
|
|||
| 2S
27.06.16 — 12:52 |
Ошибка потока… |
||
| vde69
1 — 27.06.16 — 12:56 |
1. с типовой — не надо |
||
| 2S
2 — 27.06.16 — 13:00 |
бэка нет, базу принесли на попробовать «поднять». |
||
| Ёпрст
3 — 27.06.16 — 13:01 |
нужна только конфиг, вторую можешь вообще прибить |
||
|
vde69 4 — 27.06.16 — 13:02 |
configsave — выгрузи а потом загрузи в config только разумеется на копии делай |
TurboConf — расширение возможностей Конфигуратора 1С
![]()
Помогите и мне пожалуйста, мне кажется у меня ситуация попроще. конфигурация бухгалтерия проф 2.0 (2.0.60.4) типовая на поддержке без изменений. Обновления успешно ставятся, все индексируется и тестируется, пишет ошибок нет. Все пляски по гилеву делала, кроме пункта «проверить обработкой все метаданным все строковые реквизиты (проверяем наличие и удаляем сивмолы 0x1a & 0xFFFF )» у меня нет опыта программирования. Замену Configsave через Tool 1CD тоже сделала, не помогло.
Ошибка вылезает при обращении к отчету «Оборотно-сальдовая ведомость по счету».
При тестировании программой Tool 1CD «Тест формата потока» похоже найдена таблица, в которой проблема.
«Ошибка тестирования Ошибка определения кодировки файла»
Путь: CONFIG/8261cfe8-f981-4375-bba5-ae1484facbc2.0
Это единственная ошибка, но я не представляю, как ее исправить. При переходе на 3.0 проблема исчезает, но начинается проблема с пользователями, которые к такому шагу пока не готовы, говорят, что после НГ будут изучать, а сейчас работать надо.
При нажатии на ошибку в самой 1С вылезает сообщение перейти в конфигуратор
«{Отчет.ОборотноСальдоваяВедомостьПоСчету.МодульОбъекта(671)}: Ошибка при вызове метода контекста (Получить)
СтруктураПараметров = СохраненнаяНастройка.ХранилищеНастроек.Получить();
по причине:
Ошибка формата потока»
«
| 1C | ||
|
«
Прошу помощи, скажите, где стукнуть, при условии, что я не разу ни программист, но умею пользоваться умными программами типа Tool 1CD?
Кстати, выгрузка данных универсальной выгрузкой с диска ИТС в чистую базу с той же версией не помогла, много документов продублировалось и остатки перепутались.
Добавлено через 1 час 46 минут
Не знаю, насколько я правильно сделала, обновила конфигурацию до последней версии, и потом из чистой базы с последней версией выгрузила конфигурацию в свою. Вроде бы пока работает, надеюсь, что не будет никаких проблем. Теоретически наверное должны быть, но повезло, что конфигурация типовая. Хотелось бы все-таки вылечить ее по-человечески все-таки, но не представляю, как в этот конфиг влезть и поменять ту некорректную строчку.
cfg = configparser.ConfigParser()
cfg.read(cfg_path+'/config.cfg')
a_text = configparser.ConfigParser()
a_text.read('data')
Ошибка
Traceback (most recent call last):
File "bot.py", line 70, in <module>
a_text.read('data')
File "/usr/lib/python3.5/configparser.py", line 696, in read
self._read(fp, filename)
File "/usr/lib/python3.5/configparser.py", line 1012, in _read
for lineno, line in enumerate(fp, start=1):
File "/usr/lib/python3.5/encodings/ascii.py", line 26, in decode
return codecs.ascii_decode(input, self.errors)[0]
UnicodeDecodeError: 'ascii' codec can't decode byte 0xd0 in position 15: ordinal not in range(128)
Такая ошибка появляется только при запуске на сервере, на ПК все нормально. Возможно ошибка в локали.
Источник статьи
https://blog.csdn.net/cgl125167016/article/details/78666432
Модификация кодировки файла
IntelliJ IDEA может изменить кодировку файла проекта в меню Файл -> Настройки -> Редактор -> Кодировка файла.

- Глобальная кодировка IDE по умолчанию — UTF-8, а в Project Encoding по умолчанию используется GBK операционной системы, который обычно изменяется на UTF-8.
- IntelliJ IDEA может устанавливать специальные параметры кодировки для файла свойств, также рекомендуется изменить кодировку на UTF-8. Одним из ключевых моментов являются свойства.
Transparent native-to-ascii conversion, Обычно необходимо установить флажок, иначе комментарии в файле свойств не будут отображаться на китайском языке. - IntelliJ IDEA не только поддерживает параметры кодирования для всего проекта, но также поддерживает параметры кодирования для каталогов и файлов. Если вы хотите установить кодировку каталога, может быть опция всплывающей операции, требующая преобразования кодировки. Настоятельно рекомендуется сделать резервную копию файла перед преобразованием, иначе процесс преобразования может быть искажен и не может быть восстановлен.
Кроме того, кодировку отдельных файлов также можно настроить так

Может выскочить такая пуля

ReloadУказывает на перезагрузку с новым кодом, новый код не будет сохранен в файлConvertУказывает, что новый код используется для преобразования, и новый код будет сохранен в файл- Содержит файлы китайского кода,
ConvertКитайские иероглифы в будущем могут быть искажены, поэтому сделайте резервную копию при преобразовании, иначе процесс преобразования может быть искажен и не может быть восстановлен.
Ошибки компиляции, вызванные проблемами кодирования
Ошибка компиляции:Символ не найден、Незавершенный строковый литералРешения для других:
- Поскольку файлы в кодировке UTF-8 делятся
С спецификациейИ никтоBOMПо умолчанию в IntelliJ IDEA используется компилятор.javac, И эту компиляцию можно только скомпилироватьНет спецификацииМногие пользователи Eclipse часто сталкиваются с этой проблемой при использовании IntelliJ IDEA для разработки проектов Eclipse. В основном потому, что компилятор EclipseEclipse, Этот компилятор поддерживаетС спецификациейФайл скомпилирован. Поэтому решение — удалить спецификацию для этого файла. - Чтобы удалить спецификацию партиями, вы можете в Google:
Удалить спецификацию в пакете、Пакетное преобразование без спецификацииТакие как ключевые слова, различные решения уже доступны в Интернете - Если ни одна из вышеперечисленных проблем не может быть решена, и вы также подтверждаете, что кодировка конфигурации IntelliJ IDEA — UTF-8, а кодировка файла ошибок также UTF-8 без спецификации, то есть еще одна возможность, что эта ситуация также может возникнуть: конфигурация проекта Проблема с файлом. Файл конфигурации кодировки проекта находится в: / директория проекта / .idea / encodings.xml. Если вы можете изменить этот файл, вы можете изменить его. Если нет, удалите весь каталог .idea, перезапустите IntelliJ IDEA и перенастройте этот проект.
Консоль Tomcat выводит искаженные символы
Если ваша консоль Tomcat выводит искаженные символы и вы убедились, что шрифт, установленный в настройках шрифта консоли в этой статье, содержит китайский язык, то вы также можете попробовать добавить к параметрам виртуальной машины Tomcat:-Dfile.encoding=UTF-8Как показано

Решение проблем с кодировкой в териминале Ubuntu
10 декабря, 2015
Вариант №1
В случае проблем с кодировкой необходимо воспользоваться конфигуратором.
sudo dpkg-reconfigure console-setup
Дальнейшие настройки
Для кого предназначена клавиатура: Выбираем Russia
Раскладка клавиатуры: Выбираем Russia
Используемая кодировка в консоли: Выбираем UTF-8
Используемая таблица символов: Выбираем кириллица славянские языки… (5 пункт)
Консольный шрифт: Выбираем TerminusBold
Размер шрифта: Выбираем 16.
Применяем указанные настройки при старте системы, для этого открываем для редактирования конфигурационный файл /etc/rc.local:
$ sudo nano /etc/rc.local
3. Добавляем выделенную строку:
#!/bin/sh -e
#
# rc.local
#
# This script is executed at the end of each multiuser runlevel.
# Make sure that the script will «exit 0» on success or any other
# value on error.
#
# In order to enable or disable this script just change the execution
# bits.
#
# By default this script does nothing.
setupcon
exit 0
Вариант №2
Переустановить русскую локаль (не помогает в Ubuntu 15.4 — 15.10)
Источник
Кое-что о проблемах с кодировками в убунту.
Я не ставил себе цель решить все проблемы, но хотел написать решения, о которых не писалось на хабре.
В основном коснусь кодировок в icq.
Итак начнем с IM. Хорошая хозяйка может взять на заметку несколько следующих фактов. Миранда прекрасно ладит как с utf так и с 1251. qip принимает только 1251 и не желает работать с utf. Pidgin настроеный на utf не принимает 1251. Pidgin настроенный на 1251 принимает utf но отсылает в ответ все равно 1251.
Резюмирую предыдущий параграф, могу сказать что пока корректнее всего работает с кодировками миранда, но ее надо запускать таким образом: env LC_ALL=ru_RU.cp1251 wine miranda.exe иначе она не будет работать с cp1251.
UPD
Прошу собого внимания тех, кто пользуется пиджином
Pidgin получает сообщения из офлайна кракозябрами.
Пользователь Zeboton подсказал, что в свойствах Pidgin надо писать не cp1251 а WINDOWS-1251 тогда проблема исчезает.
Я сам проверял, действительно так.
/UPD
Вообще метод запуска LC_ALL=ru_RU.cp1251 wine программа.exe может применяться ко всем виндовым программам с проблемными кодировками, но я думаю что этим я америку не открыл.
У вас было такое, что вы вставляете нормальный диск а кириллические названия выглядят примерно так: «. «.
Проблема, как ни странно, в том (по крайней мере с моими дисками), что он НЕ примонтировался В СИСТЕМНОЙ КОДИРОВКЕ UTF8!
Если вам попался такой диск попробуйте примонтировать с опцией -o iocharset=utf8. Если буквы проявили свою кириллическую сущность, то можете прописать в fstab опцию iocharset=utf8 к сиди-рому.
И немного про субтитры в mplayer.
С начала находим шрифт с поддержкой кириллицы, хотя бы ту же тахому. Кладем в home/юзер/.mplayer. Находим там же файл config.
Пишем в него:
font=/home/юзер/.mplayer/tahoma.ttf
subcp=«utf8»
Если сабы у вас с 1251 последнюю строчку следует заменить на
subcp = «cp1251»
UPD
Пользователь non7top подсказал, что для автоопределения кодировки в mplayer вместо subcp = «cp1251» надо написать:
subcp = enca:ru:cp1251
при этом должна быть установлена enca.
Тут немного о кодироваках в аудиофойлах и проигрывателях.
Собственно пока все. Если вы считаете что какую-либо проблему надо решать по-другому либо знаете как решить другую — пишите. Поправки тоже принимаются.
Источник
Кодировка в Gedit
Содержание
Описание проблемы
Ubuntu по умолчанию использует кодировку текстовых файлов UTF-8, однако некоторые операционные системы используют другие кодировки (например, русская версия Microsoft Windows использует CP-1251). Из-за разницы в кодировках могут возникнуть проблемы при открытии текстовых файлов в редакторе Gedit — они будут нечитаемыми. Данная статья предлагает несколько простых способов решения этой проблемы.
Настройка Gedit на автоопределение кодировки
Gedit может автоматически определить нужную кодировку. Для этого его нужно немного настроить.
Вариант 1.
Запускаем dconf-editor и переходим в
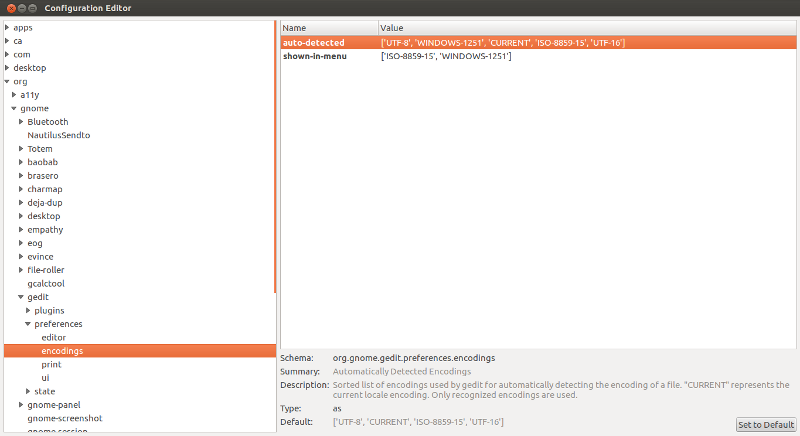
Редактируем ключ auto_detected 3) , вписывая нужную нам кодировку
Вариант 2.
Выполните в терминале команду:
Откроется Редактор Конфигурации GNOME. В нем откройте для редактирования ключ auto_detected 4) . 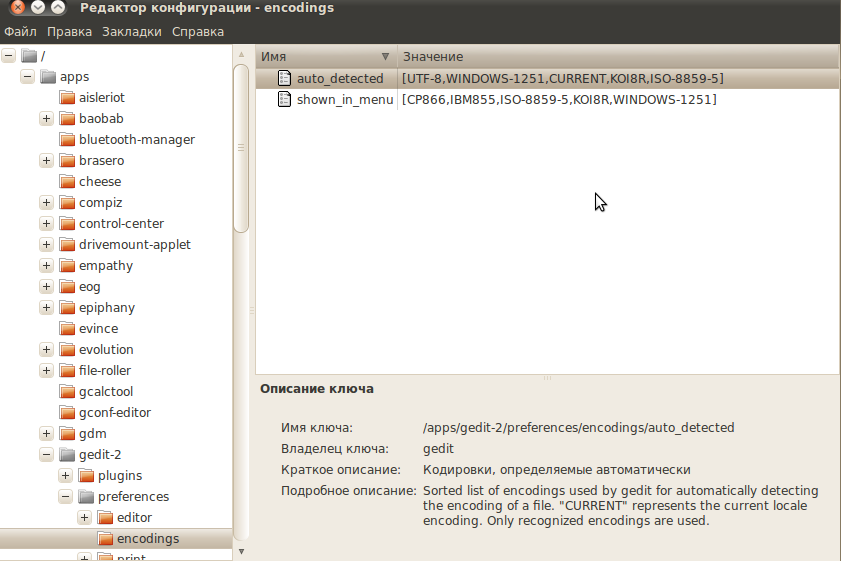 В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор.
В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор. 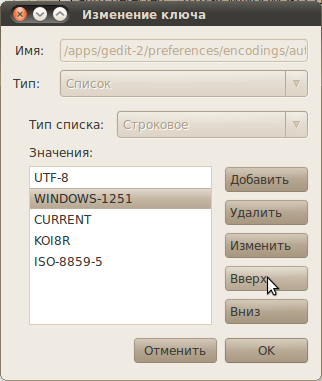
Вариант 3. Выполните в терминале команду:
Для Ubuntu 16.04:
Для Ubuntu Mate 16.04:
Данный способ является самым быстрым.
Теперь, если вы откроете файл с кодировкой WINDOWS-1251 — он будет правильно отображаться в Gedit.
Смена кодировки открытого файла
С помощью системы плагинов можно добавить возможность выбора кодировки уже открытого файла.
/.local/share/gedit/plugins (если такой папки нет, то её нужно создать)
После этого в главном меню Файл появляется пункт «Encoding», который позволяет менять кодировку в уже открытом документе.
Источник
Справочная информация
про свой опыт решения некоторых проблем и использования ряда возможностей ОС и приложений
понедельник, 4 февраля 2019 г.
Автоопределение кодировки в xed (Linux Mint)

По умолчанию текстовый редактор xed не осуществляет определения кодировки текста. В результате чего при открытии текстовых файлов, набранных в Блоноте Windows имеется следующая картина:
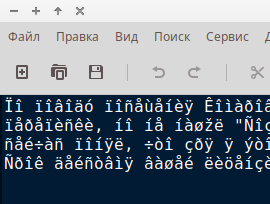
Чтобы текст отображался нормально выполните в терминале одну из двух команд, указанных ниже. Если команда не соответствует, то терминал выдаст какое-либо сообщение. При правильной команде терминал после некоторого «размышления» вернётся к состоянию готовности к приёму команд.
Для Linux Mint xfce 18.3 и 19.* вводить вторую команду.
gsettings set org.x.editor auto-detected-encodings «[‘UTF-8’, ‘WINDOWS-1251’, ‘KOI8-R’, ‘CP866’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»
gsettings set org.x.editor.preferences.encodings auto-detected «[‘UTF-8’, ‘WINDOWS-1251’, ‘KOI8-R’, ‘CP866’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]»
При открытии проблемного файла снова вопрос с повестки дня был снят.
Источник
проблемы с кодировкой
Всем доброго времени суток, возникла вот такая проблема, поставил линукс(mint) и теперь в текстовых файлах не распознает русский язык который раньше был введен, когда ввожу новый оно его видит, но до закрытия файлика, когда снова открываю, обрадто ироглифы, подскажите пожауста как с этим боротса( и прозьба детально обьяснить как побороть(в линуксе я чайник))

Нажми ALT и F2.
Там набери xterm и нажми enter.
В запущенном терминале веди команду locate.
Очень хочется посмотреть на то, что она скажет.

Есть кодировка файла, есть текуцая кодировка (отображения и ввода информации) называется locale в POSIX- системах (Linux — посикс система).
Если кодировки файла и locale не совпадают при просмотре ты видишь иероглифы. Ещё иегорлифы бывают если неправильно настроено средство вывода (программа-терминал).
Для того чтобы определить текущую кодировку есть команда locale. Там будет что-то вроде: en_US.UTF-8, где UTF-8 — это и будет кодировка вывода.
Для того чтобы посмотреть файл в другой кодировке надо либо поменять кодировку текущей локаль(сильно не рекомендуется, часто нужно перенастраивать терминал), либо перекодировать файл.
Тренированный юниксоид определяет кодировку файла и системную локаль на глаз по результату вывода файла на терминал. после определения кодировки выполняется программа iconv для файла (или recode, мне она нравится больше, но iconv есть везде), например cat abc.txt | iconv -f CP1251 -t UTF8 >abc.utf8.txt, после чего смотрится преобразованный файл.
Все это не извращение а очень полезно, т.к. любая программа может работать с разными локалями и на разных языках, достаточно просто сказать LANG=ch_CH mc и вам mc будет на китайском.
Потому что в файлах, которые вы создавали в винде, была кодировка CP1251. А теперь ваш текстовый редактор открывает их используя кодировку текущей локали (команда locale), которая скорее всего UTF-8.
Это не значит что для того чтобы редактировать эти файлы вам придётся менять локаль.
Просто не все редакторы умеют [корректно] распознавать кодировки или их нужно настраивать.
gedit из гнома вроде бы сносно определяет кодировку, жаль только что хоть меню для настройки кодировки там даже есть, оно, в лучших традициях сраного ХИГа, появляется только если gedit не может определить кодировку файла.
Можно и не париться, а просто сконвертить все txt-шки в кошерный UTF8 с помощью enconv.
Ну вы и страшные вещи пишете тут) Только новичков пугаете.
vim например хорошо определяет кодировки после небольшой допилки, а смотреть кодировку фала можно с помощью enca.
Источник