
В этой статье вы узнаете, что вы можете делать, когда при загрузке сервера возникают общие проблемы. В статье описываются общие подходы, которые помогают исправить некоторые из наиболее распространенных проблем, которые могут возникнуть при загрузке Linux.
Понимание процедуры загрузки в Linux RHEL7/CentOS
Чтобы исправить проблемы с загрузкой, важно хорошо понимать процедуру загрузки. Если проблемы возникают во время загрузки, вы должны понимать, на какой стадии процедуры загрузки возникает проблема, чтобы можно было выбрать соответствующий инструмент для устранения проблемы.
Следующие шаги суммируют, как процедура загрузки происходит в Linux.
1. Выполнение POST: машина включена. Из системного ПО, которым может быть UEFI или классический BIOS, выполняется самотестирование при включении питания (POST) и аппаратное обеспечение, необходимое для запуска инициализации системы.
2. Выбор загрузочного устройства: В загрузочной прошивке UEFI или в основной загрузочной записи находится загрузочное устройство.
3. Загрузка загрузчика: с загрузочного устройства находится загрузчик. На Red Hat/CentOS это обычно GRUB 2.
4. Загрузка ядра: Загрузчик может представить пользователю меню загрузки или может быть настроен на автоматический запуск Linux по умолчанию. Для загрузки Linux ядро загружается вместе с initramfs. Initramfs содержит модули ядра для всего оборудования, которое требуется для загрузки, а также начальные сценарии, необходимые для перехода к следующему этапу загрузки. На RHEL 7/CentOS initramfs содержит полную операционную систему (которая может использоваться для устранения неполадок).
5. Запуск /sbin/init: Как только ядро загружено в память, загружается первый из всех процессов, но все еще из initramfs. Это процесс /sbin/init, который связан с systemd. Демон udev также загружается для дальнейшей инициализации оборудования. Все это все еще происходит из образа initramfs.
6. Обработка initrd.target: процесс systemd выполняет все юниты из initrd.target, который подготавливает минимальную операционную среду, в которой корневая файловая система на диске монтируется в каталог /sysroot. На данный момент загружено достаточно, чтобы перейти к установке системы, которая была записана на жесткий диск.
7. Переключение на корневую файловую систему: система переключается на корневую файловую систему, которая находится на диске, и в этот момент может также загрузить процесс systemd с диска.
8. Запуск цели по умолчанию (default target): Systemd ищет цель по умолчанию для выполнения и запускает все свои юниты. В этом процессе отображается экран входа в систему, и пользователь может проходить аутентификацию. Обратите внимание, что приглашение к входу в систему может быть запрошено до успешной загрузки всех файлов модуля systemd. Таким образом, просмотр приглашения на вход в систему не обязательно означает, что сервер еще полностью функционирует.
На каждом из перечисленных этапов могут возникнуть проблемы из-за неправильной настройки или других проблем. Таблица суммирует, где настроена определенная фаза и что вы можете сделать, чтобы устранить неполадки, если что-то пойдет не так.
| Фаза загрузки | Где настроено | Как попытаться починить |
| POST | Железо (F2, Esc, F10, или другая кнопка) | Замена железа |
| Выбор загрузочного устройства | BIOS/UEFI конфигурация или загрузочное устройство | Замена железа или использовать восстановление системы |
| Загрузка загрузчика (GRUB 2) | grub2-install и редактирует в /etc/defaults/grub | Приглашение GRUB для загрузки и изменения в /etc/defaults/grub, после чего следует выполнить grub2-mkconfig. |
| Загрузка ядра | Редактирует конфигурацию GRUB и /etc/dracut.conf | Приглашение GRUB для загрузки и изменения в /etc/defaults/grub, после чего следует выполнить grub2-mkconfig. |
| Запуск /sbin/init | Компиляция в initramfs | init = kernel аргумент загрузки, rd.break аргумент загрузки ядра |
| Обработка initrd.target | Компиляция в initramfs | Обычно ничего не требуется |
| Переключение на корневую файловую систему | /etc/fstab | /etc/fstab |
| Запуск цели по умолчанию | /etc/systemd/system/default.target | Запустить rescue.target как аргумент при загрузке ядра |
Передача аргементов в GRUB 2 ядру во время загрузки
Если сервер не загружается нормально, приглашение загрузки GRUB предлагает удобный способ остановить процедуру загрузки и передать конкретные параметры ядру во время загрузки. В этой части вы узнаете, как получить доступ к приглашению к загрузке и как передать конкретные аргументы загрузки ядру во время загрузки.
Когда сервер загружается, вы кратко видите меню GRUB 2. Смотри быстро, потому что это будет длиться всего несколько секунд. В этом загрузочном меню вы можете ввести e, чтобы войти в режим, в котором вы можете редактировать команды, или c, чтобы ввести полную командную строку GRUB.
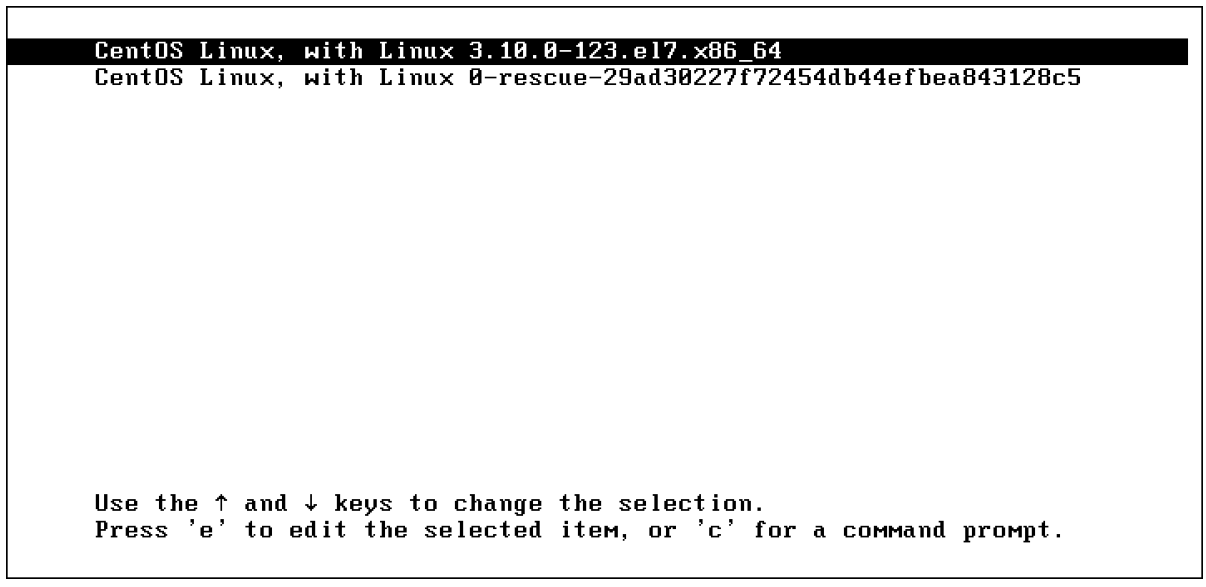 После передачи e в загрузочное меню GRUB вы увидите интерфейс, показанный на скриншоте ниже. В этом интерфейсе прокрутите вниз, чтобы найти раздел, начинающийся с linux16 /vmlinuz, за которым следует множество аргументов. Это строка, которая сообщает GRUB, как запустить ядро, и по умолчанию это выглядит так:
После передачи e в загрузочное меню GRUB вы увидите интерфейс, показанный на скриншоте ниже. В этом интерфейсе прокрутите вниз, чтобы найти раздел, начинающийся с linux16 /vmlinuz, за которым следует множество аргументов. Это строка, которая сообщает GRUB, как запустить ядро, и по умолчанию это выглядит так:
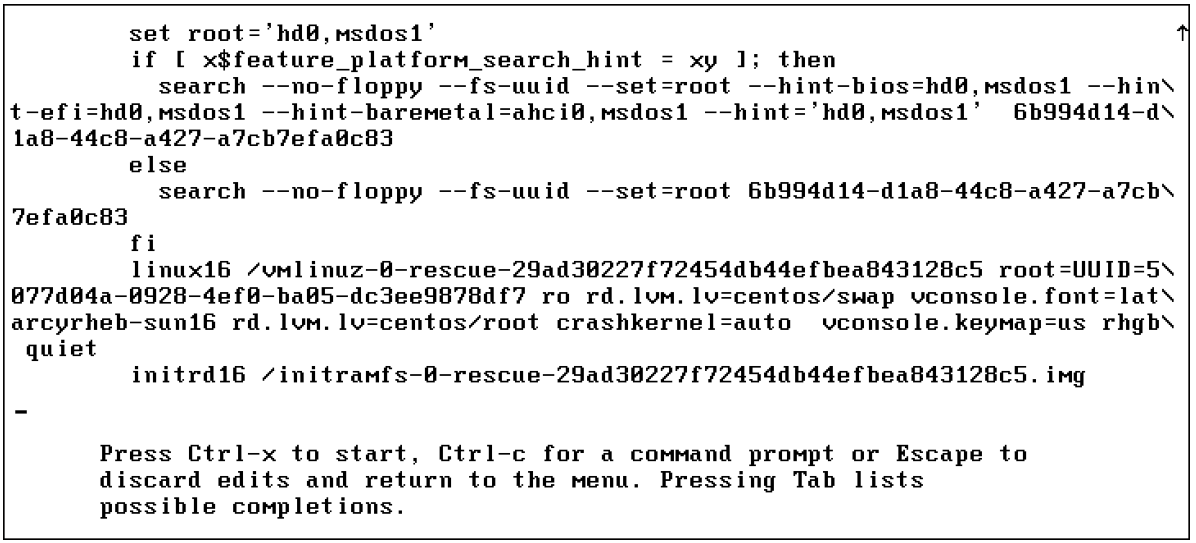
После ввода параметров загрузки, которые вы хотите использовать, нажмите Ctrl + X, чтобы запустить ядро с этими параметрами. Обратите внимание, что эти параметры используются только один раз и не являются постоянными. Чтобы сделать их постоянными, вы должны изменить содержимое файла конфигурации /etc/default/grub и использовать grub2-mkconfig -o /boot/grub2/grub.cfg, чтобы применить изменение.
Когда у вас возникли проблемы, у вас есть несколько вариантов (целей), которые вы можете ввести в приглашении загрузки GRUB:
■ rd.break Это останавливает процедуру загрузки, пока она еще находится в стадии initramfs.
Эта опция полезна, если у вас нет пароля root.
■ init=/bin/sh или init=/bin/bash Указывает, что оболочка должна быть запущена сразу после загрузки ядра и initrd. Это полезный вариант, но не лучший, потому что в некоторых случаях вы потеряете консольный доступ или пропустите другие функции.
■ systemd.unit=emergency.target Входит в минимальный режим, когда загружается минимальное количество системных юнитов.
Требуется пароль root.
Чтобы увидеть, что загружено только очень ограниченное количество файлов юнитов, вы можете ввести команду systemctl list-units.
■ systemd.unit=rescue.target Команда запускает еще несколько системных юнитов, чтобы привести вас в более полный рабочий режим. Требуется пароль root.
Чтобы увидеть, что загружено только очень ограниченное количество юнит-файлов, вы можете ввести команду systemctl list-units.
Запуск целей(targets) устранения неполадок в Linux
1. (Пере)загружаем Linux. Когда отобразиться меню GRUB, нажимаем e;
2. Находим строку, которая начинается на linux16 /vmlinuz. В конце строки вводим systemd.unit=rescue.target и удаляем rhgb quit;
3. Жмем Ctrl+X, чтобы начать загрузку с этими параметрами. Вводим пароль от root;
4. Вводим systemctl list-units и смотрим. Будут показаны все юнит-файлы, которые загружены в данный момент и соответственно загружена базовая системная среда;
5. Вводим systemctl show-environment. Видим переменные окружения в режиме rescue.target;
6. Перезагружаемся reboot;
7. Когда отобразится меню GRUB, нажимаем e. Находим строку, которая начинается на linux16 /vmlinuz. В конце строки вводим systemd.unit=emergency.target и удаляем rhgb quit;
8. Снова вводим пароль от root;
9. Система загрузилась в режиме emergency.target;
10. Вводим systemctl list-units и видим, что загрузился самый минимум из юнит-файлов.
Устранение неполадок с помощью загрузочного диска Linux
Еще один способ восстановления работоспособности Linux использовать образ операционки.
Если вам повезет меньше, вы увидите мигающий курсор в системе, которая вообще не загружается. Если это произойдет, вам нужен аварийный диск. Образ восстановления по умолчанию для Linux находится на установочном диске. При загрузке с установочного диска вы увидите пункт меню «Troubleshooting». Выберите этот пункт, чтобы получить доступ к параметрам, необходимым для ремонта машины.

Выбрав «Troubleshooting», появится выбор из 4-х опций.
- Install CentOS 7 in Basic Graphics Mode: эта опция переустанавливает систему. Не используйте её, если не хотите устранить неполадки в ситуации, когда обычная установка не работает и вам необходим базовый графический режим. Как правило, вам никогда не нужно использовать эту опцию для устранения неисправностей при установке.
- Rescue a CentOS System: это самая гибкая система спасения. Это должен быть первый вариант выбора при использовании аварийного диска.
- Run a Memory Test: если вы столкнулись с ошибками памяти, это позволяет пометить плохие микросхемы памяти, чтобы ваша машина могла нормально загружаться.
- Boot from local drive: здесь я думаю всё понятно.
ВНИМАНИЕ!
После запуска «Rescue a CentOS System» обычно требуется включить полный доступ к установке на диске. Обычно аварийный диск обнаруживает вашу установку и монтирует ее в каталог /mnt/sysimage. Чтобы исправить доступ к файлам конфигурации и их расположениям по умолчанию, поскольку они должны быть доступны на диске, используйте команду chroot /mnt/sysimage, чтобы сделать содержимое этого каталога реальной рабочей средой. Если вы не используете команду chroot, многие утилиты не будут работать, потому что, если они записывают в файл конфигурации, это будет версия файла конфигурации, существующего на диске восстановления (и по этой причине только для чтения). Использование команды chroot гарантирует, что все пути к файлам конфигурации верны.
Пример использования «Rescue a CentOS System»
1. Перезагружаем сервер с установочным диском Centos 7. Загружаемся и выбираем «Troubleshooting«.
2. В меню траблшутинга выбираем «Rescue a CentOS System» и загружаемся.
3. Система восстановления теперь предлагает вам найти установленную систему Linux и смонтировать ее в /mnt/sysimage. Выберите номер 1, чтобы продолжить: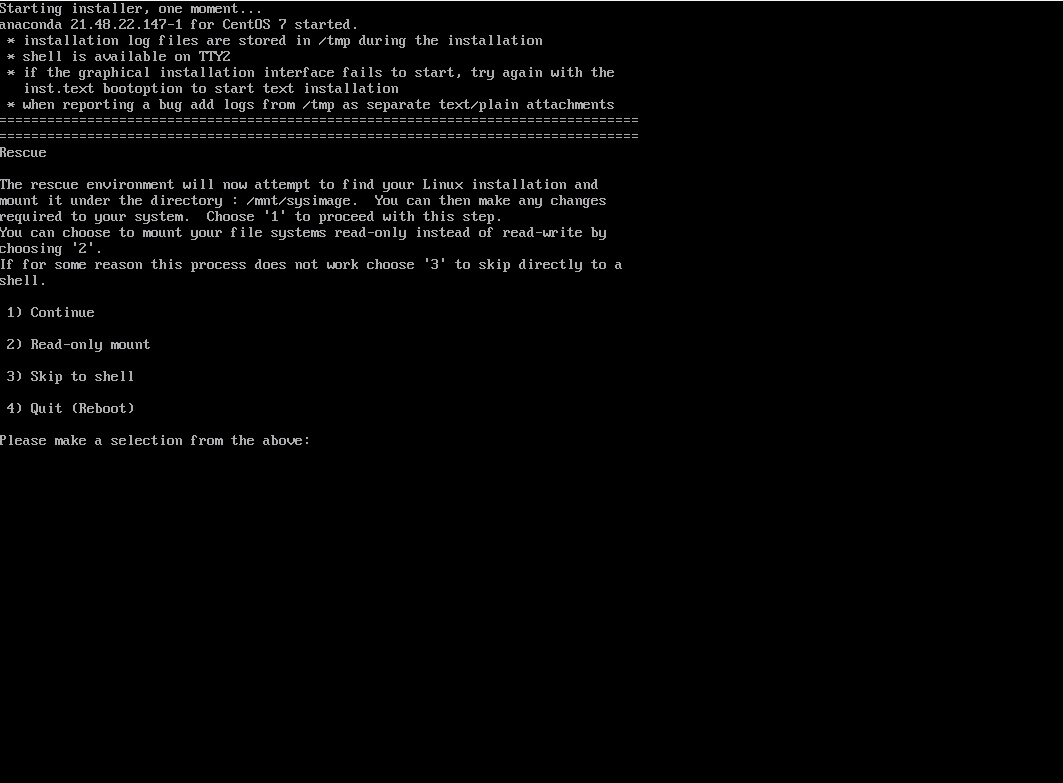
4. Если была найдена правильная установка CentOS, вам будет предложено, чтобы система была смонтирована в /mnt/sysimage. В этот момент вы можете дважды нажать Enter, чтобы получить доступ к оболочке восстановления.
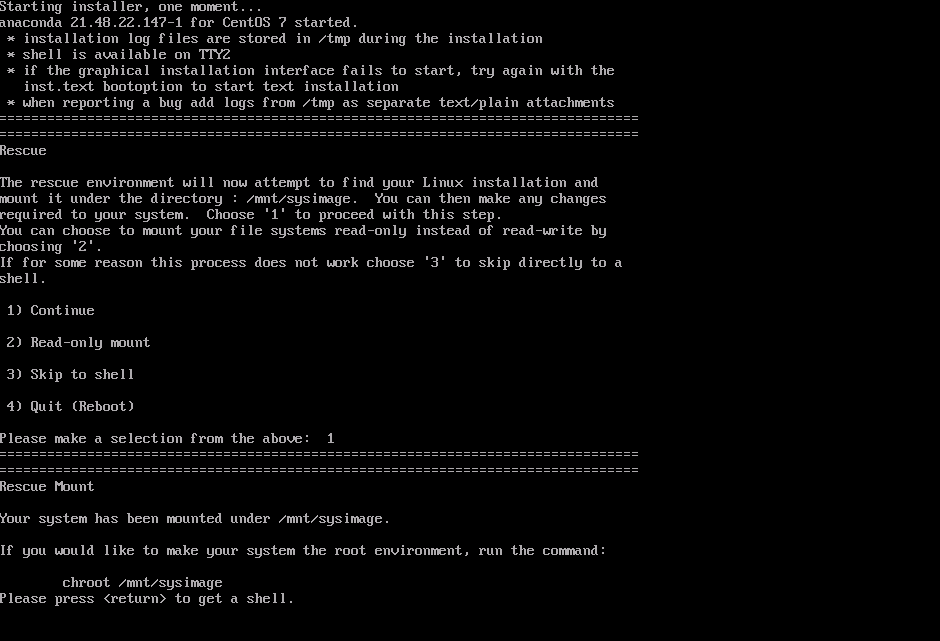
5. Ваша система Linux на данный момент доступна через каталог /mnt/sysimage. Введите chroot /mnt/sysimage. На этом этапе у вас есть доступ к корневой файловой системе, и вы можете получить доступ ко всем инструментам, которые необходимы для восстановления доступа к вашей системе.
Переустановка GRUB с помощью аварийного диска
Одна из распространенных причин, по которой вам нужно запустить аварийный диск, заключается в том, что загрузчик GRUB 2 не работает. Если это произойдет, вам может понадобиться установить его снова. После того, как вы восстановили доступ к своему серверу с помощью аварийного диска, переустановить GRUB 2 несложно, и он состоит из двух этапов:
- Убедитесь, что вы поместили содержимое каталога /mnt/sysimage в текущую рабочую среду.
- Используйте команду grub2-install, а затем имя устройства, на котором вы хотите переустановить GRUB 2. Если это виртуальная машина KVM используйте команду grub2-install /dev/vda и на физическом сервере или виртуальная машина VMware, HyperV или Virtual Box, это grub2-install /dev/sda.
Повторное создание Initramfs с помощью аварийного диска
Иногда initramfs также может быть поврежден. Если это произойдет, вы не сможете загрузить свой сервер в нормальном рабочем режиме. Чтобы восстановить образ initramfs после загрузки в среду восстановления, вы можете использовать команду dracut. Если используется без аргументов, эта команда создает новый initramfs для загруженного в данный момент ядра.
Кроме того, вы можете использовать команду dracut с несколькими опциями для создания initramfs для конкретных сред ядра. Существует также файл конфигурации с именем /etc/dracut.conf, который можно использовать для включения определенных параметров при повторном создании initramfs.
Конфигурация dracut рассредоточена по разным местам:
- /usr/lib/dracut/dracut.conf.d/*.conf содержит системные файлы конфигурации по умолчанию.
- /etc/dracut.conf.d содержит пользовательские файлы конфигурации dracut.
- /etc/dracut.conf используется в качестве основного файла конфигурации.
Вот так выглядит по умолчанию файл /etc/dracut.conf:
[root@server1 ~]# cat /etc/dracut.conf
# PUT YOUR CONFIG HERE OR IN separate files named *.conf
# in /etc/dracut.conf.d
# SEE man dracut.conf(5)
# Sample dracut config file
#logfile=/var/log/dracut.log
#fileloglvl=6
# Exact list of dracut modules to use. Modules not listed here are not going
# to be included. If you only want to add some optional modules use
# add_dracutmodules option instead.
#dracutmodules+=""
# dracut modules to omit
#omit_dracutmodules+=""
# dracut modules to add to the default
#add_dracutmodules+=""
# additional kernel modules to the default
#add_drivers+=""
# list of kernel filesystem modules to be included in the generic
initramfs
#filesystems+=""
# build initrd only to boot current hardware
#hostonly="yes"
#
# install local /etc/mdadm.conf
#mdadmconf="no"
# install local /etc/lvm/lvm.conf
#lvmconf="no"
# A list of fsck tools to install. If it is not specified, module's
hardcoded
# default is used, currently: "umount mount /sbin/fsck* xfs_db xfs_
check
# xfs_repair e2fsck jfs_fsck reiserfsck btrfsck". The installation is
# opportunistic, so non-existing tools are just ignored.
#fscks=""
# inhibit installation of any fsck tools
#nofscks="yes"
# mount / and /usr read-only by default
#ro_mnt="no"
# set the directory for temporary files
# default: /var/tmp
#tmpdir=/tmpИсправление общих проблем
В пределах статьи, подобной этой, невозможно рассмотреть все возможные проблемы, с которыми можно столкнуться при работе с Linux. Однако есть некоторые проблемы, которые встречаются чаще, чем другие. Ниже некоторые наиболее распространенные проблемы.
Переустановка GRUB 2
Код загрузчика не исчезает просто так, но иногда может случиться, что загрузочный код GRUB 2 будет поврежден. В этом случае вам лучше знать, как переустановить GRUB 2. Точный подход зависит от того, находится ли ваш сервер в загрузочном состоянии. Если это так, то довольно просто переустановить GRUB 2. Просто введите grub2-installи имя устройства, на которое вы хотите его установить. У команды есть много различных опций для точной настройки того, что именно будет установлено, но вам, вероятно, они не понадобятся, потому что по умолчанию команда устанавливает все необходимое, чтобы ваша система снова загрузилась.
Становится немного сложнее, если ваш сервер не загружается.
Если это произойдет, вам сначала нужно запустить систему восстановления и восстановить доступ к вашему серверу из системы восстановления. После монтирования файловых систем вашего сервера в /mnt/sysimage и использования chroot /mnt/sysimage, чтобы сделать смонтированный образ системы вашим корневым образом: Просто запустите grub2-install, чтобы установить GRUB 2 на желаемое установочное устройство. Но если вы находитесь на виртуальной машине KVM, запустите grub2-install /dev/vda, а если вы находитесь на физическом диске, запустите grub2-install /dev/sda.
Исправление Initramfs
В редких случаях может случиться так, что initramfs будет поврежден. Если вы тщательно проанализируете процедуру загрузки, вы узнаете, что у вас есть проблема с initramfs, потому что вы никогда не увидите, как корневая файловая система монтируется в корневой каталог, и при этом вы не увидите запуска каких-либо системных модулей. Если вы подозреваете, что у вас есть проблема с initramfs, ее легко создать заново. Чтобы воссоздать его, используя все настройки по умолчанию (что в большинстве случаев нормально), вы можете просто запустить команду dracut —force. (Без —force команда откажется перезаписать ваши существующие initramfs.)
При запуске команды dracut вы можете использовать файл конфигурации /etc/dracut.conf, чтобы указать, что именно записывается в initramfs. В этом файле конфигурации вы можете увидеть такие параметры, как lvmconf = «no», которые можно использовать для включения или выключения определенных функций. Используйте эти параметры, чтобы убедиться, что у вас есть все необходимые функции в initramfs.
Восстановление после проблем с файловой системой
Если вы неправильно настроили монтирование файловой системы, процедура загрузки может просто закончиться сообщением «Give root password for maintenance.». Это сообщение, в частности, генерируется командой fsck, которая пытается проверить целостность файла системы в /etc/fstab при загрузке. Если fsck терпит неудачу, требуется ручное вмешательство, которое может привести к этому сообщению во время загрузки. Убедитесь, что вы знаете, что делать, когда это происходит с вами!
Если упомянуто устройство, которого нет, или если в UUID, который используется для монтирования устройства, есть ошибка, например, systemd сначала ожидает, вернется ли устройство само по себе. Если этого не происходит, выдается сообщение «Give root password for maintenance.». Если это произойдет, вы должны сначала ввести пароль root. Затем вы можете ввести journalctl -xb, как предлагается, чтобы увидеть, записываются ли в журнал соответствующие сообщения, содержащие информацию о том, что не так. Если проблема ориентирована на файловую систему, введите mount -o remount, rw /, чтобы убедиться, что корневая файловая система смонтирована только для чтения, проанализировать, что не так в файле /etc/fstab, и исправить это.
Если вы видите подобный текст, то у вас есть проблема с /etc/fstab: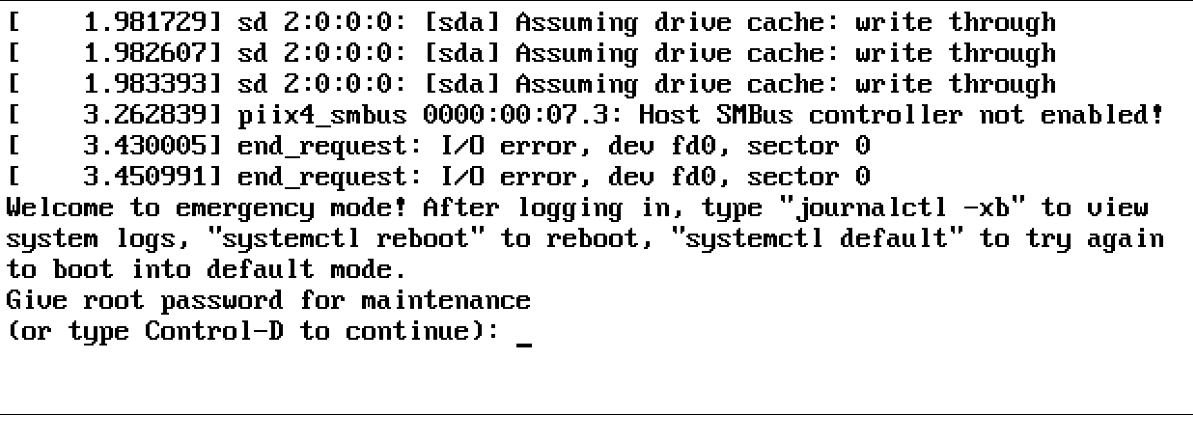
В этой статье вы узнали, как устранить неполадки при загрузке CentOS. Так же вы узнали, что происходит при загрузке сервера и в какие конкретные моменты вы можете вмешиваться, чтобы исправить неисправности. Вы также узнали, что делать в некоторых конкретных случаях.
![]() Это заметка из разряда «Для Linux-новичков». При очередном развёртывании CentOS Linux 7.2 на физический сервер столкнулся с проблемой невозможности запуска программы установки ОС, получая ошибку:
Это заметка из разряда «Для Linux-новичков». При очередном развёртывании CentOS Linux 7.2 на физический сервер столкнулся с проблемой невозможности запуска программы установки ОС, получая ошибку:
Failed to scan disk [имя устройства]
For some reason we were unable to locate a disklabel on a disk that the kernel is reporting patitions on…
 После изучения проблемы выяснилось, что физические диски HDD, которые были установлены в сервер, и на которые предполагалось выполнить установку CentOS Linux, ранее использовались в другом сервере, и на них была установлена OC Microsoft Windows Server. При этом разделы, созданные на дисках ОС Windows с этих самых дисков не были удалены и, по всей видимости, какой-то из разделов диска «сильно смущал» программу установки CentOS.
После изучения проблемы выяснилось, что физические диски HDD, которые были установлены в сервер, и на которые предполагалось выполнить установку CentOS Linux, ранее использовались в другом сервере, и на них была установлена OC Microsoft Windows Server. При этом разделы, созданные на дисках ОС Windows с этих самых дисков не были удалены и, по всей видимости, какой-то из разделов диска «сильно смущал» программу установки CentOS.
Первое, что может прийти в голову неискушённому Linux-администратору, это найти другой сервер с уже работающей системой, куда можно подключить такие диски и удалить оттуда все старые разделы для возможности дальнейшего беспроблемного использования в программе установки CentOS. Однако, я предполагаю, что может возникнуть ситуация, когда такой возможности не будет. Поэтому в данной заметке я опишу то, как быстро исправить данную проблему при помощи самой же программы установки CentOS и без всяких излишних физических манипуляций с дисками.
Итак, получив данное сообщение об ошибке, нам нужно удалить все старые разделы имеющиеся на нашем диске. Для этого, как предложено в сообщении об ошибке нажмём сочетание клавиш Ctrl-Alt-F1, откроется специальная консоль инсталлятора anaconda

Здесь с помощью комбинации клавиш Alt-Tab мы сможем переместиться в режим командной строки (пункт 2:shell)

Выполним команду fdisk -l, чтобы получить информацию о всех доступных загруженному экземпляру CentOS дисковых устройствах и их разметке:

Как видим, утилите fdisk не очень нравится таблица разделов на нашем диске, а некоторые разделы диска она не может даже распознать. Однако в нашей ситуации все эти старые разделы нам не нужны, более того, они нам мешают, и поэтому воспользуемся утилитой parted, чтобы удалить с диска все эти разделы.
# parted /dev/cciss/c0d0
где /dev/cciss/d0d0 это имя проблемного диска со старыми разделами. В командном интерфейсе утилиты parted нам достаточно будет ввести пару команд, чтобы пересоздать на диске таблицу разделов, удалив тем самым всю информацию о старых разделах…
(parted) mklabel msdos
(parted) quit

После этого можно будет перезагрузить наш сервер и вернуться к процессу установки ОС, где теперь проблемы с определением диска уже быть не должно.
Это руководство посвящено ручному устранению проблем с конфигурацией файловой системы или повреждениями, которые останавливают процесс загрузки.
Диагностика и устранение проблем файловой системы
Ошибки в /etc/fstab и поврежденные файловые системы могут помешать загрузке системы.
В большинстве случаев systemd переходит в оболочку аварийного восстановления, для которой требуется пароль root.
В следующей таблице перечислены некоторые распространенные ошибки и их результаты.
Основные проблемы с файловой системой
| Проблема | Результат |
|---|---|
| Поврежденная файловая система | systemd пытается восстановить файловую систему. Если проблема слишком серьезна для автоматического исправления, система переводит пользователя в аварийную оболочку. |
| Несуществующее устройство или UUID, указанные в /etc/fstab |
systemd ждет установленное количество времени, ожидая, когда устройство станет доступным. Если устройство не становится доступным, система переводит пользователя в аварийную оболочку по истечении времени ожидания. |
| Несуществующая точка монтирования в /etc/fstab | Система перенаправляет пользователя в аварийную оболочку. |
|
Неправильный параметр монтирования в /etc/fstab |
Система перенаправляет пользователя в аварийную оболочку. |
Во всех случаях администраторы могут также использовать файл /etc/fstab для диагностики и устранения проблемы, поскольку файловые системы не монтируются до отображения аварийной оболочки.
Примечание: при использовании аварийной оболочки для решения проблем с файловой системой не забудьте запустить systemctl daemon-reload после редактирования /etc/fstab.
Без этой перезагрузки systemd может продолжать использовать старую версию.
Параметр nofail в записи в файле /etc/fstab позволяет системе загружаться, даже если монтирование этой файловой системы не удалось.
Не используйте эту опцию при нормальных обстоятельствах.
При отсутствии сбоя приложение может запуститься с отсутствующим хранилищем, что может иметь серьезные последствия.
Earlier with CentOS/RHEL 5 and 6 we used to use tune2fs to force file system check on boot and repair file system. There we used to change maximum mount count using tune2fs -c 4 /dev/disk-name command and then creating an empty file forcefsck under the file system to be checked. Now starting with CentOS/RHEL 7 those methods are not supported. Hence creating /forcefsck will not force file system check on boot with RHEL/CentOS 7/8 Linux.
Lab Environment
I have created a Virtual Machine using Oracle VirtualBox installed on Linux server. I have installed CentOS 8 on this virtual machine but the same steps will work on RHEL 7/8 or CentOS 7.
In this article we will cover below topics:
- Creating the files /forcefsck and /fsckoptions doesn’t work on CentOS/RHEL 7/8 Linux.
- How to perform filesystem check on next reboot at startup stage and repair file system, using systemd-fsck?
- How to perform non-interactive force fsck during reboot stage to repair file system, as by default the fsck will await user input for every error?
Step 1: Update GRUB2 to force file system check on boot
With systemd-219-19.el7 the kernel command line option of fsck.repair= and fsck.mode= was added in RHEL 7.2.
ALSO READ: Step-by-Step Tutorial: Install and configure vnc server RHEL/CentOS 7
So we can use fsck.mode=force to perform and force file system check on boot (next reboot). This can be combined with fsck.repair=yes to answer yes to fsck command out (if any errors found). So with this fsck will perform necessary correction in the file system at boot stage without any manual intervention.
Next append fsck.mode=force and fsck.repair=yes under GRUB_CMDLINE_LINUX in /etc/sysconfig/grub file as shown below
[root@centos-8 ~]# cat /etc/sysconfig/grub GRUB_TIMEOUT=5 GRUB_DISTRIBUTOR="$(sed 's, release .*$,,g' /etc/system-release)" GRUB_DEFAULT=saved GRUB_DISABLE_SUBMENU=true GRUB_TERMINAL_OUTPUT="console" GRUB_CMDLINE_LINUX="crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet fsck.mode=force fsck.repair=yes" GRUB_DISABLE_RECOVERY="true" GRUB_ENABLE_BLSCFG=true
From man page of systemd-fsck
KERNEL COMMAND LINE
systemd-fsck understands one kernel command line parameter:
fsck.mode=
One of "auto", "force", "skip". Controls the mode of operation. The default is "auto", and ensures that
file system checks are done when the file system checker deems them necessary. "force" unconditionally
results in full file system checks. "skip" skips any file system checks.
fsck.repair=
One of "preen", "yes", "no". Controls the mode of operation. The default is " preen", and will
automatically repair problems that can be safely fixed. "yes " will answer yes to all questions by fsck
and "no" will answer no to all questions.
Step 2: Rebuild GRUB2 in CentOS/RHEL 7/8
HINT:
Below command is for legacy BIOS, on UEFI-based machines: ~]# grub2-mkconfig -o /boot/efi/EFI/redhat/grub.cfg
[root@centos-8 ~]# grub2-mkconfig -o /boot/grub2/grub.cfg
Generating grub configuration file ...
done
We are all done here to force file system check on boot (next reboot) using systemd-fsck. Next reboot your CentOS/RHEL 7/8 Linux host to verify the steps
ALSO READ: How to clear all timeouts in JavaScript? [SOLVED]
Step 3: Verify the configuration
Post reboot connect to your Linux host using putty or any other CLI tool. You need to check the boot logs which you can either check using dmesg or journalctl -b or journalctl --boot
[root@centos-8 ~]# journalctl --boot Jan 17 03:11:55 centos-8.example.com dracut-cmdline[195]: Using kernel command line parameters: BOOT_IMAGE=(hd0,msdos1)/vmlinuz-4.18.0-80.11.2.el8_0.x86_64 root=/dev/mapper/rhel-root ro crashkernel=auto resume=/dev/mapper/rhel-swap rd.lvm.lv=rhel/root rd.lvm.lv=rhel/swap rhgb quiet fsck.mode=force fsck.repair=yes <Output trimmed> Jan 17 03:11:57 centos-8.example.com systemd[1]: Starting File System Check on /dev/mapper/rhel-root... Jan 17 03:11:57 centos-8.example.com systemd[1]: Reached target Remote File Systems (Pre). Jan 17 03:11:57 centos-8.example.com systemd[1]: Reached target Remote File Systems. Jan 17 03:11:57 centos-8.example.com systemd-fsck[485]: e2fsck 1.44.3 (10-July-2018) Jan 17 03:11:57 centos-8.example.com systemd-fsck[485]: Pass 1: Checking inodes, blocks, and sizes Jan 17 03:11:57 centos-8.example.com systemd-fsck[485]: Pass 2: Checking directory structure Jan 17 03:11:58 centos-8.example.com kernel: random: crng init done Jan 17 03:11:58 centos-8.example.com kernel: random: 7 urandom warning(s) missed due to ratelimiting Jan 17 03:11:58 centos-8.example.com systemd-fsck[485]: Pass 3: Checking directory connectivity Jan 17 03:11:58 centos-8.example.com systemd-fsck[485]: Pass 4: Checking reference counts Jan 17 03:11:58 centos-8.example.com systemd-fsck[485]: Pass 5: Checking group summary information Jan 17 03:11:58 centos-8.example.com systemd-fsck[485]: /dev/mapper/rhel-root: 199444/889440 files (0.1% non-contiguous), 1190592/3555328 blocks Jan 17 03:11:58 centos-8.example.com systemd[1]: Mounting /sysroot... <Output trimmed>
Here as you see systemd-fsck was called at called to force file system check at boot stage. Here since there were no errors the fsck check went on smoothly.
ALSO READ: How to check Transparent HugePage usage per process in Linux with examples
Lastly I hope the steps from the article to force file system check on boot (next reboot) in RHEL/CentOS 7/8 Linux was helpful. So, let me know your suggestions and feedback using the comment section.
References:
How to force fsck during the boot in RHEL7?
Related Searches: linux file system check on boot. disk check runs at every startup. Creating the files /forcefsck and /fsckoptions doesn’t work on CentOS/RHEL 7/8 Linux. How to force filesystem check during boot time, using systemd? How to answer yes, to all questions by fsck automatically during boot time? shutdown force fsck in CentOS/RHEL 7/8. How to repair file system on next reboot in Linux.
Didn’t find what you were looking for? Perform a quick search across GoLinuxCloud
Introduction
This troubleshooting guide describes common problems and solutions for instances that fail to boot correctly. This guide applies to:
-
AlmaLinux
-
CentOS 7 and 8
-
Rocky Linux
-
VzLinux
High-level Overview
The boot sequence of events:
-
Power + post.
-
Firmware device search.
-
Firmware reads bootloader.
-
Boot loader loads config (grub2).
-
Boot loader loads kernel and initramfs.
-
Boot loader passes control to the kernel.
-
Kernel initializes hardware + executes
/sbin/initas pid 1. -
Systemd executes all initrd targets (mounts filesystem on
/sysroot). -
Kernel root FS switched from initramfs root (
/sysroot) to system rootfs (/) and systemd re-executes as system version. -
Systemd looks for default target and starts/stops units as configured while automatically solving dependencies and login page appears.
For more information on the boot process, refer to the official OS documentation for your system.
Systemd Targets
Targets are dependency checks. They have a «before» and «after» configuration for exactly what services are required to meet that target. For example: arp.ethernet.service, firewalld.service, and so forth need to be started and working before network.target can be reached. If it is not reached, services such as httpd, nfs, and ldap cannot be started. 4 targets can be set.
-
graphical.target (GUI interface)
-
multi-user.target (multi user mode, text based login)
-
rescue.target (sulogin prompt, basic system initialization)
-
emergency.target (sulogin prompt, initramfs pivot complete and system root mounted on / as read only)
To view the current default boot target, use the following:
systemctl get-default
You can change this at run time by isolating the target. This will start/stop all services associated with the new target, so use caution (see systemctl isolate new.target).
Single User Mode
There are times when you will need to boot into single user mode to fix an issue with the operating system. This example demonstrates how to use the rescue.target which is «single user mode».
-
Interrupt the grub2 menu by pressing «e» to edit when prompted with the grub menu.
-
Find the line that specifies the kernel version (vmlinuz) and append the following to it:
systemd.unit=rescue.target -
Press «Ctrl+x» to start.
-
You will then be prompted with the root password to continue, once you exit the rescue shell, the boot process will continue to load your default target.
Recover the Root Password
If you need to recover credentials, use this method to gaining access to the instance.
-
Reboot the system.
-
Interrupt the grub2 menu by pressing «e» to edit when prompted with the grub menu.
-
Move the cursor to the end of the line that specifies the kernel (vmlinuz). You may want to remove all other consoles other than TTY0, however, this step may not be necessary for your environment.
-
Append
rd.break(no quotes), which will break the boot process just before the control is handed from initramfs to the actual system. -
Ctrl+x to boot.
A root shell is presented with the root filesystem mounted in read-only mode on /sysroot.
Remount it with write privileges as /sysroot.
# mount -oremount,rw /sysroot
Switch to a chroot jail.
# chroot /sysroot
Change the password for the desired user.
# passwd example-username
If you use SELinux, you should consider re-labeling all files before continuing the boot process. Skip this part if you don’t use SELinux.
# touch /.autorelabel
Use the exit to exit the chroot jail. Use exit a second time, and the system will cleanly boot from the point we interrupted it.
Review Boot Logs
It can be useful to view logs of previous failed boot attempts. The journald logs are usually stored in memory and released on boot. If you make the logs persistent, they can be examined with the journalctl tool. Follow these steps if you need to set up persistent boot logging.
As root, create the log file.
# mkdir -p 2775 /var/log/journal && chown :systemd-journal /var/log/journal
# systemctl restart systemd-journald
To inspect the logs of a previous boot, use the -b option with journalctl. Without any arguments, -b will filter output only to messages about the last boot. A negative number for this argument will filter on previous boots. For example:
# journalctl -b-1 -p err
This will show you the error logs from the boot that occurred before the most recent. You should change the numerical value to reflect the boot you need to view.
Repair Filesystem Errors
One of the most common boot time errors is a misconfigured /etc/fstab file. You CANNOT use the rescue.target to fix an /etc/fstab error. Most of these issues will require us to use the emergency.target since «rescue» requires a more functional system.
The following are examples of problems that require the emergency.target:
-
Corrupt file system.
-
Non-existent UUID in
/etc/fstab. -
Non-existent mount point in
/etc/fstab. -
Incorrect mount option in
/etc/fstab.
Important: After editing the /etc/fstab file in emergency mode, you must run the following for safety measures:
# systemctl daemon-reload
Here is a walkthrough example of booting into emergency mode to remove a false entry in /etc/fstab.
-
Interrupt the grub2 menu by pressing «e» to edit when prompted with the grub menu.
-
Find the line that specifies the kernel version (vmlinuz) and append the following to it:
systemd.unit=emergency.target -
Press «Ctrl+x» to boot.
-
You will be prompted with the root password to continue.
-
Remount
/so that we can make changes to thefstabfile:# mount -oremount,rw / -
We can use the
mountcommand to see which entry is causing the error:# mount -a -
Remove the offending entry from the
fstabfile. -
Use
mount -aagain to make sure the error has been resolved. -
Use
systemctl daemon-reloadto reload all unit files, and recreate the entire dependency tree.
Once you exit the emergency shell, the system will finish booting from the emergency target.
Bootloader Issues with Grub 2
The /boot/grub2/grub.cfg file is the main configuration file. DO NOT ever edit this file manually. Instead, use grub2-mkconfig to generate the new grub2 config using a set of different configuration files and the list of the installed kernels. The grub2-mkconfig command will look at /etc/default/grub for options such as the default menu timeout and kernel command line to use, then use a set of scripts in /etc/grub.d/ to generate the resulting configuration file.
Here is an textual diagram of this relationship.
/boot/grub2/grub.cfg
|
|__________________
| |
/etc/default/grub /etc/grub.d/*
Important: To edit the main grub.cfg file, you will need to make the desired changes to /etc/default/grub and to files in /etc/grub.d/ and then create a new grub.cfg by running:
# grub2-mkconfig > /boot/grub2/grub.cfg
It is important to understand the syntax of the /boot/grub2/grub.cfg file before troubleshooting.
-
First, bootable entries are encoded inside ‘menuentry’ blocks. In these blocks,
linux16andinitrd16lines point to the kernel to be loaded from disk (along with the kernel command line) and the initramfs to be loaded. During interactive editing at boot, tab is used to find these lines. -
The «set root» lines inside those blocks do not point to the root file system, but instead point to the file system from which grub2 should load the kernel and initramfs files. The syntax is
harddrive.partitionwherehd0is the first hard drive in the system andhd1is the second. The partitions are indicated asmsdos1for the first MBR partition orgpt1for the first GPT partition.
Example from /boot/grub2/grub.cfg:
### BEGIN /etc/grub.d/10_linux ###
menuentry 'CentOS Linux (3.10.0-514.26.2.el7.x86_64) 7 (Core)' --class centos --class gnu-linux --class gnu --class os --unrestricted $menuentry_id_option 'gnulinux-3.10.0-514.el7.x86_64-advanced-a2531d12-46f8-4a0f-8a5c-b48d6ef71275' {
load_video
set gfxpayload=keep
insmod gzio
insmod part_msdos
insmod ext2
set root='hd0,msdos1'
if [ x$feature_platform_search_hint = xy ]; then
search --no-floppy --fs-uuid --set=root --hint='hd0,msdos1' 123455ae-46f8-4a0f-8a5c-b48d6ef71275
else
search --no-floppy --fs-uuid --set=root 123455ae-46f8-4a0f-8a5c-b48d6ef71275
fi
If you need to re-install the bootloader on a device, use the following command.
# grub2-install <device>
Fix a Broken Grub
Follow these steps when troubleshooting a system that does not boot after reaching the grub2 menu.
- You should start by editing the grub menu and searching for syntax errors. If you find one, correct it and get into the system to make persistent changes to fix the problem.
If you cannot find any errors, refer to the above section to boot into the emergency target. You will need to remount root (/) again.
-
View the current grub2 configuration with the following command:
# grub2-mkconfig -
If you do not see any errors, its likely that someone edited the
/boot/grub2/grub.cfgfile. Do not modify this file. Rebuild the config with the following command:# grub2-mkconfig > /boot/grub2/grub.cfg
Once you have rebuilt the grub config, the system should reboot properly.
The operating systems break and crash. We as sysadmin are always looking for the root cause analysis so as to avoid such failures in the future. In this post, we will look at the basic troubleshooting of booting issues. This is a high-level overview and things can get pretty deep depending on the booting issue.
Inspecting Logs
Looking at the logs of previously failed boots can be useful. If the system journals are persistent across reboots, you can use the journalctl tool to inspect those logs.
Remember that by default, the system journals are kept in the /run/log/journal directory, which means the journals are cleared when the system reboots. To store journals in the /var/log/journal directory, which persists across reboots, set the Storage parameter to persistent in /etc/systemd/journald.conf.
[ro[email protected] ~]# vim /etc/systemd/journald.conf
..
[Journal]
Storage=persistent
...
[[email protected] ~]# systemctl restart systemd-journald.service
To inspect the logs of a previous boot, use the -b option of journalctl. Without any arguments, the -b option only displays messages since the last boot. With a negative number as an argument, it displays the logs of previous boots.
[[email protected] ~]# journalctl -b -1 -p err
This command shows all messages rated as an error or worse from the previous boot.
Repairing systemd boot issue
To troubleshoot service startup issues at boot time, Red Hat Enterprise Linux 8 makes the following tools available.
Enabling the Early Debug Shell
By enabling the debug-shell service with systemctl enable debug-shell.service, the system spawns a root shell on TTY9 (Ctrl+Alt+F9) early during the boot sequence. This shell is automatically logged in as root, so that administrators can debug the system while the operating system is still booting.
WARNING Do not forget to disable the debug-shell.service service when you are done debugging, because it leaves an unauthenticated root shell open to anyone with local console access.
Using the Emergency and Rescue Targets
By appending either systemd.unit=rescue.target or systemd.unit=emergency.target to the kernel command line from the boot loader, the system spawns into a rescue or emergency shell instead of starting normally. Both of these shells require the root password.
The emergency target keeps the root file system mounted read-only, while the rescue target waits for sysinit.target to complete, so that more of the system is initialized, such as the logging service or the file systems. The root user at this point can not make changes to /etc/fstab until the drive is remounted in a read write state mount -o remount,rw /
Administrators can use these shells to fix any issues that prevent the system from booting normally; for example, a dependency loop between services, or an incorrect entry in /etc/fstab. Exiting from these shells continues with the regular boot process.
Identifying Stuck Jobs
During startup, systemd spawns a number of jobs. If some of these jobs cannot complete, they block other jobs from running. To inspect the current job list, administrators can use the systemctl list-jobs command. Any jobs listed as running must complete before the jobs listed as waiting can continue.
В этой статье вы узнаете, что вы можете делать, когда при загрузке сервера возникают общие проблемы. В статье описываются общие подходы, которые помогают исправить некоторые из наиболее распространенных проблем, которые могут возникнуть при загрузке Linux.
Понимание процедуры загрузки в Linux RHEL7/CentOS
Чтобы исправить проблемы с загрузкой, важно хорошо понимать процедуру загрузки. Если проблемы возникают во время загрузки, вы должны понимать, на какой стадии процедуры загрузки возникает проблема, чтобы можно было выбрать соответствующий инструмент для устранения проблемы.
Следующие шаги суммируют, как процедура загрузки происходит в Linux.
1. Выполнение POST: машина включена. Из системного ПО, которым может быть UEFI или классический BIOS, выполняется самотестирование при включении питания (POST) и аппаратное обеспечение, необходимое для запуска инициализации системы.
2. Выбор загрузочного устройства: В загрузочной прошивке UEFI или в основной загрузочной записи находится загрузочное устройство.
3. Загрузка загрузчика: с загрузочного устройства находится загрузчик. На Red Hat/CentOS это обычно GRUB 2.
4. Загрузка ядра: Загрузчик может представить пользователю меню загрузки или может быть настроен на автоматический запуск Linux по умолчанию. Для загрузки Linux ядро загружается вместе с initramfs. Initramfs содержит модули ядра для всего оборудования, которое требуется для загрузки, а также начальные сценарии, необходимые для перехода к следующему этапу загрузки. На RHEL 7/CentOS initramfs содержит полную операционную систему (которая может использоваться для устранения неполадок).
5. Запуск /sbin/init: Как только ядро загружено в память, загружается первый из всех процессов, но все еще из initramfs. Это процесс /sbin/init, который связан с systemd. Демон udev также загружается для дальнейшей инициализации оборудования. Все это все еще происходит из образа initramfs.
6. Обработка initrd.target: процесс systemd выполняет все юниты из initrd.target, который подготавливает минимальную операционную среду, в которой корневая файловая система на диске монтируется в каталог /sysroot. На данный момент загружено достаточно, чтобы перейти к установке системы, которая была записана на жесткий диск.
7. Переключение на корневую файловую систему: система переключается на корневую файловую систему, которая находится на диске, и в этот момент может также загрузить процесс systemd с диска.
8. Запуск цели по умолчанию (default target): Systemd ищет цель по умолчанию для выполнения и запускает все свои юниты. В этом процессе отображается экран входа в систему, и пользователь может проходить аутентификацию. Обратите внимание, что приглашение к входу в систему может быть запрошено до успешной загрузки всех файлов модуля systemd. Таким образом, просмотр приглашения на вход в систему не обязательно означает, что сервер еще полностью функционирует.
На каждом из перечисленных этапов могут возникнуть проблемы из-за неправильной настройки или других проблем. Таблица суммирует, где настроена определенная фаза и что вы можете сделать, чтобы устранить неполадки, если что-то пойдет не так.
| Фаза загрузки | Где настроено | Как попытаться починить |
| POST | Железо (F2, Esc, F10, или другая кнопка) | Замена железа |
| Выбор загрузочного устройства | BIOS/UEFI конфигурация или загрузочное устройство | Замена железа или использовать восстановление системы |
| Загрузка загрузчика (GRUB 2) | grub2-install и редактирует в /etc/defaults/grub | Приглашение GRUB для загрузки и изменения в /etc/defaults/grub, после чего следует выполнить grub2-mkconfig. |
| Загрузка ядра | Редактирует конфигурацию GRUB и /etc/dracut.conf | Приглашение GRUB для загрузки и изменения в /etc/defaults/grub, после чего следует выполнить grub2-mkconfig. |
| Запуск /sbin/init | Компиляция в initramfs | init = kernel аргумент загрузки, rd.break аргумент загрузки ядра |
| Обработка initrd.target | Компиляция в initramfs | Обычно ничего не требуется |
| Переключение на корневую файловую систему | /etc/fstab | /etc/fstab |
| Запуск цели по умолчанию | /etc/systemd/system/default.target | Запустить rescue.target как аргумент при загрузке ядра |
Передача аргементов в GRUB 2 ядру во время загрузки
Если сервер не загружается нормально, приглашение загрузки GRUB предлагает удобный способ остановить процедуру загрузки и передать конкретные параметры ядру во время загрузки. В этой части вы узнаете, как получить доступ к приглашению к загрузке и как передать конкретные аргументы загрузки ядру во время загрузки.
Когда сервер загружается, вы кратко видите меню GRUB 2. Смотри быстро, потому что это будет длиться всего несколько секунд. В этом загрузочном меню вы можете ввести e, чтобы войти в режим, в котором вы можете редактировать команды, или c, чтобы ввести полную командную строку GRUB.
После передачи e в загрузочное меню GRUB вы увидите интерфейс, показанный на скриншоте ниже. В этом интерфейсе прокрутите вниз, чтобы найти раздел, начинающийся с linux16 /vmlinuz, за которым следует множество аргументов. Это строка, которая сообщает GRUB, как запустить ядро, и по умолчанию это выглядит так:
После ввода параметров загрузки, которые вы хотите использовать, нажмите Ctrl + X, чтобы запустить ядро с этими параметрами. Обратите внимание, что эти параметры используются только один раз и не являются постоянными. Чтобы сделать их постоянными, вы должны изменить содержимое файла конфигурации /etc/default/grub и использовать grub2-mkconfig -o /boot/grub2/grub.cfg, чтобы применить изменение.
Когда у вас возникли проблемы, у вас есть несколько вариантов (целей), которые вы можете ввести в приглашении загрузки GRUB:
■ rd.break Это останавливает процедуру загрузки, пока она еще находится в стадии initramfs.
Эта опция полезна, если у вас нет пароля root.
■ init=/bin/sh или init=/bin/bash Указывает, что оболочка должна быть запущена сразу после загрузки ядра и initrd. Это полезный вариант, но не лучший, потому что в некоторых случаях вы потеряете консольный доступ или пропустите другие функции.
■ systemd.unit=emergency.target Входит в минимальный режим, когда загружается минимальное количество системных юнитов.
Требуется пароль root.
Чтобы увидеть, что загружено только очень ограниченное количество файлов юнитов, вы можете ввести команду systemctl list-units.
■ systemd.unit=rescue.target Команда запускает еще несколько системных юнитов, чтобы привести вас в более полный рабочий режим. Требуется пароль root.
Чтобы увидеть, что загружено только очень ограниченное количество юнит-файлов, вы можете ввести команду systemctl list-units.
Запуск целей(targets) устранения неполадок в Linux
1. (Пере)загружаем Linux. Когда отобразиться меню GRUB, нажимаем e;
2. Находим строку, которая начинается на linux16 /vmlinuz. В конце строки вводим systemd.unit=rescue.target и удаляем rhgb quit;
3. Жмем Ctrl+X, чтобы начать загрузку с этими параметрами. Вводим пароль от root;
4. Вводим systemctl list-units и смотрим. Будут показаны все юнит-файлы, которые загружены в данный момент и соответственно загружена базовая системная среда;
5. Вводим systemctl show-environment. Видим переменные окружения в режиме rescue.target;
6. Перезагружаемся reboot;
7. Когда отобразится меню GRUB, нажимаем e. Находим строку, которая начинается на linux16 /vmlinuz. В конце строки вводим systemd.unit=emergency.target и удаляем rhgb quit;
8. Снова вводим пароль от root;
9. Система загрузилась в режиме emergency.target;
10. Вводим systemctl list-units и видим, что загрузился самый минимум из юнит-файлов.
Устранение неполадок с помощью загрузочного диска Linux
Еще один способ восстановления работоспособности Linux использовать образ операционки.
Если вам повезет меньше, вы увидите мигающий курсор в системе, которая вообще не загружается. Если это произойдет, вам нужен аварийный диск. Образ восстановления по умолчанию для Linux находится на установочном диске. При загрузке с установочного диска вы увидите пункт меню «Troubleshooting». Выберите этот пункт, чтобы получить доступ к параметрам, необходимым для ремонта машины.
Выбрав «Troubleshooting», появится выбор из 4-х опций.
- Install CentOS 7 in Basic Graphics Mode: эта опция переустанавливает систему. Не используйте её, если не хотите устранить неполадки в ситуации, когда обычная установка не работает и вам необходим базовый графический режим. Как правило, вам никогда не нужно использовать эту опцию для устранения неисправностей при установке.
- Rescue a CentOS System: это самая гибкая система спасения. Это должен быть первый вариант выбора при использовании аварийного диска.
- Run a Memory Test: если вы столкнулись с ошибками памяти, это позволяет пометить плохие микросхемы памяти, чтобы ваша машина могла нормально загружаться.
- Boot from local drive: здесь я думаю всё понятно.
ВНИМАНИЕ!
После запуска «Rescue a CentOS System» обычно требуется включить полный доступ к установке на диске. Обычно аварийный диск обнаруживает вашу установку и монтирует ее в каталог /mnt/sysimage. Чтобы исправить доступ к файлам конфигурации и их расположениям по умолчанию, поскольку они должны быть доступны на диске, используйте команду chroot /mnt/sysimage, чтобы сделать содержимое этого каталога реальной рабочей средой. Если вы не используете команду chroot, многие утилиты не будут работать, потому что, если они записывают в файл конфигурации, это будет версия файла конфигурации, существующего на диске восстановления (и по этой причине только для чтения). Использование команды chroot гарантирует, что все пути к файлам конфигурации верны.
Пример использования «Rescue a CentOS System»
1. Перезагружаем сервер с установочным диском Centos 7. Загружаемся и выбираем «Troubleshooting«.
2. В меню траблшутинга выбираем «Rescue a CentOS System» и загружаемся.
3. Система восстановления теперь предлагает вам найти установленную систему Linux и смонтировать ее в /mnt/sysimage. Выберите номер 1, чтобы продолжить:
4. Если была найдена правильная установка CentOS, вам будет предложено, чтобы система была смонтирована в /mnt/sysimage. В этот момент вы можете дважды нажать Enter, чтобы получить доступ к оболочке восстановления.
5. Ваша система Linux на данный момент доступна через каталог /mnt/sysimage. Введите chroot /mnt/sysimage. На этом этапе у вас есть доступ к корневой файловой системе, и вы можете получить доступ ко всем инструментам, которые необходимы для восстановления доступа к вашей системе.
Переустановка GRUB с помощью аварийного диска
Одна из распространенных причин, по которой вам нужно запустить аварийный диск, заключается в том, что загрузчик GRUB 2 не работает. Если это произойдет, вам может понадобиться установить его снова. После того, как вы восстановили доступ к своему серверу с помощью аварийного диска, переустановить GRUB 2 несложно, и он состоит из двух этапов:
- Убедитесь, что вы поместили содержимое каталога /mnt/sysimage в текущую рабочую среду.
- Используйте команду grub2-install, а затем имя устройства, на котором вы хотите переустановить GRUB 2. Если это виртуальная машина KVM используйте команду grub2-install /dev/vda и на физическом сервере или виртуальная машина VMware, HyperV или Virtual Box, это grub2-install /dev/sda.
Повторное создание Initramfs с помощью аварийного диска
Иногда initramfs также может быть поврежден. Если это произойдет, вы не сможете загрузить свой сервер в нормальном рабочем режиме. Чтобы восстановить образ initramfs после загрузки в среду восстановления, вы можете использовать команду dracut. Если используется без аргументов, эта команда создает новый initramfs для загруженного в данный момент ядра.
Кроме того, вы можете использовать команду dracut с несколькими опциями для создания initramfs для конкретных сред ядра. Существует также файл конфигурации с именем /etc/dracut.conf, который можно использовать для включения определенных параметров при повторном создании initramfs.
Конфигурация dracut рассредоточена по разным местам:
- /usr/lib/dracut/dracut.conf.d/*.conf содержит системные файлы конфигурации по умолчанию.
- /etc/dracut.conf.d содержит пользовательские файлы конфигурации dracut.
- /etc/dracut.conf используется в качестве основного файла конфигурации.
Вот так выглядит по умолчанию файл /etc/dracut.conf:
[root@server1 ~]# cat /etc/dracut.conf
# PUT YOUR CONFIG HERE OR IN separate files named *.conf
# in /etc/dracut.conf.d
# SEE man dracut.conf(5)
# Sample dracut config file
#logfile=/var/log/dracut.log
#fileloglvl=6
# Exact list of dracut modules to use. Modules not listed here are not going
# to be included. If you only want to add some optional modules use
# add_dracutmodules option instead.
#dracutmodules+=""
# dracut modules to omit
#omit_dracutmodules+=""
# dracut modules to add to the default
#add_dracutmodules+=""
# additional kernel modules to the default
#add_drivers+=""
# list of kernel filesystem modules to be included in the generic
initramfs
#filesystems+=""
# build initrd only to boot current hardware
#hostonly="yes"
#
# install local /etc/mdadm.conf
#mdadmconf="no"
# install local /etc/lvm/lvm.conf
#lvmconf="no"
# A list of fsck tools to install. If it is not specified, module's
hardcoded
# default is used, currently: "umount mount /sbin/fsck* xfs_db xfs_
check
# xfs_repair e2fsck jfs_fsck reiserfsck btrfsck". The installation is
# opportunistic, so non-existing tools are just ignored.
#fscks=""
# inhibit installation of any fsck tools
#nofscks="yes"
# mount / and /usr read-only by default
#ro_mnt="no"
# set the directory for temporary files
# default: /var/tmp
#tmpdir=/tmpИсправление общих проблем
В пределах статьи, подобной этой, невозможно рассмотреть все возможные проблемы, с которыми можно столкнуться при работе с Linux. Однако есть некоторые проблемы, которые встречаются чаще, чем другие. Ниже некоторые наиболее распространенные проблемы.
Переустановка GRUB 2
Код загрузчика не исчезает просто так, но иногда может случиться, что загрузочный код GRUB 2 будет поврежден. В этом случае вам лучше знать, как переустановить GRUB 2. Точный подход зависит от того, находится ли ваш сервер в загрузочном состоянии. Если это так, то довольно просто переустановить GRUB 2. Просто введите grub2-installи имя устройства, на которое вы хотите его установить. У команды есть много различных опций для точной настройки того, что именно будет установлено, но вам, вероятно, они не понадобятся, потому что по умолчанию команда устанавливает все необходимое, чтобы ваша система снова загрузилась.
Становится немного сложнее, если ваш сервер не загружается.
Если это произойдет, вам сначала нужно запустить систему восстановления и восстановить доступ к вашему серверу из системы восстановления. После монтирования файловых систем вашего сервера в /mnt/sysimage и использования chroot /mnt/sysimage, чтобы сделать смонтированный образ системы вашим корневым образом: Просто запустите grub2-install, чтобы установить GRUB 2 на желаемое установочное устройство. Но если вы находитесь на виртуальной машине KVM, запустите grub2-install /dev/vda, а если вы находитесь на физическом диске, запустите grub2-install /dev/sda.
Исправление Initramfs
В редких случаях может случиться так, что initramfs будет поврежден. Если вы тщательно проанализируете процедуру загрузки, вы узнаете, что у вас есть проблема с initramfs, потому что вы никогда не увидите, как корневая файловая система монтируется в корневой каталог, и при этом вы не увидите запуска каких-либо системных модулей. Если вы подозреваете, что у вас есть проблема с initramfs, ее легко создать заново. Чтобы воссоздать его, используя все настройки по умолчанию (что в большинстве случаев нормально), вы можете просто запустить команду dracut —force. (Без —force команда откажется перезаписать ваши существующие initramfs.)
При запуске команды dracut вы можете использовать файл конфигурации /etc/dracut.conf, чтобы указать, что именно записывается в initramfs. В этом файле конфигурации вы можете увидеть такие параметры, как lvmconf = «no», которые можно использовать для включения или выключения определенных функций. Используйте эти параметры, чтобы убедиться, что у вас есть все необходимые функции в initramfs.
Восстановление после проблем с файловой системой
Если вы неправильно настроили монтирование файловой системы, процедура загрузки может просто закончиться сообщением «Give root password for maintenance.». Это сообщение, в частности, генерируется командой fsck, которая пытается проверить целостность файла системы в /etc/fstab при загрузке. Если fsck терпит неудачу, требуется ручное вмешательство, которое может привести к этому сообщению во время загрузки. Убедитесь, что вы знаете, что делать, когда это происходит с вами!
Если упомянуто устройство, которого нет, или если в UUID, который используется для монтирования устройства, есть ошибка, например, systemd сначала ожидает, вернется ли устройство само по себе. Если этого не происходит, выдается сообщение «Give root password for maintenance.». Если это произойдет, вы должны сначала ввести пароль root. Затем вы можете ввести journalctl -xb, как предлагается, чтобы увидеть, записываются ли в журнал соответствующие сообщения, содержащие информацию о том, что не так. Если проблема ориентирована на файловую систему, введите mount -o remount, rw /, чтобы убедиться, что корневая файловая система смонтирована только для чтения, проанализировать, что не так в файле /etc/fstab, и исправить это.
Если вы видите подобный текст, то у вас есть проблема с /etc/fstab:
В этой статье вы узнали, как устранить неполадки при загрузке CentOS. Так же вы узнали, что происходит при загрузке сервера и в какие конкретные моменты вы можете вмешиваться, чтобы исправить неисправности. Вы также узнали, что делать в некоторых конкретных случаях.