
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux для этого существует несколько утилит, одна из самых используемых это grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим что такое команда grep Linux, подробно разберём синтаксис и возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Название команды grep расшифровывается как «search globally for lines matching the regular expression, and print them». Это одна из самых востребованных команд в терминале Linux, которая входит в состав проекта GNU. До того как появился проект GNU, существовала утилита предшественник grep, тем же названием, которая была разработана в 1973 году Кеном Томпсоном для поиска файлов по содержимому в Unix. А потом уже была разработана свободная утилита с той же функциональностью в рамках GNU.
Grep дает очень много возможностей для фильтрации текста. Вы можете выбирать нужные строки из текстовых файлов, отфильтровать вывод команд, и даже искать файлы в файловой системе, которые содержат определённые строки. Утилита очень популярна, потому что она уже предустановлена прочти во всех дистрибутивах.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [/путь/к/файлу/или/папке…]
Или:
$ команда | grep [опции] шаблон
Здесь:
- Опции — это дополнительные параметры, с помощью которых указываются различные настройки поиска и вывода, например количество строк или режим инверсии.
- Шаблон — это любая строка или регулярное выражение, по которому будет выполняться поиск.
- Имя файла или папки — это то место, где будет выполняться поиск. Как вы увидите дальше, grep позволяет искать в нескольких файлах и даже в каталоге, используя рекурсивный режим.
Возможность фильтровать стандартный вывод пригодится, например, когда нужно выбрать только ошибки из логов или отфильтровать только необходимую информацию из вывода какой-либо другой утилиты.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
- -E, —extended-regexp — включить расширенный режим регулярных выражений (ERE);
- -F, —fixed-strings — рассматривать шаблон поиска как обычную строку, а не регулярное выражение;
- -G, —basic-regexp — интерпретировать шаблон поиска как базовое регулярное выражение (BRE);
- -P, —perl-regexp — рассматривать шаблон поиска как регулярное выражение Perl;
- -e, —regexp — альтернативный способ указать шаблон поиска, опцию можно использовать несколько раз, что позволяет указать несколько шаблонов для поиска файлов, содержащих один из них;
- -f, —file — читать шаблон поиска из файла;
- -i, —ignore-case — не учитывать регистр символов;
- -v, —invert-match — вывести только те строки, в которых шаблон поиска не найден;
- -w, —word-regexp — искать шаблон как слово, отделенное пробелами или другими знаками препинания;
- -x, —line-regexp — искать шаблон как целую строку, от начала и до символа перевода строки;
- -c — вывести количество найденных строк;
- —color — включить цветной режим, доступные значения: never, always и auto;
- -L, —files-without-match — выводить только имена файлов, будут выведены все файлы в которых выполняется поиск;
- -l, —files-with-match — аналогично предыдущему, но будут выведены только файлы, в которых есть хотя бы одно вхождение;
- -m, —max-count — остановить поиск после того как будет найдено указанное количество строк;
- -o, —only-matching — отображать только совпавшую часть, вместо отображения всей строки;
- -h, —no-filename — не выводить имя файла;
- -q, —quiet — не выводить ничего;
- -s, —no-messages — не выводить ошибки чтения файлов;
- -A, —after-content — показать вхождение и n строк после него;
- -B, —before-content — показать вхождение и n строк после него;
- -C — показать n строк до и после вхождения;
- -a, —text — обрабатывать двоичные файлы как текст;
- —exclude — пропустить файлы имена которых соответствуют регулярному выражению;
- —exclude-dir — пропустить все файлы в указанной директории;
- -I — пропускать двоичные файлы;
- —include — искать только в файлах, имена которых соответствуют регулярному выражению;
- -r — рекурсивный поиск по всем подпапкам;
- -R — рекурсивный поиск включая ссылки;
Все самые основные опции рассмотрели, теперь давайте перейдём к примерам работы команды grep Linux.
Примеры использования grep
Давайте перейдём к практике. Сначала рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep.
1. Поиск текста в файле
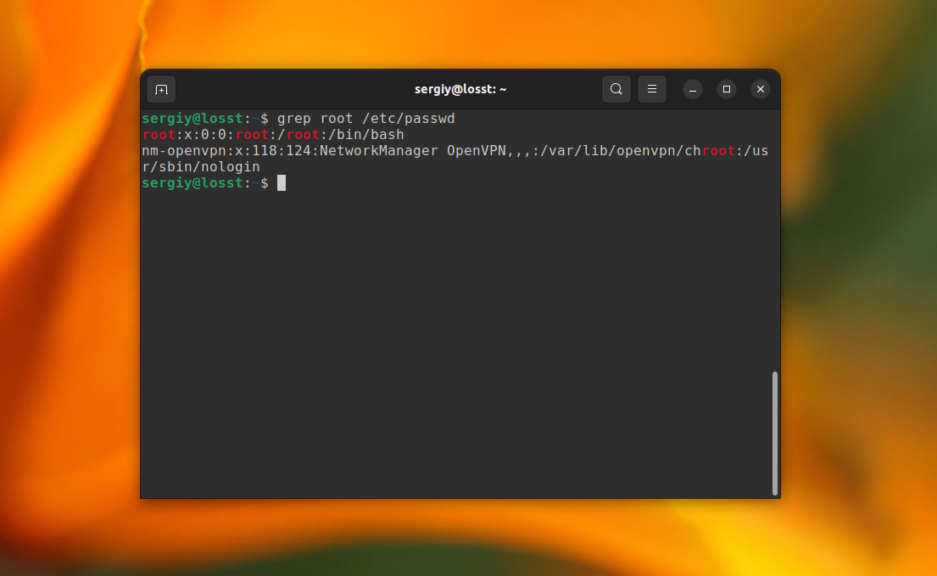
В первом примере мы будем искать информацию о пользователе root в файле со списком пользователей Linux /etc/passwd. Для этого выполните следующую команду:
grep root /etc/passwd
В результате вы получите что-то вроде этого:
С помощью опции -i можно указать, что регистр символов учитывать не нужно. Например, давайте найдём все строки содержащие вхождение слова time в том же файле:
grep -i "time" /etc/passwd
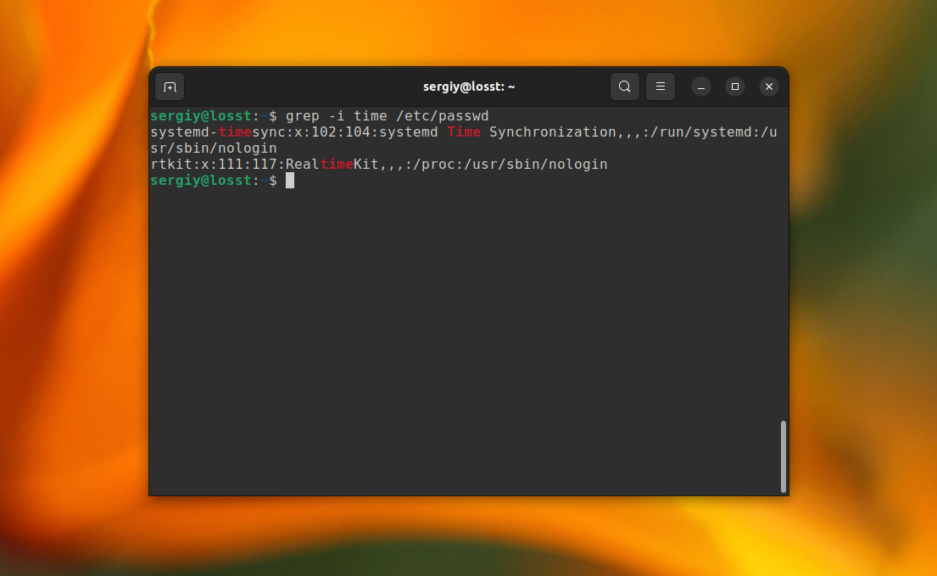
В этом случае Time, time, TIME и другие вариации слова будут считаться эквивалентными. Ещё, вы можете указать несколько условий для поиска, используя опцию -e. Например:
grep -e "root" -e "daemon" /etc/passwd
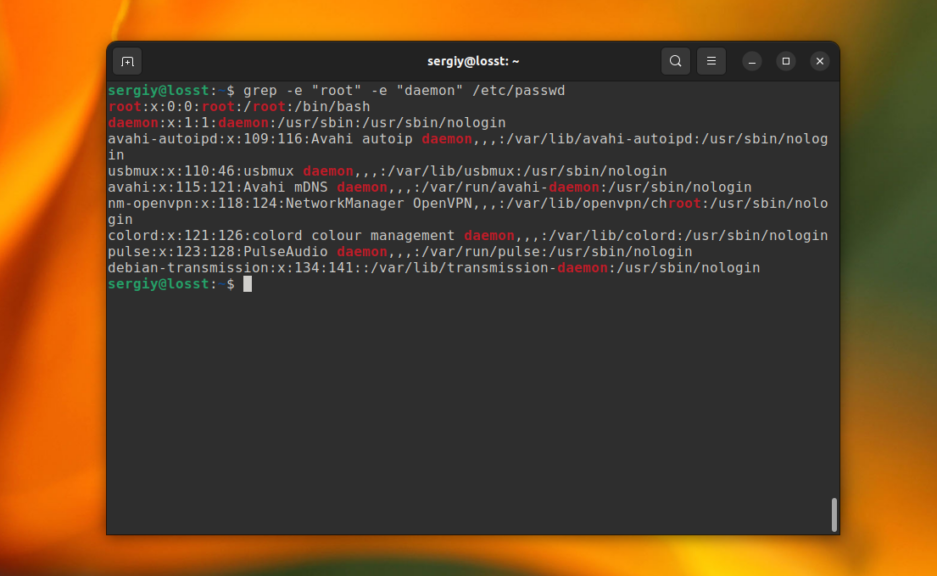
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
grep -n 'root' /etc/passwd
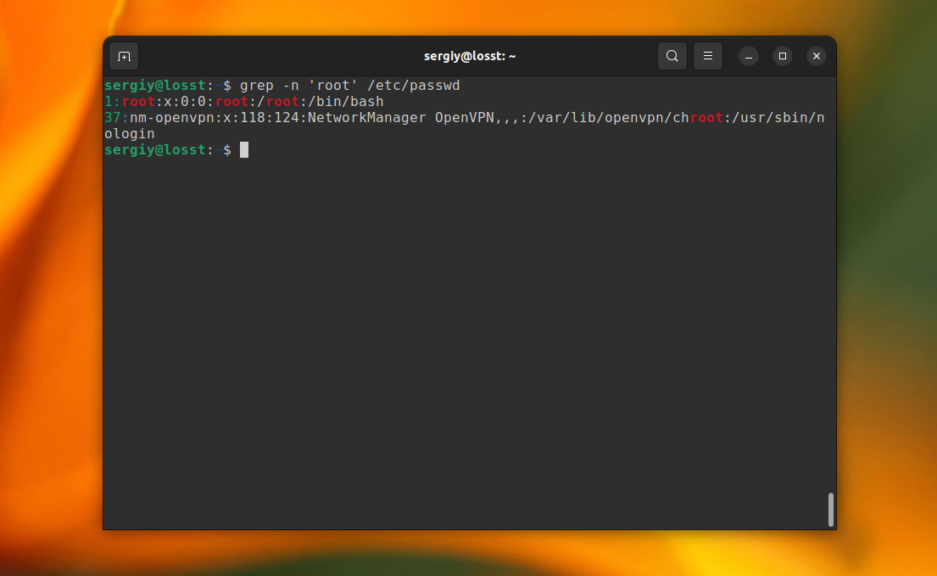
Это всё хорошо работает пока ваш поисковый запрос не содержит специальных символов. Например, если вы попытаетесь найти все строки, которые содержат символ «[» в файле /etc/grub/00_header, то получите ошибку, что это регулярное выражение не верно. Для того чтобы этого избежать, нужно явно указать, что вы хотите искать строку с помощью опции -F:
grep -F "[" /etc/grub.d/00_header
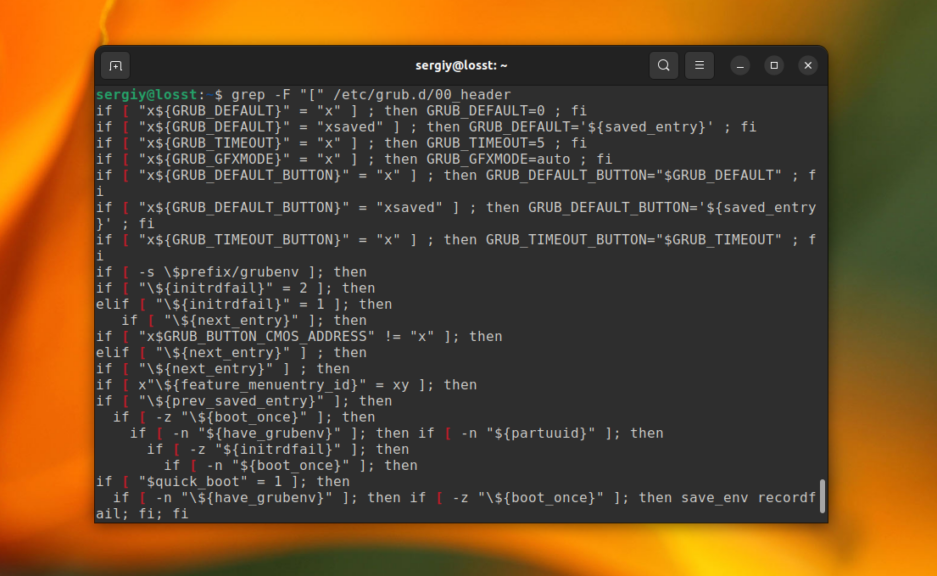
Теперь вы знаете как выполняется поиск текста файлах grep.
2. Фильтрация вывода команды
Для того чтобы отфильтровать вывод другой команды с помощью grep достаточно перенаправить его используя оператор |. А файл для самого grep указывать не надо. Например, для того чтобы найти все процессы gnome можно использовать такую команду:
ps aux | grep "gnome"
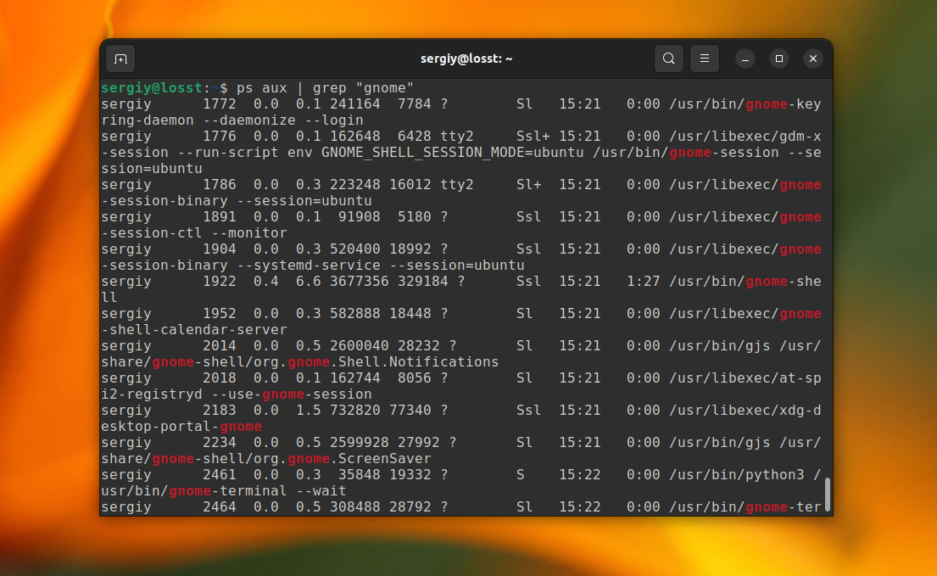
В остальном всё работает аналогично.
3. Базовые регулярные выражения
Утилита grep поддерживает несколько видов регулярных выражений. Это базовые регулярные выражения (BRE), которые используются по умолчанию и расширенные (ERE). Базовые регулярные выражение поддерживает набор символов, позволяющих описать каждый определённый символ в строке. Это: ., *, [], [^], ^ и $. Например, вы можете найти строки, которые начитаются на букву r:
grep "^r" /etc/passwd
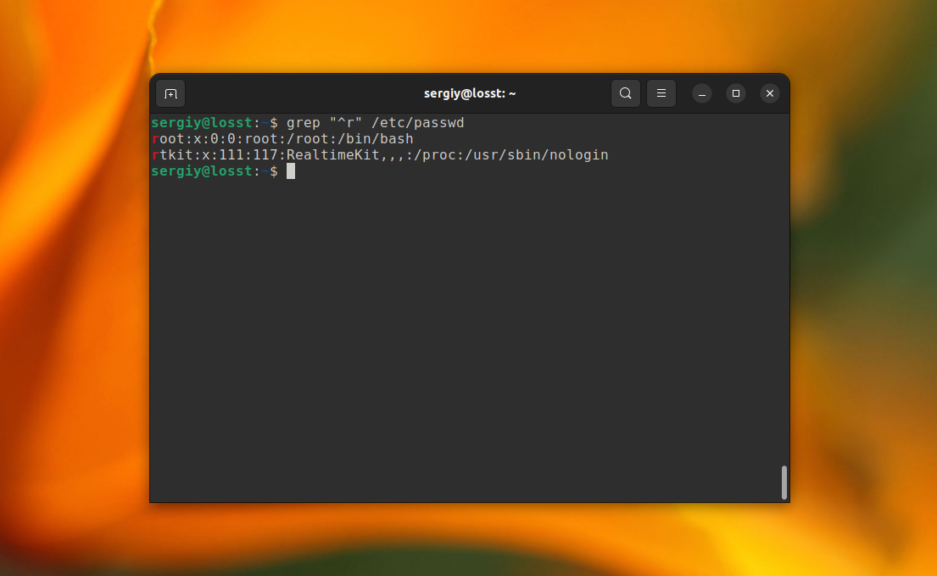
Или же строки, которые содержат большие буквы:
grep "[A-Z]" /etc/passwd
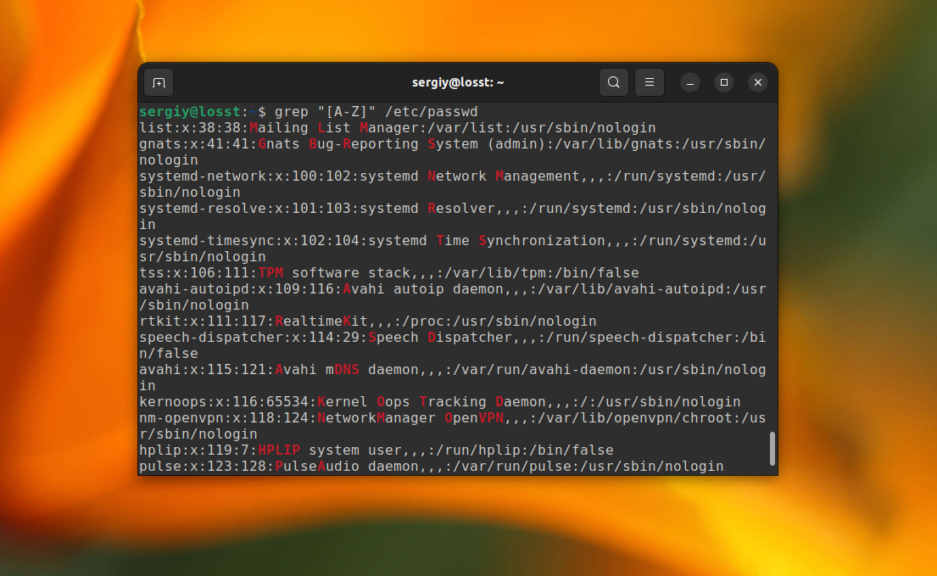
А так можно найти все строки, которые заканчиваются на ready в файле /var/log/dmesg:
grep "ready$" /var/log/dmesg
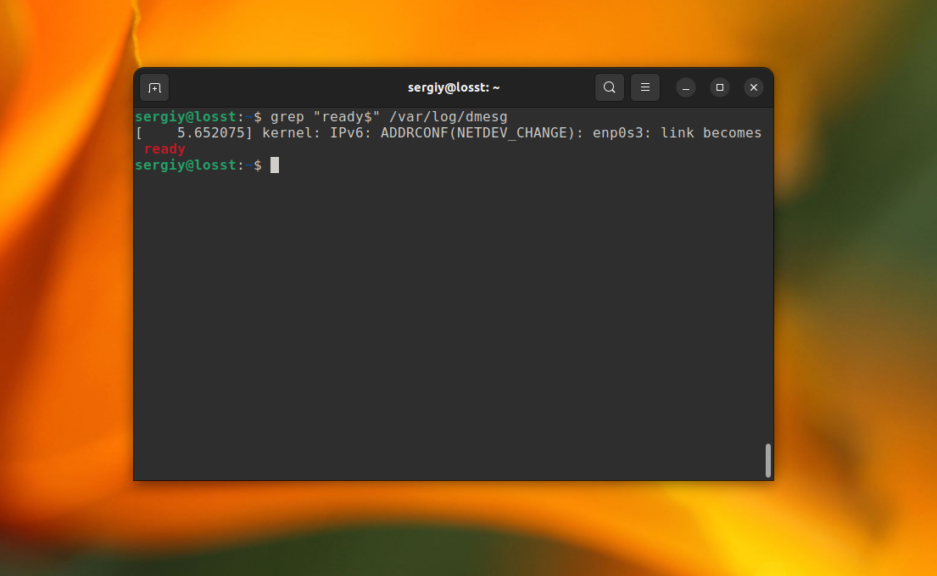
Но используя базовый синтаксис вы не можете указать точное количество этих символов.
4. Расширенные регулярные выражения
В дополнение ко всем символам из базового синтаксиса, в расширенном синтаксисе поддерживаются также такие символы:
- + — одно или больше повторений предыдущего символа;
- ? — ноль или одно повторение предыдущего символа;
- {n,m} — повторение предыдущего символа от n до m раз;
- | — позволяет объединять несколько паттернов.
Для активации расширенного синтаксиса нужно использовать опцию -E. Например, вместо использования опции -e, можно объединить несколько слов для поиска вот так:
grep -E "root|daemon" /etc/passwd
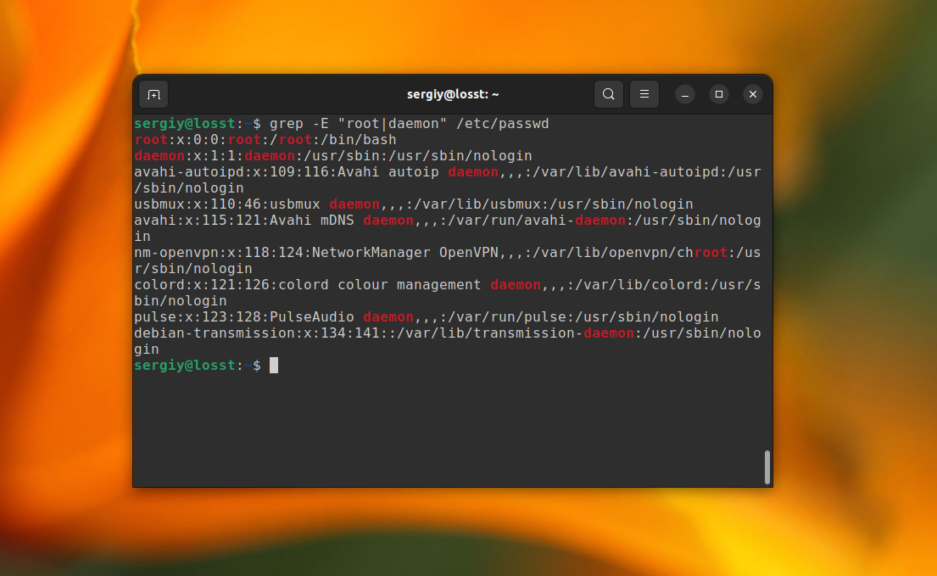
Вообще, регулярные выражения grep — это очень обширная тема, в этой статье я лишь показал несколько примеров. Как вы увидели, поиск текста в файлах grep становиться ещё эффективнее. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим её и пойдем дальше.
5. Вывод контекста
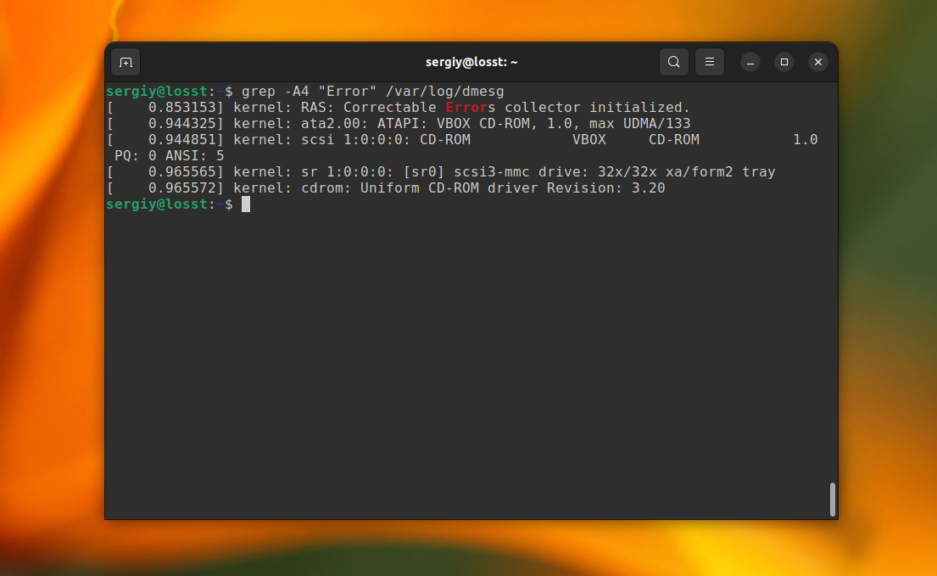
Иногда бывает очень полезно вывести не только саму строку со вхождением, но и строки до и после неё. Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в /var/log/dmesg по шаблону «Error»:
grep -A4 "Error" /var/log/dmesg
Выведет строку с вхождением и 4 строчки после неё:
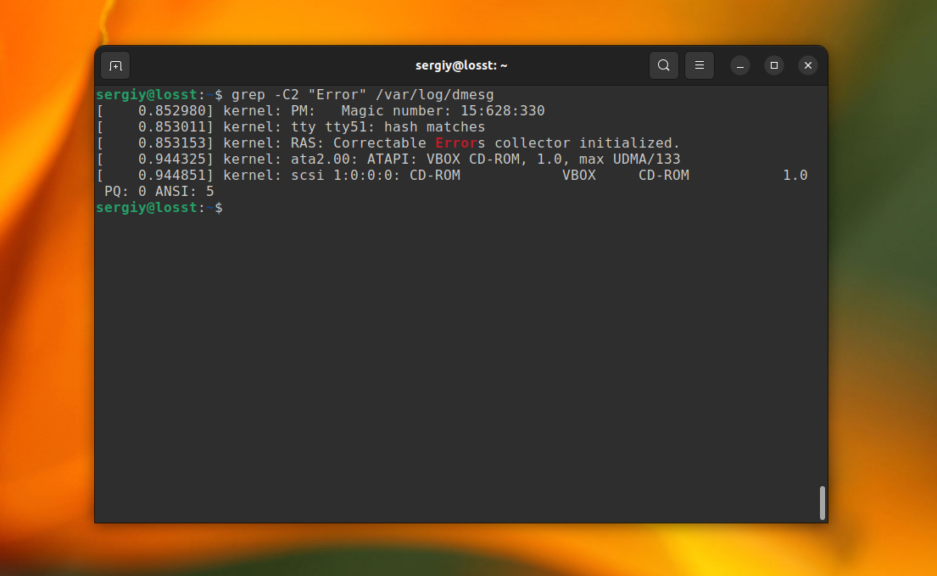
grep -B4 "Error" /var/log/dmesg
Эта команда выведет строку со вхождением и 4 строчки до неё. А следующая выведет по две строки с верху и снизу от вхождения.
grep -C2 "Error" /var/log/dmesg
6. Рекурсивный поиск в grep
До этого мы рассматривали поиск в определённом файле или выводе команд. Но grep также может выполнить поиск текста в нескольких файлах, размещённых в одном каталоге или подкаталогах. Для этого нужно использовать опцию -r. Например, давайте найдём все файлы, которые содержат строку Kernel в папке /var/log:
grep -r "Kernel" /var/log
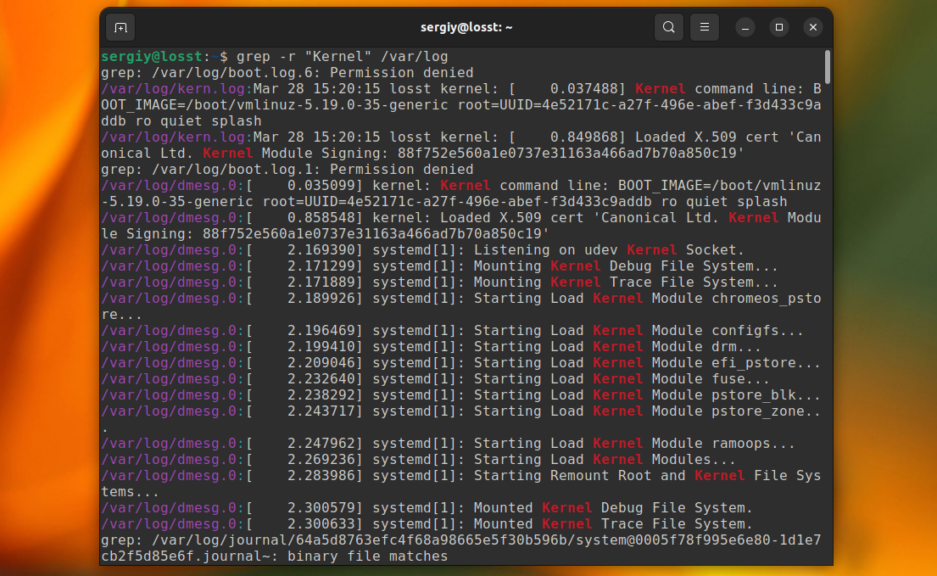
Папка с вашими файлами может содержать двоичные файлы, в которых поиск выполнять обычно не надо. Для того чтобы их пропускать используйте опцию -I:
grep -rI "Kernel" /var/log
Некоторые файлы доступны только суперпользователю и для того чтобы выполнять по ним поиск вам нужно запускать grep с помощью sudo. Или же вы можете просто скрыть сообщения об ошибках чтения и пропускать такие файлы с помощью опции -s:
grep -rIs "Kernel" /var/log
7. Выбор файлов для поиска
С помощью опций —include и —exclude вы можете фильтровать файлы, которые будут принимать участие в поиске. Например, для того чтобы выполнить поиск только по файлам с расширением .log в папке /var/log используйте такую команду:
grep -r --include="*.log" "Kernel" /var/log
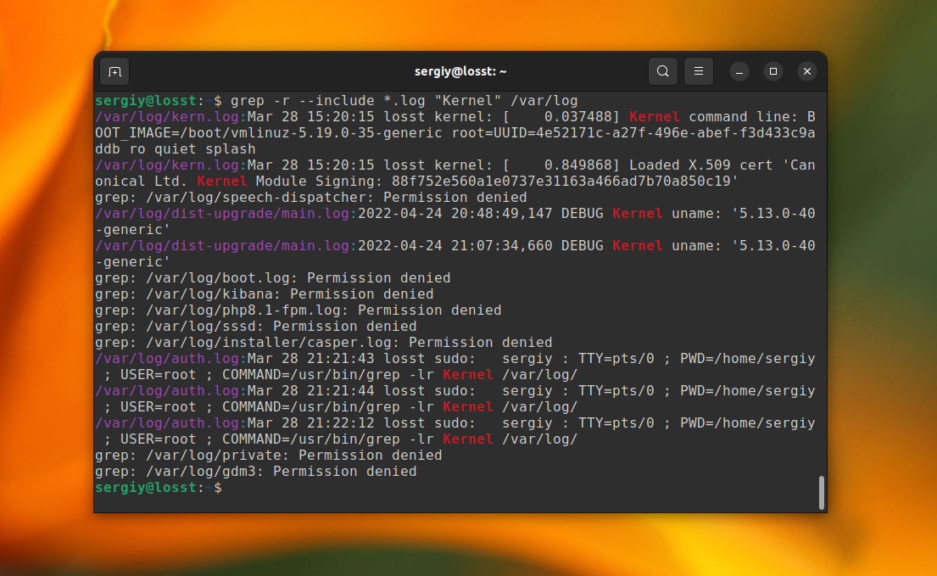
А для того чтобы исключить все файлы с расширением .journal надо использовать опцию —exclude:
grep -r --exclude="*.journal" "Kernel" /var/log
8. Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux строки, которые включают только искомые слова полностью с помощью опции -w. Например:
grep -w "root" /etc/passwd
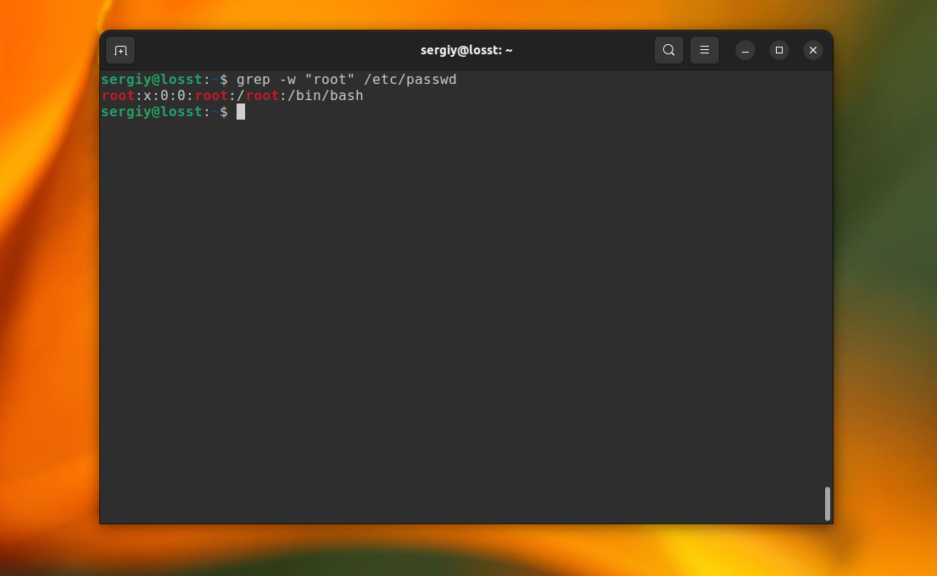
9. Количество строк
Утилита grep может сообщить, сколько строк с определенным текстом было найдено файле. Для этого используется опция -c (счетчик). Например:
grep -c 'Kernel' /var/log/dmesg
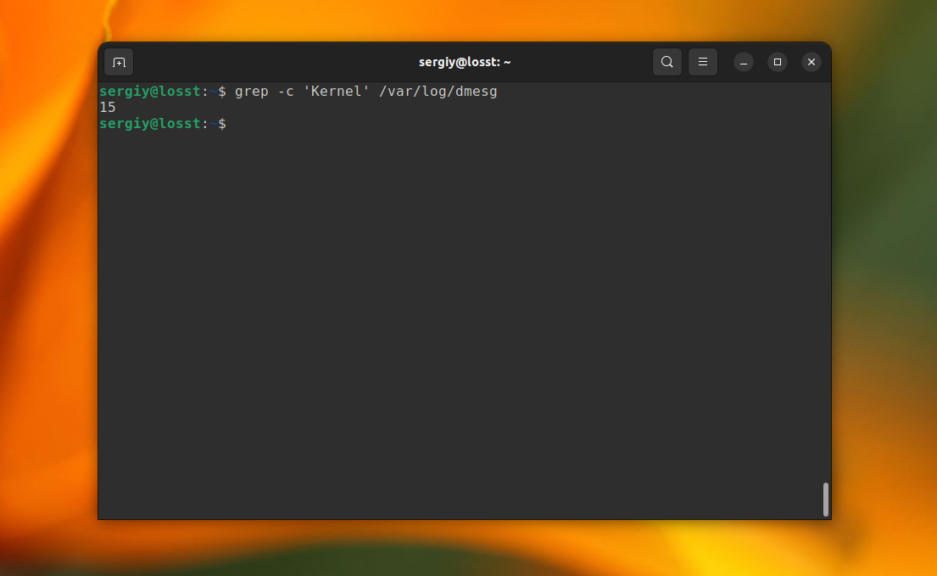
10. Инвертированный поиск
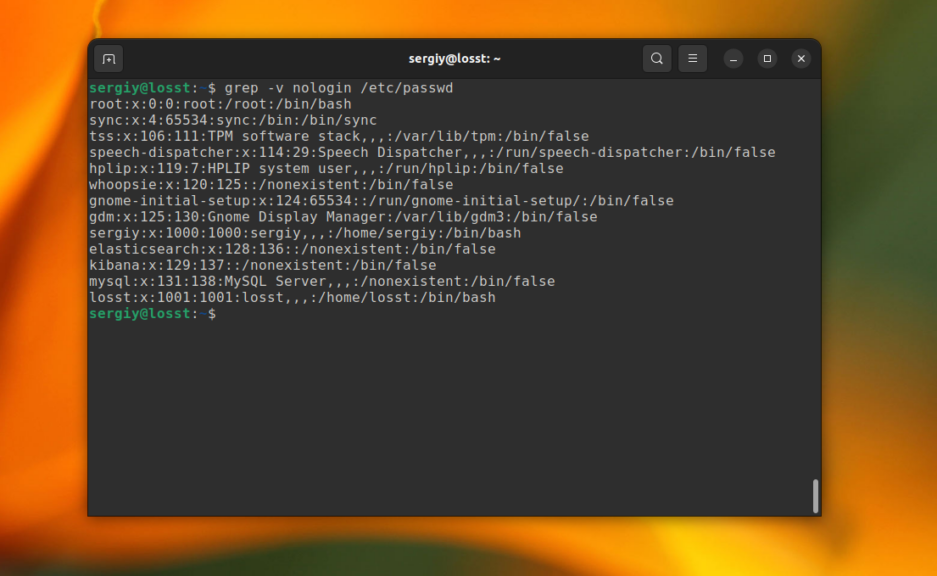
Команда grep Linux может быть использована для поиска строк, которые не содержат указанное слово. Например, так можно вывести только те строки, которые не содержат слово nologin:
grep -v nologin /etc/passwd
11. Вывод имен файлов
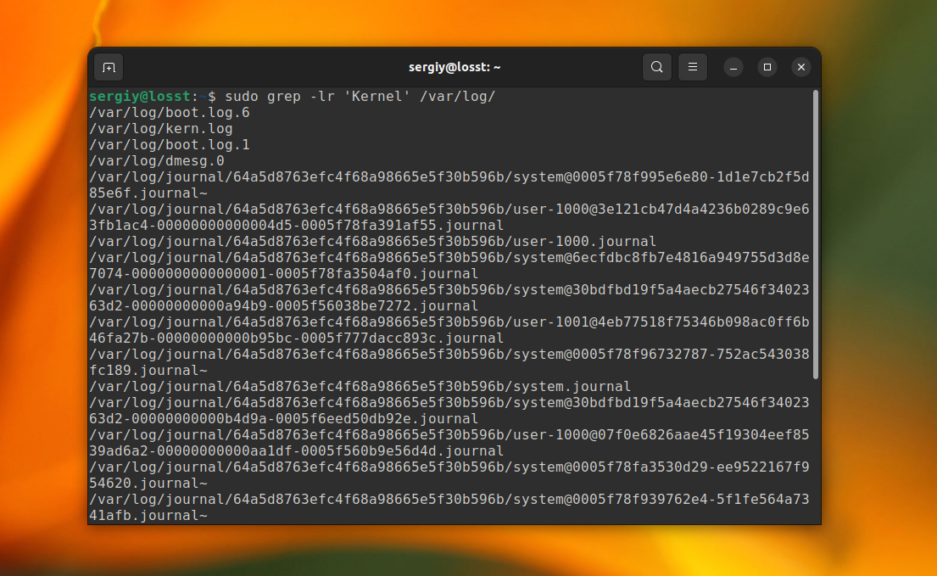
Вы можете указать grep выводить только имена файлов, в которых было хотя бы одно вхождение с помощью опции -l. Например, следующая команда выведет все имена файлов из каталога /var/log, при поиске по содержимому которых было обнаружено вхождение Kernel:
grep -lr 'Kernel' /var/log/
12. Цветной вывод
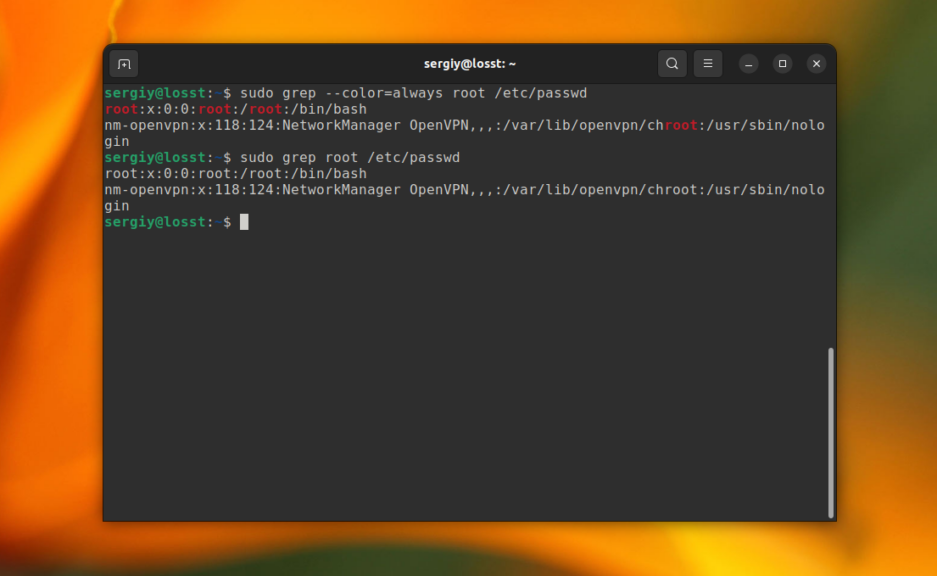
По умолчанию grep не будет подсвечивать совпадения цветом. Но в большинстве дистрибутивов прописан алиас для grep, который это включает. Однако, когда вы используйте команду c sudo это работать не будет. Для включения подсветки вручную используйте опцию —color со значением always:
sudo grep --color=always root /etc/passwd
Получится:
Выводы
Вот и всё. Теперь вы знаете что представляет из себя команда grep Linux, а также как ею пользоваться для поиска файлов и фильтрации вывода команд. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Время на прочтение
10 мин
Количество просмотров 12K
Моя самая любимая часть в статическом анализе кода — это выдвижение гипотез о потенциальных ошибках в коде с последующей их проверкой.
Пример гипотезы:
Функции strpos легко передать аргументы в неправильном порядке. Но есть вероятность, что даже на нескольких миллионах строк кода подобная диагностика не «выстрелит», поэтому на неудачные гипотезы тратить много времени не хочется.
Сегодня я покажу как выполнять простейший статический анализ с помощью утилиты phpgrep без написания кода.
Предпосылки
Вот уже несколько месяцев я занимаюсь поддержкой PHP линтера NoVerify (почитать о котором можно в статье NoVerify: линтер для PHP от Команды ВКонтакте).
Время от времени в команде появляются идеи для новых диагностик. Идей может быть много, а проверить хочется все, особенно если предложенная проверка нацелена на выявление критических дефектов.
Ранее я активно разрабатывал go-critic и ситуация была схожей, с той лишь разницей, что анализировались исходники на Go, а не на PHP. Когда я узнал об утилите gogrep, мой мир перевернулся. Как видно из названия, эта утилита имеет что-то общее с grep’ом, только поиск производится не по регулярным выражениям, а по синтаксическим шаблонам (позже объясню, что это значит).
Я уже не хотел жить без умного grep, поэтому в один вечер решил сесть и написать phpgrep.
Анализируемый корпус
Чтобы было увлекательно, мы сразу погрузимся в применение. Будем анализировать небольшой набор достаточно известных и крупных PHP проектов, доступных на GitHub.
В наш набор попали следующие проекты:
Для людей, которые замышляют то, что мы с вами замышляем, это очень аппетитный набор.
Итак, поехали!
Использование присваивания в качестве выражения
Если присваивание используется как выражение, причём:
- контекст ожидает результат логической операции (логическое условие) и
- правая часть выражения не имеет побочных эффектов и является константной,
то, скорее всего, в коде ошибка.
Для начала, возьмём за «логический контекст» следующие конструкции:
- Выражение внутри «
if ($cond)«. - Условие тернарного оператора: «
$cond ? $x : $y«. - Условия продолжений циклов «
while ($cond)» и «for ($init; $cond; $post)«.
В правой части присваивания мы ожидаем константы или литералы.
Зачем на нужны такие ограничения?
Начнём с (1):
# утилита поиска по синтаксическим шаблонам
# | производим поиск по текущей директории (и всем дочерним)
# | |
# | |
phpgrep . 'if ($_ = []) $_' # 1
# |
# |
# строка шаблона поиска
# Дополнительные 3 шаблона через отдельные запуски.
phpgrep . 'if ($_ = ${"const"}) $_' # 2
phpgrep . 'if ($_ = ${"str"}) $_' # 3
phpgrep . 'if ($_ = ${"num"}) $_' # 4Здесь мы видим 4 шаблона, единственным различием между которыми выступает присваиваемое выражение (RHS). Начнём с первого из них.
Шаблон «if ($_ = []) $_» захватывает if, у которого любому выражению присваивается пустой массив. $_ сопоставляется с любым expression или statement.
литерал пустого массива (RHS)
|
if ($_ = []) $_
| |
| любое тело if'а, причём не важно, с {} или без
любой LHS у присваиванияВ следующих примерах используются более сложные группы const, str и num. В отличие от $_ они описывают ограничения на совместимые операции.
const— именованная константа или константа класса.str— строковой литерал любого типа.num— числовой литерал любого типа.
Этих шаблонов достаточно, чтобы добиться нескольких срабатываний на корпусе.
⎆ moodle/blocks/rss_client/viewfeed.php#L37:
if ($courseid = SITEID) {
$courseid = 0;
}Вторым срабатыванием в moodle стала зависимость ADOdb. В upstream библиотеки проблема всё ещё присутствует.
⎆ ADOdb/drivers/adodb-odbtp.inc.php#L741:

В этом фрагменте прекрасно многое, но для нас релевантна только первая строка. Вместо сравнения поля databaseType мы выполняем присваивание и всегда входим внутрь условия.
Ещё одно интересное место, где мы хотим выполнять действия только для «корректных» записей, но, вместо этого, выполняем их всегда и, более того, отмечаем любую запись как корректную!
⎆ moodle/question/format/blackboard_six/formatqti.php#L598:
// For BB Fill in the Blank, only interested in correct answers.
if ($response->feedback = 'correct') {
// ...
}Расширенный список шаблонов для этой проверки
Повторим то, что мы изучили:
- Шаблоны выглядят как PHP-код, который они находят.
$_обозначает «что угодно». Можно сравнить с.в регулярных выражениях.${"<class>"}работает как$_с ограничением на тип элементов AST.
Стоит ещё подчеркнуть, что всё, кроме переменных, сопоставляется дословно (literally). Это значит, что шаблону «array(1, 2 + 3)» будет удовлетворять лишь идентичный по синтаксической структуре код (пробелы не влияют). С другой стороны, шаблону «array($_, $_)» удовлетворяет любой литерал массива из двух элементов.
Сравнение выражения с самим собой
Потребность сравнить что-либо с самим собой возникает очень редко. Это может быть проверка на NaN, но как минимум в половине случаев это ошибка copy/paste.
⎆ Wikia/app/extensions/SemanticDrilldown/includes/SD_FilterValue.php#L103:
if ( $fv1->month == $fv1->month ) return 0;Справа должно быть «$fv2->month«.
Для выражения повторяющихся частей в шаблоне мы используем переменные с именами, отличными от «_«. Механизм повторений в шаблоне похож на обратные ссылки в регулярных выражениях.
Шаблон «$x == $x» будет как раз тем, что найдёт пример выше. Вместо «x» может использоваться любое имя. Здесь важно лишь то, чтобы имена были идентичны. Переменные шаблона, которые имеют различающиеся имена, не обязаны иметь совпадающее содержимое при захвате.
Следующий пример найден с помощью «$x <= $x«.
⎆ Drupal/core/modules/views/tests/src/Unit/ViewsDataTest.php#L166:
$prev = $base_tables[$base_tables_keys[$i - 1]];
$current = $base_tables[$base_tables_keys[$i]];
$this->assertTrue(
$prev['weight'] <= $current['weight'] &&
$prev['title'] <= $prev['title'], // <-------------- ошибка
'The tables are sorted as expected.');Дублирующиеся подвыражения
Теперь, когда мы знаем про возможности повторяемых подвыражений, мы можем составить множество любопытных шаблонов.
Один из моих любимцев — «$_ ? $x : $x«.
Это тернарный оператор, у которого true/false ветки идентичны.
⎆ joomla-cms/libraries/src/User/UserHelper.php#L522:
return ($show_encrypt) ? '{SHA256}' . $encrypted : '{SHA256}' . $encrypted;Обе ветви дублируются, что подсказывает о потенциальной проблеме в коде. Если мы посмотрим на код вокруг, то сможем понять, что там должно было быть вместо этого. В угоду читабельности я вырезал часть кода и сократил название переменной $encrypted до $enc.
case 'crypt-blowfish':
return ($show_encrypt ? '{crypt}' : '') . crypt($plaintext, $salt);
case 'md5-base64':
return ($show_encrypt) ? '{MD5}' . $enc : $enc;
case 'ssha':
return ($show_encrypt) ? '{SSHA}' . $enc : $enc;
case 'smd5':
return ($show_encrypt) ? '{SMD5}' . $enc : $enc;
case 'sha256':
return ($show_encrypt) ? '{SHA256}' . $enc : '{SHA256}' . $enc;
default:
return ($show_encrypt) ? '{MD5}' . $enc : $enc;Я бы поставил на то, что коду необходим следующий патч:
- ($show_encrypt) ? '{SHA256}' . $encrypted : '{SHA256}' . $encrypted;
+ ($show_encrypt) ? '{SHA256}' . $encrypted : $encrypted;Опасные приоритеты операций в PHP
Хорошей мерой предосторожности в PHP является использование группирующих скобочек везде, где важно иметь правильный порядок вычислений.
Во многих языках программирования выражение «x & mask != 0» имеет интуитивный смысл. Если mask описывает какой-то бит, то данный код проверяет, что в x этот бит не равен нулю. К сожалению, для PHP это выражение будет вычисляться так: «x & (mask != 0)«, что почти всегда не то что вам нужно.
WordPress, Joomla и moodle используют SimplePie.
⎆ SimplePie/library/SimplePie/Locator.php#L254
⎆ SimplePie/library/SimplePie/Locator.php#L384
⎆ SimplePie/library/SimplePie/Locator.php#L412
⎆ SimplePie/library/SimplePie/Sanitize.php#L349
⎆ SimplePie/library/SimplePie.php#L1634
$feed->method & SIMPLEPIE_FILE_SOURCE_REMOTE === 0SIMPLEPIE_FILE_SOURCE_REMOTE определён как 1, поэтому выражение будет эквивалентно:
$feed->method & (1 === 0)
// =>
$feed->method & falseПримеры шаблонов для поиска
Продолжая тему неожиданных приоритетов операций, вы можете почитать про тернарный оператор в PHP. На хабре этому даже посвятили статью: Порядок выполнения тернарного оператора.
Можно ли такие места найти с помощью phpgrep? Ответ: да!
phpgrep . '$_ == $_ ? $_ : $_ ? $_ : $_'
phpgrep . '$_ != $_ ? $_ : $_ ? $_ : $_'Прелести проверки URL с помощью регулярных выражений
⎆ Wikia/app/maintenance/wikia/updateCentralInterwiki.inc#L95:
if ( preg_match( '/(wowwiki.com|wikia.com|falloutvault.com)/', $url ) ) {
$local = 1;
} else {
$local = 0;
}По задумке автора кода, мы проверяем URL на совпадение с одним из 3-х вариантов. К сожалению, символ . не экранирован, что приведёт к тому, что вместо falloutvault.com мы можем завести себе falloutvaultxcom на любом домене и пройти проверку.

Это не PHP-специфичная ошибка. В любом приложении, где валидация выполняется через регулярные выражения и частью проверяемой строки является мета-символ, есть риск забыть экранирование там, где оно нужно, и получить уязвимость.
Найти такие места можно с помощью запуска phpgrep:
phpgrep . 'preg_match(${"pat:str"}, ${"*"})' 'pat~[^\].(com|ru|net|org)b'Мы вводим именованный подшаблон pat, который захватывает любой строковой литерал, а затем применяем к нему фильтр из регулярного выражения.
Фильтры можно применять к любой переменной шаблона. Кроме регулярных выражений есть также структурные операторы = и !=. Полный список можно найти в документации.
${"*"} захватывает произвольное количество любых аргументов, поэтому нам можно не волноваться за опциональные параметры функции preg_match.
Дубликаты ключей в литерале массива
В PHP вы не получите никакого предупреждения, если выполните этот код:
<?php
var_dump(['a' => 1, 'a' => 2]);
// Результат: array(1) {["a"]=> int(2)}Мы можем найти такие массивы с помощью phpgrep:
[${"*"}, $k => $_, ${"*"}, $k => $_, ${"*"}]Этот шаблон можно расшифровать так: «литерал массива, в котором есть хотя бы два идентичных ключа в произвольной позиции». Выражения ${"*"} помогают нам описать «произвольную позицию», допуская 0-N элементов до, между и после интересующих нас ключей.
⎆ Wikia/app/extensions/wikia/WikiaMiniUpload/WikiaMiniUpload_body.php#L23:
$script_a = [
'wmu_back' => wfMessage( 'wmu_back' )->escaped(),
'wmu_back' => wfMessage( 'wmu_back' )->escaped(),
// ...
];В данном случае это не является грубой ошибкой, но мне известны случаи, когда дублирование ключей в крупных (100+ элементов) массивах несло как минимум неожиданное поведение, в котором один из ключей перекрывал значение другого.
На этом наш краткий экскурс на примерах окончен. Если вам хочется ещё, в конце статьи описано, как получить все результаты.
Что же такое phpgrep?
Большая часть редакторов и IDE используют для поиска кода (если это не поиск по специальному символу типа класса или переменной) обычный текстовой поиск — проще говоря, что-то вроде grep’а.
Вы вводите «$x«, находите «$x«. Вам могут быть доступны регулярные выражения, тогда вы можете пытаться, по сути, парсить PHP-код регулярками. Иногда это даже работает, если ищется что-то вполне определённое и простое — например, «любая переменная с некоторым суффиксом». Но если эта переменная с суффиксом должна быть частью другого составного выражения, возникают трудности.
phpgrep — это инструмент для удобного поиска PHP-кода, который позволяет искать не с помощью text-oriented регулярок, а с помощью syntax-aware шаблонов.
Syntax-aware означает, что язык шаблонов отражает целевой язык, а не оперирует отдельными символами, как это делают регулярные выражения. Нам также нет никакой разницы до форматирования кода, важна лишь его структура.
Опциональный контент: Quick Start
Quick start
Установка
Для amd64 есть готовые релизные сборки под Linux и Windows, но если у вас установлен Go, то достаточно одной команды, чтобы получить свежий бинарник под вашу платформу:
go get -v github.com/quasilyte/phpgrep/cmd/phpgrepЕсли $GOPATH/bin находится в системном $PATH, то команда phpgrep станет сразу же доступной. Чтобы это проверить, попробуйте запустить команду с параметром -help:
phpgrep -helpЕсли же ничего не происходит, найдите, куда Go установил бинарник и добавьте его в переменную окружения $PATH.
Старый и надёжный способ посмотреть $GOPATH, даже если он не выставлен явно:
go env GOPATHИспользование
Создайте тестовый файл hello.php:
<?php
function f(...$xs) {}
f(10);
f(20);
f(30);
f($x);
f();Запустите на нём phpgrep:
# phpgrep hello.php 'f(${"x:int"})' 'x!=20'
hello.php:3: f(10)
hello.php:5: f(30)Мы нашли все вызовы функции f с одним аргументом-числом, значение которого не равно 20.
Как работает phpgrep
Для разбора PHP используется библиотека github.com/z7zmey/php-parser. Она достаточно хороша, но некоторые ограничения phpgrep следуют из особенностей используемого парсера. Особенно много трудностей возникает при попытках нормально работать со скобочками.
Принцип работы phpgrep прост:
- строится AST из входного шаблона, разбираются фильтры;
- для каждого входного файла строится полное AST-дерево;
- обходим AST каждого файла, пытаясь найти такие поддеревья, которые совпадают с шаблоном;
- для каждого результата применяется список фильтров;
- все результаты, которые прошли фильтры, печатаются на экран.
Самое интересное — это как именно сопоставляются на равенство два AST-узла. Иногда тривиально: один-к-одному, а мета-узлы могут захватывать более одного элемента. Примерами мета-узлов является ${"*"} и ${"str"}.
Заключение
Было бы нечестно говорить о phpgrep, не упомянув structural search and replace (SSR) из PhpStorm. Они решают похожие задачи, причём у SSR есть свои преимущества, например, интеграция в IDE, а phpgrep может похвастаться тем, что является standalone программой, которую гораздо проще поставить, например, на CI.
Помимо прочего, phpgrep — это ещё и библиотека, которую можно использовать в своих программах для матчинга PHP кода. Особенно это полезно для линтеров и кодогенерации.
Буду рад, если этот инструмент будет вам полезен. Если же эта статья просто мотивирует вас посмотреть в сторону вышеупомянутого SSR, тоже хорошо.

Дополнительные материалы
Полный список шаблонов, который был использован для анализа, можно найти в файле patterns.txt. Рядом с этим файлом можно найти скрипт phpgrep-lint.sh, упрощающий запуск phpgrep со списком шаблонов.
В статье не дан полный список срабатываний, но вы можете воспроизвести эксперимент, произведя клонирование всех названых репозиториев и запустив phpgrep-lint.sh на них.
Черпать вдохновение на шаблоны проверок можно, например, из статей PVS studio. Мне очень понравилась Logical Expressions: Mistakes Made by Professionals, которая трансформируется во что-то такое:
# Для "x != y || x != z":
phpgrep . '$x != $a || $x != $b'
phpgrep . '$x !== $a || $x != $b'
phpgrep . '$x != $a || $x !== $b'
phpgrep . '$x !== $a || $x !== $b'Вам также может быть интересна презентация phpgrep: syntax-aware code search.
В статье используются изображения гоферов, которые были созданы через gopherkon.
Джон Бамбенек и Агнешка Клус
2009
перевод В.Айсин
Вступление
Скорее всего, если вы какое-то время работали в системе Linux в качестве системного администратора или разработчика, вы использовали команду grep. Инструмент устанавливается по умолчанию почти на каждую установку Linux, BSD и Unix, независимо от дистрибутива, и даже доступен для Windows (с wingrep или через Cygwin).
GNU и Free Software Foundation распространяют grep как часть своего набора инструментов с открытым исходным кодом. Другие версии grep распространяются для других операционных систем, но в этой книге основное внимание уделяется версии GNU, поскольку на данный момент она является наиболее распространенной.
Команда grep позволяет пользователю быстро и легко находить текст в заданном файле или выводить его. Предоставляя строку для поиска, grep распечатает только строки, содержащие эту строку, и может распечатать соответствующие номера строк для этого текста. «Простое» использование команды хорошо известно, но существует множество более сложных применений, которые делают grep мощным инструментом поиска.
Цель этой книги — собрать всю информацию, которая может понадобиться администратору или разработчику, в небольшое руководство, которое можно носить с собой. Хотя «простое» использование grep не требует особого образования, продвинутые приложения и использование регулярных выражений могут стать довольно сложными. Название инструмента фактически является аббревиатурой от «Global RegularExpression Print», что указывает на его назначение.
GNU grep на самом деле представляет собой комбинацию четырех различных инструментов, каждый со своим уникальным стилем поиска текста: основные регулярные выражения, расширенные регулярные выражения, фиксированные строки и регулярные выражения в стиле Perl. Существуют и другие реализации программ, подобных grep, например, agrep, zipgrep и grep-подобные функции в .NET, PHP и SQL. В этом руководстве будут описаны особенности и сильные стороны каждого стиля.
Официальный сайт grep: http://www.gnu.org/software/grep/. Он содержит информацию о проекте и некоторую краткую документацию. Исходный код grep составляет всего 712 КБ, а текущая версия на момент написания — 2.5.3. Этот карманный справочник актуален для этой версии, но информация в целом будет действительна для более ранних и более поздних версий.
Важно отметить, что текущая версия grep, поставляемая с Mac OS X 10.5.5 — 2.5.1; тем не менее, большинство параметров в этой книге по-прежнему будут работать в этой версии. Помимо программы GNU, существуют и другие программы «grep», которые обычно устанавливаются по умолчанию в HP-UX, AIX и более старых версиях Solaris. По большей части синтаксис регулярных выражений в этих версиях очень похож, но параметры различаются. Эта книга имеет дело исключительно с версией GNU, потому что она более надежна и мощна, чем другие версии.
Условные обозначения, используемые в этой книге
В этой книге используются следующие типографские условные обозначения:
Курсив
Обозначает команды, новые термины, URL-адреса, адреса электронной почты, имена файлов, расширения файлов, пути, каталоги и служебные программы Unix.
Моноширинный шрифт
Указывает параметры, переключатели, переменные, атрибуты, ключи, функции, типы, классы, пространства имен, методы, модули, свойства, параметры, значения, объекты, события, обработчики событий, теги XML, теги HTML, макросы, содержимое файлов или вывод команд.
Моноширинный курсивный шрифт
Показывает текст, который следует заменить значениями, введенными пользователем.
Использование примеров кода
Эта книга предназначена для того, чтобы помочь вам выполнить свою работу. Как правило, вы можете использовать код из этой книги в своих программах и документации. Вам не нужно связываться с нами для получения разрешения, если вы не воспроизводите значительную часть кода. Например, для написания программы, использующей несколько фрагментов кода из этой книги, не требуется разрешения. Для продажи или распространения компакт-дисков с примерами из книг О’Рейли требуется разрешение. Чтобы ответить на вопрос, цитируя эту книгу и цитируя пример кода, не требуется разрешения. Для включения значительного количества примеров кода из этой книги в документацию по вашему продукту требуется разрешение.
Мы ценим, но не требуем указания авторства. Атрибуция обычно включает название, автора, издателя и ISBN. Например: «grep Pocket Reference — Джон Бамбенек и Агнешка Клус. Copyright 2009, Джон Бамбенек и Агнешка Клус, 978-0-596-15360-1».
Если вы считаете, что использование примеров кода выходит за рамки добросовестного использования или разрешения, предоставленного здесь, не стесняйтесь обращаться к нам по адресу permissions@oreilly.com.
Комментарии и вопросы
Комментарии и вопросы, касающиеся этой книги, просьба направлять издателю:
O’Reilly Media, Inc.
1005 Gravenstein Highway North
Sebastopol, CA 95472
800-998-9938 (в США или Канаде)
707-829-0515 (международный или местный)
707-829-0104 (факс)
У нас есть веб-страница для этой книги, где мы перечисляем исправления, примеры и любую дополнительную информацию. Вы можете получить доступ к этой странице по адресу:
http://www.oreilly.com/catalog/9780596153601
Чтобы оставить комментарий или задать технические вопросы по этой книге, отправьте электронное письмо по адресу:
bookquestions@oreilly.com
Для получения дополнительной информации о наших книгах, конференциях, ресурсных центрах и сети O’Reilly посетите наш веб-сайт:
http://www.oreilly.com
Благодарности
От Джона Бамбенека
Я хотел бы поблагодарить Изабель Канкл и остальную команду О’Рейли, стоящую за редактированием и выпуском этой книги. Моя жена и сын заслуживают благодарности за поддержку и любовь, когда я завершил этот проект. Мой соавтор, Агнешка, сыграла неоценимую роль в облегчении выполнения обременительной задачи по написанию книги; она внесла большой вклад в этот проект. Брайан Кребс из The Washington Post заслуживает похвалы за идею написания этой книги. Время, проведенное в Internet Storm Center, позволило мне поработать с некоторыми из лучших специалистов в области информационной безопасности, и их отзывы оказались чрезвычайно полезными в процессе технической проверки. Особая благодарность адресована Чарльзу Хэмби, Марку Хофману и Дональду Смиту. И, наконец, закусочная Merry Anne’s Diner в центре Шампейна, штат Иллинойс, заслуживает благодарности за то, что позволила мне часами появляться среди ночи, чтобы занять один из их столиков, пока я это писал.
От Агнешки Клус
Во-первых, я хочу поблагодарить своего соавтора Джона Бамбенека за возможность поработать над этой книгой. Для меня это определенно было литературным приключением. Это открыло окна возможностей и дало мне возможность заглянуть в мир, который иначе я бы попасть не смогла. Я также хотел бы поблагодарить мою семью и друзей за их поддержку и терпение.
Концептуальный обзор
Команда grep предоставляет множество способов поиска строк текста в файле или потоке вывода. Например, можно найти все экземпляры указанного слова или строки в файле. Это может быть полезно, например, для извлечения определенных записей журнала из объемных системных журналов. В файлах можно искать определенные шаблоны, например типичный образец номера кредитной карты. Такая гибкость делает grep мощным инструментом для обнаружения наличия (или отсутствия) информации в файлах. Есть два способа ввода данных в grep, каждый из которых имеет свои особенности.
Во-первых, grep можно использовать для поиска заданного файла или файлов в системе. Например, файлы на диске можно искать на предмет наличия (или отсутствия) определенного содержимого. grep также можно использовать для отправки вывода другой команды, которая затем будет искать желаемый контент. Например, grep можно использовать для извлечения важной информации из команды, которая в противном случае выдает чрезмерный объем вывода.
При поиске в текстовых файлах grep можно использовать для поиска определенной строки во всех файлах во всей файловой системе. Например, номера социального страхования следуют известному шаблону, поэтому можно выполнить поиск в каждом текстовом файле в системе, чтобы найти вхождения этих номеров в его файлы (например, для академической среды, чтобы соответствовать федеральным законам о конфиденциальности). По умолчанию возвращается имя файла и строка текста, содержащая эту строку, но также можно включить номера строк.
Кроме того, grep может проверять вывод команды, чтобы найти вхождения строки. Например, системный администратор может запустить сценарий для обновления программного обеспечения в системе, которая имеет большой объем «отладочной» информации и может заботиться только о том, чтобы видеть сообщения об ошибках. В этом случае команда grep может искать строку (например, «ERROR»), которая указывает на ошибки, отфильтровывая информацию, которую администратор не хочет видеть.
Как правило, команда grep предназначена для поиска только текстового вывода или текстовых файлов. Команда позволит вам искать двоичные (или другие нетекстовые) файлы, но в этом отношении утилита ограничена. Уловки для поиска информации в двоичных файлах с помощью grep (т.е., с помощью команды strings) описаны в последнем разделе («Дополнительные советы и приемы с grep»).
Хотя обычно можно интегрировать grep в управление текстом или выполнение операций «поиск и замена», это не самый эффективный способ выполнить работу. Программы sed и awk более удобны для выполнения таких функций.
Есть два основных способа поиска с помощью grep: поиск фиксированных строк и поиск шаблонов текста. Поиск фиксированных строк довольно прост. Однако поиск шаблона может очень быстро усложниться, в зависимости от того, насколько изменчив этот желаемый шаблон. Для поиска текста с переменным содержанием используйте регулярные выражения.
Введение в регулярные выражения
Регулярные выражения, источник букв «re» в «grep», являются основой для создания мощного и гибкого инструмента обработки текста. Выражения могут добавлять, удалять, разделять и вообще управлять всеми видами текста и данных. Это простые инструкции, которые расширяют возможности пользователя по обработке файлов, особенно в сочетании с другими командами. При правильном применении регулярные выражения могут значительно упростить сложную задачу.
Многие различные команды в мире Unix/Linux используют некоторые формы регулярных выражений в дополнение к некоторым языкам программирования. Например, команды sed и awk используют регулярные выражения не только для поиска информации, но и для управления ею.
На самом деле существует множество различных разновидностей регулярных выражений. Например, и Java, и Perl имеют собственный синтаксис для регулярных выражений. Некоторые приложения имеют свои собственные версии регулярных выражений, например Sendmail и Oracle. GNU grep использует версию регулярных выражений GNU, которая очень похожа (но не идентична) регулярным выражениям POSIX.
На самом деле, большинство разновидностей регулярных выражений очень похожи, но у них есть ключевые различия. Например, некоторые экранированные символы, метасимволы или специальные операторы будут вести себя по-разному в зависимости от того, какой тип регулярных выражений вы используете. Незначительные различия между разновидностями могут привести к совершенно разным результатам при использовании одного и того же выражения с разными типами регулярных выражений. В этой книге будут затронуты только регулярные выражения, используемые grep и Perlstyle grep (grep -P).
Обычно регулярные выражения включаются в команду grep в следующем формате:
grep [options] [regexp] [filename]Регулярные выражения состоят из двух типов символов: обычных текстовых символов, называемых литералами, и специальных символов, таких как звездочка (*), называемых метасимволами. Метапоследовательность позволяет использовать метасимволы в качестве литералов или определять специальные символы или условия (например, границы слов или «символы табуляции»). Строка, которую мы надеемся найти, является целевой строкой (target string). Регулярное выражение (regular expression) — это особый шаблон поиска, который вводится для поиска определенной целевой строки. Это может быть то же самое, что и целевая строка, или может включать некоторые функции регулярных выражений, обсуждаемые далее.
Кавычки и регулярные выражения
Обычно регулярное выражение (или regxp) помещается в одинарные кавычки (символ на клавиатуре под двойной кавычкой, а не под клавишей тильды [~]). Для этого есть несколько причин. Во-первых, обычно оболочки Unix интерпретируют пробел как конец аргумента и начало нового. В только что показанном формате вы видите синтаксис команды grep, в котором регулярное выражение отделяется от имени файла пробелом. Что делать, если в строке, которую вы хотите найти, есть символ «пробел»? Кавычки сообщают grep (или другой команде Unix), где аргумент начинается и останавливается, когда задействованы пробелы или другие специальные символы.
Другая причина заключается в том, что различные типы кавычек могут означать разные вещи с помощью команд оболочки, таких как grep. Например, использование одинарной кавычки под клавишей тильды (также называемой обратным апострофом) указывает оболочке выполнить все внутри этих кавычек как команду, а затем использовать это как строку. Например:
grep `whoami` filenameбудет запускать команду whoami (которая возвращает имя пользователя, запускающего оболочку в системах Unix), а затем использовать эту строку для поиска. Например, если бы я вошел в систему с именем пользователя «bambenek», grep будет искать filename с использованием «bambenek».
Однако двойные кавычки работают так же, как одинарные, но с одним важным отличием. С двойными кавычками становится возможным использовать переменные среды как часть шаблона поиска:
grep "$HOME" filenameПеременная среды HOME обычно является абсолютным путем к домашнему каталогу вошедшего в систему пользователя. Только что показанная команда grep определит значение переменной HOME, а затем выполнит поиск по этой строке. Если вы поместите $HOME в одинарные кавычки, он не распознает его как переменную среды.
Важно создать регулярное выражение с правильным типом кавычек, потому что разные типы могут давать совершенно разные результаты. Начальные и конечные кавычки должны быть одинаковыми, иначе будет сгенерирована ошибка, сообщающая вам, что ваш синтаксис неверен. Обратите внимание, что можно комбинировать использование разных кавычек для объединения функций. Это будет обсуждаться позже в разделе «Дополнительные советы и приемы с grep».
Метасимволы
Помимо кавычек, положение и комбинация других специальных символов по-разному влияют на регулярное выражение. Например, следующая команда ищет в файле name.list букву «e», за которой следует «a»:
grep -e 'e[a]' name.listНо просто добавив символ каретки ^, вы меняете все значение выражения. Теперь вы ищете букву «е», за которой следует все, что не является буквой «а»:
grep -e 'e[^a]' name.listПоскольку метасимволы помогают определить манипуляцию, важно с ними ознакомиться. В таблице 1 приведен список регулярно используемых специальных символов и их значений.
Таблица 1. Метасимволы регулярного выражения
(Из книги Джеффри Э. Фридла «Освоение регулярных выражений» (О’Рейли) с некоторыми дополнениями).
| Метасимвол | Имя | Совпадения |
|---|---|---|
| Элементы, соответствующие одному символу | ||
| . | Точка | Один любой символ |
| […] | Класс символов | Любой символ, указанный в скобках |
| [^…] | Отрицательный класс символов | Любой символ, не указанный в скобках |
| char | Escape-символ | Символ после косой черты; используется, когда вы хотите найти «специальный» символ, такой как «$» (т.е. используете «$»). |
| Элементы, соответствующие позиции | ||
| ^ | Каретка | Начало строки |
| $ | Знак доллара | Конец строки |
| < | Обратная косая черта и символ меньше | Начало слова |
| > | Обратная косая черта и символ больше | Конец слова |
| Квантификаторы | ||
| ? | Знак вопроса | Ноль или одно предыдущее выражение |
| * | Звездочка | Любое число (включая ноль); иногда используется как общий подстановочный знак |
| + | Плюс | Одно или несколько из предыдущих выражений |
| {N} | Точное совпадение | Точное совпадение N раз |
| {N,} | По крайней мере | По крайней мере N раз |
| {min,max} | Указанный диапазон | Соответствие диапазону от min до max раз |
| Другое | ||
| | | Чередование | Соответствует любому заданному выражению |
| — | Дефис | Обозначает диапазон |
| (…) | Круглые скобки | Используются для ограничения диапазона изменения |
| 1, 2, … | Обратная ссылка | Соответствует тексту, ранее указанному в круглых скобках (например, первый набор, второй набор и т.д.) |
| b | Граница слова | Пакетные символы, которые обычно обозначают конец слова (например, пробел, точка и т.д.) |
| B | Обратная косая черта | Это альтернатива использованию «\» для сопоставления обратной косой черты, используемой для удобства чтения |
| w | Символ слова | Используется для сопоставления любого символа «слова» (т.е. любой буквы, числа, и символа подчеркивания) |
| W | Не символ слова | Соответствует любому символу, который не используется в словах (т.е. не букве, не цифре и не знаку подчеркивания) |
| ` | Начало буфера | Соответствует началу буфера, отправляемому в grep |
| ‘ | Конец буфера | Соответствует концу буфера, отправляемому в grep |
Таблица ссылается на что-то, известное как метасимвол. Бывают случаи, когда вам потребуется искать буквальный символ, который обычно используется в качестве метасимвола. Например, предположим, что вы ищете суммы, содержащие знак доллара в файле price.list:
grep '[1-9]$' price.listВ результате поиск будет пытаться сопоставить числа в конце строки. Это определенно не то, чего вы хотите. Используя метасимвол, экранированный обратной косой чертой (), вы избегаете такой путаницы:
grep '[1-9]$' price.listМетасимвол $ становится литералом и поэтому ищется в price.list как строка.
Например, возьмем текстовый файл (price.list) со следующим содержимым:
123
123$
Использование двух только что показанных команд дает следующие результаты:
$ grep '[1-9]$' price.list
123$
$ grep '[1-9]$' price.list
123
В первом примере команда искала настоящий символ доллара. Во втором примере знак доллара имел значение своего особого метасимвола и соответствовал концу строки, а значит, соответствовал бы только тем строкам, которые заканчивались числом. Следует помнить о значении этих специальных символов, поскольку они могут существенно повлиять на то, как обрабатывается поиск.
Вот краткое изложение метасимволов регулярных выражений, а также несколько примеров, чтобы прояснить, как они используются:
. (любой одиночный символ)
Символ «точка» — один из немногих типов подстановочных знаков, доступных в регулярных выражениях. Этот конкретный подстановочный знак будет соответствовать любому одиночному символу. Это полезно, если пользователь желает создать шаблон поиска с некоторыми неизвестными ему символами в середине. Например, следующий шаблон grep будет соответствовать «red», «rod», «rad», «rzd» и так далее:
'r.d'Этот символ «точка» можно использовать повторно с любым интервалом, необходимым для поиска нужного содержания.
[...] (класс символов)
«Класс символов» — один из наиболее гибких инструментов, и он появляется снова и снова при использовании регулярных выражений. Есть два основных способа использования классов символов: указать диапазон и указать список символов. Важным моментом является то, что класс символов будет соответствовать только одному символу:
'[a-f]'
'[aeiou]'
Первый шаблон будет искать любую букву между «a» и «f». Диапазоны могут быть прописными, строчными буквами или цифрами. Также может использоваться комбинация диапазонов, например [a-fA-F0-5]. Второй пример будет искать любой из заданных символов, в данном случае гласные. Класс символов также может включать в себя список специальных символов, но их нельзя использовать в качестве диапазона.
[^...] (отрицание)
Класс символов «отрицание» позволяет пользователю искать что угодно, кроме определенного символа или набора символов. Например, пользователь, которому не нравятся четные числа, может использовать следующий шаблон поиска:
'..[^24680]'Это будет искать любой трехсимвольный шаблон, который не заканчивается четным числом. Любой список или диапазон символов может быть помещен в инвертируемый символьный класс.
(escape)
«escape» — это один из метасимволов, который может иметь несколько значений в зависимости от того, как он используется. Когда он помещается перед другим метасимволом, он означает, что этот символ следует рассматривать как буквальный символ, а не как его особое значение. (Его также можно использовать в сочетании с другими символами, такими как b или ', чтобы передать особое значение. Эти конкретные комбинации будут рассмотрены позже.) Рассмотрим следующие два примера:
'.'
'.'
Первый пример будет соответствовать любому одиночному символу и вернет каждый фрагмент текста в файле. Во втором примере будет соответствовать только фактический символ «точки». Escape указывает регулярному выражению игнорировать особое значение метасимвола и обрабатывать его в обычном режиме.
^ (начало строки)
Когда символ каретки используется вне класса символов, это больше не означает отрицание; вместо этого это означает начало строки. Если он используется сам по себе, он будет соответствовать каждой строке на экране, потому что каждая строка имеет начало. Более полезно, когда пользователь хочет сопоставить строки текста, начинающиеся с определенного шаблона:
'^red'Этот шаблон будет соответствовать только строкам, начинающимся с «red», а не всем, которые содержат слово «red». Это полезно для структурированной коммуникации или языков программирования, например, где строки могут начинаться с определенных строк, содержащих важную информацию (например, #DEFINE в Си). Однако смысл теряется, если он не находится в начале строки.
$ (конец строки)
Как обсуждалось ранее, знак доллара соответствует концу строки. Используемый отдельно, он будет соответствовать каждой строке в потоке, кроме последней строки, которая заканчивается символом «конца файла» вместо символа «конца строки». Это полезно для поиска строк, которые имеют желаемое значение в конце строки. Например:
'-$'найдет все строки, последним символом которых является тире, что типично для слов с переносом, когда они слишком длинные, чтобы поместиться в одной строке. Это выражение найдет только те строки, в которых слова через дефис разделены между строками.
< (начало слова)
Если пользователь хотел создать шаблон поиска, который соответствует началу слова, и шаблон, вероятно, повторяется внутри слова (но не в начале), можно использовать этот конкретный escape-код. Например, возьмем следующий пример:
'<un'Этот шаблон будет соответствовать словам, начинающимся с префикса «un», таким как «unimaginable», «undetected» или «undervalued». Он не будет соответствовать таким словам, как «funding», «blunder» или «sun». Он определяет начало слова, ища пробел или другое «разделение», которое указывает на начало нового слова (точка, запятая и т.д.).
> (конец слова)
Подобно предыдущему экранированию, этот шаблон будет соответствовать концу слова. После символов ищется символ «разделения», обозначающий конец слова (пробел, табуляция, точка, запятая и т.д.). Например:
'ing>'будет соответствовать словам, оканчивающимся на «ing» (например, «spring»), а не словам, которые просто содержат «ing» (например, «kingdom»).
* (общий подстановочный знак)
Звездочка, вероятно, является наиболее часто используемым метасимволом. Это общий подстановочный знак, классифицируемый как квантификатор, который специально используется для повторяющихся шаблонов. Для некоторых метасимволов вы можете назначить минимальные и максимальные границы, которые управляют количеством, выводимым из шаблона, но звездочка не устанавливает никаких ограничений или границ. Нет ограничений на количество пробелов до или после символа. Предположим, пользователь хочет знать, описаны ли различные форматы конкретного установщика в файле. Результаты этой простой команды:
'install.*file'результаты должны вывести все строки, содержащие «install» (с любым количеством текста между ними), а затем «file». Необходимо использовать символ точки; в противном случае он будет соответствовать только «installfile», а не итерациям «install» и «file» с символами между ними.
- (диапазон)
При использовании внутри класса символов в квадратных скобках символ тире указывает диапазон значений вместо необработанного списка значений. Когда тире используется вне класса символов в квадратных скобках, оно интерпретируется как буквальный символ тире без его специального значения.
'[0-5]'# (обратные ссылки)
Обратные ссылки позволяют повторно использовать ранее сопоставленный шаблон для определения будущих совпадений. Формат обратной ссылки: , за которым следует номер шаблона в последовательности (слева направо), на которую ссылаются. Обратные ссылки более подробно описаны в разделе «Дополнительные советы и приемы с grep».
b (граница слова)
Последовательность b относится к любому символу, который указывает, что слово началось или закончилось (аналогично > и <, обсуждавшимся ранее). В этом случае не имеет значения, начало или конец слова; он просто ищет знаки препинания или пробелы. Это особенно полезно, когда вы ищете строку, которая может быть отдельным словом или набором символов в другом, несвязанном слове:
'bheartb'Это совпадало бы с точным словом «heart» и не более того (не «disheartening», не «hearts» и т.д.). Если вы ищете определенное слово, числовое значение или строку и не хотите получать совпадения, когда эти слова или значения являются частью другого значения, необходимо использовать b, > или <.
B (обратная косая черта)
Последовательность B — это особенный случай, потому что он не сам по себе escape, а скорее псевдоним для другого. В этом случае B идентичен \, а именно, чтобы интерпретировать символ косой черты буквально в шаблоне поиска, а не с его особым значением. Цель этого псевдонима — сделать шаблон поиска более читабельным и избежать двойных косых черт, которые могут иметь неоднозначное значение в сложных выражениях.
'c:Bwindows'В этом примере выполняется поиск строки «c:windows».
w и W (словесные или несловесные символы)
Последовательности w и W идут рука об руку, потому что их значения противоположны. w будет соответствовать любому символу «слово» и эквивалентно '[a-zA-Z0-9_]'. W будет соответствовать любому другому символу (включая непечатаемые), который не попадает в категорию «словесный символ». Это может быть полезно при анализе структурированных файлов, в которых текст вставлен со специальными символами (например, :, $, % и т.д.).
` (начало буфера)
Эта метапоследовательность, как и «начало строки», будет соответствовать началу буфера, поскольку он передается тому, что обрабатывает регулярное выражение. Поскольку grep работает со строками, буфер и строка обычно синонимичны (но не всегда). Этот переход используется так же, как и метапоследовательность «начало строки», о которой говорилось ранее.
' (конец буфера)
Этот переход похож на метапоследовательность «конец строки», за исключением того, что он ищет конец буфера, который передается тому, что обрабатывает регулярное выражение. В обоих случаях экранирования буфера в начале и в конце они используются крайне редко, и вместо них проще использовать начало и конец строки.
Ниже приводится список метасимволов, используемых в расширенных регулярных выражениях:
? (необязательное совпадение)
Использование вопросительного знака имеет иное значение, чем при обычном использовании подстановочных знаков имени файла (GLOB). В GLOB символ ? означает любой одиночный символ. В регулярных выражениях это означает, что предыдущий символ (или строка, если помещается после подшаблона) является «необязательным» шаблоном соответствия. Это позволяет использовать несколько условий соответствия с одним шаблоном регулярного выражения. Например:
'colors?'будет соответствовать как «color», так и «colors». Символ «s» является необязательным совпадением, поэтому, если он отсутствует, он не вызывает сбоя в шаблоне.
+ (повторяющееся совпадение)
Знак плюс указывает, что регулярное выражение ищет совпадение с одним или несколькими предыдущими символами (или подшаблоном). Например:
'150+'соответствует 150 с любым количеством дополнительных нулей (например, 1500, 15000, 1500000 и т.д.).
{N} (совпадение ровно N раз)
Скобки, помещенные после символа, указывают на конкретное количество повторений для поиска. Например:
'150{3}b'соответствует 15, за которым следуют 3 нуля. Значит, 1500 не будет совпадать, а 15000 подойдет. Обратите внимание на использование метапоследовательности b «граница слова». В этом случае, если желаемое совпадение — именно «15000» и нет проверки границы слова, «150000», «150002345» или «15000asdf» будут соответствовать также потому, что все они содержат желаемую строку поиска «15000».
{N,} (совпадение не менее N раз)
Как и в предыдущем примере, добавление числа и запятой после него означает, что регулярное выражение будет искать не менее N повторений. Например:
'150{3,}b'будет соответствовать «15», за которым следует по крайней мере три нуля, и поэтому «15», «150» и «1500» не будут совпадать. Используйте экранирование границы слова, чтобы избежать случаев, когда требуется точное совпадение определенного числа. (например, «1500003456», «15000asdf» и т. д.). Использование b проясняет смысл.
{N,M} (совпадение от N до M раз)
Если вы хотите сопоставить несколько чисел между двумя значениями повторений, можно указать оба значения между фигурными скобками, разделенными запятой. Например:
'150{2,3}b'совпадут «1500» и «15000» и больше ничего.
| (чередование (или))
Символ «вертикальная черта» указывает на чередование внутри регулярного выражения. Подумайте об этом как о способе дать регулярному выражению возможность выбора условий совпадения с одним выражением. Например:
'apple|orange|banana|peach'будет соответствовать любой из указанных строк, независимо от того, попадают ли другие в область поиска. В этом случае, если в тексте есть «apple», «orange», «banana» или «peach», он будет соответствовать этому содержанию.
() (подшаблон)
Последняя важная особенность расширенных регулярных выражений — это возможность создавать подшаблоны. Это позволяет регулярным выражениям, которые повторяют целые строки, использовать чередование для целых строк, иметь обратные ссылки и делать регулярные выражения более читаемыми:
'(red|blue) plate'
'(150){3}'
Первый пример будет соответствовать либо «red plate», либо «blue plate». Без круглых скобок регулярное выражение 'red|blue plate' соответствовало бы «red» (обратите внимание на отсутствие слова «plate») или «blue plate». Подшаблоны в скобках помогают ограничить диапазон чередования. Во втором примере регулярное выражение будет соответствовать «150150150». Без круглых скобок будет соответствовать «15000». Скобки позволяют сопоставить при повторении целых строк вместо отдельных символов. Метасимволы обычно универсальны для различных команд grep, таких как egrep, fgrep и grep -P. Однако бывают случаи, когда символ имеет другой смысл. Любые различия будут обсуждаться в разделе, относящемся к этой команде.
Классы символов POSIX
Кроме того, регулярные выражения поставляются с набором определений символов POSIX, которые создают сокращения для поиска определенных классов символов. В таблице 2 показан список этих сокращений и их значение. POSIX — это в основном набор стандартов, созданных Институтом инженеров по электротехнике и радиоэлектронике (IEEE) для описания поведения операционных систем в стиле Unix. Он очень старый, но большая часть его содержимого все еще используется. Среди прочего, в POSIX есть определения того, как регулярные выражения должны работать с такими утилитами оболочки, как grep.
Таблица 2. Определения символов POSIX
| Определение POSIX | Содержание определения символа |
|---|---|
| [:alpha:] | Любой алфавитный символ, независимо от регистра |
| [:digit:] | Любой числовой символ |
| [:alnum:] | Любой алфавитный или цифровой символ |
| [:blank:] | Пробелы или символы табуляции |
| [:xdigit:] | Шестнадцатеричные символы; любое число или символы A-F или a-f |
| [:punct:] | Любой знак препинания |
| [:print:] | Любой печатный символ (не управляющие символы) |
| [:space:] | Любой пробельный символ |
| [:graph:] | Исключить символы пробела |
| [:upper:] | Любая заглавная буква |
| [:lower:] | Любая строчная буква |
| [:cntrl:] | Управляющие символы |
Многие из этих определений POSIX являются более удобочитаемыми эквивалентами классов символов. Например, [:upper:] можно также записать как [A-Z], и для этого используется меньше символов. Для некоторых других классов, таких как [:cntrl:], нет хороших эквивалентов классов символов. Чтобы использовать их в регулярном выражении, просто разместите их так же, как и класс символов. Важно отметить, что одно размещение этих определений символов POSIX будет соответствовать только одному одиночному символу. Чтобы сопоставить повторения классов символов, вам придется повторить определение. Например:
'[:digit:]'
'[:digit:][:digit:][:digit:]'
'[:digit:]{3}'
В первом примере будет сопоставлен любой единственный числовой символ. Во втором примере будут сопоставлены только трехзначные числа (или более длинные). Третий пример — это более чистый и короткий способ написания второго примера. Многие энтузиасты регулярных выражений стараются достичь как можно большего с помощью как можно меньшего количества нажатий клавиш. Покажите им второй пример, и они могут блевануть от отвращения. Третий пример — более эффективный способ сделать то же самое.
Создание регулярного выражения
Как и в алгебре, у grep есть правила приоритета обработки. Повторение обрабатывается перед объединением. Конкатенация обрабатывается перед чередованием. Строки объединяются, просто находясь рядом друг с другом внутри регулярного выражения — специального символа для обозначения объединения не существует.
Например, возьмите следующее регулярное выражение:
'pat{2}ern|red'В этом примере повторение обрабатывается первым, что дает два «t». Затем строки соединяются, образуя «pattern» на одной стороне пайпа и «red» — на другой. Затем чередование обрабатывается, создавая регулярное выражение, которое будет искать «pattern» или «red». Однако что, если вы захотите выполнить поиск по словам «patpatern», «red», «pattern» или «pattred»? В этом случае, как и в алгебре, круглые скобки «отменяют» правила старшинства. Например:
2 + 3 / 5
(2 + 3) / 5
Эти два математических уравнения дают разные результаты из-за скобок. Здесь концепция та же:
'(pat){2}ern|red'
'pat{2}(ern|red)'
В первом примере сначала будет объединено слово «pat», а затем оно будет повторяться дважды, в результате чего будут получены строки поиска «patpatern» и «red». Во втором примере сначала обрабатывается подшаблон чередования, поэтому регулярное выражение будет искать «pattern» и «pattred». Использование круглых скобок может помочь вам настроить регулярное выражение для соответствия определенному содержимому в зависимости от того, как вы его создаете. Даже если нет необходимости отменять правила приоритета для конкретного регулярного выражения, иногда имеет смысл использовать круглые скобки для улучшения читаемости.
Регулярное выражение может продолжаться, пока одинарная кавычка не закрыта. Например:
$ grep 'patt
> ern' filename
Здесь одинарная кавычка не заканчивалась до того, как пользователь нажал клавишу Return сразу после второго «t» (пробел не был нажат). В следующей строке отображается приглашение командной строки >, которое указывает, что он все еще ожидает завершения строки, прежде чем обработать команду. Пока вы продолжаете нажимать Return, он будет выдавать вам подсказку, пока вы не нажмете Ctrl-C, чтобы разорвать или закрыть цитату, после чего он обработает команду. Это позволяет вводить длинные регулярные выражения в командной строке (или в сценарии оболочки), не забивая их все в одну строку, что потенциально делает их менее удобочитаемыми.
В этом случае регулярное выражение ищет слово «pattern». Команда игнорирует переносы и не вводит их в само регулярное выражение, поэтому можно нажать Enter в середине слова и продолжить с того места, где вы остановились. Забота об удобочитаемости важна, потому что «пробельные» клавиши не так легко увидеть, что делает этот пример отличным претендентом на подшаблоны, помогающие сделать регулярное выражение более понятным.
Также можно использовать несколько разных групп строк с собственными кавычками. Например:
'patt''ern'будет искать слово «pattern», как если бы оно было набрано с ожидаемым регулярным выражением 'pattern'. Этот пример не очень практичен, и нет веских причин делать это с помощью простого текста. Однако при объединении разных типов цитат этот метод позволяет использовать преимущества каждого типа цитат для создания регулярного выражения с использованием переменных среды и/или вывода команд. Например:
$ echo $HOME/home/bambenek$ whoamibambenek
показывает, что переменная окружения $HOME установлена в /home/bambenek и что вывод команды whoami — «bambenek». Итак, следующее регулярное выражение:
'username:'`whoami`' and home directory
is '"$HOME"
будет соответствовать строке «username:bambenek and home directory is /home/bambenek» путем вставки в вывод команды whoami и настройки переменной окружения $HOME. Это краткий обзор регулярных выражений и способов их использования. Сложности регулярных выражений посвящены целые книги, но этого учебника достаточно, чтобы вы начали понимать, что вам нужно знать, чтобы использовать команду grep.
Основы grep
Есть два способа использовать grep. Первый проверяет файлы следующим образом:
grep regexp filenamegrep ищет указанное регулярное выражение в данном файле (filename). Второй метод использования grep — это проверка «стандартного ввода». Например:
cat filename | grep regexpВ этом случае команда cat отобразит содержимое файла. Вывод этой команды передается в команду grep, которая затем отображает только те строки, которые содержат данное регулярное выражение. Две только что показанные команды дают одинаковые результаты, потому что команда cat просто передает файл без изменений, но вторая форма полезна для «греппинга» других команд, которые изменяют их ввод.
Когда grep вызывается без аргумента имени файла и без передачи какого-либо ввода, он позволяет вам вводить текст и повторяет его, как только получит строку, содержащую регулярное выражение. Для выхода нажмите Ctrl-D.
Иногда вывод бывает очень большим, и его трудно прокрутить в терминале. Обычно это происходит с большими файлами, которые часто содержат повторяющиеся фразы, например, журнал ошибок. В этих случаях передача вывода по конвейеру в команду more или less будет «разбивать на страницы» его так, чтобы одновременно отображался только один экран текста:
grep regexp filename | moreДругой способ упростить просмотр вывода — перенаправить результаты в новый файл, а затем открыть выходной файл в текстовом редакторе позже:
grep regexp filename > newfilenameКроме того, может быть полезно искать строки, содержащие несколько шаблонов, а не только один. В следующем примере текстовый файл editinginfo содержит дату, имя пользователя и файл, который был отредактирован этим пользователем в указанную дату. Если администратора интересуют только файлы, редактируемые «Смитом», он набирает следующее:
cat editinginfo | grep SmithРезультат будет выглядеть так:
May 20, 2008
June 21, 2008
.
.
Администратор может пожелать сопоставить несколько шаблонов, что может быть выполнено путем «сцепления» команд grep вместе. Теперь мы знакомы с командой cat filename | grep regexp и знаем, что она делает. Отправляя второй grep по конвейеру вместе с любым количеством конвейерных команд grep, вы создаете очень точный поиск:
cat filename | grep regexp | grep regexp2В этом случае команда ищет строки в filename, которые содержат как regexp, так и regexp2. В частности, grep будет искать regexp2 в результатах поиска grep для regexp. Используя предыдущий пример, если администратор хотел видеть каждую дату, когда Смит редактировал какой-либо файл, кроме hi.txt, он мог бы выполнить следующую команду:
cat editinginfo | grep Smith | grep -v hi.txtРезультатом будет следующий вывод:
June 21, 2008 Smith world.txt
Важно отметить, что «объединение» команд grep в большинстве случаев неэффективно. Часто регулярное выражение может быть создано для объединения нескольких условий в один поиск.
Например, вместо предыдущего примера, который объединяет три разные команды, то же самое можно сделать с помощью:
grep Smith | grep -v hi.txtИспользование символа вертикальной черты приведет к запуску одной команды и предоставит результаты этой команды следующей команде в последовательности. В этом случае grep ищет строки, в которых есть «Smith», и отправляет эти результаты следующей команде grep, которая исключает строки, содержащие «hi.txt». Если поиск может быть выполнен с использованием меньшего количества команд или с меньшим количеством решений, которые необходимо принимать, тем более эффективно он будет. Для небольших файлов производительность не является проблемой, но при поиске в файлах журнала размером в гигабайты производительность может быть важным фактором.
Если вы хотите выполнять поиск по контенту, который непрерывно передается в потоковом режиме, следует использовать команды конвейерной передачи. Например, если вы хотите в реальном времени отслеживать указанный контент в файле журнала, она может использовать следующую команду:
tail -f /var/log/messages | grep WARNINGЭта команда откроет последние 10 строк файлов /var/log/messages (обычно это главный файл системного журнала в системе Linux), но оставит файл открытым и распечатает все содержимое, помещенное в файл, пока он работает ( параметр -f для tail часто называется «follow»). Таким образом, только что показанная команда будет искать любую запись, содержащую строку «WARNING», отображать ее на консоли и игнорировать все другие сообщения.
Важно отметить, что grep будет искать строку и, как только увидит новую строку, перезапустит весь поиск со следующей строки. Это означает, что если вы ищете предложение с помощью grep, существует вполне реальная вероятность того, что символ новой строки в середине предложения в файле помешает вам найти это предложение напрямую. Даже указание символа новой строки в шаблоне поиска не решит эту проблему. Некоторые текстовые редакторы и приложения для повышения производительности просто переносят слова в строки, не помещая символ новой строки, поэтому поиск в этих случаях не лишен смысла, но это важное ограничение, о котором следует помнить.
Чтобы получить подробную информацию о реализации регулярных выражений на вашем конкретном компьютере, просмотрите справочные страницы regex и re_format. Однако важно отметить, что не все функции и возможности регулярных выражений встроены в grep. Например, поиск и замена недоступны. Что еще более важно, есть некоторые полезные метапоследовательности, которые по умолчанию отсутствуют.
Например, d — это метапоследовательность, которая соответствует любому числовому символу (от 0 до 9) в некоторых регулярных выражениях. Однако, похоже, это недоступно с помощью grep при стандартном распространении и параметрах компиляции (за исключением Perlstyle grep, который будет рассмотрен позже). В этом руководстве делается попытка охватить то, что доступно по умолчанию в стандартной установке, и попытаться стать авторитетным источником информации о возможностях и ограничениях grep.
Программа grep на самом деле представляет собой пакет из четырех различных программ сопоставления с образцом, которые используют разные модели регулярного выражения. Каждая система сопоставления с образцом имеет свои сильные и слабые стороны, и каждая из них будет подробно рассмотрена в следующих разделах. Мы начнем с исходной модели, которую мы назовем базовой grep.
Основные регулярные выражения (grep или grep -G)
В этом разделе основное внимание уделяется базовым функциям grep. Большинство флагов для базового grep одинаково применимы и к другим версиям, которые мы обсудим позже.
Базовый grep или grep -G — это тип сопоставления с шаблоном по умолчанию, который используется при вызове grep. grep интерпретирует данный набор шаблонов как базовое регулярное выражение при выполнении команды. Это вызываемая программа grep по умолчанию, поэтому параметр -G почти всегда избыточен.
Как и любая команда, grep имеет несколько параметров, которые контролируют как найденные совпадения, так и способ отображения результатов grep. Версия GNU grep предлагает большинство параметров, перечисленных в следующих подразделах.
Контроль соответствия
-e pattern, --regexp=pattern
grep -e -style doc.txtГарантирует, что grep распознает шаблон как аргумент регулярного выражения. Полезно, если регулярное выражение начинается с дефиса, что делает его похожим на параметр команды. В этом случае grep будет искать строки, соответствующие «-style».
-f file, --file=file
grep -f pattern.txt searchhere.txtБерет шаблоны из file. Эта опция позволяет вам вводить все шаблоны, которые вы хотите сопоставить, в файл, называемый здесь pattern.txt. Затем grep ищет все шаблоны из pattern.txt в указанном файле searchhere.txt. Шаблоны аддитивны; то есть grep возвращает каждую строку, соответствующую любому шаблону. В файле шаблонов должен быть указан один шаблон в каждой строке. Если файл pattern.txt пуст, ничего не будет найдено.
-i, --ignore-case
grep -i 'help' me.txtИгнорирует использование заглавных букв в заданных регулярных выражениях либо через командную строку, либо в файле регулярных выражений, заданных параметром -f. В приведенном здесь примере выполняется поиск в файле me.txt строки «help» с любой итерацией строчных и прописных букв в слове («HELP», «HelP» и т.д.). Похожий, но устаревший синоним этой опции — -y.
-v, --invert-match
grep -v oranges filenameВозвращает несоответствующие строки вместо совпадающих. В этом случае выводом будет каждая строка в filename, не содержащая шаблона «oranges».
-w, --word-regexp
grep -w 'xyz' filenameСоответствует только в том случае, если вводимый текст совпадает со словами полностью. В этом примере недостаточно, чтобы строка содержала три буквы «xyz» подряд; вокруг них должны быть пробелы или знаки препинания. Буквы, цифры и символ подчеркивания считаются частью слова; любой другой символ считается границей слова, как и начало и конец строки. Это эквивалент помещения b в начало и конец регулярного выражения.
-x, --line-regexp
grep -x 'Hello, world!' filenameПодобно -w, но должно соответствовать всей строке. Этот пример соответствует только строкам, полностью состоящим из «Hello, world!». Строки с дополнительным содержанием не будут сопоставлены. Это может быть полезно для анализа файлов журнала на предмет определенного содержимого, которое может включать случаи, которые вам неинтересны.
Общий контроль вывода
-c, --count
grep -c contact.html access.logВместо обычного вывода вы получаете только количество строк, совпадающих в каждом входном файле. В приведенном здесь примере grep просто вернет количество обращений к файлу contact.html через журнал доступа веб-сервера.
grep -c -v contact.html access.logВ этом примере возвращается количество всех строк, не соответствующих данной строке. Это будет каждый раз, когда кто-то будет обращаться к файлу, не совпадающему с contact.html на веб-сервере.
--color[=WHEN], --colour[=WHEN]
grep -color[=auto] regexp filenameПредполагая, что терминал может поддерживать цвет, grep раскрасит шаблон на выходе. Это делается путем окружения совпадающей (непустой) строки, совпадающих строк, контекстных строк, имен файлов, номеров строк, смещения байтов и разделителей метапоследовательностей, которые терминал распознает как цветные маркеры. Цвет определяется переменной окружения GREP_COLORS (обсуждается позже). WHEN имеет три варианта: never, always и auto.
-l, --files-with-match
grep -l "ERROR:" *.logВместо обычного вывода печатает только имена входных файлов, содержащих шаблон. Как и в случае с -L, поиск останавливается на первом совпадении. Если администратора просто интересуют имена файлов, которые содержат шаблон, но не хочет выводить все совпадающие строки, эта опция выполняет эту функцию. Это может сделать grep более эффективным, остановив поиск, как только он найдет соответствующий шаблон, вместо продолжения поиска по всему файлу. Это часто называют «ленивым сопоставлением».
-L , --files-without-match
grep -L 'ERROR:' *.logВместо обычного вывода печатает только имена входных файлов, которые не содержат совпадений. Например, в примере печатаются все файлы журнала, не содержащие отчетов об ошибках. Это эффективное использование grep, потому что он прекращает поиск каждого файла, когда находит какое-либо совпадение, вместо того, чтобы продолжать поиск во всем файле для нескольких совпадений.
-m NUM, --max-count=NUM
grep -m 10 'ERROR:' *.logЭтот параметр указывает grep прекратить чтение файла после совпадения NUM строк (в этом примере только 10 строк содержат «ERROR:»). Это полезно для чтения больших файлов, где вероятно повторение, например файлов журналов. Если вы просто хотите увидеть, присутствуют ли строки, не переполняя терминал, используйте эту опцию. Это помогает различать распространенные и периодические ошибки, как в примере здесь.
-o, --only-matching
grep -o pattern filenameПечатает только соответствующий текст, а не всю строку ввода. Это особенно полезно при реализации grep для проверки раздела диска или двоичного файла на наличие нескольких шаблонов. Это выведет шаблон, который был сопоставлен, без содержимого, которое могло бы вызвать проблемы для терминала.
-q, --quiet, --silent
grep -q pattern filenameПодавляет вывод. Команда по-прежнему передает полезную информацию, потому что можно проверить статус выхода команды grep (0 — успех, если совпадение найдено, 1, если совпадение не найдено, 2, если программа не может быть запущена из-за ошибки). Этот параметр используется в сценариях для определения наличия шаблона в файле без отображения ненужного вывода.
-s, --no-messages
grep -s pattern filenameНезаметно отбрасывает все сообщения об ошибках, возникающие из-за несуществующих файлов или ошибок разрешений. Это полезно для сценариев, которые ищут всю файловую систему без прав root, и, таким образом, скорее всего, столкнутся с ошибками разрешений, которые могут быть нежелательными. С другой стороны, это также будет скрывать полезную диагностическую информацию, что может означать, что проблемы могут быть не обнаружены.
Управление префиксом выходной строки
-b, --byte-offset
grep -b pattern filenameОтображает байтовое смещение каждого совпадающего текста вместо номера строки. Первый байт в файле — это байт 0, и подсчитываются невидимые символы завершения строки (новая строка в Unix). Поскольку по умолчанию печатаются целые строки, отображаемое число является байтовым смещением начала строки. Это особенно полезно для анализа двоичных файлов, создания (или обратного проектирования) исправлений или других задач, где номера строк не имеют смысла.
grep -b -o pattern filenameПараметр -o печатает смещение вместе с самим совпадающим шаблоном, а не со всей совпадающей строкой, содержащей шаблон. Это заставляет grep печатать байтовое смещение начала совпадающей строки вместо совпадающей строки.
-H, --with-filename
grep -H pattern filenameВключает имя файла перед каждой печатаемой строкой и используется по умолчанию, когда для поиска вводится более одного файла. Это полезно при поиске только одного файла, и вы хотите, чтобы имя файла содержалось в выводе. Обратите внимание, что здесь используются относительные (не абсолютные) пути и имена файлов.
-h, --no-filename
grep -h pattern *Противоположность -H. Когда задействовано более одного файла, подавляется печать имени файла перед каждым выводом. Это значение по умолчанию, когда задействован только один файл или стандартный ввод. Это полезно для подавления имен файлов при поиске целых каталогов.
--label=LABEL
gzip -cd file.gz | grep --label=LABEL patternКогда ввод берется из стандартного ввода (например, когда вывод другого файла перенаправляется в grep), опция --label добавит к строке префикс LABEL. В этом примере команда gzip отображает содержимое несжатого файла внутри file.gz, а затем передает его в grep.
-n, --line-number
grep -n pattern filenameВключает номер для каждой отображаемой строки, где первая строка файла — 1. Это может быть полезно при отладке кода, позволяя вам войти в файл и указать конкретный номер строки для начала редактирования.
-T, --initial-tab
grep -T pattern filenameВставляет табуляцию перед каждой совпадающей строкой, помещая табуляцию между информацией, сгенерированной grep, и совпадающими строками. Эта опция полезна для уточнения макета. Например, он может отделить номера строк, байтовые смещения, метки и т.д., от совпадающего текста.
-u, --unix-byte-offsets
grep -u -b pattern filenameЭтот параметр работает только на платформах MS-DOS и Microsoft Windows, и его нужно вызывать с помощью -b. Эта опция вычислит байтовое смещение, как если бы он работал в системе Unix, и удалит символы возврата каретки.
-Z, --null
grep -Z pattern filenameПечатает ASCII NUL (нулевой байт) после каждого имени файла. Это полезно при обработке имен файлов, которые могут содержать специальные символы (например, возврат каретки).
Управление контекстной строкой
-A NUM, --after-context=NUM
grep -A 3 Copyright filenameПредлагает контекст для совпадающих строк путем печати NUM строк, следующих за каждым совпадением. Разделитель групп (--) помещается между каждым набором совпадений. В этом случае он напечатает следующие три строки после соответствующей строки. Это полезно, например, при поиске в исходном коде. В приведенном здесь примере будут напечатаны три строки после любой строки, содержащей «Copyright», которая обычно находится в верхней части файлов исходного кода.
-B NUM, --before-context=NUM
grep -B 3 Copyright filenameТа же концепция, что и опция -A NUM, за исключением того, что она печатает строки перед совпадением, а не после него. В этом случае он напечатает три строки перед соответствующей строкой. Это полезно, например, при поиске в исходном коде. В приведенном здесь примере будут напечатаны три строки перед любой строкой, содержащей «Copyright», которая обычно находится в верхней части файлов исходного кода.
-C NUM, -NUM, --context=NUM
grep -C 3 Copyright filenameПараметр -C NUM работает так, как если бы пользователь ввел оба параметра -A NUM и -B NUM. Он отобразит NUM строк до и после совпадения. Разделитель групп (--) помещается между каждым набором совпадений. В этом случае будут напечатаны три строки выше и ниже совпадающей строки. Опять же, это полезно, например, при поиске в исходном коде. В приведенном здесь примере будут напечатаны три строки до и после любой строки, содержащей «Copyright», которая обычно находится в верхней части файлов исходного кода.
Выбор файла и каталога
-a , --text
grep -a pattern filenameЭквивалент опции --binary-files=text, позволяющий обрабатывать двоичный файл, как если бы это был текстовый файл.
--binary-files=TYPE
grep --binary-files=TYPE pattern filenameTYPE может быть binary, without-match или text. Когда grep впервые исследует файл, он определяет, является ли файл «двоичным» файлом (файлом, в основном состоящим из нечитаемого человеком текста), и соответствующим образом изменяет свой вывод. По умолчанию, совпадение в двоичном файле приводит к тому, что grep просто отображает сообщение «Binary file somefile.bin matches». Поведение по умолчанию также можно указать с помощью параметра --binary-files=binary.
Когда TYPE не совпадает (without-match), grep не выполняет поиск в двоичном файле и продолжает работу, как если бы в нем не было совпадений (эквивалент опции -l). Когда TYPE является текстом, двоичный файл обрабатывается как текст (эквивалент опции -a). Когда TYPE не совпадает, grep просто пропускает эти файлы и не выполняет поиск по ним. Иногда --binary-files=text выводит двоичный мусор, и терминал может интерпретировать часть этого мусора как команды, которые, в свою очередь, могут сделать терминал нечитаемым до сброса. Чтобы исправить это, используйте команды tput init и tput reset.
-D ACTION, --devices=ACTION
grep -D read 123-45-6789 /dev/hda1Если входным файлом является специальный файл, такой как FIFO или сокет, этот флаг сообщает grep, как действовать дальше. По умолчанию grep обрабатывает эти файлы, как если бы они были обычными файлами в системе. Если ACTION установлено в skip, grep будет игнорировать их. В этом примере выполняется поиск показанного фальшивого номера социального страхования по всему разделу диска. Когда ACTION установлено в read, grep будет читать через устройство, как если бы это был обычный файл.
-d ACTION, --directories=ACTION
grep -d ACTION pattern filenameЭтот флаг сообщает grep, как обрабатывать каталоги, представленные как входные файлы. Когда ACTION read, он читает каталог, как если бы это был файл. recurse ищет файлы в этом каталоге (так же, как опция -R), а skip пропускает каталог без поиска в нем.
--exclude=GLOB
grep --exclude=PATTERN pathУточняет список входных файлов, указывая grep игнорировать файлы, имена которых соответствуют указанному шаблону. PATTERN может быть полным именем файла или может содержать типичные подстановочные знаки «file-globbing», которые оболочка использует при сопоставлении файлов (*,? И []). Например, --exclude=*.exe пропустит все файлы с расширением .exe.
--exclude-from=FILE
grep --exclude-from=FILE pathПодобно опции --exclude, за исключением того, что она берет список шаблонов из указанного имени файла, в котором каждый шаблон перечисляется в отдельной строке. grep проигнорирует все файлы, соответствующие любым строкам в списке заданных шаблонов.
--exclude-dir=DIR
grep --exclude-dir=DIR pattern pathЛюбые каталоги в пути, соответствующем шаблону DIR, будут исключены из рекурсивного поиска. В этом случае необходимо указать фактическое имя каталога (относительное имя или абсолютный путь), чтобы его можно было игнорировать. Этот параметр также должен использоваться с параметром -r или параметром -d recurse, чтобы быть актуальным.
-l
grep -l pattern filenameТо же, что и параметр --binary-files=without-match. Когда grep находит двоичный файл, он предполагает, что в этом файле нет совпадений.
--include=GLOB
grep --include=*.log pattern filenameОграничивает поиск входными файлами, имена которых соответствуют заданному шаблону (в данном случае файлы, заканчивающиеся на .log). Этот параметр особенно полезен при поиске в каталогах с помощью параметра -R. Файлы, не соответствующие заданному шаблону, игнорируются. Имя файла может быть указано целиком или может содержать типичные подстановочные знаки «file-globbing», которые оболочка использует при сопоставлении файлов (*, ? и []).
-R, -r, --recursive
grep -R pattern path
grep -r pattern path
Ищет все файлы в каждом каталоге, отправленном в grep как входной файл.
Другие параметры
--line-buffered
grep --line-buffered pattern filenameИспользует буферизацию строки для вывода. Вывод буферизации строки обычно приводит к снижению производительности. По умолчанию grep использует небуферизованный вывод. Обычно это вопрос предпочтений.
--mmap
grep --mmap pattern filenameИспользует функцию mmap() вместо функции read() для обработки данных. Это может привести к повышению производительности, но может вызвать ошибки, если есть проблема ввода-вывода или файл сжимается во время поиска.
-U, --binary
grep -U pattern filenameПараметр, специфичный для MS-DOS/Windows, заставляющий grep обрабатывать все файлы как двоичные. Обычно grep удаляет символы возврата каретки перед сопоставлением с образцом; эта опция отменяет такое поведение. Однако это требует от вас более внимательного отношения к написанию шаблонов. Например, если содержимое файла содержит шаблон, но имеет символ новой строки посередине, поиск этого шаблона не найдет содержимого.
-V, --version
Просто выводит информацию о версии grep и завершает работу.
-z, --null-data
grep -z patternСтроки ввода обрабатываются так, как если бы каждая из них оканчивалась нулевым байтом или символом ASCII NUL вместо новой строки. Аналогично параметрам -Z или --null, за исключением того, что этот параметр работает с вводом, а не выводом.
Последнее ограничение базового grep: метасимволы «расширенных» регулярных выражений — ?, +, {, }, |, ( и ) — не работают с базовым grep. Функции, предоставляемые этими символами, существуют, если вы поставите перед ними метапоследовательность. Подробнее об этом в следующем разделе.
Расширенные регулярные выражения (egrep или grep -E)
grep -E и egrep — это одна и та же команда. Команды ищут в файлах шаблоны, которые были интерпретированы как расширенные регулярные выражения. Расширенное регулярное выражение выходит за рамки простого использования ранее упомянутых параметров; он использует дополнительные метасимволы для создания более сложных и мощных поисковых строк. Что касается параметров командной строки, grep -E и grep используют одни и те же параметры — единственная разница заключается в том, как они обрабатывают шаблон поиска:
?
? в выражении несет значение необязательного. Любой символ, предшествующий вопросительному знаку, может появляться или не появляться в целевой строке. Например, вы ищете слово «behavior», которое также можно записать как «behaviour». Вместо использования параметра или (|) вы можете использовать команду:
egrep 'behaviou?r' filenameВ результате поиск будет успешным как для «behavior», так и для «behaviour», поскольку он будет одинаково относиться к присутствию или отсутствию буквы «u».
+
Знак плюс будет смотреть на предыдущий символ и допускать неограниченное количество повторений при поиске совпадающих строк. Например, следующая команда будет соответствовать как «pattern1», так и «pattern11111», но не будет соответствовать «pattern»:
egrep 'pattern1 +' filename{n,m}
Фигурные скобки используются для определения того, сколько раз шаблон должен быть повторен, прежде чем совпадение произойдет. Например, вместо поиска «patternnnn» вы можете ввести следующую команду:
egrep 'pattern{4}' filenameЭто будет соответствовать любой строке, содержащей «patternnnn», без необходимости набирать повторяющиеся строки. Чтобы сопоставить хотя бы четыре повторения, вы должны использовать следующую команду:
egrep 'pattern{4,}' filenameС другой стороны, посмотрите на следующий пример:
egrep 'pattern{,4}' filenameНесмотря на то, что это соответствовало бы уже используемым соглашениям, это неверно. Только что показанная команда не приведет к совпадениям, потому что возможность иметь «не более чем X» совпадений недоступна.
Чтобы сопоставить от четырех до шести повторений, используйте следующее:
egrep 'pattern{4,6}' filename|
Этот символ, используемый в регулярном выражении, означает «или». В результате вертикальная черта (|) позволяет объединить несколько шаблонов в одно выражение. Например, предположим, что вам нужно найти одно из двух имен в файле. Вы можете ввести следующую команду:
egrep ‘name1|name2’ filename
Он будет соответствовать строкам, содержащим «name1» или «name2».
()
Скобки могут использоваться для «группировки» определенных строк текста с целью обратных ссылок, чередования или просто для удобства чтения. Кроме того, использование круглых скобок может помочь разрешить любую двусмысленность в том, что именно пользователь хочет от шаблона поиска. Паттерны, помещенные в круглые скобки, часто называют подшаблонами.
Также круглые скобки ограничивают вертикальную черту (|). Это позволяет пользователю более точно определить, какие строки являются частью операции «или» или входят в ее объем. Например, для поиска строк, содержащих «pattern» или «pattarn», вы должны использовать следующую команду:
egrep 'patt(a|e)rn' filenameБез круглых скобок шаблон поиска был бы patta|ern, который будет соответствовать, если будет найдена строка «patta» или «ern», и результат сильно отличается от намерения.
В основных регулярных выражениях обратная косая черта () отменяет поведение метасимвола и заставляет поиск соответствовать символу в буквальном смысле. То же самое происходит в egrep, но есть исключение. Метасимвол { не поддерживается традиционным egrep. Хотя некоторые версии интерпретируют { буквально, его следует избегать в шаблонах egrep. Вместо этого следует использовать [{] для сопоставления символа без использования специального значения.
Не совсем верно, что базовый grep также не имеет этих метасимволов. Они есть, но их нельзя использовать напрямую. Каждому из специальных метасимволов в расширенных регулярных выражениях должен предшествовать метасимвол, чтобы прояснить его особое значение. Обратите внимание, что это противоположность нормальному экранированию, которое обычно лишает особого смысла.
В таблице 3 показано, как использовать метасимволы расширенных регулярных выражений с базовой командой grep.
Таблица 3. Сравнение базовых и расширенных регулярных выражений
| Базовые регулярные выражения | Расширенные регулярные выражения |
|---|---|
| ‘(red)’ | ‘(red)’ |
| ‘а{1,3}’ | ‘а{1,3}’ |
| ‘behavioriou?r’ | ‘behavioriou?r’ |
| ‘pattern+’ | ‘pattern+’ |
Из таблицы 3 вы понимаете, почему люди предпочитают просто использовать расширенный grep, когда они хотят использовать расширенные регулярные выражения. Помимо удобства, также легко забыть поместить необходимый escape-код в базовые регулярные выражения, что приведет к тому, что шаблон не будет возвращать никаких совпадений. Идеальное регулярное выражение должно быть четким и содержать как можно меньше символов.
Фиксированные строки (fgrep или grep -F)
В следующем разделе мы обсудим grep -F или fgrep. fgrep известен как фиксированная строка или быстрый grep. Он известен как «быстрый grep» из-за отличной производительности по сравнению с grep и egrep. Это достигается за счет полного отказа от регулярных выражений и поиска определенного строкового шаблона. Это полезно для точного поиска определенного статического контента, аналогично тому, как работает Google.
Команда для вызова fgrep:
fgrep string_pattern filenameПо замыслу, fgrep должен работать быстро и без интенсивных функций; в результате может потребоваться более ограниченный набор параметров командной строки. Самые распространенные из них:
-b
fgrep -b string_pattern filenameПоказывает номер блока, в котором был найден string_pattern. Поскольку по умолчанию печатаются целые строки, отображаемый номер байта является байтовым смещением начала строки.
-c
fgrep -c string_pattern filenameПодсчитывается количество строк, содержащих один или несколько экземпляров string_pattern.
-e, -string
fgrep -e string_pattern filenameИспользуется для поиска более чем одного шаблона или когда string_pattern начинается с дефиса. Хотя вы можете использовать символ новой строки, чтобы указать более одной строки, вместо этого вы можете использовать несколько параметров -e, что полезно при написании сценариев:
fgrep -e string_pattern1
-e string_pattern2 filename
-f file
fgrep -f string_pattern filenameВыводит результаты поиска в новый файл вместо печати непосредственно в терминал. Это не похоже на поведение опции -f в grep; там он указывает входной файл шаблона поиска.
-h
fgrep -h string_pattern filenameКогда поиск выполняется более чем в одном файле, использование -h останавливает отображение filenames в fgrep до совпадающего вывода.
-i
fgrep -i string_pattern filenameПараметр -i указывает fgrep игнорировать заглавные буквы, содержащиеся в string_pattern, при сопоставлении с шаблоном.
-l
fgrep -l string_pattern filenameОтображает файлы, содержащие string_pattern, но не сами совпадающие строки.
-n
fgrep -n строковый_шаблон имя_файла
fgrep -n string_pattern filenameРаспечатывает номер строки перед строкой, которая соответствует заданному string_pattern.
-v
fgrep -v string_pattern filenameСоответствует любым строкам, которые не содержат заданный string_pattern.
-x
fgrep -x string_pattern filenameРаспечатывает строки, которые полностью соответствуют string_pattern. Это поведение fgrep по умолчанию, поэтому обычно его не нужно указывать.
Регулярные выражения в стиле Perl (grep -P)
Регулярные выражения в стиле Perl используют библиотеку Perl-совместимых регулярных выражений (PCRE) для интерпретации шаблона и выполнения поиска. Как следует из названия, этот стиль использует реализацию регулярных выражений Perl. У Perl есть преимущество, потому что язык был оптимизирован для поиска текста и манипуляций с ним. В результате PCRE может быть более эффективным и более функциональным для поиска контента. Как следствие, это может быть ужасно запутанным и сложным. Другими словами, использование PCRE для поиска информации похоже на использование на себе травки для операции на головном мозге: он выполняет свою работу с минимальными усилиями, но это ужасный беспорядок.
Конкретные функции и параметры поиска с помощью PCRE не зависят от самого grep, а используют библиотеку libpcre и базовую версию Perl. Это означает, что он может сильно различаться между машинами и операционными системами. Обычно справочные страницы pcrepattern или pcre предоставляют машинно-зависимую информацию о параметрах, доступных на вашем компьютере. Ниже приводится общий набор функций поиска PCRE, которые должны быть доступны на большинстве машин.
Также обратите внимание, что регулярные выражения в стиле Perl могут присутствовать или не присутствовать по умолчанию в вашей операционной системе. Системы на основе Fedora и Red Hat, как правило, включают их (при условии, что вы устанавливаете библиотеку PCRE), но Debian, например, не включает регулярные выражения в стиле Perl по умолчанию в своем пакете grep. Вместо этого они поставляют программу pcregrep, которая предоставляет очень похожие функции на grep -P. Разумеется, отдельные лица могут скомпилировать свой собственный двоичный файл grep, который включает поддержку PCRE, если они того пожелают.
Чтобы проверить, встроена ли поддержка регулярных выражений в стиле Perl в вашу версию grep, выполните следующую команду (или что-то подобное):
$ grep -P test /bin/ls
grep: The -P option is not supported
Обычно это означает, что при сборке grep не удалось найти библиотеку libpcre или что она была намеренно отключена с помощью параметра конфигурации --disable-perl-regexp при компиляции. Решение состоит в том, чтобы либо установить libpcre и перекомпилировать grep, либо найти подходящий пакет для вашей операционной системы.
Общая форма использования grep в стиле Perl:
grep -P options pattern fileВажно отметить, что, в отличие от grep -F и grep -E, здесь нет команды «pgrep». Команда pgrep используется для поиска запущенных процессов на машине. Все те же параметры командной строки, которые присутствуют для grep, будут работать с grep -P; Единственная разница в том, как обрабатывается шаблон. PCRE предоставляет дополнительные метасимволы и классы символов, которые можно использовать для расширения возможностей поиска. За исключением дополнительных метасимволов и классов, шаблон строится так же, как и типичное регулярное выражение.
В этом разделе рассматриваются только четыре аспекта параметров PCRE: типы символов, восьмеричный поиск, свойства символов и параметры PCRE.
Типы символов
Хотя здесь есть некоторое совпадение со стандартным grep, PCRE поставляется со своим собственным набором метасимволов, которые обеспечивают более надежный набор сопоставлений. Таблица 4 содержит список экранирований, доступных в PCRE.
Таблица 4. Особые побеги PCRE
| a | Соответствует символу «alarm» (HEX 07). |
| cX | Соответствует Ctrl-X, где X — любая буква |
| e | Соответствует escape-символу (HEX 1B) |
| f | Соответствует символу подачи формы (HEX 0C) |
| n | Соответствует символу новой строки (HEX 0A) |
| r | Соответствует возврату каретки (HEX 0D) |
| t | Соответствует символу табуляции (HEX 09) |
| d | Любая десятичная цифра |
| D | Любой недесятичный символ |
| s | Любой пробельный символ |
| S | Любой непробельный символ |
| w | Любой символ «слова» |
| W | Любой «несловесный» символ. |
| b | Соответствует границе слова |
| B | Соответствует любому символу не на границе слова |
| A | Соответствует началу текста |
| Z | Соответствует концу текста или перед новой строкой |
| z | Соответствует концу текста |
| G | Соответствует первой подходящей позиции |
Восьмеричный поиск
Для поиска восьмеричных знаков используйте метасимвол /, за которым следует восьмеричное число метасимвола. Например, чтобы найти «пробел», используйте /40 или /040. Однако это одна из областей, где PCRE может быть неоднозначным, если вы не будете осторожны. Метасимвол / также может использоваться для обратной ссылки (ссылка на предыдущий шаблон, данный PCRE).
Например, /1 — это обратная ссылка на первый образец в списке, а не на восьмеричный символ 1. Чтобы избежать двусмысленности, самый простой способ — указать восьмеричный символ как трехзначное число. В режиме UTF-8 разрешено до 777. Все однозначные числа, указанные после косой черты, интерпретируются как обратная ссылка, а если шаблонов больше XX, то XX также интерпретируется как обратная ссылка.
Кроме того, PCRE может выполнять поиск по символу в шестнадцатеричном формате или по строке символов, представленных в шестнадцатеричном формате. Например, x0b будет искать шестнадцатеричный символ 0b. Для поиска шестнадцатеричной строки просто используйте x{0b0b....}, где строка заключена в фигурные скобки.
Свойства символа
Кроме того, PCRE поставляется с набором функций, которые будут искать символы на основе их свойств. Он бывает двух видов: язык и тип символов. Для этого используется последовательность p или P. p ищет, присутствует ли данное свойство, тогда как P соответствует любому символу, где его нет.
Например, для поиска наличия (или отсутствия) символов, принадлежащих определенному языку, вы должны использовать p{Greek} для поиска греческих символов. С другой стороны, P{Greek} будет соответствовать любому символу, не входящему в набор символов греческого языка. Для получения полного списка доступных языков обратитесь к странице руководства для конкретной реализации pcrepattern в вашей системе.
Другой набор свойств относится к атрибутам данного символа (прописные буквы, пунктуация и т.д.). Заглавная буква обозначает основную группу символов, а строчная буква относится к подгруппе. Если указана только заглавная буква (например, /p{L}), сопоставляются все подгруппы. В таблице 5 приведен полный список кодов свойств.
Таблица 5. Свойства символа PCRE
| C | Другое | No | Другой номер |
| Cc | Control | P | Пунктуация |
| Cf | Format | Pc | Пунктуация соединителя |
| Cn | Без назначения | Pd | Пунктуация тире |
| Co | Частное использование | Pe | Закрытие знаков препинания |
| Cs | Заменитель | Pf | Конечная пунктуация |
| L | Буква | Пи | Начальная пунктуация |
| Ll | Строчные буквы | Po | Другая пунктуация |
| Lm | Модификатор | Ps | Открытая пунктуация |
| Lo | Другая буква | S | Символ |
| Lt | Заглавный регистр | Sc | Символ валюты |
| Lu | Прописные буквы | Sk | Символ модификатора |
| M | Отметка | Sm | Математический символ |
| Mc | Отметка расстояния | Так | Другой символ |
| Me | Заключительная метка | Z | Разделитель |
| Mn | Метка без интервала | Zl | Разделитель строк |
| N | Число | Zp | Разделитель абзаца |
| Nd | Десятичное число | Zs | Разделитель пробелов |
| Nl | Буквенный номер |
Эти свойства позволяют создавать более надежные шаблоны с меньшим количеством символов на основе большого количества свойств. Однако одно важное замечание: если pcre компилируется вручную, для поддержки этих параметров необходимо использовать параметр конфигурации --enable-unicode-properties. Некоторые пакеты libpcre (например, пакеты Fedora или Debian) имеют это встроенное средство (особенно международно ориентированные), а другие нет. Чтобы проверить, встроена ли поддержка в pcre, выполните следующее (или что-то в этом роде):
$ grep -P 'p{Cc}' /bin/ls
grep: support for P, p, and X has not been compiled
Это сообщение об ошибке о компиляции поддержки связано с pcre, а не с grep, что не совсем интуитивно понятно. Решение состоит в том, чтобы либо найти лучший пакет, либо скомпилировать свой собственный с правильными параметрами.
Опции PCRE
Наконец, есть четыре различных параметра, которые могут изменить способ поиска текста PCRE: PCRE_CASELESS (i), PCRE_MULTILINE (m), PCRE_DOTALL (s) и PCRE_EXTENDED (x). PCRE_CASELESS будет соответствовать шаблонам независимо от различий в заглавных буквах. По умолчанию PCRE обрабатывает строку текста как одну строку, даже если присутствует несколько символов n. PCRE_MULTILINE позволит обрабатывать эти символы n как строки, поэтому, если используется $ или ^, он будет искать строки на основе наличия n и фактических жестких строк в строке поиска.
PCRE_DOTALL заставляет PCRE интерпретировать метасимвол . (точка) для включения новой строки при сопоставлении с «подстановочными знаками». PCRE_EXTENDED полезен для включения комментариев (помещенных в неэкранированные символы #) в сложные строки поиска.
Чтобы включить эти параметры, поместите указанную букву параметра в круглые скобки со знаком вопроса в начале. Например, чтобы создать шаблон, который будет искать слово «copyright» в регистронезависимом формате, вы должны использовать следующий шаблон:
'(?i)copyright'В скобках можно использовать любую комбинацию букв. Эти параметры можно разместить так, чтобы они работали только с частью строки поиска: просто поместите их в начало той части строки, где параметр должен вступить в силу. Чтобы отменить вариант, поставьте перед буквой - (дефис). Например:
'Copy(?i)righ(?-i)t'Это будет соответствовать «CopyRIGHt», «CopyrIgHt» и «Copyright», но не будет соответствовать «COPYright» или «CopyrighT».
'(?imsx)copy(?-sx)right'Это установит все параметры PCRE, которые мы обсуждали, но как только он достигнет символа «r», PCRE_DOTALL и PCRE_EXTENDED будут отключены.
Если использование регулярных выражений на основе Perl кажется сложным, это потому, что это так. Это гораздо больше, чем можно здесь обсудить, но главное преимущество PCRE — это его гибкость и мощность, которые выходят далеко за рамки того, что могут делать регулярные выражения. Обратной стороной является большая сложность и двусмысленность, которые могут возникнуть.
Введение в grep-релевантные переменные среды
В предыдущих примерах мы познакомились с концепцией переменных среды и их влиянием на grep. Переменные среды позволяют настраивать параметры и поведение grep по умолчанию, определяя параметры среды оболочки, тем самым облегчая вашу жизнь. Выполните команду env в терминале, чтобы вывести все текущие параметры. Ниже приводится пример того, что вы можете увидеть:
$ env
USER=user
LOGNAME=user
HOME=/home/user
PATH=/usr/local/sbin:/usr/local/bin:/usr
/sbin:/usr/bin:/sbin:/bin:/usr/X11R6/bin:.
SHELL=/usr/local/bin/tcsh
OSTYPE=linux
LS_COLORS=no=0:fi=0:di=36:ln=33:ex=32
:bd=0:cd=0:pi=0:so=0:do=0:or=31
VISUAL=vi
EDITOR=vi
MANPATH=/usr/local/man:/usr/man:/usr
/share/man:/usr/X11R6/man
...
Управляя файлом .profile в вашем домашнем каталоге, вы можете вносить постоянные изменения в переменные. Например, используя только что показанный результат, предположим, что вы решили сменить EDITOR с vi на vim. В .profile введите:
setenv EDITOR vimПосле записи изменений это гарантирует, что vim будет редактором по умолчанию для каждого сеанса, использующего этот .profile. В предыдущих примерах используются некоторые встроенные переменные, но если вы разбираетесь в коде, нет никаких ограничений (за исключением вашего воображения) на переменные, которые вы создаете и устанавливаете.
Повторюсь, grep — мощный инструмент поиска благодаря множеству доступных пользователю опций. Переменные ничем не отличаются. Есть несколько конкретных вариантов, о которых мы подробно расскажем позже. Однако следует отметить, что grep возвращается к языку C, когда переменные LC_foo, LC_ALL или LANG не установлены, когда локальный каталог не установлен или когда не соблюдается поддержка национального языка (NLS).
Начнем с того, что «locale» — это соглашение, используемое для общения на определенном языке. Например, когда вы устанавливаете для переменной LANG или language значение English, вы используете соглашения, связанные с английским языком, для взаимодействия с системой. Когда компьютер запускается, по умолчанию используются соглашения, установленные в ядре, но эти настройки можно изменить.
LC_ALL на самом деле не переменная, а скорее макрос, который позволяет вам выполнить «set locale» для всех целей. Хотя LC_foo — это параметр, зависящий от локали для множества наборов символов, foo можно заменить на ALL, COLLATE, CTYPE, MONETARY или TIME, и это лишь некоторые из них. Затем они устанавливаются для создания общих языковых соглашений для среды, но становится возможным использовать соглашения одного языка для установки формата для представления денег, а другие — для временных соглашений.
Как это связано с grep? Например, многие классы символов POSIX зависят от того, какая конкретная локаль используется. PCRE также активно заимствует из настроек локали, особенно для классов символов, которые он использует. Поскольку grep предназначен для поиска текста в текстовых файлах, то, как язык обрабатывается на компьютере, имеет значение, и это определяется локалью.
Для большинства пользователей можно оставить настройки локали по умолчанию. Пользователи, которые хотят выполнять поиск на других языках или хотят работать на языке, отличном от языка системной среды, могут захотеть изменить их.
Теперь, когда мы ознакомились с концепцией локали, переменные среды, специфичные для grep, следующие:
GREP_OPTIONSЭта переменная переопределяет «скомпилированные» параметры по умолчанию для grep. Это как если бы они были помещены в командную строку как сами параметры. Например, предположим, что вы хотите создать переменную для параметра --binary-files и установить для нее текст. Следовательно, --binary-files автоматически подразумевает --binary-files=text, без необходимости записывать его. Однако --binary-files можно переопределить определенными и разными переменными (например, --binary-files=without-match).
Этот параметр особенно полезен для сценариев, где набор «default options» можно указать один раз в переменных среды, и на него больше не нужно ссылаться. Однако есть одна проблема: любые параметры, установленные с помощью GREP_OPTIONS, будут интерпретироваться, как если бы они были помещены в командную строку. Это означает, что параметры командной строки не переопределяют переменную среды, и если они конфликтуют, grep выдаст ошибку. Например:
$ export GREP_OPTIONS=-E
$ grep -G '(red)' test
grep: conflicting matchers specified
При установке параметров в эту переменную среды необходимо проявлять некоторую осторожность и внимание, и почти всегда лучше устанавливать только те параметры, которые имеют общий характер (например, как обрабатывать двоичные файлы или устройства, использовать ли цвет, так далее.).
GREP_COLORS (или GREP_COLOR для более старых версий)Эта переменная определяет цвет, который будет использоваться для выделения совпадающего шаблона. Это вызывается с параметром —color[=WHEN], где WHEN — never, auto или always. Параметр должен быть двузначным числом из списка в Таблице 6, которое соответствует определенному цвету.
Таблица 6. Список вариантов цвета
| Цвет | Цветовой код |
|---|---|
| Черный (Black) | 0;30 |
| Темно-серый (Dark gray) | 1;30 |
| Синий (Blue) | 0;34 |
| Голубой (Light blue) | 1;34 |
| Зеленый (Green) | 0;32 |
| Светло-зеленый (Light green) | 1;32 |
| Голубой (Cyan) | 0;36 |
| Светло-голубой (Light cyan) | 1;36 |
| Красный (Red) | 0;31 |
| Светло-красный (Light red) | 1;31 |
| Фиолетовый (Purple) | 0;35 |
| Светло-фиолетовый (Light purple) | 1;35 |
| Коричневый (Brown) | 0;33 |
| Желтый (Yellow) | 1;33 |
| Светло-серый (Light gray) | 0;37 |
| Белый (White) | 1;37 |
Цвета необходимо указывать в определенном синтаксисе, потому что выделение также охватывает дополнительные поля, а не только совпадающие слова. По умолчанию установлено следующее:
GREP_COLORS='ms=01;31:mc=01;31:sl=:cx=:fn=35:ln=32:bn=32:se=36'Если желаемый цвет начинается с 0 (например, с 0;30, который является черным), 0 можно отбросить, чтобы сократить настройку. Если настройки оставлены пустыми, используется обычный текст цвета терминала по умолчанию. ms обозначает совпадающую строку (т.е. введенный вами шаблон), mc соответствует контексту (т.е. строки, показанные с параметром -C), sl обозначает цвет выбранных строк, cx — цвет для выбранного контекста, fn — цвет имени файла (если показан), ln — цвет номеров строк (если показан), bn — номеров байтов (если показан), а se — цвет разделителя.
LC_ALL, LC_COLLATE, LANGЭти переменные должны быть указаны в таком порядке, но в конечном итоге они определяют подборку или расположение в правильной последовательности выраженных диапазонов. Например, это может быть последовательность букв для алфавита.
LC_ALL, LC_CTYPE, LANGЭти переменные определяют LC_CTYPE или тип символов, которые будет использовать grep. Например, какие символы являются пробелами, какие будут фидом формы и т.д.
LC_ALL, LC_MESSAGES, LANGЭти переменные определяют локаль MESSAGES и язык, на котором grep будет выводить сообщения. Это яркий пример того, как grep возвращается к языку Си по умолчанию, то есть к американскому английскому языку.
POSIXLY_CORRECTЕсли установлено, grep следует требованиям POSIX.2, согласно которым любые параметры, следующие за именами файлов, рассматриваются также как имена файлов. В противном случае эти параметры обрабатываются так, как если бы они перемещались перед именами файлов и рассматривались как параметры. Например, grep -E string filename -C 3 интерпретирует «-C 3» как имена файлов, а не как параметр. Кроме того, в POSIX.2 указано, что любые нераспознанные параметры помечаются как «illegal» — по умолчанию в GNU grep они рассматриваются как «invalid».
Выбор между типами grep и соображениями производительности
Теперь, когда мы рассмотрели все четыре программы grep, вопрос в том, как определить, какие из них использовать для данной задачи. Для большинства рутинных задач люди склонны использовать стандартную команду grep (grep -G), потому что производительность не является проблемой при поиске небольших файлов и когда нет необходимости в сложных шаблонах поиска. Как правило, основной grep — это выбор по умолчанию для большинства людей, и поэтому возникает вопрос, когда имеет смысл использовать что-то еще.
Когда использовать grep -E
Хотя с помощью grep -G можно сделать почти все, что можно сделать с помощью grep -E, последний имеет то преимущество, что позволяет выполнить задачу с меньшим количеством символов без противоречащего здравому смыслу экранирования, описанного ранее. Все дополнительные функции в расширенных регулярных выражениях связаны с квантификаторами или подшаблонами. Кроме того, если требуется значительное использование обратных ссылок, идеально подходят расширенные регулярные выражения.
Когда использовать grep -F
Есть одно предварительное условие для использования grep -F, и если пользователь не может удовлетворить это требование, grep -F просто не подходит. А именно, любой шаблон поиска для grep -F не может содержать никаких метасимволов, escape-символов, подстановочных знаков или альтернатив. Его производительность выше, но за счет утраты части функциональности.
Тем не менее, grep -F чрезвычайно полезен для быстрого поиска в больших объемах данных строго определенных строк, что делает его идеальным инструментом для быстрого поиска в огромных файлах журнала. Фактически, довольно легко разработать надежный сценарий «log watching» с помощью команды grep -F и хорошего текстового файла, в котором перечислены важные слова или фразы, которые следует извлечь из файлов журнала для анализа.
Еще одно хорошее применение grep -F — это поиск в почтовых журналах и почтовых папках для обеспечения доставки электронной почты пользователям, особенно в системах с большим количеством почтовых учетных записей. Это стало возможным благодаря присвоению каждому сообщению электронной почты уникального идентификатора сообщения. Например:
grep -FHr MESSAGE-ID /var/mailЭта команда будет искать фиксированную строку MESSAGE-ID для всех файлов внутри /var/mail (и рекурсивно просматривать все подкаталоги), а затем отображать совпадение, а также имя файла. Это быстрый и понятный способ узнать, у каких пользователей есть конкретное сообщение в почтовом ящике. Настоящим преимуществом является то, что эту информацию можно проверить без необходимости заглядывать в почтовый ящик пользователя и решать проблемы конфиденциальности при чтении почты других людей. На самом деле вы можете захотеть выполнить поиск в каталогах почтовых ящиков и папках для спама, которые обычно не хранятся в /var/mail, но вы понимаете, как это работает.
Когда использовать grep -P
Регулярные выражения в стиле Perl, несомненно, являются наиболее мощными из всех стилей, представленных в этой книге. Они также являются наиболее сложными, подвержены ошибкам пользователя и потенциально способны снизить производительность системы, если они будут выполнены неправильно. Однако это явно лучший стиль из всех форматов регулярных выражений, используемых в этой книге.
По этой причине многие приложения предпочитают использовать PCRE вместо регулярных выражений GNU. Например, популярная система обнаружения вторжений snort использует PCRE для сопоставления плохих пакетов в сети. Шаблоны написаны грамотно, так что потери пакетов могут быть очень незначительными, даже если одна машина может искать все пакеты, проходящие через полностью загруженный 100-мегабитный или гигабитный интерфейс. Как было сказано ранее, правильное написание регулярного выражения имеет тенденцию быть более важным, чем конкретный формат регулярного выражения, который вы используете.
Некоторые люди просто предпочитают использовать grep -P по умолчанию (например, указав -P внутри своей переменной среды GREP_OPTIONS). Если поиск будет осуществляться «международным» способом, классы символов языка PCRE значительно упростят это. PCRE поставляется с гораздо большим количеством классов символов для точной настройки регулярного выражения, помимо того, что возможно, например, с определениями POSIX. Наиболее важно то, что возможность использовать различные параметры PCRE (например, PCRE_MULTILINE) позволяет выполнять поиск более мощными способами, чем регулярные выражения GNU.
Для простых и умеренно сложных регулярных выражений достаточно grep -E. Однако есть ограничения, которые могут подтолкнуть пользователя к PCRE. Это компромисс между сложностью и функциональностью. PCRE также помогает пользователям создавать регулярные выражения, которые можно почти сразу же перенести непосредственно в сценарии Perl (или перенести из сценариев Perl) без необходимости выполнять большой перевод.
Последствия для производительности
В большинстве случаев производительность grep не является проблемой. Даже файлы размером в мегабайты можно быстро найти с помощью любой из специальных программ grep без какой-либо заметной разницы в производительности. Очевидно, что чем больше файл, тем больше времени занимает поиск. Для поиска в гигабайтах или терабайтах данных, когда важна производительность, grep -F, вероятно, является хорошим решением, но только если можно создать шаблон поиска без использования каких-либо метасимволов, чередований или обратных ссылок. Это не всегда так.
Чем больше «вариантов» дано grep, тем больше времени занимает конкретный поиск. Например, использование множества чередований заставляет grep искать строки несколько раз, а не только один раз. Это может быть необходимо для данного шаблона поиска, но иногда чередование может быть переписано как класс символов. Например:
grep -E '(0|2|4|6|8)' filename
grep -E '[02468]' filename
При сравнении двух примеров, очевидно, что второй работает лучше, потому что не используется чередование, и строки не нужно искать несколько раз. Избегайте чередования, когда существуют другие альтернативы, выполняющие то же самое.
Безусловно, самая большая причина снижения производительности при использовании grep — это использование обратных ссылок. Время, необходимое grep для выполнения команды, увеличивается почти экспоненциально с использованием дополнительных обратных ссылок. По сути, обратные ссылки могут стать удобными псевдонимами для предыдущих подшаблонов; однако производительность пострадает. Обратные ссылки не следует использовать, если производительность вызывает беспокойство и по этой причине подшаблоны не используют чередование. См. следующий раздел для более подробного обсуждения обратных ссылок.
В заключение, среди grep -G, grep -E и grep -P нет большого влияния на производительность; это в основном зависит от того, как построено само регулярное выражение. Тем не менее, grep -P предоставляет больше возможностей для снижения производительности, но также и максимальную гибкость для соответствия большому разнообразию контента.
Дополнительные советы и хитрости с grep
Как упоминалось ранее, grep можно очень эффективно использовать для поиска содержимого в файлах или в файловой системе. Можно использовать предыдущие совпадения для поиска более поздних строк (так называемые обратные ссылки). Есть также множество уловок для поиска закрытой личной информации и даже для поиска двоичных строк в двоичных файлах. В следующих разделах обсуждаются некоторые дополнительные советы и приемы.
Обратные ссылки
Программа grep может выполнять поиск на основе нескольких предыдущих условий. Например, если вы хотите найти все строки, в которых многократно используется определенный набор слов, один шаблон grep не будет работать; однако это можно сделать с помощью обратных ссылок.
Предположим, вы хотите найти любую строку, в которой есть несколько экземпляров слов «red», «blue» или «green». Представьте себе следующий текстовый файл:
The red dog fetches the green ball.
The green dog fetches the blue ball.
The blue dog fetches the blue ball.
Только третья строка повторяет использование того же цвета. Шаблон регулярного выражения '(red|green|blue)*(red|green|blue)' вернет все три строки. Чтобы решить эту проблему, вы можете использовать обратные ссылки:
grep -E '(red|green|blue).*1' filenameЭта команда соответствует только третьей строке, как и предполагалось. Для расширенных регулярных выражений для указания обратной ссылки можно использовать только одну цифру (т.е. Вы можете ссылаться только на девятую обратную ссылку). Используя регулярные выражения в стиле Perl, теоретически вы можете иметь намного больше (как минимум две цифры).
Это может быть использовано для проверки синтаксиса XML (т.е. «открывающие» и «закрывающие» теги одинаковы), синтаксиса HTML (сопоставление всех строк с различными открывающими и закрывающими «заголовочными» тегами, такими как <h1>, <h2> и т.д.), или даже проанализировать написание на предмет бессмысленного повторения модных словечек.
Важно отметить, что обратные ссылки требуют использования скобок для определения номеров ссылок. grep будет читать шаблон поиска слева направо, и, начиная с первого найденного подшаблона в скобках, он начнет нумерацию с 1.
Обычно обратные ссылки используются, когда подшаблон содержит чередование, как в предыдущем примере. Однако не требуется, чтобы подшаблон действительно содержал чередование. Например, предполагая, что существует большой подшаблон, на который вы хотите позже сослаться в регулярном выражении, вы можете использовать обратную ссылку в качестве искусственного «псевдонима» для этого подшаблона без необходимости набирать весь шаблон несколько раз. Например:
grep -E '(I am the very model of a
modern major general.).*1' filename
будет искать повторы предложения «I am the very model of a modern major general», разделенные любым количеством необязательного содержимого. Это, безусловно, уменьшает количество нажатий клавиш и делает регулярное выражение более управляемым, но также вызывает некоторые проблемы с производительностью, как обсуждалось ранее. Пользователь должен взвесить преимущества удобства и производительности, в зависимости от того, чего он пытается достичь.
Поиск двоичных файлов
До этого момента казалось, что grep можно было использовать только для поиска текстовых строк в текстовых файлах. Это то, для чего он чаще всего используется, но grep также может искать строки в двоичных файлах.
Важно отметить, что «текстовые» файлы существуют на компьютерах в основном для удобства чтения человеком. Компьютеры говорят исключительно в двоичном и машинном коде. Полный набор символов ASCII состоит из 255 символов, из которых только около 60 являются «удобочитаемыми». Однако многие компьютерные программы также содержат текстовые строки. Например, экраны «help», имена файлов, сообщения об ошибках и ожидаемый ввод пользователя могут отображаться в виде текста внутри двоичных файлов.
Команда grep практически не делает различий между поиском в текстовых или двоичных файлах. Пока вы скармливаете ему шаблоны (даже двоичные шаблоны), он с радостью будет искать в любом файле шаблоны, которые вы ему предписываете для поиска. Он выполняет начальную проверку, чтобы увидеть, является ли файл двоичным, и соответствующим образом изменяет способ отображения результатов (если вы вручную не укажете другое поведение):
bash$ grep help /bin/ls
Binary file /bin/ls matches
Эта команда ищет строку «help» в двоичном файле ls. Вместо того, чтобы показывать строку, в которой появляется текст, он просто указывает на то, что совпадение было найдено. Причина снова связана с тем фактом, что компьютерные программы являются двоичными и поэтому не читаются человеком. Например, в программах нет «строк». В двоичных файлах не добавляются разрывы строк, потому что они могут изменить код — это просто функция, позволяющая сделать текстовые файлы более удобочитаемыми, поэтому grep сообщает вам только о том, есть ли совпадение. Чтобы получить представление о типе текста в двоичном файле, вы можете использовать команду strings. Например, strings /bin/ls перечислит все текстовые строки в команде ls.
Есть еще один способ поиска двоичных файлов, который также специфичен для двоичных данных. В этом случае вам нужно полагаться на некоторые уловки, потому что вы не можете вводить двоичные данные напрямую с обычной клавиатуры. Вместо этого вам нужно использовать специальную форму регулярного выражения для ввода шестнадцатеричного эквивалента данных, которые вы хотите найти. Например, если вы хотите найти двоичный файл с шестнадцатеричной строкой ABAA, вы должны ввести следующую команду:
bash$ grep '[xabaa]' test.hex
Binary file test.hex matches
Общий формат — ввести /x, а затем шестнадцатеричную строку, которую вы хотите сопоставить. Нет никаких реальных ограничений на размер строки, которую вы можете ввести. Этот тип поиска может быть полезен при анализе вредоносных программ. Например, платформа metasploit (http://www.metasploit.org) может генерировать двоичные полезные данные для использования удаленных машин. Эта полезная нагрузка может использоваться для создания удаленной оболочки, добавления учетных записей или выполнения других вредоносных действий.
Используя шестнадцатеричный поиск, можно было бы определить по двоичным строкам, какие полезные данные metasploit использовались в реальной атаке. Кроме того, если вы можете определить уникальную шестнадцатеричную строку, которая использовалась в вирусе, вы можете создать базовый антивирусный сканер с помощью grep. Фактически, многие старые антивирусные сканеры делали более или менее именно это, ища уникальные двоичные строки в файлах по списку известных плохих шестнадцатеричных сигнатур.
Многие сообщения о переполнении буфера или эксплойте написаны на Си, и обычно каждую шестнадцатеричную цифру в Си записывают с помощью метасимвола x. Например, возьмите следующую полезную нагрузку эксплойта переполнения буфера:
"xebx17x5ex89x76x08x31xc0x88x46
x07x89x46x0cxb0x0bx89xf3x8dx4e
x08x31xd2xcdx80xe8xe4xffxffxff
x2fx62x69x6ex2fx73x68x58";Может быть более выгодно написать регулярное выражение таким же образом вместо того, чтобы печатать всю шестнадцатеричную строку, если только по той или иной причине, кроме как разрешить копирование и вставку из кода эксплойта. Любой способ может сработать — это ваше предпочтение. Только что показанный эксплойт работает против машин Red Hat 5 и 6 (не Enterprise Red Hat), поэтому этот конкретный код бесполезен, но нетрудно найти код эксплойта в дикой природе.
Интересно отметить, что этот метод не работает для поиска файлов, которые распознаются как текстовые. Например, если вы попытаетесь найти текст в текстовом файле, используя шестнадцатеричный эквивалент кодов ASCII, grep не найдет содержимое. Поиск шестнадцатеричных строк работает только для файлов, которые grep распознает как «двоичные».
Полезные рецепты
Ниже приводится краткий список полезных рецептов grep для поиска определенных классов контента. Поскольку доступность регулярных выражений на основе Perl варьируется, в списке будут использоваться расширенные рецепты в стиле grep, хотя Perl во многих случаях будет работать быстрее.
Ввод этих команд в командную строку и возврат вывода по умолчанию на экран может не иметь особого смысла, если вы хотите найти конфиденциальную информацию в разделе. Было бы разумнее использовать параметры -l и -r для рекурсии по всей файловой системе и отображения совпадающих имен файлов вместо целых строк.
Для многих рецептов имеет смысл ставить b до и после строки. Это гарантирует, что в контенте есть какие-то пробелы до и после него, что предотвращает случай, когда вы ищете 9-значное число, которое выглядит как номер социального страхования, но дает ложноположительные совпадения для 29-значных чисел.
Наконец, эти шаблоны (и, возможно, другие, которые могут иметь смысл) могут быть помещены в файл и использованы в качестве списка входных шаблонов, переданных в grep, так что все они ищутся одновременно.
IP-адреса
$ grep -E 'b[0-9]{1,3}(.[0-9]{1,3}){3}
b' patterns
123.24.45.67
312.543.121.1
Этот шаблон поможет указать IP-адреса в файле. Важно отметить, что [0–9] можно было бы так же легко заменить на [:digit:] для лучшей читаемости. Однако большинство пользователей предпочитают использовать меньше нажатий клавиш по сравнению с удобочитаемостью, когда им предоставляется выбор. Второе примечание: это также найдет строки, которые не являются действительными IP-адресами, например, второй из перечисленных в примере. Регулярные выражения работают с отдельными символами, и нет хорошего способа указать grep искать диапазон значений от 1 до 255. В этом случае могут быть ложные срабатывания. Более сложная формула, гарантирующая, что ложные срабатывания не регистрируются, выглядит так:
$ grep -E 'b((25[0-5]|2[0-4][0-9]|[01]?
[0-9][0-9]?).){3}(25[0-5]|2[0-4][0-9]|
[01]?[0-9][0-9]?)b' patterns
В этом случае он гарантирует, что найдет IP-адреса с октетом от 0 до 255, установив комбинацию шаблонов, которые будут работать. Это гарантирует совпадение исключительно IP-адресов, но это более сложно и имеет более низкую производительность.
MAC-адреса
$ grep -Ei 'b[0-9a-f]{2}
(:[0-9a-f]{2}){5}b' patterns
ab:14:ed:41:aa:00
В этом случае добавляется дополнительная опция -i, поэтому использование заглавных букв не учитывается. Как и в случае с IP-рецептом, [:xdigit:] можно использовать вместо [0-9a-f], если требуется лучшая читаемость.
Email-адреса
$ grep -Ei 'b[a-z0-9]{1,}@*.
(com|net|org|uk|mil|gov|edu)b' patterns
test@some.com
test@some.edu
test@some.co.uk
Список, показанный здесь, представляет собой лишь частичное подмножество доменов верхнего уровня, которые в настоящее время одобрены для использования. Например, можно искать только адреса в США, поэтому результат .uk может не иметь особого смысла. Возможно, целью является выявление явных спамеров в почтовых журналах, и в этом случае можно посоветовать поиск домена верхнего уровня .info (мы никогда не встречали никого, кто получал бы легитимную электронную почту из этого домена верхнего уровня). Показанный узор в основном является отправной точкой для настройки.
Номера телефонов США
$ grep -E 'b((|)[0-9]{3}
()|-|)-|)[0-9]{3}(-|)[0-9]{4}b'
patterns
(312)-555-1212
(312) 555-1212
312-555-1212
3125551212
В этом случае схема немного сложнее из-за большого разнообразия телефонных номеров в США. Могут быть пробелы, дефисы, круглые скобки или вообще ничего. Обратите внимание на то, как круглые скобки указывают на присутствие различных символов, включая отсутствие символа вообще.
Номера социального страхования
$ grep -E 'b[0-9]{3}( |-|)
[0-9]{2}( |-|)[0-9]{4}b' patterns
333333333
333 33 3333
333-33-3333
Номера социального страхования являются ключом к идентификации личности в Соединенных Штатах, поэтому использование этого идентификатора становится все более ограниченным. Многие организации в настоящее время активно ищут все файлы в системе для номеров социального страхования с помощью таких инструментов, как Spider. Этот инструмент не намного сложнее, чем список этих рецептов grep. Однако в этом случае схема намного проще, чем для телефонных номеров.
Номера кредитных карт
Для большинства номеров кредитных карт это выражение работает:
$ grep -E 'b[0-9]{4}(( |-|)
[0-9]{4}){3}b' patterns
1234 5678 9012 3456
1234567890123456
1234-5678-9012-3456
Номера карт American Express будут улавливаться этим выражением:
$ grep -E 'b[0-9]{4}( |-|)
[0-9]{6}( |-|)[0-9]{5}b' patterns
1234-567890-12345
123456789012345
1234 567890 12345
Эти две версии существуют, потому что American Express использует другой шаблон, чем остальные кредитные карты. Однако основная идея остается той же: поиск групп чисел, которые соответствуют общему шаблону номера кредитной карты.
Защищенный авторским правом или конфиденциальный материал
Наконец, во многих организациях есть внутренние классификации данных, которые упрощают идентификацию конфиденциальной информации внутри организации. Будем надеяться, что эти классификации данных содержат необходимый текст, который должен отображаться в документе. Эти строки можно просто ввести в качестве шаблонов поиска в grep (или fgrep), чтобы быстро определить, где на диске может находиться защищенная информация, особенно на тех машинах, которым эта информация не принадлежит.
Большинство форматов файлов с текстом не являются настоящими файлами ASCII, но обычно текстовое содержимое можно найти и идентифицировать внутри файла. Например, вы можете использовать команду grep для поиска определенных строк в файлах Word, даже если эти файлы нельзя просмотреть в терминале.
Например, если ваша корпорация использует тег «ACME Corp. — Proprietary and Confidential», вы можете использовать следующую команду для поиска файлов с таким содержимым:
fgrep -l 'ACME Corp. -
Proprietary and Confidential' patterns
Поиск в большом количестве файлов
Как и многие команды оболочки, команда grep обрабатывает большое количество файлов в данной команде. Например, grep sometext * проверяет каждое имя файла в текущем каталоге на предмет «sometext». Однако существует ограничение на количество файлов, которые можно обработать одной командой. Если вы попросите grep обработать слишком много файлов, появится сообщение об ошибке «Too Many Files» или что-то подобное (в зависимости от вашей оболочки).
Инструмент под названием xargs может обойти это ограничение. Однако, чтобы вызвать его, требуется некоторая осмотрительность. Например, для поиска «ABCDEFGH» в каждом файле в системе можно использовать следующую команду:
find / -print | xargs grep 'ABCDEFGH'Она будет искать в каждом файле на машине строку «ABCDEFGH», но не будет встречаться с типичными ошибками, которые возникают, когда открыто слишком много файлов. Обычно это ограничение является функцией ядра, которая позволяет выделить только определенное количество страниц памяти для аргументов командной строки. За исключением перекомпиляции ядра для большего значения, лучше всего использовать xargs.
Совпадение шаблонов в нескольких строках
В начале этой книги мы говорили, что grep не может сопоставлять строки, если они занимают несколько строк, но это не совсем так. Хотя большинство версий grep не могут легко обрабатывать несколько строк, grep -P может решить эту проблему в многострочном режиме. Например, возьмите следующий файл:
red
dog
Обычные уловки grep, даже указание символа новой строки, не будут соответствовать, если вы хотите найти строку с «red» и следующую строку «dog».
$ grep -E 'redndog' test
$ grep -G 'redndog' test
$ grep -F 'redndog' test
Однако это возможно, если вы используете PCRE_MULTILINE с grep -P:
$ grep -P '(?m)redndog' test
red
dog
Это позволяет пользователю преодолеть ограничение в grep, когда он будет проверять только отдельные строки. Это также одна из многих причин, по которым grep -P обычно используется для более мощных поисковых приложений.
Наконец, существует множество веб-сайтов и форумов, где вы можете найти полезные шаблоны регулярных выражений для конкретных приложений. Скорее всего, другие использовали регулярные выражения и grep для извлечения содержимого из того же приложения. Возможности безграничны.
Рекомендации
- Справочная страница re_format(7)
- Справочная страница regex(3)
- Справочная страница grep(1)
- Справочная страница pcre(3)
- Справочная страница pcrepattern(3)
- Friedl, Jeffery E.F. (2006). Mastering Regular Expressions. O’Reilly Media, Inc.
Команда grep, которая означает global regular expression print (печать глобального регулярного выражения) , является одной из самых универсальных команд в терминальной среде Linux. Это чрезвычайно мощная программа, которая позволяет пользователю сортировать ввод в соответствии со сложными правилами, что делает ее довольно популярным звеном в многочисленных цепочках команд. Команда grep в основном используется для поиска в тексте или файле строк, содержащих совпадения с указанными словами / строками. По умолчанию grep отображает совпавшие строки, и его можно использовать для поиска строк текста, соответствующкго регулярному выражению.
1. Базовый синтаксис команды grep
Базовый синтаксис команды grep следующий:
grep 'word' filename
grep 'word' file1 file2 file3
grep 'string1 string2' filename
cat otherfile | grep 'something'
command | grep 'something'
command option1 | grep 'data'
grep --color 'data' fileName2. Как использовать команду grep для поиска в файле
В первом примере я буду искать пользователя «tom» в файле passwd Linux. Для поиска пользователя «vasya» в файле /etc/passwd необходимо ввести следующую команду:
grep vasya /etc/passwdНиже приведен пример вывода:
vasya:x:1001:1001:,,,:/home/vasya:/bin/bash
У вас есть возможность указать grep игнорировать регистр слов, то есть сопоставить abc, Abc, ABC и все возможные комбинации с параметром -i, как показано ниже:
grep -i "Vasya" /etc/passwd![]()
3. Рекурсивное использование grep
Если у вас есть куча текстовых файлов в иерархии каталогов, например файлы конфигурации Apache в /etс/apache2/, и вы хотите найти файл, в котором определен конкретный текст, то используйте параметр -r команды grep, чтобы выполнить рекурсивный поиск. Это выполнит рекурсивную операцию поиска по файлам для строки «192.168.10.9» (как показано ниже) в каталоге /etc/apache2/ и во всех его подкаталогах:
grep -r "mydomain.com" /etc/apache2/В качестве альтернативы можно использовать следующую команду:
grep -R "mydomain.com" /etc/apache2/Ниже приведены примеры результатов аналогичного поиска на сервере Nginx:
grep -r "mydomain.com" /etc/nginx/
/etc/nginx/sites-available/mydomain.com.vhost: if ($http_host != "www.mydomain.com") {Здесь вы увидите результат для mydomain.com в отдельной строке, которой предшествует имя файла (например, /etc/nginx/sites-available/mydomain.com.vhost), в котором он был найден. Включение имен файлов в выходные данные можно легко подавить с помощью параметра -h (как описано ниже): grep -h -R “mydomain.com” /etc/nginx/
Ниже приведен пример вывода:
grep -r "mydomain.com" /etc/nginx/
if ($http_host != "www.mydomain.com") {4. Использование grep для поиска только слов
Когда вы ищете abc, grep будет выводить все найленные совпадения, а именно kbcabc, abc123, aarfbc35 и тому подобное, не подчиняясь границам слов. Вы можете заставить команду grep выбирать только те строки, которые содержат целые слова (тех, которые соответствуют только слову abc), как показано ниже:
grep -w "abc" file.txt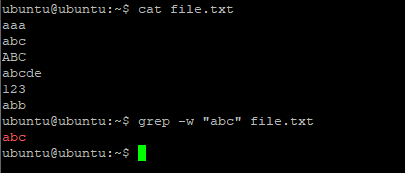
5. Использование grep для поиска двух разных слов
Чтобы найти два разных слова, вы должны использовать команду egrep, как показано ниже:
egrep -w 'word1|word2' /path/to/file6. Подсчет строк для совпадающих слов
Команда grep может сообщать, сколько раз конкретный шаблон был сопоставлен для каждого файла, используя параметр -c (count) (как показано ниже):
grep -c 'word'/path/to/file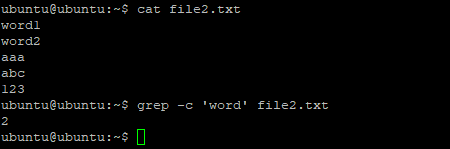
Кроме того, пользователи могут использовать опцию ‘-n’ перед каждой выходной строкой с номером строки в текстовом файле, из которого она была получена (как показано ниже):
grep -n 'word' file2.txt

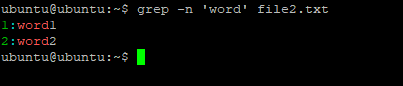
7.Инвертирование совпадения
Пользователи могут использовать параметр -v для печати инвертирования совпадения, что означает, что совпадение будет соответствовать только тем строкам, которые не содержат данное слово. Например, нужно вывести все строки, которые не содержат слова vasya:
grep -v vasya /path/to/file8. Как вывести только имена совпадающих файлов
Чтобы вывести список имен файлов, в содержании которых упоминается определенное слово, нужно использовать параметр -l. Например, найдем файлы с расширением .txt, содержащие слово «word2», с помощью следующей команды:
grep -l 'word2' *.txt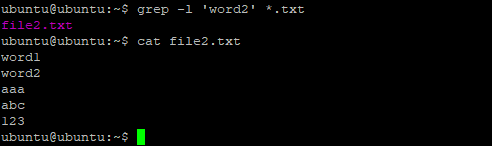
9. Как заставить команду grep обрабатывать несколько шаблонов поиска
Могут возникнуть ситуации, когда вы захотите выполнить поиск по нескольким шаблонам в файле (или наборе файлов). В таких сценариях следует использовать параметр командной строки ‘ -e’ .
Предположим, что вы хотите искать слова «как», «к» и «ковать» во всех текстовых файлах, имеющихся в вашем текущем рабочем каталоге, тогда вот как вы можете это сделать:
grep -e aaa -e bbb -e ccc *.txtВот команда в действии:
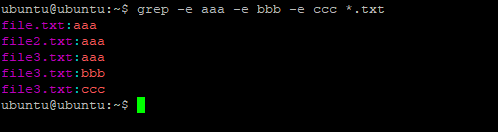
Параметр командной строки « -e» также помогает в сценариях, в которых шаблон начинается с дефиса (-). Например, если вы хотите найти, скажем, “-zyx”, то следующая команда не поможет:
grep -zyx *.txtКогда вы используете параметр командной строки -e, команда понимает, что именно вы пытаетесь найти в этом случае:
grep -e -zyx *.txtВот обе команды в действии:

10. Как ограничить вывод grep определенным количеством строк
Если вы хотите ограничить вывод grep определенным количеством строк, вы можете сделать это с помощью параметра командной строки ‘ -m’ . Например, предположим, что вы хотите найти слово «word» в file3.txt, которое содержит следующие строки:
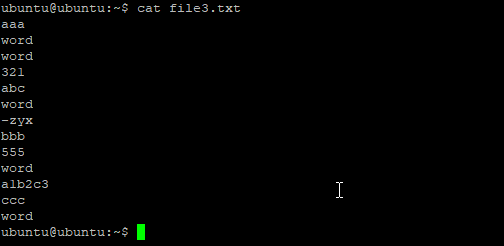
Требуется, чтобы grep прекратил поиск после того, как были найдены 3 строки, содержащие искомый шаблон. Итак, для этого вы можете выполнить следующую команду:
grep "word -m3 file3.txtВот результат:

11. Как заставить grep получать шаблоны из файла
Вы также можете заставить команду grep получать шаблоны поиска из файла. Параметр командной строки инструмента -f позволяет это сделать.
Например, предположим, что вы хотите найти во всех файлах .txt в текущем каталоге слова «aaa» и «abc», но хотите передать эти входные строки через файл с именем, скажем, «input», тогда вот как вы можете сделай это:
grep -f input *.txtВот команда в действии:
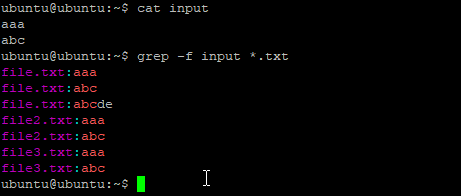
12. Как заставить grep отображать только те строки, которые полностью соответствуют шаблону поиска
До сих пор мы видели, что по умолчанию grep соответствует и отображает полные строки, содержащие шаблоны поиска. Но если требуется, чтобы grep отображал только те строки, которые полностью соответствуют искомому шаблону, то это можно сделать с помощью параметра командной строки ‘-x’.
Например, предположим, что файл file.txt содержит следующие строки:
И шаблон, который вы хотите найти, – это «how are you?». Поэтому, чтобы убедиться, что grep отображает только строки, полностью соответствующие этому шаблону, используйте его следующим образом:
grep -x "how are you?" *.txtВот команда в действии:

13. Как заставить grep ничего не отображать в выводе
Могут возникнуть ситуации, когда вам не понадобится команда grep для вывода каких-либо данных. Вместо этого вы просто хотите знать, было ли найдено совпадение на основе статуса выхода команды. Этого можно добиться с помощью параметра командной строки -q.
В то время как опция -q отключает вывод, статус выхода инструмента может быть подтвержден с помощью команды ‘echo $?’. Команда завершается со статусом «0», когда она успешна (то есть совпадение было найдено), либо завершается со статусом «1», когда совпадение найдено не было.
На следующем снимке экрана показаны как успешные, так и неудачные сценарии:
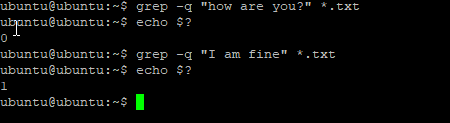
14. Как заставить grep отображать имя файлов, которые не содержат шаблон поиска
По умолчанию команда grep отображает имена файлов, содержащих шаблон поиска (а также совпадающие строки). Это вполне логично, ведь именно этого и следовало ожидать от этого инструмента. Однако могут быть случаи, когда требуется получить имена тех файлов, которые не содержат искомый шаблон.
Это также возможно с помощью grep – параметры -L позволяют это сделать. Так, например, чтобы найти все те текстовые файлы в текущем каталоге, которые не содержат слова «how», вы можете выполнить следующую команду:
grep -L "how" *.txtВот команда в действии:

15. Как подавить сообщения об ошибках, создаваемые grep
При желании вы также можете заставить grep отключать все сообщения об ошибках, отображаемые в выводе. Это можно сделать с помощью параметра командной строки -s. Например, рассмотрим следующий сценарий, в котором grep выдает ошибку / предупреждение, относящееся к каталогу, с которым он сталкивается:
Подавить ошибки в grep
В таком случае помогает опция командной строки -s. См. ниже.
Переключатель grep -s
Итак, вы можете видеть, что сообщение об ошибке / предупреждении отключено.
16. Как сделать так, чтобы grep рекурсивно выполнял поиск по каталогам
Как видно из примера, использованного в предыдущем пункте, команда grep по умолчанию не выполняет рекурсивный поиск. Чтобы убедиться, что ваш поиск grep является рекурсивным, используйте параметр командной строки -d и передайте ему значение «recurse».
grep -d recurse "word" *Примечание 1. Сообщение об ошибке / предупреждении, связанное с каталогом, которое мы обсуждали в предыдущем пункте, также можно отключить с помощью параметра -d – все, что вам нужно сделать, это передать ему значение «recurse».
Примечание 2. Используйте параметр –exclude -dir = [DIR] ‘, чтобы исключить каталоги, соответствующие шаблону DIR, из рекурсивного поиска.
17. Как заставить grep завершать имена файлов символом NULL
Как мы уже обсуждали, параметр командной строки -l команды grep используется, когда вы хотите, чтобы инструмент отображал только имена файлов в выводе. Например:

Теперь вы должны знать, что каждое имя в приведенном выше выводе отделяется / заканчивается символом новой строки. Вот как вы можете это проверить:
Перенаправьте вывод в файл, а затем распечатайте содержимое файла:
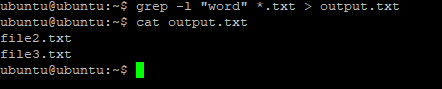
Таким образом, вывод команды cat подтверждает наличие символа новой строки между именами файлов.
Но, как вы, возможно, уже знаете, символ новой строки также может быть частью имени файла. Поэтому, когда речь идет о случаях, когда имена файлов содержат новую строку, и они также разделяются / завершаются новой строкой, становится сложно работать с выводом grep (особенно при доступе к выводу через скрипт).
Было бы хорошо, если бы разделительный / завершающий символ не был новой строкой. Что ж, grep предоставляет параметр командной строки -Z, который следит за тем, чтобы имена файлов сопровождались символом NULL, а не символом новой строки.
Итак, в нашем случае команда выглядит так:
grep -lZ "word" *.txtВот как мы подтвердили наличие символа NULL:

Ниже приведен соответствующий параметр командной строки, который вам следует знать:
-z, --null-data
Treat the input as a set of lines, each terminated by a zero byte (the ASCII NUL character) insteadof a newline. Like the -Z or --null option, this option can be used with commands like sort -z to process arbitrary file names.Рассматривайте ввод как набор строк, каждая из которых заканчивается нулевым байтом (символ ASCII NUL) вместо новой строки. Как и параметр -Z или –null, этот параметр можно использовать с такими командами, как sort -z, для обработки произвольных имен файлов.
Содержание
- Поиск текста в файлах Linux
- Что такое grep?
- Синтаксис grep
- Опции
- Примеры использования
- Поиск текста в файлах
- Вывести несколько строк
- Регулярные выражения в grep
- Рекурсивное использование grep
- Поиск слов в grep
- Поиск двух слов
- Количество вхождений строки
- Инвертированный поиск в grep
- Вывод имени файла
- Цветной вывод в grep
- Выводы
- Команда Grep в Linux (поиск текста в файлах)
- Командный синтаксис grep
- Искать строку в файлах
- Инвертировать соответствие (исключить)
- Использование Grep для фильтрации вывода команды
- Рекурсивный поиск
- Показать только имя файла
- Поиск без учета регистра
- Искать полные слова
- Показать номера строк
- Подсчет совпадений
- Бесшумный режим
- Основное регулярное выражение
- Расширенные регулярные выражения
- Поиск нескольких строк (шаблонов)
- Строки печати перед матчем
- Печатать строки после матча
- Выводы
- ПОИСК ПО СОДЕРЖИМОМУ ФАЙЛОВ — СИНТАКСИС GREP
- ЧТО ТАКОЕ GREP?
- СИНТАКСИС GREP
- ОПЦИИ
- ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
- ПОИСК ТЕКСТА В ФАЙЛАХ
- ВЫВЕСТИ НЕСКОЛЬКО СТРОК
- РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ В GREP
- РЕКУРСИВНОЕ ИСПОЛЬЗОВАНИЕ GREP
- ПОИСК СЛОВ В GREP
- ПОИСК ДВУХ СЛОВ
- КОЛИЧЕСТВО ВХОЖДЕНИЙ СТРОКИ
- ИНВЕРТИРОВАННЫЙ ПОИСК В GREP
- ВЫВОД ИМЕНИ ФАЙЛА
- ЦВЕТНОЙ ВЫВОД В GREP
- ВЫВОДЫ
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Регулярные выражения в Linux
- egrep (Extended grep)
- Про fgrep
- Рекурсивный rgrep
- Команда sed
- ИТ База знаний
- Полезно
- Навигация
- Серверные решения
- Телефония
- Корпоративные сети
- Руководство по команде grep в Linux
- Про Linux за 5 минут | Что это или как финский студент перевернул мир?
- Для чего мы пользуемся grep-ом?
- Поиск строк
- Поиск по нескольким параметрам
- Разница между grep, egrep fgrep, pgrep, zgrep
- Разница между find и grep
- Рекурсивный поиск
- Найти пробелы и табуляцию
- Использование регулярных выражений
Поиск текста в файлах Linux
Иногда может понадобится найти файл, в котором содержится определённая строка или найти строку в файле, где есть нужное слово. В Linux всё это делается с помощью одной очень простой, но в то же время мощной утилиты grep. С её помощью можно искать не только строки в файлах, но и фильтровать вывод команд, и много чего ещё.
В этой инструкции мы рассмотрим, как выполняется поиск текста в файлах Linux, подробно разберём возможные опции grep, а также приведём несколько примеров работы с этой утилитой.
Что такое grep?
Утилита grep решает множество задач, в основном она используется для поиска строк, соответствующих строке в тексте или содержимому файлов. Также она может находить по шаблону или регулярным выражениям. Команда в считанные секунды найдёт файл с нужной строчкой, текст в файле или отфильтрует из вывода только пару нужных строк. А теперь давайте рассмотрим, как ей пользоваться.
Синтаксис grep
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [имя файла. ]
$ команда | grep [опции] шаблон
Возможность фильтровать стандартный вывод пригодится,например, когда нужно выбрать только ошибки из логов или найти PID процесса в многочисленном отчёте утилиты ps.
Опции
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
Все самые основные опции рассмотрели и даже больше, теперь перейдём к примерам работы команды grep Linux.
Примеры использования
С теорией покончено, теперь перейдём к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
Поиск текста в файлах
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
grep User /etc/passwd
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
Вывести несколько строк
Например, мы хотим выбрать все ошибки из лог-файла, но знаем, что в следующей строчке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк. Ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после неё:
Выведет целевую строку и 4 строчки до неё:
Выведет по две строки с верху и снизу от вхождения.
Регулярные выражения в grep
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
grep «^Nov 10» messages.1
Nov 10 01:12:55 gs123 ntpd[2241]: time reset +0.177479 s
Nov 10 01:17:17 gs123 ntpd[2241]: synchronized to LOCAL(0), stratum 10
grep «terminating.$» messages
Jul 12 17:01:09 cloneme kernel: Kernel log daemon terminating.
Oct 28 06:29:54 cloneme kernel: Kernel log daemon terminating.
Найдём все строки, которые содержат цифры:
grep «4» /var/log/Xorg.0.log
Рекурсивное использование grep
В выводе вы получите:
Здесь перед найденной строкой указано имя файла, в котором она была найдена. Вывод имени файла легко отключить с помощью опции -h:
ServerName zendsite.localhost
DocumentRoot /var/www/localhost/htdocs/zendsite
Поиск слов в grep
Когда вы ищете строку abc, grep будет выводить также kbabc, abc123, aafrabc32 и тому подобные комбинации. Вы можете заставить утилиту искать по содержимому файлов в Linux только те строки, которые выключают искомые слова с помощью опции -w:
Поиск двух слов
Можно искать по содержимому файла не одно слово, а два сразу:
Количество вхождений строки
Утилита grep может сообщить, сколько раз определённая строка была найдена в каждом файле. Для этого используется опция -c (счетчик):
C помощью опции -n можно выводить номер строки, в которой найдено вхождение, например:
Инвертированный поиск в grep
Команда grep Linux может быть использована для поиска строк в файле, которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
Вывод имени файла
Вы можете указать grep выводить только имя файла, в котором было найдено заданное слово с помощью опции -l. Например, следующая команда выведет все имена файлов, при поиске по содержимому которых было обнаружено вхождение primary:
Цветной вывод в grep
Также вы можете заставить программу выделять другим цветом вхождения в выводе:

Выводы
Вот и всё. Мы рассмотрели использование команды grep для поиска и фильтрации вывода команд в операционной системе Linux. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Источник
Команда Grep в Linux (поиск текста в файлах)
Команда grep означает «печать глобального регулярного выражения», и это одна из самых мощных и часто используемых команд в Linux.
grep ищет в одном или нескольких входных файлах строки, соответствующие заданному шаблону, и записывает каждую соответствующую строку в стандартный вывод. Если файлы не указаны, grep читает из стандартного ввода, который обычно является выводом другой команды.
Командный синтаксис grep
Синтаксис команды grep следующий:
Пункты в квадратных скобках необязательны.
Чтобы иметь возможность искать файл, пользователь, выполняющий команду, должен иметь доступ для чтения к файлу.
Искать строку в файлах
Наиболее простое использование команды grep — поиск строки (текста) в файле.
Результат должен выглядеть примерно так:
Если в строке есть пробелы, вам нужно заключить ее в одинарные или двойные кавычки:
Инвертировать соответствие (исключить)
Например, чтобы распечатать строки, не содержащие строковый nologin вы должны использовать:
Использование Grep для фильтрации вывода команды
Вывод команды может быть отфильтрован с помощью grep через конвейер, и на терминал будут напечатаны только строки, соответствующие заданному шаблону.
Например, чтобы узнать, какие процессы выполняются в вашей системе как пользовательские www-data вы можете использовать следующую команду ps :
Рекурсивный поиск
Вот пример, показывающий, как искать строку linuxize.com во всех файлах внутри каталога /etc :
Вывод будет включать совпадающие строки с префиксом полного пути к файлу:
Показать только имя файла
Результат будет выглядеть примерно так:
Поиск без учета регистра
По умолчанию grep чувствителен к регистру. Это означает, что символы верхнего и нижнего регистра рассматриваются как разные.
Например, при поиске Zebra без какой-либо опции следующая команда не покажет никаких результатов, т.е. есть совпадающие строки:
Указание «Зебра» будет соответствовать «зебре», «ZEbrA» или любой другой комбинации букв верхнего и нижнего регистра для этой строки.
Искать полные слова
При поиске строки grep отобразит все строки, в которых строка встроена в строки большего размера.
Например, если вы ищете «gnu», все строки, в которых «gnu» встроено в слова большего размера, такие как «cygnus» или «magnum», будут найдены:
Показать номера строк
Например, чтобы отобразить строки из файла /etc/services содержащие строку bash префиксом совпадающего номера строки, вы можете использовать следующую команду:
Результат ниже показывает нам, что совпадения находятся в строках 10423 и 10424.
Подсчет совпадений
Бесшумный режим
Вот пример использования grep в тихом режиме в качестве тестовой команды в операторе if :
Основное регулярное выражение
GNU Grep имеет три набора функций регулярных выражений : базовый, расширенный и Perl-совместимый.
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, где все символы, кроме метасимволов, на самом деле являются регулярными выражениями, которые соответствуют друг другу.
Ниже приведен список наиболее часто используемых метасимволов:
Используйте символ ^ (каретка) для сопоставления выражения в начале строки. В следующем примере строка kangaroo будет соответствовать только в том случае, если она встречается в самом начале строки.
Чтобы избежать специального значения следующего символа, используйте символ (обратная косая черта).
Расширенные регулярные выражения
Сопоставьте и извлеките все адреса электронной почты из данного файла:
Сопоставьте и извлеките все действительные IP-адреса из данного файла:
Поиск нескольких строк (шаблонов)
По умолчанию grep интерпретирует шаблон как базовое регулярное выражение, в котором метасимволы, такие как | теряют свое особое значение, и необходимо использовать их версии с обратной косой чертой.
Строки печати перед матчем
Например, чтобы отобразить пять строк ведущего контекста перед совпадающими строками, вы должны использовать следующую команду:
Печатать строки после матча
Например, чтобы отобразить пять строк конечного контекста после совпадающих строк, вы должны использовать следующую команду:
Выводы
Команда grep позволяет искать шаблон внутри файлов. Если совпадение найдено, grep печатает строки, содержащие указанный шаблон.
Если у вас есть какие-либо вопросы или отзывы, не стесняйтесь оставлять комментарии.
Источник
ПОИСК ПО СОДЕРЖИМОМУ ФАЙЛОВ — СИНТАКСИС GREP
ЧТО ТАКОЕ GREP?
Команда Grep, (расшифровывается как global regular expression print) одна из самых популярных команд в терминале Linux, которая входит в состав проекта GNU. В первую очередь потому, что это очень мощная утилита, которая дает возможность пользователям сортировать и фильтровать текст на основе сложных правил.
Это позволяет применять ее для решения различных задач. Утилита grep, в основном, используется для поиска строк, соответствующих строке в тексте или содержимом файлов. Также она может быть использована для поиска по шаблону или регулярным выражениям. С помощью нее удобно в считаные секунды найти файл в файловой системе с нужной строчкой, найти текст в файле или отфильтровать из вывода команды только пару нужных строк. А теперь давайте рассмотрим как пользоваться командой.
СИНТАКСИС GREP
Синтаксис команды выглядит следующим образом:
$ grep [опции] шаблон [имя файла…]
$ команда | grep [опции] шаблон
Как видите grep умеет не только выполнять поиск в файлах linux, но и может фильтровать стандартный вывод, это очень удобная функция, когда нужно выбрать только ошибки из логов или найти PID процесса в многочисленном выводе утилиты ps.
ОПЦИИ
Давайте рассмотрим самые основные опции утилиты, которые помогут более эффективно выполнять поиск текста в файлах grep:
Все самые основные опции рассмотрели, и даже больше, теперь перейдем к примерам работы команды grep linux.
ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ
С теорией покончено, теперь перейдем к практике. Рассмотрим несколько основных примеров поиска внутри файлов Linux с помощью grep, которые могут вам понадобиться в повседневной жизни.
ПОИСК ТЕКСТА В ФАЙЛАХ
В первом примере мы будем искать пользователя User в файле паролей Linux. Чтобы выполнить поиск текста grep в файле /etc/passwd введите следующую команду:
grep User /etc/passwd
В результате вы получите что-то вроде этого, если, конечно, существует такой пользователь:
А теперь не будем учитывать регистр во время поиска. Тогда комбинации ABC, abc и Abc с точки зрения программы будут одинаковы:
ВЫВЕСТИ НЕСКОЛЬКО СТРОК
Например, мы хотим выбрать все ошибки из лог файла, но знаем что в следующей сточке после ошибки может содержаться полезная информация, тогда с помощью grep отобразим несколько строк, ошибки будем искать в Xorg.log по шаблону «EE»:
Выведет строку с вхождением и 4 строчки после нее.
Выведет целевую строку и 4 строчки до нее
Выведет по две строки с верху и снизу от вхождения.
РЕГУЛЯРНЫЕ ВЫРАЖЕНИЯ В GREP
Поиск вхождения в начале строки с помощью спецсимвола «^», например, выведем все сообщения за ноябрь:
grep «^Nov 10» messages.1
Nov 10 01:12:55 gs123 ntpd[2241]: time reset +0.177479 s
Nov 10 01:17:17 gs123 ntpd[2241]: synchronized to LOCAL(0), stratum 10
Поиск в конце строки, спецсимвол «$»:
grep «terminating.$» messages
Jul 12 17:01:09 cloneme kernel: Kernel log daemon terminating.
Oct 28 06:29:54 cloneme kernel: Kernel log daemon terminating.
Найдем все строки которые содержат цифры:
grep «1» /var/log/Xorg.0.log
Вообще, регулярные выражения grep это очень обширная тема, в этой статье я лишь показал несколько примеров, чтобы дать вам понять что это. Как вы увидели, таким образом, поиск текста в файлах grep становиться еще гибче. Но на полное объяснение этой темы нужна целая статья, поэтому пока пропустим их и пойдем дальше.
РЕКУРСИВНОЕ ИСПОЛЬЗОВАНИЕ GREP
В выводе вы получите:
ServerName zendsite.localhost
DocumentRoot /var/www/localhost/htdocs/zendsite
ПОИСК СЛОВ В GREP
ПОИСК ДВУХ СЛОВ
Можно искать по содержимому файла не одно слово, а целых несколько. Чтобы искать два разных слова используйте команду egrep:
КОЛИЧЕСТВО ВХОЖДЕНИЙ СТРОКИ
ИНВЕРТИРОВАННЫЙ ПОИСК В GREP
Команда grep linux может быть использована для поиска строк в файле Linux которые не содержат указанное слово. Например, вывести только те строки, которые не содержат слово пар:
ВЫВОД ИМЕНИ ФАЙЛА
ЦВЕТНОЙ ВЫВОД В GREP
Также вы можете заставить программу выделять другим цветом вхождения в выводе:

ВЫВОДЫ
Вот и все. Мы рассмотрели все что касается использования команды grep для осуществления поиска и фильтрации вывода команд в операционной системе Linux. При правильном применении эта утилита станет мощным инструментом в ваших руках. Если у вас остались вопросы, пишите в комментариях!
Источник
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Регулярные выражения в Linux
На регулярной основе
Интересным вопросом в Linux системах, является управление регулярными выражениями. Это полезный и необходимый навык не только профессионалам своего дела, системным администраторам, но, а также и обычным пользователям линуксоподобных операционных систем. В данной статье я постараюсь раскрыть, как создавать регулярные выражения и как их применять на практике в каких-либо целях. Основной областью применение регулярных выражений является поиск информации и файлов в линуксоподобных операционных системах.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Для работы в основном используются следующие символы:
Регулярные выражения в основном используются со следующими командами:
А особенно с утилитой grep. Данная утилита используется для сортировки результатов чего либо, передавая ей результаты по конвейеру. Эта утилита осуществляет поиск и передачу на стандартный вывод результат его. ЕЕ можно запускать с различными ключами, но можно использовать ее другие варианты, которые представлены выше.
И есть еще потоковый текстовый редактор. Это не полноценный текстовый редактор, он просто получает информацию построчно и обрабатывает. После чего выводит на стандартный вывод. Он не изменяет текстовый вывод или текстовый поток, он просто редактирует перед тем как вывести его для нас на экран.
Начнем со следующего. Создадим один пустой файл file1.txt, через команду touch. Создадим в текстовом редакторе в той же директории файл file.txt.

Как мы видим в файле file.txt просто набор слов. Далее мы с помощью данных слов посмотрим, как работают команды.


Посмотрим содержимое нашего каталога командой ls, а затем отфильтруем только то, что заканчивается на «ile«.

Получается следующее, когда мы даем на ввод команде grep шаблон и где искать, он работает с файлом, а когда мы даем команду ls она выводи содержимое каталога и мы это содержимое передаем по конвейеру на команду grep с заданным шаблоном. Соответственно grep фильтрует переданное содержимое согласно шаблона и выводит на экран. Получается, что команде grep дали, то команда и обработала.

Наглядно можно посмотреть на рисунке выше. Мы просматриваем командой cat содержимое файла и подаем на ввод команде grep с фильтрацией по шаблону.


Попробуем рассмотреть другую команду egrep.
egrep (Extended grep)
Данная команда позволяет использовать более расширенный набор шаблонов. Рассмотрим следующий пример команды:
Шаблон заключается в одинарные кавычки, для того чтобы экранировать символы, и команда egrep поняла, что это относится к ней и воспринимала выражение как шаблон. Сам же шаблон означает, что поиск будет искать слова, в начале строки (знак ^) содержащие букву b или d.

Мы видим, что команда вернула слова, начинающиеся с буквы b или d. Рассмотрим другой вариант использования команды egrep. Например:

Усложним еще шаблон. Возьмем следующий:
Усложняя выражение, мы добавили диапазон заглавных букв сказав команде grep искать диапазон маленьких или диапазон больших букв с начала строки.

Вот теперь все хорошо. Слова с Заглавными буквами тоже отобразились.
Про fgrep

Рекурсивный rgrep

Как мы видим grep не может искать в папках. Для таких случаев и используется утилита rgrep.
Дает следующую картину.

Совершенно спокойно в папке найдено было, то что подходило под шаблон.
Команда sed

В данном редакторе мы можем ему сказать использовать регулярные выражения, для этого необходимо добавить ключ -r. У данного редактора очень большой функционал.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps
Источник
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Руководство по команде grep в Linux
Читать между строк
То, что система Linux предоставляет пользователю большое многообразие разного функционала уже не секрет. На одном из прошлых материалов мы рассмотрели, как и где можно использовать команду find. В этой же статье мы на примерах разберём команду grep, мощный инструмент системных администраторов.

Про Linux за 5 минут | Что это или как финский студент перевернул мир?
Для чего мы пользуемся grep-ом?
Grep это утилита командной строки Linux, который даёт пользователям возможность вести поиск строки. С его помощью можно даже искать конкретные слова в файле. Также можно передать вывод любой команды в grep, что сильно упрощает работу во время поиска и траблшутинга.
Возьмём команду ls. Сама по себе она выводит список всех файлов и папок.

Но если нужно найти конкретную папку или один файл среди сотни других, то мы можем передать вывод команды ls в grep через вертикальную черту (|), а уже grep-у параметром передать нужное слово.

Если команда grep ничего не вернула, значит искомого файла/папки не существует в данной директории.

Поиск строк
Если же нужно найти не одно слово, а словосочетание или целое предложение, то параметр команды grep должно быть выделено кавычками. Grep поддерживает как одинарные, так и двойные кавычки.

Несмотря на то, что команда grep чаще используется как своего рода фильтр для других команд, но её также можно использовать отдельно как на примере ниже.

В этом примере мы вели поиск указанных в кавычках слов в файле Students.txt и команда grep успешно справилась со своей задачей.
Поиск по нескольким параметрам
Команде grep можно передавать не один параметр, а несколько. Для этого перед каждым аргументом пишется ключ e. Эту команду система понимает, как «или-или» и выводит все вхождения указанных слов. Заметьте, что кавычками выделена только строка, которая содержит пробел.

Разница между grep, egrep fgrep, pgrep, zgrep
Исторически разные версии Linux-а включали разновидности команды grep. Хотя в современных версия систем базовая команда grep поддерживает все возможности, которыми обладают egrep fgrep, pgrep, zgrep, но все же их тоже стоит рассмотреть.

Как видно из вывода man grep (мануал по команде grep), все эти версии всего лишь разные названия основной команды. Например, egrep это тоже самое, что и grep E (помните, командная строка Linux регистрозависимая и команды grep e и grep E интерпретируются по разному). Этой команде в качестве шаблона передается расширенное регулярное выражение. Существует очень много разных ситуаций, где можно воспользоваться этой командой. Например, две команды ниже эквивалентны и выводят все строки, в которых есть две подряд идущих буквы «p».

Fgrep это команда grep F, которая обрабатывает переданный шаблон как список фиксированных данных строкового типа. Эта команда полезна, когда в шаблоне используются зарезервированные для регулярных выражений символы, которые при обычно grep пришлось бы экранировать.

Команда pgrep используется для поиска конкретного процесса, запущенного в системе и возвращает идентификатор указанного процесса (PID). Команда ниже выводит PID процесса sshd. Почти такого же результата можно достичь если запустить команду ps e | grep sshd.

Команда zgrep используется для поиска указанного шаблона в заархивированных файлах, что очень удобно так как не приходится сначала разархивировать файл, а потом уже вести поиск.

Zgrep также работает с tar архивами, но ограничивается лишь выводом информации о том, нашла ли она соответствие или нет. Это замечание мы сделали потому, что чаще всего gzip-ом архивируются tar файлы.

Разница между find и grep
Те, кто только начинает пользоваться командной строкой Linux должны понимать, что find и grep это две разные команды, которые имеют совсем разные функции, даже если оба используются для «поиска» чего-либо.
При поиске файлов grep-ом удобно пользоваться для фильтрации вывода команды find, как и было показано в начале материала. Но если нужно найти какой-то файл в системе по его названию или части названия (при этом используется маска *), то лучше всего обратиться к find. Она выведёт точно расположение искомого файла.

Рекурсивный поиск
Чтобы вести поиск по указанному шаблону среди всех файлов во всех папках и подпапках, команду grep нужно запустить с ключом r. Команда выведет все файлы, где найдено совпадение с указанным шаблоном, а также путь к ним. По умолчанию поиск ведется по текущей директории и поддиректориях.

Найти пробелы и табуляцию
Как и было отмечено ранее, если в шаблоне поиска содержится пробел, то мы должны выделять строку кавычками. Это мы можем использовать для поиска пробелов и знаков табуляции в файле. О том как вставить табуляцию чуть позже.


Эта фишка очень помогает при поиске среди конфигурационных файлов системы, так как значения от параметров отделяются табуляцией.
Использование регулярных выражений
Регулярные выражения сильно расширяют возможности команды grep, что позволяет нам вести более гибкий поиск. Далее мы рассмотрим несколько вариантов использования регулярных выражений.
[квадратные скобки] они используются чтобы проверить на соответствие одному из указанных символов.

[-] знак дефиса означает диапазон значений. Это могут быть как буквы, так и цифры.

Вторая команда вывела то же, что и первая, но здесь мы обошлись знаком диапазона.
^ каретка используется для поиска строк, которые начинаются с указанного шаблона. Команда ниже выведет все строки, которые начинаются с буквы «А».

[^] но между квадратными скобками смысл каретки меняется. Здесь он исключает из поиска следующие за ней символы или диапазон символов.

$ знак доллара означает конец строки. Команда выведет только те строки, в конце которых встречает указанный шаблон.

.точка обозначает один любой символ. Чтобы указать несколько любых символов, можно написать символ точку нужное количество раз.
Источник