
Статья публикуется в переводе, автор оригинального текста Victor Zhou.
***
Термин «нейронные сети» сейчас можно услышать из каждого утюга, и многие верят, будто это что-то очень сложное. На самом деле нейронные сети совсем не такие сложные, как может показаться! Мы разберемся, как они работают, реализовав одну сеть с нуля на Python.
Эта статья предназначена для полных новичков, не имеющих никакого опыта в машинном обучении. Поехали!
1. Составные элементы: нейроны
Прежде всего нам придется обсудить нейроны, базовые элементы нейронной сети. Нейрон принимает несколько входов, выполняет над ними кое-какие математические операции, а потом выдает один выход. Вот как выглядит нейрон с двумя входами:
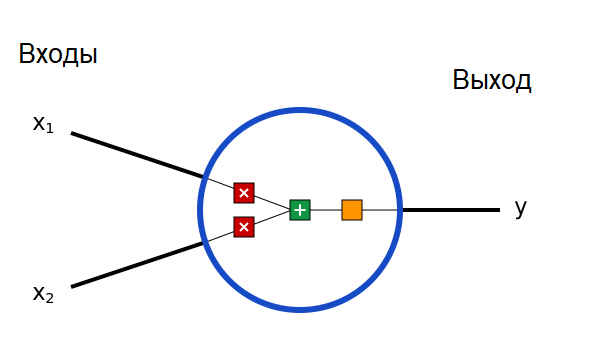
Внутри нейрона происходят три операции. Сначала значения входов умножаются на веса:
Затем взвешенные входы складываются, и к ним прибавляется значение порога b:
Наконец, полученная сумма проходит через функцию активации:
Функция активации преобразует неограниченные значения входов в выход, имеющий ясную и предсказуемую форму. Одна из часто используемых функций активации – сигмоида:
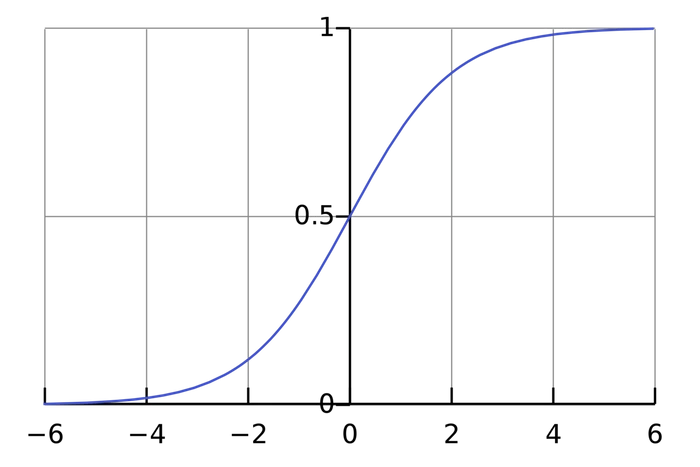
Сигмоида выдает результаты в интервале (0, 1). Можно представить, что она «упаковывает» интервал от минус бесконечности до плюс бесконечности в (0, 1): большие отрицательные числа превращаются в числа, близкие к 0, а большие положительные – к 1.
Простой пример
Допустим, наш двухвходовой нейрон использует сигмоидную функцию активации и имеет следующие параметры:
w=[0, 1] – это всего лишь запись w1=0, w2=1 в векторном виде. Теперь зададим нашему нейрону входные данные: x=[2, 3]. Мы используем скалярное произведение векторов, чтобы записать формулу в сжатом виде:
Наш нейрон выдал 0.999 при входах x=[2, 3]. Вот и все! Процесс передачи значений входов дальше, чтобы получить выход, называется прямой связью (feed forward).
Пишем код для нейрона
Настало время написать свой нейрон! Мы используем NumPy, популярную и мощную расчетную библиотеку для Python, которая поможет нам с вычислениями:
import numpy as np
def sigmoid(x):
# Наша функция активации: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
class Neuron:
def __init__(self, weights, bias):
self.weights = weights
self.bias = bias
def feedforward(self, inputs):
# Умножаем входы на веса, прибавляем порог, затем используем функцию активации
total = np.dot(self.weights, inputs) + self.bias
return sigmoid(total)
weights = np.array([0, 1]) # w1 = 0, w2 = 1
bias = 4 # b = 4
n = Neuron(weights, bias)
x = np.array([2, 3]) # x1 = 2, x2 = 3
print(n.feedforward(x)) # 0.9990889488055994
Узнаете эти числа? Это тот самый пример, который мы только что рассчитали! И мы получили тот же результат – 0.999.
2. Собираем нейронную сеть из нейронов
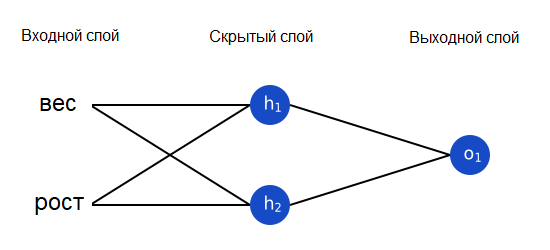
Нейронная сеть – это всего лишь несколько нейронов, соединенных вместе. Вот как может выглядеть простая нейронная сеть:
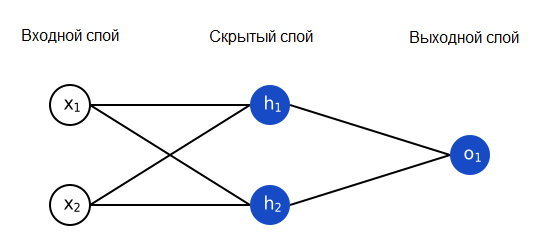
У этой сети два входа, скрытый слой с двумя нейронами (h1 и h2) и выходной слой с одним нейроном (o1). Обратите внимание, что входы для o1 – это выходы из h1 и h2. Именно это создает из нейронов сеть.
Замечание
Скрытый слой – это любой слой между входным (первым) слоем сети и выходным (последним). Скрытых слоев может быть много!
Пример: прямая связь
Давайте используем сеть, изображенную выше, и будем считать, что все нейроны имеют одинаковые веса w=[0, 1], одинаковые пороговые значения b=0, и одинаковую функцию активации – сигмоиду. Пусть h1, h2 и o1 обозначают выходные значения соответствующих нейронов.
Что получится, если мы подадим на вход x=[2, 3]?
Если подать на вход нашей нейронной сети x=[2, 3], на выходе получится 0.7216. Достаточно просто, не правда ли?
Нейронная сеть может иметь любое количество слоев, и в этих слоях может быть любое количество нейронов. Основная идея остается той же: передавайте входные данные по нейронам сети, пока не получите выходные значения. Для простоты мы будем использовать сеть, показанную выше, до конца статьи.
Пишем код нейронной сети
Давайте реализуем прямую связь для нашей нейронной сети. Напомним, как она выглядит:
import numpy as np
# ... вставьте сюда код из предыдущего раздела
class OurNeuralNetwork:
'''
Нейронная сеть с:
- 2 входами
- скрытым слоем с 2 нейронами (h1, h2)
- выходным слоем с 1 нейроном (o1)
Все нейроны имеют одинаковые веса и пороги:
- w = [0, 1]
- b = 0
'''
def __init__(self):
weights = np.array([0, 1])
bias = 0
# Используем класс Neuron из предыдущего раздела
self.h1 = Neuron(weights, bias)
self.h2 = Neuron(weights, bias)
self.o1 = Neuron(weights, bias)
def feedforward(self, x):
out_h1 = self.h1.feedforward(x)
out_h2 = self.h2.feedforward(x)
# Входы для o1 - это выходы h1 и h2
out_o1 = self.o1.feedforward(np.array([out_h1, out_h2]))
return out_o1
network = OurNeuralNetwork()
x = np.array([2, 3])
print(network.feedforward(x)) # 0.7216325609518421
Мы снова получили 0.7216! Похоже, наша сеть работает.
3. Обучаем нейронную сеть (часть 1)
Допустим, у нас есть следующие измерения:
| Имя | Вес (в фунтах) | Рост (в дюймах) | Пол |
| Алиса | 133 (54.4 кг) | 65 (165,1 см) | Ж |
| Боб | 160 (65,44 кг) | 72 (183 см) | М |
| Чарли | 152 (62.2 кг) | 70 (178 см) | М |
| Диана | 120 (49 кг) | 60 (152 см) | Ж |
Давайте обучим нашу нейронную сеть предсказывать пол человека по его росту и весу.
Мы будем представлять мужской пол как 0, женский – как 1, а также сдвинем данные, чтобы их было проще использовать:
| Имя | Вес (минус 135) | Рост (минус 66) | Пол |
| Алиса | -2 | -1 | 1 |
| Боб | 25 | 6 | 0 |
| Чарли | 17 | 4 | 0 |
| Диана | -15 | -6 | 1 |
Замечание
Я выбрал величину сдвигов (135 и 66), чтобы числа выглядели попроще. Обычно сдвигают на среднее значение.
Потери
Прежде чем обучать нашу нейронную сеть, нам нужно как-то измерить, насколько «хорошо» она работает, чтобы она смогла работать «лучше». Это измерение и есть потери (loss).
Мы используем для расчета потерь среднюю квадратичную ошибку (mean squared error, MSE):
Давайте рассмотрим все используемые переменные:
- n – это количество измерений, в нашем случае 4 (Алиса, Боб, Чарли и Диана).
- y представляет предсказываемое значение, Пол.
- ytrue – истинное значение переменной («правильный ответ»). Например, для Алисы ytrue будет равна 1 (женский пол).
- ypred – предсказанное значение переменной. Это то, что выдаст наша нейронная сеть.
(ytrue-ypred)2 называется квадратичной ошибкой. Наша функция потерь просто берет среднее значение всех квадратичных ошибок – поэтому она и называется средней квадратичной ошибкой. Чем лучшими будут наши предсказания, тем меньшими будут наши потери!
Лучшие предсказания = меньшие потери.
Обучение нейронной сети = минимизация ее потерь.
Пример расчета потерь
Предположим, что наша сеть всегда возвращает 0 – иными словами, она уверена, что все люди мужчины. Насколько велики будут наши потери?
| Имя | ytrue | ypred | (ytrue-ypred)2 |
| Алиса | 1 | 0 | 1 |
| Боб | 0 | 0 | 0 |
| Чарли | 0 | 0 | 0 |
| Диана | 1 | 0 | 1 |
Пишем функцию средней квадратичной ошибки
Вот небольшой кусок кода, который рассчитает наши потери. Если вы не понимаете, почему он работает, прочитайте в руководстве NumPy про операции с массивами.
import numpy as np
def mse_loss(y_true, y_pred):
# y_true и y_pred - массивы numpy одинаковой длины.
return ((y_true - y_pred) ** 2).mean()
y_true = np.array([1, 0, 0, 1])
y_pred = np.array([0, 0, 0, 0])
print(mse_loss(y_true, y_pred)) # 0.5
Отлично. Идем дальше!
4. Обучаем нейронную сеть (часть 2)
Теперь у нас есть четкая цель: минимизировать потери нейронной сети. Мы знаем, что можем изменять веса и пороги нейронов, чтобы изменить ее предсказания, но как нам делать это таким образом, чтобы минимизировать потери?
Внимание: математика!
Этот раздел использует частные производные по нескольким переменным. Если вы плохо знакомы с дифференциальным исчислением, можете просто пропускать математические формулы.
Для простоты давайте представим, что в нашем наборе данных только одна Алиса.
| Имя | Вес (минус 135) | Рост (минус 66) | Пол |
| Алиса | -2 | -1 | 1 |
Тогда средняя квадратичная ошибка будет квадратичной ошибкой только для Алисы:
Другой метод – это рассматривать функцию потерь как функцию от весов и порогов. Давайте отметим все веса и пороги нашей нейронной сети:
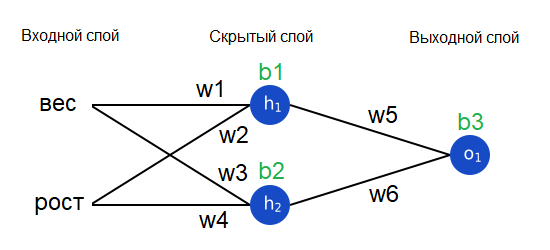
Теперь мы можем записать функцию потерь как функцию от нескольких переменных:
Предположим, мы хотим отрегулировать w1. Как изменится значение потери L при изменении w1? На этот вопрос может ответить частная производная dL/dw1. Как мы ее рассчитаем?
Не падайте духом!
Здесь математика становится более сложной. Возьмите бумагу и ручку, чтобы не отставать – это поможет вам понять, что происходит.
Прежде всего, давайте перепишем эту частную производную через dypred/dw1, воспользовавшись цепным правилом:
Мы можем рассчитать dL/dypred, поскольку мы уже выяснили выше, что L=(1-ypred)2:
Теперь давайте решим, что делать с dypred/dw1. Обозначая выходы нейронов, как прежде, h1, h2 и o1, получаем:
Вспомните, что f() – это наша функция активации, сигмоида. Поскольку w1 влияет только на h1 (но не на h2), мы можем снова использовать цепное правило и записать:
Мы можем сделать то же самое для dh1/dw1, снова применяя цепное правило:
В этой формуле x1 – это вес, а x2 – рост. Вот уже второй раз мы встречаем f'(x) – производную сигмоидной функции! Давайте вычислим ее:
Мы используем эту красивую форму для f'(x) позже. На этом мы закончили! Мы сумели разложить dL/dw1 на несколько частей, которые мы можем рассчитать:
Такой метод расчета частных производных «от конца к началу» называется методом обратного распространения (backpropagation).
Уффф. Здесь было очень много символов, так что не страшно, если вы пока не все понимаете. Давайте покажем, как это работает, на практическом примере!
Пример. Считаем частную производную
Мы по-прежнему считаем, что наш набор данных состоит из одной Алисы:
| Имя | Вес (минус 135) | Рост (минус 66) | Пол |
| Алиса | -2 | -1 | 1 |
Давайте инициализируем все веса как 1, а все пороги как 0. Если мы выполним прямой проход по нейронной сети, то получим:
Наша сеть выдает ypred=0.524, что находится примерно на полпути между Мужским полом (0) и Женским (1). Давайте рассчитаем dL/dw1:
Напоминаем:
Ранее мы получили формулу для производной сигмоиды f'(x)=f(x)(1-f(x))
Вот и все! Результат говорит нам, что при увеличении w1, функция ошибки чуть-чуть повышается.
Обучение: стохастический градиентный спуск
Теперь у нас есть все нужные инструменты для обучения нейронной сети! Мы используем алгоритм оптимизации под названием стохастический градиентный спуск (stochastic gradient descent), который определит, как мы будем изменять наши веса и пороги для минимизации потерь. Фактически, он заключается в следующей формуле обновления:
Скорость обучения определяет, как быстро наша сеть учится. Все, что мы делаем – это вычитаем eta*dL/dw1 из w1:
- Если dL/dw1 положительна, w1 уменьшится, что уменьшит L.
- Если dL/dw1 отрицательна, w1 увеличится, что также уменьшит L.
Если мы сделаем то же самое для каждого веса и порога в сети, потери будут постепенно уменьшаться, и наша сеть будет выдавать более точные результаты.
Процесс обучения сети будет выглядеть примерно так:
- Выбираем одно наблюдение из набора данных. Именно то, что мы работаем только с одним наблюдением, делает наш градиентный спуск стохастическим.
- Считаем все частные производные функции потерь по всем весам и порогам (dL/dw1, dL/dw2 и т.д.)
- Используем формулу обновления, чтобы обновить значения каждого веса и порога.
- Снова переходим к шагу 1.
Пишем код всей нейронной сети
Наконец настало время реализовать всю нейронную сеть.
| Имя | Вес (минус 135) | Рост (минус 66) | Пол |
| Алиса | -2 | -1 | 1 |
| Боб | 25 | 6 | 0 |
| Чарли | 17 | 4 | 0 |
| Диана | -15 | -6 |
import numpy as np
def sigmoid(x):
# Сигмоидная функция активации: f(x) = 1 / (1 + e^(-x))
return 1 / (1 + np.exp(-x))
def deriv_sigmoid(x):
# Производная сигмоиды: f'(x) = f(x) * (1 - f(x))
fx = sigmoid(x)
return fx * (1 - fx)
def mse_loss(y_true, y_pred):
# y_true и y_pred - массивы numpy одинаковой длины.
return ((y_true - y_pred) ** 2).mean()
class OurNeuralNetwork:
'''
Нейронная сеть с:
- 2 входами
- скрытым слоем с 2 нейронами (h1, h2)
- выходной слой с 1 нейроном (o1)
*** DISCLAIMER ***:
Следующий код простой и обучающий, но НЕ оптимальный.
Код реальных нейронных сетей совсем на него не похож. НЕ копируйте его!
Изучайте и запускайте его, чтобы понять, как работает эта нейронная сеть.
'''
def __init__(self):
# Веса
self.w1 = np.random.normal()
self.w2 = np.random.normal()
self.w3 = np.random.normal()
self.w4 = np.random.normal()
self.w5 = np.random.normal()
self.w6 = np.random.normal()
# Пороги
self.b1 = np.random.normal()
self.b2 = np.random.normal()
self.b3 = np.random.normal()
def feedforward(self, x):
# x is a numpy array with 2 elements.
h1 = sigmoid(self.w1 * x[0] + self.w2 * x[1] + self.b1)
h2 = sigmoid(self.w3 * x[0] + self.w4 * x[1] + self.b2)
o1 = sigmoid(self.w5 * h1 + self.w6 * h2 + self.b3)
return o1
def train(self, data, all_y_trues):
'''
- data - массив numpy (n x 2) numpy, n = к-во наблюдений в наборе.
- all_y_trues - массив numpy с n элементами.
Элементы all_y_trues соответствуют наблюдениям в data.
'''
learn_rate = 0.1
epochs = 1000 # сколько раз пройти по всему набору данных
for epoch in range(epochs):
for x, y_true in zip(data, all_y_trues):
# --- Прямой проход (эти значения нам понадобятся позже)
sum_h1 = self.w1 * x[0] + self.w2 * x[1] + self.b1
h1 = sigmoid(sum_h1)
sum_h2 = self.w3 * x[0] + self.w4 * x[1] + self.b2
h2 = sigmoid(sum_h2)
sum_o1 = self.w5 * h1 + self.w6 * h2 + self.b3
o1 = sigmoid(sum_o1)
y_pred = o1
# --- Считаем частные производные.
# --- Имена: d_L_d_w1 = "частная производная L по w1"
d_L_d_ypred = -2 * (y_true - y_pred)
# Нейрон o1
d_ypred_d_w5 = h1 * deriv_sigmoid(sum_o1)
d_ypred_d_w6 = h2 * deriv_sigmoid(sum_o1)
d_ypred_d_b3 = deriv_sigmoid(sum_o1)
d_ypred_d_h1 = self.w5 * deriv_sigmoid(sum_o1)
d_ypred_d_h2 = self.w6 * deriv_sigmoid(sum_o1)
# Нейрон h1
d_h1_d_w1 = x[0] * deriv_sigmoid(sum_h1)
d_h1_d_w2 = x[1] * deriv_sigmoid(sum_h1)
d_h1_d_b1 = deriv_sigmoid(sum_h1)
# Нейрон h2
d_h2_d_w3 = x[0] * deriv_sigmoid(sum_h2)
d_h2_d_w4 = x[1] * deriv_sigmoid(sum_h2)
d_h2_d_b2 = deriv_sigmoid(sum_h2)
# --- Обновляем веса и пороги
# Нейрон h1
self.w1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w1
self.w2 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_w2
self.b1 -= learn_rate * d_L_d_ypred * d_ypred_d_h1 * d_h1_d_b1
# Нейрон h2
self.w3 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w3
self.w4 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_w4
self.b2 -= learn_rate * d_L_d_ypred * d_ypred_d_h2 * d_h2_d_b2
# Нейрон o1
self.w5 -= learn_rate * d_L_d_ypred * d_ypred_d_w5
self.w6 -= learn_rate * d_L_d_ypred * d_ypred_d_w6
self.b3 -= learn_rate * d_L_d_ypred * d_ypred_d_b3
# --- Считаем полные потери в конце каждой эпохи
if epoch % 10 == 0:
y_preds = np.apply_along_axis(self.feedforward, 1, data)
loss = mse_loss(all_y_trues, y_preds)
print("Epoch %d loss: %.3f" % (epoch, loss))
# Определим набор данных
data = np.array([
[-2, -1], # Алиса
[25, 6], # Боб
[17, 4], # Чарли
[-15, -6], # Диана
])
all_y_trues = np.array([
1, # Алиса
0, # Боб
0, # Чарли
1, # Диана
])
# Обучаем нашу нейронную сеть!
network = OurNeuralNetwork()
network.train(data, all_y_trues)
По мере обучения сети ее потери постепенно уменьшаются:
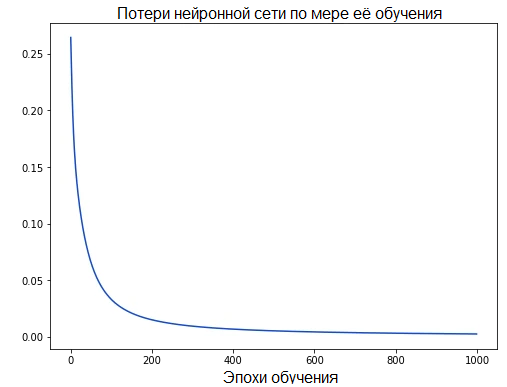
Теперь мы можем использовать нашу сеть для предсказания пола:
# Делаем пару предсказаний
emily = np.array([-7, -3]) # 128 фунтов (52.35 кг), 63 дюйма (160 см)
frank = np.array([20, 2]) # 155 pounds (63.4 кг), 68 inches (173 см)
print("Эмили: %.3f" % network.feedforward(emily)) # 0.951 - Ж
print("Фрэнк: %.3f" % network.feedforward(frank)) # 0.039 - М
Что теперь?
Вы сделали это! Давайте перечислим все, что мы с вами сделали:
- Определили нейроны, составные элементы нейронных сетей.
- Использовали сигмоидную функцию активации для наших нейронов.
- Увидели, что нейронные сети – это всего лишь несколько нейронов, соединенных друг с другом.
- Создали набор данных, в котором Вес и Рост были входными данными (или признаками), а Пол – выходным (или меткой).
- Узнали о функции потерь и средней квадратичной ошибке (MSE).
- Поняли, что обучение нейронной сети – это всего лишь минимизация ее потерь.
- Использовали метод обратного распространения (backpropagation) для расчета частных производных.
- Использовали стохастический градиентный спуск (SGD) для обучения нашей сети.
Перед вами – множество путей, на которых вас ждет масса нового и интересного:
- Экспериментируйте с большими и лучшими нейронными сетями, используя подходящие библиотеки вроде Tensorflow, Keras и PyTorch.
- Создайте свою первую нейронную сеть с помощью Keras.
- Прочитайте остальные статьи из серии «Нейронные сети с нуля».
- Исследуйте другие функции активации, кроме сигмоиды, например, Softmax.
- Исследуйте другие оптимизаторы, кроме стохастического градиентного спуска.
Спасибо за внимание!
***
На Python создают прикладные приложения, пишут тесты и бэкенд веб-приложений, автоматизируют задачи в системном администрировании, его используют в нейронных сетях и анализе больших данных. Язык можно изучить самостоятельно, но на это придется потратить немало времени. Если вы хотите быстро понять основы программирования на Python, обратите внимание на онлайн-курс «Библиотеки программиста». За 30 уроков (15 теоретических и 15 практических занятий) под руководством практикующих экспертов вы не только изучите основы синтаксиса, но и освоите две интегрированные среды разработки (PyCharm и Jupyter Notebook), работу со словарями, парсинг веб-страниц, создание ботов для Telegram и Instagram, тестирование кода и даже анализ данных. Чтобы процесс обучения стал более интересным и комфортным, студенты получат от нас обратную связь. Кураторы и преподаватели курса ответят на все вопросы по теме лекций и практических занятий.
Перевод
Ссылка на автора
Алгоритм обратного распространения — это классическая искусственная нейронная сеть с прямой связью.
Эта техника до сих пор используется для тренировки большого глубокое обучение сетей.
В этом руководстве вы узнаете, как реализовать алгоритм обратного распространения с нуля с помощью Python.
После завершения этого урока вы узнаете:
- Как переадресовать входные данные для вычисления выходных данных.
- Как распространять ошибки и обучать сеть.
- Как применить алгоритм обратного распространения к реальной задаче прогнозного моделирования.
Давайте начнем.
- Обновление ноябрь 2016: Исправлена ошибка в функции activ (). Спасибо Алекс!
- Обновление январь / 2017: Изменено вычисление fold_size в cross_validation_split (), чтобы оно всегда было целым числом. Исправляет проблемы с Python 3.
- Обновление январь / 2017: Обновлена небольшая ошибка в update_weights (). Спасибо, Томаш!
- Обновление апрель / 2018: Добавлена прямая ссылка на набор данных CSV.
- Обновление Авг / 2018: Протестировано и обновлено для работы с Python 3.6.

Описание
В этом разделе дается краткое введение в алгоритм обратного распространения и набор данных семян пшеницы, которые мы будем использовать в этом руководстве.
Алгоритм обратного распространения
Алгоритм обратного распространения — это контролируемый метод обучения для многослойных сетей прямой связи из области искусственных нейронных сетей.
Прямые нейронные сети вдохновлены обработкой информации одной или нескольких нейронных клеток, называемых нейронами. Нейрон принимает входные сигналы через свои дендриты, которые передают электрический сигнал в тело клетки. Аксон передает сигнал в синапсы, которые являются связями аксона клетки с дендритами другой клетки.
Принцип обратного распространения заключается в моделировании заданной функции путем изменения внутренних весовых коэффициентов входных сигналов для получения ожидаемого выходного сигнала. Система обучается с использованием метода контролируемого обучения, где ошибка между выходными данными системы и известным ожидаемым выходным значением представляется системе и используется для изменения ее внутреннего состояния.
Технически алгоритм обратного распространения — это метод обучения весов в многослойной нейронной сети с прямой связью. Как таковой, он требует, чтобы сетевая структура была определена из одного или нескольких уровней, где один уровень полностью связан со следующим уровнем. Стандартная сетевая структура — это один входной слой, один скрытый слой и один выходной слой.
Обратное распространение можно использовать как для задач классификации, так и для задач регрессии, но в этом руководстве мы сосредоточимся на классификации.
В задачах классификации наилучшие результаты достигаются, когда сеть имеет один нейрон в выходном слое для каждого значения класса. Например, проблема 2-классовой или двоичной классификации со значениями классов A и B. Эти ожидаемые результаты должны быть преобразованы в двоичные векторы с одним столбцом для каждого значения класса. Например, [1, 0] и [0, 1] для A и B соответственно. Это называется горячим кодированием.
Набор данных семян пшеницы
Набор данных семян включает в себя прогнозирование видов с учетом измерений семян из разных сортов пшеницы.
Есть 201 записей и 7 числовых входных переменных. Это проблема классификации с 3 выходными классами. Шкала для каждого числового входного значения варьируется, поэтому может потребоваться некоторая нормализация данных для использования с алгоритмами, которые взвешивают входные данные, такие как алгоритм обратного распространения.
Ниже приведен образец первых 5 строк набора данных.
15.26,14.84,0.871,5.763,3.312,2.221,5.22,1
14.88,14.57,0.8811,5.554,3.333,1.018,4.956,1
14.29,14.09,0.905,5.291,3.337,2.699,4.825,1
13.84,13.94,0.8955,5.324,3.379,2.259,4.805,1
16.14,14.99,0.9034,5.658,3.562,1.355,5.175,1При использовании алгоритма нулевого правила, который прогнозирует наиболее распространенное значение класса, базовая точность задачи составляет 28,095%.
Вы можете узнать больше и загрузить набор данных семян из UCI Хранилище Машинного Обучения,
Загрузите набор данных seed и поместите его в текущий рабочий каталог с именем файлаseeds_dataset.csv,
Набор данных представлен в формате табуляции, поэтому его необходимо преобразовать в CSV с помощью текстового редактора или программы для работы с электронными таблицами.
Обновите, загрузите набор данных в формате CSV напрямую:
- Скачать набор данных семян пшеницы
Руководство
Этот урок разбит на 6 частей:
- Инициализировать сеть.
- Вперед Распространять.
- Ошибка обратного распространения.
- Сеть поездов.
- Предсказать.
- Пример набора данных семян.
Эти шаги обеспечат основу, необходимую для реализации алгоритма обратного распространения с нуля и применения его к собственным задачам прогнозного моделирования.
1. Инициализировать сеть
Давайте начнем с чего-то простого, создания новой сети, готовой к обучению.
Каждый нейрон имеет набор весов, которые необходимо поддерживать. Один вес для каждого входного соединения и дополнительный вес для смещения. Нам нужно будет хранить дополнительные свойства для нейрона во время обучения, поэтому мы будем использовать словарь для представления каждого нейрона и сохранять свойства по именам, таким как ‘веса‘Для весов.
Сеть организована в слои. Входной слой на самом деле просто строка из нашего набора обучающих данных Первый настоящий слой — это скрытый слой. Затем следует выходной слой, который имеет один нейрон для каждого значения класса.
Мы организуем слои как массивы словарей и будем рассматривать всю сеть как массив слоев.
Хорошей практикой является инициализация весов сети небольшими случайными числами. В этом случае мы будем использовать случайные числа в диапазоне от 0 до 1.
Ниже приведена функция с именемinitialize_network ()это создает новую нейронную сеть, готовую к обучению. Он принимает три параметра: количество входов, количество нейронов в скрытом слое и количество выходов.
Вы можете видеть, что для скрытого слоя мы создаемn_hiddenнейроны и каждый нейрон в скрытом слое имеетn_inputs + 1веса, один для каждого входного столбца в наборе данных и дополнительный для смещения.
Вы также можете видеть, что выходной слой, который подключается к скрытому слою, имеетn_outputsнейроны, каждый сn_hidden + 1веса. Это означает, что каждый нейрон в выходном слое соединяется (имеет вес) с каждым нейроном в скрытом слое.
# Initialize a network
def initialize_network(n_inputs, n_hidden, n_outputs):
network = list()
hidden_layer = [{'weights':[random() for i in range(n_inputs + 1)]} for i in range(n_hidden)]
network.append(hidden_layer)
output_layer = [{'weights':[random() for i in range(n_hidden + 1)]} for i in range(n_outputs)]
network.append(output_layer)
return networkДавайте проверим эту функцию. Ниже приведен полный пример, который создает небольшую сеть.
from random import seed
from random import random
# Initialize a network
def initialize_network(n_inputs, n_hidden, n_outputs):
network = list()
hidden_layer = [{'weights':[random() for i in range(n_inputs + 1)]} for i in range(n_hidden)]
network.append(hidden_layer)
output_layer = [{'weights':[random() for i in range(n_hidden + 1)]} for i in range(n_outputs)]
network.append(output_layer)
return network
seed(1)
network = initialize_network(2, 1, 2)
for layer in network:
print(layer)Запустив пример, вы можете увидеть, что код распечатывает каждый слой по одному. Вы можете видеть, что скрытый слой имеет один нейрон с 2 входными весами плюс смещение. Выходной слой имеет 2 нейрона, каждый с 1 весом плюс смещение.
[{'weights': [0.13436424411240122, 0.8474337369372327, 0.763774618976614]}]
[{'weights': [0.2550690257394217, 0.49543508709194095]}, {'weights': [0.4494910647887381, 0.651592972722763]}]Теперь, когда мы знаем, как создать и инициализировать сеть, давайте посмотрим, как мы можем использовать ее для вычисления результата.
2. Вперед Распространение
Мы можем вычислить выход из нейронной сети, распространяя входной сигнал через каждый уровень, пока выходной уровень не выведет свои значения.
Мы называем это продвижением вперед.
Это метод, который нам понадобится для генерации прогнозов во время обучения, который необходимо будет исправить, и это метод, который нам понадобится после обучения сети для прогнозирования новых данных.
Мы можем разбить распространение вперед на три части:
- Активация нейронов.
- Передача нейронов.
- Вперед Распространение.
2.1. Активация нейронов
Первым шагом является вычисление активации одного нейрона с учетом входных данных.
Входными данными может быть строка из нашего обучающего набора данных, как в случае со скрытым слоем. Это также могут быть выходы от каждого нейрона в скрытом слое, в случае выходного слоя.
Активация нейрона рассчитывается как взвешенная сумма входов. Очень похоже на линейную регрессию.
activation = sum(weight_i * input_i) + biasкудавесвес сети,входявляется входом,яэто индекс веса или ввода исмещениеэто специальный вес, который не имеет входных данных для умножения (или вы можете думать, что входные данные всегда равны 1,0).
Ниже приведена реализация этого в функции с именемактивировать (), Вы можете видеть, что функция предполагает, что смещение является последним весом в списке весов. Это помогает здесь и позже сделать код легче для чтения.
# Calculate neuron activation for an input
def activate(weights, inputs):
activation = weights[-1]
for i in range(len(weights)-1):
activation += weights[i] * inputs[i]
return activationТеперь давайте посмотрим, как использовать активацию нейронов.
2.2. Нейрон Трансфер
Как только нейрон активирован, нам нужно перенести активацию, чтобы увидеть, что на самом деле представляет собой выход нейрона.
Различные передаточные функции могут быть использованы. Традиционно использовать функция активации сигмовидной кишки, но вы также можете использовать танх (тангенс гиперболический) функция для передачи выходов. Совсем недавно передаточная функция выпрямителя был популярен в крупных сетях глубокого обучения.
Функция активации сигмоида выглядит как S-образная форма, ее также называют логистической функцией. Он может принимать любое входное значение и производить число от 0 до 1 на S-кривой. Это также функция, из которой мы можем легко рассчитать производную (наклон), которая понадобится нам позже при ошибке обратного распространения.
Мы можем передать функцию активации с помощью функции сигмоида следующим образом:
output = 1 / (1 + e^(-activation))кудаеявляется основанием натуральных логарифмов (Номер Эйлера).
Ниже приведена функция с именемперечислить()который реализует сигмовидное уравнение.
# Transfer neuron activation
def transfer(activation):
return 1.0 / (1.0 + exp(-activation))Теперь, когда у нас есть кусочки, давайте посмотрим, как они используются.
2,3. Прямое распространение
Вперед, распространение входных данных просто.
Мы работаем через каждый слой нашей сети, вычисляя выходы для каждого нейрона. Все выходы из одного слоя становятся входами для нейронов на следующем слое.
Ниже приведена функция с именемforward_propagate ()это реализует прямое распространение для ряда данных из нашего набора данных с нашей нейронной сетью.
Вы можете видеть, что выходное значение нейрона хранится в нейроне с именем ‘выход«. Вы также можете увидеть, что мы собираем выходные данные для слоя в массиве с именемnew_inputsэто становится массивомвходныеи используется в качестве входных данных для следующего слоя.
Функция возвращает выходные данные из последнего слоя, также называемого выходным слоем.
# Forward propagate input to a network output
def forward_propagate(network, row):
inputs = row
for layer in network:
new_inputs = []
for neuron in layer:
activation = activate(neuron['weights'], inputs)
neuron['output'] = transfer(activation)
new_inputs.append(neuron['output'])
inputs = new_inputs
return inputsДавайте соединим все эти части и протестируем прямое распространение нашей сети.
Мы определяем нашу сеть, встроенную одним скрытым нейроном, который ожидает 2 входных значения, и выходной слой с двумя нейронами.
from math import exp
# Calculate neuron activation for an input
def activate(weights, inputs):
activation = weights[-1]
for i in range(len(weights)-1):
activation += weights[i] * inputs[i]
return activation
# Transfer neuron activation
def transfer(activation):
return 1.0 / (1.0 + exp(-activation))
# Forward propagate input to a network output
def forward_propagate(network, row):
inputs = row
for layer in network:
new_inputs = []
for neuron in layer:
activation = activate(neuron['weights'], inputs)
neuron['output'] = transfer(activation)
new_inputs.append(neuron['output'])
inputs = new_inputs
return inputs
# test forward propagation
network = [[{'weights': [0.13436424411240122, 0.8474337369372327, 0.763774618976614]}],
[{'weights': [0.2550690257394217, 0.49543508709194095]}, {'weights': [0.4494910647887381, 0.651592972722763]}]]
row = [1, 0, None]
output = forward_propagate(network, row)
print(output)Выполнение примера распространяет входной шаблон [1, 0] и выдает выходное значение, которое печатается. Поскольку выходной слой имеет два нейрона, мы получаем список из двух чисел в качестве вывода.
Фактические выходные значения на данный момент просто бессмыслица, но затем мы начнем изучать, как сделать веса в нейронах более полезными.
[0.6629970129852887, 0.7253160725279748]3. Ошибка обратного распространения
Алгоритм обратного распространения назван по способу обучения весов.
Ошибка рассчитывается между ожидаемыми выходами и выходами, передаваемыми по сети. Эти ошибки затем распространяются в обратном направлении через сеть от выходного уровня к скрытому слою, назначая вину за ошибку и обновляя веса по мере их появления.
Математика для ошибки обратного распространения коренится в исчислении, но мы останемся на высоком уровне в этом разделе и сосредоточимся на том, что рассчитывается и как, а не почему расчеты принимают эту конкретную форму.
Эта часть разбита на две части.
- Передача Производная.
- Ошибка обратного распространения.
3.1. Производная передача
Учитывая выходное значение от нейрона, нам нужно вычислить его наклон.
Мы используем передаточную функцию сигмоида, производную которой можно рассчитать следующим образом:
derivative = output * (1.0 - output)Ниже приведена функция с именемtransfer_derivative ()который реализует это уравнение.
# Calculate the derivative of an neuron output
def transfer_derivative(output):
return output * (1.0 - output)Теперь посмотрим, как это можно использовать.
3.2. Ошибка обратного распространения
Первым шагом является вычисление ошибки для каждого выходного нейрона, это даст нам наш сигнал ошибки (вход) для распространения в обратном направлении по сети.
Ошибка для данного нейрона может быть рассчитана следующим образом:
error = (expected - output) * transfer_derivative(output)кудаожидаемыйявляется ожидаемым выходным значением для нейрона,выходэто выходное значение для нейрона иtransfer_derivative ()вычисляет наклон выходного значения нейрона, как показано выше.
Этот расчет ошибки используется для нейронов в выходном слое. Ожидаемое значение — это само значение класса. В скрытом слое все немного сложнее.
Сигнал ошибки для нейрона в скрытом слое рассчитывается как взвешенная ошибка каждого нейрона в выходном слое. Подумайте об ошибке, связанной с перемещением весов выходного слоя к нейронам в скрытом слое.
Обратно распространяющийся сигнал ошибки накапливается и затем используется для определения ошибки для нейрона в скрытом слое следующим образом:
error = (weight_k * error_j) * transfer_derivative(output)кудаerror_jэто сигнал ошибки отJй нейрон в выходном слое,weight_kэто вес, который соединяетКТретий нейрон к текущему нейрону и выход — это выход для текущего нейрона.
Ниже приведена функция с именемbackward_propagate_error ()который реализует эту процедуру.
Вы можете видеть, что сигнал ошибки, рассчитанный для каждого нейрона, хранится с именем «delta». Вы можете видеть, что слои сети перебираются в обратном порядке, начиная с выхода и работая в обратном направлении. Это гарантирует, что нейроны в выходном слое сначала рассчитывают значения «дельта», которые нейроны в скрытом слое могут использовать в последующей итерации. Я выбрал имя «дельта», чтобы отразить изменение, которое ошибка вносит в нейрон (например, дельта веса).
Вы можете видеть, что сигнал ошибки для нейронов в скрытом слое накапливается от нейронов в выходном слое, где скрыт номер нейронаJтакже индекс веса нейрона в выходном слоенейрон [грузики ‘] [J],
# Backpropagate error and store in neurons
def backward_propagate_error(network, expected):
for i in reversed(range(len(network))):
layer = network[i]
errors = list()
if i != len(network)-1:
for j in range(len(layer)):
error = 0.0
for neuron in network[i + 1]:
error += (neuron['weights'][j] * neuron['delta'])
errors.append(error)
else:
for j in range(len(layer)):
neuron = layer[j]
errors.append(expected[j] - neuron['output'])
for j in range(len(layer)):
neuron = layer[j]
neuron['delta'] = errors[j] * transfer_derivative(neuron['output'])Давайте соберем все части вместе и посмотрим, как это работает.
Мы определяем фиксированную нейронную сеть с выходными значениями и распространяем ожидаемый выходной шаблон. Полный пример приведен ниже.
# Calculate the derivative of an neuron output
def transfer_derivative(output):
return output * (1.0 - output)
# Backpropagate error and store in neurons
def backward_propagate_error(network, expected):
for i in reversed(range(len(network))):
layer = network[i]
errors = list()
if i != len(network)-1:
for j in range(len(layer)):
error = 0.0
for neuron in network[i + 1]:
error += (neuron['weights'][j] * neuron['delta'])
errors.append(error)
else:
for j in range(len(layer)):
neuron = layer[j]
errors.append(expected[j] - neuron['output'])
for j in range(len(layer)):
neuron = layer[j]
neuron['delta'] = errors[j] * transfer_derivative(neuron['output'])
# test backpropagation of error
network = [[{'output': 0.7105668883115941, 'weights': [0.13436424411240122, 0.8474337369372327, 0.763774618976614]}],
[{'output': 0.6213859615555266, 'weights': [0.2550690257394217, 0.49543508709194095]}, {'output': 0.6573693455986976, 'weights': [0.4494910647887381, 0.651592972722763]}]]
expected = [0, 1]
backward_propagate_error(network, expected)
for layer in network:
print(layer)При выполнении примера печатается сеть после обратного распространения ошибки. Вы можете видеть, что значения ошибок рассчитываются и сохраняются в нейронах для выходного слоя и скрытого слоя.
[{'output': 0.7105668883115941, 'weights': [0.13436424411240122, 0.8474337369372327, 0.763774618976614], 'delta': -0.0005348048046610517}]
[{'output': 0.6213859615555266, 'weights': [0.2550690257394217, 0.49543508709194095], 'delta': -0.14619064683582808}, {'output': 0.6573693455986976, 'weights': [0.4494910647887381, 0.651592972722763], 'delta': 0.0771723774346327}]Теперь давайте использовать обратное распространение ошибки для обучения сети.
4. Сеть поездов
Сеть обучается с использованием стохастического градиентного спуска.
Это включает в себя несколько итераций представления обучающего набора данных в сеть и для каждой строки данных, передавая входные данные, распространяя ошибку в обратном направлении и обновляя веса сети.
Эта часть разбита на две части:
- Обновление весов.
- Сеть поездов.
4.1. Обновление весов
Как только ошибки рассчитаны для каждого нейрона в сети с помощью метода обратного распространения, описанного выше, их можно использовать для обновления весов.
Веса сети обновляются следующим образом:
weight = weight + learning_rate * error * inputкудавесзаданный вес,learning_rateэто параметр, который вы должны указать,ошибкаошибка, рассчитанная по процедуре обратного распространения для нейрона ивходэто входное значение, вызвавшее ошибку
Та же процедура может использоваться для обновления веса смещения, за исключением того, что нет входного термина или входное значение является фиксированным значением 1,0.
Скорость обучения определяет, насколько изменить вес, чтобы исправить ошибку. Например, значение 0,1 обновит вес на 10% от суммы, которую он мог бы обновить. Предпочтительными являются малые скорости обучения, которые вызывают более медленное обучение в течение большого количества итераций обучения. Это увеличивает вероятность того, что сеть найдет хороший набор весов на всех уровнях, а не самый быстрый набор весов, которые минимизируют ошибку (так называемая преждевременная сходимость).
Ниже приведена функция с именемupdate_weights ()который обновляет весовые коэффициенты для сети с учетом входной строки данных, скорости обучения и предполагает, что прямое и обратное распространение уже выполнено.
Помните, что вход для выходного слоя представляет собой набор выходов из скрытого слоя.
# Update network weights with error
def update_weights(network, row, l_rate):
for i in range(len(network)):
inputs = row[:-1]
if i != 0:
inputs = [neuron['output'] for neuron in network[i - 1]]
for neuron in network[i]:
for j in range(len(inputs)):
neuron['weights'][j] += l_rate * neuron['delta'] * inputs[j]
neuron['weights'][-1] += l_rate * neuron['delta']Теперь мы знаем, как обновить вес сети, давайте посмотрим, как мы можем сделать это многократно.
4.2. Сеть поездов
Как уже упоминалось, сеть обновляется с использованием стохастического градиентного спуска.
Это включает в себя первый цикл для фиксированного числа эпох и в каждой эпохе обновление сети для каждой строки в наборе обучающих данных.
Поскольку обновления производятся для каждого шаблона обучения, этот тип обучения называется онлайн-обучением. Если ошибки были накоплены за период до обновления весов, это называется периодическим обучением или пакетным градиентным спуском.
Ниже приведена функция, которая реализует обучение уже инициализированной нейронной сети с заданным набором обучающих данных, скоростью обучения, фиксированным числом эпох и ожидаемым количеством выходных значений.
Ожидаемое количество выходных значений используется для преобразования значений класса в обучающих данных в одно горячее кодирование. Это двоичный вектор с одним столбцом для каждого значения класса, чтобы соответствовать выходу сети. Это необходимо для расчета ошибки для выходного слоя.
Вы также можете видеть, что ошибка квадрата суммы между ожидаемым выходом и выходом сети накапливается каждую эпоху и печатается. Это полезно для отслеживания того, насколько сеть изучает и совершенствует каждую эпоху.
# Train a network for a fixed number of epochs
def train_network(network, train, l_rate, n_epoch, n_outputs):
for epoch in range(n_epoch):
sum_error = 0
for row in train:
outputs = forward_propagate(network, row)
expected = [0 for i in range(n_outputs)]
expected[row[-1]] = 1
sum_error += sum([(expected[i]-outputs[i])**2 for i in range(len(expected))])
backward_propagate_error(network, expected)
update_weights(network, row, l_rate)
print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))Теперь у нас есть все для обучения сети. Мы можем собрать пример, который включает в себя все, что мы видели до сих пор, включая инициализацию сети и обучение сети на небольшом наборе данных.
Ниже приведен небольшой надуманный набор данных, который мы можем использовать для тестирования нашей нейронной сети.
X1 X2 Y
2.7810836 2.550537003 0
1.465489372 2.362125076 0
3.396561688 4.400293529 0
1.38807019 1.850220317 0
3.06407232 3.005305973 0
7.627531214 2.759262235 1
5.332441248 2.088626775 1
6.922596716 1.77106367 1
8.675418651 -0.242068655 1
7.673756466 3.508563011 1Ниже приведен полный пример. Мы будем использовать 2 нейрона в скрытом слое. Это проблема двоичной классификации (2 класса), поэтому в выходном слое будет два нейрона. Сеть будет обучаться в течение 20 эпох со скоростью обучения 0,5, что является высоким показателем, потому что мы готовим так мало итераций.
from math import exp
from random import seed
from random import random
# Initialize a network
def initialize_network(n_inputs, n_hidden, n_outputs):
network = list()
hidden_layer = [{'weights':[random() for i in range(n_inputs + 1)]} for i in range(n_hidden)]
network.append(hidden_layer)
output_layer = [{'weights':[random() for i in range(n_hidden + 1)]} for i in range(n_outputs)]
network.append(output_layer)
return network
# Calculate neuron activation for an input
def activate(weights, inputs):
activation = weights[-1]
for i in range(len(weights)-1):
activation += weights[i] * inputs[i]
return activation
# Transfer neuron activation
def transfer(activation):
return 1.0 / (1.0 + exp(-activation))
# Forward propagate input to a network output
def forward_propagate(network, row):
inputs = row
for layer in network:
new_inputs = []
for neuron in layer:
activation = activate(neuron['weights'], inputs)
neuron['output'] = transfer(activation)
new_inputs.append(neuron['output'])
inputs = new_inputs
return inputs
# Calculate the derivative of an neuron output
def transfer_derivative(output):
return output * (1.0 - output)
# Backpropagate error and store in neurons
def backward_propagate_error(network, expected):
for i in reversed(range(len(network))):
layer = network[i]
errors = list()
if i != len(network)-1:
for j in range(len(layer)):
error = 0.0
for neuron in network[i + 1]:
error += (neuron['weights'][j] * neuron['delta'])
errors.append(error)
else:
for j in range(len(layer)):
neuron = layer[j]
errors.append(expected[j] - neuron['output'])
for j in range(len(layer)):
neuron = layer[j]
neuron['delta'] = errors[j] * transfer_derivative(neuron['output'])
# Update network weights with error
def update_weights(network, row, l_rate):
for i in range(len(network)):
inputs = row[:-1]
if i != 0:
inputs = [neuron['output'] for neuron in network[i - 1]]
for neuron in network[i]:
for j in range(len(inputs)):
neuron['weights'][j] += l_rate * neuron['delta'] * inputs[j]
neuron['weights'][-1] += l_rate * neuron['delta']
# Train a network for a fixed number of epochs
def train_network(network, train, l_rate, n_epoch, n_outputs):
for epoch in range(n_epoch):
sum_error = 0
for row in train:
outputs = forward_propagate(network, row)
expected = [0 for i in range(n_outputs)]
expected[row[-1]] = 1
sum_error += sum([(expected[i]-outputs[i])**2 for i in range(len(expected))])
backward_propagate_error(network, expected)
update_weights(network, row, l_rate)
print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))
# Test training backprop algorithm
seed(1)
dataset = [[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]]
n_inputs = len(dataset[0]) - 1
n_outputs = len(set([row[-1] for row in dataset]))
network = initialize_network(n_inputs, 2, n_outputs)
train_network(network, dataset, 0.5, 20, n_outputs)
for layer in network:
print(layer)При запуске примера сначала выводится ошибка квадрата суммы в каждую эпоху обучения. Мы можем видеть тенденцию уменьшения этой ошибки с каждой эпохой.
После обучения распечатывается сеть с отображением изученных весов. Также все еще в сети находятся выходные и дельта-значения, которые можно игнорировать. Мы могли бы обновить нашу функцию обучения, чтобы удалить эти данные, если мы хотим.
>epoch=0, lrate=0.500, error=6.350
>epoch=1, lrate=0.500, error=5.531
>epoch=2, lrate=0.500, error=5.221
>epoch=3, lrate=0.500, error=4.951
>epoch=4, lrate=0.500, error=4.519
>epoch=5, lrate=0.500, error=4.173
>epoch=6, lrate=0.500, error=3.835
>epoch=7, lrate=0.500, error=3.506
>epoch=8, lrate=0.500, error=3.192
>epoch=9, lrate=0.500, error=2.898
>epoch=10, lrate=0.500, error=2.626
>epoch=11, lrate=0.500, error=2.377
>epoch=12, lrate=0.500, error=2.153
>epoch=13, lrate=0.500, error=1.953
>epoch=14, lrate=0.500, error=1.774
>epoch=15, lrate=0.500, error=1.614
>epoch=16, lrate=0.500, error=1.472
>epoch=17, lrate=0.500, error=1.346
>epoch=18, lrate=0.500, error=1.233
>epoch=19, lrate=0.500, error=1.132
[{'weights': [-1.4688375095432327, 1.850887325439514, 1.0858178629550297], 'output': 0.029980305604426185, 'delta': -0.0059546604162323625}, {'weights': [0.37711098142462157, -0.0625909894552989, 0.2765123702642716], 'output': 0.9456229000211323, 'delta': 0.0026279652850863837}]
[{'weights': [2.515394649397849, -0.3391927502445985, -0.9671565426390275], 'output': 0.23648794202357587, 'delta': -0.04270059278364587}, {'weights': [-2.5584149848484263, 1.0036422106209202, 0.42383086467582715], 'output': 0.7790535202438367, 'delta': 0.03803132596437354}]Как только сеть обучена, мы должны использовать ее для прогнозирования.
5. Предсказать
Делать прогнозы с помощью обученной нейронной сети достаточно просто.
Мы уже видели, как распространять входной шаблон для получения выходного сигнала. Это все, что нам нужно сделать, чтобы сделать прогноз. Мы можем непосредственно использовать выходные значения как вероятность того, что шаблон принадлежит каждому выходному классу.
Возможно, было бы более полезно превратить этот вывод в четкое предсказание класса. Мы можем сделать это, выбрав значение класса с большей вероятностью. Это также называется функция arg max,
Ниже приведена функция с именемпредсказать, ()который реализует эту процедуру. Возвращает индекс в выходных данных сети, который имеет наибольшую вероятность. Предполагается, что значения класса были преобразованы в целые числа, начиная с 0.
# Make a prediction with a network
def predict(network, row):
outputs = forward_propagate(network, row)
return outputs.index(max(outputs))Мы можем соединить это с нашим кодом выше для входного распространения и с нашим небольшим надуманным набором данных, чтобы проверить предсказания с уже обученной сетью. Пример жестко кодирует сеть, обученную на предыдущем шаге.
Полный пример приведен ниже.
from math import exp
# Calculate neuron activation for an input
def activate(weights, inputs):
activation = weights[-1]
for i in range(len(weights)-1):
activation += weights[i] * inputs[i]
return activation
# Transfer neuron activation
def transfer(activation):
return 1.0 / (1.0 + exp(-activation))
# Forward propagate input to a network output
def forward_propagate(network, row):
inputs = row
for layer in network:
new_inputs = []
for neuron in layer:
activation = activate(neuron['weights'], inputs)
neuron['output'] = transfer(activation)
new_inputs.append(neuron['output'])
inputs = new_inputs
return inputs
# Make a prediction with a network
def predict(network, row):
outputs = forward_propagate(network, row)
return outputs.index(max(outputs))
# Test making predictions with the network
dataset = [[2.7810836,2.550537003,0],
[1.465489372,2.362125076,0],
[3.396561688,4.400293529,0],
[1.38807019,1.850220317,0],
[3.06407232,3.005305973,0],
[7.627531214,2.759262235,1],
[5.332441248,2.088626775,1],
[6.922596716,1.77106367,1],
[8.675418651,-0.242068655,1],
[7.673756466,3.508563011,1]]
network = [[{'weights': [-1.482313569067226, 1.8308790073202204, 1.078381922048799]}, {'weights': [0.23244990332399884, 0.3621998343835864, 0.40289821191094327]}],
[{'weights': [2.5001872433501404, 0.7887233511355132, -1.1026649757805829]}, {'weights': [-2.429350576245497, 0.8357651039198697, 1.0699217181280656]}]]
for row in dataset:
prediction = predict(network, row)
print('Expected=%d, Got=%d' % (row[-1], prediction))При выполнении примера выводится ожидаемый результат для каждой записи в наборе обучающих данных, за которым следует четкое предсказание, сделанное сетью.
Это показывает, что сеть достигает 100% точности в этом небольшом наборе данных.
Expected=0, Got=0
Expected=0, Got=0
Expected=0, Got=0
Expected=0, Got=0
Expected=0, Got=0
Expected=1, Got=1
Expected=1, Got=1
Expected=1, Got=1
Expected=1, Got=1
Expected=1, Got=1Теперь мы готовы применить наш алгоритм обратного распространения к реальному набору данных.
6. Набор данных семян пшеницы
В этом разделе применяется алгоритм обратного распространения к набору данных семян пшеницы.
Первым шагом является загрузка набора данных и преобразование загруженных данных в числа, которые мы можем использовать в нашей нейронной сети. Для этого мы будем использовать вспомогательную функциюload_csv ()загрузить файл,str_column_to_float ()преобразовать строковые числа в числа с плавающей запятой иstr_column_to_int ()преобразовать столбец класса в целочисленные значения.
Входные значения различаются по масштабу и должны быть нормализованы в диапазоне от 0 до 1. Обычно рекомендуется нормализовать входные значения в диапазоне выбранной передаточной функции, в данном случае сигмоидальной функции, которая выводит значения в диапазоне от 0 до 1. .dataset_minmax ()а такжеnormalize_dataset ()вспомогательные функции были использованы для нормализации входных значений.
Мы оценим алгоритм с использованием k-кратной перекрестной проверки с 5-кратным увеличением. Это означает, что 201/5 = 40,2 или 40 записей будут в каждом сгибе. Мы будем использовать вспомогательные функцииevaluate_algorithm ()оценить алгоритм с перекрестной проверкой иaccuracy_metric ()рассчитать точность прогнозов.
Новая функция с именемback_propagation ()был разработан для управления приложением алгоритма Backpropagation, сначала инициализируя сеть, обучая ее на наборе обучающих данных, а затем используя обученную сеть, чтобы делать прогнозы на тестовом наборе данных.
Полный пример приведен ниже.
# Backprop on the Seeds Dataset
from random import seed
from random import randrange
from random import random
from csv import reader
from math import exp
# Load a CSV file
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# Convert string column to float
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# Convert string column to integer
def str_column_to_int(dataset, column):
class_values = [row[column] for row in dataset]
unique = set(class_values)
lookup = dict()
for i, value in enumerate(unique):
lookup[value] = i
for row in dataset:
row[column] = lookup[row[column]]
return lookup
# Find the min and max values for each column
def dataset_minmax(dataset):
minmax = list()
stats = [[min(column), max(column)] for column in zip(*dataset)]
return stats
# Rescale dataset columns to the range 0-1
def normalize_dataset(dataset, minmax):
for row in dataset:
for i in range(len(row)-1):
row[i] = (row[i] - minmax[i][0]) / (minmax[i][1] - minmax[i][0])
# Split a dataset into k folds
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# Calculate accuracy percentage
def accuracy_metric(actual, predicted):
correct = 0
for i in range(len(actual)):
if actual[i] == predicted[i]:
correct += 1
return correct / float(len(actual)) * 100.0
# Evaluate an algorithm using a cross validation split
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in fold]
accuracy = accuracy_metric(actual, predicted)
scores.append(accuracy)
return scores
# Calculate neuron activation for an input
def activate(weights, inputs):
activation = weights[-1]
for i in range(len(weights)-1):
activation += weights[i] * inputs[i]
return activation
# Transfer neuron activation
def transfer(activation):
return 1.0 / (1.0 + exp(-activation))
# Forward propagate input to a network output
def forward_propagate(network, row):
inputs = row
for layer in network:
new_inputs = []
for neuron in layer:
activation = activate(neuron['weights'], inputs)
neuron['output'] = transfer(activation)
new_inputs.append(neuron['output'])
inputs = new_inputs
return inputs
# Calculate the derivative of an neuron output
def transfer_derivative(output):
return output * (1.0 - output)
# Backpropagate error and store in neurons
def backward_propagate_error(network, expected):
for i in reversed(range(len(network))):
layer = network[i]
errors = list()
if i != len(network)-1:
for j in range(len(layer)):
error = 0.0
for neuron in network[i + 1]:
error += (neuron['weights'][j] * neuron['delta'])
errors.append(error)
else:
for j in range(len(layer)):
neuron = layer[j]
errors.append(expected[j] - neuron['output'])
for j in range(len(layer)):
neuron = layer[j]
neuron['delta'] = errors[j] * transfer_derivative(neuron['output'])
# Update network weights with error
def update_weights(network, row, l_rate):
for i in range(len(network)):
inputs = row[:-1]
if i != 0:
inputs = [neuron['output'] for neuron in network[i - 1]]
for neuron in network[i]:
for j in range(len(inputs)):
neuron['weights'][j] += l_rate * neuron['delta'] * inputs[j]
neuron['weights'][-1] += l_rate * neuron['delta']
# Train a network for a fixed number of epochs
def train_network(network, train, l_rate, n_epoch, n_outputs):
for epoch in range(n_epoch):
for row in train:
outputs = forward_propagate(network, row)
expected = [0 for i in range(n_outputs)]
expected[row[-1]] = 1
backward_propagate_error(network, expected)
update_weights(network, row, l_rate)
# Initialize a network
def initialize_network(n_inputs, n_hidden, n_outputs):
network = list()
hidden_layer = [{'weights':[random() for i in range(n_inputs + 1)]} for i in range(n_hidden)]
network.append(hidden_layer)
output_layer = [{'weights':[random() for i in range(n_hidden + 1)]} for i in range(n_outputs)]
network.append(output_layer)
return network
# Make a prediction with a network
def predict(network, row):
outputs = forward_propagate(network, row)
return outputs.index(max(outputs))
# Backpropagation Algorithm With Stochastic Gradient Descent
def back_propagation(train, test, l_rate, n_epoch, n_hidden):
n_inputs = len(train[0]) - 1
n_outputs = len(set([row[-1] for row in train]))
network = initialize_network(n_inputs, n_hidden, n_outputs)
train_network(network, train, l_rate, n_epoch, n_outputs)
predictions = list()
for row in test:
prediction = predict(network, row)
predictions.append(prediction)
return(predictions)
# Test Backprop on Seeds dataset
seed(1)
# load and prepare data
filename = 'seeds_dataset.csv'
dataset = load_csv(filename)
for i in range(len(dataset[0])-1):
str_column_to_float(dataset, i)
# convert class column to integers
str_column_to_int(dataset, len(dataset[0])-1)
# normalize input variables
minmax = dataset_minmax(dataset)
normalize_dataset(dataset, minmax)
# evaluate algorithm
n_folds = 5
l_rate = 0.3
n_epoch = 500
n_hidden = 5
scores = evaluate_algorithm(dataset, back_propagation, n_folds, l_rate, n_epoch, n_hidden)
print('Scores: %s' % scores)
print('Mean Accuracy: %.3f%%' % (sum(scores)/float(len(scores))))Была построена сеть с 5 нейронами в скрытом слое и 3 нейронами в выходном слое. Сеть была подготовлена для 500 эпох с темпом обучения 0,3. Эти параметры были найдены с небольшой пробой и ошибкой, но вы можете сделать это намного лучше.
При выполнении примера выводится средняя точность классификации для каждого сгиба, а также средняя производительность по всем сгибам.
Вы можете видеть, что обратное распространение и выбранная конфигурация достигли средней точности классификации около 93%, что значительно лучше, чем алгоритм нулевого правила, который немного лучше, чем точность 28%.
Scores: [92.85714285714286, 92.85714285714286, 97.61904761904762, 92.85714285714286, 90.47619047619048]
Mean Accuracy: 93.333%расширения
В этом разделе перечислены расширения к учебнику, которые вы можете изучить.
- Параметры алгоритма настройки, Попробуйте большие или меньшие сети, обученные дольше или короче. Посмотрите, сможете ли вы улучшить производительность набора данных seed.
- Дополнительные методы, Поэкспериментируйте с различными методами инициализации веса (такими как небольшие случайные числа) и различными передаточными функциями (такими как tanh).
- Больше слоев, Добавьте поддержку для большего количества скрытых слоев, обученных так же, как один скрытый слой, используемый в этом руководстве.
- регрессия, Измените сеть так, чтобы в выходном слое был только один нейрон, и чтобы было предсказано реальное значение. Выберите регрессионный набор данных для практики. Линейная передаточная функция может использоваться для нейронов в выходном слое, или выходные значения выбранного набора данных могут быть масштабированы до значений между 0 и 1.
- Пакетный градиентный спуск, Измените процедуру обучения с онлайн на пакетный градиентный спуск и обновляйте веса только в конце каждой эпохи.
Вы пробовали какие-либо из этих расширений?
Поделитесь своим опытом в комментариях ниже.
Обзор
В этом руководстве вы узнали, как реализовать алгоритм обратного распространения с нуля.
В частности, вы узнали:
- Как переслать распространение входа для расчета выхода сети.
- Как обратно распространять ошибки и обновлять вес сети.
- Как применить алгоритм обратного распространения к реальному набору данных.
У вас есть вопросы?
Задайте свои вопросы в комментариях ниже, и я сделаю все возможное, чтобы ответить.
Практическая работа №1: Реализация метода обратного распространения ошибки для двухслойной полностью связанной нейронной сети
Задача
Требуется вывести расчетные формулы и спроектировать программную реализацию метода обратного распространения ошибки для двухслойной полносвязной нейронной сети. Обучение и тестирование сети происходит на наборе данных MNIST, функция активации скрытого слоя – relu, функция активации выходного слоя – softmax, функция ошибки – кросс-энтропия.

Математическая модель
Модель нейрона описывается следующими уравнениями:
где – входной сигнал, – синаптический вес сигнала , – функция активации, – смещение
Прямой ход
Для получения предсказания сети, производится прямой ход: для каждого нейрона последовательно, от начальных слоёв к конечным, вычисляется линейная активация входных сигналов, к ней применяется функция активации, после чего этот сигнал передаётся на следующий слой. В случае данной архитектуры:
где – выход скрытого слоя, – функция активации скрытого слоя (relu), – вход сети, – выход сети, – функция активации выходного слоя (softmax),
Метод обратного распространения ошибки
Метод обратного распространения ошибки определяет стратегию выбора весов сети 𝑤 с использованием градиентных методов оптимизации.
Схема обратного распространения ошибки состоит из следующих этапов:
-
Прямой проход по нейронной сети. На данном этапе вычисляются значения выходных сигналов каждого слоя, а так же производные их функций активации.
-
Вычисление значений целевой функции и её производной.
Целевая функция – кросс-энтропия, вычисляется как
где
– ожидаемый выход (метки)Производную целевой функции по весам можно вывести следующим образом:
По весам второго слоя:
из условия
получаемПо весам первого слоя
-
Обратный проход нейронной сети и корректировка весов
-
Повторение этапов 1-3 до выполнения условия останова
Описание программной реализации
Network.py
Содержит реализацию нейронной сети
Класс NN содержит данные и методы для работы с сетью
Поля класса NN:
_input_size – размер входного слоя
_hidden_size – размер скрытого слоя
_output_size – размер выходного слоя
_w1, _b1 – массивы для хранения весов и смещений первого слоя
_w2, _b2 – массивы для хранения весов и смещений второго слоя
Методы класса NN:
_forward(input) – прямой проход сети. Возвращает выходной сигнал первого и второго слоя
_calculate_dE(input, label, output1, output2) – вычисление градиента функции ошибки. Возвращает градиент функции по весам и биасам первого и второго слоёв
_backprop(learning_rate, size, dEb1, dEb2) – корректировка весов сети при помощи посчитанных градиентов
init_weights() – инициализация весов нормальным распределением с дисперсией 1/10
fit(input, label, validate_data = None, batch_size = 100, learning_rate = 0.1, epochs = 100) – пакетное обучение сети на epochs эпохах, скоростью обучения learning_rate, размером пакета batch_size. Выводит точность и значение целевой функции на каждой эпохе
predict(input) – получение предсказания сети
utils.py:
Содержит вспомогательные функции.
relu(X) – функция relu
reluD(X) – производная функции relu
calcilate_E(predict, label) – подсчёт функции ошибки на основании предсказания сети и верной разметки
calculate_acc(prediction ,label) – посчёт точности на основании предсказания сети и верной разметки
main.py
Обучает сеть из класса NN на MNIST с параметрами из аргументов запуска. Измеряет время обучения.
Аргументы:
-
—hidden – количество нейронов в скрытом слое
-
—epochs – количество эпох обучения
-
—lr – скорость обучения
-
—batch – размер пакета
Как вызывать:
python main.py --hidden 30 --epochs 20 --lr 0,1 --batch 100
(в примере указаны параметры по умолчанию)
Эксперименты
Размер скрытого слоя: 30, эпох: 20, скорость обучения: 0,1, размер пакета: 100
train accuracy: 0.9729 train error: 0.0913
validate accuracy: 0.9613 validate error: 0.1238
Time: 28.309726 seconds
Размер скрытого слоя: 10, эпох: 20, скорость обучения: 0,1, размер пакета: 100
train accuracy: 0.9469 train error: 0.1805
validate accuracy: 0.9404 validate error: 0.2013
Time: 18.23942 seconds
Размер скрытого слоя: 10, эпох: 20, скорость обучения: 0,1, размер пакета: 100
train accuracy: 0.9874 train error: 0.0467
validate accuracy: 0.9721 validate error: 0.0878
Time: 58.233283 seconds
Размер скрытого слоя: 30, эпох: 50, скорость обучения: 0,1, размер пакета: 100
train accuracy: 0.9875 train error: 0.0418
validate accuracy: 0.9678 validate error: 0.1216
Time: 70.004101 seconds
Размер скрытого слоя: 30, эпох: 20, скорость обучения: 0,5, размер пакета: 100
train accuracy: 0.9766 train error: 0.0732
validate accuracy: 0.9622 validate error: 0.1614
Time: 26.213141 seconds
Размер скрытого слоя: 30, эпох: 30, скорость обучения: 0,05, размер пакета: 100
train accuracy: 0.971 train error: 0.0998
validate accuracy: 0.9625 validate error: 0.1225
Time: 40.577051 seconds
Размер скрытого слоя: 30, эпох: 20, скорость обучения: 0,1, размер пакета: 10
train accuracy: 0.9724 train error: 0.0928
validate accuracy: 0.9533 validate error: 0.2423
Time: 65.179444 seconds
Размер скрытого слоя: 30, эпох: 20, скорость обучения: 0,1, размер пакета: 1000
train accuracy: 0.9268 train error: 0.2588
validate accuracy: 0.9264 validate error: 0.2576
Time: 25.455479 seconds
This article aims to implement a deep neural network from scratch. We will implement a deep neural network containing a hidden layer with four units and one output layer. The implementation will go from very scratch and the following steps will be implemented.
Algorithm:
1. Visualizing the input data 2. Deciding the shapes of Weight and bias matrix 3. Initializing matrix, function to be used 4. Implementing the forward propagation method 5. Implementing the cost calculation 6. Backpropagation and optimizing 7. prediction and visualizing the output
Architecture of the model:
The architecture of the model has been defined by the following figure where the hidden layer uses the Hyperbolic Tangent as the activation function while the output layer, being the classification problem uses the sigmoid function.
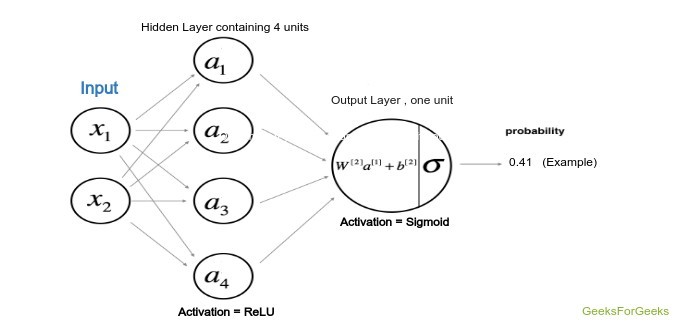
Model Architecture
Weights and bias:
The weights and the bias that is going to be used for both the layers have to be declared initially and also among them the weights will be declared randomly in order to avoid the same output of all units, while the bias will be initialized to zero. The calculation will be done from the scratch itself and according to the rules given below where W1, W2 and b1, b2 are the weights and bias of first and second layer respectively. Here A stands for the activation of a particular layer.
![begin{array}{c} z^{[1]}=W^{[1]} x+b^{[1]} \ a^{[1](i)}=tanh left(z^{[1]}right) \ z^{[2]}=W^{[2]} a^{[1]}+b^{[2]} \ hat{y}=a^{[2]}=sigmaleft(z^{[2]}right) \ y_{text {prediction}}=left{begin{array}{ll} 1 & text { if } a^{[2]}>0.5 \ 0 & text { otherwise } end{array}right. end{array}](https://www.geeksforgeeks.org/wp-content/ql-cache/quicklatex.com-beb931e1824689405f9a1fc9197ca37e_l3.png "Rendered by QuickLaTeX.com")
Cost Function:
The cost function of the above model will pertain to the cost function used with logistic regression. Hence, in this tutorial we will be using the cost function:

Cost Function:
The cost function of the above model will pertain to the cost function used with logistic regression. Hence, in this tutorial we will be using the cost function:
Code: Visualizing the data
import numpy as np
import matplotlib.pyplot as plt
from planar_utils import plot_decision_boundary, sigmoid, load_planar_dataset
X, Y = load_planar_dataset()
plt.scatter(X[0, :], X[1, :], c = Y, s = 40, cmap = plt.cm.Spectral);
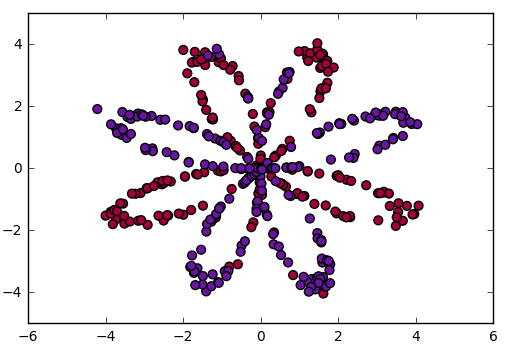
Code: Initializing the Weight and bias matrix
Here is the number of hidden units is four, so, the W1 weight matrix will be of shape (4, number of features) and bias matrix will be of shape (4, 1) which after broadcasting will add up to the weight matrix according to the above formula. Same can be applied to the W2.
W1 = np.random.randn(4, X.shape[0]) * 0.01
b1 = np.zeros(shape =(4, 1))
W2 = np.random.randn(Y.shape[0], 4) * 0.01
b2 = np.zeros(shape =(Y.shape[0], 1))
Code: Forward Propagation :
Now we will perform the forward propagation using the W1, W2 and the bias b1, b2. In this step the corresponding outputs are calculated in the function defined as forward_prop.
def forward_prop(X, W1, W2, b1, b2):
Z1 = np.dot(W1, X) + b1
A1 = np.tanh(Z1)
Z2 = np.dot(W2, A1) + b2
A2 = sigmoid(Z2)
cache = {"Z1": Z1,
"A1": A1,
"Z2": Z2,
"A2": A2}
return A2, cache
Code: Defining the cost function :
def compute_cost(A2, Y):
m = Y.shape[1]
cost_sum = np.multiply(np.log(A2), Y) + np.multiply((1 - Y), np.log(1 - A2))
cost = - np.sum(logprobs) / m
cost = np.squeeze(cost)
return cost
Code: Finally back-propagating function:
This is a very crucial step as it involves a lot of linear algebra for implementation of backpropagation of the deep neural nets. The Formulas for finding the derivatives can be derived with some mathematical concept of linear algebra, which we are not going to derive here. Just keep in mind that dZ, dW, db are the derivatives of the Cost function w.r.t Weighted sum, Weights, Bias of the layers.
def back_propagate(W1, b1, W2, b2, cache):
A1 = cache['A1']
A2 = cache['A2']
dZ2 = A2 - Y
dW2 = (1 / m) * np.dot(dZ2, A1.T)
db2 = (1 / m) * np.sum(dZ2, axis = 1, keepdims = True)
dZ1 = np.multiply(np.dot(W2.T, dZ2), 1 - np.power(A1, 2))
dW1 = (1 / m) * np.dot(dZ1, X.T)
db1 = (1 / m) * np.sum(dZ1, axis = 1, keepdims = True)
W1 = W1 - learning_rate * dW1
b1 = b1 - learning_rate * db1
W2 = W2 - learning_rate * dW2
b2 = b2 - learning_rate * db2
return W1, W2, b1, b2
Code: Training the custom model Now we will train the model using the functions defined above, the epochs can be put as per the convenience and power of the processing unit.
for i in range(0, num_iterations):
A2, cache = forward_propagation(X, W1, W2, b1, b2)
cost = compute_cost(A2, Y)
W1, W2, b1, b2 = backward_propagation(W1, b1, W2, b2, cache)
if print_cost and i % 1000 == 0:
print ("Cost after iteration % i: % f" % (i, cost))
Output with learnt params
After training the model, take the weights and predict the outcomes using the forward_propagate function above then use the values to plot the figure of output. You will have similar output.
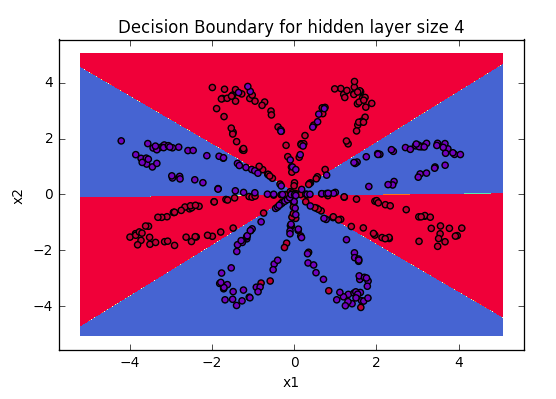
Visualizing the boundaries of data
Conclusion:
Deep Learning is a world in which the thrones are captured by the ones who get to the basics, so, try to develop the basics so strong that afterwards, you may be the developer of a new architecture of models which may revolutionalize the community.
Last Updated :
08 Jun, 2020
Like Article
Save Article
На предыдущих
занятиях мы с вами рассматривали НС с выбранными весами, либо устанавливали их,
исходя из определенных математических соображений. Это можно сделать, когда
сеть относительно небольшая. Но при увеличении числа нейронов и связей, ручной
подбор становится попросту невозможным и возникает задача нахождения весовых
коэффициентов связей НС. Этот процесс и называют обучением нейронной сети.
Один из
распространенных подходов к обучению заключается в последовательном
предъявлении НС векторов наблюдений и последующей корректировки весовых
коэффициентов так, чтобы выходное значение совпадало с требуемым:
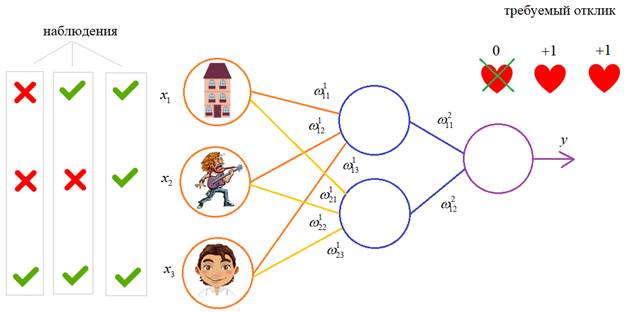
Это называется обучение
с учителем, так как для каждого вектора мы знаем нужный ответ и именно его
требуем от нашей НС.
Теперь, главный
вопрос: как построить алгоритм, который бы наилучшим образом находил весовые
коэффициенты. Наилучший – это значит, максимально быстро и с максимально
близкими выходными значениями для требуемых откликов. В общем случае эта задача
не решена. Нет универсального алгоритма обучения. Поэтому, лучшее, что мы можем
сделать – это выбрать тот алгоритм, который хорошо себя зарекомендовал в
прошлом. Основной «рабочей лошадкой» здесь является алгоритм back propagation (обратного
распространения ошибки), который, в свою очередь, базируется на алгоритме градиентного
спуска.
Сначала, я думал
рассказать о нем со всеми математическими выкладками, но потом решил этого не
делать, а просто показать принцип работы и рассмотреть реализацию конкретного
примера на Python.
Чтобы все лучше
понять, предположим, что у нас имеется вот такая полносвязная НС прямого
распространения с весами связей, выбранными произвольным образом в диапазоне от
[-0.5; 0,5]. Здесь верхний индекс показывает принадлежность к тому или иному слою
сети. Также, каждый нейрон имеет некоторую активационную функцию ![]() :
:
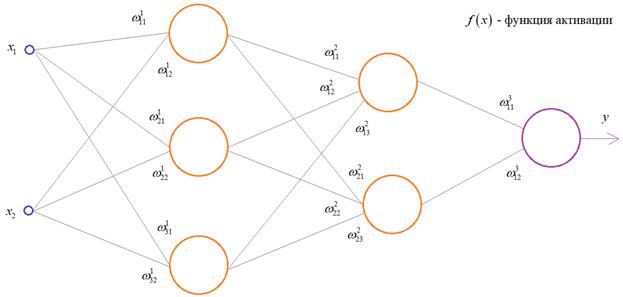
На первом шаге
делается прямой проход по сети. Мы пропускаем вектор наблюдения ![]() через
через
эту сеть, и запоминаем все выходные значения нейронов скрытых слоев:
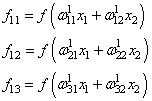
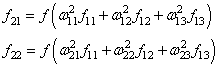
и последнее
выходное значение y:
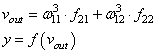
Далее, мы знаем
требуемый отклик d для текущего вектора ![]() ,
,
значит для него можно вычислить ошибку работы НС. Она будет равна:
![]()
На данный момент
все должно быть понятно. Мы на первом занятии подробно рассматривали процесс
распространения сигнала по НС. И вы это уже хорошо себе представляете. А вот
дальше начинается самое главное – корректировка весов. Для этого делается
обратный проход по НС: от последнего слоя – к первому.
Итак, у нас есть
ошибка e и некая функция
активации нейронов ![]() .
.
Первое, что нам нужно – это вычислить локальный градиент для выходного нейрона.
Это делается по формуле:
![]()
Этот момент
требует пояснения. Смотрите, ранее используемая пороговая функция:
![]()
нам уже не
подходит, т.к. она не дифференцируема на всем диапазоне значений x. Вместо этого
для сетей с небольшим числом слоев, часто применяют или гиперболический
тангенс:
![]()
или логистическую
функцию:
![]()
Фактически, они
отличаются только тем, что первая дает выходной интервал [-1; 1], а вторая – [0;
1]. И мы уже берем ту, которая нас больше устраивает в данной конкретной
ситуации. Например, выберем логистическую функцию.
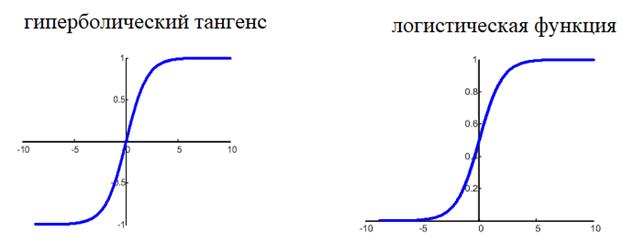
Ее производная
функции по аргументу x дает очень простое выражение:
![]()
Именно его мы и
запишем в нашу формулу вычисления локального градиента:
![]()
Но, так как
![]()
то локальный
градиент последнего нейрона, равен:
![]()
Отлично, это
сделали. Теперь у нас есть все, чтобы выполнить коррекцию весов. Начнем со
связи ![]() ,
,
формула будет такой:
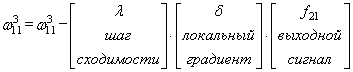
Для второй связи
все то же самое, только входной сигнал берется от второго нейрона:
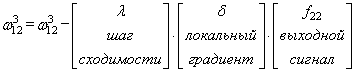
Здесь у вас
может возникнуть вопрос: что такое параметр λ и где его брать? Он
подбирается самостоятельно, вручную самим разработчиком. В самом простом случае
можно попробовать следующие значения:
![]()
(Мы подробно о
нем говорили на занятии по алгоритму градиентного спуска):
Итак, мы с вами
скорректировали связи последнего слоя. Если вам все это понятно, значит, вы уже
практически поняли весь алгоритм обучения, потому что дальше действуем подобным
образом. Переходим к нейрону следующего с конца слоя и для его входящих связей
повторим ту же саму процедуру. Но для этого, нужно знать значение его
локального градиента. Определяется он просто. Локальный градиент последнего
нейрона взвешивается весами входящих в него связей. Полученные значения на
каждом нейроне умножаются на производную функции активации, взятую в точках
входной суммы:
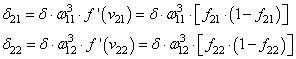
А дальше
действуем по такой же самой схеме, корректируем входные связи по той же
формуле:
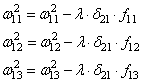
И для второго
нейрона:
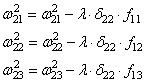
Осталось
скорректировать веса первого слоя. Снова вычисляем локальные градиенты для
нейронов первого слоя, но так как каждый из них имеет два выхода, то сначала
вычисляем сумму от каждого выхода:
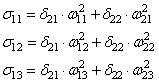
А затем,
значения локальных градиентов на нейронах первого скрытого слоя:
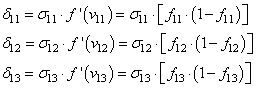
Ну и осталось
выполнить коррекцию весов первого слоя все по той же формуле:
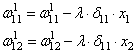
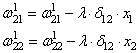
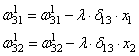
В результате, мы
выполнили одну итерацию алгоритма обучения НС. На следующей итерации мы должны
взять другой входной вектор из нашего обучающего множества. Лучше всего это
сделать случайным образом, чтобы не формировались возможные ложные
закономерности в последовательности данных при обучении НС. Повторяя много раз
этот процесс, весовые связи будут все точнее описывать обучающую выборку.
Отлично, процесс
обучения в целом мы рассмотрели. Но какой критерий качества минимизировался
алгоритмом градиентного спуска? В действительности, мы стремились получить
минимум суммы квадратов ошибок для обучающей выборки:
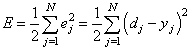
То есть, с
помощью алгоритма градиентного спуска веса корректируются так, чтобы
минимизировать этот критерий качества работы НС. Позже мы еще увидим, что на
практике используется не только такой, но и другие критерии.
Вот так, в целом
выглядит идея работы алгоритма обучения по методу обратного распространения
ошибки. Давайте теперь в качестве примера обучим следующую НС:
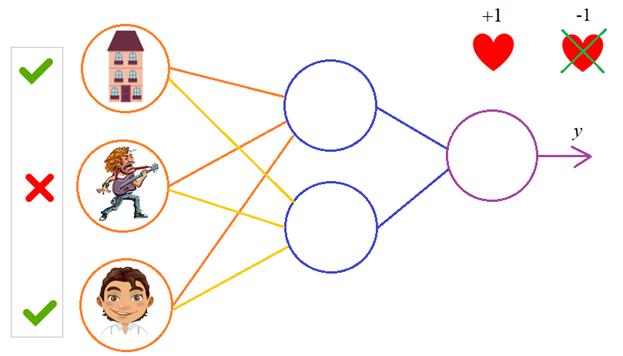
В качестве
обучающего множества выберем все возможные варианты (здесь 1 – это да, -1 – это
нет):
|
Вектор |
Требуемый |
|
[-1, -1, -1] |
-1 |
|
[-1, -1, |
1 |
|
[-1, 1, -1] |
-1 |
|
[-1, 1, 1] |
1 |
|
[1, -1, -1] |
-1 |
|
[1, -1, 1] |
1 |
|
[1, 1, -1] |
-1 |
|
[1, 1, 1] |
-1 |
На каждой
итерации работы алгоритма, мы будем подавать случайно выбранный вектор и
корректировать веса, чтобы приблизиться к значению требуемого отклика.
В качестве
активационной функции выберем гиперболический тангенс:
![]()
со значением
производной:
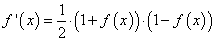
Программа на Python будет такой:
lesson 3. Back propagation.py
Ну, конечно, это
довольно простой, примитивный пример, частный случай, когда мы можем обучить НС
так, чтобы она вообще не выдавала никаких ошибок. Часто, в задачах обучения встречаются
варианты, когда мы этого сделать не можем и, конечно, какой-то процент ошибок
всегда остается. И наша задача сделать так, чтобы этих ошибок было как можно
меньше. Но более подробно как происходит обучение, какие нюансы существуют, как
создавать обучающую выборку, как ее проверять и так далее, мы об этом подробнее
будем говорить уже на следующем занятии.