

Существует две фундаментальные стратегии: обработка исправимых ошибок (исключения, коды возврата по ошибке, функции-обработчики) и неисправимых (assert(), abort()). В каких случаях какую стратегию лучше использовать?
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
- Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
Программистские ошибки
Это худший вид ошибок. Для их обработки я стараюсь сделать так, чтобы мои ошибки были связаны только с вызовами функций, то есть с плохими параметрами. Прочие типы программистских ошибок могут быть пойманы только в runtime, с помощью отладочных макросов (assertion macros), раскиданных по коду.
При работе с плохими параметрами есть две стратегии: дать им определённое или неопределённое поведение.
Если исходное требование для функции — запрет на передачу ей плохих параметров, то, если их передать, это считается неопределённым поведением и должно проверяться не самой функцией, а оператором вызова (caller). Функция должна делать только отладочное подтверждение (debug assertion).
С другой стороны, если отсутствие плохих параметров не является частью исходных требований, а документация определяет, что функция будет бросать bad_parameter_exception при передаче ей плохого параметра, то передача — это хорошо определённое поведение (бросание исключения или любая другая стратегия обработки исправимых ошибок), и функция всегда должна это проверять.
В качестве примера рассмотрим получающие функции (accessor functions) std::vector<T>operator[] говорится, что индекс должен быть в пределах валидного диапазона, при этом at() сообщает нам, что функция кинет исключение, если индекс не попадает в диапазон. Более того, большинство реализаций стандартных библиотек обеспечивают режим отладки, в котором проверяется индекс operator[], но технически это неопределённое поведение, оно не обязано проверяться.
Примечание: необязательно бросать исключение, чтобы получилось определённое поведение. Пока это не упомянуто в исходных условиях для функции, это считается определённым. Всё, что прописано в исходных условиях, не должно проверяться функцией, это неопределённое поведение.
Когда нужно проверять только с помощью отладочных подтверждений, а когда — постоянно?
К сожалению, однозначного рецепта нет, решение зависит от конкретной ситуации. У меня есть лишь одно проверенное правило, которому я следую при разработке API. Оно основано на наблюдении, что проверять исходные условия должен вызывающий, а не вызываемый. А значит, условие должно быть «проверяемым» для вызывающего. Также условие «проверяемое», если можно легко выполнить операцию, при которой значение параметра всегда будет правильным. Если для параметра это возможно, то это получается исходное условие, а значит, проверяется только посредством отладочного подтверждения (а если слишком дорого, то вообще не проверяется).
Но конечное решение зависит от многих других факторов, так что очень трудно дать какой-то общий совет. По умолчанию я стараюсь свести к неопределённому поведению и использованию только подтверждений. Иногда бывает целесообразно обеспечить оба варианта, как это делает стандартная библиотека с operator[] и at().
Хотя в ряде случаев это может быть ошибкой.
Об иерархии std::exception
Если в качестве стратегии обработки исправимых ошибок вы выбрали исключения, то рекомендуется создать новый класс и наследовать его от одного из классов исключений стандартной библиотеки.
Я предлагаю наследовать только от одного из этих четырёх классов:
std::bad_alloc: для сбоев выделения памяти.std::runtime_error: для общих runtime-ошибок.std::system_error(производное отstd::runtime_error): для системных ошибок с кодами ошибок.std::logic_error: для программистских ошибок с определённым поведением.
Обратите внимание, что в стандартной библиотеке разделяются логические (то есть программистские) и runtime-ошибки. Runtime-ошибки — более широкое определение, чем «системные». Оно описывает «ошибки, обнаруживаемые только при выполнении программы». Такая формулировка не слишком информативна. Лично я использую её для плохих параметров, которые не являются исключительно программистскими ошибками, а могут возникнуть и по вине пользователей. Но это можно определить лишь глубоко в стеке вызовов. Например, плохое форматирование комментариев в standardese приводит к исключению при парсинге, проистекающему из std::runtime_error. Позднее оно ловится на соответствующем уровне и фиксируется в логе. Но я не стал бы использовать этот класс иначе, как и std::logic_error.
Подведём итоги
Есть два пути обработки ошибок:
- как исправимые: используются исключения или возвращаемые значения (в зависимости от ситуации/религии);
- как неисправимые: ошибки журналируются, а программа прерывается.
Подтверждения — это особый вид стратегии обработки неисправимых ошибок, только в режиме отладки.
Есть три основных источника ошибок, каждый требует особого подхода:
- Пользовательские ошибки не должны обрабатываться как ошибки на верхних уровнях программы. Всё, что вводит пользователь, должно проверяться соответствующим образом. Это может обрабатываться как ошибки только на нижних уровнях, которые не взаимодействуют с пользователями напрямую. Применяется стратегия обработки исправимых ошибок.
- Системные ошибки могут обрабатываться в рамках любой из двух стратегий, в зависимости от типа и тяжести. Библиотеки должны работать как можно гибче.
- Программистские ошибки, то есть плохие параметры, могут быть запрещены исходными условиями. В этом случае функция должна использовать только проверку с помощью отладочных подтверждений. Если же речь идёт о полностью определённом поведении, то функции следует предписанным образом сообщать об ошибке. Я стараюсь по умолчанию следовать сценарию с неопределённым поведением и определяю для функции проверку параметров лишь тогда, когда это слишком трудно сделать на стороне вызывающего.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Проблема
Я работаю над проектом foonathan/memory. Это решение предоставляет различные классы выделения памяти (allocator classes), так что в качестве примера рассмотрим структуру функции выделения.
Для простоты возьмём malloc(). Она возвращает указатель на выделяемую память. Если выделить память не получается, то возвращается nullptr, то есть NULL, то есть ошибочное значение.
У этого решения есть недостатки: вам нужно проверять каждый вызов malloc(). Если вы забудете это сделать, то выделите несуществующую память. Кроме того, по своей натуре коды ошибок транзитивны: если вызвать функцию, которая может вернуть код ошибки, и вы не можете его проигнорировать или обработать, то вы тоже должны вернуть код ошибки.
Это приводит нас к ситуации, когда чередуются нормальные и ошибочные ветви кода. Исключения в таком случае выглядят более подходящим решением. Благодаря им вы сможете обрабатывать ошибки только тогда, когда вам это нужно, а в противном случае — достаточно тихо передать их обратно вызывающему.
Это можно расценить как недостаток.
Но в подобных ситуациях исключения имеют также очень большое преимущество: функция выделения памяти либо возвращает валидную память, либо вообще ничего не возвращает. Это функция «всё или ничего», возвращаемое значение всегда будет валидным. Это полезное следствие согласно принципу Скотта Майера «Make interfaces hard to use incorrectly and easy to use correctly».
Учитывая вышесказанное, можно утверждать, что вам следует использовать исключения в качестве механизма обработки ошибок. Этого мнения придерживается большинство разработчиков на С++, включая и меня. Но проект, которым я занимаюсь, — это библиотека, предоставляющая средства выделения памяти, и предназначена она для приложений, работающих в реальном времени. Для большинства разработчиков подобных приложений (особенно для игроделов) само использование исключений — исключение.
Каламбур детектед.
Чтобы уважить эту группу разработчиков, моей библиотеке лучше обойтись без исключений. Но мне и многим другим они нравятся за элегантность и простоту обработки ошибок, так что ради других разработчиков моей библиотеке лучше использовать исключения.
Так что же делать?
Идеальное решение: возможность включать и отключать исключения по желанию. Но, учитывая природу исключений, нельзя просто менять их местами с кодами ошибок, поскольку у нас не будет внутреннего кода проверки на ошибки — весь внутренний код опирается на предположение о прозрачности исключений. И даже если бы внутри можно было использовать коды ошибок и преобразовывать их в исключения, это лишило бы нас большинства преимуществ последних.
К счастью, я могу определить, что вы делаете, когда обнаруживаете ошибку нехватки памяти: чаще всего вы журналируете это событие и прерываете программу, поскольку она не может корректно работать без памяти. В таких ситуациях исключения — просто способ передачи контроля другой части кода, которая журналирует и прерывает программу. Но есть старый и эффективный способ передачи контроля: указатель функции (function pointer), то есть функция-обработчик (handler function).
Если у вас включены исключения, то вы просто их бросаете. В противном случае вызываете функцию-обработчика и затем прерываете программу. Это предотвратит бесполезную работу функции-обработчика, та позволит программе продолжить выполняться в обычном режиме. Если не прервать, то произойдёт нарушение обязательного постусловия функции: всегда возвращать валидный указатель. Ведь на выполнении этого условия может быть построена работа другого кода, да и вообще это нормальное поведение.
Я называю такой подход обработкой исключений и придерживаюсь его при работе с памятью.
Решение 1: обработчик исключений
Если вам нужно обработать ошибку в условиях, когда наиболее распространённым поведением будет «журналировать и прервать», то можно использовать обработчика исключений. Это такая функция-обработчик, которая вызывается вместо бросания объекта-исключения. Её довольно легко реализовать даже в уже существующем коде. Для этого нужно поместить управление обработкой в класс исключений и обернуть в макрос выражение throw.
Сначала дополним класс и добавим функции для настройки и, возможно, запрашивания функции-обработчика. Я предлагаю делать это так же, как стандартная библиотека обрабатывает std::new_handler:
class my_fatal_error
{
public:
// тип обработчика, он должен брать те же параметры, что и конструктор,
// чтобы у них была одинаковая информация
using handler = void(*)( ... );
// меняет функцию-обработчика
handler set_handler(handler h);
// возвращает текущего обработчика
handler get_handler();
... // нормальное исключение
};Поскольку это входит в область видимости класса исключений, вам не нужно именовать каким-то особым образом. Отлично, нам же легче.
Если исключения включены, то для удаления обработчика можно использовать условное компилирование (conditional compilation). Если хотите, то также напишите обычный подмешанный класс (mixin class), дающий требуемую функциональность.
Конструктор исключений элегантен: он вызывает текущую функцию-обработчика, передавая ей требуемые аргументы из своих параметров. А затем комбинирует с последующим макросом throw:
If```cpp #if EXCEPTIONS #define THROW(Ex) throw (Ex) #else #define THROW(Ex) (Ex), std::abort() #endif> Такой макрос throw также предоставляется [foonathan/compatiblity](https://github.com/foonathan/compatibility).
Можно использовать его и так:
```cpp
THROW(my_fatal_error(...))
Если у вас включена поддержка исключений, то будет создан и брошен объект-исключение, всё как обычно. Но если поддержка выключена, то объект-исключение всё равно будет создан, и — это важно — только после этого произойдёт вызов std::abort(). А поскольку конструктор вызывает функцию-обработчика, то он и работает, как требуется: вы получаете точку настройки для журналирования ошибки. Благодаря же вызову std::abort() после конструктора пользователь не может нарушить постусловие.
Когда я работаю с памятью, то при включённых исключениях у меня также включён и обработчик, который вызывается при бросании исключения.
Так что при этой методике вам ещё будет доступна определённая степень кастомизации, даже если вы отключите исключения. Конечно, замена неполноценная, мы только журналируем и прерываем работу программы, без дальнейшего продолжения. Но в ряде случаев, в том числе при исчерпании памяти, это вполне пригодное решение.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);
При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
Решение 2: предоставить две перегрузки
Если недостаточно обработчика исключений, то нужно предоставить две перегрузки. Одна использует код возврата, а вторая бросает исключение.
Если рассматриваемая функция не имеет возвращаемого значения, то можете её использовать для кода ошибки. В противном случае вам придётся возвращать недопустимое значение для сигнализирования об ошибке — как nullptr в вышеприведённом примере, — а также установить выходной параметр для кода ошибки, если хотите предоставить вызывающему дополнительную информацию.
Пожалуйста, не используйте глобальную переменную errno или что-то типа GetLastError()!
Если возвращаемое значение не содержит недопустимое значение для обозначения сбоя, то по мере возможности используйте std::optional или что-то похожее.
Перегрузка исключения (exception overload) может — и должна — быть реализована в рамках версии с кодом ошибки, как это показано выше. Если компилируете без исключений, сотрите перегрузку с помощью условного компилирования.
std::system_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
std::expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected<void*, std::error_code> try_malloc(...);
В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Заключение
Если вы создаёте библиотеки, то иногда приходится обеспечивать максимальную гибкость использования. Под этим подразумевается и разнообразие средств обработки ошибок: иногда требуются коды возврата, иногда — исключения.
Одна из возможных стратегий — улаживание этих противоречий с помощью обработчика исключений. Просто удостоверьтесь, что когда нужно, то вызывается callback, а не бросается исключение. Это замена для критических ошибок, которая в любом случае будет журналироваться перед прерыванием работы программы. Как таковой этот способ не универсален, вы не можете переключаться в одной программе между двумя версиями. Это лишь обходное решение при отключённой поддержке исключений.
Более гибкий подход — просто предоставить две перегрузки, одну с исключениями, а вторую без. Это даст пользователям максимальную свободу, они смогут выбирать ту версию, что лучше подходит в их ситуации. Недостаток этого подхода: вам придётся больше потрудиться при создании библиотеки.
Содержание
- 1 Методы обработки ошибок
- 2 Исключения
- 3 Классификация исключений
- 3.1 Проверяемые исключения
- 3.2 Error
- 3.3 RuntimeException
- 4 Обработка исключений
- 4.1 try-catch-finally
- 4.2 Обработка исключений, вызвавших завершение потока
- 4.3 Информация об исключениях
- 5 Разработка исключений
- 6 Исключения в Java7
- 7 Примеры исключений
- 8 Гарантии безопасности
- 9 Источники
Методы обработки ошибок
1. Не обрабатывать.
2. Коды возврата. Основная идея — в случае ошибки возвращать специальное значение, которое не может быть корректным. Например, если в методе есть операция деления, то придется проверять делитель на равенство нулю. Также проверим корректность аргументов a и b:
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
return null;
}
//...
if (Math.abs(b) < EPS) {
return null;
} else {
return a / b;
}
}
При вызове метода необходимо проверить возвращаемое значение:
Double d = f(a, b); if (d != null) { //... } else { //... }
Минусом такого подхода является необходимость проверки возвращаемого значения каждый раз при вызове метода. Кроме того, не всегда возможно определить тип ошибки.
3.Использовать флаг ошибки: при возникновении ошибки устанавливать флаг в соответствующее значение:
boolean error; Double f(Double a, Double b) { if ((a == null) || (b == null)) { error = true; return null; } //... if (Math.abs(b) < EPS) { error = true; return b; } else { return a / b; } }
error = false; Double d = f(a, b); if (error) { //... } else { //... }
Минусы такого подхода аналогичны минусам использования кодов возврата.
4.Можно вызвать метод обработки ошибки и возвращать то, что вернет этот метод.
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
return nullPointer();
}
//...
if (Math.abs(b) < EPS) {
return divisionByZero();
} else {
return a / b;
}
}
Но в таком случае не всегда возможно проверить корректность результата вызова основного метода.
5.В случае ошибки просто закрыть программу.
if (Math.abs(b) < EPS) { System.exit(0); return this; }
Это приведет к потере данных, также невозможно понять, в каком месте возникла ошибка.
Исключения
В Java возможна обработка ошибок с помощью исключений:
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
throw new IllegalArgumentException("arguments of f() are null");
}
//...
return a / b;
}
Проверять b на равенство нулю уже нет необходимости, так как при делении на ноль метод бросит непроверяемое исключение ArithmeticException.
Исключения позволяют:
- разделить обработку ошибок и сам алгоритм;
- не загромождать код проверками возвращаемых значений;
- обрабатывать ошибки на верхних уровнях, если на текущем уровне не хватает данных для обработки. Например, при написании универсального метода чтения из файла невозможно заранее предусмотреть реакцию на ошибку, так как эта реакция зависит от использующей метод программы;
- классифицировать типы ошибок, обрабатывать похожие исключения одинаково, сопоставлять специфичным исключениям определенные обработчики.
Каждый раз, когда при выполнении программы происходит ошибка, создается объект-исключение, содержащий информацию об ошибке, включая её тип и состояние программы на момент возникновения ошибки.
После создания исключения среда выполнения пытается найти в стеке вызовов метод, который содержит код, обрабатывающий это исключение. Поиск начинается с метода, в котором произошла ошибка, и проходит через стек в обратном порядке вызова методов. Если не было найдено ни одного подходящего обработчика, выполнение программы завершается.
Таким образом, механизм обработки исключений содержит следующие операции:
- Создание объекта-исключения.
- Заполнение stack trace’а этого исключения.
- Stack unwinding (раскрутка стека) в поисках нужного обработчика.
Классификация исключений
Класс Java Throwable описывает все, что может быть брошено как исключение. Наследеники Throwable — Exception и Error — основные типы исключений. Также RuntimeException, унаследованный от Exception, является существенным классом.
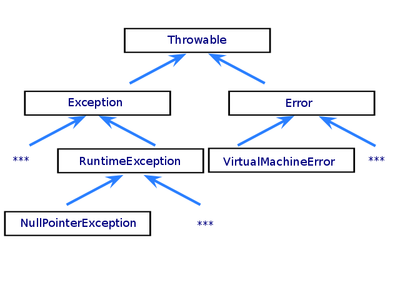
Иерархия стандартных исключений
Проверяемые исключения
Наследники класса Exception (кроме наслеников RuntimeException) являются проверяемыми исключениями(checked exception). Как правило, это ошибки, возникшие по вине внешних обстоятельств или пользователя приложения – неправильно указали имя файла, например. Эти исключения должны обрабатываться в ходе работы программы, поэтому компилятор проверяет наличие обработчика или явного описания тех типов исключений, которые могут быть сгенерированы некоторым методом.
Все исключения, кроме классов Error и RuntimeException и их наследников, являются проверяемыми.
Error
Класс Error и его подклассы предназначены для системных ошибок. Свои собственные классы-наследники для Error писать (за очень редкими исключениями) не нужно. Как правило, это действительно фатальные ошибки, пытаться обработать которые довольно бессмысленно (например OutOfMemoryError).
RuntimeException
Эти исключения обычно возникают в результате ошибок программирования, такие как ошибки разработчика или неверное использование интерфейса приложения. Например, в случае выхода за границы массива метод бросит OutOfBoundsException. Такие ошибки могут быть в любом месте программы, поэтому компилятор не требует указывать runtime исключения в объявлении метода. Теоретически приложение может поймать это исключение, но разумнее исправить ошибку.
Обработка исключений
Чтобы сгенерировать исключение используется ключевое слово throw. Как и любой объект в Java, исключения создаются с помощью new.
if (t == null) { throw new NullPointerException("t = null"); }
Есть два стандартных конструктора для всех исключений: первый — конструктор по умолчанию, второй принимает строковый аргумент, поэтому можно поместить подходящую информацию в исключение.
Возможна ситуация, когда одно исключение становится причиной другого. Для этого существует механизм exception chaining. Практически у каждого класса исключения есть конструктор, принимающий в качестве параметра Throwable – причину исключительной ситуации. Если же такого конструктора нет, то у Throwable есть метод initCause(Throwable), который можно вызвать один раз, и передать ему исключение-причину.
Как и было сказано раньше, определение метода должно содержать список всех проверяемых исключений, которые метод может бросить. Также можно написать более общий класс, среди наследников которого есть эти исключения.
void f() throws InterruptedException, IOException { //...
try-catch-finally
Код, который может бросить исключения оборачивается в try-блок, после которого идут блоки catch и finally (Один из них может быть опущен).
try { // Код, который может сгенерировать исключение }
Сразу после блока проверки следуют обработчики исключений, которые объявляются ключевым словом catch.
try { // Код, который может сгенерировать исключение } catch(Type1 id1) { // Обработка исключения Type1 } catch(Type2 id2) { // Обработка исключения Type2 }
Сatch-блоки обрабатывают исключения, указанные в качестве аргумента. Тип аргумента должен быть классом, унаследованного от Throwable, или самим Throwable. Блок catch выполняется, если тип брошенного исключения является наследником типа аргумента и если это исключение не было обработано предыдущими блоками.
Код из блока finally выполнится в любом случае: при нормальном выходе из try, после обработки исключения или при выходе по команде return.
NB: Если JVM выйдет во время выполнения кода из try или catch, то finally-блок может не выполниться. Также, например, если поток выполняющий try или catch код остановлен, то блок finally может не выполниться, даже если приложение продолжает работать.
Блок finally удобен для закрытия файлов и освобождения любых других ресурсов. Код в блоке finally должен быть максимально простым. Если внутри блока finally будет брошено какое-либо исключение или просто встретится оператор return, брошенное в блоке try исключение (если таковое было брошено) будет забыто.
import java.io.IOException; public class ExceptionTest { public static void main(String[] args) { try { try { throw new Exception("a"); } finally { throw new IOException("b"); } } catch (IOException ex) { System.err.println(ex.getMessage()); } catch (Exception ex) { System.err.println(ex.getMessage()); } } }
После того, как было брошено первое исключение — new Exception("a") — будет выполнен блок finally, в котором будет брошено исключение new IOException("b"), именно оно будет поймано и обработано. Результатом его выполнения будет вывод в консоль b. Исходное исключение теряется.
Обработка исключений, вызвавших завершение потока
При использовании нескольких потоков бывают ситуации, когда поток завершается из-за исключения. Для того, чтобы определить с каким именно, начиная с версии Java 5 существует интерфейс Thread.UncaughtExceptionHandler. Его реализацию можно установить нужному потоку с помощью метода setUncaughtExceptionHandler. Можно также установить обработчик по умолчанию с помощью статического метода Thread.setDefaultUncaughtExceptionHandler.
Интерфейс Thread.UncaughtExceptionHandler имеет единственный метод uncaughtException(Thread t, Throwable e), в который передается экземпляр потока, завершившегося исключением, и экземпляр самого исключения. Когда поток завершается из-за непойманного исключения, JVM запрашивает у потока UncaughtExceptionHandler, используя метод Thread.getUncaughtExceptionHandler(), и вызвает метод обработчика – uncaughtException(Thread t, Throwable e). Все исключения, брошенные этим методом, игнорируются JVM.
Информация об исключениях
-
getMessage(). Этот метод возвращает строку, которая была первым параметром при создании исключения; -
getCause()возвращает исключение, которое стало причиной текущего исключения; -
printStackTrace()печатает stack trace, который содержит информацию, с помощью которой можно определить причину исключения и место, где оно было брошено.
Exception in thread "main" java.lang.IllegalStateException: A book has a null property
at com.example.myproject.Author.getBookIds(Author.java:38)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
Caused by: java.lang.NullPointerException
at com.example.myproject.Book.getId(Book.java:22)
at com.example.myproject.Author.getBookIds(Author.java:35)
Все методы выводятся в обратном порядке вызовов. В примере исключение IllegalStateException было брошено в методе getBookIds, который был вызван в main. «Caused by» означает, что исключение NullPointerException является причиной IllegalStateException.
Разработка исключений
Чтобы определить собственное проверяемое исключение, необходимо создать наследника класса java.lang.Exception. Желательно, чтобы у исключения был конструкор, которому можно передать сообщение:
public class FooException extends Exception { public FooException() { super(); } public FooException(String message) { super(message); } public FooException(String message, Throwable cause) { super(message, cause); } public FooException(Throwable cause) { super(cause); } }
Исключения в Java7
- обработка нескольких типов исключений в одном
catch-блоке:
catch (IOException | SQLException ex) {...}
В таких случаях параметры неявно являются final, поэтому нельзя присвоить им другое значение в блоке catch.
Байт-код, сгенерированный компиляцией такого catch-блока будет короче, чем код нескольких catch-блоков.
-
Tryс ресурсами позволяет прямо вtry-блоке объявлять необходимые ресурсы, которые по завершению блока будут корректно закрыты (с помощью методаclose()). Любой объект реализующийjava.lang.AutoCloseableможет быть использован как ресурс.
static String readFirstLineFromFile(String path) throws IOException { try (BufferedReader br = new BufferedReader(new FileReader(path))) { return br.readLine(); } }
В приведенном примере в качестве ресурса использутся объект класса BufferedReader, который будет закрыт вне зависимосити от того, как выполнится try-блок.
Можно объявлять несколько ресурсов, разделяя их точкой с запятой:
public static void viewTable(Connection con) throws SQLException { String query = "select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEES"; try (Statement stmt = con.createStatement(); ResultSet rs = stmt.executeQuery(query)) { //Work with Statement and ResultSet } catch (SQLException e) { e.printStackTrace; } }
Во время закрытия ресурсов тоже может быть брошено исключение. В try-with-resources добавленна возможность хранения «подавленных» исключений, и брошенное try-блоком исключение имеет больший приоритет, чем исключения получившиеся во время закрытия. Получить последние можно вызовом метода getSuppressed() от исключения брошенного try-блоком.
- Перебрасывание исключений с улучшенной проверкой соответствия типов.
Компилятор Java SE 7 тщательнее анализирует перебрасываемые исключения. Рассмотрим следующий пример:
static class FirstException extends Exception { } static class SecondException extends Exception { } public void rethrowException(String exceptionName) throws Exception { try { if ("First".equals(exceptionName)) { throw new FirstException(); } else { throw new SecondException(); } } catch (Exception ex) { throw e; } }
В примере try-блок может бросить либо FirstException, либо SecondException. В версиях до Java SE 7 невозможно указать эти исключения в декларации метода, потому что catch-блок перебрасывает исключение ex, тип которого — Exception.
В Java SE 7 вы можете указать, что метод rethrowException бросает только FirstException и SecondException. Компилятор определит, что исключение Exception ex могло возникнуть только в try-блоке, в котором может быть брошено FirstException или SecondException. Даже если тип параметра catch — Exception, компилятор определит, что это экземпляр либо FirstException, либо SecondException:
public void rethrowException(String exceptionName) throws FirstException, SecondException { try { // ... } catch (Exception e) { throw e; } }
Если FirstException и SecondException не являются наследниками Exception, то необходимо указать и Exception в объявлении метода.
Примеры исключений
- любая операция может бросить
VirtualMachineError. Как правило это происходит в результате системных сбоев. -
OutOfMemoryError. Приложение может бросить это исключение, если, например, не хватает места в куче, или не хватает памяти для того, чтобы создать стек нового потока. -
IllegalArgumentExceptionиспользуется для того, чтобы избежать передачи некорректных значений аргументов. Например:
public void f(Object a) { if (a == null) { throw new IllegalArgumentException("a must not be null"); } }
IllegalStateExceptionвозникает в результате некорректного состояния объекта. Например, использование объекта перед тем как он будет инициализирован.
Гарантии безопасности
При возникновении исключительной ситуации, состояния объектов и программы могут удовлетворять некоторым условиям, которые определяются различными типами гарантий безопасности:
- Отсутствие гарантий (no exceptional safety). Если было брошено исключение, то не гарантируется, что все ресурсы будут корректно закрыты и что объекты, методы которых бросили исключения, могут в дальнейшем использоваться. Пользователю придется пересоздавать все необходимые объекты и он не может быть уверен в том, что может переиспозовать те же самые ресурсы.
- Отсутствие утечек (no-leak guarantee). Объект, даже если какой-нибудь его метод бросает исключение, освобождает все ресурсы или предоставляет способ сделать это.
- Слабые гарантии (weak exceptional safety). Если объект бросил исключение, то он находится в корректном состоянии, и все инварианты сохранены. Рассмотрим пример:
class Interval { //invariant: left <= right double left; double right; //... }
Если будет брошено исключение в этом классе, то тогда гарантируется, что ивариант «левая граница интервала меньше правой» сохранится, но значения left и right могли измениться.
- Сильные гарантии (strong exceptional safety). Если при выполнении операции возникает исключение, то это не должно оказать какого-либо влияния на состояние приложения. Состояние объектов должно быть таким же как и до вызовов методов.
- Гарантия отсутствия исключений (no throw guarantee). Ни при каких обстоятельствах метод не должен генерировать исключения. В Java это невозможно, например, из-за того, что
VirtualMachineErrorможет произойти в любом месте, и это никак не зависит от кода. Кроме того, эту гарантию практически невозможно обеспечить в общем случае.
Источники
- Обработка ошибок и исключения — Сайт Георгия Корнеева
- Лекция Георгия Корнеева — Лекториум
- The Java Tutorials. Lesson: Exceptions
- Обработка исключений — Википедия
- Throwable (Java Platform SE 7 ) — Oracle Documentation
- try/catch/finally и исключения — www.skipy.ru
Исключения (исключительные ситуации, exceptions) являются механизмом обработки ошибок, который пришел на смену возврату кода ошибки функциями. Тем не менее, многие разработчики до сих пор используют возврат кода ошибки вместо исключений — в частности очень многие участники конференции C++ Russia 2015 говорили об этом, включая разработчиков Яндекса.
В заметке мы рассмотрим:
- обработку каких ошибок можно выполнять с использованием исключений;
- синтаксические конструкции, введенные в языки для обработки исключений (примерно одинаковые в разных языках программирования — Java, C++, C# и др.).;
- рекомендации по использованию исключений (в т.ч. по книгам о чистоте кода);
Несмотря на то, что примеры программ приводятся на С++, тут не приводятся особенности отдельных языков программирования, связанные с обработкой исключений, а описываются лишь принципы, общие для большинства языков.
Что следует понимать под ошибкой?
Исключения являются механизмом обработки ошибок, при этом под ошибкой имеется ввиду любая ситуация, в которой функция не может продолжить корректное выполнение из-за каких-либо внешних факторов:
- функция отправки данных по сети (через сокет) не может знать как в вашем конкретном приложении должен обрабатываться разрыв соединения;
- функция, выполняющая запрос к базе данных может вырабатывать исключение в случаях если база стала недоступна или в запросе допущена ошибка;
- было бы хорошо, если бы функция вычисления квадратного корня не завершала аварийно работу программы в случае если на вход подано отрицательное число, а вырабатывала бы исключение.
Способы обработки ошибок
Таким образом, под ошибкой надо понимать только те проблемы, которые функция не может решить локально. В этих случаях функция должна как-то известить того, кто ее вызвал о сложившейся проблеме, есть различные способы сделать это:
- возврат кода ошибки. Например, если при отправке сообщения по сети выяснится, что соединение разорвано, функция отправки может вернуть единицу, а при успешной отправке — ноль;
- вернуть заведомо некорректный результат. Например, функция
malloc, выделяющая память в языке Си при ошибке (невозможности выделить память) возвращает ноль, а в остальных случаях — начальный адрес выделенного фрагмента; - вернуть любое допустимое значение и выставить глобальный флаг ошибки (в языке С++ для этого может использоваться глобальная переменная
errno. - аварийно завершить работу (в С++ для этого используются функции
abortилиexit); - выработать исключение (подробнее написано ниже);
Конечно, помимо завершения работы, вы всегда можете записать описание сложившейся ситуации в log-файл (поток cerr в С++) или вывести на экран.
Аварийное завершение работы — это худший способ обработки ошибки, т.к. программист фактически расписывается в своей неспособности что-то исправить.
С точки зрения последовательности выполнения команд, возврат кода ошибки ничем не отличается от возврата некорректного значения или выставления флага ошибки в глобальный объект. Во всех этих случаях функция, которая не знает как корректно обработать входные данные передает эти обязанности непосредственно коду, который ее вызвал. Чаще всего это работает хорошо, однако:
- если вызывающий код не обрабатывает код ошибки (он ведь не обязан это делать), то он продолжает вычисления, но уже с некорректными данными. Такая ситуация выявится не сразу, ведь вы можете получить некорректный результат или аварийный останов совсем с другом месте. Например, в библиотеке Qt есть функция преобразования строки в целое число:
int QString::toInt(bool * ok = 0, int base = 10) const
В случае ошибки она вернет ноль и присвоит значениеfalseаргументуok(который вообще не является обязательным). Если наш код вызывает эту функцию для строки, не являющейся целым число — то он продолжит выполнение, получив в качестве результата ноль (вполне корректное, но неверное значение); - далеко не всегда удается правильно обработать ошибку непосредственно в коде, вызвавшем функцию. В результате получается примерно следующая ситуация:
bool foo(QString str) { bool ok; string.toInt(&ok); if (false == ok) { return false; } // ... some actions } bool bar() { QString str; // ... some actions if (false == foo(str)) return fasle; } }Что в этом плохого? — значительная часть кода делает лишь то, что доставляет код ошибки до точки, в которой его можно корректно обработать. Притом, ни одна из всех этих функций не обязана это делать, т.е. вы в любой момент можете потерять ошибку и приступить к долгой отладке.
В этом контексте, исключения можно рассматривать как механизм доставки информации об ошибки до точки программы, где эту ошибку наиболее естественно обрабатывать. Доставка ошибки при этом будет выполняться точно также, как и серия операторов return в приведенном выше фрагменте кода — каждая функция получившая исключение передает управление «наверх» (раскручивая стек), процесс продолжается до тех пор, пока исключение не попадет в блок trt{}, содержащий обработчик, совместимый с типом исключения.
Исключением также называют объект, некоторого класса, являющийся представлением ошибки (исключительного случая).
Синтаксические конструкции механизма обработки исключений
Фрагмент кода, внутри которого могут вырабатываться исключения должен быть помещен в блок try{}, к которому могут быть добавлены обработчики — блоки catch(ExceptionType) {}. Функция может вырабатывать исключения при помощи оператора throw. Например:
try {
socket = connect_to_server(host); // throw BadHostException or ServerNotAvailableException
send_message(socket, message); // throw ServerNotAvailableException or BadMsgException
}
catch(BadHostException exception) {
// BadHostException hadler
// can charge other host from user
}
catch(ServerNotAvailableException exception) {
// ServerNotAvailableException handler
// can reconnect for example
}
catch(BadMsgException exception) {
// BadMsgException hadler
// can notify user by window
}
catch(...) {
// other types of exceptions hadler
}
При возникновении исключения (вызове throw) в какой либо из функций начинается раскрутка стека (в том числе освобождается память из под всех локальных объектов), до тех пор, пока не будет обнаружен подходящий catch в функции, которая непосредственно или косвенно вызвала функцию, сгенерировавшую исключение.
Исключения могут организовываться в иерархии посредством наследования. Например, в стандартной библиотеке C++ определен базовый класс std::exception, от которого наследуется std::logic_error (класс логических ошибок), являющий базовым для std::out_of_range. Для фрагмента кода, рассмотренного выше, мог быть выделен класс NetworkException, базовый для BadHostException и ServerNotAvailableException. При этом, если при обработке нам не важно какие именно проблемы с сетью произошли — мы можем написать обработчик для базового класса.
К блоку try{} может быть написано несколько обработчиков, совместимых с одним и тем же типом исключения. Блоки catch обрабатываются в порядке их перечисления, поэтому будет выбран тот, который описан выше. Например:
catch(BadHostException exception) {
// BadHostException hadler
}
catch(NetworkException exception) {
// all network exceptions, but not BadHostException
}
catch(ServerNotAvailableException exception) {
// never call, because ServerNotAvailableException was hanled as NetworkException
}
Рекомендации по использованию исключений
Выше описаны общие (подходящие для большинства языков) принципы обработки исключений. Однако, в каждом языке есть свои тонкости. Так, например, в языке Java есть ключевое слово finally, задающее фрагмент кода, который будет выполнен при возникновении исключения любого вида. В языке C++, например: надо учитывать то, что при обработке throw создается копия исключения; в обработчике исключения запись throw; позволяет передать текущее исключение дальше без копирования; и множество других тонкостей [3]. Во многих языках можно задать спецификацию исключений для функции (используйте спецификации исключений), т.е. список исключений, которые могут выходить из нее — если вдруг какой-либо участок кода начнет вырабатывать новый тип исключения — вы получите ошибку на этапе компиляции. Изучите особенности реализации механизма исключений для своего языка программирования.
Исключения являются более безопасным и удобным механизмом, чем коды ошибок — за счет спецификации исключений компилятор гарантирует, что вы не пропустите по невнимательности обработку ошибки, кроме того, ошибки будут сами доставляться до подходящего обработчика. Страуструп пишет, что в ряде случаев только за счет использования исключений удается сократить объем кода обработки ошибок в два раза [1]. В связи с этим, следует использовать исключения вместо кодов ошибок, такой подход окажет положительное влияние на архитектуру всего приложения.
Роберт Мартин рекомендует начинать написание функции с try-catch-finally. Это заставит программиста еще раз задумать о том, какие ошибки могут произойти — на самом деле, почти любая функция может столкнуться с ситуациями, в которых не сможет продолжить вычисления [2].
Старайтесь использовать иерархии исключений. Нередко, внутри библиотеки может вырабатываться огромное количество разных видов исключений, однако пользователю могут быть не важны детали проблемы — например, ему достаточно знать, что видеокарта не поддерживает нужный ему набор функций, но совершенно ненужно знать почему. Мартин советует определять классы исключений в контексте потребностей вызывающей стороны [2], однако чаще всего этого можно достичь при помощи иерархий, т.к. клиент всегда сможет обработать как конкретные, так и базовые классы исключений.
Пишите код, безопасный с точки зрения исключений (exception-safe)
Что такое «код, безопасный с точки зрения исключений»? Пусть имеется какой-то произвольный фрагмент кода. Где-то в процессе выполнения этого кода генерируется исключение и перехватывается снаружи. Этот фрагмент кода безопасен с точки зрения исключений если он, в идеале, отвечает следующим требованиям:
- Все ресурсы, выделенные внутри блока try до генерации исключения, должны быть корректно освобождены;
- Все объекты, созданные внутри блока try до генерации исключения, должны быть корректно уничтожены;
- Должен произойти полный откат всех изменений в системе, внесенных кодом, который выполнился от начала блока try до момента генерации исключения.
Эти три пункта указываются почти в любой литературе, в которой идет речь о безопасности с точки зрения исключений. По большому счету, первые два пункта это частные случаи более общего правила, указанного в третьем пункте. Код, безопасный с точи зрения исключений, это код, обладающий транзакционным поведением.
Транзакционность и «бизнес-логика»
Блоками try следует охватывать те участки кода, которые должны иметь транзакционное поведение с точки зрения «бизнес-логики» самой программы.
Рассмотрим в качестве примера графический редактор, имеющий multi-dialog интерфейс, и следующий сценарий работы: пользователь выбирает у главном меню «Open file(s)», выделяет десять картинок и нажимает «Open». Восемь картинок загружаются корректно, загрузка девятой генерирует исключение.
Для того, чтобы понять, какой именно участок кода следует охватить блоком try, необходимо решить, какая именно логика работы с точки зрения сценария должна быть реализована. В рассматриваемом примере возможны два очевидных варианта, и оба вполне имеют право на существование. Первый — открыть только те картинки, которые корректно загрузились и показать сообщение об ошибке. Второй — показать сообщение об ошибке и выбросить все успешно загруженные картинки, тем самым выполнив полный откат системы. В первом случае элементом транзакции является код загрузки отдельно взятой картинки — он и берется в блок try. Во втором случае элементом транзакции является код загрузки множества картинок, то есть фрагмент, находящийся на один логический этаж выше.
Итак, блоками try следует охватывать участки кода, которые должны представлять собой транзакцию с точки зрения «бизнес-логики». При этом следует стараться расположить блок try как можно выше относительно вложенности функциональности, делая шаги вверх по этажам до тех пор, пока языковая транзакция не начнет противоречить логике, которая должна быть реализована в программе. И логика эта, как показывает практика, может быть очень разнообразной.
Обеспечение транзакционности
Некоторые авторитетные люди, чьи книги издаются чуть ли не миллионными тиражами, утверждают, что одна из причин, по которой исключения лучше чем коды ошибок, заключается в том, что код, занимающийся ремонтом программы можно отделить от логики работы программы, поместив его в блоки catch. К сожалению, этот подход устарел уже на следующий день после выхода первого Стандарта языка C++, а его использование говорит о полном непонимании всей прелести языка.
В идеале, весь код по ремонту программы должен быть реализован на уровне описания типов, то есть так или иначе посредством идиомы владения. В блоках catch следует содержать только код, занимающийся оповещением об ошибке. Если это оконное приложение, то достаточно показать MessageBox, если серверная система, то сделать запись в лог или отправить сообщение по почте.
Следует внимательно следить за тем, чтобы способ оповещения об ошибке не генерировал исключений, поскольку исключение при попытке проинформировать об ошибке — ситуация не из приятных. Если требуется оповестить об ошибке способом, который может сгенерировать исключение (например — отправка сообщения по почте), то такую работу лучше осуществлять в очереди отложенных задач в отдельном потоке, добавляя в блоке catch негенерирующим исключения способом новую отложенную задачу.
Типы данных
Практически во всех ситуациях наиболее естественный тип данных для пользовательских исключений с точки зрения C++ это тип, так или иначе производный от std::exception. Моя рекомендация состоит в том, чтобы в качестве типа данных для пользовательских исключений использовать std::runtime_error, или его наследников, если это необходимо.
Некоторые люди (не буду показывать пальцем) используют оператор new для генерации исключений и перехватывают их по указателю. Такая конструкция в свое время была (а может быть и до сих пор есть) в макросах Visual Assist-а. Такой подход в C++ в корне неверен — применять его можно только в языках со сборщиком мусора (gc). Использование такого подхода в C++ говорит о полном непонимании механизма исключений. Генерировать исключения следует по значению, перехватывать — по константной ссылке.
Классификация и оповещение
Любая ошибка имеет причину и влечет следствие. Используйте виртуальную функцию std::exception::what() для того, чтобы получить человеческое описание причины возникновения ошибки.
Различные варианты наследников std::runtime_error помогут классифицировать тип ошибки для правильного способа оповещения, и, если это все же по каким-то причинам необходимо, для выполнения необходимых действий по приведению программы в корректное работоспособное состояние. Например, исключения различных подсистем могут иметь различный тип данных.
namespace network
{
class error : public std::runtime_error
{
virtual char const* what() const;
};
} // namespace network
namespace ui
{
class error : public std::runtime_error
{
virtual char const* what() const;
};
} // namespace ui
int main()
{
application app;
while(app.alive())
{
try
{
app.run();
}
catch(network::error const& e)
{
std::cout << "Network exception: " << e.what() << std::endl;
mailto("admin@microsoft.com", e.what());
}
catch(ui::error const& e)
{
std::cout << "UI exception: " << e.what() << std::endl;
message_box(e.what());
}
catch(std::exception const& e)
{
std::cout << "Exception: " << e.what() << std::endl;
}
}
return 0;
}
Следствие ошибки напрямую зависит от того места, где исключение было перехвачено. Следствие любого перехваченного исключения в коде, безопасном с точки зрения исключений, это откат системы на блок try, в котором это исключение было сгенерированно. То есть, говоря по-простому, следствие это «что не получилось сделать», в то время как причина это «почему это не получилось сделать». Место генерации исключения и его тип — это причина, место его перехвата — это следствие.
Составление сообщения об ошибке — очень ответственная задача, с которой, к сожалению, зачастую не справляются даже самые крупные программные продукты. Хорошее сообщение об ошибке должно содержать информацию как о причине ошибки, так и о ее следствии. Вот пример хорошего сообщения об ошибке:
Не могу загрузить изображение (следствие):
недостаточно прав для чтения файла 001.jpg (причина)
Подведем итоги
В этой статье я уделил много времени описанию того, что стоит понимать под исключительной ситуацией (ошибкой). Это очень важно, т.к. может возникать соблазн использовать этот механизм для других целей. Даже если это сработает эффективно в каком-либо случае, код будет очень трудно читаться.
Можно порассуждать о том, должна ли функция вычисления квадратного корня или оператор деления вырабатывать исключения при отрицательном или нулевом значениях аргумента. Во-первых это могло быть не эффективно, во-вторых, скорее всего гораздо удобнее в таких случаях проверить корректность аргумента до вызова функции, чем обрабатывать ошибки после. Однако, подобная предварительная проверка была бы не эффективной например для функции преобразования строки в число.
Тут же, можно вспомнить, что исключения не используются во многих проектах по причинам недостаточной эффективности — например в Яндекс.Браузере. Кроме того, исключения не использовались в библиотеке Qt (по крайней мере 4.х версии) из-за сложности их реализации на некоторых архитектурах. Тот факт, что в настоящее время библиотека Qt сейчас использует механизм исключений означает, что его поддерживает подавляющее большинство компиляторов С++ под самые разные платформы.
Мое личное мнение — нужно стараться использовать исключения вместо кодов ошибок, однако при этом надо думать и об архитектуре приложения, и об удобстве использования ваших классов и функций. В большинстве случаев исключения помогут вам написать более чистый, понятный и безопасный код. В совсем редких случаях они окажут какое-либо заметное влияние на производительность, ведь исключения вообще не должны вырабатываться в программе часто — это механизм обработки ошибок, которые не должны сыпаться как из рога изобилия.
Пишите код, транзакционный с точки зрения исключений. Реализуйте транзакционность на уровне описания типов данных, максимально минимизируя ремонт программы в блоках catch. Сопоставляйте блокам try соответствующие транзакции с точки зрения «бизнес-логики». Используйте std::runtime_error или его наследников в качестве типов данных для исключений. Генерируйте исключения по значению, перехватывайте по константной ссылке. Классифицируйте ошибки, если это необходимо. Предоставляйте понятное человеку сообщение об ошибке; указывайте как причину, так и следствие. Оповещайте об исключении способом, не генерирующим исключения.
Литература по теме обработки исключений:
- Б. Страуструп Язык программирования С++. Специальное издание. Пер. с англ. – М.: Издательство Бином, 2011 г. – 1136 с.
- Мартин Р. Чистый код. Создание, анализ и рефакторинг. Библиотека программиста. – СПб.: Питер, 2014. – 464 с.
- Мейерс С. Эффективное использование С++. 35 новых рекомендаций по улучшению ваших программ и проектов. – М.: ДМК Пресс, 2014. – 294с.
Данная статья является переводом. Ссылка на оригинал.
В статье рассмотрим:
- Объект Error
- Try…catch
- Throw
- Call stack
- Наименование функций
- Парадигму асинхронного программирования Promise
Представьте, как разрабатываете RESTful web API на Node.js.
- Пользователи отправляют запросы к серверу для получения данных.
- Вопрос времени, когда в программу придут значения, которые не ожидались.
- В таком случае, когда программа получит эти значения, пользователи будут рады видеть подробное и конкретное описание ошибки.
- В случае когда нет соответствующего обработчика ошибки, отобразится стандартное сообщение об ошибке. Таким образом, пользователь увидит сообщение об ошибке «Невозможно выполнить запрос», что не несет полезной информации о том, что произошло.
- Поэтому стоит уделять внимание обработке ошибок, чтобы наша программа стала безопасной, отказоустойчивой, высокопроизводительной и без ошибок.
Анатомия Объекта Error
Первое, с чего стоит начать изучение – это объект Error.
Разберем на примере:
throw new Error('database failed to connect');
Здесь происходят две вещи: создается объект Error и выбрасывается исключение.
Начнем с рассмотрения объекта Error, и того, как он работает. К ключевому слову throw вернемся чуть позже.
Объект Error представляет из себя реализацию функции конструктора, которая использует набор инструкций (аргументы и само тело конструктора) для создания объекта.
Тем не менее, что же такое объекты ошибок? Почему они должны быть однородными? Это важные вопросы, поэтому давайте перейдем к ним.
Первым аргументом для объекта Error является его описание.
Описание – это понятная человеку строка объекта ошибки. Также эта строка появляется в консоли, когда что-то пошло не так.
Объекты ошибок также имеют свойство name, которое рассказывает о типе ошибки. Когда создается нативный объект ошибки, то свойство name по умолчанию содержит Error. Вы также можете создать собственный тип ошибки, расширив нативный объект ошибки следующим образом:
class FancyError extends Error {
constructor(args){
super(args);
this.name = "FancyError"
}
}
console.log(new Error('A standard error'))
// { [Error: A standard error] }
console.log(new FancyError('An augmented error'))
// { [Your fancy error: An augmented error] name: 'FancyError' }
Обработка ошибок становится проще, когда у нас есть согласованность в объектах.
Ранее мы упоминали, что хотим, чтобы объекты ошибок были однородными. Это поможет обеспечить согласованность в объекте ошибки.
Теперь давайте поговорим о следующей части головоломки – throw.
Ключевое слово Throw
Создание объектов ошибок – это не конец истории, а только подготовка ошибки к отправке. Отправка ошибки заключается в том, чтобы выбросить исключение. Но что значит выбросить? И что это значит для нашей программы?
Throw делает две вещи: останавливает выполнение программы и находит зацепку, которая мешает выполнению программы.
Давайте рассмотрим эти идеи одну за другой:
- Когда JavaScript находит ключевое слово
throw, первое, что он делает – предотвращает запуск любых других функций. Остановка снижает риск возникновения любых дальнейших ошибок и облегчает отладку программ. - Когда программа остановлена, JavaScript начнет отслеживать последовательную цепочку функций, которые были вызваны для достижения оператора
catch. Такая цепочка называется стек вызовов (англ. call stack). Ближайшийcatch, который находит JavaScript, является местом, где возникает выброшенное исключение. Если операторыtry/catchне найдены, тогда возникает исключение, и процесс Node.js завершиться, что приведет к перезапуску сервера.
Бросаем исключения на примере
Мы рассмотрели теорию, а теперь давайте изучим пример:
function doAthing() {
byDoingSomethingElse();
}
function byDoingSomethingElse() {
throw new Error('Uh oh!');
}
function init() {
try {
doAthing();
} catch(e) {
console.log(e);
// [Error: Uh oh!]
}
}
init();
Здесь в функции инициализации init() предусмотрена обработка ошибок, поскольку она содержит try/catch блок.
init() вызывает функцию doAthing(), которая вызывает функцию byDoingSomethingElse(), где выбрасывается исключение. Именно в этот момент ошибки, программа останавливается и начинает отслеживать функцию, вызвавшую ошибку. Далее в функции init() и выполняет оператор catch. С помощью оператора catch мы решаем что делать: подавить ошибку или даже выдать другую ошибку (для распространения вверх).
Стек вызовов
То, что показано в приведенном выше примере – это проработанный пример стека вызовов. Как и большинство языков, JavaScript использует концепцию, известную как стек вызовов.
Но как работает стек вызовов?
Всякий раз, когда вызывается функция, она помещается в стек, а при завершении удаляется из стека. Именно от этого стека мы получили название «трассировки стека».
Трассировка стека – это список функций, которые были вызваны до момента, когда в программе произошло исключение.
Она часто выглядит так:
Error: Uh oh!
at byDoingSomethingElse (/filesystem/aProgram.js:7:11)
at doAthing (/filesystem/aProgram.js:3:5)
at init (/filesystem/aProgram.js:12:9)
at Object.<anonymous> (/filesystem/aProgram.js:19:1)
at Module._compile (internal/modules/cjs/loader.js:689:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:700:10)
at Module.load (internal/modules/cjs/loader.js:599:32)
at tryModuleLoad (internal/modules/cjs/loader.js:538:12)
at Function.Module._load (internal/modules/cjs/loader.js:530:3)
at Function.Module.runMain (internal/modules/cjs/loader.js:742:12)
На этом этапе вам может быть интересно, как стек вызовов помогает нам с обработкой ошибок Node.js. Давайте поговорим о важности стеков вызовов.
Стек вызовов предоставляет «хлебные крошки», помогая проследить путь, который привел к исключению(ошибке).
Почему у нас должны быть функции без имен? Иногда в наших программах мы хотим определить маленькие одноразовые функции, которые выполняют небольшую задачу. Мы не хотим утруждать себя задачей давать им имена, но именно эти анонимные функции могут вызвать у нас всевозможные головные боли. Анонимная функция удаляет имя функции из нашего стека вызовов, что делает наш стек вызовов значительно более сложным в использовании.
Обратите внимание, что присвоить имена функциям в JavaScript не так просто. Итак, давайте кратко рассмотрим различные способы определения функций, и рассмотрим некоторые ловушки в именовании функций.
Как называть функции
Чтобы понять, как называть функции, давайте рассмотрим несколько примеров:
// анонимная функция
const one = () => {};
// анонимная функция
const two = function () {};
// функция с явным названием
const three = function explicitFunction() {};
Вот три примера функций.
Первая – это лямбда (или стрелочная функция). Лямбда функции по своей природе анонимны. Не запутайтесь. Имя переменной one не является именем функции. Имя функции следующее за ключевым словом function необязательно. Но в этом примере мы вообще ничего не передаем, поэтому наша функция анонимна.
Примечание
Не помогает и то, что некоторые среды выполнения JavaScript, такие как V8, могут иногда угадывать имя вашей функции. Это происходит, даже если вы его не даете.
Во втором примере мы получили функциональное выражение. Это очень похоже на первый пример. Это анонимная функция, но просто объявленная с помощью ключевого слова function вместо синтаксиса жирной стрелки.
В последнем примере объявление переменной с подходящим именем explicitFunction. Это показывает, что это единственная функция, у которой соответствующее имя.
Как правило, рекомендуется указывать это имя везде, где это возможно, чтобы иметь более удобочитаемую трассировку стека.
Обработка асинхронных исключений
Мы познакомились с объектом ошибок, ключевым словом throw, стеком вызовов и наименованием функций. Итак, давайте обратим наше внимание на любопытный случай обработки асинхронных ошибок. Почему? Потому что асинхронный код ведет себя не так, как ожидаем. Асинхронное программирование необходимо каждому программисту на Node.js.
Javascript – это однопоточный язык программирования, а это значит, что Javascript запускается с использованием одного процессора. Из этого следует, что у нас есть блокирующий и неблокирующий код. Блокирующий код относится к тому, будет ли ваша программа ожидать завершения асинхронной задачи, прежде чем делать что-либо еще. В то время как неблокирующий код относится к тому, где вы регистрируете обратный вызов (callback) для выполнения после завершения задачи.
Стоит упомянуть, что есть два основных способа обработки асинхронности в JavaScript: promises (обещания или промисы) и callback (функция обратного вызова). Мы намеренно игнорируем async/wait, чтобы избежать путаницы, потому что это просто сахар поверх промисов.
В статье мы сфокусируемся на промисах. Существует консенсус в отношении того, что для приложений промисы превосходят обратные вызовы с точки зрения стиля программирования и эффективности. Поэтому в этой статье проигнорируем подход с callback-ами, и предположим, что вместо него вы выберете promises.
Примечание
Существует множество способов конвертировать код на основе callback-ов в promises. Например, вы можете использовать такую утилиту, как promisify, или обернуть свои обратные вызовы в промисы, например, так:
var request = require('request'); //http wrapped module
function requestWrapper(url, callback) {
request.get(url, function (err, response) {
if (err) {
callback(err);
} else {
callback(null, response);
}
})
}
Мы разберемся с этой ошибкой, обещаю!
Давайте взглянем на анатомию обещаний.
Промисы в JavaScript – это объект, представляющий будущее значение. Promise API позволяют нам моделировать асинхронный код так же, как и синхронный. Также стоит отметить, что обещание обычно идет в цепочке, где выполняется одно действие, затем другое и так далее.
Но что все это значит для обработки ошибок Node.js?
Промисы элегантно обрабатывают ошибки и перехватывают любые ошибки, которые им предшествовали в цепочке. С помощью одного обработчика обрабатывается множество ошибок во многих функциях.
Изучим код ниже:
function getData() {
return Promise.resolve('Do some stuff');
}
function changeDataFormat() {
// ...
}
function storeData(){
// ...
}
getData()
.then(changeDataFormat)
.then(storeData)
.catch((e) => {
// Handle the error!
})
Здесь видно, как объединить обработку ошибок для трех различных функций в один обработчик, т. е. код ведет себя так же, как если бы три функции заключались в синхронный блок try/catch.
Отлавливать или не отлавливать?
На данном этапе стоит спросить себя, повсеместно ли добавляется .catch к промисам, поскольку это опционально. Из-за проблем с сетью, аппаратного сбоя или истекшего времени ожидания в асинхронных вызовах возникает исключение. По этим причинам указывайте программе, что делать в случаях невыполнения промиса.
Запомните «Золотое правило» – каждый раз обрабатывать исключения в обещаниях.
Риски асинхронного try/catch
Мы приближаемся к концу в нашем путешествии по обработке ошибок в Node.js. Пришло время поговорить о ловушках асинхронного кода и оператора try/catch.
Вам может быть интересно, почему промис предоставляет метод catch, и почему мы не можем просто обернуть нашу реализацию промиса в try/catch. Если бы вы сделали это, то результаты были бы не такими, как вы ожидаете.
Рассмотрим на примере:
try {
throw new Error();
} catch(e) {
console.log(e); // [Error]
}
try {
setTimeout(() => {
throw new Error();
}, 0);
} catch(e) {
console.log(e); // Nothing, nada, zero, zilch, not even a sound
}
try/catch по умолчанию синхронны, что означает, что если асинхронная функция выдает ошибку в синхронном блоке try/catch, ошибка не будет брошена.
Однозначно это не то, что ожидаем.
***
Подведем итог! Необходимо использовать обработчик промисов, когда мы имеем дело с асинхронным кодом, а в случае с синхронным кодом подойдет try/catch.
Заключение
Из этой статьи мы узнали:
- как устроен объект Error;
- научились создавать свои собственные ошибки;
- как работает стек вызовов;
- практики наименования функций, для удобочитаемой трассировки стека;
- как обрабатывать асинхронные исключения.
***
Материалы по теме
- 🗄️ 4 базовых функции для работы с файлами в Node.js
- Цикл событий: как выполняется асинхронный JavaScript-код в Node.js
- Обработка миллионов строк данных потоками на Node.js
Аннотация: Попытка классификации ошибок. Сообщение об ошибке с помощью возвращаемого значения. Исключительные ситуации. Обработка исключительных ситуаций, операторы try и catch.
Виды ошибок
Существенной частью любой программы является обработка ошибок.
Прежде чем перейти к описанию средств языка Си++, предназначенных
для обработки ошибок, остановимся немного на том,какие, собственно, ошибки
мы будем рассматривать.
Ошибки компиляции пропустим:пока все они не исправлены,
программа не готова, и запустить ее нельзя. Здесь мы будем рассматривать
только ошибки, происходящие во время выполнения программы.
Первый вид ошибок, который всегда приходит в голову – это ошибки
программирования. Сюда относятся ошибки в алгоритме, в логике
программы и чисто программистские ошибки. Ряд возможных ошибок
мы называли ранее (например, при работе с указателями), но гораздо
больше вы узнаете на собственном горьком опыте.
Теоретически возможно написать программу без таких ошибок. Во
многом язык Си++ помогает предотвратить ошибки во время выполнения
программы,осуществляя строгий контроль на стадии компиляции.
Вообще, чем строже контроль на стадии компиляции, тем меньше ошибок
остается при выполнении программы.
Перечислим некоторые средства языка, которые помогут избежать ошибок:
-
Контроль типов. Случаи использования недопустимых операций
и смешения несовместимых типов будут обнаружены компилятором. - Обязательное объявление имен до их использования. Невозможно
вызвать функцию с неверным числом аргументов. При изменении определения
переменной или функции легко обнаружить все места, где она
используется. - Ограничение видимости имен, контексты имен. Уменьшается возможность
конфликтов имен, неправильного переопределения имен.
Самым важным средством уменьшения вероятности ошибок является
объектно-ориентированный подход к программированию, который поддерживает
язык Си++. Наряду с преимуществами объектного программирования,
о которых мы говорили ранее, построение программы из классов позволяет
отлаживать классы по отдельности и строить программы из надежных
составных «кирпичиков», используя одни и те же классы многократно.
Несмотря на все эти положительные качества языка, остается «простор»
для написания ошибочных программ. По мере рассмотрения
свойств языка, мы стараемся давать рекомендации, какие возможности
использовать, чтобы уменьшить вероятность ошибки.
Лучше исходить из того, что идеальных программ не существует, это
помогает разрабатывать более надежные программы. Самое главное –
обеспечить контроль данных, а для этого необходимо проверять в программе
все, что может содержать ошибку. Если в программе предполагается
какое-то условие, желательно проверить его, хотя бы в начальной
версии программы, до того, как можно будет на опыте убедиться, что это
условие действительно выполняется. Важно также проверять указатели,
передаваемые в качестве аргументов, на равенство нулю; проверять, не
выходят ли индексы за границы массива и т.п.
Ну и решающими качествами, позволяющими уменьшить количество ошибок,
являются внимательность, аккуратность и опыт.
Второй вид ошибок – «предусмотренные», запланированные ошибки.
Если разрабатывается программа диалога с пользователем, такая
программа обязана адекватно реагировать и обрабатывать неправильные
нажатия клавиш. Программа чтения текста должна учитывать возможные
синтаксические ошибки. Программа передачи данных по телефонной линии
должна обрабатывать помехи и возможные сбои при передаче. Такие ошибки – это, вообще говоря, не ошибки с точки зрения программы, а
плановые ситуации, которые она обрабатывает.
Третий вид ошибок тоже в какой-то мере предусмотрен. Это исключительные
ситуации, которые могут иметь место, даже если в программе
нет ошибок . Например, нехватка памяти для создания нового объекта.
Или сбой диска при извлечении информации из базы данных.
Именно обработка двух последних видов ошибок и рассматривается в последующих
разделах. Граница между ними довольно условна. Например,
для большинства программ сбой диска – исключительная ситуация, но
для операционной системы сбой диска должен быть предусмотрен и должен
обрабатываться. Скорее два типа можно разграничить по тому, какая
реакция программы должна быть предусмотрена. Если после плановых ошибок программа должна продолжать работать, то после исключительных
ситуаций надо лишь сохранить уже вычисленные данные и завершить программу.
Возвращаемое значение как признак ошибки
Простейший способ сообщения об ошибках предполагает использование возвращаемого значения функции или метода. Функция сохранения
объекта в базе данных может возвращать логическое значение: true в
случае успешного сохранения, false – в случае ошибки.
class Database
{
public:
bool SaveObject(const Object& obj);
};
Соответственно, вызов метода должен выглядеть так:
if (database.SaveObject(my_obj) == false ){
//обработка ошибки
}
Обработка ошибки, разумеется, зависит от конкретной программы.
Типична ситуация, когда при многократно вложенных вызовах функций
обработка происходит на несколько уровней выше, чем уровень, где ошибка произошла. В таком случае результат, сигнализирующий об ошибке,
придется передавать во всех вложенных вызовах.
int main()
{
if (fun1()==false ) //обработка ошибки
return 1;
}
bool
fun1()
{
if (fun2()==false )
return false ;
return true ;
}
bool
fun2()
{
if (database.SaveObject(obj)==false )
return false ;
return true ;
}
Если функция или метод должны возвращать какую-то величину в качестве
результата, то особое, недопустимое, значение этой величины используется в
качестве признака ошибки. Если метод возвращает указатель,
выдача нулевого указателя применяется в качестве признака ошибки. Если
функция вычисляет положительное число, возврат — 1 можно использовать
в качестве признака ошибки.
Иногда невозможно вернуть признак ошибки в качестве возвращаемого значения.
Примером является конструктор объекта, который не может вернуть значение. Как же сообщить о том, что во время инициализации объекта что-то было не так?
Распространенным решением является дополнительный атрибут
объекта – флаг, отражающий состояние объекта. Предположим, конструктор
класса Database должен соединиться с сервером базы данных.
class Database
{
public :
Database(const char *serverName);
...
bool Ok(void) const {return okFlag;};
private :
bool okFlag;
};
Database::Database(const char*serverName)
{
if (connect(serverName)==true )
okFlag =true ;
else
okFlag =false ;
}
int main()
{
Database database("db-server");
if (!database.Ok()){
cerr <<"Ошибка соединения с базой данных"<<endl;
return 0;
}
return 1;
}
Лучше вместо метода Ok, возвращающего значение флага okFlag,
переопределить операцию ! (отрицание).
class Database
{
public :
bool operator !()const {return !okFlag;};
};
Тогда проверка успешности соединения с базой данных будет выглядеть так:
if (!database){
cerr <<"Ошибка соединения с базой
данных"<<endl;
}
Следует отметить, что лучше избегать такого построения классов,
при котором возможны ошибки в конструкторе. Из конструктора можно
выделить соединение с сервером базы данных в отдельный метод Open:
class Database
{
public :
Database();
bool Open(const char*serverName);
}
и тогда отпадает необходимость в операции ! или методе Ok().
Использование возвращаемого значения в качестве признака ошибки –
метод почти универсальный. Он применяется, прежде всего, для обработки
запланированных ошибочных ситуаций. Этот метод имеет ряд
недостатков. Во-первых, приходится передавать признак ошибки через
вложенные вызовы функций. Во-вторых, возникают неудобства, если
метод или функция уже возвращают значение, и приходится либо модифицировать
интерфейс, либо придумывать специальное » ошибочное »
значение. В-третьих, логика программы оказывается запутанной из-за
сплошных условных операторов if с проверкой на ошибочное значение.