
Change that to
# for Python 2.5+
import sys
try:
d = open("p0901aus.txt","w")
except Exception, ex:
print "Unsuccessful."
print ex
sys.exit(0)
# for Python 3
import sys
import codecs
try:
d = codecs.open("p0901aus.txt","w","utf-8")
except Exception as ex:
print("Unsuccessful.")
print(ex)
sys.exit(0)
The W is case-sensitive. I do not want to hit you with all the Python syntax at once, but it will be useful for you to know how to display what exception was raised, and this is one way to do it.
Also, you are opening the file for writing, not reading. Is that what you wanted?
If there is already a document named p0901aus.txt, and you want to read it, do this:
#for Python 2.5+
import sys
try:
d = open("p0901aus.txt","r")
print "Awesome, I opened p0901aus.txt. Here is what I found there:"
for l in d:
print l
except Exception, ex:
print "Unsuccessful."
print ex
sys.exit(0)
#for Python 3+
import sys
import codecs
try:
d = codecs.open("p0901aus.txt","r","utf-8")
print "Awesome, I opened p0901aus.txt. Here is what I found there:"
for l in d:
print(l)
except Exception, ex:
print("Unsuccessful.")
print(ex)
sys.exit(0)
You can of course use the codecs in Python 2.5 also, and your code will be higher quality («correct») if you do. Python 3 appears to treat the Byte Order Mark as something between a curiosity and line noise which is a bummer.
Last updated on
Feb 10, 2022
In this post, you can find several solutions for:
SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
While this error can appear in different situations the reason for the error is one and the same:
- there are special characters( escape sequence — characters starting with backslash — » ).
- From the error above you can recognize that the culprit is ‘U’ — which is considered as unicode character.
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
- codec can’t decode bytes in position 2-3: truncated xXX escape
- codec can’t decode bytes in position 2-3: truncated uXXXX escape
- another possible errors for SyntaxError: (unicode error) ‘unicodeescape’ will be raised for ‘x’, ‘u’
Step #1: How to solve SyntaxError: (unicode error) ‘unicodeescape’ — Double slashes for escape characters
Let’s start with one of the most frequent examples — windows paths. In this case there is a bad character sequence in the string:
import json
json_data=open("C:Userstest.txt").read()
json_obj = json.loads(json_data)
The problem is that U is considered as a special escape sequence for Python string. In order to resolved you need to add second escape character like:
import json
json_data=open("C:\Users\test.txt").read()
json_obj = json.loads(json_data)
Step #2: Use raw strings to prevent SyntaxError: (unicode error) ‘unicodeescape’
If the first option is not good enough or working then raw strings are the next option. Simply by adding r (for raw string literals) to resolve the error. This is an example of raw strings:
import json
json_data=open(r"C:Userstest.txt").read()
json_obj = json.loads(json_data)
If you like to find more information about Python strings, literals
2.4.1 String literals
In the same link we can find:
When an r' or R’ prefix is present, backslashes are still used to quote the following character, but all backslashes are left in the string. For example, the string literal r»n» consists of two characters: a backslash and a lowercase `n’.
Step #3: Slashes for file paths -SyntaxError: (unicode error) ‘unicodeescape’
Another possible solution is to replace the backslash with slash for paths of files and folders. For example:
«C:Userstest.txt»
will be changed to:
«C:/Users/test.txt»
Since python can recognize both I prefer to use only the second way in order to avoid such nasty traps. Another reason for using slashes is your code to be uniform and homogeneous.
Step #4: PyCharm — SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape
The picture below demonstrates how the error will look like in PyCharm. In order to understand what happens you will need to investigate the error log.
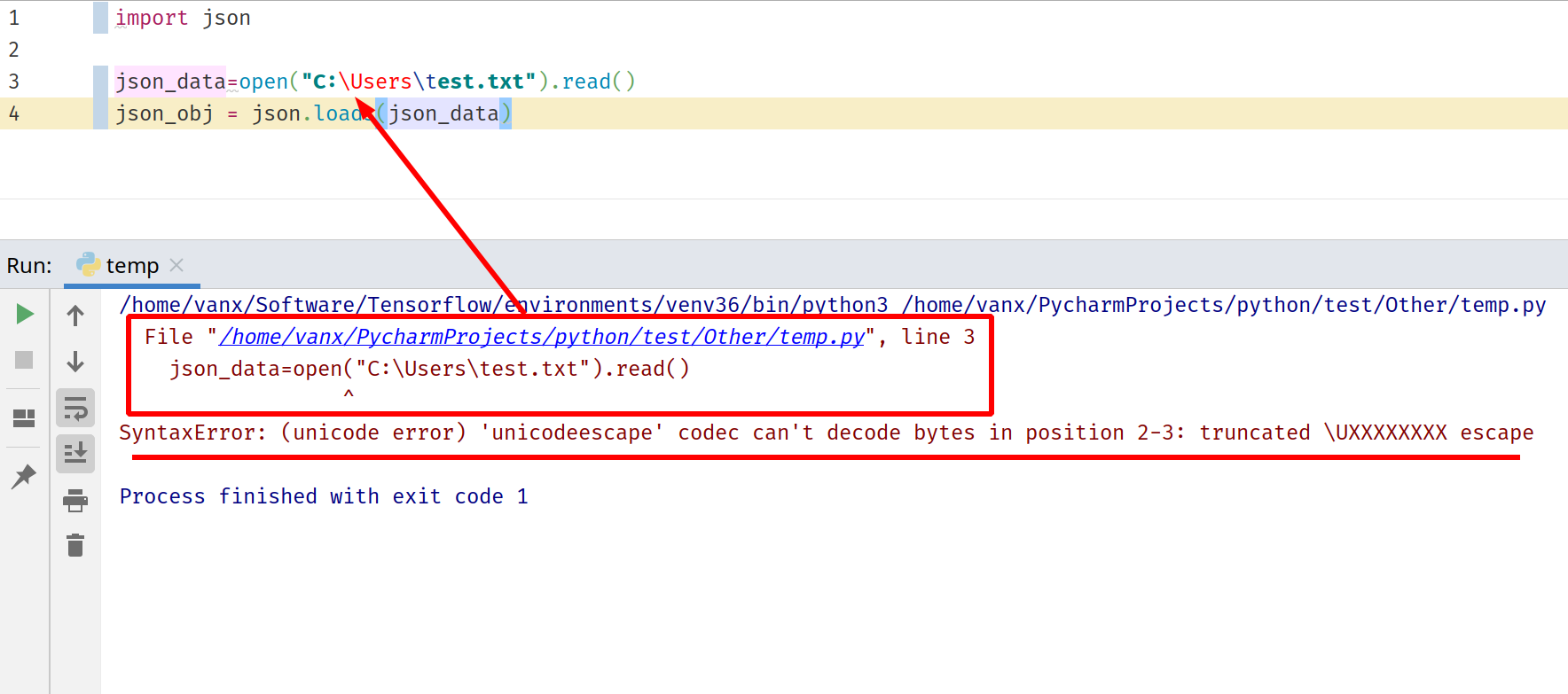
The error log will have information for the program flow as:
/home/vanx/Software/Tensorflow/environments/venv36/bin/python3 /home/vanx/PycharmProjects/python/test/Other/temp.py
File "/home/vanx/PycharmProjects/python/test/Other/temp.py", line 3
json_data=open("C:Userstest.txt").read()
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escape
You can see the latest call which produces the error and click on it. Once the reason is identified then you can test what could solve the problem.
Table of Contents
Hide
- What is SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
- How to fix SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
- Solution 1 – Using Double backslash (\)
- Solution 2 – Using raw string by prefixing ‘r’
- Solution 3 – Using forward slash
- Conclusion
The SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape occurs if you are trying to access a file path with a regular string.
In this tutorial, we will take a look at what exactly (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape means and how to fix it with examples.
The Python String literals can be enclosed in matching single quotes (‘) or double quotes (“).
String literals can also be prefixed with a letter ‘r‘ or ‘R‘; such strings are called raw strings and use different rules for backslash escape sequences.
They can also be enclosed in matching groups of three single or double quotes (these are generally referred to as triple-quoted strings).
The backslash () character is used to escape characters that otherwise have a special meaning, such as newline, backslash itself, or the quote character.
Now that we have understood the string literals. Let us take an example to demonstrate the issue.
import pandas
# read the file
pandas.read_csv("C:UsersitsmycodeDesktoptest.csv")
Output
File "c:PersonalIJSCodeprogram.py", line 4
pandas.read_csv("C:UsersitsmycodeDesktoptest.csv") ^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated UXXXXXXXX escapeWe are using the single backslash in the above code while providing the file path. Since the backslash is present in the file path, it is interpreted as a special character or escape character (any sequence starting with ‘’). In particular, “U” introduces a 32-bit Unicode character.
How to fix SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape?
Solution 1 – Using Double backslash (\)
In Python, the single backslash in the string is interpreted as a special character, and the character U(in users) will be treated as the Unicode code point.
We can fix the issue by escaping the backslash, and we can do that by adding an additional backslash, as shown below.
import pandas
# read the file
pandas.read_csv("C:\Users\itsmycode\Desktop\test.csv")Solution 2 – Using raw string by prefixing ‘r’
We can also escape the Unicode by prefixing r in front of the string. The r stands for “raw” and indicates that backslashes need to be escaped, and they should be treated as a regular backslash.
import pandas
# read the file
pandas.read_csv("C:\Users\itsmycode\Desktop\test.csv")Solution 3 – Using forward slash
Another easier way is to avoid the backslash and instead replace it with the forward-slash character(/), as shown below.
import pandas
# read the file
pandas.read_csv("C:/Users/itsmycode/Desktop/test.csv")
Conclusion
The SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated UXXXXXXXX escape occurs if you are trying to access a file path and provide the path as a regular string.
We can solve the issue by escaping the single backslash with a double backslash or prefixing the string with ‘r,’ which converts it into a raw string. Alternatively, we can replace the backslash with a forward slash.
Srinivas Ramakrishna is a Solution Architect and has 14+ Years of Experience in the Software Industry. He has published many articles on Medium, Hackernoon, dev.to and solved many problems in StackOverflow. He has core expertise in various technologies such as Microsoft .NET Core, Python, Node.JS, JavaScript, Cloud (Azure), RDBMS (MSSQL), React, Powershell, etc.
Sign Up for Our Newsletters
Subscribe to get notified of the latest articles. We will never spam you. Be a part of our ever-growing community.
By checking this box, you confirm that you have read and are agreeing to our terms of use regarding the storage of the data submitted through this form.
PEP: Python3 and UnicodeDecodeError
This is a PEP describing the behaviour of Python3 on UnicodeDecodeError. It’s a draft, don’t hesitate to comment it. This document suppose that my patch to allow bytes filenames is accepted which is not the case today.
While I was writing this document I found poential problems in Python3. So here is a TODO list (things to be checked):
- FIXME: When bytearray is accepted or not?
- FIXME: Allow bytes/str mix for shutil.copy*()? The ignore callback will get bytes or unicode?
Can anyone write a section about bytes encoding in Unicode using escape sequence?
What is the best tool to work on a PEP? I hate email threads, and I would prefer SVN / Mercurial / anything else.
Python3 and UnicodeDecodeError for the command line, environment variables and filenames
Introduction
Python3 does its best to give you texts encoded as a valid unicode characters strings. When it hits an invalid bytes sequence (according to the used charset), it has two choices: drops the value or raises an UnicodeDecodeError. This document present the behaviour of Python3 for the command line, environment variables and filenames.
Example of an invalid bytes sequence: ::
>>> str(b'xff', 'utf8') UnicodeDecodeError: 'utf8' codec can't decode byte 0xff (...)
whereas the same byte sequence is valid in another charset like ISO-8859-1: ::
>>> str(b'xff', 'iso-8859-1') 'ÿ'
Default encoding
Python uses «UTF-8» as the default Unicode encoding. You can read the default charset using sys.getdefaultencoding(). The «default encoding» is used by PyUnicode_FromStringAndSize().
A function sys.setdefaultencoding() exists, but it raises a ValueError for charset different than UTF-8 since the charset is hardcoded in PyUnicode_FromStringAndSize().
Command line
Python creates a nice unicode table for sys.argv using mbstowcs(): ::
$ ./python -c 'import sys; print(sys.argv)' 'Ho hé !' ['-c', 'Ho hé !']
On Linux, mbstowcs() uses LC_CTYPE environement variable to choose the encoding. On an invalid bytes sequence, Python quits directly with an exit code 1. Example with UTF-8 locale:
$ python3.0 $(echo -e 'invalid:xff') Could not convert argument 1 to string
Environment variables
Python uses «_wenviron» on Windows which are contains unicode (UTF-16-LE) strings. On other OS, it uses «environ» variable and the UTF-8 charset. It drops a variable if its key or value is not convertible to unicode. Example:
env -i HOME=/home/my PATH=$(echo -e "xff") python
>>> import os; list(os.environ.items())
[('HOME', '/home/my')]
Both key and values are unicode strings. Empty key and/or value are allowed.
Python ignores invalid variables, but values still exist in memory. If you run a child process (eg. using os.system()), the «invalid» variables will also be copied.
Filenames
Introduction
Python2 uses byte filenames everywhere, but it was also possible to use unicode filenames. Examples:
- os.getcwd() gives bytes whereas os.getcwdu() always returns unicode
-
os.listdir(unicode) creates bytes or unicode filenames (fallback to bytes on UnicodeDecodeError), os.readlink() has the same behaviour
- glob.glob() converts the unicode pattern to bytes, and so create bytes filenames
- open() supports bytes and unicode
Since listdir() mix bytes and unicode, you are not able to manipulate easily filenames:
>>> path=u'.'
>>> for name in os.listdir(path):
... print repr(name)
... print repr(os.path.join(path, name))
...
u'valid'
u'./valid'
'invalidxff'
Traceback (most recent call last):
...
File "/usr/lib/python2.5/posixpath.py", line 65, in join
path += '/' + b
UnicodeDecodeError: 'ascii' codec can't decode byte 0xff (...)
Python3 supports both types, bytes and unicode, but disallow mixing them. If you ask for unicode, you will always get unicode or an exception is raised.
You should only use unicode filenames, except if you are writing a program fixing file system encoding, a backup tool or you users are unable to fix their broken system.
Windows
Microsoft Windows since Windows 95 only uses Unicode (UTF-16-LE) filenames. So you should only use unicode filenames.
Non Windows (POSIX)
POSIX OS like Linux uses bytes for historical reasons. In the best case, all filenames will be encoded as valid UTF-8 strings and Python creates valid unicode strings. But since system calls uses bytes, the file system may returns an invalid filename, or a program can creates a file with an invalid filename.
An invalid filename is a string which can not be decoded to unicode using the default file system encoding (which is UTF-8 most of the time).
A robust program will have to use only the bytes type to make sure that it can open / copy / remove any file or directory.
Filename encoding
Python use:
- «mbcs» on Windows
- or «utf-8» on Mac OS X
- or nl_langinfo(CODESET) on OS supporting this function
- or UTF-8 by default
«mbcs» is not a valid charset name, it’s an internal charset saying that Python will use the function MultiByteToWideChar() to decode bytes to unicode. This function uses the current codepage to decode bytes string.
You can read the charset using sys.getfilesystemencoding(). The function may returns None if Python is unable to determine the default encoding.
PyUnicode_DecodeFSDefaultAndSize() uses the default file system encoding, or UTF-8 if it is not set.
On UNIX (and other operating systems), it’s possible to mount different file systems using different charsets. sys.getdefaultencoding() will be the same for the different file systems since this encoding is only used between Python and the Linux kernel, not between the kernel and the file system which may uses a different charset.
Display a filename
Example of a function formatting a filename to display it to human eyes: ::
from sys import getfilesystemencoding
def format_filename(filename):
return str(filename, getfilesystemencoding(), 'replace')
Example: format_filename(‘rxffport.doc’) gives ‘r�port.doc’ with the UTF-8 encoding.
Functions producing filenames
Policy: for unicode arguments: drop invalid bytes filenames; for bytes arguments: return bytes
- os.listdir()
- glob.glob()
This behaviour (drop silently invalid filenames) is motivated by the fact to if a directory of 1000 files only contains one invalid file, listdir() fails for the whole directory. Or if your directory contains 1000 python scripts (.py) and just one another document with an invalid filename (eg. r�port.doc), glob.glob(‘*.py’) fails whereas all .py scripts have valid filename.
Policy: for an unicode argument: raise an UnicodeDecodeError on invalid filename; for an bytes argument: return bytes
- os.readlink()
Policy: create unicode directory or raise an UnicodeDecodeError
- os.getcwd()
Policy: always returns bytes
- os.getcwdb()
Functions for filename manipulation
Policy: raise TypeError on bytes/str mix
- os.path.*(), eg. os.path.join()
- fnmatch.*()
Functions accessing files
Policy: accept both bytes and str
- io.open()
- os.open()
- os.chdir()
- os.stat(), os.lstat()
- os.rename()
- os.unlink()
- shutil.*()
os.rename(), shutil.copy*(), shutil.move() allow to use bytes for an argment, and unicode for the other argument
bytearray
In most cases, bytearray() can be used as bytes for a filename.
Unicode normalisation
Unicode characters can be normalized in 4 forms: NFC, NFD, NFKC or NFKD. Python does never normalize strings (nor filenames). No operating system does normalize filenames. So the users using different norms will be unable to retrieve their file. Don’t panic! All users use the same norm.
Use unicodedata.normalize() to normalize an unicode string.
Introduction
The following error message is a common Python error, the «SyntaxError» represents a Python syntax error and the «unicodeescape» means that we made a mistake in using unicode escape character.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-5: truncated UXXXXXXXX escapeSimply to put, the «SyntaxError» can be occurred accidentally in Python and it is often happens because the (ESCAPE CHARACTER) is misused in a python string, it caused the unicodeescape error.
(Note: «escape character» can convert your other character to be a normal character.)
SyntaxError Example
Let’s look at an example:
print('It's a nice day.')Looks like we want to print «It’s a nice day.«, right? But the program will report an error message.
File "<stdin>", line 1
print('It's a nice day.')
^
SyntaxError: invalid syntaxThe reason is very easy-to-know. In Python, we can use print('xxx') to print out xxx. But in our code, if we had used the ' character, the Python interpreter will misinterpret the range of our characters so it will report an error.
To solve this problem, we need to add an escape character «» to convert our ‘ character to be a normal character, not a superscript of string.
print('It's a nice day.')Output:
It's a nice day.We print it successfully!
So how did the syntax error happen? Let me talk about my example:
One day, I run my program for experiment, I saved some data in a csv file. In order for this file can be viewed on the Windows OS, I add a new code uFFEF in the beginning of file.
This is «BOM» (Byte Order Mark), Explain to the system that the file format is «Big-Ending«.
I got the error message.
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-5: truncated UXXXXXXXX escapeAs mentioned at the beginning of this article, this is an escape character error in Python.
Solutions
There are three solutions you can try:
- Add a «r» character in the right of string
- Change
to be/ - Change
to be\
Solution 1: Add a «r» character in the beginning of string.
title = r'uFFEF'After we adding a r character at right side of python string, it means a complete string not anything else.
Solution 2: Change /.
open("C:UsersClayDesktoptest.txt")Change to:
open("C:/Users/Clay/Desktop/test.txt")This way is avoid to use escape character.
Solution 3: Change \.
open("C:UsersClayDesktoptest.txt")Change the code to:
open("C:\Users\Clay\Desktop\test.txt")It is similar to the solution 2 that it also avoids the use of escape characters.
The above are three common solutions. We can run normally on Windows.
Reference
- https://stackoverflow.com/questions/37400974/unicode-error-unicodeescape-codec-cant-decode-bytes-in-position-2-3-trunca
- https://community.alteryx.com/t5/Alteryx-Designer-Discussions/Error-unicodeescape-codec-can-t-decode-bytes/td-p/427540
Read More
- [Solved][Python] ModuleNotFoundError: No module named ‘cStringIO’