
Статья обновлена 10.07.2022
Что такое погрешность измерения
Любой расчет состоит из истинного и вычисляемого значения. При этом всегда должны учитываться значения ошибки или погрешности. Погрешность — это расхождение между истинным значением и вычисляемым. В маркетинге выделяют следующие виды погрешностей.
- Математическая погрешность. Она описывается алгебраической формулой и бывает абсолютной, относительной и приведенной. Абсолютная погрешность измерения — это разница между вычисляемым и истинным значением. Относительная погрешность вычисляется в процентном соотношении истинного значения и полученного. Вычисление погрешности приведенной схоже с относительной, указывается она также в процентах, но дает разницу между нормирующей шкалой и полученными данными, то есть между эталонными и полученными значениями.
- Оценочная погрешность. В маркетинге она бывает случайной и систематической. Случайная погрешность возникает из-за любых факторов, которые случайным образом влияют на измерение переменной в выборке. Систематическая погрешность вызывается факторами, которые систематически влияют на измерение переменной в выборке.
Математическая погрешность: формула для каждого типа
Если определение погрешности можно провести точным путем, она считается математической. Зачем нужно вычисление этого значения в маркетинге?
Погрешности возникают настолько часто, что популярной практикой в исследованиях является включение значения погрешности в окончательные результаты. Для этого используются формулы. Математическая погрешность — это значение, которое отражает разницу между выборкой и фактическим результатом. Если при расчетах учитывалась погрешность, в тексте исследования указывается что-то вроде: «Абсолютная погрешность для этих данных составляет 3,25%». Погрешность можно вычислить с любыми цифрами: количество человек, участвующих в опросе, погрешность суммы, затраченной на маркетинговый бюджет, и так далее.
Формулы погрешностей вычисляются следующим образом.
Абсолютная погрешность измерений: формула
Формула дает разницу между измеренным и реальным значением.

Относительная погрешность: формула
Формула использует значение абсолютной погрешности и вычисляется в процентах по отношению к фактическому значению.

Приведенная погрешность: формула
Формула также использует значение абсолютной погрешности. В чем измеряется приведенная погрешность? Тоже в процентах, но в качестве «эталона» используется не реальное значение, а единица измерения любой нормирующей шкалы. Например, для обычной линейки это значение равно 1 мм.

Классификация оценочной погрешности
Определение погрешности в оценках — это всегда методическая погрешность, то есть допустимое значение ошибки, основанное на методах проведения исследования. Погрешность метода вызывает два типа погрешностей — случайные и систематические. Таблица погрешностей в графической форме покажет все возможные типы.
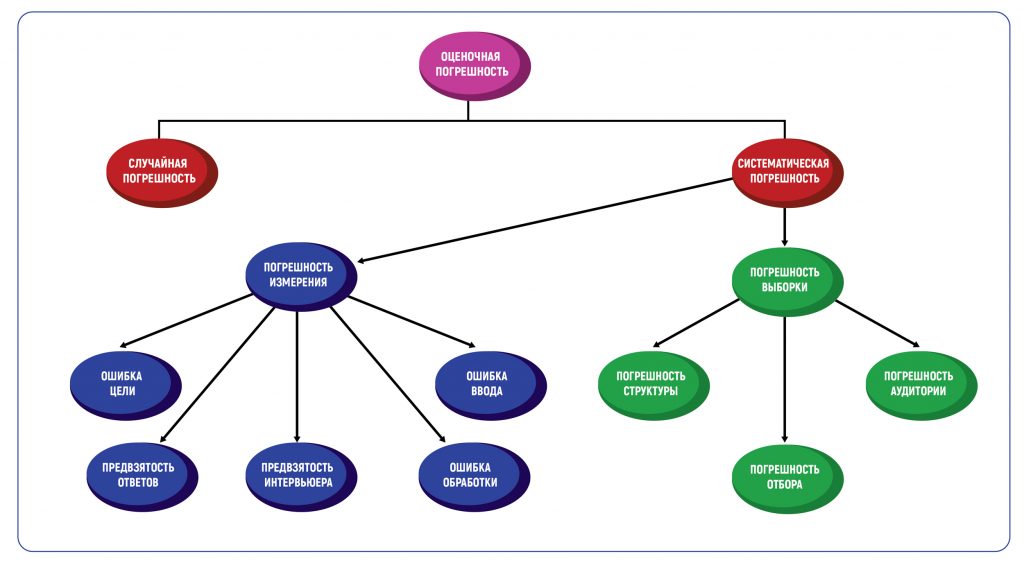
Что такое случайная погрешность
Случайная погрешность бывает статической и динамической. Динамическая погрешность возникает, когда мы имеем дело с меняющимися значениями — например, количество человек в выборке при маркетинговом исследовании. Статическая погрешность описывает ошибки при вычислении неизменных величин — вроде количества вопросов в вопроснике. Все они относятся к случайным погрешностям.
Типичный пример возникновения случайной погрешности — настроение участников маркетингового опроса. Как известно, эмоциональный настрой человека всегда влияет на его производительность. В ходе тестирования одни люди могут быть в хорошем расположении духа, а другие — в «миноре». Если настроение влияет на их ответы по заданному критерию выборки, это может искусственно завышать или занижать наблюдаемые оценки. Например, в случае с истинным значением 1 случайная погрешность может дать как -0,8, так и +0,5 к этому числу. Очень часто это случается при оценке времени ответа, например.
Случайная погрешность добавляет изменчивости данным, но не оказывает постоянного влияния на всю выборку. Вместо этого она произвольно изменяет измеряемые значения в диапазоне. В маркетинговой практике считается, что все случайные погрешности в распределении перекрывают друг друга и практически не влияют на конечный результат. Поэтому случайная погрешность считается «шумом» и в расчет не принимается. Эту погрешность нельзя устранить совсем, но можно уменьшить, просто увеличив размер выборки.
Что такое систематическая погрешность
Систематическая погрешность существует в результатах исследования, если эти результаты показывают устойчивую тенденцию к отклонению от истинных значений. Иными словами, если полученные цифры постоянно выше или ниже расчетных, речь идет о том, что в данных имеется систематическая погрешность.
В маркетинговых исследованиях есть два основных типа систематической погрешности: погрешность выборки и погрешность измерения.
Погрешность выборки
Погрешность выборки возникает, когда выборка, используемая в исследовании, не репрезентативна для всей совокупности данных. Типы такой погрешности включают погрешность структуры, погрешность аудитории и погрешность отбора.
Погрешность структуры
Погрешность структуры возникает из-за использования неполной или неточной основы для выборки. Распространенным источником такой погрешности в рамках маркетинговых исследований является проведение какого-либо опроса по телефону на основе существующего телефонного справочника или базы данных абонентов. Многие данные там указаны неполно или неточно — например, если люди недавно переехали или изменили свой номер телефона. Также такие данные часто указывают неполную или неверную демографию.
Если в качестве основы для исследования взят телефонный справочник, оно подвержено погрешности структуры, так как не учитывает всех возможных респондентов.
Погрешность аудитории
Погрешность аудитории возникает, если исследователь не знает, как определить аудиторию для исследования. Пример — оценка результатов исследования, проведенного среди клиентов крупного банка. Доля ответов на анкету составила чуть менее 1%. Анализ профессий всех опрошенных показал, что процент пенсионеров среди них в 20 раз выше, чем в целом по городу. Если эта группа значительно различается по интересующим переменным, то результаты будут неверными из-за погрешности аудитории.
Погрешность отбора
Даже если маркетологи правильно определили структуру и аудиторию, они не застрахованы от погрешности отбора. Она возникает, когда процедуры отбора являются неполными, неправильными или не соблюдаются должным образом. Например, интервьюеры при полевом исследовании могут избегать людей, которые живут в муниципальных домах. Потому что, по их мнению, жители вряд ли согласятся пройти такой опрос. Если жители муниципальных домов отличаются от тех, кто проживает в домах бизнес-класса, в результаты опроса будет внесена погрешность отбора.
Как минимизировать погрешность выборки
- Знайте свою аудиторию.
Знайте, кто покупает ваш продукт, использует его, работает с вами и так далее. Имея базовую социально-экономическую информацию, можно составить стабильную выборку целевой аудитории. Маркетинговые исследования часто касаются одной конкретной группы населения — например, пользователей Facebook или молодых мам. - Разделите аудиторию на группы.
Вместо случайной выборки разбейте аудиторию на группы в соответствии с их численностью в общей совокупности данных. Например, если люди с определенной демографией составляют 35% населения, убедитесь, что 35% респондентов исследования отвечают этому условию. - Увеличьте размер выборки.
Больший размер выборки приводит к более точному результату.
Погрешность измерения
Погрешность измерения представляет собой серьезную угрозу точности исследования. Она возникает, когда существует разница между искомой информацией — то есть истинным значением, и информацией, фактически полученной в процессе измерения. К таким погрешностям приводят различные недостатки процесса исследования. Погрешность измерения, в основном, вызывается человеческим фактором — например, формулировкой вопросника, ошибками ввода данных и необъективными выводами.
К погрешностям измерения приводят следующие виды ошибок.
Ошибка цели
Ошибка цели возникает, когда существует несоответствие между информацией, фактически необходимой для решения проблемы, и данными , которые собирает исследование. Например, компания Kellogg впустую потратила миллионы на разработку завтраков для снижения уровня холестерина. Реальный вопрос, который нужно было бы задать в исследовании, заключался в том, купят ли люди овсяные хлопья для решения своей проблемы. Ответ «Нет» обошелся бы компании дешевле.
Предвзятость ответов
Некоторые люди склонны отвечать на конкретный вопрос определенным образом. Тогда возникает предвзятость ответа. Предвзятость ответа может быть результатом умышленной фальсификации или неосознанного искажения фактов.
Умышленная фальсификация происходит, когда респонденты целенаправленно дают неверные ответы на вопросы. Есть много причин, по которым люди могут сознательно искажать информацию. Например, они хотят скрыть или хотят казаться лучше, чем есть на самом деле.
Бессознательное искажение информации происходит, когда респондент пытается быть правдивым, но дает неточный ответ. Этот тип предвзятости может возникать из-за формата вопроса, его содержания или по другим причинам.
Предвзятость интервьюера
Интервьюер оказывает влияние на респондента — сознательно или бессознательно. Одежда, возраст, пол, выражение лица, язык тела или тон голоса могут повлиять на ответы некоторых или всех респондентов.
Ошибка обработки
Примеры включают наводящие вопросы или элементы дизайна анкеты, которые затрудняют запись ответов или приводят к ошибкам в них.
Ошибка ввода
Это ошибки, возникающие при вводе информации. Например, документ может быть отсканирован неправильно, и его данные по ошибке перенесутся неверно. Или люди, заполняющие опросы на смартфоне или ноутбуке, могут нажимать не те клавиши.
Виды проводимых маркетинговых исследований различны, поэтому универсальных рецептов не существует. Мы дадим несколько общих советов, используемых для минимизации систематических погрешностей разного типа.
Как минимизировать погрешность измерения
- Предварительно протестируйте.
Погрешностей обработки и предвзятости можно избежать, если проводить предварительные тесты вопросника до начала основных интервью. - Проводите выборку случайным образом.
Чтобы устранить предвзятость, при выборке респондентов можно включать каждого четвертого человека из общего списка. - Тренируйте команду интервьюеров и наблюдателей.
Отбор и обучение тех, кто проводит исследования, должен быть тщательным. Особое внимание нужно уделять соблюдению инструкций в ходе каждого исследования. - Всегда выполняйте проверку сделанных записей.
Чтобы исключить ошибки ввода, все данные, вводимые для компьютерного анализа, должны быть перепроверены как минимум дважды.
Мир без ошибок не может существовать. Но понимание факторов, влияющих на маркетинговые исследования и измеряемые погрешности, имеет важное значение для сбора качественных данных.
![]()
Загрузить PDF
![]()
Загрузить PDF
Абсолютная ошибка – это разность между измеренным значением и фактическим значением.[1]
Эта ошибка характеризует точность измерений. Если вам известны фактическое и измеренное значения, можно с легкостью вычислить абсолютную ошибку. Но иногда фактическое значение не дано, поэтому в качестве абсолютной ошибки пользуются максимально возможной ошибкой.[2]
Если даны фактическое значение и относительная ошибка, можно вычислить абсолютную ошибку.
-

1
Запишите формулу для вычисления абсолютной ошибки. Формула:
, где – абсолютная ошибка (разность между измеренным и фактическим значениями), – измеренное значение, – фактическое значение.[3]
-
2
Подставьте в формулу фактическое значение. Фактическое значение должно быть дано; в противном случае используйте принятое опорное значение. Фактическое значение подставьте вместо
.
- Например, нужно измерить длину футбольного поля. Фактическая длина (принятая опорная длина) футбольного поля равна 105 м (именно такое значение рекомендуется FIFA). Таким образом, фактическое значение равно 105 м: .
- Например, нужно измерить длину футбольного поля. Фактическая длина (принятая опорная длина) футбольного поля равна 105 м (именно такое значение рекомендуется FIFA). Таким образом, фактическое значение равно 105 м:
-
3
Подставьте в формулу измеренное значение. Оно будет дано; в противном случае измерьте величину (длину или ширину и так далее). Измеренное значение подставьте вместо
.
- Например, вы измерили длину футбольного поля и получили значение 104 м. Таким образом, измеренное значение равно 104 м: .
- Например, вы измерили длину футбольного поля и получили значение 104 м. Таким образом, измеренное значение равно 104 м:
-
4
Вычтите фактическое значение из измеренного значения. Так как абсолютная ошибка всегда положительна, возьмите абсолютное значение этой разницы, то есть не учитывайте знак «минус».[4]
Так вы вычислите абсолютную ошибку.- В нашем примере: , то есть абсолютная ошибка измерения равна 1 м.
Реклама
- В нашем примере:











-
1
Запишите формулу для вычисления относительной ошибки. Формула:
, где – относительная ошибка (отношение абсолютной ошибки к фактическому значению), – измеренное значение, – фактическое значение.[5]
-
2
Подставьте в формулу относительную ошибку. Скорее всего, она будет дана в виде десятичной дроби. Относительную ошибку подставьте вместо
.
- Например, если относительная ошибка равна 0,02, формула запишется так: .
- Например, если относительная ошибка равна 0,02, формула запишется так:
-
3
Подставьте в формулу фактическое значение. Оно будет дано. Фактическое значение подставьте вместо
.
- Например, если фактическое значение равно 105 м, формула запишется так: .
- Например, если фактическое значение равно 105 м, формула запишется так:
-
4
Умножьте обе стороны уравнения на фактическое значение. Так вы избавитесь от дроби.
-
5
Прибавьте фактическое значение к каждой стороне уравнения. Так вы найдете
, то есть измеренное значение.
-
6
Вычтите фактическое значение из измеренного значения. Так как абсолютная ошибка всегда положительна, возьмите абсолютное значение этой разницы, то есть не учитывайте знак «минус».[6]
Так вы вычислите абсолютную ошибку.- Например, если измеренное значение равно 107,1 м, а фактическое значение равно 105 м, вычисления запишутся так: . Таким образом, абсолютная ошибка равна 2,1 м.
Реклама
- Например, если измеренное значение равно 107,1 м, а фактическое значение равно 105 м, вычисления запишутся так:











-
1
Определите единицу измерения. То есть выясните, было ли значение измерено с точностью до сантиметра, метра и так далее. Возможно, эта информация будет дана (например, «длина поля измерена с точностью до метра»). Чтобы определить единицу измерения, посмотрите на то, как округлено данное значение.[7]
- Например, если измеренная длина поля равна 106 м, значение было округлено до метров. Таким образом, единица измерения равна 1 м.
-
2
-
3
Используйте максимально возможную ошибку в качестве абсолютной ошибки.[9]
Так как абсолютная ошибка всегда положительна, возьмите абсолютное значение этой разницы, то есть не учитывайте знак «минус».[10]
Так вы вычислите абсолютную ошибку.- Например, если измеренная длина поля равна м, то есть абсолютная ошибка равна 0,5 м.
Реклама
- Например, если измеренная длина поля равна




Советы
- Если фактическое значение не указано, найдите принятое опорное или теоретическое значение.
Реклама
Об этой статье
Эту страницу просматривали 25 760 раз.
Была ли эта статья полезной?
Что такое Стандартная формула ошибки?
Стандартная ошибка — это ошибка, которая возникает в распределении выборки при выполнении статистического анализа. Это вариант стандартного отклонения, так как оба понятия соответствуют мерам спреда. Высокая стандартная ошибка соответствует более высокому разбросу данных для взятой выборки. Вычисление формулы стандартной ошибки выполняется для выборки. В то же время стандартное отклонение определяет генеральную совокупность.
Оглавление
- Что такое Стандартная формула ошибки?
- Объяснение
- Пример формулы стандартной ошибки
- Калькулятор стандартной ошибки
- Актуальность и использование
- Стандартная формула ошибки в Excel
- Рекомендуемые статьи
Следовательно, стандартная ошибка среднего значения будет выражаться и определяться в соответствии с соотношением, описанным следующим образом:
σ͞x = σ/√n

Здесь,
- Стандартная ошибка, выраженная как σ͞x.
- Стандартное отклонение совокупности выражается как σ.
- Количество переменных в выборке, выраженное как n.
В статистическом анализе среднее значение, медиана и мода являются центральной тенденцией. Центральная тенденция Центральная тенденция — это статистическая мера, которая отображает центральную точку всего распределения данных, и вы можете найти ее с помощью 3 различных мер, т. е. среднего, медианы и моды.Подробнее меры. Стандартное отклонение, дисперсия и стандартная ошибка среднего классифицируются как меры изменчивости. Стандартная ошибка среднего для выборочных данных напрямую связана со стандартным отклонением большей совокупности и обратно пропорциональна или связана с квадратным корнем. число. Чтобы использовать эту функцию, введите термин =SQRT и нажмите клавишу табуляции, которая вызовет функцию SQRT. Более того, эта функция принимает один аргумент из нескольких переменных, используемых для создания выборки. Следовательно, если размер выборки Размер выборкиФормула размера выборки отображает соответствующий диапазон генеральной совокупности, в которой проводится эксперимент или опрос. Он измеряется с использованием размера генеральной совокупности, критического значения нормального распределения при требуемом доверительном уровне, доли выборки и предела погрешности. Если больше, то может быть равная вероятность того, что стандартная ошибка также будет большой.
Объяснение
Можно объяснить формулу для стандартной ошибки среднего, используя следующие шаги:
- Определите и организуйте выборку и определите количество переменных.
- Затем среднее значение выборки соответствует количеству переменных, присутствующих в выборке.
- Затем определите стандартное отклонение выборки.
- Затем определите квадратный корень из числа переменных, включенных в выборку.
- Теперь разделите стандартное отклонение, вычисленное на шаге 3, на полученное значение на шаге 4, чтобы получить стандартную ошибку.
Пример формулы стандартной ошибки
Ниже приведены примеры формул для расчета стандартной ошибки.
.free_excel_div{фон:#d9d9d9;размер шрифта:16px;радиус границы:7px;позиция:относительная;margin:30px;padding:25px 25px 25px 45px}.free_excel_div:before{content:»»;фон:url(центр центр без повтора #207245;ширина:70px;высота:70px;позиция:абсолютная;верх:50%;margin-top:-35px;слева:-35px;граница:5px сплошная #fff;граница-радиус:50%} Вы можете скачать этот шаблон стандартной формулы ошибки Excel здесь — Стандартная формула ошибки Шаблон Excel
Пример №1
Возьмем в качестве примера акции ABC. В течение 30 лет акции приносили средний долларовый доход в размере 45 долларов. Кроме того, было замечено, что акции приносят прибыль со стандартным отклонением в 2 доллара. Помогите инвестору рассчитать общую стандартную ошибку средней доходности, предлагаемой акцией ABC.
Решение:
- Стандартное отклонение (σ) = $2
- Количество лет (n) = 30
- Средняя доходность в долларах = 45 долларов.
Расчет стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 2 доллара США/√30
- = 2 доллара США / 5,4773
Стандартная ошибка,

- σx = 0,3651 доллара США
Таким образом, инвестиция предлагает инвестору стандартную долларовую ошибку в среднем 0,36515 доллара при удерживании позиции ABC в течение 30 лет. Однако, если бы акции сохранялись для более высокого инвестиционного горизонта, то стандартная ошибка среднего значения в долларах значительно уменьшилась бы.
Пример #2
Возьмем в качестве примера инвестора, который получил следующую доходность акций XYZ:
Год инвестиций Предлагаемая доходность120%225%35%410%
Помогите инвестору рассчитать общую стандартную ошибку средней доходности акций XYZ.
Решение:
Сначала определите среднее значение доходности, как показано ниже: –

- ͞X = (x1+x2+x3+x4)/количество лет
- = (20+25+5+10)/4
- =15%
Теперь определите стандартное отклонение доходности, как показано ниже: –

- σ = √ ((x1-͞X)2 + (x2-͞X)2 + (x3-͞X)2 + (x4-͞X)2) / √ (количество лет -1)
- = √ ((20-15) 2 + (25-15) 2 + (5-15) 2 + (10-15) 2) / √ (4-1)
- = (√ (5) 2 + (10) 2 + (-10) 2 + (-5) 2 ) / √ (3)
- = (√25+100+100+25)/ √ (3)
- =√250/√3
- =√83,3333
- «=» 9,1287%
Теперь вычисление стандартной ошибки выглядит следующим образом:

- σ͞x = σ/√n
- = 9,128709/√4
- = 9,128709/2
Стандартная ошибка,

- σx = 4,56%
Таким образом, инвестиции предлагают инвестору стандартную ошибку в долларах в среднем 4,56% при удержании позиции XYZ в течение 4 лет.
Калькулятор стандартной ошибки
Вы можете использовать следующий калькулятор.
.cal-tbl td{ верхняя граница: 0 !важно; }.cal-tbl tr{ высота строки: 0.5em; } Только экран @media и (минимальная ширина устройства: 320 пикселей) и (максимальная ширина устройства: 480 пикселей) { .cal-tbl tr{ line-height: 1em !important; } } σnСтандартная формула ошибки
Формула стандартной ошибки =σ =√n 0 = 0√0
Актуальность и использование
Стандартная ошибка имеет тенденцию быть высокой, если размер выборки для анализа мал. Следовательно, выборка всегда берется из большей совокупности, которая включает больший размер переменных. Это всегда помогает статистику определить достоверность среднего значения выборки относительно среднего значения генеральной совокупности.
Большая стандартная ошибка говорит статистику, что выборка неоднородна в отношении среднего значения генеральной совокупности. Относительно населения наблюдается большой разброс в выборке. Точно так же небольшая стандартная ошибка говорит статистику, что выборка однородна относительно среднего значения генеральной совокупности. Отсутствуют или незначительные различия в выборке относительно населения.
Не следует смешивать его со стандартным отклонением. Вместо этого следует рассчитать стандартное отклонение для всей совокупности. Стандартная ошибкаСтандартная ошибкаСтандартная ошибка (SE) — это метрика, которая измеряет точность выборочного распределения, обозначающего совокупность, с использованием стандартного отклонения. Другими словами, это мера дисперсии среднего значения выборки, связанная со средним значением генеральной совокупности, а не стандартное отклонение. С другой стороны, оно определяется для среднего значения выборки.
Стандартная формула ошибки в Excel
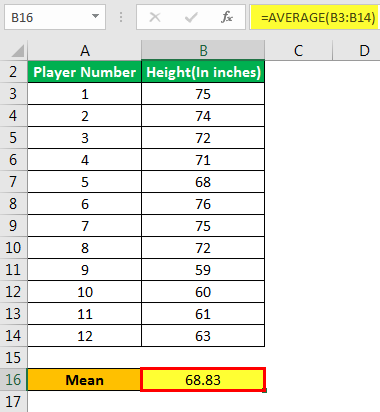
Теперь давайте возьмем пример Excel, чтобы проиллюстрировать концепцию стандартной формулы ошибки в шаблоне Excel ниже. Предположим, администрация школы хочет определить стандартную ошибку среднего значения роста футболистов.
Выборка состоит из следующих значений: –

Помогите администрации оценить стандартную ошибку среднего значения.
Шаг 1: Определите среднее значение, как показано ниже: –
Шаг 2: Определите стандартное отклонение, как показано ниже: –

Шаг 3: Определите стандартную ошибку среднего значения, как показано ниже: –

Следовательно, стандартная ошибка среднего значения для футболистов составляет 1,846 дюйма. Руководство должно заметить, что оно значительно велико. Таким образом, выборочные данные, взятые для анализа, неоднородны и имеют большую дисперсию.
Руководству следует либо исключить более мелких игроков, либо добавить игроков значительно выше, чтобы сбалансировать средний рост футбольной команды, заменив их людьми с меньшим ростом по сравнению с их сверстниками.
Рекомендуемые статьи
Эта статья была руководством по формуле стандартной ошибки. Здесь мы обсуждаем формулу для расчета среднего значения, стандартную ошибку, примеры и загружаемый лист Excel. Вы можете узнать больше из следующих статей: –
- Формула рентабельности EBITDA
- Формула валовой прибыли
- Формула относительного стандартного отклонения
- Формула погрешности
Материал из MachineLearning.
Перейти к: навигация, поиск
Содержание
- 1 Введение
- 1.1 Постановка вопроса. Виды погрешностей
- 2 Виды мер точности
- 3 Предельные погрешности
- 4 Погрешности округлений при представлении чисел в компьютере
- 5 Погрешности арифметических операций
- 6 Погрешности вычисления функций
- 7 Числовые примеры
- 8 Список литературы
- 9 См. также
Введение
Постановка вопроса. Виды погрешностей
Процесс исследования исходного объекта методом математического моделирования и вычислительного эксперимента неизбежно носит приближенный характер, так как на каждом этапе вносятся погрешности. Построение математической модели связано с упрощением исходного явления, недостаточно точным заданием коэффициентов уравнения и других входных данных. По отношению к численному методу, реализующему данную математическую модель, указанные погрешности являются неустранимыми, поскольку они неизбежны в рамках данной модели.
При переходе от математической модели к численному методу возникают погрешности, называемые погрешностями метода. Они связаны с тем, что всякий численный метод воспроизводит исходную математическую модель приближенно. Наиболее типичными погрешностями метода являются погрешность дискретизации и погрешность округления.
При построении численного метода в качестве аналога исходной математической задачи обычно рассматривается её дискретная модель. Разность решений дискретизированной задачи и исходной называется погрешностью дискретизации. Обычно дискретная модель зависит от некоторого параметра (или их множества) дискретизации, при стремлении которого к нулю должна стремиться к нулю и погрешность дискретизации.
Дискретная модель представляет собой систему большого числа алгебраических уравнений. Для её решения используется тот или иной численный алгоритм. Входные данные этой системы, а именно коэффициенты и правые части, задаются в ЭВМ не точно, а с округлением. В процессе работы алгоритма погрешности округления обычно накапливаются, и в результате, решение, полученное на ЭВМ, будет отличаться от точного решения дискретизированной задачи. Результирующая погрешность называется погрешностью округления (вычислительной погрешностью). Величина этой погрешности определяется двумя факторами: точностью представления вещественных чисел в ЭВМ и чувствительностью данного алгоритма к погрешностям округления.
Итак, следует различать погрешности модели, дискретизации и округления. В вопросе преобладания какой-либо погрешности ответ неоднозначен. В общем случае нужно стремиться, чтобы все погрешности имели один и тот же порядок. Например, нецелесообразно пользоваться разностными схемами, имеющими точность 10−6, если коэффициенты исходных уравнений задаются с точностью 10−2.
Виды мер точности
Мерой точности вычислений являются абсолютные и относительные погрешности. Абсолютная погрешность определяется формулой
где – приближение к точному значению .
Относительная погрешность определяется формулой
Относительная погрешность часто выражается в процентах. Абсолютная и относительная погрешности тесно связаны с понятием верных значащих цифр. Значащими цифрами числа называют все цифры в его записи, начиная с первой ненулевой цифры слева. Например, число 0,000129 имеет три значащих цифры. Значащая цифра называется верной, если абсолютная погрешность числа не превышает половины веса разряда, соответствующего этой цифре. Например, , абсолютная погрешность . Записывая число в виде
имеем , следовательно, число имеет две верных значащих цифр (9 и 3).
В общем случае абсолютная погрешность должна удовлетворять следующему неравенству:
где — порядок (вес) старшей цифры, — количество верных значащих цифр.
В рассматриваемом примере .
Относительная погрешность связана с количеством верных цифр приближенного числа соотношением:
где — старшая значащая цифра числа.
Для двоичного представления чисел имеем .
Тот факт, что число является приближенным значением числа с абсолютной погрешностью , записывают в виде
причем числа и записываются с одинаковым количеством знаков после запятой, например, или .
Запись вида
означает, что число является приближенным значение числа с относительной погрешностью .
Так как точное решение задачи как правило неизвестно, то погрешности приходится оценивать через исходные данные и особенности алгоритма. Если оценка может быть вычислена до решения задачи, то она называется априорной. Если оценка вычисляется после получения приближенного решения задачи, то она называется апостериорной.
Очень часто степень точности решения задачи характеризуется некоторыми косвенными вспомогательными величинами. Например точность решения системы алгебраических уравнений
характеризуется невязкой
где — приближенное решение системы.
Причём невязка достаточно сложным образом связана с погрешностью решения , причём если невязка мала, то погрешность может быть значительной.
Предельные погрешности
Пусть искомая величина является функцией параметров — приближенное значение . Тогда предельной абсолютной погрешностью называется величина
Предельной относительной погрешностью называется величина .
Пусть — приближенное значение . Предполагаем, что — непрерывно дифференцируемая функция своих аргументов. Тогда, по формуле Лагранжа,
где .
Отсюда
где .
Можно показать, что при малых эта оценка не может быть существенно улучшена. На практике иногда пользуются грубой (линейной) оценкой
где .
Несложно показать, что:
- — предельная погрешность суммы или разности равна сумме предельных погрешностей.
- — предельная относительная погрешность произведения или частного приближенного равна сумме предельных относительных погрешностей.
Погрешности округлений при представлении чисел в компьютере
Одним из основных источников вычислительных погрешностей является приближенное представление чисел в компьютере, обусловленное конечностью разрядной сетки (см. Международный стандарт представления чисел с плавающей точкой в ЭВМ). Число , не представимое в компьютере, подвергается округлению, т. е. заменяется близким числом , представимым в компьютере точно.
Найдем границу относительной погрешности представления числа с плавающей точкой. Допустим, что применяется простейшее округление – отбрасывание всех разрядов числа, выходящих за пределы разрядной сетки. Система счисления – двоичная. Пусть надо записать число, представляющее бесконечную двоичную дробь
где , — цифры мантиссы.
Пусть под запись мантиссы отводится t двоичных разрядов. Отбрасывая лишние разряды, получим округлённое число
Абсолютная погрешность округления в этом случае равна
Наибольшая погрешность будет в случае , тогда
Т.к. , где — мантисса числа , то всегда . Тогда и относительная погрешность равна . Практически применяют более точные методы округления и погрешность представления чисел равна
( 1 )
т.е. точность представления чисел определяется разрядностью мантиссы .
Тогда приближенно представленное в компьютере число можно записать в виде , где – «машинный эпсилон» – относительная погрешность представления чисел.
Погрешности арифметических операций
При вычислениях с плавающей точкой операция округления может потребоваться после выполнения любой из арифметических операций. Так умножение или деление двух чисел сводится к умножению или делению мантисс. Так как в общем случае количество разрядов мантисс произведений и частных больше допустимой разрядности мантиссы, то требуется округление мантиссы результатов. При сложении или вычитании чисел с плавающей точкой операнды должны быть предварительно приведены к одному порядку, что осуществляется сдвигом вправо мантиссы числа, имеющего меньший порядок, и увеличением в соответствующее число раз порядка этого числа. Сдвиг мантиссы вправо может привести к потере младших разрядов мантиссы, т.е. появляется погрешность округления.
Округленное в системе с плавающей точкой число, соответствующее точному числу , обозначается через (от англ. floating – плавающий). Выполнение каждой арифметической операции вносит относительную погрешность, не большую, чем погрешность представления чисел с плавающей точкой (1). Верна следующая запись:
где — любая из арифметических операций, .
Рассмотрим трансформированные погрешности арифметических операций. Арифметические операции проводятся над приближенными числами, ошибка арифметических операций не учитывается (эту ошибку легко учесть, прибавив ошибку округления соответствующей операции к вычисленной ошибке).
Рассмотрим сложение и вычитание приближенных чисел. Абсолютная погрешность алгебраической суммы нескольких приближенных чисел равна сумме абсолютных погрешностей слагаемых.
Если сумма точных чисел равна
сумма приближенных чисел равна
где — абсолютные погрешности представления чисел.
Тогда абсолютная погрешность суммы равна
Относительная погрешность суммы нескольких чисел равна
( 2 )
где — относительные погрешности представления чисел.
Из (2) следует, что относительная погрешность суммы нескольких чисел одного и того же знака заключена между наименьшей и наибольшей из относительных погрешностей слагаемых:
При сложении чисел разного знака или вычитании чисел одного знака относительная погрешность может быть очень большой (если числа близки между собой). Так как даже при малых величина может быть очень малой. Поэтому вычислительные алгоритмы необходимо строить таким образом, чтобы избегать вычитания близких чисел.
Необходимо отметить, что погрешности вычислений зависят от порядка вычислений. Далее будет рассмотрен пример сложения трех чисел.
( 3 )
При другой последовательности действий погрешность будет другой:
Из (3) видно, что результат выполнения некоторого алгоритма, искаженный погрешностями округлений, совпадает с результатом выполнения того же алгоритма, но с неточными исходными данными. Т.е. можно применять обратный анализ: свести влияние погрешностей округления к возмущению исходных данных. Тогда вместо (3) будет следующая запись:
где
При умножении и делении приближенных чисел складываются и вычитаются их относительные погрешности.
-
-
- ≅
с точностью величин второго порядка малости относительно .
Тогда .
Если , то ≅
При большом числе n арифметических операций можно пользоваться приближенной статистической оценкой погрешности арифметических операций, учитывающей частичную компенсацию погрешностей разных знаков:
где – суммарная погрешность, – погрешность выполнения операций с плавающей точкой, – погрешность представления чисел с плавающей точкой.
Погрешности вычисления функций
Рассмотрим трансформированную погрешность вычисления значений функций.
Абсолютная трансформированная погрешность дифференцируемой функции , вызываемая достаточно малой погрешностью аргумента , оценивается величиной .
Если , то .
Абсолютная погрешность дифференцируемой функции многих аргументов , вызываемая достаточно малыми погрешностями аргументов оценивается величиной:
-
- .
Если , то .
Практически важно определить допустимую погрешность аргументов и допустимую погрешность функции (обратная задача). Эта задача имеет однозначное решение только для функций одной переменной , если дифференцируема и :
-
- .
Для функций многих переменных задача не имеет однозначного решения, необходимо ввести дополнительные ограничения. Например, если функция наиболее критична к погрешности , то:
-
- (погрешностью других аргументов пренебрегаем).
Если вклад погрешностей всех аргументов примерно одинаков, то применяют принцип равных влияний:
Числовые примеры
Специфику машинных вычислений можно пояснить на нескольких элементарных примерах.
ПРИМЕР 1. Вычислить все корни уравнения
Точное решение задачи легко найти:
Если компьютер работает при , то свободный член в исходном уравнении будет округлен до и, с точки зрения представления чисел с плавающей точкой, будет решаться уравнение , т.е. , что, очевидно, неверно. В данном случае малые погрешности в задании свободного члена привели, независимо от метода решения, к погрешности в решении .
ПРИМЕР 2. Решается задача Коши для обыкновенного дифференциального уравнения 2-го порядка:
Общее решение имеет вид:
При заданных начальных данных точное решение задачи: , однако малая погрешность в их задании приведет к появлению члена , который при больших значениях аргумента может существенно исказить решение.
ПРИМЕР 3. Пусть необходимо найти решение обыкновенного дифференциального уравнения:
Его решение: , однако значение известно лишь приближенно: , и на самом деле .
Соответственно, разность будет:
Предположим, что необходимо гарантировать некоторую заданную точность вычислений всюду на отрезке . Тогда должно выполняться условие:
Очевидно, что:
Отсюда можно получить требования к точности задания начальных данных при .
Таким образом, требование к заданию точности начальных данных оказываются в раз выше необходимой точности результата решения задачи. Это требование, скорее всего, окажется нереальным.
Решение оказывается очень чувствительным к заданию начальных данных. Такого рода задачи называются плохо обусловленными.
ПРИМЕР 4. Решением системы линейных алгебраических уравнений (СЛАУ):
является пара чисел .
Изменив правую часть системы на , получим возмущенную систему:
с решением , сильно отличающимся от решения невозмущенной системы. Эта система также плохо обусловлена.
ПРИМЕР 5. Рассмотрим методический пример вычислений на модельном компьютере, обеспечивающем точность . Проанализируем причину происхождения ошибки, например, при вычитании двух чисел, взятых с точностью до третьей цифры после десятичной точки , разность которых составляет .
В памяти машины эти же числа представляются в виде:
-
- , причем и
Тогда:
Относительная ошибка при вычислении разности будет равна:
Очевидно, что , т.е. все значащие цифры могут оказаться неверными.
ПРИМЕР 6. Рассмотрим рекуррентное соотношение
Пусть при выполнении реальных вычислений с конечной длиной мантиссы на -м шаге возникла погрешность округления, и вычисления проводятся с возмущенным значением , тогда вместо получим , т.е. .
Следовательно, если , то в процессе вычислений погрешность, связанная с возникшей ошибкой округления, будет возрастать (алгоритм неустойчив). В случае погрешность не возрастает и численный алгоритм устойчив.
Список литературы
- А.А.Самарский, А.В.Гулин. Численные методы. Москва «Наука», 1989.
- http://www.mgopu.ru/PVU/2.1/nummethods/Chapter1.htm
- http://www.intuit.ru/department/calculate/calcmathbase/1/4.html
См. также
- Практикум ММП ВМК, 4й курс, осень 2008
Пусть
![]() непрерывно
непрерывно
дифференцируемая функция,
![]() —
—
приближенные значения ее аргументов,
для которых
![]() —
—
известные абсолютные погрешности.
Для
погрешности приближенного значения
функции
![]() по
по
формуле Лагранжа получаем
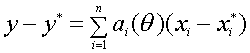 ,
,
где

Заменяя
 , получаем
, получаем
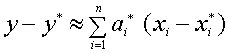
Оценка погрешности
соответственно:
 ,
,
где

Или
 ( 5) ,
( 5) ,
где
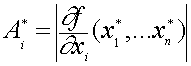 (6)
(6)
3.2.
Погрешность суммы
Пусть
задана функция
![]()
Тогда
из (5) , (6)
 ,
,![]() .
.
Для абсолютной
погрешности получаем
![]() .
.
Относительная
погрешность
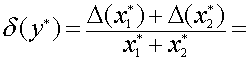
 .
.
Пусть
![]() ,
,![]() ,
,
тогда![]() ,
,
т.е. при сложении приближенных величин
относительная погрешность не возрастает.
3.3.
Погрешность разности
Пусть
задана функция
![]()
Тогда аналогично
предыдущему абсолютная погрешность
![]() .
.
Для относительной
погрешности имеем формулу
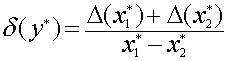 .
.
Отсюда
следует, что если приближенные значения
![]() и
и![]() близки
близки
друг к другу, то относительная погрешность
их разности![]() может оказаться намного больше
может оказаться намного больше![]() и
и![]() .
.
3.4.
Погрешность произведения
Пусть
задана функция ![]()
Тогда абсолютная
погрешность
![]() .
.
Относительная
погрешность
 .
.
3.5.
Погрешность частного
Пусть
задана функция 
Тогда абсолютная
погрешность
 .
.
Относительная
погрешность

3.6.
Обратная задача оценки погрешности
Иногда
возникает задача определения допустимой
погрешности аргументов, при которой
погрешность значений функции будет не
более заданной величины
![]() .
.
Используем
ранее полученное неравенство ( 6 )
 .
.
Должно
быть
 .
.
При
n=1 вопрос
решается однозначно:

При
n>1
возможны разные подходы:
1. Считать погрешности
всех аргументов одинаковыми
![]()
Тогда
получаем 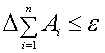 , следовательно
, следовательно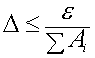
2.
Считать, что вклад погрешности каждого
аргумента в погрешность результата
одинаков.  ,
,
тогда

Если
для разных аргументов достижение
определенной точности их задания
существенно различается, то можно ввести
функцию стоимости
![]() затрат
затрат
на задание точки![]() с
с
заданными абсолютными погрешностями![]() и
и
искать ее минимум в области
![]() ,
, ![]()
4. Вычисление погрешности арифметических действий в среде Mathcad .
Настройка
среды MathCad
(системные
переменные ).
Изменение
значений системных переменных производят
во вкладке Встроенные
переменные
диалогового окна Math
Options
команды Математика
Опции.
1)
Допустимая
погрешность — значение системной
переменной TOL
(по
умолчанию TOL =10-3).
Установить
TOL:=10—5.
2)
Изменение
количества цифр в результате после
разделяющей точки
производят
во вкладке Результат
диалогового
окна Количество
десятичных позиций команды
Формат
Результат.
Установить
равным 6 (по
умолчанию равно 3) , что на 1 больше
порядка величины
TOL
– для возможности округления конечного
результата
.
Пример
4.1.Вычисление погрешности операций
сложения , вычитания , умножения и
деления.
Пусть
числа x и y заданы с абсолютными
погрешностями
![]() x
x
и![]() y
y
x
: = 2.5378
![]() x
x
: = 0.0001
y : = 2.536![]() y
y
: = 0.001
Тогда относительные
погрешности чисел
 ,
,
![]() ,
,  ,
,
![]()
Найдем погрешности
суммы и разности чисел
S1
: = x + y
![]() S1
S1
: =
![]() x
x
+
![]() y
y

![]() S1
S1
= 1.1 x 10-3
![]()
S2
: = x — y
![]() S2
S2
: =
![]() x
x
+
![]() y
y

![]() S2
S2
= 1.1 x 10-3
![]()
Относительная
погрешность разности в 
раз больше относительной погрешности
суммы!
Пример
4.2. Погрешность
функции многих переменных.
![]()
![]()


Пусть
x : = -3.59 y : = 0.467
z : = 563.2
По
приведенным начальным условиям считаем,
что абсолютные погрешности равны
![]() x
x
: = 0.01
![]() y
y
: = 0.001![]() z
z
: = 0.1
Значение
функции равно : f ( x, y, z ) = 6.64198865
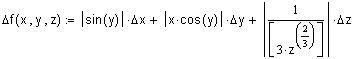

![]() f
f
( x, y, z ) = 1.234 x 10
-3
![]() f
f
( x, y, z ) = 8.196 x 10
-3
Пример
4.3. Постановка
задачи:
Дан
ряд
![]()
![]() .
.
Найти
сумму ряда S
аналитически.
Вычислить
значения частичных сумм ряда S![]() =
=![]() и найти величину погрешности при
и найти величину погрешности при
значениях значениях![]() =
=![]() ,
,![]() ,
,![]() ,
,![]() ,
,![]() .
.
Построить
гистограмму зависимости верных цифр
результата от
![]() .
.
Аналитическое
решение задачи:
S![]() =
=
![]()
![]()
=
![]()

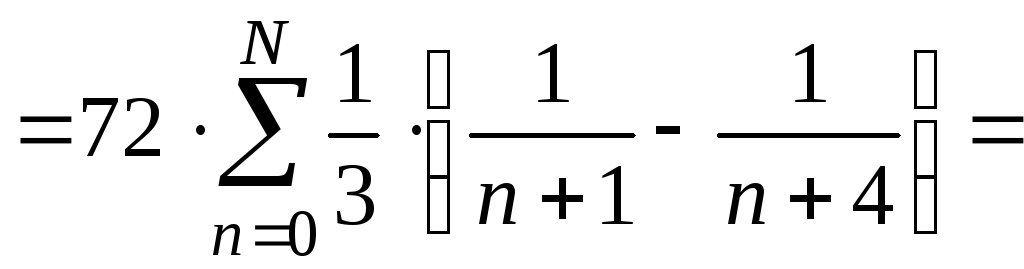
 ,
,
![]() .
.
ОТВЕТ:
S
=![]()
![]()
= 44.
Введем
функцию
S(N)=
 .
.
Тогда
абсолютную погрешность можно определить
с помощью функции
d(S(N))
=![]() .
.
Tексты
программ:


Гистограмма
Результаты
вычислительного эксперимента:
Значение
частичной Величина абсолютной
Количество
суммы
ряда погрешности
верных цифр
S(10)=38.439560439
d(10)=5.56
![]()
S(100)=43.3009269
d(100)=0.699
![]() 2
2
S(1000)=43.9282153
d(1000)=0.072
![]() 3
3
S(10000)=43.992802
d(10000)=0.0072
![]() 4
4
S(100000)=43.9992802159957
d(100000)=0.00072
![]() 5
5
Вывод:
Как
видно из приведенного вычислительного
эксперимента, увеличение числа членов
ряда в 10 раз по сравнению с предыдущим
случаем увеличивает число верных цифр
в ответе на 1.
Соседние файлы в папке MMM
- #
- #
- #
16.02.2016436.7 Кб47PZ-1 MathCAD.mcd
- #
- #
- #
- #
- #
- #
- #
- #
Процентная ошибка в наборе данных — это разница между точным и приблизительным значениями по сравнению с исходным значением. Эта процентная ошибка выражается в процентах и, следовательно, умножается на 100.
Вы можете выразить процентную ошибку как абсолютную ошибку или относительную ошибку. Ошибки могут возникать из-за ошибки точности в машине, ошибки вычислений, ошибки измерения или условий окружающей среды.
Процентные ошибки помогают нам определить, насколько значительны наши ошибки во время любого анализа. Более мелкие процентные ошибки означают, что мы близки к исходному значению, в то время как более существенные процентные ошибки означают значительное расхождение между фактическим значением и приблизительным значением.
Например, ошибка в 2% будет означать, что мы очень близки к исходному значению, а ошибка в 56% будет означать огромную разницу между фактическим и приблизительным значением.
Ошибки при измерении широко распространены, потому что руки могут трястись во время измерений, инструменты могут быть неисправны, материал может быть неточным и т. д.
Расчет процента ошибки
Для расчета процентной ошибки необходимо иметь два доступных значения. Одно точное значение, а второе приблизительное значение. Вычтите оба этих значения, а затем разделите их на исходное значение. Поскольку процентная ошибка выражается в виде процентов, умножьте полученное таким образом число на 100. Другими словами, процентная ошибка — это относительная ошибка, умноженная на 100.
Процентная ошибка = [(Actual Value – Expected Value) / Expected Value] × 100
Компоненты формулы
Фактическое значение: Фактическое значение указывает числовое значение конкретного показания. Фактическое значение должно было быть записано при снятии показаний, но из-за некоторых ошибок мы не смогли записать это значение. Это обычное значение, которое идеально подходит для проведения расчетов.
Ожидаемое значение: Ожидаемое значение указывает на показания, записанные во время эксперимента. В большинстве случаев оно не похоже на фактическое значение из-за ошибки. Ошибки могут быть вызваны неисправностью машины, ошибкой при снятии показаний или факторами окружающей среды, такими как воздух или сломанные и поврежденные инструменты.
Некоторые примеры
Пример 1
Мальчик измерял площадь треугольника и, по его словам, получил 462 кв.см. Однако первоначальная площадь квадрата равна 465 кв.см. Вычислите процент ошибки.
Решение
Значение измеряемой площади = 462 кв.см
Значение фактической площади = 465 кв. см.
Расчет
Разница фактического значения – измеренного значения: 465-462 = 3
Итак, 3 — это ошибка измерения.
Разделите ошибку на фактическое значение – 3/465 = 0,00645.
Умножив полученное значение на 100 – 0,00645 X 100 = 0,64%.
Следовательно, процентная ошибка при вычислении площади треугольника составляет 0,64%.
Пример 2
Предположим, вы планировали вечеринку, на которой должно было присутствовать около 20 человек, а успели прийти только 18 человек. Вычислите процент ошибки в вашей оценке.
Решение
Первоначальное ожидаемое количество людей = 20
Пришедших = 18
Расчет
Разница фактического значения – конечного значения = 20 – 18 = 2
Итак, 2 — это ошибка здесь.
Разделите ошибку на фактическое значение – 2/20 = 0,1.
Умножение значения на 100 – 0,1 X 100 = 10%
Следовательно, процентная ошибка в оценке количества гостей составляет 10%.
Пример 3
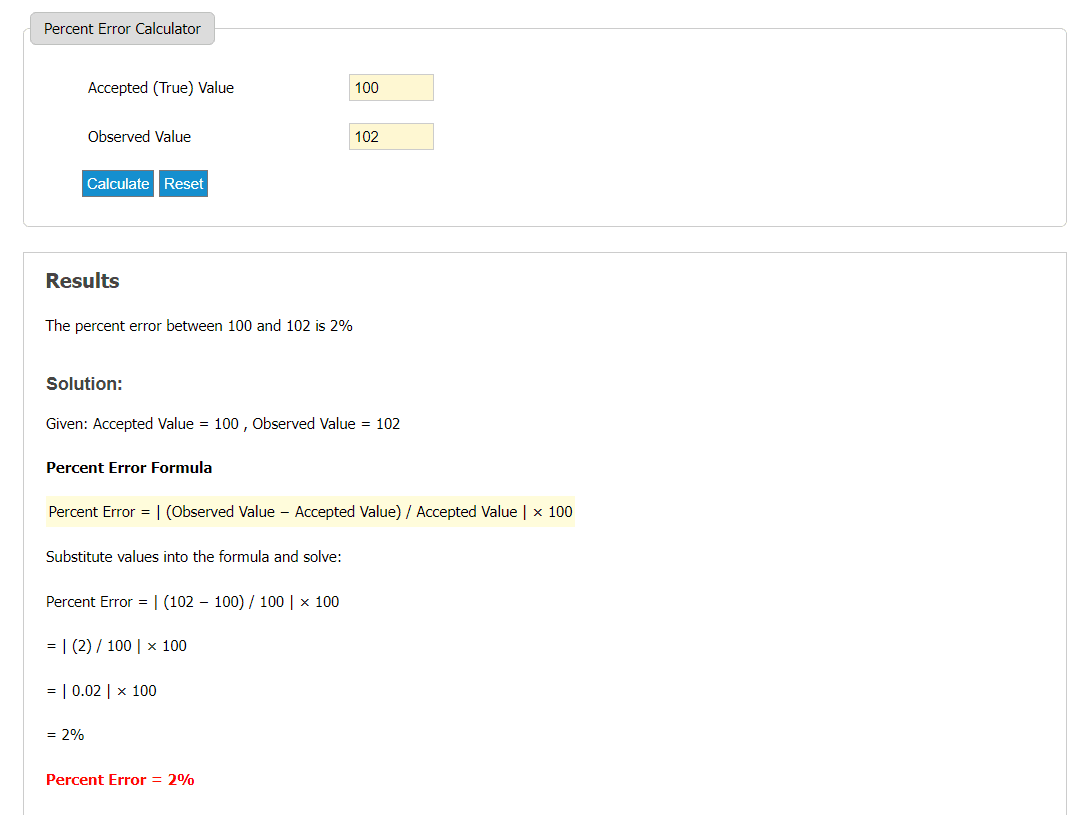
Предположим, вы провели эксперимент по измерению температуры кипения воды и в ходе эксперимента обнаружили, что результат равен 102 °C. Фактическая температура замерзания воды составляет 100°С.
Решение
Фактическая температура кипения воды = 100°С.
Зарегистрированная температура кипения воды = 102°C
Расчет
Разница между фактическим значением и расчетным значением = 100 -102 = 2°C (процентная ошибка никогда не может быть отрицательной, поэтому мы оставляем ее только положительной).
Итак, 2 — это ошибка здесь.
Разделите ошибку на фактическое значение – 2/100 = 0,02.
Умножение полученного значения на 100 – 0,02 X 100 = 2%
Следовательно, процентная погрешность измерения температуры кипения воды составляет 2%.
Реальные сценарии, в которых важна процентная ошибка
- Процентная ошибка играет важную роль, помогая вам определить, была ли конкретная задача, которую вы выполнили, на должном уровне или нет. Это поможет вам указать на ваши ошибки.
- Процентная погрешность может быть полезной в лабораторных процедурах и на крупных предприятиях, где недопустима малейшая ошибка.
- Процентная ошибка также находит свое применение, когда нам нужно выполнить оптовый заказ, и в его выполнении не может быть никаких ошибок.
- В научных лабораториях использование процентной ошибки имеет решающее значение.
Процентная ошибка против абсолютной ошибки
Абсолютная погрешность измерения – это разница между фактическим и расчетным значениями. Единица основной ошибки такая же, как и начальное значение.
Пример
Предположим, вы планировали купить 2 кг манго, а продавец отмерил для вас 1,98 кг. Абсолютная ошибка в этом случае составит 2 – 1,98 = 0,02.
С другой стороны, процентная ошибка рассчитывается путем деления абсолютной ошибки на исходное значение, а затем умножения полученного ответа на 100. Процентная ошибка является безразмерной величиной.
В приведенном выше примере абсолютная ошибка составляет 0,02.
Теперь, чтобы вычислить процентную ошибку, мы разделим ее на 20.
0,02/20 = 0,001
Таким образом, процентная ошибка в этом случае составляет 0,001 X 100 = 0,1%.
Процентная ошибка против относительной ошибки
Относительная ошибка в любом расчете — это абсолютная ошибка, деленная на фактическое значение. Это означает, что процентная ошибка представляет собой разницу между истинным значением и наблюдаемым значением, деленную на фактическое значение.
Пример
Синоптики ожидали, что температура сегодня будет 38°C. Однако она поднялась до 42°C.
Сначала мы находим разницу между двумя числами, т. е. ожидаемым значением и фактическим значением.
42° – 38° = 4°С
Теперь для расчета относительной погрешности мы делим это число на фактическое число, то есть на 38°C.
4/38 = 0,1052
С другой стороны, процентная ошибка — это относительная ошибка, умноженная на 100.
В приведенном выше примере процентная ошибка составит 0,1052 X 100 = 10,52%.
Теперь вы можете обнаружить, что довольно легко вычислить процентную ошибку, относительную ошибку или абсолютную ошибку.
Вы можете упростить расчет процентных ошибок, воспользовавшись помощью нескольких онлайн-калькуляторов процентных ошибок. Теперь вам не придется задаваться вопросом, как рассчитать процентную ошибку, потому что эти калькуляторы могут сделать все это за вас.
Инструменты расчета погрешности
№1. Калькулятор Суп
В Калькулятор Суп помогает рассчитать процентную ошибку между экспериментальным значением и фактическим значением. Все, что вам нужно сделать, это ввести значения и дождаться результатов. Калькулятор сам производит все расчеты и выдает точные результаты.
На странице отображаются два разных столбца, в которых вы вводите значения чисел, для которых хотите рассчитать процентную ошибку, и позволяете калькулятору делать остальную часть магии.
№ 2. Калькулятор.net
Калькулятор.net имеет два столбца, в которые вы вводите фактические и оценочные значения, а остальные расчеты выполняет калькулятор. Это удобно, когда есть много выборок данных, которые вы хотите рассчитать, и у вас нет времени вручную вычислять процентную ошибку в каждом случае. Калькулятор упрощает процесс и дает ответ сразу, без особых задержек.

Процентные ошибки неизбежны. Вы можете только уменьшить их значение, но не будет никакого инцидента, когда показание процентной ошибки станет равным нулю. Он может быть приблизительно равен нулю, но никогда не может быть точным нулем.
№3. Хорошие калькуляторы
Многие онлайн-калькуляторы могут помочь вам решить проблемы с процентной ошибкой. Из них одним из самых удобных является Хорошие калькуляторы. В этом калькуляторе вы просто вводите оценочное и исходное значение, и он автоматически выдает результаты.
Это избавит вас от хлопот, связанных с выполнением обширных вычислений, и сбережет ваше время. Вы можете быстро решить комплексные расчеты за считанные секунды и сэкономить много времени.
Таким образом, калькулятор идеально подходит для расчета процентной ошибки, когда у вас есть под рукой обширные данные, но у вас мало времени.
Вывод
Ошибки в расчетах могут полностью испортить любой проект или исследование. Здесь вы можете воспользоваться помощью онлайн-калькуляторов процентных ошибок, чтобы выполнить работу более эффективно и без человеческих ошибок.
Если вы занимаетесь финансами, вы можете взглянуть на некоторые из этих калькуляторов процента прибыли.
Содержание
- Расчет ошибки средней арифметической
- Способ 1: расчет с помощью комбинации функций
- Способ 2: применение инструмента «Описательная статистика»
- Вопросы и ответы

Стандартная ошибка или, как часто называют, ошибка средней арифметической, является одним из важных статистических показателей. С помощью данного показателя можно определить неоднородность выборки. Он также довольно важен при прогнозировании. Давайте узнаем, какими способами можно рассчитать величину стандартной ошибки с помощью инструментов Microsoft Excel.
Расчет ошибки средней арифметической
Одним из показателей, которые характеризуют цельность и однородность выборки, является стандартная ошибка. Эта величина представляет собой корень квадратный из дисперсии. Сама дисперсия является средним квадратном от средней арифметической. Средняя арифметическая вычисляется делением суммарной величины объектов выборки на их общее количество.
В Экселе существуют два способа вычисления стандартной ошибки: используя набор функций и при помощи инструментов Пакета анализа. Давайте подробно рассмотрим каждый из этих вариантов.
Способ 1: расчет с помощью комбинации функций
Прежде всего, давайте составим алгоритм действий на конкретном примере по расчету ошибки средней арифметической, используя для этих целей комбинацию функций. Для выполнения задачи нам понадобятся операторы СТАНДОТКЛОН.В, КОРЕНЬ и СЧЁТ.
Для примера нами будет использована выборка из двенадцати чисел, представленных в таблице.

- Выделяем ячейку, в которой будет выводиться итоговое значение стандартной ошибки, и клацаем по иконке «Вставить функцию».
- Открывается Мастер функций. Производим перемещение в блок «Статистические». В представленном перечне наименований выбираем название «СТАНДОТКЛОН.В».
- Запускается окно аргументов вышеуказанного оператора. СТАНДОТКЛОН.В предназначен для оценивания стандартного отклонения при выборке. Данный оператор имеет следующий синтаксис:
=СТАНДОТКЛОН.В(число1;число2;…)«Число1» и последующие аргументы являются числовыми значениями или ссылками на ячейки и диапазоны листа, в которых они расположены. Всего может насчитываться до 255 аргументов этого типа. Обязательным является только первый аргумент.
Итак, устанавливаем курсор в поле «Число1». Далее, обязательно произведя зажим левой кнопки мыши, выделяем курсором весь диапазон выборки на листе. Координаты данного массива тут же отображаются в поле окна. После этого клацаем по кнопке «OK».
- В ячейку на листе выводится результат расчета оператора СТАНДОТКЛОН.В. Но это ещё не ошибка средней арифметической. Для того, чтобы получить искомое значение, нужно стандартное отклонение разделить на квадратный корень от количества элементов выборки. Для того, чтобы продолжить вычисления, выделяем ячейку, содержащую функцию СТАНДОТКЛОН.В. После этого устанавливаем курсор в строку формул и дописываем после уже существующего выражения знак деления (/). Вслед за этим клацаем по пиктограмме перевернутого вниз углом треугольника, которая располагается слева от строки формул. Открывается список недавно использованных функций. Если вы в нем найдете наименование оператора «КОРЕНЬ», то переходите по данному наименованию. В обратном случае жмите по пункту «Другие функции…».
- Снова происходит запуск Мастера функций. На этот раз нам следует посетить категорию «Математические». В представленном перечне выделяем название «КОРЕНЬ» и жмем на кнопку «OK».
- Открывается окно аргументов функции КОРЕНЬ. Единственной задачей данного оператора является вычисление квадратного корня из заданного числа. Его синтаксис предельно простой:
=КОРЕНЬ(число)Как видим, функция имеет всего один аргумент «Число». Он может быть представлен числовым значением, ссылкой на ячейку, в которой оно содержится или другой функцией, вычисляющей это число. Последний вариант как раз и будет представлен в нашем примере.
Устанавливаем курсор в поле «Число» и кликаем по знакомому нам треугольнику, который вызывает список последних использованных функций. Ищем в нем наименование «СЧЁТ». Если находим, то кликаем по нему. В обратном случае, опять же, переходим по наименованию «Другие функции…».
- В раскрывшемся окне Мастера функций производим перемещение в группу «Статистические». Там выделяем наименование «СЧЁТ» и выполняем клик по кнопке «OK».
- Запускается окно аргументов функции СЧЁТ. Указанный оператор предназначен для вычисления количества ячеек, которые заполнены числовыми значениями. В нашем случае он будет подсчитывать количество элементов выборки и сообщать результат «материнскому» оператору КОРЕНЬ. Синтаксис функции следующий:
=СЧЁТ(значение1;значение2;…)В качестве аргументов «Значение», которых может насчитываться до 255 штук, выступают ссылки на диапазоны ячеек. Ставим курсор в поле «Значение1», зажимаем левую кнопку мыши и выделяем весь диапазон выборки. После того, как его координаты отобразились в поле, жмем на кнопку «OK».
- После выполнения последнего действия будет не только рассчитано количество ячеек заполненных числами, но и вычислена ошибка средней арифметической, так как это был последний штрих в работе над данной формулой. Величина стандартной ошибки выведена в ту ячейку, где размещена сложная формула, общий вид которой в нашем случае следующий:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13))Результат вычисления ошибки средней арифметической составил 0,505793. Запомним это число и сравним с тем, которое получим при решении поставленной задачи следующим способом.










Но дело в том, что для малых выборок (до 30 единиц) для большей точности лучше применять немного измененную формулу. В ней величина стандартного отклонения делится не на квадратный корень от количества элементов выборки, а на квадратный корень от количества элементов выборки минус один. Таким образом, с учетом нюансов малой выборки наша формула приобретет следующий вид:
=СТАНДОТКЛОН.В(B2:B13)/КОРЕНЬ(СЧЁТ(B2:B13)-1)

Урок: Статистические функции в Экселе
Способ 2: применение инструмента «Описательная статистика»
Вторым вариантом, с помощью которого можно вычислить стандартную ошибку в Экселе, является применение инструмента «Описательная статистика», входящего в набор инструментов «Анализ данных» («Пакет анализа»). «Описательная статистика» проводит комплексный анализ выборки по различным критериям. Одним из них как раз и является нахождение ошибки средней арифметической.
Но чтобы воспользоваться данной возможностью, нужно сразу активировать «Пакет анализа», так как по умолчанию в Экселе он отключен.
- После того, как открыт документ с выборкой, переходим во вкладку «Файл».
- Далее, воспользовавшись левым вертикальным меню, перемещаемся через его пункт в раздел «Параметры».
- Запускается окно параметров Эксель. В левой части данного окна размещено меню, через которое перемещаемся в подраздел «Надстройки».
- В самой нижней части появившегося окна расположено поле «Управление». Выставляем в нем параметр «Надстройки Excel» и жмем на кнопку «Перейти…» справа от него.
- Запускается окно надстроек с перечнем доступных скриптов. Отмечаем галочкой наименование «Пакет анализа» и щелкаем по кнопке «OK» в правой части окошка.
- После выполнения последнего действия на ленте появится новая группа инструментов, которая имеет наименование «Анализ». Чтобы перейти к ней, щелкаем по названию вкладки «Данные».
- После перехода жмем на кнопку «Анализ данных» в блоке инструментов «Анализ», который расположен в самом конце ленты.
- Запускается окошко выбора инструмента анализа. Выделяем наименование «Описательная статистика» и жмем на кнопку «OK» справа.
- Запускается окно настроек инструмента комплексного статистического анализа «Описательная статистика».
В поле «Входной интервал» необходимо указать диапазон ячеек таблицы, в которых находится анализируемая выборка. Вручную это делать неудобно, хотя и можно, поэтому ставим курсор в указанное поле и при зажатой левой кнопке мыши выделяем соответствующий массив данных на листе. Его координаты тут же отобразятся в поле окна.
В блоке «Группирование» оставляем настройки по умолчанию. То есть, переключатель должен стоять около пункта «По столбцам». Если это не так, то его следует переставить.
Галочку «Метки в первой строке» можно не устанавливать. Для решения нашего вопроса это не важно.
Далее переходим к блоку настроек «Параметры вывода». Здесь следует указать, куда именно будет выводиться результат расчета инструмента «Описательная статистика»:
- На новый лист;
- В новую книгу (другой файл);
- В указанный диапазон текущего листа.
Давайте выберем последний из этих вариантов. Для этого переставляем переключатель в позицию «Выходной интервал» и устанавливаем курсор в поле напротив данного параметра. После этого клацаем на листе по ячейке, которая станет верхним левым элементом массива вывода данных. Её координаты должны отобразиться в поле, в котором мы до этого устанавливали курсор.
Далее следует блок настроек определяющий, какие именно данные нужно вводить:
- Итоговая статистика;
- К-ый наибольший;
- К-ый наименьший;
- Уровень надежности.
Для определения стандартной ошибки обязательно нужно установить галочку около параметра «Итоговая статистика». Напротив остальных пунктов выставляем галочки на свое усмотрение. На решение нашей основной задачи это никак не повлияет.
После того, как все настройки в окне «Описательная статистика» установлены, щелкаем по кнопке «OK» в его правой части.
- После этого инструмент «Описательная статистика» выводит результаты обработки выборки на текущий лист. Как видим, это довольно много разноплановых статистических показателей, но среди них есть и нужный нам – «Стандартная ошибка». Он равен числу 0,505793. Это в точности тот же результат, который мы достигли путем применения сложной формулы при описании предыдущего способа.










Урок: Описательная статистика в Экселе
Как видим, в Экселе можно произвести расчет стандартной ошибки двумя способами: применив набор функций и воспользовавшись инструментом пакета анализа «Описательная статистика». Итоговый результат будет абсолютно одинаковый. Поэтому выбор метода зависит от удобства пользователя и поставленной конкретной задачи. Например, если ошибка средней арифметической является только одним из многих статистических показателей выборки, которые нужно рассчитать, то удобнее воспользоваться инструментом «Описательная статистика». Но если вам нужно вычислить исключительно этот показатель, то во избежание нагромождения лишних данных лучше прибегнуть к сложной формуле. В этом случае результат расчета уместится в одной ячейке листа.
Как рассчитать процент ошибки
Как рассчитать процент ошибки

Процентная ошибка или процентная ошибка выражает в процентах разницу между приблизительным или измеренным значением и точным или известным значением. Это используется в науке, чтобы сообщить разницу между измеренным или экспериментальным значением и истинным или точным значением. Вот как рассчитать процент ошибки, с примером расчета.
Ключевые моменты: процент ошибок
- Цель расчета процентной погрешности состоит в том, чтобы измерить, насколько близко измеренное значение к истинному значению.
- Процентная ошибка (процентная ошибка) — это разница между экспериментальным и теоретическим значением, деленная на теоретическое значение, умноженное на 100, чтобы получить процент.
- В некоторых полях процентная ошибка всегда выражается как положительное число. В других случаях правильно иметь положительное или отрицательное значение. Знак может быть сохранен, чтобы определить, падают ли записанные значения выше или ниже ожидаемых значений.
- Процент ошибок является одним из типов ошибок. Абсолютная и относительная погрешность — два других распространенных вычисления. Процент ошибок является частью всестороннего анализа ошибок.
- Ключом к правильному сообщению процентной ошибки является то, чтобы знать, нужно ли сбрасывать знак (положительный или отрицательный) в расчете, и сообщать значение, используя правильное количество значащих цифр.
Формула процентной ошибки
Процентная ошибка — это разница между измеренным и известным значением, деленная на известное значение, умноженное на 100%.
Для многих приложений процент ошибки выражается как положительное значение. Абсолютное значение ошибки делится на принятое значение и выражается в процентах.
| принятое значение — экспериментальное значение | принятое значение х 100%
Для химии и других наук принято сохранять отрицательное значение. Важна ли ошибка положительная или отрицательная. Например, вы не ожидаете, что будет иметь место положительная процентная ошибка при сравнении фактического теоретического выхода в химической реакции. Если бы было рассчитано положительное значение, это дало бы подсказки относительно потенциальных проблем с процедурой или неучтенных реакций.
При сохранении знака ошибки вычисление представляет собой экспериментальное или измеренное значение минус известное или теоретическое значение, деленное на теоретическое значение и умноженное на 100%.
процентная ошибка = экспериментальное значение — теоретическое значение / теоретическое значение х 100%
Этапы расчета процента ошибок
- Вычтите одно значение из другого. Порядок не имеет значения, если вы отбрасываете знак, но вы вычитаете теоретическое значение из экспериментального значения, если сохраняете отрицательные знаки. Это значение является вашей «ошибкой».
- Разделите ошибку на точное или идеальное значение (не на ваше экспериментальное или измеренное значение). Это даст десятичное число.
- Преобразуйте десятичное число в процент, умножив его на 100.
- Добавьте символ процента или%, чтобы сообщить о вашем процентном значении ошибки.
Пример расчета процента ошибок
В лаборатории вам дают блок алюминия. Вы измеряете размеры блока и его смещение в контейнере с известным объемом воды. Вы рассчитываете плотность блока из алюминия равной 2,68 г / см. 3 , Вы посмотрите на плотность алюминиевого блока при комнатной температуре и обнаружите, что она составляет 2,70 г / см. 3 , Рассчитайте процентную погрешность вашего измерения.
- Вычтите одно значение из другого:
2.68 — 2.70 = -0.02 - В зависимости от того, что вам нужно, вы можете отказаться от любого отрицательного знака (принять абсолютное значение): 0,02
Это ошибка. - Разделите ошибку на истинное значение: 0,02 / 2,70 = 0,0074074
- Умножьте это значение на 100%, чтобы получить процентную ошибку:
0,0074074 х 100% = 0,74% (выражено с использованием 2 значащих цифр).
Значимые цифры важны в науке. Если вы сообщаете об ответе, используя слишком много или слишком мало, он может считаться неправильным, даже если вы правильно настроили проблему.
Процент ошибок по сравнению с абсолютной и относительной ошибкой
Процентная ошибка связана с абсолютной ошибкой и относительной ошибкой. Разница между экспериментальным и известным значением является абсолютной ошибкой. Когда вы делите это число на известное значение, вы получаете относительную ошибку. Процентная ошибка — это относительная ошибка, умноженная на 100%.
MPE – средняя процентная ошибка в Excel
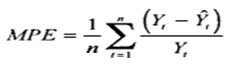 Из данной статьи вы узнаете:
Из данной статьи вы узнаете:
- Для чего нужна средняя процентная ошибка;
- Как она рассчитывается.
+ сможете скачать пример расчета в Excel.
MPE (mean percentage error) — средняя процентная ошибка прогноза.
MPE – средняя процентная ошибка прогноза используется в случаях, когда надо определить модель прогноза дает последовательно завышенные прогнозы или последовательно заниженные прогнозы.
Если значение больше нуля, то прогнозы последовательно занижены, т.е. в среднем меньше факта.
Если ошибка меньше нуля, то прогнозы последовательно завышены, т.е. модель делает прогноз в среднем выше факта.
Как рассчитать среднюю процентную ошибку?
- Рассчитываем ошибку для каждого значения модели;
- Делим на фактические данные ошибку в каждый момент времени.
Рассчитываем среднее по пункту 2, и получает среднюю процентную ошибку — MPE:
Рассчитаем на примере прогноза объема продаж:
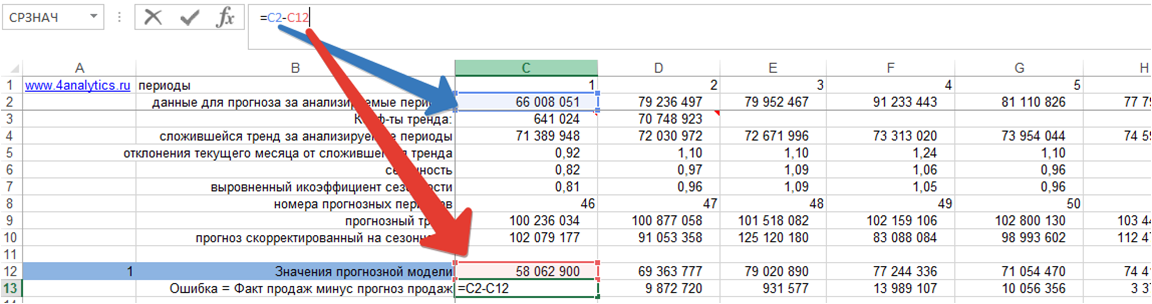
1. Ошибка = фактические продаж минус значения прогнозной модели для каждого момента времени:
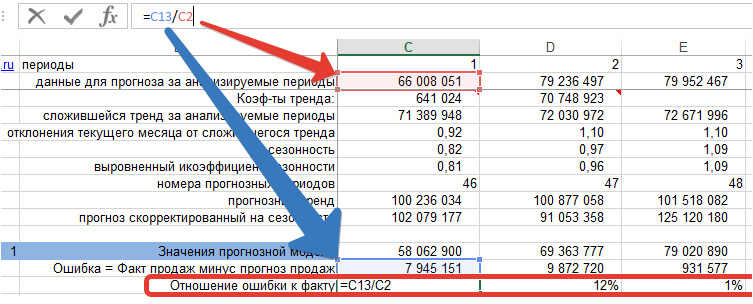
2. Делим ошибку на фактические продажи для каждого периода времени:
3. Рассчитываем среднее значение % ошибки — MPE:
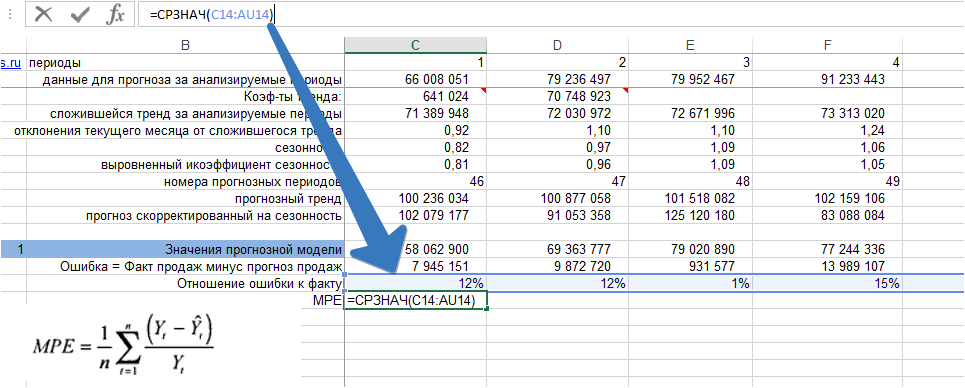
Мы видим, что средняя процентная ошибка у нас получилась -0,65% — это говорит о том, что модель прогноза в среднем дает завышенные прогноза на 0,65%:
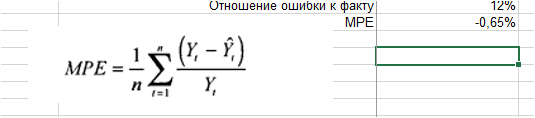
Из данной статьи вы узнали, для чего использовать среднюю процентную ошибку прогноза — MPE и как ее рассчитать в Excel.
Если у вас остались вопросы, пожалуйста, задавайте в комментариях, буду рад помочь!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel .
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
6 способов посчитать проценты от суммы с калькулятором и без
Простейшие формулы помогут узнать, выгодны ли скидки, и не нарушить пропорцию классного рецепта.
1. Как посчитать проценты, разделив число на 100
Так вы найдёте числовой эквивалент 1%. Дальше всё зависит от вашей цели. Чтобы посчитать проценты от суммы, умножьте их на размер 1%. Чтобы перевести число в проценты, разделите его на размер 1%.
Пример 1
Вы заходите в супермаркет и видите акцию на кофе. Его обычная цена — 458 рублей, сейчас действует скидка 7%. Но у вас есть карта магазина, и по ней пачка обойдётся в 417 рублей.
Чтобы понять, какой вариант выгоднее, надо перевести 7% в рубли.
Разделите 458 на 100. Для этого нужно просто сместить запятую, отделяющую целую часть числа от дробной, на две позиции влево. 1% равен 4,58 рубля.
Умножьте 4,58 на 7, и вы получите 32,06 рубля.
Теперь остаётся отнять от обычной цены 32,06 рубля. По акции кофе обойдётся в 425,94 рубля. Значит, выгоднее купить его по карте.
Пример 2
Вы видите, что игра в Steam стоит 1 000 рублей, хотя раньше продавалась за 1 500 рублей. Вам интересно, сколько процентов составила скидка.
Разделите 1 500 на 100. Сместив запятую на две позиции влево, вы получите 15. Это 1% от старой цены.
Теперь новую цену разделите на размер 1%. 1 000 / 15 = 66,6666%.
100% – 66,6666% = 33,3333%.Такую скидку предоставил магазин.
2. Как посчитать проценты, разделив число на 10
Этот способ похож на предыдущий, но считать с его помощью гораздо быстрее. Но только если речь идёт о процентах, кратных пяти.
Сначала вы находите размер 10%, а потом делите или умножаете его, чтобы получить нужное количество процентов.
Пример
Допустим, вы кладёте на депозит 530 тысяч рублей на 12 месяцев. Процентная ставка составляет 5%, капитализации не предусмотрено. Вы хотите узнать, сколько денег заберёте через год.
В первую очередь надо вычислить 10% от суммы. Разделите её на 10, передвинув запятую влево на один знак. Вы получите 53 тысячи.
Чтобы узнать, сколько составляют 5%, разделите результат на 2. Это 26,5 тысячи.
Если бы в примере речь шла о 30%, нужно было бы умножить 53 на 3. Для расчёта 25% пришлось бы умножить 53 на 2 и прибавить 26,5.
В любом случае такими крупными числами оперировать довольно просто.
3. Как посчитать проценты, составив пропорцию
Составлять пропорции — одно из наиболее полезных умений, которому вас научили в школе. С его помощью можно посчитать любые проценты. Выглядит пропорция так:
сумма, составляющая 100% : 100% = часть суммы : доля в процентном соотношении.
Или можно записать её так: a : b = c : d.
Обычно пропорция читается как «а относится к b так же, как с относится к d». Произведение крайних членов пропорции равно произведению её средних членов. Чтобы узнать неизвестное число из этого равенства, нужно решить простейшее уравнение.
Пример 1
Для примера вычислений используем рецепт быстрого брауни. Вы хотите его приготовить и купили подходящую плитку шоколада массой 90 г, но не удержались и откусили кусочек-другой. Теперь у вас только 70 г шоколада, и вам нужно узнать, сколько масла положить вместо 200 г.
Сначала вычисляем процентную долю оставшегося шоколада.
90 г : 100% = 70 г : Х, где Х — масса оставшегося шоколада.
Х = 70 × 100 / 90 = 77,7%.
Теперь составляем пропорцию, чтобы выяснить, сколько масла нам нужно:
200 г : 100% = Х : 77,7%, где Х — нужное количество масла.
Х = 77,7 × 200 / 100 = 155,4.
Следовательно, в тесто нужно положить примерно 155 г масла.
Пример 2
Пропорция подойдёт и для расчёта выгодности скидок. Например, вы видите блузку за 1 499 рублей со скидкой 13%.
Сначала узнайте, сколько стоит блузка в процентах. Для этого отнимите 13 от 100 и получите 87%.
Составьте пропорцию: 1 499 : 100 = Х : 87.
Х = 87 × 1 499 / 100.
Заплатите 1 304,13 рубля и носите блузку с удовольствием.
4. Как посчитать проценты с помощью соотношений
В некоторых случаях можно воспользоваться простыми дробями. Например, 10% — это 1/10 числа. И чтобы узнать, сколько это будет в цифрах, достаточно разделить целое на 10.
- 20% — 1/5, то есть нужно делить число на 5;
- 25% — 1/4;
- 50% — 1/2;
- 12,5% — 1/8;
- 75% — это 3/4. Значит, придётся разделить число на 4 и умножить на 3.
Пример
Вы нашли брюки за 2 400 рублей со скидкой 25%, но у вас в кошельке только 2 000 рублей. Чтобы узнать, хватит ли денег на обновку, проведите серию несложных вычислений:
100% — 25% = 75% — стоимость брюк в процентах от первоначальной цены после применения скидки.
2 400 / 4 × 3 = 1 800. Именно столько рублей стоят брюки.
5. Как посчитать проценты с помощью калькулятора
Если без калькулятора вам жизнь не мила, все вычисления можно делать с его помощью. А можно поступить ещё проще.
- Чтобы посчитать проценты от суммы, введите число, равное 100%, знак умножения, затем нужный процент и знак %. Для примера с кофе вычисления будут выглядеть так: 458 × 7%.
- Чтобы узнать сумму за вычетом процентов, введите число, равное 100%, минус, размер процентной доли и знак %: 458 – 7%.
- Аналогично можно складывать, как в примере с депозитом: 530 000 + 5%.
6. Как посчитать проценты с помощью онлайн-сервисов
Не все проценты можно посчитать в уме и даже на калькуляторе. Если речь идёт о доходности вклада, переплатах по ипотеке или налогах, требуются сложные формулы. Они учтены в некоторых онлайн-сервисах.
Planetcalc
На сайте собраны разные калькуляторы, которые высчитывают не только проценты. Здесь есть сервисы для кредиторов, инвесторов, предпринимателей и всех тех, кто не любит считать в уме.
Калькулятор — справочный портал
Ещё один сервис с калькуляторами на любой вкус.
Allcalc
Каталог онлайн-калькуляторов, 60 из которых предназначены для подсчёта финансов. Можно вычислить налоги и пени, размер субсидии на ЖКУ и многое другое.
Как рассчитать процент ошибки
Из данной статьи вы узнаете:
- Для чего нужна средняя процентная ошибка;
- Как она рассчитывается.
+ сможете скачать пример расчета в Excel.
MPE (mean percentage error) — средняя процентная ошибка прогноза.
MPE – средняя процентная ошибка прогноза используется в случаях, когда надо определить модель прогноза дает последовательно завышенные прогнозы или последовательно заниженные прогнозы.
Если значение больше нуля, то прогнозы последовательно занижены, т.е. в среднем меньше факта.
Если ошибка меньше нуля, то прогнозы последовательно завышены, т.е. модель делает прогноз в среднем выше факта.
Как рассчитать среднюю процентную ошибку?
- Рассчитываем ошибку для каждого значения модели;
- Делим на фактические данные ошибку в каждый момент времени.
Рассчитываем среднее по пункту 2, и получает среднюю процентную ошибку — MPE:
Рассчитаем на примере прогноза объема продаж:
1. Ошибка = фактические продаж минус значения прогнозной модели для каждого момента времени:
2. Делим ошибку на фактические продажи для каждого периода времени:
3. Рассчитываем среднее значение % ошибки — MPE:
Мы видим, что средняя процентная ошибка у нас получилась -0,65% — это говорит о том, что модель прогноза в среднем дает завышенные прогноза на 0,65%:
Из данной статьи вы узнали, для чего использовать среднюю процентную ошибку прогноза — MPE и как ее рассчитать в Excel.
Если у вас остались вопросы, пожалуйста, задавайте в комментариях, буду рад помочь!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:
- Novo Forecast Lite — автоматический расчет прогноза в Excel .
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Как определить существенность ошибки в бухгалтерской отчетности
Ошибиться при составлении бухгалтерской отчетности может каждый. Главное — исправить ошибку. А порядок ее исправления зависит от двух моментов: является ли ошибка существенной и в каком периоде она обнаружен а пп. 3, 5— 11, 14 ПБУ 22/2010 .
Существенная ошибка — ошибка, которая в отдельности или вместе с другими ошибками за тот же период может повлиять на экономические решения пользователей, принимаемые ими на основе бухотчетности этого период а пп. 3, 5— 11, 14 ПБУ 22/2010 .
Как вносить исправления в учет
Что такое существенность ошибки
Критерий существенности ошибки вы определяете и устанавливаете сами, прописав его в учетной политик е п. 3 ПБУ 22/2010 ; п. 4 ПБУ 1/2008 . Он должен быть обоснованным.
ВАРИАНТ 1. Можно ориентироваться на те же правила определения существенности показателя, что содержатся в ПБУ 9/99 о доходах и ПБУ 10/99 о расходах. Напомним, там сказано, что доход (расход) по определенному виду деятельности показывается в отчетности отдельно, если он составляет 5% и более от общей суммы доходов (расходов) за отчетный перио д п. 18.1 ПБУ 9/99 ; п. 21.1 ПБУ 10/99 . По аналогии можно закрепить в учетной политике, что ошибка является существенной, если она искажает показатель за отчетный период более чем на 5%.
ВАРИАНТ 2. Можно оценивать существенность ошибки исходя из удельного веса статьи баланса, при отражении которой допущена ошибка, в валюте баланса. К примеру, неправильно определен срок полезного использования ОС. Его цена не превышает сотни тысяч рублей. А стоимость всех активов компании исчисляется миллионами. Понятно, что допущенная ошибка не повлияет на принятие собственниками компании решений по этой бухотчетности. Другое дело, если компания купила недвижимость, но несвоевременно отразила ее стоимость на балансе, а других ОС у компании нет. Такую ошибку уже нужно признать существенной.
ВАРИАНТ 3. Может быть использован такой качественный показатель, как вид деятельности. Например, ваш основной вид деятельности — торговля, неосновной — аренда. Можно установить, что ошибки, допущенные в учете по аренде, всегда несущественны.
ВАРИАНТ 4. Можно прописать, что существенность ошибки будет оцениваться по каждому конкретному случаю отдельно исходя из влияния этой ошибки на финансовый результат и имущественное положение организации. То есть какой-либо единый критерий не устанавливать.
ВАРИАНТ 5. Если вы составляете отчетность исключительно для сдачи в инспекцию (собственники ею не интересуются), то можно ориентироваться на норму КоАП: если показатель какой-либо статьи (строки) бухотчетности искажен в результате ошибки на 10% и более, то это грубое нарушение правил бухучета, за которое руководителю грозит штраф от 2 тыс. до 3 тыс. руб . ст. 15.11 КоАП РФ То есть можно установить, что существенной будет ошибка, искажающая показатель строки бухотчетности не менее чем на 10%.
Пример. Определение вида допущенной ошибки
/ условие / Организация за декабрь 2011 г. ошибочно начислила амортизацию в размере 200 000 руб. вместо 250 000 руб.
При этом до выявления ошибки показатели, на которые влияет эта ошибка, были следующие:
- остаточная стоимость основных средств (из баланса) — 900 000 руб.;
- прибыль от продаж (из отчета о прибылях и убытках) — 1 000 000 руб.;
- прибыль до налогообложения (из отчета о прибылях и убытках) — 270 000 руб.;
- чистая прибыль (из отчета о прибылях и убытках) — 216 000 руб.;
- себестоимость продаж (из отчета о прибылях и убытках) — 700 000 руб.;
- сумма налога на прибыль (из отчета о прибылях и убытках) — 54 000 руб.
В налоговом учете допущена такая же ошибка — разниц нет.
В учетной политике организация установила, что существенной является ошибка, приводящая к искажению любой строки бухотчетности не менее чем на 10%.
/ решение / Посмотрим, является ли ошибка существенной.
ШАГ 1. Рассчитаем сумму ошибки: 250 000 руб. – 200 000 руб. = 50 000 руб.
ШАГ 2. Рассчитаем процент искажения каждой строки бухгалтерского баланса и отчета о прибылях и убытках, на которые влияет отражение амортизации.
Если проведение
неоднократных измерений физической
величины даёт повторяющиеся результаты,
то это означает, что в данных условиях
преобладают приборные погрешности. В
этих случаях погрешность прямых измерений
определяется приборной погрешностью.
Если неоднократные
измерения дают некоторый разброс
результатов, то это означает присутствие
случайных ошибок. Если число измерений
неограниченно возрастает, то для
определения среднего значения и дисперсии
можно воспользоваться формулами (3) …
(7). На практике число измерений всегда
ограничено, поэтому существует
конечная вероятность того, что истинное
значение среднеквадратичного
отклонения отличается от вычисленного
по формуле (6). Поэтому при небольшом
числе измерений для оценки величины
пользуются
соотношениями, вытекающими из так
называемого распределения Стьюдента,
которое при неограниченном увеличении
числа измерений стремится к нормальному
распределению (5).
В соответствии с
этой методикой сначала находится
среднеарифметическое значение измеряемой
величины по формуле (3).
Следующим шагом
для оценки точности найденного
среднеарифметического значения будет
вычисление вспомогательной величины
S:
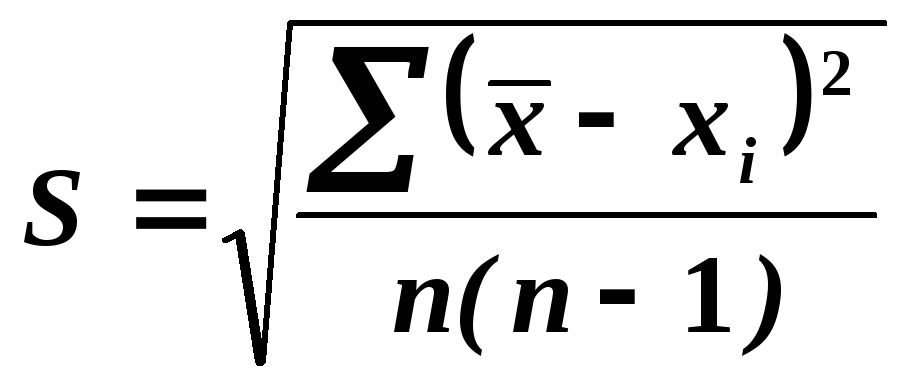 (9)
(9)
Из Таблицы 1
коэффициентов Стьюдента находим
вспомогательный коэффициент ,
зависящий от числа измерений n и
доверительной вероятности Р. Этот
коэффициент совместно с величиной S
позволяет рассчитать доверительный
интервал x.
Абсолютная
погрешность значения искомой величины
«а», найденной как среднеарифметическое
из n измерений составит:
![]() (10)
(10)
Искомая величина
«а» представляется в виде:
![]() (11)
(11)
Дисперсия всей
совокупности измерений случайной
величины «х»
будет равна S2.
7. Расчёт ошибок косвенных измерений
Пусть искомая
величина А
при выбранном
методе косвенных измерений рассчитывается
по формуле:
A
= f(x1
,x2
,x3
,…,xn
) (12)
где x1,x2,…,xn
— величины, найденные в результате прямых
измерений, с учётом ошибок о которых
шла речь выше. Из-за этих ошибок величина
«А»
так же будет определяться с ошибками.
Пусть X1,X2,…,XN
— значения f(x1
,x2
,x3
,…,xn
), вычисленные
для разных серий измерений (x1,x2,…,xn).
Таблица 1
Таблица коэффициентов
Стьюдента
|
Число измерений |
Доверительная |
|||||
|
0.7 |
0.8 |
0.9 |
0.95 |
0.99 |
0.999 |
|
|
2 |
2.0 |
3.1 |
6.3 |
12.7 |
63.7 |
636.6 |
|
3 |
1.3 |
1.9 |
2.9 |
4.3 |
9.9 |
31.6 |
|
4 |
1.3 |
1.6 |
2.4 |
3.2 |
5.8 |
12.9 |
|
5 |
1.2 |
1.5 |
2.1 |
2.8 |
4.6 |
8.6 |
|
10 |
1.1 |
1.4 |
1.8 |
2.3 |
3.3 |
4.8 |
|
15 |
1.1 |
1.3 |
1.8 |
2.1 |
3.0 |
4.1 |
|
20 |
1.1 |
1.3 |
1.7 |
2.1 |
2.9 |
3.9 |
Абсолютной ошибкой
косвенных измерений, по аналогии с
абсолютной ошибкой прямых измерений,
называют разность между истинным
значением «А» и её значениями,
полученными в результате измерений:
![]() (13)
(13)
Размерность
абсолютной ошибки совпадает с размерностью
определяемой величины. Относительной
ошибкой косвенных измерений называют
отвлечённое число:
![]() (14)
(14)
Иногда относительную
ошибку выражают в процентах:
![]() (15)
(15)
Для определения
величины «А» в формулах (12)…(15) по
теории
вероятностей
следует брать величину Х, которую можно
определить двумя способами:
1) А
= Х
= (Х1
+ Х2
+…+Хn)/n
(16)
2) A
= X
= f(x1
+ x2
+…+xn)
(17)
где x1,
x2
,…, xn
определяют по формуле (3). Если ошибки
измерений малы, то оба способа дают
практически тождественные результаты.
Рассмотрим способы
нахождения ошибки величины А,
определённой из косвенных измерений,
по найденным значениям оши
бок прямых измерений.
Выше отмечалось, что возможны различные
соотношения между приборной систематической
и случайными ошибками.
1-й случай. Преобладают
приборные ошибки. В этом случае можно
дать только оценку максимальной ошибки.
Формулы для нахождения предельной
ошибки косвенных измерений по внешнему
виду совпадают с формулами дифференциального
исчисления. В связи с этим для предельной
абсолютной ошибки используется формула:
![]() (18)
(18)
а для расчёта
предельной относительной ошибки пригодна
фор
— 19 —
мула:
![]() (19)
(19)
Формулы для расчёта
предельных ошибок некоторых часто
встречающихся функций, когда приборные
ошибки превышают случайные, приведены
в Таблице 2. Эти выражения легко
рассчитываются по формулам (18) и (19).
2-й случай. Преобладают
случайные ошибки. Для определения
среднеквадратичной ошибки теория
вероятностей даёт следующую формулу:
![]() (20)
(20)
Относительная
ошибка вычисляется по формуле:
![]() (21)
(21)
При выполнении
промежуточных расчётов необходимо
помнить, что число точных цифр в результате
расчётов не может увеличиваться. Поэтому
промежуточные результаты округляют,
сохраняя
1…2 избыточных
знака. При этом последующие цифры,
меньшие
5,отбрасываются;если
первая из отбрасываемых цифр больше 5,
то последняя из
оставшихся цифр увеличивается на
единицу. Ес
ли первая
отбрасываемая цифра 5, то предыдущая
цифра остаётся
без изменений,
если она чётная, и увеличивается на
единицу, если
она нечётная.
Выражения для среднеквадратичной ошибки
некоторых часто встречающихся функций
приведены в Таблице 3. Для определения
ошибок косвенных измерений используют
большую из инструментальной или случайной
ошибок прямого измерения.
Соседние файлы в папке TIU-11
- #
- #
- #
- #
- #
- #