
Добрый день!
На сайте при тестировании конфигурации, были проблемы с кодировкой, ругался на latin1.
Я исправил ошибку стандартными средствами, как было указано в рекомендации и вроде еще выполнил пару команд (точно не помню, было давно):
Получил запросы на все таблицы
SEL ECT CONCAT(‘ALT ER TABLE `’, t.`TABLE_SCHEMA`, ‘`.`’, t.`TABLE_NAME`, ‘` CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;’) as sqlcode
FR OM `information_schema`.`TABLES` t
WHERE 1
AND t.`TABLE_SCHEMA` = ‘`DB_NAME`’
ORDER BY 1
и выполнил для каждой таблицы:
ALT ER TABLE `DB_NAME`.`TABLE_NAME` CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
При проверке сайта стало все ок:
Кодировка соединения (check_mysql_connection_charset): Ok
character_set_connection=utf8, collation_connection=utf8_unicode_ci, character_set_results=utf8
Кодировка базы данных (check_mysql_db_charset): Ok
CHARSET=utf8, COLLATION=utf8_unicode_ci
НО! Выползла куча багов при работе со строковыми функциями. Похоже, где то я не до правил) Я заглянул в базу и увидел в кодировках полный бардак:
character_set_client utf8mb4
character_set_connection utf8mb4
character_set_database latin1
character_set_results utf8mb4
character_set_server latin1
character_set_system utf8
collation_connection utf8mb4_unicode_ci
collation_database latin1_swedish_ci
collation_server latin1_swedish_ci
Подскажите, как лучше всего исправить и привести базу и сайт к единой кодировке (UTF8utf8_unicode_ci наверно????) и самое главное что бы базу не загубить)

7 сентября 2020
Как исправить ошибку на платформе 1С битрикс :
Ошибка! Кодировки таблиц имеют ошибки, общее число ошибок: , из них автоматически могут быть исправлены: 0. А также ошибку отсутствия русского языка в highload-блоках

Структура базы данных
Замечание. Не проверено из-за ошибок кодировки таблиц
Показываю на примере хостинга reg.ru.
Нажимаем на знак вопроса, справа от текста ошибки, и смотрим журнал проверки системы:
……………………………………………………………………………..
Кодировка поля «UF_FULL_DESCRIPTION» таблицы «b_emarketcolor» (latin1) отличается от кодировки базы (utf8)
Кодировка поля «UF_XML_ID» таблицы «b_emarketcolor» (latin1) отличается от кодировки базы (utf8)
Кодировка поля «UF_LINK» таблицы «b_emarketcolor» (latin1) отличается от кодировки базы (utf8)
Кодировка таблицы «b_emarketcomments» (latin1) отличается от кодировки базы (utf8)
…………………………………………..
Заходим в панель управления хостинга ispmanager, выбираем базу, нажимаем перейти.

Заходим в панель управления phpMyAdmin, выбираем базу, находим нужную таблицу с неправильной кодировкой.

Нажимаем кнопку структура и исправляем. Нажимаем кнопку сохранить справа.

Входим в меню Операции сверху.

Также изменяем на нужную кодировку. Нажимаем на кнопку вперед справа.
Таким же образом поправляется ошибка в highload-блоках при отсутствии русского языка. Вместо него видим только знаки вопроса ???????.
Возврат к списку
- 1. Проверка кодировки
- 2. Исправление кодировки для template1
В процессе настройки сервера для сайта, пришлось столкнуться с некоторыми проблемами. В частности с проблемой кодировки базы данных PostgreSQL. Дело в том, что при установке PostgreSQL, шаблоны баз данных создавались с кодировкой LATIN1, а сайт работает на Django, с использованием кодировки UTF8. В результате, при попытке вставки данных выпадала следующая ошибка:
ERROR: encoding UTF8 does not match locale en_US Detail: The chosen LC_CTYPE setting requires encoding LATIN1.Поискав информацию, удалось найти несколько решений, среди которых было решение, которое позволяет пересоздать шаблон базы данных с кодировкой UTF8. Но пройдёмся внимательно по симптомам задачи.
Проверка кодировки
Для проверки кодировки, применяемой на сервере и в базе данных, необходимо выполнить следующие команды.
Заходим в режим работы с PoctgreSQL:
sudo -u postgres psqlpsql — это утилита для работы с базами данных, а postgres — это супер пользователь PostgreSQL.
И выполняем следующие команды:
postgres=# SHOW SERVER_ENCODING; server_encoding ----------------- LATIN1 (1 row) postgres=# l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+---------+-------+----------------------- postgres | postgres | LATIN1 | en_US | en_US | template0 | postgres | LATIN1 | en_US | en_US | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | LATIN1 | en_US | en_US | =c/postgres + | | | | | postgres=CTc/postgres (3 rows)В выводе будет показана кодировка LATIN1, как для сервера, так и для баз данных.
Исправление кодировки для template1
А теперь исправим кодировку template1, который используется для создания баз данных.
postgres=# UPDATE pg_database SET datistemplate = FALSE WHERE datname = 'template1'; postgres=# DROP DATABASE Template1; postgres=# CREATE DATABASE template1 WITH owner=postgres ENCODING = 'UTF-8' lc_collate = 'en_US.utf8' lc_ctype = 'en_US.utf8' template template0; postgres=# UPDATE pg_database SET datistemplate = TRUE WHERE datname = 'template1';В данном случае сначала мы указываем, что template1 не является шаблоном для баз данных. Удаляем данный шаблон. Потом создаём новый шаблон с кодировкой UTF8 и устанавливаем данную базу данных в качестве шаблона для новых баз данных. Дальше новые базы данных будут создаваться с кодировкой UTF8.
И проверим, в какой кодировке у нас находиться шаблон template1, сам сервер, кстати, будет по-прежнему в кодировке LATIN1
postgres=# l List of databases Name | Owner | Encoding | Collate | Ctype | Access privileges -----------+----------+----------+------------+------------+----------------------- postgres | postgres | LATIN1 | en_US | en_US | template0 | postgres | LATIN1 | en_US | en_US | =c/postgres + | | | | | postgres=CTc/postgres template1 | postgres | UTF8 | en_US.utf8 | en_US.utf8 | (3 rows)
![]() Официальный сертифицированный
Официальный сертифицированный
хостинг для продуктов 1С Битрикс
Битрикс-стандарт INFO Оптимизированные тарифы для быстрой работы корпоративных и информационных сайтов на 1С Битрикс.
14.02.2020
При тестировании конфигурации в 1С Битрикс может возникать ошибка:
Ошибка! Сравнение для базы (utf8_general_ci) отличается от сравнения для соединения (utf8_unicode_ci).
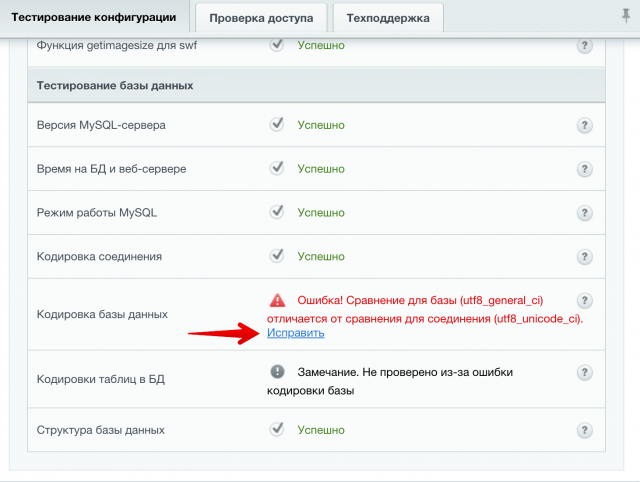
Данная ошибка не является критично, но рекомендуется исправить ее. В системе есть возможность автоматического исправления. Нажмите на ссылку «Исправить» и продолжите операцию.
После автоматического исправления снова запустите тестирование конфигурации. Ошибка должна исчезнуть.
Обратите внимание:
Ошибки связанные с кодировкой таблиц и структуры базы данных должны исправляться ПОСЛЕ исправления текущей, в противном случае база данных может повредиться. Строго следуйте порядку исправления ошибок по списку.
Концепция и все материалы с сайта btrxboost.com включающие в себя текстовую, графическую, видео, аудио и маркетинговую информацию, защищены российским и международным законодательством. В соответствии с соглашением об охране авторских прав и интеллектуальной собственности (ст. №1259, №1260, гл. 70 “Авторское право” ГК РФ от 18.12.2006 № 230-ФЗ) и согласно сертификату собственности авторских прав на информационные материалы RID 07N-4M-48 от 12.08.2012, а также сертификата DMCA id: f25cb914-aba8-4988-a116-13afb399bba2 от 21.06.2019.
В случае нарушений данных правил, применяются следующие меры: подача официального заявления в судебные органы в т.ч. с эскалацией запроса хостинг-провайдеру на котором расположен сайт-нарушитель, а также подача запроса на исключение сайта-нарушителя из поисковых систем согласно “Online Copyright Infringement Liability Limitation Act” по ч. II, раздел 512 к закону об авторском праве по DMCA.
Mysql поддерживает много кодировок и это нередко является головной болью для программистов. Самая частая проблема — кракозяблы вместо русского текста. Это происходит из за того, что текст либо лежит на сервере, либо отдается клиенту в неверной кодировке. Последнее(а иногда и первое) решается проще всего. Устанавливаем кодировку соединения (в utf8 в примере) сразу после установления соединения
|
mysql_set_charset(‘utf8’); // или mysql_query(‘SET NAMES «utf8″‘); |
Хуже, когда скрипт отдает в базу, данные в верной кодировке, а в ответ получаем кракозяблы или вопросики. Или когда часть таблиц в верной кодировке, часть нет.. В таких случаях придется разбираться детально.
|
mysql_query(«SHOW VARIABLES LIKE ‘char%’» ); /* character_set_client: latin1 character_set_connection: latin1 character_set_database: utf8 character_set_filesystem: binary character_set_results: latin1 character_set_server: cp1251 character_set_system: utf8 character_sets_dir: usrlocalmysql-5.1sharecharsets */ |
Этот запрос обязательно проверять в самом скрипте, а не в phpmyadmin, где могут быть установлены другие параметры
character_set_client— кодировка, в которой данные будут поступать от клиентаcharacter_set_connection— по умолчанию для всего, что в рамках соединения не имеет кодировкиcharacter_set_database— кодировка по умолчанию для базcharacter_set_filesystem— кодировка для работы с файловой системой (LOAD DATA INFILE, SELECT … INTO OUTFILE, и т.д.)character_set_results— кодировка, в которой будет выбран результатcharacter_set_server— кодировка, в которой работает серверcharacter_set_system— идентификаторы MySQL, всегда UTF8character_sets_dir— папка с кодировками
По умолчанию после установки mysql сервер, который устанавливается ленивым хостеромадмином имеет кодировку latin1. Соответственно указанные выше глобальные переменные будут в latin1. Базы соответственно по умолчанию и таблицы так же. И именно на это стоит обратить в самом начале обратить внимание, чтобы проблемы не всплывали позднее.
В идеальном варианте, нам следуетпривести все отмеченные цветом кодировки к единому значению. Тогда мы просто будем избавлены от мелких ошибок с кодировкой. Фактически, если мы работаем с хостингом, то на (3) и (6) мы повлиять не сможем. Но и это не страшно если настроены остальные три параметра. Mysql умет перекодировать на лету если правильно настроена кодировка соединения.
Ну и наконец, основной вопрос, что делать если одна из mysql таблиц(или несколько) в неверной кодировке и на сайте видны кракозяблывопросики?
1. Выяснить кодировку таблицы.
|
mysql > SHOW CREATE TABLE `files` ————————————————————————— CREATE TABLE `files` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `iNode` int(10) unsigned NOT NULL, `pid` int(10) unsigned NOT NULL, `sName` varchar(128) CHARACTER SET latin1 COLLATE latin1_general_ci NOT NULL, `sTitle` varchar(128) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL, PRIMARY KEY (`id`), KEY `iNode` (`iNode`) ) ENGINE=MyISAM DEFAULT CHARSET=utf8 |
В этой таблице поле sName в кодировке latin1, если у нас соединение в другой кодировке, то мы увидим кракозябры.
2. Поэтому дальше проверим кодировку соединения, sql запросом SHOW VARIABLES LIKE ‘character_set_client’. Замечу, что php функция mysqli_client_encoding(), нам не подойдет, так как она отображает кодировку только на момент соединения.
3. Если кодировка соединения не совпала с кодировкой одного из полей таблицы, то 2 очевидных варианта.
Если у нас все таблицы в одной кодировке, то проще поменять кодировку соединения .
А как исправить неверную кодировку поля таблицы?
Для этого выполним 2 запроса
|
ALTER TABLE files CHANGE sName sName BLOB; ALTER TABLE files CHANGE sName sName VARCHAR(128) CHARACTER SET utf8; |
Нельзя обойтись только вторым запросом. Важно выполнить оба. Первый преобразовывает данные в двоичные, второй запрос, преобразовывает данные в строковые сменив кодировку.. Т.е. по сути мы не измениили двоичные данные, мы изменили правило формирования символов. Если бы мы попробовали обойтись только вторым запросом, то получили бы ошибочный набор.
Развернут apache и MySQL на Ubuntu 14.04LTS.
Вывод SHOW VARIABLES LIKE'character%'
Variable_name — Value
character_set_client — utf8
character_set_connection — utf8
character_set_database — utf8
character_set_filesystem — binary
character_set_results — utf8
character_set_server — utf8
character_set_system — utf8
character_sets_dir — /usr/share/mysql/charsets/
Вывод SHOW VARIABLES LIKE 'collation%';
Variable_name — Value
collation_connection — utf8_general_ci
collation_database — utf8_general_ci
collation_server — utf8_general_ci
php подключение к базе и вывод кодировки:
<?php
header('Content-Type: text/html; charset=utf-8');
require_once ('../config.php');
// Create connection
$conn = new mysqli(DB_URL, DB_USER, DB_PASS, DB_NAME);
printf("Изначальная кодировка: %sn", $conn->character_set_name());
mysqli_query($conn, "SET NAMES 'UTF-8'");
printf("А теперь: %sn", $conn->character_set_name());
$conn->set_charset("utf8");
// Check connection
if ($conn->connect_error) {
die("Connection failed: " . $conn->connect_error);
}
Вывод браузера
Изначальная кодировка: latin1 А теперь: latin1
Думаю, это главная причина проблемы, связанной с незаписывающимися кириллическими данными в БД из формы. Числа пишутся, кириллица — нет.
09.11.2021
После установки Битрикса на новый сервер возникла проблема, при «самопроверке» CMS, сообщение:
Ошибка! Кодировка соединения с базой данных должна быть utf8, текущее значение: utf8mb3

Сам Битрикс рекомендовал:

но в конфигурационных файлах все был прописано верно.
Проверка Битрикса выполняется через Настройки — Инструменты — Проверка системы (/bitrix/admin/site_checker.php)
.
В итоге пришлось решать вопрос исправлением файла bitrix/modules/main/classes/general/site_checker.php, в блоке ниже, заменил
utf8 на utf8mb3 и
utf8_unicode_ci на utf8mb3_unicode_ci
if (defined('BX_UTF') && BX_UTF === true)
{
if ($character_set_connection != 'utf8mb3')
$strError = GetMessage("SC_CONNECTION_CHARSET_WRONG", array('#VAL#' => 'utf8', '#VAL1#' => $character_set_connection));
elseif ($collation_connection != 'utf8mb3_unicode_ci')
$strError = GetMessage("SC_CONNECTION_COLLATION_WRONG_UTF", array('#VAL#' => $collation_connection));
}
Ошибка! Сравнение для базы (utf8_general_ci) отличается от сравнения для соединения (utf8_unicode_ci)
If I am sending utf-8 data to a mysql db which has a charset of utf-8 but a collation of latin1 would that be a problem? and why?
what does the collation do in this case?
I am getting mangled up data when I extract it from the db, will a collation change fix that?
Update
The mangled data in the DB is for example like this:
Töst
It should be like:
Täst
correct?
asked Dec 17, 2010 at 15:28
![]()
mahatmanichmahatmanich
10.6k5 gold badges59 silver badges81 bronze badges
About your error: make sure you send SET NAMES utf8 to your SQL server before INSERTing the data.
answered Dec 17, 2010 at 15:47
![]()
PellePelle
6,3804 gold badges33 silver badges50 bronze badges
1
It wouldn’t be a problem, per-se. The collation controls things like sort order & how comparisons are accomplished.
It is likely that the mangled data is being caused by something else.
answered Dec 17, 2010 at 15:37
![]()
ClarusClarus
2,24116 silver badges27 bronze badges
Collation relates to how different characters will be compared. This could cause issues if you are comparing utf-8 data with a latin1 collation since you may get different results than what you expect. Changing the collation will not stop the data from being mangled.
answered Dec 17, 2010 at 15:38
![]()
JimJim
22.2k6 gold badges52 silver badges80 bronze badges
If I am sending utf-8 data to a mysql db which has a charset of utf-8 but a collation of latin1 would that be a problem? and why?
what does the collation do in this case?
I am getting mangled up data when I extract it from the db, will a collation change fix that?
Update
The mangled data in the DB is for example like this:
Töst
It should be like:
Täst
correct?
asked Dec 17, 2010 at 15:28
![]()
mahatmanichmahatmanich
10.6k5 gold badges59 silver badges81 bronze badges
About your error: make sure you send SET NAMES utf8 to your SQL server before INSERTing the data.
answered Dec 17, 2010 at 15:47
![]()
PellePelle
6,3804 gold badges33 silver badges50 bronze badges
1
It wouldn’t be a problem, per-se. The collation controls things like sort order & how comparisons are accomplished.
It is likely that the mangled data is being caused by something else.
answered Dec 17, 2010 at 15:37
![]()
ClarusClarus
2,24116 silver badges27 bronze badges
Collation relates to how different characters will be compared. This could cause issues if you are comparing utf-8 data with a latin1 collation since you may get different results than what you expect. Changing the collation will not stop the data from being mangled.
answered Dec 17, 2010 at 15:38
![]()
JimJim
22.2k6 gold badges52 silver badges80 bronze badges
7 сентября 2020
Как исправить ошибку на платформе 1С битрикс :
Ошибка! Кодировки таблиц имеют ошибки, общее число ошибок: , из них автоматически могут быть исправлены: 0. А также ошибку отсутствия русского языка в highload-блоках
Структура базы данных
Замечание. Не проверено из-за ошибок кодировки таблиц
Показываю на примере хостинга reg.ru.
Нажимаем на знак вопроса, справа от текста ошибки, и смотрим журнал проверки системы:
……………………………………………………………………………..
Кодировка поля «UF_FULL_DESCRIPTION» таблицы «b_emarketcolor» (latin1) отличается от кодировки базы (utf8)
Кодировка поля «UF_XML_ID» таблицы «b_emarketcolor» (latin1) отличается от кодировки базы (utf8)
Кодировка поля «UF_LINK» таблицы «b_emarketcolor» (latin1) отличается от кодировки базы (utf8)
Кодировка таблицы «b_emarketcomments» (latin1) отличается от кодировки базы (utf8)
…………………………………………..
Заходим в панель управления хостинга ispmanager, выбираем базу, нажимаем перейти.
Заходим в панель управления phpMyAdmin, выбираем базу, находим нужную таблицу с неправильной кодировкой.
Нажимаем кнопку структура и исправляем. Нажимаем кнопку сохранить справа.
Входим в меню Операции сверху.
Также изменяем на нужную кодировку. Нажимаем на кнопку вперед справа.
Таким же образом поправляется ошибка в highload-блоках при отсутствии русского языка. Вместо него видим только знаки вопроса ???????.
Возврат к списку
Время на прочтение
3 мин
Количество просмотров 22K
 В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
В связи с тем, что довольно много людей обращается с просьбой помочь исправить проблему с кодировками MySQL, решил написать статью с описанием, как «лечить» наиболее часто встречающиеся случаи.
В статье описывается не то, как первоначально правильно настроить кодировки MySQL (об этом уже довольно много написано), а о случаях, когда есть довольно большие таблицы с неправильными кодировками и нужно всё исправить.
Самое плохое в неправильно настроенных кодировках — то, что зачастую проблему сложно обнаружить, и с первого взгляда может казаться, что сайт работает правильно, и никаких проблем нет.
Небольшое отступление. Sypex Viewer
В какой-то момент надоело отправлять людей в громоздкий phpMyAdmin, и была написана крошечная утилитка Sypex Viewer. Она представляет собой один PHP-файл, использует современные Web 2.0 технологии AJAX, JSON и другие. Основные задачи, которые ставилась при создании — минимальный вес, и максимальное удобство и скорость работы. В дальнейшем в примерах будут скриншоты из неё, но все те же действия можно сделать и в phpMyAdmin.
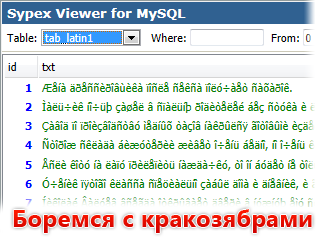
Данные в cp1251 таблицы в latin1
Наверное, самая популярная проблема. Когда данные в кодировке cp1251 (Windows-1251), а у таблиц указана кодировка по умолчанию latin1. Такие ситуации возникают в следующих случаях:
- при неграмотном обновлении с версии MySQL меньше 4.1 на более новые;
- очень часто возникает в «буржуйских» скриптах, которых вполне устраивает кодировка по умолчанию, и они «забывают», что неплохо бы указывать кодировку, как таблиц, так и соединения;
- также бывают случаи, когда переезжают с одного сервера (у которого установлена дефолтная кодировка cp1251, в частности, так сделано в Денвере) на другой (у которого стоит стандартная кодировка latin1).
В результате на сайте вроде как всё нормально, но если посмотреть в Sypex Viewer, то русские символы будут выглядеть как «кракозябры» (как их обычно называют пользователи).
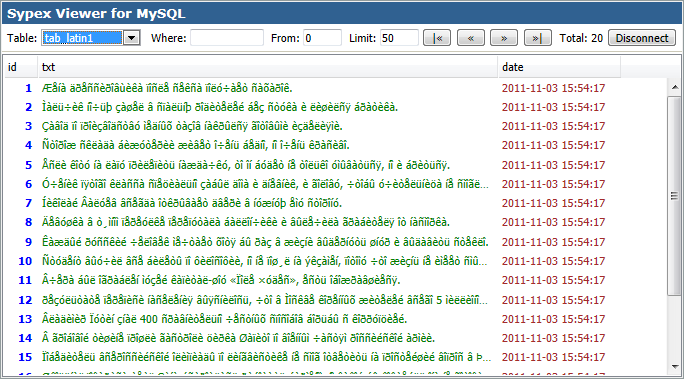
В статье я рассмотрю один из вариантов преобразование кодировок с помощью бесплатного php-скрипта Sypex Dumper, в качестве готового решения.
- На вкладке «Экспорт» выбираем нужные таблицы.
- Кодировка должна быть auto (остальные параметры неважны, можно комментарий добавить, например, «Дамп перед исправлением кодировки»).
- Нажимаем «Выполнить». Теперь у нас есть бэкап (его в любом случае желательно делать при любых преобразованиях базы данных).
- Переходим на вкладку «Импорт»
- Выбираем только что сделанный файл бэкапа.
- Выбираем кодировку cp1251 и помечаем опцию «Коррекция кодировки».
- Нажимаем «Выполнить».
- Вот и всё заходим в Sypex Viewer, чтобы убедиться, что русские символы выводятся корректно.

Данные и таблицы в utf8, но кодировка соединения latin1
Теперь рассмотрим более запущенный случай. Набирающая популярность в последнее время проблема, в связи с повальным увлечением UTF-8. Создатели софта стали переводить свои детища на UTF-8, но и тут не всё так гладко, как хотелось бы.
Возникает проблема в основном в случае, когда у таблиц указана кодировка UTF-8, данные в UTF-8, но кодировка соединения установлена по умолчанию latin1 (типичный пример, vBulletin 4, хоть там и есть в конфигах настройка кодировки соединения, но она закомментирована по умолчанию).
В результате в MySQL присылаются данные в UTF-8, но поскольку указана кодировка соединения latin1, то MySQL пытается преобразовать данные из latin1 в UTF-8. В итоге русские символы выглядят так:
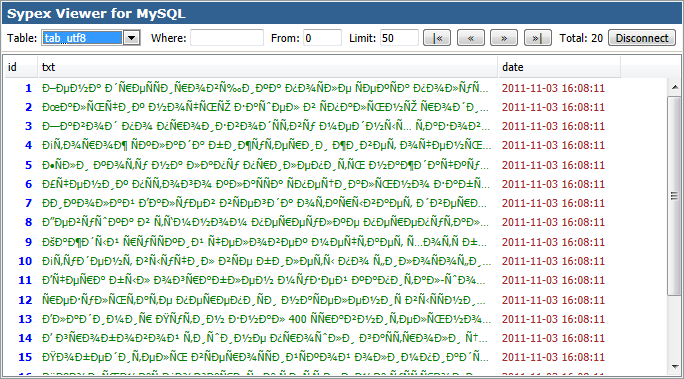
Ситуация более запущенная, но исправляется проблема почти также, как в первом случае, только в пункте 2 нужно выбрать кодировку latin1, а в пункте 6 нужно выбрать utf8 кодировку.
Изменение кодировки
Также часто встречающаяся проблема преобразования кодировки из cp1251 в UTF-8. До выполнения этого шага обязательно убедитесь, что русские символы у вас правильно показываются в Sypex Viewer или phpMyAdmin, если это не так, то предварительно исправьте кодировку.
Итак, опять заходим в Sypex Dumper.
- Во вкладке «Экспорт» выбираем нужные таблицы.
- Устанавливаем кодировку, в которую хотите преобразовать таблицы, в данном случае utf8.
- Нажимаем «Выполнить».
- После чего заходим в «Импорт» и выбираем нужный файл.
- Выставляем кодировку utf8 и опцию «Коррекция кодировки».
- Нажимаем «Выполнить».
- Вот и всё таблицы в UTF-8. Не забываем, что нужно еще установить кодировку соединения, сконвертировать ваши скрипты и шаблоны в UTF-8, выставить правильную кодировку в заголовках.
Кодировка соединения
Не забываем, что после исправлений кодировки, нужно убедиться, что ваши скрипты используют правильную кодировку соединения (в принципе, это будет сразу видно, они будут неправильно показывать русские символы без нужной кодировки соединения). У некоторых она выставляется в настройках, в некоторых придется добавить самостоятельно.
Для чего достаточно пройтись поиском по файлам, и найти где вызывается функция mysql_connect (или mysqli_connect). После этой строки нужно добавить строку которая укажет кодировку соединения.
mysql_query("SET NAMES 'cp1251'");Где вместо cp1251, указать нужную кодировку соединения.
Не забывайте перед преобразованиями кодировок делать бэкап, тут как с презервативами, лучше пусть он будет и не понадобится, чем когда понадобится — его не будет.
P.S. Спасибо Шортикам за веселый контент для примеров.
![]() Официальный сертифицированный
Официальный сертифицированный
хостинг для продуктов 1С Битрикс
14.02.2020
При тестировании конфигурации в 1С Битрикс может возникать ошибка:
Ошибка! Сравнение для базы (utf8_general_ci) отличается от сравнения для соединения (utf8_unicode_ci).
Данная ошибка не является критично, но рекомендуется исправить ее. В системе есть возможность автоматического исправления. Нажмите на ссылку «Исправить» и продолжите операцию.
После автоматического исправления снова запустите тестирование конфигурации. Ошибка должна исчезнуть.
Обратите внимание:
Ошибки связанные с кодировкой таблиц и структуры базы данных должны исправляться ПОСЛЕ исправления текущей, в противном случае база данных может повредиться. Строго следуйте порядку исправления ошибок по списку.
Концепция и все материалы с сайта btrxboost.com включающие в себя текстовую, графическую, видео, аудио и маркетинговую информацию, защищены российским и международным законодательством. В соответствии с соглашением об охране авторских прав и интеллектуальной собственности (ст. №1259, №1260, гл. 70 “Авторское право” ГК РФ от 18.12.2006 № 230-ФЗ) и согласно сертификату собственности авторских прав на информационные материалы RID 07N-4M-48 от 12.08.2012, а также сертификата DMCA id: f25cb914-aba8-4988-a116-13afb399bba2 от 21.06.2019.
В случае нарушений данных правил, применяются следующие меры: подача официального заявления в судебные органы в т.ч. с эскалацией запроса хостинг-провайдеру на котором расположен сайт-нарушитель, а также подача запроса на исключение сайта-нарушителя из поисковых систем согласно “Online Copyright Infringement Liability Limitation Act” по ч. II, раздел 512 к закону об авторском праве по DMCA.
Решение, как исправить ошибку при штатной проверке системы в «1С-Битрикс», примерный текст ошибки «Сравнение для базы отличается от сравнения для соединения»
UTF-8
SELECT CONCAT('ALTER TABLE `', t.`TABLE_SCHEMA`, '`.`', t.`TABLE_NAME`, '` CONVERT TO CHARACTER SET utf8 COLLATE utf8_general_ci;') as sqlcode
FROM `information_schema`.`TABLES` t
WHERE 1
AND t.`TABLE_SCHEMA` = 'db_name'
ORDER BY 1
Windows-1251
SELECT CONCAT('ALTER TABLE `', t.`TABLE_SCHEMA`, '`.`', t.`TABLE_NAME`, '` CONVERT TO CHARACTER SET cp1251 COLLATE cp1251_general_ci;') as sqlcode
FROM `information_schema`.`TABLES` t
WHERE 1
AND t.`TABLE_SCHEMA` = 'db_name'
ORDER BY 1