
В статистике регрессия — это метод, который можно использовать для анализа взаимосвязи между переменными-предикторами и переменной-откликом.
Когда вы используете программное обеспечение (например, R, SAS, SPSS и т. д.) для выполнения регрессионного анализа, вы получите в качестве выходных данных таблицу регрессии, в которой суммируются результаты регрессии. Важно уметь читать эту таблицу, чтобы понимать результаты регрессионного анализа.
В этом руководстве рассматривается пример регрессионного анализа и дается подробное объяснение того, как читать и интерпретировать выходные данные таблицы регрессии.
Пример регрессии
Предположим, у нас есть следующий набор данных, который показывает общее количество часов обучения, общее количество сданных подготовительных экзаменов и итоговый балл за экзамен, полученный для 12 разных студентов:

Чтобы проанализировать взаимосвязь между учебными часами и сданными подготовительными экзаменами и окончательным экзаменационным баллом, который получает студент, мы запускаем множественную линейную регрессию, используя отработанные часы и подготовительные экзамены, взятые в качестве переменных-предикторов, и итоговый экзаменационный балл в качестве переменной ответа.
Мы получаем следующий вывод:

Проверка соответствия модели
В первом разделе показано несколько различных чисел, которые измеряют соответствие регрессионной модели, т. е. насколько хорошо регрессионная модель способна «соответствовать» набору данных.

Вот как интерпретировать каждое из чисел в этом разделе:
Несколько R
Это коэффициент корреляции.Он измеряет силу линейной зависимости между переменными-предикторами и переменной отклика. R, кратный 1, указывает на идеальную линейную зависимость, тогда как R, кратный 0, указывает на отсутствие какой-либо линейной зависимости. Кратный R — это квадратный корень из R-квадрата (см. ниже).
В этом примере множитель R равен 0,72855 , что указывает на довольно сильную линейную зависимость между предикторами часов обучения и подготовительных экзаменов и итоговой оценкой экзаменационной переменной ответа.
R-квадрат
Его часто записывают как r 2 , а также называют коэффициентом детерминации.Это доля дисперсии переменной отклика, которая может быть объяснена предикторной переменной.
Значение для R-квадрата может варьироваться от 0 до 1. Значение 0 указывает, что переменная отклика вообще не может быть объяснена предикторной переменной. Значение 1 указывает, что переменная отклика может быть полностью объяснена без ошибок с помощью переменной-предиктора.
В этом примере R-квадрат равен 0,5307 , что указывает на то, что 53,07% дисперсии итоговых экзаменационных баллов можно объяснить количеством часов обучения и количеством сданных подготовительных экзаменов.
Связанный: Что такое хорошее значение R-квадрата?
Скорректированный R-квадрат
Это модифицированная версия R-квадрата, которая была скорректирована с учетом количества предикторов в модели. Он всегда ниже R-квадрата. Скорректированный R-квадрат может быть полезен для сравнения соответствия различных моделей регрессии друг другу.
В этом примере скорректированный R-квадрат равен 0,4265.
Стандартная ошибка регрессии
Стандартная ошибка регрессии — это среднее расстояние, на которое наблюдаемые значения отклоняются от линии регрессии. В этом примере наблюдаемые значения отклоняются от линии регрессии в среднем на 7,3267 единиц.
Связанный: Понимание стандартной ошибки регрессии
Наблюдения
Это просто количество наблюдений в нашем наборе данных. В этом примере общее количество наблюдений равно 12 .
Тестирование общей значимости регрессионной модели
В следующем разделе показаны степени свободы, сумма квадратов, средние квадраты, F-статистика и общая значимость регрессионной модели.

Вот как интерпретировать каждое из чисел в этом разделе:
Степени свободы регрессии
Это число равно: количеству коэффициентов регрессии — 1. В этом примере у нас есть член пересечения и две переменные-предикторы, поэтому у нас всего три коэффициента регрессии, что означает, что степени свободы регрессии равны 3 — 1 = 2 .
Всего степеней свободы
Это число равно: количество наблюдений – 1. В данном примере у нас 12 наблюдений, поэтому общее количество степеней свободы 12 – 1 = 11 .
Остаточные степени свободы
Это число равно: общая df – регрессионная df.В этом примере остаточные степени свободы 11 – 2 = 9 .
Средние квадраты
Средние квадраты регрессии рассчитываются как регрессия SS / регрессия df.В этом примере регрессия MS = 546,53308/2 = 273,2665 .
Остаточные средние квадраты вычисляются как остаточный SS / остаточный df.В этом примере остаточная MS = 483,1335/9 = 53,68151 .
F Статистика
Статистика f рассчитывается как регрессия MS/остаточная MS. Эта статистика показывает, обеспечивает ли регрессионная модель лучшее соответствие данным, чем модель, которая не содержит независимых переменных.
По сути, он проверяет, полезна ли регрессионная модель в целом. Как правило, если ни одна из переменных-предикторов в модели не является статистически значимой, общая F-статистика также не является статистически значимой.
В этом примере статистика F равна 273,2665/53,68151 = 5,09 .
Значение F (P-значение)
Последнее значение в таблице — это p-значение, связанное со статистикой F. Чтобы увидеть, значима ли общая модель регрессии, вы можете сравнить p-значение с уровнем значимости; распространенные варианты: 0,01, 0,05 и 0,10.
Если p-значение меньше уровня значимости, имеется достаточно доказательств, чтобы сделать вывод о том, что регрессионная модель лучше соответствует данным, чем модель без переменных-предикторов. Этот вывод хорош, потому что он означает, что переменные-предикторы в модели действительно улучшают соответствие модели.
В этом примере p-значение равно 0,033 , что меньше обычного уровня значимости 0,05. Это указывает на то, что регрессионная модель в целом статистически значима, т. е. модель лучше соответствует данным, чем модель без переменных-предикторов.
Тестирование общей значимости регрессионной модели
В последнем разделе показаны оценки коэффициентов, стандартная ошибка оценок, t-stat, p-значения и доверительные интервалы для каждого термина в регрессионной модели.

Вот как интерпретировать каждое из чисел в этом разделе:
Коэффициенты
Коэффициенты дают нам числа, необходимые для записи оценочного уравнения регрессии:
у шляпа знак равно б 0 + б 1 Икс 1 + б 2 Икс 2 .
В этом примере расчетное уравнение регрессии имеет вид:
итоговый балл за экзамен = 66,99 + 1,299 (часы обучения) + 1,117 (подготовительные экзамены)
Каждый отдельный коэффициент интерпретируется как среднее увеличение переменной отклика на каждую единицу увеличения данной переменной-предиктора при условии, что все остальные переменные-предикторы остаются постоянными. Например, для каждого дополнительного часа обучения среднее ожидаемое увеличение итогового экзаменационного балла составляет 1,299 балла при условии, что количество сданных подготовительных экзаменов остается постоянным.
Перехват интерпретируется как ожидаемый средний итоговый балл за экзамен для студента, который учится ноль часов и не сдает подготовительных экзаменов. В этом примере ожидается, что учащийся наберет 66,99 балла, если он будет заниматься ноль часов и не сдавать подготовительных экзаменов. Однако будьте осторожны при интерпретации перехвата выходных данных регрессии, потому что это не всегда имеет смысл.
Например, в некоторых случаях точка пересечения может оказаться отрицательным числом, что часто не имеет очевидной интерпретации. Это не означает, что модель неверна, это просто означает, что перехват сам по себе не должен интерпретироваться как означающий что-либо.
Стандартная ошибка, t-статистика и p-значения
Стандартная ошибка — это мера неопределенности оценки коэффициента для каждой переменной.
t-stat — это просто коэффициент, деленный на стандартную ошибку. Например, t-stat для часов обучения составляет 1,299 / 0,417 = 3,117.
В следующем столбце показано значение p, связанное с t-stat. Это число говорит нам, является ли данная переменная отклика значимой в модели. В этом примере мы видим, что значение p для часов обучения равно 0,012, а значение p для подготовительных экзаменов равно 0,304. Это указывает на то, что количество учебных часов является важным предиктором итогового экзаменационного балла, а количество подготовительных экзаменов — нет.
Доверительный интервал для оценок коэффициентов
В последних двух столбцах таблицы представлены нижняя и верхняя границы 95% доверительного интервала для оценок коэффициентов.
Например, оценка коэффициента для часов обучения составляет 1,299, но вокруг этой оценки есть некоторая неопределенность. Мы никогда не можем знать наверняка, является ли это точным коэффициентом. Таким образом, 95-процентный доверительный интервал дает нам диапазон вероятных значений истинного коэффициента.
В этом случае 95% доверительный интервал для часов обучения составляет (0,356, 2,24). Обратите внимание, что этот доверительный интервал не содержит числа «0», что означает, что мы вполне уверены, что истинное значение коэффициента часов обучения не равно нулю, т. е. является положительным числом.
Напротив, 95% доверительный интервал для Prep Exams составляет (-1,201, 3,436). Обратите внимание, что этот доверительный интервал действительно содержит число «0», что означает, что истинное значение коэффициента подготовительных экзаменов может быть равно нулю, т. е. несущественно для прогнозирования результатов итоговых экзаменов.
Дополнительные ресурсы
Понимание нулевой гипотезы для линейной регрессии
Понимание F-теста общей значимости в регрессии
Как сообщить о результатах регрессии
В
линейной регрессии обычно оценивается
значимость не только уравнения в целом,
но и отдельных его параметров. С этой
целью по каждому из параметров определяется
его стандартная ошибка: тb
и
та.
Стандартная
ошибка коэффициента регрессии параметра
b
рассчитывается
по формуле:
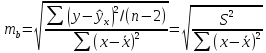
Где
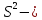
остаточная дисперсия на одну степень
свободы.
Отношение
коэффициента регрессии к его стандартной
ошибке дает t-статистику,
которая подчиняется статистике Стьюдента
при
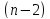
степенях
свободы. Эта статистика применяется
для проверки статистической значимости
коэффициента регрессии и для расчета
его доверительных интервалов.
Для
оценки значимости коэффициента регрессии
его величину сравнивают с его стандартной
ошибкой, т.е. определяют фактическое
значение t-критерия
Стьюдента:
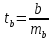 ,
,
которое затем сравнивают с табличным
значением при определенном уровне
значимостиα
и
числе степеней свободы
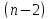 .
.
Справедливо
равенство
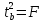
Доверительный
интервал для коэффициента регрессии
определяется как
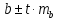 .
.
Стандартная
ошибка параметра а
определяется
по формуле
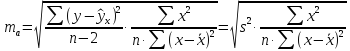
Процедура
оценивания значимости данного параметра
не отличается от рассмотренной выше
для коэффициента регрессии: вычисляется
t-критерий:
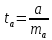
Его
величина сравнивается с табличным
значением при
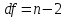
степенях свободы.
Значимость
линейного коэффициента корреляции
проверяется на основе величины ошибки
коэффициента корреляции mr:
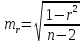
Фактическое
значение t-критерия
Стьюдента определяется как
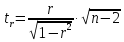
Данная
формула свидетельствует, что в парной
линейной регрессии
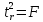 ,
,
ибо как уже указывалось,
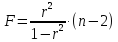 .
.
Кроме того,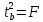 ,
,
следовательно,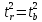 .
.
Таким
образом, проверка гипотез о значимости
коэффициентов регрессии и корреляции
равносильна проверке гипотезы о
значимости линейного уравнения регрессии.
Рассмотренную
формулу оценки коэффициента корреляции
рекомендуется применять при большом
числе наблюдений, а также если r
не близко к +1 или –1.
2.3 Интервальный прогноз на основе линейного уравнения регрессии
В
прогнозных расчетах по уравнению
регрессии определяется предсказываемое
yр
значение
как точечный прогноз
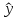 х
х
при
хр
= хk
т.
е. путем подстановки в линейное уравнение
регрессии
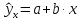
соответствующего
значения х.
Однако
точечный прогноз явно нереален, поэтому
он дополняется расчетом стандартной
ошибки
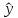 х,
х,
т.
е.
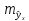 ,
,
и
соответственно мы получаем интервальную
оценку прогнозного значения у*:
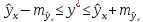
Считая,
что прогнозное значение фактора хр
= хk
получим
следующую формулу расчета стандартной
ошибки предсказываемого по линии
регрессии значения, т. е.
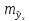
имеет выражение:
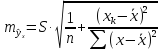
Рассмотренная
формула стандартной ошибки предсказываемого
среднего значения у
при
заданном значении хk
характеризует
ошибку положения линии регрессии.
Величина стандартной ошибки
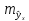 достигает
достигает
минимума при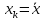
и
возрастает по мере того, как «удаляется»
от
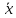 в любом направлении. Иными словами, чем
в любом направлении. Иными словами, чем
больше разность между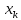 и
и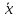 ,
,
тем больше ошибка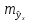 ,
,
с
которой предсказывается среднее значение
у
для
заданного значения
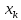 .
.
Можно ожидать наилучшие результаты
прогноза, если признак-фактор х находится
в центре области наблюдений х, и нельзя
ожидать хороших результатов прогноза
при удалении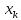 .
.
от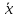 . Если же значение
. Если же значение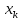 .
.
оказывается за пределами наблюдаемых
значенийх,
используемых при построении линейной
регрессии, то результаты прогноза
ухудшаются в зависимости от того,
насколько
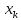 .
.
отклоняется от области наблюдаемых
значений факторах.
На
графике, приведенном на рис. 1, доверительные
границы для
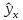
представляют
собой гиперболы, расположенные по обе
стороны от линии регрессии. Рис. 1
показывает, как изменяются пределы в
зависимости от изменения
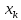 .:
.:
две гиперболы по обе стороны от линии
регрессии определяют 95 %-ные доверительные
интервалы для среднего значенияу
при
заданном значении х.
Однако
фактические значения у
варьируют
около среднего значения
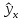 .
.
Индивидуальные
значения у
могут
отклоняться от
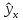
на
величину случайной ошибки ε, дисперсия
которой оценивается как остаточная
дисперсия на одну степень свободы
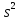 .
.
Поэтому ошибка предсказываемого
индивидуального значенияу
должна включать не только стандартную
ошибку
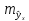 ,
,
но и случайную ошибкуs.
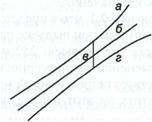
Рис.
1. Доверительный интервал линии регрессии:
а
— верхняя
доверительная граница; б
— линия
регрессии;
в
— доверительный
интервал для
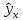
при
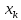 ;
;
г
— нижняя
доверительная граница.
Средняя
ошибка прогнозируемого индивидуального
значения у
составит:
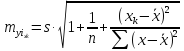
При
прогнозировании на основе уравнения
регрессии следует помнить, что величина
прогноза зависит не только от стандартной
ошибки индивидуального значения у,
но
и от точности прогноза значения фактора
х.
Его
величина может задаваться на основе
анализа других моделей исходя из
конкретной ситуации, а также анализа
динамики данного фактора.
Рассмотренная
формула средней ошибки индивидуального
значения признака у
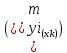 может
может
быть использована также для оценки
существенности различия предсказываемого
значения и некоторого гипотетического
значения.
11
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
When we fit a regression model to a dataset, we’re often interested in how well the regression model “fits” the dataset. Two metrics commonly used to measure goodness-of-fit include R-squared (R2) and the standard error of the regression, often denoted S.
This tutorial explains how to interpret the standard error of the regression (S) as well as why it may provide more useful information than R2.
Standard Error vs. R-Squared in Regression
Suppose we have a simple dataset that shows how many hours 12 students studied per day for a month leading up to an important exam along with their exam score:

If we fit a simple linear regression model to this dataset in Excel, we receive the following output:

R-squared is the proportion of the variance in the response variable that can be explained by the predictor variable. In this case, 65.76% of the variance in the exam scores can be explained by the number of hours spent studying.
The standard error of the regression is the average distance that the observed values fall from the regression line. In this case, the observed values fall an average of 4.89 units from the regression line.
If we plot the actual data points along with the regression line, we can see this more clearly:

Notice that some observations fall very close to the regression line, while others are not quite as close. But on average, the observed values fall 4.19 units from the regression line.
The standard error of the regression is particularly useful because it can be used to assess the precision of predictions. Roughly 95% of the observation should fall within +/- two standard error of the regression, which is a quick approximation of a 95% prediction interval.
If we’re interested in making predictions using the regression model, the standard error of the regression can be a more useful metric to know than R-squared because it gives us an idea of how precise our predictions will be in terms of units.
To illustrate why the standard error of the regression can be a more useful metric in assessing the “fit” of a model, consider another example dataset that shows how many hours 12 students studied per day for a month leading up to an important exam along with their exam score:

Notice that this is the exact same dataset as before, except all of the values are cut in half. Thus, the students in this dataset studied for exactly half as long as the students in the previous dataset and received exactly half the exam score.
If we fit a simple linear regression model to this dataset in Excel, we receive the following output:

Notice that the R-squared of 65.76% is the exact same as the previous example.
However, the standard error of the regression is 2.095, which is exactly half as large as the standard error of the regression in the previous example.
If we plot the actual data points along with the regression line, we can see this more clearly:

Notice how the observations are packed much more closely around the regression line. On average, the observed values fall 2.095 units from the regression line.
So, even though both regression models have an R-squared of 65.76%, we know that the second model would provide more precise predictions because it has a lower standard error of the regression.
The Advantages of Using the Standard Error
The standard error of the regression (S) is often more useful to know than the R-squared of the model because it provides us with actual units. If we’re interested in using a regression model to produce predictions, S can tell us very easily if a model is precise enough to use for prediction.
For example, suppose we want to produce a 95% prediction interval in which we can predict exam scores within 6 points of the actual score.
Our first model has an R-squared of 65.76%, but this doesn’t tell us anything about how precise our prediction interval will be. Luckily we also know that the first model has an S of 4.19. This means a 95% prediction interval would be roughly 2*4.19 = +/- 8.38 units wide, which is too wide for our prediction interval.
Our second model also has an R-squared of 65.76%, but again this doesn’t tell us anything about how precise our prediction interval will be. However, we know that the second model has an S of 2.095. This means a 95% prediction interval would be roughly 2*2.095= +/- 4.19 units wide, which is less than 6 and thus sufficiently precise to use for producing prediction intervals.
Further Reading
Introduction to Simple Linear Regression
What is a Good R-squared Value?