
Число обнаруживаемых или исправляемых ошибок.
При применении двоичных кодов учитывают
только дискретные искажения, при которых
единица переходит в нуль (1 → 0) или нуль
переходит в единицу (0 → 1). Переход 1 →
0 или 0 → 1 только в одном элементе кодовой
комбинации называют единичной ошибкой
(единичным искажением). В общем случае
под кратностью ошибки подразумевают
число позиций кодовой комбинации, на
которых под действием помехи одни
символы оказались заменёнными на другие.
Возможны двукратные (t= 2) и многократные (t> 2) искажения элементов в кодовой
комбинации в пределах 0 <t<n.
Минимальное кодовое расстояние является
основным параметром, характеризующим
корректирующие способности данного
кода. Если код используется только для
обнаружения ошибок кратностью t0,
то необходимо и достаточно, чтобы
минимальное кодовое расстояние было
равно
dmin
> t0
+ 1. (13.10)
В этом случае никакая комбинация из t0ошибок не может перевести одну разрешённую
кодовую комбинацию в другую разрешённую.
Таким образом, условие обнаружения всех
ошибок кратностьюt0можно записать в виде:
t0≤ dmin — 1. (13.11)
Чтобы можно было исправить все ошибки
кратностью tии менее, необходимо иметь минимальное
расстояние, удовлетворяющее условию:
![]() . (13.12)
. (13.12)
В этом случае любая кодовая комбинация
с числом ошибок tиотличается от каждой разрешённой
комбинации не менее чем вtи+ 1 позициях. Если условие (13.12) не выполнено,
возможен случай, когда ошибки кратностиtисказят переданную
комбинацию так, что она станет ближе к
одной из разрешённых комбинаций, чем к
переданной или даже перейдёт в другую
разрешённую комбинацию. В соответствии
с этим, условие исправления всех ошибок
кратностью не болееtиможно записать в виде:
tи
≤(dmin
— 1) / 2 . (13.13)
Из (13.10) и (13.12) следует, что если код
исправляет все ошибки кратностью tи,
то число ошибок, которые он может
обнаружить, равноt0= 2∙tи. Следует
отметить, что соотношения (13.10) и (13.12)
устанавливают лишь гарантированное
минимальное число обнаруживаемых или
исправляемых ошибок при заданномdminи не ограничивают возможность обнаружения
ошибок большей кратности. Например,
простейший код с проверкой на чётность
сdmin= 2 позволяет обнаруживать не только
одиночные ошибки, но и любое нечётное
число ошибок в пределахt0<n.
Корректирующие возможности кодов.
Вопрос о минимально необходимой
избыточности, при которой код обладает
нужными корректирующими свойствами,
является одним из важнейших в теории
кодирования. Этот вопрос до сих пор не
получил полного решения. В настоящее
время получен лишь ряд верхних и нижних
оценок (границ), которые устанавливают
связь между максимально возможным
минимальным расстоянием корректирующего
кода и его избыточностью.
Так, граница Плоткинадаёт верхнюю
границу кодового расстоянияdminпри заданном числе разрядовnв
кодовой комбинации и числе информационных
разрядовm, и для
двоичных кодов:
![]() (13.14)
(13.14)
или
![]() при
при![]() . (13.15)
. (13.15)
Верхняя граница Хеммингаустанавливает
максимально возможное число разрешённых
кодовых комбинаций (2m)
любого помехоустойчивого кода при
заданных значенияхnиdmin:
 , (13.16)
, (13.16)
где
![]() —
—
число сочетаний изnэлементов поiэлементам.
Отсюда можно получить выражение для
оценки числа проверочных символов:
 . (13.17)
. (13.17)
Для значений (dmin/n)
≤ 0,3 разница между границей Хемминга и
границей Плоткина сравнительно невелика.
Граница Варшамова-Гильбертадля
больших значенийnопределяет нижнюю
границу для числа проверочных разрядов,
необходимого для обеспечения заданного
кодового расстояния:
 . (13.18)
. (13.18)
Отметим, что для некоторых частных
случаев Хемминг получил простые
соотношения, позволяющие определить
необходимое число проверочных символов:
![]() дляdmin= 3,
дляdmin= 3,
![]() дляdmin= 4.
дляdmin= 4.
Блочные коды с dmin= 3 и 4 в литературе обычно называют кодами
Хемминга.
Все приведенные выше оценки дают
представление о верхней границе числаdminпри фиксированных значенияхnиmили оценку снизу числа проверочных
символовkпри заданныхmиdmin.
Существующие методы построения избыточных
кодов решают в основном задачу нахождения
такого алгоритма кодирования и
декодирования, который позволял бы
наиболее просто построить и реализовать
код с заданным значением dmin.
Поэтому различные корректирующие коды
при одинаковыхdminсравниваются по сложности кодирующего
и декодирующего устройств. Этот критерий
является в ряде случаев определяющим
при выборе того или иного кода.
Соседние файлы в папке ЛБ_3
- #
- #
14.04.2015937 б72KodHemmig.m
- #
14.04.20150 б64ЛБ_3.exe
Содержание
- 1 Исправление ошибок в помехоустойчивом кодировании
- 2 Параметры помехоустойчивого кодирования
- 3 Контроль чётности
- 4 Классификация помехоустойчивых кодов
- 5 Код Хэмминга
- 5.1 Декодирование кода Хэмминга
- 5.2 Расстояние Хэмминга
- 6 Помехоустойчивые коды
- 6.1 Компромиссы при использовании помехоустойчивых кодов
- 6.2 Необходимость чередования (перемежения)
Назначение помехоустойчивого кодирования – защита информации от помех и ошибок при передаче и хранении информации. Помехоустойчивое кодирование необходимо для устранения ошибок, которые возникают в процессе передачи, хранения информации. При передачи информации по каналу связи возникают помехи, ошибки и небольшая часть информации теряется.

Без использования помехоустойчивого кодирования было бы невозможно передавать большие объемы информации (файлы), т.к. в любой системе передачи и хранении информации неизбежно возникают ошибки.
Рассмотрим пример CD диска. Там информация хранится прямо на поверхности диска, в углублениях, из-за того, что все дорожки на поверхности, часто диск хватаем пальцами, елозим по столу и из-за этого без помехоустойчивого кодирования, информацию извлечь не получится.

Использование кодирования позволяет извлекать информацию без потерь даже с поврежденного CD/DVD диска, когда какая либо область становится недоступной для считывания.
В зависимости от того, используется в системе обнаружение или исправление ошибок с помощью помехоустойчивого кода, различают следующие варианты:
- запрос повторной передачи (Automatic Repeat reQuest, ARQ): с помощью помехоустойчивого кода выполняется только обнаружение ошибок, при их наличии производится запрос на повторную передачу пакета данных;
- прямое исправление ошибок (Forward Error Correction, FEC): производится декодирование помехоустойчивого кода, т. е. исправление ошибок с его помощью.
Возможен также гибридный вариант, чтобы лишний раз не гонять информацию по каналу связи, например получили пакет информации, попробовали его исправить, и если не смогли исправить, тогда отправляется запрос на повторную передачу.
Исправление ошибок в помехоустойчивом кодировании
Любое помехоустойчивое кодирование добавляет избыточность, за счет чего и появляется возможность восстановить информацию при частичной потере данных в канале связи (носителе информации при хранении). В случае эффективного кодирования убирали избыточность, а в помехоустойчивом кодировании добавляется контролируемая избыточность.
Простейший пример – мажоритарный метод, он же многократная передача, в котором один символ передается многократно, а на приемной стороне принимается решение о том символе, количество которых больше.
Допустим есть 4 символа информации, А, B, С,D, и эту информацию повторяем несколько раз. В процессе передачи информации по каналу связи, где-то возникла ошибка. Есть три пакета (A1B1C1D1|A2B2C2D2|A3B3C3D3), которые должны нести одну и ту же информацию.

Но из картинки справа, видно, что второй символ (B1 и C1) они отличаются друг от друга, хотя должны были быть одинаковыми. То что они отличаются, говорит о том, что есть ошибка.
Необходимо найти ошибку с помощью голосования, каких символов больше, символов В или символов С? Явно символов В больше, чем символов С, соответственно принимаем решение, что передавался символ В, а символ С ошибочный.
Для исправления ошибок нужно, как минимум 3 пакета информации, для обнаружения, как минимум 2 пакета информации.
Параметры помехоустойчивого кодирования
Первый параметр, скорость кода R характеризует долю информационных («полезных») данных в сообщении и определяется выражением: R=k/n=k/m+k
- где n – количество символов закодированного сообщения (результата кодирования);
- m – количество проверочных символов, добавляемых при кодировании;
- k – количество информационных символов.
Параметры n и k часто приводят вместе с наименованием кода для его однозначной идентификации. Например, код Хэмминга (7,4) значит, что на вход кодера приходит 4 символа, на выходе 7 символов, Рида-Соломона (15, 11) и т.д.
Второй параметр, кратность обнаруживаемых ошибок – количество ошибочных символов, которые код может обнаружить.
Третий параметр, кратность исправляемых ошибок – количество ошибочных символов, которые код может исправить (обозначается буквой t).
Контроль чётности
Самый простой метод помехоустойчивого кодирования это добавление одного бита четности. Есть некое информационное сообщение, состоящее из 8 бит, добавим девятый бит.
Если нечетное количество единиц, добавляем 0.
1 0 1 0 0 1 0 0 | 0
Если четное количество единиц, добавляем 1.
1 1 0 1 0 1 0 0 | 1
Если принятый бит чётности не совпадает с рассчитанным битом чётности, то считается, что произошла ошибка.
1 1 0 0 0 1 0 0 | 1
Под кратностью понимается, всевозможные ошибки, которые можно обнаружить. В этом случае, кратность исправляемых ошибок 0, так как мы не можем исправить ошибки, а кратность обнаруживаемых 1.
Есть последовательность 0 и 1, и из этой последовательности составим прямоугольную матрицу размера 4 на 4. Затем для каждой строки и столбца посчитаем бит четности.
Прямоугольный код – код с контролем четности, позволяющий исправить одну ошибку:

И если в процессе передачи информации допустим ошибку (ошибка нолик вместо единицы, желтым цветом), начинаем делать проверку. Нашли ошибку во втором столбце, третьей строке по координатам. Чтобы исправить ошибку, просто инвертируем 1 в 0, тем самым ошибка исправляется.
Этот прямоугольный код исправляет все одно-битные ошибки, но не все двух-битные и трех-битные.
Рассчитаем скорость кода для:
- 1 1 0 0 0 1 0 0 | 1
Здесь R=8/9=0,88
- И для прямоугольного кода:
Здесь R=16/24=0,66 (картинка выше, двадцать пятую единичку (бит четности) не учитываем)
Более эффективный с точки зрения скорости является первый вариант, но зато мы не можем с помощью него исправлять ошибки, а с помощью прямоугольного кода можно. Сейчас на практике прямоугольный код не используется, но логика работы многих помехоустойчивых кодов основана именно на прямоугольном коде.
Классификация помехоустойчивых кодов
- Непрерывные — процесс кодирования и декодирования носит непрерывный характер. Сверточный код является частным случаем непрерывного кода. На вход кодера поступил один символ, соответственно, появилось несколько на выходе, т.е. на каждый входной символ формируется несколько выходных, так как добавляется избыточность.
- Блочные (Блоковые) — процесс кодирования и декодирования осуществляется по блокам. С точки зрения понимания работы, блочный код проще, разбиваем код на блоки и каждый блок кодируется в отдельности.
По используемому алфавиту:
- Двоичные. Оперируют битами.
- Не двоичные (код Рида-Соломона). Оперируют более размерными символами. Если изначально информация двоичная, нужно эти биты превратить в символы. Например, есть последовательность 110 110 010 100 и нужно их преобразовать из двоичных символов в не двоичные, берем группы по 3 бита — это будет один символ, 6, 6, 2, 4 — с этими не двоичными символами работают не двоичные помехоустойчивые коды.
Блочные коды делятся на
- Систематические — отдельно не измененные информационные символы, отдельно проверочные символы. Если на входе кодера присутствует блок из k символов, и в процессе кодирования сформировали еще какое-то количество проверочных символов и проверочные символы ставим рядом к информационным в конец или в начало. Выходной блок на выходе кодера будет состоять из информационных символов и проверочных.
- Несистематические — символы исходного сообщения в явном виде не присутствуют. На вход пришел блок k, на выходе получили блок размером n, блок на выходе кодера не будет содержать в себе исходных данных.
В случае систематических кодов, выходной блок в явном виде содержит в себе, то что пришло на вход, а в случае несистематического кода, глядя на выходной блок нельзя понять что было на входе.

Смотря на картинку выше, код 1 1 0 0 0 1 0 0 | 1 является систематическим, на вход поступило 8 бит, а на выходе кодера 9 бит, которые в явном виде содержат в себе 8 бит информационных и один проверочный.

Код Хэмминга
Код Хэмминга — наиболее известный из первых самоконтролирующихся и самокорректирующихся кодов. Позволяет устранить одну ошибку и находить двойную.

Код Хэмминга (7,4) — 4 бита на входе кодера и 7 на выходе, следовательно 3 проверочных бита. С 1 по 4 информационные биты, с 6 по 7 проверочные (см. табл. выше). Пятый проверочный бит y5, это сумма по модулю два 1-3 информационных бит. Сумма по модулю 2 это вычисление бита чётности.
Декодирование кода Хэмминга
Декодирование происходит через вычисление синдрома по выражениям:

Синдром это сложение бит по модулю два. Если синдром не нулевой, то исправление ошибки происходит по таблице декодирования:

Расстояние Хэмминга
Расстояние Хэмминга — число позиций, в которых соответствующие символы двух кодовых слов одинаковой длины различны. Если рассматривать два кодовых слова, (пример на картинке ниже, 1 0 1 1 0 0 1 и 1 0 0 1 1 0 1) видно что они отличаются друг от друга на два символа, соответственно расстояние Хэмминга равно 2.

Кратность исправляемых ошибок и обнаруживаемых, связано минимальным расстоянием Хэмминга. Любой помехоустойчивый код добавляет избыточность с целью увеличить минимальное расстояние Хэмминга. Именно минимальное расстояние Хэмминга определяет помехоустойчивость.
Помехоустойчивые коды
Современные коды более эффективны по сравнению с рассматриваемыми примерами. В таблице ниже приведены Коды Боуза-Чоудхури-Хоквингема (БЧХ)

Из таблицы видим, что там один класс кода БЧХ, но разные параметры n и k.
- n — количество символов на входе.
- k — количество символов на выходе.
- t — кратность исправляемых ошибок.
- Отношение k/n — скорость кода.
- G (энергетический выигрыш) — величина, показывающая на сколько можно уменьшить отношение сигнал/шум (Eb/No) для обеспечения заданной вероятности ошибки.
Несмотря на то, что скорость кода близка, количество исправляемых ошибок может быть разное. Количество исправляемых ошибок зависит от той избыточности, которую добавим и от размера блока. Чем больше блок, тем больше ошибок он исправляет, даже при той же самой избыточности.
Пример: помехоустойчивые коды и двоичная фазовая манипуляция (2-ФМн). На графике зависимость отношения сигнал шум (Eb/No) от вероятности ошибки. За счет применения помехоустойчивых кодов улучшается помехоустойчивость.

Из графика видим, код Хэмминга (7,4) на сколько увеличилась помехоустойчивость? Всего на пол Дб это мало, если применить код БЧХ (127, 64) выиграем порядка 4 дБ, это хороший показатель.
Компромиссы при использовании помехоустойчивых кодов
Чем расплачиваемся за помехоустойчивые коды? Добавили избыточность, соответственно эту избыточность тоже нужно передавать. Нужно: увеличивать пропускную способность канала связи, либо увеличивать длительность передачи.

Компромисс:
- Достоверность vs полоса пропускания.
- Мощность vs полоса пропускания.
- Скорость передачи данных vs полоса пропускания
Необходимость чередования (перемежения)
Все помехоустойчивые коды могут исправлять только ограниченное количество ошибок t. Однако в реальных системах связи часто возникают ситуации сгруппированных ошибок, когда в течение непродолжительного времени количество ошибок превышает t.
Например, в канале связи шумов мало, все передается хорошо, ошибки возникают редко, но вдруг возникла импульсная помеха или замирания, которые повредили на некоторое время процесс передачи, и потерялся большой кусок информации. В среднем на блок приходится одна, две ошибки, а в нашем примере потерялся целый блок, включая информационные и проверочные биты. Сможет ли помехоустойчивый код исправить такую ошибку? Эта проблема решаема за счет перемежения.
Пример блочного перемежения:

На картинке, всего 5 блоков (с 1 по 25). Код работает исправляя ошибки в рамках одного блока (если в одном блоке 1 ошибка, код его исправит, а если две то нет). В канал связи отдается информация не последовательно, а в перемешку. На выходе кодера сформировались 5 блоков и эти 5 блоков будем отдавать не по очереди а в перемешку. Записали всё по строкам, но считывать будем, чтобы отправлять в канал связи, по столбцам. Информация в блоках перемешалась. В канале связи возникла ошибка и мы потеряли большой кусок. В процессе приема, мы опять составляем таблицу, записываем по столбцам, но считываем по строкам. За счет того, что мы перемешали большое количество блоков между собой, групповая ошибка равномерно распределится по блокам.
Корректирующий код (также помехоустойчивый код) — код (b) , предназначенный для обнаружения и исправления ошибок (b) .
Основная техника — добавление при записи (передаче) в полезные данные специальным образом структурированной избыточной информации (например, контрольного числа (b) ), а при чтении (приёме) использование такой избыточной информации для обнаружения и исправления ошибки. Число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода.
Коды обнаружения ошибок (которые могут только установить факт ошибки) принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить бо́льшее число ошибок, чем был способен исправить). Коды, исправляющие ошибки, применяются в системах цифровой связи (b) , в том числе: спутниковой, радиорелейной, сотовой, передаче данных по телефонным каналам, а также в системах хранения информации, в том числе магнитных и оптических. Коды, обнаруживающие ошибки, применяются в сетевых протоколах (b) различных уровней (b) .
По способу работы с данными коды, исправляющие ошибки, делятся на блоковые[⇨], делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные[⇨], работающие с данными как с непрерывным потоком.
Блоковые коды
Блоковый код, разбивающий информацию на фрагменты длиной бит и преобразующий их в кодовые слова длиной бит обычно обозначают ; при этом число называется скоростью кода. Если исходные бит код оставляет неизменными, и добавляет проверочных, такой код называется систематическим, иначе — несистематическим.
Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из информационных бит сопоставляется бит кодового слова. Однако хороший код должен удовлетворять как минимум следующим критериям:
- способность исправлять как можно большее число ошибок,
- как можно меньшая избыточность,
- простота кодирования и декодирования.
Приведённые требования в общем случае противоречат друг другу, поэтому существует большое количество кодов, каждый из которых пригоден для определённого круга задач. Практически все используемые коды являются линейными (b) , это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования.
Линейные коды общего вида
Линейный блоковый код — такой код, что множество его кодовых слов образует -мерное линейное подпространство в -мерном линейном пространстве (b) , изоморфное (b) пространству -битных векторов (b) .
Это значит, что операция кодирования соответствует умножению исходного -битного вектора на невырожденную матрицу (b) , называемую порождающей матрицей.
Для ортогонального (b) по отношению к подпространства и матрицы , задающей базис (b) этого подпространства, и для любого вектора справедливо:
- .
Минимальное расстояние и корректирующая способность
Расстоянием Хэмминга (метрикой Хэмминга) между двумя кодовыми словами и называется количество отличных бит на соответствующих позициях:
- .
Минимальное расстояние Хэмминга является важной характеристикой линейного блокового кода. Она показывает, насколько «далеко» расположены коды друг от друга. Она определяет другую, не менее важную характеристику — корректирующую способность (b) :
- .
Корректирующая способность (b) определяет, сколько ошибок передачи кода (типа ) можно гарантированно исправить. То есть вокруг каждого кодового слова имеем -окрестность (b) , которая состоит из всех возможных вариантов передачи кодового слова с числом ошибок () не более . Никакие две окрестности двух любых кодовых слов не пересекаются друг с другом, так как расстояние между кодовыми словами (то есть центрами этих окрестностей) всегда больше двух их радиусов.
Таким образом, получив искажённую кодовую комбинацию из , декодер принимает решение, что исходной была кодовая комбинация , исправляя тем самым не более ошибок.
Например, при наличии всего двух кодовых слов и с расстоянием Хэмминга между ними, равным 3, ошибка в одном бите слова может быть исправлена, так как даже в этом случае принятое слово ближе к кодовому слову , чем к . Но если каналом были внесены ошибки в двух битах (в которых отличалось от ), то результат ошибочной передачи окажется ближе к , чем , и декодер примет решение, что передавалось слово .
Коды Хэмминга
Коды Хэмминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хэмминга может быть представлен в таком виде, что синдром:
- ,
где — принятый вектор, будет равен номеру позиции, в которой произошла ошибка. Это свойство позволяет сделать декодирование очень простым.
Общий метод декодирования линейных кодов
Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова соответствует наиболее вероятное переданное слово . Однако данный метод требует применения огромных таблиц уже для кодовых слов сравнительно небольшой длины.
Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора вычисляется синдром. Поскольку , где — кодовое слово, а — вектор ошибки, то . Затем с помощью таблицы по синдрому определяется вектор ошибки, с помощью которого определяется переданное кодовое слово. При этом таблица получается гораздо меньше, чем при использовании предыдущего метода.
Линейные циклические коды
Несмотря на то, что декодирование линейных кодов значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды (b) , кроме более простого декодирования, обладают и другими важными свойствами.
Циклическим кодом является линейный код (b) , обладающий следующим свойством: если является кодовым словом, то его циклическая перестановка также является кодовым словом.
Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово представляется в виде полинома . При этом циклический сдвиг кодового слова эквивалентен умножению многочлена на по модулю (b) .
Чаще всего используются двоичные циклические коды (то есть могут принимать значения 0 или 1).
Порождающий многочлен
Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему (генераторному) многочлену . Порождающий многочлен является делителем .
С помощью порождающего многочлена осуществляется кодирование циклическим кодом. В частности:
- несистематическое кодирование осуществляется путём умножения кодируемого вектора на : ;
- систематическое кодирование осуществляется путём «дописывания» к кодируемому слову остатка от деления на , то есть .
Коды CRC
Коды CRC (англ. (b) cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путём деления на . Ввиду того, что исправление ошибок не требуется, проверка правильности передачи может производиться точно так же.
Таким образом, вид многочлена задаёт конкретный код CRC. Примеры наиболее популярных полиномов:
| Название кода | Степень | Полином |
|---|---|---|
| CRC-12 | 12 | |
| CRC-16 | 16 | |
| CRC-CCITT (b) | 16 | |
| CRC-32 | 32 |
Коды БЧХ
Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача.
Коды коррекции ошибок Рида — Соломона
Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (b) (октетами (b) ).
Математически коды Рида — Соломона являются кодами БЧХ (b) .
Преимущества и недостатки блоковых кодов
Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ (b) ), менее высока.
Свёрточные коды

Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных. Такие коды, как правило, порождаются дискретной линейной инвариантной во времени системой (b) . Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании.
Кодирование свёрточным кодом производится с помощью регистра сдвига (b) , отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше.
Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби (b) , который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия (b) .
Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок.
Каскадное кодирование. Итеративное декодирование
Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение.
Например, популярной является следующая конструкция: данные кодируются кодом Рида — Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона.
Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако декодирование требует больших ресурсов. К таким кодам относят турбо-коды (b) и LDPC-коды (b) (коды Галлагера).
Оценка эффективности кодов
Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ (b) ).
Граница Хэмминга и совершенные коды
Пусть имеется двоичный блоковый код с корректирующей способностью (b) . Тогда справедливо неравенство (называемое границей Хэмминга):
Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хэмминга (b) . Часто применяемые на практике коды с большой корректирующей способностью (b) (такие, как коды Рида — Соломона (b) ) не являются совершенными.
Литература
Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных. Такие коды, как правило, порождаются дискретной линейной инвариантной во времени системой (b) . Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании. Кодирование свёрточным кодом производится с помощью регистра сдвига (b) , отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше. Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби (b) , который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия (b) . Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок. Каскадное кодирование. Итеративное декодированиеПреимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение. Например, популярной является следующая конструкция: данные кодируются кодом Рида — Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона. Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако декодирование требует больших ресурсов. К таким кодам относят турбо-коды (b) и LDPC-коды (b) (коды Галлагера). Оценка эффективности кодовЭффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ (b) ). Граница Хэмминга и совершенные кодыПусть имеется двоичный блоковый код с корректирующей способностью (b) . Тогда справедливо неравенство (называемое границей Хэмминга): Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хэмминга (b) . Часто применяемые на практике коды с большой корректирующей способностью (b) (такие, как коды Рида — Соломона (b) ) не являются совершенными. Литература
7.1. Классификация корректирующих кодовВ каналах с помехами эффективным средством повышения достоверности передачи сообщений является помехоустойчивое кодирование. Оно основано на применении специальных кодов, которые корректируют ошибки, вызванные действием помех. Код называется корректирующим, если он позволяет обнаруживать или обнаруживать и исправлять ошибки при приеме сообщений. Код, посредством которого только обнаруживаются ошибки, носит название обнаруживающего кода. Исправление ошибки при таком кодировании обычно производится путем повторения искаженных сообщений. Запрос о повторении передается по каналу обратной связи. Код, исправляющий обнаруженные ошибки, называется исправляющим, кодом. В этом случае фиксируется не только сам факт наличия ошибок, но и устанавливается, какие кодовые символы приняты ошибочно, что позволяет их исправить без повторной передачи. Известны также коды, в которых исправляется только часть обнаруженных ошибок, а остальные ошибочные комбинации передаются повторно. Для того чтобы «од обладал корректирующими способностями, в кодовой последовательности должны содержаться дополнительные (избыточные) символы, предназначенные для корректирования ошибок. Чем больше избыточность кода, тем выше его корректирующая способность. Помехоустойчивые коды могут быть построены с любым основанием. Ниже рассматриваются только двоичные коды, теория которых разработана наиболее полно. В настоящее время известно большое количество корректирующих кодов, отличающихся как принципами построения, так и основными характеристиками. Рассмотрим их простейшую классификацию, дающую представление об основных группах, к которым принадлежит большая часть известных кодов [12]. На рис. 7.1 показана схема, поясняющая классификацию, проведенную по способам построения корректирующих кодов. Все известные в настоящее время коды могут быть разделены на две большие группы: блочные и непрерывные. Блочные коды характеризуются тем, что последовательность передаваемых символов разделена на блоки операции кодирования и декодирования в каждом блоке производятся отдельно. Отличительной особенностью непрерывных кодов является то, что первичная последовательность символов, несущих информацию, непрерывно преобразуется по определенному закону в другую последовательность, содержащую избыточное число символов. Здесь процессы кодирования и декодирования не требуют деления кодовых символов на блоки.
Рис. 7.1. Классификация корректирующих кодов Разновидностями как блочных, так и непрерывных кодов являются разделимые и неразделимые коды. В разделимых кодах всегда можно выделить информационные символы, содержащие передаваемую информацию, и контрольные (проверочные) символы, которые являются избыточными и служат ‘исключительно для коррекции ошибок. В неразделимых кодах такое разделение символов провести невозможно. Наиболее многочисленный класс разделимых кодов составляют линейные коды. Основная их особенность состоит в том, что контрольные символы образуются как линейные комбинации информационных символов. В свою очередь, линейные коды могут быть |разбиты на два подкласса: систематические и несистематические. Все двоичные систематические коды являются групповыми. Последние характеризуются принадлежностью кодовых комбинаций к группе, обладающей тем свойством, что сумма по модулю два любой пары комбинаций снова дает комбинацию, принадлежащую этой группе. Линейные коды, которые не могут быть отнесены к подклассу систематических, называются несистематическими. Вертикальными прямоугольниками на схеме рис. 7.1 представлены некоторые конкретные коды, описанные в последующих параграфах. 7.2. Принципы помехоустойчивого кодированияВ теории помехоустойчивого кодирования важным является вопрос об использовании избыточности для корректирования возникающих при передаче ошибок. Здесь удобно рассмотреть блочные моды, в которых всегда имеется возможность выделить отдельные кодовые комбинации. Напомним, что для равномерных кодов, которые в дальнейшем только и будут изучаться, число возможных комбинаций равно M=2n, где п — значность кода. В обычном некорректирующем коде без избыточности, например в коде Бодо, число комбинаций М выбирается равным числу сообщений алфавита источника М0и все комбинации используются для передачи информации. Корректирующие коды строятся так, чтобы число комбинаций М превышало число сообщений источника М0. Однако в.этом случае лишь М0комбинаций из общего числа используется для передачи информации. Эти комбинации называются разрешенными, а остальные М—М0комбинаций носят название запрещенных. На приемном конце в декодирующем устройстве известно, какие комбинации являются разрешенными и какие запрещенными. Поэтому если переданная разрешенная комбинация в результате ошибки преобразуется в некоторую запрещенную комбинацию, то такая ошибка будет обнаружена, а при определенных условиях исправлена. Естественно, что ошибки, приводящие к образованию другой разрешенной комбинации, не обнаруживаются. Различие между комбинациями равномерного кода принято характеризовать расстоянием, равным числу символов, которыми отличаются комбинации одна от другой. Расстояние d
Для любого кода d Расстояние между комбинациями
Рис. 7.2. Геометрическое представление разрешенных и запрещенных кодовых комбинаций При искажении меньшего числа символов комбинация
Если g>d, то некоторые ошибки также обнаруживаются. Однако полной гарантии обнаружения ошибок здесь нет, так как ошибочная комбинация ib этом случае может совпасть с какой-либо разрешенной комбинацией. Минимальное кодовое расстояние, при котором обнаруживаются любые одиночные ошибки, d=2. Процедура исправления ошибок в процессе декодирования сводится к определению переданной комбинации по известной принятой. Расстояние между переданной разрешенной комбинацией и принятой запрещенной комбинацией d0 равно кратности ошибок g. Если ошибки в символах комбинации происходят независимо относительно друг друга, то вероятность искажения некоторых g символов в n-значной комбинации будет равна:
где
Минимальное значение d, при котором еще возможно исправление любых одиночных ошибок, равно 3. Возможно также построение таких кодов, в которых часть ошибок исправляется, а часть только обнаруживается. Так, в соответствии с рис. 7.2в ошибки кратности Существуют двоичные системы связи, в которых решающее устройство выдает, кроме обычных символов 0 и 1, еще так называемый символ стирания
а остальные символы приняты без ошибок, то такая комбинация полностью восстанавливается. Действительно, для восстановления всех символов Если Таким образом, при фиксированном кодовом расстоянии максимально возможная кратность корректируемых ошибок достигается в кодах, которые обнаруживают ошибки или .восстанавливают стертые символы. Исправление ошибок представляет собой более трудную задачу, практическое решение которой сопряжено с усложнением кодирующих и декодирующих устройств. Поэтому исправляющие «оды обычно используются для корректирования ошибок малой кратности. Корректирующая способность кода возрастает с увеличением d. При фиксированном числе разрешенных комбинаций М
что, в свою очередь, требует избыточного числа символов r=n—k, где k — количество символов в комбинации кода без избыточности. Можно ввести понятие избыточности кода и количественно определить ее по аналогии с (6.12) как
При независимых ошибках вероятность определенного сочетания g ошибочных символов в n-значной кодовой комбинации выражается ф-лой ((7.2), а количество всевозможных сочетаний g ошибочных символов в комбинации зависит от ее длины и определяется известной формулой числа сочетаний
Отсюда полная вероятность ошибки кратности g, учитывающая все сочетания ошибочных символов, равняется:
Используя (7.7), можно записать формулы, определяющие вероятность отсутствия ошибок в кодовой комбинации, т. е. вероятность правильного приема
и вероятность правильного корректирования ошибок
Здесь суммирование ‘Производится по всем значениям кратности ошибок g, которые обнаруживаются и исправляются. Таким образом, вероятность некорректируемых ошибок равна:
Анализ ф-лы (7.8) показывает, что при малой величине Р0и сравнительно небольших значениях п наиболее вероятны ошибки малой кратности, которые и необходимо корректировать в первую очередь. Вероятность Р Общая задача, которая ставится при создании кода, заключается, в достижении наименьших значений Р В соответствии с общим принципом корректирования ошибок, основанным на использовании разрешенных и запрещенных комбинаций, необходимо сравнивать принятую комбинацию со всеми комбинациями данного кода. В результате М сопоставлений и принимается решение о переданной комбинации. Этот способ декодирования логически является наиболее простым, однако он требует сложных устройств, так как в них должны запоминаться все М комбинаций кода. Поэтому на практике чаще всего используются коды, которые позволяют с помощью ограниченного числа преобразований принятых кодовых символов извлечь из них всю информацию о корректируемых ошибках. Изучению таких кодов и посвящены последующие разделы. 7.3. Систематические кодыИзучение конкретных способов помехоустойчивого кодирования начнем с систематических кодов, которые в соответствии с классификацией (рис. 7.1) относятся к блочным разделимым кодам, т. е. к кодам, где операции кодирования осуществляются независимо в пределах каждой комбинации, состоящей из информационных и контрольных символов. Остановимся кратко на общих принципах построения систематических кодов. Если обозначить информационные символы буквами с, а контрольные — буквами е, то любую кодовую комбинацию, содержащую k информационных и r контрольных символов, можно представить последовательностью: Процесс кодирования на передающем конце сводится к образованию контрольных символов, которые выражаются в виде линейной функции информационных символов:
Здесь Затем производится сравнение обеих групп контрольных символов путем их суммирования по модулю два:
Полученное число X называется контрольным числом или синдромом. С его помощью можно обнаружить или исправить часть ошибок. Если ошибки в принятой комбинации отсутствуют, то все суммы Для исправления ошибок знание одного факта их возникновения является недостаточным. Необходимо указать номер ошибочно принятых символов. С этой целью каждому сочетанию исправляемых ошибок в комбинации присваивается одно из контрольных чисел, что позволяет по известному контрольному числу определить место положения ошибок и исправить их. Контрольное число X записывается в двоичной системе, поэтому общее количество различных контрольных чисел, отличающихся от нуля, равно
Формула (7.11) позволяет при заданном количестве информационных символов k определить необходимое число контрольных символов r, с помощью которых исправляются все одиночные ошибки. 7.4. Код с чётным числом единиц. Инверсионный кодРассмотрим некоторые простейшие систематические коды, применяемые только для обнаружения ошибок. Одним из кодов подобного типа является код с четным числом единиц. Каждая комбинация этого кода содержит, помимо информационных символов, один контрольный символ, выбираемый равным 0 или 1 так, чтобы сумма единиц в комбинации всегда была четной. Примером могут служить пятизначные комбинации кода Бодо, к которым добавляется шестой контрольный символ: 10101,1 и 01100,0. Правило вычисления контрольного символа можно выразить на основании (7.9) в следующей форме:
Это позволяет в декодирующем устройстве сравнительно просто производить обнаружение ошибок путем проверки на четность. Нарушение четности имеет место при появлении однократных, трехкратных и в общем, случае ошибок нечетной кратности, что и дает возможность их обнаружить. Появление четных ошибок не изменяет четности суммы (7.12), поэтому такие ошибки не обнаруживаются. На основании ,(7.8) вероятность необнаруженной ошибки равна:
К достоинствам кода следует отнести простоту кодирующих и декодирующих устройств, а также малую .избыточность Значительно лучшими корректирующими способностями обладает инверсный код, который также применяется только для обнаружения ошибок. С принципом построения такого кода удобно ознакомиться на примере двух комбинаций: 11000, 11000 и 01101, 10010. В каждой комбинации символы до запятой являются информационными, а последующие — контрольными. Если количество единиц в информационных символах четное, т. е. сумма этих символов
равна нулю, то контрольные символы представляют собой простое повторение информационных. В противном случае, когда число единиц нечетное и сумма (7.13) равна 1, контрольные символы получаются из информационных посредством инвертирования, т. е. путем замены всех 0 на 1, а 1 на 0. Математическая форма записи образования контрольных символов имеет вид Анализ показывает, что при
Для g>4 вероятность необнаруженных ошибок еще меньше. Поэтому при достаточно малых вероятностях ошибочных символов ро можно полагать, что полная вероятность необнаруженных ошибок Инверсный код обладает высокой обнаруживающей способностью, однако она достигается ценой сравнительно большой избыточности, которая, как нетрудно определить, составляет величину 7.5. Коды ХэммингаК этому типу кодов обычно относят систематические коды с расстоянием d=3, которые позволяют исправить все одиночные ошибки (7.3). Рассмотрим построение семизначного кода Хэмминга, каждая комбинация которого содержит четыре информационных и триконтрольных символа. Такой код, условно обозначаемый (7.4), удовлетворяет неравенству (7.11) и имеет избыточность Если информационные символы с занимают в комбинация первые четыре места, то последующие три контрольных символа образуются по общему правилу (7.9) как суммы: Декодирование осуществляется путем трех проверок на четность (7.10):
Так как х равно 0 или 1, то всего может быть восемь контрольных чисел Х=х1х2х3: 000, 100, 010, 001, 011, 101, 110 и 111. Первое из них имеет место в случае правильного приема, а остальные семь появляются при наличии искажений и должны использоваться для определения местоположения одиночной ошибки в семизначной комбинации. Выясним, каким образом устанавливается взаимосвязь между контрольными числами я искаженными символами. Если искажен один из контрольных символов: Таблица 7.1
Порядок присвоения контрольных чисел ошибочным информационным символам может устанавливаться любой, например, как показано в табл. 7.1. Нетрудно показать, что этому распределению контрольных чисел соответствуют коэффициенты Таблица 7.2
Если подставить коэффициенты
При искажении одного из информационных символов становятся равными единице те суммы х, в которые входит этот символ. Легко проверить, что получающееся в этом случае контрольное число
Передаваемая комбинация при этом будет
Вычисленное таким образом контрольное число Здесь был рассмотрен простейший способ построения и декодирования кодовых комбинаций, в которых первые места отводились информационным символам, а соответствие между контрольными числами и ошибками определялось таблице. Вместе с тем существует более изящный метод отыскания одиночных ошибок, предложенный впервые самим Хэммингом. При этом методе код строится так, что контрольное число в двоичной системе счисления сразу указывает номер искаженного символа. Правда, в этом случае контрольные символы необходимо располагать среди информационных, что усложняет процесс кодирования. Для кода (7.4) символы в комбинации должны размещаться в следующем порядке:
Так, если произошла ошибка в информационном символе с’5 то контрольное число В заключение отметим, что в коде (7.4) при появлении многократных ошибок контрольное число также может отличаться от нуля. Однако декодирование в этом случае будет проведено неправильно, так как оно рассчитано на исправление лишь одиночных ошибок. 7.6. Циклические кодыВажное место среди систематических кодов занимают циклические коды. Свойство цикличности состоит в том, что циклическая перестановка всех символов кодовой комбинации Комбинации циклического кода, выражаемые двоичными числами, для удобства преобразований обычно определяют в виде полиномов, коэффициенты которых равны 0 или 1. Примером этому может служить следующая запись:
Помимо цикличности, кодовые комбинации обладают другим важным свойством. Если их представить в виде полиномов, то все они делятся без остатка на так называемый порождающий полином G(z) степени Построение комбинаций циклических кодов возможно путем умножения комбинации первичного кода A*(z) ,на порождающий полином G(z): A(z)=A*(z)G(z). Умножение производится по модулю zn и в данном случае сводится к умножению по обычным правилам с приведением подобных членов по модулю два. В полученной таким способом комбинации A(z) в явном виде не содержатся информационные символы, однако они всегда могут быть выделены в результате обратной операции: деления A(z) на G(z). Другой способ кодирования, позволяющий представить кодовую комбинацию в виде информационных и контрольных символов, заключается в следующем. К комбинации первичного кода дописывается справа г нулей, что эквивалентно повышению полинома A*(z) на ,г разрядов, т. е. умножению его на гг. Затем произведение zrA*(z) делится на порождающий полином. B общем случае результат деления состоит из целого числа Q(z) и остатка R(z). Отсюда
Вычисленный остаток К(г) я используется для образования комбинации циклического кода в виде суммы A(z)=zrA*(z)@R(z). Так как сложение и вычитание по модулю два дают один и тот же результат, то нетрудно заметить, что A(z) = Q(z)G(z), т. е. полученная комбинация удовлетворяет требованию делимости на порождающий полином. Степень полинома R{z) не превышает r—1, поэтому он замещает нули в комбинации z Для примера рассмотрим циклический код c n = 7, k=4, r=3 и G(z)=z3-z+1=1011. Необходимо закодировать комбинацию A*(z)=z*+1 = 1001. Тогда z
Окончательно получаем В А(z) высшие четыре разряда занимают информационные символы, а остальные при — контрольные. Контрольные символы в циклическом коде могут быть вычислены по общим ф-лам (7.9), однако здесь определение коэффициентов Процедура декодирования принятых комбинаций также основана на использовании полиномов G(z). Если ошибок в процессе передачи не было, то деление принятой комбинации A(z) на G(z) дает целое число. При наличии корректируемых ошибок в результате деления образуется остаток, который и позволяет обнаружить или исправить ошибки. Кодирующие и декодирующие устройства циклических кодов в большинстве случаев обладают сравнительной простотой, что следует считать одним из основных их преимуществ. Другим важным достоинством этих кодов является их способность корректировать пачки ошибок, возникающие в реальных каналах, где действуют импульсные и сосредоточенные помехи или наблюдаются замирания сигнала. В теории кодирования весом кодовых комбинаций принято называть .количество единиц, которое они содержат. Если все комбинации кода имеют одинаковый вес, то такой код называется кодом с постоянным весом. Коды с постоянным весом относятся к классу блочных неразделимых кодов, так как здесь не представляется возможным выделить информационные и контрольные символы. Из кодов этого типа наибольшее распространение получил обнаруживающий семизначный код 3/4, каждая разрешенная комбинация которого имеет три единицы и четыре нуля. Известен также код 2/5. Примером комбинаций кода 3/4 могут служить следующие семизначные последовательности: 1011000, 0101010, 0001110 и т. д. Декодирование принятых комбинаций сводится к определению их веса. Если он отличается от заданного, то комбинация принята с ошибкой. Этот код обнаруживает все ошибки нечетной краткости и часть ошибок четной кратности. Не обнаруживаются только так называемые ошибки смещения, сохраняющие неизменным вес комбинации. Ошибки смещения характеризуются тем, что число искаженных единиц всегда равно числу искаженных нулей. Можно показать, что вероятность необнаруженной ошибки для кода 3/4 равна:
В этом коде из общего числа комбинаций М = 27=128 разрешенными являются лишь
Код 3/4 находит применение при частотной манипуляции в каналах с селективными замираниями, где вероятность ошибок смещения невелика. 7.8. Непрерывные кодыИз непрерывных кодов, исправляющих ошибки, наиболее известны коды Финка—Хагельбаргера, в которых контрольные символы образуются путем линейной операции над двумя или более информационными символами. Принцип построения этих кодов рассмотрим на примере простейшего цепного кода. Контрольные символы в цепном коде формируются путем суммирования двух информационных символов, расположенных один относительно другого на определенном расстоянии:
Расстояние между информационными символами l=k—i определяет основные свойства кода и называется шагом сложения. Число контрольных символов при таком способе кодирования равно числу информационных символов, поэтому избыточность кода
Рис. 7.3. Образование и размещение контрольных символов в цепном коде Финка—Хагельбаргера При декодировании из принятых информационных символов по тому же правилу (7.19) формируется вспомогательная последовательность контрольных символов е», которая сравнивается с принятой последовательностью контрольных символов е’ (рис. 7.36). Если произошла ошибка в информационном символе, например, c‘k, то это вызовет искажения сразу двух символов e«k и e«km, что и обнаружится в результате их сравнения с Важное преимущество непрерывных кодов состоит в их способности исправлять не только одиночные ошибки, но я группы (пакеты) ошибок. Если задержка контрольных символов выбрана равной 2l, то можно показать, что максимальная длина исправляемого пакета ошибок также равна 2l при интервале между пакетами не менее 6l+1. Таким образом, возможность исправления длинных пакетов связана с увеличением шага сложения, а следовательно, и с усложнением кодирующих и декодирующих устройств. Вопросы для повторения1. Как могут быть классифицированы корректирующие коды? 2. Каким образом исправляются ошибки в кодах, которые только их обнаруживают? 3. В чем состоят основные принципы корректирования ошибок? 4. Дайте определение кодового расстояния. 5. При каких условиях код может обнаруживать или исправлять ошибки? 6. Как используется корректирующий код в системах со стиранием? 7. Какие характеристики определяют корректирующие способности кода? 8. Как осуществляется построение кодовых комбинаций в систематических кодах? 9. На чем основан принцип корректирования ошибок с использованием контрольного числа? 10. Объясните метод построения кода с четным числом единиц. 11. Как осуществляется процедура кодирования в семизначном коде Хэмминга? 12. Почему семизначный код 3/4 не обнаруживает ошибки смещения? 13. Каким образом производится непрерывное кодирование? 14. От чего зависит длина пакета исправляемых ошибок в коде Финка—Хагельбаргера? Обнаруже́ние оши́бок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи. Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды). Содержание
Способы борьбы с ошибкамиВ процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях сетевой модели OSI). В системах связи возможны несколько стратегий борьбы с ошибками:
Коды обнаружения и исправления ошибокКорректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении. Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода. С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её. В действительности используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить). По способу работы с данными коды, исправляющие ошибки, делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком. Блоковые кодыПусть кодируемая информация делится на фрагменты длиной Если исходные Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач. Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования. Линейные коды общего видаЛинейный блоковый код — такой код, что множество его кодовых слов образует Это значит, что операция кодирования соответствует умножению исходного Пусть Минимальное расстояние и корректирующая способностьРасстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами
Минимальное расстояние Хемминга
Корректирующая способность определяет, сколько ошибок передачи кода (типа Таким образом, получив искажённую кодовую комбинацию из Поясним на примере. Предположим, что есть два кодовых слова Коды ХеммингаКоды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
Общий метод декодирования линейных кодовЛюбой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора Линейные циклические кодыНесмотря на то, что декодирование линейных кодов значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами. Циклическим кодом является линейный код, обладающий следующим свойством: если Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть Порождающий (генераторный) полиномМожно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности: Коды CRCКоды CRC (англ. cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путём деления Таким образом, вид полинома
Коды БЧХКоды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача. Коды коррекции ошибок Рида — СоломонаКоды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами). Математически коды Рида — Соломона являются кодами БЧХ. Преимущества и недостатки блоковых кодовХотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока. Свёрточные коды
Свёрточный кодер ( Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных. Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании. Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше. Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия. Преимущества и недостатки свёрточных кодовСвёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок. Каскадное кодирование. Итеративное декодированиеПреимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение. Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона. Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера). Сетевое кодированиеОценка эффективности кодовЭффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ). Граница Хемминга и совершенные кодыПусть имеется двоичный блоковый Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными. Энергетический выигрышПри передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом, при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения. Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования. Применение кодов, исправляющих ошибкиКоды, исправляющие ошибки, применяются:
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней. Автоматический запрос повторной передачиСистемы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса: Запрос ARQ с остановками (stop-and-wait ARQ)Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем, как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание. Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть передается ошибочный блок и все последующие). Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)При этом подходе осуществляется передача только ошибочно принятых блоков данных. См. также
Литература
Ссылки
В информатике и телекоммуникациях, коды Хэмминга являются семейством линейного исправления ошибок коды. Коды Хэмминга могут обнаруживать до двух битовых ошибок или исправлять однобитовые ошибки без обнаружения неисправленных ошибок. Напротив, простой код четности не может исправлять ошибки и может обнаруживать только нечетное количество битов с ошибкой. Коды Хэмминга — это совершенные коды, то есть они достигают наивысшей возможной скорости для кодов с их длиной блока и минимальным расстоянием, равным трем. Ричард В. Хэмминг изобрел коды Хэмминга в 1950 году как способ автоматического исправления ошибок, вносимых считывающими устройствами перфокарт. В своей оригинальной статье Хэмминг развил свою общую идею, но специально сосредоточился на коде Хэмминга (7,4), который добавляет три бита четности к четырем битам данных. В математические термины, коды Хэмминга — это класс двоичных линейных кодов. Для каждого целого числа r ≥ 2 существует код с длиной блока n = 2 — 1 и длиной сообщения k = 2 — r — 1. Следовательно, скорость кодов Хэмминга равна R = k / n = 1 — r / (2 — 1), что является максимально возможным для кодов с минимальным расстоянием, равным трем (т. е. минимальное количество битовых изменений, необходимых для перехода от любого кодового слова к любому другому кодовому слову, равно трем) и длина блока 2-1. Матрица проверки на четность кода Хэмминга строится путем перечисления всех столбцов длины r, которые не равны нулю, что означает, что двойной код из код Хэмминга — это сокращенный код Адамара. Матрица проверки на четность имеет свойство, состоящее в том, что любые два столбца являются попарно линейно независимыми. Из-за ограниченной избыточности, которую коды Хэмминга добавляют к данным, они могут обнаруживать и исправлять ошибки только при низком уровне ошибок. Это случай компьютерной памяти (ECC-память ), где битовые ошибки крайне редки, а коды Хэмминга широко используются. В этом контексте часто используется расширенный код Хэмминга, имеющий один дополнительный бит четности. Расширенные коды Хэмминга достигают расстояния Хэмминга, равного четырем, что позволяет декодеру различать, когда возникает не более одной однобитовой ошибки, и когда возникают любые двухбитовые ошибки. В этом смысле расширенные коды Хэмминга предназначены для исправления одиночной ошибки и обнаружения двойной ошибки, сокращенно SECDED . Содержание
ИсторияРичард Хэмминг, изобретатель кодов Хэмминга, работал в Bell Labs в конце 1940-х годов над компьютером Bell Model V., электромеханическая релейная машина с временем цикла в секундах. Ввод подавался на перфоленту шириной семь восьмых дюйма, которая имела до шести отверстий в ряду. В будние дни при обнаружении ошибок в реле машина останавливалась и мигала, чтобы операторы могли исправить проблему. В нерабочее время и в выходные дни, когда не было операторов, машина просто переходила к следующему заданию. Хэмминг работал по выходным и все больше разочаровывался в необходимости перезапускать свои программы с нуля из-за обнаруженных ошибок. В записанном на пленку интервью Хэмминг сказал: «И поэтому я сказал:« Черт побери, если машина может обнаружить ошибку, почему она не может определить местоположение ошибки и исправить ее? »». В течение следующих нескольких лет он работал над проблемой исправления ошибок, разрабатывая все более мощный набор алгоритмов. В 1950 году он опубликовал то, что теперь известно как код Хэмминга, который до сих пор используется в таких приложениях, как память ECC. Коды, предшествующие ХэммингуРяд простых кодов обнаружения ошибок использовался и до Коды Хэмминга, но ни один из них не был столь же эффективен, как коды Хэмминга в том же объеме. ЧетностьЧетность добавляет один бит, который указывает, было ли количество единиц (битовых позиций со значением один) в предыдущих данных четным или нечетное. Если при передаче изменяется нечетное количество битов, сообщение изменит четность, и в этот момент может быть обнаружена ошибка; однако бит, который изменился, мог быть самим битом четности. Наиболее распространенное соглашение состоит в том, что значение четности, равное единице, указывает, что в данных есть нечетное количество единиц, а значение четности, равное нулю, указывает, что существует четное количество единиц. Если количество измененных битов четное, контрольный бит будет действительным и ошибка не будет обнаружена. Более того, четность не указывает, какой бит содержит ошибку, даже если он может ее обнаружить. Данные должны быть полностью отброшены и повторно переданы с нуля. В шумной среде передачи успешная передача может занять много времени или может никогда не произойти. Однако, хотя качество проверки четности оставляет желать лучшего, поскольку он использует только один бит, этот метод дает наименьшие накладные расходы. Код два из пятиКод два из пяти — это схема кодирования, которая использует пять битов, состоящих ровно из трех нулей и двух единиц. Это дает десять возможных комбинаций, достаточных для представления цифр 0–9. Эта схема может обнаруживать все одиночные битовые ошибки, все битовые ошибки с нечетными номерами и некоторые битовые ошибки с четными номерами (например, переворачивание обоих 1-битов). Однако он по-прежнему не может исправить ни одну из этих ошибок. ПовторениеДругой используемый в то время код повторял каждый бит данных несколько раз, чтобы гарантировать, что он был отправлен правильно. Например, если бит данных, который должен быть отправлен, равен 1, код повторения n = 3 отправит 111. Если три полученных бита не идентичны, во время передачи произошла ошибка. Если канал достаточно чистый, большую часть времени в каждой тройке будет изменяться только один бит. Следовательно, 001, 010 и 100 соответствуют 0 биту, а 110, 101 и 011 соответствуют 1 биту, причем большее количество одинаковых цифр (‘0’ или ‘1’) указывает, что бит данных должен быть. Код с этой способностью восстанавливать исходное сообщение при наличии ошибок известен как код исправления ошибок. Этот код с тройным повторением является кодом Хэмминга с m = 2, поскольку имеется два бита четности и 2 — 2 — 1 = 1 бит данных. Однако такие коды не могут правильно исправить все ошибки. В нашем примере, если канал переворачивает два бита и получатель получает 001, система обнаружит ошибку, но сделает вывод, что исходный бит равен 0, что неверно. Если мы увеличим размер битовой строки до четырех, мы сможем обнаружить все двухбитовые ошибки, но не сможем исправить их (количество битов четности четное); при пяти битах мы можем как обнаруживать, так и исправлять все двухбитовые ошибки, но не все трехбитные ошибки. Более того, увеличение размера строки битов четности неэффективно, так как в нашем исходном случае пропускная способность снижается в три раза, а эффективность резко падает, когда мы увеличиваем количество дублирований каждого бита для обнаружения и исправьте больше ошибок. Коды ХэммингаЕсли в сообщение включено больше исправляющих ошибок битов, и если эти биты могут быть расположены так, что разные неправильные биты дают разные результаты ошибок, то плохие биты могут быть идентифицированы. В семибитном сообщении существует семь возможных однобитовых ошибок, поэтому три бита контроля ошибок потенциально могут указывать не только на то, что произошла ошибка, но и на то, какой бит вызвал ошибку. Хэмминг изучил существующие схемы кодирования, включая две из пяти, и обобщил их концепции. Для начала он разработал номенклатуру для описания системы, включая количество битов данных и битов исправления ошибок в блоке. Например, четность включает в себя один бит для любого слова данных, поэтому, предполагая ASCII слова с семью битами, Хэмминг описал это как код (8,7), всего восемь битов, из которых семь являются данными. Пример повторения будет (3,1), следуя той же логике. Кодовая скорость — это второе число, деленное на первое, для нашего примера с повторением 1/3. Хэмминг также заметил проблемы с переворачиванием двух или более битов и описал это как «расстояние» (теперь оно называется расстоянием Хэмминга, после него). Четность имеет расстояние 2, поэтому одно переключение бита можно обнаружить, но не исправить, и любые два изменения бита будут невидимы. Повторение (3,1) имеет расстояние 3, так как три бита необходимо перевернуть в одной и той же тройке, чтобы получить другое кодовое слово без видимых ошибок. Он может исправлять однобитовые ошибки или обнаруживать, но не исправлять, двухбитовые ошибки. Повторение (4,1) (каждый бит повторяется четыре раза) имеет расстояние 4, поэтому переворот трех битов можно обнаружить, но не исправить. Когда три бита в одной группе меняются местами, могут возникнуть ситуации, когда попытка исправить приведет к неправильному кодовому слову. Как правило, код с расстоянием k может обнаруживать, но не исправлять k — 1 ошибок. Хэмминга интересовали сразу две проблемы: как можно больше увеличить расстояние и в то же время как можно больше увеличить скорость кода. В 1940-х годах он разработал несколько схем кодирования, которые значительно улучшили существующие коды. Ключом ко всем его системам было перекрытие битов четности, чтобы им удавалось проверять друг друга, а также данные. Общий алгоритмСледующий общий алгоритм генерирует код исправления одиночных ошибок (SEC) для любого количества битов. Основная идея состоит в том, чтобы выбрать биты с исправлением ошибок так, чтобы индекс-XOR (XOR всех битовых позиций, содержащих 1) был равен 0. Мы используем позиции 1, 10, 100 и т. Д. ( в двоичном формате) в качестве битов исправления ошибок, что гарантирует возможность установки битов исправления ошибок так, чтобы индекс-исключающее ИЛИ всего сообщения был равен 0. Если получатель получает строку с индексом-исключающее ИЛИ 0, он может заключить повреждений не было, в противном случае индекс-XOR указывает индекс поврежденного бита. Алгоритм может быть выведен из следующего описания:
Если байт данных, который должен быть закодирован, равен 10011010, то слово данных (с использованием _ для представления битов четности) будет __1_001_1010, а кодовое слово — 011100101010. Выбор четности, четной или нечетной, не имеет значения, но один и тот же выбор должен использоваться как для кодирования, так и для декодирования. Это общее правило можно показать визуально:
Обнаружение ошибок в технике связи — действие, направленное на контроль целостности данных при записи/воспроизведении информации или при её передаче по линиям связи. Исправление ошибок (коррекция ошибок) — процедура восстановления информации после чтения её из устройства хранения или канала связи. Для обнаружения ошибок используют коды обнаружения ошибок, для исправления — корректирующие коды (коды, исправляющие ошибки, коды с коррекцией ошибок, помехоустойчивые коды). Способы борьбы с ошибками[]В процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях модели OSI). В системах связи возможны несколько стратегий борьбы с ошибками:
Коды обнаружения и исправления ошибок[]Корректирующие коды — коды, служащие для обнаружения или исправления ошибок, возникающих при передаче информации под влиянием помех, а также при её хранении. Для этого при записи (передаче) в полезные данные добавляют специальным образом структурированную избыточную информацию (контрольное число), а при чтении (приёме) её используют для того, чтобы обнаружить или исправить ошибки. Естественно, что число ошибок, которое можно исправить, ограничено и зависит от конкретного применяемого кода. С кодами, исправляющими ошибки, тесно связаны коды обнаружения ошибок. В отличие от первых, последние могут только установить факт наличия ошибки в переданных данных, но не исправить её. В действительности, используемые коды обнаружения ошибок принадлежат к тем же классам кодов, что и коды, исправляющие ошибки. Фактически, любой код, исправляющий ошибки, может быть также использован для обнаружения ошибок (при этом он будет способен обнаружить большее число ошибок, чем был способен исправить). По способу работы с данными коды, исправляющие ошибки делятся на блоковые, делящие информацию на фрагменты постоянной длины и обрабатывающие каждый из них в отдельности, и свёрточные, работающие с данными как с непрерывным потоком. Блоковые коды[]Пусть кодируемая информация делится на фрагменты длиной Если исходные Задать блоковый код можно по-разному, в том числе таблицей, где каждой совокупности из
Нетрудно видеть, что приведённые требования противоречат друг другу. Именно поэтому существует большое количество кодов, каждый из которых пригоден для своего круга задач. Практически все используемые коды являются линейными. Это связано с тем, что нелинейные коды значительно сложнее исследовать, и для них трудно обеспечить приемлемую лёгкость кодирования и декодирования. Линейные коды общего вида[]Линейный блоковый код — такой код, что множество его кодовых слов образует Это значит, что операция кодирования соответствует умножению исходного Пусть Минимальное расстояние и корректирующая способность[]
Расстоянием Хемминга (метрикой Хемминга) между двумя кодовыми словами Минимальное расстояние Хемминга
Корректирующая способность определяет, сколько ошибок передачи кода (типа Таким образом получив искажённый код из Поясним на примере. Предположим, что есть два кодовых слова Коды Хемминга[]Коды Хемминга — простейшие линейные коды с минимальным расстоянием 3, то есть способные исправить одну ошибку. Код Хемминга может быть представлен в таком виде, что синдром
Общий метод декодирования линейных кодов[]Любой код (в том числе нелинейный) можно декодировать с помощью обычной таблицы, где каждому значению принятого слова Для линейных кодов этот метод можно существенно упростить. При этом для каждого принятого вектора Линейные циклические коды[]Несмотря на то, что декодирование линейных кодов уже значительно проще декодирования большинства нелинейных, для большинства кодов этот процесс всё ещё достаточно сложен. Циклические коды, кроме более простого декодирования, обладают и другими важными свойствами. Циклическим кодом является линейный код, обладающий следующим свойством: если Слова циклического кода удобно представлять в виде многочленов. Например, кодовое слово В дальнейшем, если не указано иное, мы будем считать, что циклический код является двоичным, то есть Порождающий (генераторный) полином[]Можно показать, что все кодовые слова конкретного циклического кода кратны определённому порождающему полиному С помощью порождающего полинома осуществляется кодирование циклическим кодом. В частности: Коды CRC[]Коды CRC (cyclic redundancy check — циклическая избыточная проверка) являются систематическими кодами, предназначенными не для исправления ошибок, а для их обнаружения. Они используют способ систематического кодирования, изложенный выше: «контрольная сумма» вычисляется путем деления Таким образом, вид полинома
Коды БЧХ[]Коды Боуза — Чоудхури — Хоквингема (БЧХ) являются подклассом циклических кодов. Их отличительное свойство — возможность построения кода БЧХ с минимальным расстоянием не меньше заданного. Это важно, потому что, вообще говоря, определение минимального расстояния кода есть очень сложная задача. Математически полинома Коды коррекции ошибок Рида — Соломона[]Коды Рида — Соломона — недвоичные циклические коды, позволяющие исправлять ошибки в блоках данных. Элементами кодового вектора являются не биты, а группы битов (блоки). Очень распространены коды Рида-Соломона, работающие с байтами (октетами). Математически коды Рида — Соломона являются кодами БЧХ. Преимущества и недостатки блоковых кодов[]Хотя блоковые коды, как правило, хорошо справляются с редкими, но большими пачками ошибок, их эффективность при частых, но небольших ошибках (например, в канале с АБГШ), менее высока. Свёрточные коды[] Файл:ECC NASA standard coder.png Свёрточный кодер ( Свёрточные коды, в отличие от блоковых, не делят информацию на фрагменты и работают с ней как со сплошным потоком данных. Свёрточные коды, как правило, порождаются дискретной линейной инвариантной во времени системой. Поэтому, в отличие от большинства блоковых кодов, свёрточное кодирование — очень простая операция, чего нельзя сказать о декодировании. Кодирование свёрточным кодом производится с помощью регистра сдвига, отводы от которого суммируются по модулю два. Таких сумм может быть две (чаще всего) или больше. Декодирование свёрточных кодов, как правило, производится по алгоритму Витерби, который пытается восстановить переданную последовательность согласно критерию максимального правдоподобия. Преимущества и недостатки свёрточных кодов[]Свёрточные коды эффективно работают в канале с белым шумом, но плохо справляются с пакетами ошибок. Более того, если декодер ошибается, на его выходе всегда возникает пакет ошибок. Каскадное кодирование. Итеративное декодирование[]Преимущества разных способов кодирования можно объединить, применив каскадное кодирование. При этом информация сначала кодируется одним кодом, а затем другим, в результате получается код-произведение. Например, популярной является следующая конструкция: данные кодируются кодом Рида-Соломона, затем перемежаются (при этом символы, расположенные близко, помещаются далеко друг от друга) и кодируются свёрточным кодом. На приёмнике сначала декодируется свёрточный код, затем осуществляется обратное перемежение (при этом пачки ошибок на выходе свёрточного декодера попадают в разные кодовые слова кода Рида — Соломона), и затем осуществляется декодирование кода Рида — Соломона. Некоторые коды-произведения специально сконструированы для итеративного декодирования, при котором декодирование осуществляется в несколько проходов, каждый из которых использует информацию от предыдущего. Это позволяет добиться большой эффективности, однако, декодирование требует больших ресурсов. К таким кодам относят турбо-коды и LDPC-коды (коды Галлагера). Оценка эффективности кодов[]Эффективность кодов определяется количеством ошибок, которые тот может исправить, количеством избыточной информации, добавление которой требуется, а также сложностью реализации кодирования и декодирования (как аппаратной, так и в виде программы для ЭВМ). Граница Хемминга и совершенные коды[]
Пусть имеется двоичный блоковый Коды, удовлетворяющие этой границе с равенством, называются совершенными. К совершенным кодам относятся, например, коды Хемминга. Часто применяемые на практике коды с большой корректирующей способностью (такие, как коды Рида — Соломона) не являются совершенными. Энергетический выигрыш[]При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения. Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования. Применение кодов, исправляющих ошибки[]Коды, исправляющие ошибки, применяются:
Коды, обнаруживающие ошибки, применяются в сетевых протоколах различных уровней. Автоматический запрос повторной передачи[]Системы с автоматическим запросом повторной передачи (ARQ — Automatic Repeat reQuest) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса: Запрос ARQ с остановками (stop-and-wait ARQ)[]Идея этого метода заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание. Непрерывный запрос ARQ с возвратом (continuous ARQ with pullback)[]Для этого метода необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть, передается ошибочный блок и все последующие). Непрерывный запрос ARQ с выборочным повторением (continuous ARQ with selective repeat)[]При этом подходе осуществляется передача только ошибочно принятых блоков данных. См. также[]
Литература[]
Ссылки[] Имеется викиучебник по теме:
Эта страница использует содержимое раздела Википедии на русском языке. Оригинальная статья находится по адресу: Обнаружение и исправление ошибок. Список первоначальных авторов статьи можно посмотреть в истории правок. Эта статья так же, как и статья, размещённая в Википедии, доступна на условиях CC-BY-SA . Возможно, вам также будет интересно:
Подписаться
авторизуйтесь
0 комментариев
Старые
|
|---|
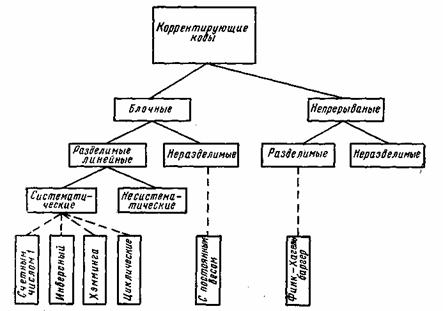
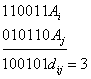
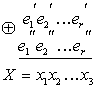
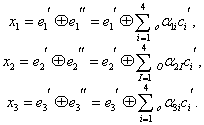

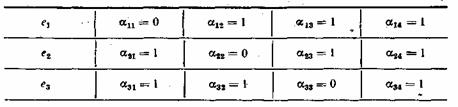
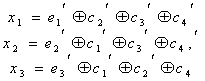
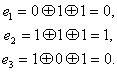
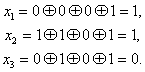
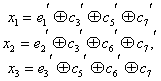
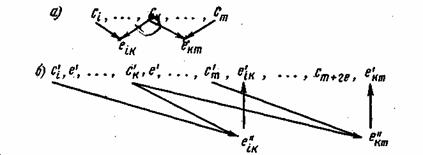














































 Код Хэмминга (7,4) (с r = 3)
Код Хэмминга (7,4) (с r = 3) . Если вычесть биты четности, у нас останется 2 m — m — 1 { displaystyle 2 ^ {m} -m-1}
. Если вычесть биты четности, у нас останется 2 m — m — 1 { displaystyle 2 ^ {m} -m-1} бит, которые мы можем использовать для данных. При изменении m мы получаем все возможные коды Хэмминга:
бит, которые мы можем использовать для данных. При изменении m мы получаем все возможные коды Хэмминга:



 Графическое изображение четырех битов данных и трех битов четности и какие биты четности применяются к каким битам данных
Графическое изображение четырех битов данных и трех битов четности и какие биты четности применяются к каким битам данных  называется (каноническим) образующая матрица линейного (n, k) кода,
называется (каноническим) образующая матрица линейного (n, k) кода, называется матрицей проверки на четность.
называется матрицей проверки на четность. , матрица из нулей.
, матрица из нулей. и матрица проверки на четность H { displaystyle mathbf {H}}
и матрица проверки на четность H { displaystyle mathbf {H}} :
:

 будет вектор-строкой бит двоичных данных, a → = [a 1, a 2, a 3, a 4 ], ai ∈ {0, 1} { displaystyle { vec {a}} = [a_ {1}, a_ {2}, a_ {3}, a_ {4}], quad a_ {i} in {0,1 }}
будет вектор-строкой бит двоичных данных, a → = [a 1, a 2, a 3, a 4 ], ai ∈ {0, 1} { displaystyle { vec {a}} = [a_ {1}, a_ {2}, a_ {3}, a_ {4}], quad a_ {i} in {0,1 }}![{ displaystyle { vec {a}} = [a_ {1 }, a_ {2}, a_ {3}, a_ {4}], quad a_ {i} in {0,1 }}](https://wikimedia.org/api/rest_v1/media/math/render/svg/898ddf319567d4af0acecf5c7fd450f5f466e28b) . Кодовое слово x → { displaystyle { vec {x}}}
. Кодовое слово x → { displaystyle { vec {x}}} для любого из 16 возможных векторов данных a → { displaystyle { vec {a}}}
для любого из 16 возможных векторов данных a → { displaystyle { vec {a}}} , где операция суммирования выполняется по модулю 2.
, где операция суммирования выполняется по модулю 2.![{ displaystyle { vec {a}} = [1,0,1,1]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/e838e2ec81e9fe6223596b61f747b195d3d338fb) . Используя образующую матрицу G { displaystyle G}
. Используя образующую матрицу G { displaystyle G}
 Тот же [7,4] пример выше с дополнительным битом четности. Эта диаграмма не предназначена для соответствия матрице H.
Тот же [7,4] пример выше с дополнительным битом четности. Эта диаграмма не предназначена для соответствия матрице H. 


