
Проверка орфографии текста
Символов всего: {{ сharactersFull }}
Без пробелов: {{ сharacters }}
Слов: {{ words }}
Язык орфографии:
PRO версия:
- {{ error }}
Авторерайт
Автозамена
Заменять существительные
Заменять глаголы
Заменять прилагательные
Заменять остальные части речи
Какой синоним использовать для замены?
первый
случайный
% автозамен
Скачать отчет
{{ infoService }}

Онлайн сервис «Текстовод.Орфография» решает много задач:
-
Проверка на ошибки до 250-ти страниц (что составляет приблизительно пол миллиона символов). В процессе работы программа делит большой текст на части и осуществляет проверку.
-
Выявление орфографических, грамматических, синтаксических, морфологических, логических ошибок, а также ошибок в согласовании.
-
Поиск задвоенных знаков препинания.
-
Обнаружение пропущенных или лишних символов, повторяющихся слов.
-
Сохранение структуры и оформления введённого текста.
-
Автоматическая поправка опечаток и мелких ошибок. Корректировка ненужных пробелов (перед знаками препинания, после них) — в строгом соответствии с нормами оформления текста.
-
Подсчёт количества символов и слов. Сервис берёт во внимание пробелы.
-
Проверка текстов на нескольких языках.
-
Память установленного языка (для пользователей, прошедших регистрацию).
-
Автоудаление дублей пробелов.
Также, на странице Текстовод.Орфография можно сразу проверить текст на уникальность, воспользоваться синонимайзером и авторерайтом.
Если вам удобнее проверять орфографию со смартфона, воспользуйтесь нашим приложением (доступно для Android и IOS).
Кроме того, вы можете пользоваться нашим API.
На сайте Текстовод вы можете проверить:
-
10 000 символов (за одну проверку) — для не зарегистрированных пользователей,
-
100 000 символов — для зарегистрированных пользователей,
-
500 000 символов — для пользователей, имеющих PRO версию.
Минимальное количество слов — одно.
PRO версия
Помимо доступа к большему количеству символов на проверку, данный пакет открывает для вас отдельную очередь — отчего работа сервиса значительно ускоряется.
Также, обладатели PRO версии не видят рекламу.
Чтобы подключить данный пакет, достаточно пополнить баланс и выбрать необходимые функции.
Проверить орфографию очень просто:
-
Добавьте текст в рабочее окно. Если он не помещается, поставьте галочку PRO-версия.
-
Проверка начнётся, когда вы нажмёте кнопку «Орфография».
-
Возможные ошибки подсвечиваются другим цветом.
-
Для редактирования ошибки, наведите на неё курсор и выберите требуемый вариант исправления.
Историю ваших проверок всегда можно найти. Для этого нужно кликнуть на «история» внизу формы.
Программа работает со следующими языками:
Arabic, Belarusian, Breton, Catalan, Catalan (Valencian), Chinese, Danish, Dutch, English, English (Australian), English (Canadian), English (GB), English (New Zealand), English (South African), English (US), Esperanto, French, Galician, German, German (Austria), German (Germany), German (Swiss), Greek, Irish, Italian, Japanese, Khmer, Persian, Polish, Portuguese, Portuguese (Angola preAO), Portuguese (Brazil), Portuguese (Moçambique preAO), Portuguese (Portugal), Romanian, Russian, Simple German, Slovak, Slovenian, Spanish, Swedish, Tagalog, Tamil, Ukrainian.
-
В предустановках — русский язык.
-
Язык определяется автоматически, но вы всегда можете внести коррективы.
-
Текстовод использует мультиязычный словарь.
Инструмент проверки текста на орфографические и грамматические ошибки онлайн, позволит исправить
самые громоздкие
ошибки, с высокой степенью точности и скорости, а
также улучшить свой письменный русский язык.
Если возможно несколько исправлений, вам будет предложено выбрать одно из них.
Слова в которых допущены ошибки выделяются разными цветами, можно кликнуть на подсвеченное слово,
посмотреть описание ошибки
и выбрать исправленный вариант.
Инструмент поддерживает 8 языков.
Символов в тексте
0
Без пробелов
0
Количество слов
0
Вставьте ваш текст для проверки
Ваш текст проверяется
Орфография
Написать текст без каких-либо орфографических или пунктуационных ошибок достаточно сложно даже
специалистам.
Наша автоматическая проверка
орфографии
может помочь профессионалам, студентам, владельцам веб-сайтов, блогерам и авторам получать текст
практически без ошибок. Это не только поможет им исправить текст, но и
получить информацию о том, почему использование слова неправильно в данном контексте.
Что входит в проверку текста?
- грамматические ошибки;
- стиль;
- логические ошибки;
- проверка заглавных/строчных букв;
- типографика;
- проверка пунктуации;
- общие правила правописания;
- дополнительные правила;
Грамматика
Для поиска грамматических ошибок инструмент содержит более 130 правил.
- Деепричастие и предлог
- Деепричастие и предлог
- «Не» с прилагательными/причастиями
- «Не» с наречиями
- Числительные «оба/обе»
- Согласование прилагательного с существительным
- Число глагола при однородных членах
- И другие
Грамматические ошибки вида: «Идя по улице, у меня развязался шнурок»
-
Грамматическая ошибка: Идя по улице, у меня…
-
Правильно выражаться: Когда я шёл по улице, у меня развязался шнурок.
Пунктуация
Чтобы найти пунктуационные ошибки и правильно расставить запятые в тексте, инструмент содержит более
60 самых важных правил.
- Пунктуация перед союзами
- Слова не являющиеся вводными
- Сложные союзы не разделяются «тогда как», «словно как»
- Союзы «а», «но»
- Устойчивое выражение
- Цельные выражения
- Пробелы перед знаками препинания
- И другие
Разберем предложение, где пропущена запятая «Парень понял как мальчик сделал эту модель»
-
Пунктуационная ошибка, пропущена запятая: Парень понял,
-
«Парень понял, как мальчик сделал эту модель»
Какие языки поддерживает инструмент?
Для поиска ошибок вы можете вводить текст не только на Русском
языке, инструмент поддерживает проверку орфографии на Английском, Немецком и Французском
Приложение доступно в Google Play
![]()
Все курсы > Анализ и обработка данных > Занятие 5
На прошлом занятии, посвященном практике EDA, мы работали с «чистыми данными», то есть такими данными, в которых нет ни ошибок, ни пропущенных значений. К сожалению, так бывает далеко не всегда.
Сегодня мы научимся очищать данные от дубликатов, неверных и плохо отформатированных значений, а также исправлять ошибки в дате и времени. На следующем занятии мы поговорим про работу с пропусками.
Откроем ноутбук к этому занятию⧉
Ошибки в данных могут встречаться по многим причинам. Они могут быть связаны с человеческим фактором, например, простой невнимательностью, или вызваны сбоями в работе записывающего какие-либо показатели оборудования.
В качестве примера мы будем использовать несложный датасет, в котором содержатся данные за 2019 год об отдельных финансовых показателях сети магазинов одежды, представленной в нескольких городах мира. В частности, нам доступна следующая информация:
- month — за какой месяц сделана запись
- profit — прибыль (profit) по сети
- MoM — изменение выручки (revenue) сети по отношению к предыдущему месяцу
- high — магазин с наибольшей маржинальностью (margin) продаж
Создадим датафрейм из словаря.
|
financials = pd.DataFrame({‘month’ : [’01/01/2019′, ’01/02/2019′, ’01/03/2019′, ’01/03/2019′, ’01/04/2019′, ’01/05/2019′, ’01/06/2019′, ’01/07/2019′, ’01/08/2019′, ’01/09/2019′, ’01/10/2019′, ’01/11/2019′, ’01/12/2019′, ’01/12/2019′], ‘profit’ : [‘1.20$’, ‘1.30$’, ‘1.25$’, ‘1.25$’, ‘1.27$’, ‘1.11$’, ‘1.23$’, ‘1.20$’, ‘1.31$’, ‘1.24$’, ‘1.18$’, ‘1.17$’, ‘1.23$’, ‘1.23$’], ‘MoM’ : [0.03, —0.02, 0.01, 0.02, —0.01, —0.015, 0.017, 0.04, 0.02, 0.01, 0.00, —0.01, 2.00, 2.00], ‘high’ : [‘Dubai’, ‘Paris’, ‘singapour’, ‘singapour’, ‘moscow’, ‘Paris’, ‘Madrid’, ‘moscow’, ‘london’, ‘london’, ‘Moscow’, ‘Rome’, ‘madrid’, ‘madrid’] }) financials |
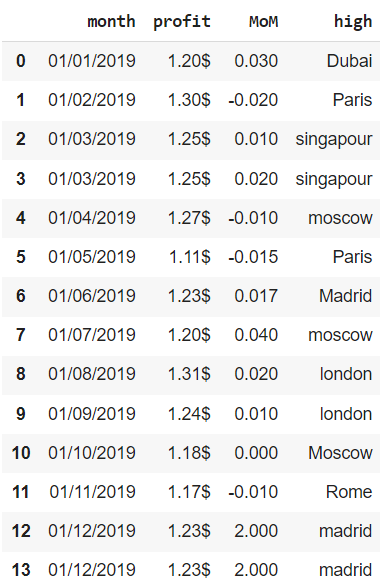
Воспользуемся методом .info() для получения общей информации о датасете.
|
<class ‘pandas.core.frame.DataFrame’> RangeIndex: 14 entries, 0 to 13 Data columns (total 4 columns): # Column Non-Null Count Dtype — —— ————— —— 0 month 14 non-null object 1 profit 14 non-null object 2 MoM 14 non-null float64 3 high 14 non-null object dtypes: float64(1), object(3) memory usage: 576.0+ bytes |
Перейдем к поиску ошибок в данных.
Дубликаты
Поиск дубликатов
Заметим, что хотя данные представлены за 12 месяцев, в датафрейме тем не менее содержится 14 значений. Это заставляет задуматься о дубликатах (duplicates) или повторяющихся значениях. Воспользуемся методом .duplicated(). На выходе мы получим логический массив, в котором повторяющееся значение обозначено как True.
|
# keep = ‘first’ (параметр по умолчанию) # помечает как дубликат (True) ВТОРОЕ повторяющееся значение financials.duplicated(keep = ‘first’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# keep = ‘last’ соответственно считает дубликатом ПЕРВОЕ повторяющееся значение financials.duplicated(keep = ‘last’) |
|
0 False 1 False 2 False 3 False 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 True 13 False dtype: bool |
Результат метода .duplicated() можно использовать как фильтр.
|
# с параметром keep = ‘last’ будет выведено наблюдение с индексом 12 financials[financials.duplicated(keep = ‘last’)] |

Также заметим, что если смотреть по месяцам, у нас две дублирующихся записи, а не одна. В частности, повторяется запись не только за декабрь, но и за март. Проверим это с помощью параметра subset.
|
# с помощью параметра subset мы ищем дубликаты по конкретным столбцам financials.duplicated(subset = [‘month’]) |
|
0 False 1 False 2 False 3 True 4 False 5 False 6 False 7 False 8 False 9 False 10 False 11 False 12 False 13 True dtype: bool |
|
# посчитаем количество дубликатов по столбцу month financials.duplicated(subset = [‘month’]).sum() |
Создадим новый фильтр и выведем дубликаты по месяцам.
|
# укажем параметр keep = ‘last’, больше доверяя, таким образом, # последнему записанному за конкретный месяц значению financials[financials.duplicated(subset = [‘month’], keep = ‘last’)] |

Аналогичным образом мы можем посмотреть на неповторяющиеся значения.
|
( ~ financials.duplicated(subset = [‘month’])).sum() |
Этот логический массив можно также использовать как фильтр.
|
financials[ ~ financials.duplicated(subset = [‘month’], keep = ‘last’)] |
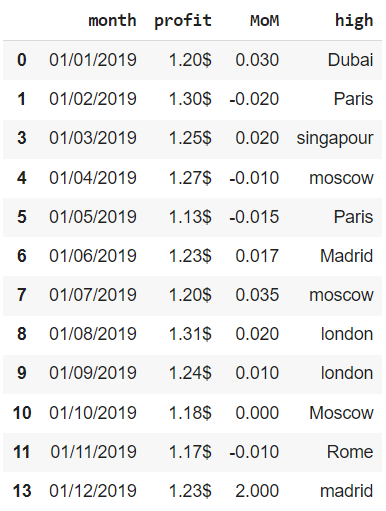
Обратите внимание, индекс остался прежним (из него просто выпали наблюдения 2 и 12). Мы исправим эту неточность при удалении дубликатов.
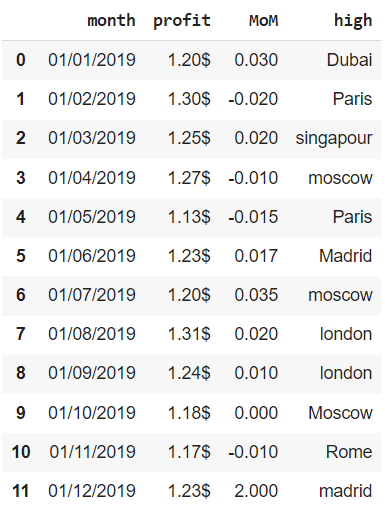
Удаление дубликатов
Метод .drop_duplicates() удаляет дубликаты из датафрейма и, по сути, принимает те же параметры, что и метод .duplicated().
|
# параметр ignore_index создает новый индекс financials.drop_duplicates(keep = ‘last’, subset = [‘month’], ignore_index = True, inplace = True) financials |
Неверные значения
Распространенным типом ошибок в данных являются неверные значения.
Базовый подход к поиску неверных значений — проверить, что данные не противоречат своей природе. Например, цена товара не может быть отрицательной.
В нашем случае мы видим, что в столбце MoM все строки отражают доли процента, а последняя строка — проценты. Из-за этого сильно искажается, например, средний показатель изменения выручки за год.
|
# рассчитаем среднемесячный рост financials.MoM.mean() |
С учетом имеющихся данных вряд ли среднее изменение выручки (в месячном, а не годовом выражении) составило 17,3%. Заменим проценты на доли процента.
|
# заменим 2% на 0.02 financials.iloc[11, 2] = 0.02 |
Вновь рассчитаем средний показатель.
Новое среднее значение 0,8% выглядит гораздо реалистичнее.
Форматирование значений
Тип str вместо float
Попробуем сложить данные о прибыли.
|
‘1.20$1.30$1.25$1.27$1.13$1.23$1.20$1.31$1.24$1.18$1.17$1.23$’ |
Так как столбец profit содержит тип str, произошло объединение (concatenation) строк. Преобразуем данные о прибыли в тип float.
|
# вначале удалим знак доллара с помощью метода .strip() financials[‘profit’] = financials[‘profit’].str.strip(‘$’) # затем воспользуемся знакомым нам методом .astype() financials[‘profit’] = financials[‘profit’].astype(‘float’) |
Проверим полученный результат с помощью нового для нас ключевого слова assert (по-англ. «утверждать»).
Если условие идущее после assert возвращает True, программа продолжает исполняться. В противном случае Питон выдает AssertionError.
Приведем пример.
|
# напишем простейшую функцию деления одного числа на другое def division(a, b): # если делитель равен нулю, Питон выдаст ошибку (текст ошибки указывать не обязательно) assert b != 0 , ‘На ноль делить нельзя’ return round(a / b, 2) |
|
# попробуем разделить 5 на 0 division(5, 0) |

Выражение
b != 0 превратилось в False и Питон выдал ошибку. Теперь вернемся к нашему коду.
|
# проверим превратился ли тип данных во float assert financials.profit.dtype == float |
Сообщения об ошибке не появилось, значит выражение верное (True). Теперь снова рассчитаем прибыль за год.
Названия городов с заглавной буквы
Остается сделать так, чтобы названия всех городов в столбце high начинались с заглавной буквы. Для этого подойдет метод .title().
|
financials[‘high’] = financials[‘high’].str.title() financials |
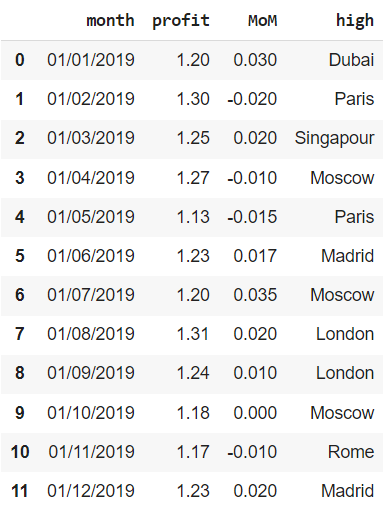
Дата и время
Как мы уже знаем, с датой и временем гораздо удобнее работать, когда они представляют собой объект datetime. В этом случае мы можем использовать все возможности Питона по анализу и прогнозированию временных рядов.
Начнем с того, что воспользуемся функцией pd.to_datetime(), которой передадим столбец month и формат, которого следует придерживаться при создании объекта datetime.
|
# запишем дату в формате datetime в столбец date1 financials[‘date1’] = pd.to_datetime(financials[‘month’], format = ‘%d/%m/%Y’) financials |

Мы получили верный результат. Как и должно быть в Pandas на первом месте в столбце date1 стоит год, затем месяц и наконец день. Теперь давайте попросим Питон самостоятельно определить формат даты.
|
# для этого подойдет параметр infer_datetime_format = True financials[‘date2’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True) financials |

У нас снова получилось создать объект datetime, однако возникла одна сложность. Функция pd.to_datetime() предположила, что в столбце month данные содержатся в американском формате (месяц/день/год), тогда как у нас они записаны в европейском (день/месяц/год). Из-за этого в столбце date2 мы получили первые 12 дней января, а не 12 месяцев 2019 года.
|
# исправить неточность с месяцем можно с помощью параметра dayfirst = True financials[‘date3’] = pd.to_datetime(financials[‘month’], infer_datetime_format = True, dayfirst = True) financials |

Теперь мы снова получили верный формат.
|
# убедимся, что столбцы с датами имеют тип данных datetime financials.dtypes |
|
month object profit float64 MoM float64 high object date1 datetime64[ns] date2 datetime64[ns] date3 datetime64[ns] dtype: object |
Удалим избыточные столбцы и сделаем дату индексом.
|
financials.set_index(‘date3’, drop = True, inplace = True) # drop = True удаляет столбец date3 financials.drop(labels = [‘month’, ‘date1’, ‘date2’], axis = 1, inplace = True) financials.index.rename(‘month’, inplace = True) financials |
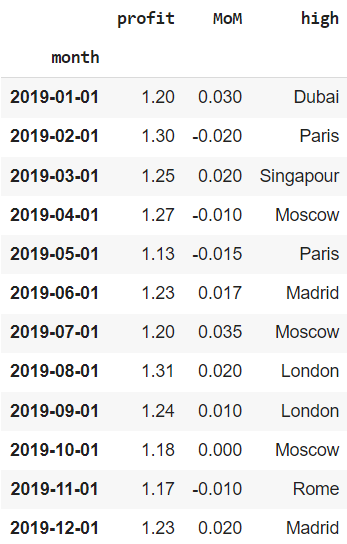
Посмотрим на еще один интересный инструмент. Предположим, что мы ошиблись с годом (вместо 2019 у нас на самом деле данные за 2020 год) или просто хотим создать индекс с датой с нуля. Для таких случаев подойдет функция pd.data_range().
|
# создадим последовательность из 12 месяцев, # передав начальный период (start), общее количество периодов (periods) # и день начала каждого периода (MS, т.е. month start) range = pd.date_range(start = ‘1/1/2020’, periods = 12, freq = ‘MS’) # сделаем эту последовательность индексом датафрейма financials.index = range financials |
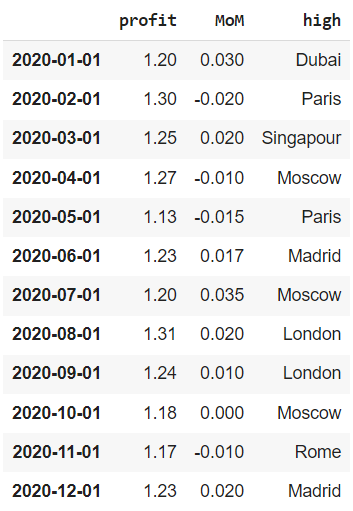
Как мы уже знаем, когда индекс имеет тип данных datetime, мы можем делать срезы по датам.
|
# напоминаю, что для datetime конечная дата входит в срез financials[‘2020-01’: ‘2020-06’] |

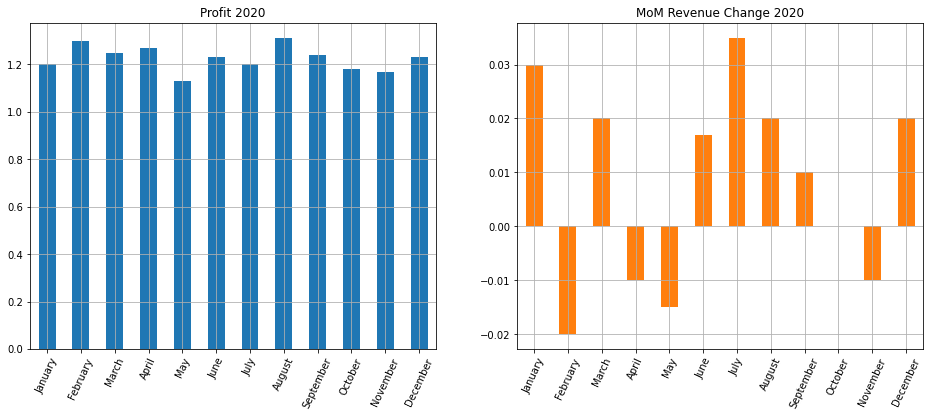
Завершим раздел про дату и время построением двух подграфиков. Для этого вначале преобразуем индекс из объекта datetime обратно в строковый формат с помощью метода .strftime().
|
# будем выводить только месяцы (%B), так как все показатели у нас за 2020 год financials.index = financials.index.strftime(‘%B’) financials |

Теперь используем метод .plot() библиотеки Pandas с параметром subplots = True.
|
# построим графики для размера прибыли и изменения выручки за месяц financials[[‘profit’, ‘MoM’]].plot(subplots = True, # обозначим, что хотим несколько подграфиков layout = (1,2), # зададим сетку kind = ‘bar’, # укажем тип диаграммы rot = 65, # повернем деления шкалы оси x grid = True, # добавим сетку figsize = (16, 6), # укажем размер figure legend = False, # уберем легенду title = [‘Profit 2020’, ‘MoM Revenue Change 2020’]); # добавим заголовки |
Подведем итог
Сегодня мы рассмотрели типичные ошибки в данных и способы их исправления. В частности, мы изучили как выявить и удалить дубликаты, обнаружить неверные значения и скорректировать неподходящий формат. Кроме того, мы еще раз обратились к объекту datetime и посмотрели на возможности изменения даты и времени.
Перейдем к работе с пропущенными значениями.
#1
![]()
Budulianin
-

- Members
-
- 9 сообщений
Новый участник


- ФИО:Григорий

Отправлено 22 февраля 2013 — 09:34
Всем привет
У меня возник вопрос. На данный момент я считаю, что регрессионное тестирование — тестирование функциональности, которая уже присутствовала, после введения новой функциональности.
А проверка исправлений, без введения новой функциональности это не регрессия. Прав ли я?
Если посмотреть в вики то проверка исправлений, без введения новой функциональности это new bug-fix?
-
0
- Наверх
#2
![]()
tab15
Отправлено 22 февраля 2013 — 11:26
По терминологии ISQTB. Все правильно, только проверка исправлений это ретесты(re-testing)
-
0
- Наверх
#3
![]()
Budulianin
Budulianin
-
- Members
-
- 9 сообщений
Новый участник
- ФИО:Григорий
Отправлено 22 февраля 2013 — 11:31
По терминологии ISQTB. Все правильно, только проверка исправлений это ретесты(re-testing)
Что именно правильно? киньте ссыль на эту терминологию пожалуйста.
-
0
- Наверх
#4
![]()
tab15
Отправлено 22 февраля 2013 — 12:47
По терминологии ISQTB. Все правильно, только проверка исправлений это ретесты(re-testing)
Что именно правильно? киньте ссыль на эту терминологию пожалуйста.
Правильно у вас на счет регрессных тестов.
Вот например http://www.istqb.org…s/glossary.html
-
0
- Наверх
#5
![]()
Budulianin
Budulianin
-
- Members
-
- 9 сообщений
Новый участник
- ФИО:Григорий
Отправлено 22 февраля 2013 — 13:21
По терминологии ISQTB. Все правильно, только проверка исправлений это ретесты(re-testing)
Что именно правильно? киньте ссыль на эту терминологию пожалуйста.
Правильно у вас на счет регрессных тестов.
Вот например http://www.istqb.org…s/glossary.html
а по поводу — Если посмотреть в вики то проверка исправлений, без введения новой функциональности это new bug-fix?
-
0
- Наверх
#6
![]()
MissLeman

Отправлено 25 февраля 2013 — 11:11
проверка исправлений, без введения новой функциональности это new bug-fix?
А я почему-то всегда думала, что это defect validation. Разве нет?
-
0
- Наверх
#7
![]()
astenix
Отправлено 26 февраля 2013 — 11:05
На данный момент я считаю, что регрессионное тестирование
Почему регрессионное тестирование называется регрессионным?
-
0
- Наверх
#8
![]()
adzynia
Отправлено 02 июня 2013 — 17:48
-
0
- Наверх
#9
![]()
AnastasiaM88
AnastasiaM88
-
- Members
-
- 68 сообщений
Новый участник

- ФИО:Анастасия
- Город:Ростов-на-Дону
Отправлено 11 июня 2013 — 14:02
Я в сфере тестирования ПО — новичок.  Занимаюсь самообучением (знакомые тестировщики направляют, что где можно почитать, изучить, послушать веб-уроки по основам).
Занимаюсь самообучением (знакомые тестировщики направляют, что где можно почитать, изучить, послушать веб-уроки по основам).
Подскажите, корректно ли такое определение и понимание регрессионного тестирования (регрессионное тестирование):
» Регрессионное тестирование — это вид тестирования направленный на проверку изменений, сделанных в приложении или окружающей среде (починка дефекта, слияние кода, миграция на другую операционную систему, базу данных, веб сервер или сервер приложения), для подтверждения того факта, что существующая ранее функциональность работает как и прежде.
Сам по себе термин «Регрессионное тестирование», в зависимости от контекста использования может иметь разный смысл. Сэм Канер, к примеру, описал 3 основных типа регрессионного тестирования:
Регрессия багов (Bug regression) — попытка доказать, что исправленная ошибка на самом деле не исправлена
Регрессия старых багов (Old bugs regression) — попытка доказать, что недавнее изменение кода или данных сломало исправление старых ошибок, т.е. старые баги стали снова воспроизводиться.
Регрессия побочного эффекта (Side effect regression) — попытка доказать, что недавнее изменение кода или данных сломало другие части разрабатываемого приложения
»
-
0
- Наверх
#10
![]()
SALar

Отправлено 12 июня 2013 — 14:08
В связи с тем, что терминология не устоялась правильным будет и то, и то, и то.
важнее другое знание:
Регрессия багов (Bug regression) — попытка доказать, что исправленная ошибка на самом деле не исправлена
Необходимость данного тестирования говорит о проблемах процесса. Скорее всего, или программисты не умеют читать, или тестировщики не умеют писать.
Регрессия старых багов (Old bugs regression) — попытка доказать, что недавнее изменение кода или данных сломало исправление старых ошибок, т.е. старые баги стали снова воспроизводиться.
Необходимость данного тестирования говорит о проблемах процесса. В первую очередь я бы покопал управление версиями.
Регрессия побочного эффекта (Side effect regression) — попытка доказать, что недавнее изменение кода или данных сломало другие части разрабатываемого приложения
Необходимость данного тестирования говорит о проблемах процесса. Вероятнее всего, не было архитектора.
PS. А еще кто нибудь придет и скажет, что:
РЕГРЕССИЯ [regression] — зависимость среднего значения какой-либо случайной величины от некоторой другой величины или нескольких величин (в последнем случае — имеем множественную Р.). Следовательно, при регрессионной связи одному и тому же значению x величины X (в отличие от функциональной связи) могут соответствовать разные случайные значения величины Y. Распределение этих значений называется условным распределением Y при данном X = x.
Регрессия — (regression) -1. В психиатрии — возвращение к более раннему, незрелому уровню функционирования организма изза неспособности адекватно функционировать на более высоком уровне. Данный термин может применяться, например, по отношению к состоянию находящегося в больнице человека, который становится несдержанным и чересчур требовательным. Также он может применяться по отношению к какой-либо единичной психологической функции; например, психоаналитики считают, что либидо представляет собой регрессию к более ранней стадии развития человека. 2. Стадия заболевания, во время которой происходит убыль симптомов болезни и наступает полное выздоровление больного.
ПРОГРЕСС И РЕГРЕСС (от латинских слов рrоgressus — движение вперед, успех, и regrеssus — обратное движение) — широко употребляемые в политологии понятия, обозначающие противоположные направления эволюции.
Ну вы поняли.
-
0
- Наверх
#11
![]()
negro
negro
- ФИО:Себастьян Переро
- Город:Скотопригоньевск
Отправлено 14 июня 2013 — 21:08
…и то, и то, и то…
Допустим, есть ПО, работая с которым Разработчик:
— ничего не исправил и не сломал
— не исправил, что надо, и сломал другое
— исправил, что надо, но другое сломал
— всё в коде починил, но неадекватно произвёл сборку продукта
Затем ПО передали Тестировщику, который:
— искал, но не нашёл баги
— нашёл баги не там, где их надо было искать
— закрыл актуальные баг-репорты
— не понимая требований, накидал неадекватных баг-репортов
— подтвердил, что ПО работает стабильно как и прежде — криво и хромая
При этом 100% имел место факт тестирования, направленного на проверку ПО с попыткой доказать…
И что?
Это и есть регрессионное тестирование?
Ну вы поняли
SALar, а я не понял — почему одну половину вашего комментария занимает копи-пэст мыслей AnastasiaM88 из коммента выше, а другую — цитаты неуместных определений из области математики, медицины и политологии?
-
0
- Наверх
#12
![]()
Wolonter
Wolonter
- ФИО:Макс
- Город:Екатеринбург


Отправлено 20 июня 2013 — 06:46
Необходимость данного тестирования говорит о проблемах процесса. Скорее всего, или программисты не умеют читать, или тестировщики не умеют писать.
…
Необходимость данного тестирования говорит о проблемах процесса. В первую очередь я бы покопал управление версиями.
…
Необходимость данного тестирования говорит о проблемах процесса. Вероятнее всего, не было архитектора.
Все правильно. Вообще, наличие багов говорит о проблемах процесса. И в идеальном мире тестировщики не нужны.
А в нашем неидеальном мире вместо того, чтоб нанять бесконечно мудрых руководителей, которые исправят все проблемы процесса, проклятые капиталисты нанимают низкоквалифицированных тестировщиков, которые занимаются регрессионным тестированием.
По теме — регрессия — тестирование того, что уже было протестировано. Не?
-
0
- Наверх
#13
![]()
negro
negro
- ФИО:Себастьян Переро
- Город:Скотопригоньевск
Отправлено 23 июня 2013 — 16:16
По теме… Не?
Неа! признак регрессии — это не то, чтобы новая функциональность или тестирование того, что уже было протестировано, а тестирование так, как это уже тестировалось раньше…
-
0
- Наверх
#14
![]()
Фрося
Фрося
- ФИО:Радилова Елена Игоревна
Отправлено 26 июля 2013 — 12:58
Нашла сейчас:
«Методы реализации регрессионного тестирования по расширенным тестовым наборам»
http://planetadisser…is_7503373.html
Диссертация..
хм… даже не задумывалась, что есть какие-то методы.
Есть у кого опыт? Применения методов?
-
0
Почему-то по пятницам особо остро хочется быть блондинкой….
- Наверх
Регрессионные виды тестирования (Regression testing)
Регрессионное тестирование (regression testing): Тестирование уже протестированной программы, проводящееся после модификации для уверенности в том, что процесс модификации не внес или не активизировал ошибки в областях, не подвергавшихся изменениям. Проводится после изменений в коде программного продукта или его окружении. (ISTQB)
Регресс — это противоположность прогресса. Любое ПО по мере прогресса в функционале неизбежно усложняется, увеличиваются взаимосвязи в функциях и т.п., и чтобы убедиться в том, что в существующей системе не начинается регресс, полезно иногда проводить ее полное тестирование. И уж тем более логично перетестировать всё, что можно, если в систему были внесены какие-то существенные изменения. Но этого недостаточно. По-сути, проблема намного серьезнее — мы каждый раз не знаем, что принесет с собой новая функциональность в системе. Нам каждый раз надо предположить/узнать/протестировать новые взаимодействия в системе, а не тестировать только новые функции в изоляции от остальных. Старый функционал с новым если начинают пересекаться — надо заново расчехлять аналитику, выявлять новые ситуации, которые могут возникнуть, писать новые тест-кейсы, которые затрагивают уже не столько функциональные, сколько интеграционные аспекты. Поэтому выяснение «не наступил ли регресс» (внимание, не путать с «не наступила ли регрессия») — постоянная задача, которую также необходимо решать в контексте maintenance testing.
Регрессионное тестирование (Regression Testing) — собирательное название для всех видов тестирования программного обеспечения связанных с изменениями, направленных на обнаружение ошибок в уже протестированных участках исходного кода, на проверку того, что новая функциональность не зааффектила (affect) старую. Такие ошибки — когда после внесения изменений в программу перестаёт работать то, что должно было продолжать работать, — называют регрессионными ошибками (regression bugs). Регрессионные тесты должны быть частью релизного цикла (Release Cycle) и учитываться при тестовой оценке (test estimation).
При корректировках программы необходимо гарантировать сохранение качества. Для этого используется регрессионное тестирование — дорогостоящая, но необходимая деятельность в рамках maintenance testing, направленная на перепроверку корректности измененной программы. В соответствии со стандартным определением, регрессионное тестирование — это выборочное тестирование, позволяющее убедиться, что изменения не вызвали нежелательных побочных эффектов, или что измененная система по-прежнему соответствует требованиям. Регрессионное тестирование обычно проводится перед релизом новой версии приложения. Это происходит следующим образом: в течение какого-то времени делаются какие-то фичи и другие задачи, они тестируются по отдельности и сливаются в общую ветку (мастер/девелоп — чаще всего эта ветка называется в зависимости от процессов в проекте). Дальше, когда время подходит к релизу от ветки девелопа создается ветка релиза, из которой собирается релиз-кандидат и на нем уже проводят регресс.
Главной задачей maintenance testing является реализация систематического процесса обработки изменений в коде. После каждой модификации программы необходимо удостовериться, что на функциональность программы не оказал влияния модифицированный код. Если такое влияние обнаружено, говорят о регрессионном дефекте. Для регрессионного тестирования функциональных возможностей, изменение которых не планировалось, используются ранее разработанные тесты. Одна из целей регрессионного тестирования состоит в том, чтобы, в соответствии с используемым критерием покрытия кода (например, критерием покрытия потока операторов или потока данных), гарантировать тот же уровень покрытия, что и при полном повторном тестировании программы. Для этого необходимо запускать тесты, относящиеся к измененным областям кода или функциональным возможностям.
Другая цель регрессионного тестирования состоит в том, чтобы удостовериться, что программа функционирует в соответствии со своей спецификацией, и что изменения не привели к внесению новых ошибок в ранее протестированный код. Эта цель всегда может быть достигнута повторным выполнением всех тестов регрессионного набора, но более перспективно отсеивать тесты, на которых выходные данные модифицированной и старой программы не могут различаться. Важной задачей регрессионного тестирования является также уменьшение стоимости и сокращение времени выполнения тестов.
Можно заключить, что регрессионное тестирование выполняется чтобы минимизировать регрессионные риски. То есть, риски того, что при очередном изменении продукт перестанет выполнять свои функции. С регрессионным тестированием плотно связана другая активность — импакт анализ (Impact Analysis, анализ влияния изменений). Итоговая область регрессии называется Regression Scope / Scope of Regression.
Классификация регрессионного тестирования:
- Проверить всё (Retest All): Как следует из названия, все тест-кейсы в наборе тестов повторно выполняются, чтобы гарантировать отсутствие ошибок, возникших из-за изменения кода. Это дорогостоящий метод, поскольку он требует больше времени и ресурсов по сравнению с другими методами;
- Минимизация набора тестов (test suite minimization) стремится уменьшить размер тестового набора за счет устранения избыточных тестовых примеров из тестового набора;
- Задача выбора теста (test case selection) связана с проблемой выбора подмножества тестов, которые будут использоваться для проверки измененных частей программного обеспечения. Для этого требуется выбрать подмножество тестов из предыдущей версии, которые могут обнаруживать неисправности, основываясь на различных стратегиях. Большинство задокументированных методов регрессионного тестирования сосредоточены именно на этой технике. Обычная стратегия состоит в том, чтобы сосредоточить внимание на отождествления модифицированных частей SUT (system under test) и для выбора тестовых случаев, имеющих отношение к ним. Например, техника полного повторного тестирования (retest-all) — один из наивных типов выбора регрессионного теста путем повторного выполнения всех видов тестов от предыдущей версии на новой. Она часто используется в промышленности из-за её простого и быстрого внедрения. Тем не менее, её способность обнаружения неисправностей ограничена. Таким образом, значительный объём работ связан с разработкой эффективных и масштабируемых селективных методов;
- Задача определения приоритетов теста (test case prioritization). Ее цели заключаются в выполнении заказанных тестов на основе какого-либо критерия. Например, на основе истории, базы или требований, которые, как ожидается, приведут к более раннему выявлению неисправностей или помогут максимизировать некоторые другие полезные свойства;
- Гибридный: Гибридный метод представляет собой комбинацию выборочного и приоритезации. Вместо того, чтобы выбирать весь набор тестов, выберите только те тест-кейсы, которые повторно выполняются в зависимости от их приоритета;
Типы регрессии по Канеру:
- Регрессия багов (Bug regression) — попытка доказать, что исправленная ошибка на самом деле не исправлена;
- Регрессия старых багов (Old bugs regression) — попытка доказать, что недавнее изменение кода или данных сломало исправление старых ошибок, т.е. старые баги стали снова воспроизводиться;
- Регрессия побочного эффекта (Side effect regression) — попытка доказать, что недавнее изменение кода или данных сломало другие части разрабатываемого приложения;
Регрессия в Agile:
В Agile продукт разрабатывается в рамках короткой итерации, называемой спринтом, которая длится 2-4 недели. В Agile существует несколько итераций, поэтому это тестирование играет важную роль, поскольку в итерациях добавляется новая функциональность или изменения кода. Набор регрессионных тестов должен быть подготовлен на начальном этапе и обновляться с каждым спринтом. В Agile проверки регрессии делятся на две категории:
- Регрессия уровня спринта (Sprint Level Regression): выполняется в основном для новых функций или улучшений, внесенных в последний спринт. Тест-кейсы из набора тестов выбираются в соответствии с новыми добавленными функциями или сделанными улучшениями;
- Сквозная регрессия (End to End Regression): включает в себя все тест-кейсы, которые должны быть повторно выполнены для сквозного тестирования всего продукта, охватывая все основные функции;
Смоук тестирование (Smoke testing)
Тест «на дым» (smoke test): Выборка из общего числа запланированных тестовых сценариев, покрывающая основную функциональность компонента или системы. Проводится с целью удостовериться, что базовые функции программы в целом работают корректно, без углубления в детали. Ежедневная сборка и тест «на дым» являются передовыми практическими методами. См. входной тест, тест верификации сборки. (ISTQB)
Тест верификации сборки (build verification test): Набор автоматических тестов, валидирующих целостность каждой новой сборки и верифицирующих ее ключевую/базовую функциональность, стабильность и тестируемость. Данный вид тестирования используется там, где присутствует высокая частота сборок (например, проекты с использованием гибких методологий разработки) и выполняется для каждой новой сборки перед передачей ее в тестирования. См. также регрессионное тестирование, тест «на дым». (ISTQB)
Smoke testing, BVT — Build Verification Testing, BAT — Builds Acceptance Testing, Breath Testing, Shakeout/Shakedown Testing, Intake test, а также в русскоязычных вариантах дымовое, на дым, дымное, тестирование сборки и т.п. — это подмножество регрессионного тестирования, короткий цикл тестов, выполняемый для каждой новой сборки для подтверждения того, что ПО после внесенных изменений стартует и выполняет основные функции без критических и блокирующих дефектов. В случае отсутствия блокеров Smoke testing объявляется пройденным, и команда QA может начинать дальнейшее тестирование полного цикла, в противном случае, сборка объявляется дефектной, что делает дальнейшее тестирование пустой тратой времени и ресурсов. В таком случае сборка возвращается на доработку и исправление. Smoke testing обычно используется для Integration, Acceptance and System Testing.
Если мы говорим про сайт интернет-магазина, то сценарий может быть следующим:
- Сайт открывается
- Можно выбрать случайный товар и добавить его в корзину
- Можно оформить и оплатить заказ
Если мы говорим про мобильное приложение, например, messenger, то:
- Приложение устанавливается и запускается
- Можно авторизоваться
- Можно написать сообщение случайном контакту
Небольшая шпаргалка по степени важности:
- smoke — самое важное. Тест-кейсы играют очень важную роль на этом уровне тестирования, поэтому предел метрик (metric limit) часто соответствует 100% или примерно 100%;
- critical path — повседневное. Тесты критического пути запускаются для проверки функциональности, используемой типичными пользователями в их повседневной деятельности. Есть много пользователей, которые обычно используют определенную часть функциональности приложения, которую необходимо проверить, как только smoke этап будет успешно завершен. Здесь лимит метрик немного ниже, чем у smoke, и соответствует 70-80-90% в зависимости от цели проекта;
- extended — все. Выполняется для изучения всей функциональности, указанной в требованиях. Проверяется даже функциональность с низким приоритетом. При этом в этом тестировании нужно понимать, какой функционал наиболее ценный, а какой менее важный. При условии, что у вас достаточно времени или других ресурсов, тесты на этом уровне можно использовать для требований с низким приоритетом;
Примечание. В русском языке термин ошибочно переводят как проверка дыма, корректнее уж говорить “на дым”. История термина: Первое свое применение этот термин получил у печников, которые, собрав печь, закрывали все заглушки, затапливали ее и смотрели, чтобы дым шел только из положенных мест. Повторное «рождение» термина произошло в радиоэлектронике. Первое включение нового радиоэлектронного устройства, пришедшего из производства, совершается на очень короткое время (меньше секунды). Затем инженер руками ощупывает все микросхемы на предмет перегрева. Сильно нагревшаяся за эту секунду микросхема может свидетельствовать о грубой ошибке в схеме. Если первое включение не выявило перегрева, то прибор включается снова на большее время. Проверка повторяется. И так далее несколько раз. Выражение «smoke-test» используется инженерами в шуточном смысле, так как появления дыма, а значит и порчи частей устройства, стараются избежать.
Санити тестирование (Sanity testing)
Тест работоспособности (sanity test): См. тест «на дым». (ISTQB)
Другие источники:
Sanity testing также является подмножеством регрессионного тестирования и выполняется до или вместо полной регрессии, но после smoke. Эти два подвида похожи, но в целом Sanity используется на более стабильных билдах для определения работоспособности определенной части приложения после внесения изменений.
Примечание. Санитарным это тестирование в русскоязычной среде назвалось по совершенно непонятным причинам, но гуглится только так. На самом же деле дословно переводится как тестирование на вменяемость / разумность / работоспособность / согласованность или по версии ISTQB “Тест работоспособности”.
Подтверждающее, повторное тестирование (confirmation testing, re-testing)
Подтверждающее тестирование (confirmation testing): Тестирование, при котором выполняются тестовые сценарии, которые были не пройдены при последнем запуске, с целью подтвердить успешность исправлений. (ISTQB)
Повторное тестирование — это тип тестирования, выполняемый в новой сборке по проваленному на старой сборке тест-кейсу с тем же окружением и данными, для проверки того, что этот дефект теперь устранен. Ре-тест выполняется перед sanity-тестированием, приоритет ре-теста выше регрессионных проверок, поэтому оно должно выполняться перед ними.
Тестирование N+1 (N+1 testing)
Вариант регрессионного тестирования представлен как N+1. В этом методе тестирование выполняется в несколько циклов, в которых ошибки, обнаруженные в тестовом цикле «N», устраняются и повторно тестируются в тестовом цикле N + 1. Цикл повторяется, пока не будет найдено ни одной ошибки.
Разница между повторным и регрессионным тестированием:
- Регрессионное тестирование проводится для подтверждения того, что недавнее изменение программы или кода не оказало неблагоприятного воздействия на существующие функции. Повторное тестирование проводится для подтверждения того, что тест-кейсы, которые не прошли, проходят после устранения дефектов;
- Цель регрессионного тестирования подтвердить, что новые изменения кода не должны иметь побочных эффектов для существующих функций. Повторное тестирование проводится на основе исправлений дефектов.;
- Проверка дефектов не является частью регрессионного тестирования. Проверка дефекта является частью повторного тестирования;
- В зависимости от проекта и наличия ресурсов, регрессионное тестирование может проводиться параллельно с повторным тестированием. Приоритет повторного тестирования выше, чем регрессионное тестирование, поэтому оно проводится перед регрессионным тестированием;
- Регрессионное тестирование называется общим (generic) тестированием. Повторное тестирование — это плановое (planned) тестирование;
- Регрессионное тестирование проводится для пройденных Test case. Повторное тестирование проводится только для неудачных тестов;
- Регрессионное тестирование проверяет наличие неожиданных побочных эффектов. Повторное тестирование гарантирует, что первоначальная ошибка была исправлена;
- Test case для регрессионного тестирования могут быть получены из функциональной спецификации, user tutorials and manuals, а также defect reports в отношении исправленных проблем. Test case для повторного тестирования не могут быть получены до начала тестирования;
Может ли быть ситуация, когда регрессия проводится не после изменений в коде?
Да, в ситуациях с внешними факторами: изменения в БД, версии ОС и т.п.
Источники:
- Maintenance, Regression testing and Re-testing
- Регрессионное тестирование
- Тестировщики нужны — пост “Регресс для самых маленьких”
- QA Outsourcing: Smoke Testing, Critical Path Testing, Extended Testing
- What Is Regression Testing? Definition, Tools, Method, And Example
- В чём разница Smoke, Sanity, Regression, Re-test и как их различать?
- Difference Between Retesting and Regression Testing
- Top 150 Software Testing Interview Questions and Answers for Freshers and Experienced
Дополнительный материал:
- ГОСТ Р 56920-2016/ISO/IEC/IEEE 29119-1:2013 “D.6 Подпроцесс регрессионного тестирования”, “D.7 Подпроцесс повторного тестирования”
- Лекция 11: Регрессионное тестирование: цели и задачи, условия применения, классификация тестов и методов отбора
- Black Box Software Testing PART 11 — REGRESSION TESTING by Cem Kaner + 2005 year version
- Епифанов Н. А. — Методы реализации регрессионного тестирования по расширенным тестовым наборам
- Anti-Regression Approaches: Impact Analysis and Regression Testing Compared and Combined — Part I: Introduction and Impact Analysis
- Anti-Regression Approaches — Part II: Regression Prevention and Detection Using Static Techniques
- Как сохранить нервы тестировщика или ускорить регресс с 8 до 2 часов
- Регрессионное тестирование или Regression Testing
- QA Outsourcing: Smoke Testing, Critical Path Testing, Extended Testing
- Антирегрессионное тестирование — минимизируйте затраты
- Способы сокращения регрессионного тестирования
- Курс Тестирование ПО. Занятие 26. Регрессионное тестирование (Regression Testing)
- История о бесконечном регрессионном тестировании
Материал из Национальной библиотеки им. Н. Э. Баумана
Последнее изменение этой страницы: 21:22, 25 мая 2017.
Регрессионное тестирование — это исследование, испытание программного обеспечения (иными словами, тестирование), направленное на обнаружение ошибок в уже проверенных участках программ (или исходных кодах). Производится, чтобы исправить регрессионные ошибки (баги, которые появляются не во время написания программы, а при добавлении новых участков кода или исправлении допущенных ранее промахов в синтаксисе кода). Регрессионные ошибки- это когда после внесения изменений в программу перестаёт работать то, что должно было продолжать работать. Цель регрессионного тестирования – убедиться в том, что

исправлении существующих проблем не привело к новым ошибкам в уже проверенных участках кода программы. Как правило, для регрессионного тестирования используются тестовые случаи, написанные на ранних стадиях разработки и тестирования. Тестовый случай-это набор условий, при которых тестировщик будет определять, удовлетворяется ли заранее определённое требование.
Понятие «Регрессионное тестирование», в зависимости от контекста использования может иметь разный смысл. Основные типы: регрессия багов, регрессия старых багов, регрессия побочного эффекта. Регрессия багов (англ. Bug regression) — попытка доказать, что исправленная ошибка на самом деле не была исправлена. Регрессия старых багов (англ. Old bugs regression) — попытка доказать, что недавнее изменение кода или данных сломало исправление старых ошибок, то есть старые баги стали снова воспроизводиться. Регрессия побочного эффекта (англ. Side effect regression) — попытка доказать, что недавнее изменение кода или данных сломало другие части разрабатываемого приложения.
Хотя регрессионное тестирование может быть выполнено вручную, зачастую это делается с помощью специализированных программ, позволяющих выполнять все регрессионные тесты автоматически. В некоторых проектах используются инструменты для автоматического прогона регрессионных тестов через заданный интервал времени. Обычно это выполняется после каждой удачной компиляции (в небольших проектах) либо каждую ночь или каждую неделю.
Регрессионное программирование — часть экстремального программирования. В этой методологии проектная документация заменяется на расширяемое, повторяемое и автоматизированное тестирование всего программного пакета на каждой стадии процесса разработки программного обеспечения. Также регрессионное тестирование может быть использовано для проверки качества программы[Источник 1][Источник 2].
Содержание
- 1 Типы, виды и направления регрессионного тестирования
- 1.1 Автоматизация регрессионных тестов
- 1.2 Регрессия багов
- 1.3 Регрессия старых ошибок
- 2 Задачи регрессионного тестирования
- 3 Преимущества и недостатки регрессивного тестирования
- 3.1 Преимущества
- 3.2 Недостатки
- 4 Источники
Типы, виды и направления регрессионного тестирования
Различают два основных типа тестов: функциональные и нефункциональные. Функциональные тесты основываются на функциях, которые выполняет система. Могут проводиться на компонентном, интеграционном, системном и приемочном уровнях. Основные аспекты, по которым проводится тестирование-требования и бизнес-процессы. При работе над требованиями требуется составить список того, что должно быть протестировано. При этом удобно было бы выделить приоритетные детали, чтобы определиться с направлением работы. Это нужно, чтобы не оставить без внимания весь самый важный функционал. При тестировании бизнес-процессов упор делается именно на них, то есть прогоняются сценарии каждодневной работы. Нефункциональные тесты направлены на проверку всех свойств, которые не относят к функциям системы. Из них можно привести такие параметры, как надежность, производительность, удобство, масштаб, безопасность, портативность.
Тесты могут быть выражены в виде скриптов, наборов, комплектов для запуска. Регрессия проводится в трех основных направлениях: багов, старых проблем. побочных эффектов.
Автоматизация регрессионных тестов
Под автоматизированным тестированием программного обеспечения понимают процесс верификации ПО, во время которого основные функции и задачи, такие как запуск, инициализация и выполнение, а также анализ и выдача результатов, проводятся автоматически, с применением соответствующего инструментария. Это действие выполняется техническим специалистом, отвечающим за создание, отладку и поддержку в рабочем состоянии тест-скриптов, тестовых наборов и инструментария. Работа может проводиться с различным программным обеспечением, в том числе и регрессионное тестирование автоматизированных систем.
Регрессия багов
Это подразумевает под собой поиск проблем, которые официально «были устранены», но есть основания полагать, что они до сих пор существуют. Особенность данного вида проверок заключается в том, что необходимо проверять все действия с определённым объектом в различных комбинациях. В первую очередь тестируют соответствие реальности сообщения об устранении проблемы по тому механизму, благодаря которому она была выявлена. Регрессионное тестирование верстки в данном случае помогает удостовериться в отсутствии нежелательных эффектов.
Регрессия старых ошибок
Подразумевает под собой ситуации, когда недавнее изменение кода в одной части приложения сделало нерабочим некоторые или все другие части разрабатываемой программы. В качестве указания о наличии таких проблем служит отсутствие работоспособности в одной или нескольких частях программы. Задача тестера определить все проблемные места[Источник 3].
Задачи регрессионного тестирования
Основная задача регрессионного тестирования -проверка того, что исправление ошибки не коснулось существующей функциональности. Из-за частого выполнения одних и тех же наборов сценариев, рекомендуется использовать автоматизированные регрессионные тесты, что позволит сократить сроки тестирования. Остальные задачи:
- Проверка и утверждение исправления ошибки;
- Тестирование последствия исправлений, так как внесенные исправления могут привнести ошибку в код который исправно работал;
- Гарантировать функциональную преемственность и совместимость новой версии (релиза, патча) с предыдущими;
- Уменьшение стоимости и сокращение времени выполнения тестов[Источник 4].
Преимущества и недостатки регрессивного тестирования
Преимущества
- Сокращение количества дефектов в системе к моменту релиза;
- Исключение деградации качества системы при росте функциональности;
- Уменьшение вероятности критических ошибок при эксплуатации.
Недостатки
Регрессионное тестирование может ввести много ненужных накладных расходов, поскольку это требует много ручного труда.
Источники
- ↑ Регрессионное тестирование или Regression Testing // протестинг.ru URL: http://www.protesting.ru/testing/types/regression.html (дата обращения 25.05.2017)
- ↑ Регрессионное тестирование программного обеспечения. Что такое регрессионное тестирование // FB.ru URL: http://fb.ru/article/224734/regressionnoe-testirovanie-programmnogo-obespecheniya-chto-takoe-regressionnoe-testirovanie
- ↑
Регрессионное тестирование программного обеспечения// getbug URL: http://getbug.ru/regressionnoe-testirovanie-programmnogo-obespecheniya/ (дата обращения 25.05.2017) - ↑ Тестирование. Фундаментальная теория // Хабрхабр URL:https://habrahabr.ru/post/279535/(дата обращения 25.05.2017)
После проведения необходимых изменений,
таких как исправление бага/дефекта,
программное обеспечение должно быть
пере тестировано для подтверждения
того факта, что проблема была действительно
решена. Ниже перечислены виды тестирования,
которые необходимо проводить после
установки программного обеспечения,
для подтверждения работоспособности
приложения или правильности осуществленного
исправления дефекта:
-
Дымовое
тестирование (Smoke Testing).
«При вводе в эксплуатацию нового
оборудования («железа») считалось,
что тестирование прошло удачно, если
из установки не пошел дым.»
В области же тестирования программного
обеспечения, оно применяется для
поверхностной проверки всех модулей
приложения на предмет работоспособности
и наличия быстро находимых критических
и блокирующих дефектов.
По результатам данного вида делается
вывод о том, принимается или нет
установленная версия программного
обеспечения в тестирование, эксплуатацию
или на поставку заказчику.
-
Регрессионное
тестирование (Regression Testing) — это вид
тестирования направленный на проверку
изменений, сделанных в приложении или
окружающей среде (починка дефекта,
слияние кода, миграция на другую
операционную систему, базу данных, веб
сервер или сервер приложения), для
подтверждения того факта, что существующая
ранее функциональность работает как
и прежде. Как правило, для регрессионного
тестирования используются тест кейсы,
написанные на ранних стадиях разработки
и тестирования. Это дает гарантию того,
что изменения в новой версии приложения
не повредили уже существующую
функциональность.
Регрессия багов (Bug regression) — попытка
доказать, что исправленная ошибка на
самом деле не исправлена.
Регрессия старых багов (Old bugs regression) —
попытка доказать, что недавнее изменение
кода или данных сломало исправление
старых ошибок, т.е. старые баги стали
снова воспроизводиться.
Регрессия побочного эффекта (Side effect
regression) — попытка доказать, что недавнее
изменение кода или данных сломало другие
части разрабатываемого приложения.
-
Тестирование
сборки (Build
Verification Test).
Тестирование направленное на определение
соответствия, выпущенной версии,
критериям качества для начала тестирования.
По своим целям является аналогом Дымового
Тестирования, направленного на приемку
новой версии в дальнейшее тестирование
или эксплуатацию. Вглубь оно может
проникать дальше, в зависимости от
требований к качеству выпущенной версии.
-
Санитарное
тестирование или проверка
согласованности/исправности (Sanity
Testing).
Санитарное тестирование — это
узконаправленное тестирование достаточное
для доказательства того, что конкретная
функция работает согласно заявленным
в спецификации требованиям. Является
подмножеством регрессионного тестирования.
Используется для определения
работоспособности определенной части
приложения после изменений произведенных
в ней или окружающей среде. Обычно
выполняется вручную.
1.1.6. Внедрение тестирования
Необходимо рассмотреть варианты и
процесс внедрения тестирования на
различных стадиях создания проекта.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Привет, Вы узнаете про регрессионное тестирование, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
регрессионное тестирование, regression testing , настоятельно рекомендую прочитать все из категории Качество и тестирование программного обеспечения. Quality Assurance..
регрессионное тестирование — это вид тестирования направленный на проверку изменений, сделанных в приложении или окружающей среде (починка дефекта, слияние кода, миграция на другую операционную систему, базу данных, веб сервер или сервер приложения), для подтверждения того факта, что существующая ранее функциональность работает как и прежде (см. также Санитарное тестирование или проверка согласованности/исправности). Регрессионными могут быть какфункциональные, так и нефункциональные тесты.
Как правило, для регрессионного тестирования используются тест кейсы, написанные на ранних стадиях разработки и тестирования. Это дает гарантию того, что изменения в новой версии приложения не повредили уже существующую функциональность. Рекомендуется делатьавтоматизацию регрессионных тестов, для ускорения последующего процесса тестирования и обнаружения дефектов на ранних стадиях разработки программного обеспечения.
Сам по себе термин «Регрессионное тестирование», в зависимости от контекста использования может иметь разный смысл. Сэм Канер, к примеру, описал 3 основных типа регрессионного тестирования:
- Регрессия багов (Bug regression) — попытка доказать, что исправленная ошибка на самом деле не исправлена
- Регрессия старых багов (Old bugs regression) — попытка доказать, что недавнее изменение кода или данных сломало исправление старых ошибок, т.е. старые баги стали снова воспроизводиться.
- Регрессия побочного эффекта (Side effect regression) — попытка доказать, что недавнее изменение кода или данных сломало другие части разрабатываемого приложения
Регрессио́нное тести́рование (англ. regression testing, от лат. regressio — движение назад) — собирательное название для всех видов тестирования программного обеспечения, направленных на обнаружение ошибок в уже протестированных участках исходного кода. Такие ошибки — когда после внесения изменений в программу перестает работать то, что должно было продолжать работать, — называют регрессионными ошибками (англ. regression bugs).
Регрессионное тестирование (по некоторым[каким?] источникам) включает new bug-fix — проверка исправления вновь найденного дефекта, old bug-fix — проверка, что исправленный ранее и верифицированный дефект не воспроизводится в системе снова, а также side-effect — проверка того, что не нарушилась работоспособность работающей ранее функциональности, если ее код мог быть затронут при исправлении некоторых дефектов в другой функциональности. Обычно используемые методы регрессионного тестирования включают повторные прогоны предыдущих тестов, а также проверки, не попали ли регрессионные ошибки в очередную версию в результате слияния кода.
Из опыта разработки ПО известно, что повторное появление одних и тех же ошибок — случай достаточно частый. Иногда это происходит из-за слабой техники управления версиями или по причине человеческой ошибки при работе с системой управления версиями. Но настолько же часто решение проблемы бывает «недолго живущим»: после следующего изменения в программе решение перестает работать. И наконец, при переписывании какой-либо части кода часто всплывают те же ошибки, что были в предыдущей реализации.
Поэтому считается хорошей практикой при исправлении ошибки создать тест на нее и регулярно прогонять его при последующих изменениях программы. Хотя регрессионное тестирование может быть выполнено и вручную, но чаще всего это делается с помощью специализированных программ, позволяющих выполнять все регрессионные тесты автоматически. В некоторых проектах даже используются инструменты для автоматического прогона регрессионных тестов через заданный интервал времени. Обычно это выполняется после каждой удачной компиляции (в небольших проектах) либо каждую ночь или каждую неделю.
Регрессионное тестирование является неотъемлемой частью экстремального программирования . Об этом говорит сайт https://intellect.icu . В этой методологии проектная документация заменяется на расширяемое, повторяемое и автоматизированное тестирование всего программного пакета на каждой стадии процесса разработки программного обеспечения.
Использование
Регрессионное тестирование может быть использовано не только для проверки корректности программы, часто оно также используется для оценки качества полученного результата. Так, при разработке компилятора при прогоне регрессионных тестов рассматривается размер получаемого кода, скорость его выполнения и время компиляции каждого из тестовых примеров.
Классификация
В своей статье S. Yoo and M. Harman предоставляют следующую классификацию регрессионного тестирования:
- Минимизация набора тестов (англ. test suite minimization) стремится уменьшить размер тестового набора за счет устранения избыточных тестовых примеров из тестового набора.
- Задача определения приоритетов теста (англ. test case prioritization). Ее цели заключаются в выполнении заказанных тестов на основе какого-либо критерия. Например, на основе истории, базы или требований, которые, как ожидается, приведут к более раннему выявлению неисправностей или помогут максимизировать некоторые другие полезные свойства.
- Задача выбора теста (англ. test case selection) связана с проблемой выбора подмножества тестов, которые будут использоваться для проверки измененных частей программного обеспечения. Для этого требуется выбрать подмножество тестов из предыдущей версии, которые могут обнаруживать неисправности, основываясь на различных стратегиях. Большинство задокументированных методов регрессионного тестирования сосредоточены именно на этой технике. Обычная стратегия состоит в том, чтобы сосредоточить внимание на отождествления модифицированных частей SUT (англ. SUT — system under test ) и для выбора тестовых случаев, имеющих отношение к ним. Например, техника полного повторного тестирования (англ. retest-all) – один из наивных типов выбора регрессивного теста путем повторного выполнения всех видов тестов от предыдущей версии на новой. Она часто используется в промышленности из-за ее простого и быстрого внедрения. Тем не менее, ее способность обнаружения неисправностей ограничена. Таким образом, значительный объем работ связан с разработкой эффективных и масштабируемых селективных методов.
- Гибридный тест. Является сочетанием задач на определение приоритетов и выбора.
Задача минимизации наборов
Тест минимизации наборов стремится уменьшить размер тестового набора путем устранения тестовых случаев из набора тестов на основе данного критерия. Существует три подхода, первый из которых применяет автоматизированное тестирование безопасности для обнаружения уязвимостей путем изучения неисправностей приложений, которые могут выявлять известные вредоносные программы, как вирусы или черви. Этот подход учитывает только проваленные тесты из предыдущей версии для повторного запуска в новой версии системы после устранения неисправности.
Другой же подход предназначен для обнаружения и устранения уязвимостей второстепенных релизов веб-приложений. В нем настраивается жесткая связь со страницами предыдущей версии при помощи итераторов, которые выбираются для изучения веб-страниц, которые содержат уязвимости.
И, наконец, третий подход предлагает тестирование с самоадаптацией системы для уже известных неудач. Авторы избегают воспроизведения уже известных ошибок, рассматривая только те тесты для выполнения, которые выявили известные неудачи в предыдущих версиях.
Задача с определением приоритетов
Тестовая задача на определение приоритетов касается правильного упорядочения тестов, что максимизирует желаемые свойства, такие как раннее выявление неисправностей. Кроме того, в настоящее время подходы к расстановке приоритетов рассматривают только уязвимости.
Один из методов предлагает основанные на ошибках приоритетные тесты, которые непосредственно используют знание об их способности обнаруживать неисправности.
Другой же предлагает изменяемую систему записи-воспроизведения, которая позволяет переписать записанную исполненную версию приложения в новую, модифицированную. Их выполнение является приоритетным из-за определения оптимального изменяемого переписывания на основе функции затрат и измерения разности между первоначальным исполнением и измененным при повторе.
Задача выбора тестов
Метод выбора позволяет выбрать подмножество или все тестовые случаи, чтобы проверить измененные части программного обеспечения. Следующие подходы тестируют механизмы и безопасности, и уязвимости.
- Подход, основанный на диаграмме состояния (UML-based), регрессионного тестирования для требований безопасности аутентификации, конфиденциальности, доступности, авторизации и целостность. Тесты, представленные в виде диаграммы последовательности, выбираются на основе теста изменения требований.
- Подход к улучшению регрессионного тестирования на основе нефункциональных требований онтологий. Тесты выбираются на основе изменений и воздействий анализа нефункциональных требований, таких как безопасность, производительность и надежность. Каждый тест связан с измененным требованием, которое выбирается для регрессивного тестирования.
- Подход для обеспечения проверки дополнительных доказательств для сертификации требований безопасности услуг. Этот подход основан на обнаружении изменений в тестовой модели обслуживания, которая будет определять, должны ли быть созданы новые тестовые случаи или существующие будут отобраны для повторного выполнения на выделенном сервисе.
- Подход к разработке безопасных систем оцениваемых по общим критериям. В этом подходе тестовые задания по требованиям безопасности создаются вручную и представлены в виде диаграммы последовательности. В случае изменения при необходимости пишутся новые тесты, а затем все тесты выполняются на новой версии.
- Подход к требованиям тестирования безопасности веб-сервиса релизов. Пользователь службы может периодически повторно выполнить набор тестов, направленных против сервиса чтобы проверить, что пользователь по-прежнему обладает правильными правами.
- Coverage-based метод отбора для эволюционного тестирования политик безопасности, каждая из которых включает в себя последовательность правил для определения, какие кто имеет допуск к ресурсу и при каких условиях.
Преимущества и недостатки
Регрессионное тестирование выполняется при внесении изменений в существующие функциональные возможности программного обеспечения или, если есть ошибка исправления в программном обеспечении. Регрессионное тестирование может быть реализовано за счет нескольких подходов. Прохождение модифицированной программой всех тестов успешно обеспечивает уверенность в том, что изменения, внесенные в программное обеспечение, не повлияли на существующие функциональные возможности, которые должны быть неизменными в любом случае.
В гибком процессе управления проектами, где жизненный цикл разработки программного обеспечения очень короткий, не хватает ресурсов, и изменения в программное обеспечение вносятся очень часто. Регрессионное тестирование может ввести много ненужных накладных расходов.
Как правило, регрессионное тестирование осуществляется с помощью средств автоматизации, но нынешнее поколение инструментов регрессионного тестирования не предназначено для обработки приложений баз данных. По этой причине при выполнении регрессионного теста на приложениях, использующих базы данных, могут возникнуть незапланированные траты, поскольку это потребует много ручного труда.
Цитаты
Фундаментальная проблема при сопровождении программ состоит в том, что исправление одной ошибки с большой вероятностью (20—50 %) влечет появление новой. Поэтому весь процесс идет по принципу «два шага вперед, шаг назад».
Почему не удается устранять ошибки более аккуратно? Во-первых, даже скрытый дефект проявляет себя как отказ в каком-то одном месте. В действительности же он часто имеет разветвления по всей системе, обычно неочевидные. Всякая попытка исправить его минимальными усилиями приведет к исправлению локального и очевидного, но если только структура не является очень ясной, или документация очень хорошей, отдаленные последствия этого исправления останутся незамеченными. Во-вторых, ошибки обычно исправляет не автор программы, а зачастую младший программист или стажер.
Вследствие внесения новых ошибок сопровождение программы требует значительно больше системной отладки на каждый оператор, чем при любом другом виде программирования. Теоретически, после каждого исправления нужно прогнать весь набор контрольных примеров, по которым система проверялась раньше, чтобы убедиться, что она каким-нибудь непонятным образом не повредилась. На практике такое возвратное (регрессионное) тестирование действительно должно приближаться к этому теоретическому идеалу, и оно очень дорого стоит.
— Ф. Брукс Мифический человеко-месяц или как создаются программные системы
См. Также
- Контроль качества
- Разработка через тестирование
- Дымовое тестирование
К сожалению, в одной статье не просто дать все знания про регрессионное тестирование. Но я — старался.
Если ты проявишь интерес к раскрытию подробностей,я обязательно напишу продолжение! Надеюсь, что теперь ты понял что такое регрессионное тестирование, regression testing
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Качество и тестирование программного обеспечения. Quality Assurance.

Часть речи
Говоря о том, как пишется «исправлено», стоит отметить, что огромное значение оказывает то, какой частью речи выражена конструкция. Однако определить это может быть не так просто, как кажется. Очень многие писатели путают слово с другими частями речи, в результате чего применяют к нему совершенно неподходящее правило и делают в тексте массу ошибок. Единственно верный вариант — провести синтаксический анализ предложения, в котором употреблено интересующее слово: «Я не мог верить тому, что все было исправлено, поскольку список выглядел точно так же, как и в предыдущем случае». Однако делать это нужно по инструкции:

- Найти грамматическую основу предложения, то есть определить его главные члены. Для этого необходимо внимательно прочитать конструкцию и понять, о чем в ней говорится. Вот все подлежащие и сказуемые: «я не могу верить», «все было исправлено», «список выглядел точно так же».
- Определить второстепенные члены предложения. Делать это необходимо даже в том случае, если то, чем выражена интересующая конструкция, уже определено. Ведь нередко бывает так, что какое-нибудь наречие или краткое причастие, которое должно было выступать в роли именной части сказуемого, попросту «зависает» в тексте.
- Надписать над каждым словом, чем именно оно выражено. Чтобы определить это с максимальной точностью, необходимо знать не только то, на какие вопросы отвечает та или иная часть речи, но и какую роль она выполняет. К примеру, прилагательные обозначают признак предмета, а наречия — признак действия.
Пользуясь этой инструкцией, можно определить, что слово «не исправлено» является второй частью составного именного сказуемого. Из школьного курса известно, что оно может быть выражено практически любой частью речи, однако, задав от главного слова вопрос к зависимому — было каково? — исправлено, можно сделать вывод о том, что приходится иметь дело с кратким причастием. Об этом же свидетельствует и лексическое значение конструкции «все исправлено» — обозначает признак предмета и отвечает на тот вопрос, который характерен для краткого причастия.
Морфологический разбор
Чтобы понять, как правильно писать «исправлено», будет весьма полезно определить, как именно было образовано слово. Сделать это не так сложно, если знать, что краткие формы страдательных причастий образуются от полных путем усечения окончания. Вот несколько примеров:
- исправленный документ — документ исправлен;
- исправленное правило — правило исправлено;
- исправленная конструкция — конструкция исправлена.
Аналогичное правило действует в отношении слова правленные.

Из примеров становится понятно, что усекается не только несколько букв из окончания, но и одна буква «н» из суффикса. Это характерно для каждого краткого причастия, благодаря чему можно сделать вывод о том, что эта часть речи всегда пишется с одной буквой «н» в суффиксе. Причем наличие противопоставления или зависимых слов в предложении никак не отразится на этом. Писатель просто должен запомнить, что в кратких причастиях пишется всего одна буква «н».
Стоит отметить, что такой способ образования характерен только для тех случаев, когда речь идет о прошедшем времени. Если же необходимо образовать форму настоящего времени, то делается это путем отсечения окончания «им», «ом» или «ем». Вот лишь три наиболее простых примера:
- изучаемый курс — курс изучаем;
- хранимый артефакт — артефакт храним;
- выполняемый доклад — доклад выполняем.
Также стоит отметить, что это касается и тех слов, которые имеют в своем составе отрицательную приставку «не», например, неисправленный — не исправлено или не исправленный — не исправлено. Наличие «не» в слове никак не отражается на правоприменение по поводу «н» или «нн» в суффиксе, однако правописание отрицательной частицы с кратким причастием — тема, которая сама по себе заслуживает отдельного упоминания.
Из всего этого можно сделать вывод о том, что в кратких причастиях прошедшего времени в любом случае будет писаться в суффиксе одна «н».
Однако сложность темы заключается вовсе не в том, что столь простую истину трудно запомнить. Просто очень многие писатели путают причастия с другими частями речи, поскольку сходство действительно практически идентично. Именно поэтому так важно уметь правильно проводить синтаксический анализ, а также знать некоторые приемы, которые помогут упростить работу.
Отглагольные прилагательные
Из курса 10 класса старшей школы ученикам стало известно, что помимо причастий в русском языке также присутствуют отглагольные прилагательные (ОП), которые очень сильно похожи друг на друга по внешнему виду, но имеют принципиально разные лексические значения. Вот несколько примеров:
- летящие листья (причастие) — летучие облака (ОП);
- позолоченный рожок (причастие) — золоченое кольцо (ОП);
- раненный в руку (причастие) — раненый солдат (ОП);
- рассеянные тучи (причастие) — рассеянный мальчик (прилагательное).

Само собой, правописание «н» и «нн» в кратких прилагательных и причастиях совершенно отличается, поэтому важно научиться отличать эти части речи друг от друга. Сделать это можно сразу несколькими способами:

- Взглянуть на лексическое значение конструкции. Причастия обычно говорят о том, что действие совершалось в определенный промежуток времени: «Мне довелось подправить рукопись, используя для этого ручку, которая была неисправлена» (прошедшее время, а отглагольные прилагательные, образованные от глаголов, обычно обозначают постоянный признак предмета: «Ручка неисправлена (в настоящий момент), поэтому я не могу отредактировать статью, провести проверочную работу или хотя бы написать заявление или договор».
- Посмотреть на наличие приставок в слове. Только в причастиях (полных или кратких) будет находиться приставка «по», а в ОП ее не будет — «Исправлять недочеты позолоченного украшения — все равно что откорректировать запись на листке бумаги» и «Для того, чтобы подправить недочет в золоченом кольце, мне потребуется устранить все неровности с помощью шлифовальной машинки». Само собой, применить этот пункт получается далеко не всегда, однако он может быть крайне полезным в некоторых случаях.
- Взглянуть на наличие зависимых (пояснительных слов). У причастия они могут иметься, причем в довольно большом количестве: «Раненный в левую руку солдат пытался починить уже давно исправленный механиком автомобиль». В ОП пояснительные конструкции всегда будут отсутствовать: «Раненый солдат писал письмо матери по заранее составленному образцу» — тоже весьма полезный способ, который позволяет быстро найти причастия (особенно краткие) на письме.
- Попробовать заменить конструкцию придаточным определительным. Вместо причастий обычно можно поставить глагол со словом «который» — лепестки рассеяны ветром — лепестки, которые рассеял ветер. С отглагольными прилагательными удается лишь подобрать синоним: рассеянный ребенок — невнимательный ребенок. Именно этим методом предпочитает пользоваться большинство учеников и писателей, поскольку он является практически беспроигрышным.
Таким образом, если правильно определить часть речи, то удастся подобрать правило, которое подходит к конкретному случаю. Но сколько же букв «н» писать в отглагольном прилагательном, если его все-таки удастся найти?
Правило «н» и «нн» в ОП
Если выйдеттак, что слово «исправлено» выражено не причастием, а отглагольным прилагательным, то к нему придется применять совершенно другое правило. Кроме того, придется обратить внимание на наличие определенных слов внутри самой конструкции. Правило, что в кратких прилагательных (пусть и отглагольных) пишется столько же букв «н», сколько и в полных, от которых они образованы. В начальной же форме «нн» пишется в следующих случаях:

- Если прилагательное образовано от глагола совершенного вида (укороченный, проведенный, сложенный и так далее). Определить их можно по вопросу, в котором имеется приставка «с» (что сделать? — укоротить, провести, сложить). Исключение составляют несколько устоявшихся слов, правописание которых следует смотреть в орфографическом словаре: контуженый (солдат), раненый (офицер), названый (отец).
- Если слово оканчивается на «ованный» или «еванный», например, неорганизованный, малеванный, избалованный и так далее. Исключение составляют слова: клеваный, жеваный, кованый.
- В прилагательных — неожиданный, чеканный, нечаянный, медленный, священный, неслыханный, желанный, негаданный, невиданный, нежданный — в этих исключениях всегда пишется две буквы «н».
Слово «исправлено» (в роли краткого прилагательного) не относится к исключениям, поэтому в суффиксе вполне может писаться 2 буквы «н» в том случае, если оно образовано от глагола совершенного вида (что сделать?) «исправить». Однако справедливости ради стоит отметить, что в большинстве случаев конструкция будет являться все-таки причастием, а это значит, что в краткой форме будет писаться всего одна «н».
Значение слова «исправить»
Тема с одной и двумя буквами «н» в кратких причастиях и кратких отглагольных прилагательных является одной из самых сложных в русском языке, поскольку даже эксперту не всегда с первого раза понятно, какая именно часть речи находится перед ним. Однако если часто иметь дело с теми или иными конструкциями, то у человека может выработаться интуиция. В будущем шестое чувство будет подсказывать, сколько букв «н» нужно вставить в конструкции в данном случае, поскольку мозг уже имел дело с похожим случаем когда-то давно. Однако для этого придется научиться разбираться в лексических значениях похожих слов:

- исправлено (КП) — что-то было кем-то исправлено и теперь его можно использовать;
- исправлено (краткое ОП) — что-то отличается хорошими качествами на данный момент;
- исправиться (глагол СВ) — провести работу над собой в лучшую сторону;
- исправляться (глагол СВ в настоящем времени) — проводить работу над собой в данный момент;
- исправимый (отглагольное прилагательное) — что-то подлежит возможности изменения в лучшую сторону;
- поправить (глагол с приставкой «по») — провести какую-то мелкую доработку, например, заправить двигатель маслом;
- исправный (ОП) — предмет, находящийся в рабочем состоянии и не нуждающийся в восстановлении;
- исправление (существительное) — работа, проводимая с целью улучшить качества предмета;
- исправленый — (полное причастие) — предмет, который был кем-то исправлен в прошлом;
- правленый — (причастие без приставки) — объект, который был слегка усовершенствован.

И это лишь основные лексические формы, которые встречаются на письме гораздо чаще других. За более детальной информацией можно обратиться к специальному справочнику. Само собой, запомнить все «переводы» слов из орфографического словаря будет невозможно, однако у каждого человека есть интуиция, которая позволяет примерно сопоставлять различные слова в одной категории, чтобы подбирать к ним одно и то же подходящее правило.
Если научиться верно находить лексическое значение, то со временем даже не потребуется задумываться над тем, почему в одном случае пишется «н», а другом — «нн». Интуиция просто будет подсказывать, как написать конструкцию, и в большинстве случаев окажется полностью права. Нужно лишь как можно больше времени уделять синтаксическим разборам и чтению, чтобы увеличивать свой словарный запас.
Еще слова со сложным написанием:
- откорректированный
Морфологический разбор «исправлены»
На чтение 3 мин. Опубликовано 26.02.2021
В данной статье мы рассмотрим слово «исправлены», являющееся причастием. Ниже мы дадим морфологический разбор слова и укажем его возможные синтаксические роли.
Если вы хотите разобрать другое слово, то укажите его в форме поиска.
«Исправлены» (причастие)
Значение слова «исправить» по словарю С. И. Ожегова
- Сделать лучше, освободив от каких-нибудь недостатков, пороков
- Устранить в чем-нибудь неисправность, повреждение, недостатки
Морфологический разбор причастия
- I Часть речи: причастие;
- IIНачальная форма: исправить;
- IIIМорфологические признаки:
- А. Постоянные признаки:
- страдательное
- невозвратное
- переходное
- прошедшее время
- совершенный вид
- Б. Непостоянные признаки:
-
- множественное число, краткая форма
- IV Синтаксическая роль:
Полная и краткая форма страдательных причастий (совершенный вид)
| Форма | Мужской род | Средний род | Женский род | Множественное число |
|---|---|---|---|---|
| полная | Какой?исправленный | Какое?исправленное | Какая?исправленная | Какие?исправленные |
| краткая | Каков?исправлен | Каково?исправлено | Какова?исправлена | Каковы?исправлены |
Падежи страдательных причастий (совершенный вид)
| Падеж | Мужской род | Средний род | Женский род | Множественное число |
|---|---|---|---|---|
| именительный | Какой?исправленный | Какое?исправленное | Какая?исправленная | Какие?исправленные |
| родительный | Какого?исправленного | Какого?исправленного | Какой?исправленной | Каких?исправленных |
| дательный | Какому?исправленному | Какому?исправленному | Какой?исправленной | Каким?исправленным |
| винительный | Какого? Какой?исправленного, исправленный | Какого? Какое?исправленное | Какую?исправленную | Каких? Какие?исправленные, исправленных |
| творительный | Каким?исправленным | Каким?исправленным | Какой?исправленною, исправленной | Каким?исправленными |
| предложный | О каком?исправленном | О каком?исправленном | О какой?исправленной | О каких?исправленных |
Разобрать другое слово
Введите слово для разбора:Найти
Причастия совершенного вида образуются от глаголов совершенного вида и обозначают завершённое действие.
Совершенного вида могут быть и действительные, и страдательные причастия прошедшего времени:
- действительное: дедушка, починивший машину — дедушка, который (что сделал?) починил машину;
- страдательное: игрушка, купленная в магазине — игрушка, которую (что сделали?) купили в магазине.
Невозвратные причастия образуются от невозвратных глаголов (без постфикса -ся (-сь)). Могут быть:
- переходными и непереходными: мама, одевающая дочку (перех.); собака, идущая на поводке (неперех.);
- действительными и страдательными: дети, гуляющие в парке (действ.); обед, приготовленный бабушкой (страд.).
Переходные причастия образуются от переходных глаголов, обозначают, что действие направлено на другой объект.
Могут сочетаться с существительными и местоимениями в винительном падеже (вопросы «кого?», «что?») без предлога.
Страдательные причастия обозначают признак предмета, над которым совершил действие кто-то другой.
Могут быть:
- прошедшего и настоящего времени: мороженое, купленное мамой (прош. вр.); звук, слышимый издалека (наст. вр.);
- совершенного (только в прошедшем времени) и несовершенного вида: чемодан, собранный в поездку (сов.); чемодан, собираемый в поездку (несов.);
- полными и краткими: посуда (какая?), вымытая дочкой (полн.); посуда (какова?) вымыта дочкой (крат.).
Страдательные причастия образуются только от переходных глаголов.
Краткие причастия отвечают на вопросы «каков?», «какова?», «каково?», «каковы?» и бывают только страдательными:
- клубника (какова?) выращена на грядке, трава (какова?) скошена газонокосилкой, девочки (каковы?) одеты нарядно, звук (каков?) слышим издалека.
Краткие причастия меняются по числам и родам, но не склоняются по падежам.
→
исправлены — кр. причастие, прош. вр., страд, мн. ч.
Часть речи: инфинитив — исправить
Часть речи: глагол
Часть речи: деепричастие
Часть речи: причастие
Действительное причастие:
| Настоящее время | ||||
|---|---|---|---|---|
| Единственное число | Множественное число | |||
| Мужской род | Женский род | Средний род | ||
| Им. | ||||
| Рд. | ||||
| Дт. | ||||
| Вн. | ||||
| Тв. | ||||
| Пр. |
Страдательное причастие:
| Настоящее время | ||||
|---|---|---|---|---|
| Единственное число | Множественное число | |||
| Мужской род | Женский род | Средний род | ||
| Им. | ||||
| Рд. | ||||
| Дт. | ||||
| Вн. | ||||
| Тв. | ||||
| Пр. |
Часть речи: кр. причастие
Страдательное причастие:
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Ошибка в написании слова «исправлено» – распространённое явление. Многие люди не знают, как правильно – «исправлено» или «исправленно», и оттого совершают ошибки. Как этого избежать?
Читайте в статье
- Как правильно и почему?
- Морфемный разбор
- Примеры предложений
- Синонимы
- Неправильное написание
- Резюме
Как правильно и почему?
Ключом к разгадке станет понимание того, какой частью речи является слово «исправлено».
Это – краткое причастие, образованное от причастия в страдательном залоге «исправленный». Оно даёт ответ на вопрос «что сделано?». Казалось бы, раз в «родном» слове двойная «н», то и в производных от него должна сохраняться эта особенность. Но нет, это так не работает.
Правило гласит, что краткие страдательные причастия имеют одну букву «н», и наличие двух таких букв у «родной» лексемы на это не влияет. То есть, единственный правильный вариант тут – «исправлено». Правило работает во всех случаях: «зачитанный» – «зачитано», «просмотренный» – «просмотрено», и далее по аналогии.
Морфемный разбор
Итак, написание слова мы уже прояснили. Следующий шаг – разбор на структурные части:
исправлено
- корень – «правл»;
- «ис» – приставка;
- «ен» – суффикс;
- основа слова – «исправлен»;
- «о» – окончание.
Примеры предложений
В закреплении изученного (вот, кстати: «изученное», но «изучено»!) помогут несколько образцов фраз с этой лексемой:
- В журнале корректором исправлено число. Очевидно, проделки шаловливых учеников.
- Всё, в чём я наломал дров, может быть мною же исправлено.
- Наше плачевное положение сейчас, наконец, исправлено: это можно констатировать.
- Это заявление исправлено Вашей рукой?
Синонимы
Данное слово можно заменить в предложении одним из смысловых аналогов:
- поправлено;
- подправлено;
- подкорректировано;
- отремонтировано;
- отредактировано;
- починено;
- отрегулировано;
- отреставрировано.
Неправильное написание
Писать это слово с двумя «н» – «исправленно» – нарушение лексических норм. Это противоречит правилам.
Резюме
Краткое причастие «исправлено» имеет только один правильный способ написания – с одной «н».
Это регламентировано правилами написания кратких страдательных причастий. Слово «исправленно» является ошибочным.