
В прошлом посте я поведала историю о том, как иногда бывает: все работает по ТЗ, но в прод выводить нельзя!
Если вкратце — в интернет-магазине сделали возможность видеть в профиле участника все его отзывы к товарам. Надеялись, что принесет добро, а участники пошли выискивать компромат на «неугодных». Функционал убрали, стали дорабатывать (видимо).
Добавили возможность указать видимость отзыва во время его написания:
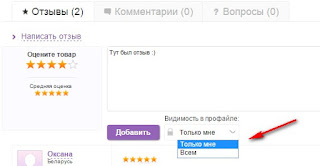
Теперь можно выбирать, будет ли отзыв виден
А сегодня зашла на форум и увидела такую фразу: «Сейчас видимость своего профайла Пользователь может выбрать в Личном Кабинете самостоятельно».
Мне же любопытно, я пошла искать ![]()
Зашла в свои отзывы и увидела большую кнопку изменения видимости.

Теперь можно выбирать, будет ли отзыв виден
А сегодня зашла на форум и увидела такую фразу: «Сейчас видимость своего профайла Пользователь может выбрать в Личном Кабинете самостоятельно».
Мне же любопытно, я пошла искать ![]()
Зашла в свои отзывы и увидела большую кнопку изменения видимости.
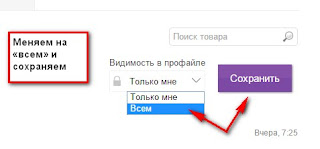
Попробуем, попробуем…
Поменяла на «всем» и попробовала сохранить
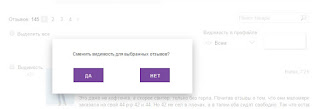
Вылезло чудное сообщение «а вы уверены…?»
Вылезло чудное сообщение «а вы уверены…?»
Раскина на них нет! Винда же научила — видишь такое ужасное сообщение, раздражайся и кликай «ДА!», даже если успел передумать. Подтверждаем свои действия и…

Увы и ах. Некая ошибка входных данных. И думай, что хочешь. Как пользователю понять из такого текста, в чем он ошибся?
См также:
Сообщения об ошибках — тоже документация, тестируйте их!
Давайте заведем это как баг! Прежде чем скакать заводить, надо локализовать и выяснить точные шаги воспроизведения. Оказывается, это не такая кнопка, которая меняет сразу и все. Слева от отзывов стоят чек-боксы выбора. Нужно отметить нужные и изменять видимость им:

Увы и ах. Некая ошибка входных данных. И думай, что хочешь. Как пользователю понять из такого текста, в чем он ошибся?
См также:
Сообщения об ошибках — тоже документация, тестируйте их!
Давайте заведем это как баг! Прежде чем скакать заводить, надо локализовать и выяснить точные шаги воспроизведения. Оказывается, это не такая кнопка, которая меняет сразу и все. Слева от отзывов стоят чек-боксы выбора. Нужно отметить нужные и изменять видимость им:
Так еще выбирать надо было!
Попробуем. Выделяем чек-бокс, меняем видимость — ошибки нет. Ничего не выбираем — ошибка есть. То есть фейл на простейшем граничном условии. Ноль и пустоту проверять стоит всегда ![]()
Оформляем по шаблону:
****************************************************************
«Ошибка входных данных» при смене видимости у 0 отзывов
Шаги для воспроизведения
- Войти в личный кабинет, «Мои отзывы» — https://lk.wildberries.ru/discussion/feedback (тут были тестовые данные для входа)
- Нажать «Сохранить» у блока «Видимость в профайле», ничего не выбрав, см рис «1. Сохранение».
- Подтвердить действие.
Результат
См рис «2. Ошибка» — появляется сообщение «Ошибка входных данных».
Ожидаемый результат
Текст должен пояснять пользователю, что он должен сделать для исправления ситуации. Например: «Ни один отзыв не выбран. Сменить видимость для всех?» и при выборе «да» система меняет видимость у всех отзывов, не заставляя пользователя выполнять дополнительные действия.
Также желательно не допустить такую ситуацию в принципе. Для этого можно:
— По умолчанию изменять видимость для всего (галка «Выбрать все» по-умолчанию, но ее можно снять)
— Подписать под кнопкой «Выберите отзывы, для которых хотите изменить видимость. По-умолчанию меняется для всех».
Это сильно лучше, чем дополнительный pop-up с текстом об ошибке
****************************************************************
Еще тут стоит поставить улучшение на то, чтобы убрать шаг 3 из описания бага, убрать это сообщение об ошибке. Будет вам в качестве домашнего задания, описать и обосновать ![]()
См также:
Шаблон улучшения — Как продумывать свое улучшение с примером, когда это приводит к отказу от постановки задачи.
Как заводить задачи в баг-трекер → подробнее о том, как ставить задачу и заполнять обязательные поля.
PS — добавила пост в общую копилку багов.
PPS — магазин я люблю и уважаю, эти посты не о том, «какие они плохие». Баги бывают повсюду, я показываю начинающим тестировщикам, что их много. И их можно и нужно искать повсюду, набивать руку.
Я показываю примеры, где такие баги встречаются. И, разумеется, чем больше функционала, тем выше вероятность появления багов. Поэтому у вайлдберрис я постоянно что-то такое нахожу после очередного релиза. Но магазин молодец, развивается, новые фичи делает! И часто выпускает фичи в тестовом режиме, так что это просто кладезь для начинающих тестировщиков =)
Типы компьютерных уязвимостей
Многие IDS предоставляют описания атак, которые они определяют. Это описание часто включает типы уязвимостей, которые используют атаки. Данная информация является очень полезной после того, как атака произошла, потому что системный администратор может исследовать и скорректировать использованную уязвимость. NIST рекомендует использовать ICAT Metabase проект для исследования и фиксации уязвимостей в сетях организации. ICAT содержит тысячи примеров реальных компьютерных уязвимостей со ссылками на детальное описание. ICAT доступна по адресу http://icat.nist.gov.
Здесь мы обсудим основные типы уязвимостей. Может быть предложено много различных схем для их классификации, мы не будем перечислять их все. Ниже приведен список некоторых наиболее общих типов.
Ошибка корректности входных данных
При такой ошибке входные данные, полученные некоторой системой, не проверяются на корректность, в результате чего возникает уязвимость, которая может быть использована с помощью посылки определенной входной последовательности. Существует два основных типа ошибок корректности входа: переполнение буфера и ошибки граничных условий.
Переполнение буфера
При переполнении буфера входные данные, получаемые системой, являются длиннее, чем ожидаемая длина входа, но система не проверяет данный факт. Входной буфер заполняется и переполняет память, выделенную для входных данных. При грамотном конструировании таких входных данных, выходящих за границу выделенного для них буфера, атакующий может заставить систему выполнять команды от имени атакующего.
Ошибка граничного условия
При такой ошибке входные данные, полученные системой, вызывают в системе нарушение некоторого граничного условия. Данное нарушение само по себе и представляет уязвимость. Например, у системы может переполниться память, дисковое пространство или ширина пропускания сети. Другим примером данной уязвимости является переменная, которая может достигнуть своего максимального значения и перейти в минимальное. Еще одним примером с переменной может быть множество таких ситуаций, как возникновение деления на ноль. Ошибка граничного условия является подмножеством класса ошибок корректности входа. Хотя можно показать, что переполнение буфера является типом ошибки граничного условия, мы поместим данную ошибку в отдельную категорию, понимая ее важность и тот факт, что переполнение буфера возникает чаще других ошибок.
Ошибка управления доступом
При такой ошибке система является уязвимой, потому что механизм управления доступом не функционирует. Проблема заключается не в конфигурации механизма управления доступом, а в самом механизме.
Исключительное условие при обработке ошибки
При возникновении исключительного условия при обработке ошибки система также иногда может стать уязвимой.
Ошибка окружения
При такой ошибке окружение, в котором система инсталлирована, каким-либо образом приводит к тому, что система становится уязвимой. Это может произойти, например, при непредвиденном взаимодействии приложения и ОС или при взаимодействии двух приложений на некотором хосте. Такая уязвимая система может быть правильно сконфигурирована и с большой вероятностью безопасна в тестовом окружении разработчиков, но какие-то предположения, касающиеся безопасности, были нарушены в инсталлируемом окружении.
Ошибка конфигурирования
Ошибка конфигурирования возникает, когда установки управления определены таким образом, что система стала уязвимой. Данная уязвимость говорит не о том, как система была разработана, а о том, как администратор сконфигурировал систему. Можно также считать конфигурационной ошибкой ситуацию, при которой система поставляется от разработчика со слабой, с точки зрения безопасности, конфигурацией.
Race-условие
Race-условия цикла возникают, если существует задержка между временем, когда система проверяет, что операция допустима моделью безопасности, и временем, когда система реально выполняет операцию. Реальная проблема возникает, если окружение в течение интервала времени, когда была выполнена проверка безопасности, и времени, когда была выполнена операция, изменилось таким образом, что модель безопасности более не разрешает операцию. Атакующий имеет возможность в течение данного небольшого окна выполнить незаконные действия, подобные записи в файл паролей, пока состояние является привилегированным.
Будущие направления развития IDS
Хотя функция аудита системы, которая являлась первоначальной задачей IDS, стала формальной дисциплиной за последние пятьдесят лет, поле для исследований IDS все еще остается обширным, большинство исследований датировано не позднее 1980-х годов. Более того, широкое коммерческое использование IDS не начиналось до середины 1990-х.
Intrusion Detection и Vulnerability Assessment является быстро развивающейся областью исследований.
Коммерческое использование IDS находится в стадии формирования. Некоторые коммерческие IDS получили негативную публичную оценку за большое число ложных срабатываний, неудобные интерфейсы управления и получения отчетов, огромное количество отчетов об атаках, плохое масштабирование и плохую интеграцию с системами сетевого управления. Тем не менее потребность в хороших IDS возрастает, поэтому с большой вероятностью эти проблемы будут успешно решаться в ближайшее время.
Ожидается, что улучшение качества функционирования IDS будет осуществляться аналогично антивирусному ПО. Раннее антивирусное ПО создавало большое число ложных тревог при нормальных действиях пользователя и не определяло все известные вирусы. Однако сейчас положение существенно улучшилось, антивирусное ПО стало прозрачным для пользователей и достаточно эффективным.
Более того – очень вероятно, что основные возможности IDS скоро станут ключевыми в сетевой инфраструктуре (такой как роутеры, мосты и коммутаторы) и в операционных системах. При этом, скорее всего, разработчики IDS сфокусируют свое внимание на решении проблем, связанных с масштабируемостью и управляемостью IDS.
Имеются также и другие тенденции, которые, скорее всего, будут влиять на функциональности IDS следующего поколения. Существует заметное движение в сторону аппаратно-программных (appliance) решений для IDS. Также вероятно, что в будущем некоторые функции определения соответствия шаблону могут быть реализованы в аппаратуре, что увеличит скорость обработки.
Наконец, механизмы, связанные с управлением рисками в области сетевой безопасности, будут оказывать влияние на требования к IDS.
Добавлено 31 мая 2021 в 22:08
Большинство программ, имеющих какой-либо пользовательский интерфейс, должны обрабатывать вводимые пользователем данные. В программах, которые мы писали, мы использовали std::cin, чтобы попросить пользователя ввести текст. Поскольку ввод текста имеет произвольную форму (пользователь может вводить что угодно), пользователю очень легко ввести данные, которые не ожидаются.
При написании программ вы всегда должны учитывать, как пользователи (непреднамеренно или наоборот) будут использовать ваши программы некорректно. Хорошо написанная программа будет предвидеть, как пользователи будут использовать ее неправильно, и либо аккуратно обработает эти случаи, либо вообще предотвратит их появление (если это возможно). Программа, которая хорошо обрабатывает случаи ошибок, называется надежной.
В этом уроке мы подробно рассмотрим способы, которыми пользователь может вводить недопустимые текстовые данные через std::cin, и покажем вам несколько разных способов обработки таких случаев.
std::cin, буферы и извлечение
Чтобы обсудить, как std::cin и operator>> могут давать сбой, сначала полезно немного узнать, как они работают.
Когда мы используем operator>> для получения пользовательского ввода и помещения его в переменную, это называется «извлечением». Соответственно, в этом контексте оператор >> называется оператором извлечения.
Когда пользователь вводит данные в ответ на операцию извлечения, эти данные помещаются в буфер внутри std::cin. Буфер (также называемый буфером данных) – это просто часть памяти, отведенная для временного хранения данных, пока они перемещаются из одного места в другое. В этом случае буфер используется для хранения пользовательских входных данных, пока они ожидают извлечения в переменные.
При использовании оператора извлечения происходит следующая процедура:
- Если во входном буфере уже есть данные, то для извлечения используются они.
- Если входной буфер не содержит данных, пользователя просят ввести данные для извлечения (так бывает в большинстве случаев). Когда пользователь нажимает Enter, во входной буфер помещается символ ‘n’.
operator>>извлекает столько данных из входного буфера, сколько может, в переменную (игнорируя любые начальные пробельные символы, такие как пробелы, табуляции или ‘n’).- Любые данные, которые не могут быть извлечены, остаются во входном буфере для следующего извлечения.
Извлечение завершается успешно, если из входного буфера извлечен хотя бы один символ. Любые неизвлеченные входные данные остаются во входном буфере для дальнейшего извлечения. Например:
int x{};
std::cin >> x;Если пользователь вводит «5a», 5 будет извлечено, преобразовано в целое число и присвоено переменной x. А «an» останется во входном потоке для следующего извлечения.
Извлечение не выполняется, если входные данные не соответствуют типу переменной, в которую они извлекаются. Например:
int x{};
std::cin >> x;Если бы пользователь ввел ‘b’, извлечение не удалось бы, потому что ‘b’ не может быть извлечено в переменную типа int.
Проверка ввода
Процесс проверки того, соответствуют ли пользовательские входные данные тому, что ожидает программа, называется проверкой ввода.
Есть три основных способа проверки ввода:
- встроенный (по мере печати пользователя):
- прежде всего, не позволить пользователю вводить недопустимые данные;
- пост-запись (после печати пользователя):
- позволить пользователю ввести в строку всё, что он хочет, затем проверить правильность строки и, если она корректна, преобразовать строку в окончательный формат переменной;
- позволить пользователю вводить всё, что он хочет, позволить
std::cinиoperator>>попытаться извлечь данные и обработать случаи ошибок.
Некоторые графические пользовательские интерфейсы и расширенные текстовые интерфейсы позволяют проверять входные данные, когда пользователь их вводит (символ за символом). В общем случае, программист предоставляет функцию проверки, которая принимает входные данные, введенные пользователем, и возвращает true, если входные данные корректны, и false в противном случае. Эта функция вызывается каждый раз, когда пользователь нажимает клавишу. Если функция проверки возвращает истину, клавиша, которую только что нажал пользователь, принимается. Если функция проверки возвращает false, введенный пользователем символ отбрасывается (и не отображается на экране). Используя этот метод, вы можете гарантировать, что любые входные данные, вводимые пользователем, гарантированно будут корректными, потому что любые недопустимые нажатия клавиш обнаруживаются и немедленно отбрасываются. Но, к сожалению, std::cin не поддерживает этот стиль проверки.
Поскольку строки не имеют никаких ограничений на ввод символов, извлечение гарантированно завершится успешно (хотя помните, что std::cin прекращает извлечение на первом неведущем пробельном символе). После того, как строка введена, программа может проанализировать эту строку, чтобы узнать, корректна она или нет. Однако анализ строк и преобразование вводимых строк в другие типы (например, числа) может быть сложной задачей, поэтому это делается только в редких случаях.
Чаще всего мы позволяем std::cin и оператору извлечения выполнять эту тяжелую работу. В этом методе мы позволяем пользователю вводить всё, что он хочет, заставляем std::cin и operator>> попытаться извлечь данные и справиться с последствиями, если это не удастся. Это самый простой способ, о котором мы поговорим ниже.
Пример программы
Рассмотрим следующую программу-калькулятор, в которой нет обработки ошибок:
#include <iostream>
double getDouble()
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
return x;
}
char getOperator()
{
std::cout << "Enter one of the following: +, -, *, or /: ";
char op{};
std::cin >> op;
return op;
}
void printResult(double x, char operation, double y)
{
switch (operation)
{
case '+':
std::cout << x << " + " << y << " is " << x + y << 'n';
break;
case '-':
std::cout << x << " - " << y << " is " << x - y << 'n';
break;
case '*':
std::cout << x << " * " << y << " is " << x * y << 'n';
break;
case '/':
std::cout << x << " / " << y << " is " << x / y << 'n';
break;
}
}
int main()
{
double x{ getDouble() };
char operation{ getOperator() };
double y{ getDouble() };
printResult(x, operation, y);
return 0;
}Эта простая программа просит пользователя ввести два числа и математический оператор.
Enter a double value: 5
Enter one of the following: +, -, *, or /: *
Enter a double value: 7
5 * 7 is 35Теперь подумайте, где неверный ввод пользователя может нарушить работу этой программы.
Сначала мы просим пользователя ввести несколько чисел. Что, если он введет что-то, отличающееся от числа (например, ‘q’)? В этом случае извлечение не удастся.
Во-вторых, мы просим пользователя ввести один из четырех возможных символов. Что, если он введет символ, отличный от ожидаемых? Мы сможем извлечь входные данные, но пока не обрабатываем то, что происходит после.
В-третьих, что, если мы попросим пользователя ввести символ, а он введет строку типа «*q hello». Хотя мы можем извлечь нужный нам символ ‘*’, в буфере останутся дополнительные входные данные, которые могут вызвать проблемы в будущем.
Типы недопустимых входных текстовых данных
Обычно мы можем разделить ошибки ввода текста на четыре типа:
- извлечение входных данных выполняется успешно, но входные данные не имеют смысла для программы (например, ввод ‘k’ в качестве математического оператора);
- извлечение входных данных выполняется успешно, но пользователь вводит дополнительные данные (например, вводя «*q hello» в качестве математического оператора);
- ошибка извлечения входных данных (например, попытка ввести ‘q’ при запросе ввода числа);
- извлечение входных данных выполнено успешно, но пользователь выходит за пределы значения числа.
Таким образом, чтобы сделать наши программы устойчивыми, всякий раз, когда мы запрашиваем у пользователя ввод, мы в идеале должны определить, может ли произойти каждый из вышеперечисленных возможных вариантов, и если да, написать код для обработки этих случаев.
Давайте разберемся в каждом из этих случаев и в том, как их обрабатывать с помощью std::cin.
Случай ошибки 1: извлечение успешно, но входные данные не имеют смысла
Это самый простой случай. Рассмотрим следующий вариант выполнения приведенной выше программы:
Enter a double value: 5
Enter one of the following: +, -, *, or /: k
Enter a double value: 7В этом случае мы попросили пользователя ввести один из четырех символов, но вместо этого он ввел ‘k’. ‘k’ – допустимый символ, поэтому std::cin успешно извлекает его в переменную op, и она возвращается в main. Но наша программа не ожидала этого, поэтому она не обрабатывает этот случай правильно (и, таким образом, ничего не выводит).
Решение здесь простое: выполните проверку ввода. Обычно она состоит из 3 шагов:
- убедитесь, что пользовательский ввод соответствует вашим ожиданиям;
- если да, верните значение вызывающей функции;
- если нет, сообщите пользователю, что что-то пошло не так, и попросите его повторить попытку.
Вот обновленная функция getOperator(), которая выполняет проверку ввода.
char getOperator()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter one of the following: +, -, *, or /: ";
char operation{};
std::cin >> operation;
// Проверяем, ввел ли пользователь подходящие данные
switch (operation)
{
case '+':
case '-':
case '*':
case '/':
return operation; // возвращаем символ вызывающей функции
default: // в противном случае сообщаем пользователю, что пошло не так
std::cout << "Oops, that input is invalid. Please try again.n";
}
} // и попробуем еще раз
}Как видите, мы используем цикл while для бесконечного цикла до тех пор, пока пользователь не предоставит допустимые данные. Если он этого не делает, мы просим его повторить попытку, пока он не даст нам правильные данные, не закроет программу или не уничтожит свой компьютер.
Случай ошибки 2: извлечение успешно, но с посторонними входными данными
Рассмотрим следующий вариант выполнения приведенной выше программы:
Enter a double value: 5*7Как думаете, что будет дальше?
Enter a double value: 5*7
Enter one of the following: +, -, *, or /: Enter a double value: 5 * 7 is 35Программа выводит правильный ответ, но форматирование испорчено. Давайте подробнее разберемся, почему.
Когда пользователь вводит «5*7» в качестве вводных данных, эти данные попадают в буфер. Затем оператор >> извлекает 5 в переменную x, оставляя в буфере «*7n». Затем программа напечатает «Enter one of the following: +, -, *, or /:». Однако когда был вызван оператор извлечения, он видит символы «*7n», ожидающие извлечения в буфере, поэтому он использует их вместо того, чтобы запрашивать у пользователя дополнительные данные. Следовательно, он извлекает символ ‘*’, оставляя в буфере «7n».
После запроса пользователя ввести другое значение double, из буфера извлекается 7 без ожидания ввода пользователя. Поскольку у пользователя не было возможности ввести дополнительные данные и нажать Enter (добавляя символ новой строки), все запросы в выводе идут вместе в одной строке, даже если вывод правильный.
Хотя программа работает, выполнение запутано. Было бы лучше, если бы любые введенные посторонние символы просто игнорировались. К счастью, символы игнорировать легко:
// очищаем до 100 символов из буфера или пока не будет удален символ 'n'
std::cin.ignore(100, 'n');Этот вызов удалит до 100 символов, но если пользователь ввел более 100 символов, мы снова получим беспорядочный вывод. Чтобы игнорировать все символы до следующего символа ‘n’, мы можем передать std::numeric_limits<std::streamsize>::max() в std::cin.ignore(). std::numeric_limits<std::streamsize>::max() возвращает наибольшее значение, которое может быть сохранено в переменной типа std::streamsize. Передача этого значения в std::cin.ignore() приводит к отключению проверки счетчика.
Чтобы игнорировать всё, вплоть до следующего символа ‘n’, мы вызываем
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');Поскольку эта строка довольно длинная для того, что она делает, будет удобнее обернуть ее в функцию, которую можно вызвать вместо std::cin.ignore().
#include <limits> // для std::numeric_limits
void ignoreLine()
{
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');
}Поскольку последний введенный пользователем символ должен быть ‘n’, мы можем указать std::cin игнорировать символы в буфере, пока не найдет символ новой строки (который также будет удален).
Давайте обновим нашу функцию getDouble(), чтобы игнорировать любой посторонний ввод:
double getDouble()
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
ignoreLine();
return x;
}Теперь наша программа будет работать, как ожидалось, даже если мы введем «5*7» при первом запросе ввода – 5 будет извлечено, а остальные символы из входного буфера будут удалены. Поскольку входной буфер теперь пуст, при следующем выполнении операции извлечения данные у пользователя будут запрашиваться правильно!
Случай ошибки 3: сбой при извлечении
Теперь рассмотрим следующий вариант выполнения нашей программы калькулятора:
Enter a double value: aНеудивительно, что программа работает не так, как ожидалось, но интересно, как она дает сбой:
Enter a double value: a
Enter one of the following: +, -, *, or /: Enter a double value: и программа внезапно завершается.
Это очень похоже на случай ввода посторонних символов, но немного отличается. Давайте посмотрим подробнее.
Когда пользователь вводит ‘a’, этот символ помещается в буфер. Затем оператор >> пытается извлечь ‘a’ в переменную x, которая имеет тип double. Поскольку ‘a’ нельзя преобразовать в double, оператор >> не может выполнить извлечение. В этот момент происходят две вещи: ‘a’ остается в буфере, а std::cin переходит в «режим отказа».
Находясь в «режиме отказа», будущие запросы на извлечение входных данных будут автоматически завершаться ошибкой. Таким образом, в нашей программе калькулятора вывод запросов всё еще печатается, но любые запросы на дальнейшее извлечение игнорируются. Программа просто выполняется до конца, а затем завершается (без вывода результата потому, что мы не прочитали допустимую математическую операцию).
К счастью, мы можем определить, завершилось ли извлечение сбоем, и исправить это:
if (std::cin.fail()) // предыдущее извлечение не удалось?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
}Вот и всё!
Давайте, интегрируем это в нашу функцию getDouble():
double getDouble()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
if (std::cin.fail()) // предыдущее извлечение не удалось?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
}
else // иначе наше извлечение прошло успешно
{
ignoreLine();
return x; // поэтому возвращаем извлеченное нами значение
}
}
}Примечание. До C++11 неудачное извлечение не приводило к изменению извлекаемой переменной. Это означает, что если переменная была неинициализирована, она останется неинициализированной в случае неудачного извлечения. Однако, начиная с C++11, неудачное извлечение из-за недопустимого ввода приведет к тому, что переменная будет инициализирована нулем. Инициализация нулем означает, что для переменной установлено значение 0, 0.0, «» или любое другое значение, в которое 0 преобразуется для этого типа.
Случай ошибки 4: извлечение успешно, но пользователь выходит за пределы значения числа
Рассмотрим следующий простой пример:
#include <cstdint>
#include <iostream>
int main()
{
std::int16_t x{}; // x - 16 бит, может быть от -32768 до 32767
std::cout << "Enter a number between -32768 and 32767: ";
std::cin >> x;
std::int16_t y{}; // y - 16 бит, может быть от -32768 до 32767
std::cout << "Enter another number between -32768 and 32767: ";
std::cin >> y;
std::cout << "The sum is: " << x + y << 'n';
return 0;
}Что произойдет, если пользователь введет слишком большое число (например, 40000)?
Enter a number between -32768 and 32767: 40000
Enter another number between -32768 and 32767: The sum is: 32767В приведенном выше случае std::cin немедленно переходит в «режим отказа», но также присваивает переменной ближайшее значение в диапазоне. Следовательно, x остается с присвоенным значением 32767. Дополнительные входные данные пропускаются, оставляя y с инициализированным значением 0. Мы можем обрабатывать этот вид ошибки так же, как и неудачное извлечение.
Примечание. До C++11 неудачное извлечение не приводило к изменению извлекаемой переменной. Это означает, что если переменная была неинициализирована, в случае неудачного извлечения она останется неинициализированной. Однако, начиная с C++11, неудачное извлечение вне диапазона приведет к тому, что переменной будет присвоено ближайшее значение в диапазоне.
Собираем всё вместе
Вот наш пример калькулятора с полной проверкой ошибок:
#include <iostream>
#include <limits>
void ignoreLine()
{
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');
}
double getDouble()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter a double value: ";
double x{};
std::cin >> x;
// Проверяем на неудачное извлечение
if (std::cin.fail()) // предыдущее извлечение не удалось?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
std::cout << "Oops, that input is invalid. Please try again.n";
}
else
{
ignoreLine(); // удаляем любые посторонние входные данные
// пользователь не может ввести бессмысленное значение double,
// поэтому нам не нужно беспокоиться о его проверке
return x;
}
}
}
char getOperator()
{
while (true) // Цикл, пока пользователь не введет допустимые данные
{
std::cout << "Enter one of the following: +, -, *, or /: ";
char operation{};
std::cin >> operation;
ignoreLine();
// Проверяем, ввел ли пользователь осмысленные данные
switch (operation)
{
case '+':
case '-':
case '*':
case '/':
return operation; // возвращаем символ вызывающей функции
default: // в противном случае сообщаем пользователю, что пошло не так
std::cout << "Oops, that input is invalid. Please try again.n";
}
} // и попробуем еще раз
}
void printResult(double x, char operation, double y)
{
switch (operation)
{
case '+':
std::cout << x << " + " << y << " is " << x + y << 'n';
break;
case '-':
std::cout << x << " - " << y << " is " << x - y << 'n';
break;
case '*':
std::cout << x << " * " << y << " is " << x * y << 'n';
break;
case '/':
std::cout << x << " / " << y << " is " << x / y << 'n';
break;
default: // Надежность означает также обработку неожиданных параметров,
// даже если getOperator() гарантирует, что op в этой
// конкретной программе корректен
std::cerr << "Something went wrong: printResult() got an invalid operator.n";
}
}
int main()
{
double x{ getDouble() };
char operation{ getOperator() };
double y{ getDouble() };
printResult(x, operation, y);
return 0;
}Заключение
При написании программы подумайте о том, как пользователи будут неправильно использовать вашу программу, особенно при вводе текста. Для каждой точки ввода текста учтите:
- Могло ли извлечение закончиться неудачей?
- Может ли пользователь ввести больше, чем ожидалось?
- Может ли пользователь ввести бессмысленные входные данные?
- Может ли пользователь переполнить входные данные?
Вы можете использовать операторы if и булеву логику, чтобы проверить, являются ли входные данные ожидаемыми и осмысленными.
Следующий код очистит любые посторонние входные данные:
std::cin.ignore(std::numeric_limits<std::streamsize>::max(), 'n');Следующий код будет проверять и исправлять неудачные извлечения или переполнение:
if (std::cin.fail()) // предыдущее извлечение не удалось или закончилось переполнением?
{
// да, давайте разберемся с ошибкой
std::cin.clear(); // возвращаем нас в "нормальный" режим работы
ignoreLine(); // и удаляем неверные входные данные
}Наконец, используйте циклы, чтобы попросить пользователя повторно ввести данные, если исходные входные данные были недопустимыми.
Примечание автора
Проверка ввода важна и полезна, но она также делает примеры более сложными и трудными для понимания. Соответственно, на будущих уроках мы, как правило, не будем проводить никакой проверки вводимых данных, если они не имеют отношения к чему-то, чему мы пытаемся научить.
Теги
C++ / CppLearnCppstd::cinДля начинающихОбнаружение ошибокОбработка ошибокОбучениеПрограммирование

Привет, сегодня я хочу поговорить о том, с чем мы рано или поздно сталкиваемся, имея много доменной логики — и даже не микросервисную, — а хотя бы просто сервисную архитектуру.
В ожидании комбинаторного взрыва
Я работаю в команде сервиса расписания занятий, который оркестрирует весь процесс подбора преподавателя в Skyeng. Когда новый клиент хочет найти учителя, нам приходит запрос: «ID ученика такой-то хочет заниматься с такого-то числа и в такое-то время». Чтобы подобрать преподавателя, мы идем в сервисы других команд:
- в CRM — чтобы определить, что за услуга сейчас должна быть оказана: занятия английским, математикой или по одному из новых экспериментальных предметов,
- в сервис рейтинга — чтобы отсортировать преподавателей по данной услуге, лучше подходящих для данного ученика,
- и в сам сервис преподавателей, который хранит информацию, кто берёт новых учеников — и много-много других нюансов.
На самом деле, сервисов больше, но даже на этом масштабе можно отследить проблему. Каждый сервис пишет своя команда: и ее разработчики возвращают ошибки, как придумали.

Гипотетическая ситуация, когда все сервисы упали сразу, может обернуться такими ответами.
У каждого сервиса может быть куча вариантов ошибок, и мы должны обрабатывать все их виды на своей стороне. При интеграции любого нового сервиса мы увеличим кучу кода, которая не имеет отношения к бизнес-логике, но которую нужно будет поддерживать. Более того, подключая новый сервис, мы не можем быть уверены, что документация не изменится.
Бывает и такое — бизнес приходит и просит «А добавьте тут…» Допустим, у нас есть форма ввода данных, в ней 10 полей, мы валидируем девять, а десятое — это комментарий, он опционален. В один день нас просят добавить валидацию на комментарий. Фронт говорит: «Если придет такой-то код, я у себя доработаю». Ты пишешь новую обработку: и вот на 10 ошибок у фронта появляется 10 обработчиков, а еще у тебя есть разные вариации if-ов, else-ов и т.д.
При этом сами ошибки возникают редко — и это тоже проблема.

При взаимодействии между сервисами мы используем REST, а он как таковой не регламентирует нам форматы, кроме того, что основан на HTTP.
Все мы знаем какие-то определенные наборы ошибок, а остальные вряд ли можем вспомнить без словаря. В итоге, видя какой-то ответ, мы тратим время на осознание, что он значит на самом деле, — а это сильно влияет на скорость тушения пожара на проде, разбора логов и каких-то еще критичных ситуаций.
Давайте попробуем решить эту проблему
Мы c командой посмотрели обсуждения в комьюнити, посмотрели ролики на ютубе, статьи на хабре (вот интересный хабра-холивар про 200-й ответ). Похоливарили внутри. Пришли к выводу, что серебряной пули не существует… и пошли своим путем. Ввели единый формат, при котором у нас есть:
1. Поле «data» для полезной нагрузки — скажем, вот так может выглядеть успешный ответ:
{
"data": [
{
"field1": 1
},
{
"field2": 2
}
],
"errors": null
}
2. И поле «errors» для ошибок.
...
"data": null,
"errors": [
{
"property": null,
"error": {
"message": "The selected time is alr...",
"code": "selected_time_already_taken"
}
}
]
…
Поля data и errors в ответе не могут быть заполнены одновременно.
У нас большое разнообразие ошибок, поэтому на каждую вариацию мы добавили свои правила.
Ошибки бизнес-логики возвращают код 200 и список ошибок в поле errors. Мы не должны падать, например, если у преподавателя превышено количество учеников, которых он может вести. Поэтому решили отображать на фронт полезную ошибку.
Если это не ошибка бизнес-логики, возвращаем соответствующий по смыслу HTTP-код. Но вы скажете, что в таком случае проблема разнообразия ошибок никуда не уходит. Поэтому их тоже нужно подразделять:
- Непредвиденные ошибки: где-то что-то забыли, линтер не допроверил — всякое бывает.
- Инфраструктурные ошибки — например, ошибки Redis Cluster, ошибка связанности или если приложение не дождалось чего-нибудь другого. Мы понимаем, что у сервиса что-то произошло в эту секунду, и можем отреагировать с помощью retry. Такие ошибки удобно обрабатывать с помощью воркера, который периодически ходит по сервисам и опрашивает их: прошел, собрал метрики, хоп — что-то отвалилось, сделали retry.
- Ошибки валидации входных данных. Они вылазят где-то на тестингах, на dev-режиме, — и должны быть максимально полезными для разработчика. Мы используем Symfony serializer и validator, чтобы маппить все, что пришло на вход: чтобы не просто узнать, что Error validation, а понять, что именно не так, мы выделили отдельный класс ошибок, которые выдаются массивом.
Пример ошибок, которые используем
Первое, что нам нужно четко понимать, — у нас произошла, скажем, ошибка валидации или ошибка инфраструктуры? Нужно как-то разделять это на уровне кода — и не бесконечными if в бизнес-логике, а именно на уровне инструмента языка.
Мы создали иерархию Exception. Например, делаем базовый класс ValidationException и от него наследуем всё, что зависит от валидации. Это может быть TeacherValidationException. А у него свои наследники — NicknameException, AgeException и так далее.
Дальше делаем Exception, который хранит подробную информацию о бизнес-ошибке. Бывают ситуации, когда нам важно понимать, на каком слое что-то пошло не так. Тогда каждого слоя мы получаем свои Exception: есть API-репозиторий с APIRepositoryException, выше идет сервис, у него есть ServiceException, потом идёт Exception контроллера и т.д.
Остается сделать единую точку выхода из приложения, которая позволит отлавливать все исключения и выдавать код формате с data и errors. Это просто — сейчас так или иначе все фреймворки позволяют отлавливать Exception ивентами.
Вот как это выглядит на практике:
class ValidationException extends Exception
interface HttpExceptionInterface extends ThrowableValidationException — бросаем, если Symfony validator собрал что-то, что не позволяет нам продолжить дальше. Здесь же есть HttpExceptionInterface, который кидает Guzzle, дабы мы понимали, какой ответ http, какой response, какие headers и так далее нам пришли.
class SomeServiceException extends ExceptionSomeServiceException — у каждого сервиса есть FeaturesException или какой-нибудь ещё Exception, которые позволяют нам пробрасывать информацию между слоями приложения. Мы можем понять, что у нас произошла бизнес-ошибка, и вывести ее на фронт, либо подавить и отдать ответ о том, что мы ответим позже. Это дает вариативность в нашей логике.
interface ConventionalResponseExceptionInterface extends Throwable
{
public function getConventionalCode(): string;
public function getProperty(): ?string;
}ConventionalResponseExceptionInterface — есть интерфейс бизнес-ошибки, фронту нужно получить информацию и вывести текст. Мы на бэкенде рулим тем, что увидит пользователь. В поле Property у нас может быть запись teacher — то есть, что-то произошло на стороне учителя. А ConventionalCode — это какой это уникальный код ошибки. Допустим, это может быть «Selected time have already taken» — выбранное время уже занято. Фронт по факту пишет один обработчик на такие типы ошибок, а мы просто бросаем Exception, который наследует такой интерфейс. Он возвращает все нужные данные, а фронт добавляет в обработку ошибок этот код. Больше ничего дорабатывать не нужно.
Как внедрить на практике
Самое главное — мы не можем сказать бизнесу, что «решили всё переписать, чтобы у нас все работало». Такие вещи делаются с сохранением обратной совместимости: вы вводите API версии 2, которое теперь работает с нужным форматом, и делаете доработки на уровне middleware, либо OnKernelRequest, чтобы каждый раз не проверять, новая это апишка или старая.
Подключаем единый обработчик исключений. Так как мы используем Symfony, то просто сконфигурировали listener, который подписан на события onKernelException. По факту, он перехватывает и обрабатывает любое исключение, которое возникает в системе — при версиях PHP старше семёрки проблем не возникает.
kernel.listener.conventional:
class: ConventionalApiExceptionListener
tags:
- {
name: kernel.event_listener,
event: kernel.exception,
method: onKernelException
}Сам код listener-а очень большой, покажу интересный кусок: приходит event, он содержит в себе instance Exception-а, мы проверяем, к какому типу ошибки это относится, и в зависимости от этого формируем список наших ошибок.
switch (true) {
case $exception instanceof ConventionalResponseExceptionInterface:
...
break;
case $exception instanceof ValidationException:
...
break;
case $exception instanceof BadRequestHttpException:
...
break;
case $exception instanceof HttpExceptionInterface:
...
break;
case $exception instanceof SomeServiceException:
...
break;
default:
...
}В случае, если приходит ConventionalResponseException, мы знаем, что есть уникальный код и текст ошибки, какая-то подробная информация, — упаковываем это и выводим так, чтобы фронт тоже это понимал. А если пришёл ValidationException, он уже содержит в себе весь список ошибок, — и нам нужно просто преобразовать его в наш формат.
В логах есть три уровня приоритета — info, warning и critical. В зависимости от приоритета, ошибки попадают в разные хранилища: не критичное в файлы, критичное в Slack. Бизнес-ошибки уходят в info, всё остальное у нас либо warning, либо critical.
Отдельно скажу про 500-е. Мы проверяем environment, и на дев-стенде и тестингах позволяем себе вывести весь стэктрейс пятисотки. Если это прод, мы просто меняем ошибку на текст Internal Error и делаем проброс в Sentry, а Sentry стучится в Slack к разработчику: «Бросай все, горим».
Спойлер
После того, как мы вели регламенты, про которые я сегодня расскажу, у нас увеличилась скорость тушения пожаров (̶х̶о̶т̶я̶,̶ ̶к̶о̶н̶е̶ч̶н̶о̶,̶ ̶б̶и̶з̶н̶е̶с̶ ̶д̶у̶м̶а̶е̶т̶,̶ ̶ч̶т̶о̶ ̶у̶ ̶н̶а̶с̶ ̶п̶о̶ж̶а̶р̶о̶в̶ ̶н̶е̶т̶)̶.
А теперь нам нужно как-то отличить ошибки от других сервисов по нашему регламенту на нашей стороне.
К старым апишкам мы проверки, о которых расскажу, не применяем, — только к тем, о которых договорились. Допустим, у нас есть какой-то service class, который ходит на чужой API, с котором договорились.
Проверяем, корректен ли ответ: если пришел не JSON — сразу бросаем Exception.
try {
$decodedResponse = json_decode($contents, true, 512, JSON_THROW_ON_ERROR);
} catch (Throwable $exception) {
return false;
}Также проверяем HTTP-статусы: есть 4 варианта, о которых мы договорились, что это корректная ситуация.
$isHttpStatusOk = in_array(
$code,
[
Response::HTTP_OK,
Response::HTTP_CREATED,
Response::HTTP_ACCEPTED,
Response::HTTP_NO_CONTENT,
],
true
);
if ($isHttpStatusOk === false) {
return false;
}Если отсутствуют ключи data или errors, — тоже считаем, что это не по регламенту. В остальном — главное, чтобы ошибок не было: если в поле errors не пришло ошибок, значит все ок.
if (!array_key_exists('errors', $decodedResponse)
||
!array_key_exists('data', $decodedResponse)
) {
return false;
}
return $decodedResponse['errors'] === null;Положив этот код в trait, мы используем его в фасадах нескольких API-репозиториев: и теперь нам не нужно добавлять новый обработчик на каждый чих, а затем тыкать все апишки — упадут или нет.
В каких случаях подход дает выгоду, в чем минусы, как поддерживать
Ни в коем случае не предлагаю бессмысленно и беспощадно транслировать такую практику на всех и вся. Мы сами используем регламент ограниченно: договорились с несколькими командами, с чьими сервисами взаимодействуем чаще всего. Например, это команда сервисов для учителей: они ходят к нам за расписанием, мы к ним за данными о преподавателях. У нас много разных кейсов взаимодействия: и, договорившись один раз, мы выиграли в скорости разбора логов и тушения пожаров.
Но есть нюансы, которые мы уже увидели на практике:
- Подход требует ответственного отношения от старших разработчиков и тимлидов: мы должны поддерживать при разработке единый формат. В каждом код-ревью нужно вникать и понимать, тот ли тип Exception-а вернулся, если что — создать новый, назвать его корректно, наследовать его от нужного типа ошибки. А когда регламент поменяется (его придется менять), потому что у вас появилась новая договоренность с другими командами, нужно не полениться сходить к соседям и сделать pull request.
- Регламент усложнит онбординг новичков: но зато когда человек вник, увидев ошибку в логах, он будет четко понимать, что произошло и куда бежать.
Но несмотря на эти трудности — мы довольны. Экономим время при обнаружении ошибки и добавление новых однотипных ошибок. А как устроено у вас?
О том, как можно проверять значения, введёные пользователем
В любых программных продуктах, будь то windows-приложение или web-сайт, получение информации от пользователей зачастую осуществляется с помощью форм ввода данных.
Конечно же, нельзя быть абсолютно уверенным, что пользователь введёт именно то, что нужно, поэтому все данные необходимо тщательно проверить.
Как правило, алгоритм проверки этих данных один и тот же: «Если значение поля удовлетворяет требованию, то проверить следующее требование, иначе вывести сообщение об ошибке. Перейти к проверке значения следующего поля».
На практике это выливается с довольно длинные последовательности «if-else». Лично мне это жутко не нравилось, так как сложно с первого взгляда определить, какие поля как проверяются и какие сообщения выдаются в случае ошибок. А ведь полей в форме может быть и десять, тогда код проверки вообще затягивается. Вобщем, я задумался над тем, как можно минимизировать объём работ и вот что из этого получилось.
Я представил проверку как преобразование значения одного типа в значение другого типа (например, проверка того, что в поле введено чило, это преобразование строки в число). Тоесть проверка — это некая функция, имеющая сигнатуру делегата System.Converter<T, U>.
Для проверки значение помещаем в класс обёртку:
Суть проверки заключается в последовательном вызове методов-расширений для объектов класса ValidationStep<T>, которые опять же возращают объект класса ValidationStep<T>. Это позволяет создавать цепочки проверок. Вот пример таких методов-расширений:
Первый метод используется, чтобы можно было проверять объекты любых типов, торой метод осуществляет проверку на соответствие предикату, а третий на возможность преобразования значения из одного типа в другой. Также можно написать любые другие проверки, например на соответствие целого числа диапазону. Главное, что в случае неудачной проверки должно возникать исключение ValidationException, которое содержит сообщение с текстом ошибки.
Для осуществления самой проверки можно использовать следующий класс, который будет заниматься перехватом исключений:
А теперь о том, как это использовать. Допустим нам нужно проверить текстовое поле (tb1) и убедиться, что в него введено целое число в диапазоне от 0 до 10. Это можно сделать так:
Учитывая, что проверок может быть больше, да и число полей в форме, как правило, больше одного, такой способ проверок может быть очень даже удобен.
Проверка корректности данных
Проверке корректности данных, вводимых пользователем необходимо уделять достаточно большое внимание, поскольку необработанные ошибки, возникающие при вводе неправильном вводе данных, приводят к ошибкам в работе скрипта, зачастую катастрофическим. Предположим, вы создаете форму для отправки пользователем письма, при этом адрес электронной почты необходимо вводить пользователю. В этом случае, для корректной работы программы вы должны сделать, по крайней мере, две вещи:
- Проверить, что поле, в которое заносится электронный адрес непустое (поскольку пользователь может просто забыть ввести адрес, и, если этот случай необработан, возникнет ошибочная ситуация);
- Проверить соответствие введенного адреса с помощью регулярного выражения.
Кроме чистых ошибок пользователя, необходимо также исключить ситуации, в которых возможно злонамеренное введение некорректных данных, к примеру, различных скриптов. Для этого вводимый пользователем текст необходимо обработать функциями удаления HTML-тегов (для исключения возможности написания скриптов на JavaScript и Visual Basic) и обратных слешей (для исключения возможности написания скриптов на Perl). Т. о. минимальный набор действий, необходимый для проверки корректности данных, вводимых пользователем, включает следующие этапы:
- проверка того, что пользователь ввел данные
- проверка допустимости вводимых пользователем данных (как правило, осуществляется при помощи регулярных выражений)
- обработка текста, введенного пользователем функцией htmlspecialchars для удаления HTML-тегов
- обработка текста, введенного пользователем функцией stripslashes для удаления обратных слешей
Проверка на пустоту поля
Проверка того, что пользователь ввел данные, может осуществляться, к примеру, с помощью функции isset:
Для этой же цели можно использовать функцию empty:
На практике удобно сначала проверить, не пустой ли action формы, а потом уже проверять различные его составляющие: поле имя, e-mail и т. д. К примеру:
Проверка допустимости вводимых данных
Пусть нам надо проверить данные формы для отправки сообщения гостевой книги. Как правило, такая проверка осуществляется при помощи регулярных выражений. Рассмотрим пример, в котором создается регулярное выражение для проверки адреса электронной почты.
Будем исходить из того, что адрес должен иметь вид something@server.com. Как видим, у адреса две составляющие — имя пользователя и имя домена, которые разделены знаком @. В имени пользователя могут присутствовать буквы нижнего и верхнего регистров, цифры, знаки подчеркивания и минуса, точки. Для проверки разделителя между именем пользователя и именем домена в выражение требуется добавить +@. Таким образом, регулярное выражение, проверяющее имя пользователя и наличие разделителя имеет следующий вид:
Для проверки доменного имени добавляем такое выражение:
Объединяя эти шаги, получаем следующее регулярное выражение для проверки адресов электронной почты:
Точно таким же образом вы можете проверить и остальные заполняемые пользователем поля.
Удаление HTML — тегов и обратных слешей
Как уже говорилось, вводимый пользователем текст необходимо обработать функциями удаления HTML-тегов (для исключения возможности написания скриптов на JavaScript и Visual Basic) и обратных слешей (для исключения возможности написания скриптов на Perl). К примеру, если переменная $name содержит текст с именем пользователя, то обработка этого текста выглядит так:
Если Вам нужна частная профессиональная консультация от авторов многих книг Кузнецова М.В. и Симдянова И.В., добро пожаловать в наш Консультационный Центр SoftTime.
Динамические формы — проверка ввода на JavaScript
При разработке страниц, содержащих HTML формы ввода, нужно всегда помнить, что есть обязательная информация, есть необязательная. Если пользователь при вводе, например, не заполнит обязательное поле «email», то на сервере в момент отработки скрипта и записи в базу данных может возникнуть ошибка.
Как правило, разработчики Web-приложений учитывают это, и если какие-то данные не были приняты на сервере CGI-скриптом, то последний возвращает опять страницу с «руганью» и формой для дозаполнения, тем самым избегая ошибки времени исполнения на сервере.
Но каждая передача данных на сервер — это лишнее время (с точки зрения пользователя), и лишняя загрузка сервера, на котором исполняется CGI-скрипт, что опять-таки за собой тянет увеличение времени ожидания. Поэтому, имея практически на каждом компьютере такие мощные средства, как JavaScript, реализованные в браузерах версий 4 и выше, вполне можно заставлять страницу саму себя проверять на корректность ввода данных в формы.
Известно, что HTML документ имеет объектно-ориентированную структуру, а посему, с помощью свойств и методов можно проверять объекты типа «элемент формы» на наличие в них данных.
В первую очередь, форма.
Стоит обратить внимание на две вещи:
- Вызов функции checkform() на событие onSubmit(т.е. на нажатие кнопки Submit)
- Атрибут required в двух полях — Name и E-mail
Значит в момент отправки формы вызывается функция checkform(). Вот она:
В общем — все понятно: передаем в качестве параметра форму, перебираем все элементы, если элемент имеет атрибут required, — проверяем его функцией isEmpty(). Если функция возвращает истину, — то строка пустая, если нет — то заполнена. Если строка пустая, то имя этого поля добавляется в переменную errMSG. Если errMSG оказывается не пустой строкой, то выводим сообщение об ошибке, и возвращаем в форму false, вследствие чего форма не отправляется на сервер.
Проверка правильности заполнения формы во время ввода
Можно проверять заполнение формы во время ввода данных в элементы управления. При этом надо отрабатывать события на этих элементах.
В данном случае обрабатывается событие onKeyPress.:
Где event.keyCode = скан-код нажатой клавиши.
Можно проверять элементы формы во время заполнения формы. Для этого нужно отрабатывать событие OnChange:
В данном случае после изменения поля отрабатывает скрипт, который проверяет, что было введено — текст или число, и изменяет стиль оформления данного элемента управления.:
Если использовать проверку правильности заполнения формы с помощью JavaScript , то можно здорово облегчить жизнь и пользователю и себе, особенно, когда придется писать CGI-скрипт и предусматривать внештатные ситуации типа несовпадения типов данных.
Перевод материала Эммануэля Сербонуа о том, как анализировать действия пользователей и сделать дизайн, который не заведёт их в тупик.
Материал подготовлен командой онлайн-школы английского языка Skyeng.
Многим разработчикам нравится строить системы. Мы всё продумываем и обращаем внимание на детали. Заботимся о том, чтобы всё работало, и всегда стремимся к тому, чтобы пользователю было удобно. Но на этапе разработки нам постоянно кажется, что при взаимодействии с нашей системой все будут вести себя одинаково.
Переходим сюда, свайпаем, нажимаем здесь — ура, вы совершили покупку.
Потом проводим тесты, чтобы узнать, как пользователи на самом деле взаимодействуют с системой. Что-то меняем, корректируем, тестируем снова — и узнаём, что пользователь всё равно действует согласно своему восприятию, а не нашему плану. И отклонения от идеального сценария всегда приводят к непредсказуемым и неожиданным результатам и ошибкам.
Дизайнерам зачастую сложно признать, что невозможно спроектировать систему, которая будет полностью застрахована от человеческого фактора. Все делают ошибки. Даже пользователи.
Человеческий фактор — по-прежнему основная причина катастроф и аварий в самых разных сферах, будь то медицина, ядерная энергетика или освоение космоса.
Давайте рассмотрим типы ошибок. Почему они происходят, каковы стратегии их исправления и как предугадывать их во время разработки.
Я использую термин «система» в широком смысле — для описания цифровых продуктов, потоков, реальных систем.
Сколько типов ошибок существует
Джеймс Ризон, заслуженный профессор Манчестерского университета, подробно исследовавший эту тему, выделяет две категории: промахи и ошибки.
Промах — когда намерение не совпадает с действием.
- Промахи-действия: вы разблокировали телефон, чтобы позвонить маме, но перед этим решили зайти в Instagram.
- Провалы в памяти: выйдя из дома, вы оставили ключ в дверном замке.
Ошибка — когда цель и результат действий оценены неверно.
- Ошибки, основанные на правилах: врач ставит правильный диагноз, но назначает неверное лечение.
- Ошибки, основанные на знаниях: вы много нажимаете Enter, когда компьютер зависает, ошибочно полагая, что это чем-то поможет.
- Ошибки, связанные с памятью: вы забыли завершить задачу, потому что пришло уведомление в Instagram, и отвлеклись.
О чём нужно помнить
Большинство наших повседневных ошибок — это промахи. Они — результат автоматических, неосознанных процессов. Вы планируете совершить одно действие, но оказывается, что делаете другое.
Ошибки иногда называют намеренными или ошибками планирования, и они осознанные. Вы хотите достичь определённого результата, но сознательно действуете неправильно.
Когда я искал материал для этой статьи, я наткнулся на PDF с большим количеством примеров, опубликованный на сайте Управления по охране труда Великобритании.
Почему случаются ошибки
Как вы наверняка знаете, человеческие ошибки происходят по многим причинам. Наиболее важные из них:
- Предвзятость при принятии решений.
- Работа в состоянии стресса.
- Работа в неестественных условиях.
Кратко рассмотрим каждую из этих причин.
Предвзятость при принятии решений
Я выбрал три наиболее распространённых фактора ошибок. Это поможет понять, к чему они приводят.
- Эффект фокусировки: склонность придавать слишком большое значение одному аспекту события. Возможно, вам больше знакомы понятия «эффект якоря» или просто «узость взглядов».
- Иллюзия корреляции: тенденция видеть связь между двумя несвязанными событиями.
- Доверие автоматизации: тенденция чрезмерно полагаться на автоматизированные системы, что может приводить к тому, что неверная информация, выдаваемая системой, будет препятствовать принятию верных решений.
Люди в принципе предрасположены ко множеству ошибок. В «Википедии» есть список с большим количеством примеров.
В начале работы над проектом я бы посоветовал составить список ошибок, которые предположительно будут влиять на решения пользователей, и подтверждать или отвергать их во время тестирования.
Работа в условиях стресса (закон Йеркса — Додсона)
Ещё в 1908 году психологи Роберт Йеркс и Джон Додсон обнаружили связь между стрессом (называемым в психологии возбуждением) и производительностью.
Небольшой стресс (до одного балла по десятибалльной шкале) может помочь вам выполнить задачу, потому что это повышает внимательность, но при слишком большом стрессе производительность снижается.
Конечно, исследования показывают, что оптимальное количество стресса, или возбуждения, зависит от сложности задачи.
- Низкое напряжение и низкая сложность равносильны скуке.
- Небольшое напряжение и высокая сложность дают наилучшую производительность, и следовательно, человек совершает меньше ошибок.
- Большой стресс и высокая сложность приводят к снижению производительности и увеличению количества ошибок.
В качестве оптимальной практики при создании систем следует учитывать уровень нагрузки среды, в которой используется система, поскольку это может существенно повлиять на человеческий фактор.
Работа в неестественных условиях
Знание условий, в которых люди будут использовать систему, также крайне важно при разработке проектов. В ходе тестирования с участием пользователей можно выявить неестественные условия, в которых будет использоваться система, и компенсировать их за счёт механизмов исправления ошибок.
Вот некоторые сценарии, в которых пользователи могут оказаться во время работы.
- Необходимость сохранять бдительность в течение длительных периодов времени.
- Необходимость постоянно предоставлять точные данные в определённый промежуток времени.
- Работа в среде, где человека постоянно отвлекают.
- Работа с большими объёмами разнообразных данных.
Как люди решают проблемы
При изучении поведения людей, проходивших юзабилити-тесты, возникло несколько моделей решения проблем и исправления ошибок.
Вот самые важные из них, которые следует принимать во внимание при моделировании поведения пользователя.
Систематическое исследование
Это оптимальная модель поведения, с наибольшей вероятностью приводящая к успешному решению задачи. Люди пробуют все доступные варианты в определённом порядке, пока не найдут нужный.
Пример. Ваша задача — открыть приложение «Обратная связь» на телефоне с новой операционной системой, которая отображает приложения только с помощью иконок. Вы открываете каждое приложение сверху вниз, пока не найдёте нужное.
Метод проб и ошибок
Это ещё один распространённый метод, хотя он и считается менее эффективным и продуктивным, чем метод систематического исследования. Люди случайным образом пробуют разные варианты, пока не найдут тот, который им нужен.
Пример: ваша задача — сделать снимок экрана на новом телефоне. Вы будете случайным образом пробовать сочетания кнопок и жестов, чтобы выполнить свою задачу.
Упрямство
Человек выбирает один конкретный способ решения задачи. Он продолжает многократно повторять одно и то же действие или комбинацию действий, даже если это не приводит к результату, и верит, что этот метод когда-нибудь сработает.
Пример. Задача — воспроизвести любимую песню в музыкальном приложении. Вы открываете приложение и нажимаете большую иконку Play, перезапуская и повторяя тот же процесс, хотя с самого начала кнопка не работала.
Материал по теме: статья Амстердамского университета.
Дизайн с учётом человеческого фактора
Теперь мы знаем, сколько существует типов ошибок, почему они происходят и как люди обычно их исправляют. Человеческий фактор нельзя устранить, но он необязательно должен приводить к катастрофическим последствиям.
Рассмотрим несколько приёмов проектирования, которые можно использовать в ходе разработки для снижения влияния человеческого фактора.
1. Предотвращать ошибки
Это хороший вариант, потому что он позволяет предотвращать ошибки ещё до того, как человек их допустит. Так у пользователя появляется ощущение безопасности и стабильности.
Методы:
- Ограничения: человек допустит меньше ошибок при вводе номера кредитной карты, если в это поле можно будет вводить только числа.
- Последовательность: человек с меньшей долей вероятности допустит ошибку при пользовании сайтом, если кнопка подтверждения всегда будет с правой стороны. При этом у человека строится определённая модель системы, и он допускает меньше ошибок.
- Понятные метафоры: значок мусорной корзины для большинства пользователей означает удаление, потому что это чёткая и узнаваемая метафора, что делает вероятность недопонимания очень низкой.
2. Прощать ошибки
Возможность исправлять ошибки — положительное свойство системы, поскольку позволяет исследовать её функции без страха сделать что-то не так.
Методы:
- Приглашение к действию: кнопки должны выглядеть как что-то, на что можно нажать.
- Возможность отмены: необратимые действия легко совершить по ошибке, поэтому в системе должна быть возможность отмены на случай промаха или изменения решения пользователя.
- Журнал истории: в системе должен быть журнал действий, чтобы пользователи могли выявлять и исправлять любые возможные ошибки.
3. Объяснять
Каждый разработчик интерфейсов знает, что люди не читают текст на экране последовательно, слово за словом. Они бегло просматривают текст. Это не значит, что мы вообще не должны использовать пояснительный текст. Отсутствие коммуникации — это самый нежелательный вариант, который может сильно ограничить возможности системы в работе с человеческим фактором
Методы:
- Сообщения с подтверждением: для действий, которые пользователи собираются выполнить (и результатов этих действий), должны появляться сообщения с краткими и понятными формулировками.
- Предупреждения: система должна чётко указывать на возможную ошибку с помощью знаков, предупреждений и подсказок.
- Справочные разделы: легкодоступные, хорошо структурированные и ориентированные на пользователя FAQ, справочные страницы или экраны, инструкции в виде карточек, табличек, памяток.
Дополнительные техники
- Снижение когнитивной нагрузки: благодаря простому и интуитивно понятному дизайну или уменьшению количества визуальных, звуковых сигналов (это также снижает стресс).
- Поддержка: с помощью специально разработанного онбординга, советов, клиентской службы поддержки, видеоруководств или тренингов в форме курсов.
Реальность такова, что всегда что-то идёт не так: коллега делает ошибку в файле в совместном доступе, компания выпускает приложение со множеством ошибок, инженер создаёт систему, которая непригодна для использования, потому что он недостаточно хорошо понимает своего пользователя.
Именно поэтому мы должны стремиться лучше понимать человеческую природу, знать её сильные и слабые стороны и использовать это в своих проектах.
ЛЕКЦИЯ 30
Тема 3.8 Защитное программирование
1. Способы проявления ошибок.
2. Принципы защитного программирования.
3. Рекомендации по защитному программированию.
1. Способы проявления ошибок
Любая из ошибок программирования,
которая не обнаруживается на этапах компиляции и компоновки программ, в
конечном счете может проявиться тремя способами: привести к выдаче системного
сообщения об ошибке, «зависанию» компьютера и получению неверных результатов.
 |
Рисунок 1 — Способы проявления ошибок
Однако до того как результат работы
программы становится фатальным, ошибки обычно много раз проявляются в виде
неверных промежуточных результатов, неверных управляющих переменных, неверных
типах данных, индексах структур данных и т.д. (рисунок 3.1). А это значит, что
часть ошибок можно попытаться обнаружить и нейтрализовать, пока они еще не
привели к тяжелым последствиям. Для этого используется защитное
программирование. При его использовании существенно уменьшается вероятность
получения неверных результатов.
Защитное программирование – это такой стиль написания программ, при котором появляющиеся ошибки
легко обнаруживаются и идентифицируются программистом.
Детальный анализ ошибок и их возможных
ранних проявлений показывает, что целесообразно проверять:
—
правильность выполнения операций ввода-вывода;
—
допустимость промежуточных результатов (значений
управляющих переменных, значений индексов, типов данных, значений числовых
аргументов и т.д.).
Проверка
правильности операций ввода-вывода.
Причины неверного определения исходных
данных:
—
внутренние ошибки – ошибки устройств ввода-вывода
или программного обеспечения;
—
внешние ошибки – ошибки пользователя.
Различают:
—
ошибки передачи (аппаратные средства, например,
вследствие неисправности, искажают данные);
—
ошибки преобразования (программа неверно
преобразует исходные данные из входного формата во внутренний);
—
ошибки перезаписи (пользователь ошибается при вводе
данных, например, вводит лишний или другой символ);
—
ошибки данных (пользователь вводит неверные
данные).
Ошибки передачи обычно контролируются
аппаратно.
Для защиты от ошибок преобразования
данные после ввода обычно сразу демонстрируют пользователю. При этом выполняют
сначала преобразование во внутренний формат, а затем обратно. Предотвратить все
ошибки на данном этапе сложно, поэтому соответствующие фрагменты программы
тщательно тестируют.
Обнаружить и устранить ошибки
перезаписи можно только, если пользователь вводит избыточные данные, например
контрольные суммы. Если ввод избыточных данных нежелателен, то следует проверять
вводимые данные, хотя бы контролировать интервалы возможных значений, которые
обычно определены в техническом задании, и выводить введенные данные для
проверки пользователю.
Неверные данные может обнаружить
только пользователь.
Проверка
допустимости промежуточных результатов.
Эта проверка позволяет снизить
вероятность позднего проявления не только ошибок неверного определения данных,
но и некоторых ошибок кодирования и проектирования. Для этого используют в
программе переменные, для которых существуют ограничения, например, связанные с
сущность моделируемых процессов.
Предотвращение
накопления погрешностей.
Чтобы снизить погрешность результатов
вычислений, необходимо соблюдать следующие рекомендации:
—
избегать вычитания близких чисел (машинный ноль);
—
избегать деления больших чисел на малые;
—
сложение длинной последовательности чисел начинать
с меньших по абсолютной величине;
—
стремиться по возможности уменьшать количество
операций;
—
использовать методы с известными оценками
погрешностей;
—
не использовать условие равенства вещественных
чисел;
—
вычисления производить с двойной точность, а
результат выдавать – с одинарной.
Обработка
исключений.
Поскольку полный контроль данных на
входе и в процессе вычислений не возможен, следует предусмотреть перехват
обработки аварийных ситуаций.
Для перехвата и обработки аппаратно и
программно фиксируемых ошибок в некоторых языках программирования предусмотрены
средства обработки исключений. Использование их позволяет
пользователю не допустить выдачи пользователю сообщения об аварийном завершении
программы, ничего ему не говорящего. Вместо этого программист получает
возможность предусмотреть действия, которые позволят исправить эту ошибку или
выдать пользователю сообщение с точным описанием ситуации и продолжить работу.
2. Принципы защитного программирования
Существуют три основных принципа
защитного программирования:
1.
Общее недоверие. Для каждого модуля входные данные должны
тщательно анализироваться в предположении, что они могут быть ошибочными.
2.
Немедленное
обнаружение. Каждая
ошибка должна быть выявлена как можно раньше, это упрощает установление ее
причины.
3.
Изолирование ошибки. Ошибки в одном модуле должны быть изолированы
так, чтобы не допустить их влияние на другие модули.
3. Рекомендации по защитному программированию
Рекомендации по защитному
программированию:
— Делайте проверку области значений переменных.
— Выполняйте контроль правдоподобности значений
переменных, которые не должны превышать некоторых констант или значений других
переменных
— Контролируйте итоги вычислений.
— Включайте автоматические проверки (например,
контроль переполнения или потери точности).
— Проверяйте длину элементов информации.
— Проверяйте коды возврата функций.
Этот раздел посвящен ошибкам людей, про ошибки программ мы говорили в первой части.
Проектирование ошибок. Ошибки пользователя
Антонина Хисаметдинова, UX-дизайнер
ИНТЕРФЕЙСЫ

Чтобы не совершать ошибок, надо все время быть очень внимательным. Но это невозможно физически. Так уж устроен человеческий мозг.
В этой статье я расскажу о базовых правилах, которые помогают снизить вероятность пользовательских ошибок.
Правило 1. Поместите сообщение в фокус внимания
Как это делается? Рассмотрим типичный пример.

При входе в личный кабинет Invision сообщение об ошибке выводится выше полей формы. Предполагается, что пользователь прочтет фразу «Упс. Логин или пароль неправильные» и проверит, правильно ли введены логин и пароль.
Однако на самом деле происходит нечто иное. Статистика показывает, что зачастую пользователь вновь и вновь пытается ввести пароль, прежде чем догадается проверить логин.
Такое поведение легко объяснимо. В случае ошибки логин остается на месте, а поле пароля очищается. Это изменение привлекает больше внимания, чем текст, выделенный красным. Когда пользователь нажимает на кнопку входа, он сконцентрирован на зоне ввода пароля.
Эта область называется фокусом внимания.

Следите за фокусом внимания.
На нашей картинке текст об ошибке оказался далеко за пределами этой зоны. Пользователь видит красную надпись периферическим зрением и, не читая текст, делает предположение, что ошибся в пароле.
Часто, чтобы решить проблему, достаточно разместить сообщение об ошибке там, где пользователь точно заметит его.
Правило 2. Покажите, где именно возникла ошибка
Само по себе это правило достаточно простое, и бо́льшая часть сервисов уже не нарушают его.

Но что если возникает ситуация, когда вы не можете точно показать, где пользователь совершает ошибку?
При авторизации через плагин Invision для Sketch оба поля ввода — и логина, и пароля — выделяются красным, при этом пароль выделяется. Таким образом, пользователю предлагают проверить, где он сделал ошибку. Получается куда более понятно и наглядно. Не надо стирать пароль, если ошибка возможна не только в нем.
Правило «Показывайте, где ошибка» часто нарушают неосознанно, ведь легко забыть, что ошибка это не только реакция на действие пользователя. Также проблема может возникнуть, когда пользователь еще только собирается что-то сделать.
Рассмотрим на примере. В последнее время наблюдается тенденция «дизейблить» недоступные действия. Например, пока пользователь не заполнит все поля на сайте «Госуслуги», кнопка «Сохранить» не станет активной.

Человек может просто не догадаться, почему кнопка серая и неактивная. Он наверняка попытается нажать на нее, даже если где-то на странице написано «заполните все поля». Настроив аналитику, вы можете выяснить, как часто люди кликают на серую кнопку. А исходя из полученных данных, уже можно принять решение, надо ли дезактивировать кнопку в вашем случае.
Впрочем, возможность проводить такие эксперименты есть не у всех, поэтому рекомендую использовать проверенный паттерн — оставлять кнопку активной, а при клике на нее выводить сообщение об ошибке, если обязательные поля остались незаполненными.

Про тексты в таких сообщениях поговорим ниже.
Не заставляйте пользователя самому искать ошибки. Сообщения об ошибках должны помогать ему быстрее разобраться с интерфейсом.
Правило 3. Используйте понятные формулировки без лишних слов
Иногда мало просто указать, где возникла ошибка, чтобы пользователь понял, что пошло не так. Важно не только где выводится сообщение об ошибке, но и как оно сформулировано.
Каковы самые частые проблемы интерфейсных текстов?
1. Слишком много текста

Текст не должен быть слишком длинным. Вряд ли пользователи будут вникать в такие пассажи. Пишите как можно короче.
2. Запутанные формулировки

В приложении Xiaomi mi fit на вопрос «Отменить изменения?» предлагается два ответа «отмена» и «отменить». Подобные формулировки ставят пользователя в тупик.
Эта проблема широко распространена. Посмотрите на пример ниже.

Это окно не предостерегает пользователя от потери несохраненных действий. Ключевое действие здесь — отмена изменений, пользователь может нажать эту кнопку автометически или задуматься, чем отличаются кнопки между собой. Отменить или отмена?
В примере ниже показано, как можно уберечь пользователя от потери несохраненных изменений. Не нужно читать тест, чтобы понять, что нужно сделать.

Сообщение об ошибке должно помогать решить проблему, а не приводить в ступор.
Правило 4. Подскажите, как исправить ошибку
Следующий уровень, повышающий качество сообщения об ошибке, — это подсказки. Объясню на примере, подсмотренном на этом курсе.
Электронные кассы самообслуживания состоят из терминала и двух весовых платформ. Платформы нужны, чтобы подтвердить вес каждого просканированного товара.

Сканируешь товар и кладешь его на весы с другой стороны. На первый взгляд всё просто.
Однако разработчики интерфейсов для касс обратили внимание на одну часто повторяющуюся ошибку. Если товар небольшой (например, бутылка сока), многие покупатели забывают вернуть его на весовую платформу и пытаются сразу просканировать второй товар. Из-за этого сканер перестает работать и пользователи просят помощи у сотрудников зала.
Решить проблему помогло одно маленькое сообщение об ошибке, которое подсказывало пользователям, как исправить дело.

Если человек сканировал второй товар, не вернув на весы первый, на экране появлялся тултип «Сначала положите этот товар». Однако первым делом надо было привлечь внимание пользователя, чтобы сообщение было замечено (помним про фокус внимания).
Поэтому появление окна с сообщением об ошибке сопровождалось звуком «би-би-би», который заставлял покупателя прервать монотонное сканирование и поднять глаза на экран. Он видел, что нужно сделать, и ставил бутылку воды на весы.
Таким образом, в 90% случаев люди стали обходиться без вызова помощника. Подсказывая пользователю, как исправить ошибку самому, можно сэкономить время обслуживающего персонала.
Правило 5. Сохраняйте работу пользователя
Позаботьтесь о том, чтобы пользователю не приходилось повторять свои действия из-за ошибки.
Запоминайте данные, если пользователь случайно закрыл поп-ап или обновил страницу. Сохраняйте все, что можно сохранить. Не очищайте поля, заполненные без ошибок. И так далее. Без примеров эти рекомендации бесполезны, поэтому давайте рассмотрим два кейса.
Пример первый — проблемы с регистрацией
Ниже на картинке показан кусочек пути пользователя при регистрации в приложении финансового сервиса Revolut. При первом входе надо ввести свой номер телефона.

Обратите внимание, что сервис автоматически подставил в номер телефона код России +7. После подтверждения номера телефона кодом из СМС следует заполнить профиль: ввести имя, фамилию и год рождения.
Когда я заполнила всё и нажала «далее», выскочил поп-ап «Пожалуйста, используйте только латинские символы». Черт! Ладно, введу все заново. Лучше бы приложение сразу подсказало, что требуется латиница.
Далее нужно заполнить адресную информацию. При этом страна определилась автоматически и написана кириллицей. Но я-то знаю, что надо вводить латиницей!

Всплывающее окно говорит: «Мы не оказываем услуги в вашей стране». Они знали, что я нахожусь в России, с самого первого экрана, где заботливо подставили код страны при вводе телефона. Первое, что приходит в голову: вот блин. Эти ребята тратят мое время, как будто оно ничего не значит. Мне неприятно. Почему нельзя сразу сказать, что в России сервис не работает?
Пример второй — great UX!
Отличный дизайн — незаметен. Semrush — один из немногих сервисов, которые запоминают ваш логин и не заставляют вводить его заново, если вы пытаетесь восстановить пароль.

Никто не любит, когда не уважают его время. Поэтому не заставляйте пользователя заново вводить текст или повторять другие действия, если он ошибся.
Перевели статью о том, как разработать ментальную модель и ее составные части: модели пользователя, ценности, взаимодействия, объекта и данных.
Разбираемся, как писать тексты на уведомлениях с техническими ошибками, чтобы не раздражать пользователей и давать им максимум полезной информации.
Рассказываем, зачем прорабатывать ошибочные пользовательские сценарии. Статья по мотивам выступления UX-дизайнера «Собаки Павловой» на Heisenbug 2017 Moscow.