
Всем привет!
Новичок в программировании в 1С. У меня вопрос-проблема с реквизитом в управляемом приложении.
У документа «Задача» есть реквизит с именем «Конец». Обычная форма списка работает, а вот в управляемой при открытии появляется ошибка:
«Ошибка при выполнении запроса. Ошибка при выполнении запроса.
по причине:
Ошибка генерации макета
по причине:
Ошибка при получении информации о поле «Конец»
по причине:
Ошибка в выражении «Конец»
по причине:
Синтаксическая ошибка»
Аналогичная ошибка в СКД с этим же реквизитом.
Изменил имя на «Конец_», и всё заработало.
Как я понимаю, реквизит Конец нельзя использовать в языке запросов, потому что там это ключевое слово для операции Выбор. А форма списка в управляемом приложении формируется по запросу.
Интересует почему при установке имени реквизита 1С не предупреждает, что имя «плохое»? Есть ли ещё какие-то плохие имена реквизитов?
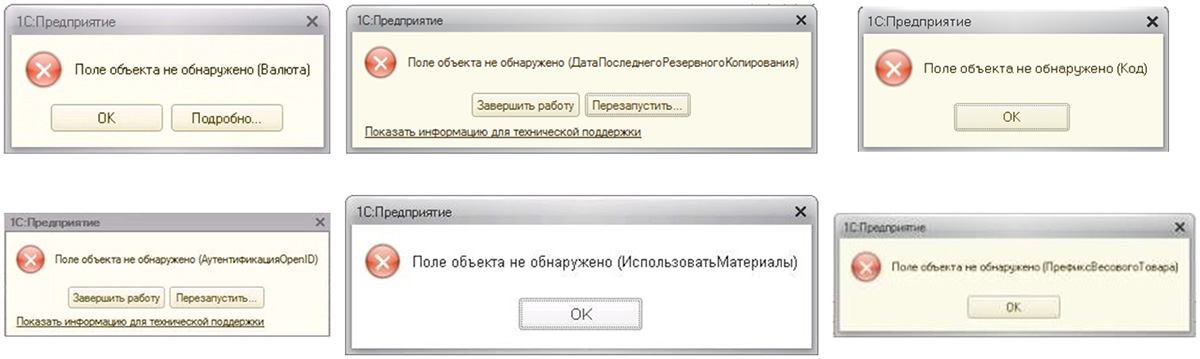
Иногда случается, что после обновления 1С пишет «Поле объекта не обнаружено», с указанием на тот или иной объект. Это может случиться при входе в программу, при заполнении какой-либо формы и т.п.
Если вдуматься в суть сообщения, то очевидно, что программа не может найти заданный пользователем объект. Такая ситуация характерна для установки нового релиза, работающего на устаревшей платформе. В этом случае устаревшие механизмы платформы не учитывают изменений релиза и обращаются к атрибуту, которого уже не существует.

Приглашаем на
бесплатный вебинар!
06 июня в 11:00 мск
1 час
Модуль, к которому идет обращение, перестает работать, но работу программа может не прерывать. Когда ошибка находится в модуле приложения или обработки, то при его запуске программа может и не запуститься.
Обновление платформы
При этом важно посмотреть на описание поставки, которое открывается при установке обновления. Там обязательно указывают рекомендации по использованию версии платформы.
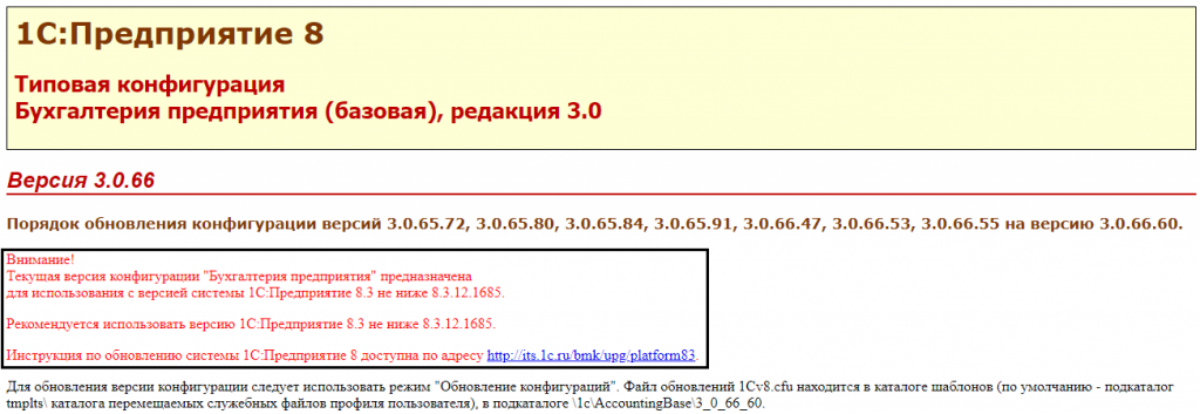
Таким образом, первый и основной вариант решения проблемы – это обновление платформы «1С:Предприятие».
Чтобы посмотреть, какая платформа у нас установлена, необходимо зайти в пункт меню «Сервис» — «О программе», где в верхней строке мы видим версию нашей платформы и сравниваем с рекомендуемой, при установке обновления конфигурации.

Очистка настроек пользователя
Ошибка может возникнуть даже при обновленной платформе программы, например, после обновления конфигурации, при нажатии кнопки «Подбор» в документе реализация, стало появляться сообщение «Поле объекта не обнаружено (Валюта)». В чем здесь может быть причина, ведь платформа обновлена? Какие-то параметры программы могут быть зафиксированы в настройках у пользователя, и для устранения ошибки достаточно очистить его настройки. В «1С:Бухгалтерия 3.0» этот пункт находится в «Администрирование» — «Настройки программы» — «Настройки пользователя и прав».
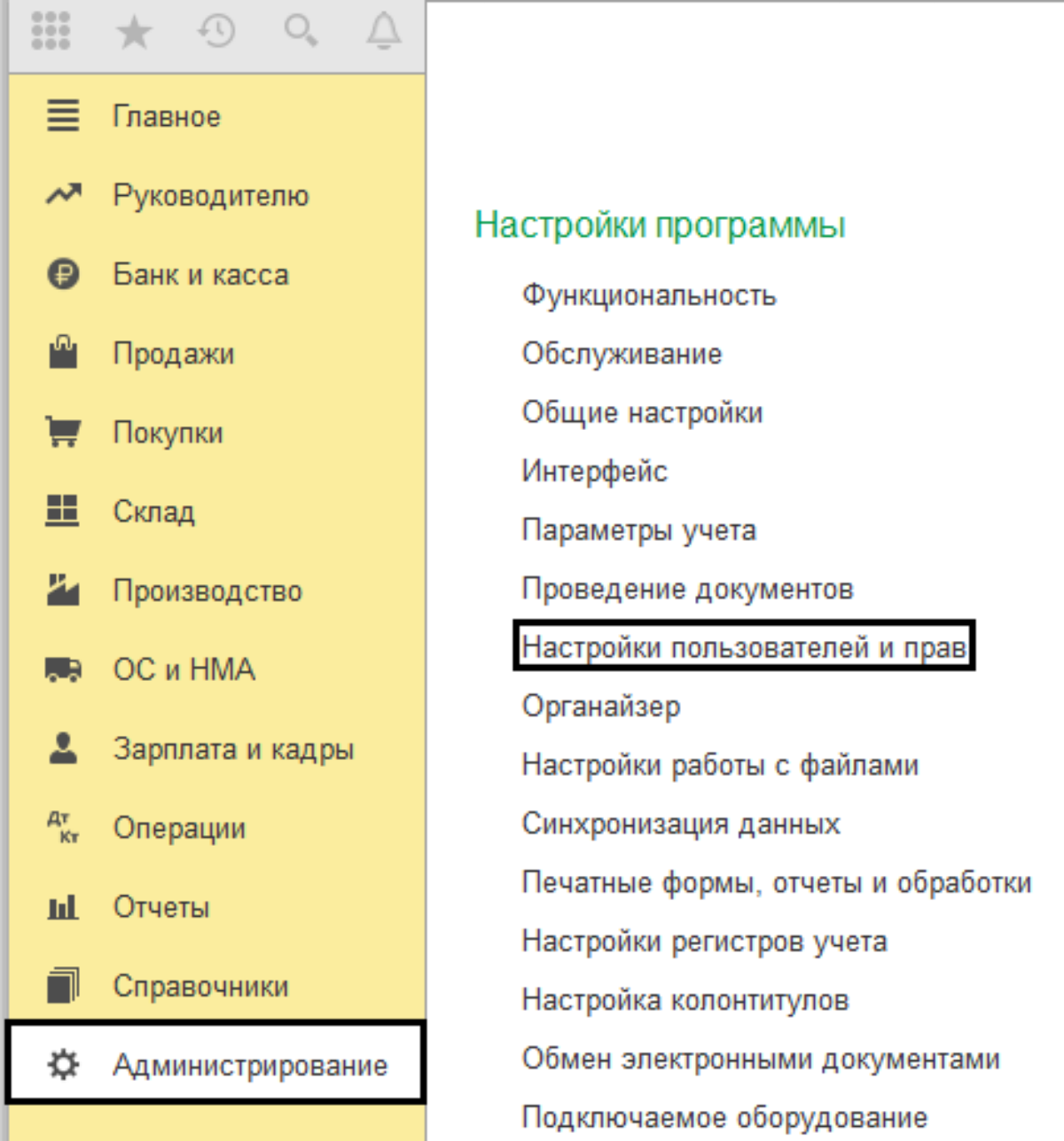
В подразделе «Персональные настройки пользователя» переходим по гиперссылке «Очистка настроек», где мы можем выбрать – очистить настройки у всех пользователей или только у выбранного. Также мы можем выбрать – очистить все настройки или какие-то отдельные виды настроек.
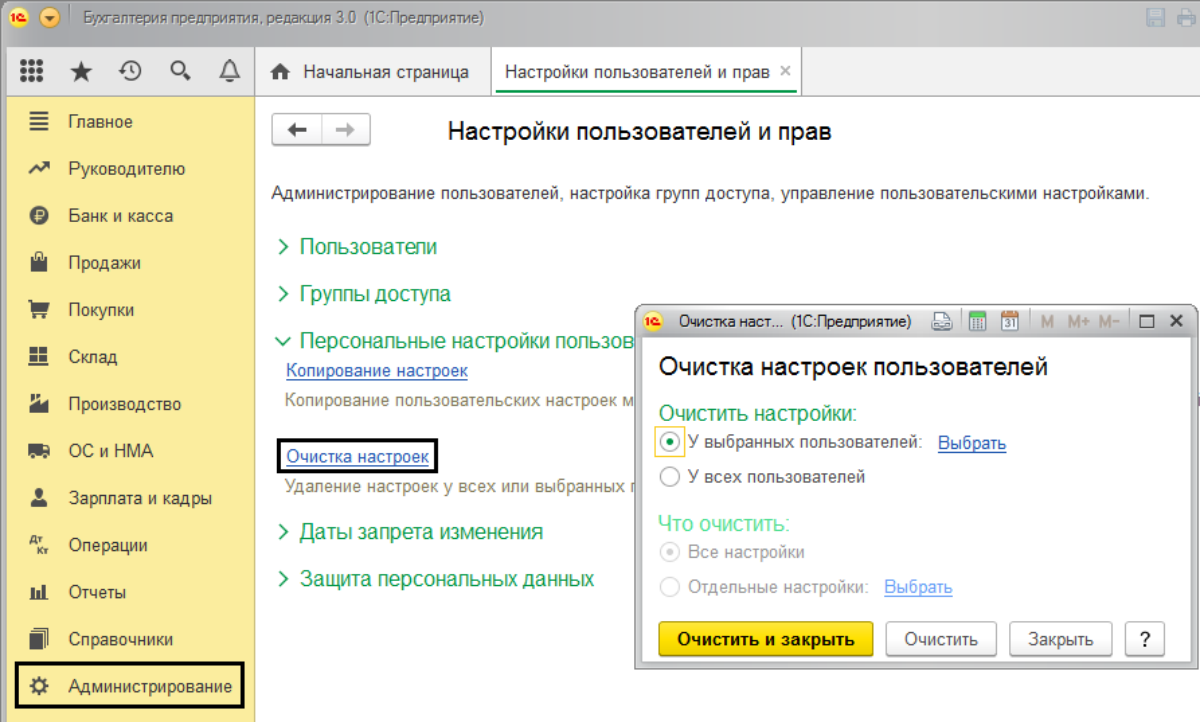
При этом пункт «Отдельные виды настроек» доступен только при очистке настроек конкретного пользователя.
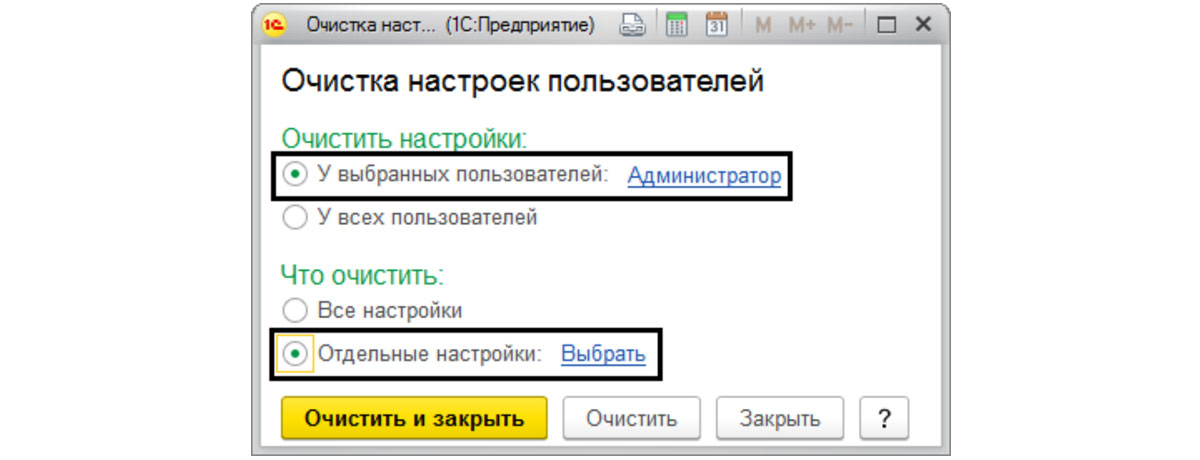
Перед нами откроются настройки пользователя, в которых как раз он и мог использовать устаревшие объекты, на которые и ссылается ошибка программы. Мы можем выбрать конкретную настройку (по подсказке ошибки) или очистить все настройки.
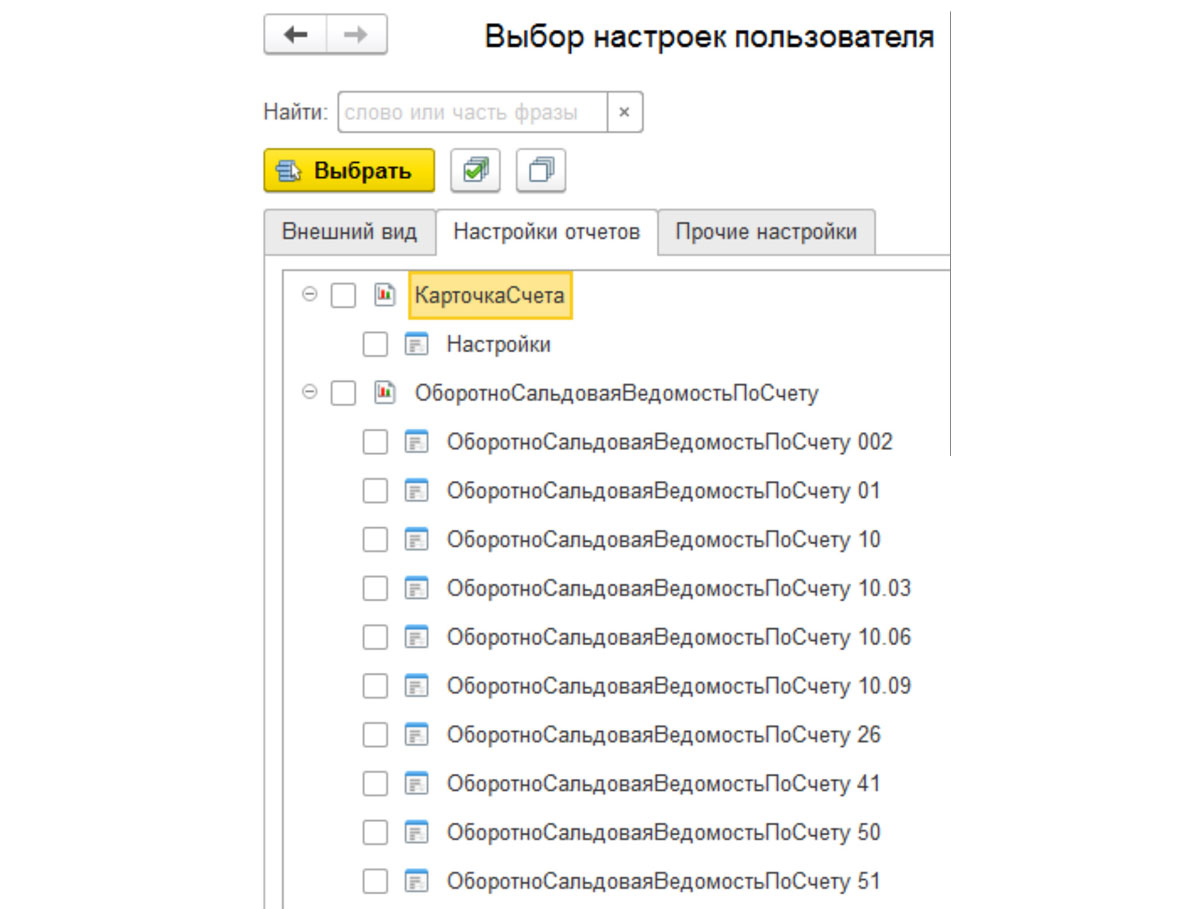
Тестирование и исправление информационной базы
В том случае, если возникновение ошибки не связано с платформой и настройками пользователя, то возможно произошел просто сбой в информационной базе, который повредил указанный объект. В таком случае рекомендуется провести «Тестирование и исправление информационной базы», в режиме Конфигуратор, в пункте меню «Администрирование». Обратите внимание, что работа в конфигураторе требует определенных знаний, поэтому, если вы не уверены в своих силах, обращайтесь за консультацией по программе 1С к специалистам.
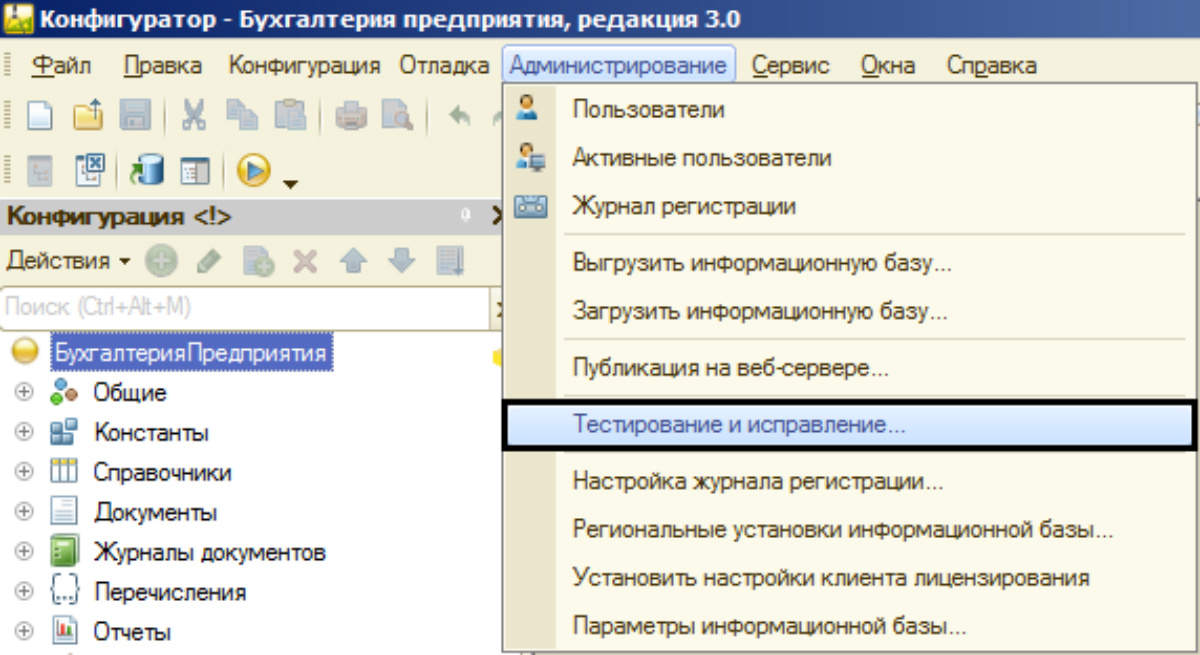
В тестировании и исправлении необходимо проверить логическую и ссылочную целостность базы. Если произошло необнаружение объекта, мы можем задать настройки программе проверки, что делать с такими объектами – создавать объекты, очищать ссылки или не изменять.

При выборе варианта «Создавать объекты», программа при обнаружении несуществующей ссылки на объект формирует элемент, своего рода заглушку. При выборе варианта – «Очищать ссылки» или «Удалять объект», некорректные ссылки будут просто удалены. Если оставить переключатель в положении – «Не изменять», программа просто укажет нам на этот объект, не предпринимая никаких действий. Этот вариант нам явно не поможет.
Таким образом, любой ошибке в программе 1С есть логическое объяснение. Если у вас остались вопросы, связанные с исправлением ошибок, и вы нуждаетесь в консультации по программе 1С, звоните, а также оставляйте заявки на нашем сайте. Наши специалисты свяжутся с вами в кратчайшие сроки.
Специфика современных версий учетных программ обуславливается использованием многоуровневого кода. Логично, что чем сложнее структура — тем выше вероятность возникновения внеплановых ситуаций, с которыми приходится сталкиваться рядовым пользователям конфигурации. В отдельных случаях даже сотрудники администрирующих служб предприятия не всегда способны сразу определить исходную причину появления неполадок, поэтому работа по устранению неудобств может занять немало времени. Одной из наиболее часто встречающихся проблем является классическая ошибка SDBL 1С, источники и способы устранения которой мы и рассмотрим в сегодняшнем обзоре.

Общее представление
Взаимодействуя с учетной программой, пользователи выполняют различные операции, каждая из которых, так или иначе, формирует запрос к базе данных. Создание нового документа, интеграция библиотеки, плановое обновление — во время любого из процессов есть вероятность получить в ответ уведомление от системы, свидетельствующее о том, что одна из логических цепочек была нарушена. Распространенный вариант — когда на экране появляется сообщение об ошибке SDBL 1С ожидается выражение (pos = 6) (а также 15, 57, 198, 250, 469, или любой другой номерной идентификатор).
Фактически это говорит о наличии технического сбоя, с которым чаще всего сталкиваются пользователи, самостоятельно обновляющие конфигурацию автоматическими средствами. Важно понимать, что при работе с программой (и в том числе при установке новых релизов) необходимо иметь определенный уровень навыков и знаний, достаточный для внесения изменений и управления функциональными возможностями платформы.

Впрочем, сильно переживать не стоит. Появление ошибки SDBL 1С еще не значит, что структура базы данных предприятия разрушена полностью — в большинстве случаев исправить проблему можно при помощи стандартного набора способов, реализовать которые под силу даже начинающим пользователям.
Причины возникновения
Один из главных факторов, о котором многие забывают в процессе работы с учетной системой — необходимость соответствия платформы и конфигурации обновления. То есть перед тем как начать использовать новый релиз, нужно создать условия, в которых он сможет нормально функционировать. Простейший вариант — доверить контроль за установкой профильному специалисту, который поможет избежать технических сбоев в программе.
Если говорить об уже упомянутой ранее ошибке SDBL 1С «ожидается выражение (pos = 144)» (или 48, 153, 13 — не столь принципиально), то в этом случае ключевым обстоятельством становится повреждение базы данных, обусловленное нарушением системных логических циклов. К числу распространенных причин возникновения, отмечаемых специалистами, относят не только применение устаревшей конфигурации или платформы, но также и проблемы, связанные с серверным кешем. Кроме того, всегда существует вероятность случайного запуска с некорректной учетной записи, не обладающей достаточным набором прав.

Чаще всего системные ошибки происходят в процессе очередного обновления БД, а также при обращении к ней — через запрос на добавление документов, во время тестовой проверки логической целостности, или же в иных ситуациях. Критической проблемой при установке расширений может стать и «некорректное использование LOCAL/GLOBAL в SET GENERATION», не позволяющее полноценно сохранить базу даже после выборочного удаления. Стоит отметить, что стандартное решение в виде перезагрузки программы обычно не помогает, поэтому для восстановления работоспособности придется воспользоваться альтернативными методиками.
Какие сообщения возникают

Уведомление о технических неполадках отражает специфику возникшей проблемы, и может появиться как во время обновления конфигурации, так и в процессе работы с обменом данных. Как правило, текст в информационном окне раскрывает специфику возникшей ошибки SDBL 1С: «не является именем поля», «ожидается идентификатор» или «выход за пределы размерности результата 1C», и т. д.
Встречаются и вспомогательные приписки, причем их количество зависит от конкретной неточности, допущенной в ходе сборки и настройки обновленного расширения:
-
предпринята попытка ввести неприемлемый тип значения «NULL»;
-
пропущена точка с запятой;
-
нарушение индексирования с полным текстом;
-
неоднозначное определение некоторого поля;
-
отсутствует выражение (pos =) — с различными числовыми идентификаторами в скобках.
Практика работы с типовыми конфигурациями показывает, что количество сообщений достаточно велико, и определенно выходит за рамки приведенного списка, в котором собраны только наиболее часто встречающиеся варианты.

Готовые решения для всех направлений

Ускорьте работу сотрудников склада при помощи мобильной автоматизации. Навсегда устраните ошибки при приёмке, отгрузке, инвентаризации и перемещении товара.
Узнать больше

Мобильность, точность и скорость пересчёта товара в торговом зале и на складе, позволят вам не потерять дни продаж во время проведения инвентаризации и при приёмке товара.
Узнать больше

Обязательная маркировка товаров — это возможность для каждой организации на 100% исключить приёмку на свой склад контрафактного товара и отследить цепочку поставок от производителя
Узнать больше

Скорость, точность приёмки и отгрузки товаров на складе — краеугольный камень в E-commerce бизнесе. Начни использовать современные, более эффективные мобильные инструменты.
Узнать больше

Повысьте точность учета имущества организации, уровень контроля сохранности и перемещения каждой единицы. Мобильный учет снизит вероятность краж и естественных потерь.
Узнать больше

Повысьте эффективность деятельности производственного предприятия за счет внедрения мобильной автоматизации для учёта товарно-материальных ценностей.
Узнать больше

Первое в России готовое решение для учёта товара по RFID-меткам на каждом из этапов цепочки поставок.
Узнать больше

Исключи ошибки сопоставления и считывания акцизных марок алкогольной продукции при помощи мобильных инструментов учёта.
Узнать больше

Получение сертифицированного статуса партнёра «Клеверенс» позволит вашей компании выйти на новый уровень решения задач на предприятиях ваших клиентов..
Узнать больше

Используй современные мобильные инструменты для проведения инвентаризации товара. Повысь скорость и точность бизнес-процесса.
Узнать больше
Показать все решения по автоматизации
Устранение ошибки SDBL 1С
Попытки справиться с возникающими проблемами самостоятельно не всегда заканчиваются одинаково успешно, поскольку в каждой отдельно взятой ситуации влияние оказывают разнообразные факторы — как в самой системе, так и за ее пределами.
В связи с этим главной рекомендацией специалистов является регулярное резервное копирование, позволяющее без особого труда восстановить исходные данные в случае наступления критических обстоятельств. Оптимальный график предусматривает не только ежедневное ночное создание копий, но также и дополнительное резервирование перед каждой значительной операцией, будь то обновление или закрытие периода. Автоматизированная архивация базы реализуется встроенным функционалом учетной программы, а восстановление из Конфигуратора занимает минимум времени, позволяя откатиться к рабочему состоянию практически без прерывания процесса.

Практически любая ошибка SDBL 1С — «недопустимый символ (pos = 40)», «пропущена точка с запятой», или «ожидается имя таблицы 21», может быть устранена путем выполнения несложного набора действий. Перечень доступных вариантов выглядит следующим образом:
-
Удаление кэшированных данных — как на пользовательском рабочем месте, так и на основном сервере, где произошел технический сбой. Для реализации процедуры очистки кэша достаточно закрыть учетную программу, открыть «Проводник», найти, выбрать и удалить набор папок из раздела «Application Data». Отличить нужные элементы проще всего по названию, которое выглядит как хаотичный набор символов — например, «ac5c8bm4-y65k-4s23-a9g8-2dcttp0b15da».
-
Использование функционала Конфигуратора, позволяющего провести тестирование и исправление информационной базы. В этом случае необходимо найти поврежденную ИБ, выбрать ее и перейти в раздел «Администрирование», после чего активировать встроенную функцию для теста и корректировки ошибок.
-
Перезагрузка сервера, на котором расположены программные приложения системы 1С. Самый простой вариант — включение и выключение всех взаимосвязанных SQL-сервисов, включая агент. Для выполнения задачи нужно зайти на нужный серверный источник, выделить агентскую службу, вызвать контекстное меню и остановить процесс. Аналогичные действия повторяем на SQL со служебными процедурами Server и Agent. Повторная активация осуществляется в обратном порядке.
-
Выгрузка БД в отдельный DT-файл с последующей повторной «заливкой». По сути, метод напоминает стандартную перезагрузку системы — структура записывается в файловом формате, что позволяет упорядочить проблемные разделы. Для выполнения процедуры достаточно открыть меню управления учетной программой, найти в категории «Администрирование» функцию «Выгрузить информационную базу», и после ее завершения выбрать опцию «Загрузить ИБ», используя сформированный файл.
-
Откат к последней резервной копии. Один из самых простых и доступных вариантов — конечно, в том случае, если архивирование данных проводится на регулярной основе, а не только перед закрытием периодов. Вообще, решение записывать текущее состояние перед каждым внесением изменений может избавить от большинства проблем, связанных с техническими сбоями. Даже если вы столкнетесь с уведомлением о том, что «ожидается имя поля», или получите ошибку «таблица 1С inforg не создана в новом поколении», источник которой не всегда понятен даже опытным пользователям — загрузка последней копии просто вернет систему к исходному состоянию. Для резервирования допускается использование как SQL MS, так и Конфигуратора учетной программы — через последовательную выгрузку файлов в уже упомянутом DT формате.
-
Обновление платформы через сайт информационно-технологического сопровождения разработчиков, доступный всем лицензированным пользователям продукта. Функционал портала ИТС позволяет установить последнюю редакцию, актуальную на момент обращения, инсталляция которой производится как на основной сервер, так и на рабочие места клиента.
Как правило, один из перечисленных методов позволяет добиться желаемого результата, устраняя проблему в работе учетной системы. В ситуациях, когда применить готовое решение так и не удалось, есть резервный вариант, отличающийся высокой вероятностью успешного исхода. Очистка в менеджере SQL 1С таблиц ConfigChngR и ExtProps, что за последние годы стало уже привычным способом восстановления для большинства специалистов, осуществляется стандартной командой Delete.
На что еще обратить внимание при устранении ошибок SDBL, и как реализовать рассмотренные методы? Сейчас разберемся.
Права доступа
Пожалуй, самая простая причина неполадок, которая тем не менее все еще встречаться на практике — попытка запустить систему через учетную запись, не обладающую соответствующими полномочиями. Убедитесь, что профиль для запуска выбран корректно, чтобы не провоцировать сбои собственными действиями.
Перезагрузка серверов 1С и SQL
Это один из простейших методов восстановления, единственным обязательным условием, для применения которого является выход всех пользователей из базы. Убедившись, что доступ открыт, зайдите на сервер и последовательно выключите агент программы Server и SQL-agent, после чего запустите их в обратном порядке.
Удаление кэшированных данных

Создание кэша представляет собой процесс буферизации информации, используемой базой чаще всего, и, как правило, относящейся к статичной категории. Кэширование позволяет ускорить программный цикл — так, если говорить об учетных системах, оптимизация затрагивает загрузку файлов конфигурации, исключая необходимость постоянного обращения к основному серверу. Однако на практике встречаются случаи некорректной обработки программным обеспечением подобных задач, что в конечном счете становится причиной неправильной работы платформы.
Перечень факторов, обуславливающих нарушение логических циклов, весьма обширен, и охватывает не только динамические обновления системной структуры, но и технические сбои программного или аппаратного характера. В некоторых случаях для устранения ошибки SDBL 1С «ожидается имя поля/таблицы (pos = 21, 45, 48…)» достаточно почистить кэш, сохраненный на сервере, либо на рабочем месте пользователя.
Стандартный путь к месту хранения кэшированных данных выглядит следующим образом:
-
«%userprofile%AppDataRoaming1C1Cv8» и «%userprofile%AppDataLocal1C1Cv8» — для операционных систем начиная с Windows 7.
-
«%userprofile%Local SettingsApplication Data1C1Cv8» и «%userprofile%Application Data1C1Cv8» — для тех, кто все еще продолжает работать на ХР.
Откройте каталог, расположенный по указанному адресу, выделите и удалите все хранящиеся в нем папки, имя которых представляет собой сгенерированный автоматически набор цифр и букв (вроде «abg7n8ty4-brt9r893-am…»). Стоит отметить, что во время чистки кэша нужно быть особенно внимательными, поскольку в директории также могут находиться поисковый индекс и журналы регистрации 1С, которые не требуют удаления.
Загрузка DT-файла

Этот метод может показаться немного странным, поскольку фактически не предполагает внесения каких-либо корректировок в основную структуру данных. Однако в действительности выгрузка БД в отдельный файл, сохраняемый в формате DT, с последующим обращением к ней же, нередко позволяет восстановить нормальную работу программы. Алгоритм достаточно прост — в режиме Конфигуратора нужно выбрать раздел «Администрирование», использовать опцию «Выгрузить ИБ» (указав каталог для сохранения), после чего повторно залить сформированную базу обратно в систему.
Тестирование и исправление
Еще одна удобная функция, доступная в режиме корректировки конфигурации — встроенный инструментарий, предназначенный для теста и внесения коррективов. В отдельных ситуациях может возникнуть проблема с запуском Конфигуратора — вместо этого можно воспользоваться специальной утилитой chdbfl.exe, представляющей собой упрощенный программный аналог с идентичным функционалом. Приложение находится в каталоге «bin», поэтому найти его не составляет особого труда — как через стандартный путь «C:Program Files (x86)1cv88.3bin», так и через опцию поиска, предлагаемую операционной системой.

Для использования программы достаточно указать расположение проблемной базы данных, и запустить цикл тестирования. При желании можно активировать опцию автоматического исправления выявленных ошибок — в противном случае утилита ограничится диагностикой, и сформирует перечень технических неполадок в отдельном реестре.
Обновление платформы
Еще одно простое решение, предусматривающее использование сайта технической поддержки разработчиков 1С. Скачайте дистрибутив актуального релиза, распакуйте архив и активируйте инсталлятор setup.exe — система обновится автоматически.
Очистка таблиц базы данных
Если ни один из вышеперечисленных способов не дал желаемого результата — остается вариант с удалением табличных значений БД, вызывающих появление ошибки, расположенных в каталогах ConfigChngR и ExtProps. Для этого применяется скрипт менеджера SQL, с указанием информационного раздела и командой delete from. В этом случае лучше всего обратиться к профильному специалисту, поскольку некорректное восстановление может привести к более серьезным последствиям.
Заключение
Автоматизация учетных процессов — важный аспект, позволяющий оптимизировать работу компании. Ошибки SDBL 1С встречаются достаточно часто, поэтому стоит заранее позаботиться об оперативном устранении возможных проблем. Мобильные решения, предлагаемые компанией «Клеверенс», гарантируют квалифицированную поддержку, а также помогут решить задачи, связанные с учетом данных на предприятии.
Количество показов: 9756
Несоответствие условий запроса индексам таблицы Секции условий запросов (ГДЕ, ПО)
- Неэффективное использование индексов
- Избыточная блокировка записей таблиц при чтении в транзакции
- Добавить недостающие (для эффективного использования индекса) условия, если это не поменяет логики
- Создать подходящий индекс путем индексирования полей или изменения структуры метаданных. В случае изменения порядка следования измерений в регистре — проверить не ухудшит ли данная модификация другие запросы
Максимальная эффективность достигается если будет использован покрывающий индекс Важно Подзапросы в условиях (ГДЕ, параметрах виртуальных таблиц) Секции условий запросов (ГДЕ, ПО) На уровне СУБД происходит неявное соединение с вложенным запросом, оптимизатор может неверно оценить количество строк в подзапросе и выбрать неоптимальный план выполнения Поместить подзапрос в отдельную временную таблицу и обращаться к ней Критично если оптимизатор СУБД может ошибиться с количеством строк в подзапросе условия, например: обращение происходит к виртуальной таблице; во вложенном запросе есть условие отбора; в подзапросе используется вложенный запрос Важно Использование условия ИЛИ в запросах Секции условий запросов (ГДЕ, ПО) Возможно неэффективное использование индекса
- Разделить запрос на части и объединить используя ОБЪЕДИНИТЬ ВСЕ
- Пересмотреть запрос и постараться уйти от использования ИЛИ
Не требуется если ИЛИ соединяет условия на равенство по одному и тому же полю (когда можно заменить на «В») По необходимости Условия в запросе за скобками параметров виртуальных таблиц Секции условий запросов (ГДЕ, ПО) В SQL не существует понятия виртуальных таблиц, данный механизм разработан 1С. Платформа 1С:Предприятие самостоятельно формирует текст SQL-запроса, в том числе преобразует запрос к виртуальной таблице в сложный SQL-запрос к таблицам СУБД. Таким образом, указание параметров виртуальных таблиц формирует более оптимальный SQL-запрос за счет более ранней фильтрации Перенести условия в параметры виртуальных таблиц, если от этого не поменяется логика Для виртуальных таблиц СрезПервых, СрезПоследних регистра сведений может поменяться логика Важно Использование условия ГДЕ вместо условия соединения Секции условий запросов (ГДЕ, ПО) Условие в секции соединения будет обработано раньше чем условие секции ГДЕ, таким образом фильтрация произойдет раньше и количество строк, возвращенных после соединения, может быть меньше, что приведет к сокращению времени выполнения следующих операций запроса Перенести условие из ГДЕ в условие соединения, если от этого не поменяется логика Если есть соединение запросов и логика конечного запроса не изменится Рекомендуется Использование условия на «НЕ РАВНО» или «НЕ» Секции условий запросов (ГДЕ, ПО) Неэффективное использование индекса. Оптимизатор не сможет установить условие отбора по данному полю в индексе Пересмотреть запрос и постараться уйти от использования данного условия По необходимости Выполнение преобразований над индексированным полем Секции условий запросов (ГДЕ, ПО) Неэффективное использование индекса. Оптимизатор не сможет установить условие отбора по данному полю в индексе
- Пересмотреть запрос и постараться уйти от использования
- Изменить структуру хранения (хранить вычисленное значение)
Рекомендуется Отбор по строковому значению Секции условий запросов (ГДЕ, ПО) Поиск по строковым столбцам использует индекс только в случае, если используется условие равенства или условие ПОДОБНО «Строка%» Использовать условие на равенство или ПОДОБНО «Строка%» Рекомендуется Соединение с подзапросами Соединения в запросе Оптимизатор может неверно оценить предполагаемое количество строк и выбрать неоптимальный план запроса Поместить подзапрос в отдельную временную таблицу Важно Соединение с виртуальными таблицами Соединения в запросе Виртуальная таблица на уровне СУБД представляет из себя вложенный запрос. Оптимизатор может неверно оценить предполагаемое количество строк и выбрать неоптимальный план запроса Поместить подзапрос в отдельную временную таблицу Важно Обращение через точку к полям составного типа Соединения в запросе Неявное соединение со всеми таблицами составного типа
- Использовать выражение типа: ВЫРАЗИТЬ(ПолеРодитель КАК Метаданное).Поле
- Использовать выражение типа: ВЫБОР КОГДА ТИПЗНАЧЕНИЯ(ПолеРодитель)=ТИП(Метаданное) ТОГДА ВЫРАЗИТЬ(ПолеРодитель КАК Метаданное).Поле …
Важно Сложные запросы, использующие большое количество соединений Соединения в запросе Увеличивается время поиска оптимального плана запроса. Может быть не найден оптимальный план запроса за отведенное время.
- Пересмотреть запрос, постараться уйти
- Разделить запрос на части, помещая каждую из них во временную таблицу
Важно Неоптимальное использование RLS платформы Прочие Усложняется запрос к базе данных путем добавления условия ограничения прав доступа что может привести к неоптимальному выполнению запроса
- Не использовать механизм платформы, а написать свой механизм прав доступ
- Условия RLS должны быть примитивного вида
- Не назначать несколько ролей пользователю с разными условиями доступа
Рекомендуется Расчет остатков/оборотов по таблицам документов и таблицам движений регистров Прочие Для регистров накопления, бухгалтерии в на уровне СУБД создаются таблицы, в которых содержатся итоговые (агрегированные) данные, обращение к которым значительно уменьшает время выполнения запроса Использовать виртуальные таблицы регистров Важно Запросы виды ВЫБРАТЬ * ИЗ … Прочие Могут тянуться лишние данные, например табличные части или реквизит типа ХранилищеЗначений. Также возможно что на момент написания таких данных не будет, но они могут появиться в дальнейшем Явно указать поля выбора Важно Использование ОБЪЕДИНИТЬ вместо ОБЪЕДИНИТЬ ВСЕ, если того не требует задача Прочие ОБЪЕДИНИТЬ требует большего количества времени для выполнения, т.к. исключает неуникальные записи Использовать ОБЪЕДИНИТЬ ВСЕ если логикой не требуется исключение неуникальные записей Важно При использовании ДЛЯ ИЗМЕНЕНИЯ в автоматическом режиме, не указывать таблицы для блокировки Прочие Если не указаны таблицы явно, будут заблокированы все таблицы используемые в запросе Указать необходимые таблицы для блокировки Важно Применение избыточного агрегирования в виртуальных таблицах накопления, бухгалтерии Прочие Виртуальные таблицы сами агрегируют результат Не использовать дополнительное агрегирование Важно Выполнение запросов в цикле, в т.ч. через объектную модель Прочие Большое количество-клиент серверных вызовов Пересмотреть и отказаться Важно Выполнение запросов через объектную модель Прочие Могут тянуться лишние данные т.к. объект читается полностью. При этом если у объекта присутствуют табличные части, чтение будет происходить в транзакции, что может негативно сказаться на параллельности работы Пересмотреть и отказаться По необходимости
Для формирования и выполнения запросов к таблицам базы данных в платформе 1С используется специальный объект языка программирования Запрос. Создается этот объект вызовом конструкции Новый Запрос. Запрос удобно использовать, когда требуется получить сложную выборку данных, сгруппированную и отсортированную необходимым образом. Классический пример применения запроса — получение сводки по состоянию регистра накопления на определенный момент времени. Так же, механизм запросов позволяет легко получать информацию в различных временных разрезах.

Текст запроса – это инструкция, в соответствии с которой должен быть выполнен запрос. В тексте запроса описывается:
- таблицы информационной базы, используемые в качестве источников данных запроса;
- поля таблиц, которые требуется обрабатывать в запросе;
- правила группировки;
- сортировки результатов;
- и т. д.
Инструкция составляется на специальном языке – языке запросов и состоит из отдельных частей – секций, предложений, ключевых слов, функций, арифметических и логических операторов, комментариев, констант и параметров.
Язык запросов платформы 1С очень похож на синтаксис других SQL-языков, но имеются отличия. Основными преимуществами встроенного языка запросов являются: разыменование полей, наличие виртуальных таблиц, удобная работа с итогами, нетипизированные поля в запросах.
Рекомендации по написанию запросов к базе данных на языке запросов платформы 1С:
1) Текст запроса может содержать предопределенные данные конфигурации, такие как:
- значения перечислений;
- предопределенные данные:
- справочников;
- планов видов характеристик;
- планов счетов;
- планов видов расчетов;
- пустые ссылки;
- значения точек маршрута бизнес-процессов.
Также текст запроса может содержать значения системных перечислений, которые могут быть присвоены полям в таблицах базы данных: ВидДвиженияНакопления, ВидСчета и ВидДвиженияБухгалтерии. Обращение в запросах к предопределенным данным конфигурации и значениям системных перечислений осуществляется с помощью литерала функционального типа ЗНАЧЕНИЕ. Данный литерал позволяет повысить удобочитаемость запроса и уменьшить количество параметров запроса.
Пример использования литерала ЗНАЧЕНИЕ:
- ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.Москва)
- ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.ПустаяСсылка)
- ГДЕ ТипТовара = ЗНАЧЕНИЕ(Перечисление.ВидыТоваров.Услуга)
- ГДЕ ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
- ГДЕ ТочкаМаршрута = ЗНАЧЕНИЕ(БизнесПроцесс.БизнесПроцесс1.ТочкаМаршрута.Действие1
2) Использование инструкции АВТОУПОРЯДОЧИВАНИЕ в запросе может сильно время выполнения запроса, поэтому, если сортировка не требуется, то лучше вообще ее не использовать. Во большинстве случаях лучше всего применять сортировку с помощью инструкции УПОРЯДОЧИТЬ ПО.
Автоупорядочивание работает по следующим принципам:
- Если в запросе было указано предложение УПОРЯДОЧИТЬ ПО, то каждая ссылка на таблицу, находящаяся в этом предложении, будет заменена полями, по которым по умолчанию сортируется таблица (для справочников это код или наименование, для документов – дата документа). Если поле для упорядочивания ссылается на иерархический справочник, то будет применена иерархическая сортировка по этому справочнику.
- Если в запросе отсутствует предложение УПОРЯДОЧИТЬ ПО, но есть предложение ИТОГИ, тогда результат запроса будет упорядочен по полям, присутствующим в предложении ИТОГИ после ключевого слова ПО, в той же последовательности и, в случае если итоги рассчитывались по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
- Если в запросе отсутствуют предложения УПОРЯДОЧИТЬ ПО и ИТОГИ, но есть предложение СГРУППИРОВАТЬ ПО, тогда результат запроса будет упорядочен по полям, присутствующим в предложении, в той же последовательности и, в случае если группировка велась по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
- В случае же, если в запросе отсутствуют предложения и УПОРЯДОЧИТЬ ПО, ИТОГИ и СГРУППИРОВАТЬ ПО, результат будет упорядочен по полям сортировки по умолчанию для таблиц, из которых выбираются данные, в порядке их появления в запросе.
- В случае, если запрос содержит предложение ИТОГИ, каждый уровень итогов упорядочивается отдельно.
3) Что бы избежать повторного запроса к базе данных при выводе результата запроса пользователю (например, построение запроса или отображение результата запроса с помощью табличного документа) полезно использовать инструкцию ПРЕДСТАВЛЕНИЕССЫЛКИ, которая позволяет получать представление ссылочного значения. Пример:
Код 1C v 8.х
ВЫБРАТЬ
ПРЕДСТАВЛЕНИЕССЫЛКИ(РасходнаяНакладнаяСостав.Номенклатура) КАК НоменклатураПредставление<br> Так же возможно использование инструкции ПРЕДСТАВЛЕНИЕ — предназначена для получения строкового представления значения произвольного типа. Отличие этих инструкций в том, что в первом случае, если инструкции передать ссылку, результатом будет строка, В остальных случаях результатом будет значение переданного параметра. Во втором случае, результатом инструкции всегда будет строка!
4) Если в запросе имеется поле с составным типом, то для таких полей возникает необходимость привести значения поля к какому-либо определенному типу с помощью инструкции ВЫРАЗИТЬ, что позволит убрать лишние таблицы из левого соединения с полем составного типа данных и ускорить выполнение запроса. Пример:
Имеется регистра накопления ОстаткиТоваров, у которого поле Регистратор имеет составной тип. В запросе выбираются Дата и Номер документов ПоступлениеТоваров, при этом при обращении к реквизитам документа через поле Регистратор не происходит множество левых соединений таблицы регистра накопления с таблицами документов-регистраторов.
Код 1C v 8.х
ВЫБРАТЬ
ВЫРАЗИТЬ(ОстаткиТоваров.Регистратор КАК Документ.ПоступлениеТоваров).Номер КАК НомерПоступления,
ВЫРАЗИТЬ(ОстаткиТоваров.Регистратор КАК Документ.ПоступлениеТоваров).Дата КАК ДатаПоступления
ИЗ
РегистрНакопления.ОстаткиТоваров КАК ОстаткиТоваров<br> Если приведение типа считается не осуществимым, то результатом приведения типа будет значение NULL.
5) Не стоит забывать про инструкцию РАЗРЕШЕННЫЕ, которая означает, что запрос выберет только те записи, на которые у текущего пользователя есть права. Если данное слово не указать, то в случае, когда запрос выберет записи, на которые у пользователя нет прав, запрос отработает с ошибкой.
6) В случае, если в запросе используется объединение, и в некоторых частях объединения присутствуют вложенные таблицы (документ с табличной частью), а в некоторых нет, возникает необходимость дополнения списка выборки полями – пустыми вложенными таблицами. Делается это при помощи ключевого слова ПУСТАЯТАБЛИЦА, после которого в скобках указываются псевдонимы полей, из которых будет состоять вложенная таблица. Пример:
Код 1C v 8.х
// Выбрать поля Номер и Состав
// из виртуальной таблицы Документ.РасхНакл
ВЫБРАТЬ Ссылка.Номер, ПУСТАЯТАБЛИЦА.(Ном, Тов, Кол) КАК Состав
ИЗ Документ.РасхНакл
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ Ссылка.Номер, Состав.(НомерСтроки, Товар, Количество)
ИЗ Документ.РасхНакл Документ.РасходнаяНакладная.Состав.*<br> 7) Что бы в результат запроса не попали повторяющиеся строки, следует использовать инструкцию РАЗЛИЧНЫЕ, потому что так нагляднее и понятнее, а инструкция СГРУППИРОВАТЬ ПО применяется для группировки с помощью агрегатных функций. Ксати, при использовании агрегатных функций предложение СГРУППИРОВАТЬ ПО может быть и не указано совсем, при этом все результаты запроса будут сгруппированы в одну единственную строку. Пример:
Код 1C v 8.х
// Необходимо узнать, каким вообще контрагентам
// отгружался товар за период.
Выбрать Различные
Документ.РасходнаяНакладная.Контрагент<br> Инструкция СГРУППИРОВАТЬ ПО позволяет обращаться к полям верхнего уровня, без группировки результатов по этим полям, если агрегатные функции применены к полям вложенной таблицы. Хотя в справке 1С написано, при группировке результатов запроса в списке полей выборки обязательно должны быть указаны агрегатные функции, а помимо агрегатных функций в списке полей выборки допускается указывать только поля, по которым осуществляется группировка. Пример:
Код 1C v 8.х
ВЫБРАТЬ
ПоступлениеТоваровИУслуг.Товары.(СУММА(Количество),Номенклатура),
ПоступлениеТоваровИУслуг.Ссылка,
ПоступлениеТоваровИУслуг.Контрагент
ИЗ
Документ.ПоступлениеТоваровИУслуг КАК ПоступлениеТоваровИУслуг
СГРУППИРОВАТЬ ПО
ПоступлениеТоваровИУслуг.Товары.(Номенклатура)<br> 9) Инструкция ЕСТЬNULL предназначена для замены значения NULL на другое значение, но не забываем, что второй параметр будет преобразован к типу первого в случае, если тип первого параметра является строкой или числом.
10) При обращении к главной таблице можно в условии обратиться к данным подчиненной таблицы. Такая возможность называется разыменование полей подчиненной таблицы.
Пример (поиск документов, содержащих в табличной части определенный товар):
Код 1C v 8.х
ВЫБРАТЬ
Приходная.Ссылка
ИЗ
Документ.Приходная Где Приходная.Товары.Номенклатура =Номенклатура.<br> Преимущество этого запроса перед запросом к подчиненной таблице Приходная.Товары в том, что если есть дубли в документах, результат запроса вернет только уникальные документы без использования ключевого слова РАЗЛИЧНЫЕ.
11) Интересный вариант оператора В — это проверка вхождения упорядоченного набора в множество таких наборов (Поле1, Поле2, … , ПолеN) В (Поле1, Поле2, … , ПолеN).
Пример:
Код 1C v 8.х
ВЫБРАТЬ
Контрагенты.Ссылка
ГДЕ
(Контрагенты.Ссылка, Товары.Ссылка) В
(ВЫБРАТЬ Продажи.Покупатель, Продажи.Товар
ИЗ РегистрНакопления.Продажи КАК Продажи)
ИЗ
Справочник.Контрагенты,
Справочник.Товары<br> 12) При любой возможности используйте виртуальные таблицы запросов. При создании запроса система предоставляет в качестве источников данных некоторое количество виртуальных таблиц — это таблицы, которые так же являются результатом запроса, который система формирует в момент выполнения соответствующего участка кода.
Разработчик может самостоятельно получить те же самые данные, которые система предоставляет ему в качестве виртуальных таблиц, однако алгоритм получения этих данных не будет оптимизирован, так как:
Все виртуальные таблицы параметризованы, т. е. разработчику предоставляется возможность задать некоторые параметры, которые система будет использовать при формировании запроса создания виртуальной таблицы. В зависимости от того, какие параметры виртуальной таблицы указаны разработчиком, система может формировать РАЗЛИЧНЫЕ запросы для получения одной и той же виртуальной таблицы, причем они будут оптимизированы с точки зрения переданных параметров.
Не всегда разработчик имеет возможность получить доступ к тем данным, к которым имеет доступ система.
13) В клиент-серверном варианте работы функция ПОДСТРОКА() реализуется при помощи функции SUBSTRING() соответствующего оператора SQL, передаваемого серверу баз данных SQL Server, который вычисляет тип результата функции SUBSTRING() по сложным правилам в зависимости от типа и значений ее параметров, а так же в зависимости от контекста, в котором она используется. В большинстве случаев эти правила не оказывают влияния на выполнение запроса, но бывают случаи, когда для выполнения запроса существенна максимальная длина строки результата, вычисленная SQL Server. Важно иметь в виду, что в некоторых контекстах использования функции ПОДСТРОКА() максимальная длина ее результата может оказаться равной максимальной длине строки ограниченной длины, которая в SQL Server равна 4000 символам. Это может привести к неожиданному аварийному завершению выполнения запроса:
Microsoft OLE DB Provider for SQL Server: Warning: The query processor could not produce a query plan from the optimizer because the total length of all the columns in the GROUP BY or ORDER BY clause exceeds 8000 bytes.
HRESULT=80040E14, SQLSTATE=42000, native=8618
Чтобы избежать такой ошибки, не рекомендуют использовать функцию ПОДСТРОКА() с целью приведения строк неограниченной длины к строкам ограниченной длины. Вместо нее лучше использовать операцию приведения типа ВЫРАЗИТЬ().
14) С осторожностью используйте ИЛИ в конструкции ГДЕ, так как использование условия с ИЛИ может значительно «утяжелить» запрос. Решить проблему можно конструкцией ОБЪЕДИНИТЬ ВСЕ. Пример:
Код 1C v 8.х
ВЫБРАТЬ
_ДемоКонтрагенты.НаименованиеПолное
ИЗ
Справочник._ДемоКонтрагенты КАК _ДемоКонтрагенты
ГДЕ
_ДемоКонтрагенты.Ссылка =Ссылка1
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
_ДемоКонтрагенты.НаименованиеПолное
ИЗ
Справочник._ДемоКонтрагенты КАК _ДемоКонтрагенты
ГДЕ
_ДемоКонтрагенты.Ссылка =Ссылка2<br> 15) Условие НЕ В в конструкции ГДЕ увеличивает время исполнения запроса, так как это своего рода НЕ (ИЛИ1 ИЛИ2 … ИЛИn), поэтому для больших таблиц старайтесь использовать ЛЕВОЕ СОЕДИНЕНИЕ с условием ЕСТЬ NULL. Пример:
Код 1C v 8.х
ВЫБРАТЬ
_ДемоКонтрагенты.Ссылка
ИЗ
Справочник._ДемоКонтрагенты КАК _ДемоКонтрагенты
ЛЕВОЕ СОЕДИНЕНИЕ Документ._ДемоЗаказПокупателя КАК _ДемоЗаказПокупателя
ПО _ДемоКонтрагенты.Ссылка = _ДемоЗаказПокупателя.Контрагент
ГДЕ
_ДемоЗаказПокупателя.Контрагент ЕСТЬ NULL<br> 16) При использовании Временных таблиц нужно индексировать поля условий и соединений в этих таблицах, НО, при использовании индексов запрос может выполняться еще медленнее. Поэтому необходимо анализировать каждый запрос с применением индекса и без, замерять скорость выполнения запроса и принимать окончательное решение.
Если вы помещаете во временную таблицу данные, которые изначально индексированы по некоторым полям, то во временной таблице индекса по этим полям уже не будет.
17) Если вы не используете Менеджер временных таблиц, то явно удалять временную таблицу не требуется, она будет удалена после завершения выполнения пакетного запроса, иначе следует удалить временную таблицу одним из способов: командой УНИЧТОЖИТЬ в запросе, вызвать метод МенеджерВременныхТаблиц.Закрыть().
Источник
И в дополнении видео от Евгения Гилева : Типовые ошибки при написании запросов на 1С:
‘Этот материал я переписал из диска ИТС для рассмотрения и возможной дискуссии на тему оптимизации запросов https://its.1c.ru/db/metod8dev#content:5842:hdoc
Такую статью я рекомендую всем программистам 1С прочитать внимательно, так как язык запросов – этот основной инструмент платформы 1С. В статье приводятся типичные причины неоптимальной работы запросов, диагностируемые на уровне кода конфигурации, и рассматриваются методики оптимизации запросов.
Основные причины неоптимальной работы запросов
1. Cоединения с подзапросами
Не следует использовать соединения с подзапросами. Следует соединять друг с другом только объекты метаданных или временные таблицы. Если запрос использует соединения с подзапросами, то его следует переписать с использованием временных таблиц.
Пример неоптимального опасного запроса, использующего соединение с подзапросом в правой части соединения используется подзапрос:
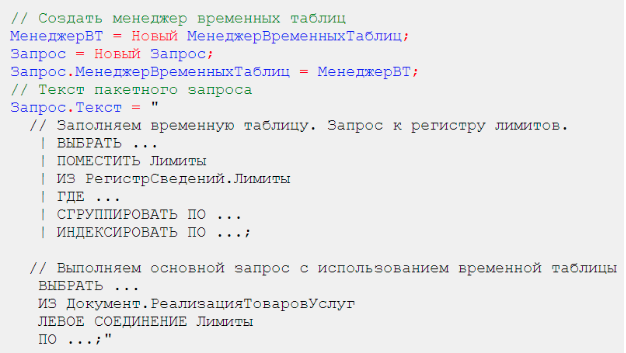
ВЫБРАТЬ ... ИЗ Документ.РеализацияТоваровУслуг ЛЕВОЕ СОЕДИНЕНИЕ ( ВЫБРАТЬ ИЗ РегистрСведений.Лимиты ГДЕ ... СГРУППИРОВАТЬ ПО ... ) ПО ...
Для оптимизации запроса следует разбить его на несколько отдельных запросов (по числу подзапросов, используемых в соединениях). Эти запросы рекомендуется поместить в один пакетный запрос.
// Создать менеджер временных таблиц МенеджерВТ = Новый МенеджерВременныхТаблиц; Запрос = Новый Запрос; Запрос.МенеджерВременныхТаблиц = МенеджерВТ; // Текст пакетного запроса Запрос.Текст = " // Заполняем временную таблицу. Запрос к регистру лимитов. | ВЫБРАТЬ ... | ПОМЕСТИТЬ Лимиты | ИЗ РегистрСведений.Лимиты | ГДЕ ... | СГРУППИРОВАТЬ ПО ... | ИНДЕКСИРОВАТЬ ПО ...; // Выполняем основной запрос с использованием временной таблицы ВЫБРАТЬ ... ИЗ Документ.РеализацияТоваровУслуг ЛЕВОЕ СОЕДИНЕНИЕ Лимиты ПО ...;" Внимание! очень важно в данном примере проиндексировать созданную временную таблицу. В качестве индексных полей следует указать все поля, которые используются в условии соединения.
2. Cоединения с виртуальными таблицами
Если в запросе используется соединение с виртуальной таблицей языка запросов 1С:Предприятия (например, “РегистрНакопления.Товары.Остатки()“) и запрос работает с неудовлетворительной производительностью, то рекомендуется вынести обращение к виртуальной таблице в отдельный запрос с сохранением результатов во временной таблице. То есть, следует использовать ту же рекомендацию, что и в случае соединения с подзапросом (см Пункт 1).
Дело в том, что виртуальные таблицы, используемые в языке запросов 1С:Предприятия, могут разворачиваться в подзапросы при трансляции в язык SQL. Это связано с тем, что виртуальная таблица часто (но не всегда) получает данные из нескольких физических таблиц СУБД. Если вы используете соединение с виртуальной таблицей, то на уровне SQL оно может быть в некоторых случаях реализовано, как соединение с подзапросом. В этом случае оптимизатор СУБД может точно так же выбрать неоптимальный план, как при работе с подзапросом, использованным в языке 1С:Предприятия в явном виде.
3. Несоответствие индексов и условий запроса
Условия используются в следующих секциях запроса:
- ВЫБРАТЬ … ИЗ … ГДЕ <условие>
- СОЕДИНЕНИЕ … ПО <условие>
- ВЫБРАТЬ … ИЗ <ВиртуальнаяТаблица>(, <условие>)
- ИМЕЮЩИЕ <условие>
Для этих всех условий, использованных в запросе, должны быть подходящие подходящие индексы для оптимизации отбора данных по условию. Причем, подходящим является индекс, удовлетворяющий следующим требованиям:
- Требование 1 . Индекс содержит все поля перечисленные в условии;
- Требование 2. Эти поля находятся в самом начале индекса;
- Требование 3. Эти поля идут подряд, то есть между ними не «вклиниваются» поля, не участвующие в условии запроса;
Основные идексы, создаваемые 1С:Предприятием:
- индекс по уникальному идентификатору (ссылке) для всех объектных сущностей (справочники, документы и т.д.);
- индекс по регистратору (ссылке на документ) для таблиц движений регистров, подчиненных регистратору;
- индекс периоду и значениям всех измерений для итоговых таблиц регистров накопления;
- индекс периоду, счету и значениям всех измерений для итоговых таблиц регистров бухгалтерии.
В тех случаях, когда автоматически созданных индексов недостаточно, можно дополнительно проиндексировать реквизиты объекта метаданных в конфигураторе. Однако, следует иметь в виду, что создание индекса ускоряет процесс поиска информации, но может несколько замедлить процесс ее изменения пользователем (добавления, редактирования и удаления) в режиме запуска 1С предприятия. Поэтому индексы следует создавать осознанно и только в том случае, если точно известен запрос, для которого такой индекс необходим. Не следует создавать индексы “на всякий случай” или заведомо избыточные индексы. Например никогда не следует дополнительно индексировать первое измерение регистра, поскольку для поиска по значению первого измерения подходит основной индекс таблицы итогов, который автоматически создаст платформа.
В конфигурации описан регистр накопления ТоварыНаСкладах:

Платформа 1С:Предприятие автоматически создаст для таблицы остатков данного регистра индекс по периоду и всем измерениям в том порядке, в котором они перечислены в конфигураторе.
Рассмотрим несколько примеров запросов и проанализируем, смогут ли они оптимально выполняться при такой структуре данных.
Запрос 1
Запрос.Текст = "ВЫБРАТЬ | ТоварыНаСкладахОстатки.Склад, | ТоварыНаСкладахОстатки.Номенклатура, | ТоварыНаСкладахОстатки.Качество |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки(, Номенклатура = &Номенклатура) КАК ТоварыНаСкладахОстатки";
В данном случае нарушено требование 2. В условии отсутствует отбор по первому полю индекса (Склад). Такой запрос не сможет выполниться оптимально. Для его выполнения серверу СУБД придется перебирать (сканировать) все записи таблицы. Время выполнения этой операции напрямую зависит от количества записей в таблице остатков регистра и может быть очень большим (и будет увеличиваться с ростом количества данных).
Варианты оптимизации:
- Проиндексировать измерение «Номенклатура»
- Поставить измерение «Номенклатура» первым в списке измерений. Будьте внимательны при использовании этого метода. В конфигурации могут присутствовать другие запросы, которые могут замедлиться в результате этой перестановки.
Запрос 2
Запрос.Текст = "ВЫБРАТЬ | ТоварыНаСкладахОстатки.Склад, | ТоварыНаСкладахОстатки.Номенклатура, | ТоварыНаСкладахОстатки.Качество |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки( | , | Качество = &Качество | И Склад = &Склад) КАК ТоварыНаСкладахОстатки";
В данном случае нарушено требование 3. Между измерениями «Склад» и «Качество» в структуре регистра находится измерение «Номенклатура», которое не задано в условии запроса. Этот запрос так же не сможет выполняться оптимально. При его выполнении СУБД выполнит поиск по первому полю индекса, но затем вынужденно просканирует некоторую его часть. Сканирование приведет к увеличению времени выполнения запроса и к блокировке избыточных записей в таблице, то есть к снижению общей пропускной способности системы.
Варианты оптимизации:
- Добавить в запрос условие по измерению «Номенклатура»
- Убрать из запроса условие по измерению «Качество»
- Перенести «Номенклатуру» из измерений в реквизиты
- Поменять местами измерения «Номенклатура» и «Качество
Запрос 3
Запрос.Текст = "ВЫБРАТЬ | ТоварыНаСкладахОстатки.Склад, | ТоварыНаСкладахОстатки.Номенклатура, | ТоварыНаСкладахОстатки.Качество, | ТоварыНаСкладахОстатки.КоличествоОстаток |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки( | , | Номенклатура = &Номенклатура | И Склад = &Склад) КАК ТоварыНаСкладахОстатки";
В этом случае требования соответствия индекса и запроса не нарушены. Данный запрос будет выполнен СУБД оптимальным способом. Обратите внимание на то, что порядок следования условий в запросе не обязан совпадать с порядком следования полей в индексе. Это не является проблемой и будет нормально обработано СУБД.
4. Использование логического ИЛИ в условиях
4.1 Использование логического ИЛИ в секции ГДЕ запроса
Не следует использовать ИЛИ в секции ГДЕ запроса. Это может привести к тому, что СУБД не сможет использовать индексы таблиц и будет выполнять сканирование, что увеличит время работы запроса и вероянтность возникновения блокировок. Вместо этого следует разбить один запрос на несколько и объединить результаты.
Например, запрос
ВЫБРАТЬ Товар.Наименование ИЗ Справочник.Товары КАК Товар ГДЕ Артикул = "001" ИЛИ Артикул = "002"
следует заменить на запрос
ВЫБРАТЬ Товар.Наименование ИЗ Справочник.Товары КАК Товар ГДЕ Артикул = "001" |ОБЪЕДИНИТЬ ВСЕ |ВЫБРАТЬ Товар.Наименование ИЗ Справочник.Товары КАК Товар ГДЕ Артикул = "002"
4.2 . Включение пользователей в несколько ролей, каждая из которых имеет RLS
1С RLS (Record Level Security) или ограничение прав на уровне записи — это настройка прав пользователей в системе 1С, которая позволяет разделить права для пользователей в разрезе динамически меняющихся данных.
Если в конфигурации описано несколько ролей с условиями RLS, то не следует назначать одному пользователю более одной такой роли. Если один пользователь будет включен, например, в две роли с RLS – бухгалтер и кадровик, то при выполнении всех его запросов к их условиям будут добавляться условия обоих RLS с использованием логического ИЛИ. Таким образом, даже если в исходном запросе нет условия ИЛИ, оно появится там после добавления условий RLS. Такой запрос так же может выполняться неоптимально – медленно и с избыточными блокировками.
Вместо этого следует создать “смешанную” роль – “бухгалтер-кадровик” и прописать ее RLS таким образом, чтобы избежать использования ИЛИ в условии, а пользователя включить в эту одну роль.
4. 3 Использование ИЛИ в условиях соединения
Не рекомендуется использовать логическое ИЛИ в условиях соединения, то есть в секции ПО запроса. Это так же может привести к выбору неоптимального плана и медленной работе запроса. Простого универсального способа переписать такой запрос без использования ИЛИ не существует. Следует проанализировать решаемую задачу и попытаться найти другой алгоритм ее решения.
5.Использование подзапросов в условии соединения
Не следует использовать подзапросы в условии соединения. Это может привести к значительному замедлению запроса и (в отдельных случаях) к его полной неработоспособности на некоторых СУБД. Пример запроса с использованием подзапроса в условии соединения:
Запрос.Текст = "ВЫБРАТЬ | ОстаткиТоваров.Номенклатура КАК Номенклатура, | Цены.Цена КАК ЦенаПрошлогоМесяца |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки(...) КАК ОстаткиТоваров | ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.Цена КАК Цены | ПО Цены.Номенклатура = ОстаткиТоваров.Номенклатура И | Цены.Период В ( | ВЫБРАТЬ МАКСИМУМ(ЦеныПрошлогоМесяца.Период) | ИЗ РегистрСведений.Цена КАК ЦеныПрошлогоМесяца | ГДЕ ЦеныПрошлогоМесяца.Период < НАЧАЛОПЕРИОДА(ОстаткиТоваров.Период, МЕСЯЦ) | И ЦеныПрошлогоМесяца.Номенклатура = ОстаткиТоваров.Номенклатура | ) | ГДЕ ОстаткиТоваров.Склад = &Склад";
В данном случае подзапрос в условии соединения используется для получения как бы “среза последних” на конец предыдущего периода. Причем, для каждой номенклатуры период может быть разным. Подобный запрос рекомендуется переписать с использованием временных таблиц. Например, это можно сделать следующим образом:
Запрос.Текст = " // Максимальные даты установки цен в прошлом периоде для данных номенклатур |ВЫБРАТЬ | ОстаткиТоваров.Номенклатура КАК Номенклатура, | МАКСИМУМ(Цены.Период) КАК Период |ПОМЕСТИТЬ ДатыПоНоменклатурам |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки(...) КАК ОстаткиТоваров | ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.Цена КАК Цены | ПО Цены.Номенклатура = ОстаткиТоваров.Номенклатура И | Цены.Период < НАЧАЛОПЕРИОДА(ОстаткиТоваров.Период, МЕСЯЦ) | СГРУППИРОВАТЬ ПО ОстаткиТоваров.Номенклатура | ГДЕ ОстаткиТоваров.Склад = &Склад; // Выбрать данные по цене за найденный период |ВЫБРАТЬ | ДатыПоНоменклатурам.Номенклатура КАК Номенклатура, | Цены.Цена КАК ЦенаПрошлогоМесяца |ИЗ ДатыПоНоменклатурам | ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.Цена КАК Цены | ПО Цены.Номенклатура = ОстаткиТоваров.Номенклатура И | Цены.Период = ДатыПоНоменклатурам.Период ";
6.Получение данных через точку от полей составного типа
Если в запросе используется получение значения через точку от поля составного ссылочного типа, то при выполнении этого запроса будет выполняться соединение со всеми таблицами объектов, входящими в этот составной тип. В результате SQL текст запроса чрезвычайно усложняется, и при его выполнении оптимизатор СУБД может выбрать неоптимальный план. Это может привести к серьезным проблемам производительности и даже к неработоспособности запроса в отдельных случаях.
В частности, не рекомендуется обращаться к реквизитам регистратора регистра (например, “ТоварыНаСкладах.Регистратор.Дата”) и т.п. При этом не важно в какой части запроса вы используете реквизит, полученный через точку от поля составного типа – в списке возвращаемых полей, в условии и т.п. Во всех случаях такое обращение может привести к проблемам производительности.
Общая рекомендация заключается в том, чтобы по возможности ограничить количество соединений в таких запросах. Для этого можно использовать следующие приемы:
- Избегайте избыточности при создании полей составных ссылочных типов. Указывайте ровно столько возможных типов для данного поля, сколько необходимо. Не следует без необходимости использовать типы “любая ссылка” или “ссылка на любой документ” и т.п. Вместо этого следует более тщательно проанализировать прикладную логику и назначить для поля ровно те возможные типы ссылок, которые необходимы для решения задачи.
- При необходимости жертвуйте компактностью хранения данных ради производительности. Если в запросе вам понадобилось значение, полученное через ссылку, то, возможно, это значение можно хранить непосредственно в данном объекте. Например, если при работе с регистром вам требуется информация о дате регистратора, вы можете завести в регистре соответствующий реквизит и назначать ему значение при проведении документов. Это приведет к дублированию информации и некоторому (незначительному) увеличению ее объема, но может существенно повысить производительность и стабильность работы запроса.
- При необходимости жертвуйте компактностью и универсальностью кода ради производительности. Как правило, для выполнения конкретного запроса в данных условиях не нужны все возможные типы данной ссылки. В этом случае, следует ограничить количество возможных типов при помощи функции ВЫРАЗИТЬ. Если данный запрос является универсальным и используется в нескольких разных ситуациях (где типы ссылки могут быть разными), то можно формировать запрос динамически, подставляя в функцию ВЫРАЗИТЬ тот тип, который необходим при данных условиях. Это увеличит объем исходного кода и, возможно, сделает его менее универсальным, но может существенно повысить производительность и стабильность работы запроса.
Пример
В данном запросе используется обращение к реквизитам регистратора. Регистратор является полем составного типа, которое может принимать значения ссылки на один из 56 видов документов.
Запрос.Текст = "ВЫБРАТЬ | Продажи.Регистратор.Номер, | Продажи.Регистратор.Дата, | Продажи.Контрагент, | Продажи.Количество, | Продажи.Стоимость |ИЗ | РегистрНакопления.Продажи КАК Продажи |ГДЕ ...
SQL-текст этого запроса будет включать 56 левых соединений с таблицами документов. Это может привести к серьезным проблемам производительности при выполнении запроса. Однако, для решения данной конкретной задачи нет необходимости соединяться со всеми 56 видами документов. Условия запроса таковы, что при его выполнении будут выбраны только движения документов “РеализацияТоваровУслуг” и “ЗаказыПокупателя”. В этом случае мы можем значительно ускорить работу запроса, ограничив количество соединений при помощи функции ВЫРАЗИТЬ().
Запрос.Текст = "ВЫБРАТЬ | ВЫБОР | КОГДА Продажи.Регистратор ССЫЛКА Документ.РеализацияТоваровУслуг | ТОГДА ВЫРАЗИТЬ(Продажи.Регистратор КАК Документ.РеализацияТоваровУслуг).Номер | КОГДА Продажи.Регистратор ССЫЛКА Документ.ЗаказПокупателя | ТОГДА ВЫРАЗИТЬ(Продажи.Регистратор КАК Документ.ЗаказПокупателя).Номер | КОНЕЦ ВЫБОРА КАК Номер, | ВЫБОР | КОГДА Продажи.Регистратор ССЫЛКА Документ.РеализацияТоваровУслуг | ТОГДА ВЫРАЗИТЬ(Продажи.Регистратор КАК Документ.РеализацияТоваровУслуг).Дата | КОГДА Продажи.Регистратор ССЫЛКА Документ.ЗаказПокупателя | ТОГДА ВЫРАЗИТЬ(Продажи.Регистратор КАК Документ.ЗаказПокупателя).Дата | КОНЕЦ ВЫБОРА КАК Дата, | Продажи.Контрагент, | Продажи.Количество, | Продажи.Стоимость |ИЗ | РегистрНакопления.Продажи КАК Продажи |ГДЕ | Продажи.Регистратор ССЫЛКА Документ.РеализацияТоваровУслуг | ИЛИ Продажи.Регистратор ССЫЛКА Документ.ЗаказыПокупателя";
Этот запрос является более громоздким и, возможно, менее универсальным (он не будет правильно работать для других ситуаций – когда возможны другие значения типов регистратора). Однако, при его выполнении будет сформирован SQL запрос, который будет содержать всего два соединения с таблицами документов. Такой запрос будет работать значительно быстрее и стабильнее, чем запрос в его первоначальном виде.
7. Фильтрация виртуальных таблиц без использования параметров
При использовании виртуальных таблиц в запросах, следует передавать в параметры таблиц все условия, относящиеся к данной виртуальной таблице. Не рекомендуется фильтровать виртуальные таблицы при помощи условий в секции ГДЕ и т.п. Такой запрос будет возвращать правильный (с точки зрения функциональности) результат, но СУБД будет намного сложнее выбрать оптимальный план для его выполнения. В некоторых случаях это может привести к ошибкам оптимизатора СУБД и значительному замедлению работы запроса.
Например, следующий запрос использует секцию ГДЕ запроса для выборки из виртуальной таблицы.
Запрос.Текст = "ВЫБРАТЬ | Номенклатура |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки() |ГДЕ | Склад = &Склад";
Возможно, что в результате выполнения этого запроса сначала будут выбраны все записи виртуальной таблицы, а затем из них будет отобрана часть, соответствующая заданному условию. Было бы оптимальным вариантом ограничивать количество выбираемых записей на самом раннем этапе обработки запроса. Для этого следует передать условия в параметры виртуальной таблицы.
Запрос.Текст = "ВЫБРАТЬ | Номенклатура |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки(, Склад = &Склад)";
С чего начинается анализ возможных причин сбоев?
Мероприятия по поиску возможных причин перегрузки системы следует искать не в хаотическом порядке, а постепенно, переходя от одного блока к другому, применяя систематический подход. Тогда в 1С оптимизация запросов окажется эффективной.
Вот наиболее частые проблемные места, ведущие к снижению скорости работы СУБД:
- неправильное использование подзапросов при написании запросов;
- некорректная работа системы при обработке виртуальных таблиц;
- неправильный индекс и некорректное условие запроса;
- логическая операция
ИЛИ, неправильное ее использование; - неправильные запросы в соединениях;
- ошибки обработки таблиц с данными при использовании фильтров;
- значения полей составных типов и многие другие.
Рассмотрим некоторые из перечисленных.
Обработка подзапросов в запросах
При использовании подзапросов в соединениях довольно часто возникают различные ошибки на системном уровне. И это неправильно. Эффективнее организовать связь исключительно между объектами метаданных или таблицами, временно создаваемыми.

Подзапрос имеет меньший приоритет, поэтому он будет выполнен значительно позже, что скажется на скорости его обработки даже при малой загрузке сервера. Также будет обеспечена явная нестабильность, это будет зависеть от определенных условий. Кроме этого, различные СУБД такие запросы обрабатывают по-разному, что также сказывается на скорости.
Важно! Временные таблицы появились в версиях 1С 8.2 и 8.3, поэтому если вы до сих пор используете 8.0, то мы рекомендуем обновиться, потому что появится не только эта возможность, но и много других полезных вещиц.
Разработка и оптимизация запросов в 1С должна выполняться правильно с учетом требований СУБД, поэтому при использовании соединений к подзапросам рекомендуется разделить их на столько частей, сколько имеется соединений.
После чего формируется единый пакетный запрос с их использованием. Таким образом, создается временная таблица, которая сразу же должна быть проиндексирована. А, точнее, проиндексированы все используемые поля.
Если запрос неправильно сформирован, имеется в виду с использованием нескольких подзапросов, то оптимизатор сервера, используемый в конкретной СУБД, может неправильно отрабатывать его.
То есть он может запутаться в нескольких соединениях. Но если соединения сформируются в 2 таблицы, то оптимизатор сможет достаточно быстро выяснить объем выборок. Но в случае если одна из выборок содержит подзапрос, то будет затруднительно сразу определить количество возвращаемых записей.
Переписанный код с использованием временных таблиц, конечно, имеет намного больший размер, но зато оптимизатору будет легче работать с ним, следовательно, система значительно ускориться.
Логическое ИЛИ
Для построения функций при создании сложных запросов часто используется функция логическое ИЛИ. Но из-за некоторых особенностей работы с ней, она может быть применена некорректно, из-за чего могут возникать проблемы в работе системы. Рассмотрим 2 наиболее частых случая, где используется эта функция:
- В секции
ГДЕ.Для правильного составления крайне не рекомендуется пользоваться операцией
ИЛИв секцияхГДЕ. Если это правило не соблюдено, то СУБД не проиндексирует ее, а просто просканирует.Что не даст желаемого результата. А так как она не получит требуемых данных, то произойдет блокировка. Лучше его разбить на несколько отдельных, а после, сконфигурировать их.
Пример:
Запрос
ВЫБРАТЬ… ИЗ … КАК … ГДЕ …1 ИЛИ 2луче заменить на блок:ВЫБРАТЬ … ИЗ … КАК … ГДЕ …1 ОБЪЕДИНИТЬ ВСЕ ВЫБРАТЬ … ИЗ … КАК … ГДЕ …2 - Несколько ролей с RLS на одного пользователя.
Не используйте
ИЛИв запросах при работе с пользователями с несколькими ролями и RLS. Из-за этого сильно снизится скорость обработки данных или появится блокировка. Необходимо объединять смешанные роли, например, бухгалтер-кадровик и стараться прописывать RLS без возможной вставки в него логической операцииИЛИ.
Условия соединения с ИЛИ
Разработка и оптимизация запросов в 1С предприятие в условиях соединения должна выполняться без ИЛИ при написании запроса в секциях соединения ПО. Это чревато проблемами выбора неоптимального плана, кроме этого заметно замедляется функционирование СУБД.
Как обрабатывать виртуальные таблицы
СУБД иногда неправильно работает в случаях неправильного соединения записей с виртуальными таблицами. Решение данной проблемы кроется во вложении виртуальной таблицы во временную. Не забыть выполнить индексацию соединенных полей запроса ВТ. В результате система создаст подзапрос для выборки. Но возникнет новая проблема, подобно случаю обработки запросов с подзапросами.
Отборы в неиндексируемых полях
Качественная оптимизация запросов в 1С 8.2 исключает использование запросов по неиндексируемым полям. Такие конструкции являются полным противоречием правил оптимизации. Для решения проблемы лучше непосредственно в запросе реализовать отбор по неиндексируемым полям. Если была использована ВТ, то лучше проиндексировать именно поля соединения.
Для стабильной работы СУБД, каждое из условий должно содержать индекс, содержащий поля условия, находящиеся в самом начале. Отборы должны следовать подряд без вставки в них других значений.
Если система не сможет подобрать индексы, то сканированию будет подвержена таблица данных целиком. Что затянется надолго, и станет очередной причиной блокировки всех данных.
Работа с фильтрами данных в таблицах
Правильной считается оптимизация кода 1С только при построении отбора не используя секцию ГДЕ. Ее наличие приведет к получению системой всех данных таблицы и после выберет нужные. Именно поэтому процесс накладывания фильтров на реквизиты должен выполняться исключительно с использованием параметров временной таблицы.
Как получать значения полей составных типов
Когда при составлении запроса на получение сведений из таблицы используется точка, то СУБД свяжет левым соединением не все таблицы. А столько, сколько возможно типов в поле составного типа. Еще не рекомендуется, выполняя оптимизацию, использовать регистратор. Он относится к составному типу данных. В них есть все типы документов, имеющие доступ к записи в регистр.
Для ускорения процесс обработки данных СУБД, рекомендуется сократить часть записей или разделить их. Можно добавить данных в реквизиты.
Довольно часто начинающие 1С разработчики сталкиваются с ошибками, которых достаточно легко избежать. Ниже мы рассмотрим топ 11 ошибок и способы их исправления. Также доступна видеоверсия статьи
Содержание
Поле объекта не обнаружено
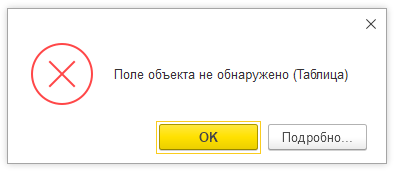
Существует множество статей, которые описывают возможные причины возникновения в 1С ошибки “Поле объекта не обнаружено”. Порой это связывают с обновлением платформы, обновлением типового релиза, или с какими-то другими причинами.
Мы же будем оперировать фактами. В конце статьи прилагается внешняя обработка, в которой воспроизведена данная ошибка.
Такое сообщение платформа выдает, когда пытается обратиться к свойству объекта языка, которого у данного объекта нет. Не важно, что это за объект – документ, справочник, таблица значений , или сообщение пользователю.
- Удалили табличную часть, к которой обращаемся в коде?
- Переименовали реквизит, а в коде не исправили?
- Заменили значение со ссылки на неопределено?
Вуаля – платформа выдаст ошибку “Поле объекта не обнаружено”!
Как исправить? Исходя из природы ошибки – переименовать реквизит на нужное имя, отредактировать код, или использовать правильные обращения к стандартным свойствам объекта.
Например, у объекта “СообщениеПользователю” нет свойства “Таблица”, и следующий код приведет к ошибке:
Сообщение = Новый СообщениеПользователю;
Сообщение.Таблица = “Ошибка”;
Индекс находится за границами массива
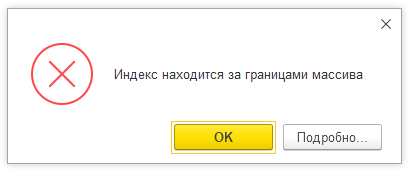
Что означает такое сообщение системы? Как правило, с данной ошибкой разработчик сталкивается при некорректной работе с коллекциями. Самые частые случаи появления ошибки “Индекс находится за границами массива”.
- Использование при обходе коллекции количества элементов вместо индекса. Индексы начинаются с нуля, а количество элементов – с единицы. Поэтому следующий код гарантированно приведет к ошибке: Массив[Массив.Количество()]
- Последствия удаления элементов из коллекции, очистки коллекции или замены коллекции на пустую
- Ошибочное увеличение счетчика в цикле “Для”
Как исправить? Для удаления элементов из коллекции по условию – использовать обратный цикл. Добавлять условие на соответствие счетчика цикла и индекса массива. Не увеличивать счетчик внутри кода цикла Для … Цикл … КонецЦикла
Обращение к процедуре как к функции
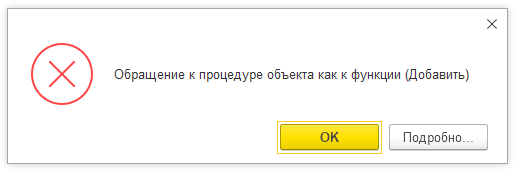
Суть этой ошибки в том, что процедура не может возвращать значение. И если мы в коде используем вызов процедуры справа от знака присваивания, это приведет к ошибке.
Данная ошибка имеет две вариации – если используется стандартная процедура из методов какого-нибудь объекта, то фраза будет звучать “Обращение к процедуре объекта как к функции”. Если же использовать процедуру, объявленную в коде, то текст ошибки будет “Обращение к процедуре как к функции”.
При этом ошибка использования процедуры объекта является ошибкой времени выполнения – т.е. на этапе сохранения и проверки конфигурации платформа эту ошибку не обнаружит.
А вот неправильное использование процедуры синтаксическая проверка (Ctrl + F7) успешно обнаруживает, и не даст сохранить конфигурацию или внешнюю обработку/отчет, пока ошибка не будет устранена.
Рассмотрим два примера:
1. Воспроизведем ошибку “Обращение к процедуре как к функции”. При этом платформа не даст сохранить изменения, т.к. не проходит синтакс-контроль.

2. Воспроизведем ошибку “Обращение к процедуре объекта как к функции”. Здесь мы неверно используем метод объекта массива “Добавить”, который является процедурой.

Как исправить? Ошибка тривиальная, и исправление тоже. Чаще всего, достаточно внимательно прочитать описание методов объекта во встроенной справке или синтакс-помощнике. Если метод является процедурой, то значений он возвращать не может. Следовательно, нужно модифицировать код так, чтобы такого ошибочного вызова не было.
Если же используется процедура, объявленная в коде, возможно, есть необходимость изменить ее на функцию, либо также скорректировать код, который эту процедуру использует.
Процедура не может возвращать значение
Родственная предыдущей ошибка. Для того, чтобы код возвращал какое-то значение, следует этот код размещать в функции, а не в процедуре.
В процедуре можно написать ключевое слово “Возврат” без параметров. Это будет означать выход из процедуры.
Следующий код является ошибочным, т.к. в теле процедуры Возврат используется с параметром:
Процедура ПроцедураНеМожетВозвращатьЗначение(Команда) Возврат "Ошибка"; КонецПроцедуры
Как исправить? Платформа сама подсказывает, в каком месте кода ошибка. Нужно изменить текст модуля – либо удалить параметр у ключевого слова Возврат, либо убрать его вовсе, либо изменить процедуру на функцию – зависит от того, какая логика у вашей процедуры, и как вы предполагаете ее использовать.
Переменная не определена
Такой текст ошибки платформа 1С выдает на этапе синтаксического контроля, при сохранении конфигурации, внешнего отчета или обработки.
Причин у этой ошибки может быть несколько.
- Опечатка в имени переменной
- Обращение к переменной, которая нигде в области видимости не объявлена (неявной инициализацией с присвоением значения, явным образом с использованием ключевого слова “Перем”, или передана в качестве параметра)
- Написание на клиенте серверного кода. Например, обращение к менеджеру справочников “Справочники”, и т.п. Клиентская часть приложения “не видит ” серверные объекты языка
- Также ошибка может появиться, если ранее код использовался в режиме толстого клиента, но после был запущен в тонком клиенте.
Как исправить?
Внимательно следить за правильностью набранного кода, своевременно объявлять переменные или передавать их в качестве параметров. Писать серверный код только в серверных модулях, а также использовать соответствующие инструкции препроцессора, например “&НаСервере”.
Значение не является значением объектного типа
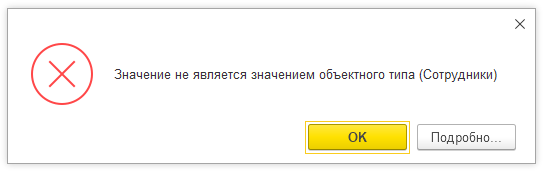
Ошибка “Значение не является значением объектного типа” может возникнуть при неверном обращении к объекту языка. Объектный тип – это такие объекты языка, которые содержат в себе другие объекты – свойства, реквизиты и т.п. Эти свойства доступны через точку, например “Объект.СвойствоЭтогоОбъекта”
Но если через точку попытаться использовать какое-то значение, которое внутри себя свойств не имеет – например, любое значение примитивного типа – это и приведет к ошибке.
Разберем более сложный пример:
&НаСервере Процедура ЗначениеНеЯвляетсяЗначениемОбъектногоТипаНаСервере(Справочники = Ложь) Сообщить(Справочники.Сотрудники.ПустаяСсылка()); КонецПроцедуры
Ошибка может быть “плавающей”. Если вместо параметра по умолчанию “Справочники = Ложь” будет передан менеджер справочников, то ошибки возникать не будет. А если вызвать процедуру без параметров, то будет использоваться параметр по умолчанию с типом Булево, что и приведет к ошибке.
Чаще всего чтобы исправить ошибку, нужно в отладчике посмотреть, какой тип значения используется. Можно внести изменения в код, чтобы обеспечить корректное поведение (например, в запросе вместо наименования товара выбрать ссылку, и в коде через точку уже обращаться к свойствам ссылки, а не текстового наименования). А можно добавить проверку на нужный тип значения. Т.е. – если значение того типа, который мы ожидаем – выполняем код. Иначе – не выполняем.
Ошибка при вызове метода контекста
В языке 1С у разных объектов (запросов, справочников, табличных документов и др.) есть предопределенные методы, предусмотренные платформой. Обращение к этим методам требует соблюдения порядка и параметров, правильного синтаксиса и соблюдения условий использования. Например, при чтении табличного документа из файла он не должен быть открыт в другой программе, при подключении к http-соединению оно должно быть доступно, и т.п.
Если эти условия не соблюдать, платформа в зависимости от версии может выдавать сообщения вида “Ошибка при вызове метода контекста”, и далее будут следовать более подробные сведения об ошибке – стек вызовов, приведших к ошибке, номер строки и позиции в строке, где произошла ошибка.
Чаще всего ошибка при вызове метода контекста встречается в следующих методах:
- Записать
- Прочитать
- Выполнить
- Создать
- ПроверитьВывод
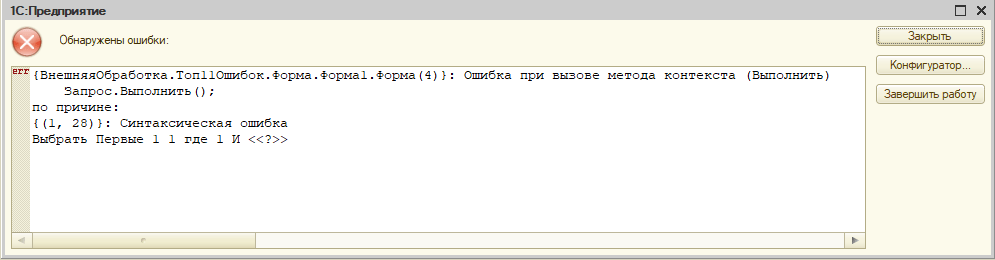
Разберем эту ошибку на примере метода Выполнить объекта Запрос:
Запрос = Новый Запрос("ВЫБРАТЬ ПЕРВЫЕ 1 1 ГДЕ ИСТИНА И");
Запрос.Выполнить();
В тексте запроса допущена ошибка – после первого условия “ГДЕ ИСТИНА” указан оператор И, но после него нет еще одного условия. В результате при попытке выполнения запроса, платформа вернет ошибку.
Для исправления ошибки зачастую достаточно внимательно использовать методы, при необходимости уточнять порядок, количество и тип параметров – это можно сделать в справке или синтакс-помощнике (встать курсором на имя метода в коде, и нажать сочетание клавиш Ctrl+F1). В случае запроса – нужно передавать синтаксически корректный текст запроса; в случае проверки вывода на печать – в системе должен быть установлен принтер; в случае подключения к почте – должны быть корректно указаны логин и пароль, и т.п.
Тип не может быть выбран в запросе в 1С 8.3 (8.2)
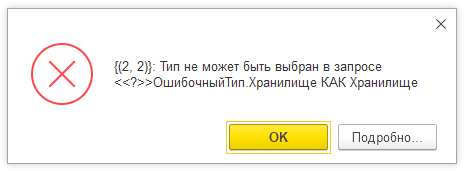
С такой ошибкой начинающие разработчики (да и не только начинающие 😉 ) сталкиваются чаще всего, при чтении запросом данных из таблиц значений, либо из регистров сведений. Все дело в том, что запросы поддерживают далеко не все типы значений. Так, например, нельзя запросом выбрать тип Картинка, ХранилищеЗначений, Шрифт, и многие другие типы, которые не относятся к примитивным или ссылочным типам значений.
Так, если ресурс регистра сведений имеет тип ХранилищеЗначений, выбрать его запросом будет нельзя. Также, если в таблицу значений поместить значения не подходящих типов, а после передать эту таблицу в качестве параметра-источника данных, выполнение запроса также приведет к ошибке “Тип не может быть выбран в запросе”.
Еще одна ситуация, когда запрос будет выдавать ошибку – если таблица значений, которая передается в качестве параметра, имеет не типизированные колонки.
Неверно:
//ТЗОшибочныйТип.Колонки.Добавить("Контрагент");
Верно:
//ТЗОшибочныйТип.Колонки.Добавить("Контрагент", Новый ОписаниеТипов("СправочникСсылка.Контрагенты"));
Для исправления ошибки нужно правильным образом инициализировать колонки таблицы значений, а также не обращаться в запросе к полям, типы которых запросами не поддерживаются.

Платформа будет выдавать такое сообщение, если в коде используются методы, приводящие к открытию модальных окон. Модальные окна – это окна, которые при открытии блокируют весь остальной интерфейс. В 1С есть несколько модальных методов – например – “Вопрос”, “ОткрытьЗначение”, “Предупреждение”. Кроме того, в коде может использоваться модальный синтаксис открытия форм: “ОткрытьМодально()”
Если в свойствах конфигурации выбран режим использования модальности “Не использовать”, то выполнение модальных методов будет приводить к этой ошибке “Использование в 1С модальных окон в данном режиме запрещено”.
Для устранения ошибки можно пойти несколькими путями. Как водится, один – быстрый, другой – правильный 🙂
Быстрый способ – переключить режим использования модальности в положение “Использовать”.
Более правильный способ – использовать в коде немодальные вызовы методов. Например, у метода “Вопрос” есть немодальный аналог – “ПоказатьВопрос”, у метода “Предупреждение” – “ПоказатьПредупреждение”, и т.п. Чаще всего об этих методах дополнительно указано в синтакс-помощнике и справке.
Кроме того, в последних версиях платформы появились асинхронные методы – “ВопросАсинх”, “ПредупреждениеАсинх” и др. Появление этих методов позволяет писать более простой и понятный асинхронный код, и направлено в первую очередь, на более полноценную поддержку браузерами и работу в веб-клиенте.
1С 8.3 и 8.2: Запись с такими ключевыми полями существует!
Данная ошибка появляется при некорректной записи в регистр сведений. Чаще всего с этой ошибкой сталкиваются начинающие разработчики, не до конца понимающие механизмы работы с ключевыми полями (измерениями).
Суть ошибки следующая – регистр сведений позволяет записать запись (строку таблицы) с уникальным набором ключевых полей – а для периодических регистров также и поля Период. Если следующая запись полностью повторяет значение ключевых полей, но осуществляется методом Записать с параметром Замещать = Истина, то запись в таблице регистра просто заменится на идентичную.
Однако если поместить две абсолютно одинаковые записи в набор записей, и попытаться его записать – платформа выдаст ошибку. Еще один распространенный случай, когда 1С сообщает “Запись с такими ключевыми полями существует” – это запись в периодический регистр сведений с периодичностью от “День” и выше, подчиненный регистратору.
В типовых конфигурациях часто эту ошибку можно воспроизвести, если в пользовательском режиме создать два документа “Установка цен номенклатуры” с одной и той же номенклатурой и за один и тот же день. Попытка провести второй документ приведет к ошибке.
В случае, когда ошибка возникает не в результате действий пользователя, а при выполнении кода, чтобы устранить ее, чаще всего необходимо проанализировать алгоритм записи в регистр. Если запись осуществляется одним набором данных, его предварительно нужно свернуть до уникальных записей. Например, выгрузить в таблицу значений, свернуть, и загрузить в набор записей.
Поле объекта недоступно для записи в 1С
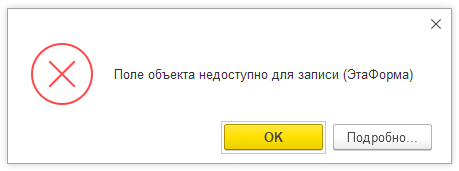
Чаще всего начинающие программисты 1С сталкиваются с этой ошибкой в двух ситуациях.
Первый случай – это попытка редактирования системных полей, недоступных для записи. Например, в модуле формы сама форма будет содержаться в объекте ЭтаФорма. И попытка присвоить этому реквизиту любое значение приведет к ошибке “Поле объекта недоступно для записи”.
Второй случай – и с ним новички как раз допускают больше всего ошибок – это попытка редактирования полей ссылки, а не самого объекта. Чаще всего код выглядит примерно так:
Элемент = Справочники.Сотрудники.НайтиПоКоду("12345");
Элемент.Наименование = "Новое наименование";
Исполнение данного кода приведет к ошибке, т.к. поля ссылки доступны только для чтения, а метод НайтиПоКоду вернет именно ссылку. Чтобы можно было внести изменения, следует из ссылки получить сам объект – используя соответствующий метод ПолучитьОбъект().
Для исправления ошибки зачастую достаточно получить объект из ссылки. В случае же попытки редактирования свойств, доступных только на чтение самый правильный подход – анализировать имеющуюся документацию по этим свойствам, и не пытаться присваивать им значения, если платформа этого не предусматривает.
Ссылка на обработку
По ссылке вы можете скачать внешнюю обработку, в которой воспроизводится большая часть ошибок, описанных в статье. Для воспроизведения части ошибок нужно будет убрать комментарии в коде.
Заключение
Как видите, зачастую ошибки тривиальны, и достаточно просто исправляются. Общие рекомендации – внимательно читать документацию и справку, корректно использовать методы, активно пользоваться отладчиком. Если вы новичок, и хотите освоить программирование в 1С с нуля – могу предложить приобрести мой базовый курс для начинающих. Более подробная информация – по ссылке.
Ниже раскрывается «кухня» выполнения запросов кода конфигурации 1С:Предприятие 8 и «ингредиенты», определяющие производительность запросов. Будет приведена информация о фактической работе запроса, которая помогает понять, какая требуется оптимизация. Показаны методы повышения производительности запросов.
Для того чтобы разработчик имел возможность использовать запросы для реализации собственных алгоритмов, в 1С:Предприятии реализован язык запросов. Этот язык основан на SQL, но при этом содержит значительное количество расширений (виртуальные таблицы, обращение через точку и т.п.), ориентированных на отражение специфики финансово-экономических задач и на максимальное сокращение усилий по разработке прикладных решений.
Модель работы с базой данных, реализованная в 1С:Предприятии 8, позволяет разработчику сосредоточиться на создании бизнес-логики приложения и не заботиться о структурах таблиц, преобразованиях типов данных и пр.
Платформа 1С:Предприятия обеспечивает операции исполнения запросов, описания структур данных и манипулирования данными, транслируя их в соответствующие команды. В случае клиент-серверного варианта работы — это команды MS SQL Server 2005, IBM DB2 или PostgreSQL.
«Внутренняя кухня» на примере MS SQL Server
Возьмем пример запроса 1С и проследим за путем его исполнения.
Воспользуюсь обработкой «Консоль запросов» с диска ИТС и выполню простенький запрос:

Большинство запросов, это инструкция «ВЫБРАТЬ …», поэтому мне кажется будет правильным дальше опираться на эту инструкцию.
Для знакомых с языком SQL команда «ВЫБРАТЬ» — это перевод на русский язык команды SELECT (кстати, если писать в 1С на английском языке, то запросы 1С становятся еще больше похожими на запросы SQL).
Давайте проследим путь выполнения этого запроса.
Путь прохождения запроса

Прежде всего не пугайтесь :). Расшифрую рисунок (он хоть и немного устарел, но суть сохранилась). Мы — это «пользователь» на рисунке. В консоли запросов я нажимаю кнопку «Выполнить».
Код обработки выполняется на клиенте (но в принципе может и на сервере 1С:Предприятие), он проходит по сети и попадает на рабочий сервер приложений, где транслируется в SQL запрос.
Отслеживание запросов технологическим журналом
С помощью обработки (тоже с диска ИТС) «Настройка технологического журнала» я создаю файл logcfg.xml, который будет логировать запросы к субд.
Содержимое файла у меня было такое:
<?xml version=»1.0″?>
<config xmlns=»http://v8.1c.ru/v8/tech-log»>
<dump create=»false» location=»» type=»0″/>
<log history=»1″ location=»E:Commonlogs»>
<event>
<eq property=»name» value=»dbmssql»/>
</event>
<property name=»all»/>
</log>
</config>
Текст logcfg.xml содержит фильтр dbmssql на сбор всех запросов к MS SQL Server.

затем открыл файл технологического лога
Для моего запроса в консоли запросов в логе появились такие строчки:
45:44.1727-1,DBMSSQL,3,process=rphost,p:processName=bi,t:clientID=15,t:applicationName=1CV8,t:computerName=TESTCENTER,t:connectID=10,Usr=Тест,Trans=0,dbpid=52,Sql=
‘SELECT
_InfoReg482_Q_000_T_001._Fld484 AS f_1
FROM
_InfoReg482 _InfoReg482_Q_000_T_001 WITH(NOLOCK)
WHERE
_InfoReg482_Q_000_T_001._Fld483RRef = ?
p_0: 0x9455005056C0000811DCE204C649E3E8
‘,Rows=1,RowsAffected=-1
45:44.2031-0,Context,1,process=rphost,p:processName=bi,t:clientID=15,t:applicationName=1CV8,t:computerName=TESTCENTER,t:connectID=10,Usr=Тест,Context=’
Обработка.КонсольЗапросов.Форма.Форма : 458 : мРезЗапроса = ОбъектЗапрос.Выполнить();’
У нас появился SQL запрос к «страшному и непонятному» имени таблицы базы данных «_InfoReg482 _InfoReg482_Q_000_T_001», плюс «загадочные» поля таблицы «_Fld484» и «_Fld483RRef».
Тут надо дать комментарий почему мы не увидели запроса 1С. У нас есть «контекст запроса» — 458 строка модуля Обработка.КонсольЗапросов.Форма — мРезЗапроса = ОбъектЗапрос.Выполнить();
Встаньте в эту строчку отладчиком конфигуратора и для ОбъектЗапрос.Текст содержимым будет запрос 1С.
Но это мы знаем исходный запрос, и поэтому можем догадаться, что за «_InfoReg482» таблица на самом деле.
Но когда исходный запрос неизвестен, чтобы получить соответствие имен таблиц базы данных объектам метаданным используете наш сервис.
Возвращаемся к нашей схеме прохождения запроса.
Сервер приложений 1С:Предприятие является клиентом для СУБД MS SQL Server и передает исследованный нами SQL запрос на сервер СУБД.
Запрос выполняет сервер СУБД и затем по обратной цепочки возвращает ответ.
В этой статье сконцентрируемся на подробностях исполнения запроса сервером субд, так как язык SQL предназначен для формулирования запросов в терминах СУБД (таблицы и поля).
При выполнении запроса:
SELECT
_InfoReg482_Q_000_T_001._Fld484 AS f_1
FROM
_InfoReg482 _InfoReg482_Q_000_T_001 WITH(NOLOCK)
WHERE
_InfoReg482_Q_000_T_001._Fld483RRef = ?
мы говорим, что нужно получить «_InfoReg482_Q_000_T_001._Fld484», но не говорим, «как это получить»!
Дело в том, что один и тот же запрос может быть выполнен множеством разных способов:
-Части запроса можно обрабатывать в разном порядке
-Можно использовать разные индексы
Это связано с механизмом субд — оптимизатором запросов.
Оптимизатор запросов СУБД
Оптимизатор запросов осуществляет поиск наиболее оптимального плана выполнения запросов из всех возможных для заданного запроса. Один и тот же результат может быть получен СУБД различными способами (планами выполнения запросов), которые могут существенно отличаться как по затратам ресурсов, так и по времени выполнения. Задача оптимизации заключается в нахождении оптимального способа.
План выполнения запроса — это такая перестановка всех исходных выбираемых таблиц, реляционное соединение которых в выбранной последовательности, представленное в процедурном виде, может быть выполнено за минимальное число операций.
Планы выполнения запроса сравниваются исходя из следующих факторов:
- потенциальное число строк, извлекаемое из каждой таблицы, получаемое из статистики;
- наличие индексов ( подразумевается, что вы уже прочли мою статью об индексах);
- возможность выполнения слияний (merge-join).
.gif)
Что из всего этого следует:
Перед выполнением запроса формируется его ПЛАН выполнения.
- Полностью определяет, как будет выполняться запрос
- Формируется автоматически сервером СУБД
- Повлиять на план средствами 1С:Предприятие можно только косвенно
Давайте «посмотрим» план выполнения нашего запроса.

Страшно и непонятно, если не знать английского 🙂
Давайте разберемся в этой схеме плана запроса.
Для выполнения выбора (SELECT …) поля _InfoReg482_Q_000_T_001._Fld484 (он находится в составе возвращаемых данных Output List) оптимизатор запросов принял решение выполнить перебор всех записей (Clustered Index Scan в заголовке операции (единственной) плана) кластерного индекса таблицы _InfoReg482_ByPeriod_TRN (об этом подсказывает раздел object).
Напоминаю, чтобы получить соответствие имен таблиц базы данных объектам метаданным используйте наш сервис.

Привожу для справки работу оператора сканирования (перебора) кластерного индекса:
Clustered Index Scan – логический и физический оператор сканирует кластеризованный индекс, определенный в колонке Argument.
Если есть опциональный параметр WHERE:(), то возвращаются только те строки, которые соответствуют параметру. Если колонка Argument содержит параметр ORDERED, процессор запроса предложит вывод строк в том порядке, в котором они отсортированы в кластерном индексе. Если упорядочения нет, индекс будет отсканирован самым оптимальным образом (но не гарантируется, что вывод будет отсортирован).
В нашем примере плана опциональный параметр отсутствует.
Основная причина недостаточной производительности запросов — неоптимальный план выполнения запроса.
Для того, чтобы устранять проблемы производительности, необходимо понять причины.
Причины, по которым СУБД может выбирать неоптимальный план (наиболее известные)
- Несоответствие индексов и условий запросов (проблема «покрывающих» запросов описана в моей статье)
- Большая вложенность подзапросов и соединения с вложенными подзапросами
- Некоренное использование параметров виртуальных таблиц
- Отсутствие функции ВЫРАЗИТЬ для полей составного типа
- Получение лишних полей через точку
Но прежде, чем перейдем к разбору софтверных нюансов, хочется ОБРАТИТЬ ВНИМАНИЕ, что
сильная загруженность ресурсов сервера на выбор плана влияет НЕПРЕДСКАЗУЕМО!
Это означает, что если у вас сервер «не тянет», то результат оптимизации кода конечно снизит нагрузку и улучшит производительность, но вот ВЫПОЛНИТЬ САМУ ОТЛАДКУ и оптимизировать код на таком сервере сложно и НЕТ ГАРАНТИЙ!
В качестве примера обычно рассказываю такую ситуацию. Допустим Вы нашли медленный запрос и знаете как его улучшить. Чтобы оценить на практике результаты, Вы должны сначала выполнить замер производительности на исходном коде, затем на оптимизированном. А как можно интерпретировать результаты, если в момент время замера исходного запроса сервер был загружен на 70%, а в момент второго на 99%. Можно ли доверять таким замерам? Нет.
Несоответствие индексов и условий запросов
В своей статье, посвященной индексом, мы сказали, что что нас интересуют влияние индексов на быстродействие запросов.
Индексы наиболее подходят для задач следующего типа:
- Запросы, которые указывают «узкие» критерии поиска. Такие запросы должны считывать лишь небольшое число строк, отвечающих определенным критериям.
- Запросы, которые указывают диапазон значений. Эти запросы также должны считывать небольшое количество строк.
- Поиск, который используется в операциях связывания. Колонки, которые часто используются как ключи связывания, прекрасно подходят для индексов.
- Поиск, при котором данные считываются в определенном порядке. Если результирующий набор данных должен быть отсортирован в порядке кластеризованного индекса, то сортировка не нужна, поскольку результирующий набор данных уже заранее отсортирован. Например, если кластеризованный индекс создан по колонкам lastname (фамилия), firstname (имя), а для приложения требуется сортировка по фамилии и затем по имени, то здесь нет необходимости добавлять инструкцию ORDER BY.
Правда при всей полезности индексов, есть одно очень важное НО – индекс должен быть «эффективно используемым» и должен позволять находить данные с использованием меньшего числа операций ввода-вывода и объема системных ресурсов.
В запросах кода конфигурации использование индексов зависит условий, на которые есть смысл обратить внимание:
- ВЫБРАТЬ … ИЗ … ГДЕ <условие>
- СОЕДИНЕНИЕ … ПО <условие>
- ВЫБРАТЬ … ИЗ <ВиртуальнаяТаблица>(, <условие>)
- ИМЕЮЩИЕ <условие>
Если в системе нет индекса, который мог бы эффективно использоваться для данного запроса, то необходимо рассмотреть одну из следующих возможностей:
- Установить свойство «Индексировать»
- Изменить порядок следования измерений в регистре
Следует учитывать, что максимально эффективный индекс в самом начале содержит все поля, перечисленные в условии. Необходимо проанализировать все условия, имеющиеся в запросе и проверить, есть ли для них подходящие индексы.
Для определения создания индексов (индексирования) можно использовать:
- Знание используемого количества строк в таблице (чаще всего записей в справочнике, регистре сведений, последовательности и т.д.)
- Знание запроса, использующего таблицы (записи объектов метаданных)
Почему так происходит?
Предлагаю выполнить несколько примеров. Сначала займемся практикой, а потом сделаем выводы из наблюдений и познакомимся с теорией.
Пример 1
Создайте справочник с реквизитом. Пусть это будет «Склады» с реквизитом «МОЛ». Заполните справочник, сгенерировав например обработкой несколько тысяч записей, с разными значениями реквизита «МОЛ».

Выполните (например в консоли запросов) такой запрос, использующий отбор «ГДЕ»:

Для того, чтобы получить неискаженную информацию, выполните запрос Transact-SQL (здесь приложен файл) к базе данных с помощью SQL Server Management Studio:
USE MyDataBase1C
GO
exec sp_msforeachtable N’UPDATE STATISTICS ? WITH FULLSCAN’
GO
DBCC UPDATEUSAGE (MyDataBase1C)
GO
DBCC FREEPROCCACHE
,где MyDataBase1C — имя базы данных информационной базы 1С:Предприятие.
Далее используя SQL Server Profiler и приложенный здесь шаблон включите «трассировку» для вашей базы данных.
После выполнения запроса кода конфигурации в MS SQL Server будет «транслирован» запрос Transact-SQL.
Выделите событие Showplan XML Statistics Profile, и Вы уведете картинку плана запроса, похожу на мою.

Подробней приемы работы с планом запроса можно посмотреть здесь http://technet.microsoft.com/ru-ru/magazine/cc137757.aspx
Предлагаю обратить внимание на название операции физического исполнения логической команды SELECT (ВЫБРАТЬ) — Clustered Index Scan.
Теперь изменим у реквизита свойство Индексировать.

И после перезапуска конфигуратора (у нас будет создан индекс) повторить наблюдение за планом запроса.

Что произошло? Тот же самый запрос, выполняясь в MS SQL Server в этот раз выполняется другими физическим оператором — Clustered Index Seek. А если еще точнее, двумя операциями Clustered Index Seek и результаты объединяются физической операцией Nested Loops.
Даже если не смотреть на колонки Duration (длительность) и Read (чтение с диска), то можно сделать вывод — индексы влияют на способ выполнения логических операторов (в нашем случаи SELECT). При этом могут применять разные комбинации физических операторов.
Пример 2
В нашем примере будем выполнять один и тот же запрос к регистру накопления.

Сначала выполним размещения измерения номенклатура последним по порядку, и выключим индексирование этого реквизита, выполним запрос. Затем включим индексирование и повторим запрос.
Для анализа используем профайлер с такими настройками:

Запрос к неиндексированной «Номенклатуре» регистра.

Длительность Duration в моем замере составила 60 мс.
Теперь запрос с индексированным вариантом:

Интересно, что в 1С:Предприятии код запроса мы не трогали, более того, и в MS SQL Server логический текст запроса тоже остался тем же.
А вот физические операторы изменились.
Почему же оптимизатор запросов ведет себя по-разному?
Для этого надо понимать различия между физическими операторами, применяющимися для логических запросов. Ниже немного теории.
Сканирование таблицы или индекса
На сканирование указывает наличие в плане запроса одной из следующих операций:
- TABLE SCAN
- CLUSTERED INDEX SCAN (это наши пример 1 и 2)
- INDEX SCAN
Операция сканирования указывает на неоптимальную работу запроса, но не всегда, а только при выполнении следующих условий:
- Таблица содержит большое количество записей
- Запрос возвращает маленькое количество записей
Операция сканирования всегда указывает на то, что для оптимального выполнения данного запроса нет подходящего индекса.

Вид операции Table Scan. Значок нам как бы подсказывает, что происходит перебор всех записей таблицы.

Вид операции Clustered Index Scan
Отдельно выделим операцию поиска по кластеризованному индексы с условием.
Поиск в индексе по неполному условию
На выполнение поиска по неполному условию указывает наличие в плане запроса операции:
- INDEX SEEK … WHERE
Данная операция аналогична сканированию таблицы или индекса, но при ее выполнении сканируется не вся таблица, а только ее часть.
Операция поиска по неполному условию указывает на неоптимальную работу запроса не всегда, а только при выполнении следующих условий:
- Сканируемая область (ограниченная условием SEEK) содержит большое количество записей
- Запрос возвращает маленькое количество записей
Операция поиска по неполному условию так же указывает на отсутствие подходящего индекса.

Вид операции Index Seek
Избегать конструкции ПОДОБНО (LIKE)
При работе с отборами удобно выполнять поиск контрагента не по наименованию, а путем установки отбора по условию «Содержит» по полю «Наименование». Однако это отрицательно сказывается на производительности из-за невозможности использования индексов и так приводит к запросам:
ВЫБРАТЬ .. ИЗ Справочник.Контрагенты
ГДЕ Наименование ПОДОБНО «%СтрокаПоиска%»
В таком запросе будет выполнен полный перебор всех записей таблицы. Это отрицательно сказывается на производительности.
Примечание. В последних версиях MS SQL Server LIKE стал уметь в некоторых случаях использовать поиск, но это все равно не лучший оператор.
Большая вложенность подзапросов и соединения с вложенными подзапросами
Сервер СУБД с трудом оптимизирует такие конструкции как
Если в тексте встречаются конструкции вида:
ВЫБРАТЬ ИЗ <запрос1>
ЛЕВОЕ СОЕДИНЕНИЕ (
ВЫБРАТЬ ИЗ <подзапрос1>
) ПО …
особенно, если <запрос1> или <подзапрос1> содержат не физические таблицы, а также вложенные запросы, потому что:
- Неизвестно, сколько записей вернет подзапрос
- Неизвестно, какой способ соединения лучше использовать
- Выбирается тот способ, который сам по себе проще (NESTED LOOPS)
- Это приводит к сильному падению производительности
Рассмотрим более подробно суть проблемы.
Соединение в цикле
На выполнение соединения в цикле указывает наличие в плане запроса операции:
- NESTED LOOPS
Операция соединения в цикле указывает на неоптимальную работу запроса не всегда, а только в том случае если ведущий подзапрос возвращает значительное количество записей.
В этом случае следует попытаться упростить запрос:
- Использовать временные таблицы вместо подзапросов
- Уменьшить вложенность подзапросов
- По возможности исключить соединения с подзапросами
В некоторых случаях данный симптом может так же указывать на отсутствие подходящего индекса.
Большая вложенность запросов
Другой момент – это возможные ошибки в сложных вложенных запросах (на момент написания характерны для ЗУП). Если запрос выполняет неоправданно долго, упростите его с помощью временных таблиц.
МенеджерВТ = Новый МенеджерВременныхТаблиц;
Подзапрос = Новый Запрос;
Подзапрос.МенеджерВременныхТаблиц = МенеджерВТ;
Подзапрос.Текст = «
| ВЫБРАТЬ …
| ПОМЕСТИТЬ МояВременнаяТаблица
| ИЗ <подзапрос1>
| ГДЕ…
| ИНДЕКСИРОВАТЬ ПО…
«;
Обратите внимание на то, что для оптимизации работы запроса почти всегда необходимо проиндексировать создаваемую временную таблицу. Индекс должен быть подобран таким образом, чтобы СУБД могла его использовать при соединении с временной таблицей. То есть, в индексе должны быть перечислены все поля, которые используются в условии соединения.
После того, как подзапрос выделен в отдельный запрос, следует выполнить его и оценить скорость его работы. Для того, чтобы оптимизировать основной запрос, подзапрос должен работать достаточно быстро сам по себе.
Если производительность запроса оказалась недостаточной, возможно это говорит о том, что подзапрос по-прежнему слишком сложен. То есть, необходимо его дальнейшее упрощение еще раз.
Как решать такую проблему: вместо использования соединений с вложенными подзапросами следует использовать временные таблицы.
- Заполняем временную таблицу результатом вложения
- Выполняем основной запрос
Резюме. При решении вопросов производительности в MS SQL Server обратите внимание на физические операторы плана запроса:
- Сканирование таблицы или индекса
- Поиск в индексе по неполному условию
- Соединение в цикле
Оптимизатор СУБД выбирает и анализирует лишь некоторое количество вариантов выполнения запроса и выбирает “лучший из них”. При количестве таблиц больше 8 скорее всего все варианты точно не будут проверены — даже математически слишком много комбинаций за отведенное ограниченное время.
При этом возникает вероятность, что по-настоящему оптимальный вариант остался даже не рассмотренным. Поэтому чтобы помочь оптимизатору СУБД в выборе оптимального варианта выполнения нашего запроса рекомендуется придерживаться следующих правил:
- По возможности условие ИЛИ заменять операцией ОБЪЕДИНЕНИТЬ ВСЕ.Чтобы убедиться в том, что нужна замена, можно сделать так: выполнить запрос с условием на равенство по одиночному значению поля, а потом запрос с условиемИЛИ по этому полю на большой таблице. Если второй запрос выполняется намного дольше, чем первый, то данный запрос можно переписать.
- Условие “не равно” (<>) тоже может отключать использование индекса. Например если необходимо исключить большую часть таблицы, а поле отбора проиндексировано, – есть смысл переписать запрос на вариант ОБЪЕДИНЕНИТЬ ВСЕ
- В условиях соединений, стараться обходиться без использования вложенных запросов и виртуальных таблиц, а так же лишних разыменований (выражений через несколько точек). Вложенные запросы и виртуальные таблицы рекомендую заменить на временные таблицы.
- Стараться избегать в условии “В ИЕРАРХИИ” содержания пустой ссылки. Возможно ситуация когда оптимизатор СУБД начнет проверять каждый элемент справочника на принадлежность корню (т.е. самому справочнику), теряя на этом время.
- Следует использовать ОБЪЕДИНИТЬ ВСЕ вместо ОБЪЕДИНИТЬ, если наличие одинаковых записей не критично. Оператор ОБЪЕДИНИТЬ использует дополнительные операции, которые могут занять много времени.
- Условие “ПОДОБНО” подавляет использование индекса.
- Если запрос содержит несколько условий, то они должны располагаться в порядке уменьшения эффекта от выбора. То есть первым надо делать то условие, которое максимально уменьшит результирующую таблицу.
- Максимально использовать индексы таблиц. Необходимо стараться чтобы для всех условий, использованных в запросе, имелись подходящие индексы. Подходящий индекс – это индекс, который содержит все поля перечисленные в условии, эти поля находятся в самом начале индекса и они расположены вместе, т.е между ними нет других полей.
- Не рекомендуется фильтровать виртуальные таблицы при помощи условий в секции ГДЕ и т.п. Надо использовать только параметры.
- Стараться для ссылочных полей, по которым будет вывод, получать представление сразу в запросе, т.е. использовать конструкцию “ПРЕДСТАВЛЕНИЕ(НашаСсылка)“
- Если в запросе реализовано соединение двух и более таблиц, то эти таблицы должны стоять в запросе в порядке уменьшения количества записей в них, а в части условий (ГДЕ) первым должно стоять условие на первую таблицу.
- Если запрос содержит условие для проиндексированного (относится к некластерному индексу) поля маленькой таблицы, которая может быть считана за одно обращение к памяти, то лучше убрать индекс с этого поля в конфигурации.
- Условия вхождения значений полей в результаты вложенных запросов лучше заменять на внутренние соединение по равенству этого поля для ситуаций, когда есть вероятность получения больших размеров таблиц результатов вложенных запросов. Т.е. конструкцию “Поле1 В (Выбрать Поле1 из Таблица2)” заменить на “ВНУТРЕННЕЕ СОЕДИНЕНИЕ Таблица2 По Таблица1.Поле1 = Таблица2.Поле1“
- Для составных типов смотрите http://infostart.ru/public/184361/
- Пример оптимизации тут
Влияние данных на выбор плана
Одним из критерием, которыми руководствуется оптимизатор при создании плана исполнения запроса — это количество строк в таблице. Мы не будем сейчас говорить, о том что механизм блокировок тоже меняет свое поведение и влияет на производительность. Сформулирую лишь собственные наблюдения, собранные «грабли».
Если в конфигурации есть «аналитика» (субконто, измерения) участвующая в итогах и она не используется, то возможны неоправдано излишнее торможение. Что делать: особенно если это типовая конфигурация, либо заполнить справочник сотней «фиктивных» строк, если позволяет бизнес-логика, либо отказаться от этой аналитики.
Время проведения документа с 50, 500, 5000 и 50000 строчками вряд ли будет иметь линейную зависимость замедления. В какой-то момент «где-то» система упрется в узкое место и скорость проведения резко упадет. В качестве рекомендаций можно посоветовать нагрузочное тестирование именно с тем количеством строк, которое реально используется на предприятии.
Влияние статистики на выбор плана
С объемом данных и его разнородности в рамках таблицы сильно связано «знание» оптимизатора с помощью статистик распределения. Как правило, СУБД не знает и не может знать точное число строк в таблице (даже для выполнения запроса SELECT COUNT(*) FROM TABLE выполняется сканирование первичного индекса), поскольку в базе могут храниться одновременно несколько образов одной и той же таблицы с различным числом строк. Сбор статистики для построения гистограмм осуществляется либо специальными командами СУБД, либо фоновыми процессами СУБД.
Из практических можно отметить уже данные рекомендации моей статьи по обслуживанию MS SQL Server выполнять принудительно или регламентной процедурой команду SQL:
exec sp_msforeachtable N’UPDATE STATISTICS ? WITH FULLSCAN’
Влияние механизмов кэширования запросов (их компиляции перед исполением).
Кеш запросов используется для уменьшения времени ответа СУБД для часто используемых запросов.
План выполнения запроса помещается в кеш и ассоциируется с синтаксическим деревом или текстом запроса. Впоследствии, если семантика входящего запроса соответствует семантике некоторого запроса, помещенного в кеш, то СУБД использует сохраненный план выполнения, а не генерирует его.
При очень высокой загруженности СУБД может использовать скомпилированной запрос с устаревшей статистикой или другими неактуальными данными. Инструкция
DBCC FREEPROCCACHE
используется для аккуратной очистки кэша планов. Внимание, просто так эту процедуру «гонять» не надо. Слишком частое использование, да еще при не интенсивном вводе данных скорее ухудшит работу, чем улучшит.
Влияние RLS
1. При использовании у пользователя большого количества групп нужно создавать новую группу, которая бы содержала в себе эквивалент это множества групп. Т.е. проверять одну группу значительно лучше чем десяток.
2. Разбивайте запрос на несколько частей. Старайтесь как можно большее количество участков запроса выносить в привилегированный модуль. Под «RLS» должна остаться только та таблица и кусок запроса, без которой потеряется смысл проверки доступа к записи.
Способы поиска проблемных запросов
Для того, чтобы выполнить анализ эффективности использования индексов, сначала надо определить проблемный запрос.
Если Вы выполняете разработку и работаете с конкретным участком кода, то поиск выполнять не требуется, разве что сверить с хронометражем отладчика.
Однако гораздо чаще вопрос поиска неэффективных запросов происходит на реально работающих системах. Есть несколько методов, которые имеют свои преимущества и недостатки.
Поиск длительных запросов опросом пользователей и отладчиком
Метод имеет кучу недостатков и ограничений. Пожалуй проще сказать, когда его можно использовать. Если пользователь жалуется на долгое проведение документа или построение отчета, и при этом нет блокировок, т.е. работает одинаково долго как в многопользовательском, так и в монопольном режиме. Кроме того, отладчиком по-умолчанию можно отлаживать только код клиентской части. Для включения отладки на сервере Вам придется перезапускать сервер приложений и лезть в реестр. А именно
[HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServices1C:Enterprise 8.1 Server Agent]
«ImagePath«=
по умолчанию «C:Program Files1cv81binragent.exe» -srvc -agent -regport 1541 -port 1540 -range 1560:1591 -d «C:Program Files1cv81server»
надо «C:Program Files1cv81binragent.exe» -srvc -agent -regport 1541 -port 1540 -range 1560:1591 -debug -d «C:Program Files1cv81server»
Таким образом, это самый дешевый и простой способ исследования медленных запросов. Он наиболее известен 1С специалистам.
Поиск длительных запросов технологическим журналом
Метод хорош тем, что скорее всего Вам не придется перезапускать сервер приложений и не требует дополнительных трат денег, поскольку технологический журнал является штатным средством платформы.
Недостаток — нужно иметь навык работы с технологическим журналом или потратить время на его освоения. Облегчает работу обработка с диска ИТС «Настройка технологического журнала».
Также недостатком можно считать дополнительные усилия по разбору собранных данных, так как никакого ранжирования по частоте запросов и их длительности нет.
Поиск длительных запросов с помощью бесплатного сервиса Анализа долгих запросов
Этот метод наиболее хорош в сложных случаях, когда вообще нет уверенности в том, что именно есть длительный запрос, а не проблема ожиданий на блокировках. Кроме того сервис Анализа долгих запросов сам ранжирует собранные проблемные запросы и говорит, в каком порядке их надо решать.
Поиск длительных запросов SQL Server Profiler-ом
Последний способ для страдающих ностальгией по 90м годам, когда администраторы баз данных куда больше ценились (и это было вполне обосновано). Способ не то чтобы для извращенцев, но квалификации требует наибольшей из всех перечисленных здесь способов, а эффективность не гарантируется.
Вариант настройки SQL Server Profiler
- Events:
- Stored Procedures RPC:Comleted
- TSQL SQL:BatchCompleted
- Performance Showplan Statistics Profile
- Performance Showplan XML Statistics Profile
- Колонки данных:
- Все
- Column Filters:
- Все условия фильтрации, включенные по умолчанию
- DatabaseName
- Like <имя базы данных>
- Duration
- Greater then or equal <длительность запроса в миллисекундах>
Все полученные запросы следует сгруппировать, просуммировав общее время выполнения. Суммарное время выполнения можно использовать в качестве ранга данного запроса. Группа одинаковых запросов, которые в сумме выполнялись максимальное время, имеет наивысший ранг. Этот запрос должен рассматриваться в первую очередь.
Имеется возможность автоматизировать ранжирование групп запросов. Для этого следует сохранить трассировку в таблицу SQL и выполнить, например, следующий запрос:
select substring(TextData, 1, 100), SUM(Duration)
from MySQLTrace
group by substring(TextData, 1, 100)
order by SUM(Duration) desc
В результате будет получен список групп запросов (по совпадению первых 100 символов), отсортированный по убыванию суммарного времени выполнения всех запросов группы, то есть по убыванию ранга данного запроса.
Ну, вообще Вы поняли, что будет не скучно :).
Поиск отсутствующих индексов средствами MS SQL Server
Так получилось, что задача поиска отсутствующих индексов характерна не только 1С-приложениям, но и вообще любым клиентам MS SQL Server. Задача вообще-то не очень простая, как вы уже могли заметить. Поэтому для «закоренелых sql-щиков» не могу не осветить еще несколько моментов.
Помощник по настройке ядра СУБД (Database Engine Tuning Advisor)
Помощник по настройке ядра СУБД (часто обозначают DTA)— это инструмент для анализа влияния рабочей нагрузки на производительность в одной или нескольких базах данных. Рабочая нагрузка представляет собой набор инструкций Transact-SQL, которые выполняются в отношении баз данных, нуждающихся в настройке. Другими словами данный инструмент позволяет человеку непонимая, как используются оптимизатором ресурсы, использовать советы самого сервера, дающего рекомендации «мол такой индекс надо сделать, а этот лишний».
Поскольку мы работаем с 1С:Предприятие 8, то SQL-щики могут соблазниться на подобную кажущуюся легкость решения проблемы.
Подводными камнями является «мягкая» привязка структуры информационной базы к именам таблиц в базе данных MS SQL Server. Именя таблиц генерируются платформой автоматически и нет гарантий в постоянном соответствии метаданных к именам таблиц.
Вообщем такой подход решения проблемы методически неверен.
Однако я бы не стал вообще о нем упоминать, если бы не одно но. Рекомендованные индексы помощником DTA можно расмотреть для создания подобных индексов уже средствами 1С:Предприятие. Более подробно об управлении индексов смотрите в моей статьте.
Как пользоваться DTA.
1. Вам необходимо профайлером собрать «рабочую нагрузку». Это означает, что вы не просто включаете на подробную запись запросов профайлер и из под своей сессии делаете одно-два проведений документов или построений отчетов. Вам нужна запись реальных действий пользователей за весь рабочий день. Разумеется слово рабочий день подразумевает не время с 10.00 до 18.00, а реальная работа пользователей в это время.
2. В составе трассировки обязательно должны быть и выполненные запросы, и планы запросов.
3. Сохранить трассировку в файл.

4. Выполнить анализ файла с помощью DTA, указав сохранять структуру существующих таблиц и индексов.

После старта анализа мастер будет некоторое время оценивать данные нагрузки и выдаст рекомендации.

Сохраняем скрипт в файл и с помощью уже выше озвученой обработку смотрим на содержимое колонок индексов.

Очень желательно создавать индексы не средствами СУБД, но если вы решите все таки использовать скрипт, советую продумывать отслеживание эффективности подобных индексов.
Вы можете также прочить в январьском номере 2008 года статью Яна Стерка «Открытие скрытых данных для оптимизации производительности приложений».
Часть приемов экспериментально реализована в моей обработке.
Мегаэкстремальный способ препарирования запросов
Есть такой прием — подсказка USE PLAN в запросе.
| Внимание! |
|---|
| Руководства планов с неправильным использованием подсказок в запросе могут привести к проблемам при компиляции во время выполнения и ухудшению производительности. Руководства планов должны применяться только опытными разработчиками и администраторами баз данных. |
Руководства планов SQL могут только применяются к инструкциям и пакетам, часто выполняющимся приложением с помощью системной хранимой процедуры sp_executesql (платформа 1С:Предприятие не все запросы генерирует в таким способом, но многие).
Влияние оптимизатора запроса от редакции СУБД
См. здесь
Ошибки, как правило, совершают начинающие программисты, не имеющие достаточного опыта в своей деятельности. Можно эти ошибки по разному классифицировать. Мы же в рамках статьи разделим их на две группы. В конечном итоге они приводят к:
- неоправданному расходу ресурсов компьютера (сервера);
- искажению данных при чтении или записи.
Содержание
- Получение данных не из регистра
- Запрос в цикле и обращение через точку
- Ошибки в запросах к таблицам регистров
- Неверный контекст выполнения процедур и функций
Получение данных не из регистра
Достоверной информацией учетной системы принято считать данные регистров. Если же какой-либо отчет получает данные из таблиц документов, то это является грубой ошибкой. Данное решение очень медленно работает, может приводить к ошибкам блокировок, не является гибким и может давать искажение результатов отчета.
То есть правильно придерживаться такой схемы:
Документ – Регистр – Отчет.
Запрос в цикле и обращение через точку
Примером такой ошибки является конструкция типа:
Пока Выборка.Следующий() Цикл
А = Выборка.Ссылка.Договор;
КонецЦикла;
Как видим, внутри цикла мы делаем так называемый неявный запрос.
Тем самым, во-первых, мы расходуем ресурсы. В цикле может быть огромное число итераций, в каждую из которых система выполнит запрос.
Во-вторых, даже без цикла такая конструкция неоптимальна, потому что платформа инициализирует все поля объекта Выборка.Ссылка.
Да, новичкам так банально проще писать, но это грубая ошибка с точки зрения производительности. Правильно запросом получить необходимый набор полей.
ВЫБРАТЬ
ПоступлениеТоваровУслуг.Ссылка,
ПоступлениеТоваровУслуг.Ссылка.Договор
ИЗ
Документ.ПоступлениеТоваровУслуг КАК ПоступлениеТоваровУслуг
ГДЕ ПоступлениеТоваровУслуг.Ссылка = &Ссылка
Ошибки в запросах к таблицам регистров
Грубейшей ошибкой является использование конструкции ГДЕ … в запросе к таблице регистра накопления вместо того, чтобы установить отбор в параметрах виртуальной таблицы.
Также часто начинающие забывают при левом соединении накладывать фильтр в параметрах виртуальной таблицы, если Вы присоединяете записи виртуальной таблицы.
Приведем пример:
ВЫБРАТЬ
ПоступлениеТоваровУслугТовары.Номенклатура,
ПоступлениеТоваровУслугТовары.Количество,
ЦеныНоменклатурыСрезПервых.Цена
ИЗ
Документ.ПоступлениеТоваровУслуг.Товары КАК ПоступлениеТоваровУслугТовары
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ЦеныНоменклатуры.СрезПервых КАК ЦеныНоменклатурыСрезПервых
ПО ПоступлениеТоваровУслугТовары.Номенклатура = ЦеныНоменклатурыСрезПервых.Номенклатура
В этом случае платформа выберет все записи таблицы регистра сведений “Цены номенклатуры”, а потом отбросит ненужные. Результат Вы получите, только система потратит впустую ресурсы.
Неверный контекст выполнения процедур и функций
При разработке в режиме управляемого приложения мы можем использовать так называемые директивы компиляции – &НаКлиенте, &НаСервере, &НаСервереБезКонтекста и прочие.
Так вот при написании кода необходимо понимать суть клиент-серверной архитектуры. Новички же часто весь код выполняют на сервере, потому что им так проще. Но в таком случае опять может происходить напрасная трата ресурсов сервера. Если говорить совсем просто, необходимо стремиться избавить сервер от лишней работы, а также избегать напрасной передачи всех данных формы на сервер и обратно.
Автор в рамках данной статьи не ставит своей целью показать все ошибки начинающих программистов. Ошибок много (как и программистов), и их делают все, но самое главное в процессе работы – не совершать их в будущем. А для этого необходимо постоянно работать над повышением своей квалификации.
Рекомендуем Вам делать “аудит” своих работ, которые имеют определенный срок давности.
скд неверные параметры «*»
Автор svv1979, 13 фев 2015, 11:43
0 Пользователей и 2 гостей просматривают эту тему.
Выручка/100 * [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))]
скд неверные параметры «*»
Если написать просто [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] тогда выводиться значение там например 2
У общего реквизита тип число
ЦитироватьВыручка/100 * [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))]
а это откуда? из макета?
если помогло нажмите: Спасибо!
Цитата: LexaK от 13 фев 2015, 12:31
ЦитироватьВыручка/100 * [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))]
а это откуда? из макета?
Забыл написать это пользовательское поле
попробуйте так:
Выручка/100 * Число([Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))])
сам такие конструкции не пробовал…
может лучше в вычисляемые поля поместить?
Добавлено: 13 фев 2015, 14:41
да-а-а, на Число() у меня ругается в пользовательском поле
ошибка в том что какая-то переменная в вашей формуле не является числом!
или проверьте что бы все числами были, или надо найти способ как не из числа получить число, может глобальные функции преобразования попробуете?
Добавлено: 13 фев 2015, 14:51
зато Выбор Когда Тогда Конец работает — можно кейс построить! как вариант!
если помогло нажмите: Спасибо!
Цитата: LexaK от 13 фев 2015, 13:59
попробуйте так:Выручка/100 * Число([Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))])
сам такие конструкции не пробовал…
может лучше в вычисляемые поля поместить?
Добавлено: 13 фев 2015, 14:41
да-а-а, на Число() у меня ругается в пользовательском поле
ошибка в том что какая-то переменная в вашей формуле не является числом!
или проверьте что бы все числами были, или надо найти способ как не из числа получить число, может глобальные функции преобразования попробуете?Добавлено: 13 фев 2015, 14:51
зато Выбор Когда Тогда Конец работает — можно кейс построить! как вариант!
{mngbase/dcsexpsuserfield.lf(8)}: Ошибка при вызове метода контекста (УстановитьПредставлениеВыраженияДетальныхЗаписей)
Data.SetDetailRecordExpressionPresentation(DetailRecordExpressionPresentation);
по причине:
Синтаксическая ошибка «Число»
Добавлено: 13 фев 2015, 17:08
Это общий реквизит номенклатуры(ДополнительныеРеквизитыИСведения) с типом значения число(1С 8.3 УТ 11.1)
В наборе СКД так и обозначено Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))
Да изменяю отчет Валовая прибыль по подразделениям в розницу
сделайте расчет этого поля в запросе и не парьтесь,
пользовательские поля, тем более расчеты там, это для очень продвинутых юзеров,
которые секут в
Языке выражений системы компоновки данных !!!
если помогло нажмите: Спасибо!
Цитата: LexaK от 13 фев 2015, 17:41
сделайте расчет этого поля в запросе и не парьтесь,
пользовательские поля, тем более расчеты там, это для очень продвинутых юзеров,
которые секут в
Языке выражений системы компоновки данных !!!
Да я посмотрел реквизит имел тип строка
Я так особо не конфигурирую так в меру необходимости
Выбор
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «0.5»
Тогда 0.5
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «1»
Тогда 1
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «2»
Тогда 2
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «3»
Тогда 3
Есть ли возможность проще преобразовать строку в число
Добавлено: 13 фев 2015, 23:16
Цитата: svv1979 от 13 фев 2015, 20:39
Цитата: LexaK от 13 фев 2015, 17:41
сделайте расчет этого поля в запросе и не парьтесь,
пользовательские поля, тем более расчеты там, это для очень продвинутых юзеров,
которые секут в
Языке выражений системы компоновки данных !!!Да я посмотрел реквизит имел тип строка
Я так особо не конфигурирую так в меру необходимостиВыбор
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «0.5»
Тогда 0.5
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «1»
Тогда 1
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «2»
Тогда 2
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «3»
Тогда 3Есть ли возможность проще преобразовать строку в число
Цитата: svv1979 от 13 фев 2015, 20:39
Цитата: LexaK от 13 фев 2015, 17:41
сделайте расчет этого поля в запросе и не парьтесь,
пользовательские поля, тем более расчеты там, это для очень продвинутых юзеров,
которые секут в
Языке выражений системы компоновки данных !!!Да я посмотрел реквизит имел тип строка
Я так особо не конфигурирую так в меру необходимостиВыбор
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «0.5»
Тогда 0.5
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «1»
Тогда 1
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «2»
Тогда 2
Когда [Номенклатура.Для расчета ЗП Продавца (Справочник «Номенклатура» (Общие))] = «3»
Тогда 3Есть ли возможность проще преобразовать строку в число
Все решилась проблема предистория такая был перенос из ут 10 в 11
Номенклатура был параметр категории сформировал отчет сохранил в Excel
сделал загрузку в ут 11 и он записал значение общего реквизита с типом строка
хотя в конфигурации назначен ему тип число вот такая история
при загрузке назначил загружаемому реквизиту тип число и все пошло:zebzdr:
И спасибо за помощь!!!
Содержание:
1. Ошибка при установке значения атрибута контекста
2. Ошибка при получении значения атрибута контекста
Одной из наиболее частых ошибок исполнения кода 1С являются ошибки, связанные с установкой реквизита либо получением реквизита через точку, либо ошибка при вызове функции или процедуры через точку. Все данные объекты являются атрибутами информационных объектов-владельцев, к которым они принадлежат. Рассмотрим примеры таких ошибок и причины их возникновения.
1. Ошибка при установке значения атрибута контекста
Ошибка при установке значения атрибута контекста говорит нам о невозможности присвоить выбранное значение определенному атрибуту информационного объекта. Вызвано это либо несовпадением типа атрибута и присваиваемого ей значения, отсутствием возможности присвоить значение выбранному атрибуту, так как его можно только читать, но не записывать в него, отсутствием прав у текущего пользователя на запись значений в данный атрибут. Например, в реквизит «ДатаДокумента» с типом «Дата» пытаемся записать строку, в реквизит с типом данных ссылки на документ пытаемся записать не ссылку, а объект, полученный по ссылке, что невозможно из-за несоответствия типов, что приводит к ошибке установки значения атрибута.
Другой пример – проходя циклом выборку запроса, пытаемся в колонку выборки записать значение, что невозможно, так как значения выборки запроса можно только считывать, а для того, чтобы можно было полученные из запроса данные изменять в коде, нужно пользоваться не выборкой, а выгружать результат запроса в таблицу значений, в таком случае в цикле по ней можно будет менять значения в колонках, но только на значения, соответствующие типу колонки. Либо у пользователя, под которым выполняется код, нет прав на изменение даты документа, при попытке записать в данный реквизит новую дату, будет выведено сообщение об ошибке установке значения, но в причине будет указано отсутствие прав у пользователя.
2. Ошибка при получении значения атрибута контекста
Ошибка при получении значения атрибута контекста указывает на невозможность прочитать значение атрибута объекта в силу его отсутствия, либо отсутствия прав на его чтение. Например, обращение к несуществующему реквизиту объекта, несуществующему полю выборки из запроса, несуществующему свойству элемента формы и т.п. Так же как пример можно рассмотреть получение текущего пользователя из параметров сеанса — если данный параметр сеанса не установлен, то тоже будет выведена ошибка получения значения атрибута контекста, но в причине будет указана попытка получения неинициализированного значения параметра сеанса.
При возникновении данных ошибок значения атрибута в 1Св первую очередь следует проверить существование атрибута, к которому обращаются, затем проверить совпадение типов значений атрибута и присваиваемого ему значения, затем уже проверить права на установку либо чтение значения. Проверить, является ли дело в правах либо дать права на действия с атрибутом, можно, установив привилегированный режим для совершения действия с данным атрибутом, прописав перед строчкой с ошибкой УстановитьПривилегированныйРежим(Истина), после строчки — УстановитьПривилегированныйРежим(Ложь).
Специалист компании «Кодерлайн»
Александр Суворов
Несоответствие условий запроса индексам таблицы Секции условий запросов (ГДЕ, ПО)
- Неэффективное использование индексов
- Избыточная блокировка записей таблиц при чтении в транзакции
- Добавить недостающие (для эффективного использования индекса) условия, если это не поменяет логики
- Создать подходящий индекс путем индексирования полей или изменения структуры метаданных. В случае изменения порядка следования измерений в регистре — проверить не ухудшит ли данная модификация другие запросы
Максимальная эффективность достигается если будет использован покрывающий индекс Важно Подзапросы в условиях (ГДЕ, параметрах виртуальных таблиц) Секции условий запросов (ГДЕ, ПО) На уровне СУБД происходит неявное соединение с вложенным запросом, оптимизатор может неверно оценить количество строк в подзапросе и выбрать неоптимальный план выполнения Поместить подзапрос в отдельную временную таблицу и обращаться к ней Критично если оптимизатор СУБД может ошибиться с количеством строк в подзапросе условия, например: обращение происходит к виртуальной таблице; во вложенном запросе есть условие отбора; в подзапросе используется вложенный запрос Важно Использование условия ИЛИ в запросах Секции условий запросов (ГДЕ, ПО) Возможно неэффективное использование индекса
- Разделить запрос на части и объединить используя ОБЪЕДИНИТЬ ВСЕ
- Пересмотреть запрос и постараться уйти от использования ИЛИ
Не требуется если ИЛИ соединяет условия на равенство по одному и тому же полю (когда можно заменить на «В») По необходимости Условия в запросе за скобками параметров виртуальных таблиц Секции условий запросов (ГДЕ, ПО) В SQL не существует понятия виртуальных таблиц, данный механизм разработан 1С. Платформа 1С:Предприятие самостоятельно формирует текст SQL-запроса, в том числе преобразует запрос к виртуальной таблице в сложный SQL-запрос к таблицам СУБД. Таким образом, указание параметров виртуальных таблиц формирует более оптимальный SQL-запрос за счет более ранней фильтрации Перенести условия в параметры виртуальных таблиц, если от этого не поменяется логика Для виртуальных таблиц СрезПервых, СрезПоследних регистра сведений может поменяться логика Важно Использование условия ГДЕ вместо условия соединения Секции условий запросов (ГДЕ, ПО) Условие в секции соединения будет обработано раньше чем условие секции ГДЕ, таким образом фильтрация произойдет раньше и количество строк, возвращенных после соединения, может быть меньше, что приведет к сокращению времени выполнения следующих операций запроса Перенести условие из ГДЕ в условие соединения, если от этого не поменяется логика Если есть соединение запросов и логика конечного запроса не изменится Рекомендуется Использование условия на «НЕ РАВНО» или «НЕ» Секции условий запросов (ГДЕ, ПО) Неэффективное использование индекса. Оптимизатор не сможет установить условие отбора по данному полю в индексе Пересмотреть запрос и постараться уйти от использования данного условия По необходимости Выполнение преобразований над индексированным полем Секции условий запросов (ГДЕ, ПО) Неэффективное использование индекса. Оптимизатор не сможет установить условие отбора по данному полю в индексе
- Пересмотреть запрос и постараться уйти от использования
- Изменить структуру хранения (хранить вычисленное значение)
Рекомендуется Отбор по строковому значению Секции условий запросов (ГДЕ, ПО) Поиск по строковым столбцам использует индекс только в случае, если используется условие равенства или условие ПОДОБНО «Строка%» Использовать условие на равенство или ПОДОБНО «Строка%» Рекомендуется Соединение с подзапросами Соединения в запросе Оптимизатор может неверно оценить предполагаемое количество строк и выбрать неоптимальный план запроса Поместить подзапрос в отдельную временную таблицу Важно Соединение с виртуальными таблицами Соединения в запросе Виртуальная таблица на уровне СУБД представляет из себя вложенный запрос. Оптимизатор может неверно оценить предполагаемое количество строк и выбрать неоптимальный план запроса Поместить подзапрос в отдельную временную таблицу Важно Обращение через точку к полям составного типа Соединения в запросе Неявное соединение со всеми таблицами составного типа
- Использовать выражение типа: ВЫРАЗИТЬ(ПолеРодитель КАК Метаданное).Поле
- Использовать выражение типа: ВЫБОР КОГДА ТИПЗНАЧЕНИЯ(ПолеРодитель)=ТИП(Метаданное) ТОГДА ВЫРАЗИТЬ(ПолеРодитель КАК Метаданное).Поле …
Важно Сложные запросы, использующие большое количество соединений Соединения в запросе Увеличивается время поиска оптимального плана запроса. Может быть не найден оптимальный план запроса за отведенное время.
- Пересмотреть запрос, постараться уйти
- Разделить запрос на части, помещая каждую из них во временную таблицу
Важно Неоптимальное использование RLS платформы Прочие Усложняется запрос к базе данных путем добавления условия ограничения прав доступа что может привести к неоптимальному выполнению запроса
- Не использовать механизм платформы, а написать свой механизм прав доступ
- Условия RLS должны быть примитивного вида
- Не назначать несколько ролей пользователю с разными условиями доступа
Рекомендуется Расчет остатков/оборотов по таблицам документов и таблицам движений регистров Прочие Для регистров накопления, бухгалтерии в на уровне СУБД создаются таблицы, в которых содержатся итоговые (агрегированные) данные, обращение к которым значительно уменьшает время выполнения запроса Использовать виртуальные таблицы регистров Важно Запросы виды ВЫБРАТЬ * ИЗ … Прочие Могут тянуться лишние данные, например табличные части или реквизит типа ХранилищеЗначений. Также возможно что на момент написания таких данных не будет, но они могут появиться в дальнейшем Явно указать поля выбора Важно Использование ОБЪЕДИНИТЬ вместо ОБЪЕДИНИТЬ ВСЕ, если того не требует задача Прочие ОБЪЕДИНИТЬ требует большего количества времени для выполнения, т.к. исключает неуникальные записи Использовать ОБЪЕДИНИТЬ ВСЕ если логикой не требуется исключение неуникальные записей Важно При использовании ДЛЯ ИЗМЕНЕНИЯ в автоматическом режиме, не указывать таблицы для блокировки Прочие Если не указаны таблицы явно, будут заблокированы все таблицы используемые в запросе Указать необходимые таблицы для блокировки Важно Применение избыточного агрегирования в виртуальных таблицах накопления, бухгалтерии Прочие Виртуальные таблицы сами агрегируют результат Не использовать дополнительное агрегирование Важно Выполнение запросов в цикле, в т.ч. через объектную модель Прочие Большое количество-клиент серверных вызовов Пересмотреть и отказаться Важно Выполнение запросов через объектную модель Прочие Могут тянуться лишние данные т.к. объект читается полностью. При этом если у объекта присутствуют табличные части, чтение будет происходить в транзакции, что может негативно сказаться на параллельности работы Пересмотреть и отказаться По необходимости
Для формирования и выполнения запросов к таблицам базы данных в платформе 1С используется специальный объект языка программирования Запрос. Создается этот объект вызовом конструкции Новый Запрос. Запрос удобно использовать, когда требуется получить сложную выборку данных, сгруппированную и отсортированную необходимым образом. Классический пример применения запроса — получение сводки по состоянию регистра накопления на определенный момент времени. Так же, механизм запросов позволяет легко получать информацию в различных временных разрезах.
Текст запроса – это инструкция, в соответствии с которой должен быть выполнен запрос. В тексте запроса описывается:
- таблицы информационной базы, используемые в качестве источников данных запроса;
- поля таблиц, которые требуется обрабатывать в запросе;
- правила группировки;
- сортировки результатов;
- и т. д.
Инструкция составляется на специальном языке – языке запросов и состоит из отдельных частей – секций, предложений, ключевых слов, функций, арифметических и логических операторов, комментариев, констант и параметров.
Язык запросов платформы 1С очень похож на синтаксис других SQL-языков, но имеются отличия. Основными преимуществами встроенного языка запросов являются: разыменование полей, наличие виртуальных таблиц, удобная работа с итогами, нетипизированные поля в запросах.
Рекомендации по написанию запросов к базе данных на языке запросов платформы 1С:
1) Текст запроса может содержать предопределенные данные конфигурации, такие как:
- значения перечислений;
- предопределенные данные:
- справочников;
- планов видов характеристик;
- планов счетов;
- планов видов расчетов;
- пустые ссылки;
- значения точек маршрута бизнес-процессов.
Также текст запроса может содержать значения системных перечислений, которые могут быть присвоены полям в таблицах базы данных: ВидДвиженияНакопления, ВидСчета и ВидДвиженияБухгалтерии. Обращение в запросах к предопределенным данным конфигурации и значениям системных перечислений осуществляется с помощью литерала функционального типа ЗНАЧЕНИЕ. Данный литерал позволяет повысить удобочитаемость запроса и уменьшить количество параметров запроса.
Пример использования литерала ЗНАЧЕНИЕ:
- ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.Москва)
- ГДЕ Город = ЗНАЧЕНИЕ(Справочник.Города.ПустаяСсылка)
- ГДЕ ТипТовара = ЗНАЧЕНИЕ(Перечисление.ВидыТоваров.Услуга)
- ГДЕ ВидДвижения = ЗНАЧЕНИЕ(ВидДвиженияНакопления.Приход)
- ГДЕ ТочкаМаршрута = ЗНАЧЕНИЕ(БизнесПроцесс.БизнесПроцесс1.ТочкаМаршрута.Действие1
2) Использование инструкции АВТОУПОРЯДОЧИВАНИЕ в запросе может сильно время выполнения запроса, поэтому, если сортировка не требуется, то лучше вообще ее не использовать. Во большинстве случаях лучше всего применять сортировку с помощью инструкции УПОРЯДОЧИТЬ ПО.
Автоупорядочивание работает по следующим принципам:
- Если в запросе было указано предложение УПОРЯДОЧИТЬ ПО, то каждая ссылка на таблицу, находящаяся в этом предложении, будет заменена полями, по которым по умолчанию сортируется таблица (для справочников это код или наименование, для документов – дата документа). Если поле для упорядочивания ссылается на иерархический справочник, то будет применена иерархическая сортировка по этому справочнику.
- Если в запросе отсутствует предложение УПОРЯДОЧИТЬ ПО, но есть предложение ИТОГИ, тогда результат запроса будет упорядочен по полям, присутствующим в предложении ИТОГИ после ключевого слова ПО, в той же последовательности и, в случае если итоги рассчитывались по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
- Если в запросе отсутствуют предложения УПОРЯДОЧИТЬ ПО и ИТОГИ, но есть предложение СГРУППИРОВАТЬ ПО, тогда результат запроса будет упорядочен по полям, присутствующим в предложении, в той же последовательности и, в случае если группировка велась по полям – ссылкам, то по полям сортировки по умолчанию таблиц, на которые были ссылки.
- В случае же, если в запросе отсутствуют предложения и УПОРЯДОЧИТЬ ПО, ИТОГИ и СГРУППИРОВАТЬ ПО, результат будет упорядочен по полям сортировки по умолчанию для таблиц, из которых выбираются данные, в порядке их появления в запросе.
- В случае, если запрос содержит предложение ИТОГИ, каждый уровень итогов упорядочивается отдельно.
3) Что бы избежать повторного запроса к базе данных при выводе результата запроса пользователю (например, построение запроса или отображение результата запроса с помощью табличного документа) полезно использовать инструкцию ПРЕДСТАВЛЕНИЕССЫЛКИ, которая позволяет получать представление ссылочного значения. Пример:
Код 1C v 8.х
ВЫБРАТЬ
ПРЕДСТАВЛЕНИЕССЫЛКИ(РасходнаяНакладнаяСостав.Номенклатура) КАК НоменклатураПредставление<br> Так же возможно использование инструкции ПРЕДСТАВЛЕНИЕ — предназначена для получения строкового представления значения произвольного типа. Отличие этих инструкций в том, что в первом случае, если инструкции передать ссылку, результатом будет строка, В остальных случаях результатом будет значение переданного параметра. Во втором случае, результатом инструкции всегда будет строка!
4) Если в запросе имеется поле с составным типом, то для таких полей возникает необходимость привести значения поля к какому-либо определенному типу с помощью инструкции ВЫРАЗИТЬ, что позволит убрать лишние таблицы из левого соединения с полем составного типа данных и ускорить выполнение запроса. Пример:
Имеется регистра накопления ОстаткиТоваров, у которого поле Регистратор имеет составной тип. В запросе выбираются Дата и Номер документов ПоступлениеТоваров, при этом при обращении к реквизитам документа через поле Регистратор не происходит множество левых соединений таблицы регистра накопления с таблицами документов-регистраторов.
Код 1C v 8.х
ВЫБРАТЬ
ВЫРАЗИТЬ(ОстаткиТоваров.Регистратор КАК Документ.ПоступлениеТоваров).Номер КАК НомерПоступления,
ВЫРАЗИТЬ(ОстаткиТоваров.Регистратор КАК Документ.ПоступлениеТоваров).Дата КАК ДатаПоступления
ИЗ
РегистрНакопления.ОстаткиТоваров КАК ОстаткиТоваров<br> Если приведение типа считается не осуществимым, то результатом приведения типа будет значение NULL.
5) Не стоит забывать про инструкцию РАЗРЕШЕННЫЕ, которая означает, что запрос выберет только те записи, на которые у текущего пользователя есть права. Если данное слово не указать, то в случае, когда запрос выберет записи, на которые у пользователя нет прав, запрос отработает с ошибкой.
6) В случае, если в запросе используется объединение, и в некоторых частях объединения присутствуют вложенные таблицы (документ с табличной частью), а в некоторых нет, возникает необходимость дополнения списка выборки полями – пустыми вложенными таблицами. Делается это при помощи ключевого слова ПУСТАЯТАБЛИЦА, после которого в скобках указываются псевдонимы полей, из которых будет состоять вложенная таблица. Пример:
Код 1C v 8.х
// Выбрать поля Номер и Состав
// из виртуальной таблицы Документ.РасхНакл
ВЫБРАТЬ Ссылка.Номер, ПУСТАЯТАБЛИЦА.(Ном, Тов, Кол) КАК Состав
ИЗ Документ.РасхНакл
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ Ссылка.Номер, Состав.(НомерСтроки, Товар, Количество)
ИЗ Документ.РасхНакл Документ.РасходнаяНакладная.Состав.*<br> 7) Что бы в результат запроса не попали повторяющиеся строки, следует использовать инструкцию РАЗЛИЧНЫЕ, потому что так нагляднее и понятнее, а инструкция СГРУППИРОВАТЬ ПО применяется для группировки с помощью агрегатных функций. Ксати, при использовании агрегатных функций предложение СГРУППИРОВАТЬ ПО может быть и не указано совсем, при этом все результаты запроса будут сгруппированы в одну единственную строку. Пример:
Код 1C v 8.х
// Необходимо узнать, каким вообще контрагентам
// отгружался товар за период.
Выбрать Различные
Документ.РасходнаяНакладная.Контрагент<br> Инструкция СГРУППИРОВАТЬ ПО позволяет обращаться к полям верхнего уровня, без группировки результатов по этим полям, если агрегатные функции применены к полям вложенной таблицы. Хотя в справке 1С написано, при группировке результатов запроса в списке полей выборки обязательно должны быть указаны агрегатные функции, а помимо агрегатных функций в списке полей выборки допускается указывать только поля, по которым осуществляется группировка. Пример:
Код 1C v 8.х
ВЫБРАТЬ
ПоступлениеТоваровИУслуг.Товары.(СУММА(Количество),Номенклатура),
ПоступлениеТоваровИУслуг.Ссылка,
ПоступлениеТоваровИУслуг.Контрагент
ИЗ
Документ.ПоступлениеТоваровИУслуг КАК ПоступлениеТоваровИУслуг
СГРУППИРОВАТЬ ПО
ПоступлениеТоваровИУслуг.Товары.(Номенклатура)<br> 9) Инструкция ЕСТЬNULL предназначена для замены значения NULL на другое значение, но не забываем, что второй параметр будет преобразован к типу первого в случае, если тип первого параметра является строкой или числом.
10) При обращении к главной таблице можно в условии обратиться к данным подчиненной таблицы. Такая возможность называется разыменование полей подчиненной таблицы.
Пример (поиск документов, содержащих в табличной части определенный товар):
Код 1C v 8.х
ВЫБРАТЬ
Приходная.Ссылка
ИЗ
Документ.Приходная Где Приходная.Товары.Номенклатура =Номенклатура.<br> Преимущество этого запроса перед запросом к подчиненной таблице Приходная.Товары в том, что если есть дубли в документах, результат запроса вернет только уникальные документы без использования ключевого слова РАЗЛИЧНЫЕ.
11) Интересный вариант оператора В — это проверка вхождения упорядоченного набора в множество таких наборов (Поле1, Поле2, … , ПолеN) В (Поле1, Поле2, … , ПолеN).
Пример:
Код 1C v 8.х
ВЫБРАТЬ
Контрагенты.Ссылка
ГДЕ
(Контрагенты.Ссылка, Товары.Ссылка) В
(ВЫБРАТЬ Продажи.Покупатель, Продажи.Товар
ИЗ РегистрНакопления.Продажи КАК Продажи)
ИЗ
Справочник.Контрагенты,
Справочник.Товары<br> 12) При любой возможности используйте виртуальные таблицы запросов. При создании запроса система предоставляет в качестве источников данных некоторое количество виртуальных таблиц — это таблицы, которые так же являются результатом запроса, который система формирует в момент выполнения соответствующего участка кода.
Разработчик может самостоятельно получить те же самые данные, которые система предоставляет ему в качестве виртуальных таблиц, однако алгоритм получения этих данных не будет оптимизирован, так как:
Все виртуальные таблицы параметризованы, т. е. разработчику предоставляется возможность задать некоторые параметры, которые система будет использовать при формировании запроса создания виртуальной таблицы. В зависимости от того, какие параметры виртуальной таблицы указаны разработчиком, система может формировать РАЗЛИЧНЫЕ запросы для получения одной и той же виртуальной таблицы, причем они будут оптимизированы с точки зрения переданных параметров.
Не всегда разработчик имеет возможность получить доступ к тем данным, к которым имеет доступ система.
13) В клиент-серверном варианте работы функция ПОДСТРОКА() реализуется при помощи функции SUBSTRING() соответствующего оператора SQL, передаваемого серверу баз данных SQL Server, который вычисляет тип результата функции SUBSTRING() по сложным правилам в зависимости от типа и значений ее параметров, а так же в зависимости от контекста, в котором она используется. В большинстве случаев эти правила не оказывают влияния на выполнение запроса, но бывают случаи, когда для выполнения запроса существенна максимальная длина строки результата, вычисленная SQL Server. Важно иметь в виду, что в некоторых контекстах использования функции ПОДСТРОКА() максимальная длина ее результата может оказаться равной максимальной длине строки ограниченной длины, которая в SQL Server равна 4000 символам. Это может привести к неожиданному аварийному завершению выполнения запроса:
Microsoft OLE DB Provider for SQL Server: Warning: The query processor could not produce a query plan from the optimizer because the total length of all the columns in the GROUP BY or ORDER BY clause exceeds 8000 bytes.
HRESULT=80040E14, SQLSTATE=42000, native=8618
Чтобы избежать такой ошибки, не рекомендуют использовать функцию ПОДСТРОКА() с целью приведения строк неограниченной длины к строкам ограниченной длины. Вместо нее лучше использовать операцию приведения типа ВЫРАЗИТЬ().
14) С осторожностью используйте ИЛИ в конструкции ГДЕ, так как использование условия с ИЛИ может значительно «утяжелить» запрос. Решить проблему можно конструкцией ОБЪЕДИНИТЬ ВСЕ. Пример:
Код 1C v 8.х
ВЫБРАТЬ
_ДемоКонтрагенты.НаименованиеПолное
ИЗ
Справочник._ДемоКонтрагенты КАК _ДемоКонтрагенты
ГДЕ
_ДемоКонтрагенты.Ссылка =Ссылка1
ОБЪЕДИНИТЬ ВСЕ
ВЫБРАТЬ
_ДемоКонтрагенты.НаименованиеПолное
ИЗ
Справочник._ДемоКонтрагенты КАК _ДемоКонтрагенты
ГДЕ
_ДемоКонтрагенты.Ссылка =Ссылка2<br> 15) Условие НЕ В в конструкции ГДЕ увеличивает время исполнения запроса, так как это своего рода НЕ (ИЛИ1 ИЛИ2 … ИЛИn), поэтому для больших таблиц старайтесь использовать ЛЕВОЕ СОЕДИНЕНИЕ с условием ЕСТЬ NULL. Пример:
Код 1C v 8.х
ВЫБРАТЬ
_ДемоКонтрагенты.Ссылка
ИЗ
Справочник._ДемоКонтрагенты КАК _ДемоКонтрагенты
ЛЕВОЕ СОЕДИНЕНИЕ Документ._ДемоЗаказПокупателя КАК _ДемоЗаказПокупателя
ПО _ДемоКонтрагенты.Ссылка = _ДемоЗаказПокупателя.Контрагент
ГДЕ
_ДемоЗаказПокупателя.Контрагент ЕСТЬ NULL<br> 16) При использовании Временных таблиц нужно индексировать поля условий и соединений в этих таблицах, НО, при использовании индексов запрос может выполняться еще медленнее. Поэтому необходимо анализировать каждый запрос с применением индекса и без, замерять скорость выполнения запроса и принимать окончательное решение.
Если вы помещаете во временную таблицу данные, которые изначально индексированы по некоторым полям, то во временной таблице индекса по этим полям уже не будет.
17) Если вы не используете Менеджер временных таблиц, то явно удалять временную таблицу не требуется, она будет удалена после завершения выполнения пакетного запроса, иначе следует удалить временную таблицу одним из способов: командой УНИЧТОЖИТЬ в запросе, вызвать метод МенеджерВременныхТаблиц.Закрыть().
Источник
И в дополнении видео от Евгения Гилева : Типовые ошибки при написании запросов на 1С:
‘Этот материал я переписал из диска ИТС для рассмотрения и возможной дискуссии на тему оптимизации запросов https://its.1c.ru/db/metod8dev#content:5842:hdoc
Такую статью я рекомендую всем программистам 1С прочитать внимательно, так как язык запросов – этот основной инструмент платформы 1С. В статье приводятся типичные причины неоптимальной работы запросов, диагностируемые на уровне кода конфигурации, и рассматриваются методики оптимизации запросов.
Основные причины неоптимальной работы запросов
1. Cоединения с подзапросами
Не следует использовать соединения с подзапросами. Следует соединять друг с другом только объекты метаданных или временные таблицы. Если запрос использует соединения с подзапросами, то его следует переписать с использованием временных таблиц.
Пример неоптимального опасного запроса, использующего соединение с подзапросом в правой части соединения используется подзапрос:
ВЫБРАТЬ ... ИЗ Документ.РеализацияТоваровУслуг ЛЕВОЕ СОЕДИНЕНИЕ ( ВЫБРАТЬ ИЗ РегистрСведений.Лимиты ГДЕ ... СГРУППИРОВАТЬ ПО ... ) ПО ...
Для оптимизации запроса следует разбить его на несколько отдельных запросов (по числу подзапросов, используемых в соединениях). Эти запросы рекомендуется поместить в один пакетный запрос.
// Создать менеджер временных таблиц МенеджерВТ = Новый МенеджерВременныхТаблиц; Запрос = Новый Запрос; Запрос.МенеджерВременныхТаблиц = МенеджерВТ; // Текст пакетного запроса Запрос.Текст = " // Заполняем временную таблицу. Запрос к регистру лимитов. | ВЫБРАТЬ ... | ПОМЕСТИТЬ Лимиты | ИЗ РегистрСведений.Лимиты | ГДЕ ... | СГРУППИРОВАТЬ ПО ... | ИНДЕКСИРОВАТЬ ПО ...; // Выполняем основной запрос с использованием временной таблицы ВЫБРАТЬ ... ИЗ Документ.РеализацияТоваровУслуг ЛЕВОЕ СОЕДИНЕНИЕ Лимиты ПО ...;" Внимание! очень важно в данном примере проиндексировать созданную временную таблицу. В качестве индексных полей следует указать все поля, которые используются в условии соединения.
2. Cоединения с виртуальными таблицами
Если в запросе используется соединение с виртуальной таблицей языка запросов 1С:Предприятия (например, “РегистрНакопления.Товары.Остатки()“) и запрос работает с неудовлетворительной производительностью, то рекомендуется вынести обращение к виртуальной таблице в отдельный запрос с сохранением результатов во временной таблице. То есть, следует использовать ту же рекомендацию, что и в случае соединения с подзапросом (см Пункт 1).
Дело в том, что виртуальные таблицы, используемые в языке запросов 1С:Предприятия, могут разворачиваться в подзапросы при трансляции в язык SQL. Это связано с тем, что виртуальная таблица часто (но не всегда) получает данные из нескольких физических таблиц СУБД. Если вы используете соединение с виртуальной таблицей, то на уровне SQL оно может быть в некоторых случаях реализовано, как соединение с подзапросом. В этом случае оптимизатор СУБД может точно так же выбрать неоптимальный план, как при работе с подзапросом, использованным в языке 1С:Предприятия в явном виде.
3. Несоответствие индексов и условий запроса
Условия используются в следующих секциях запроса:
- ВЫБРАТЬ … ИЗ … ГДЕ <условие>
- СОЕДИНЕНИЕ … ПО <условие>
- ВЫБРАТЬ … ИЗ <ВиртуальнаяТаблица>(, <условие>)
- ИМЕЮЩИЕ <условие>
Для этих всех условий, использованных в запросе, должны быть подходящие подходящие индексы для оптимизации отбора данных по условию. Причем, подходящим является индекс, удовлетворяющий следующим требованиям:
- Требование 1 . Индекс содержит все поля перечисленные в условии;
- Требование 2. Эти поля находятся в самом начале индекса;
- Требование 3. Эти поля идут подряд, то есть между ними не «вклиниваются» поля, не участвующие в условии запроса;
Основные идексы, создаваемые 1С:Предприятием:
- индекс по уникальному идентификатору (ссылке) для всех объектных сущностей (справочники, документы и т.д.);
- индекс по регистратору (ссылке на документ) для таблиц движений регистров, подчиненных регистратору;
- индекс периоду и значениям всех измерений для итоговых таблиц регистров накопления;
- индекс периоду, счету и значениям всех измерений для итоговых таблиц регистров бухгалтерии.
В тех случаях, когда автоматически созданных индексов недостаточно, можно дополнительно проиндексировать реквизиты объекта метаданных в конфигураторе. Однако, следует иметь в виду, что создание индекса ускоряет процесс поиска информации, но может несколько замедлить процесс ее изменения пользователем (добавления, редактирования и удаления) в режиме запуска 1С предприятия. Поэтому индексы следует создавать осознанно и только в том случае, если точно известен запрос, для которого такой индекс необходим. Не следует создавать индексы “на всякий случай” или заведомо избыточные индексы. Например никогда не следует дополнительно индексировать первое измерение регистра, поскольку для поиска по значению первого измерения подходит основной индекс таблицы итогов, который автоматически создаст платформа.
В конфигурации описан регистр накопления ТоварыНаСкладах:
Платформа 1С:Предприятие автоматически создаст для таблицы остатков данного регистра индекс по периоду и всем измерениям в том порядке, в котором они перечислены в конфигураторе.
Рассмотрим несколько примеров запросов и проанализируем, смогут ли они оптимально выполняться при такой структуре данных.
Запрос 1
Запрос.Текст = "ВЫБРАТЬ | ТоварыНаСкладахОстатки.Склад, | ТоварыНаСкладахОстатки.Номенклатура, | ТоварыНаСкладахОстатки.Качество |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки(, Номенклатура = &Номенклатура) КАК ТоварыНаСкладахОстатки";
В данном случае нарушено требование 2. В условии отсутствует отбор по первому полю индекса (Склад). Такой запрос не сможет выполниться оптимально. Для его выполнения серверу СУБД придется перебирать (сканировать) все записи таблицы. Время выполнения этой операции напрямую зависит от количества записей в таблице остатков регистра и может быть очень большим (и будет увеличиваться с ростом количества данных).
Варианты оптимизации:
- Проиндексировать измерение «Номенклатура»
- Поставить измерение «Номенклатура» первым в списке измерений. Будьте внимательны при использовании этого метода. В конфигурации могут присутствовать другие запросы, которые могут замедлиться в результате этой перестановки.
Запрос 2
Запрос.Текст = "ВЫБРАТЬ | ТоварыНаСкладахОстатки.Склад, | ТоварыНаСкладахОстатки.Номенклатура, | ТоварыНаСкладахОстатки.Качество |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки( | , | Качество = &Качество | И Склад = &Склад) КАК ТоварыНаСкладахОстатки";
В данном случае нарушено требование 3. Между измерениями «Склад» и «Качество» в структуре регистра находится измерение «Номенклатура», которое не задано в условии запроса. Этот запрос так же не сможет выполняться оптимально. При его выполнении СУБД выполнит поиск по первому полю индекса, но затем вынужденно просканирует некоторую его часть. Сканирование приведет к увеличению времени выполнения запроса и к блокировке избыточных записей в таблице, то есть к снижению общей пропускной способности системы.
Варианты оптимизации:
- Добавить в запрос условие по измерению «Номенклатура»
- Убрать из запроса условие по измерению «Качество»
- Перенести «Номенклатуру» из измерений в реквизиты
- Поменять местами измерения «Номенклатура» и «Качество
Запрос 3
Запрос.Текст = "ВЫБРАТЬ | ТоварыНаСкладахОстатки.Склад, | ТоварыНаСкладахОстатки.Номенклатура, | ТоварыНаСкладахОстатки.Качество, | ТоварыНаСкладахОстатки.КоличествоОстаток |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки( | , | Номенклатура = &Номенклатура | И Склад = &Склад) КАК ТоварыНаСкладахОстатки";
В этом случае требования соответствия индекса и запроса не нарушены. Данный запрос будет выполнен СУБД оптимальным способом. Обратите внимание на то, что порядок следования условий в запросе не обязан совпадать с порядком следования полей в индексе. Это не является проблемой и будет нормально обработано СУБД.
4. Использование логического ИЛИ в условиях
4.1 Использование логического ИЛИ в секции ГДЕ запроса
Не следует использовать ИЛИ в секции ГДЕ запроса. Это может привести к тому, что СУБД не сможет использовать индексы таблиц и будет выполнять сканирование, что увеличит время работы запроса и вероянтность возникновения блокировок. Вместо этого следует разбить один запрос на несколько и объединить результаты.
Например, запрос
ВЫБРАТЬ Товар.Наименование ИЗ Справочник.Товары КАК Товар ГДЕ Артикул = "001" ИЛИ Артикул = "002"
следует заменить на запрос
ВЫБРАТЬ Товар.Наименование ИЗ Справочник.Товары КАК Товар ГДЕ Артикул = "001" |ОБЪЕДИНИТЬ ВСЕ |ВЫБРАТЬ Товар.Наименование ИЗ Справочник.Товары КАК Товар ГДЕ Артикул = "002"
4.2 . Включение пользователей в несколько ролей, каждая из которых имеет RLS
1С RLS (Record Level Security) или ограничение прав на уровне записи — это настройка прав пользователей в системе 1С, которая позволяет разделить права для пользователей в разрезе динамически меняющихся данных.
Если в конфигурации описано несколько ролей с условиями RLS, то не следует назначать одному пользователю более одной такой роли. Если один пользователь будет включен, например, в две роли с RLS – бухгалтер и кадровик, то при выполнении всех его запросов к их условиям будут добавляться условия обоих RLS с использованием логического ИЛИ. Таким образом, даже если в исходном запросе нет условия ИЛИ, оно появится там после добавления условий RLS. Такой запрос так же может выполняться неоптимально – медленно и с избыточными блокировками.
Вместо этого следует создать “смешанную” роль – “бухгалтер-кадровик” и прописать ее RLS таким образом, чтобы избежать использования ИЛИ в условии, а пользователя включить в эту одну роль.
4. 3 Использование ИЛИ в условиях соединения
Не рекомендуется использовать логическое ИЛИ в условиях соединения, то есть в секции ПО запроса. Это так же может привести к выбору неоптимального плана и медленной работе запроса. Простого универсального способа переписать такой запрос без использования ИЛИ не существует. Следует проанализировать решаемую задачу и попытаться найти другой алгоритм ее решения.
5.Использование подзапросов в условии соединения
Не следует использовать подзапросы в условии соединения. Это может привести к значительному замедлению запроса и (в отдельных случаях) к его полной неработоспособности на некоторых СУБД. Пример запроса с использованием подзапроса в условии соединения:
Запрос.Текст = "ВЫБРАТЬ | ОстаткиТоваров.Номенклатура КАК Номенклатура, | Цены.Цена КАК ЦенаПрошлогоМесяца |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки(...) КАК ОстаткиТоваров | ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.Цена КАК Цены | ПО Цены.Номенклатура = ОстаткиТоваров.Номенклатура И | Цены.Период В ( | ВЫБРАТЬ МАКСИМУМ(ЦеныПрошлогоМесяца.Период) | ИЗ РегистрСведений.Цена КАК ЦеныПрошлогоМесяца | ГДЕ ЦеныПрошлогоМесяца.Период < НАЧАЛОПЕРИОДА(ОстаткиТоваров.Период, МЕСЯЦ) | И ЦеныПрошлогоМесяца.Номенклатура = ОстаткиТоваров.Номенклатура | ) | ГДЕ ОстаткиТоваров.Склад = &Склад";
В данном случае подзапрос в условии соединения используется для получения как бы “среза последних” на конец предыдущего периода. Причем, для каждой номенклатуры период может быть разным. Подобный запрос рекомендуется переписать с использованием временных таблиц. Например, это можно сделать следующим образом:
Запрос.Текст = " // Максимальные даты установки цен в прошлом периоде для данных номенклатур |ВЫБРАТЬ | ОстаткиТоваров.Номенклатура КАК Номенклатура, | МАКСИМУМ(Цены.Период) КАК Период |ПОМЕСТИТЬ ДатыПоНоменклатурам |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки(...) КАК ОстаткиТоваров | ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.Цена КАК Цены | ПО Цены.Номенклатура = ОстаткиТоваров.Номенклатура И | Цены.Период < НАЧАЛОПЕРИОДА(ОстаткиТоваров.Период, МЕСЯЦ) | СГРУППИРОВАТЬ ПО ОстаткиТоваров.Номенклатура | ГДЕ ОстаткиТоваров.Склад = &Склад; // Выбрать данные по цене за найденный период |ВЫБРАТЬ | ДатыПоНоменклатурам.Номенклатура КАК Номенклатура, | Цены.Цена КАК ЦенаПрошлогоМесяца |ИЗ ДатыПоНоменклатурам | ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.Цена КАК Цены | ПО Цены.Номенклатура = ОстаткиТоваров.Номенклатура И | Цены.Период = ДатыПоНоменклатурам.Период ";
6.Получение данных через точку от полей составного типа
Если в запросе используется получение значения через точку от поля составного ссылочного типа, то при выполнении этого запроса будет выполняться соединение со всеми таблицами объектов, входящими в этот составной тип. В результате SQL текст запроса чрезвычайно усложняется, и при его выполнении оптимизатор СУБД может выбрать неоптимальный план. Это может привести к серьезным проблемам производительности и даже к неработоспособности запроса в отдельных случаях.
В частности, не рекомендуется обращаться к реквизитам регистратора регистра (например, “ТоварыНаСкладах.Регистратор.Дата”) и т.п. При этом не важно в какой части запроса вы используете реквизит, полученный через точку от поля составного типа – в списке возвращаемых полей, в условии и т.п. Во всех случаях такое обращение может привести к проблемам производительности.
Общая рекомендация заключается в том, чтобы по возможности ограничить количество соединений в таких запросах. Для этого можно использовать следующие приемы:
- Избегайте избыточности при создании полей составных ссылочных типов. Указывайте ровно столько возможных типов для данного поля, сколько необходимо. Не следует без необходимости использовать типы “любая ссылка” или “ссылка на любой документ” и т.п. Вместо этого следует более тщательно проанализировать прикладную логику и назначить для поля ровно те возможные типы ссылок, которые необходимы для решения задачи.
- При необходимости жертвуйте компактностью хранения данных ради производительности. Если в запросе вам понадобилось значение, полученное через ссылку, то, возможно, это значение можно хранить непосредственно в данном объекте. Например, если при работе с регистром вам требуется информация о дате регистратора, вы можете завести в регистре соответствующий реквизит и назначать ему значение при проведении документов. Это приведет к дублированию информации и некоторому (незначительному) увеличению ее объема, но может существенно повысить производительность и стабильность работы запроса.
- При необходимости жертвуйте компактностью и универсальностью кода ради производительности. Как правило, для выполнения конкретного запроса в данных условиях не нужны все возможные типы данной ссылки. В этом случае, следует ограничить количество возможных типов при помощи функции ВЫРАЗИТЬ. Если данный запрос является универсальным и используется в нескольких разных ситуациях (где типы ссылки могут быть разными), то можно формировать запрос динамически, подставляя в функцию ВЫРАЗИТЬ тот тип, который необходим при данных условиях. Это увеличит объем исходного кода и, возможно, сделает его менее универсальным, но может существенно повысить производительность и стабильность работы запроса.
Пример
В данном запросе используется обращение к реквизитам регистратора. Регистратор является полем составного типа, которое может принимать значения ссылки на один из 56 видов документов.
Запрос.Текст = "ВЫБРАТЬ | Продажи.Регистратор.Номер, | Продажи.Регистратор.Дата, | Продажи.Контрагент, | Продажи.Количество, | Продажи.Стоимость |ИЗ | РегистрНакопления.Продажи КАК Продажи |ГДЕ ...
SQL-текст этого запроса будет включать 56 левых соединений с таблицами документов. Это может привести к серьезным проблемам производительности при выполнении запроса. Однако, для решения данной конкретной задачи нет необходимости соединяться со всеми 56 видами документов. Условия запроса таковы, что при его выполнении будут выбраны только движения документов “РеализацияТоваровУслуг” и “ЗаказыПокупателя”. В этом случае мы можем значительно ускорить работу запроса, ограничив количество соединений при помощи функции ВЫРАЗИТЬ().
Запрос.Текст = "ВЫБРАТЬ | ВЫБОР | КОГДА Продажи.Регистратор ССЫЛКА Документ.РеализацияТоваровУслуг | ТОГДА ВЫРАЗИТЬ(Продажи.Регистратор КАК Документ.РеализацияТоваровУслуг).Номер | КОГДА Продажи.Регистратор ССЫЛКА Документ.ЗаказПокупателя | ТОГДА ВЫРАЗИТЬ(Продажи.Регистратор КАК Документ.ЗаказПокупателя).Номер | КОНЕЦ ВЫБОРА КАК Номер, | ВЫБОР | КОГДА Продажи.Регистратор ССЫЛКА Документ.РеализацияТоваровУслуг | ТОГДА ВЫРАЗИТЬ(Продажи.Регистратор КАК Документ.РеализацияТоваровУслуг).Дата | КОГДА Продажи.Регистратор ССЫЛКА Документ.ЗаказПокупателя | ТОГДА ВЫРАЗИТЬ(Продажи.Регистратор КАК Документ.ЗаказПокупателя).Дата | КОНЕЦ ВЫБОРА КАК Дата, | Продажи.Контрагент, | Продажи.Количество, | Продажи.Стоимость |ИЗ | РегистрНакопления.Продажи КАК Продажи |ГДЕ | Продажи.Регистратор ССЫЛКА Документ.РеализацияТоваровУслуг | ИЛИ Продажи.Регистратор ССЫЛКА Документ.ЗаказыПокупателя";
Этот запрос является более громоздким и, возможно, менее универсальным (он не будет правильно работать для других ситуаций – когда возможны другие значения типов регистратора). Однако, при его выполнении будет сформирован SQL запрос, который будет содержать всего два соединения с таблицами документов. Такой запрос будет работать значительно быстрее и стабильнее, чем запрос в его первоначальном виде.
7. Фильтрация виртуальных таблиц без использования параметров
При использовании виртуальных таблиц в запросах, следует передавать в параметры таблиц все условия, относящиеся к данной виртуальной таблице. Не рекомендуется фильтровать виртуальные таблицы при помощи условий в секции ГДЕ и т.п. Такой запрос будет возвращать правильный (с точки зрения функциональности) результат, но СУБД будет намного сложнее выбрать оптимальный план для его выполнения. В некоторых случаях это может привести к ошибкам оптимизатора СУБД и значительному замедлению работы запроса.
Например, следующий запрос использует секцию ГДЕ запроса для выборки из виртуальной таблицы.
Запрос.Текст = "ВЫБРАТЬ | Номенклатура |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки() |ГДЕ | Склад = &Склад";
Возможно, что в результате выполнения этого запроса сначала будут выбраны все записи виртуальной таблицы, а затем из них будет отобрана часть, соответствующая заданному условию. Было бы оптимальным вариантом ограничивать количество выбираемых записей на самом раннем этапе обработки запроса. Для этого следует передать условия в параметры виртуальной таблицы.
Запрос.Текст = "ВЫБРАТЬ | Номенклатура |ИЗ | РегистрНакопления.ТоварыНаСкладах.Остатки(, Склад = &Склад)";
С чего начинается анализ возможных причин сбоев?
Мероприятия по поиску возможных причин перегрузки системы следует искать не в хаотическом порядке, а постепенно, переходя от одного блока к другому, применяя систематический подход. Тогда в 1С оптимизация запросов окажется эффективной.
Вот наиболее частые проблемные места, ведущие к снижению скорости работы СУБД:
- неправильное использование подзапросов при написании запросов;
- некорректная работа системы при обработке виртуальных таблиц;
- неправильный индекс и некорректное условие запроса;
- логическая операция
ИЛИ, неправильное ее использование; - неправильные запросы в соединениях;
- ошибки обработки таблиц с данными при использовании фильтров;
- значения полей составных типов и многие другие.
Рассмотрим некоторые из перечисленных.
Обработка подзапросов в запросах
При использовании подзапросов в соединениях довольно часто возникают различные ошибки на системном уровне. И это неправильно. Эффективнее организовать связь исключительно между объектами метаданных или таблицами, временно создаваемыми.
Подзапрос имеет меньший приоритет, поэтому он будет выполнен значительно позже, что скажется на скорости его обработки даже при малой загрузке сервера. Также будет обеспечена явная нестабильность, это будет зависеть от определенных условий. Кроме этого, различные СУБД такие запросы обрабатывают по-разному, что также сказывается на скорости.
Важно! Временные таблицы появились в версиях 1С 8.2 и 8.3, поэтому если вы до сих пор используете 8.0, то мы рекомендуем обновиться, потому что появится не только эта возможность, но и много других полезных вещиц.
Разработка и оптимизация запросов в 1С должна выполняться правильно с учетом требований СУБД, поэтому при использовании соединений к подзапросам рекомендуется разделить их на столько частей, сколько имеется соединений.
После чего формируется единый пакетный запрос с их использованием. Таким образом, создается временная таблица, которая сразу же должна быть проиндексирована. А, точнее, проиндексированы все используемые поля.
Если запрос неправильно сформирован, имеется в виду с использованием нескольких подзапросов, то оптимизатор сервера, используемый в конкретной СУБД, может неправильно отрабатывать его.
То есть он может запутаться в нескольких соединениях. Но если соединения сформируются в 2 таблицы, то оптимизатор сможет достаточно быстро выяснить объем выборок. Но в случае если одна из выборок содержит подзапрос, то будет затруднительно сразу определить количество возвращаемых записей.
Переписанный код с использованием временных таблиц, конечно, имеет намного больший размер, но зато оптимизатору будет легче работать с ним, следовательно, система значительно ускориться.
Логическое ИЛИ
Для построения функций при создании сложных запросов часто используется функция логическое ИЛИ. Но из-за некоторых особенностей работы с ней, она может быть применена некорректно, из-за чего могут возникать проблемы в работе системы. Рассмотрим 2 наиболее частых случая, где используется эта функция:
- В секции
ГДЕ.Для правильного составления крайне не рекомендуется пользоваться операцией
ИЛИв секцияхГДЕ. Если это правило не соблюдено, то СУБД не проиндексирует ее, а просто просканирует.Что не даст желаемого результата. А так как она не получит требуемых данных, то произойдет блокировка. Лучше его разбить на несколько отдельных, а после, сконфигурировать их.
Пример:
Запрос
ВЫБРАТЬ… ИЗ … КАК … ГДЕ …1 ИЛИ 2луче заменить на блок:ВЫБРАТЬ … ИЗ … КАК … ГДЕ …1 ОБЪЕДИНИТЬ ВСЕ ВЫБРАТЬ … ИЗ … КАК … ГДЕ …2 - Несколько ролей с RLS на одного пользователя.
Не используйте
ИЛИв запросах при работе с пользователями с несколькими ролями и RLS. Из-за этого сильно снизится скорость обработки данных или появится блокировка. Необходимо объединять смешанные роли, например, бухгалтер-кадровик и стараться прописывать RLS без возможной вставки в него логической операцииИЛИ.
Условия соединения с ИЛИ
Разработка и оптимизация запросов в 1С предприятие в условиях соединения должна выполняться без ИЛИ при написании запроса в секциях соединения ПО. Это чревато проблемами выбора неоптимального плана, кроме этого заметно замедляется функционирование СУБД.
Как обрабатывать виртуальные таблицы
СУБД иногда неправильно работает в случаях неправильного соединения записей с виртуальными таблицами. Решение данной проблемы кроется во вложении виртуальной таблицы во временную. Не забыть выполнить индексацию соединенных полей запроса ВТ. В результате система создаст подзапрос для выборки. Но возникнет новая проблема, подобно случаю обработки запросов с подзапросами.
Отборы в неиндексируемых полях
Качественная оптимизация запросов в 1С 8.2 исключает использование запросов по неиндексируемым полям. Такие конструкции являются полным противоречием правил оптимизации. Для решения проблемы лучше непосредственно в запросе реализовать отбор по неиндексируемым полям. Если была использована ВТ, то лучше проиндексировать именно поля соединения.
Для стабильной работы СУБД, каждое из условий должно содержать индекс, содержащий поля условия, находящиеся в самом начале. Отборы должны следовать подряд без вставки в них других значений.
Если система не сможет подобрать индексы, то сканированию будет подвержена таблица данных целиком. Что затянется надолго, и станет очередной причиной блокировки всех данных.
Работа с фильтрами данных в таблицах
Правильной считается оптимизация кода 1С только при построении отбора не используя секцию ГДЕ. Ее наличие приведет к получению системой всех данных таблицы и после выберет нужные. Именно поэтому процесс накладывания фильтров на реквизиты должен выполняться исключительно с использованием параметров временной таблицы.
Как получать значения полей составных типов
Когда при составлении запроса на получение сведений из таблицы используется точка, то СУБД свяжет левым соединением не все таблицы. А столько, сколько возможно типов в поле составного типа. Еще не рекомендуется, выполняя оптимизацию, использовать регистратор. Он относится к составному типу данных. В них есть все типы документов, имеющие доступ к записи в регистр.
Для ускорения процесс обработки данных СУБД, рекомендуется сократить часть записей или разделить их. Можно добавить данных в реквизиты.
Довольно часто начинающие 1С разработчики сталкиваются с ошибками, которых достаточно легко избежать. Ниже мы рассмотрим топ 11 ошибок и способы их исправления. Также доступна видеоверсия статьи
Содержание
Поле объекта не обнаружено
Существует множество статей, которые описывают возможные причины возникновения в 1С ошибки “Поле объекта не обнаружено”. Порой это связывают с обновлением платформы, обновлением типового релиза, или с какими-то другими причинами.
Мы же будем оперировать фактами. В конце статьи прилагается внешняя обработка, в которой воспроизведена данная ошибка.
Такое сообщение платформа выдает, когда пытается обратиться к свойству объекта языка, которого у данного объекта нет. Не важно, что это за объект – документ, справочник, таблица значений , или сообщение пользователю.
- Удалили табличную часть, к которой обращаемся в коде?
- Переименовали реквизит, а в коде не исправили?
- Заменили значение со ссылки на неопределено?
Вуаля – платформа выдаст ошибку “Поле объекта не обнаружено”!
Как исправить? Исходя из природы ошибки – переименовать реквизит на нужное имя, отредактировать код, или использовать правильные обращения к стандартным свойствам объекта.
Например, у объекта “СообщениеПользователю” нет свойства “Таблица”, и следующий код приведет к ошибке:
Сообщение = Новый СообщениеПользователю;
Сообщение.Таблица = “Ошибка”;
Индекс находится за границами массива
Что означает такое сообщение системы? Как правило, с данной ошибкой разработчик сталкивается при некорректной работе с коллекциями. Самые частые случаи появления ошибки “Индекс находится за границами массива”.
- Использование при обходе коллекции количества элементов вместо индекса. Индексы начинаются с нуля, а количество элементов – с единицы. Поэтому следующий код гарантированно приведет к ошибке: Массив[Массив.Количество()]
- Последствия удаления элементов из коллекции, очистки коллекции или замены коллекции на пустую
- Ошибочное увеличение счетчика в цикле “Для”
Как исправить? Для удаления элементов из коллекции по условию – использовать обратный цикл. Добавлять условие на соответствие счетчика цикла и индекса массива. Не увеличивать счетчик внутри кода цикла Для … Цикл … КонецЦикла
Обращение к процедуре как к функции
Суть этой ошибки в том, что процедура не может возвращать значение. И если мы в коде используем вызов процедуры справа от знака присваивания, это приведет к ошибке.
Данная ошибка имеет две вариации – если используется стандартная процедура из методов какого-нибудь объекта, то фраза будет звучать “Обращение к процедуре объекта как к функции”. Если же использовать процедуру, объявленную в коде, то текст ошибки будет “Обращение к процедуре как к функции”.
При этом ошибка использования процедуры объекта является ошибкой времени выполнения – т.е. на этапе сохранения и проверки конфигурации платформа эту ошибку не обнаружит.
А вот неправильное использование процедуры синтаксическая проверка (Ctrl + F7) успешно обнаруживает, и не даст сохранить конфигурацию или внешнюю обработку/отчет, пока ошибка не будет устранена.
Рассмотрим два примера:
1. Воспроизведем ошибку “Обращение к процедуре как к функции”. При этом платформа не даст сохранить изменения, т.к. не проходит синтакс-контроль.
2. Воспроизведем ошибку “Обращение к процедуре объекта как к функции”. Здесь мы неверно используем метод объекта массива “Добавить”, который является процедурой.
Как исправить? Ошибка тривиальная, и исправление тоже. Чаще всего, достаточно внимательно прочитать описание методов объекта во встроенной справке или синтакс-помощнике. Если метод является процедурой, то значений он возвращать не может. Следовательно, нужно модифицировать код так, чтобы такого ошибочного вызова не было.
Если же используется процедура, объявленная в коде, возможно, есть необходимость изменить ее на функцию, либо также скорректировать код, который эту процедуру использует.
Процедура не может возвращать значение
Родственная предыдущей ошибка. Для того, чтобы код возвращал какое-то значение, следует этот код размещать в функции, а не в процедуре.
В процедуре можно написать ключевое слово “Возврат” без параметров. Это будет означать выход из процедуры.
Следующий код является ошибочным, т.к. в теле процедуры Возврат используется с параметром:
Процедура ПроцедураНеМожетВозвращатьЗначение(Команда) Возврат "Ошибка"; КонецПроцедуры
Как исправить? Платформа сама подсказывает, в каком месте кода ошибка. Нужно изменить текст модуля – либо удалить параметр у ключевого слова Возврат, либо убрать его вовсе, либо изменить процедуру на функцию – зависит от того, какая логика у вашей процедуры, и как вы предполагаете ее использовать.
Переменная не определена
Такой текст ошибки платформа 1С выдает на этапе синтаксического контроля, при сохранении конфигурации, внешнего отчета или обработки.
Причин у этой ошибки может быть несколько.
- Опечатка в имени переменной
- Обращение к переменной, которая нигде в области видимости не объявлена (неявной инициализацией с присвоением значения, явным образом с использованием ключевого слова “Перем”, или передана в качестве параметра)
- Написание на клиенте серверного кода. Например, обращение к менеджеру справочников “Справочники”, и т.п. Клиентская часть приложения “не видит ” серверные объекты языка
- Также ошибка может появиться, если ранее код использовался в режиме толстого клиента, но после был запущен в тонком клиенте.
Как исправить?
Внимательно следить за правильностью набранного кода, своевременно объявлять переменные или передавать их в качестве параметров. Писать серверный код только в серверных модулях, а также использовать соответствующие инструкции препроцессора, например “&НаСервере”.
Значение не является значением объектного типа
Ошибка “Значение не является значением объектного типа” может возникнуть при неверном обращении к объекту языка. Объектный тип – это такие объекты языка, которые содержат в себе другие объекты – свойства, реквизиты и т.п. Эти свойства доступны через точку, например “Объект.СвойствоЭтогоОбъекта”
Но если через точку попытаться использовать какое-то значение, которое внутри себя свойств не имеет – например, любое значение примитивного типа – это и приведет к ошибке.
Разберем более сложный пример:
&НаСервере Процедура ЗначениеНеЯвляетсяЗначениемОбъектногоТипаНаСервере(Справочники = Ложь) Сообщить(Справочники.Сотрудники.ПустаяСсылка()); КонецПроцедуры
Ошибка может быть “плавающей”. Если вместо параметра по умолчанию “Справочники = Ложь” будет передан менеджер справочников, то ошибки возникать не будет. А если вызвать процедуру без параметров, то будет использоваться параметр по умолчанию с типом Булево, что и приведет к ошибке.
Чаще всего чтобы исправить ошибку, нужно в отладчике посмотреть, какой тип значения используется. Можно внести изменения в код, чтобы обеспечить корректное поведение (например, в запросе вместо наименования товара выбрать ссылку, и в коде через точку уже обращаться к свойствам ссылки, а не текстового наименования). А можно добавить проверку на нужный тип значения. Т.е. – если значение того типа, который мы ожидаем – выполняем код. Иначе – не выполняем.
Ошибка при вызове метода контекста
В языке 1С у разных объектов (запросов, справочников, табличных документов и др.) есть предопределенные методы, предусмотренные платформой. Обращение к этим методам требует соблюдения порядка и параметров, правильного синтаксиса и соблюдения условий использования. Например, при чтении табличного документа из файла он не должен быть открыт в другой программе, при подключении к http-соединению оно должно быть доступно, и т.п.
Если эти условия не соблюдать, платформа в зависимости от версии может выдавать сообщения вида “Ошибка при вызове метода контекста”, и далее будут следовать более подробные сведения об ошибке – стек вызовов, приведших к ошибке, номер строки и позиции в строке, где произошла ошибка.
Чаще всего ошибка при вызове метода контекста встречается в следующих методах:
- Записать
- Прочитать
- Выполнить
- Создать
- ПроверитьВывод
Разберем эту ошибку на примере метода Выполнить объекта Запрос:
Запрос = Новый Запрос("ВЫБРАТЬ ПЕРВЫЕ 1 1 ГДЕ ИСТИНА И");
Запрос.Выполнить();
В тексте запроса допущена ошибка – после первого условия “ГДЕ ИСТИНА” указан оператор И, но после него нет еще одного условия. В результате при попытке выполнения запроса, платформа вернет ошибку.
Для исправления ошибки зачастую достаточно внимательно использовать методы, при необходимости уточнять порядок, количество и тип параметров – это можно сделать в справке или синтакс-помощнике (встать курсором на имя метода в коде, и нажать сочетание клавиш Ctrl+F1). В случае запроса – нужно передавать синтаксически корректный текст запроса; в случае проверки вывода на печать – в системе должен быть установлен принтер; в случае подключения к почте – должны быть корректно указаны логин и пароль, и т.п.
Тип не может быть выбран в запросе в 1С 8.3 (8.2)
С такой ошибкой начинающие разработчики (да и не только начинающие 😉 ) сталкиваются чаще всего, при чтении запросом данных из таблиц значений, либо из регистров сведений. Все дело в том, что запросы поддерживают далеко не все типы значений. Так, например, нельзя запросом выбрать тип Картинка, ХранилищеЗначений, Шрифт, и многие другие типы, которые не относятся к примитивным или ссылочным типам значений.
Так, если ресурс регистра сведений имеет тип ХранилищеЗначений, выбрать его запросом будет нельзя. Также, если в таблицу значений поместить значения не подходящих типов, а после передать эту таблицу в качестве параметра-источника данных, выполнение запроса также приведет к ошибке “Тип не может быть выбран в запросе”.
Еще одна ситуация, когда запрос будет выдавать ошибку – если таблица значений, которая передается в качестве параметра, имеет не типизированные колонки.
Неверно:
//ТЗОшибочныйТип.Колонки.Добавить("Контрагент");
Верно:
//ТЗОшибочныйТип.Колонки.Добавить("Контрагент", Новый ОписаниеТипов("СправочникСсылка.Контрагенты"));
Для исправления ошибки нужно правильным образом инициализировать колонки таблицы значений, а также не обращаться в запросе к полям, типы которых запросами не поддерживаются.
Платформа будет выдавать такое сообщение, если в коде используются методы, приводящие к открытию модальных окон. Модальные окна – это окна, которые при открытии блокируют весь остальной интерфейс. В 1С есть несколько модальных методов – например – “Вопрос”, “ОткрытьЗначение”, “Предупреждение”. Кроме того, в коде может использоваться модальный синтаксис открытия форм: “ОткрытьМодально()”
Если в свойствах конфигурации выбран режим использования модальности “Не использовать”, то выполнение модальных методов будет приводить к этой ошибке “Использование в 1С модальных окон в данном режиме запрещено”.
Для устранения ошибки можно пойти несколькими путями. Как водится, один – быстрый, другой – правильный 🙂
Быстрый способ – переключить режим использования модальности в положение “Использовать”.
Более правильный способ – использовать в коде немодальные вызовы методов. Например, у метода “Вопрос” есть немодальный аналог – “ПоказатьВопрос”, у метода “Предупреждение” – “ПоказатьПредупреждение”, и т.п. Чаще всего об этих методах дополнительно указано в синтакс-помощнике и справке.
Кроме того, в последних версиях платформы появились асинхронные методы – “ВопросАсинх”, “ПредупреждениеАсинх” и др. Появление этих методов позволяет писать более простой и понятный асинхронный код, и направлено в первую очередь, на более полноценную поддержку браузерами и работу в веб-клиенте.
1С 8.3 и 8.2: Запись с такими ключевыми полями существует!
Данная ошибка появляется при некорректной записи в регистр сведений. Чаще всего с этой ошибкой сталкиваются начинающие разработчики, не до конца понимающие механизмы работы с ключевыми полями (измерениями).
Суть ошибки следующая – регистр сведений позволяет записать запись (строку таблицы) с уникальным набором ключевых полей – а для периодических регистров также и поля Период. Если следующая запись полностью повторяет значение ключевых полей, но осуществляется методом Записать с параметром Замещать = Истина, то запись в таблице регистра просто заменится на идентичную.
Однако если поместить две абсолютно одинаковые записи в набор записей, и попытаться его записать – платформа выдаст ошибку. Еще один распространенный случай, когда 1С сообщает “Запись с такими ключевыми полями существует” – это запись в периодический регистр сведений с периодичностью от “День” и выше, подчиненный регистратору.
В типовых конфигурациях часто эту ошибку можно воспроизвести, если в пользовательском режиме создать два документа “Установка цен номенклатуры” с одной и той же номенклатурой и за один и тот же день. Попытка провести второй документ приведет к ошибке.
В случае, когда ошибка возникает не в результате действий пользователя, а при выполнении кода, чтобы устранить ее, чаще всего необходимо проанализировать алгоритм записи в регистр. Если запись осуществляется одним набором данных, его предварительно нужно свернуть до уникальных записей. Например, выгрузить в таблицу значений, свернуть, и загрузить в набор записей.
Поле объекта недоступно для записи в 1С
Чаще всего начинающие программисты 1С сталкиваются с этой ошибкой в двух ситуациях.
Первый случай – это попытка редактирования системных полей, недоступных для записи. Например, в модуле формы сама форма будет содержаться в объекте ЭтаФорма. И попытка присвоить этому реквизиту любое значение приведет к ошибке “Поле объекта недоступно для записи”.
Второй случай – и с ним новички как раз допускают больше всего ошибок – это попытка редактирования полей ссылки, а не самого объекта. Чаще всего код выглядит примерно так:
Элемент = Справочники.Сотрудники.НайтиПоКоду("12345");
Элемент.Наименование = "Новое наименование";
Исполнение данного кода приведет к ошибке, т.к. поля ссылки доступны только для чтения, а метод НайтиПоКоду вернет именно ссылку. Чтобы можно было внести изменения, следует из ссылки получить сам объект – используя соответствующий метод ПолучитьОбъект().
Для исправления ошибки зачастую достаточно получить объект из ссылки. В случае же попытки редактирования свойств, доступных только на чтение самый правильный подход – анализировать имеющуюся документацию по этим свойствам, и не пытаться присваивать им значения, если платформа этого не предусматривает.
Ссылка на обработку
По ссылке вы можете скачать внешнюю обработку, в которой воспроизводится большая часть ошибок, описанных в статье. Для воспроизведения части ошибок нужно будет убрать комментарии в коде.
Заключение
Как видите, зачастую ошибки тривиальны, и достаточно просто исправляются. Общие рекомендации – внимательно читать документацию и справку, корректно использовать методы, активно пользоваться отладчиком. Если вы новичок, и хотите освоить программирование в 1С с нуля – могу предложить приобрести мой базовый курс для начинающих. Более подробная информация – по ссылке.
Ниже раскрывается «кухня» выполнения запросов кода конфигурации 1С:Предприятие 8 и «ингредиенты», определяющие производительность запросов. Будет приведена информация о фактической работе запроса, которая помогает понять, какая требуется оптимизация. Показаны методы повышения производительности запросов.
Для того чтобы разработчик имел возможность использовать запросы для реализации собственных алгоритмов, в 1С:Предприятии реализован язык запросов. Этот язык основан на SQL, но при этом содержит значительное количество расширений (виртуальные таблицы, обращение через точку и т.п.), ориентированных на отражение специфики финансово-экономических задач и на максимальное сокращение усилий по разработке прикладных решений.
Модель работы с базой данных, реализованная в 1С:Предприятии 8, позволяет разработчику сосредоточиться на создании бизнес-логики приложения и не заботиться о структурах таблиц, преобразованиях типов данных и пр.
Платформа 1С:Предприятия обеспечивает операции исполнения запросов, описания структур данных и манипулирования данными, транслируя их в соответствующие команды. В случае клиент-серверного варианта работы — это команды MS SQL Server 2005, IBM DB2 или PostgreSQL.
«Внутренняя кухня» на примере MS SQL Server
Возьмем пример запроса 1С и проследим за путем его исполнения.
Воспользуюсь обработкой «Консоль запросов» с диска ИТС и выполню простенький запрос:
Большинство запросов, это инструкция «ВЫБРАТЬ …», поэтому мне кажется будет правильным дальше опираться на эту инструкцию.
Для знакомых с языком SQL команда «ВЫБРАТЬ» — это перевод на русский язык команды SELECT (кстати, если писать в 1С на английском языке, то запросы 1С становятся еще больше похожими на запросы SQL).
Давайте проследим путь выполнения этого запроса.
Путь прохождения запроса
Прежде всего не пугайтесь :). Расшифрую рисунок (он хоть и немного устарел, но суть сохранилась). Мы — это «пользователь» на рисунке. В консоли запросов я нажимаю кнопку «Выполнить».
Код обработки выполняется на клиенте (но в принципе может и на сервере 1С:Предприятие), он проходит по сети и попадает на рабочий сервер приложений, где транслируется в SQL запрос.
Отслеживание запросов технологическим журналом
С помощью обработки (тоже с диска ИТС) «Настройка технологического журнала» я создаю файл logcfg.xml, который будет логировать запросы к субд.
Содержимое файла у меня было такое:
<?xml version=»1.0″?>
<config xmlns=»http://v8.1c.ru/v8/tech-log»>
<dump create=»false» location=»» type=»0″/>
<log history=»1″ location=»E:Commonlogs»>
<event>
<eq property=»name» value=»dbmssql»/>
</event>
<property name=»all»/>
</log>
</config>
Текст logcfg.xml содержит фильтр dbmssql на сбор всех запросов к MS SQL Server.
затем открыл файл технологического лога
Для моего запроса в консоли запросов в логе появились такие строчки:
45:44.1727-1,DBMSSQL,3,process=rphost,p:processName=bi,t:clientID=15,t:applicationName=1CV8,t:computerName=TESTCENTER,t:connectID=10,Usr=Тест,Trans=0,dbpid=52,Sql=
‘SELECT
_InfoReg482_Q_000_T_001._Fld484 AS f_1
FROM
_InfoReg482 _InfoReg482_Q_000_T_001 WITH(NOLOCK)
WHERE
_InfoReg482_Q_000_T_001._Fld483RRef = ?
p_0: 0x9455005056C0000811DCE204C649E3E8
‘,Rows=1,RowsAffected=-1
45:44.2031-0,Context,1,process=rphost,p:processName=bi,t:clientID=15,t:applicationName=1CV8,t:computerName=TESTCENTER,t:connectID=10,Usr=Тест,Context=’
Обработка.КонсольЗапросов.Форма.Форма : 458 : мРезЗапроса = ОбъектЗапрос.Выполнить();’
У нас появился SQL запрос к «страшному и непонятному» имени таблицы базы данных «_InfoReg482 _InfoReg482_Q_000_T_001», плюс «загадочные» поля таблицы «_Fld484» и «_Fld483RRef».
Тут надо дать комментарий почему мы не увидели запроса 1С. У нас есть «контекст запроса» — 458 строка модуля Обработка.КонсольЗапросов.Форма — мРезЗапроса = ОбъектЗапрос.Выполнить();
Встаньте в эту строчку отладчиком конфигуратора и для ОбъектЗапрос.Текст содержимым будет запрос 1С.
Но это мы знаем исходный запрос, и поэтому можем догадаться, что за «_InfoReg482» таблица на самом деле.
Но когда исходный запрос неизвестен, чтобы получить соответствие имен таблиц базы данных объектам метаданным используете наш сервис.
Возвращаемся к нашей схеме прохождения запроса.
Сервер приложений 1С:Предприятие является клиентом для СУБД MS SQL Server и передает исследованный нами SQL запрос на сервер СУБД.
Запрос выполняет сервер СУБД и затем по обратной цепочки возвращает ответ.
В этой статье сконцентрируемся на подробностях исполнения запроса сервером субд, так как язык SQL предназначен для формулирования запросов в терминах СУБД (таблицы и поля).
При выполнении запроса:
SELECT
_InfoReg482_Q_000_T_001._Fld484 AS f_1
FROM
_InfoReg482 _InfoReg482_Q_000_T_001 WITH(NOLOCK)
WHERE
_InfoReg482_Q_000_T_001._Fld483RRef = ?
мы говорим, что нужно получить «_InfoReg482_Q_000_T_001._Fld484», но не говорим, «как это получить»!
Дело в том, что один и тот же запрос может быть выполнен множеством разных способов:
-Части запроса можно обрабатывать в разном порядке
-Можно использовать разные индексы
Это связано с механизмом субд — оптимизатором запросов.
Оптимизатор запросов СУБД
Оптимизатор запросов осуществляет поиск наиболее оптимального плана выполнения запросов из всех возможных для заданного запроса. Один и тот же результат может быть получен СУБД различными способами (планами выполнения запросов), которые могут существенно отличаться как по затратам ресурсов, так и по времени выполнения. Задача оптимизации заключается в нахождении оптимального способа.
План выполнения запроса — это такая перестановка всех исходных выбираемых таблиц, реляционное соединение которых в выбранной последовательности, представленное в процедурном виде, может быть выполнено за минимальное число операций.
Планы выполнения запроса сравниваются исходя из следующих факторов:
- потенциальное число строк, извлекаемое из каждой таблицы, получаемое из статистики;
- наличие индексов ( подразумевается, что вы уже прочли мою статью об индексах);
- возможность выполнения слияний (merge-join).
Что из всего этого следует:
Перед выполнением запроса формируется его ПЛАН выполнения.
- Полностью определяет, как будет выполняться запрос
- Формируется автоматически сервером СУБД
- Повлиять на план средствами 1С:Предприятие можно только косвенно
Давайте «посмотрим» план выполнения нашего запроса.
Страшно и непонятно, если не знать английского 🙂
Давайте разберемся в этой схеме плана запроса.
Для выполнения выбора (SELECT …) поля _InfoReg482_Q_000_T_001._Fld484 (он находится в составе возвращаемых данных Output List) оптимизатор запросов принял решение выполнить перебор всех записей (Clustered Index Scan в заголовке операции (единственной) плана) кластерного индекса таблицы _InfoReg482_ByPeriod_TRN (об этом подсказывает раздел object).
Напоминаю, чтобы получить соответствие имен таблиц базы данных объектам метаданным используйте наш сервис.
Привожу для справки работу оператора сканирования (перебора) кластерного индекса:
Clustered Index Scan – логический и физический оператор сканирует кластеризованный индекс, определенный в колонке Argument.
Если есть опциональный параметр WHERE:(), то возвращаются только те строки, которые соответствуют параметру. Если колонка Argument содержит параметр ORDERED, процессор запроса предложит вывод строк в том порядке, в котором они отсортированы в кластерном индексе. Если упорядочения нет, индекс будет отсканирован самым оптимальным образом (но не гарантируется, что вывод будет отсортирован).
В нашем примере плана опциональный параметр отсутствует.
Основная причина недостаточной производительности запросов — неоптимальный план выполнения запроса.
Для того, чтобы устранять проблемы производительности, необходимо понять причины.
Причины, по которым СУБД может выбирать неоптимальный план (наиболее известные)
- Несоответствие индексов и условий запросов (проблема «покрывающих» запросов описана в моей статье)
- Большая вложенность подзапросов и соединения с вложенными подзапросами
- Некоренное использование параметров виртуальных таблиц
- Отсутствие функции ВЫРАЗИТЬ для полей составного типа
- Получение лишних полей через точку
Но прежде, чем перейдем к разбору софтверных нюансов, хочется ОБРАТИТЬ ВНИМАНИЕ, что
сильная загруженность ресурсов сервера на выбор плана влияет НЕПРЕДСКАЗУЕМО!
Это означает, что если у вас сервер «не тянет», то результат оптимизации кода конечно снизит нагрузку и улучшит производительность, но вот ВЫПОЛНИТЬ САМУ ОТЛАДКУ и оптимизировать код на таком сервере сложно и НЕТ ГАРАНТИЙ!
В качестве примера обычно рассказываю такую ситуацию. Допустим Вы нашли медленный запрос и знаете как его улучшить. Чтобы оценить на практике результаты, Вы должны сначала выполнить замер производительности на исходном коде, затем на оптимизированном. А как можно интерпретировать результаты, если в момент время замера исходного запроса сервер был загружен на 70%, а в момент второго на 99%. Можно ли доверять таким замерам? Нет.
Несоответствие индексов и условий запросов
В своей статье, посвященной индексом, мы сказали, что что нас интересуют влияние индексов на быстродействие запросов.
Индексы наиболее подходят для задач следующего типа:
- Запросы, которые указывают «узкие» критерии поиска. Такие запросы должны считывать лишь небольшое число строк, отвечающих определенным критериям.
- Запросы, которые указывают диапазон значений. Эти запросы также должны считывать небольшое количество строк.
- Поиск, который используется в операциях связывания. Колонки, которые часто используются как ключи связывания, прекрасно подходят для индексов.
- Поиск, при котором данные считываются в определенном порядке. Если результирующий набор данных должен быть отсортирован в порядке кластеризованного индекса, то сортировка не нужна, поскольку результирующий набор данных уже заранее отсортирован. Например, если кластеризованный индекс создан по колонкам lastname (фамилия), firstname (имя), а для приложения требуется сортировка по фамилии и затем по имени, то здесь нет необходимости добавлять инструкцию ORDER BY.
Правда при всей полезности индексов, есть одно очень важное НО – индекс должен быть «эффективно используемым» и должен позволять находить данные с использованием меньшего числа операций ввода-вывода и объема системных ресурсов.
В запросах кода конфигурации использование индексов зависит условий, на которые есть смысл обратить внимание:
- ВЫБРАТЬ … ИЗ … ГДЕ <условие>
- СОЕДИНЕНИЕ … ПО <условие>
- ВЫБРАТЬ … ИЗ <ВиртуальнаяТаблица>(, <условие>)
- ИМЕЮЩИЕ <условие>
Если в системе нет индекса, который мог бы эффективно использоваться для данного запроса, то необходимо рассмотреть одну из следующих возможностей:
- Установить свойство «Индексировать»
- Изменить порядок следования измерений в регистре
Следует учитывать, что максимально эффективный индекс в самом начале содержит все поля, перечисленные в условии. Необходимо проанализировать все условия, имеющиеся в запросе и проверить, есть ли для них подходящие индексы.
Для определения создания индексов (индексирования) можно использовать:
- Знание используемого количества строк в таблице (чаще всего записей в справочнике, регистре сведений, последовательности и т.д.)
- Знание запроса, использующего таблицы (записи объектов метаданных)
Почему так происходит?
Предлагаю выполнить несколько примеров. Сначала займемся практикой, а потом сделаем выводы из наблюдений и познакомимся с теорией.
Пример 1
Создайте справочник с реквизитом. Пусть это будет «Склады» с реквизитом «МОЛ». Заполните справочник, сгенерировав например обработкой несколько тысяч записей, с разными значениями реквизита «МОЛ».
Выполните (например в консоли запросов) такой запрос, использующий отбор «ГДЕ»:
Для того, чтобы получить неискаженную информацию, выполните запрос Transact-SQL (здесь приложен файл) к базе данных с помощью SQL Server Management Studio:
USE MyDataBase1C
GO
exec sp_msforeachtable N’UPDATE STATISTICS ? WITH FULLSCAN’
GO
DBCC UPDATEUSAGE (MyDataBase1C)
GO
DBCC FREEPROCCACHE
,где MyDataBase1C — имя базы данных информационной базы 1С:Предприятие.
Далее используя SQL Server Profiler и приложенный здесь шаблон включите «трассировку» для вашей базы данных.
После выполнения запроса кода конфигурации в MS SQL Server будет «транслирован» запрос Transact-SQL.
Выделите событие Showplan XML Statistics Profile, и Вы уведете картинку плана запроса, похожу на мою.
Подробней приемы работы с планом запроса можно посмотреть здесь http://technet.microsoft.com/ru-ru/magazine/cc137757.aspx
Предлагаю обратить внимание на название операции физического исполнения логической команды SELECT (ВЫБРАТЬ) — Clustered Index Scan.
Теперь изменим у реквизита свойство Индексировать.
И после перезапуска конфигуратора (у нас будет создан индекс) повторить наблюдение за планом запроса.
Что произошло? Тот же самый запрос, выполняясь в MS SQL Server в этот раз выполняется другими физическим оператором — Clustered Index Seek. А если еще точнее, двумя операциями Clustered Index Seek и результаты объединяются физической операцией Nested Loops.
Даже если не смотреть на колонки Duration (длительность) и Read (чтение с диска), то можно сделать вывод — индексы влияют на способ выполнения логических операторов (в нашем случаи SELECT). При этом могут применять разные комбинации физических операторов.
Пример 2
В нашем примере будем выполнять один и тот же запрос к регистру накопления.
Сначала выполним размещения измерения номенклатура последним по порядку, и выключим индексирование этого реквизита, выполним запрос. Затем включим индексирование и повторим запрос.
Для анализа используем профайлер с такими настройками:
Запрос к неиндексированной «Номенклатуре» регистра.
Длительность Duration в моем замере составила 60 мс.
Теперь запрос с индексированным вариантом:
Интересно, что в 1С:Предприятии код запроса мы не трогали, более того, и в MS SQL Server логический текст запроса тоже остался тем же.
А вот физические операторы изменились.
Почему же оптимизатор запросов ведет себя по-разному?
Для этого надо понимать различия между физическими операторами, применяющимися для логических запросов. Ниже немного теории.
Сканирование таблицы или индекса
На сканирование указывает наличие в плане запроса одной из следующих операций:
- TABLE SCAN
- CLUSTERED INDEX SCAN (это наши пример 1 и 2)
- INDEX SCAN
Операция сканирования указывает на неоптимальную работу запроса, но не всегда, а только при выполнении следующих условий:
- Таблица содержит большое количество записей
- Запрос возвращает маленькое количество записей
Операция сканирования всегда указывает на то, что для оптимального выполнения данного запроса нет подходящего индекса.
Вид операции Table Scan. Значок нам как бы подсказывает, что происходит перебор всех записей таблицы.
Вид операции Clustered Index Scan
Отдельно выделим операцию поиска по кластеризованному индексы с условием.
Поиск в индексе по неполному условию
На выполнение поиска по неполному условию указывает наличие в плане запроса операции:
- INDEX SEEK … WHERE
Данная операция аналогична сканированию таблицы или индекса, но при ее выполнении сканируется не вся таблица, а только ее часть.
Операция поиска по неполному условию указывает на неоптимальную работу запроса не всегда, а только при выполнении следующих условий:
- Сканируемая область (ограниченная условием SEEK) содержит большое количество записей
- Запрос возвращает маленькое количество записей
Операция поиска по неполному условию так же указывает на отсутствие подходящего индекса.
Вид операции Index Seek
Избегать конструкции ПОДОБНО (LIKE)
При работе с отборами удобно выполнять поиск контрагента не по наименованию, а путем установки отбора по условию «Содержит» по полю «Наименование». Однако это отрицательно сказывается на производительности из-за невозможности использования индексов и так приводит к запросам:
ВЫБРАТЬ .. ИЗ Справочник.Контрагенты
ГДЕ Наименование ПОДОБНО «%СтрокаПоиска%»
В таком запросе будет выполнен полный перебор всех записей таблицы. Это отрицательно сказывается на производительности.
Примечание. В последних версиях MS SQL Server LIKE стал уметь в некоторых случаях использовать поиск, но это все равно не лучший оператор.
Большая вложенность подзапросов и соединения с вложенными подзапросами
Сервер СУБД с трудом оптимизирует такие конструкции как
Если в тексте встречаются конструкции вида:
ВЫБРАТЬ ИЗ <запрос1>
ЛЕВОЕ СОЕДИНЕНИЕ (
ВЫБРАТЬ ИЗ <подзапрос1>
) ПО …
особенно, если <запрос1> или <подзапрос1> содержат не физические таблицы, а также вложенные запросы, потому что:
- Неизвестно, сколько записей вернет подзапрос
- Неизвестно, какой способ соединения лучше использовать
- Выбирается тот способ, который сам по себе проще (NESTED LOOPS)
- Это приводит к сильному падению производительности
Рассмотрим более подробно суть проблемы.
Соединение в цикле
На выполнение соединения в цикле указывает наличие в плане запроса операции:
- NESTED LOOPS
Операция соединения в цикле указывает на неоптимальную работу запроса не всегда, а только в том случае если ведущий подзапрос возвращает значительное количество записей.
В этом случае следует попытаться упростить запрос:
- Использовать временные таблицы вместо подзапросов
- Уменьшить вложенность подзапросов
- По возможности исключить соединения с подзапросами
В некоторых случаях данный симптом может так же указывать на отсутствие подходящего индекса.
Большая вложенность запросов
Другой момент – это возможные ошибки в сложных вложенных запросах (на момент написания характерны для ЗУП). Если запрос выполняет неоправданно долго, упростите его с помощью временных таблиц.
МенеджерВТ = Новый МенеджерВременныхТаблиц;
Подзапрос = Новый Запрос;
Подзапрос.МенеджерВременныхТаблиц = МенеджерВТ;
Подзапрос.Текст = «
| ВЫБРАТЬ …
| ПОМЕСТИТЬ МояВременнаяТаблица
| ИЗ <подзапрос1>
| ГДЕ…
| ИНДЕКСИРОВАТЬ ПО…
«;
Обратите внимание на то, что для оптимизации работы запроса почти всегда необходимо проиндексировать создаваемую временную таблицу. Индекс должен быть подобран таким образом, чтобы СУБД могла его использовать при соединении с временной таблицей. То есть, в индексе должны быть перечислены все поля, которые используются в условии соединения.
После того, как подзапрос выделен в отдельный запрос, следует выполнить его и оценить скорость его работы. Для того, чтобы оптимизировать основной запрос, подзапрос должен работать достаточно быстро сам по себе.
Если производительность запроса оказалась недостаточной, возможно это говорит о том, что подзапрос по-прежнему слишком сложен. То есть, необходимо его дальнейшее упрощение еще раз.
Как решать такую проблему: вместо использования соединений с вложенными подзапросами следует использовать временные таблицы.
- Заполняем временную таблицу результатом вложения
- Выполняем основной запрос
Резюме. При решении вопросов производительности в MS SQL Server обратите внимание на физические операторы плана запроса:
- Сканирование таблицы или индекса
- Поиск в индексе по неполному условию
- Соединение в цикле
Оптимизатор СУБД выбирает и анализирует лишь некоторое количество вариантов выполнения запроса и выбирает “лучший из них”. При количестве таблиц больше 8 скорее всего все варианты точно не будут проверены — даже математически слишком много комбинаций за отведенное ограниченное время.
При этом возникает вероятность, что по-настоящему оптимальный вариант остался даже не рассмотренным. Поэтому чтобы помочь оптимизатору СУБД в выборе оптимального варианта выполнения нашего запроса рекомендуется придерживаться следующих правил:
- По возможности условие ИЛИ заменять операцией ОБЪЕДИНЕНИТЬ ВСЕ.Чтобы убедиться в том, что нужна замена, можно сделать так: выполнить запрос с условием на равенство по одиночному значению поля, а потом запрос с условиемИЛИ по этому полю на большой таблице. Если второй запрос выполняется намного дольше, чем первый, то данный запрос можно переписать.
- Условие “не равно” (<>) тоже может отключать использование индекса. Например если необходимо исключить большую часть таблицы, а поле отбора проиндексировано, – есть смысл переписать запрос на вариант ОБЪЕДИНЕНИТЬ ВСЕ
- В условиях соединений, стараться обходиться без использования вложенных запросов и виртуальных таблиц, а так же лишних разыменований (выражений через несколько точек). Вложенные запросы и виртуальные таблицы рекомендую заменить на временные таблицы.
- Стараться избегать в условии “В ИЕРАРХИИ” содержания пустой ссылки. Возможно ситуация когда оптимизатор СУБД начнет проверять каждый элемент справочника на принадлежность корню (т.е. самому справочнику), теряя на этом время.
- Следует использовать ОБЪЕДИНИТЬ ВСЕ вместо ОБЪЕДИНИТЬ, если наличие одинаковых записей не критично. Оператор ОБЪЕДИНИТЬ использует дополнительные операции, которые могут занять много времени.
- Условие “ПОДОБНО” подавляет использование индекса.
- Если запрос содержит несколько условий, то они должны располагаться в порядке уменьшения эффекта от выбора. То есть первым надо делать то условие, которое максимально уменьшит результирующую таблицу.
- Максимально использовать индексы таблиц. Необходимо стараться чтобы для всех условий, использованных в запросе, имелись подходящие индексы. Подходящий индекс – это индекс, который содержит все поля перечисленные в условии, эти поля находятся в самом начале индекса и они расположены вместе, т.е между ними нет других полей.
- Не рекомендуется фильтровать виртуальные таблицы при помощи условий в секции ГДЕ и т.п. Надо использовать только параметры.
- Стараться для ссылочных полей, по которым будет вывод, получать представление сразу в запросе, т.е. использовать конструкцию “ПРЕДСТАВЛЕНИЕ(НашаСсылка)“
- Если в запросе реализовано соединение двух и более таблиц, то эти таблицы должны стоять в запросе в порядке уменьшения количества записей в них, а в части условий (ГДЕ) первым должно стоять условие на первую таблицу.
- Если запрос содержит условие для проиндексированного (относится к некластерному индексу) поля маленькой таблицы, которая может быть считана за одно обращение к памяти, то лучше убрать индекс с этого поля в конфигурации.
- Условия вхождения значений полей в результаты вложенных запросов лучше заменять на внутренние соединение по равенству этого поля для ситуаций, когда есть вероятность получения больших размеров таблиц результатов вложенных запросов. Т.е. конструкцию “Поле1 В (Выбрать Поле1 из Таблица2)” заменить на “ВНУТРЕННЕЕ СОЕДИНЕНИЕ Таблица2 По Таблица1.Поле1 = Таблица2.Поле1“
- Для составных типов смотрите http://infostart.ru/public/184361/
- Пример оптимизации тут
Влияние данных на выбор плана
Одним из критерием, которыми руководствуется оптимизатор при создании плана исполнения запроса — это количество строк в таблице. Мы не будем сейчас говорить, о том что механизм блокировок тоже меняет свое поведение и влияет на производительность. Сформулирую лишь собственные наблюдения, собранные «грабли».
Если в конфигурации есть «аналитика» (субконто, измерения) участвующая в итогах и она не используется, то возможны неоправдано излишнее торможение. Что делать: особенно если это типовая конфигурация, либо заполнить справочник сотней «фиктивных» строк, если позволяет бизнес-логика, либо отказаться от этой аналитики.
Время проведения документа с 50, 500, 5000 и 50000 строчками вряд ли будет иметь линейную зависимость замедления. В какой-то момент «где-то» система упрется в узкое место и скорость проведения резко упадет. В качестве рекомендаций можно посоветовать нагрузочное тестирование именно с тем количеством строк, которое реально используется на предприятии.
Влияние статистики на выбор плана
С объемом данных и его разнородности в рамках таблицы сильно связано «знание» оптимизатора с помощью статистик распределения. Как правило, СУБД не знает и не может знать точное число строк в таблице (даже для выполнения запроса SELECT COUNT(*) FROM TABLE выполняется сканирование первичного индекса), поскольку в базе могут храниться одновременно несколько образов одной и той же таблицы с различным числом строк. Сбор статистики для построения гистограмм осуществляется либо специальными командами СУБД, либо фоновыми процессами СУБД.
Из практических можно отметить уже данные рекомендации моей статьи по обслуживанию MS SQL Server выполнять принудительно или регламентной процедурой команду SQL:
exec sp_msforeachtable N’UPDATE STATISTICS ? WITH FULLSCAN’
Влияние механизмов кэширования запросов (их компиляции перед исполением).
Кеш запросов используется для уменьшения времени ответа СУБД для часто используемых запросов.
План выполнения запроса помещается в кеш и ассоциируется с синтаксическим деревом или текстом запроса. Впоследствии, если семантика входящего запроса соответствует семантике некоторого запроса, помещенного в кеш, то СУБД использует сохраненный план выполнения, а не генерирует его.
При очень высокой загруженности СУБД может использовать скомпилированной запрос с устаревшей статистикой или другими неактуальными данными. Инструкция
DBCC FREEPROCCACHE
используется для аккуратной очистки кэша планов. Внимание, просто так эту процедуру «гонять» не надо. Слишком частое использование, да еще при не интенсивном вводе данных скорее ухудшит работу, чем улучшит.
Влияние RLS
1. При использовании у пользователя большого количества групп нужно создавать новую группу, которая бы содержала в себе эквивалент это множества групп. Т.е. проверять одну группу значительно лучше чем десяток.
2. Разбивайте запрос на несколько частей. Старайтесь как можно большее количество участков запроса выносить в привилегированный модуль. Под «RLS» должна остаться только та таблица и кусок запроса, без которой потеряется смысл проверки доступа к записи.
Способы поиска проблемных запросов
Для того, чтобы выполнить анализ эффективности использования индексов, сначала надо определить проблемный запрос.
Если Вы выполняете разработку и работаете с конкретным участком кода, то поиск выполнять не требуется, разве что сверить с хронометражем отладчика.
Однако гораздо чаще вопрос поиска неэффективных запросов происходит на реально работающих системах. Есть несколько методов, которые имеют свои преимущества и недостатки.
Поиск длительных запросов опросом пользователей и отладчиком
Метод имеет кучу недостатков и ограничений. Пожалуй проще сказать, когда его можно использовать. Если пользователь жалуется на долгое проведение документа или построение отчета, и при этом нет блокировок, т.е. работает одинаково долго как в многопользовательском, так и в монопольном режиме. Кроме того, отладчиком по-умолчанию можно отлаживать только код клиентской части. Для включения отладки на сервере Вам придется перезапускать сервер приложений и лезть в реестр. А именно
[HKEY_LOCAL_MACHINESYSTEMCurrentControlSetServices1C:Enterprise 8.1 Server Agent]
«ImagePath«=
по умолчанию «C:Program Files1cv81binragent.exe» -srvc -agent -regport 1541 -port 1540 -range 1560:1591 -d «C:Program Files1cv81server»
надо «C:Program Files1cv81binragent.exe» -srvc -agent -regport 1541 -port 1540 -range 1560:1591 -debug -d «C:Program Files1cv81server»
Таким образом, это самый дешевый и простой способ исследования медленных запросов. Он наиболее известен 1С специалистам.
Поиск длительных запросов технологическим журналом
Метод хорош тем, что скорее всего Вам не придется перезапускать сервер приложений и не требует дополнительных трат денег, поскольку технологический журнал является штатным средством платформы.
Недостаток — нужно иметь навык работы с технологическим журналом или потратить время на его освоения. Облегчает работу обработка с диска ИТС «Настройка технологического журнала».
Также недостатком можно считать дополнительные усилия по разбору собранных данных, так как никакого ранжирования по частоте запросов и их длительности нет.
Поиск длительных запросов с помощью бесплатного сервиса Анализа долгих запросов
Этот метод наиболее хорош в сложных случаях, когда вообще нет уверенности в том, что именно есть длительный запрос, а не проблема ожиданий на блокировках. Кроме того сервис Анализа долгих запросов сам ранжирует собранные проблемные запросы и говорит, в каком порядке их надо решать.
Поиск длительных запросов SQL Server Profiler-ом
Последний способ для страдающих ностальгией по 90м годам, когда администраторы баз данных куда больше ценились (и это было вполне обосновано). Способ не то чтобы для извращенцев, но квалификации требует наибольшей из всех перечисленных здесь способов, а эффективность не гарантируется.
Вариант настройки SQL Server Profiler
- Events:
- Stored Procedures RPC:Comleted
- TSQL SQL:BatchCompleted
- Performance Showplan Statistics Profile
- Performance Showplan XML Statistics Profile
- Колонки данных:
- Все
- Column Filters:
- Все условия фильтрации, включенные по умолчанию
- DatabaseName
- Like <имя базы данных>
- Duration
- Greater then or equal <длительность запроса в миллисекундах>
Все полученные запросы следует сгруппировать, просуммировав общее время выполнения. Суммарное время выполнения можно использовать в качестве ранга данного запроса. Группа одинаковых запросов, которые в сумме выполнялись максимальное время, имеет наивысший ранг. Этот запрос должен рассматриваться в первую очередь.
Имеется возможность автоматизировать ранжирование групп запросов. Для этого следует сохранить трассировку в таблицу SQL и выполнить, например, следующий запрос:
select substring(TextData, 1, 100), SUM(Duration)
from MySQLTrace
group by substring(TextData, 1, 100)
order by SUM(Duration) desc
В результате будет получен список групп запросов (по совпадению первых 100 символов), отсортированный по убыванию суммарного времени выполнения всех запросов группы, то есть по убыванию ранга данного запроса.
Ну, вообще Вы поняли, что будет не скучно :).
Поиск отсутствующих индексов средствами MS SQL Server
Так получилось, что задача поиска отсутствующих индексов характерна не только 1С-приложениям, но и вообще любым клиентам MS SQL Server. Задача вообще-то не очень простая, как вы уже могли заметить. Поэтому для «закоренелых sql-щиков» не могу не осветить еще несколько моментов.
Помощник по настройке ядра СУБД (Database Engine Tuning Advisor)
Помощник по настройке ядра СУБД (часто обозначают DTA)— это инструмент для анализа влияния рабочей нагрузки на производительность в одной или нескольких базах данных. Рабочая нагрузка представляет собой набор инструкций Transact-SQL, которые выполняются в отношении баз данных, нуждающихся в настройке. Другими словами данный инструмент позволяет человеку непонимая, как используются оптимизатором ресурсы, использовать советы самого сервера, дающего рекомендации «мол такой индекс надо сделать, а этот лишний».
Поскольку мы работаем с 1С:Предприятие 8, то SQL-щики могут соблазниться на подобную кажущуюся легкость решения проблемы.
Подводными камнями является «мягкая» привязка структуры информационной базы к именам таблиц в базе данных MS SQL Server. Именя таблиц генерируются платформой автоматически и нет гарантий в постоянном соответствии метаданных к именам таблиц.
Вообщем такой подход решения проблемы методически неверен.
Однако я бы не стал вообще о нем упоминать, если бы не одно но. Рекомендованные индексы помощником DTA можно расмотреть для создания подобных индексов уже средствами 1С:Предприятие. Более подробно об управлении индексов смотрите в моей статьте.
Как пользоваться DTA.
1. Вам необходимо профайлером собрать «рабочую нагрузку». Это означает, что вы не просто включаете на подробную запись запросов профайлер и из под своей сессии делаете одно-два проведений документов или построений отчетов. Вам нужна запись реальных действий пользователей за весь рабочий день. Разумеется слово рабочий день подразумевает не время с 10.00 до 18.00, а реальная работа пользователей в это время.
2. В составе трассировки обязательно должны быть и выполненные запросы, и планы запросов.
3. Сохранить трассировку в файл.
4. Выполнить анализ файла с помощью DTA, указав сохранять структуру существующих таблиц и индексов.
После старта анализа мастер будет некоторое время оценивать данные нагрузки и выдаст рекомендации.
Сохраняем скрипт в файл и с помощью уже выше озвученой обработку смотрим на содержимое колонок индексов.
Очень желательно создавать индексы не средствами СУБД, но если вы решите все таки использовать скрипт, советую продумывать отслеживание эффективности подобных индексов.
Вы можете также прочить в январьском номере 2008 года статью Яна Стерка «Открытие скрытых данных для оптимизации производительности приложений».
Часть приемов экспериментально реализована в моей обработке.
Мегаэкстремальный способ препарирования запросов
Есть такой прием — подсказка USE PLAN в запросе.
| Внимание! |
|---|
| Руководства планов с неправильным использованием подсказок в запросе могут привести к проблемам при компиляции во время выполнения и ухудшению производительности. Руководства планов должны применяться только опытными разработчиками и администраторами баз данных. |
Руководства планов SQL могут только применяются к инструкциям и пакетам, часто выполняющимся приложением с помощью системной хранимой процедуры sp_executesql (платформа 1С:Предприятие не все запросы генерирует в таким способом, но многие).
Влияние оптимизатора запроса от редакции СУБД
См. здесь
Ошибки, как правило, совершают начинающие программисты, не имеющие достаточного опыта в своей деятельности. Можно эти ошибки по разному классифицировать. Мы же в рамках статьи разделим их на две группы. В конечном итоге они приводят к:
- неоправданному расходу ресурсов компьютера (сервера);
- искажению данных при чтении или записи.
Содержание
- Получение данных не из регистра
- Запрос в цикле и обращение через точку
- Ошибки в запросах к таблицам регистров
- Неверный контекст выполнения процедур и функций
Получение данных не из регистра
Достоверной информацией учетной системы принято считать данные регистров. Если же какой-либо отчет получает данные из таблиц документов, то это является грубой ошибкой. Данное решение очень медленно работает, может приводить к ошибкам блокировок, не является гибким и может давать искажение результатов отчета.
То есть правильно придерживаться такой схемы:
Документ – Регистр – Отчет.
Запрос в цикле и обращение через точку
Примером такой ошибки является конструкция типа:
Пока Выборка.Следующий() Цикл
А = Выборка.Ссылка.Договор;
КонецЦикла;
Как видим, внутри цикла мы делаем так называемый неявный запрос.
Тем самым, во-первых, мы расходуем ресурсы. В цикле может быть огромное число итераций, в каждую из которых система выполнит запрос.
Во-вторых, даже без цикла такая конструкция неоптимальна, потому что платформа инициализирует все поля объекта Выборка.Ссылка.
Да, новичкам так банально проще писать, но это грубая ошибка с точки зрения производительности. Правильно запросом получить необходимый набор полей.
ВЫБРАТЬ
ПоступлениеТоваровУслуг.Ссылка,
ПоступлениеТоваровУслуг.Ссылка.Договор
ИЗ
Документ.ПоступлениеТоваровУслуг КАК ПоступлениеТоваровУслуг
ГДЕ ПоступлениеТоваровУслуг.Ссылка = &Ссылка
Ошибки в запросах к таблицам регистров
Грубейшей ошибкой является использование конструкции ГДЕ … в запросе к таблице регистра накопления вместо того, чтобы установить отбор в параметрах виртуальной таблицы.
Также часто начинающие забывают при левом соединении накладывать фильтр в параметрах виртуальной таблицы, если Вы присоединяете записи виртуальной таблицы.
Приведем пример:
ВЫБРАТЬ
ПоступлениеТоваровУслугТовары.Номенклатура,
ПоступлениеТоваровУслугТовары.Количество,
ЦеныНоменклатурыСрезПервых.Цена
ИЗ
Документ.ПоступлениеТоваровУслуг.Товары КАК ПоступлениеТоваровУслугТовары
ЛЕВОЕ СОЕДИНЕНИЕ РегистрСведений.ЦеныНоменклатуры.СрезПервых КАК ЦеныНоменклатурыСрезПервых
ПО ПоступлениеТоваровУслугТовары.Номенклатура = ЦеныНоменклатурыСрезПервых.Номенклатура
В этом случае платформа выберет все записи таблицы регистра сведений “Цены номенклатуры”, а потом отбросит ненужные. Результат Вы получите, только система потратит впустую ресурсы.
Неверный контекст выполнения процедур и функций
При разработке в режиме управляемого приложения мы можем использовать так называемые директивы компиляции – &НаКлиенте, &НаСервере, &НаСервереБезКонтекста и прочие.
Так вот при написании кода необходимо понимать суть клиент-серверной архитектуры. Новички же часто весь код выполняют на сервере, потому что им так проще. Но в таком случае опять может происходить напрасная трата ресурсов сервера. Если говорить совсем просто, необходимо стремиться избавить сервер от лишней работы, а также избегать напрасной передачи всех данных формы на сервер и обратно.
Автор в рамках данной статьи не ставит своей целью показать все ошибки начинающих программистов. Ошибок много (как и программистов), и их делают все, но самое главное в процессе работы – не совершать их в будущем. А для этого необходимо постоянно работать над повышением своей квалификации.
Рекомендуем Вам делать “аудит” своих работ, которые имеют определенный срок давности.