
Причина ошибки «Out of memory» на VPS
(3).png)
Каждому виртуальному серверу назначается фиксированный объём оперативной памяти, в зависимости от выбранного тарифного плана: от 1ГБ до 32ГБ.
Когда запущенные процессы и приложения хотят получить больше памяти, операционная система обычно начинает случайным образом выбирать некоторые процессы и принудительно завершать их в аварийном режиме.
В результате некоторые службы на сервере перестают работать, сервер часто перегружается и «зависает» в целом, выдавая ошибку «out of memory» (OOM) — нехватка операционной памяти.
Если процесс завершается в целях экономии памяти, она регистрируется в системных журналах и хранится в /var/log/, где вы можете найти подобное сообщения о нехватке памяти:
Jav 11 17:12:34 ovzhost114 kernel: [63353551.892881] Out of memory in UB 33222955: OOM
killed process 110919 (mysqld) score 0 vm:404635kB, rss:06665kB, swap:0kB
В зависимости от дистрибутива Linux и конфигурации системы, вид этой записи может меняться.
Как решить ошибку «Out of memory» на VPS
Узнайте какие процессы запущены
Вам нужно узнать обо всех запущенных процессах и сколько оперативной памяти они потребляют.
- Использование памяти можно отслеживать, например, с помощью команды:
free -h,
которая предоставляет текущую статистику памяти. К примеру, результаты, предоставленные системой в 1ГБ, будут выглядеть примерно так:
| total | used | free | shared | buffers |
cached |
|
|
Mem |
993M | 738M | 255M | 5.7M | 64M |
439M |
|
-/+ buffers/cache: |
234M | 759M | ||||
|
Swap: |
0B | 0B | 0B |
- Ещё одним полезным инструментом для мониторинга памяти является «top», который отображает полезную, постоянно обновляемую информацию об использовании памяти и ЦП, времени выполнения процессов и другой статистике. Это особенно полезно для определения ресурсоёмких задач.
Программа будет работать до тех пор, пока вы не выйдете их неё нажатием «q». Использование ресурсов отображается в процентах и предоставляет лаконичный обзор нагрузки на вашу систему.
(3).png)
Снизьте потребление оперативной памяти
Ограничьте работу ресурсоёмких плагинов и удалите лишние расширения и плагины сайта.
Оптимизируйте настройки MySQL с помощью Mysqltuner
Mysqltuner – это высокопроизводительный сценарий для настройки MySQL, который предоставляет подробную информацию о состоянии и работоспособности сервера MySQL, и даёт конкретные рекомендации по улучшению и повышению производительности.
- Чтобы установить mysqltuner, запустите следующие команды, в зависимости от ОС:
Debian/Ubuntu:
sudo apt-get -y install mysqltuner
CentOS:
sudo yum -y install mysqltuner
- Теперь можно запустить Mysqltuner: mysqltuner
В результате анализа вы получите крайне полезную информацию. Обратите внимание на раздел Recommendations.
- После строки Variables to adjust указаны параметры, которые следует изменить или дописать в случае их отсутствия в файле my.cnf.
Вы сможете найти этот файл в директории:
Debian/Ubuntu:
/etc/mysql/my.cnf
CentOS:
/etc/my.cnf
- Перезагрузите MySQL с помощью команд:
Debian/Ubuntu:
sudo /etc/init.d/mysql restart
CentOS:
sudo systemctl restart mariadb
Оптимизируйте настройки Apache
Неправильная настройка параметров Apache может стать огромной головной болью и привести к нехватке оперативной памяти VPS.
Вы можете выполнить следующие действия:
- Измените файл httpd.conf следующим образом. Такие параметры подходят для сервера с оперативной памятью в 1 ГБ.
|
KeepAlive Off MaxKeepAliveRequests |
100 |
|
KeepAliveTimeout |
15 |
|
StartServers |
2 |
|
ServerLimit |
2 |
|
MinSpareThreads |
50 |
|
MaxSpareThreads |
100 |
|
ThreadLimit |
100 |
|
ThreadsPerChild |
50 |
|
MaxClients |
100 |
|
MaxRequestsPerChild |
10000 |
- Кроме того, этот код можно внести в отдельный файл с расширением .conf и сохранить его в директории /etc/httpd/conf.d.
- Перезагрузите Apache: apachectl restart
Установите Nginx
Nginx служит хорошим балансировщиком нагрузки в сочетании с Apache и потребляет значительно меньше памяти. Больше о нём вы сможете узнать из нашей статьи Что такое nginx и как правильно его настроить.
Включите кэширование контента
Включение кэша вашего сайта уменьшит возникающие ошибки. Этот способ будет особенно полезен, если ваш сайт получает огромный объём трафика.
Перейдите на более высокий тарифный план
При нехватке оперативной памяти рекомендуется выбрать другой тариф VPS. Вы можете ознакомиться с тарифами VDS/VPS на нашем сайте.
Закажите услугу «Администрирование по запросу»
Услуга «Администрирование по запросу» может существенно облегчить вам решение этой проблемы. Просто доверьтесь специалистам RU-CENTER, и они сделают всю сложную работу за вас.
Время на прочтение
17 мин
Количество просмотров 70K
Приветствую, Хабр!
Немного лирики
Сегодня, 2015-03-21, я решил сделать пол-дела, и всё-таки начать писать статью о том, как же всё-таки начать понимать, что же делать с OOM, да и вообще научиться ковырять heap-dump’ы (буду называть их просто дампами, для простоты речи. Также я постараюсь избегать англицизмов, где это возможно).
Задуманный мной объём «работ» по написанию этой статьи кажется мне не однодневным, а посему статья должна появиться лишь
через пару недель
спустя день.
В этой статье я постараюсь разжевать, что делать с дампами в Java, как понять причину или приблизиться к причине возникновения OOM, посмотреть на инструменты для анализа дампов, инструмент (один, да) для мониторинга хипа, и вообще вникнуть в это дело для общего развития. Исследуются такие инструменты, как JVisualVM (рассмотрю некоторые плагины к нему и OQL Console), Eclipse Memory Analyzing Tool.
Очень много понаписал, но надеюсь, что всё только по делу 
Предыстория
Для начала нужно понять, как возникает OOM. Кому-то это может быть ещё неизвестно.
Представьте себе, что есть какой-то верхний предел занимаемой оперативки для приложения. Пусть это будет гигабайт ОЗУ.
Само по себе возникновение OOM в каком-то из потоков ещё не означает, что именно этот поток «выжрал» всю свободную память, да и вообще не означает, что именно тот кусок кода, который привёл к OOM, виноват в этом.
Вполне нормальна ситуация, когда какой-то поток чем-то занимался, поедая память, «дозанимался» этим до состояния «ещё немного, и я лопну», и завершил выполнение, приостановившись. А в это время какой-то другой поток решил запросить для своей маленькой работы ещё немного памяти, сборщик мусора попыжылся, конечно, но мусора уже в памяти не нашёл. В этом случае как раз и возникает OOM, не связанный с источником проблемы, когда стектрейс покажет совсем не того виновника падения приложения.
Есть и другой вариант. Около недели я исследовал, как улучшить жизнь парочки наших приложений, чтобы они перестали себя нестабильно вести. И ещё недельку-две потратил на то, чтобы привести их в порядок. В общей сложности пара недель времени, которые растянулись на полтора месяца, ведь занимался я не только этими проблемами.
Из найденного: сторонняя библиотека, и, конечно же, некоторые неучтённые вещи в вызовах хранимых процедур.
В одном приложении симптомы были следующие: в зависимости от нагрузки на сервис, оно могло упасть через сутки, а могло через двое. Если помониторить состояние памяти, то было видно, что приложение постепенно набирало «размер», и в определённый момент просто ложилось.
С другим приложением несколько интереснее. Оно может вести себя хорошо длительный срок, а могло перестать отвечать минут через 10 после перезагрузки, или вдруг внезапно упасть, сожрав всю свободную память (это я уже сейчас вижу, наблюдая за ним). А после обновления версии, когда была изменена и версия Tomcat с 7й до 8й, и JRE, оно вдруг в одну из пятниц (проработав вменяемо до этого ни много ни мало — 2 недели) начало творить такие вещи, что стыдно признаваться в этом.
В обоих историях очень полезны оказались дампы, благодаря им удалось отыскать все причины падений, подружившись с такими инструментами, как JVisualVM (буду называть его JVVM), Eclipse Memory Analyzing Tool (MAT) и языком OQL (может быть я не умею его правильно готовить в MAT, но мне оказалось легче подружиться с реализацией OQL именно в JVVM).
Ещё вам понадобится свободная оперативка для того, чтобы было куда загружать дампы. Её объём должен быть соизмерим с размером открываемого дампа.
Начало
Итак, начну потихоньку раскрывать карты, и начну именно с JVVM.
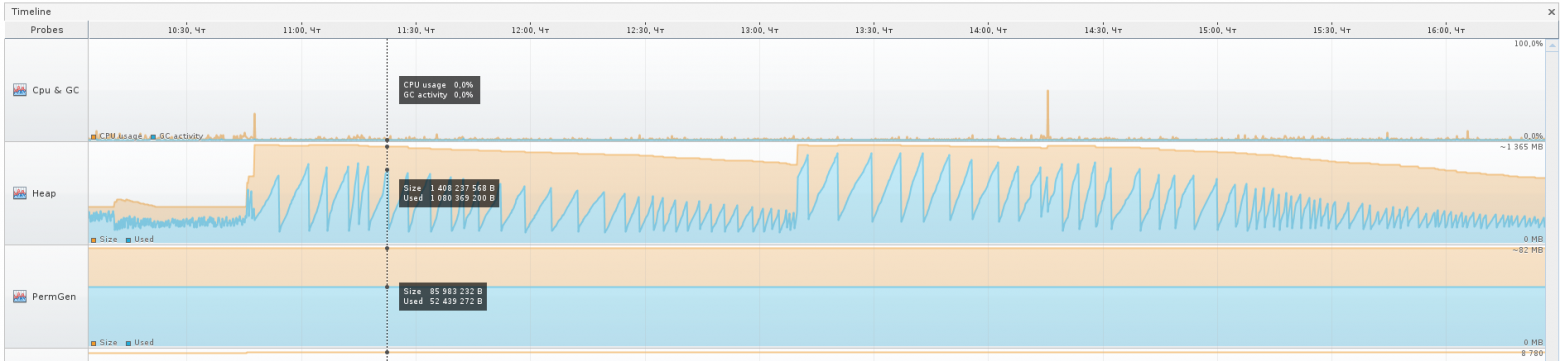
Этот инструмент в соединении с jstatd и jmx позволяет удалённо наблюдать за жизнью приложения на сервере: Heap, процессор, PermGen, количество потоков и классов, активность потоков, позволяет проводить профилирование.
Также JVVM расширяем, и я не преминул воспользоваться этой возможностью, установив некоторые плагины, которые позволили куда больше вещей, например, следить и взаимодействать с MBean’ами, наблюдать за деталями хипа, вести длительное наблюдение за приложением, держа в «голове» куда больший период метрик, чем предоставляемый вкладкой Monitor час.

Вот так выглядит набор установленных плагинов.
Visual GC (VGC) позволяет видеть метрики, связанные с хипом.
Детальнее о том, из чего состоит хип в этой нашей Java
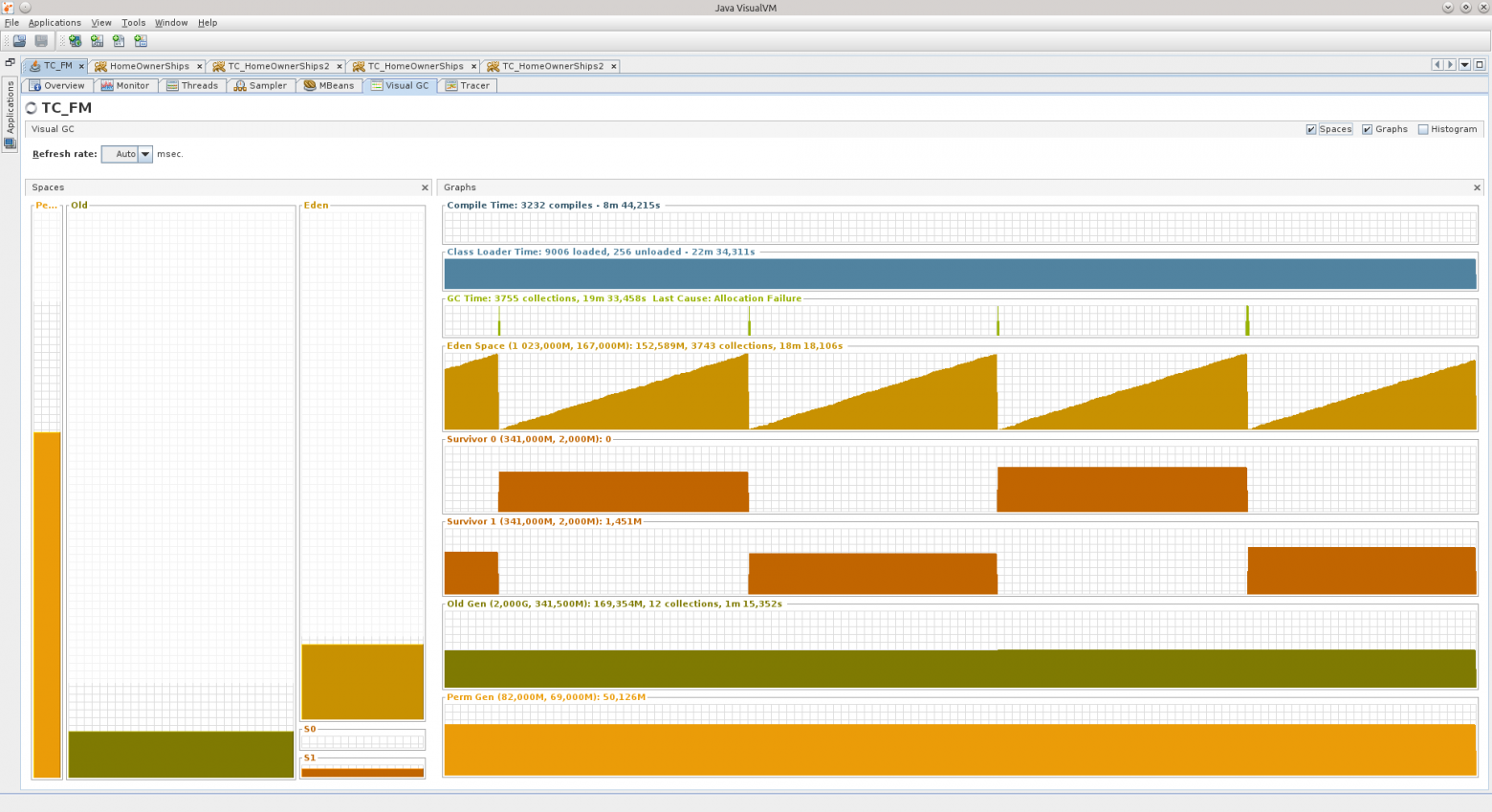

Вот два скриншота вкладки VGC, которые показывают, как ведут себя два разных приложения.
Слева Вы можете увидеть такие разделы хипа, как Perm Gen, Old Gen, Survivor 0, Survivor 1, и Eden Space.
Все эти составляющие — участки в оперативке, в которую и складываются объекты.
PermGen — Permanent Generation — область памяти в JVM, предназначенная для хранения описания классов Java и некоторых дополнительных данных.
Old Gen — это область памяти для достаточно старых объектов, которые пережили несколько перекладываний с места на место в Survivor-областях, и в момент какого-то очередного переливания попадают в область «старых» объектов.
Survivor 0 и 1 — это области, в которые попадают объекты, которые после создания объекта в Eden Space пережили его чистку, то есть не стали мусором на момент, когда Eden Space начал чиститься Garbage Collector’ом (GC). При каждом запуске чистки Eden Space объекты из активного в текущий момент Survivor’а перекладываются в пассивный, плюс добавляются новые, и после этого Survivor’ы меняются статусами, пассивный становится активным, а активный — пассивным.
Eden Space — область памяти, в которой новые объекты порождаются. При нехватке памяти в этой области запускается цикл GC.
Каждая из этих областей может быть отрегулирована по размеру в процессе работы приложения самой виртуальной машиной.
Если вы указываете -Xmx в 2 гигабайта, например, то это не означает, что все 2 гигабайта будут сразу же заняты (если не запускать сразу что-то активно кушающее память, конечно же). Виртуальная машина сначала постарается держать себя «в узде».
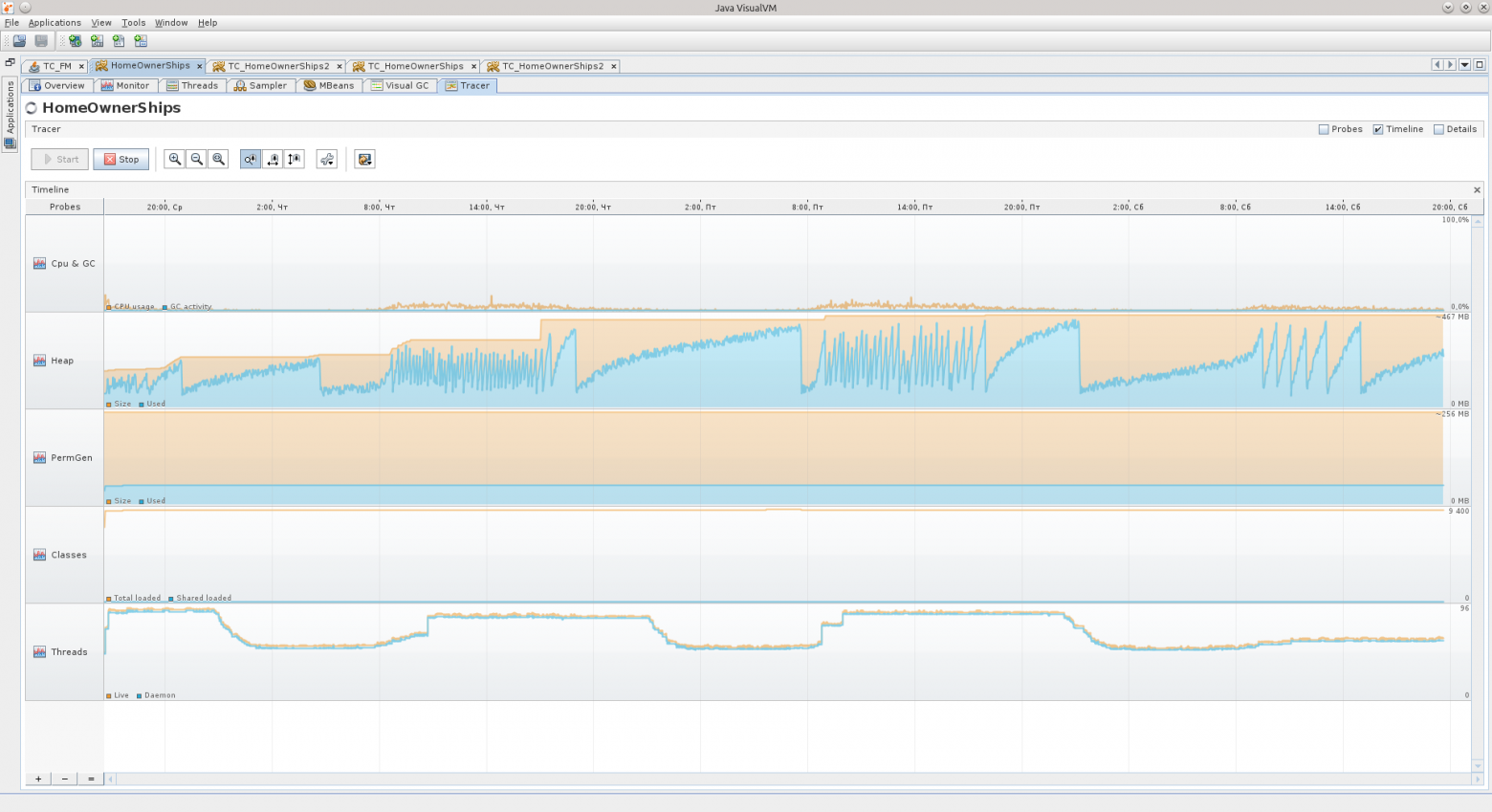
На третьем скриншоте видно неактивную стадию приложения, которое не используется на выходных — Eden растёт равномерно, Survivor’ы перекладываются через равные промежутки времени, Old практически не растёт. Приложение проработало больше 90 часов, и в принципе JVM считает, что приложению требуется не так уж и много, около 540 МБ.
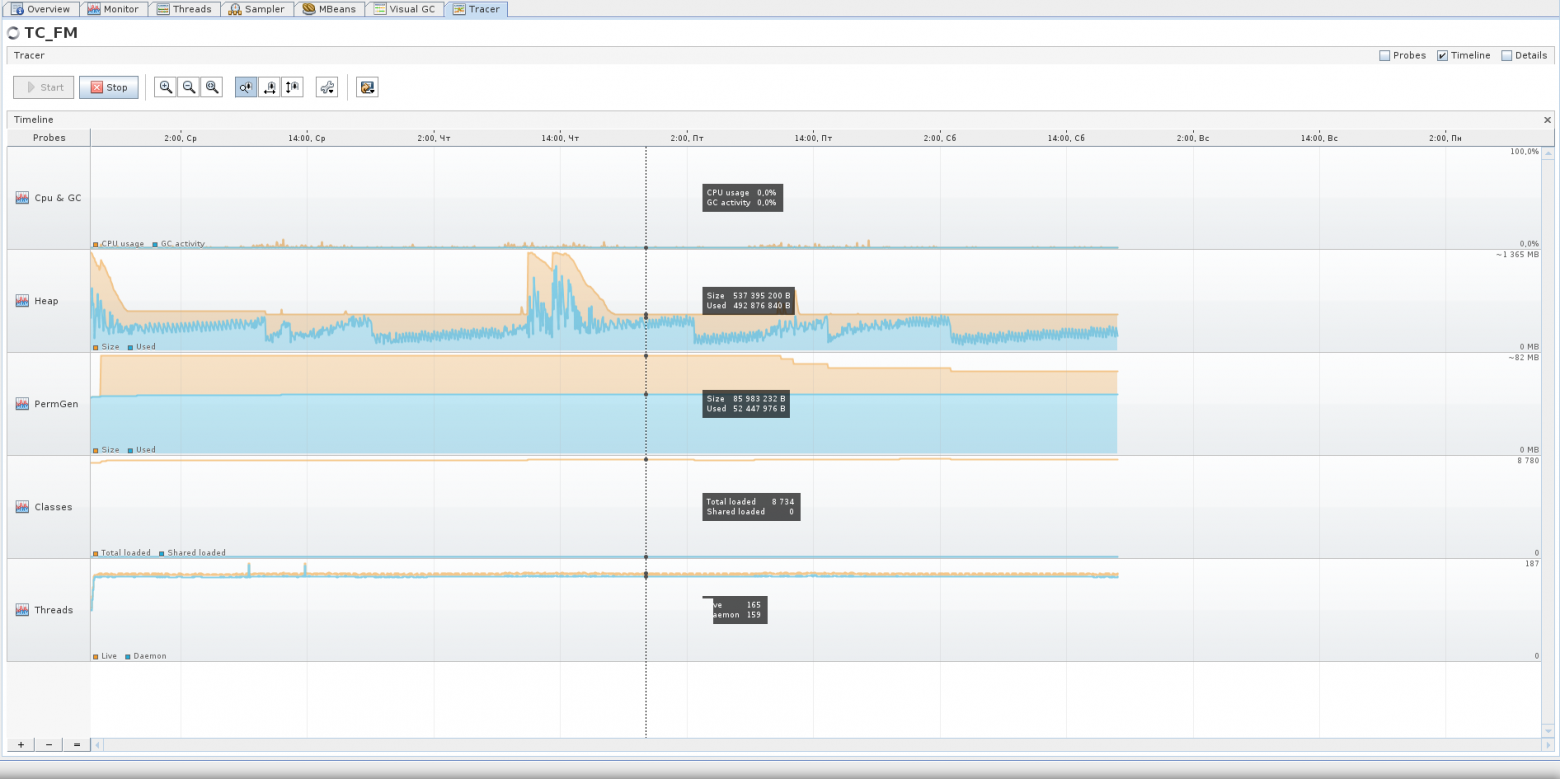
Бывают пиковые ситуации, когда виртуальная машина даже выделяет под хип гораздо больше памяти, но я думаю, что это какие-то ещё «неучтёнки», о которых я расскажу детальнее ниже по тексту, а может просто виртуальная машина выделила больше памяти под Eden, например, чтобы объекты в нём успевали стать мусором до следующего цикла очистки.

Участки, которые на следующем скриншоте я обозначил красным — это как раз возрастание Old, когда некоторые объекты не успевают стать мусором, чтобы быть удалёнными из памяти ранее, и всё-таки попадают в Old. Синий участок — исключение. На протяжении красных участков можно видеть гребёнку — это Eden так себя ведёт.
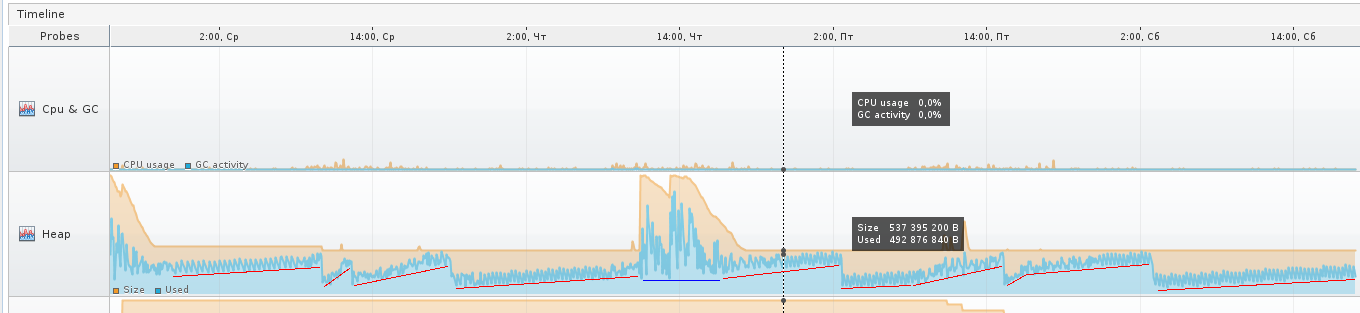
На протяжении синего участка скорее всего виртуальная машина решила, что нужно увеличить размер Eden-области, потому как при увеличении масштаба в Tracer’е видно, что GC перестал «частить» и таких мелких колебаний, как ранее, теперь нет, колебания стали медленными и редкими.
Перейдём ко второму приложению:
В нём Eden напоминает мне какой-то уровень из Mortal Kombat, арену с шипами. Была такая, кажется… А График GC — шипы из NFS Hot Pursuit, вот те вот, плоские ещё.
Числа справа от названий областей указывают:
1) что Eden имеет размер в 50 мегабайт, и то, что нарисовано в конце графика, последнее из значений на текущий момент — занято 25 мегабайт. Всего он может вырости до 546 мегабайт.
2) что Old может вырости до 1,333 гига, сейчас занимает 405 МБ, и забит на 145,5 МБ.
Так же для Survivor-областей и Perm Gen.
Для сравнения — вот Вам Tracer-график за 75 часов работы второго приложения, думаю, кое-какие выводы вы сможете сделать из него. Например, что активная фаза у этого приложения — с 8:30 до 17:30 в рабочие дни, и что даже на выходных оно тоже работает
Если вы вдруг увидели в своём приложении, что Old-область заполнена — попробуйте просто подождать, когда она переполнится, скорее всего она заполнена уже мусором.
Мусор — это объекты, на которые нет активных ссылок из других объектов, или целые комплексы таких объектов (например, какое-то «облако» взаимосвязанных оъектов может стать мусором, если набор ссылок указывает только на объекты внутри этого «облака», и ни на один объект в этом «облаке» ничто не ссылается «снаружи»).
Это был краткий пересказ того, что я узнал про структуру хипа за время, пока гуглил.
Предпосылки
Итак, случилось сразу две вещи:
1) после перехода на более новые библиотеки/томкеты/джавы в одну из пятниц приложение, которое я уже долгое время веду, вдруг стало вести себя из рук вон плохо спустя две недели после выставления.
2) мне на рефакторинг отдали проект, который тоже вёл себя до некоторого времени не очень хорошо.
Я уже не помню, в каком точно порядке произошли эти события, но после «чёрной пятницы» я решил наконец-то разобраться с дампами памяти детальнее, чтобы это более не было для меня чёрным ящиком. Предупреждаю, что какие-то детали я мог уже запамятовать.
По первому случаю симптомы были такие: все потоки, отвественные за обработку запросов, выжраны, на базу данных открыто всего 11 соединений, и те не сказать, что используются, база говорила, что они в состоянии recv sleep, то есть ожидают, когда же их начнут использовать.
После перезагрузки приложение оживало, но прожить могло недолго, вечером той же пятницы жило дольше всего, но уже после окончания рабочего дня таки снова свалилось. Картина всегда была одинаковой: 11 соединений к базе, и лишь один, вроде бы, что-то делает.
Память, кстати, была на минимуме. Сказать, что OOM привёл меня к поиску причин, не могу, однако полученные знания при поиске причин позволили начать активную борьбу с OOM.
Когда я открыл дамп в JVVM, из него было сложно что-либо понять.
Подсознание подсказывало, что причина где-то в работе с базой.
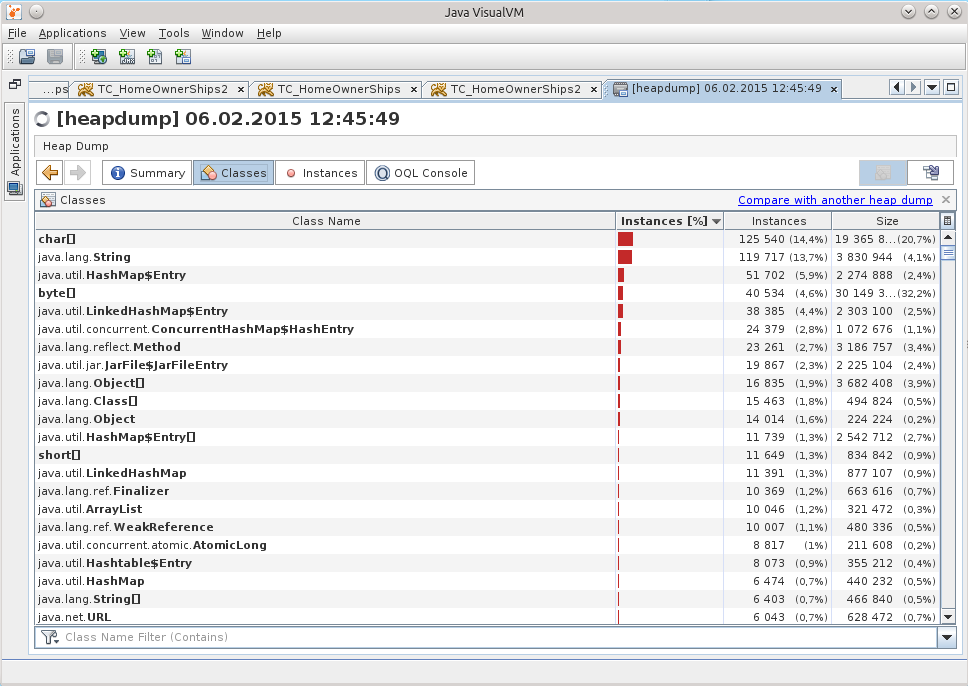
Поиск среди классов сказал мне, что в памяти аж 29 DataSource, хотя должно быть всего 7.
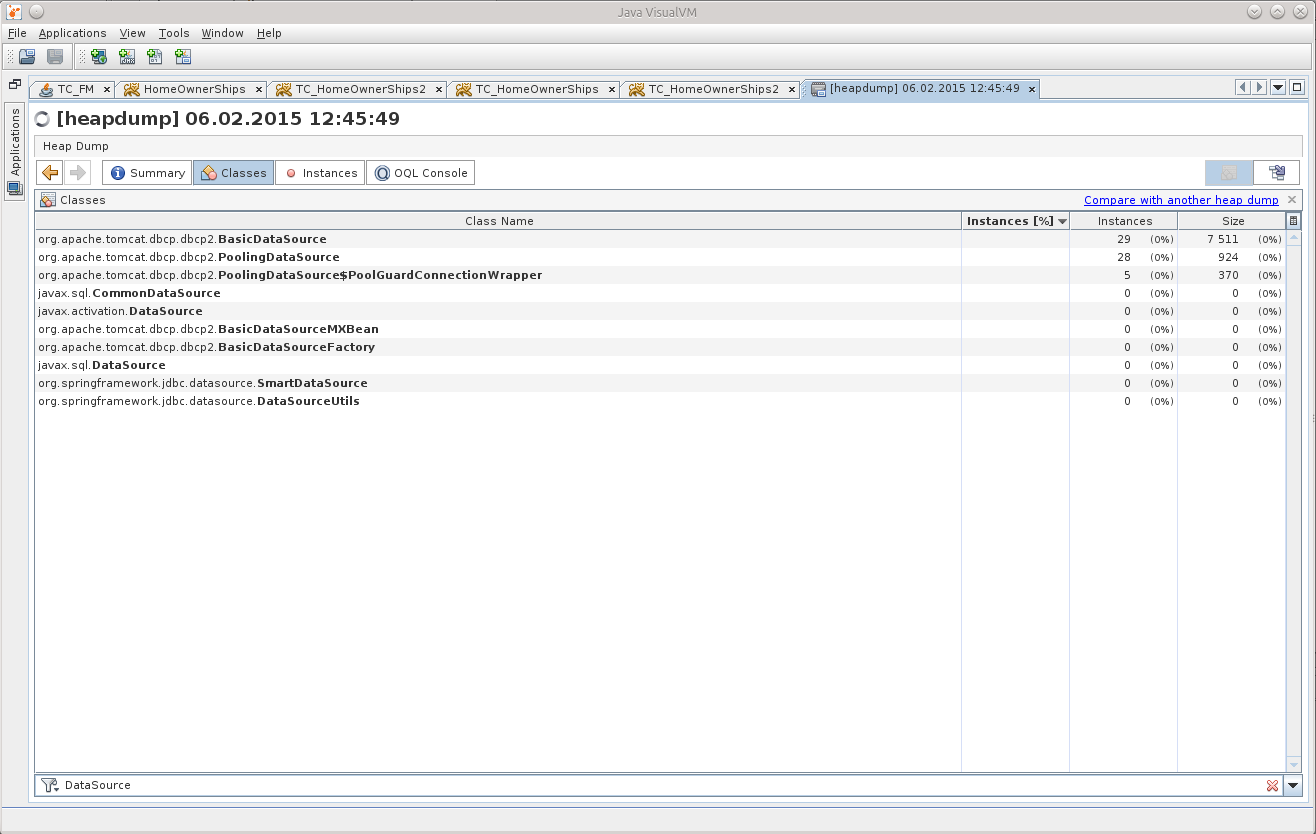
Это и дало мне точку, от которой можно было бы оттолкнуться, начать распутывать клубок.
OQL
Сидеть переклацывать в просмотровщике все эти объекты было некогда, и моё внимание наконец-то привлекла вкладка OQL Console, я подумал, что вот он, момент истины — я или начну использовать её на полную катушку, или так и забью на всё это.
Прежде, чем начать, конечно же был задан вопрос гуглу, и он любезно предоставил шпаргалку (cheat sheet) по использованию OQL в JVVM: http://visualvm.java.net/oqlhelp.html
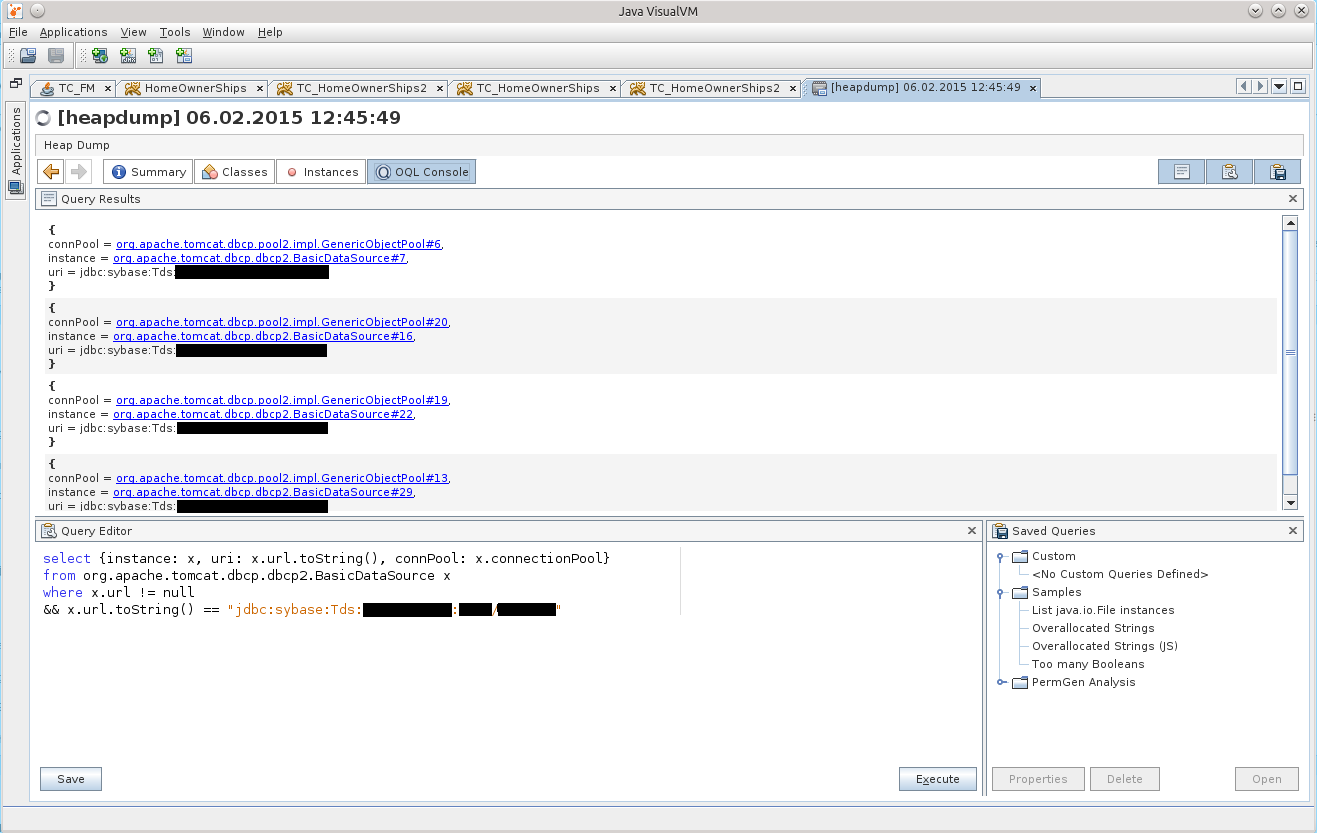
Сначала обилие сжатой информации привело меня в уныние, но после применения гугл-фу на свет таки появился вот такой OQL-запрос:
select {instance: x, uri: x.url.toString(), connPool: x.connectionPool}
from org.apache.tomcat.dbcp.dbcp2.BasicDataSource x
where x.url != null
&& x.url.toString() == "jdbc:sybase:Tds:айпишник:порт/базаДанных"
Это уже исправленная и дополненная, финальная версия этого запроса
Результат можно увидеть на скриншоте:
После нажатия на BasicDataSource#7 мы попадаем на нужный объект во вкладке Instances:

Через некоторое время до меня дошло, что есть одно несхождение с конфигурацией, указанной в теге Resource в томкете, в файле /conf/context.xml. Ведь в дампе параметр maxTotal имеет значение 8, в то время, как мы указывали maxActive равным 20…
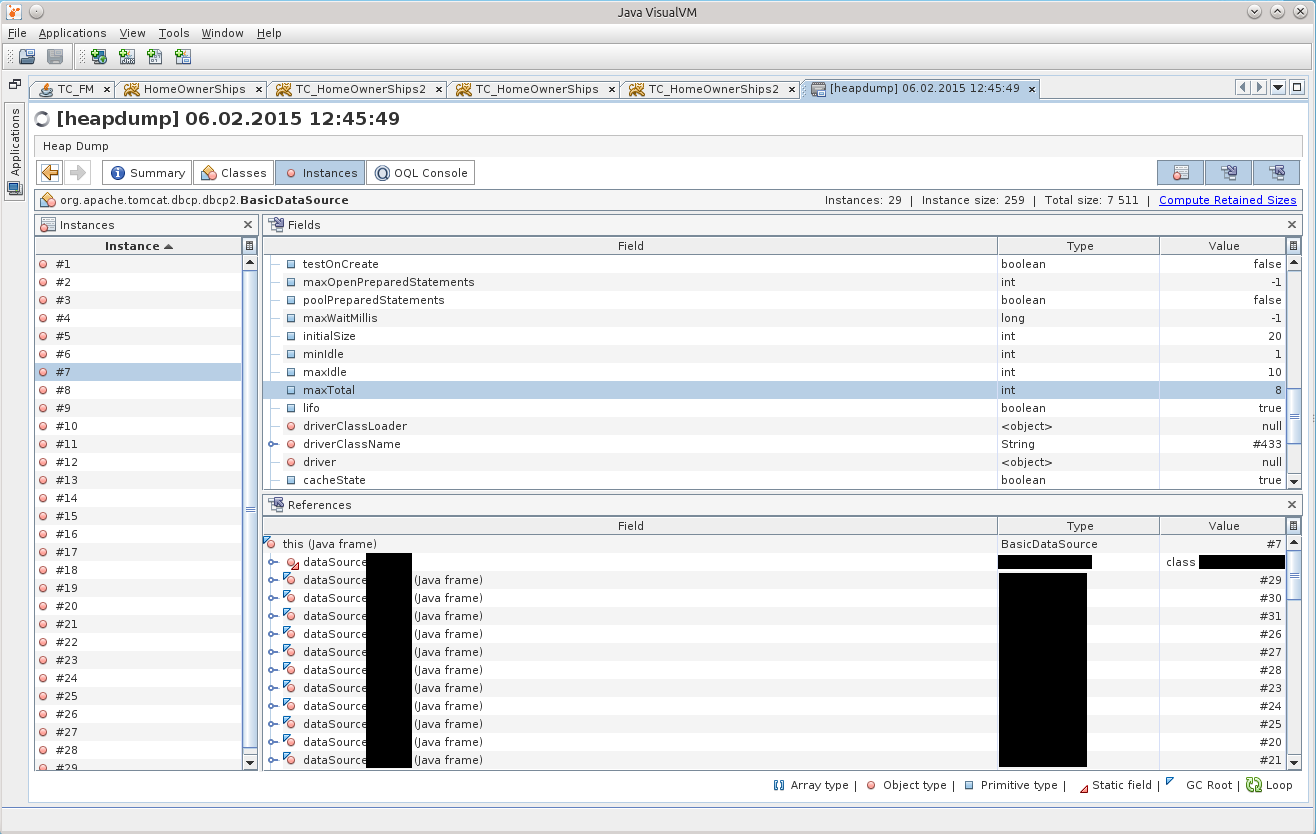
Тут-то до меня и начало доходить, что приложение жило с неправильной конфигурацией пула соединений все эти две недели!
Для краткости напишу тут, что в случае, если вы используете Tomcat и в качестве пула соединений — DBCP, то в 7м томкете используется DBCP версии 1.4, а в 8м томкете — уже DBCP 2.0, в котором, как я потом выяснил, решили переименовать некоторые параметры! А про maxTotal вообще на главной странице сайта написано
http://commons.apache.org/proper/commons-dbcp/
«Users should also be aware that some configuration options (e.g. maxActive to maxTotal) have been renamed to align them with the new names used by Commons Pool 2.»
Причины
Обозвал их по всякому, успокоился, и решил разобраться.
Как оказалось, класс BasicDataSourceFactory просто напросто получает этот самый Resource, смотрит, есть ли нужные ему параметры, и забирает их в порождаемый объект BasicDataSource, молча игнорируя напрочь всё, что его не интересует.
Так и получилось, что они переименовали самые весёлые параметры, maxActive => maxTotal, maxWait => maxWaitMillis, removeAbandoned => removeAbandonedOnBorrow & removeAbandonedOnMaintenance.
По умолчанию maxTotal, как и ранее, равен 8; removeAbandonedOnBorrow, removeAbandonedOnMaintenance = false, maxWaitMillis устанавливается в значение «ждать вечно».
Получилось, что пул оказался сконфигурирован с минимальным количеством соединений; в случае, если заканчиваются свободные соединения — приложение молча ждёт, когда они освободятся; и добивает всё молчанка в логах по поводу «заброшенных» соединений — то, что могло бы сразу показать, в каком именно месте
программист мудак
код хватает соединение, но не отдаёт его обратно по окончанию своей работы.
Это сейчас вся мозаика сложилась быстро, а добывались эти знания дольше.
«Так быть не должно», решил я, и запилил патчик (https://issues.apache.org/jira/browse/DBCP-435, выразился в http://svn.apache.org/viewvc/commons/proper/dbcp/tags/DBCP_2_1/src/main/java/org/apache/commons/dbcp2/BasicDataSourceFactory.java?view=markup ), патч был принят и вошёл в версию DBCP 2.1. Когда и если Tomcat 8 обновит версию DBCP до 2.1+, думаю, что админам откроются многие тайны про их конфигурации Resource
По поводу этого происшествия мне лишь осталось рассказать ещё одну деталь — какого чёрта в дампе было аж 29 DataSource’ов вместо всего 7 штук. Разгадка кроется в банальной арифметике, 7*4=28 +1=29.
Детальнее о том, почему нельзя закидывать Resource в файл /conf/context.xml томкета
На каждую подпапку внутри папки /webapps поднимается своя копия /conf/context.xml, а значит то количество Resource, которые там есть, следует умножать на количество приложений, чтобы получить общее количество пулов, поднятых в памяти томкета. На вопрос «что в этом случае делать?» ответ будет таким: нужно вынести все объявления Resource из /conf/context.xml в файл /conf/server.xml, внутрь тега GlobalNamingResources. Там Вы можете найти один, имеющийся по умолчанию, Resource name=«UserDatabase», вот под ним и размещайте свои пулы. Далее необходимо воспользоваться тегом ResourceLink, его желательно поместить в приложение, в проекте, внутрь файла /META-INF/context.xml — это так называемый «per-app context», то есть контекст, который содержит объявления компонентов, которые будут доступны только для разворачиваемого приложения. У ResourceLink параметры name и global могут содержать одинаковые значения.
Для примера:
<ResourceLink name="jdbc/MyDB" global="jdbc/MyDB" type="javax.sql.DataSource"/>
Эта ссылка будет выхватывать из глобально объявленных ресурсов DataSource с именем «jdbc/MyDB», и ресурс станет доступен приложению.
ResourceLink можно (но не нужно) разместить и в /conf/context.xml, но в этом случае доступ к ресурсам, объявленным глобально, будет у всех приложений, пусть даже и не будет столько копий DataSource в памяти.
Ознакомиться с деталями можно вот тут: GlobalNamingResources — http://tomcat.apache.org/tomcat-7.0-doc/config/globalresources.html#Environment_Entries, ResourceLink — http://tomcat.apache.org/tomcat-7.0-doc/config/globalresources.html#Resource_Links, также можно просмотреть эту страницу: tomcat.apache.org/tomcat-7.0-doc/config/context.html.
Для TC8 эти же страницы: http://tomcat.apache.org/tomcat-8.0-doc/config/globalresources.html и http://tomcat.apache.org/tomcat-8.0-doc/config/context.html .
После этого всё стало ясно: 11 соединений было потому, что в одном, активном DataSource было съедено 8 соединений (maxTotal = 8), и ещё по minIdle=1 в трёх других неиспользуемых DataSource-копиях.
В ту пятницу мы откатились на Tomcat 7, который лежал рядышком, и ждал, когда от него избавятся, это дало время спокойно во всём разобраться.
Плюс позже, уже на TC7, обнаружилась утечка соединений, всё благодаря removeAbandoned+logAbandoned. DBCP радостно сообщил в логфайл catalina.log о том, что
"org.apache.tomcat.dbcp.dbcp.AbandonedTrace$AbandonedObjectException: DBCP object created 2015-02-10 09:34:20 by the following code was never closed:
at org.apache.tomcat.dbcp.dbcp.AbandonedTrace.setStackTrace(AbandonedTrace.java:139)
at org.apache.tomcat.dbcp.dbcp.AbandonedObjectPool.borrowObject(AbandonedObjectPool.java:81)
at org.apache.tomcat.dbcp.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:106)
at org.apache.tomcat.dbcp.dbcp.BasicDataSource.getConnection(BasicDataSource.java:1044)
at наш.пакет.СуперКласс.getConnection(СуперКласс.java:100500)
at наш.пакет.СуперКласс.плохойПлохойМетод(СуперКласс.java:100800)
at наш.пакет.СуперКласс.вполнеВменяемыйМетод2(СуперКласс.java:100700)
at наш.пакет.СуперКласс.вполнеВменяемыйМетод1(СуперКласс.java:100600)
ещё куча строк..."
Вот этот вот плохойПлохойМетод имеет в сигнатуре Connection con, но внутри была конструкция «con = getConnection();», которая и стала камнем преткновения. СуперКласс вызывается редко, поэтому на него и не обращали внимания так долго. Плюс к этому, вызовы происходили, я так понимаю, не во время рабочего дня, так что даже если что-то и подвисало, то никому уже не было дела до этого. А в ТуСамуюПятницу просто звёзды сошлись, начальнику департамента заказчика понадобилось посмотреть кое-что
Приложение №2
Что же касается «события №2» — мне отдали приложение на рефакторинг, и оно на серверах тут же вздумало упасть.
Дампы попали уже ко мне, и я решил попробовать поковырять и их тоже.
Открыл дамп в JVVM, и «чё-то приуныл»:
Что можно понять из Object[], да ещё и в таком количестве?
( Опытный человек, конечно же, увидел уже причину, правда? )
Так у меня зародилась мысль «ну неужели никто ранее не занимался этим, ведь наверняка уже есть готовый инструмент!». Так я наткнулся на этот вопрос на StackOverflow: http://stackoverflow.com/questions/2064427/recommendations-for-a-heap-analysis-tool-for-java.
Посмотрев предложенные варианты, я решил остановиться на MAT, надо было попробовать хоть что-то, а это открытый проект, да ещё и с куда бОльшим количеством голосов, чем у остальных пунктов.
Eclipse Memory Analyzing Tool
Итак, MAT.
Рекомендую скачивать последнюю версию Eclipse, и устанавливать MAT туда, потому как самостоятельная версия MAT ведёт себя плохо, там какая-то чертовщина с диалогами, в них не видно содержимого в полях. Быть может кто-то подскажет в комментариях, чего ему не хватает, но я решил проблему, установив MAT в Eclipse.
Открыв дамп в MAT я запросил выполнение Leak Suspects Report.
Удивлению не было предела, честно говоря.
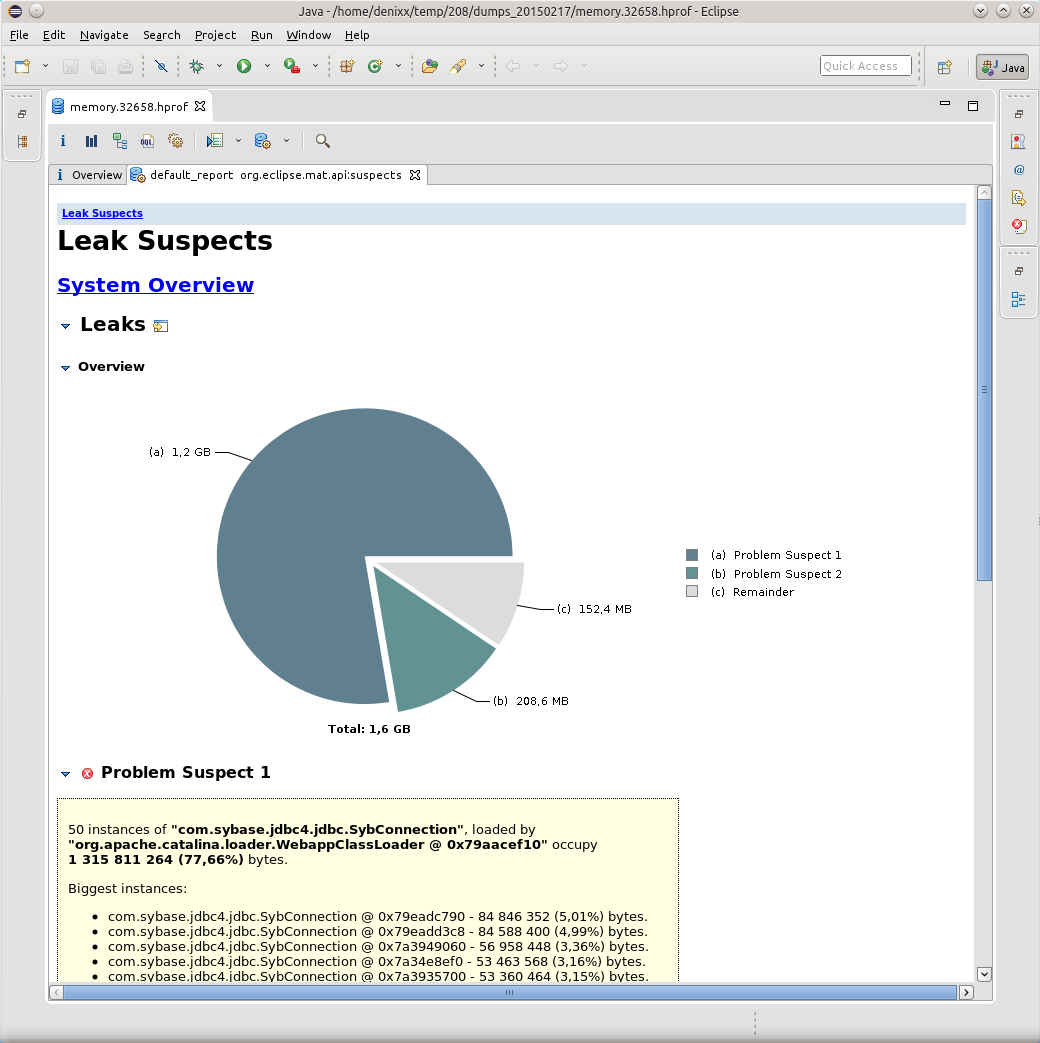
1.2 гига весят соединения в базу.
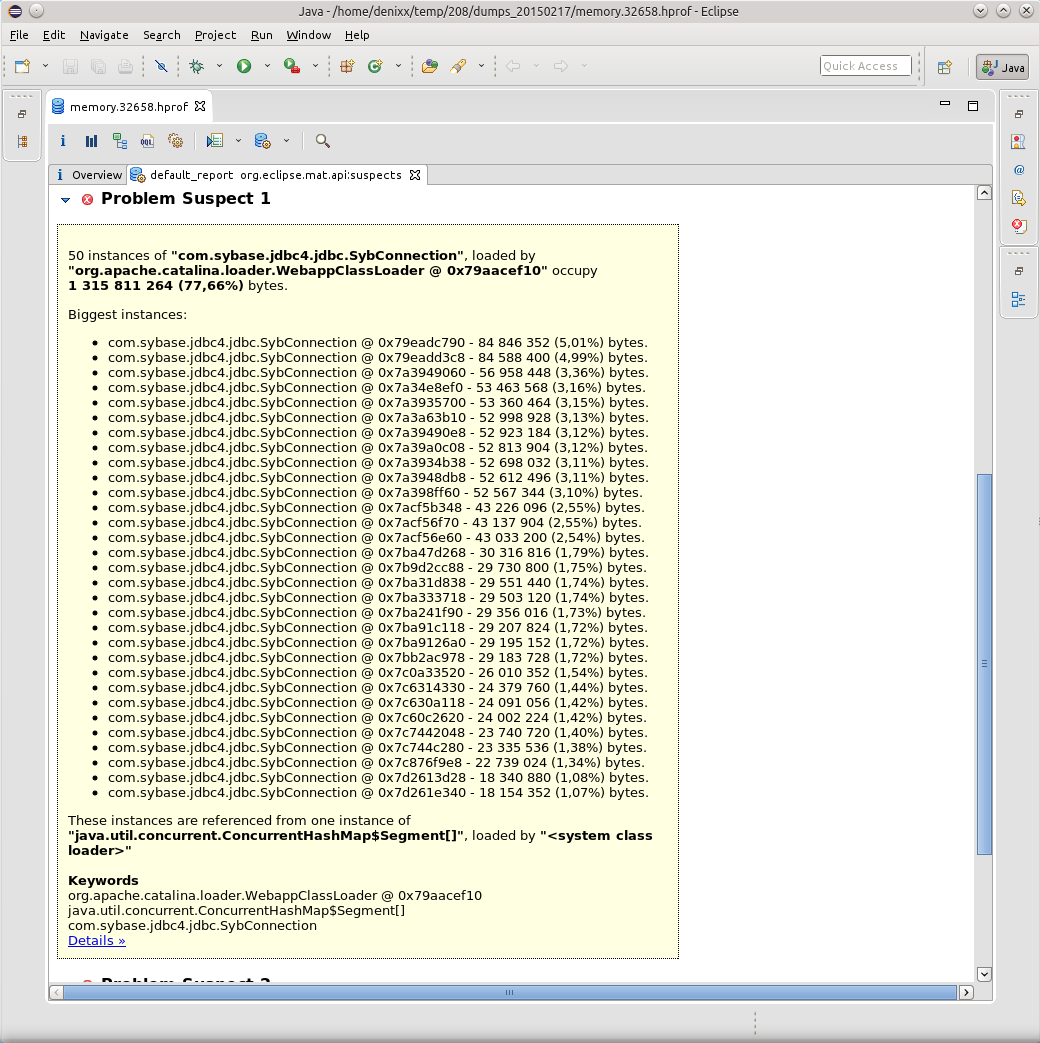
Каждое соединение весит от 17 до 81 мегабайта.
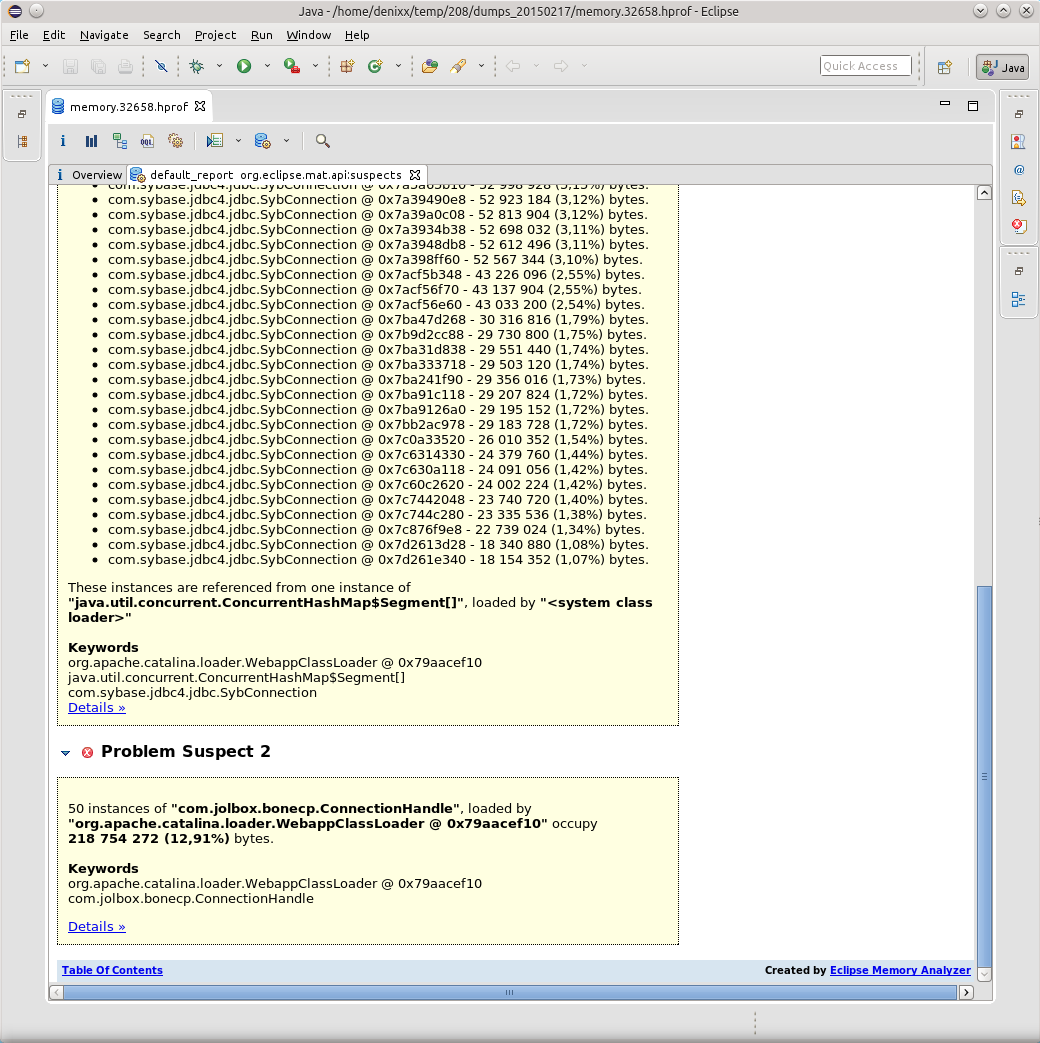
Ну и ещё «немного» сам пул.
Визуализировать проблему помог отчёт Dominator Tree:
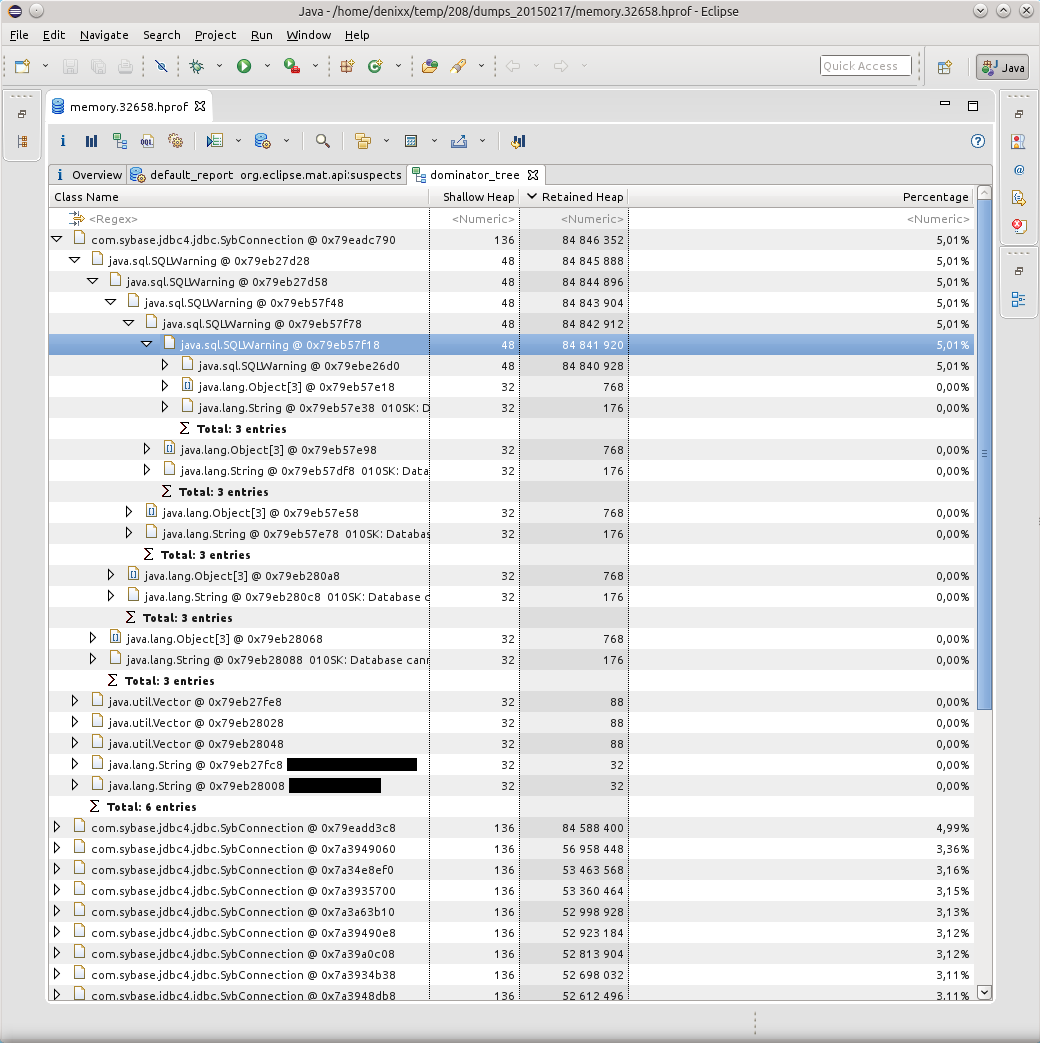
Причиной всех падений оказались километры SQLWarning’ов, база настойчиво пыталась дать понять, что «010SK: Database cannot set connection option SET_READONLY_TRUE.», а пул соединений BoneCP не вычищает SQLWarning’и после освобождения и возврата соединений в пул (может быть это где-то можно сконфигурировать? Подскажите, если кто знает).
Гугл сказал, что такая проблема с Sybase ASE известна ещё с 2004 года: https://forum.hibernate.org/viewtopic.php?f=1&t=932731
Если вкратце, то «Sybase ASE doesn’t require any optimizations, therefore setReadOnly() produces a SQLWarning.», и указанные решения всё ещё работают.
Однако это не совсем решение проблемы, потому как решение проблемы — это когда при возврате соединения в пул все уведомления базы очищаются в силу того, что они уже никогда никому не понадобятся.
И DBCP таки умеет делать это: http://svn.apache.org/viewvc/commons/proper/dbcp/tags/DBCP_1_4/src/java/org/apache/commons/dbcp/PoolableConnectionFactory.java?view=markup, метод passivateObject(Object obj), в строке 687 можно увидеть conn.clearWarnings();, этот вызов и спасает от километров SQLWarning’ов в памяти.
Об этом я узнал из тикета: https://issues.apache.org/jira/browse/DBCP-102
Также мне подсказали про вот такой тикет в багтрекере: https://issues.apache.org/jira/browse/DBCP-234, но он касается уже версии DBCP 2.0.
В итоге я перевёл приложение на DBCP (пусть и версии 1.4). Пусть нагрузка на сервис и немаленькая (от 800 до 2к запросов в минуту), но всё же приложение ведёт себя хорошо, а это главное. И правильно сделал, потому как BoneCP уже пять месяцев не поддерживается, правда, ему на смену пришёл HikariCP. Нужно будет посмотреть, как дела в его исходниках…
Сражаемся с OOM
Впечатлившись тем, как MAT мне всё разложил по полочкам, я решил не забрасывать этот действенный инструмент, и позже он мне пригодился, потому как в первом приложении ещё остались всяческие «неучтёнки» — неучтённые вещи в коде приложения или коде хранимых процедур, которые иногда приводят к тому, что приложение склеивает ласты. Я их отлавливаю до сих пор.
Вооружившись обоими инструментами, я принялся ковырять каждый присланный дамп в поисках причин падения по OOM.
Как правило все OOM приводили меня к TaskThread.
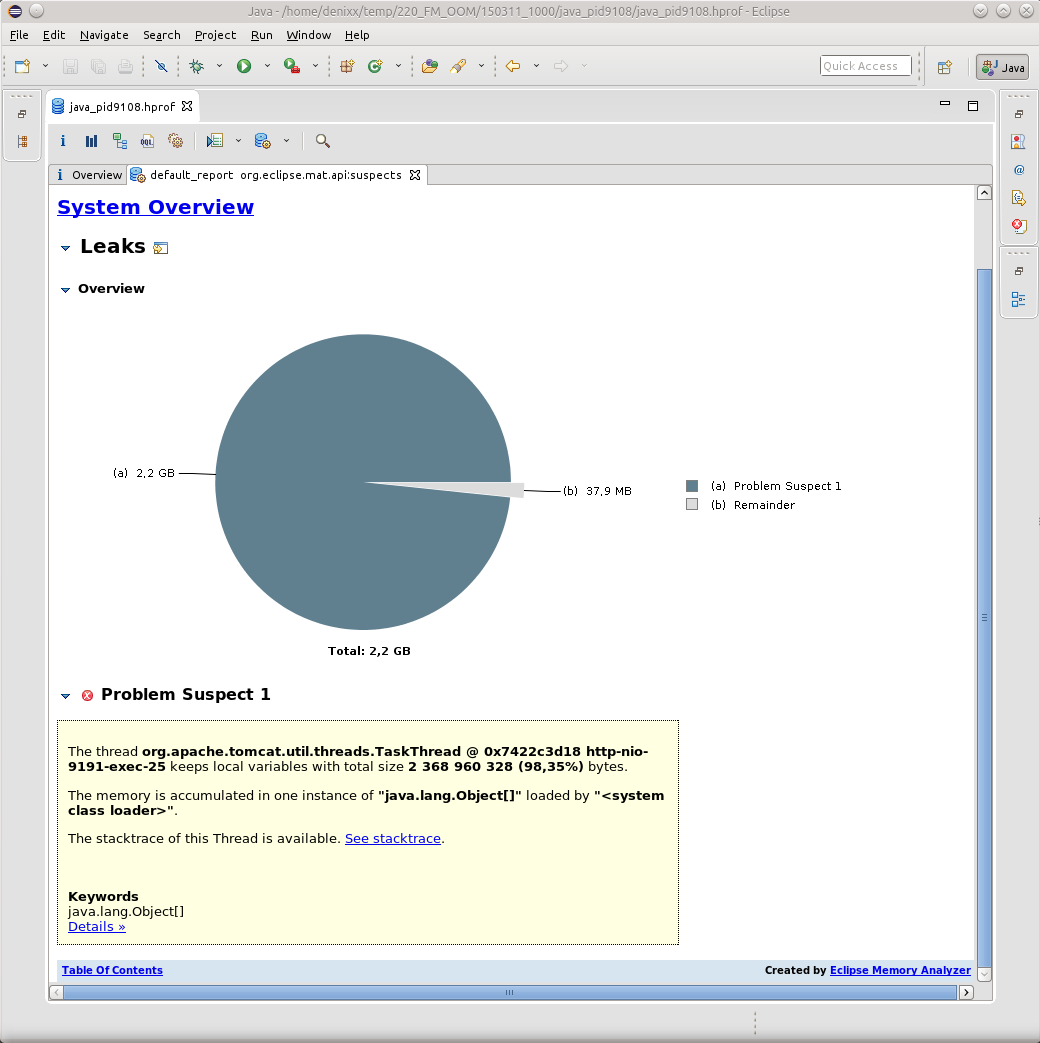
И если нажать на надпись See stacktrace, то да, это будет как раз банальный случай, когда какой-то поток вдруг внезапно упал при попытке отмаршалить результат своей работы.
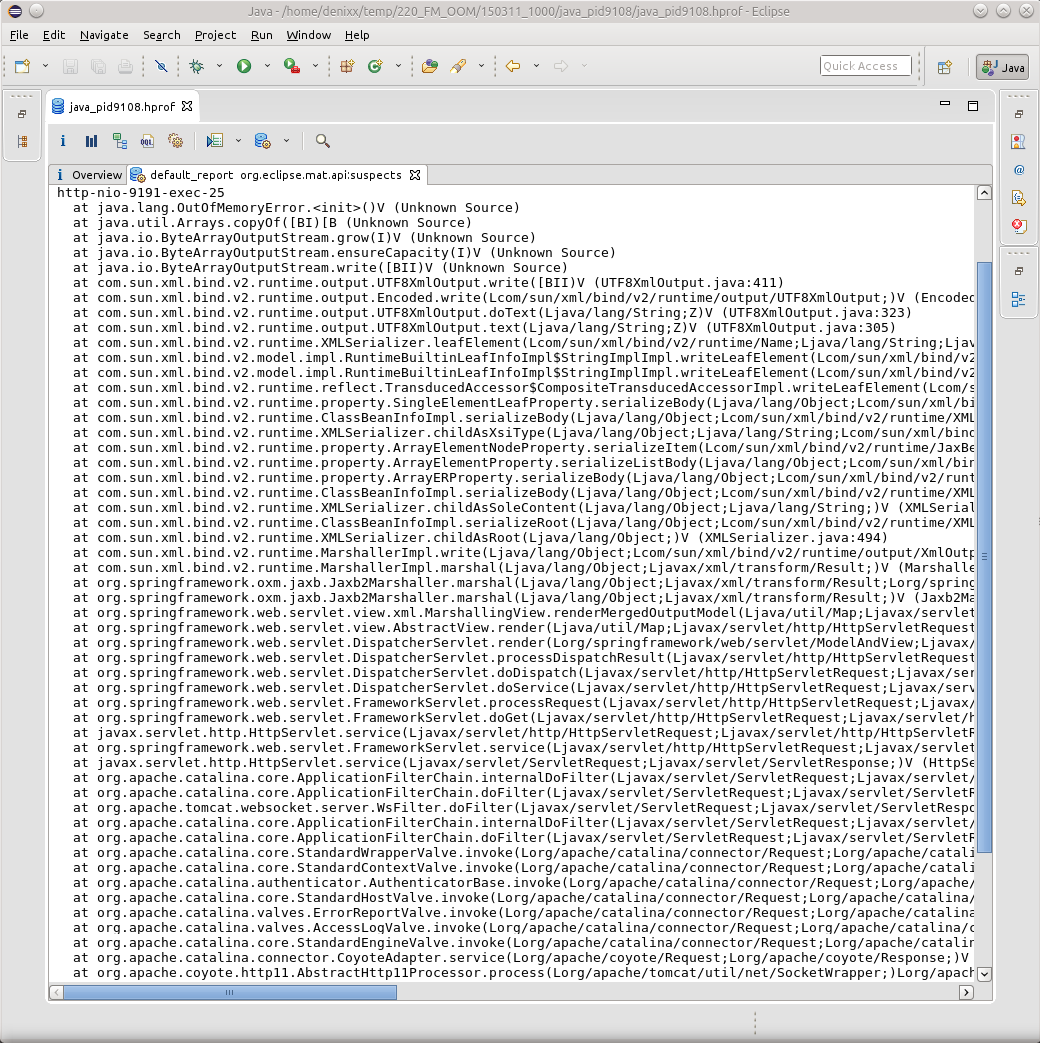
Однако здесь ничто не указывает на причину возникновения OOM, здесь лишь результат. Найти причину мне пока-что, в силу незнания всей магии OQL в MAT, помогает именно JVVM.
Загружаем дамп там, и пытаемся отыскать причину!
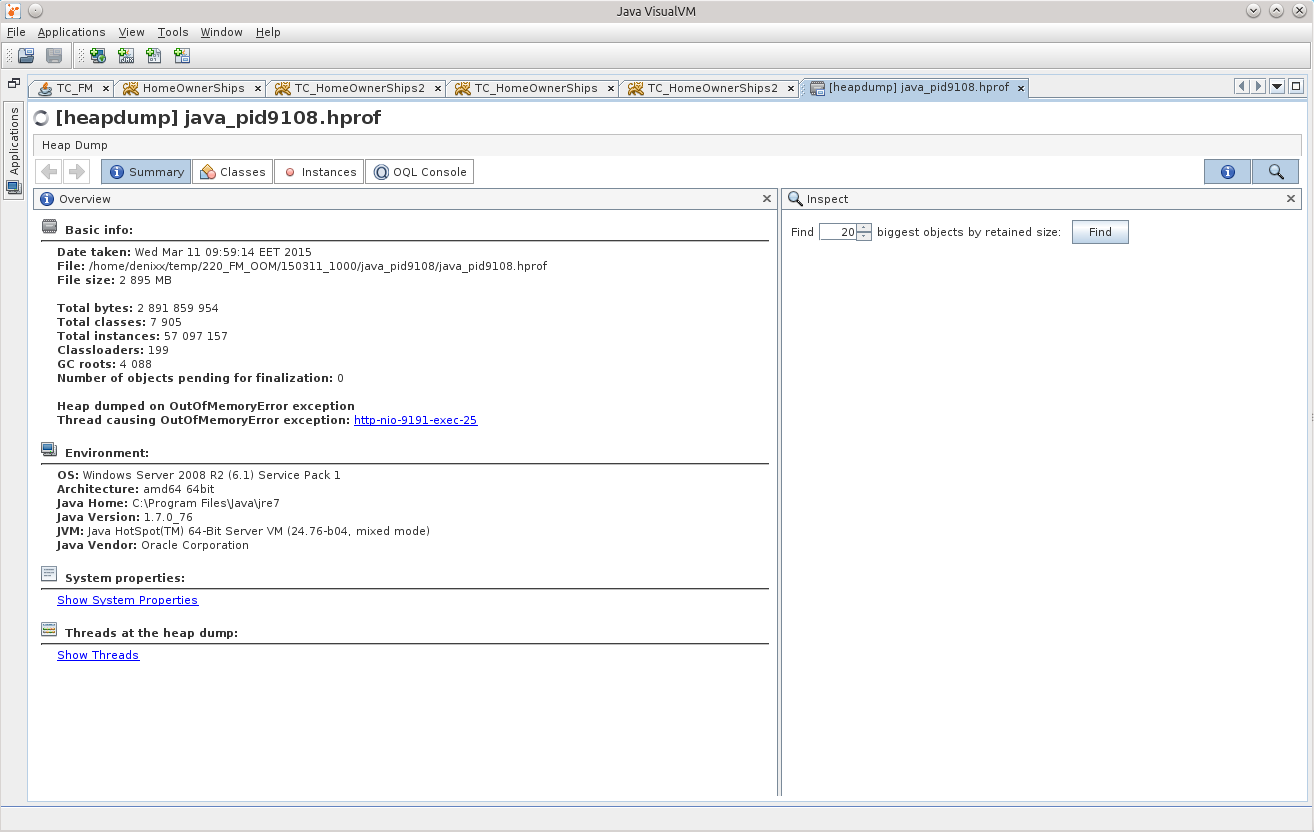
Искать мне следует, конечно же, именно вещи, связанные с базой данных, а посему попробуем сначала посмотреть, есть ли в памяти Statement’ы.
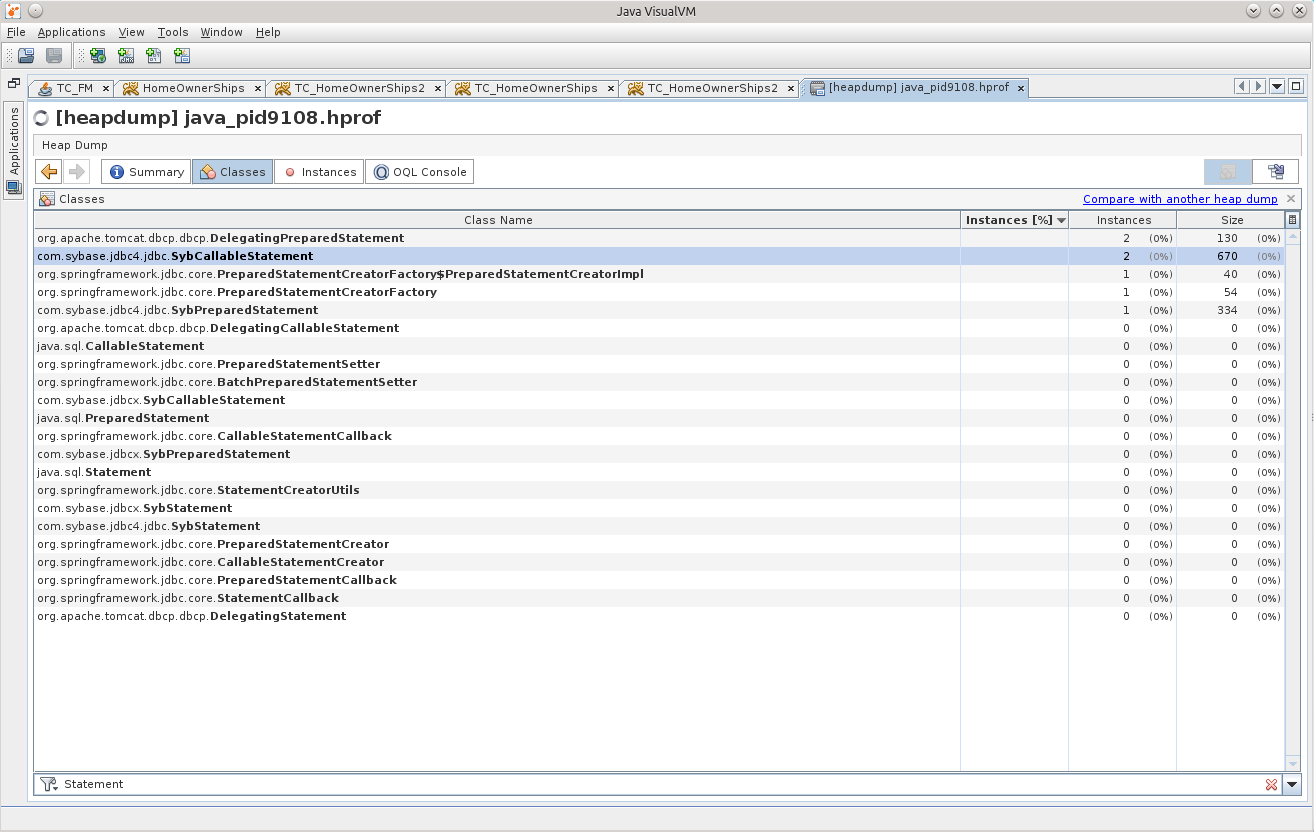
Два SybCallableStatement, и один SybPreparedStatement.
Думаю, что дело усложнится, если Statement’ов будет куда больше, но немного подрихтовав один из следующих запросов, указав в where нужные условия, думаю, всё у Вас получится. Плюс, конечно же, стоит хорошенько посмотреть в MAT, что за результаты пытается отмаршалить поток, какой объект, и станет понятнее, какой именно из Statement’ов необходимо искать.
select {
instance: x,
stmtQuery: x._query.toString(),
params: map(x._paramMgr._params, function(obj1) {
if (obj1 != null) {
if (obj1._parameterAsAString != null) {
return '''+obj1._parameterAsAString.toString()+''';
} else {
return "null";
}
} else {
return "null";
}
})
}
from com.sybase.jdbc4.jdbc.SybCallableStatement x
where x._query != null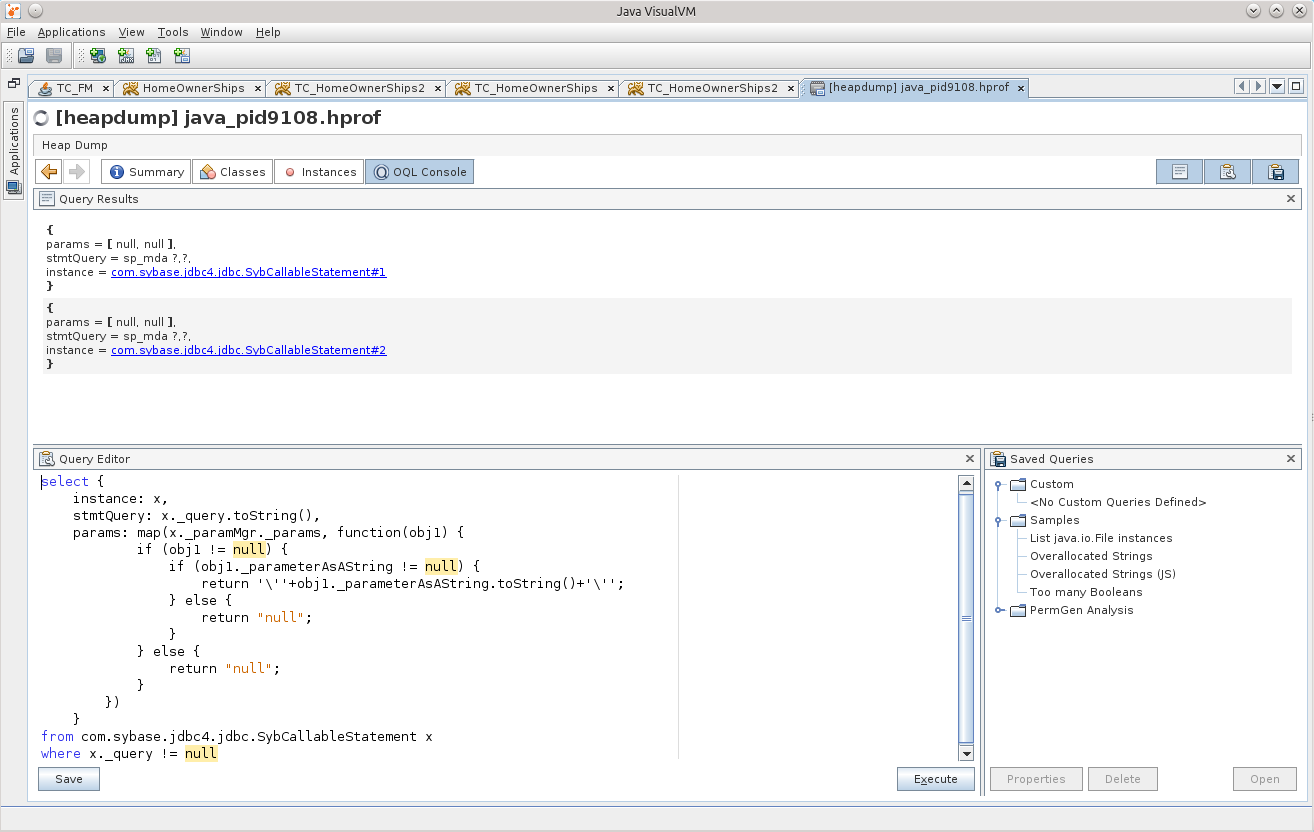
Не то, это «внутренние» вызовы.
select {
instance: x,
stmtQuery: x._query.toString(),
params: map(x._paramMgr._params, function(obj1) {
if (obj1 != null) {
if (obj1._parameterAsAString != null) {
return '''+obj1._parameterAsAString.toString()+''';
} else {
return "null";
}
} else {
return "null";
}
})
}
from com.sybase.jdbc4.jdbc.SybPreparedStatement x
where x._query != null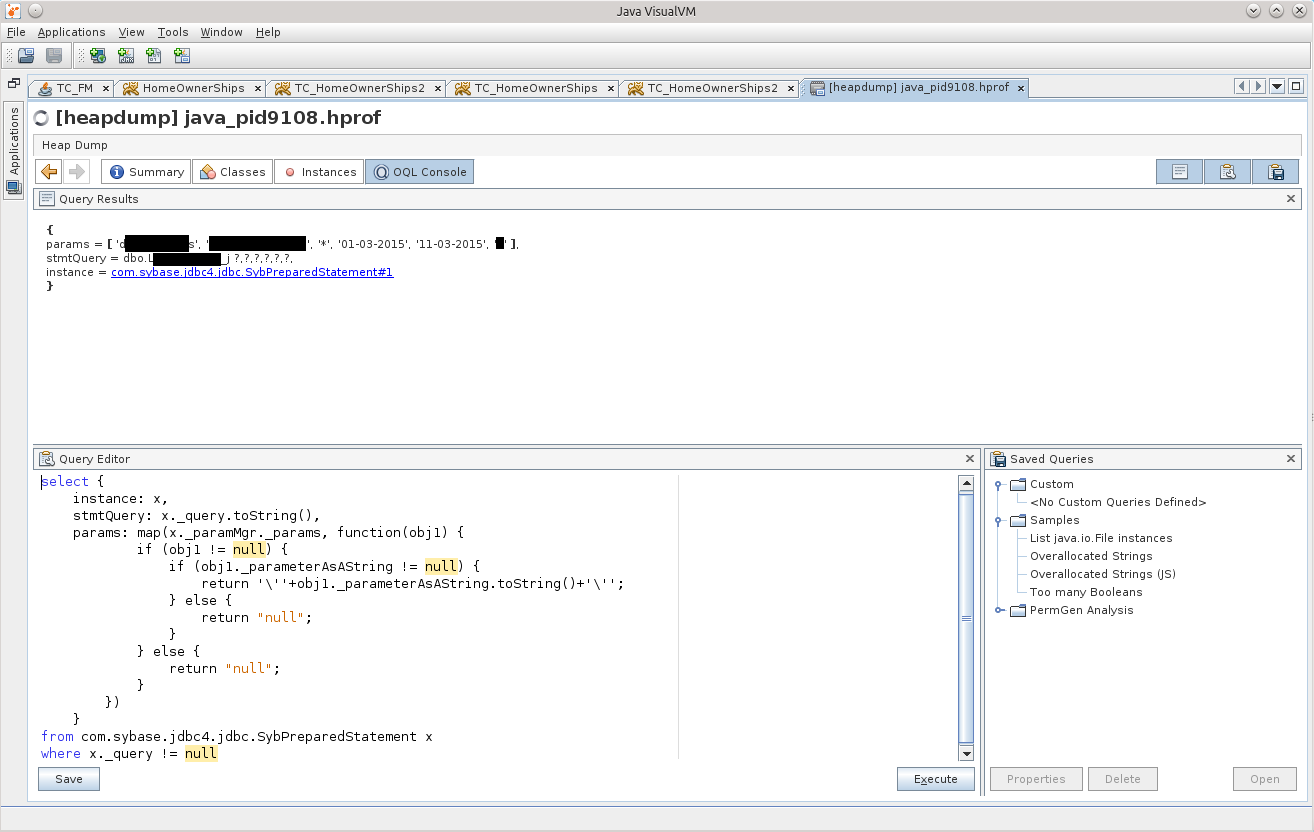
А вот и дичь!
Для чистоты эксперимента можно кинуть такой же запрос в любимой БД-IDE, и он будет очень долго отрабатывать, а если покопаться в недрах хранимки, то будет понятно, что там просто из базы, которая нам не принадлежит, выбирается 2 миллиона строк по такому запросу с такими параметрами. Эти два миллиона даже влазят в память приложения, но вот попытка отмаршалить результат становится фатальной для приложения. Такое себе харакири.
При этом GC старательно убирает все улики, но не спасло его это, всё же источник остался в памяти, и он будет наказан.
Почему-то после всего этого рассказа почувствовал себя тем ещё неудачником.
Прощание
Вот и закончилось моё повествование, надеюсь, Вам понравилось
Хотел бы выразить благодарность своему начальнику, он дал мне время во всём этом разобраться. Считаю эти новые знания очень полезными.
Спасибо девушкам из Scorini за неизменно вкусный кофе, но они не прочтут этих слов благодарности — я даже сомневаюсь, что они знают о существовании Хабрахабра
Хотелось бы увидеть в комментариях ещё больше полезной инфы и дополнений, буду очень благодарен.
Думаю, самое время почитать документацию к MAT…
UPD1: Да, совсем забыл рассказать про такие полезные вещи, как создание дампов памяти.
docs.oracle.com/javase/7/docs/webnotes/tsg/TSG-VM/html/clopts.html#gbzrr
Опции
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/disk2/dumps
весьма полезны для генерации дампов в момент падения приложения по OutOfMemoryError,
а также существует возможность снять дамп памяти с приложения «наживо», посреди его работы.
Для этого существует утилита jmap.
Пример вызова для винды:
«C:installPSToolsPsExec.exe» -s «C:Program FilesJavajdk1.7.0_55binjmap.exe» -dump:live,format=b,file=C:dump.hprof 3440
последний параметр — это PID java-процесса. Приложение PsExec из набора PSTools позволяет запускать другие приложения с правами системы, для этого служит ключ «-s». Опция live полезна, чтобы перед сохранением дампа вызвать GC, очистив память от мусора. В случае, когда возникает OOM, чистить память незачем, там уже не осталось мусора, так что не ищите, как можно установить опцию live в случае возникновения OOM.
UPD2 (2015-10-28) | Случай номер два три
(Было принято решение дописать это сюда как апдейт, а не пилить новую статью о том же самом):
Ещё один интересный случай, но уже с Оракловой базой.
Один из проектов использует фичу с XML, проводит поиски по содержимому сохранённого XML-документа. В общем, этот проект иногда давал о себе знать тем, что вдруг внезапно один из инстансов переставал подавать признаки жизни.
Почуяв «хороший» случай потренироваться
на кошках
, я решил посмотреть его дампы памяти.
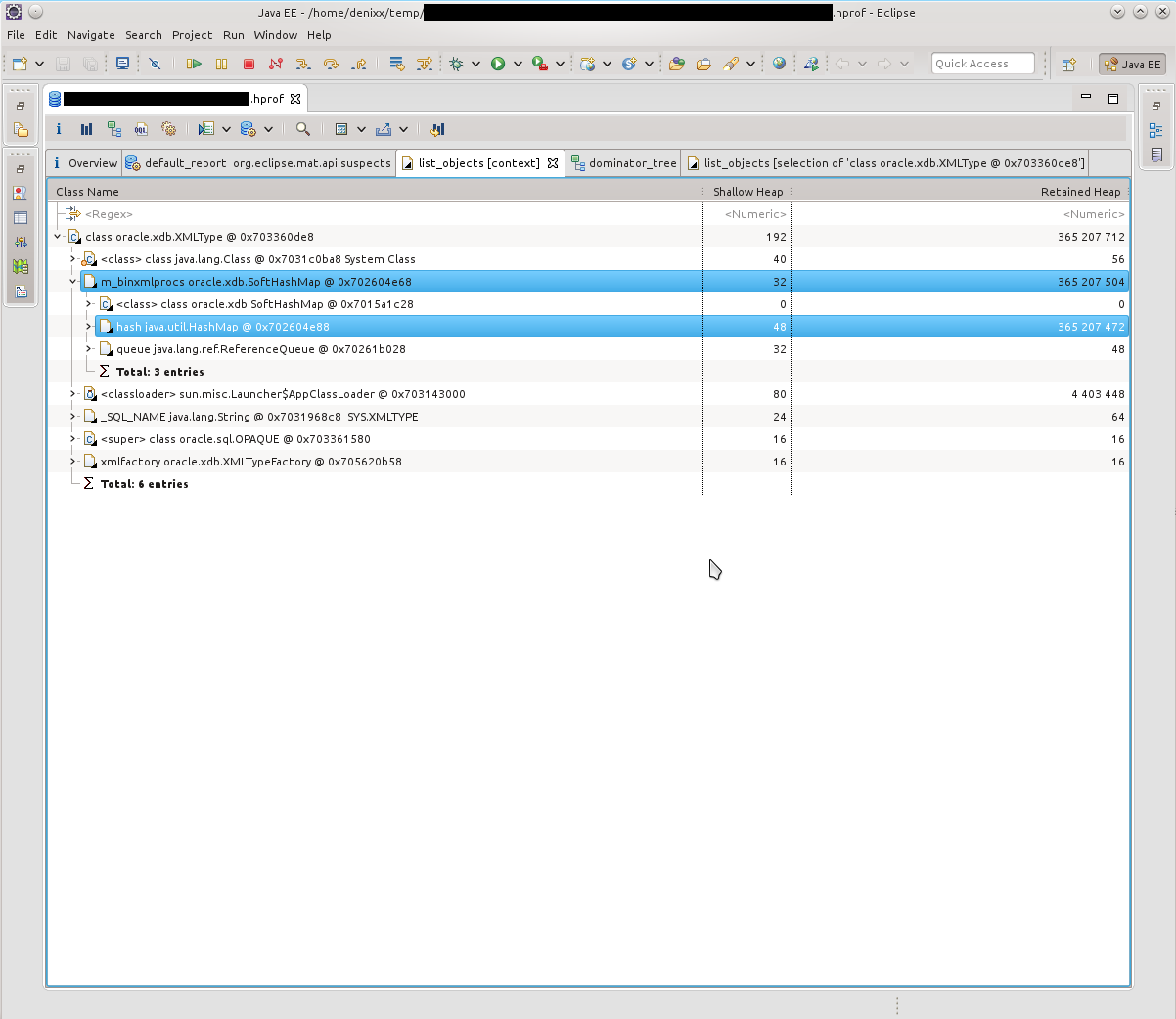
Первое, что я увидел, было «у вас тут много коннектов в памяти осталось». 21к!!! И какой-то интересный oracle.xdb.XMLType тоже давал жару. «Но это же Оракл!», вертелось у меня в голове. Забегая вперёд скажу что таки да, он виноват.
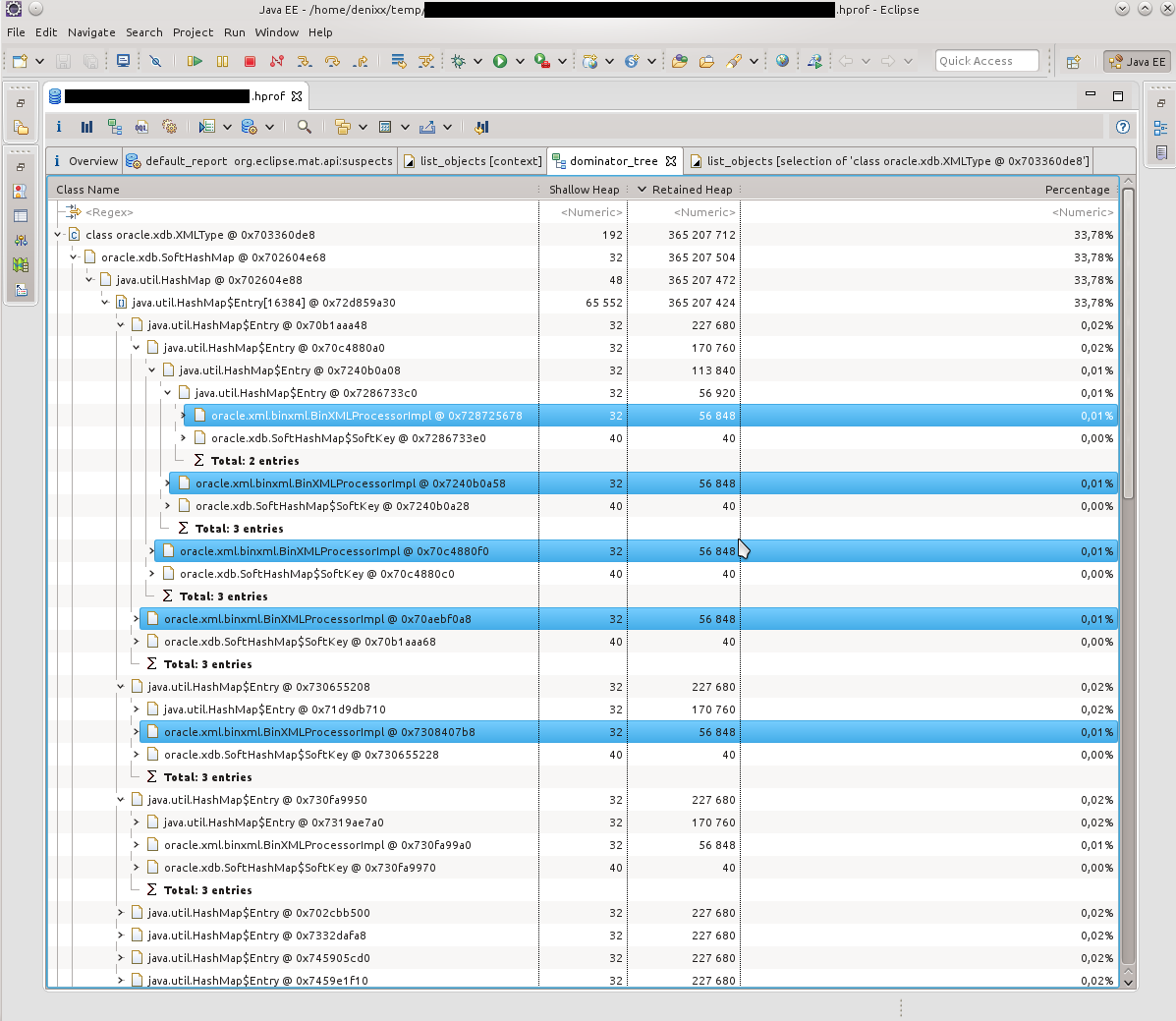
Итак, видим кучу T4CConnection, которые лежат в HashMap$Entry. Обратил внимание сразу, что вроде бы и SoftHashMap, что, вроде как, должно означать, что оно не должно вырастать до таких размеров. Но результат видите и сами — 50-60 килобайт в коннекте, и их реально МНОГО.
Посмотрев, что собой представляют HashMap$Entry — увидел, что примерно картина одинакова, всё связано с SoftHashMap, с Оракловыми коннектами.
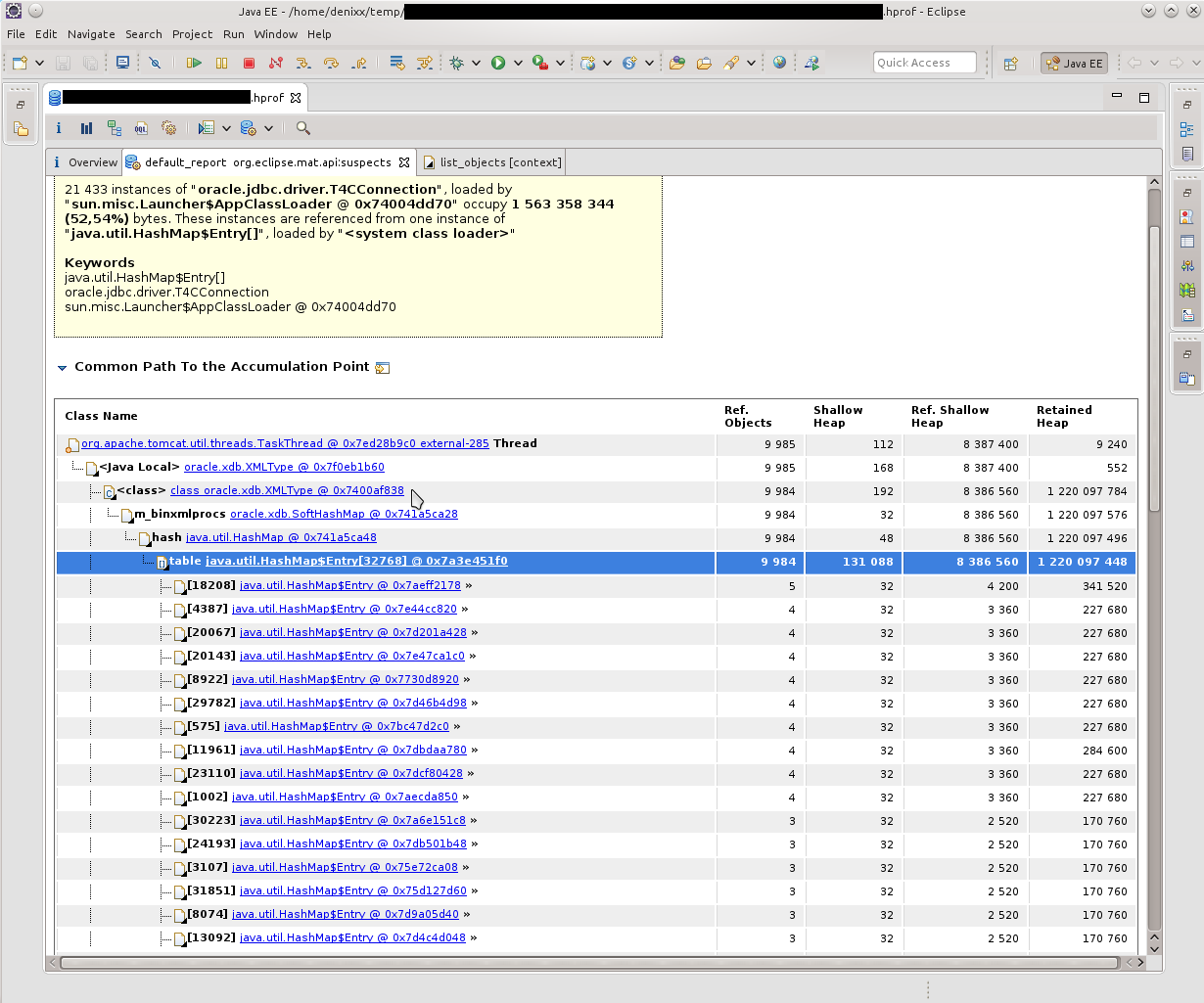
Что, собственно, подтверждалось такой картинкой. HashMap$Entry было просто море, и они более-менее сакуммулировались внутри oracle.xdb.SoftHashMap.
В следующем дампе картина была примерно такой же. По Dominator Tree было видно, что внутри каждого Entry находится тяжёлый такой BinXmlProcessorImpl.
-=-=-
Если учесть, что я в тот момент был не силён в том, что такое xdb, и как он связан с XML, то, несколько растерявшись, я решил, что надо бы погуглить, быть может кто-то уже в курсе, что со всем этим нужно делать. И чутьё не обмануло, по запросу «oracle.xdb.SoftHashMap T4CConnection» нашлось
раз piotr.bzdyl.net/2014/07/memory-leak-in-oracle-softhashmap.html
и два leakfromjavaheap.blogspot.com/2014/02/memory-leak-detection-in-real-life.html
Утвердившись, что тут всё-таки косяк у Оракла, дело оставалось за малым.
Попросил администратора БД посмотреть информацию по обнаруженной проблеме:
xxx: Ключевые слова: SoftHashMap XMLType
yyy: Bug 17537657 Memory leak from XDB in oracle.xdb.SoftHashMap
yyy: The fix for 17537657 is first included in
12.2 (Future Release)
12.1.0.2 (Server Patch Set)
12.1.0.1.4 Database Patch Set Update
12.1.0.1 Patch 11 on Windows Platforms
yyy: нда. Описание
Description
When calling either getDocument() using the thin driver, or getBinXMLStream()
using any driver, memory leaks occur in the oracle.xdb.SoftHashMap class.
BinXMLProcessorImpl classes accumulate in this SoftHashMap, but are never
removed.
xxx: Всё так и есть
Вот описание фикса: updates.oracle.com/Orion/Services/download?type=readme&aru=18629243 (для доступа требуется учётка в Оракл).
-=-=-
После применения фикса инстансы нашего приложения живут уже месяц, и пока без эксцессов. *постучал по дереву* *поплевал через левое плечо*
Успехов Вам в поисках!
Часто при анализе неполадок на сервере в выводе утилиты dmesg приходится встречать сообщения о OOM и прекращении ядром процессов MySQL. Ошибка Out of memory MySQL — ситуация при которой системе не хватает оперативной памяти для нормального функционирования, при возникновении подобной ситуации ядро принудительно завершает процесс MySQL. Процесс MySQL будет завершен если система сочтет его самым малозначительный процессом.
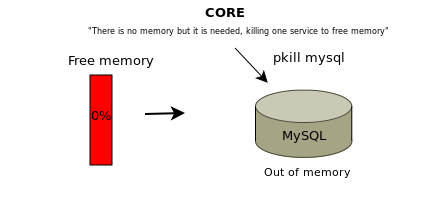
В случае если сервер используется для размещения веб-сайтов ресурсы при этом становятся недоступны поскольку пропадает соединение с сервером баз данных. Вместо контента сайтов может отображаться ошибка 500 или ошибка о невозможности подключиться к базе данных.
Чаще всего вопрос решается запуском MySQL
service mysql start
Однако, часто при «убийстве» процесса ядром происходит повреждение таблиц баз данных. Обычно их можно починить используя утилиту myisamchk, но случаются и ситуации когда MySQL не запускается и после починки таблиц.
Работы по устранению неисправностей в этом случае могут занять определенное время, сайты на сервере при этом будут продолжать оставаться недоступны.
В Linux существует возможность дать ядру указание на то какие процессу убивать не следует. При необходимости можно задать в качестве такого процесса процесс, выполняемый от имени сервера баз данных.
Делается это при помощи cgroups или cgroup (начиная с версии ядра 4.5).
В рамках статьи вдаваться в особенности работы cgroups не будем, приведем лишь способ решения поставленной задачи — ограждение процесса MySQL от убийства ядром.
Добавим в tasks идентификатор процесса MySQL
ps aux | grep mysql
В выводе видим нужный PID, помещаем его в tasks
echo PID > /sys/fs/cgroup/cpuset/group0/tasks
где PID — идентификатор процесса
cgroups позволяет управлять памятью, в том числе создавать ограничения для механизма срабатывающего при нехватке RAM:
echo 1 > /sys/fs/cgroup/memory/group0/memory.oom_control
cat /sys/fs/cgroup/memory/group0/memory.oom_control
oom_killdisable 1
under_oom 0
При преувеличении потребления памяти сейчас процесс убит не будет, ядро выберет другую жертву и принудительно завершит работу другой службы, серверу баз данных и таблицам БД угрожать при выполнении описанных действий ничего не будет.
Используя cgroups мы поместили процесс в группу, группу затем добавили в подсистему.
Самым лучшим решением если подобные ситуации появляются регулярно является увеличение количества RAM.
Читайте про то как исправить таблицы после сбоя если они имеют тип InnoDB (упомянутая утилита myisamchk в этом случае не поможет).
Пользуясь базами данных любой программы 1С, сотрудники предприятий и организаций часто сталкиваются с непредвиденными ситуациями. Пожалуй, одна из самых частых — когда работа программы внезапно завершается по причине того, что администратор разорвал контакт с сервером.
В данном случае Microsoft OLE DB Provider for SQL Server выдаёт такую информацию: «Неопознанная ошибка hresult 80004005». При этом главным признаком проблемы является невозможность выгрузить информацию в базу.
Следует отметить, что ошибки, содержащие именно код 80004005, встречаются постоянно. У них есть особая классификация, которую при желании можно найти в соответствующей литературе.
Каждому виртуальному серверу назначается фиксированный объём оперативной памяти, в зависимости от выбранного тарифного плана: от 1ГБ до 32ГБ.
Когда запущенные процессы и приложения хотят получить больше памяти, операционная система обычно начинает случайным образом выбирать некоторые процессы и принудительно завершать их в аварийном режиме.
В результате некоторые службы на сервере перестают работать, сервер часто перегружается и «зависает» в целом, выдавая ошибку «out of memory» (OOM) — нехватка операционной памяти.
Если процесс завершается в целях экономии памяти, она регистрируется в системных журналах и хранится в /var/log/, где вы можете найти подобное сообщения о нехватке памяти:
Jav 11 17:12:34 ovzhost114 kernel: [63353551.892881] Out of memory in UB 33222955: OOM
killed process 110919 (mysqld) score 0 vm:404635kB, rss:06665kB, swap:0kB
В зависимости от дистрибутива Linux и конфигурации системы, вид этой записи может меняться.
Как решить ошибку «Out of memory» на VPS
Узнайте какие процессы запущены
Вам нужно узнать обо всех запущенных процессах и сколько оперативной памяти они потребляют.
- Использование памяти можно отслеживать, например, с помощью команды:
free -h,
которая предоставляет текущую статистику памяти. К примеру, результаты, предоставленные системой в 1ГБ, будут выглядеть примерно так:
| total | used | free | shared | buffers |
cached |
|
|
Mem |
993M | 738M | 255M | 5.7M | 64M |
439M |
|
-/+ buffers/cache: |
234M | 759M | ||||
|
Swap: |
0B | 0B | 0B |
- Ещё одним полезным инструментом для мониторинга памяти является «top», который отображает полезную, постоянно обновляемую информацию об использовании памяти и ЦП, времени выполнения процессов и другой статистике. Это особенно полезно для определения ресурсоёмких задач.
Программа будет работать до тех пор, пока вы не выйдете их неё нажатием «q». Использование ресурсов отображается в процентах и предоставляет лаконичный обзор нагрузки на вашу систему.
Снизьте потребление оперативной памяти
Ограничьте работу ресурсоёмких плагинов и удалите лишние расширения и плагины сайта.
Оптимизируйте настройки MySQL с помощью Mysqltuner
Mysqltuner – это высокопроизводительный сценарий для настройки MySQL, который предоставляет подробную информацию о состоянии и работоспособности сервера MySQL, и даёт конкретные рекомендации по улучшению и повышению производительности.
- Чтобы установить mysqltuner, запустите следующие команды, в зависимости от ОС:
Debian/Ubuntu:
sudo apt-get -y install mysqltuner
CentOS:
sudo yum -y install mysqltuner
- Теперь можно запустить Mysqltuner: mysqltuner
В результате анализа вы получите крайне полезную информацию. Обратите внимание на раздел Recommendations.
- После строки Variables to adjust указаны параметры, которые следует изменить или дописать в случае их отсутствия в файле my.cnf.
Вы сможете найти этот файл в директории:
Debian/Ubuntu:
/etc/mysql/my.cnf
CentOS:
/etc/my.cnf
- Перезагрузите MySQL с помощью команд:
Debian/Ubuntu:
sudo /etc/init.d/mysql restart
CentOS:
sudo systemctl restart mariadb
Оптимизируйте настройки Apache
Неправильная настройка параметров Apache может стать огромной головной болью и привести к нехватке оперативной памяти VPS.
Вы можете выполнить следующие действия:
- Измените файл httpd.conf следующим образом. Такие параметры подходят для сервера с оперативной памятью в 1 ГБ.
|
KeepAlive Off MaxKeepAliveRequests |
100 |
|
KeepAliveTimeout |
15 |
|
StartServers |
2 |
|
ServerLimit |
2 |
|
MinSpareThreads |
50 |
|
MaxSpareThreads |
100 |
|
ThreadLimit |
100 |
|
ThreadsPerChild |
50 |
|
MaxClients |
100 |
|
MaxRequestsPerChild |
10000 |
- Кроме того, этот код можно внести в отдельный файл с расширением .conf и сохранить его в директории /etc/httpd/conf.d.
- Перезагрузите Apache: apachectl restart
Установите Nginx
Nginx служит хорошим балансировщиком нагрузки в сочетании с Apache и потребляет значительно меньше памяти. Больше о нём вы сможете узнать из нашей статьи Что такое nginx и как правильно его настроить.
Включите кэширование контента
Включение кэша вашего сайта уменьшит возникающие ошибки. Этот способ будет особенно полезен, если ваш сайт получает огромный объём трафика.
Перейдите на более высокий тарифный план
При нехватке оперативной памяти рекомендуется выбрать другой тариф VPS. Вы можете ознакомиться с тарифами VDS/VPS на нашем сайте.
Закажите услугу «Администрирование по запросу»
Услуга «Администрирование по запросу» может существенно облегчить вам решение этой проблемы. Просто доверьтесь специалистам RU-CENTER, и они сделают всю сложную работу за вас.
Время на прочтение
17 мин
Количество просмотров 70K
Приветствую, Хабр!
Немного лирики
Сегодня, 2015-03-21, я решил сделать пол-дела, и всё-таки начать писать статью о том, как же всё-таки начать понимать, что же делать с OOM, да и вообще научиться ковырять heap-dump’ы (буду называть их просто дампами, для простоты речи. Также я постараюсь избегать англицизмов, где это возможно).
Задуманный мной объём «работ» по написанию этой статьи кажется мне не однодневным, а посему статья должна появиться лишь
через пару недель
спустя день.
В этой статье я постараюсь разжевать, что делать с дампами в Java, как понять причину или приблизиться к причине возникновения OOM, посмотреть на инструменты для анализа дампов, инструмент (один, да) для мониторинга хипа, и вообще вникнуть в это дело для общего развития. Исследуются такие инструменты, как JVisualVM (рассмотрю некоторые плагины к нему и OQL Console), Eclipse Memory Analyzing Tool.
Очень много понаписал, но надеюсь, что всё только по делу
Предыстория
Для начала нужно понять, как возникает OOM. Кому-то это может быть ещё неизвестно.
Представьте себе, что есть какой-то верхний предел занимаемой оперативки для приложения. Пусть это будет гигабайт ОЗУ.
Само по себе возникновение OOM в каком-то из потоков ещё не означает, что именно этот поток «выжрал» всю свободную память, да и вообще не означает, что именно тот кусок кода, который привёл к OOM, виноват в этом.
Вполне нормальна ситуация, когда какой-то поток чем-то занимался, поедая память, «дозанимался» этим до состояния «ещё немного, и я лопну», и завершил выполнение, приостановившись. А в это время какой-то другой поток решил запросить для своей маленькой работы ещё немного памяти, сборщик мусора попыжылся, конечно, но мусора уже в памяти не нашёл. В этом случае как раз и возникает OOM, не связанный с источником проблемы, когда стектрейс покажет совсем не того виновника падения приложения.
Есть и другой вариант. Около недели я исследовал, как улучшить жизнь парочки наших приложений, чтобы они перестали себя нестабильно вести. И ещё недельку-две потратил на то, чтобы привести их в порядок. В общей сложности пара недель времени, которые растянулись на полтора месяца, ведь занимался я не только этими проблемами.
Из найденного: сторонняя библиотека, и, конечно же, некоторые неучтённые вещи в вызовах хранимых процедур.
В одном приложении симптомы были следующие: в зависимости от нагрузки на сервис, оно могло упасть через сутки, а могло через двое. Если помониторить состояние памяти, то было видно, что приложение постепенно набирало «размер», и в определённый момент просто ложилось.
С другим приложением несколько интереснее. Оно может вести себя хорошо длительный срок, а могло перестать отвечать минут через 10 после перезагрузки, или вдруг внезапно упасть, сожрав всю свободную память (это я уже сейчас вижу, наблюдая за ним). А после обновления версии, когда была изменена и версия Tomcat с 7й до 8й, и JRE, оно вдруг в одну из пятниц (проработав вменяемо до этого ни много ни мало — 2 недели) начало творить такие вещи, что стыдно признаваться в этом.
В обоих историях очень полезны оказались дампы, благодаря им удалось отыскать все причины падений, подружившись с такими инструментами, как JVisualVM (буду называть его JVVM), Eclipse Memory Analyzing Tool (MAT) и языком OQL (может быть я не умею его правильно готовить в MAT, но мне оказалось легче подружиться с реализацией OQL именно в JVVM).
Ещё вам понадобится свободная оперативка для того, чтобы было куда загружать дампы. Её объём должен быть соизмерим с размером открываемого дампа.
Начало
Итак, начну потихоньку раскрывать карты, и начну именно с JVVM.
Этот инструмент в соединении с jstatd и jmx позволяет удалённо наблюдать за жизнью приложения на сервере: Heap, процессор, PermGen, количество потоков и классов, активность потоков, позволяет проводить профилирование.
Также JVVM расширяем, и я не преминул воспользоваться этой возможностью, установив некоторые плагины, которые позволили куда больше вещей, например, следить и взаимодействать с MBean’ами, наблюдать за деталями хипа, вести длительное наблюдение за приложением, держа в «голове» куда больший период метрик, чем предоставляемый вкладкой Monitor час.
Вот так выглядит набор установленных плагинов.
Visual GC (VGC) позволяет видеть метрики, связанные с хипом.
Детальнее о том, из чего состоит хип в этой нашей Java
Вот два скриншота вкладки VGC, которые показывают, как ведут себя два разных приложения.
Слева Вы можете увидеть такие разделы хипа, как Perm Gen, Old Gen, Survivor 0, Survivor 1, и Eden Space.
Все эти составляющие — участки в оперативке, в которую и складываются объекты.
PermGen — Permanent Generation — область памяти в JVM, предназначенная для хранения описания классов Java и некоторых дополнительных данных.
Old Gen — это область памяти для достаточно старых объектов, которые пережили несколько перекладываний с места на место в Survivor-областях, и в момент какого-то очередного переливания попадают в область «старых» объектов.
Survivor 0 и 1 — это области, в которые попадают объекты, которые после создания объекта в Eden Space пережили его чистку, то есть не стали мусором на момент, когда Eden Space начал чиститься Garbage Collector’ом (GC). При каждом запуске чистки Eden Space объекты из активного в текущий момент Survivor’а перекладываются в пассивный, плюс добавляются новые, и после этого Survivor’ы меняются статусами, пассивный становится активным, а активный — пассивным.
Eden Space — область памяти, в которой новые объекты порождаются. При нехватке памяти в этой области запускается цикл GC.
Каждая из этих областей может быть отрегулирована по размеру в процессе работы приложения самой виртуальной машиной.
Если вы указываете -Xmx в 2 гигабайта, например, то это не означает, что все 2 гигабайта будут сразу же заняты (если не запускать сразу что-то активно кушающее память, конечно же). Виртуальная машина сначала постарается держать себя «в узде».
На третьем скриншоте видно неактивную стадию приложения, которое не используется на выходных — Eden растёт равномерно, Survivor’ы перекладываются через равные промежутки времени, Old практически не растёт. Приложение проработало больше 90 часов, и в принципе JVM считает, что приложению требуется не так уж и много, около 540 МБ.
Бывают пиковые ситуации, когда виртуальная машина даже выделяет под хип гораздо больше памяти, но я думаю, что это какие-то ещё «неучтёнки», о которых я расскажу детальнее ниже по тексту, а может просто виртуальная машина выделила больше памяти под Eden, например, чтобы объекты в нём успевали стать мусором до следующего цикла очистки.
Участки, которые на следующем скриншоте я обозначил красным — это как раз возрастание Old, когда некоторые объекты не успевают стать мусором, чтобы быть удалёнными из памяти ранее, и всё-таки попадают в Old. Синий участок — исключение. На протяжении красных участков можно видеть гребёнку — это Eden так себя ведёт.
На протяжении синего участка скорее всего виртуальная машина решила, что нужно увеличить размер Eden-области, потому как при увеличении масштаба в Tracer’е видно, что GC перестал «частить» и таких мелких колебаний, как ранее, теперь нет, колебания стали медленными и редкими.
Перейдём ко второму приложению:
В нём Eden напоминает мне какой-то уровень из Mortal Kombat, арену с шипами. Была такая, кажется… А График GC — шипы из NFS Hot Pursuit, вот те вот, плоские ещё.
Числа справа от названий областей указывают:
1) что Eden имеет размер в 50 мегабайт, и то, что нарисовано в конце графика, последнее из значений на текущий момент — занято 25 мегабайт. Всего он может вырости до 546 мегабайт.
2) что Old может вырости до 1,333 гига, сейчас занимает 405 МБ, и забит на 145,5 МБ.
Так же для Survivor-областей и Perm Gen.
Для сравнения — вот Вам Tracer-график за 75 часов работы второго приложения, думаю, кое-какие выводы вы сможете сделать из него. Например, что активная фаза у этого приложения — с 8:30 до 17:30 в рабочие дни, и что даже на выходных оно тоже работает
Если вы вдруг увидели в своём приложении, что Old-область заполнена — попробуйте просто подождать, когда она переполнится, скорее всего она заполнена уже мусором.
Мусор — это объекты, на которые нет активных ссылок из других объектов, или целые комплексы таких объектов (например, какое-то «облако» взаимосвязанных оъектов может стать мусором, если набор ссылок указывает только на объекты внутри этого «облака», и ни на один объект в этом «облаке» ничто не ссылается «снаружи»).
Это был краткий пересказ того, что я узнал про структуру хипа за время, пока гуглил.
Предпосылки
Итак, случилось сразу две вещи:
1) после перехода на более новые библиотеки/томкеты/джавы в одну из пятниц приложение, которое я уже долгое время веду, вдруг стало вести себя из рук вон плохо спустя две недели после выставления.
2) мне на рефакторинг отдали проект, который тоже вёл себя до некоторого времени не очень хорошо.
Я уже не помню, в каком точно порядке произошли эти события, но после «чёрной пятницы» я решил наконец-то разобраться с дампами памяти детальнее, чтобы это более не было для меня чёрным ящиком. Предупреждаю, что какие-то детали я мог уже запамятовать.
По первому случаю симптомы были такие: все потоки, отвественные за обработку запросов, выжраны, на базу данных открыто всего 11 соединений, и те не сказать, что используются, база говорила, что они в состоянии recv sleep, то есть ожидают, когда же их начнут использовать.
После перезагрузки приложение оживало, но прожить могло недолго, вечером той же пятницы жило дольше всего, но уже после окончания рабочего дня таки снова свалилось. Картина всегда была одинаковой: 11 соединений к базе, и лишь один, вроде бы, что-то делает.
Память, кстати, была на минимуме. Сказать, что OOM привёл меня к поиску причин, не могу, однако полученные знания при поиске причин позволили начать активную борьбу с OOM.
Когда я открыл дамп в JVVM, из него было сложно что-либо понять.
Подсознание подсказывало, что причина где-то в работе с базой.
Поиск среди классов сказал мне, что в памяти аж 29 DataSource, хотя должно быть всего 7.
Это и дало мне точку, от которой можно было бы оттолкнуться, начать распутывать клубок.
OQL
Сидеть переклацывать в просмотровщике все эти объекты было некогда, и моё внимание наконец-то привлекла вкладка OQL Console, я подумал, что вот он, момент истины — я или начну использовать её на полную катушку, или так и забью на всё это.
Прежде, чем начать, конечно же был задан вопрос гуглу, и он любезно предоставил шпаргалку (cheat sheet) по использованию OQL в JVVM: http://visualvm.java.net/oqlhelp.html
Сначала обилие сжатой информации привело меня в уныние, но после применения гугл-фу на свет таки появился вот такой OQL-запрос:
select {instance: x, uri: x.url.toString(), connPool: x.connectionPool}
from org.apache.tomcat.dbcp.dbcp2.BasicDataSource x
where x.url != null
&& x.url.toString() == "jdbc:sybase:Tds:айпишник:порт/базаДанных"
Это уже исправленная и дополненная, финальная версия этого запроса
Результат можно увидеть на скриншоте:
После нажатия на BasicDataSource#7 мы попадаем на нужный объект во вкладке Instances:
Через некоторое время до меня дошло, что есть одно несхождение с конфигурацией, указанной в теге Resource в томкете, в файле /conf/context.xml. Ведь в дампе параметр maxTotal имеет значение 8, в то время, как мы указывали maxActive равным 20…
Тут-то до меня и начало доходить, что приложение жило с неправильной конфигурацией пула соединений все эти две недели!
Для краткости напишу тут, что в случае, если вы используете Tomcat и в качестве пула соединений — DBCP, то в 7м томкете используется DBCP версии 1.4, а в 8м томкете — уже DBCP 2.0, в котором, как я потом выяснил, решили переименовать некоторые параметры! А про maxTotal вообще на главной странице сайта написано
http://commons.apache.org/proper/commons-dbcp/
«Users should also be aware that some configuration options (e.g. maxActive to maxTotal) have been renamed to align them with the new names used by Commons Pool 2.»
Причины
Обозвал их по всякому, успокоился, и решил разобраться.
Как оказалось, класс BasicDataSourceFactory просто напросто получает этот самый Resource, смотрит, есть ли нужные ему параметры, и забирает их в порождаемый объект BasicDataSource, молча игнорируя напрочь всё, что его не интересует.
Так и получилось, что они переименовали самые весёлые параметры, maxActive => maxTotal, maxWait => maxWaitMillis, removeAbandoned => removeAbandonedOnBorrow & removeAbandonedOnMaintenance.
По умолчанию maxTotal, как и ранее, равен 8; removeAbandonedOnBorrow, removeAbandonedOnMaintenance = false, maxWaitMillis устанавливается в значение «ждать вечно».
Получилось, что пул оказался сконфигурирован с минимальным количеством соединений; в случае, если заканчиваются свободные соединения — приложение молча ждёт, когда они освободятся; и добивает всё молчанка в логах по поводу «заброшенных» соединений — то, что могло бы сразу показать, в каком именно месте
программист мудак
код хватает соединение, но не отдаёт его обратно по окончанию своей работы.
Это сейчас вся мозаика сложилась быстро, а добывались эти знания дольше.
«Так быть не должно», решил я, и запилил патчик (https://issues.apache.org/jira/browse/DBCP-435, выразился в http://svn.apache.org/viewvc/commons/proper/dbcp/tags/DBCP_2_1/src/main/java/org/apache/commons/dbcp2/BasicDataSourceFactory.java?view=markup ), патч был принят и вошёл в версию DBCP 2.1. Когда и если Tomcat 8 обновит версию DBCP до 2.1+, думаю, что админам откроются многие тайны про их конфигурации Resource
По поводу этого происшествия мне лишь осталось рассказать ещё одну деталь — какого чёрта в дампе было аж 29 DataSource’ов вместо всего 7 штук. Разгадка кроется в банальной арифметике, 7*4=28 +1=29.
Детальнее о том, почему нельзя закидывать Resource в файл /conf/context.xml томкета
На каждую подпапку внутри папки /webapps поднимается своя копия /conf/context.xml, а значит то количество Resource, которые там есть, следует умножать на количество приложений, чтобы получить общее количество пулов, поднятых в памяти томкета. На вопрос «что в этом случае делать?» ответ будет таким: нужно вынести все объявления Resource из /conf/context.xml в файл /conf/server.xml, внутрь тега GlobalNamingResources. Там Вы можете найти один, имеющийся по умолчанию, Resource name=«UserDatabase», вот под ним и размещайте свои пулы. Далее необходимо воспользоваться тегом ResourceLink, его желательно поместить в приложение, в проекте, внутрь файла /META-INF/context.xml — это так называемый «per-app context», то есть контекст, который содержит объявления компонентов, которые будут доступны только для разворачиваемого приложения. У ResourceLink параметры name и global могут содержать одинаковые значения.
Для примера:
<ResourceLink name="jdbc/MyDB" global="jdbc/MyDB" type="javax.sql.DataSource"/>
Эта ссылка будет выхватывать из глобально объявленных ресурсов DataSource с именем «jdbc/MyDB», и ресурс станет доступен приложению.
ResourceLink можно (но не нужно) разместить и в /conf/context.xml, но в этом случае доступ к ресурсам, объявленным глобально, будет у всех приложений, пусть даже и не будет столько копий DataSource в памяти.
Ознакомиться с деталями можно вот тут: GlobalNamingResources — http://tomcat.apache.org/tomcat-7.0-doc/config/globalresources.html#Environment_Entries, ResourceLink — http://tomcat.apache.org/tomcat-7.0-doc/config/globalresources.html#Resource_Links, также можно просмотреть эту страницу: tomcat.apache.org/tomcat-7.0-doc/config/context.html.
Для TC8 эти же страницы: http://tomcat.apache.org/tomcat-8.0-doc/config/globalresources.html и http://tomcat.apache.org/tomcat-8.0-doc/config/context.html .
После этого всё стало ясно: 11 соединений было потому, что в одном, активном DataSource было съедено 8 соединений (maxTotal = 8), и ещё по minIdle=1 в трёх других неиспользуемых DataSource-копиях.
В ту пятницу мы откатились на Tomcat 7, который лежал рядышком, и ждал, когда от него избавятся, это дало время спокойно во всём разобраться.
Плюс позже, уже на TC7, обнаружилась утечка соединений, всё благодаря removeAbandoned+logAbandoned. DBCP радостно сообщил в логфайл catalina.log о том, что
"org.apache.tomcat.dbcp.dbcp.AbandonedTrace$AbandonedObjectException: DBCP object created 2015-02-10 09:34:20 by the following code was never closed:
at org.apache.tomcat.dbcp.dbcp.AbandonedTrace.setStackTrace(AbandonedTrace.java:139)
at org.apache.tomcat.dbcp.dbcp.AbandonedObjectPool.borrowObject(AbandonedObjectPool.java:81)
at org.apache.tomcat.dbcp.dbcp.PoolingDataSource.getConnection(PoolingDataSource.java:106)
at org.apache.tomcat.dbcp.dbcp.BasicDataSource.getConnection(BasicDataSource.java:1044)
at наш.пакет.СуперКласс.getConnection(СуперКласс.java:100500)
at наш.пакет.СуперКласс.плохойПлохойМетод(СуперКласс.java:100800)
at наш.пакет.СуперКласс.вполнеВменяемыйМетод2(СуперКласс.java:100700)
at наш.пакет.СуперКласс.вполнеВменяемыйМетод1(СуперКласс.java:100600)
ещё куча строк..."
Вот этот вот плохойПлохойМетод имеет в сигнатуре Connection con, но внутри была конструкция «con = getConnection();», которая и стала камнем преткновения. СуперКласс вызывается редко, поэтому на него и не обращали внимания так долго. Плюс к этому, вызовы происходили, я так понимаю, не во время рабочего дня, так что даже если что-то и подвисало, то никому уже не было дела до этого. А в ТуСамуюПятницу просто звёзды сошлись, начальнику департамента заказчика понадобилось посмотреть кое-что
Приложение №2
Что же касается «события №2» — мне отдали приложение на рефакторинг, и оно на серверах тут же вздумало упасть.
Дампы попали уже ко мне, и я решил попробовать поковырять и их тоже.
Открыл дамп в JVVM, и «чё-то приуныл»:
Что можно понять из Object[], да ещё и в таком количестве?
( Опытный человек, конечно же, увидел уже причину, правда? )
Так у меня зародилась мысль «ну неужели никто ранее не занимался этим, ведь наверняка уже есть готовый инструмент!». Так я наткнулся на этот вопрос на StackOverflow: http://stackoverflow.com/questions/2064427/recommendations-for-a-heap-analysis-tool-for-java.
Посмотрев предложенные варианты, я решил остановиться на MAT, надо было попробовать хоть что-то, а это открытый проект, да ещё и с куда бОльшим количеством голосов, чем у остальных пунктов.
Eclipse Memory Analyzing Tool
Итак, MAT.
Рекомендую скачивать последнюю версию Eclipse, и устанавливать MAT туда, потому как самостоятельная версия MAT ведёт себя плохо, там какая-то чертовщина с диалогами, в них не видно содержимого в полях. Быть может кто-то подскажет в комментариях, чего ему не хватает, но я решил проблему, установив MAT в Eclipse.
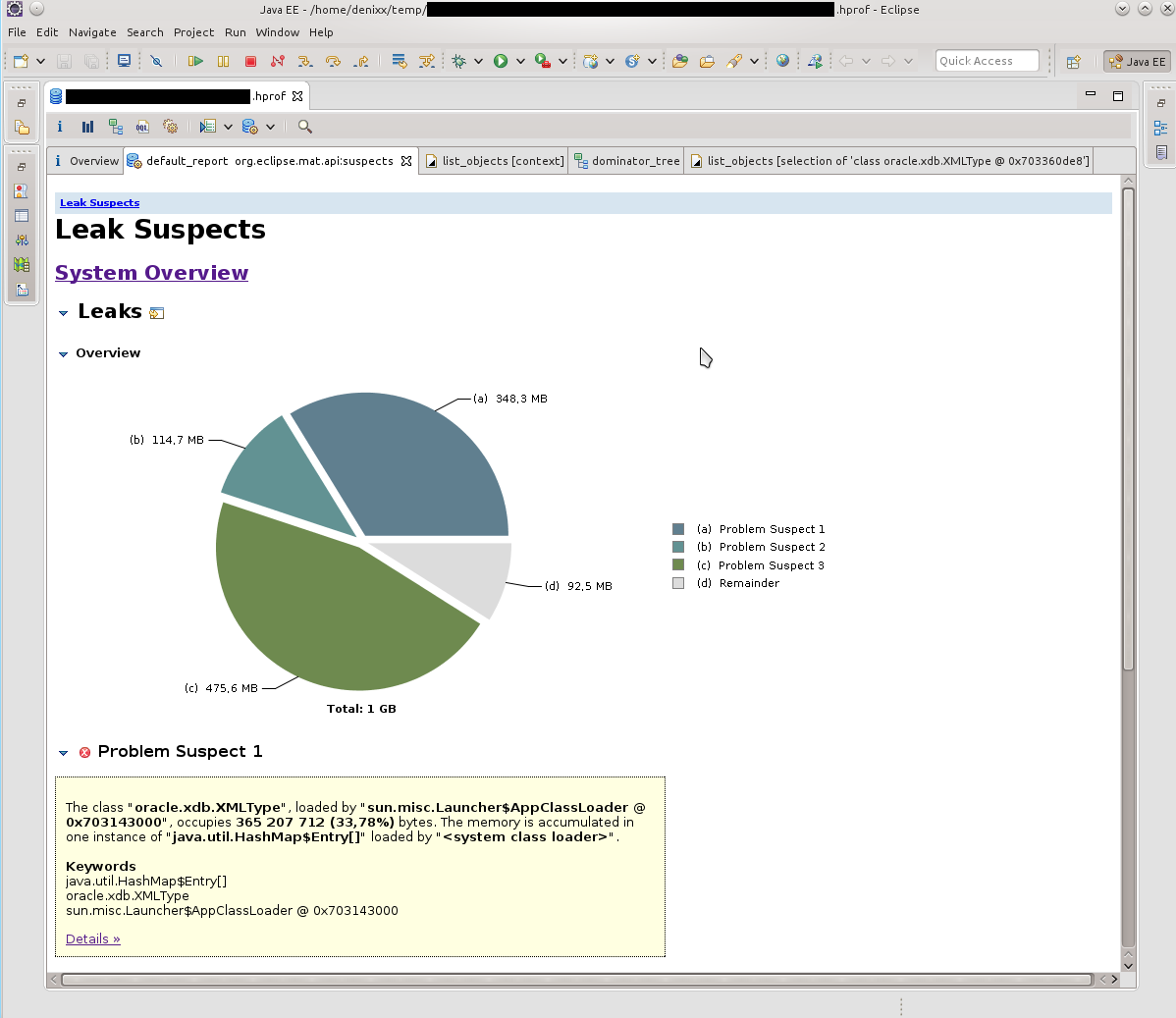
Открыв дамп в MAT я запросил выполнение Leak Suspects Report.
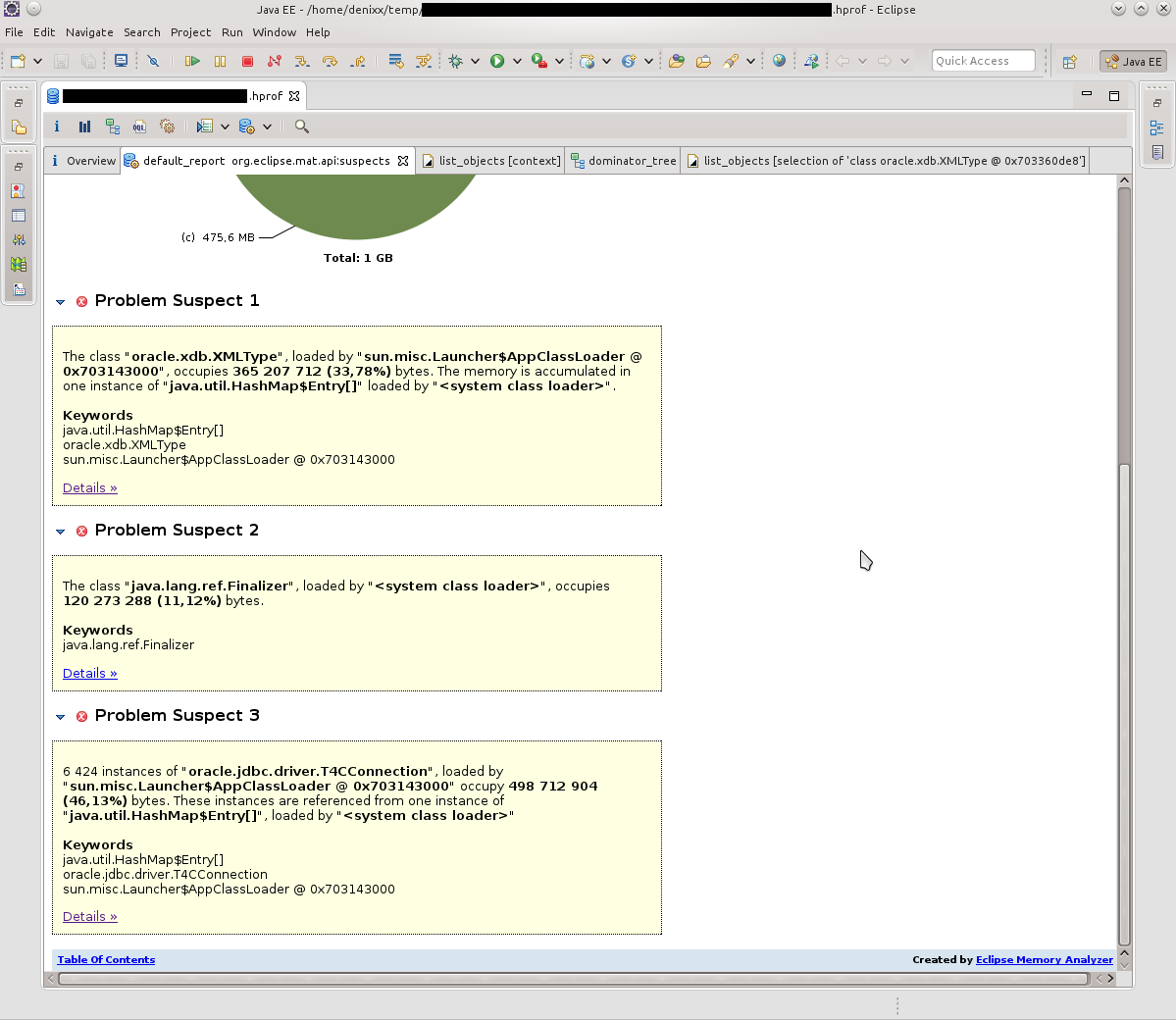
Удивлению не было предела, честно говоря.
1.2 гига весят соединения в базу.
Каждое соединение весит от 17 до 81 мегабайта.
Ну и ещё «немного» сам пул.
Визуализировать проблему помог отчёт Dominator Tree:
Причиной всех падений оказались километры SQLWarning’ов, база настойчиво пыталась дать понять, что «010SK: Database cannot set connection option SET_READONLY_TRUE.», а пул соединений BoneCP не вычищает SQLWarning’и после освобождения и возврата соединений в пул (может быть это где-то можно сконфигурировать? Подскажите, если кто знает).
Гугл сказал, что такая проблема с Sybase ASE известна ещё с 2004 года: https://forum.hibernate.org/viewtopic.php?f=1&t=932731
Если вкратце, то «Sybase ASE doesn’t require any optimizations, therefore setReadOnly() produces a SQLWarning.», и указанные решения всё ещё работают.
Однако это не совсем решение проблемы, потому как решение проблемы — это когда при возврате соединения в пул все уведомления базы очищаются в силу того, что они уже никогда никому не понадобятся.
И DBCP таки умеет делать это: http://svn.apache.org/viewvc/commons/proper/dbcp/tags/DBCP_1_4/src/java/org/apache/commons/dbcp/PoolableConnectionFactory.java?view=markup, метод passivateObject(Object obj), в строке 687 можно увидеть conn.clearWarnings();, этот вызов и спасает от километров SQLWarning’ов в памяти.
Об этом я узнал из тикета: https://issues.apache.org/jira/browse/DBCP-102
Также мне подсказали про вот такой тикет в багтрекере: https://issues.apache.org/jira/browse/DBCP-234, но он касается уже версии DBCP 2.0.
В итоге я перевёл приложение на DBCP (пусть и версии 1.4). Пусть нагрузка на сервис и немаленькая (от 800 до 2к запросов в минуту), но всё же приложение ведёт себя хорошо, а это главное. И правильно сделал, потому как BoneCP уже пять месяцев не поддерживается, правда, ему на смену пришёл HikariCP. Нужно будет посмотреть, как дела в его исходниках…
Сражаемся с OOM
Впечатлившись тем, как MAT мне всё разложил по полочкам, я решил не забрасывать этот действенный инструмент, и позже он мне пригодился, потому как в первом приложении ещё остались всяческие «неучтёнки» — неучтённые вещи в коде приложения или коде хранимых процедур, которые иногда приводят к тому, что приложение склеивает ласты. Я их отлавливаю до сих пор.
Вооружившись обоими инструментами, я принялся ковырять каждый присланный дамп в поисках причин падения по OOM.
Как правило все OOM приводили меня к TaskThread.
И если нажать на надпись See stacktrace, то да, это будет как раз банальный случай, когда какой-то поток вдруг внезапно упал при попытке отмаршалить результат своей работы.
Однако здесь ничто не указывает на причину возникновения OOM, здесь лишь результат. Найти причину мне пока-что, в силу незнания всей магии OQL в MAT, помогает именно JVVM.
Загружаем дамп там, и пытаемся отыскать причину!
Искать мне следует, конечно же, именно вещи, связанные с базой данных, а посему попробуем сначала посмотреть, есть ли в памяти Statement’ы.
Два SybCallableStatement, и один SybPreparedStatement.
Думаю, что дело усложнится, если Statement’ов будет куда больше, но немного подрихтовав один из следующих запросов, указав в where нужные условия, думаю, всё у Вас получится. Плюс, конечно же, стоит хорошенько посмотреть в MAT, что за результаты пытается отмаршалить поток, какой объект, и станет понятнее, какой именно из Statement’ов необходимо искать.
select {
instance: x,
stmtQuery: x._query.toString(),
params: map(x._paramMgr._params, function(obj1) {
if (obj1 != null) {
if (obj1._parameterAsAString != null) {
return '''+obj1._parameterAsAString.toString()+''';
} else {
return "null";
}
} else {
return "null";
}
})
}
from com.sybase.jdbc4.jdbc.SybCallableStatement x
where x._query != null
Не то, это «внутренние» вызовы.
select {
instance: x,
stmtQuery: x._query.toString(),
params: map(x._paramMgr._params, function(obj1) {
if (obj1 != null) {
if (obj1._parameterAsAString != null) {
return '''+obj1._parameterAsAString.toString()+''';
} else {
return "null";
}
} else {
return "null";
}
})
}
from com.sybase.jdbc4.jdbc.SybPreparedStatement x
where x._query != null
А вот и дичь!
Для чистоты эксперимента можно кинуть такой же запрос в любимой БД-IDE, и он будет очень долго отрабатывать, а если покопаться в недрах хранимки, то будет понятно, что там просто из базы, которая нам не принадлежит, выбирается 2 миллиона строк по такому запросу с такими параметрами. Эти два миллиона даже влазят в память приложения, но вот попытка отмаршалить результат становится фатальной для приложения. Такое себе харакири.
При этом GC старательно убирает все улики, но не спасло его это, всё же источник остался в памяти, и он будет наказан.
Почему-то после всего этого рассказа почувствовал себя тем ещё неудачником.
Прощание
Вот и закончилось моё повествование, надеюсь, Вам понравилось
Хотел бы выразить благодарность своему начальнику, он дал мне время во всём этом разобраться. Считаю эти новые знания очень полезными.
Спасибо девушкам из Scorini за неизменно вкусный кофе, но они не прочтут этих слов благодарности — я даже сомневаюсь, что они знают о существовании Хабрахабра
Хотелось бы увидеть в комментариях ещё больше полезной инфы и дополнений, буду очень благодарен.
Думаю, самое время почитать документацию к MAT…
UPD1: Да, совсем забыл рассказать про такие полезные вещи, как создание дампов памяти.
docs.oracle.com/javase/7/docs/webnotes/tsg/TSG-VM/html/clopts.html#gbzrr
Опции
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/disk2/dumps
весьма полезны для генерации дампов в момент падения приложения по OutOfMemoryError,
а также существует возможность снять дамп памяти с приложения «наживо», посреди его работы.
Для этого существует утилита jmap.
Пример вызова для винды:
«C:installPSToolsPsExec.exe» -s «C:Program FilesJavajdk1.7.0_55binjmap.exe» -dump:live,format=b,file=C:dump.hprof 3440
последний параметр — это PID java-процесса. Приложение PsExec из набора PSTools позволяет запускать другие приложения с правами системы, для этого служит ключ «-s». Опция live полезна, чтобы перед сохранением дампа вызвать GC, очистив память от мусора. В случае, когда возникает OOM, чистить память незачем, там уже не осталось мусора, так что не ищите, как можно установить опцию live в случае возникновения OOM.
UPD2 (2015-10-28) | Случай номер два три
(Было принято решение дописать это сюда как апдейт, а не пилить новую статью о том же самом):
Ещё один интересный случай, но уже с Оракловой базой.
Один из проектов использует фичу с XML, проводит поиски по содержимому сохранённого XML-документа. В общем, этот проект иногда давал о себе знать тем, что вдруг внезапно один из инстансов переставал подавать признаки жизни.
Почуяв «хороший» случай потренироваться
на кошках
, я решил посмотреть его дампы памяти.
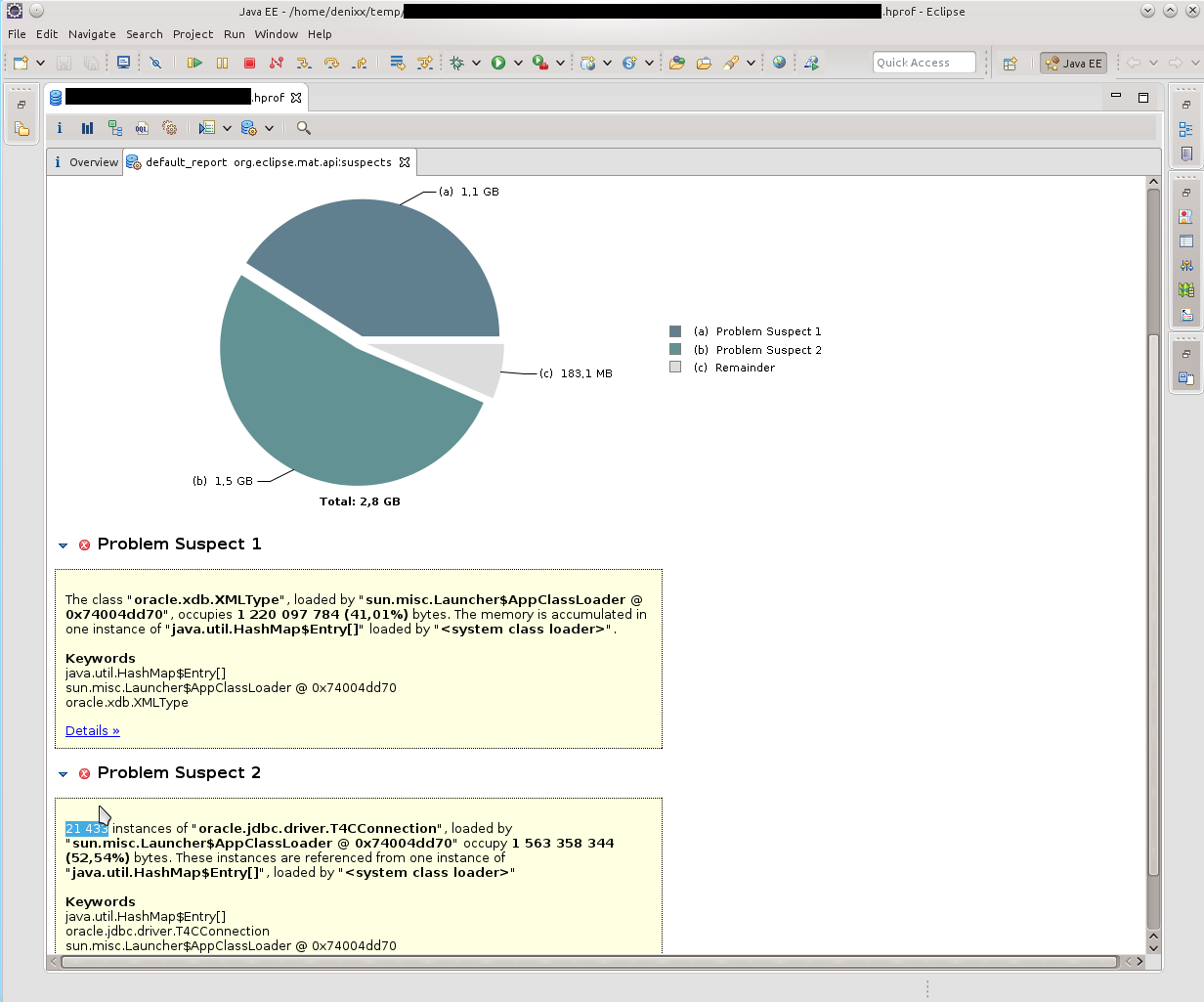
Первое, что я увидел, было «у вас тут много коннектов в памяти осталось». 21к!!! И какой-то интересный oracle.xdb.XMLType тоже давал жару. «Но это же Оракл!», вертелось у меня в голове. Забегая вперёд скажу что таки да, он виноват.
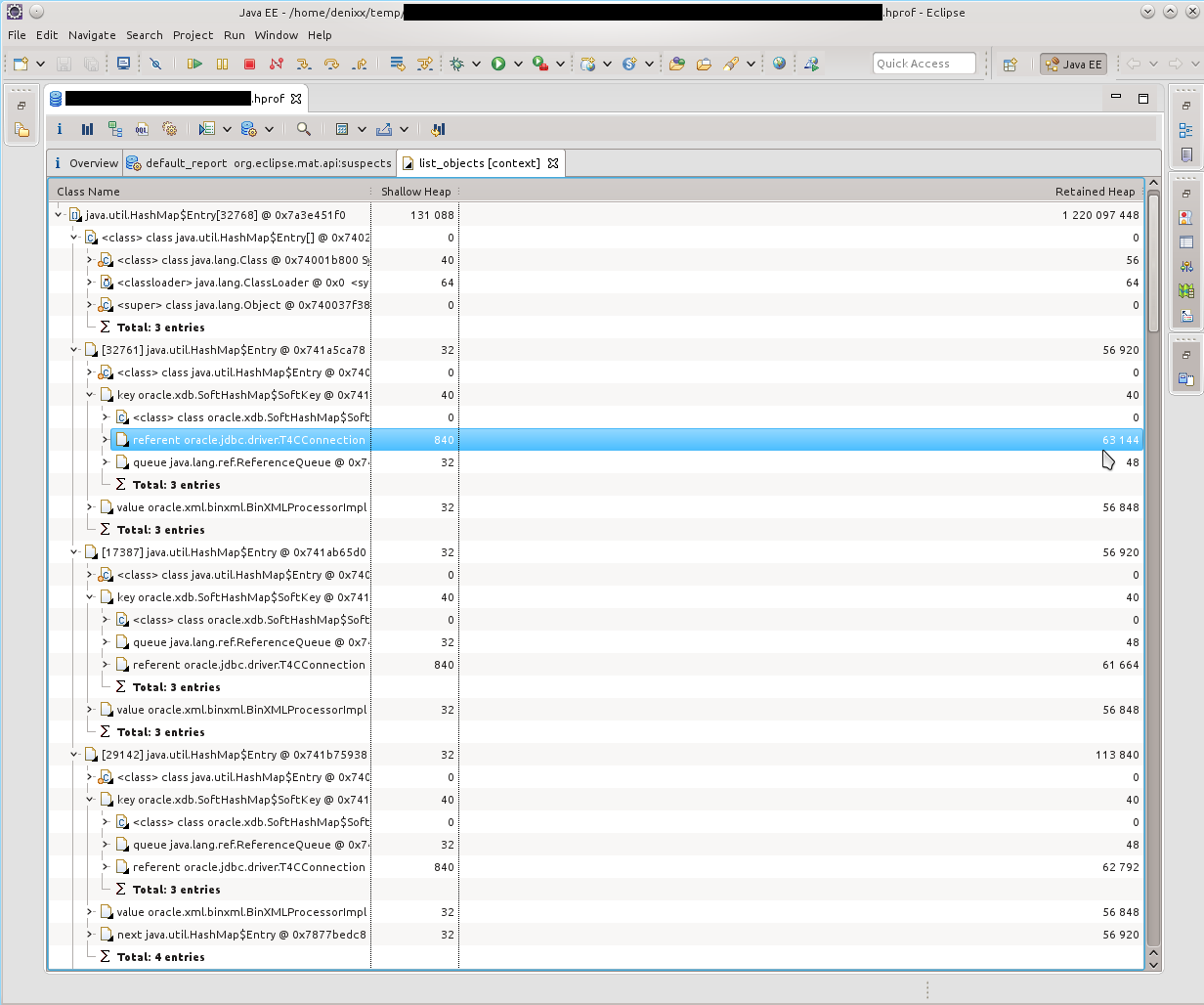
Итак, видим кучу T4CConnection, которые лежат в HashMap$Entry. Обратил внимание сразу, что вроде бы и SoftHashMap, что, вроде как, должно означать, что оно не должно вырастать до таких размеров. Но результат видите и сами — 50-60 килобайт в коннекте, и их реально МНОГО.
Посмотрев, что собой представляют HashMap$Entry — увидел, что примерно картина одинакова, всё связано с SoftHashMap, с Оракловыми коннектами.
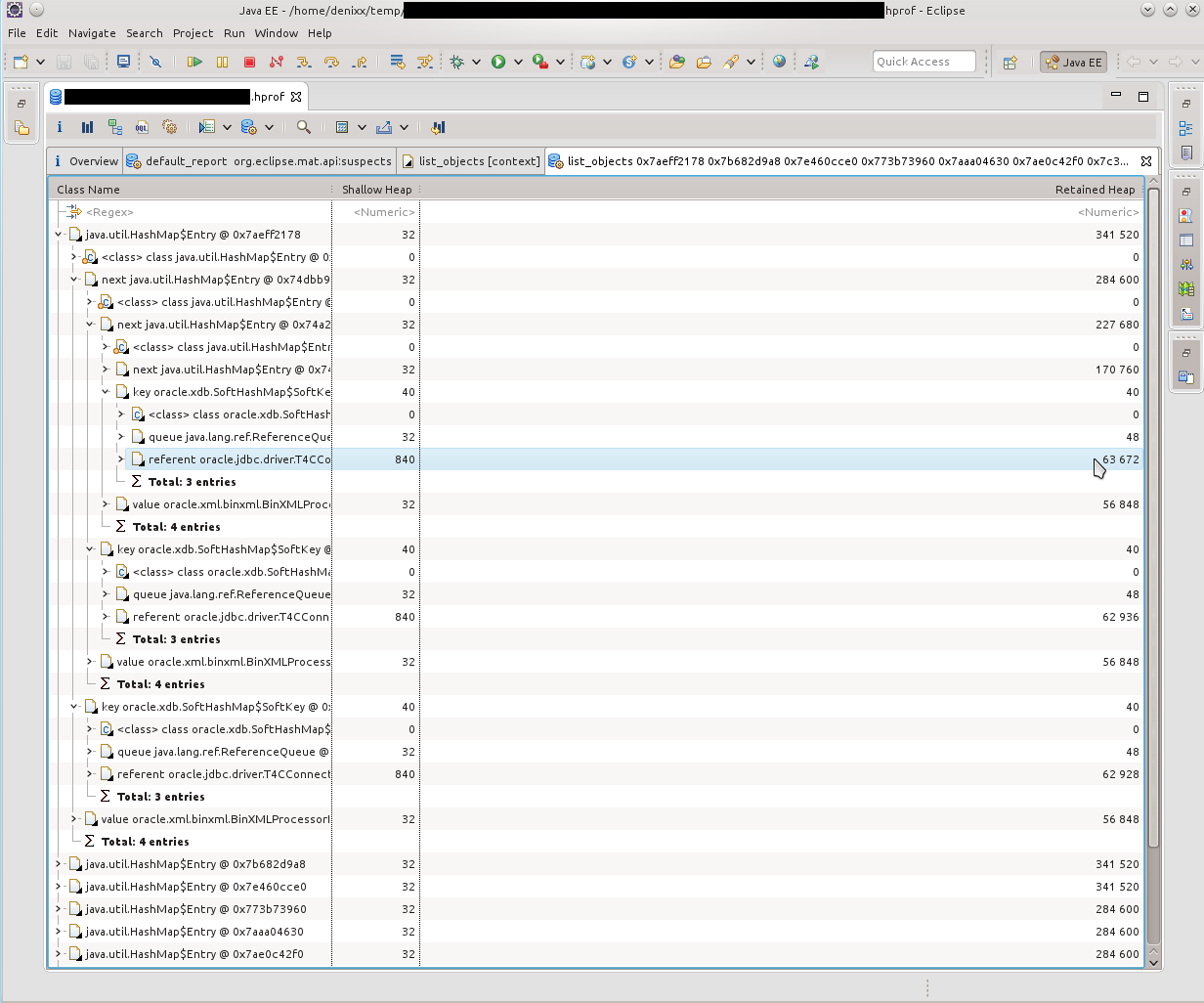
Что, собственно, подтверждалось такой картинкой. HashMap$Entry было просто море, и они более-менее сакуммулировались внутри oracle.xdb.SoftHashMap.
В следующем дампе картина была примерно такой же. По Dominator Tree было видно, что внутри каждого Entry находится тяжёлый такой BinXmlProcessorImpl.
-=-=-
Если учесть, что я в тот момент был не силён в том, что такое xdb, и как он связан с XML, то, несколько растерявшись, я решил, что надо бы погуглить, быть может кто-то уже в курсе, что со всем этим нужно делать. И чутьё не обмануло, по запросу «oracle.xdb.SoftHashMap T4CConnection» нашлось
раз piotr.bzdyl.net/2014/07/memory-leak-in-oracle-softhashmap.html
и два leakfromjavaheap.blogspot.com/2014/02/memory-leak-detection-in-real-life.html
Утвердившись, что тут всё-таки косяк у Оракла, дело оставалось за малым.
Попросил администратора БД посмотреть информацию по обнаруженной проблеме:
xxx: Ключевые слова: SoftHashMap XMLType
yyy: Bug 17537657 Memory leak from XDB in oracle.xdb.SoftHashMap
yyy: The fix for 17537657 is first included in
12.2 (Future Release)
12.1.0.2 (Server Patch Set)
12.1.0.1.4 Database Patch Set Update
12.1.0.1 Patch 11 on Windows Platforms
yyy: нда. Описание
Description
When calling either getDocument() using the thin driver, or getBinXMLStream()
using any driver, memory leaks occur in the oracle.xdb.SoftHashMap class.
BinXMLProcessorImpl classes accumulate in this SoftHashMap, but are never
removed.
xxx: Всё так и есть
Вот описание фикса: updates.oracle.com/Orion/Services/download?type=readme&aru=18629243 (для доступа требуется учётка в Оракл).
-=-=-
После применения фикса инстансы нашего приложения живут уже месяц, и пока без эксцессов. *постучал по дереву* *поплевал через левое плечо*
Успехов Вам в поисках!
Часто при анализе неполадок на сервере в выводе утилиты dmesg приходится встречать сообщения о OOM и прекращении ядром процессов MySQL. Ошибка Out of memory MySQL — ситуация при которой системе не хватает оперативной памяти для нормального функционирования, при возникновении подобной ситуации ядро принудительно завершает процесс MySQL. Процесс MySQL будет завершен если система сочтет его самым малозначительный процессом.
В случае если сервер используется для размещения веб-сайтов ресурсы при этом становятся недоступны поскольку пропадает соединение с сервером баз данных. Вместо контента сайтов может отображаться ошибка 500 или ошибка о невозможности подключиться к базе данных.
Чаще всего вопрос решается запуском MySQL
service mysql start
Однако, часто при «убийстве» процесса ядром происходит повреждение таблиц баз данных. Обычно их можно починить используя утилиту myisamchk, но случаются и ситуации когда MySQL не запускается и после починки таблиц.
Работы по устранению неисправностей в этом случае могут занять определенное время, сайты на сервере при этом будут продолжать оставаться недоступны.
В Linux существует возможность дать ядру указание на то какие процессу убивать не следует. При необходимости можно задать в качестве такого процесса процесс, выполняемый от имени сервера баз данных.
Делается это при помощи cgroups или cgroup (начиная с версии ядра 4.5).
В рамках статьи вдаваться в особенности работы cgroups не будем, приведем лишь способ решения поставленной задачи — ограждение процесса MySQL от убийства ядром.
Добавим в tasks идентификатор процесса MySQL
ps aux | grep mysql
В выводе видим нужный PID, помещаем его в tasks
echo PID > /sys/fs/cgroup/cpuset/group0/tasks
где PID — идентификатор процесса
cgroups позволяет управлять памятью, в том числе создавать ограничения для механизма срабатывающего при нехватке RAM:
echo 1 > /sys/fs/cgroup/memory/group0/memory.oom_control
cat /sys/fs/cgroup/memory/group0/memory.oom_control
oom_killdisable 1
under_oom 0
При преувеличении потребления памяти сейчас процесс убит не будет, ядро выберет другую жертву и принудительно завершит работу другой службы, серверу баз данных и таблицам БД угрожать при выполнении описанных действий ничего не будет.
Используя cgroups мы поместили процесс в группу, группу затем добавили в подсистему.
Самым лучшим решением если подобные ситуации появляются регулярно является увеличение количества RAM.
Читайте про то как исправить таблицы после сбоя если они имеют тип InnoDB (упомянутая утилита myisamchk в этом случае не поможет).
Пользуясь базами данных любой программы 1С, сотрудники предприятий и организаций часто сталкиваются с непредвиденными ситуациями. Пожалуй, одна из самых частых — когда работа программы внезапно завершается по причине того, что администратор разорвал контакт с сервером.
В данном случае Microsoft OLE DB Provider for SQL Server выдаёт такую информацию: «Неопознанная ошибка hresult 80004005». При этом главным признаком проблемы является невозможность выгрузить информацию в базу.
Следует отметить, что ошибки, содержащие именно код 80004005, встречаются постоянно. У них есть особая классификация, которую при желании можно найти в соответствующей литературе.
Для начала нужно провести проверку конфигурации. Там может содержаться мусор (иными, словами, информация, которая является некорректной). Необходимо проверить конфигурацию с помощью соответствующей команды. Вы увидите флажок, предназначенный для того, чтобы проверить её логическую целостность. Если имеются проблемы, пользователь будет уведомлен об этом с помощью сообщения.
Данные, являющиеся неверными, система удалит в автоматическом режиме, но для этого нужно дать ей доступ, чтобы она изменила главный объект. К примеру, если вы работаете в облачном хранилище, его надо просто захватить.
Поддержка конфигурации требует её проверки и у поставщиков. С этой целью:
- нужно сохранить данные о конфигурации поставщиков. Для этого используйте CF-файл;
- теперь необходимо провести загрузку файла в обновлённую базу;
- выполните операцию, которая описана в п.1.
При получении сообщения об исправлении ошибки имейте в виду то, что конфигурация, имеющаяся у поставщика, содержала неправильные данные. Если такое произошло, снимите свою конфигурацию с поддержки и установите её снова. При этом её надо объединить с новой (от поставщика).
Сейчас уже любой релиз, который выпускает 1С, не имеет таких сложностей.
Сопутствующая проблема и методы её решения
С ситуацией, описанной ранее, тесно связана ещё одна, происходящая параллельно. Выглядит она так: 10007066.
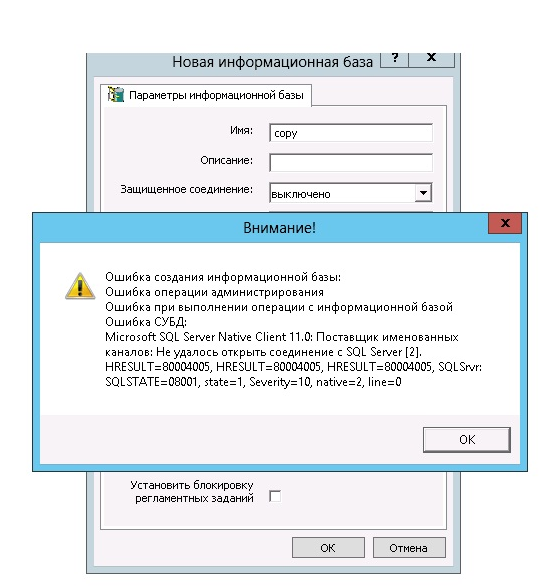
Суть проблемы: когда используется СУБД MS SQL SERVER, во время записи объекта из базы с несколькими колонками (например, «Значения» и «Хранилища»), часто случается другой тип ошибки.
Выглядит она таким образом:
Ошибка СУБД:Microsoft OLE DB Provider for SQL Server: String data length mismatchHRESULT=80004005.
Когда происходит ошибка 1с hresult clr 80004005, программа завершает свою работу в аварийном режиме.
Если вы ознакомитесь во время загрузки программы со специальным журналом (речь идёт о технологическом журнале), там есть табличка, содержащая информацию об этих хранилищах.
С помощью средств MS SQL Server Query Analizer нужно найти в табличке несколько колонок image и сделать для каждой следующий запрос
select top 10 DATALENGTH(_Fld4044 from _InfoReg4038 order by DATALENGTH(_Fld4044) desc
При этом, со стороны стандартных проверок, проводимых платформой (chdbfl), поступит информация о том, что база полностью в порядке.
Ошибка выделения памяти hresult 80004005 (на английском это out of memory for query result 1с) может происходить вследствие различных причин, имеющей общую черту. Для системы 1С это, прежде всего, недостаток оперативной памяти. Если говорить точнее, речь идёт о некорректном применении возможностей памяти, поэтому для решения задачи лучше использовать несколько косвенных алгоритмов.
Необходимо сделать рестарт (перезапуск) сервера. Таким образом памяти, которая доступна для работы, временно станет больше. Также есть возможность воспользоваться сервером в 64 разряда, содержащем приложения.
Исходя из опыта, ошибка СУБД hresult 80004005 чаще определяется двумя факторами:
- данные хранятся в хранилище значений (реквизите);
- в таблице конфигураций содержатся двоичные данные объёмом более 120 мегабайт.
Когда советы от сотрудников 1С не приносят результата (ошибка 1с hresult 80004005 остаётся), попробуйте воспользоваться другой пошаговой инструкцией:
Наши постоянные клиенты по 1С:









- используйте все базы, включив у них все фоновые задачи;
- в 8.1.11. должен появиться переключатель о запрете на фоновые задачи (во время создания базы);
- сделайте перезапуск сервера.
Имеет смысл проверки работоспособности. Тем не менее вследствие утечек памяти проблема может возникнуть снова — после перезапуска. В этом случае целесообразно:
- воспользоваться инструментами sql и сделать бэкап;
- снять базу с поддержки;
- выгрузить cf.
Во время любых действий следует копировать файлы в резерв, так как в любой момент может возникнуть необходимость возвращения к исходному статусу информации. Далее надо убрать в менеджменте консоли (config) запись «более 120 мегабайт» и провести загрузку конфигурации (не объединять, а загрузить).
Есть ещё один способ, с помощью которого неопознанная ошибка субд hresult 80004005 может быть исправлена. Нужно открыть конфигуратор и снять конфигурацию, не сохраняя её. Далее, сохранив, нужно поместить её в отдельный файл без сохранения её изменённого вида.
Выполните в SQL операцию, предназначенную для конкретной базы:
DELETE FROM dbo.Config WHERE DataSize > 125829120
После выполнения этой команды проведите загрузку сохранённой конфигурации.
Что касается радикальных шагов, используемых в особо трудных ситуациях, иногда помогает такая схема:
- удалите таблицу config из базы данных, воспользовавшись менеджментом консоли DROP TABLE [dbo].[Config];
- проведите загрузку конфигурации (не «объединить»,а именно «загрузить»).
После проведения проверки проблема должна уйти.
- Стоимость работ специалистов IT Rush — 2000 руб./час
- Абонемент от 50 часов в месяц – 1900 руб./час
- Абонемент от 100 часов в месяц – 1800 руб./час
Нам доверяют:
Database errors can present themselves in the form of ‘503 Service Unavailable’ or ‘500 Server Error’ in websites.
As part of our Outsourced Tech Support services for web hosts, database errors are a commonly resolved issue for customers who report website issues.
To know the exact cause for the MySQL error, we examine the MySQL service error logs and the server logs.
If the MySQL service crashed due to memory issues, the logs would show these information:
101011 2:41:17 [ERROR] mysqld: Out of memory (Needed 116817914 bytes) 101011 2:41:17 [ERROR] mysqld: Out of memory (Needed 98689909 bytes) 101011 2:41:17 [ERROR] mysqld: Out of memory (Needed 92789259 bytes)
Today, we’ll see what causes ‘mysqld: out of memory’ errors and how we fix those.
‘mysqld: out of memory’ – How we tackle this error
The ‘Out of memory’ error is a pretty straight forward message that shows that the server is running short of memory.
The memory allocated to MySQL service isn’t enough to handle the process requirements. And the easiest way out, is to examine server memory and upgrade the RAM.
But RAM upgrade is not always the ideal solution, nor a cost-effective one. If the query or process is a memory-hogging one, it can eventually eat up the added memory too, and lead to errors in no time.
At times, the memory allocation to the MySQL service may not be adequate. It is possible to tweak the MySQL service and allot the optimal memory for it.
When Bobcares’ Support Engineers perform server management, we consider all the possibilities and manage them one by one, before initiating a RAM upgrade.
‘mysqld: out of memory’ errors – How we prevent them
When a MySQL based website or application gives out memory error, it shows that MySQL does not have enough memory to store the results of the query executed.
Today, we’ll see the causes for ‘mysqld: out of memory’ that we’ve come across, and how we deal with them.
1. Unoptimized tables and queries
Most websites are built over CMS software and are database driven. Customization, plugins, third party apps, all these can involve complex code or poor quality queries.
These software can involve complicated sort and join queries, which can hog up all memory and cause MySQL to crash. Finding the sources of memory leaks is the first step.
Over time, the databases can grow in size and also fragments can form in them due to data deletions. Both these factors lead to memory wastage.
By examining the MySQL processes, slow queries and database sizes, we pinpoint the problem makers and take actions to fix them.
2. MySQL server configuration
The memory allocated to MySQL service depends on the various parameters configured in it. An approximate formula for MySQL memory usage is:
Maximum MySQL Memory Usage = innodb_buffer_pool_size + key_buffer_size + ((read_buffer_size + read_rnd_buffer_size + sort_buffer_size + join_buffer_size) X max_connections)
The buffer pool size, read, sort and join buffer sizes, max connections, temporary table size, all of them together determine the memory used.
In the servers we manage, we optimize the MySQL service to use the optimal memory, which does not exceed 60% of overall available RAM. This is done in an iterative manner, with tweaks done till the ideal value is reached.
[OK] Maximum reached memory usage: 2.0G (1.59% of installed RAM) [OK] Maximum possible memory usage: 26.9G (21.45% of installed RAM)
Allotting the optimal memory to MySQL service helps to ensure that MySQL does not crash due to insufficient memory and it is given the ideal resources that it needs.
3. Resource consuming processes
At times, there can be applications such as Java, Python, PHP, Coldfusion, backup software, 3rd party applications, etc. that consume too much memory.
There can be users who abuse the server resources, if not constrained well. Such processes and users can gobble up the entire server memory and crash services like MySQL.
To arrest a single process from abusing the server resources, we tweak all server applications to use not more than a fixed share of available memory. Setting user account limits is another precautionary measure.
4. Inadequate RAM
When every other aspect is examined and ruled out as not the reason, we can conclude that the server is not having sufficient memory for executing all the processes in it.
With the help of memory monitoring tools, we monitor the memory usage of various processes over time. Constant ‘Out of memory’ errors, even with normal traffic, indicate insufficient memory.
total used free shared buff/cache available Mem: 3645 1781 720 171 1143 1625 Swap: 3839 618 3221
If the memory is found to be inadequate, we initiate RAM upgrade, instance modification, container recreation, server migration, etc. as appropriate to the server scenario that we handle.
Conclusion
Database errors are a commonly encountered issue in web servers. Today we saw why “mysqld: out of memory” error happens in websites and how our Support Engineers prevent it.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.
SEE SERVER ADMIN PLANS
var google_conversion_label = «owonCMyG5nEQ0aD71QM»;