
Optical Character Recognition, commonly referred to as OCR, is the process of converting scanned images of letters and words into a electronic versions. For example, you can use the Recognize Text feature in Acrobat DC to convert an image of a page into a searchable version in which you can select text, comment on it and even edit it.
OCR is an imperfect process. While some very good originals will process at or near 100% accuracy, if you feed Acrobat a poor quality document, results will suffer. So, yes, a fax of a fax of fax is not going to OCR well. Scanned documents may also contain handwriting which seldom is recognized as text.
OCR affects search quality and that should be a concern to legal professionals. Consider a contract that may be part of your case. Perhaps the only place your client’s name can be found in the document is in handwritten Name and Signature fields.
If you use Acrobat (or other tools) to search for your client name, no result will be returned. Since your client’s name is an important term for most cases, you might want to consider correcting key documents to enhance search results.
Fortunately, Acrobat DC includes tools to help you audit OCR quality and correct OCR errors.
Auditing OCR Quality
Acrobat offers a feature in Preflight called “Make OCR Text Visible” which can help you audit OCR quality. Here’s how to use it:
- OCR the document or open a previously OCR’d document.
Tip: Choose the Enhance Scans option in the Right Hand Pane, then choose Recognize Text - In the Right Hand Pane
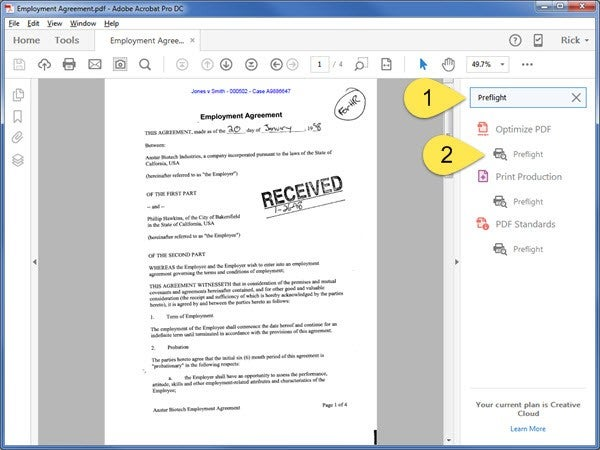
- Enter Preflight in the search field
- Click the Preflight tool
-

- The Preflight window opens.
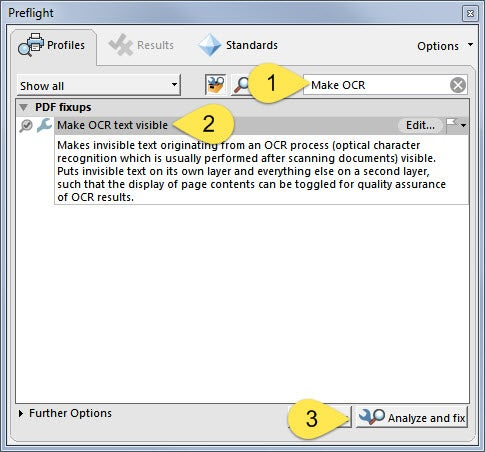
- In the search field, enter Make OCR
- Select the Make OCR text visible fixup function
- Click Analyze and Fix
-

- Acrobat will ask you to renamed the file. I suggest adding “_QA” to the file name.
Looking at the Results
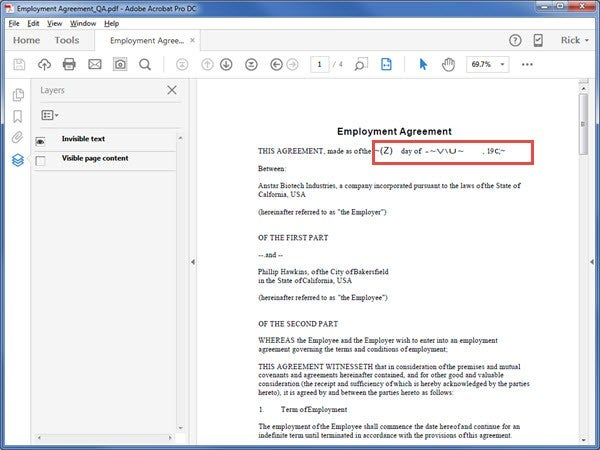
To QA the document, first open the Layers Panel in the file:
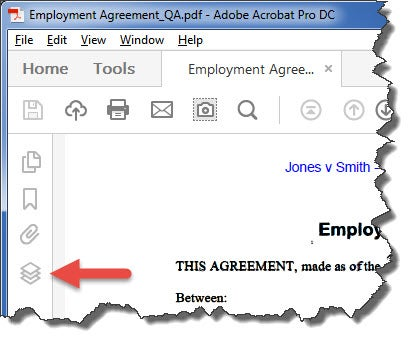
The Layers panel show two layers:
- Invisible text
- Visible Page Content
In the image below, both layers are turned on which means that the original scanned image is showing.
I added a red oiutline to some handwritten text in the document. Do you think Acrobat will recognize the handwriting? Let’s see . . .
Click the Visible Page Content eyeball to turn the layer off:
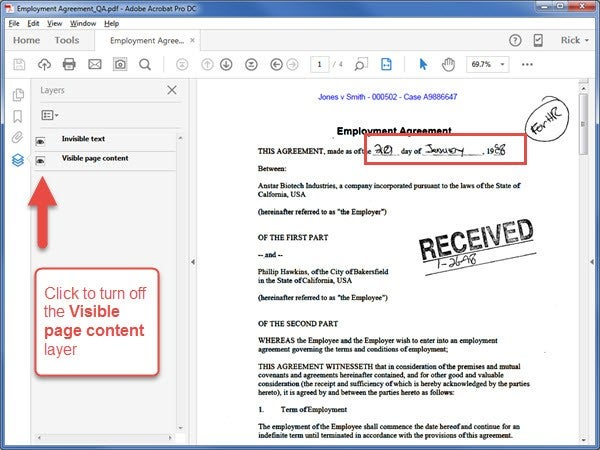
Now, only the OCR text is visible in the document. I’ve added a red outline to show you that Acrobat did not recognize the handwritten text.
Correcting OCR Text in Acrobat
Acrobat makes it possible to correct OCR errors to enhance search quality. This can be a time-consuming process, but may be worthwhile when archiving high-value documents or in situations where you can identify certain documents in a case for which you want to ensure good search results.
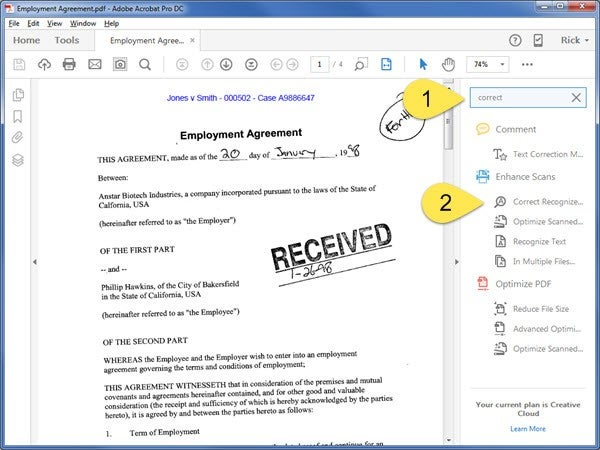
To correct OCR in document:
- OCR the document or open a previously OCR’d document
- In the Right Hand Panel:
- Click in the Search field and type “Correct”
- Click Correct Recognized Text
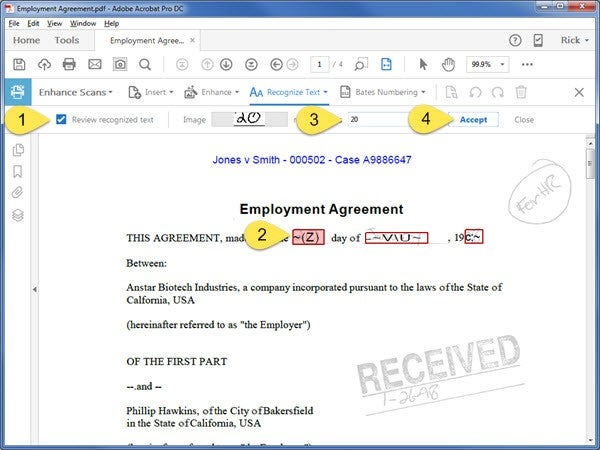
- The Correct Text function appears
- Enable Review Recognized text
- Select a suspect on the page. It will be highlighted in red.
- Enter the correct text for the error
- Click the Accept button
Your Corrections are Found
Tap CMD/CTRL-F to open the Find widget.
Once corrections are made, Acrobat will find the corrected text, even the text you have assigned to handwritten portions of the document:

Tips for Correcting Text
- You can toggle “Review Recognized Text” on or off to see the original scanned text
- You can make all corrections “mouse free”. Simply hit TAB to move the cursor to the correction text field and Enter to Accept.
- Your document may contain artifacts such as smudges or marks which Acrobat could see as text. Simply clear the correction text field and Acrobat will show “This is not text” in the correction field:
-

- You can assign Preflight steps such as “Make OCR Visible” and other steps mentioned in this article to Actions which let you automate multi-step processes.
Оптическое распознавание символов (OCR) может быть лучше, чем нарезанный хлеб, для тех, кто должен преобразовывать страницы текста в редактируемый текст. может быть, у вас есть страницы текста, которые вы сканируете на свой компьютер, и теперь их нужно преобразовать в редактируемую форму. Может быть, не хватает времени, чтобы печатать, или просто слишком много, чтобы печатать. Что ж, оптическое распознавание символов может помочь именно в этом. Вы можете отсканировать страницы на компьютер и открыть их с помощью Adobe Acrobat и попытаться использовать функцию распознавания текста, чтобы распознать текст и предоставить редактируемую версию. Как только вы собираетесь исполнить танец победы, вы получаете сообщение об ошибке Acrobat не может выполнить распознавание (OCR) на этой странице, поскольку эта страница содержит отображаемый текст.
Acrobat Professional имеет возможности OCR, которые позволяют сохранять отсканированные документы в формате RTF или в виде документов Microsoft Word, как Doc, так и Docx. Может быть случай, когда вы открываете документ в Adobe Acrobat Professional и видите текст, однако Acrobat выдает ошибку. Acrobat не может использовать OCR для текста, это может быть вызвано несколькими причинами.
- Рендерируемый/редактируемый текст
- Искаженный или размытый источник
- Некачественный оригинал
- Графика и формы
Acrobat не смог выполнить распознавание (OCR) на этой странице, поскольку эта страница содержит отображаемый текст.
1]Рендерируемый/редактируемый текст
Воспроизводимый текст — это редактируемый текст, существующий в файле, для которого вы хотите выполнить распознавание символов. Acrobat не может выполнять распознавание текста в документе, содержащем отображаемый текст. Это наименее очевидная причина ошибки сканирования OCR, потому что мы всегда предполагаем, что читаемый текст также должен сканироваться OCR.
Решение:
Есть два способа справиться с ошибкой, если это проблема.
- Попытайтесь получить копию документа, в котором нет отображаемого текста.
- Преобразуйте PDF в TIFF, затем обратно в PDF и повторите попытку распознавания текста.
Чтобы преобразовать PDF в TIFF, откройте его в Acrobat и выберите «Файл», затем «Сохранить как». Когда появится диалоговое окно «Сохранить как», выберите TIFF (*.tif, *.tiff) в списке «Тип файла». Укажите место, где вы хотите сохранить файл, затем нажмите «Сохранить». Acrobat сохраняет каждую страницу PDF-документа в виде отдельного последовательно пронумерованного файла TIFF. Затем вы открываете каждый из файлов TIFF и используете Acrobat для их распознавания.
Если вы хотите объединить документы в один, сделайте следующее:
- Откройте Acrobat, выберите «Файл», затем «Создать PDF», затем «Из нескольких файлов».
- Нажмите кнопку Обзор, чтобы выбрать и добавить каждый файл PDF. Расположите файлы так, как вы хотите, чтобы они отображались в новом PDF-файле.
- Выберите ОК.
2]Искаженный или размытый источник
Размытый документ
Еще одна причина, по которой Acrobat не может выполнить распознавание текста в документе, заключается в том, что он имеет низкое разрешение. Документы с низким разрешением могут стать размытыми, и Acrobat не сможет выполнять для них распознавание символов.
Решение:
Получите источник документа с высоким разрешением. Если вы сканируете бумажный документ, отрегулируйте разрешение сканера так, чтобы он выполнял сканирование с более высоким разрешением.
Искаженный документ
Возможно, Acrobat не сможет выполнить распознавание текста в документе, который не выровнен должным образом. Возможно, документ был отсканирован неправильно, поэтому Acrobat не может выполнить для него распознавание символов.
Решение:
Перед началом сканирования убедитесь, что бумага, с которой вы сканируете, ровная. Вы также можете открыть искаженный документ в Photoshop и выпрямить его. Вот пост, который покажет вам, как использовать инструмент выпрямления в фотошопе. Этот инструмент может помочь вам выпрямить отсканированный документ перед выполнением оптического распознавания символов в Acrobat.
3]Некачественный оригинал
Если исходный материал имеет низкое качество, например факс, Acrobat может не выполнить его распознавание должным образом. Затем вам придется стремиться получить лучшее качество или рискнуть исправить вывод.
Решение:
Получите источник лучшего качества для выполнения OCR. Если документ низкого качества — это все, что у вас есть, вам, возможно, придется запустить OCR и надеяться, что хотя бы некоторые из них будут распознаны, а затем ввести недостающие части.
4]Графика и формы
Документы, в которых смешаны графика и формы, не будут обрабатываться OCR в Acrobat. Документы, которые будут использоваться для OCR с помощью Acrobat, не должны содержать графики или смешанные формы, иначе это может привести к ошибке, или вывод может быть неверным.
Решение:
Найдите текстовую версию документа для выполнения оптического распознавания символов. Возможно, вам также придется выполнить распознавание документа с графикой и формами, если это сработает, вам, возможно, придется внести исправления в вывод.
Что такое OCR в Adobe Acrobat?
OCR — это процесс, с помощью которого Acrobat проверяет пиксельный текст или изображение. Каждый символ распознается и превращается в текст. Acrobat сравнивает форму изображения и толщину линии со шрифтами, уже установленными на вашем ПК, в процессе распознавания текста. Ниже приведены причины ошибки сканирования OCR.
Какой формат файла не подходит для OCR?
Формат файла JPEG не является лучшим для сохранения для OCR, поскольку JPEG имеет тенденцию терять свое качество при каждом сохранении. Даже если вы конвертируете JPEG в PDF, он все равно может иметь низкое качество. Лучше всего сохранять документы в формате PDF или TIFF, если вы собираетесь выполнять в них распознавание символов.
Тонны архивных бумаг, чеков и счетов проходят сканирование и оцифровку во многих отраслях: в розничной торговле, логистике, банковских услугах и т.п. Компании получают конкурентное преимущество, если быстро оцифровывают и находят нужную информацию.
В 2020 году нам тоже пришлось решать проблему качественной оцифровки документов, и над этим проектом мы с коллегами работали совместно с компанией Verigram. Вот как мы проводили оцифровку документов на примере заказа клиентом SIM-карты прямо из дома.
Оцифровка позволила нам автоматически заполнять юридические документы и заявки на услуги, а также открыла доступ к аналитике фискальных чеков, отслеживанию динамики цен и суммарных трат.
Для преобразования различных типов документов (отсканированные документы, PDF-файлы или фото с цифровой камеры) в редактируемые форматы с возможностью поиска мы используем технологию оптического распознавания символов – Optical Character Recognition (OCR).

Работа со стандартными документами: постановка задачи
Заказ SIM-карты для пользователя выглядит так:
-
пользователь решает заказать SIM-карту;
-
скачивает приложение;
-
фотографирует удостоверение личности для автоматического заполнения анкеты;
-
курьер доставляет SIM-карту.

Важно: пользователь фотографирует удостоверение личности своим смартфоном со специфическим разрешением камеры, качеством, архитектурой и другими особенностями. А на выходе мы получаем текстовое представление информации загруженного изображения.
Цель проекта OCR: построить быструю и точную кросc-платформенную модель, занимающую небольшой объем памяти на устройстве.

Верхнеуровневая последовательность обработки изображения стандартного документа выглядит так:
-
Выделяются границы документа, исключая не интересующий нас фон и исправляя перспективу изображения документа.
-
Выделяются интересующие нас поля: имя, фамилия, год рождения и т.п. На их основе можно построить модель предсказания соответствующего текстового представления для каждого поля.
-
Post-processing: модель вычищает предсказанный текст.

Локализация границ документа
Загруженное с камеры устройства изображение документа сравнивается с набором заранее подготовленных масок стандартных документов: фронтальная или задняя часть удостоверения, документ нового или старого образца, страницы паспорта или водительские права.

Предварительно делаем pre-processing обработку изображения и в результате ряда морфологических операций получаем соответствующее бинарное (черно-белое) представление.
Техника работает так: в каждом типе документа есть фиксированные поля, не меняющиеся по ширине и высоте. Например, название документа в правом верхнем углу как на картинке ниже. Они служат опорными полями, от которых рассчитывается расстояние до других полей документа. Если количество обнаруженных полей от опорного выше определенного порога для проверочной маски, мы останавливаемся на ней. Так подбирается подходящая маска.

Результат:
-
исправляется перспектива изображения;
-
определяется тип документа;
-
изображение обрезается по найденной маске c удалением фона.
В нашем примере мы выявили, что загруженное фото — это фронтальная часть удостоверения личности Республики Казахстан образца позднее 2014 года. Зная координаты полей, соответствующие этой маске, мы их локализуем и вырезаем для дальнейшей обработки.

Следующий этап — распознавание текста. Но перед этим расскажу, как происходит сбор данных для обучения модели.
Распознавание текста
Данные для обучения
Мы подготавливаем данные для обучения одним из следующих способов.
Первый способ используется, если достаточно реальных данных. Тогда мы выделяем и маркируем поля с помощью аннотационного инструмента CVAT. На выходе получаем XML-файл с названием полей и их атрибутами. Если вернуться к примеру, для обучения модели по распознаванию текста, на вход подаются всевозможные локализованные поля и их соответствующие текстовые представления, считающиеся истинными.

Но чаще всего реальных данных недостаточно или полученный набор не содержит весь словарь символов (например, в реальных данных могут не употребляться некоторые буквы вроде «ъ» или «ь»). Чтобы получить большой набор бесплатных данных и избежать ошибок аннотаторов при заполнении, можно создать синтетические данные с аугментацией.
Сначала генерируем рандомный текст на основе интересующего нас словаря (кириллица, латиница и т.п.) на белом фоне, накладываем на каждый текст 2D-трансформации (повороты, сдвиги, масштабирование и их комбинации), а затем склеиваем их в слово или текст. Другими словами, синтезируем текст на картинке.

Показательный пример 2D-трансформации представлен в библиотеке для Python Text-Image-Augmentation-python. На вход подается произвольное изображение (слева), к которому могут применяться разные виды искажений.




После 2D-трансформации на изображение текста добавляются композитные эффекты аугментации: блики, размытия, шумы в виде линий и точек, фон и прочее.

Так можно создать обучающую выборку.

Распознавание текста
Следующий этап — распознавание текста стандартного документа. Мы уже подобрали маску и вырезали поля с текстовой информацией. Дальше можно действовать одним из двух способов: сегментировать символы и распознавать каждый по отдельности или предсказывать текст целиком.
Посимвольное распознавание текста

В этом методе строится две модели. Первая сегментирует буквы: находит начало и конец каждого символа на изображении. Вторая модель распознает каждый символ по отдельности, а затем склеивает все символы.
Предсказывание локального текста без сегментации (end-2-end-решение)

Мы использовали второй вариант — распознавание текста без сегментирования на буквы, потому что этот метод оказался для нас менее трудозатратным и более производительным.
В теории, создается нейросетевая модель, которая выдает копию текста, изображение которого подается на вход. Так как текст на изображении может быть написан от руки, искажен, растянут или сжат, символы на выходе модели могут дублироваться.

Чтобы обойти проблему дублирования символов, добавим спецсимвол, например «-», в словарь. На этапе обучения каждое текстовое представление кодируется по следующим правилам декодировки:
-
два и более повторяющихся символа, встретившиеся до следующего спецсимвола, удаляются, остается только один;
-
повторение спецсимвола удаляется.

Так во время тренировочного процесса на вход подается изображение, которое проходит конволюционный и рекуррентный слои, после чего создается матрица вероятностей встречаемости символов на каждом шаге.

Истинное значение получает различные представления с соответствующей вероятностью за счет СТС-кодировки. Задача обучения — максимизировать сумму всех представлений истинного значения. После распознавания текста и выбора его представления проводится декодировка, описанная выше.
Архитектура модели по распознаванию текста
Мы попробовали обучить модель на разных архитектурах нейросетей с использованием и без использования рекуррентных слоев по схеме, описанной выше. В итоге остановились на варианте без использования рекуррентных слоев. Также для придания ускорения inference части, мы использовали идеи сетей MobileNet разных версий. Граф нашей модели выглядел так:

Методы декодирования
Хочу выделить два наиболее распространенных метода декодирования: CTC_Greedy_Decoder и Beam_Search.
CTC_Greedy_Decoder-метод на каждом шаге берет индекс, с наибольшей вероятностью соответствующий определенному символу. После чего удаляются дублирующиеся символы и спецсимвол, заданный при тренировке.
Метод «Beam_Search» — лучевой алгоритм, в основании которого лежит принцип: следующий предсказанный символ зависит от предыдущего предсказанного символа. Условные вероятности совстречаемости символов максимизируются и выводится итоговый текст.
Post-processing

Есть вероятность, что в продакшене при скоринге на новых данных модель может ошибаться. Нужно исключить такие моменты или заранее предупредить пользователя о том, что распознавание не получилось, и попросить переснять документ. В этом нам помогает простая процедура постобработки, которая может проверять на предсказание только ограниченного словаря для конкретного поля. Например, для числовых полей выдавать только число.
Другим примером постобработки являются поля с ограниченным набором значений, которые подбираются по словарю на основе редакторского расстояния. Проверка на допустимость значений: в поле даты рождения не могут быть даты 18 века.
Оптимизация модели
Техники оптимизации
На предыдущем этапе мы получили модель размером 600 килобайт, из-за чего распознавание были слишком медленным. Нужно было оптимизировать модель с фокусом на увеличение скорости распознавания текста и уменьшение размера.
В этом нам помогли следующие техники:
-
Квантование модели, при котором вычисления вещественных чисел переводятся в более быстрые целочисленные вычисления.

-
«Стрижка» (pruning) ненужных связей. Некоторые веса имеют маленькую магнитуду и оказывают малый эффект на предсказание, их можно обрезать.

-
Для увеличения скорости распознавания текста используются мобильные версии архитектур нейросеток, например, MobileNetV1 или MobileNetV2.
Так, в результате оптимизации мы получили снижение качества всего на 0,5 %, при этом скорость работы увеличилась в 6 раз, а размер модели снизился до 60 килобайт.
Вывод модели в продуктив
Процесс вывода модели в продуктив выглядит так:

Мы создаем 32-битную TensorFlow модель, замораживаем ее и сохраняем с дополнительными оптимизациями типа weight или unit pruning. Проводим дополнительное 8-битное квантование. После чего компилируем модель в Android- или iOS-библиотеку и деплоим ее в основной проект.
Рекомендации
-
На этапе развертывания задавайте статическое выделение тензоров в графе модели. Например, в нашем случае скорость увеличилась в два раза после указания фиксированного размера пакета (Batch size).
-
Не используйте LSTМ- и GRU-сети для обучения на синтетических данных, так как они проверяют совстречаемость символов. В случайно сгенерированных синтетических данных последовательность символов не соответствует реальной ситуации. Помимо этого они вызывают эффект уменьшения скорости, что важно для мобильных устройств, особенно для старых версий.
-
Аккуратно подбирайте шрифты для обучающей выборки. Подготовьте для вашего словаря набор шрифтов, допустимых для отрисовки интересующих символов. Например, шрифт OCR B Regular не подходит для кириллического словаря.

-
Пробуйте тренировать собственные модели, поскольку не все opensource-библиотеки могут подойти. Перед тем как тренировать собственные модели, мы пробовали Tesseract и ряд других решений. Так как мы планировали развертывать библиотеку на Android и iOS, их размер был слишком большим. Кроме того, качество распознавания этих библиотек было недостаточным.
Компьютерное распознавание визуального текста
 Воспроизвести медиа Видео процесса сканирования и оптического распознавания символов в реальном времени (OCR) с портативным сканером.
Воспроизвести медиа Видео процесса сканирования и оптического распознавания символов в реальном времени (OCR) с портативным сканером.
Оптическое распознавание символов или оптическое распознавание символов (OCR ) — это электронное или механическое преобразование изображений набранного, рукописного или напечатанного текста в машинно-кодированный текст, будь то из отсканированного документа, фотографии документа, фотографии сцены (например, текста на вывесках и рекламных щитах на альбомной фотографии) или из текста субтитров, наложенного на изображение (например, из телевизионной передачи).
Широко используется как форма ввода данных из печатных бумажных записей данных — будь то паспортные документы, счета-фактуры, выписки из банка, компьютеризированные квитанции, визитные карточки, почта, распечатки статических данных или любая подходящая документация — это распространенный метод оцифровки p закрашенные тексты, чтобы их можно было редактировать в электронном виде, искать, хранить более компактно, отображать в режиме онлайн и использовать в машинных процессах, таких как когнитивные вычисления, машинный перевод, (извлечение) преобразование текста в речь, ключевые данные и интеллектуальный анализ текста. OCR — это область исследований в области распознавания образов, искусственного интеллекта и компьютерного зрения.
. Ранние версии требовали обучения с изображениями каждого символа и работы с одним шрифтом. вовремя. В настоящее время распространены передовые системы, способные обеспечить высокую степень точности распознавания для большинства шрифтов, и с поддержкой различных входных форматов файлов цифровых изображений. Некоторые системы способны воспроизводить форматированный вывод, который близко соответствует исходной странице, включая изображения, столбцы и другие нетекстовые компоненты.
Содержание
- 1 История
- 1.1 Слепые и слабовидящие пользователи
- 2 Приложения
- 3 Типы
- 4 Методы
- 4.1 Предварительная обработка
- 4.2 Распознавание текста
- 4.3 Постобработка
- 4.4 Оптимизация для конкретных приложений
- 5 Обходные пути
- 5.1 Принудительное усиление ввода
- 5.2 Краудсорсинг
- 6 Точность
- 7 Unicode
- 8 См. Также
- 9 Ссылки
- 10 Внешние ссылки
История
Раннее оптическое распознавание символов можно проследить до технологий, включающих телеграфию и создание считывающих устройств для слепых. В 1914 году Эмануэль Голдберг разработал машину, которая считывала символы и преобразовывала их в стандартный телеграфный код. Одновременно Эдмунд Фурнье д’Альбе разработал Optophone, портативный сканер, который при перемещении по печатной странице выдавал тона, соответствующие определенным буквам или символам.
В конце 1920-х и в 1930-е годы Эмануэль Голдберг разработал то, что он назвал «статистической машиной» для поиска в архивах микрофильмов с использованием системы оптического распознавания кода. В 1931 году ему был выдан патент США № 1838389 на изобретение. Патент был приобретен IBM.
Слепыми и слабовидящими пользователями
В 1974 году Рэй Курцвейл основал компанию Kurzweil Computer Products, Inc. и продолжил разработку универсальных font OCR, который может распознавать текст, напечатанный практически любым шрифтом (Курцвейлу часто приписывают изобретение омни-шрифтового OCR, но оно использовалось компаниями, включая CompuScan, в конце 1960-х и 1970-х годах). Курцвейл решил, что лучшим применением этой технологии было бы создание читающей машины для слепых, которая позволила бы слепым людям читать им текст вслух с помощью компьютера. Это устройство потребовало изобретения двух технологий — планшетного сканера CCD и синтезатора текста в речь. 13 января 1976 года успешный готовый продукт был представлен во время широко освещаемой пресс-конференции, которую возглавили Курцвейл и руководители Национальной федерации слепых. В 1978 году компания Kurzweil Computer Products начала продавать коммерческую версию компьютерной программы оптического распознавания символов. LexisNexis был одним из первых клиентов и купил программу для загрузки юридических и новостных документов в свои зарождающиеся онлайн-базы данных. Два года спустя Курцвейл продал свою компанию Xerox, которая была заинтересована в дальнейшей коммерциализации преобразования текста с бумаги в компьютер. В конце концов Xerox выделила его под названием Scansoft, которое объединилось с Nuance Communications.
. В 2000-х годах OCR стало доступно онлайн как услуга (WebOCR) в облачных вычислениях , а также в мобильных приложениях, таких как перевод в реальном времени иноязычных знаков на смартфон. С появлением смартфонов и смарт-очков OCR можно использовать в приложениях для мобильных устройств, подключенных к Интернету, которые извлекают текст, снятый с помощью камеры устройства. Эти устройства, которые не имеют встроенных в операционную систему функций OCR, обычно используют OCR API для извлечения текста из файла изображения, захваченного и предоставленного устройством. OCR API возвращает извлеченный текст вместе с информацией о местоположении обнаруженного текста в исходном изображении обратно в приложение устройства для дальнейшей обработки (например, преобразования текста в речь) или отображения.
Для наиболее распространенных систем письма доступны различные коммерческие системы и системы распознавания текста с открытым исходным кодом, включая латиницу, кириллицу, арабский, иврит, индийский язык, бенгальский (Bangla), деванагари, тамильский, китайский, японский и корейские символы.
Приложения
Механизмы OCR были разработаны во многие виды приложений OCR для конкретных областей, таких как OCR квитанций, OCR счетов, OCR проверки, OCR юридических документов счетов.
Их можно использовать для:
- ввода данных для деловых документов, например Чек, паспорт, счет, выписка из банка и квитанция
- Автоматическое распознавание номерных знаков
- В аэропортах для распознавания паспорта и извлечения информации
- Автоматическое извлечение ключевой информации из страховых документов
- Распознавание дорожных знаков
- Извлечение информации с визитной карточки в список контактов
- Более быстрое создание текстовых версий печатных документов, например сканирование книг для Project Gutenberg
- Сделайте электронные изображения печатных документов доступными для поиска, например Google Книги
- Преобразование рукописного ввода в режиме реального времени для управления компьютером (перьевые вычисления )
- Обезвреживание CAPTCHA систем защиты от ботов, хотя они специально разработаны для предотвращения распознавания текста. также может использоваться для проверки надежности антибот-систем CAPTCHA.
- Вспомогательные технологии для слепых и слабовидящих пользователей
- Написание инструкций для транспортных средств путем идентификации изображений САПР в базе данных, которые подходят для конструкция транспортного средства изменяется в реальном времени.
- Обеспечение возможности поиска в отсканированных документах путем преобразования их в файлы PDF с возможностью поиска
Типы
- Оптическое распознавание символов (OCR) — нацелено на машинописный текст, один глиф или символов за раз.
- Оптическое распознавание слов — предназначено для машинописного текста, по одному слову за раз (для языков, в которых используется пробел как разделитель слов ). (Обычно просто «OCR».)
- Интеллектуальное распознавание символов (ICR) — также предназначено для рукописного печатного текста или курсив текст по одному глифу или символу, обычно с использованием машинного обучения.
- интеллектуального распознавания слов (IWR) — также предназначен для рукописного печатного текста или курсивного текст, по одному слову за раз. Это особенно полезно для языков, в которых глифы не разделяются курсивом.
OCR обычно является автономным процессом, который анализирует статический документ. Существуют облачные сервисы, которые предоставляют онлайн-сервис OCR API. Анализ движения рукописного ввода можно использовать в качестве входных данных для распознавания рукописного ввода. Вместо того, чтобы просто использовать формы глифов и слов, этот метод позволяет фиксировать движения, такие как порядок, в котором отрисовываются сегменты , направление и характер опускания и подъема пера. Эта дополнительная информация может повысить точность сквозного процесса. Эта технология также известна как «распознавание символов в режиме онлайн», «динамическое распознавание символов», «распознавание символов в реальном времени» и «интеллектуальное распознавание символов».
Методы
Предварительная обработка
Программное обеспечение оптического распознавания текста часто «предварительно обрабатывает» изображения, чтобы повысить шансы на успешное распознавание. Методы включают:
- Де- перекос — если документ не был правильно выровнен при сканировании, его, возможно, потребуется наклонить на несколько градусов по часовой стрелке или против часовой стрелки, чтобы линии текста были идеально горизонтальными или вертикальными.
- Удаление пятен — удаление положительных и отрицательных пятен, сглаживание краев.
- Бинаризация — преобразование изображения из цветного или шкалы серого в черно-белое (так называемое «двоичное изображение «, потому что есть два цвета). Задача бинаризации выполняется как простой способ отделения текста (или любого другого желаемого компонента изображения) от фона. Сама задача бинаризации необходима, поскольку большинство коммерческих алгоритмов распознавания работают только с двоичными изображениями, поскольку это оказывается проще сделать. Кроме того, эффективность этапа бинаризации в значительной степени влияет на качество этапа распознавания символов, и при выборе бинаризации, используемой для данного типа входного изображения, принимаются осторожные решения; поскольку качество метода бинаризации, используемого для получения двоичного результата, зависит от типа входного изображения (отсканированный документ, текстовое изображение сцены, исторически ухудшенный документ и т. д.).
- Удаление строки — очищает неглиф. блоки и строки
- Анализ макета или «зонирование» — определяет столбцы, абзацы, заголовки и т. д. как отдельные блоки. Особенно важно в макетах с несколькими столбцами и таблицах.
- Обнаружение строк и слов — Устанавливает базовую линию для форм слов и символов, при необходимости разделяет слова.
- Распознавание скриптов — В многоязычных документов, сценарий может изменяться на уровне слов, и, следовательно, идентификация сценария необходима, прежде чем можно будет вызвать правильное распознавание текста для обработки конкретного сценария.
- Изоляция символов или «сегментация» — для каждого -символьный OCR, несколько символов, которые связаны из-за артефактов изображения, должны быть разделены; отдельные символы, которые разбиты на несколько частей из-за артефактов, должны быть соединены.
- Нормализовать соотношение сторон и масштаб
Сегментация шрифтов с фиксированным шагом выполняется относительно просто путем выравнивания изображения по однородной сетке на основе того места, где вертикальные линии сетки реже всего пересекают черные области. Для пропорциональных шрифтов необходимы более сложные методы, потому что пробелы между буквами иногда могут быть больше, чем между словами, а вертикальные линии могут пересекать более одного символа.
Распознавание текста
Существует два основных типа базового алгоритма OCR, который может создавать ранжированный список символов-кандидатов.
- Матричное сопоставление включает в себя сравнение изображения с сохраненным глифом на попиксельной основе; это также известно как «сопоставление с образцом», «распознавание образов » или «корреляция изображения ». Это зависит от того, чтобы входной глиф был правильно изолирован от остальной части изображения, а также от того, что сохраненный глиф имеет аналогичный шрифт и тот же масштаб. Этот метод лучше всего работает с машинописным текстом и не работает при обнаружении новых шрифтов. Это метод, который использовался в раннем оптическом распознавании текста на основе физических фотоэлементов, причем довольно непосредственно.
- Извлечение признаков разбивает глифы на «особенности», такие как линии, замкнутые контуры, направление линий и пересечения линий. Функции извлечения уменьшают размерность представления и делают процесс распознавания эффективным с точки зрения вычислений. Эти функции сравниваются с абстрактным векторным представлением символа, которое может быть сведено к одному или нескольким прототипам глифов. К этому типу оптического распознавания текста применимы общие методы обнаружения признаков в компьютерном зрении, которые обычно встречаются в «интеллектуальном» распознавании рукописного ввода и, действительно, в большинстве современных программ оптического распознавания символов. классификаторы, такие как алгоритм k-ближайших соседей, используются для сравнения характеристик изображения с сохраненными характеристиками глифов и выбора ближайшего совпадения.
Программное обеспечение, такое как Cuneiform и Tesseract использует двухпроходный подход к распознаванию символов. Второй проход известен как «адаптивное распознавание» и использует формы букв, распознанные с высокой степенью достоверности на первом проходе, чтобы лучше распознать оставшиеся буквы на втором проходе. Это полезно для необычных шрифтов или низкокачественных сканированных изображений, где шрифт искажен (например, размыт или блеклый).
Современное программное обеспечение для распознавания текста, например, OCRopus или Tesseract, использует нейронные сети, которые были обучены распознавать целые строки текста вместо сосредоточения внимания на отдельных символах.
Результат OCR может быть сохранен в стандартизованном формате ALTO, специальной XML-схеме, поддерживаемой Библиотекой Конгресса США. Другие распространенные форматы включают hOCR и PAGE XML.
Список программ оптического распознавания символов см. В разделе Сравнение программ оптического распознавания символов.
Постобработка
Точность распознавания текста может быть увеличена, если вывод ограничен lexicon — список слов, которые могут встречаться в документе. Это могут быть, например, все слова английского языка или более техническая лексика для определенной области. Этот метод может быть проблематичным, если документ содержит слова, которых нет в лексиконе, например имена собственные. Tesseract использует свой словарь, чтобы влиять на шаг сегментации символов для повышения точности.
Выходной поток может быть потоком обычного текста или файлом символов, но более сложные системы OCR могут сохранить исходный макет страницы и создать, например, аннотированный PDF, который включает как исходное изображение страницы, так и текстовое представление с возможностью поиска.
«Анализ ближайшего соседа» может использовать частоты совпадения для исправления ошибок, отмечая, что определенные слова часто встречаются вместе. Например, «Вашингтон, округ Колумбия». обычно гораздо чаще встречается в английском, чем «Вашингтонский DOC».
Знание грамматики сканируемого языка также может помочь определить, является ли слово, вероятно, глаголом или существительным, например, обеспечивая большую точность.
Алгоритм Расстояние Левенштейна также использовался в постобработке OCR для дальнейшей оптимизации результатов OCR API.
Оптимизация для конкретного приложения
В последние годы основные поставщики технологий оптического распознавания символов начали настраивать системы оптического распознавания текста, чтобы более эффективно обрабатывать определенные типы ввода. Помимо лексики, связанной с конкретным приложением, более высокая производительность может быть достигнута за счет учета бизнес-правил, стандартных выражений или обширной информации, содержащейся в цветных изображениях. Эта стратегия называется «Ориентированное на приложение OCR» или «Настраиваемое OCR» и была применена к OCR номерных знаков, счетов, снимков экрана, Удостоверения личности, водительские права и производство автомобилей.
The New York Times адаптировала технологию OCR в свой собственный инструмент Document Helper, который позволяет им интерактивная новостная команда для ускорения обработки документов, требующих проверки. Они отмечают, что это позволяет им обрабатывать до 5400 страниц в час, чтобы подготовить репортеров к просмотру содержания.
Обходные пути
Существует несколько методов решения проблемы характера распознавание средствами, отличными от улучшенных алгоритмов OCR.
Принудительное улучшение качества ввода
Специальные шрифты, например шрифты OCR-A, OCR-B или MICR, с точным заданный размер, интервалы и характерные формы символов позволяют повысить точность транскрипции при обработке банковских чеков. Однако по иронии судьбы несколько известных механизмов распознавания текста были разработаны для захвата текста в популярных шрифтах, таких как Arial или Times New Roman, и не могут захватывать текст в этих специализированных шрифтах, которые сильно отличаются от широко используемых шрифтов. Поскольку Google Tesseract можно обучить распознавать новые шрифты, он может распознавать шрифты OCR-A, OCR-B и MICR.
«Поля гребней» — это заранее напечатанные поля, которые побуждают людей писать более разборчиво — один глиф за коробку. Они часто печатаются «выпадающим цветом», который может быть легко удален системой OCR.
Palm OS использовала специальный набор глифов, известный как «Graffiti «, которые похожи на печатные английские символы, но упрощены или изменены для облегчения распознавания на аппаратном обеспечении платформы с ограниченными вычислительными возможностями. Пользователи должны научиться писать эти специальные символы.
Зональное распознавание текста ограничивает изображение определенной частью документа. Это часто называют «шаблоном OCR».
Краудсорсинг
Краудсорсинг люди для распознавания символов могут быстро обрабатывать изображения, такие как компьютерное оптическое распознавание символов, но с более высокой точностью распознавания изображений, чем это достигается с помощью компьютеров. Практические системы включают Amazon Mechanical Turk и reCAPTCHA. Национальная библиотека Финляндии разработала онлайн-интерфейс для пользователей, позволяющих исправлять тексты с оптическим распознаванием текста в стандартизированном формате ALTO. Краудсорсинг также использовался не для непосредственного распознавания символов, а для приглашения разработчиков программного обеспечения к разработке алгоритмов обработки изображений, например, посредством использования рейтинговых турниров.
Точность
По заказу США Департамент энергетики (DOE), Институт исследований информатики (ISRI) имел миссию способствовать совершенствованию автоматизированных технологий для понимания документов, напечатанных на машинах, и провел наиболее авторитетный из Ежегодных испытаний точности распознавания текста с 1992 по 1996.
Распознавание латиницей, машинописный текст по-прежнему не является 100% точным даже при наличии четких изображений. Одно исследование, основанное на распознавании газетных страниц 19-го и начала 20-го веков, пришло к выводу, что посимвольная точность оптического распознавания текста для коммерческого программного обеспечения оптического распознавания текста варьировалась от 81% до 99%; Полная точность может быть достигнута с помощью проверки человеком или аутентификации по словарю данных. Другие области, в том числе распознавание рукописного ввода, скорописного почерка и печатного текста в других шрифтах (особенно тех символов восточноазиатского языка, у которых есть много штрихов для одного символа) — все еще являются предметом активных исследований. База данных MNIST обычно используется для проверки способности систем распознавать рукописные цифры.
Уровни точности можно измерить несколькими способами, и то, как они измеряются, может сильно повлиять на сообщаемый уровень точности. Например, если контекст слова (в основном словарный запас слов) не используется для исправления программным обеспечением, обнаруживающим несуществующие слова, коэффициент символьных ошибок в 1% (точность 99%) может привести к коэффициенту ошибок в 5% (точность 95%).) или хуже, если измерение основано на том, было ли распознано каждое слово целиком без неправильных букв.
Примером трудностей, присущих оцифровке старого текста, является неспособность OCR различать длинные символы «» s «и» f «символы.
Веб-системы оптического распознавания текста для распознавания напечатанного вручную текста на лету стали хорошо известны как коммерческие продукты в последние годы (см. История планшетных ПК ). Уровень точности от 80% до 90% для аккуратных, чистых символов, напечатанных вручную, может быть достигнут с помощью программного обеспечения для перьевых вычислений, но этот уровень точности по-прежнему выражается в десятках ошибок на странице, что делает технологию полезной только в очень ограниченное применение.
Распознавание скорописного текста — активная область исследований, где показатели распознавания даже ниже, чем у рукописного текста. Более высокая скорость распознавания общего скорописного шрифта, вероятно, будет невозможна без использования контекстной или грамматической информации. Например, распознать целые слова из словаря проще, чем пытаться разобрать отдельные символы из сценария. Чтение строки суммы чека (которая всегда является выписанным числом) является примером, когда использование меньшего словаря может значительно повысить скорость распознавания. Формы отдельных курсивных символов сами по себе просто не содержат достаточно информации для точного (более 98%) распознавания всего рукописного курсива.
Большинство программ позволяют пользователям устанавливать «степень достоверности». Это означает, что если программное обеспечение не достигает желаемого уровня точности, пользователь может быть уведомлен для проверки вручную.
Ошибка, вызванная сканированием OCR, иногда называется «scanno» (по аналогии с термином «typo» ).
Unicode
Символы для поддержки OCR были добавлены в Unicode Стандарт в июне 1993 года, с выпуском версии 1.1.
Некоторые из этих символов отображены из шрифтов, относящихся к MICR, OCR-A или OCR-B.
| Оптическое распознавание символов. Таблица кодов официального консорциума Unicode (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U + 244x | ⑀ | ⑁ | ⑂ | ⑃ | ⑄ | ⑅ | ⑆ | ⑇ | ⑈ | ⑉ | ⑊ | |||||
| U + 245x | ||||||||||||||||
Примечания
|
См. также
- AI-эффект
- Приложения искусственного интеллекта
- Сравнение программ оптического распознавания символов
- Вычислительная лингвистика
- Цифровая библиотека
- Электронная почта
- Цифровое перо
- Институциональное хранилище
- Разборчивость
- Список новых технологий
- Решение для распознавания символов живыми чернилами
- Распознавание символов с помощью магнитных чернил
- Музыка OCR
- OCR в Индийские языки
- Оптический знак распознавание
- Схема искусственного интеллекта
- Распознавание эскиза
- Распознавание речи
- Механизм распознавания текста Tesseract
- Запись голоса
Ссылки
Внешние ссылки
| На Викискладе есть материалы, связанные с Оптическое распознавание символов . |
- Unicode OCR — Hex Диапазон: 2440-245F Оптическое распознавание символов в Unicode
- Аннотированная библиография ссылок на распознавание символов рукописного ввода и перьевые вычисления
Распознавание текста OCR
Сегодня в российских вузах все чаще при проверке магистерских диссертаций, выпускных квалификационных работ, курсовых, рефератов и контрольных работ на некорректные заимствования (плагиат) стали применять метод OCR — оптическое распознавание текста. Обойти его бывает зачастую сложнее, чем классическую систему антиплагиатвуз.
Сервис распознавания текстовой информации очень актуален. Сканированные документы или книги нужно перевести в формат, пригодный для редактирования. Кроме того, тексты занимают на порядок меньше места, чем даже хорошо сжатые изображения. Экономится пространство на постоянных носителях, оперативная память и ресурсы процессора по обработке файлов.
Повысить оригинальность
Преимущества онлайн-сервиса
Выполненное онлайн распознавание OCR имеет следующие преимущества по сравнению с установкой офлайн-программы:
—
меньше нагружается локальный компьютер, тексты распознаются на сервере;
—
постоянное улучшение распознавания текста, незаметное для пользователей внедрение новых алгоритмов;
—
широкий выбор форматов для конвертации.
Процедура OCR занимает огромные процессорные ресурсы, локальное исполнение других программ заметно тормозится. Передача данных через Интернет нагружает компьютер гораздо меньше, даже при сравнительно больших размерах файлов с текстом. Идущий на распознавание текст может находиться в графическом формате (JPG, PNG, GIF, BMP) или предварительно обработанном и сжатом (PDF, DJV). Результат распознавания текста выдается в таких форматах, как TXT, RTF, DOC, или взятых из операционной системы Linux. Это позволяет не зависеть от системы и установленных программ, которые часто выпускаются только для определенного окружения, например, под MS Windows.
Качество исходников и результатов
OCR online будет эффективным, когда графические источники отличаются высоким качеством. Это касается как сканирования текста, так и предобработки графики, к примеру, контрастирования, выделения переходов между светлыми и темными участками. Желательна строгая ориентация строк по вертикали и букв по горизонтали, без перегибов страниц. Лучше всего распознаются контрастные символы, как черные на белом фоне. Узнавание, скажем, зеленых на красном фоне может быть затруднено, но такие материалы встречаются крайне редко, в основном для целей тестирования распознающей программы. Для уверенности в правильности узнавания символов рекомендуется проводить вычитку текстов после машинной обработки. Еще ни один алгоритм OCR не достиг 100% качества и сравнимых с человеком навыков узнавания.

Выбор языка
Современный онлайн сервис OCR выполняет все более интеллектуальные действия на исходном материале. В частности, исправляет грамматические ошибки, делает предположения плохо различимых символах, ориентируясь на словарь. Если одна буква в слове неразличима, возможна коррекция дефектов сканирования или бумажного носителя. Работа корректора ошибок существенно зависит от выбранного пользователем языка. В особенности это касается близких по происхождению языков, как русский, украинский и белорусский. Используются словари, включающие десятки тысяч словоформ, что дает возможность распознавать материалы, необходимые узким специалистам (технические, медицинские, исторические).
Послесловие
Таким образом, проверка в системе антиплагиатвуз с оптическим распознаванием текста во многих случаях позволяет распознать, применял ли студент для того, чтобы повысить уникальность, систему технического кодирования, различные невидимые вставки в текст. Однако, современные сервисы борьбы с плагиатом не стоят на месте и некоторые научились корректно повышать уникальность, не меняя при этом текст визуально. В частности, это сервис, позволяющий повысить оригинальность (антиплагиат) с высокой степенью эффективности – сервис АнтиплагиAD. Стоимость повышения уникальности в Антиплагиатвуз + OCR такая же, как и в «обычном» Антиплагиатвузе
Почему тысячи клиентов выбирают нас
—
Повышение уникальности текста до необходимого процента
—
Время, необходимое на обработку — не более 5 минут
—
Текст внешне остается неизменным, как и таблицы и формулы
—
Круглосуточная система работы, автоматизация процесса
—
Поддержка клиентов по телефону и другим видам связи
—
Возможность неоднократно корректировать процент оригинальности бесплатно
—
Доступ к закрытому преподавательскому отчету по системе антиплагиат.вуз
—
Анонимность согласно федеральному закону №152, данные клиента не подлежат разглашению и передаче третьим лицам