможная дисперсия переменной в схеме Бернулли достигается при p*=0,5. Она равна 0,5*(1-0,5)=0,25. Отсюда легко рассчитать максимальную стандартную ошибку доли, полученную по некоторой выборке.

Изобразим эту зависимость на диаграмме.

График имеет знакомую конфигурацию: ошибка уменьшается с замедлением. Так, при объеме выборки равной 100 наблюдениям стандартная ошибка (максимально возможная!) равна 0,05 (или 5 процентных пункта). При n=1000 стандартная ошибка доли составляет всего 0,0158 (или 1,58 процентных пункта). Повторюсь, что это максимум. Именно поэтому опросы общественно мнения редко превышают 1500-2000 человек (чтобы еще была возможность разбить данные на группы достаточно размера).
На практике довольно часто приходится анализировать бинарные данные. Это может быть анкетирование покупателей, контроль качества продукции и много чего еще. Поэтому доля, как оценка вероятности наступления интересующего события, – довольно распространенный показатель. Дисперсия и стандартная ошибка доли используется в расчете приблизительных доверительных интервалов вероятности и в проверке статистических гипотез.
Поделиться в социальных сетях:
Выборочная оценка всегда ошибочна. Так, стандартная ошибка средней показывает разброс средней. Для бинарной переменной (с двумя возможными значениями) средней арифметической является доля «успехов». В этой статье показано, как рассчитать дисперсию и стандартную ошибку доли.
Долю используют в качестве выборочной оценки вероятности. Обозначим долю как p*, а истинную вероятность как p . При бесконечно большом количестве наблюдений доля p* стремится к теоретической вероятности p. Этот факт известен со времен Якоба Бернулли.
Дисперсия и стандартная ошибка доли
Обратимся вначале к дисперсии биномиальной переменной. Если истинная вероятность p не известна, то используют ее оценку p*.
![]()
где B – сумма «успехов» в выборке;
n – количество наблюдений;
p* – оценка вероятности, т.е. доля «успехов».
Нас интересует дисперсия величины B/n. Согласно одному из свойств дисперсии, постоянный множитель выносится за скобки и возводится в квадрат.
Получаем формулу дисперсию доли:
![]()
Почти полная аналогия со средней арифметической. В числителе дисперсия самой переменной (1 или 0), внизу – объем выборки.
Стандартная ошибка доли – корень из дисперсии:
Стандартная ошибка доли при увеличении выборки ведет себя так же, как и стандартная ошибка средней: чем больше выборка, тем меньше ошибка, но при этом уменьшение постоянно замедляется.
Как известно, максимально возможная дисперсия переменной в схеме Бернулли достигается при p*=0,5. Она равна 0,5*(1-0,5)=0,25. Отсюда легко рассчитать максимальную стандартную ошибку доли, полученную по некоторой выборке.
Изобразим эту зависимость на диаграмме.
График имеет знакомую конфигурацию: ошибка уменьшается с замедлением. Так, при объеме выборки равной 100 наблюдениям стандартная ошибка (максимально возможная!) равна 0,05 (или 5 процентных пункта). При n=1000 стандартная ошибка доли составляет всего 0,0158 (или 1,58 процентных пункта). Повторюсь, что это максимум. Именно поэтому опросы общественно мнения редко превышают 1500-2000 человек (чтобы еще была возможность разбить данные на группы достаточно размера).
На практике довольно часто приходится анализировать бинарные данные. Это может быть анкетирование покупателей, контроль качества продукции и много чего еще. Поэтому доля, как оценка вероятности наступления интересующего события, – довольно распространенный показатель. Дисперсия и стандартная ошибка доли используется в расчете приблизительных доверительных интервалов вероятности и в проверке статистических гипотез.
Поделиться в социальных сетях:
Точность оценки долей
Если бы в наших руках были данные по
всем членам совокупности, то не было бы
никаких проблем связанных с точностью
оценок. Однако нам всегда приходится
довольствоваться ограниченной выборкой.
Поэтому возникает вопрос, насколько
точно доли в выборке соответствуют
долям в совокупности.

Рис. 5.4. А. Из совокупности марсиан, среди
которых 150 зеленых и 50 розовых, извлекли
случайную выборку из 10 особей. В выборку
попало 5 зеленых и 5 розовых марсиан, на
рисунке они помечены черным. Б. В таком
виде данные предстанут перед исследователем,
который не может наблюдать всю совокупность
и вынужден судить о ней по выборке.
Оценка доли розовых марсиан p = 5/10 = 0,5.
Как любая выборочная оценка, оценка
доли (обозначим ее p^) отражает
долю р в совокупности, но отклоняется
от нее в силу случайности. Рассмотрим
теперь не совокупность марсиан, а
совокупность всех значений p^ ,
вычисленных по выборкам объемом 10
каждая. (Из совокупности в 200 членов
можно получить более 106 таких
выборок). По аналогии со стандартной
ошибкой среднего найдем стандартную
ошибку доли. Для этого нужно
охарактеризовать разброс выборочных
оценок доли, то есть рассчитать стандартное
отклонение совокупности p^.
![]()
где σ p^ — стандартная ошибка
доли, σ — стандартное отклонение, n —
объем выборки.

Заменив в приведенной формуле истинное
значение доли ее оценкой p^ ,
получим оценку стандартной ошибки доли:

Из центральной предельной теоремы
вытекает, что при достаточно большом
объеме выборки выборочная оценка p^
приближенно подчиняется
нормальному распределению, имеющему
среднее р и стандартное отклонение σˆp
. Однако при значениях р, близких к 0 или
1, и при малом объеме выборки это не так.
При какой численности выборки можно
пользоваться приведенным способом
оценки? Математическая статистика
утверждает, что нормальное распределение
служит хорошим приближением, если np^
и n(1-p^)
превосходят 5. Напомним, что примерно
95% всех членов нормально распределенной
совокупности находятся в пределах двух
стандартных отклонений от среднего.
Поэтому если перечисленные условия
соблюдены, то с вероятностью 95% можно
утверждать, что истинное значение р
лежит в пределах np^
и n(1-p^).
Вернемся на минуту к сравнению операционной
летальности при галотановой и морфиновой
анестезии. Напомним, что при использовании
галотана летальность составила 13,1%
(численность группы — 61 больной), а при
использовании морфина —
14,9% (численность группы — 67 больных).
Стандартная ошибка доли для группы


Если учесть, что различие в летальности
составило лишь 2%, то маловероятно, чтобы
оно было обусловлено чем-нибудь, кроме
случайного характера выборки.
Перечислим те предпосылки, на которых
основан излагаемый подход. Мы изучаем
то, что в статистике принято называть
независимыми испытаниями Бернулли.
Эти испытания обладают следующими
свойствами.
• Каждое отдельное испытание имеет
ровно два возможных взаимно исключающих
исхода.
• Вероятность данного исхода одна и та
же в любом испытании.
• Все испытания независимы друг от
друга.
21
Соседние файлы в папке Старый материал
- #
- #
- #
- #
- #
- #
- #
Стандартная ошибка пропорции: формула и пример
17 авг. 2022 г.
читать 1 мин
Часто в статистике нас интересует оценка доли людей в популяции с определенной характеристикой.
Например, нас может заинтересовать оценка доли жителей определенного города, поддерживающих новый закон.
Вместо того, чтобы ходить и спрашивать каждого жителя, поддерживают ли они закон, мы вместо этого собираем простую случайную выборку и выясняем, сколько жителей в выборке поддерживают закон.
Затем мы рассчитали бы долю выборки (p̂) как:
Пример формулы пропорции:
р̂ = х / п
куда:
- x: количество лиц в выборке с определенной характеристикой.
- n: общее количество лиц в выборке.
Затем мы использовали бы эту пропорцию выборки для оценки доли населения. Например, если 47 из 300 жителей выборки поддержали новый закон, то выборочная доля будет рассчитана как 47/300 = 0,157 .
Это означает, что наша наилучшая оценка доли жителей в населении, поддержавших закон, будет равна 0,157 .
Однако нет никакой гарантии, что эта оценка будет точно соответствовать истинной доле населения, поэтому мы обычно также рассчитываем стандартную ошибку доли .
Это рассчитывается как:
Стандартная ошибка формулы пропорции:
Стандартная ошибка = √ p̂(1-p̂) / n
Например, если p̂ = 0,157 и n = 300, то мы рассчитали бы стандартную ошибку пропорции как:
Стандартная ошибка пропорции = √ 0,157 (1-0,157) / 300 = 0,021
Затем мы обычно используем эту стандартную ошибку для расчета доверительного интервала для истинной доли жителей, поддерживающих закон.
Это рассчитывается как:
Доверительный интервал для формулы доли населения:
Доверительный интервал = p̂ +/- z * √ p̂(1-p̂) / n
Глядя на эту формулу, легко увидеть, что чем больше стандартная ошибка пропорции, тем шире доверительный интервал .
Обратите внимание, что z в формуле — это z-значение, которое соответствует популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z-значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Например, вот как рассчитать 95% доверительный интервал для истинной доли жителей города, поддерживающих новый закон:
- 95% ДИ = p̂ +/- z * √ p̂(1-p̂) / n
- 95% ДИ = 0,157 +/- 1,96 * √ 0,157 (1-0,157) / 300
- 95% ДИ = 0,157 +/- 1,96*(0,021)
- 95% ДИ = [0,10884, 0,19816]
Таким образом, с уверенностью 95% можно сказать, что истинная доля жителей города, поддерживающих новый закон, составляет от 10,884% до 19,816%.
Дополнительные ресурсы
Стандартная ошибка калькулятора пропорций
Доверительный интервал для калькулятора пропорций
Что такое доля населения?
Точность оценки долей
Если бы в наших руках были данные по
всем членам совокупности, то не было бы
никаких проблем связанных с точностью
оценок. Однако нам всегда приходится
довольствоваться ограниченной выборкой.
Поэтому возникает вопрос, насколько
точно доли в выборке соответствуют
долям в совокупности.
Рис. 5.4. А. Из совокупности марсиан, среди
которых 150 зеленых и 50 розовых, извлекли
случайную выборку из 10 особей. В выборку
попало 5 зеленых и 5 розовых марсиан, на
рисунке они помечены черным. Б. В таком
виде данные предстанут перед исследователем,
который не может наблюдать всю совокупность
и вынужден судить о ней по выборке.
Оценка доли розовых марсиан p = 5/10 = 0,5.
Как любая выборочная оценка, оценка
доли (обозначим ее p^) отражает
долю р в совокупности, но отклоняется
от нее в силу случайности. Рассмотрим
теперь не совокупность марсиан, а
совокупность всех значений p^ ,
вычисленных по выборкам объемом 10
каждая. (Из совокупности в 200 членов
можно получить более 106 таких
выборок). По аналогии со стандартной
ошибкой среднего найдем стандартную
ошибку доли. Для этого нужно
охарактеризовать разброс выборочных
оценок доли, то есть рассчитать стандартное
отклонение совокупности p^.
![]()
где σ p^ — стандартная ошибка
доли, σ — стандартное отклонение, n —
объем выборки.
Заменив в приведенной формуле истинное
значение доли ее оценкой p^ ,
получим оценку стандартной ошибки доли:
Из центральной предельной теоремы
вытекает, что при достаточно большом
объеме выборки выборочная оценка p^
приближенно подчиняется
нормальному распределению, имеющему
среднее р и стандартное отклонение σˆp
. Однако при значениях р, близких к 0 или
1, и при малом объеме выборки это не так.
При какой численности выборки можно
пользоваться приведенным способом
оценки? Математическая статистика
утверждает, что нормальное распределение
служит хорошим приближением, если np^
и n(1-p^)
превосходят 5. Напомним, что примерно
95% всех членов нормально распределенной
совокупности находятся в пределах двух
стандартных отклонений от среднего.
Поэтому если перечисленные условия
соблюдены, то с вероятностью 95% можно
утверждать, что истинное значение р
лежит в пределах np^
и n(1-p^).
Вернемся на минуту к сравнению операционной
летальности при галотановой и морфиновой
анестезии. Напомним, что при использовании
галотана летальность составила 13,1%
(численность группы — 61 больной), а при
использовании морфина —
14,9% (численность группы — 67 больных).
Стандартная ошибка доли для группы
Если учесть, что различие в летальности
составило лишь 2%, то маловероятно, чтобы
оно было обусловлено чем-нибудь, кроме
случайного характера выборки.
Перечислим те предпосылки, на которых
основан излагаемый подход. Мы изучаем
то, что в статистике принято называть
независимыми испытаниями Бернулли.
Эти испытания обладают следующими
свойствами.
• Каждое отдельное испытание имеет
ровно два возможных взаимно исключающих
исхода.
• Вероятность данного исхода одна и та
же в любом испытании.
• Все испытания независимы друг от
друга.
21
Соседние файлы в папке Старый материал
- #
- #
- #
- #
- #
- #
- #
При обследовании 500 образцов изделий, отобранных из партии готовой продукции предприятия в случайном порядке, 40 оказались нестандартными.
С вероятностью 0,954 определите пределы, в которых находится доля нестандартной продукции, выпускаемой заводом.
Решение:
Рассчитаем долю нестандартной продукции в выборочной совокупности:
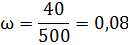
Средняя ошибка выборочной доли при повторном отборе рассчитывается по формуле:
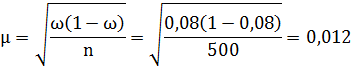
где n – численность выборки.
С вероятностью 0,954 рассчитаем предельную ошибку выборочной доли по формуле:
Δ = μ × t
где
t – коэффициент доверия.
Значение коэффициента доверия t определяется в зависимости от того, с какой доверительной вероятностью надо гарантировать результаты выборочного наблюдения и берётся из готовых таблиц.
При Р = 0,954, t = 2.
Δ = t * μ = 2 * 0,012 = 0,024
С вероятностью 0,954 можно утверждать, что доля нестандартной продукции в партии товара колеблется:
ω – Δ ˂ р ˂ ω + Δ
0,08 – 0,02 ˂ р ˂ 0,08+0,02
0,06 ˂ р ˂ 0,10
или
6% ˂ р ˂ 10%
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.

Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности


Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.

|
 ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических группЗдесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, 
|
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:





Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:





То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
 |
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.