
I have the following code,
df = pd.read_csv(CsvFileName)
p = df.pivot_table(index=['Hour'], columns='DOW', values='Changes', aggfunc=np.mean).round(0)
p.fillna(0, inplace=True)
p[["1Sun", "2Mon", "3Tue", "4Wed", "5Thu", "6Fri", "7Sat"]] = p[["1Sun", "2Mon", "3Tue", "4Wed", "5Thu", "6Fri", "7Sat"]].astype(int)
It has always been working until the csv file doesn’t have enough coverage (of all week days). For e.g., with the following .csv file,
DOW,Hour,Changes
4Wed,01,237
3Tue,07,2533
1Sun,01,240
3Tue,12,4407
1Sun,09,2204
1Sun,01,240
1Sun,01,241
1Sun,01,241
3Tue,11,662
4Wed,01,4
2Mon,18,4737
1Sun,15,240
2Mon,02,4
6Fri,01,1
1Sun,01,240
2Mon,19,2300
2Mon,19,2532
I’ll get the following error:
KeyError: "['5Thu' '7Sat'] not in index"
It seems to have a very easy fix, but I’m just too new to Python to know how to fix it.
I have a dataframe called delivery and when I print(delivery.columns) I get the following:
Index(['Complemento_endereço', 'cnpj', 'Data_fundação', 'Número',
'Razão_social', 'CEP', 'situacao_cadastral', 'situacao_especial', 'Rua',
'Nome_Fantasia', 'last_revenue_normalized', 'last_revenue_year',
'Telefone', 'email', 'Capital_Social', 'Cidade', 'Estado',
'Razão_social', 'name_bairro', 'Natureza_Jurídica', 'CNAE', '#CNAE',
'CNAEs_secundários', 'Pessoas', 'percent'],
dtype='object')
Well, we can clearly see that there is a column ‘Rua’.
Also, if I print(delivery.Rua) I get a proper result:
82671 R JUDITE MELO DOS SANTOS
817797 R DOS GUAJAJARAS
180081 AV MARCOS PENTEADO DE ULHOA RODRIGUES
149373 AL MARIA TEREZA
455511 AV RANGEL PESTANA
...
Even if I write «if ‘Rua’ in delivery.columns: print(‘here I am’)» it does print the ‘here I am’. So ‘Rua’ is in fact there.
Well, in the immediate line after I have this code:
delivery=delivery.set_index('cnpj')[['Razão_social','Nome_Fantasia','Data_fundação','CEP','Estado','Cidade','Bairro','Rua','Número','Complemento_endereço','Telefone','email','Capital_Social', 'CNAE', '#CNAE', 'Natureza_Jurídica','Pessoas' ]]
And voilá, I get this weird error:
Traceback (most recent call last):
File "/file.py", line 45, in <module>
'Telefone', 'email', 'Capital_Social', 'Cidade', 'Estado',
'Razão_social', 'name_bairro', 'Natureza_Jurídica', 'CNAE', '#CNAE',
'Telefone','email','Capital_Social', 'CNAE', '#CNAE', 'Natureza_Jurídica','Pessoas' ]]
'CNAEs_secundários', 'Pessoas', 'percent'],
File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/pandas/core/frame.py", line 1991, in __getitem__
dtype='object')
return self._getitem_array(key)
File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/pandas/core/frame.py", line 2035, in _getitem_array
indexer = self.ix._convert_to_indexer(key, axis=1)
File "/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/pandas/core/indexing.py", line 1214, in _convert_to_indexer
raise KeyError('%s not in index' % objarr[mask])
KeyError: "['Rua'] not in index"
Can someone help? I tried stackoverflow but no one could help. I’m starting to think I’m crazy and ‘Rua’ is an illusion of my troubled mind.
ADDITIONAL INFO
I’m using this code right before the error line:
delivery=pd.DataFrame()
for i in selection.index:
sample=groups.get_group(selection['#CNAE'].loc[i]).sample(selection['samples'].loc[i])
delivery=pd.concat((delivery,sample)).sort_values('Capital_Social',ascending=False)
print(delivery.columns)
print(delivery.Rua)
print(delivery.set_index('cnpj').columns)
delivery=delivery.set_index('cnpj')[['Razão_social','Nome_Fantasia','Data_fundação','CEP','Estado','Cidade','Bairro','Rua','Número','Complemento_endereço',
'Telefone','email','Capital_Social', 'CNAE', '#CNAE', 'Natureza_Jurídica','Pessoas' ]]
EDIT
New weird stuff:
I gave up and deleted ‘Rua’ from that last piece of code, wishing that it would work. For my surprise, I had the same problem but now with the column ‘Número’.
delivery=delivery.set_index('cnpj')[['Razão_social','Nome_Fantasia','Data_fundação','CEP','Estado','Cidade','Bairro','Número','Complemento_endereço',
'Telefone','email','Capital_Social', 'CNAE', '#CNAE', 'Natureza_Jurídica' ]]
KeyError: "['Número'] not in index"
EDIT 2
And then I gave up on ‘Número’ and took it out. Then the same problem happened with ‘Complemento_endereço’. Then I deleted ‘Complemento_endereço’. And it happend to ‘Telefone’ and so on.
** EDIT 3 **
If I do a pd.show_versions(), that’s the output:
INSTALLED VERSIONS
commit: None
python: 3.5.0.final.0
python-bits: 64
OS: Darwin
OS-release: 16.5.0
machine: x86_64
processor: i386
byteorder: little
LC_ALL: None
LANG: None
pandas: 0.18.1
nose: None
pip: 8.1.2
setuptools: 18.2
Cython: None
numpy: 1.11.0
scipy: 0.17.1
statsmodels: 0.6.1
xarray: None
IPython: None
sphinx: None
patsy: 0.4.1
dateutil: 2.5.3
pytz: 2016.4
blosc: None
bottleneck: None
tables: None
numexpr: None
matplotlib: 1.5.1
openpyxl: None
xlrd: 1.0.0
xlwt: None
xlsxwriter: None
lxml: None
bs4: 4.5.1
html5lib: None
httplib2: None
apiclient: None
sqlalchemy: 1.1.3
pymysql: 0.7.11.None
psycopg2: None
jinja2: None
boto: None
pandas_datareader: None
None
xtrain is a numpy array
from sklearn.linear_model import LogisticRegression
outer_kfold = KFold(n_splits=5, random_state=27, shuffle=True)
final_scores = list()
for train, test in outer_kfold.split(xtrain):
x_train, x_test = xtrain[train], xtrain[test]
y_train, y_test = ytrain[train], ytest[test]
model=LogisticRegression()
model.fit(x_train, y_train)
preds = model.predict(x_test)
final_scores.append(accuracy_score(y_test, preds))
print("Score:", final_scores[-1])
print("nAverage Score:", np.average(final_scores))
model=LogisticRegression()
model.fit(x_train, y_train)
preds = model.predict(x_test)
final_scores.append(accuracy_score(y_test, preds))
print("Score:", final_scores[-1])
print("nAverage Score:", np.average(final_scores))
Error
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
/var/folders/vd/lb0gkn7j2t34s4ljbgdb7g5r0000gn/T/ipykernel_1376/2946208749.py in <module>
5 for train, test in outer_kfold.split(xtrain):
6 x_train, x_test = xtrain[train], xtrain[test]
----> 7 y_train, y_test = ytrain[train], ytest[test]
8
9 model=LogisticRegression()
/opt/homebrew/Caskroom/miniforge/base/envs/tensorflow/lib/python3.9/site-packages/pandas/core/series.py in __getitem__(self, key)
964 return self._get_values(key)
965
--> 966 return self._get_with(key)
967
968 def _get_with(self, key):
/opt/homebrew/Caskroom/miniforge/base/envs/tensorflow/lib/python3.9/site-packages/pandas/core/series.py in _get_with(self, key)
999 # (i.e. self.iloc) or label-based (i.e. self.loc)
1000 if not self.index._should_fallback_to_positional():
-> 1001 return self.loc[key]
1002 else:
1003 return self.iloc[key]
/opt/homebrew/Caskroom/miniforge/base/envs/tensorflow/lib/python3.9/site-packages/pandas/core/indexing.py in __getitem__(self, key)
929
930 maybe_callable = com.apply_if_callable(key, self.obj)
--> 931 return self._getitem_axis(maybe_callable, axis=axis)
932
933 def _is_scalar_access(self, key: tuple):
/opt/homebrew/Caskroom/miniforge/base/envs/tensorflow/lib/python3.9/site-packages/pandas/core/indexing.py in _getitem_axis(self, key, axis)
1151 raise ValueError("Cannot index with multidimensional key")
1152
-> 1153 return self._getitem_iterable(key, axis=axis)
1154
1155 # nested tuple slicing
/opt/homebrew/Caskroom/miniforge/base/envs/tensorflow/lib/python3.9/site-packages/pandas/core/indexing.py in _getitem_iterable(self, key, axis)
1091
1092 # A collection of keys
-> 1093 keyarr, indexer = self._get_listlike_indexer(key, axis)
1094 return self.obj._reindex_with_indexers(
1095 {axis: [keyarr, indexer]}, copy=True, allow_dups=True
/opt/homebrew/Caskroom/miniforge/base/envs/tensorflow/lib/python3.9/site-packages/pandas/core/indexing.py in _get_listlike_indexer(self, key, axis)
1312 keyarr, indexer, new_indexer = ax._reindex_non_unique(keyarr)
1313
-> 1314 self._validate_read_indexer(keyarr, indexer, axis)
1315
1316 if needs_i8_conversion(ax.dtype) or isinstance(
/opt/homebrew/Caskroom/miniforge/base/envs/tensorflow/lib/python3.9/site-packages/pandas/core/indexing.py in _validate_read_indexer(self, key, indexer, axis)
1375
1376 not_found = list(ensure_index(key)[missing_mask.nonzero()[0]].unique())
-> 1377 raise KeyError(f"{not_found} not in index")
1378
1379
KeyError: '[7, 39, 44, 45, 54, 58, 74, 79, 82, 90, 94, 98, 99, 103, 108, 115, 116, 119, 130, 134, 147, 157, 159, 161, 177, 186, 188, 192, 201, 203, 217, 218, 219, 220, 229, 231, 234, 239, 248, 250, 254, 273, 276, 285, 288, 291, 299, 301, 305, 307, 308, 313, 314, 321, 324, 325, 331, 342, 343, 345, 347, 354, 368, 372, 386, 394, 407, 413, 433, 438, 442, 447, 448, 462, 470, 481, 487, 496, 503, 507, 513, 517, 536, 538, 545, 554, 558, 559, 569, 573, 574, 587, 589, 592, 596, 599, 602, 605, 607, 608, 623, 627, 634, 642, 644, 650, 654, 662, 664, 666, 675, 687, 691, 705, 712, 714, 716, 717, 718, 724, 729, 755, 758, 761, 781, 783, 793, 802, 813, 822, 823, 847, 858, 859, 863, 867, 871, 874, 895, 900, 911, 925, 941, 946, 951, 955, 958, 961, 963, 968, 975, 982, 995, 1002, 1005, 1028, 1038, 1041, 1049, 1050, 1051, 1060, 1063, 1070, 1071, 1073, 1075, 1089, 1117, 1122, 1139, 1144, 1145, 1153, 1155, 1156, 1159, 1160, 1162, 1167, 1169, 1172, 1177, 1178, 1183, 1190, 1197, 1198, 1213, 1217, 1221, 1224, 1225, 1227, 1233, 1253, 1256, 1262, 1264, 1266, 1271, 1282, 1287, 1288, 1289, 1297, 1299, 1305, 1307, 1308, 1322, 1328, 1331, 1332, 1342, 1347, 1356, 1373, 1380, 1392, 1406, 1409, 1416, 1422, 1447, 1454, 1458, 1463, 1494, 1508, 1513, 1519, 1520, 1525, 1532, 1534, 1536, 1540, 1544, 1550, 1554, 1564, 1578, 1604, 1614, 1620, 1624, 1628, 1652, 1657, 1664, 1676, 1682, 1683, 1685, 1686, 1692, 1703, 1711, 1717, 1720, 1729, 1732, 1735, 1736, 1740, 1743, 1745, 1748, 1750, 1753, 1758, 1768, 1773, 1785, 1790, 1793, 1814, 1817, 1827, 1828, 1829, 1851, 1857, 1873, 1885, 1892, 1909, 1917, 1924, 1929, 1933, 1939, 1945, 1947, 1956, 1958, 1961, 1971, 1988, 1989, 1990, 2017, 2019, 2025, 2031, 2040, 2045, 2054, 2064, 2065, 2089, 2090, 2097, 2098, 2119, 2120, 2134, 2136, 2140, 2157, 2161, 2164, 2168, 2174, 2181, 2196, 2209, 2229, 2252, 2255, 2262, 2271, 2285, 2296, 2325, 2328, 2331, 2333, 2345, 2349, 2351, 2353, 2355, 2362, 2363, 2364, 2377, 2378, 2385, 2398, 2402, 2403, 2407, 2408, 2411, 2437, 2438, 2445, 2450, 2456, 2458, 2481, 2487, 2488, 2489, 2491, 2495, 2505, 2512, 2514, 2532, 2537, 2539, 2550, 2567, 2570, 2573, 2586, 2588, 2593, 2597, 2605, 2606, 2608, 2615, 2619, 2624, 2637, 2639, 2640, 2645, 2652, 2653, 2656, 2657, 2666, 2677, 2684, 2688, 2694, 2696, 2698, 2701, 2702, 2704, 2706, 2711, 2722, 2723, 2735, 2736, 2755, 2773, 2774, 2776, 2787, 2800, 2807, 2812, 2815, 2820, 2827, 2831, 2837, 2842, 2856, 2858, 2861, 2864, 2866, 2868, 2878, 2883, 2887, 2889, 2897, 2899, 2900, 2901, 2909, 2917, 2918, 2919, 2921, 2927, 2929, 2932, 2939, 2954, 2959, 2981, 2989, 2999, 3001, 3005, 3014, 3016, 3023, 3032, 3039, 3053, 3069, 3072, 3079, 3080, 3081, 3092, 3095, 3099, 3100, 3108, 3111, 3112, 3126, 3134, 3140, 3144, 3153, 3157, 3165, 3167, 3191, 3196, 3198, 3207, 3210, 3211, 3224, 3234, 3242, 3248, 3265, 3272, 3283, 3285, 3287, 3291, 3293, 3304, 3329, 3338, 3339, 3369, 3370, 3371, 3376, 3382, 3384, 3391, 3397, 3419, 3422, 3423, 3426, 3427, 3431, 3435, 3455, 3458, 3461, 3463, 3472, 3473, 3477, 3484, 3485, 3489, 3491, 3492, 3498, 3500, 3502, 3504, 3505, 3511, 3516, 3522, 3531, 3532, 3554, 3563, 3565, 3571, 3585, 3588, 3593, 3595, 3611, 3619, 3628, 3636, 3644, 3645, 3658, 3662, 3663, 3665, 3669, 3675, 3680, 3689, 3690, 3692, 3696, 3715, 3716, 3729, 3737, 3738, 3741, 3755, 3761, 3762, 3767, 3769, 3771, 3777, 3784, 3789, 3792, 3801, 3802, 3803, 3807, 3808, 3811, 3812, 3816, 3819, 3823, 3829, 3830, 3832, 3834, 3835, 3849, 3862, 3865, 3866, 3872, 3878, 3891, 3897, 3901, 3903, 3906, 3916, 3920, 3925, 3928, 3935, 3938, 3943, 3945, 3954, 3963, 3979, 3985, 3986, 3988, 3993, 4008, 4023, 4029, 4040, 4045, 4051, 4058, 4060, 4067, 4071, 4076, 4078, 4084, 4086, 4089, 4098, 4106, 4109, 4113, 4117, 4124, 4133, 4140, 4145, 4152, 4154, 4158, 4165, 4175, 4184, 4192, 4194, 4195, 4203, 4205, 4207, 4224, 4227, 4228, 4230, 4232, 4236, 4253, 4258, 4261, 4268, 4269, 4272, 4276, 4288, 4290, 4295, 4296, 4301, 4305, 4306, 4322, 4326, 4331, 4332, 4364, 4367, 4369, 4370, 4381, 4382, 4396, 4399, 4406, 4410, 4422, 4423, 4424, 4425, 4429, 4437, 4444, 4445, 4446, 4460, 4462, 4464, 4479, 4481, 4482, 4484, 4486, 4487, 4492, 4495, 4497, 4503, 4510, 4514, 4520, 4530, 4544, 4546, 4556, 4557, 4558, 4563, 4569, 4571, 4575, 4576, 4583, 4586, 4589, 4591, 4594, 4599, 4613, 4621, 4627, 4629, 4636, 4646, 4649, 4652, 4656, 4661, 4673, 4678, 4679, 4685, 4688, 4695, 4698, 4705, 4706, 4708, 4714, 4727, 4728, 4732, 4736, 4737, 4741, 4744, 4748, 4757, 4760, 4797, 4844, 4846, 4848, 4859, 4870, 4874, 4888, 4897, 4907, 4914, 4925, 4926, 4928, 4932, 4939, 4951, 4953, 4954, 4958, 4964, 4966, 4976, 4977, 4980, 4983, 4984, 4992, 5005, 5013, 5014, 5021, 5041, 5042, 5051, 5053, 5063, 5065, 5066, 5069, 5073, 5078, 5080, 5083, 5084, 5089, 5090, 5112, 5114, 5116, 5118, 5137, 5142, 5160, 5163, 5173, 5180, 5189, 5196, 5198, 5206, 5207, 5210, 5211, 5216, 5221, 5224, 5232, 5234, 5240, 5241, 5243, 5244, 5247, 5260, 5261, 5265, 5281, 5282, 5289, 5290, 5301, 5309, 5311, 5316, 5319, 5323, 5328, 5329, 5345, 5347, 5355, 5364, 5365, 5368, 5375, 5376, 5388, 5389, 5402, 5407, 5408, 5414, 5418, 5430, 5433, 5438, 5443, 5451, 5455, 5460, 5461, 5476, 5477, 5478, 5483, 5487, 5488, 5492, 5493, 5495, 5509, 5513, 5522, 5531, 5535, 5549, 5552, 5555, 5557, 5558, 5564, 5570, 5583, 5590, 5592, 5599, 5603, 5604, 5615, 5629, 5638, 5640, 5641, 5644, 5648, 5651, 5668, 5669, 5676, 5680, 5682, 5684, 5689, 5699, 5727, 5729, 5735, 5736, 5738, 5748, 5756, 5757, 5761, 5764, 5765, 5774, 5792, 5793, 5796, 5799, 5803, 5817, 5822, 5824, 5832, 5833, 5838, 5872, 5877, 5878, 5887, 5888, 5899, 5910, 5915, 5916, 5921, 5944, 5946, 5950, 5959, 5987, 5989, 5991, 5992, 5993, 5996, 6005, 6012, 6013, 6021, 6027, 6034, 6037, 6042, 6046, 6049, 6054, 6055, 6058, 6061, 6063, 6064, 6070, 6075, 6077, 6083, 6087, 6091, 6102, 6117, 6126, 6129, 6137, 6147, 6149, 6160, 6168, 6170, 6181, 6184, 6189, 6190, 6191, 6192, 6200, 6211, 6213, 6215, 6219, 6228, 6233, 6238, 6240, 6252, 6257, 6260, 6262, 6274, 6275, 6279, 6280, 6302, 6303, 6305, 6315, 6335, 6364, 6366, 6368, 6377, 6384, 6385, 6386, 6392, 6397, 6404, 6418, 6426, 6442, 6446, 6450, 6453] not in index'
У меня есть следующий код,
df = pd.read_csv(CsvFileName)
p = df.pivot_table(index=['Hour'], columns='DOW', values='Changes', aggfunc=np.mean).round(0)
p.fillna(0, inplace=True)
p[["1Sun", "2Mon", "3Tue", "4Wed", "5Thu", "6Fri", "7Sat"]] = p[["1Sun", "2Mon", "3Tue", "4Wed", "5Thu", "6Fri", "7Sat"]].astype(int)
Он всегда работал до тех пор, пока в csv-файле недостаточно покрытия (для всех дней недели). Например, со следующим файлом .csv,
DOW,Hour,Changes
4Wed,01,237
3Tue,07,2533
1Sun,01,240
3Tue,12,4407
1Sun,09,2204
1Sun,01,240
1Sun,01,241
1Sun,01,241
3Tue,11,662
4Wed,01,4
2Mon,18,4737
1Sun,15,240
2Mon,02,4
6Fri,01,1
1Sun,01,240
2Mon,19,2300
2Mon,19,2532
Я получу следующую ошибку:
KeyError: "['5Thu' '7Sat'] not in index"
Кажется, что это очень легко исправить, но я слишком плохо знаком с Python, чтобы знать, как это исправить.
3 ответа
Лучший ответ
Используйте reindex, чтобы получить все столбцы вам нужны. Он сохранит те, которые уже есть, и в противном случае будет помещен в пустые столбцы
p = p.reindex(columns=['1Sun', '2Mon', '3Tue', '4Wed', '5Thu', '6Fri', '7Sat'])
Итак, весь ваш пример кода должен выглядеть так:
df = pd.read_csv(CsvFileName)
p = df.pivot_table(index=['Hour'], columns='DOW', values='Changes', aggfunc=np.mean).round(0)
p.fillna(0, inplace=True)
columns = ["1Sun", "2Mon", "3Tue", "4Wed", "5Thu", "6Fri", "7Sat"]
p = p.reindex(columns=columns)
p[columns] = p[columns].astype(int)
26
nbro
7 Дек 2018 в 10:19
Я была такая же проблема.
Во время первой разработки я использовал файл .csv (запятую как разделитель), который я немного изменил перед сохранением. После сохранения запятые стали точкой с запятой.
В Windows это зависит от экрана настройки «Язык и региональные стандарты», где вы найдете разделитель списка. Это символьные приложения Windows, ожидающие быть разделителем CSV.
При тестировании из совершенно нового файла я столкнулся с этой проблемой.
Я удалил аргумент ‘sep’ в методе read_csv раньше:
df1 = pd.read_csv('myfile.csv', sep=',');
После:
df1 = pd.read_csv('myfile.csv');
Таким образом, проблема исчезла.
0
Emma
2 Авг 2019 в 15:36
У меня была очень похожая проблема. Я получил ту же ошибку, потому что CSV содержал пробелы в заголовке. Мой CSV содержал заголовок «Пол», и он был указан как:
[['Gender']]
Если вам достаточно легко получить доступ к CSV, вы можете использовать формулу Excel trim(), чтобы обрезать любые пробелы в ячейках.
Или удали это так
df.columns = df.columns.to_series().apply(lambda x: x.strip())
12
diimdeep
10 Май 2018 в 14:24
Improve Article
Save Article
Like Article
Improve Article
Save Article
Like Article
In this article, we will discuss how to fix the KeyError in pandas. Pandas KeyError occurs when we try to access some column/row label in our DataFrame that doesn’t exist. Usually, this error occurs when you misspell a column/row name or include an unwanted space before or after the column/row name.
The link to dataset used is here
Example
Python3
import pandas as pd
df = pd.read_csv('data.csv')
Output:
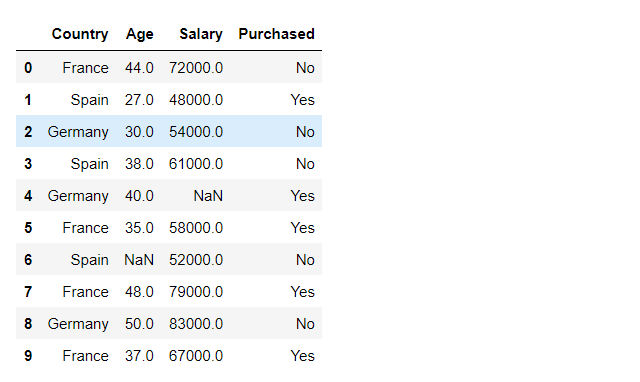
Reproducing keyError :
Python3
output:
KeyError: 'country'
Since there is no column with the name country we get a KeyError.
How to Fix the KeyError?
We can simply fix the error by correcting the spelling of the key. If we are not sure about the spelling we can simply print the list of all column names and crosscheck.
Python3
print(df.columns.tolist())
Output:
['Country', 'Age', 'Salary', 'Purchased']
Using the Correct Spelling of the Column
Python3
Output:
0 France 1 Spain 2 Germany 3 Spain 4 Germany 5 France 6 Spain 7 France 8 Germany 9 France Name: Country, dtype: object
If we want to avoid errors raised by the compiler when an invalid key is passed, we can use df.get(‘your column’) to print column value. No error is raised if the key is invalid.
Syntax : DataFrame.get( ‘column_name’ , default = default_value_if_column_is_not_present)
Python3
df.get('country', default="no_country")
Output:
'no_country'
But when we will use correct spelling we will get the value of the column instead of the default value.
Python3
df.get('Country', default="no_country")
Output:
0 France 1 Spain 2 Germany 3 Spain 4 Germany 5 France 6 Spain 7 France 8 Germany 9 France Name: Country, dtype: object
Last Updated :
28 Nov, 2021
Like Article
Save Article