
Here’s a javascript implementation of the levenshteinDistance algorithm which gives you a measure of how different two sequences of characters are. In this example, I compare each word in a series of test source strings to a particular candidate word. There are many ways to extend this further such as understanding plural forms and not discounting a match that only diffs in plurality. Anyway, here’s the implementation with a link to a demo below:
function levenshteinDistance (s, t) {
if (!s.length) return t.length;
if (!t.length) return s.length;
return Math.min(
levenshteinDistance(s.substr(1), t) + 1,
levenshteinDistance(t.substr(1), s) + 1,
levenshteinDistance(s.substr(1), t.substr(1)) + (s.charAt(0).toLowerCase() !== t.charAt(0).toLowerCase() ? 1 : 0)
);
}
var testStrings = [
"People are afraid of monters.",
"Mansters are very scary, even in the daytime",
"I like mnsters.",
"I like a big, scary monser"
];
var candidateWord = "monsters";
var words;
var results = [];
for (var i = 0; i < testStrings.length; i++) {
words = testStrings[i].split(/[s.,<>;:'"{}[]]+/);
for (var j = 0; j < words.length; j++) {
if (words[j]) {
results.push({word: words[j], score: levenshteinDistance(words[j], candidateWord)});
}
}
}
And, a working demo: http://jsfiddle.net/jfriend00/3xEwj/
After sorting the output, it shows these scores for each of the words in the test string (lower score means smaller difference, so better match):
Score: 1
monters
Mansters
mnsters
Score: 2
monser
Score: 6
scary
very
scary
Score: 7
People
of
even
in
are
daytime
like
like
are
the
Score: 8
I
I
a
big
afraid
You can package up this logic however you want. You can set a threshold for how much difference you are willing to tolerate and then just use that threshold as a binary match. For example, you could set your threshold at 2 so that any score less than or equal to 2 means it’s a match.
Исправляем опечатки в поисковых запросах
Время на прочтение
14 мин
Количество просмотров 17K
Наверное, любой сервис, на котором вообще есть поиск, рано или поздно приходит к потребности научиться исправлять ошибки в пользовательских запросах. Errare humanum est; пользователи постоянно опечатываются и ошибаются, и качество поиска от этого неизбежно страдает — а с ним и пользовательский опыт.
При этом каждый сервис обладает своей спецификой, своим лексиконом, которым должен уметь оперировать исправитель опечаток, что в значительной мере затрудняет применение уже существующих решений. Например, такие запросы пришлось научиться править нашему опечаточнику:
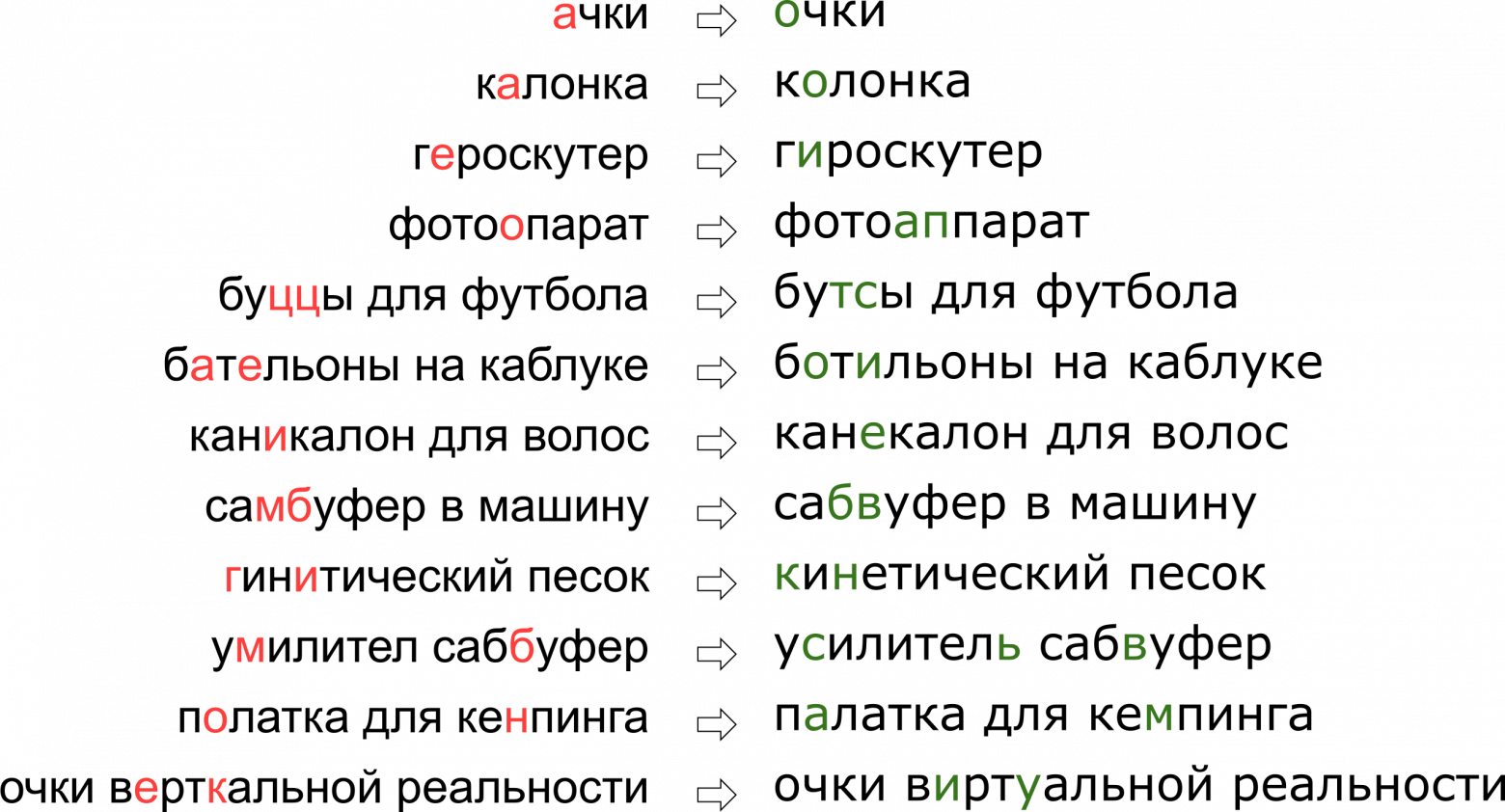
Может показаться, что мы отказали пользователю в его мечте о вертикальной реальности, но на самом деле буква К просто стоит на клавиатуре рядом с буквой У.
В этой статье мы разберём один из классических подходов к исправлению опечаток, от построения модели до написания кода на Python и Go. И в качестве бонуса — видео с моего доклада «”Очки верткальной реальности”: исправляем опечатки в поисковых запросах» на Highload++.
Постановка задачи
Итак, нам пришёл опечатанный запрос и его надо исправить. Обычно математически задача ставится таким образом:
Эта постановка — самая элементарная — предполагает, что если нам пришёл запрос из нескольких слов, то мы исправляем каждое слово по отдельности. В реальности, конечно, мы захотим исправлять всю фразу целиком, учитывая сочетаемость соседних слов; об этом я расскажу ниже, в разделе “Как исправлять фразы”.
Неясных моментов здесь два — где взять словарь и как посчитать  . Первый вопрос считается простым. В 1990 году [1] словарь собирали из базы утилиты spell и доступных в электронном виде словарей; в 2009 году в Google [4] поступили проще и просто взяли топ самых популярных слов в Интернете (вместе с популярными ошибочными написаниями). Этот подход взял и я для построения своего опечаточника.
. Первый вопрос считается простым. В 1990 году [1] словарь собирали из базы утилиты spell и доступных в электронном виде словарей; в 2009 году в Google [4] поступили проще и просто взяли топ самых популярных слов в Интернете (вместе с популярными ошибочными написаниями). Этот подход взял и я для построения своего опечаточника.
Второй вопрос сложнее. Хотя бы потому, что его решение обычно начинается с применения формулы Байеса!

Теперь вместо исходной непонятной вероятности нам нужно оценить две новые, чуть более понятные:  — вероятность того, что при наборе слова
— вероятность того, что при наборе слова  можно опечататься и получить
можно опечататься и получить  , и
, и  — в принципе вероятность использования пользователем слова .
— в принципе вероятность использования пользователем слова .
Как оценить ? Очевидно, что пользователь с большей вероятностью путает А с О, чем Ъ с Ы. А если мы исправляем текст, распознанный с отсканированного документа, то велика вероятность путаницы между rn и m. Так или иначе, нам нужна какая-то модель, описывающая ошибки и их вероятности.
Такая модель называется noisy channel model (модель зашумлённого канала; в нашем случае зашумлённый канал начинается где-то в центре Брока пользователя и заканчивается по другую сторону его клавиатуры) или более коротко error model — модель ошибок. Эта модель, которой ниже посвящен отдельный раздел, будет ответственна за учёт как орфографических ошибок, так и, собственно, опечаток.
Оценить вероятность использования слова — — можно по-разному. Самый простой вариант — взять за неё частоту, с которой слово встречается в некотором большом корпусе текстов. Для нашего опечаточника, учитывающего контекст фразы, потребуется, конечно, что-то более сложное — ещё одна модель. Эта модель называется language model, модель языка.
Модель ошибок
Первые модели ошибок считали , подсчитывая вероятности элементарных замен в обучающей выборке: сколько раз вместо Е писали И, сколько раз вместо ТЬ писали Т, вместо Т — ТЬ и так далее [1]. Получалась модель с небольшим числом параметров, способная выучить какие-то локальные эффекты (например, что люди часто путают Е и И).
В наших изысканиях мы остановились на более развитой модели ошибок, предложенной в 2000 году Бриллом и Муром [2] и многократно использованной впоследствии (например, специалистами Google [4]). Представим, что пользователи мыслят не отдельными символами (спутать Е и И, нажать К вместо У, пропустить мягкий знак), а могут изменять произвольные куски слова на любые другие — например, заменять ТСЯ на ТЬСЯ, У на К, ЩА на ЩЯ, СС на С и так далее. Вероятность того, что пользователь опечатался и вместо ТСЯ написал ТЬСЯ, обозначим  — это параметр нашей модели. Если для всех возможных фрагментов
— это параметр нашей модели. Если для всех возможных фрагментов  мы можем посчитать
мы можем посчитать  , то искомую вероятность набора слова s при попытке набрать слово w в модели Брилла и Мура можно получить следующим образом: разобьем всеми возможными способами слова w и s на более короткие фрагменты так, чтобы фрагментов в двух словах было одинаковое количество. Для каждого разбиения посчитаем произведение вероятностей всех фрагментов w превратиться в соответствующие фрагменты s. Максимум по всем таким разбиениям и примем за значение величины :
, то искомую вероятность набора слова s при попытке набрать слово w в модели Брилла и Мура можно получить следующим образом: разобьем всеми возможными способами слова w и s на более короткие фрагменты так, чтобы фрагментов в двух словах было одинаковое количество. Для каждого разбиения посчитаем произведение вероятностей всех фрагментов w превратиться в соответствующие фрагменты s. Максимум по всем таким разбиениям и примем за значение величины :

Давайте посмотрим на пример разбиения, возникающего при вычислении вероятности напечатать «аксесуар» вместо «аксессуар»:

Как вы наверняка заметили, это пример не очень удачного разбиения: видно, что части слов легли друг под другом не так удачно, как могли бы. Если величины  и
и  ещё не так плохи, то
ещё не так плохи, то  и
и  , скорее всего, сделают итоговый «счёт» этого разбиения совсем печальным. Более удачное разбиение выглядит как-то так:
, скорее всего, сделают итоговый «счёт» этого разбиения совсем печальным. Более удачное разбиение выглядит как-то так:

Здесь всё сразу стало на свои места, и видно, что итоговая вероятность будет определяться преимущественно величиной  .
.
Как вычислить 
Несмотря на то, что возможных разбиений для двух слов имеется порядка  , с помощью динамического программирования алгоритм вычисления можно сделать довольно быстрым — за
, с помощью динамического программирования алгоритм вычисления можно сделать довольно быстрым — за  . Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
. Сам алгоритм при этом будет очень сильно напоминать алгоритм Вагнера-Фишера для вычисления расстояния Левенштейна.
Мы заведём прямоугольную таблицу, строки которой будут соответствовать буквам правильного слова, а столбцы — опечатанного. В ячейке на пересечении строки i и столбца j к концу алгоритма будет лежать в точности вероятность получить s[:j] при попытке напечатать w[:i]. Для того, чтобы её вычислить, достаточно вычислить значения всех ячеек в предыдущих строках и столбцах и пробежаться по ним, домножая на соответствующие . Например, если у нас заполнена таблица
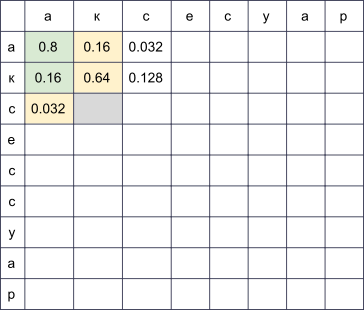
, то для заполнения ячейки в четвёртой строке и третьем столбце (серая) нужно взять максимум из величин  и
и  . При этом мы пробежались по всем ячейкам, подсвеченным на картинке зелёным. Если также рассматривать модификации вида
. При этом мы пробежались по всем ячейкам, подсвеченным на картинке зелёным. Если также рассматривать модификации вида  и
и  , то придётся пробежаться и по ячейкам, подсвеченным жёлтым.
, то придётся пробежаться и по ячейкам, подсвеченным жёлтым.
Сложность этого алгоритма, как я уже упомянул выше, составляет : мы заполняем таблицу  , и для заполнения ячейки (i, j) нужно
, и для заполнения ячейки (i, j) нужно  операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины
операций. Впрочем, если мы ограничим рассмотрение фрагментами не больше какой-то ограниченной длины  (например, не больше двух букв, как в [4]), сложность уменьшится до
(например, не больше двух букв, как в [4]), сложность уменьшится до  . Для русского языка в своих экспериментах я брал
. Для русского языка в своих экспериментах я брал  .
.
Как максимизировать
Мы научились находить за полиномиальное время — это хорошо. Но нам нужно научиться быстро находить наилучшие слова во всём словаре. Причём наилучшие не по , а по ! На деле нам достаточно получить какой-то разумный топ (например, лучшие 20) слов по , который мы потом отправим в модель языка для выбора наиболее подходящих исправлений (об этом ниже).
Чтобы научиться быстро проходить по всему словарю, заметим, что таблица, представленная выше, будет иметь много общего для двух слов с общими префиксами. Действительно, если мы, исправляя слово «аксесуар», попробуем заполнить её для двух словарных слов «аксессуар» и «аксессуары», мы заметим, что первые девять строк в них вообще не отличаются! Если мы сможем организовать проход по словарю так, что у двух последующих слов будут достаточно длинные общие префиксы, мы сможем круто сэкономить вычисления.
И мы сможем. Давайте возьмём словарные слова и составим из них trie. Идя по нему поиском в глубину, мы получим желаемое свойство: большинство шагов — это шаги от узла к его потомку, когда у таблицы достаточно дозаполнить несколько последних строк.
Этот алгоритм, при некоторых дополнительных оптимизациях, позволяет нам перебирать словарь типичного европейского языка в 50-100 тысяч слов в пределах сотни миллисекунд [2]. А кэширование результатов сделает процесс ещё быстрее.
Как получить
Вычисление для всех рассматриваемых фрагментов — самая интересная и нетривиальная часть построения модели ошибок. Именно от этих величин будет зависеть её качество.
Подход, использованный в [2, 4], сравнительно прост. Давайте найдём много пар  , где
, где  — правильное слово из словаря, а
— правильное слово из словаря, а  — его опечатанный вариант. (Как именно их находить — чуть ниже.) Теперь нужно извлечь из этих пар вероятности конкретных опечаток (замен одних фрагментов на другие).
— его опечатанный вариант. (Как именно их находить — чуть ниже.) Теперь нужно извлечь из этих пар вероятности конкретных опечаток (замен одних фрагментов на другие).
Для каждой пары возьмём составляющие её и и построим соответствие между их буквами, минимизирующее расстояние Левенштейна:

Теперь мы сразу видим замены: а → а, е → и, с → с, с → пустая строка и так далее. Также мы видим замены двух и более символов: ак → ак, се → си, ес → ис, сс → с, сес → сис, есс → ис и прочая, и прочая. Все эти замены необходимо посчитать, причём каждую столько раз, сколько слово s встречается в корпусе (если мы брали слова из корпуса, что очень вероятно).
После прохода по всем парам за вероятность принимается количество замен α → β, встретившихся в наших парах (с учётом встречаемости соответствующих слов), делённое на количество повторений фрагмента α.
Как найти пары ? В [4] предлагается такой подход. Возьмём большой корпус сгенерированного пользователями контента (UGC). В случае Google это были просто тексты сотен миллионов веб-страниц; в нашем — миллионы пользовательских поисковых запросов и отзывов. Предполагается, что обычно правильное слово встречается в корпусе чаще, чем любой из ошибочных вариантов. Так вот, давайте для каждого слова находить близкие к нему по Левенштейну слова из корпуса, которые значительно менее популярны (например, в десять раз). Популярное возьмём за , менее популярное — за . Так мы получим пусть и шумный, но зато достаточно большой набор пар, на котором можно будет провести обучение.
Этот алгоритм подбора пар оставляет большое пространство для улучшений. В [4] предлагается только фильтр по встречаемости ( в десять раз популярнее, чем ), но авторы этой статьи пытаются делать опечаточник, не используя какие-либо априорные знания о языке. Если мы рассматриваем только русский язык, мы можем, например, взять набор словарей русских словоформ и оставлять только пары со словом , найденном в словаре (не лучшая идея, потому что в словаре, скорее всего, не будет специфичной для сервиса лексики) или, наоборот, отбрасывать пары со словом s, найденном в словаре (то есть почти гарантированно не являющимся опечатанным).
Чтобы повысить качество получаемых пар, я написал несложную функцию, определяющую, используют ли пользователи два слова как синонимы. Логика простая: если слова w и s часто встречаются в окружении одних и тех же слов, то они, вероятно, синонимы — что в свете их близости по Левенштейну значит, что менее популярное слово с большой вероятностью является ошибочной версией более популярного. Для этих расчётов я использовал построенную для модели языка ниже статистику встречаемости триграмм (фраз из трёх слов).
Модель языка
Итак, теперь для заданного словарного слова w нам нужно вычислить — вероятность его использования пользователем. Простейшее решение — взять встречаемость слова в каком-то большом корпусе. Вообще, наверное, любая модель языка начинается с собирания большого корпуса текстов и подсчёта встречаемости слов в нём. Но ограничиваться этим не стоит: на самом деле при вычислении P(w) мы можем учесть также и фразу, слово в которой мы пытаемся исправить, и любой другой внешний контекст. Задача превращается в задачу вычисления  , где одно из — слово, в котором мы исправили опечатку и для которого мы теперь рассчитываем , а остальные — слова, окружающие исправляемое слово в пользовательском запросе.
, где одно из — слово, в котором мы исправили опечатку и для которого мы теперь рассчитываем , а остальные — слова, окружающие исправляемое слово в пользовательском запросе.
Чтобы научиться учитывать их, стоит пройтись по корпусу ещё раз и составить статистику n-грамм, последовательностей слов. Обычно берут последовательности ограниченной длины; я ограничился триграммами, чтобы не раздувать индекс, но тут всё зависит от вашей силы духа (и размера корпуса — на маленьком корпусе даже статистика по триграммам будет слишком шумной).
Традиционная модель языка на основе n-грамм выглядит так. Для фразы  её вероятность вычисляется по формуле
её вероятность вычисляется по формуле

где  — непосредственно частота слова, а
— непосредственно частота слова, а  — вероятность слова
— вероятность слова  при условии, что перед ним идут
при условии, что перед ним идут  — не что иное, как отношение частоты триграммы
— не что иное, как отношение частоты триграммы  к частоте биграммы . (Заметьте, что эта формула — просто результат многократного применения формулы Байеса.)
к частоте биграммы . (Заметьте, что эта формула — просто результат многократного применения формулы Байеса.)
Иными словами, если мы захотим вычислить  , обозначив частоту произвольной n-граммы за
, обозначив частоту произвольной n-граммы за  , мы получим формулу
, мы получим формулу

Логично? Логично. Однако трудности начинаются, когда фразы становятся длиннее. Что, если пользователь ввёл впечатляющий своей подробностью поисковый запрос в десять слов? Мы не хотим держать статистику по всем 10-граммам — это дорого, а данные, скорее всего, будут шумными и не показательными. Мы хотим обойтись n-граммами какой-то ограниченной длины — например, уже предложенной выше длины 3.
Здесь-то и пригождается формула выше. Давайте предположим, что на вероятность слова появиться в конце фразы значительно влияют только несколько слов непосредственно перед ним, то есть что

Положив , для более длинной фразы получим формулу

Обратите внимание: фраза состоит из пяти слов, но в формуле фигурируют n-граммы не длиннее трёх. Это как раз то, чего мы добивались.
Остался один тонкий момент. Что, если пользователь ввёл совсем странную фразу и соответствующих n-грамм у нас в статистике и нет вовсе? Было бы легко для незнакомых n-грамм положить  , если бы на эту величину не надо было делить. Здесь на помощь приходит сглаживание (smoothing), которое можно делать разными способами; однако подробное обсуждение серьёзных подходов к сглаживанию вроде Kneser-Ney smoothing выходит далеко за рамки этой статьи.
, если бы на эту величину не надо было делить. Здесь на помощь приходит сглаживание (smoothing), которое можно делать разными способами; однако подробное обсуждение серьёзных подходов к сглаживанию вроде Kneser-Ney smoothing выходит далеко за рамки этой статьи.
Как исправлять фразы
Обговорим последний тонкий момент перед тем, как перейти к реализации. Постановка задачи, которую я описал выше, подразумевала, что есть одно слово и его надо исправить. Потом мы уточнили, что это одно слово может быть в середине фразы среди каких-то других слов и их тоже нужно учесть, выбирая наилучшее исправление. Но в реальности пользователи просто присылают нам фразы, не уточняя, какое слово написано с ошибкой; нередко в исправлении нуждается несколько слов или даже все.
Подходов здесь может быть много. Можно, например, учитывать только левый контекст слова в фразе. Тогда, идя по словам слева направо и по мере необходимости исправляя их, мы получим новую фразу какого-то качества. Качество будет низким, если, например, первое слово оказалось похоже на несколько популярных слов и мы выберем неправильный вариант. Вся оставшаяся фраза (возможно, изначально вообще безошибочная) будет подстраиваться нами под неправильное первое слово и мы можем получить на выходе полностью нерелевантный оригиналу текст.
Можно рассматривать слова по отдельности и применять некий классификатор, чтобы понимать, опечатано данное слово или нет, как это предложено в [4]. Классификатор обучается на вероятностях, которые мы уже умеем считать, и ряде других фичей. Если классификатор говорит, что нужно исправлять — исправляем, учитывая имеющийся контекст. Опять-таки, если несколько слов написаны с ошибкой, принимать решение насчёт первого из них придётся, опираясь на контекст с ошибками, что может приводить к проблемам с качеством.
В реализации нашего опечаточника мы использовали такой подход. Давайте для каждого слова в нашей фразе найдём с помощью модели ошибок топ-N словарных слов, которые могли иметься в виду, сконкатенируем их во фразы всевозможными способами и для каждой из  получившихся фраз, где
получившихся фраз, где  — количество слов в исходной фразе, посчитаем честно величину
— количество слов в исходной фразе, посчитаем честно величину

Здесь — слова, введённые пользователем, — подобранные для них исправления (которые мы сейчас перебираем), а  — коэффициент, определяемый сравнительным качеством модели ошибок и модели языка (большой коэффициент — больше доверяем модели языка, маленький коэффициент — больше доверяем модели ошибок), предложенный в [4]. Итого для каждой фразы мы перемножаем вероятности отдельных слов исправиться в соответствующие словарные варианты и ещё домножаем это на вероятность всей фразы в нашем языке. Результат работы алгоритма — фраза из словарных слов, максимизирующая эту величину.
— коэффициент, определяемый сравнительным качеством модели ошибок и модели языка (большой коэффициент — больше доверяем модели языка, маленький коэффициент — больше доверяем модели ошибок), предложенный в [4]. Итого для каждой фразы мы перемножаем вероятности отдельных слов исправиться в соответствующие словарные варианты и ещё домножаем это на вероятность всей фразы в нашем языке. Результат работы алгоритма — фраза из словарных слов, максимизирующая эту величину.
Так, стоп, что? Перебор фраз?
К счастью, за счёт того, что мы ограничили длину n-грамм, найти максимум по всем фразам можно гораздо быстрее. Вспомните: выше мы упростили формулу для  так, что она стала зависеть только от частот n-грамм длины не выше трёх:
так, что она стала зависеть только от частот n-грамм длины не выше трёх:

Если мы домножим эту величину на  и попытаемся максимизировать по
и попытаемся максимизировать по  , мы увидим, что достаточно перебрать всевозможные
, мы увидим, что достаточно перебрать всевозможные  и
и  и решить задачу для них — то есть для фраз
и решить задачу для них — то есть для фраз  . Итого задача решается динамическим программированием за
. Итого задача решается динамическим программированием за  .
.
Реализация
Собираем корпус и считаем n-граммы
Сразу оговорюсь: данных в моём распоряжении было не так много, чтобы заводить какой-то сложный MapReduce. Так что я просто собрал все тексты отзывов, комментариев и поисковых запросов на русском языке (описания товаров, увы, приходят на английском, а использование результатов автоперевода скорее ухудшило, чем улучшило результаты) с нашего сервиса в один текстовый файл и поставил сервер на ночь считать триграммы простым скриптом на Python.
В качестве словарных я брал топ слов по частотности так, чтобы получалось порядка ста тысяч слов. Исключались слишком длинные слова (больше 20 символов) и слишком короткие (меньше трёх символов, кроме захардкоженных известных русских слов). Отдельно пощадил слова по регулярке r"^[a-z0-9]{2}$" — чтобы уцелели версии айфонов и другие интересные идентификаторы длины 2.
При подсчёте биграмм и триграмм во фразе может встретиться несловарное слово. В этом случае это слово я выбрасывал и бил всю фразу на две части (до и после этого слова), с которыми работал отдельно. Так, для фразы «А вы знаете, что такое «абырвалг»? Это… ГЛАВРЫБА, коллега» учтутся триграммы “а вы знаете”, “вы знаете что”, “знаете что такое” и “это главрыба коллега” (если, конечно, слово “главрыба” попадёт в словарь…).
Обучаем модель ошибок
Дальше всю обработку данных я проводил в Jupyter. Статистика по n-граммам грузится из JSON, производится постобработка, чтобы быстро находить близкие друг к другу по Левенштейну слова, и для пар в цикле вызывается (довольно громоздкая) функция, выстраивающая слова и извлекающая короткие правки вида сс → с (под спойлером).
Код на Python
def generate_modifications(intended_word, misspelled_word, max_l=2):
# Выстраиваем буквы слов оптимальным по Левенштейну образом и
# извлекаем модификации ограниченной длины. Чтобы после подсчёта
# расстояния восстановить оптимальное расположение букв, будем
# хранить в таблице помимо расстояний указатели на предыдущие
# ячейки: memo будет хранить соответствие
# i -> j -> (distance, prev i, prev j).
# Дальше немного непривычно страшного Python кода - вот что
# бывает, когда язык используется не по назначению!
m, n = len(intended_word), len(misspelled_word)
memo = [[None] * (n+1) for _ in range(m+1)]
memo[0] = [(j, (0 if j > 0 else -1), j-1) for j in range(n+1)]
for i in range(m + 1):
memo[i][0] = i, i-1, (0 if i > 0 else -1)
for j in range(1, n + 1):
for i in range(1, m + 1):
if intended_word[i-1] == misspelled_word[j-1]:
memo[i][j] = memo[i-1][j-1][0], i-1, j-1
else:
best = min(
(memo[i-1][j][0], i-1, j),
(memo[i][j-1][0], i, j-1),
(memo[i-1][j-1][0], i-1, j-1),
)
# Отдельная обработка для перепутанных местами
# соседних букв (распространённая ошибка при
# печати).
if (i > 1
and j > 1
and intended_word[i-1] == misspelled_word[j-2]
and intended_word[i-2] == misspelled_word[j-1]
):
best = min(best, (memo[i-2][j-2][0], i-2, j-2))
memo[i][j] = 1 + best[0], best[1], best[2]
# К концу цикла расстояние по Левенштейну между исходными словами # хранится в memo[m][n][0].
# Теперь восстанавливаем оптимальное расположение букв.
s, t = [], []
i, j = m, n
while i >= 1 or j >= 1:
_, pi, pj = memo[i][j]
di, dj = i - pi, j - pj
if di == dj == 1:
s.append(intended_word[i-1])
t.append(misspelled_word[j-1])
if di == dj == 2:
s.append(intended_word[i-1])
s.append(intended_word[i-2])
t.append(misspelled_word[j-1])
t.append(misspelled_word[j-2])
if 1 == di > dj == 0:
s.append(intended_word[i-1])
t.append("")
if 1 == dj > di == 0:
s.append("")
t.append(misspelled_word[j-1])
i, j = pi, pj
s.reverse()
t.reverse()
# Генерируем модификации длины не выше заданной.
for i, _ in enumerate(s):
ss = ts = ""
while len(ss) < max_l and i < len(s):
ss += s[i]
ts += t[i]
yield ss, ts
i += 1
Сам подсчёт правок выглядит элементарно, хотя длиться может долго.
Применяем модель ошибок
Эта часть реализована в виде микросервиса на Go, связанного с основным бэкендом через gRPC. Реализован алгоритм, описанный самими Бриллом и Муром [2], с небольшими оптимизациями. Работает он у меня в итоге примерно вдвое медленнее, чем заявляли авторы; не берусь судить, дело в Go или во мне. Но по ходу профилировки я узнал о Go немного нового.
- Не используйте
math.Max, чтобы считать максимум. Это примерно в три раза медленнее, чемif a > b { b = a }! Только взгляните на реализацию этой функции:// Max returns the larger of x or y. // // Special cases are: // Max(x, +Inf) = Max(+Inf, x) = +Inf // Max(x, NaN) = Max(NaN, x) = NaN // Max(+0, ±0) = Max(±0, +0) = +0 // Max(-0, -0) = -0 func Max(x, y float64) float64 func max(x, y float64) float64 { // special cases switch { case IsInf(x, 1) || IsInf(y, 1): return Inf(1) case IsNaN(x) || IsNaN(y): return NaN() case x == 0 && x == y: if Signbit(x) { return y } return x } if x > y { return x } return y }Если только вам ВДРУГ не нужно, чтобы +0 обязательно был больше -0, не используйте
math.Max. - Не используйте хэш-таблицу, если можете использовать массив. Это, конечно, довольно очевидный совет. Мне пришлось перенумеровывать символы юникода в числа в начале программы так, чтобы использовать их как индексы в массиве потомков узла trie (такой lookup был очень частой операцией).
- Коллбеки в Go недёшевы. В ходе рефакторинга во время код ревью некоторые мои потуги сделать decoupling ощутимо замедлили программу при том, что формально алгоритм не изменился. С тех пор я остаюсь при мнении, что оптимизирующему компилятору Go есть, куда расти.
Применяем модель языка
Здесь без особых сюрпризов был реализован алгоритм динамического программирования, описанный в разделе выше. На этот компонент пришлось меньше всего работы — самой медленной частью остаётся применение модели ошибок. Поэтому между этими двумя слоями было дополнительно прикручено кэширование результатов модели ошибок в Redis.
Результаты
По итогам этой работы (занявшей примерно человекомесяц) мы провели A/B тест опечаточника на наших пользователях. Вместо 10% пустых выдач среди всех поисковых запросов, которые мы имели до внедрения опечаточника, их стало 5%; в основном оставшиеся запросы приходятся на товары, которых просто нет у нас на платформе. Также увеличилось количество сессий без второго поискового запроса (и ещё несколько метрик такого рода, связанных с UX). Метрики, связанные с деньгами, впрочем, значимо не изменились — это было неожиданно и сподвигло нас к тщательному анализу и перепроверке других метрик.
Заключение
Стивену Хокингу как-то сказали, что каждая включенная им в книгу формула вдвое уменьшит число читателей. Что ж, в этой статье их порядка полусотни — поздравляю тебя, один из примерно  читателей, добравшихся до этого места!
читателей, добравшихся до этого места!
Бонус
Ссылки
[1] M. D. Kernighan, K. W. Church, W. A. Gale. A Spelling Correction Program Based on a Noisy Channel Model. Proceedings of the 13th conference on Computational linguistics — Volume 2, 1990.
[2] E.Brill, R. C. Moore. An Improved Error Model for Noisy Channel Spelling Correction. Proceedings of the 38th Annual Meeting on Association for Computational Linguistics, 2000.
[3] T. Brants, A. C. Popat, P. Xu, F. J. Och, J. Dean. Large Language Models in Machine Translation. Proceedings of the 2007 Conference on Empirical Methods in Natural Language Processing.
[4] C. Whitelaw, B. Hutchinson, G. Y. Chung, G. Ellis. Using the Web for Language Independent Spellchecking and Autocorrection. Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 2.
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux для этого существует несколько утилит, одна из самых используемых это grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим что такое команда grep Linux, подробно разберём синтаксис и возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Название команды grep расшифровывается как «search globally for lines matching the regular expression, and print them». Это одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. До того как появился проект GNU, существовала утилита предшественник grep, тем же названием, которая была разработана в 1973 году Кеном Томпсоном для поиска файлов по содержимому в Unix. А потом уже была разработана свободная утилита с той же функциональностью в рамках GNU.
Grep дает очень много возможностей для фильтрации текста. Вы можете выбирать нужные строки из текстовых файлов, отфильтровать вывод команд, и даже искать файлы в файловой системе, которые содержат определённые строки. Утилита очень популярна, потому что она уже предустановлена прочти во всех дистрибутивах.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [/путь/к/файлу/или/папке…]
Или:
$ команда | grep [опции] шаблон
Здесь:
- Опции — это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например количество строк или режим инверсии.
- Шаблон — это любая строка или регулярное выражение, по которому будет выполняться поиск.
- Имя файла или папки — это то место, где будет выполняться поиск. Как вы увидите дальше, grep позволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Возможность фильтровать стандартный вывод пригодится, например, когда нужно выбрать только ошибки из логов или отфильтровать только необходимую информацию из вывода какой-либо другой утилиты.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -E, —extended-regexp — включить расширенный режим регулярных выражений (ERE);
- -F, —fixed-strings — рассматривать шаблон поиска как обычную строку, а не регулярное выражение;
- -G, —basic-regexp — интерпретировать шаблон поиска как базовое регулярное выражение (BRE);
- -P, —perl-regexp — рассматривать шаблон поиска как регулярное выражение Perl;
- -e, —regexp — альтернативный способ указать шаблон поиска, опцию можно использовать несколько раз, что позволяет указать несколько шаблонов для поиска файлов, содержащих один из них;
- -f, —file — читать шаблон поиска из файла;
- -i, —ignore-case — не учитывать регистр символов;
- -v, —invert-match — вывести только те строки, в которых шаблон поиска не найден;
- -w, —word-regexp — искать шаблон как слово, отделенное пробелами или другими знаками препинания;
- -x, —line-regexp — искать шаблон как целую строку, от начала и до символа перевода строки;
- -c — вывести количество найденных строк;
- —color — включить цветной режим, доступные значения: never, always и auto;
- -L, —files-without-match — выводить только имена файлов, будут выведены все файлы в которых выполняется поиск;
- -l, —files-with-match — аналогично предыдущему, но будут выведены только файлы, в которых есть хотя бы одно вхождение;
- -m, —max-count — остановить поиск после того как будет найдено указанное количество строк;
- -o, —only-matching — отображать только совпавшую часть, вместо отображения всей строки;
- -h, —no-filename — не выводить имя файла;
- -q, —quiet — не выводить ничего;
- -s, —no-messages — не выводить ошибки чтения файлов;
- -A, —after-content — показать вхождение и n строк после него;
- -B, —before-content — показать вхождение и n строк после него;
- -C — показать n строк до и после вхождения;
- -a, —text — обрабатывать двоичные файлы как текст;
- —exclude — пропустить файлы имена которых соответствуют регулярному выражению;
- —exclude-dir — пропустить все файлы в указанной директории;
- -I — пропускать двоичные файлы;
- —include — искать только в файлах, имена которых соответствуют регулярному выражению;
- -r — рекурсивный поиск по всем подпапкам;
- -R — рекурсивный поиск включая ссылки;
Все самые основные опции рассмотрели, теперь давайте перейдём к примерам работы команды grep Linux.
Примеры использования grep
Давайте перейдём к практике. Сначала рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep.
1. Поиск текста в файле
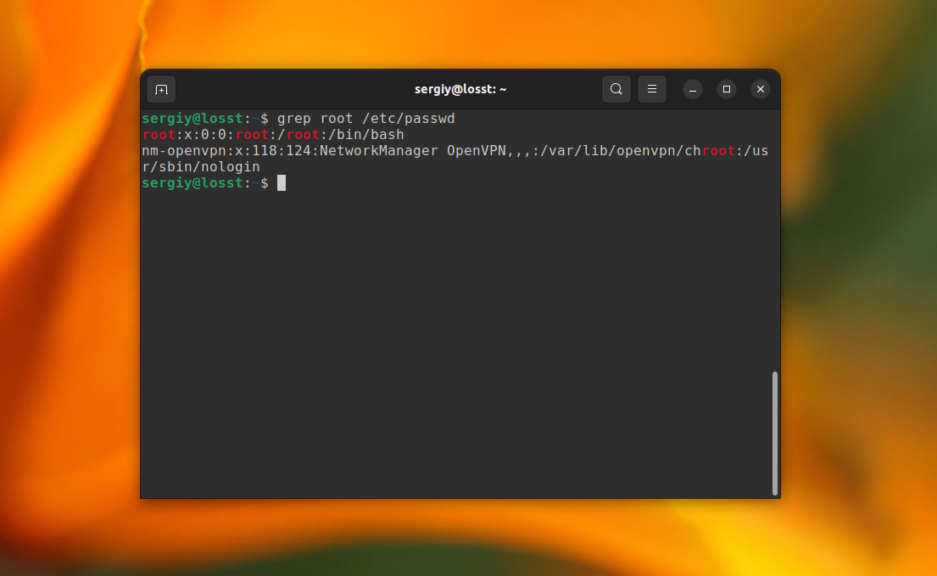
В первом примере мы будем искать информацию о пользователе root в файле со списком пользователей Linux /etc/passwd. Для этого выполните следующую команду:
grep root /etc/passwd
В результате вы получите что-то вроде этого:
С помощью опции -i можно указать, что регистр символов учитывать не нужно. Например, давайте найдём все строки содержащие вхождение слова time в том же файле:
grep -i "time" /etc/passwd
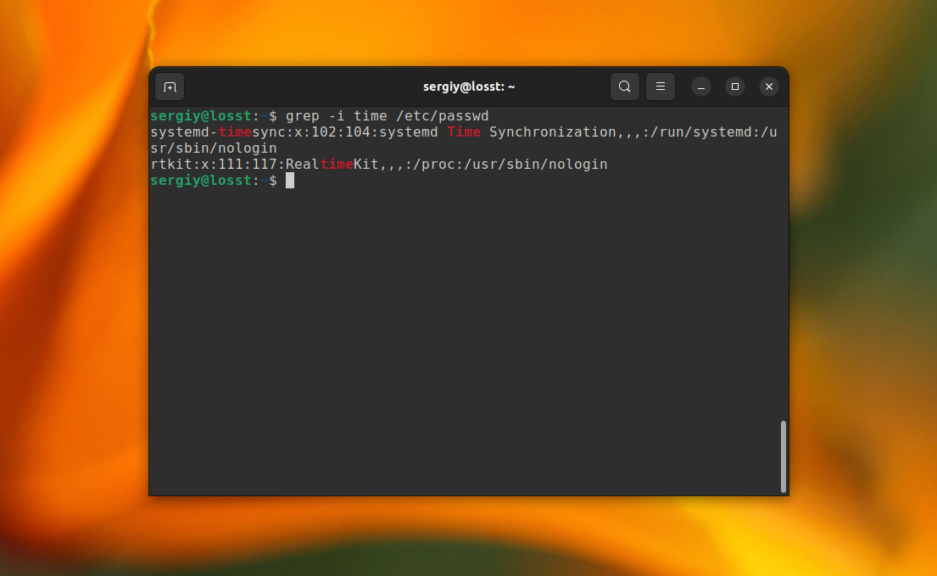
В этом случае Time, time, TIME и другие вариации слова будут считаться эквивалентными. Ещё, вы можете указать несколько условий для поиска, используя опцию -e. Например:
grep -e "root" -e "daemon" /etc/passwd
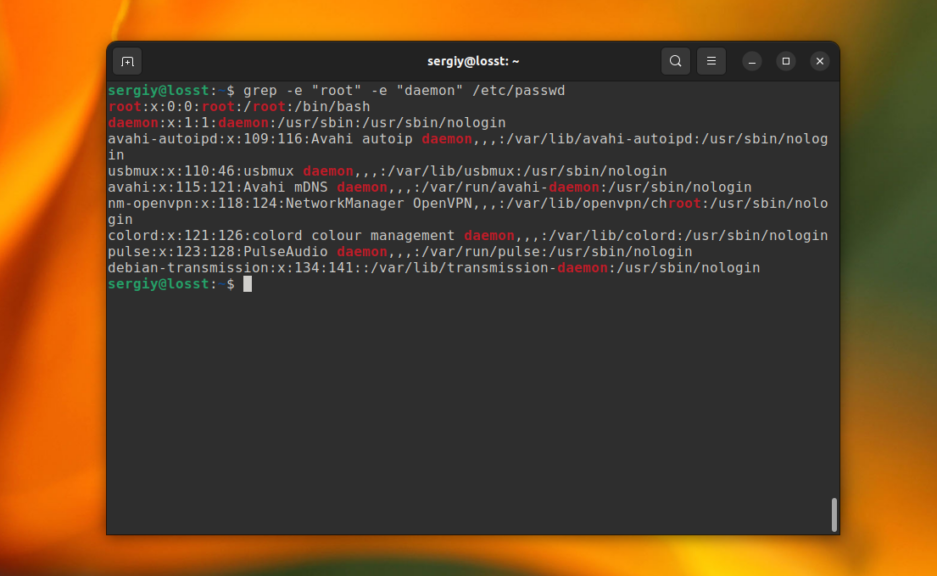
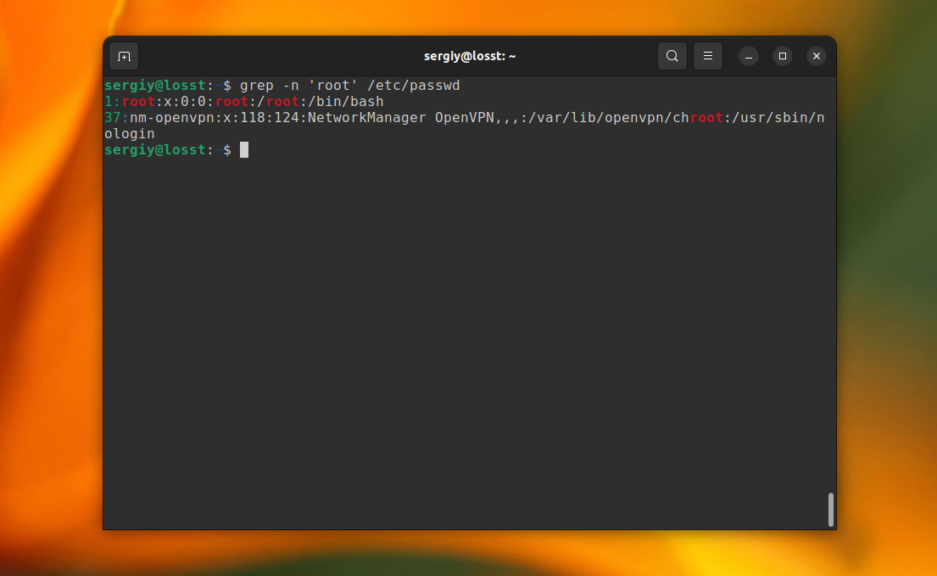
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
grep -n 'root' /etc/passwd
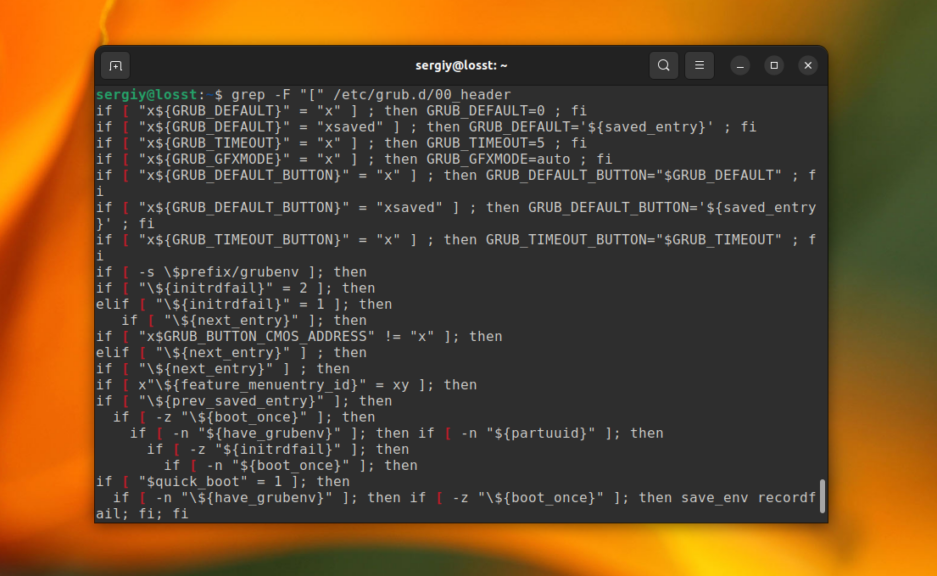
Это всё хорошо работает пока ваш поисковый запрос не содержит специальных символов. Например, если вы попытаетесь найти все строки, которые содержат символ «[» в файле /etc/grub/00_header, то получите ошибку, что это регулярное выражение не верно. Для того чтобы этого избежать, нужно явно указать, что вы хотите искать строку с помощью опции -F:
grep -F "[" /etc/grub.d/00_header
Теперь вы знаете как выполняется поиск текста файлах grep.
2. Фильтрация вывода команды
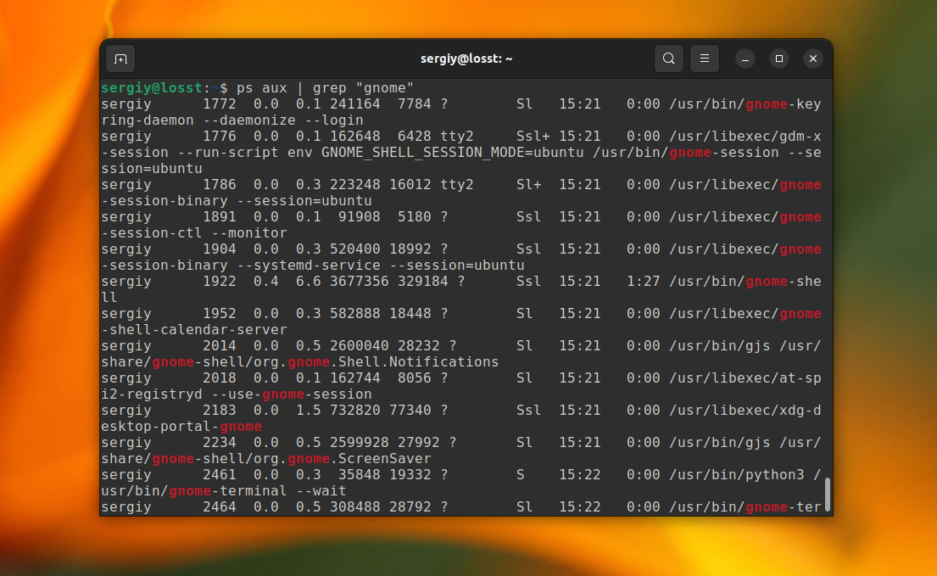
Для того чтобы отфильтровать вывод другой команды с помощью grep достаточно перенаправить его используя оператор |. А файл для самого grep указывать не надо. Например, для того чтобы найти все процессы gnome можно использовать такую команду:
ps aux | grep "gnome"
В остальном всё работает аналогично.
3. Базовые регулярные выражения
Утилита grep поддерживает несколько видов регулярных выражений. Это базовые регулярные выражения (BRE), которые используются по умолчанию и расширенные (ERE). Базовые регулярные выражение поддерживает набор символов, позволяющих описать каждый определённый символ в строке. Это: ., *, [], [^], ^ и $. Например, вы можете найти строки, которые начитаются на букву r:
grep "^r" /etc/passwd
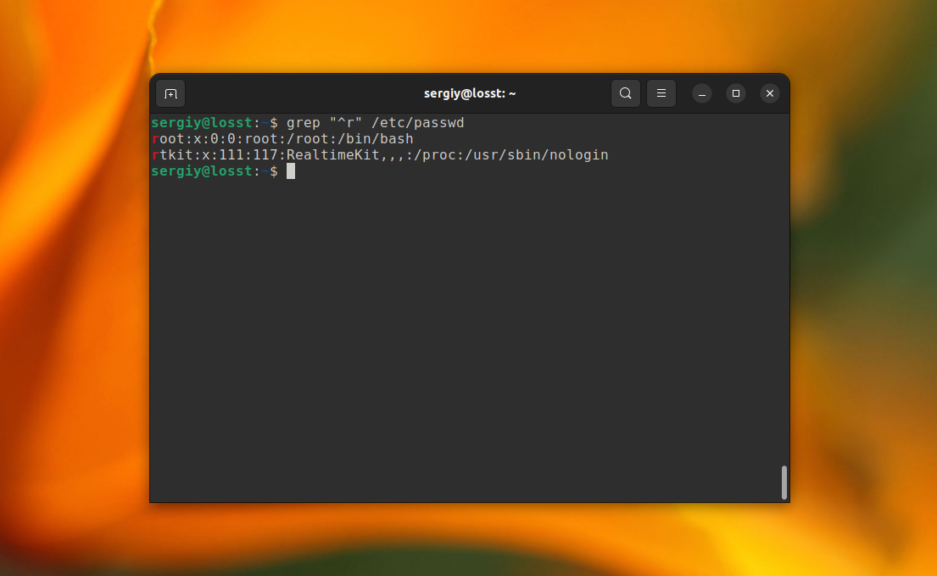
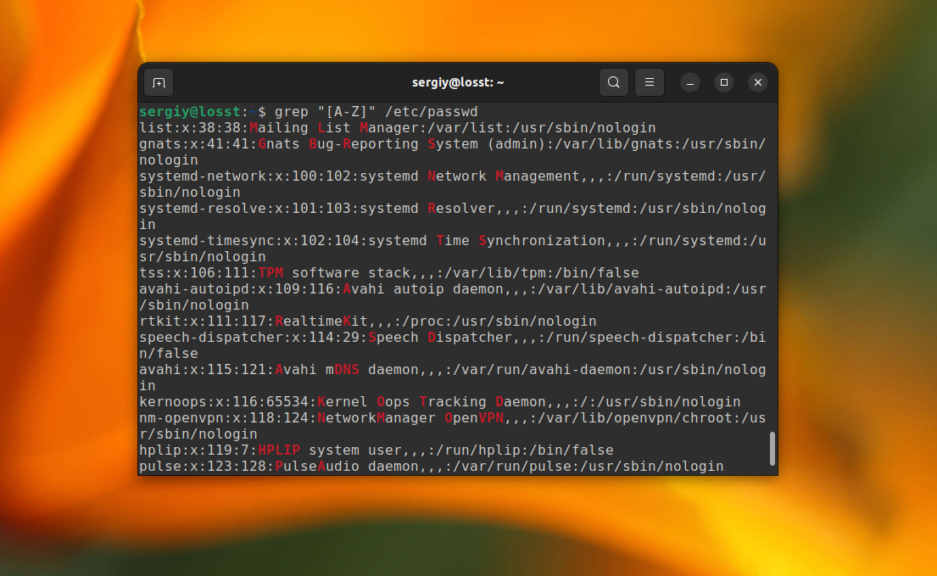
Или же строки, которые содержат большие буквы:
grep "[A-Z]" /etc/passwd
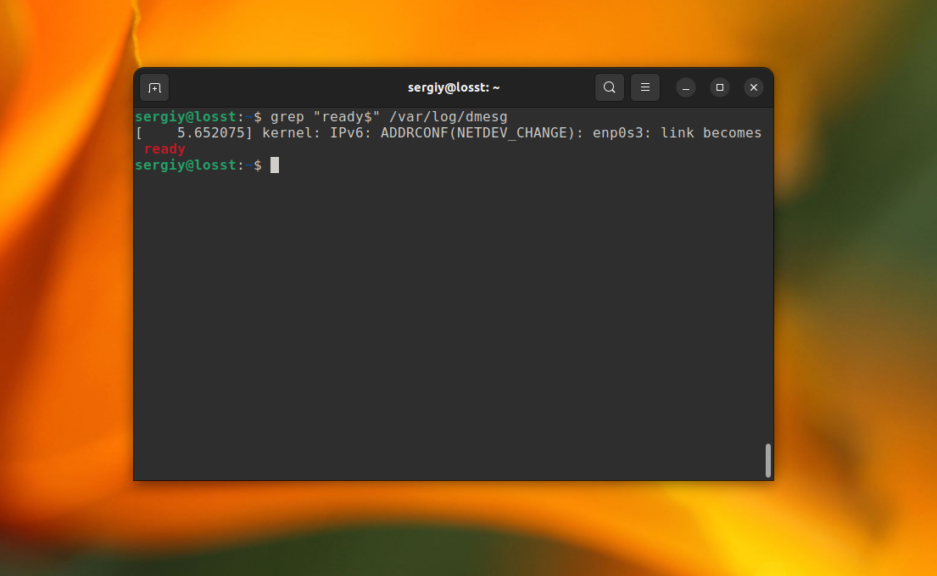
А так можно найти все строки, которые заканчиваются на ready в файле /var/log/dmesg:
grep "ready$" /var/log/dmesg
Но используя базовый синтаксис вы не можете указать точное количество этих символов.
4. Расширенные регулярные выражения
В дополнение ко всем символам из базового синтаксиса, в расширенном синтаксисе поддерживаются также такие символы:
- + — одно или больше повторений предыдущего символа;
- ? — ноль или одно повторение предыдущего символа;
- {n,m} — повторение предыдущего символа от n до m раз;
- | — позволяет объединять несколько паттернов.
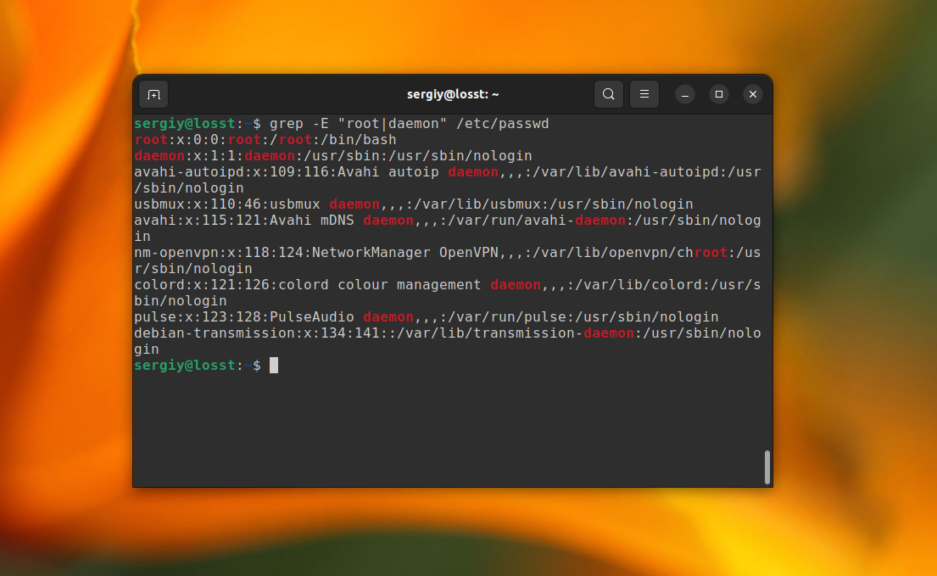
Для активации расширенного синтаксиса нужно использовать опцию -E. Например, вместо использования опции -e, можно объединить несколько слов для поиска вот так:
grep -E "root|daemon" /etc/passwd
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
5. Вывод контекста
Иногда бывает очень полезно вывести не только саму строку со вхождением, но и строки до и после неё. Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в /var/log/dmesg по шаблону «Error»:
grep -A4 "Error" /var/log/dmesg
Выведет строку с вхождением и 4 строчки после неё:
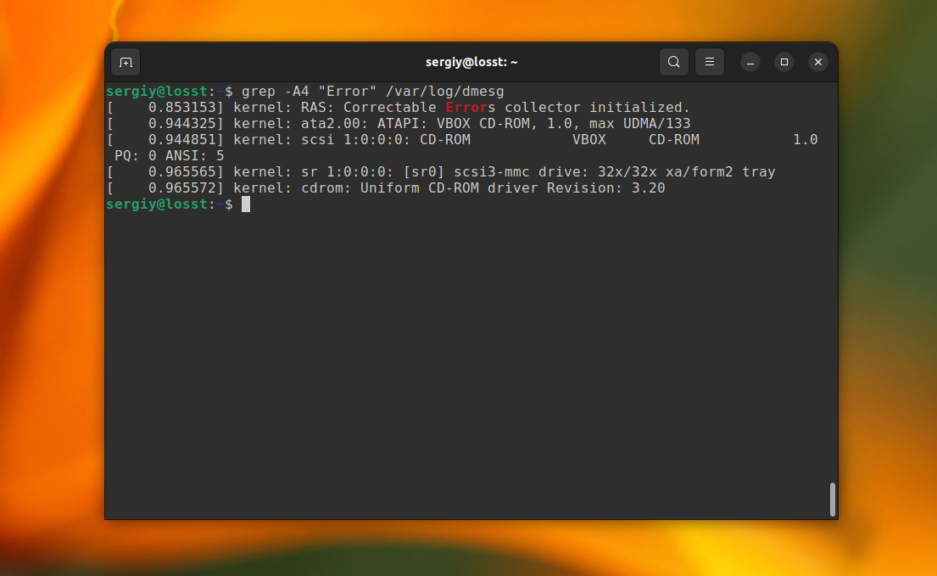
grep -B4 "Error" /var/log/dmesg
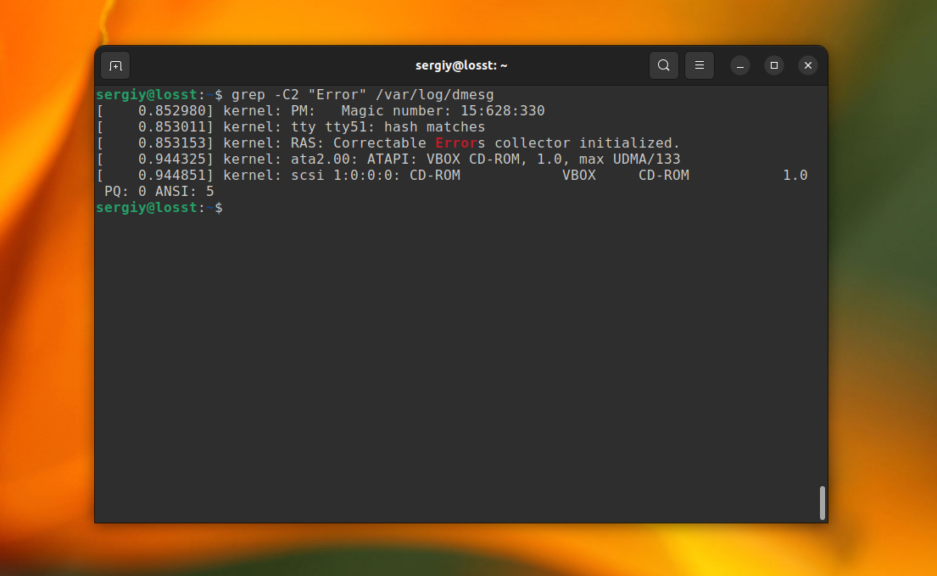
Эта команда выведет строку со вхождением и 4 строчки до неё. А следующая выведет по две строки с верху и снизу от вхождения.
grep -C2 "Error" /var/log/dmesg
6. Рекурсивный поиск в grep
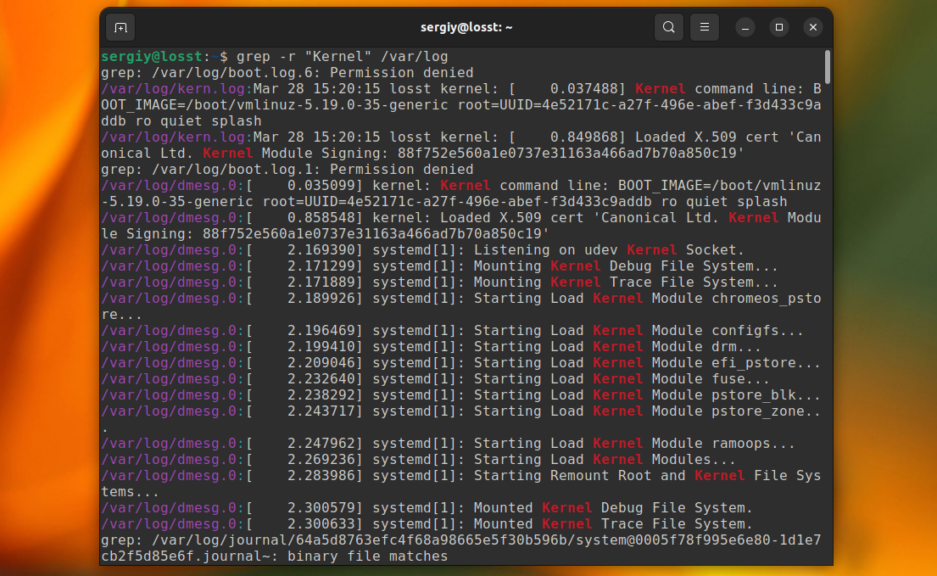
До этого мы рассматривали поиск в определённом файле или выводе команд. Но grep также может выполнить поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах. Для этого нужно использовать опцию -r. Например, давайте найдём все файлы, которые содержат строку Kernel в папке /var/log:
grep -r "Kernel" /var/log
Папка с вашими файлами может содержать двоичные файлы, в которых поиск выполнять обычно не надо. Для того чтобы их пропускать используйте опцию -I:
grep -rI "Kernel" /var/log
Некоторые файлы доступны только суперпользователю и для того чтобы выполнять по ним поиск вам нужно запускать grep с помощью sudo. Или же вы можете просто скрыть сообщения об ошибках чтения и пропускать такие файлы с помощью опции -s:
grep -rIs "Kernel" /var/log
7. Выбор файлов для поиска
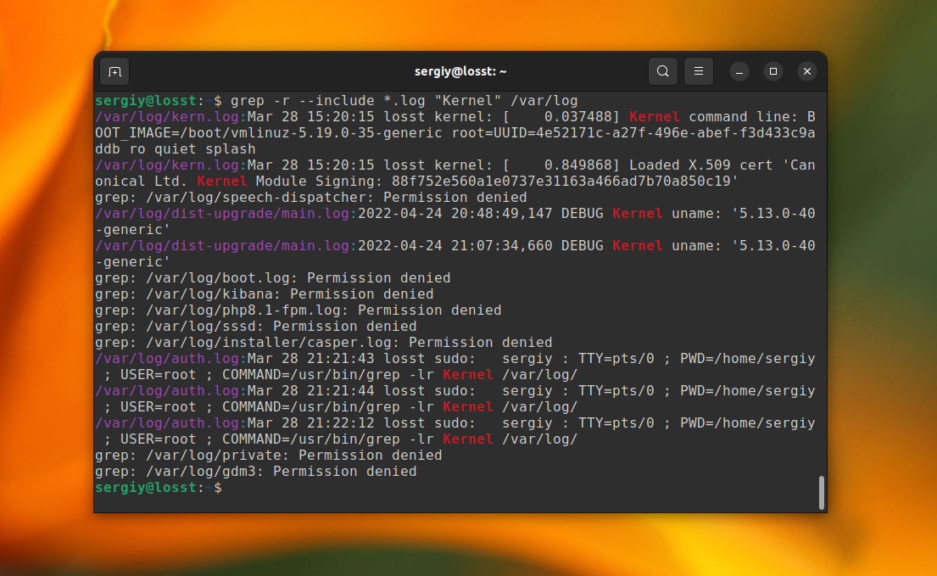
С помощью опций —include и —exclude вы можете фильтровать файлы, которые будут принимать участие в поиске. Например, для того чтобы выполнить поиск только по файлам с расширением .log в папке /var/log используйте такую команду:
grep -r --include="*.log" "Kernel" /var/log
А для того чтобы исключить все файлы с расширением .journal надо использовать опцию —exclude:
grep -r --exclude="*.journal" "Kernel" /var/log
8. Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux строки, которые включают только искомые слова полностью с помощью опции -w. Например:
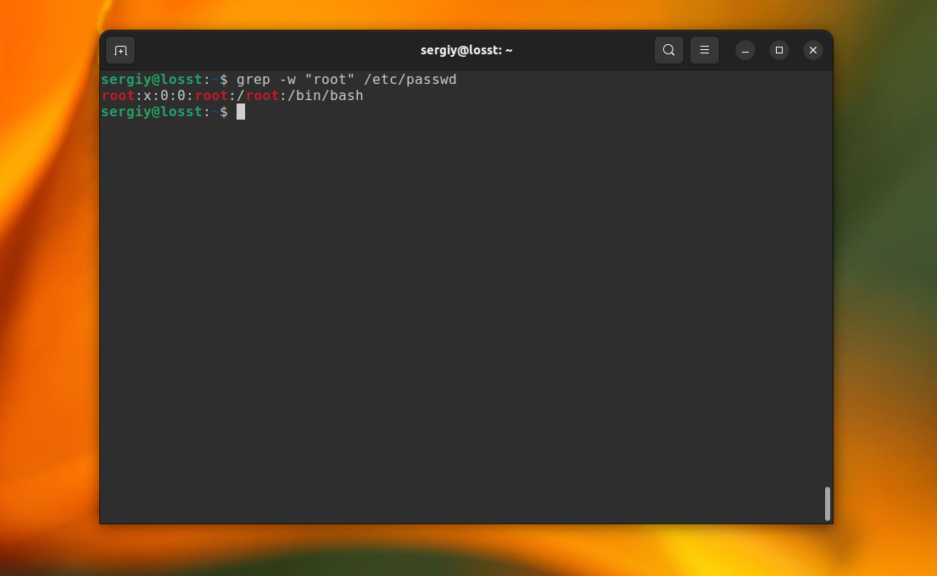
grep -w "root" /etc/passwd
9. Количество строк
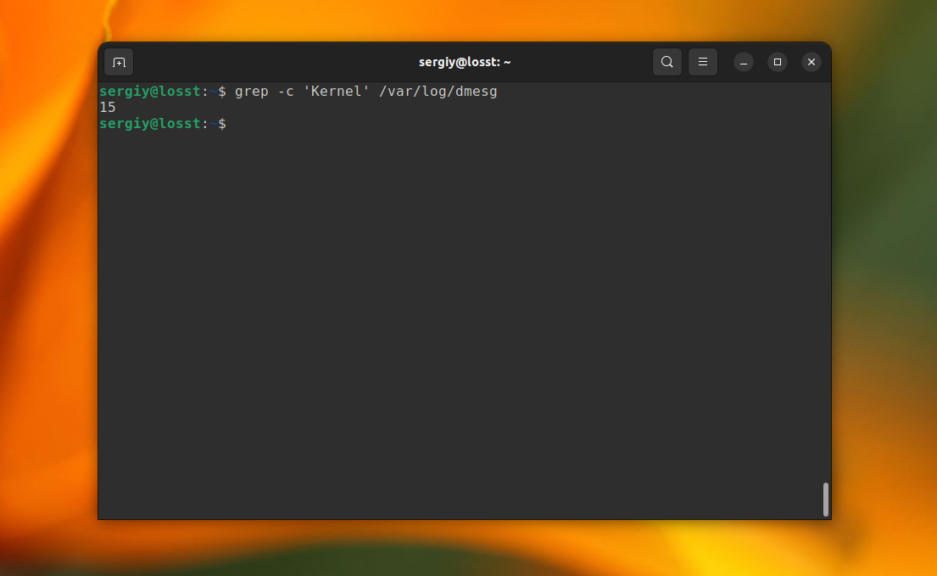
Утилита grep может сообщить, сколько строк с определенным текстом было найдено файле. Для этого используется опция -c (счетчик). Например:
grep -c 'Kernel' /var/log/dmesg
10. Инвертированный поиск
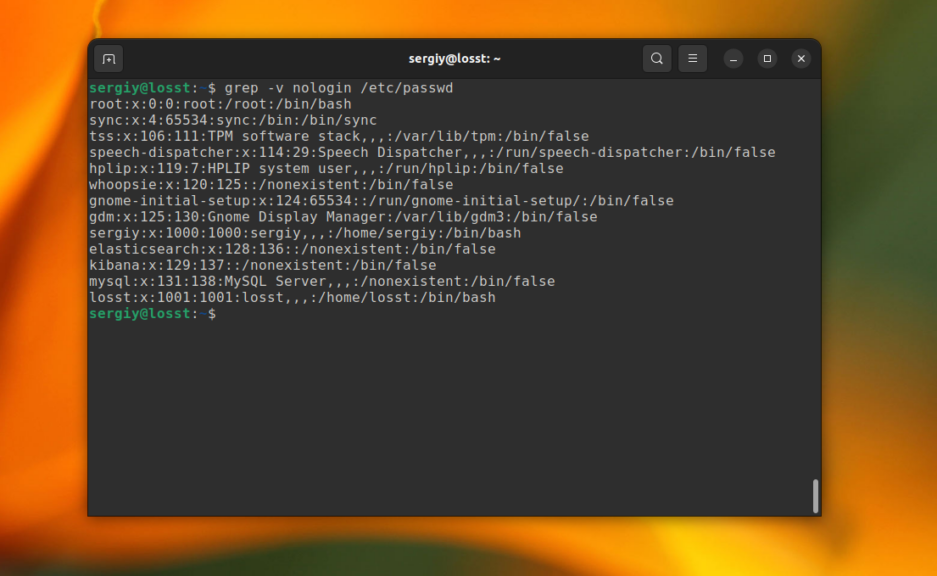
Команда grep Linux может быть использована для поиска строк, которые не содержат указанное слово. Например, так можно вывести только те строки, которые не содержат слово nologin:
grep -v nologin /etc/passwd
11. Вывод имен файлов
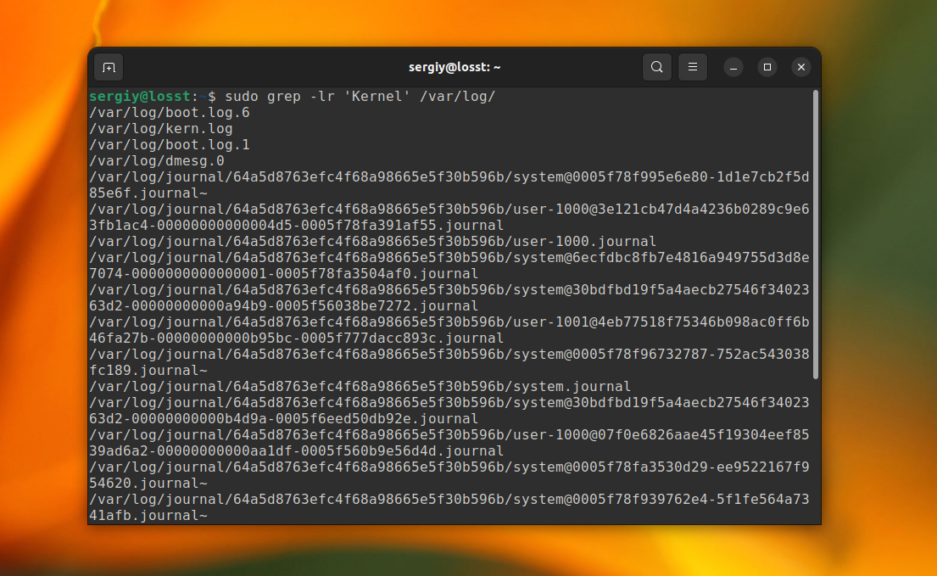
Вы можете указать grep выводить только имена файлов, в которых было хотя бы одно вхождение с помощью опции -l. Например, следующая команда выведет все имена файлов из каталога /var/log, при поиске по содержимому которых было обнаружено вхождение Kernel:
grep -lr 'Kernel' /var/log/
12. Цветной вывод
По умолчанию grep не будет подсвечивать совпадения цветом. Но в большинстве дистрибутивов прописан алиас для grep, который это включает. Однако, когда вы используйте команду c sudo это работать не будет. Для включения подсветки вручную используйте опцию —color со значением always:
sudo grep --color=always root /etc/passwd
Получится:
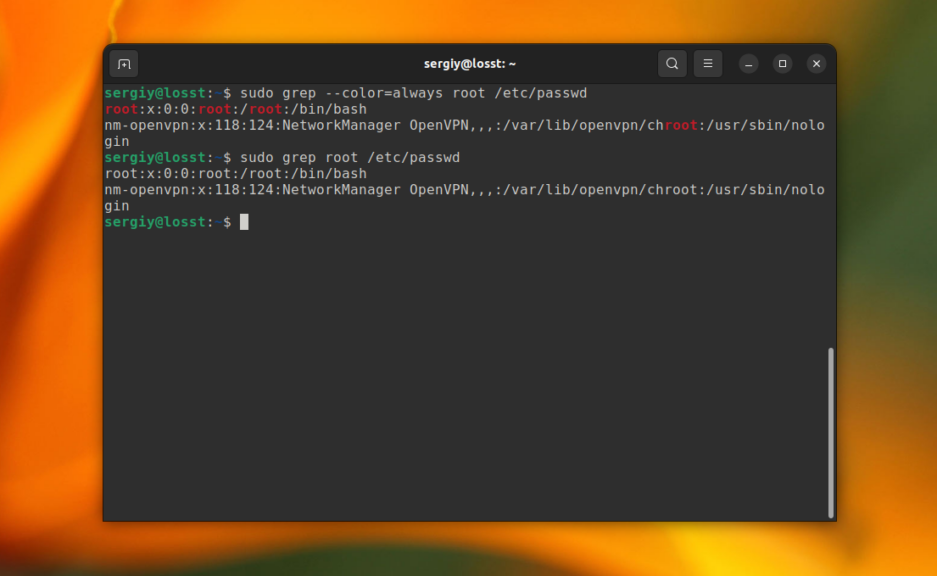
Выводы
Вот и всё. Теперь вы знаете что представляет из себя команда grep Linux, а также как ею пользоваться для поиска файлов и фильтрации вывода команд. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Здравствуйте, стоит задача реализовать полнотекстовый поиск по сайту.
К примеру в базе данных имеется таблица products, в ней поля title, description, image. Как реализовать поиск, чтобы он искал по ключевым словам, например «Визитки» «Везитки» «Визиктки», т.е. если пользователь ввел запрос с ошибкой, ему все равно выдало нужный результат.
Заранее спасибо.
![]()
Мелкий
21.3k3 золотых знака27 серебряных знаков53 бронзовых знака
задан 26 янв 2017 в 14:24
![]()
3
Вам нужен фонетический поиск. Вот реализация на php и статья о нем на Хабре
Там есть функция, преобразующая слова в фонетический код:
dmstring('Арнольд Шварцнеггер') //== 096830 479465
dmstring('Орнольд Шворцнегир') //== 096830 479465
Получаете код и заносите его в БД в отдельное поле.
Затем при поиске кодируйте поисковый запрос с помощью этой-же функции и ищите по полю с фонетическими кодами.
ответ дан 26 янв 2017 в 14:29
![]()
CrantiszCrantisz
9,7102 золотых знака15 серебряных знаков49 бронзовых знаков
Онлайн приложение Расширенный поиск по документам представляет собой систему полнотекстового поиска по текстовому содержимому документов и имеет следующие возможности:
- Три режима поиска: всех слов из запроса, любого слова из запроса, целой фразы.
- Регистрозависимый и регистронезависимый поиск.
- Нечеткий поиск (приблизительное сопоставление строк) с возможностью задания значения нечеткости от 1 до 9.
- Поиск с подстановочными знаками (поддерживаются знаки: «?» – для одиночного символа, «*» – для группы символов или пустой подстроки).
- Поиск различных словоформ, синонимов и омофонов.
- Поддерживается более 80 различных форматов (список поддерживаемых форматов).
- Поддерживается распознавание текста на изображениях – отдельных и встроенных в документы.
Система полнотекстового поиска GroupDocs.Search, на базе которой построено данное приложение, имеет гораздо более широкие возможности, например:
- Продвинутый логический поиск – слова запроса могут комбинироваться логическими операторами в выражение произвольной сложности.
- Для нечеткого поиска может задаваться функция зависимости нечеткости от длины слова линейная или ступенчатая.
- Продвинутый поиск слов по шаблону с подстановочными знаками.
- Фасетный поиск в любом поле документа.
- Продвинутый поиск диапазонов чисел и дат в любом формате.
Расширенный поиск в данном веб приложении выполняется в два этапа:
- Индексирование документов.
- Поиск в индексе.
Результаты поиска формируются в виде:
- Списка сегментов текста содержащих слова и фразы запроса.
- Целого извлеченного текста документа с подсветкой найденных слов и фраз.
- Постранично отформатированного документа с подсветкой найденных слов и фраз.