
In information theory, a low-density parity-check (LDPC) code is a linear error correcting code, a method of transmitting a message over a noisy transmission channel.[1][2] An LDPC code is constructed using a sparse Tanner graph (subclass of the bipartite graph).[3] LDPC codes are capacity-approaching codes, which means that practical constructions exist that allow the noise threshold to be set very close to the theoretical maximum (the Shannon limit) for a symmetric memoryless channel. The noise threshold defines an upper bound for the channel noise, up to which the probability of lost information can be made as small as desired. Using iterative belief propagation techniques, LDPC codes can be decoded in time linear to their block length.
LDPC codes are finding increasing use in applications requiring reliable and highly efficient information transfer over bandwidth-constrained or return-channel-constrained links in the presence of corrupting noise. Implementation of LDPC codes has lagged behind that of other codes, notably turbo codes. The fundamental patent for turbo codes expired on August 29, 2013.[4][5]
LDPC codes are also known as Gallager codes, in honor of Robert G. Gallager, who developed the LDPC concept in his doctoral dissertation at the Massachusetts Institute of Technology in 1960.[6][7] LDPC codes have also been shown to have ideal combinatorial properties. In his dissertation, Gallager showed that LDPC codes achieve the Gilbert–Varshamov bound for linear codes over binary fields with high probability. In 2020 it was shown that Gallager’s LDPC codes achieve list decoding capacity and also achieve the Gilbert–Varshamov bound for linear codes over general fields. [8]
History[edit]
Impractical to implement when first developed by Gallager in 1963,[9] LDPC codes were forgotten until his work was rediscovered in 1996.[10] Turbo codes, another class of capacity-approaching codes discovered in 1993, became the coding scheme of choice in the late 1990s, used for applications such as the Deep Space Network and satellite communications. However, the advances in low-density parity-check codes have seen them surpass turbo codes in terms of error floor and performance in the higher code rate range, leaving turbo codes better suited for the lower code rates only.[11]
Applications[edit]
In 2003, an irregular repeat accumulate (IRA) style LDPC code beat six turbo codes to become the error-correcting code in the new DVB-S2 standard for digital television.[12] The DVB-S2 selection committee made decoder complexity estimates for the turbo code proposals using a much less efficient serial decoder architecture rather than a parallel decoder architecture. This forced the turbo code proposals to use frame sizes on the order of one half the frame size of the LDPC proposals.[citation needed]
In 2008, LDPC beat convolutional turbo codes as the forward error correction (FEC) system for the ITU-T G.hn standard.[13] G.hn chose LDPC codes over turbo codes because of their lower decoding complexity (especially when operating at data rates close to 1.0 Gbit/s) and because the proposed turbo codes exhibited a significant error floor at the desired range of operation.[14]
LDPC codes are also used for 10GBASE-T Ethernet, which sends data at 10 gigabits per second over twisted-pair cables. As of 2009, LDPC codes are also part of the Wi-Fi 802.11 standard as an optional part of 802.11n and 802.11ac, in the High Throughput (HT) PHY specification.[15] LDPC is a mandatory part of 802.11ax (Wi-Fi 6).[16]
Some OFDM systems add an additional outer error correction that fixes the occasional errors (the «error floor») that get past the LDPC correction inner code even at low bit error rates.
For example:
The Reed-Solomon code with LDPC Coded Modulation (RS-LCM) uses a Reed-Solomon outer code.[17] The DVB-S2, the DVB-T2 and the DVB-C2 standards all use a BCH code outer code to mop up residual errors after LDPC decoding.[18]
5G NR uses polar code for the control channels and LDPC for the data channels.[19][20]
Although LDPC code has had its success in commercial hard disk drives, to fully exploit its error correction capability in SSDs demands unconventional fine-grained flash memory sensing, leading to an increased memory read latency. LDPC-in-SSD[21] is an effective approach to deploy LDPC in SSD with a very small latency increase, which turns LDPC in SSD into a reality. Since then, LDPC has been widely adopted in commercial SSDs in both customer-grades and enterprise-grades by major storage venders. Many TLC (and later) SSDs are using LDPC codes. A fast hard-decode (binary erasure) is first attempted, which can fall back into the slower but more powerful soft decoding.[22]
Operational use[edit]
LDPC codes functionally are defined by a sparse parity-check matrix. This sparse matrix is often randomly generated, subject to the sparsity constraints—LDPC code construction is discussed later. These codes were first designed by Robert Gallager in 1960.[7]
Below is a graph fragment of an example LDPC code using Forney’s factor graph notation. In this graph, n variable nodes in the top of the graph are connected to (n−k) constraint nodes in the bottom of the graph.
This is a popular way of graphically representing an (n, k) LDPC code. The bits of a valid message, when placed on the T’s at the top of the graph, satisfy the graphical constraints. Specifically, all lines connecting to a variable node (box with an ‘=’ sign) have the same value, and all values connecting to a factor node (box with a ‘+’ sign) must sum, modulo two, to zero (in other words, they must sum to an even number; or there must be an even number of odd values).
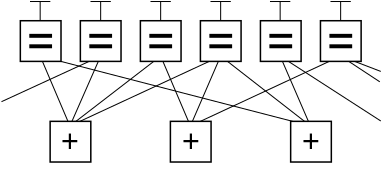
Ignoring any lines going out of the picture, there are eight possible six-bit strings corresponding to valid codewords: (i.e., 000000, 011001, 110010, 101011, 111100, 100101, 001110, 010111). This LDPC code fragment represents a three-bit message encoded as six bits. Redundancy is used, here, to increase the chance of recovering from channel errors. This is a (6, 3) linear code, with n = 6 and k = 3.
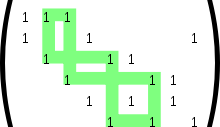
Again ignoring lines going out of the picture, the parity-check matrix representing this graph fragment is

In this matrix, each row represents one of the three parity-check constraints, while each column represents one of the six bits in the received codeword.
In this example, the eight codewords can be obtained by putting the parity-check matrix H into this form  through basic row operations in GF(2):
through basic row operations in GF(2):

Step 1: H.
Step 2: Row 1 is added to row 3.
Step 3: Row 2 and 3 are swapped.
Step 4: Row 1 is added to row 3.
From this, the generator matrix G can be obtained as  (noting that in the special case of this being a binary code
(noting that in the special case of this being a binary code  ), or specifically:
), or specifically:

Finally, by multiplying all eight possible 3-bit strings by G, all eight valid codewords are obtained. For example, the codeword for the bit-string ‘101’ is obtained by:
 ,
,

where  is symbol of mod 2 multiplication.
is symbol of mod 2 multiplication.
As a check, the row space of G is orthogonal to H such that 
The bit-string ‘101’ is found in as the first 3 bits of the codeword ‘101011’.
Example encoder[edit]

During the encoding of a frame, the input data bits (D) are repeated and distributed to a set of constituent encoders. The constituent encoders are typically accumulators and each accumulator is used to generate a parity symbol. A single copy of the original data (S0,K-1) is transmitted with the parity bits (P) to make up the code symbols. The S bits from each constituent encoder are discarded.
The parity bit may be used within another constituent code.
In an example using the DVB-S2 rate 2/3 code the encoded block size is 64800 symbols (N=64800) with 43200 data bits (K=43200) and 21600 parity bits (M=21600). Each constituent code (check node) encodes 16 data bits except for the first parity bit which encodes 8 data bits. The first 4680 data bits are repeated 13 times (used in 13 parity codes), while the remaining data bits are used in 3 parity codes (irregular LDPC code).
For comparison, classic turbo codes typically use two constituent codes configured in parallel, each of which encodes the entire input block (K) of data bits. These constituent encoders are recursive convolutional codes (RSC) of moderate depth (8 or 16 states) that are separated by a code interleaver which interleaves one copy of the frame.
The LDPC code, in contrast, uses many low depth constituent codes (accumulators) in parallel, each of which encode only a small portion of the input frame. The many constituent codes can be viewed as many low depth (2 state) «convolutional codes» that are connected via the repeat and distribute operations. The repeat and distribute operations perform the function of the interleaver in the turbo code.
The ability to more precisely manage the connections of the various constituent codes and the level of redundancy for each input bit give more flexibility in the design of LDPC codes, which can lead to better performance than turbo codes in some instances. Turbo codes still seem to perform better than LDPCs at low code rates, or at least the design of well performing low rate codes is easier for turbo codes.
As a practical matter, the hardware that forms the accumulators is reused during the encoding process. That is, once a first set of parity bits are generated and the parity bits stored, the same accumulator hardware is used to generate a next set of parity bits.
Decoding[edit]
As with other codes, the maximum likelihood decoding of an LDPC code on the binary symmetric channel is an NP-complete problem. Performing optimal decoding for a NP-complete code of any useful size is not practical.
However, sub-optimal techniques based on iterative belief propagation decoding give excellent results and can be practically implemented. The sub-optimal decoding techniques view each parity check that makes up the LDPC as an independent single parity check (SPC) code. Each SPC code is decoded separately using soft-in-soft-out (SISO) techniques such as SOVA, BCJR, MAP, and other derivates thereof. The soft decision information from each SISO decoding is cross-checked and updated with other redundant SPC decodings of the same information bit. Each SPC code is then decoded again using the updated soft decision information. This process is iterated until a valid codeword is achieved or decoding is exhausted. This type of decoding is often referred to as sum-product decoding.
The decoding of the SPC codes is often referred to as the «check node» processing, and the cross-checking of the variables is often referred to as the «variable-node» processing.
In a practical LDPC decoder implementation, sets of SPC codes are decoded in parallel to increase throughput.
In contrast, belief propagation on the binary erasure channel is particularly simple where it consists of iterative constraint satisfaction.
For example, consider that the valid codeword, 101011, from the example above, is transmitted across a binary erasure channel and received with the first and fourth bit erased to yield ?01?11. Since the transmitted message must have satisfied the code constraints, the message can be represented by writing the received message on the top of the factor graph.
In this example, the first bit cannot yet be recovered, because all of the constraints connected to it have more than one unknown bit. In order to proceed with decoding the message, constraints connecting to only one of the erased bits must be identified. In this example, only the second constraint suffices. Examining the second constraint, the fourth bit must have been zero, since only a zero in that position would satisfy the constraint.
This procedure is then iterated. The new value for the fourth bit can now be used in conjunction with the first constraint to recover the first bit as seen below. This means that the first bit must be a one to satisfy the leftmost constraint.

Thus, the message can be decoded iteratively. For other channel models, the messages passed between the variable nodes and check nodes are real numbers, which express probabilities and likelihoods of belief.
This result can be validated by multiplying the corrected codeword r by the parity-check matrix H:

Because the outcome z (the syndrome) of this operation is the three × one zero vector, the resulting codeword r is successfully validated.
After the decoding is completed, the original message bits ‘101’ can be extracted by looking at the first 3 bits of the codeword.
While illustrative, this erasure example does not show the use of soft-decision decoding or soft-decision message passing, which is used in virtually all commercial LDPC decoders.
Updating node information[edit]
In recent years[when?], there has also been a great deal of work spent studying the effects of alternative schedules for variable-node and constraint-node update. The original technique that was used for decoding LDPC codes was known as flooding. This type of update required that, before updating a variable node, all constraint nodes needed to be updated and vice versa. In later work by Vila Casado et al.,[23] alternative update techniques were studied, in which variable nodes are updated with the newest available check-node information.[citation needed]
The intuition behind these algorithms is that variable nodes whose values vary the most are the ones that need to be updated first. Highly reliable nodes, whose log-likelihood ratio (LLR) magnitude is large and does not change significantly from one update to the next, do not require updates with the same frequency as other nodes, whose sign and magnitude fluctuate more widely.[citation needed]
These scheduling algorithms show greater speed of convergence and lower error floors than those that use flooding. These lower error floors are achieved by the ability of the Informed Dynamic Scheduling (IDS)[23] algorithm to overcome trapping sets of near codewords.[24]
When nonflooding scheduling algorithms are used, an alternative definition of iteration is used. For an (n, k) LDPC code of rate k/n, a full iteration occurs when n variable and n − k constraint nodes have been updated, no matter the order in which they were updated.[citation needed]
Code construction[edit]
For large block sizes, LDPC codes are commonly constructed by first studying the behaviour of decoders. As the block size tends to infinity, LDPC decoders can be shown to have a noise threshold below which decoding is reliably achieved, and above which decoding is not achieved,[25] colloquially referred to as the cliff effect. This threshold can be optimised by finding the best proportion of arcs from check nodes and arcs from variable nodes. An approximate graphical approach to visualising this threshold is an EXIT chart.[citation needed]
The construction of a specific LDPC code after this optimization falls into two main types of techniques:[citation needed]
- Pseudorandom approaches
- Combinatorial approaches
Construction by a pseudo-random approach builds on theoretical results that, for large block size, a random construction gives good decoding performance.[10] In general, pseudorandom codes have complex encoders, but pseudorandom codes with the best decoders can have simple encoders.[26] Various constraints are often applied to help ensure that the desired properties expected at the theoretical limit of infinite block size occur at a finite block size.[citation needed]
Combinatorial approaches can be used to optimize the properties of small block-size LDPC codes or to create codes with simple encoders.[citation needed]
Some LDPC codes are based on Reed–Solomon codes, such as the RS-LDPC code used in the 10 Gigabit Ethernet standard.[27] Compared to randomly generated LDPC codes, structured LDPC codes—such as the LDPC code used in the DVB-S2 standard—can have simpler and therefore lower-cost hardware—in particular, codes constructed such that the H matrix is a circulant matrix.[28]
Yet another way of constructing LDPC codes is to use finite geometries. This method was proposed by Y. Kou et al. in 2001.[29]
LDPC codes vs. turbo codes[edit]
LDPC codes can be compared with other powerful coding schemes, e.g. turbo codes.[30] In one hand, BER performance of turbo codes is influenced by low codes limitations.[31] LDPC codes have no limitations of minimum distance,[32] that indirectly means that LDPC codes may be more efficient on relatively large code rates (e.g. 3/4, 5/6, 7/8) than turbo codes. However, LDPC codes are not the complete replacement: turbo codes are the best solution at the lower code rates (e.g. 1/6, 1/3, 1/2).[33][34]
See also[edit]
People[edit]
- Richard Hamming
- Claude Shannon
- David J. C. MacKay
- Irving S. Reed
- Michael Luby
Theory[edit]
- Graph theory
- Hamming code
- Sparse graph code
- Expander code
Applications[edit]
- G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable)
- 802.3an or 10GBASE-T (10 gigabit/s Ethernet over twisted pair)
- CMMB (China Multimedia Mobile Broadcasting)
- DVB-S2 / DVB-T2 / DVB-C2 (digital video broadcasting, 2nd generation)
- DMB-T/H (digital video broadcasting)[35]
- WiMAX (IEEE 802.16e standard for microwave communications)
- IEEE 802.11n-2009 (Wi-Fi standard)
- DOCSIS 3.1
- ATSC 3.0 (Next generation North America digital terrestrial broadcasting)
- 3GPP (5G-NR data channel)
Other capacity-approaching codes[edit]
- Turbo codes
- Serial concatenated convolutional codes
- Online codes
- Fountain codes
- LT codes
- Raptor codes
- Repeat-accumulate codes (a class of simple turbo codes)
- Tornado codes (LDPC codes designed for erasure decoding)
- Polar codes
References[edit]
- ^ David J.C. MacKay (2003) Information theory, Inference and Learning Algorithms, CUP, ISBN 0-521-64298-1, (also available online)
- ^ Todd K. Moon (2005) Error Correction Coding, Mathematical Methods and Algorithms. Wiley, ISBN 0-471-64800-0 (Includes code)
- ^ Amin Shokrollahi (2003) LDPC Codes: An Introduction
- ^ US 5446747
- ^ NewScientist, Communication speed nears terminal velocity, by Dana Mackenzie, 9 July 2005
- ^ Larry Hardesty (January 21, 2010). «Explained: Gallager codes». MIT News. Retrieved August 7, 2013.
- ^ a b [1] R. G. Gallager, «Low density parity check codes,» IRE Trans. Inf. Theory, vol. IT-8, no. 1, pp. 21- 28, Jan. 1962.
- ^ [2] J. Moshieff, N. Resch, N. Ron-Zewi, S. Silas, M. Wootters, «Low-density parity-check codes achieve list-decoding capacity,» SIAM Journal on Computing, FOCS20-38-FOCS20-73.
- ^ Robert G. Gallager (1963). Low Density Parity Check Codes (PDF). Monograph, M.I.T. Press. Retrieved August 7, 2013.
- ^ a b David J.C. MacKay and Radford M. Neal, «Near Shannon Limit Performance of Low Density Parity Check Codes,» Electronics Letters, July 1996
- ^ Telemetry Data Decoding, Design Handbook
- ^ Presentation by Hughes Systems Archived 2006-10-08 at the Wayback Machine
- ^ HomePNA Blog: G.hn, a PHY For All Seasons
- ^ IEEE Communications Magazine paper on G.hn Archived 2009-12-13 at the Wayback Machine
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009», IEEE, October 29, 2009, accessed March 21, 2011.
- ^ «IEEE SA — IEEE 802.11ax-2021». IEEE Standards Association. Retrieved May 22, 2022.
- ^
Chih-Yuan Yang, Mong-Kai Ku.
http://123seminarsonly.com/Seminar-Reports/029/26540350-Ldpc-Coded-Ofdm-Modulation.pdf
«LDPC coded OFDM modulation for high spectral efficiency transmission» - ^
Nick Wells.
«DVB-T2 in relation to the DVB-x2 Family of Standards» Archived 2013-05-26 at the Wayback Machine - ^ «5G Channel Coding» (PDF). Archived from the original (PDF) on December 6, 2018. Retrieved January 6, 2019.
- ^ Maunder, Robert (September 2016). «A Vision for 5G Channel Coding» (PDF). Archived from the original (PDF) on December 6, 2018. Retrieved January 6, 2019.
- ^ Kai Zhao, Wenzhe Zhao, Hongbin Sun, Tong Zhang, Xiaodong Zhang, and Nanning Zheng (2013). » LDPC-in-SSD: Making Advanced Error Correction Codes Work Effectively in Solid State Drives» (PDF). FAST’ 13. pp. 243–256.
{{cite conference}}: CS1 maint: multiple names: authors list (link) - ^ «Soft-Decoding in LDPC based SSD Controllers». EE Times. 2015.
- ^ a b A.I. Vila Casado, M. Griot, and R.Wesel, «Informed dynamic scheduling for belief propagation decoding of LDPC codes,» Proc. IEEE Int. Conf. on Comm. (ICC), June 2007.
- ^ T. Richardson, «Error floors of LDPC codes,» in Proc. 41st Allerton Conf. Comm., Control, and Comput., Monticello, IL, 2003.
- ^ Thomas J. Richardson and M. Amin Shokrollahi and Rüdiger L. Urbanke, «Design of Capacity-Approaching Irregular Low-Density Parity-Check Codes,» IEEE Transactions on Information Theory, 47(2), February 2001
- ^ Thomas J. Richardson and Rüdiger L. Urbanke, «Efficient Encoding of Low-Density Parity-Check Codes,» IEEE Transactions on Information Theory, 47(2), February 2001
- ^
Ahmad Darabiha, Anthony Chan Carusone, Frank R. Kschischang.
«Power Reduction Techniques for LDPC Decoders» - ^
Zhengya Zhang, Venkat Anantharam, Martin J. Wainwright, and Borivoje Nikolic.
«An Efficient 10GBASE-T Ethernet LDPC Decoder Design With Low Error Floors». - ^ Y. Kou, S. Lin and M. Fossorier, «Low-Density Parity-Check Codes
Based on Finite Geometries: A Rediscovery and New Results,» IEEE
Transactions on Information Theory, vol. 47, no. 7, November 2001, pp. 2711-
2736. - ^ Tahir, B., Schwarz, S., & Rupp, M. (2017, May). BER comparison between Convolutional, Turbo, LDPC, and Polar codes. In 2017 24th International Conference on Telecommunications (ICT) (pp. 1-7). IEEE.
- ^ Moon Todd, K. Error correction coding: mathematical methods and algorithms. 2005 by John Wiley & Sons. ISBN 0-471-64800-0. — p.614
- ^ Moon Todd, K. Error correction coding: mathematical methods and algorithms. 2005 by John Wiley & Sons. ISBN 0-471-64800-0. — p.653
- ^ Andrews, Kenneth S., et al. «The development of turbo and LDPC codes for deep-space applications.» Proceedings of the IEEE 95.11 (2007): 2142-2156.
- ^ Hassan, A.E.S., Dessouky, M., Abou Elazm, A. and Shokair, M., 2012. Evaluation of complexity versus performance for turbo code and LDPC under different code rates. Proc. SPACOMM, pp.93-98.
- ^ «IEEE Spectrum: Does China Have the Best Digital Television Standard on the Planet?». spectrum.ieee.org. Archived from the original on December 12, 2009.
External links[edit]
- Introducing Low-Density Parity-Check Codes (by Sarah J Johnson, 2010)
- LDPC Codes – a brief Tutorial (by Bernhard Leiner, 2005)
- LDPC Codes (TU Wien) Archived February 28, 2019, at the Wayback Machine
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, discusses LDPC codes in Chapter 47.
- Iterative Decoding of Low-Density Parity Check Codes (by Venkatesan Guruswami, 2006)
- LDPC Codes: An Introduction (by Amin Shokrollahi, 2003)
- Belief-Propagation Decoding of LDPC Codes (by Amir Bennatan, Princeton University)
- Turbo and LDPC Codes: Implementation, Simulation, and Standardization (West Virginia University)
- Information theory and coding (Marko Hennhöfer, 2011, TU Ilmenau) — discusses LDPC codes at pages 74–78.
- LDPC codes and performance results
- DVB-S.2 Link, Including LDPC Coding (MatLab)
- Source code for encoding, decoding, and simulating LDPC codes is available from a variety of locations:
- Binary LDPC codes in C
- Binary LDPC codes for Python (core algorithm in C)
- LDPC encoder and LDPC decoder in MATLAB
- A Fast Forward Error Correction Toolbox (AFF3CT) in C++11 for fast LDPC simulations
In information theory, a low-density parity-check (LDPC) code is a linear error correcting code, a method of transmitting a message over a noisy transmission channel.[1][2] An LDPC code is constructed using a sparse Tanner graph (subclass of the bipartite graph).[3] LDPC codes are capacity-approaching codes, which means that practical constructions exist that allow the noise threshold to be set very close to the theoretical maximum (the Shannon limit) for a symmetric memoryless channel. The noise threshold defines an upper bound for the channel noise, up to which the probability of lost information can be made as small as desired. Using iterative belief propagation techniques, LDPC codes can be decoded in time linear to their block length.
LDPC codes are finding increasing use in applications requiring reliable and highly efficient information transfer over bandwidth-constrained or return-channel-constrained links in the presence of corrupting noise. Implementation of LDPC codes has lagged behind that of other codes, notably turbo codes. The fundamental patent for turbo codes expired on August 29, 2013.[4][5]
LDPC codes are also known as Gallager codes, in honor of Robert G. Gallager, who developed the LDPC concept in his doctoral dissertation at the Massachusetts Institute of Technology in 1960.[6][7] LDPC codes have also been shown to have ideal combinatorial properties. In his dissertation, Gallager showed that LDPC codes achieve the Gilbert–Varshamov bound for linear codes over binary fields with high probability. In 2020 it was shown that Gallager’s LDPC codes achieve list decoding capacity and also achieve the Gilbert–Varshamov bound for linear codes over general fields. [8]
History[edit]
Impractical to implement when first developed by Gallager in 1963,[9] LDPC codes were forgotten until his work was rediscovered in 1996.[10] Turbo codes, another class of capacity-approaching codes discovered in 1993, became the coding scheme of choice in the late 1990s, used for applications such as the Deep Space Network and satellite communications. However, the advances in low-density parity-check codes have seen them surpass turbo codes in terms of error floor and performance in the higher code rate range, leaving turbo codes better suited for the lower code rates only.[11]
Applications[edit]
In 2003, an irregular repeat accumulate (IRA) style LDPC code beat six turbo codes to become the error-correcting code in the new DVB-S2 standard for digital television.[12] The DVB-S2 selection committee made decoder complexity estimates for the turbo code proposals using a much less efficient serial decoder architecture rather than a parallel decoder architecture. This forced the turbo code proposals to use frame sizes on the order of one half the frame size of the LDPC proposals.[citation needed]
In 2008, LDPC beat convolutional turbo codes as the forward error correction (FEC) system for the ITU-T G.hn standard.[13] G.hn chose LDPC codes over turbo codes because of their lower decoding complexity (especially when operating at data rates close to 1.0 Gbit/s) and because the proposed turbo codes exhibited a significant error floor at the desired range of operation.[14]
LDPC codes are also used for 10GBASE-T Ethernet, which sends data at 10 gigabits per second over twisted-pair cables. As of 2009, LDPC codes are also part of the Wi-Fi 802.11 standard as an optional part of 802.11n and 802.11ac, in the High Throughput (HT) PHY specification.[15] LDPC is a mandatory part of 802.11ax (Wi-Fi 6).[16]
Some OFDM systems add an additional outer error correction that fixes the occasional errors (the «error floor») that get past the LDPC correction inner code even at low bit error rates.
For example:
The Reed-Solomon code with LDPC Coded Modulation (RS-LCM) uses a Reed-Solomon outer code.[17] The DVB-S2, the DVB-T2 and the DVB-C2 standards all use a BCH code outer code to mop up residual errors after LDPC decoding.[18]
5G NR uses polar code for the control channels and LDPC for the data channels.[19][20]
Although LDPC code has had its success in commercial hard disk drives, to fully exploit its error correction capability in SSDs demands unconventional fine-grained flash memory sensing, leading to an increased memory read latency. LDPC-in-SSD[21] is an effective approach to deploy LDPC in SSD with a very small latency increase, which turns LDPC in SSD into a reality. Since then, LDPC has been widely adopted in commercial SSDs in both customer-grades and enterprise-grades by major storage venders. Many TLC (and later) SSDs are using LDPC codes. A fast hard-decode (binary erasure) is first attempted, which can fall back into the slower but more powerful soft decoding.[22]
Operational use[edit]
LDPC codes functionally are defined by a sparse parity-check matrix. This sparse matrix is often randomly generated, subject to the sparsity constraints—LDPC code construction is discussed later. These codes were first designed by Robert Gallager in 1960.[7]
Below is a graph fragment of an example LDPC code using Forney’s factor graph notation. In this graph, n variable nodes in the top of the graph are connected to (n−k) constraint nodes in the bottom of the graph.
This is a popular way of graphically representing an (n, k) LDPC code. The bits of a valid message, when placed on the T’s at the top of the graph, satisfy the graphical constraints. Specifically, all lines connecting to a variable node (box with an ‘=’ sign) have the same value, and all values connecting to a factor node (box with a ‘+’ sign) must sum, modulo two, to zero (in other words, they must sum to an even number; or there must be an even number of odd values).
Ignoring any lines going out of the picture, there are eight possible six-bit strings corresponding to valid codewords: (i.e., 000000, 011001, 110010, 101011, 111100, 100101, 001110, 010111). This LDPC code fragment represents a three-bit message encoded as six bits. Redundancy is used, here, to increase the chance of recovering from channel errors. This is a (6, 3) linear code, with n = 6 and k = 3.
Again ignoring lines going out of the picture, the parity-check matrix representing this graph fragment is
In this matrix, each row represents one of the three parity-check constraints, while each column represents one of the six bits in the received codeword.
In this example, the eight codewords can be obtained by putting the parity-check matrix H into this form through basic row operations in GF(2):
Step 1: H.
Step 2: Row 1 is added to row 3.
Step 3: Row 2 and 3 are swapped.
Step 4: Row 1 is added to row 3.
From this, the generator matrix G can be obtained as (noting that in the special case of this being a binary code ), or specifically:
Finally, by multiplying all eight possible 3-bit strings by G, all eight valid codewords are obtained. For example, the codeword for the bit-string ‘101’ is obtained by:
- ,
where is symbol of mod 2 multiplication.
As a check, the row space of G is orthogonal to H such that
The bit-string ‘101’ is found in as the first 3 bits of the codeword ‘101011’.
Example encoder[edit]
During the encoding of a frame, the input data bits (D) are repeated and distributed to a set of constituent encoders. The constituent encoders are typically accumulators and each accumulator is used to generate a parity symbol. A single copy of the original data (S0,K-1) is transmitted with the parity bits (P) to make up the code symbols. The S bits from each constituent encoder are discarded.
The parity bit may be used within another constituent code.
In an example using the DVB-S2 rate 2/3 code the encoded block size is 64800 symbols (N=64800) with 43200 data bits (K=43200) and 21600 parity bits (M=21600). Each constituent code (check node) encodes 16 data bits except for the first parity bit which encodes 8 data bits. The first 4680 data bits are repeated 13 times (used in 13 parity codes), while the remaining data bits are used in 3 parity codes (irregular LDPC code).
For comparison, classic turbo codes typically use two constituent codes configured in parallel, each of which encodes the entire input block (K) of data bits. These constituent encoders are recursive convolutional codes (RSC) of moderate depth (8 or 16 states) that are separated by a code interleaver which interleaves one copy of the frame.
The LDPC code, in contrast, uses many low depth constituent codes (accumulators) in parallel, each of which encode only a small portion of the input frame. The many constituent codes can be viewed as many low depth (2 state) «convolutional codes» that are connected via the repeat and distribute operations. The repeat and distribute operations perform the function of the interleaver in the turbo code.
The ability to more precisely manage the connections of the various constituent codes and the level of redundancy for each input bit give more flexibility in the design of LDPC codes, which can lead to better performance than turbo codes in some instances. Turbo codes still seem to perform better than LDPCs at low code rates, or at least the design of well performing low rate codes is easier for turbo codes.
As a practical matter, the hardware that forms the accumulators is reused during the encoding process. That is, once a first set of parity bits are generated and the parity bits stored, the same accumulator hardware is used to generate a next set of parity bits.
Decoding[edit]
As with other codes, the maximum likelihood decoding of an LDPC code on the binary symmetric channel is an NP-complete problem. Performing optimal decoding for a NP-complete code of any useful size is not practical.
However, sub-optimal techniques based on iterative belief propagation decoding give excellent results and can be practically implemented. The sub-optimal decoding techniques view each parity check that makes up the LDPC as an independent single parity check (SPC) code. Each SPC code is decoded separately using soft-in-soft-out (SISO) techniques such as SOVA, BCJR, MAP, and other derivates thereof. The soft decision information from each SISO decoding is cross-checked and updated with other redundant SPC decodings of the same information bit. Each SPC code is then decoded again using the updated soft decision information. This process is iterated until a valid codeword is achieved or decoding is exhausted. This type of decoding is often referred to as sum-product decoding.
The decoding of the SPC codes is often referred to as the «check node» processing, and the cross-checking of the variables is often referred to as the «variable-node» processing.
In a practical LDPC decoder implementation, sets of SPC codes are decoded in parallel to increase throughput.
In contrast, belief propagation on the binary erasure channel is particularly simple where it consists of iterative constraint satisfaction.
For example, consider that the valid codeword, 101011, from the example above, is transmitted across a binary erasure channel and received with the first and fourth bit erased to yield ?01?11. Since the transmitted message must have satisfied the code constraints, the message can be represented by writing the received message on the top of the factor graph.
In this example, the first bit cannot yet be recovered, because all of the constraints connected to it have more than one unknown bit. In order to proceed with decoding the message, constraints connecting to only one of the erased bits must be identified. In this example, only the second constraint suffices. Examining the second constraint, the fourth bit must have been zero, since only a zero in that position would satisfy the constraint.
This procedure is then iterated. The new value for the fourth bit can now be used in conjunction with the first constraint to recover the first bit as seen below. This means that the first bit must be a one to satisfy the leftmost constraint.
Thus, the message can be decoded iteratively. For other channel models, the messages passed between the variable nodes and check nodes are real numbers, which express probabilities and likelihoods of belief.
This result can be validated by multiplying the corrected codeword r by the parity-check matrix H:
Because the outcome z (the syndrome) of this operation is the three × one zero vector, the resulting codeword r is successfully validated.
After the decoding is completed, the original message bits ‘101’ can be extracted by looking at the first 3 bits of the codeword.
While illustrative, this erasure example does not show the use of soft-decision decoding or soft-decision message passing, which is used in virtually all commercial LDPC decoders.
Updating node information[edit]
In recent years[when?], there has also been a great deal of work spent studying the effects of alternative schedules for variable-node and constraint-node update. The original technique that was used for decoding LDPC codes was known as flooding. This type of update required that, before updating a variable node, all constraint nodes needed to be updated and vice versa. In later work by Vila Casado et al.,[23] alternative update techniques were studied, in which variable nodes are updated with the newest available check-node information.[citation needed]
The intuition behind these algorithms is that variable nodes whose values vary the most are the ones that need to be updated first. Highly reliable nodes, whose log-likelihood ratio (LLR) magnitude is large and does not change significantly from one update to the next, do not require updates with the same frequency as other nodes, whose sign and magnitude fluctuate more widely.[citation needed]
These scheduling algorithms show greater speed of convergence and lower error floors than those that use flooding. These lower error floors are achieved by the ability of the Informed Dynamic Scheduling (IDS)[23] algorithm to overcome trapping sets of near codewords.[24]
When nonflooding scheduling algorithms are used, an alternative definition of iteration is used. For an (n, k) LDPC code of rate k/n, a full iteration occurs when n variable and n − k constraint nodes have been updated, no matter the order in which they were updated.[citation needed]
Code construction[edit]
For large block sizes, LDPC codes are commonly constructed by first studying the behaviour of decoders. As the block size tends to infinity, LDPC decoders can be shown to have a noise threshold below which decoding is reliably achieved, and above which decoding is not achieved,[25] colloquially referred to as the cliff effect. This threshold can be optimised by finding the best proportion of arcs from check nodes and arcs from variable nodes. An approximate graphical approach to visualising this threshold is an EXIT chart.[citation needed]
The construction of a specific LDPC code after this optimization falls into two main types of techniques:[citation needed]
- Pseudorandom approaches
- Combinatorial approaches
Construction by a pseudo-random approach builds on theoretical results that, for large block size, a random construction gives good decoding performance.[10] In general, pseudorandom codes have complex encoders, but pseudorandom codes with the best decoders can have simple encoders.[26] Various constraints are often applied to help ensure that the desired properties expected at the theoretical limit of infinite block size occur at a finite block size.[citation needed]
Combinatorial approaches can be used to optimize the properties of small block-size LDPC codes or to create codes with simple encoders.[citation needed]
Some LDPC codes are based on Reed–Solomon codes, such as the RS-LDPC code used in the 10 Gigabit Ethernet standard.[27] Compared to randomly generated LDPC codes, structured LDPC codes—such as the LDPC code used in the DVB-S2 standard—can have simpler and therefore lower-cost hardware—in particular, codes constructed such that the H matrix is a circulant matrix.[28]
Yet another way of constructing LDPC codes is to use finite geometries. This method was proposed by Y. Kou et al. in 2001.[29]
LDPC codes vs. turbo codes[edit]
LDPC codes can be compared with other powerful coding schemes, e.g. turbo codes.[30] In one hand, BER performance of turbo codes is influenced by low codes limitations.[31] LDPC codes have no limitations of minimum distance,[32] that indirectly means that LDPC codes may be more efficient on relatively large code rates (e.g. 3/4, 5/6, 7/8) than turbo codes. However, LDPC codes are not the complete replacement: turbo codes are the best solution at the lower code rates (e.g. 1/6, 1/3, 1/2).[33][34]
See also[edit]
People[edit]
- Richard Hamming
- Claude Shannon
- David J. C. MacKay
- Irving S. Reed
- Michael Luby
Theory[edit]
- Graph theory
- Hamming code
- Sparse graph code
- Expander code
Applications[edit]
- G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable)
- 802.3an or 10GBASE-T (10 gigabit/s Ethernet over twisted pair)
- CMMB (China Multimedia Mobile Broadcasting)
- DVB-S2 / DVB-T2 / DVB-C2 (digital video broadcasting, 2nd generation)
- DMB-T/H (digital video broadcasting)[35]
- WiMAX (IEEE 802.16e standard for microwave communications)
- IEEE 802.11n-2009 (Wi-Fi standard)
- DOCSIS 3.1
- ATSC 3.0 (Next generation North America digital terrestrial broadcasting)
- 3GPP (5G-NR data channel)
Other capacity-approaching codes[edit]
- Turbo codes
- Serial concatenated convolutional codes
- Online codes
- Fountain codes
- LT codes
- Raptor codes
- Repeat-accumulate codes (a class of simple turbo codes)
- Tornado codes (LDPC codes designed for erasure decoding)
- Polar codes
References[edit]
- ^ David J.C. MacKay (2003) Information theory, Inference and Learning Algorithms, CUP, ISBN 0-521-64298-1, (also available online)
- ^ Todd K. Moon (2005) Error Correction Coding, Mathematical Methods and Algorithms. Wiley, ISBN 0-471-64800-0 (Includes code)
- ^ Amin Shokrollahi (2003) LDPC Codes: An Introduction
- ^ US 5446747
- ^ NewScientist, Communication speed nears terminal velocity, by Dana Mackenzie, 9 July 2005
- ^ Larry Hardesty (January 21, 2010). «Explained: Gallager codes». MIT News. Retrieved August 7, 2013.
- ^ a b [1] R. G. Gallager, «Low density parity check codes,» IRE Trans. Inf. Theory, vol. IT-8, no. 1, pp. 21- 28, Jan. 1962.
- ^ [2] J. Moshieff, N. Resch, N. Ron-Zewi, S. Silas, M. Wootters, «Low-density parity-check codes achieve list-decoding capacity,» SIAM Journal on Computing, FOCS20-38-FOCS20-73.
- ^ Robert G. Gallager (1963). Low Density Parity Check Codes (PDF). Monograph, M.I.T. Press. Retrieved August 7, 2013.
- ^ a b David J.C. MacKay and Radford M. Neal, «Near Shannon Limit Performance of Low Density Parity Check Codes,» Electronics Letters, July 1996
- ^ Telemetry Data Decoding, Design Handbook
- ^ Presentation by Hughes Systems Archived 2006-10-08 at the Wayback Machine
- ^ HomePNA Blog: G.hn, a PHY For All Seasons
- ^ IEEE Communications Magazine paper on G.hn Archived 2009-12-13 at the Wayback Machine
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009», IEEE, October 29, 2009, accessed March 21, 2011.
- ^ «IEEE SA — IEEE 802.11ax-2021». IEEE Standards Association. Retrieved May 22, 2022.
- ^
Chih-Yuan Yang, Mong-Kai Ku.
http://123seminarsonly.com/Seminar-Reports/029/26540350-Ldpc-Coded-Ofdm-Modulation.pdf
«LDPC coded OFDM modulation for high spectral efficiency transmission» - ^
Nick Wells.
«DVB-T2 in relation to the DVB-x2 Family of Standards» Archived 2013-05-26 at the Wayback Machine - ^ «5G Channel Coding» (PDF). Archived from the original (PDF) on December 6, 2018. Retrieved January 6, 2019.
- ^ Maunder, Robert (September 2016). «A Vision for 5G Channel Coding» (PDF). Archived from the original (PDF) on December 6, 2018. Retrieved January 6, 2019.
- ^ Kai Zhao, Wenzhe Zhao, Hongbin Sun, Tong Zhang, Xiaodong Zhang, and Nanning Zheng (2013). » LDPC-in-SSD: Making Advanced Error Correction Codes Work Effectively in Solid State Drives» (PDF). FAST’ 13. pp. 243–256.
{{cite conference}}: CS1 maint: multiple names: authors list (link) - ^ «Soft-Decoding in LDPC based SSD Controllers». EE Times. 2015.
- ^ a b A.I. Vila Casado, M. Griot, and R.Wesel, «Informed dynamic scheduling for belief propagation decoding of LDPC codes,» Proc. IEEE Int. Conf. on Comm. (ICC), June 2007.
- ^ T. Richardson, «Error floors of LDPC codes,» in Proc. 41st Allerton Conf. Comm., Control, and Comput., Monticello, IL, 2003.
- ^ Thomas J. Richardson and M. Amin Shokrollahi and Rüdiger L. Urbanke, «Design of Capacity-Approaching Irregular Low-Density Parity-Check Codes,» IEEE Transactions on Information Theory, 47(2), February 2001
- ^ Thomas J. Richardson and Rüdiger L. Urbanke, «Efficient Encoding of Low-Density Parity-Check Codes,» IEEE Transactions on Information Theory, 47(2), February 2001
- ^
Ahmad Darabiha, Anthony Chan Carusone, Frank R. Kschischang.
«Power Reduction Techniques for LDPC Decoders» - ^
Zhengya Zhang, Venkat Anantharam, Martin J. Wainwright, and Borivoje Nikolic.
«An Efficient 10GBASE-T Ethernet LDPC Decoder Design With Low Error Floors». - ^ Y. Kou, S. Lin and M. Fossorier, «Low-Density Parity-Check Codes
Based on Finite Geometries: A Rediscovery and New Results,» IEEE
Transactions on Information Theory, vol. 47, no. 7, November 2001, pp. 2711-
2736. - ^ Tahir, B., Schwarz, S., & Rupp, M. (2017, May). BER comparison between Convolutional, Turbo, LDPC, and Polar codes. In 2017 24th International Conference on Telecommunications (ICT) (pp. 1-7). IEEE.
- ^ Moon Todd, K. Error correction coding: mathematical methods and algorithms. 2005 by John Wiley & Sons. ISBN 0-471-64800-0. — p.614
- ^ Moon Todd, K. Error correction coding: mathematical methods and algorithms. 2005 by John Wiley & Sons. ISBN 0-471-64800-0. — p.653
- ^ Andrews, Kenneth S., et al. «The development of turbo and LDPC codes for deep-space applications.» Proceedings of the IEEE 95.11 (2007): 2142-2156.
- ^ Hassan, A.E.S., Dessouky, M., Abou Elazm, A. and Shokair, M., 2012. Evaluation of complexity versus performance for turbo code and LDPC under different code rates. Proc. SPACOMM, pp.93-98.
- ^ «IEEE Spectrum: Does China Have the Best Digital Television Standard on the Planet?». spectrum.ieee.org. Archived from the original on December 12, 2009.
External links[edit]
- Introducing Low-Density Parity-Check Codes (by Sarah J Johnson, 2010)
- LDPC Codes – a brief Tutorial (by Bernhard Leiner, 2005)
- LDPC Codes (TU Wien) Archived February 28, 2019, at the Wayback Machine
- The on-line textbook: Information Theory, Inference, and Learning Algorithms, by David J.C. MacKay, discusses LDPC codes in Chapter 47.
- Iterative Decoding of Low-Density Parity Check Codes (by Venkatesan Guruswami, 2006)
- LDPC Codes: An Introduction (by Amin Shokrollahi, 2003)
- Belief-Propagation Decoding of LDPC Codes (by Amir Bennatan, Princeton University)
- Turbo and LDPC Codes: Implementation, Simulation, and Standardization (West Virginia University)
- Information theory and coding (Marko Hennhöfer, 2011, TU Ilmenau) — discusses LDPC codes at pages 74–78.
- LDPC codes and performance results
- DVB-S.2 Link, Including LDPC Coding (MatLab)
- Source code for encoding, decoding, and simulating LDPC codes is available from a variety of locations:
- Binary LDPC codes in C
- Binary LDPC codes for Python (core algorithm in C)
- LDPC encoder and LDPC decoder in MATLAB
- A Fast Forward Error Correction Toolbox (AFF3CT) in C++11 for fast LDPC simulations
Число обнаруживаемых или исправляемых ошибок.
При применении двоичных кодов учитывают
только дискретные искажения, при которых
единица переходит в нуль (1 → 0) или нуль
переходит в единицу (0 → 1). Переход 1 →
0 или 0 → 1 только в одном элементе кодовой
комбинации называют единичной ошибкой
(единичным искажением). В общем случае
под кратностью ошибки подразумевают
число позиций кодовой комбинации, на
которых под действием помехи одни
символы оказались заменёнными на другие.
Возможны двукратные (t= 2) и многократные (t> 2) искажения элементов в кодовой
комбинации в пределах 0 <t<n.
Минимальное кодовое расстояние является
основным параметром, характеризующим
корректирующие способности данного
кода. Если код используется только для
обнаружения ошибок кратностью t0,
то необходимо и достаточно, чтобы
минимальное кодовое расстояние было
равно
dmin
> t0
+ 1. (13.10)
В этом случае никакая комбинация из t0ошибок не может перевести одну разрешённую
кодовую комбинацию в другую разрешённую.
Таким образом, условие обнаружения всех
ошибок кратностьюt0можно записать в виде:
t0≤ dmin — 1. (13.11)
Чтобы можно было исправить все ошибки
кратностью tии менее, необходимо иметь минимальное
расстояние, удовлетворяющее условию:
![]() . (13.12)
. (13.12)
В этом случае любая кодовая комбинация
с числом ошибок tиотличается от каждой разрешённой
комбинации не менее чем вtи+ 1 позициях. Если условие (13.12) не выполнено,
возможен случай, когда ошибки кратностиtисказят переданную
комбинацию так, что она станет ближе к
одной из разрешённых комбинаций, чем к
переданной или даже перейдёт в другую
разрешённую комбинацию. В соответствии
с этим, условие исправления всех ошибок
кратностью не болееtиможно записать в виде:
tи
≤(dmin
— 1) / 2 . (13.13)
Из (13.10) и (13.12) следует, что если код
исправляет все ошибки кратностью tи,
то число ошибок, которые он может
обнаружить, равноt0= 2∙tи. Следует
отметить, что соотношения (13.10) и (13.12)
устанавливают лишь гарантированное
минимальное число обнаруживаемых или
исправляемых ошибок при заданномdminи не ограничивают возможность обнаружения
ошибок большей кратности. Например,
простейший код с проверкой на чётность
сdmin= 2 позволяет обнаруживать не только
одиночные ошибки, но и любое нечётное
число ошибок в пределахt0<n.
Корректирующие возможности кодов.
Вопрос о минимально необходимой
избыточности, при которой код обладает
нужными корректирующими свойствами,
является одним из важнейших в теории
кодирования. Этот вопрос до сих пор не
получил полного решения. В настоящее
время получен лишь ряд верхних и нижних
оценок (границ), которые устанавливают
связь между максимально возможным
минимальным расстоянием корректирующего
кода и его избыточностью.
Так, граница Плоткинадаёт верхнюю
границу кодового расстоянияdminпри заданном числе разрядовnв
кодовой комбинации и числе информационных
разрядовm, и для
двоичных кодов:
![]() (13.14)
(13.14)
или
![]() при
при![]() . (13.15)
. (13.15)
Верхняя граница Хеммингаустанавливает
максимально возможное число разрешённых
кодовых комбинаций (2m)
любого помехоустойчивого кода при
заданных значенияхnиdmin:
 , (13.16)
, (13.16)
где
![]() —
—
число сочетаний изnэлементов поiэлементам.
Отсюда можно получить выражение для
оценки числа проверочных символов:
 . (13.17)
. (13.17)
Для значений (dmin/n)
≤ 0,3 разница между границей Хемминга и
границей Плоткина сравнительно невелика.
Граница Варшамова-Гильбертадля
больших значенийnопределяет нижнюю
границу для числа проверочных разрядов,
необходимого для обеспечения заданного
кодового расстояния:
 . (13.18)
. (13.18)
Отметим, что для некоторых частных
случаев Хемминг получил простые
соотношения, позволяющие определить
необходимое число проверочных символов:
![]() дляdmin= 3,
дляdmin= 3,
![]() дляdmin= 4.
дляdmin= 4.
Блочные коды с dmin= 3 и 4 в литературе обычно называют кодами
Хемминга.
Все приведенные выше оценки дают
представление о верхней границе числаdminпри фиксированных значенияхnиmили оценку снизу числа проверочных
символовkпри заданныхmиdmin.
Существующие методы построения избыточных
кодов решают в основном задачу нахождения
такого алгоритма кодирования и
декодирования, который позволял бы
наиболее просто построить и реализовать
код с заданным значением dmin.
Поэтому различные корректирующие коды
при одинаковыхdminсравниваются по сложности кодирующего
и декодирующего устройств. Этот критерий
является в ряде случаев определяющим
при выборе того или иного кода.
Соседние файлы в папке ЛБ_3
- #
- #
14.04.2015937 б72KodHemmig.m
- #
14.04.20150 б64ЛБ_3.exe
Код с малой плотностью проверок на чётность (LDPC-код от англ. Low-density parity-check code, LDPC-code, низкоплотностный код) — используемый в передаче информации код, частный случай блокового линейного кода с проверкой чётности. Особенностью является малая плотность значимых элементов проверочной матрицы, за счёт чего достигается относительная простота реализации средств кодирования.
Также называют кодом Галлагера, по имени автора первой работы на тему LDPC-кодов.
Предпосылки
В 1948 году Шеннон опубликовал свою работу по теории передачи информации. Одним из ключевых результатов работы считается теорема о передачи информации для канала с шумами, которая говорит о возможности свести вероятность ошибки передачи по каналу к минимуму при выборе достаточного большой длины ключевого слова — единицы информации передаваемой по каналу[1].

![]()
Упрощённая схема передачи информации по каналу с шумами.
При передаче информации её поток разбивается на блоки определённой (чаще всего) длины, которые преобразуются кодером (кодируются) в блоки, называемыми ключевыми словами. Ключевые слова передаются по каналу, возможно с искажениями. На принимающей стороне декодер преобразует ключевые слова в поток информации, исправляя (по возможности) ошибки передачи.
Теорема Шеннона утверждает, что при определённых условиях вероятность ошибки декодирования (то есть невозможность декодером исправить ошибку передачи) можно уменьшить, выбрав большую длину ключевого слова. Однако, данная теорема (и работа вообще) не показывает, как можно выбрать большую длину, а точнее как эффективно организовать процесс кодирования и декодирования информации с большой длиной ключевых слов. Если предположить, что в кодере и декодере есть некие таблицы соответствия между входным блоком информации и соответствующим кодовым словом, то такие таблицы будут занимать очень много места. Для двоичного симметричного канала без памяти (если говорить упрощённо, то на вход кодера поступает поток из нулей и единиц) количество различных блоков составляет 2n, где n — количество бит (нулей или единиц) которые будут преобразовываться в одно кодовое слово. Для 8 бит это 256 блоков информации, каждый из которых будет содержать в себе соответствующее кодовое слово. Причём кодовое слово обычно большей длины, так как содержит в себе дополнительные биты для защиты от ошибок передачи данных. Поэтому одним из способов кодирования является использование проверочной матрицы, которые позволяют за одно математическое действие (умножение строки на матрицу) выполнить декодирование кодового слова. Аналогичным образом каждой проверочной матрице соответствует порождающая матрица, аналогичным способом одной операцией умножения строки на матрицу генерирующей кодовой слово.
Таким образом, для сравнительно коротких кодовых слов кодеры и декодеры могут просто содержать в памяти все возможные варианты, или даже реализовывать их в виде полупроводниковой схемы. Для большего размера кодового слова эффективнее хранить порождающую и проверочную матрицу. Однако, при длинах блоков в несколько тысяч бит хранение матриц размером, соответственно, в мегабиты, уже становится неэффективным. Одним из способов решения данной проблемы становится использования кодов с малой плотностью проверок на чётность, когда в проверяющей матрице количество единиц сравнительно мало, что позволяет эффективнее организовать процесс хранения матрицы или же напрямую реализовать процесс декодирования с помощью полупроводниковой схемы.
Первой работой на эту тему стала работа Роберта Галлагера «Low-Density Parity-Check Codes» 1963 года[2] (основы которой были заложены в его докторской диссертации 1960 года). В работе учёный описал требования к таким кодам, описал возможные способы построения и способы их оценки. Поэтому часто LDPC-коды называют кодами Галлагера. В русской научной литературе коды также называют низкоплотностными кодами или кодами с малой плотностью проверок на чётность.
Однако, из-за сложности в реализации кодеров и декодеров эти коды не использовались[3]. Лишь много позже, с развитием телекоммуникационных технологий, снова возрос интерес к передаче информации с минимальными ошибками. Несмотря на сложность реализации по сравнению с турбо-кодом, отсутствие преград к использованию (незащищённость патентами) сделало LDPC-коды привлекательными для телекоммуникационной отрасли, и фактически стали стандартом де-факто. В 2003 году LDPC-код, вместо турбо-кода, стал частью стандарта DVB-S2 спутниковой передачи данных для цифрового телевидения. Аналогичная замена произошла и в стандарте DVB-T2 для цифрового наземного телевизионного вещания[4].
LDPC-коды
LDPC-коды описываются низкоплотностой проверочной матрицей, содержащей в основном нули и относительно малое количество единиц. По определению, если каждая строка матрицы содержит ровно  и каждый столбец ровно
и каждый столбец ровно  единиц, то код называют регулярным (в противном случае — нерегулярным). В общем случае количество единиц в матрице имеет порядок
единиц, то код называют регулярным (в противном случае — нерегулярным). В общем случае количество единиц в матрице имеет порядок  , то есть растёт линейно с увеличением длины кодового блока (количества столбцов проверочной матрицы).
, то есть растёт линейно с увеличением длины кодового блока (количества столбцов проверочной матрицы).
Обычно рассматриваются матрицы больших размеров. Например, в работе Галлагера в разделе экспериментальных результатов используются «малые» количества строк n=124, 252, 504 и 1008 строк (число столбцов проверочной матрицы немного больше). На практике применяются матрицы с большим количеством элементов — от 10 до 100 тысяч строк. Однако количество единиц в строке или в столбце остаётся достаточно малым, обычно меньшим 10. Замечено, что коды с тем же количеством элементов на строку или столбец, но с большим размером, обладают лучшими характеристиками.
![]()
Проверочная матрица LDPC-кода (9, 2, 3) с минимальным циклом длины 8
Важной характеристикой матрицы LDPC-кода является отсутствие циклов определённого размера. Под циклом длины 4 понимают образование в проверочной матрице прямоугольника, в углах которого стоят единицы. Отсутствие цикла длины 4 можно также определить через скалярное произведение столбцов (или строк) матрицы. Если каждое попарное скалярное произведение всех столбцов (или строк) матрицы не более 1, это говорит об отсутствии цикла длины 4. Циклы большей длины (6, 8, 10 и т. д.) можно определить, если в проверочной матрице построить граф, вершинами которого являются единицы, а рёбра — все возможные соединения вершин, параллельные сторонам матрицы (то есть вертикальные или горизонтальные линии). Минимальный цикл в этом графе и будет минимальным циклом в проверочной матрице LDPC-кода. Очевидно, что цикл будет иметь длину как минимум 4, а не 3, так как рёбра графа должны быть параллельны сторонам матрицы. Вообще, любой цикл в этом графе будет иметь чётную длину, минимальный размер 4, а максимальный размер обычно не играет роли (хотя, очевидно, он не более, чем количество узлов в графе, то есть n×k).
Описание LPDC-кода возможно несколькими способами:
- проверочной матрицей
- двудольным графом
- другим графическим способом
- специальные способы
Последний способ является условным обозначением группы представлений кодов, которые построены по заданным правилам-алгоритмам, таким, что для повторного воспроизведения кода достаточно знать лишь инициализирующие параметры алгоритма, и, разумеется, сам алгоритм построения. Однако данный способ не является универсальным и не может описать все возможные LDPC-коды.
Способ задания кода проверочной матрицей является общепринятым для линейных кодов, когда каждая строка матрицы является элементом некоторого множества кодовых слов. Если все строки линейно-независимы, строки матрицы могут рассматриваться как базис множества всех кодовых векторов кода. Однако использование данного способа создаёт сложности для представления матрицы в памяти кодера — необходимо хранить все строки или столбцы матрицы в виде набора двоичных векторов, из-за чего размер матрицы становится равен  бит.
бит.
![]()
Представление LDPC-кода в виде двудольного графа
Распространённым графическим способом является представление кода в виде двудольного графа. Сопоставим все  строк матрицы нижним вершинам графа, а
строк матрицы нижним вершинам графа, а  столбцов — верхним, и соединим верхние и нижние вершины графа, если на пересечении соответствующих строк и столбцов стоят единицы.
столбцов — верхним, и соединим верхние и нижние вершины графа, если на пересечении соответствующих строк и столбцов стоят единицы.
К другим графическим способам относят преобразования двудольного графа, происходящие без фактического изменения самого кода. Например, можно все верхние вершины графа представить в виде треугольников, а все нижние — в виде квадратов, после чего расположить рёбра и вершины графа на двухмерной поверхности в порядке, удобном для визуального понимания структуры кода. Например, такое представление используется в качестве иллюстраций в книгах Девида Маккея.
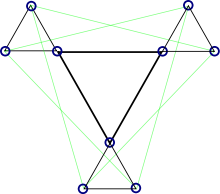
![]()
Представление (9, 2, 3) LDPC-кода в виде графа специального вида. Матрица кода приведена выше.
Вводя дополнительные правила графического отображения и построения LDPC-кода, можно добиться, что в процессе построения код получит определённые свойства. Например, если использовать граф, вершинами которого являются только столбцы проверочной матрицы, а строки изображаются многогранниками, построенными на вершинах графа, то следование правилу «два многогранника не разделяют одно ребро» позволяет избавиться от циклов длины 4.
При использовании специальных процедур построения кода могут использоваться и свои способы представления, хранения и обработки (кодирования и декодирования).
Построение кода
В настоящее время используются два принципа построения проверочной матрицы кода. Первый основан на генерации начальной проверочной матрицы с помощью псевдослучайного генератора. Коды, полученные таким способом называют случайными (англ. random-like codes). Второй — использование специальных методов, основанных, например, на группах и конечных полях. Коды, полученные этими способами называют структурированными. Лучшие результаты по исправлению ошибок показывают именно случайные коды, однако структурированные коды позволяют использовать методы оптимизации процедур хранения, кодирования и декодирования, а также получать коды с более предсказуемыми характеристиками.
В своей работе Галлагер предпочёл с помощью генератора псевдослучайных чисел создать начальную проверочную матрицу небольшого размера с заданными характеристиками, а далее увеличить её размер, дублируя матрицу и используя метод перемешивания строк и столбцов для избавления от циклов определённой длины.
В 2003 году Джеймсом МакГованом и Робертом Вильямсоном был предложен способ удаления циклов из матрицы LDPC-кода, в связи с чем стало возможным в начале сгенерировать матрицу с заданными характеристиками (n, j, k), а затем удалить из неё циклы. Так происходит в схеме Озарова-Вайнера[5].
В 2007 году в журнале «IEEE Transactions on Information Threory» была опубликована статья об использовании конечных полей для построения квази-цикличных LDPC-кодов для каналов с аддитивным белым Гауссовым шумом и двоичных каналов со стиранием.
Декодирование
Как и для любого другого линейного кода, для декодирования используется свойство ортогональности порождающей и транспонированной проверочной матриц:

где  — порождающая матрица, и
— порождающая матрица, и  — проверочная. Тогда для каждого принятого без ошибок кодового слова выполняется отношение
— проверочная. Тогда для каждого принятого без ошибок кодового слова выполняется отношение
- ,
 ,
,а для принятого кодового слова с ошибкой:
- ,
 ,
,где  — принятый вектор,
— принятый вектор,  — синдром. В случае, если после умножения принятого кодового слова на транспонированную проверочную матрицу получается ноль, блок считается принятым без ошибок. В противном случае используются специальные методы для определения местоположения ошибки и её исправления. Для LDPC-кода стандартные способы исправления оказываются слишком трудоёмкими — их относят к классу NP-полных задач, что, учитывая большую длину блока, не может применяться на практике. Вместо них применяют метод вероятностного итеративного декодирования, исправляющую большую долю ошибок за границей половины кодового расстояния[6].
— синдром. В случае, если после умножения принятого кодового слова на транспонированную проверочную матрицу получается ноль, блок считается принятым без ошибок. В противном случае используются специальные методы для определения местоположения ошибки и её исправления. Для LDPC-кода стандартные способы исправления оказываются слишком трудоёмкими — их относят к классу NP-полных задач, что, учитывая большую длину блока, не может применяться на практике. Вместо них применяют метод вероятностного итеративного декодирования, исправляющую большую долю ошибок за границей половины кодового расстояния[6].
Рассмотрим[7] симметричный канал без памяти со входом  и аддитивным гауссовым шумом
и аддитивным гауссовым шумом  . Для принятого кодового слова
. Для принятого кодового слова  нужно найти соответствующий наиболее вероятный вектор
нужно найти соответствующий наиболее вероятный вектор  , такой что
, такой что
- .
- Определим
-
- ;
- ;
- где — принятое значение n-го символа кодового слова (которое для данного канала имеет проивзольное значение, обычно в рамках ).
-
- Будем использовать слово «бит» для обозначения отдельных элементов вектора , и слово «проверка» для обозначения строк проверочной матрицы . Обозначим через набор битов, которые будут участвовать в m-ой проверке. Аналогично, обозначим набор проверок, в которых участвует бит n. (То есть перечислим индексы ненулевых элементов для каждой строки и для каждого столбца проверочной матрицы ).
- Инициализируем матрицы и значениями и соответственно
- (Горизонтальный шаг)
-
- (Вертикальный шаг)
-
- где для каждого и выбраное даёт:
- Теперь также обновляем «псевдопостериорные вероятности» того, что биты вектора принимают значения 0 или 1:
- Также, как и ранее, выбирается таким образом, что
-
 ;
; ;
; — принятое значение n-го символа кодового слова (которое для данного канала имеет проивзольное значение, обычно в рамках
— принятое значение n-го символа кодового слова (которое для данного канала имеет проивзольное значение, обычно в рамках  ).
). набор битов, которые будут участвовать в m-ой проверке. Аналогично, обозначим
набор битов, которые будут участвовать в m-ой проверке. Аналогично, обозначим  набор проверок, в которых участвует бит n. (То есть перечислим индексы ненулевых элементов для каждой строки и для каждого столбца проверочной матрицы
набор проверок, в которых участвует бит n. (То есть перечислим индексы ненулевых элементов для каждой строки и для каждого столбца проверочной матрицы  и
и  значениями
значениями  и
и  соответственно
соответственно





 и
и  даёт:
даёт:



 выбирается таким образом, что
выбирается таким образом, что

Данные значения используются воссоздания вектора x. Если полученный вектор удовлетворяет  , то алгоритм на этом прерывается, иначе повторяются горизонтальный и вертикальные шаги. Если же алгоритм продолжается до некоторого шага (например, 100), то он прерывается и блок объявляется принятым с ошибкой.
, то алгоритм на этом прерывается, иначе повторяются горизонтальный и вертикальные шаги. Если же алгоритм продолжается до некоторого шага (например, 100), то он прерывается и блок объявляется принятым с ошибкой.
Известно, что данный алгоритм даёт точное значение вектора (то есть, совпадающее с классическими способами), если проверочная матрица не содержит циклов[8].
Примечания
- ↑ Shannon C.E. A Mathematical Theory of Communication // Bell System Technical Journal. — 1948. — Т. 27. — С. 379-423, 623–656.
- ↑ Gallager, R. G. Low Density Parity Check Codes. — Cambridge: M.I.T. Press, 1963. — P. 90.
- ↑ David J.C. MacKay Information theory, inference and learning algorithms. — CUP, 2003. — ISBN 0-521-64298-1
- ↑ Dr. Lin-Nan Lee LDPC Codes, Application to Next Generation Communication Systems // IEEE Semiannual Vehicular Technology Conference. — October, 2003.
- ↑ Ю.В. Косолапов. О применении схемы озарова-вайнера для защиты информации в беспроводных многоканальных системах передачи данных // Информационное противодействие угрозам терроризма : Научно-практический журнал. — 2007. — № 10. — С. 111-120.
- ↑ В. Б. Афанасьев, Д. К. Зигангиров «О некоторых конструкциях низкоплотностных кодов с компонентным кодом Рида-Соломона»
- ↑ David J.C. MacKay, Radford M. Neal Near Shannon Limit Performance of Low Density Parity Check Codes
- ↑ J. Pearl. Probabilistic Reasoning in Intelligent Systems: Networks of Plausible Inference. Morgan Kaufmann, San Mateo, 1988.
См. также
- Турбо-код