
![]()
Сообщение от Kenny_Dalglish

Как это?
линкеру не сообщили, что нужно линковаться с библиотекой.
![]()
Сообщение от Kenny_Dalglish
зве ошибок на этапе компиляции не должно было появится?
нет. ошибки линкера — это ошибки линковки, а не компиляции.
![]()
Сообщение от Kenny_Dalglish
Вроде бы все подключено.
нет, не подключенно.
и вообще, прекращайте мыслить в такой манере.
очевидно жеж: если бы было подключенно,
этой темы бы не существовало.
зайдите в свойства проекта (у вас ведьвижуал студия),
в раздел Linker
и укажите там имя библиотеки,
и путь, где её можно найти.
![]()
Сообщение от Kenny_Dalglish
Если у Вас депрессия не обязательно это показывать в публичном месте.
а если у меня нет депрессии,
что тогда обязательно/не обязательно
мне делать в публичном/любом другом месте?
вы находитесь на форуме программистов, а не блондинок.
ваше условие — дырявое насквозь.
любой компилятор ткнул бы вас носом в:
«результат возвращается не на всех ветках if»
Добавлено 17 марта 2021 в 22:08
Продолжим обсуждение диаграммы из предыдущей статьи «0.4 – Введение в разработку на C++»:
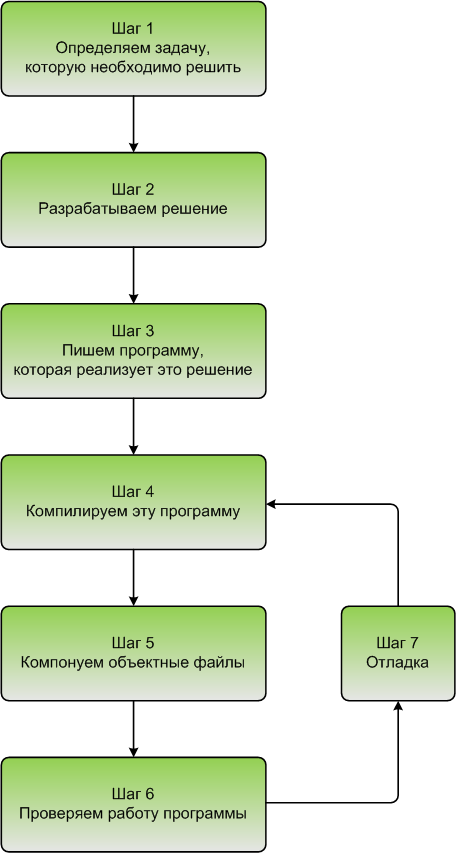
Обсудим шаги 4–7.
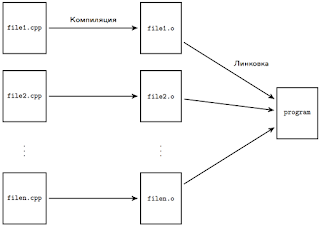
Шаг 4. Компиляция исходного кода
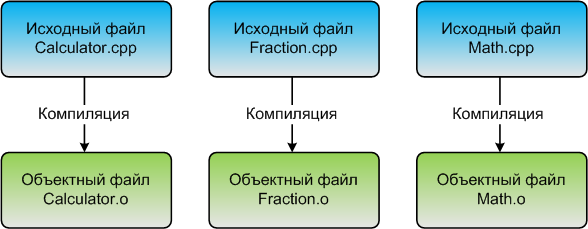
Чтобы скомпилировать программу на C++, мы используем компилятор C++, который последовательно просматривает каждый файл исходного кода (.cpp) в вашей программе и выполняет две важные задачи:
Сначала он проверяет ваш код, чтобы убедиться, что он соответствует правилам языка C++. В противном случае компилятор выдаст вам ошибку (и номер соответствующей строки), чтобы помочь точно определить, что нужно исправить. Процесс компиляции будет прерван, пока ошибка не будет исправлена.
Во-вторых, он переводит исходный код C++ в файл машинного кода, называемый объектным файлом. Объектные файлы обычно имеют имена name.o или name.obj, где name совпадает с именем файла .cpp, из которого он был создан.
Если бы в вашей программе было бы 3 файла .cpp, компилятор сгенерировал бы 3 объектных файла:
Компиляторы C++ доступны для многих операционных систем. Мы скоро обсудим установку компилятора, поэтому сейчас нет необходимости останавливаться на этом.
Шаг 5. Компоновка (линковка) объектных файлов и библиотек
После того, как компилятор создал один или несколько объектных файлов, включается другая программа, называемая компоновщиком (линкером). Работа компоновщика состоит из трех частей:
Во-первых, взять все объектные файлы, сгенерированные компилятором, и объединить их в единую исполняемую программу.
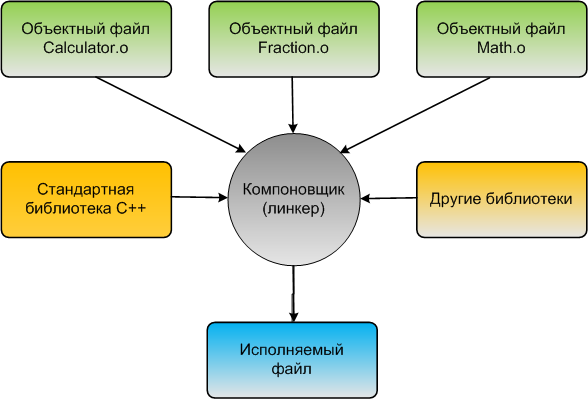
Во-вторых, помимо возможности связывать объектные файлы, компоновщик (линкер) также может связывать файлы библиотек. Файл библиотеки – это набор предварительно скомпилированного кода, который был «упакован» для повторного использования в других программах.
Ядро языка C++ на самом деле довольно небольшое и лаконичное (и вы узнаете многое о нем в последующих статьях). Однако C++ также поставляется с обширной библиотекой, называемой стандартной библиотекой C++ (обычно сокращенно «стандартная библиотека», или STL), которая предоставляет дополнительные функции, которые вы можете использовать в своих программах. Одна из наиболее часто используемых частей стандартной библиотеки C++ – это библиотека iostream, которая содержит функции для печати текста на мониторе и получения от пользователя ввода с клавиатуры. Почти каждая написанная программа на C++ в той или иной форме использует стандартную библиотеку, поэтому она часто подключается к вашим программам. Большинство компоновщиков автоматически подключают стандартную библиотеку, как только вы используете какую-либо ее часть, так что, как правило, вам не о чем беспокоиться.
Вы также можете при желании выполнить линковку с другими библиотеками. Например, если вы собрались написать программу, которая воспроизводит звук, вы, вероятно, не захотите писать свой собственный код для чтения звуковых файлов с диска, проверки их правильности или выяснения, как маршрутизировать звуковые данные к операционной системе или оборудованию для воспроизведения через динамик – это потребует много работы! Вместо этого вы, вероятно, загрузили бы библиотеку, которая уже знала, как это сделать, и использовали бы ее. О том, как связывать библиотеки (и создавать свои собственные!), мы поговорим в приложении.
В-третьих, компоновщик обеспечивает правильное разрешение всех межфайловых зависимостей. Например, если вы определяете что-то в одном файле .cpp, а затем используете это в другом файле .cpp, компоновщик соединит их вместе. Если компоновщик не может связать ссылку с чем-то с ее определением, вы получите ошибку компоновщика, и процесс линковки будет прерван.
Как только компоновщик завершит линковку всех объектных файлов и библиотек (при условии, что всё идет хорошо), вы получите исполняемый файл, который затем можно будет запустить!
Для продвинутых читателей
Для сложных проектов в некоторых средах разработки используется make-файл (makefile), который представляет собой файл, описывающий, как собрать программу (например, какие файлы компилировать и связывать, или обрабатывать какими-либо другими способами). О том, как писать и поддерживать make-файлы, написаны целые книги, и они могут быть невероятно мощным инструментом. Однако, поскольку make-файлы не являются частью ядра языка C++, и вам не нужно их использовать для продолжения изучения, мы не будем обсуждать их в рамках данной серии статей.
Шаги 6 и 7. Тестирование и отладка
Это самое интересное (надеюсь)! Вы можете запустить исполняемый файл и посмотреть, выдаст ли он ожидаемый результат!
Если ваша программа работает, но работает некорректно, то пора немного ее отладить, чтобы выяснить, что не так. Мы обсудим, как тестировать ваши программы и как их отлаживать, более подробно в ближайшее время.
Интегрированные среды разработки (IDE)
Обратите внимание, что шаги 3, 4, 5 и 7 включают в себя использование программного обеспечения (редактор, компилятор, компоновщик, отладчик). Хотя для каждого из этих действий вы можете использовать отдельные программы, программный пакет, известный как интегрированная среда разработки (IDE), объединяет все эти функции вместе. Мы обсудим IDE и установим одну из них в следующем разделе.
Теги
C++ / CppLearnCppДля начинающихКомпиляторЛинкерОбучениеПрограммирование
Что такое компиляция?
Компиляция — преобразование одностороннее, нельзя восстановить исходный код.
Для того, чтобы скомпилировать программу на C++ для некоторой архитектуры X, необязательно устанавливать компилятор С++ на компьютер с архитектурой X.
Не каждая программа, написанная на компилируемом языке, переносима. Т.е. не любая программа, написанная на компилируемом языке, будет работать везде одинаково.
Плюсы и минусы компилируемости в машинный код
Плюсы:
- эффективность: программа компилируется и оптимизируется для конкретного процессора;
- нет необходимости устанавливать сторонние приложения, такие как интерпретатор или виртуальная машина (т.е. для запуска программы, написаной на компилируемом языке, не требуется установка компилятора).
Минусы:
- нужно компилировать для каждой платформы (т.е. программу, написанную на языке, который компилируется в машинный код, недостаточно скомпилировать однажды чтобы её можно было запускать на любой платформе);
- сложность внесения изменения в программу — нужно перекомпилировать заново.
Общая схема
Компиляция — преобразование одностороннее, нельзя восстановить исходный код.
Для того, чтобы скомпилировать программу на C++ для некоторой архитектуры X, необязательно устанавливать компилятор С++ на компьютер с архитектурой X.
Не каждая программа, написанная на компилируемом языке, переносима. Т.е. не любая программа, написанная на компилируемом языке, будет работать везде одинаково.
Плюсы и минусы компилируемости в машинный код
Плюсы:
- эффективность: программа компилируется и оптимизируется для конкретного процессора;
- нет необходимости устанавливать сторонние приложения, такие как интерпретатор или виртуальная машина (т.е. для запуска программы, написаной на компилируемом языке, не требуется установка компилятора).
Минусы:
- нужно компилировать для каждой платформы (т.е. программу, написанную на языке, который компилируется в машинный код, недостаточно скомпилировать однажды чтобы её можно было запускать на любой платформе);
- сложность внесения изменения в программу — нужно перекомпилировать заново.
Общая схема
g++ — это такая обёртка над несколькими программами:
- над препроцессором;
- над непосредственно компилятором;
- и над линковщиком.
g++ может сама решать, что вызывать, если не просить что-то делать специально, а просто изначально дать ей файлы, то g++ сама догадается что с ними нужно сделать.
g++ main.cpp square.cpp -o program
Этап 1: препроцессор
Язык препроцессора – это специальный язык программирования, встроенный в C++. Препроцессор работает с кодом на C++ как с текстом.
Команды языка препроцессора называют директивами, все директивы начинаются со знака #. Директива #include позволяет подключать заголовочные файлы к файлам кода.
- #include <foo.h> — библиотечный заголовочный файл,
- #include «bar.h» — локальный заголовочный файл.
Препроцессор заменяет директиву #include «bar.h» на содержимое файла bar.h.
Можно попросить компилятор вызвать только препроцессор и посмотреть что получится. Для компилятора g++ можно использовать ключ -E.
- g++ -E square.cpp -o square_preprocessed.cpp
- g++ -E main.cpp -o main_preprocessed.cpp
Этап 2: компиляция
На вход компилятору поступает код на C++ после обработки препроцессором.
Каждый файл с кодом компилируется отдельно и независимо от других файлов с кодом. Компилируется только файлы с кодом (т.е. *.cpp).
Заголовочные файлы сами по себе ни во что не компилируются, только в составе файлов с кодом.
На выходе компилятора из каждого файла с кодом получается “объектный файл” — бинарный файл со скомпилированным кодом (с расширением .o или .obj).
Если в коде C++ вы вызывает не объявленную функцию, то это ошибка этапа компиляции.
Можно «скормить» файлы с кодом непосредственно компилятору. Для компилятора g++ можно использовать ключ -c.
- g++ -c main.cpp
- g++ -c square.cpp
На выходе получается файлы с расширением .o — это объектные файлы.
- main.o
- square.o
Можно попросить компилятор g++ показать некоторое содержимое объектных файлов, но сам по себе смотреть объектный файл не интересно (там бинарная информация), но можно посмотреть его ассемблированный вид.
g++ -S square.cpp
Получится файл square.s.
Этап 3: линковка (компоновка)
На этом этапе все объектные файлы объединяются в один исполняемый (или библиотечный) файл. При этом происходит подстановка адресов функций в места их вызова.
По каждому объектному файлу строится таблица всех функций, которые в нём определены.
На этапе компоновки важно, что каждая функция имеет уникальное имя. В C++ может быть две функции с одним именем, но разными параметрами. Имена функций искажаются (mangle) таким образом, что в их имени кодируются их параметры.
Например, компилятор GCC превратит имя функции foo
в _Z3fooid. Компилятор g++ также предоставляет возможность обратного преобразования.
c++filt -n _Z3fooid
foo(int, double)
Заметим, что в полученной сигнатуре не участвует возвращаемое значение, потому что в C++ не может быть двух функций с одинаковым именем и одинаковыми параметрами, но разными возвращаемыми значениями.
Аналогично функциям в линковке нуждаются глобальные переменные.
Точка входа — функция, вызываемая при запуске программы. По умолчанию — это функция main:
или
int main(int argc, char ** argv) { return 0; }
Даже для программы, состоящей всего из одного файла и из одной пустой функции int main() { return 0; } все равно требуется ликовка.
Если в коде C++ вы вызываете функцию, которая была объявлена, но не была определена, то это ошибка этапа линковки.
Для того чтобы собрать объектные файлы в один файл их нужно «скормить» компилятору и указать имя исполняемого файла:
g++ square.o main.o -o program
Лекция 3
Многофайловая компоновка
Говорят, что переменная описана (определена), если она объявлена и под неё
выделена память. Рассмотрим следующий пример, пусть в проекте есть два файла:
/* a.cpp */
extern int n; // "Где-то дальше определено"
void f(int); // Предварительное объявление
void main() {
n = 5; f(n);
}
/* b.cpp */
#include <iostream>
int i; // Описание переменной
// Определение функции
void f(int i) {
std::cout << i;
}
В C++ имеет место независимая компиляция: все файлы проекта компилируются
независимо один от другого. Компиляция состоит из этапа собственно компиляции
и этапа линковки.

Заголовочные файлы
Содержат заголовки всех функций и объявления переменных, обычно имеют
расширение *.h (header). Теперь можно вынести объявления функций из всех
файлов в один (заголовочный):
/* myheader.h */
extern int n;
void f(int);
/* myheader.cpp */
#include <iostream>
int n;
void f(int i) {
std::cout << i;
}
/* a.cpp */
#include "myheader.h"
void main() {
n = 5; f(n);
}
/* b.cpp */
#include "myheader.h"
void makeZero() {
n = 0;
}
Имена пользовательских заголовочных файлов в директиве include
заключаются в двойные кавычки, а имена стандартных заголовочных файлов —
в угловые скобки. Стандартные заголовочные файлы расположены в /INCLUDE.
Поиск пользовательских файлов производится в текущем каталоге.
Замечание: inline-функции не сохраняются в исходном коде, так как больше не
используются (а сразу встраиваются на место вызова). Чтобы воспользоваться
такими функциями в другой единице компиляции, их нужно поместить в
заголовочный файл.
Содержимое заголовочных файлов
Что может содержать заголовочный файл:
| Пример | |
|---|---|
| Определения типов | struct point { int x, y; }; |
| Шаблоны типов | template<class T> class V { /* ... */ } |
| Описания функций | extern int strlen(const char*); |
| Определения встраиваемых функций | inline char get() { return *p++; } |
| Описания данных | extern int a; |
| Определения констант | const float pi = 3.141593; |
| Перечисления | enum bool { false, true }; |
| Описания имен | class Matrix; |
| Команды включения файлов | #include <signal.h> |
| Макроопределения | #define Case break;case |
| Комментарии | /* проверка на конец файла */ |
В заголовочном файле никогда не должно быть:
| Пример | |
|---|---|
| Определений обычных функций | char get() { return *p++; } |
| Определений данных | int a; |
| Определений составных констант | const tb[i] = { /* ... */ }; |
Глобальные описания в C++ и необходимость пространств имен
При простом определении глобальных сущностей они объединяются в глобальном пространстве имен. Для создания локального пространства имен используется ключевое слово namespace.
namespace MyNamespace{
... // содержимое пространства имён: типы, функции, что-угодно…
}
Пространства имен и заголовочные файлы
Прототипы функций и глобальные переменные в заголовочных файлах, особенно в крупных проектах, необходимо заключать в пространства имен.
/* header.h */
namespace MyNamespace{
extern int n;
void f();
}
Основные этапы сборки проекта
- Препроцессирование.
- Компиляция каждого
*.cpp-файла в объектный код (файлы*.objили*.o). - Линковка — сборка всех объектных файлов в один исполняемый
(*.exeилиELF).
Ошибки во время линковки
- Одинаковые объявления в одном пространстве имен.
- Ошибки при использовании
#include "*.cpp"(грубая ошибка). - Отсутствие описания функции.
- Отсутствие
main()во всех файлах проектах. - Несколько объявлений
main().
Особенности линковки
- Константы имеют внутреннюю линковку.
inline-функции «погибают» при компиляции.
При сборке программы с включенными опциями для GCOV можно получить ошибку на этапе линковки следующего вида:
/usr/bin/ld: ./a.out: hidden symbol `__gcov_merge_add’ in /usr/lib/gcc/i486-linux-gnu/4.1.3/libgcov.a(_gcov_merge_add.o) is referenced by DSO
/usr/bin/ld: final link failed: Nonrepresentable section on output
Скорее всего причина заключается в том, что к исполняемому модулю линкуются библиотеки, которые тоже были скомпилированы с опциями -fprofile-arcs -ftest-coverage.
Простой пример, иллюстрирующий проблему.
Даны два файла:
=== a.cpp
#include <stdio.h>
extern unsigned long myfunc ();
int main (int argc, char **argv)
{
unsigned long z = myfunc();
printf("%08xn", z);
return 0;
}
=== b.cpp
#include <time.h>
unsigned long myfunc ()
{
return time(0);
}
Из файла b.cpp делаем статическую библиотеку libmy.a, а из файла a.cpp — исполняемый модуль a.out:
g++ -c -fprofile-arcs -ftest-coverage b.cpp
g++ -shared -o libmy.a ./b.o
g++ -c -fprofile-arcs -ftest-coverage a.cpp
g++ -o a.out a.o -L. -lmy
Получаем ошибку вида «undefined reference to `__gcov_init’» — забыли подключить библиотеку libgcov.a.
Подключаем к сборке требуемую библиотеку как обычно:
g++ -c -fprofile-arcs -ftest-coverage b.cpp
g++ -shared -o libmy.a ./b.o
g++ -c -fprofile-arcs -ftest-coverage a.cpp
g++ -o a.out a.o -L. -lmy -lgcov
Вот здесь-то и получаем странную ошибку:
/usr/bin/ld: ./a.out: hidden symbol `__gcov_merge_add' in /usr/lib/gcc/i486-linux-gnu/4.1.3/libgcov.a(_gcov_merge_add.o) is referenced by DSO
/usr/bin/ld: final link failed: Nonrepresentable section on output
Исправить это просто. Нужно подключить библиотеку libgcov.a не только к сборке исполняемого модуля, но и к сборке статической библиотеки:
g++ -c -fprofile-arcs -ftest-coverage b.cpp
g++ -shared -o libmy.a ./b.o -lgcov
g++ -c -fprofile-arcs -ftest-coverage a.cpp
g++ -o a.out a.o -L. -lmy -lgcov
Вот и всё. Так нужно поступить с каждой библиотекой, исходный код которой скомпилирован с опциями -fprofile-arcs -ftest-coverage.
![]()
Сообщение от Kenny_Dalglish
Как это?
линкеру не сообщили, что нужно линковаться с библиотекой.
![]()
Сообщение от Kenny_Dalglish
зве ошибок на этапе компиляции не должно было появится?
нет. ошибки линкера — это ошибки линковки, а не компиляции.
![]()
Сообщение от Kenny_Dalglish
Вроде бы все подключено.
нет, не подключенно.
и вообще, прекращайте мыслить в такой манере.
очевидно жеж: если бы было подключенно,
этой темы бы не существовало.
зайдите в свойства проекта (у вас ведьвижуал студия),
в раздел Linker
и укажите там имя библиотеки,
и путь, где её можно найти.
![]()
Сообщение от Kenny_Dalglish
Если у Вас депрессия не обязательно это показывать в публичном месте.
а если у меня нет депрессии,
что тогда обязательно/не обязательно
мне делать в публичном/любом другом месте?
вы находитесь на форуме программистов, а не блондинок.
ваше условие — дырявое насквозь.
любой компилятор ткнул бы вас носом в:
«результат возвращается не на всех ветках if»
Процесс компиляции программ
- Запись лекции №1
- Запись лекции №2
- Запись лекции №3
- Практика
Зачем нам нужно это изучать?
- У студентов часто возникают с этим проблемы — когда компилятор пишет ошибку, а человек не понимает, что ему говорят.
- Если вы делаете ошибку в организации программы, причём такую ошибку, которая сразу к проблеме не приводит, то бывает такое, что при компиляции чуть-чуть по-другому всё сломается. Причём даже в крупных компаниях
такое случается.
Самое интересное, что ни в одной литературе про компиляцию не рассказывается (в совсем базовой считается что это сложно, а в продвинутой — что вы всё знаете), а все кто это знает,
говорят, что пришло с опытом.
Базовые знания об этапах компиляции.
Обычно мы компилируем программу как g++ program.cpp. А вот чего мы пока не знаем, так это того, что g++ не делает всю работу самостоятельно, а вызывает другие команды, которые выполняют компиляцию по частям. И если посмотреть, что там, то происходит cc1plus, потом as, в конце collect2, который вызывает ld. Давайте попытаемся это повторить.
Дальше будет перечисление стадий с указанием двух моментов: как их можно выполнить руками и какое расширение обычно имеет результат этой стадии.
- Препроцессирование. Выполняется при помощи g++ -E (если дополнительно передать ключ -P, то вывод будет чуть короче), выходной файл обычно имеет расширение .i. На файл с расширением .i можно и глазами посмотреть — в нём будет куча текста вместо
#include, а потом наш код. Собственно,#include— директива препроцессора, которая тупо вставляет указанный файл в то место, где написана. Также препроцессор занимается макросами (#define). О них позже. - Трансляция. Выполняется при помощи g++ -S, выходной файл обычно имеет расширение .s. «Трансляция» — это (с английского) «перевод». Кого и куда переводим? Наш язык в ассемблер. Если передать параметр -masm=intel, можно уточнить, в какой именно ассемблер переводить (как было сказано в 01_asm, ассемблеры отличаются в зависимости от инструмента).
- Ассемблирование. Выполняется специальной утилитой as, выходной файл обычно имеет расширение .o (и называется объектным файлом). На данном этапе не происходит ничего интересного — просто инструкции, которые были в ассемблере, перегоняются в машинный код. Поэтому файлы .o бесполезно смотреть глазами, они бинарные, для этого есть специальные утилиты, например, objdump. Про него будет рассказано чуть позже.
- Линковка. Выполняется простым вызовом g++ от объектного файла. На выходе даёт исполняемый файл. Нужна, если файлов несколько: мы запускаем препроцессор, трансляцию и ассемблирование независимо для каждого файла, а объединяются они только на этапе линковки. Независимые .cpp файлы называют единицами трансляции. Разумеется, только в одной единице должен быть
main. В этомmain‘е, кстати, можно не делатьreturn 0, его туда вставит компилятор.
Сто́ит сказать, что информация о линковке верна до появления модулей в C++20, где можно доставать данные одного файла для другого. Там появляется зависимость файлов друг от друга, а значит компилировать их надо в определённом порядке.
Классическая схема этапов компиляции выглядит так:

Есть похожая статья на хабре по теме.
Объявление и определение.
Очень хочется слинковать вот это:
// a.cpp: int main() { f(); }
// b.cpp: #include <cstdio> void f() { printf("Hello, world!n"); }
Это не компилируется, а точнее ошибка происходит на этапе трансляции a.cpp. В тексте ошибки написано, что f не определена в области видимости. Всё потому, что для того чтобы вызвать функцию, надо что-то про неё знать. Например, если мы передаём в функцию int — это один ассемблерный код, а если double — то совершенно другой (потому что разные calling convention’ы могут быть). Поэтому на этапе трансляции нужно знать сигнатуру функции. Чтобы указать эту сигнатуру, в C++ есть объявления:
// a.cpp: void f(); // Вот это объявление. int main() { f(); }
// b.cpp: #include <cstdio> void f() { printf("Hello world"); }
Когда мы пишем функцию и точку с запятой — это объявление/декларация (declaration). Это значит, что где-то в программе такая функция есть. А когда мы пишем тело функции в фигурных скобках — это определение (definition).
Кстати, написать объявление бывает полезно даже если у нас один файл. Например, в таком файле:
#include <cstdio> int main() { f(); } void f() { printf("Hello, worldn"); }
Это не компилируется, и дело в том, что компилятор смотрит файл сверху вниз, и когда доходит до вызова функции f внутри main, он ещё не дошёл до её определения. Тут можно переставить функции местами, да, но если у нас есть взаиморекурсивные функции, то там переставить их не получится — только написать декларацию.
Ошибки линковки. Инструменты nm и objdump. Ключевое слово static.
Рассмотрим такой пример:
// a.cpp #include <cstdio> void f() { printf("Hello, a.cpp!n"); }
// b.cpp #include <cstdio> void f() { printf("Hello, b.cpp!n"); }
// main.cpp void f(); int main() { f(); }
Тут вам на этапе линковки напишут, что функция f() определяется дважды. Чтобы красиво посмотреть, как это работает, можно использовать утилиту nm. Когда вы сгенерируете a.o и вызовете nm -C a.o, то увидите что-то такое:
U puts
0000000000000000 T f()
Что делает ключ -C, оставим на потом. На то что тут находится puts вместо printf, тоже обращать внимание не надо, это просто такая оптимизация компилятора — когда можно заменить printf на puts, заменяем.
А обратить внимание надо на то, что puts не определена (об этом нам говорит буква U), а функция f() — определена в секции .text (буква T). У main.cpp, понятно, будет неопределённая функция f() и определённая main. Поэтому, имея эти объектные файлы, можно слинковать main.cpp и a.cpp, а можно — main.cpp и b.cpp. Без перекомпиляции. Но нельзя все три вместе, ведь f() будет определена дважды.
Если мы хотим посмотреть на объектные файлы поподробнее, нам понадобится утилита objdump. У неё есть бесчисленное много ключей, которые говорят, что мы хотим увидеть. Например -x — выдать вообще всё. Нам сейчас нужно -d — дизассемблирование и -r — релокации. Когда мы вызовем objdump -dr -Mintel -C main.o, мы увидим, что на месте вызова функции f находится call и нули. Потому что неизвестно, где эта функция, надо на этапе линковки подставить её адрес. А чтобы узнать, что именно подставить, есть релокации, которые информацию об этом и содержат. В общем случае релокация — информация о том, какие изменения нужно сделать с программой, чтобы файл можно было запустить.
Давайте теперь вот на что посмотрим. Пусть в нашем файле определена функция f(). И где-то по случайному совпадению далеко-далеко также определена функция f(). Понятно, что оно так не слинкуется. Но мы можем иметь ввиду, что наша функция f нужна только нам и никак наружу не торчит. Для этого имеется специальный модификатор: static. Если сделать на такие функции nm, то можно увидеть символ t вместо T, который как раз обозначает локальность для единицы трансляции. Вообще функции, локальные для одного файла сто́ит помечать как static в любом случае, потому что это ещё помогает компилятору сделать оптимизации.
Глобальные переменные.
Для глобальных переменных всё то же самое, что и для функций: например, мы также можем сослаться на глобальную переменную из другого файла. Только тут другой синтаксис:
extern int x; // Объявление. int x; // Определение.
И точно также в глобальных переменных можно писать static. А теперь пример:
// a.cpp extern int a; void f(); int main() { f(); a = 5; f(); }
// b.cpp #include <cstdio> int a; void f() { printf("%dn", a); }
В первый раз вам выведут 0, потому что глобальные переменные инициализируются нулями. Локальные переменные хранятся на стеке, и там какие данные были до захода в функцию, те там и будут. А глобальные выделяются один раз, и ОС даёт вам их проинициализированные нулём (иначе там могут быть чужие данные, их нельзя отдавать).
Декорирование имён. extern "C".
Обсуждённая нами модель компиляции позволяет использовать несколько разных языков программирования. Пока ЯП умеет транслироваться в объектные файлы, проблемы могут возникнуть только на этапе линковки. Например, никто не мешает вам взять уже готовый ассемблерник и скомпилировать его с .cpp файлом. Но в вызове ассемблера есть одна проблема. Тут надо поговорить о такой вещи как extern "C". В языке C всё было так: имя функции и имя символа для линковщика — это одно и то же. Если мы скомпилируем файл
// a.c <-- C, не C++. void foo(int) { // ... }
То имя символа, которое мы увидим в nm будет foo. А в C++ появилась перегрузка функций, то есть void foo(int) и void foo(double) — это две разные функции, обе из которых можно вызывать. Поэтому одно имя символа присвоить им нельзя. Так что компилятор mangle’ит/декорирует имена, то есть изменяет их так, чтобы символы получились уникальными. nm даже может выдать вам эти имена (в данном случае получится _Z3fooi и _Z3food). Но у вас есть и возможность увидеть их по-человечески: для этого существует уже упомянутый ключ -C, который если передать программе nm, то она раздекорирует всё обратно и выдаст вам имена человекочитаемо. objdump‘у этот ключ дать тоже можно. А ещё есть утилита
c++filt, которая по имени символа даёт сигнатуру функции.
Так вот, extern "C" говорит, что при линковке нам не нужно проводить декорацию. И если у нас в ассемблерном файле написано fibonacci:, то вам и нужно оставить имя символа как есть:
extern "C" uint32_t fibonacci(uint32_t n);
У функций с разными сигнатурами, но помеченных как extern "C", после компиляции не будет информации об типах их аргументов, поэтому это слинкуется, но работать не будет (ну либо будет, но тут UB, так как, например, типы аргументов ожидаются разные).
Линковка со стандартной библиотекой.
Возьмём теперь объявление printf из cstdio и вставим его объявление вручную:
extern "C" int printf(const char*, ...); int main() { printf("Hello, world!"); }
Такая программа тоже работает. А где определение printf, возникает вопрос? А вот смотрите. На этапе связывания
связываются не только ваши файлы. Помимо этого в параметры связывания добавляются несколько ещё объектных файлов и несколько библиотек. В нашей модели мира хватит информации о том, что библиотека — просто набор объектных файлов. И вот при линковке вам дают библиотеку стандартную библиотеку C++ (-lstdc++), математическую библиотеку (-lm), библиотеку -libgcc, чтобы если вы делаете арифметику в 128-битных числах, то компилятор мог вызвать функцию __udivti3 (деление), и кучу всего ещё. В нашем случае нужна одна — -lc, в которой и лежит printf. А ещё один из объектных файлов, с которыми вы линкуетесь, содержит функцию _start (это может быть файл crt1.o), которая вызывает main.
Headers (заголовочные файлы). Директива #include.
Если мы используем одну функцию во многих файлах, то нам надо писать её сигнатуру везде. А если мы её меняем, то вообще повеситься можно. Поэтому так не делают. А как делают? А так: декларация выделяется в отдельный файл. Это файл имеет расширение .h и называется заголовочным. По сути это же происходит в стандартной библиотеке. Подключаются заголовочные файлы директивой #include <filename>, если они из какой-то библиотеки, или #include "filename", если он ваш. В чём разница? Стандартное объяснение — тем, что треугольные скобки сначала ищут в библиотеках, а потом в вашей программе, а кавычки — наоборот. На самом желе у обоих вариантов просто есть список путей, где искать файл, и эти списки разные.
Но с заголовками нужно правильно работать. Например, нельзя делать #include "a.cpp". Почему? Потому что все определённые в a.cpp функции и переменные просочатся туда, куда вы его подключили. И если файл у вас один, то ещё ничего, а если больше, то в каждом, где написано #include "a.cpp", будет определение, а значит определение одного и того же объекта будет написано несколько раз.
Аналогичной эффект будет, если писать определение сразу в заголовочном файле, не надо так.
К сожалению, у директивы #include есть несколько нюансов.
Предотвращение повторного включения.
Давайте поговорим про структуры. Что будет, если мы в заголовочном файле создадим struct, и подключим этот файл? Да ничего. Абсолютно ничего. Сгенерированный ассемблерный код будет одинаковым. У структур нет определения по сути, потому что они не генерируют код. Поэтому их пишут в заголовках. При этом их методы можно (но не нужно) определять там же, потому что они воспринимаются компилятором как inline. А кто такой этот inline и как он работает — смотри дальше. Но со структурами есть один нюанс. Рассмотрим вот что:
// a.cpp: #include "y.h" // --> `struct x{};`. #include "z.h" // --> `struct x{};` ошибка компиляции, повторное определение.
Стандартный способ это поправить выглядит так:
// x.h: #ifndef X_H // Если мы уже определили макрос, то заголовок целиком игнорируется. #define X_H // Если не игнорируется, то помечаем, что файл мы подключили. struct x {}; #endif // В блок #ifndef...#endif заключается весь файл целиком.
Это называется include guard. Ещё все возможные компиляторы поддерживают #pragma once (эффект как у include guard, но проще). И на самом деле #pragma once работает лучше, потому что не опирается на имя файла, например. Но его нет в стандарте, что грустно.
Есть один нюанс с #pragma once‘ом. Если у вас есть две жёстких ссылки на один файл, то у него проблемы. Если у вас include guard, то интуитивно понятно, что такое разные файлы — когда макросы у них разные. А вот считать ли разными файлами две жёстких ссылки на одно и то же — вопрос сложный. Другое дело, что делать так, чтобы источники содержали жёсткие
или символические ссылки, уже довольно странно.
Forward-декларации.
// a.h #ifndef A_H #define A_H #include "b.h" // Nothing, then `struct b { ... };` struct a { b* bb; }; #endif
// b.h #ifndef B_H #define B_H #include "a.h" // Nothing, then `struct a { ... };` struct b { a* aa; }; #endif
// main.cpp #include "a.h" // `struct b { ... }; struct a { ... };` #include "b.h" // Nothing.
Понятно, в чём проблема заключается. Мы подключаем a.h, в нём — b.h, в нём, поскольку мы уже зашли в a.h, include guard нам его блокирует. И мы сначала определяем структуру b, а потом — a. И при просмотре структуры b, мы не будем знать, что такое a.
Для этого есть конструкция, называемая forward-декларацией. Она выглядит так:
// a.h #ifndef A_H #define A_H struct b; struct a { b* bb; }; #endif
// b.h #ifndef B_H #define B_H struct a; struct b { a* aa; }; #endif
Чтобы завести указатель, нам не надо знать содержимое структуры. Поэтому мы просто говорим, что b — это некоторая структура, которую мы дальше определим.
Вообще forward-декларацию в любом случае лучше использовать вместо подключения заголовочных файлов (если возможно, конечно). Почему?
- Во-первых, из-за времени компиляции. Большое количество подключений в заголовочных файлах негативно влияет на него, потому что если меняется header, то необходимо перекомпилировать все файлы, которые подключают его (даже не непосредственно), что может быть долго.
- Второй момент — когда у нас цикл из заголовочных файлов, это всегда ошибка, даже если там нет проблем как в примере, потому что результат компиляции зависит от того, что вы подключаете первым.
Пока структуру не определили, структура — это incomplete type. Например, на момент объявление struct b; в коде выше, b — incomplete. Кстати, в тот момент, когда вы находитесь в середине определения класса, он всё ещё incomplete.
Все, что можно с incomplete типами делать — это объявлять функции с их использованием и создавать указатель. Становятся полным типом после определения.
Пока что информация об incomplete-типах нам ни к чему, но она выстрелит позже.
Правило единственного определения.
А теперь такой пример:
// a.cpp #include <iostream> struct x { int a; // padding double b; int c; int d; }; x f(); int main() { x xx = f(); std::cout << xx.a << " " << xx.b << " " << xx.c << " " << xx.d << std::endl; }
// b.cpp struct x { int a; int b; int c; int d; int e; }; x f() { x result; result.a = 1; result.b = 2; result.c = 3; result.d = 4; result.e = 5; return result; };
Тут стоит вспомнить, что структуры при линковке не играют никакой роли, то есть линковщику всё равно, что у нас структура x определена в двух местах. Поэтому такая программа отлично скомпилируется и запустится, но тем не менее она является некорректной. По стандарту такая программа будет работать неизвестно как, а по жизни данные поедут. А именно 2 пропадёт из-за выравнивания double, 3 и 4 превратятся в одно число (double), а 5 будет на своём месте, а x::e из файла a.cpp будет просто не проинициализирован. Правило, согласно которому так нельзя, называется one-definition rule/правило единственного определения. Кстати, нарушением ODR является даже тасовка полей.
Inlining.
int foo(int a, int b) { return a + b; } int bar(int a, int b) { return foo(a, b) - a; }
Если посмотреть на ассемблерный код для bar, то там не будет вызова функции foo, а будет return b;. Это называется inlining — когда мы берём тело одной функции и вставляем внутрь другой как оно есть. Это связано, например, со стилем программирования в текущем мире (много маленьких функций, которые делают маленькие вещи) — мы убираем все эти абстракции, сливаем функции в одну и потом оптимизируем что там есть.
Но есть один нюанс…
Модификатор inline.
// a.c void say_hello(); int main() { say_hello(); }
// b.c #include <cstdio> void say_hello() { printf("Hello, world!n"); }
Тут не произойдёт inlining, а почему? А потому что компилятор умеет подставлять тело функций только внутри одной единицы трансляции (так как inlining происходит на момент трансляции, а тогда у компилятора нет функций из других единиц).
Тут умеренно умалчивается, что модель компиляции, которую мы обсуждаем — древняя и бородатая. Мы можем передать ключ -flto в компилятор, тогда всё будет за’inline’ено. Дело в том, что при включенном режиме linking time optimization, мы откладываем на потом генерацию кода и генерируем его на этапе линковки. В таком случае линковка может занимать много времени, поэтому применяется при сборке с оптимизациями. Подробнее о режиме LTO — сильно позже.
Но тем не менее давайте рассмотрим, как без LTO исправить проблему с отсутствием inlining’а. Мы можем написать в заголовочном файле тело, это поможет, но это, как мы знаем, ошибка компиляции. Хм-м, ну, можно не только написать функцию в заголовочном файле, но и пометить её как static, но это, даёт вам свою функцию на каждую единицу трансляции, что, во-первых, бывает просто не тем, что вы хотите, а во-вторых, кратно увеличивает размер выходного файла.
Поэтому есть модификатор inline. Он нужен для того, чтобы линковщик не дал ошибку нарушения ODR. Модификатор inline напрямую никак не влияет на то, что функции встраиваются.. Если посмотреть на inline через nm, то там увидим W (weak) — из нескольких функций можно выбрать любую (предполагается, что все они одинаковые).
По сути inline — указание компилятору, что теперь за соблюдением ODR следите вы, а не он. И если ODR вы нарушаете, то это неопределённое поведение (ill-formed, no diagnostic required). ill-formed, no diagnostic required — это ситуация, когда программа некорректна, но никто не заставляет компилятор вам об этом говорить. Он может (у GCC есть такая возможность: если дать g++ ключи -flto -Wodr, он вам об этом скажет), но не обязан. А по жизни линковщик выберет произвольную из имеющихся функций (например, из первой единицы трансляции или вообще разные в разных местах):
// a.cpp #include <cstdio> inline void f() { printf("Hello, a.cpp!n"); } void g(); int main() { f(); g(); }
// b.cpp inline void f() { printf("Hello, b.cpp!n"); } void g() { f(); }
Если скомпилировать этот код с оптимизацией, обе функции f будут за’inline’ены, и всё будет хорошо. Если без, то зависит от порядка файлов: g++ a.cpp b.cpp может вполне выдавать Hello, a.cpp! два раза, а g++ b.cpp a.cpp — Hello, b.cpp! два раза.
Если нужно именно за’inline’ить функцию, то есть нестандартизированные модификаторы типа __forceinline, однако даже они могут игнорироваться компилятором. Inlining функции может снизить производительность: на эту тему можно послушать доклад Антона Полухина на C++ Russia 2017.
Остальные команды препроцессора.
#include обсудили уже вдоль и поперёк. Ещё есть директивы #if, #ifdef, #ifndef, #else, #elif, #endif, которые дают условную компиляцию. То есть если выполнено какое-то условие, можно выполнить один код, а иначе — другой.
Определение макроса.
И ещё есть макросы: определить макрос (#define) и разопределить макрос (#undef):
#define PI 3.14159265 double circumference(double r) { return 2 * PI * r; }
Текст, который идет после имени макроса, называется replacement. Replacement отделяется от имени макроса пробелом и распространяется до конца строки. Все вхождения идентификатора PI ниже этой директивы будут заменены на replacement. Самый простой макрос — object-like, его вы видите выше, чуть более сложный — function-like:
#define MIN(x, y) x < y ? x : y printf("%d", MIN(4, 5));
Что нам нужно про это знать — макросы работают с токенами. Они не знают вообще ничего о том, что вы делаете. Вы можете написать
#include <cerrno> int main() { int errno = 42; }
И получить отрешённое от реальности сообщение об ошибке. А дело всё в том, что это на этапе препроцессинга раскрывается, например, так:
int main() { int (*__errno_location()) = 42; }
И тут компилятор видит более отъявленный бред, нежели называние переменной так, как нельзя.
Что ещё не видит препроцессор, так это синтаксическую структуру и приоритет операций. Более страшные вещи получаются, когда пишется что-то такое:
#define MUL(x, y) x * y int main() { int z = MUL(2, 1 + 1); }
Потому что раскрывается это в
int main() { int z = 2 * 1 + 1; }
Это не то что вы хотите. Поэтому когда вы такое пишите, нужно во-первых, все аргументы запихивать в скобки, во-вторых — само выражение тоже, а в-третьих, это вас никак не спасёт от чего-то такого:
#define max(a, b) ((a) < (b) ? (a) : (b)) int main() { int x = 1; int y = 2; int z = max(x++, ++y); }
Поэтому перед написанием макросов три раза подумайте, нужно ли оно, а если нужно, будьте очень аккуратны. А ещё, если вы используете отладчик, то он ничего не знает про макросы, зачем ему знать. Поэтому в отладчике написать «вызов макроса» Вы обычно не можете. Cм. также FAQ Бьярна Страуструпа о том, почему макросы — это плохо.
Ещё #define позволяет переопределять макросы.
#define STR "abc" const char* first = STR; // "abc". #define STR "def" const char* second = STR; // "def".
Replacement макроса не препроцессируется при определении макроса, но результат раскрытия макроса препроцессируется повторно:
#define Y foo #define X Y // Это не `#define X foo`. #define Y bar // Это не `#define foo bar`. X // Раскрывается `X` -> `Y` -> `bar`.
Также по спецификации препроцессор никогда не должен раскрывать макрос изнутри самого себя, а оставлять вложенный идентификатор как есть:
#define M { M } M // Раскрывается в { M }.
Ещё пример:
#define A a{ B } #define B b{ C } #define C c{ A } A // a{ b{ c{ A } } } B // b{ c{ a{ B } } } C // c{ a{ b{ C } } }
Условная компиляция. Проверка макроса.
Директивы #ifdef, #ifndef, #if, #else, #elif, #endif позволяют отпрепроцессировать часть файла, лишь при определенном условии. Директивы #ifdef, #ifndef проверяют определен ли указанный макрос. Например, они полезны для разной компиляции:
#ifdef __x86_64__ typedef unsigned long uint64_t; #else typedef unsigned long long uint64_t; #endif
Директива #if позволяет проверить произвольное арифметическое выражение.
#define TWO 2 #if TWO + TWO == 4 // ... #endif
Директива #if препроцессирует свой аргумент, а затем парсит то, что получилось как арифметическое выражение. Если после препроцессирования в аргументе #if остаются идентификаторы, то они заменяются на 0, кроме идентификатора true, который заменяется на 1.
Одно из применений #ifndef — это include guard, которые уже обсуждались ранее.
Константы.
Понадобилась нам, например, $pi$. Традиционно в C это делалось через #define. Но у препроцессора, как мы знаем, есть куча проблем. В случае с константой PI ничего не случится, вряд ли кто-то будет называть переменную так, особенно большими буквами, но всё же.
А в C++ (а позже и в C) появился const. Но всё же, зачем он нужен, почему нельзя просто написать глобальную переменную double PI = 3.141592;?
- Во-первых, константы могут быть оптимизированы компилятором. Если вы делаете обычную переменную, компилятор обязан её взять из памяти (или регистров), ведь в другом файле кто-то мог её поменять. А если вы напишете
const, то у вас не будет проблем ни с оптимизацией (ассемблер будет как при#define), ни с адекватностью сообщений об ошибках. - Во-вторых, она несёт документирующую функцию, когда вы пишете
constс указателями. Если в заголовке функции написаноconst char*, то вы точно знаете, что вы передаёте в неё строку, которая не меняется, а еслиchar*, то, скорее всего, меняется (то есть функция создана для того, чтобы менять). - В-третьих, имея
const, компилятор может вообще не создавать переменную: если мы напишемreturn PI * 2, то там будет возвращаться константа, и никакого умножения на этапе исполнения.
Кстати, как вообще взаимодействует const с указателями? Посмотрим на такой пример:
int main() { const int MAGIC = 42; int* p = &MAGIC; }
Так нельзя, это имеет фундаментальную проблему: вы можете потом записать *p = 3, и это всё порушит. Поэтому вторая строка не компилируется, и её надо заменить на
Но тут нужно вот на что посмотреть. У указателя в некотором смысле два понятия неизменяемости. Мы же можем сделать так:
int main() { const int MAGIC = 42; const int* p = &MAGIC; // ... p = nullptr; }
Кто нам мешает так сделать? Да никто, нам нельзя менять содержимое p, а не его самого. А если вы хотите написать, что нельзя менять именно сам указатель, то это не const int*/int const*, а int* const. Если вам нужно запретить оба варианта использования, то, что логично, const int* const или int const* const. То есть
int main() { int* a; *a = 1; // ok. a = nullptr; // ok. const int* b; // Синоним `int const* b;` *b = 1; // Error. b = nullptr; // ok. int* const c; *c = 1; // ok. c = nullptr; // Error. const int* const d; // Синоним `int const* const d;` *d = 1; // Error. d = nullptr; // Error. }
Теперь вот на что посмотрим:
int main() { int a = 3; const int b = 42; int* pa = &a; // 1. const int* pca = &a; // 2. int* pb = &b; // 3. const int* pcb = &b; // 4. }
Что из этого содержит ошибку? Ну, в третьем точно ошибка, это мы уже обсудили. Также первое и четвёртое точно корректно. А что со вторым? Ну, нарушает ли второе чьи-то права? Ну, нет. Или как бы сказали на парадигмах программирования, никто не нарушает контракт, мы только его расширяем (дополнительно обещая неизменяемость), а значит всё должно быть хорошо. Ну, так и работают неявные преобразования в C++, вы можете навешивать const везде, куда хотите, но не можете его убирать.
Константными могут быть и составные типы (в частности, структуры). Тогда у этой структуры просто будут константными все поля.
Добрый день!
Приходится компилировать свой проект из командной строки с помощью g++
g++ main.cpp -lglfw3 -lgdi32 -lopengl32 -lglew32 -lopengl32Эта команда успешно выполняется. Но в той IDE , где я пытаюсь его собрать (QtCreator) вылезает следующая ошибка:
'memset' was not declared in this scope
inline void PropVariantInit (PROPVARIANT *pvar) { memset (pvar, 0, sizeof (PROPVARIANT)); }причем файл qmake настроен подобным образом:
TARGET = learning
TEMPLATE = app
DEFINES += QT_DEPRECATED_WARNINGS
CONFIG += c++11
LIBS += -lglfw3 -lgdi32 -lopengl32 -lglew32 -lopengl32
SOURCES +=
main.cppАналогичным образом указаны бинарные файлы библиотек, но линковщик не находит функцию выше при попытке собрать проект в IDE. Подскажите пожалуйста, почему так может быть
Решение ошибок сборки⚓︎
При сборке пакетов иногда происходят ошибки.
В данном разделе будет описано решение наиболее распространённых ошибок.
Стадии, на которых может произойти ошибка⚓︎
Ошибка может произойти на любой стадии, однако чаще всего это случается после ввода make.
При этом в первую очередь определите действие, которое завершилось ошибкой — сделать это можно, просмотрев команду, завершившуюся с ошибкой.
В частности, если команда даётся компилятору (cc, gcc или clang), то произошла ошибка компиляции. Эти ошибки, обычно, наиболее трудны в решении.
Если команда даётся ld, то ошибка произошла при линковке.
Также ошибка может произойти, например, при построении документации. В этом случае самым простым вариантом будет отключение выполнения этого шага.
Общие принципы решения ошибок⚓︎
Убедитесь что ошибка воспроизводима — выполните make clean, а потом повторите make.
Если ошибка не исчезла, то прочитайте лог (хотя бы последние 30 строк).
Практически всегда там будет сказано о том, что за ошибка произошла.
Попробуйте поискать в интернете по частям лога, возможно, решение этой ошибки уже было где-либо описано.
Ошибки компиляции⚓︎
Ошибки компиляции — наиболее сложные в своём решении.
gcc всегда сообщает строку, в которой произошла ошибка — проверьте её.
Не найден заголовок⚓︎
Весьма простая ошибка.
Вывод⚓︎
dummy.c:1:10: fatal error: blablabla: No such file or directory
1 | #include <blablabla>
| ^~~~~~~~~~~
compilation terminated.
Имя заголовка и файла может быть другим.
Решение⚓︎
Поищите этот заголовок в папке /usr/include и директории с исходным кодом пакета. Если он существует, то добавьте в переменную CPPFLAGS параметр -I/путь/к/директории/с/этим/заголовком. Если он не существует — установите пакет, который его предоставляет.
Ошибки линковки⚓︎
В процессе линковки несколько объектных файлов соединяются в один, и к ним подключаются библиотеки.
undefined reference to …⚓︎
Данная ошибка вызвана тем, что необходимая библиотека не была подключена.
Решение⚓︎
Попытайтесь определить, исходя из лога, какая библиотека не была подключена. Добавьте в переменную CFLAGS параметр -lsomelib (не надо указывать название файла библиотеки), например, -lcurses.
Ошибки configure⚓︎
Обычно они происходят из-за отсутствия зависимостей или их неработоспособности.