
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий: .
.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия .
.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Соседние файлы в папке Лекции 2 семестр
- #
- #
- #
- #
8 июля 2021 г.
При проверке гипотез нулевая гипотеза — это гипотеза по умолчанию, которая утверждает, что между переменными нет статистической значимости. Исследователь проверяет нулевую гипотезу, чтобы увидеть, достаточно ли статистической значимости, чтобы опровергнуть ее, и это иногда приводит к ошибке типа 1 или типа 2. Если вы занимаетесь проверкой гипотез как частью своей работы, важно понимать, как ошибки типа 1 и типа 2 могут повлиять на ваши результаты.
В этой статье мы объясним, что такое ошибки типа 1 и типа 2, рассмотрим, как они могут возникнуть, обсудим их важность в исследованиях и приведем примеры, которые помогут вам понять эти концепции.
Ошибки типа 1 и типа 2 относятся к неправильным определениям нулевой гипотезы, но они различаются тем, что исследователь считает верным или ложным в отношении гипотезы. Ошибка 1-го типа, также называемая ложноположительной, возникает, когда исследователь отвергает нулевую гипотезу, которая является истинной, и решает, что существует статистически значимое различие, которого не существует. Ошибка типа 2 является обратной ошибкой типа 1. Также известная как ложный отрицательный результат, она возникает, когда исследователь не отвергает нулевую гипотезу, когда альтернативная гипотеза верна.
Например, в судебном деле нулевая гипотеза будет заключаться в том, что обвиняемый невиновен, пока его вина не будет доказана, а альтернативная гипотеза будет состоять в том, что он виновен. Есть четыре возможных исхода в отношении истинного характера дела:
-
Истинно отрицательный: признан невиновным в суде и невиновен на самом деле.
-
Ложное срабатывание: признан виновным в суде, но на самом деле невиновен.
-
Ложноотрицательный: признан невиновным в суде, но на самом деле виновен.
-
Истинно положительный: признан виновным в суде и фактически виновен
В приведенном выше примере второй и третий результаты являются ошибками типа 1 и типа 2 соответственно. В случае ложного срабатывания присяжные ошибочно отвергают нулевую гипотезу, утверждающую, что подсудимый невиновен. В случае ложноотрицательного результата они ошибочно не отвергают нулевую гипотезу.
Почему возникают ошибки первого рода?
Есть два фактора, которые обычно способствуют возникновению ошибок 1-го рода:
Шанс
Проверка гипотез никогда не бывает стопроцентной, поэтому всегда есть возможность сделать неверные выводы на основе имеющихся данных. Как правило, данные поступают из выборочной совокупности, относительно небольшой выборки лиц, предназначенных для обозначения более широкой демографической группы. Иногда данные, генерируемые выборочными совокупностями, искажают выводы, которые не обязательно отражают интересы всего населения. Это переменная, которую исследователи не могут контролировать, но они могут помочь смягчить ее, выбрав более крупные выборки.
Злоупотребление служебным положением
Иногда ошибки 1-го рода возникают из-за неправильной исследовательской практики. Например, исследователи могут неосознанно исказить результаты теста, завершив его слишком рано. Им может показаться, что у них достаточно данных, хотя стандартная практика рекомендует продолжить тест. В качестве альтернативы они могут сделать вывод, несмотря на то, что им не удалось достичь соответствующего уровня статистической значимости. Исследователи могут избежать выводов типа 1, связанных с злоупотреблением служебным положением, если будут следовать протоколам исследований и обеспечивать надежность своей практики.
Почему возникают ошибки второго рода?
Основным фактором, способствующим возникновению ошибок 2-го рода, является размер выборки. Чем больше размер выборки, тем больше вероятность обнаружения различий в статистическом тесте. Например, если вы хотите проверить, относятся ли студенты колледжа положительно или отрицательно к определенному продукту, группа из трех человек может выразить только два к одному разнообразию или вообще ничего не сказать. Для сравнения, выборка из 1000 человек с большей вероятностью вызовет широкий спектр мнений и, таким образом, более точно отразит большую часть населения.
Какова важность ошибок типа 1 по сравнению с ошибками типа 2?
Ошибки типа 1 и типа 2 являются значительными из-за последствий, которые они имеют в реальных приложениях. Ошибки типа 1 обычно приводят к ненужному использованию ресурсов без какой-либо выгоды. Например, если исследователь-медик совершает ошибку 1-го рода в отношении эффективности нового лечения, он может подтвердить ошибочность исследований и методов, что может привести к созданию лекарства, не приносящего облегчения.
Ошибки 2-го типа важны тем, что могут помешать выделению ресурсов и выполнению необходимых действий. Например, при скрининге пациента на наличие заболевания ложноотрицательный результат может свидетельствовать о том, что пациент здоров, хотя на самом деле он нуждается в медицинском вмешательстве.
Примеры ошибок типа 1 и типа 2
Рассмотрим эти примеры ошибок типа 1 и типа 2, чтобы помочь вам понять, что они из себя представляют:
Пример ошибки 1 рода
Медицинский исследователь проверяет эффективность домашнего средства от головной боли. Нулевая гипотеза состоит в том, что домашнее средство не влияет на головную боль, в то время как альтернативная гипотеза состоит в том, что оно лечит головную боль. Исследователь набирает выборку из 20 пациентов с хроническими головными болями и назначает лекарство половине из них в течение одного месяца. Половина, не получающая лекарство, продолжает страдать от хронических головных болей, в то время как у шести человек из оставшейся половины головные боли прекратились.
На основании вышеизложенного исследователь отвергает нулевую гипотезу. Однако, учитывая небольшое количество тех, кто испытал облегчение, могут возникнуть сомнения относительно того, было ли это лекарство или посторонний фактор, который улучшил состояние шести участников. Если эти шесть участников использовали другие средства от головной боли вместе с тестируемым средством, вполне вероятно, что исследователь совершил ошибку 1-го типа.
Пример ошибки 2 рода
Интернет-магазин хочет знать, могут ли изменения дизайна его веб-сайта помочь увеличить продажи. Нулевая гипотеза состоит в том, что изменения дизайна не влияют на продажи, а альтернативная гипотеза говорит об обратном. Продавец проводит A/B-тестирование, в ходе которого сравниваются две версии сайта, существующая версия и обновленная версия. Три дня мониторят продажи на основе существующей версии. Затем в течение следующих трех дней они представляют новую версию и смотрят, как она повлияет на продажи. По истечении шести дней они не видят значительных изменений в показателях продаж.
Однако возможно, что увеличение периодов наблюдения для каждой версии сайта привело бы к статистически значимой разнице. Если бы розничный продавец отслеживал продажи в течение одного месяца каждый и заметил увеличение продаж во втором месяце, он совершил бы ошибку второго рода, ошибочно приняв нулевую гипотезу.
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Содержание
- 1 Определения
- 2 О смысле ошибок первого и второго рода
- 3 Вероятности ошибок (уровень значимости и мощность)
- 4 Примеры использования
- 4.1 Радиолокация
- 4.2 Компьютеры
- 4.2.1 Компьютерная безопасность
- 4.2.2 Фильтрация спама
- 4.2.3 Вредоносное программное обеспечение
- 4.2.4 Поиск в компьютерных базах данных
- 4.2.5 Оптическое распознавание текстов (OCR)
- 4.2.6 Досмотр пассажиров и багажа
- 4.2.7 Биометрия
- 4.3 Массовая медицинская диагностика (скрининг)
- 4.4 Медицинское тестирование
- 4.5 Исследования сверхъестественных явлений
- 5 См. также
- 6 Примечания
Определения[править | править исходный текст]
Пусть дана выборка  из неизвестного совместного распределения
из неизвестного совместного распределения  , и поставлена бинарная задача проверки статистических гипотез:
, и поставлена бинарная задача проверки статистических гипотез:

где  — нулевая гипотеза, а
— нулевая гипотеза, а  — альтернативная гипотеза. Предположим, что задан статистический критерий
— альтернативная гипотеза. Предположим, что задан статистический критерий
 ,
,
 ,
,сопоставляющий каждой реализации выборки  одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
одну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , и она точно определена статистическим критерием, то есть .
- Распределение выборки соответствует гипотезе , но она неверно отвергнута статистическим критерием, то есть .
 соответствует гипотезе
соответствует гипотезе  .
. .
.Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно. [1][2]
| Верная гипотеза | |||
|---|---|---|---|
| |
|
||
| Результат применения критерия |
|
верно принята |
неверно принята (Ошибка второго рода) |
| |
неверно отвергнута (Ошибка первого рода) |
верно отвергнута |
О смысле ошибок первого и второго рода[править | править исходный текст]
Как видно из вышеприведённого определения, ошибки первого и второго рода являются взаимно-симметричными, то есть если поменять местами гипотезы и , то ошибки первого рода превратятся в ошибки второго рода и наоборот. Тем не менее, в большинстве практических ситуаций путаницы не происходит, поскольку принято считать, что нулевая гипотеза соответствует состоянию «по умолчанию» (естественному, наиболее ожидаемому положению вещей) — например, что обследуемый человек здоров, или что проходящий через рамку металлодетектора пассажир не имеет запрещённых металлических предметов. Соответственно, альтернативная гипотеза обозначает противоположную ситуацию, которая обычно трактуется как менее вероятная, неординарная, требующая какой-либо реакции.
С учётом этого ошибку первого рода часто называют ложной тревогой, ложным срабатыванием или ложноположительным срабатыванием — например, анализ крови показал наличие заболевания, хотя на самом деле человек здоров, или металлодетектор выдал сигнал тревоги, сработав на металлическую пряжку ремня. Слово «положительный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают положительный результат (т.е. показывают наличие заболевания у пациента), когда на самом деле пациент этим заболеванием не страдает. Такой результат называется ложноположительным.
В других областях обычно используют словосочетания со схожим смыслом, например, «ложное срабатывание», «ложная тревога» и т.п. В информационных технологиях часто используют английский термин false positive без перевода.
Из-за возможности ложных срабатываний не удаётся полностью автоматизировать борьбу со многими видами угроз. Как правило, вероятность ложного срабатывания коррелирует с вероятностью пропуска события (ошибки второго рода). То есть: чем более чувствительна система, тем больше опасных событий она детектирует и, следовательно, предотвращает. Но при повышении чувствительности неизбежно вырастает и вероятность ложных срабатываний. Поэтому чересчур чувствительно (параноидально) настроенная система защиты может выродиться в свою противоположность и привести к тому, что побочный вред от неё будет превышать пользу.
Соответственно, ошибку второго рода иногда называют пропуском события или ложноотрицательным срабатыванием — человек болен, но анализ крови этого не показал, или у пассажира имеется холодное оружие, но рамка металлодетектора его не обнаружила (например, из-за того, что чувствительность рамки отрегулирована на обнаружение только очень массивных металлических предметов).
Слово «отрицательный» в данном случае не имеет отношения к желательности или нежелательности самого события.
Термин широко используется в медицине. Например, тесты, предназначенные для диагностики заболеваний, иногда дают отрицательный результат (т.е. показывают отсутствие заболевания у пациента), когда на самом деле пациент страдает этим заболеванием. Такой результат называется ложноотрицательным.
В других областях обычно используют словосочетания со схожим смыслом, например, «пропуск события», и т.п. В информационных технологиях часто используют английский термин false negative без перевода.
Степень чувствительности системы защиты должна представлять собой компромисс между вероятностью ошибок первого и второго рода. Где именно находится точка баланса, зависит от оценки рисков обоих видов ошибок.
Вероятности ошибок (уровень значимости и мощность)[править | править исходный текст]
Вероятность ошибки первого рода при проверке статистических гипотез называют уровнем значимости и обычно обозначают греческой буквой  (отсюда название -errors).
(отсюда название -errors).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, на письме обозначается греческой буквой  (отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле
(отсюда -errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле  . Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
. Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
Обе эти характеристики обычно вычисляются с помощью так называемой функции мощности критерия. В частности, вероятность ошибки первого рода есть функция мощности, вычисленная при нулевой гипотезе. Для критериев, основанных на выборке фиксированного объема, вероятность ошибки второго рода есть единица минус функция мощности, вычисленная в предположении, что распределение наблюдений соответствует альтернативной гипотезе. Для последовательных критериев это также верно, если критерий останавливается с вероятностью единица (при данном распределении из альтернативы).
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости, которым задаются при проверке статистических гипотез. Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
Примеры использования[править | править исходный текст]
Радиолокация[править | править исходный текст]
В задаче радиолокационного обнаружения воздушных целей, прежде всего, в системе ПВО ошибки первого и второго рода, с формулировкой «пропуск цели» и «ложная тревога» являются одним из основных элементов как теории, так и практики построения радиолокационных станций. Вероятно, это первый пример последовательного применения статистических методов в целой технической области.
Компьютеры[править | править исходный текст]
Понятия ошибок первого и второго рода широко используются в области компьютеров и программного обеспечения.
Компьютерная безопасность[править | править исходный текст]
Наличие уязвимостей в вычислительных системах приводит к тому, что приходится, с одной стороны, решать задачу сохранения целостности компьютерных данных, а с другой стороны — обеспечивать нормальный доступ легальных пользователей к этим данным (см. компьютерная безопасность). Moulton (1983, с.125) отмечает, что в данном контексте возможны следующие нежелательные ситуации:
- когда авторизованные пользователи классифицируются как нарушители (ошибки первого рода)
- когда нарушители классифицируются как авторизованные пользователи (ошибки второго рода)
Фильтрация спама[править | править исходный текст]
Ошибка первого рода происходит, когда механизм блокировки/фильтрации спама ошибочно классифицирует легитимное email-сообщение как спам и препятствует его нормальной доставке. В то время как большинство «антиспам»-алгоритмов способны блокировать/фильтровать большой процент нежелательных email-сообщений, гораздо более важной задачей является минимизировать число «ложных тревог» (ошибочных блокировок нужных сообщений).
Ошибка второго рода происходит, когда антиспам-система ошибочно пропускает нежелательное сообщение, классифицируя его как «не спам». Низкий уровень таких ошибок является индикатором эффективности антиспам-алгоритма.
Пока не удалось создать антиспамовую систему без корреляции между вероятностью ошибок первого и второго рода. Вероятность пропустить спам у современных систем колеблется в пределах от 1% до 30%. Вероятность ошибочно отвергнуть валидное сообщение — от 0,001 % до 3 %. Выбор системы и её настроек зависит от условий конкретного получателя: для одних получателей риск потерять 1% хорошей почты оценивается как незначительный, для других же потеря даже 0,1% является недопустимой.
Вредоносное программное обеспечение[править | править исходный текст]
Понятие ошибки первого рода также используется, когда антивирусное программное обеспечение ошибочно классифицирует безвредный файл как вирус. Неверное обнаружение может быть вызвано особенностями эвристики, либо неправильной сигнатурой вируса в базе данных. Подобные проблемы могут происходить также и с антитроянскими и антишпионскими программами.
Поиск в компьютерных базах данных[править | править исходный текст]
При поиске в базе данных к ошибкам второго рода можно отнести документы, которые выдаются поиском, несмотря на их иррелевантность (несоответствие) поисковому запросу. Ошибочные срабатывания характерны для полнотекстового поиска, когда поисковый алгоритм анализирует полные тексты всех хранимых в базе данных документов и пытается найти соответствия одному или нескольким терминам, заданным пользователем в запросе.
Большинство ложных срабатываний обусловлены сложностью естественных языков, многозначностью слов: например, «home» может обозначать как «место проживания человека», так и «корневую страницу веб-сайта». Число подобных ошибок может быть снижено за счёт использования специального словаря. Однако это решение относительно дорогое, поскольку подобный словарь и разметка документов (индексирование) должны создаваться экспертом.
Оптическое распознавание текстов (OCR)[править | править исходный текст]
Разнообразные детектирующие алгоритмы нередко выдают ошибки первого рода. Программное обеспечение оптического распознавания текстов может распознать букву «a» в ситуации, когда на самом деле изображены несколько точек, которые используемый алгоритм расценил как «a».
Досмотр пассажиров и багажа[править | править исходный текст]
Ошибки первого рода регулярно встречаются каждый день в компьютерных системах предварительного досмотра пассажиров в аэропортах. Установленные в них детекторы предназначены для предотвращения проноса оружия на борт самолёта; тем не менее, уровень чувствительности в них зачастую настраивается настолько высоко, что много раз за день они срабатывают на незначительные предметы, такие как ключи, пряжки ремней, монеты, мобильные телефоны, гвозди в подошвах обуви и т.п. (см. обнаружение взрывчатых веществ, металлодетекторы).
Таким образом, соотношение числа ложных тревог (идентифицикация благопристойного пассажира как правонарушителя) к числу правильных срабатываний (обнаружение действительно запрещённых предметов) очень велико.
Биометрия[править | править исходный текст]
Ошибки первого и второго рода являются большой проблемой в системах биометрического сканирования, использующих распознавание радужной оболочки или сетчатки глаза, черт лица и т.д. Такие сканирующие системы могут ошибочно отождествить кого-то с другим, «известным» системе человеком, информация о котором хранится в базе данных (к примеру, это может быть лицо, имеющее право входа в систему, или подозреваемый преступник и т.п.). Противоположной ошибкой будет неспособность системы распознать легитимного зарегистрированного пользователя, или опознать подозреваемого в преступлении.[3]
Массовая медицинская диагностика (скрининг)[править | править исходный текст]
В медицинской практике есть существенное различие между скринингом и тестированием:
- Скрининг включает в себя относительно дешёвые тесты, которые проводятся для большой группы людей при отсутствии каких-либо клинических признаков болезни (например, мазок Папаниколау).
- Тестирование подразумевает гораздо более дорогие, зачастую инвазивные, процедуры, которые проводятся только для тех, у кого проявляются клинические признаки заболевания, и которые, в основном, применяются для подтверждения предполагаемого диагноза.
К примеру, в большинстве штатов в США обязательно прохождение новорожденными процедуры скрининга на оксифенилкетонурию и гипотиреоз, помимо других врождённых аномалий. Несмотря на высокий уровень ошибок первого рода, эти процедуры скрининга считаются целесообразными, поскольку они существенно увеличивают вероятность обнаружения этих расстройств на самой ранней стадии.[4]
Простые анализы крови, используемые для скрининга потенциальных доноров на ВИЧ и гепатит, имеют существенный уровень ошибок первого рода; однако в арсенале врачей есть гораздо более точные (и, соответственно, дорогие) тесты для проверки, действительно ли человек инфицирован каким-либо из этих вирусов.
Возможно, наиболее широкие дискуссии вызывают ошибки первого рода в процедурах скрининга на рак груди (маммография). В США уровень ошибок первого рода в маммограммах достигает 15%, это самый высокий показатель в мире.[5] Самый низкий уровень наблюдается в Нидерландах, 1%.[6]
Медицинское тестирование[править | править исходный текст]
Ошибки второго рода являются существенной проблемой в медицинском тестировании. Они дают пациенту и врачу ложное убеждение, что заболевание отсутствует, в то время как в действительности оно есть. Это зачастую приводит к неуместному или неадекватному лечению. Типичным примером является доверие результатам кардиотестирования при выявлении коронарного атеросклероза, хотя известно, что кардиотестирование выявляет только те затруднения кровотока в коронарной артерии, которые вызваны стенозом.
Ошибки второго рода вызывают серьёзные и трудные для понимания проблемы, особенно когда искомое условие является широкораспространённым. Если тест с 10%-ным уровнем ошибок второго рода используется для обследования группы, где вероятность «истинно-положительных» случаев составляет 70%, то многие отрицательные результаты теста окажутся ложными. (См. Теорему Байеса).
Ошибки первого рода также могут вызывать серьёзные и трудные для понимания проблемы. Это происходит, когда искомое условие является редким. Если уровень ошибок первого рода у теста составляет один случай на десять тысяч, но в тестируемой группе образцов (или людей) вероятность «истинно-положительных» случаев составляет в среднем один случай на миллион, то большинство положительных результатов этого теста будут ложными.[7]
Исследования сверхъестественных явлений[править | править исходный текст]
Термин ошибка первого рода был взят на вооружение исследователями в области паранормальных явлений и привидений для описания фотографии или записи или какого-либо другого свидетельства, которое ошибочно трактуется как имеющее паранормальное происхождение — в данном контексте ошибка первого рода — это какое-либо несостоятельное «медиасвидетельство» (изображение, видеозапись, аудиозапись и т.д.), которое имеет обычное объяснение.[8]
См. также[править | править исходный текст]
- Статистическая значимость
- Атака второго рода
- Случаи ложного срабатывания систем предупреждения о ракетном нападении
- Receiver_operating_characteristic
Примечания[править | править исходный текст]
- ↑ ГОСТ Р 50779.10-2000. «Статистические методы. Вероятность и основы статистики. Термины и определения.». Стр. 26
- ↑ Valerie J. Easton, John H. McColl. Statistics Glossary: Hypothesis Testing.
- ↑ Данный пример как раз характеризует случай, когда классификация ошибок будет зависеть от назначения системы: если биометрическое сканирование используется для допуска сотрудников (нулевая гипотеза: «проходящий сканирование человек действительно является сотрудником»), то ошибочное отождествление будет ошибкой второго рода, а «неузнавание» — ошибкой первого рода; если же сканирование используется для опознания преступников (нулевая гипотеза: «проходящий сканирование человек не является преступником»), то ошибочное отождествление будет ошибкой первого рода, а «неузнавание» — ошибкой второго рода.
- ↑ Относительно скрининга новорожденных, последние исследования показали, что количество ошибок первого рода в 12 раз больше, чем количество верных обнаружений (Gambrill, 2006. [1])
- ↑ Одним из последствий такого высокого уровня ошибок первого рода в США является то, что за произвольный 10-летний период половина обследуемых американских женщин получают как минимум одну ложноположительную маммограмму. Такие ошибочные маммограммы обходятся дорого, приводя к ежегодным расходам в 100 миллионов долларов на последующее (ненужное) лечение. Кроме того, они вызывают излишнюю тревогу у женщин. В результате высокого уровня подобных ошибок первого рода в США, примерно у 90-95% женщин, получивших хотя бы раз в жизни положительную маммограмму, на самом деле заболевание отсутствует.
- ↑ Наиболее низкие уровни этих ошибок наблюдаются в северной Европе, где маммографические плёнки считываются дважды, и для дополнительного тестирования устанавливается повышенное пороговое значение (высокий порог снижает статистическую эффективность теста).
- ↑ Вероятность того, что выдаваемый тестом результат окажется ошибкой первого рода, может быть вычислена при помощи Теоремы Байеса.
- ↑ На некоторых сайтах приведены примеры ошибок первого рода, например: Атлантическое Сообщество Паранормальных явлений (The Atlantic Paranormal Society, TAPS) (недоступная ссылка с 13-05-2013 (398 дней)) и Морстаунская организация по Исследованию Привидений (Moorestown Ghost Research) (недоступная ссылка с 13-05-2013 (398 дней) — история).
Ошибки первого и второго рода
Выдвинутая гипотеза
может быть правильной или неправильной,
поэтому возникает необходимость её
проверки. Поскольку проверку производят
статистическими методами, её называют
статистической. В итоге статистической
проверки гипотезы в двух случаях может
быть принято неправильное решение, т.
е. могут быть допущены ошибки двух родов.
Ошибка первого
рода состоит в том, что будет отвергнута
правильная гипотеза.
Ошибка второго
рода состоит в том, что будет принята
неправильная гипотеза.
Подчеркнём, что
последствия этих ошибок могут оказаться
весьма различными. Например, если
отвергнуто правильное решение «продолжать
строительство жилого дома», то эта
ошибка первого рода повлечёт материальный
ущерб: если же принято неправильное
решение «продолжать строительство»,
несмотря на опасность обвала стройки,
то эта ошибка второго рода может повлечь
гибель людей. Можно привести примеры,
когда ошибка первого рода влечёт более
тяжёлые последствия, чем ошибка второго
рода.
Замечание 1.
Правильное решение может быть принято
также в двух случаях:
-
гипотеза принимается,
причём и в действительности она
правильная; -
гипотеза отвергается,
причём и в действительности она неверна.
Замечание 2.
Вероятность совершить ошибку первого
рода принято обозначать через
![]() ;
;
её называют уровнем значимости. Наиболее
часто уровень значимости принимают
равным 0,05 или 0,01. Если, например, принят
уровень значимости, равный 0,05, то это
означает, что в пяти случаях из ста
имеется риск допустить ошибку первого
рода (отвергнуть правильную гипотезу).
Статистический
критерий проверки нулевой гипотезы.
Наблюдаемое значение критерия
Для проверки
нулевой гипотезы используют специально
подобранную случайную величину, точное
или приближённое распределение которой
известно. Обозначим эту величину в целях
общности через
![]() .
.
Статистическим
критерием
(или просто критерием) называют случайную
величину
![]() ,
,
которая служит для проверки нулевой
гипотезы.
Например, если
проверяют гипотезу о равенстве дисперсий
двух нормальных генеральных совокупностей,
то в качестве критерия
![]() принимают отношение исправленных
принимают отношение исправленных
выборочных дисперсий:.
Эта величина
случайная, потому что в различных опытах
дисперсии принимают различные, наперёд
неизвестные значения, и распределена
по закону Фишера – Снедекора.
Для проверки
гипотезы по данным выборок вычисляют
частные значения входящих в критерий
величин и таким образом получают частное
(наблюдаемое) значение критерия.
Наблюдаемым
значением
![]() называют значение критерия, вычисленное
называют значение критерия, вычисленное
по выборкам. Например, если по двум
выборкам найдены исправленные выборочные
дисперсии![]() и
и![]() ,
,
то наблюдаемое значение критерия.
Критическая
область. Область принятия гипотезы.
Критические точки
После выбора
определённого критерия множество всех
его возможных значений разбивают на
два непересекающихся подмножества:
одно из них содержит значения критерия,
при которых нулевая гипотеза отвергается,
а другая – при которых она принимается.
Критической
областью называют совокупность значений
критерия, при которых нулевую гипотезу
отвергают.
Областью принятия
гипотезы (областью допустимых значений)
называют совокупность значений критерия,
при которых гипотезу принимают.
Основной принцип
проверки статистических гипотез можно
сформулировать так: если наблюдаемое
значение критерия принадлежит критической
области – гипотезу отвергают, если
наблюдаемое значение критерия принадлежит
области принятия гипотезы – гипотезу
принимают.
Поскольку критерий
![]() — одномерная случайная величина, все её
— одномерная случайная величина, все её
возможные значения принадлежат некоторому
интервалу. Поэтому критическая область
и область принятия гипотезы также
являются интервалами и, следовательно,
существуют точки, которые их разделяют.
Критическими
точками (границами)
![]() называют точки, отделяющие критическую
называют точки, отделяющие критическую
область от области принятия гипотезы.
Различают
одностороннюю (правостороннюю или
левостороннюю) и двустороннюю критические
области.
Правосторонней
называют критическую область, определяемую
неравенством
![]() >
>![]() ,
,
где![]() — положительное число.
— положительное число.
Левосторонней
называют критическую область, определяемую
неравенством
![]() <
<![]() ,
,
где![]() — отрицательное число.
— отрицательное число.
Односторонней
называют правостороннюю или левостороннюю
критическую область.
Двусторонней
называют критическую область, определяемую
неравенствами
![]() где
где![]() .
.
В частности, если
критические точки симметричны относительно
нуля, двусторонняя критическая область
определяется неравенствами ( в
предположении, что
![]() >0):
>0):
![]() ,
,
или равносильным неравенством
![]() .
.
Отыскание
правосторонней критической области
Как найти критическую
область? Обоснованный ответ на этот
вопрос требует привлечения довольно
сложной теории. Ограничимся её элементами.
Для определённости начнём с нахождения
правосторонней критической области,
которая определяется неравенством
![]() >
>![]() ,
,
где![]() >0.
>0.
Видим, что для отыскания правосторонней
критической области достаточно найти
критическую точку. Следовательно,
возникает новый вопрос: как её найти?
Для её нахождения
задаются достаточной малой вероятностью
– уровнем значимости
![]() .
.
Затем ищут критическую точку![]() ,
,
исходя из требования, чтобы при условии
справедливости нулевой гипотезы
вероятность того, критерий![]() примет значение, большее
примет значение, большее![]() ,
,
была равна принятому уровню значимости:
Р(![]() >
>![]() )=
)=![]() .
.
Для каждого критерия
имеются соответствующие таблицы, по
которым и находят критическую точку,
удовлетворяющую этому требованию.
Замечание 1.
Когда
критическая точка уже найдена, вычисляют
по данным выборок наблюдаемое значение
критерия и, если окажется, что
![]() >
>![]() ,
,
то нулевую гипотезу отвергают; если же![]() <
<![]() ,
,
то нет оснований, чтобы отвергнуть
нулевую гипотезу.
Пояснение. Почему
правосторонняя критическая область
была определена, исходя из требования,
чтобы при справедливости нулевой
гипотезы выполнялось соотношение
Р(![]() >
>![]() )=
)=![]() ?
?
(*)
Поскольку вероятность
события
![]() >
>![]() мала (
мала (![]() — малая вероятность), такое событие при
— малая вероятность), такое событие при
справедливости нулевой гипотезы, в силу
принципа практической невозможности
маловероятных событий, в единичном
испытании не должно наступить. Если всё
же оно произошло, т.е. наблюдаемое
значение критерия оказалось больше![]() ,
,
то это можно объяснить тем, что нулевая
гипотеза ложна и, следовательно, должна
быть отвергнута. Таким образом, требование
(*) определяет такие значения критерия,
при которых нулевая гипотеза отвергается,
а они и составляют правостороннюю
критическую область.
Замечание 2.
Наблюдаемое значение критерия может
оказаться большим
![]() не потому, что нулевая гипотеза ложна,
не потому, что нулевая гипотеза ложна,
а по другим причинам (малый объём выборки,
недостатки методики эксперимента и
др.). В этом случае, отвергнув правильную
нулевую гипотезу, совершают ошибку
первого рода. Вероятность этой ошибки
равна уровню значимости![]() .
.
Итак, пользуясь требованием (*), мы с
вероятностью![]() рискуем совершить ошибку первого рода.
рискуем совершить ошибку первого рода.
Замечание 3. Пусть
нулевая гипотеза принята; ошибочно
думать, что тем самым она доказана.
Действительно, известно, что один пример,
подтверждающий справедливость некоторого
общего утверждения, ещё не доказывает
его. Поэтому более правильно говорить,
«данные наблюдений согласуются с нулевой
гипотезой и, следовательно, не дают
оснований её отвергнуть».
На практике для
большей уверенности принятия гипотезы
её проверяют другими способами или
повторяют эксперимент, увеличив объём
выборки.
Отвергают гипотезу
более категорично, чем принимают.
Действительно, известно, что достаточно
привести один пример, противоречащий
некоторому общему утверждению, чтобы
это утверждение отвергнуть. Если
оказалось, что наблюдаемое значение
критерия принадлежит критической
области, то этот факт и служит примером,
противоречащим нулевой гипотезе, что
позволяет её отклонить.
Отыскание
левосторонней и двусторонней критических
областей***
Отыскание
левосторонней и двусторонней критических
областей сводится (так же, как и для
правосторонней) к нахождению соответствующих
критических точек. Левосторонняя
критическая область определяется
неравенством
![]() <
<![]() (
(![]() <0).
<0).
Критическую точку находят, исходя из
требования, чтобы при справедливости
нулевой гипотезы вероятность того, что
критерий примет значение, меньшее![]() ,
,
была равна принятому уровню значимости:
Р(![]() <
<![]() )=
)=![]() .
.
Двусторонняя
критическая область определяется
неравенствами
![]() Критические
Критические
точки находят, исходя из требования,
чтобы при справедливости нулевой
гипотезы сумма вероятностей того, что
критерий примет значение, меньшее![]() или большее
или большее![]() ,
,
была равна принятому уровню значимости:
![]() .
.
(*)
Ясно, что критические
точки могут быть выбраны бесчисленным
множеством способов. Если же распределение
критерия симметрично относительно нуля
и имеются основания (например, для
увеличения мощности) выбрать симметричные
относительно нуля точки (-
![]() )и
)и![]() (
(![]() >0),
>0),
то
![]() Учитывая (*), получим
Учитывая (*), получим
![]() .
.
Это соотношение
и служит для отыскания критических
точек двусторонней критической области.
Критические точки находят по соответствующим
таблицам.
Дополнительные
сведения о выборе критической области.
Мощность критерия
Мы строили
критическую область, исходя из требования,
чтобы вероятность попадания в неё
критерия была равна
![]() при условии, что нулевая гипотеза
при условии, что нулевая гипотеза
справедлива. Оказывается целесообразным
ввести в рассмотрение вероятность
попадания критерия в критическую область
при условии, что нулевая гипотеза неверна
и, следовательно, справедлива конкурирующая.
Мощностью критерия
называют вероятность попадания критерия
в критическую область при условии, что
справедлива конкурирующая гипотеза.
Другими словами, мощность критерия есть
вероятность того, что нулевая гипотеза
будет отвергнута, если верна конкурирующая
гипотеза.
Пусть для проверки
гипотезы принят определённый уровень
значимости и выборка имеет фиксированный
объём. Остаётся произвол в выборе
критической области. Покажем, что её
целесообразно построить так, чтобы
мощность критерия была максимальной.
Предварительно убедимся, что если
вероятность ошибки второго рода (принять
неправильную гипотезу) равна
![]() ,
,
то мощность равна 1-![]() .
.
Действительно, если![]() — вероятность ошибки второго рода, т.е.
— вероятность ошибки второго рода, т.е.
события «принята нулевая гипотеза,
причём справедливо конкурирующая», то
мощность критерия равна 1 —![]() .
.
Пусть мощность 1
—
![]() возрастает; следовательно, уменьшается
возрастает; следовательно, уменьшается
вероятность![]() совершить ошибку второго рода. Таким
совершить ошибку второго рода. Таким
образом, чем мощность больше, тем
вероятность ошибки второго рода меньше.
Итак, если уровень
значимости уже выбран, то критическую
область следует строить так, чтобы
мощность критерия была максимальной.
Выполнение этого требования должно
обеспечить минимальную ошибку второго
рода, что, конечно, желательно.
Замечание 1.
Поскольку вероятность события «ошибка
второго рода допущена» равна
![]() ,
,
то вероятность противоположного события
«ошибка второго рода не допущена» равна
1 —![]() ,
,
т.е. мощности критерия. Отсюда следует,
что мощность критерия есть вероятность
того, что не будет допущена ошибка
второго рода.
Замечание 2. Ясно,
что чем меньше вероятности ошибок
первого и второго рода, тем критическая
область «лучше». Однако при заданном
объёме выборки уменьшить одновременно
![]() и
и![]() невозможно; если уменьшить
невозможно; если уменьшить![]() ,
,
то![]() будет возрастать. Например, если принять
будет возрастать. Например, если принять![]() =0,
=0,
то будут приниматься все гипотезы, в
том числе и неправильные, т.е. возрастает
вероятность![]() ошибки второго рода.
ошибки второго рода.
Как же выбрать
![]() наиболее целесообразно? Ответ на этот
наиболее целесообразно? Ответ на этот
вопрос зависит от «тяжести последствий»
ошибок для каждой конкретной задачи.
Например, если ошибка первого рода
повлечёт большие потери, а второго рода
– малые, то следует принять возможно
меньшее![]() .
.
Если
![]() уже выбрано, то, пользуясь теоремой Ю.
уже выбрано, то, пользуясь теоремой Ю.
Неймана и Э.Пирсона, можно построить
критическую область, для которой![]() будет минимальным и, следовательно,
будет минимальным и, следовательно,
мощность критерия максимальной.
Замечание 3.
Единственный способ одновременного
уменьшения вероятностей ошибок первого
и второго рода состоит в увеличении
объёма выборок.
Сущность задачи проверки статистических гипотез
Статистическая гипотеза
—
представляет собой некоторое предположение о законе
распределения случайной величины или о параметрах этого закона,
формулируемое на основе выборки.
Примерами статистических гипотез являются предположения: генеральная
совокупность распределена по экспоненциальному закону; математические
ожидания двух экспоненциально распределенных выборок равны друг другу. В
первой из них высказано предположение о виде закона распределения, а во
второй – о параметрах двух распределений. Гипотезы, в основе которых
нет никаких допущений о конкретном виде закона распределения, называют непараметрическими, в противном случае – параметрическими.
Гипотезу, утверждающую, что различие между
сравниваемыми характеристиками отсутствует, а наблюдаемые отклонения
объясняются лишь случайными колебаниями в выборках, на основании которых
производится сравнение, называют нулевой (основной) гипотезой и обозначают Н0. Наряду с основной гипотезой рассматривают и альтернативную (конкурирующую, противоречащую) ей гипотезу Н1. И если нулевая гипотеза будет отвергнута, то будет иметь место альтернативная гипотеза.
Различают простые и сложные гипотезы. Гипотезу называют простой, если она однозначно характеризует параметр распределения случайной величины.
Например, если l
является параметром экспоненциального распределения, то гипотеза Н0 о равенстве l
=10 – простая гипотеза. Сложной называют гипотезу, которая состоит из конечного или бесконечного множества простых гипотез. Сложная гипотеза Н0 о неравенстве l
> 10 состоит из бесконечного множества простых гипотез Н0 о равенстве l
=bi , где bi – любое число, большее 10. Гипотеза Н0
о том, что математическое ожидание нормального распределения равно двум
при неизвестной дисперсии, тоже является сложной. Сложной гипотезой
будет предположение о распределении случайной величины Х по нормальному закону, если не фиксируются конкретные значения математического ожидания и дисперсии.
Проверка гипотезы основывается на вычислении
некоторой случайной величины – критерия, точное или приближенное
распределение которого известно. Обозначим эту величину через z, ее значение является функцией от элементов выборки z=z(x1, x2, …, xn).
Процедура проверки гипотезы предписывает каждому значению критерия одно
из двух решений – принять или отвергнуть гипотезу. Тем самым все
выборочное пространство и соответственно множество значений критерия
делятся на два непересекающихся подмножества S0 и S1. Если значение критерия z попадает в область S0, то гипотеза принимается, а если в область S1, – гипотеза отклоняется. Множество S0называется областью принятия гипотезы или областью допустимых значений, а множество S1 – областью отклонения гипотезы или критической областью.
Выбор одной области однозначно определяет и другую область.
Принятие или отклонение гипотезы Н0 по
случайной выборке соответствует истине с некоторой вероятностью и, соответственно,
возможны два рода ошибок.
Ошибка первого рода
—
возникает с вероятностью a тогда, когда отвергается верная гипотеза Н0 и принимается конкурирующая гипотеза Н1.
Ошибка второго рода
—
возникает с вероятностью b в том случае, когда принимается неверная гипотеза Н0, в то время как справедлива конкурирующая гипотеза Н1.
Доверительная вероятность – это вероятность не совершить ошибку первого рода и принять верную гипотезу Н0.
Вероятность отвергнуть ложную гипотезу Н0 называется мощностью критерия.
Следовательно, при проверке гипотезы возможны четыре варианта исходов, табл. 3.1.
Таблица 3.1.
| Гипотеза Н0 | Решение | Вероятность | Примечание |
| Верна | Принимается | 1–a | Доверительная вероятность |
| Отвергается | a | Вероятность ошибки первого рода | |
| Неверна | Принимается | b | Вероятность ошибки второго рода |
| Отвергается | 1–b | Мощность критерия |
Например, рассмотрим случай, когда некоторая несмещенная оценка параметра q
вычислена по выборке объема n, и эта оценка имеет плотность распределения f(q
), рис. 3.1.
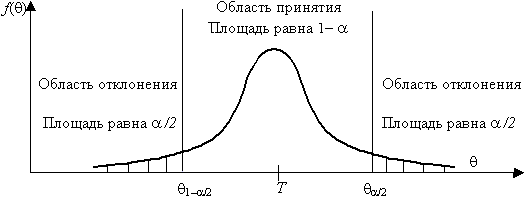
Рис. 3.1. Области и отклонения гипотезы
Предположим, что истинное значение оцениваемого параметра равно Т. Если рассматривать гипотезу Н0 о равенстве q
=Т, то насколько велико должно быть различие между q
и Т, чтобы эту гипотезу отвергнуть. Ответить на данный вопрос
можно в статистическом смысле, рассматривая вероятность достижения
некоторой заданной разности между q
и Т на основе выборочного распределения параметра q
.
Целесообразно полагать одинаковыми значения вероятности выхода параметра q
за нижний и верхний пределы интервала. Такое допущение во многих
случаях позволяет минимизировать доверительный интервал, т.е. повысить
мощность критерия проверки. Суммарная вероятность того, что параметр q
выйдет за пределы интервала с границами q
1–a
/2 и q
a
/2, составляет величину a
. Эту величину следует выбрать настолько
малой, чтобы выход за пределы интервала был маловероятен. Если оценка
параметра попала в заданный интервал, то в таком случае нет оснований
подвергать сомнению проверяемую гипотезу, следовательно, гипотезу
равенства q
=Т можно принять. Но если после получения
выборки окажется, что оценка выходит за установленные пределы, то в этом
случае есть серьезные основания отвергнуть гипотезу Н0. Отсюда следует, что вероятность допустить ошибку первого рода равна a
(равна уровню значимости критерия).
Если предположить, например, что истинное значение параметра в действительности равно Т+d, то согласно гипотезе Н0 о равенстве q
=Т – вероятность того, что оценка параметра q
попадет в область принятия гипотезы, составит b
, рис. 3.2.
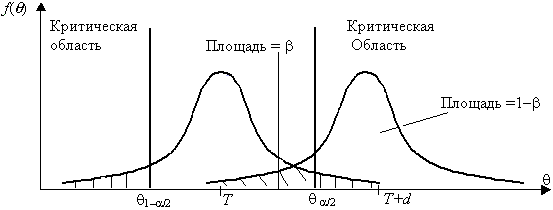
При заданном объеме выборки вероятность совершения ошибки первого рода можно уменьшить, снижая уровень значимости a
. Однако при этом увеличивается вероятность ошибки второго рода b
(снижается мощность критерия). Аналогичные рассуждения можно провести для случая, когда истинное значение параметра равно Т – d.
Единственный способ уменьшить обе вероятности состоит
в увеличении объема выборки (плотность распределения оценки параметра
при этом становится более «узкой»). При выборе критической области
руководствуются правилом Неймана – Пирсона: следует так выбирать
критическую область, чтобы вероятность a
была мала, если гипотеза верна, и велика в противном случае. Однако выбор конкретного значения a
относительно произволен. Употребительные значения лежат в пределах от
0,001 до 0,2. В целях упрощения ручных расчетов составлены таблицы
интервалов с границами q
1–a
/2 и q
a
/2 для типовых значений a
и различных способов построения критерия.
При выборе уровня значимости необходимо учитывать
мощность критерия при альтернативной гипотезе. Иногда большая мощность
критерия оказывается существеннее малого уровня значимости, и его
значение выбирают относительно большим, например 0,2. Такой выбор
оправдан, если последствия ошибок второго рода более существенны, чем
ошибок первого рода. Например, если отвергнуто правильное решение
«продолжить работу пользователей с текущими паролями», то ошибка первого
рода приведет к некоторой задержке в нормальном функционировании
системы, связанной со сменой паролей. Если же принято решения не менять
пароли, несмотря на опасность несанкционированного доступа посторонних
лиц к информации, то эта ошибка повлечет более серьезные последствия.
В зависимости от сущности проверяемой гипотезы и
используемых мер расхождения оценки характеристики от ее теоретического
значения применяют различные критерии. К числу наиболее часто
применяемых критериев для проверки гипотез о законах распределения
относят критерии хи-квадрат Пирсона, Колмогорова, Мизеса, Вилкоксона, о
значениях параметров – критерии Фишера, Стьюдента.
3.2. Типовые распределения
При проверке гипотез широкое применение находит ряд
теоретических законов распределения. Наиболее важным из них является
нормальное распределение. С ним связаны распределения хи-квадрат,
Стьюдента, Фишера, а также интеграл вероятностей. Для указанных законов
функции распределения аналитически не представимы. Значения функций
определяются по таблицам или с использованием стандартных процедур
пакетов прикладных программ. Указанные таблицы обычно построены в целях
удобства проверки статистических гипотез в ущерб теории распределений –
они содержат не значения функций распределения, а критические значения
аргумента z(a
).
Для односторонней критической области z(a
) = z1–a
, т.е. критическое значение аргумента z(a
) соответствует квантили z1–a
уровня 1– a
, так как 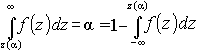 , рис. 3.3.
, рис. 3.3.
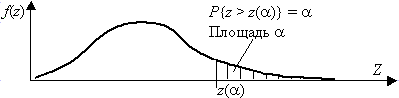
Для двусторонней критической области, с уровнем значимости a , размер левой области a 2, правой a 1 (a 1+a 2=a ), рис. 3.4. Значения z(a 2) и z(a 1) связаны с квантилями распределения соотношениями z(a 1)=z1–a 1, z(a 2)=za 2, так как 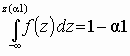 , . Для симметричной функции плотности распределения f(z) критическую область выбирают из условия a 1=a 2=a /2 (обеспечивается наибольшая мощность критерия). В таком случае левая и правая границы будут равны |z(a /2)|.
, . Для симметричной функции плотности распределения f(z) критическую область выбирают из условия a 1=a 2=a /2 (обеспечивается наибольшая мощность критерия). В таком случае левая и правая границы будут равны |z(a /2)|.
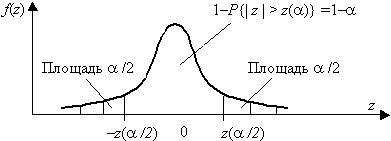
Рис. 3.4. Двусторонняя критическая область
Нормальное распределение
Этот вид распределения является наиболее важным в
связи с центральной предельной теоремой теории вероятностей:
распределение суммы независимых случайных величин стремится к
нормальному с увеличением их количества при произвольном законе
распределения отдельных слагаемых, если слагаемые обладают конечной
дисперсией. Так как реальные физические явления часто представляют собой
результат суммарного воздействия многих факторов, то в таких случаях
нормальное распределение является хорошим приближением наблюдаемых
значений. Функция плотности нормального распределения
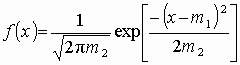
(3.1)
– унимодальная, симметричная, аргумент х может принимать любые действительные значения, рис. 3.5.
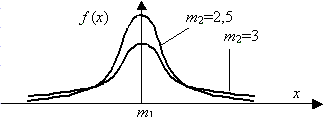
Рис. 3.5. Плотность нормального распределения
Функция плотности нормального распределения стандартизованной величины u имеет вид:
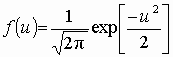
Вычисление значений функции распределения Ф(u) для стандартизованного неотрицательного аргумента u (u ³
0) можно произвести с помощью полинома наилучшего приближения [9, стр. 694]
Ф(u)= 1– 0,5(1 + 0,196854u + 0,115194u2 +
+ 0,000344u3 + 0,019527u4)– 4.(3.2)
Такая аппроксимация обеспечивает абсолютную ошибку не более 0,00025. Для вычисления Ф(u) в области отрицательных значений стандартизованного аргумента u (u<0) следует воспользоваться свойством симметрии нормального распределения Ф(u) = 1 –Ф(–u).
Иногда в справочниках вместо значений функции Ф(u) приводят значения интеграла вероятностей
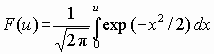
, u > 0.(3.3)
Интеграл вероятностей связан с функцией нормального распределения соотношением Ф(u) = 0,5 + F(u).
Распределение хи-квадрат
Распределению хи-квадрат (c
2-распределению) с k степенями свободы соответствует распределение суммы 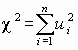 квадратов n стандартизованных случайных величин ui, каждая из которых распределена по нормальному закону, причем k из них независимы, n ³
квадратов n стандартизованных случайных величин ui, каждая из которых распределена по нормальному закону, причем k из них независимы, n ³
k. Функция плотности распределения хи-квадрат с k степенями свободы
![]()
, xі0,(3.4)
где х = c
2, Г(k/2) – гамма-функция.
Число степеней свободы k определяет количество независимых слагаемых в выражении для c
2. Функция плотности при k, равном одному или двум, – монотонная, а при k >2 – унимодальная, несимметричная, рис. 3.6.
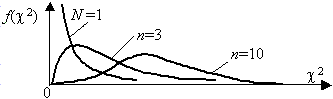
Рис. 3.6. Плотность распределения хи-квадрат
Математическое ожидание и дисперсия величины c
2 равны соответственно k и 2k.
Распределение хи-квадрат является частным случаем более общего
гамма-распределения, а величина, равная корню квадратному из хи-квадрат с
двумя степенями свободы, подчиняется распределению Рэлея.
С увеличением числа степеней свободы (k >30) распределение хи-квадрат приближается к нормальному распределению с математическим ожиданием k и дисперсией 2k. В таких случаях критическое значение c 2(k; a ) » u1– a (k, 2k), где u1– a (k, 2k) – квантиль нормального распределения. Погрешность аппроксимации не превышает нескольких процентов.
Распределение Стьюдента
Распределение Стьюдента (t-распределение, предложено в 1908 г. английским статистиком В. Госсетом, публиковавшим научные труды под псевдонимом Student) характеризует распределение случайной величины 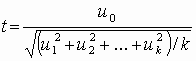 , где u0, u1, …, uk взаимно независимые нормально распределенные случайные величины с нулевым средним и конечной дисперсией. Аргумент t не зависит от дисперсии слагаемых. Функция плотности распределения Стьюдента
, где u0, u1, …, uk взаимно независимые нормально распределенные случайные величины с нулевым средним и конечной дисперсией. Аргумент t не зависит от дисперсии слагаемых. Функция плотности распределения Стьюдента
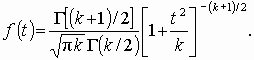
(3.5)
Величина k
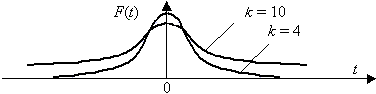
характеризует количество степеней свободы. Плотность распределения –
унимодальная и симметричная функция, похожая на нормальное
распределение, рис. 3.7.
Область изменения аргумента t от –Ґ
до Ґ
. Математическое ожидание и дисперсия равны 0 и k/(k–2) соответственно, при k>2.
По сравнению с нормальным распределение Стьюдента более пологое, оно
имеет меньшую дисперсию. Это отличие заметно при небольших значениях k,
что следует учитывать при проверке статистических гипотез (критические
значения аргумента распределения Стьюдента превышают аналогичные
показатели нормального распределения). Таблицы распределения содержат
значения для односторонней или двусторонней критической области.
Распределение Стьюдента применяется для описания ошибок выборки при k Ј 30. При k >100 данное распределение практически соответствует нормальному, для 30 < k < 100 различия между распределением Стьюдента и нормальным распределением составляют несколько процентов. Поэтому относительно оценки ошибок малыми считаются выборки объемом не более 30 единиц, большими – объемом более 100 единиц. При аппроксимации распределения Стьюдента нормальным распределением для односторонней критической области вероятность Р{t> t(k; a )} = u1– a (0, k/(k–2)), где u1– a (0, k/(k–2)) – квантиль нормального распределения. Аналогичное соотношение можно составить и для двусторонней критической области.
Распределение Фишера
Распределению Р.А. Фишера (F-распределению Фишера – Снедекора) подчиняется случайная величина х =[(y1/k1)/(y2/k2)],равная отношению двух случайных величин у1и у2, имеющих хи-квадрат распределение с k1 и k2 степенями свободы. Область изменения аргумента х от 0 до ¥
. Плотность распределения
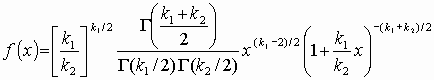
.(3.6)
В этом выражении k1обозначает число степеней свободы величины y1 с большей дисперсией, k2– число степеней свободы величины y2 с меньшей дисперсией. Плотность распределения – унимодальная, несимметричная, рис. 3.8.
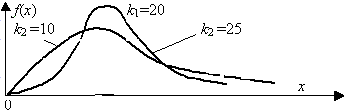
Рис. 3.8. Плотность распределения Фищера
Математическое ожидание случайной величины х равно k2/(k2–2) при k2>2, дисперсия т2 = [2 k22 (k1+k2–2)]/[k1(k2–2)2(k2–4)] при k2 > 4. При k1 > 30 и k2 > 30 величина х распределена приближенно нормально с центром (k1 – k2)/(2 k1 k2) и дисперсией (k1 + k2)/(2 k1 k2).
3.3. Проверка гипотез о законе распределения
Обычно сущность проверки гипотезы о законе распределения ЭД заключается в следующем. Имеется выборка ЭД фиксированного объема, выбран или известен вид закона распределения генеральной совокупности. Необходимо оценить по этой выборке параметры закона, определить степень согласованности ЭД и выбранного закона распределения, в котором параметры заменены их оценками. Пока не будем касаться способов нахождения оценок параметров распределения, а рассмотрим только вопрос проверки согласованности распределений с использованием наиболее употребительных критериев.
Критерий хи-квадрат К. Пирсона
Использование этого критерия основано на применении такой меры (статистики) расхождения между теоретическим F(x) и эмпирическим распределением Fп(x), которая приближенно подчиняется закону распределения c
2. Гипотеза Н0
о согласованности распределений проверяется путем анализа распределения
этой статистики. Применение критерия требует построения статистического
ряда.
Итак, пусть выборка представлена статистическим рядом с количеством разрядов y
. Наблюдаемая частота попаданий в i-й разряд ni. В соответствии с теоретическим законом распределения ожидаемая частота попаданий в i-й разряд составляет Fi. Разность между наблюдаемой и ожидаемой частотой составит величину (n i – Fi). Для нахождения общей степени расхождения между F(x) и Fп(x) необходимо подсчитать взвешенную сумму квадратов разностей по всем разрядам статистического ряда
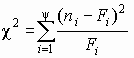
.(3.7)
Величина c
2 при неограниченном увеличении n
имеет распределение хи-квадрат (асимптотически распределена как
хи-квадрат). Это распределение зависит от числа степеней свободы k, т.е. количества независимых значений слагаемых в выражении (3.7). Число степеней свободы равно числу y
минус число линейных связей, наложенных на выборку. Одна связь
существует в силу того, что любая частота может быть вычислена по
совокупности частот в оставшихся y
– 1 разрядах. Кроме того, если параметры распределения неизвестны
заранее, то имеется еще одно ограничение, обусловленное подгонкой
распределения к выборке. Если по выборке определяются f
параметров распределения, то число степеней свободы составит k=y
– f
–1.
Область принятия гипотезы Н0 определяется условием c
2£
c
2(k;a
), где c
2(k;a
) – критическая точка распределения хи-квадрат с уровнем значимости a
. Вероятность ошибки первого рода равна a
, вероятность ошибки второго рода четко определить нельзя, потому что
существует бесконечно большое множество различных способов несовпадения
распределений. Мощность критерия зависит от количества разрядов и объема
выборки. Критерий рекомендуется применять при n>200, допускается применение при n>40, именно при таких условиях критерий состоятелен (как правило, отвергает неверную нулевую гипотезу).
Пример 3.1. Проверить с помощью критерия
хи-квадрат гипотезу о нормальности распределения случайной величины,
представленной статистическим рядом в табл. 2.4 при уровне значимости a
= 0,05.
Решение. В примере 2.3 были вычислены значения оценок моментов: m
1=27,51, m
2 = 0,91, s
= 0,96. На основе табл. 2.4 построим табл. 3.2, иллюстрирующую расчеты.
Таблица 3.2
| Номер интервала, i | 1 | 2 | 3 | 4 | 5 | 6 |
| n i | 5 | 9 | 10 | 9 | 5 | 6 |
| xi | 26,37 | 26,95 | 27,53 | 28,12 | 28,70 | ¥ |
| F(xi) | 0,117 | 0,280 | 0,508 | 0,737 | 0,892 | 1 |
|
D Fi |
0,117 | 0,166 | 0,228 | 0,228 | 0,155 | 0,108 |
| Fi | 5,148 | 7,304 | 10,032 | 10,032 | 6,820 | 4,752 |
| (ni —Fi)2/Fi | 0,004 | 0,394 | 0,0001 | 0,1062 | 0,486 | 0,328 |
В этой таблице:
ni – частота попаданий элементов выборки в i-й интервал;
xi – верхняя граница i-го интервала;
F(xi) – значение функции нормального распределения;
D
Fi – теоретическое значение вероятности попадания случайной величины в i-й интервал
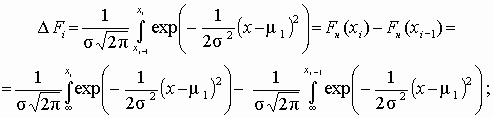
Fi = D
Fi*n – теоретическая частота попадания случайной величины в i-й интервал;
(n i – Fi)2/Fi – взвешенный квадрат отклонения.
Для нормального закона возможные значения случайной величины лежат в диапазоне от – ¥
до ¥
, поэтому при расчетах оценок вероятностей крайний левый и крайний правый интервалы расширяются до – ¥
и ¥
соответственно. Вычислить значения функции нормального распределения
можно, воспользовавшись стандартными функциями табличного процессора или
полиномом наилучшего приближения.
Сумма взвешенных квадратов отклонения c 2=1,32. Число степеней свободы k=6–1–2=3 (уклонения связаны линейным соотношением  , кроме того, на уклонения наложены еще две связи, так как по выборке были определены два параметра распределения). Критическое значение c 2(3;0,05)= 7,815 определяется по табл. П.3 приложения. Поскольку соблюдается условие c 2 <c 2(3;0,05), то полученный результат нельзя считать значимым и гипотеза о нормальном распределении генеральной совокупности не противоречит ЭД.
, кроме того, на уклонения наложены еще две связи, так как по выборке были определены два параметра распределения). Критическое значение c 2(3;0,05)= 7,815 определяется по табл. П.3 приложения. Поскольку соблюдается условие c 2 <c 2(3;0,05), то полученный результат нельзя считать значимым и гипотеза о нормальном распределении генеральной совокупности не противоречит ЭД.
Критерий А.Н. Колмогорова
Для применения критерия А.Н. Колмогорова ЭД требуется
представить в виде вариационного ряда (ЭД недопустимо объединять в
разряды). В качестве меры расхождения между теоретической F(x) и эмпирической Fn(x) функциями распределения непрерывной случайной величины Х используется модуль максимальной разностиdn = max|F(x) — Fn(x)|.
(3.8)
А.Н. Колмогоров доказал, что какова бы ни была функция распределения F(x) величины Х при неограниченном увеличении количества наблюдений n функция распределения случайной величины dn 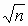 асимптотически приближается к функции распределения
асимптотически приближается к функции распределения 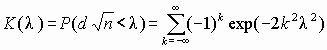 . Иначе говоря, критерий А.Н. Колмогорова характеризует вероятность того, что величина dn не будет превосходить параметр l для любой теоретической функции распределения. Уровень значимости a выбирается из условия
. Иначе говоря, критерий А.Н. Колмогорова характеризует вероятность того, что величина dn не будет превосходить параметр l для любой теоретической функции распределения. Уровень значимости a выбирается из условия 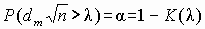 , в силу предположения, что почти невозможно получить это равенство, когда существует соответствие между функциями F(x) и Fn(x). Критерий А.Н. Колмогорова позволяет проверить согласованность распределений по малым выборкам, он проще критерия хи-квадрат, поэтому его часто применяют на практике. Но требуется учитывать два обстоятельства.
, в силу предположения, что почти невозможно получить это равенство, когда существует соответствие между функциями F(x) и Fn(x). Критерий А.Н. Колмогорова позволяет проверить согласованность распределений по малым выборкам, он проще критерия хи-квадрат, поэтому его часто применяют на практике. Но требуется учитывать два обстоятельства.
Во-первых, в точном соответствии с условиями его применения необходимо пользоваться следующим соотношением
![]()
где
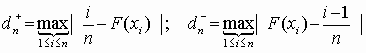
Во-вторых, условия применения критерия
предусматривают, что теоретическая функция распределения известна
полностью (известны вид функции и ее параметры). Но на практике
параметры обычно неизвестны и оцениваются по ЭД. Это приводит к
завышению значения вероятности соблюдения нулевой гипотезы, т.е.
повышается риск принять в качестве правдоподобной гипотезу, которая
плохо согласуется с ЭД (повышается вероятность совершить ошибку второго
рода). В качестве меры противодействия такому выводу следует увеличить
уровень значимости a
, приняв его равным 0,1 – 0,2, что приведет к уменьшению зоны допустимых отклонений.
Пример 3.2. Проверить с помощью критерия А.Н.
Колмогорова гипотезу о том, что ЭД, представленные в табл. 2.3,
подчиняются нормальному распределению при уровне значимости a
=0,1.
Решение. Исходные данные и результаты
вычислений сведены в табл. 3.3. Необходимые вычисления можно провести с
использованием табличного процессора: значение эмпирической функции
распределения Fn(xi)=i/44; значения теоретической функции F(xi) – это значение функции нормального распределения в точке xi.
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| xi | 25,79 | 25,98 | 25,98 | 26,12 | 26,13 | 26,49 | 26,52 | 26,60 | 26,66 | 26,69 | 26,74 |
| Fn(xi) | 0,023 | 0,046 | 0,068 | 0,091 | 0,114 | 0,136 | 0,159 | 0,182 | 0,204 | 0,227 | 0,250 |
| F(xi) | 0,036 | 0,055 | 0,055 | 0,073 | 0,075 | 0,144 | 0,151 | 0,170 | 0,188 | 0,196 | 0,211 |
| dn+ | 0,014 | 0,009 | 0,013 | 0,018 | 0,038 | 0,008 | 0,008 | 0,012 | 0,016 | 0,032 | 0,039 |
| dn— | 0,036 | 0,032 | 0,010 | 0,005 | 0,016 | 0,031 | 0,014 | 0,011 | 0,006 | 0,009 | 0,016 |
| i | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| xi | 26,85 | 26,90 | 26,91 | 26,96 | 27,02 | 27,11 | 27,19 | 27,21 | 27,28 | 27,30 | 27,38 |
| Fn(xi) | 0,273 | 0,296 | 0,318 | 0,341 | 0,364 | 0,386 | 0,409 | 0,432 | 0,455 | 0,477 | 0,500 |
| F(xi) | 0,246 | 0,263 | 0,267 | 0,284 | 0,305 | 0,337 | 0,371 | 0,378 | 0,406 | 0,412 | 0,447 |
| dn+ | 0,027 | 0,032 | 0,051 | 0,057 | 0,059 | 0,050 | 0,038 | 0,054 | 0,049 | 0,065 | 0,053 |
| dn— | 0,004 | 0,010 | 0,028 | 0,034 | 0,036 | 0,027 | 0,015 | 0,031 | 0,026 | 0,042 | 0,031 |
| i | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 |
| xi | 27,40 | 27,49 | 27,64 | 27,66 | 27,71 | 27,78 | 27,89 | 27,89 | 28,01 | 28,10 | 28,11 |
| Fn(xi) | 0,523 | 0,546 | 0,568 | 0,591 | 0,614 | 0,636 | 0,659 | 0,682 | 0,705 | 0,727 | 0,750 |
| F(xi) | 0,456 | 0,492 | 0,555 | 0,561 | 0,583 | 0,610 | 0,656 | 0,656 | 0,701 | 0,731 | 0,735 |
| dn+ | 0,067 | 0,053 | 0,013 | 0,030 | 0,031 | 0,026 | 0,003 | 0,026 | 0,003 | 0,004 | 0,015 |
| dn— | 0,044 | 0,031 | 0,010 | 0,007 | 0,008 | 0,003 | 0,019 | 0,003 | 0,020 | 0,027 | 0,008 |
| i | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 |
| xi | 28,37 | 28,38 | 28,50 | 28,63 | 28,67 | 28,90 | 28,99 | 28,99 | 29,03 | 29,12 | 29,28 |
| Fn(xi) | 0,773 | 0,795 | 0,818 | 0,841 | 0,864 | 0,886 | 0,909 | 0,932 | 0,955 | 0,977 | 1,000 |
| F(xi) | 0,817 | 0,819 | 0,851 | 0,879 | 0,888 | 0,928 | 0,939 | 0,940 | 0,944 | 0,954 | 0,968 |
| dn+ | 0,044 | 0,024 | 0,032 | 0,038 | 0,024 | 0,042 | 0,030 | 0,008 | 0,010 | 0,024 | 0,032 |
| dn— | 0,067 | 0,046 | 0,055 | 0,061 | 0,047 | 0,064 | 0,053 | 0,031 | 0,013 | 0,001 | 0,009 |
В данном примере максимальные значения dn+ и dn–одинаковы и равны 0,067. Из табл. П.1 при a =0,1 найдем l =1,22. Для n=44 критическое значение 0,184. Поскольку величина max dn=0,067 меньше критического значения, гипотеза о принадлежности выборки нормальному закону не отвергается.
Критерий Мизеса
В качестве меры различия теоретической функции распределения F(x) и эмпирической Fn(x) по критерию Мизеса (критерию w
2) выступает средний квадрат отклонений по всем значениям аргумента x
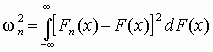
(3.9)
Статистика критерия
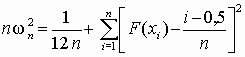
(3.10)
При неограниченном увеличении n существует предельное распределение статистики nw
n2. Задав значение вероятности a
можно определить критические значения nw
n2(a
). Проверка гипотезы о законе распределения осуществляется обычным образом: если фактическое значение nw
n2окажется больше критического или равно ему, то согласно критерию Мизеса с уровнем значимости a
гипотеза Но о том, что закон распределения генеральной совокупности соответствует F(x), должна быть отвергнута.
Пример 3.3. Проверить с помощью критерия
Мизеса гипотезу о том, что ЭД, представленные вариационным рядом, табл.
2.3, подчиняются нормальному распределению при уровне значимости a
= 0,1.
Решение. Исходные данные и результаты вычислений представлены в табл. 3.4.
| i | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| xi | 25,79 | 25,98 | 25,98 | 26,12 | 26,13 | 26,49 | 26,52 | 26,60 | 26,66 | 26,69 | 26,74 |
| Fn(xi) | 0,011 | 0,034 | 0,057 | 0,080 | 0,102 | 0,125 | 0,148 | 0,171 | 0,193 | 0,216 | 0,237 |
| F(xi) | 0,036 | 0,055 | 0,055 | 0,073 | 0,075 | 0,144 | 0,151 | 0,170 | 0,188 | 0,196 | 0,211 |
|
D i |
0,618 | 0,429 | 0,003 | 0,047 | 0,726 | 0,378 | 0,009 | 0,000 | 0,025 | 0,409 | 0,742 |
| i | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| xi | 26,85 | 26,90 | 26,91 | 26,96 | 27,02 | 27,11 | 27,19 | 27,21 | 27,28 | 27,30 | 27,38 |
| Fn(xi) | 0,261 | 0,284 | 0,307 | 0,330 | 0,352 | 0,375 | 0,398 | 0,421 | 0,443 | 0,466 | 0,489 |
| F(xi) | 0,246 | 0,263 | 0,267 | 0,284 | 0,305 | 0,337 | 0,371 | 0,378 | 0,406 | 0,412 | 0,447 |
|
D i |
0,231 | 0,439 | 1,572 | 2,071 | 2,243 | 1,467 | 0,717 | 1,790 | 1,391 | 2,866 | 1,755 |
| i | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 | 31 | 32 | 33 |
| xi | 27,40 | 27,49 | 27,64 | 27,66 | 27,71 | 27,78 | 27,89 | 27,89 | 28,01 | 28,10 | 28,11 |
| Fn(xi) | 0,511 | 0,534 | 0,557 | 0,580 | 0,602 | 0,625 | 0,648 | 0,671 | 0,693 | 0,716 | 0,739 |
| F(xi) | 0,456 | 0,492 | 0,555 | 0,561 | 0,583 | 0,610 | 0,656 | 0,656 | 0,701 | 0,731 | 0,735 |
|
D i |
3,103 | 1,765 | 0,003 | 0,332 | 0,374 | 0,216 | 0,063 | 0,213 | 0,067 | 0,238 | 0,013 |
| I | 34 | 35 | 36 | 37 | 38 | 39 | 40 | 41 | 42 | 43 | 44 |
| xi | 28,37 | 28,38 | 28,50 | 28,63 | 28,67 | 28,90 | 28,99 | 28,99 | 29,03 | 29,12 | 29,28 |
| Fn(xi) | 0,761 | 0,784 | 0,807 | 0,830 | 0,852 | 0,875 | 0,898 | 0,921 | 0,943 | 0,966 | 0,989 |
| F(xi) | 0,817 | 0,819 | 0,851 | 0,879 | 0,888 | 0,928 | 0,939 | 0,940 | 0,944 | 0,954 | 0,968 |
|
D i |
3,090 | 1,230 | 1,908 | 2,461 | 1,271 | 2,791 | 1,737 | 0,381 | 0,001 | 0,149 | 0,432 |
В этой таблице:
Fn(xi)=(i–0,5)/44 – значение эмпирической функции распределения;
F(xi) – значение теоретической функции распределения, соответствует значению функции нормального распределения в точке xi;
D
i =1000[Fn(xi) – F(xi)]2 .Здесь масштабный множитель 1000 введен для удобства отображения данных в таблице, при расчетах он не используется.
Критическое значение статистики критерия Мизеса при заданном уровне значимости равно 0,347, табл. П.2. Фактическое значение статистики , что меньше критического значения. Следовательно, гипотеза Н0 не противоречит имеющимся данным.
Достоинством критерия Мизеса является быстрая
сходимость к предельному закону, для этого достаточно не менее 40
наблюдений в области часто используемых на практике больших значений nw
n (а не несколько сот, как для критерия хи-квадрат).
Сопоставляя возможности различных критериев,
необходимо отметить следующие особенности. Критерий Пирсона устойчив к
отдельным случайным ошибкам в ЭД. Однако его применение требует
группирования данных по интервалам, выбор которых относительно
произволен и подвержен противоречивым рекомендациям. Критерий
Колмогорова слабо чувствителен к виду закона распределения и подвержен
влиянию помех в исходной выборке, но прост в применении. Критерий Мизеса
имеет ряд общих свойств с критерием Колмогорова: оба основаны
непосредственно на результатах наблюдения и не требуют построения
статистического ряда, что повышает объективность выводов; оба не
учитывают уменьшение числа степеней свободы при определении параметров
распределения по выборке, а это ведет к риску принятия ошибочной
гипотезы. Их предпочтительно применять в тех случаях, когда параметры
закона распределения известны априори, например, при проверке датчиков
случайных чисел.
При проверке гипотез о законе распределения следует
помнить, что слишком хорошее совпадение с выбранным законом
распределения может быть обусловлено некачественным экспериментом
(“подчистка” ЭД) или предвзятой предварительной обработкой результатов
(некоторые результаты отбрасываются или округляются).
Выбор критерия проверки гипотезы относительно
произволен. Разные критерии могут давать различные выводы о
справедливости гипотезы, окончательное заключение в таком случае
принимается на основе неформальных соображений. Точно также нет
однозначных рекомендаций по выбору уровня значимости.
Рассмотренный подход к проверке гипотез, основанный
на применении специальных таблиц критических точек распределения,
сложился в эпоху «ручной» обработки ЭД, когда наличие таких таблиц
существенно снижало трудоемкость вычислений. В настоящее время
математические пакеты включают процедуры вычисления стандартных функций
распределений, что позволяет отказаться от использования таблиц, но
может потребовать изменения правил проверки. Например, соблюдению
гипотезы Н0 соответствует такое значение функции распределения критерия, которое не превышает значение доверительной вероятности 1– a
(оценка статистики критерия соответствует доверительному интервалу). В
частности, для примера 3.1 значение статистики критерия хи-квадрат равно
1,318. А значение функции
распределения хи-квадрат для этого значения аргумента при трех степенях
свободы составляет 0,275, что меньше доверительной вероятности 0,95.
Следовательно, нет оснований отвергать нулевую гипотезу.