
В статье приведены решения наиболее часто возникающих проблем, связанных с работой VMmanager KVM.
Проблемы с панелью управления
Обновление ПО кластера VMmanager KVM до VMmanager Cloud
Такое обновление не поддерживается.
VMmanager зависает и тормозит, в логе фигурирует ошибка «too many connections»
Наиболее частой причиной такой проблемы является зависание libvirt. Проверьте, что libvirt отвечает, попробуйте его перезапустить.
Какие процессы важны для VMmanager? Что можно отслеживать?
Важен процесс ihttpd. Также на серверах должен быть запущен libvirt.
Какие единицы измерения используются в панели управления?
В панели управления используются KiB и MiB:
- KiB (кибибайт) — 2 в степени 10 = 1024;
- MiB (мебибайт) — 2 в степени 20 = 1048576.
Что отлично от привычных KB и MB:
- MB (мегабайт) — 10 в степени 6 = 1000000;
- KB (килобайт) — 10 в степени 3 = 1000.
Формирование виртуальной машины:
- если требуется создать виртуальную машину c 2GB оперативной памяти, то в форме редактирования необходимо указать 1907MiB (точное значение 2GB = 1907,35MiB);
- если требуется создать диск виртуальной машины размером 15GB, то в панели необходимо указать 14305Mib;
- обратите внимание на калькулятор величин от Google.
Проблемы с узлами кластера
После добавления виртуальной машины один из узлов кластера становится недоступен, а при попытке подключения к нему по SSH происходит подключение к виртуальной машине
При выдаче IP-адресов виртуальным машинам из той же подсети, в которой выделены IP-адреса для узлов кластера, возможна выдача IP-адреса, присвоенного узлу кластера. Вследствие этого узел будет недоступен. Для избежания данной проблемы зарезервируйте адреса узлов кластера в локальной базе IP-адресов или в IPmanager, если настроена интеграция.
Для освобождения занятого адреса виртуальной машиной выделите для неё новый IP-адрес. Перейдите в Управление → Виртуальные машины → IP-адреса. Создайте новый IP-адрес и удалите адрес, который пересекается с адресом узла кластера. Для использования виртуальной машиной нового IP-адреса измените настройки сетевого интерфейса и перезапустите сеть командой:
systemctl restart networkBASH
Ошибка при добавлении узла кластера: «Ошибка установки пакетов ‘vmmanager-kvm-pkg-vmnode’ на удалённом сервере. Дополнительная информация доступна в журнале панели управления»
Причина: пакет libguestfs устанавливается только в интерактивном режиме.
Решение: установите пакет vmmanager-kvm-pkg-vmnode из консоли.
Не добавляется узел с операционной системой CentOS
Возможная проблема — не устанавливаются необходимые пакеты. Причина — отсутствие подключённого репозитория epel. Возможная причина — неверная дата на сервере — репозиторий не находится. Проверьте и исправьте при необходимости время и дату и повторите попытку.
Не добавляется узел. Ошибка: «Невозможно применить правила брандмауэра: ошибка в синтаксисе iptables»
В логах vmmgr.log при этом видно ошибку запуска скрипта /etc/libvirt/hooks/firewall.sh:
# /etc/libvirt/hooks/firewall.sh
# Generated by VMmanager KVM on Сбт Апр 18 21:31:18 CEST 2015 *filter
# ISPsystem firewall rules
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
-F INPUT
-F FORWARD
COMMIT --------------------------------
ip6tables-restore v1.4.7: ip6tables-restore: unable to initialize table 'filter'
Error occurred at line: 2
Try 'ip6tables-restore -h' or 'ip6tables-restore --help' for more information.BASH
Для решения проблемы закомментируйте строки в конфигурационном файле /etc/modprobe.d/ipv6.conf и перезапустите модуль ipv6.
Утилиты управления кластером
Выполнение команды на всех узлах кластера:
/usr/local/mgr5/sbin/nodectl --op exec --target all --cmd 'echo "Hello, world!"'BASH
Переход по SSH на узел кластера:
/usr/local/mgr5/sbin/nodectl login <id узла кластера>BASH
Просмотр списка узлов кластера:
/usr/local/mgr5/sbin/nodectl listBASH
Проблемы с хранилищами
Проблемы с LVM-хранилищем
Невозможно создать хранилище с типом LVM. При попытке добавить новый узел в кластер иногда возникает ошибка «unsupported configuration: cannot find any matching source devices for logical volume group»
Убедитесь, что команды LVM подтверждают существование физических томов, которые планируется добавить. Попробуйте удалить хранилище и узел кластера и добавить заново. Удаление хранилища выполняется с помощью команды:
virsh pool-undefine название-хранилища.BASH
Проблемы с сетевым LVM-хранилищем
Не удаётся обнаружить группу томов на узлах
Если команда vgs на узлах не отображает группу томов LVM с iSCSI-хранилища, проверьте, работает ли с ней iscsi-target. Для этого на узле таргета выполните команду:
tgtadm -m target --op showBASH
Если в списке lun необходимый раздел отсутствует, добавьте его вручную:
tgtadm -m logicalunit --op new --tid 1 -b /dev/sda2 --lun 1BASH
После этого перезагрузите tgtd, переподключите узлы к таргету и выполните на узлах pvscan для обнаружения пула.
Проблема при подключении нового узла кластера
После внесения изменений в файл /etc/tgt/targets.conf (например, требуется подключить ещё один узел и был добавлен ещё один initiator-address) узел не удаётся подключить (команда iscsiadm -m discovery -t st -p … возвращает «iscsiadm: No portals found»). Причина, скорее всего, заключается в том, что сервис фактически не перезапускается и не перечитывает конфигурационный файл, пока к нему подключены клиенты.
При перезагрузке сервиса убедитесь, что он перезапустился:
service tgtd stop
killall -9 tgtd
service tgtd startBASH
![]()
Обратите внимание!
Команда killall -9 tgtd уничтожит процессы сервиса tgtd, при этом возможна потеря данных.
Проблемы с iSCSI-хранилищем
Requested operation is not valid: storage pool is not active
Ошибка возникает, если есть проблемы с iSCSI-хранилищем. Проверьте статус службы tgtd на сервере с хранилищем (должна быть запущена). Если проблема появляется при добавлении нового узла, то подключитесь по SSH на добавляемый узел и выполните команду:
virsh pool-list --allBASH
Если в выводе команды присутствует строка вида iSCSI-UGLY_004 | не активен | yes, то можно попробовать удалить это хранилище и добавить узел ещё раз:
virsh pool-undefine iSCSI-UGLY_004BASH
internal error Child process (/sbin/iscsiadm —mode discovery —type sendtargets —portal xxx.xxx.xxx.xxx:3260,1) status unexpected: exit status 255
VMmanager не может подключиться к серверу с iSCSI по 3260 порту. Причин может быть несколько:
- SELinux должен быть отключён;
- Нужный порт закрыт в файерволе.
Ошибка: «operation failed: Storage source conflict with pool: ‘…’ «
Эта ошибка может появляться на этапе создания хранилища типа dir или netfs. Означает, что на сервере уже существует хранилище данного типа, которое расположено в той же директории, что и создаваемое.
Решение: Найти и удалить существующее хранилище на всех узлах кластера:
virsh pool-list
virsh pool-dumpxml <pool-name>
virsh pool-destroy <pool-name>
virsh pool-undefine <pool-name>BASH
Проблемы с RBD-хранилищем
Ошибка при добавлении хранилища на узел кластера
ceph auth get-or-create client.vmmgr mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=isptest' key for client.vmmgr exists but cap osd does not matchBASH
Решение: Зайдите на монитор и удалите пользователя client.vmmgr
ceph auth del client.vmmgrBASH
Требуется сменить IP-адрес Ceph-монитора
Для создаваемых виртуальных машин:
Непосредственно на самом Ceph-мониторе IP-адрес может быть изменён вручную администратором Ceph-хранилища. В базе MySQL «vmmgr» на мастере VMmanager в таблице «metapool» необходимо заменить поле «srchostname» на новый узел. В таблице «rbdmonitor» убедитесь, что значение «metapool» соответствует значению «id» из таблицы «metapool». После правки базы удалите кэш:
rm -rf /usr/local/mgr5/var/.db.cache.vm*BASH
Затем перезапустите панель управления:
Для существующих виртуальных машин выполните следующие команды:
sed -i 's/old_IP/new_IP/g' /etc/libvirt/qemu/*.xml
virsh define /etc/libvirt/qemu/*.xmlBASH
Пояснения
old_IP — заменяемый IP-адрес.
new_IP — новый IP-адрес.
Проблемы с GlusterFS-хранилищем
При размещении двух хранилищ VMmanager в одном и том же томе и директории GlusterFS, но с разными типами (QCOW2 и RAW) невозможно выполнить перемещение виртуального диска между этими хранилищами
Используйте разные директории на сетевом хранилище для избежания такой ситуации.
Импорт виртуальных машин из другого VMmanager или из другого сервера с libvirt напрямую в хранилище GlusterFS не работает, так как драйвер libvirt не поддерживает запись содержимого диска из потока
Для решения проблемы при определении параметров импорта укажите перенос в хранилище другого типа, а затем переместите диски импортированных машин в хранилище GlusterFS.
Проблемы с NFS-хранилищем
Проблема при создании виртуального диска
Если libvirt не может создать образ в хранилище, а в логе /var/log/syslog присутствуют подобные строки:
rpc.idmapd[706]: nss_getpwnam: name 'root@testers' does not map into domain 'ispsystem.net'.BASH
Для решения проблемы в файле /etc/idmapd.conf на сервере и клиенте укажите корректное и одинаковое значение параметра «Domain». После редактирования перезагрузите сервер и клиент, повторно добавьте хранилище в VMmanager.
Проблема при удалении данных из хранилища
Если диски, созданные в хранилище NFS, не удаляются с ошибкой: Ошибка libvirt при выполнении операции «VolDelete»: «cannot unlink file ‘/nfs-pool/volume’: Permission denied».
В /var/log/messages содержится подобное сообщение:
Sep 16 13:11:07 client nfsidmap[7340]: nss_getpwnam: name 'www-data@lan' does not map into domain 'localdomain'BASH
Для решения проблемы в файле /etc/idmapd.conf на сервере и клиенте укажите корректное и одинаковое значение параметра «Domain». После редактирования перезагрузите сервер и клиент, повторно добавьте хранилище в VMmanager.
Проблемы с виртуальными дисками
Ошибка libvirt при изменении размера диска
Ошибка libvirt при выполнении операции «Grow»: «unknown procedure: 260».
Эта ошибка чаще всего возникает из-за устаревшей версии libvirt. Обновите libvirt.
Ошибка: «Не удалось примонтировать диски виртуальной машины» при смене пароля
Проблема проявляется при попытке сменить пароль для виртуальной машины с файловой системой XFS внутри, размещённой на хост-сервере с ext4 и ядром версии менее 3.10. Для более точной диагностики запустите вручную команду:
guestmount -v -x -a <образ_диска> -i <путь к точке монтирования>BASH
Если в выводе видны сообщения «mount: wrong fs type, bad option, bad superblock», то работа с этой машиной с помощью libguestfs невозможна. Причина — неполная поддержка гостевой xfs в ядре RHEL/CentOS 6. Подробнее см. virt-inspector can’t obtain info from rhel7.3 guest image on rhel6.9 host. К сожалению, по заявлениям разработчиков libguestfs, это поведение не может быть исправлено.
Проблемы с настройкой сети
IPv6 на Ubuntu 12.04
При добавлении узла кластера с IPv6-адресом выводится ошибка: «Невозможно подключиться к серверу XXX. Возможно, на сервере не работают службы ssh или libvirt-bin».
В логах:
Mar 13 13:26:09 [2157:0x95E700] virt TRACE ErrorCallback libvirt error code=38 message=Cannot recv data: ssh: external/libcrypto.so.1.0.0: no version information available (required by ssh) : Connection reset by peertname [2a01:230:2:3::3]: Name or service not known
Mar 13 13:26:09 [2157:0x95E700] virt DEBUG vir_host.cpp:70 Connect to qemu+ssh://[2a01:230:2:3::3]/system?keyfile=etc/ssh_id_rsa
Mar 13 13:26:09 [2157:0x95E700] err ERROR Error: Type: 'vir_connection'
Mar 13 13:26:09 [2157:0x95E700] virt TRACE Fail libvirt message: 'Cannot recv data: ssh: external/libcrypto.so.1.0.0: no version information available (required by ssh)BASH
Эта ошибка является багом Ubuntu 12.04. Подробнее см. на launchpad.
Решение: Добавьте узел с IPv4 адресом.
Проблемы с виртуальными машинами
Проблемы при создании виртуальных машин
Ошибка при создании виртуальной машины: «ERROR: Exception 1: Insufficient RAM for VM creation», хотя в Swap ещё достаточно оперативной памяти
Свободная оперативная память — это free + cached. Swap не учитывается.
При попытке создания виртуальной машины возникает ошибка. Ошибка libvirt при выполнении операции «Start»: «internal error Process exited while reading console log output: qemu-kvm: -chardev pty,id=charserial0: Failed to create chardev».
Для решения проблемы выполните команду:
mount -n -t devpts -o remount,mode=0620,gid=5 devpts /dev/ptsBASH
При попытке создания виртуальной машины возникает ошибка. Ошибка libvirt при выполнении операции «Start»: «internal error cannot create rule since ebtables tool is missing»
Проверьте вывод команды lsmod |grep ebt. Если нет результата, значит в ядре нет поддержки ebtables. Пересоберите ядро либо скачайте другое и правкой grub.conf измените порядок загрузки.
Проблемы с установкой операционной системы
Установщик не может скачать файл ответов
Эта ошибка может быть обнаружена при подключении к виртуальной машине по VNC.
Причин может быть несколько:
- IP-адрес виртуальной машины не может быть прикреплён к узлу кластера, на котором эта машина создана. Так бывает, например, если IP-адреса в дата-центре привязаны к MAC-адресам.
- Не работает резолвер на виртуальной машине. В качестве резолвера используется первый резолвер с родительского сервера (файл /etc/resolv.conf).
- VMmanager пытается предоставить файл ответов по внутреннему IP-адресу, который не доступен снаружи, а установщик скачивает файл ответов через внешнюю сеть.
- В настройках ihttpd настроен redirect для http-соединений. IP-адрес, на который будет предоставлен файл ответов, VMmanager получает от ihttpd и узнать его можно с помощью команды:
/usr/local/mgr5/sbin/ihttpdBASH
Не удаётся полностью получить preseed-файл при установке Debian
Для решения проблемы уберите опцию «nocunked» в файле конфигурации ihttpd (по умолчанию /usr/local/mgr5/etc/ihttpd.conf).
После этого перезапустите сервис ihttpd.
Проблемы с установкой Windows 2016 на виртуальной машине: В VNC наблюдается, что установка зависла на этапе загрузки
Встречается на серверах с версией QEMU 1.5, 0.12, 1.1.2.
Решение: при создании виртуальной машины включите режим эмуляции процессора host-passthrough. Для QEMU 2.6 установка этих шаблонов работает без необходимости изменения режима эмуляции, но иногда может потребоваться перезапуск службы libvirt (service libvirtd restart) (если было обновление системы).
При установке FreeBSD-amd64 на некоторых типах процессоров могут возникнуть проблемы:
- установка зависает;
- при подключении по VNC наблюдается ошибка:

- нет реакции на нажатие клавиш.
В таких случаях рекомендуем использовать образы FreeBSDx32. Также для решения проблемы помогает установка kernel-lt. Подробнее см. http://elrepo.org/tiki/kernel-lt.
Проблемы с доступностью виртуальных машин
Виртуальная машина недоступна после перезагрузки
Проверьте следующее:
- Узлы кластера должны иметь связь с мастер-сервером.
- Сервис vmwatch-master на мастер-сервере слушает нужный IP-адрес (IP-адрес определяет параметр VmwatchListenIp конфигурационного файла VMmanager). Если адрес не задан явно, используется адрес подключённого локального узла кластера. Если локального узла кластера нет, используется первый IP-адрес первого интерфейса. После изменения конфигурации запустите переконфигурирование сервисов из консоли с помощью команды:
/usr/local/mgr5/sbin/mgrctl -m vmmgr vmwatch.configureBASH
Проблемы с миграцией виртуальных машин
Ошибка, возникающая при живой миграции: virt TRACE ErrorCallback libvirt error code=38 message=Unable to read from monitor: Connection reset by peer.
Такая ошибка возникает в некоторых конфигурациях с версией libvirt 0.9.12.3 при выборе типа сетевого интерфейса виртуальной машины «virtio». Для успешной живой миграции в настройках сетевого интерфейса виртуальной машины укажите модель эмулируемого сетевого устройства отличную от «virtio», например «e1000». Для изменения этого параметра у существующей виртуальной машины потребуется её перезагрузка.
Ошибка: «internal error: unable to execute QEMU command ‘migrate’: this feature or command is not currently supported».
Эта ошибка возникает при попытке мигрировать включённую виртуальную машину на кластере с CentOS-7. Это вызвано ошибкой QEMU на CentOS-7.
Возможные пути решения:
- Отключите виртуальную машину и мигрируйте в выключенном состоянии.
-
Установите QEMU из репозитория centos-release-qemu-ev. Все команды выполняются в консоли каждого узла кластера от имени суперпользователя (root):
yum install centos-release-qemu-ev yum updateBASH
Будут обновлены все установленные пакеты, для которых доступно обновление. В списке обновляемых пакетов должны присутствовать:
libcacard-ev qemu-img-ev qemu-kvm-common-ev qemu-kvm-ev qemu-kvm-tools-evBASH
После обновления QEMU/KVM перезапустите виртуальные машины и сервис libvirtd.
Ошибка миграции и резервного копирования для виртуальных машин с диском qcow2 на серверах с версией QEMU 2.6
Не создаются резервные копии и не выполняется миграция виртуальных машин с виртуальным диском qcow2 и созданным внутри снапшотом во включённом состоянии. Версия QEMU 2.6, версия libvirt 2.0.
Эта проблема является ошибкой QEMU 2.6. Исправление вошло в QEMU 2.7.
Возможные пути решения:
- Перезагрузите виртуальную машину. После перезагрузки можно продолжать работу;
- Обновите QEMU до версии 2.7. Этот вариант не тестировался и не гарантируется его эффективность. Используйте на свой страх и риск.
В процессе миграции виртуальной машины размер диска LVM незначительно изменяется в большую сторону
Эта проблема является ошибкой QEMU. Подробнее см. https://bugs.launchpad.net/qemu/+bug/1449687 https://bugzilla.redhat.com/show_bug.cgi?id=1219541.
Исправить её можно только в QEMU. Варианта два: мигрировать выключенную машину или использовать qemu-img convert после миграции для уплотнения диска.
Ошибка: «Attempt to migrate guest to the same host».
Если миграция виртуальной машины не происходит и в логе var/migratevm.log появляется эта ошибка, то причины могут быть следующие:
- На узлах кластера установлен один и тот же hostname. Решение: исправьте hostname. Отредактируйте файлы /etc/hostname и /etc/hosts, замените в них старое имя сервера на новое.
-
Узлы кластера имеют одинаковый product_uuid. Для проверки запустите команду на всех узлах кластера:
cat /sys/class/dmi/id/product_uuidBASH
Если значения совпадают, то проблема действительно в одинаковом product_uuid. Решение: на узлах кластера, у которых совпадают product_uuid, отредактируйте файл /etc/libvirt/libvirtd.conf. Раскомментируйте строку:
#host_uuid = "00000000-0000-0000-0000-000000000000"BASH
Значение host_uuid заполните самостоятельно. Значение не может состоять из всех одинаковых цифр. Для создания uuid можно использовать утилиту uuidgen. После этого необходимо перезапустить Libvirt.
Ошибка libvirt при выполнении операции «Define»: «unknown OS type hvm»
В большинстве случаев проблема решается перезагрузкой сервера. Также рекомендуется проверить состояние аппаратной виртуализации в BIOS:
modprobe kvm
egrep '^flags.*(vmx|svm)' /proc/cpuinfoBASH
Если ответ пустой, то виртуализация отключена, включите.
Миграция виртуальной машины <наименование vm> невозможна: происходит процесс резервного копирования
Если в панели управления запущен процесс резервного копирования и виртуальная машина находится в списке для резервного копирования, то любые действия по отношению к данной виртуальной машине заблокированы. Блокировка продлится до окончания процесса резервного копирования.
Проблемы с импортом виртуальных машин
Ошибка ERROR Error: Type: ‘host_missing’ Object: Value: при импорте
Ошибка означает, что не найден ни один подходящий узел кластера для импорта. Убедитесь, что на хранилище, выбранном для импорта, достаточно свободного места. Убедитесь, что для создания виртуальной машины достаточно оперативной памяти.
Ошибка ERROR Error: Type: ‘xml’ Object: ‘parse_file’ Value: ‘/nfsshare/metainfo.xml’ при импорте
Для решения проблемы создайте файл /nfsshare/metainfo.xml. Содержимое файла можно скопировать из metainfo.xml любого шаблона ОС.
Где хранятся шаблоны ОС у VMmanager?
В папке: /nfsshare
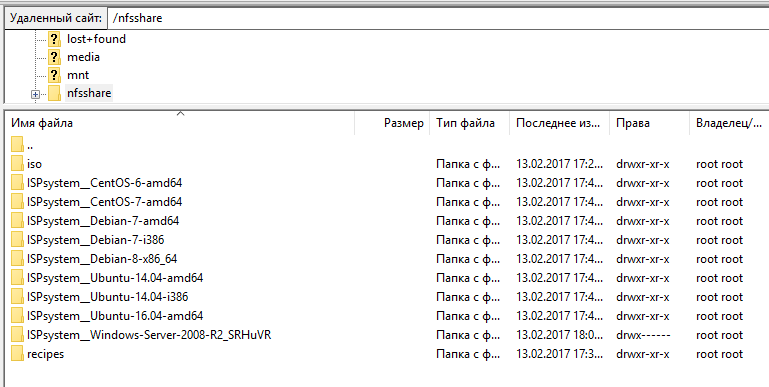
Где хранятся ISO файлы ОС?
В папке: /nfsshare/iso
VMmanager не запускается?!
Здесь может быть несколько проблем.
— Все место на сервере занято, например диск 120 GB SSD, а вы взяли и установили шаблоны ОС полностью все и заняли все свободное место на сервере.
— Неправильно настроен nginx для приема запросов и передачи запросов ihttpd.
— Неправильная настройка SSL сертификатов для панели.
Как хранятся файлы VPS?
В папке /vm.
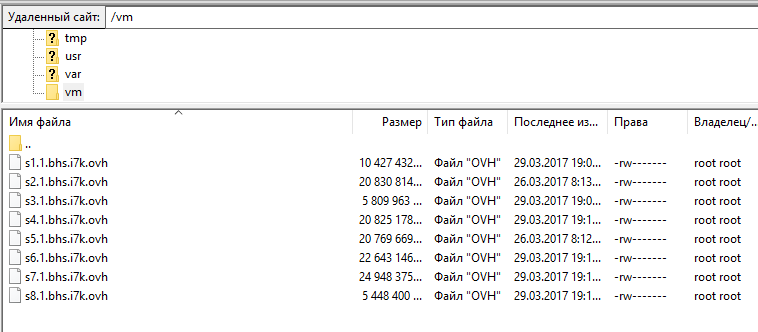
Можно через rsync выкачивать файлы VPS или через раздел резервное копирование.
Если зайти в список VPS выводит: «Не удалось выполнить запрос к базе данных» почему?
Может быть так что нету места на диске просто. Надо освободить место. Команда df -h для просмотра свободного места на диске.
Можно ставить разные ОС на серверы кластера для панели?
На всех узлах кластера должна быть такая же операционная система, как и на сервере, на котором установлен VMmanager.
Ошибка libvirt при выполнении операции «Start»: «unable to stat: /nfsshare/ISPsystem__Debian-8-x86_64/linux: No such file or directory»?
Надо ждать пока не продублируются шаблоны на ноду в папку /nfsshare.
Как решить ошибку libvirt: could not find capabilities for arch=x86_64 domaintype=kvm?
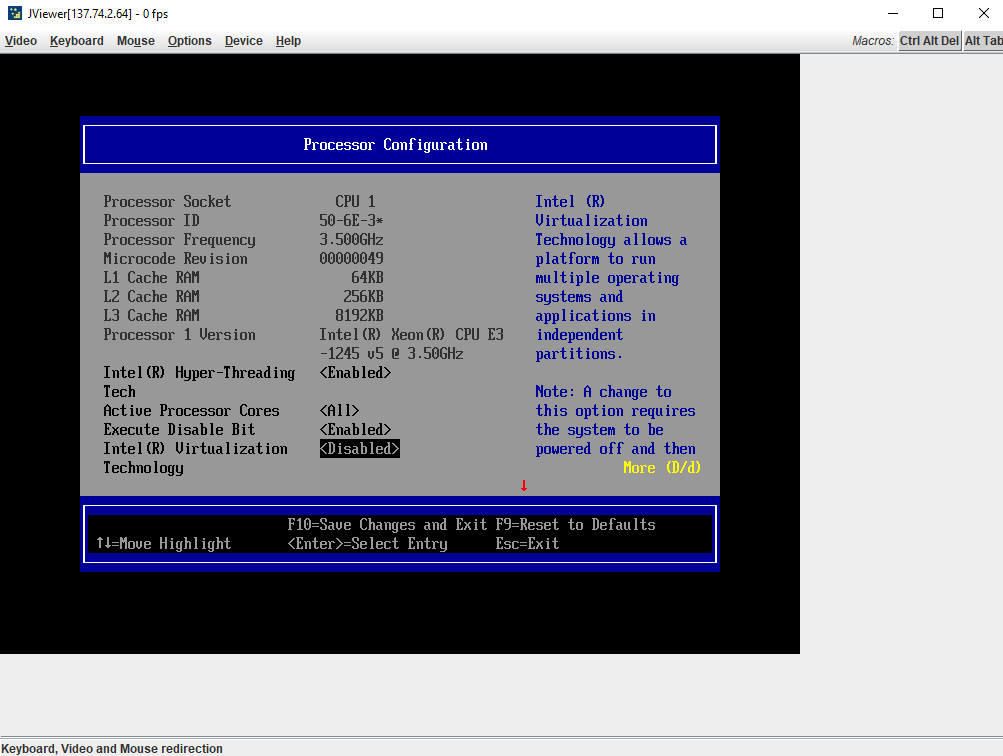
Включить в BIOS виртуализацию.
FAQ может пополнятся в зависимости от проблем.
Только зарегистрированные и авторизованные пользователи могут оставлять комментарии.

- нет реакции на нажатие клавиш.
В таких случаях рекомендуем использовать образы FreeBSDx32. Также для решения проблемы помогает установка kernel-lt. Подробнее см. http://elrepo.org/tiki/kernel-lt.
Проблемы с доступностью виртуальных машин
Виртуальная машина недоступна после перезагрузки
Проверьте следующее:
- Узлы кластера должны иметь связь с мастер-сервером.
- Сервис vmwatch-master на мастер-сервере слушает нужный IP-адрес (IP-адрес определяет параметр VmwatchListenIp конфигурационного файла VMmanager). Если адрес не задан явно, используется адрес подключённого локального узла кластера. Если локального узла кластера нет, используется первый IP-адрес первого интерфейса. После изменения конфигурации запустите переконфигурирование сервисов из консоли с помощью команды:
/usr/local/mgr5/sbin/mgrctl -m vmmgr vmwatch.configureBASH
Проблемы с миграцией виртуальных машин
Ошибка, возникающая при живой миграции: virt TRACE ErrorCallback libvirt error code=38 message=Unable to read from monitor: Connection reset by peer.
Такая ошибка возникает в некоторых конфигурациях с версией libvirt 0.9.12.3 при выборе типа сетевого интерфейса виртуальной машины «virtio». Для успешной живой миграции в настройках сетевого интерфейса виртуальной машины укажите модель эмулируемого сетевого устройства отличную от «virtio», например «e1000». Для изменения этого параметра у существующей виртуальной машины потребуется её перезагрузка.
Ошибка: «internal error: unable to execute QEMU command ‘migrate’: this feature or command is not currently supported».
Эта ошибка возникает при попытке мигрировать включённую виртуальную машину на кластере с CentOS-7. Это вызвано ошибкой QEMU на CentOS-7.
Возможные пути решения:
- Отключите виртуальную машину и мигрируйте в выключенном состоянии.
-
Установите QEMU из репозитория centos-release-qemu-ev. Все команды выполняются в консоли каждого узла кластера от имени суперпользователя (root):
yum install centos-release-qemu-ev yum updateBASH
Будут обновлены все установленные пакеты, для которых доступно обновление. В списке обновляемых пакетов должны присутствовать:
libcacard-ev qemu-img-ev qemu-kvm-common-ev qemu-kvm-ev qemu-kvm-tools-evBASH
После обновления QEMU/KVM перезапустите виртуальные машины и сервис libvirtd.
Ошибка миграции и резервного копирования для виртуальных машин с диском qcow2 на серверах с версией QEMU 2.6
Не создаются резервные копии и не выполняется миграция виртуальных машин с виртуальным диском qcow2 и созданным внутри снапшотом во включённом состоянии. Версия QEMU 2.6, версия libvirt 2.0.
Эта проблема является ошибкой QEMU 2.6. Исправление вошло в QEMU 2.7.
Возможные пути решения:
- Перезагрузите виртуальную машину. После перезагрузки можно продолжать работу;
- Обновите QEMU до версии 2.7. Этот вариант не тестировался и не гарантируется его эффективность. Используйте на свой страх и риск.
В процессе миграции виртуальной машины размер диска LVM незначительно изменяется в большую сторону
Эта проблема является ошибкой QEMU. Подробнее см. https://bugs.launchpad.net/qemu/+bug/1449687 https://bugzilla.redhat.com/show_bug.cgi?id=1219541.
Исправить её можно только в QEMU. Варианта два: мигрировать выключенную машину или использовать qemu-img convert после миграции для уплотнения диска.
Ошибка: «Attempt to migrate guest to the same host».
Если миграция виртуальной машины не происходит и в логе var/migratevm.log появляется эта ошибка, то причины могут быть следующие:
- На узлах кластера установлен один и тот же hostname. Решение: исправьте hostname. Отредактируйте файлы /etc/hostname и /etc/hosts, замените в них старое имя сервера на новое.
-
Узлы кластера имеют одинаковый product_uuid. Для проверки запустите команду на всех узлах кластера:
cat /sys/class/dmi/id/product_uuidBASH
Если значения совпадают, то проблема действительно в одинаковом product_uuid. Решение: на узлах кластера, у которых совпадают product_uuid, отредактируйте файл /etc/libvirt/libvirtd.conf. Раскомментируйте строку:
#host_uuid = "00000000-0000-0000-0000-000000000000"BASH
Значение host_uuid заполните самостоятельно. Значение не может состоять из всех одинаковых цифр. Для создания uuid можно использовать утилиту uuidgen. После этого необходимо перезапустить Libvirt.
Ошибка libvirt при выполнении операции «Define»: «unknown OS type hvm»
В большинстве случаев проблема решается перезагрузкой сервера. Также рекомендуется проверить состояние аппаратной виртуализации в BIOS:
modprobe kvm
egrep '^flags.*(vmx|svm)' /proc/cpuinfoBASH
Если ответ пустой, то виртуализация отключена, включите.
Миграция виртуальной машины <наименование vm> невозможна: происходит процесс резервного копирования
Если в панели управления запущен процесс резервного копирования и виртуальная машина находится в списке для резервного копирования, то любые действия по отношению к данной виртуальной машине заблокированы. Блокировка продлится до окончания процесса резервного копирования.
Проблемы с импортом виртуальных машин
Ошибка ERROR Error: Type: ‘host_missing’ Object: Value: при импорте
Ошибка означает, что не найден ни один подходящий узел кластера для импорта. Убедитесь, что на хранилище, выбранном для импорта, достаточно свободного места. Убедитесь, что для создания виртуальной машины достаточно оперативной памяти.
Ошибка ERROR Error: Type: ‘xml’ Object: ‘parse_file’ Value: ‘/nfsshare/metainfo.xml’ при импорте
Для решения проблемы создайте файл /nfsshare/metainfo.xml. Содержимое файла можно скопировать из metainfo.xml любого шаблона ОС.
Где хранятся шаблоны ОС у VMmanager?
В папке: /nfsshare
Где хранятся ISO файлы ОС?
В папке: /nfsshare/iso
VMmanager не запускается?!
Здесь может быть несколько проблем.
— Все место на сервере занято, например диск 120 GB SSD, а вы взяли и установили шаблоны ОС полностью все и заняли все свободное место на сервере.
— Неправильно настроен nginx для приема запросов и передачи запросов ihttpd.
— Неправильная настройка SSL сертификатов для панели.
Как хранятся файлы VPS?
В папке /vm.
Можно через rsync выкачивать файлы VPS или через раздел резервное копирование.
Если зайти в список VPS выводит: «Не удалось выполнить запрос к базе данных» почему?
Может быть так что нету места на диске просто. Надо освободить место. Команда df -h для просмотра свободного места на диске.
Можно ставить разные ОС на серверы кластера для панели?
На всех узлах кластера должна быть такая же операционная система, как и на сервере, на котором установлен VMmanager.
Ошибка libvirt при выполнении операции «Start»: «unable to stat: /nfsshare/ISPsystem__Debian-8-x86_64/linux: No such file or directory»?
Надо ждать пока не продублируются шаблоны на ноду в папку /nfsshare.
Как решить ошибку libvirt: could not find capabilities for arch=x86_64 domaintype=kvm?
Включить в BIOS виртуализацию.
FAQ может пополнятся в зависимости от проблем.
Только зарегистрированные и авторизованные пользователи могут оставлять комментарии.
При действиях с дисками и разделами на них с использованием командной строки и DISKPART вместо предполагаемого результата вы можете получить сообщение о том, что произошла ошибка службы виртуальных дисков с пояснениями, такими как: Указанный диск нельзя преобразовать, Устройство уже используется, Удаление не допускается для текущего загрузочного или системного тома или Нет носителя в устройстве.
В этой инструкции подробно о различных ошибках службы виртуальных дисков в DISKPART, что они означают и как можно их исправить.
Указанный диск нельзя преобразовать, к таким дискам относятся компакт-диски и DVD-диски

Ошибка службы виртуальных дисков «Указанный диск нельзя преобразовать. К таким дискам относятся компакт-диски и DVD-диски» возникает при выполнении команд преобразования дисков между таблицами разделов MBR и GPT. Основные причины:
- Вы действительно пробуете преобразовать диск, который не может быть преобразован.
- Вы хотите конвертировать жесткий диск или SSD в GPT или MBR, но предварительно не очистили его.
В последнем случае ситуацию можно исправить, при условии, что на диске (на всех его разделах) нет важных данных:
- Перед преобразованием, выбрав диск командой select disk N, очистите его командой clean — это удалить все разделы и все данные со всего физического диска.
- Используйте команды convert gpt или convert mbr для преобразования.
Для начинающих пользователей уточню:
- если диск разбит на несколько разделов, мы не можем конвертировать только один раздел, только весь физический диск целиком, поскольку «GPT» и «MBR» относится к самой структуре разделов и всему диску.
- DISKPART не позволяет выполнить преобразование на не очищенном от разделов диске.
Если вам необходимо сохранить данные, для конвертации можно использовать сторонние программы для работы с разделами на дисках (в последний раз, когда я тестировал, эта функция была доступна бесплатно в DiskGenius), а если на диске уже установлена Windows 10 или Windows 11 и необходимо преобразование в GPT, можно использовать встроенную системную утилиту mbr2gpt.exe для конвертации без потери данных.
Удаление не допускается для текущего загрузочного или системного тома, а также томов с файлами подкачки, аварийного дампа и спящего режима

Указанная в подзаголовке ошибка службы виртуальных дисков говорит именно о том, что можно прочесть в тексте: вы пробуете выполнить действие, вероятнее всего — удаление, с разделом диска, на котором находится одно из:
- Загрузчик текущей ОС Windows (например, EFI-раздел FAT32)
- Сама операционная система, из которой вы производите указанные действия: мы не можем удалить том, с которого работает Windows, запущенная в настоящий момент.
- Файл подкачки, файлы гибернации, аварийного дампа памяти, спящего режима
Чаще всего причина — именно первый случай, при условии, что у пользователя на компьютере есть более одного HDD или SSD, система установлена на одном из них и он хочет очистить и отформатировать второй, а загрузчик текущей системы находится именно на том диске.
Возможное решение здесь: отключить диск, который требуется очистить, создать раздел с загрузчиком на диске с системой (или выполнить восстановление загрузчика), как описано в статье Восстановление загрузчика Windows 11 (подойдет и для Windows 10), убедиться, что загрузка работает исправно, вернуть диск, загрузиться с использованием нового загрузочного раздела и выполнить необходимые действия с диском.
Если ситуация отличается, и ошибка возникает с диском, на котором нет системы или загрузчика, можно попробовать:
- Временно отключить файл подкачки.
- Отключить сохранение дампов памяти.
- Отключить гибернацию.
- Если вы перемещали какие-то иные системные элементы на диск, с которым нужно выполнить действие, откатите сделанные настройки.
И выполнить перезагрузку компьютера после этого.
Ещё одна возможность выполнить операции с диском или разделом — использовать командную строку в среде восстановления, как описано в инструкциях Среда восстановления Windows 11, Среда восстановления Windows 10. Ошибка в этом случае, вероятнее всего не появится (зависит от конкретных дисков и разделов), однако существует риск удалить что-то критически важное для работы текущей операционной системы.
Не допускается очистка диска, содержащего текущий загрузочный или системный тома

Причины ошибки — те же, что и в предыдущем случае, как и возможные способы решения. Чаще всего проблема в том, что раздел с загрузчиком текущей ОС находится на диске отличном от места нахождения самой ОС.
В отличие от предыдущего случая, ошибка возникает не при удалении разделов, а при попытке очистить диск полностью.

Ошибка службы виртуальных дисков: Нет носителя в устройстве — одна из самых неприятных ситуаций, чаще всего возникающих с флешками или картами памяти. Причины и сценарии появления ошибки бывают разными:
- Накопитель читался и был исправен, но при выполнении команд DISKPART через некоторое время сообщил об ошибке «Нет носителя в устройстве». Возможные причины: проблемы с подключением накопителя (в том числе флешки или карты памяти), проблемы с USB-хабом или кардридером при их использовании, проблемы с разъемами USB. Обычно после повторного подключения накопителя его можно попробовать форматировать снова: лучше использовать другие разъемы, USB 2.0 вместо 3.0, избегать использования USB-хабов. По возможности следует проверить работу с накопителем на другом компьютере или ноутбуке, так как проблема в некоторых случаях бывает вызвана неисправностями электропитания на конкретном устройстве.
- Неисправности накопителя. Для флешки или SD-карты имеет смысл проверить, смогут ли выполнить исправление и форматирование специализированные программы «для ремонта» флешек.
- Проблема с питанием, недостаток мощности при питании по USB для внешних дисков SSD/HDD.
- В устройстве действительно нет накопителя: например, некоторые кард-ридеры, даже без подключенных карт памяти могут иметь букву и определяться как диск. При операциях с такими «дисками» можно получить сообщение о том, что нет носителя в устройстве.
В некоторых случаях при такой ошибке, особенно если она происходит с разными USB-накопителями, может помочь установка оригинальных драйверов чипсета и контроллеров USB с сайта производителя материнской платы ПК или ноутбука.
Если ваша ситуация схожа, но отличается в деталях от представленных в статье выше, опишите её в подробностях — не исключено, что решение вашей проблемы также удастся найти.
В статье приведены решения наиболее часто возникающих проблем, связанных с работой VMmanager Cloud.
Проблемы с панелью управления
Обновление ПО кластера VMmanager KVM до VMmanager Cloud
Такое обновление не поддерживается.
VMmanager зависает и тормозит, в логе фигурирует ошибка «too many connections»
Наиболее частой причиной такой проблемы является зависание libvirt. Проверьте, что libvirt отвечает, попробуйте его перезапустить.
Какие процессы важны для VMmanager? Что можно отслеживать?
Важен процесс ihttpd. Также на серверах должен быть запущен libvirt.
Какие единицы измерения используются в панели управления?
В панели управления используются KiB и MiB:
- KiB (кибибайт) — 2 в степени 10 = 1024;
- MiB (мебибайт) — 2 в степени 20 = 1048576.
Что отлично от привычных KB и MB:
- MB (мегабайт) — 10 в степени 6 = 1000000;
- KB (килобайт) — 10 в степени 3 = 1000.
Формирование виртуальной машины:
- если требуется создать виртуальную машину c 2GB оперативной памяти, то в форме редактирования необходимо указать 1907MiB (точное значение 2GB = 1907,35MiB);
- если требуется создать диск виртуальной машины размером 15GB, то в панели необходимо указать 14305Mib;
- обратите внимание на калькулятор величин от Google.
Проблемы с узлами кластера
После добавления виртуальной машины один из узлов кластера становится недоступен, а при попытке подключения к нему по SSH происходит подключение к виртуальной машине
При выдаче IP-адресов виртуальным машинам из той же подсети, в которой выделены IP-адреса для узлов кластера, возможна выдача IP-адреса, присвоенного узлу кластера. Вследствие этого узел будет недоступен. Для избежания данной проблемы зарезервируйте адреса узлов кластера в локальной базе IP-адресов или в IPmanager, если настроена интеграция.
Для освобождения занятого адреса виртуальной машиной выделите для неё новый IP-адрес. Перейдите в Управление → Виртуальные машины → IP-адреса. Создайте новый IP-адрес и удалите адрес, который пересекается с адресом узла кластера. Для использования виртуальной машиной нового IP-адреса измените настройки сетевого интерфейса и перезапустите сеть командой:
systemctl restart networkBASH
Ошибка при добавлении узла кластера: «Ошибка установки пакетов ‘vmmanager-kvm-pkg-vmnode’ на удалённом сервере. Дополнительная информация доступна в журнале панели управления»
Причина: пакет libguestfs устанавливается только в интерактивном режиме.
Решение: установите пакет vmmanager-kvm-pkg-vmnode из консоли.
Не добавляется узел с операционной системой CentOS
Возможная проблема — не устанавливаются необходимые пакеты. Причина — отсутствие подключённого репозитория epel. Возможная причина — неверная дата на сервере — репозиторий не находится. Проверьте и исправьте при необходимости время и дату и повторите попытку.
Не добавляется узел. Ошибка: «Невозможно применить правила брандмауэра: ошибка в синтаксисе iptables»
В логах vmmgr.log при этом видно ошибку запуска скрипта /etc/libvirt/hooks/firewall.sh:
# /etc/libvirt/hooks/firewall.sh
# Generated by VMmanager KVM on Сбт Апр 18 21:31:18 CEST 2015 *filter
# ISPsystem firewall rules
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPT
-F INPUT
-F FORWARD
COMMIT --------------------------------
ip6tables-restore v1.4.7: ip6tables-restore: unable to initialize table 'filter'
Error occurred at line: 2
Try 'ip6tables-restore -h' or 'ip6tables-restore --help' for more information.BASH
Для решения проблемы закомментируйте строки в конфигурационном файле /etc/modprobe.d/ipv6.conf и перезапустите модуль ipv6.
Утилиты управления кластером
Выполнение команды на всех узлах кластера:
/usr/local/mgr5/sbin/nodectl --op exec --target all --cmd 'echo "Hello, world!"'BASH
Переход по SSH на узел кластера:
/usr/local/mgr5/sbin/nodectl login <id узла кластера>BASH
Просмотр списка узлов кластера:
/usr/local/mgr5/sbin/nodectl listBASH
Изменение мастер-узла (при этом изменяются приоритеты серверов и VMmanager запускается на указанном сервере):
/usr/local/mgr5/sbin/cloudctl -c relocate -m <id узла кластера> BASH
Восстановление работоспособности в VMmanager Cloud
Восстановление виртуальных машин
При отказе узла кластера виртуальные машины, работающие на этом узле, восстанавливаются на другом работоспособном узле кластера. Для этого необходимо, чтобы виртуальные диски виртуальных машин были расположены в сетевых хранилищах. Если для диска виртуальной машины использовалось локальное хранилище, виртуальная машина не будут восстановлена, поскольку ее данные становятся недоступными.
Восстановление виртуальных машин на работоспособных узлах кластера начинается сразу же при отказе узла кластера. Процесс восстановления последовательный, при этом выполняются следующие действия для каждой виртуальной машины:
- выбирается узел кластера, на котором будет создана виртуальная машина. Подробнее об алгоритме см. в статье Настройка распределения виртуальных машин по узлам кластера;
- создаётся виртуальная машина с такими же параметрами, как и на отказавшем узле кластера;
- подключается сетевой диск машины и происходит ее запуск.
Процедура восстановления логируется в общем логе VMmanager — vmmgr.log, запись в логе при восстановлении машины:
Пояснения
id — это номер виртуальной машины в базе данных VMmanager (база данных mysql — vmmgr, таблица vm).
Восстановление узла кластера
Узел кластера считается отказавшим и отсоединяется от кластера, если он не отвечает более 1 секунды. Обратите внимание, что перезагрузка сервера длится дольше. В связи с этим необходимо учитывать, что после перезагрузки узел кластера потребуется восстанавливать. Нельзя одновременно перезагружать узлы кластера таким образом, что количество продолжающих работать узлов будет меньше кворума.
После того, как узел кластера оказался недоступным, система corolistener изменяет файлы конфигурации на всех живых узлах кластера. Для последующего восстановления узла кластера:
- убедитесь, что все сервисы на узле функционируют в штатном порядке;
- верните узел в кворум. Для этого нажмите Настройка кластера → Узлы кластера → Присоединить;
- синхронизируйте конфигурационный файл corosync с другими узлами:
/usr/local/mgr5/sbin/mgrctl -m vmmgr cloud.conf.rebuildBASH
- запустите систему corosync:
/etc/init.d/corosync startBASH
- запустите сервис corolistener:
/usr/local/mgr5/sbin/corolistener -c startBASH
Восстановление кластера после потери кворума
VMmanager Cloud реплицируется на все узлы кластера, чтобы обеспечить отказоустойчивость самой панели. При этом запускается VMmanager только на одном узле кластера. После потери кворума бывают ситуации, когда VMmanager не может запуститься даже на узле кластера с максимальным приоритетом.
Алгоритм восстановления кластера:
- На мастер-сервере:
- Удалите опцию Option ClusterEnabled из конфигурационного файла (по умолчанию /usr/local/mgr5/etc/vmmgr.conf).
-
Убедитесь в наличии файла /tmp/.lock.vmmgr.service. Если файл отсутствует, создайте его:
touch /tmp/.lock.vmmgr.serviceBASH
-
Добавьте IP-адрес лицензии на интерфейс vmbr0:
ip addr add <IP-адрес> dev vmbr0BASH
- На узлах кластера:
-
Убедитесь в наличии файлов /usr/local/mgr5/var/disabled. Если файл отсутствует, создайте его:
touch /usr/local/mgr5/var/disabledBASH
-
Убедитесь в отсутствии файла /tmp/.lock.vmmgr.service. Если файл присутствует, удалите его:
rm /tmp/.lock.vmmgr.serviceBASH
- Убедитесь в отсутствии на интерфейсе vmbr0 IP-адреса лицензии.
- Запустите панель управления.
- Включите облачные функции в интерфейсе панели управления.
-
Проблемы с хранилищами
Проблемы с LVM-хранилищем
Невозможно создать хранилище с типом LVM. При попытке добавить новый узел в кластер иногда возникает ошибка «unsupported configuration: cannot find any matching source devices for logical volume group»
Убедитесь, что команды LVM подтверждают существование физических томов, которые планируется добавить. Попробуйте удалить хранилище и узел кластера и добавить заново. Удаление хранилища выполняется с помощью команды:
virsh pool-undefine название-хранилища.BASH
Проблемы с сетевым LVM-хранилищем
Не удаётся обнаружить группу томов на узлах
Если команда vgs на узлах не отображает группу томов LVM с iSCSI-хранилища, проверьте, работает ли с ней iscsi-target. Для этого на узле таргета выполните команду:
tgtadm -m target --op showBASH
Если в списке lun необходимый раздел отсутствует, добавьте его вручную:
tgtadm -m logicalunit --op new --tid 1 -b /dev/sda2 --lun 1BASH
После этого перезагрузите tgtd, переподключите узлы к таргету и выполните на узлах pvscan для обнаружения пула.
Проблема при подключении нового узла кластера
При перезагрузке сервиса убедитесь, что он перезапустился:
service tgtd stop
killall -9 tgtd
service tgtd startBASH
![]()
Обратите внимание!
Команда killall -9 tgtd уничтожит процессы сервиса tgtd, при этом возможна потеря данных.
Проблемы с iSCSI-хранилищем
Requested operation is not valid: storage pool is not active
Ошибка возникает, если есть проблемы с iSCSI-хранилищем. Проверьте статус службы tgtd на сервере с хранилищем (должна быть запущена). Если проблема появляется при добавлении нового узла, то подключитесь по SSH на добавляемый узел и выполните команду:
virsh pool-list --allBASH
Если в выводе команды присутствует строка вида iSCSI-UGLY_004 | не активен | yes, то можно попробовать удалить это хранилище и добавить узел ещё раз:
virsh pool-undefine iSCSI-UGLY_004BASH
internal error Child process (/sbin/iscsiadm —mode discovery —type sendtargets —portal xxx.xxx.xxx.xxx:3260,1) status unexpected: exit status 255
VMmanager не может подключиться к серверу с iSCSI по 3260 порту. Причин может быть несколько:
- SELinux должен быть отключён;
- Нужный порт закрыт в файерволе.
Ошибка: «operation failed: Storage source conflict with pool: ‘…’ «
Эта ошибка может появляться на этапе создания хранилища типа dir или netfs. Означает, что на сервере уже существует хранилище данного типа, которое расположено в той же директории, что и создаваемое.
Решение: Найти и удалить существующее хранилище на всех узлах кластера:
virsh pool-list
virsh pool-dumpxml <pool-name>
virsh pool-destroy <pool-name>
virsh pool-undefine <pool-name>BASH
Проблемы с RBD-хранилищем
Ошибка при добавлении хранилища на узел кластера
ceph auth get-or-create client.vmmgr mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=isptest' key for client.vmmgr exists but cap osd does not matchBASH
Решение: Зайдите на монитор и удалите пользователя client.vmmgr
ceph auth del client.vmmgrBASH
Требуется сменить IP-адрес Ceph-монитора
Для создаваемых виртуальных машин:
Непосредственно на самом Ceph-мониторе IP-адрес может быть изменён вручную администратором Ceph-хранилища. В базе MySQL «vmmgr» на мастере VMmanager в таблице «metapool» необходимо заменить поле «srchostname» на новый узел. В таблице «rbdmonitor» убедитесь, что значение «metapool» соответствует значению «id» из таблицы «metapool». После правки базы удалите кэш:
rm -rf /usr/local/mgr5/var/.db.cache.vm*BASH
Затем перезапустите панель управления:
Для существующих виртуальных машин выполните следующие команды:
sed -i 's/old_IP/new_IP/g' /etc/libvirt/qemu/*.xml
virsh define /etc/libvirt/qemu/*.xmlBASH
Пояснения
old_IP — заменяемый IP-адрес.
new_IP — новый IP-адрес.
Проблемы с GlusterFS-хранилищем
При размещении двух хранилищ VMmanager в одном и том же томе и директории GlusterFS, но с разными типами (QCOW2 и RAW) невозможно выполнить перемещение виртуального диска между этими хранилищами
Используйте разные директории на сетевом хранилище для избежания такой ситуации.
Импорт виртуальных машин из другого VMmanager или из другого сервера с libvirt напрямую в хранилище GlusterFS не работает, так как драйвер libvirt не поддерживает запись содержимого диска из потока
Для решения проблемы при определении параметров импорта укажите перенос в хранилище другого типа, а затем переместите диски импортированных машин в хранилище GlusterFS.
Проблемы с NFS-хранилищем
Проблема при создании виртуального диска
Если libvirt не может создать образ в хранилище, а в логе /var/log/syslog присутствуют подобные строки:
rpc.idmapd[706]: nss_getpwnam: name 'root@testers' does not map into domain 'ispsystem.net'.BASH
Для решения проблемы в файле /etc/idmapd.conf на сервере и клиенте укажите корректное и одинаковое значение параметра «Domain». После редактирования перезагрузите сервер и клиент, повторно добавьте хранилище в VMmanager.
Проблема при удалении данных из хранилища
Если диски, созданные в хранилище NFS, не удаляются с ошибкой: Ошибка libvirt при выполнении операции «VolDelete»: «cannot unlink file ‘/nfs-pool/volume’: Permission denied».
В /var/log/messages содержится подобное сообщение:
Для решения проблемы в файле /etc/idmapd.conf на сервере и клиенте укажите корректное и одинаковое значение параметра «Domain». После редактирования перезагрузите сервер и клиент, повторно добавьте хранилище в VMmanager.
Проблемы с виртуальными дисками
Ошибка libvirt при изменении размера диска
Ошибка libvirt при выполнении операции «Grow»: «unknown procedure: 260».
Эта ошибка чаще всего возникает из-за устаревшей версии libvirt. Обновите libvirt.
Ошибка: «Не удалось примонтировать диски виртуальной машины» при смене пароля
Проблема проявляется при попытке сменить пароль для виртуальной машины с файловой системой XFS внутри, размещённой на хост-сервере с ext4 и ядром версии менее 3.10. Для более точной диагностики запустите вручную команду:
guestmount -v -x -a <образ_диска> -i <путь к точке монтирования>BASH
Если в выводе видны сообщения «mount: wrong fs type, bad option, bad superblock», то работа с этой машиной с помощью libguestfs невозможна. Причина — неполная поддержка гостевой xfs в ядре RHEL/CentOS 6. Подробнее см. virt-inspector can’t obtain info from rhel7.3 guest image on rhel6.9 host. К сожалению, по заявлениям разработчиков libguestfs, это поведение не может быть исправлено.
Проблемы с настройкой сети
IPv6 на Ubuntu 12.04
При добавлении узла кластера с IPv6-адресом выводится ошибка: «Невозможно подключиться к серверу XXX. Возможно, на сервере не работают службы ssh или libvirt-bin».
В логах:
Mar 13 13:26:09 [2157:0x95E700] virt TRACE ErrorCallback libvirt error code=38 message=Cannot recv data: ssh: external/libcrypto.so.1.0.0: no version information available (required by ssh) : Connection reset by peertname [2a01:230:2:3::3]: Name or service not known
Mar 13 13:26:09 [2157:0x95E700] virt DEBUG vir_host.cpp:70 Connect to qemu+ssh://[2a01:230:2:3::3]/system?keyfile=etc/ssh_id_rsa
Mar 13 13:26:09 [2157:0x95E700] err ERROR Error: Type: 'vir_connection'
Mar 13 13:26:09 [2157:0x95E700] virt TRACE Fail libvirt message: 'Cannot recv data: ssh: external/libcrypto.so.1.0.0: no version information available (required by ssh)BASH
Эта ошибка является багом Ubuntu 12.04. Подробнее см. на launchpad.
Решение: Добавьте узел с IPv4 адресом.
Проблемы с виртуальными машинами
Проблемы при создании виртуальных машин
Ошибка при создании виртуальной машины: «ERROR: Exception 1: Insufficient RAM for VM creation», хотя в Swap ещё достаточно оперативной памяти
Свободная оперативная память — это free + cached. Swap не учитывается.
При попытке создания виртуальной машины возникает ошибка. Ошибка libvirt при выполнении операции «Start»: «internal error Process exited while reading console log output: qemu-kvm: -chardev pty,id=charserial0: Failed to create chardev».
Для решения проблемы выполните команду:
mount -n -t devpts -o remount,mode=0620,gid=5 devpts /dev/ptsBASH
При попытке создания виртуальной машины возникает ошибка. Ошибка libvirt при выполнении операции «Start»: «internal error cannot create rule since ebtables tool is missing»
Проверьте вывод команды lsmod |grep ebt. Если нет результата, значит в ядре нет поддержки ebtables. Пересоберите ядро либо скачайте другое и правкой grub.conf измените порядок загрузки.
Проблемы с установкой операционной системы
Установщик не может скачать файл ответов
Эта ошибка может быть обнаружена при подключении к виртуальной машине по VNC.
Причин может быть несколько:
- IP-адрес виртуальной машины не может быть прикреплён к узлу кластера, на котором эта машина создана. Так бывает, например, если IP-адреса в дата-центре привязаны к MAC-адресам.
- Не работает резолвер на виртуальной машине. В качестве резолвера используется первый резолвер с родительского сервера (файл /etc/resolv.conf).
- VMmanager пытается предоставить файл ответов по внутреннему IP-адресу, который не доступен снаружи, а установщик скачивает файл ответов через внешнюю сеть.
- В настройках ihttpd настроен redirect для http-соединений. IP-адрес, на который будет предоставлен файл ответов, VMmanager получает от ihttpd и узнать его можно с помощью команды:
/usr/local/mgr5/sbin/ihttpdBASH
Берётся верхний из списка IP-адрес, подходящий по протоколу. Если эта команда показывает верхним внутренний IP-адрес, установщик не сможет получить файл ответов. Сконфигурируйте ihttpd, первым указав внешний IP-адрес.
Не удаётся полностью получить preseed-файл при установке Debian
Для решения проблемы уберите опцию «nocunked» в файле конфигурации ihttpd (по умолчанию /usr/local/mgr5/etc/ihttpd.conf).
После этого перезапустите сервис ihttpd.
Проблемы с установкой Windows 2016 на виртуальной машине: В VNC наблюдается, что установка зависла на этапе загрузки
Встречается на серверах с версией QEMU 1.5, 0.12, 1.1.2.
Решение: при создании виртуальной машины включите режим эмуляции процессора host-passthrough. Для QEMU 2.6 установка этих шаблонов работает без необходимости изменения режима эмуляции, но иногда может потребоваться перезапуск службы libvirt (service libvirtd restart) (если было обновление системы).
При установке FreeBSD-amd64 на некоторых типах процессоров могут возникнуть проблемы:
- установка зависает;
- при подключении по VNC наблюдается ошибка:

- нет реакции на нажатие клавиш.
В таких случаях рекомендуем использовать образы FreeBSDx32. Также для решения проблемы помогает установка kernel-lt. Подробнее см. http://elrepo.org/tiki/kernel-lt.
Проблемы с доступностью виртуальных машин
Виртуальная машина недоступна после перезагрузки
Проверьте следующее:
- Узлы кластера должны иметь связь с мастер-сервером.
- Сервис vmwatch-master на мастер-сервере слушает нужный IP-адрес (IP-адрес определяет параметр VmwatchListenIp конфигурационного файла VMmanager). Если адрес не задан явно, используется адрес подключённого локального узла кластера. Если локального узла кластера нет, используется первый IP-адрес первого интерфейса. После изменения конфигурации запустите переконфигурирование сервисов из консоли с помощью команды:
/usr/local/mgr5/sbin/mgrctl -m vmmgr vmwatch.configureBASH
Проблемы с миграцией виртуальных машин
Ошибка, возникающая при живой миграции: virt TRACE ErrorCallback libvirt error code=38 message=Unable to read from monitor: Connection reset by peer
Такая ошибка возникает в некоторых конфигурациях с версией libvirt 0.9.12.3 при выборе типа сетевого интерфейса виртуальной машины «virtio». Для успешной живой миграции в настройках сетевого интерфейса виртуальной машины укажите модель эмулируемого сетевого устройства отличную от «virtio», например «e1000». Для изменения этого параметра у существующей виртуальной машины потребуется её перезагрузка.
Ошибка: «internal error: unable to execute QEMU command ‘migrate’: this feature or command is not currently supported»
Эта ошибка возникает при попытке мигрировать включённую виртуальную машину на кластере с CentOS-7. Это вызвано ошибкой QEMU на CentOS-7.
Возможные пути решения:
- Отключите виртуальную машину и мигрируйте в выключенном состоянии.
-
Установите QEMU из репозитория centos-release-qemu-ev. Все команды выполняются в консоли каждого узла кластера от имени суперпользователя (root):
yum install centos-release-qemu-ev yum updateBASH
Будут обновлены все установленные пакеты, для которых доступно обновление. В списке обновляемых пакетов должны присутствовать:
libcacard-ev qemu-img-ev qemu-kvm-common-ev qemu-kvm-ev qemu-kvm-tools-evBASH
После обновления QEMU/KVM перезапустите виртуальные машины и сервис libvirtd.
Ошибка миграции и резервного копирования для виртуальных машин с диском qcow2 на серверах с версией QEMU 2.6
Не создаются резервные копии и не выполняется миграция виртуальных машин с виртуальным диском qcow2 и созданным внутри снапшотом во включённом состоянии. Версия QEMU 2.6, версия libvirt 2.0.
Данная проблема является ошибкой QEMU 2.6. Исправление вошло в QEMU 2.7.
Возможные пути решения:
- Перезагрузите виртуальную машину. После перезагрузки можно продолжать работу;
- Обновите QEMU до версии 2.7. Этот вариант не тестировался и не гарантируется его эффективность. Используйте на свой страх и риск.
В процессе миграции виртуальной машины размер диска LVM незначительно изменяется в большую сторону
Эта проблема является ошибкой QEMU. Подробнее см. https://bugs.launchpad.net/qemu/+bug/1449687 https://bugzilla.redhat.com/show_bug.cgi?id=1219541.
Исправить её можно только в QEMU. Варианта два: мигрировать выключенную машину или использовать qemu-img convert после миграции для уплотнения диска.
Ошибка: «Attempt to migrate guest to the same host».
Если миграция виртуальной машины не происходит и в логе var/migratevm.log появляется эта ошибка, то причины могут быть следующие:
- На узлах кластера установлен один и тот же hostname. Решение: исправьте hostname. Отредактируйте файлы /etc/hostname и /etc/hosts, замените в них старое имя сервера на новое.
-
Узлы кластера имеют одинаковый product_uuid. Для проверки запустите команду на всех узлах кластера:
cat /sys/class/dmi/id/product_uuidBASH
Если значения совпадают, то проблема действительно в одинаковом product_uuid. Решение: на узлах кластера, у которых совпадают product_uuid, отредактируйте файл /etc/libvirt/libvirtd.conf. Раскомментируйте строку:
#host_uuid = "00000000-0000-0000-0000-000000000000"BASH
Значение host_uuid заполните самостоятельно. Значение не может состоять из всех одинаковых цифр. Для создания uuid можно использовать утилиту uuidgen. После этого необходимо перезапустить Libvirt.
Ошибка libvirt при выполнении операции «Define»: «unknown OS type hvm»
В большинстве случаев проблема решается перезагрузкой сервера. Также рекомендуем проверить состояние аппаратной виртуализации в BIOS:
modprobe kvme
grep '^flags.*(vmx|svm)' /proc/cpuinfoBASH
Если ответ пустой, то виртуализация отключена, включите.
Миграция виртуальной машины <наименование vm> невозможна: происходит процесс резервного копирования
Если в панели управления запущен процесс резервного копирования и виртуальная машина находится в списке для резервного копирования, то любые действия по отношению к данной виртуальной машине заблокированы. Блокировка продлится до окончания процесса резервного копирования.
Проблемы с импортом виртуальных машин
Ошибка ERROR Error: Type: ‘host_missing’ Object: Value: при импорте
Ошибка означает, что не найден ни один подходящий узел кластера для импорта. Убедитесь, что на хранилище, выбранном для импорта, достаточно свободного места. Убедитесь, что для создания виртуальной машины достаточно оперативной памяти.
Ошибка ERROR Error: Type: ‘xml’ Object: ‘parse_file’ Value: ‘/nfsshare/metainfo.xml’ при импорте
Для решения проблемы создайте файл /nfsshare/metainfo.xml. Содержимое файла можно скопировать из metainfo.xml любого шаблона ОС.
1 минуту назад, Jack Shepard сказал:
ну ошибка линуксовая. KVM окружение, ошибка с выделением памяти под виртуальную машину. Это вам надо писать в суппорт где дедик арендуете.
да уже создал тикет,жду,думал,мб что-то дефолтное,заметил,что этот дедик сам офался когда я не работал на нем,приходилось запускать,дня 3-4 такое было,а сейчас вот это,другой дедик на этом сервисе работает
![]()
- нет реакции на нажатие клавиш.
В таких случаях рекомендуем использовать образы FreeBSDx32. Также для решения проблемы помогает установка kernel-lt. Подробнее см. http://elrepo.org/tiki/kernel-lt.
Проблемы с доступностью виртуальных машин
Виртуальная машина недоступна после перезагрузки
Проверьте следующее:
- Узлы кластера должны иметь связь с мастер-сервером.
- Сервис vmwatch-master на мастер-сервере слушает нужный IP-адрес (IP-адрес определяет параметр VmwatchListenIp конфигурационного файла VMmanager). Если адрес не задан явно, используется адрес подключённого локального узла кластера. Если локального узла кластера нет, используется первый IP-адрес первого интерфейса. После изменения конфигурации запустите переконфигурирование сервисов из консоли с помощью команды:
/usr/local/mgr5/sbin/mgrctl -m vmmgr vmwatch.configureBASH
Проблемы с миграцией виртуальных машин
Ошибка, возникающая при живой миграции: virt TRACE ErrorCallback libvirt error code=38 message=Unable to read from monitor: Connection reset by peer
Такая ошибка возникает в некоторых конфигурациях с версией libvirt 0.9.12.3 при выборе типа сетевого интерфейса виртуальной машины «virtio». Для успешной живой миграции в настройках сетевого интерфейса виртуальной машины укажите модель эмулируемого сетевого устройства отличную от «virtio», например «e1000». Для изменения этого параметра у существующей виртуальной машины потребуется её перезагрузка.
Ошибка: «internal error: unable to execute QEMU command ‘migrate’: this feature or command is not currently supported»
Эта ошибка возникает при попытке мигрировать включённую виртуальную машину на кластере с CentOS-7. Это вызвано ошибкой QEMU на CentOS-7.
Возможные пути решения:
- Отключите виртуальную машину и мигрируйте в выключенном состоянии.
-
Установите QEMU из репозитория centos-release-qemu-ev. Все команды выполняются в консоли каждого узла кластера от имени суперпользователя (root):
yum install centos-release-qemu-ev yum updateBASH
Будут обновлены все установленные пакеты, для которых доступно обновление. В списке обновляемых пакетов должны присутствовать:
libcacard-ev qemu-img-ev qemu-kvm-common-ev qemu-kvm-ev qemu-kvm-tools-evBASH
После обновления QEMU/KVM перезапустите виртуальные машины и сервис libvirtd.
Ошибка миграции и резервного копирования для виртуальных машин с диском qcow2 на серверах с версией QEMU 2.6
Не создаются резервные копии и не выполняется миграция виртуальных машин с виртуальным диском qcow2 и созданным внутри снапшотом во включённом состоянии. Версия QEMU 2.6, версия libvirt 2.0.
Данная проблема является ошибкой QEMU 2.6. Исправление вошло в QEMU 2.7.
Возможные пути решения:
- Перезагрузите виртуальную машину. После перезагрузки можно продолжать работу;
- Обновите QEMU до версии 2.7. Этот вариант не тестировался и не гарантируется его эффективность. Используйте на свой страх и риск.
В процессе миграции виртуальной машины размер диска LVM незначительно изменяется в большую сторону
Эта проблема является ошибкой QEMU. Подробнее см. https://bugs.launchpad.net/qemu/+bug/1449687 https://bugzilla.redhat.com/show_bug.cgi?id=1219541.
Исправить её можно только в QEMU. Варианта два: мигрировать выключенную машину или использовать qemu-img convert после миграции для уплотнения диска.
Ошибка: «Attempt to migrate guest to the same host».
Если миграция виртуальной машины не происходит и в логе var/migratevm.log появляется эта ошибка, то причины могут быть следующие:
- На узлах кластера установлен один и тот же hostname. Решение: исправьте hostname. Отредактируйте файлы /etc/hostname и /etc/hosts, замените в них старое имя сервера на новое.
-
Узлы кластера имеют одинаковый product_uuid. Для проверки запустите команду на всех узлах кластера:
cat /sys/class/dmi/id/product_uuidBASH
Если значения совпадают, то проблема действительно в одинаковом product_uuid. Решение: на узлах кластера, у которых совпадают product_uuid, отредактируйте файл /etc/libvirt/libvirtd.conf. Раскомментируйте строку:
#host_uuid = "00000000-0000-0000-0000-000000000000"BASH
Значение host_uuid заполните самостоятельно. Значение не может состоять из всех одинаковых цифр. Для создания uuid можно использовать утилиту uuidgen. После этого необходимо перезапустить Libvirt.
Ошибка libvirt при выполнении операции «Define»: «unknown OS type hvm»
В большинстве случаев проблема решается перезагрузкой сервера. Также рекомендуем проверить состояние аппаратной виртуализации в BIOS:
modprobe kvme
grep '^flags.*(vmx|svm)' /proc/cpuinfoBASH
Если ответ пустой, то виртуализация отключена, включите.
Миграция виртуальной машины <наименование vm> невозможна: происходит процесс резервного копирования
Если в панели управления запущен процесс резервного копирования и виртуальная машина находится в списке для резервного копирования, то любые действия по отношению к данной виртуальной машине заблокированы. Блокировка продлится до окончания процесса резервного копирования.
Проблемы с импортом виртуальных машин
Ошибка ERROR Error: Type: ‘host_missing’ Object: Value: при импорте
Ошибка означает, что не найден ни один подходящий узел кластера для импорта. Убедитесь, что на хранилище, выбранном для импорта, достаточно свободного места. Убедитесь, что для создания виртуальной машины достаточно оперативной памяти.
Ошибка ERROR Error: Type: ‘xml’ Object: ‘parse_file’ Value: ‘/nfsshare/metainfo.xml’ при импорте
Для решения проблемы создайте файл /nfsshare/metainfo.xml. Содержимое файла можно скопировать из metainfo.xml любого шаблона ОС.
1 минуту назад, Jack Shepard сказал:
ну ошибка линуксовая. KVM окружение, ошибка с выделением памяти под виртуальную машину. Это вам надо писать в суппорт где дедик арендуете.
да уже создал тикет,жду,думал,мб что-то дефолтное,заметил,что этот дедик сам офался когда я не работал на нем,приходилось запускать,дня 3-4 такое было,а сейчас вот это,другой дедик на этом сервисе работает
![]()
Hello.
When I tried to setup deepops cluster with virtual mode for testing, it failed with libvirt provider at launching vagrant box. What I did is like
step1: clone deepops repository into local
step2: copy virtual/Vagrantfile-ubuntu to virtual/Vagrantfile
step3: run virtual/vagrant_startup.sh
It looks like the dependency packages are installed (e.g. host-manager plugin) successfully but the vagrant up failed. I paste the execution log since vagrant up called, here.
+ vagrant up --provider=libvirt
Bringing machine 'virtual-mgmt' up with 'libvirt' provider...
Bringing machine 'virtual-login' up with 'libvirt' provider...
Bringing machine 'virtual-gpu01' up with 'libvirt' provider...
==> virtual-mgmt: An error occurred. The error will be shown after all tasks complete.
==> virtual-gpu01: An error occurred. The error will be shown after all tasks complete.
==> virtual-login: An error occurred. The error will be shown after all tasks complete.
An error occurred while executing multiple actions in parallel.
Any errors that occurred are shown below.
An error occurred while executing the action on the 'virtual-mgmt'
machine. Please handle this error then try again:
There was error while creating libvirt storage pool: Call to virStoragePoolDefineXML failed: operation failed: Storage source conflict with pool: 'images'
An error occurred while executing the action on the 'virtual-login'
machine. Please handle this error then try again:
There was error while creating libvirt storage pool: Call to virStoragePoolDefineXML failed: operation failed: Storage source conflict with pool: 'images'
An error occurred while executing the action on the 'virtual-gpu01'
machine. Please handle this error then try again:
There was error while creating libvirt storage pool: Call to virStoragePoolDefineXML failed: operation failed: Storage source conflict with pool: 'images'
Any idea to fix this problem?
![]()
@bloodeagle40234 — It seems like you might have an existing storage pool. Can you check?
$ virsh pool-list --all
Name State Autostart
-------------------------------------------
default active no
The name of the pool should be default. If yours is images instead, do the following…
$ virsh pool-destroy images
Pool images destroyed
$ virsh pool-undefine images
Pool images has been undefined
![]()
PS: if there is a reason why you need to keep the pool named images, you can reference that instead in the Vagrantfile…
Vagrant.configure("2") do |config|
...
config.vm.provider :libvirt do |libvirt|
libvirt.storage_pool_name = "images"
end
...
end
![]()
Thanks a lot! Actually,
$ virsh pool-undefine images
Pool images has been undefined
This resolved my problem, once I did just virsh pool-destroy images ever though.
The problem occurred even I just clean installed the libvirt tools via apt in Ubuntu 16.04 xenial so perhaps, images might be a default.
Anyway, it looks my vm launched successfully, thanks.