
Рад снова всех приветствовать, и сегодня продолжим планомерно двигаться в выбранном направлении. Речь, конечно, о масштабном разборе искусственных нейронных сетей для решения широкого спектра задач. Продолжим ровно с того момента, на котором остановились в предыдущей части, и это означает, что героем данного поста будет ключевой процесс — обучение нейронных сетей.
- Градиентный спуск
- Функция ошибки
- Метод обратного распространения ошибки
- Пример расчета
Тема эта крайне важна, поскольку именно процесс обучения позволяет сети начать выполнять задачу, для которой она, собственно, и предназначена. То есть нейронная сеть функционирует не по какому-либо жестко заданному на этапе проектирования алгоритму, она совершенствуется в процессе анализа имеющихся данных. Этот процесс и называется обучением нейронной сети. Математически суть процесса обучения заключается в корректировке значений весов синапсов (связей между имеющимися нейронами). Изначально значения весов задаются случайно, затем производится обучение, результатом которого будут новые значения синаптических весов. Это все мы максимально подробно разберем как раз в этой статье.
На своем сайте я всегда придерживаюсь концепции, при которой теоретические выкладки по максимуму сопровождаются практическими примерами для максимальной наглядности. Так мы поступим и сейчас 👍
Итак, суть заключается в следующем. Пусть у нас есть простейшая нейронная сеть, которую мы хотим обучить (продолжаем рассматривать сети прямого распространения):

То есть на входы нейронов I1 и I2 мы подаем какие-либо числа, а на выходе сети получаем соответственно новое значение. При этом нам необходима некая выборка данных, включающая в себя значения входов и соответствующее им, правильное, значение на выходе:
| bold{I_1} | bold{I_2} | bold{O_{net}} |
|---|---|---|
| x_{11} | x_{12} | y_{1} |
| x_{21} | x_{22} | y_{2} |
| x_{31} | x_{32} | y_{3} |
| … | … | … |
| x_{N1} | x_{N2} | y_{N} |
Допустим, сеть выполняет суммирование значений на входе, тогда данный набор данных может быть таким:
| bold{I_1} | bold{I_2} | bold{O_{net}} |
|---|---|---|
| 1 | 4 | 5 |
| 2 | 7 | 9 |
| 3 | 5 | 8 |
| … | … | … |
| 1000 | 1500 | 2500 |
Эти значения и используются для обучения сети. Как именно — рассмотрим чуть ниже, пока сконцентрируемся на идее процесса в целом. Для того, чтобы иметь возможность тестировать работу сети в процессе обучения, исходную выборку данных делят на две части — обучающую и тестовую. Пусть имеется 1000 образцов, тогда можно 900 использовать для обучения, а оставшиеся 100 — для тестирования. Эти величины взяты исключительно ради наглядности и демонстрации логики выполнения операций, на практике все зависит от задачи, размер обучающей выборки может спокойно достигать и сотен тысяч образцов.
Итак, итог имеем следующий — обучающая выборка прогоняется через сеть, в результате чего происходит настройка значений синаптических весов. Один полный проход по всей выборке называется эпохой. И опять же, обучение нейронной сети — это процесс, требующий многократных экспериментов, анализа результатов и творческого подхода. Все перечисленные параметры (размер выборки, количество эпох обучения) могут иметь абсолютно разные значения для разных задач и сетей. Четкого правила тут просто нет, в этом и кроется дополнительный шарм и изящность )
Возвращаемся к разбору, и в результате прохода обучающей выборки через сеть мы получаем сеть с новыми значениями весов синапсов.
Далее мы через эту, уже обученную в той или иной степени, сеть прогоняем тестовую выборку, которая не участвовала в обучении. При этом сеть выдает нам выходные значения для каждого образца, которые мы сравниваем с теми верными значениями, которые имеем.
Анализируем нашу гипотетическую выборку:

Таким образом, для тестирования подаем на вход сети значения x_{(M+1)1}, x_{(M+1)2} и проверяем, чему равен выход, ожидаем очевидно значение y_{(M+1)}. Аналогично поступаем и для оставшихся тестовых образцов. После чего мы можем сделать вывод, успешно или нет работает сеть. Например, сеть дает правильный ответ для 90% тестовых данных, дальше уже встает вопрос — устраивает ли нас данная точность или процесс обучения необходимо повторить, либо провести заново, изменив какие-либо параметры сети.
В этом и заключается суть обучения нейронных сетей, теперь перейдем к деталям и конкретным действиям, которые необходимо осуществить для выполнения данного процесса. Двигаться снова будем поэтапно, чтобы сформировать максимально четкую и полную картину. Поэтому начнем с понятия градиентного спуска, который используется при обучении по методу обратного распространения ошибки. Обо всем этом далее…
Обучение нейронных сетей. Градиентный спуск.
Рассмотрев идею процесса обучения в целом, на данном этапе мы можем однозначно сформулировать текущую цель — необходимо определить математический алгоритм, который позволит рассчитать значения весовых коэффициентов таким образом, чтобы ошибка сети была минимальна. То есть грубо говоря нам необходима конкретная формула для вычисления:
Здесь Delta w_{ij} — величина, на которую необходимо изменить вес синапса, связывающего нейроны i и j нашей сети. Соответственно, зная это, необходимо на каждом этапе обучения производить корректировку весов связей между всеми элементами нейронной сети. Задача ясна, переходим к делу.
Пусть функция ошибки от веса имеет следующий вид:
Для удобства рассмотрим зависимость функции ошибки от одного конкретного веса:

В начальный момент мы находимся в некоторой точке кривой, а для минимизации ошибки попасть мы хотим в точку глобального минимума функции:
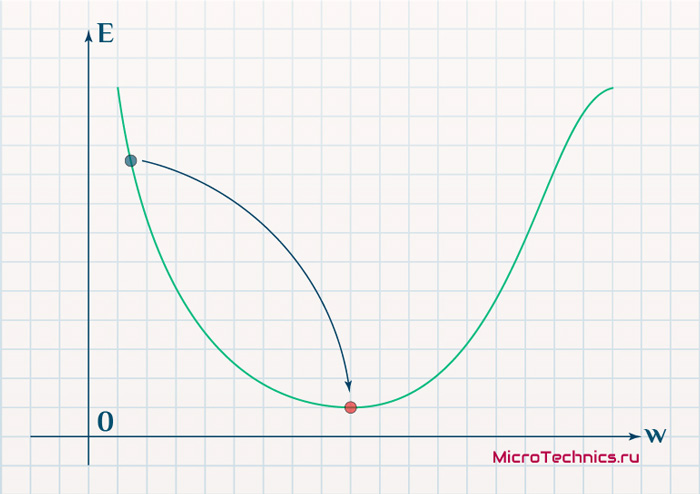
Нанесем на график вектора градиентов в разных точках. Длина векторов численно равна скорости роста функции в данной точке, что в свою очередь соответствует значению производной функции по данной точке. Исходя из этого, делаем вывод, что длина вектора градиента определяется крутизной функции в данной точке:
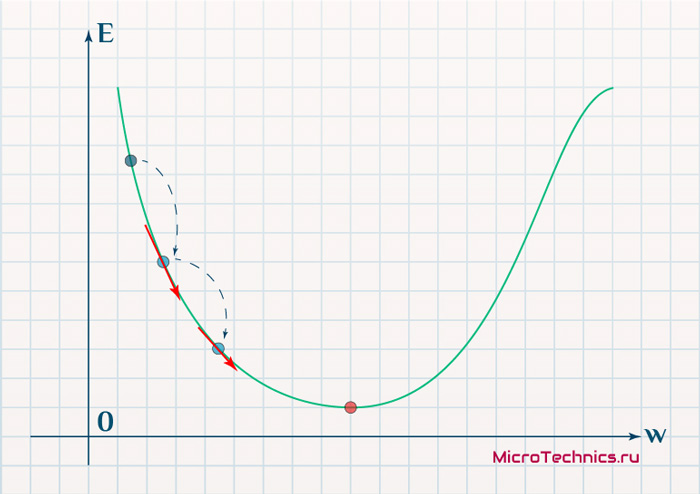
Вывод прост — величина градиента будет уменьшаться по мере приближения к минимуму функции. Это важный вывод, к которому мы еще вернемся. А тем временем разберемся с направлением вектора, для чего рассмотрим еще несколько возможных точек:
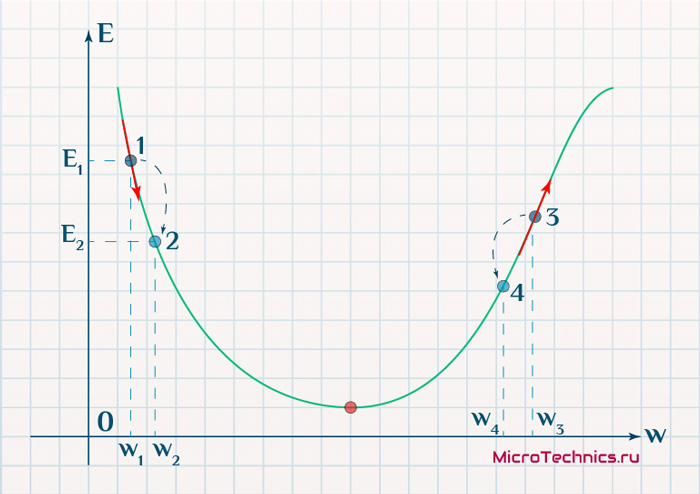
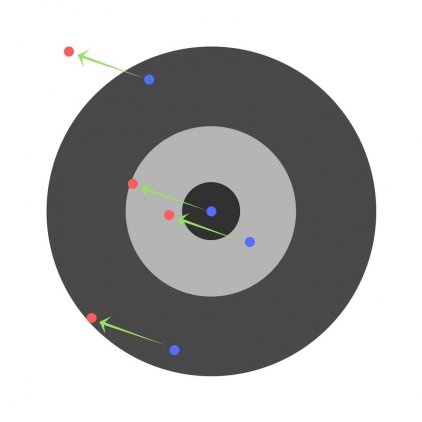
Находясь в точке 1, целью является перейти в точку 2, поскольку в ней значение ошибки меньше (E_2 < E_1), а глобальная задача по-прежнему заключается в ее минимизации. Для этого необходимо изменить величину w на некое значение Delta w (Delta w = w_2 — w_1 > 0). При всем при этом в точке 1 градиент отрицательный. Фиксируем данные факты и переходим к точке 3, предположим, что мы находимся именно в ней.
Тогда для уменьшения ошибки наш путь лежит в точку 4, а необходимое изменение значения: Delta w = w_4 — w_3 < 0. Градиент же в точке 3 положителен. Этот факт также фиксируем.
А теперь соберем воедино эту информацию в виде следующей иллюстрации:
| Переход | bold{Delta w} | Знак bold{Delta w} | Градиент |
|---|---|---|---|
| 1 rArr 2 | w_2 — w_1 | + | — |
| 3 rArr 4 | w_4 — w_3 | — | + |
Вывод напрашивается сам собой — величина, на которую необходимо изменить значение w, в любой точке противоположна по знаку градиенту. И, таким образом, представим эту самую величину в виде:
Delta w = -alpha cdot frac{dE}{dw}
Имеем в наличии:
- Delta w — величина, на которую необходимо изменить значение w.
- frac{dE}{dw} — градиент в этой точке.
- alpha — скорость обучения.
Собственно, логика метода градиентного спуска и заключается в данном математическом выражении, а именно в том, что для минимизации ошибки необходимо изменять w в направлении противоположном градиенту. В контексте нейронных сетей имеем искомый закон для корректировки весов синаптических связей (для синапса между нейронами i и j):
Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}}
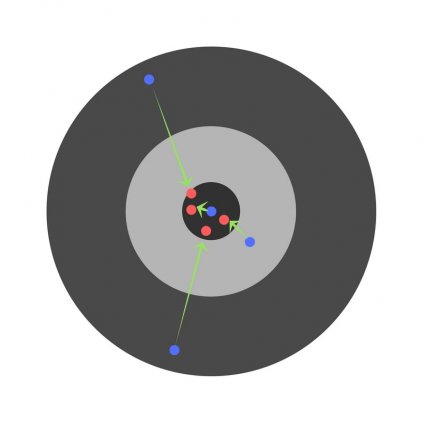
Более того, вспомним о важном свойстве, которое мы отдельно пометили. И заключается оно в том, что величина градиента будет уменьшаться по мере приближения к минимуму функции. Что это нам дает? А то, что в том случае, если наша текущая дислокация далека от места назначения, то величина, корректирующая вес связи, будет больше. А это обеспечит скорейшее приближение к цели. При приближении к целевому пункту, величина frac{dE}{dw_{ij}} будет уменьшаться, что поможет нам точнее попасть в нужную точку, а кроме того, не позволит нам ее проскочить. Визуализируем вышеописанное:
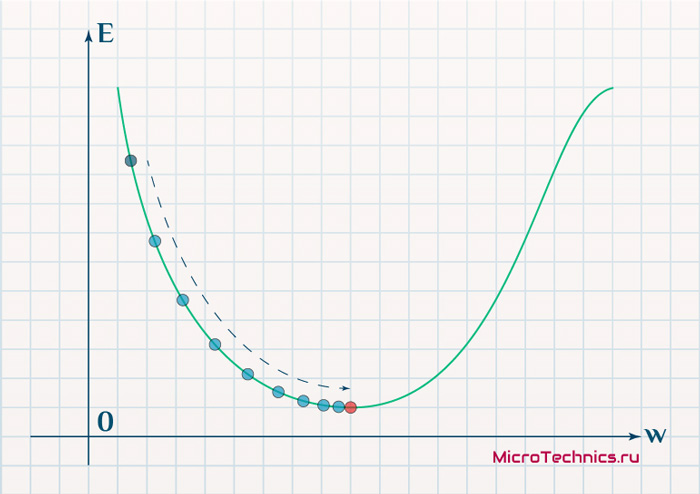
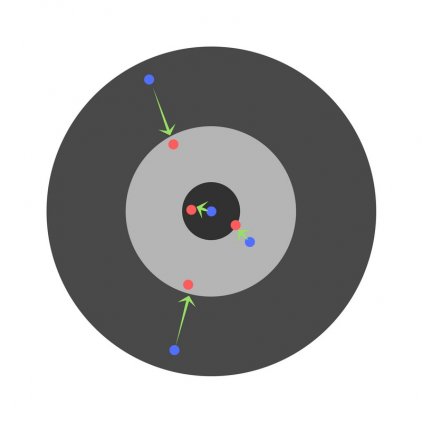
Скорость же обучения несет в себе следующий смысл. Она определяет величину каждого шага при поиске минимума ошибки. Слишком большое значение приводит к тому, что точка может «перепрыгнуть» через нужное значение и оказаться по другую сторону от цели:
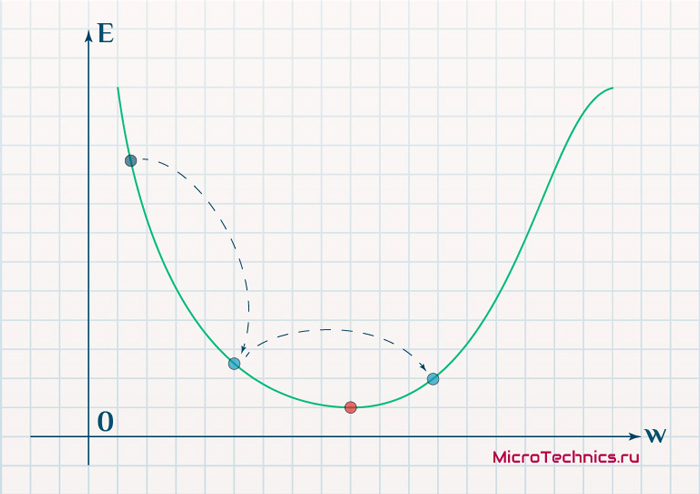
Если же величина будет мала, то это приведет к тому, что спуск будет осуществляться очень медленно, что также является нежелательным эффектом. Поэтому скорость обучения, как и многие другие параметры нейронной сети, является очень важной величиной, для которой нет единственно верного значения. Все снова зависит от конкретного случая и оптимальная величина определяется исключительно исходя из текущих условий.
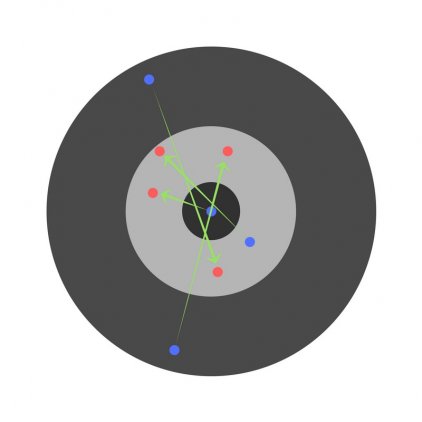
И даже на этом еще не все, здесь присутствует один важный нюанс, который в большинстве статей опускается, либо вовсе не упоминается. Реальная зависимость может иметь совсем другой вид:
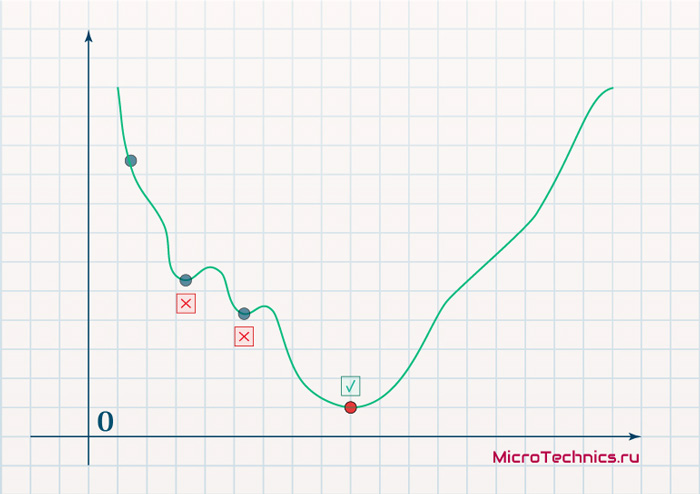
Из чего вытекает потенциальная возможность попадания в локальный минимум, вместо глобального, что является большой проблемой. Для предотвращения данного эффекта вводится понятие момента обучения и формула принимает следующий вид:
Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}} + gamma cdot Delta w_{ij}^{t - 1}
То есть добавляется второе слагаемое, которое представляет из себя произведение момента на величину корректировки веса на предыдущем шаге.
Итого, резюмируем продвижение к цели:
- Нашей задачей было найти закон, по которому необходимо изменять величину весов связей между нейронами.
- Наш результат — Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}} + gamma cdot Delta w_{ij}^{t — 1} — именно то, что и требовалось 👍
И опять же, полученный результат логичным образом перенаправляет нас на следующий этап, ставя вопросы — что из себя представляет функция ошибки, и как определить ее градиент.
Обучение нейронных сетей. Функция ошибки.
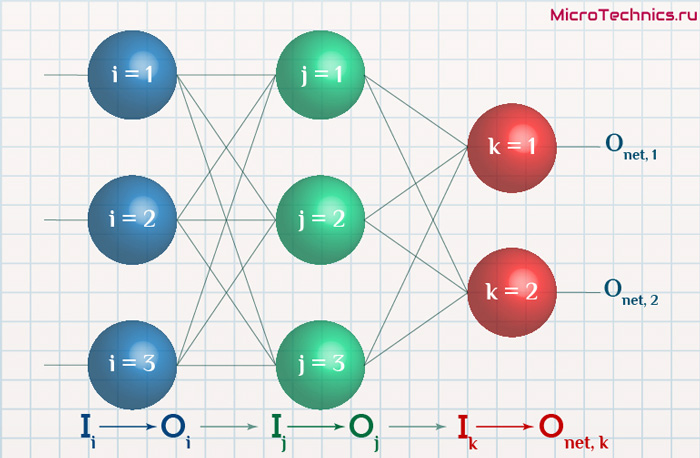
Начнем с того, что определимся с тем, что у нас в наличии, для этого вернемся к конкретной нейронной сети. Пусть вид ее таков:
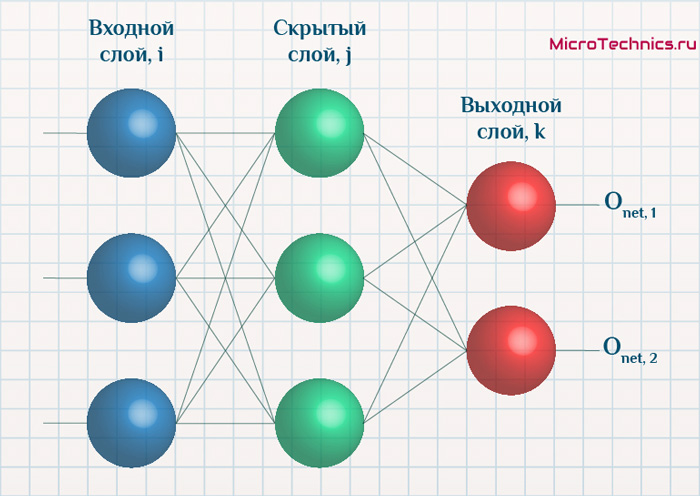
Интересует нас, в первую очередь, часть, относящаяся к нейронам выходного слоя. Подав на вход определенные значения, получаем значения на выходе сети: O_{net, 1} и O_{net, 2}. Кроме того, поскольку мы ведем речь о процессе обучения нейронной сети, то нам известны целевые значения: O_{correct, 1} и O_{correct, 2}. И именно этот набор данных на этом этапе является для нас исходным:
- Известно: O_{net, 1}, O_{net, 2}, O_{correct, 1} и O_{correct, 2}.
- Необходимо определить величины Delta w_{ij} для корректировки весов, для этого нужно вычислить градиенты (frac{dE}{dw_{ij}}) для каждого из синапсов.
Полдела сделано — задача четко сформулирована, начинаем деятельность по поиску решения.
В плане того, как определять ошибку, первым и самым очевидным вариантом кажется простая алгебраическая разность. Для каждого из выходных нейронов:
E_k = O_{correct, k} - O_{net, k}
Дополним пример числовыми значениями:
| Нейрон | bold{O_{net}} | bold{O_{correct}} | bold{E} |
|---|---|---|---|
| 1 | 0.9 | 0.5 | -0.4 |
| 2 | 0.2 | 0.6 | 0.4 |
Недостатком данного варианта является то, что в том случае, если мы попытаемся просуммировать ошибки нейронов, то получим:
E_{sum} = e_1 + e_2 = -0.4 + 0.4 = 0
Что не соответствует действительности (нулевая ошибка, говорит об идеальной работе нейронной сети, по факту оба нейрона дали неверный результат). Так что вариант с разностью откидываем за несостоятельностью.
Вторым, традиционно упоминаемым, методом вычисления ошибки является использование модуля разности:
E_k = | O_{correct, k} - O_{net, k} |
Тут в действие вступает уже проблема иного рода:
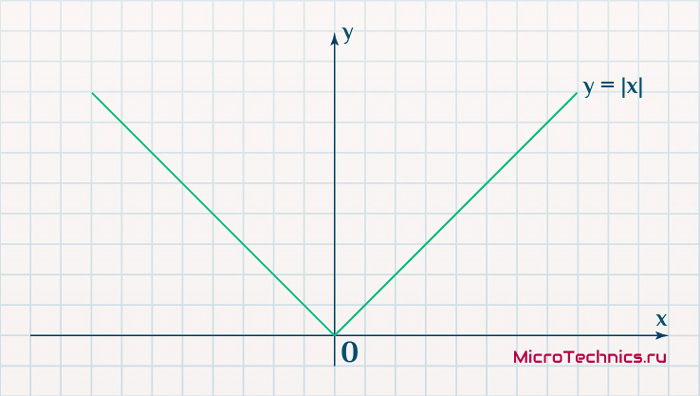
Функция, бесспорно, симпатична, но при приближении к минимуму ее градиент является постоянной величиной, скачкообразно меняясь при переходе через точку минимума. Это нас также не устраивает, поскольку, как мы обсуждали, концепция заключалась в том числе в том, чтобы по мере приближения к минимуму значение градиента уменьшалось.
В итоге хороший результат дает зависимость (для выходного нейрона под номером k):
E_k = (O_{correct, k} - O_{net, k})^2
Функция по многим своим свойствам идеально удовлетворяет нуждам обучения нейронной сети, так что выбор сделан, остановимся на ней. Хотя, как и во многих аспектах, качающихся нейронных сетей, данное решение не является единственно и неоспоримо верным. В каких-то случаях лучше себя могут проявить другие зависимости, возможно, что какой-то вариант даст большую точность, но неоправданно высокие затраты производительности при обучении. В общем, непаханное поле для экспериментов и исследований, это и привлекательно.
Краткий вывод промежуточного шага, на который мы вышли:
- Имеющееся: frac{dE}{dw_{jk}} = frac{d}{d w_{jk}}(O_{correct, k} — O_{net, k})^2.
- Искомое по-прежнему: Delta w_{jk}.
Несложные диффернциально-математические изыскания выводят на следующий результат:
frac{dE}{d w_{jk}} = -(O_{correct, k} - O_{net, k}) cdot f{Large{prime}}(sum_{j}w_{jk}O_j) cdot O_j
Здесь эти самые изыскания я все-таки решил не вставлять, дабы не перегружать статью, которая и так выходит объемной. Но в случае необходимости и интереса, отпишите в комментарии, я добавлю вычисления и закину их под спойлер, как вариант.
Освежим в памяти структуру сети:
Формулу можно упростить, сгруппировав отдельные ее части:
- (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(sum_{j}w_{jk}O_j) — ошибка нейрона k.
- O_j — тут все понятно, выходной сигнал нейрона j.
f{Large{prime}}(sum_{j}w_{jk}O_j) — значение производной функции активации. Причем, обратите внимание, что sum_{j}w_{jk}O_j — это не что иное, как сигнал на входе нейрона k (I_{k}). Тогда для расчета ошибки выходного нейрона: delta_k = (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(I_k).
Итог: frac{dE}{d w_{jk}} = -delta_k cdot O_j.
Одной из причин популярности сигмоидальной функции активности является то, что ее производная очень просто выражается через саму функцию:
f{'}(x) = f(x)medspace (1medspace-medspace f(x))
Данные алгебраические вычисления справедливы для корректировки весов между скрытым и выходным слоем, поскольку для расчета ошибки мы используем просто разность между целевым и полученным результатом, умноженную на производную.
Для других слоев будут незначительные изменения, касающиеся исключительно первого множителя в формуле:
frac{dE}{d w_{ij}} = -delta_j cdot O_i
Который примет следующий вид:
delta_j = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j)
То есть ошибка для элемента слоя j получается путем взвешенного суммирования ошибок, «приходящих» к нему от нейронов следующего слоя и умножения на производную функции активации. В результате:
frac{dE}{d w_{ij}} = -(sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j) cdot O_i
Снова подводим промежуточный итог, чтобы иметь максимально полную и структурированную картину происходящего. Вот результаты, полученные нами на двух этапах, которые мы успешно миновали:
- Ошибка:
- выходной слой: delta_k = (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(I_k)
- скрытые слои: delta_j = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j)
- Градиент: frac{dE}{d w_{ij}} = -delta_j cdot O_i
- Корректировка весовых коэффициентов: Delta w_{ij} = -alpha cdot frac{dE}{dw_{ij}} + gamma cdot Delta w_{ij}^{t — 1}
Преобразуем последнюю формулу:
Delta w_{ij} = alpha cdot delta_j cdot O_i + gamma cdot Delta w_{ij}^{t - 1}
Из этого мы делаем вывод, что на данный момент у нас есть все, что необходимо для того, чтобы произвести обучение нейронной сети. И героем следующего подраздела будет алгоритм обратного распространения ошибки.
Метод обратного распространения ошибки.
Данный метод является одним из наиболее распространенных и популярных, чем и продиктован его выбор для анализа и разбора. Алгоритм обратного распространения ошибки относится к методам обучение с учителем, что на деле означает необходимость наличия целевых значений в обучающих сетах.
Суть же метода подразумевает наличие двух этапов:
- Прямой проход — входные сигналы двигаются в прямом направлении, в результате чего мы получаем выходной сигнал, из которого в дальнейшем рассчитываем значение ошибки.
- Обратный проход — обратное распространение ошибки — величина ошибки двигается в обратном направлении, в результате происходит корректировка весовых коэффициентов связей сети.
Начальные значения весов (перед обучением) задаются случайными, есть ряд методик для выбора этих значений, я опишу в отдельном материале максимально подробно. Пока вот можно полистать — ссылка.
Вернемся к конкретному примеру для явной демонстрации этих принципов:
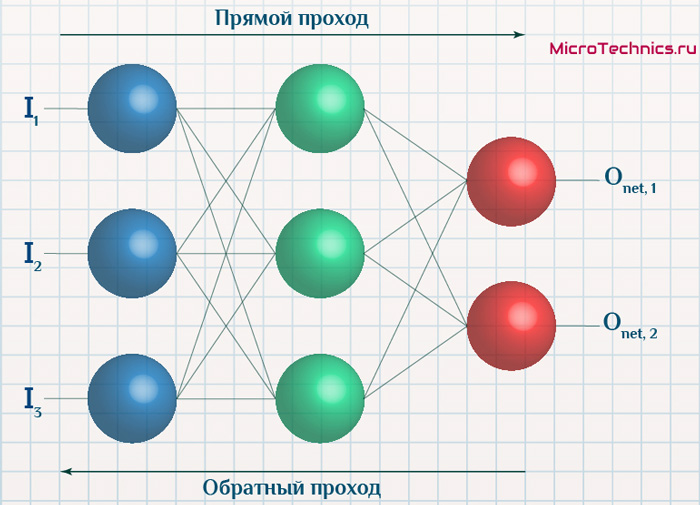
Итак, имеется нейронная сеть, также имеется набор данных обучающей выборки. Как уже обсудили в начале статьи — обучающая выборка представляет из себя набор образцов (сетов), каждый из которых состоит из значений входных сигналов и соответствующих им «правильных» значений выходных величин.
Процесс обучения нейронной сети для алгоритма обратного распространения ошибки будет таким:
- Прямой проход. Подаем на вход значения I_1, I_2, I_3 из обучающей выборки. В результате работы сети получаем выходные значения O_{net, 1}, O_{net, 2}. Этому целиком и полностью был посвящен предыдущий манускрипт.
- Рассчитываем величины ошибок для всех слоев:
- для выходного: delta_k = (O_{correct, k} — O_{net, k}) cdot f{Large{prime}}(I_k)
- для скрытых: delta_j = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_j)
- Далее используем полученные значения для расчета Delta w_{ij} = alpha cdot delta_j cdot O_i + gamma cdot Delta w_{ij}^{t — 1}
- И финишируем, рассчитывая новые значения весов: w_{ij medspace new} = w_{ij} + Delta w_{ij}
- На этом один цикл обучения закончен, данные шаги 1 — 4 повторяются для других образцов из обучающей выборки.
Обратный проход завершен, а вместе с ним и одна итерация процесса обучения нейронной сети по данному методу. Собственно, обучение в целом заключается в многократном повторении этих шагов для разных образцов из обучающей выборки. Логику мы полностью разобрали, при повторном проведении операций она остается в точности такой же.
Таким образом, максимально подробно концентрируясь именно на сути и логике процессов, мы в деталях разобрали метод обратного распространения ошибки. Поэтому переходим к завершающей части статьи, в которой разберем практический пример, произведя полностью все вычисления для конкретных числовых величин. Все в рамках продвигаемой мной концепции, что любая теоретическая информация на порядок лучше может быть осознана при применении ее на практике.
Пример расчетов для метода обратного распространения ошибки.
Возьмем нейронную сеть и зададим начальные значения весов:
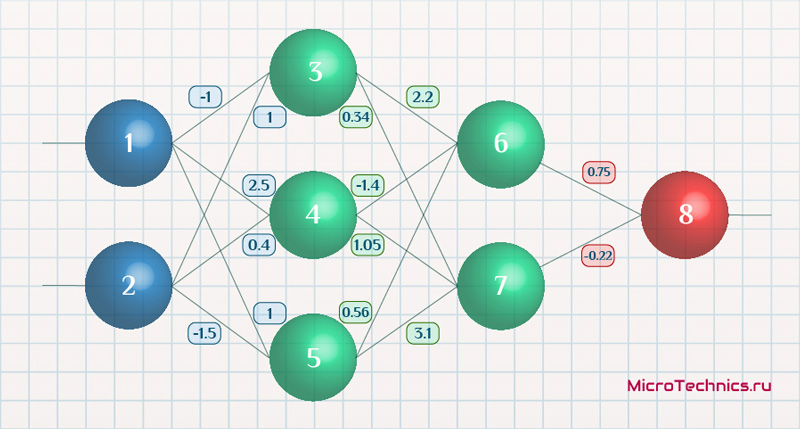
Здесь я задал значения не в соответствии с существующими на сегодняшний день методами, а просто случайным образом для наглядности примера.
В качестве функции активации используем сигмоиду:
f(x) = frac{1}{1 + e^{-x}}
И ее производная:
f{Large{prime}}(x) = f(x)medspace (1medspace-medspace f(x))
Берем один образец из обучающей выборки, пусть будут такие значения:
- Входные: I_1 = 0.6, I_1 = 0.7.
- Выходное: O_{correct} = 0.9.
Скорость обучения alpha пусть будет равна 0.3, момент — gamma = 0.1. Все готово, теперь проведем полный цикл для метода обратного распространения ошибки, то есть прямой проход и обратный.
Прямой проход.
Начинаем с выходных значений нейронов 1 и 2, поскольку они являются входными, то:
O_1 = I_1 = 0.6 \ O_2 = I_2 = 0.7
Значения на входе нейронов 3, 4 и 5:
I_3 = O_1 cdot w_{13} + O_2 cdot w_{23} = 0.6 cdot (-1medspace) + 0.7 cdot 1 = 0.1 \
I_4 = 0.6 cdot 2.5 + 0.7 cdot 0.4 = 1.78 \
I_5 = 0.6 cdot 1 + 0.7 cdot (-1.5medspace) = -0.45
На выходе этих же нейронов первого скрытого слоя:
O_3 = f(I3medspace) = 0.52 \ O_4 = 0.86\ O_5 = 0.39
Продолжаем аналогично для следующего скрытого слоя:
I_6 = O_3 cdot w_{36} + O_4 cdot w_{46} + O_5 cdot w_{56} = 0.52 cdot 2.2 + 0.86 cdot (-1.4medspace) + 0.39 cdot 0.56 = 0.158 \
I_7 = 0.52 cdot 0.34 + 0.86 cdot 1.05 + 0.39 cdot 3.1 = 2.288 \
O_6 = f(I_6) = 0.54 \
O_7 = 0.908
Добрались до выходного нейрона:
I_8 = O_6 cdot w_{68} + O_7 cdot w_{78} = 0.54 cdot 0.75 + 0.908 cdot (-0.22medspace) = 0.205 \
O_8 = O_{net} = f(I_8) = 0.551
Получили значение на выходе сети, кроме того, у нас есть целевое значение O_{correct} = 0.9. То есть все, что необходимо для обратного прохода, имеется.
Обратный проход.
Как мы и обсуждали, первым этапом будет вычисление ошибок всех нейронов, действуем:
delta_8 = (O_{correct} - O_{net}) cdot f{Large{prime}}(I_8) = (O_{correct} - O_{net}) cdot f(I_8) cdot (1-f(I_8)) = (0.9 - 0.551medspace) cdot 0.551 cdot (1-0.551medspace) = 0.0863 \
delta_7 = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_7) = (delta_8 cdot w_{78}) cdot f{Large{prime}}(I_7) = 0.0863 cdot (-0.22medspace) cdot 0.908 cdot (1 - 0.908medspace) = -0.0016 \
delta_6 = 0.086 cdot 0.75 cdot 0.54 cdot (1 - 0.54medspace) = 0.016 \
delta_5 = (sum_{k}{}{delta_kmedspace w_{jk}}) cdot f{Large{prime}}(I_5) = (delta_7 cdot w_{57} + delta_6 cdot w_{56}) cdot f{Large{prime}}(I_7) = (-0.0016 cdot 3.1 + 0.016 cdot 0.56) cdot 0.39 cdot (1 - 0.39medspace) = 0.001 \
delta_4 = (-0.0016 cdot 1.05 + 0.016 cdot (-1.4)) cdot 0.86 cdot (1 - 0.86medspace) = -0.003 \
delta_3 = (-0.0016 cdot 0.34 + 0.016 cdot 2.2) cdot 0.52 cdot (1 - 0.52medspace) = -0.0087
С расчетом ошибок закончили, следующий этап — расчет корректировочных величин для весов всех связей. Для этого мы вывели формулу:
Delta w_{ij} = alpha cdot delta_j cdot O_i + gamma cdot Delta w_{ij}^{t - 1}
Как вы помните, Delta w_{ij}^{t — 1} — это величина поправки для данного веса на предыдущей итерации. Но поскольку у нас это первый проход, то данное значение будет нулевым, соответственно, в данном случае второе слагаемое отпадает. Но забывать о нем нельзя. Продолжаем калькулировать:
Delta w_{78} = alpha cdot delta_8 cdot O_7 = 0.3 cdot 0.0863 cdot 0.908 = 0.0235 \
Delta w_{68} = 0.3 cdot 0.0863 cdot 0.54= 0.014 \
Delta w_{57} = alpha cdot delta_7 cdot O_5 = 0.3 cdot (−0.0016medspace) cdot 0.39= -0.00019 \
Delta w_{47} = 0.3 cdot (−0.0016medspace) cdot 0.86= -0.0004 \
Delta w_{37} = 0.3 cdot (−0.0016medspace) cdot 0.52= -0.00025 \
Delta w_{56} = alpha cdot delta_6 cdot O_5 = 0.3 cdot 0.016 cdot 0.39= 0.0019 \
Delta w_{46} = 0.3 cdot 0.016 cdot 0.86= 0.0041 \
Delta w_{36} = 0.3 cdot 0.016 cdot 0.52= 0.0025 \
Delta w_{25} = alpha cdot delta_5 cdot O_2 = 0.3 cdot 0.001 cdot 0.7= 0.00021 \
Delta w_{15} = 0.3 cdot 0.001 cdot 0.6= 0.00018 \
Delta w_{24} = alpha cdot delta_4 cdot O_2 = 0.3 cdot (-0.003medspace) cdot 0.7= -0.00063 \
Delta w_{14} = 0.3 cdot (-0.003medspace) cdot 0.6= -0.00054 \
Delta w_{23} = alpha cdot delta_3 cdot O_2 = 0.3 cdot (−0.0087medspace) cdot 0.7= -0.00183 \
Delta w_{13} = 0.3 cdot (−0.0087medspace) cdot 0.6= -0.00157
И самый что ни на есть заключительный этап — непосредственно изменение значений весовых коэффициентов:
w_{78 medspace new} = w_{78} + Delta w_{78} = -0.22 + 0.0235 = -0.1965 \
w_{68 medspace new} = 0.75+ 0.014 = 0.764 \
w_{57 medspace new} = 3.1 + (−0.00019medspace) = 3.0998\
w_{47 medspace new} = 1.05 + (−0.0004medspace) = 1.0496\
w_{37 medspace new} = 0.34 + (−0.00025medspace) = 0.3398\
w_{56 medspace new} = 0.56 + 0.0019 = 0.5619 \
w_{46 medspace new} = -1.4 + 0.0041 = -1.3959 \
w_{36 medspace new} = 2.2 + 0.0025 = 2.2025 \
w_{25 medspace new} = -1.5 + 0.00021 = -1.4998 \
w_{15 medspace new} = 1 + 0.00018 = 1.00018 \
w_{24 medspace new} = 0.4 + (−0.00063medspace) = 0.39937 \
w_{14 medspace new} = 2.5 + (−0.00054medspace) = 2.49946 \
w_{23 medspace new} = 1 + (−0.00183medspace) = 0.99817 \
w_{13 medspace new} = -1 + (−0.00157medspace) = -1.00157\
И на этом данную масштабную статью завершаем, конечно же, не завершая на этом деятельность по использованию нейронных сетей. Так что всем спасибо за прочтение, любые вопросы пишите в комментариях и на форуме, ну и обязательно следите за обновлениями и новыми материалами, до встречи!
Нейронная сеть — попытка с помощью математических моделей воспроизвести работу человеческого мозга для создания машин, обладающих искусственным интеллектом.
Искусственная нейронная сеть обычно обучается с учителем. Это означает наличие обучающего набора (датасета), который содержит примеры с истинными значениями: тегами, классами, показателями.
Неразмеченные наборы также используют для обучения нейронных сетей, но мы не будем здесь это рассматривать.
Например, если вы хотите создать нейросеть для оценки тональности текста, датасетом будет список предложений с соответствующими каждому эмоциональными оценками. Тональность текста определяют признаки (слова, фразы, структура предложения), которые придают негативную или позитивную окраску. Веса признаков в итоговой оценке тональности текста (позитивный, негативный, нейтральный) зависят от математической функции, которая вычисляется во время обучения нейронной сети.
Раньше люди генерировали признаки вручную. Чем больше признаков и точнее подобраны веса, тем точнее ответ. Нейронная сеть автоматизировала этот процесс.
Искусственная нейронная сеть состоит из трех компонентов:
- Входной слой;
- Скрытые (вычислительные) слои;
- Выходной слой.
Обучение нейросетей происходит в два этапа:
- Прямое распространение ошибки;
- Обратное распространение ошибки.
Во время прямого распространения ошибки делается предсказание ответа. При обратном распространении ошибка между фактическим ответом и предсказанным минимизируется.
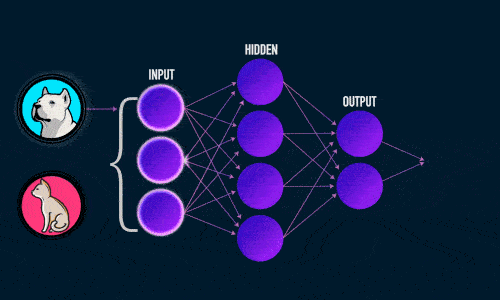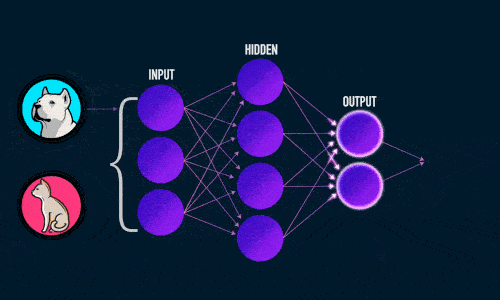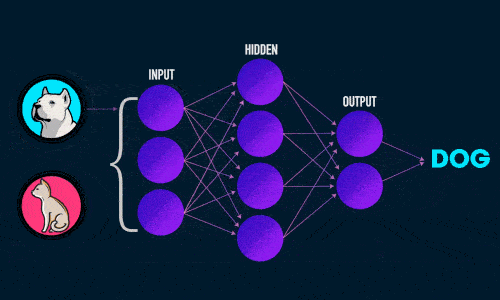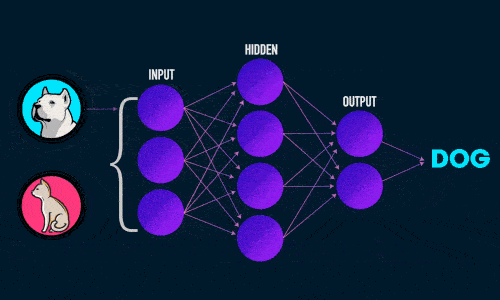
Прямое распространение ошибки
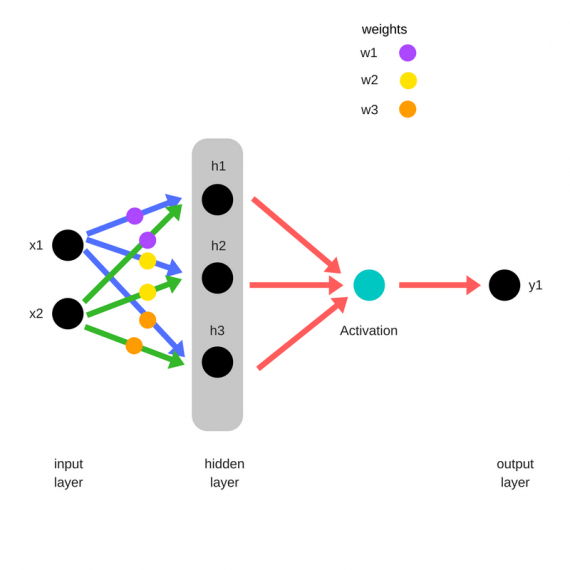
Зададим начальные веса случайным образом:
- w1
- w2
- w3
Умножим входные данные на веса для формирования скрытого слоя:
- h1 = (x1 * w1) + (x2 * w1)
- h2 = (x1 * w2) + (x2 * w2)
- h3 = (x1 * w3) + (x2 * w3)
Выходные данные из скрытого слоя передается через нелинейную функцию (функцию активации), для получения выхода сети:
- y_ = fn(h1 , h2, h3)
Обратное распространение
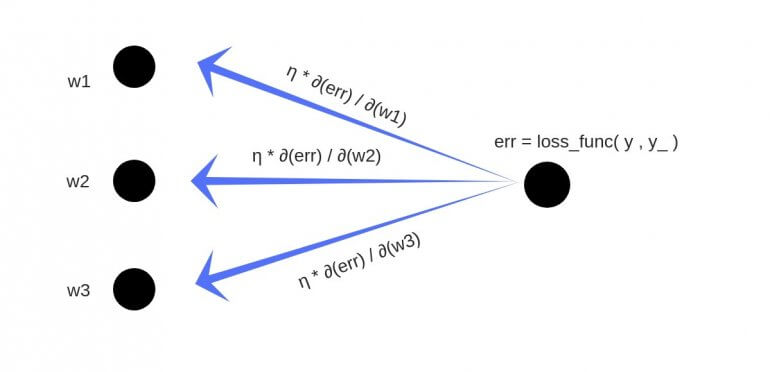
- Суммарная ошибка (total_error) вычисляется как разность между ожидаемым значением «y» (из обучающего набора) и полученным значением «y_» (посчитанное на этапе прямого распространения ошибки), проходящих через функцию потерь (cost function).
- Частная производная ошибки вычисляется по каждому весу (эти частные дифференциалы отражают вклад каждого веса в общую ошибку (total_loss)).
- Затем эти дифференциалы умножаются на число, называемое скорость обучения или learning rate (η).
Полученный результат затем вычитается из соответствующих весов.
В результате получатся следующие обновленные веса:
- w1 = w1 — (η * ∂(err) / ∂(w1))
- w2 = w2 — (η * ∂(err) / ∂(w2))
- w3 = w3 — (η * ∂(err) / ∂(w3))
То, что мы предполагаем и инициализируем веса случайным образом, и они будут давать точные ответы, звучит не вполне обоснованно, тем не менее, работает хорошо.

 Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
Если вы знакомы с рядами Тейлора, обратное распространение ошибки имеет такой же конечный результат. Только вместо бесконечного ряда мы пытаемся оптимизировать только его первый член.
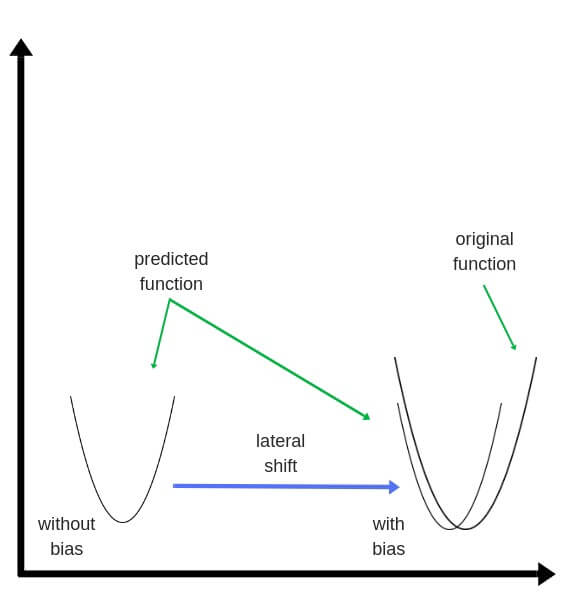
Смещения – это веса, добавленные к скрытым слоям. Они тоже случайным образом инициализируются и обновляются так же, как скрытый слой. Роль скрытого слоя заключается в том, чтобы определить форму базовой функции в данных, в то время как роль смещения – сдвинуть найденную функцию в сторону так, чтобы она частично совпала с исходной функцией.
Частные производные
Частные производные можно вычислить, поэтому известно, какой был вклад в ошибку по каждому весу. Необходимость производных очевидна. Представьте нейронную сеть, пытающуюся найти оптимальную скорость беспилотного автомобиля. Eсли машина обнаружит, что она едет быстрее или медленнее требуемой скорости, нейронная сеть будет менять скорость, ускоряя или замедляя автомобиль. Что при этом ускоряется/замедляется? Производные скорости.
Разберем необходимость частных производных на примере.
Предположим, детей попросили бросить дротик в мишень, целясь в центр. Вот результаты:
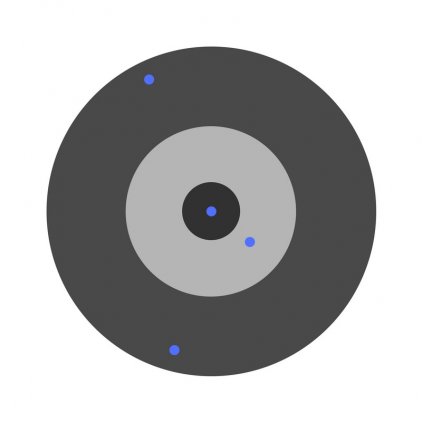
Теперь, если мы найдем общую ошибку и просто вычтем ее из всех весов, мы обобщим ошибки, допущенные каждым. Итак, скажем, ребенок попал слишком низко, но мы просим всех детей стремиться попадать в цель, тогда это приведет к следующей картине:
Ошибка нескольких детей может уменьшиться, но общая ошибка все еще увеличивается.
Найдя частные производные, мы узнаем ошибки, соответствующие каждому весу в отдельности. Если выборочно исправить веса, можно получить следующее:
Гиперпараметры
Нейронная сеть используется для автоматизации отбора признаков, но некоторые параметры настраиваются вручную.
Скорость обучения (learning rate)
Скорость обучения является очень важным гиперпараметром. Если скорость обучения слишком мала, то даже после обучения нейронной сети в течение длительного времени она будет далека от оптимальных результатов. Результаты будут выглядеть примерно так:
С другой стороны, если скорость обучения слишком высока, то сеть очень быстро выдаст ответы. Получится следующее:
Функция активации (activation function)
Функция активации — это один из самых мощных инструментов, который влияет на силу, приписываемую нейронным сетям. Отчасти, она определяет, какие нейроны будут активированы, другими словами и какая информация будет передаваться последующим слоям.
Без функций активации глубокие сети теряют значительную часть своей способности к обучению. Нелинейность этих функций отвечает за повышение степени свободы, что позволяет обобщать проблемы высокой размерности в более низких измерениях. Ниже приведены примеры распространенных функций активации:
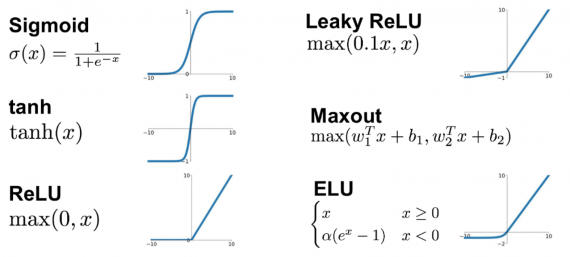
Функция потери (loss function)
Функция потерь находится в центре нейронной сети. Она используется для расчета ошибки между реальными и полученными ответами. Наша глобальная цель — минимизировать эту ошибку. Таким образом, функция потерь эффективно приближает обучение нейронной сети к этой цели.
Функция потерь измеряет «насколько хороша» нейронная сеть в отношении данной обучающей выборки и ожидаемых ответов. Она также может зависеть от таких переменных, как веса и смещения.
Функция потерь одномерна и не является вектором, поскольку она оценивает, насколько хорошо нейронная сеть работает в целом.
Некоторые известные функции потерь:
- Квадратичная (среднеквадратичное отклонение);
- Кросс-энтропия;
- Экспоненциальная (AdaBoost);
- Расстояние Кульбака — Лейблера или прирост информации.
Cреднеквадратичное отклонение – самая простая фукция потерь и наиболее часто используемая. Она задается следующим образом:
Функция потерь в нейронной сети должна удовлетворять двум условиям:
- Функция потерь должна быть записана как среднее;
- Функция потерь не должна зависеть от каких-либо активационных значений нейронной сети, кроме значений, выдаваемых на выходе.
Глубокие нейронные сети
Глубокое обучение (deep learning) – это класс алгоритмов машинного обучения, которые учатся глубже (более абстрактно) понимать данные. Популярные алгоритмы нейронных сетей глубокого обучения представлены на схеме ниже.
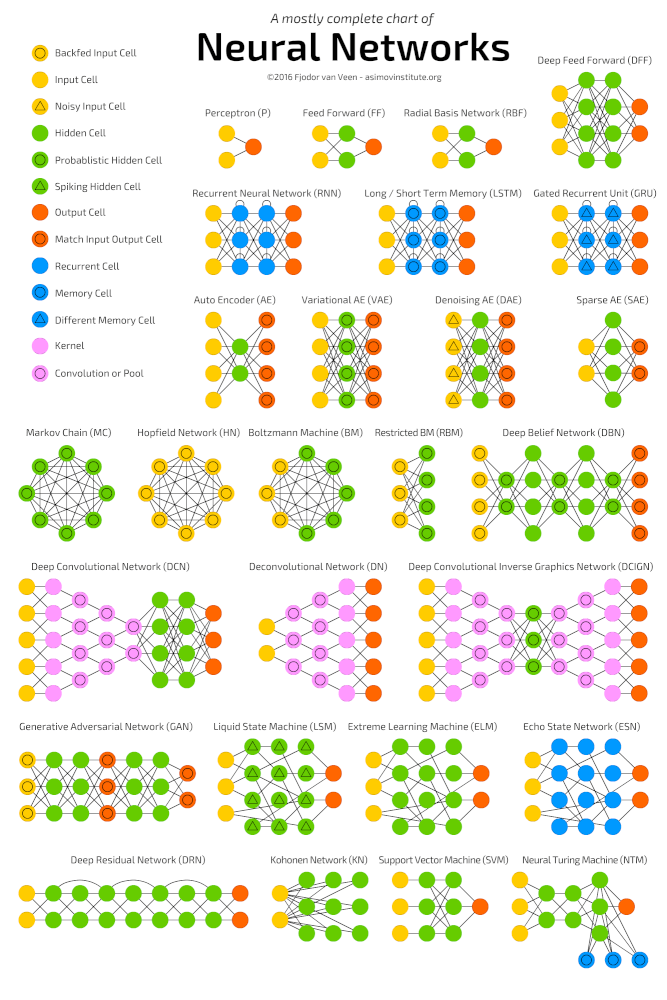
Более формально в deep learning:
- Используется каскад (пайплайн, как последовательно передаваемый поток) из множества обрабатывающих слоев (нелинейных) для извлечения и преобразования признаков;
- Основывается на изучении признаков (представлении информации) в данных без обучения с учителем. Функции более высокого уровня (которые находятся в последних слоях) получаются из функций нижнего уровня (которые находятся в слоях начальных слоях);
- Изучает многоуровневые представления, которые соответствуют разным уровням абстракции; уровни образуют иерархию представления.
Пример
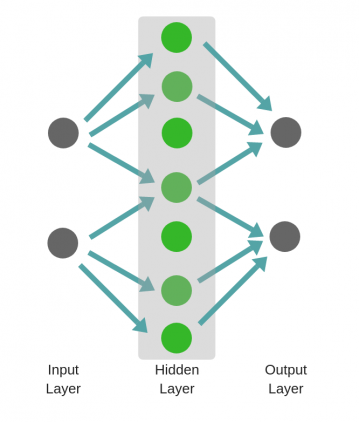
Рассмотрим однослойную нейронную сеть:
Здесь, обучается первый слой (зеленые нейроны), он просто передается на выход.
В то время как в случае двухслойной нейронной сети, независимо от того, как обучается зеленый скрытый слой, он затем передается на синий скрытый слой, где продолжает обучаться:
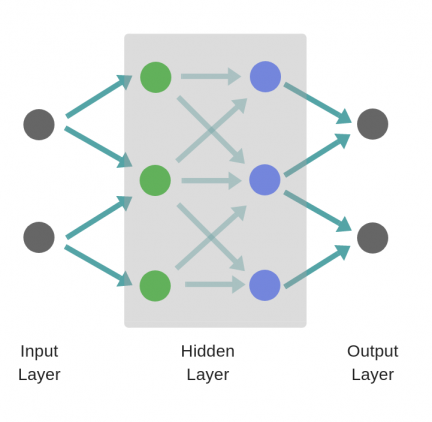
Следовательно, чем больше число скрытых слоев, тем больше возможности обучения сети.
Не следует путать с широкой нейронной сетью.
В этом случае большое число нейронов в одном слое не приводит к глубокому пониманию данных. Но это приводит к изучению большего числа признаков.
Пример:
Изучая английскую грамматику, требуется знать огромное число понятий. В этом случае однослойная широкая нейронная сеть работает намного лучше, чем глубокая нейронная сеть, которая значительно меньше.
Но
В случае изучения преобразования Фурье, ученик (нейронная сеть) должен быть глубоким, потому что не так много понятий, которые нужно знать, но каждое из них достаточно сложное и требует глубокого понимания.
Главное — баланс
Очень заманчиво использовать глубокие и широкие нейронные сети для каждой задачи. Но это может быть плохой идеей, потому что:
- Обе требуют значительно большего количества данных для обучения, чтобы достичь минимальной желаемой точности;
- Обе имеют экспоненциальную сложность;
- Слишком глубокая нейронная сеть попытается сломать фундаментальные представления, но при этом она будет делать ошибочные предположения и пытаться найти псевдо-зависимости, которые не существуют;
- Слишком широкая нейронная сеть будет пытаться найти больше признаков, чем есть. Таким образом, подобно предыдущей, она начнет делать неправильные предположения о данных.
Проклятье размерности
Проклятие размерности относится к различным явлениям, возникающим при анализе и организации данных в многомерных пространствах (часто с сотнями или тысячами измерений), и не встречается в ситуациях с низкой размерностью.
Грамматика английского языка имеет огромное количество аттрибутов, влияющих на нее. В машинном обучении мы должны представить их признаками в виде массива/матрицы конечной и существенно меньшей длины (чем количество существующих признаков). Для этого сети обобщают эти признаки. Это порождает две проблемы:
- Из-за неправильных предположений появляется смещение. Высокое смещение может привести к тому, что алгоритм пропустит существенную взаимосвязь между признаками и целевыми переменными. Это явление называют недообучение.
- От небольших отклонений в обучающем множестве из-за недостаточного изучения признаков увеличивается дисперсия. Высокая дисперсия ведет к переобучению, ошибки воспринимаются в качестве надежной информации.
Компромисс
На ранней стадии обучения смещение велико, потому что выход из сети далек от желаемого. А дисперсия очень мала, поскольку данные имеет пока малое влияние.
В конце обучения смещение невелико, потому что сеть выявила основную функцию в данных. Однако, если обучение слишком продолжительное, сеть также изучит шум, характерный для этого набора данных. Это приводит к большому разбросу результатов при тестировании на разных множествах, поскольку шум меняется от одного набора данных к другому.
Действительно,
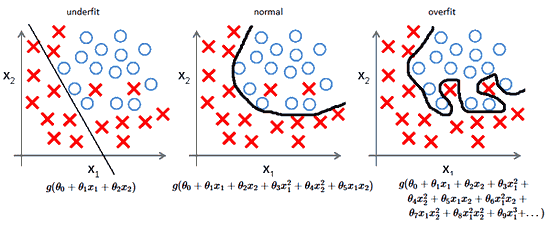
алгоритмы с большим смещением обычно в основе более простых моделей, которые не склонны к переобучению, но могут недообучиться и не выявить важные закономерности или свойства признаков. Модели с маленьким смещением и большой дисперсией обычно более сложны с точки зрения их структуры, что позволяет им более точно представлять обучающий набор. Однако они могут отображать много шума из обучающего набора, что делает их прогнозы менее точными, несмотря на их дополнительную сложность.
Следовательно, как правило, невозможно иметь маленькое смещение и маленькую дисперсию одновременно.
Сейчас есть множество инструментов, с помощью которых можно легко создать сложные модели машинного обучения, переобучение занимает центральное место. Поскольку смещение появляется, когда сеть не получает достаточно информации. Но чем больше примеров, тем больше появляется вариантов зависимостей и изменчивостей в этих корреляциях.
В этой статье мы узнаем о нейронных сетях прямого распространения, также известных как сети с глубокой прямой связью или многослойные персептроны. Они составляют основу многих важных нейронных сетей, используемых в последнее время, таких как сверточные нейронные сетиએ (широко используемые в приложениях компьютерного зрения), рекуррентные нейронные сетиએ (широко используемые для понимания естественного языка и последовательного обучения) и так далее. Мы постараемся понять важные концепции, используя интуитивно понятную игрушку и не будем вдаваясь в математику. Если вы хотите погрузиться в глубокое обучение, но не обладаете достаточным опытом в области статистики и машинного обучения, то эта статья станет идеальной отправной точкой.
Мы будем использовать сеть прямого распространения для решения задачи двоичной классификации. В машинном обучении классификация — это тип метода контролируемого обучения, в котором задача состоит в том, чтобы разделить образцы данных на заранее определенные группы с помощью функции принятия решений. Когда есть только две группы, это называется двоичной классификацией. На приведенном ниже рисунке показан пример. Точки синего цвета принадлежат одной группе (или классу), а оранжевые точки — другой. Воображаемые линии, разделяющие группы, называются границами принятия решений. Функция принятия решения извлекается из набора помеченных образцов, который называется обучающими данными, а процесс обучения функции принятия решения называется обучением.
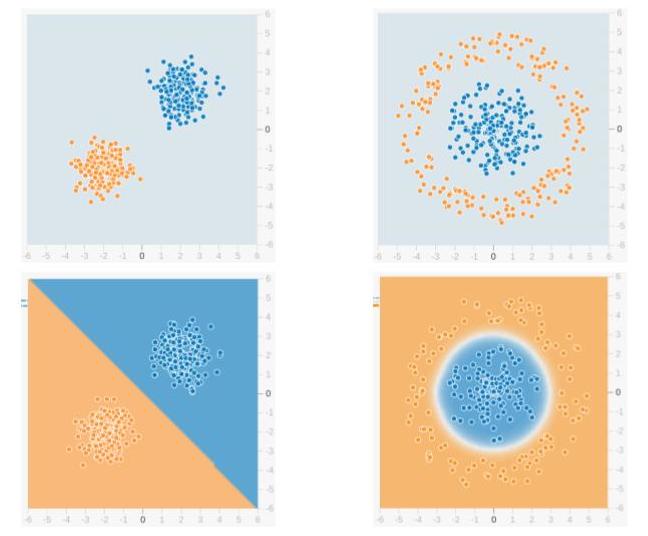
В приведенном примере верхняя строка показывает два разных распределения данных, а нижняя строка показывает границу решения. На левом изображении показан пример данных, которые можно разделить линейно. Это означает, что линейная граница (например, прямой линии) достаточно, чтобы разделить данные на группы. С другой стороны, изображение справа показывает пример данных, которые нельзя разделить линейно. Граница решения в этом случае должна быть круговой или многоугольной, как показано на рисунке.
1. Что есть нейронная сеть?
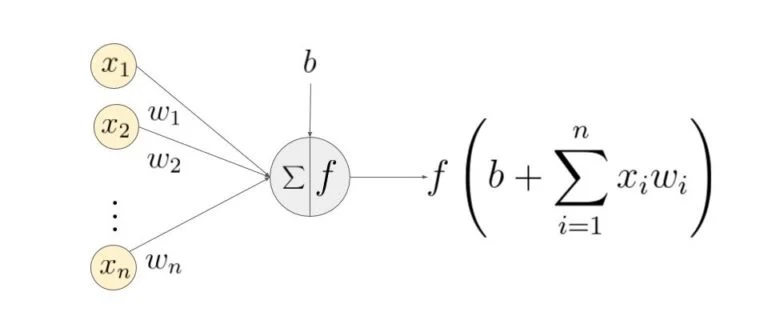
Ниже приведен пример нейронной сети прямого распространения. Это направленный ациклический граф, что означает, что в сети нет обратных связей или петель. У него есть входной слой, выходной слой и скрытый слой. Как правило, может быть несколько скрытых слоев. Каждый узел в слое — нейрон, который можно рассматривать как основной процессор нейронной сети. Искусственный нейрон — это основная единица нейронной сети. Принципиальная схема нейрона приведена ниже. Как видно выше, он работает в два этапа: вычисляет взвешенную сумму своих входных данных, а затем применяет функцию активации для нормализации суммы. Функции активации могут быть линейными или нелинейными. Также, есть веса, связанные с каждым входом нейрона. Это параметры, которые сеть должна приобрести на этапе обучения. Функция активацииએ используется как орган принятия решений на выходе нейрона. Нейрон изучает линейные или нелинейные границы принятия решений на основе функции активации. Он также оказывает нормализующее влияние на выход нейронов, что предотвращает выход нейронов после нескольких слоев, чтобы стать очень большим, за счет каскадного эффекта. Есть три наиболее часто используемых функции активации. Сигмоидаએ Ниже приведен пример нейронной сети прямого распространения. Это направленный ациклический граф, что означает, что в сети нет обратных связей или петель. У него есть входной слой, выходной слой и скрытый слой. Как правило, может быть несколько скрытых слоев. Каждый узел в слое — нейрон, который можно рассматривать как основной процессор нейронной сети. Искусственный нейрон — это основная единица нейронной сети. Принципиальная схема нейрона приведена ниже. Как видно выше, он работает в два этапа: вычисляет взвешенную сумму своих входных данных, а затем применяет функцию активации для нормализации суммы. Функции активации могут быть линейными или нелинейными. Также, есть веса, связанные с каждым входом нейрона. Это параметры, которые сеть должна приобрести на этапе обучения. Функция активацииએ используется как орган принятия решений на выходе нейрона. Нейрон изучает линейные или нелинейные границы принятия решений на основе функции активации. Он также оказывает нормализующее влияние на выход нейронов, что предотвращает выход нейронов после нескольких слоев, чтобы стать очень большим, за счет каскадного эффекта. Есть три наиболее часто используемых функции активации. Сигмоидаએ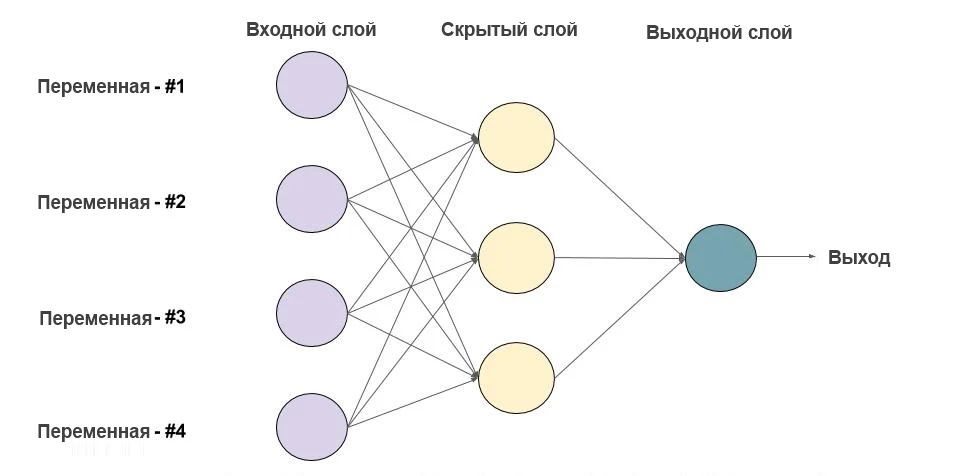
1.1. Что есть нейрон?
1.2. Функции активации
Он отображает входные данные (ось x) на значения от 0 до 1.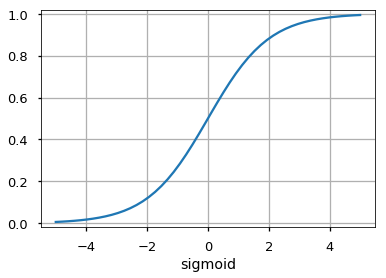
1.1. Что есть нейрон?
1.2. Функции активации
Он отображает входные данные (ось x) на значения от 0 до 1.
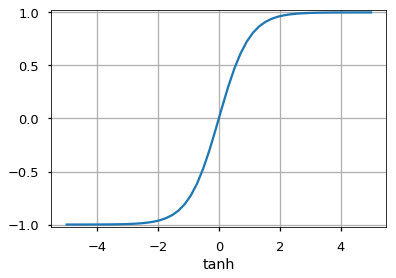
Tanh
Похожа на сигмовидную функцию, но отображает входные данные в значения от -1 до 1.
Rectified Linear Unit (ReLU)
Он позволяет проходить через него только положительным значениям. Отрицательные значения отображаются на ноль.
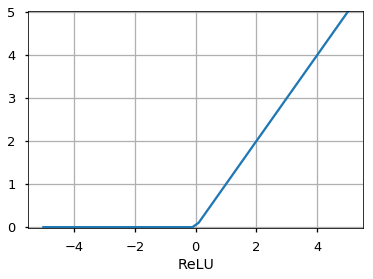
Функция активацииએ может быть другой, например, функция Unit Step, leaky ReLU, Noisy ReLU, Exponential LU и т.д., которые имеют свои плюсы и минусы.
1.3. Входной слой
Это первый слой нейронной сети. Он используется для передачи и приёма входных данных или функций в сеть.
1.4. Выходной слой
Это слой, который выдает прогнозы. Функция активации, используемая на этом уровне, различается для разных задач. Для задачи двоичной классификации мы хотим, чтобы на выходе было либо 0, либо 1. Таким образом, используется сигмовидная функция активации. Для задачи мультиклассовой классификации используется Softmaxએ (воспринимайте это как обобщение сигмоида на несколько классов). Для задачи регрессии, когда результат не является предопределенной категорией, мы можем просто использовать линейную единицу.
1.5. Скрытый слой
Сеть прямого распространения применяет к входу ряд функций. Имея несколько скрытых слоев, мы можем вычислять сложные функции, каскадируя более простые функции. Предположим, мы хотим вычислить седьмую степень числа, но хотим, чтобы вещи были простыми (поскольку их легко понять и реализовать). Вы можете использовать более простые степени, такие как квадрат и куб, для вычисления функций более высокого порядка. Точно так же вы можете вычислять очень сложные функции с помощью этого каскадного эффекта. Наиболее широко используемый скрытый блок — это тот, где функция активацииએ использует выпрямленный линейный блок (ReLU). Выбор скрытых слоёв — очень активная область исследований в машинном обучении. Тип скрытого слоя отличает разные типы нейронных сетей, такие как CNNએ, RNNએ и т.д. Количество скрытых слоев называется глубиной нейронной сети. Вы можете задать вопрос: сколько слоев в сети делают ее глубокой? На это нет правильного ответа. В общем случае, более глубокие сети могут научиться более сложным функциям.
1.6. Как сеть учится?
Обучающие образцы передаются по сети, и выходные данные, полученные от сети, сравниваются с фактическими выходными данными. Эта ошибка используется для изменения веса нейронов таким образом, чтобы ошибка постепенно уменьшалась. Это делается с помощью алгоритма обратного распространения ошибки, также называемого обратным распространением. Итеративная передача пакетов данных по сети и обновление весов для уменьшения ошибки называется стохастический градиентный спускએ (SGD). Величина, на которую изменяются веса, определяется параметром, называемым «Скорость обучения». Подробности SGD и backprop будут описаны в отдельном посте.
2.Зачем использовать скрытые слои?
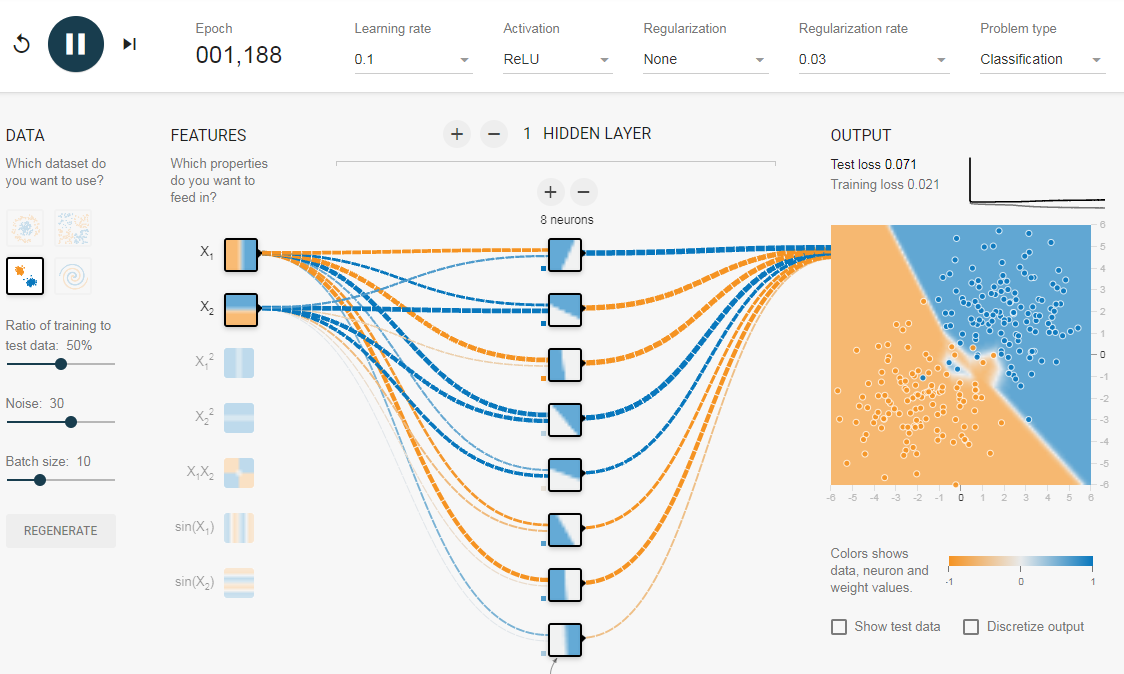
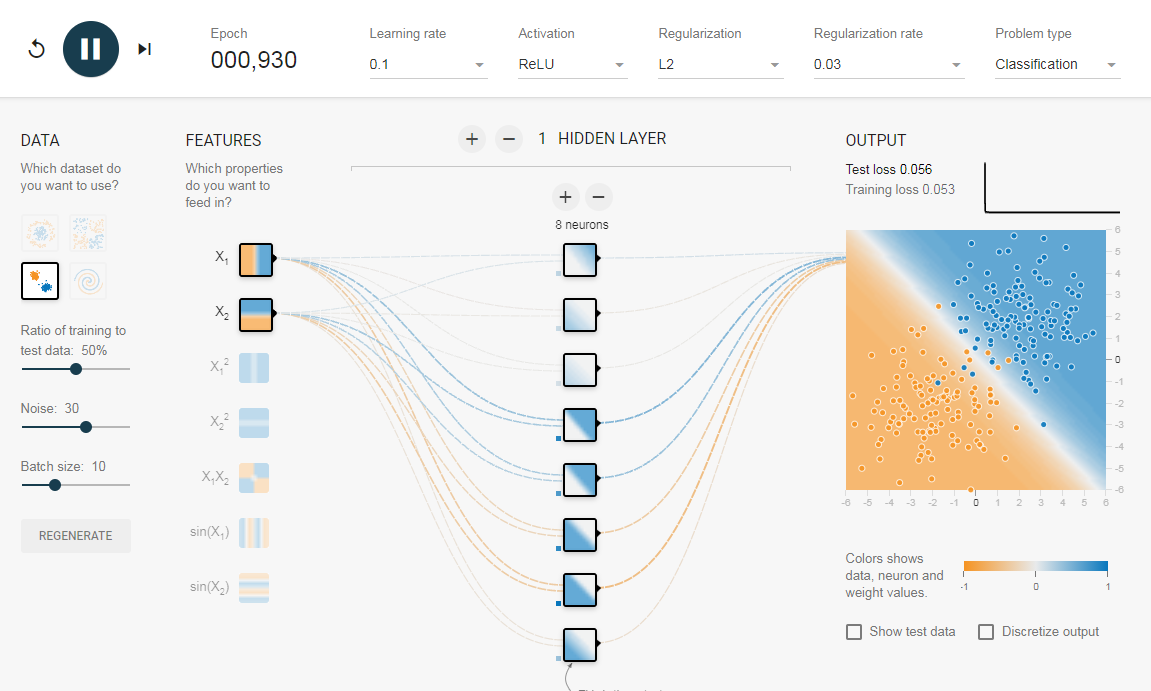
Чтобы понять значение скрытых слоев, мы попытаемся решить проблему двоичной классификации без скрытых слоев. Для этого мы будем использовать интерактивную платформу от Google, plays.tensorflow.org, которая представляет собой веб-приложение, где вы можете создавать простые нейронные сети с прямой связью и видеть эффекты обучения в реальном времени. Вы можете поиграть, изменив количество скрытых слоев, количество нейронов в скрытом слое, тип функции активации, тип данных, скорость обучения, параметры регуляризации и т.д. Выше приведен снимок экрана веб-страницы. На приведенной выше странице вы можете выбрать данные и нажать кнопку воспроизведения, чтобы начать обучение. Нам нужна сеть без скрытого слоя, который я создал по этой ссылке. Здесь нет скрытых слоев, поэтому он становится простым нейроном, способным изучать линейную границу принятия решения. Мы можем выбрать тип данных в верхнем левом углу. В случае линейно разделяемых данных (3-й тип), он сможет получить (когда вы нажмете кнопку воспроизведения) линейную границу, как показано ниже. Однако, если вы выберете первые данные, вы не сможете для них узнать границу кругового решения. Поскольку данные находятся в круговой области, можно сказать, что использование квадратов значений функций в качестве входных данных может помочь. Оказывается, после обучения нейрон сможет найти круговую границу принятия решения. Теперь, если вы выберете 2-е данные, та же конфигурация не сможет узнать соответствующую границу решения. Опять же интуитивно кажется, что граница решения — это коническое сечение (например, парабола или гипербола). Итак, если мы включим продукт функции (например, X_1 X_2), нейрон сможет узнать желаемую границу принятия решения. Описанные эксперименты показали: Добавив скрытый слой, как показано в этой ссылке, мы можем избавиться от этой функции проектирования и получить единую сеть, которая может изучить все три границы принятия решений. Нейронная сеть с одним скрытым слоем с нелинейными функциями активации считается универсальным аппроксиматором функций, теорема Цыбенкоએ (т.е. способной к обучению любой функции). Однако количество единиц в скрытом слое не фиксировано. Результат добавления скрытого слоя всего с 3 нейронами показан ниже: Как мы видели в предыдущем разделе, многослойная сеть может изучать нелинейные границы принятия решений. Однако, если в данных есть шум (что часто бывает), сеть может попытаться изучить нелинейность, вносимую шумом, пытаясь подогнать зашумленные выборки. В таких случаях зашумленные образцы следует рассматривать как выбросы. В этой ссылке я добавил немного шума к линейно разделяемым данным. Также, чтобы продемонстрировать идею, я увеличил количество скрытых нейронов. На приведенном выше рисунке можно увидеть, что граница принятия решения очень старается приспособить зашумленные выборки, чтобы уменьшить ошибку. Но, как видите, это ошибочно из-за шумных сэмплов. Другими словами, сеть будет неустойчивой при наличии шума. Это явление называется переобучением. В таких случаях, ошибка обучающих данных может уменьшиться, но сеть плохо работает с невидимыми данными. Это видно по кривым потерь в правом верхнем углу. Потери в обучении уменьшаются, но потери в тестах увеличиваются. Также, можно видеть, что некоторые веса стали очень большими (очень толстые соединения или вы можете увидеть веса, если наведете курсор на соединения). Это можно исправить, наложив некоторые ограничения на значения весов (например, не позволяя весам становиться очень высокими). Это называется регуляризацией. Мы накладываем ограничения на остальные параметры сети. В некотором смысле мы не полностью доверяем обучающим данным и хотим, чтобы сеть усвоила «хорошие» границы принятия решений. Я добавил регуляризацию L2 в приведенную выше конфигурацию по этой ссылке, и результат показан ниже. После включения регуляризации L2 граница принятия решения, изученная сетью, становится более гладкой и аналогичной случаю, когда не было шума. Эффект регуляризации также можно увидеть из кривых потерь и значений весов. В следующем посте, если он случится мы узнаем, как реализовать нейронную сеть прямого распространения в Keras для решения нескольких проблема классификации и узнайте ещё больше о сетях прямого распространения. Использованы материалы Understanding Feedforward Neural Networks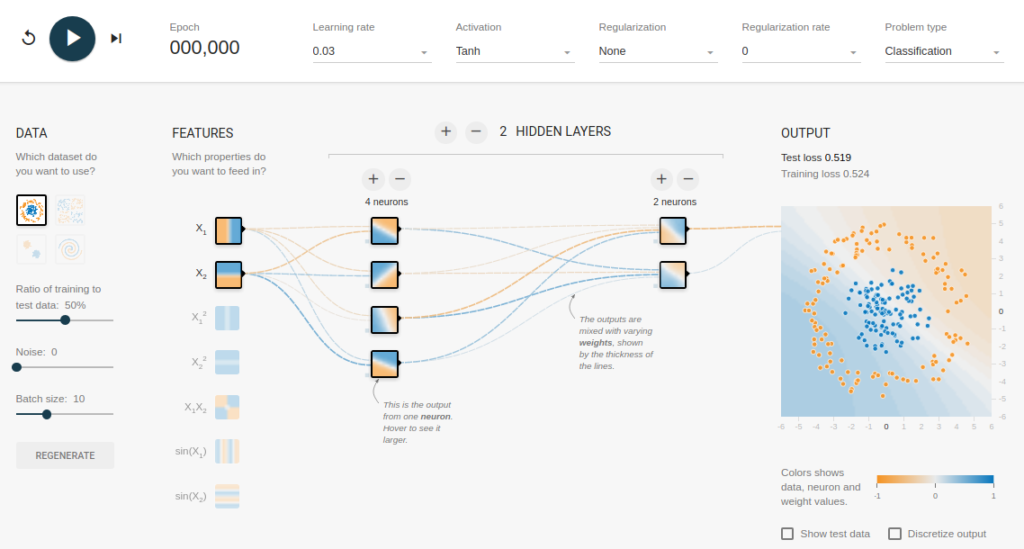
Он покажет вам изученную границу решения и кривые потерь в правом верхнем углу.2.1. Без скрытого слоя
2.2. Добавление скрытого слоя
3. Регуляризация

Нейросети кажутся людям чем-то очень сложным и запутанным, однако это вовсе не так. Простую нейросеть можно написать менее чем за час с нуля. В нашей статье мы создадим нейронную сеть прямого распространения (также называемую многослойным перцептроном), используя лишь массивы, циклы и условные операторы, а значит этот код легко можно будет перенести на любой язык программирования, предоставляющий эти возможности. А если язык предоставляет библиотеку для матричных и векторных вычислений (как, например, numpy в языке Python, то написание займёт ещё меньше времени).
Что такое нейросеть?
Согласно Википедии, искусственная нейронная сеть (ИНС), или Artificial Neural Network (ANN) — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма.
Более простыми словами, это некий чёрный ящик, который превращает входные данные в выходные, или, говоря более математическим языком, является отображением пространства входных признаков X в пространство выходных признаков Y: X → Y. То есть мы хотим найти какую-то функцию F, которая сможет выполнять это преобразование. Для начала этой информации нам будет достаточно. Для более подробного ознакомления рекомендуем ознакомиться с этой статьёй на хабре.
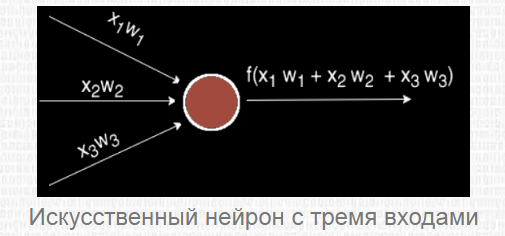
Коротко об искусственном нейроне
Чаще всего в подобных статьях начинают расписывать устройство биологического нейрона, связь с его искусственной моделью и прочую лирику. Мы же этого делать не будем, а сразу перейдём к сути. Искусственный нейрон — это всего лишь взвешенная сумма значений входного вектора элементов, которая передаётся на нелинейную функцию активации: z = f(y), где y = w0·x0 + w1·x1 + ... + wm - 1·xm - 1. Здесь w0, ..., wm - 1 — коэффициенты, веса каждого элемента вектора, x0, ..., xm - 1 — значения входного вектора X, y — взвешенная сумма элементов X, а z — результат применения функции активации. Мы вернёмся к функции активации немного позднее, а пока давайте придумаем, как вместо одного выходного значения получить n.

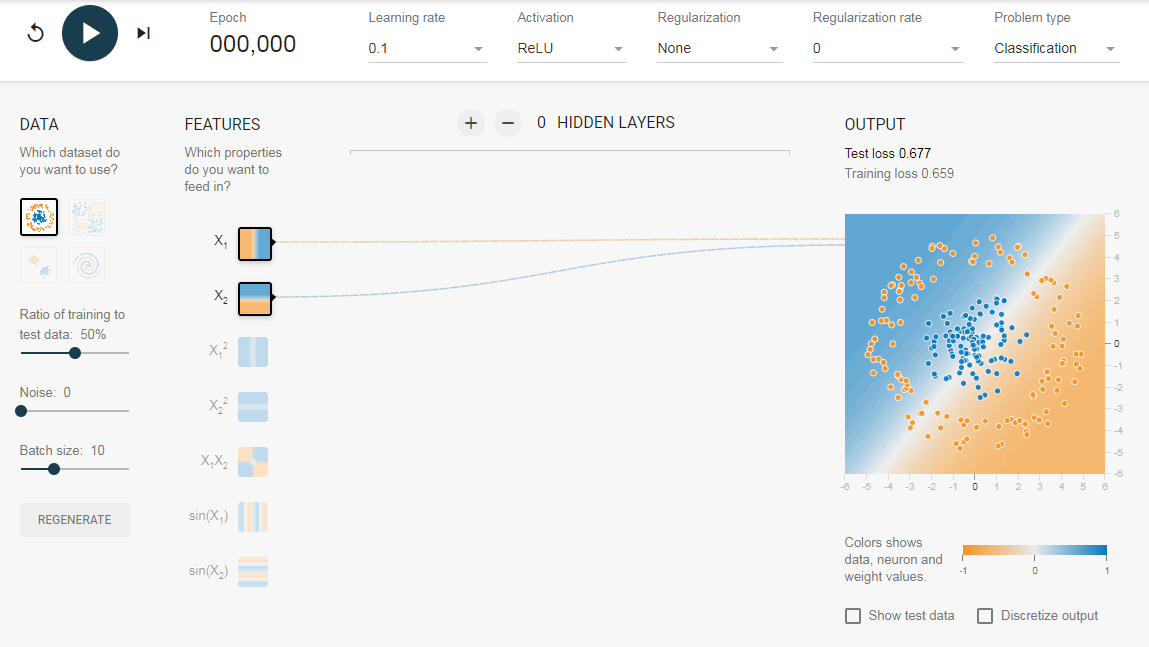
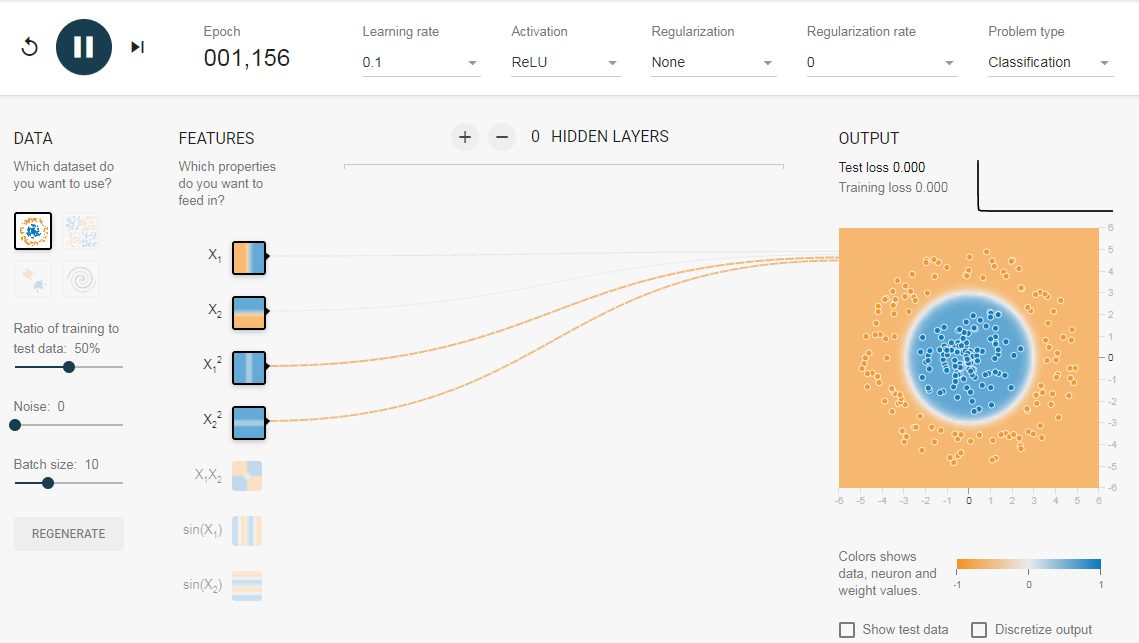
Чтобы понять значение скрытых слоев, мы попытаемся решить проблему двоичной классификации без скрытых слоев. Для этого мы будем использовать интерактивную платформу от Google, plays.tensorflow.org, которая представляет собой веб-приложение, где вы можете создавать простые нейронные сети с прямой связью и видеть эффекты обучения в реальном времени. Вы можете поиграть, изменив количество скрытых слоев, количество нейронов в скрытом слое, тип функции активации, тип данных, скорость обучения, параметры регуляризации и т.д. Выше приведен снимок экрана веб-страницы.
На приведенной выше странице вы можете выбрать данные и нажать кнопку воспроизведения, чтобы начать обучение.
Он покажет вам изученную границу решения и кривые потерь в правом верхнем углу.
2.1. Без скрытого слоя
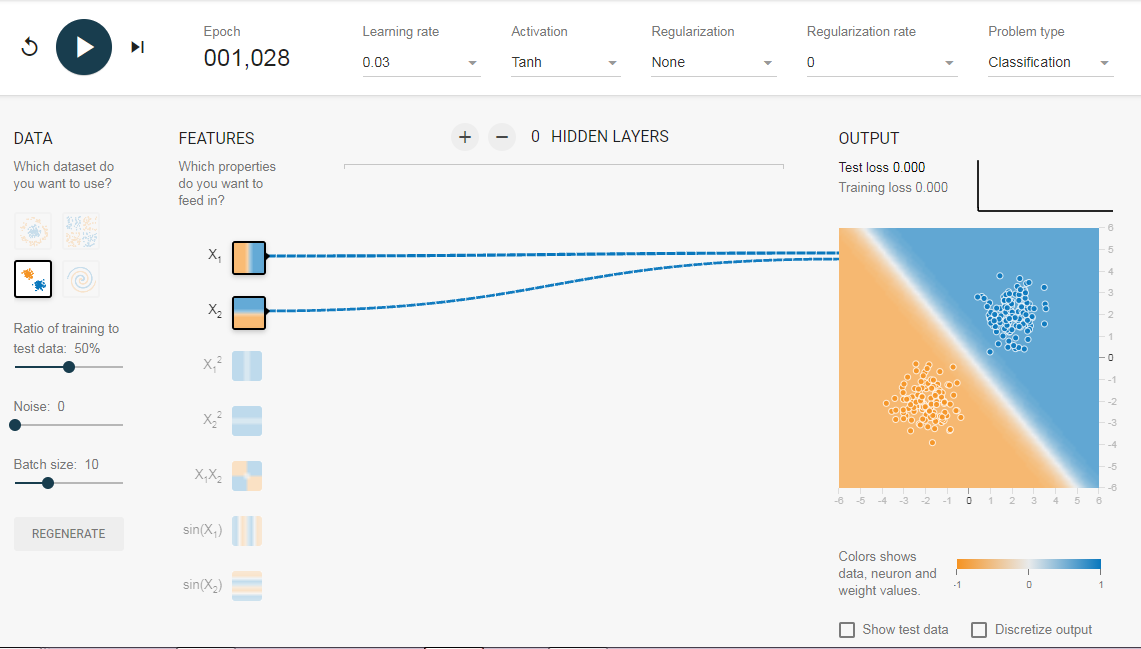
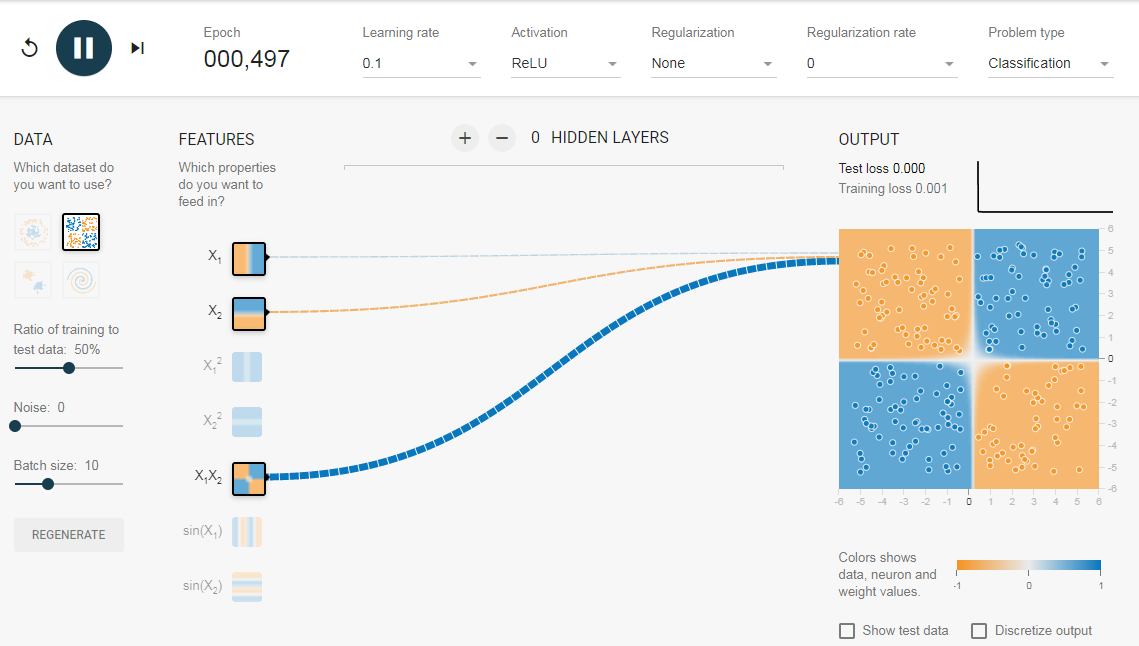
Нам нужна сеть без скрытого слоя, который я создал по этой ссылке. Здесь нет скрытых слоев, поэтому он становится простым нейроном, способным изучать линейную границу принятия решения. Мы можем выбрать тип данных в верхнем левом углу. В случае линейно разделяемых данных (3-й тип), он сможет получить (когда вы нажмете кнопку воспроизведения) линейную границу, как показано ниже.
Однако, если вы выберете первые данные, вы не сможете для них узнать границу кругового решения.
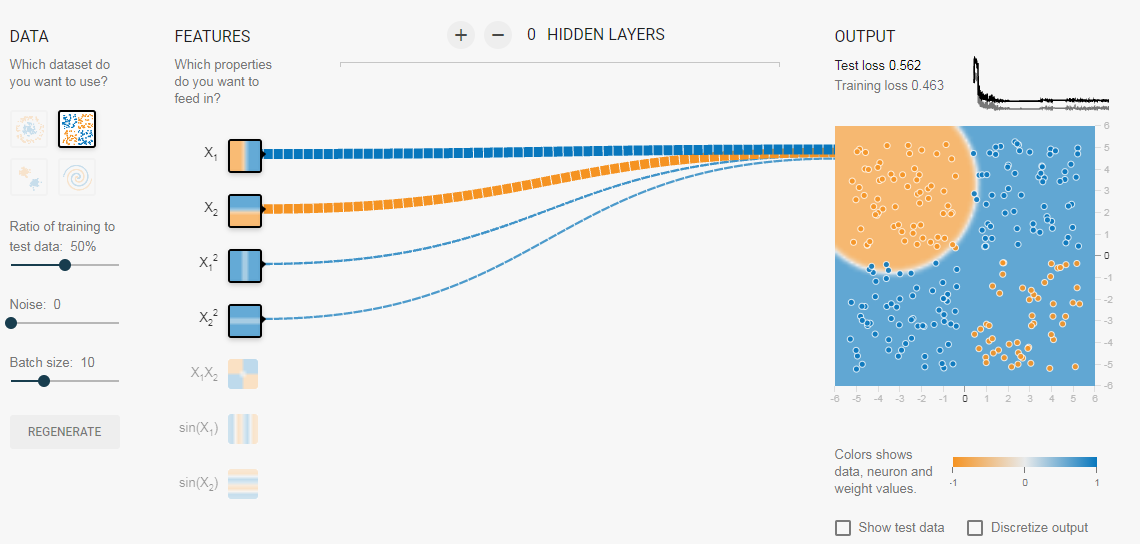
Поскольку данные находятся в круговой области, можно сказать, что использование квадратов значений функций в качестве входных данных может помочь. Оказывается, после обучения нейрон сможет найти круговую границу принятия решения.
Теперь, если вы выберете 2-е данные, та же конфигурация не сможет узнать соответствующую границу решения.
Опять же интуитивно кажется, что граница решения — это коническое сечение (например, парабола или гипербола). Итак, если мы включим продукт функции (например, X_1 X_2), нейрон сможет узнать желаемую границу принятия решения.
Описанные эксперименты показали:
- Используя один нейрон, мы можем узнать только линейную границу решения.
- Нам пришлось придумать преобразования функций (например, квадрат функций или продукт функций) путем визуализации данных. Этот шаг может быть сложным для данных, которые нелегко визуализировать.
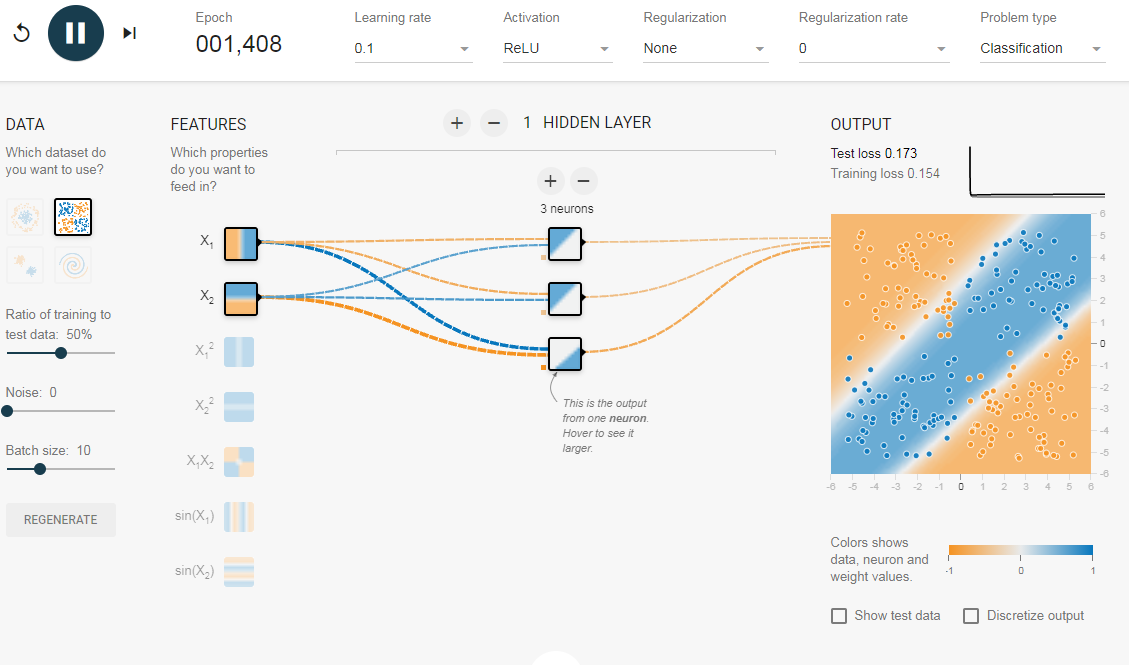
2.2. Добавление скрытого слоя
Добавив скрытый слой, как показано в этой ссылке, мы можем избавиться от этой функции проектирования и получить единую сеть, которая может изучить все три границы принятия решений. Нейронная сеть с одним скрытым слоем с нелинейными функциями активации считается универсальным аппроксиматором функций, теорема Цыбенкоએ (т.е. способной к обучению любой функции). Однако количество единиц в скрытом слое не фиксировано. Результат добавления скрытого слоя всего с 3 нейронами показан ниже:
3. Регуляризация
Как мы видели в предыдущем разделе, многослойная сеть может изучать нелинейные границы принятия решений. Однако, если в данных есть шум (что часто бывает), сеть может попытаться изучить нелинейность, вносимую шумом, пытаясь подогнать зашумленные выборки. В таких случаях зашумленные образцы следует рассматривать как выбросы. В этой ссылке я добавил немного шума к линейно разделяемым данным. Также, чтобы продемонстрировать идею, я увеличил количество скрытых нейронов.
На приведенном выше рисунке можно увидеть, что граница принятия решения очень старается приспособить зашумленные выборки, чтобы уменьшить ошибку. Но, как видите, это ошибочно из-за шумных сэмплов. Другими словами, сеть будет неустойчивой при наличии шума. Это явление называется переобучением. В таких случаях, ошибка обучающих данных может уменьшиться, но сеть плохо работает с невидимыми данными. Это видно по кривым потерь в правом верхнем углу.
Потери в обучении уменьшаются, но потери в тестах увеличиваются. Также, можно видеть, что некоторые веса стали очень большими (очень толстые соединения или вы можете увидеть веса, если наведете курсор на соединения). Это можно исправить, наложив некоторые ограничения на значения весов (например, не позволяя весам становиться очень высокими). Это называется регуляризацией. Мы накладываем ограничения на остальные параметры сети. В некотором смысле мы не полностью доверяем обучающим данным и хотим, чтобы сеть усвоила «хорошие» границы принятия решений. Я добавил регуляризацию L2 в приведенную выше конфигурацию по этой ссылке, и результат показан ниже.
После включения регуляризации L2 граница принятия решения, изученная сетью, становится более гладкой и аналогичной случаю, когда не было шума. Эффект регуляризации также можно увидеть из кривых потерь и значений весов.
В следующем посте, если он случится мы узнаем, как реализовать нейронную сеть прямого распространения в Keras для решения нескольких проблема классификации и узнайте ещё больше о сетях прямого распространения.
Использованы материалы Understanding Feedforward Neural Networks
Нейросети кажутся людям чем-то очень сложным и запутанным, однако это вовсе не так. Простую нейросеть можно написать менее чем за час с нуля. В нашей статье мы создадим нейронную сеть прямого распространения (также называемую многослойным перцептроном), используя лишь массивы, циклы и условные операторы, а значит этот код легко можно будет перенести на любой язык программирования, предоставляющий эти возможности. А если язык предоставляет библиотеку для матричных и векторных вычислений (как, например, numpy в языке Python, то написание займёт ещё меньше времени).
Что такое нейросеть?
Согласно Википедии, искусственная нейронная сеть (ИНС), или Artificial Neural Network (ANN) — математическая модель, а также её программное или аппаратное воплощение, построенная по принципу организации и функционирования биологических нейронных сетей — сетей нервных клеток живого организма.
Более простыми словами, это некий чёрный ящик, который превращает входные данные в выходные, или, говоря более математическим языком, является отображением пространства входных признаков X в пространство выходных признаков Y: X → Y. То есть мы хотим найти какую-то функцию F, которая сможет выполнять это преобразование. Для начала этой информации нам будет достаточно. Для более подробного ознакомления рекомендуем ознакомиться с этой статьёй на хабре.
Коротко об искусственном нейроне
Чаще всего в подобных статьях начинают расписывать устройство биологического нейрона, связь с его искусственной моделью и прочую лирику. Мы же этого делать не будем, а сразу перейдём к сути. Искусственный нейрон — это всего лишь взвешенная сумма значений входного вектора элементов, которая передаётся на нелинейную функцию активации: z = f(y), где y = w0·x0 + w1·x1 + ... + wm - 1·xm - 1. Здесь w0, ..., wm - 1 — коэффициенты, веса каждого элемента вектора, x0, ..., xm - 1 — значения входного вектора X, y — взвешенная сумма элементов X, а z — результат применения функции активации. Мы вернёмся к функции активации немного позднее, а пока давайте придумаем, как вместо одного выходного значения получить n.
Нейронный слой
Один нейрон способен входной вектор превратить в одну точку, однако по условию мы хотим получить несколько точек, так как выходной вектор Y может иметь произвольную размерность, определяемую лишь конкретной ситуацией (один выход для XOR, 10 выходов для определения принадлежности к одному из 10 классов и т.д.). Как же нам получить n точек, преобразуя элементы входного вектора X? Оказывается, всё довольно просто: для того, чтобы получить n выходных значений, необходимо использовать не один нейрон, а n. Тогда для каждого из элементов выходного вектора Y будет использовано ровно n различных взвешенных сумм от вектора X. То есть мы получаем, что
zi = f(yi) = f(wi0·x0 + wi1·x1 + ... + wim - 1·xm - 1)
Если внимательно посмотреть, то оказывается, что написанная выше формула является определением умножения матрицы на вектор. И действительно, если взять матрицу W размера n на m и умножить её на вектор X размерности m, то получится другой вектор размерности n, то есть ровно то, что нам и нужно. Таким образом, получение выходного вектора по входному для n нейронов можно записать в более удобной матричной форме: Y = W·X, где W — матрица весовых коэффициентов, X — входной вектор и Y — выходной вектор. Однако полученный вектор является неактивированным состоянием (промежуточным, не выходным) всех нейронов, а чтобы получить выходное значение, необходимо каждое неактивированное значение подать на вход функции активации. Результат её применения и будет выходным значением слоя.

Пример нейронной сети с двумя входами, пятью нейронами в скрытом слое и одним выходом
Забегая вперёд скажем о том, что нередко используют последовательность нейронных слоёв для более глубокого обучения сети и большей формализации данных. Поэтому для получения итогового выходного вектора необходимо проделать описанную выше операцию несколько раз подряд от одного слоя к другому. Тогда для первого слоя входным вектором будет X, а для всех последующих входом будет являться выход предыдущего слоя. К примеру, сеть с 3 скрытыми слоями может выглядеть так:

Функция активации
Функция активации — это функция, которая добавляет в сеть нелинейность, благодаря чему нейроны могут довольно точно имитировать любую функцию. Наиболее распространёнными функциями активации являются:
- Сигмоида:
f(x) = 1 / (1 + e-x) - Гиперболический тангенс:
f(x) = tanh(x) - ReLU:
f(x) = max(x,0)
У каждой из них есть свои особенности, но об этом лучше почитать в другой статье.
Давайте писать код
Теперь нам достаточно знаний, чтобы написать код получения результата нейронной сети. Мы будем писать код на языке C#, однако, уверяем, код будет практически идентичным для других языков программирования. Давайте разберёмся, что нам потребуется для реализации сети прямого распространения:
- Вектор (входные, выходные);
- Матрица (каждый слой содержит матрицу весовых коэффициентов);
- Нейросеть
1. Вектор:
- Вектор можно создавать из количества элементов (длины);
- Вектор можно создавать из перечисления вещественных чисел;
- Можно получать значения по индексу i.
- Можно изменять значения по индексу i.
Напишем же это:
class Vector {
public double[] v; // значения вектора
public int n; // длина вектора
// конструктор из длины
public Vector(int n) {
this.n = n; // копируем длину
v = new double[n]; // создаём массив
}
// создание вектора из вещественных значений
public Vector(params double[] values) {
n = values.Length;
v = new double[n];
for (int i = 0; i < n; i++)
v[i] = values[i];
}
// обращение по индексу
public double this[int i] {
get { return v[i]; } // получение значение
set { v[i] = value; } // изменение значения
}
}
2. Матрица:
- Матрицу можно создавать из числа строк, столбцов и генератора случайных чисел для заполнения случайными значениями;
- Можно получать значения по индексам i и j;
- Можно изменять значения по индексам i и j;
Напишем же это:
class Matrix {
double[][] v; // значения матрицы
public int n, m; // количество строк и столбцов
// создание матрицы заданного размера и заполнение случайными числами из интервала (-0.5, 0.5)
public Matrix(int n, int m, Random random) {
this.n = n;
this.m = m;
v = new double[n][];
for (int i = 0; i < n; i++) {
v[i] = new double[m];
for (int j = 0; j < m; j++)
v[i][j] = random.NextDouble() - 0.5; // заполняем случайными числами
}
}
// обращение по индексу
public double this[int i, int j] {
get { return v[i][j]; } // получение значения
set { v[i][j] = value; } // изменение значения
}
}
3. Сама нейросеть:
class Network {
Matrix[] weights; // матрицы весов слоя
int layersN; // число слоёв
// создание сети из массива количества нейронов в каждом слое
public Network(int[] sizes) {
Random random = new Random(DateTime.Now.Millisecond); // создаём генератор случайных чисел
layersN = sizes.Length - 1; // запоминаем число слоёв
weights = new Matrix[layersN]; // создаём массив матриц
// для каждого слоя создаём матрицы весовых коэффициентов
for (int k = 1; k < sizes.Length; k++) {
weights[k - 1] = new Matrix(sizes[k], sizes[k - 1], random);
}
}
// получение выхода сети (прямое распространение)
Vector Forward(Vector input) {
Vector output; // будущий выходной вектор
for (int k = 0; k < layersN; k++) {
output = new Vector(weights[k].n); // создаём новый выходной вектор для каждого слоя
for (int i = 0; i < weights[k].n; i++) {
double y = 0; // неактивированный выход нейрона
for (int j = 0; j < weights[k].m; j++)
y += weights[k][i, j] * input[j];
// выполняем активацию с помощью сигмоидальной функции
output[i] = 1 / (1 + Math.Exp(-y));
// выполняем активацию с помощью гиперболического тангенса
// output[i] = Math.Tanh(y);
// выполняем активацию с помощью ReLU
// output[i] = Math.Max(0, y);
}
}
return output;
}
}
Сеть есть, но её ответы случайны. Как обучать?
На данный момент мы имеем случайную (необученную) нейронную сеть, которая может по входному вектору input выдать случайный ответ, однако нам требуется ответы, удовлетворяющие конкретной задаче. Чтобы добиться этого нашу сеть необходимо обучить. Для этого нам необходима база тренировочных примеров, то есть множество пар векторов X – Y, на которых будет обучаться сеть. Обучать нейросеть мы будем с помощью алгоритма обратного распространения ошибки. Если кратко, то он работает следующим образом:
- Подать на вход сети обучающий пример (один входной вектор)
- Распространить сигнал по сети вперёд (получить выход сети)
- Вычислить ошибку (разница получившегося и ожидаемого векторов)
- Распространить ошибку на предыдущие слои
- Обновить весовые коэффициенты для уменьшения ошибки
Сам же алгоритм обучения выглядит так:
error = 0 epoch = 1 повторять: Для каждого обучающего примера: Найти ошибку e = f - d Прибавить к error сумму квадратов значений e Распространить ошибку к первому слою Обновить веса если error < eps выйти если epoch > maxEpoch выйти из-за ограничения на число эпох epoch = epoch + 1
Обучаем нейронную сеть
Для обратного распространения ошибки нам потребуется знать значения входов, выходов и значения производных функции активации сети на каждом из слоёв, поэтому создадим структуру LayerT, в которой будет 3 вектора: x — вход слоя, z — выход слоя, df — производная функции активации. Также для каждого слоя потребуются векторы дельт, поэтому добавим в наш класс ещё и их. С учётом вышесказанного наш класс станет выглядеть так:
class Network {
struct LayerT {
public Vector x; // вход слоя
public Vector z; // активированный выход слоя
public Vector df; // производная функции активации слоя
}
Matrix[] weights; // матрицы весов слоя
LayerT[] L; // значения на каждом слое
Vector[] deltas; // дельты ошибки на каждом слое
int layersN; // число слоёв
public Network(int[] sizes) {
Random random = new Random(DateTime.Now.Millisecond); // создаём генератор случайных чисел
layersN = sizes.Length - 1; // запоминаем число слоёв
weights = new Matrix[layersN]; // создаём массив матриц весовых коэффициентов
L = new LayerT[layersN]; // создаём массив значений на каждом слое
deltas = new Vector[layersN]; // создаём массив для дельт
for (int k = 1; k < sizes.Length; k++) {
weights[k - 1] = new Matrix(sizes[k], sizes[k - 1], random); // создаём матрицу весовых коэффициентов
L[k - 1].x = new Vector(sizes[k - 1]); // создаём вектор для входа слоя
L[k - 1].z = new Vector(sizes[k]); // создаём вектор для выхода слоя
L[k - 1].df = new Vector(sizes[k]); // создаём вектор для производной слоя
deltas[k - 1] = new Vector(sizes[k]); // создаём вектор для дельт
}
}
// прямое распространение
public Vector Forward(Vector input) {
for (int k = 0; k < layersN; k++) {
if (k == 0) {
for (int i = 0; i < input.n; i++)
L[k].x[i] = input[i];
}
else {
for (int i = 0; i < L[k - 1].z.n; i++)
L[k].x[i] = L[k - 1].z[i];
}
for (int i = 0; i < weights[k].n; i++) {
double y = 0;
for (int j = 0; j < weights[k].m; j++)
y += weights[k][i, j] * L[k].x[j];
// активация с помощью сигмоидальной функции
L[k].z[i] = 1 / (1 + Math.Exp(-y));
L[k].df[i] = L[k].z[i] * (1 - L[k].z[i]);
// активация с помощью гиперболического тангенса
//L[k].z[i] = Math.Tanh(y);
//L[k].df[i] = 1 - L[k].z[i] * L[k].z[i];
// активация с помощью ReLU
//L[k].z[i] = y > 0 ? y : 0;
//L[k].df[i] = y > 0 ? 1 : 0;
}
}
return L[layersN - 1].z; // возвращаем результат
}
}
Обратное распространение ошибки
Перейдём к обратному распространению ошибки. В качестве функции оценки сети E(W) возьмём среднее квадратичное отклонение: E = 0.5·Σ(y1i - y2i)2. Чтобы найти значение ошибки E, нам нужно найти сумму квадратов разности значений вектора, который выдала сеть в качестве ответа, и вектора, который мы ожидаем увидеть при обучении. Также нам потребуется найти дельту для каждого слоя, причём для последнего слоя она будет равна вектору разности полученного и ожидаемого векторов, умноженному (покомпонентно) на вектор значений производных последнего слоя: δlast = (zlast - d)·f'last, где zlast — выход последнего слоя сети, d — ожидаемый вектор сети, f'last — вектор значений производной функции активации последнего слоя.
Теперь, зная дельту последнего слоя, мы можем найти дельты всех предыдущих слоёв. Для этого нужно умножить транспонированную матрицы текущего слоя на дельту текущего слоя и затем умножить полученный вектор на вектор производных функции активации предыдущего слоя:
δk-1 = WTk·δk·f'k.
Что ж, давайте реализуем это в коде:
// обратное распространение
void Backward(Vector output, ref double error) {
int last = layersN - 1;
error = 0; // обнуляем ошибку
for (int i = 0; i < output.n; i++) {
double e = L[last].z[i] - output[i]; // находим разность значений векторов
deltas[last][i] = e * L[last].df[i]; // запоминаем дельту
error += e * e / 2; // прибавляем к ошибке половину квадрата значения
}
// вычисляем каждую предудущю дельту на основе текущей с помощью умножения на транспонированную матрицу
for (int k = last; k > 0; k--) {
for (int i = 0; i < weights[k].m; i++) {
deltas[k - 1][i] = 0;
for (int j = 0; j < weights[k].n; j++)
deltas[k - 1][i] += weights[k][j, i] * deltas[k][j];
deltas[k - 1][i] *= L[k - 1].df[i]; // умножаем получаемое значение на производную предыдущего слоя
}
}
}
Изменение весов
Для того, чтобы уменьшить ошибку сети нужно изменить весовые коэффициенты каждого слоя. Как же именно нужно менять весовые коэффициенты матриц на каждом слое? Оказывается, всё довольно просто. Для этого используется метод градиентного спуска, а значит нам необходимо вычислить градиент по весам и сделать шаг в отрицательную сторону от этого градиента. На этапе прямого распространения мы зачем-то запоминали входные сигналы, а при обратном распространении ошибки мы вычисляли дельты в каждом слое. Именно их мы и будем сейчас использовать для нахождения градиента! Градиент по весам равен перемножению входного вектора и вектора дельт (не покомпонентно). Поэтому, чтобы обновить весовые коэффициенты и уменьшить тем самым ошибку сети нужно всего лишь вычесть из матрицы весов результат перемножения дельт и входных векторов, умноженный на скорость обучения. Это можно записать в таком виде: Wt+1 = Wt - η·δ·X, где Wt+1 — новая матрица весов, Wt — текущая матрица весов, X — входное значение слоя, δ — дельта этого слоя. Почему именно так с математической точки зрения хорошо описано в этой статье.
// обновление весовых коэффициентов, alpha - скорость обучения
void UpdateWeights(double alpha) {
for (int k = 0; k < layersN; k++) {
for (int i = 0; i < weights[k].n; i++) {
for (int j = 0; j < weights[k].m; j++) {
weights[k][i, j] -= alpha * deltas[k][i] * L[k].x[j];
}
}
}
}
Обучение сети
Теперь, имея методы прямого распространения сигнала, обратного распространения ошибки и изменения весовых коэффициентов, нам остаётся лишь соединить всё вместе в один метод обучения.
public void Train(Vector[] X, Vector[] Y, double alpha, double eps, int epochs) {
int epoch = 1; // номер эпохи
double error; // ошибка эпохи
do {
error = 0; // обнуляем ошибку
// проходимся по всем элементам обучающего множества
for (int i = 0; i < X.Length; i++) {
Forward(X[i]); // прямое распространение сигнала
Backward(Y[i], ref error); // обратное распространение ошибки
UpdateWeights(alpha); // обновление весовых коэффициентов
}
Console.WriteLine("epoch: {0}, error: {1}", epoch, error); // выводим в консоль номер эпохи и величину ошибку
epoch++; // увеличиваем номер эпохи
} while (epoch <= epochs && error > eps);
}
Сеть готова. Давайте же её чему-нибудь научим!
Тренируем нейросеть на функции XOR
Почему функция XOR так интересна? Просто потому, что её невозможно получить одним нейроном: 0 ^ 0 = 0, 0 ^ 1 = 1, 1 ^ 0 = 1, 1 ^ 1 = 0. Однако она легко получается увеличением числа нейронов. Мы же попробуем выполнить обучение сети с 3 нейронами в скрытом слое и 1 выходным (так как выход у нас всего один). Для этого нам необходимо создать массив векторов X и Y с обучающими данными и саму нейросеть:
В этой статье поговорим о том, как создавать нейросети и в качестве примера рассмотрим, как сделать нейронную сеть прямого распространения с нуля. Для реализации поставленной задачи воспользуемся языком программирования C#.
Только ленивый не слышал сегодня о существовании и разработке нейронных сетей и такой сфере, как машинное обучение. Для некоторых создание нейросети кажется чем-то очень запутанным, однако на самом деле они создаются не так уж и сложно. Как же их делают? Давайте попробуем самостоятельно создать нейросеть прямого распространения, которую еще называют многослойным перцептроном. В процессе работы будем использовать лишь циклы, массивы и условные операторы. Что означает этот набор данных? Только то, что нам подойдет любой язык программирования, поддерживающий вышеперечисленные возможности. Если же у языка есть библиотеки для векторных и матричных вычислений (вспоминаем NumPy в Python), то реализация с их помощью займет совсем немного времени. Но мы не ищем легких путей и воспользуемся C#, причем полученный код по своей сути будет почти аналогичным и для прочих языков программирования.
Что же такое нейронная сеть?
Под искусственной нейронной сетью (ИНС) понимают математическую модель (включая ее программное либо аппаратное воплощение), которая построена и работает по принципу функционирования биологических нейросетей — речь идет о нейронных сетях нервных клеток живых организмов.
Говоря проще, ИНС можно назвать неким «черным ящиком», превращающим входные данные в выходные данные. Если же посмотреть на это с точки зрения математики, то речь идет о том, чтобы отобразить пространство входных X-признаков в пространство выходных Y-признаков: X → Y. Таким образом, нам надо найти некую F-функцию, которая сможет выполнить данное преобразование. На первом этапе этой информации достаточно в качестве основы.
Какую роль играет искусственный нейрон?
В нашей статье мы не будем вдаваться в лирику и рассказывать об устройстве биологического нейрона в контексте его связи с искусственной моделью. Лучше сразу перейдем к делу.
Искусственный нейрон представляет собой взвешенную сумму векторных значений входных элементов. Эта сумма передается на нелинейную функцию активации f:

Но об активации поговорим после, т. к. сейчас стоит задача узнать, каким образом вместо одного выходного значения можно получить n-значений.
Нейрослой
Один нейрон может превратить в одну точку входной вектор, но по условию мы желаем получить несколько точек, т. к. выходное Y способно иметь произвольную размерность, которая определяется лишь ситуацией (один выход для XOR, десять выходов, чтобы определить принадлежность к одному из десяти классов, и так далее). Каким же образом получить n точек? На деле все просто: для получения n выходных значений, надо задействовать не один нейрон, а n. В результате для каждого элемента выходного Y будет использовано n разных взвешенных сумм от X. В итоге мы придем к следующему соотношению:
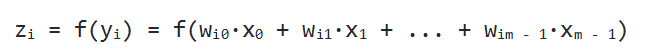
Давайте внимательно посмотрим на него. Вышенаписанная формула — это не что иное, как определение умножения матрицы на вектор. И в самом деле, если мы возьмем матрицу W размера n на m и выполним ее умножение на X размерности m, то мы получим другое векторное значение n-размерности, то есть как раз то, что надо.
Таким образом, мы можем записать похожее выражение в более удобной матричной форме:

Но полученный вектор представляет собой неактивированное состояние (промежуточное, невыходное) всех нейронов, а для того, чтобы нам получить выходное значение, нужно каждое неактивированное значение подать на вход вышеупомянутой функции активации. Итогом ее применения и станет выходное значение слоя.
Ниже показан пример нейронной сети, имеющей 2 входа, 5 нейронов и 1 выход:

Последовательность нейрослоев часто применяют для более глубокого обучения нейронной сети и большей формализации имеющихся данных. Именно поэтому, чтобы получить итоговый выходной вектор, нужно проделать вышеописанную операцию пару раз подряд по направлению от одного слоя к другому. В результате для 1-го слоя входным вектором будет являться X, а для последующих входом будет выход предыдущего слоя. То есть нейронная сеть может выглядеть следующим образом:
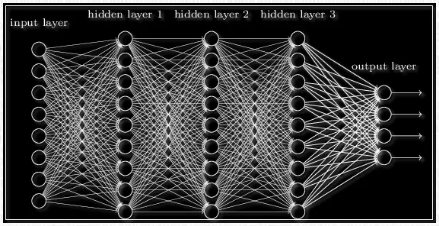
Функция активации
Речь идет о функции, добавляющей в нейронную сеть нелинейность. В результате нейроны смогут относительно точно сымитировать любую функцию. Широко распространены следующие функции активации:

Каждая из них имеет свои особенности.
Пишем код
Теперь мы знаем достаточно, чтобы создать простую нейронную сеть. Чтобы сделать то, что задумали, нам потребуются:
- Вектор.
- Матрица (каждый слой включает в себя матрицу весовых коэффициентов).
- Нейронная сеть.
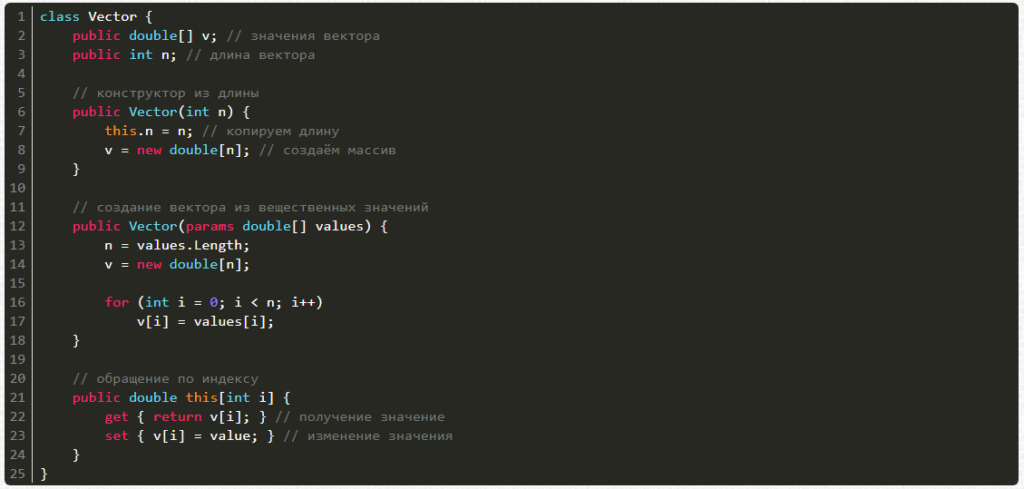
Начнем с вектора. Создавать его можно:
- из количества элементов;
- из перечисления вещественных чисел.
Также мы можем получать и менять значения по индексу i.
Пишем код:
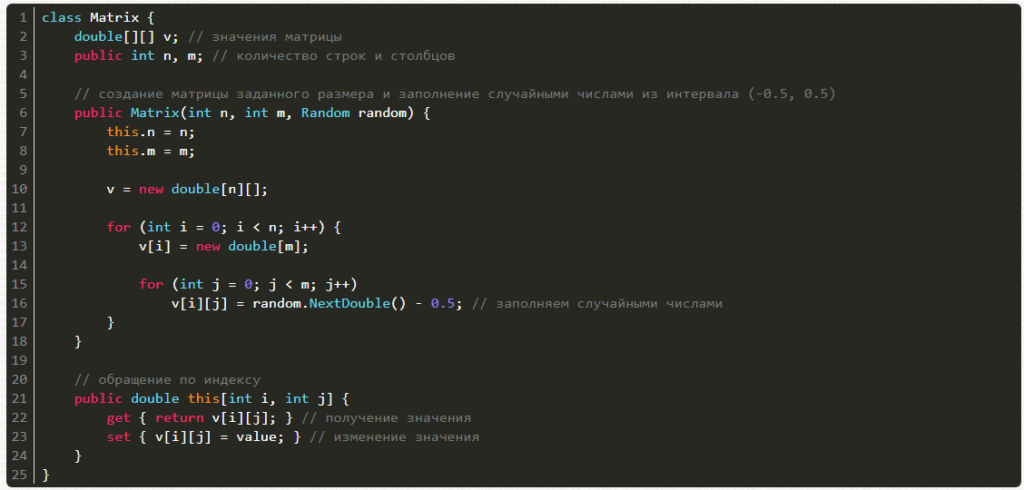
Теперь очередь матрицы. Ее можно создавать из числа строк и столбцов, а также генератора случайных чисел, причем есть возможность получать и менять значения по индексам i и j.
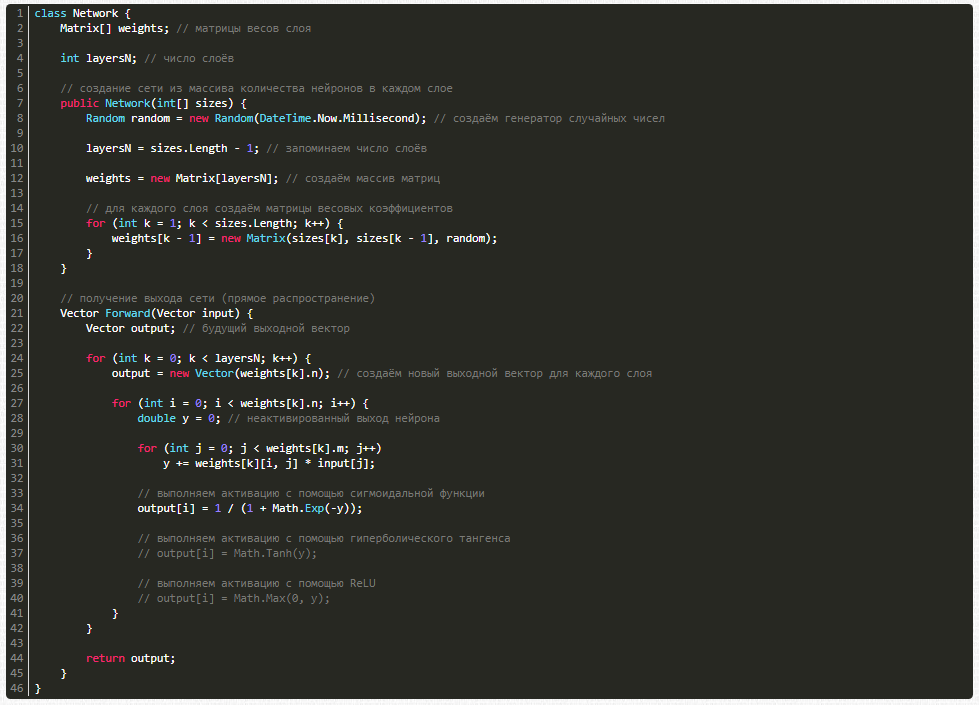
А вот и сама нейронная сеть:
Как будем обучать?
Пусть у нас уже есть нейронная сеть, но ведь ее ответы являются случайными, то есть наша нейросеть не обучена. Сейчас она способна лишь по входному вектору input выдавать случайный ответ, но нам нужны ответы, которые удовлетворяют конкретной поставленной задаче. Дабы этого достичь, сеть надо обучить. Здесь потребуется база тренировочных примеров и множество пар X — Y, на которых и будет происходить обучение, причем с использованием известного алгоритма обратного распространения ошибки.
Некоторые особенности работы этого алгоритма:
- на вход сети подается обучающий пример (1 входной вектор);
- сигнал распространяется по нейросети вперед (получаем выход сети);
- вычисляется ошибка (это разница между получившимся и ожидаемым векторами);
- ошибка распространяется на предыдущие слои;
- происходит обновление весовых коэффициентов в целях уменьшения ошибки.
Вот как выглядит алгоритм обучения:

Переходим к обучению
Для обратного распространения ошибки нужно знать значения выходов и входов, а также значения производных функции активации нейросети, причем послойно, следовательно, нужно создать структуру LayerT, где будут три векторных значения:
- x — вход слоя,
- z — выход,
- df — производная функции активации.
Для каждого слоя нам потребуются векторы дельт, в результате чего надо будет добавить в класс еще и их. В итоге класс будет выглядеть следующим образом:
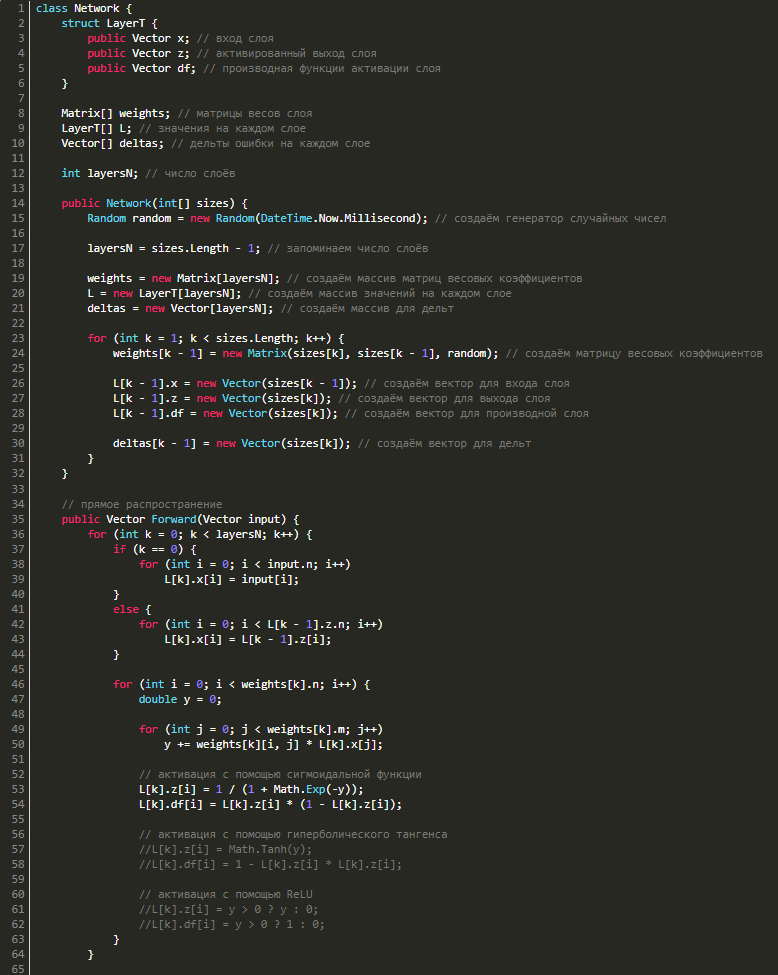
Несколько слов об обратном распространении ошибки
В качестве функции оценки нейросети E(W) мы берем среднее квадратичное отклонение:
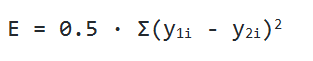
Дабы найти значение ошибки E, надо найти сумму квадратов разности векторных значений, которые были выданы нейронной сетью в виде ответа, а также вектора, который ожидается увидеть при обучении. Еще надо будет найти дельту каждого слоя и учесть, что для последнего слоя дельта будет равняться векторной разности фактического и ожидаемого результатов, покомпонентно умноженной на векторное значение производных последнего слоя:

Когда мы узнаем дельту последнего слоя, мы сможем найти дельты и всех предыдущих слоев. Чтобы это сделать, нужно будет лишь перемножить для текущего слоя транспонированную матрицу с дельтой, а потом перемножить результат с вектором производных функции активации предыдущего слоя:
![]()
Смотрим реализацию в коде:
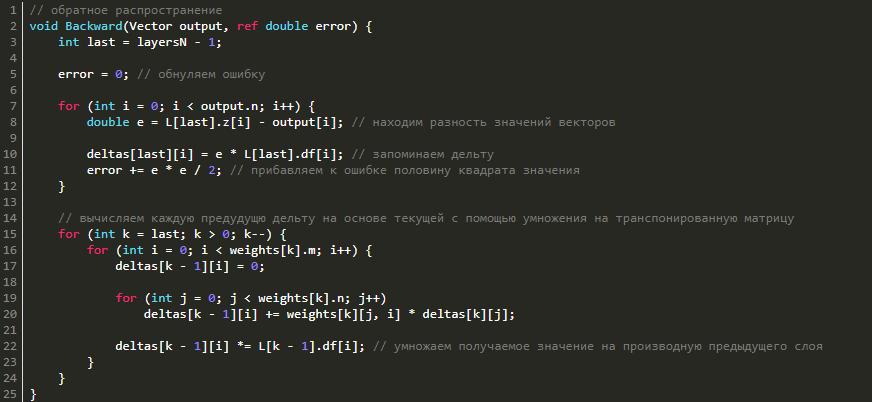
Обновление весовых коэффициентов
Для уменьшения ошибки нейронной сети надо поменять весовые коэффициенты, причем послойно. Каким же образом это осуществить? Ничего сложного в этом нет: надо воспользоваться методом градиентного спуска. То есть нам надо рассчитать градиент по весам и сделать шаг от полученного градиента в отрицательную сторону. Давайте вспомним, что на этапе прямого распространения мы запоминали входные сигналы, а во время обратного распространения ошибки вычисляли дельты, причем послойно. Как раз ими и надо воспользоваться в целях нахождения градиента. Градиент по весам будет равняться не по компонентному перемножению дельт и входного вектора. Дабы обновить весовые коэффициенты, снизив таким образом ошибку нейросети, нужно просто вычесть из матрицы весов итог перемножения входных векторов и дельт, помноженный на скорость обучения. Все вышеперечисленное можно записать в следующем виде:

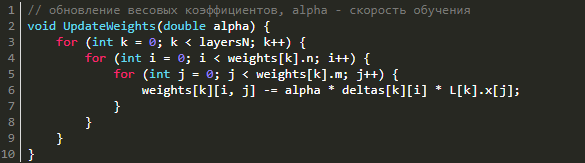
Вот оно, обучение!
Теперь мы имеем все нужные нам методы, поэтому остается лишь всё это вместе соединить, сформировав единый метод обучения.
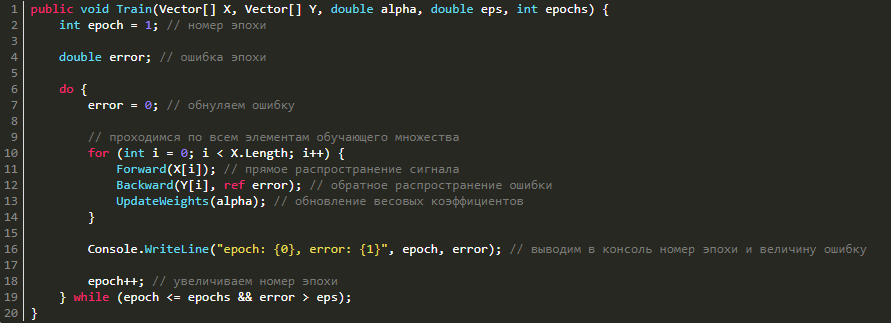
Наша сеть готова, но мы пока ее еще ничему не научили. Сейчас это исправим.
Тренировка нейронной сети. Функции XOR
Функция XOR интересна тем, что ее нельзя получить одним нейроном:
![]()
Но ее легко получить путем увеличения количества нейронов. Давайте попробуем реализовать обучение с тремя нейронами в скрытом слое и одним выходным (выход ведь у нас только один). Чтобы все получилось, создадим массив X и Y, имеющий обучающие данные и саму нейронную сеть:
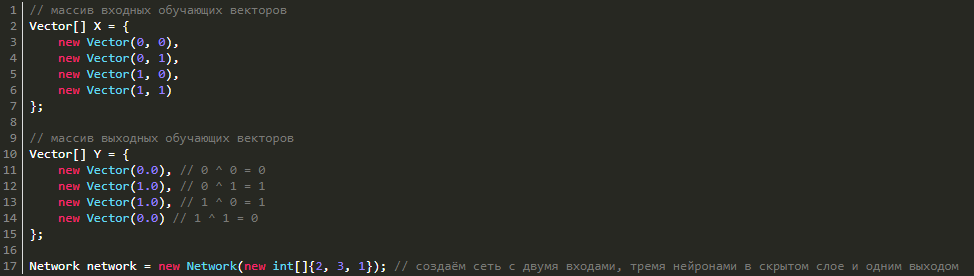
Теперь запускаем обучение с параметрами ниже:
- скорость обучения — 0.5,
- количество эпох — 100000,
- значение ошибки — 1e-7.
![]()
Выполнив обучение, посмотрим итоги, для чего надо будет сделать прямой проход для всех элементов:

В итоге вывод будет следующим:

Результаты
Мы написали нейронную сеть прямого распространения и не только написали, но и обучили ее функции XOR. Также была обеспечена универсальность, поэтому эту нейросеть можно обучать на любых данных — потребуется лишь:
- подготовить 2 векторных обучающих массива векторов X и Y,
- подобрать параметры,
- запустить само обучение,
- наблюдать за процессом.
Однако помните, что если используется сигмоидальная функция активации, выходные числа не будут больше единицы, что означает, что для обучения данным, которые существенно больше единицы, нужно будет нормировать их, приводя к отрезку [0, 1].
Надеемся, что материал был вам полезен и теперь вы знаете, как сделать нейросеть, и какие нюансы разработки стоит учитывать. Если же интересуют более продвинутые знания, обратите внимание на курсы, которые разработала команда Otus:

По материалам: https://programforyou.ru/poleznoe/pishem-neuroset-pryamogo-rasprostraneniya.