
Время на прочтение
6 мин
Количество просмотров 16K
Почти все разработчики так или иначе постоянно работают с api по http, клиентские разработчики работают с api backend своего сайта или приложения, а бэкендеры «дергают» бэкенды других сервисов, как внутренних, так и внешних. И мне кажется, одна из самых главных вещей в хорошем API это формат передачи ошибок. Ведь если это сделано плохо/неудобно, то разработчик, использующий это API, скорее всего не обработает ошибки, а клиенты будут пользоваться молчаливо ломающимся продуктом.
За 7 лет я как поддерживал множество legacy API, так и разрабатывал c нуля. И я поработал, наверное, с большинством стратегий по возвращению ошибок, но каждая из них создавала дискомфорт в той или иной мере. В последнее время я нащупал оптимальный вариант, о котором и хочу рассказать, но с начала расскажу о двух наиболее популярных вариантах.
№1: HTTP статусы
Если почитать апологетов REST, то для кодов ошибок надо использовать HTTP статусы, а текст ошибки отдавать в теле или в специальном заголовке. Например:
Success:
HTTP 200 GET /v1/user/1
Body: { name: 'Вася' }Error:
HTTP 404 GET /v1/user/1
Body: 'Не найден пользователь'Если у вас примитивная бизнес-логика или API из 5 url, то в принципе это нормальный подход. Однако как-только бизнес-логика станет сложнее, то начнется ряд проблем.
Http статусы предназначались для описания ошибок при передаче данных, а про логику вашего приложения никто не думал. Статусов явно не хватает для описания всего разнообразия ошибок в вашем проекте, да они и не были для этого предназначены. И тут начинается натягивание «совы на глобус»: все начинают спорить, какой статус ошибки дать в том или ином случае. Пример: Есть API для task manager. Какой статус надо вернуть в случае, если пользователь хочет взять задачу, а ее уже взял в работу другой пользователь? Ссылка на http статусы. И таких проблемных примеров можно придумать много.
REST скорее концепция, чем формат общения из чего следует неоднозначность использования статусов. Разработчики используют статусы как им заблагорассудится. Например, некоторые API при отсутствии сущности возвращают 404 и текст ошибки, а некоторые 200 и пустое тело.
Бэкенд разработчику в проекте непросто выбрать статус для ошибки, а клиентскому разработчику неочевидно какой статус предназначен для того или иного типа ошибок бизнес-логики. По-хорошему в проекте придется держать enum для того, чтобы описать какие ошибки относятся к тому или иному статусу.
Когда бизнес-логика приложения усложняется, начинают делать как-то так:
HTTP 400 PUT /v1/task/1 { status: 'doing' }
Body: { error_code: '12', error_message: 'Задача уже взята другим исполнителем' }
Из-за ограниченности http статусов разработчики начинают вводить “свои” коды ошибок для каждого статуса и передавать их в теле ответа. Другими словами, пользователю API приходится писать нечто подобное:
if (status === 200) {
// Success
} else if (status === 500) {
// some code
} else if (status === 400) {
if (body.error_code === 1) {
// some code
} else if (body.error_code === 2) {
// some code
} else {
// some code
}
} else if (status === 404) {
// some code
} else {
// some code
}Из-за этого ветвление клиентского кода начинает стремительно расти: множество http статусов и множество кодов в самом сообщении. Для каждого ошибочного http статуса необходимо проверить наличие кодов ошибок в теле сообщения. От комбинаторного взрыва начинает конкретно пухнуть башка! А значит обработку ошибок скорее всего сведут к сообщению типа “Произошла ошибка” или к молчаливому некорректному поведению.
Многие системы мониторинга сервисов привязываются к http статусам, но это не помогает в мониторинге, если статусы используются для описания ошибок бизнес логики. Например, у нас резкий всплеск ошибок 429 на графике. Это началась DDOS атака, или кто-то из разработчиков выбрал неудачный статус?
Итог: Начать с таким подходом легко и просто и для простого API это вполне подойдет. Но если логика стала сложнее, то использование статусов для описания того, что не укладывается в заданные рамки протокола http приводит к неоднозначности использования и последующим костылям для работы с ошибками. Или что еще хуже к формализму, что ведет к неприятному пользовательскому опыту.
№2: На все 200
Есть другой подход, даже более старый, чем REST, а именно: на все ошибки связанные с бизнес-логикой возвращать 200, а уже в теле ответа есть информация об ошибке. Например:
Вариант 1:
Success:
HTTP 200 GET /v1/user/1
Body: { ok: true, data: { name: 'Вася' } }
Error:
HTTP 200 GET /v1/user/1
Body: { ok: false, error: { code: 1, msg: 'Не найден пользователь' } }Вариант 2:
Success:
HTTP 200 GET /v1/user/1
Body: { data: { name: 'Вася' }, error: null }
Error:
HTTP 200 GET /v1/user/1
Body: { data: null, error: { code: 1, msg: 'Не найден пользователь' } }
На самом деле формат зависит от вас или от выбранной библиотеки для реализации коммуникации, например JSON-API.
Звучит здорово, мы теперь отвязались от http статусов и можем спокойно ввести свои коды ошибок. У нас больше нет проблемы “впихнуть невпихуемое”. Выбор нового типа ошибки не вызывает споров, а сводится просто к введению нового числового номера (например, последовательно) или строковой константы. Например:
module.exports = {
NOT_FOUND: 1,
VALIDATION: 2,
// ….
}
module.exports = {
NOT_FOUND: ‘NOT_AUTHORIZED’,
VALIDATION: ‘VALIDATION’,
// ….
}
Клиентские разработчики просто основываясь на кодах ошибок могут создать классы/типы ошибок и притом не бояться, что сервер вернет один и тот же код для разных типов ошибок (из-за бедности http статусов).
Обработка ошибок становится менее ветвящейся, множество http статусов превратились в два: 200 и все остальные (ошибки транспорта).
if (status === 200) {
if (body.error) {
var error = body.error;
if (error.code === 1) {
// some code
} else if (error.code === 2) {
// some code
} else {
// some code
}
} else {
// Success
}
} else {
// transport erros
}
В некоторых случаях, если есть библиотека десериализации данных, она может взять часть работы на себя. Писать SDK вокруг такого подхода проще нежели вокруг той или иной имплементации REST, ведь реализация зависит от того, как это видел автор. Кроме того, теперь никто не вызовет случайное срабатывание alert в мониторинге из-за того, что выбрал неудачный код ошибки.
Но неудобства тоже есть:
-
Избыточность полей при передаче данных, т.е. нужно всегда передавать 2 поля: для данных и для ошибки. Это усложняет чтение логов и написание документации.
-
При использовании средств отладки (Chrome DevTools) или других подобных инструментов вы не сможете быстро найти ошибочные запросы бизнес логики, придется обязательно заглянуть в тело ответа (ведь всегда 200)
-
Мониторинг теперь точно будет срабатывать только на ошибки транспорта, а не бизнес-логики, но для мониторинга логики надо будет дописывать парсинг тела сообщения.
В некоторых случаях данный подход вырождается в RPC, то есть по сути вообще отказываются от использования url и шлют все на один url методом POST, а в теле сообщения передают все параметры. Мне кажется это не правильным, ведь url это прекрасный именованный namespace, зачем от этого отказываться, не понятно?! Кроме того, RPC создает проблемы:
-
нельзя кэшировать по http GET запросы, так как замешали чтение и запись в один метод POST
-
нельзя делать повторы для неудавшихся GET запросов (на backend) на реверс-прокси (например, nginx) по указанной выше причине
-
имеются проблемы с документированием – swagger и ApiDoc не подходят, а удобных аналогов я не нашел
Итог: Для сложной бизнес-логики с большим количеством типов ошибок такой подход лучше, чем расплывчатый REST, не зря в проектах c “разухабистой” бизнес-логикой часто именно такой подход и используют.
№3: Смешанный
Возьмем лучшее от двух миров. Мы выберем один http статус, например, 400 или 422 для всех ошибок бизнес-логики, а в теле ответа будем указывать код ошибки или строковую константу. Например:
Success:
HTTP 200 /v1/user/1
Body: { name: 'Вася' }Error:
HTTP 400 /v1/user/1
Body: { error: { code: 1, msg: 'Не найден пользователь' } }Коды:
-
200 – успех
-
400 – ошибка бизнес логики
-
остальное ошибки в транспорте
Тело ответа для удачного запроса у нас имеет произвольную структуру, а вот для ошибки есть четкая схема. Мы избавляемся от избыточности данных (поле ошибки/данных) благодаря использованию http статуса в сравнении со вторым вариантом. Клиентский код упрощается в плане обработки ошибки (в сравнении с первым вариантом). Также мы снижаем его вложенность за счет использования отдельного http статуса для ошибок бизнес логики (в сравнении со вторым вариантом).
if (status === 200) {
// Success
} else if (status === 400) {
if (body.error.code === 1) {
// some code
} else if (body.error.code === 2) {
// some code
} else {
// some code
}
} else {
// transport erros
}
Мы можем расширять объект ошибки для детализации проблемы, если хотим. С мониторингом все как во втором варианте, дописывать парсинг придется, но и риска “стрельбы” некорректными alert нету. Для документирования можем спокойно использовать Swagger и ApiDoc. При этом сохраняется удобство использования инструментов разработчика, таких как Chrome DevTools, Postman, Talend API.
Итог: Использую данный подход уже в нескольких проектах, где множество типов ошибок и все крайне довольны, как клиентские разработчики, так и бэкендеры. Внедрение новой ошибки не вызывает споров, проблем и противоречий. Данный подход объединяет преимущества первого и второго варианта, при этом код более читабельный и структурированный.
Самое главное какой бы формат ошибок вы бы не выбрали лучше обговорить его заранее и следовать ему. Если эту вещь пустить на “самотек”, то очень скоро обработка ошибок в проекте станет невыносимо сложной для всех.
P.S. Иногда ошибки любят передавать массивом
{ error: [{ code: 1, msg: 'Не найден пользователь' }] }Но это актуально в основном в двух случаях:
-
Когда наш API выступает в роли сервиса без фронтенда (нет сайта/приложения). Например, сервис платежей.
-
Когда в API есть url для загрузки какого-нибудь длинного отчета в котором может быть ошибка в каждой строке/колонке. И тогда для пользователя удобнее, чтобы ошибки в приложении сразу показывались все, а не по одной.
В противном случае нет особого смысла закладываться сразу на массив ошибок, потому что базовая валидация данных должна происходить на клиенте, зато код упрощается как на сервере, так и на клиенте. А user-experience хакеров, лезущих напрямую в наше API, не должен нас волновать?HTTP
Skip to content
В статье описано, как использовать функцию ЕСЛИОШИБКА в Excel для обнаружения ошибок и замены их пустой ячейкой, другим значением или определённым сообщением. Покажем примеры, как использовать функцию ЕСЛИОШИБКА с функциями визуального просмотра и сопоставления индексов, а также как она сравнивается с ЕСЛИ ОШИБКА и ЕСНД.
«Дайте мне точку опоры, и я переверну землю», — сказал однажды Архимед. «Дайте мне формулу, и я заставлю ее вернуть ошибку», — сказал бы пользователь Excel. Здесь мы не будем рассматривать, как получить ошибки в Excel. Мы узнаем, как предотвратить их, чтобы ваши таблицы были чистыми, а формулы — понятными и точными.
Итак, вот о чем мы поговорим:
Что означает функция Excel ЕСЛИОШИБКА
Функция ЕСЛИОШИБКА (IFERROR по-английски) предназначена для обнаружения и устранения ошибок в формулах и вычислениях. Это значит, что функция ЕСЛИОШИБКА должна выполнить определенные действия, если видит какую-либо ошибку. Более конкретно, она проверяет формулу и, если вычисление дает ошибку, то она возвращает какое-то другое значение, которое вы ей укажете. Если же всё хорошо, то просто возвращает результат формулы.
Синтаксис функции Excel ЕСЛИОШИБКА следующий:
ЕСЛИОШИБКА(значение; значение_если_ошибка)
Где:
- Значение (обязательно) — что проверять на наличие ошибок. Это может быть формула, выражение или ссылка на ячейку.
- Значение_если_ошибка (обязательно) — что возвращать при обнаружении ошибки. Это может быть пустая строка (получится пустая ячейка), текстовое сообщение, числовое значение, другая формула или вычисление.
Например, при делении двух столбцов чисел можно получить кучу разных ошибок, если в одном из столбцов есть пустые ячейки, нули или текст.
Рассмотрим простой пример:

Чтобы этого не произошло, используйте формулу ЕСЛИОШИБКА, чтобы перехватывать и обрабатывать их нужным вам образом.
Если ошибка, то пусто
Укажите пустую строку (“”) в аргументе значение_если_ошибка, чтобы вернуть пустую ячейку, если обнаружена ошибка:
=ЕСЛИОШИБКА(A4/B4; «»)
Вернемся к нашему примеру и используем ЕСЛИОШИБКА:

Как видите по сравнению с первым скриншотом, вместо стандартных сообщений мы видим просто пустые ячейки.
Если ошибка, то показать сообщение
Вы также можете отобразить собственное сообщение вместо стандартного обозначения ошибок Excel:
=ЕСЛИОШИБКА(A4/B4; «Ошибка в вычислениях»)
Перед вами – третий вариант нашей небольшой таблицы.

5 фактов, которые нужно знать о функции ЕСЛИОШИБКА в Excel
- ЕСЛИОШИБКА в Excel обрабатывает все типы ошибок, включая #ДЕЛ/0!, #Н/Д, #ИМЯ?, #NULL!, #ЧИСЛО!, #ССЫЛКА! и #ЗНАЧ!.
- В зависимости от содержимого аргумента значение_если_ошибка функция может заменить ошибки вашим текстовым сообщением, числом, датой или логическим значением, результатом другой формулы или пустой строкой (пустой ячейкой).
- Если аргумент значение является пустой ячейкой, он обрабатывается как пустая строка (»’), но не как ошибка.
- ЕСЛИОШИБКА появилась в Excel 2007 и доступна во всех последующих версиях Excel 2010, Excel 2013, Excel 2016, Excel 2019, Excel 2021 и Excel 365.
- Чтобы перехватывать ошибки в Excel 2003 и более ранних версиях, используйте функцию ЕОШИБКА в сочетании с функцией ЕСЛИ, например как показано ниже:
=ЕСЛИ(ЕОШИБКА(A4/B4);»Ошибка в вычислениях»;A4/B4)
Далее вы увидите, как можно использовать ЕСЛИОШИБКА в Excel в сочетании с другими функциями для выполнения более сложных задач.
ЕСЛИОШИБКА с функцией ВПР
Часто встречающаяся задача в Excel – поиск нужного значения в таблице в соответствии с определёнными критериями. И не всегда этот поиск бывает успешным. Одним из наиболее распространенных применений функции ЕСЛИОШИБКА является сообщение пользователям, что искомое значение не найдено в базе данных. Для этого вы заключаете формулу ВПР в функцию ЕСЛИОШИБКА примерно следующим образом:
ЕСЛИОШИБКА(ВПР( … );»Не найдено»)
Если искомое значение отсутствует в таблице, которую вы просматриваете, обычная формула ВПР вернет ошибку #Н/Д:

Для лучшего понимания таблицы и улучшения ее внешнего вида, заключите функцию ВПР в ЕСЛИОШИБКА и покажите более понятное для пользователя сообщение:
=ЕСЛИОШИБКА(ВПР(D3; $A$3:$B$5; 2;ЛОЖЬ); «Не найдено»)
На скриншоте ниже показан пример ЕСЛИОШИБКА вместе с ВПР в Excel:

Если вы хотите перехватывать только #Н/Д, но не все подряд ошибки, используйте функцию ЕНД вместо ЕСЛИОШИБКА. Она просто возвращает ИСТИНА или ЛОЖЬ в зависимости от появления ошибки #Н/Д. Поэтому нам здесь еще понадобится функция ЕСЛИ, чтобы обработать эти логические значения:
=ЕСЛИ(ЕНД(ВПР(D3; $A$3:$B$5; 2;ЛОЖЬ)); «Не найдено»;ВПР(D3; $A$3:$B$5; 2;ЛОЖЬ))
Дополнительные примеры формул Excel ЕСЛИОШИБКА ВПР можно также найти в нашей статье Как убрать сообщение #Н/Д в ВПР?
Вложенные функции ЕСЛИОШИБКА для выполнения последовательных ВПР
В ситуациях, когда вам нужно выполнить несколько операций ВПР в зависимости от того, была ли предыдущая ВПР успешной или неудачной, вы можете вложить две или более функции ЕСЛИОШИБКА одну в другую.
Предположим, у вас есть несколько отчетов о продажах из региональных отделений вашей компании, и вы хотите получить сумму по определенному идентификатору заказа. С ячейкой В9 в качестве критерия поиска (номер заказа) и тремя небольшими таблицами поиска (таблица 1, 2 и 3), формула выглядит следующим образом:
=ЕСЛИОШИБКА(ВПР(B9;A3:B6;2;0);ЕСЛИОШИБКА(ВПР(B9;D3:E6;2;0);ЕСЛИОШИБКА(ВПР(B9;G3:H6;2;0);»Не найден»)))
Результат будет выглядеть примерно так, как на рисунке ниже:

То есть, если поиск завершился неудачей (то есть, ошибкой) первой таблице, начинаем искать во второй, и так далее. Если нигде ничего не нашли, получим сообщение «Не найден».
ЕСЛИОШИБКА в формулах массива
Как вы, наверное, знаете, формулы массива в Excel предназначены для выполнения нескольких вычислений внутри одной формулы. Если вы в аргументе значение функции ЕСЛИОШИБКА укажете формулу или выражение, которое возвращает массив, она также обработает и вернет массив значений для каждой ячейки в указанном диапазоне. Пример ниже поможет пояснить это.
Допустим, у вас есть Сумма в столбце B и Цена в столбце C, и вы хотите вычислить Количество. Это можно сделать с помощью следующей формулы массива, которая делит каждую ячейку в диапазоне B2:B4 на соответствующую ячейку в диапазоне C2:C4, а затем суммирует результаты:
=СУММ(($B$2:$B$4/$C$2:$C$4))
Формула работает нормально, пока в диапазоне делителей нет нулей или пустых ячеек. Если есть хотя бы одно значение 0 или пустая строка, то возвращается ошибка: #ДЕЛ/0! Из-за одной некорректной позиции мы не можем получить итоговый результат.

Чтобы исправить эту ситуацию, просто вложите деление внутрь формулы ЕСЛИОШИБКА:
=СУММ(ЕСЛИОШИБКА($B$2:$B$4/$C$2:$C$4;0))

Что делает эта формула? Делит значение в столбце B на значение в столбце C в каждой строке (3500/100, 2000/50 и 0/0) и возвращает массив результатов {35; 40; #ДЕЛ/0!}. Функция ЕСЛИОШИБКА перехватывает все ошибки #ДЕЛ/0! и заменяет их нулями. Затем функция СУММ суммирует значения в итоговом массиве {35; 40; 0} и выводит окончательный результат (35+40=75).
Примечание. Помните, что ввод формулы массива должен быть завершен нажатием комбинации Ctrl + Shift + Enter (если у вас не Office365 или Excel2021 – они понимают формулы массива без дополнительных телодвижений).
ЕСЛИОШИБКА или ЕСЛИ + ЕОШИБКА?
Теперь, когда вы знаете, как использовать функцию ЕСЛИОШИБКА в Excel, вы можете удивиться, почему некоторые люди все еще склоняются к использованию комбинации ЕСЛИ + ЕОШИБКА. Есть ли у этого старого метода преимущества по сравнению с ЕСЛИОШИБКА?
В старые недобрые времена Excel 2003 и более ранних версий, когда ЕСЛИОШИБКА не существовало, совместное использование ЕСЛИ и ЕОШИБКА было единственным возможным способом перехвата ошибок. Это просто немного более сложный способ достижения того же результата.
Например, чтобы отловить ошибки ВПР, вы можете использовать любую из приведенных ниже формул.
В Excel 2007 — Excel 2016:
ЕСЛИОШИБКА(ВПР( … ); «Не найдено»)
Во всех версиях Excel:
ЕСЛИ(ЕОШИБКА(ВПР(…)); «Не найдено»; ВПР(…))
Обратите внимание, что в формуле ЕСЛИ ЕОШИБКА ВПР вам нужно дважды выполнить ВПР. Чтобы лучше понять, расшифруем: если ВПР приводит к ошибке, вернуть «Не найдено», в противном случае вывести результат ВПР.
А вот простой пример формулы Excel ЕСЛИ ЕОШИБКА ВПР:
=ЕСЛИ(ЕОШИБКА(ВПР(D2; A2:B5;2;ЛОЖЬ)); «Не найдено»; ВПР(D2; A2:B5;2;ЛОЖЬ ))

ЕСЛИОШИБКА против ЕСНД
Представленная в Excel 2013, ЕСНД (IFNA в английской версии) — это еще одна функция для проверки формулы на наличие ошибок. Его синтаксис похож на синтаксис ЕСЛИОШИБКА:
ЕСНД(значение; значение_если_НД)
Чем ЕСНД отличается от ЕСЛИОШИБКА? Функция ЕСНД перехватывает только ошибки #Н/Д, тогда как ЕСЛИОШИБКА обрабатывает все типы ошибок.
В каких ситуациях вы можете использовать ЕСНД? Когда нецелесообразно скрывать все ошибки. Например, при работе с важными данными вы можете захотеть получать предупреждения о возможных ошибках в вашем наборе данных (случайном делении на ноль и т.п.), а стандартные сообщения об ошибках Excel с символом «#» могут быть яркими визуальными индикаторами проблем.
Давайте посмотрим, как можно создать формулу, отображающую сообщение «Не найдено» вместо ошибки «Н/Д», которая появляется, когда искомое значение отсутствует в наборе данных, но при этом вы будете видеть все другие ошибки Excel.
Предположим, вы хотите получить Количество из таблицы поиска в таблицу с результатами, как показано на рисунке ниже. Проще всего было бы использовать ЕСЛИОШИБКА с ВПР. Таблица приобрела бы красивый вид, но при этом за надписью «Не найдено» были бы скрыты не только ошибки поиска, но и все другие ошибки. И мы не заметили бы, что в исходной таблице поиска у нас есть ошибка деления на ноль, так как не заполнена цена персиков. Поэтому более разумно использовать ЕСНД, чтобы с ее помощью обработать только ошибки поиска:
=ЕСНД(ВПР(F3; $A$3:$D$6; 4;ЛОЖЬ); «Не найдено»)

Или подойдет комбинация ЕСЛИ ЕНД для старых версий Excel:
=ЕСЛИ(ЕНД(ВПР(F3; $A$3:$D$6; 4;ЛОЖЬ));»Не найдено»; ВПР(F3; $A$3:$D$6; 4;ЛОЖЬ))
Как видите, формула ЕСНД с ВПР возвращает «Не найдено» только для товара, которого нет в таблице поиска (Сливы). Для персиков она показывает #ДЕЛ/0! что указывает на то, что наша таблица поиска содержит ошибку деления на ноль.
Рекомендации по использованию ЕСЛИОШИБКА в Excel
Итак, вы уже знаете, что функция ЕСЛИОШИБКА — это самый простой способ отлавливать ошибки в Excel и маскировать их пустыми ячейками, нулевыми значениями или собственными сообщениями. Однако это не означает, что вы должны обернуть каждую формулу в функцию обработки ошибок.
Эти простые рекомендации могут помочь вам сохранить баланс.
- Не ловите ошибки без весомой на то причины.
- Оберните в ЕСЛИОШИБКА только ту часть формулы, где по вашему мнению могут возникнуть проблемы.
- Чтобы обрабатывать только определенные ошибки, используйте другую функцию обработки ошибок с меньшей областью действия:
- ЕСНД или ЕСЛИ ЕНД для обнаружения только ошибок #H/Д.
- ЕОШ для обнаружения всех ошибок, кроме #Н/Д.
Мы постарались рассказать, как можно использовать функцию ЕСЛИОШИБКА в Excel. Примеры перехвата и обработки ошибок могут быть полезны и для «чайников», и для более опытных пользователей.
Также рекомендуем:
Отладка – это процесс локализации и исправления ошибок,
обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора
программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Для исправления ошибки необходимо определить ее причину, т.е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Отладка программы – один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами;
•операционной системы;
•среды и языка программирования;
•реализуемых процессов;
•природы и специфики различных ошибок;
•методик отладки и соответствующих программных средств.
9.1Классификация ошибок
Всоответствии с этапом обработки, на котором проявляются ошибки, различают:
•синтаксические ошибки;
•ошибки компоновки;
•ошибки выполнения.
Ошибки
|
Ошибки |
Ошибки |
Ошибки |
|||
|
компиляции |
компоновки |
выполнения |
|||
9.1 Классификация ошибок (2)
Синтаксические ошибки
Синтаксические ошибки относятся к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения.
Чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор.
Всвязи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом.
Кпервым, безусловно, можно отнести Паскаль, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы.
Ко вторым – С со всеми его модификациями.
9.1 Классификация ошибок (3)
Ошибки компоновки
Ошибки компоновки связаны с проблемами, обнаруженными при разрешении внешних ссылок.
Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения
К самой непредсказуемой группе относятся ошибки выполнения.
Они могут иметь разную природу, и соответственно по-разному проявляться.
Часть ошибок обнаруживается и документируется операционной системой.
Выделяют четыре способа проявления таких ошибок:
9.1Классификация ошибок (4)
•появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т.п.;
•появление сообщения об ошибке, обнаруженные операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т.п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
9.1 Классификация ошибок (5)
Все возможные причины ошибок выполнения можно разделить на следующие группы:
Ошибки
выполнения
Ошибки определения данных
Ошибки
передачи
Ошибки
преобразования
Ошибки
перезаписи
Неправильные
данные
Логические
ошибки
|
Проектирования |
Кодирования |
|||||
|
Неприменимый |
Некорректная |
|||||
|
работас |
||||||
|
метод |
||||||
|
переменными |
||||||
|
Неверный |
||||||
|
Некорректные |
||||||
|
алгоритм |
||||||
|
вычисления |
||||||
|
Неверная |
Ошибки |
|||||
|
структураданных |
||||||
|
межмодульных |
||||||
|
Другие |
интерфейсов |
|||||
|
Неправильнаяреализация |
||||||
|
алгоритма |
||||||
|
Другие |
||||||
Ошибки накопления погрешностей
Игнорирование
ограничений разрядной сетки
Игнорирование
способов
уменьшения
погрешности
9.2 Методы отладки
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. При этом можно использовать различные методы:
•метод тестирования;
•метод индукции;
•метод дедукции;
•метод обратного прослеживания.
Метод тестирования
Самый простой и естественный способ данной группы предлагает при обнаружении ошибки выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, если ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используется как составная часть других методов отладки
9.2 Методы отладки(2)
Метод индукции
Метод основан на тщательном анализе симптомов ошибки, которыми могут проявляться как неверные результаты
вычислений или как сообщение об ошибке.
Процесс отладки с использованием метода индукции можно представить в виде алгоритма.
Самый ответственный этап – получение необходимой информации об ошибке. Дополнительную информацию можно получить в результате выполнения схожих
тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Начало
Выявлениесимптомов ошибки
Организацияданных обошибке
Изучениеих взаимосвязей
Выдвижениегипотезы
Доказательство
гипотезы
|
Гипотеза |
нет |
|
доказана? |
|
|
да |
Нахождениеошибки
Конец
|
9.2 Методы отладки(2) |
|||||||||||||||
|
Метод дедукции |
Начало |
||||||||||||||
|
По |
методу |
дедукции |
вначале |
||||||||||||
|
Перечисление |
|||||||||||||||
|
формируют |
множество |
причин, |
|||||||||||||
|
возможныхпричин |
|||||||||||||||
|
которые могли бы вызвать данное |
|||||||||||||||
|
проявление |
ошибки. |
Затем |
Сборновыхданных |
Использование |
|||||||||||
|
анализируя причины, исключают |
те, |
процессаисключения |
|||||||||||||
|
которые |
противоречат |
имеющимся |
да |
Исключены |
|||||||||||
|
данным. |
|||||||||||||||
|
все? |
|||||||||||||||
|
Если все причины исключены, то следует |
нет |
||||||||||||||
|
Доказательство |
|||||||||||||||
|
выполнить |
дополнительное |
||||||||||||||
|
гипотезы |
|||||||||||||||
|
тестирование |
исследуемого |
||||||||||||||
|
фрагмента. |
Гипотеза |
нет |
|||||||||||||
|
В |
противном |
случае |
наиболее |
доказана? |
да |
||||||||||
|
вероятную |
гипотезу |
пытаются |
|||||||||||||
|
Нахождениеошибки |
|||||||||||||||
|
доказать. |
Если |
гипотеза |
объясняет |
||||||||||||
|
полученные |
признаки |
ошибки, |
то |
||||||||||||
|
ошибка найдена, иначе – проверяют |
Конец |
||||||||||||||
|
следующую причину. |
9.3 Общая методика отладки ПО
Можно предложить следующую методику отладки программного обеспечения, написанного на универсальных языках программирования для выполнения в операционных системах MS DOS и Win32:
•1 этап. Изучение проявления ошибки.
•2 этап. Локализации ошибки .
•3 этап. Определение причины ошибки.
•4 этап. Исправление ошибки .
•5 этап. Повторное тестирование.
Следует иметь в виду, что процесс отладки можно существенно упростить, если следовать основным рекомендациям структурного подхода к программированию.
Логическая ошибка, или алогизм, — это ход мысли, нарушающий какие-то законы или правила логики.
Если ошибка допущена неумышленно, ее называют паралогизмом.
Когда ошибка допускается преднамеренно, ее обычно именуют софизмом, хотя, как увидим далее, многие из софизмов не сводятся к логической ошибке.
Ошибки в доказательствах уже обсуждались. Рассмотрим теперь ошибки в определениях, в делениях (классификациях) и софизмы.
Все определения делятся на неявные и явные.
Явное определение — это определение, имеющее форму равенства двух понятий (определяемого и определяющего).
Неявное определение — определение, не имеющее формы равенства двух понятий.
К неявным относятся определения путем указания отрывка текста, в котором встречается определяемое понятие, определения посредством показа предмета, подпадающего под это понятие, и т. п. В явных определениях отождествляются, приравниваются друг к другу два имени. Одно — определяемое имя, содержание которого требуется раскрыть, другое — определяющее имя, решающее эту задачу.
Обычное словарное определение гиперболы: «Гипербола — это стилистическая фигура, состоящая в образном преувеличении, например: „Наметали стог выше тучи“». Определяющая часть выражается словами «стилистическая фигура, состоящая.» и слагается из двух частей. Сначала понятие гиперболы подводится под более широкое понятие «стилистическая фигура». Затем гипербола отграничивается от всех других стилистических фигур. Это достигается указанием признака «образное преувеличение», присущего только гиперболе и отсутствующего у других стилистических фигур, за которые можно было бы принять гиперболу. Явное определение гиперболы дополняется примером.
К явным определениям, и в частности к классическим, предъявляется ряд достаточно простых и очевидных требований. Их называют правилами определения.
1. Определяемое и определяющее понятия должны быть взаимозаменяемы. Если в каком-то предложении встречается одно из этих понятий, всегда должна существовать возможность заменить его другим. При этом предложение, истинное до замены, должно остаться истинным и после нее.
Для определений через род и видовое отличие это правило формулируется как правило соразмерности определяемого и определяющего понятий: совокупности предметов, охватываемые ими, должны быть одними и теми же.
Соразмерны, например, имена «гомотипия» и «сходство симметричных органов» (скажем, правой и левой руки). Соразмерны также «голкипер» и «вратарь», «нонсенс» и «бессмыслица». Встретив в каком-то предложении слово «нонсенс», мы вправе заменить его на «бессмыслицу» и наоборот.
Если объем определяющего понятия шире, чем объем определяемого, говорят об ошибке слишком широкого определения. Такую ошибку мы допустили бы, определив, к примеру, ромб просто как плоский четырехугольник. В этом случае к ромбам были бы отнесены и трапеции, и все прямоугольники, а не только те, у которых равны все стороны.
Если объем определяющего понятия уже объема определяемого, имеет место ошибка слишком узкого определения. Такую ошибку допускает, в частности, тот, кто определяет ромб как плоский четырехугольник, у которого все стороны и все углы равны. Ромб в этом случае отождествляется со своим частным случаем — квадратом, и из числа ромбов исключаются четырехугольники, у которых не все углы равны.
2. Нельзя определять имя через само себя или определять его через такое другое имя, которое, в свою очередь, определяется через него. Это правило запрещает порочный круг.
Содержат очевидный круг определения «Война есть война» и «Театр — это театр, а не кинотеатр». Задача определения — раскрыть содержание ранее неизвестного имени и сделать его известным. Определение, содержащее круг, разъясняет неизвестное через него же. В итоге неизвестное так и остается неизвестным. Истину можно, к примеру, определить как верное отражение действительности, но только при условии, что до этого верное отражение действительности не определялось как такое, которое даст истину.
3. Определение должно быть ясным. Это означает, что в определяющей части могут использоваться только имена, известные и понятные тем, на кого рассчитано определение. Желательно также, чтобы в этой части не встречались образы, метафоры, сравнения, т. е. все то, что не предполагает однозначного и ясного истолкования.
Можно определить, к примеру, пролегомены как пропедевтику. Но такое определение будет ясным лишь для тех, кто знает, что пропедевтика — это введение в какую-либо науку.
Не особенно ясны определения «Архитектура — это застывшая музыка», «Овал — круг в стесненных обстоятельствах», «Дети — это цветы жизни» и т. п. Они образны, иносказательны, ничего не говорят об определяемом предмете прямо и по существу, каждый человек может понимать их по-своему.
Ясность не является, конечно, абсолютной и неизменной характеристикой. Ясное для одного может оказаться не совсем понятным для другого и совершенно темным и невразумительным для третьего. Представления о ясности меняются и с углублением знаний. На первых порах изучения каких-то объектов даже не вполне совершенное их определение может быть воспринято как успех. Но в дальнейшем первоначальные определения начинают казаться все более туманными. Встает вопрос о замене их более ясными определениями, соответствующими новому, более высокому уровню знания.
Интересно отметить, что наши обычные загадки представляют собой, в сущности, своеобразные определения. Формулировка загадки — это половина определения, его определяющая часть. Отгадка — вторая его половина, определяемая часть. «Утром — на четырех ногах, днем — на двух, вечером — на трех. Что это?» Понятно, что это — человек в разные периоды своей жизни. Саму загадку можно переформулировать так, что она станет одним из возможных его определений.
Контекстуальный характер определений хорошо заметен на некоторых вопросах, подобных загадкам. Сформулированные для конкретного круга людей, они могут казаться странными или даже непонятными за его пределами.
Древний китайский буддист Дэн Инь-фэн однажды задал такую загадку своим ученикам. «Люди умирают сидя и лежа, некоторые умирают даже стоя. А кто умер вниз головой?» — «Мы такого не знаем», — ответили ученики. Тогда Дэн встал на голову и. умер.
Сейчас такого рода «загадка» кажется абсурдом. Но в то давнее время, когда жил Дэн, в атмосфере полемики с существующими обычаями и ритуалом его «загадка» и предложенная им «разгадка» показались вполне естественными. Во всяком случае, его сестра, присутствовавшая при этом, заметила только: «Живой ты, Дэн, пренебрегал обычаями и правилами и вот теперь, будучи мертвым, опять нарушаешь общественный порядок!»
| < Предыдущая | Следующая > |
|---|

Многие компании считают, что работают и принимают решения на основе данных, но часто это не так. Ведь для того чтобы управление велось на основе данных, их, эти самые данные, недостаточно только собрать и свести в статистику.
Намного важнее провести правильный анализ, а для этого они должны быть «чисты».
Разбираться в чистоте данных и в основных качественных параметрах я начну с этой статьи.
Для достоверной аналитики должны быть соблюдены все «П» данных: правильные, правильно собранные, собранные в правильной форме, в правильном месте и в правильное время.
Если один из параметров нарушен, это может сказаться на достоверности всей аналитики, а значит нужно понимать, на что важно обращать внимание при работе с данными.
Главные аспекты качества данных
Доступность
У аналитиков должен быть доступ к необходимым данным, но, кроме этого, доступ должен быть и к инструментам, используемым в аналитике.
Точность
Все данные должны быть достоверны, а также указаны допустимые погрешности.
Точная температура — хорошие данные, а устаревший адрес, телефон или e-mail — нехорошие данные.
Взаимосвязанность
Всегда должна быть возможность связать одни данные с другими. Например, к номеру заказа должна быть привязана информация о клиенте, его адрес, контактная и платежная информации.
Полнота
Данные должны быть «жирными» и со всеми частями. «Инвалиды» с отсутствующей частью информации могут помешать получить качественную аналитику.
Непротиворечивость
Если данные не согласованы и противоречат друг другу, значит где-то закралась ошибка.
Так если адрес клиента присутствует в двух базах, то он должен совпадать. В противном случае необходимо выбрать один источник достоверным и игнорировать остальные до исправления ошибок.
Однозначность
Каждое поле с информацией должно иметь полноценное описание, не допускающее двусмысленных значений.
Релевантность
Данные должны соответствовать характеру анализа.
Например, статистика сезонных миграций леммингов слабо относится к сезонным колебаниям биржевых курсов.

Тот самый лемминг, не влияющий на биржевые курсы.
Надежность
Надежные данные — это одновременно полная и точная информация.
Своевременность
Бич российского бизнеса — несвоевременные данные.
Часто случается, что данные еще не успели обработать и проанализировать, а они уже устарели.
С устаревшими данными нельзя работать в построении кратковременной стратегии, их можно использовать только как основу для долгосрочного стратегического планирования и прогнозирования.
Еще один недостаток устаревших данных — они стали уже почти бесполезны, а компания несет издержки по их хранению и обработке.
Ошибка в любом из пунктов может привести к частичной или полной непригодности данных для использования, или, что хуже, к неправильным выводам, сделанным на основе ошибочных данных.
Данные с ошибками

Василиск — в его описании явно закралась ошибка.
Ошибки появляются на любом этапе работы с данными, и зачастую аналитики уже не могут повлиять на их исправление, так как данные специалисты являются заключительным звеном в работе с материалом и не могут контролировать сбор и обработку информации.
Давайте разберем основные причины возникновения ошибок и способы, которые помогут их избежать.
Генерация данных
Самая частая и очевидная причина ошибок: тут могут быть как технические причины, так и влияние человеческого фактора.
В случае технических причин и сбоев все решается калибровкой и правильной настройкой инструментов сбора информации.
Когда ремонт и калибровка не помогают в решении вопроса и данные продолжают поступать недостоверными, тогда одна из возможных причин — ненадежность приборов.
Так ИК-датчики, измеряющие расстояние до ближайшей стены при картографировании местности, могут давать погрешность метр и более или сбрасывать собранные данные. Доверять показаниям настолько ненадежных датчиков нельзя.
Человеческий фактор также может проявляться по-разному. Например, сотрудники могут не знать как правильно собирать данные или не уметь работать с инструментом, могут быть невнимательными или уставшими, не знать инструкции или неправильно их понимать.
▍Самое надежное и простое решение — стандартизировать как можно больше этапов процесса сбора данных.
Ввод данных
При ручной генерации данных необходимо их зафиксировать, на этом этапе возникает множество ошибок.
Как бы не расширялся электронный документооборот, многие данные до попадания в компьютер проходят через бумажные носители.
Ошибки часто случаются при расшифровке рукописных данных. Большинство исследований по решению ошибок расшифровки проводится в медицинской сфере, так как из-за малейших неточностей под угрозу ставится здоровье и жизнь пациента.
Так исследование показало, что 46% медицинских ошибок обусловлено неточностью при расшифровке рукописных данных. А уровень ошибок в медицинских базах данных достигал 26%, есть предположение, что это связано с тем, что персонал неправильно понял или не смог разобрать написанное от руки.
Так, например, некоторые результаты медицинских опросов населения показывают, что рост взрослого человека может быть 53 см или 112 см. И если в первом случае понятно, что закралась ошибка, и скорее всего рост реципиента был 153 см, то во втором случае рост может быть как правильным, так и ошибочным. При опросах часто встречаются ошибки-очепятки, такие как «аллергия на окошек» или вес 156 кг вместо 56 кг.
В среднем ошибки делятся на четыре типа:
- Запись
Ошибка, при которой данные были изначально записаны неверно. - Вставка
Появление дополнительного символа.
Например: 53,247 ► 523,247. - Удаление
Потеря одного или нескольких символов.
Например: 53,247 ► 53,27. - Перемена мест
Просто берем и меняем два или более символов местами.
Например: 53,247 ► 52,437.
Отдельно стоит рассмотреть диттографию (случайное повторение символа) и гаплографию (пропуск повторяющихся символов). С этими ошибками часто сталкиваются ученые, занимающиеся восстановлением поврежденных или переписанных от руки древних текстов. И это еще одна проблема, связанная с некачественными данными.
Часто ошибки встречаются в написании дат, а еще чаще при столкновении разных стандартов, таких как американский (месяц/день/год) и европейский (день/месяц/год).
И если иногда ясно, что это ошибка (23 марта — 3/25), то в других случаях она может быть не замечена (3 апреля — 3 / 5 или 5/3?).
Как снизить количество ошибок

Гиппогриф — гордое и величественное мифическое животное, разновидность грифонов. Да, на гравюре тоже он, но с ошибками в описании.
Первым действием нужно сократить количество этапов генерации данных до ввода. Если вы можете избежать участия бумажного носителя, как передаточного звена, исключайте его.
В электронных формах следует ввести проверку значений, особенно это важно при введении структурированных данных: индекс, номер телефона и код города, БИК, СНИЛС и р/с.
Во многих данных есть четкая структура, которая помогает снизить ошибки — это может быть и количество символов, и их разбивка по группам, и иные виды форматов.
▍При возможности исключайте ручной ввод данных и предлагайте оператору или пользователю выбрать значение из выпадающего списка.
Если же количество вариантов велико, то можно использовать форму вопрос-ответ с заключительным подтверждением правильности введенных данных.
Идеально — исключить человеческий фактор при вводе данных и автоматизировать процесс.
При расшифровке данных хорошо себя зарекомендовал «принцип двойной записи».
При использовании этого метода два сотрудника независимо друг от друга занимаются расшифровкой, а после результаты сравниваются и перепроверяются данные, в которых обнаружены расхождения.
Интересный метод проверки данных используется при передаче данных в цифровом формате.
Так, например, в номерах банковских счетов используется контрольное число (сумма).
Контрольное число — это когда после передаваемого номера добавляется число, используемое для проверки данных и обнаружения ошибок.
Так для числа 94121 контрольным числом будет 8, при последовательном складывании цифр получается сумма 17, продолжаем складывание и получаем 17=1+7=8.
Передаем 941218, а при получении система проводит обратные расчеты и, если сумма не совпадает, то число будет отмечено как ошибочное.
Контрольных чисел может быть несколько, по одному на каждый блок цифр.
У этого метода есть недостатки, связанные с ошибкой перестановки символов, но это лучше чем ничего.
На этом я закончу вводную статью по сбору данных и контролю их качества. Если информация была для вас полезна, то я буду рад обратной связи.
Возможно, вы с чем-то не согласны или хотите поделиться своими методами и наработками — приглашаю в комментарии и надеюсь на увлекательное и полезное обсуждение.
Всем спасибо за внимание и хорошего дня!
Источник информации
 Автор: Карл Андерсон
Автор: Карл Андерсон
Аналитическая культура. От сбора данных до бизнес-результатов
Creating a Data-Driven Organization
ISBN: 978-5-00100-781-4
Издательство: Манн, Иванов и Фербер
Подборка по базе: ТИПОВАЯ ЗАДАЧА № 2. ОПРЕДЕЛЕНИЕ СТАТИЧЕСКОЙ УСТОЙЧИВОСТИ ПРМ.doc, Л№2 Причины отказов программного обеспечения, признаки появления, Понятие, виды и структура бизнес плана.pdf, 4курсовая работа автодор Виды социальных услуг точно.rtf, 1. Статистика ошибок и дефектов в комплексах программ и их харак, Бланк отчета ПЗ 4.1.4. Определение класса защищенности ГИС — .do, 2022 Курсовая ГП Договор понятие значение виды! доработка 2.docx, Тема Определение коммерческой скорости и сроков.docx, Модуль 2. Виды конфликтов, ПЗ 2.doc, Диктант виды предложений.docx
Виды ошибок. Определение ошибок ПО. Классификация ошибок
Ошибки в программах могут допускаться от самого начального этапа составления алгоритма решения задачи до окончательного оформления программы. Разновидностей ошибок достаточно много. Рассмотрим некоторые группы ошибок и соответствующие примеры:
| Вид ошибки | Пример |
| Неправильная постановка задачи | Правильное решение неверно сформулированной задачи |
| Неверный алгоритм | Выбор алгоритма, который привел к неточному или неэффективному решению задачи |
| Ошибка анализа | Неполный перечень ситуаций, которые могут возникнуть при решении задачи, наличие логических ошибок |
| Семантические ошибки | Неправильное понимание порядка выполнение оператора |
| Синтаксические ошибки | Нарушение правил, которые определяются выбранным ЯП |
| Ошибки при выполнении операций | Использование слишком большого числа, деление на ноль, извлечение квадратного корня из отрицательного не комплексного числа и т.д. |
| Ошибки в данных | Неправильно определен возможный диапазон изменения данных |
| Опечатки | Неправильное использование схожих по внешнему виду символов |
| Ошибки ввода/вывода | Неправильное считывание входных данных, неправильное задание форматов данных |
Также, ошибки могут относится к самым разным частям кода:
- ошибки обращения к данным,
- ошибки описания данных,
- ошибки вычислений,
- ошибки при сравнении,
- ошибки в передаче управления,
- ошибки ввода-вывода,
- ошибки интерфейса,
 Ошибки
Ошибки компоновки Ошибки компиляции |
| Классификация ошибок по этапу обработки программы |
 Ошибки выполнения
Ошибки определения данных
Проектирования
|
| Классификация ошибок этапа выполнения |





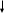


Ошибки анализа.
Связаны либо с неполным учетом ситуации, которые могут возникнуть, либо с неверным решением задачи.
К первому случаю относятся, например, пренебрежение возможностью появления отрицательных значений переменных, малых и больших величин.
Во втором случае обычно имеют место крупные и мелкие логические ошибки, из которых можно назвать:
- Отсутствие заданий начальных значений переменных.
- Неверные условия окончания цикла.
- Неверную индексацию цикла.
- Отсутствие задания условий инициирования цикла.
- Неправильное указание ветви алгоритма для продолжения процесса решения задачи.
Ошибки общего характера.
После того, как найден подходящий алгоритм решения задачи, на этапе программирования также могут появиться ошибки, независимо от выбранного языка.
Такими ошибками могут быть:
- ошибки из-за недостаточного знания или понимания программистом языка программирования или самой машины
- ошибки, допущенные при программировании алгоритма, когда команды, используемые в программе, не обеспечивают последовательности событий, установленной алгоритмом.
Ошибки физического характера.
Можно назвать несколько типов ошибок, вызываемых неверными действиями разработчика:
- Пропуск некоторых операторов.
- Отсутствие необходимых данных.
- Непредусмотренные данные.
- Неверный формат данных.
Большое значение для успешной отладки программы имеют простота и рациональность ее кодирования. Когда программа написана аккуратно и логично, легче избежать ошибок или выявить их в случае возникновения.
Следует избегать возможных «костылей», т.к. чем их больше, тем труднее отладка программы для самого автора, а кто-то другой этого сделать просто не сможет.
Правильность программ.
Любые программы — правильные в отношении их логического построения только для определенного типа данных, поэтому необходимо четко определить область значений данных, в которой программа способна функционировать. Необходимо вводить операторы, позволяющие проверить, находятся ли данные в установленных границах.
Нарушение правильности может проявляться двумя способами:
- неверная синтаксическая конструкция программы
- программа выдает неверные результаты
Правильность синтаксиса означает, что должны быть точно сформированы наименования переменных; арифметические и логические операции должны подчиняться определенным синтаксическим правилам и т.п.
Синтаксические ошибки.
Выявление транслятором синтаксических ошибок представляет собой самый важный и необходимый этап отладки программы.
Если под синтаксической ошибкой понимать «всякое нарушение требований языка программирования», то следует признать, что многие ошибки остаются необнаруженными.
В качестве примеров синтаксических ошибок можно назвать:
- пропуск необходимого знака пунктуации
- несогласованность скобок
- пропуск нужных скобок
- неправильное формирование оператора
- неверное образование имени переменной
- неправильное использование арифметических операторов
- неверное написание зарезервированных слов
Примерами синтаксических ошибок, охватывающих взаимодействие двух или более операторов, могут служить:
- Противоречивые команды.
- Отсутствие условий окончания цикла.
- Дублирование или отсутствие меток.
- Отсутствие описания массива.
- Запрещенный переход.
Советы по устранению ошибок:
- Если ошибок много, то в первую очередь устранить очевидные.
- Обратиться к руководству по программированию на данном языке (справка).
- Выбрать хороший отладочный компилятор.
Неопределенные переменные.
Распространенными источниками программных ошибок являются неопределенные переменные и переменные, для которых не заданы начальные значения.
Определение начальных значений:
- Присваивание.
- Ввод.
- Чтение из файла.
Разные прогоны программы с одними и теми же данными могут привести к различным результатам.
Обнаружение ошибок.
Ситуации, по которым мы определяем, что в программе есть ошибка:
- Отсутствует уверенность в том, что программа начала выполняться.
- Программа начала выполняться, но произошел преждевременный останов с выдачей или без выдачи сообщений о системной ошибке.
- Программа начала выполняться, но зациклилась.
- Программа выдала неправильную информацию.
Любая из этих ситуаций требует проверки последовательности выполнения команд. Обычно для этого пригодна трассировка. Процесс обнаружения ошибок характеризуется выявлением двух мест в программе:
- точки обнаружения
- точки происхождения
Точка обнаружения — место в программе, где ошибка себя проявляет или становится очевидной.
Точка происхождения — место в программе, где возникают условия для появления ошибки.
Точка обнаружения выявляется первой и служит отправным пунктом для поиска точки происхождения. Действительная ошибка исходит не из точки обнаружения, а из точки происхождения.

Юлия Валерьевна Шульгина
Эксперт по предмету «Логика»
преподавательский стаж — 10 лет
Задать вопрос автору статьи
Характеристика определения и сходных с определением приемов
Определение 1
Ошибки при определении понятий в логике – это нарушения правил, по которым должна реализоваться логическая операция, направленная на раскрытие содержания понятия, отличение предмета, отражаемого понятием, от других сходных предметов, установление значения слова или выражения.
Любое определение состоит из двух основных элементов:
- того, что определяется (определяемого понятия, definiendum);
- того, при помощи чего определяется (определяющего понятия, definiens).
Итак, определение как логическая операция состоит в придании языковому выражению (слову, словосочетанию) точного смысла. Целью определения является уточнение содержания используемых понятий. Задачей определения выступает выделение системы признаков, общей и отличительной для предметов, которые обозначаются рассматриваемым термином.
Китайский язык для начинающих
Научись писать, понимать и воспроизводить текстовую информацию
Выбрать занятия
Иногда дать определение (т.е. однозначно и полностью задать значение термина) невозможно. Тогда прибегают к приемам, сходным с определением:
- указанию (остенсивному определению), т. е. разъяснению выражений путем непосредственного указания на предметы (процессы, явления), ими обозначаемые. Маленькие дети усваивают значения большинства терминов именно таким способом. Также остенсивные определения могут использоваться при изучении иностранного языка;
- описанию, т. е. перечислению некоторых признаков предметов, позволяющих их отличить (обнаружить). Прием описания относится к эмпирическому уровню познания, на котором происходит выявление свойств изучаемых предметов;
- характеристике, т. е. указанию существенных (в том или ином отношении) отличительных признаков. Характеристика близка к настоящему определению, но отличие состоит в том, что у характеристики нет цели отграничить, отличить характеризуемый предмет от всех остальных;
- сравнению, т. е. косвенной характеристике, состоящей в указании общих и отличных черт предметов рассматриваемого класса по сравнению с предметами другого класса.
«Ошибки при определении понятий в логике» 👇
Классификация определений
В зависимости от того, что определяется (сам предмет или просто утверждается новое обозначающее его имя) выделяют два вида определений:
- реальные (касающиеся предметов). Их цель – раскрыть содержание, взаимосвязи и существенные признаки предмета;
- номинальные (касающиеся имен). Их цель – указать, что из перечисленного в определении именуется вводимым термином.
Определение 2
Номинальным определением называют соглашение, касающееся смысла и способа употребления термина (определяемого понятия), объясняющее значение имени (слова, термина), обозначающего конкретное понятие.
Другими словами, в номинальном определении характеризуется термин, обозначающий конкретное понятие.
Пример номинального определения: «Электролиты – это вещества, растворы (расплавы) которых проводят электрический ток».
Определение 3
Реальное определение – это указание на существенные отличительные признаки класса предметов, который обозначается языковым выражением, раскрывающее отличительные особенности или признаки определяемого понятия.
Пример реального определения: «Правосудие – это деятельность суда, заключающаяся в разбирательстве и разрешении гражданских и уголовных дел».
Разница между номинальными и реальными определениями состоит в различении описания и предписания. Описание предполагает указание на присущие предмету признаки. Если описание адекватно предмету, оно является истинным, если не адекватно – ложным. Поэтому реальное определение может быть истинным или ложным. В случае с предписанием ситуация иная. Предписание указывает, каким предмет должен быть, а не какой он уже есть. Поэтому у номинального определения нет истинностного значения.
По форме определения бывают:
- явными (имеющими форму «А есть В» или «А, если и только если В»);
- неявными (в которых нет четкого различия между определяемой и определяющей частями).
Правила определения и типовые ошибки
Ко всем определениям – независимо от их вида и формы – предъявляются определенные требования, сформулированные в виде правил.
Первое правило: определение должно быть соразмерным. В определении объем определяемого термина должен быть равен объему определяющего термина. Если это правило нарушается, могут возникнуть ошибки:
-
Слишком широкое определение (если объем определяющего термина больше, чем объем определяемого термина).
Пример 1
Пример слишком широкого определения: «Море – это часть водной поверхности». Под это определение подходят не только моря, но и озера, и океаны, и даже лужи.
-
Слишком узкое определение (если объем определяющего термина меньше, чем объем определяемого термина).
Пример 2
Пример слишком узкого определения: «Биология – это наука о растениях и животных». На самом деле, этими направлениями занимаются отдельные разделы биологии; биология в целом охватывает более общие и широкие вопросы.
Второе правило: определение не должно порождать круг. Это значит, что должны быть выполнены условия:
- определяющая часть явного определения не должна содержать определяемый термин;
- термины, используемые в определяющей части, не должны определяться через определяемый термин.
Если это правило нарушается, могут возникнуть следующие ошибки:
-
Порочный круг. В этом случае смысл термина из определяющей части раскрывается в другом определении через исходный определяемый термин.
Пример 3
Пример порочного круга: «Материя – это все, не являющееся сознанием; сознание – это все, не являющееся материей».
-
Тавтологическое определение. Тавтология является разновидностью порочного круга, когда определяющий термин выражается повторением определяемого.
Пример 4
Пример тавтологичного определения: «Дождливая погода – это погода, когда идет дождь».
Третье правило: определение должно быть ясным. Если это правило нарушается, формируется неясное определение (с двусмысленным, метафорическим и непонятным определяющим термином).
Пример 5
Пример неясного определения: «Такса – это колбаса с лапами». Если человек не знает, что такса – это порода собаки, по такому определению он даже не сможет разобраться, идет речь о живом существе или о блюде (форме изготовления колбасы).
Находи статьи и создавай свой список литературы по ГОСТу
Поиск по теме
Отладка программы — один их самых сложных этапов разработки программного обеспечения, требующий глубокого знания:
•специфики управления используемыми техническими средствами,
•операционной системы,
•среды и языка программирования,
•реализуемых процессов,
•природы и специфики различных ошибок,
•методик отладки и соответствующих программных средств.
Отладка — это процесс локализации и исправления ошибок, обнаруженных при тестировании программного обеспечения. Локализацией называют процесс определения оператора программы, выполнение которого вызвало нарушение нормального вычислительного процесса. Доя исправления ошибки необходимо определить ее причину, т. е. определить оператор или фрагмент, содержащие ошибку. Причины ошибок могут быть как очевидны, так и очень глубоко скрыты.
Вцелом сложность отладки обусловлена следующими причинами:
•требует от программиста глубоких знаний специфики управления используемыми техническими средствами, операционной системы, среды и языка программирования, реализуемых процессов, природы и специфики различных ошибок, методик отладки и соответствующих программных средств;
•психологически дискомфортна, так как необходимо искать собственные ошибки и, как правило, в условиях ограниченного времени;
•возможно взаимовлияние ошибок в разных частях программы, например, за счет затирания области памяти одного модуля другим из-за ошибок адресации;
•отсутствуют четко сформулированные методики отладки.
Всоответствии с этапом обработки, на котором проявляются ошибки, различают (рис. 10.1):
синтаксические ошибки — ошибки, фиксируемые компилятором (транслятором, интерпретатором) при выполнении синтаксического и частично семантического анализа программы; ошибки компоновки — ошибки, обнаруженные компоновщиком (редактором связей) при объединении модулей программы;
ошибки выполнения — ошибки, обнаруженные операционной системой, аппаратными средствами или пользователем при выполнении программы.
Синтаксические ошибки. Синтаксические ошибки относят к группе самых простых, так как синтаксис языка, как правило, строго формализован, и ошибки сопровождаются развернутым комментарием с указанием ее местоположения. Определение причин таких ошибок, как правило, труда не составляет, и даже при нечетком знании правил языка за несколько прогонов удается удалить все ошибки данного типа.
Следует иметь в виду, что чем лучше формализованы правила синтаксиса языка, тем больше ошибок из общего количества может обнаружить компилятор и, соответственно, меньше ошибок будет обнаруживаться на следующих этапах. В связи с этим говорят о языках программирования с защищенным синтаксисом и с незащищенным синтаксисом. К первым, безусловно, можно отнести Pascal, имеющий очень простой и четко определенный синтаксис, хорошо проверяемый при компиляции программы, ко вторым — Си со всеми его модификациями. Чего стоит хотя бы возможность выполнения присваивания в условном операторе в Си, например:
if (c = n) x = 0; /* в данном случае не проверятся равенство с и n, а выполняется присваивание с значения n, после чего результат операции сравнивается с нулем, если программист хотел выполнить не присваивание, а сравнение, то эта ошибка будет обнаружена только на этапе выполнения при получении результатов, отличающихся от ожидаемых */
Ошибки компоновки. Ошибки компоновки, как следует из названия, связаны с проблемами,
обнаруженными при разрешении внешних ссылок. Например, предусмотрено обращение к подпрограмме другого модуля, а при объединении модулей данная подпрограмма не найдена или не стыкуются списки параметров. В большинстве случаев ошибки такого рода также удается быстро локализовать и устранить.
Ошибки выполнения. К самой непредсказуемой группе относятся ошибки выполнения. Прежде всего они могут иметь разную природу, и соответственно по-разному проявляться. Часть ошибок обнаруживается и документируется операционной системой. Выделяют четыре способа проявления таких ошибок:
• появление сообщения об ошибке, зафиксированной схемами контроля выполнения машинных команд, например, переполнении разрядной сетки, ситуации «деление на ноль», нарушении адресации и т. п.;
•появление сообщения об ошибке, обнаруженной операционной системой, например, нарушении защиты памяти, попытке записи на устройства, защищенные от записи, отсутствии файла с заданным именем и т. п.;
•«зависание» компьютера, как простое, когда удается завершить программу без перезагрузки операционной системы, так и «тяжелое», когда для продолжения работы необходима перезагрузка;
•несовпадение полученных результатов с ожидаемыми.
Примечание. Отметим, что, если ошибки этапа выполнения обнаруживает пользователь, то в двух первых случаях, получив соответствующее сообщение, пользователь в зависимости от своего характера, степени необходимости и опыта работы за компьютером, либо попробует понять, что произошло, ища свою вину, либо обратится за помощью, либо постарается никогда больше не иметь дела с этим продуктом. При «зависании» компьютера пользователь может даже не сразу понять, что происходит что-то не то, хотя его печальный опыт и заставляет волноваться каждый раз, когда компьютер не выдает быстрой реакции на введенную команду, что также целесообразно иметь в виду. Также опасны могут быть ситуации, при которых пользователь получает неправильные результаты и использует их в своей работе.
Причины ошибок выполнения очень разнообразны, а потому и локализация может оказаться крайне сложной. Все возможные причины ошибок можно разделить на следующие группы:
•неверное определение исходных данных,
•логические ошибки,
•накопление погрешностей результатов вычислений (рис. 10.2).
Н е в е р н о е о п р е д е л е н и е и с х о д н ы х д а н н ы х происходит, если возникают любые ошибки при выполнении операций ввода-вывода: ошибки передачи, ошибки преобразования, ошибки перезаписи и ошибки данных. Причем использование специальных технических средств и программирование с защитой от ошибок (см.§ 2.7) позволяет обнаружить и предотвратить только часть этих ошибок, о чем безусловно не следует забывать.
Л о г и ч е с к и е о ш и б к и имеют разную природу. Так они могут следовать из ошибок, допущенных при проектировании, например, при выборе методов, разработке алгоритмов или определении структуры классов, а могут быть непосредственно внесены при кодировании модуля.
Кпоследней группе относят:
ошибки некорректного использования переменных, например, неудачный выбор типов данных, использование переменных до их инициализации, использование индексов, выходящих за границы определения массивов, нарушения соответствия типов данных при использовании явного или неявного переопределения типа данных, расположенных в памяти при использовании нетипизированных переменных, открытых массивов, объединений, динамической памяти, адресной арифметики и т. п.;
ошибки вычислений, например, некорректные вычисления над неарифметическими переменными, некорректное использование целочисленной арифметики, некорректное преобразование типов данных в процессе вычислений, ошибки, связанные с незнанием приоритетов выполнения операций для арифметических и логических выражений, и т. п.;
ошибки межмодульного интерфейса, например, игнорирование системных соглашений, нарушение типов и последовательности при передачи параметров, несоблюдение единства единиц измерения формальных и фактических параметров, нарушение области действия локальных и глобальных переменных;
другие ошибки кодирования, например, неправильная реализация логики программы при кодировании, игнорирование особенностей или ограничений конкретного языка программирования.
На к о п л е н и е п о г р е ш н о с т е й результатов числовых вычислений возникает, например, при некорректном отбрасывании дробных цифр чисел, некорректном использовании приближенных методов вычислений, игнорировании ограничения разрядной сетки представления вещественных чисел в ЭВМ и т. п.
Все указанные выше причины возникновения ошибок следует иметь в виду в процессе отладки. Кроме того, сложность отладки увеличивается также вследствие влияния следующих факторов:
опосредованного проявления ошибок;
возможности взаимовлияния ошибок;
возможности получения внешне одинаковых проявлений разных ошибок;
отсутствия повторяемости проявлений некоторых ошибок от запуска к запуску – так называемые стохастические ошибки;
возможности устранения внешних проявлений ошибок в исследуемой ситуации при внесении некоторых изменений в программу, например, при включении в программу диагностических фрагментов может аннулироваться или измениться внешнее проявление ошибок;
написания отдельных частей программы разными программистами.
Методы отладки программного обеспечения
Отладка программы в любом случае предполагает обдумывание и логическое осмысление всей имеющейся информации об ошибке. Большинство ошибок можно обнаружить по косвенным признакам посредством тщательного анализа текстов программ и результатов тестирования без получения дополнительной информации. При этом используют различные методы:
ручного тестирования;
индукции;
дедукции;
обратного прослеживания.
Метод ручного тестирования. Это — самый простой и естественный способ данной группы. При обнаружении ошибки необходимо выполнить тестируемую программу вручную, используя тестовый набор, при работе с которым была обнаружена ошибка.
Метод очень эффективен, но не применим для больших программ, программ со сложными вычислениями и в тех случаях, когда ошибка связана с неверным представлением программиста о выполнении некоторых операций.
Данный метод часто используют как составную часть других методов отладки.
Метод индукции. Метод основан на тщательном анализе симптомов ошибки, которые могут проявляться как неверные результаты вычислений или как сообщение об ошибке. Если компьютер просто «зависает», то фрагмент проявления ошибки вычисляют, исходя из последних полученных результатов и действий пользователя. Полученную таким образом информацию организуют и тщательно изучают, просматривая соответствующий фрагмент программы. В результате этих действий выдвигают гипотезы об ошибках, каждую из которых проверяют. Если гипотеза верна, то детализируют информацию об ошибке, иначе — выдвигают другую гипотезу. Последовательность выполнения отладки методом индукции показана на рис. 10.3 в виде схемы алгоритма.
Самый ответственный этап — выявление симптомов ошибки. Организуя данные об ошибке, целесообразно записать все, что известно о ее проявлениях, причем фиксируют, как ситуации, в которых фрагмент с ошибкой выполняется нормально, так и ситуации, в которых ошибка проявляется. Если в результате изучения данных никаких гипотез не появляется, то необходима дополнительная информация об ошибке. Дополнительную информацию можно получить, например, в результате выполнения схожих тестов.
В процессе доказательства пытаются выяснить, все ли проявления ошибки объясняет данная гипотеза, если не все, то либо гипотеза не верна, либо ошибок несколько.
Метод дедукции. По методу дедукции вначале формируют множество причин, которые могли бы вызвать данное проявление ошибки. Затем анализируя причины, исключают те, которые противоречат имеющимся данным. Если все причины исключены, то следует выполнить дополнительное тестирование исследуемого фрагмента. В противном случае наиболее вероятную гипотезу пытаются доказать. Если гипотеза объясняет полученные признаки ошибки, то ошибка найдена, иначе — проверяют следующую причину (рис. 10.4).
Метод обратного прослеживания. Для небольших программ эффективно применение метода обратного прослеживания. Начинают с точки вывода неправильного результата. Для этой точки строится гипотеза о значениях основных переменных, которые могли бы привести к получению имеющегося результата. Далее, исходя из этой гипотезы, делают предложения о значениях переменных в предыдущей точке. Процесс продолжают, пока не обнаружат причину ошибки.
В поисковых функциях Excel: ВПР, ГПР, ПОИСКПОЗ чаще всего в третьем аргументе используется значение ЛОЖЬ или 0. Так пользователь заставляет искать в исходной таблице только точные совпадения значений при поиске. Если в поисковой функции будет в третьем аргументе определено точное совпадение, а искомое значение не будет найдено в таблице, тогда функция возвращает ошибку с кодом #Н/Д!
Формула ЕСЛИОШИБКА обработки ошибок функции ВПР в Excel
Ошибка #Н/Д! пригодится в анализе моделей данных Excel, так как информирует пользователя и программу о том, что не было найдено соответственное значение. Однако если большая часть такой модели данных будет использована в отчетах, то код ошибки #Н/Д! будет смотреться некорректно. Для этого Excel предлагает функции, которые проверяют результаты вычислений на ошибки и позволяют возвращать другие альтернативные значения.
Ниже на рисунке представлена таблица фирм с фамилиями их руководителей. Вторая таблица содержит те же фамилии и соответствующие им оклады. Функция ВПР используется для соединения двух таблиц в одну. Но не по всем руководителям имеются данные об их окладах, поэтому часто встречается код ошибки #Н/Д! в результатах вычисления функции ВПР.
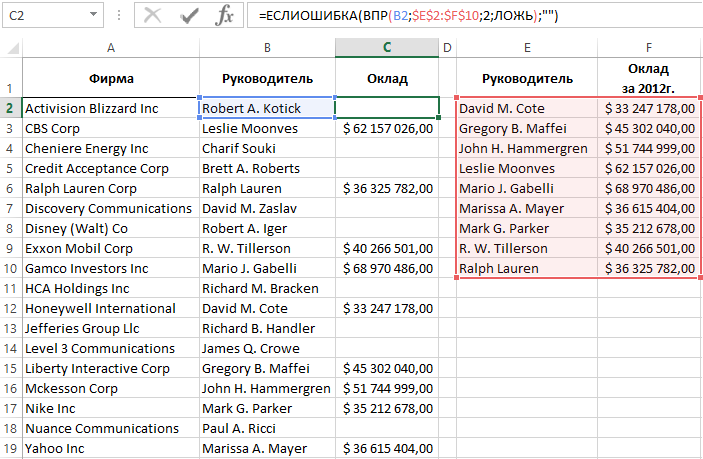
Формула, изображенная на следующем рисунке уже изменена. Она использует функцию ЕСЛИОШИБКА и возвращает пустую строку в том случае если искомое значение не найдено в исходной таблице:
Пользователи часто называют эту функцию «скрывающая ошибки». Так как она позволяет определить и укрыть любые ошибки, которые можно после этого воспринимать по-другому. А не сметить этими некрасивыми кодами в отчетах для презентации.
Первый аргумент функции ЕСЛИОШИБКА – это выражение или формула, а во втором аргументе следует указать альтернативное значение, которое должно отображаться при возникновении ошибки. Если в первом аргументе выражение или формула вернет ошибку, тогда функция вместо его значения возвратит второй аргумент. В противные случаи будет возвращено значение первого аргумента.
В данном примере альтернативным значением является пустая строка (двойные кавычки без каких-либо символов между ними). Благодаря этому отчет более читабельный и имеет презентабельный вид. Данная функция может возвращать любое значение, например, «Нет данных» или число 0.
Функции для работы с кодами ошибок в Excel
Функция ЕСЛИОШИБКА проверяет каждую ошибку, которую способна вернуть формула в Excel. Но следует использовать ее с определенной осторожностью. Ведь она способна скрывать все ошибки без разбора и даже такие важные как: #ДЕЛ/0! или #ЧИСЛО! и т.п.
Чтобы скрывать только определенную группу ошибок Excel предлагает еще 3 других функций:
- ЕОШИБКА – возвращает логическое значение ИСТИНА если ее аргумент содержит ошибку: #Н/Д, #ЗНАЧ!, #ССЫЛКА!, #ДЕЛ/0!, #ЧИСЛО!, #ИМЯ? или #ПУСТО.
- ЕОШ – функция возвращает ИСТИНА если ее аргумент содержит любую ошибку, кроме #Н/Д!
- ЕНД – возвращает значение ИСТИНА если ее аргумент содержит ошибку с кодом #Н/Д! или ЛОЖЬ если аргумент содержит любое значение или любую другую ошибку.
Три выше описанные функции для обработки ошибок в Excel возвращают логические значения ИСТИНА или ЛОЖЬ наиболее часто используются вместе с функцией ЕСЛИ.
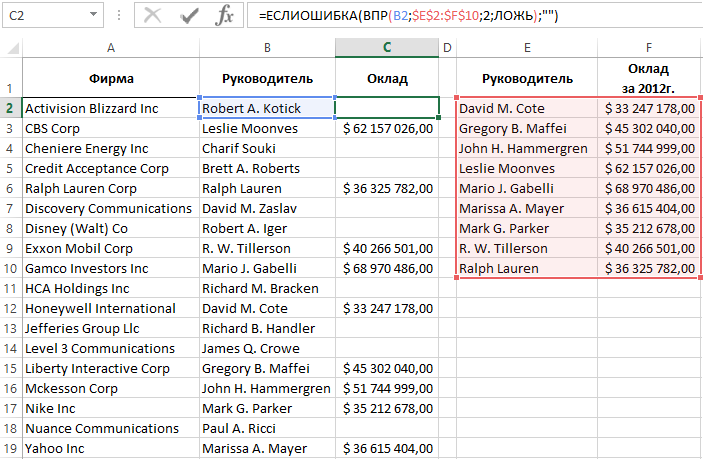
Формула ЕСЛИ и ЕДН для ошибок ВПР без функции ЕСЛИОШИБКА в Excel
Бескомпромиссная функция обработки ошибок ЕСЛИОШИБКА появилась в программе Excel начиная с 2010-й версии. Для проверки ошибок в старших версиях Excel наиболее часто использовалась функция ЕНД:
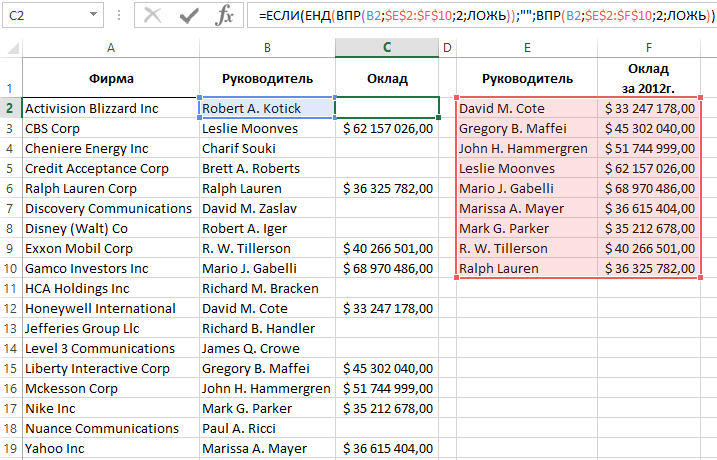
Функция ЕНД возвращает логическое значение ИСТИНА если в ее аргументе находится только один тип ошибок – #Н/Д! Или же значение ЛОЖЬ при любых других значениях. В данной формуле функция ЕСЛИ помогает функции ЕНД. Если была получена ошибка #Н/Д! формула возвращает пустую строку – указано во втором аргументе функции ЕСЛИ. В противные случаи возвращается результат вычисления функции ВПР – указано в третьем аргументе ЕСЛИ.
Главным недостатком такой формулы является необходимость дублировать функцию ВПР:
- первый разу внутри функции ЕНД;
- второй раз в третьем аргументе ЕСЛИ.
Это значит, что Excel должен два раза выполнять функцию ВПР для одной и той же ячейки. Если на листе содержится множество таких формул, тогда их пересчет требует много времени и системных ресурсов. Очень неудобно будет работать с такими файлами. Возникнет необходимость отключения автоматического пересчета формул: «ФОРМУЛЫ»-«Вычисления»-«Параметры вычислений»-«Вручную».
Все курсы > Анализ и обработка данных > Занятие 5
На прошлом занятии, посвященном практике EDA, мы работали с «чистыми данными», то есть такими данными, в которых нет ни ошибок, ни пропущенных значений. К сожалению, так бывает далеко не всегда.
Сегодня мы научимся очищать данные от дубликатов, неверных и плохо отформатированных значений, а также исправлять ошибки в дате и времени. На следующем занятии мы поговорим про работу с пропусками.
Откроем ноутбук к этому занятию⧉
Ошибки в данных могут встречаться по многим причинам. Они могут быть связаны с человеческим фактором, например, простой невнимательностью, или вызваны сбоями в работе записывающего какие-либо показатели оборудования.
В качестве примера мы будем использовать несложный датасет, в котором содержатся данные за 2019 год об отдельных финансовых показателях сети магазинов одежды, представленной в нескольких городах мира. В частности, нам доступна следующая информация:
- month — за какой месяц сделана запись
- profit — прибыль (profit) по сети
- MoM — изменение выручки (revenue) сети по отношению к предыдущему месяцу
- high — магазин с наибольшей маржинальностью (margin) продаж
Создадим датафрейм из словаря.
|
financials = pd.DataFrame({‘month’ : [’01/01/2019′, ’01/02/2019′, ’01/03/2019′, ’01/03/2019′, ’01/04/2019′, ’01/05/2019′, ’01/06/2019′, ’01/07/2019′, ’01/08/2019′, ’01/09/2019′, ’01/10/2019′, ’01/11/2019′, ’01/12/2019′, ’01/12/2019′], ‘profit’ : [‘1.20$’, ‘1.30$’, ‘1.25$’, ‘1.25$’, ‘1.27$’, ‘1.11$’, ‘1.23$’, ‘1.20$’, ‘1.31$’, ‘1.24$’, ‘1.18$’, ‘1.17$’, ‘1.23$’, ‘1.23$’], ‘MoM’ : [0.03, —0.02, 0.01, 0.02, —0.01, —0.015, 0.017, 0.04, 0.02, 0.01, 0.00, —0.01, 2.00, 2.00], ‘high’ : [‘Dubai’, ‘Paris’, ‘singapour’, ‘singapour’, ‘moscow’, ‘Paris’, ‘Madrid’, ‘moscow’, ‘london’, ‘london’, ‘Moscow’, ‘Rome’, ‘madrid’, ‘madrid’] }) financials |
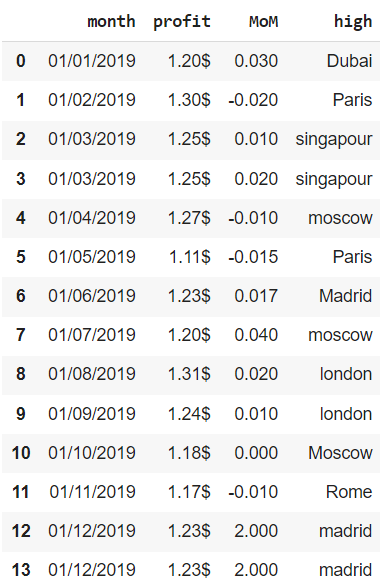
Воспользуемся методом .info() для получения общей информации о датасете.
|
<class ‘pandas.core.frame.DataFrame’> RangeIndex: 14 entries, 0 to 13 Data columns (total 4 columns): # Column Non-Null Count Dtype — —— ————— —— 0 month 14 non-null object 1 profit 14 non-null object 2 MoM 14 non-null float64 3 high 14 non-null object dtypes: float64(1), object(3) memory usage: 576.0+ bytes |
Перейдем к поиску ошибок в данных.
Дубликаты
Поиск дубликатов
Заметим, что хотя данные представлены за 12 месяцев, в датафрейме тем не менее содержится 14 значений. Это заставляет задуматься о дубликатах (duplicates) или повторяющихся значениях. Воспользуемся методом .duplicated(). На выходе мы получим логический массив, в котором повторяющееся значение обозначено как True.
|
# keep = ‘first’ (параметр по умолчанию) # помечает как дубликат (True) ВТОРОЕ повторяющееся значение financials.duplicated(keep = ‘first’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# keep = ‘last’ соответственно считает дубликатом ПЕРВОЕ повторяющееся значение financials.duplicated(keep = ‘last’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 True 13 False dtype: bool |
Результат метода .duplicated() можно использовать как фильтр.
|
# с параметром keep = ‘last’ будет выведено наблюдение с индексом 12 financials[financials.duplicated(keep = ‘last’)] |

Также заметим, что если смотреть по месяцам, у нас две дублирующихся записи, а не одна. В частности, повторяется запись не только за декабрь, но и за март. Проверим это с помощью параметра subset.
|
# с помощью параметра subset мы ищем дубликаты по конкретным столбцам financials.duplicated(subset = [‘month’]) |
|
0 False 1 False 2 False 3 True 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# посчитаем количество дубликатов по столбцу month financials.duplicated(subset = [‘month’]).sum() |
Создадим новый фильтр и выведем дубликаты по месяцам.
|
# укажем параметр keep = ‘last’, больше доверяя, таким образом, # последнему записанному за конкретный месяц значению financials[financials.duplicated(subset = [‘month’], keep = ‘last’)] |

Аналогичным образом мы можем посмотреть на неповторяющиеся значения.
|
( ~ financials.duplicated(subset = [‘month’])).sum() |
Этот логический массив можно также использовать как фильтр.
|
financials[ ~ financials.duplicated(subset = [‘month’], keep = ‘last’)] |
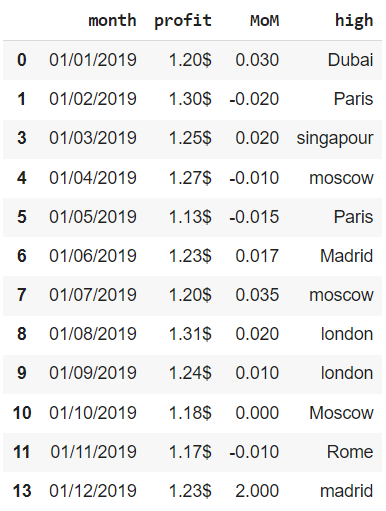
Обратите внимание, индекс остался прежним (из него просто выпали наблюдения 2 и 12). Мы исправим эту неточность при удалении дубликатов.
Удаление дубликатов
Метод .drop_duplicates() удаляет дубликаты из датафрейма и, по сути, принимает те же параметры, что и метод .duplicated().
|
# параметр ignore_index создает новый индекс financials.drop_duplicates(keep = ‘last’, subset = [‘month’], ignore_index = True, inplace = True) financials |
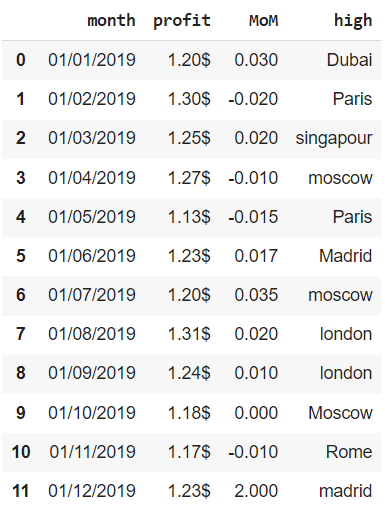
Неверные значения
Распространенным типом ошибок в данных являются неверные значения.
Базовый подход к поиску неверных значений — проверить, что данные не противоречат своей природе. Например, цена товара не может быть отрицательной.
В нашем случае мы видим, что в столбце MoM все строки отражают доли процента, а последняя строка — проценты. Из-за этого сильно искажается, например, средний показатель изменения выручки за год.
|
# рассчитаем среднемесячный рост financials.MoM.mean() |
С учетом имеющихся данных вряд ли среднее изменение выручки (в месячном, а не годовом выражении) составило 17,3%. Заменим проценты на доли процента.
|
# заменим 2% на 0.02 financials.iloc[11, 2] = 0.02 |
Вновь рассчитаем средний показатель.
Новое среднее значение 0,8% выглядит гораздо реалистичнее.
Форматирование значений
Тип str вместо float
Попробуем сложить данные о прибыли.
|
‘1.20$1.30$1.25$1.27$1.13$1.23$1.20$1.31$1.24$1.18$1.17$1.23$’ |
Так как столбец profit содержит тип str, произошло объединение (concatenation) строк. Преобразуем данные о прибыли в тип float.
|
# вначале удалим знак доллара с помощью метода .strip() financials[‘profit’] = financials[‘profit’].str.strip(‘$’) # затем воспользуемся знакомым нам методом .astype() financials[‘profit’] = financials[‘profit’].astype(‘float’) |
Проверим полученный результат с помощью нового для нас ключевого слова assert (по-англ. «утверждать»).
Если условие идущее после assert возвращает True, программа продолжает исполняться. В противном случае Питон выдает AssertionError.
Приведем пример.
|
# напишем простейшую функцию деления одного числа на другое def division(a, b): # если делитель равен нулю, Питон выдаст ошибку (текст ошибки указывать не обязательно) assert b != 0 , ‘На ноль делить нельзя’ return round(a / b, 2) |
|
# попробуем разделить 5 на 0 division(5, 0) |

Выражение
b != 0 превратилось в False и Питон выдал ошибку. Теперь вернемся к нашему коду.
|
# проверим превратился ли тип данных во float assert financials.profit.dtype == float |
Сообщения об ошибке не появилось, значит выражение верное (True). Теперь снова рассчитаем прибыль за год.
Названия городов с заглавной буквы
Остается сделать так, чтобы названия всех городов в столбце high начинались с заглавной буквы. Для этого подойдет метод .title().
|
financials[‘high’] = financials[‘high’].str.title() financials |
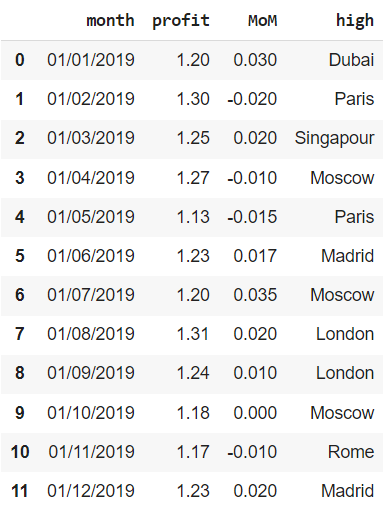
Дата и время
Как мы уже знаем, с датой и временем гораздо удобнее работать, когда они представляют собой объект datetime. В этом случае мы можем использовать все возможности Питона по анализу и прогнозированию временных рядов.
Начнем с того, что воспользуемся функцией pd.to_datetime(), которой передадим столбец month и формат, которого следует придерживаться при создании объекта datetime.
|
# запишем дату в формате datetime в столбец date1 financials[‘date1’] = pd.to_datetime(financials[‘month’], format = ‘%d/%m/%Y’) financials |

Мы получили верный результат. Как и должно быть в Pandas на первом месте в столбце date1 стоит год, затем месяц и наконец день. Теперь давайте попросим Питон самостоятельно определить формат даты.
|
# для этого подойдет параметр infer_datetime_format = True financials[‘date2’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True) financials |

У нас снова получилось создать объект datetime, однако возникла одна сложность. Функция pd.to_datetime() предположила, что в столбце month данные содержатся в американском формате (месяц/день/год), тогда как у нас они записаны в европейском (день/месяц/год). Из-за этого в столбце date2 мы получили первые 12 дней января, а не 12 месяцев 2019 года.
|
# исправить неточность с месяцем можно с помощью параметра dayfirst = True financials[‘date3’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True, dayfirst = True) financials |

Теперь мы снова получили верный формат.
|
# убедимся, что столбцы с датами имеют тип данных datetime financials.dtypes |
|
month object profit float64 MoM float64 high object date1 datetime64[ns] date2 datetime64[ns] date3 datetime64[ns] dtype: object |
Удалим избыточные столбцы и сделаем дату индексом.
|
financials.set_index(‘date3’, drop = True, inplace = True) # drop = True удаляет столбец date3 financials.drop(labels = [‘month’, ‘date1’, ‘date2’], axis = 1, inplace = True) financials.index.rename(‘month’, inplace = True) financials |
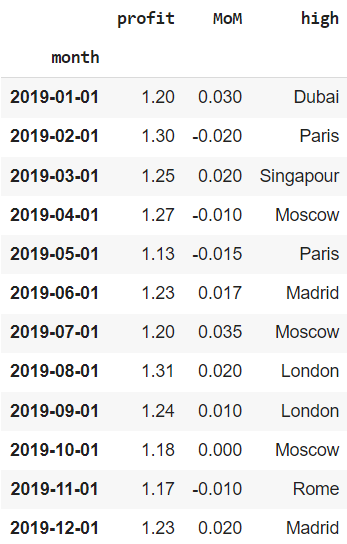
Посмотрим на еще один интересный инструмент. Предположим, что мы ошиблись с годом (вместо 2019 у нас на самом деле данные за 2020 год) или просто хотим создать индекс с датой с нуля. Для таких случаев подойдет функция pd.data_range().
|
# создадим последовательность из 12 месяцев, # передав начальный период (start), общее количество периодов (periods) # и день начала каждого периода (MS, т.е. month start) range = pd.date_range(start = ‘1/1/2020’, periods = 12, freq = ‘MS’) # сделаем эту последовательность индексом датафрейма financials.index = range financials |
Как мы уже знаем, когда индекс имеет тип данных datetime, мы можем делать срезы по датам.
|
# напоминаю, что для datetime конечная дата входит в срез financials[‘2020-01’: ‘2020-06’] |

Завершим раздел про дату и время построением двух подграфиков. Для этого вначале преобразуем индекс из объекта datetime обратно в строковый формат с помощью метода .strftime().
|
# будем выводить только месяцы (%B), так как все показатели у нас за 2020 год financials.index = financials.index.strftime(‘%B’) financials |

Теперь используем метод .plot() библиотеки Pandas с параметром subplots = True.
|
# построим графики для размера прибыли и изменения выручки за месяц financials[[‘profit’, ‘MoM’]].plot(subplots = True, # обозначим, что хотим несколько подграфиков layout = (1,2), # зададим сетку kind = ‘bar’, # укажем тип диаграммы rot = 65, # повернем деления шкалы оси x grid = True, # добавим сетку figsize = (16, 6), # укажем размер figure legend = False, # уберем легенду title = [‘Profit 2020’, ‘MoM Revenue Change 2020’]); # добавим заголовки |
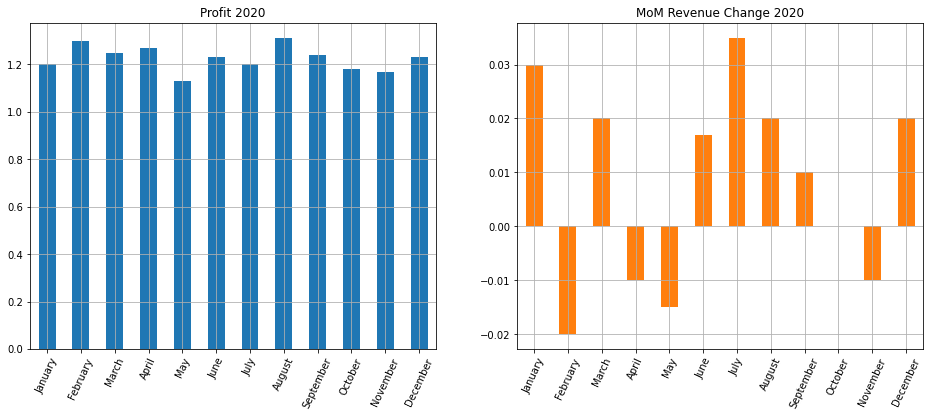
Подведем итог
Сегодня мы рассмотрели типичные ошибки в данных и способы их исправления. В частности, мы изучили как выявить и удалить дубликаты, обнаружить неверные значения и скорректировать неподходящий формат. Кроме того, мы еще раз обратились к объекту datetime и посмотрели на возможности изменения даты и времени.
Перейдем к работе с пропущенными значениями.