

Основной задачей при управлении запасами является определение объема пополнения, то есть, сколько необходимо заказать поставщику. При расчете этого объема используется несколько параметров — сколько будет продано в будущем, за какое время происходит пополнение, какие остатки у нас на складе и какое количество уже заказано у поставщика. То, насколько правильно мы определим эти параметры, будет влиять на то, будет ли достаточно товара на складе или его будет слишком много. Но наибольшее влияние на эффективность управления запасами влияет то, насколько точен будет прогноз. Многие считают, что это вообще основной вопрос в управлении запасами. Действительно, точность прогнозирования очень важный параметр. Поэтому важно понимать, как его оценивать. Это важно и для выявления причин дефицитов или неликвидов, и при выборе программных продуктов для прогнозирования продаж и управления запасами.
В данной статье я представила несколько формул для расчета точности прогноза и ошибки прогнозирования. Кроме этого, вы сможете скачать файлы с примерами расчетов этого показателя.
Статистические методы
Для оценки прогноза продаж используются статистические оценки Оценка ошибки прогнозирования временного ряда. Самый простой показатель – отклонение факта от прогноза в количественном выражении.
В практике рассчитывают ошибку прогнозирования по каждой отдельной позиции, а также рассчитывают среднюю ошибку прогнозирования. Следующие распространенные показатели ошибки относятся именно к показателям средних ошибок прогнозирования.
К ним относятся:
MAPE – средняя абсолютная ошибка в процентах

где Z(t) – фактическое значение временного ряда, а  – прогнозное.
– прогнозное.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных методов иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
ME – средняя ошибка

Встречается еще другое название этого показателя — Bias (англ. – смещение) демонстрирует величину отклонения, а также — в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
 .
.
.
SD – стандартное отклонение

где ME – есть средняя ошибка, определенная по формуле выше.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже. Скачать пример расчета в Excel >>>
Связь точности и ошибки прогнозирования
В начале этого обсуждения разберемся с определениями.
Ошибка прогноза — апостериорная величина отклонения прогноза от действительного состояния объекта. Если говорить о прогнозе продаж, то это показатель отклонения фактических продаж от прогноза.
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE, встречается еще название этого показателя Forecast Accuracy. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности. Показатель точности прогноза выражается в процентах:
- Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно. Нужно сразу оговориться, что такого показателя никогда не будет, основное свойство прогноза в том, что он всегда ошибочен.
- Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда. Говоря о высокой точности, мы говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Не имеет значения, что именно вы будете отслеживать, но важно, чтобы вы сравнивали модели прогнозирования или целевые показатели по одному показателю – ошибка прогноза или точность прогнозирования.
Ранее я использовала оценку MAPE, до тех пор пока не встретила формулу, которую рекомендует Валерий Разгуляев.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Оценка ошибки прогноза – формула Валерия Разгуляева (сайт http://upravlenie-zapasami.ru/)
Одной из самых используемых формул оценки ошибки прогнозирования является следующая формула:

где: P – это прогноз, а S – факт за тот же месяц. Однако у этой формулы есть серьезное ограничение — как оценить ошибку, если факт равен нулю? Возможный ответ, что в таком случае D = 100% – который означает, что мы полностью ошиблись. Однако простой пример показывает, что такой ответ — не верен:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
300% |
|
№3 |
1 |
4 |
75% |
Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки Валерий Разгуляев рекомендует использовать следующую формулу:

В таком случае для тех же примеров ошибка рассчитается иначе:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
75% |
|
№3 |
1 |
4 |
75% |
Как мы видим, в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
Визуальный метод – графический
Визуальный метод состоит в том, что мы на график выводим значение прогнозной модели и факта продаж по тем моделям, которые хотим сравнить. Далее сравниваем визуально, насколько прогнозная модель близка к фактическим продажам. Давайте рассмотрим на примере. В таблице представлены две прогнозные модели, а также фактические продажи по этому товару за тот же период. Для наглядности мы также рассчитали ошибку прогнозирования по обеим моделям.

По графикам очевидно, что модель 2 описывает лучше продажи этого товара. Оценка ошибки прогнозирования тоже это показывает – 65% и 31% ошибка прогнозирования по модели 1 и модели 2 соответственно.


Недостатком данного метода является то, что небольшую разницу между моделями сложно выявить — разницу в несколько процентов сложно оценить по диаграмме. Однако эти несколько процентов могут существенно улучшить качество прогнозирования и планирования пополнения запасов в целом.
Использование формул ошибки прогнозирования на практике
Практический аспект оценки ошибки прогнозирования я вывела отдельным пунктом. Это связано с тем, что все статистические методы расчета показателя ошибки прогнозирования рассчитывают то, насколько мы ошиблись в прогнозе в количественных показателях. Давайте теперь обсудим, насколько такой показатель будет полезен в вопросах управления запасами. Дело в том, что основная цель управления запасами — обеспечить продажи, спрос наших клиентов. И, в конечном счете, максимизировать доход и прибыль компании. А эти показатели оцениваются как раз в стоимостном выражении. Таким образом, нам важно при оценке ошибки прогнозирования понимать какой вклад каждая позиция внесла в объем продаж в стоимостном выражении. Когда мы оцениваем ошибку прогнозирования в количественном выражении мы предполагаем, что каждый товар имеет одинаковый вес в общем объеме продаж, но на самом деле это не так – есть очень дорогие товары, есть товары, которые продаются в большом количестве, наша группа А, а есть не очень дорогие товары, есть товары которые вносят небольшой вклад в объем продаж. Другими словами большая ошибка прогнозирования по товарам группы А будет нам «стоить» дороже, чем низкая ошибка прогнозирования по товарам группы С, например. Для того, чтобы наша оценка ошибки прогнозирования была корректной, релевантной целям управления запасами, нам необходимо оценивать ошибку прогнозирования по всем товарам или по отдельной группе не по средними показателями, а средневзвешенными с учетом прогноза и факта в стоимостном выражении.
Пример расчета такой оценки Вы сможете увидеть в файле Excel.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
При этом нужно помнить, что для оценки ошибки прогнозирования по отдельным позициям мы рассчитываем по количеству, но вот если нам важно понять в целом ошибку прогнозирования по компании, например, для оценки модели, которую используем, то нам нужно рассчитывать не среднюю оценку по всем товарам, а средневзвешенную с учетом стоимостной оценки. Оценку можно брать по ценам себестоимости или ценам продажи, это не играет большой роли, главное, эти же цены (тип цен) использовать при всех расчетах.
Для чего используется ошибка прогнозирования
В первую очередь, оценка ошибки прогнозирования нам необходима для оценки того, насколько мы ошибаемся при планировании продаж, а значит при планировании поставок товаров. Если мы все время прогнозируем продажи значительно больше, чем потом фактически продаем, то вероятнее всего у нас будет излишки товаров, и это невыгодно компании. В случае, когда мы ошибаемся в обратную сторону – прогнозируем продажи меньше чем фактические продажи, с большой вероятностью у нас будут дефициты и компания не дополучит прибыль. В этом случае ошибка прогнозирования служит индикатором качества планирования и качества управления запасами.
Индикатором того, что повышение эффективности возможно за счет улучшения качества прогнозирования. За счет чего можно улучшить качество прогнозирования мы не будем здесь рассматривать, но одним из вариантов является поиск другой модели прогнозирования, изменения параметров расчета, но вот насколько новая модель будет лучше, как раз поможет показатель ошибки прогнозирования или точности прогноза. Сравнение этих показателей по нескольким моделям поможет определить ту модель, которая дает лучше результат.
В идеальном случае, мы можем так подбирать модель для каждой отдельной позиции. В этом случае мы будем рассчитывать прогноз по разным товарам по разным моделям, по тем, которые дают наилучший вариант именно для конкретного товара.
Также этот показатель можно использовать при выборе автоматизированного инструмента для прогнозирования спроса и управления запасами. Вы можете сделать тестовые расчеты прогноза в предлагаемой программе и сравнить ошибку прогнозирования полученного прогноза с той, которая есть у вашей существующей модели. Если у предлагаемого инструмента ошибка прогнозирования меньше. Значит, этот инструмент можно рассматривать для применения в компании. Кроме этого, показатель точности прогноза или ошибки прогнозирования можно использовать как KPI сотрудников, которые отвечают за подготовку прогноза продаж или менеджеров по закупкам, в том случае, если они рассчитывают прогноз будущих продаж при расчете заказа.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Если вы хотите повысить эффективность управления запасами и увеличить оборачиваемость товарных запасов, предлагаю изучить мастер-класс «Как увеличить оборачиваемость товарных запасов».
Источник: сайт http://uppravuk.net/
Ошибка прогнозирования: виды, формулы, примеры

Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.

- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:

Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Об авторе

HeinzBr
Автор статей и создатель сайта SHTEM.RU
Ошибка прогнозирования: виды, формулы, примеры
HeinzBr
Автор статей и создатель сайта SHTEM.RU
Ошибка прогнозирования: виды, формулы, примеры
Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.
- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.
- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:
- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.
- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:
Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Об авторе
HeinzBr
Автор статей и создатель сайта SHTEM.RU
Ошибка прогнозирования
Поскольку
будущее никогда нельзя в точности
предугадать по прошлому, то прогноз
будущего спроса всегда будет содержать
в себе ошибки в той или иной степени.
Модель экспоненциального сглаживания
прогнозирует средний уровень спроса.
Поэтому следует построить модель так,
чтобы уменьшить разность между прогнозом
и фактическим уровнем спроса. Эта
разность называется ошибкой прогнозирования.
Ошибка
прогнозирования выражается такими
показателями, как среднеквадратическое
отклонение, вариация или среднее
абсолютное отклонение. Раньше среднее
абсолютное отклонение использовалось
в качестве основного измерителя ошибки
прогнозирования при использовании
модели экспоненциального сглаживания.
Среднеквадратическое отклонение
отвергли из-за того, что рассчитывать
его сложнее, чем среднее абсолютное
отклонение, и у компьютеров на это просто
не хватало памяти. Сейчас у компьютеров
достаточно памяти, и теперь
среднеквадратическое отклонение
используется чаще.
Ошибку
прогнозирования можно определить с
помощью следующей формулы:
ОШИБКА
ПРОГНОЗА = ФАКТИЧЕСКИЙ СПРОС – ПРОГНОЗ
СПРОСА
Е
Рис. 3а. Нормальное
распределение ошибок прогноза

HeinzBr
Автор статей и создатель сайта SHTEM.RU
Ошибка прогнозирования
Поскольку
будущее никогда нельзя в точности
предугадать по прошлому, то прогноз
будущего спроса всегда будет содержать
в себе ошибки в той или иной степени.
Модель экспоненциального сглаживания
прогнозирует средний уровень спроса.
Поэтому следует построить модель так,
чтобы уменьшить разность между прогнозом
и фактическим уровнем спроса. Эта
разность называется ошибкой прогнозирования.
Ошибка
прогнозирования выражается такими
показателями, как среднеквадратическое
отклонение, вариация или среднее
абсолютное отклонение. Раньше среднее
абсолютное отклонение использовалось
в качестве основного измерителя ошибки
прогнозирования при использовании
модели экспоненциального сглаживания.
Среднеквадратическое отклонение
отвергли из-за того, что рассчитывать
его сложнее, чем среднее абсолютное
отклонение, и у компьютеров на это просто
не хватало памяти. Сейчас у компьютеров
достаточно памяти, и теперь
среднеквадратическое отклонение
используется чаще.
Ошибку
прогнозирования можно определить с
помощью следующей формулы:
ОШИБКА
ПРОГНОЗА = ФАКТИЧЕСКИЙ СПРОС – ПРОГНОЗ
СПРОСА
Е
Рис. 3а. Нормальное
распределение ошибок прогноза
сли
прогноз спроса представляет собой
среднее арифметическое фактического
спроса, то сумма ошибок прогнозирования
за определенное количество временных
периодов будет равна нулю. Следовательно,
значение ошибки можно отыскать путем
суммирования квадратов ошибок
прогнозирования, что позволяет избежать
взаимного устранения положительных и
отрицательных ошибок прогнозирования.
Эта сумма делится на количество наблюдений
и затем из нее извлекается квадратный
корень. Показатель корректируется с
уменьшением одной степени свободы,
которая теряется при составлении
прогноза. В результате, уравнение
среднеквадратического отклонения имеет
вид:
 ,
,
г де
де
SE
– средняя ошибка прогнозирования; Ai
– фактический спрос в период i;
Fi
– прогноз на период i;
N
– размер временного ряда.
Ф
Рис. 3б. Скошенное
распределение ошибок прогноза
орма распределения ошибок
прогнозирования является важной, когда
формулируются вероятностные утверждения
о степени надежности прогноза. Две
типовые формы распределения ошибок
прогнозирования показаны на рисунке
3.
Полагая,
что модель прогнозирования отражает
средние значения фактического спроса
достаточно хорошо и отклонения фактических
продаж от прогноза относительно невелики
по сравнению с абсолютной величиной
продаж, то вполне вероятно предположить
нормальное распределение ошибок
прогнозирования. В тех же случаях, когда
ошибка прогнозирования сопоставима по
величине с величиной спроса, имеет место
скошенное, или усеченное нормальное
распределение ошибок прогноза.
Определить
тип распределения в конкретной ситуации
можно с помощью теста на соответствие
критерию согласия хи-квадрат. В качестве
альтернативы можно использовать другой
тест, с помощью которого можно определить,
является ли распределение симметричным
(нормальным) или экспоненциальным
(разновидность скошенного распределения):
При
нормальном распределении около 2%
наблюдаемых значений превышают значение,
равное сумме среднего и удвоенного
значения среднеквадратического
отклонения. При экспоненциальном
распределении около 2% наблюдаемых
значений превышают среднее на величину
среднеквадратического отклонения,
умноженного на коэффициент 2,75.
Следовательно, в первом случае используется
нормальное распределение, а во втором
случае – экспоненциальное.
Пример.
Снова вернемся к нашему примеру. В
базовой модели экспоненциального
сглаживания были получены следующие
результаты:
-
Квартал
I
II
III
IV
Прошлый
год1
200700
900
1
100Текущий
год1
4001
000F3
= ?Прогноз
1
200779
1
005
Оценим
стандартную ошибку прогнозирования по
данным за первый и второй кварталы
текущего года, по которым нам известны
фактические и прогнозные значения.
Допустим, что спрос имеет нормальное
распределение относительно прогноза.
Рассчитаем границы доверительного
интервала с вероятностью 95% для третьего
квартала.
Стандартная
ошибка прогнозирования:
![]()
Используя
таблицу А (см. Приложение I), определяем
коэффициент z95%
= 1,96 и получаем границы доверительного
интервала по формуле:
Y
= F3
z(SE)
=1005
1,96298
= 1064
584,2
Следовательно,
с 95%-й вероятностью границы доверительного
интервала прогноза спроса на третий
квартал текущего года составляют
значения:
420,8
< Y
< 1589,2
Основной задачей при управлении запасами является определение объема пополнения, то есть, сколько необходимо заказать поставщику. При расчете этого объема используется несколько параметров — сколько будет продано в будущем, за какое время происходит пополнение, какие остатки у нас на складе и какое количество уже заказано у поставщика. То, насколько правильно мы определим эти параметры, будет влиять на то, будет ли достаточно товара на складе или его будет слишком много. Но наибольшее влияние на эффективность управления запасами влияет то, насколько точен будет прогноз. Многие считают, что это вообще основной вопрос в управлении запасами. Действительно, точность прогнозирования очень важный параметр. Поэтому важно понимать, как его оценивать. Это важно и для выявления причин дефицитов или неликвидов, и при выборе программных продуктов для прогнозирования продаж и управления запасами.
В данной статье я представила несколько формул для расчета точности прогноза и ошибки прогнозирования. Кроме этого, вы сможете скачать файлы с примерами расчетов этого показателя.
Статистические методы
Для оценки прогноза продаж используются статистические оценки Оценка ошибки прогнозирования временного ряда. Самый простой показатель – отклонение факта от прогноза в количественном выражении.
В практике рассчитывают ошибку прогнозирования по каждой отдельной позиции, а также рассчитывают среднюю ошибку прогнозирования. Следующие распространенные показатели ошибки относятся именно к показателям средних ошибок прогнозирования.
К ним относятся:
MAPE – средняя абсолютная ошибка в процентах
где Z(t) – фактическое значение временного ряда, а – прогнозное.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных методов иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
ME – средняя ошибка
Встречается еще другое название этого показателя — Bias (англ. – смещение) демонстрирует величину отклонения, а также — в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MSE – среднеквадратичная ошибка
.
RMSE – квадратный корень из среднеквадратичной ошибки
.
.
SD – стандартное отклонение
где ME – есть средняя ошибка, определенная по формуле выше.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже. Скачать пример расчета в Excel >>>
Связь точности и ошибки прогнозирования
В начале этого обсуждения разберемся с определениями.
Ошибка прогноза — апостериорная величина отклонения прогноза от действительного состояния объекта. Если говорить о прогнозе продаж, то это показатель отклонения фактических продаж от прогноза.
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE, встречается еще название этого показателя Forecast Accuracy. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности. Показатель точности прогноза выражается в процентах:
- Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно. Нужно сразу оговориться, что такого показателя никогда не будет, основное свойство прогноза в том, что он всегда ошибочен.
- Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда. Говоря о высокой точности, мы говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Не имеет значения, что именно вы будете отслеживать, но важно, чтобы вы сравнивали модели прогнозирования или целевые показатели по одному показателю – ошибка прогноза или точность прогнозирования.
Ранее я использовала оценку MAPE, до тех пор пока не встретила формулу, которую рекомендует Валерий Разгуляев.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Оценка ошибки прогноза – формула Валерия Разгуляева (сайт http://upravlenie-zapasami.ru/)
Одной из самых используемых формул оценки ошибки прогнозирования является следующая формула:
где: P – это прогноз, а S – факт за тот же месяц. Однако у этой формулы есть серьезное ограничение — как оценить ошибку, если факт равен нулю? Возможный ответ, что в таком случае D = 100% – который означает, что мы полностью ошиблись. Однако простой пример показывает, что такой ответ — не верен:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
300% |
|
№3 |
1 |
4 |
75% |
Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки Валерий Разгуляев рекомендует использовать следующую формулу:
В таком случае для тех же примеров ошибка рассчитается иначе:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
75% |
|
№3 |
1 |
4 |
75% |
Как мы видим, в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
Визуальный метод – графический
Визуальный метод состоит в том, что мы на график выводим значение прогнозной модели и факта продаж по тем моделям, которые хотим сравнить. Далее сравниваем визуально, насколько прогнозная модель близка к фактическим продажам. Давайте рассмотрим на примере. В таблице представлены две прогнозные модели, а также фактические продажи по этому товару за тот же период. Для наглядности мы также рассчитали ошибку прогнозирования по обеим моделям.
По графикам очевидно, что модель 2 описывает лучше продажи этого товара. Оценка ошибки прогнозирования тоже это показывает – 65% и 31% ошибка прогнозирования по модели 1 и модели 2 соответственно.
Недостатком данного метода является то, что небольшую разницу между моделями сложно выявить — разницу в несколько процентов сложно оценить по диаграмме. Однако эти несколько процентов могут существенно улучшить качество прогнозирования и планирования пополнения запасов в целом.
Использование формул ошибки прогнозирования на практике
Практический аспект оценки ошибки прогнозирования я вывела отдельным пунктом. Это связано с тем, что все статистические методы расчета показателя ошибки прогнозирования рассчитывают то, насколько мы ошиблись в прогнозе в количественных показателях. Давайте теперь обсудим, насколько такой показатель будет полезен в вопросах управления запасами. Дело в том, что основная цель управления запасами — обеспечить продажи, спрос наших клиентов. И, в конечном счете, максимизировать доход и прибыль компании. А эти показатели оцениваются как раз в стоимостном выражении. Таким образом, нам важно при оценке ошибки прогнозирования понимать какой вклад каждая позиция внесла в объем продаж в стоимостном выражении. Когда мы оцениваем ошибку прогнозирования в количественном выражении мы предполагаем, что каждый товар имеет одинаковый вес в общем объеме продаж, но на самом деле это не так – есть очень дорогие товары, есть товары, которые продаются в большом количестве, наша группа А, а есть не очень дорогие товары, есть товары которые вносят небольшой вклад в объем продаж. Другими словами большая ошибка прогнозирования по товарам группы А будет нам «стоить» дороже, чем низкая ошибка прогнозирования по товарам группы С, например. Для того, чтобы наша оценка ошибки прогнозирования была корректной, релевантной целям управления запасами, нам необходимо оценивать ошибку прогнозирования по всем товарам или по отдельной группе не по средними показателями, а средневзвешенными с учетом прогноза и факта в стоимостном выражении.
Пример расчета такой оценки Вы сможете увидеть в файле Excel.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
При этом нужно помнить, что для оценки ошибки прогнозирования по отдельным позициям мы рассчитываем по количеству, но вот если нам важно понять в целом ошибку прогнозирования по компании, например, для оценки модели, которую используем, то нам нужно рассчитывать не среднюю оценку по всем товарам, а средневзвешенную с учетом стоимостной оценки. Оценку можно брать по ценам себестоимости или ценам продажи, это не играет большой роли, главное, эти же цены (тип цен) использовать при всех расчетах.
Для чего используется ошибка прогнозирования
В первую очередь, оценка ошибки прогнозирования нам необходима для оценки того, насколько мы ошибаемся при планировании продаж, а значит при планировании поставок товаров. Если мы все время прогнозируем продажи значительно больше, чем потом фактически продаем, то вероятнее всего у нас будет излишки товаров, и это невыгодно компании. В случае, когда мы ошибаемся в обратную сторону – прогнозируем продажи меньше чем фактические продажи, с большой вероятностью у нас будут дефициты и компания не дополучит прибыль. В этом случае ошибка прогнозирования служит индикатором качества планирования и качества управления запасами.
Индикатором того, что повышение эффективности возможно за счет улучшения качества прогнозирования. За счет чего можно улучшить качество прогнозирования мы не будем здесь рассматривать, но одним из вариантов является поиск другой модели прогнозирования, изменения параметров расчета, но вот насколько новая модель будет лучше, как раз поможет показатель ошибки прогнозирования или точности прогноза. Сравнение этих показателей по нескольким моделям поможет определить ту модель, которая дает лучше результат.
В идеальном случае, мы можем так подбирать модель для каждой отдельной позиции. В этом случае мы будем рассчитывать прогноз по разным товарам по разным моделям, по тем, которые дают наилучший вариант именно для конкретного товара.
Также этот показатель можно использовать при выборе автоматизированного инструмента для прогнозирования спроса и управления запасами. Вы можете сделать тестовые расчеты прогноза в предлагаемой программе и сравнить ошибку прогнозирования полученного прогноза с той, которая есть у вашей существующей модели. Если у предлагаемого инструмента ошибка прогнозирования меньше. Значит, этот инструмент можно рассматривать для применения в компании. Кроме этого, показатель точности прогноза или ошибки прогнозирования можно использовать как KPI сотрудников, которые отвечают за подготовку прогноза продаж или менеджеров по закупкам, в том случае, если они рассчитывают прогноз будущих продаж при расчете заказа.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме. Скачать пример расчета в Excel >>>
Если вы хотите повысить эффективность управления запасами и увеличить оборачиваемость товарных запасов, предлагаю изучить мастер-класс «Как увеличить оборачиваемость товарных запасов».
Источник: сайт http://uppravuk.net/
Что такое ошибка прогноза в статистике? (Определение и примеры)
17 авг. 2022 г.
читать 2 мин
В статистике ошибка прогнозирования относится к разнице между прогнозируемыми значениями, сделанными некоторой моделью, и фактическими значениями.
Ошибка прогноза часто используется в двух случаях:
1. Линейная регрессия: используется для прогнозирования значения некоторой переменной непрерывного отклика.
Обычно мы измеряем ошибку прогноза модели линейной регрессии с помощью метрики, известной как RMSE , что означает среднеквадратичную ошибку.
Он рассчитывается как:
СКО = √ Σ(ŷ i – y i ) 2 / n
куда:
- Σ — это символ, который означает «сумма»
- ŷ i — прогнозируемое значение для i -го наблюдения
- y i — наблюдаемое значение для i -го наблюдения
- n — размер выборки
2. Логистическая регрессия: используется для прогнозирования значения некоторой бинарной переменной отклика.
Одним из распространенных способов измерения ошибки прогнозирования модели логистической регрессии является метрика, известная как общий коэффициент ошибочной классификации.
Он рассчитывается как:
Общий коэффициент ошибочной классификации = (# неверных прогнозов / # всего прогнозов)
Чем ниже значение коэффициента ошибочной классификации, тем лучше модель способна предсказать результаты переменной отклика.
В следующих примерах показано, как на практике рассчитать ошибку прогнозирования как для модели линейной регрессии, так и для модели логистической регрессии.
Пример 1: Расчет ошибки прогноза в линейной регрессии
Предположим, мы используем регрессионную модель, чтобы предсказать количество очков, которое 10 игроков наберут в баскетбольном матче.
В следующей таблице показаны прогнозируемые очки по модели и фактические очки, набранные игроками:

Мы рассчитали бы среднеквадратичную ошибку (RMSE) как:
- СКО = √ Σ(ŷ i – y i ) 2 / n
- СКО = √(((14-12) 2 +(15-15) 2 +(18-20) 2 +(19-16) 2 +(25-20) 2 +(18-19) 2 +(12- 16) 2 +(12-20) 2 +(15-16) 2 +(22-16) 2 ) / 10)
- СКО = 4
Среднеквадратическая ошибка равна 4. Это говорит нам о том, что среднее отклонение между прогнозируемыми набранными баллами и фактическими набранными баллами равно 4.
Связанный: Что считается хорошим значением RMSE?
Пример 2: Расчет ошибки прогноза в логистической регрессии
Предположим, мы используем модель логистической регрессии, чтобы предсказать, попадут ли 10 баскетболистов из колледжа в НБА.
В следующей таблице показан прогнозируемый результат для каждого игрока по сравнению с фактическим результатом (1 = выбран на драфте, 0 = не выбран на драфте):

Мы рассчитали бы общий коэффициент ошибочной классификации как:
- Общий коэффициент ошибочной классификации = (# неверных прогнозов / # всего прогнозов)
- Общий коэффициент ошибочной классификации = 4/10
- Общий коэффициент ошибочной классификации = 40%
Общий уровень ошибочной классификации составляет 40% .
Это значение довольно велико, что указывает на то, что модель не очень хорошо предсказывает, будет ли игрок выбран на драфте.
Дополнительные ресурсы
Следующие руководства содержат введение в различные типы методов регрессии:
Введение в простую линейную регрессию
Введение в множественную линейную регрессию
Введение в логистическую регрессию
Для анализа результатов расчета прогноза, в продолжение ряда вы можете рассчитать следующие ошибки:
- MAPE – средняя абсолютная ошибка в % . Ошибка оценивает на сколько велики ошибки в сравнении со значением ряда и с ошибками в соседних рядах.
Подробнее читайте в статье на нашем сайте: http://4analytics.ru/metodi-analiza/mape-%E2%80%93-srednyaya-absolyutnaya-oshibka-praktika-primeneniya.html - MRPE – средняя относительная ошибка в %, оценивает на сколько велика дельта между фактом и прогнозом. Чем ближе к 100%, тем больше ошибка, чем ближе к нулю, тем ошибка меньше.
- MSE – средняя квадратическая ошибка, подчеркивает большие ошибки за счет возведения каждой ошибки в квадрат.
Подробнее читайте в статье на нашем сайте:
http://4analytics.ru/metodi-analiza/mse-%E2%80%93-srednekvadraticheskaya-oshibka-v-excel.html - MPE – средняя процентная ошибка – показывает завышен или занижен прогноз относительно факта. Если ошибка меньше нулю, то прогноз последовательно завышен, если ошибка больше нуля, то прогноз последовательно занижен.
Подробнее читайте в статье на нашем сайте:
http://4analytics.ru/metodi-analiza/mpe-%E2%80%93-srednyaya-procentnaya-oshibka-v-excel.html - MAD – среднее абсолютное отклонение. Используется, когда важно измерить ошибку в тех же единицах, что и исходный ряд.
Подробнее читайте в статье на нашем сайте:
http://4analytics.ru/planirovanie-i-prognozirovanie-praktika/dopolnitelnie-oborotnie-sredstva-za-schet-povisheniya-tochnosti-prognoza.html - A MAPE – ошибка, которая показывает отклонение средних значений ряда к средним значениям модели прогноза. Имеет значение при неравномерном перераспределении значений ряда по периодам.
- S MAPE – ошибка, которая показывает отклонение суммы значения ряда к сумме значений модели прогноза. Имеет значение при неравномерном перераспределении значений ряда по периодам.
А также 2 показателя «Точность прогноза»:
- Точность прогноза = 1 – МАРЕ
- Точность прогноза 2 = 1 – MRPE
Для расчета ошибок одновременно с прогнозом, нажимаем кнопку «Расчет ошибок» в меню «FORECAST»

В открывшемся окне выбираем нужные для расчета ошибки:
Теперь при расчете прогноза, в продолжение ряда, программа автоматически сделает расчет отмеченных Вами ошибок:

Когда перед компанией встают задачи прогнозирования спроса для управления товарными запасами, обычно появляется вопрос, связанный с выбором метода прогнозирования. Но как определить, какой метод лучше? Однозначного ответа на этот вопрос нет. Однако, исходя из нашей практики, самым распространенным методам оценки точности прогноза является средняя абсолютная процентная ошибка (MAPE). Также используются средняя абсолютная ошибка (MAE) и средняя квадратичная ошибка прогнозирования (RMSE).
Ошибка прогноза в данном случае – это разница между фактическим значением спроса и его прогнозным значением. Т.е, чем больше будет ошибка прогнозирования, тем менее точен прогноз. Например, при ошибке прогнозирования 5%, точность прогноза будет составлять 95%. Изначально MAPE использовалась для прогнозирования временных рядов, которые имеют регулярное нормальное распределение, такие как, например, потребление электроэнергии. И только после ее стали применять для оценки прогноза спроса. На практике ошибку могут рассчитывать по каждой позиции товара, а также среднюю оценку по всем товарным группам.
Несмотря на то, что большинство компаний до сих пор используют вышеописанные методы для оценки, мы считаем, что они не достаточно корректны и не подходят для применения в реальном бизнесе. Для простоты изложения, выделим три ключевых момента, которые приводят к некорректным выводам при использовании вышеописанных методов оценки. Назовем их ошибка №1, №2 и №3. Сначала мы подробно опишем эти ошибки, а потом расскажем, как наши методы сравнения помогаю их ликвидировать.
О некорректности использования MAPE, RMSE и других распространенных ошибок
Ошибка № 1 заключается в том, что используемые методы больше относятся к математике, нежели к бизнесу, по той причине, что это обезличенные цифры (или проценты), которые ничего не говорят про деньги. Бизнесу же нужно принимать решения на основе выгоды, которую он получит в деньгах. Например, ошибка в 80% на первый взгляд звучит устрашающие. Но в реальности за ней могут скрываться совершенно разные вещи. Ошибка по гвоздям со стоимостью одного гвоздя в 0,5 рублей – это одни потери. Но они совершенно несопоставимы с потерями от продажи промышленного оборудования стоимостью 700 000 рублей с той же величиной ошибки прогнозирования. Ко всему прочему также больше значение имеет объем продукции, что тоже никак не учитывается данными ошибками прогнозирования.
Второй важный момент (ошибка №2), который не учитывают данные оценки прогнозирования – это заморозка денежных средств в запасах и недополученная прибыль от дефицита продукции на складе. Например, если мы прогнозируем продажу 20 колесных дисков, а по факту продали 15. То это одна цена ошибки – 5 колесных дисков, которые потребуют затраты на хранение на определенное время, и как следствие стоимость замороженных оборотных средств под определенный процент. Если рассмотреть обратную ситуацию – прогнозируем продажу 20 дисков, спрос составляет 25 штук. Это уже упущенная прибыль, которая составляет разницу сумм закупки и реализации продукции. По сути мы имеет одну и ту же ошибку прогнозирования, но результат от нее может быть совершенно разным.
Третий ключевой момент (ошибка №3) – описанные ошибки распространяются только на точечный прогноз спроса и не описывают страховой запас. А он в некоторых случаях может составлять от 20% до 70% от общих товарных запасов на складе. Поэтому, какой бы точный не был прогноз с точки зрения описанных выше методов, мы все равно не оцениваем точность страхового запаса, а значит реальные данные могут быть значительно искажены.
Критерии, привязанные к прибыльности бизнеса
Учитывая описанные выше недостатки ошибок прогнозирования, такой подход не является корректным и надежным для сравнения алгоритмов. Ко всему прочему он зачастую оторван от реального бизнеса. Используемый же нами подход позволяет оценить точность алгоритмов в деньгах, рассчитать стоимость ошибки прогнозирования на понятном для бизнеса языке финансов. Таким образом это позволяет нам ликвидировать ошибку №1.
В случае с ошибкой № 2, мы рассчитываем два различных значения. Если прогноз окажется меньше реального спроса, то он приведет к дефициту, экономический урон от которого рассчитывается, как количество недопроданных товаров, умноженное на разность цен закупки и реализации. Например, вы закупаете колесные диски по 3000 рублей за штуку и продаете по 4000. Прогноз на месяц составил 1000 дисков, реальный спрос оказался 1200 штук. Экономический урон будет равен:
(1200-1000)*(4000-3000)=200 000 рублей.
В случае превышения прогноза над реальным спросом компания понесет убытки по хранению продукции. Экономический урон будет равен сумме затрат на нереализованную продукцию, помноженную на ставку альтернативных вложений за этот период. Предположим, что реальный спрос в предыдущем примере оказался 800 дисков и вам пришлось хранить диски еще один месяц. Пусть ставка альтернативных вложений составляет 20% в год. Тогда экономический урон будет равен
(1000-800)*3000*0,2/12=10 000 рублей.
Соответственно, в каждом конкретном случае, мы будет учитывать одно из этих значений.
Для того, чтобы ликвидировать ошибку № 3, мы сравниваем алгоритмы с использованием понятия уровень сервиса. Уровень сервиса (здесь и далее — уровень сервиса II рода, fill rate) – это доля спроса, которую мы гарантировано покроем с использованием имеющихся на складе запасов в течении периода их пополнения. Например, уровень сервиса 90% означает, что мы удовлетворим 90% спроса. На первый взгляд может показаться логичным, что уровень сервиса всегда должен составлять 100%. Тогда и прибыль будет максимальна. Но в реальных ситуациях зачастую дело обстоит иначе: удовлетворение 100% уровня сервиса приводит к сильному перезатариванию склада, а для товаров с ограниченными сроками годности еще и к списанию. И убытки от затрат на хранение, списания просроченной продукции и недополученной прибыли от вложения свободных денег в итоге снизят прибыть от реализации, в случае если бы мы поддерживали уровень сервиса 95%. Нужно заметить, что для каждой отдельной позиции товаров будет свой оптимальный уровень сервиса.
Подробнее о уровне сервиса, его видах и примерах расчета читайте в статье «Что такое уровень сервиса и почему он важен.»
Так как страховой запас может составлять значительную долю, его нельзя игнорировать при сравнении алгоритмов (как это делается при расчете ошибок MAPE, RMSE и т.д.). Поэтому мы делаем сравнение не прогноза, а оптимального запаса с заданным уровнем сервиса. Оптимальный запас для заданного уровня сервиса – это такое количество товаров, которое нужно хранить на складе, чтобы получить максимум прибыли от реализации товаров и одновременно сократить издержки на хранение до минимума.
В качестве основного критерия (критерий №1) качества прогнозирования мы используем суммарное значение потерь для заданного уровня сервиса, о котором писали выше (исправление ошибки №2). Таким образом мы оцениваем потери в денежном выражении при использовании данного конкретного алгоритма. Чем меньше потери — тем точнее работает алгоритм.
Здесь нужно заметить, что для разных уровней сервиса оптимальный запас тоже может различаться. И в одном случае прогноз будет точно в него попадать, а в другом возможны перекосы в большую, либо меньшую сторону. Так как многие компании не рассчитывают оптимальный уровень сервиса, а используют заданный заранее, значение основного критерия мы вычисляем для всех самых распространенных уровней сервиса: 70%, 75%, 80%, 85%, 90%, 95%, 98%, 99% и суммируем потери. Таким образом мы можем проверить, насколько хорошо в целом работает модель.
Для компаний, которые, считают оптимальный уровень сервиса мы используем дополнительный критерий (критерий №2) для оценки. В общем виде он выглядит как соотношение потерь на оптимальном уровне сервиса по ожидаемому (модельному) распределению продаж и по реальному распределению продаж (по факту). Прогнозируемое значение оптимального уровня сервиса не всегда соответствует оптимальному значению уже на реальном распределении продаж. Поэтому мы должны сравнивать ошибку между прогнозом объема продаж на оптимальном (по модели) уровне сервиса и реальным объемом продаж, обеспечивающим оптимальное значение уровня сервиса по реальным данным.
Что проиллюстрировать применение данного критерия, вернемся к нашему примеру с дисками. Предположим, что прогнозное значение оптимального уровня сервиса для него составляет 90%, а оптимальный объем запаса для этого случая примем равным 3000 колесных дисков. Пусть в первом случае реальный уровень сервиса оказался выше прогнозного и составил 92%. Соответственно объем заказов также вырос и составил 3300 дисков. Ошибка прогнозирования будет рассчитываться как разность между реальным и фактическим объемом продаж, умноженная на разность цен реализации. Итого, мы имеем:
(3300-3000)*(4000-3000)=300 000 рублей.
Теперь представим обратную ситуацию: реальный уровень сервиса оказался меньше прогнозного и составил 87%. Реальный объем продаж при этом составил 2850 дисков. Ошибка прогнозирования будет рассчитана, как сумма затрат на нереализованную продукцию, умноженную на ставку альтернативных вложений за этот период (в качестве примера берем период сроком месяц и ставку равную 20% годовых). Итоговое значение критерия будет равно:
(3000-2850)*3000*0,2/12 = 7500 рублей
Конечно, в идеальном случае, мы должны рассчитывать ошибку только при оптимальном уровне сервиса, между прогнозным и реальным значениями. Но так как не все компании еще перешли на оптимальный уровень сервиса, мы вынуждены использовать два критерия.
Используемые нами критерии в отличие от классических математических ошибок, показывают суммарные потери в деньгах при применении той или иной модели. Соответственно, наилучшей будет модель, которая обеспечивает минимальные потери. Такой подход позволят бизнес-пользователям оценить работу различных алгоритмов на понятном им языке.
Пример сравнения точности прогнозирования системы Forecast NOW c методом ARIMA (на базе номенклатуры бытовой химии):
|
Критерий (потери в рублях) |
Forecast NOW! |
ARIMA |
Разность |
|
Критерий №1 (потери на оптимальном уровне сервиса) |
92 997 114 |
169 916 601 |
82,71% |
|
Критерий №2 |
4 188 749 |
7 611 365 |
81,71% |
|
Критерий №1 (суммарное значение по распространенным уровням сервиса) |
820 099 299 |
1 550 434 475 |
89,05% |
Пример сравнения точности прогнозирования системы Forecast NOW c методом Кростона (на базе номенклатуры бытовой химии):
|
Критерий (потери в рублях) |
Forecast NOW! |
Метод Кростона |
Разность |
|
Критерий №1 (потери на оптимальном уровне сервиса) |
6 379 616 |
8 328 509 |
30,55% |
|
Критерий №2 |
1 076 984 |
1 341 537 |
24,56% |
|
Критерий №1 (суммарное значение по распространенным уровням сервиса) |
128 690 989 |
161 891 666 |
20,51% |
Оценка ошибки прогнозирования временного ряда
Работая с научными публикациями, сталкиваюсь с различными показателями ошибок прогнозирования временных рядов. Среди всех встречающихся оценок ошибки прогнозирования стоит отметить две, которые в настоящее время, являются самыми популярными: MAE и MAPE.
Пусть ошибка есть разность:
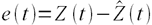 ,
,
где Z(t) – фактическое значение временного ряда, а  – прогнозное.
– прогнозное.
Тогда формулы для оценок ошибки прогнозирования временных рядов для N отчетов можно записать в следующем виде.
MAPE – средняя абсолютная ошибка в процентах
 .
.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
 .
.
ME – средняя ошибка
 .
.
SD – стандартное отклонение
 , где ME – есть средняя ошибка, определенная по формуле выше.
, где ME – есть средняя ошибка, определенная по формуле выше.
Связь точности и ошибки прогнозирования
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE
Величину точности оценивать не принято, говоря о прогнозировании всегда оценивают, то есть определяют значение именно ошибки прогноза, то есть величину MAPE и/или MAE. Однако нужно понимать, что если MAPE = 5%, то точность прогнозирования = 95%. Говоря о высокой точности, мы всегда говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности.
При этом величина MAPE является количественной оценкой именно ошибки, и эта величина нам ясно говорит и о точности прогнозирования, исходя из приведенной выше простой формулы. Таким образом, оценивая ошибку, мы всегда оцениваем точность прогнозирования.
Перевод
Ссылка на автора
Показатели эффективности прогнозирования по временным рядам дают сводку об умениях и возможностях модели прогноза, которая сделала прогнозы.
Есть много разных показателей производительности на выбор. Может быть непонятно, какую меру использовать и как интерпретировать результаты.
В этом руководстве вы узнаете показатели производительности для оценки прогнозов временных рядов с помощью Python.
Временные ряды, как правило, фокусируются на прогнозировании реальных значений, называемых проблемами регрессии. Поэтому показатели эффективности в этом руководстве будут сосредоточены на методах оценки реальных прогнозов.
После завершения этого урока вы узнаете:
- Основные показатели выполнения прогноза, включая остаточную ошибку прогноза и смещение прогноза.
- Вычисления ошибок прогноза временного ряда, которые имеют те же единицы, что и ожидаемые результаты, такие как средняя абсолютная ошибка.
- Широко используются вычисления ошибок, которые наказывают большие ошибки, такие как среднеквадратическая ошибка и среднеквадратичная ошибка.
Давайте начнем.

Ошибка прогноза (или остаточная ошибка прогноза)
ошибка прогноза рассчитывается как ожидаемое значение минус прогнозируемое значение.
Это называется остаточной ошибкой прогноза.
forecast_error = expected_value - predicted_valueОшибка прогноза может быть рассчитана для каждого прогноза, предоставляя временной ряд ошибок прогноза.
В приведенном ниже примере показано, как можно рассчитать ошибку прогноза для серии из 5 прогнозов по сравнению с 5 ожидаемыми значениями. Пример был придуман для демонстрационных целей.
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
forecast_errors = [expected[i]-predictions[i] for i in range(len(expected))]
print('Forecast Errors: %s' % forecast_errors)При выполнении примера вычисляется ошибка прогноза для каждого из 5 прогнозов. Список ошибок прогноза затем печатается.
Forecast Errors: [-0.2, 0.09999999999999998, -0.1, -0.09999999999999998, -0.2]Единицы ошибки прогноза совпадают с единицами прогноза. Ошибка прогноза, равная нулю, означает отсутствие ошибки или совершенный навык для этого прогноза.
Средняя ошибка прогноза (или ошибка прогноза)
Средняя ошибка прогноза рассчитывается как среднее значение ошибки прогноза.
mean_forecast_error = mean(forecast_error)Ошибки прогноза могут быть положительными и отрицательными. Это означает, что при вычислении среднего из этих значений идеальная средняя ошибка прогноза будет равна нулю.
Среднее значение ошибки прогноза, отличное от нуля, указывает на склонность модели к превышению прогноза (положительная ошибка) или занижению прогноза (отрицательная ошибка). Таким образом, средняя ошибка прогноза также называется прогноз смещения,
Ошибка прогноза может быть рассчитана непосредственно как среднее значение прогноза. В приведенном ниже примере показано, как среднее значение ошибок прогноза может быть рассчитано вручную.
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
forecast_errors = [expected[i]-predictions[i] for i in range(len(expected))]
bias = sum(forecast_errors) * 1.0/len(expected)
print('Bias: %f' % bias)При выполнении примера выводится средняя ошибка прогноза, также известная как смещение прогноза.
Bias: -0.100000Единицы смещения прогноза совпадают с единицами прогнозов. Прогнозируемое смещение нуля или очень маленькое число около нуля показывает несмещенную модель.
Средняя абсолютная ошибка
средняя абсолютная ошибка или MAE, рассчитывается как среднее значение ошибок прогноза, где все значения прогноза вынуждены быть положительными.
Заставить ценности быть положительными называется сделать их абсолютными. Это обозначено абсолютной функциейабс ()или математически показано как два символа канала вокруг значения:| Значение |,
mean_absolute_error = mean( abs(forecast_error) )кудаабс ()делает ценности позитивными,forecast_errorодна или последовательность ошибок прогноза, иимею в виду()рассчитывает среднее значение.
Мы можем использовать mean_absolute_error () функция из библиотеки scikit-learn для вычисления средней абсолютной ошибки для списка прогнозов. Пример ниже демонстрирует эту функцию.
from sklearn.metrics import mean_absolute_error
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
mae = mean_absolute_error(expected, predictions)
print('MAE: %f' % mae)При выполнении примера вычисляется и выводится средняя абсолютная ошибка для списка из 5 ожидаемых и прогнозируемых значений.
MAE: 0.140000Эти значения ошибок приведены в исходных единицах прогнозируемых значений. Средняя абсолютная ошибка, равная нулю, означает отсутствие ошибки.
Средняя квадратическая ошибка
средняя квадратическая ошибка или MSE, рассчитывается как среднее значение квадратов ошибок прогноза. Возведение в квадрат значений ошибки прогноза заставляет их быть положительными; это также приводит к большему количеству ошибок.
Квадратные ошибки прогноза с очень большими или выбросами возводятся в квадрат, что, в свою очередь, приводит к вытягиванию среднего значения квадратов ошибок прогноза, что приводит к увеличению среднего квадрата ошибки. По сути, оценка дает худшую производительность тем моделям, которые делают большие неверные прогнозы.
mean_squared_error = mean(forecast_error^2)Мы можем использовать mean_squared_error () функция из scikit-learn для вычисления среднеквадратичной ошибки для списка прогнозов. Пример ниже демонстрирует эту функцию.
from sklearn.metrics import mean_squared_error
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
mse = mean_squared_error(expected, predictions)
print('MSE: %f' % mse)При выполнении примера вычисляется и выводится среднеквадратическая ошибка для списка ожидаемых и прогнозируемых значений.
MSE: 0.022000Значения ошибок приведены в квадратах от предсказанных значений. Среднеквадратичная ошибка, равная нулю, указывает на совершенное умение или на отсутствие ошибки.
Среднеквадратическая ошибка
Средняя квадратичная ошибка, описанная выше, выражается в квадратах единиц прогнозов.
Его можно преобразовать обратно в исходные единицы прогнозов, взяв квадратный корень из среднего квадрата ошибки Это называется среднеквадратичная ошибка или RMSE.
rmse = sqrt(mean_squared_error)Это можно рассчитать с помощьюSQRT ()математическая функция среднего квадрата ошибки, рассчитанная с использованиемmean_squared_error ()функция scikit-learn.
from sklearn.metrics import mean_squared_error
from math import sqrt
expected = [0.0, 0.5, 0.0, 0.5, 0.0]
predictions = [0.2, 0.4, 0.1, 0.6, 0.2]
mse = mean_squared_error(expected, predictions)
rmse = sqrt(mse)
print('RMSE: %f' % rmse)При выполнении примера вычисляется среднеквадратичная ошибка.
RMSE: 0.148324Значения ошибок RMES приведены в тех же единицах, что и прогнозы. Как и в случае среднеквадратичной ошибки, среднеквадратическое отклонение, равное нулю, означает отсутствие ошибки.
Дальнейшее чтение
Ниже приведены некоторые ссылки для дальнейшего изучения показателей ошибки прогноза временных рядов.
- Раздел 3.3 Измерение прогнозирующей точности, Практическое прогнозирование временных рядов с помощью R: практическое руководство,
- Раздел 2.5 Оценка точности прогноза, Прогнозирование: принципы и практика
- scikit-Learn Metrics API
- Раздел 3.3.4. Метрики регрессии, scikit-learn API Guide
Резюме
В этом руководстве вы обнаружили набор из 5 стандартных показателей производительности временных рядов в Python.
В частности, вы узнали:
- Как рассчитать остаточную ошибку прогноза и как оценить смещение в списке прогнозов.
- Как рассчитать среднюю абсолютную ошибку прогноза, чтобы описать ошибку в тех же единицах, что и прогнозы.
- Как рассчитать широко используемые среднеквадратические ошибки и среднеквадратичные ошибки для прогнозов.
Есть ли у вас какие-либо вопросы о показателях эффективности прогнозирования временных рядов или об этом руководстве?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
Когда перед компанией встают задачи прогнозирования спроса для управления товарными запасами, обычно появляется вопрос, связанный с выбором метода прогнозирования. Но как определить, какой метод лучше?
Однозначного ответа на этот вопрос нет. Однако, исходя из нашей практики, самым распространенным методам оценки точности прогноза является средняя абсолютная процентная ошибка (MAPE) . Также используются средняя абсолютная ошибка (MAE) и средняя квадратичная ошибка прогнозирования (RMSE).
Ошибка прогноза в данном случае – это разница между фактическим значением спроса и его прогнозным значением. Т. е, чем больше будет ошибка прогнозирования, тем менее точен прогноз. Например, при ошибке прогнозирования 5%, точность прогноза будет составлять 95%. Изначально MAPE использовалась для прогнозирования временных рядов, которые имеют регулярное нормальное распределение, такие как, например, потребление электроэнергии. И только после ее стали применять для оценки прогноза спроса. На практике ошибку могут рассчитывать по каждой позиции товара, а также среднюю оценку по всем товарным группам.
Несмотря на то, что большинство компаний до сих пор используют вышеописанные методы для оценки, мы считаем, что они не достаточно корректны и не подходят для применения в реальном бизнесе. Для простоты изложения, выделим три ключевых момента, которые приводят к некорректным выводам при использовании вышеописанных методов оценки. Назовем их ошибка № 1, № 2 и № 3. Сначала мы подробно опишем эти ошибки, а потом расскажем, как наши методы сравнения помогаю их ликвидировать.
О некорректности использования MAPE, RMSE и других распространенных ошибок
Ошибка № 1 заключается в том, что используемые методы больше относятся к математике, нежели к бизнесу, по той причине, что это обезличенные цифры (или проценты) , которые ничего не говорят про деньги. Бизнесу же нужно принимать решения на основе выгоды, которую он получит в деньгах. Например, ошибка в 80% на первый взгляд звучит устрашающие. Но в реальности за ней могут скрываться совершенно разные вещи. Ошибка по гвоздям со стоимостью одного гвоздя в 0,5 рублей – это одни потери. Но они совершенно несопоставимы с потерями от продажи промышленного оборудования стоимостью 700 000 рублей с той же величиной ошибки прогнозирования. Ко всему прочему также больше значение имеет объем продукции, что тоже никак не учитывается данными ошибками прогнозирования.
Второй важный момент (ошибка №2), который не учитывают данные оценки прогнозирования – это заморозка денежных средств в запасах и недополученная прибыль от дефицита продукции на складе. Например, если мы прогнозируем продажу 20 колесных дисков, а по факту продали 15. То это одна цена ошибки – 5 колесных дисков, которые потребуют затраты на хранение на определенное время, и как следствие стоимость замороженных оборотных средств под определенный процент. Если рассмотреть обратную ситуацию – прогнозируем продажу 20 дисков, спрос составляет 25 штук. Это уже упущенная прибыль, которая составляет разницу сумм закупки и реализации продукции. По сути мы имеет одну и ту же ошибку прогнозирования, но результат от нее может быть совершенно разным.
Третий ключевой момент (ошибка №3) – описанные ошибки распространяются только на точечный прогноз спроса и не описывают страховой запас. А он в некоторых случаях может составлять от 20% до 70% от общих товарных запасов на складе. Поэтому, какой бы точный не был прогноз с точки зрения описанных выше методов, мы все равно не оцениваем точность страхового запаса, а значит реальные данные могут быть значительно искажены.
Критерии, привязанные к прибыльности бизнеса
Учитывая описанные выше недостатки ошибок прогнозирования, такой подход не является корректным и надежным для сравнения алгоритмов. Ко всему прочему он зачастую оторван от реального бизнеса. Используемый же нами подход позволяет оценить точность алгоритмов в деньгах, рассчитать стоимость ошибки прогнозирования на понятном для бизнеса языке финансов. Таким образом это позволяет нам ликвидировать ошибку №1.
В случае с ошибкой № 2, мы рассчитываем два различных значения. Если прогноз окажется меньше реального спроса, то он приведет к дефициту, экономический урон от которого рассчитывается, как количество недопроданных товаров, умноженное на разность цен закупки и реализации. Например, вы закупаете колесные диски по 3000 рублей за штуку и продаете по 4000. Прогноз на месяц составил 1000 дисков, реальный спрос оказался 1200 штук. Экономический урон будет равен:
(1200-1000)*(4000-3000)=200 000 рублей.
В случае превышения прогноза над реальным спросом компания понесет убытки по хранению продукции. Экономический урон будет равен сумме затрат на нереализованную продукцию, помноженную на ставку альтернативных вложений за этот период. Предположим, что реальный спрос в предыдущем примере оказался 800 дисков и вам пришлось хранить диски еще один месяц. Пусть ставка альтернативных вложений составляет 20% в год. Тогда экономический урон будет равен
(1000-800)*3000*0,2/12=10 000 рублей.
Соответственно, в каждом конкретном случае, мы будет учитывать одно из этих значений.
Для того, чтобы ликвидировать ошибку № 3, мы сравниваем алгоритмы с использованием понятия уровень сервиса. Уровень сервиса (здесь и далее — уровень сервиса II рода, fill rate) – это доля спроса, которую мы гарантировано покроем с использованием имеющихся на складе запасов в течении периода их пополнения. Например, уровень сервиса 90% означает, что мы удовлетворим 90% спроса. На первый взгляд может показаться логичным, что уровень сервиса всегда должен составлять 100%. Тогда и прибыль будет максимальна. Но в реальных ситуациях зачастую дело обстоит иначе: удовлетворение 100% уровня сервиса приводит к сильному перезатариванию склада, а для товаров с ограниченными сроками годности еще и к списанию. И убытки от затрат на хранение, списания просроченной продукции и недополученной прибыли от вложения свободных денег в итоге снизят прибыть от реализации, в случае если бы мы поддерживали уровень сервиса 95%. Нужно заметить, что для каждой отдельной позиции товаров будет свой оптимальный уровень сервиса.
Так как страховой запас может составлять значительную долю, его нельзя игнорировать при сравнении алгоритмов (как это делается при расчете ошибок MAPE, RMSE и т. д.) . Поэтому мы делаем сравнение не прогноза, а оптимального запаса с заданным уровнем сервиса. Оптимальный запас для заданного уровня сервиса – это такое количество товаров, которое нужно хранить на складе, чтобы получить максимум прибыли от реализации товаров и одновременно сократить издержки на хранение до минимума.
В качестве основного критерия (критерий №1) качества прогнозирования мы используем суммарное значение потерь для заданного уровня сервиса, о котором писали выше (исправление ошибки №2). Таким образом мы оцениваем потери в денежном выражении при использовании данного конкретного алгоритма. Чем меньше потери — тем точнее работает алгоритм.
Здесь нужно заметить, что для разных уровней сервиса оптимальный запас тоже может различаться. И в одном случае прогноз будет точно в него попадать, а в другом возможны перекосы в большую, либо меньшую сторону. Так как многие компании не рассчитывают оптимальный уровень сервиса, а используют заданный заранее, значение основного критерия мы вычисляем для всех самых распространенных уровней сервиса: 70%, 75%, 80%, 85%, 90%, 95%, 98%, 99% и суммируем потери. Таким образом мы можем проверить, насколько хорошо в целом работает модель.
Для компаний, которые, считают оптимальный уровень сервиса мы используем дополнительный критерий (критерий №2) для оценки. В общем виде он выглядит как соотношение потерь на оптимальном уровне сервиса по ожидаемому (модельному) распределению продаж и по реальному распределению продаж (по факту) . Прогнозируемое значение оптимального уровня сервиса не всегда соответствует оптимальному значению уже на реальном распределении продаж. Поэтому мы должны сравнивать ошибку между прогнозом объема продаж на оптимальном (по модели) уровне сервиса и реальным объемом продаж, обеспечивающим оптимальное значение уровня сервиса по реальным данным.
Что проиллюстрировать применение данного критерия, вернемся к нашему примеру с дисками. Предположим, что прогнозное значение оптимального уровня сервиса для него составляет 90%, а оптимальный объем запаса для этого случая примем равным 3000 колесных дисков. Пусть в первом случае реальный уровень сервиса оказался выше прогнозного и составил 92%. Соответственно объем заказов также вырос и составил 3300 дисков. Ошибка прогнозирования будет рассчитываться как разность между реальным и фактическим объемом продаж, умноженная на разность цен реализации. Итого, мы имеем:
(3300-3000)*(4000-3000)=300 000 рублей.
Теперь представим обратную ситуацию: реальный уровень сервиса оказался меньше прогнозного и составил 87%. Реальный объем продаж при этом составил 2850 дисков. Ошибка прогнозирования будет рассчитана, как сумма затрат на нереализованную продукцию, умноженную на ставку альтернативных вложений за этот период (в качестве примера берем период сроком месяц и ставку равную 20% годовых) . Итоговое значение критерия будет равно:
(3000-2850)*3000*0,2/12 = 7500 рублей
Конечно, в идеальном случае, мы должны рассчитывать ошибку только при оптимальном уровне сервиса, между прогнозным и реальным значениями. Но так как не все компании еще перешли на оптимальный уровень сервиса, мы вынуждены использовать два критерия.
Используемые нами критерии в отличие от классических математических ошибок, показывают суммарные потери в деньгах при применении той или иной модели. Соответственно, наилучшей будет модель, которая обеспечивает минимальные потери. Такой подход позволят бизнес-пользователям оценить работу различных алгоритмов на понятном им языке.
Пример сравнения точности прогнозирования системы Forecast NOW c методом ARIMA (на базе номенклатуры бытовой химии) :
Пример сравнения точности прогнозирования системы Forecast NOW c методом Кростона (на базе номенклатуры бытовой химии) :
Насколько корректно на ваш взгляд считать ошибки, а не деньги? Предлагаем порассуждать на эту тему в комментариях!
Ошибка прогнозирования
Поскольку
будущее никогда нельзя в точности
предугадать по прошлому, то прогноз
будущего спроса всегда будет содержать
в себе ошибки в той или иной степени.
Модель экспоненциального сглаживания
прогнозирует средний уровень спроса.
Поэтому следует построить модель так,
чтобы уменьшить разность между прогнозом
и фактическим уровнем спроса. Эта
разность называется ошибкой прогнозирования.
Ошибка
прогнозирования выражается такими
показателями, как среднеквадратическое
отклонение, вариация или среднее
абсолютное отклонение. Раньше среднее
абсолютное отклонение использовалось
в качестве основного измерителя ошибки
прогнозирования при использовании
модели экспоненциального сглаживания.
Среднеквадратическое отклонение
отвергли из-за того, что рассчитывать
его сложнее, чем среднее абсолютное
отклонение, и у компьютеров на это просто
не хватало памяти. Сейчас у компьютеров
достаточно памяти, и теперь
среднеквадратическое отклонение
используется чаще.
Ошибку
прогнозирования можно определить с
помощью следующей формулы:
ОШИБКА
ПРОГНОЗА = ФАКТИЧЕСКИЙ СПРОС – ПРОГНОЗ
СПРОСА
Е
Рис. 3а. Нормальное
распределение ошибок прогноза
сли
прогноз спроса представляет собой
среднее арифметическое фактического
спроса, то сумма ошибок прогнозирования
за определенное количество временных
периодов будет равна нулю. Следовательно,
значение ошибки можно отыскать путем
суммирования квадратов ошибок
прогнозирования, что позволяет избежать
взаимного устранения положительных и
отрицательных ошибок прогнозирования.
Эта сумма делится на количество наблюдений
и затем из нее извлекается квадратный
корень. Показатель корректируется с
уменьшением одной степени свободы,
которая теряется при составлении
прогноза. В результате, уравнение
среднеквадратического отклонения имеет
вид:
,
где
SE
– средняя ошибка прогнозирования; Ai
– фактический спрос в период i;
Fi
– прогноз на период i;
N
– размер временного ряда.
Ф
Рис. 3б. Скошенное
распределение ошибок прогноза
орма распределения ошибок
прогнозирования является важной, когда
формулируются вероятностные утверждения
о степени надежности прогноза. Две
типовые формы распределения ошибок
прогнозирования показаны на рисунке
3.
Полагая,
что модель прогнозирования отражает
средние значения фактического спроса
достаточно хорошо и отклонения фактических
продаж от прогноза относительно невелики
по сравнению с абсолютной величиной
продаж, то вполне вероятно предположить
нормальное распределение ошибок
прогнозирования. В тех же случаях, когда
ошибка прогнозирования сопоставима по
величине с величиной спроса, имеет место
скошенное, или усеченное нормальное
распределение ошибок прогноза.
Определить
тип распределения в конкретной ситуации
можно с помощью теста на соответствие
критерию согласия хи-квадрат. В качестве
альтернативы можно использовать другой
тест, с помощью которого можно определить,
является ли распределение симметричным
(нормальным) или экспоненциальным
(разновидность скошенного распределения):
При
нормальном распределении около 2%
наблюдаемых значений превышают значение,
равное сумме среднего и удвоенного
значения среднеквадратического
отклонения. При экспоненциальном
распределении около 2% наблюдаемых
значений превышают среднее на величину
среднеквадратического отклонения,
умноженного на коэффициент 2,75.
Следовательно, в первом случае используется
нормальное распределение, а во втором
случае – экспоненциальное.
Пример.
Снова вернемся к нашему примеру. В
базовой модели экспоненциального
сглаживания были получены следующие
результаты:
-
Квартал
I
II
III
IV
Прошлый
год1
200700
900
1
100Текущий
год1
4001
000F3
= ?Прогноз
1
200779
1
005
Оценим
стандартную ошибку прогнозирования по
данным за первый и второй кварталы
текущего года, по которым нам известны
фактические и прогнозные значения.
Допустим, что спрос имеет нормальное
распределение относительно прогноза.
Рассчитаем границы доверительного
интервала с вероятностью 95% для третьего
квартала.
Стандартная
ошибка прогнозирования:
![]()
Используя
таблицу А (см. Приложение I), определяем
коэффициент z95%
= 1,96 и получаем границы доверительного
интервала по формуле:
Y
= F3
z(SE)
=1005
1,96298
= 1064
584,2
Следовательно,
с 95%-й вероятностью границы доверительного
интервала прогноза спроса на третий
квартал текущего года составляют
значения:
420,8
< Y
< 1589,2
Время на прочтение
31 мин
Количество просмотров 4.9K
Часть 1 – Энтропия
Часть 2 – Mutual Information
В этой 3-й части мы поговорим про Machine Learning, а именно, про задачу прогноза, в контексте теории информации.
Понятие Mututal Information (MI) связано с задачей прогноза. Собственно, задачу прогноза можно рассматривать как задачу извлечения информации о сигнале из факторов. Какая-то часть информации о сигнале содержится в факторах. И если вы напишите функцию, которая по факторам вычисляет число близкое к сигналу, то это и будет демонстрацией того, что вы смогли извлечь MI между сигналом и факторами.
Что такое Machine Learning?
Чтобы двигаться дальше, нам нужны базовые понятия из ML, такие как: факторы, target, Loss-функция, обучающий и тестовый пулы, overfitting и underfitting и их варианты, регуляризация, разные виды утечки данных.
Факторы (features) – это то, что вам даётся на вход, а сигнал (target) – это то, что нужно спрогнозировать, используя факторы. Например, вам нужно спрогнозировать температуру завтра в 12:00 в определённом городе – это target, а дано вам множество чисел про сегодня и предыдущие дни: температура, давление, влажность, направление и сила ветра в этом и соседних городах в разное время дня – это факторы.
Обучающие Данные – это множество примеров (aka сэмплов) с известными правильными ответами, то есть строчки в таблице, в которой есть и поля с факторами features=(f1, f2, …, fn), и поле target. Данные принято делить на две части – обучающий пул (train set) и тестовый пул (test set). Выглядит это примерно так.
Обучающий пул:
|
id |
f1 |
f2 |
… |
target |
predict |
|
1 |
1.234 |
3.678 |
… |
1.23 |
? |
|
2 |
2.345 |
6.123 |
… |
2.34 |
? |
|
… |
… |
… |
… |
… |
… |
|
18987 |
1.432 |
3.444 |
…. |
5.67 |
? |
Тестовый пул:
|
id |
f1 |
f2 |
… |
target |
predict |
|
18988 |
6.321 |
6.545 |
… |
4.987 |
? |
|
18989 |
4.123 |
2.348 |
… |
3.765 |
? |
|
… |
… |
… |
… |
…. |
… |
|
30756 |
2.678 |
3.187 |
… |
2.593 |
? |
В общих чертах задачу прогноза можно сформулировать в духе соревнования на kaggle.com:
Задача прогноза (задача ML). Вам дан обучающий пул. Реализуйте в виде кода функцию ![]() которая по заданным факторам возвращает значение, максимально близкое к target. Мера близости задана с помощью Loss-функции, и значение этой функции называется ошибкой прогноза:
которая по заданным факторам возвращает значение, максимально близкое к target. Мера близости задана с помощью Loss-функции, и значение этой функции называется ошибкой прогноза: ![]() где
где ![]() Качество прогноза определяется средним значением ошибки во время применения этого прогноза в жизни, но по факту для оценки этой средней ошибки будет использоваться некоторый тестовый пул, который от вас скрыт.
Качество прогноза определяется средним значением ошибки во время применения этого прогноза в жизни, но по факту для оценки этой средней ошибки будет использоваться некоторый тестовый пул, который от вас скрыт.
У величины ![]() есть специальное название – невязка. Два популярных варианта Loss-функции для задач прогноза вещественной величины – это:
есть специальное название – невязка. Два популярных варианта Loss-функции для задач прогноза вещественной величины – это:
-
средний квадрат невязки, что также называют среднеквадратической ошибкой или mse (mean square error);
-
средний модуль невязки, что также называют L1-ошибкой.
На практике задача ML более общая и высокоуровневая. А именно, нужно разработать в меру универсальную ML-модель – способ получения функций ![]() по данному обучающему пулу и заданной Loss-функции. А также нужно уметь делать model evaluation: мониторить качество прогноза в работающей системе, уметь обновлять обученные модели (пошагово, делая новые версии, или модифицируя внутренние веса модели в режиме online), улучшать качество модели, контролировать чистоту и качество факторов.
по данному обучающему пулу и заданной Loss-функции. А также нужно уметь делать model evaluation: мониторить качество прогноза в работающей системе, уметь обновлять обученные модели (пошагово, делая новые версии, или модифицируя внутренние веса модели в режиме online), улучшать качество модели, контролировать чистоту и качество факторов.
Процесс получения функции ![]() по обучающему пулу называется обучением. Популярны такие варианты ML-моделей (классы моделей):
по обучающему пулу называется обучением. Популярны такие варианты ML-моделей (классы моделей):
-
Линейная модель, в которой
 , и процесс обучения сводится к подбору параметров
, и процесс обучения сводится к подбору параметров  , что делается обычно методом градиентного спуска.
, что делается обычно методом градиентного спуска. -
Gradient boosted trees (GBT) – модель, в которой функция выглядит как сумма нескольких слагаемых (сотен, тысяч), где каждое слагаемое – это решающее дерево, в узлах которого находятся условия на факторы, а в листьях – конкретные числа; каждое слагаемое можно представлять как какую-то систему вложенных if-конструкций с условиями на значения факторов, где в конечных узлах находятся просто числа. GBT – это не только про то, что решение есть сумма деревьев, но и вполне конкретный алгоритм получения этих слагаемых. Для обучения GBT есть много готовых программ: CatBoost, xgboost. См. статью на хабре.
-
Neural Networks – в простейшем базовом варианте это модель вида
 , где
, где  – матрицы, размеры которых определяет разработчик модели, факторы представлены в виде вектора
– матрицы, размеры которых определяет разработчик модели, факторы представлены в виде вектора  , оператор
, оператор  соответствует умножению вектора на матрицу с последующим обнулением всех отрицательных чисел в результирующем векторе. Операторы выполняются в порядке справа налево – это важно в случае наличия такого обнуления. Матрицы называются слоями нейросети, а количество матриц – глубиной нейросети. Вместо обнуления отрицательных можно брать произвольные другие нелинейные преобразования. Если бы не было нелинейных преобразований после умножения вектора на матрицу, все матрицы можно было бы «схлопнуть» в одну и пространство возможных функций не отличалось бы того, что задаётся линейной моделью. Я описал линейную архитектуру нейросети, но возможны и более сложные, например,
соответствует умножению вектора на матрицу с последующим обнулением всех отрицательных чисел в результирующем векторе. Операторы выполняются в порядке справа налево – это важно в случае наличия такого обнуления. Матрицы называются слоями нейросети, а количество матриц – глубиной нейросети. Вместо обнуления отрицательных можно брать произвольные другие нелинейные преобразования. Если бы не было нелинейных преобразований после умножения вектора на матрицу, все матрицы можно было бы «схлопнуть» в одну и пространство возможных функций не отличалось бы того, что задаётся линейной моделью. Я описал линейную архитектуру нейросети, но возможны и более сложные, например,  .
. Кроме самых разных поэлементных нелинейных преобразования и умножения на матрицу в нейросетях могут использоваться операторы скалярного произведения векторов и оператор поэлементного максимума для двух векторов одной размерности, объединения векторов в один более длинный и др. Можно думать об общей архитектуре для функции
 , когда на вход поступает вектор, а дальше с помощью операторов
, когда на вход поступает вектор, а дальше с помощью операторов  , нелинейных функций
, нелинейных функций  и весов
и весов  конструируется ответ. В этом смысле нейросети могут представлять самой функции довольно общего вида. По факту, архитектуру функции
конструируется ответ. В этом смысле нейросети могут представлять самой функции довольно общего вида. По факту, архитектуру функции  называют нейросетью тогда, когда в ней присутствует что-то похожее на цепочку вида
называют нейросетью тогда, когда в ней присутствует что-то похожее на цепочку вида  . А так, мы по сути имеем задачу регрессии – подобрать параметры (веса) в параметрически заданной функции, чтобы минимизировать ошибку. Есть множество методов обучения нейросетей, они в своем большинстве итерационные, и за шаг изменения весов отвечает модуль, который программисты называют оптимизатором, см. например AdamOptimizer.
. А так, мы по сути имеем задачу регрессии – подобрать параметры (веса) в параметрически заданной функции, чтобы минимизировать ошибку. Есть множество методов обучения нейросетей, они в своем большинстве итерационные, и за шаг изменения весов отвечает модуль, который программисты называют оптимизатором, см. например AdamOptimizer.
Терминология ML
В регрессионном анализе появилось много важных терминов, которые позволяют лучше понять содержание задачи прогноза и не делать типичных ошибок. Эти термины практически без изменений перекочевали в ML. Здесь я изложу базовые понятия, стараясь отмечать связи с теорией информации.
Overfitting
Overfitting (переобучение) – это когда выбранная вами модель сложнее, чем реальность, стоящая за target И/ИЛИ данных слишком мало, чтобы позволить себе обучать такую сложную модель. Есть две основные причины overfitting:
-
too complex model: Устройство модели сильно сложнее, чем реальность или в своей сложности ей не соответствует. Проще это визуализировать на примере однофакторной модели.
Пусть в обучающем пуле 11 точек а модель – суть многочлен 10-й степени. Можно подобрать такие коэффициенты в многочлене, что он «заглянет» в каждую точку обучающего пула, но при этом не будет обладать хорошим качеством прогноза:
а модель – суть многочлен 10-й степени. Можно подобрать такие коэффициенты в многочлене, что он «заглянет» в каждую точку обучающего пула, но при этом не будет обладать хорошим качеством прогноза:, а отклонения от неё – это или шум, или что-то, объясняемое факторами, которых у нас нет")
Голубая линия – многочлен 10 степени,
который смог в точности воспроизвести обучающий пул из 11 точек.
Но правильная модель скорее линейная (чёрная линия), а отклонения от неё – это или шум, или что-то, объясняемое факторами, которых у нас нетМногочлен 10-й степени – это очевидный и часто используемый пример переобучения. Многочлены невысокой степени, но от многих переменных тоже могут давать overfitting. Например, вы можете подбирать модель predict = многочлен степени 3 от 100 факторов (кстати, сколько в нём коэффициентов?), в то время как реальность соответствует predict = многочлен степени 2 от факторов + случайный шум. При этом, если у вас данных довольно много, то классические методы регрессии могут дать приемлемый результат, и коэффициенты при членах степени 3 будут очень маленькими. Эти члены степени 3 будут вносить маленький вклад в ответ при прогнозе для типичных значений факторов (как в случае с интерполяцией). Но в зоне крайних значений факторов, где прогноз уже скорее экстраполяция, а не интерполяция, высокие степени будут вносить заметный вклад и портить качество прогноза. Ну и, конечно, когда данных мало, шум может начать восприниматься за чистую монету, и прогноз будет стараться заглянуть в каждую точку обучающего пула.
-
insufficient train data: Модель может более менее соответствовать реальности, но при этом вы можете не иметь достаточное количество обучающих данных. Приведём опять пример с многочленом: пусть и реальность и ваша модель есть многочлен 3-й степени от двух факторов. Этот многочлен задаётся 10 коэффициентами, то есть пространство возможных прогнозаторов у вас 10-мерное. Если в обучающем пуле у вас 9 примеров, то, записав равенство «многочлен(featuresi) = targeti» для каждого примера, вы получите 9 уравнений на эти коэффициенты, и их недостаточно, чтобы однозначно определить 10 коэффициентов. В пространстве возможных прогнозаторов вы получите прямую и каждая точка на этой прямой есть прогнозатор, который идеально повторяет то, что у вас в обучающем пуле. Вы можете случайно выбирать один из них, и это с высокой вероятностью будет плохой прогнозатор.
-
Важное замечание про обучение многопараметрических моделей. Пример выше может показаться искусственным, но правда в том, что современные нейросетевые модели могут содержать миллионы параметров или даже больше. Например, языковая модель GPT3 содержит 175 млрд. параметров.
Если в вашей модели N = 175 млрд. параметров, а размер обучающего пула M = 1 млрд, то в общем случае вы имеете бесконечное множество моделей идеально подходящих под обучающий лог, и это множество – суть многообразие размерности N — M = 174 млрд.
В случае с глубокими многопараметрическими нейросетями эффект «insufficient train data» проявляется в полный рост, если действовать неправильно. А именно, если искать строгий минимум ошибки на обучающем пуле, то получается плохой, overfitted, прогнозатор. Поэтому на практике так не делают. Выработаны интересные техники и интуиция про то, как обучать модель с N параметрами на M примерах, где M заметно меньше N. Используются регуляризационные добавки к Loss-функции (L2, L1), Stochastic Gradient Descent, Dropout Layers, Early Stopping, prunning и другие техники.
ВАЖНО: Знание этих техник и умение их применять во многом и определяет экспертизу в ML.
-
, а отклонения от неё – это или шум, или что-то, объясняемое факторами, которых у нас нет")
Underfitting
Underfitting – это когда модель прогноза проще, чем реальность. Также как и в случае с overfitting здесь есть две основных причины:
-
too simplistic model: выбрана слишком простая модель, сильно упрощающая то, что в реальности стоит за target. Такие случаи по-прежнему встречаются в продакшене, и обычно это линейные модели. Линейные модели привлекают своей простотой и наличием математических теорем, обосновывающих и описывающих их предиктивные способности. Но можно с уверенностью сказать, что если вы решите с помощью линейных моделей прогнозировать курс валют, погоду, вероятность покупки или вероятность возврата кредита, то вы получите слабую модель – under-fitted weak model.
-
too early stopping: обычно процессы обучения моделей итеративны, и если проделать слишком мало итераций, то получается недообученная модель;
Data leakage
Data leakage – это когда вы во время обучения использовали то, что есть в тестовом пуле или данные, которые недоступны или отличаются от тех, что будут доступны на практике при применении модели в жизни. Модели, которые сумеют воспользоваться этой утечкой, будут иметь неоправданно низкую ошибку на тестовом пуле и выбраны для использования в жизни. Есть несколько видов data leakage:
-
утечка таргета в факторы: Если, в задаче с прогнозом температуры вы добавите фактор – средняя температура за K дней, и в эти K дней при обучении случайно попадёт в том числе и целевой день, на который нужно сделать прогноз, то вы получите испорченный или нерабочий прогнозатор. Могут быть более сложные утечки через факторы. В случае прогноза какого-то будущего события вы должны многократно убедиться, что при вычислении факторов для обучающего пула не используются данные, которые получены во время этого события или после.
-
простая утечка тестового пула: Иногда всё просто – в обучающий пул попадают строчки из тестового пула.
-
утечка через подбор гиперпараметров: Правило, что для обучения разрешено использовать только обучающий пул, обманчиво просто. Здесь можно легко обмануться. Типичный пример неявной утечки – это подбор гиперапараметров при обучении. У всякого алгоритма обучения есть гиперпараметры. Например, у градиентного спуска есть параметр «скорость обучения» и параметр, задающий критерий останова. Ещё вы к Loss-функции можете добавить регуляризационные компоненты
 и
и  , и вот вам ещё два гиперапараметра
, и вот вам ещё два гиперапараметра и . Приставка «гипер» используется, чтобы отличать внутренние параметры модели (веса), от параметров влияющих на процесс обучения.
и . Приставка «гипер» используется, чтобы отличать внутренние параметры модели (веса), от параметров влияющих на процесс обучения.
Итак, предположим, вы решили в цикле проверять разные гиперпараметры обучения и выбрать те гиперпараметры, на которых достигается минимум ошибки на тестовом пуле. Надо понимать, что здесь происходит утечка тестового пула в модель. «Засаду», которая здесь скрывается, легко понять, именно с точки зрения теории информации. Когда вы задаете вопрос, чему равна ошибка на тестовом пуле, вы получаете информацию о тестовом пуле. А когда вы, на основании этой информации, принимаете какие-то решение, влияющие в конечном итоге на веса вашей модели, то значит биты этой информации оказываются в весах модели.
Ещё можно проиллюстрировать концепцию утечки тестового пула доведя до абсурда понятие гиперапараметров. Ведь разница между весами (параметрами) и гиперпараметрами (параметрами процесса обучения) чисто формальная. Давайте веса модели, например коэффициенты многочлена 10 степени все назовоём гиперапараметрами, а процесса обучения у нас не будет (множество внутренних весов у нас будет пустым). И давайте запустим безумный цикл по перебору всех возможных комбинаций значений гиперпараметров (каждый параметр будем перебирать от -1000 до +1000 с шагом ) и вычислению ошибки на тестовом пуле. Понятно, что через условные миллиард лет мы найдём такую комбинацию параметров, которая даёт очень маленькую ошибку на тестовом пуле и картинку выше мы сможем запостить снова, но уже с другой подписью:
) и вычислению ошибки на тестовом пуле. Понятно, что через условные миллиард лет мы найдём такую комбинацию параметров, которая даёт очень маленькую ошибку на тестовом пуле и картинку выше мы сможем запостить снова, но уже с другой подписью: 
Голубая линия – многочлен 10 степени,
который смог в точности воспроизвести тестовый пул из 11 точек.Этот прогнозатор будет хорошо себя показывать на тестовом пуле, а в жизни – плохо.
-
На практике используются модели с тысячами или миллионами весов и описанные эффекты проявляются на пулах больших размеров, особенно при наличии утечки данных из будущего (см. ниже).
-
Надо понимать, что утечка теста через подбор гиперпараметров так или иначе всегда происходит. Даже если вы сделали специальный валидационный пул для подбора гиперпараметров, а тестовый пул никак не использовали для подбора гиперпараметров, всё равно наступает момент вычисления метрики качества на тестовом пуле. А потом наступает момент, когда у вас есть несколько моделей, измеренных на тестовом пуле, и вы выбираете лучшую модель по метрике на тесте. Этот момент выбора также можно назвать утечкой, но не всегда нужно бояться этой утечки.
-
Важное замечание про то, когда нужно боятся этой утечки. Если эффективная сложность модели (см. определение ниже) у вас сотни или больше бит, то можно не боятся утечки такого сорта и не выделять специальный пул для подбора гиперпараметров – логарифм числа выстрелов для подбора гиперпараметров должен быть заметно меньше сложности модели.
-
-
утечка данных из будущего: например, когда вы обучаете прогнозаторы вероятности клика на рекламное объявление, то в идеале обучающий пул должен содержать данные, доступные исключительно на даты меньше даты X, где X – минимальная дата событий в тестовом пуле. Иначе возможны хитрые утечки типа следующей. Пусть мы взяли множества событий показы рекламы размеченной target = 1 для кликнутых событий показа, и target = 0 для некликнутой. И пусть мы разбили множество событий на тестовый и обучающий пул не по границе даты X, а случайным образом, например, в пропорции 50:50. Известно, что пользователи любят кликать сразу на несколько объявлений одной тематики подряд в течение нескольких минут, отбирая нужный товар или услугу. И тогда такие серии нескольких кликов будут случайно делиться на две части – одна пойдёт в обучающий, другая – в тестовый пул. Можно искусственным образом сделать модель с утечкой: возьмём самую хорошую правильную модель без утечки и дополнительно запомним факты «пользователь U кликал на тематику T» из обучающего лога. Затем при использовании модели будем совсем ненамного повышать вероятность клика для случаев (U, T) из этого множества. Это улучшит модель с точки зрения ошибки на тестовом пуле, но ухудшит её с точки применения на практике на новых данных. Мы описали искусственную модель, но несложно представить естественный механизм такого запоминания пар (U, T) и завышения вероятности для них в нейросетях и других популярных алгоритмах ML. Наличие таких утечек из будущего усугубляет проблему утечки через гиперпараметры. На таком тестовом пуле с утечкой будут выигрывать модели перекрученные в сторону запоминания данных. Более общим образом эту проблему можно описать так: модель может переобучиться под test set, если MI между примером в train set и примером в test set больше, чем между примером в train set и реальным примером при использовании модели в жизни.
Задачи
Задача 3.1. Пусть реальность такова, что ![]() где
где ![]() – случайное число из
– случайное число из ![]()
![]() Фактор
Фактор![]() сэмплируется из
сэмплируется из ![]() Сколько в среднем нужно обучающих данных, чтобы, имея соответствующую реальности модель, получить оценки весов равные истинным с точностью до среднеквадратичной ошибки
Сколько в среднем нужно обучающих данных, чтобы, имея соответствующую реальности модель, получить оценки весов равные истинным с точностью до среднеквадратичной ошибки ![]() ? Считайте, что априорное распределение весов – это нормальное распределение
? Считайте, что априорное распределение весов – это нормальное распределение ![]() Запишите ответ как функцию от
Запишите ответ как функцию от ![]() ,
, ![]() ,
, ![]() Как ошибка прогноза зависит от размера обучающего лога?
Как ошибка прогноза зависит от размера обучающего лога?
Ответ
Есть такой способ получения ответа «от физиков». Пусть размер обучающего лога равен ![]() . Из задачи 1.16 мы имеем интуицию, что
. Из задачи 1.16 мы имеем интуицию, что ![]() . Константа
. Константа ![]() в этой задаче является функцией от
в этой задаче является функцией от ![]() и
и ![]() . Но есть ли зависимость
. Но есть ли зависимость ![]() от
от ![]() На самом деле нет. Действительно, шум
На самом деле нет. Действительно, шум ![]() как бы стирает цифры в десятичной записи значения
как бы стирает цифры в десятичной записи значения ![]() , начиная с какого-то места после десятичной точки. При увеличении
, начиная с какого-то места после десятичной точки. При увеличении ![]() остается больше значащих цифр и ровно настолько больше значащих цифр мы узнаем про коэффициенты
остается больше значащих цифр и ровно настолько больше значащих цифр мы узнаем про коэффициенты ![]() И тем самым при увеличении
И тем самым при увеличении ![]() позиция в десятичной записи
позиция в десятичной записи ![]() , начиная с которой есть неопределённость остается той же. Из того, что
, начиная с которой есть неопределённость остается той же. Из того, что ![]() не участвует в формуле и из соображений размерности, формула должна выглядеть так
не участвует в формуле и из соображений размерности, формула должна выглядеть так
![]()
Где константа ![]() вычисляется эмпирически равна примерно 0.9. Соответственно получаем ответ
вычисляется эмпирически равна примерно 0.9. Соответственно получаем ответ ![]() .
.
Ошибка самого значения ![]() равна
равна
![]()
Это следствие того, что при сложении двух независимых случайных величин ![]() и
и ![]() дисперсии складываются. Они должны быть независимы при правильном прогнозе, потому то если они зависимы, то модель можно улучшить, сделав некую калибровку прогноза.
дисперсии складываются. Они должны быть независимы при правильном прогнозе, потому то если они зависимы, то модель можно улучшить, сделав некую калибровку прогноза.
Таким образом, в этой задаче прогноза и многих практических задачах есть неустранимая ошибка ![]() . Она определяет две вещи:
. Она определяет две вещи:
(1) то, какую ошибку вы получите для случая очень большого обучающего пула (при ![]() имеем
имеем ![]() )
)
(2) а также размер пула, необходимый для достижения какой-либо заданной ошибки внутренних параметров, квадратично зависит от этой неустранимой ошибки: ![]()
Неустранимая ошибка ![]() определяется количеством информации в сигнале, которая в принципе отсутствует в ваших факторах. Размер обучающего лога, необходимый для получения модели определённой точности mse, квадратично зависит от этой ошибки:
определяется количеством информации в сигнале, которая в принципе отсутствует в ваших факторах. Размер обучающего лога, необходимый для получения модели определённой точности mse, квадратично зависит от этой ошибки:
![]()
Тут у кого-то может возникнуть не совсем верная интуиция про то, что важно уменьшить эту ошибку, и что добавление каких-либо факторов, в которых может быть скрыта новая информация про сигнал, – крайне полезное мероприятие. Иногда так и есть. Но на самом деле, когда у вас больше факторов, у вас больше и внутренних весов, и вам нужно больше информации, чтобы узнать первые значащие цифры весов. Увеличение сложности модели при добавлении новых факторов порой обнуляет полезный эффект от новой информации, если не увеличивать размер обучающего лога (увеличивать число строчек в обучающем пуле), особенно в случае, когда новые факторы менее информативны, чем существующие.
К тому же факторы часто зависимы и сами по себе содержат в себе шумную компоненту. Контроль пользы от новых факторов и отбор факторов (feature selection) – это отдельная сложная тема для разговора.
Задача 3.2. Пусть реальность такова, что target есть многочлен 2-й степени от 10 факторов, при этом коэффициенты в многочлене – это числа разово сэмплированные из ![]() а факторы – независимые случайные числа из
а факторы – независимые случайные числа из ![]() . Сколько нужно данных в обучающем логе, чтобы получить приемлемое качество прогноза, когда все факторы лежат на отрезке [-1, 1], для случая, когда модель верна, то есть является многочленом 2-й степени?
. Сколько нужно данных в обучающем логе, чтобы получить приемлемое качество прогноза, когда все факторы лежат на отрезке [-1, 1], для случая, когда модель верна, то есть является многочленом 2-й степени?
А если модель есть многочлен 3-й степени?
Задача 3.3. Постройте модель пользователей, которые в каждый момент времени склонны больше кликать на объявления какой-то одной тематики, заинтересовавшей их в данный момент, и убедитесь, что деление пула на обучающий и тестовый пул не по времени, а случайно, приводит к утечке данных из будущего.
Можно взять, например, такую модель. У каждого пользователя есть 10 любимых тематик, мы их знаем и храним в профиле пользователя. Пользовательская активность разделена на сессии, каждая сессия длится 5 минут, и во время сессии каждый пользователь видит ровно 10 объявлений по одной из его 10 тематик, тематика из любимых выбирается случайно. В каждую сессию пользователь интересуется одной из этих 10 тематик особенно сильно, и нет никаких факторов, позволяющих угадать, какой именно. Вероятность клика для такой «горячей» тематики в 2 раза больше, чем обычно. Для каждого пользователя по истории его кликов мы хорошо знаем вероятности клика для его 10 тематик, и пусть, если их упорядочить по интересности для конкретного пользователя, вектор этих вероятностей равен {0.10, 0.11, 0.12, …, 0.19} .
Идентификатор пользователя и номер категории и есть доступные нам факторы. Насколько можно увеличить правдоподобие прогноза вероятности на тестовом пуле, если предположить, что каждая сессия разделилась ровно пополам между тестовым и обучающим пулами (5 событий пошли в один пул и 5 – во второй), и статистику по 5 событиям из обучающего пула можно использовать для прогноза вероятности клика на 5 других?
Предлагается экспериментально получить overfitting из-за утечки данных из будущего , используя какую-либо программу для ML, например, CatBoost.
Определение 3.1. Имплементационная![]() -сложность функции (
-сложность функции (![]() -ИС) – это то, сколько бит информации о функции нужно передать от одного программиста другому, чтобы тот смог её воспроизвести со среднеквадратичной ошибкой не более, чем
-ИС) – это то, сколько бит информации о функции нужно передать от одного программиста другому, чтобы тот смог её воспроизвести со среднеквадратичной ошибкой не более, чем ![]() . Два программиста предварительно договариваются о параметрическом семействе функций и априорном распределении параметров (весов) этого семейства.
. Два программиста предварительно договариваются о параметрическом семействе функций и априорном распределении параметров (весов) этого семейства.
Эффективная сложность модели – это минимальная имплементационная сложность функции среди всех возможных функций, которые дают такое же качество прогноза такое, что и данная модель.
Задача 3.4. Какая средняя ![]() -ИС функции вида
-ИС функции вида

от n факторов, в которой веса сэмплированы из распределения ![]() , а факторы сэмплируются из
, а факторы сэмплируются из ![]() .
.
Ответ
При фиксированных факторах погрешность функции определяется погрешностями весов по формуле
![]()
В среднем по всем возможным значениям факторов получаем ![]() . Если мы хотим
. Если мы хотим ![]() , то веса нужно передавать с точностью
, то веса нужно передавать с точностью ![]() .
.
Таким образом, согласно ответу в задаче 1.9, в среднем нужно будет передать ![]() бит. Здесь видно важное свойство очень сложных моделей – для определения сложности сложной модели не так важно какое и насколько хорошее у вас априорное знание о весах, и не так важно, какая вам требуется точность или какая точность по факту достигается. Основная компонента в ИС модели это
бит. Здесь видно важное свойство очень сложных моделей – для определения сложности сложной модели не так важно какое и насколько хорошее у вас априорное знание о весах, и не так важно, какая вам требуется точность или какая точность по факту достигается. Основная компонента в ИС модели это ![]() , где n – некое эффективное количество весов, равноправно и с пользой участвующих в модели.
, где n – некое эффективное количество весов, равноправно и с пользой участвующих в модели.
Задача 3.5. Функция t(id) задаётся таблицей как функция от одного фактора – id категории. Есть N = 1 млн. категорий, их доли в данных различны, и можно считать, что их доли получены сэмплированием 1 млн. чисел из экспоненциального распределения с последующей нормализацией, чтобы сумма долей была 1 (такое сэмплирование соответствует разовому сэмплированию из распределения Дирихле с параметрами {1,1,…,1} – 1 млн. единичек). Значения функции t для этих категорий сэмплированы из бета-распределения![]()
![]() независимо от их доли.
независимо от их доли.
Какова средняя![]() -ИС таких функции?
-ИС таких функции?
Ответ
Во-первых, давайте опишем поведение этой функции в районе очень маленьких ![]() . Когда
. Когда ![]() , мы вынуждены хранить табличную функцию – 1 млн. значений. Можно численно или по формуле из википедии почитать энтропию бета-распределения
, мы вынуждены хранить табличную функцию – 1 млн. значений. Можно численно или по формуле из википедии почитать энтропию бета-распределения ![]() . Далее можно положить, что мы хотим передать другому программисту, что значение t для какой-то конкретной категории i лежит в районе некоторого фиксированного значения
. Далее можно положить, что мы хотим передать другому программисту, что значение t для какой-то конкретной категории i лежит в районе некоторого фиксированного значения ![]() с разрешённой погрешностью
с разрешённой погрешностью ![]() . Это все равно что сузить «колпак» распределения
. Это все равно что сузить «колпак» распределения ![]() до, скажем, нормального распределения
до, скажем, нормального распределения ![]() Разница энтропий
Разница энтропий ![]() и
и ![]() равна примерно
равна примерно ![]() . Это надо сделать для 1 миллиона категорий, поэтому для очень маленьких
. Это надо сделать для 1 миллиона категорий, поэтому для очень маленьких ![]() ответ
ответ ![]() .
.
Для больших ![]() (но всё ещё заметно меньше 1) работает другая стратегия. Давайте разобьем промежуток [0,1] на одинаковые отрезки длины
(но всё ещё заметно меньше 1) работает другая стратегия. Давайте разобьем промежуток [0,1] на одинаковые отрезки длины ![]() , и будем для каждой категории передавать номер отрезка, в который попало значение функции для этой категория. Эта информация имеет объём
, и будем для каждой категории передавать номер отрезка, в который попало значение функции для этой категория. Эта информация имеет объём ![]() (см. задачу 1.7). В результате в каждом ответе наша ошибка будет ограничена длиной отрезка, в который мы попали. Если ответом считать середину отрезка и предполагать равномерность распределения (что допустимо, когда отрезки маленькие), то ошибка в рамках отрезка длины
(см. задачу 1.7). В результате в каждом ответе наша ошибка будет ограничена длиной отрезка, в который мы попали. Если ответом считать середину отрезка и предполагать равномерность распределения (что допустимо, когда отрезки маленькие), то ошибка в рамках отрезка длины ![]() равна
равна ![]() . Таким образом, чтобы получить заданную среднюю ошибку
. Таким образом, чтобы получить заданную среднюю ошибку ![]() , нужно брать отрезки длиной
, нужно брать отрезки длиной ![]() . Итого ответ равен
. Итого ответ равен ![]() .
.
Оба подхода дают ответ вида ![]() . Идея использования фильтра Блюма для хранения множеств категорий для каждого отрезка даёт тот же результат.
. Идея использования фильтра Блюма для хранения множеств категорий для каждого отрезка даёт тот же результат.
Задача 3.6. Пусть в предыдущей задаче смысл функции – вероятность клика на рекламное объявление. Перенумеруем все категории в порядке убывания их истинной доли и обозначим порядковый номер как order_id, а исходный случайный идентификатор как id. Предлагается рассмотреть разные варианты ML с огрублением номера (идентификатора) категории до натурального числа от 1 до 1000. Это ограничение может быть связано, например, с тем, что вы хотите хранить статистику по историческим данным, и у вас есть возможность хранить только 1000 пар (показы, клики). Варианты огрубления идентификатора категории:
(a) огрубленный идентификатор равный id’ = id // 1000 (целочисленное деление на 1000);
(b) огрубленный идентификатор равный id’ = order_id для топовых 999 категорий по доле, а всем остальным назначить идентификатор 1000;
(с) какой-то другой способ огрубления id’ = G(id), где G – детерминированная функция, которую вы можете сконструировать на базе статистики кликов на 100 млн показов, где каждый показ имеет какую-то категорию с вероятностью ровной доле категорий, а клик происходит согласно вероятности клика для этой категории.
Оцените значение ошибки error в этих трёх вариантах, где ![]() а
а![]() , а
, а ![]() – это значение
– это значение ![]() для идеального прогноза
для идеального прогноза ![]() .
.
Задача 3.7. Пусть реальность такова, что ![]() , где
, где ![]() – это шум, случайное число из
– это шум, случайное число из ![]() . А ваша модель
. А ваша модель![]()
где веса ![]() вам неизвестны и имеют априорное распределение лапласа со средним 0 и дисперсией 1. Последние 5 факторов модели по факту бесполезны для прогноза. Какого размера должен быть обучающий пул, чтобы получить среднеквадратическую ошибку прогноза
вам неизвестны и имеют априорное распределение лапласа со средним 0 и дисперсией 1. Последние 5 факторов модели по факту бесполезны для прогноза. Какого размера должен быть обучающий пул, чтобы получить среднеквадратическую ошибку прогноза
![]() .
.
Сгенерируйте три пула №1, №2, №3 c размерами 50, 50, 100000 и узнайте как лучше действовать – (а), (б) или (в):
(а) соединить два пула в один и на основании объединённого пула найти наилучшие веса, минимизирующие ![]() на этом пуле
на этом пуле
(б) для различных пар ![]() , найти наилучшие веса, минимизирующие
, найти наилучшие веса, минимизирующие ![]() на пуле №1; из всех пар выбрать такую пару
на пуле №1; из всех пар выбрать такую пару ![]() ,
, ![]() , на которых достигается минимум
, на которых достигается минимум ![]() на пуле №2; пары
на пуле №2; пары ![]() предлагается взять из множества
предлагается взять из множества ![]() где
где ![]() и
и ![]() геометрические прогрессии с
геометрические прогрессии с ![]() от
от![]() до 1. Нарисуйте график ошибки как функцию от
до 1. Нарисуйте график ошибки как функцию от ![]() , положив
, положив![]() .
.
(в) соединить два пула в один и на основании объединённого пула найти наилучшие веса, минимизирующие ![]() на этом пуле; значения
на этом пуле; значения ![]() ,
, ![]() взять из пункт (б).
взять из пункт (б).
Метод тем лучше, чем меньше ошибка на пуле №3, который соответствует применению модели в реальности. Стабилен ли победитель, когда вы генерируете новые пулы? Нарисуйте таблицу 3×3 mse ошибок на трёх пулах в этих трёх методах.
Как падает ошибка на пуле №3 с ростом размеров пулов №1 и №2?
Задача 3.8. Пусть реальность такова, что ![]() , где
, где
Какая будет mse ошибка прогноза в среднем на достаточно больших тестовых и обучающих пулах по различным вариантам функции ![]() (то есть для различных вариантов сэмплирования коэффициентов
(то есть для различных вариантов сэмплирования коэффициентов ![]() ) для случая, когда ваша модель есть
) для случая, когда ваша модель есть
-
(а0)
 с истинными значениями коэффициентов.
с истинными значениями коэффициентов. -
(б0)
 с истинными значениями коэффициентов.
с истинными значениями коэффициентов. -
(в0)
 с истинными значениями коэффициентов.
с истинными значениями коэффициентов. -
(а1)
с обучением (то есть с коэффициентами, полученными регрессией). -
(б1)
с обучением, без знания, какие коэффициенты равны 0. -
(в1)
с обучением, без знания, какие коэффициенты равны 0. -
(в2)
с обучением и знанием, какие именно коэффициенты равны 0. -
(г1)
 нейросеть глубины d = 5, размер внутренних слоёв h=5 (внутренние матрицы имеют размер h x h).
нейросеть глубины d = 5, размер внутренних слоёв h=5 (внутренние матрицы имеют размер h x h).
Достаточно большой обучающий пул – это такой пул, удвоение которого не даёт заметного уменьшения ошибки на тесте.
Достаточно большой тестовый пул – это такой пул, конечность размера которого не вносит ошибки, сравнимой с ошибкой самой модели. То есть достаточно большой тестовый пул не позволит вам критично ошибиться в ранжировании моделей. Разрешающая способность тестового пула – это разница в качествах модели, которую тестовый пул позволяет с уверенностью констатировать. В нашей задаче нужно правильно ранжировать перечисленные 6 моделей.
Пронаблюдайте явление переобучения в этих моделях (кроме первых двух), уменьшив размер обучающего пула до некоторого значения. Для каждой модели это будет свой размер. Попробуйте избавится от явления переобучения
1) добавляя к Loss-функции регуляризационные члены ![]()
![]() ;
;
2) используя early stopping;
3) используя SGD;
4) меняя архитектуру нейросети;
5) добавляя Dropout;
6) комбинацию перечисленных методов.
Интересно также на этой задаче изучить как растёт степень переобучения и падает качество модели с ростом количества (лишних) параметров. В модели (в1) для начала можно взять только те коэффициенты, которые на самом деле не равны нулю. И потом можно проверить несколько вариантов с добавлением в модель какого-то количества случайно выбранных лишних коэффициентов. Нарисуйте график роста ошибки модели от логарифма числа коэффициентов в модели. Нарисуйте график изменения ошибки нейросетевой модели (г1) как функцию от числа внутренних слоёв и размера слоёв.
Задача 3.9. Пусть реальность такова, что

где
Как зависит ошибка определения весов ![]() от размера обучающего лога
от размера обучающего лога ![]() и
и ![]()
Ответ
В первом приближении ответ равен

И это хорошее приближение для случая ![]() (
(![]() заметно больше
заметно больше ![]() ).
).
При n = 0 наилучшая оценка весов равна 0, и ошибка этой оценки равна 1, и она медленно убывает при росте n до числа m. Затем ошибка падает заметно быстрее и с ростом n приближается к асимптоте (1). С помощью численных экспериментов можно получить такой график:

Ось X нормирована на m, то есть X=1 соответствует n = m.
Красная линия соответствует функции 1/n.
Если у кого-то есть хороший ответ про аналитическое приближение в окрестности n ~ m, пишите в личку.
Задача 3.10. Пусть реальность такова, что

где
Как будет выглядеть наилучший прогноз, если вам известны точные значения весов![]()
Как лучше всего реализовать обучение в этой задаче (когда веса неизвестны и их надо «обучить»)?
Ответ
Рассмотрим частную задачу про добавление нового фактора ![]() к имеющемуся прогнозу
к имеющемуся прогнозу ![]() . Пусть
. Пусть

Можно ли уменьшить ошибку mse, взяв новый прогноз
![]()
Текущая ошибка равна дисперсии ![]() Ошибка нового прогноза будет равна
Ошибка нового прогноза будет равна ![]() она меньше старой ошибки, если
она меньше старой ошибки, если ![]()
Давайте построим последовательность улучшений прогноза

Числа ![]() равны 0 или 1 – это индикаторы того, берём мы фактор
равны 0 или 1 – это индикаторы того, берём мы фактор ![]() в линейный прогноз или нет.
в линейный прогноз или нет. ![]() , где
, где

Потом, если мы возьмём первый фактор, ошибка будет равна
![]()
Логично брать новый фактор ![]() в линейный прогноз тогда, когда
в линейный прогноз тогда, когда ![]()
В итоге ошибка конечного прогноза равна

Итак в случае линейного прогноза и известных весов ![]() можно брать или не брать слагаемые, и логично быть слагаемые
можно брать или не брать слагаемые, и логично быть слагаемые ![]() с теми факторами
с теми факторами ![]() в которых дисперсия шума меньше, чем дисперсия самого незашумлённого фактора
в которых дисперсия шума меньше, чем дисперсия самого незашумлённого фактора ![]() . Но ведь кроме вариантов «брать» и «не брать» есть ещё вариант брать с другим, меньшим по модулю весом. Кроме того, модель прогноза не обязательно должна быть линейной. Правильное решение задачи выглядит сложнее, в действительности мы всегда можем извлечь пользу из фактора, если в нём есть новая информация, даже если он очень зашумлён.
. Но ведь кроме вариантов «брать» и «не брать» есть ещё вариант брать с другим, меньшим по модулю весом. Кроме того, модель прогноза не обязательно должна быть линейной. Правильное решение задачи выглядит сложнее, в действительности мы всегда можем извлечь пользу из фактора, если в нём есть новая информация, даже если он очень зашумлён.
Пусть у нас есть два несмещённых прогноза ![]() и
и ![]() и их ошибки равны
и их ошибки равны

Тогда, если бы они были абсолютно независимыми, то из них можно было бы сконструировать новый более точный прогноз о формуле

И погрешность этого прогноза была бы равна

То есть ![]()
Почему это верно для независимых прогнозов, предлагается разобраться самостоятельно. Это случай, когда, например, две независимые группы исследователей выдают свои оценки массы бозона Хиггса с погрешностями и нужно их скомбинировать.
В нашем случае оценки зависимы, в ошибках
![]()
есть общая часть ![]() – общая неустранимая ошибка для этих двух прогнозов. При комбинировании мы как бы комбинируем только две независимые части
– общая неустранимая ошибка для этих двух прогнозов. При комбинировании мы как бы комбинируем только две независимые части ![]() и
и ![]() и получаем ответ
и получаем ответ

где
![]()
Итого:

И ошибка у такого прогноза будет

что меньше погрешностей ![]() и
и ![]() обоих прогнозов
обоих прогнозов ![]() и
и ![]()
Итоговая формула наилучшего линейного прогноза выглядит так

А ошибка этого прогноза равна

Итак, при известных весах все факторы пригодятся. Но когда у нас веса неизвестны и недостаточно большой обучающий пул, приходится некоторые факторы откидывать.
Веса можно оценить по формуле
![]()
Посмотрим, чему равно это выражение в пределе, когда обучающий лог большой и avg можно заменить на мат. ожидание. Если все факторы изначально отнормированы так, чтобы их среднее было равно нулю, то

А средний квадрат фактора равен
![]()
Таким образом выражение ![]() в пределе равно
в пределе равно ![]() , то есть в точности тому, что нужно подставить в формулу
, то есть в точности тому, что нужно подставить в формулу ![]() . Величина
. Величина ![]() будет вычислена с погрешностью, то есть будет иметь отклонение от
будет вычислена с погрешностью, то есть будет иметь отклонение от ![]() – из-за конечности обучающего пула (нормировка будет неидеальной, и средние величины по выборке будут отличаться от истинных мат. ожиданий). Пусть нам дана оценка среднего квадрата относительной погрешности:
– из-за конечности обучающего пула (нормировка будет неидеальной, и средние величины по выборке будут отличаться от истинных мат. ожиданий). Пусть нам дана оценка среднего квадрата относительной погрешности:

Если мы не берём в прогноз слагаемое ![]() , то дополнительное слагаемое к квадрату ошибки (от потери истинного слагаемого
, то дополнительное слагаемое к квадрату ошибки (от потери истинного слагаемого ![]() ) равно
) равно ![]() Если же мы вместо
Если же мы вместо ![]() берём
берём ![]() , то дополнительное слагаемое к квадрату ошибки равно
, то дополнительное слагаемое к квадрату ошибки равно

Здесь мы просто
-
вынесли за скобки

-
разделили выражение в скобках на две части, которые являются независимыми случайными величинами со средним равным 0.
Если это выражение больше ![]() то фактор лучше отбросить. Выражение в итоге упрощается до
то фактор лучше отбросить. Выражение в итоге упрощается до

Таким образом, если относительная погрешность ![]() оценки
оценки ![]() больше 1, то фактор лучше отбросить. Погрешность
больше 1, то фактор лучше отбросить. Погрешность ![]() можно оценить, например, методом бутстрэпа.
можно оценить, например, методом бутстрэпа.
Из этого ответа можно вывести следующую интуитивную идею – если при градиентном спуске (обычном или стохастическом) во время последних итераций какой-то вес в модели менял знак, то лучше его выставить в 0.
Квадратичная Loss-функция и Mutual Information
Обычно задача прогноза формулируется как задача минимизации ошибки:
ML-task №3.1: По данному обучающему пулу обучите модель ![]() , которая минимизирует среднюю ошибку
, которая минимизирует среднюю ошибку ![]() . Качество прогноза будет измеряться по средней ошибке на скрытом тестовом пуле.
. Качество прогноза будет измеряться по средней ошибке на скрытом тестовом пуле.
Но можно попробовать сформулировать задачу прогноза как задачу максимизации MI.
ML-task №3.2: По данному обучающему пулу обучите модель ![]() такую, что
такую, что
Это короткая, но не совсем правильная формулировка, требующая ряд уточнений. А именно, уточнения требуют следующие моменты:
-
В каком смысле пара
 может интерпретироваться как пара зависимых случайных величин?
может интерпретироваться как пара зависимых случайных величин? -
Требование несмещённости выглядит недостижимым, если множество данных, на котором мы обучаемся и тестируемся, конечно и фиксированно.
Эти моменты, в принципе, решаются просто. При тестировании мы как бы сэмплируем пример из потенциально бесконечного пула и получаем пару случайных величин ![]() А несмещённость нужно понимать так, как этот обычно делают в мат. статистике в регрессионных задачах – несмещённость в среднем по всем возможным обучающим и тестовым пулам, а не на данных конкретных пулах.
А несмещённость нужно понимать так, как этот обычно делают в мат. статистике в регрессионных задачах – несмещённость в среднем по всем возможным обучающим и тестовым пулам, а не на данных конкретных пулах.
Подробнее
Детерминированная функция![]() интерпретируется как случайная величина следующим образом: мы сэмплируем строчку из тестового пула, берём из неё набор факторов
интерпретируется как случайная величина следующим образом: мы сэмплируем строчку из тестового пула, берём из неё набор факторов ![]() и
и ![]() , подставляем факторы в функцию и получаем значение
, подставляем факторы в функцию и получаем значение ![]() и пару зависимых случайных величин
и пару зависимых случайных величин ![]() .
.
Требование несмещённости следует воспринимать как несмещённость в среднем при рассмотрении обучающего и тестового пулов как случайных величин. То есть конкретный конечный обучающий пул однозначно даст модель со смещённым прогнозом – среднее значение разницы ![]() не будет равно нулю в среднем на случайном примере из потенциально бесконечного тестового пула. Но можно рассмотреть разницу
не будет равно нулю в среднем на случайном примере из потенциально бесконечного тестового пула. Но можно рассмотреть разницу ![]() , где среднее берётся по всевозможным моделям, которые можно было бы получить, обучаясь на гипотетических обучающих пулах и тестируя на гипотетических тестовых пулах. Другой вариант легализации несмещённости – это требование несмещённости в пределе, при стремлении размера обучающего пула в бесконечность. Такие интерпретации несмещённости дают шанс на существование решения задачи ML-task №3.2.2. Но честно говоря, ни инженеры, ни теоретики ML не уделяют вопросу смещённости большого внимания, как это обычно делается в методах мат. статистики. ML-щики это признают, и открыто предпочитают тестировать и оценивать свои методы на искусственных или реальных задачах по метрикам ошибки, не анализируя их смещённость.
, где среднее берётся по всевозможным моделям, которые можно было бы получить, обучаясь на гипотетических обучающих пулах и тестируя на гипотетических тестовых пулах. Другой вариант легализации несмещённости – это требование несмещённости в пределе, при стремлении размера обучающего пула в бесконечность. Такие интерпретации несмещённости дают шанс на существование решения задачи ML-task №3.2.2. Но честно говоря, ни инженеры, ни теоретики ML не уделяют вопросу смещённости большого внимания, как это обычно делается в методах мат. статистики. ML-щики это признают, и открыто предпочитают тестировать и оценивать свои методы на искусственных или реальных задачах по метрикам ошибки, не анализируя их смещённость.
Но мне требование несмещённости потребовалось, чтобы переформулировать задачу прогноза в терминах максимизации MI.
Итак, мы будем позволять себе воспринимать тестовый пул как источник случайных примеров и использовать терминологию теории вероятности.
Определение 3.2: Loss-функцию равную мат. ожиданию квадратичной ошибки ![]() будем называть
будем называть ![]() – ошибкой или квадратичной ошибкой или mse. А Loss-функцию
– ошибкой или квадратичной ошибкой или mse. А Loss-функцию ![]() будем называть
будем называть ![]() – ошибкой.
– ошибкой.
Утверждение 3.1: Пусть ваша модель в задаче ML-task №3.2.2 или ML-task №3.2.1 такова, что невязка ![]() обладает двумя свойствами:
обладает двумя свойствами:
-
Является нормальной величиной с нулевым средним (то есть прогноз не смещён) при любом фиксированное значении
. -
Имеет дисперсию, которая не зависит от
.
Тогда задачи ML-task №3.1 и ML-task №3.2 эквивалентны для Loss=mse, то есть задача «maximize MI» даёт тот же ответ, что и задача «minimize mse-ошибку».
Конечно, описанные в утверждении свойства редко встречаются на практике, но тем не менее, этот факт интересен.
Во-первых, эти свойства достижимы тогда, когда вектор из ![]() факторов и
факторов и ![]() -а
-а ![]() является измерением многомерной нормальной величины, а именно, так и будет, если
является измерением многомерной нормальной величины, а именно, так и будет, если ![]() есть линейная комбинация нескольких независимых гауссовских величин, некоторые из которых нам известны и даны как факторы. Тогда прогноз естественно тоже искать как линейную комбинацию данных факторов.
есть линейная комбинация нескольких независимых гауссовских величин, некоторые из которых нам известны и даны как факторы. Тогда прогноз естественно тоже искать как линейную комбинацию данных факторов.
В этом случае
![]() ,
,
где ![]() и есть среднее значение квадратичной ошибки прогноза, то есть
и есть среднее значение квадратичной ошибки прогноза, то есть ![]() , а
, а ![]() — дисперсия
— дисперсия ![]() -а (см. задачу 2.8 про MI двух зависимых нормальных величин). Понятно, что в этом случае задача максимизации
-а (см. задачу 2.8 про MI двух зависимых нормальных величин). Понятно, что в этом случае задача максимизации ![]() эквивалентна задаче минимизации
эквивалентна задаче минимизации ![]()
Надо понимать, что хотя чистый и не зависящий от![]() гаусс для ошибки
гаусс для ошибки ![]() на практике не встречается, тем не менее, распределение
на практике не встречается, тем не менее, распределение ![]() при фиксированном
при фиксированном ![]() часто выглядит как гауссовский «колокол» с центром в
часто выглядит как гауссовский «колокол» с центром в ![]() , и утверждение про эквивалентность тоже почти верно, а именно, задача максимизации MI эквивалентна задаче минимизации ошибки в
, и утверждение про эквивалентность тоже почти верно, а именно, задача максимизации MI эквивалентна задаче минимизации ошибки в ![]() -подобной метрике, где усреднение делается с весом, неким образом зависящим от
-подобной метрике, где усреднение делается с весом, неким образом зависящим от ![]() .
.
Точнее так — если колокол распределения ![]() одномодальный, симметричный, с квадратичной вершинкой, то и найдётся и эквивалентная задача про максимизацию MI. Это мы обсудим ниже.
одномодальный, симметричный, с квадратичной вершинкой, то и найдётся и эквивалентная задача про максимизацию MI. Это мы обсудим ниже.
А сейчас попробуем доказать утверждение про эквивалентность задач «maximize MI» и «minimize L2» для случая, описанного в утверждении 3.1.
Введём короткие обозначения t = target, p = predict.
Доказательство основано на том, что мы просто записываем значение ![]() в таком виде:
в таком виде:
![]()
Величина ![]() не зависит от прогноза и равна
не зависит от прогноза и равна ![]() Величина
Величина ![]() равна
равна ![]() где как
где как ![]() мы обозначили дисперсию прогнозируемой величины при заданном значении прогноза. Согласно второму условию утверждения она константа. В случае несмещённого прогноза это
мы обозначили дисперсию прогнозируемой величины при заданном значении прогноза. Согласно второму условию утверждения она константа. В случае несмещённого прогноза это![]() (то есть как раз квадратичная ошибка) при условии
(то есть как раз квадратичная ошибка) при условии ![]()
Выражение ![]() — суть просто усреднение по пулу.
— суть просто усреднение по пулу.
Если ![]() не зависит от значения
не зависит от значения ![]() то мы получим нужное утверждение. Действительно,
то мы получим нужное утверждение. Действительно,

Максимизация этого выражения равносильна минимизации mse. Конец доказательства.
Для большего понимания распишем более подробно выражение

Интегрирование
![]()
снова соответствует просто усреднению по пулу, а выражение ![]() и есть то, что нужно интерпретировать как значение ошибки. Если перейти к дискретизированному случаю, и вспомнить про кодирование Хаффмана, то
и есть то, что нужно интерпретировать как значение ошибки. Если перейти к дискретизированному случаю, и вспомнить про кодирование Хаффмана, то ![]() есть количество бит, которое требуется для записи кода значения
есть количество бит, которое требуется для записи кода значения ![]() (с точностью до
(с точностью до ![]() ) при условии, что известно значение
) при условии, что известно значение ![]() . Если прогноз не смещен, и он нам дан, то, чтобы закодировать
. Если прогноз не смещен, и он нам дан, то, чтобы закодировать ![]() с некоторой заданной точностью, проще записать код для невязки
с некоторой заданной точностью, проще записать код для невязки ![]() , которая есть случайная величина с нулевым средним и меньшим значением дисперсии, нежели дисперсия
, которая есть случайная величина с нулевым средним и меньшим значением дисперсии, нежели дисперсия ![]() . Эти рассуждения наводят ещё на одну формулировку задачи прогноза как задачи максимизации MI:
. Эти рассуждения наводят ещё на одну формулировку задачи прогноза как задачи максимизации MI:
ML-task №3.3: По данному обучающему пулу обучите модель ![]() такую, чтобы задача кодирования невязки
такую, чтобы задача кодирования невязки ![]() с точностью до
с точностью до ![]() требовала минимального количества бит.
требовала минимального количества бит.
В этой задаче имеется в виду наивное кодирование чисел, когда записываются все значащие цифры. Например, пусть фиксирована точность ![]() , тогда число
, тогда число ![]() логично кодировать как «-123». Здесь мы тратим один бит на знак (+ или — в начале), далее нас не интересуют все цифры начиная с седьмого места после десятичной точки, и мы записываем только значащие цифры, не перечисляя лидирующие нули, и мы понимаем, что последняя цифра в коде стоит на шестом места после десятичной точки. В таком кодировании чем меньше ошибка в среднем, тем меньше бит потребуется для кодирования всех ошибок на тестовом пуле. Значение
логично кодировать как «-123». Здесь мы тратим один бит на знак (+ или — в начале), далее нас не интересуют все цифры начиная с седьмого места после десятичной точки, и мы записываем только значащие цифры, не перечисляя лидирующие нули, и мы понимаем, что последняя цифра в коде стоит на шестом места после десятичной точки. В таком кодировании чем меньше ошибка в среднем, тем меньше бит потребуется для кодирования всех ошибок на тестовом пуле. Значение ![]() должно быть достаточно мало. Но поверх этого наивного кодирования важно применить ещё кодирование Хаффмана, чтобы различие в вероятностях разных ошибок позволило дополнительно сжать данные.
должно быть достаточно мало. Но поверх этого наивного кодирования важно применить ещё кодирование Хаффмана, чтобы различие в вероятностях разных ошибок позволило дополнительно сжать данные.
В этой формулировке мы как бы невольны назначать свою Loss-функцию. Некоторые склонны рассматривать это как критерий правильного выбора Loss-функции: если вы минимизируйте mse, то хорошо, когда ![]() с ростом обучающего и тестового пулов стремится к
с ростом обучающего и тестового пулов стремится к ![]() , то есть распределение невязки близко к нормальному, а когда вы минимизируйте L1— ошибку, то хорошо, если
, то есть распределение невязки близко к нормальному, а когда вы минимизируйте L1— ошибку, то хорошо, если ![]() стремится к
стремится к ![]() , то есть распределение невязки близко к распределению Лапласа. В общем случае ожидается приближённое равенство
, то есть распределение невязки близко к распределению Лапласа. В общем случае ожидается приближённое равенство![]() и если это не так, то либо вы «недоделали ML», либо ваша задача не относится к классу хороших.
и если это не так, то либо вы «недоделали ML», либо ваша задача не относится к классу хороших.
Видимо, при определённых условиях, верны рассуждения и в другую сторону. Если у вас есть идеальное решение задачи ML-task №3.3, то изучив распределение невязки для её решения, вы узнаёте какую Loss-функцию нужно использовать, чтобы извлечь максимум информации о сигнале.
Log-Likelihood и Mutual Information
Пример задачи из жизни: Реализуйте детерминированную функцию
![]()
прогнозирующую вероятность p того, что пользователь кликнет на данное рекламное объявление.
Задачи такого типа, когда нужно спрогнозировать булеву величину (величину, принимающую значения «Да» или «Нет»), называются задачами бинарной классификации (Binary Classification Problems).
Для их решения обычно используется метод максимизации правдоподобия, а именно, предполагается, что прогноз ![]() должен возвращать вещественное число от 0 до 1, соответствующее вероятности того, что
должен возвращать вещественное число от 0 до 1, соответствующее вероятности того, что ![]() (пользователь кликнет на рекламу). При обучении прогнозатора на обучающем множестве можно подбирать такие значения внутренних параметров модели (aka весов), на которых достигается максимальная вероятность видеть то, что находится в обучающем множестве.
(пользователь кликнет на рекламу). При обучении прогнозатора на обучающем множестве можно подбирать такие значения внутренних параметров модели (aka весов), на которых достигается максимальная вероятность видеть то, что находится в обучающем множестве.
Обычно максимизируется не просто вероятность, а комбинация этой вероятности и регуляризационной компоненты. Никто не ограничивает разработчиков прогнозаторов в том, как именно должна выглядеть эта регуляризационная компонента. И вообще, алгоритм обучения может быть любым, важны лишь следующие два момента:
-
во время обучения алгоритм не «видит» данных из тестового пула;
-
прогнозаторы сравниваются по оценке вероятностей событий на тестовом пуле.
Вероятность видеть то, что мы видим в пуле, в применении к модели называется правдоподобием модели (model likelihood). То есть мы говорим ‘вероятность события’ и ‘правдоподобие модели’, но не говорим ‘вероятность модели’ или ‘правдоподобие событий’.
Вот пример тестового пула из трёх строчек:
|
i |
f1 |
f1 |
f1 |
target |
predict= |
P(target=0) |
|
1 |
… |
… |
… |
0 |
|
|
|
2 |
… |
… |
… |
1 |
|
|
|
3 |
… |
… |
… |
0 |
|
|
|
|
Удобнее оперировать значением LogLikelihood:
![]()
Строчки с ![]() входят в суммарный LogLikelihood как
входят в суммарный LogLikelihood как ![]() , а строчки с
, а строчки с ![]() — как
— как ![]() .
.
В упрощённом виде задача бинарной классификации выглядит так:
ML-task №3.4: Дан обучающий лог. Найдите детерминированную функцию ![]() чтобы значение
чтобы значение ![]() на тестовом пуле было максимально.
на тестовом пуле было максимально.
Сформулируем аналогичную задачу в терминах максимизации MI.
ML-task №3.5: Найдите детерминированную функцию ![]() чтобы случайная дискретная величина
чтобы случайная дискретная величина ![]() принимающая значения 0 и 1 с вероятностями
принимающая значения 0 и 1 с вероятностями ![]() имела максимально возможное значение взаимной информации
имела максимально возможное значение взаимной информации ![]() с величиной
с величиной ![]() .
.
Утверждение 3.2: Если ваша модель такова, что ![]() является случайной величиной с нулевым средним (то есть прогноз не смещён), тогда задачи ML-task №3.2.2 и ML-task №3.2.1 эквивалентны, то есть задача «maximize MI(target, predict)» даёт тот же ответ, что и задача «maximize LogLikilihood».
является случайной величиной с нулевым средним (то есть прогноз не смещён), тогда задачи ML-task №3.2.2 и ML-task №3.2.1 эквивалентны, то есть задача «maximize MI(target, predict)» даёт тот же ответ, что и задача «maximize LogLikilihood».
То, что прогноз не смещён или, другими словами, не требует калибровки не является сложным требованием. В задачах классификации, если вы используете Gradient Boosted Trees или нейросети с правильными гиперпараметрами (скорость обучения, число итераций) прогноз получается несмещённым. А именно, если вы берёте события с![]() то получаете множество событий с
то получаете множество событий с
![]()
В задачах классификации строчки, у которых target = 1 мне привычно называть кликами (clicks), а строчки с target = 0 – некликами (notclicks). Клики + неклики дают множество всех событий, которые называются показами (impressions). Фактическое отношение кликов к показам называется CTR — Click Through Rate.
Чтобы доказать утверждение 3.2, давайте воспользуемся решением задачи:
Задача 3.10. Как по N измерениям двух случайных величин — дискретной величины ![]() , принимающей значения от 1 до M, и булевой случайной величины
, принимающей значения от 1 до M, и булевой случайной величины ![]() оценить значение
оценить значение ![]() ?
?
Можно думать про эту задачу так: ![]() — это некоторая категориальная величина про рекламное объявление, её значения интерпретировать как идентификатор класса, а
— это некоторая категориальная величина про рекламное объявление, её значения интерпретировать как идентификатор класса, а ![]() — это индикатор того, был ли клик. Данные про измерение пар
— это индикатор того, был ли клик. Данные про измерение пар ![]() — это просто лог кликов и некликов.
— это просто лог кликов и некликов.
Для решения этой задачи удобно воспользоваться формулой
![]()
Значение ![]() , где
, где ![]() — средний CTR по всему логу.
— средний CTR по всему логу.
Значение ![]() , где
, где ![]() — CTR по событиям, в которых
— CTR по событиям, в которых ![]() , что естественно называть CTR в классе i. Подставляем это в формулу и получаем:
, что естественно называть CTR в классе i. Подставляем это в формулу и получаем:
.

Давайте займёмся первым слагаемым и запишем его в виде суммы по классам:



Подставив это в выражение для MI, и поместив обе части в одну сумму по классам, получим итоговое выражение для MI:

В последнем равенстве мы заменили суммирование по классам на суммирование по строчкам лога, чтобы показать близость формулы с формулой LogLikelihood.
В случае, когда классы есть просто корзины прогноза, и прогноз не смещён, то есть средний прогноз в корзине совпадает с реальным ![]() в корзине, имеем:
в корзине, имеем:

А если прогноз равен константе ![]() , то выражение для правдоподобия равно
, то выражение для правдоподобия равно

Замена ![]() на
на ![]() валидна, так как выражения c логарифмами константны и среднее значение
валидна, так как выражения c логарифмами константны и среднее значение ![]() по всем impressions равно
по всем impressions равно ![]() .
.
B здесь мы видим, что итоговое выражение для MI есть просто нормированная разница двух выражений для LogLikelihood:

То есть ![]() в случае несмещённого прогноза есть линейная функция от LogLikelihood.
в случае несмещённого прогноза есть линейная функция от LogLikelihood.
Кстати, величина ![]() называется Log Likelihood Ratio двух прогнозаторов, и её естественно нормировать на количество событий (impressions). В качестве
называется Log Likelihood Ratio двух прогнозаторов, и её естественно нормировать на количество событий (impressions). В качестве ![]() часто берут какой-нибудь простейший прогноз, в нашем случае, это константный прогноз. Часто имеет смысл мониторить график величины LogLikelihoodRatio / impressions, а не LogLikelihood / impressions, беря в качестве бейслайнового прогноза
часто берут какой-нибудь простейший прогноз, в нашем случае, это константный прогноз. Часто имеет смысл мониторить график величины LogLikelihoodRatio / impressions, а не LogLikelihood / impressions, беря в качестве бейслайнового прогноза ![]() какой-либо робастный (простой, надёжный неломающийся) прогноз, основанный на небольшом числе факторов. Также иногда можно брать
какой-либо робастный (простой, надёжный неломающийся) прогноз, основанный на небольшом числе факторов. Также иногда можно брать ![]() , для некоторого
, для некоторого ![]() , чтобы устранить корреляцию или антикорреляцию с
, чтобы устранить корреляцию или антикорреляцию с ![]() и лучше видеть точки поломок прогноза.
и лучше видеть точки поломок прогноза.
Итак, для несмещённого прогноза величина MI между прогнозом и сигналом равна удельному (нормированному на число строк) Log Likelihood Ratio вашего прогноза и наилучшего константного прогноза.
Оценка Mutual Information = Machine Learning
Два утверждения — 3.1 и 3.2 — говорят о том, что Mutual Information является метрикой качества, которая в некоторых допущениях соответствует двум метрикам в задачах прогноза — квадратичной ошибке в задаче прогноза вещественной величины с нормальным распределением и LogLikelihood в задаче бинарной классификации.
Сама величина Mutual Information не может использоваться как Loss-функция, потому что она не является метрикой на данных, то есть не представляется как сумма значений Loss-функции по элементам пула. Смысл «соответствия» можно пояснить так: практически все Loss-функции в конечном итоге занимаются максимизацией Mutual Information predict-а и target-а, но с разными дополнительными добавками.
Возможно, свет на это прольют следующие два утверждения (опять без доказательства):
Утверждение 3.3: Если у вас есть прогноз на факторах ![]() , и есть новый фактор
, и есть новый фактор ![]() такой что
такой что ![]() то при достаточно большом обучающем логе этот фактор уменьшит вашу Loss-функцию, если она нормальная. Loss-функция называется нормальной если она падает, когда вы в любом элементе пула значение predict приближаете к target. Квадратичная ошибка mse,
то при достаточно большом обучающем логе этот фактор уменьшит вашу Loss-функцию, если она нормальная. Loss-функция называется нормальной если она падает, когда вы в любом элементе пула значение predict приближаете к target. Квадратичная ошибка mse, ![]() -ошибка, LogLikelihood — это всё нормальные Loss-функции. Далее будем считать, что Loss-функция нормальная.
-ошибка, LogLikelihood — это всё нормальные Loss-функции. Далее будем считать, что Loss-функция нормальная.
Произвольное монотонное преобразование прогноза будем называть калибровкой прогноза.
Утверждение 3.4 (требует уточнения условий): Если вы нашли такое изменение весов (ака внутренних параметров) вашей модели, которое увеличивает ![]() то после надлежащей калибровки прогноза вырастет и ваша Loss-функция.
то после надлежащей калибровки прогноза вырастет и ваша Loss-функция.
В этих утверждениях нельзя заменить MI на какую-то Loss-функцию. Например, если вы делаете изменение весов вашей модели, которое уменьшает![]() -ошибку, то это не значит, что будет падать и
-ошибку, то это не значит, что будет падать и ![]() -ошибка даже после надлежащей калибровки прогноза под
-ошибка даже после надлежащей калибровки прогноза под ![]() . Такая выделенность MI связана с тем, что, как уже было сказано выше, она не совсем Loss-функция и по своей природе допускает любую калибровку (то есть не меняется при произвольной строго монотонной калибровке прогноза).
. Такая выделенность MI связана с тем, что, как уже было сказано выше, она не совсем Loss-функция и по своей природе допускает любую калибровку (то есть не меняется при произвольной строго монотонной калибровке прогноза).
Задача 3.11: Докажите, что для случая, когда ![]() , где
, где ![]() случайный шум, и модель соответствует реальности, при увеличении обучающего лога веса стремятся к правильным значениям весов для обоих Loss-функций
случайный шум, и модель соответствует реальности, при увеличении обучающего лога веса стремятся к правильным значениям весов для обоих Loss-функций ![]() и
и![]() . При этом в случае, если шум имеет симметричное распределение, обе Loss-функций дают несмещённый прогноз.
. При этом в случае, если шум имеет симметричное распределение, обе Loss-функций дают несмещённый прогноз.
Задача 3.12: Приведите пример модели и реального target, когда Loss-функции ![]() и
и ![]() дают разные прогнозы даже на очень большом обучающем пуле, так что один нельзя перевести во второй никаким монотонным преобразованием (один прогноз нельзя получить калибровкой второго).
дают разные прогнозы даже на очень большом обучающем пуле, так что один нельзя перевести во второй никаким монотонным преобразованием (один прогноз нельзя получить калибровкой второго).
Утверждение 3.5: Задача оценки ![]() эквивалентна задаче построения прогноза
эквивалентна задаче построения прогноза ![]() в какой-то Loss-функции.
в какой-то Loss-функции.
Это утверждение говорит, что истинное значение mi примерно равно supremum ![]() всем парам (ML-метод, Loss-функция), где
всем парам (ML-метод, Loss-функция), где
ML-метод ::= («структура модели», «метод получения весов модели»),
«метод получения весов модели» ::= («алгоритм», «гиперпараметры алгоритма»),
а равенство тем точнее, чем больше обучающий пул.
Собственно та пара (ML-метод, Loss-функция), которая даст самое большое значение ![]() близкое к mi, и есть модель, самая близкая к реальности, то есть тому, как на самом деле связаны
близкое к mi, и есть модель, самая близкая к реальности, то есть тому, как на самом деле связаны ![]() и target.
и target.
Итак: Мы сформулировали две глубокие связи между задачами прогноза и MI:
-
Во-первых, максимизация MI в некотором смысле соответствует задаче минимизации какой-то Loss-функции
-
Во-вторых, «оценка MI» = «ML», а именно, задача оценки
 эквивалентна задаче построения прогноза
эквивалентна задаче построения прогноза  для какой-то Loss-функции. И собственно, ML-метод и Loss-функция, которые дают максимум
для какой-то Loss-функции. И собственно, ML-метод и Loss-функция, которые дают максимум  и является наиболее правдоподобной моделью.
и является наиболее правдоподобной моделью.