
Проблема
Ошибка при запросе датасета RPT_APP_START
Решение
Данная ошибка говорит о том, что:
- Не импортировались технические отчеты.
- Проверьте, есть ли у Reporter’a подключение к базе данных.
- Проверьте гранты на схемы, скорее всего они отсутствуют.
- Добавьте гранты.
- Заново импортируйте отчеты.
- Не был запрошен указанный датасет, т.к. отсутствует подключение к БД у службы iNet: Reporter.
- Подключение в датасете RPT_APP_START указано некорректное подключение к БД.
- Необходимо зайти в rNav.exe и проверить корректность подключения у данного датасета.
Похожие статьи
Аналитика в Yandex DataLens в пределах CSV
- Загрузка CSV через Yandex Cloud
- Yandex Object Storage
- Yandex Query
- Yandex Datalens
- Варианты применения
- Простая загрузка через Python
- Файловые менеджеры для Windows и Mac
- Еще больше подключений к Object Storage
- Две таблицы из Google Sheets (Гугл Таблиц) через CSV
- Создание дашборда
- Обновление CSV
- Публичный доступ
- Загрузка CSV через Yandex Cloud
- Публичный доступ к дашборду из Google Sheets
- Автоматизация
Загрузка CSV через Yandex Cloud
На самом деле, это более перспективный способ загрузки таблиц. Неважен источник, если можете получить таблицу или csv, то обновлять его можно уже автоматически. Google Sheets, Яндекс Таблицы, локальные базы данных, базы данных без белого IP, CRM и ETL системы. При этом схема более понятная, чем выгрузка в базы данных Яндекса. На этапе формирования можно склеивать таблицы, вычислять поля, обновлять не всю таблицу, а «дописывать» только новые строки. Плюсом является большой объем бесплатного хранения в Yandex Cloud (100 ГБ), Yandex Query и Yandex Datalens бесплатные. В общем, со средним объемом данных, все будет бесплатно.
Yandex Object Storage
Начинаем с самого начала. Открываем Datalens.

Нажимаем на Все сервисы.

Находим и выбираем Object Storage.

Нам предлагают создать наше первое облако. Нажимаем Создать.

Откроется консоль управления. В левом верхнем углу нажимаем Создать ресурс, в выпавшем списке выбираем Бакет.
Бакет — это Логическая сущность, которая помогает организовать хранение объектов. Если проще — это папка.

Откроется страница создания бакета.

Сразу откроется окно создания платежного аккаунта. Заполняем поля.

Вводим данные карты, спишут 11 рублей, подтверждаем кодом от банка.

Все заполнили, получаем грант на 4 тысячи, нажимаем Создать.

Возвращаемся к созданию бакета. вводим имя бакета. Максимальный размер ставим Без ограничения.
Без ограничения, значит, что бакет будет автоматически масштабироваться, т.е. увеличиваться. Выставляя ограничения, мы резервируем место, но нам это не надо.
Доступ на чтение объектов ставим Публичный. Нажимаем Создать бакет.

Баскет готов. Нажимаем на наш бакет.

Перетаскиваем в бакет наш csv, архивированный zip.
Yandex Query

Открываем Все сервисы.

Находим и нажимаем Yandex Query.

В левом верхнем углу находим меню, нажимаем Ещё, в выпавшем меню выбираем Соединения.

Нажимаем + Создать.

Настройка соединения. Вписываем любое имя в Имя. Тип выбираем Object Storage. Видимость Публичная. Аутентификация бакета Приватный. Облако и каталог выбираем наше. Бакет выбираем наш. Сервисный аккаунт будет пустой — нажимаем Create new.

Откроется новая вкладка с аккаунтами. Нажимаем в правом верхнем углу Создать сервисный аккаунт.

В поле Имя вводим любое имя. В Роли в каталоге выбираем editor. Там много ролей, проще в поисковой строке набрать. Нажимаем Создать.

Появится новый сервисный аккаунт и сверху меню, выбрать Создать статический ключ доступа. В окне выбрать Создать. Появится Новый ключ. Скопируйте его на жесткий диск, он потом понадобится.

Возвращаемся на вкладку Yandex Query. Теперь в селекторе Сервисный аккаунт появился выбор свежесозданного аккаунта, выбираем его и нажимаем Проверить. Должно появиться зеленое сообщение Соединение успешно. Нажать Создать.

В левом верхнем углу находим меню, нажимаем Ещё, в выпавшем меню выбираем Привязки.

Нажимаем + Создать.

В Параметры соединения выбираем Object Storage. В Соединение выбираем наше созданное соединение.
В Параметры привязки к данным в поле Имя вписываем любое имя, лучше такое-же, как и соединение. Область видимости выбираем Публичная. В Путь ставим слэш /, так как файлы у нас будут лежать в корне бакета. Если будут папка, то соответственно путь от корня бакета. Но проще иметь один бакет чисто под таблицу.

В Сжатие выбираем gsip, так как у нас csv сжат gzip. В Формат выбираем csv_with_names, то есть таблица с заголовками. Разделитель выбираем ;, так как csv записан в таком формате.

Дальше идут колонки, которые нам нужны. Вписываем в Имя название колонки, в Тип выбираем тип данных колонки. Чекбокс Обязательно, значит, что в колонке обязательно должны быть данные, если будет хоть одна пустая ячейка, будет ошибка. Подробнее про типы данных в документации Yandex Cloud.
Будьте внимательны, если в csv формат данных вида
31.11.2022будет ошибка, дата должна быть вида2022-11-31. Конвертируйте дату перед отправкой вObject Storage.
Колонки партиционированния не заполняем. Нажимаем Предпросмотр.

В нижней части появится наша таблица. Нажимаем Создать.

В Привязках нажать эту кнопку.

В выпавшем меню выбрать SELECT.

В правом окне появится SQL запрос, скопируем его без нижней строчки LIMIT 10;, он нам понадобится при создании датасета.
Yandex DataLens
Открываем Datalens.

Создать подключение
Выбираем Yandex Query

В Облако и каталог выбираем наше облако. В поле Сервисный аккаунт выбираем наш аккаунт. Уровень доступа SQL запросов ставим в Разрешить подзапросы датасетах и запросы из чартов. Нажимаем Создать подключение. Вводим название подключения.

В правом верхнем углу нажимаем Создать датасет.

Должно автоматически открыться окно Источник с SQL подзапросом.

Вставляем наш SQL запрос и нажимаем Применить.

Ну вот и все. Мы настроили трансляцию с Object Storage в Datalens.
Варианты применения
Простая загрузка через Python
Задаем идентификаторы, которые получили при регистрации сервисного аккаунта. Задаем имя бакета, в который будем загружать и имя файла, который надо загрузить. Возвращает список файлов, которые уже естьв бакете. На скрипт можно повесить cron или Менеджер задач для периодического выполнения.
import boto3
import gzip
import shutil
import os.path
key_id = 'идентификатор ключа' # Получили при регистрации сервисного аккаунта
access_key = 'секретный ключ' # Получили при регистрации сервисного аккаунта
bucket_name = 'имя бакета'
file_name = 'load.csv' # файл который нужно загрузить
session = boto3.session.Session(
aws_access_key_id = key_id,
aws_secret_access_key = access_key,
)
s3 = session.client(
service_name='s3',
endpoint_url='https://storage.yandexcloud.net'
)
def func_upload(filename, bucket):
with open(filename, 'rb') as f_in:
with gzip.open(filename+'.gz', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
s3.upload_file(filename+'.gz', bucket, filename+'.gz')
# Получить список объектов в бакете
for key in s3.list_objects(Bucket=bucket)['Contents']:
print(key['Key'])
def func_upload(file_name, bucket_name)
Файловые менеджеры для Windows и Mac

CyberDuck

WinSCP
Еще больше подключений к Object Storage
Все подключения описаны на странице документации Object Storage.
Наверняка их еще больше, так как используется популярный протокол Amazon S3.
Две таблицы из Google Sheets (Гугл Таблиц) через CSV.
В подключении Datalens
Google Sheetsможно подключить только один лист из Таблиц. Но что делать, если надо две или более таблиц, которые связаны друг с другом по отдельным колонкам. Очевидно, что заполнять одну большую таблицу. Но бывает, что таблицы заполняются автоматически, например CRM, или их ведет другой отдел, или сотрудники, которым «вот так удобно». Или нужен публичный доступ к дашборду. Datalens отключили материализацию и для подключенияGoogle Sheetsпубличный доступ недоступен. В общем, будем справляться сами, разработчикам не до нашей песочницы с 500 000 строками таблиц в Google Sheets, мы, если по футбольному, Первая лига. Поймите их правильно, такие объемы для баз данных это ерунда, они работают в основном на подключение к большим базам данных. Но мы как-нибудь потом попробуем с нашими Google Sheets влезть в высшую лигу.
Что делать, работаем через подключение File то есть CSV. Трудозатратнее, обновление вручную, но больше возможностей.
- можем объединятьджойнить несколько листов из Таблиц, даже из разных документов;
- полученный дашборд можно сделать публичным;
- остается возможность обновления данных вручную.
Создание дашборда
Давайте рассмотрим простой пример работы с Google Sheets через CSV. Есть Таблица с двумя листами.
Первый лист таблицы с основными показателями.

Вторая лист таблицы, в которой нас интересует колонка Стоимость

Как видно, две таблицы объединяют колонки Наименование и Название. Названия разные, но данные в них одинаковые. Главное найти колонки с идентичными данными в двух таблицах и желательно, чтобы во второй таблице эти значения были уникальными. Например, если во второй таблице Карандаш в одной строке будет стоить 20, а в другой строке Карандаш будет стоить 15, будут неверно объединены таблицы, так как программа не смотрит на другие данные. В таких случаях надо сделать уникальные названия, например второй Карандаш переименовать в Карандаш эконом. Но это делать надо до начала экспорта в Datalens.
Продолжаем. Экспортируем каждый лист в формате CSV на свой жесткий диск.

Файл -> Скачать -> Формат CSV (.csv). В диалоговом окне сохраняем на жесткий диск.
Переходим на Datalens.

Выбираем Создать подключение

Выбираем File

Нажимаем + Загрузить файлы. В диалоговом окне выбираем файлы, которые мы скачали с Таблиц, можно все сразу выделить и загрузить.

Итак, наши файлы загрузились, выбирая их в левом столбце, в правом можно посмотреть их содержимое (на предпросмотре все строки не загружаются, только часть!). Типы значений в столбцах определились правильно, то есть колонка Дата как дата (пиктограмма календарика), Заказ и Количество как числа (пиктограмма решетки), Наименование как строковое значение (пиктограмма А). Если тип определен неправильно, можно нажать пиктограмму и изменить его. Но в первую очередь это значит, что где-то в данных есть значение другого типа. Например, в столбце Количество, в одной строке вместо 0 внесено буквами ноль. Тогда интерпретатор весь столбец обозначит как строковый. Такие вещи надо править непосредственно в Google Sheets.
Нажимаем на Создать подключение в правом верхнем углу.

Вводим название нашего подключения. Важно помнить, что одинаковых имен быть не должно. То есть, нельзя назвать Подключение, Датасет, Чарт и Дашборд одним именем, будет всплывать ошибка. Добавляйте префиксы к названию: MyBIproject_connection, MyBIproject-DataSet, mybiproject_chart_gain, etc. Можно выбрать папку, куда все добро сохранять, нажав на значок >

Нажимаем Создать датасет в правом верхнем углу.

Перетаскиваем наши листы из левой колонки Таблицы в правое пустое поле.

Получаем сообщение об ошибке Датасет не прошел валидацию. Это произошло потому, что Datalens не нашел колонок с ОДИНАКОВЫМ названием. Как мы помним, у нас идентичные колонки называются Наименование и Название. Давайте исправим это. Нажимаем на сдвоенный красный кружок в правом поле.

Открывается диалог связей между нашими листами. Нажимаем на Добавить связь.

Появятся селекторы с выпадающим списком полей в наших листах. Выбираем соответственно Наименование и Название.

Нажимаем на Применить.

Чудо свершилось! Мы подружили два наших листа. Внизу страницы, в Предпросмотре, мы видим новую объединенную таблицу. Нажимаем в левом верхнем углу селектор Поля.

В этой вкладке нужно выбрать агрегацию для числовых типов, то есть как будет представляться наше число. Например, у нас есть колонка Заказы в которой у нас числа. Но, по сути, заказ — это одна единица, и когда мы хотим получить количество всех заказов, мы их считаем по одному, а не сумму номеров заказов. К тому же номера заказов у нас повторяются (смотрите исходные таблицы). Поэтому надо подсказать Datalens, что это поле у нас уникальное, поэтому выбираем в поле Агрегация напротив имени Заказ выбираем Количество уникальных. Для имен Количество и Стоимость выбираем агрегацию Сумма. Нажимаем в правом верхнем углу Сохранить. Вводим название нашего датасета.
В принципе, мы уже сделали все, что нужно. Дальше строим на основе этого Датасета строим чарты и дашборды. Но давайте проявим немного терпения и дойдем до конца, ведь нам надо еще обновлять данные и опубликовать созданный дашборд. Прошу прошения у тех, кто это уже все знает, за подробности, но кто-то первый раз будет это делать. Нажимаем в правом верхнем углу Создать чарт.

Делаем самый простой чарт. Перетаскиваем из левого поля измерение Дата в поле -> Х. Перетаскиваем из левого поля измерение Наименование в поле Цвета.

Пока столбцы у нас пустые, надо посчитать выручку по дням. Для этого создадим новый показатель Выручка. В левом поле возле поиска нажимаем значок + и выбираем Поле.

Слева у нас все поля, нажимаем на Количество, поле автоматически вставится в формулу

Слева у нас все поля, нажимаем на Количество, поле автоматически вставится в формулу. Вводим с клавиатуры символ * и нажимаем на поле Стоимость. Мы получили простую формулу где перемножаем количество товара на стоимость единицы товара. В правом верхнем поле Наименование поля вводим название Выручка. Нажимаем кнопку Создать.

Перетаскиваем из левого поля наш новый показатель Выручка в поле Y. Теперь у нас появились столбцы, с выручкой по дням и разбивкой по Наименованию. Нажимаем в правом верхнем углу Сохранить.

Вводим название чарта. В самом левом столбце с пиктограммами находим Дашборд и нажимаем на него.

В правом верхнем углу выбираем Создать дашборд. Вводим название дашборда.

В правом верхнем углу выбираем выпадающий селектор Добавить в нем выбираем Чарт.

Нажимаем Чарт Выбрать и в всплывшем окне выбираем чарт, который мы только что создали. В левом нижнем углу нажимаем Добавить.

Нажимаем в правом верхнем углу Сохранить.

Все мы создали свой дашборд. Теперь изучим его. У нас есть выручка по дням по наименованиям. Но если посмотреть на нашу первую таблицу в Google Sheets, мы увидим, что
02.11.2022 был заказ на 100 линеек, но в дашборде линеек нет. Это произошло потому, что у нас во второй таблице в Google Sheets нет Наименования Линейка, поэтому, при слиянии двух таблиц, у линейки стоимости нет, соответственно, при вычислении выручка будет 0. Давайте исправим это и проведем обновление нашего дашборда.
Обновление CSV

Заходим на Google Sheets в наш документ на второй лист. Добавляем строку со стоимостью для Линейка.

Переходим на первый лист. Добавляем строку 03.11.2022 128 Карандаш 300. Экспортируем каждый лист в формате CSV на свой жесткий диск.
Файл -> Скачать -> Формат CSV (.csv). В диалоговом окне сохраняем на жесткий диск. На жестком диске уже есть эти листы, поэтому выбираем их и заменяем.

Возвращаемся на Datalens. В самом левом столбце с пиктограммами находим Подключения и нажимаем на него. В всплывшем окне выбираем наше подключение.

В левом столбце выбираем первый лист и нажимаем на ... возле него. В менюшке выбираем Заменить. В диалоговом окне выбираем csv файл первого листа, который мы только что пересохранили с Google Sheets.

Файл обновился, и мы видим, что в левом столбце появились группы Новые файлы и Загруженные ранее. Выбираем второй файл и повторяем операцию обновления.

Все файлы обновлены, в предпросмотре справа мы видим, что строк 03.11.2022 появилась. В самом левом столбце с пиктограммами находим Дашборды и нажимаем на него (если закрыли вкладку с созданным дашбордом). Выбираем наш дашборд. Если вкладку не закрывали, просто обновите окно браузера (F5).

Мы видим, что все, что мы внесли в документе в Google Sheets, теперь у нас в дашборде. Появилась линейка, которая раньше не считалась, и заказы от 03.11.2022. По сути, создав дашборд на csv один раз, потом проводим только обновление файлов в подключении.
Публичный доступ
В самом начале в Datalens была такая фича — материализация. Это когда загруженные данные записывались на внутренние сервера Datalens, то есть делался слепок с данных, и появлялась возможность большого количества обращений к дашборду, то есть не происходили постоянно новые запросы SQL, которые нагружали бы бесплатный Datalens. Это как если товар в магазине продавался бы не с полок, а со склада. То есть продавец за каждым товаром бегал бы на склад. Пока пользователей было немного, серверы наверное вытягивали. Сейчас популярность и нагрузка растет, разработчики задумались над этим и пока экспериментируют.
Для дашбордов, созданных на основе CSV файлов доступен публичный доступ. Допустим, мы собрали информацию/статистику, сделали визуализацию ее на дашборде и хотим поделиться со всеми. Или мы создали дашборд для презентации нашего продукта/бизнеса, мы можем оправить ее любому человеку, и он без установки каких-либо программ может ее просмотреть. И для визуальной презентации нужен только браузер с подключенным интернетом. Удобно же.
Для этого достаточно включить Публичный доступ. Открываем наш дашборд.

В левом верхнем углу после символа звездочки нажимаем на ... . В выпавшем меню выбираем Публичный доступ.

В открывшемся окне, слева от надписи Доступен по ссылке, переключаем селектор. Во всплывшем окне нажимаем Продолжить.

Дашборд и все связанные объекты стали публичными. Справа от селектора появилась Публичная ссылка. Копируем ее, нажимаем Применить.

Открываем другой браузер, где не входили под учетной записью Яндекса, вставляем. Все работает.
Публичный доступ к дашборду из Google Sheets
Публичный доступ к дашборду из Google Sheets в настоящее время можно реализовать только через CSV. Реализуем все по инструкции.
Давайте будем честны. В Google Sheets таблице будет максимум миллион строк (при 5 колонках), объем — не более 100 Мб. Ежедневное добавление строк в Google Sheets не такое существенное, чтобы нельзя было раз в сутки обновить вручную. Если бы было по другому, давно бы перешли на нормальную базу данных. По аналогии с магазином, это все равно, что каждый день возить только длинномером товары в маленький сельский магазин.
Автоматизация
Что в этом процессе можно автоматизировать?
- получение csv файлов из Google Sheets без открытия самих таблиц;
- объединение двух и более таблиц в csv по ключевым колонкам;
- склеивание в один файл csv нескольких одинаковых таблиц (когда кончается лимит на строки в одном документе, заводят следующий и таблица продолжается).
Данные — это душа каждой модели машинного обучения. В этой статье мы расскажем о том, почему лучшие команды мира, занимающиеся машинным обучением, тратят больше 80% своего времени на улучшение тренировочных данных.
Точность ИИ-модели напрямую зависит от качества данных для обучения.
Современные глубокие нейронные сети во время обучения оптимизируют миллиарды параметров.
Но если ваши данные плохо размечены, это выльется в миллиарды ошибочно обученных признаков и многие часы потраченного впустую времени.
Мы не хотим, чтобы такое случилось с вами. В своей статье мы представим лучшие советы и хитрости для улучшения качества вашего датасета.
Что такое данные для обучения ИИ?
Под данными для обучения понимается исходный набор данных, передаваемый модели машинного обучения, на котором обучается модель.
Люди лучше всего учатся на примерах, и машинам тоже нужен набор данных, чтобы узнавать из него паттерны.
Данные обучения — это данные, которые мы используем для обучения алгоритма машинного обучения.
В большинстве случаев данные обучения содержат пары «входящие данные: аннотация», собранные из различных источников, которые используются для обучения модели выполнению конкретной задачи с высоким уровнем точности.
Они могут состоять из сырых данных (изображений, текстов или звука), содержащих аннотации, например, ограничивающие прямоугольники, метки или связи.
Модели машинного обучения изучают аннотации данных обучения, чтобы в будущем обрабатывать новые, неразмеченные данные.
Данные обучения при контролируемом и неконтролируемом обучении
В чём разница датасета для контролируемого и неконтролируемого обучения?
При контролируемом обучении люди размечают данные и сообщают модели именно то, что ей нужно найти.
Например, в сфере распознавания спама входящими данными является любой текст, а метка даёт понять, является ли сообщение спамом.
Контролируемое обучение строже, потому что мы не позволяем модели делать собственные выводы на основе данных вне пределов, аннотированных нашими метками.
При неконтролируемом обучении люди передают модели сырые данные без меток, а модель находит в данных паттерны. Например, распознавая уровень схожести или различия двух примеров данных на основании общих извлечённых признаков.
Это помогает модели делать заключения и приходить к выводам, например, разделять похожие изображения или объединять их в кластеры.
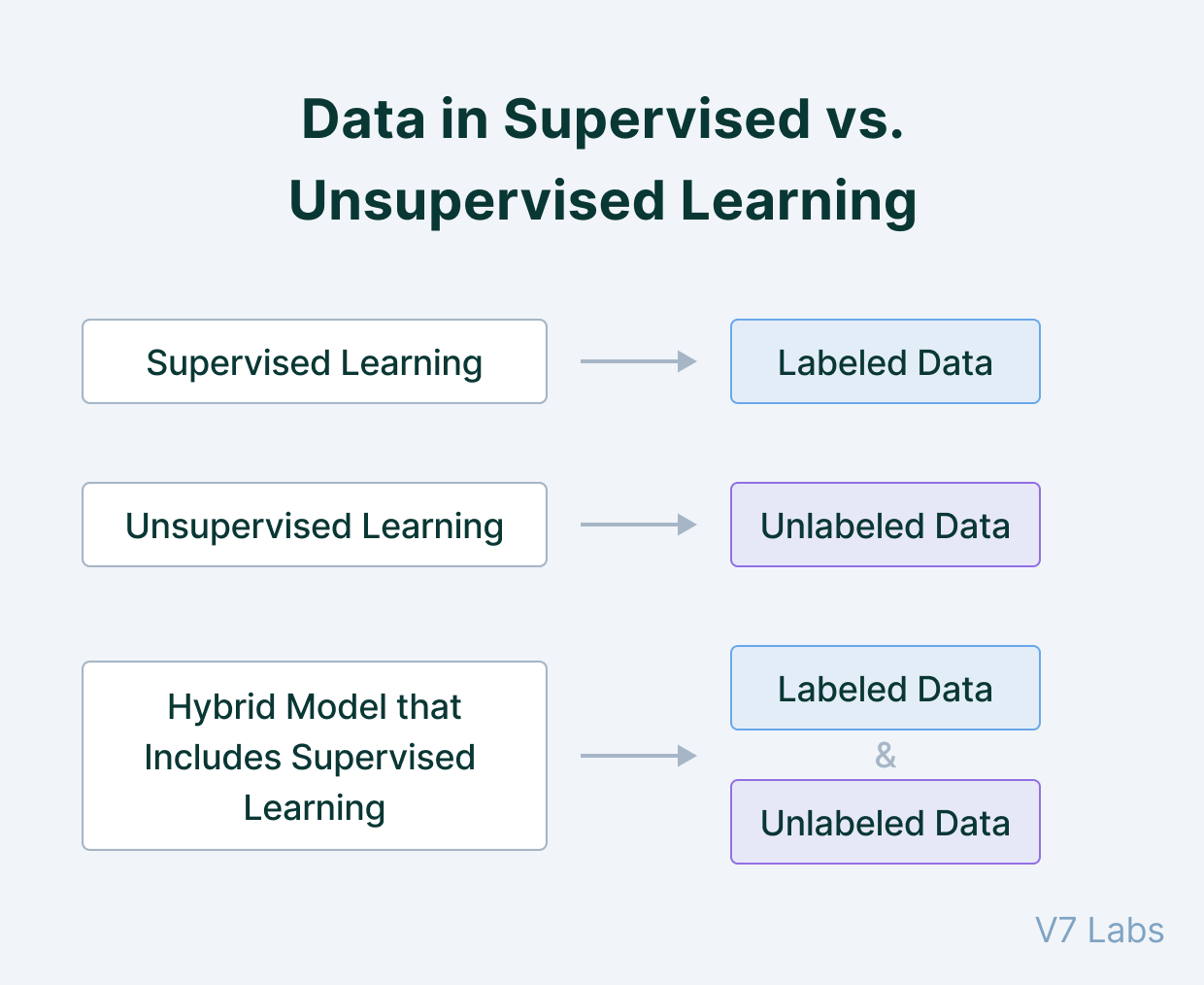
Обучение с частичным контролем (semi-supervised learning) — это сочетание двух вышеперечисленных типов: данные частично размечаются людьми, а часть прогнозов оставляют на усмотрение модели.
Обучение с частичным контролем часто используется, когда люди могут направить модель в нужном направлении работы, но сами прогнозы становится сложно аннотировать из-за слишком большого количества нюансов.
В реальности нет такого понятия, как полностью контролируемое или неконтролируемое обучение, существуют только различные степени контроля.
Контролируемое обучение: процесс работы с данными обучения
Все методики обучения начинаются со сбора сырых данных из различных источников.
Сырые данные могут иметь любой вид: текст, изображения, звуки, видео и т.д. Однако чтобы сообщить модели, что необходимо находить в этих данных, вы должны добавить аннотации.
Эти аннотации позволяют контролировать обучение, гарантировав, что модель сфокусируется на указанных вами признаках, а не будет экстраполировать выводы из других коррелированных (но не обусловленных) элементов данных.
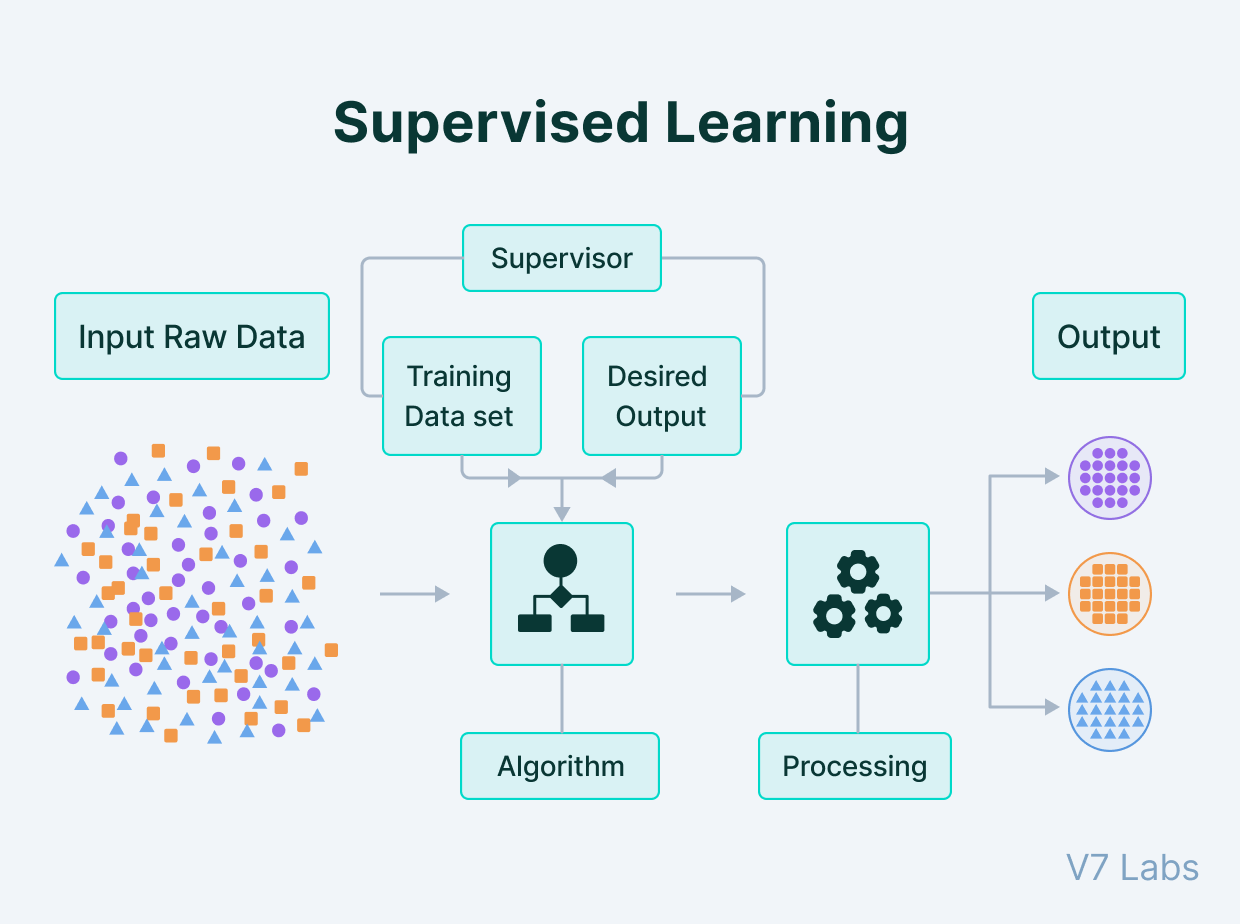
Все входящие данные должны иметь соответствующую метку, позволяющую машине двигаться в направлении того, как должен выглядеть прогноз. Такой обработанный набор данных можно получить при помощи людей, а иногда и других моделей ML, достаточно точных для надёжного проставления меток.
После того, как размеченный набор данных готов к передаче ИИ, начинается этап обучения.
На нём модель пытается выявить важные признаки, общие для всех примеров, которым вы назначили метки. Например, если вы сегментировали несколько легковых автомобилей на снимках, то она поймёт, что колёса, зеркала заднего вида и ручки дверей являются признаками, коррелирующими с легковым автомобилем.
Модели непрерывно тестируют сами себя на наборе данных валидации, подготовленном перед этапом обучения.
После завершения модели выполняют последнюю проверку на тестовом датасете (наборе, который модель ранее никогда не видела); это даёт нам понимание о качестве работы модели на релевантных новых примерах.
Наборы данных для обучения, валидации и тестирования являются частями данных обучения. Чем больше данных обучения у вас есть, тем выше точность модели.
Теперь давайте дадим определения некоторым популярным терминам, которые вы можете встретить при работе с датасетами.
Что такое размеченные данные?
Размеченные данные — это данные, дополненные метками/классами, содержащими значимую информацию.
Вот несколько примеров размеченных данных: изображения с меткой «кошка»/«собака», электронные письма/сообщения, размеченные как спам, прогнозы цен фондовых рынков (меткой является состояние в будущем), определение злокачественности узелков с их выделением многоугольником, аудиофайлы с информацией о том, какие слова в них произнесены.
Точно размеченные данные позволяют машине распознавать паттерны в соответствии с задачей, поэтому они широко используются в решении сложных задач.
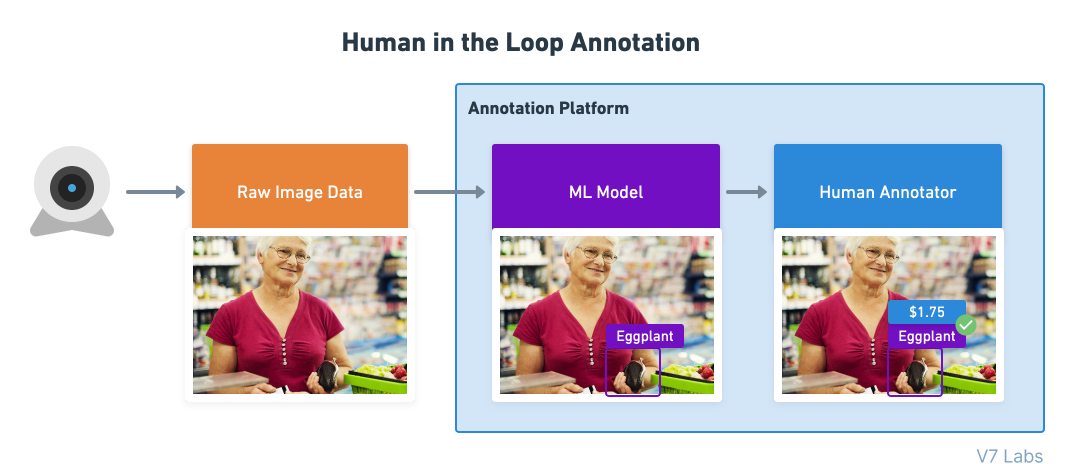
Кто такой оператор в контуре управления?
Процесс «оператор в контуре управления» (human in the loop, HITL) используется тогда, когда модель только частично способна решить задачу, и часть работы передаётся живому человеку.
Примером human in the loop является разметка данных при помощи модели, когда модель ML создаёт первоначальные прогнозы, а человек дополняет их метками, исправлениями или другими типами аннотаций, не поддерживаемыми моделью.
Люди обеспечивают непрерывную обратную связь, улучшающую качество работы модели.
Обычно люди используют инструменты аннотирования для разметки сырых данных, чтобы помочь машинам обучаться и делать прогнозы. Они валидируют полученные моделью результаты и проверяют прогнозы, когда машина не уверена в своих результатах, чтобы убедиться, что обучение модели происходит в нужном направлении.
Однако иногда люди постоянно остаются в контуре управления, добавляя в данные новые метки, создание которых нельзя полностью доверить моделям.
Например, во многих автоматизированных системах медицинской диагностики или системах идентификации личности задействуются операторы в контуре управления, чтобы не оставлять на долю алгоритмов машинного обучения выбор окончательного важного решения.
В этом контуре машины и люди работают рука об руку!
Датасеты для обучения, валидации и тестирования
Ни одну ИИ-модель невозможно обучить и протестировать на одних и тех же данных.
Почему? Всё просто — оценка модели будет смещенной, потому что модель тестируется на том, что она уже знает. Это аналогично тому, как если бы мы давали на экзамене студентам те же вопросы, на которые они уже ответили в классе. Так мы не узнаем, запомнил ли студент ответы или действительно понял тему.
Те же правила применимы и к моделям машинного обучения.
Вот их процентные соотношения объёмов данных:

Данные обучения (Training data) — не менее 60% данных должно использоваться для обучения.
Данные валидации (Validation data) — выборка (10-20%) из общего набора данных, используемая для валидации и периодически проверяемая на модели во время обучения. Этот набор данных валидации должен представлять собой репрезентативную выборку из набора данных обучения.
Данные тестирования (Test data) — этот набор данных используется для тестирования модели после её полного обучения. Он отделяется и от набора обучения, и от набора валидации. После обучения и валидации модель тестируется на наборе тестирования. Данные в наборе тестирования должны выглядеть точно так же, как будут выглядеть реальные данные после развёртывания модели.
В общем наборе данных может быть несколько наборов тестирования.
Каждый набор тестирования можно использовать для проверки того, достаточно ли модель обучилась для конкретного сценария применения. Например, модель беспилотного вождения, наученная распознавать пешеходов, может обучаться на видео, снятом по всей территории США.

Её основной набор тестирования может состоять из перемешанных данных всех штатов страны, однако вам может потребоваться создать отдельные наборы тестирования для конкретных сценариев. Например:
- Набор тестирования для вождения на закате
- Набор тестирования для снежного климата
- Набор тестирования для вождения в сильные бури
- Набор тестирования для ситуаций, когда объектив камеры загрязнился или поцарапан.
Эти наборы тестирования обычно хранятся в системе управления наборами данных и вручную подбираются дата-саентистами. Поэтому они являются свидетельством того, что вы полностью понимаете, как выглядят ваши данные и что вы соответствующим образом пометили все краевые сценарии, чтобы из них можно было создавать наборы тестирования.
Наборы тестирования используются не только для оценки качества работы ИИ-моделей. Иногда они применяются для тестирования качества работы и живых аннотаторов.
Такие наборы называются «золотыми наборами» (Gold Set).
Gold Set — идеальный золотой стандарт
Выборка тщательно размеченных изображений, точно описывающих то, как выглядит эталонно верная разметка, называется gold set.
Эти наборы изображений используются как уменьшенные наборы тестирования для живых аннотаторов, или как часть вводного обучения, или их примешивают к задачам разметки, чтобы убедиться, что качество работы аннотатора не ухудшается из-за его плохой работы или из-за изменения инструкций.
Gold sets обычно позволяют проверять следующие аспекты:
- Время выполнения задачи.
- Точность каждой аннотации
- Рост качества работы с повышением опыта
- Ухудшение качества работы после изменения инструкций
Слепые этапы — несколько проходов, выполняемых разными аннотаторами
Слепые этапы — это задачи аннотирования, при которых несколько людей (или моделей) присваивают метки независимо друг от друга; при этом этап считается пройденным, только если все они сойдутся на одном результате.
Слепые этапы используются для создания сверхточных данных обучения и автоматизации проверок контроля качества. Аннотаторы очень часто пропускают объекты, но двое или несколько аннотаторов пропустят один и тот же объект с меньшей вероятностью.
Разметка на слепых этапах выполняется параллельно и каждый участник не может видеть прогресс остальных.
Когда все аннотаторы завершат свою версию задания, оно проходит через проверку консенсусом, валидирующую, что аннотаторы сошлись на одном решении. Если это не так или если решения недостаточно совпадают друг с другом пространственно, то задача передаётся живому контролёру, которые вносит исправления; при этом совершивший ошибку аннотатор уведомляется, чтобы он мог улучшить свою работу.

Какой объём данных обучения вам нужен?
Простой ответ: чтобы на каждый возможный класс из вашего сценария было не менее чем 1000 обучающих примеров.
Почему 1000? Если вы используете 10% данных в качестве набора тестирования, то сможете определить точность класса с погрешностью по крайней мере в 1%.
Для справки:
1000 примеров — это достаточный набор данных.
10000 — отличный набор данных.
100 тысяч-1 миллион — превосходный набор данных.
Если у вас есть 1 миллион размеченных примеров каких-нибудь данных, то вы будете одним из лидеров среди команд разработчиков ИИ.
Некоторые компании сегодня обучают модели на миллиардах изображений, видео и аудиосэмплов. Эти наборы данных имеют множество наборов тестирования и многократно размечены для увеличения масштабов задач.
Да, теоретически вы можете обучить модель на 100 примерах каких-то данных. Например, V7 позволяет обучить модель всего на 100 примерах, однако на новых примерах качество будет довольно низким.

Высококачественные модели обучаются на больших объёмах данных обучения, и на то есть причины — современные архитектуры нейронных сетей великолепно работают, потому что способны эффективно хранить множество весов (параметров). Однако если у вас мало данных обучения, то вы сможете использовать только долю потенциала своей модели.
Размер набора данных также зависит от области вашей задачи и дисперсии каждого класса.
Если вы планируете распознать каждый батончик Mars в мире, то дисперсия исчерпается после 10000 примеров. Модель научится каждому возможному углу, типу освещения и степени помятости упаковки.
Однако если вам требуется обобщённый распознаватель людей, то набор из 10000 сэмплов будет только небольшой частью вариаций размеров, поз и типов внешностей и одежды. Поэтому для класса с высокой дисперсией, например, «человек», требуется гораздо больше данных обучения.
Пять сложных аспектов в вычислении количества данных обучения
Вот некоторые из факторов, сильно влияющих на размер финального датасета:
Размер имеющегося корпуса сырых данных
Сколько данных уже есть в системе?
Если сырые данные отсутствуют, то обеспечьте возможность их сбора в том масштабе, который необходим в вашем случае. Например, если вы работаете на логистическую компанию, обрабатывающую по 10000 счетов в день, то это хороший показатель того, каким должен быть набор данных тестирования, то есть набор данных обучения должен состоять не менее чем из 100000 файлов, чтобы можно было точно сравнивать его с качеством работы человека.
Дисперсия классов
Насколько разрежена репрезентация меток, которые вам нужно распознавать?
Если ваша цель заключается в распознавании очень равномерного набора объектов, то вы можете обойтись несколькими тысячами примеров. Если вам нужно идентифицировать что-то разнообразное, например, автомобильные номера всех стран при различных погодных и световых условиях, то для достижения надёжных результатов ваш набор данных должен содержать несколько сотен примеров каждого возможного сценария. Количество классов пропорционально увеличивает требования к размеру наборов данных.
Тип классификации
Вы выполняете распознавание объектов или семантическую сегментацию?
Каждый тип задачи классификации требует своего количества данных обучения. В задачах распознавания объектов необходимо вычислить количество ожидаемых экземпляров объектов. Если вы ожидаете только одного объекта на файл, то будете обучать модель чуть медленнее, чем при 4-5 объектах.
Текущие изменения
Будет ли ваше распределение (содержимое того, что должен представлять собой набор данных) меняться со временем?
Например, если вы создаёте распознаватель мобильных телефонов, то вам придётся периодически добавлять новые данные обучения для учёта новых моделей. Если вы делаете распознаватель лиц, то нужно учесть использование масок.
Инструменты тоже меняются со временем — камеры современных телефонов делают HDR-снимки в высоком разрешении, и модели, обученные на таких данных, будут работать качественнее.
Сложность вашей модели
Чем больше весов в вашей модели, тем больше требуется данных обучения.
Другими словами, с увеличением сложности модели растёт и необходимый размер датасета. Современные глубокие нейронные сети могут хранить миллионы или даже миллиарды параметров. Следовательно, сложность модели почти никогда не является узким местом — всегда стремитесь к увеличению объёмов данных обучения, чтобы улучшить качество работы вашей модели.
Если вы используете классическое машинное обучение или работаете на устройствах с ограниченными ресурсами, то выгода от многомилионных наборов данных будет минимальной.
Как вычислить необходимое количество данных для обучения?
Приблизительного вычисления количества необходимых данных более чем достаточно для начала работы. Вот пара способов, которые помогут в этом:
Правило десяток
Это самый распространённый из способов примерной оценки.
Это правило гласит, что модель требует в десять раз больше данных, чем у неё есть степеней свободы. Под степенью свободы понимается любой параметр, влияющий на модель, или любой атрибут, от которого зависят выходные данные модели.
Кривые обучения
Это более логичный подход, построенный на опыте.
Кривая обучения демонстрирует взаимосвязь между качеством работы модели машинного обучения и размером датасета. Мы создаём график результатов работы модели в зависимости от увеличения размера набора данных на каждой итерации.
Вот пороговый размер набора данных, после которого качество работы модели начинает стагнировать или уменьшаться.

Как повысить качество данных для обучения ИИ?
Высокое качество разметки датасета необходимо для точной работы модели машинного обучения.
Под термином «качественные данные» подразумеваются очищенные данные, содержащие все атрибуты, от которых зависит обучение модели.
Мы можем замерить качество по постоянству и точности размеченных данных.
Давайте рассмотрим этот аспект подробнее, чтобы понять, как гарантировать качество данных.
4 характеристики качественных данных для обучения ML моделей
- Релевантность (relevancy) — набор данных должен содержать только те признаки, которые предоставляют модели значимую информацию. Выявление важных признаков — сложная задача, требующая знания области и чёткого понимания того, какие признаки стоит учитывать, а какие нужно устранить.
- Постоянство (consistency) — схожие примеры должны иметь схожие метки, обеспечивая однородность набора данных.
- Однородность (uniformity) — значения всех атрибутов должны быть сравнимыми для всех данных. Неравномерности или наличие выбросов в наборах данных отрицательно влияют на качество данных обучения.
- Полнота (comprehensiveness) — набор данных должен содержать достаточное количество параметров или признаков, чтобы не осталось неохваченных пограничных случаев. Набор данных должен содержать достаточно сэмплов этих пограничных случаев, чтобы модель могла обучиться и им.
Что влияет на качество данных обучения?
Есть три основных фактора, непосредственно влияющих на качество данных обучения.
Люди, процесс и инструменты (People, Process, Tool, P-P-T) — вот три компонента, жизненно необходимые любому бизнес-процессу.
Давайте рассмотрим каждый из них.
Люди
Качество начинается с человеческих ресурсов, которым дали задачу разметки. Выбор и обучение работников существенно влияют на эффективность работы и окончательные результаты. Обучение под конкретную задачу — ключ к повышению качества данных.
Процесс
Это последовательность действий, которые работники выполняют для сбора и разметки данных, за которыми следует процесс контроля качества.
Инструменты
Многие платформы предоставляют компаниям инструменты, помогающие людям в реализации процесса. Также они автоматизируют некоторые части процесса для максимизации качества данных.

Как подготовить данные обучения: рекомендации
Теперь давайте рассмотрим рекомендации по подготовке данных обучения.
Очистка данных
Сырые данные могут быть очень грязными и повреждёнными во многих смыслах. При отсутствии надлежащей очистки они могут искажать результаты и заставить ИИ-модель создавать ошибочные результаты.
Очистка данных — это процесс исправления или удаления неправильных, повреждённых, дублированных данных в пределах набора данных. Этапы процесса очистки данных зависят от конкретного набора данных.
Рекомендации:
- Проверяйте наличие дубликатов — в наборе данных может несколько раз присутствовать один и тот же пример данных. Это может быть вызвано сбором данных из разных источников, в результате чего в них оказываются схожие данные. Их необходимо удалить, поскольку они могут привести модель к переобучению на некоторые паттерны и созданию ложных прогнозов.
- Устраните выбросы — некоторые части данных ведут себя не так, как остальные данные. Примером может служить SessionID, постоянно встречающийся в данных weblog. Это может происходить из-за каких-то злонамеренных действий, которые не нужно передавать нашей модели. Поэтому слежение за выбросами — один из способов устранения данных, которые не должны передаваться машине.
- Исправьте структурные ошибки — в некоторых случаях в наборе данных может быть ошибочная разметка. Например, «Cat» и «cat» считаются различными классами, а «caat» и «cat» различаются из-за опечатки, приводящей к ошибочному распределению классов.
- Проверяйте отсутствующие значения — в наборе данных могут быть элементы, для примеров данных которых отсутствуют атрибуты/признаки. Решить эту проблему можно, просто не включив эти элементы в набор данных обучения.
Разметка данных
Разметка данных — это процесс, в котором мы присваиваем данным значение в виде класса или метки.
Разметку данных могут выполнять сотрудники, операторы в контуре управления или любые автоматизированные машины, ускоряющие процесс разметки.
Рекомендации:
- Создайте золотой стандарт — в сфере разметки данных дата-саентисты и специалисты считаются золотым стандартом, размечающим сырые данные с максимальной чувствительностью и точностью. Их разметка считается ориентиром для команды аннотаторов и может использоваться как ответы при скриннинге вариантов аннотаций.
- Не используйте слишком много меток — разделение набора данных на большое количество классов может запутывать сотрудников при его аннотировании. Кроме того, для выбора среди множества меток потребуется анализ большего количества признаков. Например, аннотаторам будет сложно размечать данные такими классами, как «Very Expensive», «Expensive», «Less Expensive».
- Используйте несколько проходов — разметка данных должна выполняться несколькими аннотаторами. Это необходимо для повышения общего качества данных. Хотя это требует больше времени и увеличивает затраты ресурсов, такой подход используется для установления консенсуса в команде.
- Создайте систему проверки — для снижения вероятности ошибок готовая разметка данных должна проверяться другим человеком или при помощи проверок самосовершенствования. Благодаря этому любой аннотатор сможет понять, в чём ему можно совершенствоваться, его уровень точности и вид обучения, необходимый для улучшения его работы.
Теперь давайте поговорим о том, где мы можем найти релевантные данные для наших проектов data science и глубокого обучения.
4 способа поиска высококачественных наборов данных обучения
Если вы ищете качественные данных для своих бизнес-процессов или хотите построить свою первую модель компьютерного зрения, критически важно иметь доступ к качественным наборам данных.
Вот несколько способов, которые можно применить для их получения.
Открытые наборы данных и поисковые движки
Первый метод — исследование таких вариантов, как открытые наборы данных, онлайн-форумы по машинному обучению и поисковые движки наборов данных, которые бесплатны и относительно просты в работе. Существует множество веб-сайтов, предоставляющих доступ к разнообразным бесплатным наборам данных, например, Google Dataset Search, Kaggle, Reddit, репозиторий UCI. Необходимо будет только предварительно обработать данные, чтобы они подходили конкретно к вашей задаче.
Скрейпинг веб-данных
Этот метод в основном используется в случаях, когда в качестве разнообразных входящих данных нам нужны данные из множества источников. Сбор данных выполняется извлечением данных из различных публичных онлайн-ресурсов, например, правительственных веб-сайтов или соцсетей.
Собственные данные
Иногда вышеперечисленные варианты не очень хорошо подходят для сбора датесета.
В этом случае необходимо рассмотреть возможные варианты, реализуемые внутри компании. Например, если вы работаете над чат-ботом, предназначенным для ответа на вопросы студентов, вместо использования наборов данных NLP можно попробовать извлечь данные из бесед научных руководителей и студентов, если логи и сообщения где-то хранятся.
Расширение данных
В некоторых случаях мы не можем собрать данные, соответствующие нашим потребностям.
Вместо этого можно чуть-чуть изменить данные, чтобы расширить набор данных. Под расширением данных (data augmentation) подразумевается применение различных преобразований к исходным данным для генерации новых данных, соответствующих требованиям. Например, в случае работы с изображениями размер датасета можно увеличить такими простыми операциями, как поворот, изменение цвета, яркости и т.д.
Качественные данные обучения: основные выводы
В конце давайте повторим всё то, что мы узнали из этого руководства по качественным данным обучения:
- Данными обучения называются данные, применяемые для тренировки алгоритма машинного обучения.
- Точность модели зависит от используемых данных — подавляющую часть времени дата-инженер занимается подготовкой качественных данных обучения.
- Контролируемое обучение использует размеченные данные, а неконтролируемое использует сырые, неразмеченные данные.
- Необходимы высококачественные наборы данных для обучения и валидации и отдельный независимый набор данных для тестирования.
- Золотой набор (gold set) — это выборка точно размеченных данных, идеально отображающая то, как должна выглядеть правильная разметка.
- Чтобы достичь качественных результатов, необходим существенный объём данных обучения для репрезентации всех возможных случаев с не менее чем 1000 сэмплов данных.
- 4 характеристики качественных данных обучения: релевантность содержимого, постоянство, однородность и полнота.
- Используемые вами инструменты очистки, разметки и аннотирования данных играют важнейшую роль в том, чтобы готовую модель можно было использовать в реальных условиях.
Просмотров 1.2к. Опубликовано 19.12.2022
Обновлено 19.12.2022
Каждый сайт, который создает компания, должен отвечать принятым стандартам. В первую очередь затем, чтобы он попадал в поисковую выдачу и был удобен для пользователей. Если код страниц содержит ошибки, неточности, он становится “невалидным”, то есть не соответствующим требованиям. В результате интернет-ресурс не увидят пользователи или информация на нем будет отображаться некорректно.
В этой статье рассмотрим, что такое валидность, какие могут быть ошибки в HTML-разметке и как их устранить.
Содержание
- Что такое HTML-ошибка валидации и зачем она нужна
- Чем опасны ошибки в разметке
- Как проверить ошибки валидации
- Предупреждения
- Ошибки
- Пример прохождения валидации для страницы сайта
- Как исправить ошибку валидации
- Плагины для браузеров, которые помогут найти ошибки в коде
- Коротко о главном
Что такое HTML-ошибка валидации и зачем она нужна
Под понятием “валидация” подразумевается процесс онлайн-проверки HTML-кода страницы на соответствие стандартам w3c. Эти стандарты были разработаны Организацией всемирной паутины и стандартов качества разметки. Сама организация продвигает идею унификации сайтов по HTML-коду — чтобы каждому пользователю, вне зависимости от браузера или устройства, было удобно использовать ресурс.
Если код отвечает стандартам, то его называют валидным. Браузеры могут его прочитать, загрузить страницы, а поисковые системы легко находят страницу по соответствующему запросу.
Чем опасны ошибки в разметке
Ошибки валидации могут разными — видимыми для глаза простого пользователя или такими, которые можно засечь только с помощью специальных программ. В первом случае кроме технических проблем, ошибки в разметке приводят к негативному пользовательскому опыту.
К наиболее распространённым последствиям ошибок в коде HTML-разметки также относят сбои в нормальной работе сайта и помехи в продвижении ресурса в поисковых системах.
Рассмотрим несколько примеров, как ошибки могут проявляться при работе:
- Медленно подгружается страница
Согласно исследованию Unbounce, более четверти пользователей покидают страницу, если её загрузка занимает более 3 секунд, ещё треть уходит после 6 секунд;
- Не видна часть текстовых, фото и видео-блоков
Эта проблема делает контент для пользователей неинформативным, поэтому они в большинстве случаев уходят со страницы, не досмотрев её до конца;
- Страница может остаться не проиндексированной
Если поисковый робот распознает недочёт в разметке, он может пропустить страницу и прервать её размещение в поисковых системах;
- Разное отображение страниц на разных устройствах
Например, на компьютере или ноутбуке страница будет выглядеть хорошо, а на мобильных гаджетах половина кнопок и изображений будет попросту не видна.
Из-за этих ошибок пользователь не сможет нормально работать с ресурсом. Единственное решение для него — закрыть вкладку и найти нужную информацию на другом сайте. Так количество посетителей сайта постепенно уменьшается, он перестает попадать в поисковую выдачу — в результате ресурс становится бесполезным и пропадает в пучине Интернета.
Как проверить ошибки валидации
Владельцы ресурсов используют 2 способа онлайн-проверки сайтов на наличие ошибок — технический аудит или использование валидаторов.
Первый случай подходит для серьёзных проблем и масштабных сайтов. Валидаторами же пользуются ежедневно. Наиболее популярный — сервис The W3C Markup Validation Service. Он сканирует сайт и сравнивает код на соответствие стандартам W3C. Валидатор выдаёт 2 типа несоответствий разметки стандартам W3C: предупреждения и ошибки.
Давайте рассмотрим каждый из типов чуть подробнее.
Предупреждения
Предупреждения отмечают незначительные проблемы, которые не влияют на работу ресурса. Они появляются из-за расхождений написания разметки со стандартами W3C.
Тем не менее, предупреждения всё равно нужно устранять, так как из-за них сайт может работать медленнее — например, по сравнению с конкурентами с такими же сайтами.
Примером предупреждения может быть указание на отсутствие тега alt у изображения.
Ошибки
Ошибки — это те проблемы, которые требуют обязательного устранения.
Они представляют угрозу для корректной работы сайта: например, из-за них могут скрываться разные блоки — текстовые, фото, видео. А в некоторых более запущенных случаях содержимое страницы может вовсе не отображаться, и сам ресурс не будет загружаться. Поэтому после проверки уделять внимание ошибкам с красными отметками нужно в первую очередь.
Распространённым примером ошибки может быть отсутствие тега <!DOCTYPE html> в начале страницы, который помогает информации преобразоваться в разметку.
Пример прохождения валидации для страницы сайта
Рассмотрим процесс валидации на примере сайта avavax.ru, который создали на WordPress.
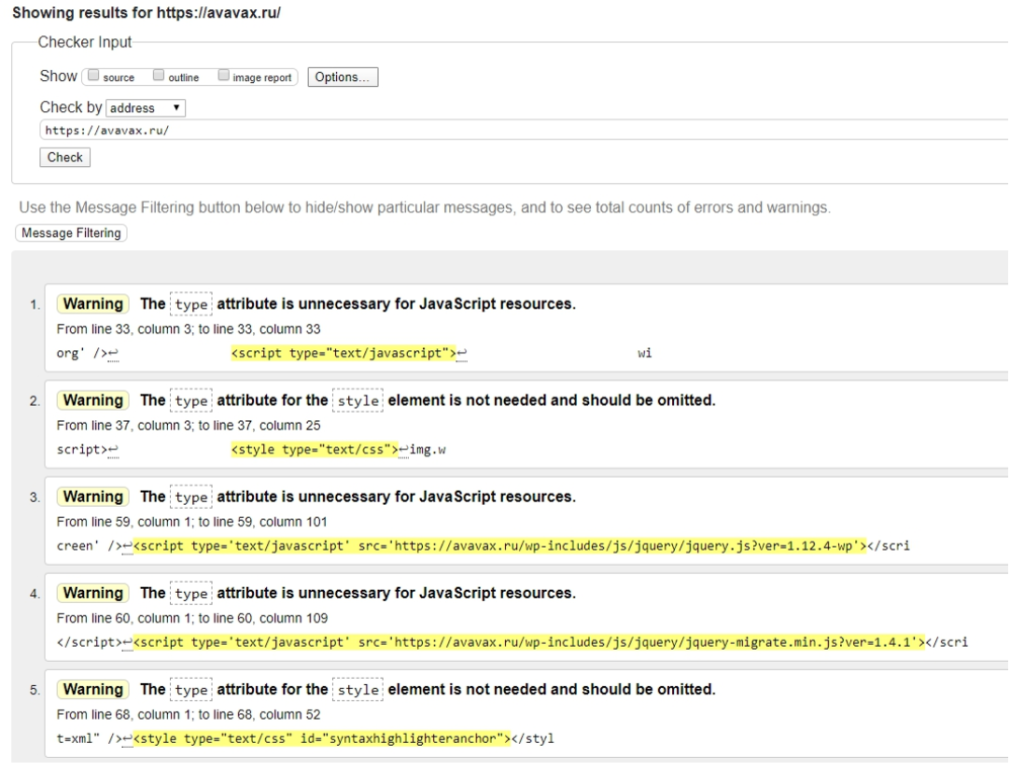
В результате проверки валидатор выдал 17 замечаний. После анализа отчета их можно свести к 3 основным:
- атрибут ‘text/javascript’ не требуется при подключении скрипта;
- атрибут ‘text/css’ не требуется при подключении стиля;
- у одного из элементов section нет внутри заголовка h1-h6.
Первое и второе замечания генерирует сам движок WordPress, поэтому разработчикам не нужно их убирать. Третье же замечание предполагает, что каждый блок текста должен иметь заголовок, даже если это не всегда необходимо или видно для читателя.
Решить проблемы с предупреждениями для стилей и скриптов можно через добавление кода в файл темы function.php.
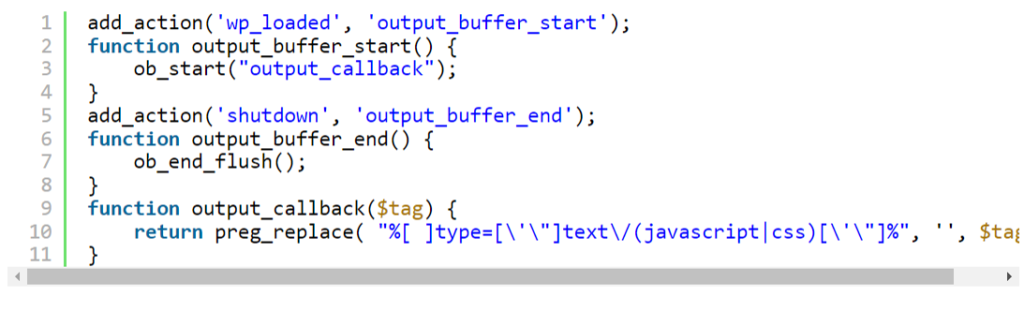
Для этого на хук wp_loaded нужно повесить функцию output_buffer_start(), которая загрузит весь генерируемый код html в буфер. При выводе в буфер вызывается функция output_callback($tag), которая просматривает все теги, находит нежелательные атрибуты с помощью регулярных выражений и заменяет их пробелами. Затем на хук ‘shutdown вешается функция output_buffer_end(), которая возвращает обработанное содержимое буфера.
Для исправления семантики на сайте нужно использовать заголовки. Валидатор выдаёт предупреждение на секцию about, которая содержит фото и краткий текст. Валидатор требует, чтобы в каждой секции был заголовок. Для исправления предупреждения нужно добавить заголовок, но сделать это так, чтобы его не было видно пользователям:
- Добавить заголовок в код: <h3>Обо мне</h3>
Отключить отображение заголовка:
1 #about h3 {
2 display: none;
3 }
После этой части заголовок будет в коде, но валидатор его увидит, а посетитель — нет.
За 3 действия удалось убрать все предупреждения, чтобы качество кода устроило валидатор. Это подтверждается зелёной строкой с надписью: “Document checking completed. No errors or warnings to show”.
Как исправить ошибку валидации
Всё зависит от того, какими техническими знаниями обладает владелец ресурса. Он может сделать это сам, вручную. Делать это нужно постепенно, разбирая ошибку за ошибкой. Но нужно понимать, что если при проверке валидатором было выявлено 100 проблем — все 100 нужно обязательно решить.
Поэтому если навыков и знаний не хватает, лучше привлечь сторонних специалистов для улучшения качества разметки. Это могут быть как фрилансеры, так и профессиональные веб-агентства. При выборе хорошего специалиста, результат будет гарантироваться в любом случае, но лучше, чтобы в договоре оказания услуг будут чётко прописаны цели проведения аудита и гарантии решения проблем с сайтом.
Если объём работ большой, выгоднее заказать профессиональный аудит сайта. С его помощью можно обнаружить разные виды ошибок, улучшить внешний вид и привлекательность интернет-ресурса для поисковых ботов, обычных пользователей, а также повысить скорость загрузки страниц, сделать качественную верстку и избавиться от переспама.
Плагины для браузеров, которые помогут найти ошибки в коде
Для поиска ошибок валидации можно использовать и встроенные в браузеры плагины. Они помогут быстро находить неточности еще на этапе создания кода.
Для каждого браузера есть свой адаптивный плагин:
- HTML Validator для браузера Firefox;
- HTML Validator for Chrome;
- HTML5 Editor для Opera.
С помощью этих инструментов можно не допускать проблем, которые помешают нормальному запуску сайта. Плагины помогут оценить качество внешней и внутренней оптимизации, контента и другие характеристики.
Коротко о главном
Валидация — процесс выявления проблем с HTML-разметкой сайта и ее соответствия стандартам W3C. Это унифицированные правила, с помощью которых сайт может нормально работать и отображаться и для поисковых роботов, и для пользователей.
Проверку ресурса можно проводить тремя путями: валидаторами, специалистам полномасштабного аудита и плагинами в браузере. В большинстве случаев валидатор — самое удобное и быстрое решение для поиска проблем. С его помощью можно выявить 2 типа проблем с разметкой — предупреждения и ошибки.
Работать необходимо сразу с двумя типами ошибок. Даже если предупреждение не приведет к неисправности сайта, оставлять без внимания проблемные блоки нельзя, так как это снизит привлекательность ресурса в глазах пользователя. Ошибки же могут привести к невозможности отображения блоков на сайте, понижению сайта в поисковой выдаче или полному игнорированию ресурса со стороны поискового бота.
Даже у крупных сайтов с миллионной аудиторией, например, Яндекс.Дзен или ВКонтакте, есть проблемы с кодом. Но комплексный подход к решению проблем помогает устранять серьёзные моменты своевременно. Нужно развивать сайт всесторонне, чтобы получить результат от его существования и поддержки. Если самостоятельно разобраться с проблемами не получается, не стоит “доламывать” — лучше обратиться за помощью к профессионалам, например, агентствам по веб-аудиту.
Аналитика в Yandex DataLens в пределах CSV
- Загрузка CSV через Yandex Cloud
- Yandex Object Storage
- Yandex Query
- Yandex Datalens
- Варианты применения
- Простая загрузка через Python
- Файловые менеджеры для Windows и Mac
- Еще больше подключений к Object Storage
- Две таблицы из Google Sheets (Гугл Таблиц) через CSV
- Создание дашборда
- Обновление CSV
- Публичный доступ
- Загрузка CSV через Yandex Cloud
- Публичный доступ к дашборду из Google Sheets
- Автоматизация
Загрузка CSV через Yandex Cloud
На самом деле, это более перспективный способ загрузки таблиц. Неважен источник, если можете получить таблицу или csv, то обновлять его можно уже автоматически. Google Sheets, Яндекс Таблицы, локальные базы данных, базы данных без белого IP, CRM и ETL системы. При этом схема более понятная, чем выгрузка в базы данных Яндекса. На этапе формирования можно склеивать таблицы, вычислять поля, обновлять не всю таблицу, а «дописывать» только новые строки. Плюсом является большой объем бесплатного хранения в Yandex Cloud (100 ГБ), Yandex Query и Yandex Datalens бесплатные. В общем, со средним объемом данных, все будет бесплатно.
Yandex Object Storage
Начинаем с самого начала. Открываем Datalens.
Нажимаем на Все сервисы.
Находим и выбираем Object Storage.
Нам предлагают создать наше первое облако. Нажимаем Создать.
Откроется консоль управления. В левом верхнем углу нажимаем Создать ресурс, в выпавшем списке выбираем Бакет.
Бакет — это Логическая сущность, которая помогает организовать хранение объектов. Если проще — это папка.
Откроется страница создания бакета.
Сразу откроется окно создания платежного аккаунта. Заполняем поля.
Вводим данные карты, спишут 11 рублей, подтверждаем кодом от банка.
Все заполнили, получаем грант на 4 тысячи, нажимаем Создать.
Возвращаемся к созданию бакета. вводим имя бакета. Максимальный размер ставим Без ограничения.
Без ограничения, значит, что бакет будет автоматически масштабироваться, т.е. увеличиваться. Выставляя ограничения, мы резервируем место, но нам это не надо.
Доступ на чтение объектов ставим Публичный. Нажимаем Создать бакет.
Баскет готов. Нажимаем на наш бакет.
Перетаскиваем в бакет наш csv, архивированный zip.
Yandex Query
Открываем Все сервисы.
Находим и нажимаем Yandex Query.
В левом верхнем углу находим меню, нажимаем Ещё, в выпавшем меню выбираем Соединения.
Нажимаем + Создать.
Настройка соединения. Вписываем любое имя в Имя. Тип выбираем Object Storage. Видимость Публичная. Аутентификация бакета Приватный. Облако и каталог выбираем наше. Бакет выбираем наш. Сервисный аккаунт будет пустой — нажимаем Create new.
Откроется новая вкладка с аккаунтами. Нажимаем в правом верхнем углу Создать сервисный аккаунт.
В поле Имя вводим любое имя. В Роли в каталоге выбираем editor. Там много ролей, проще в поисковой строке набрать. Нажимаем Создать.
Появится новый сервисный аккаунт и сверху меню, выбрать Создать статический ключ доступа. В окне выбрать Создать. Появится Новый ключ. Скопируйте его на жесткий диск, он потом понадобится.
Возвращаемся на вкладку Yandex Query. Теперь в селекторе Сервисный аккаунт появился выбор свежесозданного аккаунта, выбираем его и нажимаем Проверить. Должно появиться зеленое сообщение Соединение успешно. Нажать Создать.
В левом верхнем углу находим меню, нажимаем Ещё, в выпавшем меню выбираем Привязки.
Нажимаем + Создать.
В Параметры соединения выбираем Object Storage. В Соединение выбираем наше созданное соединение.
В Параметры привязки к данным в поле Имя вписываем любое имя, лучше такое-же, как и соединение. Область видимости выбираем Публичная. В Путь ставим слэш /, так как файлы у нас будут лежать в корне бакета. Если будут папка, то соответственно путь от корня бакета. Но проще иметь один бакет чисто под таблицу.
В Сжатие выбираем gsip, так как у нас csv сжат gzip. В Формат выбираем csv_with_names, то есть таблица с заголовками. Разделитель выбираем ;, так как csv записан в таком формате.
Дальше идут колонки, которые нам нужны. Вписываем в Имя название колонки, в Тип выбираем тип данных колонки. Чекбокс Обязательно, значит, что в колонке обязательно должны быть данные, если будет хоть одна пустая ячейка, будет ошибка. Подробнее про типы данных в документации Yandex Cloud.
Будьте внимательны, если в csv формат данных вида
31.11.2022будет ошибка, дата должна быть вида2022-11-31. Конвертируйте дату перед отправкой вObject Storage.
Колонки партиционированния не заполняем. Нажимаем Предпросмотр.
В нижней части появится наша таблица. Нажимаем Создать.
В Привязках нажать эту кнопку.
В выпавшем меню выбрать SELECT.
В правом окне появится SQL запрос, скопируем его без нижней строчки LIMIT 10;, он нам понадобится при создании датасета.
Yandex DataLens
Открываем Datalens.
Создать подключение
Выбираем Yandex Query
В Облако и каталог выбираем наше облако. В поле Сервисный аккаунт выбираем наш аккаунт. Уровень доступа SQL запросов ставим в Разрешить подзапросы датасетах и запросы из чартов. Нажимаем Создать подключение. Вводим название подключения.
В правом верхнем углу нажимаем Создать датасет.
Должно автоматически открыться окно Источник с SQL подзапросом.
Вставляем наш SQL запрос и нажимаем Применить.
Ну вот и все. Мы настроили трансляцию с Object Storage в Datalens.
Варианты применения
Простая загрузка через Python
Задаем идентификаторы, которые получили при регистрации сервисного аккаунта. Задаем имя бакета, в который будем загружать и имя файла, который надо загрузить. Возвращает список файлов, которые уже естьв бакете. На скрипт можно повесить cron или Менеджер задач для периодического выполнения.
import boto3
import gzip
import shutil
import os.path
key_id = 'идентификатор ключа' # Получили при регистрации сервисного аккаунта
access_key = 'секретный ключ' # Получили при регистрации сервисного аккаунта
bucket_name = 'имя бакета'
file_name = 'load.csv' # файл который нужно загрузить
session = boto3.session.Session(
aws_access_key_id = key_id,
aws_secret_access_key = access_key,
)
s3 = session.client(
service_name='s3',
endpoint_url='https://storage.yandexcloud.net'
)
def func_upload(filename, bucket):
with open(filename, 'rb') as f_in:
with gzip.open(filename+'.gz', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
s3.upload_file(filename+'.gz', bucket, filename+'.gz')
# Получить список объектов в бакете
for key in s3.list_objects(Bucket=bucket)['Contents']:
print(key['Key'])
def func_upload(file_name, bucket_name)
Файловые менеджеры для Windows и Mac
CyberDuck
WinSCP
Еще больше подключений к Object Storage
Все подключения описаны на странице документации Object Storage.
Наверняка их еще больше, так как используется популярный протокол Amazon S3.
Две таблицы из Google Sheets (Гугл Таблиц) через CSV.
В подключении Datalens
Google Sheetsможно подключить только один лист из Таблиц. Но что делать, если надо две или более таблиц, которые связаны друг с другом по отдельным колонкам. Очевидно, что заполнять одну большую таблицу. Но бывает, что таблицы заполняются автоматически, например CRM, или их ведет другой отдел, или сотрудники, которым «вот так удобно». Или нужен публичный доступ к дашборду. Datalens отключили материализацию и для подключенияGoogle Sheetsпубличный доступ недоступен. В общем, будем справляться сами, разработчикам не до нашей песочницы с 500 000 строками таблиц в Google Sheets, мы, если по футбольному, Первая лига. Поймите их правильно, такие объемы для баз данных это ерунда, они работают в основном на подключение к большим базам данных. Но мы как-нибудь потом попробуем с нашими Google Sheets влезть в высшую лигу.
Что делать, работаем через подключение File то есть CSV. Трудозатратнее, обновление вручную, но больше возможностей.
- можем объединятьджойнить несколько листов из Таблиц, даже из разных документов;
- полученный дашборд можно сделать публичным;
- остается возможность обновления данных вручную.
Создание дашборда
Давайте рассмотрим простой пример работы с Google Sheets через CSV. Есть Таблица с двумя листами.
Первый лист таблицы с основными показателями.
Вторая лист таблицы, в которой нас интересует колонка Стоимость
Как видно, две таблицы объединяют колонки Наименование и Название. Названия разные, но данные в них одинаковые. Главное найти колонки с идентичными данными в двух таблицах и желательно, чтобы во второй таблице эти значения были уникальными. Например, если во второй таблице Карандаш в одной строке будет стоить 20, а в другой строке Карандаш будет стоить 15, будут неверно объединены таблицы, так как программа не смотрит на другие данные. В таких случаях надо сделать уникальные названия, например второй Карандаш переименовать в Карандаш эконом. Но это делать надо до начала экспорта в Datalens.
Продолжаем. Экспортируем каждый лист в формате CSV на свой жесткий диск.
Файл -> Скачать -> Формат CSV (.csv). В диалоговом окне сохраняем на жесткий диск.
Переходим на Datalens.
Выбираем Создать подключение
Выбираем File
Нажимаем + Загрузить файлы. В диалоговом окне выбираем файлы, которые мы скачали с Таблиц, можно все сразу выделить и загрузить.
Итак, наши файлы загрузились, выбирая их в левом столбце, в правом можно посмотреть их содержимое (на предпросмотре все строки не загружаются, только часть!). Типы значений в столбцах определились правильно, то есть колонка Дата как дата (пиктограмма календарика), Заказ и Количество как числа (пиктограмма решетки), Наименование как строковое значение (пиктограмма А). Если тип определен неправильно, можно нажать пиктограмму и изменить его. Но в первую очередь это значит, что где-то в данных есть значение другого типа. Например, в столбце Количество, в одной строке вместо 0 внесено буквами ноль. Тогда интерпретатор весь столбец обозначит как строковый. Такие вещи надо править непосредственно в Google Sheets.
Нажимаем на Создать подключение в правом верхнем углу.
Вводим название нашего подключения. Важно помнить, что одинаковых имен быть не должно. То есть, нельзя назвать Подключение, Датасет, Чарт и Дашборд одним именем, будет всплывать ошибка. Добавляйте префиксы к названию: MyBIproject_connection, MyBIproject-DataSet, mybiproject_chart_gain, etc. Можно выбрать папку, куда все добро сохранять, нажав на значок >
Нажимаем Создать датасет в правом верхнем углу.
Перетаскиваем наши листы из левой колонки Таблицы в правое пустое поле.
Получаем сообщение об ошибке Датасет не прошел валидацию. Это произошло потому, что Datalens не нашел колонок с ОДИНАКОВЫМ названием. Как мы помним, у нас идентичные колонки называются Наименование и Название. Давайте исправим это. Нажимаем на сдвоенный красный кружок в правом поле.
Открывается диалог связей между нашими листами. Нажимаем на Добавить связь.
Появятся селекторы с выпадающим списком полей в наших листах. Выбираем соответственно Наименование и Название.
Нажимаем на Применить.
Чудо свершилось! Мы подружили два наших листа. Внизу страницы, в Предпросмотре, мы видим новую объединенную таблицу. Нажимаем в левом верхнем углу селектор Поля.
В этой вкладке нужно выбрать агрегацию для числовых типов, то есть как будет представляться наше число. Например, у нас есть колонка Заказы в которой у нас числа. Но, по сути, заказ — это одна единица, и когда мы хотим получить количество всех заказов, мы их считаем по одному, а не сумму номеров заказов. К тому же номера заказов у нас повторяются (смотрите исходные таблицы). Поэтому надо подсказать Datalens, что это поле у нас уникальное, поэтому выбираем в поле Агрегация напротив имени Заказ выбираем Количество уникальных. Для имен Количество и Стоимость выбираем агрегацию Сумма. Нажимаем в правом верхнем углу Сохранить. Вводим название нашего датасета.
В принципе, мы уже сделали все, что нужно. Дальше строим на основе этого Датасета строим чарты и дашборды. Но давайте проявим немного терпения и дойдем до конца, ведь нам надо еще обновлять данные и опубликовать созданный дашборд. Прошу прошения у тех, кто это уже все знает, за подробности, но кто-то первый раз будет это делать. Нажимаем в правом верхнем углу Создать чарт.
Делаем самый простой чарт. Перетаскиваем из левого поля измерение Дата в поле -> Х. Перетаскиваем из левого поля измерение Наименование в поле Цвета.
Пока столбцы у нас пустые, надо посчитать выручку по дням. Для этого создадим новый показатель Выручка. В левом поле возле поиска нажимаем значок + и выбираем Поле.
Слева у нас все поля, нажимаем на Количество, поле автоматически вставится в формулу
Слева у нас все поля, нажимаем на Количество, поле автоматически вставится в формулу. Вводим с клавиатуры символ * и нажимаем на поле Стоимость. Мы получили простую формулу где перемножаем количество товара на стоимость единицы товара. В правом верхнем поле Наименование поля вводим название Выручка. Нажимаем кнопку Создать.
Перетаскиваем из левого поля наш новый показатель Выручка в поле Y. Теперь у нас появились столбцы, с выручкой по дням и разбивкой по Наименованию. Нажимаем в правом верхнем углу Сохранить.
Вводим название чарта. В самом левом столбце с пиктограммами находим Дашборд и нажимаем на него.
В правом верхнем углу выбираем Создать дашборд. Вводим название дашборда.
В правом верхнем углу выбираем выпадающий селектор Добавить в нем выбираем Чарт.
Нажимаем Чарт Выбрать и в всплывшем окне выбираем чарт, который мы только что создали. В левом нижнем углу нажимаем Добавить.
Нажимаем в правом верхнем углу Сохранить.
Все мы создали свой дашборд. Теперь изучим его. У нас есть выручка по дням по наименованиям. Но если посмотреть на нашу первую таблицу в Google Sheets, мы увидим, что
02.11.2022 был заказ на 100 линеек, но в дашборде линеек нет. Это произошло потому, что у нас во второй таблице в Google Sheets нет Наименования Линейка, поэтому, при слиянии двух таблиц, у линейки стоимости нет, соответственно, при вычислении выручка будет 0. Давайте исправим это и проведем обновление нашего дашборда.
Обновление CSV
Заходим на Google Sheets в наш документ на второй лист. Добавляем строку со стоимостью для Линейка.
Переходим на первый лист. Добавляем строку 03.11.2022 128 Карандаш 300. Экспортируем каждый лист в формате CSV на свой жесткий диск.
Файл -> Скачать -> Формат CSV (.csv). В диалоговом окне сохраняем на жесткий диск. На жестком диске уже есть эти листы, поэтому выбираем их и заменяем.
Возвращаемся на Datalens. В самом левом столбце с пиктограммами находим Подключения и нажимаем на него. В всплывшем окне выбираем наше подключение.
В левом столбце выбираем первый лист и нажимаем на ... возле него. В менюшке выбираем Заменить. В диалоговом окне выбираем csv файл первого листа, который мы только что пересохранили с Google Sheets.
Файл обновился, и мы видим, что в левом столбце появились группы Новые файлы и Загруженные ранее. Выбираем второй файл и повторяем операцию обновления.
Все файлы обновлены, в предпросмотре справа мы видим, что строк 03.11.2022 появилась. В самом левом столбце с пиктограммами находим Дашборды и нажимаем на него (если закрыли вкладку с созданным дашбордом). Выбираем наш дашборд. Если вкладку не закрывали, просто обновите окно браузера (F5).
Мы видим, что все, что мы внесли в документе в Google Sheets, теперь у нас в дашборде. Появилась линейка, которая раньше не считалась, и заказы от 03.11.2022. По сути, создав дашборд на csv один раз, потом проводим только обновление файлов в подключении.
Публичный доступ
В самом начале в Datalens была такая фича — материализация. Это когда загруженные данные записывались на внутренние сервера Datalens, то есть делался слепок с данных, и появлялась возможность большого количества обращений к дашборду, то есть не происходили постоянно новые запросы SQL, которые нагружали бы бесплатный Datalens. Это как если товар в магазине продавался бы не с полок, а со склада. То есть продавец за каждым товаром бегал бы на склад. Пока пользователей было немного, серверы наверное вытягивали. Сейчас популярность и нагрузка растет, разработчики задумались над этим и пока экспериментируют.
Для дашбордов, созданных на основе CSV файлов доступен публичный доступ. Допустим, мы собрали информацию/статистику, сделали визуализацию ее на дашборде и хотим поделиться со всеми. Или мы создали дашборд для презентации нашего продукта/бизнеса, мы можем оправить ее любому человеку, и он без установки каких-либо программ может ее просмотреть. И для визуальной презентации нужен только браузер с подключенным интернетом. Удобно же.
Для этого достаточно включить Публичный доступ. Открываем наш дашборд.
В левом верхнем углу после символа звездочки нажимаем на ... . В выпавшем меню выбираем Публичный доступ.
В открывшемся окне, слева от надписи Доступен по ссылке, переключаем селектор. Во всплывшем окне нажимаем Продолжить.
Дашборд и все связанные объекты стали публичными. Справа от селектора появилась Публичная ссылка. Копируем ее, нажимаем Применить.
Открываем другой браузер, где не входили под учетной записью Яндекса, вставляем. Все работает.
Публичный доступ к дашборду из Google Sheets
Публичный доступ к дашборду из Google Sheets в настоящее время можно реализовать только через CSV. Реализуем все по инструкции.
Давайте будем честны. В Google Sheets таблице будет максимум миллион строк (при 5 колонках), объем — не более 100 Мб. Ежедневное добавление строк в Google Sheets не такое существенное, чтобы нельзя было раз в сутки обновить вручную. Если бы было по другому, давно бы перешли на нормальную базу данных. По аналогии с магазином, это все равно, что каждый день возить только длинномером товары в маленький сельский магазин.
Автоматизация
Что в этом процессе можно автоматизировать?
- получение csv файлов из Google Sheets без открытия самих таблиц;
- объединение двух и более таблиц в csv по ключевым колонкам;
- склеивание в один файл csv нескольких одинаковых таблиц (когда кончается лимит на строки в одном документе, заводят следующий и таблица продолжается).
Аналитика в Yandex DataLens в пределах CSV
- Загрузка CSV через Yandex Cloud
- Yandex Object Storage
- Yandex Query
- Yandex Datalens
- Варианты применения
- Простая загрузка через Python
- Файловые менеджеры для Windows и Mac
- Еще больше подключений к Object Storage
- Две таблицы из Google Sheets (Гугл Таблиц) через CSV
- Создание дашборда
- Обновление CSV
- Публичный доступ
- Загрузка CSV через Yandex Cloud
- Публичный доступ к дашборду из Google Sheets
- Автоматизация
Загрузка CSV через Yandex Cloud
На самом деле, это более перспективный способ загрузки таблиц. Неважен источник, если можете получить таблицу или csv, то обновлять его можно уже автоматически. Google Sheets, Яндекс Таблицы, локальные базы данных, базы данных без белого IP, CRM и ETL системы. При этом схема более понятная, чем выгрузка в базы данных Яндекса. На этапе формирования можно склеивать таблицы, вычислять поля, обновлять не всю таблицу, а «дописывать» только новые строки. Плюсом является большой объем бесплатного хранения в Yandex Cloud (100 ГБ), Yandex Query и Yandex Datalens бесплатные. В общем, со средним объемом данных, все будет бесплатно.
Yandex Object Storage
Начинаем с самого начала. Открываем Datalens.
Нажимаем на Все сервисы.
Находим и выбираем Object Storage.
Нам предлагают создать наше первое облако. Нажимаем Создать.
Откроется консоль управления. В левом верхнем углу нажимаем Создать ресурс, в выпавшем списке выбираем Бакет.
Бакет — это Логическая сущность, которая помогает организовать хранение объектов. Если проще — это папка.
Откроется страница создания бакета.
Сразу откроется окно создания платежного аккаунта. Заполняем поля.
Вводим данные карты, спишут 11 рублей, подтверждаем кодом от банка.
Все заполнили, получаем грант на 4 тысячи, нажимаем Создать.
Возвращаемся к созданию бакета. вводим имя бакета. Максимальный размер ставим Без ограничения.
Без ограничения, значит, что бакет будет автоматически масштабироваться, т.е. увеличиваться. Выставляя ограничения, мы резервируем место, но нам это не надо.
Доступ на чтение объектов ставим Публичный. Нажимаем Создать бакет.
Баскет готов. Нажимаем на наш бакет.
Перетаскиваем в бакет наш csv, архивированный zip.
Yandex Query
Открываем Все сервисы.
Находим и нажимаем Yandex Query.
В левом верхнем углу находим меню, нажимаем Ещё, в выпавшем меню выбираем Соединения.
Нажимаем + Создать.
Настройка соединения. Вписываем любое имя в Имя. Тип выбираем Object Storage. Видимость Публичная. Аутентификация бакета Приватный. Облако и каталог выбираем наше. Бакет выбираем наш. Сервисный аккаунт будет пустой — нажимаем Create new.
Откроется новая вкладка с аккаунтами. Нажимаем в правом верхнем углу Создать сервисный аккаунт.
В поле Имя вводим любое имя. В Роли в каталоге выбираем editor. Там много ролей, проще в поисковой строке набрать. Нажимаем Создать.
Появится новый сервисный аккаунт и сверху меню, выбрать Создать статический ключ доступа. В окне выбрать Создать. Появится Новый ключ. Скопируйте его на жесткий диск, он потом понадобится.
Возвращаемся на вкладку Yandex Query. Теперь в селекторе Сервисный аккаунт появился выбор свежесозданного аккаунта, выбираем его и нажимаем Проверить. Должно появиться зеленое сообщение Соединение успешно. Нажать Создать.
В левом верхнем углу находим меню, нажимаем Ещё, в выпавшем меню выбираем Привязки.
Нажимаем + Создать.
В Параметры соединения выбираем Object Storage. В Соединение выбираем наше созданное соединение.
В Параметры привязки к данным в поле Имя вписываем любое имя, лучше такое-же, как и соединение. Область видимости выбираем Публичная. В Путь ставим слэш /, так как файлы у нас будут лежать в корне бакета. Если будут папка, то соответственно путь от корня бакета. Но проще иметь один бакет чисто под таблицу.
В Сжатие выбираем gsip, так как у нас csv сжат gzip. В Формат выбираем csv_with_names, то есть таблица с заголовками. Разделитель выбираем ;, так как csv записан в таком формате.
Дальше идут колонки, которые нам нужны. Вписываем в Имя название колонки, в Тип выбираем тип данных колонки. Чекбокс Обязательно, значит, что в колонке обязательно должны быть данные, если будет хоть одна пустая ячейка, будет ошибка. Подробнее про типы данных в документации Yandex Cloud.
Будьте внимательны, если в csv формат данных вида
31.11.2022будет ошибка, дата должна быть вида2022-11-31. Конвертируйте дату перед отправкой вObject Storage.
Колонки партиционированния не заполняем. Нажимаем Предпросмотр.
В нижней части появится наша таблица. Нажимаем Создать.
В Привязках нажать эту кнопку.
В выпавшем меню выбрать SELECT.
В правом окне появится SQL запрос, скопируем его без нижней строчки LIMIT 10;, он нам понадобится при создании датасета.
Yandex DataLens
Открываем Datalens.
Создать подключение
Выбираем Yandex Query
В Облако и каталог выбираем наше облако. В поле Сервисный аккаунт выбираем наш аккаунт. Уровень доступа SQL запросов ставим в Разрешить подзапросы датасетах и запросы из чартов. Нажимаем Создать подключение. Вводим название подключения.
В правом верхнем углу нажимаем Создать датасет.
Должно автоматически открыться окно Источник с SQL подзапросом.
Вставляем наш SQL запрос и нажимаем Применить.
Ну вот и все. Мы настроили трансляцию с Object Storage в Datalens.
Варианты применения
Простая загрузка через Python
Задаем идентификаторы, которые получили при регистрации сервисного аккаунта. Задаем имя бакета, в который будем загружать и имя файла, который надо загрузить. Возвращает список файлов, которые уже естьв бакете. На скрипт можно повесить cron или Менеджер задач для периодического выполнения.
import boto3
import gzip
import shutil
import os.path
key_id = 'идентификатор ключа' # Получили при регистрации сервисного аккаунта
access_key = 'секретный ключ' # Получили при регистрации сервисного аккаунта
bucket_name = 'имя бакета'
file_name = 'load.csv' # файл который нужно загрузить
session = boto3.session.Session(
aws_access_key_id = key_id,
aws_secret_access_key = access_key,
)
s3 = session.client(
service_name='s3',
endpoint_url='https://storage.yandexcloud.net'
)
def func_upload(filename, bucket):
with open(filename, 'rb') as f_in:
with gzip.open(filename+'.gz', 'wb') as f_out:
shutil.copyfileobj(f_in, f_out)
s3.upload_file(filename+'.gz', bucket, filename+'.gz')
# Получить список объектов в бакете
for key in s3.list_objects(Bucket=bucket)['Contents']:
print(key['Key'])
def func_upload(file_name, bucket_name)
Файловые менеджеры для Windows и Mac
CyberDuck
WinSCP
Еще больше подключений к Object Storage
Все подключения описаны на странице документации Object Storage.
Наверняка их еще больше, так как используется популярный протокол Amazon S3.
Две таблицы из Google Sheets (Гугл Таблиц) через CSV.
В подключении Datalens
Google Sheetsможно подключить только один лист из Таблиц. Но что делать, если надо две или более таблиц, которые связаны друг с другом по отдельным колонкам. Очевидно, что заполнять одну большую таблицу. Но бывает, что таблицы заполняются автоматически, например CRM, или их ведет другой отдел, или сотрудники, которым «вот так удобно». Или нужен публичный доступ к дашборду. Datalens отключили материализацию и для подключенияGoogle Sheetsпубличный доступ недоступен. В общем, будем справляться сами, разработчикам не до нашей песочницы с 500 000 строками таблиц в Google Sheets, мы, если по футбольному, Первая лига. Поймите их правильно, такие объемы для баз данных это ерунда, они работают в основном на подключение к большим базам данных. Но мы как-нибудь потом попробуем с нашими Google Sheets влезть в высшую лигу.
Что делать, работаем через подключение File то есть CSV. Трудозатратнее, обновление вручную, но больше возможностей.
- можем объединятьджойнить несколько листов из Таблиц, даже из разных документов;
- полученный дашборд можно сделать публичным;
- остается возможность обновления данных вручную.
Создание дашборда
Давайте рассмотрим простой пример работы с Google Sheets через CSV. Есть Таблица с двумя листами.
Первый лист таблицы с основными показателями.
Вторая лист таблицы, в которой нас интересует колонка Стоимость
Как видно, две таблицы объединяют колонки Наименование и Название. Названия разные, но данные в них одинаковые. Главное найти колонки с идентичными данными в двух таблицах и желательно, чтобы во второй таблице эти значения были уникальными. Например, если во второй таблице Карандаш в одной строке будет стоить 20, а в другой строке Карандаш будет стоить 15, будут неверно объединены таблицы, так как программа не смотрит на другие данные. В таких случаях надо сделать уникальные названия, например второй Карандаш переименовать в Карандаш эконом. Но это делать надо до начала экспорта в Datalens.
Продолжаем. Экспортируем каждый лист в формате CSV на свой жесткий диск.
Файл -> Скачать -> Формат CSV (.csv). В диалоговом окне сохраняем на жесткий диск.
Переходим на Datalens.
Выбираем Создать подключение
Выбираем File
Нажимаем + Загрузить файлы. В диалоговом окне выбираем файлы, которые мы скачали с Таблиц, можно все сразу выделить и загрузить.
Итак, наши файлы загрузились, выбирая их в левом столбце, в правом можно посмотреть их содержимое (на предпросмотре все строки не загружаются, только часть!). Типы значений в столбцах определились правильно, то есть колонка Дата как дата (пиктограмма календарика), Заказ и Количество как числа (пиктограмма решетки), Наименование как строковое значение (пиктограмма А). Если тип определен неправильно, можно нажать пиктограмму и изменить его. Но в первую очередь это значит, что где-то в данных есть значение другого типа. Например, в столбце Количество, в одной строке вместо 0 внесено буквами ноль. Тогда интерпретатор весь столбец обозначит как строковый. Такие вещи надо править непосредственно в Google Sheets.
Нажимаем на Создать подключение в правом верхнем углу.
Вводим название нашего подключения. Важно помнить, что одинаковых имен быть не должно. То есть, нельзя назвать Подключение, Датасет, Чарт и Дашборд одним именем, будет всплывать ошибка. Добавляйте префиксы к названию: MyBIproject_connection, MyBIproject-DataSet, mybiproject_chart_gain, etc. Можно выбрать папку, куда все добро сохранять, нажав на значок >
Нажимаем Создать датасет в правом верхнем углу.
Перетаскиваем наши листы из левой колонки Таблицы в правое пустое поле.
Получаем сообщение об ошибке Датасет не прошел валидацию. Это произошло потому, что Datalens не нашел колонок с ОДИНАКОВЫМ названием. Как мы помним, у нас идентичные колонки называются Наименование и Название. Давайте исправим это. Нажимаем на сдвоенный красный кружок в правом поле.
Открывается диалог связей между нашими листами. Нажимаем на Добавить связь.
Появятся селекторы с выпадающим списком полей в наших листах. Выбираем соответственно Наименование и Название.
Нажимаем на Применить.
Чудо свершилось! Мы подружили два наших листа. Внизу страницы, в Предпросмотре, мы видим новую объединенную таблицу. Нажимаем в левом верхнем углу селектор Поля.
В этой вкладке нужно выбрать агрегацию для числовых типов, то есть как будет представляться наше число. Например, у нас есть колонка Заказы в которой у нас числа. Но, по сути, заказ — это одна единица, и когда мы хотим получить количество всех заказов, мы их считаем по одному, а не сумму номеров заказов. К тому же номера заказов у нас повторяются (смотрите исходные таблицы). Поэтому надо подсказать Datalens, что это поле у нас уникальное, поэтому выбираем в поле Агрегация напротив имени Заказ выбираем Количество уникальных. Для имен Количество и Стоимость выбираем агрегацию Сумма. Нажимаем в правом верхнем углу Сохранить. Вводим название нашего датасета.
В принципе, мы уже сделали все, что нужно. Дальше строим на основе этого Датасета строим чарты и дашборды. Но давайте проявим немного терпения и дойдем до конца, ведь нам надо еще обновлять данные и опубликовать созданный дашборд. Прошу прошения у тех, кто это уже все знает, за подробности, но кто-то первый раз будет это делать. Нажимаем в правом верхнем углу Создать чарт.
Делаем самый простой чарт. Перетаскиваем из левого поля измерение Дата в поле -> Х. Перетаскиваем из левого поля измерение Наименование в поле Цвета.
Пока столбцы у нас пустые, надо посчитать выручку по дням. Для этого создадим новый показатель Выручка. В левом поле возле поиска нажимаем значок + и выбираем Поле.
Слева у нас все поля, нажимаем на Количество, поле автоматически вставится в формулу
Слева у нас все поля, нажимаем на Количество, поле автоматически вставится в формулу. Вводим с клавиатуры символ * и нажимаем на поле Стоимость. Мы получили простую формулу где перемножаем количество товара на стоимость единицы товара. В правом верхнем поле Наименование поля вводим название Выручка. Нажимаем кнопку Создать.
Перетаскиваем из левого поля наш новый показатель Выручка в поле Y. Теперь у нас появились столбцы, с выручкой по дням и разбивкой по Наименованию. Нажимаем в правом верхнем углу Сохранить.
Вводим название чарта. В самом левом столбце с пиктограммами находим Дашборд и нажимаем на него.
В правом верхнем углу выбираем Создать дашборд. Вводим название дашборда.
В правом верхнем углу выбираем выпадающий селектор Добавить в нем выбираем Чарт.
Нажимаем Чарт Выбрать и в всплывшем окне выбираем чарт, который мы только что создали. В левом нижнем углу нажимаем Добавить.
Нажимаем в правом верхнем углу Сохранить.
Все мы создали свой дашборд. Теперь изучим его. У нас есть выручка по дням по наименованиям. Но если посмотреть на нашу первую таблицу в Google Sheets, мы увидим, что
02.11.2022 был заказ на 100 линеек, но в дашборде линеек нет. Это произошло потому, что у нас во второй таблице в Google Sheets нет Наименования Линейка, поэтому, при слиянии двух таблиц, у линейки стоимости нет, соответственно, при вычислении выручка будет 0. Давайте исправим это и проведем обновление нашего дашборда.
Обновление CSV
Заходим на Google Sheets в наш документ на второй лист. Добавляем строку со стоимостью для Линейка.
Переходим на первый лист. Добавляем строку 03.11.2022 128 Карандаш 300. Экспортируем каждый лист в формате CSV на свой жесткий диск.
Файл -> Скачать -> Формат CSV (.csv). В диалоговом окне сохраняем на жесткий диск. На жестком диске уже есть эти листы, поэтому выбираем их и заменяем.
Возвращаемся на Datalens. В самом левом столбце с пиктограммами находим Подключения и нажимаем на него. В всплывшем окне выбираем наше подключение.
В левом столбце выбираем первый лист и нажимаем на ... возле него. В менюшке выбираем Заменить. В диалоговом окне выбираем csv файл первого листа, который мы только что пересохранили с Google Sheets.
Файл обновился, и мы видим, что в левом столбце появились группы Новые файлы и Загруженные ранее. Выбираем второй файл и повторяем операцию обновления.
Все файлы обновлены, в предпросмотре справа мы видим, что строк 03.11.2022 появилась. В самом левом столбце с пиктограммами находим Дашборды и нажимаем на него (если закрыли вкладку с созданным дашбордом). Выбираем наш дашборд. Если вкладку не закрывали, просто обновите окно браузера (F5).
Мы видим, что все, что мы внесли в документе в Google Sheets, теперь у нас в дашборде. Появилась линейка, которая раньше не считалась, и заказы от 03.11.2022. По сути, создав дашборд на csv один раз, потом проводим только обновление файлов в подключении.
Публичный доступ
В самом начале в Datalens была такая фича — материализация. Это когда загруженные данные записывались на внутренние сервера Datalens, то есть делался слепок с данных, и появлялась возможность большого количества обращений к дашборду, то есть не происходили постоянно новые запросы SQL, которые нагружали бы бесплатный Datalens. Это как если товар в магазине продавался бы не с полок, а со склада. То есть продавец за каждым товаром бегал бы на склад. Пока пользователей было немного, серверы наверное вытягивали. Сейчас популярность и нагрузка растет, разработчики задумались над этим и пока экспериментируют.
Для дашбордов, созданных на основе CSV файлов доступен публичный доступ. Допустим, мы собрали информацию/статистику, сделали визуализацию ее на дашборде и хотим поделиться со всеми. Или мы создали дашборд для презентации нашего продукта/бизнеса, мы можем оправить ее любому человеку, и он без установки каких-либо программ может ее просмотреть. И для визуальной презентации нужен только браузер с подключенным интернетом. Удобно же.
Для этого достаточно включить Публичный доступ. Открываем наш дашборд.
В левом верхнем углу после символа звездочки нажимаем на ... . В выпавшем меню выбираем Публичный доступ.
В открывшемся окне, слева от надписи Доступен по ссылке, переключаем селектор. Во всплывшем окне нажимаем Продолжить.
Дашборд и все связанные объекты стали публичными. Справа от селектора появилась Публичная ссылка. Копируем ее, нажимаем Применить.
Открываем другой браузер, где не входили под учетной записью Яндекса, вставляем. Все работает.
Публичный доступ к дашборду из Google Sheets
Публичный доступ к дашборду из Google Sheets в настоящее время можно реализовать только через CSV. Реализуем все по инструкции.
Давайте будем честны. В Google Sheets таблице будет максимум миллион строк (при 5 колонках), объем — не более 100 Мб. Ежедневное добавление строк в Google Sheets не такое существенное, чтобы нельзя было раз в сутки обновить вручную. Если бы было по другому, давно бы перешли на нормальную базу данных. По аналогии с магазином, это все равно, что каждый день возить только длинномером товары в маленький сельский магазин.
Автоматизация
Что в этом процессе можно автоматизировать?
- получение csv файлов из Google Sheets без открытия самих таблиц;
- объединение двух и более таблиц в csv по ключевым колонкам;
- склеивание в один файл csv нескольких одинаковых таблиц (когда кончается лимит на строки в одном документе, заводят следующий и таблица продолжается).
только что развернули мой проект на моем сервере отчетов.
У меня есть несколько наборов данных, которые ссылаются на представления, существующие в БД на этом сервере.
когда я пытаюсь войти в любую часть отчета, я получаю это сообщение:
An error has occurred during report processing. (rsProcessingAborted)
Query execution failed for dataset 'dataset1'. (rsErrorExecutingCommand)
For more information about this error navigate to the report server on the local server machine, or enable remote errors
кто может помочь?
16 ответов
Я включил удаленные ошибки, чтобы определить проблему.
Я определил, что столбец в определенном наборе данных (одно из моих представлений) выдает ошибку.
поэтому, используя инструмент «SQL Delta», я сравнил версию разработки базы данных с живой версией на сервере отчетов. Я заметил, что у одного из представлений был дополнительный столбец на сервере разработки, который не был на живой версии БД.
SQL Delta сгенерировал скрипт, который мне нужно было запустить чтобы обновить представление в моей live db.
Я запустил этот скрипт, повторно запустил отчет, все сработало.
я обнаружил аналогичное сообщение об ошибке. Я смог исправить это, не включив удаленные ошибки.
в Построителе отчетов 3.0, когда я использовал Run кнопка для запуска отчета, появилось предупреждение об ошибке, говоря
An error has occurred during report processing. (rsProcessingAborted)
[OK] [Details...]
нажатие кнопки «подробности» дало мне текстовое поле, в котором я видел этот текст:
For more information about this error navigate to the report server
on the local server machine, or enable remote errors
----------------------------
Query execution failed for dataset 'DataSet1'. (rsErrorExecutingCommand)
Я был смущен и расстроен, потому что в моем отчете не было набора данных с именем’DataSet1‘. Я даже открыл .rdl файл в тексте редактор, чтобы быть уверенным. Через некоторое время я заметил, что в текстовом поле под тем, что я мог прочитать, было больше текста. Полное сообщение об ошибке:
For more information about this error navigate to the report server
on the local server machine, or enable remote errors
----------------------------
Query execution failed for dataset 'DataSet1'. (rsErrorExecutingCommand)
----------------------------
The execution failed for the shared data set 'CustomerDetailsDataSet'.
(rsDataSetExecutionError)
----------------------------
An error has occurred during report processing. (rsProcessingAborted)
Я сделал имеют общий набор данных с именем ‘CustomerDetailsDataSet‘. Я открыл запрос (который был полным SQL-запросом, введенным в текстовом режиме) в SQL Server Management Studio и запустил его там. Я получил сообщения об ошибках, которые явно указывали на определенную таблицу, где столбец, который я использовал, был переименован и изменен.
от в этот момент было просто изменить мой запрос, чтобы он работал с новым столбцом, а затем вставить эту модификацию в общий набор данных»CustomerDetailsDataSet‘, а затем подтолкните отчет в Построителе отчетов, чтобы распознать изменение общего набора данных.
после этого исправления мои отчеты больше не вызывали эту ошибку.
Я испытал ту же проблему, это было связано с безопасностью, не предоставляемой части таблиц. просмотрите, что ваш пользователь имеет доступ к базам данных/ таблицам/представлениям/функциям и т. д., используемым отчетом.
Я только что занимался этим же вопросом. Убедитесь, что в запросе указано полное имя источника без использования ярлыков. Visual Studio может распознавать ярлыки, но приложение служб reporting services может не распознавать таблицы, из которых должны поступать данные. Надеюсь, это поможет.
Как и многие другие здесь, у меня была такая же ошибка. В моем случае это было потому, что разрешение было отказано на хранимую процедуру раньше. Он был разрешен, когда пользователю, связанному с источником данных, было предоставлено это разрешение.
У меня была аналогичная проблема с сообщением об ошибке
для получения дополнительной информации об этой ошибке, перейдите к серверу отчетов на
локальный сервер или включить удаленное выполнение запроса ошибок
ошибка набора данных «PrintInvoice».
решение:
1) ошибка может быть с набором данных в некоторых случаях вы всегда можете проверить, заполняет ли набор данных точные данные, которые вы ожидаете, перейдя в свойства набора данных и выбрав «конструктор запросов» и попробуйте «выполнить», если вы можете успешно вытащить поля, которые вы ожидаете, то вы можете быть уверены, что нет никаких проблем с набором данных, который приведет нас к следующему решению.
2) несмотря на то, что в сообщении об ошибке говорится «выполнение запроса не удалось для набора данных», другие вероятные шансы связаны с подключением источника данных, убедитесь, что вы подключились к правильному источнику данных, который имеет необходимые таблицы, и у вас есть разрешения на доступ к этому источнику данных.
в моей ситуации, я создал новый отчет SSRS и новую хранимую процедуру для набора данных. Я забыл добавить хранимую процедуру в роль базы данных, которая имела разрешение на ее выполнение. Как только я добавил разрешения на роль базы данных SQL с EXECUTE, все было в порядке!
сообщение об ошибке, обнаруженное пользователем, было » во время отрисовки клиента произошла ошибка. Произошла ошибка при обработке отчета (rsProcessingAborted). Не удалось выполнить запрос для набора данных «Имя dataset1′. (rsErrorExecutingCommand) для получения дополнительной информации…»
решение для меня пришло из GShenanigan:
вам необходимо проверить ваш лог-файлы на сервера SSRS более подробно. Они будут где-то вроде: C:Program файлы (x86)Microsoft SQL ServerMSRS10_50.DEVReporting ServicesLogFiles»
Я смог найти проблему разрешений в таблице базы данных, на которую ссылается представление, которое не было таким же, как где было представление. Я был сосредоточен на разрешениях на база данных view, так что это помогло определить, где была ошибка.
У меня также была очень похожая проблема с очень похожим сообщением об ошибке. Моя проблема заключалась в том, что база данных не может быть подключен. В нашем случае у нас есть зеркальные базы данных, и строка подключения не указала партнера по отработке отказа. Поэтому, когда база данных не могла подключиться, она никогда не шла к зеркалу и бросала эту ошибку. Как только я указал партнера по отказоустойчивости в строке подключения для моего источника данных, он решил проблему.
BIGHAP: ПРОСТАЯ РАБОТА ВОКРУГ ЭТОЙ ПРОБЛЕМЫ.
Я столкнулся с той же проблемой при работе со списками SharePoint, что и источник данных, и прочитал блоги выше, которые были очень полезны. Я внес изменения в имена источников данных и объектов данных и поля запросов в Visual Studio, и запрос работал в visual Studio. Я смог развернуть отчет в SharePoint, но когда я попытался открыть его, я получил ту же ошибку.
Я догадался, что проблема в том, что я необходимо повторно развернуть источник данных и набор данных в SharePoint, чтобы синхронизировать все изменения в инструментах визуализации.
Я перераспределил источник данных, набор данных и отчет в sharePoint, и это сработало.
Как указано в одном из блогов, хотя visual studio разрешила изменения, внесенные мной в dataset и datasource, если вы не настроили visual studio для автоматического повторного развертывания datasource и dataset при развертывании отчета(что может быть опасно, поскольку это может повлиять другие отчеты, которые совместно используют эти объекты) эта ошибка может возникнуть.
Итак, конечно, исправление заключается в том, что в этом случае вам нужно повторно развернуть источник данных, набор данных и отчет для решения проблемы.
Я также столкнулся с той же проблемой — я проверил ниже вещи, чтобы исправить эту проблему,
-
если вы недавно изменили имя указывающей базы данных в источнике данных
затем сначала убедитесь, что все процедуры хранилища для этого отчета существуют
на измененной базе данных. -
если есть несколько суб-отчетов по основному отчету, убедитесь, что каждый
отчет индивидуально работает отлично. -
также проверьте панель безопасности — пользователь должен иметь доступ к базам данных/
таблицы / представления / функции для этого доклада.
иногда нам также нужно проверить dataset1 — хранимая процедура. Как будто вы пытаетесь показать отчет с user1 и если у этого пользователя нет access(rights) предоставленной (dataset1 database) база данных, то он будет бросать ту же ошибку, что и выше, поэтому должен проверить пользователь имеет доступ dbreader in SQL-сервер.
кроме того, если эта процедура хранения содержит некоторую другую базу данных (база данных 2) как
Select * from XYZ inner join Database2..Table1 on ... where...
тогда пользователь также должен иметь доступ к этой базе данных.
Примечание: вы можете проверить файлы журнала на этот путь для получения более подробной информации,
C:Program FilesMicrosoft SQL ServerMSRS11.SQLEXPRESSReporting Services
очень благодарен, что я нашел этот отличный пост. Что касается моего случая, у пользователя, выполняющего хранимую процедуру, не было EXECUTE разрешения. Решение предоставить EXECUTE разрешения для пользователя в хранимой процедуре, добавив следующий код в конец хранимой процедуры.
GRANT EXECUTE ON dbo.StoredProcNameHere TO UsernameRunningreports
GO
Я получил ту же ошибку, но это сработало и решило мою проблему
если отчет подключен к серверу Analysis server, предоставьте необходимые разрешения пользователю (который обращается к серверу reporting server для просмотра отчетов) в вашей модели сервера analysis server.
Сделать это Добавить пользователя в роли модели или Куба и разверните модель на сервере analysis server.
использование SSRS, построителя отчетов 3.0, MSSQL 2008 и запрос к базе данных Oracle 11G,
Я обнаружил, что хранимая процедура oracle работает хорошо, дает последовательные результаты без ошибок. Когда я попытался принести данные в SSRS, я получил ошибку, как указано в запросе OP. Я обнаружил, что данные загружаются и отображаются только в том случае, если я удалил параметры (не очень хорошая идея).
При дальнейшем рассмотрении я обнаружил, что в разделе свойства набора данных>параметры я установил дату начала в parameterName P_Start и значение параметра @P_Start.
добавление значения параметра как [@P_Start] очистило проблему, и данные загружаются хорошо, с параметрами на месте.
эта проблема была вызвана потерянным именем входа SQL. Я запустил свой любимый скрипт sp_fixusers, и ошибка была решена. Приведенное выше предложение взглянуть на журналы было хорошим…и это привело меня к ответу.
Это может быть проблема с разрешением для процедуры просмотра или хранения
Всем привет!
Взял за основу намеки на решение в одном из ответов к вопросу об этой же задаче, так как мое решение было очень похожим по сути.
Помогите понять, на каком датасете программа отработает не правильно, что бы я мог сам найти ошибку? Я сам напридумывал датасетов, но везде, вроде как, работает корректно.
А вообще, если команда JavaRush это прочтет, то у меня есть пожелание — если программа не проходит валидацию, показывайте хотя бы на каком датасете она не проходит. На ошибке легче учиться, если ты видишь в чем ты ошибаешься 
package com.javarush.task.task19.task1916;
import javax.sound.sampled.Line;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
/*
Отслеживаем изменения
*/
public class Solution {
public static List<LineItem> lines = new ArrayList<LineItem>();
public static void main(String[] args) throws Exception{
BufferedReader reader = new BufferedReader(new InputStreamReader(System.in));
BufferedReader fileBufferedReader1 = new BufferedReader(new FileReader(reader.readLine()));
BufferedReader fileBufferedReader2 = new BufferedReader(new FileReader(reader.readLine()));
reader.close();
ArrayList<LineItem> lines = new ArrayList<LineItem>();
ArrayList<String> file1Lines = new ArrayList<>();
ArrayList<String> file2Lines = new ArrayList<>();
//HashSet<String> mergedFiles = new HashSet<>();
while (true){
String line = fileBufferedReader1.readLine();
if (line == null){
break;
}
file1Lines.add(line);
//mergedFiles.add(line);
}
while (true){
String line = fileBufferedReader2.readLine();
if (line == null){
break;
}
file2Lines.add(line);
//mergedFiles.add(line);
}
fileBufferedReader1.close();
fileBufferedReader2.close();
for (int i = 0; i < file1Lines.size() && i < file2Lines.size(); i++){
try{
if (file1Lines.get(i).equals(file2Lines.get(i))){
lines.add(new LineItem(Type.SAME, file2Lines.get(i)));
file1Lines.remove(i);
file2Lines.remove(i);
i—;
}
else if (file1Lines.get(i + 1).equals(file2Lines.get(i))){
lines.add(new LineItem(Type.REMOVED, file1Lines.get(i)));
file1Lines.remove(i);
i—;
}
else if (file1Lines.get(i).equals(file2Lines.get(i + 1))){
lines.add(new LineItem(Type.ADDED, file2Lines.get(i)));
file2Lines.remove(i);
i—;
}
}catch (Exception e){}
}
while (!file1Lines.isEmpty()){
lines.add(new LineItem(Type.REMOVED, file1Lines.get(0)));
file1Lines.remove(0);
}
while (!file2Lines.isEmpty()){
lines.add(new LineItem(Type.ADDED, file2Lines.get(0)));
file2Lines.remove(0);
}
// for (LineItem line: lines){
// System.out.println(line.type + » » + line.line);
// }
}
public static enum Type {
ADDED, //добавлена новая строка
REMOVED, //удалена строка
SAME //без изменений
}
public static class LineItem {
public Type type;
public String line;
public LineItem(Type type, String line) {
this.type = type;
this.line = line;
}
}
}