

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
ШПАРГАЛКА (скопируйте ссылку или текст)
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет
Содержание курса лекций “Статистика”
Выборочное наблюдение как источник статистической информации в изучении социально-экономических явлений и процессов

Статистическая методология исследования массовых явлений различает, как известно, два способа наблюдения в зависимости от полноты охвата объекта: сплошное и несплошное. Разновидностью несплошного наблюдения является выборочное, которое в условиях рыночных отношений в России находит все более широкое применение. Переход статистики РФ на международные стандарты системы национального счетоводства требует более широкого применения выборки для получения и анализа показателей СНС не только в промышленности, но и в других секторах экономики.
Под выборочным наблюдением понимается несплошное наблюдение, при котором статистическому обследованию (наблюдению) подвергаются единицы изучаемой совокупности, отобранные случайным способом. Выборочное наблюдение ставит перед собой задачу ‑ по обследуемой части дать характеристику всей совокупности единиц при условии соблюдения всех правил и принципов проведения статистического наблюдения и научно организованной работы по отбору единиц.
К выборочному наблюдению статистика прибегает по различным причинам. На современном этапе появилось множество субъектов хозяйственной деятельности, которые характерны для рыночной экономики. Речь идет об акционерных обществах, малых и совместных предприятиях, фермерских хозяйствах и т.д. Сплошное обследование этих статистических совокупностей, состоящих из десятков и сотен тысяч единиц, потребовало бы огромных материальных, финансовых и иных затрат. Использование же выборочного обследования позволяет значительно сэкономить силы и средства, что имеет немаловажное значение.
Наряду с экономией ресурсов одной из причин превращения выборочного наблюдения в важнейший источник статистической информации является возможность значительно ускорить получение необходимых данных. Ведь при обследовании, скажем, 10% единиц совокупности будет затрачено гораздо меньше времени, а результаты могут быть представлены быстрее, и будут более актуальными. Фактор времени важен для статистического исследования особенно в условиях изменяющейся социально-экономической ситуации.
Реализация выборочного метода базируется на понятиях генеральной и выборочной совокупностей.
Генеральной совокупностью называется вся исходная изучаемая статистическая совокупность, из которой на основе отбора единиц или групп единиц формируется совокупность выборочная. Поэтому генеральную совокупность также называют основой выборки.
Отбор единиц в выборочную совокупность может быть повторным или бесповторным.
При повторном отборе попавшая в выборку единица подвергается обследованию, т.е. регистрации значений ее признаков, возвращается в генеральную совокупность и наравне с другими единицами участвует в дальнейшей процедуре отбора. Таким образом, некоторые единицы могут попадать в выборку дважды, трижды или даже большее число раз. И при изучении выборочной совокупности они будут рассматриваться как отдельные независимые наблюдения.
Отметим, что число единиц генеральной совокупности, участвующих в отборе, при таком подходе остается постоянным. Поэтому вероятность попадания в выборку для всех единиц совокупности на протяжении всего процесса отбора также не меняется.
На практике методология повторного отбора обычно используется в тех случаях, когда объем генеральной совокупности не известен и теоретически возможно повторение единиц с уже встречавшимися значениями всех регистрируемых признаков.
Например, при проведении маркетинговых исследований мы не можем сколько-нибудь точно оценить, какое число потребителей предпочитают стиральный порошок конкретной торговой марки, сколько покупателей предпочитают делать покупки именно в данном супермаркете и т.д. Поэтому возможно повторение совершенно идентичных единиц как по причине практически неограниченных объемов совокупности, так и вследствие возможной повторной регистрации. Предположим, при проведении обследования один и тот же покупатель может дважды прийти в магазин и дважды подвергнуться обследованию.
При выборочном контроле качества продукции объем генеральной совокупности также часто не определен, так как процесс производства может осуществляться постоянно, каждый день дополняя генеральную совокупность новыми единицами-изделиями. Поэтому в выборочную совокупность могут попасть два и более изделий с абсолютно одинаковыми характеристиками. Следовательно, и в этом случае при обработке результатов выборки необходимо ориентироваться на методологию, используемую при повторном отборе.
При бесповоротном отборе попавшая в выборку единица подвергается обследованию и в дальнейшей процедуре отбора не участвует. Такой отбор целесообразен и практически возможен в тех случаях, когда объем генеральной совокупности четко определен. Получаемые при этом результаты, как правило, являются более точными по сравнению с результатами, основанными на повторной выборке.
Как уже отмечалось выше, выборочное наблюдение всегда связано с определенными ошибками получаемых характеристик. Эти ошибки называются ошибками репрезентативности (представительности).
Ошибки репрезентативности обусловлены тем обстоятельством, что выборочная совокупность не может по всем параметрам в точности воспроизвести совокупность генеральную. Получаемые расхождения или ошибки репрезентативности позволяют заключить, в какой степени попавшие в выборку единицы могут представлять всю генеральную совокупность. При этом следует различать систематические и случайные ошибки репрезентативности.
Систематические ошибки репрезентативности связаны с нарушением принципов формирования выборочной совокупности. Например, вследствие каких-либо причин, связанных с организацией отбора, в выборку попали единицы, характеризующиеся несколько большими или, наоборот, несколько меньшими по сравнению с другими единицами значениями наблюдаемых признаков. В этом случае и рассчитанные выборочные характеристики будут завышенными или заниженными.
Случайные ошибки репрезентативности обусловлены действием случайных факторов, не содержащих каких-либо элементов системности в направлении воздействия на рассчитываемые выборочные характеристики. Но даже при строгом соблюдении всех принципов формирования выборочной совокупности выборочные и генеральные характеристики будут несколько различаться. Получаемые случайные ошибки могут быть статистически оценены и учтены при распространении результатов выборочного наблюдения на всю генеральную совокупность. Оценка ошибок выборочного наблюдения основана на теоремах теории вероятностей.
При дальнейшем рассмотрении теории и методов выборочного наблюдения используются следующие общепринятые условные обозначения:
N ‑ объем (число единиц) генеральной совокупности;
n ‑ объем (число единиц) выборочной совокупности;
![]()
‑ генеральная средняя, т.е. среднее значение изучаемого признака по генеральной совокупности (средняя прибыль, средняя величина активов, средняя численность работников предприятия и т.п.);
![]()
‑ выборочная средняя,
т.е. среднее значение изучаемого признака по выборочной совокупности;
М ‑ численность единиц генеральной совокупности, обладающих определенным вариантом или вариантами изучаемого признака (численность городского населения, численность сельского населения, количество бракованных изделий, число нерентабельных предприятий и т.п.);
р ‑ генеральная доля, т.е. доля единиц, обладающих определенным вариантом или вариантами изучаемого признака, во всей генеральной совокупности (доля городского населения в общей численности населения, доля бракованной продукции в общем выпуске, доля нерентабельных предприятий в общей численности предприятий и т.п.); определяетcя как
m ‑ численность единиц выборочной совокупности, обладающих определенным вариантом или вариантами изучаемого признака;
w ‑ выборочная доля, т.е. доля единиц, обладающих определенным вариантом или вариантами изучаемого признака, в выборочной совокупности,
определяется как ;
![]()
‑ средняя ошибка выборки;
![]()
‑ предельная ошибка выборки;
![]()
‑ коэффициент доверия, определяемый в зависимости от уровня вероятности.
Ошибка выборки или отклонение выборочной средней от средней генеральной находится в прямой зависимости от дисперсии изучаемого признака в генеральной совокупности, и в обратной зависимости ‑ от объема выборки.
Таким образом среднюю ошибку выборки можно представить как

(10.1)
При проведении выборочного наблюдения дисперсия изучаемого признака в генеральной совокупности, как правило, не известна. В то же время, между генеральной дисперсией и средней из всех возможных выборочных дисперсий существует следующее соотношение:

(10.2)
В связи с тем, что на практике в большинстве случаев из генеральной совокупности в определенный момент времени производится только одна выборка, дисперсия изучаемого признака по этой выборке и используется при расчете ошибки.
Учитывая, что при достаточно большом объеме выборки отношение  близко к 1, формула средней ошибки повторной выборки принимает следующий вид:
близко к 1, формула средней ошибки повторной выборки принимает следующий вид:

(10.3)
Где ‑ ![]() дисперсия изучаемого признака по выборочной совокупности.
дисперсия изучаемого признака по выборочной совокупности.
При определении возможных границ значений характеристик генеральной совокупности рассчитывается предельная ошибка выборки, которая зависит от величины ее средней ошибки и уровня вероятности, с которым гарантируется, что генеральная средняя не выйдет за указанные границы.
Согласно теореме А.М. Ляпунова, вероятность той или иной величины предельной ошибки, при достаточно большом объеме выборочной совокупности, подчиняется нормальному закону распределения и может быть определена на основе интеграла Лапласа.
Значения интеграла Лапласа при различных величинах t табулированы и представлены в статистических справочниках.
При обобщении результатов выборочного наблюдения наиболее часто используются следующие уровни вероятности и соответствующие им значения t:
Таблица 10.1 ‑ !!!Некоторые значения t
| Вероятность, рi. | 0,683 | 0,866 | 0,954 | 0,988 | 0,997 | 0,999 |
| Значение t | 1,0 | 1,5 | 2,0 | 2,5 | 3,0 | 3,5 |
Например, если при расчете предельной ошибки выборки мы используем значение t=2, то с вероятностью 0,954 можно утверждать, что расхождение между выборочной средней и генеральной средней не превысит двукратной величины средней ошибки выборки.
Теоретической основой для определения границ генеральной доли, т.е. доли единиц, обладающих тем или иным вариантом признака, является теорема Вернули. Согласно данной теореме вероятность получения сколь угодно малого расхождения между выборочной долей и генеральной долей при достаточно большом объеме выборки будет стремиться к единице. С учетом того, что вероятность расхождения между выборочной и генеральной долями подчиняется нормальному закону распределения, эта вероятность также определяется по функции F(t) при заданном значении t.
Процесс подготовки и проведения выборочного наблюдения включает ряд последовательных этапов:
- Определение цели обследования.
- Установление границ генеральной совокупности.
- Составление программы наблюдения и программы разработки данных
- Определение вида выборки, процента отбора и метода отбора
- Отбор и регистрация наблюдаемых признаков у отобранных единиц.
- Насчет выборочных характеристик и их ошибок.
- Распространение полученных результатов на генеральную совокупность.
В зависимости от состава и структуры генеральной совокупности выбирается вид выборки или способ отбора.
К наиболее распространенным на практике видам относятся:
- собственно-случайная (простая случайная) выборка;
- механическая (систематическая) выборка;
- типическая (стратифицированная, расслоенная) выборка;
- серийная (гнездовая) выборка.
Отбор единиц из генеральной совокупности может быть комбинированным, многоступенчатым и многофазным.
Комбинированный отбор предполагает объединение нескольких видов выборки. Так, например, можно комбинировать типическую и серийную, серийную и собственно-случайную выборки. Ошибка такой выборки определяется ступенчатостью отбора.
Многоступенчатым называется отбор, при котором из генеральной совокупности сначала извлекаются укрупненные группы, потом ‑ более мелкие и так до тех пор, пока не будут отобраны те единицы, которые подвергаются обследованию.
Многофазная выборка, в отличие от многоступенчатой, предполагает сохранение одной и той же единицы отбора на всех этапах его проведения; при этом отобранные на каждой стадии единицы подвергаются обследованию, каждый раз – по более расширенной программе.
Собственно-случайная (простая случайная) выборка заключается в отборе единиц из генеральной совокупности наугад или наудачу без каких-либо элементов системности.
Однако прежде чем производить собственно-случайный отбор, необходимо убедиться, что все без исключения единицы генеральной совокупности имеют абсолютно равные шансы попадания в выборку, в списках или перечне отсутствуют пропуски, игнорирования отдельных единиц и т.п. Следует также установить четкие границы генеральной совокупности таким образом, чтобы включение или не включение в нее отдельных единиц не вызывало сомнений. Так, например, при обследовании студентов необходимо указать, будут ли приниматься во внимание лица, находящиеся в академическом отпуске, студенты негосударственных вузов, военных училищ и т.п.; при обследовании торговых предприятий важно определиться, включит ли генеральная совокупность торговые павильоны, коммерческие палатки и прочие подобные объекты.
Технически собственно-случайный отбор проводят методом жеребьевки или по таблице случайных чисел.
Расчет ошибок позволяет решить одну из главных проблем организации выборочного наблюдения – оценить репрезентативность (представительность) выборочной совокупности.
Различают среднюю и предельную ошибки выборки. Эти два вида связаны следующим соотношением:

(10.4)
Величина средней ошибки выборки рассчитывается дифференцированно в зависимости от способа отбора и процедуры выборки.
Так, при собственно-случайном повторном отборе средняя ошибка определяется по формуле:

(10.5)
а при расчете средней ошибки собственно-случайной бесповторной выборки:

(10.6)
Расчет средней и предельной ошибок выборки позволяет определить возможные пределы, в которых будут находиться характеристики генеральной совокупности.
Например, для выборочной средней такие пределы устанавливаются на основе следующих соотношений:

(10.7)
где ![]() и
и ![]() ‑ генеральная и выборочная средняя соответственно;
‑ генеральная и выборочная средняя соответственно;
![]() ‑ предельная ошибка выборочной средней.
‑ предельная ошибка выборочной средней.
Пример.
При проверке веса импортируемого груза на таможне методом случайной повторной выборки было отобрано 200 изделий. В результате был установлен средний вес изделия 30 г. при среднем квадратическом отклонении 4 г. С вероятностью 0,997 определите пределы, в которых находится средний вес изделия в генеральной совокупности.
Решение. Рассчитаем сначала предельную ошибку выборки. Так как при р = 0,997, t = 3, она равна:
Определим пределы генеральной средней:
 или
или

Вывод: Следовательно, с вероятностью 0,997 можно утверждать, что средний вес изделий в генеральной совокупности находится в пределах от 29,16 г. до 30,84 г.
Пример 2.
В городе проживает 250 тыс. семей. Для определения среднего числа детей в семье была организована 2%-ная случайная бесповторная выборка семей. По ее результатам было получено следующее распределение семей по числу детей:
Таблица 10.2 ‑ Распределение семей по числу детей в городе N
| Число детей в семье | 0 | 1 | 2 | 3 | 4 | 5 |
| Количество
семей |
1000 | 2000 | 1200 | 400 | 200 | 200 |
С вероятностью 0,954 определите пределы, в которых будет находиться среднее число детей в генеральной совокупности.
Решение. В начале на основе имеющегося распределения семей определим выборочные среднюю и дисперсию:
Таблица 10.3 ‑ Вспомогательная таблица для расчета среднего числа детей
|
Число детей в семье, х; |
Количество семей, f | ||||
|
0 1 2 3 4 5 |
1000 2000 1200 400 200 200 |
0
2000 2400 1200 800 1000 |
-1,5
-0,5 0,5 1,5 2,5 3,5 |
2,25
0,25 0,25 2,25 6,25 12,25 |
2250 500 300 900 1250 2450 |
|
Итого |
5000 | 7400 | – | – | 7650 |


Вычислим теперь предельную ошибку выборки (с учетом того, что при р = 0,954 t = 2).

Следовательно, пределы генеральной средней:

Таким образом, с вероятностью 0,954 можно утверждать, что среднее число детей в семьях города практически не отличается от 1,5, т.е. в среднем на каждые две семьи приходится три ребенка.
Наряду с определением ошибок выборки и пределов для генеральной средней эти же показатели могут быть определены для доли признака.
В этом случае особенности расчета связаны с определением дисперсии доли, которая вычисляется так:

(10.8)
где ![]() ‑ доля единиц, обладающих данным признаком в выборочной совокупности, определяемая как отношение количества соответствующих единиц к объему выборки.
‑ доля единиц, обладающих данным признаком в выборочной совокупности, определяемая как отношение количества соответствующих единиц к объему выборки.
Тогда, например, при собственно-случайном повторном отборе для определения предельной ошибки выборки используется следующая формула:

(10.9)
Соответственно, при бесповторном отборе:

(10.10)
Пределы доли признака в генеральной совокупности p выглядят следующим образом:

(10.11)
Рассмотрим пример.
С целью определения средней фактической продолжительности рабочего дня в государственном учреждении с численностью служащих 480 человек, в январе 2009 г. было проведена 25%-ная случайная бесповторная выборка. По результатам наблюдения оказалось, что у 10% обследованных потери времени достигали более 45 мин. в день. С вероятностью 0,683 установите пределы, в которых находится генеральная доля служащих с потерями рабочего времени более 45 мин. в день.
Решение. Определим объем выборочной совокупности:
n= 480 х 0,25 = 120 чел.
Выборочная доля w равна по условию 10%.
Учитывая, что при р = 0,683 t=1, вычислим предельную ошибку выборочной доли:

Пределы доли признака в генеральной совокупности:

Таким образом, с вероятностью 0,683 можно утверждать, что доля работников учреждения с потерями рабочего времени более 45 мин. в день находится в пределах от 7,6% до 12,4%.
Мы рассмотрели определение границ генеральной средней и генеральной доли по результатам уже проведенного выборочного наблюдения, при известном объеме выборки или проценте отбора. На этапе же проектирования выборочного наблюдения именно объем выборочной совокупности и требует определения.
Для определения необходимого объема собственно-случайной повторной выборки применяют следующую формулу:

(10.12)
Полученный на основе использования данной формулы результат всегда округляется в большую сторону. Например, если мы получили, что необходимый объем выборки составляет 493,1 единицы, то обследовав 493 единицы мы не достигнем требуемой точности. Поэтому, для достижения желаемого результата обследованием должны быть охвачены 494 единицы.
С другой стороны, рассчитанное значение необходимого объема выборки свободно может быть увеличено в большую сторону на несколько единиц. Если мы располагаем необходимыми ресурсами, если по причинам организационного порядка (компактность расположения единиц, фиксированная нагрузка на каждого регистратора и т.п.) мы вполне можем охватить больший объем, то включение в выборочную совокупность 500 или, например, 550 единиц только уменьшит значения полученных случайной и предельной ошибок.
При определении необходимого объема выборки для определения границ генеральной доли задача оценки вариации решается значительно проще. Если дисперсия изучаемого альтернативного признака неизвестна, то можно использовать ее максимальное возможное значение:

Например, предприятию связи с вероятностью 0,954 необходимо определить удельный вес телефонный разговоров продолжительностью менее 1 минуты с предельной ошибкой 2%. Сколько разговоров нужно обследовать в порядке собственно-случайного повторного отбора для решения этой задачи?
Для получения ответа на поставленный вопрос воспользуемся формулой (10.12) и будем ориентироваться на максимальную возможную дисперсию доли телефонных разговоров такой продолжительности. Расчет приводит к следующему результату:

Таким образом, обследованием должны быть охвачены не менее 2500 разговоров на предмет их продолжительности.
Необходимый объем собственно-случайной бесповторной выборки может быть определен по следующей формуле:

(10.13)
Укажем на одну особенность формулы (10.13). При проведении вычислений объем генеральной совокупности должен быть выражен только в единицах, а не в тысячах или в миллионах единиц.
Например, подставив в данную формулу общую численность населения региона, выраженную в тысячах человек, мы не получим правильное значение необходимой численности выборки, также выраженное в тысячах человек, как это иногда бывает в других расчетах. Результат вычислений будет неверен.
Механическая выборка может быть применена в тех случаях, когда генеральная совокупность каким-либо образом упорядочена, т.е. имеется определенная последовательность в расположении единиц (табельные номера работников, списки избирателей, телефонные номера респондентов, номера домов и квартир и т.п.). Для проведения отбора желательно, чтобы все единицы также имели порядковые номера от 1 до N.
Для проведения механической выборки устанавливается пропорция отбора, которая определяется соотнесением объемов выборочной и генеральной совокупностей.
Так, если из совокупности в 500000 единиц предполагается отобрать 10000 единиц, то пропорция отбора составит

Отбор единиц осуществляется в соответствии с установленной пропорцией через равные интервалы.
Например, при пропорции 1:50 (2%-ная выборка) отбирается каждая 50-я единица, при пропорции 1:20 (5%-ная выборка) – каждая 20-я единица и т.д.
Интервал отбора также можно определить как частное от деления 100% на установленный процент отбора.
Так, например при 2%-ном отборе интервал составит 50 (100%:2%), при 4%-ном отборе ‑ 25 (100%:4%). В тех случаях, когда результат деления получается дробным, сформировать выборку механическим способом при строгом соблюдении процента отбора не представляется возможным.
Например, по этой причине нельзя сформировать 3%-ную или 6%-ную выборки.
Генеральную совокупность при механическом отборе можно ранжировать или упорядочить по величине изучаемого или коррелирующего с ним признака, что позволит повысить репрезентативность выборки. Однако в этом случае возрастает опасность систематической ошибки, связанной с занижением значений изучаемого признака (если из каждого интервала регистрируется первое значение) или его завышением (если из каждого интервала регистрируется последнее значение). Поэтому целесообразно из каждого интервала отбирать центральную или одну из двух центральных единиц.
Например, при 5%-ной выборке интервал отбора составит 20 единиц, тогда отбор целесообразно начинать с 10-й или с 11-й единицы. В первом случае в выборку попадут 10, 30, 50, 70 и с таким же интервалом последующие единицы; во втором случае – единицы с номерами 11,31,51,71 и т.д.
При механической выборке также может появиться опасность систематической ошибки, обусловленной случайным совпадением выбранного интервала и циклических закономерностей в расположении единиц генеральной совокупности. Так, при переписи населения 1989 г. в ходе 25%-го выборочного обследования семей имела место опасность попадания в выборку квартир только одного типа (например, только однокомнатных или только трехкомнатных), так как на лестничных площадках многих типовых домов располагаются именно по 4 квартиры. Чтобы избежать систематической ошибки, в каждом новом подъезде счетчик менял начало отбора.
Для определения средней ошибки механической выборки, а также необходимой ее численности, используются соответствующие формулы, применяемые при собственно-случайном бесповторном отборе(10.6 и 10.13). При этом, определив необходимую численность выборки и сопоставив ее с объемом генеральной совокупности, как правило, приходится производить соответствующее округление для получения целочисленного интервала отбора.
Например, в области зарегистрировано 12000 фермерских хозяйств. Определим, сколько из них нужно отобрать в порядке механического отбора для определения средней площади сельхозугодий с ошибкой ± 2 га. (Р=0,997). По результатам ранее проведенного обследования известно, что среднее квадратическое отклонение площади сельхозугодий составляет 8 га. Произведем расчет, воспользовавшись формулой (10.13).

С учетом полученного необходимого объема выборки (143 фермерских хозяйства) определим интервал отбора: 12000:143=83,9.
Определенный таким способом интервал всегда округляется в меньшую сторону, так как при округлении в большую сторону произведенная выборка не достигнет рассчитанного по формуле необходимого объема.
Следовательно, в нашем примере, из общего списка фермерских хозяйств необходимо отобрать для обследования каждое 83-е хозяйство. При этом процент отбора составит 1,2% (100% : 83).
Типический отбор целесообразно использовать в тех случаях, когда все единицы генеральной совокупности объединены в несколько крупных типических групп.. Такие группы также называют стартами или слоями, в связи с чем типический отбор также называют стратифицированным или расслоенным. При обследованиях населения в качестве типических групп могут быть выбраны области, районы, социальные, возрастные или образовательные группы, при обследовании предприятий – отрасли или подотрасли, формы собственности и т.п.
Рассматривать генеральную совокупность в разрезе нескольких крупных групп единиц имеет смысл только в том случае, если средние значения изучаемых признаков по группам существенно различаются. Например, с большой уверенностью можно предположить, что доходы населения крупного города будут в среднем выше доходов населения, проживающего в сельской местности; численность работников промышленного предприятия в среднем будет выше численности работников торгового или сельскохозяйственного предприятия; средний возраст студентов будет значительно меньше среднего возраста занятого населения и, тем более, пенсионеров. В то же время, нет никакого смысла при выделении типических групп ориентироваться на признак, не связанный или очень слабо связанный с изучаемым.
Отбор единиц в выборочную совокупность из каждой типической группы осуществляется собственно-случайным или механическим способом. Поскольку в выборочную совокупность в той или иной пропорции обязательно попадают представители всех групп, типизация генеральной совокупности позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. В то же время, в выделенных типических группах обследуются далеко не все единицы, а только включенные в выборку. Следовательно, на величине полученной ошибки будет сказываться различие между единицами внутри этих групп, т.е. внутригрупповая вариация. Поэтому, ошибка типической выборки будет определяться величиной не общей дисперсии, а только ее части – средней из внутригрупповых дисперсий.
При типической выборке, пропорциональной объему типических групп, число единиц, подлежащих отбору из каждой группы, определяется следующим образом:

(10.14)
Где Ni – объем i-ой группы. а ni ‑ объем выборки из i-ой группы.
Пример. Предположим, общая численность населения области составляет 1,5 млн. чел., в том числе городское – 900 тыс. чел. и сельское – 600 тыс. чел. Если в ходе выборочного наблюдения планируется обследовать 100 тыс. жителей, то эта численность должна быть поделена пропорционально объему типических групп следующим образом:

Средняя ошибка типической выборки определяется по формулам:

(10.15)
 (10.16)
(10.16)
где ![]() – средняя из внутригрупповых дисперсий.
– средняя из внутригрупповых дисперсий.
При выборке, пропорциональной дифференциации признака, число наблюдений по каждой группе рассчитывается по формуле:

(10.17)
Где ![]() ‑ среднее отклонение признака в i-ой группе.
‑ среднее отклонение признака в i-ой группе.
Cредняя ошибка такого отбора определяется следующим образом:

(10.18)

(10.19)
Отбор, пропорциональный дифференциации признака, дает лучшие результаты, однако на практике его применение затруднено вследствие трудности получения сведений о вариации до проведения выборочного наблюдения.
Таблица 10.4 ‑ Результаты обследования рабочих предприятия
| Цех | Всего рабочих, человек | Обследовано, человек | Число дней временной нетрудоспособности за год | |
| средняя | дисперсия | |||
| I
II III |
1000
1400 800 |
100
140 80 |
18
12 15 |
49
25 16 |
Рассмотрим оба варианта типической выборки на условном примере. Предположим, 10% бесповторный типический отбор рабочих предприятия, пропорциональный размерам цехов, проведенный с целью оценки потерь из-за временной нетрудоспособности, привел к следующим результатам (табл. 10.4)
Рассчитаем среднюю из внутригрупповых дисперсий:

Определим среднюю и предельную ошибки выборки (с вероятностью 0,954):

Рассчитаем выборочную среднюю:

С вероятностью 0,954 можно сделать вывод, что среднее число дней временной нетрудоспособности одного рабочего в целом по предприятию находится в пределах:

Воспользуемся полученными внутригрупповыми дисперсиями для проведения отбора пропорционального дифференциации признака. Определим необходимый объем выборки по каждому цеху:


С учетом полученных значений рассчитаем среднюю ошибку выборки:

В данном случае средняя, а следовательно, и предельная ошибки будут несколько меньше, что отразится и на границах генеральной средней.
Серийный отбор. Данный способ отбора удобен в тех случаях, когда единицы совокупности объединены в небольшие группы или серии. В качестве таких серий могут рассматриваться упаковки с определенным количеством готовой продукции, партии товара, студенческие группы, бригады и другие объединения. Сущность серийной выборки заключается в собственно-случайном или механическом отборе серий, внутри которых производится сплошное обследование единиц.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка серийной выборки (при отборе равновеликих серий) зависит от величины только межгрупповой (межсерийной) дисперсии и определяется по следующим формулам:

(10.20)

(10.21)
Где r ‑ число отобранных серий; R ‑ общее число серий.
Межгрупповую дисперсию вычисляют следующим образом:
 (10.22)
(10.22)
где ![]() ‑ средняя i-й серии;
‑ средняя i-й серии;
![]() ‑ общая средняя по всей выборочной совокупности.
‑ общая средняя по всей выборочной совокупности.
Пример.
В области, состоящей из 20 районов, проводилось выборочное обследование урожайности на основе отбора серий (районов). Выборочные средние по районам составили соответственно 14,5 ц/га; 16 ц/га; 15,5 ц/га; 15 ц/га и 14 ц/га. С вероятностью 0,954 определите пределы урожайности во всей области.
Решение. Рассчитаем общую среднюю:

Межгрупповая (межсерийная) дисперсия равна:

Определим теперь предельную ошибку серийной бесповторной выборки (t = 2 при р = 0,954):

Вывод: Следовательно, урожайность будет с вероятностью 0,954 находиться в пределах:

Определение необходимого объема выборки
При проектировании выборочного наблюдения возникает вопрос о необходимой численности выборки. Эта численность может быть определена на базе допустимой ошибки при выборочном наблюдении, исходя из вероятности, на основе которой можно гарантировать величину устанавливаемой ошибки, и, наконец, на базе способа отбора.
Формулы необходимого объема выборки для различных способов формирования выборочной совокупности могут быть выведены из соответствующих соотношений, используемых при расчете предельных ошибок выборки. Приведем наиболее часто применяемые на практике выражения необходимого объема выборки:
– собственно-случайная и механическая выборка:

(10.23)

(10.24)
– типическая выборка:

(10.25)

(10.26)
– серийная выборка:

(10.27)

(10.28)
При этом в зависимости от целей исследования дисперсии и ошибки выборки могут быть рассчитаны для средней величины или доли признака.
Рассмотрим примеры определения необходимого объема выборки при различных способах формирования выборочной совокупности.
Пример.
В 100 туристических агентствах города предполагается провести обследование среднемесячного количества реализованных путевок методом механического отбора. Какова должна быть численность выборки, чтобы с вероятностью 0,683 ошибка не превышала 3 путевок, если по данным пробного обследования дисперсия составляет 225.
Решение. Рассчитаем необходимый объем выборки:

Пример.
С целью определения доли сотрудников коммерческих банков области в возрасте старше 40 лет предполагается организовать типическую выборку пропорциональную численности сотрудников мужского и женского пола с механическим отбором внутри групп. Общее число сотрудников банков составляет 12 тыс. чел., в том числе 7 тыс. мужчин и 5 тыс. женщин.
На основании предыдущих обследований известно, что средняя из внутригрупповых дисперсий составляет 1600. Определите необходимый объем выборки при вероятности 0,997 и ошибке 5%.
Решение. Рассчитаем общую численность типической выборки:

Вычислим теперь объем отдельных типических групп:

Вывод: Таким образом, необходимый объем выборочной совокупности сотрудников банков составляет 550 чел., в т.ч. 319 мужчин и 231 женщина.
Пример.
В акционерном обществе 200 бригад рабочих. Планируется проведение выборочного обследования с целью определения удельного веса рабочих, имеющих профессиональные заболевания. Известно, что межсерийная дисперсия доли равна 225. С вероятностью 0,954 рассчитайте необходимое количество бригад для обследования рабочих, если ошибка выборки не должна превышать 5%.
Решение. Необходимое количество бригад рассчитаем на основе формулы объема серийной бесповторной выборки:

Содержание курса лекций “Статистика”
Контрольные задания
Самостоятельно проведите выборочное наблюдение и произведите соответствующие расчеты.
Любое выборочное
наблюдение ставит своей задачей
определение среднего размера признака
или доли единиц, обладающих данным
признаком, и распространение полученных
характеристик выборочной совокупности
на генеральную совокупность.
Ошибки
репрезентативности
возникают вследствие различия структуры
выборочной и генеральной совокупности.
Структура генеральной
совокупности вполне однозначна, и ей
соответствует вполне определенное
значение среднего размера (или доли)
изучаемого признака. Выборочная же
совокупность формируется на основе
случайного отбора, в силу этого ее состав
отличается от состава генеральной
совокупности, отличается, естественно,
и значение среднего размера (или доли)
изучаемого признака.
Если из одной и той
же генеральной совокупности производится
несколько выборок, то в каждую из них
попадут разные единицы и, следовательно,
каждой выборочной совокупности будет
соответствовать своя средняя. Отсюда
следует важный вывод: выборочная
средняя, в отличие от генеральной, –
величина переменная. Переменной или
случайной величиной будет и ошибка
репрезентативности.
В практических
статистических работах выборочное
наблюдение проводится один раз, поэтому
фактически приходится иметь дело с
одной из множества выборочных средних,
но с какой именно – сказать невозможно.
Чтобы получить суждение о точности
результатов выборочного наблюдения,
математическая статистика дает формулу
средней ошибки,
т.е. средней величины из всех возможных
ошибок при бесчисленном множестве
случайных выборок.
При бесконечно
большом числе выборок получится кривая
частот, которая представляет кривую
выборочного распределения.
Рассмотрим
выборочное распределение средней
величины.
Такое распределение будет являться
нормальным или приближаться к нему по
мере увеличения объема выборки независимо
от того, имеет или не имеет нормальное
распределение та генеральная совокупность,
из которой взяты выборки. С увеличением
числа выборок средняя для всех выборок
будет приближаться к генеральной
средней. По выборочному распределению
может быть рассчитана средняя
квадратическая ошибка репрезентативности:
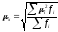 ,
,
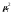 — квадрат ошибки
— квадрат ошибки
репрезентативности для i-й
выборки,
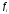 — число выборок с
— число выборок с
одинаковым значением выборочной средней.
Среднее квадратическое
отклонение выборочных средних от
генеральной средней называется средней
ошибкой выборочной средней (средней
ошибкой выборки для средней величины
признака):
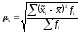 /
/
Поскольку, как
правило, генеральная средняя неизвестна,
этой формулой нельзя воспользоваться.
Кроме того, в социально-экономических
исследованиях выборки из одной и той
же совокупности не производятся
многократно. Поэтому используют
нижеприведенную формулу, исходя из
того, что средняя ошибка выборки зависит
от колеблемости признака в генеральной
совокупности и числа отобранных единиц.
Средняя ошибка
выборки для средней величины признака
определяется по формуле:
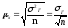 ,
,
где
2г
– дисперсия количественного признака
в генеральной совокупности.
Следовательно,
средняя ошибка выборки тем больше, чем
больше вариация в генеральной совокупности,
и тем меньше, чем больше объем выборки.
Т.о. можно утверждать,
что отклонение выборочной средней
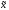 от генеральной средней
от генеральной средней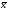 в среднем равно
в среднем равно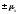 .
.
Ошибка конкретной выборки может принимать
различные значения, но ее отношение к
средней ошибке практически не превышает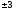 ,
,
если величина объема выборки достаточно
большая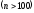 .
.
Отношение ошибки
конкретной выборки к средней квадратической
ошибке называется нормированным
отклонением
 :
: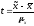 .
.
Распределение
нормированного отклонения выборочной
средней от генеральной средней при
численности выборки
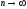 определяется следующим уравнением:
определяется следующим уравнением: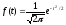 (1)
(1)
Данное уравнение
называют стандартным
уравнением нормальной кривой.
Величина
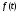 достигает максимума при
достигает максимума при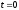 ,
,
в этом случае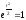 .
.
На рис. приведен
график кривой распределения нормированных
отклонений ошибок выборочных средних
 .
.
Рис.
Ординаты соответствуют
плотностям вероятности при том или ином
значении
 .
.
Для того, чтобы определить вероятность
значений в интервале от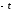 до
до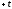 ,
,
следует найти отношение части площади
кривой, заключенной между ординатами,
соответствующими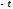 и
и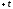 ко всей площади кривой. Вся площадь под
ко всей площади кривой. Вся площадь под
кривой нормального распределения
вероятностей принимается за единицу.
Площадь нормальной
кривой, заключенную между ординатами
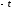 и
и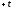 ,
,
определяют, интегрируя функцию (1) –интеграл
Лапласа.
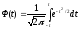
Имеются таблицы
интеграла Лапласа, которые содержат
значения вероятностей для нормированных
отклонений
 .
.
Значения функции Ф(t) табулированы при
разных значениях, например:
при t=1 P()
= Ф(1) = 0,683;
при t=2 P(2)
= Ф(2) = 0,9545;
при t=3 P(3)
= Ф(3) = 0,9973 и т.д.
Это вероятность
того, что ошибка попадет в заданные
пределы.
В общем виде
=t
характеризует
предельную
ошибку
выборки, показывающую максимально
возможное расхождение выборочной и
генеральной характеристик при
заданной вероятности
этого утверждения. Т.о. о величине ошибки
можно судить с определенной вероятностью.
Так, при t=2 возможная
ошибка
не превысит 2,
что гарантируется с вероятностью 0,9545.
Это значит, что в 9545 выборках из 10000
подобных максимальная ошибка не выйдет
за пределы 2
где
 – это коэффициент доверия.
– это коэффициент доверия.
При проведении
выборочного учета массовых
социально-экономических явлений
считается достаточным максимальный
размах ошибки выборки 3.
На практике наиболее
часто пользуются значениями вероятности
Р=0,95 (t=1,96), Р=0,99 (t=2,58) и Р=0,999 (t=3,28),
гарантирующими репрезентативность
выборки соответственно с ошибкой 5; 1;
0,1%.
Предельная ошибка
выборки позволяет определять предельные
значения характеристик генеральной
совокупности при заданной вероятности,
т.е. их доверительные
интервалы.
Поэтому вероятность
Р называется доверительной,
она представляет собой вероятность
того, что ошибка выборки не превысит
некоторую заданную величину ,
т.е. генеральная
средняя
находится где-то в пределах
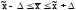 (от
(от
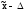 до
до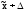 ),
),
генеральная доля
– в пределах
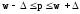 (от w–
(от w–
до w+).
Как мы определили
выше, средняя
ошибка выборки для средней величины
признака
определяется по формуле:
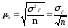 ,
,
где
2г
– дисперсия количественного признака
в генеральной совокупности.
Если при выборочном
наблюдении изучению подлежит альтернативный
признак, то средняя
ошибка выборки для доли единиц,
обладающих данным признаком, определяется
по теореме Я. Бернулли:
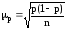 ,
,
где
p – доля единиц, обладающих данным
качеством, в генеральной совокупности;
p(1-p) – дисперсия альтернативного признака
в генеральной совокупности.
Приведенные формулы
средних ошибок выборки практически
непригодны для расчета. В них фигурирует
дисперсия признака в генеральной
совокупности, которая неизвестна, как
неизвестна и генеральная доля, генеральная
средняя. Поскольку в теории вероятности
доказано, что
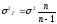 ,
,
то при большом
объеме выборки дисперсии генеральной
2г
и выборочной 2
совокупностей равны. (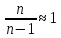 ).
).
Это дает основание исчислять среднюю
ошибку выборки по значениям выборочной
дисперсии2
для средней и w(1–w) для доли признака:
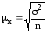 ,
,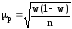 ,
,
где
w – доля признака в выборочной совокупности.
Наряду с абсолютной
величиной предельной ошибки выборки
рассчитывается и относительная
ошибка
выборки, которая определяется отношением
предельной ошибки средней или доли к
соответствующей характеристике
выборочной совокупности:
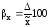 ;
;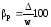 .
.
При проведении
выборочного наблюдения в экономических
исследованиях преимущественно стремятся
к тому, чтобы относительная ошибка
репрезентативности выборки не превышала
5 … 10%.
Вывод формул
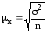 ,
,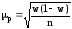 ,
,
исходит из схемы
повторной
выборки. На
практике повторная выборка, при которой
численность генеральной совокупности
остается неизменной (т.е.отобранная
единица возвращается в генеральную
совокупность и снова может быть отобрана),
встречается редко (например, при изучении
населения в качестве пользователей,
пациентов, избирателей).
Обычно отбор
организуется по схеме бесповторной
выборки, при которой отобранная единица
после обследования в генеральную
совокупность не возвращается и в
дальнейшей выборке не участвует.
При бесповторной
выборке численность генеральной
совокупности в процессе отбора сокращается
на
1–n/N, где n/N –
доля отобранных единиц.
В связи с этим
формулы ошибки выборки приобретают
следующий вид:
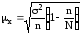 ;
;
 .
.
Так как доля единиц
генеральной совокупности, не попавших
в выборку (1–n/N), всегда меньше единицы,
то ошибка выборки при бесповторном
отборе при прочих равных условиях
меньше, чем при повторном отборе.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Содержание курса лекций “Статистика”
Выборочное наблюдение как источник статистической информации в изучении социально-экономических явлений и процессов
Статистическая методология исследования массовых явлений различает, как известно, два способа наблюдения в зависимости от полноты охвата объекта: сплошное и несплошное. Разновидностью несплошного наблюдения является выборочное, которое в условиях рыночных отношений в России находит все более широкое применение. Переход статистики РФ на международные стандарты системы национального счетоводства требует более широкого применения выборки для получения и анализа показателей СНС не только в промышленности, но и в других секторах экономики.
Под выборочным наблюдением понимается несплошное наблюдение, при котором статистическому обследованию (наблюдению) подвергаются единицы изучаемой совокупности, отобранные случайным способом. Выборочное наблюдение ставит перед собой задачу ‑ по обследуемой части дать характеристику всей совокупности единиц при условии соблюдения всех правил и принципов проведения статистического наблюдения и научно организованной работы по отбору единиц.
К выборочному наблюдению статистика прибегает по различным причинам. На современном этапе появилось множество субъектов хозяйственной деятельности, которые характерны для рыночной экономики. Речь идет об акционерных обществах, малых и совместных предприятиях, фермерских хозяйствах и т.д. Сплошное обследование этих статистических совокупностей, состоящих из десятков и сотен тысяч единиц, потребовало бы огромных материальных, финансовых и иных затрат. Использование же выборочного обследования позволяет значительно сэкономить силы и средства, что имеет немаловажное значение.
Наряду с экономией ресурсов одной из причин превращения выборочного наблюдения в важнейший источник статистической информации является возможность значительно ускорить получение необходимых данных. Ведь при обследовании, скажем, 10% единиц совокупности будет затрачено гораздо меньше времени, а результаты могут быть представлены быстрее, и будут более актуальными. Фактор времени важен для статистического исследования особенно в условиях изменяющейся социально-экономической ситуации.
Реализация выборочного метода базируется на понятиях генеральной и выборочной совокупностей.
Генеральной совокупностью называется вся исходная изучаемая статистическая совокупность, из которой на основе отбора единиц или групп единиц формируется совокупность выборочная. Поэтому генеральную совокупность также называют основой выборки.
Отбор единиц в выборочную совокупность может быть повторным или бесповторным.
При повторном отборе попавшая в выборку единица подвергается обследованию, т.е. регистрации значений ее признаков, возвращается в генеральную совокупность и наравне с другими единицами участвует в дальнейшей процедуре отбора. Таким образом, некоторые единицы могут попадать в выборку дважды, трижды или даже большее число раз. И при изучении выборочной совокупности они будут рассматриваться как отдельные независимые наблюдения.
Отметим, что число единиц генеральной совокупности, участвующих в отборе, при таком подходе остается постоянным. Поэтому вероятность попадания в выборку для всех единиц совокупности на протяжении всего процесса отбора также не меняется.
На практике методология повторного отбора обычно используется в тех случаях, когда объем генеральной совокупности не известен и теоретически возможно повторение единиц с уже встречавшимися значениями всех регистрируемых признаков.
Например, при проведении маркетинговых исследований мы не можем сколько-нибудь точно оценить, какое число потребителей предпочитают стиральный порошок конкретной торговой марки, сколько покупателей предпочитают делать покупки именно в данном супермаркете и т.д. Поэтому возможно повторение совершенно идентичных единиц как по причине практически неограниченных объемов совокупности, так и вследствие возможной повторной регистрации. Предположим, при проведении обследования один и тот же покупатель может дважды прийти в магазин и дважды подвергнуться обследованию.
При выборочном контроле качества продукции объем генеральной совокупности также часто не определен, так как процесс производства может осуществляться постоянно, каждый день дополняя генеральную совокупность новыми единицами-изделиями. Поэтому в выборочную совокупность могут попасть два и более изделий с абсолютно одинаковыми характеристиками. Следовательно, и в этом случае при обработке результатов выборки необходимо ориентироваться на методологию, используемую при повторном отборе.
При бесповоротном отборе попавшая в выборку единица подвергается обследованию и в дальнейшей процедуре отбора не участвует. Такой отбор целесообразен и практически возможен в тех случаях, когда объем генеральной совокупности четко определен. Получаемые при этом результаты, как правило, являются более точными по сравнению с результатами, основанными на повторной выборке.
Как уже отмечалось выше, выборочное наблюдение всегда связано с определенными ошибками получаемых характеристик. Эти ошибки называются ошибками репрезентативности (представительности).
Ошибки репрезентативности обусловлены тем обстоятельством, что выборочная совокупность не может по всем параметрам в точности воспроизвести совокупность генеральную. Получаемые расхождения или ошибки репрезентативности позволяют заключить, в какой степени попавшие в выборку единицы могут представлять всю генеральную совокупность. При этом следует различать систематические и случайные ошибки репрезентативности.
Систематические ошибки репрезентативности связаны с нарушением принципов формирования выборочной совокупности. Например, вследствие каких-либо причин, связанных с организацией отбора, в выборку попали единицы, характеризующиеся несколько большими или, наоборот, несколько меньшими по сравнению с другими единицами значениями наблюдаемых признаков. В этом случае и рассчитанные выборочные характеристики будут завышенными или заниженными.
Случайные ошибки репрезентативности обусловлены действием случайных факторов, не содержащих каких-либо элементов системности в направлении воздействия на рассчитываемые выборочные характеристики. Но даже при строгом соблюдении всех принципов формирования выборочной совокупности выборочные и генеральные характеристики будут несколько различаться. Получаемые случайные ошибки могут быть статистически оценены и учтены при распространении результатов выборочного наблюдения на всю генеральную совокупность. Оценка ошибок выборочного наблюдения основана на теоремах теории вероятностей.
При дальнейшем рассмотрении теории и методов выборочного наблюдения используются следующие общепринятые условные обозначения:
N ‑ объем (число единиц) генеральной совокупности;
n ‑ объем (число единиц) выборочной совокупности;
![]()
‑ генеральная средняя, т.е. среднее значение изучаемого признака по генеральной совокупности (средняя прибыль, средняя величина активов, средняя численность работников предприятия и т.п.);
![]()
‑ выборочная средняя,
т.е. среднее значение изучаемого признака по выборочной совокупности;
М ‑ численность единиц генеральной совокупности, обладающих определенным вариантом или вариантами изучаемого признака (численность городского населения, численность сельского населения, количество бракованных изделий, число нерентабельных предприятий и т.п.);
р ‑ генеральная доля, т.е. доля единиц, обладающих определенным вариантом или вариантами изучаемого признака, во всей генеральной совокупности (доля городского населения в общей численности населения, доля бракованной продукции в общем выпуске, доля нерентабельных предприятий в общей численности предприятий и т.п.); определяетcя как
m ‑ численность единиц выборочной совокупности, обладающих определенным вариантом или вариантами изучаемого признака;
w ‑ выборочная доля, т.е. доля единиц, обладающих определенным вариантом или вариантами изучаемого признака, в выборочной совокупности,
определяется как ;
![]()
‑ средняя ошибка выборки;
![]()
‑ предельная ошибка выборки;
![]()
‑ коэффициент доверия, определяемый в зависимости от уровня вероятности.
Ошибка выборки или отклонение выборочной средней от средней генеральной находится в прямой зависимости от дисперсии изучаемого признака в генеральной совокупности, и в обратной зависимости ‑ от объема выборки.
Таким образом среднюю ошибку выборки можно представить как
(10.1)
При проведении выборочного наблюдения дисперсия изучаемого признака в генеральной совокупности, как правило, не известна. В то же время, между генеральной дисперсией и средней из всех возможных выборочных дисперсий существует следующее соотношение:
(10.2)
В связи с тем, что на практике в большинстве случаев из генеральной совокупности в определенный момент времени производится только одна выборка, дисперсия изучаемого признака по этой выборке и используется при расчете ошибки.
Учитывая, что при достаточно большом объеме выборки отношение близко к 1, формула средней ошибки повторной выборки принимает следующий вид:
(10.3)
Где ‑ ![]() дисперсия изучаемого признака по выборочной совокупности.
дисперсия изучаемого признака по выборочной совокупности.
При определении возможных границ значений характеристик генеральной совокупности рассчитывается предельная ошибка выборки, которая зависит от величины ее средней ошибки и уровня вероятности, с которым гарантируется, что генеральная средняя не выйдет за указанные границы.
Согласно теореме А.М. Ляпунова, вероятность той или иной величины предельной ошибки, при достаточно большом объеме выборочной совокупности, подчиняется нормальному закону распределения и может быть определена на основе интеграла Лапласа.
Значения интеграла Лапласа при различных величинах t табулированы и представлены в статистических справочниках.
При обобщении результатов выборочного наблюдения наиболее часто используются следующие уровни вероятности и соответствующие им значения t:
Таблица 10.1 ‑ !!!Некоторые значения t
| Вероятность, рi. | 0,683 | 0,866 | 0,954 | 0,988 | 0,997 | 0,999 |
| Значение t | 1,0 | 1,5 | 2,0 | 2,5 | 3,0 | 3,5 |
Например, если при расчете предельной ошибки выборки мы используем значение t=2, то с вероятностью 0,954 можно утверждать, что расхождение между выборочной средней и генеральной средней не превысит двукратной величины средней ошибки выборки.
Теоретической основой для определения границ генеральной доли, т.е. доли единиц, обладающих тем или иным вариантом признака, является теорема Вернули. Согласно данной теореме вероятность получения сколь угодно малого расхождения между выборочной долей и генеральной долей при достаточно большом объеме выборки будет стремиться к единице. С учетом того, что вероятность расхождения между выборочной и генеральной долями подчиняется нормальному закону распределения, эта вероятность также определяется по функции F(t) при заданном значении t.
Процесс подготовки и проведения выборочного наблюдения включает ряд последовательных этапов:
- Определение цели обследования.
- Установление границ генеральной совокупности.
- Составление программы наблюдения и программы разработки данных
- Определение вида выборки, процента отбора и метода отбора
- Отбор и регистрация наблюдаемых признаков у отобранных единиц.
- Насчет выборочных характеристик и их ошибок.
- Распространение полученных результатов на генеральную совокупность.
В зависимости от состава и структуры генеральной совокупности выбирается вид выборки или способ отбора.
К наиболее распространенным на практике видам относятся:
- собственно-случайная (простая случайная) выборка;
- механическая (систематическая) выборка;
- типическая (стратифицированная, расслоенная) выборка;
- серийная (гнездовая) выборка.
Отбор единиц из генеральной совокупности может быть комбинированным, многоступенчатым и многофазным.
Комбинированный отбор предполагает объединение нескольких видов выборки. Так, например, можно комбинировать типическую и серийную, серийную и собственно-случайную выборки. Ошибка такой выборки определяется ступенчатостью отбора.
Многоступенчатым называется отбор, при котором из генеральной совокупности сначала извлекаются укрупненные группы, потом ‑ более мелкие и так до тех пор, пока не будут отобраны те единицы, которые подвергаются обследованию.
Многофазная выборка, в отличие от многоступенчатой, предполагает сохранение одной и той же единицы отбора на всех этапах его проведения; при этом отобранные на каждой стадии единицы подвергаются обследованию, каждый раз – по более расширенной программе.
Собственно-случайная (простая случайная) выборка заключается в отборе единиц из генеральной совокупности наугад или наудачу без каких-либо элементов системности.
Однако прежде чем производить собственно-случайный отбор, необходимо убедиться, что все без исключения единицы генеральной совокупности имеют абсолютно равные шансы попадания в выборку, в списках или перечне отсутствуют пропуски, игнорирования отдельных единиц и т.п. Следует также установить четкие границы генеральной совокупности таким образом, чтобы включение или не включение в нее отдельных единиц не вызывало сомнений. Так, например, при обследовании студентов необходимо указать, будут ли приниматься во внимание лица, находящиеся в академическом отпуске, студенты негосударственных вузов, военных училищ и т.п.; при обследовании торговых предприятий важно определиться, включит ли генеральная совокупность торговые павильоны, коммерческие палатки и прочие подобные объекты.
Технически собственно-случайный отбор проводят методом жеребьевки или по таблице случайных чисел.
Расчет ошибок позволяет решить одну из главных проблем организации выборочного наблюдения – оценить репрезентативность (представительность) выборочной совокупности.
Различают среднюю и предельную ошибки выборки. Эти два вида связаны следующим соотношением:
(10.4)
Величина средней ошибки выборки рассчитывается дифференцированно в зависимости от способа отбора и процедуры выборки.
Так, при собственно-случайном повторном отборе средняя ошибка определяется по формуле:
(10.5)
а при расчете средней ошибки собственно-случайной бесповторной выборки:
(10.6)
Расчет средней и предельной ошибок выборки позволяет определить возможные пределы, в которых будут находиться характеристики генеральной совокупности.
Например, для выборочной средней такие пределы устанавливаются на основе следующих соотношений:
(10.7)
где ![]() и
и ![]() ‑ генеральная и выборочная средняя соответственно;
‑ генеральная и выборочная средняя соответственно;
![]() ‑ предельная ошибка выборочной средней.
‑ предельная ошибка выборочной средней.
Пример.
При проверке веса импортируемого груза на таможне методом случайной повторной выборки было отобрано 200 изделий. В результате был установлен средний вес изделия 30 г. при среднем квадратическом отклонении 4 г. С вероятностью 0,997 определите пределы, в которых находится средний вес изделия в генеральной совокупности.
Решение. Рассчитаем сначала предельную ошибку выборки. Так как при р = 0,997, t = 3, она равна:
Определим пределы генеральной средней:
или
Вывод: Следовательно, с вероятностью 0,997 можно утверждать, что средний вес изделий в генеральной совокупности находится в пределах от 29,16 г. до 30,84 г.
Пример 2.
В городе проживает 250 тыс. семей. Для определения среднего числа детей в семье была организована 2%-ная случайная бесповторная выборка семей. По ее результатам было получено следующее распределение семей по числу детей:
Таблица 10.2 ‑ Распределение семей по числу детей в городе N
| Число детей в семье | 0 | 1 | 2 | 3 | 4 | 5 |
| Количество
семей |
1000 | 2000 | 1200 | 400 | 200 | 200 |
С вероятностью 0,954 определите пределы, в которых будет находиться среднее число детей в генеральной совокупности.
Решение. В начале на основе имеющегося распределения семей определим выборочные среднюю и дисперсию:
Таблица 10.3 ‑ Вспомогательная таблица для расчета среднего числа детей
|
Число детей в семье, х; |
Количество семей, f | ||||
|
0 1 2 3 4 5 |
1000 2000 1200 400 200 200 |
0
2000 2400 1200 800 1000 |
-1,5
-0,5 0,5 1,5 2,5 3,5 |
2,25
0,25 0,25 2,25 6,25 12,25 |
2250 500 300 900 1250 2450 |
|
Итого |
5000 | 7400 | – | – | 7650 |
Вычислим теперь предельную ошибку выборки (с учетом того, что при р = 0,954 t = 2).
Следовательно, пределы генеральной средней:
Таким образом, с вероятностью 0,954 можно утверждать, что среднее число детей в семьях города практически не отличается от 1,5, т.е. в среднем на каждые две семьи приходится три ребенка.
Наряду с определением ошибок выборки и пределов для генеральной средней эти же показатели могут быть определены для доли признака.
В этом случае особенности расчета связаны с определением дисперсии доли, которая вычисляется так:
(10.8)
где ![]() ‑ доля единиц, обладающих данным признаком в выборочной совокупности, определяемая как отношение количества соответствующих единиц к объему выборки.
‑ доля единиц, обладающих данным признаком в выборочной совокупности, определяемая как отношение количества соответствующих единиц к объему выборки.
Тогда, например, при собственно-случайном повторном отборе для определения предельной ошибки выборки используется следующая формула:
(10.9)
Соответственно, при бесповторном отборе:
(10.10)
Пределы доли признака в генеральной совокупности p выглядят следующим образом:
(10.11)
Рассмотрим пример.
С целью определения средней фактической продолжительности рабочего дня в государственном учреждении с численностью служащих 480 человек, в январе 2009 г. было проведена 25%-ная случайная бесповторная выборка. По результатам наблюдения оказалось, что у 10% обследованных потери времени достигали более 45 мин. в день. С вероятностью 0,683 установите пределы, в которых находится генеральная доля служащих с потерями рабочего времени более 45 мин. в день.
Решение. Определим объем выборочной совокупности:
n= 480 х 0,25 = 120 чел.
Выборочная доля w равна по условию 10%.
Учитывая, что при р = 0,683 t=1, вычислим предельную ошибку выборочной доли:
Пределы доли признака в генеральной совокупности:
Таким образом, с вероятностью 0,683 можно утверждать, что доля работников учреждения с потерями рабочего времени более 45 мин. в день находится в пределах от 7,6% до 12,4%.
Мы рассмотрели определение границ генеральной средней и генеральной доли по результатам уже проведенного выборочного наблюдения, при известном объеме выборки или проценте отбора. На этапе же проектирования выборочного наблюдения именно объем выборочной совокупности и требует определения.
Для определения необходимого объема собственно-случайной повторной выборки применяют следующую формулу:
(10.12)
Полученный на основе использования данной формулы результат всегда округляется в большую сторону. Например, если мы получили, что необходимый объем выборки составляет 493,1 единицы, то обследовав 493 единицы мы не достигнем требуемой точности. Поэтому, для достижения желаемого результата обследованием должны быть охвачены 494 единицы.
С другой стороны, рассчитанное значение необходимого объема выборки свободно может быть увеличено в большую сторону на несколько единиц. Если мы располагаем необходимыми ресурсами, если по причинам организационного порядка (компактность расположения единиц, фиксированная нагрузка на каждого регистратора и т.п.) мы вполне можем охватить больший объем, то включение в выборочную совокупность 500 или, например, 550 единиц только уменьшит значения полученных случайной и предельной ошибок.
При определении необходимого объема выборки для определения границ генеральной доли задача оценки вариации решается значительно проще. Если дисперсия изучаемого альтернативного признака неизвестна, то можно использовать ее максимальное возможное значение:
Например, предприятию связи с вероятностью 0,954 необходимо определить удельный вес телефонный разговоров продолжительностью менее 1 минуты с предельной ошибкой 2%. Сколько разговоров нужно обследовать в порядке собственно-случайного повторного отбора для решения этой задачи?
Для получения ответа на поставленный вопрос воспользуемся формулой (10.12) и будем ориентироваться на максимальную возможную дисперсию доли телефонных разговоров такой продолжительности. Расчет приводит к следующему результату:
Таким образом, обследованием должны быть охвачены не менее 2500 разговоров на предмет их продолжительности.
Необходимый объем собственно-случайной бесповторной выборки может быть определен по следующей формуле:
(10.13)
Укажем на одну особенность формулы (10.13). При проведении вычислений объем генеральной совокупности должен быть выражен только в единицах, а не в тысячах или в миллионах единиц.
Например, подставив в данную формулу общую численность населения региона, выраженную в тысячах человек, мы не получим правильное значение необходимой численности выборки, также выраженное в тысячах человек, как это иногда бывает в других расчетах. Результат вычислений будет неверен.
Механическая выборка может быть применена в тех случаях, когда генеральная совокупность каким-либо образом упорядочена, т.е. имеется определенная последовательность в расположении единиц (табельные номера работников, списки избирателей, телефонные номера респондентов, номера домов и квартир и т.п.). Для проведения отбора желательно, чтобы все единицы также имели порядковые номера от 1 до N.
Для проведения механической выборки устанавливается пропорция отбора, которая определяется соотнесением объемов выборочной и генеральной совокупностей.
Так, если из совокупности в 500000 единиц предполагается отобрать 10000 единиц, то пропорция отбора составит
Отбор единиц осуществляется в соответствии с установленной пропорцией через равные интервалы.
Например, при пропорции 1:50 (2%-ная выборка) отбирается каждая 50-я единица, при пропорции 1:20 (5%-ная выборка) – каждая 20-я единица и т.д.
Интервал отбора также можно определить как частное от деления 100% на установленный процент отбора.
Так, например при 2%-ном отборе интервал составит 50 (100%:2%), при 4%-ном отборе ‑ 25 (100%:4%). В тех случаях, когда результат деления получается дробным, сформировать выборку механическим способом при строгом соблюдении процента отбора не представляется возможным.
Например, по этой причине нельзя сформировать 3%-ную или 6%-ную выборки.
Генеральную совокупность при механическом отборе можно ранжировать или упорядочить по величине изучаемого или коррелирующего с ним признака, что позволит повысить репрезентативность выборки. Однако в этом случае возрастает опасность систематической ошибки, связанной с занижением значений изучаемого признака (если из каждого интервала регистрируется первое значение) или его завышением (если из каждого интервала регистрируется последнее значение). Поэтому целесообразно из каждого интервала отбирать центральную или одну из двух центральных единиц.
Например, при 5%-ной выборке интервал отбора составит 20 единиц, тогда отбор целесообразно начинать с 10-й или с 11-й единицы. В первом случае в выборку попадут 10, 30, 50, 70 и с таким же интервалом последующие единицы; во втором случае – единицы с номерами 11,31,51,71 и т.д.
При механической выборке также может появиться опасность систематической ошибки, обусловленной случайным совпадением выбранного интервала и циклических закономерностей в расположении единиц генеральной совокупности. Так, при переписи населения 1989 г. в ходе 25%-го выборочного обследования семей имела место опасность попадания в выборку квартир только одного типа (например, только однокомнатных или только трехкомнатных), так как на лестничных площадках многих типовых домов располагаются именно по 4 квартиры. Чтобы избежать систематической ошибки, в каждом новом подъезде счетчик менял начало отбора.
Для определения средней ошибки механической выборки, а также необходимой ее численности, используются соответствующие формулы, применяемые при собственно-случайном бесповторном отборе(10.6 и 10.13). При этом, определив необходимую численность выборки и сопоставив ее с объемом генеральной совокупности, как правило, приходится производить соответствующее округление для получения целочисленного интервала отбора.
Например, в области зарегистрировано 12000 фермерских хозяйств. Определим, сколько из них нужно отобрать в порядке механического отбора для определения средней площади сельхозугодий с ошибкой ± 2 га. (Р=0,997). По результатам ранее проведенного обследования известно, что среднее квадратическое отклонение площади сельхозугодий составляет 8 га. Произведем расчет, воспользовавшись формулой (10.13).
С учетом полученного необходимого объема выборки (143 фермерских хозяйства) определим интервал отбора: 12000:143=83,9.
Определенный таким способом интервал всегда округляется в меньшую сторону, так как при округлении в большую сторону произведенная выборка не достигнет рассчитанного по формуле необходимого объема.
Следовательно, в нашем примере, из общего списка фермерских хозяйств необходимо отобрать для обследования каждое 83-е хозяйство. При этом процент отбора составит 1,2% (100% : 83).
Типический отбор целесообразно использовать в тех случаях, когда все единицы генеральной совокупности объединены в несколько крупных типических групп.. Такие группы также называют стартами или слоями, в связи с чем типический отбор также называют стратифицированным или расслоенным. При обследованиях населения в качестве типических групп могут быть выбраны области, районы, социальные, возрастные или образовательные группы, при обследовании предприятий – отрасли или подотрасли, формы собственности и т.п.
Рассматривать генеральную совокупность в разрезе нескольких крупных групп единиц имеет смысл только в том случае, если средние значения изучаемых признаков по группам существенно различаются. Например, с большой уверенностью можно предположить, что доходы населения крупного города будут в среднем выше доходов населения, проживающего в сельской местности; численность работников промышленного предприятия в среднем будет выше численности работников торгового или сельскохозяйственного предприятия; средний возраст студентов будет значительно меньше среднего возраста занятого населения и, тем более, пенсионеров. В то же время, нет никакого смысла при выделении типических групп ориентироваться на признак, не связанный или очень слабо связанный с изучаемым.
Отбор единиц в выборочную совокупность из каждой типической группы осуществляется собственно-случайным или механическим способом. Поскольку в выборочную совокупность в той или иной пропорции обязательно попадают представители всех групп, типизация генеральной совокупности позволяет исключить влияние межгрупповой дисперсии на среднюю ошибку выборки. В то же время, в выделенных типических группах обследуются далеко не все единицы, а только включенные в выборку. Следовательно, на величине полученной ошибки будет сказываться различие между единицами внутри этих групп, т.е. внутригрупповая вариация. Поэтому, ошибка типической выборки будет определяться величиной не общей дисперсии, а только ее части – средней из внутригрупповых дисперсий.
При типической выборке, пропорциональной объему типических групп, число единиц, подлежащих отбору из каждой группы, определяется следующим образом:
(10.14)
Где Ni – объем i-ой группы. а ni ‑ объем выборки из i-ой группы.
Пример. Предположим, общая численность населения области составляет 1,5 млн. чел., в том числе городское – 900 тыс. чел. и сельское – 600 тыс. чел. Если в ходе выборочного наблюдения планируется обследовать 100 тыс. жителей, то эта численность должна быть поделена пропорционально объему типических групп следующим образом:
Средняя ошибка типической выборки определяется по формулам:
(10.15)
(10.16)
где ![]() – средняя из внутригрупповых дисперсий.
– средняя из внутригрупповых дисперсий.
При выборке, пропорциональной дифференциации признака, число наблюдений по каждой группе рассчитывается по формуле:
(10.17)
Где ![]() ‑ среднее отклонение признака в i-ой группе.
‑ среднее отклонение признака в i-ой группе.
Cредняя ошибка такого отбора определяется следующим образом:
(10.18)
(10.19)
Отбор, пропорциональный дифференциации признака, дает лучшие результаты, однако на практике его применение затруднено вследствие трудности получения сведений о вариации до проведения выборочного наблюдения.
Таблица 10.4 ‑ Результаты обследования рабочих предприятия
| Цех | Всего рабочих, человек | Обследовано, человек | Число дней временной нетрудоспособности за год | |
| средняя | дисперсия | |||
| I
II III |
1000
1400 800 |
100
140 80 |
18
12 15 |
49
25 16 |
Рассмотрим оба варианта типической выборки на условном примере. Предположим, 10% бесповторный типический отбор рабочих предприятия, пропорциональный размерам цехов, проведенный с целью оценки потерь из-за временной нетрудоспособности, привел к следующим результатам (табл. 10.4)
Рассчитаем среднюю из внутригрупповых дисперсий:
Определим среднюю и предельную ошибки выборки (с вероятностью 0,954):
Рассчитаем выборочную среднюю:
С вероятностью 0,954 можно сделать вывод, что среднее число дней временной нетрудоспособности одного рабочего в целом по предприятию находится в пределах:
Воспользуемся полученными внутригрупповыми дисперсиями для проведения отбора пропорционального дифференциации признака. Определим необходимый объем выборки по каждому цеху:
С учетом полученных значений рассчитаем среднюю ошибку выборки:
В данном случае средняя, а следовательно, и предельная ошибки будут несколько меньше, что отразится и на границах генеральной средней.
Серийный отбор. Данный способ отбора удобен в тех случаях, когда единицы совокупности объединены в небольшие группы или серии. В качестве таких серий могут рассматриваться упаковки с определенным количеством готовой продукции, партии товара, студенческие группы, бригады и другие объединения. Сущность серийной выборки заключается в собственно-случайном или механическом отборе серий, внутри которых производится сплошное обследование единиц.
Поскольку внутри групп (серий) обследуются все без исключения единицы, средняя ошибка серийной выборки (при отборе равновеликих серий) зависит от величины только межгрупповой (межсерийной) дисперсии и определяется по следующим формулам:
(10.20)
(10.21)
Где r ‑ число отобранных серий; R ‑ общее число серий.
Межгрупповую дисперсию вычисляют следующим образом:
(10.22)
где ![]() ‑ средняя i-й серии;
‑ средняя i-й серии;
![]() ‑ общая средняя по всей выборочной совокупности.
‑ общая средняя по всей выборочной совокупности.
Пример.
В области, состоящей из 20 районов, проводилось выборочное обследование урожайности на основе отбора серий (районов). Выборочные средние по районам составили соответственно 14,5 ц/га; 16 ц/га; 15,5 ц/га; 15 ц/га и 14 ц/га. С вероятностью 0,954 определите пределы урожайности во всей области.
Решение. Рассчитаем общую среднюю:
Межгрупповая (межсерийная) дисперсия равна:
Определим теперь предельную ошибку серийной бесповторной выборки (t = 2 при р = 0,954):
Вывод: Следовательно, урожайность будет с вероятностью 0,954 находиться в пределах:
Определение необходимого объема выборки
При проектировании выборочного наблюдения возникает вопрос о необходимой численности выборки. Эта численность может быть определена на базе допустимой ошибки при выборочном наблюдении, исходя из вероятности, на основе которой можно гарантировать величину устанавливаемой ошибки, и, наконец, на базе способа отбора.
Формулы необходимого объема выборки для различных способов формирования выборочной совокупности могут быть выведены из соответствующих соотношений, используемых при расчете предельных ошибок выборки. Приведем наиболее часто применяемые на практике выражения необходимого объема выборки:
– собственно-случайная и механическая выборка:
(10.23)
(10.24)
– типическая выборка:
(10.25)
(10.26)
– серийная выборка:
(10.27)
(10.28)
При этом в зависимости от целей исследования дисперсии и ошибки выборки могут быть рассчитаны для средней величины или доли признака.
Рассмотрим примеры определения необходимого объема выборки при различных способах формирования выборочной совокупности.
Пример.
В 100 туристических агентствах города предполагается провести обследование среднемесячного количества реализованных путевок методом механического отбора. Какова должна быть численность выборки, чтобы с вероятностью 0,683 ошибка не превышала 3 путевок, если по данным пробного обследования дисперсия составляет 225.
Решение. Рассчитаем необходимый объем выборки:
Пример.
С целью определения доли сотрудников коммерческих банков области в возрасте старше 40 лет предполагается организовать типическую выборку пропорциональную численности сотрудников мужского и женского пола с механическим отбором внутри групп. Общее число сотрудников банков составляет 12 тыс. чел., в том числе 7 тыс. мужчин и 5 тыс. женщин.
На основании предыдущих обследований известно, что средняя из внутригрупповых дисперсий составляет 1600. Определите необходимый объем выборки при вероятности 0,997 и ошибке 5%.
Решение. Рассчитаем общую численность типической выборки:
Вычислим теперь объем отдельных типических групп:
Вывод: Таким образом, необходимый объем выборочной совокупности сотрудников банков составляет 550 чел., в т.ч. 319 мужчин и 231 женщина.
Пример.
В акционерном обществе 200 бригад рабочих. Планируется проведение выборочного обследования с целью определения удельного веса рабочих, имеющих профессиональные заболевания. Известно, что межсерийная дисперсия доли равна 225. С вероятностью 0,954 рассчитайте необходимое количество бригад для обследования рабочих, если ошибка выборки не должна превышать 5%.
Решение. Необходимое количество бригад рассчитаем на основе формулы объема серийной бесповторной выборки:
Содержание курса лекций “Статистика”
Контрольные задания
Самостоятельно проведите выборочное наблюдение и произведите соответствующие расчеты.
Согласно теории выборочного метода, неоднократно подтвержденной практикой, опрашивать всех нет необходимости, а можно опросить лишь часть группы, которая может быть в тысячи раз меньше. Эта маленькая часть называется выборкой (или выборочной совокупностью), а большая группа, которую она представляет, называется генеральной совокупностью.
При этом если выборка сформирована правильно, выводы, полученные на основе изучения выборки, могут быть перенесены и на генеральную совокупность. Например, если в выборке женщины значимо чаще, чем мужчины, пользуются дезодорантами, то делается вывод, что и в генеральной совокупности (например, в исследованном городе) присутствует такая закономерность.
Процесс переноса выводов с выборки на генеральную совокупность называется генерализацией. А свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Для более комфортного запоминания термина на рис.1.
приведены иллюстрации, когда выборка отражает свойства генеральной совокупности и когда свойства выборки отличаются от свойств генеральной совокупности.



Рис.1. Иллюстративные примеры соответствия (несоответствия) свойств генеральной совокупности и выборки
Не стоит путать понятие репрезентативности с такими понятиями как валидность и релевантность, хотя они тоже относятся к характеристикам качества исследования. В социальных науках валидность понимается довольно широко, но чаще всего – как обоснованность.
Понятие валидности относится не к выборке, а к исследовательской методике. Методика или измерение (анкета, блок вопросов, тест) считается валидным, если фиксирует именно то понятие или свойство, которое планируется измерить.
Например, если мы захотим оценить уровень лояльности клиента к магазину и выберем для этого лишь показатель частоты посещения магазина, валидность этого подхода будет неполной: возможно, респондент часто заходит в магазин только из-за банкомата, который там установлен.
Валидная методика в данном примере должна включать и другие показатели: предпочтение магазина, суммы покупок в этом и других магазинах, готовность переключиться на другие магазины, готовность рекомендовать магазин и др.
При установлении валидности решающую роль играет обоснование и последующая проверка гипотезы релевантности, то есть соответствия измеряемых параметров характеристикам исследуемого объекта.
Житейский пример нерелевантности – измерять уровень счастья человека количеством денег у него (хотя, наверное, не все с этим согласятся).
Очевидный пример нерелевантности – попытка измерить массу тела по его температуре.
Но вернемся к понятию репрезентативности. В то время как точность измерений зависит от размера выборки, размер выборки не гарантирует ее репрезентативности.
Репрезентативность выборки главным образом обеспечивается способом отбора ее участников (респондентов).
Примером явного нарушения репрезентативности может послужить шутка о том, что интернет-опрос показал, что 100% людей пользуется интернетом.
Можно выделить несколько вариантов нарушения репрезентативности выборки: когда опрошены не те люди и когда опрошено слишком много (или мало) определенных людей (например, женщин намного больше, чем мужчин). Кроме того, чем меньше размер выборки, тем меньше вероятность того, что она будет репрезентативной. Например, допустим, 1% населения мог бы заинтересоваться новой услугой.
Это 1 из 100 людей. Если размер выборки составляет всего 60 человек, то в вашей выборке может отсутствовать человек, который, скорее всего, будет заинтересован в услуге. Ваша выборка менее репрезентативна, потому что она меньше. Ваши результаты будут разными в зависимости от того, содержит ли ваша выборка одного из этих людей или нет.
Пример репрезентативной и нерепрезентативной выборки показан на рис.2.

Рис.2. Пример репрезентативной и нерепрезентативной выборки
На рис.3 показана та же по составу генеральная совокупность, но с другим расположением объектов внутри круга.

Рис.3. Пример репрезентативной и нерепрезентативной выборки при другом расположении объектов генеральной совокупности
Говоря простым языком, репрезентативная выборка – это такая выборка, в которой представлены все подгруппы, важные для исследования. Помимо этого, характер распределения рассматриваемых параметров в выборке должен быть таким же, как в генеральной совокупности.
Простой случайный отбор респондентов представляется оптимальным способом формирования репрезентативной выборки.
Поскольку в этом случае у любого представителя генеральной совокупности одинаковая вероятность попасть в выборку, в нее попадут люди с разными характеристиками пропорционально их долям в генеральной совокупности.
В итоге выборка будет представлять собой нечто вроде уменьшенной копии генеральной совокупности.
Случайность отбора респондентов в выборку обеспечивается разными способами.
Например, для телефонного опроса жителей города берется база данных всех телефонных номеров, и номера респондентов случайным образом выбираются компьютером (с использованием генератора случайных чисел).
При уличном опросе интервьюеров распределяют по случайно выбранным точкам и инструктируют опрашивать каждого N-ного прохожего.
Наглядным примером репрезентативной выборки может служить пицца. Если целая пицца – это генеральная совокупность, которую мы хотим изучить, то кусок пиццы – это выборка.
Как правило, достаточно одного куска пиццы, чтобы судить обо всей пицце (при условии, что ингредиенты равномерно распределены по ее поверхности). Таким образом, кусок пиццы пиццы на рис.
4 – это репрезентативная выборка из пиццы.

Рис.4. Наглядный пример репрезентативной выборки (пицца)
Важно отметить, что не любой кусок пиццы будет репрезентативной выборкой. Разные способы получения куска пиццы могут принципиально повлиять на качество исследования и выводы, которые будут получены при анализе каждого варианта выборки (рис.4)
(рисунок в сушильной камере, готовится к публикации)
Рис.5. Наглядный пример формирования репрезентативной и нерепрезентативной выборки.
Еще один показательный пример формирования репрезентативной выборки – кастрюля, содержимое которой мы должны узнать (допустим, там скрывается борщ). Мы только один раз можем зачерпнуть из кастрюли ложкой (провести исследование). В нашем примере ложка – это выборка, а содержимое кастрюли – генеральная совокупность.
Если мы зачерпнем сверху, то придем к выводу, что в кастрюле бульон. Если снизу – решим, что в кастрюле мясо. Зачерпнув где-то посередине, мы получим картошку или капусту. В любом из трех случаев выводы будут неверны.
Чтобы получить достоверный результат, нам стоит хорошенько перемешать содержимое кастрюли, перед тем как пробовать его.
Перемешивание в данном случае – аналог процедуры простого случайного отбора, поскольку оно предоставляет всем ингредиентам примерно равную вероятность попадания в ложку-выборку (или тарелку-выборку).

Рис.6. Борщ как модель, демонстрирующая репрезентативность выборки.
В реальности применить простой случайный отбор респондентов не всегда удается в полной мере. Например, мы можем абсолютно корректно отобрать в выборку нужное количество номеров домашних телефонов случайным образом, но при их прозвоне выяснится, что дозвониться и поговорить удается преимущественно с пенсионерами, а «поймать» дома молодежь и работающих людей получается плохо.
Возвращаясь к примеру с борщом, если у нас вместо кастрюли – огромный ресторанный котел, а в руках все та же обычная ложка, перемешивание будет неэффективным. Чтобы решить задачу, потребуются иные подходы.
Например, мы можем теоретически разделить глубину котла на несколько слоев и постараться зачерпнуть содержимое из каждого слоя (из случайного места слоя: не только в центре, но и по краям). Таким образом, наша итоговая выборка будет состоять уже из нескольких выборок и при этом адекватно отражать содержимое всех слоев котла.
Подобные альтернативные подходы называются типами выборки, которых придумано достаточно много для того, чтобы максимизировать репрезентативность выборки в сложных условиях реального мира.
Последствия нарушения репрезентативности выборки: некорректные выводы исследования, выброшенный на ветер бюджет исследования, финансовые потери вследствие применения неправильных выводов.
Вы можете выбрать валидную исследовательскую методику, рассчитать объем выборки, обеспечивающий приемлемую точность измерений, но, если выборка исследования нерепрезентативна, получить достоверную информацию не удастся.
- ПРИМЕРЫ НАРУШЕНИЯ РЕПРЕЗЕНТАТИВНОСТИ ВЫБОРКИ
- ПРЕДВЫБОРНЫЙ ОПРОС
- Самым известным примером нарушения репрезентативности выборки является история провала американского журнала «Литературный дайджест».
В 1936 году журнал в очередной раз провел почтовый опрос общественного мнения о вероятных результатах грядущих президентских выборов в США. До 1936 года опрос всегда правильно предсказывал победителя. Опрос 1936 года показал, что победителем с большим отрывом станет кандидат от республиканцев, но в итоге победителем оказался представитель демократов.
Таким образом, гигантская выборка (около 2,4 млн. человек) не обеспечила достоверных результатов. В чем же заключалась причина ошибки?
Называются две основные причины провала: смещение при формировании выборки и смещение вследствие отказа респондентов от участия в опросе.
Прежде всего, журнал включил своих подписчиков в список для рассылки анкет и, желая расширить выборку, использовал два других доступных тогда списка граждан: зарегистрированных автовладельцев и пользователей телефонов.
Во времена Великой Депрессии представители этих групп отличались от остального населения более высоким доходом, как и подписчики самого журнала.
Таким образом, полученная база для рассылки не являлась корректным отражением структуры населения США.
Вторая проблема с опросом заключалась в том, что из 10 миллионов человек, чьи имена были в первоначальном списке рассылки, только 2,4 миллиона ответили на опрос. Вероятно, высокий процент отказов был связан с тем, что опрос проводился по почте.
Уже в те времена американцы относились к почтовым рассылкам как к спаму. Таким образом, размер выборки составил примерно одну четверть от того, что первоначально планировалось.
Когда доля ответивших низка (как это было в данном случае), считается, что исследование страдает от необъективности ответов.
У этой истории две морали: Большая, но неправильно сформированная выборка гораздо хуже маленькой, но правильно сформированной выборки. При проведении опроса не упускайте из внимания смещение отбора и смещение в результате отказов.
СИСТЕМАТИЧЕСКАЯ ОШИБКА ВЫЖИВШЕГО
Пример из военной практики. Во Вторую мировую войну американские военные столкнулись со следующей проблемой. Не все американские бомбардировщики после задания возвращались на базу.
На вернувшихся самолетах оставалось множество пробоин от выстрелов противника, но распределены они были неравномерно: больше всего на фюзеляже и прочих частях, меньше в топливной системе и гораздо меньше — в двигателе.
Командованию казалось логичным, что в наиболее поврежденных местах нужно установить больше брони. Привлеченный к решению задачи математик возразил: данные как раз показывают, что самолет, получивший пробоины в этих местах, еще может вернуться на базу.
А самолет, которому попали в бензобак или двигатель, выходит из строя и не возвращается. Поэтому укреплять следует те места, которые у вернувшихся самолетов повреждены меньше всего.

Рис .7. Пробоины на вернувшихся самолётах. Получившие повреждения в других местах не смогли вернуться на базу
Эта задача служит примером нарушения репрезентативности выборки, когда в нее включены не те респонденты: в данном случае, вернувшиеся самолеты, в то время как не вернувшиеся проигнорированы.
Применительно к маркетинговым исследованиям, эта ситуация подобна следующей. При опросе клиентов бизнеса будет ошибкой опрашивать только текущих клиентов и не опрашивать потерянных клиентов (а какие «пробоины» получили они?).
НЕПРАВИЛЬНЫЕ МЕСТА ОПРОСА
При опросе посетителей ТРЦ важно правильно расставить интервьюеров. Например, если поставить интервьюеров только у главного входа, в выборку не попадут посетители, приехавшие в ТРЦ на автомобиле и попавшие в него через парковку.
Как следствие, выводы, полученные на собранных данных, будут корректны только для той части посетителей, которые приходят в ТРЦ пешком, а значит, делают меньше покупок, не покупают габаритные товары, живут ближе к ТРЦ, чем приезжающие на автомобиле.
ОТСУТСТВИЕ КВОТИРОВАНИЯ
Другой пример. Бывает, что в разных районах города сбор анкет идет с разной скоростью: где-то (например, в центре города) большой пешеходный поток и у людей есть время на участие в опросе (отдыхающие, в отпуске, офисные сотрудники на обеде), а на окраинах либо мало людей на улицах, либо все спешат на работу и отказываются участвовать.
В результате, если не ограничивать доли районов, в выборке будут преобладать люди из центрального района, которые могут значимо отличаться от остальных людей родом занятий, уровнем дохода и образования, уровнем осведомленности о магазинах и др.
Таким образом, собранная выборка уже не будет репрезентативной по отношению к населению всего города.
ОНЛАЙН-ОПРОСЫ (ОНЛАЙН-ПАНЕЛИ)
Несмотря на многие положительные стороны онлайн-опросов, такие как экономичность, оперативность сбора информации, удобство ее обработки и т. д., некоторые их особенности напрямую угрожают репрезентативности исследования:
- Во-первых, участники онлайн-опросов – это, как правило, активные пользователи интернета, хорошо в нем разбирающиеся и больше подверженные влиянию интернет-культуры, чем обычные люди.
- Во-вторых, люди, у которых есть время и желание регулярно участвовать в онлайн-опросах за небольшое вознаграждение, скорее всего, значительно отличаются от остальных людей как по социально-демографическим, так и по психографическим характеристикам.
- В-третьих, профессиональное участие в опросах приводит к так называемой профессиональной деформации, когда ответы респондентов на вопросы новых исследований обусловлены предыдущим опытом, но не жизненным, а опытом участия в других опросах.
- Таким образом, в данном случае возникает та ситуация, когда опрашиваются не те люди, хотя по формальным характеристикам они подходят под описание целевой аудитории.
- ВЫВОДЫ
- Итак, чтобы получить достаточно точные данные об интересующей нас группе людей, необязательно опрашивать их всех, благодаря свойству репрезентативности выборки.
- «Чем больше, тем лучше» – неправильный подход к формированию выборки.
Небольшая репрезентативная выборка лучше большой, но нерепрезентативной выборки. Применительно к выборке не стоит пугаться слова «случайная». Это вовсе не значит, что в исследовании будут получены случайные результаты. Напротив, случайный подход к формированию выборки делает ее максимально похожей на генеральную совокупность, а значит, репрезентативной.
При проектировании выборки следует учитывать опасность смещения структуры выборки вследствие особенностей сбора информации и других условий.
Источник: https://scanmarket.ru/blog/reprezentativnost-vyborki
Ошибки выборки
Чтобы оценить степень точности выборочного наблюдения, необходимо оценить величину ошибок, которые могут возникнуть в процессе проведения выборочного наблюдения.

Статистическое исследование может осуществляться по данным несплошного наблюдения, основная цель которого состоит в получении характеристик изучаемой совокупности по обследованной ее части. Одним из наиболее распространенных в статистике методов, применяющих несплошное наблюдение, является выборочный метод.
Под выборочным понимается метод статистического исследования, при котором обобщающие показатели изучаемой совокупности устанавливаются по некоторой ее части на основе положений случайного отбора.
При выборочном методе обследованию подвергается сравнительно небольшая часть всей изучаемой совокупности (обычно до 5 — 10%, реже до 15 — 25%). При этом подлежащая изучению статистическая совокупность, из которой производится отбор части единиц, называется генеральной совокупностью.
Отобранная из генеральной совокупности некоторая часть единиц, подвергающаяся обследованию, называется выборочной совокупностью
или просто выборкой.
Значение выборочного метода состоит в том, что при минимальной численности обследуемых единиц проведение исследования осуществляется в более короткие сроки и с минимальными затратами труда и средств. Это повышает оперативность статистической информации, уменьшает ошибки регистрации.
В проведении ряда исследований выборочный метод является единственно возможным, например, при контроле качества продукции (товара), если проверка сопровождается уничтожением или разложением на составные части обследуемых образцов (определение сахаристости фруктов, клейковины печеного хлеба, установление носкости обуви, прочности тканей на разрыв и т.д.).
- Проведение исследования социально — экономических явлений выборочным методом складывается из ряда последовательных этапов:
- 1) обоснование (в соответствии с задачами исследования) целесообразности применения выборочного метода;
- 2) составление программы проведения статистического исследования выборочным методом;
- 3) решение организационных вопросов сбора и обработки исходной информации;
4) установление доли выборки, т.е. части подлежащих обследованию единиц генеральной совокупности;
- 5) обоснование способов формирования выборочной совокупности;
- 6) осуществление отбора единиц из генеральной совокупности для их обследования;
- 7) фиксация в отобранных единицах (пробах) изучаемых признаков;
-
 статистическая обработка полученной в выборке информации с определением обобщающих характеристик изучаемых признаков;
статистическая обработка полученной в выборке информации с определением обобщающих характеристик изучаемых признаков; - 9) определение количественной оценки ошибки выборки;
- 10) распространение обобщающих выборочных характеристик на генеральную совокупность.
- В генеральной совокупности доля единиц, обладающих изучаемым признаком, называется генеральной долей (обозначается р), а средняя величина изучаемого варьирующего признака — генеральной средней (обозначается ).
- В выборочной совокупности долю изучаемого признака называют выборочной долей, или частостью (обозначается ), а среднюю величину в выборке — выборочной средней (обозначается ).
- Пример.
 статистическая обработка полученной в выборке информации с определением обобщающих характеристик изучаемых признаков;
статистическая обработка полученной в выборке информации с определением обобщающих характеристик изучаемых признаков;При контрольной проверке качества хлебобулочных изделий проведено 5%-ное выборочное обследование партии нарезных батонов из муки высшего сорта. При этом из 100 отобранных в выборку батонов 90 шт. соответствовали требованиям стандарта. Средний вес одного батона в выборке составлял 500,5 г при среднем квадратическом отклонении г.
- На основе полученных в выборке данных нужно установить возможные значения доли стандартных изделий и среднего веса одного изделия во всей партии.
- Прежде всего устанавливаются характеристики выборочной совокупности. Выборочная доля, или частость, определяется из отношения единиц, обладающих изучаемым признаком m, к общей численности единиц выборочной совокупности n:
Поскольку из 100 изделий, попавших в выборку n, 90 ед. оказались стандартными m, то показатель частости равен: = 90:100=0,9.
Средний вес изделия в выборке х = 500,5 г определен взвешиванием. Но полученные показатели частости (0,9) и средней величины (500,5 г) характеризуют долю стандартной продукции и средний вес одного изделия лишь в выборке. Дляопределения соответствующих показателей для всей партии товара надо установить возможные при этом значения ошибки выборки.
Ошибка выборки — это объективно возникающее расхождение между характеристиками выборки и генеральной совокупности. Она зависит от ряда факторов: степени вариации изучаемого признака, численности выборки, методом отбора единиц в выборочную совокупность, принятого уровня достоверности результата исследования.
- Определение ошибки выборочной средней.
- При случайном повторном отборе средняя ошибка выборочной средней рассчитывается по формуле:
- ,
- где — средняя ошибка выборочной средней;
- — дисперсия выборочной совокупности;
- n — численность выборки.
- При бесповторном отборе она рассчитывается по формуле:
 ,
,- где N — численность генеральной совокупности.
- Определение ошибки выборочной доли.
- При повторном отборе средняя ошибка выборочной доли рассчитывается по формуле:
 ,
,- где — выборочная доля единиц, обладающих изучаемым признаком;
- — число единиц, обладающих изучаемым признаком;
- — численность выборки.
- При бесповторном способе отбора средняя ошибка выборочной доли определяется по формулам:

- Предельная ошибка выборки связана со средней ошибкой выборки отношением:
- .
- При этом t как коэффициент кратности средней ошибки выборки зависит от значения вероятности Р, с которой гарантируется величина предельной ошибки выборки.
- Предельная ошибка выборки при бесповторном отборе определяется по следующим формулам:


Предельная ошибка выборки при повторном отборе определяется по формуле:
![]()
.
Источник: https://www.ekonomstat.ru/lektsii-po-distsipline-statistika/36-obshhaja-teorija-statistiki-lekcii/834-oshibki-vyborki.html
116. Ошибка репрезентативности, методика вычисления ошибки средней и относительной величины
В статистике выделяют два основных метода исследования – сплошной и выборочный. При проведении выборочного исследования обязательным является соблюдение следующих требований: репрезентативность выборочной совокупности и достаточное число единиц наблюдений.
При выборе единиц наблюдения возможны Ошибки смещения, т. е. такие события, появление которых не может быть точно предсказуемым. Эти ошибки являются объективными и закономерными.
При определении степени точности выборочного исследования оценивается величина ошибки, которая может произойти в процессе выборки – Случайная ошибка репрезентативности (M) – Является фактической разностью между средними или относительными величинами, полученными при проведении выборочного исследования и аналогичными величинами, которые были бы получены при проведении исследования на генеральной совокупности.
- Оценка достоверности результатов исследования предусматривает определение:
- 1. ошибки репрезентативности
- 2. доверительных границ средних (или относительных) величин в генеральной совокупности
- 3. достоверности разности средних (или относительных) величин (по критерию t)
- Расчет ошибки репрезентативности (mм) средней арифметической величины (М):
- , где σ – среднее квадратическое отклонение; n – численность выборки (>30).
- Расчет ошибки репрезентативности (mР) относительной величины (Р):
- , где Р – соответствующая относительная величина (рассчитанная, например, в %);
- Q =100 – Ρ% – величина, обратная Р; n – численность выборки (n>30)
В клинических и экспериментальных работах довольно часто приходится использовать Малую выборку, Когда число наблюдений меньше или равно 30. При малой выборке для расчета ошибок репрезентативности, как средних, так и относительных величин, Число наблюдений уменьшается на единицу, т. е.
![]()
Величина ошибки репрезентативности зависит от объема выборки: чем больше число наблюдений, тем меньше ошибка. Для оценки достоверности выборочного показателя принят следующий подход: показатель (или средняя величина) должен в 3 раза превышать свою ошибку, в этом случае он считается достоверным.
Знание величины ошибки недостаточно для того, чтобы быть уверенным в результатах выборочного исследования, так как конкретная ошибка выборочного исследования может быть значительно больше (или меньше) величины средней ошибки репрезентативности.
Для определения точности, с которой исследователь желает получить результат, в статистике используется такое понятие, как вероятность безошибочного прогноза, которая является характеристикой надежности результатов выборочных медико-биологических статистических исследований.
Обычно, при проведении медико-биологических статистических исследований используют вероятность безошибочного прогноза 95% или 99%.
В наиболее ответственных случаях, когда необходимо сделать особенно важные выводы в теоретическом или практическом отношении, используют вероятность безошибочного прогноза 99,7%
- Определенной степени вероятности безошибочного прогноза соответствует определенная величина Предельной ошибки случайной выборки (Δ – дельта), которая определяется по формуле:
- Δ=t * m, где t – доверительный коэффициент, который при большой выборке при вероятности безошибочного прогноза 95% равен 2,6; при вероятности безошибочного прогноза 99% – 3,0; при вероятности безошибочного прогноза 99,7% – 3,3, а при малой выборке определяется по специальной таблице значений t Стьюдента.
- Используя предельную ошибку выборки (Δ), можно определить Доверительные границы, в которых с определенной вероятностью безошибочного прогноза заключено действительное значение статистической величины, Характеризующей всю генеральную совокупность (средней или относительной).
- Для определения доверительных границ используются следующие формулы:
- 1) для средних величин:
![]()
Мвыб – средняя величина, Полученная при проведении исследования на выборочной совокупности; t – доверительный коэффициент, значение которого определяется степенью вероятности безошибочного прогноза, с которой исследователь желает получить результат; mM – ошибка репрезентативности средней величины.
2) для относительных величин:
![]()
Доверительные границы показывают, в каких пределах может колебаться размер выборочного показателя в зависимости от причин случайного характера.
При малом числе наблюдений (n
Источник: https://uchenie.net/116-oshibka-reprezentativnosti-metodika-vychisleniya-oshibki-srednej-i-otnositelnoj-velichiny/
Ошибки репрезентативности. Ошибки выборки
Любое выборочное наблюдение ставит своей задачей определение среднего размера признака или доли единиц, обладающих данным признаком, и распространение полученных характеристик выборочной совокупности на генеральную совокупность.
Ошибки репрезентативности возникают вследствие различия структуры выборочной и генеральной совокупности.
Структура генеральной совокупности вполне однозначна, и ей соответствует вполне определенное значение среднего размера (или доли) изучаемого признака. Выборочная же совокупность формируется на основе случайного отбора, в силу этого ее состав отличается от состава генеральной совокупности, отличается, естественно, и значение среднего размера (или доли) изучаемого признака.
Если из одной и той же генеральной совокупности производится несколько выборок, то в каждую из них попадут разные единицы и, следовательно, каждой выборочной совокупности будет соответствовать своя средняя. Отсюда следует важный вывод: выборочная средняя, в отличие от генеральной, – величина переменная. Переменной или случайной величиной будет и ошибка репрезентативности.
В практических статистических работах выборочное наблюдение проводится один раз, поэтому фактически приходится иметь дело с одной из множества выборочных средних, но с какой именно – сказать невозможно.
Чтобы получить суждение о точности результатов выборочного наблюдения, математическая статистика дает формулу средней ошибки, т.е.
средней величины из всех возможных ошибок при бесчисленном множестве случайных выборок.
При бесконечно большом числе выборок получится кривая частот, которая представляет кривую выборочного распределения.
Рассмотрим выборочное распределение средней величины.
Такое распределение будет являться нормальным или приближаться к нему по мере увеличения объема выборки независимо от того, имеет или не имеет нормальное распределение та генеральная совокупность, из которой взяты выборки.
С увеличением числа выборок средняя для всех выборок будет приближаться к генеральной средней. По выборочному распределению может быть рассчитана средняя квадратическая ошибка репрезентативности:
Среднее квадратическое отклонение выборочных средних от генеральной средней называется средней ошибкой выборочной средней (средней ошибкой выборки для средней величины признака):

Поскольку, как правило, генеральная средняя неизвестна, этой формулой нельзя воспользоваться. Кроме того, в социально-экономических исследованиях выборки из одной и той же совокупности не производятся многократно. Поэтому используют нижеприведенную формулу, исходя из того, что средняя ошибка выборки зависит от колеблемости признака в генеральной совокупности и числа отобранных единиц.
Средняя ошибка выборки для средней величины признака определяется по формуле:
![]()
где s2г – дисперсия количественного признака в генеральной совокупности.
Следовательно, средняя ошибка выборки тем больше, чем больше вариация в генеральной совокупности, и тем меньше, чем больше объем выборки.
Т.о. можно утверждать, что отклонение выборочной средней от генеральной средней в среднем равно . Ошибка конкретной выборки может принимать различные значения, но ее отношение к средней ошибке практически не превышает , если величина объема выборки достаточно большая .
- Отношение ошибки конкретной выборки к средней квадратической ошибке называется нормированным отклонением :
- .
- Распределение нормированного отклонения выборочной средней от генеральной средней при численности выборки определяется следующим уравнением:
- (1)
Данное уравнение называют стандартным уравнением нормальной кривой. Величина достигает максимума при , в этом случае .
На рис. приведен график кривой распределения нормированных отклонений ошибок выборочных средних .
Рис.
Ординаты соответствуют плотностям вероятности при том или ином значении . Для того, чтобы определить вероятность значений в интервале от до , следует найти отношение части площади кривой, заключенной между ординатами, соответствующими и ко всей площади кривой. Вся площадь под кривой нормального распределения вероятностей принимается за единицу.
- Площадь нормальной кривой, заключенную между ординатами и , определяют, интегрируя функцию (1) – интеграл Лапласа.
- Имеются таблицы интеграла Лапласа, которые содержат значения вероятностей для нормированных отклонений . Значения функции Ф(t) табулированы при разных значениях, например:
- при t=1 P(D£ m) = Ф(1) = 0,683;
- при t=2 P(D£2m) = Ф(2) = 0,9545;
при t=3 P(D£3m) = Ф(3) = 0,9973 и т.д.
- Это вероятность того, что ошибка попадет в заданные пределы.
- В общем виде
- D=tm
характеризует предельную ошибку выборки, показывающую максимально возможное расхождение выборочной и генеральной характеристик при заданной вероятности этого утверждения. Т.о. о величине ошибки можно судить с определенной вероятностью.
- Так, при t=2 возможная ошибка D не превысит 2m, что гарантируется с вероятностью 0,9545. Это значит, что в 9545 выборках из 10000 подобных максимальная ошибка не выйдет за пределы ±2m,
- где – это коэффициент доверия.
- При проведении выборочного учета массовых социально-экономических явлений считается достаточным максимальный размах ошибки выборки ±3m.
- На практике наиболее часто пользуются значениями вероятности Р=0,95 (t=1,96), Р=0,99 (t=2,58) и Р=0,999 (t=3,28), гарантирующими репрезентативность выборки соответственно с ошибкой 5; 1; 0,1%.
Предельная ошибка выборки позволяет определять предельные значения характеристик генеральной совокупности при заданной вероятности, т.е. их доверительные интервалы.
Поэтому вероятность Р называется доверительной, она представляет собой вероятность того, что ошибка выборки не превысит некоторую заданную величину D, т.е. генеральная средняя находится где-то в пределах
- (от до ),
- генеральная доля – в пределах
- (от w–D до w+D).
- Как мы определили выше, средняя ошибка выборки для средней величины признака определяется по формуле:
- ,
- где s2г – дисперсия количественного признака в генеральной совокупности.
- Если при выборочном наблюдении изучению подлежит альтернативный признак, то средняя ошибка выборки для доли единиц, обладающих данным признаком, определяется по теореме Я. Бернулли:
- ,
- где p – доля единиц, обладающих данным качеством, в генеральной совокупности; p(1-p) – дисперсия альтернативного признака в генеральной совокупности.
Приведенные формулы средних ошибок выборки практически непригодны для расчета. В них фигурирует дисперсия признака в генеральной совокупности, которая неизвестна, как неизвестна и генеральная доля, генеральная средняя. Поскольку в теории вероятности доказано, что
,
то при большом объеме выборки дисперсии генеральной s2г и выборочной s2 совокупностей равны. ( ). Это дает основание исчислять среднюю ошибку выборки по значениям выборочной дисперсии s2 для средней и w(1–w) для доли признака:
- , ,
- где w – доля признака в выборочной совокупности.
- Наряду с абсолютной величиной предельной ошибки выборки рассчитывается и относительная ошибка выборки, которая определяется отношением предельной ошибки средней или доли к соответствующей характеристике выборочной совокупности:
- ; .
При проведении выборочного наблюдения в экономических исследованиях преимущественно стремятся к тому, чтобы относительная ошибка репрезентативности выборки не превышала 5 … 10%.
Вывод формул , ,
исходит из схемы повторной выборки. На практике повторная выборка, при которой численность генеральной совокупности остается неизменной (т.е.отобранная единица возвращается в генеральную совокупность и снова может быть отобрана), встречается редко (например, при изучении населения в качестве пользователей, пациентов, избирателей).
- Обычно отбор организуется по схеме бесповторной выборки, при которой отобранная единица после обследования в генеральную совокупность не возвращается и в дальнейшей выборке не участвует.
- При бесповторной выборке численность генеральной совокупности в процессе отбора сокращается на
- 1–n/N, где n/N – доля отобранных единиц.
- В связи с этим формулы ошибки выборки приобретают следующий вид:
- ; .
- Так как доля единиц генеральной совокупности, не попавших в выборку (1–n/N), всегда меньше единицы, то ошибка выборки при бесповторном отборе при прочих равных условиях меньше, чем при повторном отборе.
Источник: https://infopedia.su/10x41a.html
2.2.2. Стихийная выборка
Исследователь при
применении данного метода в некоторой
степени контролирует выборку (например,
публикуя анкету в журнале, он обращается
только к читателям этого журнала), но
решение о включении в выборку принимает
сам респондент.
То есть, её размер заранее
часто не известен, а определяется
конкретным условием — активностью
респондентов. Значит, нельзя и заранее
определить структуру массива респондентов,
которые заполнят и вернут анкеты.
Поэтому
этот метод не претендует на репрезентативность
выборки, а выводы исследования очень
часто распространяются только на
опрошенную совокупность.
Сферы применения
стихийной выборки:
-
анкеты, публикуемые в газетах и журналах;
-
почтовые опросы1;
-
опросы покупателей в залах супермаркетов;
-
опрос пассажиров на остановках и в общественном транспорте2.
2.3. Многоступенчатая и одноступенчатая выборки
Выборка делится
на одноступенчатую и многоступенчатую
по количеству ступеней в отборе.
Одноступенчатая выборка предполагает,
что из генеральной совокупности сразу
осуществляется отбор респондентов для
опроса.
Процедура же многоступенчатой
выборки включает несколько ступеней,
при этом на каждой из них единица отбора
меняется. «Различают единицы отбора
первой ступени (первичные единицы),
единицы отбора вторичной ступени
(вторичные единицы) и так далее.
Объекты
самой нижней ступени, с которых ведется
непосредственный сбор информации,
называются единицами наблюдения»3.
Например, задача исследования – изучение
свободного времени студентов всей
страны.
Процедура будет
строиться следующим образом:
-
отбор регионов;
-
отбор города в них, где есть вузы;
-
отбор учебных заведений, в которых будет проводиться исследование;
-
выбор академических групп;
-
отбор студентов.
Многоступенчатая
выборка осуществляется не в локальных
масштабах, а в региональных, общенациональных,
международных. Использовать одноступенчатую
выборку в таких масштабах нерационально,
да и очень дорого обойдётся такое
исследование. Многоступенчатая выборка
в этом плане экономична и упрощает
подход к выбору объекта.
- Но нужно
учитывать, что чем больше ступеней в
выборке, тем больше будет ошибка
репрезентативности, возрастёт вероятность
погрешностей, что приведёт к искажению
результатов исследования4. - Рассмотрев
некоторые типы выборок, необходимо
также уяснить, что такое объем выборки
и какие бывают ошибки выборки и как их
избежать. - В
формировании выборочной совокупности
важную роль играет определение ее объема
и обеспечение репрезентативности.
«Если тип выборки
говорит о том, как попадают люди в
выборочную совокупность, то объём
выборки сообщает о том, какое их
количество попало сюда»2. То есть объем выборки – это количество
единиц попавших в выборочную совокупность.
И очень важно, чтобы выборка была
репрезентативной, то есть не искажала
представлений о генеральной совокупности
вцелом3.
«Требования репрезентативности выборки
означают, что по выделенным параметрам
(критериям) состав обследуемых должен
приближаться к соответствующим пропорциям
в генеральной совокупности»4.
Одна из ключевых
проблем, встающих, как правило, перед
социологом, решающим: доверять полученным
в ходе него данным или нет, это то, сколько
же человек должно быть опрошено для
того, чтобы получить действительно
репрезентативную информацию.
К сожалению,
единой и четкой формулы, используя
которую можно было бы рассчитать
оптимальный объем выборочной совокупности,
не существует в природе. И объясняется
это весьма просто.
Дело в том, что
определение объема выборочной совокупности
– это проблема не столько статистическая,
сколько содержательная.
Иными словами,
объем выборочной совокупности зависит
от множества факторов, основные из них
следующие:
-
затраты на сбор информации, включая временные;
-
стремление к определённой статистической достоверности результатов, которую надеется получить исследователь;
-
ценность и новизна информации, получаемой в результате опроса5.
Объем
выборки обусловлен степенью однородности
или неоднородности, генеральной
совокупности, количеством характеризующих
ее признаков.
Однородной считается совокупность,
в которой контролируемый признак,
например уровень грамотности, распределён
равномерно, то есть не образует пустот
и сгущений, тогда опросив лишь несколько
человек, можно сделать вывод о том, что
большинство людей грамотны.
Чем более
однородна генеральная совокупность,
тем меньше объем выборки. Например,
«допустим, мы осуществляем отбор из
генеральной совокупности в 2000 человек,
контролируя состав выборочной совокупности
по признаку «пол»»: 70% мужчин и 30% женщин.
Согласно теории вероятности, можно
предположить, что примерно среди каждых
десяти отбираемых респондентов встретятся
три женщины. Если мы хотим опросить по
крайней мерее 90 женщин, то исходя из
вышеупомянутого соотношения, нам
необходимо отобрать не менее 300 человек.
А теперь предположим, что в генеральной
совокупности 90% мужчин и 10% женщин. В
этом случае, чтобы в выборочную
совокупность попало 90 женщин, необходимо
отобрать уже не менее 900 человек»1.
Из примера видно, что объем выборки
зависит от разброса признака (дисперсии),
и его нужно вычислять по признаку,
дисперсия значений которого наибольшая.
«Степень
однородности социального объекта
зависит, в сущности, от того, насколько
детально мы намерены его исследовать.
Практически любой, самый «элементарный»
объект оказывается чрезвычайно сложным.
Лишь в анализе мы представляем его как
относительно простой, выделяя те или
иные его свойства.
Чем более основательным
и детальным будет анализ, чем больше
свойств данного объекта мы намерены
принять во внимание в их сочетании, а
не изолированно, тем больше должен быть
объем выборки»2.
Существуют, так
называемые «правила левой руки» для
определения размера выборки (таблица
1)»3:
| Размер выборки растёт | Размер выборки уменьшается |
| — при необходимости опубликовать данные для отдельных подгрупп (размеры подвыборок при этом суммируются, и выборка в целом растёт пропорционально числу подгрупп); | — при исследовании организаций, институтов и прочих «первичных единиц отбора», если сравнительно невелика величина генеральной совокупности, из которой производится отбор(например, совокупности сотрудников рекламных агентств, школьников, пациентов и т.п.); |
| — при проведении общенациональных обследований, когда велика генеральная совокупность; | — при проведении локальных и региональных исследований; |
Источник: https://studfile.net/preview/5996791/page:7/
Ошибки выборки
Расхождения между величиной какого-либо показателя, найденного посредством статистического наблюдения, и действительными его размерами называются ошибками наблюдения. В зависимости от причин возникновения различают ошибки регистрации и ошибки ре- пр ез ентативн о сти.
Ошибки регистрации возникают в результате неправильного установления фактов или ошибочной записи в процессе наблюдения или опроса. Они бывают случайными или систематическими.
Случайные ошибки регистрации могут быть допущены как опрашиваемыми в их ответах, так и регистраторами. Систематические ошибки могут быть и преднамеренными, и непреднамеренными. Преднамеренные — сознательные, тенденциозные искажения действительного положения дела.
Непреднамеренные вызываются различными случайными причинами (небрежность, невнимательность).
Ошибки репрезентативности (представительности) возникают в результате неполного обследования и в случае, если обследуемая совокупность недостаточно полно воспроизводит генеральную совокупность. Они могут быть случайными и систематическими.
Случайные ошибки репрезентативности — это отклонения, возникающие при несплошном наблюдении из-за того, что совокупность отобранных единиц наблюдения (выборка) неполно воспроизводит всю совокупность в целом. Систематические ошибки репрезентативности — это отклонения, возникающие вследствие нарушения принципов случайного отбора единиц.
Ошибки репрезентативности органически присущи выборочному наблюдению и возникают в силу того, что выборочная совокупность не полностью воспроизводит генеральную.
Избежать ошибок репрезентативности нельзя, однако, пользуясь методами теории вероятностей, основанными на использовании предельных теорем закона больших чисел, эти ошибки можно свести к минимальным значениям, границы которых устанавливаются с достаточно большой точностью.
Ошибки выборки — разность между характеристиками выборочной и генеральной совокупности. Для среднего значения ошибка будет определяться по формуле
Величина называется предельной ошибкой выборки.
Предельная ошибка выборки — величина случайная. Исследованию закономерностей случайных ошибок выборки посвящены предельные теоремы закона больших чисел. Наиболее полно эти закономерности раскрыты в теоремах П.Л. Чебышева и А.М. Ляпунова.
Теорему П.Л. Чебышева применительно к рассматриваемому методу можно сформулировать следующим образом: при достаточно большом числе независимых наблюдений можно с вероятностью, близкой к единице (т.е.
почти с достоверностью), утверждать, что отклонение выборочной средней от генеральной будет сколько угодно малым. В теореме П.Л. Чебышева доказано, что величина ошибки не должна превышать tp .
В свою очередь величина Р, выражающая среднее квадратическое отклонение выборочной средней от генеральной средней, зависит от колеблемости признака в генеральной совокупности о- и числа отобранных единиц п. Эта зависимость выражается формулой
- где Р зависит также от способа производства выборки.
- Величину М = о2 называют средней ошибкой выборки. В этом V п
- выражении а2 — генеральная дисперсия, п — объем выборочной совокупности.
Рассмотрим, как влияет на величину средней ошибки число отбираемых единиц п. Логически нетрудно убедиться, что при отборе большого числа единиц расхождения между средними будут меньше, т.е.
существует обратная связь между средней ошибкой выборки и числом отобранных единиц.
При этом здесь образуется не просто обратная математическая зависимость, а такая зависимость, которая показывает, что квадрат расхождения между средними обратно пропорционален числу отобранных единиц.
Увеличение колеблемости признака влечет за собой увеличение среднего квадратического отклонения, а, следовательно, и ошибки. Если предположить, что все единицы будут иметь одинаковую величину признака, то среднее квадратическое отклонение станет равно нулю и ошибка выборки также исчезнет.
Тогда нет необходимости применять выборку. Однако следует иметь в виду, что величина колеблемости признака в генеральной совокупности не известна, поскольку не известны размеры единиц в ней. Можно рассчитать лишь колеблемость признака в выборочной совокупности.
Соотношение между дисперсиями генеральной и выборочной совокупности выражается формулой
Поскольку величина п при достаточно больших п близка к 1, п — 1
можно приближенно считать, что выборочная дисперсия равна генеральной дисперсии, т.е. Орен ж •
Следовательно, средняя ошибка выборки показывает, какие возможны отклонения характеристик выборочной совокупности от соответствующих характеристик генеральной совокупности. Однако о величине этой ошибки можно судить с определенной вероятностью. На величину вероятности указывает множитель t.
Теорема А.М. Ляпунова. А.М. Ляпунов доказал, что распределение выборочных средних (следовательно, и их отклонений от генеральной средней) при достаточно большом числе независимых наблюдений приближенно нормально при условии, что генеральная совокупность обладает конечной средней и ограниченной дисперсией.
Математически теорему Ляпунова можно записать так:
- Где
- где я = 3,14 — математическая постоянная;
- — предельная ошибка выборки, которая дает возможность выяснить, в каких пределах находится величина генеральной средней.
- Значения этого интеграла для различных значений коэффициента доверия t вычислены и приводятся в специальных математических таблицах. В частности, при:
Поскольку t указывает на вероятность расхождения х — х , т.е.
на вероятность того, на какую величину генеральная средняя будет отличаться от выборочной средней, то это может быть прочитано так: с вероятностью 0,683 можно утверждать, что разность между выборочной и генеральной средними не превышает одной величины средней ошибки выборки.
Другими словами, в 68,3% случаев ошибка репрезентативности не выйдет за пределы ±Ц. С вероятностью 0,954 можно утверждать, что ошибка репрезентативности не превышает ± 2р (т.е. в 95% случаев). С вероятностью 0,997, т.е.
довольно близкой к единице, можно ожидать, что разность между выборочной и генеральной средней не превзойдет трехкратной средней ошибки выборки и т.д.
- Логически связь здесь выглядит довольно ясно: чем больше пределы, в которых допускается возможная ошибка, тем с большей вероятностью судят о ее величине.
- Зная выборочную среднюю величину признака (х) и предельную ошибку выборки можно определить границы (пределы), в
- которых заключена генеральная средняя
Источник: https://bstudy.net/710108/ekonomika/oshibki_vyborki