
Выборочная оценка всегда ошибочна. Так, стандартная ошибка средней показывает разброс средней. Для бинарной переменной (с двумя возможными значениями) средней арифметической является доля «успехов». В этой статье показано, как рассчитать дисперсию и стандартную ошибку доли.
Долю используют в качестве выборочной оценки вероятности. Обозначим долю как p*, а истинную вероятность как p . При бесконечно большом количестве наблюдений доля p* стремится к теоретической вероятности p. Этот факт известен со времен Якоба Бернулли.
Дисперсия и стандартная ошибка доли
Обратимся вначале к дисперсии биномиальной переменной. Если истинная вероятность p не известна, то используют ее оценку p*.
![]()
где B – сумма «успехов» в выборке;
n – количество наблюдений;
p* – оценка вероятности, т.е. доля «успехов».
Нас интересует дисперсия величины B/n. Согласно одному из свойств дисперсии, постоянный множитель выносится за скобки и возводится в квадрат.
Получаем формулу дисперсию доли:
![]()
Почти полная аналогия со средней арифметической. В числителе дисперсия самой переменной (1 или 0), внизу – объем выборки.
Стандартная ошибка доли – корень из дисперсии:

Стандартная ошибка доли при увеличении выборки ведет себя так же, как и стандартная ошибка средней: чем больше выборка, тем меньше ошибка, но при этом уменьшение постоянно замедляется.
Как известно, максимально возможная дисперсия переменной в схеме Бернулли достигается при p*=0,5. Она равна 0,5*(1-0,5)=0,25. Отсюда легко рассчитать максимальную стандартную ошибку доли, полученную по некоторой выборке.

Изобразим эту зависимость на диаграмме.

График имеет знакомую конфигурацию: ошибка уменьшается с замедлением. Так, при объеме выборки равной 100 наблюдениям стандартная ошибка (максимально возможная!) равна 0,05 (или 5 процентных пункта). При n=1000 стандартная ошибка доли составляет всего 0,0158 (или 1,58 процентных пункта). Повторюсь, что это максимум. Именно поэтому опросы общественно мнения редко превышают 1500-2000 человек (чтобы еще была возможность разбить данные на группы достаточно размера).
На практике довольно часто приходится анализировать бинарные данные. Это может быть анкетирование покупателей, контроль качества продукции и много чего еще. Поэтому доля, как оценка вероятности наступления интересующего события, – довольно распространенный показатель. Дисперсия и стандартная ошибка доли используется в расчете приблизительных доверительных интервалов вероятности и в проверке статистических гипотез.
Поделиться в социальных сетях:
Выборочная оценка всегда ошибочна. Так, стандартная ошибка средней показывает разброс средней. Для бинарной переменной (с двумя возможными значениями) средней арифметической является доля «успехов». В этой статье показано, как рассчитать дисперсию и стандартную ошибку доли.
Долю используют в качестве выборочной оценки вероятности. Обозначим долю как p*, а истинную вероятность как p . При бесконечно большом количестве наблюдений доля p* стремится к теоретической вероятности p. Этот факт известен со времен Якоба Бернулли.
Дисперсия и стандартная ошибка доли
Обратимся вначале к дисперсии биномиальной переменной. Если истинная вероятность p не известна, то используют ее оценку p*.
![]()
где B – сумма «успехов» в выборке;
n – количество наблюдений;
p* – оценка вероятности, т.е. доля «успехов».
Нас интересует дисперсия величины B/n. Согласно одному из свойств дисперсии, постоянный множитель выносится за скобки и возводится в квадрат.
Получаем формулу дисперсию доли:
![]()
Почти полная аналогия со средней арифметической. В числителе дисперсия самой переменной (1 или 0), внизу – объем выборки.
Стандартная ошибка доли – корень из дисперсии:
Стандартная ошибка доли при увеличении выборки ведет себя так же, как и стандартная ошибка средней: чем больше выборка, тем меньше ошибка, но при этом уменьшение постоянно замедляется.
Как известно, максимально возможная дисперсия переменной в схеме Бернулли достигается при p*=0,5. Она равна 0,5*(1-0,5)=0,25. Отсюда легко рассчитать максимальную стандартную ошибку доли, полученную по некоторой выборке.
Изобразим эту зависимость на диаграмме.
График имеет знакомую конфигурацию: ошибка уменьшается с замедлением. Так, при объеме выборки равной 100 наблюдениям стандартная ошибка (максимально возможная!) равна 0,05 (или 5 процентных пункта). При n=1000 стандартная ошибка доли составляет всего 0,0158 (или 1,58 процентных пункта). Повторюсь, что это максимум. Именно поэтому опросы общественно мнения редко превышают 1500-2000 человек (чтобы еще была возможность разбить данные на группы достаточно размера).
На практике довольно часто приходится анализировать бинарные данные. Это может быть анкетирование покупателей, контроль качества продукции и много чего еще. Поэтому доля, как оценка вероятности наступления интересующего события, – довольно распространенный показатель. Дисперсия и стандартная ошибка доли используется в расчете приблизительных доверительных интервалов вероятности и в проверке статистических гипотез.
Поделиться в социальных сетях:
Точность оценки долей
Если бы в наших руках были данные по
всем членам совокупности, то не было бы
никаких проблем связанных с точностью
оценок. Однако нам всегда приходится
довольствоваться ограниченной выборкой.
Поэтому возникает вопрос, насколько
точно доли в выборке соответствуют
долям в совокупности.

Рис. 5.4. А. Из совокупности марсиан, среди
которых 150 зеленых и 50 розовых, извлекли
случайную выборку из 10 особей. В выборку
попало 5 зеленых и 5 розовых марсиан, на
рисунке они помечены черным. Б. В таком
виде данные предстанут перед исследователем,
который не может наблюдать всю совокупность
и вынужден судить о ней по выборке.
Оценка доли розовых марсиан p = 5/10 = 0,5.
Как любая выборочная оценка, оценка
доли (обозначим ее p^) отражает
долю р в совокупности, но отклоняется
от нее в силу случайности. Рассмотрим
теперь не совокупность марсиан, а
совокупность всех значений p^ ,
вычисленных по выборкам объемом 10
каждая. (Из совокупности в 200 членов
можно получить более 106 таких
выборок). По аналогии со стандартной
ошибкой среднего найдем стандартную
ошибку доли. Для этого нужно
охарактеризовать разброс выборочных
оценок доли, то есть рассчитать стандартное
отклонение совокупности p^.
![]()
где σ p^ — стандартная ошибка
доли, σ — стандартное отклонение, n —
объем выборки.

Заменив в приведенной формуле истинное
значение доли ее оценкой p^ ,
получим оценку стандартной ошибки доли:

Из центральной предельной теоремы
вытекает, что при достаточно большом
объеме выборки выборочная оценка p^
приближенно подчиняется
нормальному распределению, имеющему
среднее р и стандартное отклонение σˆp
. Однако при значениях р, близких к 0 или
1, и при малом объеме выборки это не так.
При какой численности выборки можно
пользоваться приведенным способом
оценки? Математическая статистика
утверждает, что нормальное распределение
служит хорошим приближением, если np^
и n(1-p^)
превосходят 5. Напомним, что примерно
95% всех членов нормально распределенной
совокупности находятся в пределах двух
стандартных отклонений от среднего.
Поэтому если перечисленные условия
соблюдены, то с вероятностью 95% можно
утверждать, что истинное значение р
лежит в пределах np^
и n(1-p^).
Вернемся на минуту к сравнению операционной
летальности при галотановой и морфиновой
анестезии. Напомним, что при использовании
галотана летальность составила 13,1%
(численность группы — 61 больной), а при
использовании морфина —
14,9% (численность группы — 67 больных).
Стандартная ошибка доли для группы


Если учесть, что различие в летальности
составило лишь 2%, то маловероятно, чтобы
оно было обусловлено чем-нибудь, кроме
случайного характера выборки.
Перечислим те предпосылки, на которых
основан излагаемый подход. Мы изучаем
то, что в статистике принято называть
независимыми испытаниями Бернулли.
Эти испытания обладают следующими
свойствами.
• Каждое отдельное испытание имеет
ровно два возможных взаимно исключающих
исхода.
• Вероятность данного исхода одна и та
же в любом испытании.
• Все испытания независимы друг от
друга.
21
Соседние файлы в папке Старый материал
- #
- #
- #
- #
- #
- #
- #
Выборочная оценка всегда ошибочна. Так, стандартная ошибка средней показывает разброс средней. Для бинарной переменной (с двумя возможными значениями) средней арифметической является доля «успехов». В этой статье показано, как рассчитать дисперсию и стандартную ошибку доли.
Долю используют в качестве выборочной оценки вероятности. Обозначим долю как p*, а истинную вероятность как p . При бесконечно большом количестве наблюдений доля p* стремится к теоретической вероятности p. Этот факт известен со времен Якоба Бернулли.
Дисперсия и стандартная ошибка доли
Обратимся вначале к дисперсии биномиальной переменной. Если истинная вероятность p не известна, то используют ее оценку p*.
![]()
где B – сумма «успехов» в выборке;
n – количество наблюдений;
p* – оценка вероятности, т.е. доля «успехов».
Нас интересует дисперсия величины B/n. Согласно одному из свойств дисперсии, постоянный множитель выносится за скобки и возводится в квадрат.
Получаем формулу дисперсию доли:
![]()
Почти полная аналогия со средней арифметической. В числителе дисперсия самой переменной (1 или 0), внизу – объем выборки.
Стандартная ошибка доли – корень из дисперсии:
Стандартная ошибка доли при увеличении выборки ведет себя так же, как и стандартная ошибка средней: чем больше выборка, тем меньше ошибка, но при этом уменьшение постоянно замедляется.
Как известно, максимально возможная дисперсия переменной в схеме Бернулли достигается при p*=0,5. Она равна 0,5*(1-0,5)=0,25. Отсюда легко рассчитать максимальную стандартную ошибку доли, полученную по некоторой выборке.
Изобразим эту зависимость на диаграмме.
График имеет знакомую конфигурацию: ошибка уменьшается с замедлением. Так, при объеме выборки равной 100 наблюдениям стандартная ошибка (максимально возможная!) равна 0,05 (или 5 процентных пункта). При n=1000 стандартная ошибка доли составляет всего 0,0158 (или 1,58 процентных пункта). Повторюсь, что это максимум. Именно поэтому опросы общественно мнения редко превышают 1500-2000 человек (чтобы еще была возможность разбить данные на группы достаточно размера).
На практике довольно часто приходится анализировать бинарные данные. Это может быть анкетирование покупателей, контроль качества продукции и много чего еще. Поэтому доля, как оценка вероятности наступления интересующего события, – довольно распространенный показатель. Дисперсия и стандартная ошибка доли используется в расчете приблизительных доверительных интервалов вероятности и в проверке статистических гипотез.
Поделиться в социальных сетях:
Точность оценки долей
Если бы в наших руках были данные по
всем членам совокупности, то не было бы
никаких проблем связанных с точностью
оценок. Однако нам всегда приходится
довольствоваться ограниченной выборкой.
Поэтому возникает вопрос, насколько
точно доли в выборке соответствуют
долям в совокупности.
Рис. 5.4. А. Из совокупности марсиан, среди
которых 150 зеленых и 50 розовых, извлекли
случайную выборку из 10 особей. В выборку
попало 5 зеленых и 5 розовых марсиан, на
рисунке они помечены черным. Б. В таком
виде данные предстанут перед исследователем,
который не может наблюдать всю совокупность
и вынужден судить о ней по выборке.
Оценка доли розовых марсиан p = 5/10 = 0,5.
Как любая выборочная оценка, оценка
доли (обозначим ее p^) отражает
долю р в совокупности, но отклоняется
от нее в силу случайности. Рассмотрим
теперь не совокупность марсиан, а
совокупность всех значений p^ ,
вычисленных по выборкам объемом 10
каждая. (Из совокупности в 200 членов
можно получить более 106 таких
выборок). По аналогии со стандартной
ошибкой среднего найдем стандартную
ошибку доли. Для этого нужно
охарактеризовать разброс выборочных
оценок доли, то есть рассчитать стандартное
отклонение совокупности p^.
![]()
где σ p^ — стандартная ошибка
доли, σ — стандартное отклонение, n —
объем выборки.
Заменив в приведенной формуле истинное
значение доли ее оценкой p^ ,
получим оценку стандартной ошибки доли:
Из центральной предельной теоремы
вытекает, что при достаточно большом
объеме выборки выборочная оценка p^
приближенно подчиняется
нормальному распределению, имеющему
среднее р и стандартное отклонение σˆp
. Однако при значениях р, близких к 0 или
1, и при малом объеме выборки это не так.
При какой численности выборки можно
пользоваться приведенным способом
оценки? Математическая статистика
утверждает, что нормальное распределение
служит хорошим приближением, если np^
и n(1-p^)
превосходят 5. Напомним, что примерно
95% всех членов нормально распределенной
совокупности находятся в пределах двух
стандартных отклонений от среднего.
Поэтому если перечисленные условия
соблюдены, то с вероятностью 95% можно
утверждать, что истинное значение р
лежит в пределах np^
и n(1-p^).
Вернемся на минуту к сравнению операционной
летальности при галотановой и морфиновой
анестезии. Напомним, что при использовании
галотана летальность составила 13,1%
(численность группы — 61 больной), а при
использовании морфина —
14,9% (численность группы — 67 больных).
Стандартная ошибка доли для группы
Если учесть, что различие в летальности
составило лишь 2%, то маловероятно, чтобы
оно было обусловлено чем-нибудь, кроме
случайного характера выборки.
Перечислим те предпосылки, на которых
основан излагаемый подход. Мы изучаем
то, что в статистике принято называть
независимыми испытаниями Бернулли.
Эти испытания обладают следующими
свойствами.
• Каждое отдельное испытание имеет
ровно два возможных взаимно исключающих
исхода.
• Вероятность данного исхода одна и та
же в любом испытании.
• Все испытания независимы друг от
друга.
21
Соседние файлы в папке Старый материал
- #
- #
- #
- #
- #
- #
- #
Стандартная ошибка пропорции: формула и пример
17 авг. 2022 г.
читать 1 мин
Часто в статистике нас интересует оценка доли людей в популяции с определенной характеристикой.
Например, нас может заинтересовать оценка доли жителей определенного города, поддерживающих новый закон.
Вместо того, чтобы ходить и спрашивать каждого жителя, поддерживают ли они закон, мы вместо этого собираем простую случайную выборку и выясняем, сколько жителей в выборке поддерживают закон.
Затем мы рассчитали бы долю выборки (p̂) как:
Пример формулы пропорции:
р̂ = х / п
куда:
- x: количество лиц в выборке с определенной характеристикой.
- n: общее количество лиц в выборке.
Затем мы использовали бы эту пропорцию выборки для оценки доли населения. Например, если 47 из 300 жителей выборки поддержали новый закон, то выборочная доля будет рассчитана как 47/300 = 0,157 .
Это означает, что наша наилучшая оценка доли жителей в населении, поддержавших закон, будет равна 0,157 .
Однако нет никакой гарантии, что эта оценка будет точно соответствовать истинной доле населения, поэтому мы обычно также рассчитываем стандартную ошибку доли .
Это рассчитывается как:
Стандартная ошибка формулы пропорции:
Стандартная ошибка = √ p̂(1-p̂) / n
Например, если p̂ = 0,157 и n = 300, то мы рассчитали бы стандартную ошибку пропорции как:
Стандартная ошибка пропорции = √ 0,157 (1-0,157) / 300 = 0,021
Затем мы обычно используем эту стандартную ошибку для расчета доверительного интервала для истинной доли жителей, поддерживающих закон.
Это рассчитывается как:
Доверительный интервал для формулы доли населения:
Доверительный интервал = p̂ +/- z * √ p̂(1-p̂) / n
Глядя на эту формулу, легко увидеть, что чем больше стандартная ошибка пропорции, тем шире доверительный интервал .
Обратите внимание, что z в формуле — это z-значение, которое соответствует популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z-значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Например, вот как рассчитать 95% доверительный интервал для истинной доли жителей города, поддерживающих новый закон:
- 95% ДИ = p̂ +/- z * √ p̂(1-p̂) / n
- 95% ДИ = 0,157 +/- 1,96 * √ 0,157 (1-0,157) / 300
- 95% ДИ = 0,157 +/- 1,96*(0,021)
- 95% ДИ = [0,10884, 0,19816]
Таким образом, с уверенностью 95% можно сказать, что истинная доля жителей города, поддерживающих новый закон, составляет от 10,884% до 19,816%.
Дополнительные ресурсы
Стандартная ошибка калькулятора пропорций
Доверительный интервал для калькулятора пропорций
Что такое доля населения?
Стандартная ошибка пропорции: формула и пример
17 авг. 2022 г.
читать 1 мин
Часто в статистике нас интересует оценка доли людей в популяции с определенной характеристикой.
Например, нас может заинтересовать оценка доли жителей определенного города, поддерживающих новый закон.
Вместо того, чтобы ходить и спрашивать каждого жителя, поддерживают ли они закон, мы вместо этого собираем простую случайную выборку и выясняем, сколько жителей в выборке поддерживают закон.
Затем мы рассчитали бы долю выборки (p̂) как:
Пример формулы пропорции:
р̂ = х / п
куда:
- x: количество лиц в выборке с определенной характеристикой.
- n: общее количество лиц в выборке.
Затем мы использовали бы эту пропорцию выборки для оценки доли населения. Например, если 47 из 300 жителей выборки поддержали новый закон, то выборочная доля будет рассчитана как 47/300 = 0,157 .
Это означает, что наша наилучшая оценка доли жителей в населении, поддержавших закон, будет равна 0,157 .
Однако нет никакой гарантии, что эта оценка будет точно соответствовать истинной доле населения, поэтому мы обычно также рассчитываем стандартную ошибку доли .
Это рассчитывается как:
Стандартная ошибка формулы пропорции:
Стандартная ошибка = √ p̂(1-p̂) / n
Например, если p̂ = 0,157 и n = 300, то мы рассчитали бы стандартную ошибку пропорции как:
Стандартная ошибка пропорции = √ 0,157 (1-0,157) / 300 = 0,021
Затем мы обычно используем эту стандартную ошибку для расчета доверительного интервала для истинной доли жителей, поддерживающих закон.
Это рассчитывается как:
Доверительный интервал для формулы доли населения:
Доверительный интервал = p̂ +/- z * √ p̂(1-p̂) / n
Глядя на эту формулу, легко увидеть, что чем больше стандартная ошибка пропорции, тем шире доверительный интервал .
Обратите внимание, что z в формуле — это z-значение, которое соответствует популярным вариантам выбора уровня достоверности:
| Уровень достоверности | z-значение | | — | — | | 0,90 | 1,645 | | 0,95 | 1,96 | | 0,99 | 2,58 |
Например, вот как рассчитать 95% доверительный интервал для истинной доли жителей города, поддерживающих новый закон:
- 95% ДИ = p̂ +/- z * √ p̂(1-p̂) / n
- 95% ДИ = 0,157 +/- 1,96 * √ 0,157 (1-0,157) / 300
- 95% ДИ = 0,157 +/- 1,96*(0,021)
- 95% ДИ = [0,10884, 0,19816]
Таким образом, с уверенностью 95% можно сказать, что истинная доля жителей города, поддерживающих новый закон, составляет от 10,884% до 19,816%.
Дополнительные ресурсы
Стандартная ошибка калькулятора пропорций
Доверительный интервал для калькулятора пропорций
Что такое доля населения?
Точность оценки долей
Если бы в наших руках были данные по
всем членам совокупности, то не было бы
никаких проблем связанных с точностью
оценок. Однако нам всегда приходится
довольствоваться ограниченной выборкой.
Поэтому возникает вопрос, насколько
точно доли в выборке соответствуют
долям в совокупности.
Рис. 5.4. А. Из совокупности марсиан, среди
которых 150 зеленых и 50 розовых, извлекли
случайную выборку из 10 особей. В выборку
попало 5 зеленых и 5 розовых марсиан, на
рисунке они помечены черным. Б. В таком
виде данные предстанут перед исследователем,
который не может наблюдать всю совокупность
и вынужден судить о ней по выборке.
Оценка доли розовых марсиан p = 5/10 = 0,5.
Как любая выборочная оценка, оценка
доли (обозначим ее p^) отражает
долю р в совокупности, но отклоняется
от нее в силу случайности. Рассмотрим
теперь не совокупность марсиан, а
совокупность всех значений p^ ,
вычисленных по выборкам объемом 10
каждая. (Из совокупности в 200 членов
можно получить более 106 таких
выборок). По аналогии со стандартной
ошибкой среднего найдем стандартную
ошибку доли. Для этого нужно
охарактеризовать разброс выборочных
оценок доли, то есть рассчитать стандартное
отклонение совокупности p^.
![]()
где σ p^ — стандартная ошибка
доли, σ — стандартное отклонение, n —
объем выборки.
Заменив в приведенной формуле истинное
значение доли ее оценкой p^ ,
получим оценку стандартной ошибки доли:
Из центральной предельной теоремы
вытекает, что при достаточно большом
объеме выборки выборочная оценка p^
приближенно подчиняется
нормальному распределению, имеющему
среднее р и стандартное отклонение σˆp
. Однако при значениях р, близких к 0 или
1, и при малом объеме выборки это не так.
При какой численности выборки можно
пользоваться приведенным способом
оценки? Математическая статистика
утверждает, что нормальное распределение
служит хорошим приближением, если np^
и n(1-p^)
превосходят 5. Напомним, что примерно
95% всех членов нормально распределенной
совокупности находятся в пределах двух
стандартных отклонений от среднего.
Поэтому если перечисленные условия
соблюдены, то с вероятностью 95% можно
утверждать, что истинное значение р
лежит в пределах np^
и n(1-p^).
Вернемся на минуту к сравнению операционной
летальности при галотановой и морфиновой
анестезии. Напомним, что при использовании
галотана летальность составила 13,1%
(численность группы — 61 больной), а при
использовании морфина —
14,9% (численность группы — 67 больных).
Стандартная ошибка доли для группы
Если учесть, что различие в летальности
составило лишь 2%, то маловероятно, чтобы
оно было обусловлено чем-нибудь, кроме
случайного характера выборки.
Перечислим те предпосылки, на которых
основан излагаемый подход. Мы изучаем
то, что в статистике принято называть
независимыми испытаниями Бернулли.
Эти испытания обладают следующими
свойствами.
• Каждое отдельное испытание имеет
ровно два возможных взаимно исключающих
исхода.
• Вероятность данного исхода одна и та
же в любом испытании.
• Все испытания независимы друг от
друга.
21
Соседние файлы в папке Старый материал
- #
- #
- #
- #
- #
- #
- #
Стандартная ошибка
Стандартная ошибка — это стандартное отклонение выборочного распределения статистики. Этот термин также может использоваться для оценки (хорошего предположения) этого стандартного отклонения, взятого из выборки всей группы.
Среднее значение некоторой части группы (называемой выборкой) является обычным способом оценки среднего значения для всей группы. Часто бывает слишком сложно или стоит слишком много денег, чтобы измерить всю группу. Но если измерить другую выборку, то ее среднее значение будет немного отличаться от первой выборки. Стандартная ошибка среднего — это способ узнать, насколько близка средняя по выборке к средней по всей группе. Это способ узнать, насколько вы можете быть уверены в среднем значении по выборке.
В реальных измерениях истинное значение стандартного отклонения среднего для всей группы обычно неизвестно. Поэтому термин стандартная ошибка часто используется для обозначения близкого к истинному значению для всей группы. Чем больше измерений в выборке, тем ближе к истинному значению для всей группы.
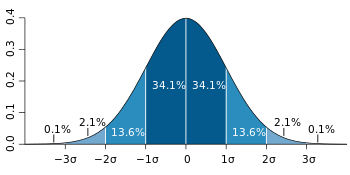
![]()
Для значения, отобранного с несмещенной нормально распределенной ошибкой, выше показана доля выборок, которые будут находиться в пределах 0, 1, 2 и 3 стандартных отклонений выше и ниже фактического значения.
Как найти стандартную ошибку среднего значения
Один из способов найти стандартную ошибку среднего — это множество выборок. Сначала находят среднее значение для каждой выборки. Затем находят среднее и стандартное отклонение этих средних по выборкам. Стандартное отклонение для всех средних по выборке и есть стандартная ошибка среднего. Это может быть большой объем работы. Иногда иметь большое количество образцов слишком сложно или стоит слишком много денег.
Другой способ найти стандартную ошибку среднего — использовать уравнение, для которого нужна только одна выборка. Стандартная ошибка среднего обычно оценивается по стандартному отклонению для выборки из всей группы (стандартное отклонение выборки), деленному на квадратный корень из размера выборки.
S E x ¯ = s n {displaystyle SE_{bar {x}} ={frac {s}{sqrt {n}}}} 
где
s — стандартное отклонение выборки (т.е. выборочная оценка стандартного отклонения популяции), и
n — количество измерений в выборке.
Насколько большой должна быть выборка, чтобы оценка стандартной ошибки среднего была близка к фактической стандартной ошибке среднего для всей группы? В выборке должно быть не менее шести измерений. Тогда стандартная ошибка среднего для выборки будет находиться в пределах 5% от стандартной ошибки среднего, если бы измерялась вся группа.
Исправления для некоторых случаев
Существует еще одно уравнение, которое можно использовать, если количество измерений составляет 5% или более от всей группы:
Существуют специальные уравнения, которые необходимо использовать, если образец имеет менее 20 измерений.
Иногда выборка поступает из одного места, хотя вся группа может быть рассредоточена. Кроме того, иногда выборка может быть сделана за короткий промежуток времени, когда вся группа охватывает более длительный период. В этом случае числа в выборке не являются независимыми. Тогда используются специальные уравнения, чтобы попытаться исправить это.
Полезность
Практический результат: Можно быть более уверенным в среднем значении, если провести больше измерений в выборке. Тогда стандартная ошибка среднего значения будет меньше, поскольку стандартное отклонение делится на большее число. Однако, чтобы сделать неопределенность (стандартную ошибку среднего) среднего значения в два раза меньше, размер выборки (n) должен быть в четыре раза больше. Это происходит потому, что стандартное отклонение делится на квадратный корень из размера выборки. Чтобы сделать неопределенность на одну десятую больше, размер выборки (n) должен быть в сто раз больше!
Стандартные ошибки легко вычисляются и часто используются, потому что:
- Если известна стандартная ошибка нескольких отдельных величин, то во многих случаях можно легко рассчитать стандартную ошибку некоторой функции этих величин;
- Если вероятностное распределение значения известно, его можно использовать для расчета хорошего приближения к точному доверительному интервалу; и
- Если распределение вероятности неизвестно, для оценки доверительного интервала можно использовать другие уравнения
- Когда размер выборки становится очень большим, принцип центральной предельной теоремы показывает, что числа в выборке очень похожи на числа во всей группе (они имеют нормальное распределение).
Относительная стандартная ошибка
Относительная стандартная ошибка (RSE) — это стандартная ошибка, деленная на среднее значение. Это число меньше единицы. Умножение его на 100% дает его в процентах от среднего значения. Это помогает показать, является ли неопределенность важной или нет. Например, рассмотрим два исследования доходов домохозяйств, в результате которых среднее значение по выборке составляет $50 000. Если стандартная ошибка одного опроса составляет $10 000, а другого — $5 000, то относительные стандартные ошибки равны 20% и 10% соответственно. Опрос с меньшей относительной стандартной ошибкой лучше, потому что он имеет более точное измерение (неопределенность меньше).
На самом деле, люди, которым необходимо знать средние значения, часто решают, насколько мала должна быть неопределенность, прежде чем они решат использовать информацию. Например, Национальный центр статистики здравоохранения США не сообщает среднее значение, если относительная стандартная ошибка превышает 30%. NCHS также требует не менее 30 наблюдений для того, чтобы оценка была представлена в отчете. []
Пример
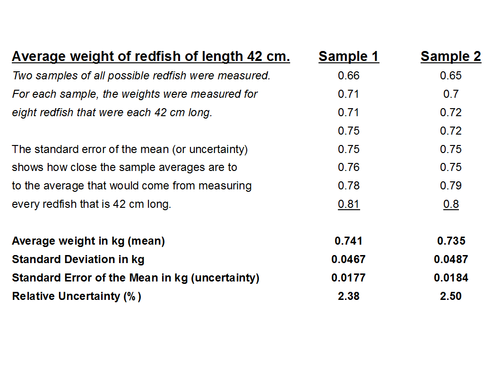
Например, в воде Мексиканского залива водится много красной рыбы. Чтобы узнать, сколько в среднем весит красноперка длиной 42 см, невозможно измерить всех красноперок длиной 42 см. Вместо этого можно измерить некоторых из них. Рыба, которую измеряют, называется образцом. В таблице показан вес двух образцов красноперки длиной 42 см. Средний (средний) вес первого образца составляет 0,741 кг. Средний (средний) вес второго образца — 0,735 кг, что немного отличается от первого образца. Каждое из этих средних значений немного отличается от среднего значения, которое было бы получено при измерении каждой красной рыбы длиной 42 см (что в любом случае невозможно).
Неопределенность среднего значения можно использовать для того, чтобы узнать, насколько близки средние значения выборок к среднему значению, которое было бы получено в результате измерения всей группы. Неопределенность среднего оценивается как стандартное отклонение для выборки, деленное на квадратный корень из числа выборок минус один. Из таблицы видно, что неопределенности в средних для двух выборок очень близки друг к другу. Кроме того, относительная неопределенность — это неопределенность среднего значения, деленная на среднее значение, умноженное на 100%. Относительная неопределенность в данном примере составляет 2,38% и 2,50% для двух образцов.
Зная неопределенность среднего, можно узнать, насколько близко выборочное среднее к среднему, которое было бы получено в результате измерения всей группы. Среднее по всей группе находится между а) средним по выборке плюс неопределенность в среднем и б) средним по выборке минус неопределенность в среднем. В данном примере средний вес всей красноперки длиной 42 см в Мексиканском заливе, как ожидается, составит 0,723-0,759 кг по первой выборке и 0,717-0,753 по второй выборке.
![]()
.jpg)
![]()
Пример красной рыбы (также известной как красный барабан, Sciaenops ocellatus), используемой в примере.
Что такое Стандартная формула ошибки?
Стандартная ошибка — это ошибка, которая возникает в распределении выборки при выполнении статистического анализа. Это вариант стандартного отклонения, так как оба понятия соответствуют мерам спреда. Высокая стандартная ошибка соответствует более высокому разбросу данных для взятой выборки. Вычисление формулы стандартной ошибки выполняется для выборки. В то же время стандартное отклонение определяет генеральную совокупность.
Оглавление
- Что такое Стандартная формула ошибки?
- Объяснение
- Пример формулы стандартной ошибки
- Калькулятор стандартной ошибки
- Актуальность и использование
- Стандартная формула ошибки в Excel
- Рекомендуемые статьи
Следовательно, стандартная ошибка среднего значения будет выражаться и определяться в соответствии с соотношением, описанным следующим образом:
σ͞x = σ/√n

Здесь,
- Стандартная ошибка, выраженная как σ͞x.
- Стандартное отклонение совокупности выражается как σ.
- Количество переменных в выборке, выраженное как n.
В статистическом анализе среднее значение, медиана и мода являются центральной тенденцией. Центральная тенденция Центральная тенденция — это статистическая мера, которая отображает центральную точку всего распределения данных, и вы можете найти ее с помощью 3 различных мер, т. е. среднего, медианы и моды.Подробнее меры. Стандартное отклонение, дисперсия и стандартная ошибка среднего классифицируются как меры изменчивости. Стандартная ошибка среднего для выборочных данных напрямую связана со стандартным отклонением большей совокупности и обратно пропорциональна или связана с квадратным корнем. число. Чтобы использовать эту функцию, введите термин =SQRT и нажмите клавишу табуляции, которая вызовет функцию SQRT. Более того, эта функция принимает один аргумент из нескольких переменных, используемых для создания выборки. Следовательно, если размер выборки Размер выборкиФормула размера выборки отображает соответствующий диапазон генеральной совокупности, в которой проводится эксперимент или опрос. Он измеряется с использованием размера генеральной совокупности, критического значения нормального распределения при требуемом доверительном уровне, доли выборки и предела погрешности. Если больше, то может быть равная вероятность того, что стандартная ошибка также будет большой.
Объяснение
Можно объяснить формулу для стандартной ошибки среднего, используя следующие шаги:
- Определите и организуйте выборку и определите количество переменных.
- Затем среднее значение выборки соответствует количеству переменных, присутствующих в выборке.
- Затем определите стандартное отклонение выборки.
- Затем определите квадратный корень из числа переменных, включенных в выборку.
- Теперь разделите стандартное отклонение, вычисленное на шаге 3, на полученное значение на шаге 4, чтобы получить стандартную ошибку.
Пример формулы стандартной ошибки
Ниже приведены примеры формул для расчета стандартной ошибки.
.free_excel_div{фон:#d9d9d9;размер шрифта:16px;радиус границы:7px;позиция:относительная;margin:30px;padding:25px 25px 25px 45px}.free_excel_div:before{content:»»;фон:url(центр центр без повтора #207245;ширина:70px;высота:70px;позиция:абсолютная;верх:50%;margin-top:-35px;слева:-35px;граница:5px сплошная #fff;граница-радиус:50%} Вы можете скачать этот шаблон стандартной формулы ошибки Excel здесь — Стандартная формула ошибки Шаблон Excel
Пример №1
Возьмем в качестве примера акции ABC. В течение 30 лет акции приносили средний долларовый доход в размере 45 долларов. Кроме того, было замечено, что акции приносят прибыль со стандартным отклонением в 2 доллара. Помогите инвестору рассчитать общую стандартную ошибку средней доходности, предлагаемой акцией ABC.
Решение:
- Стандартное отклонение (σ) = $2
- Количество лет (n) = 30
- Средняя доходность в долларах = 45 долларов.
Расчет стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 2 доллара США/√30
- = 2 доллара США / 5,4773
Стандартная ошибка,

- σx = 0,3651 доллара США
Таким образом, инвестиция предлагает инвестору стандартную долларовую ошибку в среднем 0,36515 доллара при удерживании позиции ABC в течение 30 лет. Однако, если бы акции сохранялись для более высокого инвестиционного горизонта, то стандартная ошибка среднего значения в долларах значительно уменьшилась бы.
Пример #2
Возьмем в качестве примера инвестора, который получил следующую доходность акций XYZ:
Год инвестиций Предлагаемая доходность120%225%35%410%
Помогите инвестору рассчитать общую стандартную ошибку средней доходности акций XYZ.
Решение:
Сначала определите среднее значение доходности, как показано ниже: –

- ͞X = (x1+x2+x3+x4)/количество лет
- = (20+25+5+10)/4
- =15%
Теперь определите стандартное отклонение доходности, как показано ниже: –

- σ = √ ((x1-͞X)2 + (x2-͞X)2 + (x3-͞X)2 + (x4-͞X)2) / √ (количество лет -1)
- = √ ((20-15) 2 + (25-15) 2 + (5-15) 2 + (10-15) 2) / √ (4-1)
- = (√ (5) 2 + (10) 2 + (-10) 2 + (-5) 2 ) / √ (3)
- = (√25+100+100+25)/ √ (3)
- =√250/√3
- =√83,3333
- «=» 9,1287%
Теперь вычисление стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 9,128709/√4
- = 9,128709/2
Стандартная ошибка,

- σx = 4,56%
Таким образом, инвестиции предлагают инвестору стандартную ошибку в долларах в среднем 4,56% при удержании позиции XYZ в течение 4 лет.
Калькулятор стандартной ошибки
Вы можете использовать следующий калькулятор.
.cal-tbl td{ верхняя граница: 0 !важно; }.cal-tbl tr{ высота строки: 0.5em; } Только экран @media и (минимальная ширина устройства: 320 пикселей) и (максимальная ширина устройства: 480 пикселей) { .cal-tbl tr{ line-height: 1em !important; } } σnСтандартная формула ошибки
Формула стандартной ошибки =σ =√n 0 = 0√0
Актуальность и использование
Стандартная ошибка имеет тенденцию быть высокой, если размер выборки для анализа мал. Следовательно, выборка всегда берется из большей совокупности, которая включает больший размер переменных. Это всегда помогает статистику определить достоверность среднего значения выборки относительно среднего значения генеральной совокупности.
Большая стандартная ошибка говорит статистику, что выборка неоднородна в отношении среднего значения генеральной совокупности. Относительно населения наблюдается большой разброс в выборке. Точно так же небольшая стандартная ошибка говорит статистику, что выборка однородна относительно среднего значения генеральной совокупности. Отсутствуют или незначительные различия в выборке относительно населения.
Не следует смешивать его со стандартным отклонением. Вместо этого следует рассчитать стандартное отклонение для всей совокупности. Стандартная ошибкаСтандартная ошибкаСтандартная ошибка (SE) — это метрика, которая измеряет точность выборочного распределения, обозначающего совокупность, с использованием стандартного отклонения. Другими словами, это мера дисперсии среднего значения выборки, связанная со средним значением генеральной совокупности, а не стандартное отклонение. С другой стороны, оно определяется для среднего значения выборки.
Стандартная формула ошибки в Excel
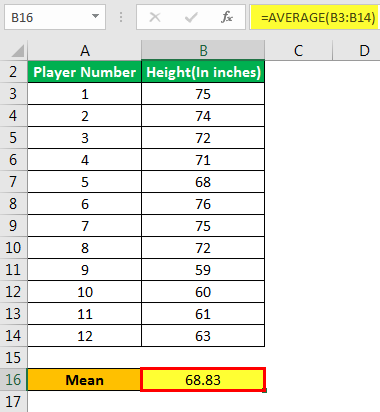
Теперь давайте возьмем пример Excel, чтобы проиллюстрировать концепцию стандартной формулы ошибки в шаблоне Excel ниже. Предположим, администрация школы хочет определить стандартную ошибку среднего значения роста футболистов.
Выборка состоит из следующих значений: –

Помогите администрации оценить стандартную ошибку среднего значения.
Шаг 1: Определите среднее значение, как показано ниже: –
Шаг 2: Определите стандартное отклонение, как показано ниже: –

Шаг 3: Определите стандартную ошибку среднего значения, как показано ниже: –

Следовательно, стандартная ошибка среднего значения для футболистов составляет 1,846 дюйма. Руководство должно заметить, что оно значительно велико. Таким образом, выборочные данные, взятые для анализа, неоднородны и имеют большую дисперсию.
Руководству следует либо исключить более мелких игроков, либо добавить игроков значительно выше, чтобы сбалансировать средний рост футбольной команды, заменив их людьми с меньшим ростом по сравнению с их сверстниками.
Рекомендуемые статьи
Эта статья была руководством по формуле стандартной ошибки. Здесь мы обсуждаем формулу для расчета среднего значения, стандартную ошибку, примеры и загружаемый лист Excel. Вы можете узнать больше из следующих статей: –
- Формула рентабельности EBITDA
- Формула валовой прибыли
- Формула относительного стандартного отклонения
- Формула погрешности