
I’m running postgresql 9.3 on a machine with 32GB ram, with 0 swap. There are up to 200 clients connected. There’s 1 other 4GB process running on the box. How do I interpret this error log message? How can I prevent the out of memory error? Allow swapping? Add more memory to the machine? Allow fewer client connections? Adjust a setting?
example pg_top:
last pid: 6607; load avg: 3.59, 2.32, 2.61; up 16+09:17:29 20:49:51
113 processes: 1 running, 111 sleeping, 1 uninterruptable
CPU states: 22.5% user, 0.0% nice, 4.9% system, 63.2% idle, 9.4% iowait
Memory: 29G used, 186M free, 7648K buffers, 23G cached
DB activity: 2479 tps, 1 rollbs/s, 217 buffer r/s, 99 hit%, 11994 row r/s, 3820 row w/s
DB I/O: 0 reads/s, 0 KB/s, 0 writes/s, 0 KB/s
DB disk: 149.8 GB total, 46.7 GB free (68% used)
Swap:
example top showing the only other significant 4GB process on the box:
top - 21:05:09 up 16 days, 9:32, 2 users, load average: 2.73, 2.91, 2.88
Tasks: 247 total, 3 running, 244 sleeping, 0 stopped, 0 zombie
%Cpu(s): 22.1 us, 4.1 sy, 0.0 ni, 62.9 id, 9.8 wa, 0.0 hi, 0.7 si, 0.3 st
KiB Mem: 30827220 total, 30642584 used, 184636 free, 7292 buffers
KiB Swap: 0 total, 0 used, 0 free. 23449636 cached Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
7407 postgres 20 0 7604928 10172 7932 S 29.6 0.0 2:51.27 postgres
10469 postgres 20 0 7617716 176032 160328 R 11.6 0.6 0:01.48 postgres
10211 postgres 20 0 7630352 237736 208704 S 10.6 0.8 0:03.64 postgres
18202 elastic+ 20 0 8726984 4.223g 4248 S 9.6 14.4 883:06.79 java
9711 postgres 20 0 7619500 354188 335856 S 7.0 1.1 0:08.03 postgres
3638 postgres 20 0 7634552 1.162g 1.127g S 6.6 4.0 0:50.42 postgres
postgresql.conf:
max_connections = 1000 # (change requires restart)
shared_buffers = 7GB # min 128kB
work_mem = 40MB # min 64kB
maintenance_work_mem = 1GB # min 1MB
effective_cache_size = 20GB
....
log:
ERROR: out of memory
DETAIL: Failed on request of size 67108864.
STATEMENT: SELECT "package_texts".* FROM "package_texts" WHERE "package_texts"."id" = $1 LIMIT 1
TopMemoryContext: 798624 total in 83 blocks; 11944 free (21 chunks); 786680 used
TopTransactionContext: 8192 total in 1 blocks; 7328 free (0 chunks); 864 used
Prepared Queries: 253952 total in 5 blocks; 136272 free (18 chunks); 117680 used
Type information cache: 24240 total in 2 blocks; 3744 free (0 chunks); 20496 used
Operator lookup cache: 24576 total in 2 blocks; 11888 free (5 chunks); 12688 used
TableSpace cache: 8192 total in 1 blocks; 3216 free (0 chunks); 4976 used
MessageContext: 8192 total in 1 blocks; 6976 free (0 chunks); 1216 used
Operator class cache: 8192 total in 1 blocks; 1680 free (0 chunks); 6512 used
smgr relation table: 24576 total in 2 blocks; 5696 free (4 chunks); 18880 used
TransactionAbortContext: 32768 total in 1 blocks; 32736 free (0 chunks); 32 used
Portal hash: 8192 total in 1 blocks; 1680 free (0 chunks); 6512 used
PortalMemory: 8192 total in 1 blocks; 7888 free (0 chunks); 304 used
PortalHeapMemory: 1024 total in 1 blocks; 568 free (0 chunks); 456 used
ExecutorState: 32928 total in 3 blocks; 15616 free (5 chunks); 17312 used
printtup: 34002024 total in 2 blocks; 7056 free (7 chunks); 33994968 used
ExprContext: 0 total in 0 blocks; 0 free (0 chunks); 0 used
ExprContext: 0 total in 0 blocks; 0 free (0 chunks); 0 used
ExprContext: 0 total in 0 blocks; 0 free (0 chunks); 0 used
Relcache by OID: 24576 total in 2 blocks; 12832 free (3 chunks); 11744 used
CacheMemoryContext: 1372624 total in 24 blocks; 38832 free (0 chunks); 1333792 used
CachedPlanSource: 7168 total in 3 blocks; 3080 free (1 chunks); 4088 used
CachedPlanQuery: 7168 total in 3 blocks; 2992 free (1 chunks); 4176 used
CachedPlanSource: 15360 total in 4 blocks; 7128 free (5 chunks); 8232 used
CachedPlanQuery: 15360 total in 4 blocks; 3320 free (1 chunks); 12040 used
CachedPlanSource: 3072 total in 2 blocks; 552 free (0 chunks); 2520 used
CachedPlanQuery: 7168 total in 3 blocks; 1592 free (1 chunks); 5576 used
CachedPlanSource: 3072 total in 2 blocks; 536 free (0 chunks); 2536 used
... 2 Thousand snipped lines of CachedPlans ...
CachedPlanSource: 15360 total in 4 blocks; 7128 free (5 chunks); 8232 used
CachedPlanQuery: 15360 total in 4 blocks; 3320 free (1 chunks); 12040 used
CachedPlanSource: 7168 total in 3 blocks; 3880 free (3 chunks); 3288 used
CachedPlanQuery: 7168 total in 3 blocks; 4032 free (1 chunks); 3136 used
CachedPlanSource: 7168 total in 3 blocks; 3936 free (3 chunks); 3232 used
CachedPlanQuery: 7168 total in 3 blocks; 4032 free (1 chunks); 3136 used
CachedPlanSource: 7168 total in 3 blocks; 3080 free (1 chunks); 4088 used
CachedPlanQuery: 7168 total in 3 blocks; 2992 free (1 chunks); 4176 used
CachedPlanSource: 7168 total in 3 blocks; 3872 free (2 chunks); 3296 used
CachedPlanQuery: 7168 total in 3 blocks; 4032 free (1 chunks); 3136 used
pg_toast_17305_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
index_package_raises_on_natural_key: 3072 total in 2 blocks; 1648 free (1 chunks); 1424 used
index_package_extensions_on_natural_key: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
index_package_mixins_on_natural_key: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
index_package_mixins_on_includes_id: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
package_texts_pkey: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
index_package_file_objects_on_natural_key: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
index_package_symbols_on_natural_key: 3072 total in 2 blocks; 1136 free (1 chunks); 1936 used
index_package_symbols_on_full_name: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
index_package_symbols_on_alias_for_id: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
package_symbols_pkey: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_toast_17313_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
index_packages_on_natural_key: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
packages_pkey: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
index_package_files_on_natural_key: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
package_files_pkey: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_toast_2619_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
index_projects_on_user_id: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
index_projects_on_type: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
index_projects_on_name_and_type: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
index_projects_on_claim_ticket: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
ruby_gem_metadata_pkey: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_constraint_contypid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_constraint_conrelid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_constraint_conname_nsp_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
pg_attrdef_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_attrdef_adrelid_adnum_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
pg_index_indrelid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_db_role_setting_databaseid_rol_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_opclass_am_name_nsp_index: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
pg_foreign_data_wrapper_name_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_enum_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_class_relname_nsp_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
pg_foreign_server_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_statistic_relid_att_inh_index: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
pg_cast_source_target_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
pg_language_name_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_collation_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_amop_fam_strat_index: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
pg_index_indexrelid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_ts_template_tmplname_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_ts_config_map_index: 3072 total in 2 blocks; 1784 free (2 chunks); 1288 used
pg_opclass_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_foreign_data_wrapper_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_event_trigger_evtname_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_ts_dict_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_event_trigger_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_conversion_default_index: 3072 total in 2 blocks; 1784 free (2 chunks); 1288 used
pg_operator_oprname_l_r_n_index: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
pg_trigger_tgrelid_tgname_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_enum_typid_label_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_ts_config_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_user_mapping_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_opfamily_am_name_nsp_index: 3072 total in 2 blocks; 1784 free (2 chunks); 1288 used
pg_foreign_table_relid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_type_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_aggregate_fnoid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_constraint_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_rewrite_rel_rulename_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_ts_parser_prsname_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_ts_config_cfgname_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_ts_parser_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_operator_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_namespace_nspname_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_ts_template_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_amop_opr_fam_index: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
pg_default_acl_role_nsp_obj_index: 3072 total in 2 blocks; 1784 free (2 chunks); 1288 used
pg_collation_name_enc_nsp_index: 3072 total in 2 blocks; 1784 free (2 chunks); 1288 used
pg_range_rngtypid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_ts_dict_dictname_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_type_typname_nsp_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
pg_opfamily_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_class_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_proc_proname_args_nsp_index: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
pg_attribute_relid_attnum_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
pg_proc_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_language_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_namespace_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_amproc_fam_proc_index: 3072 total in 2 blocks; 1736 free (2 chunks); 1336 used
pg_foreign_server_name_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_attribute_relid_attnam_index: 1024 total in 1 blocks; 16 free (0 chunks); 1008 used
pg_conversion_oid_index: 1024 total in 1 blocks; 200 free (0 chunks); 824 used
pg_user_mapping_user_server_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_conversion_name_nsp_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_authid_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_auth_members_member_role_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_tablespace_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_database_datname_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_auth_members_role_member_index: 1024 total in 1 blocks; 64 free (0 chunks); 960 used
pg_database_oid_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
pg_authid_rolname_index: 1024 total in 1 blocks; 152 free (0 chunks); 872 used
MdSmgr: 24576 total in 2 blocks; 13984 free (0 chunks); 10592 used
ident parser context: 0 total in 0 blocks; 0 free (0 chunks); 0 used
hba parser context: 7168 total in 3 blocks; 304 free (1 chunks); 6864 used
LOCALLOCK hash: 8192 total in 1 blocks; 1680 free (0 chunks); 6512 used
Timezones: 83472 total in 2 blocks; 3744 free (0 chunks); 79728 used
ErrorContext: 8192 total in 1 blocks; 8160 free (6 chunks); 32 used
I’m trying to run a query that should return around 2000 rows, but my RDS-hosted PostgreSQL 9.3 database is giving me the error «out of memory DETAIL: Failed on request of size 2048.».
What does that mean? My instance has 3GB of memory, so what would be limiting it enough to run out of memory with such a small query?
Edit:
SHOW work_mem;
"1024GB"
I can’t show the full SQL, but it’s attempting to perform a pivot. I have two primary tables, library and book, which points back to a library record. My query attempts to find the most popular book for each of the last 12 months for each library record, and join them to a separate column in the result queryset, to have something like:
library_id, month_1_book_id, month_2_book_id, month_3_book_id, ...
Explain shows this results in quite a few loops:
explain
select * from myapp_library_get_monthly_popular
where id in (5495060, 5495059, 5495048)
Nested Loop Left Join (cost=3645798.54..3750412.91 rows=3 width=2980)
-> Nested Loop Left Join (cost=3645798.10..3750388.98 rows=3 width=2994)
-> Nested Loop Left Join (cost=3645797.66..3750365.05 rows=3 width=2976)
-> Nested Loop Left Join (cost=3645797.23..3750341.13 rows=3 width=2958)
-> Nested Loop Left Join (cost=3645796.79..3750317.20 rows=3 width=2940)
-> Nested Loop Left Join (cost=3645796.35..3750293.27 rows=3 width=2922)
-> Nested Loop Left Join (cost=3645795.91..3750269.35 rows=3 width=2904)
-> Nested Loop Left Join (cost=3645795.48..3750245.42 rows=3 width=2886)
-> Nested Loop Left Join (cost=3645795.04..3750221.49 rows=3 width=2868)
-> Nested Loop Left Join (cost=3645794.60..3750197.57 rows=3 width=2850)
-> Nested Loop Left Join (cost=3645794.16..3750173.64 rows=3 width=2832)
-> Nested Loop Left Join (cost=3645793.73..3750149.71 rows=3 width=2814)
-> Hash Join (cost=3645793.29..3750125.79 rows=3 width=2796)
Hash Cond: (c.category_id = ct.id)
-> Hash Join (cost=3645792.24..3750124.70 rows=3 width=2578)
Hash Cond: (c.company_id = cp.id)
-> Hash Join (cost=3645791.18..3750123.59 rows=3 width=2360)
Hash Cond: (c_1.id = c.id)
-> HashAggregate (cost=3645772.11..3695454.20 rows=3974567 width=8)
-> Hash Right Join (cost=2178696.20..3595882.33 rows=9977957 width=8)
Hash Cond: (u.library_id = c_1.id)
Join Filter: (u.period_start_date >= ((max(u_1.period_start_date)) - '1 year'::interval))
-> Seq Scan on myapp_book u (cost=0.00..594004.70 rows=29933870 width=12)
-> Hash (cost=2129014.12..2129014.12 rows=3974567 width=8)
-> Hash Join (cost=1960095.02..2129014.12 rows=3974567 width=8)
Hash Cond: (c_2.id = c_1.id)
-> HashAggregate (cost=1780709.26..1820454.93 rows=3974567 width=8)
-> Hash Right Join (cost=288688.46..1556205.24 rows=29933870 width=8)
Hash Cond: (u_1.library_id = c_2.id)
-> Seq Scan on myapp_book u_1 (cost=0.00..594004.70 rows=29933870 width=8)
-> Hash (cost=239006.38..239006.38 rows=3974567 width=4)
-> Hash Join (cost=2.11..239006.38 rows=3974567 width=4)
Hash Cond: (c_2.category_id = ct_1.id)
-> Hash Join (cost=1.07..184355.03 rows=3974567 width=8)
Hash Cond: (c_2.company_id = cp_1.id)
-> Seq Scan on myapp_library c_2 (cost=0.00..129703.67 rows=3974567 width=12)
-> Hash (cost=1.03..1.03 rows=3 width=4)
-> Seq Scan on myapp_company cp_1 (cost=0.00..1.03 rows=3 width=4)
-> Hash (cost=1.02..1.02 rows=2 width=4)
-> Seq Scan on myapp_category ct_1 (cost=0.00..1.02 rows=2 width=4)
-> Hash (cost=129703.67..129703.67 rows=3974567 width=4)
-> Seq Scan on myapp_library c_1 (cost=0.00..129703.67 rows=3974567 width=4)
-> Hash (cost=19.02..19.02 rows=3 width=2328)
-> Index Scan using myapp_library_pkey on myapp_library c (cost=0.43..19.02 rows=3 width=2328)
Index Cond: (id = ANY ('{5495060,5495059,5495048}'::integer[]))
-> Hash (cost=1.03..1.03 rows=3 width=222)
-> Seq Scan on myapp_company cp (cost=0.00..1.03 rows=3 width=222)
-> Hash (cost=1.02..1.02 rows=2 width=222)
-> Seq Scan on myapp_category ct (cost=0.00..1.02 rows=2 width=222)
-> Index Scan using myapp_book_pkey on myapp_book u_01 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[1])
-> Index Scan using myapp_book_pkey on myapp_book u_02 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[2])
-> Index Scan using myapp_book_pkey on myapp_book u_03 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[3])
-> Index Scan using myapp_book_pkey on myapp_book u_04 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[4])
-> Index Scan using myapp_book_pkey on myapp_book u_05 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[5])
-> Index Scan using myapp_book_pkey on myapp_book u_06 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[6])
-> Index Scan using myapp_book_pkey on myapp_book u_07 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[7])
-> Index Scan using myapp_book_pkey on myapp_book u_08 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[8])
-> Index Scan using myapp_book_pkey on myapp_book u_09 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[9])
-> Index Scan using myapp_book_pkey on myapp_book u_10 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[10])
-> Index Scan using myapp_book_pkey on myapp_book u_11 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[11])
-> Index Scan using myapp_book_pkey on myapp_book u_12 (cost=0.44..7.97 rows=1 width=22)
Index Cond: (id = ((array_agg(u.id)))[12])
The RDS instance has 3.75 GB of memory, but RDS appears to limit work_mem to at most 2 GB.
My query is contained in a view, so if I want to target specific libraries, I query the view with those IDs, as you see above. The problem seems to be how Postgres plans using the view. If I run the raw query, without the view, the results return instantly. It’s only when I wrap my query in a view, and query IDs from that that I get a memory error.
Время на прочтение
5 мин
Количество просмотров 44K

Когда в Linux сервер базы данных непредвиденно завершает работу, нужно найти причину. Причин может быть несколько. Например, SIGSEGV — сбой из-за бага в бэкенд-сервере. Но это редкость. Чаще всего просто заканчивается пространство на диске или память. Если закончилось пространство на диске, выход один — освободить место и перезапустить базу данных.
Out-Of-Memory Killer
Когда у сервера или процесса заканчивается память, Linux предлагает 2 пути решения: обрушить всю систему или завершить процесс (приложение), который съедает память. Лучше, конечно, завершить процесс и спасти ОС от аварийного завершения. В двух словах, Out-Of-Memory Killer — это процесс, который завершает приложение, чтобы спасти ядро от сбоя. Он жертвует приложением, чтобы сохранить работу ОС. Давайте сначала обсудим, как работает OOM и как его контролировать, а потом посмотрим, как OOM Killer решает, какое приложение завершить.
Одна из главных задач Linux — выделять память процессам, когда они ее просят. Обычно процесс или приложение запрашивают у ОС память, а сами используют ее не полностью. Если ОС будет выдавать память всем, кто ее просит, но не планирует использовать, очень скоро память закончится, и система откажет. Чтобы этого избежать, ОС резервирует память за процессом, но фактически не выдает ее. Память выделяется, только когда процесс действительно собирается ее использовать. Случается, что у ОС нет свободной памяти, но она закрепляет память за процессом, и когда процессу она нужна, ОС выделяет ее, если может. Минус в том, что иногда ОС резервирует память, но в нужный момент свободной памяти нет, и происходит сбой системы. OOM играет важную роль в этом сценарии и завершает процессы, чтобы уберечь ядро от паники. Когда принудительно завершается процесс PostgreSQL, в логе появляется сообщение:
Out of Memory: Killed process 12345 (postgres).Если в системе мало памяти и освободить ее невозможно, вызывается функция out_of_memory. На этом этапе ей остается только одно — завершить один или несколько процессов. OOM-killer должен завершать процесс сразу или можно подождать? Очевидно, что, когда вызывается out_of_memory, это связано с ожиданием операции ввода-вывода или подкачкой страницы на диск. Поэтому OOM-killer должен сначала выполнить проверки и на их основе решить, что нужно завершить процесс. Если все приведенные ниже проверки дадут положительный результат, OOM завершит процесс.
Выбор процесса
Когда заканчивается память, вызывается функция out_of_memory(). В ней есть функция select_bad_process(), которая получает оценку от функции badness(). Под раздачу попадет самый «плохой» процесс. Функция badness() выбирает процесс по определенным правилам.
- Ядру нужен какой-то минимум памяти для себя.
- Нужно освободить много памяти.
- Не нужно завершать процессы, которые используют мало памяти.
- Нужно завершить минимум процессов.
- Сложные алгоритмы, которые повышают шансы на завершение для тех процессов, которые пользователь сам хочет завершить.
Выполнив все эти проверки, OOM изучает оценку (oom_score). OOM назначает oom_score каждому процессу, а потом умножает это значение на объем памяти. У процессов с большими значениями больше шансов стать жертвами OOM Killer. Процессы, связанные с привилегированным пользователем, имеют более низкую оценку и меньше шансов на принудительное завершение.
postgres=# SELECT pg_backend_pid();
pg_backend_pid
----------------
3813
(1 row)Идентификатор процесса Postgres — 3813, поэтому в другой оболочке можно получить оценку, используя этот параметр ядра oom_score:
vagrant@vagrant:~$ sudo cat /proc/3813/oom_score
2Если вы совсем не хотите, чтобы OOM-Killer завершил процесс, есть еще один параметр ядра: oom_score_adj. Добавьте большое отрицательное значение, чтобы снизить шансы на завершение дорогого вам процесса.
sudo echo -100 > /proc/3813/oom_score_adjЧтобы задать значение oom_score_adj, установите OOMScoreAdjust в блоке сервиса:
[Service]
OOMScoreAdjust=-1000Или используйте oomprotect в команде rcctl.
rcctl set <i>servicename</i> oomprotect -1000Принудительное завершение процесса
Когда один или несколько процессов уже выбраны, OOM-Killer вызывает функцию oom_kill_task(). Эта функция отправляет процессу сигнал завершения. В случае нехватки памяти oom_kill() вызывает эту функцию, чтобы отправить процессу сигнал SIGKILL. В лог ядра записывается сообщение.
Out of Memory: Killed process [pid] [name].Как контролировать OOM-Killer
В Linux можно включать и отключать OOM-Killer (хотя последнее не рекомендуется). Для включения и отключения используйте параметр vm.oom-kill. Чтобы включить OOM-Killer в среде выполнения, выполните команду sysctl.
sudo -s sysctl -w vm.oom-kill = 1Чтобы отключить OOM-Killer, укажите значение 0 в этой же команде:
sudo -s sysctl -w vm.oom-kill = 0Результат этой команды сохранится не навсегда, а только до первой перезагрузки. Если нужно больше постоянства, добавьте эту строку в файл /etc/sysctl.conf:
echo vm.oom-kill = 1 >>/etc/sysctl.confЕще один способ включения и отключения — написать переменную panic_on_oom. Значение всегда можно проверить в /proc.
$ cat /proc/sys/vm/panic_on_oom
0Если установить значение 0, то когда закончится память, kernel panic не будет.
$ echo 0 > /proc/sys/vm/panic_on_oomЕсли установить значение 1, то когда закончится память, случится kernel panic.
echo 1 > /proc/sys/vm/panic_on_oomOOM-Killer можно не только включать и выключать. Мы уже говорили, что Linux может зарезервировать для процессов больше памяти, чем есть, но не выделять ее по факту, и этим поведением управляет параметр ядра Linux. За это отвечает переменная vm.overcommit_memory.
Для нее можно указывать следующие значения:
0: ядро само решает, стоит ли резервировать слишком много памяти. Это значение по умолчанию в большинстве версий Linux.
1: ядро всегда будет резервировать лишнюю память. Это рискованно, ведь память может закончиться, потому что, скорее всего, однажды процессы затребуют положенное.
2: ядро не будет резервировать больше памяти, чем указано в параметре overcommit_ratio.
В этом параметре вы указываете процент памяти, для которого допустимо избыточное резервирование. Если для него нет места, память не выделяется, в резервировании будет отказано. Это самый безопасный вариант, рекомендованный для PostgreSQL. На OOM-Killer влияет еще один элемент — возможность подкачки, которой управляет переменная cat /proc/sys/vm/swappiness. Эти значения указывают ядру, как обрабатывать подкачку страниц. Чем больше значение, тем меньше вероятности, что OOM завершит процесс, но из-за операций ввода-вывода это негативно сказывается на базе данных. И наоборот — чем меньше значение, тем выше вероятность вмешательства OOM-Killer, но и производительность базы данных тоже выше. Значение по умолчанию 60, но если вся база данных помещается в память, лучше установить значение 1.
Итоги
Пусть вас не пугает «киллер» в OOM-Killer. В данном случае киллер будет спасителем вашей системы. Он «убивает» самые нехорошие процессы и спасает систему от аварийного завершения. Чтобы не приходилось использовать OOM-Killer для завершения PostgreSQL, установите для vm.overcommit_memory значение 2. Это не гарантирует, что OOM-Killer не придется вмешиваться, но снизит вероятность принудительного завершения процесса PostgreSQL.
06.09.17 — 08:02
Добрый день,прошу помощи в решении проблемы
пользую 1с 8.3.9.2309 + PostgreSql 9.4.2-1.1C происходит ошибка при загрузке базы dt ,ошибка 53200 error out of memory detail failed on request of size 536870912
ОС windows server 2016 standard,аналогичная проблема и на других ос
Пробовал менять настройки конфига pg,сейчас они такие
Это из основных как я полагаю интересующих :
shared_buffers = 64MB # min 128kB
temp_buffers = 256MB # min 800kB
work_mem = 128MB # min 64kB
maintenance_work_mem = 256MB # min 1MB
effective_cache_size = 6GB
——————————————
Всего оперативной памяти 16gb
Причём конкретно только одна база не загружается (она исправна,её тестировал БП 2.0)
ещё пробовал увеличить файл подкачки на диске С
Помогите кто сталкивался с такой же проблемой?кто её решил?
1 — 06.09.17 — 08:10
разрядность PostgreSql какая?
2 — 06.09.17 — 08:12
(1) 64 разрядная как и windows server
3 — 06.09.17 — 08:21
В логе вот что пишет:
pg_authid_rolname_index: 1024 total in 1 blocks; 552 free (0 chunks); 472 used
MdSmgr: 8192 total in 1 blocks; 6544 free (0 chunks); 1648 used
LOCALLOCK hash: 8192 total in 1 blocks; 2880 free (0 chunks); 5312 used
Timezones: 79320 total in 2 blocks; 5968 free (0 chunks); 73352 used
ErrorContext: 8192 total in 1 blocks; 8176 free (0 chunks); 16 used
2017-09-04 18:55:43 MSK ERROR: out of memory
2017-09-04 18:55:43 MSK DETAIL: Failed on request of size 536870912.
2017-09-04 18:55:43 MSK CONTEXT: COPY config, line 328, column binarydata
2017-09-04 18:55:43 MSK STATEMENT: COPY Config FROM STDIN BINARY
4 — 06.09.17 — 08:21
попробуй в work_mem указать немного больше чем от тебя просят
5 — 06.09.17 — 08:22
ставил 256 и 512
6 — 06.09.17 — 08:22
и да, этот ДТ куда-то вообще загружается? Он точно не битый?
7 — 06.09.17 — 08:23
(5) переведи «on request of size 536870912»
8 — 06.09.17 — 08:25
(6) Да как файловая база он загружается
9 — 06.09.17 — 08:27
(6) и точно не битый делал тестирование и исправление и chdbfl,без ошибок
10 — 06.09.17 — 08:30
(7)размер по запросу 536870912,полагаю что не хватает памяти загрузить какую то таблицу
11 — 06.09.17 — 08:31
а где её увеличить!?или может какой то другой параметр нужно увеличить
12 — 06.09.17 — 08:34
(11) 536 больше 512?
13 — 06.09.17 — 08:36
(12) я понял к чему ты,я пробовал и 1024 ставить
14 — 06.09.17 — 08:36
(12) но вот только не везде
15 — 06.09.17 — 08:39
Попробую work_mem выставить > 536 ,но смогу попробовать вечером
16 — 06.09.17 — 08:52
(15) сделай сразу побольше чтобы наверняка
17 — 06.09.17 — 09:07
(16) да 1024 поставлю,отпишусь по результату
18 — 06.09.17 — 09:20
и temp_buffers тоже.
19 — 06.09.17 — 09:30
shared_buffers рекомендуется делать побольше. 1/4 — 1/3 RAM.
maintenance_work_mem в 1/2 RAM или больше (до RAM-shared_buffers)
20 — 06.09.17 — 09:40
(19) если не ошибаюсь то пробовал я ставить и больше 1 gb в
shared_buffers или temp_buffers служба pg перестаёт запускаться
21 — 06.09.17 — 11:01
(16) Попробывал,выставить 1024 work_mem,shared_buffers,temp_buffers ошибка всё равно выходит
22 — 06.09.17 — 11:04
Увидел вот какой момент,в свойствах Pg есть строка версии где написано PostgreSQL 9.4.2,complited by Visual C++ build 1500, 32-bit
23 — 06.09.17 — 11:06
мне эта строка не нравится,типа используются компоненты Visual C++ 32 бита,посмотрел на давно созданном сервере тоже на pg там 64 стоит м.б дело в этом!?
24 — 06.09.17 — 11:26
Похоже что да,вроде как ура..грузит ,но ошибку не выкидывает
25 — 06.09.17 — 11:36
победа,парни дико извиняюсь,3 дня не в ту сторону смотрел,не тот дистрибутив поставил поставил общий,а надо было postgresql-9.4.2-1.1C_x64
26 — 06.09.17 — 11:49
(25) Теперь научился отличать приложения х64 от х86?
27 — 06.09.17 — 11:55
(12) они равны
Johan
28 — 06.09.17 — 12:35
(26) Да,я поставил не посмотрев,а в описании в pg и сервис написано 64 Bit,а вот когда увидел строку версии ,тогда меня смутило
Пользуясь базами данных любой программы 1С, сотрудники предприятий и организаций часто сталкиваются с непредвиденными ситуациями. Пожалуй, одна из самых частых — когда работа программы внезапно завершается по причине того, что администратор разорвал контакт с сервером.
В данном случае Microsoft OLE DB Provider for SQL Server выдаёт такую информацию: «Неопознанная ошибка hresult 80004005». При этом главным признаком проблемы является невозможность выгрузить информацию в базу.
Следует отметить, что ошибки, содержащие именно код 80004005, встречаются постоянно. У них есть особая классификация, которую при желании можно найти в соответствующей литературе.
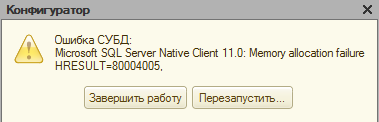
Для начала нужно провести проверку конфигурации. Там может содержаться мусор (иными, словами, информация, которая является некорректной). Необходимо проверить конфигурацию с помощью соответствующей команды. Вы увидите флажок, предназначенный для того, чтобы проверить её логическую целостность. Если имеются проблемы, пользователь будет уведомлен об этом с помощью сообщения.
Данные, являющиеся неверными, система удалит в автоматическом режиме, но для этого нужно дать ей доступ, чтобы она изменила главный объект. К примеру, если вы работаете в облачном хранилище, его надо просто захватить.
Поддержка конфигурации требует её проверки и у поставщиков. С этой целью:
- нужно сохранить данные о конфигурации поставщиков. Для этого используйте CF-файл;
- теперь необходимо провести загрузку файла в обновлённую базу;
- выполните операцию, которая описана в п.1.
При получении сообщения об исправлении ошибки имейте в виду то, что конфигурация, имеющаяся у поставщика, содержала неправильные данные. Если такое произошло, снимите свою конфигурацию с поддержки и установите её снова. При этом её надо объединить с новой (от поставщика).
Сейчас уже любой релиз, который выпускает 1С, не имеет таких сложностей.
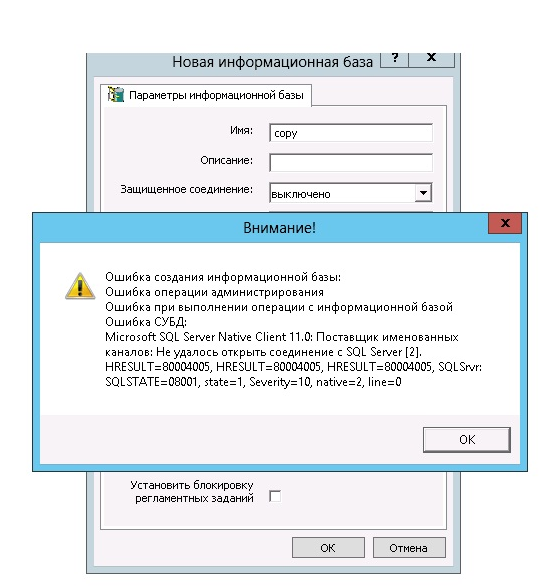
Сопутствующая проблема и методы её решения
С ситуацией, описанной ранее, тесно связана ещё одна, происходящая параллельно. Выглядит она так: 10007066.
Суть проблемы: когда используется СУБД MS SQL SERVER, во время записи объекта из базы с несколькими колонками (например, «Значения» и «Хранилища»), часто случается другой тип ошибки.
Выглядит она таким образом:
Ошибка СУБД:Microsoft OLE DB Provider for SQL Server: String data length mismatchHRESULT=80004005.
Когда происходит ошибка 1с hresult clr 80004005, программа завершает свою работу в аварийном режиме.
Если вы ознакомитесь во время загрузки программы со специальным журналом (речь идёт о технологическом журнале), там есть табличка, содержащая информацию об этих хранилищах.
С помощью средств MS SQL Server Query Analizer нужно найти в табличке несколько колонок image и сделать для каждой следующий запрос
select top 10 DATALENGTH(_Fld4044 from _InfoReg4038 order by DATALENGTH(_Fld4044) desc
При этом, со стороны стандартных проверок, проводимых платформой (chdbfl), поступит информация о том, что база полностью в порядке.
Ошибка выделения памяти hresult 80004005 (на английском это out of memory for query result 1с) может происходить вследствие различных причин, имеющей общую черту. Для системы 1С это, прежде всего, недостаток оперативной памяти. Если говорить точнее, речь идёт о некорректном применении возможностей памяти, поэтому для решения задачи лучше использовать несколько косвенных алгоритмов.
Необходимо сделать рестарт (перезапуск) сервера. Таким образом памяти, которая доступна для работы, временно станет больше. Также есть возможность воспользоваться сервером в 64 разряда, содержащем приложения.
Исходя из опыта, ошибка СУБД hresult 80004005 чаще определяется двумя факторами:
- данные хранятся в хранилище значений (реквизите);
- в таблице конфигураций содержатся двоичные данные объёмом более 120 мегабайт.
Когда советы от сотрудников 1С не приносят результата (ошибка 1с hresult 80004005 остаётся), попробуйте воспользоваться другой пошаговой инструкцией:
Наши постоянные клиенты по 1С:









- используйте все базы, включив у них все фоновые задачи;
- в 8.1.11. должен появиться переключатель о запрете на фоновые задачи (во время создания базы);
- сделайте перезапуск сервера.
Имеет смысл проверки работоспособности. Тем не менее вследствие утечек памяти проблема может возникнуть снова — после перезапуска. В этом случае целесообразно:
- воспользоваться инструментами sql и сделать бэкап;
- снять базу с поддержки;
- выгрузить cf.
Во время любых действий следует копировать файлы в резерв, так как в любой момент может возникнуть необходимость возвращения к исходному статусу информации. Далее надо убрать в менеджменте консоли (config) запись «более 120 мегабайт» и провести загрузку конфигурации (не объединять, а загрузить).
Есть ещё один способ, с помощью которого неопознанная ошибка субд hresult 80004005 может быть исправлена. Нужно открыть конфигуратор и снять конфигурацию, не сохраняя её. Далее, сохранив, нужно поместить её в отдельный файл без сохранения её изменённого вида.
Выполните в SQL операцию, предназначенную для конкретной базы:
DELETE FROM dbo.Config WHERE DataSize > 125829120
После выполнения этой команды проведите загрузку сохранённой конфигурации.
Что касается радикальных шагов, используемых в особо трудных ситуациях, иногда помогает такая схема:
- удалите таблицу config из базы данных, воспользовавшись менеджментом консоли DROP TABLE [dbo].[Config];
- проведите загрузку конфигурации (не «объединить»,а именно «загрузить»).
После проведения проверки проблема должна уйти.
- Стоимость работ специалистов IT Rush — 2000 руб./час
- Абонемент от 50 часов в месяц – 1900 руб./час
- Абонемент от 100 часов в месяц – 1800 руб./час