

Существует две фундаментальные стратегии: обработка исправимых ошибок (исключения, коды возврата по ошибке, функции-обработчики) и неисправимых (assert(), abort()). В каких случаях какую стратегию лучше использовать?
Виды ошибок
Ошибки возникают по разным причинам: пользователь ввёл странные данные, ОС не может дать вам обработчика файла или код разыменовывает (dereferences) nullptr. Каждая из описанных ошибок требует к себе отдельного подхода. По причинам ошибки делятся на три основные категории:
- Пользовательские ошибки: здесь под пользователем подразумевается человек, сидящий перед компьютером и действительно «использующий» программу, а не какой-то программист, дёргающий ваш API. Такие ошибки возникают тогда, когда пользователь делает что-то неправильно.
- Системные ошибки появляются, когда ОС не может выполнить ваш запрос. Иными словами, причина системных ошибок — сбой вызова системного API. Некоторые возникают потому, что программист передал системному вызову плохие параметры, так что это скорее программистская ошибка, а не системная.
- Программистские ошибки случаются, когда программист не учитывает предварительные условия API или языка программирования. Если API требует, чтобы вы не вызывали
foo()с0в качестве первого параметра, а вы это сделали, — виноват программист. Если пользователь ввёл0, который был переданfoo(), а программист не написал проверку вводимых данных, то это опять же его вина.
Каждая из описанных категорий ошибок требует особого подхода к их обработке.
Пользовательские ошибки
Сделаю очень громкое заявление: такие ошибки — на самом деле не ошибки.
Все пользователи не соблюдают инструкции. Программист, имеющий дело с данными, которые вводят люди, должен ожидать, что вводить будут именно плохие данные. Поэтому первым делом нужно проверять их на валидность, сообщать пользователю об обнаруженных ошибках и просить ввести заново.
Поэтому не имеет смысла применять к пользовательским ошибкам какие-либо стратегии обработки. Вводимые данные нужно как можно скорее проверять, чтобы ошибок не возникало.
Конечно, такое не всегда возможно. Иногда проверять вводимые данные слишком дорого, иногда это не позволяет сделать архитектура кода или разделение ответственности. Но в таких случаях ошибки должны обрабатываться однозначно как исправимые. Иначе, допустим, ваша офисная программа будет падать из-за того, что вы нажали backspace в пустом документе, или ваша игра станет вылетать при попытке выстрелить из разряженного оружия.
Если в качестве стратегии обработки исправимых ошибок вы предпочитаете исключения, то будьте осторожны: исключения предназначены только для исключительных ситуаций, к которым не относится большинство случаев ввода пользователями неверных данных. По сути, это даже норма, по мнению многих приложений. Используйте исключения только тогда, когда пользовательские ошибки обнаруживаются в глубине стека вызовов, вероятно, внешнего кода, когда они возникают редко или проявляются очень жёстко. В противном случае лучше сообщать об ошибках с помощью кодов возврата.
Системные ошибки
Обычно системные ошибки нельзя предсказать. Более того, они недетерминистские и могут возникать в программах, которые до этого работали без нареканий. В отличие от пользовательских ошибок, зависящих исключительно от вводимых данных, системные ошибки — настоящие ошибки.
Но как их обрабатывать, как исправимые или неисправимые?
Это зависит от обстоятельств.
Многие считают, что ошибка нехватки памяти — неисправимая. Зачастую не хватает памяти даже для обработки этой ошибки! И тогда приходится просто сразу же прерывать выполнение.
Но падение программы из-за того, что ОС не может выделить сокет, — это не слишком дружелюбное поведение. Так что лучше бросить исключение и позволить catch аккуратно закрыть программу.
Но бросание исключения — не всегда правильный выбор.
Кто-то даже скажет, что он всегда неправильный.
Если вы хотите повторить операцию после её сбоя, то обёртывание функции в try-catch в цикле — медленное решение. Правильный выбор — возврат кода ошибки и цикличное исполнение, пока не будет возвращено правильное значение.
Если вы создаёте вызов API только для себя, то просто выберите подходящий для своей ситуации путь и следуйте ему. Но если вы пишете библиотеку, то не знаете, чего хотят пользователи. Дальше мы разберём подходящую стратегию для этого случая. Для потенциально неисправимых ошибок подойдёт «обработчик ошибок», а при других ошибках необходимо предоставить два варианта развития событий.
Обратите внимание, что не следует использовать подтверждения (assertions), включающиеся только в режиме отладки. Ведь системные ошибки могут возникать и в релизной сборке!
Программистские ошибки
Это худший вид ошибок. Для их обработки я стараюсь сделать так, чтобы мои ошибки были связаны только с вызовами функций, то есть с плохими параметрами. Прочие типы программистских ошибок могут быть пойманы только в runtime, с помощью отладочных макросов (assertion macros), раскиданных по коду.
При работе с плохими параметрами есть две стратегии: дать им определённое или неопределённое поведение.
Если исходное требование для функции — запрет на передачу ей плохих параметров, то, если их передать, это считается неопределённым поведением и должно проверяться не самой функцией, а оператором вызова (caller). Функция должна делать только отладочное подтверждение (debug assertion).
С другой стороны, если отсутствие плохих параметров не является частью исходных требований, а документация определяет, что функция будет бросать bad_parameter_exception при передаче ей плохого параметра, то передача — это хорошо определённое поведение (бросание исключения или любая другая стратегия обработки исправимых ошибок), и функция всегда должна это проверять.
В качестве примера рассмотрим получающие функции (accessor functions) std::vector<T>operator[] говорится, что индекс должен быть в пределах валидного диапазона, при этом at() сообщает нам, что функция кинет исключение, если индекс не попадает в диапазон. Более того, большинство реализаций стандартных библиотек обеспечивают режим отладки, в котором проверяется индекс operator[], но технически это неопределённое поведение, оно не обязано проверяться.
Примечание: необязательно бросать исключение, чтобы получилось определённое поведение. Пока это не упомянуто в исходных условиях для функции, это считается определённым. Всё, что прописано в исходных условиях, не должно проверяться функцией, это неопределённое поведение.
Когда нужно проверять только с помощью отладочных подтверждений, а когда — постоянно?
К сожалению, однозначного рецепта нет, решение зависит от конкретной ситуации. У меня есть лишь одно проверенное правило, которому я следую при разработке API. Оно основано на наблюдении, что проверять исходные условия должен вызывающий, а не вызываемый. А значит, условие должно быть «проверяемым» для вызывающего. Также условие «проверяемое», если можно легко выполнить операцию, при которой значение параметра всегда будет правильным. Если для параметра это возможно, то это получается исходное условие, а значит, проверяется только посредством отладочного подтверждения (а если слишком дорого, то вообще не проверяется).
Но конечное решение зависит от многих других факторов, так что очень трудно дать какой-то общий совет. По умолчанию я стараюсь свести к неопределённому поведению и использованию только подтверждений. Иногда бывает целесообразно обеспечить оба варианта, как это делает стандартная библиотека с operator[] и at().
Хотя в ряде случаев это может быть ошибкой.
Об иерархии std::exception
Если в качестве стратегии обработки исправимых ошибок вы выбрали исключения, то рекомендуется создать новый класс и наследовать его от одного из классов исключений стандартной библиотеки.
Я предлагаю наследовать только от одного из этих четырёх классов:
std::bad_alloc: для сбоев выделения памяти.std::runtime_error: для общих runtime-ошибок.std::system_error(производное отstd::runtime_error): для системных ошибок с кодами ошибок.std::logic_error: для программистских ошибок с определённым поведением.
Обратите внимание, что в стандартной библиотеке разделяются логические (то есть программистские) и runtime-ошибки. Runtime-ошибки — более широкое определение, чем «системные». Оно описывает «ошибки, обнаруживаемые только при выполнении программы». Такая формулировка не слишком информативна. Лично я использую её для плохих параметров, которые не являются исключительно программистскими ошибками, а могут возникнуть и по вине пользователей. Но это можно определить лишь глубоко в стеке вызовов. Например, плохое форматирование комментариев в standardese приводит к исключению при парсинге, проистекающему из std::runtime_error. Позднее оно ловится на соответствующем уровне и фиксируется в логе. Но я не стал бы использовать этот класс иначе, как и std::logic_error.
Подведём итоги
Есть два пути обработки ошибок:
- как исправимые: используются исключения или возвращаемые значения (в зависимости от ситуации/религии);
- как неисправимые: ошибки журналируются, а программа прерывается.
Подтверждения — это особый вид стратегии обработки неисправимых ошибок, только в режиме отладки.
Есть три основных источника ошибок, каждый требует особого подхода:
- Пользовательские ошибки не должны обрабатываться как ошибки на верхних уровнях программы. Всё, что вводит пользователь, должно проверяться соответствующим образом. Это может обрабатываться как ошибки только на нижних уровнях, которые не взаимодействуют с пользователями напрямую. Применяется стратегия обработки исправимых ошибок.
- Системные ошибки могут обрабатываться в рамках любой из двух стратегий, в зависимости от типа и тяжести. Библиотеки должны работать как можно гибче.
- Программистские ошибки, то есть плохие параметры, могут быть запрещены исходными условиями. В этом случае функция должна использовать только проверку с помощью отладочных подтверждений. Если же речь идёт о полностью определённом поведении, то функции следует предписанным образом сообщать об ошибке. Я стараюсь по умолчанию следовать сценарию с неопределённым поведением и определяю для функции проверку параметров лишь тогда, когда это слишком трудно сделать на стороне вызывающего.
Гибкие методики обработки ошибок в C++
Иногда что-то не работает. Пользователи вводят данные в недопустимом формате, файл не обнаруживается, сетевое соединение сбоит, в системе кончается память. Всё это ошибки, и их надо обрабатывать.
Это относительно легко сделать в высокоуровневых функциях. Вы точно знаете, почему что-то пошло не так, и можете обработать это соответствующим образом. Но в случае с низкоуровневыми функциями всё не так просто. Они не знают, что пошло не так, они знают лишь о самом факте сбоя и должны сообщить об этом тому, кто их вызвал.
В C++ есть два основных подхода: коды возврата ошибок и исключения. Сегодня широко распространено использование исключений. Но некоторые не могут / думают, что не могут / не хотят их использовать — по разным причинам.
Я не буду принимать чью-либо сторону. Вместо этого я опишу методики, которые удовлетворят сторонников обоих подходов. Особенно методики пригодятся разработчикам библиотек.
Проблема
Я работаю над проектом foonathan/memory. Это решение предоставляет различные классы выделения памяти (allocator classes), так что в качестве примера рассмотрим структуру функции выделения.
Для простоты возьмём malloc(). Она возвращает указатель на выделяемую память. Если выделить память не получается, то возвращается nullptr, то есть NULL, то есть ошибочное значение.
У этого решения есть недостатки: вам нужно проверять каждый вызов malloc(). Если вы забудете это сделать, то выделите несуществующую память. Кроме того, по своей натуре коды ошибок транзитивны: если вызвать функцию, которая может вернуть код ошибки, и вы не можете его проигнорировать или обработать, то вы тоже должны вернуть код ошибки.
Это приводит нас к ситуации, когда чередуются нормальные и ошибочные ветви кода. Исключения в таком случае выглядят более подходящим решением. Благодаря им вы сможете обрабатывать ошибки только тогда, когда вам это нужно, а в противном случае — достаточно тихо передать их обратно вызывающему.
Это можно расценить как недостаток.
Но в подобных ситуациях исключения имеют также очень большое преимущество: функция выделения памяти либо возвращает валидную память, либо вообще ничего не возвращает. Это функция «всё или ничего», возвращаемое значение всегда будет валидным. Это полезное следствие согласно принципу Скотта Майера «Make interfaces hard to use incorrectly and easy to use correctly».
Учитывая вышесказанное, можно утверждать, что вам следует использовать исключения в качестве механизма обработки ошибок. Этого мнения придерживается большинство разработчиков на С++, включая и меня. Но проект, которым я занимаюсь, — это библиотека, предоставляющая средства выделения памяти, и предназначена она для приложений, работающих в реальном времени. Для большинства разработчиков подобных приложений (особенно для игроделов) само использование исключений — исключение.
Каламбур детектед.
Чтобы уважить эту группу разработчиков, моей библиотеке лучше обойтись без исключений. Но мне и многим другим они нравятся за элегантность и простоту обработки ошибок, так что ради других разработчиков моей библиотеке лучше использовать исключения.
Так что же делать?
Идеальное решение: возможность включать и отключать исключения по желанию. Но, учитывая природу исключений, нельзя просто менять их местами с кодами ошибок, поскольку у нас не будет внутреннего кода проверки на ошибки — весь внутренний код опирается на предположение о прозрачности исключений. И даже если бы внутри можно было использовать коды ошибок и преобразовывать их в исключения, это лишило бы нас большинства преимуществ последних.
К счастью, я могу определить, что вы делаете, когда обнаруживаете ошибку нехватки памяти: чаще всего вы журналируете это событие и прерываете программу, поскольку она не может корректно работать без памяти. В таких ситуациях исключения — просто способ передачи контроля другой части кода, которая журналирует и прерывает программу. Но есть старый и эффективный способ передачи контроля: указатель функции (function pointer), то есть функция-обработчик (handler function).
Если у вас включены исключения, то вы просто их бросаете. В противном случае вызываете функцию-обработчика и затем прерываете программу. Это предотвратит бесполезную работу функции-обработчика, та позволит программе продолжить выполняться в обычном режиме. Если не прервать, то произойдёт нарушение обязательного постусловия функции: всегда возвращать валидный указатель. Ведь на выполнении этого условия может быть построена работа другого кода, да и вообще это нормальное поведение.
Я называю такой подход обработкой исключений и придерживаюсь его при работе с памятью.
Решение 1: обработчик исключений
Если вам нужно обработать ошибку в условиях, когда наиболее распространённым поведением будет «журналировать и прервать», то можно использовать обработчика исключений. Это такая функция-обработчик, которая вызывается вместо бросания объекта-исключения. Её довольно легко реализовать даже в уже существующем коде. Для этого нужно поместить управление обработкой в класс исключений и обернуть в макрос выражение throw.
Сначала дополним класс и добавим функции для настройки и, возможно, запрашивания функции-обработчика. Я предлагаю делать это так же, как стандартная библиотека обрабатывает std::new_handler:
class my_fatal_error
{
public:
// тип обработчика, он должен брать те же параметры, что и конструктор,
// чтобы у них была одинаковая информация
using handler = void(*)( ... );
// меняет функцию-обработчика
handler set_handler(handler h);
// возвращает текущего обработчика
handler get_handler();
... // нормальное исключение
};Поскольку это входит в область видимости класса исключений, вам не нужно именовать каким-то особым образом. Отлично, нам же легче.
Если исключения включены, то для удаления обработчика можно использовать условное компилирование (conditional compilation). Если хотите, то также напишите обычный подмешанный класс (mixin class), дающий требуемую функциональность.
Конструктор исключений элегантен: он вызывает текущую функцию-обработчика, передавая ей требуемые аргументы из своих параметров. А затем комбинирует с последующим макросом throw:
If```cpp #if EXCEPTIONS #define THROW(Ex) throw (Ex) #else #define THROW(Ex) (Ex), std::abort() #endif> Такой макрос throw также предоставляется [foonathan/compatiblity](https://github.com/foonathan/compatibility).
Можно использовать его и так:
```cpp
THROW(my_fatal_error(...))
Если у вас включена поддержка исключений, то будет создан и брошен объект-исключение, всё как обычно. Но если поддержка выключена, то объект-исключение всё равно будет создан, и — это важно — только после этого произойдёт вызов std::abort(). А поскольку конструктор вызывает функцию-обработчика, то он и работает, как требуется: вы получаете точку настройки для журналирования ошибки. Благодаря же вызову std::abort() после конструктора пользователь не может нарушить постусловие.
Когда я работаю с памятью, то при включённых исключениях у меня также включён и обработчик, который вызывается при бросании исключения.
Так что при этой методике вам ещё будет доступна определённая степень кастомизации, даже если вы отключите исключения. Конечно, замена неполноценная, мы только журналируем и прерываем работу программы, без дальнейшего продолжения. Но в ряде случаев, в том числе при исчерпании памяти, это вполне пригодное решение.
А если я хочу продолжить работу после бросания исключения?
Методика с обработчиком исключений не позволяет этого сделать в связи с постусловием кода. Как же тогда продолжить работу?
Ответ прост — никак. По крайней мере, это нельзя сделать так же просто, как в других случаях. Нельзя просто так вернуть код ошибки вместо исключения, если функция на это не рассчитана.
Есть только одно решение: сделать две функции. Одна возвращает код ошибки, а вторая бросает исключения. Клиенты, которым нужны исключения, будут использовать второй вариант, остальные — первый.
Извините, что говорю такие очевидные вещи, но ради полноты изложения я должен был об этом сказать.
Для примера снова возьмём функцию выделения памяти. В этом случае я использую такие функции:
void* try_malloc(..., int &error_code) noexcept;
void* malloc(...);
При сбое выделения памяти первая версия возвращает nullptr и устанавливает error_code в коде ошибки. Вторая версия не возвращает nullptr, зато бросает исключение. Обратите внимание, что в рамках первой версии очень легко реализовать вторую:
void* malloc(...)
{
auto error_code = 0;
auto res = try_malloc(..., error_code);
if (!res)
throw malloc_error(error_code);
return res;
}Не делайте этого в обратной последовательности, иначе вам придётся ловить исключение, а это дорого. Также это не даст нам скомпилировать код без включённой поддержки исключений. Если сделаете, как показано, то можете просто стереть другую перегрузку (overload) с помощью условного компилирования.
Но даже если у вас включена поддержка исключений, клиенту всё равно может понадобиться вторая версия. Например, когда нужно выделить наибольший возможный объём памяти, как в нашем примере. Будет проще и быстрее вызывать в цикле и проверять по условию, чем ловить исключение.
Решение 2: предоставить две перегрузки
Если недостаточно обработчика исключений, то нужно предоставить две перегрузки. Одна использует код возврата, а вторая бросает исключение.
Если рассматриваемая функция не имеет возвращаемого значения, то можете её использовать для кода ошибки. В противном случае вам придётся возвращать недопустимое значение для сигнализирования об ошибке — как nullptr в вышеприведённом примере, — а также установить выходной параметр для кода ошибки, если хотите предоставить вызывающему дополнительную информацию.
Пожалуйста, не используйте глобальную переменную errno или что-то типа GetLastError()!
Если возвращаемое значение не содержит недопустимое значение для обозначения сбоя, то по мере возможности используйте std::optional или что-то похожее.
Перегрузка исключения (exception overload) может — и должна — быть реализована в рамках версии с кодом ошибки, как это показано выше. Если компилируете без исключений, сотрите перегрузку с помощью условного компилирования.
std::system_error
Подобная система идеально подходит для работы с кодами ошибок в С++ 11.
Она возвращает непортируемый (non-portable) код ошибки std::error_code, то есть возвращаемый функцией операционной системы. С помощью сложной системы библиотечных средств и категорий ошибок вы можете добавить собственные коды ошибок, или портируемые std::error_condition. Для начала почитайте об этом здесь. Если нужно, то можете использовать в функции кода ошибки std::error_code. А для функции исключения есть подходящий класс исключения: std::system_error. Он берёт std::error_code и применяется для передачи этих ошибок в виде исключений.
Эту или подобную систему должны использовать все низкоуровневые функции, являющиеся закрытыми обёртками ОС-функций. Это хорошая — хотя и сложная — альтернатива службе кодов ошибок, предоставляемой операционной системой.
Да, и мне ещё нужно добавить подобное в функции виртуальной памяти. На сегодняшний день они не предоставляют коды ошибок.
std::expected
Выше упоминалось о проблеме, когда у вас нет возвращаемого значения, содержащего недопустимое значение, которое можно использовать для сигнализирования об ошибке. Более того, выходной параметр — не лучший способ получения кода ошибки.
А глобальные переменные вообще не вариант!
В № 4109 предложено решение: std::expected. Это шаблон класса, который также хранит возвращаемое значение или код ошибки. В вышеприведённом примере он мог бы использоваться так:
std::expected<void*, std::error_code> try_malloc(...);
В случае успеха std::expected будет хранить не-null указатель памяти, а при сбое — std::error_code. Сейчас эта методика работает при любых возвращаемых значениях. Комбинация std::expected и функции исключения определённо допускает любые варианты использования.
Заключение
Если вы создаёте библиотеки, то иногда приходится обеспечивать максимальную гибкость использования. Под этим подразумевается и разнообразие средств обработки ошибок: иногда требуются коды возврата, иногда — исключения.
Одна из возможных стратегий — улаживание этих противоречий с помощью обработчика исключений. Просто удостоверьтесь, что когда нужно, то вызывается callback, а не бросается исключение. Это замена для критических ошибок, которая в любом случае будет журналироваться перед прерыванием работы программы. Как таковой этот способ не универсален, вы не можете переключаться в одной программе между двумя версиями. Это лишь обходное решение при отключённой поддержке исключений.
Более гибкий подход — просто предоставить две перегрузки, одну с исключениями, а вторую без. Это даст пользователям максимальную свободу, они смогут выбирать ту версию, что лучше подходит в их ситуации. Недостаток этого подхода: вам придётся больше потрудиться при создании библиотеки.
В C++ различают ошибки времени компиляции и ошибки времени выполнения. Ошибки первого типа обнаруживает компилятор до запуска программы. К ним относятся, например, синтаксические ошибки в коде. Ошибки второго типа проявляются при запуске программы. Примеры ошибок времени выполнения: ввод некорректных данных, некорректная работа с памятью, недостаток места на диске и т. д. Часто такие ошибки могут привести к неопределённому поведению программы.
Некоторые ошибки времени выполнения можно обнаружить заранее с помощью проверок в коде. Например, такими могут быть ошибки, нарушающие инвариант класса в конструкторе. Обычно, если ошибка обнаружена, то дальнейшее выполение функции не имеет смысла, и нужно сообщить об ошибке в то место кода, откуда эта функция была вызвана. Для этого предназначен механизм исключений.
Коды возврата и исключения
Рассмотрим функцию, которая считывает со стандартного потока возраст и возвращает его вызывающей стороне. Добавим в функцию проверку корректности возраста: он должен находиться в диапазоне от 0 до 128 лет. Предположим, что повторный ввод возраста в случае ошибки не предусмотрен.
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
// Что вернуть в этом случае?
}
return age;
}
Что вернуть в случае некорректного возраста? Можно было бы, например, договориться, что в этом случае функция возвращает ноль. Но тогда похожая проверка должна быть и в месте вызова функции:
int main() {
if (int age = ReadAge(); age == 0) {
// Произошла ошибка
} else {
// Работаем с возрастом age
}
}
Такая проверка неудобна. Более того, нет никакой гарантии, что в вызывающей функции программист вообще её напишет. Фактически мы тут выбрали некоторое значение функции (ноль), обозначающее ошибку. Это пример подхода к обработке ошибок через коды возврата. Другим примером такого подхода является хорошо знакомая нам функция main. Только она должна возвращать ноль при успешном завершении и что-либо ненулевое в случае ошибки.
Другим способом сообщить об обнаруженной ошибке являются исключения. С каждым сгенерированным исключением связан некоторый объект, который как-то описывает ошибку. Таким объектом может быть что угодно — даже целое число или строка. Но обычно для описания ошибки заводят специальный класс и генерируют объект этого класса:
#include <iostream>
struct WrongAgeException {
int age;
};
int ReadAge() {
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Здесь в случае ошибки оператор throw генерирует исключение, которое представлено временным объектом типа WrongAgeException. В этом объекте сохранён для контекста текущий неправильный возраст age. Функция досрочно завершает работу: у неё нет возможности обработать эту ошибку, и она должна сообщить о ней наружу. Поток управления возвращается в то место, откуда функция была вызвана. Там исключение может быть перехвачено и обработано.
Перехват исключения
Мы вызывали нашу функцию ReadAge из функции main. Обработать ошибку в месте вызова можно с помощью блока try/catch:
int main() {
try {
age = ReadAge(); // может сгенерировать исключение
// Работаем с возрастом age
} catch (const WrongAgeException& ex) { // ловим объект исключения
std::cerr << "Age is not correct: " << ex.age << "n";
return 1; // выходим из функции main с ненулевым кодом возврата
}
// ...
}
Мы знаем заранее, что функция ReadAge может сгенерировать исключение типа WrongAgeException. Поэтому мы оборачиваем вызов этой функции в блок try. Если происходит исключение, для него подбирается подходящий catch-обработчик. Таких обработчиков может быть несколько. Можно смотреть на них как на набор перегруженных функций от одного аргумента — объекта исключения. Выбирается первый подходящий по типу обработчик и выполняется его код. Если же ни один обработчик не подходит по типу, то исключение считается необработанным. В этом случае оно пробрасывается дальше по стеку — туда, откуда была вызвана текущая функция. А если обработчик не найдётся даже в функции main, то программа аварийно завершается.
Усложним немного наш пример, чтобы из функции ReadAge могли вылетать исключения разных типов. Сейчас мы проверяем только значение возраста, считая, что на вход поступило число. Но предположим, что поток ввода досрочно оборвался, или на входе была строка вместо числа. В таком случае конструкция std::cin >> age никак не изменит переменную age, а лишь возведёт специальный флаг ошибки в объекте std::cin. Наша переменная age останется непроинициализированной: в ней будет лежать неопределённый мусор. Можно было бы явно проверить этот флаг в объекте std::cin, но мы вместо этого включим режим генерации исключений при таких ошибках ввода:
int ReadAge() {
std::cin.exceptions(std::istream::failbit);
int age;
std::cin >> age;
if (age < 0 || age >= 128) {
throw WrongAgeException(age);
}
return age;
}
Теперь ошибка чтения в операторе >> у потока ввода будет приводить к исключению типа std::istream::failure. Функция ReadAge его не обрабатывает. Поэтому такое исключение покинет пределы этой функции. Поймаем его в функции main:
int main() {
try {
age = ReadAge(); // может сгенерировать исключения разных типов
// Работаем с возрастом age
} catch (const WrongAgeException& ex) {
std::cerr << "Age is not correct: " << ex.age << "n";
return 1;
} catch (const std::istream::failure& ex) {
std::cerr << "Failed to read age: " << ex.what() << "n";
return 1;
} catch (...) {
std::cerr << "Some other exceptionn";
return 1;
}
// ...
}
При обработке мы воспользовались функцией ex.what у исключения типа std::istream::failure. Такие функции есть у всех исключений стандартной библиотеки: они возвращают текстовое описание ошибки.
Обратите внимание на третий catch с многоточием. Такой блок, если он присутствует, будет перехватывать любые исключения, не перехваченные ранее.
Исключения стандартной библиотеки
Функции и классы стандартной библиотеки в некоторых ситуациях генерируют исключения особых типов. Все такие типы выстроены в иерархию наследования от базового класса std::exception. Иерархия классов позволяет писать обработчик catch сразу на группу ошибок, которые представлены базовым классом: std::logic_error, std::runtime_error и т. д.
Вот несколько примеров:
-
Функция
atу контейнеровstd::array,std::vectorиstd::dequeгенерирует исключениеstd::out_of_rangeпри некорректном индексе. -
Аналогично, функция
atуstd::map,std::unordered_mapи у соответствующих мультиконтейнеров генерирует исключениеstd::out_of_rangeпри отсутствующем ключе. -
Обращение к значению у пустого объекта
std::optionalприводит к исключениюstd::bad_optional_access. -
Потоки ввода-вывода могут генерировать исключение
std::ios_base::failure.
Исключения в конструкторах
В главе 3.1 мы написали класс Time. Этот класс должен был соблюдать инвариант на значение часов, минут и секунд: они должны были быть корректными. Если на вход конструктору класса Time передавались некорректные значения, мы приводили их к корректным, используя деление с остатком.
Более правильным было бы сгенерировать в конструкторе исключение. Таким образом мы бы явно передали сообщение об ошибке во внешнюю функцию, которая пыталась создать объект.
class Time {
private:
int hours, minutes, seconds;
public:
// Заведём класс для исключения и поместим его внутрь класса Time как в пространство имён
class IncorrectTimeException {
};
Time::Time(int h, int m, int s) {
if (s < 0 || s > 59 || m < 0 || m > 59 || h < 0 || h > 23) {
throw IncorrectTimeException();
}
hours = h;
minutes = m;
seconds = s;
}
// ...
};
Генерировать исключения в конструкторах — совершенно нормальная практика. Однако не следует допускать, чтобы исключения покидали пределы деструкторов. Чтобы понять причины, посмотрим подробнее, что происходит при генерации исключения.
Свёртка стека
Вспомним класс Logger из предыдущей главы. Посмотрим, как он ведёт себя при возникновении исключения. Воспользуемся в этом примере стандартным базовым классом std::exception, чтобы не писать свой класс исключения.
#include <exception>
#include <iostream>
void f() {
std::cout << "Welcome to f()!n";
Logger x;
// ...
throw std::exception(); // в какой-то момент происходит исключение
}
int main() {
try {
Logger y;
f();
} catch (const std::exception&) {
std::cout << "Something happened...n";
return 1;
}
}
Мы увидим такой вывод:
Logger(): 1 Welcome to f()! Logger(): 2 ~Logger(): 2 ~Logger(): 1 Something happened...
Сначала создаётся объект y в блоке try. Затем мы входим в функцию f. В ней создаётся объект x. После этого происходит исключение. Мы должны досрочно покинуть функцию. В этот момент начинается свёртка стека (stack unwinding): вызываются деструкторы для всех созданных объектов в самой функции и в блоке try, как если бы они вышли из своей области видимости. Поэтому перед обработчиком исключения мы видим вызов деструктора объекта x, а затем — объекта y.
Аналогично, свёртка стека происходит и при генерации исключения в конструкторе. Напишем класс с полем Logger и сгенерируем нарочно исключение в его конструкторе:
#include <exception>
#include <iostream>
class C {
private:
Logger x;
public:
C() {
std::cout << "C()n";
Logger y;
// ...
throw std::exception();
}
~C() {
std::cout << "~C()n";
}
};
int main() {
try {
C c;
} catch (const std::exception&) {
std::cout << "Something happened...n";
}
}
Вывод программы:
Logger(): 1 // конструктор поля x C() Logger(): 2 // конструктор локальной переменной y ~Logger(): 2 // свёртка стека: деструктор y ~Logger(): 1 // свёртка стека: деструктор поля x Something happened...
Заметим, что деструктор самого класса C не вызывается, так как объект в конструкторе не был создан.
Механизм свёртки стека гарантирует, что деструкторы для всех созданных автоматических объектов или полей класса в любом случае будут вызваны. Однако он полагается на важное свойство: деструкторы самих классов не должны генерировать исключений. Если исключение в деструкторе произойдёт в момент свёртки стека при обработке другого исключения, то программа аварийно завершится.
Пример с динамической памятью
Подчеркнём, что свёртка стека работает только с автоматическими объектами. В этом нет ничего удивительного: ведь за временем жизни объектов, созданных в динамической памяти, программист должен следить самостоятельно. Исключения вносят дополнительные сложности в ручное управление динамическими объектами:
void f() {
Logger* ptr = new Logger(); // конструируем объект класса Logger в динамической памяти
// ...
g(); // вызываем какую-то функцию
// ...
delete ptr; // вызываем деструктор и очищаем динамическую память
}
На первый взгляд кажется, что в этом коде нет ничего опасного: delete вызывается в конце функции. Однако функция g может сгенерировать исключение. Мы не перехватываем его в нашей функции f. Механизм свёртки уберёт со стека лишь сам указатель ptr, который является автоматической переменной примитивного типа. Однако он ничего не сможет сделать с объектом в памяти, на которую ссылается этот указатель. В логе мы увидим только вызов конструктора класса Logger, но не увидим вызова деструктора. Нам придётся обработать исключение вручную:
void f() {
Logger* ptr = new Logger();
// ...
try {
g();
} catch (...) { // ловим любое исключение
delete ptr; // вручную удаляем объект
throw; // перекидываем объект исключения дальше
}
// ...
delete ptr;
}
Здесь мы перехватываем любое исключение и частично обрабатываем его, удаляя объект в динамической памяти. Затем мы прокидываем текущий объект исключения дальше с помощью оператора throw без аргументов.
Согласитесь, этот код очень далёк от совершенства. При непосредственной работе с объектами в динамической памяти нам приходится оборачивать в try/catch любую конструкцию, из которой может вылететь исключение. Понятно, что такой код чреват ошибками. В главе 3.6 мы узнаем, как с точки зрения C++ следует работать с такими ресурсами, как память.
Гарантии безопасности исключений
Предположим, что мы пишем свой класс-контейнер, похожий на двусвязный список. Наш контейнер позволяет добавлять элементы в хранилище и отдельно хранит количество элементов в некотором поле elementsCount. Один из инвариантов этого класса такой: значение elementsCount равно реальному числу элементов в хранилище.
Не вдаваясь в детали, давайте посмотрим, как могла бы выглядеть функция добавления элемента.
template <typename T>
class List {
private:
struct Node { // узел двусвязного списка
T element;
Node* prev = nullptr; // предыдущий узел
Node* next = nullptr; // следующий узел
};
Node* first = nullptr; // первый узел списка
Node* last = nullptr; // последний узел списка
int elementsCount = 0;
public:
// ...
size_t Size() const {
return elementsCount;
}
void PushBack(const T& elem) {
++elementsCount;
// Конструируем в динамической памяти новой узел списка
Node* node = new Node(elem, last, nullptr);
// Связываем новый узел с остальными узлами
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
}
};
Не будем здесь рассматривать другие функции класса — конструкторы, деструктор, оператор присваивания… Рассмотрим функцию PushBack. В ней могут произойти такие исключения:
-
Выражение
newможет сгенерировать исключениеstd::bad_allocиз-за нехватки памяти. -
Конструктор копирования класса
Tможет сгенерировать произвольное исключение. Этот конструктор вызывается при инициализации поляelementсоздаваемого узла в конструкторе классаNode. В этом случаеnewведёт себя как транзакция: выделенная перед этим динамическая память корректно вернётся системе.
Эти исключения не перехватываются в функции PushBack. Их может перехватить код, из которого PushBack вызывался:
#include <iostream>
class C; // какой-то класс
int main() {
List<C> data;
C element;
try {
data.PushBack(element);
} catch (...) { // не получилось добавить элемент
std::cout << data.Size() << "n"; // внезапно 1, а не 0
}
// работаем дальше с data
}
Наша функция PushBack сначала увеличивает счётчик элементов, а затем выполняет опасные операции. Если происходит исключение, то в классе List нарушается инвариант: значение счётчика elementsCount перестаёт соответствовать реальности. Можно сказать, что функция PushBack не даёт гарантий безопасности.
Всего выделяют четыре уровня гарантий безопасности исключений (exception safety guarantees):
-
Гарантия отсутствия сбоев. Функции с такими гарантиями вообще не выбрасывают исключений. Примерами могут служить правильно написанные деструктор и конструктор перемещения, а также константные функции вида
Size. -
Строгая гарантия безопасности. Исключение может возникнуть, но от этого объект нашего класса не поменяет состояние: количество элементов останется прежним, итераторы и ссылки не будут инвалидированы и т. д.
-
Базовая гарантия безопасности. При исключении состояние объекта может поменяться, но оно останется внутренне согласованным, то есть, инварианты будут соблюдаться.
-
Отсутсвие гарантий. Это довольно опасная категория: при возникновении исключений могут нарушаться инварианты.
Всегда стоит разрабатывать классы, обеспечивающие хотя бы базовую гарантию безопасности. При этом не всегда возможно эффективно обеспечить строгую гарантию.
Переместим в нашей функции PushBack изменение счётчика в конец:
void PushBack(const T& elem) {
Node* node = new Node(elem, last, nullptr);
if (last != nullptr) {
last->next = node;
} else {
first = node;
}
last = node;
++elementsCount; // выполнится только если раньше не было исключений
}
Теперь такая функция соответствует строгой гарантии безопасности.
В документации функций из классов стандартной библиотеки обычно указано, какой уровень гарантии они обеспечивают. Рассмотрим, например, гарантии безопасности класса std::vector.
-
Деструктор, функции
empty,size,capacity, а такжеclearпредоставляют гарантию отсутствия сбоев. -
Функции
push_backиresizeпредоставляют строгую гарантию. -
Функция
insertпредоставляет лишь базовую гарантию. Можно было бы сделать так, чтобы она предоставляла строгую гарантию, но за это пришлось бы заплатить её эффективностью: при вставке в середину вектора пришлось бы делать реаллокацию.
Функции класса, которые гарантируют отсутсвие сбоев, следует помечать ключевым словом noexcept:
class C {
public:
void f() noexcept {
// ...
}
};
С одной стороны, эта подсказка позволяет компилятору генерировать более эффективный код. С другой — эффективно обрабатывать объекты таких классов в стандартных контейнерах. Например, std::vector<C> при реаллокации будет использовать конструктор перемещения класса C, если он помечен как noexcept. В противном случае будет использован конструктор копирования, который может быть менее эффективен, но зато позволит обеспечить строгую гарантию безопасности при реаллокации.
Обработка ошибок увеличивает отказоустойчивость кода, защищая его от потенциальных сбоев, которые могут привести к преждевременному завершению работы.

Прежде чем переходить к обсуждению того, почему обработка исключений так важна, и рассматривать встроенные в Python исключения, важно понять, что есть тонкая грань между понятиями ошибки и исключения.
Ошибку нельзя обработать, а исключения Python обрабатываются при выполнении программы. Ошибка может быть синтаксической, но существует и много видов исключений, которые возникают при выполнении и не останавливают программу сразу же. Ошибка может указывать на критические проблемы, которые приложение и не должно перехватывать, а исключения — состояния, которые стоит попробовать перехватить. Ошибки — вид непроверяемых и невозвратимых ошибок, таких как OutOfMemoryError, которые не стоит пытаться обработать.
Обработка исключений делает код более отказоустойчивым и помогает предотвращать потенциальные проблемы, которые могут привести к преждевременной остановке выполнения. Представьте код, который готов к развертыванию, но все равно прекращает работу из-за исключения. Клиент такой не примет, поэтому стоит заранее обработать конкретные исключения, чтобы избежать неразберихи.
Ошибки могут быть разных видов:
- Синтаксические
- Недостаточно памяти
- Ошибки рекурсии
- Исключения
Разберем их по очереди.
Синтаксические ошибки (SyntaxError)
Синтаксические ошибки часто называют ошибками разбора. Они возникают, когда интерпретатор обнаруживает синтаксическую проблему в коде.
Рассмотрим на примере.
a = 8
b = 10
c = a b
File "", line 3
c = a b
^
SyntaxError: invalid syntax
Стрелка вверху указывает на место, где интерпретатор получил ошибку при попытке исполнения. Знак перед стрелкой указывает на причину проблемы. Для устранения таких фундаментальных ошибок Python будет делать большую часть работы за программиста, выводя название файла и номер строки, где была обнаружена ошибка.
Недостаточно памяти (OutofMemoryError)
Ошибки памяти чаще всего связаны с оперативной памятью компьютера и относятся к структуре данных под названием “Куча” (heap). Если есть крупные объекты (или) ссылки на подобные, то с большой долей вероятности возникнет ошибка OutofMemory. Она может появиться по нескольким причинам:
- Использование 32-битной архитектуры Python (максимальный объем выделенной памяти невысокий, между 2 и 4 ГБ);
- Загрузка файла большого размера;
- Запуск модели машинного обучения/глубокого обучения и много другое;
Обработать ошибку памяти можно с помощью обработки исключений — резервного исключения. Оно используется, когда у интерпретатора заканчивается память и он должен немедленно остановить текущее исполнение. В редких случаях Python вызывает OutofMemoryError, позволяя скрипту каким-то образом перехватить самого себя, остановить ошибку памяти и восстановиться.
Но поскольку Python использует архитектуру управления памятью из языка C (функция malloc()), не факт, что все процессы восстановятся — в некоторых случаях MemoryError приведет к остановке. Следовательно, обрабатывать такие ошибки не рекомендуется, и это не считается хорошей практикой.
Ошибка рекурсии (RecursionError)
Эта ошибка связана со стеком и происходит при вызове функций. Как и предполагает название, ошибка рекурсии возникает, когда внутри друг друга исполняется много методов (один из которых — с бесконечной рекурсией), но это ограничено размером стека.
Все локальные переменные и методы размещаются в стеке. Для каждого вызова метода создается стековый кадр (фрейм), внутрь которого помещаются данные переменной или результат вызова метода. Когда исполнение метода завершается, его элемент удаляется.
Чтобы воспроизвести эту ошибку, определим функцию recursion, которая будет рекурсивной — вызывать сама себя в бесконечном цикле. В результате появится ошибка StackOverflow или ошибка рекурсии, потому что стековый кадр будет заполняться данными метода из каждого вызова, но они не будут освобождаться.
def recursion():
return recursion()
recursion()
---------------------------------------------------------------------------
RecursionError Traceback (most recent call last)
in
----> 1 recursion()
in recursion()
1 def recursion():
----> 2 return recursion()
... last 1 frames repeated, from the frame below ...
in recursion()
1 def recursion():
----> 2 return recursion()
RecursionError: maximum recursion depth exceeded
Ошибка отступа (IndentationError)
Эта ошибка похожа по духу на синтаксическую и является ее подвидом. Тем не менее она возникает только в случае проблем с отступами.
Пример:
for i in range(10):
print('Привет Мир!')
File "", line 2
print('Привет Мир!')
^
IndentationError: expected an indented block
Исключения
Даже если синтаксис в инструкции или само выражение верны, они все равно могут вызывать ошибки при исполнении. Исключения Python — это ошибки, обнаруживаемые при исполнении, но не являющиеся критическими. Скоро вы узнаете, как справляться с ними в программах Python. Объект исключения создается при вызове исключения Python. Если скрипт не обрабатывает исключение явно, программа будет остановлена принудительно.
Программы обычно не обрабатывают исключения, что приводит к подобным сообщениям об ошибке:
Ошибка типа (TypeError)
a = 2
b = 'PythonRu'
a + b
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
in
1 a = 2
2 b = 'PythonRu'
----> 3 a + b
TypeError: unsupported operand type(s) for +: 'int' and 'str'
Ошибка деления на ноль (ZeroDivisionError)
10 / 0
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
in
----> 1 10 / 0
ZeroDivisionError: division by zero
Есть разные типы исключений в Python и их тип выводится в сообщении: вверху примеры TypeError и ZeroDivisionError. Обе строки в сообщениях об ошибке представляют собой имена встроенных исключений Python.
Оставшаяся часть строки с ошибкой предлагает подробности о причине ошибки на основе ее типа.
Теперь рассмотрим встроенные исключения Python.
Встроенные исключения
BaseException
+-- SystemExit
+-- KeyboardInterrupt
+-- GeneratorExit
+-- Exception
+-- StopIteration
+-- StopAsyncIteration
+-- ArithmeticError
| +-- FloatingPointError
| +-- OverflowError
| +-- ZeroDivisionError
+-- AssertionError
+-- AttributeError
+-- BufferError
+-- EOFError
+-- ImportError
| +-- ModuleNotFoundError
+-- LookupError
| +-- IndexError
| +-- KeyError
+-- MemoryError
+-- NameError
| +-- UnboundLocalError
+-- OSError
| +-- BlockingIOError
| +-- ChildProcessError
| +-- ConnectionError
| | +-- BrokenPipeError
| | +-- ConnectionAbortedError
| | +-- ConnectionRefusedError
| | +-- ConnectionResetError
| +-- FileExistsError
| +-- FileNotFoundError
| +-- InterruptedError
| +-- IsADirectoryError
| +-- NotADirectoryError
| +-- PermissionError
| +-- ProcessLookupError
| +-- TimeoutError
+-- ReferenceError
+-- RuntimeError
| +-- NotImplementedError
| +-- RecursionError
+-- SyntaxError
| +-- IndentationError
| +-- TabError
+-- SystemError
+-- TypeError
+-- ValueError
| +-- UnicodeError
| +-- UnicodeDecodeError
| +-- UnicodeEncodeError
| +-- UnicodeTranslateError
+-- Warning
+-- DeprecationWarning
+-- PendingDeprecationWarning
+-- RuntimeWarning
+-- SyntaxWarning
+-- UserWarning
+-- FutureWarning
+-- ImportWarning
+-- UnicodeWarning
+-- BytesWarning
+-- ResourceWarning
Прежде чем переходить к разбору встроенных исключений быстро вспомним 4 основных компонента обработки исключения, как показано на этой схеме.
Try: он запускает блок кода, в котором ожидается ошибка.Except: здесь определяется тип исключения, который ожидается в блокеtry(встроенный или созданный).Else: если исключений нет, тогда исполняется этот блок (его можно воспринимать как средство для запуска кода в том случае, если ожидается, что часть кода приведет к исключению).Finally: вне зависимости от того, будет ли исключение или нет, этот блок кода исполняется всегда.
В следующем разделе руководства больше узнаете об общих типах исключений и научитесь обрабатывать их с помощью инструмента обработки исключения.
Ошибка прерывания с клавиатуры (KeyboardInterrupt)
Исключение KeyboardInterrupt вызывается при попытке остановить программу с помощью сочетания Ctrl + C или Ctrl + Z в командной строке или ядре в Jupyter Notebook. Иногда это происходит неумышленно и подобная обработка поможет избежать подобных ситуаций.
В примере ниже если запустить ячейку и прервать ядро, программа вызовет исключение KeyboardInterrupt. Теперь обработаем исключение KeyboardInterrupt.
try:
inp = input()
print('Нажмите Ctrl+C и прервите Kernel:')
except KeyboardInterrupt:
print('Исключение KeyboardInterrupt')
else:
print('Исключений не произошло')
Исключение KeyboardInterrupt
Стандартные ошибки (StandardError)
Рассмотрим некоторые базовые ошибки в программировании.
Арифметические ошибки (ArithmeticError)
- Ошибка деления на ноль (Zero Division);
- Ошибка переполнения (OverFlow);
- Ошибка плавающей точки (Floating Point);
Все перечисленные выше исключения относятся к классу Arithmetic и вызываются при ошибках в арифметических операциях.
Деление на ноль (ZeroDivisionError)
Когда делитель (второй аргумент операции деления) или знаменатель равны нулю, тогда результатом будет ошибка деления на ноль.
try:
a = 100 / 0
print(a)
except ZeroDivisionError:
print("Исключение ZeroDivisionError." )
else:
print("Успех, нет ошибок!")
Исключение ZeroDivisionError.
Переполнение (OverflowError)
Ошибка переполнение вызывается, когда результат операции выходил за пределы диапазона. Она характерна для целых чисел вне диапазона.
try:
import math
print(math.exp(1000))
except OverflowError:
print("Исключение OverFlow.")
else:
print("Успех, нет ошибок!")
Исключение OverFlow.
Ошибка утверждения (AssertionError)
Когда инструкция утверждения не верна, вызывается ошибка утверждения.
Рассмотрим пример. Предположим, есть две переменные: a и b. Их нужно сравнить. Чтобы проверить, равны ли они, необходимо использовать ключевое слово assert, что приведет к вызову исключения Assertion в том случае, если выражение будет ложным.
try:
a = 100
b = "PythonRu"
assert a == b
except AssertionError:
print("Исключение AssertionError.")
else:
print("Успех, нет ошибок!")
Исключение AssertionError.
Ошибка атрибута (AttributeError)
При попытке сослаться на несуществующий атрибут программа вернет ошибку атрибута. В следующем примере можно увидеть, что у объекта класса Attributes нет атрибута с именем attribute.
class Attributes(obj):
a = 2
print(a)
try:
obj = Attributes()
print(obj.attribute)
except AttributeError:
print("Исключение AttributeError.")
2
Исключение AttributeError.
Ошибка импорта (ModuleNotFoundError)
Ошибка импорта вызывается при попытке импортировать несуществующий (или неспособный загрузиться) модуль в стандартном пути или даже при допущенной ошибке в имени.
import nibabel
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
in
----> 1 import nibabel
ModuleNotFoundError: No module named 'nibabel'
Ошибка поиска (LookupError)
LockupError выступает базовым классом для исключений, которые происходят, когда key или index используются для связывания или последовательность списка/словаря неверна или не существует.
Здесь есть два вида исключений:
- Ошибка индекса (
IndexError); - Ошибка ключа (
KeyError);
Ошибка ключа
Если ключа, к которому нужно получить доступ, не оказывается в словаре, вызывается исключение KeyError.
try:
a = {1:'a', 2:'b', 3:'c'}
print(a[4])
except LookupError:
print("Исключение KeyError.")
else:
print("Успех, нет ошибок!")
Исключение KeyError.
Ошибка индекса
Если пытаться получить доступ к индексу (последовательности) списка, которого не существует в этом списке или находится вне его диапазона, будет вызвана ошибка индекса (IndexError: list index out of range python).
try:
a = ['a', 'b', 'c']
print(a[4])
except LookupError:
print("Исключение IndexError, индекс списка вне диапазона.")
else:
print("Успех, нет ошибок!")
Исключение IndexError, индекс списка вне диапазона.
Ошибка памяти (MemoryError)
Как уже упоминалось, ошибка памяти вызывается, когда операции не хватает памяти для выполнения.
Ошибка имени (NameError)
Ошибка имени возникает, когда локальное или глобальное имя не находится.
В следующем примере переменная ans не определена. Результатом будет ошибка NameError.
try:
print(ans)
except NameError:
print("NameError: переменная 'ans' не определена")
else:
print("Успех, нет ошибок!")
NameError: переменная 'ans' не определена
Ошибка выполнения (Runtime Error)
Ошибка «NotImplementedError»
Ошибка выполнения служит базовым классом для ошибки NotImplemented. Абстрактные методы определенного пользователем класса вызывают это исключение, когда производные методы перезаписывают оригинальный.
class BaseClass(object):
"""Опередляем класс"""
def __init__(self):
super(BaseClass, self).__init__()
def do_something(self):
# функция ничего не делает
raise NotImplementedError(self.__class__.__name__ + '.do_something')
class SubClass(BaseClass):
"""Реализует функцию"""
def do_something(self):
# действительно что-то делает
print(self.__class__.__name__ + ' что-то делает!')
SubClass().do_something()
BaseClass().do_something()
SubClass что-то делает!
---------------------------------------------------------------------------
NotImplementedError Traceback (most recent call last)
in
14
15 SubClass().do_something()
---> 16 BaseClass().do_something()
in do_something(self)
5 def do_something(self):
6 # функция ничего не делает
----> 7 raise NotImplementedError(self.__class__.__name__ + '.do_something')
8
9 class SubClass(BaseClass):
NotImplementedError: BaseClass.do_something
Ошибка типа (TypeError)
Ошибка типа вызывается при попытке объединить два несовместимых операнда или объекта.
В примере ниже целое число пытаются добавить к строке, что приводит к ошибке типа.
try:
a = 5
b = "PythonRu"
c = a + b
except TypeError:
print('Исключение TypeError')
else:
print('Успех, нет ошибок!')
Исключение TypeError
Ошибка значения (ValueError)
Ошибка значения вызывается, когда встроенная операция или функция получают аргумент с корректным типом, но недопустимым значением.
В этом примере встроенная операция float получат аргумент, представляющий собой последовательность символов (значение), что является недопустимым значением для типа: число с плавающей точкой.
try:
print(float('PythonRu'))
except ValueError:
print('ValueError: не удалось преобразовать строку в float: 'PythonRu'')
else:
print('Успех, нет ошибок!')
ValueError: не удалось преобразовать строку в float: 'PythonRu'
Пользовательские исключения в Python
В Python есть много встроенных исключений для использования в программе. Но иногда нужно создавать собственные со своими сообщениями для конкретных целей.
Это можно сделать, создав новый класс, который будет наследовать из класса Exception в Python.
class UnAcceptedValueError(Exception):
def __init__(self, data):
self.data = data
def __str__(self):
return repr(self.data)
Total_Marks = int(input("Введите общее количество баллов: "))
try:
Num_of_Sections = int(input("Введите количество разделов: "))
if(Num_of_Sections < 1):
raise UnAcceptedValueError("Количество секций не может быть меньше 1")
except UnAcceptedValueError as e:
print("Полученная ошибка:", e.data)
Введите общее количество баллов: 10
Введите количество разделов: 0
Полученная ошибка: Количество секций не может быть меньше 1
В предыдущем примере если ввести что-либо меньше 1, будет вызвано исключение. Многие стандартные исключения имеют собственные исключения, которые вызываются при возникновении проблем в работе их функций.
Недостатки обработки исключений в Python
У использования исключений есть свои побочные эффекты, как, например, то, что программы с блоками try-except работают медленнее, а количество кода возрастает.
Дальше пример, где модуль Python timeit используется для проверки времени исполнения 2 разных инструкций. В stmt1 для обработки ZeroDivisionError используется try-except, а в stmt2 — if. Затем они выполняются 10000 раз с переменной a=0. Суть в том, чтобы показать разницу во времени исполнения инструкций. Так, stmt1 с обработкой исключений занимает больше времени чем stmt2, который просто проверяет значение и не делает ничего, если условие не выполнено.
Поэтому стоит ограничить использование обработки исключений в Python и применять его в редких случаях. Например, когда вы не уверены, что будет вводом: целое или число с плавающей точкой, или не уверены, существует ли файл, который нужно открыть.
import timeit
setup="a=0"
stmt1 = '''
try:
b=10/a
except ZeroDivisionError:
pass'''
stmt2 = '''
if a!=0:
b=10/a'''
print("time=",timeit.timeit(stmt1,setup,number=10000))
print("time=",timeit.timeit(stmt2,setup,number=10000))
time= 0.003897680000136461
time= 0.0002797570000439009
Выводы!
Как вы могли увидеть, обработка исключений помогает прервать типичный поток программы с помощью специального механизма, который делает код более отказоустойчивым.
Обработка исключений — один из основных факторов, который делает код готовым к развертыванию. Это простая концепция, построенная всего на 4 блоках: try выискивает исключения, а except их обрабатывает.
Очень важно поупражняться в их использовании, чтобы сделать свой код более отказоустойчивым.
Исключения
- Исключения
- Введение
- Иерархия исключений
- Проверяемые и непроверяемые
- Иерархия
- Классификация
- Error и Exception
- Работа с исключениями
- Обработка исключений
- Правила try/catch/finally
- Расположение catch блоков
- Транзакционность
- Делегирование
- Методы и практики работы с исключительными ситуацими
- Собственные исключения
- Реагирование через re-throw
- Не забывайте указывать причину возникновения исключения
- Сохранение исключения
- Логирование
- Чего нельзя делать при обработке исключений
- Try-with-resources или try-с-ресурсами
- Общие советы
- Избегайте генерации исключений, если их можно избежать простой проверкой
- Предпочитайте
Optional, если отсутствие значения — не исключительная ситуация - Заранее обдумывайте контракты методов
- Предпочитайте исключения кодам ошибок и
booleanфлагам-признакам успеха
- Обработка исключений
- Исключения и статические блоки
- Многопоточность и исключения
- Проверяемые исключения и их необходимость
- Заключение
- Полезные ссылки
Введение
Начав заниматься программированием, мы, к своему удивлению, обнаружили, что не так уж просто заставить программы делать задуманное. Я могу точно вспомнить момент, когда я понял, что большая часть моей жизни с этих пор будет посвящена поиску ошибок в собственных программах.
(c) Морис Уилкс.
Предположим, вам понадобилась программа, считывающая содержимое файла.
В целом, здесь нет ничего сложного и код, выполняющий поставленную задачу, мог бы выглядеть как-то так:
public List<String> readAll(String path) { BufferedReader br = new BufferedReader(new FileReader(path)); String line; List<String> lines = new ArrayList<>(); while ((line = br.readLine()) != null) { lines.add(line); } return lines; }
И это был бы вполне рабочий вариант, если бы не одно но: мы живём не в идеальном мире. Код, приведённый выше, рассчитан на то, что всё работает идеально: путь до файла указан верный, файл можно прочитать, во время чтения с файлом ничего не происходит, место хранения файла работает без ошибок и еще огромное количество предположений.
Однако, как показывает практика, мир не идеален, а нас повсюду преследуют ошибки и проблемы. Кто-то может указать путь до несуществующего файла, во время чтения может произойти ошибка, например, файл повреждён или удален в процессе чтения и т.д.
Игнорирование подобных ситуаций недопустимо, так как это ведет к нестабильно и непредсказуемо работающему коду.
Значит, на такие ситуации надо реагировать.
Самая простая реакция — это возвращать boolean — признак успеха или некоторый код ошибки, например, какое-то число.
Пусть, 0 — это код удачного завершения приложения, 1 — это аварийное завершение и т.д.
Мы получаем код возврата и уже на него реагируем.
Подобный ход имеет право на жизнь, однако, он крайне неудобен в повседневной разработке с её тысячами возможных ошибок и проблемных ситуаций.
Во-первых, он слишком немногословен, так как необходимо помнить что означает каждый код возврата, либо постоянно сверяться с таблицей расшифровки, где они описаны.
Во-вторых, такой подход предоставляет не совсем удобный способ обработки возникших ошибок. Более того, нередки ситуации, когда в месте возникновения ошибки непонятно, как реагировать на возникшую проблему. В таком случае было бы удобнее делегировать обработку ошибки вызывающему коду, до места, где будет понятно как реагировать на ошибку.
В-третьих, и это, на мой взгляд, самое главное — это небезопасно, так как подобный способ можно легко проигнорировать.
Lots of newbie’s coming in from the C world complain about exceptions and the fact that they have to put exception handling all over the place—they want to just write their code. But that’s stupid: most C code never checks return codes and so it tends to be very fragile. If you want to build something really robust, you need to pay attention to things that can go wrong, and most folks don’t in the C world because it’s just too damn hard.
One of the design principles behind Java is that I don’t care much about how long it takes to slap together something that kind of works. The real measure is how long it takes to write something solid.In Java you can ignore exceptions, but you have to willfully do it. You can’t accidentally say, «I don’t care.» You have to explicitly say, «I don’t care.»
(c) James Gosling.
Поэтому, в Java используется другой механизм работы с такими ситуациями: исключения.
Что такое исключение? В некотором смысле можно сказать, что исключение — это некоторое сообщение, уведомляющее о проблеме, незапланированном поведении.
В нашем примере с чтением содержимого файла, источником такого сообщения может являться BufferedReader или FileReader. Сообщению необходим получатель/обработчик, чтобы перехватить его и что-то сделать, как-то отреагировать.
Важно понимать, что генерация исключения ломает поток выполнения программы, так как либо это сообщение будет перехвачено и обработано каким-то зарегистрированным получателем, либо программа завершится.
Что значит «ломает поток выполнения программы»?
Представьте, что по дороге едет грузовик. Движение машины и есть поток выполнения программы. Вдруг водитель видит, что впереди разрушенный мост — исключение, ошибка. Теперь он либо поедет по объездной дороге, т.е перехватит и отреагирует на исключение, либо остановится и поездка будет завершена.

Исключения могут быть разных типов, под разные ситуации, а значит и получателей(обработчиков) может быть несколько — на каждый отдельный тип может быть своя реакция, свой обработчик.
Исключение также может хранить информацию о возникшей проблеме: причину, описание-комментарий и т.д.
Исходя из описания можно сказать, что исключение — это объект некоторого, специально для этого предназначенного, класса. Так как проблемы и ошибки бывают разного рода, их можно классифицировать и логически разделить, значит и классы исключений можно выстроить в некоторую иерархию.
Как генерировать исключения и регистрировать обработчики мы рассмотрим позднее, а пока давайте взглянем на иерархию этих классов.
Иерархия исключений
Ниже приведена иерархия исключений:

Картинка большая, чтобы лучше запоминалась.
Для начала разберем загадочные подписи checked и unchecked на рисунке.
Проверяемые и непроверяемые
Все исключения в Java делятся на два типа: проверяемые (checked) и непроверяемые исключения (unchecked).
Как видно на рисунке, java.lang.Throwable и java.lang.Exception относятся к проверяемым исключениям, в то время как java.lang.RuntimeException и java.lang.Error — это непроверяемые исключения.
Принадлежность к тому или иному типу каждое исключение наследует от родителя.
Это значит, что наследники java.lang.RuntimeException будут unchecked исключениями, а наследники java.lang.Exception — checked.
Что это за разделение?
В первую очередь напомним, что Java — это компилируемый язык, а значит, помимо runtime(время выполнения кода), существует ещё и compile-time(то, что происходит во время компиляции).
Так вот проверяемые исключения — это исключения, на которые разработчик обязан отреагировать, т.е написать обработчики, и наличие этих обработчиков будет проверено на этапе компиляции. Ваш код не будет скомпилирован, если какое-то проверяемое исключение не обработано, компилятор этого не допустит.
Непроверяемые исключения — это исключения времени выполнения. Компилятор не будет от вас требовать обработки непроверяемых исключений.
В чём же смысл этого разделения на проверяемые и непроверяемые исключения?
Я думаю так: проверяемые исключения в Java — это ситуации, которые разработчик никак не может предотвратить и исключение является одним из вариантов нормальной работы кода.
Например, при чтении файла требуется обрабатывать java.io.FileNotFoundException и java.io.IOException, которые является потомками java.io.Exception.
Потому, что отсутствие файла или ошибка работы с вводом/выводом — это вполне допустимая ситуация при чтении.
С другой стороны, java.lang.RuntimeException — это скорее ошибки разработчика.
Например, java.lang.NullPointerException — это ошибка обращения по null ссылке, данную ситуацию можно предотвратить: проверить ссылку на null перед вызовом.
Представьте, что вы едете по дороге, так вот предупредительные знаки — это проверяемые исключения. Например, знак «Осторожно, дети!» говорит о том, что рядом школа и дорогу может перебежать ребенок. Вы обязаны отреагировать на это, не обязательно ребенок перебежит вам дорогу, но вы не можете это проконтролировать, но в данном месте — это нормальная ситуация, ведь рядом школа.
Делать абсолютно все исключения проерямыми — не имеет никакого смысла, потому что вы просто с ума сойдете, пока будете писать обработчики таких ситуаций. Да и зачастую это будет только мешать: представьте себе дорогу, которая утыкана постоянными предупредительными знаками, на которые вы должны реагировать. Ехать по такой дороге будет крайне утомительно.
Разделение на проверяемые и непроверяемые исключения существует только в
Java, в других языках программирования, таких какScala,Groovy,KotlinилиPython, все исключения непроверяемые.Это довольно холиварная тема и свои мысли по ней я изложу в конце статьи.
Теперь рассмотрим непосредственно иерархию исключений.
Иерархия
Итак, корнем иерархии является java.lang.Throwable, у которого два наследника: java.lang.Exception и java.lang.Error.
В свою очередь java.lang.Exception является родительским классом для java.lang.RuntimeException.
Занятно, что класс
java.lang.Throwableназван так, как обычно называют интерфейсы, что иногда вводит в заблуждение новичков. Однако помните, что это класс! Запомнить это довольно просто, достаточно держать в уме то, что исключения могут содержать состояние (например, информация о возникшей проблеме).
Так как в Java все классы являются наследниками java.lang.Object, то и исключения (будучи тоже классами) наследуют все стандартные методы, такие как equals, hashCode, toString и т.д.
Раз мы работаем с классами, то можно с помощью наследования создавать свои собственные иерархии исключений, добавляя в них какое-то специфическое поведение и состояние.
Чтобы создать свой собственный класс исключение необходимо отнаследоваться от одного из классов в иерархии исключений. При этом помните, что наследуется еще и тип исключения: проверяемое или непроверяемое.
Классификация
Каждый тип исключения отвечает за свою область ошибок.
-
java.lang.ExceptionЭто ситуации, которые разработчик никак не может предотвратить, например, не получилось закрыть файловый дескриптор или отослать письмо, и исключение является одним из вариантов нормальной работы кода.
Это проверяемые исключения, мы обязаны на такие исключения реагировать, это будет проверено на этапе компиляции.
Пример:
java.io.IOException,java.io.FileNotFoundException. -
java.lang.RuntimeExceptionЭто ситуации, когда основной причиной ошибки является сам разработчик, например, происходит обращение к
nullссылке, деление на ноль, выход за границы массива и т.д. При этом исключение не является одним из вариантов нормальной работы кода.Это непроверяемые исключения, реагировать на них или нет решает разработчик.
Пример:
java.lang.NullPointerException. -
java.lang.ErrorЭто критические ошибки, аварийные ситуации, после которых мы с трудом или вообще не в состоянии продолжить работу. Например, закончилась память, переполнился стек вызовов и т.д.
Это непроверяемые исключения, реагировать на них или нет решает разработчик.
Реагировать на подобные ошибки следует только в том случае, если разработчик точно знает как поступить в такой ситуации. Перехватывать такие ошибки не рекомендуется, так как чаще всего разработчик не знает как реагировать на подобного рода аварийные ситуации.
Теперь перейдем к вопросу: в чем же разница между java.lang.Error и java.lang.Exception?
Error и Exception
Все просто. Исключения java.lang.Error — это более серьезная ситуация, нежели java.lang.Exception.
Это серьезные проблемы в работе приложения, которые тяжело исправить, либо вообще неясно, можно ли это сделать.
Это не просто исключительная ситуация — это ситуация, в которой работоспособность всего приложения под угрозой! Например, исключение java.lang.OutOfMemoryError, сигнализирующее о том, что кончается память или java.lang.StackOverflowError – переполнение стека вызовов, которое можно встретить при бесконечной рекурсии.
Согласитесь, что если не получается преобразовать строку к числу, то это не та ситуация, когда все приложение должно завершаться. Это ситуация, после которой приложение может продолжить работать.
Да, это неприятно, что вы не смогли найти файл по указанному пути, но не настолько критично, как переполнение стека вызовов.
Т.е разница — в логическом разделении.
Поэтому, java.lang.Error и его наследники используются только для критических ситуаций.
Работа с исключениями
Обработка исключений
Корнем иерархии является класс java.lang.Throwable, т.е. что-то «бросаемое».
А раз исключения бросаются, то для обработки мы будем ловить их!
В Java исключения ловят и обрабатывают с помощью конструкции try/catch/finally.
При заключении кода в один или несколько блоков try указывается потенциальная возможность выбрасывания исключения в этом месте, все операторы, которые могут сгенерировать исключение, помещаются в этом блоке.
В блоках catch перечисляются исключения, на которые решено реагировать. Тут определяются блоки кода, предназначенные для решения возникших проблем. Это и есть объявление тех самых получателей/обработчиков исключений.
Пример:
public class ExceptionHandling { public static void main(String[] args) { try { // код } catch(FileNotFoundException fnf) { // обработчик на FileNotFoundException } } }
Тот тип исключения, что указывается в catch блоке можно расценивать как фильтр, который перехватывает все исключения того типа, что вы указали и всех его потомков, расположенных ниже по иерархии.
Представьте себе просеивание муки. Это процесс целью которого является удаление посторонних частиц, отличающихся по размерам от частиц муки. Вы просеиваете через несколько фильтров муку, так как вам не нужны крупные комочки, осколки и другие посторонние частицы, вам нужна именно мука определенного качества. И в зависимости от выставленных фильтров вы будете перехватывать разные частицы, комочки и т.д. Эти частицы и есть исключения. И если выставляется мелкий фильтр, то вы словите как крупные частицы, так и мелкие.
Точно также и в Java, ставя фильтр на java.lang.RuntimeException вы ловите не только java.lang.RuntimeException, но и всех его наследников! Ведь эти потомки — это тоже runtime ошибки!
В блоке finally определяется код, который будет всегда выполнен, независимо от результата выполнения блоков try/catch. Этот блок будет выполняться независимо от того, выполнился или нет блок try до конца, было ли сгенерировано исключение или нет, и было ли оно обработано в блоке catch или нет.
Пример:
public class ExceptionHandling { public static void main(String[] args) { try { // some code } catch(FileNotFoundException fnf) { // обработчик 1 } catch(RuntimeException re) { // обработчик 2 } finally { System.out.println("Hello from finally block."); } } }
В примере выше объявлен try блок с кодом, который потенциально может сгенерировать исключения, после try блока описаны два обработчика исключений, на случай генерации FileNotFoundException и на случай генерации любого RuntimeException.
Объект исключения доступен по ссылке exception.
Правила try/catch/finally
-
Блок
tryнаходится перед блокомcatchилиfinally. При этом должен присутствовать хотя бы один из этих блоков. -
Между
try,catchиfinallyне может быть никаких операторов. -
Один блок
tryможет иметь несколькоcatchблоков. В таком случае будет выполняться первый подходящий блок.Поэтому сначала должны идти более специальные блоки обработки исключений, а потом уже более общие.
-
Блок
finallyбудет выполнен всегда, кроме случая, когдаJVMпреждевременно завершит работу или будет сгенерировано исключение непосредственно в самомfinallyблоке. -
Допускается использование вложенных конструкций
try/catch/finally.public class ExceptionHandling { public static void main(String[] args) { try { try { // some code } catch(FileNotFoundException fnf) { // обработчик 1 } } catch(RuntimeException re) { // обработчик 2 } finally { System.out.println("Hello from finally block."); } } }
Вопрос:
Каков результат выполнения примера выше, если в блоке try не будет сгенерировано ни одного исключения?
Ответ:
Будет выведено на экран: «Hello from finally block.».
Так как блок finally выполняется всегда.
Вопрос:
Теперь немного видоизменим код, каков результат выполнения будет теперь?
public class ExceptionHandling { public static void main(String[] args) { try { return; } finally { System.out.println("Hello from finally block"); } } }
Ответ:
На экран будет выведено: Hello from finally block.
Вопрос:
Плохим тоном считается прямое наследование от java.lang.Throwable.
Это строго не рекомендуется делать, почему?
Ответ:
Наследование от наиболее общего класса, а в данном случае от корневого класса иерархии, усложняет обработку ваших исключений. Проблему надо стараться локализовать, а не делать ее описание/объявление максимально общим. Согласитесь, что java.lang.IllegalArgumentException говорит гораздо больше, чем java.lang.RuntimeException. А значит и реакция на первое исключение будет более точная, чем на второе.
Далее приводится несколько примеров перехвата исключений разных типов:
Обработка java.lang.RuntimeException:
try { String numberAsString = "one"; Double res = Double.valueOf(numberAsString); } catch (RuntimeException re) { System.err.println("Error while convert string to double!"); }
Результатом будет печать на экран: Error while convert string to double!.
Обработка java.lang.Error:
try { throw new Error(); } catch (RuntimeException re) { System.out.println("RuntimeException"); } catch (Error error) { System.out.println("ERROR"); }
Результатом будет печать на экран: ERROR.
Расположение catch блоков
Как уже было сказано, один блок try может иметь несколько catch блоков. В таком случае будет выполняться первый подходящий блок.
Это значит, что порядок расположения catch блоков важен.
Рассмотрим ситуацию, когда некоторый используемый нами метод может выбросить два разных исключения:
void method() throws Exception { if (new Random((System.currentTimeMillis())).nextBoolean()) { throw new Exception(); } else { throw new IOException(); } }
Конструкция
new Random((System.currentTimeMillis())).nextBoolean()генерирует нам случайное значениеfalseилиtrue.
Для обработки исключений этого метода написан следующий код:
try { method(); } catch (Exception e) { // Обработчик 1 } catch (IOException e) { // Обработчик 2 }
Все ли хорошо с приведенным выше кодом?
Нет, код выше неверен, так как обработчик java.io.IOException в данном случае недостижим. Все дело в том, что первый обработчик, ответсвенный за Exception, перехватит все исключения, а значит не может быть ситуации, когда мы сможем попасть во второй обработчик.
Снова вспомним пример с мукой, приведенный в начале.
Так вот песчинка, которую мы ищем, это и есть наше исключение, а каждый фильтр это catch блок.
Если первым установлен фильтр ловить все, что является Exception и его потомков, то до фильтра ловить все, что является IOException и его потомков ничего не дойдет, так как верхний фильтр уже перехватит все песчинки.
Отсюда следует правило:
Сначала должны идти более специальные блоки обработки исключений, а потом уже более общие.
А что если на два разных исключения предусмотрена одна и та же реакция? Написание двух одинаковых catch блоков не приветствуется, ведь дублирование кода — это зло.
Поэтому допускается объединить два catch блока с помощью |:
try { method2(); } catch (IllegalArgumentException | IndexOutOfBoundsException e) { // Обработчик }
Вопрос:
Есть ли способ перехватить все возможные исключения?
Ответ:
Есть! Если взглянуть еще раз на иерархию, то можно отметить, что java.lang.Throwable является родительским классом для всех исключений, а значит, чтобы поймать все, необходимо написать что-то в виде:
try { method(); } catch (Throwable t) { // Обработчик }
Однако, делать так не рекомендуется, что наталкивает на следующий вопрос.
Вопрос:
Почему перехватывать java.lang.Throwable — плохо?
Ответ:
Дело в том, что написав:
try { method(); } catch (Throwable t) { // catch all }
Будут перехвачены абсолютно все исключения: и java.lang.Exception, и java.lang.RuntimeException, и java.lang.Error, и все их потомки.
И как реагировать на все? При этом надо учесть, что обычно на java.lang.Error исключений вообще не ясно как реагировать. А значит, мы можем неверно отреагировать на исключение и вообще потерять данные. А ловить то, что не можешь и не собирался обрабатывать — плохо.
Поэтому перехватывать все исключения — плохая практика.
Вопрос-Тест:
Что будет выведено на экран при запуске данного куска кода?
public static void main(String[] args) { try { try { throw new Exception("0"); } finally { if (true) { throw new IOException("1"); } System.err.println("2"); } } catch (IOException ex) { System.err.println(ex.getMessage()); } catch (Exception ex) { System.err.println("3"); System.err.println(ex.getMessage()); } }
Ответ:
При выполнении данного кода выведется «1».
Давайте разберем почему.
Мы кидаем исключение во вложенном try блоке: throw new Exception("0");.
После этого поток программы ломается и мы попадаем в finally блок:
if (true) { throw new IOException("1"); } System.err.println("2");
Здесь мы гарантированно зайдем в if и кинем уже новое исключение: throw new IOException("1");.
При этом вся информация о первом исключении будет потеряна! Ведь мы никак не отреагировали на него, а в finally блоке и вовсе ‘перезатерли’ новым исключением.
На try, оборачивающий наш код, настроено два фильтра: первый на IOException, второй на Exception.
Так как порядок расположения задан так, что мы прежде всего смотрим на IOException, то и сработает этот фильтр, который выполнит следующий код:
System.err.println(ex.getMessage());
Именно поэтому выведется 1.
Транзакционность
Важным моментом, который нельзя пропустить, является то, что try блок не транзакционный.
Под термином
транзакционностья имею в виду то, что либо действия будут выполнены целиком и успешно, либо не будут выполнены вовсе.
Что это значит?
Это значит, что при возникновении исключения в try блоке все совершенные действия не откатываются к изначальному состоянию, а так и остаются совершенными.
Все выделенные ресурсы так и остаются занятыми, в том числе и при возникновении исключения.
По сути именно поэтому и существует finally блок, так как туда, как уже было сказано выше, мы зайдем в любом случае, то там и освобождают выделенные ресурсы.
Вопрос:
Работа с объектами из try блока в других блоках невозможна:
public class ExceptionExample { public static void main(String[] args) { try { String line = "hello"; } catch (Exception e) { System.err.println(e); } // Compile error System.out.println(line); // Cannot resolve symbol `line` } }
Почему?
Ответ:
Потому что компилятор не может нам гарантировать, что объекты, объявленные в try-блоке, были созданы.
Ведь могло быть сгенерировано исключение. Тогда после места, где было сгенерировано исключение, оставшиеся действия не будут выполнены, а значит возможна ситуация, когда объект не будет создан. Следовательно и работать с ним нельзя.
Вернемся к примеру с грузовиком, чтобы объяснить все вышесказанное.
Объездная здесь — это catch блок, реакция на исключительную ситуацию. Если добавить еще несколько объездных дорог, несколько catch блоков, то водитель выберет наиболее подходящий путь, наиболее подходящий и удобный catch блок, что объясняет важность расположения этих блоков.
Транзакционность на этом примере объясняется тем, что если до этого водитель где-то оплатил проезд по мосту, то деньги ему автоматически не вернутся, необходимо будет написать в поддержку или куда-то пожаловаться на управляющую компанию.
Делегирование
Выше было разобрано то, как обрабатывать исключения. Однако, иногда возникают ситуации, когда в нет конкретного понимания того, как обрабатывать возникшее исключение. В таком случае имеет смысл делегировать задачу обработки исключения коду, который вызвал ваш метод, так как вызывающий код чаще всего обладает более обширными сведениями об источнике проблемы или об операции, которая сейчас выполняется.
Делегирование исключения производится с помощью ключевого слова throws, которое добавляется после сигнатуры метода.
Пример:
// Код написан только для ознакомительной цели, не стоит с него брать пример! String readLine(String path) throws IOException { BufferedReader br = new BufferedReader(...); String line = br.readLine(); return line; }
Таким образом обеспечивается передача объявленного исключения в место вызова метода. И то, как на него реагировать уже становится заботой вызывающего этот метод.
Поэтому реагировать и писать обработчики на те исключения, которые мы делегировали, внутри метода уже не надо.
Механизм throws введен для проброса проверяемых исключений.
Разумеется, с помощью throws можно описывать делегирование как проверяемых, так и непроверяемых исключений.
Однако перечислять непроверяемые не стоит, такие исключения не контролируются в compile time.
Перечисление непроверяемых исключений бессмысленно, так как это примерно то же самое, что перечислять все, что может с вами случиться на улице.
Теперь пришла пора рассмотреть методы обработки исключительных ситуаций.
Методы и практики работы с исключительными ситуацими
Главное и основное правило при работе с исключениями звучит так:
На исключения надо либо реагировать, либо делегировать, но ни в коем случае не игнорировать.
Определить когда надо реагировать, а когда делегировать проще простого. Задайте вопрос: «Знаю ли я как реагировать на это исключение?».
Если ответ «да, знаю», то реагируйте, пишите обработчик и код, отвечающий за эту реакцию, если не знаете что делать с исключением, то делегируйте вызывающему коду.
Собственные исключения
Выше мы уже затронули то, что исключения это те же классы и объекты.
И иногда удобно выстроить свою иерархию исключений, заточенных под конкретную задачу. Дабы более гибко обрабатывать и реагировать на те исключительные ситуации, которые специфичны решаемой задаче.
Например, пусть есть некоторый справочник:
class Catalog { Person findPerson(String name); }
В данном случае нам надо обработать ситуации, когда name является null, когда в каталоге нет пользователя с таким именем.
Если генерировать на все ситуации java.lang.Exception, то обработка ошибок будет крайне неудобной.
Более того, хотелось бы явно выделить ошибку, связанную с тем, что пользователя такого не существует.
Очевидно, что стандартное исключение для этого случая не существует, а значит вполне логично создать свое.
class PersonNotFoundException extends RuntimeException { private String name; // some code }
Обратите внимание, что имя Person, по которому в каталоге не смогли его найти, выделено в свойство класса name.
Теперь при использовании этого метода проще реагировать на различные ситуации, такие как null вместо имени, а проблему с отсутствием Person в каталоге можно отдельно вынести в свой catch блок.
Реагирование через re-throw
Часто бывает необходимо перехватить исключение, сделать запись о том, что случилось (в файл лога, например) и делегировать его вызывающему коду.
Как уже было сказано выше, в рамках конструкции try/catch/finally можно сгенерировать другое исключение.
Такой подход называется re-throw.
Исключение перехватывается в catch блоке, совершаются необходимые действия, например, запись в лог или создание нового, более конкретного для контекста задачи, исключения и повторная генерация исключения.
Как это выглядит на практике:
try { Reader readerConf = .... readerConf.readConfig(); } catch(IOException ex) { System.err.println("Log exception: " + ex); throw new ConfigException(ex); }
Во время чтения конфигурационного файла произошло исключение java.io.IOException, в catch блоке оно было перехвачено, сделана запись в консоль о проблеме, после чего было создано новое, более конкретное, исключение ConfigException, с указанием причины (перехваченное исключение, ссылка на которое ex) и оно было проброшено дальше.
По итогу, из метода с приведенным кодом, в случае ошибки чтения конфигурации, будет выброшено ConfigException.
Для чего мы здесь так поступили?
Это полезно для более гибкой обработки исключений.
В примере выше чтение конфигурации генерирует слишком общее исключение, так как java.io.IOException это довольно общее исключение, но проблема в примере выше понятна: работа с этим конфигурационным файлом невозможна.
Значит и сообщить лучше именно как о том, что это не абстрактный java.io.IOException, а именно ConfigException. При этом, так как перехваченное исключение было передано новому в конструкторе, т.е. указалась причина возникновения (cause) ConfigException, то при выводе на консоль или обработке в вызывающем коде будет понятно почему ConfigException был создан.
Также, можно было добавить еще и текстовое описание к сгенерированному ConfigException, более подробно описывающее произошедшую ситуацию.
Еще одной важной областью применения re-throw бывает преобразование проверяемых исключений в непроверяемые.
В Java 8 даже добавили исключение java.io.UncheckedIOException, которое предназначено как раз для того, чтобы сделать java.io.IOException непроверяемым, обернуть в unchecked обертку.
Пример:
try { Reader readerConf = .... readerConf.readConfig(); } catch(IOException ex) { System.err.println("Log exception: " + ex); throw new UncheckedIOException(ex); }
Не забывайте указывать причину возникновения исключения
В предыдущем пункте мы создали собственное исключение, которому указали причину: перехваченное исключение, java.io.IOException.
Чтобы понять как это работает, давайте рассмотрим наиболее важные поля класса java.lang.Throwable:
public class Throwable implements Serializable { /** * Specific details about the Throwable. For example, for * {@code FileNotFoundException}, this contains the name of * the file that could not be found. * * @serial */ private String detailMessage; // ... /** * The throwable that caused this throwable to get thrown, or null if this * throwable was not caused by another throwable, or if the causative * throwable is unknown. If this field is equal to this throwable itself, * it indicates that the cause of this throwable has not yet been * initialized. * * @serial * @since 1.4 */ private Throwable cause = this; // ... }
Все исключения, будь то java.lang.RuntimeException, либо java.lang.Exception имеют необходимые конструкторы для инициализации этих полей.
При создании собственного исключения не пренебрегайте этими конструкторами!
Поле cause используются для указания родительского исключения, причины. Например, выше мы перехватили java.io.IOException, прокинув свое исключение вместо него. Но причиной того, что наш код выкинул ConfigException было именно исключение java.io.IOException. И эту причину нельзя игнорировать.
Представьте, что код, использующий ваш метод также перехватил ConfigException, пробросив какое-то своё исключение, а это исключение снова кто-то перехватил и пробросил свое. Получается, что истинная причина будет просто потеряна! Однако, если каждый будет указывать cause, истинного виновника возникновения исключения, то вы всегда сможете обнаружить по этому стеку виновника.
Для получения причины возникновения исключения существует метод getCause.
public class ExceptionExample { public Config readConfig() throws ConfigException { // (1) try { Reader readerConf = ....; readerConf.readConfig(); } catch (IOException ex) { System.err.println("Log exception: " + ex); throw new ConfigException(ex); // (2) } } public void run() { try { Config config = readConfig(); // (3) } catch (ConfigException e) { Throwable t = e.getCause(); // (4) } } }
В коде выше:
- В строке (1) объявлен метод
readConfig, который может выброситьConfigException. - В строке (2) создаётся исключение
ConfigException, в конструктор которого передаетсяIOException— причина возникновения. readConfigвызывается в (3) строке кода.- А в (4) вызван метод
getCauseкоторый и вернёт причину возникновенияConfigException—IOException.
Сохранение исключения
Исключения необязательно генерировать, пробрасывать и так далее.
Выше уже упоминалось, что исключение — это Java-объект. А значит, его вполне можно присвоить переменной или свойству класса, передать по ссылке в метод и т.д.
class Reader { // A holder of the last IOException encountered private IOException lastException; // some code public void read() { try { Reader readerConf = .... readerConf.readConfig(); } catch(IOException ex) { System.err.println("Log exception: " + ex); lastException = ex; } } }
Генерация исключения это довольно дорогостоящая операция. Кроме того, исключения ломают поток выполнения программы. Чтобы не ломать поток выполнения, но при этом иметь возможность в дальнейшем отреагировать на исключительную ситуацию можно присвоить ее свойству класса или переменой.
Подобный прием использован в java.util.Scanner, где генерируемое исключение чтения потока сохраняется в свойство класса lastException.
Еще одним способом применения сохранения исключения может являться ситуация, когда надо сделать N операций, какие-то из них могут быть не выполнены и будет сгенерировано исключение, но реагировать на эти исключения будут позже, скопом.
Например, идет запись в базу данных тысячу строк построчно.
Из них 100 записей происходит с ошибкой.
Эти исключения складываются в список, а после этот список передается специальному методу, который по каждой ситуации из списка как-то отреагирует.
Т.е пока делаете операцию, копите ошибки, а потом уже реагируете.
Это похоже на то, как опрашивают 1000 человек, а негативные отзывы/голоса записывают, после чего реагируют на них. Согласитесь, было бы глупо после каждого негативного отзыва осуществлять реакцию, а потом снова возвращаться к толпе и продолжать опрос.
class Example { private List<Exception> exceptions; // some code public void parse(String s) { try { // do smth } catch(Exception ex) { exceptions.add(ex); } } private void handleExceptions() { for(Exception e : exceptions) { System.err.println("Log exception: " + e); } } }
Логирование
Когда логировать исключение?
В большинстве случаев лучше всего логировать исключение в месте его обработки. Это связано с тем, что именно в данном месте кода достаточно информации для описания возникшей проблемы — реакции на исключение. Кроме этого, одно и то же исключение при вызове одного и того же метода можно перехватывать в разных местах программы.
Также, исключение может быть частью ожидаемого поведения. В этом случае нет необходимости его логировать.
Поэтому не стоит преждевременно логировать исключение, например:
/** * Parse date from string to java.util.Date. * @param date as string * @return Date object. */ public static Date from(String date) { try { DateFormat format = new SimpleDateFormat("MMMM d, yyyy", Locale.ENGLISH); return format.parse(date); } catch (ParseException e) { logger.error("Can't parse ") throw e; } }
Здесь ParseException является частью ожидаемой работы, в ситуациях, когда строка содержит невалидные данные.
Раз происходит делегирование исключения выше (с помощью throw), то и там, где его будут обрабатывать и лучше всего логировать, а эта запись в лог будет избыточной. Хотя бы потому, что в месте обработки исключения его тоже залогируют!
Подробнее о логировании.
Чего нельзя делать при обработке исключений
-
Старайтесь не игнорировать исключения.
В частности, никогда не пишите подобный код:
try { Reader readerConf = .... readerConf.readConfig(); } catch(IOException e) { e.printStackTrace(); }
-
Не следует писать ‘универсальные’ блоки обработки исключений.
Ведь очень трудно представить себе метод, который одинаково реагировал бы на все возникающие проблемы.
Также программный код может измениться, а ‘универсальный’ обработчик исключений будет продолжать обрабатывать новые типы исключений одинаково.
Поэтому таких ситуаций лучше не допускать.
-
Старайтесь не преобразовывать более конкретные исключения в более общие.
В частности, например, не следует
java.io.IOExceptionпреобразовывать вjava.lang.Exceptionили вjava.lang.Throwable.Чем с более конкретными исключениями идет работа, тем проще реагировать и принимать решения об их обработке.
-
Старайтесь не злоупотреблять исключениями.
Если исключение можно не допустить, например, дополнительной проверкой, то лучше так и сделать.
Например, можно обезопасить себя от
java.lang.NullPointerExceptionпростой проверкой:if(ref != null) { // some code }
Try-with-resources или try-с-ресурсами
Как уже говорилось выше про finally блок, код в нем выполняется в любом случае, что делает его отличным кандидатом на место по освобождению ресурсов, учитывая нетранзакционность блока try.
Чаще всего за закрытие ресурса будет отвечать код, наподобие этого:
try { // code } finally { resource.close(); }
Освобождение ресурса (например, освобождение файлового дескриптора) — это поведение.
А за поведение в
Javaотвечают интерфейсы.
Это наталкивает на мысль, что нужен некоторый общий интерфейс, который бы реализовывали все классы, для которых необходимо выполнить какой-то код по освобождению ресурсов, т.е выполнить ‘закрытие’ в finally блоке и еще удобнее, если бы этот однообразный finally блок не нужно было писать каждый раз.
Поэтому, начиная с Java 7, была введена конструкция try-with-resources или TWR.
Для этого объявили специальный интерфейс java.lang.AutoCloseable, у которого один метод:
void close() throws Exception;
Все классы, которые будут использоваться так, как было описано выше, должны реализовать или java.lang.Closable, или java.lang.AutoCloseable.
В качестве примера, напишем код чтения содержимого файла и представим две реализации этой задачи: используя и не используя try-with-resources.
Без использования try-with-resources (пример ниже плох и служит только для демонстрации объема необходимого кода):
BufferedReader br = null; try { br = new BufferedReader(new FileReader(path)); // read from file } catch (IOException e) { // catch and do smth } finally { try { if (br != null) { br.close(); } } catch (IOException ex) { // catch and do smth } }
А теперь то же самое, но в Java 7+:
try (FileReader fr = new FileReader(path); BufferedReader br = new BufferedReader(fr)) { // read from file } catch (IOException e) { // catch and do smth }
По возможности пользуйтесь только try-with-resources.
Помните, что без реализации
java.lang.Closableилиjava.lang.AutoCloseableваш класс не будет работать сtry-with-resourcesтак, как показано выше.
Вопрос:
Получается, что используя TWR мы не пишем код для закрытия ресурсов, но при их закрытии может же тоже быть исключение! Что произойдет?
Ответ:
Точно так же, как и без TWR, исключение выбросится так, будто оно было в finally-блоке.
Помните, что TWR, грубо говоря, просто добавляет вам блок кода вида:
finally { resource.close(); }
Вопрос:
Является ли безопасной конструкция следующего вида?
try (BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("a")))) { }
Ответ:
Не совсем, если конструктор OutputStreamWriter или BufferedWriter выбросит исключение, то FileOutputStream закрыт не будет.
Пример, демонстрирующий это:
public class Main { public static void main(String[] args) throws Exception { try (ThrowingAutoCloseable throwingAutoCloseable = new ThrowingAutoCloseable(new PrintingAutoCloseable())) { // (1) } } private static class ThrowingAutoCloseable implements AutoCloseable { // (2) private final AutoCloseable other; public ThrowingAutoCloseable(AutoCloseable other) { this.other = other; throw new IllegalStateException("I always throw"); // (3) } @Override public void close() throws Exception { try { other.close(); // (4) } finally { System.out.println("ThrowingAutoCloseable is closed"); } } } private static class PrintingAutoCloseable implements AutoCloseable { // (5) public PrintingAutoCloseable() { System.out.println("PrintingAutoCloseable created"); // (6) } @Override public void close() { System.out.println("PrintingAutoCloseable is closed"); // (7) } } }
- В строке (1) происходит заворачивание одного ресурса в другой, аналогично
new BufferedWriter(new OutputStreamWriter(new FileOutputStream("a"))). ThrowingAutoCloseable(2) — такойAutoCloseable, который всегда бросает исключение (3), в (4) производится попытка закрыть полученный в конструктореAutoCloseable.PrintingAutoCloseable(5) —AutoCloseable, который печатает сообщения о своём создании (6) и закрытии (7).
В результате выполнения этой программы вывод будет примерно следующим:
PrintingAutoCloseable created
Exception in thread "main" java.lang.IllegalStateException: I always throw
at ru.misc.Main$ThrowingAutoCloseable.<init>(Main.java:19)
at ru.misc.Main.main(Main.java:9)
Как видно, PrintingAutoCloseable закрыт не был!
Вопрос:
В каком порядке закрываются ресурсы, объявленные в try-with-resources?
Ответ:
В обратном.
Пример:
public class Main { public static void main(String[] args) throws Exception { try (PrintingAutoCloseable printingAutoCloseable1 = new PrintingAutoCloseable("1"); PrintingAutoCloseable printingAutoCloseable2 = new PrintingAutoCloseable("2"); PrintingAutoCloseable printingAutoCloseable3 = new PrintingAutoCloseable("3")) { } } private static class PrintingAutoCloseable implements AutoCloseable { private final String id; public PrintingAutoCloseable(String id) { this.id = id; } @Override public void close() { System.out.println("Closed " + id); } } }
Вывод:
Closed 3
Closed 2
Closed 1
Общие советы
Избегайте генерации исключений, если их можно избежать простой проверкой
Как уже было сказано выше, исключения ломают поток выполнения программы. Если же на сгенерированное исключение не найдется обработчика, не будет подходящего catch блока, то программа и вовсе будет завершена. Кроме того, генерация исключения это довольно дорогостоящая операция.
Помните, что если исключение можно не допустить, то лучше так и сделать.
Отсюда следует первый совет: не брезгуйте дополнительными проверками.
- Не ловите
IllegalArgumentException,NullPointerException,ArrayIndexOutOfBoundsExceptionи подобные.
Потому что эти ошибки — это явная отсылка к тому, что где-то недостает проверки.
Обращение по индексу за пределами массива,NullPointerException, все эти исключения — это ошибка разработчика. - Вводите дополнительные проверки на данные, дабы избежать возникновения непроверяемых исключения
Например, запретите вводить в поле возраста не числовые значения, проверяйте ссылки на null перед обращением и т.д.
Предпочитайте Optional, если отсутствие значения — не исключительная ситуация
При написании API к каким-то хранилищам или коллекциям очень часто на отсутствие элемента генерируется исключение, как например в разделе собственные исключения.
class Catalog { Person findPerson(String name); }
Но и в этом случае генерации исключения можно избежать, если воспользоваться java.util.Optional:
Optional<Person> findPerson(String name);
Класс java.util.Optional был добавлен в Java 8 и предназначен как раз для подобных ситуаций, когда возвращаемого значения может не быть. В зависимости от задачи и контекста можно как генерировать исключение, как это сделано в примере с PersonNotFoundException, так и изменить сигнатуру метода, воспользовавшись java.util.Optional.
Отсюда следует второй совет: думайте над API ваших классов, исключений можно избежать воспользовавшись другим подходом.
Заранее обдумывайте контракты методов
Важным моментом, который нельзя не упомянуть, является то, что если в методе объявляется, что он может сгенерировать исключение (с помощью throws), то при переопределении такого метода нельзя указать более общее исключение в качестве выбрасываемого.
class Person { void hello() throws RuntimeException { // some code } } // Compile Error class PPerson extends Person { @Override void hello() throws Exception { // some code } }
Если было явно указано, что метод может сгенерировать java.lang.RuntimeException, то нельзя объявить более общее бросаемое исключение при переопределении. Но можно указать потомка:
// IllegalArgumentException - потомок RuntimeException! class PPerson extends Person { @Override void hello() throws IllegalArgumentException { // some code } }
Что, в целом логично.
Если объявляется, что метод может сгенерировать java.lang.RuntimeException, а он выбрасывает java.io.IOException, то это было бы как минимум странно.
Это объясняется и с помощью полимофризма. Пусть есть интерфейс, в котором объявлен метод, генерирующий исключение. Если полиморфно работать с объектом через общий интерфейс, то разработчик обязан обработать исключение, объявленное в интерфейсе, а если одна из реализаций интерфейса генерирует более общее исключение, то это нарушает полиморфизм. Поэтому такой код даже не скомпилируется.
При этом при переопределении можно вообще не объявлять бросаемые исключения, таким образом сообщив, что все проблемы будут решены в методе:
class PPerson extends Person { @Override void hello() { // some code } }
Отсюда следует третий совет: необходимо думать о тех исключениях, которые делегирует метод, если класс может участвовать в наследовании.
Предпочитайте исключения кодам ошибок и boolean флагам-признакам успеха
- Исключения более информативны: они позволяют передать сообщение с описанием ошибки
- Исключение практически невозможно проигнорировать
- Исключение может быть обработано кодом, находящимся выше по стеку, а
boolean-флаг или код ошибки необходимо обрабатывать здесь и сейчас
Исключения и статические блоки
Еще интересно поговорить про то, что происходит, если исключение возникает в статическом блоке.
Так вот, такие исключения оборачиваются в java.lang.ExceptionInInitializerError:
public class ExceptionHandling { static { throwRuntimeException(); } private static void throwRuntimeException() { throw new NullPointerException(); } public static void main(String[] args) { System.out.println("Hello World"); } }
Результатом будет падение со следующим стектрейсом:
java.lang.ExceptionInInitializerError Caused by: java.lang.NullPointerException at exception.test.ExceptionHandling.throwRuntimeException(ExceptionHandling.java:13) at exception.test.ExceptionHandling. (ExceptionHandling.java:8)
Многопоточность и исключения
Код в Java потоке выполняется в методе со следующей сигнатурой:
Что делает невозможным пробрасывание проверяемых исключений, т.е разработчик должен обрабатывать все проверяемые исключения внутри метода run.
Непроверяемые исключения обрабатывать необязательно, однако необработанное исключение, выброшенное из run, завершит работу потока.
Например:
public class ExceptionHandling4 { public static void main(String[] args) throws InterruptedException { Thread t = new Thread() { @Override public void run() { throw new RuntimeException("Testing unhandled exception processing."); } }; t.start(); } }
Результатом выполнения этого кода будет то, что возникшее исключение прервет поток исполнения (interrupt thread):
Exception in thread “Thread-0” java.lang.RuntimeException: Testing unhandled exception processing. at exception.test. ExceptionHandling4$1.run(ExceptionHandling4.java:27)
При использовании нескольких потоков бывают ситуации, когда надо знать, как поток завершился, из-за какого именно исключения. И, разумеется, отреагировать на это.
В таких ситуациях рекомендуется использовать Thread.UncaughtExceptionHandler.
t.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() { public void uncaughtException(Thread t, Throwable e) { System.out.println("Handled uncaught exception in thread :" + t + " Exception : " + e); } });
И вывод уже будет:
Handled uncaught exception in thread :Thread[Thread-0,5,main] Exception : java.lang.RuntimeException: Testing unhandled exception processing.
Необработанное исключение RuntimeException("Testing unhandled exception processing."), убившее поток, было перехвачено специальным зарегистрированным обработчиком.
Проверяемые исключения и их необходимость
В большинстве языков программирования, таких как C#, Scala, Groovy, Python и т.д., нет такого разделения, как в Java, на проверяемые и непроверяемые исключения.
Почему оно введено в Java было разобрано выше, а вот почему проверяемые исключения недолюбливают разработчики?
Основных причин две, это причины с: версионированием и масштабируемостью.
Представим, что вы, как разработчик библиотеки, объявили некоторый условный метод foo, бросающий исключения A, B и C:
void foo() throws A, B, C;
В следующей версии библиотеки в метод foo добавили функциональности и теперь он бросает еще новое исключение D:
void foo() throws A, B, C, D;
В таком случае новая версия библиотеки сломает код тех, кто ей пользуется. Это сравнимо с тем, что добавляется новый метод в интерфейс.
И с одной стороны, это правильно, так как в новой версии добавляется еще одно исключение и те, кто использует библиотеку должны отреагировать на все новые исключения. С другой стороны, чаще всего такие исключения будут также проброшены дальше. Все дело в том, что случаев, когда можно обработать специфический тип исключения, например тот же D или A в примере выше, и сделать в обработчике что-то интеллектуальное, можно пересчитать по пальцам одной руки.
Проблема с масштабируемостью начинается тогда, когда происходит вызов не одного, а нескольких API, каждый из которых также несет с собой проверяемые исключения. Представьте, что помимо foo, бросающего A, B, C и D, в методе hello вызывается еще и bar, который также бросает E и T исключения. Как сказано выше, как реагировать чаще всего непонятно, поэтому эти исключения делегируются вызывающему коду, из-за чего объявление метода hello выглядит совсем уж угрожающе:
void hello() throws A, B, C, D, E, T { try { foo(); bar(); } finally { // clear resources if needed } }
Все это настолько раздражающе, что чаще всего разработчики просто объявляют наиболее общее исключение в throws:
void hello() throws Exception { try { foo(); bar(); } finally { // clear resources if needed } }
А в таком случае это все равно, что сказать «метод может выбросить исключение» — это настолько общие и абстрактные слова, что смысла в throws Exception практически нет.
Также есть еще одна проблема с проверяемыми исключениями. Это то, что с проверяемыми исключениями крайне неудобно работать в lambda-ах и stream-ах:
// compilation error Lists.newArrayList("a", "asg").stream().map(e -> {throw new Exception();});
Так как с Java 8 использование lambda и stream-ов распространенная практика, то накладываемые ограничения вызовут дополнительные трудности при использовании проверяемых исключений.
Поэтому многие разработчики недолюбливают проверяемые исключения, например, оборачивая их в непроверяемые аналоги с помощью re-throw.
Мое мнение таково: на проверяемых исключениях очень хорошо учиться. Компилятор и язык сами подсказывают вам, что нельзя игнорировать исключения и требуют от вас реакции. Опять же, логическое разделение на проверяемые и непроверяемые помогает в понимании исключений, в понимании того, как и на что реагировать. В промышленной же разработке это становится уже больше раздражающим фактором.
В своей работе я стараюсь чаще использовать непроверяемые исключения, а проверяемые оборачивать в unchecked аналоги, как, например, java.io.IOException и java.io.UncheckedIOException.
Заключение
Иерархия исключений в Java.
Исключения делятся на два типа: непроверяемые(unchecked) и проверяемые(checked). Проверяемые исключения — это исключения, которые проверяются на этапе компиляции, мы обязаны на них отреагировать.
Проверяемые исключения в Java используются тогда, когда разработчик никак не может предотвратить их возникновение. Причину возникновения java.lang.RuntimeException можно проверить и устранить заранее, например, проверить ссылку на null перед вызовом метода, на объекте по ссылке. А вот с причинами проверяемых исключений так сделать не получится, так как ошибка при чтении файла может возникнуть непосредственно в момент чтения, потому что другая программа его удалила. Соответственно, при чтении файла требуется обрабатывать java.io.IOException, который является потомком java.lang.Exception.
Допускается создание собственных исключений, признак проверяемости или непроверяемости наследуется от родителя. Исключения — это такие же классы, со своим поведением и состоянием, поэтому при наследовании вполне допускается добавить дополнительное поведение или свойства классу.
Обработка исключений происходит с помощью конструкции try/catch/finally. Один блок try может иметь несколько catch блоков. В таком случае будет выполняться первый подходящий блок.
Помните, что try блок не транзакционен, все ресурсы, занятые в try ДО исключения остаются в памяти. Их надо освобождать и очищать вручную.
Если вы используете Java версии 7 и выше, то отдавайте предпочтение конструкции try-with-resources.
Основное правило:
На исключения можно реагировать, их обработку можно делегировать, но ни в коем случае нельзя их игнорировать.
Определить когда надо реагировать, а когда делегировать проще простого. Задайте вопрос: «Знаю ли я как реагировать на это исключение?».
Если ответ «да, знаю», то реагируйте, пишите обработчик и код, отвечающий за эту реакцию, если не знаете что делать с исключением, то делегируйте вызывающему коду.
Помните, что перехват java.lang.Error стоит делать только если вы точно знаете, что делаете. Восстановление после таких ошибок не всегда возможно и почти всегда нетривиально.
Не забывайте, что большинство ошибок java.lang.RuntimeException и его потомков можно избежать.
Не бойтесь создавать собственные исключения, так как это позволит писать более гибкие обработчики, а значит более точно реагировать на проблемы.
Представьте себе, что существуют пять причин, по которым может быть выброшено исключение, и во всех пяти случаях бросается
java.lang.Exception. Вы же спятите разбираться, чем именно это исключение вызвано.(c) Евгений Матюшкин.
Помните, что исключения ломают поток выполнения программы, поэтому чем раньше вы обработаете возникшую проблему, тем лучше. Отсюда же следует совет, что лучше не разбрасываться исключениями, так как помимо того, что это ломает поток выполнения, это еще и дорогостоящая операция.
Постарайтесь не создавать ‘универсальных’ обработчиков, так как это чревато трудноуловимыми ошибками.
Если исключение можно не генерировать, то лучше так и сделать. Не пренебрегайте проверками.
Старайтесь продумывать то, как вы будете реагировать на исключения, не игнорировать их, использовать только try-с-ресурсами.
Помните:
In Java you can ignore exceptions, but you have to willfully do it. You can’t accidentally say, «I don’t care.» You have to explicitly say, «I don’t care.»
(c) James Gosling.
Для закрепления материала рекомендую ознакомиться с ссылками ниже и этим материалом.
Полезные ссылки
- Книга С. Стелтинг ‘Java без сбоев: обработка исключений, тестирование, отладка’
- Oracle Java Tutorials
- Лекция Технострим Исключения
- Лекция OTUS Исключения в Java
- Лекция Ивана Пономарёва по исключениям
- Заметка Евгения Матюшкина про Исключения
- Failure and Exceptions by James Gosling
- The Trouble with Checked Exceptions by Bill Venners with Bruce Eckel
- Никто не умеет обрабатывать ошибки
- Исключения и обобщенные типы в Java
- Вопросы для закрепления
Содержание
- 1 Методы обработки ошибок
- 2 Исключения
- 3 Классификация исключений
- 3.1 Проверяемые исключения
- 3.2 Error
- 3.3 RuntimeException
- 4 Обработка исключений
- 4.1 try-catch-finally
- 4.2 Обработка исключений, вызвавших завершение потока
- 4.3 Информация об исключениях
- 5 Разработка исключений
- 6 Исключения в Java7
- 7 Примеры исключений
- 8 Гарантии безопасности
- 9 Источники
Методы обработки ошибок
1. Не обрабатывать.
2. Коды возврата. Основная идея — в случае ошибки возвращать специальное значение, которое не может быть корректным. Например, если в методе есть операция деления, то придется проверять делитель на равенство нулю. Также проверим корректность аргументов a и b:
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
return null;
}
//...
if (Math.abs(b) < EPS) {
return null;
} else {
return a / b;
}
}
При вызове метода необходимо проверить возвращаемое значение:
Double d = f(a, b); if (d != null) { //... } else { //... }
Минусом такого подхода является необходимость проверки возвращаемого значения каждый раз при вызове метода. Кроме того, не всегда возможно определить тип ошибки.
3.Использовать флаг ошибки: при возникновении ошибки устанавливать флаг в соответствующее значение:
boolean error; Double f(Double a, Double b) { if ((a == null) || (b == null)) { error = true; return null; } //... if (Math.abs(b) < EPS) { error = true; return b; } else { return a / b; } }
error = false; Double d = f(a, b); if (error) { //... } else { //... }
Минусы такого подхода аналогичны минусам использования кодов возврата.
4.Можно вызвать метод обработки ошибки и возвращать то, что вернет этот метод.
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
return nullPointer();
}
//...
if (Math.abs(b) < EPS) {
return divisionByZero();
} else {
return a / b;
}
}
Но в таком случае не всегда возможно проверить корректность результата вызова основного метода.
5.В случае ошибки просто закрыть программу.
if (Math.abs(b) < EPS) { System.exit(0); return this; }
Это приведет к потере данных, также невозможно понять, в каком месте возникла ошибка.
Исключения
В Java возможна обработка ошибок с помощью исключений:
Double f(Double a, Double b) {
if ((a == null) || (b == null)) {
throw new IllegalArgumentException("arguments of f() are null");
}
//...
return a / b;
}
Проверять b на равенство нулю уже нет необходимости, так как при делении на ноль метод бросит непроверяемое исключение ArithmeticException.
Исключения позволяют:
- разделить обработку ошибок и сам алгоритм;
- не загромождать код проверками возвращаемых значений;
- обрабатывать ошибки на верхних уровнях, если на текущем уровне не хватает данных для обработки. Например, при написании универсального метода чтения из файла невозможно заранее предусмотреть реакцию на ошибку, так как эта реакция зависит от использующей метод программы;
- классифицировать типы ошибок, обрабатывать похожие исключения одинаково, сопоставлять специфичным исключениям определенные обработчики.
Каждый раз, когда при выполнении программы происходит ошибка, создается объект-исключение, содержащий информацию об ошибке, включая её тип и состояние программы на момент возникновения ошибки.
После создания исключения среда выполнения пытается найти в стеке вызовов метод, который содержит код, обрабатывающий это исключение. Поиск начинается с метода, в котором произошла ошибка, и проходит через стек в обратном порядке вызова методов. Если не было найдено ни одного подходящего обработчика, выполнение программы завершается.
Таким образом, механизм обработки исключений содержит следующие операции:
- Создание объекта-исключения.
- Заполнение stack trace’а этого исключения.
- Stack unwinding (раскрутка стека) в поисках нужного обработчика.
Классификация исключений
Класс Java Throwable описывает все, что может быть брошено как исключение. Наследеники Throwable — Exception и Error — основные типы исключений. Также RuntimeException, унаследованный от Exception, является существенным классом.
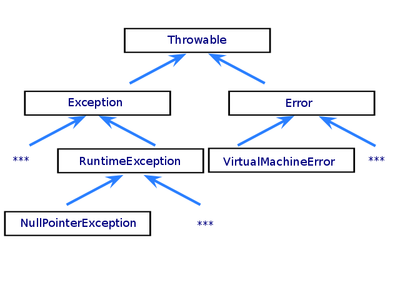
Иерархия стандартных исключений
Проверяемые исключения
Наследники класса Exception (кроме наслеников RuntimeException) являются проверяемыми исключениями(checked exception). Как правило, это ошибки, возникшие по вине внешних обстоятельств или пользователя приложения – неправильно указали имя файла, например. Эти исключения должны обрабатываться в ходе работы программы, поэтому компилятор проверяет наличие обработчика или явного описания тех типов исключений, которые могут быть сгенерированы некоторым методом.
Все исключения, кроме классов Error и RuntimeException и их наследников, являются проверяемыми.
Error
Класс Error и его подклассы предназначены для системных ошибок. Свои собственные классы-наследники для Error писать (за очень редкими исключениями) не нужно. Как правило, это действительно фатальные ошибки, пытаться обработать которые довольно бессмысленно (например OutOfMemoryError).
RuntimeException
Эти исключения обычно возникают в результате ошибок программирования, такие как ошибки разработчика или неверное использование интерфейса приложения. Например, в случае выхода за границы массива метод бросит OutOfBoundsException. Такие ошибки могут быть в любом месте программы, поэтому компилятор не требует указывать runtime исключения в объявлении метода. Теоретически приложение может поймать это исключение, но разумнее исправить ошибку.
Обработка исключений
Чтобы сгенерировать исключение используется ключевое слово throw. Как и любой объект в Java, исключения создаются с помощью new.
if (t == null) { throw new NullPointerException("t = null"); }
Есть два стандартных конструктора для всех исключений: первый — конструктор по умолчанию, второй принимает строковый аргумент, поэтому можно поместить подходящую информацию в исключение.
Возможна ситуация, когда одно исключение становится причиной другого. Для этого существует механизм exception chaining. Практически у каждого класса исключения есть конструктор, принимающий в качестве параметра Throwable – причину исключительной ситуации. Если же такого конструктора нет, то у Throwable есть метод initCause(Throwable), который можно вызвать один раз, и передать ему исключение-причину.
Как и было сказано раньше, определение метода должно содержать список всех проверяемых исключений, которые метод может бросить. Также можно написать более общий класс, среди наследников которого есть эти исключения.
void f() throws InterruptedException, IOException { //...
try-catch-finally
Код, который может бросить исключения оборачивается в try-блок, после которого идут блоки catch и finally (Один из них может быть опущен).
try { // Код, который может сгенерировать исключение }
Сразу после блока проверки следуют обработчики исключений, которые объявляются ключевым словом catch.
try { // Код, который может сгенерировать исключение } catch(Type1 id1) { // Обработка исключения Type1 } catch(Type2 id2) { // Обработка исключения Type2 }
Сatch-блоки обрабатывают исключения, указанные в качестве аргумента. Тип аргумента должен быть классом, унаследованного от Throwable, или самим Throwable. Блок catch выполняется, если тип брошенного исключения является наследником типа аргумента и если это исключение не было обработано предыдущими блоками.
Код из блока finally выполнится в любом случае: при нормальном выходе из try, после обработки исключения или при выходе по команде return.
NB: Если JVM выйдет во время выполнения кода из try или catch, то finally-блок может не выполниться. Также, например, если поток выполняющий try или catch код остановлен, то блок finally может не выполниться, даже если приложение продолжает работать.
Блок finally удобен для закрытия файлов и освобождения любых других ресурсов. Код в блоке finally должен быть максимально простым. Если внутри блока finally будет брошено какое-либо исключение или просто встретится оператор return, брошенное в блоке try исключение (если таковое было брошено) будет забыто.
import java.io.IOException; public class ExceptionTest { public static void main(String[] args) { try { try { throw new Exception("a"); } finally { throw new IOException("b"); } } catch (IOException ex) { System.err.println(ex.getMessage()); } catch (Exception ex) { System.err.println(ex.getMessage()); } } }
После того, как было брошено первое исключение — new Exception("a") — будет выполнен блок finally, в котором будет брошено исключение new IOException("b"), именно оно будет поймано и обработано. Результатом его выполнения будет вывод в консоль b. Исходное исключение теряется.
Обработка исключений, вызвавших завершение потока
При использовании нескольких потоков бывают ситуации, когда поток завершается из-за исключения. Для того, чтобы определить с каким именно, начиная с версии Java 5 существует интерфейс Thread.UncaughtExceptionHandler. Его реализацию можно установить нужному потоку с помощью метода setUncaughtExceptionHandler. Можно также установить обработчик по умолчанию с помощью статического метода Thread.setDefaultUncaughtExceptionHandler.
Интерфейс Thread.UncaughtExceptionHandler имеет единственный метод uncaughtException(Thread t, Throwable e), в который передается экземпляр потока, завершившегося исключением, и экземпляр самого исключения. Когда поток завершается из-за непойманного исключения, JVM запрашивает у потока UncaughtExceptionHandler, используя метод Thread.getUncaughtExceptionHandler(), и вызвает метод обработчика – uncaughtException(Thread t, Throwable e). Все исключения, брошенные этим методом, игнорируются JVM.
Информация об исключениях
-
getMessage(). Этот метод возвращает строку, которая была первым параметром при создании исключения; -
getCause()возвращает исключение, которое стало причиной текущего исключения; -
printStackTrace()печатает stack trace, который содержит информацию, с помощью которой можно определить причину исключения и место, где оно было брошено.
Exception in thread "main" java.lang.IllegalStateException: A book has a null property
at com.example.myproject.Author.getBookIds(Author.java:38)
at com.example.myproject.Bootstrap.main(Bootstrap.java:14)
Caused by: java.lang.NullPointerException
at com.example.myproject.Book.getId(Book.java:22)
at com.example.myproject.Author.getBookIds(Author.java:35)
Все методы выводятся в обратном порядке вызовов. В примере исключение IllegalStateException было брошено в методе getBookIds, который был вызван в main. «Caused by» означает, что исключение NullPointerException является причиной IllegalStateException.
Разработка исключений
Чтобы определить собственное проверяемое исключение, необходимо создать наследника класса java.lang.Exception. Желательно, чтобы у исключения был конструкор, которому можно передать сообщение:
public class FooException extends Exception { public FooException() { super(); } public FooException(String message) { super(message); } public FooException(String message, Throwable cause) { super(message, cause); } public FooException(Throwable cause) { super(cause); } }
Исключения в Java7
- обработка нескольких типов исключений в одном
catch-блоке:
catch (IOException | SQLException ex) {...}
В таких случаях параметры неявно являются final, поэтому нельзя присвоить им другое значение в блоке catch.
Байт-код, сгенерированный компиляцией такого catch-блока будет короче, чем код нескольких catch-блоков.
-
Tryс ресурсами позволяет прямо вtry-блоке объявлять необходимые ресурсы, которые по завершению блока будут корректно закрыты (с помощью методаclose()). Любой объект реализующийjava.lang.AutoCloseableможет быть использован как ресурс.
static String readFirstLineFromFile(String path) throws IOException { try (BufferedReader br = new BufferedReader(new FileReader(path))) { return br.readLine(); } }
В приведенном примере в качестве ресурса использутся объект класса BufferedReader, который будет закрыт вне зависимосити от того, как выполнится try-блок.
Можно объявлять несколько ресурсов, разделяя их точкой с запятой:
public static void viewTable(Connection con) throws SQLException { String query = "select COF_NAME, SUP_ID, PRICE, SALES, TOTAL from COFFEES"; try (Statement stmt = con.createStatement(); ResultSet rs = stmt.executeQuery(query)) { //Work with Statement and ResultSet } catch (SQLException e) { e.printStackTrace; } }
Во время закрытия ресурсов тоже может быть брошено исключение. В try-with-resources добавленна возможность хранения «подавленных» исключений, и брошенное try-блоком исключение имеет больший приоритет, чем исключения получившиеся во время закрытия. Получить последние можно вызовом метода getSuppressed() от исключения брошенного try-блоком.
- Перебрасывание исключений с улучшенной проверкой соответствия типов.
Компилятор Java SE 7 тщательнее анализирует перебрасываемые исключения. Рассмотрим следующий пример:
static class FirstException extends Exception { } static class SecondException extends Exception { } public void rethrowException(String exceptionName) throws Exception { try { if ("First".equals(exceptionName)) { throw new FirstException(); } else { throw new SecondException(); } } catch (Exception ex) { throw e; } }
В примере try-блок может бросить либо FirstException, либо SecondException. В версиях до Java SE 7 невозможно указать эти исключения в декларации метода, потому что catch-блок перебрасывает исключение ex, тип которого — Exception.
В Java SE 7 вы можете указать, что метод rethrowException бросает только FirstException и SecondException. Компилятор определит, что исключение Exception ex могло возникнуть только в try-блоке, в котором может быть брошено FirstException или SecondException. Даже если тип параметра catch — Exception, компилятор определит, что это экземпляр либо FirstException, либо SecondException:
public void rethrowException(String exceptionName) throws FirstException, SecondException { try { // ... } catch (Exception e) { throw e; } }
Если FirstException и SecondException не являются наследниками Exception, то необходимо указать и Exception в объявлении метода.
Примеры исключений
- любая операция может бросить
VirtualMachineError. Как правило это происходит в результате системных сбоев. -
OutOfMemoryError. Приложение может бросить это исключение, если, например, не хватает места в куче, или не хватает памяти для того, чтобы создать стек нового потока. -
IllegalArgumentExceptionиспользуется для того, чтобы избежать передачи некорректных значений аргументов. Например:
public void f(Object a) { if (a == null) { throw new IllegalArgumentException("a must not be null"); } }
IllegalStateExceptionвозникает в результате некорректного состояния объекта. Например, использование объекта перед тем как он будет инициализирован.
Гарантии безопасности
При возникновении исключительной ситуации, состояния объектов и программы могут удовлетворять некоторым условиям, которые определяются различными типами гарантий безопасности:
- Отсутствие гарантий (no exceptional safety). Если было брошено исключение, то не гарантируется, что все ресурсы будут корректно закрыты и что объекты, методы которых бросили исключения, могут в дальнейшем использоваться. Пользователю придется пересоздавать все необходимые объекты и он не может быть уверен в том, что может переиспозовать те же самые ресурсы.
- Отсутствие утечек (no-leak guarantee). Объект, даже если какой-нибудь его метод бросает исключение, освобождает все ресурсы или предоставляет способ сделать это.
- Слабые гарантии (weak exceptional safety). Если объект бросил исключение, то он находится в корректном состоянии, и все инварианты сохранены. Рассмотрим пример:
class Interval { //invariant: left <= right double left; double right; //... }
Если будет брошено исключение в этом классе, то тогда гарантируется, что ивариант «левая граница интервала меньше правой» сохранится, но значения left и right могли измениться.
- Сильные гарантии (strong exceptional safety). Если при выполнении операции возникает исключение, то это не должно оказать какого-либо влияния на состояние приложения. Состояние объектов должно быть таким же как и до вызовов методов.
- Гарантия отсутствия исключений (no throw guarantee). Ни при каких обстоятельствах метод не должен генерировать исключения. В Java это невозможно, например, из-за того, что
VirtualMachineErrorможет произойти в любом месте, и это никак не зависит от кода. Кроме того, эту гарантию практически невозможно обеспечить в общем случае.
Источники
- Обработка ошибок и исключения — Сайт Георгия Корнеева
- Лекция Георгия Корнеева — Лекториум
- The Java Tutorials. Lesson: Exceptions
- Обработка исключений — Википедия
- Throwable (Java Platform SE 7 ) — Oracle Documentation
- try/catch/finally и исключения — www.skipy.ru