
Добавить ответ
Ваше имя:
Регистрация? Это возможность подписаться на новые ответы, получать за ответы очки и призы
В ответ на сообщение
Нет

Текст с картинки:
Отправить
Маты, сообщения БОЛЬШИМИ БУКВАМИ, с грубыми ошибками, просто неуважительные или совершенно не по теме будут удаляться.
- ЕАС ОПС, Winpost и другие программы
- Почтовые программы
- ИС «Почтамт/ОПС — Почтовые отправления»
Ошибка «Неверный формат штрихкода»
выскакивает вот такая ошибка. как исправить, где взять этот контрольный разряд?
 » />
» />
- Сообщение 2
Re: Ошибка «Неверный формат штрихкода»
 автор LEXX Пн Дек 16 2013, 05:01
автор LEXX Пн Дек 16 2013, 05:01
контрольный разряд вроде сам генериться.
В вашем случаем достаточно ввести верный штрихкод и все. Вы вводете неверный.
Я не знаю как формируется контрольный разряд, но его можно просто подобрать перебором, благо там всего 2 цифры.
- Сообщение 3
Re: Ошибка «Неверный формат штрихкода»
автор alexey_nik Пн Дек 16 2013, 05:11
LEXX пишет:контрольный разряд вроде сам генериться.
В вашем случаем достаточно ввести верный штрихкод и все. Вы вводете неверный.
Я не знаю как формируется контрольный разряд, но его можно просто подобрать перебором, благо там всего 2 цифры.
штрихкод набран точно так же, как и предыдущие. изменены лишь две последние цифры. в предыдущей накладной были 27, в этой, соответственно — 28. почему в этот раз несгененировался автоматически — не знаю. две цифры? какие? я перебрал цифры от 1го до 9ти — не подошли
- Сообщение 4
Re: Ошибка «Неверный формат штрихкода»
автор LEXX Пн Дек 16 2013, 05:27
alexey_nik пишет:
в предыдущей накладной были 27, в этой, соответственно — 28.
— неверно!
Последние 2 цифры это и есть конрольный разряд, а не номер накладной. А может и одна цифра, я не помню как там для накладной контрольный разряд генерится.
- Сообщение 5
Re: Ошибка «Неверный формат штрихкода»
автор LEXX Пн Дек 16 2013, 05:32
Да у вас не ИС Почтамт Почтовые отправления, а ИС ОПС Почтовые отправления.
Просто считайте штрихкод с накладной и все, или перепешите. Не вводите вручную номер или «выдуманный» штрихкод, без контрольного разряда не введете, а перебирать разряд на каждую накладную не вариант вообще. Почитайте инструкцию, там все написано как создавать накладную.
Похожие темы
![]()
Обновлено: 10.04.2023
Но эта ошибка, похоже, говорит о том, что в исходном файле есть недопустимые данные UTF8. Это означает, что утилита copy обнаружила или догадалась, что вы передаете ей файл UTF8.
Если вы работаете в каком-либо варианте Unix, вы можете проверить кодировку (более или менее) с помощью file утилиты.
(Я думаю, что это будет работать на Mac в терминале тоже.) Не уверен, как это сделать под Windows.
Если вы используете ту же самую утилиту для файла, полученного из систем Windows (то есть для файла, не закодированного в UTF8), она, вероятно, будет отображать что-то вроде этого:
Если что-то не так, вы можете попытаться преобразовать свои входные данные в известную кодировку, изменить кодировку клиента или и то, и другое. (Мы действительно расширяем границы моих знаний о кодировках.)
Вы можете использовать утилиту iconv для изменения кодировки входных данных.
Добавление опции encoding работало в моем случае.
По-видимому, я могу просто установить кодировку на лету,
И затем повторно запустите запрос. Не уверен, какую кодировку я должен использовать, хотя.
latin1 сделал символы четкими, но большинство акцентированных символов были в верхнем регистре, где их не должно было быть. Я предположил, что это произошло из-за плохого кодирования, но я думаю, что на самом деле данные были просто плохими. Я закончил тем, что сохранил кодировку latin1, но предварительно обработал данные и исправил проблемы с корпусом.
Если вы в порядке с отбрасыванием неконвертируемых символов, вы можете использовать флаг -c
а затем скопируйте их в таблицу
iconv -f ASCII -t utf-8//IGNORE < b.txt > /a.txt
iconv: незаконная входная последовательность в позиции (некоторое число)
Чтобы найти символы без ASCII, вы можете использовать следующую команду:
Если вы удалите неверные символы, проверьте, действительно ли вам нужно преобразовать ваш файл: возможно, проблема уже решена.
Это зависит от того, какой тип машины/кодирования сгенерировал ваш файл импорта.
Ну, я столкнулся с той же проблемой. И что решило мою проблему:
выполните следующие действия для решения этой проблемы в pgadmin:
SET client_encoding = ‘ISO_8859_5’;
COPY tablename(column names) FROM ‘D:/DB_BAK/csvfilename.csv’ WITH DELIMITER ‘,’ CSV ;
Итак, я просто перекодировал файл дампа перед его воспроизведением:
В системах Debian или Ubuntu перекодирование может быть установлено через пакет.
Вы можете заменить символ обратной косой черты, например, символом канала, с sed.
Для python вам нужно использовать
Pg8000.Binary(значение) Создайте объект, содержащий двоичные данные.
вы можете попробовать это для обработки кодировки UTF8.
Краткий пример решения этой проблемы в PHP-
Так что просто конвертируйте это значение в UTF-8 перед вставкой в базу данных POSTGRES.
С этой ошибкой также очень возможно, что поле зашифровано на месте. Убедитесь, что вы смотрите на нужную таблицу, в некоторых случаях администраторы создадут незашифрованное представление, которое вы можете использовать вместо этого. Недавно я столкнулся с очень похожими проблемами.
У меня такая же ошибка, когда я пытался скопировать CSV, сгенерированный Excel, в таблицу Postgres (все на Mac). Вот как я это решил:
1) Откройте файл в Atom (используемая среда IDE)
2) Сделайте незначительное изменение в файле. Сохраните файл. Отмените изменение. Сохраните снова.
Presto! Теперь команда копирования работает.
(Я думаю, что Atom сохранил его в формате, который работал)
Откройте файл CSV с помощью Notepad++. Выберите меню Encoding Encoding in UTF-8 , затем вручную исправьте несколько ячеек.
Затем попробуйте импортировать снова.
Если ваш CSV будет экспортирован из SQL Server и содержит символы Unicode, экспортируйте его, установив кодировку UTF-8 :
Right-Click DB > Tasks > Export > ‘SQL Server Native Client 11.0’ >> ‘Flat File Destination > File name: . > Code page: UTF-8 >> .
При неправильной кодировке весь сайт или его часть отображаются в виде «кряпозяблов», т.е. непонятных символов, делающих текст нечитаемым. Такая ситуация может возникнуть при неверной настройке кодировки веб-сервера или при отсутствии настроек. Рассмотрим возможные варианты и способы устранения проблем
Неправильная кодировка HTML страниц
Создадим тестовый файлик:
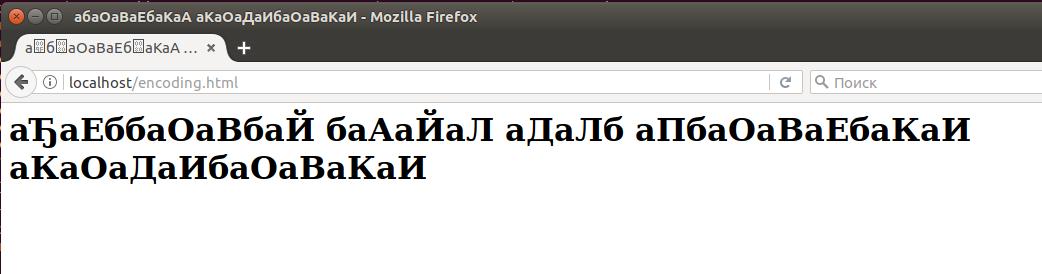
Скопируем в него следующий HTML код, в котором отсутствует указание кодировки и посмотрим, какие проблемы могут с ним возникнуть и как их решить:
Как можно видеть, кодировка браузером определена неправильно:
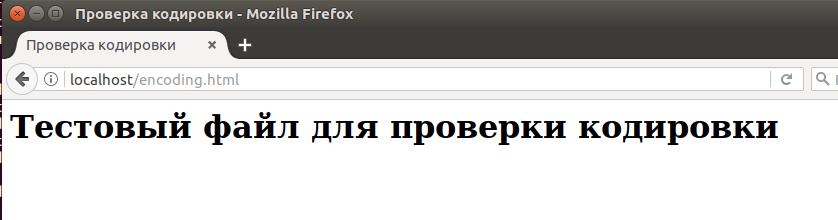
Добавим эту строку к нашему тестовому файлику, чтобы получилось так:
Как мы можем убедиться на следующем скриншоте, проблема решена:
Если кодировка вашего файла отличается от UTF-8, то вместо неё поставьте windows-1251 или ту, которая соответствует кодировке веб-страницы. Чтобы научиться определять кодировку файлов, посмотрите эту инструкцию.
Это был самый простой способ исправления проблемы с кодировкой – без изменения настроек сервера.
Вернём наш тестовый файл в исходное состояние и продолжим изучение способов указания кодировки.
Если файлы .htaccess включены настройками Apache, то эти файлы можно использовать чтобы указывать кодировку отправляемых веб-сервером страниц. Чтобы включить поддержку файлов .htaccess в конфигурационном файле Apache ( /etc/apache2/apache2.conf ) найдите группу строк
И в ней замените
После этого сервер нужно перезапустить.
Файл .htaccess должен быть размещён в той же директории, что и сайт. Мой сайт размещён в корневой директории веб-сервера. Если у вас также, то теперь в папке /var/www/html/ создайте файл .htaccess и добавьте в него директиву AddDefaultCharset после которой укажите желаемую кодировку. Примеры
Можно указать кодировку, которая будет применена только к файлам определённого формата:
Набор файлов может быть любым, например:
Следующий вариант является альтернативным и также позволяет устанавливать кодировку для файлов определённого типа, для него нужно, чтобы был включён mod_headers:
Ещё один вариант, который также можно использовать в файле .htaccess для установки кодировки UTF-8:
Если сайт на PHP, то дополнительно может понадобиться продублировать кодировку с php_value default_charset:
Как установить UTF-8 кодировку в PHP
В PHP скрипте для установки кодировки используется header, например:
Обычно вместе с кодировкой также указывают тип содержимого (в примере вариант для HTML страницы):
Ещё один вариант для RSS ленты:
Описанный способ работает только когда PHP скрипт полностью генерирует содержимое страницы. Статические страницы (такие как html) вы должны сохранять в кодировке utf-8. Большинство веб серверов обратят внимание на кодировку файла и добавят соответствующий заголовок. На самом деле, сохранение PHP файла в кодировке utf-8 приведёт к такому же результату.
Неправильная кодировка результатов из базы данных MySQL
Если ваш сайт состоит из статической части (шаблон) и динамической, которая формируется из данных, получаемых из базы данных, то может возникнуть ситуация, когда часть сайта имеет правильную кодировку, а другая часть сайта имеет неправильную. В этом случае бесполезно менять настройки веб-сервера – поскольку всё равно часть страницы будет иметь неправильную кодировку.
Нужно начать с определения кодировки ваших таблиц. Можно посмотреть в phpMyAdmin:

Обратите внимание на столбец «Сравнение», запись «utf8_unicode_ci» означает, что используется кодировка UTF-8.
Можно подключиться к СУБД MySQL и проверить кодировку таблиц без phpMyAdmin. Для этого:
Если вы забыли имя базы данных, то выполните команду:
Предположим, я хочу посмотреть кодировку для таблиц в базе данных information_schema
Если вы забыли имя таблиц, выполните:
Далее выполните команду, в которой имя_таблицы замените на настоящее имя таблицы:
Вы увидите примерно следующее:

Смотрите столбец Collation. В моём случае там utf8_general_ci, это, как и utf8_unicode_ci, кодировка UTF-8. Кстати, если вы не знаете в чём разница между кодировками utf8_general_ci, utf8_unicode_ci, utf8mb4_general_ci, utf8mb4_unicode_ci, а также какую кодировку выбрать для базы данных MySQL, то посмотрите эту статью.
Теперь, когда мы узнали кодировку (в моём случае это UTF-8), то при каждом подключении к СУБД MySQL нужно выполнять последовательно запросы:
В PHP это можно сделать примерно так:
Обратите внимание, что UTF8 вам нужно заменить на ту кодировку, которая используется для ваших таблиц.
Изменение кодировки файлов
Если вы решили пойти другим путём и вместо установки новой кодировки изменить кодировку ваших файлов, то посмотрите статью «Как конвертировать файлы в кодировку UTF-8 в Linux». В ней рассказано, как узнать текущую кодировку файлов и как конвертировать файлы в любую кодировку (не только UTF-8).
Как узнать, какую кодировку отправляет сервер
Если вы хотите узнать, какие настройки кодировки имеет веб-сервер (какую кодировку передаёт в заголовках), то воспользуйтесь следующей командой:

Какую кодировку выбрать для веб-сайта
Рекомендуется выбрать кодировку UTF-8. Это более универсальная кодировка, практически, она стала стандартом. У вас не будет проблем с отображением необычных символов и букв из других алфавитов.
ыЙТПЛБС ØàÞÚÐï ╒┌тр╪ф╪┌ПрЎ.ТруНЬ_аЭШЩ ФРбв ЬЮ.
Нет, мы не сошли с ума. Просто сегодня будем разбираться, как устранить ошибки кодировки и вернуть на сайт читаемый текст. Узнаем, как кодировка влияет на SEO-оптимизацию, и познакомимся с полезными сервисами, которые позволят вовремя идентифицировать ошибки.
Что такое кодировка, и когда возникают ошибки с отображением текста
Если вместо нормального текста на вашем сайте отображается странный набор символов, значит, есть проблемы с кодировкой. Впрочем, иногда кодировка на сайте является стандартизированной и выбрана корректно, но вместо текста все равно отображаются иероглифы.
Кодировка – это набор символов и система их передачи для последующего вывода на экран. Кроме алфавита при помощи кодировки передаются также специальные символы и цифры.
Сегодня массово используются 2 вида кодировки: Windows-1251 и UTF-8. Чаще всего «кракозябра» появляется, когда на одном сайте используется сразу несколько видов кодировки (да, такое бывает чаще, чем может показаться на первый взгляд).
Можно выделить и другие причины неполадок:
- Используется устаревший браузер.
- В браузере / программе установлена одна кодировка, на сайте – другая. В таком случае нужно поменять кодировку в программе.
- В БД и других файлах сайта указаны несовпадающие кодировки. В этом случае нужно выбрать одну кодировку для всего сайта.
Как поменять кодировку в браузере
Internet Explorer
- Открываем проблемную веб-страницу.
- Вызываем контекстное меню, кликнув правой кнопкой мыши по любому месту на странице.
- Выбираем «Кодировка».
- Кликаем Unicode (UTF-8).
Chrome
Chrome современный и модный браузер, но вот кодировку стандартными средствами поменять в нем нельзя (сюрприз!). Будем делать это через расширение.
- Открываем магазин Chrome.
- Кликаем «Расширения» в левой части экрана.
- Указываем слово «кодировка».
- Устанавливаем любое подходящее расширение.
Safari
- Выбираем пункт «Вид».
- Кликаем по разделу «Кодировка текста».
- Выбраем вариант Unicode (UTF-8).
Firefox
- Выбираем пункт «Вид».
- Кликаем по раздел «Кодировка текста».
- Нужно выбрать вариант Unicode (UTF-8).
Как выбрать кодировку
Если в качестве CMS вы используете WordPress, Joomla, Drupal, OpenCart или TYPO3, то дополнительно настраивать ничего не нужно. Эти движки по умолчанию работает именно с UTF-8. Все должно работать из коробки. Просто убедитесь, что везде прописана UTF-8.
В самых сложных случаях придется отдельно скачивать шаблоны под конкретную кодировку, предварительно создав MySQL. Последнее актуально, например, для DLE. Если же ваш cайт полностью самописный, просто проследите за тем, чтобы везде была установлена идентичная кодировка, желательно – UTF-8.
Какую кодировку выбрать
Сегодня большинство экспертов солидарны в том, что наиболее удобной кодировкой является UTF-8. Этот стандарт поддерживает большинство браузеров, баз данных, серверов и языков. Еще одно преимущество – она изначально была кроссплатформенной.
UTF-8 может закодировать любой unicode-символ. Пожалуй, именно это достоинство позволило кодировке стать одной из самых популярных в мире.
Windows-1251 известна в меньшей степени, но Windows-1251 и не отличается такой универсальностью и распространенностью как UTF-8. Проблемы с кодировкой могут встречаться на всех сайтах, даже на отлаженных площадках, которые работают в течение многих лет. Чтобы предотвратить проблемы с «кракозябрами» на своем сайте в будущем, необходимо с самого начала выбирать единую кодировку. Как вы уже догадались, лучший кандидат на эту роль – UTF-8.
Как узнать, какая кодировка используется на моем сайте
Узнать, какая кодировка используется на всем сайте или на конкретной странице, можно за несколько секунд. Для этого нужно просмотреть исходник HTML-страницы. Чтобы увидеть его, используем одновременное нажатие горячих клавиш Сtrl + U (на «Маке» активируем шорткатом Option/Alt + Command + U). Появится такое окно:
Теперь используем сочетание горячих клавиш Ctrl + F (Command + F) – откроется окно поиска. Вводим в поисковую строку атрибут charset (он же character set, кодировка документа). После этого атрибута мы увидим знак равенства. За ним и будет указана кодировка страницы.
Если атрибут charset не задан, его придется задать. Предварительно нужно проверить сайт при помощи сторонних сервисов. Один из них – Browserstack. Платформа платная, но, чтобы проверить кодировку, платить необязательно. Достаточно открыть сайт и выбрать пункт Get started free, создать аккаунт (можно просто залогиниться при помощи «Google-аккаунта»). После авторизации появится такое окно:
Выбираем интересующую нас операционную систему / устройство и вводим сайт, который нужно протестировать:
Если с кодировкой на сайте что-то не так, все ошибки будут представлены в результатах теста.
Для проверки и определения ошибок кодировки можно использовать не только Browserstack. Альтернатива – бесплатный сервис Validator. Он позволит идентифицировать кодировку сразу по нескольким данным, включая заголовки. Пример ошибки кодировки в результатах анализа Validator:
Хорошие инструменты для проверки кодировки предоставляют сервисы NetPeak и SeoFrog. Последний удобен еще тем, что позволяет проверить кодировку сразу по всем страницам сайта, а не только по одной.
Кодировка и оптимизация
Даже если кодировка на сайте не совсем обычная или отличается на разных страницах, Google и «Яндекс» все равно проиндексируют такой сайт, но при условии, что контент уникален и не переспамлен ключами. Одна из самых неприятных ошибок здесь – несовместимость кодировки веб-ресурса с той, которая используется на сервере. Даже в таком случае Google, например, способен корректно идентифицировать ошибку. Сайт будет в выдаче, если соответствующие условия были соблюдены.
Ошибки кодировки сами по себе не влияют на оптимизацию сайта прямым образом. Они сказываются на отказах и времени, проведенном на сайте, а также на иных поведенческих показателях аудитории.
Если на вашем сайте возникают ошибки кодировки, и контент отображается некорректно, то посетитель ни при каких обстоятельствах не будет тратить свое время, пытаясь настроить правильную кодировку и, тем более, пытаться ее преобразовать в читаемую. Большинство посетителей просто не знают, как это сделать, но даже если знают, не будут тратить время и точно уйдут к конкурентам на тот сайт, где содержимое изначально отображается корректно.
Устранить проблемы кодировки сложно: мало поменять ее на одной или нескольких страницах. Обычно приходится исправлять ее также в мете (одноименных тегах), БД MySQL, файле htaccess и других системных файлах сайта.
Инструкция предназначена только для опытных пользователей и не является призывом к действию. Код и настройки я привожу исключительно в качестве примера. Если вы решитесь вносить изменения в БД и системные файлы, особенно в root, обязательно сделайте резервную копию всех данных сайта!
Документы / HTML-файлы
Если возникают проблемы с документами, необходимо удостовериться в том, что они имеют одинаковую кодировку, и в том, что она вообще задана. Для этого открываем HTML-файл при помощи любого редактора, который позволяет работать с кодом. Например, через Notepad++. Открываем проблемный документ и выполняем следующую последовательность действий:
Htaccess
Теги типа meta
Именно мета-тег используется для установки требуемой кодировки. Кроме этого, в нем прописываются и другие мета-теги, которые задействованы для хранения информации, используемой браузерами. Прописываются теги типа meta в head-разделе. Выглядит следующим образом:
Этот код приводится в качестве примера. Не исключено появление ошибок.
Базы данных
Если «кракозябры» при открытии страниц так и не исчезают, придется проверять MySQL. Нас интересуют значения, прописанные в таблицах баз данных. Чтобы устранить эту проблему, необходимо подключиться к серверу через mysql root. Для этого выполняем следующие шаги:
Так мы приведем кодировку БД к единому стандарту UTF-8.
Онлайн-декодеры
Онлайн-декодеры и другие инструменты с аналогичным функционалом позволяют преобразовать «кракозябру» в читаемый текст. Foxtools – приятный и удобный декодер, который работает в автоматическом режиме. У Foxtools вообще много полезных инструментов:
2cyr – еще более функциональный инструмент, который не только преобразует «кракозябры» в читаемый текст, но и выводит множество возможных вариантов. Бывает и такое, что все варианты «расшифровки» являются некорректными:
Итоги
Чтобы вовремя идентифицировать проблемы с кодировкой на своем сайте, используйте перечисленные выше инструменты. Не забывайте и об онлайн-декодерах: они эффективно расшифровывают нечитаемый текст в случаях, когда необходимо быстро преобразовать «кракозябру». Помните, что иероглифы на сайте недопустимы, и устранять такие ошибки нужно как можно скорее. В противном случае ухудшатся поведенческие факторы, и сайт может навсегда выпасть из поисковой выдачи.
В Google и «Яндексе», соцсетях, рассылках, на видеоплатформах, у блогеров
Данная статья имеет цель собрать воедино и разобрать принципы и механизм работы кодировок текста, подробно этот механизм разобрать и объяснить. Полезна она будет тем, кто только примерно представляет, что такое кодировки текста и как они работают, чем отличаются друг от друга, почему иногда появляются не читаемые символы, какой принцип кодирования имеют разные кодировки.
Чтобы получить детальное понимание этого вопроса придется прочитать и свести воедино не одну статью и потратить довольно значительное время на это. В данном материале же это все собрано воедино и по идее должно сэкономить время и разбор на мой взгляд получился довольно подробный.
О чем будет под катом: принцип работы одно байтовых кодировок (ASCII, Windows-1251 и т.д.), предпосылки появления Unicode, что такое Unicode, Unicode-кодировки UTF-8, UTF-16, их отличия, принципиальные особенности, совместимость и несовместимость разных кодировок, принципы кодирования символов, практический разбор кодирования и декодирования.
Вопрос с кодировками сейчас конечно уже потерял актуальность, но все же знать как они работают сейчас и как работали раньше и при этом не потратить много времени на это думаю лишним не будет.
Предпосылки Unicode
Первые 7 бит (128 символов 2 7 =128) в этой кодировке были отданы под символы латинского алфавита, управляющие символы (такие как переносы строк, табуляция и т.д.) и грамматические символы. Остальные отводились под национальные языки. То есть получилось что первые 128 символов всегда одинаковые, а если хочешь закодировать свой родной язык пожалуйста, используй оставшуюся емкость. Собственно так и появился огромный зоопарк национальных кодировок. И теперь сами можете представить, вот например я находясь в России беру и создаю текстовый документ, у меня по умолчанию он создается в кодировке Windows-1251 (русская кодировка использующаяся в ОС Windows) и отсылаю его кому то, например в США. Даже то что мой собеседник знает русский язык, ему не поможет, потому что открыв мой документ на своем компьютере (в редакторе с дефолтной кодировкой той же самой ASCII) он увидит не русские буквы, а кракозябры. Если быть точнее, то те места в документе которые я напишу на английском отобразятся без проблем, потому что первые 128 символов кодировок Windows-1251 и ASCII одинаковые, но вот там где я написал русский текст, если он в своем редакторе не укажет правильную кодировку будут в виде кракозябр.
Думаю проблема с национальными кодировками понятна. Собственно этих национальных кодировок стало очень много, а интернет стал очень широким, и в нем каждый хотел писать на своем языке и не хотел чтобы его язык выглядел как кракозябры. Было два выхода, указывать для каждой страницы кодировки, либо создать одну общую для всех символов в мире таблицу символов. Победил второй вариант, так создали Unicode таблицу символов.
Небольшой практикум ASCII
Возможно покажется элементарщиной, но раз уж решил объяснять все и подробно, то это надо.
Вот таблица символов ASCII:

Тут имеем 3 колонки:
- номер символа в десятичном формате
- номер символа в шестнадцатиричном формате
- представление самого символа.
Unicode
С предпосылками создания общей таблицы для всех в мире символов, разобрались. Теперь собственно, к самой таблице. Unicode — именно эта таблица и есть (это не кодировка, а именно таблица символов). Она состоит из 1 114 112 позиций. Большинство этих позиций пока не заполнены символами, так что вряд ли понадобится это пространство расширять.
Разделено это общее пространство на 17 блоков, по 65 536 символов в каждом. Каждый блок содержит свою группу символов. Нулевой блок — базовый, там собраны наиболее употребляемые символы всех современных алфавитов. Во втором блоке находятся символы вымерших языков. Есть два блока отведенные под частное использование. Большинство блоков пока не заполнены.
Итого емкость символов юникода составляет от 0 до 10FFFF (в шестнадцатиричном виде).
Записываются символы в шестнадцатиричном виде с приставкой «U+». Например первый базовый блок включает в себя символы от U+0000 до U+FFFF (от 0 до 65 535), а последний семнадцатый блок от U+100000 до U+10FFFF (от 1 048 576 до 1 114 111).
Отлично теперь вместо зоопарка национальных кодировок, у нас есть всеобъемлющая таблица, в которой зашифрованы все символы которые нам могут пригодиться. Но тут тоже есть свои недостатки. Если раньше каждый символ был закодирован одним байтом, то теперь он может быть закодирован разным количеством байтов. Например для кодирования всех символов английского алфавита по прежнему достаточно одного байта например тот же символ «o» (англ.) имеет в юникоде номер U+006F, то есть тот же самый номер как и в ASCII — 6F в шестнадцатиричной и 111 в десятеричной. А вот для кодирования символа «U+103D5» (это древнеперсидская цифра сто) — 103D5 в шестнадцатиричной и 66 517 в десятеричной, тут нам потребуется уже три байта.
Решить эту проблему уже должны юникод-кодировки, такие как UTF-8 и UTF-16. Далее речь пойдет про них.
UTF-8 является юникод-кодировкой переменной длинны, с помощью которой можно представить любой символ юникода.
Давайте поподробнее про переменную длину, что это значит? Первым делом надо сказать, что структурной (атомарной) единицей этой кодировки является байт. То что кодировка переменной длинны, значит, что один символ может быть закодирован разным количеством структурных единиц кодировки, то есть разным количеством байтов. Так например латиница кодируется одним байтом, а кириллица двумя байтами.
Немного отступлю от темы, надо написать про совместимость ASCII и UTF
То что латинские символы и основные управляющие конструкции, такие как переносы строк, табуляции и т.д. закодированы одним байтом делает utf-кодировки совместимыми с кодировками ASCII. То есть фактически латиница и управляющие конструкции находятся на тех же самых местах как в ASCII, так и в UTF, и то что закодированы они и там и там одним байтом и обеспечивает эту совместимость.
Давайте возьмем символ «o»(англ.) из примера про ASCII выше. Помним что в таблице ASCII символов он находится на 111 позиции, в битовом виде это будет 01101111 . В таблице юникода этот символ — U+006F что в битовом виде тоже будет 01101111 . И теперь так, как UTF — это кодировка переменной длины, то в ней этот символ будет закодирован одним байтом. То есть представление данного символа в обеих кодировках будет одинаково. И так для всего диапазона символов от 0 до 128. То есть если ваш документ состоит из английского текста то вы не заметите разницы если откроете его и в кодировке UTF-8 и UTF-16 и ASCII (прим. в UTF-16 такие символы все равно будут закодированы двумя байтами, по этому вы не увидите разницы, если ваш редактор будет игнорировать нулевые байты), и так до момента пока вы не начнете работать с национальным алфавитом.
Сравним на практике как будет выглядеть фраза «Hello мир» в трех разных кодировках: Windows-1251 (русская кодировка), ISO-8859-1 (кодировка западно-европейских языков), UTF-8 (юникод-кодировка). Суть данного примера состоит в том что фраза написана на двух языках. Посмотрим как она будет выглядеть в разных кодировках.

В кодировке ISO-8859-1 нет таких символов «м», «и» и «р».
Теперь давайте поработаем с кодировками и разберемся как преобразовать строку из одной кодировки в другую и что будет если преобразование неправильное, или его нельзя осуществить из за разницы в кодировках.
Будем считать что изначально фраза была записана в кодировке Windows-1251. Исходя из таблицы выше запишем эту фразу в двоичном виде, в кодировке Windows-1251. Для этого нам потребуется всего только перевести из десятеричной или шестнадцатиричной системы (из таблицы выше) символы в двоичную.
01001000 01100101 01101100 01101100 01101111 00100000 11101100 11101000 11110000
Отлично, вот это и есть фраза «Hello мир» в кодировке Windows-1251.
Теперь представим что вы имеете файл с текстом, но не знаете в какой кодировке этот текст. Вы предполагаете что он в кодировке ISO-8859-1 и открываете его в своем редакторе в этой кодировке. Как сказано выше с частью символов все в порядке, они есть в этой кодировке, и даже находятся на тех же местах, но вот с символами из слова «мир» все сложнее. Этих символов в этой кодировке нет, а на их местах в кодировке ISO-8859-1 находятся совершенно другие символы. А конкретно «м» — позиция 236, «и» — 232. «р» — 240. И на этих позициях в кодировке ISO-8859-1 находятся следующие символы позиция 236 — символ «ì», 232 — «è», 240 — «ð»
Значит фраза «Hello мир» закодированная в Windows-1251 и открытая в кодировке ISO-8859-1 будет выглядеть так: «Hello ìèð». Вот и получается что эти две кодировки совместимы лишь частично, и корректно перекодировать строку из одной кодировке в другую не получится, потому что там просто напросто нет таких символов.
Тут и будут необходимы юникод-кодировки, а конкретно в данном случае рассмотрим UTF-8. То что символы в ней могут быть закодированы разным количеством байтов от 1 до 4 мы уже выяснили. Теперь стоит сказать что с помощью UTF могут быть закодированы не только 256 символов, как в двух предыдущих, а вобще все символы юникода
Работает она следующим образом. Первый бит каждого байта кодирующего символ отвечает не за сам символ, а за определение байта. То есть например если ведущий (первый) бит нулевой, то это значит что для кодирования символа используется всего один байт. Что и обеспечивает совместимость с ASCII. Если внимательно посмотрите на таблицу символов ASCII то увидите что первые 128 символов (английский алфавит, управляющие символы и знаки препинания) если их привести к двоичному виду, все начинаются с нулевого бита (будьте внимательны, если будете переводить символы в двоичную систему с помощью например онлайн конвертера, то первый нулевой ведущий бит может быть отброшен, что может сбить с толку).
01001000 — первый бит ноль, значит 1 байт кодирует 1 символ -> «H»
01100101 — первый бит ноль, значит 1 байт кодирует 1 символ -> «e»
Если первый бит не нулевой то символ кодируется несколькими байтами.
Для двухбайтовых символов первые три бита должны быть такие — 110
110 10000 10 111100 — в начале 110, значит 2 байта кодируют 1 символ. Второй байт в таком случае всегда начинается с 10. Итого отбрасываем управляющие биты (начальные, которые выделены красным и зеленым) и берем все оставшиеся ( 10000111100 ), переводим их в шестнадцатиричный вид (043С) -> U+043C в юникоде равно символ «м».
для трех-байтовых символов в первом байте ведущие биты — 1110
1110 1000 10 000111 10 1010101 — суммируем все кроме управляющих битов и получаем что в 16-ричной равно 103В5, U+103D5 — древнеперситдская цифра сто ( 10000001111010101 )
для четырех-байтовых символов в первом байте ведущие биты — 11110
11110 100 10 001111 10 111111 10 111111 — U+10FFFF это последний допустимый символ в таблице юникода ( 100001111111111111111 )
Теперь, при желании, можем записать нашу фразу в кодировке UTF-8.
UTF-16
UTF-16 также является кодировкой переменной длинны. Главное ее отличие от UTF-8 состоит в том что структурной единицей в ней является не один а два байта. То есть в кодировке UTF-16 любой символ юникода может быть закодирован либо двумя, либо четырьмя байтами. Давайте для понятности в дальнейшем пару таких байтов я буду называть кодовой парой. Исходя из этого любой символ юникода в кодировке UTF-16 может быть закодирован либо одной кодовой парой, либо двумя.
Начнем с символов которые кодируются одной кодовой парой. Легко посчитать что таких символов может быть 65 535 (2в16), что полностью совпадает с базовым блоком юникода. Все символы находящиеся в этом блоке юникода в кодировке UTF-16 будут закодированы одной кодовой парой (двумя байтами), тут все просто.
символ «o» (латиница) — 00000000 01101111
символ «M» (кириллица) — 00000100 00011100
Теперь рассмотрим символы за пределами базового юникод диапазона. Для их кодирования потребуется уже две кодовые пары (4 байта). И механизм их кодирования немного сложнее, давайте по порядку.
Для начала введем понятия суррогатной пары. Суррогатная пара — это две кодовые пары используемые для кодирования одного символа (итого 4 байта). Для таких суррогатных пар в таблице юникода отведен специальный диапазон от D800 до DFFF. Это значит, что при преобразовании кодовой пары из байтового вида в шестнадцатиричный вы получаете число из этого диапазона, то перед вами не самостоятельный символ, а суррогатная пара.
Чтобы закодировать символ из диапазона 10000 — 10FFFF (то есть символ для которого нужно использовать более одной кодовой пары) нужно:
- из кода символа вычесть 10000(шестнадцатиричное) (это наименьшее число из диапазона 10000 — 10FFFF)
- в результате первого пункта будет получено число не больше FFFFF, занимающее до 20 бит
- ведущие 10 бит из полученного числа суммируются с D800 (начало диапазона суррогатных пар в юникоде)
- следующие 10 бит суммируются с DC00 (тоже число из диапазона суррогатных пар)
- после этого получатся 2 суррогатные пары по 16 бит, первые 6 бит в каждой такой паре отвечают за определение того что это суррогат,
- десятый бит в каждом суррогате отвечает за его порядок если это 1 то это первый суррогат, если 0, то второй
Для примера зашифруем символ, а потом расшифруем. Возьмем древнеперсидскую цифру сто (U+103D5):
Но эта ошибка, похоже, говорит о том, что в исходном файле есть недопустимые данные UTF8. Это означает, что утилита copy обнаружила или догадалась, что вы передаете ей файл UTF8.
Если вы работаете в каком-либо варианте Unix, вы можете проверить кодировку (более или менее) с помощью file утилиты.
(Я думаю, что это будет работать на Mac в терминале тоже.) Не уверен, как это сделать под Windows.
Если вы используете ту же самую утилиту для файла, полученного из систем Windows (то есть для файла, не закодированного в UTF8), она, вероятно, будет отображать что-то вроде этого:
Если что-то не так, вы можете попытаться преобразовать свои входные данные в известную кодировку, изменить кодировку клиента или и то, и другое. (Мы действительно расширяем границы моих знаний о кодировках.)
Вы можете использовать утилиту iconv для изменения кодировки входных данных.
Добавление опции encoding работало в моем случае.
По-видимому, я могу просто установить кодировку на лету,
И затем повторно запустите запрос. Не уверен, какую кодировку я должен использовать, хотя.
latin1 сделал символы четкими, но большинство акцентированных символов были в верхнем регистре, где их не должно было быть. Я предположил, что это произошло из-за плохого кодирования, но я думаю, что на самом деле данные были просто плохими. Я закончил тем, что сохранил кодировку latin1, но предварительно обработал данные и исправил проблемы с корпусом.
Если вы в порядке с отбрасыванием неконвертируемых символов, вы можете использовать флаг -c
а затем скопируйте их в таблицу
iconv -f ASCII -t utf-8//IGNORE < b.txt > /a.txt
iconv: незаконная входная последовательность в позиции (некоторое число)
Чтобы найти символы без ASCII, вы можете использовать следующую команду:
Если вы удалите неверные символы, проверьте, действительно ли вам нужно преобразовать ваш файл: возможно, проблема уже решена.
Это зависит от того, какой тип машины/кодирования сгенерировал ваш файл импорта.
Ну, я столкнулся с той же проблемой. И что решило мою проблему:
выполните следующие действия для решения этой проблемы в pgadmin:
SET client_encoding = ‘ISO_8859_5’;
COPY tablename(column names) FROM ‘D:/DB_BAK/csvfilename.csv’ WITH DELIMITER ‘,’ CSV ;
Итак, я просто перекодировал файл дампа перед его воспроизведением:
В системах Debian или Ubuntu перекодирование может быть установлено через пакет.
Вы можете заменить символ обратной косой черты, например, символом канала, с sed.
Для python вам нужно использовать
Pg8000.Binary(значение) Создайте объект, содержащий двоичные данные.
вы можете попробовать это для обработки кодировки UTF8.
Краткий пример решения этой проблемы в PHP-
Так что просто конвертируйте это значение в UTF-8 перед вставкой в базу данных POSTGRES.
С этой ошибкой также очень возможно, что поле зашифровано на месте. Убедитесь, что вы смотрите на нужную таблицу, в некоторых случаях администраторы создадут незашифрованное представление, которое вы можете использовать вместо этого. Недавно я столкнулся с очень похожими проблемами.
У меня такая же ошибка, когда я пытался скопировать CSV, сгенерированный Excel, в таблицу Postgres (все на Mac). Вот как я это решил:
1) Откройте файл в Atom (используемая среда IDE)
2) Сделайте незначительное изменение в файле. Сохраните файл. Отмените изменение. Сохраните снова.
Presto! Теперь команда копирования работает.
(Я думаю, что Atom сохранил его в формате, который работал)
Откройте файл CSV с помощью Notepad++. Выберите меню Encoding Encoding in UTF-8 , затем вручную исправьте несколько ячеек.
Затем попробуйте импортировать снова.
Если ваш CSV будет экспортирован из SQL Server и содержит символы Unicode, экспортируйте его, установив кодировку UTF-8 :
Right-Click DB > Tasks > Export > ‘SQL Server Native Client 11.0’ >> ‘Flat File Destination > File name: . > Code page: UTF-8 >> .
Читайте также:
- Компьютерный перевести на английский
- Trimble connect for sketchup что это
- Сколько памяти занимает террария
- Как узнать путь к файлу
- Как поставить андроид 11 на планшет
![]()

×

Добрый вечер! Сгенерировал новый штрихкод, вставил его в программе для штрихкодов и мне выдается ошибка: «Ошибка кодировки: контрольный разряд, переда
-
Автор темы
VoronovaNa
-
Дата начала
10.09.2022
-
Форум
-
Форум ozon — озон как продавать товары на озон
-
Ozon / Озон
Обсуждаемые темы:
Формула ранжирования Wildberries🔥 Мини-книга «Самовыкупы на Wildberries»Самовыкупы по DBS — без товара и без покатушекCторно продаж вайлдберриз что значит?
V
VoronovaNa
New member
-
- 03.01.2022
-
- 1
-
- 0
-
- 1
-
10.09.2022
-
#1
Добрый вечер! Сгенерировал новый штрихкод, вставил его в программе для штрихкодов и мне выдается ошибка: «Ошибка кодировки: контрольный разряд, переданный введенными данными, неверен» Раньше такой проблемы не было. Что делать?
E
Ekaterina
New member
-
- 03.01.2022
-
- 1
-
- 0
-
- 1
-
10.09.2022
-
#2
Вопрос карточек товара только через раздел поддержка на портале
Для ответа нужно войти/зарегистрироваться
Поделиться:
Tumblr
Электронная почта
Ссылка
Последние темы
-
M
Пропала СПП в личном кабинете
- Автор MosesG
- Вчера в 13:08
- Ответы: 0
Wildberries / Вайлдберриз форум
-
Н
SEO на Вайлдберриз: зачем нужна поисковая оптимизация и как ее делать
- Автор Нехорошков Игорь
- Четверг в 13:24
- Ответы: 0
Wildberries / Вайлдберриз форум
-
Н
Как продвигать товары на Wildberries: самые эффективные способы
- Автор Нехорошков Игорь
- Четверг в 13:20
- Ответы: 0
Wildberries / Вайлдберриз форум
-
Н
Почему самовыкупы так эффективны и причем тут объемы продаж?
- Автор Нехорошков Игорь
- Четверг в 13:17
- Ответы: 0
Wildberries / Вайлдберриз форум
-
Н
Отзывы на Wildberries: зачем нужны селлерам и как их зарабатывать
- Автор Нехорошков Игорь
- Четверг в 13:14
- Ответы: 0
Wildberries / Вайлдберриз форум
# Размещение баннеров
Популярные теги
Вы используете устаревший браузер. Этот и другие сайты могут отображаться в нем неправильно.
Необходимо обновить браузер или попробовать использовать другой.
-
Форум
-
Форум ozon — озон как продавать товары на озон
-
Ozon / Озон
Верх
Низ
-
Леонид
- Сообщения: 329
- Зарегистрирован: 23 июл 2009, 09:53
- Откуда: Moscow
EAN-13 — неверная генерация штрих-кода. Срочно!
Столкнулись с проблемой неправильной генерации штрих-кодов в EAN-13.
Штрих-код 8005475315272 выводится почему-то как 8005475315279.
Проверил в старой версии FastReport’а — там всё выводится правильно, т.е. как 8005475315272.
Например, в EAN-128a всё также выводится верно, но нам необходимо в EAN-13.
- Вложения
-
- wrong_barcode.png (40.24 КБ) 8906 просмотров
-
Aleksey
- Сообщения: 2666
- Зарегистрирован: 22 апр 2010, 06:57
EAN-13 — неверная генерация штрих-кода. Срочно!
Сообщение
Aleksey » 22 мар 2011, 09:38
Здравствуйте,
Проверили наш продукт, контрольная цифра рассчитывается корректно и правильно.
Проверили FastReport .Net, все правильно, там контрольная цифра тоже «9».
Проверили на 4ой версии FastReport, если вводить 12 цифр, то контрольная рассчитывается правильно — «9», если вносить все 13 цифр, то контрольная цифра рассчитывается неправильно, точнее она вообще не рассчитывается, а берется последняя введенная, 13ая, в вашем случае, «2».
Спасибо.
-
Леонид
- Сообщения: 329
- Зарегистрирован: 23 июл 2009, 09:53
- Откуда: Moscow
EAN-13 — неверная генерация штрих-кода. Срочно!
Сообщение
Леонид » 22 мар 2011, 11:32
Нет, я имел ввиду FastReport, ещё версии 3.20, кот. под Delphi 7. Это я взял для сравнения наш старый проект.
Скрин в приложении. Так вот суть, если 13 цифр — 8005475315272, то в штрих-коде должно быть 13 цифр, тех же самых, разумеется.
- Вложения
-
- barcode2.png (30.74 КБ) 8895 просмотров
-
Ivan
- Сообщения: 641
- Зарегистрирован: 10 авг 2006, 05:40
- Откуда: Stimulsoft Office
EAN-13 — неверная генерация штрих-кода. Срочно!
Сообщение
Ivan » 22 мар 2011, 11:54
Здравствуйте.
В штрихкоде EAN-13 последняя цифра является контрольной и рассчитывается по определенным правилам.
Чтобы сканер мог считать штрихкод, контрольная цифра должна быть корректной.
Если последняя цифра некорректна, то сканер не сможет прочитать ваш штрихкод.
Конечно, в принципе, можно закодировать один код, а цифры написать другие.
Но это будет вводить в заблуждение пользователей, так как считанное значение не будет совпадать с цифрами под штрихкодом.
Спасибо.
-
Леонид
- Сообщения: 329
- Зарегистрирован: 23 июл 2009, 09:53
- Откуда: Moscow
EAN-13 — неверная генерация штрих-кода. Срочно!
Сообщение
Леонид » 23 мар 2011, 04:57
Действительно, штрих-код 8005475315272 действительно неверный.
Оказывается, FastReport 3.20 не рассчитывает контрольную цифру, и даже (!) сканер не считывает этот код.
Тема закрыта. Благодарю за помощь!
-
Леонид
- Сообщения: 329
- Зарегистрирован: 23 июл 2009, 09:53
- Откуда: Moscow
EAN-13 — неверная генерация штрих-кода. Срочно!
Сообщение
Леонид » 23 мар 2011, 06:56
Да нет, вы не поняли. Мы с нового года перешли уже на новый проект: C# + Oracle + Stimul, а старый был на Delphi7 + FastReport.
Это я просто взял для сравнения тот же отчёт, чтобы проверить. Оказалось — там ошибка. Так что, уже не важно, поскольку старый проект уже давно не поддерживается, и нужен пока только для сравнения некоторых данных.