
Создаю из 1125 городов базу, но высвечивается ошибка при выполнении кода. Использую postgresql и создаю запрос в pgAdmin 4
Ошибка:
ERROR: ОШИБКА: отношение "city_id_seq" уже существует
SQL-состояние: 42P07
Запрос:
CREATE TABLE city
(
id SERIAL PRIMARY KEY,
id SERIAL,
id_region integer NOT NULL,
name varchar(250) NOT NULL
);
INSERT INTO city (id, id_region, name) VALUES
(1, 1, 'Адыгейск'),
(2, 1, 'Майкоп'),
(3, 2, 'Горно-Алтайск'),
(4, 3, 'Алейск'),
(5, 3, 'Барнаул'),
(6, 3, 'Белокуриха'),
(7, 3, 'Бийск'),
(8, 3, 'Горняк'),
(9, 3, 'Заринск'),
(10, 3, 'Змеиногорск'),
(11, 3, 'Камень-на-Оби'),
(12, 3, 'Новоалтайск'),
(13, 3, 'Рубцовск'),
(14, 3, 'Славгород'),
(15, 3, 'Яровое'),
(16, 4, 'Белогорск'),
(17, 4, 'Благовещенск'),
(18, 4, 'Завитинск'),
(19, 4, 'Зея'),
(20, 4, 'Райчихинск'),
(21, 4, 'Свободный'),
(22, 4, 'Сковородино'),
(23, 4, 'Тында'),
(24, 4, 'Шимановск'),
(25, 5, 'Архангельск'),
(26, 5, 'Вельск'),
(27, 5, 'Каргополь'),
(28, 5, 'Коряжма'),
(29, 5, 'Котлас'),
(30, 5, 'Мезень'),
(31, 5, 'Мирный'),
(32, 5, 'Новодвинск'),
(33, 5, 'Няндома'),
(34, 5, 'Онега'),
(35, 5, 'Северодвинск'),
(36, 5, 'Сольвычегодск'),
(37, 5, 'Шенкурск'),
(38, 6, 'Астрахань'),
(39, 6, 'Ахтубинск'),
(40, 6, 'Знаменск'),
(41, 6, 'Камызяк'),
(42, 6, 'Нариманов'),
(43, 6, 'Харабали'),
(44, 7, 'Агидель'),
(45, 7, 'Баймак'),
(46, 7, 'Белебей'),
(47, 7, 'Белорецк'),
(48, 7, 'Бирск'),
(49, 7, 'Благовещенск'),
(50, 7, 'Давлеканово'),
(51, 7, 'Дюртюли'),
(52, 7, 'Ишимбай'),
(53, 7, 'Кумертау'),
(54, 7, 'Межгорье'),
(55, 7, 'Мелеуз'),
(56, 7, 'Нефтекамск'),
(57, 7, 'Октябрьский'),
(58, 7, 'Салават'),
(59, 7, 'Сибай'),
(60, 7, 'Стерлитамак'),
(61, 7, 'Туймазы'),
(62, 7, 'Уфа'),
(63, 7, 'Учалы'),
(64, 7, 'Янаул'),
(65, 8, 'Алексеевка'),
(66, 8, 'Белгород'),
(67, 8, 'Бирюч'),
(68, 8, 'Валуйки'),
(69, 8, 'Грайворон'),
(70, 8, 'Губкин'),
(71, 8, 'Короча'),
(72, 8, 'Новый Оскол'),
(73, 8, 'Старый Оскол'),
(74, 8, 'Строитель'),
(75, 8, 'Шебекино'),
(76, 9, 'Брянск'),
(77, 9, 'Дятьково'),
(78, 9, 'Жуковка'),
(79, 9, 'Злынка'),
(80, 9, 'Карачев'),
(81, 9, 'Клинцы'),
(82, 9, 'Мглин'),
(83, 9, 'Новозыбков'),
(84, 9, 'Почеп'),
(85, 9, 'Севск'),
(86, 9, 'Сельцо'),
(87, 9, 'Стародуб'),
(88, 9, 'Сураж'),
(89, 9, 'Трубчевск'),
(90, 9, 'Унеча'),
(91, 9, 'Фокино'),
(92, 10, 'Бабушкин'),
(93, 10, 'Гусиноозёрск'),
(94, 10, 'Закаменск'),
(95, 10, 'Кяхта'),
(96, 10, 'Северобайкальск'),
(97, 10, 'Улан-Удэ'),
(98, 11, 'Александров'),
(99, 11, 'Владимир'),
(100, 11, 'Вязники'),
(101, 11, 'Гороховец'),
(102, 11, 'Гусь-Хрустальный'),
(103, 11, 'Камешково'),
(104, 11, 'Карабаново'),
(105, 11, 'Киржач'),
(106, 11, 'Ковров'),
(107, 11, 'Кольчугино'),
(108, 11, 'Костерёво'),
(109, 11, 'Курлово'),
(110, 11, 'Лакинск'),
(111, 11, 'Меленки'),
(112, 11, 'Муром'),
(113, 11, 'Петушки'),
(114, 11, 'Покров'),
(115, 11, 'Радужный'),
(116, 11, 'Собинка'),
(117, 11, 'Струнино'),
(118, 11, 'Судогда'),
(119, 11, 'Суздаль'),
(120, 11, 'Юрьев-Польский'),
(121, 12, 'Волгоград'),
(122, 12, 'Волжский'),
(123, 12, 'Дубовка'),
(124, 12, 'Жирновск'),
(125, 12, 'Калач-на-Дону'),
(126, 12, 'Камышин'),
(127, 12, 'Котельниково'),
(128, 12, 'Котово'),
(129, 12, 'Краснослободск'),
(130, 12, 'Ленинск'),
(131, 12, 'Михайловка'),
(132, 12, 'Николаевск'),
(133, 12, 'Новоаннинский'),
(134, 12, 'Палласовка'),
(135, 12, 'Петров Вал'),
(136, 12, 'Серафимович'),
(137, 12, 'Суровикино'),
(138, 12, 'Урюпинск'),
(139, 12, 'Фролово'),
(140, 13, 'Бабаево'),
(141, 13, 'Белозерск'),
(142, 13, 'Великий Устюг'),
(143, 13, 'Вологда'),
(144, 13, 'Вытегра'),
(145, 13, 'Грязовец'),
(146, 13, 'Кадников'),
(147, 13, 'Кириллов'),
(148, 13, 'Красавино'),
(149, 13, 'Никольск'),
(150, 13, 'Сокол'),
(151, 13, 'Тотьма'),
(152, 13, 'Устюжна'),
(153, 13, 'Харовск'),
(154, 13, 'Череповец'),
(155, 14, 'Бобров'),
(156, 14, 'Богучар'),
(157, 14, 'Борисоглебск'),
(158, 14, 'Бутурлиновка'),
(159, 14, 'Воронеж'),
(160, 14, 'Калач'),
(161, 14, 'Лиски'),
(162, 14, 'Нововоронеж'),
(163, 14, 'Новохопёрск'),
(164, 14, 'Острогожск'),
(165, 14, 'Павловск'),
(166, 14, 'Поворино'),
(167, 14, 'Россошь'),
(168, 14, 'Семилуки'),
(169, 14, 'Эртиль'),
(170, 15, 'Буйнакск'),
(171, 15, 'Республика Дагестанские Огни'),
(172, 15, 'Дербент'),
(173, 15, 'Избербаш'),
(174, 15, 'Каспийск'),
(175, 15, 'Кизилюрт'),
(176, 15, 'Кизляр'),
(177, 15, 'Махачкала'),
(178, 15, 'Хасавюрт'),
...
I am trying to create a table that was dropped previously.
But when I do the CREATE TABLE A ... I am getting below error:
Relation ‘A’ already exists.
I verified doing SELECT * FROM A, but then I got another error:
Relation ‘A’ does not exists.
I already tried to find it in dS+ listing all relations, and it is not there.
To complicate this, I have tested this by creating this table in another database and I got the same error. I am thinking that could be an error when this table was dropped. Any ideas?
Here is the code: I’m using a generated code from Power SQL. I have the same error without using the sequence. It just works when I change the name and in this case I can not do that.
CREATE SEQUENCE csd_relationship_csd_relationship_id_seq;
CREATE TABLE csd_relationship (
csd_relationship_id INTEGER NOT NULL DEFAULT nextval('csd_relationship_csd_relationship_id_seq'::regclass),
type_id INTEGER NOT NULL,
object_id INTEGER NOT NULL,
CONSTRAINT csd_relationship PRIMARY KEY (csd_relationship_id)
);
![]()
asked Jan 9, 2012 at 17:55
![]()
2
I finally discover the error. The problem is that the primary key constraint name is equal the table name. I don know how postgres represents constraints, but I think the error «Relation already exists» was being triggered during the creation of the primary key constraint because the table was already declared. But because of this error, the table wasnt created at the end.
answered Jan 12, 2012 at 12:57
![]()
nsbmnsbm
5,7266 gold badges29 silver badges45 bronze badges
5
There should be no single quotes here 'A'. Single quotes are for string literals: 'some value'.
Either use double quotes to preserve the upper case spelling of «A»:
CREATE TABLE "A" ...
Or don’t use quotes at all:
CREATE TABLE A ...
… which is identical to:
CREATE TABLE a ...
… because all unquoted identifiers are folded to lower case in Postgres. See:
- Are PostgreSQL column names case-sensitive?
You can avoid problems with the index name completely by using simpler syntax:
CREATE TABLE csd_relationship (
csd_relationship_id serial PRIMARY KEY
, type_id integer NOT NULL
, object_id integer NOT NULL
);
Does the same as your original query, only it avoids naming conflicts by picking the next free identifier automatically. More about the serial type in the manual.
answered Jan 9, 2012 at 18:42
![]()
Erwin BrandstetterErwin Brandstetter
596k144 gold badges1058 silver badges1215 bronze badges
1
You cannot create a table with a name that is identical to an existing table or view in the cluster. To modify an existing table, use ALTER TABLE (link), or to drop all data currently in the table and create an empty table with the desired schema, issue DROP TABLE before CREATE TABLE.
It could be that the sequence you are creating is the culprit. In PostgreSQL, sequences are implemented as a table with a particular set of columns. If you already have the sequence defined, you should probably skip creating it. Unfortunately, there’s no equivalent in CREATE SEQUENCE to the IF NOT EXISTS construct available in CREATE TABLE. By the looks of it, you might be creating your schema unconditionally, anyways, so it’s reasonable to use
DROP TABLE IF EXISTS csd_relationship;
DROP SEQUENCE IF EXISTS csd_relationship_csd_relationship_id_seq;
before the rest of your schema update; In case it isn’t obvious, This will delete all of the data in the csd_relationship table, if there is any
![]()
jawr
8271 gold badge7 silver badges14 bronze badges
answered Jan 10, 2012 at 17:25
![]()
2
Another reason why you might get errors like «relation already exists» is if the DROP command did not execute correctly.
One reason this can happen is if there are other sessions connected to the database which you need to close first.
answered Sep 21, 2018 at 11:58
![]()
isedwardsisedwards
2,42920 silver badges29 bronze badges
In my case, I had a sequence with the same name.
answered Aug 25, 2016 at 15:06
![]()
In my case, it wasn’t until I PAUSEd the batch file and scrolled up a bit, that wasn’t the only error I had gotten. My DROP command had become DROP and so the table wasn’t dropping in the first place (thus the relation did indeed still exist). The  I’ve learned is called a Byte Order Mark (BOM). Opening this in Notepad++, re-save the SQL file with Encoding set to UTM-8 without BOM and it runs fine.
![]()
Mogsdad
44.5k21 gold badges150 silver badges272 bronze badges
answered Jan 11, 2016 at 18:25
![]()
0
You may be running the CREATE TABLE after already running it. So you may be creating a table for a second time, while the first attempt already created it.
answered May 14, 2021 at 19:03
![]()
ScottyBladesScottyBlades
11.7k5 gold badges74 silver badges81 bronze badges
In my case I was migrating from 9.5 to 9.6.
So to restore a database, I was doing :
sudo -u postgres psql -d databse -f dump.sql
Of course it was executing on the old postgreSQL database where there are datas! If your new instance is on port 5433, the correct way is :
sudo -u postgres psql -d databse -f dump.sql -p 5433
answered Oct 5, 2016 at 10:30
![]()
Sometimes this kind of error happens when you create tables with different database users and try to SELECT with a different user.
You can grant all privileges using below query.
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA schema_name TO username;
And also you can grant access for DML statements
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA schema_name TO username;
answered Nov 10, 2020 at 2:19
![]()
1
-
The problem is that the primary key constraint name is equal the table name.
-
I don’t know how postgres represents constraints, but I think the error “Relation
already exists” was being triggered during the creation of the primary key
constraint because the table was already declared. But because of this error,
the table wasnt created at the end. -
give different name to constrain
Note- go to SQL tab and check table name and constrain
Enjoy 
answered Oct 20, 2022 at 15:54
![]()
I got this error after running the terminal command «dotnet ef database update». My solution was to open the database and delete/drop tables with the same name.
answered May 4 at 11:11
![]()
|
mariammm 1 / 1 / 0 Регистрация: 24.09.2019 Сообщений: 173 |
||||
|
1 |
||||
Ошибка при попытке создать таблицу15.10.2020, 17:50. Показов 6056. Ответов 2 Метки нет (Все метки)
Пишу код и нажимаю на кнопку для создания, в первый раз всё ок, в следующие разы появляется ошибка ERROR: ОШИБКА: отношение «cabins» уже существует SQL state: 42P07
Миниатюры
0 |


|
1213 / 938 / 373 Регистрация: 02.09.2012 Сообщений: 2,862 |
|
|
15.10.2020, 23:22 |
2 |
|
Так и что тут удивительного.
1 |
|
remarkes 309 / 232 / 15 Регистрация: 01.07.2011 Сообщений: 812 Записей в блоге: 1 |
||||||||
|
17.10.2020, 18:40 |
3 |
|||||||
Потом заново создаёте таблицу вашими командами.
1 |
Содержание
- Underscore in schemaName causes error relation «databasechangelog» already exists #1604
- Comments
- Environment
- Description
- Steps To Reproduce
- Actual Behavior
- Expected/Desired Behavior
- Ошибка PostgreSQL: связь уже существует
- 9 ответы
- Common DB schema change mistakes
- Table of Contents
- Terminology
- Three categories of DB migration mistakes
- Case 1. Schema mismatch
- Case 2. Misuse of IF [NOT] EXISTS
- Case 3. Hitting statement_timeout
- Case 4. Unlimited massive change
- Case 5. Acquire an exclusive lock + wait in transaction
- Case 6. A transaction with DDL + massive DML
- Case 7. Waiting to acquire an exclusive lock for long ⇒ blocking others
- Case 8. Careless creation of an FK
- Case 9. Careless removal of an FK
- Case 10. Careless addition of a CHECK constraint
- Case 11. Careless addition of NOT NULL
- Case 12. Careless change of column’s data type
- Case 13. Careless CREATE INDEX
- Case 14. Careless DROP INDEX
- Case 15. Renaming objects
- Case 16. Add a column with DEFAULT
- Case 17. Leftovers of CREATE INDEX CONCURRENTLY
- Case 18. 4-byte integer primary keys for large tables
- Recommendations
- Share this blog post:
Underscore in schemaName causes error relation «databasechangelog» already exists #1604
Environment
Liquibase Version : 4.11
Liquibase Integration & Version: —
Liquibase Extension(s) & Version: —
Database Vendor & Version: PostgreSQL 11
Operating System Type & Version: Ubuntu 20.04.1 LTS
Description
liquibase.snapshot.JdbcDatabaseSnapshot searchs tables using:
databaseMetaData is an instance of java.sql.DatabaseMetadata. Liquibase passes schemaName to #getTables to find databasechangelog table. It is «test_schema» in our example. DatabaseMetadata#getTables accepts schemaPattern for SQL LIKE, so it uses his argument in something like:
our underscore character is a replacement for any other character, so it receives two rows for our table: one for test-schema and the second for test_schema. Then inside Liquibase it goes through compare chain and skips that received table, because it is not in our test_schema, it is in test-schema. Liquibase thinks that databasechangelog does not exist, and it tries to create it. But our test_schema already has databasechangelog table from the first run.
Steps To Reproduce
Example project: https://github.com/urvanov-ru/liquibase-schemaname/tree/main/liquibase-schemaname
We have two schemas: test-schema and test_schema in PostgreSQL database.
The first run of test project always successful. The second run fails.
Actual Behavior
Expected/Desired Behavior
The second run of https://github.com/urvanov-ru/liquibase-schemaname/tree/main/liquibase-schemaname should be successful. test-schema should use only test-schema objects, test_schema should use only test_schema objects.
I have been using Liquibase for many years. Thank you for really good project. I am really looking forward for any workaround or bugfix for the problem.
┆Issue is synchronized with this Jira Bug by Unito
┆fixVersions: Community 4.x
The text was updated successfully, but these errors were encountered:
Hi @urvanov-ru Thanks for this excellent repro and an repo that shows the issue. We will add this to our list of issues to process.
Maybe we can use databaseMetaData.getSearchStringEscape() to escape our special characters.
Any news on this issue?
I’m facing the same blocking issue on my side.
Thanks &
Cheers
Tom
I am sorry, but I had no time to do anything in this issue. I tried to fix it, but it is not one line fixing bug
@urvanov-ru
Oh ok, any news on this one? 🙂
Hi @urvanov-ru or @molivasdat
I saw you moved the issue into the Bug Backlog, any news on this? When can we expect the fix to be released? 🙂
Thanks & rest regards
Tom
Hi @tomtrapp Yes we are gearing up to start moving quick a bit quicker with our updates. Not quite there yet. The workaround for now would be use another name that does not include _ in the schema name.
The fix adds escaping for both _ and % in schema names to prevent schema name clashes caused by treating _ and % as regular expression pattern. This escaping is done for all databases except oracle, mssql, and db2z.
Special Thanks! Thank you, @urvanov-ru, for the project that reproduces the bug. As a QA, I cannot overstate how valuable this is to me.
As demonstrated in the github repro project, the steps to see the bug are:
- First Update: Run with a liquibase.properties file configured with liquibase.command.defaultSchema: test-schema and liquibase.liquibaseSchemaName:test-schema
- Second Update: Run with a liquibase.properties file configured with liquibase.command.defaultSchema: test_schema and liquibase.liquibaseSchemaName:test_schema
- Third Update: Run with the same liquibase.properties defined for second update.
- It is the third update where you see a failure (when running manually).
Postgres Validation
- Validate the third update to a database with schemas test_schema and test-schema is successful. PASS
- There is no error that DATABASECHANGELOG table already exists PASS
- The DATABASECHANGELOG table is updated correctly PASS
SQL Server Validation
This test turned out to be a no-op given that SQL Server users are not permitted to change a user’s default schema during a session. Given that the bug replicates only when both defaultSchemaName and liquibaseSchemaName are defined in the liquibase.properties file, there was no path into the bug on SQL Server.
- Validate the third update to a database with schemas test_schema and test-schema is successful. PASS
- There is no error that DATABASECHANGELOG table already exists PASS
- The DATABASECHANGELOG table is updated correctly PASS
Test Environment
Liquibase Core: escape-names-in-getTables/1270/dc4772 Pro: master/463/064632
Passing Functional Tests
Postgres 12.6
SQL Server 17
Источник
Я пытаюсь создать таблицу, которая была удалена ранее.
Но когда я делаю CREATE TABLE A .. . Я получаю сообщение об ошибке ниже:
Я подтвердил, что делаю SELECT * FROM A , но потом я получил еще одну ошибку:
Я уже пытался найти это в dS+ перечисляя все отношения, а его там нет.
Чтобы усложнить это, я протестировал это, создав эту таблицу в другой базе данных, и получил ту же ошибку. Я думаю, что это могло быть ошибкой, когда эта таблица была удалена. Любые идеи?
Вот код: я использую сгенерированный код из Power SQL. У меня такая же ошибка без использования последовательности. Это просто работает, когда я меняю имя, и в этом случае я не могу этого сделать.
CREATE TABLE ‘A’ и SELECT * FROM ‘A’ являются синтаксическими ошибками. PostgreSQL использует двойные кавычки для идентификаторов. — Joey Adams
Извините. Я не использовал одинарные кавычки. Это был плохой пример, я пытался упростить свой вопрос. Я точно расшифрую код. — nsbm
9 ответы
Я наконец обнаружил ошибку. Проблема в том, что имя ограничения первичного ключа совпадает с именем таблицы. Я не знаю, как postgres представляет ограничения, но я думаю, что ошибка «Связь уже существует» была вызвана во время создания ограничения первичного ключа, потому что таблица уже была объявлена. Но из-за этой ошибки таблица не была создана в конце.
Правильное решение — использовать serial столбец, как я указал в своем ответе. — Эрвин Брандштеттер
У меня была похожая проблема. Имена ограничений внешнего ключа являются общими для всей базы данных pg, поэтому, скопировав некоторые команды, я в конечном итоге попытался создать ограничение fk с тем же именем, что и созданное ранее (для другой таблицы), которое уже выдавало такое же «Отношение ___». существует «ошибка и привела меня сюда . +1 🙂 — 111
не могли бы вы добавить краткий пример кода правильно переименованного материала / синтаксиса — Эндрю
о, я вижу CONSTRAINT csd_relationship PRIMARY KEY (csd_relationship_id), то же имя, что и CREATE TABLE csd_relationship — Эндрю
Подчеркивая ответ @ глифа. Казалось бы, это хитрая, хотя и понятная особенность pg. — Пэт Джонс
Здесь не должно быть одинарных кавычек ‘A’ . Одиночные кавычки предназначены для строковых литералов: ‘some value’ .
Либо используйте двойные кавычки, чтобы сохранить написание буквы «A» в верхнем регистре:
Или вообще не используйте кавычки:
потому что все не цитируется идентификаторы Он автоматически переводится в нижний регистр в PostgreSQL.
Вы можете полностью избежать проблем с именем индекса, используя более простой синтаксис:
Выполняет те же функции, что и исходный запрос, только позволяет избежать конфликтов имен, автоматически выбирая следующий свободный идентификатор. Подробнее о serial введите руководство.
Извините, я на самом деле не использовал одинарные кавычки. Это был плохой пример. — нсбм
Вы не можете создать таблицу с именем, идентичным существующей таблице или представлению в кластере. Чтобы изменить существующую таблицу, используйте ALTER TABLE (ссылка на сайт), или чтобы удалить все данные, находящиеся в данный момент в таблице, и создать пустую таблицу с желаемой схемой, выполните команду DROP TABLE до CREATE TABLE .
Возможно, виновата последовательность, которую вы создаете. В PostgreSQL последовательности реализованы в виде таблицы с определенным набором столбцов. Если у вас уже есть определенная последовательность, вам, вероятно, следует пропустить ее создание. К сожалению, в CREATE SEQUENCE до IF NOT EXISTS конструкция доступна в CREATE TABLE . Судя по всему, вы в любом случае можете создавать свою схему без каких-либо условий, поэтому разумно использовать
перед остальным обновлением вашей схемы; Если это не очевидно, Это приведет к удалению всех данных в csd_relationship стол, если есть
ответ дан 23 мая ’14, 15:05
Как я уже сказал, этот стол уже был отброшен. Когда я это сделаю: УДАЛИТЬ ТАБЛИЦУ csd_relationship; ОШИБКА: таблица «csd_relationship» не существует — нсбм
Это не последовательность. Я попытался создать таблицу, не создавая последовательности, и получил ту же ошибку. — нсбм
В моем случае у меня была последовательность с таким же названием.
ответ дан 25 авг.

Еще одна причина, по которой вы можете получить такие ошибки, как «отношение уже существует», — это если DROP команда выполнялась некорректно.
Одна из причин, по которой это может произойти, заключается в том, что к базе данных подключены другие сеансы, которые необходимо закрыть в первую очередь.

В моем случае это было только после того, как я приостановил пакетный файл и немного прокрутил его вверх, это была не единственная ошибка, которую я получил. Мой DROP команда стала DROP и поэтому таблица не отбрасывалась в первую очередь (таким образом, связь действительно все еще существовала). В ï»¿ Я узнал, что это называется меткой порядка байтов (BOM). Открыв это в Notepad ++, повторно сохраните файл SQL с установленной кодировкой UTM-8 без спецификации, и он будет работать нормально.
Иногда такая ошибка возникает, когда вы создаете таблицы с разными пользователями базы данных и пытаетесь SELECT с другим пользователем. Вы можете предоставить все привилегии, используя запрос ниже.
А также вы можете предоставить доступ для операторов DML
для меня это было просто то, что я по ошибке использовал другого пользователя, но вау, это было странно. рад, что вы это разместили — кто
В моем случае я переходил с 9.5 на 9.6. Итак, чтобы восстановить базу данных, я делал:
Конечно, он выполнялся в старой базе данных postgreSQL, где есть данные! Если ваш новый экземпляр находится на порту 5433, правильный способ:
ответ дан 05 окт ’16, 11:10

Вы можете запустить CREATE TABLE после того, как уже запустил его. Таким образом, вы можете создать таблицу во второй раз, а первая попытка уже создала ее.
ответ дан 14 мая ’21, 20:05

Не тот ответ, который вы ищете? Просмотрите другие вопросы с метками postgresql identifier create-table or задайте свой вопрос.
Источник
Common DB schema change mistakes

In his article «Lesser Known PostgreSQL Features», @be_haki describes 18 Postgres features many people don’t know. I enjoyed that article, and it inspired me to write about «anti-features» – things that everyone should avoid when working in probably the riskiest field of application development – so-called «schema migrations».
This is one of my favorite topics in the field of relational databases. We all remember how MongoDB entered the stage with two clear messages: «web-scale» (let’s have sharding out-of-the-box) and «schemaless» (let’s avoid designing schemas and allow full flexibility). In my opinion, both buzzwords are an oversimplification, but if you have experience in reviewing and deploying schema changes in relational databases, you probably understand the level of difficulty, risks, and pain of scaling the process of making schema changes. My personal score: 1000+ migrations designed/reviewed/deployed during 17+ years of using Postgres in my own companies and when consulting others such as GitLab, Chewy, Miro. Here I’m going to share what I’ve learned, describing some mistakes I’ve made or observed – so probably next time you’ll avoid them.
Moreover, a strong desire to help people avoid such mistakes led me to invent the Database Lab Engine – a technology for thin cloning of databases, essential for development and testing. With it, you can clone a 10 TiB database in 10 seconds, test schema changes, and understand the risks before deployment. Most cases discussed in this article can be easily detected by such testing, and it can be done automatically in CI/CD pipelines.
As usual, I’ll be focusing on OLTP use cases (mobile and web apps), for which query execution that exceeds 1 second is normally considered too slow. Some cases discussed here are hard to notice in small databases with low activity. But I’m pretty confident that you’ll encounter most of them when your database grows to
10 TiB in size and its load reaches
10 5 –10 6 transactions per second (of course, some cases will be seen – unless deliberately prevented. – much, much earlier).
I advise you to read GitLab’s great documentation – their Migration Style Guide is full of wisdom written by those who have experience in deploying numerous Postgres schema changes in a fully automated fashion to a huge number of instances, including GitLab.com itself.
I also encourage everyone to watch PGCon-2022 – one of the key Postgres conferences; this time, it’s happening online again. On Thursday, May 26, I’ll give two talks, and one of them is called «Common DB schema change mistakes», you find the slide deck here. If you missed it, no worries – @DLangille, who has organized the conference since 2006 (thank you, Dan!), promises to publish talk videos in a few weeks.
Table of Contents
Terminology
The term «DB migration» may be confusing; it’s often used to describe the task of switching from one database system to another, moving the database, and minimizing possible negative effects (such as long downtime).
In this article, I’m going to talk about the second meaning of the term – DB schema changes having the following properties:
- «incremental»: changes are performed in steps;
- «reversible»: it is possible to «undo» any change, returning to the original state of the schema (and data; which, in some cases, may be difficult or impossible);
- «versionable»: some version control system is used (such as Git).
I prefer using the adjusted term, «DB schema migration». However, we need to remember that many schema changes imply data changes – for example, changing a column data type from integer to text requires a full table rewrite, which is a non-trivial task in heavily-loaded large databases.
Application DBA – a database engineer responsible for tasks such as DB schema design, development and deployment of changes, query performance optimization, and so on, while «Infrastructure DBA» is responsible for database provisioning, replication, backups, global configuration. The term «Application DBA» was explained by @be_haki in «Some SQL Tricks of an Application DBA».
Finally, the usual suspects in our small terminology list:
- DML – database manipulation language ( SELECT / INSERT / UPDATE / DELETE , etc.)
- DDL – data definition language ( CREATE … , ALTER … , DROP … )
Three categories of DB migration mistakes
I distinguish three big categories of DB schema migration mistakes:
- Concurrency-related mistakes. This is the largest category, usually determining a significant part of an application DBA’s experience. Some examples (skipping details; we’ll talk about them soon):
- Failure to acquire a lock
- Updating too many rows at once
- Acquired an exclusive lock and left transaction open for long
- Mistakes related to the correctness of steps – logical issues. Examples:
- Unexpected schema deviations
- Schema/app code mismatch
- Unexpected data
- Miscellaneous – mistakes related to the implementation of some specific database feature or the configuration of a particular database, e.g.:
- Reaching statement_timeout
- Use of 4-byte integer primary keys in tables that can grow
- Ignoring VACUUM behavior and bloat risks
Case 1. Schema mismatch
Let’s start with an elementary example. Assume we need to deploy the following DDL:
It worked well when we developed and tested it. But later, it failed during testing in some test/QA or staging environment, or – in the worst case – during deployment attempt on production:
Reasons for this problem may vary. For example, the table could be created by breaking the workflow (for example, manually). To fix it, we should investigate how the table was created and why the process wasn’t followed, and then we need to find a way to establish a good workflow to avoid such cases.
Unfortunately, people often choose another way to «fix» it – leading us to the second case.
Case 2. Misuse of IF [NOT] EXISTS
Observing schema mismatch errors such as those above may lead to the «give up» kind of fix: instead of finding the error’s root cause, engineers often choose to patch their code blindly. For the example above it can be the following:
If this code is used not for benchmarking or testing scripts but to define some application schema, this approach is usually a bad idea. It masks the problem with logic, adding some risks of anomalies. An obvious example of such an anomaly: an existing table that has a different structure than table we were going to create. In my example, I used an «empty» set of columns (in reality, there are always some columns – Postgres creates hidden, system columns such as xmin , xmax and ctid , you can read about them in Postgres docs, «5.5. System Columns», so each row always have a few columns; try: insert into t1 select; select ctid, xmin, xmax from t1; ).
I observe this approach quite often, probably in every other engineering team I work with. A detailed analysis of this problem is given in «Three Cases Against IF NOT EXISTS / IF EXISTS in Postgres DDL».
If you’re using a DB schema migration tool such as Sqitch, Liquibase, Flyway, or one embedded in your framework (Ruby on Rails, Django, Yii, and others have it), you probably test the migration stems in CI/CD pipelines. If you start testing the chain DO-UNDO-DO (apply the change, revert it, and re-apply again), it can help with detecting some undesired use of IF [NOT] EXISTS . Of course, keeping schemas in all environments up-to-date and respecting all observed errors, not ignoring them, and not choosing «workaround» paths such as IF [NOT] EXISTS , can be considered good engineering practices.
Case 3. Hitting statement_timeout
This one is pretty common if testing environments don’t have large tables and testing procedures are not mature:
Even if both production and non-production environments use identical statement_timeout settings, the smaller tables are, the faster queries are executed. This can easily lead to a situation when a timeout is reached only on production.
I strongly recommend testing all changes on large volumes of data so such problems will be observed much earlier in dev-test-deploy pipelines. The most powerful approach here is using thin clones of full-size databases as early in the pipelines as possible – preferably right during development. Check out our Database Lab Engine and let us know if you have questions (for example, on Twitter: @Database_Lab).
Case 4. Unlimited massive change
An UPDATE or DELETE targeting too many rows is a bad idea, as everyone knows. But why?
Potential problems that may disturb production:
- Modifying too many rows in a transaction (here, we have a single-query transaction) means that those rows will be locked for modifications until our transaction finishes. This can affect other transactions, potentially worsening the user experience. For example, if some user tries to modify one of the locked rows, their modification attempt may take very long.
- If the checkpointer is not well-tuned (for example, the max_wal_size value is left default, 1GB ), checkpoints may occur very often during such a massive operation. With full_page_writes being on (default), this leads to excessive generation of WAL data.
- Moreover, if the disk system is not powerful enough, the IO generated by the checkpointer may saturate the write capabilities of the disks, leading to general performance degradation.
- If our massive operation is based on some index and data modifications happen in pages in random order, re-visiting a single page multiple times, with untuned checkpointer and frequent checkpoints, one buffer may pass multiple dirty-clean cycles, meaning that we have redundant write operations.
- Finally, we may have two types of VACUUM/bloat issues here. First, if we’re changing a lot of tuples in a single transaction with UPDATE or DELETE, a lot of dead tuples are produced. Even if autovacuum cleans them up soon, there are high chances that such a mass of dead tuples will be directly converted to bloat, leading to extra disk consumption and potential performance degradation. Second, during the long transaction, the autovacuum cannot clean up dead tuples in any table that became dead during our transaction – until this transaction stops.
- Consider splitting the work into batches, each one being a separate transaction. If you’re working in the OLTP context (mobile or web apps), the batch size should be determined so the expected processing of any batch won’t exceed 1 second. To understand why I recommend 1 second as a soft threshold for batch processing, read the article «What is a slow SQL query?»
- Take care of VACUUMing – tune autovacuum and/or consider using explicit VACUUM calls after some number of batches processed.
- Finally, as an extra protection measure, tune the checkpointer so that even if a massive change happens, our database’s negative effect is not so acute. I recommend reading «Basics of Tuning Checkpoints» by Tomáš Vondra.
Case 5. Acquire an exclusive lock + wait in transaction
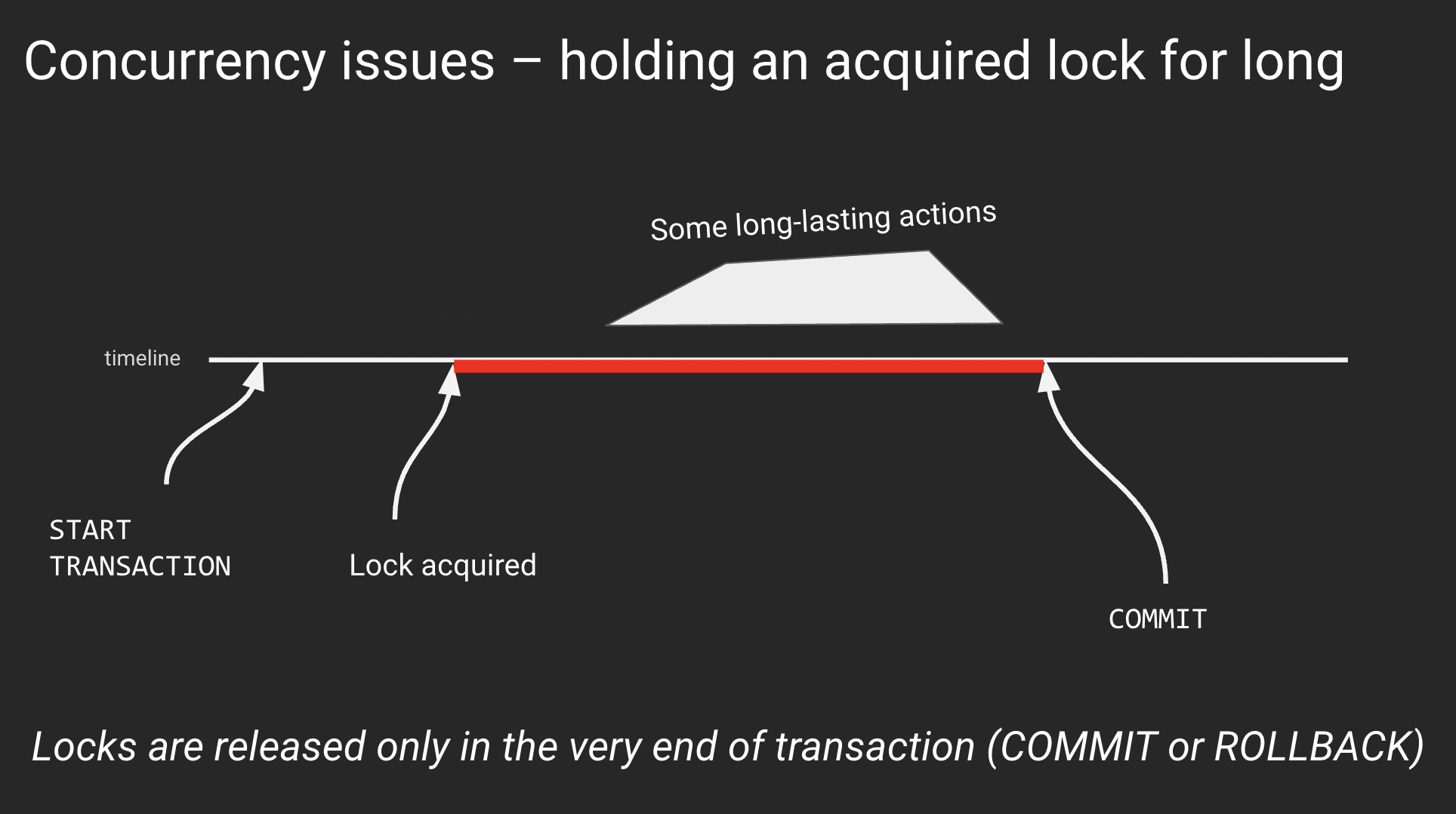
In the previous case, we touched on the problem of holding exclusive locks for long. These can be locked rows (implicitly via UPDATE or DELETE or explicitly via SELECT .. FOR UPDATE ) or database objects (example: successful ALTER TABLE inside a transaction block locks the table and holds the lock until the end of the transaction). If you need to learn more about locks in Postgres, read the article «PostgreSQL rocks, except when it blocks: Understanding locks» by Marco Slot.
An abstract example of the general issue with locking:
The reason for sitting inside a transaction after lock acquisition may vary. However, sometimes it is nothing – a simple waiting with an open transaction and acquired lock. This is the most annoying reason that can quickly lead to various performance or even partial downtime: an exclusive lock to a table blocks even SELECTs to this table.
Remember: any lock acquired in a transaction is held until the very end of this transaction. It is released only when the transaction finishes, with either COMMIT or ROLLBACK.
Every time we acquire an exclusive lock, we should think about finishing the transaction as soon as possible.
Case 6. A transaction with DDL + massive DML
This one is a subcase of the previous case. I describe it separately because it can be considered a common anti-pattern that is quite easy to encounter when developing DB migrations. Here is it in pseudocode:
If the DML step takes significant time, as we already discussed, the locks acquired on the previous step (DDL) will be held long too. This can lead to performance degradation or partial downtime.
Basic rules to follow:
- DML never should go after DDL unless they both deal with some freshly created table
- It is usually wise to split DDL and DML activities into separate transactions / migration steps
- Finally, remember that massive changes should go in batches? Each batch is a separate transaction – so if you follow this rule and have used large data volumes when testing changes in CI/CD pipelines, you should never encounter this case
Case 7. Waiting to acquire an exclusive lock for long ⇒ blocking others
This problem might happen with most ALTER commands deployed in a careless fashion – but for small, not heavily loaded databases, the chances are quite small, so the problem may remain unnoticed for a long time, until someday it hits in an ugly way, triggering the questions like «How dare could we live with this?» (I passed thru this process with a few teams, it was always quite embarrassing.)
We’ve discussed what happens when an exclusive lock is acquired and then it’s being held for too long. But what if we cannot acquire it?
This event may happen, and in heavily-loaded large databases, it’s pretty common. For example, this may happen because the autovacuum is processing the table we’re trying to modify, and it doesn’t yield – normally, it does, but not when running in the transaction ID wraparound prevention mode. This mode is considered by Postgres as a severe state that must be handled ASAP, so regular logic of autovacuum interrupting its work to allow DDL to succeed won’t work here. In this case, usually, it’s better to just wait.
But that’s not the worst part of this case. What’s really bad is the fact that while we’re waiting to acquire a lock, if our timeout settings ( statement_timeout and lock_timeout ) are set to 0 (default) or quite large (>> 1s), we’re going to block all queries to this table, even SELECTs. I talk about this particular problem in the article «Zero-downtime Postgres schema migrations need this: lock_timeout and retries».
What to do here? For all (!) DB migrations, except those that create brand new DB objects or use CREATE/DROP INDEX CONCURRENTLY (discussed below), you should have retry logic with low lock_timeout , as I describe in my article. This is a fundamental mechanism that everyone needs to have – I think at some point, either Postgres or popular DB schema migration tools will implement it so the world of application DBA will become better.
Case 8. Careless creation of an FK
In Case 5, we’ve discussed a transaction consisting of a successful DDL acquiring an exclusive lock and some actions (or lack of them) in the same transaction. But sometimes, a single-statement transaction – a DDL – can combine a lock acquisition and some work that increases the duration of the operation, leading to similar effects. That work can be either reading or data modification; the longer it lasts, the longer the operation will be, and the more risks of blocking other sessions we have.
We’ll discuss several cases with such a nature – a DDL operation whose duration is prolonged because of the need to read or modify some data. These cases are quite similar, but I want to recognize them individually because there are nuances for each one of them.
The first case in this series is the creation of a foreign key on two existing tables which are large and busy:
Here we can have two issues we’ve already discussed:
- The metadata for two tables needs to be adjusted, so we need two locks – and if one is acquired but the second one is not, and we’re waiting for it, we’re going to experience blocking issues (for both tables!)
- When an FK is introduced, Postgres needs to check the presence of this value in the referenced table for each value used in the referencing table. It may take a while – and during this time, locks are going to be held.
To avoid these issues:
- Use a two-step approach: first, define the FK with the not valid option, then, in a separate transaction, run alter table … validate constraint …;
- When the first ALTER, don’t forget about the retry logic that we discussed above. Note that two table-level exclusive locks are needed.
Case 9. Careless removal of an FK
When an FK needs to be dropped, similar considerations have to be applied as in the previous case, except that no data checks are needed. So, when dropping an FK, we need to acquire two table-level exclusive locks, and the retry logic with low lock_timeout can save us from the risks of blocking issues.
Case 10. Careless addition of a CHECK constraint
CHECK constraints are a powerful and really useful mechanism. I like them a lot because they can help us define a strict data model where major checks are done on the database side, so we have a reliable guarantee of high data quality.
The problem with adding CHECK constraints is very similar to adding foreign key constraints – but it’s simpler because we need to deal with only one table (you cannot reference another table in a CHECK constraint, unfortunately). When we add such a constraint on a large table, a full table scan needs to be performed to ensure that there is no violation of the constraint. This takes time, during which we have a partial downtime – no queries to the table are possible. (Remember the DDL + massive data change case? Here we have a subcase of that.)
Fortunately, CHECKs support the same approach as we saw for FKs: first, we define this constraint by adding the not valid option. Next, in a separate transaction, we perform validation: alter table … validate constraint …; .
Dropping such constraints doesn’t imply any risks (although, we still shouldn’t forget about retry logic with low lock_timeout when running the ALTER command).
Case 11. Careless addition of NOT NULL
This is one of my favorite cases. It is very interesting and often overlooked because, on small and mid-size tables, its negative effect can be left unnoticed. But on a table with, say, one billion rows, this case can lead to partial downtime.
When we need to forbid NULLs in a column col1 , there are two popular ways:
- Use a CHECK constraint with the expression: alter table . add constraint . (col1 is not null)
- Use a «regular» NOT NULL constraint: alter table . alter column c1 set not null
The problem with the latter is that, unlike for CHECK constraints, the definition of regular NOT NULL cannot be performed in an «online fashion», in two steps, as we saw for FKs and CHECKs.
Let’s always use CHECKs then, one could say. Agreed – the approaches are semantically identical. However, there is one important case, when only regular NOT NULL can be applicable – it’s when we define (or redefine) a primary key on an existing table with lots of data. There we must have a NOT NULL on all columns that are used in the primary key definition – or we’ll get a sudden full-table scan to install the NOT NULL constraint implicitly.
What to do about this? It depends on the Postgres version:
- Before Postgres 11, there were no «official» ways to avoid partial downtime. The only way was to ensure that no values violate the constraint and edit system catalogs explicitly, which, of course, is not recommended.
- Since Postgres 11, if NOT NULL has to be installed on a new column (quite often a case when we talk about a PK definition), we can use a nice trick:
- first, add a column with not null default -1 (considering that column is of int8 type; here we benefit from a great optimization introduced in Postgres 11 – fast creation of column with a default value; our NOT NULL is automagically introduced and enforced because all existing rows get -1 in the new column, so there are no NULL values present)
- then backfill all existing rows with values
- and in the end, drop the DEFAULT – the NOT NULL constraint will remain in its place
- Finally, in Postgres 12, another great optimization made it possible to introduce a regular, traditional NOT NULL on any column in a fully «online» fashion. What has to be done: first, create a CHECK constraint with (. is not null) expression. Next, define a regular NOT NULL constraint – due to new optimization, the mandatory scan will be skipped because now Postgres understand that there are no NULLs present, thanks to the CHECK constraint. In the end, the CHECK constraint can be dropped because it becomes redundant to our regular NOT NULL one.
Case 12. Careless change of column’s data type
One cannot simply change the data type of a column not thinking about blocking issues. In most cases, you risk getting a full table rewrite when you issue a simple alter table t1 alter column c2 type int8; .
What to do with it? Create a new column, define a trigger to mirror values from the old one, backfill (in batches, controlling dead tuples and bloat), and then switch your app to use the new column, dropping the old one when fully switched.
Case 13. Careless CREATE INDEX
This is a widely known fact – you shouldn’t use CREATE INDEX in OLTP context unless it’s an index on a brand new table that nobody is using yet.
Everyone should use CREATE INDEX CONCURRENTLY . Although, there are caveats to remember:
- it’s roughly two times slower than regular CREATE INDEX
- it cannot be used in transaction blocks
- if it fails (chances are not 0 if you’re building a unique index), an invalid index is left defined for the table, so:
- deployment system has to be prepared to retry index creation
- after failures, cleanup is needed
Case 14. Careless DROP INDEX
Unlike CREATE INDEX , the only issue with DROP INDEX is that it can lead to lock acquisition issues (see Case 7). While for ALTER, there is nothing that can be used to the issues associated with a long-waiting or failing lock acquisition, for DROP INDEX Postgres has DROP INDEX CONCURRENTLY . This looks imbalanced but probably can be explained by the fact that index recreation is what may be needed much more often than ALTER (plus, REINDEX CONCURRENTLY was added in Postgres 12).
Case 15. Renaming objects
Renaming a table or a column may become a non-trivial task in a large database receiving lots of SQL traffic.
The renaming doesn’t look like a hard task – until we look at how the application code works with the database and how changes are deployed on both ends. PostgreSQL DDL supports transactions. (Well, except CREATE INDEX CONCURRENTLY . And the fact that we need batches. And avoid long-lasting exclusive locks. And all the other bells and whistles we already discussed. ) Ideally, the deployment of application code – on all nodes that we have, and it might be hundreds or thousands – should happen inside the same transaction, so when renaming is committed, all application nodes have a new version of code already.
Of course, it’s impossible. So when renaming something, we need to find a way to avoid inconsistencies between application code and DB schema – otherwise, users will be getting errors for a significant period of time.
One approach can be: to deploy application changes first, adjusting the code to understand both old and new (not yet deployed) schema versions. Then deploy DB changes. Finally, deploy another application code change (cleanup).
Another approach is more data change intensive, but it may be easier to use for developers once properly automated. It is similar to what was already described in Case 12 (changing column’s data type):
- Create a new column (with a new name)
- Define a trigger to mirror values from the old one
- Backfill (in batches, controlling dead tuples and bloat)
- Switch your app to use the new column
- Drop the old one when fully switched
Case 16. Add a column with DEFAULT
As was already mentioned, before Postgres 11, adding a column with default was a non-trivial and data change intensive task (by default implying a full table rewrite). If you missed that feature somehow, read about it, for example, in «A Missing Link in Postgres 11: Fast Column Creation with Defaults» by @brandur.
This is a perfect example of how a long-time painful type of change can be fully automated, so the development and deployment of a DB schema change become simple and risk-free.
Case 17. Leftovers of CREATE INDEX CONCURRENTLY
As we already discussed in Case 13, a failed CREATE INDEX CONCURRENTLY leaves an invalid index behind. If migration scripts don’t expect that, fully automated retries are going to be blocked, so manual intervention would be required. To make retries fully automated, before running CREATE INDEX CONCURRENTLY , we should check if pg_indexes :
A complication here could be if the framework you’re using encourages the creation of indexes with unpredictable names – it is usually better to take control over names, making cleanup implementation straightforward.
Case 18. 4-byte integer primary keys for large tables
This is a big topic that is worth a separate article. In most cases, it doesn’t make sense to use int4 PKs when defining a new table – and the good news here is that most popular frameworks such as Rails, Django have already switched to using int8 . I personally recommend using int8 always, even if you don’t expect your table to grow right now – things may change if the project is successful.
To those who still tend to use int4 in surrogate PKs, I have a question. Consider a table with 1 billion rows, with two columns – an integer and a timestamp. Will you see the difference in size between the two versions of the table, (id int4, ts timestamptz) and (id int8, ts timestamptz) . The answer may be surprising to you (in this case, read about «Column Tetris»).
Recommendations
In addition to the recommendations provided for each specific case, here are general ones, without specific order:
- Test, test, test. Use realistic data volumes during testing. As already mentioned, Database Lab Engine (DLE) can be very useful for it.
- When testing, pay attention to how long exclusive locks are held. Check out DLE’s component called «DB Migration Checker», it can help you automate this kind of testing in CI/CD pipelines.
- For extended lock analysis, use the snipped from my blog post about lock tree analysis.
- Build better automation for deployment. There are many good examples of great automation, libraries of helpers that allow avoiding downtime and performance issues during (and after) DB migration deployment. GitLab’s migration_helpers.rb is a great example of such a set of helpers.
- Learn from others and share your knowledge! If you have another idea of what can be mentioned in the list above, send me an email ( [email protected] ) or reach me on Twitter: @samokhvalov; I’ll be happy to discuss it.

Nikolay Samokhvalov
Working on tools to balance Dev with Ops in DevOps
Database Lab by Postgres.ai
An open-source experimentation platform for PostgreSQL databases. Instantly create full-size clones of your production database and use them to test your database migrations, optimize SQL, or deploy full-size staging apps.
Источник
Я пытаюсь создать таблицу, которая была удалена ранее.
Но когда я делаю CREATE TABLE A ... Я получаю сообщение об ошибке ниже:
Отношение «А» уже существует.
Я подтвердил выполнение SELECT * FROM A, но затем получил еще одну ошибку:
Отношения «А» не существует.
Я уже пытался найти его в списке всех отношений dS+, но его там нет.
Чтобы усложнить ситуацию, я проверил это, создав эту таблицу в другой базе данных, и получил ту же ошибку. Я думаю, что это могло быть ошибкой, когда эта таблица была удалена. Любые идеи?
Вот код: я использую сгенерированный код из Power SQL. У меня такая же ошибка без использования последовательности. Это просто работает, когда я меняю имя, и в этом случае я не могу этого сделать.
CREATE SEQUENCE csd_relationship_csd_relationship_id_seq;
CREATE TABLE csd_relationship (
csd_relationship_id INTEGER NOT NULL DEFAULT nextval('csd_relationship_csd_relationship_id_seq'::regclass),
type_id INTEGER NOT NULL,
object_id INTEGER NOT NULL,
CONSTRAINT csd_relationship PRIMARY KEY (csd_relationship_id)
);
Я наконец обнаружил ошибку. Проблема в том, что имя ограничения первичного ключа совпадает с именем таблицы. Я не знаю, как postgres представляет ограничения, но я думаю, что ошибка «Связь уже существует» была вызвана во время создания ограничения первичного ключа, потому что таблица уже была объявлена. Но из-за этой ошибки таблица не была создана в конце.
68
nsbm
12 Янв 2012 в 16:57
Другая причина, по которой вы можете получить такие ошибки, как «отношение уже существует», — это неправильное выполнение команды DROP.
Одна из причин, по которой это может произойти, заключается в том, что к базе данных подключены другие сеансы, которые необходимо закрыть в первую очередь.
4
isedwards
21 Сен 2018 в 14:58
В моем случае это было только после того, как я приостановил пакетный файл и немного прокрутил его вверх, это была не единственная ошибка, которую я получил. Моя команда DROP превратилась в DROP, поэтому таблица не удалялась в первую очередь (таким образом, связь действительно все еще существовала). Я узнал, что  называется меткой порядка байтов (BOM). Открыв это в Notepad ++, повторно сохраните файл SQL с кодировкой UTM-8 без спецификации, и он будет работать нормально.
2
Mogsdad
11 Янв 2016 в 22:03
В моем случае у меня была последовательность с таким же названием.
4
Dave Van den Eynde
25 Авг 2016 в 18:06
Иногда такая ошибка возникает, когда вы создаете таблицы с разными пользователями базы данных и пытаетесь SELECT с другим пользователем. Вы можете предоставить все привилегии, используя запрос ниже.
GRANT ALL PRIVILEGES ON ALL TABLES IN SCHEMA schema_name TO username;
А также вы можете предоставить доступ для операторов DML
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA schema_name TO username;
1
Akila K Gunawardhana
10 Ноя 2020 в 05:19
В моем случае я переходил с 9.5 на 9.6. Итак, чтобы восстановить базу данных, я делал:
sudo -u postgres psql -d databse -f dump.sql
Конечно, он выполнялся в старой базе данных postgreSQL, где есть данные! Если ваш новый экземпляр находится на порту 5433, правильный способ:
sudo -u postgres psql -d databse -f dump.sql -p 5433
0
Nicolas Boisteault
5 Окт 2016 в 13:30
Возможно, вы запускаете CREATE TABLE после того, как уже запустили его. Таким образом, вы можете создать таблицу во второй раз, а первая попытка уже создала ее.
1
ScottyBlades
14 Май 2021 в 22:03