
I have a SQL file which has 140.000 rows with only insert statement. When I try to copy and paste it sometimes it will throw:
outofmemory exception
on the SQL Server. And sometimes I get
query completed with error
error when I execute whole insert statement with ‘ctrl + A’. Is there possible way to clear SQL Server cache or something for this?
![]()
Dale K
24.9k15 gold badges42 silver badges71 bronze badges
asked Dec 12, 2019 at 8:38
![]()
4
There are many reasons for this issue :
- There is insufficient memory to allocate for SSMS results for larger
results. Microsoft SQL Server Management Studio is a 32-bit process.
Therefore, it is limited to 2 GB memory. - SSMS puts an artificial limit on the text that can be displayed in
the per-database field in the results window.This limit is 64 KB in
“grid” mode and 8 KB in “text” mode. - Your result set is too large, the memory required to display ypur
query results can exceed the limit of the SSMS process. Alarge result
set can cause System.OutOfMemoryException error.
Solutions :
-
Configure the query window to output query results as text.A text
output uses less memory than the grid, and can be enough to display
the query results. To change this, follow these steps:Right click on the query window -> Click Results to -> Click Results to Text.
-
Right click the query window -> Click Results to- > Click Results To
File Then Run the SQL Query, and select the location where you want
to save the result file
answered Dec 12, 2019 at 9:50
![]()
Amira BedhiafiAmira Bedhiafi
5,5786 gold badges23 silver badges58 bronze badges
0
Привет, Хабр! Представляю вашему вниманию перевод статьи «Error and Transaction Handling in SQL Server. Part One – Jumpstart Error Handling» автора Erland Sommarskog.
1. Введение
Эта статья – первая в серии из трёх статей, посвященных обработке ошибок и транзакций в SQL Server. Её цель – дать вам быстрый старт в теме обработки ошибок, показав базовый пример, который подходит для большей части вашего кода. Эта часть написана в расчете на неопытного читателя, и по этой причине я намеренно умалчиваю о многих деталях. В данный момент задача состоит в том, чтобы рассказать как без упора на почему. Если вы принимаете мои слова на веру, вы можете прочесть только эту часть и отложить остальные две для дальнейших этапов в вашей карьере.
С другой стороны, если вы ставите под сомнение мои рекомендации, вам определенно необходимо прочитать две остальные части, где я погружаюсь в детали намного более глубоко, исследуя очень запутанный мир обработки ошибок и транзакций в SQL Server. Вторая и третья части, так же, как и три приложения, предназначены для читателей с более глубоким опытом. Первая статья — короткая, вторая и третья значительно длиннее.
Все статьи описывают обработку ошибок и транзакций в SQL Server для версии 2005 и более поздних версий.
1.1 Зачем нужна обработка ошибок?
Почему мы обрабатываем ошибки в нашем коде? На это есть много причин. Например, на формах в приложении мы проверяем введенные данные и информируем пользователей о допущенных при вводе ошибках. Ошибки пользователя – это предвиденные ошибки. Но нам также нужно обрабатывать непредвиденные ошибки. То есть, ошибки могут возникнуть из-за того, что мы что-то упустили при написании кода. Простой подход – это прервать выполнение или хотя бы вернуться на этап, в котором мы имеем полный контроль над происходящим. Недостаточно будет просто подчеркнуть, что совершенно непозволительно игнорировать непредвиденные ошибки. Это недостаток, который может вызвать губительные последствия: например, стать причиной того, что приложение будет предоставлять некорректную информацию пользователю или, что еще хуже, сохранять некорректные данные в базе. Также важно сообщать о возникновении ошибки с той целью, чтобы пользователь не думал о том, что операция прошла успешно, в то время как ваш код на самом деле ничего не выполнил.
Мы часто хотим, чтобы в базе данных изменения были атомарными. Например, задача по переводу денег с одного счета на другой. С этой целью мы должны изменить две записи в таблице CashHoldings и добавить две записи в таблицу Transactions. Абсолютно недопустимо, чтобы ошибки или сбой привели к тому, что деньги будут переведены на счет получателя, а со счета отправителя они не будут списаны. По этой причине обработка ошибок также касается и обработки транзакций. В приведенном примере нам нужно обернуть операцию в BEGIN TRANSACTION и COMMIT TRANSACTION, но не только это: в случае ошибки мы должны убедиться, что транзакция откачена.
2. Основные команды
Мы начнем с обзора наиболее важных команд, которые необходимы для обработки ошибок. Во второй части я опишу все команды, относящиеся к обработке ошибок и транзакций.
2.1 TRY-CATCH
Основным механизмом обработки ошибок является конструкция TRY-CATCH, очень напоминающая подобные конструкции в других языках. Структура такова:
BEGIN TRY
<обычный код>
END TRY
BEGIN CATCH
<обработка ошибок>
END CATCH
Если какая-либо ошибка появится в <обычный код>, выполнение будет переведено в блок CATCH, и будет выполнен код обработки ошибок.
Как правило, в CATCH откатывают любую открытую транзакцию и повторно вызывают ошибку. Таким образом, вызывающая клиентская программа понимает, что что-то пошло не так. Повторный вызов ошибки мы обсудим позже в этой статье.
Вот очень быстрый пример:
BEGIN TRY
DECLARE @x int
SELECT @x = 1/0
PRINT 'Not reached'
END TRY
BEGIN CATCH
PRINT 'This is the error: ' + error_message()
END CATCH
Результат выполнения: This is the error: Divide by zero error encountered.
Мы вернемся к функции error_message() позднее. Стоит отметить, что использование PRINT в обработчике CATCH приводится только в рамках экспериментов и не следует делать так в коде реального приложения.
Если <обычный код> вызывает хранимую процедуру или запускает триггеры, то любая ошибка, которая в них возникнет, передаст выполнение в блок CATCH. Если более точно, то, когда возникает ошибка, SQL Server раскручивает стек до тех пор, пока не найдёт обработчик CATCH. И если такого обработчика нет, SQL Server отправляет сообщение об ошибке напрямую клиенту.
Есть одно очень важное ограничение у конструкции TRY-CATCH, которое нужно знать: она не ловит ошибки компиляции, которые возникают в той же области видимости. Рассмотрим пример:
CREATE PROCEDURE inner_sp AS
BEGIN TRY
PRINT 'This prints'
SELECT * FROM NoSuchTable
PRINT 'This does not print'
END TRY
BEGIN CATCH
PRINT 'And nor does this print'
END CATCH
go
EXEC inner_spВыходные данные:
This prints
Msg 208, Level 16, State 1, Procedure inner_sp, Line 4
Invalid object name 'NoSuchTable'Как можно видеть, блок TRY присутствует, но при возникновении ошибки выполнение не передается блоку CATCH, как это ожидалось. Это применимо ко всем ошибкам компиляции, таким как пропуск колонок, некорректные псевдонимы и тому подобное, которые возникают во время выполнения. (Ошибки компиляции могут возникнуть в SQL Server во время выполнения из-за отложенного разрешения имен – особенность, благодаря которой SQL Server позволяет создать процедуру, которая обращается к несуществующим таблицам.)
Эти ошибки не являются полностью неуловимыми; вы не можете поймать их в области, в которой они возникают, но вы можете поймать их во внешней области. Добавим такой код к предыдущему примеру:
CREATE PROCEDURE outer_sp AS
BEGIN TRY
EXEC inner_sp
END TRY
BEGIN CATCH
PRINT 'The error message is: ' + error_message()
END CATCH
go
EXEC outer_spТеперь мы получим на выходе это:
This prints
The error message is: Invalid object name 'NoSuchTable'.На этот раз ошибка была перехвачена, потому что сработал внешний обработчик CATCH.
2.2 SET XACT_ABORT ON
В начало ваших хранимых процедур следует всегда добавлять это выражение:
SET XACT_ABORT, NOCOUNT ONОно активирует два параметра сессии, которые выключены по умолчанию в целях совместимости с предыдущими версиями, но опыт доказывает, что лучший подход – это иметь эти параметры всегда включенными. Поведение SQL Server по умолчанию в той ситуации, когда не используется TRY-CATCH, заключается в том, что некоторые ошибки прерывают выполнение и откатывают любые открытые транзакции, в то время как с другими ошибками выполнение последующих инструкций продолжается. Когда вы включаете XACT_ABORT ON, почти все ошибки начинают вызывать одинаковый эффект: любая открытая транзакция откатывается, и выполнение кода прерывается. Есть несколько исключений, среди которых наиболее заметным является выражение RAISERROR.
Параметр XACT_ABORT необходим для более надежной обработки ошибок и транзакций. В частности, при настройках по умолчанию есть несколько ситуаций, когда выполнение может быть прервано без какого-либо отката транзакции, даже если у вас есть TRY-CATCH. Мы видели такой пример в предыдущем разделе, где мы выяснили, что TRY-CATCH не перехватывает ошибки компиляции, возникшие в той же области. Открытая транзакция, которая не была откачена из-за ошибки, может вызвать серьезные проблемы, если приложение работает дальше без завершения транзакции или ее отката.
Для надежной обработки ошибок в SQL Server вам необходимы как TRY-CATCH, так и SET XACT_ABORT ON. Среди них инструкция SET XACT_ABORT ON наиболее важна. Если для кода на промышленной среде только на нее полагаться не стоит, то для быстрых и простых решений она вполне подходит.
Параметр NOCOUNT не имеет к обработке ошибок никакого отношения, но включение его в код является хорошей практикой. NOCOUNT подавляет сообщения вида (1 row(s) affected), которые вы можете видеть в панели Message в SQL Server Management Studio. В то время как эти сообщения могут быть полезны при работе c SSMS, они могут негативно повлиять на производительность в приложении, так как увеличивают сетевой трафик. Сообщение о количестве строк также может привести к ошибке в плохо написанных клиентских приложениях, которые могут подумать, что это данные, которые вернул запрос.
Выше я использовал синтаксис, который немного необычен. Большинство людей написали бы два отдельных выражения:
SET NOCOUNT ON
SET XACT_ABORT ONМежду ними нет никакого отличия. Я предпочитаю версию с SET и запятой, т.к. это снижает уровень шума в коде. Поскольку эти выражения должны появляться во всех ваших хранимых процедурах, они должны занимать как можно меньше места.
3. Основной пример обработки ошибок
После того, как мы посмотрели на TRY-CATCH и SET XACT_ABORT ON, давайте соединим их вместе в примере, который мы можем использовать во всех наших хранимых процедурах. Для начала я покажу пример, в котором ошибка генерируется в простой форме, а в следующем разделе я рассмотрю решения получше.
Для примера я буду использовать эту простую таблицу.
CREATE TABLE sometable(a int NOT NULL,
b int NOT NULL,
CONSTRAINT pk_sometable PRIMARY KEY(a, b))Вот хранимая процедура, которая демонстрирует, как вы должны работать с ошибками и транзакциями.
CREATE PROCEDURE insert_data @a int, @b int AS
SET XACT_ABORT, NOCOUNT ON
BEGIN TRY
BEGIN TRANSACTION
INSERT sometable(a, b) VALUES (@a, @b)
INSERT sometable(a, b) VALUES (@b, @a)
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
DECLARE @msg nvarchar(2048) = error_message()
RAISERROR (@msg, 16, 1)
RETURN 55555
END CATCHПервая строка в процедуре включает XACT_ABORT и NOCOUNT в одном выражении, как я показывал выше. Эта строка – единственная перед BEGIN TRY. Все остальное в процедуре должно располагаться после BEGIN TRY: объявление переменных, создание временных таблиц, табличных переменных, всё. Даже если у вас есть другие SET-команды в процедуре (хотя причины для этого встречаются редко), они должны идти после BEGIN TRY.
Причина, по которой я предпочитаю указывать SET XACT_ABORT и NOCOUNT перед BEGIN TRY, заключается в том, что я рассматриваю это как одну строку шума: она всегда должна быть там, но я не хочу, чтобы это мешало взгляду. Конечно же, это дело вкуса, и если вы предпочитаете ставить SET-команды после BEGIN TRY, ничего страшного. Важно то, что вам не следует ставить что-либо другое перед BEGIN TRY.
Часть между BEGIN TRY и END TRY является основной составляющей процедуры. Поскольку я хотел использовать транзакцию, определенную пользователем, я ввел довольно надуманное бизнес-правило, в котором говорится, что если вы вставляете пару, то обратная пара также должна быть вставлена. Два выражения INSERT находятся внутри BEGIN и COMMIT TRANSACTION. Во многих случаях у вас будет много строк кода между BEGIN TRY и BEGIN TRANSACTION. Иногда у вас также будет код между COMMIT TRANSACTION и END TRY, хотя обычно это только финальный SELECT, возвращающий данные или присваивающий значения выходным параметрам. Если ваша процедура не выполняет каких-либо изменений или имеет только одно выражение INSERT/UPDATE/DELETE/MERGE, то обычно вам вообще не нужно явно указывать транзакцию.
В то время как блок TRY будет выглядеть по-разному от процедуры к процедуре, блок CATCH должен быть более или менее результатом копирования и вставки. То есть вы делаете что-то короткое и простое и затем используете повсюду, не особо задумываясь. Обработчик CATCH, приведенный выше, выполняет три действия:
- Откатывает любые открытые транзакции.
- Повторно вызывает ошибку.
- Убеждается, что возвращаемое процедурой значение отлично от нуля.
Эти три действия должны всегда быть там. Мы можете возразить, что строка
IF @@trancount > 0 ROLLBACK TRANSACTIONне нужна, если нет явной транзакции в процедуре, но это абсолютно неверно. Возможно, вы вызываете хранимую процедуру, которая открывает транзакцию, но которая не может ее откатить из-за ограничений TRY-CATCH. Возможно, вы или кто-то другой добавите явную транзакцию через два года. Вспомните ли вы тогда о том, что нужно добавить строку с откатом? Не рассчитывайте на это. Я также слышу читателей, которые возражают, что если тот, кто вызывает процедуру, открыл транзакцию, мы не должны ее откатывать… Нет, мы должны, и если вы хотите знать почему, вам нужно прочитать вторую и третью части. Откат транзакции в обработчике CATCH – это категорический императив, у которого нет исключений.
Код повторной генерации ошибки включает такую строку:
DECLARE @msg nvarchar(2048) = error_message()Встроенная функция error_message() возвращает текст возникшей ошибки. В следующей строке ошибка повторно вызывается с помощью выражения RAISERROR. Это не самый простой способ вызова ошибки, но он работает. Другие способы мы рассмотрим в следующей главе.
Замечание: синтаксис для присвоения начального значения переменной в DECLARE был внедрен в SQL Server 2008. Если у вас SQL Server 2005, вам нужно разбить строку на DECLARE и выражение SELECT.
Финальное выражение RETURN – это страховка. RAISERROR никогда не прерывает выполнение, поэтому выполнение следующего выражения будет продолжено. Пока все процедуры используют TRY-CATCH, а также весь клиентский код обрабатывает исключения, нет повода для беспокойства. Но ваша процедура может быть вызвана из старого кода, написанного до SQL Server 2005 и до внедрения TRY-CATCH. В те времена лучшее, что мы могли делать, это смотреть на возвращаемые значения. То, что вы возвращаете с помощью RETURN, не имеет особого значения, если это не нулевое значение (ноль обычно обозначает успешное завершение работы).
Последнее выражение в процедуре – это END CATCH. Никогда не следует помещать какой-либо код после END CATCH. Кто-нибудь, читающий процедуру, может не увидеть этот кусок кода.
После прочтения теории давайте попробуем тестовый пример:
EXEC insert_data 9, NULLРезультат выполнения:
Msg 50000, Level 16, State 1, Procedure insert_data, Line 12
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.Давайте добавим внешнюю процедуру для того, чтобы увидеть, что происходит при повторном вызове ошибки:
CREATE PROCEDURE outer_sp @a int, @b int AS
SET XACT_ABORT, NOCOUNT ON
BEGIN TRY
EXEC insert_data @a, @b
END TRY
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
DECLARE @msg nvarchar(2048) = error_message()
RAISERROR (@msg, 16, 1)
RETURN 55555
END CATCH
go
EXEC outer_sp 8, 8Результат работы:
Msg 50000, Level 16, State 1, Procedure outer_sp, Line 9
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Мы получили корректное сообщение об ошибке, но если вы посмотрите на заголовки этого сообщения и на предыдущее поближе, то можете заметить проблему:
Msg 50000, Level 16, State 1, Procedure insert_data, Line 12
Msg 50000, Level 16, State 1, Procedure outer_sp, Line 9Сообщение об ошибке выводит информацию о расположении конечного выражения RAISERROR. В первом случае некорректен только номер строки. Во втором случае некорректно также имя процедуры. Для простых процедур, таких как наш тестовый пример, это не является большой проблемой. Но если у вас есть несколько уровней вложенных сложных процедур, то наличие сообщения об ошибке с отсутствием указания на место её возникновения сделает поиск и устранение ошибки намного более сложным делом. По этой причине желательно генерировать ошибку таким образом, чтобы можно было определить нахождение ошибочного фрагмента кода быстро, и это то, что мы рассмотрим в следующей главе.
4. Три способа генерации ошибки
4.1 Использование error_handler_sp
Мы рассмотрели функцию error_message(), которая возвращает текст сообщения об ошибке. Сообщение об ошибке состоит из нескольких компонентов, и существует своя функция error_xxx() для каждого из них. Мы можем использовать их для повторной генерации полного сообщения, которое содержит оригинальную информацию, хотя и в другом формате. Если делать это в каждом обработчике CATCH, это будет большой недостаток — дублирование кода. Вам не обязательно находиться в блоке CATCH для вызова error_message() и других подобных функций, и они вернут ту же самую информацию, если будут вызваны из хранимой процедуры, которую выполнит блок CATCH.
Позвольте представить вам error_handler_sp:
CREATE PROCEDURE error_handler_sp AS
DECLARE @errmsg nvarchar(2048),
@severity tinyint,
@state tinyint,
@errno int,
@proc sysname,
@lineno int
SELECT @errmsg = error_message(), @severity = error_severity(),
@state = error_state(), @errno = error_number(),
@proc = error_procedure(), @lineno = error_line()
IF @errmsg NOT LIKE '***%'
BEGIN
SELECT @errmsg = '*** ' + coalesce(quotename(@proc), '<dynamic SQL>') +
', Line ' + ltrim(str(@lineno)) + '. Errno ' +
ltrim(str(@errno)) + ': ' + @errmsg
END
RAISERROR('%s', @severity, @state, @errmsg)Первое из того, что делает error_handler_sp – это сохраняет значение всех error_xxx() функций в локальные переменные. Я вернусь к выражению IF через секунду. Вместо него давайте посмотрим на выражение SELECT внутри IF:
SELECT @errmsg = '*** ' + coalesce(quotename(@proc), '<dynamic SQL>') +
', Line ' + ltrim(str(@lineno)) + '. Errno ' +
ltrim(str(@errno)) + ': ' + @errmsgЦель этого SELECT заключается в форматировании сообщения об ошибке, которое передается в RAISERROR. Оно включает в себя всю информацию из оригинального сообщения об ошибке, которое мы не можем вставить напрямую в RAISERROR. Мы должны обработать имя процедуры, которое может быть NULL для ошибок в обычных скриптах или в динамическом SQL. Поэтому используется функция COALESCE. (Если вы не понимаете форму выражения RAISERROR, я рассказываю о нем более детально во второй части.)
Отформатированное сообщение об ошибке начинается с трех звездочек. Этим достигаются две цели: 1) Мы можем сразу видеть, что это сообщение вызвано из обработчика CATCH. 2) Это дает возможность для error_handler_sp отфильтровать ошибки, которые уже были сгенерированы один или более раз, с помощью условия NOT LIKE ‘***%’ для того, чтобы избежать изменения сообщения во второй раз.
Вот как обработчик CATCH должен выглядеть, когда вы используете error_handler_sp:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
EXEC error_handler_sp
RETURN 55555
END CATCHДавайте попробуем несколько тестовых сценариев.
EXEC insert_data 8, NULL
EXEC outer_sp 8, 8Результат выполнения:
Msg 50000, Level 16, State 2, Procedure error_handler_sp, Line 20
*** [insert_data], Line 5. Errno 515: Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 50000, Level 14, State 1, Procedure error_handler_sp, Line 20
*** [insert_data], Line 6. Errno 2627: Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Заголовки сообщений говорят о том, что ошибка возникла в процедуре error_handler_sp, но текст сообщений об ошибках дает нам настоящее местонахождение ошибки – как название процедуры, так и номер строки.
Я покажу еще два метода вызова ошибок. Однако error_handler_sp является моей главной рекомендацией для читателей, которые читают эту часть. Это — простой вариант, который работает на всех версиях SQL Server начиная с 2005. Существует только один недостаток: в некоторых случаях SQL Server генерирует два сообщения об ошибках, но функции error_xxx() возвращают только одну из них, и поэтому одно из сообщений теряется. Это может быть неудобно при работе с административными командами наподобие BACKUPRESTORE, но проблема редко возникает в коде, предназначенном чисто для приложений.
4.2. Использование ;THROW
В SQL Server 2012 Microsoft представил выражение ;THROW для более легкой обработки ошибок. К сожалению, Microsoft сделал серьезную ошибку при проектировании этой команды и создал опасную ловушку.
С выражением ;THROW вам не нужно никаких хранимых процедур. Ваш обработчик CATCH становится таким же простым, как этот:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
;THROW
RETURN 55555
END CATCHДостоинство ;THROW в том, что сообщение об ошибке генерируется точно таким же, как и оригинальное сообщение. Если изначально было два сообщения об ошибках, оба сообщения воспроизводятся, что делает это выражение еще привлекательнее. Как и со всеми другими сообщениями об ошибках, ошибки, сгенерированные ;THROW, могут быть перехвачены внешним обработчиком CATCH и воспроизведены. Если обработчика CATCH нет, выполнение прерывается, поэтому оператор RETURN в данном случае оказывается не нужным. (Я все еще рекомендую оставлять его, на случай, если вы измените свое отношение к ;THROW позже).
Если у вас SQL Server 2012 или более поздняя версия, измените определение insert_data и outer_sp и попробуйте выполнить тесты еще раз. Результат в этот раз будет такой:
Msg 515, Level 16, State 2, Procedure insert_data, Line 5
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 2627, Level 14, State 1, Procedure insert_data, Line 6
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Имя процедуры и номер строки верны и нет никакого другого имени процедуры, которое может нас запутать. Также сохранены оригинальные номера ошибок.
В этом месте вы можете сказать себе: действительно ли Microsoft назвал команду ;THROW? Разве это не просто THROW? На самом деле, если вы посмотрите в Books Online, там не будет точки с запятой. Но точка с запятой должны быть. Официально они отделяют предыдущее выражение, но это опционально, и далеко не все используют точку с запятой в выражениях T-SQL. Более важно, что если вы пропустите точку с запятой перед THROW, то не будет никакой синтаксической ошибки. Но это повлияет на поведение при выполнении выражения, и это поведение будет непостижимым для непосвященных. При наличии активной транзакции вы получите сообщение об ошибке, которое будет полностью отличаться от оригинального. И еще хуже, что при отсутствии активной транзакции ошибка будет тихо выведена без обработки. Такая вещь, как пропуск точки с запятой, не должно иметь таких абсурдных последствий. Для уменьшения риска такого поведения, всегда думайте о команде как о ;THROW (с точкой с запятой).
Нельзя отрицать того, что ;THROW имеет свои преимущества, но точка с запятой не единственная ловушка этой команды. Если вы хотите использовать ее, я призываю вас прочитать по крайней мере вторую часть этой серии, где я раскрываю больше деталей о команде ;THROW. До этого момента, используйте error_handler_sp.
4.3. Использование SqlEventLog
Третий способ обработки ошибок – это использование SqlEventLog, который я описываю очень детально в третьей части. Здесь я лишь сделаю короткий обзор.
SqlEventLog предоставляет хранимую процедуру slog.catchhandler_sp, которая работает так же, как и error_handler_sp: она использует функции error_xxx() для сбора информации и выводит сообщение об ошибке, сохраняя всю информацию о ней. Вдобавок к этому, она логирует ошибку в таблицу splog.sqleventlog. В зависимости от типа приложения, которое у вас есть, эта таблица может быть очень ценным объектом.
Для использования SqlEventLog, ваш обработчик CATCH должен быть таким:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
EXEC slog.catchhandler_sp @@procid
RETURN 55555
END CATCH@@procid возвращает идентификатор объекта текущей хранимой процедуры. Это то, что SqlEventLog использует для логирования информации в таблицу. Используя те же тестовые сценарии, получим результат их работы с использованием catchhandler_sp:
Msg 50000, Level 16, State 2, Procedure catchhandler_sp, Line 125
{515} Procedure insert_data, Line 5
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 50000, Level 14, State 1, Procedure catchhandler_sp, Line 125
{2627} Procedure insert_data, Line 6
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Как вы видите, сообщение об ошибке отформатировано немного не так, как это делает error_handler_sp, но основная идея такая же. Вот образец того, что было записано в таблицу slog.sqleventlog:
| logid | logdate | errno | severity | logproc | linenum | msgtext |
| 1 | 2015-01-25 22:40:24.393 | 515 | 16 | insert_data | 5 | Cannot insert … |
| 2 | 2015-01-25 22:40:24.395 | 2627 | 14 | insert_data | 6 | Violation of … |
Если вы хотите попробовать SqlEventLog, вы можете загрузить файл sqleventlog.zip. Инструкция по установке находится в третьей части, раздел Установка SqlEventLog.
5. Финальные замечания
Вы изучили основной образец для обработки ошибок и транзакций в хранимых процедурах. Он не идеален, но он должен работать в 90-95% вашего кода. Есть несколько ограничений, на которые стоит обратить внимание:
- Как мы видели, ошибки компиляции не могут быть перехвачены в той же процедуре, в которой они возникли, а только во внешней процедуре.
- Пример не работает с пользовательскими функциями, так как ни TRY-CATCH, ни RAISERROR нельзя в них использовать.
- Когда хранимая процедура на Linked Server вызывает ошибку, эта ошибка может миновать обработчик в хранимой процедуре на локальном сервере и отправиться напрямую клиенту.
- Когда процедура вызвана как INSERT-EXEC, вы получите неприятную ошибку, потому что ROLLBACK TRANSACTION не допускается в данном случае.
- Как упомянуто выше, если вы используете error_handler_sp или SqlEventLog, мы потеряете одно сообщение, когда SQL Server выдаст два сообщения для одной ошибки. При использовании ;THROW такой проблемы нет.
Я рассказываю об этих ситуациях более подробно в других статьях этой серии.
Перед тем как закончить, я хочу кратко коснуться триггеров и клиентского кода.
Триггеры
Пример для обработки ошибок в триггерах не сильно отличается от того, что используется в хранимых процедурах, за исключением одной маленькой детали: вы не должны использовать выражение RETURN (потому что RETURN не допускается использовать в триггерах).
С триггерами важно понимать, что они являются частью команды, которая запустила триггер, и в триггере вы находитесь внутри транзакции, даже если не используете BEGIN TRANSACTION.
Иногда я вижу на форумах людей, которые спрашивают, могут ли они написать триггер, который не откатывает в случае падения запустившую его команду. Ответ таков: нет способа сделать это надежно, поэтому не стоит даже пытаться. Если в этом есть необходимость, по возможности не следует использовать триггер вообще, а найти другое решение. Во второй и третьей частях я рассматриваю обработку ошибок в триггерах более подробно.
Клиентский код
У вас должна быть обработка ошибок в коде клиента, если он имеет доступ к базе. То есть вы должны всегда предполагать, что при любом вызове что-то может пойти не так. Как именно внедрить обработку ошибок, зависит от конкретной среды.
Здесь я только обращу внимание на важную вещь: реакцией на ошибку, возвращенную SQL Server, должно быть завершение запроса во избежание открытых бесхозных транзакций:
IF @@trancount > 0 ROLLBACK TRANSACTIONЭто также применимо к знаменитому сообщению Timeout expired (которое является не сообщением от SQL Server, а от API).
6. Конец первой части
Это конец первой из трех частей серии. Если вы хотели изучить вопрос обработки ошибок быстро, вы можете закончить чтение здесь. Если вы настроены идти дальше, вам следует прочитать вторую часть, где наше путешествие по запутанным джунглям обработки ошибок и транзакций в SQL Server начинается по-настоящему.
… и не забывайте добавлять эту строку в начало ваших хранимых процедур:
SET XACT_ABORT, NOCOUNT ON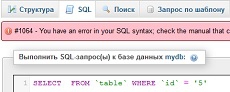
SQL-запрос — это то, что либо работает хорошо, либо не работает вообще, частично он никак работать не может, в отличие, например, от того же PHP. Как следствие, найти ошибку в SQL-запросе, просто рассматривая его — трудно, особенно если этот запрос снабжён целой кучей JOIN и UNION. Однако, в этой статье я расскажу о методе поиска ошибок в SQL-запросе.
Поскольку обычно в SQL-запрос подставляются какие-то переменные в PHP, то необходимо его сначала вывести. Сделать это можно, например, так:
<?php
$a = 5;
$query = "SELECT FROM `table` WHERE `id` = '$a'";
$result_set = $mysqli->query($query); // Не работает
echo $query; // Выводим запрос, который отправляется
?>
В результате, скрипт выведет такой запрос: SELECT FROM `table` WHERE `id` = ‘5’. Теперь чтобы найти ошибку в нём, надо зайти в phpMyAdmin, открыть базу данных, с которой происходит работа, открыть вкладку «SQL» и попытаться выполнить запрос.
И вот здесь уже ошибка будет показана, не в самой понятной форме (иногда прямо точно описывает ошибку), но она будет. Вот что написал phpMyAdmin: «#1064 — You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘FROM `table` WHERE `id` = ‘5’ ORDER BY `table`.`id` ASC LIMIT 0, 30′ at line 1«. Это означает, что ошибка рядом с FROM. Присматриваемся к этому выделенному нами небольшому участку и обнаруживаем, что мы забыли поставить «*«. Исправляем сразу в phpMyAdmin эту ошибку, убеждаемся, что запрос сработал и после этого идём исправлять ошибку уже в коде.
С помощью этого метода я нахожу абсолютно все ошибки в SQL-запросе, которые мне не удаётся обнаружить непосредственно при осмотре в PHP-коде.
Надеюсь, теперь и Вы сможете найти ошибку в любом SQL-запросе.
-

Создано 01.05.2013 10:54:01
-
Михаил Русаков

Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
Она выглядит вот так:
-
Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):

Ошибки SQL являются неотъемлемой частью работы с базами данных. Важно понимать их причины и способы решения, чтобы успешно разрабатывать и поддерживать приложения. В этой статье мы рассмотрим различные виды ошибок SQL, их возможные причины, а также методы решения таких проблем. Мы также предоставим ответы на часто задаваемые вопросы ошибках SQL и предложим полезные советы для профессионалов в области баз данных.
Основные виды ошибок SQL:
- Синтаксические ошибки
- Ошибки времени выполнения
- Логические ошибки
Синтаксические ошибки
a. Неправильное использование ключевых слов (H4 Heading) b. Ошибки в структуре запроса (H4 Heading) c. Проблемы с кавычками и скобками (H4 Heading)
Ошибки времени выполнения
a. Ошибки доступа к данным (H4 Heading) b. Ошибки ограничений целостности (H4 Heading) c. Проблемы с производительностью (H4 Heading)
Логические ошибки
a. Неправильный выбор операторов (H4 Heading) b. Ошибки в вычислениях (H4 Heading) c. Проблемы с агрегацией данных (H4 Heading)
Чтобы разобраться подробнее – приходите на бесплатный курс
- Определение типа ошибки (H3 Heading)
- Анализ причин ошибки (H3 Heading)
- Применение соответствующего решения (H3 Heading)
Определение типа ошибки
- Используйте сообщения об ошибках
- Отслеживайте контекст запроса
Анализ причин ошибки
- Проверьте синтаксис
- Проверьте права доступа
- Убедитесь, что данные корректны
Применение соответствующего решения
- Исправьте синтаксические ошибки
- Решите проблемы с данными
- Оптимизируйте запросы
Часто задаваемые вопросы
- Как наиболее эффективно найти и исправить ошибки SQL?
- Какие инструменты могут помочь в диагностике и исправлении ошибок SQL?
- Влияет ли версия базы данных на возникновение ошибок SQL?
- Как предотвратить ошибки SQL при разработке приложений?
Чтобы разобраться подробнее – приходите на бесплатный курс
Как наиболее эффективно найти и исправить ошибки SQL?
- Используйте подходящие инструменты и ресурсы для отладки
- Разбивайте сложные запросы на простые
- Протестируйте запросы с разными наборами данных
Какие инструменты могут помочь в диагностике и исправлении ошибок SQL?
- Редакторы кода с поддержкой SQL, такие как Visual Studio Code или Sublime Text
- Среды разработки баз данных, такие как SQL Server Management Studio или MySQL Workbench
- Специализированные инструменты для анализа и оптимизации запросов, такие как SQL Sentry Plan Explorer или EverSQL
Влияет ли версия базы данных на возникновение ошибок SQL?
Да, версия базы данных может влиять на возникновение ошибок SQL из-за различий в поддерживаемых функциях, синтаксисе и стандартах. Важно использовать актуальную версию базы данных и знать о возможных ограничениях или различиях между версиями.
Как предотвратить ошибки SQL при разработке приложений?
- Используйте хорошие практики проектирования баз данных и написания запросов
- Тестируйте ваш код на разных этапах разработки
- Внедряйте контроль версий и процессы код-ревью для обеспечения качества кода
- Обучайте разработчиков основам SQL и принципам работы с базами данных
Заключение:
Ошибки SQL являются неизбежным аспектом работы с базами данных, но с правильными знаниями и инструментами их можно успешно диагностировать и исправлять. Надеемся, что эта статья помогла вам лучше понять различные типы ошибок SQL, их причины и способы решения. Следуйте нашим рекомендациям и советам, чтобы свести к минимуму вероятность возникновения ошибок SQL и обеспечить надежную и эффективную работу ваших приложений с базами данных.
Дано: есть большая табличка CuteTable, в ней поле MegaField типа varchar(20), в этом поле хранятся даты определенного формата.
При попытке сделать select convert(DATETIME,MegaField,121) from CuteTable случается облом и вываливается ошибка конвертации. Я хочу узнать какая запись тлетворно влияет на табличку, и выкорчевать ее с корнем. Как это правильно сделать?
Доступен инструментарий ms sql management studio 2012.
Субд соответственно mssql 2012
задан 3 мар 2014 в 12:53
![]()
3
Используйте метод деления попалам. У большинства баз данных для select есть limit и offset. Вначале делаете запрос для первой половины данных (только не забудьте отсортировать, иначе будете долго искать). Если в первой половине нет, тогда оно гарантированно в второй половине.
При таком подходе, даже есть у Вас 10.000.000 записей, то Вам нужно не более 24 запросов.
Если же Ваша версия БД не поддерживает limitoffset, то можно просто использовать id для этой цели, даже если там есть разрывы.
ответ дан 3 мар 2014 в 16:10
![]()
KoVadimKoVadim
112k6 золотых знаков91 серебряный знак158 бронзовых знаков
3
Попробуйте так:
select * from CuteTable where isdate(MegaField)=0
ответ дан 3 мар 2014 в 14:12
![]()
msimsi
11.4k15 серебряных знаков16 бронзовых знаков
2
����� 1. ��������� �������.
����� 1. ������.
�������� ������ �� ��� �����, ���� �� �� ��������� ����� ����������, ��� ����� ������� ������ ����� ���� ������� � ������ �������. ��� �� ��ɣ� ����� ��������� � � ��������� SQL ����������.
��� ������ ��������� ������ � ������� ��������. ������ � ���� ������ ��������� ����� ������.
select * fro t1 where f1 in (1,2,1);
� �����, ����������� ��������� ��� �������� � ޣ� ��������. ���� ��������� ���� ������ � mysql cli ������ ������ �ݣ ��������:
mysql> select * fro t1 where f1 in (1,2,1);
ERROR 1064 (42000): You have an error in your SQL syntax;
check the manual that corresponds to your MySQL server version
for the right syntax to use near 'fro t1 where f1 in (1,2,1)' at line 1
�� ���� ��� �������������� ������: ������� �������� ����� o � ��������� from. ������, �� ������ ��?
����ͣ� ������ ���������. ��� ��� �� PHP. (��� ��������� ��������� �������, ��� ��� ��� ����������� ��� PHP ����������� � ������. ����������� �������� ����� �������� � �� ����� ������ ����� ������� ����� ����������������.)
$query = 'SELECT * FROM t4 WHERE f1 IN(';
for ($i = 1; $i < 101; $i ++)
$query .= "'row$i,";
$query = rtrim($query, ',');
$query .= ')';
$result = mysql_query($query);
� ������ ������ ��������� ������ ��� �������. � ��� ����� � ������ �ݣ ����� �������� �������?
� ������ � PHP ��� ������� ������� ������� echo, ������� ������������ �����:
$query = 'SELECT * FROM t4 WHERE f1 IN(';
for ($i = 1; $i < 101; $i ++)
$query .= "'row$i,";
$query = rtrim($query, ',');
$query .= ')';
echo $query;
//$result = mysql_query($query);
�������� ������:
$php phpconf2009_1.php
SELECT * FROM t4 WHERE f1 IN('row1,'row2,'row3,'row4,'row5,'row6,'row7,'row8,'row9,'row10,'row11,
'row12,'row13,'row14,'row15,'row16,'row17,'row18,'row19,'row20)
� ��� ��� ������ ���������� ����� ���������: �������� ����������� �������� � ���������
$query .= "'row$i,";
���������� �������� ��� ����������
$query .= "'row$i',";
� ������ ����� ����������� �����.
�������� ��������, ��� �� �������� ������ ������ � ��� ����, � ������� ��� �������� ����. ������� ����� ����� ������ � ������� �������, ��� � ������, ������� ���������� �� ������ ������ ��� �������� ����������.
������������� ��������� ������ ��� ��������� ����������� ������� ����������, �� ����������� ��ɣ�.
��ɣ� 1: ����������� �������� ������ ��� ������ ������� � ��� ����, � ������� ��� �������� ����.
� ��������� �� �� ������ ����� ������������ echo. �������� � ������ ��������� ������������� �������� ����������.
��������� �� ��������� ������.
�������� �������� �� web-�������� �� �������� �����������:
��������� �������
* �������
* ����
* test2
* test2
* test2
* test2
* test2
������� �������� ����� �������:
<>
��������:
<>
<Go!>
�������� � ���, ��� � ��� �����-�� ������� ������������ ��������� ������ � ���������� ������.
��������� �� ���, ������� �� ��� ��������:
$system = System::factory()
->setName($this->form->get(Field::NAME))
->setDescription(
$this->form->get(Field::DESCRIPTION)
);
DAO::system()->take($system);
���-������ �������? � ����� ������� ������� ����� ������������ � ޣ� ��������, �� � ����� ������ ��� ������ ��������, ������� ���������� ����������� ��� ������������. �ݣ ����� ������� ��� � ���� ������� �������� ����� � ����� ���� ������: � ��� ��� �� ��������� � ����, �� �������.
� PHP ���������� ����� �������� ��� ����������, ������� �������� �� ���������� �������, ����� �� ������� ��� (������) � ���� ��� �� stderr ����� ���, ��� ��������� ����, �� � ������ � �������������� �������, ��������, � Java, ���������� ���ģ��� �����������������. �� � �� ������ ��� ���������� ������.
��� �� ������? � ������ � MySQL �� ����� ��������� general query log:
mysql> set global log_output='table';
Query OK, 0 rows affected (0.00 sec)
mysql> select * from mysql.general_log;
Empty set (0.09 sec)
mysql> set global general_log='on';
Query OK, 0 rows affected (0.00 sec)
��������� ����������.
mysql> select * from mysql.general_log order by event_time desc limit 25G
*************************** 1. row ***************************
event_time: 2009-10-19 13:00:00
user_host: root[root] @ localhost []
thread_id: 10323
server_id: 60
command_type: Query
argument: select * from mysql.general_log order by event_time desc limit 25
...
*************************** 22. row ***************************
event_time: 2009-10-19 12:58:20
user_host: root[root] @ localhost [127.0.0.1]
thread_id: 10332
server_id: 60
command_type: Query
argument: INSERT INTO `system` (`id`, `name`, `description`) VALUES ('', 'test2', '')
...
mysql> set global general_log='off';
Query OK, 0 rows affected (0.08 sec)
� 22 ������ �� ����� ��� ������. �� �� �������� ����������: ������� INSERT.
��������� ��� �� ����� � ������� system:
mysql> select * from system;
+----+---------+------------------------------------------+
| id | name | description |
+----+---------+------------------------------------------+
| 1 | ������� | ��������������� ������� � ������� ������ |
| 2 | ���� | �������� �������������� ����� |
| 3 | test2 | New test |
| 4 | test2 | foobar |
| 8 | test2 | |
+----+---------+------------------------------------------+
5 rows in set (0.00 sec)
��������� ţ �����������:
mysql> show create table systemG
*************************** 1. row ***************************
Table: system
Create Table: CREATE TABLE `system` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`description` tinytext NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8
1 row in set (0.09 sec)
���� name �� �������� ����������. ������� �� ����� ������ �������� � ����������� ����� ���������: ����� ���� ������� ��� ���� ����������
(alter table system add unique(name))
���� �������� ���������� ����� �������, ����� ��� �������� �������������� �� �� ������ SQL.
�� ������ ��� ����������� ��������� ��ɣ�: ����������� general query log ��� ��������� �������, ������� �������� ������������ ���������.
��ɣ� 2: ����������� general query log, ���� ��� ����� ���������� ����� ������ ������ �������� ������������ ��������� ������ ����������.
�� ���������, ��� ����������� ������ ����� �������� ������, ��������� �������� � ����������. � ����������� ������� ����� ����������, ����� ����� � ��������� ������. ��� ���������, ������ ������� ����� ������� ������ � ������ ������ ��� ������ ����������� �������. �������, ���������� ��������, ����� ����������� ���������� ������� �� ����������. ��� �������� ����� ����������� ��������.
� ������ �� �������� ���� �������� �� ��������� �������:
mysql> select * from mysql.general_log;
Empty set (0.09 sec)
mysql> set global general_log='on';
Query OK, 0 rows affected (0.00 sec)
...
mysql> set global general_log='off';
Query OK, 0 rows affected (0.08 sec)
����� ��� ����� �������� �������� ���������� ����������, ���� �� ����� �������� general query log � ���������������� �����?
���� � ���, ��� general query log ��� �� ���� ������ �����������: �� ����������� �������� �� ������ � ��� ��� �� �������� ��� �������, �� ��� ����� ���ģ��� ������� �� ������ �� �����. ������� �� � ������ 5.1 ��� ����� ��������-��������� � ������ ��������� ������� ��� ����� ����� �������������� �������� �� MySQL ������ � ��������.
��������� ������ �������� ����� �� � ����, � � �������. ����� � ������� ����� ��� ��������� ����� ���������� �������� ��� � ��������� 2-�� ��������, ��� ��� ������� ����� �������������: �� ����������� � ��� ����� ��� � ����� ������ �������.
mysql> set global log_output='table';
Query OK, 0 rows affected (0.00 sec)

3
×
Дополнительные материалы бесплатно предоставляются только зарегистрированным пользователям.
Для скачивания исходных файлов необходимо авторизоваться под своим аккаунтом через соответствующую форму.
Для тех кто не зарегистрирован, можно это сделать на вкладке Регистрация.
⯈

Устанавливаем графический редактор GIMP
- Выбор графического редактора
- Устанавливаем программу GIMP
- Устанавливаем Руководство пользователя
Здравствуйте уважаемый посетитель!
При создании и развитии сайта не обойтись без графического редактора. Этот инструмент необходим для формирования и обработки различных графических элементов, без которых сайт попросту не сможет существовать. Поэтому в наборе инструментов вебмастера графический редактор занимает важнейшее место.
В статье Устанавливаем бесплатный графический редактор GIMP речь пойдет о бесплатной программе GIMP, которая позволяет в полной мере решать вопросы по созданию элементов дизайна веб-страниц. И будет показано, как ее установить на локальный компьютер.
Кроме того здесь можно будет посмотреть, как в этот редактор добавить встроенное «Руководство пользователя», а также приведен бесплатный видеокурс, где можно поближе с ним познакомиться.
Для тех же, кто хочет заниматься дизайном на платном Adobe Photoshop (фотошоп), здесь также упомянут и такой вариант, основанный на использовании продления льготного бесплатного периода фотошопа на неопределенное время…
Cайт на практическом примере

Здесь можно посмотреть текущее состояние сайта, создаваемого в рамках цикла статей Самописный сайт с нуля своими руками.
Исходные файлы данного сайта можно скачать из прилагаемых к статьям дополнительных материалов.
- Предыдующая статья: Обработка критических ошибок PHP
2019-03-12
Здравствуйте, уважаемый посетитель!
Ранее мы создали механизм, предусматривающий обработку ошибок в случаях обращения к несуществующим ресурсам сайта (404 Not Found), а также при возникновении различного рода событий в PHP. В принципе, этого вполне может быть достаточно для контроля работы сайта во время формировании динамической страницы.
Однако, для более полной оценки, совсем нелишним будет иметь возможность также обрабатывать и ошибки, относящиеся к языку структурированных запросов SQL (Structured Query Language), который используется для взаимодействия с базой данных.
Конечно, такие случаи обычно приводят к определенным сбоям в работе PHP, сопровождающимися выводом соответствующих сообщений, что позволяет по косвенным признакам определить наличие несоответствий SQL-запросов. Тем не менее, непосредственное их выявление может существенно упростить устранение возникших в таких ситуациях проблем.
И сегодня мы посмотрим, как можно дополнить наш сайт инструментом, который позволит обнаруживать и получать сообщения о возникших ошибках SQL-запросов, сохраняя соответствующую информацию в отдельных лог-файлах.
- Формирование ошибки SQL-запроса
- Перехват ошибок и сохранение их в лог-файле
- Проверка механизма обработки SQL-ошибок
- Исходные файлы сайта
Формирование ошибки SQL-запроса
Для того, чтобы иметь возможность обрабатывать ошибки, возникающие в SQL-запросах, необходимо в первую очередь их сформировать.
Достаточно простым решением, которое мы будем использовать, это применение встроенной PHP-функции trigger_error(). С помощью которой полученная информация о возникшем несоответствии будет генерироваться в пользовательскую ошибку с назначенным уровнем важности E_USER_ERROR, E_USER_WARNING или E_USER_NOTICE.
А с учетом того, что сформированные таким образом сообщения будут представлять обычные ошибки PHP, то можно будет их обрабатывать той же пользовательской функцией, которая была ранее создана для перехвата и идентификации не фатальных ошибок PHP.
Как практически это выглядит, можно увидеть на примере функции getLineThreeColumnThreeСondition(), обеспечивающей, наряду с другими, работу сайта с базой данных MySQL. В которой вместо ранее используемой функции die() добавлена строка, обеспечивающая формирование заданной пользовательской ошибки (выделено светлым фоном).
-
//—-Универсальная функция вывода одиночной строки по трем значениям в трех полях—-
-
function getLineThreeColumnThreeСondition($table, $column_1, $value_1, $column_2, $value_2, $column_3, $value_3) {
-
global $mysqli;
-
if (!$result = $mysqli->query(«SELECT * FROM `$table` WHERE `$column_1`=’$value_1‘ AND `$column_2`=’$value_2‘ AND `$column_3`=’$value_3‘»)) {
-
trigger_error (‘При выполнении SQL-запроса возникла ошибка: код ошибки — ‘.$mysqli->errno.‘, описание — ‘ .$mysqli->error, E_USER_ERROR);
-
}
-
return $result->fetch_assoc();
-
}
-
?>
Рис.1 Функция вывода строки по заданным условиям с формированием ошибки SQL-запроса
В этом случае, если при выполнении SQL-запроса (поз.5) возникнет какое-нибудь несоответствие, то функцией trigger_error() (поз.6) будет сформирована пользовательская ошибка с назначенным уровнем E_USER_ERROR, с указанием кода, возвращенного конструкцией $mysqli->errno, и ее описанием — $mysqli->error.
Таким образом, выполнив аналогичные изменения во всех функциях, находящихся в файлах каталога logs, мы в случае возникновения каких-либо проблем при выполнении запроса SQL обеспечим формирование соответствующей пользовательской ошибки PHP со всей необходимой для ее идентификации информацией.
Перехват ошибок и сохранение их в лог-файле
Что касается обработки сформированной ошибки, то как было отмечено, это можно сделать с использованием ранее созданного обработчика не фатальных ошибок PHP.
Для этого достаточно с помощью оператора сравнения if выделить из всех возможных вариантов пользовательскую ошибку с уровнем E_USER_ERROR, специально назначенным для такого вида сообщений.
Ниже показан последний вариант обработчика, в который добавлен дополнительный код, обеспечивающий обнаружение ошибки SQL и сохранение информации о ней в лог-файле (выделено светлым фоном).
-
//—-Перехват и обработка ошибок PHP—-
-
function errors_handler($errno, $errstr, $errfile, $errline){ //Пользовательская функция обработчика ошибок PHP
-
$errors = array( //Формирования массива констант ошибок
-
E_WARNING => ‘E_WARNING’,
-
E_NOTICE => ‘E_NOTICE’,
-
E_CORE_WARNING => ‘E_CORE_WARNING’,
-
E_COMPILE_WARNING => ‘E_COMPILE_WARNING’,
-
E_USER_ERROR => ‘E_USER_ERROR’,
-
E_USER_WARNING => ‘E_USER_WARNING’,
-
E_USER_NOTICE => ‘E_USER_NOTICE’,
-
E_STRICT => ‘E_STRICT’,
-
E_RECOVERABLE_ERROR => ‘E_RECOVERABLE_ERROR’,
-
E_DEPRECATED => ‘E_DEPRECATED’,
-
E_USER_DEPRECATED => ‘E_USER_DEPRECATED’
-
);
-
$date = date (‘Y-m-d G:i:s’); //Получение даты и времени возникновения ошибки
-
$url = $_SERVER[‘REQUEST_URI’]; //Получение URL страницы, при формировании которой произошла ошибка
-
$error_message = «$date $errors[$errno] $errstr в файле $errfile в $errline строке (URL: $url)n»; //Сформированное сообщение об ошибке
-
if ($errno == E_USER_ERROR) { //Если обнаружена пользовательская ошибка E_USER_ERROR
-
$current_date = date (‘Y_m_d’); //Получение текущей даты
-
$filename = ‘logs/sql_’.$current_date.‘.txt’; //Имя файла с директорией
-
file_put_contents($filename, $error_message, FILE_APPEND | LOCK_EX); //Добавляем сообщение об ошибке SQL в лог-файл (в конец файла). Если файла не существует, будет создан
-
}
-
else {
-
$max_message = 100; //Максимальное количество сообщений в лог-файле
-
$filename = ‘logs/warning_php.txt’; //Имя файла с директорией
-
if (file_exists($filename)) { //Если файл существует
-
$file_data = file($filename); //Считываем данные из файла в массив
-
if (count($file_data) >= $max_message){ //Если количество элементов в массиве достигает максимального значения
-
unset($file_data[0]); //Удаляем первый по списку элемент массива
-
$clean_data = implode(«», $file_data); //Преобразуем данные массива в строку
-
file_put_contents($filename, $clean_data, LOCK_EX); //Записываем преобразованные данные с удаленным сообщением обратно в файл
-
}
-
}
-
file_put_contents($filename, $error_message, FILE_APPEND | LOCK_EX); //Добавляем сообщение об ошибке в лог-файл (в конец файла). Если файла не существует, будет создан
-
}
-
}
-
set_error_handler(‘errors_handler’); //Регистрация пользовательской функции
-
?>
Рис.2 Обработчик с обнаружением и сохранением ошибок SQL
Так, при обнаружении обработчиком ошибки E_USER_ERROR (поз.20), она будет выделена и сохранена в определенном для этого случая лог-файле (поз.23) с именем $filename (поз.21), соответствующем текущей дате $current_date (поз.22).
При этом для такого вида событий порядок сохранения лог-файла несколько отличается от того, как это было определено для записи записи остальных критических и не фатальных ошибок PHP.
Если ранее предусматривалось два отдельных журнала по каждому типу ошибок, в которых записи выполняются по мере их поступления, то для SQL-запросов сохранение в лог-файле будет происходить следующим образом:
- Все записи распределяются по файлам в зависимости от даты. При этом имя файла соответствует дате его создания, например: sql_2020_03_12.txt.
- В случае, если на момент обнаружения несоответствия в запросе, файл для текущей даты существует, то информация об этом записывается в его конец.
- Если же файл с соответствующей датой отсутствует, то он автоматически создается вместе с соответствующей записью.
Такой порядок обусловлен тем, что ошибки в SQL-запросах возникают значительно реже остальных, связанных с работой PHP. И нет необходимости вести по ним отдельный, постоянной обновляемый журнал. Тем более, что несоответствия в SQL-запросах непременно вызывают другие события, фиксируемые в журналах ошибок PHP.
Также следует учесть, что такая информация является дополнительной, предназначенной для более точного определения места возникновения возникшей проблемы.
И таким образом появление в какой-то момент лог-файла с SQL-ошибкой, будет указывать, на то, что возникшие сбои в PHP в первую очередь могут быть связаны с выполнением SQL-запроса. Что весьма удобно использовать при выяснении и устранении возникших проблем в работе сайта.
А дальше, после отработки такого сигнала и решения проблемы, можно спокойно удалить этот лог-файл за ненадобностью, очистив тем самым каталог с хранящейся информацией об ошибках.
Проверка механизма обработки SQL-ошибок
Для того, чтобы убедиться в работоспособности выше созданного функционала, проверим, будут ли после внесенных дополнений выявляться несоответствия в SQL-запросах, и если да, то как они будут сохраняться в предусмотренном для этих целей лог-файле.
Для выполнения такого теста временно создадим в SQL-запросе вышеупомянутой функции getLineThreeColumnThreeСondition() какую-нибудь ошибку. Например, в имени одного из полей вместо обратной кавычки ошибочно укажем одинарную, как показано ниже (выделено красным цветом).
-
//—-Универсальная функция вывода одиночной строки по трем значениям в трех полях—-
-
function getLineThreeColumnThreeСondition($table, $column_1, $value_1, $column_2, $value_2, $column_3, $value_3) {
-
global $mysqli;
-
if (!$result = $mysqli->query(«SELECT * FROM `$table` WHERE ‘$column_1`=’$value_1‘ AND `$column_2`=’$value_2‘ AND `$column_3`=’$value_3‘»)) {
-
trigger_error (‘При выполнении SQL-запроса возникла ошибка: код ошибки — ‘.$mysqli->errno.‘, описание — ‘ .$mysqli->error, E_USER_ERROR);
-
}
-
return $result->fetch_assoc();
-
}
-
?>
Рис.3 Функция с ошибкой в SQL-запросе
А далее попробуем обратиться к какой-нибудь странице и посмотрим, как в такой ситуации будет выполняться запрос.
Как следовало ожидать, при формировании динамической страницы скрипт PHP с такой ошибкой в SQL-запросе не смог выполнить извлечение данных из БД. От чего последовало перенаправление на страницу 500, отправка по email оповещения о возникновении критической ошибки PHP и запись в журнал соответствующего сообщения.
Рис.4 Перенаправление на страницу 500 при возникновении ошибки в SQL-запросе
Но при этом, если сейчас открыть каталог logs, то можно увидеть, что кроме существующих журналов, появился также автоматически созданный файл с именем sql_2020_03_12.txt, соответствующий текущей дате.
Рис.5 Каталог со вновь созданным лог-файлом SQL-ошибок
А если открыть этот файл, то можно будет увидеть в нем сохраненную информацию об ошибке с указанием времени возникновения, кода и описания.
Рис.6 Сохраненная в лог-файле информация об ошибке
Как видно, здесь конкретно указывается о том, что в SQL-запросе рядом с именем первого по порядку поля обнаружена синтаксическая ошибка. Именно, там где и была, произведена заведомо неправильная замена символа.
Таким образом проверка подтвердила, что созданный механизм обработки ошибок, возникающих в SQL-запросах работает корректно. И теперь все такие события будут выявляться и сохраняться в отдельных лог-файлах.
Исходные файлы сайта
 Исходные файлы сайта с обновлениями, которые были сделаны в данной статье, можно скачать из прилагаемых дополнительных материалов:
Исходные файлы сайта с обновлениями, которые были сделаны в данной статье, можно скачать из прилагаемых дополнительных материалов:
- Файлы каталога www
- Таблицы базы данных MySQL
Дополнительные материалы бесплатно предоставляются только зарегистрированным пользователям.
Для скачивания исходных файлов необходимо авторизоваться под своим аккаунтом через соответствующую форму.
Для тех кто не зарегистрирован, можно это сделать на вкладке Регистрация.
С уважением,
- Следующая сатья: Сворачивание и разворачивание элементов на JavaScript
Если у Вас возникли вопросы, или есть какие-либо пожелания по представлению материала, либо заметили какие-нибудь ошибки, а быть может просто хотите выразить свое мнение, пожалуйста, оставьте свои комментарии. Такая обратная связь очень важна для возможности учета мнения посетителей.
Буду Вам за это очень признателен!
Имеем запрос, меняющий данные на MS SQL Server. Задача: отловить возникшие при выполнении запроса ошибки и откатить все уже внесенные внутри запроса изменения к состоянию на момент его запуска. Помогут нам в этом нелегком деле транзакции и блок TRY-CATCH. Когда вообще возникает необходимость? Типичный пример из учебника, последовательное удаление двух строк из разных таблиц, имеющих один и тот же код:
DELETE FROM SOME_TABLE1 WHERE SOME_ID = SOME_VALUE DELETE FROM SOME_TABLE2 WHERE SOME_ID = SOME_VALUE
Если первый оператор выполнится, а второй нет, нас поразит самое страшное проклятье любого разработчика — рассогласование данных в базе. Само собой возможно множество других ситуаций, когда частичное выполнение запроса приведет к большим проблемам.
Транзакция — это последовательность операций, которая должна или полностью выполниться успешно или не выполнится вообще. В Transact Sql она начинается командой BEGIN TRANSACTION и продолжается до выполнения команды отката ROLLBACK TRANSACTION или подтверждения COMMIT TRANSACTION. Само собой команду отката надо выполнять в случае ошибок. Как их отследить? Теоретически есть переменная @@ERROR, содержащая код ошибки или 0 в случае успешного выполнения, но на практике такой код писать нельзя
IF @@ERROR <> 0 ROLLBACK
так как переменная @@ERRROR переопределяется после каждой SQL-команды. То есть если первый DELETE вылетит с ошибкой, в переменную запишется код ошибки, если второй оператор выполнится успешно, то в переменную запишется ноль и мы ничтоже сумняшеся , подтвердим изменения.
И здесь нам придет на помощь блок TRY-CATCH, хорошо знакомый програмиирующим на C# (и не только) товарищам. Делает он хорошо знакомую вещь, отлавливает любую ошибку в блоке TRY и перебрасывает управление вместе с ошибкой в блок CATCH. В итоге мы получим вот такой код:
-- переменные для переброса данных об ошибке из CATCH в вызывающий код после отката изменений
DECLARE @errorMessage nvarchar(4000), @errorSeverity int
BEGIN TRY
BEGIN TRANSACTION
-- удаляем таблицу, копируем новую сервера, прописываем права
DROP SOME_TABLE
-- если с другим сервером возникнет проблема, нужен откат
SELECT SOME_FIELD1, SOME_FIELD2, SOME_FIELD3 INTO SOME_TABLE FROM OTHER_SERVER.OTHER_DATDABSE.dbo.OTHER_TABLE
GRANT SELECT ON OBJECT::SOME_TABLE TO some_role;
-- если дошли до этой строки, все успешно, подтверждаем изменения
COMMIT
END TRY
BEGIN CATCH
-- COMMIT должен был уменьшить эту переменную до нуля, откатываем изменения
IF @@TRANCOUNT > 0 ROLLBACK
-- выбрасываем новую ошибку в информацией из ошибки, пойманной оператором CATCH
SELECT @errorMessage = ERROR_MESSAGE(), @errorSeverity = ERROR_SEVERITY()
RAISERROR(@errorMessage, @errorSeverity, 1)
END CATCH
Более подробно:
- TRY…CATCH in SQL Server 2005 An Easier Approach to Rolling Back Transactions in the Face of an Error
- TRY…CATCH (Transact-SQL)
- BEGIN TRANSACTION (Transact-SQL)