
Можно ли использовать модули оперативной памяти (ОЗУ) от обычного компьютера в сервере? И наоборот? Чем серверная оперативная память отличается от обычной?
Следует сразу сказать, что не какой-то особой «серверной» памяти. Есть различные виды оперативной памяти, некоторые из которых подходят для серверов, а некоторые – только для обычных персональных компьютеров.
Основное отличия оперативной памяти для серверов в том, что последняя должна поддерживать технологию ECC (Error Correction Code), кода коррекции ошибок. Эта память способна обнаруживать и исправлять возникающие ошибки данных в битах памяти. Для обычных пользовательских компьютеров распознавание и автоматическая коррекция ошибок некритичны, поскольку нагрузка серверов и обычных компьютеров несравнимы между собой по объёму потоков данных, поэтому битовые сбои в обычных компьютерах происходят гораздо реже, чем в серверах.
Есть и другие отличия серверной памяти, например, буферизованная и не буферизованная память, но эти различия больше относятся к различным видам серверной памяти как таковой.
ECC
Поддержка ЕСС (Error Correction Code) – главная особенность серверной памяти, которая значительно удорожает на 10-30% цену памяти для серверов. Бывают системные администраторы, которые, желая сэкономить деньги компании, ставят в сервер память для обычного десктопа, и сервер при этом иногда работает. Но обычно это случается, во-первых, лишь для серверов начального класса, а во-вторых, возможность сбоев работы сервера значительно возрастает.
ECC даёт возможность исправлять ошибок одиночных битов в оперативной памяти. Если для обычных десктопов такие ошибки не очно критичны, то для серверов, с высокой интенсивностью вычислений, такие ошибки могут приводить к серьёзным сбоям бизнес-процессов и к убыткам предприятий.
ECC-память содержит специальные контрольные биты и дополнительные контроллеры памяти, которые управляют этими битами в специальной микросхеме модуля памяти. В них хранится код ЕСС, вносимый при записи данных. Во время считывания данных код ECC, созданный при записи корректных данных, сопоставляется с кодом ECC, созданным при чтении данных. Если код, созданный при чтении, не соответствует коду при записи, то при его дешифровке можно определить, какой бит подвергся искажению, после чего этот бит немедленно исправляется.

Рис. 1. Принцип работы ЕСС.
ECC, используется в компьютерах с повышенными требованиями устойчивости к повреждению битов данных, например, для научных или финансовых вычислений, а также в корпоративных серверах.
Некоторые системные платы и процессоры для менее критичных приложений могут не поддерживать использование памяти ЕСС, и их цена может быть ниже. Некоторые системы могут поддерживать не буферизованные модули памяти ECC, но при этом могут также работать и с не-ЕСС памятью. В этом случае, функционал ECC обеспечивается системным встроенным ПО (firmware) и такие системы могут стоить дороже.
Модули памяти с ЕСС предназначены для обеспечения большей стабильности, чем обычные модули памяти. Однако, у них есть и некоторые недостатки.
Во-первых, не каждый компьютер может поддерживать память ECC. Большинство серверов и рабочих станций поддерживает ЕСС, но мало какие обычные пользовательские компьютеры её поддерживают. Либо, они вообще с такой память не будут работать, либо функционал ECC не будет задействован.
Во-вторых, вследствие наличие дополнительного чипа ЕСС, и вообще более сложной структуры памяти ЕСС, она стоит дороже, чем обычная, на 10-30%.
В-третьих, ECC RAM немного медленнее, чем не-ЕСС, однако, ненамного, в среднем на 2-5%.

Рис. 2. Модули память ЕСС и не-ЕСС.
Итак, наличие ЕСС – основное отличие серверной оперативной памяти от обычной. Чтобы понять, чем они ещё отличаются, рассмотрим подробнее, какие вообще бывают виды оперативной памяти ОЗУ, или RAM (Random Access Memory), и какие виды, где используются.
Буферизованная и небуферизованная память
Есть два основных типа оперативной памяти ОЗУ – буферизованная (buffered) и небуферизованная (unbuffered). В буферизованной памяти есть т.н. уровень повышения мощности обработки (processing power), который ускоряет процессы записи и считывания. В такой памяти модули памяти – 4-битовые, в отличие от 8-16 битовых в небуферизованной памяти.
Основное отличие буферизованной памяти – наличие чипа буфера, который обрабатывает информацию, получаемую от процессора (CPU). Буферный чип затем посылает эту информацию в другие чипы модуля ОЗУ. Такая буферизация позволяет централизовать посылку информации из CPU в чипы ОЗУ. Например, популярный модуль ОЗУ PC3-10600 имеет 18 микросхем памяти, поэтому буферизация для взаимодействия с CPU значительно упрощает работу последнего.
При использовании небуферизованной памяти, CPU будет коммуницировать непосредственно с каждым банком памяти, таким образом, CPU будет посылать информацию на каждый чип на каждом модуле ОЗУ. Хотя при этом система получается немного более расширяемой и гибкой, однако, при этом значительно возрастает потребляемая процессором мощность, и это осложняет выполнение других задач.
В серверах используются, в основном, буферизованные ОЗУ.
Различные типы буферизованной памяти
Регистровая память (Registered Memory, RDIMM, DIMM – Dual In-line Memory Module) – имеет дополнительный чип, который выполняет промежуточные операции между CPU и чипами модулей ОЗУ. Он уменьшает количество сигналов, передаваемых между ОЗУ и CPU. Регистровая память RDIMM, в отличие от небуферизованной UDIMM (Inbuffered DIMM), снижает электрическую нагрузку на компоненты системы, однако, немного снижает производительность. Однако, при этом система может иметь более широкое адресное пространство, чем в небуферизованной памяти. Почти все типы регистровой памяти поддерживают код коррекцию ошибок ECC. Регистровую и небуферизованную память нельзя совмещать в одной системе, даже если она поддерживает оба типа.
Полностью буферизованная память (Fully Buffered Memory, FBDIMM) – это более старая версия регистровой памяти. В DDR3 такая память не используется. Полностью буферизованная память DDR2 и небуферизованная память DDR2 имели различные типоразмеры, чтобы не спутать их при установке.
Память со сниженной нагрузкой (Load Reduced Memory, LRDIMM) – более новая версия буферизованной памяти, где используется чип буфера, ещё более снижающий электрическую нагрузку. При этом снижаются или даже полностью устраняются проблемы с рангами памяти (о чем ниже), что позволяет использовать модули памяти высокой ёмкости без снижения производительности системы (или по крайней мере, снизить этот эффект). Кроме того, LRDIMM даёт возможность не стараться обязательно заполнить все гнёзда на системной плате модулями памяти. Однако, LRDIMM, также как UDIMM и RDIMM, не может сочетаться с другими стандартами в одной системе.
Ранги памяти
Ранг – это число 64-битных областей памяти. Модули памяти могут быть одно-, двух-, четырёх- и восьми-ранговые. Большого влияния на обычные компьютеры это разделение не имеет, однако, для регистровой памяти в серверах они приводят к некоторым ограничениям.

Рис. 3. Виды модулей памяти.
Модули с высшими рангами могут иметь ограничения на то, сколько модулей может быть установлено. Например, если в системе – шесть гнёзд для модулей DIMM, то для 4-ранговых модулей можно занимать только 4 гнезда. Можно ли занимать остальные два гнезда, например, 2- или 1-ранговыми модулями DIMM – зависит от параметров системы. Иногда так делать можно, но следует использовать только определённые гнезда для таких целей. Использование модулей высоких рангов иногда приводит к снижению производительности системы. Таким образом, использование того или иного ранга модулей – часто бывает вопросом компромисса между объёмом ОЗУ и производительностью системы. С одной стороны – чем выше ёмкость ОЗУ, тем выше производительность, с другой стороны, чем выше ранг (и, следовательно, больше объём ОЗУ) тем производительность может быть ниже.
Конструктивные отличия серверной памяти
Серверная память, в особенности, RDIMM и LRDIMM, может отличаться по типоразмерам от памяти для рабочих компьютеров. Кроме того, что модулях серверной памяти бывает напаяно больше компонентов, там могут ещё устанавливаться и теплоотводы, поскольку при работе памяти в сервер выделяется больше тепла, как процессором, так и памятью. Для серверных модулей памяти может также понадобиться больше пространства над ними, для отведения тепловых потоков. Иногда, это обстоятельство вынуждает приобретать специальные низкопрофильные модули VLP (Very Low Profile). Многие пользователи именно такие модули и стараются приобретать, поскольку они в любом случае обеспечивают лучший теплоотвод.
Выводы
Как видим, память серверов имеет некоторые особенности по сравнению с памятью для обычных компьютеров. Прежде всего, это необходимость использования кодов коррекции ошибок ЕСС. Если использовать для сервера обычную память без ЕСС, то либо такая система не заработает, либо её работа будет связана с рисками сбоев, что в корпоративных ИТ-системах недопустимо.
Кроме того, для серверов обычно используется буферизованная память, которая оснащена дополнительным чипом для выполнения промежуточных операции между CPU и чипами модулей DIMM.
Иногда серверная память может иметь и конструктивные особенности, например, размещаться в низкопрофильных DIMM для лучшего теплоотвода внутри корпуса сервера.
Вы ищете память, которая имеет доступ к более высоким скоростям и совместима с большим количеством платформ? Или вы ищете долговечную память, которая может работать 24 часа в сутки, 7 дней в неделю, выявлять больше ошибок, но для этого приходится жертвовать скоростью?
Модули ОЗУ (оперативной памяти) являются важной частью каждой системы, но не все модули одинаковы. Помимо емкости, частоты и задержки, модули могут характеризоваться наличием или отсутствием системы исправления ошибок (ECC).
Разница между ними заключается в том, что память ECC защитит вашу систему от потенциального сбоя, исправив любые ошибки в данных, в то время как память без ECC игнорирует такие ошибки.
Думайте о памяти без ECC как о памяти, ориентированной на скорость, а ECC – памяти, ориентированной на выносливость и надёжности.

Поскольку не все платформы поддерживают ECC-память, и не каждой системе она нужна, давайте обсудим, что такое ECC-память, как она работает и нужна ли она вам.
Что такое ECC-память
Чтобы понять, как работает память с коррекцией ошибок (ECC), сначала нужно понять, что такое однобитовая ошибка. Потому что это основная проблема, для решения которой была создан ECC.
Однобитовая ошибка – это когда один бит (двоичный 0 или 1) в данных в ОЗУ случайно изменяется на противоположное значение.
Такого рода ошибки незначительны, и компьютер может не распознать их автоматически, что может привести ко многим проблемам.
Вы можете думать об однобитовых ошибках как о метафорических сорняках на лужайке. Ваш газон – это оперативная память, а ECC-часть вашей памяти – это использование гербицида.
Память без ECC не избавит вас от «сорняков». ECC уничтожит все сорняки, но газон будет расти немного медленнее.
Однобитовые ошибки могут возникать из-за магнитных или электрических помех внутри компьютера, присутствующих в каждой системе в виде фонового излучения.

Перенапряжение, колебания температуры, удар по корпусу или даже чтение или запись данных не так, как предполагалось изначально, могут привести к однобитовой ошибке.
Память ECC позаботится об этих ошибках и исправит их до того, как они превратятся в большую проблему.
Память с ECC очень похожа на память без ECC. Самая большая разница между ними заключается в том, что память ECC обычно имеет немного дополнительной памяти, предназначенной исключительно для обеспечения того, чтобы фактическая память работала без ошибок.
ECC – это, по сути, небольшой чип на обычной планке ОЗУ, который гарантирует, что каждый бит данных, который входит и выходит, является именно тем, чем он должен быть.
Что он делает, так это то, что создаёт зашифрованный фрагмент кода из данных, записываемых в основную память, и сохраняет этот код в дополнительном бите памяти. Когда необходимо получить доступ к данным, хранящимся в основной памяти, он создаёт новый код и сравнивает этот фрагмент кода с кодом, который был сгенерирован ранее.
Если он обнаружит, что они оба одинаковы и что данные не были каким-либо образом изменены, он разрешает чтение данных. Но, если он обнаруживает, что новый код отличается от сохраненного кода, он попытается решить проблему, расшифровывая код, чтобы точно определить, в чём заключается ошибка.
Если он не сможет найти ошибку, то, по крайней мере, гарантирует, что вы будете знать, что что-то пошло не так, вместо того, чтобы молча продолжать работать.
Это похоже на сравнение хэшей MD5 при загрузке программы, чтобы убедиться, что вы загружаете именно то, что вам действительно нужно, а не другой мошеннический секретный файл.
Вот почему ECC работает немного медленнее – потому что ему приходится создавать эти дополнительные коды.
Согласно исследованиям, вероятность возникновения такой ошибки составляет одна однобитовая ошибка каждые 14-40 часов на гигабит ОЗУ.
Необходимость исправления ошибок на серверах и рабочих станциях
В системе, используемой для повседневного просмотра и игр, исправление ошибок не является необходимостью. Однако, в мире серверов и профессиональных рабочих станций ставки выше.
Если вы ведёте бизнес, специализирующийся на финансах, однобитовая ошибка может привести к сбою сервера, который потенциально может стереть транзакции с вашего сервера.
Такая ошибка памяти также может привести к ошибке транскрипции данных, что может привести к неправильному размещению десятичного разделителя или изменению числа.
Очевидно, что это наносит ущерб честности и надёжности бизнеса. Если бы вы пошли покупать кошке новую игрушку и в итоге заплатили 1000 рублей вместо 100, это было бы довольно трагично.
Если вы посетили своего врача, и счет составил 56 987 рублей вместо 5945 рублей, вы только что стали жертвой компьютерной ошибки, связанной с ECC. И вы, скорее всего, больше никогда не воспользуетесь их услугами.
Потеря времени – ещё одна проблема, которую может предотвратить память ECC. Если вы визуализируете сложные изображения в высоком разрешении или работаете с моделью глубокого обучения, необходимость начинать заново после нескольких недель обработки из-за некоторых ошибок памяти – это огромная трата времени и денег для вашего бизнеса.
Память ECC необходима и в медицинской промышленности. При уходе за пациентом точность записей имеет решающее значение, и ошибка в одном бите может привести к неправильному диагнозу, что может привести к летальному исходу.
Выбор памяти может создать или уничтожить репутацию бизнеса.
Без памяти ECC не только существует вероятность подобных ошибок, но вы также не узнаете, что они произошли, пока кто-нибудь не просмотрит данные и не найдёт ошибку. А иногда это может быть слишком поздно.
Какие платформы поддерживают память ECC
Что касается серверов, то линейки процессоров Intel Xeon и линейки серверов AMD Epyc поддерживают память ECC. Обратите внимание, что для использования памяти ECC и процессор, и используемая материнская плата должны поддерживать память ECC.
Помните аналогию с газоном и гербицидом? Думайте о процессоре и материнской плате как об инструментах, которые вы используете для эффективной работы с ECC. Вам нужны подходящие инструменты для распространения гербицидов на газоне.

На основных платформах, используемых сегодня, большинство процессоров Intel (даже некоторые бюджетные модели Celeron) будут поддерживать память ECC, если вы используете материнскую плату, совместимую с такой памятью.
С AMD все процессоры Ryzen поддерживают память ECC с совместимой материнской платой с набором микросхем X570, тогда как набор микросхем B550 не поддерживает память ECC с процессорами Ryzen 2000. Процессоры Ryzen со встроенной видеокартой или ускоренным процессором (APU), серии 3000 G и серии 4000 G потребуют от вас использования процессора PRO для поддержки ECC.
Недостатки использования памяти ECC
Наиболее распространенная проблема с памятью ECC – совместимость. Несмотря на то, что большинство современных платформ поддерживают её, вы должны убедиться, что конкретная комбинация процессора и материнской платы работает с памятью ECC.
Это менее проблематично в мире серверов, где обычно используется память ECC. Серверное оборудование обычно поддерживает ECC по умолчанию.
Ценник тоже отличается. Модули памяти с ECC дороже, чем модули без ECC из-за дополнительных функций. В зависимости от емкости, которую вы покупаете, разница в цене составляет около 10-20%.
Также наблюдается небольшой спад производительности из-за дополнительного времени, которое требуется памяти ECC для проверки наличия ошибок. По словам Corsair, можно ожидать падения около 2%.
Подведение итогов – нужна ли вам память ECC
Когда вы создаете профессиональную рабочую станцию или сервер, который должен работать круглосуточно и без выходных, память ECC просто необходима.
Обойтись без ECC в этом сценарии было бы все равно, что использовать борзую, чтобы тянуть повозку, когда вам нужна крепкая рабочая лошадка.
И разница в цене, и снижение производительности того стоят, если учесть, что вам не придётся беспокоиться о возможности однобитовой ошибки, которая вызовет у вас головную боль.
Вы ведь не хотели бы перепроверять каждую квитанцию, чтобы убедиться, что она верна, верно? Проявите такую же любезность к своим клиентам и заказчикам.
Но если всё, что вы делаете, это играете в игры и используете свой компьютер для другой некритической работы, вам, скорее всего, не понадобится ECC, и вам важнее сохранить эти 2% производительности.

В продолжение рубрики «конспект админа» хотелось бы разобраться в нюансах технологий ОЗУ современного железа: в регистровой памяти, рангах, банках памяти и прочем. Подробнее коснемся надежности хранения данных в памяти и тех технологий, которые несчетное число раз на дню избавляют администраторов от печалей BSOD.
Старые песни про новые типы
Сегодня на рынке представлены, в основном, модули с памятью DDR SDRAM: DDR2, DDR3, DDR4. Разные поколения отличаются между собой рядом характеристик — в целом, каждое следующее поколение «быстрее, выше, сильнее», а для любознательных вот табличка:
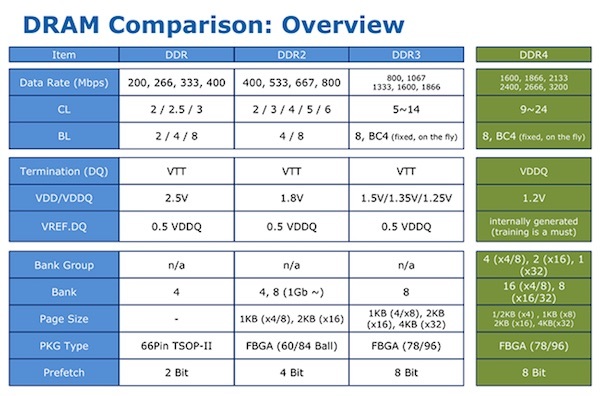
Для подбора правильной памяти больший интерес представляют сами модули:
-
RDIMM — регистровая (буферизованная) память. Удобна для установки большого объема оперативной памяти по сравнению с небуферизованными модулями. Из минусов — более низкая производительность;
-
UDIMM (unregistered DRAM) — нерегистровая или небуферизованная память — это оперативная память, которая не содержит никаких буферов или регистров;
-
LRDIMM — эти модули обеспечивают более высокие скорости при большей емкости по сравнению с двухранговыми или четырехранговыми модулями RDIMM, за счёт использования дополнительных микросхем буфера памяти;
-
HDIMM (HyperCloud DIMM, HCDIMM) — модули с виртуальными рангами, которые имеют большую плотность и обеспечивают более высокую скорость работы. Например, 4 физических ранга в таких модулях могут быть представлены для контроллера как 2 виртуальных;
-
FBDIMM — полностью буферизованная DIMM с высокой надежностью, скоростью и плотностью размещения.
Попытка одновременно использовать эти типы может вызвать самые разные печальные последствия, вплоть до порчи материнской платы или самой памяти. Но возможно использование одного типа модулей с разными характеристиками, так как они обратно совместимы по тактовой частоте. Правда, итоговая частота работы подсистемы памяти будет ограничена возможностями самого медленного модуля или контроллера памяти.
Для всех типов памяти SDRAM есть общий набор базовых характеристик, влияющий на объем и производительность:
-
частота и режим работы;
-
ранг;
-
тайминги.
Конечно, отличий на самом деле больше, но для сборки правильно работающей системы можно ограничиться этими.
Частота и режим работы
Понятно, что чем выше частота — тем выше общая производительность памяти. Но память все равно не будет работать быстрее, чем ей позволяет контроллер на материнской плате. Кроме того, все современные модули умеют работать в в многоканальном режиме, который увеличивает общую производительность до четырех раз.
Режимы работы можно условно разделить на четыре группы:
-
Single Mode — одноканальный или ассиметричный. Включается, когда в системе установлен только один модуль памяти или все модули отличаются друг от друга. Фактически, означает отсутствие многоканального доступа;
-
Dual Mode — двухканальный или симметричный. Слоты памяти группируются по каналам, в каждом из которых устанавливается одинаковый объем памяти. Это позволяет увеличить скорость работы на 5-10% в играх, и до 70% в тяжелых графических приложениях. Модули памяти необходимо устанавливать парами на разные каналы. Производители материнских плат обычно выделяют парные слоты одним цветом;
-
Triple Mode — трехканальный режим работы. Модули устанавливаются группами по три штуки — на каждый из трех каналов. Аналогично работают и последующие режимы: четырехканальные (quad-channel), восьмиканальные (8-channel memory) и т.п.
-
Flex Mode — позволяет увеличить производительность оперативной памяти при установке двух модулей различного объема, но с одинаковой частотой.
-
Для максимального быстродействия лучше устанавливать одинаковые модули с максимально возможной для системы частотой. При этом используйте установку парами или группами — в зависимости от доступного многоканального режима работы.
Ранги для памяти
Ранг (rank) — область памяти из нескольких чипов памяти в 64 бита (72 бита при наличии ECC, о чем поговорим позже). В зависимости от конструкции модуль может содержать один, два или четыре ранга.
Узнать этот параметр можно из маркировки на модуле памяти. Например уKingston число рангов легко вычислить по одной из трех букв в середине маркировки: S (Single — одногоранговая), D (Dual — двухранговая), Q (Quad — четырехранговая).
Пример полной расшифровки маркировки на модулях Kingston:
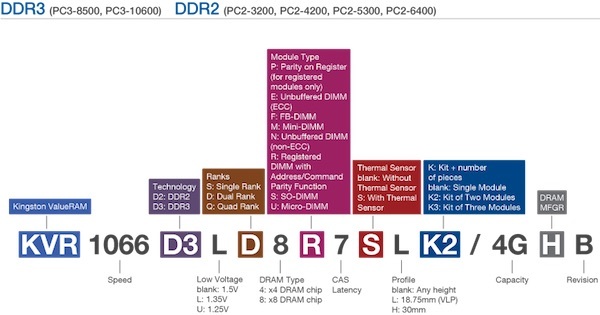
Серверные материнские платы ограничены суммарным числом рангов памяти, с которыми могут работать. Например, если максимально может быть установлено восемь рангов при уже установленных четырех двухранговых модулях, то в свободные слоты память добавить не получится.
Перед покупкой модулей есть смысл уточнить, какие типы памяти поддерживает процессор сервера. Например, Xeon E5/E5 v2 поддерживают одно-, двух- и четырехранговые регистровые модули DIMM (RDIMM), LRDIMM и не буферизированные ECC DIMM (ECC UDIMM) DDR3. А процессоры Xeon E5 v3 поддерживают одно- и двухранговые регистровые модули DIMM, а также LRDIMM DDR4.
Немного про скучные аббревиатуры таймингов
Тайминги или латентность памяти (CAS Latency, CL) — величина задержки в тактах от поступления команды до ее исполнения. Числа таймингов указывают параметры следующих операций:
-
CL (CAS Latency) — время, которое проходит между запросом процессора некоторых данных из памяти и моментом выдачи этих данных памятью;
-
tRCD (задержка от RAS до CAS) — время, которое должно пройти с момента обращения к строке матрицы (RAS) до обращения к столбцу матрицы (CAS) с нужными данными;
-
tRP (RAS Precharge) — интервал от закрытия доступа к одной строке матрицы, и до начала доступа к другой;
-
tRAS — пауза для возврата памяти в состояние ожидания следующего запроса;
-
CMD (Command Rate) — время от активации чипа памяти до обращения к ней с первой командой.
Разумеется, чем меньше тайминги — тем лучше для скорости. Но за низкую латентность придется заплатить тактовой частотой: чем ниже тайминги, тем меньше допустимая для памяти тактовая частота. Поэтому правильным выбором будет «золотая середина».
Существуют и специальные более дорогие модули с пометкой «Low Latency», которые могут работать на более высокой частоте при низких таймингах. При расширении памяти желательно подбирать модули с таймингами, аналогичными уже установленным.
RAID для оперативной памяти
Ошибки при хранении данных в оперативной памяти неизбежны. Они классифицируются как аппаратные отказы и нерегулярные ошибки (сбои). Память с контролем четности способна обнаружить ошибку, но не способна ее исправить.
Для коррекции нерегулярных ошибок применяется ECC-память, которая содержит дополнительную микросхему для обнаружения и исправления ошибок в отдельных битах.
Метод коррекции ошибок работает следующим образом:
-
При записи 64 бит данных в ячейку памяти происходит подсчет контрольной суммы, составляющей 8 бит.
-
Когда процессор считывает данные, то выполняется расчет контрольной суммы полученных данных и сравнение с исходным значением. Если суммы не совпадают — это ошибка.
-
Если ошибка однобитовая, то неправильный бит исправляется автоматически. Если двухбитовая — передается соответствующее сообщение для операционной системы.
Технология Advanced ECC способна исправлять многобитовые ошибки в одной микросхеме, и с ней возможно восстановление данных даже при отказе всего модуля DRAM.
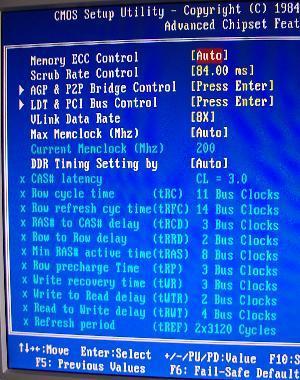
Исправление ошибок нужно отдельно включить в BIOS
Большинство серверных модулей памяти являются регистровыми (буферизованными) — они содержат регистры контроля передачи данных.
Регистры также позволяют устанавливать большие объемы памяти, но из-за них образуются дополнительные задержки в работе. Дело в том, что каждое чтение и запись буферизуются в регистре на один такт, прежде чем попадут с шины памяти в чип DRAM, поэтому регистровая память оказывается медленнее не регистровой на один такт.
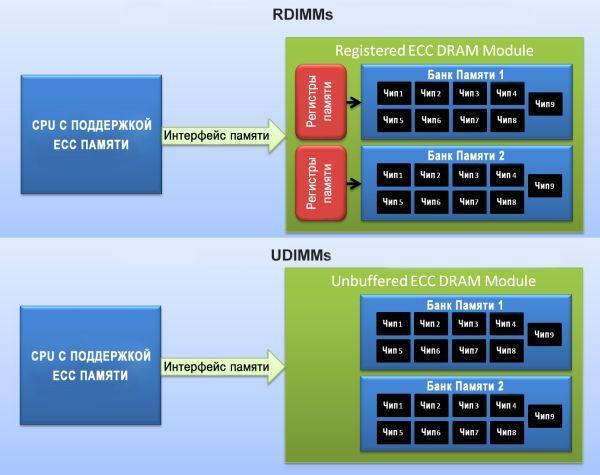
Источник — nix.ru
Все регистровые модули и память с полной буферизацией также поддерживают ECC, а вот обратное не всегда справедливо. Из соображений надежности для сервера лучше использовать регистровую память.
Многопроцессорные системы и память
Для правильной и быстрой работы нескольких процессоров, нужно каждому из них выделить свой банк памяти для доступа «напрямую». Об организации этих банков в конкретном сервере лучше почитать в документации, но общее правило такое: память распределяем между банками поровну и в каждый ставим модули одного типа.
Если пришлось поставить в сервер модули с меньшей частотой, чем требуется материнской плате — нужно включить в BIOS дополнительные циклы ожидания при работе процессора с памятью.
Для автоматического учета всех правил и рекомендаций по установке модулей можно использовать специальные утилиты от вендора. Например, у HP есть Online DDR4 (DDR3) Memory Configuration Tool.
Итого
Вместо пространственного заключения приведу общие рекомендации по выбору памяти:
-
Для многопроцессорных серверов HP рекомендуется использовать только регистровую память c функцией коррекции ошибок (ECC RDIMM), а для однопроцессорных — небуферизированную с ECC (UDIMM). Планки UDIMM для серверов HP лучше выбирать от этого же производителя, чтобы избежать самопроизвольных перезагрузок.
-
В случае с RDIMM лучше выбирать одно- и двухранговые модули (1rx4, 2rx4). Для оптимальной производительности используйте двухранговые модули памяти в конфигурациях 1 или 2 DIMM на канал. Создание конфигурации из 3 DIMM с установкой модулей в третий банк памяти значительно снижает производительность.
-
Из тех же соображений максимальной скорости желательно избегать использования четырехранговой памяти RDIMM, поскольку она снижает частоту до 1066 МГц в конфигурациях с одним модулем на канал, и до 800 МГц — в конфигурациях с двумя модулями на канал. Справедливо для серверов на базе Intel Xeon 5600 и Xeon E5/E5 v2.
Список короткий, но здесь все самое необходимое и наименее очевидное. Конечно же, старый как мир принцип RTFM никто не отменял.
ECC, от английского error-correcting code, переводиться на русский язык, как код коррекции ошибок. Встроенная в контроллёры флешек технология, обнаружения и исправления ошибок при передаче данных. ECC способна справиться только с несущественными проблемами, в тяжелых случаях флешка заблокируется на запись данных.
ЗАЧЕМ ЭТО НАДО
Если в эпоху качественных SLC и MLC микросхем флэш-памяти, не было особого смысла обращать внимание на этот механизм исправления ошибок. То сейчас когда в подавляющем количестве флешек, установлена или банально TLC-память или какая-нибудь MLC DownGrade, не стоит пренебрегать настройками ECC-механизма.
Данная технология позволяет продлить жизнь флешки до следующих затыков с ней, ведь не хочется, каждый месяц заново перепрошивать свою флешку.
Еще одной положительной чертой, является вероятность достижения максимального возможного объёма флэш-диска. Он может быть даже выше, чем изначально имел носитель, особенно у флешек с отбракованными микросхемами.
НЕДОСТАТКИ
Чем выше вы установите значение ECC-параметра, тем большую нагрузку он создаст на контроллёр флешки. А это в свою очередь, может негативно сказаться на её производительность, т.е. скорость работы. Также из заметных недостатков, высокой нагрузки, это больший разогрев флешки.
РЕКОМЕНДУЕМЫЕ ЗНАЧЕНИЯ ПАРАМЕТРА ECC
В большинстве утилитах, используется не применяемые в флэш-листах значения (например: 7b/512B и 72b/1K), а суммы определенных параметров. Как правило, в диапазоне равеном от 0 до 15, в некоторых производственных программах, ввиду поддержки крайне некачественной памяти, от 0 до 20. Для посетителей проекта USBDev.ru, я составил следующую таблицу.
| ECC Value | |
|---|---|
| MEMORY TYPE: | ECC: |
| SLC | 1 |
| MLC 32nm, 35nm, 42nm, 50nm, … | 3-4 |
| MLC 24nm, 25nm, 26nm, 32nm | 4-8 |
| MLC 21nm, 20nm, 19nm, … | 8-12 |
| TLC 27nm, 32nm, 43nm, … | 8 |
| TLC 24nm, 21nm, 19nm, … | 12-15 |
В некоторых утилитах, используется другая система координат, к примеру производственный комплекс Dyna для контроллёров SMI. На этот случай, чуть ниже можно обнаружить ссылку на особености настроек у конкретных производителей.
Немного поясню, как следует использовать таблицу данную выше. Так вот, если ваша флешка добротная (хорошо зарекомендовавший себя бренд), то выбирайте минимальное значение из неё. Для подарочных и поддельных флешек, настоятельно советую использовать максимальное значение параметра ECC, для своего типа памяти.
РЕАЛИЗАЦИЯ В ПРОИЗВОДСТВЕННЫХ УТИЛИТАХ
Далеко не во всех утилит, имеется возможность ручной корректировки ECC-опции. Можно сказать что ECC, это такая фитча Sorting-составляющей производственных утилит. Попробую кратко выразить это в таблице, для основных производителей USB-контроллёров.
| ECC Compatible Software | |
|---|---|
| Company: | Tools: |
| ALCOR | AlcorMP_UFD FC MpTool AAMP |
| CHIPSBANK | Chipsbank UMPTool CBM2093 UMPTool CBM2098 UMPTool umptool209X V68 Building Tools |
| INNOSTOR | Innostor MPTool Innostor 917 LFA MP Tool |
| PHISON | UPTool UP19_CTool UP21_CTool UP23_CTool |
| SILICON GO | KingStore Manufacture Tool SiliconGo MPTools SiliconGo MPTool2 |
| SKYMEDI | SK6221 MPTool |
| SMI | Dyna Mass Storage Production Tool |
| СТАТЬИ НА ТЕМУ ECC-КОРРЕКЦИИ | ||
|---|---|---|
| ECC значения для контроллёров Alcor с DownGrade памятью | 2015 | |
| Настройка ECC у контроллёров Silicon Motion (SMI) | 2015 | |
Для ваших вопросов, на проекте USBDev существует форум – FORUM.
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, an error correction code, sometimes error correcting code, (ECC) is used for controlling errors in data over unreliable or noisy communication channels.[1][2] The central idea is the sender encodes the message with redundant information in the form of an ECC. The redundancy allows the receiver to detect a limited number of errors that may occur anywhere in the message, and often to correct these errors without retransmission. The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[2]
ECC contrasts with error detection in that errors that are encountered can be corrected, not simply detected. The advantage is that a system using ECC does not require a reverse channel to request retransmission of data when an error occurs. The downside is that there is a fixed overhead that is added to the message, thereby requiring a higher forward-channel bandwidth. ECC is therefore applied in situations where retransmissions are costly or impossible, such as one-way communication links and when transmitting to multiple receivers in multicast. Long-latency connections also benefit; in the case of a satellite orbiting around Uranus, retransmission due to errors can create a delay of five hours. ECC information is usually added to mass storage devices to enable recovery of corrupted data, is widely used in modems, and is used on systems where the primary memory is ECC memory.
ECC processing in a receiver may be applied to a digital bitstream or in the demodulation of a digitally modulated carrier. For the latter, ECC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many ECC encoders/decoders can also generate a bit-error rate (BER) signal, which can be used as feedback to fine-tune the analog receiving electronics.
The maximum fractions of errors or of missing bits that can be corrected are determined by the design of the ECC code, so different error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced ECC systems as of 2016[3] come very close to the theoretical maximum.
Forward error correction[edit]
In telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[4][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels. The central idea is that the sender encodes the message in a redundant way, most often by using an ECC.
The redundancy allows the receiver to detect a limited number of errors that may occur anywhere in the message, and often to correct these errors without re-transmission. FEC gives the receiver the ability to correct errors without needing a reverse channel to request re-transmission of data, but at the cost of a fixed, higher forward channel bandwidth. FEC is therefore applied in situations where re-transmissions are costly or impossible, such as one-way communication links and when transmitting to multiple receivers in multicast. FEC information is usually added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, is widely used in modems, is used on systems where the primary memory is ECC memory and in broadcast situations, where the receiver does not have capabilities to request re-transmission or doing so would induce significant latency. For example, in the case of a satellite orbiting Uranus, a re-transmission because of decoding errors would create a delay of at least 5 hours.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC coders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon answers the question of how much bandwidth is left for data communication while using the most efficient code that turns the decoding error probability to zero. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. His proof is not constructive, and hence gives no insight of how to build a capacity achieving code. However, after years of research, some advanced FEC systems like polar code[3] achieve the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
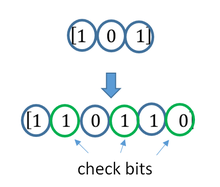
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[5]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[6][7] NOR Flash typically does not use any error correction.[6]
Classical block codes are usually decoded using hard-decision algorithms,[8] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[9]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[10] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[11] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[12]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[13] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[14] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[15] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[16]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[14][17] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[18]
- a contention-free quadratic permutation polynomial (QPP).[19] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[20]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[21]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[22] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[23] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[24]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[25]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most
 bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ a b c Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, an error correction code, sometimes error correcting code, (ECC) is used for controlling errors in data over unreliable or noisy communication channels.[1][2] The central idea is the sender encodes the message with redundant information in the form of an ECC. The redundancy allows the receiver to detect a limited number of errors that may occur anywhere in the message, and often to correct these errors without retransmission. The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[2]
ECC contrasts with error detection in that errors that are encountered can be corrected, not simply detected. The advantage is that a system using ECC does not require a reverse channel to request retransmission of data when an error occurs. The downside is that there is a fixed overhead that is added to the message, thereby requiring a higher forward-channel bandwidth. ECC is therefore applied in situations where retransmissions are costly or impossible, such as one-way communication links and when transmitting to multiple receivers in multicast. Long-latency connections also benefit; in the case of a satellite orbiting around Uranus, retransmission due to errors can create a delay of five hours. ECC information is usually added to mass storage devices to enable recovery of corrupted data, is widely used in modems, and is used on systems where the primary memory is ECC memory.
ECC processing in a receiver may be applied to a digital bitstream or in the demodulation of a digitally modulated carrier. For the latter, ECC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many ECC encoders/decoders can also generate a bit-error rate (BER) signal, which can be used as feedback to fine-tune the analog receiving electronics.
The maximum fractions of errors or of missing bits that can be corrected are determined by the design of the ECC code, so different error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced ECC systems as of 2016[3] come very close to the theoretical maximum.
Forward error correction[edit]
In telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[4][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels. The central idea is that the sender encodes the message in a redundant way, most often by using an ECC.
The redundancy allows the receiver to detect a limited number of errors that may occur anywhere in the message, and often to correct these errors without re-transmission. FEC gives the receiver the ability to correct errors without needing a reverse channel to request re-transmission of data, but at the cost of a fixed, higher forward channel bandwidth. FEC is therefore applied in situations where re-transmissions are costly or impossible, such as one-way communication links and when transmitting to multiple receivers in multicast. FEC information is usually added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, is widely used in modems, is used on systems where the primary memory is ECC memory and in broadcast situations, where the receiver does not have capabilities to request re-transmission or doing so would induce significant latency. For example, in the case of a satellite orbiting Uranus, a re-transmission because of decoding errors would create a delay of at least 5 hours.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC coders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon answers the question of how much bandwidth is left for data communication while using the most efficient code that turns the decoding error probability to zero. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. His proof is not constructive, and hence gives no insight of how to build a capacity achieving code. However, after years of research, some advanced FEC systems like polar code[3] achieve the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]
A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[5]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[6][7] NOR Flash typically does not use any error correction.[6]
Classical block codes are usually decoded using hard-decision algorithms,[8] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[9]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[10] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[11] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[12]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[13] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[14] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[15] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[16]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[14][17] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[18]
- a contention-free quadratic permutation polynomial (QPP).[19] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[20]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[21]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[22] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[23] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[24]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[25]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ a b c Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
1 |
|
|
28.10.2018, 01:03. Показов 125455. Ответов 20
что это значит я нашёл но что мне с этим делать и почему не нашёл ..
__________________ 0 |

|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 01:07 [ТС] |
2 |
|
…… Миниатюры
0 |
|
4040 / 2505 / 301 Регистрация: 22.04.2012 Сообщений: 10,745 Записей в блоге: 2 |
|
|
28.10.2018, 05:42 |
3 |
|
195 (C3) Hardware ECC Recovered — Число коррекции ошибок аппаратной частью диска (чтение, позиционирование, передача по внешнему интерфейсу). На дисках с SATA-интерфейсом значение нередко ухудшается при повышении частоты системной шины — SATA очень чувствителен к разгону. 0 |
|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 07:57 [ТС] |
4 |
|
когда комп запускаю . на самом первом окне где идёт описания всей системы , внизу есть такая надпись Fan error .. про разгон не знаю даже что это .. диск свежий купил месяца два назад .. ос постоянно слетает или выдаёт ошибки требующие то запуска для восстановления то ещё чего то, причём на старом тоже самое было с ос , но вроде 195 пункта не было . кулер работает не равномерно вначале не сразу разгоняется а рывками .. помню раньше всегда сразу крути .. Добавлено через 4 минуты 0 |
|
4040 / 2505 / 301 Регистрация: 22.04.2012 Сообщений: 10,745 Записей в блоге: 2 |
|
|
28.10.2018, 08:31 |
5 |
|
Fan error Ошибка вентилятора,скорее всего процессора.Проверьте,распознаётся ли он,пробуйте заменить.Но к харду это отношения не имеет. У сигейтов смарт выглядит не как у других производителей. Половину значений можно вообще игнорировать. 0 |

|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 09:01 [ТС] |
6 |
|
спасибо конечно ) но вот что с диском делать ? он глючит и виснет . и перестанавливать ос каждые 2 недели в месте с п/о не айс .. я увлекаюсь 3d моделирование и приходится целый набор п/о ставить …может есть ещё какие то программы которые позволят от сканировать откуда ноги растут ? 0 |
|
Модератор
20477 / 12370 / 2182 Регистрация: 23.11.2016 Сообщений: 61,810 Записей в блоге: 21 |
|
|
28.10.2018, 09:26 |
7 |
|
женя88, Вы показали смарт не полностью. Качните лучше програму Кристалдискинфо и оттуда покажите смарт. Еще — опишите, какая именно у вас мать, проц, блок питания и видеокарта. 0 |
|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 11:10 [ТС] |
8 |
|
хорошо попробую сделать .. вот что я ещё проверил , я вытащил одну планку оперативки и нова запустил викторию .. ошибка 195 была всё так же на месте , но вот следующий раздел где виктория восстанавливает битые сектора кажется , там вчера когда я с двумя планками запустил её набралось больше 50 в красной зоне .. сегодня я вытащил снова запустил и нет не одного, скрин прилагаю как иллюстрацию того о чём я веду речь .. ну и жд не глючит вроде плавно работает .. Миниатюры
0 |
|
Модератор
20477 / 12370 / 2182 Регистрация: 23.11.2016 Сообщений: 61,810 Записей в блоге: 21 |
|
|
28.10.2018, 11:26 |
9 |
|
женя88, Дело в том, что этот тест поверхности с Виктории нужно делать не с той же винды, которая стоит на самом тестируемом диске. Дело в том, что если делать с той же винды — то результат окажется искаженным, и неверным. Поэтому такие тесты делают из-под лайв-сд вообще-то. Но если вас беспокоит оперативка — то нету ничего проще. Ставьте всю вашу оперативку и проделайте ей мемтест из ДОСа, вот так. Ждёте пока пройдёт 2 прохода, и смотирте количество Эрроров (там цифра есть) 0 |
|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 11:31 [ТС] |
10 |
|
не совсем понял как расширять окно ошибок ) и я вставил обратно планки запустил викторию теперь нет ошибок в красной зоне .. я когда первый раз запустил пк у меня программа системная ошибку выдала что у меня какие то настройки кривые ну я попросил её исправить .. я думаю по этому сейчас планки не выдаю ошибки в секторах .. Миниатюры
0 |
|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 11:47 [ТС] |
11 |
|
надеюсь не чего что я с сначала нажал стоп а затем сделал скрины .. 0 |
|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 11:55 [ТС] |
12 |
|
система 0 |
|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 11:56 [ТС] |
13 |
|
…… Миниатюры
0 |
|
Модератор
20477 / 12370 / 2182 Регистрация: 23.11.2016 Сообщений: 61,810 Записей в блоге: 21 |
|
|
28.10.2018, 15:43 |
14 |
|
Решениеженя88,
когда поменяете блок питания, или исправите этот, чтобы не просаживался 1 |
 Сообщение было отмечено женя88 как решение
Сообщение было отмечено женя88 как решение
|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 21:40 [ТС] |
15 |
|
так пойдёт ? 0 |
|
0 / 0 / 0 Регистрация: 16.03.2016 Сообщений: 24 |
|
|
28.10.2018, 21:42 [ТС] |
16 |
|
ну я планировал где то через месяц купить новые комплектующие судя по всему и блок тоже .. спасибо за рекомендации .. 0 |
|
Модератор
20477 / 12370 / 2182 Регистрация: 23.11.2016 Сообщений: 61,810 Записей в блоге: 21 |
|
|
29.10.2018, 09:39 |
17 |
|
судя по всему и блок тоже В первую очередь. 0 |
|
0 / 0 / 0 Регистрация: 22.12.2019 Сообщений: 1 |
|
|
22.12.2019, 18:42 |
18 |
|
женя88, здравствуйте, проблема один в один как у Вас. Решили ли вы ее и если да, то что помогло? 0 |
|
0 / 0 / 0 Регистрация: 06.12.2016 Сообщений: 18 |
|
|
20.01.2020, 21:59 |
19 |
|
В общем что тут скажешь..сижу сейчас с такой же проблемой, компу пару месяцев.. Винда не грузит..чекдиск выдает ошибку 50… https://prnt.sc/qqerhd 0 |
|
Модератор
20477 / 12370 / 2182 Регистрация: 23.11.2016 Сообщений: 61,810 Записей в блоге: 21 |
|
|
21.01.2020, 00:38 |
20 |
|
artem-ds, создавайте свою тему, и загружайте скрины прямо на форум, скрепкой 0 |

Восстановить жесткий диск, используя специальные программы. Они позволяют протестировать винчестер, а также исправить незначительные неисправности. Зачастую, этого вполне достаточно для продолжения плодотворной работы. Из статьи вы узнаете об одной из них под названием Victoria.
Проверка жесткого диска программой Victoria полностью бесплатна. Также программа обладает множеством функций и рассчитана не только на профессионалов, но также и на неопытных пользователей. Итак, сейчас вы узнаете, как проверить жесткий диск программой Victoria.
Технология S.M.A.R.T.
Все современные накопители на жестких магнитных дисках поддерживают технологию самотестирования, анализа состояния, и накопления статистических данных об ухудшении собственных характеристик S.M.A.R.T. (Self-Monitoring Analysis and Reporting Technology). Основы S.M.A.R.T. были разработаны в 1995 г. совместными усилиями ведущих производителями жестких дисков.
В процессе совершенствования оборудования накопителей, возможности технологии также дорабатывались, и после стандарта SMART появился SMART II, затем — SMART III, который, очевидно, тоже не станет последним.
Жесткий диск в процессе своего функционирования постоянно отслеживает определенные параметры своего состояния и отражает их в специальных характеристиках — атрибутах (Attribute), сохраняющихся, как правило, в специально выделенной части дисковой поверхности, доступной только внутренней микропрограмме накопителя — служебной зоне. Данные атрибутов могут быть считаны специальным программным обеспечением.
Атрибуты идентифицируются своим цифровым номером, большинство из которых одинаково интерпретируется накопителями разных моделей. Некоторые атрибуты могут быть определены конкретным производителем оборудования, и поддерживаться только отдельными моделями накопителей.
Атрибуты состоят из нескольких полей, каждое из которых имеет определенный смысл. Обычно, программы считывания S.M.A.R.T. выдают расшифровку атрибутов в виде:
- Attribute — имя атрибута
- ID — идентификатор атрибута
- Value — текущее значение атрибута
- Threshold — минимальное пороговое значения атрибута
- Worst — самое низкое значение атрибута за все время работы накопителя
- Raw — абсолютное значение атрибута
- Type (необязательно) — тип атрибута — характеризует производительность (PR — Performance-related), характеризует сбои (ER — Error rate), счетчик событий (EC — Events count), определено производителем или не используется (SP — Self-preserve);
Для анализа состояния накопителя, пожалуй, самым важным значением атрибута является Value — условное число (обычно от 0 до 100 или до 253), заданное производителем. Значение Value изначально установлено на максимум при производстве накопителя и уменьшается в случае ухудшения его параметров. Для каждого атрибута существует пороговое значение, до достижения которого, производитель гарантирует его работоспособность — поле Threshold. Если значение Value приближается или становится меньше значения Threshold, — накопитель пора менять. Перечень атрибутов и их значения жестко не стандартизированы и определяются изготовителем накопителя, но наиболее важные из них интерпретируются одинаково. Например, атрибут с идентификатором 5 (Reallocated sector count) будет характеризовать число забракованных и переназначенных из резервной области секторов диска, и для устройств производства компании Seagate, и для Western Digital, Samsung, Maxtor.
Жесткий диск не имеет возможности, по собственной инициативе, передать данные SMART потребителю. Их считывание выполняется специальным программным обеспечением.
В настройках большинства современных BIOS материнских плат имеется пункт позволяющий запретить или разрешить считывание и анализ атрибутов SMART в процессе выполнения тестов оборудования перед выполнением начальной загрузки системы. Включение опции позволяет подпрограмме тестирования оборудования BIOS считать значения критических атрибутов и, при превышении порога, предупредить об этом пользователя. Как правило, без особой детализации:
Primary Master Hard Disk: S.M.A.R.T status BAD!, Backup and Replace.
Выполнение подпрограммы BIOS приостанавливается, чтобы привлечь внимание:
Press F1 to Resume
Таким образом, без установки или запуска дополнительного программного обеспечения, имеется возможность вовремя определить критическое состояние накопителя (при включении данной опции) средствами Базовой Системы Ввода-Вывода (BIOS).
Анализ данных S.M.A.R.T. жесткого диска
Для получения данных SMART в среде операционной системы могут использоваться специальные программы, в частности, практически все утилиты для тестирования оборудования жестких дисков.
Одной из самых популярных программ для тестирования жестких дисков является Victoria Сергея Казанского.
На сайте автора найдете последнюю версию программы, а также массу полезной информации, в том числе и подробное описание работы с Victoria.
Программа Victoria имеет две разновидности — для работы в среде DOS и, для работы в среде Windows. DOS-версия может напрямую работать с контроллером жесткого диска и обладает значительно большими возможностями по сравнению с версией для Windows.
Назначение, основные возможности и порядок использования программы найдете на сайте автора
Программа проста в использовании и позволяет оценить техническое состояние накопителя, выполнить его тестирование и некоторые настройки — уровня шума, производительности, физического объема. Режимы тестирования поверхности накопителя позволяют принудительно избавиться от сбойных секторов с помощью режима Remap нескольких видов. Вызов меню тестирования выполняется по нажатию клавиши F4 (SCAN). Пользователь имеет возможность задать.
область тестирования
Start LBA :0 — начало области (по умолчанию — 0)
End LBA :14680064 — конец области (по умолчанию — номер последнего блока диска)
Режим тестирования
Линейное чтение — последовательное чтение от начального блока до конечного
Случайное чтение — номер считываемого блока формируется случайным образом.
BUTTERFLY чтение — выполняется чтение блоков, начиная от граничных номеров (начала и конца), к центру области тестирования.
Изменение режима выполняется по нажатию клавиши «пробел»
Режим обработки ошибок
Этот пункт позволяет выполнить скрытие дефектных блоков, с использованием переназначения (ремап) из резервной области. Выбор режима выполняется клавишей «пробел». Выбранный метод работы с дефектами отображается в правом верхнем углу экрана, под часами, а также в нижней строке в момент запуска теста. Изменить режим можно в и в процессе выполнения сканирования.
Ignore Bad Blocks — программа не будет выполнять никаких действий при обнаружении ошибки.
BB = RESTORE DATA — программа попытается восстановить данные из поврежденных секторов.
BB = Classic REMAP — выполняется запись в поврежденный сектор для вызова процедуры переназначения.
BB = Advanced REMAP — улучшенный алгоритм скрытия сбойных блоков. Используется, когда не помогает классический ремап. Программа выполняет специальную последовательность операций с целью формирования признака кандидата на ремап (атрибут 197) у сбойного блока. Затем выполняется 10-кратная запись, обрабатываемая микропрограммой накопителя как обычная обработка кандидата на ремап — если есть ошибка, выполняется переназначение, если нет ошибки — блок считается нормальным и удаляется из кандидатов на ремап. Данный режим позволяет выполнить скрытие сбойных блоков без потери пользовательских данных. Конечно, только в случаях, когда накопитель технически исправен и есть свободное место в резервной области для переназначения.
BB = Fujitsu Remap — выполнение специфических алгоритмов, основанных на недокументированных возможностях некоторых моделей накопителей Fujitsu
BB = Erase 256 sect — при обнаружении сбойного сектора выполняется перезаписывание блока из 256 секторов. Пользовательские данные не сохраняются.

В процессе работы с программой можно вызвать контекстную справку клавишей F1
Расшифровка кодов ошибок в Victoria:
BBK (Bad Block Detected) — Найден бэд-блок.
UNCR (Uncorrectable Error) — Неисправимая ошибка. Не удалось скорректировать данные избыточным кодом, блок признан нечитаемым. Может быть как следствием нарушения контрольной суммы данных (софтовый Bad Block), так и неисправностью HDD;
IDNF (ID Not Found) — Не найден идентификатор сектора. Обычно говорит о разрушении микрокода или формата низкого (физического уровня) HDD . У исправных HDD такая ошибка выдается при попытке обратиться к несуществующему адресу физического сектора;
ABRT (Aborted Command) — HDD отверг команду в результате неисправности, или команда не поддерживается данным HDD (пароль, устаревшая или слишком новая модель и т.д.)
T0NF (Track 0 Not Found) — не найдена нулевая дорожку, невозможно выполнить рекалибровку на стартовый цилиндр рабочей области. На современных HDD говорит о неисправности микрокода или магнитных головок;
AMNF (Address Mark Not Found) — адресный маркер не найден, невозможно прочитать сектор, обычно в результате неисправности тракта чтения или дефекта поверхности.
Версия Victoria For Windows обладает более скромными возможностями по настройке накопителя и выбору режимов тестирования, и на данный момент не имеет поддержки русского языка , однако ей проще пользоваться и имеющихся возможностей вполне достаточно для считывания таблицы SMART и оценки технического состояния накопителя.
Программа не требует установки, просто скачайте ее по ссылке на странице загрузки сайта автора.
Программа должна выполняться под учетной записью с павами администратора. В среде Windows 7 / 8 необходимо использовать контекстное меню «Запуск от имени администратора».
Для анализа состояния SMART-атрибутов выбираем режим работы через программный интерфейс Windows — включаем кнопку API в правой верхней части основного окна. Затем выбираем накопитель для проверки — нажимаем на кнопку Standard в основном меню программы и подсвечиваем мышкой нужный диск в окне со списком. В информационном окне будет отображен паспорт накопителя — модель, версию аппаратной прошивки, серийный номер, размер и т.п. Для получения данных SMART выбираем пункт меню SMART и жмем кнопку «Get SMART». Результат будет отображен в информационном окне программы.

Краткое описание атрибутов
- 001 ( 1 ) Raw Read Error Rate — абсолютное значение ошибок считывания. Существует некоторые отличия в формировании значения данного атрибута разными производителями. Из практики могу сказать, что накопители Seagate могут иметь гигантское значение RAW этого атрибута, реально будучи в хорошем состоянии, а накопители Western Digital могут иметь его нулевым, имея критические показатели по другим характеристикам. Некоторые модели вообще могут не поддерживать данный атрибут.
- 003 ( 3 ) Spin Up Time — Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости.
- 004 ( 4 ) Start/Stop Count — Количество циклов запуск/останов шпинделя.
- 005 ( 5 ) Reallocated Sector Count — Количество переназначенных секторов. Современные накопители имеют довольно большую (тысячи секторов) резервную область поверхности накопителя для использования ее в случае ухудшения характеристик секторов из основной зоны. Если накопитель обнаруживает проблемы с записью/считыванием какого — либо сектора, то он автоматически перемещает его данные в резервную область, а данный сектор помечается как «переназначенный». Часто этот процесс называют «remapping», или «automatic defect reassignment», он выполняется микропрограммой накопителя и для пользователя (операционной системы) невидим. Поле raw value содержит общее количество переназначенных секторов. Даже некритическое, но большое значение этого поля, может привести к снижению скорости обмена данными, поскольку накопитель выполняет дополнительную операцию установки головок на дорожки резервной области, обычно расположенной в конце диска.
- 007 ( 7 ) Seek Error Rate — Частота появления ошибок позиционирования блока магнитных головок (БМГ) . Накопитель контролирует правильность установки головок на требуемую дорожку поверхности. В случае, когда установка выполнилась неверно, фиксируется ошибка и операция повторяется. Для данного накопителя причиной большого числа ошибок явился перегрев.
- 008 ( 8 ) Seek Time Performance — средняя скорость позиционирования магнитных головок. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
- 009 ( 9 ) Power-On Hours — Количество часов во включенном состоянии. Достижение предельного значения этого атрибута означает выработку накопителем заданной производителем наработки на отказ (MTBF — Mean Time Between Failures).
- 010 ( 0A ) Spin Retry Count — Количество повторных попыток старта шпинделя. После включения питания, накопитель раскручивает диски и контролирует достижение рабочей скорости вращения для данного устройства ( например 5400 , 7200, 10000 об/мин.) за определенное время. В случае неудачи — увеличивается счетчик повторов и повторяется попытка старта.
- 011 ( 0B ) Recalibration Retries — количество попыток рекалибровки, в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью накопителя. Кроме того, увеличение абсолютного значения данного атрибута может быть вызвано тем, что процедура рекалибровки используется внутренней микропрограммой накопителя для коррекции других типов ошибок.
- 012 ( 0C ) Device Power Cycle Count — Количество циклов включения/выключения диска.
- 184 ( B8 ) End-to-End error — Данный атрибут — часть технологии HP SMART IV — означает, что после передачи данных через буферную память чётность данных между контроллером компьютера и жестким диском не совпадает.
- 187 ( BB ) Reported Uncorrectable Error — Характеризует количество ошибок, которые не были исправлены микропрограммой накопителя.
- 188 ( BC ) Command Timeout Количество прерванных операций в связи с отсутствием ответа от накопителя. Обычно это значение атрибута должно быть равно нулю, и, если значение гораздо выше нуля, то, возможными причинами могут быть проблемы с питанием или окислением контактов интерфейсного кабеля.
- 189 ( BD ) High Fly Writes — Если высота полета головки над магнитной поверхностью, даже на короткое время превысит оптимальную, то записанные ею данные, в дальнейшем, могут не прочитаться. Современные накопители используют специально разработанную технологию контроля высоты полета головок, позволяющую не выполнять запись данных при неоптимальной высоте. В счетчик данного атрибута добавляется единица, а запись выполняется после установки нормальной высоты полета. Повышенное значение данного атрибута может быть вызвано внешними ударами или вибрациями, ненормальной температурой, ухудшением характеристик магнитной поверхности или головки.
- 190 ( BE ) Airflow Temperature — температура окружающей среды блока магнитных головок. Для различных моделей HDD данный атрибут отсутствует и используются атрибуты 194 или 231.
- 191 (BF ) Mechanical Shock — количество механических ударов. Вместо данного атрибута может использоваться атрибут 221.
- 192 ( C0 ) Power-off retract count — количество циклов выключений или аварийных отказов (включений/выключений питания накопителя).
- 193 ( C1 ) Load/Unload Cycle — количество циклов перемещения блока магнитных головок в зону парковки.
- 194 ( C2 ) HDA Temperature — температура самого накопителя (HDA — Hard Disk Assembly). В данном атрибуте хранятся показания встроенного температурного датчика, которым обычно служит одна из магнитных головок (как правило — нижняя ). Данные, записанные в полях атрибута отображают текущую, минимальную и максимальную температуру. Поле Worst показывает наихудшую, достигнутую за время работы накопителя, температуру (можно установить факт перегрева и его степень), Raw value — текущую температуру. Некоторые модели накопителей могут поддерживать атрибут 205 ( CD ) Thermal asperity rate (TAR) фиксирующий количество опасных перепадов температуры. В некоторых моделях накопителей вместо атрибута 194 может использоваться атрибут 231.
- 195 ( C3 ) Hardware ECC recovered — характеризует количество ошибок считывания, исправленных оборудованием накопителя с применением кода коррекции ошибок. Подобные ошибки не требуют повторного считывания сектора, и не приводят к потере скорости обмена данными, но большое их количество говорит об ухудшении параметров тракта считывания.
- 196 ( C4 ) Reallocation Event Count — Число событий переназначения сбойных секторов. В поле Raw value данного атрибута хранится общее число попыток переноса данных из нестабильных секторов в резервную область. Учитываются как успешные, так и неуспешные попытки.
- 197 ( C5 ) Current Pending Sector Count — Текущее количество нестабильных секторов. Поле Raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает кандидатами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка кандидатов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped).
- 198 ( C6 ) Uncorrectable Sector Count — Счетчик некорректируемых ошибок. Это ошибки, которые не были исправлены внутренними средствами коррекции оборудования накопителя. Может быть вызвано неисправностью отдельных элементов или отсутствием свободных секторов в резервной области диска, когда возникла необходимость переназначения.
- 199 ( C7 ) UltraDMA CRC Error Count — Счетчик ошибок, возникших при передаче данных в режиме UltraDMA . Аппаратные средства контроля передачи данных из накопителя в оперативную память обнаружили ошибку контрольной суммы. Нередко этот тип ошибки связан не столько с оборудованием накопителя, сколько с неисправным интерфейсным кабелем, нестабильным питанием, разгоном частоты шины PCI, перегревом микросхем чипсета материнской платы и т.п.
- 200 ( C8 ) Write Error Rate ( Multi-Zone Error Rate ) — Характеризует наличие ошибок при записи данных. Может быть вызвано ухудшением состояния поверхности, головок или характеристик тракта записи данных. Чем ниже значение Value, тем опаснее использовать такой накопитель.
- 201 ( C9 ) Soft Read Error Rate — количество некорректируемых ошибок чтения, обнаруженных программным обеспечением.
- 202 ( CA ) Data Address Mark Errors — количество некорректируемых ошибок при чтении собственного адреса сектора.
- 203 ( CB ) Run Out Cancel — количество ошибок, зафиксированных при выполнении коррекции данных.
- 204 ( CC ) Soft ECC Correction — количество ошибок, исправленных внутренней микропрограммой накопителя.
- 205 ( CD ) Thermal Asperity Rate — общее количество проблем, вызванных повышенной температурой.
- 206 ( CE ) Flying Height — высота полета головок над поверхностью диска.
- 207 ( CF ) Spin High Current — ток, необходимый для раскручивания двигателя.
- 208 ( D0 ) Spin Buzz — количество повторных попыток запуска двигателя из-за пониженного тока.
- 209 ( D1 ) Offline Seek Performance — производительность, определенная при выполнении внутренних тестов накопителя.
- 210 ( D2 ) Vibration During Write — вибрации, зафиксированные при выполнении операций записи.
- 211 ( D3 ) Shock During Write — удары, зафиксированные при выполнении операций записи.
- 220 ( DC ) Disk Shift — смещение блока дисков относительно вертикальной оси шпинделя. В основном возникает из-за сильного удара или падения накопителя и как правило, является сигналом для его замены.
- 221 ( DD ) G-Sense Error Rate— количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера. Обычно довольно точно характеризует условия эксплуатации ноутбуков — большое значение атрибута говорит о резких толчках и падениях при работе устройства.
- 222 ( DE ) Loaded Hours — количество часов, отработанных накопителем.
- 223 ( DF ) Load/Unload Retry Count — количество операций ввода/вывода головок в зону данных.
- 226 ( E0 ) Load-in Time — общее время нахождения головок в зоне данных.
- 228 ( E4 ) Power-Off Retract Cycle — Количество автоматических парковок магнитных головок при пропадании питания.
- 230 ( E6 ) GMR Head Amplitude — Амплитуда перемещения головок между операциями.
- 231 ( E7 ) Hard Disk Temperature — температура, зафиксированная внутренними датчиками накопителя.
Современные накопители поддерживают не только формирование атрибутов S.M.A.R.T, но и ведут дополнительные журналы статистики, а также поддерживают протокол SCT (SMART Command Transport), обеспечивающий считывание данных журналов. Журнал статистики устройства — это доступный только для чтения журнал SMART, передаваемый накопителем при получении команд READ LOG EXT, READ LOG DMA EXT или SMART READ LOG. В журналах отображается информация о выполнении встроенных тестов S.M.A.R.T ( self-test ), статистика ошибок, номера сбойных блоков LBA и т.п.
Ремап (Remap) и проверка поверхности жесткого диска
Удивительно, как долго могут существовать ошибочные представления о жестких дисках и их правильной эксплуатации. В частности, даже неплохие специалисты в области компьютерной техники, бывает, рекомендуют выполнять в среде ОС Windows полное форматирование поверхности вместо быстрого, или даже низкоуровневое форматирование. Что касается последнего, свою лепту в путаницу с форматированием вносят и некоторые производители программного обеспечения, выпускающие программы для «низкоуровневого форматирования», которые ничего не форматируют. Низкоуровневое форматирование (Low Level Format) — это разметка поверхности диска специальной служебной информацией, в соответствии с геометрией накопителя, выполняемой специальной командой посылаемой накопителю. В стандарте ST506/412, который предшествовал современному стандарту ATA (AT attachment) имелась команда 50h (Format Track), при выполнении которой производилась разметка дорожки адресными маркерами, в соответствии с геометрией диска, т.е. в соответствии с номером цилиндра, номером головки и количеством секторов на дорожке. В дальнейшем, при записи данных, эта часть информации никогда не изменялась. При выполнении команды записи данных в сектор, накопитель никогда и ничего не записывает в ту область дорожки, которая является служебной и была создана при низкоуровневом форматировании дорожек поверхности специально для этого предназначенной командой 50h.
В современных накопителях стандарта ATA команды низкоуровневого форматирования вообще отсутствуют, а рекламируемые некоторыми производителями программы для выполнения данной операции являются простыми «стиралками» данных, выполняющими запись в область данных секторов. Нет, и не может быть, никаких программ для выполнения настоящего низкоуровневого форматирования в среде любой операционной системы. Любое подобное «низкоуровневое» форматирование — это высокоуровневое форматирование логической структуры пользовательских данных.
Что же касается полного форматирования в среде Windows, то по сравнению с быстрым, сразу создающим пустое оглавление, оно просто добавляет проверку поверхности диска перед тем, как выполнить то же самое, что делает быстрое форматирование. Что также не имеет смысла, поскольку проверка и отбраковка нестабильных секторов выполняется средствами аппаратной реализации технологии S.M.A.R.T накопителя, которая с данной задачей справляется гораздо эффективнее автоматически и в непрерывном режиме. Полное форматирование имело смысл на старых дисках, которые не могли выполнять замену нестабильных секторов на сектора из резервной зоны, и такие сектора сразу становились дефектными блоками ( Bad Block ), которые исключались из файловой структуры при форматировании с проверкой поверхности. Существует также утверждение, что при полном форматировании выполняется стирание всей поверхности диска. Это тоже не соответствует действительности, что легко проверяется любыми программами мониторинга обращений к диску , например, утилитой Disk Monitor из пакета Sysinternals Suite. Программа показывает, что при полном форматировании выполняется чтение поверхности, и небольшое количество операций записи, выполняемой после проверки поверхности при формировании пустого оглавления, в самом конце работы. И даже из того факта, что существую программы для восстановления данных после форматирования ( любого, в том числе и полного ) вполне логично следует вывод – никакого стирания данных не происходит.
При записи жесткий диск не проверяет, что и как было записано в область данных сектора, кроме случаев, когда предварительная диагностика, которой накопитель занимается все «свободное время», не пометила в соответствующих журналах эти сектора, как проблемные, или кандидаты на переназначение, что отражается в атрибуте 197 SMART (Current Pending Sectors).
Кандидат — это сектор (или группа секторов), который не был считан за стандартное время и с установленным числом повторов. В режиме простоя, запустится программа самотестирования, которая попытается считать данные с применением дополнительных режимов. Если сектор будет успешно считан — программа самодиагностики попытается записать данные обратно, и если запись выполнится успешно, то из кандидатов такой сектор удалится. Если же записанная на то же место информация не будет нормально считываться, то выполнится переназначение сектора (Remap), данные запишутся в сектор из специально для этого предназначенной резервной области (spare area). В дальнейшем, всегда вместо этого сбойного сектора будут считываться данные из резервной области. А сектор-кандидат на переназначение, не исправленный программой самотестирования, увеличит значение атрибута 198 (Offline Scan UNC Sectors). Убрать такой «бед» можно только перезаписью. Но если резервная область закончилась, то все последующие кандидаты на переназначение превратятся в реальные «плохие секторы» (Bad Blocks). В этом случае программы полного форматирования и проверки поверхности могут исключить сбойный сектор из логической структуры диска, однако, использовать накопитель с закончившейся резервной областью — это очень рискованная идея, которая обязательно закончится потерей данных. Использовать такой диск можно разве что для опасных экспериментов, хранения некритичных данных, или выбросить его на помойку.
При возникновении плохих блоков (Bad Block) нередко возникает необходимость проверки принадлежности сбойного участка конкретному файлу. Для этих целей можно воспользоваться консольной утилитой NFI.EXE (NTFS File Sector Information Utility) из состава пакета Support Tools от Microsoft. Скачать 10кб
Формат командной строки
nfi.exe Диск Номер логического сектора
Подсказку по использованию NFI.EXE можно получить по команде nfi.exe /?
Букву логического диска можно задавать без двоеточия. Номер логического сектора — это номер сектора относительно начала логического диска. Обратите внимание на тот факт, что программы сканирования работают со всей поверхностью физического диска и используют нумерацию секторов, не привязанную к его логической структуре. А номер сектора, задаваемый в качестве параметра утилиты NFI.EXE — это номер сектора логического диска (раздела), и он отличается величиной смещения начального сектора раздела от начала диска. Значение номеров начальных секторов логических дисков можно получить нажав кнопку View part data вкладки «Advanced» программы Victoria For Windows.
nfi.exe C: 655234 — выдать имя файла, которому принадлежит сектор 655234
nfi.exe C: 0xBF5E34 — то же самое, но номер сектора задан в шестнадцатеричной системе счисления
В результате выполнения команды будет выдано сообщение
***Logical sector 12541492 (0xbf5e34) on drive C is in file number 49502.
WINDOWS system32 D3DCompiler_38.dll
Т.е. интересующий нас сбойный сектор принадлежит файлу D3DCompiler_38.dll в каталоге Windowssystem32. В случае, когда сбойные блоки принадлежат системным файлам Windows, возможно появление синих экранов смерти или зависаний системы с перезагрузкой. В большинстве случаев, информация о наличии сбоев дисковой подсистемы, будет отображаться в системном журнале Windows.
Для выполнения тестирования поверхности накопителя с принудительным переназначением (ремапом) сбойных секторов можно воспользоваться программами тестирования HDD, алгоритм работы которых специально разработан таким образом, чтобы «заставить» внутреннюю микропрограмму накопителя выполнить переназначение нестабильного участка.
Так, например, подобные алгоритмы будут использоваться, в упоминаемой выше программе Victoria, если выбран режим тестирования поверхности с выполнением операций восстановления или переназначения (Classic Remap, Advanced Remap :). Изначально режим выполнения теста установлен в Ignore Bad Blocks

Нажатие пробела изменяет режим обработки сбоев. При выполнении такого вида тестирования накопителя, пользовательские данные остаются в сохранности.
Добавлю, что режим Advanced Remap, хотя и является наиболее эффективным, на практике может приводить к «зависанию» микропрограммы на некоторых моделях HDD, выйти из которого можно только с использованием принудительного сброса (режим Reset, клавиша F3). После чего можно продолжить тестирование. Если в режиме Advanced Remap таймауты происходят слишком часто, имеет смысл перейти к использованию классического ремапа.
Для программы Victoria For Windows переназначение сбойных секторов включается установками режима выполнения теста в правой части основного окна. По умолчанию установлен режим Ignore — ничего не делать при обнаружении сбоя, а нужно установить режим Remap

Первую часть этого материала можно прочитать здесь.
Технология S.M.A.R.T. родилась в далеком 1995 году, так что возраст у нее почтенный. Предполагалось, что атрибуты SMART (давайте для простоты писать аббревиатуру без точек), формируемые микропрограммой жесткого диска, позволят программно оценивать состояние накопителя, а также дадут механизм для предсказания выхода его из строя. Последнее в те времена было достаточно актуально: срок жизни дисков в серверах, например, исчислялся годом-полутора, и знать, когда готовить замену, было нелишним.
Со временем многое поменялось: что-то отмерло, какие-то стороны развились сильнее (например, контроль механики диска). Первоначальный набор из десятка простейших атрибутов усложнился и разросся в несколько раз, порой менялся их смысл, многие производители ввели собственные атрибуты с не всегда ясным функционалом. Появилась масса программ для анализа SMART (как правило, невысокого качества, но с эффектным интерфейсом, да еще и за деньги) и т.п.
Так что не мешает описать современное состояние SMART. Начнем с критически важных атрибутов, ухудшение которых почти всегда свидетельствует о проблемах с накопителем. Именно их первым делом смотрят ремонтники при диагностике HDD.
- #01 Raw Read Error Rate — частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных ДО выдачи в интерфейс; на пугающе огромные цифры можно не обращать внимания.
- #03 Spin-Up Time — время раскрутки пакета пластин из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т.п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
- #05 Reallocated Sectors Count — число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор переназначенным и переносит данные в резервную область. Вот почему на современных HDD нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, на жаргоне — ремап. Поле Raw Value атрибута содержит общее количество переназначенных секторов. Чем оно больше, тем хуже состояние поверхности диска.
- #07 Seek Error Rate — частота ошибок при позиционировании блока магнитных головок (БМГ). Рост этого атрибута свидетельствует о низком качестве поверхности или о поврежденной механике накопителя. Также может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
- #10 Spin-Up Retry Count — число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута растет, то велика вероятность проблем с механикой.
- #196 Reallocation Event Count — число операций переназначения. В поле Raw Value атрибута хранится общее число попыток переноса информации со сбойных секторов в резервную область диска (она, как правило, не слишком велика — несколько тысяч секторов). Учитываются как успешные, так и неудачные операции.
- #197 Current Pending Sector Count — текущее число нестабильных секторов. Здесь хранится число секторов, являющихся кандидатами на замену. Они не были еще определены как плохие, но считывание с них происходит с затруднениями (например, не с первого раза). Если «подозрительный» сектор будет в дальнейшем считываться успешно, то он исключается из числа кандидатов. В случае же повторных ошибочных чтений накопитель попытается восстановить его и выполнить ремап.
- #198 Uncorrectable Sector Count — число секторов, при чтении которых возникают неисправимые (внутренними средствами) ошибки. Рост этого атрибута указывает на серьезные дефекты поверхности или на проблемы с механикой накопителя.
- #220 Disk Shift — сдвиг пакета пластин относительно оси шпинделя. В основном возникает из-за сильного удара или падения диска. Единица измерения неизвестна, но при сильном росте атрибута диск не жилец.
Также следует принимать во внимание и информационные атрибуты, способные много чего поведать об «истории» диска.
- #02 Throughput Performance — средняя производительность диска. Если значение атрибута уменьшается, то велика вероятность, что у накопителя есть проблемы.
- #04 Start/Stop Count — число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счетчик включения режима энергосбережения.
- #08 Seek Time Performance — средняя производительность операции позиционирования головок. Снижение значения этого атрибута свидетельствует о неполадках в механике привода головок (в первую очередь о замедленном позиционировании).
- #09 Power-On Hours (POH) — время, проведённое во включенном состоянии. Показывает общее время работы диска, единица измерения зависит от модели (не только 1 час, но и 30 мин, и даже 1 минута).
- #11 Recalibration Retries — число повторов рекалибровки в случае, если первая попытка была неудачной. Рост этого атрибута указывает на проблемы с механикой диска.
- #12 Device Power Cycle Count — число полных циклов включения-выключения диска.
- #13 Soft Read Error Rate — частота появления «программных» ошибок при чтении данных. Сюда можно отнести ошибки программного обеспечения, драйверов, файловой системы, неверную разметку диска — в общем, почти все, что не относится к аппаратной части.
- #190 Airflow Temperature — температура воздуха внутри корпуса HDD. Для дисков Seagate атрибут выдается в нормировке 100º минус температура (тем самым критический нагрев соответствует значению 45), а модели Western Digital используют нормировку 125º минус температура.
- #191 G—sense error rate — число ошибок, возникших из-за внешних нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
- #192 Power—off retract count — число зафиксированных повторов включения/выключения питания накопителя.
- #193 Load/Unload Cycle Count — число циклов перемещения БМГ в специальную парковочную зону/в рабочее положение.
- #194 HDA temperature — температура механической части диска, в просторечии банки (HDA — Hard Disk Assembly). Информация снимается со встроенного термодатчика, которым служит одна из магнитных головок, обычно нижняя в банке. В битовых полях атрибута фиксируются текущая, минимальная и максимальная температура. Не все программы, работающие со SMART, правильно разбирают эти поля, так что к их показаниям стоит относиться критично.
- #195 Hardware ECC Recovered — число ошибок, скорректированных аппаратной частью диска. Сюда входят ошибки чтения, ошибки позиционирования, ошибки передачи по внешнему интерфейсу. На дисках с SATA-интерфейсом значение нередко ухудшается при повышении частоты системной шины — SATA очень чувствителен к разгону.
- #199 UltraDMA (Ultra ATA) CRC Error Count — число ошибок, возникающих при передаче данных по внешнему интерфейсу в режиме UltraDMA (нарушения целостности пакетов и т.п.). Рост этого атрибута свидетельствует о плохом (мятом, перекрученном) кабеле и плохих контактах. Также подобные ошибки появляются при разгоне шины PCI, сбоях питания, сильных электромагнитных наводках, а иногда и по вине драйвера.
- #200 Write Error Rate/ Multi-Zone Error Rate — частота появления ошибок при записи данных. Показывает общее число ошибок записи на диск. Чем больше значение атрибута, тем хуже состояние поверхности и механики накопителя.
Как видим, большинство «интересных» атрибутов отражает функционирование механики накопителя. Технология SMART действительно позволяет предсказывать выход диска из строя в результате механических неисправностей, что, по статистике, составляет около 60% всех отказов. Полезен и мониторинг температур: перегрев головок резко ускоряет их деградацию, так что превышение опасного порога (45-55º в зависимости от модели) — сигнал срочно улучшить охлаждение диска.
Вместе с тем не следует переоценивать возможности SMART. Современные диски нередко «дохнут» на фоне отличных атрибутов, что связано с тонкими процессами дефект-менеджмента в условиях высокой плотности записи и не всегда, мягко говоря, качественных компонентов (разнобой в отдаче головок сегодня — обычное дело). Тем более SMART не способен предсказать последствия таких «форс-мажоров», как скачок напряжения, перегрев платы электроники или повреждение накопителя от удара.
Практически у всех атрибутов наибольший интерес представляет поле Raw Value: «сырые» значения наиболее информативны. Их нормировка (степень приближения к абстрактному порогу) часто ничего не дает и только запутывает дело. Поэтому и программы, полагающиеся на эти проценты, нельзя считать вполне надежными. Типичный случай для них — ложные тревоги. Программа сообщает, что новый, недавно установленный накопитель того и гляди «склеит ласты». А все дело в том, что в начале эксплуатации некоторые атрибуты SMART быстро меняются и примитивная экстраполяция приводит к пугающим пользователя прогнозам.
Я советую бесплатную программу HDDScan — она корректно понимает все атрибуты, в том числе и новые, правильно разбирает температурные показатели. Отчет выводится в виде аккуратной xml-таблицы с цветовой индикацией, которую можно сохранить или распечатать.
SMART диска WD пятилетнего возраста. О его близкой кончине свидетельствуют ненулевые значения атрибутов 1 и 200 (для WD они особенно чреваты), а также тот факт, что после ремапа атрибут 197 снова растет. Это значит, что возможности исправления дефектов исчерпаны
Крайне полезна у HDDScan возможность считывать SMART у внешних накопителей, столь распространенных сегодня. Практически ни одна другая программа этого не умеет, ведь на пути данных стоит контроллер, преобразующий интерфейс PATA/SATA в USB или FireWire. Автор целенаправленно работал в этом направлении, и ему удалось охватить широкий спектр контроллеров. Не забыты и диски с интерфейсом SCSI, до сих пор широко применяемые в серверах (атрибуты у них особые — например, выводится общее число записанных или считанных байтов за всю жизнь накопителя).
Функционал HDDScan полностью отвечает потребностям ремонтника. Когда первичную диагностику принесенного внешнего диска можно провести, не разбирая корпус, — это удобно, экономит время, а порой и сохраняет гарантию.
SMART, снятый со SCSI-диска. Здесь исторически сложились совсем другие атрибуты
⇡#Барьеры HDD
Механика давно стала ахиллесовой пятой HDD, и даже не столько из-за чувствительности к ударам и вибрации (это еще можно компенсировать), сколько из-за медлительности. Самые быстрые «дерганья» блоком магнитных головок (2-3 мс у лучших серверных моделей) в тысячи раз уступают скоростям электроники.
И принципиально ничего тут не улучшишь. Поднимать скорость вращения пакета дисков некуда, 15000 об./мин уже предел. Японцы несколько лет назад подступались к 20000 об./мин (вполне гироскопная скорость), но в итоге отказались — не выдерживают материалы, конструкция получается слишком дорогая и для массового производства слабо пригодная. В малых же сериях винчестеры выйдут золотыми, такие никто не купит — это не гироскопы, которые заменить нечем.
Выходит, уткнулись в барьер. Механику на кривой козе не объедешь. Единственный выход — поднимать плотность записи, поперечную и продольную. Продольная плотность (вдоль дорожки) влияет на производительность накопителя, т.е. на поток данных к остальным узлам компьютера. Но все равно, даже достигнутые 100-130 Мбайт/с — это для нынешних компьютеров слишком мало. Например, рядовая оперативная память (DRAM) имеет реальную производительность около 3 Гбайт/с, а кеш процессора — еще больше. Разница на порядки, и она сильно сказывается на общем быстродействии. Конечно, никто не требует от энергонезависимого накопителя, емкость которого в сотни раз превышает DRAM, такой же производительности. Но даже простое удвоение было бы заметно любому пользователю.
Поперечная плотность записи — это густота дорожек на пластине, в современных HDD она превышает 10000 на 1 миллиметр. Получается, что сама дорожка имеет ширину менее 100 нм (между прочим, нанотехнологии в чистом виде). Это позволяет резко поднять емкость в расчете на одну поверхность, а также ускоряет позиционирование за счет изощренных алгоритмов (их разработка потянула бы на пару докторских диссертаций).
Как итог, за последние годы емкость и производительность HDD значительно выросли. Все это стало возможным благодаря технологии перпендикулярной записи, которая существует уже более 20 лет, но до массового внедрения дозрела только в 2007 году. Причем емкость тогда выросла даже сильнее, чем требуется: первые терабайтные диски встретили вялый отклик пользователей. Народ просто не понимал, куда приспособить таких монстров, тем более что они поначалу строились на пяти пластинах, были капризными, шумными и горячими (речь о тогдашних флагманах Hitachi).
Потом, конечно, люди разобрались, торренты заработали в полную силу, да и количество пластин поуменьшилось. В то же время плотность записи выросла до 500-750 Гбайт на пластину (имеются в виду диски настольного сегмента с форм-фактором 3,5″). Вот-вот в массовое производство пойдут терабайтные пластины, что даст возможность выпустить винчестеры объемом до 4 Тбайт (больше четырех пластин в стандартном корпусе высотой 26,1 мм не уместить; хитачевские пятипластинные первенцы большого развития не получили).

Трехтерабайтный диск WD Caviar Green WD30EZRX, наиболее емкий на сегодня. Имеет четырехпластинный дизайн, выпускается ровно год (с 20 октября 2010 г.). Как полагается, весной и летом дешевел, но в последние дни резко подорожал из-за наводнения в Таиланде (там расположены сборочные заводы WD, и стихия блокировала подвоз комплектующих)
Увы, скорость позиционирования выросла, мягко говоря, несильно, а у массовых моделей так вообще осталась на прежнем уровне, а то и упала в угоду… тишине. Маркетологи доказали, что потребитель голосует кошельком за гигабайты в расчете на один доллар, а не за миллисекунды доступа. Поэтому и небыстры дешевые диски по сравнению с породистыми серверными собратьями. Медлительность хорошо проявляется в скорости загрузки ОС, когда надо читать с диска большое количество мелких файлов, разбросанных по пластинам. Здесь главную роль играет скорость вращения шпинделя и мощный привод БМГ, дающий возможность больших ускорений.
Между прочим, «быстрые» диски легко отличить даже на вес — они заметно тяжелее «медленных». Полноразмерная банка с утолщенными стенками, способствующая геометрической стабильности и подавлению вибраций, скоростной шпиндельный двигатель, мощные магниты позиционера, двухслойная крышка повышенной жесткости — все это прибавляет такому накопителю десятки и сотни граммов. Еще больше отрыв в серверных моделях на 15000 об./мин, где пластины уменьшенного размера окружены внушительным объемом литого алюминия, а общий вес «харда» доходит до килограмма.

Высокопроизводительный диск WD Raptor со скоростью вращения шпинделя 10 000 об./мин. При емкости 150 Гбайт весит 740 г (массовые модели той же емкости — 400-500 г). Обратите внимание на размер магнитов и толщину стенок
С удешевлением твердотельных SSD, использующихся, в первую очередь, под операционную систему, нужда в высокопроизводительных HDD стала снижаться, а сами они постепенно выделяются в особый сегмент рынка (такова, например, «черная» серия у WD). Подобными дисками комплектуются профессиональные рабочие станции с ресурсоемкими приложениями, критичными к скорости доступа. Рядовые же пользователи брать достаточно дорогие накопители не торопятся, предпочитая объем производительности.
На другом конце спектра — популярные «зеленые» модели с намеренно замедленным вращением шпинделя (5400-5900 об./мин вместо 7200) и небыстрым позиционированием головок. Дешевые, тихие, холодные и достаточно надежные, эти винчестеры идеально подходят для хранения мультимедийных данных в домашних компьютерах, внешних корпусах и сетевых хранилищах. На наших прилавках все эти Green и LP сильно потеснили другие линейки, так что в мелких «точках» порой ничего больше и не найдешь.
⇡#Расточительность магнитной записи
Намагниченность доменов жесткого диска, как и в середине двадцатого века, меняют с помощью магнитной головки, поле которой возбуждается переменным электрическим током и действует на магнитный слой через зазор. Также эта технология требует быстрого вращения пластин, прецизионного контроля положения головки и т.д. Двигатель и позиционер жесткого диска, а также управляющая ими электроника потребляют заметную мощность, да и стоят немало. Но главное — на само возбуждение магнитного поля тратится очень много энергии.
Расточительность стандартного метода магнитной записи трудно оценить, работая на персональном компьютере. Жесткие диски массовых серий даже при активной работе потребляют менее 10 Вт, что на фоне прочих комплектующих (100 Вт и более) почти незаметно. Но ваши взгляды сразу переменятся после посещения серверной комнаты какого-нибудь крупного банка, а чтобы получить впечатлений на всю оставшуюся жизнь, достаточно подойти к дисковой стойке суперкомпьютера. В шуме сотен и тысяч жестких дисков, обдувающих их вентиляторов и прецизионных кондиционеров становится понятно, сколько энергии в глобальном масштабе тратится на такую работу.
Недаром для систем хранения данных энергоэффективность в списке характеристик выходит на первый план. Вот уже и Google переводит свои дата-центры на баржи в море (вот где настоящие офшоры!). Оказывается, охлаждение СХД забортной водой радикально сокращает операционные затраты, в первую очередь за счет экономии на кондиционерах.
⇡#О питании жестких дисков
Будет ли работать обычная 220-вольтовая лампочка от 230 В? Конечно, будет. А от 240 В? Тоже. Вопрос — сколько она протянет? Понятно, что меньше или существенно меньше — это зависит от конкретной лампочки. Ей суждена яркая, но короткая жизнь.
Примерно та же ситуация и с жесткими дисками. Наивные производители проектировали их, полагаясь на стандартные +5 В и +12 В. Однако в типичном компьютерном блоке питания (БП) стабилизируется лишь линия 5 В. К чему же это приводит?
При высокой нагрузке на процессор (а современные «камни» потребляют немало) и недостаточной мощности БП линия 5 В проседает, и система стабилизации отрабатывает это дело, повышая напряжение до номинального значения. Одновременно повышается и напряжение 12 В (из-за отсутствия стабилизации по нему). В результате и так нестойкий к нагреву HDD работает еще и при повышенном напряжении, которое подается на самые греющиеся узлы — микросхему управления двигателем (на жаргоне ремонтников — «крутилка») и привод головок (т.н. «звуковая катушка»). Итог — смотри рассуждение о лампочке.


Сгоревшая «крутилка» на плате как результат повышенного напряжения и плохого охлаждения. Нередко микросхема сгорает в буквальном смысле, с пиротехническими эффектами и выгоранием дорожек на плате. Такое ремонту не подлежит
Отсюда советы по блоку питания. Чем больше его мощность, тем лучше (в разумных пределах: запас более 30-35% по отношению к реальному потреблению снижает КПД блока, так что вы будете греть комнату). Менее мощный, но фирменный БП лучше более мощного, но безродно-китайского. Помните — разгоняют не только процессоры. В первом приближении, 420 «китайских» ватт эквивалентны 300 «правильным».
По-хорошему, надо бы еще учитывать возраст БП: после 2-3 лет эксплуатации его реальная мощность заметно снижается, а выходные напряжения дрейфуют. Разумеется, в некачественных изделиях, работающих на честном китайском слове, процессы старения выражены гораздо резче. Хорошо еще, если подобный блок тихо умрет сам, а не утащит за собой в агонии половину системного блока!
Максимально допустимым считается 12,6 В (+5% от номинала). Однако у многих дисков c ростом напряжения наблюдается нелинейно-резкий нагрев упомянутых выше узлов — «крутилки» и «катушки». Поэтому я рекомендую строже контролировать БП с помощью внешнего вольтметра (датчики на материнской плате, измеряющие напряжение для BIOS и программ типа AIDA, могут быть весьма неточны).
Измерять напряжение лучше всего на разъемах Molex и обязательно под полной нагрузкой: процессор занят вычислениями с плавающей точкой, видеокарта — выводом динамичной трехмерной графики, а диск — дефрагментацией. При 12,2-12,4 В стоит призадуматься, 12,4-12,6 В — поволноваться, 12,6-13 В — бить тревогу, а в случае 13 В и выше — копить деньги на новый диск или положить гарантийный талон на видное место…

Конденсаторы (2200 мкФ, 25 В), напаянные на цепи питания HDD (желтый провод — +12 В, красный — +5 В, черный — земля). В данном случае они уменьшают пульсации напряжения, от которых блок питания издает раздражающий высокочастотный писк
Если напряжение по линии 12 В сильно завышено, а вы не боитесь паяльника и способны отличить транзистор от диода, то можете включить последний в разрыв питания HDD (напомню, линии 12 В соответствует желтый провод). Диод сыграет роль ограничителя — на его p-n переходе упадут «лишние» 0,2-0,7 В (в зависимости от типа диода), и диску станет полегче. Только диод надо брать достаточно мощный, чтобы он выдерживал пусковой ток в 2-3 А.
И без фанатизма: результирующее напряжение не должно опускаться ниже 11,7 В. В противном случае возможна неустойчивая работа диска (множественные рестарты) и даже порча данных. А некоторые модели (в частности, Seagate 7200.10 и 7200.11) могут вообще не запуститься.
⇡#Миграция с флеш
Память NAND Flash появилась много позднее, чем HDD, и переняла ряд его технологий — взять хотя бы коды ECC. Далее оба направления развивались параллельно и сравнительно независимо. Но в последнее время наметился и обратный процесс: миграция технологий с флеш-памяти на жесткие диски. Конкретно речь идет о выравнивании износа.
Как известно, любой флеш-чип имеет ограниченный ресурс по числу стираний-записей в одну ячейку. В какой-то момент стереть ее уже не удается, и она навсегда застывает с последним записанным значением. Поэтому контроллер считает количество записей в каждую страницу и в случае превышения копирует ее на менее изношенное место. В дальнейшем вся работа ведется с новым участком (этим заведует транслятор), а старая страница остается как есть и не используется. Данная технология получила название Wear Leveling. Так вот, износ есть и в жестких дисках, но там он механический и температурный. Если магнитная головка все время висит над одной дорожкой (скажем, постоянно изменяется тот или иной файл), то растет вероятность повреждения дорожки при случайных толчках или вибрации диска (например, от соседних накопителей в корзине). Головка может коснуться пластины и повредить магнитный слой со всеми вытекающими печальными последствиями. Даже если вредного контакта нет, неподвижная головка локально нагревается и пусть обратимо, но деградирует. Запись в данное место происходит менее надежно, растет вероятность последующего неустойчивого считывания (а при современных огромных плотностях записи любое отклонение параметров губительно).
Эти соображения достаточно очевидны, и прошивка серверных дисков с интерфейсом SCSI/SAS (а они весьма горячи) давно научилась перемещать головки в простое, дабы они не перегревались. Но еще лучше вместе с головкой «перебрасывать» и информацию по пластине — в этом случае описанные эффекты подавляются максимально, а надежность накопителя растет. Вот Western Digital и ввел подобный механизм в новых моделях VelociRaptor. Это дорогие высокопроизводительные диски со скоростью вращения шпинделя 10000 об./мин и пятилетней гарантией, так что Wear Leveling там уместен.


VelociRaptor снаружи и внутри. Привлекает внимание мощный радиатор. Пластины же имеют уменьшенный диаметр — это характерно для современных скоростных дисков.
Кроме того, вся линейка VelociRaptor нацелена на использование в высоконагруженных системах, в первую очередь серверах, где запись на диск ведется очень интенсивно и зачастую в одни и те же файлы (типичный пример — логи транзакций). Массовым «ширпотребным» дискам высокие нагрузки не грозят, греются они тоже умеренно, так что подобный изыск там вряд ли появится. Впрочем, поживем — увидим.
⇡#Аdvanced Format и его применение
Вот уже более 20 лет все жесткие диски имеют одинаковый размер физического сектора: 512 байт. Это минимальная порция записи на диск, позволяющая гибко управлять распределением дискового пространства. Однако с ростом объема HDD все сильнее стали проявляться недостатки такого подхода — в первую очередь неэффективное использование емкости магнитной пластины, а также высокие накладные расходы при организации потока данных.
Поэтому диски большой емкости (терабайт и выше) стали производиться по технологии Advanced Format, которая оперирует «длинными» физическими секторами в 4096 байт. Разметка магнитных пластин под AF весьма выгодна для производителя: меньше межсекторных промежутков, выше полезная емкость дорожки и всей пластины (а это, наряду с магнитными головками, самый дорогой компонент HDD). Именно Advanced Format позволил выпустить на рынок недорогие винчестеры, столь популярные ныне у потребителей аудио- и видеоконтента. AF-дисками емкостью 1-3 Тбайт комплектуются не только компьютеры, но и масса внешних накопителей, сетевых хранилищ и медиаплееров.

Один из первых дисков 3,5″ с Advanced Format, выпущенный в 2009 г
Но даром ничего не дается, новые диски уже начинают приносить в ремонт. Похоже, надежность все-таки просела. Ведь единичный сбой диска или дефект поверхности портит теперь в 8 раз больше данных пользователя, чем обычно. При физическом секторе в 4 Кбайт и эмуляции «коротких» секторов в 512 байт не будет читаться от 1 до 8 секторов. Операционная система на это реагирует понятно как: авария, все пропало! В итоге мелкая проблема на пластинах вырастает для пользователя в зависание или чего еще хуже.
Я считаю, на дисках с AF не стоит держать ОС, прикладные программы и базы данных со множеством мелких файлов. Пока что их удел — мультимедийные данные, некритичные к выпадениям.
⇡#Что стоит почитать о жестких дисках
В первую очередь рекомендую заглянуть на форум HARDW.net. Его раздел «Накопители информации» посещает множество профессиональных ремонтников и энтузиастов (почти 40 тыс. участников). Там можно найти ответы практически по любой теме, связанной с HDD, за исключением самых новых «нераскопанных» моделей. Начните с подраздела «Песочница»: на простые (в понимании профессионалов) вопросы там отвечают подробно и содержательно, а не отшивают, как в других местах, — «несите к ремонтнику».
Еще больше информации, правда, на английском языке, можно найти на портале HDDGURU. Помимо ремонтно-диагностического ПО и статей по отдельным вопросам (например, как поменять головки у диска), там есть международный форум ремонтников, а также огромный архив ресурсов по HDD (firmware, документация, фото и т.п.). Портал прививает широкий взгляд на вещи, он будет интересен подготовленным и мотивированным людям. Во всяком случае, в закрытых конференциях ремонтников ссылки на него пробегают постоянно.
Сошлюсь и на свою статью «Как продлить жизнь жестким дискам» в трех частях. Она дает начальные сведения по обращению с HDD, и хотя написана более трех лет назад, устарела мало — диски за это время принципиально не изменились, разве что стали еще менее надежными из-за свирепой экономии. Производители, застигнутые мировым кризисом, снижали свои затраты по всем направлениям, что и послужило причиной ряда громких провалов 2008-2009 гг. Об одном из них речь пойдет в продолжении этого материала, которое выйдет в ближайшее время.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.