
-

-
October 31 2018, 16:23
- Компьютеры
- Cancel
16:23 31.10.2018
Ошибка получение списка кластеров: Ошибка операции администрирования 1с не найдено ни одного сервера с размещенным сервисом

В общем образовалась вчера такая проблема при входе в консоль 1С: «Ошибка получение списка кластеров: Ошибка операции администрирования 1С: не найдено ни одного сервера с размещенным сервисом serviceName=ClusterConfigService«. Решение немного глупое, но работает.
1) Останавливаем 1С-сервак
2) Cносим в папке C:Program Files (или x86)1cv8srvinfo только папки, начинающиеся с snccntx, т.е. содержащие сессионные данные
2) Запускаем сервак, добавляем базы.
3) Все работает!
Такой способ полезен, если баз очень много и одно только добавление их по новой занимает много времени.
read more at Константин Лимонов
Перейти к содержимому
Настройка 1С
Решения по использованию программ 1С. Техподдержка. Сопровождение. Услуги программистов.
Такую ошибку поймал один из наших клиентов. В этом частном случае «виновником» был журнал регистрации. Даже не он, а дисковая система, куда сохранялись данные.
Попросту закончилось свободное место и накопилась очередь транзакций, которые уже нельзя было записать. Пользователей «повыкидывало» из баз и уже не пускало.
Полный текст ошибки:
«Не найдено ни одного сервера с размещенным сервисом
servicename=SessionDataService; Ref=<база>; sessionID=<id>;»
Вышли из ситуации так: остановили службу Агента 1С, зачистили старые неиспользуемые журналы и запустили сервер. Потом, конечно, сделали более грамотно — добавили свободного места и сократили журнал регистрации 1С.
Причины
Глубоко в проблематику не залезали. Взяли со страницы на сайте Гилева. Да, зато честно. Типовые причины:
- какая-то операция выполняется настолько часто, что накапливается очередь на исполнение;
- проблема нового формата журнала регистрации;
- слишком маленькое значение «Время засыпания неактивного сеанса» и «Время удаления спящего сеанса»;
- падение процесса rmngr или удаление сеанса административными средствами.
Варианты действий
Возможные решения. Выбирайте то, что подходит именно для вас, исходя из целесообразности. Как показывает практика, у каждого свой огород и условия. Итак, что можно сделать:
- Перезагрузите сервер 1С или выполните принудительный рестарт службы «Агент сервера 1С:Предприятия 8.3».
- Очистите кэш сервера 1С.
- Проверьте каталог, куда сохраняются файлы журнала регистрации (ЖР). Достаточно ли свободного места. Нет ли ошибок или ограничений на диске при работе с файлами.
- Переключите ЖР на старый формат, перед этим остановите службу 1С.
• В свойствах службы «Агент сервера 1С» найдите путь к файлам регистрации (опция -d «путь_к_каталогу»).
• В папке базы (…srvinforeg_xxxx<guid>) найдите папку журнала регистрации (1Cv8Log).
• Далее из папки 1Cv8Log удалите все файлы или переместите в другое место.
• В папке 1Cv8Log создайте пустой файл 1Cv8.lgf и запустите службу сервера 1С. - Остановите Агент 1С и очистите папки %temp%, %appdata%1c, %localappdata%1c в профиле пользователя, от имени которого запускается служба.
- Если у вас СУБД (MSSQL) и сервер 1С на одной машине, то настройте ограничение памяти для служб SQL.
- В консоли кластера 1С проверьте, как настроены Требования назначения функциональности (ТНФ). Добавьте общую функциональность с типом требования «Назначить» и примените требования.
- Удалите запись базы из кластера 1С, но без удаления из СУБД! А затем создайте новую регистрацию с подключением к имеющейся базе.
- Включите в настройках сервера 1С «Менеджер под каждый сервер». И посмотрите, не падает ли сервис сеансовых данных.
- Ничего не помогает? Переустановите платформу.
В случаях, когда останавливать сервер 1С нельзя, и проблема наблюдается только в одной базе — откройте Диспетчер задач и найдите неактивные процессы rphost. Завершите их принудительно. Это может сработать, если у вас настроен параметр «Количество ИБ на процесс = 1».
Пусть все получится, и сервисы 1С восстановят свою работу как требуется.
Требуется дополнительная поддержка? Наши специалисты готовы вам помочь → +7-911-500-10-11
| Разрядность платформы как причина ошибок при выполнении обработчиков обновления | оглавление | Ошибка при скачивании исправлений (патчей) |
2022-07-20T16:43:53+00:00
Оглавление
- Введение в проблему
- Что с этим делать
- Если ошибка возникает в момент обновления конфигурации базы данных
Введение в проблему
Ошибка ‘Не найдено ни одного сервера с размещенным сервисом’ является довольно распространённой для клиент-серверных баз.
О каких сервисах здесь идёт речь? Дело в том, что кластер 1с обращается за какой-то частью функциональности к рабочим серверам, то есть это часть внутренней архитектуры кластера.
И вот в какой-то момент кластер хочет воспользоваться каким-то механизмом и выясняется, что ни один из рабочих серверов не может оказать кластеру такую «услугу» (сервис), так как:
- либо у него (у рабочего сервера) в настройках не настроены должным образом требования назначения соответствующей функциональности
- либо этот рабочий сервер оказывается настолько перегружен запросами на выполнение какой-либо задачи, что отказывает кластеру в запросе
И далее кластер возвращает конфигуратору ошибку, что мол не получилось найти ни одного сервера с размещенным сервисом… и далее следует указание имени сервиса, с которым возник затык (например, IntegrationDataService, ClusterConfigService, DataEditLockService или SessionDataService).
Что с этим делать
Если возникновение ошибки постоянно — тут скорее всего дело именно в том, что для рабочих серверов не настроены должным образом требования для назначения функциональности.
Если же ошибка не регулярная — стоит искать причины, по которым возникает чрезмерная загруженность рабочих серверов, не позволяющая им оперативно обрабатывать запросы от кластера. И здесь какого-то простого и универсального совета, к сожалению, нет. Изучайте опыт других пользователей: ссылка на статьи из поиска.
Если ошибка возникает в момент обновления конфигурации базы данных
Вот пример такого отчёта по такой операции:

В общем образовалась вчера такая проблема при входе в консоль 1С: «Ошибка получение списка кластеров: Ошибка операции администрирования 1С: не найдено ни одного сервера с размещенным сервисом serviceName=ClusterConfigService«. Решение немного глупое, но работает.
1) Останавливаем 1С-сервак
2) Cносим в папке C:Program Files (или x86)1cv8srvinfo только папки, начинающиеся с snccntx, т.е. содержащие сессионные данные
2) Запускаем сервак, добавляем базы.
3) Все работает!
Такой способ полезен, если баз очень много и одно только добавление их по новой занимает много времени.
read more at Константин Лимонов
Перейти к содержимому
Настройка 1С
Решения по использованию программ 1С. Техподдержка. Сопровождение. Услуги программистов.
Такую ошибку поймал один из наших клиентов. В этом частном случае «виновником» был журнал регистрации. Даже не он, а дисковая система, куда сохранялись данные.
Попросту закончилось свободное место и накопилась очередь транзакций, которые уже нельзя было записать. Пользователей «повыкидывало» из баз и уже не пускало.
Полный текст ошибки:
«Не найдено ни одного сервера с размещенным сервисом
servicename=SessionDataService; Ref=<база>; sessionID=<id>;»
Вышли из ситуации так: остановили службу Агента 1С, зачистили старые неиспользуемые журналы и запустили сервер. Потом, конечно, сделали более грамотно — добавили свободного места и сократили журнал регистрации 1С.
Причины
Глубоко в проблематику не залезали. Взяли со страницы на сайте Гилева. Да, зато честно. Типовые причины:
- какая-то операция выполняется настолько часто, что накапливается очередь на исполнение;
- проблема нового формата журнала регистрации;
- слишком маленькое значение «Время засыпания неактивного сеанса» и «Время удаления спящего сеанса»;
- падение процесса rmngr или удаление сеанса административными средствами.
Варианты действий
Возможные решения. Выбирайте то, что подходит именно для вас, исходя из целесообразности. Как показывает практика, у каждого свой огород и условия. Итак, что можно сделать:
- Перезагрузите сервер 1С или выполните принудительный рестарт службы «Агент сервера 1С:Предприятия 8.3».
- Очистите кэш сервера 1С.
- Проверьте каталог, куда сохраняются файлы журнала регистрации (ЖР). Достаточно ли свободного места. Нет ли ошибок или ограничений на диске при работе с файлами.
- Переключите ЖР на старый формат, перед этим остановите службу 1С.
• В свойствах службы «Агент сервера 1С» найдите путь к файлам регистрации (опция -d «путь_к_каталогу»).
• В папке базы (…srvinforeg_xxxx<guid>) найдите папку журнала регистрации (1Cv8Log).
• Далее из папки 1Cv8Log удалите все файлы или переместите в другое место.
• В папке 1Cv8Log создайте пустой файл 1Cv8.lgf и запустите службу сервера 1С. - Остановите Агент 1С и очистите папки %temp%, %appdata%1c, %localappdata%1c в профиле пользователя, от имени которого запускается служба.
- Если у вас СУБД (MSSQL) и сервер 1С на одной машине, то настройте ограничение памяти для служб SQL.
- В консоли кластера 1С проверьте, как настроены Требования назначения функциональности (ТНФ). Добавьте общую функциональность с типом требования «Назначить» и примените требования.
- Удалите запись базы из кластера 1С, но без удаления из СУБД! А затем создайте новую регистрацию с подключением к имеющейся базе.
- Включите в настройках сервера 1С «Менеджер под каждый сервер». И посмотрите, не падает ли сервис сеансовых данных.
- Ничего не помогает? Переустановите платформу.
В случаях, когда останавливать сервер 1С нельзя, и проблема наблюдается только в одной базе — откройте Диспетчер задач и найдите неактивные процессы rphost. Завершите их принудительно. Это может сработать, если у вас настроен параметр «Количество ИБ на процесс = 1».
Пусть все получится, и сервисы 1С восстановят свою работу как требуется.
Требуется дополнительная поддержка? Наши специалисты готовы вам помочь → +7-911-500-10-11
| Разрядность платформы как причина ошибок при выполнении обработчиков обновления | оглавление | Ошибка при скачивании исправлений (патчей) |
2022-07-20T16:43:53+00:00
Оглавление
- Введение в проблему
- Что с этим делать
- Если ошибка возникает в момент обновления конфигурации базы данных
Введение в проблему
Ошибка ‘Не найдено ни одного сервера с размещенным сервисом’ является довольно распространённой для клиент-серверных баз.
О каких сервисах здесь идёт речь? Дело в том, что кластер 1с обращается за какой-то частью функциональности к рабочим серверам, то есть это часть внутренней архитектуры кластера.
И вот в какой-то момент кластер хочет воспользоваться каким-то механизмом и выясняется, что ни один из рабочих серверов не может оказать кластеру такую «услугу» (сервис), так как:
- либо у него (у рабочего сервера) в настройках не настроены должным образом требования назначения соответствующей функциональности
- либо этот рабочий сервер оказывается настолько перегружен запросами на выполнение какой-либо задачи, что отказывает кластеру в запросе
И далее кластер возвращает конфигуратору ошибку, что мол не получилось найти ни одного сервера с размещенным сервисом… и далее следует указание имени сервиса, с которым возник затык (например, IntegrationDataService, ClusterConfigService, DataEditLockService или SessionDataService).
Что с этим делать
Если возникновение ошибки постоянно — тут скорее всего дело именно в том, что для рабочих серверов не настроены должным образом требования для назначения функциональности.
Если же ошибка не регулярная — стоит искать причины, по которым возникает чрезмерная загруженность рабочих серверов, не позволяющая им оперативно обрабатывать запросы от кластера. И здесь какого-то простого и универсального совета, к сожалению, нет. Изучайте опыт других пользователей: ссылка на статьи из поиска.
Если ошибка возникает в момент обновления конфигурации базы данных
Вот пример такого отчёта по такой операции:
Во-первых, конкретно эту ошибку (не найден сервис IntegrationDataService в момент обновления конфигурации базы данных) 1с зарегистрировала и выпустила исправление: https://bugboard.v8.1c.ru/error/000115271
Ошибка исправлена начиная с 8.3.20.1789, 8.3.21.1302 и 8.3.22.1368.
Во-вторых, в этом случае как замечают пользователи достаточно часто помогает повторная попытка обновления конфигурации базы данных. И я реализовал этот функционал в обновляторе.
Чтобы его включить зайдите в свойства серверной базы и там на закладке «Обновление» в разделе «Сам процесс» установите опцию «Повторять попытку обновления конфигурации базы данных для известных ошибок»:
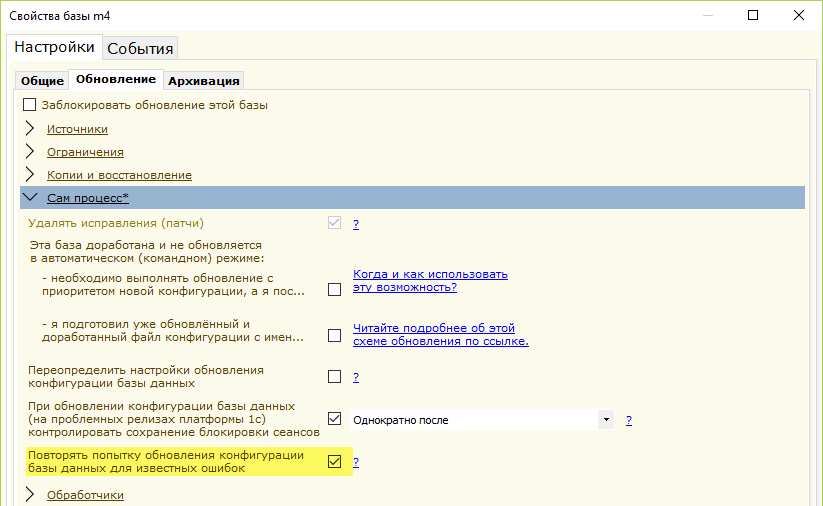
В этом случае, если обновление конфигурации базы данных вернёт код ошибки, а в логе 1с по такому обновлению будет найдена строка ‘Не найдено ни одного сервера с размещенным сервисом’ — обновлятор сделает паузу и повторит попытку обновления конфигурации базы данных.
С уважением, Владимир Милькин (преподаватель школы 1С программистов и разработчик обновлятора).

Как помочь сайту: расскажите (кнопки поделиться ниже) о нём своим друзьям и коллегам. Сделайте это один раз и вы внесете существенный вклад в развитие сайта. На сайте нет рекламы, но чем больше людей им пользуются, тем больше сил у меня для его поддержки.
Нажмите одну из кнопок, чтобы поделиться:
| Разрядность платформы как причина ошибок при выполнении обработчиков обновления | оглавление | Ошибка при скачивании исправлений (патчей) |
Я работаю в группе, которая занимается поддержкой отказоустойчивых кластеров, поэтому мне часто приходится выявлять и устранять неисправности. В этой статье будут описаны типичные проблемы, с которыми я сталкивался, с пояснением причин их возникновения и рекомендациями по их устранению
.
Проблема 1
Служба кластеров при запуске обнаруживает сети, в которые входит узел, и для каждой сети определяет сетевые адаптеры. Одна из типичных неполадок связана с тем, что отказоустойчивая кластеризация Windows Server (WSFC) допускает использование для одной сети только одного сетевого адаптера. Все прочие адаптеры этой сети игнорируются.
Предположим, что администратор настроил узел с двумя сетевыми адаптерами для одной сети:
Card1 IP Address: 10.10.10.1 Subnet Mask: 255.0.0.0 Card2 IP Address: 10.10.10.2 Subnet Mask: 255.0.0.0
Сетевой драйвер кластера (Netft.sys) для каждой сети будет использовать только один сетевой адаптер (или группу). Поэтому при данной конфигурации сеть кластера Cluster Network 1 (10.10.10.0/16) будет задействовать только сетевой адаптер Card1, тогда как сетевой адаптер Card2 будет игнорироваться, то есть не будет применяться для связи между узлами. Поскольку работает только одна сеть, при выходе Card1 из строя или утрате сетевого соединения узел не сможет взаимодействовать с другими узлами. Это единственная точка отказа. Чтобы избежать подобной ситуации, кластер следует настраивать так, чтобы между узлами существовало, как минимум, два сетевых пути. В этом случае при отказе одного из сетевых адаптеров связь между узлами будет осуществляться через другой сетевой адаптер.
Проблема 2
Вторую типичную проблему проще всего раскрыть с помощью сценариев. Опишем ее на примере двух различных конфигураций кластера: односайтовой и многосайтовой.
Односайтовый кластер. Предположим, что администратор решил изменить конфигурацию кластера, установив две сети между узлами Node1 и Node2. На узле Node1 он поменял IP-адреса и маски подсети сетевых адаптеров:
Card1 IP Address: 192.168.0.1 (Cluster Network 1) Subnet Mask: 255.255.255.0 Card2 IP Address: 10.10.10.1 (Cluster Network 2) Subnet Mask: 255.0.0.0
Кроме того, администратор поменял IP-адреса узла Node2 (192.168.0.2 и 10.10.10.2). При этом на узле Node1 в кластере он добавил группу файлового сервера, назначив ей IP-адрес 192.168.0.15.
Затем администратор протестировал кластер, чтобы убедиться в успешном переходе группы файлового сервера на узел Node2 при отработке отказа. Однако IP-адрес группы файлового сервера не виден в сети, то есть группа находится в автономном состоянии. В журнале событий системы регистрируется событие 1069, описание которого указывает на отказ ресурса с этим IP-адресом.
Причина отказа становится очевидной, если воспользоваться командой PowerShell Get-ClusterLog для вывода журнала кластера. Для этого достаточно ввести следующий набор символов:
Get-ClusterLog
Команда инициирует создание журнала кластера на каждом узле. Для построения журнала кластера только на одном узле можно добавить параметр -Node и указать имя узла. Можно также добавить параметр -TimeSpan для создания журнала только за последние x минут. Например, приведенная ниже команда предписывает построить журнал кластера на узле Node2 за последние 15 минут:
Get-ClusterLog –Node Node2 –TimeSpan 15
В результатах, представленных на экране 1, указано состояние «status 5035.».
 |
| Экран 1. Информация о состоянии 5035 в файле журнала кластера |
Это сообщение об ошибке указывает на неработоспособное состояние сети кластера. Если администратор перейдет в диспетчер отказоустойчивости кластеров, то в разделе «Сети» он увидит, что сеть 192.168.0.0/24 содержит только один сетевой адаптер для узла Node1. Однако имеется новая сеть 192.0.0.0/8, обслуживаемая сетевым адаптером узла Node2. Администратор, поменяв IP-адрес сетевого адаптера на узле Node2, не поменял маску подсети. Таким образом, ошибка 5035 возникла из-за неверной настройки сетевого адаптера.
Создавая ресурс с IP-адресом, можно указать сеть, которая будет использоваться для него. Если эта сеть не будет существовать на узле, куда данный ресурс перейдет при отработке отказа, то WSFC не поменяет сеть, используемую ресурсом. В данном примере, при том IP-адресе, который указал администратор, и маске подсети, применяемой этим IP-адресом, группа файлового сервера сможет работать только по сети Cluster Network 1 (192.168.0.0/24).
Многосайтовый кластер. В случае многосайтового кластера каждый узел обычно имеет собственную сеть со своим IP-адресом. При первоначальном создании кластера и его ролей с помощью мастера создания ресурсов вам предлагается указать IP-адрес для сетей каждого из узлов, настроенных для клиентского доступа (см. экран 2).
|
|
| Экран 2. Создание многосайтового кластера |
Мастер создания ресурсов, создавая IP-адреса и назначая имя сети, автоматически присваивает параметру зависимости этого имени сети значение «или». Это означает, что если один из IP-адресов в сети, имя также видно в сети. Создавая группы или ресурсы перед добавлением узлов из других сетей, необходимо вручную создавать эти вторичные IP-адреса и добавлять зависимость «или».
Проблема 3
Для формирования кластера необязательно быть администратором домена, но создание объектов в Active Directory (AD) требует наличия соответствующих прав. Как минимум, необходимо обладать правами на просмотр и создание объектов (Read and Create) в том подразделении (OU), где создается данный объект имени кластера (CNO). CNO – это объект-компьютер, связанный с ресурсом-кластером «Имя кластера». При создании кластера служба WSFC использует учетную запись, с которой вы регистрировались в системе, чтобы создать объект CNO в том же OU, которому принадлежат узлы. Если вы не обладаете достаточными правами в отношении данного OU, кластер не будет создан, и система выдаст ошибку, как показано на экране 3.
|
|
| Экран 3. Ошибка процесса создания кластера |
В статье «Диагностика проблем отказоустойчивых кластеров Windows Server 2012» (№ 10 за 2013 г.) я рассказывал об использовании мастера проверки конфигурации в диспетчере отказоустойчивости кластеров для выявления причин возникающих проблем. Мастер позволяет выполнять различные тесты, включая проверку настроек Active Directory. В ответ на попытку запуска этого теста без достаточных прав в отношении данного OU будет выдана ошибка, как показано на экране 4. Соответствующая настройка прав позволит вам создать кластер.
|
|
| Экран 4. Ошибка проверки настроек Active Directory |
Все другие ресурсы с сетевыми именами в кластере ассоциированы с объектами виртуальных компьютеров (VCO), создаваемыми в том же OU, что и CNO. Следовательно, при назначении ролей в кластере необходимо указать CNO с соответствующими правами (просмотр и создание) в отношении OU, поскольку CNO формирует все VCO в кластере. В противном случае новая роль будет находиться в состоянии сбоя. Тогда в журнале появится событие 1194 (см. экран 5).
|
|
| Экран 5. Событие 1194 в журнале событий системы |
Есть и другие установки локального компьютера, способные вызвать ошибки (включая ошибки отказа в доступе) при создании VCO в AD.
1. В составе локальной группы «Пользователи» больше нет группы «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
2. В локальной политике безопасности разрешение Access this computer from the network («Доступ к этому компьютеру по сети») или Add workstations to the domain («Добавление рабочих станций к домену») больше не включает группу «Прошедшие проверку пользователи». Обычно она удаляется объектами групповой политики (GPO) или шаблонами безопасности.
3. Включены следующие права доступа:
- сетевой доступ (не разрешать перечисление учетных записей SAM анонимными пользователями);
- сетевой доступ (не разрешать перечисление учетных записей SAM и общих ресурсов анонимными пользователями).
4. Ресурс имени кластера в состоянии сбоя.
Проблема 4
CNO и VCO – учетные записи компьютера и, подобно учетным записям пользователей, они имеют пароли, генерируемые AD случайным образом. По умолчанию политика домена предусматривает сброс пароля учетной записи компьютера каждые 60 дней.
СNO используется для таких операций, как добавление новых узлов к кластеру, создание новых объектов в домене и выполнение динамической миграции виртуальных машин с узла на узел. Для выполнения этих операций пароль CNO в домене должен быть актуальным. Для верности служба кластера делает попытку сброса паролей этих объектов по истечении половины срока (через 30 дней). Если пароль не сброшен на 60-дневной отметке, имя кластера не видно в сети.
Для сброса пароля необходимо выполнить восстановление в диспетчере отказоустойчивости кластеров. Как показано на экране 6, щелкните правой кнопкой имя проблемного ресурса и выберите «Дополнительные действия» и «Восстановить».
|
|
| Экран 6. Сброс пароля вручную в диспетчере отказоустойчивости кластеров |
При обращении к AD для сброса пароля диспетчер отказоустойчивости кластеров задействует учетную запись пользователя, под которой вы зарегистрировались в системе, поэтому вашей учетной записи должно быть предоставлено право на изменение пароля CNO; в противном случае восстановление не будет выполнено. Необходимо также убедиться, что включено разрешение на сброс пароля CNO и VCO, чтобы служба WSFC могла выполнять сброс при необходимости.
Проблема 5
Чтобы узел был осведомлен о том, какие узлы являются активными участниками кластера (то есть о текущем членстве), применяется ряд периодических контрольных сигналов, передаваемых между узлами по сети. Эти пакеты сигналов представляют собой UDP-датаграммы, следующие через порт 3343.
Каждый пакет включает регистрационный номер, по которому отслеживается факт приема пакета. Это работает следующим образом: узел Node1, отправляющий регистрационный номер 1111, ожидает ответного пакета, включающего 1111. Эти действия совершаются между всеми узлами каждую секунду. Если узел Node1 не получает ответного пакета, он отправляет следующий по порядку регистрационный номер (1112), и т.д.
По умолчанию, если узел не получает пять контрольных сигналов в течение пяти секунд, WSFC устанавливает факт отказа узла. Активный узел в кластере отправляет пакет на узел, где установлен отказ, чтобы завершить работу службы кластера, и регистрирует событие 1135 в журнале событий системы (см. экран 7).
|
|
| Экран 7. Событие 1135 в журнале событий системы |
Такое событие может быть вызвано несколькими причинами, многие из которых связаны с блокировкой связи через порт 3343:
1. Отказ сетевого оборудования.
2. Устаревший драйвер или устаревшая прошивка сетевого адаптера.
3. Сетевая задержка.
4. Протокол IPv6 разрешен на серверах, но параметры брандмауэра Windows выключают следующие разрешения для входящего и исходящего трафика:
- основы сетей – объявление поиска соседей;
- основы сетей – запрос поиска соседей.
5. Настройка коммутаторов, брандмауэров или маршрутизаторов не допускает прохождения трафика данных UDP-датаграмм.
6. Проблемы производительности (зависания, задержки и прочее).
7. Неправильно настроенные параметры буфера приема у драйвера сетевого адаптера.
Первым делом я всегда проверяю счетчик отброшенных принятых пакетов в составе объекта производительности сетевого интерфейса в окне системного монитора. Этот счетчик отслеживает число входящих пакетов, которые были отброшены, хотя и не было зафиксировано каких-либо ошибок, препятствующих их передаче протоколу верхнего уровня. Одна из возможных причин – необходимость освободить место в буфере.
Для добавления счетчика отброшенных принятых пакетов в окне системного монитора щелкните правой кнопкой на дисплее и выберите «Добавить счетчики». В открывшемся окне добавления счетчиков укажите нужный компьютер, выполните прокрутку и выберите счетчик «Отброшено принятых пакетов». В выпадающем списке «Экземпляры выбранного объекта» выберите нужный сетевой адаптер и нажмите «Добавить» (см. экран 8).
|
|
| Экран 8. Добавление счетчика отброшенных принятых пакетов в системный монитор |
Добавив счетчик, проверьте его среднее, минимальное и максимальное значения. Если есть значения больше нуля, это указывает на необходимость настройки буфера приема для сетевого адаптера. Проконсультируйтесь с производителем сетевого адаптера по поводу рекомендуемых параметров. Может потребоваться перезагрузка.
В отказоустойчивом кластере Windows Server 2012 R2 можно воспользоваться мастером проверки конфигурации для выполнения проверки сетевого взаимодействия. Этот тест позволяет проверить возможность информационного обмена между узлами через порт 3343. Если есть проблемы связи, то будет выдана соответствующая ошибка с указанием возможной причины.
Проблема 6
Иногда диспетчер отказоустойчивости кластеров не открывается, выдавая сообщение об ошибке (см. экран 9). В процессе открытия диспетчер отказоустойчивости кластеров устанавливает WMI-соединение с каждым узлом кластера. Сообщение об ошибке, приведенное на экране 9, указывает на то, что один из узлов имеет недопустимое пространство имен, то есть с узла был удален экземпляр Cluster WMI (Cluswmi.mof). Остается выяснить, на котором из узлов он удален, поскольку в сообщении об ошибке эта информация отсутствует.
|
|
| Экран 9. Сообщение о недопустимом пространстве имен |
В листинге приведен сценарий Windows PowerShell, позволяющий выявить узел, утративший экземпляр Cluster WMI.
Установив проблемный узел, можно ввести команду
Set-Location C:WindowsSystem32Wbem Mofcomp.exe Cluswmi.mof
Наиболее распространенной причиной утраты Cluswmi.mof узлом является устаревший способ решения проблем WMI. Для устранения неполадок WMI администраторы обычно используют команду Mofcomp.exe *.mof, позволяющую скомпилировать все файлы Managed Object Format (MOF) в репозиторий WMI. Однако дело в том, что существует довольно много файлов удаления для различных ролей и компонентов Windows, включая Cluster WMI. Поэтому файл Cluswmi.mof, устанавливаемый с помощью этой команды, впоследствии удаляется. Правильный способ восстановления репозитория WMI – с использованием команды Winmgmt.exe.
Ошибку легче предупредить
Как известно, предупредить ошибку легче, чем исправлять ее последствия. Поэтому в заключение повторю простое правило: регулярно актуализируйте состояние своих систем, применяя все обновления и исправления, касающиеся безопасности. Команда разработчиков отказоустойчивой кластеризации в Microsoft опубликовала материалы с перечнями исправлений, которые рекомендуется применить на всех кластерах. Каждой версии Windows посвящена отдельная публикация:
- «Рекомендуемые исправления и обновления для отказоустойчивых кластеров на базе Windows Server 2012 R2» (support.microsoft.com/kb/2920151/EN-US);
- «Рекомендуемые исправления и обновления для отказоустойчивых кластеров на базе Windows Server 2012» (support.microsoft.com/kb/2784261/EN-US);
- «Рекомендуемые исправления и обновления для отказоустойчивых кластеров на базе Windows Server 2008 R2» (support.microsoft.com/kb/980054/EN-US).
Материалы обновляются по мере необходимости, поэтому всегда актуальны. Замечу, что в них перечислены не все исправления, а лишь самые критичные для обеспечения стабильной работы и наиболее востребованные, исходя из числа обращений в службу поддержки Microsoft.
Листинг. Сценарий PowerShell для определения узлов с отсутствующим экземпляром Cluster WMI
$NodeNames = Get-ClusterNode
ForEach ($ClusterName in $NodeNames)
{
Write-Host -NoNewline «Testing $ClusterName»
Try
{
$result = (Get-WmiObject -Class «MSCluster_CLUSTER» `
-namespace «rootMSCluster» `
-authentication PacketPrivacy `
-computername $ClusterName -erroraction stop).__SERVER
Write-host «: Successfully queried cluster node»
}
Catch
{
Write-host -NoNewline «: Failed to query cluster node»
Write-host -ForegroundColor Red -BackgroundColor Black `
$_.Exception.Message
}
}
Если у вас возникаем ошибка вида:
Не найдено ни одного сервера с размещенным сервисом serviceName = DebugService
 или
или
Не найдено ни одного сервера с размещенным сервисом serviceName = JobService
то для исправления этой ошибки — серверу необходимо назначить функциональность:
1. Откройте Панель Администрирования серверов и перейдите в раздел Требования назначения функциональности

2. Добавите общую функциональность с типом требования Назначить

3. Примените требования

4. Все должно работать .gif)
Я указал общие требования, т.к. баз на сервере мало, нагрузки практически нет, Но требования назначения функциональности имеют более глубокий смысл:
Требование назначение функциональности определяет:
Для какого объекта требования создается требование. В качестве объекта требования могут выступать некоторые сервисы 1 кластера, клиентские соединения и произвольный объект требования. В качестве объекта требования могут выступать следующие сервисы кластера:
- Блокировок объектов.
- Времени.
- Журналов регистрации.
- Заданий.
- Нумерации.
- Полнотекстового поиска.
- Пользовательских настроек.
- Сеансовых данных.
- Транзакционных блокировок.
- Работы с внешними источниками данных через ODBC.
- Работы с внешними источниками данных через XMLA.
- Сервис лицензирования.
- Сервис фонового обновления конфигурации базы1 данных.
- Сервис тестирования.
- Сервис внешнего управления сеансами.
Определяет тип требования. Тип требования определяет, каким образом будет выполняться использование рабочего сервера:
Не назначать — означает, что рабочий сервер, для которого создано данное требование, не будет назначен для обслуживания объекта требования, подходящего под условия, заданные в требовании.
Назначать — означает, что рабочий сервер, для которого создано данное требование, будет являться одним из кандидатов на обслуживание данного объекта требования (если рабочих серверов будет несколько).
Авто — означает, что рабочий сервер может быть использован для обслуживания объекта требования в том случае, если нет рабочего сервера с явным указанием необходимости использования.
Тип требования Авто — имеет смысл использовать тогда, когда в списке требований рабочего сервера есть требование с более широким набором условий, и необходимо иметь требование для более узкого набора условий. Например, данный сервер не может обслуживать соединения клиентских приложений для всех информационных баз, кроме одной информационной базы, для которой такое обслуживание разрешено.
Дополнительные параметры, необходимые кластеру серверов для принятия решения в ряде случаев:
Имя информационной базы. Используется для уточнения требования для формирования требований для клиентских соединений и всех сервисов кластера, которые могут выступать в качестве объекта требования, кроме сервиса лицензирования.
Дополнительные параметры. Используются для уточнения требований при размещении клиентского соединения или сервиса сеансовых данных. Дополнительный параметр проверяется на совпадение с началом соответствующего параметра объекта требования. Дополнительный параметр может принимать одно из следующих значений:
Для указания конкретного фонового задания:
- BackgroundJob.CommonModule.<Имя модуля>.<Имя метода?.
- Для указания всех фоновых заданий: BackgroundJob. CommonModule .
- Для указания конкретного отчета: BackgroundJob.Report.<Имя отчета;.
- Для указания всех отчетов: BackgroundJob.Report.
- Для указания фоновой реструктуризации: SystemBackgroundJot.
- Для клиентского приложения:
- 1CV — толстый клиент.
- 1CV8CDirect- тонкий клиент в случае прямого подключения к серверу «1С:Предприятия».
- Designer — конфигуратор.
- COMConnectior — COM-соединение.
- WebServerExtensior- соединение с информационной базой через веб-сервер: веб-клиент, тонкий клиент в случае подключения через веб-сервер, Web-сервис.
Рассмотрим, как работает кластер серверов при обработке требований.
В случае необходимости выполнить размещение объекта требования, кластер выполняет следующие действия:
1. На всех серверах, входящих в состав кластера, выполняется обработка заданных для этих серверов требований назначения функциональности. Обход серверов и требований выполняется в порядке следования этих объектов в консоли кластера.2.
2. В каждом списке требований определяется первое требование, которое удовлетворяет размещаемому объекту: по собственно объекту, информационной базе и дополнительному параметру.
3. Затем полученный список рабочих серверов сортируется по признаку типа требования так, что первыми оказываются рабочие сервера с явным указанием использования. Рабочие сервера, для которых подходящее требование содержит явный запрет на использование — исключаются из списка доступных рабочих серверов. При этом назначение выполняется следующим образом:
- Есть рабочие сервера с явным указанием использования: в этом случае объект требования будет обслужен одним из этих рабочих серверов.
- Нет рабочих серверов с явным указанием использования: происходит попытка использовать рабочие сервера с автоматическим указанием использования или те рабочие серверы, для которых не указано требований.
- При размещении клиентского соединения, из списка доступных серверов будет выбран тот, в состав которого входит рабочий процесс с наивысшей доступной производительностью.
- Клиентское приложение, инициировавшее размещение объекта требования, будет завершено аварийно в одном из следующих случаях:
- Если для объекта требования список рабочих серверов оказывается пустым — нет ни одного рабочего сервера, который может обслужить объект. При этом объект требования не будет размещен и будет вызвано исключение.
- Если невозможно выполнить размещение на выбранном рабочем сервер, например, если выбранный сервер вышел из строя, и нет альтернативных рабочих серверов.