
Thought I would just report back my findings, now that I have it all working. The following client-side code (slightly abridged and anonymized) contains all the work-arounds I needed to address the prblems outlined in this thread and works on IE (8.0.6001), FF(3.5.9), and Chrome (5.0.375.55 beta). Still yet to test under older versions of browsers. Many thanks to all who responded.
I should also add that I needed to make sure that the server response needed to include:
Response.ContentType = "text/xml" ;
for it to work with IE. FF didn’t mind if the ContentType was text/HTML but IE coughed.
Code to create an XMLHTTP request:
function GetXMLHTTPRequest ()
{
var activexmodes=["Msxml2.XMLHTTP", "Microsoft.XMLHTTP"] ; //activeX versions to check for in IE
if (window.ActiveXObject) //Test for support for ActiveXObject in IE first (as XMLHttpRequest in IE7 is broken)
{
for (var i=0; i < activexmodes.length ; i++)
{
try
{
return new ActiveXObject(activexmodes[i]) ;
}
catch (e)
{ //suppress error
}
}
}
else if (window.XMLHttpRequest) // if Mozilla, Safari etc
{
return new XMLHttpRequest () ;
}
else
{
return (false) ;
}
}
Code to return the text value of a record node:
function GetRecordElement (ARecordNode, AFieldName)
{
try
{
if (ARecordNode.getElementsByTagName (AFieldName) [0].textContent != undefined)
{
return (ARecordNode.getElementsByTagName (AFieldName) [0].textContent) ; // Chrome, FF
}
if (ARecordNode.getElementsByTagName (AFieldName) [0].text != undefined)
{
return (ARecordNode.getElementsByTagName (AFieldName) [0].text) ; // IE
}
return ("unknown") ;
}
catch (Exception)
{
ReportError ("(GetRecordElement): " + Exception.description) ;
}
}
Code to perform the AJAX request:
function GetRecord (s)
{
try
{
ReportStatus ("") ;
var xmlhttp = GetXMLHTTPRequest () ;
if (xmlhttp)
{
xmlhttp.open ("GET", "blahblah.com/AJAXget.asp?...etc", true) ;
if (xmlhttp.overrideMimeType)
{
xmlhttp.overrideMimeType("text/xml") ;
}
xmlhttp.setRequestHeader ("Content-Type", "text/xml; charset="utf-8"") ;
xmlhttp.onreadystatechange = function ()
{
if (xmlhttp.readyState == 4)
{
if (xmlhttp.responseXML != null)
{
var xmlDoc = xmlhttp.responseXML;
var ResultNodes = xmlDoc.getElementsByTagName ("Result") ;
if (ResultNodes != null)
{
var PayloadNode = xmlDoc.getElementsByTagName ("Payload") ;
if (PayloadNode != null)
{
var ResultText = ResultNodes [0].firstChild.nodeValue ;
if (ResultText == "OK")
{
ReportStatus (ResultText) ;
var RecordNode = PayloadNode [0].firstChild ;
if (RecordNode != null)
{
UpdateRecordDisplay (RecordNode) ; // eventually calls GetRecordElement
}
else
{
ReportError ("RecordNode is null") ;
}
}
else
{
ReportError ("Unknown response:" + ResultText) ;
}
}
else
{
ReportError ("PayloadNode is null") ;
}
}
else
{
ReportError ("ResultNodes is null") ;
}
}
else
{
ReportError ("responseXML is null") ;
}
}
else
{
ReportStatus ("Status=" + xmlhttp.readyState) ;
}
}
ReportStatus ("Requesting data ...") ;
xmlhttp.send (null) ;
}
else
{
ReportError ("Unable to create request") ;
}
}
catch (err)
{
ReportError ("(GetRecord): " + err.description) ;
}
}

In SQL, null or NULL is a special marker used to indicate that a data value does not exist in the database. Introduced by the creator of the relational database model, E. F. Codd, SQL null serves to fulfil the requirement that all true relational database management systems (RDBMS) support a representation of «missing information and inapplicable information». Codd also introduced the use of the lowercase Greek omega (ω) symbol to represent null in database theory. In SQL, NULL is a reserved word used to identify this marker.
A null should not be confused with a value of 0. A null value indicates a lack of a value, which is not the same thing as a value of zero. For example, consider the question «How many books does Adam own?» The answer may be «zero» (we know that he owns none) or «null» (we do not know how many he owns). In a database table, the column reporting this answer would start out with no value (marked by Null), and it would not be updated with the value «zero» until we have ascertained that Adam owns no books.
SQL null is a marker, not a value. This usage is quite different from most programming languages, where null value of a reference means it is not pointing to any object.
History[edit]
E. F. Codd mentioned nulls as a method of representing missing data in the relational model in a 1975 paper in the FDT Bulletin of ACM-SIGMOD. Codd’s paper that is most commonly cited in relation with the semantics of Null (as adopted in SQL) is his 1979 paper in the ACM Transactions on Database Systems, in which he also introduced his Relational Model/Tasmania, although much of the other proposals from the latter paper have remained obscure. Section 2.3 of his 1979 paper details the semantics of Null propagation in arithmetic operations as well as comparisons employing a ternary (three-valued) logic when comparing to nulls; it also details the treatment of Nulls on other set operations (the latter issue still controversial today). In database theory circles, the original proposal of Codd (1975, 1979) is now referred to as «Codd tables».[1] Codd later reinforced his requirement that all RDBMSs support Null to indicate missing data in a 1985 two-part article published in Computerworld magazine.[2][3]
The 1986 SQL standard basically adopted Codd’s proposal after an implementation prototype in IBM System R. Although Don Chamberlin recognized nulls (alongside duplicate rows) as one of the most controversial features of SQL, he defended the design of Nulls in SQL invoking the pragmatic arguments that it was the least expensive form of system support for missing information, saving the programmer from many duplicative application-level checks (see semipredicate problem) while at the same time providing the database designer with the option not to use Nulls if they so desire; for example, in order to avoid well known anomalies (discussed in the semantics section of this article). Chamberlin also argued that besides providing some missing-value functionality, practical experience with Nulls also led to other language features which rely on Nulls, like certain grouping constructs and outer joins. Finally, he argued that in practice Nulls also end up being used as a quick way to patch an existing schema when it needs to evolve beyond its original intent, coding not for missing but rather for inapplicable information; for example, a database that quickly needs to support electric cars while having a miles-per-gallon column.[4]
Codd indicated in his 1990 book The Relational Model for Database Management, Version 2 that the single Null mandated by the SQL standard was inadequate, and should be replaced by two separate Null-type markers to indicate the reason why data is missing. In Codd’s book, these two Null-type markers are referred to as ‘A-Values’ and ‘I-Values’, representing ‘Missing But Applicable’ and ‘Missing But Inapplicable’, respectively.[5] Codd’s recommendation would have required SQL’s logic system be expanded to accommodate a four-valued logic system. Because of this additional complexity, the idea of multiple Nulls with different definitions has not gained widespread acceptance in the database practitioners’ domain. It remains an active field of research though, with numerous papers still being published.
Challenges[edit]
Null has been the focus of controversy and a source of debate because of its associated three-valued logic (3VL), special requirements for its use in SQL joins, and the special handling required by aggregate functions and SQL grouping operators. Computer science professor Ron van der Meyden summarized the various issues as: «The inconsistencies in the SQL standard mean that it is not possible to ascribe any intuitive logical semantics to the treatment of nulls in SQL.»[1] Although various proposals have been made for resolving these issues, the complexity of the alternatives has prevented their widespread adoption.
Null propagation[edit]
Arithmetic operations[edit]
Because Null is not a data value, but a marker for an absent value, using mathematical operators on Null gives an unknown result, which is represented by Null.[6] In the following example, multiplying 10 by Null results in Null:
10 * NULL -- Result is NULL
This can lead to unanticipated results. For instance, when an attempt is made to divide Null by zero, platforms may return Null instead of throwing an expected «data exception – division by zero».[6] Though this behavior is not defined by the ISO SQL standard many DBMS vendors treat this operation similarly. For instance, the Oracle, PostgreSQL, MySQL Server, and Microsoft SQL Server platforms all return a Null result for the following:
String concatenation[edit]
String concatenation operations, which are common in SQL, also result in Null when one of the operands is Null.[7] The following example demonstrates the Null result returned by using Null with the SQL || string concatenation operator.
'Fish ' || NULL || 'Chips' -- Result is NULL
This is not true for all database implementations. In an Oracle RDBMS for example NULL and the empty string are considered the same thing and therefore ‘Fish ‘ || NULL || ‘Chips’ results in ‘Fish Chips’.
Comparisons with NULL and the three-valued logic (3VL)[edit]
Since Null is not a member of any data domain, it is not considered a «value», but rather a marker (or placeholder) indicating the undefined value. Because of this, comparisons with Null can never result in either True or False, but always in a third logical result, Unknown.[8] The logical result of the expression below, which compares the value 10 to Null, is Unknown:
SELECT 10 = NULL -- Results in Unknown
However, certain operations on Null can return values if the absent value is not relevant to the outcome of the operation. Consider the following example:
SELECT NULL OR TRUE -- Results in True
In this case, the fact that the value on the left of OR is unknowable is irrelevant, because the outcome of the OR operation would be True regardless of the value on the left.
SQL implements three logical results, so SQL implementations must provide for a specialized three-valued logic (3VL). The rules governing SQL three-valued logic are shown in the tables below (p and q represent logical states)»[9] The truth tables SQL uses for AND, OR, and NOT correspond to a common fragment of the Kleene and Łukasiewicz three-valued logic (which differ in their definition of implication, however SQL defines no such operation).[10]
| p | q | p OR q | p AND q | p = q |
|---|---|---|---|---|
| True | True | True | True | True |
| True | False | True | False | False |
| True | Unknown | True | Unknown | Unknown |
| False | True | True | False | False |
| False | False | False | False | True |
| False | Unknown | Unknown | False | Unknown |
| Unknown | True | True | Unknown | Unknown |
| Unknown | False | Unknown | False | Unknown |
| Unknown | Unknown | Unknown | Unknown | Unknown |
| p | NOT p |
|---|---|
| True | False |
| False | True |
| Unknown | Unknown |
Effect of Unknown in WHERE clauses[edit]
SQL three-valued logic is encountered in Data Manipulation Language (DML) in comparison predicates of DML statements and queries. The WHERE clause causes the DML statement to act on only those rows for which the predicate evaluates to True. Rows for which the predicate evaluates to either False or Unknown are not acted on by INSERT, UPDATE, or DELETE DML statements, and are discarded by SELECT queries. Interpreting Unknown and False as the same logical result is a common error encountered while dealing with Nulls.[9] The following simple example demonstrates this fallacy:
SELECT * FROM t WHERE i = NULL;
The example query above logically always returns zero rows because the comparison of the i column with Null always returns Unknown, even for those rows where i is Null. The Unknown result causes the SELECT statement to summarily discard each and every row. (However, in practice, some SQL tools will retrieve rows using a comparison with Null.)
Null-specific and 3VL-specific comparison predicates[edit]
Basic SQL comparison operators always return Unknown when comparing anything with Null, so the SQL standard provides for two special Null-specific comparison predicates. The IS NULL and IS NOT NULL predicates (which use a postfix syntax) test whether data is, or is not, Null.[11]
The SQL standard contains the optional feature F571 «Truth value tests» that introduces three additional logical unary operators (six in fact, if we count their negation, which is part of their syntax), also using postfix notation. They have the following truth tables:[12]
| p | p IS TRUE | p IS NOT TRUE | p IS FALSE | p IS NOT FALSE | p IS UNKNOWN | p IS NOT UNKNOWN |
|---|---|---|---|---|---|---|
| True | True | False | False | True | False | True |
| False | False | True | True | False | False | True |
| Unknown | False | True | False | True | True | False |
The F571 feature is orthogonal to the presence of the boolean datatype in SQL (discussed later in this article) and, despite syntactic similarities, F571 does not introduce boolean or three-valued literals in the language. The F571 feature was actually present in SQL92,[13] well before the boolean datatype was introduced to the standard in 1999. The F571 feature is implemented by few systems however; PostgreSQL is one of those implementing it.
The addition of IS UNKNOWN to the other operators of SQL’s three-valued logic makes the SQL three-valued logic functionally complete,[14] meaning its logical operators can express (in combination) any conceivable three-valued logical function.
On systems which don’t support the F571 feature, it is possible to emulate IS UNKNOWN p by going over every argument that could make the expression p Unknown and test those arguments with IS NULL or other NULL-specific functions, although this may be more cumbersome.
Law of the excluded fourth (in WHERE clauses)[edit]
In SQL’s three-valued logic the law of the excluded middle, p OR NOT p, no longer evaluates to true for all p. More precisely, in SQL’s three-valued logic p OR NOT p is unknown precisely when p is unknown and true otherwise. Because direct comparisons with Null result in the unknown logical value, the following query
SELECT * FROM stuff WHERE ( x = 10 ) OR NOT ( x = 10 );
is not equivalent in SQL with
if the column x contains any Nulls; in that case the second query would return some rows the first one does not return, namely all those in which x is Null. In classical two-valued logic, the law of the excluded middle would allow the simplification of the WHERE clause predicate, in fact its elimination. Attempting to apply the law of the excluded middle to SQL’s 3VL is effectively a false dichotomy. The second query is actually equivalent with:
SELECT * FROM stuff; -- is (because of 3VL) equivalent to: SELECT * FROM stuff WHERE ( x = 10 ) OR NOT ( x = 10 ) OR x IS NULL;
Thus, to correctly simplify the first statement in SQL requires that we return all rows in which x is not null.
SELECT * FROM stuff WHERE x IS NOT NULL;
In view of the above, observe that for SQL’s WHERE clause a tautology similar to the law of excluded middle can be written. Assuming the IS UNKNOWN operator is present, p OR (NOT p) OR (p IS UNKNOWN) is true for every predicate p. Among logicians, this is called law of excluded fourth.
There are some SQL expressions in which it is less obvious where the false dilemma occurs, for example:
SELECT 'ok' WHERE 1 NOT IN (SELECT CAST (NULL AS INTEGER)) UNION SELECT 'ok' WHERE 1 IN (SELECT CAST (NULL AS INTEGER));
produces no rows because IN translates to an iterated version of equality over the argument set and 1<>NULL is Unknown, just as a 1=NULL is Unknown. (The CAST in this example is needed only in some SQL implementations like PostgreSQL, which would reject it with a type checking error otherwise. In many systems plain SELECT NULL works in the subquery.) The missing case above is of course:
SELECT 'ok' WHERE (1 IN (SELECT CAST (NULL AS INTEGER))) IS UNKNOWN;
Effect of Null and Unknown in other constructs[edit]
Joins[edit]
Joins evaluate using the same comparison rules as for WHERE clauses. Therefore, care must be taken when using nullable columns in SQL join criteria. In particular a table containing any nulls is not equal with a natural self-join of itself, meaning that whereas  is true for any relation R in relational algebra, a SQL self-join will exclude all rows having a Null anywhere.[15] An example of this behavior is given in the section analyzing the missing-value semantics of Nulls.
is true for any relation R in relational algebra, a SQL self-join will exclude all rows having a Null anywhere.[15] An example of this behavior is given in the section analyzing the missing-value semantics of Nulls.
The SQL COALESCE function or CASE expressions can be used to «simulate» Null equality in join criteria, and the IS NULL and IS NOT NULL predicates can be used in the join criteria as well. The following predicate tests for equality of the values A and B and treats Nulls as being equal.
(A = B) OR (A IS NULL AND B IS NULL)
CASE expressions[edit]
SQL provides two flavours of conditional expressions. One is called «simple CASE» and operates like a switch statement. The other is called a «searched CASE» in the standard, and operates like an if…elseif.
The simple CASE expressions use implicit equality comparisons which operate under the same rules as the DML WHERE clause rules for Null. Thus, a simple CASE expression cannot check for the existence of Null directly. A check for Null in a simple CASE expression always results in Unknown, as in the following:
SELECT CASE i WHEN NULL THEN 'Is Null' -- This will never be returned WHEN 0 THEN 'Is Zero' -- This will be returned when i = 0 WHEN 1 THEN 'Is One' -- This will be returned when i = 1 END FROM t;
Because the expression i = NULL evaluates to Unknown no matter what value column i contains (even if it contains Null), the string 'Is Null' will never be returned.
On the other hand, a «searched» CASE expression can use predicates like IS NULL and IS NOT NULL in its conditions. The following example shows how to use a searched CASE expression to properly check for Null:
SELECT CASE WHEN i IS NULL THEN 'Null Result' -- This will be returned when i is NULL WHEN i = 0 THEN 'Zero' -- This will be returned when i = 0 WHEN i = 1 THEN 'One' -- This will be returned when i = 1 END FROM t;
In the searched CASE expression, the string 'Null Result' is returned for all rows in which i is Null.
Oracle’s dialect of SQL provides a built-in function DECODE which can be used instead of the simple CASE expressions and considers two nulls equal.
SELECT DECODE(i, NULL, 'Null Result', 0, 'Zero', 1, 'One') FROM t;
Finally, all these constructs return a NULL if no match is found; they have a default ELSE NULL clause.
IF statements in procedural extensions[edit]
SQL/PSM (SQL Persistent Stored Modules) defines procedural extensions for SQL, such as the IF statement. However, the major SQL vendors have historically included their own proprietary procedural extensions. Procedural extensions for looping and comparisons operate under Null comparison rules similar to those for DML statements and queries. The following code fragment, in ISO SQL standard format, demonstrates the use of Null 3VL in an IF statement.
IF i = NULL THEN SELECT 'Result is True' ELSEIF NOT(i = NULL) THEN SELECT 'Result is False' ELSE SELECT 'Result is Unknown';
The IF statement performs actions only for those comparisons that evaluate to True. For statements that evaluate to False or Unknown, the IF statement passes control to the ELSEIF clause, and finally to the ELSE clause. The result of the code above will always be the message 'Result is Unknown' since the comparisons with Null always evaluate to Unknown.
Analysis of SQL Null missing-value semantics[edit]
The groundbreaking work of T. Imieliński and W. Lipski Jr. (1984)[16] provided a framework in which to evaluate the intended semantics of various proposals to implement missing-value semantics, that is referred to as Imieliński-Lipski Algebras. This section roughly follows chapter 19 of the «Alice» textbook.[17] A similar presentation appears in the review of Ron van der Meyden, §10.4.[1]
In selections and projections: weak representation[edit]
Constructs representing missing information, such as Codd tables, are actually intended to represent a set of relations, one for each possible instantiation of their parameters; in the case of Codd tables, this means replacement of Nulls with some concrete value. For example,
Emp
| Name | Age |
|---|---|
| George | 43 |
| Harriet | NULL |
| Charles | 56 |
EmpH22
| Name | Age |
|---|---|
| George | 43 |
| Harriet | 22 |
| Charles | 56 |
EmpH37
| Name | Age |
|---|---|
| George | 43 |
| Harriet | 37 |
| Charles | 56 |
The Codd table Emp may represent the relation EmpH22 or EmpH37, as pictured.
A construct (such as a Codd table) is said to be a strong representation system (of missing information) if any answer to a query made on the construct can be particularized to obtain an answer for any corresponding query on the relations it represents, which are seen as models of the construct. More precisely, if q is a query formula in the relational algebra (of «pure» relations) and if q is its lifting to a construct intended to represent missing information, a strong representation has the property that for any query q and (table) construct T, q lifts all the answers to the construct, i.e.:

(The above has to hold for queries taking any number of tables as arguments, but the restriction to one table suffices for this discussion.) Clearly Codd tables do not have this strong property if selections and projections are considered as part of the query language. For example, all the answers to
SELECT * FROM Emp WHERE Age = 22;
should include the possibility that a relation like EmpH22 may exist. However, Codd tables cannot represent the disjunction «result with possibly 0 or 1 rows». A device, mostly of theoretical interest, called conditional table (or c-table) can however represent such an answer:
Result
| Name | Age | condition |
|---|---|---|
| Harriet | ω1 | ω1 = 22 |
where the condition column is interpreted as the row doesn’t exist if the condition is false. It turns out that because the formulas in the condition column of a c-table can be arbitrary propositional logic formulas, an algorithm for the problem whether a c-table represents some concrete relation has a co-NP-complete complexity, thus is of little practical worth.
A weaker notion of representation is therefore desirable. Imielinski and Lipski introduced the notion of weak representation, which essentially allows (lifted) queries over a construct to return a representation only for sure information, i.e. if it’s valid for all «possible world» instantiations (models) of the construct. Concretely, a construct is a weak representation system if

The right-hand side of the above equation is the sure information, i.e. information which can be certainly extracted from the database regardless of what values are used to replace Nulls in the database. In the example we considered above, it’s easy to see that the intersection of all possible models (i.e. the sure information) of the query selecting WHERE Age = 22 is actually empty because, for instance, the (unlifted) query returns no rows for the relation EmpH37. More generally, it was shown by Imielinski and Lipski that Codd tables are a weak representation system if the query language is restricted to projections, selections (and renaming of columns). However, as soon as we add either joins or unions to the query language, even this weak property is lost, as evidenced in the next section.
If joins or unions are considered: not even weak representation[edit]
Consider the following query over the same Codd table Emp from the previous section:
SELECT Name FROM Emp WHERE Age = 22 UNION SELECT Name FROM Emp WHERE Age <> 22;
Whatever concrete value one would choose for the NULL age of Harriet, the above query will return the full column of names of any model of Emp, but when the (lifted) query is run on Emp itself, Harriet will always be missing, i.e. we have:
| Query result on Emp: |
|
Query result on any model of Emp: |
|
Thus when unions are added to the query language, Codd tables are not even a weak representation system of missing information, meaning that queries over them don’t even report all sure information. It’s important to note here that semantics of UNION on Nulls, which are discussed in a later section, did not even come into play in this query. The «forgetful» nature of the two sub-queries was all that it took to guarantee that some sure information went unreported when the above query was run on the Codd table Emp.
For natural joins, the example needed to show that sure information may be unreported by some query is slightly more complicated. Consider the table
J
| F1 | F2 | F3 |
|---|---|---|
| 11 | NULL |
13 |
| 21 | NULL |
23 |
| 31 | 32 | 33 |
and the query
SELECT F1, F3 FROM (SELECT F1, F2 FROM J) AS F12 NATURAL JOIN (SELECT F2, F3 FROM J) AS F23;
| Query result on J: |
|
Query result on any model of J: |
|
The intuition for what happens above is that the Codd tables representing the projections in the subqueries lose track of the fact that the Nulls in the columns F12.F2 and F23.F2 are actually copies of the originals in the table J. This observation suggests that a relatively simple improvement of Codd tables (which works correctly for this example) would be to use Skolem constants (meaning Skolem functions which are also constant functions), say ω12 and ω22 instead of a single NULL symbol. Such an approach, called v-tables or Naive tables, is computationally less expensive that the c-tables discussed above. However, it is still not a complete solution for incomplete information in the sense that v-tables are only a weak representation for queries not using any negations in selection (and not using any set difference either). The first example considered in this section is using a negative selection clause, WHERE Age <> 22, so it is also an example where v-tables queries would not report sure information.
Check constraints and foreign keys[edit]
The primary place in which SQL three-valued logic intersects with SQL Data Definition Language (DDL) is in the form of check constraints. A check constraint placed on a column operates under a slightly different set of rules than those for the DML WHERE clause. While a DML WHERE clause must evaluate to True for a row, a check constraint must not evaluate to False. (From a logic perspective, the designated values are True and Unknown.) This means that a check constraint will succeed if the result of the check is either True or Unknown. The following example table with a check constraint will prohibit any integer values from being inserted into column i, but will allow Null to be inserted since the result of the check will always evaluate to Unknown for Nulls.[18]
CREATE TABLE t ( i INTEGER, CONSTRAINT ck_i CHECK ( i < 0 AND i = 0 AND i > 0 ) );
Because of the change in designated values relative to the WHERE clause, from a logic perspective the law of excluded middle is a tautology for CHECK constraints, meaning CHECK (p OR NOT p) always succeeds. Furthermore, assuming Nulls are to be interpreted as existing but unknown values, some pathological CHECKs like the one above allow insertion of Nulls that could never be replaced by any non-null value.
In order to constrain a column to reject Nulls, the NOT NULL constraint can be applied, as shown in the example below. The NOT NULL constraint is semantically equivalent to a check constraint with an IS NOT NULL predicate.
CREATE TABLE t ( i INTEGER NOT NULL );
By default check constraints against foreign keys succeed if any of the fields in such keys are Null. For example, the table
CREATE TABLE Books ( title VARCHAR(100), author_last VARCHAR(20), author_first VARCHAR(20), FOREIGN KEY (author_last, author_first) REFERENCES Authors(last_name, first_name));
would allow insertion of rows where author_last or author_first are NULL irrespective of how the table Authors is defined or what it contains. More precisely, a null in any of these fields would allow any value in the other one, even on that is not found in Authors table. For example, if Authors contained only ('Doe', 'John'), then ('Smith', NULL) would satisfy the foreign key constraint. SQL-92 added two extra options for narrowing down the matches in such cases. If MATCH PARTIAL is added after the REFERENCES declaration then any non-null must match the foreign key, e.g. ('Doe', NULL) would still match, but ('Smith', NULL) would not. Finally, if MATCH FULL is added then ('Smith', NULL) would not match the constraint either, but (NULL, NULL) would still match it.
Outer joins[edit]

Example SQL outer join query with Null placeholders in the result set. The Null markers are represented by the word NULL in place of data in the results. Results are from Microsoft SQL Server, as shown in SQL Server Management Studio.
SQL outer joins, including left outer joins, right outer joins, and full outer joins, automatically produce Nulls as placeholders for missing values in related tables. For left outer joins, for instance, Nulls are produced in place of rows missing from the table appearing on the right-hand side of the LEFT OUTER JOIN operator. The following simple example uses two tables to demonstrate Null placeholder production in a left outer join.
The first table (Employee) contains employee ID numbers and names, while the second table (PhoneNumber) contains related employee ID numbers and phone numbers, as shown below.
|
Employee
|
PhoneNumber
|
The following sample SQL query performs a left outer join on these two tables.
SELECT e.ID, e.LastName, e.FirstName, pn.Number FROM Employee e LEFT OUTER JOIN PhoneNumber pn ON e.ID = pn.ID;
The result set generated by this query demonstrates how SQL uses Null as a placeholder for values missing from the right-hand (PhoneNumber) table, as shown below.
Query result
| ID | LastName | FirstName | Number |
|---|---|---|---|
| 1 | Johnson | Joe | 555-2323 |
| 2 | Lewis | Larry | NULL
|
| 3 | Thompson | Thomas | 555-9876 |
| 4 | Patterson | Patricia | NULL
|
Aggregate functions[edit]
SQL defines aggregate functions to simplify server-side aggregate calculations on data. Except for the COUNT(*) function, all aggregate functions perform a Null-elimination step, so that Nulls are not included in the final result of the calculation.[19]
Note that the elimination of Null is not equivalent to replacing Null with zero. For example, in the following table, AVG(i) (the average of the values of i) will give a different result from that of AVG(j):
| i | j |
|---|---|
| 150 | 150 |
| 200 | 200 |
| 250 | 250 |
NULL
|
0 |
Here AVG(i) is 200 (the average of 150, 200, and 250), while AVG(j) is 150 (the average of 150, 200, 250, and 0). A well-known side effect of this is that in SQL AVG(z) is equivalent with not SUM(z)/COUNT(*) but SUM(z)/COUNT(z).[4]
The output of an aggregate function can also be Null. Here is an example:
SELECT COUNT(*), MIN(e.Wage), MAX(e.Wage) FROM Employee e WHERE e.LastName LIKE '%Jones%';
This query will always output exactly one row, counting of the number of employees whose last name contains «Jones», and giving the minimum and maximum wage found for those employees. However, what happens if none of the employees fit the given criteria? Calculating the minimum or maximum value of an empty set is impossible, so those results must be NULL, indicating there is no answer. This is not an Unknown value, it is a Null representing the absence of a value. The result would be:
| COUNT(*) | MIN(e.Wage) | MAX(e.Wage) |
|---|---|---|
| 0 | NULL
|
NULL
|
When two nulls are equal: grouping, sorting, and some set operations[edit]
Because SQL:2003 defines all Null markers as being unequal to one another, a special definition was required in order to group Nulls together when performing certain operations. SQL defines «any two values that are equal to one another, or any two Nulls», as «not distinct».[20] This definition of not distinct allows SQL to group and sort Nulls when the GROUP BY clause (and other keywords that perform grouping) are used.
Other SQL operations, clauses, and keywords use «not distinct» in their treatment of Nulls. These include the following:
PARTITION BYclause of ranking and windowing functions likeROW_NUMBERUNION,INTERSECT, andEXCEPToperator, which treat NULLs as the same for row comparison/elimination purposesDISTINCTkeyword used inSELECTqueries
The principle that Nulls aren’t equal to each other (but rather that the result is Unknown) is effectively violated in the SQL specification for the UNION operator, which does identify nulls with each other.[1] Consequently, some set operations in SQL, like union or difference, may produce results not representing sure information, unlike operations involving explicit comparisons with NULL (e.g. those in a WHERE clause discussed above). In Codd’s 1979 proposal (which was basically adopted by SQL92) this semantic inconsistency is rationalized by arguing that removal of duplicates in set operations happens «at a lower level of detail than equality testing in the evaluation of retrieval operations.»[10]
The SQL standard does not explicitly define a default sort order for Nulls. Instead, on conforming systems, Nulls can be sorted before or after all data values by using the NULLS FIRST or NULLS LAST clauses of the ORDER BY list, respectively. Not all DBMS vendors implement this functionality, however. Vendors who do not implement this functionality may specify different treatments for Null sorting in the DBMS.[18]
Effect on index operation[edit]
Some SQL products do not index keys containing NULLs. For instance, PostgreSQL versions prior to 8.3 did not, with the documentation for a B-tree index stating that[21]
B-trees can handle equality and range queries on data that can be sorted into some ordering. In particular, the PostgreSQL query planner will consider using a B-tree index whenever an indexed column is involved in a comparison using one of these operators: < ≤ = ≥ >
Constructs equivalent to combinations of these operators, such as BETWEEN and IN, can also be implemented with a B-tree index search. (But note that IS NULL is not equivalent to = and is not indexable.)
In cases where the index enforces uniqueness, NULLs are excluded from the index and uniqueness is not enforced between NULLs. Again, quoting from the PostgreSQL documentation:[22]
When an index is declared unique, multiple table rows with equal indexed values will not be allowed. Nulls are not considered equal. A multicolumn unique index will only reject cases where all of the indexed columns are equal in two rows.
This is consistent with the SQL:2003-defined behavior of scalar Null comparisons.
Another method of indexing Nulls involves handling them as not distinct in accordance with the SQL:2003-defined behavior. For example, Microsoft SQL Server documentation states the following:[23]
For indexing purposes, NULLs compare as equal. Therefore, a unique index, or UNIQUE constraint, cannot be created if the keys are NULL in more than one row. Select columns that are defined as NOT NULL when columns for a unique index or unique constraint are chosen.
Both of these indexing strategies are consistent with the SQL:2003-defined behavior of Nulls. Because indexing methodologies are not explicitly defined by the SQL:2003 standard, indexing strategies for Nulls are left entirely to the vendors to design and implement.
Null-handling functions[edit]
SQL defines two functions to explicitly handle Nulls: NULLIF and COALESCE. Both functions are abbreviations for searched CASE expressions.[24]
NULLIF[edit]
The NULLIF function accepts two parameters. If the first parameter is equal to the second parameter, NULLIF returns Null. Otherwise, the value of the first parameter is returned.
Thus, NULLIF is an abbreviation for the following CASE expression:
CASE WHEN value1 = value2 THEN NULL ELSE value1 END
COALESCE[edit]
The COALESCE function accepts a list of parameters, returning the first non-Null value from the list:
COALESCE(value1, value2, value3, ...)
COALESCE is defined as shorthand for the following SQL CASE expression:
CASE WHEN value1 IS NOT NULL THEN value1 WHEN value2 IS NOT NULL THEN value2 WHEN value3 IS NOT NULL THEN value3 ... END
Some SQL DBMSs implement vendor-specific functions similar to COALESCE. Some systems (e.g. Transact-SQL) implement an ISNULL function, or other similar functions that are functionally similar to COALESCE. (See Is functions for more on the IS functions in Transact-SQL.)
NVL[edit]
«NVL» redirects here. For the gene, see NVL (gene).
The Oracle NVL function accepts two parameters. It returns the first non-NULL parameter or NULL if all parameters are NULL.
A COALESCE expression can be converted into an equivalent NVL expression thus:
COALESCE ( val1, ... , val{n} )
turns into:
NVL( val1 , NVL( val2 , NVL( val3 , … , NVL ( val{n-1} , val{n} ) … )))
A use case of this function is to replace in an expression a NULL by a value like in NVL(SALARY, 0) which says, ‘if SALARY is NULL, replace it with the value 0′.
There is, however, one notable exception. In most implementations, COALESCE evaluates its parameters until it reaches the first non-NULL one, while NVL evaluates all of its parameters. This is important for several reasons. A parameter after the first non-NULL parameter could be a function, which could either be computationally expensive, invalid, or could create unexpected side effects.
Data typing of Null and Unknown[edit]
The NULL literal is untyped in SQL, meaning that it is not designated as an integer, character, or any other specific data type.[25] Because of this, it is sometimes mandatory (or desirable) to explicitly convert Nulls to a specific data type. For instance, if overloaded functions are supported by the RDBMS, SQL might not be able to automatically resolve to the correct function without knowing the data types of all parameters, including those for which Null is passed.
Conversion from the NULL literal to a Null of a specific type is possible using the CAST introduced in SQL-92. For example:
represents an absent value of type INTEGER.
The actual typing of Unknown (distinct or not from NULL itself) varies between SQL implementations. For example, the following
SELECT 'ok' WHERE (NULL <> 1) IS NULL;
parses and executes successfully in some environments (e.g. SQLite or PostgreSQL) which unify a NULL boolean with Unknown but fails to parse in others (e.g. in SQL Server Compact). MySQL behaves similarly to PostgreSQL in this regard (with the minor exception that MySQL regards TRUE and FALSE as no different from the ordinary integers 1 and 0). PostgreSQL additionally implements a IS UNKNOWN predicate, which can be used to test whether a three-value logical outcome is Unknown, although this is merely syntactic sugar.
BOOLEAN data type[edit]
The ISO SQL:1999 standard introduced the BOOLEAN data type to SQL, however it’s still just an optional, non-core feature, coded T031.[26]
When restricted by a NOT NULL constraint, the SQL BOOLEAN works like the Boolean type from other languages. Unrestricted however, the BOOLEAN datatype, despite its name, can hold the truth values TRUE, FALSE, and UNKNOWN, all of which are defined as boolean literals according to the standard. The standard also asserts that NULL and UNKNOWN «may be used
interchangeably to mean exactly the same thing».[27][28]
The Boolean type has been subject of criticism, particularly because of the mandated behavior of the UNKNOWN literal, which is never equal to itself because of the identification with NULL.[29]
As discussed above, in the PostgreSQL implementation of SQL, Null is used to represent all UNKNOWN results, including the UNKNOWN BOOLEAN. PostgreSQL does not implement the UNKNOWN literal (although it does implement the IS UNKNOWN operator, which is an orthogonal feature.) Most other major vendors do not support the Boolean type (as defined in T031) as of 2012.[30] The procedural part of Oracle’s PL/SQL supports BOOLEAN however variables; these can also be assigned NULL and the value is considered the same as UNKNOWN.[31]
Controversy[edit]
Common mistakes[edit]
Misunderstanding of how Null works is the cause of a great number of errors in SQL code, both in ISO standard SQL statements and in the specific SQL dialects supported by real-world database management systems. These mistakes are usually the result of confusion between Null and either 0 (zero) or an empty string (a string value with a length of zero, represented in SQL as ''). Null is defined by the SQL standard as different from both an empty string and the numerical value 0, however. While Null indicates the absence of any value, the empty string and numerical zero both represent actual values.
A classic error is the attempt to use the equals operator = in combination with the keyword NULL to find rows with Nulls. According to the SQL standard this is an invalid syntax and shall lead to an error message or an exception. But most implementations accept the syntax and evaluate such expressions to UNKNOWN. The consequence is that no rows are found – regardless of whether rows with Nulls exist or not. The proposed way to retrieve rows with Nulls is the use of the predicate IS NULL instead of = NULL.
SELECT * FROM sometable WHERE num = NULL; -- Should be "WHERE num IS NULL"
In a related, but more subtle example, a WHERE clause or conditional statement might compare a column’s value with a constant. It is often incorrectly assumed that a missing value would be «less than» or «not equal to» a constant if that field contains Null, but, in fact, such expressions return Unknown. An example is below:
SELECT * FROM sometable WHERE num <> 1; -- Rows where num is NULL will not be returned, -- contrary to many users' expectations.
These confusions arise because the Law of Identity is restricted in SQL’s logic. When dealing with equality comparisons using the NULL literal or the UNKNOWN truth-value, SQL will always return UNKNOWN as the result of the expression. This is a partial equivalence relation and makes SQL an example of a Non-Reflexive logic.[32]
Similarly, Nulls are often confused with empty strings. Consider the LENGTH function, which returns the number of characters in a string. When a Null is passed into this function, the function returns Null. This can lead to unexpected results, if users are not well versed in 3-value logic. An example is below:
SELECT * FROM sometable WHERE LENGTH(string) < 20; -- Rows where string is NULL will not be returned.
This is complicated by the fact that in some database interface programs (or even database implementations like Oracle’s), NULL is reported as an empty string, and empty strings may be incorrectly stored as NULL.
Criticisms[edit]
The ISO SQL implementation of Null is the subject of criticism, debate and calls for change. In The Relational Model for Database Management: Version 2, Codd suggested that the SQL implementation of Null was flawed and should be replaced by two distinct Null-type markers. The markers he proposed were to stand for «Missing but Applicable» and «Missing but Inapplicable», known as A-values and I-values, respectively. Codd’s recommendation, if accepted, would have required the implementation of a four-valued logic in SQL.[5] Others have suggested adding additional Null-type markers to Codd’s recommendation to indicate even more reasons that a data value might be «Missing», increasing the complexity of SQL’s logic system. At various times, proposals have also been put forth to implement multiple user-defined Null markers in SQL. Because of the complexity of the Null-handling and logic systems required to support multiple Null markers, none of these proposals have gained widespread acceptance.
Chris Date and Hugh Darwen, authors of The Third Manifesto, have suggested that the SQL Null implementation is inherently flawed and should be eliminated altogether,[33] pointing to inconsistencies and flaws in the implementation of SQL Null-handling (particularly in aggregate functions) as proof that the entire concept of Null is flawed and should be removed from the relational model.[34] Others, like author Fabian Pascal, have stated a belief that «how the function calculation should treat missing values is not governed by the relational model.»[citation needed]
Closed-world assumption[edit]
Another point of conflict concerning Nulls is that they violate the closed-world assumption model of relational databases by introducing an open-world assumption into it.[35] The closed world assumption, as it pertains to databases, states that «Everything stated by the database, either explicitly or implicitly, is true; everything else is false.»[36] This view assumes that the knowledge of the world stored within a database is complete. Nulls, however, operate under the open world assumption, in which some items stored in the database are considered unknown, making the database’s stored knowledge of the world incomplete.
See also[edit]
- SQL
- NULLs in: Wikibook SQL
- Ternary logic
- Data manipulation language
- Codd’s 12 rules
- Check constraint
- Relational Model/Tasmania
- Relational database management system
- Join (SQL)
References[edit]
- ^ a b c d Ron van der Meyden, «Logical approaches to incomplete information: a survey» in Chomicki, Jan; Saake, Gunter (Eds.) Logics for Databases and Information Systems, Kluwer Academic Publishers ISBN 978-0-7923-8129-7, p. 344; PS preprint (note: page numbering differs in preprint from the published version)
- ^ Codd, E.F. (October 14, 1985). «Is Your Database Really Relational?». Computerworld.
- ^ Codd, E.F. (October 21, 1985). «Does Your DBMS Run By The Rules?». Computerworld.
- ^ a b Don Chamberlin (1998). A Complete Guide to DB2 Universal Database. Morgan Kaufmann. pp. 28–32. ISBN 978-1-55860-482-7.
- ^ a b Codd, E.F. (1990). The Relational Model for Database Management (Version 2 ed.). Addison Wesley Publishing Company. ISBN 978-0-201-14192-4.
- ^ a b ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.2.6: numeric value expressions..
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.2.8: string value expression. - ^
ISO/IEC (2003). ISO/IEC 9075-1:2003, «SQL/Framework». ISO/IEC. Section 4.4.2: The null value. - ^ a b Coles, Michael (June 27, 2005). «Four Rules for Nulls». SQL Server Central. Red Gate Software.
- ^ a b Hans-Joachim, K. (2003). «Null Values in Relational Databases and Sure Information Answers». Semantics in Databases. Second International Workshop Dagstuhl Castle, Germany, January 7–12, 2001. Revised Papers. Lecture Notes in Computer Science. Vol. 2582. pp. 119–138. doi:10.1007/3-540-36596-6_7. ISBN 978-3-540-00957-3.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 8.7: null predicate. - ^ C.J. Date (2004), An introduction to database systems, 8th ed., Pearson Education, p. 594
- ^ Jim Melton; Jim Melton Alan R. Simon (1993). Understanding The New SQL: A Complete Guide. Morgan Kaufmann. pp. 145–147. ISBN 978-1-55860-245-8.
- ^ C. J. Date, Relational database writings, 1991-1994, Addison-Wesley, 1995, p. 371
- ^ C.J. Date (2004), An introduction to database systems, 8th ed., Pearson Education, p. 584
- ^ Imieliński, T.; Lipski Jr., W. (1984). «Incomplete information in relational databases». Journal of the ACM. 31 (4): 761–791. doi:10.1145/1634.1886. S2CID 288040.
- ^ Abiteboul, Serge; Hull, Richard B.; Vianu, Victor (1995). Foundations of Databases. Addison-Wesley. ISBN 978-0-201-53771-0.
- ^ a b Coles, Michael (February 26, 2007). «Null Versus Null?». SQL Server Central. Red Gate Software.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 4.15.4: Aggregate functions. - ^ ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 3.1.6.8: Definitions: distinct.
- ^ «PostgreSQL 8.0.14 Documentation: Index Types». PostgreSQL. Retrieved 6 November 2008.
- ^ «PostgreSQL 8.0.14 Documentation: Unique Indexes». PostgreSQL. Retrieved November 6, 2008.
- ^ «Creating Unique Indexes». PostfreSQL. September 2007. Retrieved November 6, 2008.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.11: case expression. - ^ Jim Melton; Alan R. Simon (2002). SQL:1999: Understanding Relational Language Components. Morgan Kaufmann. p. 53. ISBN 978-1-55860-456-8.
- ^ «ISO/IEC 9075-1:1999 SQL Standard». ISO. 1999.
- ^ C. Date (2011). SQL and Relational Theory: How to Write Accurate SQL Code. O’Reilly Media, Inc. p. 83. ISBN 978-1-4493-1640-2.
- ^ ISO/IEC 9075-2:2011 §4.5
- ^ Martyn Prigmore (2007). Introduction to Databases With Web Applications. Pearson Education Canada. p. 197. ISBN 978-0-321-26359-9.
- ^ Troels Arvin, Survey of BOOLEAN data type implementation
- ^ Steven Feuerstein; Bill Pribyl (2009). Oracle PL/SQL Programming. O’Reilly Media, Inc. pp. 74, 91. ISBN 978-0-596-51446-4.
- ^ Arenhart, Krause (2012), «Classical Logic or Non-Reflexive Logic? A case of Semantic Underdetermination», Revista Portuguesa de Filosofia, 68 (1/2): 73–86, doi:10.17990/RPF/2012_68_1_0073, JSTOR 41955624.
- ^
Darwen, Hugh; Chris Date. «The Third Manifesto». Retrieved May 29, 2007. - ^
Darwen, Hugh. «The Askew Wall» (PDF). Retrieved May 29, 2007. - ^ Date, Chris (May 2005). Database in Depth: Relational Theory for Practitioners. O’Reilly Media, Inc. p. 73. ISBN 978-0-596-10012-4.
- ^ Date, Chris. «Abstract: The Closed World Assumption». Data Management Association, San Francisco Bay Area Chapter. Archived from the original on 2007-05-19. Retrieved May 29, 2007.
Further reading[edit]
- E. F. Codd. Understanding relations (installment #7). FDT Bulletin of ACM-SIGMOD, 7(3-4):23–28, 1975.
- Codd, E. F. (1979). «Extending the database relational model to capture more meaning». ACM Transactions on Database Systems. 4 (4): 397–434. CiteSeerX 10.1.1.508.5701. doi:10.1145/320107.320109. S2CID 17517212. Especially §2.3.
- Date, C.J. (2000). The Database Relational Model: A Retrospective Review and Analysis: A Historical Account and Assessment of E. F. Codd’s Contribution to the Field of Database Technology. Addison Wesley Longman. ISBN 978-0-201-61294-3.
- Klein, Hans-Joachim (1994). «How to modify SQL queries in order to guarantee sure answers». ACM SIGMOD Record. 23 (3): 14–20. doi:10.1145/187436.187445. S2CID 17354724.
- Claude Rubinson, Nulls, Three-Valued Logic, and Ambiguity in SQL: Critiquing Date’s Critique, SIGMOD Record, December 2007 (Vol. 36, No. 4)
- John Grant, Null Values in SQL. SIGMOD Record, September 2008 (Vol. 37, No. 3)
- Waraporn, Narongrit, and Kriengkrai Porkaew. «Null semantics for subqueries and atomic predicates». IAENG International Journal of Computer Science 35.3 (2008): 305-313.
- Bernhard Thalheim, Klaus-Dieter Schewe (2011). «NULL ‘Value’ Algebras and Logics». Frontiers in Artificial Intelligence and Applications. 225 (Information Modelling and Knowledge Bases XXII). doi:10.3233/978-1-60750-690-4-354.
{{cite journal}}: CS1 maint: uses authors parameter (link) - Enrico Franconi and Sergio Tessaris, On the Logic of SQL Nulls, Proceedings of the 6th Alberto Mendelzon International Workshop on Foundations of Data Management, Ouro Preto, Brazil, June 27–30, 2012. pp. 114–128
External links[edit]
- Oracle NULLs Archived 2013-04-12 at the Wayback Machine
- The Third Manifesto
- Implications of NULLs in sequencing of data
- Java bug report about jdbc not distinguishing null and empty string, which Sun closed as «not a bug»
In SQL, null or NULL is a special marker used to indicate that a data value does not exist in the database. Introduced by the creator of the relational database model, E. F. Codd, SQL null serves to fulfil the requirement that all true relational database management systems (RDBMS) support a representation of «missing information and inapplicable information». Codd also introduced the use of the lowercase Greek omega (ω) symbol to represent null in database theory. In SQL, NULL is a reserved word used to identify this marker.
A null should not be confused with a value of 0. A null value indicates a lack of a value, which is not the same thing as a value of zero. For example, consider the question «How many books does Adam own?» The answer may be «zero» (we know that he owns none) or «null» (we do not know how many he owns). In a database table, the column reporting this answer would start out with no value (marked by Null), and it would not be updated with the value «zero» until we have ascertained that Adam owns no books.
SQL null is a marker, not a value. This usage is quite different from most programming languages, where null value of a reference means it is not pointing to any object.
History[edit]
E. F. Codd mentioned nulls as a method of representing missing data in the relational model in a 1975 paper in the FDT Bulletin of ACM-SIGMOD. Codd’s paper that is most commonly cited in relation with the semantics of Null (as adopted in SQL) is his 1979 paper in the ACM Transactions on Database Systems, in which he also introduced his Relational Model/Tasmania, although much of the other proposals from the latter paper have remained obscure. Section 2.3 of his 1979 paper details the semantics of Null propagation in arithmetic operations as well as comparisons employing a ternary (three-valued) logic when comparing to nulls; it also details the treatment of Nulls on other set operations (the latter issue still controversial today). In database theory circles, the original proposal of Codd (1975, 1979) is now referred to as «Codd tables».[1] Codd later reinforced his requirement that all RDBMSs support Null to indicate missing data in a 1985 two-part article published in Computerworld magazine.[2][3]
The 1986 SQL standard basically adopted Codd’s proposal after an implementation prototype in IBM System R. Although Don Chamberlin recognized nulls (alongside duplicate rows) as one of the most controversial features of SQL, he defended the design of Nulls in SQL invoking the pragmatic arguments that it was the least expensive form of system support for missing information, saving the programmer from many duplicative application-level checks (see semipredicate problem) while at the same time providing the database designer with the option not to use Nulls if they so desire; for example, in order to avoid well known anomalies (discussed in the semantics section of this article). Chamberlin also argued that besides providing some missing-value functionality, practical experience with Nulls also led to other language features which rely on Nulls, like certain grouping constructs and outer joins. Finally, he argued that in practice Nulls also end up being used as a quick way to patch an existing schema when it needs to evolve beyond its original intent, coding not for missing but rather for inapplicable information; for example, a database that quickly needs to support electric cars while having a miles-per-gallon column.[4]
Codd indicated in his 1990 book The Relational Model for Database Management, Version 2 that the single Null mandated by the SQL standard was inadequate, and should be replaced by two separate Null-type markers to indicate the reason why data is missing. In Codd’s book, these two Null-type markers are referred to as ‘A-Values’ and ‘I-Values’, representing ‘Missing But Applicable’ and ‘Missing But Inapplicable’, respectively.[5] Codd’s recommendation would have required SQL’s logic system be expanded to accommodate a four-valued logic system. Because of this additional complexity, the idea of multiple Nulls with different definitions has not gained widespread acceptance in the database practitioners’ domain. It remains an active field of research though, with numerous papers still being published.
Challenges[edit]
Null has been the focus of controversy and a source of debate because of its associated three-valued logic (3VL), special requirements for its use in SQL joins, and the special handling required by aggregate functions and SQL grouping operators. Computer science professor Ron van der Meyden summarized the various issues as: «The inconsistencies in the SQL standard mean that it is not possible to ascribe any intuitive logical semantics to the treatment of nulls in SQL.»[1] Although various proposals have been made for resolving these issues, the complexity of the alternatives has prevented their widespread adoption.
Null propagation[edit]
Arithmetic operations[edit]
Because Null is not a data value, but a marker for an absent value, using mathematical operators on Null gives an unknown result, which is represented by Null.[6] In the following example, multiplying 10 by Null results in Null:
10 * NULL -- Result is NULL
This can lead to unanticipated results. For instance, when an attempt is made to divide Null by zero, platforms may return Null instead of throwing an expected «data exception – division by zero».[6] Though this behavior is not defined by the ISO SQL standard many DBMS vendors treat this operation similarly. For instance, the Oracle, PostgreSQL, MySQL Server, and Microsoft SQL Server platforms all return a Null result for the following:
String concatenation[edit]
String concatenation operations, which are common in SQL, also result in Null when one of the operands is Null.[7] The following example demonstrates the Null result returned by using Null with the SQL || string concatenation operator.
'Fish ' || NULL || 'Chips' -- Result is NULL
This is not true for all database implementations. In an Oracle RDBMS for example NULL and the empty string are considered the same thing and therefore ‘Fish ‘ || NULL || ‘Chips’ results in ‘Fish Chips’.
Comparisons with NULL and the three-valued logic (3VL)[edit]
Since Null is not a member of any data domain, it is not considered a «value», but rather a marker (or placeholder) indicating the undefined value. Because of this, comparisons with Null can never result in either True or False, but always in a third logical result, Unknown.[8] The logical result of the expression below, which compares the value 10 to Null, is Unknown:
SELECT 10 = NULL -- Results in Unknown
However, certain operations on Null can return values if the absent value is not relevant to the outcome of the operation. Consider the following example:
SELECT NULL OR TRUE -- Results in True
In this case, the fact that the value on the left of OR is unknowable is irrelevant, because the outcome of the OR operation would be True regardless of the value on the left.
SQL implements three logical results, so SQL implementations must provide for a specialized three-valued logic (3VL). The rules governing SQL three-valued logic are shown in the tables below (p and q represent logical states)»[9] The truth tables SQL uses for AND, OR, and NOT correspond to a common fragment of the Kleene and Łukasiewicz three-valued logic (which differ in their definition of implication, however SQL defines no such operation).[10]
| p | q | p OR q | p AND q | p = q |
|---|---|---|---|---|
| True | True | True | True | True |
| True | False | True | False | False |
| True | Unknown | True | Unknown | Unknown |
| False | True | True | False | False |
| False | False | False | False | True |
| False | Unknown | Unknown | False | Unknown |
| Unknown | True | True | Unknown | Unknown |
| Unknown | False | Unknown | False | Unknown |
| Unknown | Unknown | Unknown | Unknown | Unknown |
| p | NOT p |
|---|---|
| True | False |
| False | True |
| Unknown | Unknown |
Effect of Unknown in WHERE clauses[edit]
SQL three-valued logic is encountered in Data Manipulation Language (DML) in comparison predicates of DML statements and queries. The WHERE clause causes the DML statement to act on only those rows for which the predicate evaluates to True. Rows for which the predicate evaluates to either False or Unknown are not acted on by INSERT, UPDATE, or DELETE DML statements, and are discarded by SELECT queries. Interpreting Unknown and False as the same logical result is a common error encountered while dealing with Nulls.[9] The following simple example demonstrates this fallacy:
SELECT * FROM t WHERE i = NULL;
The example query above logically always returns zero rows because the comparison of the i column with Null always returns Unknown, even for those rows where i is Null. The Unknown result causes the SELECT statement to summarily discard each and every row. (However, in practice, some SQL tools will retrieve rows using a comparison with Null.)
Null-specific and 3VL-specific comparison predicates[edit]
Basic SQL comparison operators always return Unknown when comparing anything with Null, so the SQL standard provides for two special Null-specific comparison predicates. The IS NULL and IS NOT NULL predicates (which use a postfix syntax) test whether data is, or is not, Null.[11]
The SQL standard contains the optional feature F571 «Truth value tests» that introduces three additional logical unary operators (six in fact, if we count their negation, which is part of their syntax), also using postfix notation. They have the following truth tables:[12]
| p | p IS TRUE | p IS NOT TRUE | p IS FALSE | p IS NOT FALSE | p IS UNKNOWN | p IS NOT UNKNOWN |
|---|---|---|---|---|---|---|
| True | True | False | False | True | False | True |
| False | False | True | True | False | False | True |
| Unknown | False | True | False | True | True | False |
The F571 feature is orthogonal to the presence of the boolean datatype in SQL (discussed later in this article) and, despite syntactic similarities, F571 does not introduce boolean or three-valued literals in the language. The F571 feature was actually present in SQL92,[13] well before the boolean datatype was introduced to the standard in 1999. The F571 feature is implemented by few systems however; PostgreSQL is one of those implementing it.
The addition of IS UNKNOWN to the other operators of SQL’s three-valued logic makes the SQL three-valued logic functionally complete,[14] meaning its logical operators can express (in combination) any conceivable three-valued logical function.
On systems which don’t support the F571 feature, it is possible to emulate IS UNKNOWN p by going over every argument that could make the expression p Unknown and test those arguments with IS NULL or other NULL-specific functions, although this may be more cumbersome.
Law of the excluded fourth (in WHERE clauses)[edit]
In SQL’s three-valued logic the law of the excluded middle, p OR NOT p, no longer evaluates to true for all p. More precisely, in SQL’s three-valued logic p OR NOT p is unknown precisely when p is unknown and true otherwise. Because direct comparisons with Null result in the unknown logical value, the following query
SELECT * FROM stuff WHERE ( x = 10 ) OR NOT ( x = 10 );
is not equivalent in SQL with
if the column x contains any Nulls; in that case the second query would return some rows the first one does not return, namely all those in which x is Null. In classical two-valued logic, the law of the excluded middle would allow the simplification of the WHERE clause predicate, in fact its elimination. Attempting to apply the law of the excluded middle to SQL’s 3VL is effectively a false dichotomy. The second query is actually equivalent with:
SELECT * FROM stuff; -- is (because of 3VL) equivalent to: SELECT * FROM stuff WHERE ( x = 10 ) OR NOT ( x = 10 ) OR x IS NULL;
Thus, to correctly simplify the first statement in SQL requires that we return all rows in which x is not null.
SELECT * FROM stuff WHERE x IS NOT NULL;
In view of the above, observe that for SQL’s WHERE clause a tautology similar to the law of excluded middle can be written. Assuming the IS UNKNOWN operator is present, p OR (NOT p) OR (p IS UNKNOWN) is true for every predicate p. Among logicians, this is called law of excluded fourth.
There are some SQL expressions in which it is less obvious where the false dilemma occurs, for example:
SELECT 'ok' WHERE 1 NOT IN (SELECT CAST (NULL AS INTEGER)) UNION SELECT 'ok' WHERE 1 IN (SELECT CAST (NULL AS INTEGER));
produces no rows because IN translates to an iterated version of equality over the argument set and 1<>NULL is Unknown, just as a 1=NULL is Unknown. (The CAST in this example is needed only in some SQL implementations like PostgreSQL, which would reject it with a type checking error otherwise. In many systems plain SELECT NULL works in the subquery.) The missing case above is of course:
SELECT 'ok' WHERE (1 IN (SELECT CAST (NULL AS INTEGER))) IS UNKNOWN;
Effect of Null and Unknown in other constructs[edit]
Joins[edit]
Joins evaluate using the same comparison rules as for WHERE clauses. Therefore, care must be taken when using nullable columns in SQL join criteria. In particular a table containing any nulls is not equal with a natural self-join of itself, meaning that whereas is true for any relation R in relational algebra, a SQL self-join will exclude all rows having a Null anywhere.[15] An example of this behavior is given in the section analyzing the missing-value semantics of Nulls.
The SQL COALESCE function or CASE expressions can be used to «simulate» Null equality in join criteria, and the IS NULL and IS NOT NULL predicates can be used in the join criteria as well. The following predicate tests for equality of the values A and B and treats Nulls as being equal.
(A = B) OR (A IS NULL AND B IS NULL)
CASE expressions[edit]
SQL provides two flavours of conditional expressions. One is called «simple CASE» and operates like a switch statement. The other is called a «searched CASE» in the standard, and operates like an if…elseif.
The simple CASE expressions use implicit equality comparisons which operate under the same rules as the DML WHERE clause rules for Null. Thus, a simple CASE expression cannot check for the existence of Null directly. A check for Null in a simple CASE expression always results in Unknown, as in the following:
SELECT CASE i WHEN NULL THEN 'Is Null' -- This will never be returned WHEN 0 THEN 'Is Zero' -- This will be returned when i = 0 WHEN 1 THEN 'Is One' -- This will be returned when i = 1 END FROM t;
Because the expression i = NULL evaluates to Unknown no matter what value column i contains (even if it contains Null), the string 'Is Null' will never be returned.
On the other hand, a «searched» CASE expression can use predicates like IS NULL and IS NOT NULL in its conditions. The following example shows how to use a searched CASE expression to properly check for Null:
SELECT CASE WHEN i IS NULL THEN 'Null Result' -- This will be returned when i is NULL WHEN i = 0 THEN 'Zero' -- This will be returned when i = 0 WHEN i = 1 THEN 'One' -- This will be returned when i = 1 END FROM t;
In the searched CASE expression, the string 'Null Result' is returned for all rows in which i is Null.
Oracle’s dialect of SQL provides a built-in function DECODE which can be used instead of the simple CASE expressions and considers two nulls equal.
SELECT DECODE(i, NULL, 'Null Result', 0, 'Zero', 1, 'One') FROM t;
Finally, all these constructs return a NULL if no match is found; they have a default ELSE NULL clause.
IF statements in procedural extensions[edit]
SQL/PSM (SQL Persistent Stored Modules) defines procedural extensions for SQL, such as the IF statement. However, the major SQL vendors have historically included their own proprietary procedural extensions. Procedural extensions for looping and comparisons operate under Null comparison rules similar to those for DML statements and queries. The following code fragment, in ISO SQL standard format, demonstrates the use of Null 3VL in an IF statement.
IF i = NULL THEN SELECT 'Result is True' ELSEIF NOT(i = NULL) THEN SELECT 'Result is False' ELSE SELECT 'Result is Unknown';
The IF statement performs actions only for those comparisons that evaluate to True. For statements that evaluate to False or Unknown, the IF statement passes control to the ELSEIF clause, and finally to the ELSE clause. The result of the code above will always be the message 'Result is Unknown' since the comparisons with Null always evaluate to Unknown.
Analysis of SQL Null missing-value semantics[edit]
The groundbreaking work of T. Imieliński and W. Lipski Jr. (1984)[16] provided a framework in which to evaluate the intended semantics of various proposals to implement missing-value semantics, that is referred to as Imieliński-Lipski Algebras. This section roughly follows chapter 19 of the «Alice» textbook.[17] A similar presentation appears in the review of Ron van der Meyden, §10.4.[1]
In selections and projections: weak representation[edit]
Constructs representing missing information, such as Codd tables, are actually intended to represent a set of relations, one for each possible instantiation of their parameters; in the case of Codd tables, this means replacement of Nulls with some concrete value. For example,
Emp
| Name | Age |
|---|---|
| George | 43 |
| Harriet | NULL |
| Charles | 56 |
EmpH22
| Name | Age |
|---|---|
| George | 43 |
| Harriet | 22 |
| Charles | 56 |
EmpH37
| Name | Age |
|---|---|
| George | 43 |
| Harriet | 37 |
| Charles | 56 |
The Codd table Emp may represent the relation EmpH22 or EmpH37, as pictured.
A construct (such as a Codd table) is said to be a strong representation system (of missing information) if any answer to a query made on the construct can be particularized to obtain an answer for any corresponding query on the relations it represents, which are seen as models of the construct. More precisely, if q is a query formula in the relational algebra (of «pure» relations) and if q is its lifting to a construct intended to represent missing information, a strong representation has the property that for any query q and (table) construct T, q lifts all the answers to the construct, i.e.:
(The above has to hold for queries taking any number of tables as arguments, but the restriction to one table suffices for this discussion.) Clearly Codd tables do not have this strong property if selections and projections are considered as part of the query language. For example, all the answers to
SELECT * FROM Emp WHERE Age = 22;
should include the possibility that a relation like EmpH22 may exist. However, Codd tables cannot represent the disjunction «result with possibly 0 or 1 rows». A device, mostly of theoretical interest, called conditional table (or c-table) can however represent such an answer:
Result
| Name | Age | condition |
|---|---|---|
| Harriet | ω1 | ω1 = 22 |
where the condition column is interpreted as the row doesn’t exist if the condition is false. It turns out that because the formulas in the condition column of a c-table can be arbitrary propositional logic formulas, an algorithm for the problem whether a c-table represents some concrete relation has a co-NP-complete complexity, thus is of little practical worth.
A weaker notion of representation is therefore desirable. Imielinski and Lipski introduced the notion of weak representation, which essentially allows (lifted) queries over a construct to return a representation only for sure information, i.e. if it’s valid for all «possible world» instantiations (models) of the construct. Concretely, a construct is a weak representation system if
The right-hand side of the above equation is the sure information, i.e. information which can be certainly extracted from the database regardless of what values are used to replace Nulls in the database. In the example we considered above, it’s easy to see that the intersection of all possible models (i.e. the sure information) of the query selecting WHERE Age = 22 is actually empty because, for instance, the (unlifted) query returns no rows for the relation EmpH37. More generally, it was shown by Imielinski and Lipski that Codd tables are a weak representation system if the query language is restricted to projections, selections (and renaming of columns). However, as soon as we add either joins or unions to the query language, even this weak property is lost, as evidenced in the next section.
If joins or unions are considered: not even weak representation[edit]
Consider the following query over the same Codd table Emp from the previous section:
SELECT Name FROM Emp WHERE Age = 22 UNION SELECT Name FROM Emp WHERE Age <> 22;
Whatever concrete value one would choose for the NULL age of Harriet, the above query will return the full column of names of any model of Emp, but when the (lifted) query is run on Emp itself, Harriet will always be missing, i.e. we have:
| Query result on Emp: |
|
Query result on any model of Emp: |
|
Thus when unions are added to the query language, Codd tables are not even a weak representation system of missing information, meaning that queries over them don’t even report all sure information. It’s important to note here that semantics of UNION on Nulls, which are discussed in a later section, did not even come into play in this query. The «forgetful» nature of the two sub-queries was all that it took to guarantee that some sure information went unreported when the above query was run on the Codd table Emp.
For natural joins, the example needed to show that sure information may be unreported by some query is slightly more complicated. Consider the table
J
| F1 | F2 | F3 |
|---|---|---|
| 11 | NULL |
13 |
| 21 | NULL |
23 |
| 31 | 32 | 33 |
and the query
SELECT F1, F3 FROM (SELECT F1, F2 FROM J) AS F12 NATURAL JOIN (SELECT F2, F3 FROM J) AS F23;
| Query result on J: |
|
Query result on any model of J: |
|
The intuition for what happens above is that the Codd tables representing the projections in the subqueries lose track of the fact that the Nulls in the columns F12.F2 and F23.F2 are actually copies of the originals in the table J. This observation suggests that a relatively simple improvement of Codd tables (which works correctly for this example) would be to use Skolem constants (meaning Skolem functions which are also constant functions), say ω12 and ω22 instead of a single NULL symbol. Such an approach, called v-tables or Naive tables, is computationally less expensive that the c-tables discussed above. However, it is still not a complete solution for incomplete information in the sense that v-tables are only a weak representation for queries not using any negations in selection (and not using any set difference either). The first example considered in this section is using a negative selection clause, WHERE Age <> 22, so it is also an example where v-tables queries would not report sure information.
Check constraints and foreign keys[edit]
The primary place in which SQL three-valued logic intersects with SQL Data Definition Language (DDL) is in the form of check constraints. A check constraint placed on a column operates under a slightly different set of rules than those for the DML WHERE clause. While a DML WHERE clause must evaluate to True for a row, a check constraint must not evaluate to False. (From a logic perspective, the designated values are True and Unknown.) This means that a check constraint will succeed if the result of the check is either True or Unknown. The following example table with a check constraint will prohibit any integer values from being inserted into column i, but will allow Null to be inserted since the result of the check will always evaluate to Unknown for Nulls.[18]
CREATE TABLE t ( i INTEGER, CONSTRAINT ck_i CHECK ( i < 0 AND i = 0 AND i > 0 ) );
Because of the change in designated values relative to the WHERE clause, from a logic perspective the law of excluded middle is a tautology for CHECK constraints, meaning CHECK (p OR NOT p) always succeeds. Furthermore, assuming Nulls are to be interpreted as existing but unknown values, some pathological CHECKs like the one above allow insertion of Nulls that could never be replaced by any non-null value.
In order to constrain a column to reject Nulls, the NOT NULL constraint can be applied, as shown in the example below. The NOT NULL constraint is semantically equivalent to a check constraint with an IS NOT NULL predicate.
CREATE TABLE t ( i INTEGER NOT NULL );
By default check constraints against foreign keys succeed if any of the fields in such keys are Null. For example, the table
CREATE TABLE Books ( title VARCHAR(100), author_last VARCHAR(20), author_first VARCHAR(20), FOREIGN KEY (author_last, author_first) REFERENCES Authors(last_name, first_name));
would allow insertion of rows where author_last or author_first are NULL irrespective of how the table Authors is defined or what it contains. More precisely, a null in any of these fields would allow any value in the other one, even on that is not found in Authors table. For example, if Authors contained only ('Doe', 'John'), then ('Smith', NULL) would satisfy the foreign key constraint. SQL-92 added two extra options for narrowing down the matches in such cases. If MATCH PARTIAL is added after the REFERENCES declaration then any non-null must match the foreign key, e.g. ('Doe', NULL) would still match, but ('Smith', NULL) would not. Finally, if MATCH FULL is added then ('Smith', NULL) would not match the constraint either, but (NULL, NULL) would still match it.
Outer joins[edit]
Example SQL outer join query with Null placeholders in the result set. The Null markers are represented by the word NULL in place of data in the results. Results are from Microsoft SQL Server, as shown in SQL Server Management Studio.
SQL outer joins, including left outer joins, right outer joins, and full outer joins, automatically produce Nulls as placeholders for missing values in related tables. For left outer joins, for instance, Nulls are produced in place of rows missing from the table appearing on the right-hand side of the LEFT OUTER JOIN operator. The following simple example uses two tables to demonstrate Null placeholder production in a left outer join.
The first table (Employee) contains employee ID numbers and names, while the second table (PhoneNumber) contains related employee ID numbers and phone numbers, as shown below.
|
Employee
|
PhoneNumber
|
The following sample SQL query performs a left outer join on these two tables.
SELECT e.ID, e.LastName, e.FirstName, pn.Number FROM Employee e LEFT OUTER JOIN PhoneNumber pn ON e.ID = pn.ID;
The result set generated by this query demonstrates how SQL uses Null as a placeholder for values missing from the right-hand (PhoneNumber) table, as shown below.
Query result
| ID | LastName | FirstName | Number |
|---|---|---|---|
| 1 | Johnson | Joe | 555-2323 |
| 2 | Lewis | Larry | NULL
|
| 3 | Thompson | Thomas | 555-9876 |
| 4 | Patterson | Patricia | NULL
|
Aggregate functions[edit]
SQL defines aggregate functions to simplify server-side aggregate calculations on data. Except for the COUNT(*) function, all aggregate functions perform a Null-elimination step, so that Nulls are not included in the final result of the calculation.[19]
Note that the elimination of Null is not equivalent to replacing Null with zero. For example, in the following table, AVG(i) (the average of the values of i) will give a different result from that of AVG(j):
| i | j |
|---|---|
| 150 | 150 |
| 200 | 200 |
| 250 | 250 |
NULL
|
0 |
Here AVG(i) is 200 (the average of 150, 200, and 250), while AVG(j) is 150 (the average of 150, 200, 250, and 0). A well-known side effect of this is that in SQL AVG(z) is equivalent with not SUM(z)/COUNT(*) but SUM(z)/COUNT(z).[4]
The output of an aggregate function can also be Null. Here is an example:
SELECT COUNT(*), MIN(e.Wage), MAX(e.Wage) FROM Employee e WHERE e.LastName LIKE '%Jones%';
This query will always output exactly one row, counting of the number of employees whose last name contains «Jones», and giving the minimum and maximum wage found for those employees. However, what happens if none of the employees fit the given criteria? Calculating the minimum or maximum value of an empty set is impossible, so those results must be NULL, indicating there is no answer. This is not an Unknown value, it is a Null representing the absence of a value. The result would be:
| COUNT(*) | MIN(e.Wage) | MAX(e.Wage) |
|---|---|---|
| 0 | NULL
|
NULL
|
When two nulls are equal: grouping, sorting, and some set operations[edit]
Because SQL:2003 defines all Null markers as being unequal to one another, a special definition was required in order to group Nulls together when performing certain operations. SQL defines «any two values that are equal to one another, or any two Nulls», as «not distinct».[20] This definition of not distinct allows SQL to group and sort Nulls when the GROUP BY clause (and other keywords that perform grouping) are used.
Other SQL operations, clauses, and keywords use «not distinct» in their treatment of Nulls. These include the following:
PARTITION BYclause of ranking and windowing functions likeROW_NUMBERUNION,INTERSECT, andEXCEPToperator, which treat NULLs as the same for row comparison/elimination purposesDISTINCTkeyword used inSELECTqueries
The principle that Nulls aren’t equal to each other (but rather that the result is Unknown) is effectively violated in the SQL specification for the UNION operator, which does identify nulls with each other.[1] Consequently, some set operations in SQL, like union or difference, may produce results not representing sure information, unlike operations involving explicit comparisons with NULL (e.g. those in a WHERE clause discussed above). In Codd’s 1979 proposal (which was basically adopted by SQL92) this semantic inconsistency is rationalized by arguing that removal of duplicates in set operations happens «at a lower level of detail than equality testing in the evaluation of retrieval operations.»[10]
The SQL standard does not explicitly define a default sort order for Nulls. Instead, on conforming systems, Nulls can be sorted before or after all data values by using the NULLS FIRST or NULLS LAST clauses of the ORDER BY list, respectively. Not all DBMS vendors implement this functionality, however. Vendors who do not implement this functionality may specify different treatments for Null sorting in the DBMS.[18]
Effect on index operation[edit]
Some SQL products do not index keys containing NULLs. For instance, PostgreSQL versions prior to 8.3 did not, with the documentation for a B-tree index stating that[21]
B-trees can handle equality and range queries on data that can be sorted into some ordering. In particular, the PostgreSQL query planner will consider using a B-tree index whenever an indexed column is involved in a comparison using one of these operators: < ≤ = ≥ >
Constructs equivalent to combinations of these operators, such as BETWEEN and IN, can also be implemented with a B-tree index search. (But note that IS NULL is not equivalent to = and is not indexable.)
In cases where the index enforces uniqueness, NULLs are excluded from the index and uniqueness is not enforced between NULLs. Again, quoting from the PostgreSQL documentation:[22]
When an index is declared unique, multiple table rows with equal indexed values will not be allowed. Nulls are not considered equal. A multicolumn unique index will only reject cases where all of the indexed columns are equal in two rows.
This is consistent with the SQL:2003-defined behavior of scalar Null comparisons.
Another method of indexing Nulls involves handling them as not distinct in accordance with the SQL:2003-defined behavior. For example, Microsoft SQL Server documentation states the following:[23]
For indexing purposes, NULLs compare as equal. Therefore, a unique index, or UNIQUE constraint, cannot be created if the keys are NULL in more than one row. Select columns that are defined as NOT NULL when columns for a unique index or unique constraint are chosen.
Both of these indexing strategies are consistent with the SQL:2003-defined behavior of Nulls. Because indexing methodologies are not explicitly defined by the SQL:2003 standard, indexing strategies for Nulls are left entirely to the vendors to design and implement.
Null-handling functions[edit]
SQL defines two functions to explicitly handle Nulls: NULLIF and COALESCE. Both functions are abbreviations for searched CASE expressions.[24]
NULLIF[edit]
The NULLIF function accepts two parameters. If the first parameter is equal to the second parameter, NULLIF returns Null. Otherwise, the value of the first parameter is returned.
Thus, NULLIF is an abbreviation for the following CASE expression:
CASE WHEN value1 = value2 THEN NULL ELSE value1 END
COALESCE[edit]
The COALESCE function accepts a list of parameters, returning the first non-Null value from the list:
COALESCE(value1, value2, value3, ...)
COALESCE is defined as shorthand for the following SQL CASE expression:
CASE WHEN value1 IS NOT NULL THEN value1 WHEN value2 IS NOT NULL THEN value2 WHEN value3 IS NOT NULL THEN value3 ... END
Some SQL DBMSs implement vendor-specific functions similar to COALESCE. Some systems (e.g. Transact-SQL) implement an ISNULL function, or other similar functions that are functionally similar to COALESCE. (See Is functions for more on the IS functions in Transact-SQL.)
NVL[edit]
«NVL» redirects here. For the gene, see NVL (gene).
The Oracle NVL function accepts two parameters. It returns the first non-NULL parameter or NULL if all parameters are NULL.
A COALESCE expression can be converted into an equivalent NVL expression thus:
COALESCE ( val1, ... , val{n} )
turns into:
NVL( val1 , NVL( val2 , NVL( val3 , … , NVL ( val{n-1} , val{n} ) … )))
A use case of this function is to replace in an expression a NULL by a value like in NVL(SALARY, 0) which says, ‘if SALARY is NULL, replace it with the value 0′.
There is, however, one notable exception. In most implementations, COALESCE evaluates its parameters until it reaches the first non-NULL one, while NVL evaluates all of its parameters. This is important for several reasons. A parameter after the first non-NULL parameter could be a function, which could either be computationally expensive, invalid, or could create unexpected side effects.
Data typing of Null and Unknown[edit]
The NULL literal is untyped in SQL, meaning that it is not designated as an integer, character, or any other specific data type.[25] Because of this, it is sometimes mandatory (or desirable) to explicitly convert Nulls to a specific data type. For instance, if overloaded functions are supported by the RDBMS, SQL might not be able to automatically resolve to the correct function without knowing the data types of all parameters, including those for which Null is passed.
Conversion from the NULL literal to a Null of a specific type is possible using the CAST introduced in SQL-92. For example:
represents an absent value of type INTEGER.
The actual typing of Unknown (distinct or not from NULL itself) varies between SQL implementations. For example, the following
SELECT 'ok' WHERE (NULL <> 1) IS NULL;
parses and executes successfully in some environments (e.g. SQLite or PostgreSQL) which unify a NULL boolean with Unknown but fails to parse in others (e.g. in SQL Server Compact). MySQL behaves similarly to PostgreSQL in this regard (with the minor exception that MySQL regards TRUE and FALSE as no different from the ordinary integers 1 and 0). PostgreSQL additionally implements a IS UNKNOWN predicate, which can be used to test whether a three-value logical outcome is Unknown, although this is merely syntactic sugar.
BOOLEAN data type[edit]
The ISO SQL:1999 standard introduced the BOOLEAN data type to SQL, however it’s still just an optional, non-core feature, coded T031.[26]
When restricted by a NOT NULL constraint, the SQL BOOLEAN works like the Boolean type from other languages. Unrestricted however, the BOOLEAN datatype, despite its name, can hold the truth values TRUE, FALSE, and UNKNOWN, all of which are defined as boolean literals according to the standard. The standard also asserts that NULL and UNKNOWN «may be used
interchangeably to mean exactly the same thing».[27][28]
The Boolean type has been subject of criticism, particularly because of the mandated behavior of the UNKNOWN literal, which is never equal to itself because of the identification with NULL.[29]
As discussed above, in the PostgreSQL implementation of SQL, Null is used to represent all UNKNOWN results, including the UNKNOWN BOOLEAN. PostgreSQL does not implement the UNKNOWN literal (although it does implement the IS UNKNOWN operator, which is an orthogonal feature.) Most other major vendors do not support the Boolean type (as defined in T031) as of 2012.[30] The procedural part of Oracle’s PL/SQL supports BOOLEAN however variables; these can also be assigned NULL and the value is considered the same as UNKNOWN.[31]
Controversy[edit]
Common mistakes[edit]
Misunderstanding of how Null works is the cause of a great number of errors in SQL code, both in ISO standard SQL statements and in the specific SQL dialects supported by real-world database management systems. These mistakes are usually the result of confusion between Null and either 0 (zero) or an empty string (a string value with a length of zero, represented in SQL as ''). Null is defined by the SQL standard as different from both an empty string and the numerical value 0, however. While Null indicates the absence of any value, the empty string and numerical zero both represent actual values.
A classic error is the attempt to use the equals operator = in combination with the keyword NULL to find rows with Nulls. According to the SQL standard this is an invalid syntax and shall lead to an error message or an exception. But most implementations accept the syntax and evaluate such expressions to UNKNOWN. The consequence is that no rows are found – regardless of whether rows with Nulls exist or not. The proposed way to retrieve rows with Nulls is the use of the predicate IS NULL instead of = NULL.
SELECT * FROM sometable WHERE num = NULL; -- Should be "WHERE num IS NULL"
In a related, but more subtle example, a WHERE clause or conditional statement might compare a column’s value with a constant. It is often incorrectly assumed that a missing value would be «less than» or «not equal to» a constant if that field contains Null, but, in fact, such expressions return Unknown. An example is below:
SELECT * FROM sometable WHERE num <> 1; -- Rows where num is NULL will not be returned, -- contrary to many users' expectations.
These confusions arise because the Law of Identity is restricted in SQL’s logic. When dealing with equality comparisons using the NULL literal or the UNKNOWN truth-value, SQL will always return UNKNOWN as the result of the expression. This is a partial equivalence relation and makes SQL an example of a Non-Reflexive logic.[32]
Similarly, Nulls are often confused with empty strings. Consider the LENGTH function, which returns the number of characters in a string. When a Null is passed into this function, the function returns Null. This can lead to unexpected results, if users are not well versed in 3-value logic. An example is below:
SELECT * FROM sometable WHERE LENGTH(string) < 20; -- Rows where string is NULL will not be returned.
This is complicated by the fact that in some database interface programs (or even database implementations like Oracle’s), NULL is reported as an empty string, and empty strings may be incorrectly stored as NULL.
Criticisms[edit]
The ISO SQL implementation of Null is the subject of criticism, debate and calls for change. In The Relational Model for Database Management: Version 2, Codd suggested that the SQL implementation of Null was flawed and should be replaced by two distinct Null-type markers. The markers he proposed were to stand for «Missing but Applicable» and «Missing but Inapplicable», known as A-values and I-values, respectively. Codd’s recommendation, if accepted, would have required the implementation of a four-valued logic in SQL.[5] Others have suggested adding additional Null-type markers to Codd’s recommendation to indicate even more reasons that a data value might be «Missing», increasing the complexity of SQL’s logic system. At various times, proposals have also been put forth to implement multiple user-defined Null markers in SQL. Because of the complexity of the Null-handling and logic systems required to support multiple Null markers, none of these proposals have gained widespread acceptance.
Chris Date and Hugh Darwen, authors of The Third Manifesto, have suggested that the SQL Null implementation is inherently flawed and should be eliminated altogether,[33] pointing to inconsistencies and flaws in the implementation of SQL Null-handling (particularly in aggregate functions) as proof that the entire concept of Null is flawed and should be removed from the relational model.[34] Others, like author Fabian Pascal, have stated a belief that «how the function calculation should treat missing values is not governed by the relational model.»[citation needed]
Closed-world assumption[edit]
Another point of conflict concerning Nulls is that they violate the closed-world assumption model of relational databases by introducing an open-world assumption into it.[35] The closed world assumption, as it pertains to databases, states that «Everything stated by the database, either explicitly or implicitly, is true; everything else is false.»[36] This view assumes that the knowledge of the world stored within a database is complete. Nulls, however, operate under the open world assumption, in which some items stored in the database are considered unknown, making the database’s stored knowledge of the world incomplete.
See also[edit]
- SQL
- NULLs in: Wikibook SQL
- Ternary logic
- Data manipulation language
- Codd’s 12 rules
- Check constraint
- Relational Model/Tasmania
- Relational database management system
- Join (SQL)
References[edit]
- ^ a b c d Ron van der Meyden, «Logical approaches to incomplete information: a survey» in Chomicki, Jan; Saake, Gunter (Eds.) Logics for Databases and Information Systems, Kluwer Academic Publishers ISBN 978-0-7923-8129-7, p. 344; PS preprint (note: page numbering differs in preprint from the published version)
- ^ Codd, E.F. (October 14, 1985). «Is Your Database Really Relational?». Computerworld.
- ^ Codd, E.F. (October 21, 1985). «Does Your DBMS Run By The Rules?». Computerworld.
- ^ a b Don Chamberlin (1998). A Complete Guide to DB2 Universal Database. Morgan Kaufmann. pp. 28–32. ISBN 978-1-55860-482-7.
- ^ a b Codd, E.F. (1990). The Relational Model for Database Management (Version 2 ed.). Addison Wesley Publishing Company. ISBN 978-0-201-14192-4.
- ^ a b ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.2.6: numeric value expressions..
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.2.8: string value expression. - ^
ISO/IEC (2003). ISO/IEC 9075-1:2003, «SQL/Framework». ISO/IEC. Section 4.4.2: The null value. - ^ a b Coles, Michael (June 27, 2005). «Four Rules for Nulls». SQL Server Central. Red Gate Software.
- ^ a b Hans-Joachim, K. (2003). «Null Values in Relational Databases and Sure Information Answers». Semantics in Databases. Second International Workshop Dagstuhl Castle, Germany, January 7–12, 2001. Revised Papers. Lecture Notes in Computer Science. Vol. 2582. pp. 119–138. doi:10.1007/3-540-36596-6_7. ISBN 978-3-540-00957-3.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 8.7: null predicate. - ^ C.J. Date (2004), An introduction to database systems, 8th ed., Pearson Education, p. 594
- ^ Jim Melton; Jim Melton Alan R. Simon (1993). Understanding The New SQL: A Complete Guide. Morgan Kaufmann. pp. 145–147. ISBN 978-1-55860-245-8.
- ^ C. J. Date, Relational database writings, 1991-1994, Addison-Wesley, 1995, p. 371
- ^ C.J. Date (2004), An introduction to database systems, 8th ed., Pearson Education, p. 584
- ^ Imieliński, T.; Lipski Jr., W. (1984). «Incomplete information in relational databases». Journal of the ACM. 31 (4): 761–791. doi:10.1145/1634.1886. S2CID 288040.
- ^ Abiteboul, Serge; Hull, Richard B.; Vianu, Victor (1995). Foundations of Databases. Addison-Wesley. ISBN 978-0-201-53771-0.
- ^ a b Coles, Michael (February 26, 2007). «Null Versus Null?». SQL Server Central. Red Gate Software.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 4.15.4: Aggregate functions. - ^ ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 3.1.6.8: Definitions: distinct.
- ^ «PostgreSQL 8.0.14 Documentation: Index Types». PostgreSQL. Retrieved 6 November 2008.
- ^ «PostgreSQL 8.0.14 Documentation: Unique Indexes». PostgreSQL. Retrieved November 6, 2008.
- ^ «Creating Unique Indexes». PostfreSQL. September 2007. Retrieved November 6, 2008.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.11: case expression. - ^ Jim Melton; Alan R. Simon (2002). SQL:1999: Understanding Relational Language Components. Morgan Kaufmann. p. 53. ISBN 978-1-55860-456-8.
- ^ «ISO/IEC 9075-1:1999 SQL Standard». ISO. 1999.
- ^ C. Date (2011). SQL and Relational Theory: How to Write Accurate SQL Code. O’Reilly Media, Inc. p. 83. ISBN 978-1-4493-1640-2.
- ^ ISO/IEC 9075-2:2011 §4.5
- ^ Martyn Prigmore (2007). Introduction to Databases With Web Applications. Pearson Education Canada. p. 197. ISBN 978-0-321-26359-9.
- ^ Troels Arvin, Survey of BOOLEAN data type implementation
- ^ Steven Feuerstein; Bill Pribyl (2009). Oracle PL/SQL Programming. O’Reilly Media, Inc. pp. 74, 91. ISBN 978-0-596-51446-4.
- ^ Arenhart, Krause (2012), «Classical Logic or Non-Reflexive Logic? A case of Semantic Underdetermination», Revista Portuguesa de Filosofia, 68 (1/2): 73–86, doi:10.17990/RPF/2012_68_1_0073, JSTOR 41955624.
- ^
Darwen, Hugh; Chris Date. «The Third Manifesto». Retrieved May 29, 2007. - ^
Darwen, Hugh. «The Askew Wall» (PDF). Retrieved May 29, 2007. - ^ Date, Chris (May 2005). Database in Depth: Relational Theory for Practitioners. O’Reilly Media, Inc. p. 73. ISBN 978-0-596-10012-4.
- ^ Date, Chris. «Abstract: The Closed World Assumption». Data Management Association, San Francisco Bay Area Chapter. Archived from the original on 2007-05-19. Retrieved May 29, 2007.
Further reading[edit]
- E. F. Codd. Understanding relations (installment #7). FDT Bulletin of ACM-SIGMOD, 7(3-4):23–28, 1975.
- Codd, E. F. (1979). «Extending the database relational model to capture more meaning». ACM Transactions on Database Systems. 4 (4): 397–434. CiteSeerX 10.1.1.508.5701. doi:10.1145/320107.320109. S2CID 17517212. Especially §2.3.
- Date, C.J. (2000). The Database Relational Model: A Retrospective Review and Analysis: A Historical Account and Assessment of E. F. Codd’s Contribution to the Field of Database Technology. Addison Wesley Longman. ISBN 978-0-201-61294-3.
- Klein, Hans-Joachim (1994). «How to modify SQL queries in order to guarantee sure answers». ACM SIGMOD Record. 23 (3): 14–20. doi:10.1145/187436.187445. S2CID 17354724.
- Claude Rubinson, Nulls, Three-Valued Logic, and Ambiguity in SQL: Critiquing Date’s Critique, SIGMOD Record, December 2007 (Vol. 36, No. 4)
- John Grant, Null Values in SQL. SIGMOD Record, September 2008 (Vol. 37, No. 3)
- Waraporn, Narongrit, and Kriengkrai Porkaew. «Null semantics for subqueries and atomic predicates». IAENG International Journal of Computer Science 35.3 (2008): 305-313.
- Bernhard Thalheim, Klaus-Dieter Schewe (2011). «NULL ‘Value’ Algebras and Logics». Frontiers in Artificial Intelligence and Applications. 225 (Information Modelling and Knowledge Bases XXII). doi:10.3233/978-1-60750-690-4-354.
{{cite journal}}: CS1 maint: uses authors parameter (link) - Enrico Franconi and Sergio Tessaris, On the Logic of SQL Nulls, Proceedings of the 6th Alberto Mendelzon International Workshop on Foundations of Data Management, Ouro Preto, Brazil, June 27–30, 2012. pp. 114–128
External links[edit]
- Oracle NULLs Archived 2013-04-12 at the Wayback Machine
- The Third Manifesto
- Implications of NULLs in sequencing of data
- Java bug report about jdbc not distinguishing null and empty string, which Sun closed as «not a bug»
замечания
Значение null является значением по умолчанию для неинициализированного значения поля, тип которого является ссылочным типом.
Исключение NullPointerException (или NPE) — это исключение, которое возникает при попытке выполнить ненадлежащую операцию над ссылкой на null объект. К таким операциям относятся:
- вызов метода экземпляра на
nullцелевом объекте, - доступ к полю
nullцелевого объекта, - пытаясь проиндексировать
nullмассив или получить доступ к его длине, - используя ссылку на
nullобъект в качестве мьютекса вsynchronizedблоке, - литье ссылки на
nullобъект, - unboxing ссылку на
nullобъект и - бросая ссылку на
nullобъект.
Наиболее распространенные первопричины для NPE:
- забыв инициализировать поле с эталонным типом,
- забывая инициализировать элементы массива ссылочного типа или
- не проверяя результаты определенных методов API, которые указаны как возвращающие
nullв определенных обстоятельствах.
Примеры обычно используемых методов, возвращающих значение null включают:
- Метод
get(key)в APIMapвозвращаетnullесли вы вызываете его с помощью ключа, который не имеет сопоставления. -
getResource(path)иgetResourceAsStream(path)в APIClassLoaderиClassAPI возвращают значениеnullесли ресурс не может быть найден. - Метод
get()вReferenceAPI возвращаетnullесли сборщик мусора очистил ссылку. - Различные методы
getXxxxв API-интерфейсах Java EE возвращают значениеnullесли выgetXxxxизвлечь необязательный параметр запроса, атрибут сеанса или сеанса и т. Д.
Существуют стратегии избежания нежелательных NPE, таких как явное тестирование null или использование «Обозначения Йоды», но эти стратегии часто имеют нежелательный результат скрытия проблем в вашем коде, который действительно должен быть исправлен.
Pitfall — Ненужное использование примитивных оберток может привести к NullPointerExceptions
Иногда программисты, которые являются новыми Java, будут использовать примитивные типы и обертки взаимозаменяемо. Это может привести к проблемам. Рассмотрим этот пример:
public class MyRecord {
public int a, b;
public Integer c, d;
}
...
MyRecord record = new MyRecord();
record.a = 1; // OK
record.b = record.b + 1; // OK
record.c = 1; // OK
record.d = record.d + 1; // throws a NullPointerException
Наш класс MyRecord 1 использует инициализацию по умолчанию для инициализации значений в своих полях. Таким образом, когда мы записываем new запись, поля a и b будут установлены на ноль, а поля c и d будут установлены в null .
Когда мы пытаемся использовать инициализированные поля по умолчанию, мы видим, что поля int работают все время, но поля Integer работают в некоторых случаях, а не другие. В частности, в случае, когда не удается (с d ), что происходит в том , что выражение на правой стороне пытается распаковывать с null ссылки, и это приводит к тому , что NullPointerException быть выброшен.
Есть несколько способов взглянуть на это:
-
Если поля
cиdдолжны быть примитивными оболочками, то либо мы не должны полагаться на инициализацию по умолчанию, либо мы должны тестировать значениеnull. Для прежнего это правильный подход, если для полей вnullсостоянии не существует определенного значения. -
Если поля не должны быть примитивными обертками, то ошибочно сделать их примитивными обертками. В дополнение к этой проблеме примитивные обертки имеют дополнительные накладные расходы по сравнению с примитивными типами.
Урок здесь заключается в том, чтобы не использовать примитивные типы оберток, если вам действительно не нужно.
1 — Этот класс не является примером хорошей практики кодирования. Например, у хорошо продуманного класса не было бы публичных полей. Однако это не относится к этому примеру.
Pitfall — использование null для представления пустого массива или коллекции
Некоторые программисты считают, что это хорошая идея, чтобы сэкономить место, используя null для представления пустого массива или коллекции. Хотя это правда, что вы можете сэкономить небольшое пространство, обратная сторона заключается в том, что он делает ваш код более сложным и более хрупким. Сравните эти две версии метода суммирования массива:
Первая версия — это то, как вы обычно кодируете метод:
/**
* Sum the values in an array of integers.
* @arg values the array to be summed
* @return the sum
**/
public int sum(int[] values) {
int sum = 0;
for (int value : values) {
sum += value;
}
return sum;
}
Вторая версия — это то, как вам нужно закодировать метод, если вы привыкли использовать null для представления пустого массива.
/**
* Sum the values in an array of integers.
* @arg values the array to be summed, or null.
* @return the sum, or zero if the array is null.
**/
public int sum(int[] values) {
int sum = 0;
if (values != null) {
for (int value : values) {
sum += value;
}
}
return sum;
}
Как вы можете видеть, код немного сложнее. Это напрямую связано с решением использовать null таким образом.
Теперь рассмотрим, используется ли этот массив, который может быть null во многих местах. В каждом месте, где вы его используете, вам нужно проверить, нужно ли вам проверять значение null . Если вы пропустите null тест, который должен быть там, вы рискуете NullPointerException . Следовательно, стратегия использования null в этом случае приводит к тому, что ваше приложение становится более хрупким; т.е. более уязвимы к последствиям ошибок программиста.
Урок здесь состоит в том, чтобы использовать пустые массивы и пустые списки, когда это то, что вы имеете в виду.
int[] values = new int[0]; // always empty
List<Integer> list = new ArrayList(); // initially empty
List<Integer> list = Collections.emptyList(); // always empty
Недостаток пространства небольшой, и есть другие способы свести его к минимуму, если это стоит того.
Pitfall — «Создание хороших» неожиданных нулей
В StackOverflow мы часто видим такой код в ответах:
public String joinStrings(String a, String b) {
if (a == null) {
a = "";
}
if (b == null) {
b = "";
}
return a + ": " + b;
}
Часто это сопровождается утверждением, которое является «лучшей практикой» для проверки null чтобы избежать исключения NullPointerException .
Это лучшая практика? Короче: Нет.
Есть некоторые основополагающие предположения, которые необходимо поставить под сомнение, прежде чем мы сможем сказать, если это хорошая идея сделать это в наших joinStrings :
Что значит для «a» или «b» быть нулевым?
Значение String может быть равно нулю или больше символов, поэтому у нас уже есть способ представления пустой строки. null означает что-то другое, чем "" ? Если нет, то проблематично иметь два способа представления пустой строки.
null может исходить из неинициализированного поля или неинициализированного элемента массива. Значение может быть неинициализировано по дизайну или случайно. Если это было случайно, это ошибка.
Указывает ли нуль значение «не знаю» или «отсутствует»?
Иногда null может иметь подлинный смысл; например, что реальное значение переменной неизвестно или недоступно или «необязательно». В Java 8 класс Optional предоставляет лучший способ выразить это.
Если это ошибка (или ошибка дизайна), мы должны «сделать хорошо»?
Одна из интерпретаций кода заключается в том, что мы «делаем хороший» неожиданный null , используя пустую строку на своем месте. Правильная ли стратегия? Было бы лучше позволить NullPointerException , а затем поймать исключение дальше по стеку и зарегистрировать его как ошибку?
Проблема с «хорошим достижением» заключается в том, что она может либо скрыть проблему, либо затруднить диагностику.
Является ли это эффективным / хорошим для качества кода?
Если подход «сделать хороший» используется последовательно, ваш код будет содержать множество «защитных» нулевых тестов. Это сделает его более длинным и трудным для чтения. Более того, все эти тесты и «делать добро» могут повлиять на производительность вашего приложения.
В итоге
Если значение null является значимым значением, то проверка null случая — правильный подход. Следствием является то, что если значение null имеет смысл, то это должно быть четко документировано в javadocs любых методов, которые принимают null значение или возвращают его.
В противном случае лучше рассмотреть неожиданный null как ошибку программирования, и пусть NullPointerException произойдет, чтобы разработчик узнал, что в коде есть проблема.
Pitfall — Возвращение null вместо исключения исключения
Некоторые Java-программисты имеют общее отвращение к выбросам или распространению исключений. Это приводит к следующему коду:
public Reader getReader(String pathname) {
try {
return new BufferedReader(FileReader(pathname));
} catch (IOException ex) {
System.out.println("Open failed: " + ex.getMessage());
return null;
}
}
Так в чем проблема?
Проблема в том, что getReader возвращает значение null в качестве специального значения, чтобы указать, что Reader не может быть открыт. Теперь возвращаемое значение нужно протестировать, чтобы проверить, не является ли оно значением null до его использования. Если тест не учитывается, результатом будет исключение NullPointerException .
Здесь есть три проблемы:
-
IOExceptionбыло обнаружено слишком рано. - Структура этого кода означает, что существует риск утечки ресурса.
- Затем был
nullпотому что не было доступно «реальное»Reader.
На самом деле, предполагая, что исключение нужно было поймать раньше, было несколько альтернатив возврату null :
- Можно было бы реализовать класс
NullReader; например, когда операции API ведут себя так, как если бы читатель уже находился в позиции «конец файла». - С Java 8 можно было бы объявить
getReaderкак возвращающийOptional<Reader>.
Pitfall — не проверяет, не инициализирован ли поток ввода-вывода при его закрытии
Чтобы предотвратить утечку памяти, не следует забывать закрыть входной поток или выходной поток, чья работа выполнена. Обычно это делается с помощью заявления try catch finally без части catch :
void writeNullBytesToAFile(int count, String filename) throws IOException {
FileOutputStream out = null;
try {
out = new FileOutputStream(filename);
for(; count > 0; count--)
out.write(0);
} finally {
out.close();
}
}
Хотя приведенный выше код может выглядеть невинно, у него есть недостаток, который может сделать отладку невозможной. Если строка, где out инициализирована ( out = new FileOutputStream(filename) ), генерирует исключение, тогда out будет null когда out.close() , что приводит к неприятному исключению NullPointerException !
Чтобы этого избежать, просто убедитесь, что поток не имеет null прежде чем пытаться его закрыть.
void writeNullBytesToAFile(int count, String filename) throws IOException {
FileOutputStream out = null;
try {
out = new FileOutputStream(filename);
for(; count > 0; count--)
out.write(0);
} finally {
if (out != null)
out.close();
}
}
Еще лучший подход — try -with-resources, так как он автоматически закрывает поток с вероятностью 0, чтобы выбросить NPE без необходимости блока finally .
void writeNullBytesToAFile(int count, String filename) throws IOException {
try (FileOutputStream out = new FileOutputStream(filename)) {
for(; count > 0; count--)
out.write(0);
}
}
Pitfall — использование «нотации Yoda», чтобы избежать NullPointerException
Многие примеры кода, размещенные в StackOverflow, включают в себя следующие фрагменты:
if ("A".equals(someString)) {
// do something
}
Это предотвращает или предотвращает возможное исключение NullPointerException в случае, если someString имеет значение null . Кроме того, можно утверждать, что
"A".equals(someString)
лучше, чем:
someString != null && someString.equals("A")
(Это более красноречиво, и в некоторых случаях это может быть более эффективным. Однако, как мы утверждаем ниже, краткость может быть отрицательной.)
Тем не менее, реальная ловушка использует тест Йоды, чтобы избежать NullPointerExceptions в качестве привычки.
Когда вы пишете "A".equals(someString) вы на самом деле «делаете хорошо», когда someString имеет значение null . Но в качестве другого примера ( Pitfall — «Создание хороших» неожиданных нулей ) объясняет, что «создание хороших» null значений может быть вредным по целому ряду причин.
Это означает, что условия Йоды не являются «лучшей практикой» 1 . Если не ожидается null , лучше разрешить NullPointerException , чтобы вы могли получить отказ единичного теста (или отчет об ошибке). Это позволяет вам найти и исправить ошибку, которая вызвала появление неожиданного / нежелательного null .
Условия Yoda должны использоваться только в тех случаях, когда ожидается null потому что объект, который вы тестируете, исходит из API, который документирован как возвращающий null . И, возможно, лучше использовать один из менее привлекательных способов выражения теста, потому что это помогает выделить null тест тому, кто просматривает ваш код.
1 — Согласно Википедии : «Лучшие методы кодирования — это набор неформальных правил, которые сообщество разработчиков программного обеспечения со временем узнало, что может помочь улучшить качество программного обеспечения». , Использование нотации Yoda этого не достигает. Во многих ситуациях это делает код хуже.
Ряд пользователей (да и разработчиков) программных продуктов на языке Java могут столкнуться с ошибкой java.lang.nullpointerexception (сокращённо NPE), при возникновении которой запущенная программа прекращает свою работу. Обычно это связано с некорректно написанным телом какой-либо программы на Java, требуя от разработчиков соответствующих действий для исправления проблемы. В этом материале я расскажу, что это за ошибка, какова её специфика, а также поясню, как исправить ошибку java.lang.nullpointerexception.

Содержание
- Что это за ошибка java.lang.nullpointerexception
- Как исправить ошибку java.lang.nullpointerexception
- Для пользователей
- Для разработчиков
- Заключение
Что это за ошибка java.lang.nullpointerexception
Появление данной ошибки знаменует собой ситуацию, при которой разработчик программы пытается вызвать метод по нулевой ссылке на объект. В тексте сообщения об ошибке система обычно указывает stack trace и номер строки, в которой возникла ошибка, по которым проблему будет легко отследить.

Что в отношении обычных пользователей, то появление ошибки java.lang.nullpointerexception у вас на ПК сигнализирует, что у вас что-то не так с функционалом пакетом Java на вашем компьютере, или что программа (или онлайн-приложение), работающие на Java, функционируют не совсем корректно. Если у вас возникает проблема, при которой Java апплет не загружен, рекомендую изучить материал по ссылке.

Как исправить ошибку java.lang.nullpointerexception
Как избавиться от ошибки java.lang.nullpointerexception? Способы борьбы с проблемой можно разделить на две основные группы – для пользователей и для разработчиков.
Для пользователей
Если вы встретились с данной ошибкой во время запуска (или работы) какой-либо программы (особенно это касается minecraft), то рекомендую выполнить следующее:
- Переустановите пакет Java на своём компьютере. Скачать пакет можно, к примеру, вот отсюда;
- Переустановите саму проблемную программу (или удалите проблемное обновление, если ошибка начала появляться после такового);
- Напишите письмо в техническую поддержку программы (или ресурса) с подробным описанием проблемы и ждите ответа, возможно, разработчики скоро пофиксят баг.
- Также, в случае проблем в работе игры Майнкрафт, некоторым пользователям помогло создание новой учётной записи с административными правами, и запуск игры от её имени.


Для разработчиков
Разработчикам стоит обратить внимание на следующее:
- Вызывайте методы equals(), а также equalsIgnoreCase() в известной строке литерала, и избегайте вызова данных методов у неизвестного объекта;
- Вместо toString() используйте valueOf() в ситуации, когда результат равнозначен;
- Применяйте null-безопасные библиотеки и методы;
- Старайтесь избегать возвращения null из метода, лучше возвращайте пустую коллекцию;
- Применяйте аннотации @Nullable и @NotNull;
- Не нужно лишней автоупаковки и автораспаковки в создаваемом вами коде, что приводит к созданию ненужных временных объектов;
- Регламентируйте границы на уровне СУБД;
- Правильно объявляйте соглашения о кодировании и выполняйте их.


Заключение
При устранении ошибки java.lang.nullpointerexception важно понимать, что данная проблема имеет программную основу, и мало коррелирует с ошибками ПК у обычного пользователя. В большинстве случаев необходимо непосредственное вмешательство разработчиков, способное исправить возникшую проблему и наладить работу программного продукта (или ресурса, на котором запущен сам продукт). В случае же, если ошибка возникла у обычного пользователя (довольно часто касается сбоев в работе игры Minecraft), рекомендуется установить свежий пакет Java на ПК, а также переустановить проблемную программу.
Опубликовано 21.02.2017 Обновлено 03.09.2022
Here I will hopefully clarify my position.
That NULL = NULL evaluate to FALSE is wrong. Hacker and Mister correctly answered NULL.
Here is why. Dewayne Christensen wrote to me, in a comment to Scott Ivey:
Since it’s December, let’s use a
seasonal example. I have two presents
under the tree. Now, you tell me if I
got two of the same thing or not.
They can be different or they can be equal, you don’t know until one open both presents. Who knows? You invited two people that don’t know each other and both have done to you the same gift — rare, but not impossible §.
So the question: are these two UNKNOWN presents the same (equal, =)? The correct answer is: UNKNOWN (i.e. NULL).
This example was intended to demonstrate that «..(false or null, depending on your system)..» is a correct answer — it is not, only NULL is correct in 3VL (or is ok for you to accept a system which gives wrong answers?)
A correct answer to this question must emphasize this two points:
- three-valued logic (3VL) is counterintuitive (see countless other questions on this subject on Stackoverflow and in other forum to make sure);
- SQL-based DBMSes often do not respect even 3VL, they give wrong answers sometimes (as, the original poster assert, SQL Server do in this case).
So I reiterate: SQL does not any good forcing one to interpret the reflexive property of equality, which state that:
for any x, x = x§§ (in plain English: whatever the universe of discourse, a «thing» is always equal to itself).
.. in a 3VL (TRUE, FALSE, NULL). The expectation of people would conform to 2VL (TRUE, FALSE, which even in SQL is valid for all other values), i.e. x = x always evaluate to TRUE, for any possible value of x — no exceptions.
Note also that NULLs are valid » non-values » (as their apologists pretend them to be) which one can assign as attribute values(??) as part of relation variables. So they are acceptable values of every type (domain), not only of the type of logical expressions.
And this was my point: NULL, as value, is a «strange beast». Without euphemism, I prefer to say: nonsense.
I think that this formulation is much more clear and less debatable — sorry for my poor English proficiency.
This is only one of the problems of NULLs. Better to avoid them entirely, when possible.
§ we are concerned about values here, so the fact that the two presents are always two different physical objects are not a valid objection; if you are not convinced I’m sorry, it is not this the place to explain the difference between value and «object» semantics (Relational Algebra has value semantics from the start — see Codd’s information principle; I think that some SQL DBMS implementors don’t even care about a common semantics).
§§ to my knowledge, this is an axiom accepted (in a form or another, but always interpreted in a 2VL) since antiquity and that exactly because is so intuitive. 3VLs (is a family of logics in reality) is a much more recent development (but I’m not sure when was first developed).
Side note: if someone will introduce Bottom, Unit and Option Types as attempts to justify SQL NULLs, I will be convinced only after a quite detailed examination that will shows of how SQL implementations with NULLs have a sound type system and will clarify, finally, what NULLs (these «values-not-quite-values») really are.
In what follow I will quote some authors. Any error or omission is
probably mine and not of the original authors.
Joe Celko on SQL NULLs
I see Joe Celko often cited on this forum. Apparently he is a much respected author here. So, I said to myself: «what does he wrote about SQL NULLs? How does he explain NULLs numerous problems?». One of my friend has an ebook version of Joe Celko’s SQL for smarties: advanced SQL programming, 3rd edition. Let’s see.
First, the table of contents. The thing that strikes me most is the number of times that NULL is mentioned and in the most varied contexts:
3.4 Arithmetic and NULLs 109
3.5 Converting Values to and from NULL 110
3.5.1 NULLIF() Function 110
6 NULLs: Missing Data in SQL 185
6.4 Comparing NULLs 190
6.5 NULLs and Logic 190
6.5.1 NULLS in Subquery Predicates 191
6.5.2 Standard SQL Solutions 193
6.6 Math and NULLs 193
6.7 Functions and NULLs 193
6.8 NULLs and Host Languages 194
6.9 Design Advice for NULLs 195
6.9.1 Avoiding NULLs from the Host Programs 197
6.10 A Note on Multiple NULL Values 198
10.1 IS NULL Predicate 241
10.1.1 Sources of NULLs 242
…
and so on. It rings «nasty special case» to me.
I will go into some of these cases with excerpts from this book, trying to limit myself to the essential, for copyright reasons. I think these quotes fall within «fair use» doctrine and they can even stimulate to buy the book — so I hope that no one will complain (otherwise I will need to delete most of it, if not all). Furthermore, I shall refrain from reporting code snippets for the same reason. Sorry about that. Buy the book to read about datailed reasoning.
Page numbers between parenthesis in what follow.
NOT NULL Constraint (11)
The most important column constraint is the NOT NULL, which forbids
the use of NULLs in a column. Use this constraint routinely, and remove
it only when you have good reason. It will help you avoid the
complications of NULL values when you make queries against the data.It is not a value; it is a marker that holds a place where a value might go.
Again this «value but not quite a value» nonsense. The rest seems quite sensible to me.
(12)
In short, NULLs cause a lot of irregular features in SQL, which we will discuss
later. Your best bet is just to memorize the situations and the rules for NULLs
when you cannot avoid them.
Apropos of SQL, NULLs and infinite:
(104) CHAPTER 3: NUMERIC DATA IN SQL
SQL has not accepted the IEEE model for mathematics for several reasons.
…
If the IEEE rules for math were allowed in
SQL, then we would need type conversion rules for infinite and a way to
represent an infinite exact numeric value after the conversion. People
have enough trouble with NULLs, so let’s not go there.
SQL implementations undecided on what NULL really means in particular contexts:
3.6.2 Exponential Functions (116)
The problem is that logarithms are undefined when (x <= 0). Some SQL
implementations return an error message, some return a NULL and DB2/
400; version 3 release 1 returned *NEGINF (short for “negative infinity”)
as its result.
Joe Celko quoting David McGoveran and C. J. Date:
6 NULLs: Missing Data in SQL (185)
In their book A Guide to Sybase and SQL Server, David McGoveran
and C. J. Date said: “It is this writer’s opinion than NULLs, at least as
currently defined and implemented in SQL, are far more trouble than
they are worth and should be avoided; they display very strange and
inconsistent behavior and can be a rich source of error and confusion.
(Please note that these comments and criticisms apply to any system
that supports SQL-style NULLs, not just to SQL Server specifically.)”
NULLs as a drug addiction:
(186/187)
In the rest of this book, I will be urging you not to use
them, which may seem contradictory, but it is not. Think of a NULL
as a drug; use it properly and it works for you, but abuse it and it can ruin
everything. Your best policy is to avoid NULLs when you can and use
them properly when you have to.
My unique objection here is to «use them properly», which interacts badly with
specific implementation behaviors.
6.5.1 NULLS in Subquery Predicates (191/192)
People forget that a subquery often hides a comparison with a NULL.
Consider these two tables:…
The result will be empty. This is counterintuitive, but correct.
(separator)
6.5.2 Standard SQL Solutions (193)
SQL-92 solved some of the 3VL (three-valued logic) problems by adding
a new predicate of the form:<search condition> IS [NOT] TRUE | FALSE | UNKNOWN
But UNKNOWN is a source of problems in itself, so that C. J. Date,
in his book cited below, reccomends in chapter 4.5. Avoiding Nulls in SQL:
- Don’t use the keyword UNKNOWN in any context whatsoever.
Read «ASIDE» on UNKNOWN, also linked below.
6.8 NULLs and Host Languages (194)
However, you should know how NULLs are handled when they have
to be passed to a host program. No standard host language for
which an embedding is defined supports NULLs, which is another
good reason to avoid using them in your database schema.
(separator)
6.9 Design Advice for NULLs (195)
It is a good idea to declare all your base tables with NOT NULL
constraints on all columns whenever possible. NULLs confuse people
who do not know SQL, and NULLs are expensive.
Objection: NULLs confuses even people that know SQL well,
see below.
(195)
NULLs should be avoided in FOREIGN KEYs. SQL allows this “benefit
of the doubt” relationship, but it can cause a loss of information in
queries that involve joins. For example, given a part number code in
Inventory that is referenced as a FOREIGN KEY by an Orders table, you
will have problems getting a listing of the parts that have a NULL. This is
a mandatory relationship; you cannot order a part that does not exist.
(separator)
6.9.1 Avoiding NULLs from the Host Programs (197)
You can avoid putting NULLs into the database from the Host Programs
with some programming discipline.…
- Determine impact of missing data on programming and reporting:
Numeric columns with NULLs are a problem, because queries
using aggregate functions can provide misleading results.
(separator)
(227)
The SUM() of an empty set is always NULL. One of the most common
programming errors made when using this trick is to write a query that
could return more than one row. If you did not think about it, you might
have written the last example as: …
(separator)
10.1.1 Sources of NULLs (242)
It is important to remember where NULLs can occur. They are more than
just a possible value in a column. Aggregate functions on empty sets,
OUTER JOINs, arithmetic expressions with NULLs, and OLAP operators
all return NULLs. These constructs often show up as columns in
VIEWs.
(separator)
(301)
Another problem with NULLs is found when you attempt to convert
IN predicates to EXISTS predicates.
(separator)
16.3 The ALL Predicate and Extrema Functions (313)
It is counterintuitive at first that these two predicates are not the same in SQL:
…
But you have to remember the rules for the extrema functions—they
drop out all the NULLs before returning the greater or least values. The
ALL predicate does not drop NULLs, so you can get them in the results.
(separator)
(315)
However, the definition in the standard is worded in the
negative, so that NULLs get the benefit of the doubt.
…As you can see, it is a good idea to avoid NULLs in UNIQUE
constraints.
Discussing GROUP BY:
NULLs are treated as if they were all equal to each other, and
form their own group. Each group is then reduced to a single
row in a new result table that replaces the old one.
This means that for GROUP BY clause NULL = NULL does not
evaluate to NULL, as in 3VL, but it evaluate to TRUE.
SQL standard is confusing:
The ORDER BY and NULLs (329)
Whether a sort key value that is NULL is considered greater or less than a
non-NULL value is implementation-defined, but…… There are SQL products that do it either way.
In March 1999, Chris Farrar brought up a question from one of his
developers that caused him to examine a part of the SQL Standard that
I thought I understood. Chris found some differences between the
general understanding and the actual wording of the specification.
And so on. I think is enough by Celko.
C. J. Date on SQL NULLs
C. J. Date is more radical about NULLs: avoid NULLs in SQL, period.
In fact, chapter 4 of his SQL and Relational Theory: How to Write Accurate
SQL Code is titled «NO DUPLICATES, NO NULLS», with subchapters
«4.4 What’s Wrong with Nulls?» and «4.5 Avoiding Nulls in SQL» (follow the link:
thanks to Google Books, you can read some pages on-line).
Fabian Pascal on SQL NULLs
From its Practical Issues in Database Management — A Reference
for the Thinking Practitioner (no excerpts on-line, sorry):
10.3 Pratical Implications
10.3.1 SQL NULLs
… SQL suffers from the problems inherent in 3VL as well as from many
quirks, complications, counterintuitiveness, and outright errors [10, 11];
among them are the following:
- Aggregate functions (e.g., SUM(), AVG()) ignore NULLs (except for COUNT()).
- A scalar expression on a table without rows evaluates incorrectly to NULL, instead of 0.
- The expression «NULL = NULL» evaluates to NULL, but is actually invalid in SQL; yet ORDER BY treats NULLs as equal (whatever they precede or follow «regular» values is left to DBMS vendor).
- The expression «x IS NOT NULL» is not equal to «NOT(x IS NULL)», as is the case in 2VL.
…
All commercially implemented SQL dialects follow this 3VL approach, and, thus,
not only do they exibits these problems, but they also have spefic implementation
problems, which vary across products.
Навскидку многим кажется, что они знакомы с поведением NULL-значений в PostgreSQL, однако иногда неопределённые значения преподносят сюрпризы. Мы с коллегами написали статью на основе моего доклада с PGConf.Russia 2022 — он был полностью посвящён особенностям обработки NULL-значений в Postgres.
NULL простыми словами
Что такое SQL база данных? Согласно одному из определений, это просто набор взаимосвязанных таблиц. А что такое NULL? Обратимся к простому бытовому примеру: все мы задаём друг другу дежурный вопрос: «Как дела?». Часто мы получаем в ответ: «Да ничего…» Вот это «ничего» нам и нужно положить в базу данных — NULL: неопределённое, некорректное или неизвестное значение.

Допустим, вы суммируете две колонки, и в сотой по счёту записи наткнулись на NULL. Что тогда делать? Или возвращать ошибку, потому что так нельзя, или всё-таки как-то выполнить сложение и идти дальше. Сообщество решило в пользу второго варианта и закрепило это в стандартах языка SQL. Также договорились, что данные любого типа могут оказаться NULL, написали специальные функции и операции для обработки NULL-значений.
NULL может оказаться в столбце с любым типом данных и попасть на вход к любому оператору или функции. Соответственно, все операторы и функции как-то обрабатывают NULL, но результат обработки иногда оказывается неожиданным.
Какие значения не являются NULL?
Давайте теперь посмотрим, что не есть NULL. Ноль — это просто ноль, не NULL. Пустая строка — это пустая строка в Postgres, в отличие от Oracle. Пустой массив, пустой JSON, массив NULL-значений, пустой диапазон — это не NULL. Сложные типы, включающие NULL, уже не являются NULL.

Есть, правда, одно исключение: запись, собранная из NULL-значений, является NULL. Это сделано для совместимости со стандартом языка SQL. Однако, «под капотом» Postgres функции и операторы считают запись, состоящую из NULL-значений, NOT NULL. Ниже приведены результаты обработки такой записи для некоторых из них:
сount(row(NULL)) посчитает такую запись;
num_nulls(row(NULL)) выдаст ноль;
row(NULL) IS DISTINCT FROM NULL выдаст TRUE.
Ещё удивительнее пример с записями, содержащими NULL:
row(NULL::int, ‘Bob’::TEXT) IS NULL ожидаемо выдаст FALSE, но
row(NULL::int, ‘Bob’::TEXT) IS NOT NULL тоже выдаст FALSE!
Тем не менее, это поведение не является багом и описано в документации.
Операции с NULL
Почти все бинарные операции с NULL — сложить, вычесть, умножить, конкатенировать — дают на выходе NULL. С этим стоит быть осторожнее. Если вы к строке или к JSON конкатенируете что-то, оказавшееся NULL, то получаете на выходе NULL. А если вы ещё и сделали UPDATE в базу данных, выйдет совсем нехорошо.
Тем не менее, логическая операция TRUE OR NULL на выходе даёт TRUE. FALSE AND NULL даёт в результате FALSE. То есть существуют некоторые исключения из общего правила.

Операции сравнения
Операции сравнения — больше, меньше, больше или равно — c NULL на выходе дают NULL. При этом и сам NULL не равен самому себе. Впрочем, в PostgreSQL есть параметр transform_null_equals, который по умолчанию выключен. Если его включить, то NULL будет равен NULL.
Для проверки любого значения на NULL в Postgres предусмотрен специальный оператор — … IS NULL, … IS NOT NULL. Также может быть непривычно, что при сравнении булевых переменных с NULL или при применении оператора равенства помимо значений TRUE и FALSE возможно ещё и неизвестное значение. При этом оператор IS (NOT) UNKNOWN — это аналог IS (NOT) NULL для булевых переменных.
Операторы IS TRUE или IS FALSE для булевых переменных дают или TRUE, или FALSE. NULL в результате их применения получиться не может. Использование оператора IS TRUE позволяет писать более надёжный код, чем обычное сравнение = TRUE, которое может выдать не учтённое программистом NULL-значение и пойти «не туда».

Что если нам нужно сравнить два значения X и Y, считая, что NULL-значения равны друг другу? Можно самому написать конструкцию из логических операторов, но существует уже готовый оператор X IS (NOT) DISTINCT FROM Y. Правда, планировщик PostgreSQL плохо понимает этот оператор и может выдавать долгие планы выполнения для запросов с ним.
Cпециальные функции для работы с NULL
Обратимся к специальным функциям для работы с NULL. Всем известная coalesce возвращает первый NOT NULL аргумент. Есть nullif, есть num_nulls — этой функции можно дать сколько угодно аргументов, она посчитает количество NULL-значений. С помощью функции num_nonnulls можно посчитать NOT NULL значения.
Как правило, функции с произвольным числом аргументов игнорируют NULL. Такие функции, как greatest, concat его просто проигнорируют. При этом функция создания массивов включит NULL-значение во вновь образованный массив, за этим надо следить.

NULL и агрегатные функции
Что касается агрегатных функций, то array_agg, json_agg включают NULL в агрегат, а конкатенация строки не может вставить NULL-значение в середину строки, и поэтому она NULL игнорирует.
Статистические функции min, max, sum игнорируют NULL, а вот с выражением Count всё хитро. Count по конкретному полю посчитает только строки, где выражение NOT NULL, а вот Count со звёздочкой посчитает всё, включая NULL-значения.

Что со всем этим делать? Можно почитать в справке или потестировать, как функция обрабатывает NULL-значения. А лучше использовать выражение FILTER и в явном виде исключить все NULL-значения.
NULL и пользовательские функции
Теперь о пользовательских функциях. При создании пользовательской функции по умолчанию включен режим CALLED ON NULL INPUT, то есть при наличии NULL среди аргументов функция вызовется и будет обрабатывать это значение. Если вам это не нужно, можно использовать RETURNS NULL ON NULL INPUT либо STRICT — в этом случае функция, обнаружив NULL хотя бы в одном аргументе, сразу возвращает NULL и дальше вообще не думает — для экономии времени.

Многие системные функции в PostgreSQL определены именно как STRICT, поэтому стали возможны некоторые математические казусы. Например, NULL можно разделить на ноль, и в результате вы получите NULL — вместо ошибки деления на ноль. NULL в степени ноль тоже является NULL, хотя в математике любое число в нулевой степени, даже если это сам ноль, даёт единицу. Непонятно, правильно ли такое поведение с философской точки зрения, но вроде пока никто не жаловался.
Группировка и сортировка
Если говорить о группировке, то она считает все NULL-значения одинаковыми, так как это делает оператор IS NOT DISTINCT FROM. При сортировке есть специальные подвыражения, в которых можно указать NULLS FIRST или NULLS LAST. По умолчанию выбирается NULLS LAST, то есть считается, что неопределённые значения больше всех остальных чисел.

Сортировка работает так при создании выборки, индекса, в агрегатных функциях и оконных функциях.
NULL и записи
Когда мы формируем запись из нескольких значений, то сравниваются все NOT NULL значения. Если найдётся различие, то результат будет FALSE. Если все NOT NULL значения совпадают, и нашёлся NULL, то будет NULL.

Сравнение на больше/меньше выполняется по другим правилам. Как только попадётся не совпадающее значение, тогда оно будет больше или меньше, а если обнаружится NULL, то будет NULL.
NULL и диапазоны
С бинарными операциями разобрались, но что если у нас тернарная операция? Например, SELECT NOW BETWEEN NULL AND NULL. Получится, ожидаемо, NULL.
Однако, точно такое же выражение, сформулированное через диапазоны, неожиданно даёт TRUE. Да, с точки зрения Postgres здесь и сейчас мы находимся в неопределённом промежутке времени!

Согласно стандарту SQL, все диапазонные типы — не только временные, а все вообще —воспринимают границу NULL как бесконечность.
Я полюбопытствовал и выяснил, что промежуток от минус бесконечности до плюс бесконечности входит в промежуток от NULL до NULL, а обратное — неверно.
Выходит, что NULL здесь даже несколько больше, чем бесконечность.
Также я попытался проверить, входит ли NULL в промежуток от минус бесконечности до плюс бесконечности. Оказалось, что это неизвестно. Это контринтуитивный для меня момент: мне казалось, что полный диапазон значений от минус до плюс бесконечности должен включать в себя любое значение, в том числе и неопределённое. Но нет, в PostgreSQL это не так.
Откуда в запросах появляются NULL-значения?
Во-первых, они попадают в базу данных при вставке или обновлении и продолжают храниться в столбцах таблиц.
Во-вторых, они записываются в базу как результат подзапроса не нашедшего ни одной строки — в этом случае подзапрос вернёт вам NULL.
В-третьих, NULL-значения могут появляться в результате операции объединения LEFT JOIN.
В-четвёртых, NULL-значения появлются как результат некоторых функций при некоторых условиях.
В-пятых, их можно создать вручную, например, при использовании конструкции CASE. В каком-то хитром запросе вы можете указать, что при определённых условиях получится неизвестное значение.

Структура базы данных и NULL
Во-первых, можно запретить хранение NULL-значений в столбце. Есть специальное ограничение (constraint) NOT NULL. Крайне рекомендую так и поступать — всегда запрещать хранение NULL-значений, если только вы не планируете хранить и обрабатывать NULL именно в этом столбце.
При определении ограничения (constraint) тоже есть одна особенность: если условие возвращает NULL, это считается допустимым, и такая запись может быть вставлена.
Например, ограничение Foreign key позволяет в дочерней таблице вставить запись со ссылкой, которая является NULL. Это будет допустимо.
Ограничение CHECK (price > 0) даст вам вставить в таблицу поле для Price со значением, равным NULL.

Ограничение unique позволяет создать несколько записей со значением NULL. Правда, в PostgreSQL 14 уже появилось специальное «заклинание», которое может запретить несколько записей с NULL.
Как NULL хранится внутри записи БД?
NULL вообще не хранится среди полей записи, но если там есть хотя бы одно NULL-значение, то создаётся битовая карта неопределённых значений, которая называется t_bits. Стоит запомнить, что самое первое NULL-значение влечёт за собой создание такой карты и расход некоторого количества места.
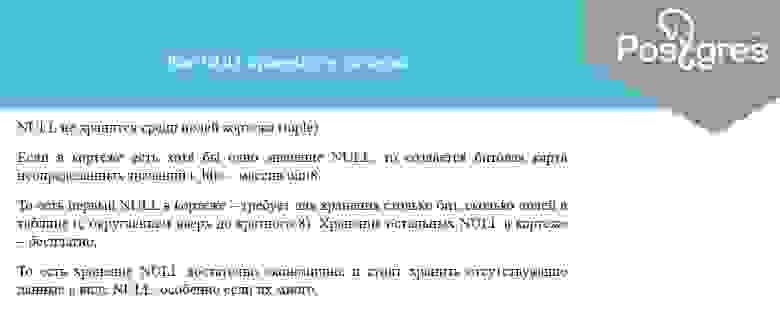
Правда, все дополнительные NULL-значения в этой записи вы уже храните бесплатно и достаточно компактно. Если вы действительно экономите каждый байт в своей базе данных, хранение NULL — правильное занятие.
NULL и индексы
Postgres хранит NULL-значения в btree-индексах. Этим он отличается от Oracle. Также Postgres может использовать такой индекс при поиске записей по NULL-значению.
Тем не менее, хранение NULL-значений в индексе для вас бесполезно, если у вас нет такого типа запросов (они довольно редки, и их можно проверить в представлении pg_stats_statements).

Также пользы не будет при большом количестве NULL-значений в индексе, и следовательно, плохой селективности. В этом случае будет дешевле сделать последовательное сканирование таблицы, а не возиться с индексом.
Вот пример случая с большим числом NULL-значений в таблице. У вас есть внешний ключ (foreign key) на какую-то родительскую таблицу, но реальная ссылка используется редко, и в основном в дочерней таблице NULL-значения.
Или же у вас может быть какой-то хитрый функциональный индекс, который часто возвращает NULL. Здесь у нас пример по JSONB-ключу key1, а если у вас в JSON этот ключ встречается нечасто, то и большинство значений будет NULL.
Если у вас NULL-значений много, то вам поможет перестроение индекса на частичный с условием WHERE <ваше поле или выражение> IS NOT NULL. То есть мы просто выкидываем такие значения из нашего индекса. Это принесёт ряд улучшений:
-
во-первых, сокращается размер индекса на дисках, в том числе на репликах и бэкапах;
-
во-вторых, уменьшится количество записей в журнал предзаписи (WAL);
-
в-третьих, освободится место в оперативной памяти и улучшится кэширование.
В моей практике были случаи, когда реально удавалось сократить размер индекса на порядок.
В поиске таких индексов поможет представление pg_stats. В нём есть поле null_frac, которое показывает долю NULL-значений в столбцах таблиц. То есть с помощью этого представления можно определить, есть ли у вас кандидаты на оптимизацию.
Сценарий аккуратного переезда вполне очевиден:
-
создаёте новый частичный индекс;
-
по представлению pg_stat_user_indexes убеждаетесь, что запросы переехали на новый индекс;
-
удаляете старый индекс.
Выводы
-
Значение NULL может преподнести некоторые сюрпризы, если вы к нему не готовы.
-
Стоит проверить, как работают с NULL вызываемые вами функции и ваш код.
-
Запрещайте NULL там, где вы не планируете его использовать явным образом.
-
Проверяйте ваши индексы на наличие NULL-значений — возможно, за счёт оптимизаций удастся сэкономить некоторое количество памяти и ресурсов процессора.
Полезные ссылки
В статье Хаки Бенита рассматриваются как раз такие переполненные NULL-значениями индексы, есть SQL запрос для их поиска в вашей базе данных и практический результат перестроения.
Классическая статья Брюса Момжиана (Bruce Momjian) под названием «NULLs Make Things Easier?» доступна здесь.
Также рекомендуем ознакомиться с книгой Егора Рогова «PostgreSQL 14 изнутри».
Что такое необъявленная ошибка:
Когда мы используем некоторую константу в нашей программе, они могут быть встроенными константами и могут быть созданы пользователем в соответствии с требованиями. Но когда мы используем некоторую константу, а они не являются встроенными и также не определены пользователем в этом состоянии, мы получаем необъявленную ошибку.
Ниже приведен код, показывающий пример необъявленной ошибки NULL:
using namespace std;
int main()
{
int * num = NULL;
return 0;
}
Приведенный выше код покажет ошибку как «необъявленная ошибка NULL» . Причина необъявленной ошибки NULL в том, что «NULL» не является встроенной константой.
Зачем нам NULL?
Когда мы создаем какой-либо указатель в нашей программе, они используются для хранения адресов. Но неинициализированные переменные-указатели очень опасны, так что мы можем присвоить им NULL, что означает, что они не указывают ни на какую ячейку памяти, поэтому наша программа работает плавно и безопасно.
Теперь, если NULL не является встроенной константой, как мы можем преодолеть необъявленную ошибку NULL.
Ниже приведен код, который используется для удаления необъявленной ошибки NULL:
- Присвоить 0: вместо присвоения NULL для num мы можем просто присвоить 0, что означает, что он не указывает какой-либо адрес, поэтому простейшим решением является просто присвоение 0.
Код ниже показывает его реализацию:usingnamespacestd;intmain(){int* num = 0;return0;} - Включите файл заголовка «stddef.h»: в файле заголовка stddef.h уже определен NULL , поэтому мы можем включить этот файл заголовка в нашу программу, и наша программа будет компилироваться и выполняться без каких-либо ошибок.
Код ниже показывает его реализацию:#include <stddef.h>intmain(){int* num = NULL;return0;} - Включите файл заголовка iostream: в C ++, если мы хотим выполнить нашу программу без необнаруженной ошибки NULL, мы можем просто включить iostream в нашу программу и сделать это без ошибок.
Код ниже показывает его реализацию:#include <iostream>usingnamespacestd;intmain(){int* num = NULL;return0;} - #define NULL 0: Используя строку #define NULL 0 в нашей программе, мы можем решить необъявленную ошибку NULL.
Код ниже показывает его реализацию:#define NULL 0usingnamespacestd;intmain(){int* num = NULL;return0;} - В новом C ++ (C ++ 11 и выше):: nullptr — это встроенная константа, поэтому мы можем использовать ее вместо NULL.
#include <iostream>usingnamespacestd;intmain(){int* num = nullptr;return0;}Хотите учиться на лучших видео и практических задачах, ознакомьтесь с базовым курсом C ++ для базового и продвинутого уровня C ++ и курсом C ++ STL для языка и STL. Чтобы завершить подготовку от изучения языка к DS Algo и многому другому, см. Полный курс подготовки к собеседованию .
In SQL, null or NULL is a special marker used to indicate that a data value does not exist in the database. Introduced by the creator of the relational database model, E. F. Codd, SQL null serves to fulfil the requirement that all true relational database management systems (RDBMS) support a representation of «missing information and inapplicable information». Codd also introduced the use of the lowercase Greek omega (ω) symbol to represent null in database theory. In SQL, NULL is a reserved word used to identify this marker.
A null should not be confused with a value of 0. A null value indicates a lack of a value, which is not the same thing as a value of zero. For example, consider the question «How many books does Adam own?» The answer may be «zero» (we know that he owns none) or «null» (we do not know how many he owns). In a database table, the column reporting this answer would start out with no value (marked by Null), and it would not be updated with the value «zero» until we have ascertained that Adam owns no books.
SQL null is a marker, not a value. This usage is quite different from most programming languages, where null value of a reference means it is not pointing to any object.
History[edit]
E. F. Codd mentioned nulls as a method of representing missing data in the relational model in a 1975 paper in the FDT Bulletin of ACM-SIGMOD. Codd’s paper that is most commonly cited in relation with the semantics of Null (as adopted in SQL) is his 1979 paper in the ACM Transactions on Database Systems, in which he also introduced his Relational Model/Tasmania, although much of the other proposals from the latter paper have remained obscure. Section 2.3 of his 1979 paper details the semantics of Null propagation in arithmetic operations as well as comparisons employing a ternary (three-valued) logic when comparing to nulls; it also details the treatment of Nulls on other set operations (the latter issue still controversial today). In database theory circles, the original proposal of Codd (1975, 1979) is now referred to as «Codd tables».[1] Codd later reinforced his requirement that all RDBMSs support Null to indicate missing data in a 1985 two-part article published in Computerworld magazine.[2][3]
The 1986 SQL standard basically adopted Codd’s proposal after an implementation prototype in IBM System R. Although Don Chamberlin recognized nulls (alongside duplicate rows) as one of the most controversial features of SQL, he defended the design of Nulls in SQL invoking the pragmatic arguments that it was the least expensive form of system support for missing information, saving the programmer from many duplicative application-level checks (see semipredicate problem) while at the same time providing the database designer with the option not to use Nulls if they so desire; for example, in order to avoid well known anomalies (discussed in the semantics section of this article). Chamberlin also argued that besides providing some missing-value functionality, practical experience with Nulls also led to other language features which rely on Nulls, like certain grouping constructs and outer joins. Finally, he argued that in practice Nulls also end up being used as a quick way to patch an existing schema when it needs to evolve beyond its original intent, coding not for missing but rather for inapplicable information; for example, a database that quickly needs to support electric cars while having a miles-per-gallon column.[4]
Codd indicated in his 1990 book The Relational Model for Database Management, Version 2 that the single Null mandated by the SQL standard was inadequate, and should be replaced by two separate Null-type markers to indicate the reason why data is missing. In Codd’s book, these two Null-type markers are referred to as ‘A-Values’ and ‘I-Values’, representing ‘Missing But Applicable’ and ‘Missing But Inapplicable’, respectively.[5] Codd’s recommendation would have required SQL’s logic system be expanded to accommodate a four-valued logic system. Because of this additional complexity, the idea of multiple Nulls with different definitions has not gained widespread acceptance in the database practitioners’ domain. It remains an active field of research though, with numerous papers still being published.
Challenges[edit]
Null has been the focus of controversy and a source of debate because of its associated three-valued logic (3VL), special requirements for its use in SQL joins, and the special handling required by aggregate functions and SQL grouping operators. Computer science professor Ron van der Meyden summarized the various issues as: «The inconsistencies in the SQL standard mean that it is not possible to ascribe any intuitive logical semantics to the treatment of nulls in SQL.»[1] Although various proposals have been made for resolving these issues, the complexity of the alternatives has prevented their widespread adoption.
Null propagation[edit]
Arithmetic operations[edit]
Because Null is not a data value, but a marker for an absent value, using mathematical operators on Null gives an unknown result, which is represented by Null.[6] In the following example, multiplying 10 by Null results in Null:
10 * NULL -- Result is NULL
This can lead to unanticipated results. For instance, when an attempt is made to divide Null by zero, platforms may return Null instead of throwing an expected «data exception – division by zero».[6] Though this behavior is not defined by the ISO SQL standard many DBMS vendors treat this operation similarly. For instance, the Oracle, PostgreSQL, MySQL Server, and Microsoft SQL Server platforms all return a Null result for the following:
String concatenation[edit]
String concatenation operations, which are common in SQL, also result in Null when one of the operands is Null.[7] The following example demonstrates the Null result returned by using Null with the SQL || string concatenation operator.
'Fish ' || NULL || 'Chips' -- Result is NULL
This is not true for all database implementations. In an Oracle RDBMS for example NULL and the empty string are considered the same thing and therefore ‘Fish ‘ || NULL || ‘Chips’ results in ‘Fish Chips’.
Comparisons with NULL and the three-valued logic (3VL)[edit]
Since Null is not a member of any data domain, it is not considered a «value», but rather a marker (or placeholder) indicating the undefined value. Because of this, comparisons with Null can never result in either True or False, but always in a third logical result, Unknown.[8] The logical result of the expression below, which compares the value 10 to Null, is Unknown:
SELECT 10 = NULL -- Results in Unknown
However, certain operations on Null can return values if the absent value is not relevant to the outcome of the operation. Consider the following example:
SELECT NULL OR TRUE -- Results in True
In this case, the fact that the value on the left of OR is unknowable is irrelevant, because the outcome of the OR operation would be True regardless of the value on the left.
SQL implements three logical results, so SQL implementations must provide for a specialized three-valued logic (3VL). The rules governing SQL three-valued logic are shown in the tables below (p and q represent logical states)»[9] The truth tables SQL uses for AND, OR, and NOT correspond to a common fragment of the Kleene and Łukasiewicz three-valued logic (which differ in their definition of implication, however SQL defines no such operation).[10]
| p | q | p OR q | p AND q | p = q |
|---|---|---|---|---|
| True | True | True | True | True |
| True | False | True | False | False |
| True | Unknown | True | Unknown | Unknown |
| False | True | True | False | False |
| False | False | False | False | True |
| False | Unknown | Unknown | False | Unknown |
| Unknown | True | True | Unknown | Unknown |
| Unknown | False | Unknown | False | Unknown |
| Unknown | Unknown | Unknown | Unknown | Unknown |
| p | NOT p |
|---|---|
| True | False |
| False | True |
| Unknown | Unknown |
Effect of Unknown in WHERE clauses[edit]
SQL three-valued logic is encountered in Data Manipulation Language (DML) in comparison predicates of DML statements and queries. The WHERE clause causes the DML statement to act on only those rows for which the predicate evaluates to True. Rows for which the predicate evaluates to either False or Unknown are not acted on by INSERT, UPDATE, or DELETE DML statements, and are discarded by SELECT queries. Interpreting Unknown and False as the same logical result is a common error encountered while dealing with Nulls.[9] The following simple example demonstrates this fallacy:
SELECT * FROM t WHERE i = NULL;
The example query above logically always returns zero rows because the comparison of the i column with Null always returns Unknown, even for those rows where i is Null. The Unknown result causes the SELECT statement to summarily discard each and every row. (However, in practice, some SQL tools will retrieve rows using a comparison with Null.)
Null-specific and 3VL-specific comparison predicates[edit]
Basic SQL comparison operators always return Unknown when comparing anything with Null, so the SQL standard provides for two special Null-specific comparison predicates. The IS NULL and IS NOT NULL predicates (which use a postfix syntax) test whether data is, or is not, Null.[11]
The SQL standard contains the optional feature F571 «Truth value tests» that introduces three additional logical unary operators (six in fact, if we count their negation, which is part of their syntax), also using postfix notation. They have the following truth tables:[12]
| p | p IS TRUE | p IS NOT TRUE | p IS FALSE | p IS NOT FALSE | p IS UNKNOWN | p IS NOT UNKNOWN |
|---|---|---|---|---|---|---|
| True | True | False | False | True | False | True |
| False | False | True | True | False | False | True |
| Unknown | False | True | False | True | True | False |
The F571 feature is orthogonal to the presence of the boolean datatype in SQL (discussed later in this article) and, despite syntactic similarities, F571 does not introduce boolean or three-valued literals in the language. The F571 feature was actually present in SQL92,[13] well before the boolean datatype was introduced to the standard in 1999. The F571 feature is implemented by few systems however; PostgreSQL is one of those implementing it.
The addition of IS UNKNOWN to the other operators of SQL’s three-valued logic makes the SQL three-valued logic functionally complete,[14] meaning its logical operators can express (in combination) any conceivable three-valued logical function.
On systems which don’t support the F571 feature, it is possible to emulate IS UNKNOWN p by going over every argument that could make the expression p Unknown and test those arguments with IS NULL or other NULL-specific functions, although this may be more cumbersome.
Law of the excluded fourth (in WHERE clauses)[edit]
In SQL’s three-valued logic the law of the excluded middle, p OR NOT p, no longer evaluates to true for all p. More precisely, in SQL’s three-valued logic p OR NOT p is unknown precisely when p is unknown and true otherwise. Because direct comparisons with Null result in the unknown logical value, the following query
SELECT * FROM stuff WHERE ( x = 10 ) OR NOT ( x = 10 );
is not equivalent in SQL with
if the column x contains any Nulls; in that case the second query would return some rows the first one does not return, namely all those in which x is Null. In classical two-valued logic, the law of the excluded middle would allow the simplification of the WHERE clause predicate, in fact its elimination. Attempting to apply the law of the excluded middle to SQL’s 3VL is effectively a false dichotomy. The second query is actually equivalent with:
SELECT * FROM stuff; -- is (because of 3VL) equivalent to: SELECT * FROM stuff WHERE ( x = 10 ) OR NOT ( x = 10 ) OR x IS NULL;
Thus, to correctly simplify the first statement in SQL requires that we return all rows in which x is not null.
SELECT * FROM stuff WHERE x IS NOT NULL;
In view of the above, observe that for SQL’s WHERE clause a tautology similar to the law of excluded middle can be written. Assuming the IS UNKNOWN operator is present, p OR (NOT p) OR (p IS UNKNOWN) is true for every predicate p. Among logicians, this is called law of excluded fourth.
There are some SQL expressions in which it is less obvious where the false dilemma occurs, for example:
SELECT 'ok' WHERE 1 NOT IN (SELECT CAST (NULL AS INTEGER)) UNION SELECT 'ok' WHERE 1 IN (SELECT CAST (NULL AS INTEGER));
produces no rows because IN translates to an iterated version of equality over the argument set and 1<>NULL is Unknown, just as a 1=NULL is Unknown. (The CAST in this example is needed only in some SQL implementations like PostgreSQL, which would reject it with a type checking error otherwise. In many systems plain SELECT NULL works in the subquery.) The missing case above is of course:
SELECT 'ok' WHERE (1 IN (SELECT CAST (NULL AS INTEGER))) IS UNKNOWN;
Effect of Null and Unknown in other constructs[edit]
Joins[edit]
Joins evaluate using the same comparison rules as for WHERE clauses. Therefore, care must be taken when using nullable columns in SQL join criteria. In particular a table containing any nulls is not equal with a natural self-join of itself, meaning that whereas is true for any relation R in relational algebra, a SQL self-join will exclude all rows having a Null anywhere.[15] An example of this behavior is given in the section analyzing the missing-value semantics of Nulls.
The SQL COALESCE function or CASE expressions can be used to «simulate» Null equality in join criteria, and the IS NULL and IS NOT NULL predicates can be used in the join criteria as well. The following predicate tests for equality of the values A and B and treats Nulls as being equal.
(A = B) OR (A IS NULL AND B IS NULL)
CASE expressions[edit]
SQL provides two flavours of conditional expressions. One is called «simple CASE» and operates like a switch statement. The other is called a «searched CASE» in the standard, and operates like an if…elseif.
The simple CASE expressions use implicit equality comparisons which operate under the same rules as the DML WHERE clause rules for Null. Thus, a simple CASE expression cannot check for the existence of Null directly. A check for Null in a simple CASE expression always results in Unknown, as in the following:
SELECT CASE i WHEN NULL THEN 'Is Null' -- This will never be returned WHEN 0 THEN 'Is Zero' -- This will be returned when i = 0 WHEN 1 THEN 'Is One' -- This will be returned when i = 1 END FROM t;
Because the expression i = NULL evaluates to Unknown no matter what value column i contains (even if it contains Null), the string 'Is Null' will never be returned.
On the other hand, a «searched» CASE expression can use predicates like IS NULL and IS NOT NULL in its conditions. The following example shows how to use a searched CASE expression to properly check for Null:
SELECT CASE WHEN i IS NULL THEN 'Null Result' -- This will be returned when i is NULL WHEN i = 0 THEN 'Zero' -- This will be returned when i = 0 WHEN i = 1 THEN 'One' -- This will be returned when i = 1 END FROM t;
In the searched CASE expression, the string 'Null Result' is returned for all rows in which i is Null.
Oracle’s dialect of SQL provides a built-in function DECODE which can be used instead of the simple CASE expressions and considers two nulls equal.
SELECT DECODE(i, NULL, 'Null Result', 0, 'Zero', 1, 'One') FROM t;
Finally, all these constructs return a NULL if no match is found; they have a default ELSE NULL clause.
IF statements in procedural extensions[edit]
SQL/PSM (SQL Persistent Stored Modules) defines procedural extensions for SQL, such as the IF statement. However, the major SQL vendors have historically included their own proprietary procedural extensions. Procedural extensions for looping and comparisons operate under Null comparison rules similar to those for DML statements and queries. The following code fragment, in ISO SQL standard format, demonstrates the use of Null 3VL in an IF statement.
IF i = NULL THEN SELECT 'Result is True' ELSEIF NOT(i = NULL) THEN SELECT 'Result is False' ELSE SELECT 'Result is Unknown';
The IF statement performs actions only for those comparisons that evaluate to True. For statements that evaluate to False or Unknown, the IF statement passes control to the ELSEIF clause, and finally to the ELSE clause. The result of the code above will always be the message 'Result is Unknown' since the comparisons with Null always evaluate to Unknown.
Analysis of SQL Null missing-value semantics[edit]
The groundbreaking work of T. Imieliński and W. Lipski Jr. (1984)[16] provided a framework in which to evaluate the intended semantics of various proposals to implement missing-value semantics, that is referred to as Imieliński-Lipski Algebras. This section roughly follows chapter 19 of the «Alice» textbook.[17] A similar presentation appears in the review of Ron van der Meyden, §10.4.[1]
In selections and projections: weak representation[edit]
Constructs representing missing information, such as Codd tables, are actually intended to represent a set of relations, one for each possible instantiation of their parameters; in the case of Codd tables, this means replacement of Nulls with some concrete value. For example,
Emp
| Name | Age |
|---|---|
| George | 43 |
| Harriet | NULL
|
| Charles | 56 |
EmpH22
| Name | Age |
|---|---|
| George | 43 |
| Harriet | 22 |
| Charles | 56 |
EmpH37
| Name | Age |
|---|---|
| George | 43 |
| Harriet | 37 |
| Charles | 56 |
The Codd table Emp may represent the relation EmpH22 or EmpH37, as pictured.
A construct (such as a Codd table) is said to be a strong representation system (of missing information) if any answer to a query made on the construct can be particularized to obtain an answer for any corresponding query on the relations it represents, which are seen as models of the construct. More precisely, if q is a query formula in the relational algebra (of «pure» relations) and if q is its lifting to a construct intended to represent missing information, a strong representation has the property that for any query q and (table) construct T, q lifts all the answers to the construct, i.e.:
(The above has to hold for queries taking any number of tables as arguments, but the restriction to one table suffices for this discussion.) Clearly Codd tables do not have this strong property if selections and projections are considered as part of the query language. For example, all the answers to
SELECT * FROM Emp WHERE Age = 22;
should include the possibility that a relation like EmpH22 may exist. However, Codd tables cannot represent the disjunction «result with possibly 0 or 1 rows». A device, mostly of theoretical interest, called conditional table (or c-table) can however represent such an answer:
Result
| Name | Age | condition |
|---|---|---|
| Harriet | ω1 | ω1 = 22 |
where the condition column is interpreted as the row doesn’t exist if the condition is false. It turns out that because the formulas in the condition column of a c-table can be arbitrary propositional logic formulas, an algorithm for the problem whether a c-table represents some concrete relation has a co-NP-complete complexity, thus is of little practical worth.
A weaker notion of representation is therefore desirable. Imielinski and Lipski introduced the notion of weak representation, which essentially allows (lifted) queries over a construct to return a representation only for sure information, i.e. if it’s valid for all «possible world» instantiations (models) of the construct. Concretely, a construct is a weak representation system if
The right-hand side of the above equation is the sure information, i.e. information which can be certainly extracted from the database regardless of what values are used to replace Nulls in the database. In the example we considered above, it’s easy to see that the intersection of all possible models (i.e. the sure information) of the query selecting WHERE Age = 22 is actually empty because, for instance, the (unlifted) query returns no rows for the relation EmpH37. More generally, it was shown by Imielinski and Lipski that Codd tables are a weak representation system if the query language is restricted to projections, selections (and renaming of columns). However, as soon as we add either joins or unions to the query language, even this weak property is lost, as evidenced in the next section.
If joins or unions are considered: not even weak representation[edit]
Consider the following query over the same Codd table Emp from the previous section:
SELECT Name FROM Emp WHERE Age = 22 UNION SELECT Name FROM Emp WHERE Age <> 22;
Whatever concrete value one would choose for the NULL age of Harriet, the above query will return the full column of names of any model of Emp, but when the (lifted) query is run on Emp itself, Harriet will always be missing, i.e. we have:
| Query result on Emp: |
|
Query result on any model of Emp: |
|
Thus when unions are added to the query language, Codd tables are not even a weak representation system of missing information, meaning that queries over them don’t even report all sure information. It’s important to note here that semantics of UNION on Nulls, which are discussed in a later section, did not even come into play in this query. The «forgetful» nature of the two sub-queries was all that it took to guarantee that some sure information went unreported when the above query was run on the Codd table Emp.
For natural joins, the example needed to show that sure information may be unreported by some query is slightly more complicated. Consider the table
J
| F1 | F2 | F3 |
|---|---|---|
| 11 | NULL |
13 |
| 21 | NULL |
23 |
| 31 | 32 | 33 |
and the query
SELECT F1, F3 FROM (SELECT F1, F2 FROM J) AS F12 NATURAL JOIN (SELECT F2, F3 FROM J) AS F23;
| Query result on J: |
|
Query result on any model of J: |
|
The intuition for what happens above is that the Codd tables representing the projections in the subqueries lose track of the fact that the Nulls in the columns F12.F2 and F23.F2 are actually copies of the originals in the table J. This observation suggests that a relatively simple improvement of Codd tables (which works correctly for this example) would be to use Skolem constants (meaning Skolem functions which are also constant functions), say ω12 and ω22 instead of a single NULL symbol. Such an approach, called v-tables or Naive tables, is computationally less expensive that the c-tables discussed above. However, it is still not a complete solution for incomplete information in the sense that v-tables are only a weak representation for queries not using any negations in selection (and not using any set difference either). The first example considered in this section is using a negative selection clause, WHERE Age <> 22, so it is also an example where v-tables queries would not report sure information.
Check constraints and foreign keys[edit]
The primary place in which SQL three-valued logic intersects with SQL Data Definition Language (DDL) is in the form of check constraints. A check constraint placed on a column operates under a slightly different set of rules than those for the DML WHERE clause. While a DML WHERE clause must evaluate to True for a row, a check constraint must not evaluate to False. (From a logic perspective, the designated values are True and Unknown.) This means that a check constraint will succeed if the result of the check is either True or Unknown. The following example table with a check constraint will prohibit any integer values from being inserted into column i, but will allow Null to be inserted since the result of the check will always evaluate to Unknown for Nulls.[18]
CREATE TABLE t ( i INTEGER, CONSTRAINT ck_i CHECK ( i < 0 AND i = 0 AND i > 0 ) );
Because of the change in designated values relative to the WHERE clause, from a logic perspective the law of excluded middle is a tautology for CHECK constraints, meaning CHECK (p OR NOT p) always succeeds. Furthermore, assuming Nulls are to be interpreted as existing but unknown values, some pathological CHECKs like the one above allow insertion of Nulls that could never be replaced by any non-null value.
In order to constrain a column to reject Nulls, the NOT NULL constraint can be applied, as shown in the example below. The NOT NULL constraint is semantically equivalent to a check constraint with an IS NOT NULL predicate.
CREATE TABLE t ( i INTEGER NOT NULL );
By default check constraints against foreign keys succeed if any of the fields in such keys are Null. For example, the table
CREATE TABLE Books ( title VARCHAR(100), author_last VARCHAR(20), author_first VARCHAR(20), FOREIGN KEY (author_last, author_first) REFERENCES Authors(last_name, first_name));
would allow insertion of rows where author_last or author_first are NULL irrespective of how the table Authors is defined or what it contains. More precisely, a null in any of these fields would allow any value in the other one, even on that is not found in Authors table. For example, if Authors contained only ('Doe', 'John'), then ('Smith', NULL) would satisfy the foreign key constraint. SQL-92 added two extra options for narrowing down the matches in such cases. If MATCH PARTIAL is added after the REFERENCES declaration then any non-null must match the foreign key, e.g. ('Doe', NULL) would still match, but ('Smith', NULL) would not. Finally, if MATCH FULL is added then ('Smith', NULL) would not match the constraint either, but (NULL, NULL) would still match it.
Outer joins[edit]
Example SQL outer join query with Null placeholders in the result set. The Null markers are represented by the word NULL in place of data in the results. Results are from Microsoft SQL Server, as shown in SQL Server Management Studio.
SQL outer joins, including left outer joins, right outer joins, and full outer joins, automatically produce Nulls as placeholders for missing values in related tables. For left outer joins, for instance, Nulls are produced in place of rows missing from the table appearing on the right-hand side of the LEFT OUTER JOIN operator. The following simple example uses two tables to demonstrate Null placeholder production in a left outer join.
The first table (Employee) contains employee ID numbers and names, while the second table (PhoneNumber) contains related employee ID numbers and phone numbers, as shown below.
|
Employee
|
PhoneNumber
|
The following sample SQL query performs a left outer join on these two tables.
SELECT e.ID, e.LastName, e.FirstName, pn.Number FROM Employee e LEFT OUTER JOIN PhoneNumber pn ON e.ID = pn.ID;
The result set generated by this query demonstrates how SQL uses Null as a placeholder for values missing from the right-hand (PhoneNumber) table, as shown below.
Query result
| ID | LastName | FirstName | Number |
|---|---|---|---|
| 1 | Johnson | Joe | 555-2323 |
| 2 | Lewis | Larry | NULL
|
| 3 | Thompson | Thomas | 555-9876 |
| 4 | Patterson | Patricia | NULL
|
Aggregate functions[edit]
SQL defines aggregate functions to simplify server-side aggregate calculations on data. Except for the COUNT(*) function, all aggregate functions perform a Null-elimination step, so that Nulls are not included in the final result of the calculation.[19]
Note that the elimination of Null is not equivalent to replacing Null with zero. For example, in the following table, AVG(i) (the average of the values of i) will give a different result from that of AVG(j):
| i | j |
|---|---|
| 150 | 150 |
| 200 | 200 |
| 250 | 250 |
NULL
|
0 |
Here AVG(i) is 200 (the average of 150, 200, and 250), while AVG(j) is 150 (the average of 150, 200, 250, and 0). A well-known side effect of this is that in SQL AVG(z) is equivalent with not SUM(z)/COUNT(*) but SUM(z)/COUNT(z).[4]
The output of an aggregate function can also be Null. Here is an example:
SELECT COUNT(*), MIN(e.Wage), MAX(e.Wage) FROM Employee e WHERE e.LastName LIKE '%Jones%';
This query will always output exactly one row, counting of the number of employees whose last name contains «Jones», and giving the minimum and maximum wage found for those employees. However, what happens if none of the employees fit the given criteria? Calculating the minimum or maximum value of an empty set is impossible, so those results must be NULL, indicating there is no answer. This is not an Unknown value, it is a Null representing the absence of a value. The result would be:
| COUNT(*) | MIN(e.Wage) | MAX(e.Wage) |
|---|---|---|
| 0 | NULL
|
NULL
|
When two nulls are equal: grouping, sorting, and some set operations[edit]
Because SQL:2003 defines all Null markers as being unequal to one another, a special definition was required in order to group Nulls together when performing certain operations. SQL defines «any two values that are equal to one another, or any two Nulls», as «not distinct».[20] This definition of not distinct allows SQL to group and sort Nulls when the GROUP BY clause (and other keywords that perform grouping) are used.
Other SQL operations, clauses, and keywords use «not distinct» in their treatment of Nulls. These include the following:
PARTITION BYclause of ranking and windowing functions likeROW_NUMBERUNION,INTERSECT, andEXCEPToperator, which treat NULLs as the same for row comparison/elimination purposesDISTINCTkeyword used inSELECTqueries
The principle that Nulls aren’t equal to each other (but rather that the result is Unknown) is effectively violated in the SQL specification for the UNION operator, which does identify nulls with each other.[1] Consequently, some set operations in SQL, like union or difference, may produce results not representing sure information, unlike operations involving explicit comparisons with NULL (e.g. those in a WHERE clause discussed above). In Codd’s 1979 proposal (which was basically adopted by SQL92) this semantic inconsistency is rationalized by arguing that removal of duplicates in set operations happens «at a lower level of detail than equality testing in the evaluation of retrieval operations.»[10]
The SQL standard does not explicitly define a default sort order for Nulls. Instead, on conforming systems, Nulls can be sorted before or after all data values by using the NULLS FIRST or NULLS LAST clauses of the ORDER BY list, respectively. Not all DBMS vendors implement this functionality, however. Vendors who do not implement this functionality may specify different treatments for Null sorting in the DBMS.[18]
Effect on index operation[edit]
Some SQL products do not index keys containing NULLs. For instance, PostgreSQL versions prior to 8.3 did not, with the documentation for a B-tree index stating that[21]
B-trees can handle equality and range queries on data that can be sorted into some ordering. In particular, the PostgreSQL query planner will consider using a B-tree index whenever an indexed column is involved in a comparison using one of these operators: < ≤ = ≥ >
Constructs equivalent to combinations of these operators, such as BETWEEN and IN, can also be implemented with a B-tree index search. (But note that IS NULL is not equivalent to = and is not indexable.)
In cases where the index enforces uniqueness, NULLs are excluded from the index and uniqueness is not enforced between NULLs. Again, quoting from the PostgreSQL documentation:[22]
When an index is declared unique, multiple table rows with equal indexed values will not be allowed. Nulls are not considered equal. A multicolumn unique index will only reject cases where all of the indexed columns are equal in two rows.
This is consistent with the SQL:2003-defined behavior of scalar Null comparisons.
Another method of indexing Nulls involves handling them as not distinct in accordance with the SQL:2003-defined behavior. For example, Microsoft SQL Server documentation states the following:[23]
For indexing purposes, NULLs compare as equal. Therefore, a unique index, or UNIQUE constraint, cannot be created if the keys are NULL in more than one row. Select columns that are defined as NOT NULL when columns for a unique index or unique constraint are chosen.
Both of these indexing strategies are consistent with the SQL:2003-defined behavior of Nulls. Because indexing methodologies are not explicitly defined by the SQL:2003 standard, indexing strategies for Nulls are left entirely to the vendors to design and implement.
Null-handling functions[edit]
SQL defines two functions to explicitly handle Nulls: NULLIF and COALESCE. Both functions are abbreviations for searched CASE expressions.[24]
NULLIF[edit]
The NULLIF function accepts two parameters. If the first parameter is equal to the second parameter, NULLIF returns Null. Otherwise, the value of the first parameter is returned.
Thus, NULLIF is an abbreviation for the following CASE expression:
CASE WHEN value1 = value2 THEN NULL ELSE value1 END
COALESCE[edit]
The COALESCE function accepts a list of parameters, returning the first non-Null value from the list:
COALESCE(value1, value2, value3, ...)
COALESCE is defined as shorthand for the following SQL CASE expression:
CASE WHEN value1 IS NOT NULL THEN value1 WHEN value2 IS NOT NULL THEN value2 WHEN value3 IS NOT NULL THEN value3 ... END
Some SQL DBMSs implement vendor-specific functions similar to COALESCE. Some systems (e.g. Transact-SQL) implement an ISNULL function, or other similar functions that are functionally similar to COALESCE. (See Is functions for more on the IS functions in Transact-SQL.)
NVL[edit]
«NVL» redirects here. For the gene, see NVL (gene).
The Oracle NVL function accepts two parameters. It returns the first non-NULL parameter or NULL if all parameters are NULL.
A COALESCE expression can be converted into an equivalent NVL expression thus:
COALESCE ( val1, ... , val{n} )
turns into:
NVL( val1 , NVL( val2 , NVL( val3 , … , NVL ( val{n-1} , val{n} ) … )))
A use case of this function is to replace in an expression a NULL by a value like in NVL(SALARY, 0) which says, ‘if SALARY is NULL, replace it with the value 0′.
There is, however, one notable exception. In most implementations, COALESCE evaluates its parameters until it reaches the first non-NULL one, while NVL evaluates all of its parameters. This is important for several reasons. A parameter after the first non-NULL parameter could be a function, which could either be computationally expensive, invalid, or could create unexpected side effects.
Data typing of Null and Unknown[edit]
The NULL literal is untyped in SQL, meaning that it is not designated as an integer, character, or any other specific data type.[25] Because of this, it is sometimes mandatory (or desirable) to explicitly convert Nulls to a specific data type. For instance, if overloaded functions are supported by the RDBMS, SQL might not be able to automatically resolve to the correct function without knowing the data types of all parameters, including those for which Null is passed.
Conversion from the NULL literal to a Null of a specific type is possible using the CAST introduced in SQL-92. For example:
represents an absent value of type INTEGER.
The actual typing of Unknown (distinct or not from NULL itself) varies between SQL implementations. For example, the following
SELECT 'ok' WHERE (NULL <> 1) IS NULL;
parses and executes successfully in some environments (e.g. SQLite or PostgreSQL) which unify a NULL boolean with Unknown but fails to parse in others (e.g. in SQL Server Compact). MySQL behaves similarly to PostgreSQL in this regard (with the minor exception that MySQL regards TRUE and FALSE as no different from the ordinary integers 1 and 0). PostgreSQL additionally implements a IS UNKNOWN predicate, which can be used to test whether a three-value logical outcome is Unknown, although this is merely syntactic sugar.
BOOLEAN data type[edit]
The ISO SQL:1999 standard introduced the BOOLEAN data type to SQL, however it’s still just an optional, non-core feature, coded T031.[26]
When restricted by a NOT NULL constraint, the SQL BOOLEAN works like the Boolean type from other languages. Unrestricted however, the BOOLEAN datatype, despite its name, can hold the truth values TRUE, FALSE, and UNKNOWN, all of which are defined as boolean literals according to the standard. The standard also asserts that NULL and UNKNOWN «may be used
interchangeably to mean exactly the same thing».[27][28]
The Boolean type has been subject of criticism, particularly because of the mandated behavior of the UNKNOWN literal, which is never equal to itself because of the identification with NULL.[29]
As discussed above, in the PostgreSQL implementation of SQL, Null is used to represent all UNKNOWN results, including the UNKNOWN BOOLEAN. PostgreSQL does not implement the UNKNOWN literal (although it does implement the IS UNKNOWN operator, which is an orthogonal feature.) Most other major vendors do not support the Boolean type (as defined in T031) as of 2012.[30] The procedural part of Oracle’s PL/SQL supports BOOLEAN however variables; these can also be assigned NULL and the value is considered the same as UNKNOWN.[31]
Controversy[edit]
Common mistakes[edit]
Misunderstanding of how Null works is the cause of a great number of errors in SQL code, both in ISO standard SQL statements and in the specific SQL dialects supported by real-world database management systems. These mistakes are usually the result of confusion between Null and either 0 (zero) or an empty string (a string value with a length of zero, represented in SQL as ''). Null is defined by the SQL standard as different from both an empty string and the numerical value 0, however. While Null indicates the absence of any value, the empty string and numerical zero both represent actual values.
A classic error is the attempt to use the equals operator = in combination with the keyword NULL to find rows with Nulls. According to the SQL standard this is an invalid syntax and shall lead to an error message or an exception. But most implementations accept the syntax and evaluate such expressions to UNKNOWN. The consequence is that no rows are found – regardless of whether rows with Nulls exist or not. The proposed way to retrieve rows with Nulls is the use of the predicate IS NULL instead of = NULL.
SELECT * FROM sometable WHERE num = NULL; -- Should be "WHERE num IS NULL"
In a related, but more subtle example, a WHERE clause or conditional statement might compare a column’s value with a constant. It is often incorrectly assumed that a missing value would be «less than» or «not equal to» a constant if that field contains Null, but, in fact, such expressions return Unknown. An example is below:
SELECT * FROM sometable WHERE num <> 1; -- Rows where num is NULL will not be returned, -- contrary to many users' expectations.
These confusions arise because the Law of Identity is restricted in SQL’s logic. When dealing with equality comparisons using the NULL literal or the UNKNOWN truth-value, SQL will always return UNKNOWN as the result of the expression. This is a partial equivalence relation and makes SQL an example of a Non-Reflexive logic.[32]
Similarly, Nulls are often confused with empty strings. Consider the LENGTH function, which returns the number of characters in a string. When a Null is passed into this function, the function returns Null. This can lead to unexpected results, if users are not well versed in 3-value logic. An example is below:
SELECT * FROM sometable WHERE LENGTH(string) < 20; -- Rows where string is NULL will not be returned.
This is complicated by the fact that in some database interface programs (or even database implementations like Oracle’s), NULL is reported as an empty string, and empty strings may be incorrectly stored as NULL.
Criticisms[edit]
The ISO SQL implementation of Null is the subject of criticism, debate and calls for change. In The Relational Model for Database Management: Version 2, Codd suggested that the SQL implementation of Null was flawed and should be replaced by two distinct Null-type markers. The markers he proposed were to stand for «Missing but Applicable» and «Missing but Inapplicable», known as A-values and I-values, respectively. Codd’s recommendation, if accepted, would have required the implementation of a four-valued logic in SQL.[5] Others have suggested adding additional Null-type markers to Codd’s recommendation to indicate even more reasons that a data value might be «Missing», increasing the complexity of SQL’s logic system. At various times, proposals have also been put forth to implement multiple user-defined Null markers in SQL. Because of the complexity of the Null-handling and logic systems required to support multiple Null markers, none of these proposals have gained widespread acceptance.
Chris Date and Hugh Darwen, authors of The Third Manifesto, have suggested that the SQL Null implementation is inherently flawed and should be eliminated altogether,[33] pointing to inconsistencies and flaws in the implementation of SQL Null-handling (particularly in aggregate functions) as proof that the entire concept of Null is flawed and should be removed from the relational model.[34] Others, like author Fabian Pascal, have stated a belief that «how the function calculation should treat missing values is not governed by the relational model.»[citation needed]
Closed-world assumption[edit]
Another point of conflict concerning Nulls is that they violate the closed-world assumption model of relational databases by introducing an open-world assumption into it.[35] The closed world assumption, as it pertains to databases, states that «Everything stated by the database, either explicitly or implicitly, is true; everything else is false.»[36] This view assumes that the knowledge of the world stored within a database is complete. Nulls, however, operate under the open world assumption, in which some items stored in the database are considered unknown, making the database’s stored knowledge of the world incomplete.
See also[edit]
- SQL
- NULLs in: Wikibook SQL
- Ternary logic
- Data manipulation language
- Codd’s 12 rules
- Check constraint
- Relational Model/Tasmania
- Relational database management system
- Join (SQL)
References[edit]
- ^ a b c d Ron van der Meyden, «Logical approaches to incomplete information: a survey» in Chomicki, Jan; Saake, Gunter (Eds.) Logics for Databases and Information Systems, Kluwer Academic Publishers ISBN 978-0-7923-8129-7, p. 344; PS preprint (note: page numbering differs in preprint from the published version)
- ^ Codd, E.F. (October 14, 1985). «Is Your Database Really Relational?». Computerworld.
- ^ Codd, E.F. (October 21, 1985). «Does Your DBMS Run By The Rules?». Computerworld.
- ^ a b Don Chamberlin (1998). A Complete Guide to DB2 Universal Database. Morgan Kaufmann. pp. 28–32. ISBN 978-1-55860-482-7.
- ^ a b Codd, E.F. (1990). The Relational Model for Database Management (Version 2 ed.). Addison Wesley Publishing Company. ISBN 978-0-201-14192-4.
- ^ a b ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.2.6: numeric value expressions..
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.2.8: string value expression. - ^
ISO/IEC (2003). ISO/IEC 9075-1:2003, «SQL/Framework». ISO/IEC. Section 4.4.2: The null value. - ^ a b Coles, Michael (June 27, 2005). «Four Rules for Nulls». SQL Server Central. Red Gate Software.
- ^ a b Hans-Joachim, K. (2003). «Null Values in Relational Databases and Sure Information Answers». Semantics in Databases. Second International Workshop Dagstuhl Castle, Germany, January 7–12, 2001. Revised Papers. Lecture Notes in Computer Science. Vol. 2582. pp. 119–138. doi:10.1007/3-540-36596-6_7. ISBN 978-3-540-00957-3.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 8.7: null predicate. - ^ C.J. Date (2004), An introduction to database systems, 8th ed., Pearson Education, p. 594
- ^ Jim Melton; Jim Melton Alan R. Simon (1993). Understanding The New SQL: A Complete Guide. Morgan Kaufmann. pp. 145–147. ISBN 978-1-55860-245-8.
- ^ C. J. Date, Relational database writings, 1991-1994, Addison-Wesley, 1995, p. 371
- ^ C.J. Date (2004), An introduction to database systems, 8th ed., Pearson Education, p. 584
- ^ Imieliński, T.; Lipski Jr., W. (1984). «Incomplete information in relational databases». Journal of the ACM. 31 (4): 761–791. doi:10.1145/1634.1886. S2CID 288040.
- ^ Abiteboul, Serge; Hull, Richard B.; Vianu, Victor (1995). Foundations of Databases. Addison-Wesley. ISBN 978-0-201-53771-0.
- ^ a b Coles, Michael (February 26, 2007). «Null Versus Null?». SQL Server Central. Red Gate Software.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 4.15.4: Aggregate functions. - ^ ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 3.1.6.8: Definitions: distinct.
- ^ «PostgreSQL 8.0.14 Documentation: Index Types». PostgreSQL. Retrieved 6 November 2008.
- ^ «PostgreSQL 8.0.14 Documentation: Unique Indexes». PostgreSQL. Retrieved November 6, 2008.
- ^ «Creating Unique Indexes». PostfreSQL. September 2007. Retrieved November 6, 2008.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.11: case expression. - ^ Jim Melton; Alan R. Simon (2002). SQL:1999: Understanding Relational Language Components. Morgan Kaufmann. p. 53. ISBN 978-1-55860-456-8.
- ^ «ISO/IEC 9075-1:1999 SQL Standard». ISO. 1999.
- ^ C. Date (2011). SQL and Relational Theory: How to Write Accurate SQL Code. O’Reilly Media, Inc. p. 83. ISBN 978-1-4493-1640-2.
- ^ ISO/IEC 9075-2:2011 §4.5
- ^ Martyn Prigmore (2007). Introduction to Databases With Web Applications. Pearson Education Canada. p. 197. ISBN 978-0-321-26359-9.
- ^ Troels Arvin, Survey of BOOLEAN data type implementation
- ^ Steven Feuerstein; Bill Pribyl (2009). Oracle PL/SQL Programming. O’Reilly Media, Inc. pp. 74, 91. ISBN 978-0-596-51446-4.
- ^ Arenhart, Krause (2012), «Classical Logic or Non-Reflexive Logic? A case of Semantic Underdetermination», Revista Portuguesa de Filosofia, 68 (1/2): 73–86, doi:10.17990/RPF/2012_68_1_0073, JSTOR 41955624.
- ^
Darwen, Hugh; Chris Date. «The Third Manifesto». Retrieved May 29, 2007. - ^
Darwen, Hugh. «The Askew Wall» (PDF). Retrieved May 29, 2007. - ^ Date, Chris (May 2005). Database in Depth: Relational Theory for Practitioners. O’Reilly Media, Inc. p. 73. ISBN 978-0-596-10012-4.
- ^ Date, Chris. «Abstract: The Closed World Assumption». Data Management Association, San Francisco Bay Area Chapter. Archived from the original on 2007-05-19. Retrieved May 29, 2007.
Further reading[edit]
- E. F. Codd. Understanding relations (installment #7). FDT Bulletin of ACM-SIGMOD, 7(3-4):23–28, 1975.
- Codd, E. F. (1979). «Extending the database relational model to capture more meaning». ACM Transactions on Database Systems. 4 (4): 397–434. CiteSeerX 10.1.1.508.5701. doi:10.1145/320107.320109. S2CID 17517212. Especially §2.3.
- Date, C.J. (2000). The Database Relational Model: A Retrospective Review and Analysis: A Historical Account and Assessment of E. F. Codd’s Contribution to the Field of Database Technology. Addison Wesley Longman. ISBN 978-0-201-61294-3.
- Klein, Hans-Joachim (1994). «How to modify SQL queries in order to guarantee sure answers». ACM SIGMOD Record. 23 (3): 14–20. doi:10.1145/187436.187445. S2CID 17354724.
- Claude Rubinson, Nulls, Three-Valued Logic, and Ambiguity in SQL: Critiquing Date’s Critique, SIGMOD Record, December 2007 (Vol. 36, No. 4)
- John Grant, Null Values in SQL. SIGMOD Record, September 2008 (Vol. 37, No. 3)
- Waraporn, Narongrit, and Kriengkrai Porkaew. «Null semantics for subqueries and atomic predicates». IAENG International Journal of Computer Science 35.3 (2008): 305-313.
- Bernhard Thalheim, Klaus-Dieter Schewe (2011). «NULL ‘Value’ Algebras and Logics». Frontiers in Artificial Intelligence and Applications. 225 (Information Modelling and Knowledge Bases XXII). doi:10.3233/978-1-60750-690-4-354.
{{cite journal}}: CS1 maint: uses authors parameter (link) - Enrico Franconi and Sergio Tessaris, On the Logic of SQL Nulls, Proceedings of the 6th Alberto Mendelzon International Workshop on Foundations of Data Management, Ouro Preto, Brazil, June 27–30, 2012. pp. 114–128
External links[edit]
- Oracle NULLs Archived 2013-04-12 at the Wayback Machine
- The Third Manifesto
- Implications of NULLs in sequencing of data
- Java bug report about jdbc not distinguishing null and empty string, which Sun closed as «not a bug»
In SQL, null or NULL is a special marker used to indicate that a data value does not exist in the database. Introduced by the creator of the relational database model, E. F. Codd, SQL null serves to fulfil the requirement that all true relational database management systems (RDBMS) support a representation of «missing information and inapplicable information». Codd also introduced the use of the lowercase Greek omega (ω) symbol to represent null in database theory. In SQL, NULL is a reserved word used to identify this marker.
A null should not be confused with a value of 0. A null value indicates a lack of a value, which is not the same thing as a value of zero. For example, consider the question «How many books does Adam own?» The answer may be «zero» (we know that he owns none) or «null» (we do not know how many he owns). In a database table, the column reporting this answer would start out with no value (marked by Null), and it would not be updated with the value «zero» until we have ascertained that Adam owns no books.
SQL null is a marker, not a value. This usage is quite different from most programming languages, where null value of a reference means it is not pointing to any object.
History[edit]
E. F. Codd mentioned nulls as a method of representing missing data in the relational model in a 1975 paper in the FDT Bulletin of ACM-SIGMOD. Codd’s paper that is most commonly cited in relation with the semantics of Null (as adopted in SQL) is his 1979 paper in the ACM Transactions on Database Systems, in which he also introduced his Relational Model/Tasmania, although much of the other proposals from the latter paper have remained obscure. Section 2.3 of his 1979 paper details the semantics of Null propagation in arithmetic operations as well as comparisons employing a ternary (three-valued) logic when comparing to nulls; it also details the treatment of Nulls on other set operations (the latter issue still controversial today). In database theory circles, the original proposal of Codd (1975, 1979) is now referred to as «Codd tables».[1] Codd later reinforced his requirement that all RDBMSs support Null to indicate missing data in a 1985 two-part article published in Computerworld magazine.[2][3]
The 1986 SQL standard basically adopted Codd’s proposal after an implementation prototype in IBM System R. Although Don Chamberlin recognized nulls (alongside duplicate rows) as one of the most controversial features of SQL, he defended the design of Nulls in SQL invoking the pragmatic arguments that it was the least expensive form of system support for missing information, saving the programmer from many duplicative application-level checks (see semipredicate problem) while at the same time providing the database designer with the option not to use Nulls if they so desire; for example, in order to avoid well known anomalies (discussed in the semantics section of this article). Chamberlin also argued that besides providing some missing-value functionality, practical experience with Nulls also led to other language features which rely on Nulls, like certain grouping constructs and outer joins. Finally, he argued that in practice Nulls also end up being used as a quick way to patch an existing schema when it needs to evolve beyond its original intent, coding not for missing but rather for inapplicable information; for example, a database that quickly needs to support electric cars while having a miles-per-gallon column.[4]
Codd indicated in his 1990 book The Relational Model for Database Management, Version 2 that the single Null mandated by the SQL standard was inadequate, and should be replaced by two separate Null-type markers to indicate the reason why data is missing. In Codd’s book, these two Null-type markers are referred to as ‘A-Values’ and ‘I-Values’, representing ‘Missing But Applicable’ and ‘Missing But Inapplicable’, respectively.[5] Codd’s recommendation would have required SQL’s logic system be expanded to accommodate a four-valued logic system. Because of this additional complexity, the idea of multiple Nulls with different definitions has not gained widespread acceptance in the database practitioners’ domain. It remains an active field of research though, with numerous papers still being published.
Challenges[edit]
Null has been the focus of controversy and a source of debate because of its associated three-valued logic (3VL), special requirements for its use in SQL joins, and the special handling required by aggregate functions and SQL grouping operators. Computer science professor Ron van der Meyden summarized the various issues as: «The inconsistencies in the SQL standard mean that it is not possible to ascribe any intuitive logical semantics to the treatment of nulls in SQL.»[1] Although various proposals have been made for resolving these issues, the complexity of the alternatives has prevented their widespread adoption.
Null propagation[edit]
Arithmetic operations[edit]
Because Null is not a data value, but a marker for an absent value, using mathematical operators on Null gives an unknown result, which is represented by Null.[6] In the following example, multiplying 10 by Null results in Null:
10 * NULL -- Result is NULL
This can lead to unanticipated results. For instance, when an attempt is made to divide Null by zero, platforms may return Null instead of throwing an expected «data exception – division by zero».[6] Though this behavior is not defined by the ISO SQL standard many DBMS vendors treat this operation similarly. For instance, the Oracle, PostgreSQL, MySQL Server, and Microsoft SQL Server platforms all return a Null result for the following:
String concatenation[edit]
String concatenation operations, which are common in SQL, also result in Null when one of the operands is Null.[7] The following example demonstrates the Null result returned by using Null with the SQL || string concatenation operator.
'Fish ' || NULL || 'Chips' -- Result is NULL
This is not true for all database implementations. In an Oracle RDBMS for example NULL and the empty string are considered the same thing and therefore ‘Fish ‘ || NULL || ‘Chips’ results in ‘Fish Chips’.
Comparisons with NULL and the three-valued logic (3VL)[edit]
Since Null is not a member of any data domain, it is not considered a «value», but rather a marker (or placeholder) indicating the undefined value. Because of this, comparisons with Null can never result in either True or False, but always in a third logical result, Unknown.[8] The logical result of the expression below, which compares the value 10 to Null, is Unknown:
SELECT 10 = NULL -- Results in Unknown
However, certain operations on Null can return values if the absent value is not relevant to the outcome of the operation. Consider the following example:
SELECT NULL OR TRUE -- Results in True
In this case, the fact that the value on the left of OR is unknowable is irrelevant, because the outcome of the OR operation would be True regardless of the value on the left.
SQL implements three logical results, so SQL implementations must provide for a specialized three-valued logic (3VL). The rules governing SQL three-valued logic are shown in the tables below (p and q represent logical states)»[9] The truth tables SQL uses for AND, OR, and NOT correspond to a common fragment of the Kleene and Łukasiewicz three-valued logic (which differ in their definition of implication, however SQL defines no such operation).[10]
| p | q | p OR q | p AND q | p = q |
|---|---|---|---|---|
| True | True | True | True | True |
| True | False | True | False | False |
| True | Unknown | True | Unknown | Unknown |
| False | True | True | False | False |
| False | False | False | False | True |
| False | Unknown | Unknown | False | Unknown |
| Unknown | True | True | Unknown | Unknown |
| Unknown | False | Unknown | False | Unknown |
| Unknown | Unknown | Unknown | Unknown | Unknown |
| p | NOT p |
|---|---|
| True | False |
| False | True |
| Unknown | Unknown |
Effect of Unknown in WHERE clauses[edit]
SQL three-valued logic is encountered in Data Manipulation Language (DML) in comparison predicates of DML statements and queries. The WHERE clause causes the DML statement to act on only those rows for which the predicate evaluates to True. Rows for which the predicate evaluates to either False or Unknown are not acted on by INSERT, UPDATE, or DELETE DML statements, and are discarded by SELECT queries. Interpreting Unknown and False as the same logical result is a common error encountered while dealing with Nulls.[9] The following simple example demonstrates this fallacy:
SELECT * FROM t WHERE i = NULL;
The example query above logically always returns zero rows because the comparison of the i column with Null always returns Unknown, even for those rows where i is Null. The Unknown result causes the SELECT statement to summarily discard each and every row. (However, in practice, some SQL tools will retrieve rows using a comparison with Null.)
Null-specific and 3VL-specific comparison predicates[edit]
Basic SQL comparison operators always return Unknown when comparing anything with Null, so the SQL standard provides for two special Null-specific comparison predicates. The IS NULL and IS NOT NULL predicates (which use a postfix syntax) test whether data is, or is not, Null.[11]
The SQL standard contains the optional feature F571 «Truth value tests» that introduces three additional logical unary operators (six in fact, if we count their negation, which is part of their syntax), also using postfix notation. They have the following truth tables:[12]
| p | p IS TRUE | p IS NOT TRUE | p IS FALSE | p IS NOT FALSE | p IS UNKNOWN | p IS NOT UNKNOWN |
|---|---|---|---|---|---|---|
| True | True | False | False | True | False | True |
| False | False | True | True | False | False | True |
| Unknown | False | True | False | True | True | False |
The F571 feature is orthogonal to the presence of the boolean datatype in SQL (discussed later in this article) and, despite syntactic similarities, F571 does not introduce boolean or three-valued literals in the language. The F571 feature was actually present in SQL92,[13] well before the boolean datatype was introduced to the standard in 1999. The F571 feature is implemented by few systems however; PostgreSQL is one of those implementing it.
The addition of IS UNKNOWN to the other operators of SQL’s three-valued logic makes the SQL three-valued logic functionally complete,[14] meaning its logical operators can express (in combination) any conceivable three-valued logical function.
On systems which don’t support the F571 feature, it is possible to emulate IS UNKNOWN p by going over every argument that could make the expression p Unknown and test those arguments with IS NULL or other NULL-specific functions, although this may be more cumbersome.
Law of the excluded fourth (in WHERE clauses)[edit]
In SQL’s three-valued logic the law of the excluded middle, p OR NOT p, no longer evaluates to true for all p. More precisely, in SQL’s three-valued logic p OR NOT p is unknown precisely when p is unknown and true otherwise. Because direct comparisons with Null result in the unknown logical value, the following query
SELECT * FROM stuff WHERE ( x = 10 ) OR NOT ( x = 10 );
is not equivalent in SQL with
if the column x contains any Nulls; in that case the second query would return some rows the first one does not return, namely all those in which x is Null. In classical two-valued logic, the law of the excluded middle would allow the simplification of the WHERE clause predicate, in fact its elimination. Attempting to apply the law of the excluded middle to SQL’s 3VL is effectively a false dichotomy. The second query is actually equivalent with:
SELECT * FROM stuff; -- is (because of 3VL) equivalent to: SELECT * FROM stuff WHERE ( x = 10 ) OR NOT ( x = 10 ) OR x IS NULL;
Thus, to correctly simplify the first statement in SQL requires that we return all rows in which x is not null.
SELECT * FROM stuff WHERE x IS NOT NULL;
In view of the above, observe that for SQL’s WHERE clause a tautology similar to the law of excluded middle can be written. Assuming the IS UNKNOWN operator is present, p OR (NOT p) OR (p IS UNKNOWN) is true for every predicate p. Among logicians, this is called law of excluded fourth.
There are some SQL expressions in which it is less obvious where the false dilemma occurs, for example:
SELECT 'ok' WHERE 1 NOT IN (SELECT CAST (NULL AS INTEGER)) UNION SELECT 'ok' WHERE 1 IN (SELECT CAST (NULL AS INTEGER));
produces no rows because IN translates to an iterated version of equality over the argument set and 1<>NULL is Unknown, just as a 1=NULL is Unknown. (The CAST in this example is needed only in some SQL implementations like PostgreSQL, which would reject it with a type checking error otherwise. In many systems plain SELECT NULL works in the subquery.) The missing case above is of course:
SELECT 'ok' WHERE (1 IN (SELECT CAST (NULL AS INTEGER))) IS UNKNOWN;
Effect of Null and Unknown in other constructs[edit]
Joins[edit]
Joins evaluate using the same comparison rules as for WHERE clauses. Therefore, care must be taken when using nullable columns in SQL join criteria. In particular a table containing any nulls is not equal with a natural self-join of itself, meaning that whereas is true for any relation R in relational algebra, a SQL self-join will exclude all rows having a Null anywhere.[15] An example of this behavior is given in the section analyzing the missing-value semantics of Nulls.
The SQL COALESCE function or CASE expressions can be used to «simulate» Null equality in join criteria, and the IS NULL and IS NOT NULL predicates can be used in the join criteria as well. The following predicate tests for equality of the values A and B and treats Nulls as being equal.
(A = B) OR (A IS NULL AND B IS NULL)
CASE expressions[edit]
SQL provides two flavours of conditional expressions. One is called «simple CASE» and operates like a switch statement. The other is called a «searched CASE» in the standard, and operates like an if…elseif.
The simple CASE expressions use implicit equality comparisons which operate under the same rules as the DML WHERE clause rules for Null. Thus, a simple CASE expression cannot check for the existence of Null directly. A check for Null in a simple CASE expression always results in Unknown, as in the following:
SELECT CASE i WHEN NULL THEN 'Is Null' -- This will never be returned WHEN 0 THEN 'Is Zero' -- This will be returned when i = 0 WHEN 1 THEN 'Is One' -- This will be returned when i = 1 END FROM t;
Because the expression i = NULL evaluates to Unknown no matter what value column i contains (even if it contains Null), the string 'Is Null' will never be returned.
On the other hand, a «searched» CASE expression can use predicates like IS NULL and IS NOT NULL in its conditions. The following example shows how to use a searched CASE expression to properly check for Null:
SELECT CASE WHEN i IS NULL THEN 'Null Result' -- This will be returned when i is NULL WHEN i = 0 THEN 'Zero' -- This will be returned when i = 0 WHEN i = 1 THEN 'One' -- This will be returned when i = 1 END FROM t;
In the searched CASE expression, the string 'Null Result' is returned for all rows in which i is Null.
Oracle’s dialect of SQL provides a built-in function DECODE which can be used instead of the simple CASE expressions and considers two nulls equal.
SELECT DECODE(i, NULL, 'Null Result', 0, 'Zero', 1, 'One') FROM t;
Finally, all these constructs return a NULL if no match is found; they have a default ELSE NULL clause.
IF statements in procedural extensions[edit]
SQL/PSM (SQL Persistent Stored Modules) defines procedural extensions for SQL, such as the IF statement. However, the major SQL vendors have historically included their own proprietary procedural extensions. Procedural extensions for looping and comparisons operate under Null comparison rules similar to those for DML statements and queries. The following code fragment, in ISO SQL standard format, demonstrates the use of Null 3VL in an IF statement.
IF i = NULL THEN SELECT 'Result is True' ELSEIF NOT(i = NULL) THEN SELECT 'Result is False' ELSE SELECT 'Result is Unknown';
The IF statement performs actions only for those comparisons that evaluate to True. For statements that evaluate to False or Unknown, the IF statement passes control to the ELSEIF clause, and finally to the ELSE clause. The result of the code above will always be the message 'Result is Unknown' since the comparisons with Null always evaluate to Unknown.
Analysis of SQL Null missing-value semantics[edit]
The groundbreaking work of T. Imieliński and W. Lipski Jr. (1984)[16] provided a framework in which to evaluate the intended semantics of various proposals to implement missing-value semantics, that is referred to as Imieliński-Lipski Algebras. This section roughly follows chapter 19 of the «Alice» textbook.[17] A similar presentation appears in the review of Ron van der Meyden, §10.4.[1]
In selections and projections: weak representation[edit]
Constructs representing missing information, such as Codd tables, are actually intended to represent a set of relations, one for each possible instantiation of their parameters; in the case of Codd tables, this means replacement of Nulls with some concrete value. For example,
Emp
| Name | Age |
|---|---|
| George | 43 |
| Harriet | NULL |
| Charles | 56 |
EmpH22
| Name | Age |
|---|---|
| George | 43 |
| Harriet | 22 |
| Charles | 56 |
EmpH37
| Name | Age |
|---|---|
| George | 43 |
| Harriet | 37 |
| Charles | 56 |
The Codd table Emp may represent the relation EmpH22 or EmpH37, as pictured.
A construct (such as a Codd table) is said to be a strong representation system (of missing information) if any answer to a query made on the construct can be particularized to obtain an answer for any corresponding query on the relations it represents, which are seen as models of the construct. More precisely, if q is a query formula in the relational algebra (of «pure» relations) and if q is its lifting to a construct intended to represent missing information, a strong representation has the property that for any query q and (table) construct T, q lifts all the answers to the construct, i.e.:
(The above has to hold for queries taking any number of tables as arguments, but the restriction to one table suffices for this discussion.) Clearly Codd tables do not have this strong property if selections and projections are considered as part of the query language. For example, all the answers to
SELECT * FROM Emp WHERE Age = 22;
should include the possibility that a relation like EmpH22 may exist. However, Codd tables cannot represent the disjunction «result with possibly 0 or 1 rows». A device, mostly of theoretical interest, called conditional table (or c-table) can however represent such an answer:
Result
| Name | Age | condition |
|---|---|---|
| Harriet | ω1 | ω1 = 22 |
where the condition column is interpreted as the row doesn’t exist if the condition is false. It turns out that because the formulas in the condition column of a c-table can be arbitrary propositional logic formulas, an algorithm for the problem whether a c-table represents some concrete relation has a co-NP-complete complexity, thus is of little practical worth.
A weaker notion of representation is therefore desirable. Imielinski and Lipski introduced the notion of weak representation, which essentially allows (lifted) queries over a construct to return a representation only for sure information, i.e. if it’s valid for all «possible world» instantiations (models) of the construct. Concretely, a construct is a weak representation system if
The right-hand side of the above equation is the sure information, i.e. information which can be certainly extracted from the database regardless of what values are used to replace Nulls in the database. In the example we considered above, it’s easy to see that the intersection of all possible models (i.e. the sure information) of the query selecting WHERE Age = 22 is actually empty because, for instance, the (unlifted) query returns no rows for the relation EmpH37. More generally, it was shown by Imielinski and Lipski that Codd tables are a weak representation system if the query language is restricted to projections, selections (and renaming of columns). However, as soon as we add either joins or unions to the query language, even this weak property is lost, as evidenced in the next section.
If joins or unions are considered: not even weak representation[edit]
Consider the following query over the same Codd table Emp from the previous section:
SELECT Name FROM Emp WHERE Age = 22 UNION SELECT Name FROM Emp WHERE Age <> 22;
Whatever concrete value one would choose for the NULL age of Harriet, the above query will return the full column of names of any model of Emp, but when the (lifted) query is run on Emp itself, Harriet will always be missing, i.e. we have:
| Query result on Emp: |
|
Query result on any model of Emp: |
|
Thus when unions are added to the query language, Codd tables are not even a weak representation system of missing information, meaning that queries over them don’t even report all sure information. It’s important to note here that semantics of UNION on Nulls, which are discussed in a later section, did not even come into play in this query. The «forgetful» nature of the two sub-queries was all that it took to guarantee that some sure information went unreported when the above query was run on the Codd table Emp.
For natural joins, the example needed to show that sure information may be unreported by some query is slightly more complicated. Consider the table
J
| F1 | F2 | F3 |
|---|---|---|
| 11 | NULL |
13 |
| 21 | NULL |
23 |
| 31 | 32 | 33 |
and the query
SELECT F1, F3 FROM (SELECT F1, F2 FROM J) AS F12 NATURAL JOIN (SELECT F2, F3 FROM J) AS F23;
| Query result on J: |
|
Query result on any model of J: |
|
The intuition for what happens above is that the Codd tables representing the projections in the subqueries lose track of the fact that the Nulls in the columns F12.F2 and F23.F2 are actually copies of the originals in the table J. This observation suggests that a relatively simple improvement of Codd tables (which works correctly for this example) would be to use Skolem constants (meaning Skolem functions which are also constant functions), say ω12 and ω22 instead of a single NULL symbol. Such an approach, called v-tables or Naive tables, is computationally less expensive that the c-tables discussed above. However, it is still not a complete solution for incomplete information in the sense that v-tables are only a weak representation for queries not using any negations in selection (and not using any set difference either). The first example considered in this section is using a negative selection clause, WHERE Age <> 22, so it is also an example where v-tables queries would not report sure information.
Check constraints and foreign keys[edit]
The primary place in which SQL three-valued logic intersects with SQL Data Definition Language (DDL) is in the form of check constraints. A check constraint placed on a column operates under a slightly different set of rules than those for the DML WHERE clause. While a DML WHERE clause must evaluate to True for a row, a check constraint must not evaluate to False. (From a logic perspective, the designated values are True and Unknown.) This means that a check constraint will succeed if the result of the check is either True or Unknown. The following example table with a check constraint will prohibit any integer values from being inserted into column i, but will allow Null to be inserted since the result of the check will always evaluate to Unknown for Nulls.[18]
CREATE TABLE t ( i INTEGER, CONSTRAINT ck_i CHECK ( i < 0 AND i = 0 AND i > 0 ) );
Because of the change in designated values relative to the WHERE clause, from a logic perspective the law of excluded middle is a tautology for CHECK constraints, meaning CHECK (p OR NOT p) always succeeds. Furthermore, assuming Nulls are to be interpreted as existing but unknown values, some pathological CHECKs like the one above allow insertion of Nulls that could never be replaced by any non-null value.
In order to constrain a column to reject Nulls, the NOT NULL constraint can be applied, as shown in the example below. The NOT NULL constraint is semantically equivalent to a check constraint with an IS NOT NULL predicate.
CREATE TABLE t ( i INTEGER NOT NULL );
By default check constraints against foreign keys succeed if any of the fields in such keys are Null. For example, the table
CREATE TABLE Books ( title VARCHAR(100), author_last VARCHAR(20), author_first VARCHAR(20), FOREIGN KEY (author_last, author_first) REFERENCES Authors(last_name, first_name));
would allow insertion of rows where author_last or author_first are NULL irrespective of how the table Authors is defined or what it contains. More precisely, a null in any of these fields would allow any value in the other one, even on that is not found in Authors table. For example, if Authors contained only ('Doe', 'John'), then ('Smith', NULL) would satisfy the foreign key constraint. SQL-92 added two extra options for narrowing down the matches in such cases. If MATCH PARTIAL is added after the REFERENCES declaration then any non-null must match the foreign key, e.g. ('Doe', NULL) would still match, but ('Smith', NULL) would not. Finally, if MATCH FULL is added then ('Smith', NULL) would not match the constraint either, but (NULL, NULL) would still match it.
Outer joins[edit]
Example SQL outer join query with Null placeholders in the result set. The Null markers are represented by the word NULL in place of data in the results. Results are from Microsoft SQL Server, as shown in SQL Server Management Studio.
SQL outer joins, including left outer joins, right outer joins, and full outer joins, automatically produce Nulls as placeholders for missing values in related tables. For left outer joins, for instance, Nulls are produced in place of rows missing from the table appearing on the right-hand side of the LEFT OUTER JOIN operator. The following simple example uses two tables to demonstrate Null placeholder production in a left outer join.
The first table (Employee) contains employee ID numbers and names, while the second table (PhoneNumber) contains related employee ID numbers and phone numbers, as shown below.
|
Employee
|
PhoneNumber
|
The following sample SQL query performs a left outer join on these two tables.
SELECT e.ID, e.LastName, e.FirstName, pn.Number FROM Employee e LEFT OUTER JOIN PhoneNumber pn ON e.ID = pn.ID;
The result set generated by this query demonstrates how SQL uses Null as a placeholder for values missing from the right-hand (PhoneNumber) table, as shown below.
Query result
| ID | LastName | FirstName | Number |
|---|---|---|---|
| 1 | Johnson | Joe | 555-2323 |
| 2 | Lewis | Larry | NULL
|
| 3 | Thompson | Thomas | 555-9876 |
| 4 | Patterson | Patricia | NULL
|
Aggregate functions[edit]
SQL defines aggregate functions to simplify server-side aggregate calculations on data. Except for the COUNT(*) function, all aggregate functions perform a Null-elimination step, so that Nulls are not included in the final result of the calculation.[19]
Note that the elimination of Null is not equivalent to replacing Null with zero. For example, in the following table, AVG(i) (the average of the values of i) will give a different result from that of AVG(j):
| i | j |
|---|---|
| 150 | 150 |
| 200 | 200 |
| 250 | 250 |
NULL
|
0 |
Here AVG(i) is 200 (the average of 150, 200, and 250), while AVG(j) is 150 (the average of 150, 200, 250, and 0). A well-known side effect of this is that in SQL AVG(z) is equivalent with not SUM(z)/COUNT(*) but SUM(z)/COUNT(z).[4]
The output of an aggregate function can also be Null. Here is an example:
SELECT COUNT(*), MIN(e.Wage), MAX(e.Wage) FROM Employee e WHERE e.LastName LIKE '%Jones%';
This query will always output exactly one row, counting of the number of employees whose last name contains «Jones», and giving the minimum and maximum wage found for those employees. However, what happens if none of the employees fit the given criteria? Calculating the minimum or maximum value of an empty set is impossible, so those results must be NULL, indicating there is no answer. This is not an Unknown value, it is a Null representing the absence of a value. The result would be:
| COUNT(*) | MIN(e.Wage) | MAX(e.Wage) |
|---|---|---|
| 0 | NULL
|
NULL
|
When two nulls are equal: grouping, sorting, and some set operations[edit]
Because SQL:2003 defines all Null markers as being unequal to one another, a special definition was required in order to group Nulls together when performing certain operations. SQL defines «any two values that are equal to one another, or any two Nulls», as «not distinct».[20] This definition of not distinct allows SQL to group and sort Nulls when the GROUP BY clause (and other keywords that perform grouping) are used.
Other SQL operations, clauses, and keywords use «not distinct» in their treatment of Nulls. These include the following:
PARTITION BYclause of ranking and windowing functions likeROW_NUMBERUNION,INTERSECT, andEXCEPToperator, which treat NULLs as the same for row comparison/elimination purposesDISTINCTkeyword used inSELECTqueries
The principle that Nulls aren’t equal to each other (but rather that the result is Unknown) is effectively violated in the SQL specification for the UNION operator, which does identify nulls with each other.[1] Consequently, some set operations in SQL, like union or difference, may produce results not representing sure information, unlike operations involving explicit comparisons with NULL (e.g. those in a WHERE clause discussed above). In Codd’s 1979 proposal (which was basically adopted by SQL92) this semantic inconsistency is rationalized by arguing that removal of duplicates in set operations happens «at a lower level of detail than equality testing in the evaluation of retrieval operations.»[10]
The SQL standard does not explicitly define a default sort order for Nulls. Instead, on conforming systems, Nulls can be sorted before or after all data values by using the NULLS FIRST or NULLS LAST clauses of the ORDER BY list, respectively. Not all DBMS vendors implement this functionality, however. Vendors who do not implement this functionality may specify different treatments for Null sorting in the DBMS.[18]
Effect on index operation[edit]
Some SQL products do not index keys containing NULLs. For instance, PostgreSQL versions prior to 8.3 did not, with the documentation for a B-tree index stating that[21]
B-trees can handle equality and range queries on data that can be sorted into some ordering. In particular, the PostgreSQL query planner will consider using a B-tree index whenever an indexed column is involved in a comparison using one of these operators: < ≤ = ≥ >
Constructs equivalent to combinations of these operators, such as BETWEEN and IN, can also be implemented with a B-tree index search. (But note that IS NULL is not equivalent to = and is not indexable.)
In cases where the index enforces uniqueness, NULLs are excluded from the index and uniqueness is not enforced between NULLs. Again, quoting from the PostgreSQL documentation:[22]
When an index is declared unique, multiple table rows with equal indexed values will not be allowed. Nulls are not considered equal. A multicolumn unique index will only reject cases where all of the indexed columns are equal in two rows.
This is consistent with the SQL:2003-defined behavior of scalar Null comparisons.
Another method of indexing Nulls involves handling them as not distinct in accordance with the SQL:2003-defined behavior. For example, Microsoft SQL Server documentation states the following:[23]
For indexing purposes, NULLs compare as equal. Therefore, a unique index, or UNIQUE constraint, cannot be created if the keys are NULL in more than one row. Select columns that are defined as NOT NULL when columns for a unique index or unique constraint are chosen.
Both of these indexing strategies are consistent with the SQL:2003-defined behavior of Nulls. Because indexing methodologies are not explicitly defined by the SQL:2003 standard, indexing strategies for Nulls are left entirely to the vendors to design and implement.
Null-handling functions[edit]
SQL defines two functions to explicitly handle Nulls: NULLIF and COALESCE. Both functions are abbreviations for searched CASE expressions.[24]
NULLIF[edit]
The NULLIF function accepts two parameters. If the first parameter is equal to the second parameter, NULLIF returns Null. Otherwise, the value of the first parameter is returned.
Thus, NULLIF is an abbreviation for the following CASE expression:
CASE WHEN value1 = value2 THEN NULL ELSE value1 END
COALESCE[edit]
The COALESCE function accepts a list of parameters, returning the first non-Null value from the list:
COALESCE(value1, value2, value3, ...)
COALESCE is defined as shorthand for the following SQL CASE expression:
CASE WHEN value1 IS NOT NULL THEN value1 WHEN value2 IS NOT NULL THEN value2 WHEN value3 IS NOT NULL THEN value3 ... END
Some SQL DBMSs implement vendor-specific functions similar to COALESCE. Some systems (e.g. Transact-SQL) implement an ISNULL function, or other similar functions that are functionally similar to COALESCE. (See Is functions for more on the IS functions in Transact-SQL.)
NVL[edit]
«NVL» redirects here. For the gene, see NVL (gene).
The Oracle NVL function accepts two parameters. It returns the first non-NULL parameter or NULL if all parameters are NULL.
A COALESCE expression can be converted into an equivalent NVL expression thus:
COALESCE ( val1, ... , val{n} )
turns into:
NVL( val1 , NVL( val2 , NVL( val3 , … , NVL ( val{n-1} , val{n} ) … )))
A use case of this function is to replace in an expression a NULL by a value like in NVL(SALARY, 0) which says, ‘if SALARY is NULL, replace it with the value 0′.
There is, however, one notable exception. In most implementations, COALESCE evaluates its parameters until it reaches the first non-NULL one, while NVL evaluates all of its parameters. This is important for several reasons. A parameter after the first non-NULL parameter could be a function, which could either be computationally expensive, invalid, or could create unexpected side effects.
Data typing of Null and Unknown[edit]
The NULL literal is untyped in SQL, meaning that it is not designated as an integer, character, or any other specific data type.[25] Because of this, it is sometimes mandatory (or desirable) to explicitly convert Nulls to a specific data type. For instance, if overloaded functions are supported by the RDBMS, SQL might not be able to automatically resolve to the correct function without knowing the data types of all parameters, including those for which Null is passed.
Conversion from the NULL literal to a Null of a specific type is possible using the CAST introduced in SQL-92. For example:
represents an absent value of type INTEGER.
The actual typing of Unknown (distinct or not from NULL itself) varies between SQL implementations. For example, the following
SELECT 'ok' WHERE (NULL <> 1) IS NULL;
parses and executes successfully in some environments (e.g. SQLite or PostgreSQL) which unify a NULL boolean with Unknown but fails to parse in others (e.g. in SQL Server Compact). MySQL behaves similarly to PostgreSQL in this regard (with the minor exception that MySQL regards TRUE and FALSE as no different from the ordinary integers 1 and 0). PostgreSQL additionally implements a IS UNKNOWN predicate, which can be used to test whether a three-value logical outcome is Unknown, although this is merely syntactic sugar.
BOOLEAN data type[edit]
The ISO SQL:1999 standard introduced the BOOLEAN data type to SQL, however it’s still just an optional, non-core feature, coded T031.[26]
When restricted by a NOT NULL constraint, the SQL BOOLEAN works like the Boolean type from other languages. Unrestricted however, the BOOLEAN datatype, despite its name, can hold the truth values TRUE, FALSE, and UNKNOWN, all of which are defined as boolean literals according to the standard. The standard also asserts that NULL and UNKNOWN «may be used
interchangeably to mean exactly the same thing».[27][28]
The Boolean type has been subject of criticism, particularly because of the mandated behavior of the UNKNOWN literal, which is never equal to itself because of the identification with NULL.[29]
As discussed above, in the PostgreSQL implementation of SQL, Null is used to represent all UNKNOWN results, including the UNKNOWN BOOLEAN. PostgreSQL does not implement the UNKNOWN literal (although it does implement the IS UNKNOWN operator, which is an orthogonal feature.) Most other major vendors do not support the Boolean type (as defined in T031) as of 2012.[30] The procedural part of Oracle’s PL/SQL supports BOOLEAN however variables; these can also be assigned NULL and the value is considered the same as UNKNOWN.[31]
Controversy[edit]
Common mistakes[edit]
Misunderstanding of how Null works is the cause of a great number of errors in SQL code, both in ISO standard SQL statements and in the specific SQL dialects supported by real-world database management systems. These mistakes are usually the result of confusion between Null and either 0 (zero) or an empty string (a string value with a length of zero, represented in SQL as ''). Null is defined by the SQL standard as different from both an empty string and the numerical value 0, however. While Null indicates the absence of any value, the empty string and numerical zero both represent actual values.
A classic error is the attempt to use the equals operator = in combination with the keyword NULL to find rows with Nulls. According to the SQL standard this is an invalid syntax and shall lead to an error message or an exception. But most implementations accept the syntax and evaluate such expressions to UNKNOWN. The consequence is that no rows are found – regardless of whether rows with Nulls exist or not. The proposed way to retrieve rows with Nulls is the use of the predicate IS NULL instead of = NULL.
SELECT * FROM sometable WHERE num = NULL; -- Should be "WHERE num IS NULL"
In a related, but more subtle example, a WHERE clause or conditional statement might compare a column’s value with a constant. It is often incorrectly assumed that a missing value would be «less than» or «not equal to» a constant if that field contains Null, but, in fact, such expressions return Unknown. An example is below:
SELECT * FROM sometable WHERE num <> 1; -- Rows where num is NULL will not be returned, -- contrary to many users' expectations.
These confusions arise because the Law of Identity is restricted in SQL’s logic. When dealing with equality comparisons using the NULL literal or the UNKNOWN truth-value, SQL will always return UNKNOWN as the result of the expression. This is a partial equivalence relation and makes SQL an example of a Non-Reflexive logic.[32]
Similarly, Nulls are often confused with empty strings. Consider the LENGTH function, which returns the number of characters in a string. When a Null is passed into this function, the function returns Null. This can lead to unexpected results, if users are not well versed in 3-value logic. An example is below:
SELECT * FROM sometable WHERE LENGTH(string) < 20; -- Rows where string is NULL will not be returned.
This is complicated by the fact that in some database interface programs (or even database implementations like Oracle’s), NULL is reported as an empty string, and empty strings may be incorrectly stored as NULL.
Criticisms[edit]
The ISO SQL implementation of Null is the subject of criticism, debate and calls for change. In The Relational Model for Database Management: Version 2, Codd suggested that the SQL implementation of Null was flawed and should be replaced by two distinct Null-type markers. The markers he proposed were to stand for «Missing but Applicable» and «Missing but Inapplicable», known as A-values and I-values, respectively. Codd’s recommendation, if accepted, would have required the implementation of a four-valued logic in SQL.[5] Others have suggested adding additional Null-type markers to Codd’s recommendation to indicate even more reasons that a data value might be «Missing», increasing the complexity of SQL’s logic system. At various times, proposals have also been put forth to implement multiple user-defined Null markers in SQL. Because of the complexity of the Null-handling and logic systems required to support multiple Null markers, none of these proposals have gained widespread acceptance.
Chris Date and Hugh Darwen, authors of The Third Manifesto, have suggested that the SQL Null implementation is inherently flawed and should be eliminated altogether,[33] pointing to inconsistencies and flaws in the implementation of SQL Null-handling (particularly in aggregate functions) as proof that the entire concept of Null is flawed and should be removed from the relational model.[34] Others, like author Fabian Pascal, have stated a belief that «how the function calculation should treat missing values is not governed by the relational model.»[citation needed]
Closed-world assumption[edit]
Another point of conflict concerning Nulls is that they violate the closed-world assumption model of relational databases by introducing an open-world assumption into it.[35] The closed world assumption, as it pertains to databases, states that «Everything stated by the database, either explicitly or implicitly, is true; everything else is false.»[36] This view assumes that the knowledge of the world stored within a database is complete. Nulls, however, operate under the open world assumption, in which some items stored in the database are considered unknown, making the database’s stored knowledge of the world incomplete.
See also[edit]
- SQL
- NULLs in: Wikibook SQL
- Ternary logic
- Data manipulation language
- Codd’s 12 rules
- Check constraint
- Relational Model/Tasmania
- Relational database management system
- Join (SQL)
References[edit]
- ^ a b c d Ron van der Meyden, «Logical approaches to incomplete information: a survey» in Chomicki, Jan; Saake, Gunter (Eds.) Logics for Databases and Information Systems, Kluwer Academic Publishers ISBN 978-0-7923-8129-7, p. 344; PS preprint (note: page numbering differs in preprint from the published version)
- ^ Codd, E.F. (October 14, 1985). «Is Your Database Really Relational?». Computerworld.
- ^ Codd, E.F. (October 21, 1985). «Does Your DBMS Run By The Rules?». Computerworld.
- ^ a b Don Chamberlin (1998). A Complete Guide to DB2 Universal Database. Morgan Kaufmann. pp. 28–32. ISBN 978-1-55860-482-7.
- ^ a b Codd, E.F. (1990). The Relational Model for Database Management (Version 2 ed.). Addison Wesley Publishing Company. ISBN 978-0-201-14192-4.
- ^ a b ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.2.6: numeric value expressions..
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.2.8: string value expression. - ^
ISO/IEC (2003). ISO/IEC 9075-1:2003, «SQL/Framework». ISO/IEC. Section 4.4.2: The null value. - ^ a b Coles, Michael (June 27, 2005). «Four Rules for Nulls». SQL Server Central. Red Gate Software.
- ^ a b Hans-Joachim, K. (2003). «Null Values in Relational Databases and Sure Information Answers». Semantics in Databases. Second International Workshop Dagstuhl Castle, Germany, January 7–12, 2001. Revised Papers. Lecture Notes in Computer Science. Vol. 2582. pp. 119–138. doi:10.1007/3-540-36596-6_7. ISBN 978-3-540-00957-3.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 8.7: null predicate. - ^ C.J. Date (2004), An introduction to database systems, 8th ed., Pearson Education, p. 594
- ^ Jim Melton; Jim Melton Alan R. Simon (1993). Understanding The New SQL: A Complete Guide. Morgan Kaufmann. pp. 145–147. ISBN 978-1-55860-245-8.
- ^ C. J. Date, Relational database writings, 1991-1994, Addison-Wesley, 1995, p. 371
- ^ C.J. Date (2004), An introduction to database systems, 8th ed., Pearson Education, p. 584
- ^ Imieliński, T.; Lipski Jr., W. (1984). «Incomplete information in relational databases». Journal of the ACM. 31 (4): 761–791. doi:10.1145/1634.1886. S2CID 288040.
- ^ Abiteboul, Serge; Hull, Richard B.; Vianu, Victor (1995). Foundations of Databases. Addison-Wesley. ISBN 978-0-201-53771-0.
- ^ a b Coles, Michael (February 26, 2007). «Null Versus Null?». SQL Server Central. Red Gate Software.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 4.15.4: Aggregate functions. - ^ ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 3.1.6.8: Definitions: distinct.
- ^ «PostgreSQL 8.0.14 Documentation: Index Types». PostgreSQL. Retrieved 6 November 2008.
- ^ «PostgreSQL 8.0.14 Documentation: Unique Indexes». PostgreSQL. Retrieved November 6, 2008.
- ^ «Creating Unique Indexes». PostfreSQL. September 2007. Retrieved November 6, 2008.
- ^
ISO/IEC (2003). ISO/IEC 9075-2:2003, «SQL/Foundation». ISO/IEC. Section 6.11: case expression. - ^ Jim Melton; Alan R. Simon (2002). SQL:1999: Understanding Relational Language Components. Morgan Kaufmann. p. 53. ISBN 978-1-55860-456-8.
- ^ «ISO/IEC 9075-1:1999 SQL Standard». ISO. 1999.
- ^ C. Date (2011). SQL and Relational Theory: How to Write Accurate SQL Code. O’Reilly Media, Inc. p. 83. ISBN 978-1-4493-1640-2.
- ^ ISO/IEC 9075-2:2011 §4.5
- ^ Martyn Prigmore (2007). Introduction to Databases With Web Applications. Pearson Education Canada. p. 197. ISBN 978-0-321-26359-9.
- ^ Troels Arvin, Survey of BOOLEAN data type implementation
- ^ Steven Feuerstein; Bill Pribyl (2009). Oracle PL/SQL Programming. O’Reilly Media, Inc. pp. 74, 91. ISBN 978-0-596-51446-4.
- ^ Arenhart, Krause (2012), «Classical Logic or Non-Reflexive Logic? A case of Semantic Underdetermination», Revista Portuguesa de Filosofia, 68 (1/2): 73–86, doi:10.17990/RPF/2012_68_1_0073, JSTOR 41955624.
- ^
Darwen, Hugh; Chris Date. «The Third Manifesto». Retrieved May 29, 2007. - ^
Darwen, Hugh. «The Askew Wall» (PDF). Retrieved May 29, 2007. - ^ Date, Chris (May 2005). Database in Depth: Relational Theory for Practitioners. O’Reilly Media, Inc. p. 73. ISBN 978-0-596-10012-4.
- ^ Date, Chris. «Abstract: The Closed World Assumption». Data Management Association, San Francisco Bay Area Chapter. Archived from the original on 2007-05-19. Retrieved May 29, 2007.
Further reading[edit]
- E. F. Codd. Understanding relations (installment #7). FDT Bulletin of ACM-SIGMOD, 7(3-4):23–28, 1975.
- Codd, E. F. (1979). «Extending the database relational model to capture more meaning». ACM Transactions on Database Systems. 4 (4): 397–434. CiteSeerX 10.1.1.508.5701. doi:10.1145/320107.320109. S2CID 17517212. Especially §2.3.
- Date, C.J. (2000). The Database Relational Model: A Retrospective Review and Analysis: A Historical Account and Assessment of E. F. Codd’s Contribution to the Field of Database Technology. Addison Wesley Longman. ISBN 978-0-201-61294-3.
- Klein, Hans-Joachim (1994). «How to modify SQL queries in order to guarantee sure answers». ACM SIGMOD Record. 23 (3): 14–20. doi:10.1145/187436.187445. S2CID 17354724.
- Claude Rubinson, Nulls, Three-Valued Logic, and Ambiguity in SQL: Critiquing Date’s Critique, SIGMOD Record, December 2007 (Vol. 36, No. 4)
- John Grant, Null Values in SQL. SIGMOD Record, September 2008 (Vol. 37, No. 3)
- Waraporn, Narongrit, and Kriengkrai Porkaew. «Null semantics for subqueries and atomic predicates». IAENG International Journal of Computer Science 35.3 (2008): 305-313.
- Bernhard Thalheim, Klaus-Dieter Schewe (2011). «NULL ‘Value’ Algebras and Logics». Frontiers in Artificial Intelligence and Applications. 225 (Information Modelling and Knowledge Bases XXII). doi:10.3233/978-1-60750-690-4-354.
{{cite journal}}: CS1 maint: uses authors parameter (link) - Enrico Franconi and Sergio Tessaris, On the Logic of SQL Nulls, Proceedings of the 6th Alberto Mendelzon International Workshop on Foundations of Data Management, Ouro Preto, Brazil, June 27–30, 2012. pp. 114–128
External links[edit]
- Oracle NULLs Archived 2013-04-12 at the Wayback Machine
- The Third Manifesto
- Implications of NULLs in sequencing of data
- Java bug report about jdbc not distinguishing null and empty string, which Sun closed as «not a bug»
Довольно часто при разработке на Java программисты сталкиваются с NullPointerException, появляющимся в самых неожиданных местах. В этой статье мы разберёмся, как это исправить и как стараться избегать появления NPE в будущем.
NullPointerException (оно же NPE) это исключение, которое выбрасывается каждый раз, когда вы обращаетесь к методу или полю объекта по ссылке, которая равна null. Разберём простой пример:
Integer n1 = null; System.out.println(n1.toString());
Здесь на первой строке мы объявили переменную типа Integer и присвоили ей значение null (то есть переменная не указывает ни на какой существующий объект).
На второй строке мы обращаемся к методу toString переменной n1. Так как переменная равна null, метод не может выполниться (переменная не указывает ни на какой реальный объект), генерируется исключение NullPointerException:
Exception in thread "main" java.lang.NullPointerException at ru.javalessons.errors.NPEExample.main(NPEExample.java:6)
Как исправить NullPointerException
В нашем простейшем примере мы можем исправить NPE, присвоив переменной n1 какой-либо объект (то есть не null):
Integer n1 = 16; System.out.println(n1.toString());
Теперь не будет исключения при доступе к методу toString и наша программа отработает корректно.
Если ваша программа упала из-за исключение NullPointerException (или вы перехватили его где-либо), вам нужно определить по стектрейсу, какая строка исходного кода стала причиной появления этого исключения. Иногда причина локализуется и исправляется очень быстро, в нетривиальных случаях вам нужно определять, где ранее по коду присваивается значение null.
Иногда вам требуется использовать отладку и пошагово проходить программу, чтобы определить источник NPE.
Как избегать исключения NullPointerException
Существует множество техник и инструментов для того, чтобы избегать появления NullPointerException. Рассмотрим наиболее популярные из них.
Проверяйте на null все объекты, которые создаются не вами
Если объект создаётся не вами, иногда его стоит проверять на null, чтобы избегать ситуаций с NullPinterException. Здесь главное определить для себя рамки, в которых объект считается «корректным» и ещё «некорректным» (то есть невалидированным).
Не верьте входящим данным
Если вы получаете на вход данные из чужого источника (ответ из какого-то внешнего сервиса, чтение из файла, ввод данных пользователем), не верьте этим данным. Этот принцип применяется более широко, чем просто выявление ошибок NPE, но выявлять NPE на этом этапе можно и нужно. Проверяйте объекты на null. В более широком смысле проверяйте данные на корректность, и консистентность.
Возвращайте существующие объекты, а не null
Если вы создаёте метод, который возвращает коллекцию объектов – не возвращайте null, возвращайте пустую коллекцию. Если вы возвращаете один объект – иногда удобно пользоваться классом Optional (появился в Java 8).
Заключение
В этой статье мы рассказали, как исправлять ситуации с NullPointerException и как эффективно предотвращать такие ситуации при разработке программ.
NULL (SQL)
NULL в Системах управления базами данных (СУБД) — специальное значение (псевдозначение), которое может быть записано в поле таблицы базы данных (БД). NULL соответствует понятию «пустое поле», то есть «поле, не содержащее никакого значения». Введено для того, чтобы различать в полях БД пустые (визуально не отображаемые) значения (например, строку нулевой длины) и отсутствующие значения (когда в поле не записано вообще никакого значения, даже пустого).
NULL означает отсутствие, неизвестность информации. Значение NULL не является значением в полном смысле слова: по определению оно означает отсутствие значения и не принадлежит ни одному типу данных. Поэтому NULL не равно ни логическому значению FALSE, ни пустой строке, ни нулю. При сравнении NULL с любым значением будет получен результат NULL, а не FALSE и не 0. Более того, NULL не равно NULL!
Содержание
Необходимость NULL в реляционных БД
- Мнение 1: NULL является необходимым и обязательным для любой БД, претендующей на реляционность. В частности без него невозможно корректно построить внешнее соединение (OUTER JOIN) строк из двух таблиц. Именно этой точки зрения придерживался Э. Кодд, явно включив его в качестве третьего из 12 правил для реляционных СУБД. Именно этот принцип закреплен в последних стандартах на язык SQL .
- Мнение 2: Значение NULL не требуется, а его использование — следствие ошибки проектирования БД. В базе данных, разработанной в полном соответствии с критериями нормализации, не может быть полей без значений, а значит, не нужно и специальное псевдозначение для таких полей. На практике, однако, из соображений эффективности, нередко оказывается удобным пренебречь некоторыми из правил нормализации, но одним из видов платы за такое пренебрежение является появление пустых полей, для которых и предназначен NULL [1] .
Использование NULL в БД
В БД, поддерживающих понятие NULL, для поля таблицы при описании определяется, может ли оно быть пустым. Если да, то в это поле можно не записывать никакого значения, и это поле будет иметь значение NULL. Также можно и явно записать в такое поле значение NULL.
Как правило, СУБД не разрешает значение NULL для полей, являющихся частью первичного ключа таблицы. В полях внешних ключей, напротив, NULL допускается. Наличие NULL в поле внешнего ключа может трактоваться как признак отсутствия связанной записи, и для такого внешнего ключа не требуется исполнение правил ссылочной целостности, обязательных для любого другого значения внешнего ключа.
Операции с NULL
Поскольку NULL не является, в общем смысле, значением, использование его в арифметических, строковых, логических и других операциях, строго говоря, некорректно. Тем не менее, большинство СУБД поддерживают такие операции, но вводят для них специальные правила:
- NULL может присваиваться переменным и записываться в поля, независимо от объявленного типа данных этих переменных (полей);
- NULL может передаваться в процедуры и функции как легальное значение параметра. Результаты выполнения такой процедуры или функции определяются операциями, выполняемыми с параметрами внутри неё.
- Любая операция сравнения с NULL (даже операция «NULL = NULL»), даёт в результате значение «неизвестность» (UNKNOWN). Окончательный результат при этом зависит от полного логического выражения в соответствии с таблицей истинности логических операций. Если сравнение с NULL есть вся логическая операция целиком (а не её часть), то результат её аналогичен FALSE (выражение вида IF <что-то> = NULL THEN <действие1> ELSE <действие2> END IF всегда будет приводить к выполнению действия2).
- Агрегатные и аналитические функции (используемые в SQL в качестве операций на множествах и списках), как правило, игнорируют значения NULL в пользу допустимых значений остальных элементов множества. Например, для функции AVG, предназначенной для нахождения среднего арифметического значения какого-либо выражения, вычисленного для каждой строки из группы, результат получается таким же, как если бы строки, содержащие для этого выражения значение NULL, вообще не содержались бы в группе.
- Существует специальная системная функция или операция (обычно expr IS [NOT] NULL), возвращающая логическое значение «истина» (TRUE), если expr является (не является) NULL и FALSE в противном случае.
Кроме того, могут существовать специальные системные функции для удобного преобразования NULL к определённым значениям, например, в Oracle имеется системная функция NVL, которая возвращает значение своего параметра, если он не NULL, или значение по умолчанию, если операнд — NULL. В стандарте SQL-92 определены две функции: NULLIF и COALESCE, поэтому их использование является более предпочтительным (если конкретная СУБД их реализует).
Ошибка дизайна
Именно так и никак иначе: null в C# — однозначно ошибочное решение, бездумно скопированное из более ранних языков.
- Самое страшное: в качестве значения любого ссылочного типа может использоваться универсальный предатель — null, на которого никак не среагирует компилятор. Зато во время исполнения легко получить нож в спину — NullReferenceException. Обрабатывать это исключение бесполезно: оно означает безусловную ошибку в коде.
- Перец на рану: сбой (NRE при попытке разыменования) может находится очень далеко от дефекта (использование null там, где ждут полноценный объект).
- Упитанный пушной зверек: null неизлечим — никакие будущие нововведения в платформе и языке не избавят нас от прокаженного унаследованного кода, который физически невозможно перестать использовать.
Этот ящик Пандоры был открыт еще при создании языка ALGOL W великим Хоаром, который позднее назвал собственную идею ошибкой на миллиард долларов.
Лучшая историческая альтернатива
Разумеется, она была, причем очевидная по современным меркам
- Унифицированный Nullable для значимых и ссылочных типов.
- Разыменование Nullable только через специальные операторы (тернарный — ?:, Элвиса — ?., coalesce — ??), предусматривающие обязательную обработку обоих вариантов (наличие или отсутствие объекта) без выбрасывания исключений.
- Примеры:
- В этом случае NRE отсутствует по определению: возможность присвоить или передать null определяется типом значения, конвертация с выбросом исключения отсутствует.
Самое трагичное, что все это не было откровением и даже новинкой уже к моменту проектирования первой версии языка. Увы, тогда матерых функциональщиков в команде Хейлсберга не было.
Лекарства для текущей реальности
Хотя прогноз очень серьезный, летального исхода можно избежать за счет применения различных практик и инструментов. Способы и их особенности пронумерованы для удобства ссылок.
Явные проверки на null в операторе if. Очень прямолинейный способ с массой серьезных недостатков.
- Гигантская масса шумового кода, единственное назначение которого — выбросить исключение поближе к месту предательства.
- Основной сценарий, загроможденный проверками, читается плохо
- Требуемую проверку легко пропустить или полениться написать
- Проверки можно добавлять отнюдь не везде (например, это нельзя сделать для автосвойств)
- Проверки не бесплатны во время выполнения.
Атрибут NotNull. Немного упрощает использование явных проверок
- Позволяет использовать статический анализ
- Поддерживается R#
- Требует добавления изрядного количества скорее вредного, чем бесполезного кода: в львиной доле вариантов использования null недопустим, а значит атрибут придется добавлять буквально везде.
Паттерн проектирования Null object. Очень хороший способ, но с ограниченной сферой применения.
- Позволяет не использовать проверок на null там, где существует эквивалент нуля в виде объекта: пустой IEnumerable, пустой массив, пустая строка, ордер с нулевой суммой и т.п. Самое впечатляющее применение — автоматическая реализация интерфейсов в мок-библиотеках.
- Бесполезен в остальных ситуация: как только вам потребовалось отличать в коде нулевой объект от остальных — вы имеете эквивалент null вместо null object, что является уже двойным предательством: неполноценный объект, который даже NRE не выбрасывает.
Конвенция о возврате живых объектов по умолчанию. Очень просто и эффективно.
Любой метод или свойство, для которых явно не заявлена возможность возвращать null, должны всегда предоставлять полноценный объект. Для поддержания достаточно выработки хорошей привычки, например, посредством ревью кода.
Конвенция о стандартных способах явно указать что свойство или метод может вернуть null: например, префикс Try или суффикс OrDefault в имени метода. Органичное дополнение к возврату полноценных объектов по умолчанию. Достоинства и недостатки те же.
Атрибут CanBeNull. Добрый антипод-близнец атрибута NotNull.
- Поддерживается R#
- Позволяет помечать явно опасные места, вместо массовой разметки по площадям как NotNull
- Неудобен в случае когда null возвращается часто.
Операторы C# (тернарный, Элвиса, coalesce)
- Позволяют элегантно и лаконично организовать проверку и обработку null значений без потери прозрачности основного сценария обработки.
- Практически не упрощают выброс ArgumentException при передаче null в качестве значения NotNull параметра.
- Покрывают лишь некоторую часть вариантов использования.
- Остальные недостатки те же, что и у проверок в лоб.
Тип Optional. Позволяет явно поддержать отсутствие объекта.
- Можно полностью исключить NRE
- Можно гарантировать наличие обработки обоих основных вариантов на этапе компиляции.
- Против легаси этот вариант немного помогает, вернее, помогает немного.
- Во время исполнения помимо дополнительных инструкций добавляется еще и memory traffic
Монада Maybe. LINQ для удобной обработки случаев как наличия, так и отсутствия объекта.
- Сочетает элегантность кода с полнотой покрытия вариантов использования.
- В сочетании с типом Optional дает кумулятивный эффект.
- Отладка затруднена, так как с точки зрения отладчика вся цепочка вызовов является одной строкой.
- Легаси по-прежнему остается ахиллесовой пятой.
- В теории почти идеал, на практике все гораздо печальнее.
- Библиотека Code Contracts скорее мертва, чем жива.
- Очень сильное замедление сборки, вплоть до невозможности использовать в цикле редактирование-компиляция-отладка.
Пакет Fody/NullGuard. Автоматические проверки на null на стероидах.
- Проверяется все: передача параметров, запись, чтение и возврат значений, даже автосвойства.
- Никакого оверхеда в исходном коде
- Никаких случайных пропусков проверок
- Поддержка атрибута AllowNull — с одной стороны это очень хорошо, а с другой — аналогичный атрибут у решарпера другой.
- С библиотеками, агрессивно использующими null, требуется довольно много ручной работы по добавлению атрибутов AllowNull
- Поддержка отключения проверки для отдельных классов и целых сборок
- Используется вплетение кода после компиляции, но время сборки растет умеренно.
- Сами проверки работают только во время выполнения.
- Гарантируется выброс исключения максимально близко к дефекту (возврату null туда, где ожидается реальный объект).
- Тотальность проверок помогает даже при работе с легаси, позволяя как можно быстрее обнаружить, пометить и обезвредить даже null, полученный из чужого кода.
- Если отсутствие объекта допустимо — NullGuard сможет помочь только при попытках передать его куда не следует.
- Вычистив дефекты в тестовой версии, можно собрать промышленную из тех же исходников с отключенными проверками, получив нулевую стоимость во время выполнения при гарантии сохранения всей прочей логики.
Ссылочные типы без возможности присвоения null (если добавят в одну из будущих версий C#)
- Проверки во время компиляции.
- Можно полностью ликвидировать NRE в новом коде.
- В реальности не реализовано, надеюсь, что только пока
- Единообразия со значимыми типами не будет.
- Легаси достанет и здесь.
Итоги
Буду краток — все выводы в таблице:
| Настоятельная рекомендация | Антипаттерн | На ваш вкус и потребности |
|---|---|---|
| 4, 5, 7, 11, 12 (когда и если будет реализовано) | 1, 2 | 3, 6, 8, 9, 10 |
На предвосхищение ООП через 20 лет не претендую, но дополнениям и критике буду очень рад.
NULL в Системах управления базами данных , которое может быть записано в поле таблицы базы данных . NULL соответствует понятию «пустое поле», то есть «поле, не содержащее никакого значения». Введено для того, чтобы различать в полях БД пустые значения (например, строку нулевой длины) и отсутствующие значения .
NULL означает отсутствие, неизвестность информации. Значение NULL не является значением в полном смысле слова: по определению оно означает отсутствие значения и не принадлежит ни одному типу данных. Поэтому NULL не равно ни логическому значению FALSE, ни пустой строке, ни нулю. При сравнении NULL с любым значением будет получен результат NULL, а не FALSE и не 0. Более того, NULL не равно NULL!
NULL в языках программирования Си и C++ — макрос , объявленный в заголовочном файле stddef.h . Константа нулевого указателя — это целочисленное константное выражение со значением 0, или такое же выражение, но приведённое к типу void *. Константа нулевого указателя, приведённая к любому типу указателей, является нулевым указателем. Гарантируется, что нулевой указатель не равен указателю на любой объект или функцию. Гарантируется, что любые два нулевых указателя равны между собой. Разыменовывание нулевого указателя является операцией с неопределённым поведением .
Иначе говоря, реализация предоставляет специальное значение — константу нулевого указателя, которую можно присвоить любому указателю и такой указатель при сравнении не будет равен любому «корректному» указателю. То есть, можно считать, что нулевой указатель не содержит корректный адрес в памяти.
Microsoft Excel часто получает ошибки, которые могут быть очень неприятными для их пользователей. Ошибки могут возникать в программах Office из-за проблем с вашей программой Office или из-за того, что вы можете сделать что-то неправильно в своем документе, слайде или электронной таблице Excel. В этом посте мы покажем вам, как исправить ошибку #NULL в Excel.
Почему #NULL отображается в Excel?
Ошибка #NULL возникает, когда вы используете неправильный оператор диапазона в формуле или когда вы используете оператор пересечения (символ пробела) между ссылками на диапазон. Ошибка #NULL указывает, что два диапазона не пересекаются.
Следуйте приведенным ниже методам, чтобы исправить ошибку #NULL в Excel:
- Вставьте двоеточие
- Вставьте запятую
1]Вставьте двоеточие
Если вы используете пробел в формуле или неправильный оператор, например, = СУММ (А2 А3)Excel вернет ошибку #NULL.
Чтобы решить эту проблему, вы должны использовать двоеточие, чтобы отделить первую ячейку от последней ячейки, например, = СУММ (A2: A3). Двоеточие используется для разделения, когда вы ссылаетесь на непрерывный диапазон ячеек в формуле.
2]Вставьте запятую
Excel вернет ошибку #NULL, если вы обратитесь к двум непересекающимся областям, например, = СУММ (A2: A3 B2: B3).
Если формула суммирует два диапазона, убедитесь, что запятая разделяет два диапазона. = СУММ (A2: A3, B2: B3).
Как избавиться от зеленой ошибки в Excel?
Всякий раз, когда вы получаете ошибку в своей электронной таблице, вы увидите зеленый треугольник слева от ячейки, где находится ошибка; Выполните следующие действия, чтобы отключить зеленый треугольник.
- Перейдите на вкладку «Файл».
- Щелкните Параметры в представлении Backstage.
- Откроется диалоговое окно параметров Excel.
- Перейдите на вкладку «Формулы» на левой панели.
- В разделе «Проверка ошибок» снимите флажок «Включить фоновую проверку ошибок».
- Нажмите «ОК».
- Зеленый треугольник в ячейке ошибки удален.
Читать: Как изменить направление клавиши Enter в Excel
Мы надеемся, что это руководство поможет вам понять, как исправить ошибку Null в Excel; если у вас есть вопросы по поводу урока, дайте нам знать в комментариях.
В статье рассказывается:
- Пример значения NULL
- Значение NULL и НЕ NULL
- Значение NULL в MySQL
- Логические операции и NULL
- Функция NULL в MySQL
- Операторы IN и NOT IN для значения NULL
- Значение NULL и пустая строка в СУБД
- Отличия между null и undefined
-

Пройди тест и узнай, какая сфера тебе подходит:
айти, дизайн или маркетинг.Бесплатно от Geekbrains
Если вы далеки от работы с базами данных, для вас может быть открытием, что ноль – это не значение NULL, хотя, признаем, они созвучны. Кроме того, NULL не является значением пустой строки, хотя можно найти поле, содержащее данные любого типа.
NULL можно представить как значение для представления неизвестного фрагмента данных (обратите внимание: не нулевого, хотя поле при этом выглядит пустым). А еще он не равен ничему, даже другому NULL. И сегодня мы поговорим об этом загадочном (на первый взгляд) значении NULL более подробно.
Итак, что вы должны знать о значении NULL? Давайте разбираться.
Представьте себе письменный стол, на котором лежат канцелярские принадлежности: 6 шариковых ручек и 2 простых карандаша. Также известно, что в ящике стола должны быть фломастеры. Но вот сколько их и есть ли они вообще — данных нет. Если нам нужно составить таблицу инвентаризации с вводом значения NULL, то выглядеть она будет так:
| InventoryID | Item | Количество |
| 1 | ручки | 6 |
| 2 | карандаши | 2 |
| 3 | фломастеры | NULL |
Как вы понимаете, принимать за «0» количество фломастеров в данном случае было бы неверным, так как подобная запись показывала бы, что фломастеров нет вообще. Но точные данные об их количестве отсутствуют, поэтому может оказаться, что несколько штук все же есть.
IS NULL и IS NOT NULL – специально созданные операторы, которые осуществляют сравнение имеющихся NULLов. IS NULL возвращает истину, если операнда является NULLом. Соответственно, если операнд не является NULLом, то значение будет ложным.
select case when null is null then ‘YES’ else ‘NO’ end from dual; — YES
select case when ‘a’ is null then ‘YES’ else ‘NO’ end from dual; — NO
IS NOT NULL имеет обратный принцип: значение будет истинным, если операнд не является NULLом, и ложным, если он таковым является.
select case when ‘a’ is NOT null then ‘YES’ else ‘NO’ end from dual; — YES
select case when null is NOT null then ‘YES’ else ‘NO’ end from dual; — NO
Учтите, что когда речь идет об отсутствующих значениях, есть особые случаи их сравнения:
- DECODE — принимает два NULLа за равные значения;
- составные индексы — в случае, когда у двух ключей есть пустые поля, но заполненные поля при этом равны между собой, то Oracle воспримет эти ключи, как равные.


Читайте также
Вот так проявляет себя DECODE:
select decode( null
, 1, ‘ONE’
, null, ‘EMPTY’ — это условие будет истинным
, ‘DEFAULT’
)
from dual;
Значение NULL в MySQL
Результат при сравнении NULLов, в зависимости от операции SQL, часто будет иметь значение NULL. Предположим, что А НЕДЕЙСТВИТЕЛЕН:
Арифметические операторы
- A + B = NULL
- A – B = NULL
- A * B = NULL
- A/B = NULL
Скачать файл
Операторы сравнения
- A = B = NULL
- A! = B = NULL
- A> B = NULL
- A!
Эти случаи — лишь часть примеров операторов, возвращающих значение NULL при равенстве NULL одного из операндов. На практике встречаются куда более сложные запросы, чья обработка затруднена количеством значений NULL. Главное, нужно понимать и планировать итоги работы с базой данных, в которой вы разрешаете значение NULL.
Логические операции и NULL
Для логических операторов AND и OR есть свои особенности при работе со значением NULL. Краткое руководство рассмотрим на примере.
Как правило, НЕИЗВЕСТНО обрабатывается так же, как и состояние ЛОЖЬ. Если выбрать из таблицы строки и вычисление условия X=NULL в предложении WHERE дало результат НЕИЗВЕСТНО, то ни одной строки не будет получено. Но есть и различия: выражение НЕ(ЛОЖЬ) вернет истину, а НЕ(ИЗВЕСТНО) вернет НЕИЗВЕСТНО.
Чаще всего с неизвестным результатом работают как с ЛОЖЬЮ:
select 1 from dual where dummy = null; — запрос не вернёт записей
При отрицании неизвестности результатом будет НЕИЗВЕСТНО:
exec test_bool( not(null = null)); — UNKNOWN
exec test_bool( not(null != null) ); — UNKNOWN
exec test_bool( not(null = ‘a’) ); — UNKNOWN
exec test_bool( not(null != ‘a’) ); — UNKNOWN
Оператор OR:
exec test_bool(null or true); — TRUE <- !!!!!
exec test_bool(null or false); — UNKNOWN
exec test_bool(null or null); — UNKNOWN
Оператор AND:
exec test_bool(null and true); — UNKNOWN
exec test_bool(null and false); — FALSE <- !!!!!
exec test_bool(null and null); — UNKNOWN
Функция NULL в MySQL
В системе MySQL есть ряд функций, позволяющих результативно работать с NULL. Это IFNULL, NULLIF и COALESCE.
- IFNULL может принять два параметра: возвращает первый аргумент, если он не является NULL, в обратном случае — возвращает второй аргумент.
- NULLIF также может принять два аргумента: если они равны, то функция возвращает NULL, в обратном случае — возвращает первый аргумент. Эта функция также будет эффективна, если в вашей таблице в столбце есть пустые строки со значением NULL.
- COALESCE может принимать список аргументов и возвращать первый аргумент не-NULL. Например, эту функцию можно применять для базы контактных данных с потенциальной возможностью в зависимости от важности информации в порядке Телефон — Электронная почта — N/A.

Топ-30 самых востребованных и высокооплачиваемых профессий 2022
Поможет разобраться в актуальной ситуации на рынке труда

Подборка 50+ ресурсов об IT-сфере
Только лучшие телеграм-каналы, каналы Youtube, подкасты, форумы и многое другое для того, чтобы узнавать новое про IT
ТОП 50+ сервисов и приложений от Geekbrains
Безопасные и надежные программы для работы в наши дни
Уже скачали 18550

Операторы IN и NOT IN для значения NULL
Чтобы понять взаимодействие этих операторов с NULLом, рассмотрим пример.
Создадим таблицу Т, состоящую из одного числового столбца А и строками: 1, 2, 3 и NULL.
create table t as select column_value a from table(sys.odcinumberlist(1,2,3,null));
Затем выполним трассировку запроса (учтите, что для этого нужно обладать ролью PLUSTRACE).
От трассировки в листингах оставлена часть filter, чтобы показать преобразование указанных в запросе условий.
set autotrace on
Теперь, после подготовительных действий, попробуем выбрать те записи, которые будут соответствовать набору (1, 2, NULL).
select * from t where a in(1,2,null); — вернёт [1,2]
— Predicate Information:
— filter(«A»=1 OR «A»=2 OR «A»=TO_NUMBER(NULL))
По какой-то причине строка с NULLом не выбрана. Возможно, это случилось потому, что вычисление предиката «А»=TO_NUMBER(NULL) вернуло состояние НЕИЗВЕСТНО. Попробуем явно указать условие включения NULLов в результаты запросов:
select * from t where a in(1,2) or a is null; — вернёт [1,2,NULL]
— Predicate Information:
— filter(«A» IS NULL OR «A»=1 OR «A»=2)
Попробуем с NOT IN:
select * from t where a not in(1,2,null); — no rows selected
— Predicate Information:
— filter(«A»<>1 AND «A»<>2 AND «A»<>TO_NUMBER(NULL))
Ни одной записи так и не появилось.

Читайте также
Это объясняется тем, что трехзначная логика NOT IN не взаимодействует с NULLами: при попадании NULL в условия отбора данных можно не ждать.
Значение NULL и пустая строка в СУБД
Oracle отличается от стандартов ANSI SQL в определении NULLов: он проводит знак равенства между NULL и пустой строкой. Эта особенность программы рождает много споров, хотя Oracle и заявляет, что, возможно, в будущих релизах будет изменен подход в обработке пустой строки, как NULL. Но в реальности проведение таких изменений сомнительно, так как под эту СУБД написано неимоверное количество кода.
![]()
Точный инструмент «Колесо компетенций»
Для детального самоанализа по выбору IT-профессии
![]()
Список грубых ошибок в IT, из-за которых сразу увольняют
Об этом мало кто рассказывает, но это должен знать каждый
![]()
Мини-тест из 11 вопросов от нашего личного психолога
Вы сразу поймете, что в данный момент тормозит ваш успех
Регистрируйтесь на бесплатный интенсив, чтобы за 3 часа начать разбираться в IT лучше 90% новичков.
Только до 2 февраля
Осталось 17 мест
Равенство пустой строки и NULL:
exec test_bool( » is null ); — TRUE
Если попытаться найти причину, почему вообще пустую строку стали считать эквивалентной NULL, то ответ можно найти в формате хранения varchar`ов и NULLов внутри блоков данных. Табличные строки Oracle хранит в структуре, представляющей собой заголовок и следующими за ним столбцы с данными.
Каждый столбец, в свою очередь, состоит из 2-х полей: длина данных в столбце (1 или 3 байта) и сами данные. При нулевой длине varchar2 в поле с данными нечего вносить, так как оно не занимает ни байта. В поле же, где указывается длина, вносится специальное значение 0xFF, что и означает отсутствие данных.
NULL Oracle представляет аналогично, то есть отсутствует поле с данными, а в поле длины данных вносится 0xFF. Так как изначально разработчики Oracle не разделяли эти два состояния, то и сейчас принцип внесения данных не изменился.

Понятие «пустая строка» допустимо толковать как абсолютное отсутствие значения, так как ее длина равна нулю. NULL же, в свою очередь, имеет длину неопределенного значения. Поэтому выражение length (») возвращает NULL, а не ожидаемый ноль.
Еще одна причина, по которой нельзя сравнивать NULL с пустой строкой: выражение val = » вернёт состояние НЕИЗВЕСТНО, так как, по сути, идентично val=NULL.
Неопределенная длина пустой строки:
select length(») from dual; — NULL
Сравнение с пустой строкой невозможно:
exec test_bool( ‘a’ != » ); — UNKNOWN
Критика такого подхода Oracle к значениям NULL и пустой строки, основывается на том, что не всегда пустая строка может означать неизвестность. Например, когда менеджер-продавец вносит данные в карточку клиента, то в поле «Контактный номер» он может указать конкретный номер; также он может указать, что номер неизвестен (NULL); но еще он может указать, что номера как такового нет (пустая строка).
С методом хранения пустых строк, предлагаемым Oracle, последний случай будет очень затруднительно осуществить. Если смотреть на этот довод критики через призму семантики, то звучит он очень убедительно. Но с другой стороны, каким образом менеджер сможет внести в поле «Контакты» пустую строку, и как в будущем он сможет отличить ее от «номер неизвестен» (NULL)?
Отличия между null и undefined
Можно сказать, что NULL – это такое значение, которое является определенным для отсутствующего объекта. UNDEFINED же означает именно неопределенность. Например:
var element;
// значение переменной element до её инициализации не определённо: undefined
element = document.getElementById(‘not-exists’);
// здесь при попытке получения несуществующего элемента, метод getElementById возвращает null
// переменная element теперь инициализирована значением null, её значение определено
Осуществляя проверку на NULL или UNDEFINED, нужно помнить о разнице в операторах равенства (==) и идентичности (===): с первым оператором производится преобразование типов.
typeof null // object (не «null» из соображений обратной совместимости)
typeof undefined // undefined
null === undefined // false
null == undefined // true
Это все то, что вы должны знать о значении NULL. Обрастая опытом и применяя некоторые уловки для избежания NullPointerException, вы научитесь делать безопасный код. Главным образом неразбериха возникает из-за того, что NULL может трактоваться как пустое значение или как неидентифицированное.
Поэтому важно документально фиксировать поведение метода, когда есть входящее значение NULL. Держите в памяти, что NULL – это значение по умолчанию ссылочных переменных. И вызывать методы экземпляра или получать доступ к переменным экземпляра, применяя NULL-ссылку, вы не можете.
Ряд пользователей (да и разработчиков) программных продуктов на языке Java могут столкнуться с ошибкой java.lang.nullpointerexception (сокращённо NPE), при возникновении которой запущенная программа прекращает свою работу. Обычно это связано с некорректно написанным телом какой-либо программы на Java, требуя от разработчиков соответствующих действий для исправления проблемы. В этом материале я расскажу, что это за ошибка, какова её специфика, а также поясню, как исправить ошибку java.lang.nullpointerexception.
Содержание
- Что это за ошибка java.lang.nullpointerexception
- Как исправить ошибку java.lang.nullpointerexception
- Для пользователей
- Для разработчиков
- Заключение
Что это за ошибка java.lang.nullpointerexception
Появление данной ошибки знаменует собой ситуацию, при которой разработчик программы пытается вызвать метод по нулевой ссылке на объект. В тексте сообщения об ошибке система обычно указывает stack trace и номер строки, в которой возникла ошибка, по которым проблему будет легко отследить.
Что в отношении обычных пользователей, то появление ошибки java.lang.nullpointerexception у вас на ПК сигнализирует, что у вас что-то не так с функционалом пакетом Java на вашем компьютере, или что программа (или онлайн-приложение), работающие на Java, функционируют не совсем корректно. Если у вас возникает проблема, при которой Java апплет не загружен, рекомендую изучить материал по ссылке.
Как исправить ошибку java.lang.nullpointerexception
Как избавиться от ошибки java.lang.nullpointerexception? Способы борьбы с проблемой можно разделить на две основные группы – для пользователей и для разработчиков.
Для пользователей
Если вы встретились с данной ошибкой во время запуска (или работы) какой-либо программы (особенно это касается minecraft), то рекомендую выполнить следующее:
- Переустановите пакет Java на своём компьютере. Скачать пакет можно, к примеру, вот отсюда;
- Переустановите саму проблемную программу (или удалите проблемное обновление, если ошибка начала появляться после такового);
- Напишите письмо в техническую поддержку программы (или ресурса) с подробным описанием проблемы и ждите ответа, возможно, разработчики скоро пофиксят баг.
- Также, в случае проблем в работе игры Майнкрафт, некоторым пользователям помогло создание новой учётной записи с административными правами, и запуск игры от её имени.
Для разработчиков
Разработчикам стоит обратить внимание на следующее:
- Вызывайте методы equals(), а также equalsIgnoreCase() в известной строке литерала, и избегайте вызова данных методов у неизвестного объекта;
- Вместо toString() используйте valueOf() в ситуации, когда результат равнозначен;
- Применяйте null-безопасные библиотеки и методы;
- Старайтесь избегать возвращения null из метода, лучше возвращайте пустую коллекцию;
- Применяйте аннотации @Nullable и @NotNull;
- Не нужно лишней автоупаковки и автораспаковки в создаваемом вами коде, что приводит к созданию ненужных временных объектов;
- Регламентируйте границы на уровне СУБД;
- Правильно объявляйте соглашения о кодировании и выполняйте их.
Заключение
При устранении ошибки java.lang.nullpointerexception важно понимать, что данная проблема имеет программную основу, и мало коррелирует с ошибками ПК у обычного пользователя. В большинстве случаев необходимо непосредственное вмешательство разработчиков, способное исправить возникшую проблему и наладить работу программного продукта (или ресурса, на котором запущен сам продукт). В случае же, если ошибка возникла у обычного пользователя (довольно часто касается сбоев в работе игры Minecraft), рекомендуется установить свежий пакет Java на ПК, а также переустановить проблемную программу.
Опубликовано 21.02.2017 Обновлено 03.09.2022