
Robots.txt — это текстовый файл, в котором прописаны указания (директивы) по индексации страниц сайта. С помощью данного файла можно указывать поисковым роботам, какие страницы на веб-ресурсе нужно сканировать и заносить в индекс (базу данных поисковой системы), а какие — нет.
Файл располагается в корневом каталоге сайта и доступен по адресу: domain.com/robots.txt.
Этот файл дает поисковым системам важные указания, которые напрямую будут влиять на результативность продвижения сайта. Использование Роботс может помочь:
- предотвращению сканирования дублированного контента и бесполезных для пользователей страниц (результаты внутреннего поиска, технические страницы и др.);
- сохранению конфиденциальности разделов веб-сайта (например, можно закрыть системную информацию CMS);
- избежать перегрузки сервера;
- эффективно расходовать краулинговый бюджет на обход полезных страниц.
С другой стороны, если robots.txt содержит неверные данные, то поисковые системы будут неправильно индексировать сайт, и в результатах поиска окажется не та информация, которая нужна.
Можно случайно запретить индексирование важных для продвижения страниц, и они не попадут в результаты поиска.
Например:
User-Agent: * Disallow: /
Эта запись говорят о том, что поисковые системы не смогут увидеть и проиндексировать ваш сайт.
Пустой или недоступный файл Роботс поисковые роботы воспринимают как разрешение на сканирование всего сайта.
Ниже приведены ссылки на инструкции по использованию файла:
- от Яндекса;
- от Google.
Какие директивы используются в robots.txt
User-agent
User-agent — основная директива, которая указывает, для какого поискового робота прописаны нижеследующие указания по индексации, например:
Для всех роботов:
User-agent: *
Для поискового робота Яндекс:
User-agent: Yandex
Для поискового робота Google:
User-agent: Googlebot
Disallow и Allow
Директива Disallow закрывает раздел или страницу от индексации. Allow — принудительно открывает страницы сайта для индексации (например, разрешает сканирование подкаталога или страницы в закрытом для обработки каталоге).
Операторы, которые используются с этими директивами: «*» и «$». Они применяются для указания шаблонов адресов при объявлении директив, чтобы не прописывать большой перечень конечных URL для блокировки.
* — спецсимвол звездочка обозначает любую последовательность символов. Например, все URL сайта, которые содержат значения, следующие после этого оператора, будут закрыты от индексации:
User-agent: *
Disallow: /cgi-bin* # блокирует доступ к страницам
# начинающимся с '/cgi-bin'
Disallow: /cgi-bin # то же самое
$ — знак доллара означает конец адреса и ограничивает действие знака «*», например:
User-agent: *
Disallow: /example$ # запрещает '/example',
# но не запрещает '/example.html'
Crawl-delay
Crawl-delay — директива, которая позволяет указать минимальный промежуток времени между окончанием загрузки одной страницы и началом загрузки следующей. Использовать ее следует в случаях, если сервер сильно загружен и не успевает обрабатывать запросы поискового робота.
User-agent: * Crawl-delay: 3.0 # задает тайм-аут в 3 секунды
С 22 февраля 2018 года Яндекс перестал учитывать директиву Crawl-delay. Чтобы задать скорость, с которой роботы будут загружать страницы сайта, используйте раздел «Скорость обхода сайта» в Яндекс.Вебмастере. Google также не поддерживает эту директиву. Для Google-бота установить частоту обращений можно в панели вебмастера Search Console. Однако роботы Bing и Yahoo соблюдает директиву Crawl-delay.
Clean-param
Директива используется только для робота Яндекса. Google и другие роботы не поддерживают Clean-param.
Директива указывает, что URL страниц содержат GET-параметры, которые не влияют на содержимое, и поэтому их не нужно учитывать при индексировании. Робот Яндекса, следуя инструкциям Clean-param, не будет обходить страницы с динамическими параметрами, которые полностью дублируют контент основных страниц.
Пример директивы Clean-param:
Clean-param: s /forum/showthread.php
Данная директива означает, что параметр «s» будет считаться незначащим для всех URL, которые начинаются с /forum/showthread.php.
Подробнее прочитать о директиве Clean-param можно в указаниях от Яндекс, ссылка на которые расположена выше.
Sitemap
Sitemap — это карта сайта для поисковых роботов, которая содержит рекомендации того, какие страницы необходимо проверить в первую очередь и с какой частотой. Наличие карты сайта помогает роботам быстрее индексировать нужные страницы.
Следует указать полный путь к странице, в которой содержится файл sitemap.
Пример использования:
Sitemap: https://www.site.ru/sitemap.xml
Пример правильно составленного файла robots.txt:
User-agent: * # нижеследующие правила задаются для всех поисковых роботов Allow: / # сайт открыт для индексации Sitemap: https://www.site.ru/sitemap.xml # карта сайта для поисковых систем
Как найти ошибки в robots.txt с помощью Labrika?
Для проверки файла robots используйте Labrika. Она позволяет увидеть 26 видов ошибок в структуре файла – это больше, чем определяет сервис Яндекса. Отчет «Ошибки robots.txt » находится в разделе «Технический аудит» левого бокового меню. В отчете приводится содержимое строк файла. При наличии в какой-либо директиве проблемы Labrika дает её описание.
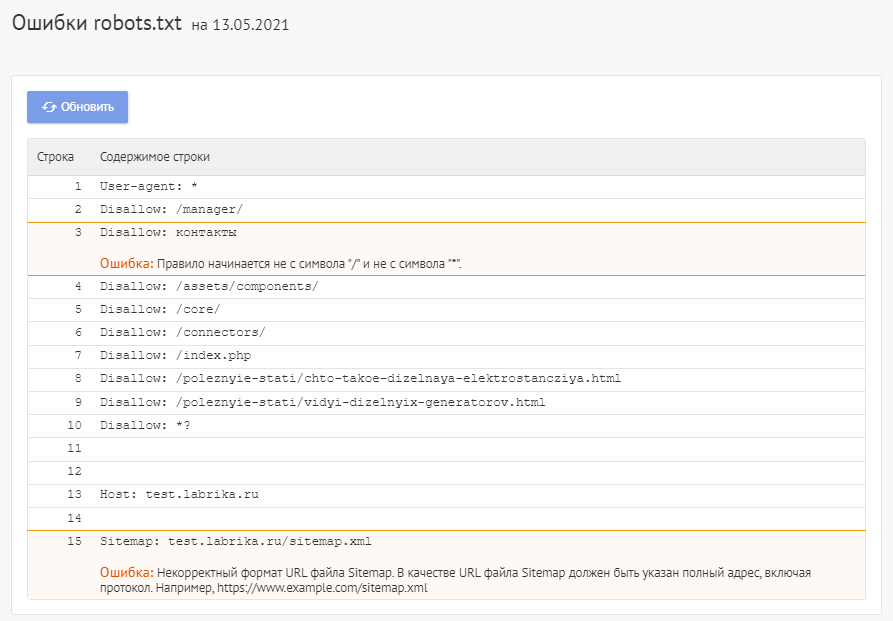
Ошибки robots.txt, которые определяет Labrika:
Сервис находит следующие:
Директива должна отделятся от правила символом «:».
Каждая действительная строка в файле Роботс должна состоять из имени поля, двоеточия и значения. Использовать пробелы не обязательно, но рекомендуется для удобства чтения. Для добавления комментария применяется символ решётки «#», который ставится перед его началом. Весь текст после символа «#» и до конца строки робот поисковой системы будет игнорировать.
Стандартный формат:
<field>:<value><#optional-comment>
Пример:
User-agent Googlebot
Пропущен символ “:”.
Правильный вариант:
User-agent: Googlebot
Пустая директива и пустое правило.
Недопустимо делать пустую строку в директиве User-agent, поскольку она указывает, для какого поискового робота предназначены инструкции.
Пример:
User-agent:
Не указан пользовательский агент.
Правильный вариант:
User-agent: название бота
Например:
User-agent: Googlebot
Директивы Allow или Disallow задаются в формате: directive: [path], где значение [path] (путь к странице или разделу) указывать не обязательно. Однако роботы игнорируют директивы Allow и Disallow без указания пути. В этом случае они могут сканировать весь контент. Пустая директива Disallow: равнозначна директиве Allow: /, то есть «не запрещать ничего».
Пример ошибки в директиве Sitemap:
Sitemap:
Не указан путь к карте сайта.
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Перед правилом нет директивы User-agent
Правило должно всегда стоять после директивы User-agent. Размещение правила перед первым именем пользовательского агента означает, что никакие сканеры не будут ему следовать.
Пример:
Disallow: /category User-agent: Googlebot
Правильный вариант:
User-agent: Googlebot Disallow: /category
Найдено несколько правил вида «User-agent: *»
Должна быть только одна директива User-agent для одного робота и только одна директива вида User-agent: * для всех роботов. Если в файле несколько раз указан один и тот же пользовательский агент с разными списками правил, то поисковым роботам будет сложно определить, какие из этих правил нужно учитывать. В результате возникает большая неопределенность в действиях роботов.
Пример:
User-agent: * Disallow: /category User-agent: * Disallow: /*.pdf.
Правильный вариант:
User-agent: * Disallow: /category Disallow: /*.pdf.
Неизвестная директива
Обнаружена директива, которая не поддерживается поисковой системой (например, не описана в правилах использования Роботс от Яндекса).
Причины этого могут быть следующие:
- была прописана несуществующая директива;
- допущен ошибочный синтаксис, использованы запрещенные символы и теги;
- эта директива может использоваться роботами других поисковых систем.
Пример:
Disalow: /catalog
Директивы «Disalow» не существует, допущена опечатка в написании слова.
Правильный вариант:
Disallow: /catalog
Количество правил в файле robots.txt превышает максимально допустимое
Поисковые роботы будут корректно обрабатывать файл robots.txt, если его размер не превышает 500 КБ. Допустимое количество правил в файле — 2048. Контент сверх этого лимита игнорируется. Чтобы не превышать его, вместо исключения каждой отдельной страницы применяйте более общие директивы.
Например, если вам нужно заблокировать сканирование файлов PDF, не запрещайте каждый отдельный файл. Вместо этого запретите все URL-адреса, содержащие .pdf, с помощью директивы:
Disallow: /*.pdf
Правило превышает допустимую длину
Правило не должно содержать более 1024 символов.
Некорректный формат правила
В файле robots.txt должен быть обычный текст в кодировке UTF-8. Поисковые системы могут проигнорировать символы, не относящиеся к коду UTF-8. В таком случае правила из файла robots.txt не будут работать.
Чтобы поисковые роботы корректно обрабатывали инструкции в файле robots.txt, все правила должны быть написаны согласно стандарту исключений для роботов (REP).
Использование кириллицы и других национальных языков
Использование кириллицы запрещено в файле robots.txt. Согласно утверждённой стандартом системе доменных имен название домена может состоять только из ограниченного набора ASCII-символов (буквы латинского алфавита, цифры от 0 до 9 и дефис). Если домен содержит символы, не относящиеся к ASCII (в том числе буквы национальных алфавитов), его нужно преобразовать с помощью Punycode в допустимый набор символов.
Пример:
User-agent: Yandex Sitemap: сайт.рф/sitemap.xml
Правильный вариант:
User-agent: Yandex Sitemap: https://xn--80aswg.xn--p1ai/sitemap.xml
Возможно, был использован недопустимый символ
Допускается использование спецсимволов «*» и «$». Например:
Disallow: /*.php$
Директива запрещает индексировать любые php файлы.
Если /*.php соответствует всем путям, которые содержат .php., то /*.php$ соответствует только тем путям, которые заканчиваются на .php.
Символ «$» прописан в середине значения
Знак «$» можно использовать только один раз и только в конце правила. Он показывает, что стоящий перед ним символ должен быть последним.
Пример:
Allow: /file$html
Правильный вариант:
Allow: /file.html$
Правило начинается не с символа «/» и не с символа «*».
Правило может начинаться только с символов «/» и «*».
Если значение пути указывается относительно корневого каталога сайта, оно должно начинаться с символа слэш «/», обозначающего корневой каталог.
Пример:
Disallow: products
Правильным вариантом будет:
Disallow: /products
или
Disallow: *products
в зависимости от того, что вы хотите исключить из индексации.
Некорректный формат URL файла Sitemap
В качестве URL файла Sitemap должен быть указан полный адрес, который содержит обозначение протокола (http:// или https://), название домена (главная страница сайта), путь к файлу карты сайта, а также имя файла.
Пример:
Sitemap: /sitemap.xml
Правильный вариант:
Sitemap: https://www.site.ru/sitemap.xml
Некорректное имя главного зеркала сайта
Директива Host указывала роботу Яндекса главное зеркало сайта, если к веб-ресурсу был доступ по нескольким доменам. Остальные поисковые роботы её не воспринимали.
Директива Host могла содержать только протокол (необязательный) и домен сайта. Прописывался протокол https, если он использовался. Указывалась только одна директива Host. Если их было несколько, робот учитывал первую.
Пример:
User-agent: Yandex Host: http://www.example.com/catalog Host: https://example.com
Правильный вариант:
User-agent: Yandex Host: https://example.com
Некорректный формат директивы Crawl-delay
При указании в директиве Crawl-delay интервала между загрузками страниц можно использовать как целые значения, так и дробные. В качестве разделителя применяется точка. Единица измерения – секунды.
К ошибкам относят:
- несколько директив
Crawl-delay; - некорректный формат директивы
Crawl-delay.
Пример:
Crawl-delay: 0,5 second
Правильный вариант:
Crawl-delay: 0.5
Некорректный формат директивы Clean-param
Labrika определяет некорректный формат директивы Clean-param, например:
В именах GET-параметров встречается два или более знака амперсанд «&» подряд:
Clean-param: sort&&session /category
Правильный вариант:
Clean-param: sort&session /category
Правило должно соответствовать виду «p0[&p1&p2&..&pn] [path]». В первом поле через символ «&» перечисляются параметры, которые роботу не нужно учитывать. Во втором поле указывается префикс пути страниц, для которых применяется правило. Параметры отделяются от префикса пути пробелом.
Имена GET-параметров должны содержать только буквы латинского алфавита, цифры, нижнее подчеркивание и дефис.
Префикс PATH URL для директивы Clean-param может включать только буквы латинского алфавита, цифры и некоторые символы: «.», «-«, «/», «*», «_».
Ошибкой считается и превышение допустимой длины правила — 500 символов.
Строка содержит BOM (Byte Order Mark) — символ U+FEFF
BOM (Byte Order Mark — маркер последовательности байтов) — символ вида U+FEFF, который находится в самом начале текста. Этот Юникод-символ используется для определения последовательности байтов при считывании информации.
Стандартные редакторы, создавая файл, могут автоматически присвоить ему кодировку UTF-8 с BOM меткой.
BOM – это невидимый символ. У него нет графического выражения, поэтому большинство редакторов его не показывает. Но при копировании этот символ может переноситься в новый документ.
Использование маркера последовательности байтов в файлах .html приводит к сбою настроек дизайна, смещению блоков, появлению нечитаемых наборов символов, поэтому рекомендуется удалять маркер из веб-скриптов и CSS-файлов.
Избавиться от ВОМ довольно сложно. Один из простых способов это сделать — открыть файл в редакторе, который может изменять кодировку документа, и пересохранить его с кодировкой UTF-8 без BOM.
Например, вы можете бесплатно скачать редактор Notepad++, открыть в нём файл с ВОМ меткой и выбрать во вкладке меню «Кодировки» пункт «Кодировать в UTF-8 (без BOM)».
Название
В наименовании должен быть использован нижний регистр букв.
Как исправить ошибки в robots.txt?
Исправьте ошибки в директивах robots.txt, следуя рекомендациям Labrika. Наш сервис проверяет файл robots.txt согласно стандарту исключений для роботов (REP), который поддерживают Google, Яндекс и большинство известных поисковых машин.
После исправления указанных в отчете Labrika ошибок нажмите кнопку «Обновить», чтобы получить свежие данные о наличии ошибок в файле robots.txt и убедиться в правильном написании директив.
Не забудьте добавить новую версию Роботс в Вебмастера.
О том, как написать правильный файл robots.txt и ответы на другие вопросы вы можете найти в отдельной статье на нашем сайте.
Robots.txt — это текстовый файл, который показывает поисковым роботам, как сканировать ваш сайт. Он защищает сайт и сервер от перегрузки из-за запросов поисковых роботов.
Если вы хотите заблокировать работу поисковых роботов, важно убедиться в корректности настроек. Это особенно важно, если вы используете динамические URL или другие методы, которые в теории генерируют бесконечное количество страниц.

В этом гайде рассматриваются самые распространенные проблемы с файлом robots.txt, их влияние на сайт и ранжирование в поисковой выдаче, а также способы решения.
Но для начала поговорим подробнее о robots.txt и его альтернативах.
Что такое файл robots.txt
Robots.txt — это файл в простом текстовом формате. Он размещается в корневом каталоге сайта (самый верхний каталог в иерархии). Если файл размещен в другом каталоге, поисковые роботы будут его игнорировать. Несмотря на всю мощь robots.txt, выглядит он как простой текстовый документ. А создать его можно за пару секунд в любом текстовом редакторе.
Выполнять функции robots.txt могут и его альтернативы. Например, метатеги. Их можно размещать в код отдельной страницы.
Можно использовать и HTTP-заголовок X-Robots-Tag, который задает настройки на уровне страницы.
Что делает robots.txt
Файл robots.txt можно использовать для множества целей. Вот несколько самых популярных.
Блокировка сканирования поисковыми роботами определенных страниц
Они все еще могут появляться в поисковой выдаче, но без текстового описания. Контент не в формате HTML тоже не будет сканироваться.
Блокировка медиафайлов для отображения в результатах поиска
Под медиафайлами понимаются изображения, видео и аудиофайлы. Если для файла предусмотрен общий доступ, он будет отображаться, но приватный контент не попадет в поисковую выдачу.

Блокировка файлов ресурсов с неважными внешними скриптами
Если у страницы заблокирован файл ресурсов, поисковые роботы посчитают, что его не существовало вовсе. Это может сказаться на индексировании.
Использование robots.txt не позволит полностью запретить отображение страницы в результатах поиска. Для этого придется добавить метатег noindex в верхнюю часть страницы.
Насколько опасны ошибки с Robots.txt
Ошибки в robots.txt приводят к определенным последствиям, но обычно не трагичным. А приведение файла в порядок позволит быстро и полностью восстановиться.
Как отмечает сам Google, у поисковых роботов достаточно гибкие алгоритмы. Поэтому незначительные ошибки в файле robots.txt никак не сказываются на их работе. В худшем случае неправильная или неподдерживаемая директива будет проигнорирована. Но если вы знаете, что в файле есть ошибки, их стоит исправить.
Шесть главных ошибок robots.txt
Если ранжирование сайта в поисковой выдаче изменилось странным образом, стоит проверить файл robots.txt. Рассмотрим шесть популярных ошибок подробно.
Ошибка № 1. Robots.txt находится не в корневом каталоге
Поисковые роботы могут найти файл robots.txt только если он расположен в корневом каталоге. Поэтому домен, например, .ru, и название файла robots.txt в URL должна разделять одна косая черта.
Если есть дополнительная папка, скорее всего, поисковые роботы не увидят файл. Сайт в этом случае функционирует так, как будто файла robots.txt нет совсем.
Чтобы исправить эту ошибку, перенесите robots.txt в корневой каталог. Для этого потребуется доступ к серверу. Некоторые системы управления содержимым по умолчанию загружают файл в подпапку с медиафайлами или подобные. Чтобы файл попал в нужное место, придется обойти эту настройку.
Ошибка № 2. Неправильное использование символа-джокера или символа подстановки
Символ-джокер — это символ, используемый для замены других символов или их последовательностей. Robots.txt поддерживает два символа-джокера:
- Звездочка, или астериск (*). Она представляет любые варианты допустимого символа. Своего рода аналог карты джокера.
- Значок доллара $. Обозначает конец URL, позволяет добавлять правила к последней части URL, например, файловое расширение.
При использовании символов-джокеров стоит придерживаться минимализма. Они могут потенциально наложить ограничения на большую часть сайта. Неправильное использование астерикса может привести к блокировке поискового робота. Чтобы решить проблему с неправильным символом-джокером, нужно его найти и переместить или удалить.
Ошибка № 3. Тег noindex в robots.txt
Эта ошибка часто встречается у сайтов, которым уже несколько лет. Google в сентябре 2019 года перестал выполнять команды метатега noindex в файле robots.txt.

Если ваш файл был создан до этой даты или содержит метатег noindex, скорее всего, страницы будут индексироваться Google.
Чтобы решить проблему, примените альтернативный метод. Вы можете добавить метатег robots в элемент страницы <head>, чтобы остановить индексацию.
Ошибка № 4. Блокировка скриптов и страниц стилей
Ограничение доступа к внутреннему JavaScript коду и Cascading Style Sheets (CSS) для поисковых роботов кажется логичным шагом. Однако поисковым роботам Google требуется доступ к CSS и JavaScript файлам, чтобы корректно сканировать HTML и PHP страницы.
Если страницы сайта странно отображаются в поисковой выдаче, проверьте, не заблокирован ли доступ поискового робота к этим внутренним файлам. Удалите соответствующую строку из файла robots.txt.
Если же вам нужна блокировка определенных файлов, вставьте исключение, которое даст поисковым роботам доступ только к нужным материалам.
Ошибка № 5. Отсутствует ссылка на файл sitemap.xml
Этот пункт относится к SEO больше всего. Файл sitemap.xml дает роботам информацию о структуре сайта и его главных страницах. Поэтому есть смысл добавить его в файл robots.txt. Его поисковые роботы Google сканируют в первую очередь.
Строго говоря, это не ошибка, и в большинстве случаев отсутствие ссылки на sitemap в robots.txt не должно влиять на функциональность и внешний вид сайта. Но если вы хотите улучшить продвижение, дополните файл robots.txt
Ошибка № 6. Доступ к страницам в разработке
Запрет сканирования поисковыми роботами рабочих страниц — серьезная ошибка. Как и предоставление им доступа к страницам, находящимся в разработке. Включите запрещающие инструкции в файл robots.txt, если сайт находится на реконструкции. Тогда пользователи не увидят «сырой» вариант.
Кстати, не забудьте убрать соответствующую строчку из файла, когда закончите. Это довольно распространенная ошибка, которая не позволит поисковым роботам правильно сканировать и индексировать сайт
Если ваш сайт еще находится в разработке, но вы видите реальный трафик, или, наоборот, запущенный сайт плохо ранжируется, проверьте строчку User-Agent в файле robots.txt.
User-Agent: *
Disallow: /
Наличие косой черты в строке Disallow делает сайт невидимым для поисковых роботов. Корректируйте строку в соответствии с нужным вам эффектом.
Как восстановиться после ошибок в robots.txt
Если ошибка в файле robots.txt повлияла на отображение в поисковой выдаче, самое главное — скорректировать файл и подтвердить, что новые правила дают нужный эффект. Проверить это можно с помощью инструментов для сканирования, например, Screaming Frog.

Когда убедитесь, что robots.txt работает верно, запросите повторное сканирование поисковыми роботами. В этом поможет Google Search Console. Добавьте обновленный файл sitemap и запросите повторное сканирование страниц, которые пострадали.
К сожалению, нет конкретного срока, в который поисковый робот проведет сканирование и страницы начнут нормально отображаться в поисковой выдаче. Все, что остается — быстро выполнить необходимые шаги и ждать, когда поисковый робот просканирует сайт.
Профилактика важнее всего
Ошибки с файлом robots.txt решаются относительно просто, но лучшим лекарством от них станет профилактика. Редактируйте файл аккуратно, привлекая опытных разработчиков, дважды все проверяйте и, если это актуально, послушайте мнение второго специалиста.
Если есть возможность, протестируйте изменения в песочнице, прежде чем применять их на реальном сервере.
Песочница — специально выделенная (изолированная) среда для безопасного исполнения компьютерных программ.
Это позволит избежать непроизвольных ошибок. И помните, если самое страшное уже случилось, не поддавайтесь панике. Проанализируйте проблему, внесите необходимые изменения в файл robots.txt и отправьте запрос на повторное сканирование. Скорее всего, нескольких дней будет достаточно, чтобы вернуться на прежние позиции в поисковой выдаче.
- 6 августа 2015
- Продвижение
- 20.8K
- 4 мин.
-
Прочесть позже
Зачем нужен файл robots.txt?
Файл robots.txt – текстовый файл, который отвечает за индексирование сайта. Здесь вы можете указать поисковым роботам, что стоит индексировать, а что индексировать не нужно. Другими словами, с помощью этого файла вы как бы говорите поисковым системам, что вот эти страницы сайта должны попасть в поиск, а остальные – нет.
Часто при создании файла robots.txt допускаются ошибки, которые приводят к некорректной его работе или вообще делают функционирование невозможным. Давайте посмотрим на самые распространенные ошибки, к чему они приводят, а также как не допустить их у себя на сайте.
- Расположение файла. Файл robots.txt должен располагаться только в корневой директиве сайта. Другими словами, у него должен быть URL вот такого вида: http://site.ru/robots.txt, где site.ru – адрес вашего ресурса в сети. Если файл robots.txt располагается не в корне сайта (у него другой URL), то роботы поисковых систем его не увидят и, следовательно, будут индексировать ваш сайт полностью (включая файлы, которые индексировать нежелательно).
- Чувствительность к регистру. Имя файла всегда прописывается только с маленькой буквы. Правильно использовать только такой вариант «robots.txt». Неправильный вариант: http://site.ru/Robots.txt. При таком написании поисковый робот, заходя на сайт, получит 404 (страница ошибки) или 301 (переадресация) ответ сервера, а должен получить 200. Только при ответе сервера кодом 200 вы сможете управлять поисковым роботом. В остальных случаях индексация пойдет так, словно файла robots.txt нет на сайте.
- Открытие на странице браузера. Файл robots.txt всегда должен открываться на странице браузера. Только так роботы смогут его правильно прочитать и использовать. Здесь все зависит от настройки серверной части системы управления сайтом. В некоторых случаях по умолчанию будет предлагаться скачать файл данного типа. В такой ситуации необходимо сделать настройки на показ, или сайт будет индексироваться так, как этого захотят поисковые роботы.
- Ошибки запрета и разрешения. Чтобы запретить доступ робота к сайту или некоторым его разделам, правильно использовать только директиву «Disallow». Например, вы хотите запретить к индексированию все страницы с результатами поиска на сайте, прописать это в файле robots.txt надо следующим образом: «Disallow: /search/». Так вы говорите роботу: «Запрети все страницы, где будет встречаться слово поиск». Если надо запретить вообще все страницы к индексации, то прописываем директиву Disallow: /. Так вы говорите роботу: «Запретить все». Неправильно здесь ставить директиву «Allow» (разрешить). Часто пытаются прописать запрет директивы такого вида: «Allow:», как бы говоря роботам: «Разрешаю к индексации ничего». Это считается ошибкой. Если же вам надо разрешить все к индексированию, то используйте директиву вот такого вида: «Allow: /». Для роботов это означает :«Разрешить все». Если вы прописываете неверные директивы, это может привести к ошибкам в индексации и робот добавит в поиск страницы, которые там быть не должны.
- Совпадение директив. Часто так бывает, что при составлении файла robots.txt для одного раздела указывают сразу 2 противоположные директивы: разрешить и запретить к индексированию (Disallow: и Allow:). Так может случиться, например, если вы сначала разрешили раздел к индексированию, а спустя время добавили информацию и хотите закрыть ее от индекса. При этом просто добавляете в коде запрещающую директиву, а разрешающую не убираете. В таких ситуациях поисковые роботы отдают предпочтение директиве Allow:. Другими словами, закрытая от индекса информация все равно будет в индексе.
- Директива Host:. Директива Host (используется для определения главного зеркала) известна только роботу Яндекса. Проблема в том, что остальные поисковые роботы не воспринимают ее или видят как ошибочную или неизвестную. Если вы ее используете в файле, то лучше определить двух ботов: все и боты Яндекса. Для Яндекса уже прописать директиву Host:. Если задать такую директиву для всех, то во многих вебмастерах это будет восприниматься как ошибка. Вот как прописать правильно для бота Яндекса:
User-Agent: Yandex
Host: site.ru - Директива Sitemap:. Файл Sitemap: показывает роботам, какие есть страницы на сайте. С его помощью поисковики узнают обо всех страницах вашего ресурса. Частая ошибка вебмастеров в том, что файл sitemap.xml располагают не в корне сайта, в то время как местоположение файла Sitemap очень важно. Оно определяет набор URL-адресов, которые можно включить в этот файл.
Например, файл Sitemap, расположенный в каталоге (вот так выглядит URL в этом случае http://primer.ru/catalog/sitemap.xml), может включать любые URL-адреса, начинающиеся с http://primer.ru/catalog/…, но не должен включать URL-адреса, начинающиеся, скажем, с http://primer.ru/images/…
Если вы располагаете неверно файл Sitemap:, то роботы неверно определят количество страниц вашего сайта, и они не попадут в индекс.
Итак, в качестве вывода запомните: файл robots.txt необходим для вашего сайта, если вы хотите, чтобы поисковые системы его индексировали и делали это так, как нужно вам. Но при этом он должен быть составлен грамотно, без ошибок. В противном случае вы рискуете получить неверную индексацию сайта.
Если возникли сложности с прописанием файла robots.txt, вы можете заказать его у наших специалистов.
© 1PS.RU, при полном или частичном копировании материала ссылка на первоисточник обязательна
Чек-лист для самостоятельного
SEO-аудита сайта
В рамках услуги SEO-аудит мы проанализировали более 1000 ресурсов. Ошибки на сайтах зачастую типичные – они повторяются из сайта в сайт. Проверьте свой самостоятельно.
Получить чек-лист
Комментарии для сайта Cackle
Если ошибиться при создании файла robots.txt, то он может оказаться бесполезным для поисковых роботов. Появится риск неверной передачи поисковым роботам нужных команд, что приведет к снижению рейтинга, изменению пользовательских показателей виртуальной площадки. Даже если сайт работает хорошо и является полноценным, проверка robots.txt ему не помешает, а только сделает его работу лучше.
Иногда в результаты поиска система включает ненужные страницы вашего Интернет-ресурса, в чем нет необходимости. Может показаться, что ничего плохого в большом количестве страниц в индексе поисковой системы нет, но это не так:
-
На лишних страницах пользователь не найдет никакой полезной информации для себя. С большей долей вероятности он и вовсе не посетит эти страницы либо задержится на них недолго;
-
В выдаче поисковика присутствуют одни и те же страницы, адреса которых различны (то есть контент дублируется);
-
Поисковым роботам приходится тратить много времени, чтобы проиндексировать совершенно ненужные страницы. Вместо индексации полезного контента они будут бесполезно блуждать по сайту. Поскольку индексировать полностью весь ресурс робот не может и делает это постранично (так как сайтов очень много), то нужная информация, которую вы бы хотели получить после ведения запроса, возможно, будет найдена не очень быстро;
-
Очень сильно нагружается сервер.
В связи с этим является целесообразным закрытие доступа поисковым роботам к некоторым страницам веб-ресурсов.
Какие же файлы и папки можно запретить индексировать:
-
Страницы поиска. Это спорный пункт. Иногда использование внутреннего поиска на сайте необходимо, для того чтобы создать релевантные страницы. Но делается это не всегда. Зачастую результатом поиска становится появление большого количества дублированных страниц. Поэтому рекомендуется закрыть страницы поиска для индексации.
-
Корзина и страница, на которой оформляют/подтверждают заказ. Их закрытие рекомендовано для сайтов онлайн-торговли и других коммерческих ресурсов, использующих форму заказа. Попадание этих страниц в индекс поисковых систем крайне нежелательно.
-
Страницы пагинации. Как правило, для них характерно автоматическое прописывание одинаковых мета-тегов. Кроме того, их используют для размещения динамического контента, поэтому в результатах выдачи появляются дубли. В связи с этим пагинация должна быть закрыта для индексации.
-
Фильтры и сравнение товаров. Закрывать их нужно онлайн-магазинам и сайтам-каталогам.
-
Страницы регистрации и авторизации. Закрывать их нужно в связи с конфиденциальностью вводимых пользователями при регистрации или авторизации данных. Недоступность этих страниц для индексации будет оценена Гуглом.
-
Системные каталоги и файлы. Каждый ресурс в Интернете состоит из множества данных (скриптов, таблиц CSS, административной части), которые не должны просматриваться роботами.
Закрыть файлы и страницы для индексации поможет файл robots.txt.
robots.txt – это обычный текстовый файл, содержащий инструкции для поисковых роботов. Когда поисковый робот оказывается на сайте, то в первую очередь занимается поиском файла robots.txt. Если же он отсутствует (или пустой), то робот будет заходить на все страницы и каталоги ресурса (в том числе и системные), находящиеся в свободном доступе, и пытаться провести их индексацию. При этом нет гарантии, что будет проиндексирована нужная вам страница, поскольку он может и не попасть на нее.
robots.txt позволяет направлять поисковые роботы на нужные страницы и не пускать на те, которые индексировать не следует. Файл может инструктировать как всех роботов сразу, так и каждого в отдельности. Если страницу сайта закрыть от индексации, то она никогда не появится в выдаче поисковой системы. Создание файла robots.txt является крайне необходимым.
Местом нахождения файла robots.txt должен быть сервер, корень вашего ресурса. Файл robots.txt любого сайта доступен для просмотра в Сети. Чтобы увидеть его, нужно после адреса ресурса добавить /robots.txt.
Как правило, файлы robots.txt различных ресурсов отличаются друг от друга. Если бездумно скопировать файл чужого сайта, то при индексации вашего поисковыми роботами возникнут проблемы. Поэтому так необходимо знать, для чего нужен файл robots.txt и инструкции (директивы), используемые при его создании.
Как проводится проверка robots.txt Яндексом
-
Проверить файл поможет специальный сервис Яндекс.Вебмастера «Анализ robots.txt». Найти его можно по ссылке: http://webmaster.yandex.ru/robots.xml
Чтобы войти в сервис, понадобится авторизация в системе. Если вы еще не проходили процедуру регистрации, то вам поможет пошаговая инструкция «Добавить сайт в Яндекс Вебмастер».
-
В предлагаемую форму вам нужно ввести содержимое файла robots.txt, который нужно проверить на наличие ошибок. Есть два способа ввода данных:
-
Заходите на сайт, используя ссылку http://ваш-сайт.ру/robots.txt, копируете содержимое в пустое поле сервиса (при отсутствии файла robots.txt вам обязательно нужно его создать!);
-
Вставляете ссылку на проверяемый файл в поле «Имя хоста», нажимаете «Загрузить robots.txt с сайта» или Enter.
-
-
Запуск проверки осуществляется нажатием команды «Проверить».
-
После того как проверка запущена, можно провести анализ результатов.
После начала проверки анализатор разбирает каждую строку содержимого поля «Текст robots.txt» и анализирует директивы, которые он содержит. Кроме того, вы узнаете, будет ли робот обходить страницы из поля «Список URL».

Составлять файл robots.txt, подходящий для вашего ресурса, можно редактированием правил. Не забывайте, что сам файл ресурса при этом остается неизменным. Для вступления изменений в силу понадобится самостоятельная загрузка новой версии файла на сайт.
При проверке директив разделов, которые предназначены для робота Яндекса (User-agent: Yandex или User-agent:*), анализатор руководствуется правилами использования robots.txt. Остальные разделы проверяются в соответствии с требованиями стандарта. Когда анализатор разбирает файл, то выводит сообщение о найденных ошибках, предупреждает, если в написании правил есть неточности, перечисляет, какие части файла предназначены для робота Яндекса.
Анализатор может посылать сообщения двух типов: ошибки и предупреждения.
Сообщение об ошибке выводится, если какая-либо строка, секция или весь файл не могут быть обработаны анализатором вследствие наличия серьезных синтаксических ошибок, которые допустили при составлении директив.
В предупреждении, как правило, сообщается об отклонении от правил, исправление которого анализатором невозможно, или о наличии потенциальной проблемы (ее может и не оказаться), причина которой – случайная опечатка или неточное составленные правила.
Сообщение об ошибке «Этот URL не принадлежит вашему домену» говорит о том, что в списке URL содержится адрес одного из зеркал вашего ресурса, к примеру, http://example.com вместо http://www.example.com (формально эти URL различны). Нужно, чтобы подлежащие проверке адреса относились к сайту, файл robots.txt которого анализируется.
Как осуществляется проверка robots.txt в Google
Инструмент Google Search Console позволяет вам провести проверку того, содержится ли в файле robots.txt запрет на сканирование роботом Googlebot определенных URL на вашем ресурсе. К примеру, у вас есть изображение, которое вы не хотите видеть в результатах поисковой выдачи Google по картинкам. С помощью инструмента вы узнаете, имеет ли робот Googlebot-Image доступ к этому изображению.
Для этого следует указать интересующий URL. После этого происходит обработка файла robots.txt инструментом проверки, аналогичная проверка роботом Googlebot. Это дает возможность определить, доступен ли этот адрес.
Кейс: VT-metall
Узнай как мы снизили стоимость привлечения заявки в 13 раз для металлообрабатывающей компании в Москве
Узнать как
Процедура проверки:
-
После выбора вашего ресурса в Google Search Console перейдите к инструменту проверки, который выдаст вам содержание файла robots.txt. Выделенный текст – это ошибки в синтаксисе или логические. Их количество указывается под окном редактирования.
-
В нижней части страницы интерфейса вы увидите специальное окно, в которое нужно ввести URL.
-
Справа появится меню, из которого необходимо выбрать робота.
-
Нажмите на кнопку «Проверить».
-
Если в результате проверки выводится сообщение с текстом «доступен», это значит, что роботам Google разрешено посещать указанную страницу. Статус «недоступен» говорит о том, что доступ к ней роботам закрыт.
-
Если нужно, вы можете изменить меню и провести новую проверку. Внимание! Автоматического внесения изменений в файл robots.txt на вашем ресурсе не произойдет.
-
Скопируйте изменения и внесите их в файл robots.txt на вашем веб-сервере.

На что нужно обратить внимание:
-
Сохранения сделанных в редакторе изменений на веб-сервере не происходит. Понадобится копирование полученного кода и вставки его в файл robots.txt.
-
Получить результаты проверки файла robots.txt инструментом могут только агенты пользователя Google и роботы, относящиеся к Google (к примеру, робот Googlebot). При этом гарантии того, что интерпретация содержания вашего файла роботами других поисковых систем будет аналогичной, нет.
15 ошибок при проверке файла robots.txt
-
Перепутанные инструкции
Наиболее распространенная ошибка в файле robots.txt – перепутанные инструкции. К примеру:
-
User-agent: /
-
Disallow: Yandex
Правильный вариант такой:
-
User-agent: Yandex
-
Disallow: /
-
-
Указание нескольких каталогов в одной инструкции Disallow
Часто владельцы Интернет-ресурсов стараются прописать все каталоги, которые они хотят запретить индексировать, в одной инструкции Disallow.
Disallow: /css/ /cgi-bin/ /images/
Такая запись не соответствует требованиям стандарта, предсказать, какой будет обработка ее разными роботами, невозможно. Одни из них могут проигнорировать пробелы. Их интерпретация записи будет такой: «Disallow: /css/cgi-bin/images/». Другими может быть использована лишь первая или последняя папка. Третьи и вовсе могут отбросить инструкцию, не поняв ее.
Есть вероятность того, что обработка этой конструкции будет именно такой, на которую рассчитывал мастер, но все же лучше написать правильно:
-
Disallow: /css/
-
Disallow: /cgi-bin/
-
Disallow: /images/
-
-
В имени файла присутствуют заглавные буквы
Правильное название файла — robots.txt, а не Robots.txt или ROBOTS.TXT.
-
Написание имени файла как robot.txt вместо robots.txt
Запомните, правильно называть файл robots.txt.
-
Оставление строки в User-agent пустой
Неправильный вариант:
-
User-agent:
-
Disallow:
Верно:
-
User-agent: *
-
Disallow:
-
-
Написание Url в директиве Host
URL нужно указывать, не используя аббревиатуру протокола передачи гипертекста (http://) и закрывающий слеш (/).
Неверная запись:
-
User-agent: Yandex
-
Disallow: /cgi-bin
-
Host: http://www.site.ru/
Правильный вариант:
-
User-agent: Yandex
-
Disallow: /cgi-bin
-
Host: www.site.ru
Корректным использование директивы host является только для робота Яндекса.
-
-
Использование в инструкции Disallow символов подстановки
Иногда, чтобы указать все файлы file1.html, file2.html, file3.html и т.д, веб-мастер может написать:
-
User-agent: *
-
Disallow: file*.html
Но делать этого нельзя, поскольку у некоторых роботов отсутствует поддержка символов подстановки.
-
-
Использование для написания комментариев и инструкций одной строки
Стандарт разрешает такие записи:
Disallow: /cgi-bin/ #запрещаем роботам индексировать cgi-bin
Раньше обработка таких строк некоторыми роботами была невозможна. Может быть, в настоящее время ни у одного поисковика не возникнет с этим проблем, но стоит ли идти на риск? Лучше размещать комментарии на отдельной строке.
-
Редирект на страницу 404-й ошибки
Нередко, если сайт не имеет файла robots.txt, то при его запросе поисковик будет переадресовывать на другую страницу. Иногда при этом не происходит отдачи статуса 404 Not Found. Роботу приходится самому разбираться, что он получил — robots.txt или обычный html-файл. Это не является проблемой, но лучше, если в корне сайта будет размещен пустой файл robots.txt.
-
Использование заглавных букв – признак плохого стиля
USER-AGENT: GOOGLEBOT
DISALLOW:
Хоть в стандарте и не регламентирована чувствительность robots.txt к регистру, нередко она имеет место у имен файлов и директорий. Кроме того, если файл robots.txt написан полностью заглавными буквами, то это считается плохим стилем.
User-agent: googlebot
Disallow:
-
Перечисление всех файлов
Неправильным будет перечислять каждый файл в директории в отдельности:
-
User-agent: *
-
Disallow: /AL/Alabama.html
-
Disallow: /AL/AR.html
-
Disallow: /Az/AZ.html
-
Disallow: /Az/bali.html
-
Disallow: /Az/bed-breakfast.html
Правильным будет закрытие от индексации полностью всей директории:
-
User-agent: *
-
Disallow: /AL/
-
Disallow: /Az/
-
-
Использование дополнительных директив в секции *
Может иметь место неправильная реакция некоторых роботов на использование дополнительных директив. Поэтому применение их в секции «*» является нежелательным.
Если директива не является стандартной (как, например, «Host»), то для нее лучше создать специальную секцию.
Неверный вариант:
-
User-agent: *
-
Disallow: /css/
-
Host: www.example.com
Правильно будет написать:
-
User-agent: *
-
Disallow: /css/
-
User-agent: Yandex
-
Disallow: /css/
-
Host: www.example.com
-
-
Отсутствие инструкции Disallow
Даже при желании использовать дополнительную директиву и не устанавливать никакой запрет, рекомендуется указывать пустой Disallow. В стандарте указана обязательность инструкции Disallow, при ее отсутствии робот может «неправильно вас понять».
Неправильно:
-
User-agent: Yandex
-
Host: www.example.com
Правильно:
-
User-agent: Yandex
-
Disallow:
-
Host: www.example.com
-
-
Неиспользование слешей, когда указывается директория
Каковы будут действия робота в этом случае?
-
User-agent: Yandex
-
Disallow: john
Согласно стандарту, индексация не будет проведена для как для файла, так и для директории с именем «john». Чтобы указать только директорию, нужно написать:
-
User-agent: Yandex
-
Disallow: /john/
-
-
Неправильное написание HTTP-заголовка
Сервер должен возвращать в HTTP-заголовке для robots.txt «Content-Type: text/plain» а, например, не «Content-Type: text/html». Если заголовок будет написан неправильно, то обработка файла некоторыми роботами будет невозможна.
Как правильно составить файл, чтобы проверка robots.txt не выявляла ошибок
Каким должен быть правильный файл robots.txt для Интернет-ресурса? Рассмотрим его структуру:
User-agent
Эта директива является основной, она определяет, для каких роботов написаны правила.
Если для любого робота, пишем:
User-agent: *
Если для конкретного бота:
User-agent: GoogleBot
Стоит отметить, что регистр символов не имеет значения в robots.txt. К примеру, юзер-агент для Google можно записать и так:
user-agent: googlebot
Приведем таблицу основных юзер-агентов различных поисковиков.
| Бот | Функция |
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
Disallow и Allow
Disallow позволяет запретить индексирование страниц и разделов Интернет-ресурса.
Allow служит для принудительного открытия их для индексирования.
Но пользоваться ими достаточно непросто.
Во-первых, нужно ознакомиться с дополнительными операторами и правилами их использования. К ним относятся: *, $ и #.
-
* —любое количество символов, даже их отсутствие. Ставить этот оператор в конце строки не обязательно, подразумевается, что она там стоит по умолчанию;
-
$ — показывает, что стоящий перед ним символ должен быть последним;
-
# — этот оператор служит для обозначения комментария, любая информация после него роботом в расчет не берется.
Как пользоваться этими операторами:
-
Disallow: *?s=
-
Disallow: /category/$
Не могут быть проиндексированы такие ссылки:
Эти ссылки, наоборот, открыты для индексации:
Во-вторых, необходимо понимание того, как выполняются правила, вложенные в файл robots.txt.
Не имеет значения, в каком порядке записаны директивы. Определение наследования правил (что открыть или закрыть от индексации) осуществляется по указанным директориям. Приведем пример.
Allow: *.css
Disallow: /template/
-
http://site.ru/template/ rel=»nofollow» — закрыто от индексирования
-
http://site.ru/template/style.css rel=»nofollow» — закрыто от индексирования
-
http://site.ru/style.css rel=»nofollow» — открыто для индексирования
-
http://site.ru/theme/style.css rel=»nofollow» — открыто для индексирования
Если необходимо открыть для индексации все файлы .css, то нужно будет дополнительно указать это для каждой папки, доступ к которой закрыт. В нашем случае:
-
Allow: *.css
-
Allow: /template/*.css
-
Disallow: /template/
Напомним еще раз: не важно, в каком порядке записаны директивы.
Sitemap
Эта директива указывает путь к XML-файлу Sitemap. URL-адрес имеет такой же вид, что и в адресной строке.
К примеру,
Sitemap: http://site.ru/sitemap.xml rel=»nofollow»
Указание директивы Sitemap возможно в любом месте файла robots.txt, при этом не требуется привязывать ее к конкретному user-agent. Разрешается указывать несколько правил Sitemap.
Host
Эта директива указывает главное зеркало ресурса (как правило, с www или без www). Помните: при указании главного зеркала пишется не http://, а https://. В случае необходимости указывается и порт.
Поддержка этой директивы возможна только ботами Яндекса и Mail.Ru. Другие роботы, в том числе и GoogleBot, эту команду не учитывают. Прописывать host можно только один раз!
Пример 1:
Host: site.ru
Пример 2:
Crawl-delay
Позволяет установить, через какой промежуток времени роботу нужно скачивать страницы ресурса. Директиву поддерживают роботы Яндекса, Mail.Ru, Bing, Yahoo. При установке интервала можно использовать как целые значения, так и дробные, используя в качестве разделителя применяется точка. Единица измерения — секунды.
Пример 1:
Crawl-delay: 3
Пример 2:
Crawl-delay: 0.5
Если нагрузка на сайт небольшая, то нет необходимости в установке этого правила. Но если результатом индексирования роботом страниц является превышение лимитов или серьезное увеличение нагрузки, приводящее к перебоям в работе сервера, то использование этой директивы целесообразно: оно позволяет снизить нагрузку.
Чем больше устанавливаемый интервал, тем меньше будет количество загрузок в течение одной сессии. Оптимальное значение для каждого ресурса свое. Сначала рекомендуется ставить небольшие значения (0.1, 0.2, 0.5), затем постепенно увеличивая их. Для роботов поисковиков, не особо важных для результатов продвижения (к примеру, Mail.Ru, Bing и Yahoo), можно сразу устанавливать значения, бóльшие, нежели для роботов Яндекса.
Clean-param
Эта директива нужна для сообщения краулеру (поисковому роботу) о ненужности индексации URL-адресов с указанными параметрами. Для правила указываются два аргумента: параметр и URL раздела. Яндекс поддерживает директиву.
Пример 1:
http://site.ru/articles/?author_id=267539 — не подвергнется индексации
Пример 2:
Clean-param: author_id sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — не подвергнется индексации
Яндексом также рекомендовано использование этой директивы, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source utm_medium utm_campaign
Другие параметры
Расширенная спецификация robots.txt содержит еще такие параметры: Request-rate и Visit-time. Но в настоящее время отсутствует поддержка их ведущими поисковиками.
Директивы нужны для следующего:
-
Request-rate: 1/5 — разрешает загрузку не более 1 страницы за 5 секунд
-
Visit-time: 0600-0845 — разрешает загрузку страниц только с 6 утра до 8:45 по Гринвичу
Для правильной настройки файла robots.txt рекомендуем использовать такой алгоритм:
-
Запретите индексировать админку сайта;
-
Закройте доступ роботам к личному кабинету, страницам авторизации и регистрации;
-
Запретите индексировать корзину, формы заказа, данные по доставке и заказам;
-
Закройте от индексирования ajax, json-скрипты;
-
Запретите индексировать папку cgi;
-
Запретите индексировать плагины, темы оформления, js, css для роботов всех поисковых систем, кроме Яндекса и Google;
-
Закройте доступ роботам к функционалу поиска;
-
Запретите индексировать служебные разделы, не являющиеся ценными для ресурса в поиске (ошибка 404, список авторов);
-
Закройте от индексирования технические дубли страниц и страницы, контент которых в той или иной степени дублирует содержимое других страниц (календари, архивы, RSS);
-
Запретите индексировать страницы с параметрами фильтров, сортировки, сравнения;
-
Запретите индексировать страницы с параметрами UTM-меток и сессий;
-
Используйте для проверки того, что проиндексировал Яндекс и Google, параметр «site:». Для этого в строку поиска введите «site:site.ru». Если в поисковой выдаче есть страницы, которые не нужно индексировать, добавьте их в robots.txt;
-
Пропишите правила Sitemap и Host;
-
Если необходимо, укажите Crawl-Delay и Clean-Param;
-
Проведите проверку корректности файла robots.txt, используя инструменты Google и Яндекса;
-
Через 14 дней проведите повторную проверку, чтобы убедиться в отсутствии в выдаче поисковых систем страниц, которые не должны индексироваться. Если таковые имеются, повторите все указанные выше пункты.
Проверка файла robots.txt имеет смысл, только если ваш сайт в порядке. Определить это поможет аудит сайта, проводимый квалифицированными специалистами.
Скачайте полезный документ по теме:
Чек-лист: Как добиваться своих целей в переговорах с клиентами
Надеемся, что наша статья о бизнес-идеях, окажется вам полезной. А если вы уже определились с направлением деятельности и активно занимаетесь развитием и продвижением своего проекта, то советуем пройти аудит сайта, чтобы представлять реальную картину возможностей вашего ресурса.

Статья опубликована: 03.01.2018
Облако тегов
Понравилась статья? Поделитесь:
Robots.txt — это полезный инструмент, с помощью которого вы можете указать поисковым роботам, как им сканировать ваш сайт.
Он не всесилен (по словам Google), но он может помочь предотвратить перегрузку вашего сайта или сервера запросами поискового робота.
Если на вашем сайте есть этот файл, вы должны быть уверены, что он прописан правильно.
Это особенно важно, если вы используете динамические URL-адреса или другие методы, которые теоретически генерируют бесконечное количество страниц.
В этой серии статей мы рассмотрим некоторые из наиболее распространенных проблем с файлом robots.txt, их влияние на ваш сайт, а также способы устранения этих проблем.
Но сначала давайте вспомним, что такое robots.txt.

На что нужно обратить внимание:
-
Сохранения сделанных в редакторе изменений на веб-сервере не происходит. Понадобится копирование полученного кода и вставки его в файл robots.txt.
-
Получить результаты проверки файла robots.txt инструментом могут только агенты пользователя Google и роботы, относящиеся к Google (к примеру, робот Googlebot). При этом гарантии того, что интерпретация содержания вашего файла роботами других поисковых систем будет аналогичной, нет.
15 ошибок при проверке файла robots.txt
-
Перепутанные инструкции
Наиболее распространенная ошибка в файле robots.txt – перепутанные инструкции. К примеру:
-
User-agent: /
-
Disallow: Yandex
Правильный вариант такой:
-
User-agent: Yandex
-
Disallow: /
-
-
Указание нескольких каталогов в одной инструкции Disallow
Часто владельцы Интернет-ресурсов стараются прописать все каталоги, которые они хотят запретить индексировать, в одной инструкции Disallow.
Disallow: /css/ /cgi-bin/ /images/
Такая запись не соответствует требованиям стандарта, предсказать, какой будет обработка ее разными роботами, невозможно. Одни из них могут проигнорировать пробелы. Их интерпретация записи будет такой: «Disallow: /css/cgi-bin/images/». Другими может быть использована лишь первая или последняя папка. Третьи и вовсе могут отбросить инструкцию, не поняв ее.
Есть вероятность того, что обработка этой конструкции будет именно такой, на которую рассчитывал мастер, но все же лучше написать правильно:
-
Disallow: /css/
-
Disallow: /cgi-bin/
-
Disallow: /images/
-
-
В имени файла присутствуют заглавные буквы
Правильное название файла — robots.txt, а не Robots.txt или ROBOTS.TXT.
-
Написание имени файла как robot.txt вместо robots.txt
Запомните, правильно называть файл robots.txt.
-
Оставление строки в User-agent пустой
Неправильный вариант:
-
User-agent:
-
Disallow:
Верно:
-
User-agent: *
-
Disallow:
-
-
Написание Url в директиве Host
URL нужно указывать, не используя аббревиатуру протокола передачи гипертекста (http://) и закрывающий слеш (/).
Неверная запись:
-
User-agent: Yandex
-
Disallow: /cgi-bin
-
Host: http://www.site.ru/
Правильный вариант:
-
User-agent: Yandex
-
Disallow: /cgi-bin
-
Host: www.site.ru
Корректным использование директивы host является только для робота Яндекса.
-
-
Использование в инструкции Disallow символов подстановки
Иногда, чтобы указать все файлы file1.html, file2.html, file3.html и т.д, веб-мастер может написать:
-
User-agent: *
-
Disallow: file*.html
Но делать этого нельзя, поскольку у некоторых роботов отсутствует поддержка символов подстановки.
-
-
Использование для написания комментариев и инструкций одной строки
Стандарт разрешает такие записи:
Disallow: /cgi-bin/ #запрещаем роботам индексировать cgi-bin
Раньше обработка таких строк некоторыми роботами была невозможна. Может быть, в настоящее время ни у одного поисковика не возникнет с этим проблем, но стоит ли идти на риск? Лучше размещать комментарии на отдельной строке.
-
Редирект на страницу 404-й ошибки
Нередко, если сайт не имеет файла robots.txt, то при его запросе поисковик будет переадресовывать на другую страницу. Иногда при этом не происходит отдачи статуса 404 Not Found. Роботу приходится самому разбираться, что он получил — robots.txt или обычный html-файл. Это не является проблемой, но лучше, если в корне сайта будет размещен пустой файл robots.txt.
-
Использование заглавных букв – признак плохого стиля
USER-AGENT: GOOGLEBOT
DISALLOW:
Хоть в стандарте и не регламентирована чувствительность robots.txt к регистру, нередко она имеет место у имен файлов и директорий. Кроме того, если файл robots.txt написан полностью заглавными буквами, то это считается плохим стилем.
User-agent: googlebot
Disallow:
-
Перечисление всех файлов
Неправильным будет перечислять каждый файл в директории в отдельности:
-
User-agent: *
-
Disallow: /AL/Alabama.html
-
Disallow: /AL/AR.html
-
Disallow: /Az/AZ.html
-
Disallow: /Az/bali.html
-
Disallow: /Az/bed-breakfast.html
Правильным будет закрытие от индексации полностью всей директории:
-
User-agent: *
-
Disallow: /AL/
-
Disallow: /Az/
-
-
Использование дополнительных директив в секции *
Может иметь место неправильная реакция некоторых роботов на использование дополнительных директив. Поэтому применение их в секции «*» является нежелательным.
Если директива не является стандартной (как, например, «Host»), то для нее лучше создать специальную секцию.
Неверный вариант:
-
User-agent: *
-
Disallow: /css/
-
Host: www.example.com
Правильно будет написать:
-
User-agent: *
-
Disallow: /css/
-
User-agent: Yandex
-
Disallow: /css/
-
Host: www.example.com
-
-
Отсутствие инструкции Disallow
Даже при желании использовать дополнительную директиву и не устанавливать никакой запрет, рекомендуется указывать пустой Disallow. В стандарте указана обязательность инструкции Disallow, при ее отсутствии робот может «неправильно вас понять».
Неправильно:
-
User-agent: Yandex
-
Host: www.example.com
Правильно:
-
User-agent: Yandex
-
Disallow:
-
Host: www.example.com
-
-
Неиспользование слешей, когда указывается директория
Каковы будут действия робота в этом случае?
-
User-agent: Yandex
-
Disallow: john
Согласно стандарту, индексация не будет проведена для как для файла, так и для директории с именем «john». Чтобы указать только директорию, нужно написать:
-
User-agent: Yandex
-
Disallow: /john/
-
-
Неправильное написание HTTP-заголовка
Сервер должен возвращать в HTTP-заголовке для robots.txt «Content-Type: text/plain» а, например, не «Content-Type: text/html». Если заголовок будет написан неправильно, то обработка файла некоторыми роботами будет невозможна.
Как правильно составить файл, чтобы проверка robots.txt не выявляла ошибок
Каким должен быть правильный файл robots.txt для Интернет-ресурса? Рассмотрим его структуру:
User-agent
Эта директива является основной, она определяет, для каких роботов написаны правила.
Если для любого робота, пишем:
User-agent: *
Если для конкретного бота:
User-agent: GoogleBot
Стоит отметить, что регистр символов не имеет значения в robots.txt. К примеру, юзер-агент для Google можно записать и так:
user-agent: googlebot
Приведем таблицу основных юзер-агентов различных поисковиков.
| Бот | Функция |
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
Disallow и Allow
Disallow позволяет запретить индексирование страниц и разделов Интернет-ресурса.
Allow служит для принудительного открытия их для индексирования.
Но пользоваться ими достаточно непросто.
Во-первых, нужно ознакомиться с дополнительными операторами и правилами их использования. К ним относятся: *, $ и #.
-
* —любое количество символов, даже их отсутствие. Ставить этот оператор в конце строки не обязательно, подразумевается, что она там стоит по умолчанию;
-
$ — показывает, что стоящий перед ним символ должен быть последним;
-
# — этот оператор служит для обозначения комментария, любая информация после него роботом в расчет не берется.
Как пользоваться этими операторами:
-
Disallow: *?s=
-
Disallow: /category/$
Не могут быть проиндексированы такие ссылки:
Эти ссылки, наоборот, открыты для индексации:
Во-вторых, необходимо понимание того, как выполняются правила, вложенные в файл robots.txt.
Не имеет значения, в каком порядке записаны директивы. Определение наследования правил (что открыть или закрыть от индексации) осуществляется по указанным директориям. Приведем пример.
Allow: *.css
Disallow: /template/
-
http://site.ru/template/ rel=»nofollow» — закрыто от индексирования
-
http://site.ru/template/style.css rel=»nofollow» — закрыто от индексирования
-
http://site.ru/style.css rel=»nofollow» — открыто для индексирования
-
http://site.ru/theme/style.css rel=»nofollow» — открыто для индексирования
Если необходимо открыть для индексации все файлы .css, то нужно будет дополнительно указать это для каждой папки, доступ к которой закрыт. В нашем случае:
-
Allow: *.css
-
Allow: /template/*.css
-
Disallow: /template/
Напомним еще раз: не важно, в каком порядке записаны директивы.
Sitemap
Эта директива указывает путь к XML-файлу Sitemap. URL-адрес имеет такой же вид, что и в адресной строке.
К примеру,
Sitemap: http://site.ru/sitemap.xml rel=»nofollow»
Указание директивы Sitemap возможно в любом месте файла robots.txt, при этом не требуется привязывать ее к конкретному user-agent. Разрешается указывать несколько правил Sitemap.
Host
Эта директива указывает главное зеркало ресурса (как правило, с www или без www). Помните: при указании главного зеркала пишется не http://, а https://. В случае необходимости указывается и порт.
Поддержка этой директивы возможна только ботами Яндекса и Mail.Ru. Другие роботы, в том числе и GoogleBot, эту команду не учитывают. Прописывать host можно только один раз!
Пример 1:
Host: site.ru
Пример 2:
Crawl-delay
Позволяет установить, через какой промежуток времени роботу нужно скачивать страницы ресурса. Директиву поддерживают роботы Яндекса, Mail.Ru, Bing, Yahoo. При установке интервала можно использовать как целые значения, так и дробные, используя в качестве разделителя применяется точка. Единица измерения — секунды.
Пример 1:
Crawl-delay: 3
Пример 2:
Crawl-delay: 0.5
Если нагрузка на сайт небольшая, то нет необходимости в установке этого правила. Но если результатом индексирования роботом страниц является превышение лимитов или серьезное увеличение нагрузки, приводящее к перебоям в работе сервера, то использование этой директивы целесообразно: оно позволяет снизить нагрузку.
Чем больше устанавливаемый интервал, тем меньше будет количество загрузок в течение одной сессии. Оптимальное значение для каждого ресурса свое. Сначала рекомендуется ставить небольшие значения (0.1, 0.2, 0.5), затем постепенно увеличивая их. Для роботов поисковиков, не особо важных для результатов продвижения (к примеру, Mail.Ru, Bing и Yahoo), можно сразу устанавливать значения, бóльшие, нежели для роботов Яндекса.
Clean-param
Эта директива нужна для сообщения краулеру (поисковому роботу) о ненужности индексации URL-адресов с указанными параметрами. Для правила указываются два аргумента: параметр и URL раздела. Яндекс поддерживает директиву.
Пример 1:
http://site.ru/articles/?author_id=267539 — не подвергнется индексации
Пример 2:
Clean-param: author_id sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — не подвергнется индексации
Яндексом также рекомендовано использование этой директивы, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source utm_medium utm_campaign
Другие параметры
Расширенная спецификация robots.txt содержит еще такие параметры: Request-rate и Visit-time. Но в настоящее время отсутствует поддержка их ведущими поисковиками.
Директивы нужны для следующего:
-
Request-rate: 1/5 — разрешает загрузку не более 1 страницы за 5 секунд
-
Visit-time: 0600-0845 — разрешает загрузку страниц только с 6 утра до 8:45 по Гринвичу
Для правильной настройки файла robots.txt рекомендуем использовать такой алгоритм:
-
Запретите индексировать админку сайта;
-
Закройте доступ роботам к личному кабинету, страницам авторизации и регистрации;
-
Запретите индексировать корзину, формы заказа, данные по доставке и заказам;
-
Закройте от индексирования ajax, json-скрипты;
-
Запретите индексировать папку cgi;
-
Запретите индексировать плагины, темы оформления, js, css для роботов всех поисковых систем, кроме Яндекса и Google;
-
Закройте доступ роботам к функционалу поиска;
-
Запретите индексировать служебные разделы, не являющиеся ценными для ресурса в поиске (ошибка 404, список авторов);
-
Закройте от индексирования технические дубли страниц и страницы, контент которых в той или иной степени дублирует содержимое других страниц (календари, архивы, RSS);
-
Запретите индексировать страницы с параметрами фильтров, сортировки, сравнения;
-
Запретите индексировать страницы с параметрами UTM-меток и сессий;
-
Используйте для проверки того, что проиндексировал Яндекс и Google, параметр «site:». Для этого в строку поиска введите «site:site.ru». Если в поисковой выдаче есть страницы, которые не нужно индексировать, добавьте их в robots.txt;
-
Пропишите правила Sitemap и Host;
-
Если необходимо, укажите Crawl-Delay и Clean-Param;
-
Проведите проверку корректности файла robots.txt, используя инструменты Google и Яндекса;
-
Через 14 дней проведите повторную проверку, чтобы убедиться в отсутствии в выдаче поисковых систем страниц, которые не должны индексироваться. Если таковые имеются, повторите все указанные выше пункты.
Проверка файла robots.txt имеет смысл, только если ваш сайт в порядке. Определить это поможет аудит сайта, проводимый квалифицированными специалистами.
Скачайте полезный документ по теме:
Чек-лист: Как добиваться своих целей в переговорах с клиентами
Надеемся, что наша статья о бизнес-идеях, окажется вам полезной. А если вы уже определились с направлением деятельности и активно занимаетесь развитием и продвижением своего проекта, то советуем пройти аудит сайта, чтобы представлять реальную картину возможностей вашего ресурса.
Статья опубликована: 03.01.2018
Облако тегов
Понравилась статья? Поделитесь:
Robots.txt — это полезный инструмент, с помощью которого вы можете указать поисковым роботам, как им сканировать ваш сайт.
Он не всесилен (по словам Google), но он может помочь предотвратить перегрузку вашего сайта или сервера запросами поискового робота.
Если на вашем сайте есть этот файл, вы должны быть уверены, что он прописан правильно.
Это особенно важно, если вы используете динамические URL-адреса или другие методы, которые теоретически генерируют бесконечное количество страниц.
В этой серии статей мы рассмотрим некоторые из наиболее распространенных проблем с файлом robots.txt, их влияние на ваш сайт, а также способы устранения этих проблем.
Но сначала давайте вспомним, что такое robots.txt.
Что такое Robots.txt?
Robots.txt – это простой текстовый файл, который помещается в корневой каталог вашего веб-сайта.
Он должен находиться именно в корневой папке; если вы поместите его в подкаталог, поисковые системы просто его проигнорируют.
Несмотря на свою важность, robots.txt часто представляет собой относительно простой документ, и базовый файл robots.txt можно создать за считанные секунды с помощью текстового редактора, например Блокнота.
Существуют и другие способы достижения тех же целей, для которых обычно используется файл robots.txt. Например, отдельные страницы могут включать метатег robots в самом коде страницы.
Вы также можете использовать HTTP-заголовок X-Robots-Tag, чтобы влиять на то, как (и будет ли) отображаться контент в результатах поиска.
Что может robots.txt?
Robots.txt может делать разные вещи, в зависимости от ваших целей:
Веб-страницы могут быть заблокированы от сканирования.
Они могут по-прежнему отображаться в результатах поиска, но не будут иметь текстового описания. Содержимое страницы, кроме HTML, также не будет сканироваться.
Медиафайлы могут быть заблокированы от появления в результатах поиска Google.
То есть изображения, видео и аудио файлы.
Общедоступный файл по-прежнему будет «существовать» в Интернете, и его можно будет посмотреть, но этот контент не будет отображаться в результатах поиска Google.
Файлы ресурсов, такие как несущественные внешние скрипты, могут быть заблокированы.
Но это означает, что если Google просканирует страницу, для загрузки которой требуется этот ресурс, робот Googlebot «увидит» версию страницы так, как если бы этот ресурс не существовал, что может повлиять на индексацию.
Вы не можете использовать robots.txt, чтобы полностью заблокировать отображение веб-страницы в результатах поиска Google.
Для этого вы должны использовать альтернативный метод, такой как добавление метатега noindex в начало страницы.
Насколько опасны ошибки robots.txt?
Ошибка в robots.txt может иметь непредвиденные последствия, но часто это не конец света.
Исправив файл robots.txt, вы сможете восстановиться после любых ошибок быстро и (как правило) в полном объеме.
В руководстве Google для веб-разработчиков говорится следующее:
«Веб-сканеры очень гибкие и, как правило, не реагируют на незначительные ошибки в файле robots.txt. Худшее, что может случиться – некорректные [или] неподдерживаемые директивы будут проигнорированы.
Если вы знаете о проблемах в файле robots.txt, их обычно легко исправить».
А вот какие ошибки встречаются чаще всего – читайте в следующей статье.
Если ваш веб-сайт ведет себя странно в результатах поиска, первое место, где стоит поискать ошибки – ваш файл robots.txt.
Давайте рассмотрим каждую из возможных ошибок.
1 Robots.txt не в корневом каталоге
Поисковые роботы могут обнаружить файл только в том случае, если он находится в корневой папке.
Вот почему между .com (или другим доменом) вашего веб-сайта и именем файла robots.txt в URL-адресе вашего файла robots.txt должна быть только косая черта:
https://example.com/robots.txt
Если там есть подпапка, ваш файл robots.txt, вероятно, не виден поисковым роботам, и ваш сайт ведет себя так, как будто этого файла вообще нет.
Чтобы решить эту проблему, переместите файл robots.txt в корневой каталог. Для этого вам потребуется root-доступ к вашему серверу.
Некоторые системы управления контентом по умолчанию загружают файлы в подкаталог media (или что-то подобное).
2. Некорректное использование подстановочных знаков
Robots.txt поддерживает два подстановочных знака:
- Звездочка * , которая представляет любые экземпляры допустимого символа.
- Знак доллара $ , обозначающий конец URL-адреса, позволяет применять правила только к последней части URL-адреса, например к расширению типа файла.
Разумно использовать эти знаки как можно реже, потому что нечаянно можно заблокировать больше, чем нужно.
Также относительно легко заблокировать доступ роботов ко всему вашему сайту с помощью неудачно расположенной звездочки.
Чтобы устранить проблему с подстановочными знаками, вам нужно найти неправильный и переместить или удалить его, чтобы файл robots.txt работал должным образом.
3. Noindex в robots.txt
Это чаще встречается на веб-сайтах, которым уже несколько лет.
Google перестал соблюдать правила noindex в файлах robots.txt с 1 сентября 2019 года.
Если ваш файл robots.txt был создан до этой даты или содержит инструкции noindex, вы, скорее всего, увидите эти страницы проиндексированными в результатах поиска Google.
Один из вариантов решения этой проблемы – метатег robots, который вы можете добавить в заголовок любой веб-страницы, которую вы хотите закрыть от индексации Google.
4. Заблокированные скрипты и таблицы стилей
Может показаться логичным заблокировать доступ сканера к внешним файлам JavaScript и каскадным таблицам стилей (CSS).
Однако помните, что роботу Googlebot нужен доступ к файлам CSS и JS, чтобы правильно «видеть» ваши HTML- и PHP-страницы.
Если ваши страницы странно отображаются в результатах Google или кажется, что Google не видит их правильно, проверьте, не блокируете ли вы доступ поискового робота к необходимым внешним файлам.
Простое решение — удалить строку из файла robots.txt, которая блокирует доступ.
5. Нет URL-адреса карты сайта
Эта ошибка напрямую касается SEO.
Вы можете включить URL-адрес вашей карты сайта в файл robots.txt.
Это не совсем ошибка, так как отсутствие карты сайта не должно негативно влиять на основную функциональность и внешний вид вашего веб-сайта в результатах поиска, но все же стоит добавить URL-адрес вашей карты сайта в robots.txt.
6. Доступ к сайтам разработки
Блокировать сканеры на вашем работающем веб-сайте нельзя, но не надо разрешать им сканировать и индексировать страницы, которые все еще находятся в стадии разработки.
Рекомендуется добавить инструкцию о запрете в файл robots.txt веб-сайта, находящегося в стадии разработки, чтобы широкая публика не увидела его, пока он не будет завершен.
Точно так же очень важно удалить инструкцию о запрете при запуске готового веб-сайта.
Забыть удалить эту строку из robots.txt — одна из самых распространенных ошибок среди веб-разработчиков.
Если кажется, что ваш недавно запущенный веб-сайт совсем не виден в поиске, поищите универсальное правило запрета пользовательского агента в файле robots.txt:
User-Agent: *
Disallow: /
Как исправить ошибки в robots.txt
Если ошибка в файле robots.txt оказывает нежелательное влияние на вид вашего веб-сайта в результатах поиска, самый первый ваш шаг – исправление файла robots.txt и проверка, что новые правила дают желаемый эффект.
Если вы уверены, что файл robots.txt работает правильно, вы можете попытаться повторно просканировать свой сайт как можно скорее.
В этом могут помочь такие платформы, как Google Search Console и Яндекс.Вебмастер.
Отправьте обновленную карту сайта и запросите повторное сканирование любых страниц, которые были нечаянно удалены из списка.
К сожалению, невозможно предсказать, сколько времени потребуется, чтобы отсутствующие страницы вновь появились в поисковом индексе Google.
Все, что вы можете сделать, это просто подождать.
Когда речь идет об ошибках robots.txt, лучше предотвратить их, чем потом исправлять.
В крупном интернет-магазине случайный подстановочный знак, который удаляет весь ваш веб-сайт из поиска, может немедленно повлиять на ваш доход.
Редактирование файла robots.txt нужно доверять только опытным разработчикам.
![]()