
Каждый браузер оснащен консольной панелью, с помощью которой разработчики проводят тестирование веб-сайта. Вкладка Elements содержит всю информацию об инспектируемом HTML-файле: теги, таблицы стилей и т.д. Но в консоли есть и другие разделы, такие как Console, Sources, Network и прочие.
Для каких целей они используются и как можно выявить ошибки через консоль – поговорим в сегодняшней статье.
Как открыть консоль на разных браузерах
Алгоритм запуска консоли (инспектора) во всех браузерах идентичен. Есть два пути: первый – запуск через специальную клавишу на клавиатуре, второй – через функцию «Посмотреть код страницы/элемента».
Например, если воспользоваться в Chrome клавишей F12, то откроется дополнительное окно с консолью.
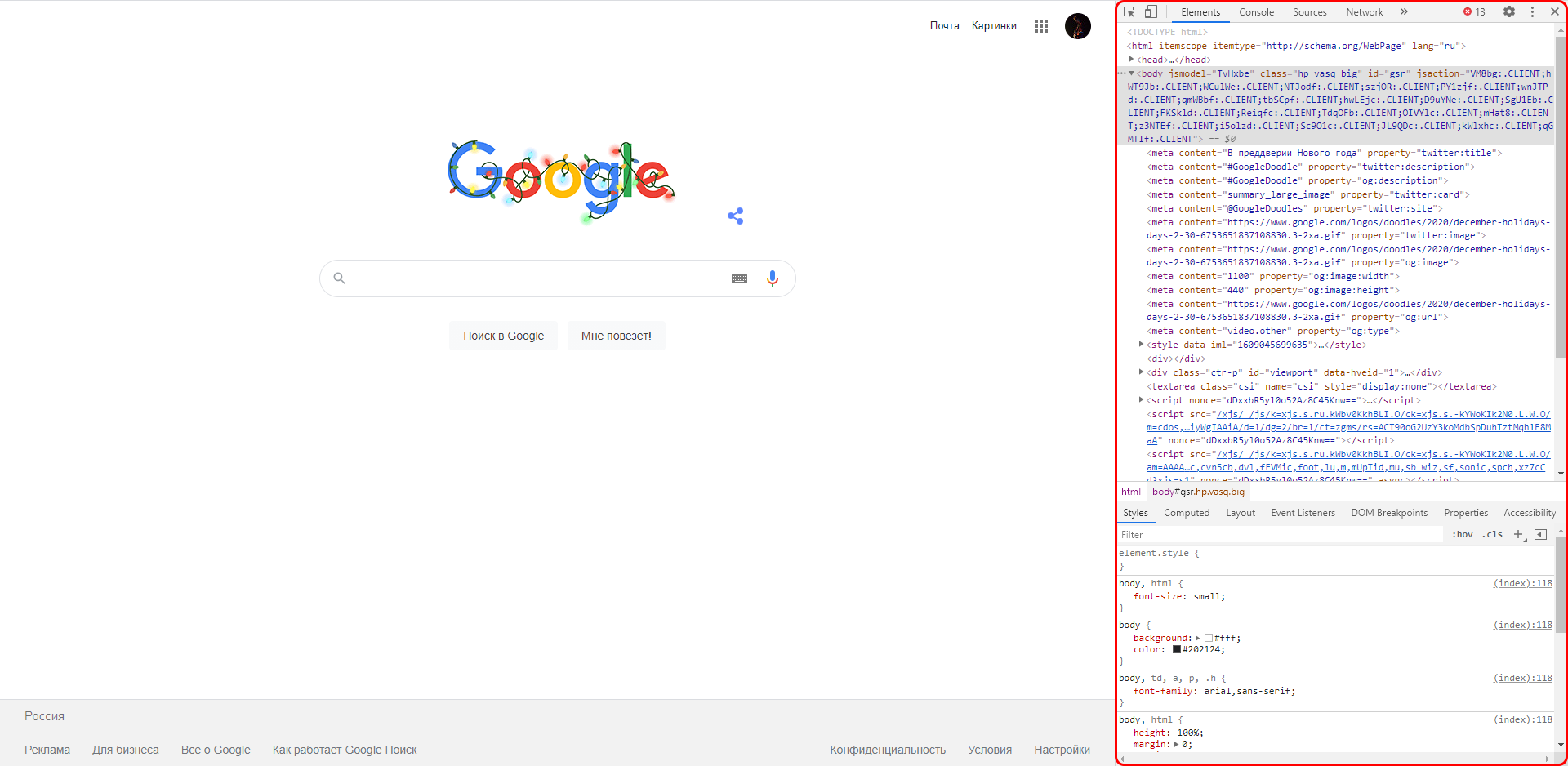
Второй путь заключается в просмотре кода текущей страницы – для этого необходимо кликнуть правой кнопкой мыши по любому элементу сайта и в отобразившемся меню выбрать опцию «Посмотреть код». Обратите внимание, что это название опции в Google Chrome, в других браузерах оно может отличаться. Например, в Яндексе функция называется «Исследовать элемент».
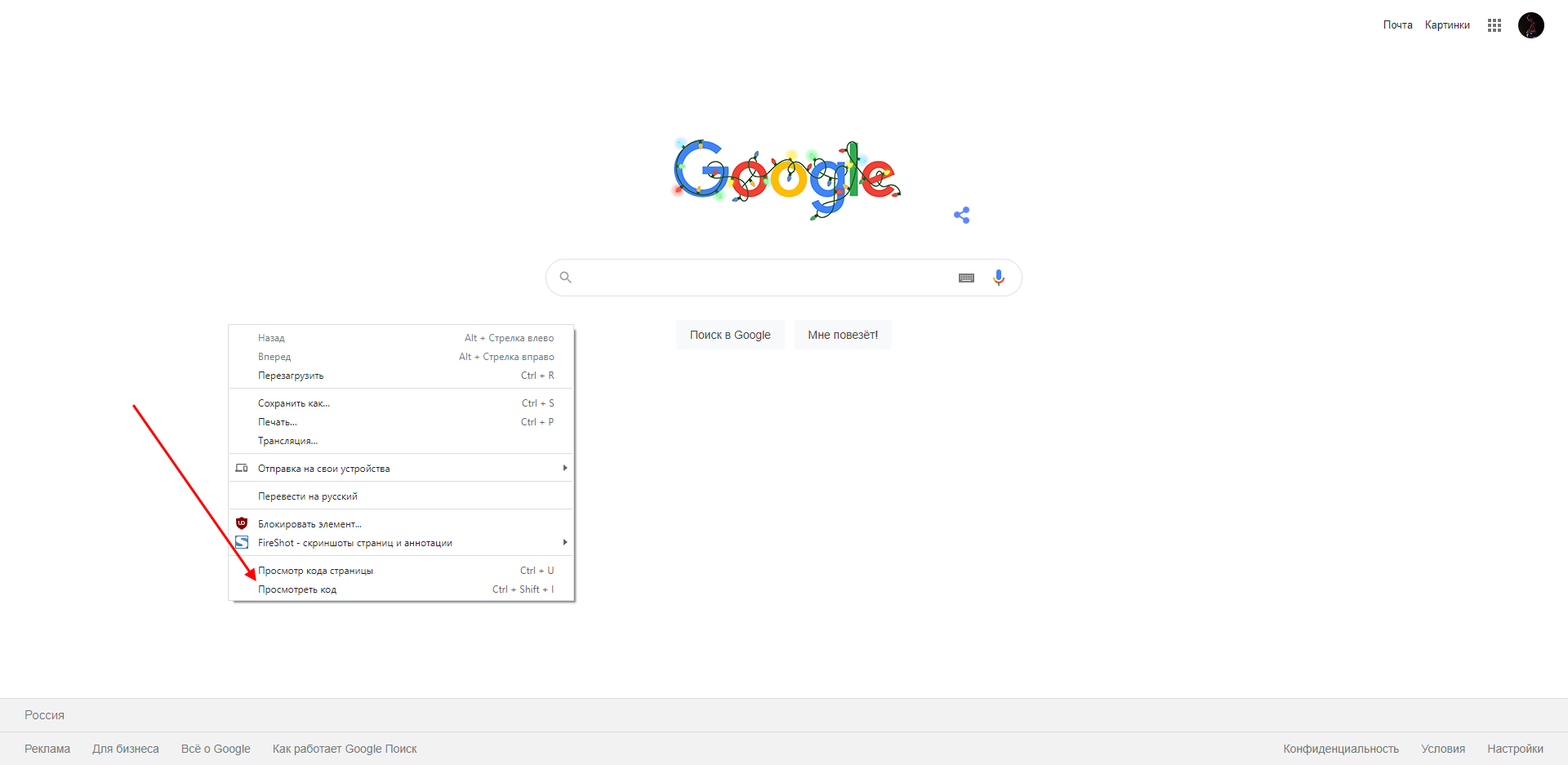
В результате перед нами снова отобразится окно, в котором будет открыта главная вкладка с кодом страницы. Подробнее о ней мы еще поговорим, а пока давайте посмотрим, как выполняется запуск консоли в браузере Safari на устройствах Mac.
Первым делом нам потребуется включить меню разработчика – для этого переходим в раздел «Настройки» и открываем подраздел «Продвинутые». Находим пункт «Показать меню «Разработка в строке меню» и отмечаем его галочкой.
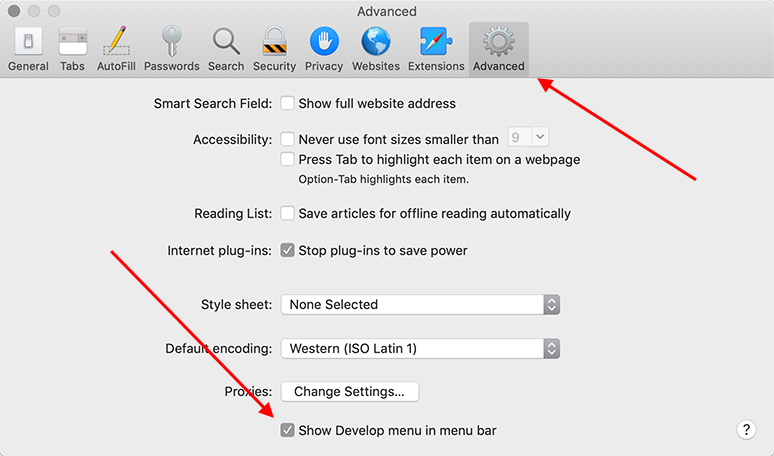
Теперь можно запустить консольное окно – достаточно воспользоваться комбинацией клавиш «Cmd+Opt+C».
Как видите, запустить консоль в браузере – дело нескольких секунд. Опция полезна, когда вы верстаете новый сайт, исправляете ошибки, проводите различные тесты.
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Подписаться
Какие вкладки есть в консоли и за что они отвечают
Консоль каждого браузера содержит практически идентичные вкладки с одним и тем же функционалом, поэтому рассмотрим каждый из блоков на примере веб-обозревателя Google Chrome.
Перед тем как перейти к разбору каждой вкладки, давайте рассмотрим основное элементы, которые могут быть полезны при работе с консолью. Первый – это включение адаптивного режима. Для этого необходимо открыть консоль и в верхнем левом углу нажать на кнопку в виде телефона/планшета.
В результате левая часть окна будет немного изменена: добавятся кнопки для выбора разрешения под нужный девайс. Например, выберем устройство iPhone X, и сайт сразу же будет выглядеть так, как он выглядел бы на телефоне.
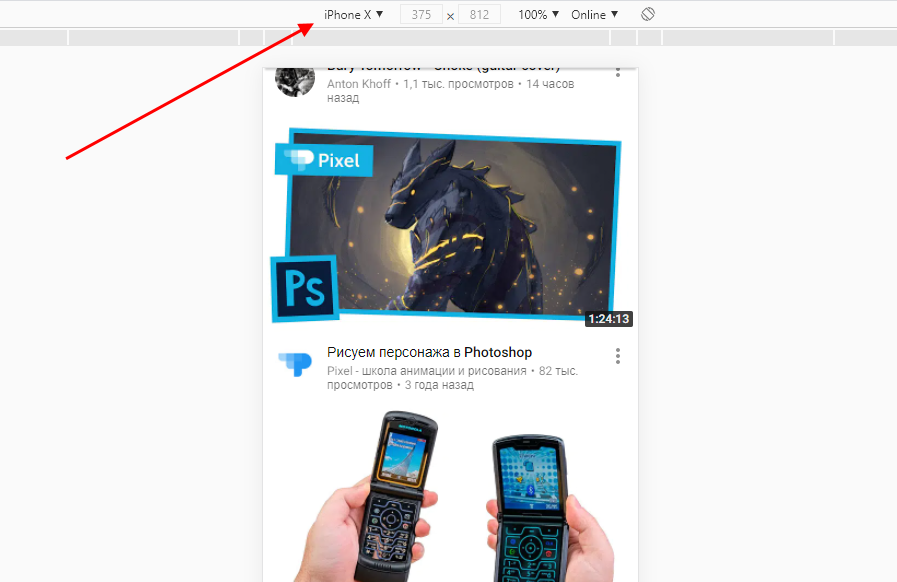
Если выбрать опцию «Responsive», то слева от страницы отобразится дополнительная линия, которую мы можем тянуть влево или вправо – с помощью нее можно подобрать необходимое разрешение страницы. Также настроить разрешение мы можем и в верхней части окна.
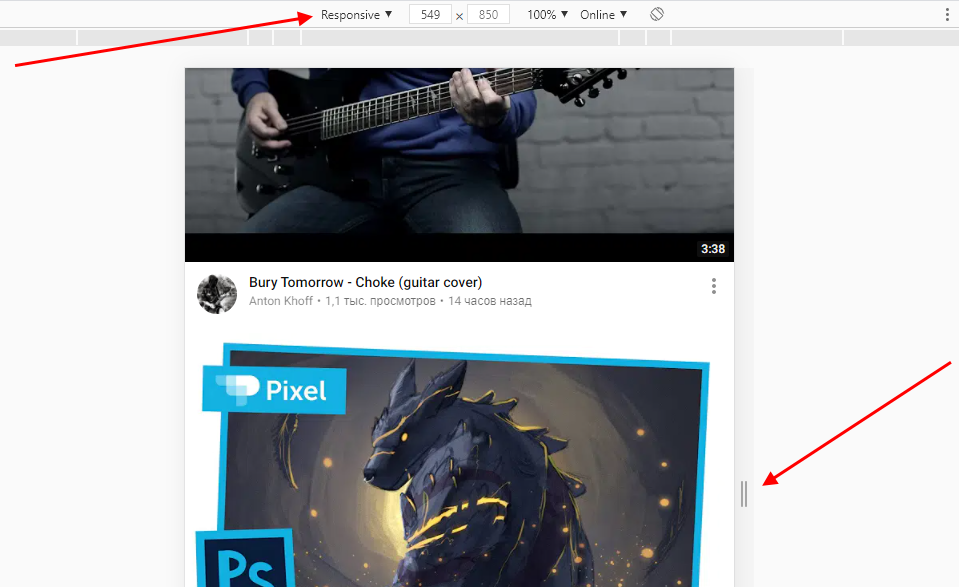
И еще одна опция, которая может быть полезна – изменение расположения консольной панели. Чтобы ей воспользоваться, необходимо в верхней правой части нажать на кнопку в виде троеточия и в строке «Dock side» изменить ориентацию. Доступные положения: справа, слева, снизу, в отдельном окне.
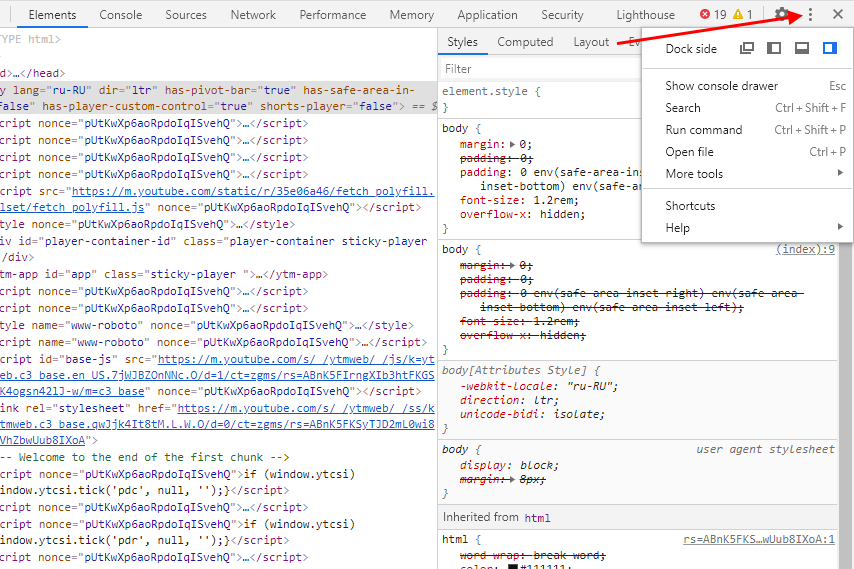
На этом стандартный набор функций консольной панели заканчивается. Давайте посмотрим, какие в ней есть вкладки и за что они отвечают.
Elements
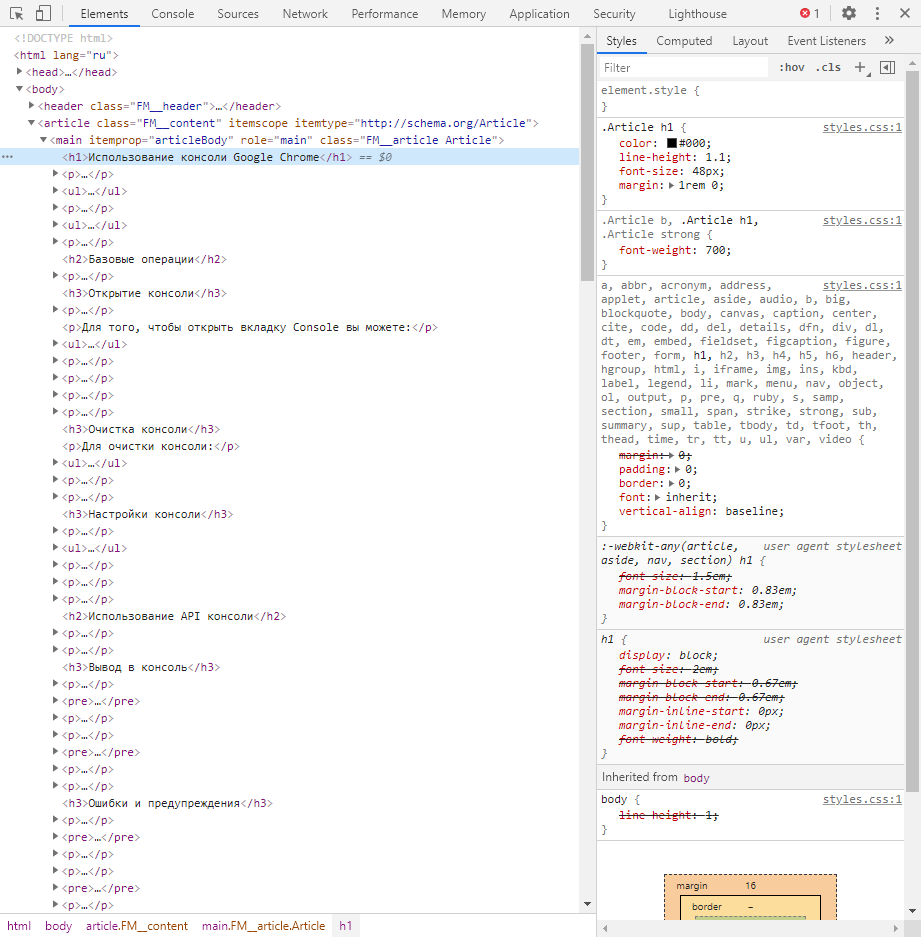
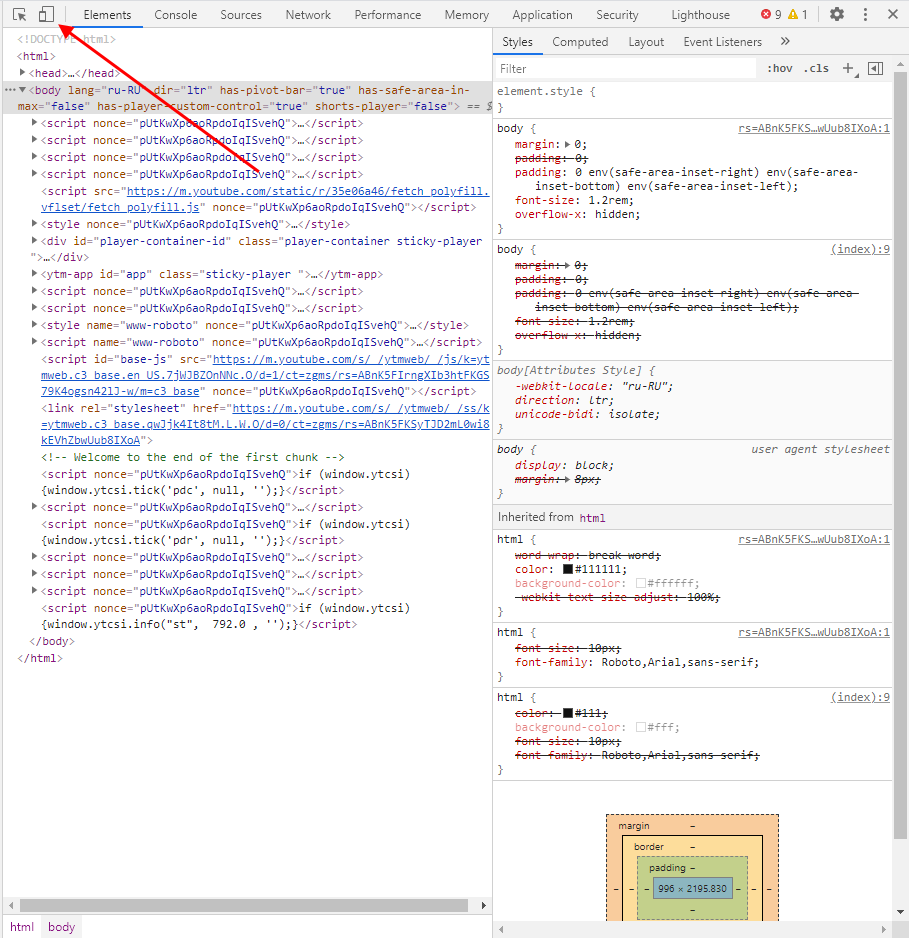
Основной компонент для верстальщиков. Он включает в себя всю информацию об открытой HTML-странице. Здесь мы можем не только посмотреть текущие теги и атрибуты, но и изменить их – в таком случае произойдет автоматическое изменение дизайна на странице. Если ее обновить, все вернется на свои места. Также открыт доступ к просмотру CSS и прочих элементов – для этого в правой части раздела идут вкладки Styles, Computed, Layout, Event Listeners, DOM Breakpoints, Properties и Accessibility.
Console
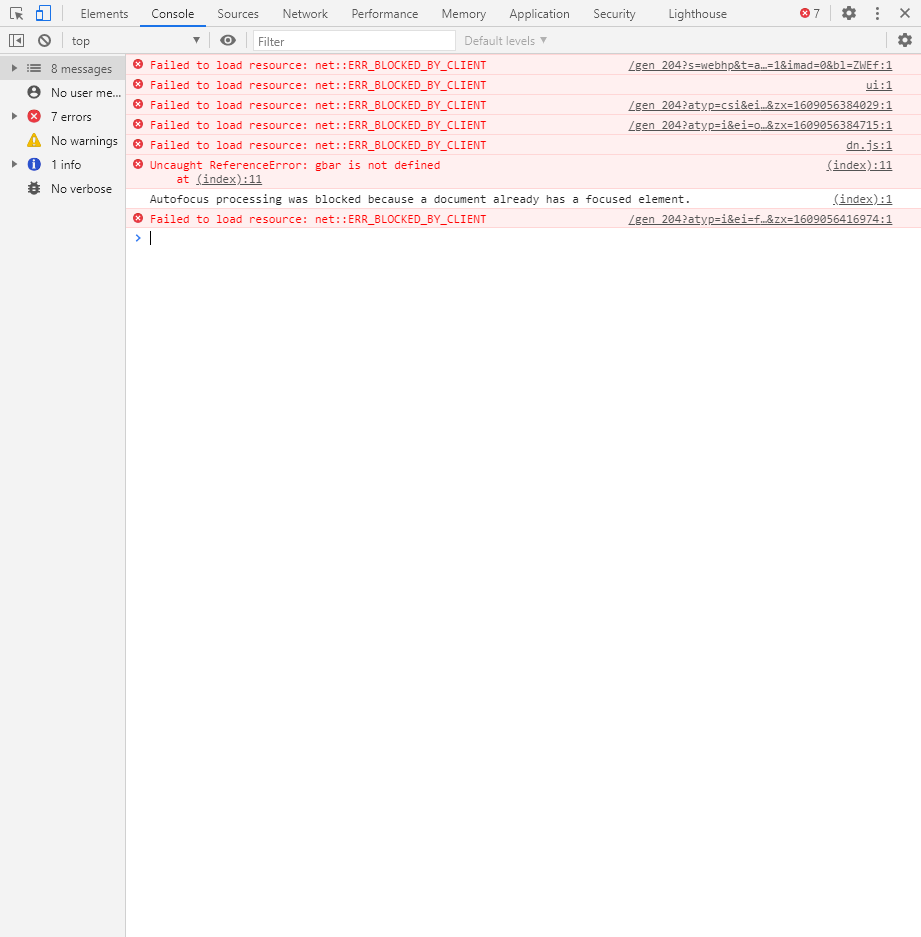
Еще одна важнейшая вкладка для верстальщиков – это Console. В ней мы можем узнать информацию о текущих ошибках на сайте, посмотреть исполняемый JavaScript-код, если он выведен в консоль с помощью метода console.log, и многое другое.
Если вам нужно очистить информацию, выведенную в консоль, то сделать это легко. Достаточно в верхнем левом углу нажать на кнопку в виде знака запрета.
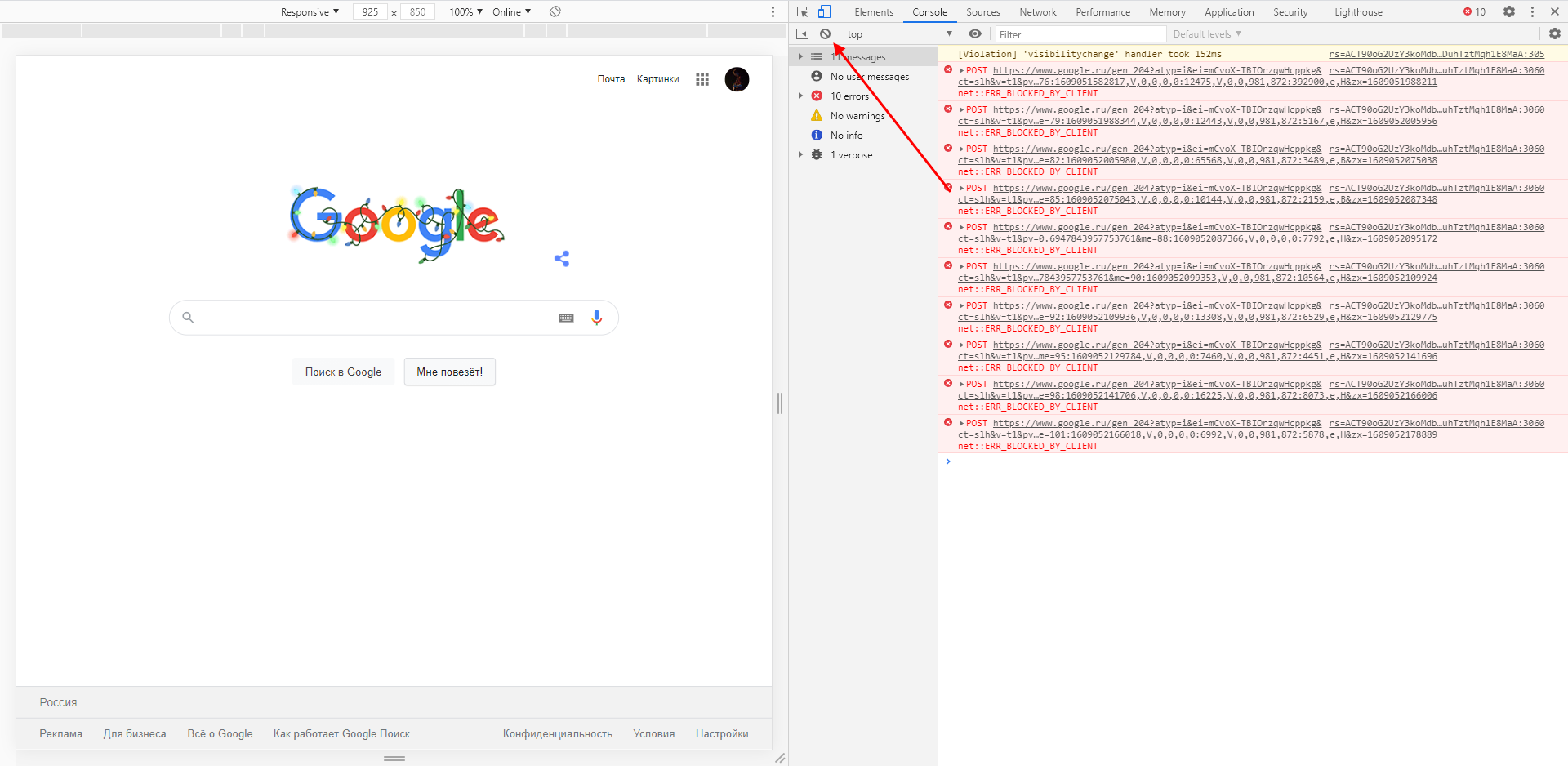
Также в данной консоли мы можем посмотреть информацию об ошибках плагина, воспользоваться поиском по слову или фразе, а также установить различные фильтры на отображаемую информацию.
Sources
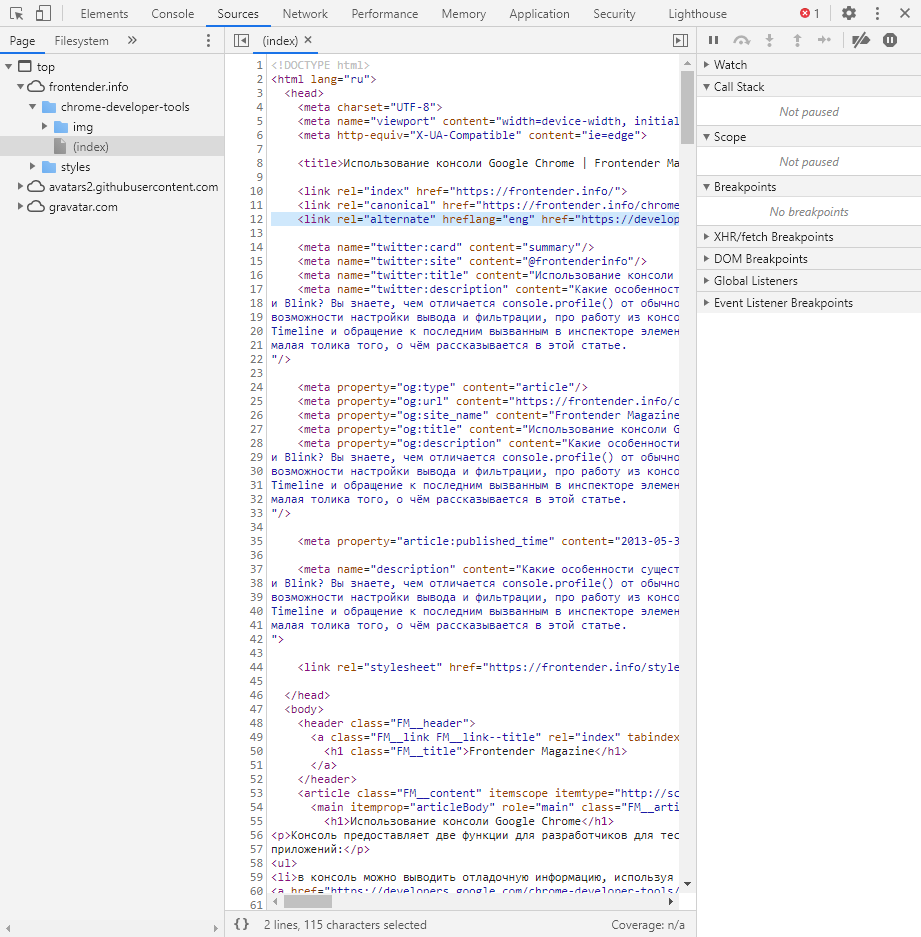
Данный раздел открывает доступ ко всей иерархии сайта: здесь мы можем посмотреть, какие используются картинки, CSS-файлы, шрифты и прочее.
Сама вкладка, как видите, разделена на 3 части. В первой содержится дерево иерархии файлов, относящихся к сайту. Вторая предназначена для просмотра содержимого этих файлов и выполнения их отладки. Для ее запуска необходимо воспользоваться последним окном.
Network
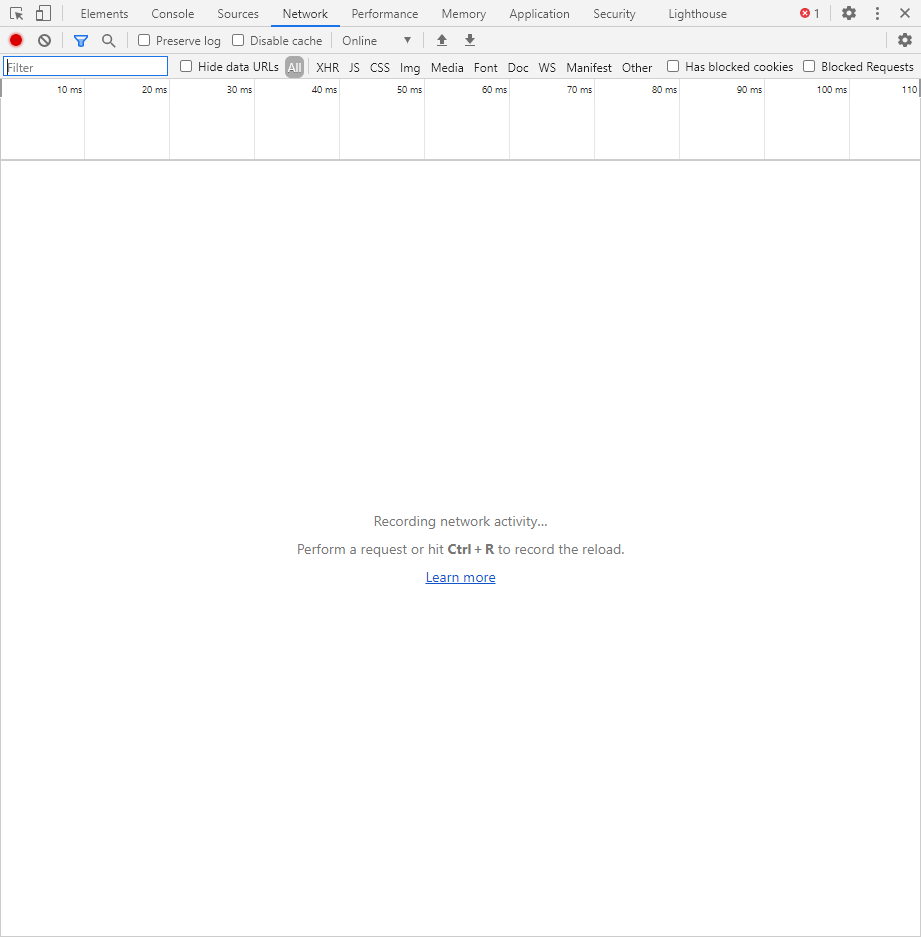
Из названия уже понятно, что данный раздел предназначен для отслеживания сетевого трафика. Его основная функция – запись сетевого журнала. Можно выявить время загрузки и обработки различных файлов, чтобы впоследствии оптимизировать страницу.
Performance
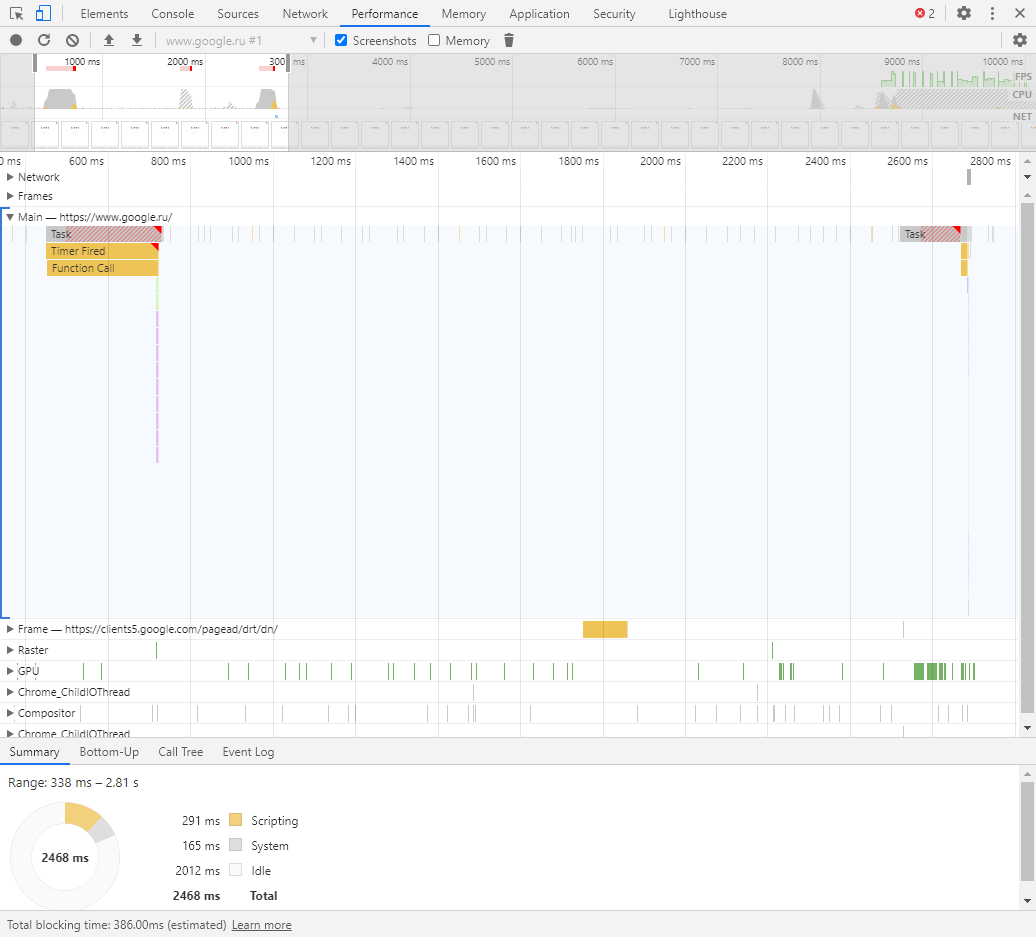
Панель отображает таймлайн использования сети, выполнения JavaScript-кода и загрузки памяти. После первоначального построения графиков будут доступны подробные данные о выполнении кода и всем жизненном цикле страницы.
Memory
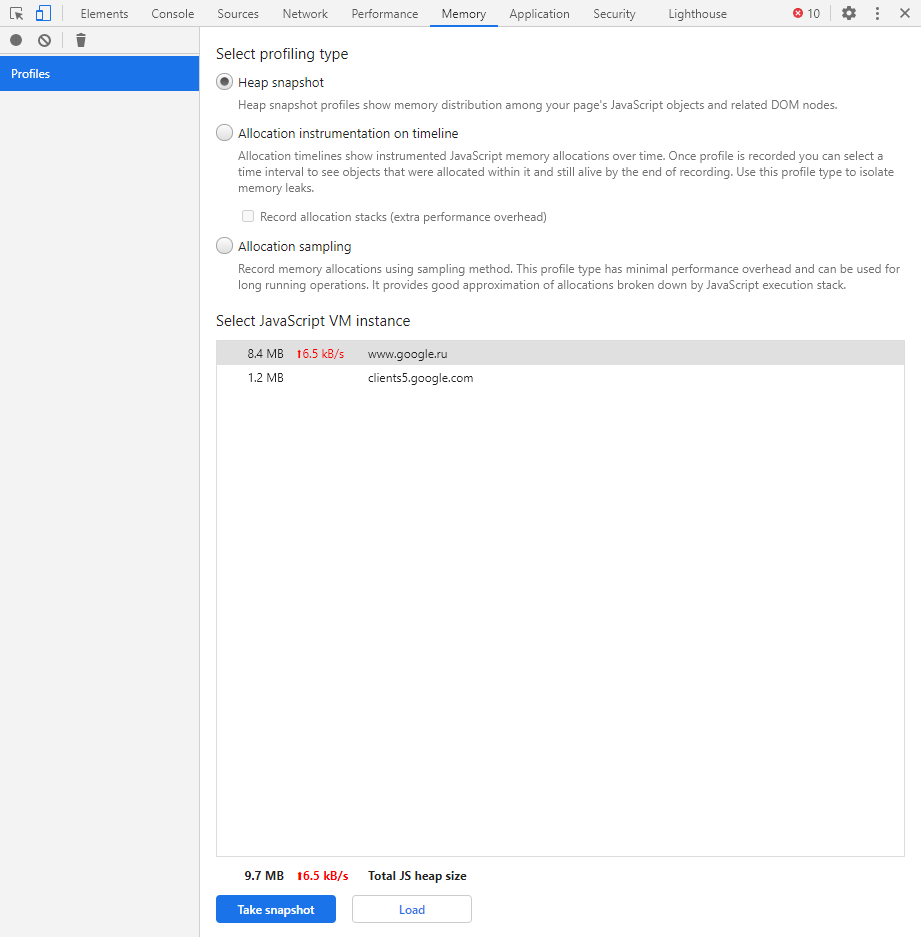
В этой вкладке можно отслеживать использование памяти веб-приложением или страницей. Мы можем узнать, где тратится много ресурсов – эту информацию в последующем можно использовать для оптимизации кода.
Application
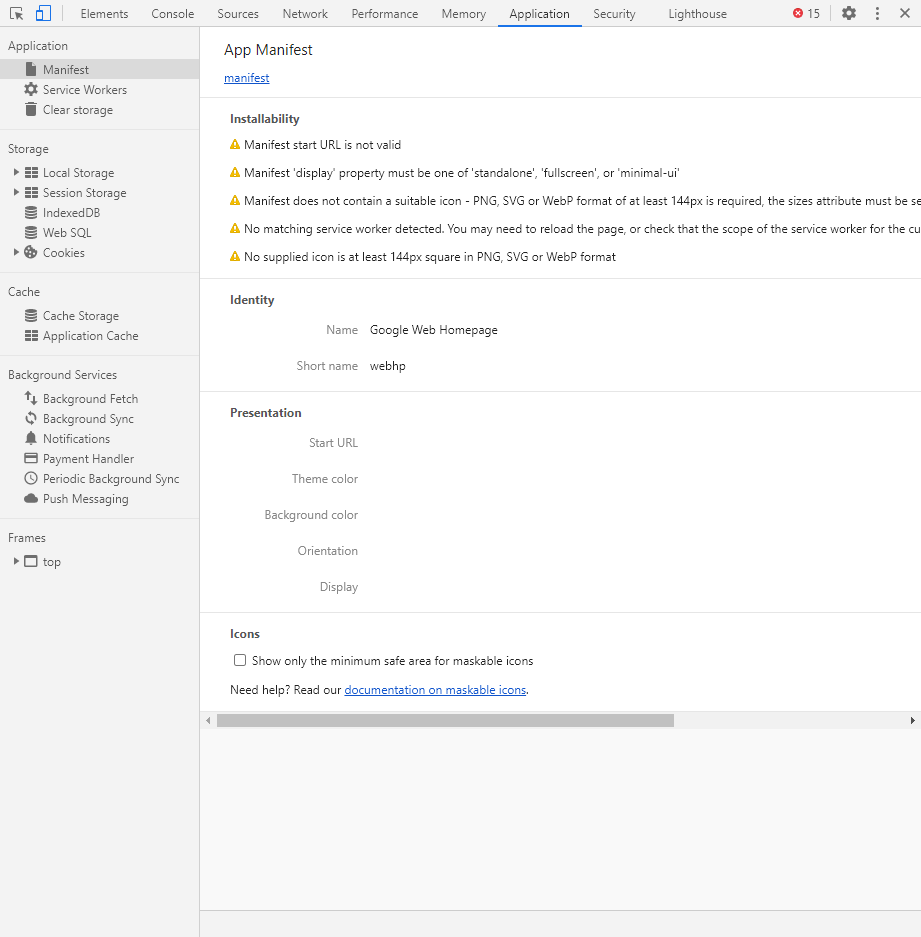
Данный раздел позволяет инспектировать и очищать все загруженные ресурсы. Мы можем взаимодействовать с HTML5 Database, Local Storage, Cookies, AppCache и другими элементами.
Основная особенность опции – чистка куки. Если вам необходимо выполнить эту процедуру, то просто откройте в левой части раздел «Cookies» и нажмите справа на значок запрета. Куки для выбранной ссылки будут очищены.
Security
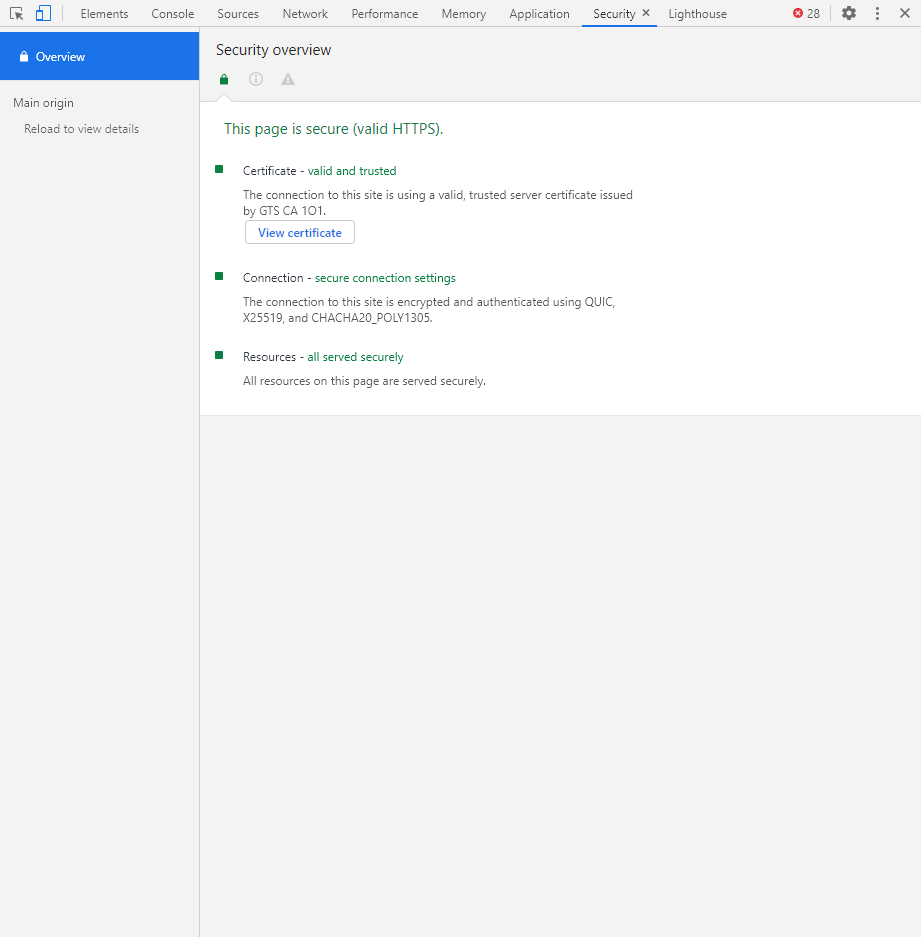
Раздел Security отображает информацию о безопасном протоколе. Если его нет, то будет сообщено, что данная страница является небезопасной. Кроме того, можно получить еще некоторые сведения о:
- проверке сертификата – подтвердил ли сайт свою подлинность TLS;
- tls-соединении – использует ли сайт современные безопасные протоколы;
- безопасности второстепенных источников.
Lighthouse
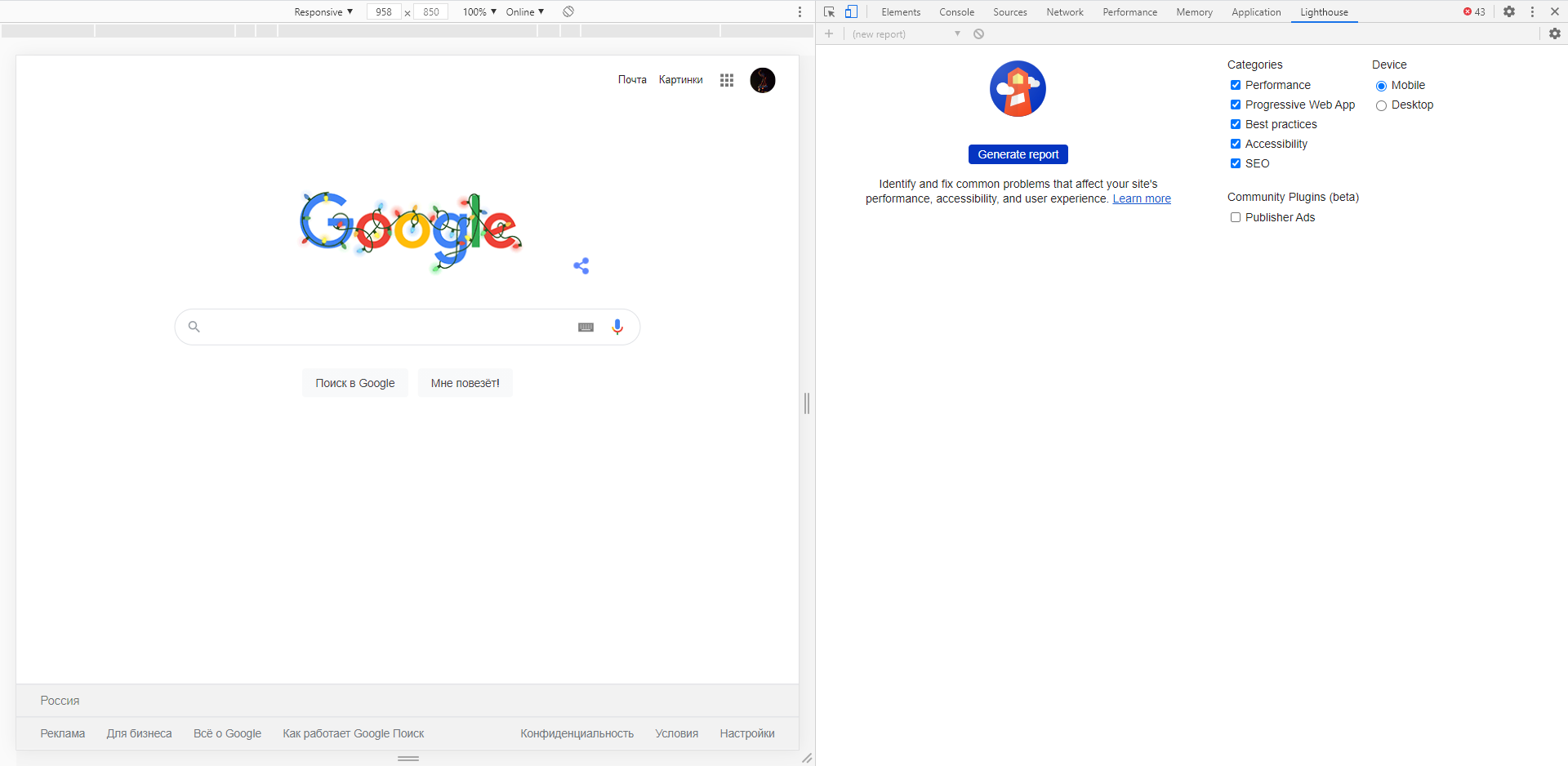
Последний раздел представляет собой инструмент аудита с открытым исходным кодом. Благодаря ему разработчики могут повысить производительность и доступность своих веб-сайтов.
Выявление основных ошибок
При возникновении возможных ошибок мы сразу будем об этом уведомлены во вкладке Console – в ней отобразится информация с красной строкой текста. Рассмотрим самые распространенные ошибки, которые могут возникать в Google Chrome, Safari и Internet Explorer:
- Uncaught TypeError: Cannot read property. Ошибка возникает в Хроме при вызове метода или чтении свойства для неопределенного объекта.
- TypeError: ‘undefined’ is not an object (evaluating). Аналогична предыдущей ошибке, но только в Safari.
- TypeError: null is not an object (evaluating). Возникает в Сафари при вызове метода или чтении свойства для нулевого объекта.
- (unknown): Script error. Обозначает ошибку скрипта.
- TypeError: Object doesn’t support property. Встречается в Internet Explorer – возникает при вызове определенного метода.
- TypeError: ‘undefined’ is not a function. Указывает на неопределенную функцию (в Chrome).
- Uncaught RangeError: Maximum call stack. Ошибка в Chrome, означающая превышение максимального размера стека.
- TypeError: Cannot read property ‘length’. Невозможно прочитать свойство.
- Uncaught TypeError: Cannot set property. Возникает, когда скрипт не может получить доступ к неопределенной переменной.
- ReferenceError: event is not defined. Обозначает невозможность получения доступа к переменной, не входящей в текущую область.
Устранение основных и прочих ошибок может быть проблематично. Если вы считаете, что они сильно мешают производительности вашего сайта, то рекомендуем поискать информацию о них в официальной документации браузера либо на тематических форумах.
Заключение
Иногда консоль пригождается не только верстальщикам – она бывает полезна для самых простых действий. Например, чтобы посмотреть мобильную версию, скачать картинку либо узнать используемый шрифт на сайте. В общем, применять консольное окно можно в различных ситуациях – как для просмотра содержимого сайта, так и для анализа потребления памяти.
Изучайте и находите свои применения этому инструменту – он может многое. Удачи!
Когда код попадает в продакшн, программист выпускает во внешний мир, вместе с полезным функционалом, ещё и ошибки. Вполне возможно, что они, например, на некоем сайте, будут иногда приводить к мелким сбоям, которые спишут на самые разные причины, так и не докопавшись до сути. Знающему своё дело разработчику хорошо бы предусмотреть какой-то механизм, благодаря которому он сможет встретиться со своими ошибками, выслушать их рассказ о тех приключениях, которые им пришлось пережить, и, в результате, их исправить.

Сегодня мы хотим поделиться с вами переводом статьи программиста Дэвида Гилбертсона, в которой он рассказывает о разработанной им экспериментальной системе, позволяющей отслеживать и воспроизводить ошибки в веб-проектах, написанных на React. Полагаем, подобный подход можно перенести и в другие среды, но обо всём по порядку.
Подходы к сбору сведений об ошибках
Возможно, вы пользуетесь такой вот простой системой сбора сведений об ошибках в веб-проектах (прошу не кидаться в меня камнями за следующий пример):
window.onerror = err => fetch(`/errors/${err}`);
Для того, чтобы посмотреть на отчёты по ошибкам, достаточно попросить дружественного айтишника дать вам файл со всеми записями о страницах 404, начинающимися с /errors, и вот оно — счастье.
Однако, тот «код», который вы при таком подходе получите, не поможет вам узнать, о том, где именно произошла ошибка. Вероятно, тут потребуется кое-что усовершенствовать и формировать сообщения об ошибках, в которых содержатся сведения о файле и о номере строки:
window.addEventListener('error', e => {
fetch('/errors', {
method: 'POST',
body: `${e.message} (in ${e.filename} ${e.lineno}:${e.colno})`,
});
});Этот код балансирует где-то на грани рамок приличия, однако, это пока всего лишь скелет чего-то более серьёзного. Если ошибка связана с конкретными данными, тогда вам сведения о номерах строк особой пользы не принесут.
Хорошо было бы, если бы у вас был полный отчёт о деятельности пользователя в момент возникновения ошибки, что даст возможность воссоздать ситуацию, в которой произошёл сбой. Например, нечто вроде этого:
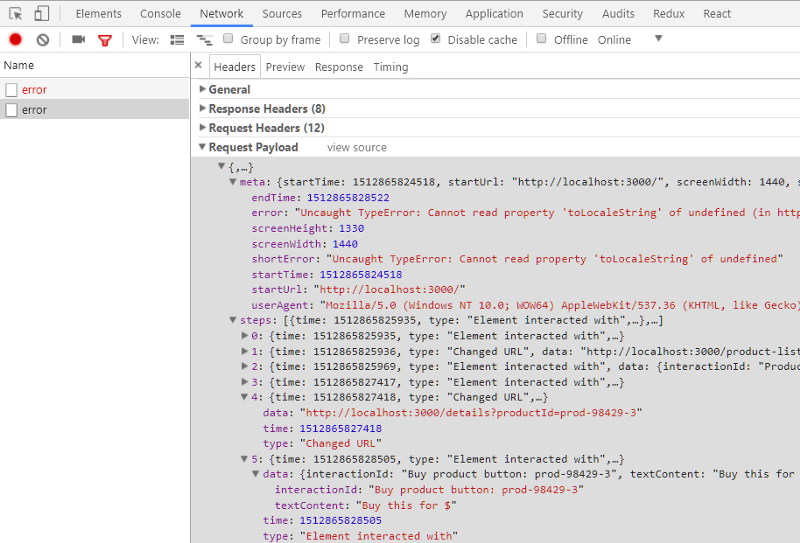
Отчёт о деятельности пользователя
Самое интересное здесь то, что пользователь перешёл к странице с подробными сведениями о товаре (шаг 4) и щёлкнул по кнопке покупки (на пятом, последнем шаге).
Я могу сразу предположить, что тут, вероятно, что-то подозрительное творится с данными для конкретного товара, поэтому я могу перейти по той же самой ссылке и нажать на кнопку покупки, на которой написано «Buy this for $».
Сделав это, я, конечно, увижу ту же самую ошибку. Этот конкретный товар не имеет цены, поэтому вызов toLocaleString и приводит к сбою. Перед нами — типичный недосмотр не слишком опытного разработчика.
Но что если порядок взаимодействия пользователя с сайтом гораздо сложнее? Может быть пользователь был на одной из многих вкладок, работа с которыми не отражается в URL, или ошибка возникла в ходе проверки данных из формы. Переход по ссылке и нажатие на кнопку такую ошибку не выявит.
Мне бы в такой ситуации хотелось иметь возможность воспроизвести все действия пользователя до момента возникновения ошибки. В идеале — просто щёлкая в ходе воспроизведения по некоей кнопке, на которой написано «Следующий шаг».
Вот как, если я не лишился воображения, я себе всё это представляю:
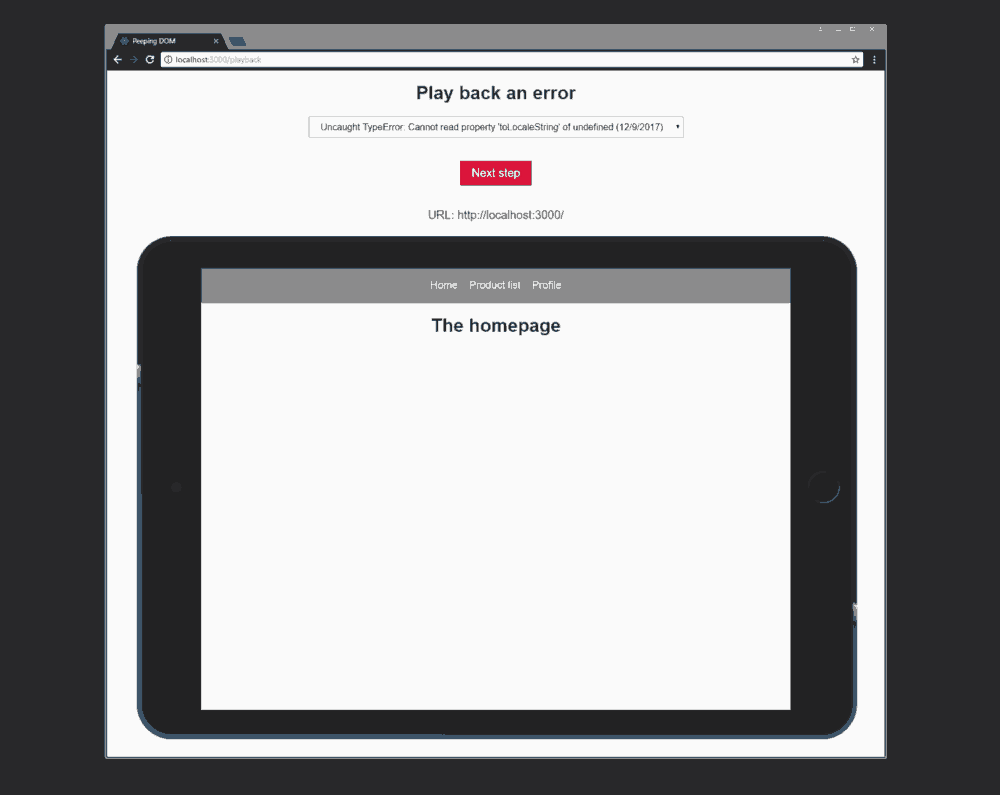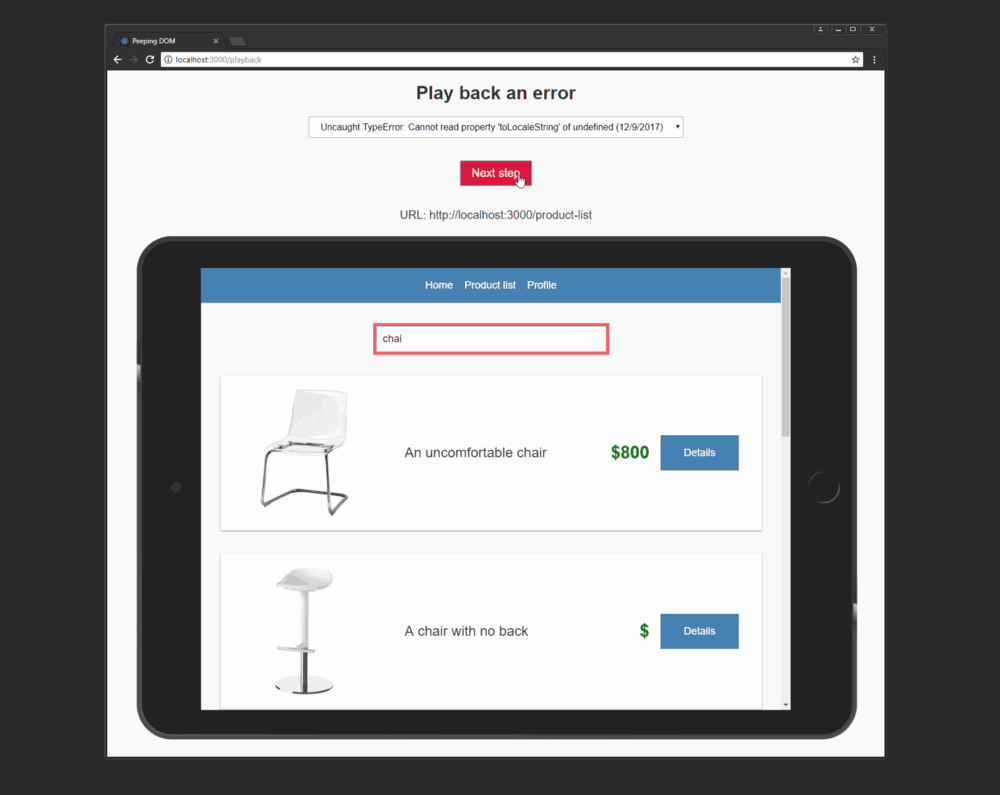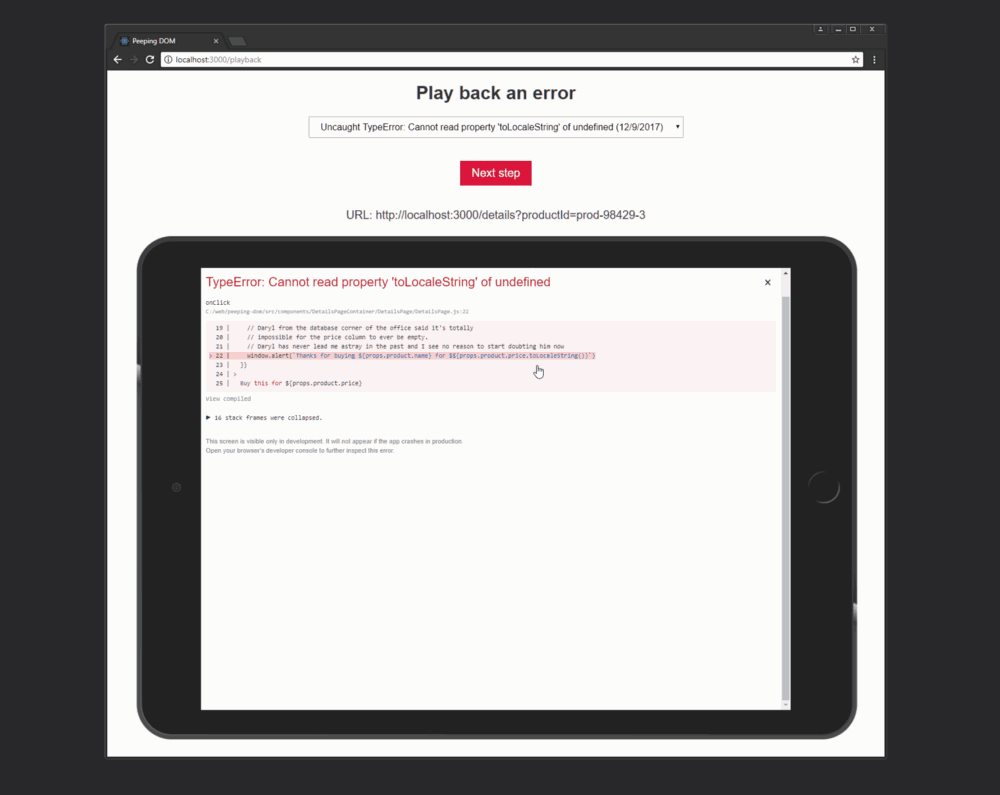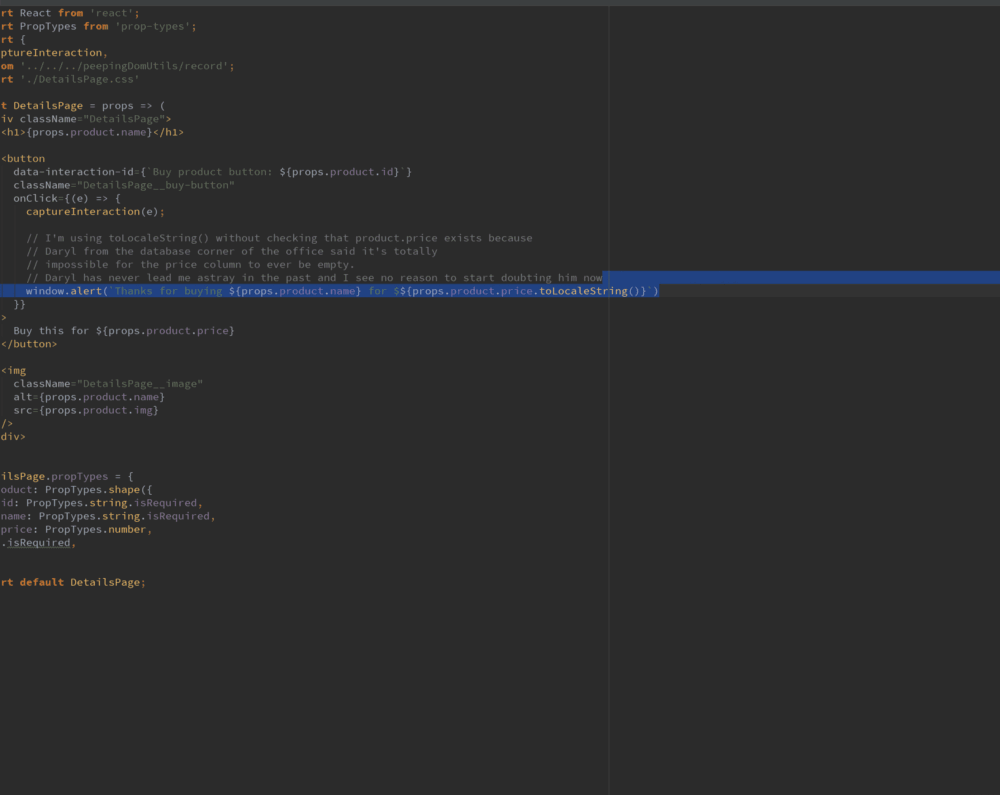
Воспроизведение действий пользователя путём наблюдения за DOM
Сведения об ошибке, выводимые на экран, и файл, открывающийся в моём редакторе — это заслуга Create React App.
Хочу отметить, что я действительно построил, в виде эксперимента, систему, которая позволяет провести нечто вроде «немодерируемого тестирование юзабилити». Я написал код, который отслеживает действия пользователя, а потом воспроизводит их, и затем спросил одного знающего человека, Джона, о том, что он обо всём этом думает. Он сказал, что это — дурацкая идея, но добавил, что мой код может быть полезен для воспроизведения ошибок.
Собственно, об этом я и хочу тут рассказать. Спасибо, Джон.
Ядро системы
Код, о котором идёт речь, можно найти здесь. Возможно, вам будет интереснее почитать его, чем мой рассказ. Ниже я показываю упрощённые версии функций и даю ссылки на их полные тексты.
У меня есть модуль, record.js, который содержит несколько функций для перехвата различных действий пользователя. Всё это попадает в объект journey, который можно передать на сервер при возникновении ошибки.
Во входной точке приложения я начинаю сбор сведений, вызвав функцию startRecording(), которая выглядит так:
const journey = {
meta: {},
steps: [],
};
export const startRecording = () => {
journey.meta.startTime = Date.now();
journey.meta.startUrl = document.location.href;
journey.meta.screenWidth = window.innerWidth;
journey.meta.screenHeight = window.innerHeight;
journey.meta.userAgent = navigator.userAgent;
};
При возникновении ошибки объект journey, например, можно отправить на сервер, для анализа. Для этого подключается соответствующий обработчик события:
window.addEventListener('error', sendErrorReport);
При этом функция sendErrorReport объявлена в том же модуле, что и объект journey:
export const sendErrorReport = (err) => {
journey.meta.endTime = Date.now();
journey.meta.error = `${err.message} (in ${err.filename} ${err.lineno}:${err.colno})`;
fetch('/error', {
method: 'POST',
body: JSON.stringify(journey)
})
.catch(console.error);
};
Кстати, если кто-то может объяснить, почему команда JSON.stringify(err) не даёт мне тело ошибки — это будет очень здорово.
Пока всё это особой пользы не приносит. Однако, сейчас у нас есть каркас, на котором можно построить всё остальное.
Если ваше приложение основано на состояниях (то есть, DOM выводится только основываясь на некоем главном состоянии), значит жить вам будет проще (и я рискну предположить, что вероятность того, что вы встретитесь с ошибками, будет меньше). При попытке воспроизвести ошибку вы можете просто воссоздать состояние, что, вероятно, даст вам возможность эту ошибку вызвать.
Если ваше приложение основано не на самых свежих технологиях, в нём применяются привязки и показ чего-либо, основанный непосредственно на том, как именно пользователь взаимодействует со страницей, тогда дело становится немного сложнее. Для воспроизведения ошибки вам понадобится воссоздать щелчки мышью, события, связанные с потерей и получением фокуса элементами, и, полагаю, нажатия на клавиши клавиатуры. Правда, затрудняюсь сказать, как быть, если пользователь вставляет нечто в поля из буфера обмена. Тут я только могу пожелать удачи в экспериментах.
Хочу признаться — я человек ленивый и эгоистичный, поэтому то, о чём буду рассказывать, будет нацелено на технологии, с которыми работаю я, а именно — на проекты, построенные на React и Redux.
Вот что именно я хочу перехватывать:
- Все диспетчеризованные действия (в результате можно будет включить «воспроизведение» изменений хранилища состояния).
- Изменения URL (а это значит — можно будет обновлять и URL).
- Щелчки по странице (это даст возможность своими глазами видеть, по каким именно кнопкам и ссылкам щёлкает пользователь).
- Скроллинг (это позволит узнать, что именно пользователь видел на странице в момент ошибки).
Перехват действий Redux
Вот код, который используется для перехвата и сохранения в объекте journey действий Redux:
export const captureActionMiddleware = () => next => action => {
journey.steps.push({
time: Date.now(),
type: INTERACTION_TYPES.REDUX_ACTION,
data: action,
});
return next(action);
};
В начале вы можете видеть конструкцию = () => next => action => {, которую просто невозможно не понять с первого взгляда. Если вы её, всё же, не поняли, почитайте это. Я, правда, вместо того, чтобы в это вникать, лучше потрачу время на что-нибудь поважнее, например, потренируюсь изображать счастливую улыбку, которая мне пригодится, когда меня будут поздравлять с днём рождения.
Самое важное, что нужно понимать в этом коде, заключается в той роли, которую он играет в проекте. А именно, он занят тем, что помещает «действия» Redux, по мере их выполнения, в объект journey.
Затем я применил вышеописанную функцию при создании хранилища Redux, передав ссылку на неё функции этого фреймворка applyMiddleware():
const store = createStore(
reducers,
applyMiddleware(captureActionMiddleware),
);
ReactDOM.render(
<Provider store={store}>
<App />
</Provider>,
document.getElementById('root')
);Запись изменений URL
Место, где выполняется перехват изменений URL зависит от того, как в приложении выполняется маршрутизация.
Роутер React не особенно хорошо помогает в деле определения изменений URL, поэтому придётся прибегнуть к такому подходу или, может быть, к такому. Хотелось бы мне, с помощью роутера React, просто задать обработчик для onRouteChange. Тут стоит отметить и то, что подобное нужно не только мне. Например, многие сталкиваются с необходимостью отправки сведений о просмотрах виртуальных страниц в Google Analytics.
Как бы там ни было, я предпочитаю писать собственную систему маршрутизации для большинства сайтов, так как это занимает всего-то минут семнадцать, а в итоге то, что получается, работает очень быстро.
Для перехвата изменений URL я подготовил следующую функцию, которая вызывается каждый раз, когда меняется URL:
export const captureCurrentUrl = () => {
journey.steps.push({
time: Date.now(),
type: INTERACTION_TYPES.URL_CHANGE,
data: document.location.href,
});
};
Я вызываю её в двух местах. Там же, где выполняю команду history.push() для обновления URL, и ещё в событии popstate, которое вызывается если пользователь нажимает кнопку Назад в браузере:
window.addEventListener('popstate', () => {
// ещё какие-то действия, необходимые для обработки события
captureCurrentUrl();
});Запись действий пользователя
Пожалуй, это самый «навязчивый» механизм перехвата информации о работе с сайтом, так как его приходится встраивать буквально повсюду. Я бы, если бы это зависело только от моих желаний, не заморачивался бы этим. Однако, мне встречались ошибки, которые, как я думал, невозможно воспроизвести, не зная о том, где именно щёлкнул пользователь.
В любом случае, задача это была интересная, поэтому тут я расскажу о её решении. При разработке на React я всегда пользуюсь компонентами <Link> и <Button>, в итоге разработка централизованной системы перехвата кликов достаточно проста. Взглянем на <Link>:
const Link = props => (
<a
href={props.to}
data-interaction-id={props.interactionId} // посмотрите сюда
onClick={(e) => {
e.preventDefault();
captureInteraction(e); // и сюда
historyManager.push(props.to);
}}
>
{props.children}
</a>
);
К тому, о чём мы тут говорим, относятся строки data-interaction-id={props.interactionId} и captureInteraction(e);.
Когда приходит время воспроизвести сессию, мне хотелось бы выделять то, по чему щёлкнул пользователь. Для этого мне нужен какой-то селектор. Могу с уверенностью заявить, что элементы, щелчки по которым я отслеживаю, имеют идентификаторы (id), но по какой-то причине, о которой я уже и не помню, я решил, что тут лучше подойдёт нечто, специально предназначенное для моей системы наблюдения за активностью пользователей.
Вот функция captureInteraction():
export const captureInteraction = (e) => {
journey.steps.push({
time: Date.now(),
type: INTERACTION_TYPES.ELEMENT_INTERACTION,
data: {
interactionId: e.target.dataset.interactionId,
textContent: e.target.textContent,
},
});
};Здесь можно найти её полный код, в котором проверяется, чтобы элемент, после воспроизведения сессии, можно было снова найти.
Как и при работе с другими сведениями, я собираю то, что мне нужно, а потом выполняю команду journey.steps.push.
Скроллинг
Мне осталось рассказать лишь о том, как я записываю данные о скроллинге для того, чтобы знать о том, какие именно части страниц просматривает пользователь. Если, например, страницу перемотали до самого низа и начали заполнять форму, воспроизведение этого без скроллинга особой пользы не принесёт.
Я собираю все последовательные события скроллинга в одно событие для того, чтобы не тратить ресурсы системы на запись множества мелких событий и использую Lodash, так как установка и очищение тайм-аутов в циклах мне не по душе.
const startScrollCapturing = () => {
function handleScroll() {
journey.steps.push({
type: INTERACTION_TYPES.SCROLL,
data: window.scrollY,
});
}
window.addEventListener('scroll', debounce(handleScroll, 200));
};В рабочей версии этого кода исключаются события, связанные со сплошным скроллингом.
Функция startScrollCapturing() вызывается при первом запуске приложения.
Дополнительные идеи
Вот небольшой список идей, не использованных в моём проекте. Возможно, вам они покажутся достойными реализации.
- Перехват нажатий на клавиши клавиатуры вроде
Escape,TabилиEnter. - Запись сведений об изменении размеров рабочего окна приложения (для тех случаев, когда важно воспроизведение происходящего с учётом позиции скроллинга).
- Вызов, в процессе воспроизведения, вместо перехвата позиции скроллинга, scrollIntoView() для элемента при его выделении.
- Создание копии
localStorageиcookies, если они влияют на поведение сайта. - И, наконец, пользователям обычно не очень-то нравится, если кто-то перехватывает и сохраняет всё, что они вводят, в особенности номера кредитных карт, пароли, и так далее. Поэтому очень важно, чтобы никто не знал о том, что во время работы с вашим сайтом его действия куда-то записываются (вы, конечно, понимаете, что я шучу).
Тут я сделал добавление после публикации исходной версии статьи. В противовес тому, что озвучено в нескольких комментариях, могу отметить, что методы, описанные в этом материале, не дают повода для дополнительного беспокойства о безопасности или о защите персональных данных. Если вы уже работаете с конфиденциальными данными пользователей, в таком случае любые требования, которые применяются к сбору и хранению таких данных, должны применяться и тогда, когда осуществляется подготовка и отправка отчётов об ошибках. Если вы, например, не выполняете автоматическое сохранение данных формы, не задавая пользователю соответствующий вопрос, значит вам не следует автоматически отправлять отчёты об ошибках, не спрашивая об этом пользователя. Если вы обязаны, перед отправкой персональных данных пользователя, получить от него согласие в виде галочки, установленной в специальном поле, то же самое нужно сделать и перед отправкой отчёта об ошибке. В отправке данных пользователя по адресу /signup, при его регистрации в системе, или по адресу /error, при возникновении ошибки, особой разницы нет. Самое главное, и там, и там, работать с данными правильно и законно.
Возможно, вы полагаете, что мы уже заканчиваем разговор, но к этому моменту мы лишь записали то, что пользователь делает на сайте. Сейчас займёмся самым интересным — воспроизведением записи.
Воспроизведение действий пользователя
Говоря о воспроизведения действий, выполненных пользователем при работе с сайтом, мне хотелось бы обсудить два вопроса:
- Интерфейс, который я используя для исследования причин ошибок путём воспроизведения действий пользователя.
- Механизм, встраиваемый в код сайта и позволяющий управлять им извне.
Интерфейс для воспроизведения действий пользователя
На странице для повторения действий пользователя используется iFrame, где открывается сайт, на котором и выполняется воспроизведение шагов, ранее записанных в объект journey.
Эта страница загружает сведения о сеансе работы, в ходе которого произошла ошибка, после чего отправляет каждый записанный шаг на сайт, что меняет его состояние, приводя в итоге к возникновению той же ошибки.
Когда я открываю данную страницу, то вижу простенький неприглядный интерфейс, после чего сайт загружается так, будто его просматривают на iPad (тут использована обычная картинка планшета, мне так больше нравится).
Вот та же самая анимированная картинка, которую я показывал в начале статьи. Здесь можно найти её код.
Процесс воспроизведения сеанса работы пользователя
Когда я нажимаю на кнопку Next step, iFrame отправляется сообщение с использованием конструкции iFrame.contentWindow.postMessage(nextStep, '*'). Тут есть одно исключение, связанное с изменениями URL. А именно, в подобной ситуации просто меняется свойство iFrame src. Для приложения это, фактически, является полным обновлением страницы, поэтому то, будет ли это работать, зависит от того, как вы переносите состояние приложения между страницами.
Если вы не знаете, то postMessage — это метод объекта Window, созданный для того, чтобы обеспечить взаимодействие между различными окнами (в данном случае это главное окно страницы и окно, открытое в iFrame).
Собственно говоря, это всё, что можно сказать о странице для воспроизведения действий пользователя.
Механизмы для управления сайтом извне
Механизм воспроизведения действий пользователя при работе с сайтом реализован в файле playback.js.
При запуске приложения я вызываю функцию, которая ожидает сообщений, которые попадают в хранилище и могут быть вызваны позже. Делается это только в режиме разработки.
const store = createStore(
// тут будут храниться сообщения
);
if (process.env.NODE_ENV === 'development') {
startListeningForPlayback(store);
}Вот где используется этот код.
Интересующая нас функция выглядит так:
export const startListeningForPlayback = (store) => {
window.addEventListener('message', (message) => {
switch (message.data.type) {
case INTERACTION_TYPES.REDUX_ACTION:
store.dispatch(message.data.data);
break;
case INTERACTION_TYPES.SCROLL:
window.scrollTo(0, message.data.data);
break;
case INTERACTION_TYPES.ELEMENT_INTERACTION:
highlightElement(message.data.data.interactionId);
break;
default:
// это - не то сообщение, которое нас интересует
return;
}
});
};Здесь можно найти её полную версию.
При работе с действиями Redux осуществляется их диспетчеризация в хранилище и больше ничего.
При воспроизведении скроллинга выполняется именно то, чего можно ожидать. В данной ситуации важно, чтобы страница имела правильную ширину. Можно заметить, взглянув в репозиторий проекта, что всё будет работать неправильно, если пользователь изменит размеры окна или, например, повернёт мобильное устройство, на котором смотрит сайт, но я думаю, что вызов scrollIntoView() — это, в любом случае, разумное решение.
Функция highlightElement() просто добавляет вокруг элемента рамку. Её код выглядит так:
function highlightElement(interactionId) {
const el = document.querySelector(`[data-interaction-id="${interactionId}"]`);
el.style.outline = '5px solid rgba(255, 0, 0, 0.67)';
setTimeout(() => {
el.style.outline = '';
}, 2000);
}Как обычно, вот — полный код этой функции.
Итоги
Мы рассмотрели простую систему сбора информации об ошибках в React/Redux приложениях. Полезна ли она на практике? Полагаю, это зависит от того, сколько ошибок проявляется в вашем проекте, и насколько сложным оказывается их поиск.
Возможно, вполне достаточно будет, при возникновении ошибки, записывать URL и сохранять сведения о ней, что позволит выявить источник проблемы. Или, возможно, система записи действий пользователя покажется вам удачной, а страница для воспроизведения сеанса работы с сайтом — нет. Если вы, например, сталкиваетесь с ошибками, которые, скажем, происходят лишь в Safari 9 на iOS, страница воспроизведения сеанса окажется бесполезной, так как с её помощью нельзя будет повторить ошибку.
Если говорить о разного рода исследованиях, об одном из которых я только что рассказал, то для меня момент истины настаёт, когда я задаю себе вопрос о том, готов ли я встроить то, что было создано в результате эксперимента, в один из моих реальных проектов. В данном случае ответ на этот вопрос отрицательный.
В любом случае, работа над системой перехвата и воспроизведения действий пользователя — это интересный опыт, который позволил мне узнать что-то новое. Кроме того, я полагаю, что однажды мне всё это может пригодиться, если надо будет по-быстрому внедрить систему мониторинга на каком-нибудь сайте.
Уважаемые читатели! Как вы обходитесь с ошибками? Предлагаем поучаствовать в опросе и поделиться вашими идеями по этому поводу.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Как вы работаете с ошибками в веб-приложениях?
26.47%
В моих проектах ошибок нет
18
7.35%
Использую систему собственной разработки
5
29.41%
Использую систему стороннего разработчика
20
Проголосовали 68 пользователей.
Воздержались 25 пользователей.
Плагин позволяет получать от посетителей сайта уведомления о ошибках на сайте.
Визуально плагин выглядит так:

Скрипты плагина расположены в директории /javascript/jquery.yapro.Spelling/
Чтобы подключить данный плагин нужно:
1. перед тегом вписать следующее:
<script language=»Javascript» type=»text/javascript» src=»/javascript/jquery.yapro.Spelling/latest.js»></script>
<script language=»Javascript» type=»text/javascript» src=»/javascript/jquery.yapro.alert/latest.js»></script>
<link href=»/javascript/jquery.yapro.alert/latest.css» type=»text/css» rel=»stylesheet»>
2. Завести себе jabber-аккаунт, например на сайте jabber.ru и вписать данные в файл /jabber.php
К примеру, если Вы завели аккаунт sergey@jabber.ru
$jabber = array(‘server’=>’jabber.ru’, ‘port’=>5222, ‘nikname’=>’sergey@jabber.ru’, ‘password’=>’sergey12345’, ‘toJID’=>’sergey@jabber.ru’);
3. Настроить sergey@jabber.ru у себя на ПК (в любом клиенте, например Miranda, QIP и т.п.)
Проверьте работу скрипта на сайте выделив текст и нажав Ctrl + Enter, после чего получите сообщение об ошибке прямо в чат-клиент.
4. В любое место страницы вставить HTML-код подсказки, что на сайте действует такой плагин:
<div style=»line-height:23px»>Ошибка в тексте? Выделите её мышкой и нажмите:
<span class=»keyButton»>Ctrl</span> + <span class=»keyButton»>Enter</span>
</div>
5. CSS-код советую применять такой:
SPAN.keyButton {
background:none repeat scroll 0 0 #ECECEC;
border-color:#FFFFFF #BBB8AB #BBB8AB #FFFFFF;
border-style:solid;
border-width:1px;
padding:1px 4px;
}
Оповещение на E-mail
Если Вы не хотите настраивать Jabber или у вас просто не получается его настроить, Вы можете получать оповещение на электронный ящик. Для этого просто создайте в директории /javascript/jquery.yapro.Spelling/ файл email.php в котором напишите свой E-mail, например так:
<?php
$email = ‘love@mal.ru’;
?>
По своему опыту скажу, очень много людей подсказывают ошибки на сайте, за это большое им спасибо.
12.01.2011 08:38

Богдан Василенко
SEO-специалист SE Ranking
По каждому запросу поисковая система подбирает релевантные результаты — страницы, подходящие по тематике, и ранжирует их, отображая в виде списка. Согласно исследованиям, 99 % пользователей находят информацию, отвечающую запросу, уже на первой странице выдачи и не пролистывают дальше. И чем выше позиция сайта в топ-10, тем больше посетителей она привлекает.
Перед тем, как распределить ресурсы в определенном порядке, поисковики оценивают их по ряду параметров. Это позволяет улучшить выдачу для пользователя, предоставляя наиболее полезные, удобные и авторитетные варианты.
В чём заключается оптимизация сайта?
Оптимизация сайта или SEO (Search Engine Optimization) представляет собой комплекс действий, цель которых — улучшить качество ресурса и адаптировать его с учётом рекомендаций поисковых систем.
SEO помогает попасть содержимому сайта в индекс, улучшить позиции его страниц при ранжировании и увеличить органический, то есть бесплатный трафик. Техническая оптимизация сайта — это важный этап SEO, направленный на работу с его внутренней частью, которая обычно скрыта от пользователей, но доступна для поисковых роботов.
Страницы представляют собой HTML-документы, и их отображение на экране — это результат воспроизведения браузером HTML-кода, от которого зависит не только внешний вид сайта, но и его производительность. Серверные файлы и внутренние настройки ресурса могут влиять на его сканирование и индексацию поисковиком.
SEO включает анализ технических параметров сайта, выявление проблем и их устранение. Это помогает повысить позиции при ранжировании, обойти конкурентов, увеличить посещаемость и прибыль.
Как обнаружить проблемы SEO на сайте?
Процесс оптимизации стоит начать с SEO-аудита — анализа сайта по самым разным критериям. Есть инструменты, выполняющие оценку определенных показателей, например, статус страниц, скорость загрузки, адаптивность для мобильных устройств и так далее. Альтернативный вариант — аудит сайта на платформе для SEO-специалистов.
Один из примеров — сервис SE Ranking, объединяющий в себе разные аналитические инструменты. Результатом SEO-анализа будет комплексный отчёт. Для запуска анализа сайта онлайн нужно создать проект, указать в настройках домен своего ресурса, и перейти в раздел «Анализ сайта». Одна из вкладок — «Отчёт об ошибках», где отображаются выявленные проблемы оптимизации.
Все параметры сайта разделены на блоки: «Безопасность», «Дублирование контента», «Скорость загрузки» и другие. При нажатии на любую из проблем появится её описание и рекомендации по исправлению. После технической SEO оптимизации и внесения корректировок следует повторно запустить аудит сайта. Увидеть, были ли устранены ошибки, можно колонке «Исправленные».
Ошибки технической оптимизации и способы их устранения
Фрагменты кода страниц, внутренние файлы и настройки сайта могут негативно влиять на его эффективность. Давайте разберём частые проблемы SEO и узнаем, как их исправить.
Отсутствие протокола HTTPS
Расширение HTTPS (HyperText Transfer Protocol Secure), которое является частью доменного имени, — это более надежная альтернатива протоколу соединения HTTP. Оно обеспечивает шифрование и сохранность данных пользователей. Сегодня многие браузеры блокируют переход по ссылке, начинающейся на HTTP, и отображают предупреждение на экране.
Поисковые системы учитывают безопасность соединения при ранжировании, и если сайт использует версию HTTP, это будет минусом не только для посетителей, но и для его позиций в выдаче.
Как исправить
Чтобы перевести ресурс на HTTPS, необходимо приобрести специальный сертификат и затем своевременно продлевать срок его действия. Настроить автоматическое перенаправление с HTTP-версии (редирект) можно в файле конфигурации .htaccess.
После перехода на безопасный протокол будет полезно выполнить аудит сайта и убедиться, что всё сделано правильно, а также при необходимости заменить неактуальные URL с HTTP среди внутренних ссылок (смешанный контент).
У сайта нет файла robots.txt
Документ robots размещают в корневой папке сайта. Его содержимое доступно по ссылке website.com/robots.txt. Этот файл представляет собой инструкцию для поисковых систем, какое содержимое ресурса следует сканировать, а какое нет. К нему роботы обращаются в первую очередь и затем начинают обход сайта.
Ограничение сканирования файлов и папок особенно актуально для экономии краулингового бюджета — общего количества URL, которое может просканировать робот на данном сайте. Если инструкция для краулеров отсутствует или составлена неправильно, это может привести к проблемам с отображением страниц в выдаче.
Как исправить
Создайте текстовый документ с названием robots в корневой папке сайта и с помощью директив пропишите внутри рекомендации по сканированию содержимого страниц и каталогов. В файле могут быть указаны виды роботов (user-agent), для которых действуют правила; ограничивающие и разрешающие команды (disallow, allow), а также ссылка на карту сайта (sitemap).
Проблемы с файлом Sitemap.xml
Карта сайта — это файл, содержащий список всех URL ресурса, которые должен обойти поисковый робот. Наличие sitemap.xml не является обязательным условием, для попадания страниц в индекс, но во многих случаях файл помогает поисковику их обнаружить.
Обработка XML Sitemap может быть затруднительна, если ее размер превышает 50 МБ или 50000 URL. Другая проблема — присутствие в карте страниц, закрытых для индексации метатегом noindex. При использовании канонических ссылок на сайте, выделяющих их похожих страниц основную, в файле sitemap должны быть указаны только приоритетные для индексации URL.
Как исправить
Если в карте сайта очень много URL и её объем превышает лимит, разделите файл на несколько меньших по размеру. XML Sitemap можно создавать не только для страниц, но и для изображений или видео. В файле robots.txt укажите ссылки на все карты сайта.
В случае, когда SEO-аудит выявил противоречия, — страницы в карте сайта, имеющие запрет индексации noindex в коде, их необходимо устранить. Также проследите, чтобы в Sitemap были указаны только канонические URL.
Дубли контента
Один из важных факторов, влияющих на ранжирование, — уникальность контента. Недопустимо не только копирование текстов у конкурентов, но и дублирование их внутри своего сайта. Это проблема особенно актуальна для больших ресурсов, например, интернет-магазинов, где описания к товарам имеют минимальные отличия.
Причиной, почему дубли страниц попадают в индекс, может быть отсутствие или неправильная настройка «зеркала» — редиректа между именем сайта с www и без. В этом случае поисковая система индексирует две идентичные страницы, например, www.website.com и website.com.
Также к проблеме дублей приводит копирование контента внутри сайта без настройки канонических ссылок, определяющих приоритетную для индексации страницу из похожих.
Как исправить
Настройте www-редиректы и проверьте с помощью SEO-аудита, не осталось ли на сайте дублей. При создании страниц с минимальными отличиями используйте канонические ссылки, чтобы указать роботу, какие из них индексировать. Чтобы не ввести в заблуждение поисковые системы, неканоническая страница должна содержать тег rel=”canonical” только для одного URL.
Страницы, отдающие код ошибки
Перед тем, как отобразить страницу на экране, браузер отправляет запрос серверу. Если URL доступен, у него будет успешный статус HTTP-состояния — 200 ОК. При возникновении проблем, когда сервер не может выполнить задачу, страница возвращает код ошибки 4ХХ или 5ХХ. Это приводит к таким негативным последствиям для сайта, как:
- Ухудшение поведенческих факторов. Если вместо запрошенной страницы пользователь видит сообщение об ошибке, например, «Page Not Found» или «Internal Server Error», он не может получить нужную информацию или завершить целевое действие.
- Исключение контента из индекса. Когда роботу долго не удается просканировать страницу, она может быть удалена из индекса поисковой системы.
- Расход краулингового бюджета. Роботы делают попытку просканировать URL, независимо от его статуса. Если на сайте много страниц с ошибками, происходит бессмысленный расход краулингового лимита.
Как исправить
После анализа сайта найдите страницы в статусе 4ХХ и 5ХХ и установите, в чём причина ошибки. Если страница была удалена, поисковая система через время исключит её из индекса. Ускорить этот процесс поможет инструмент удаления URL. Чтобы своевременно находить проблемные страницы, периодически повторяйте поиск проблем на сайте.
Некорректная настройка редиректов
Редирект — это переадресация в браузере с запрошенного URL на другой. Обычно его настраивают при смене адреса страницы и её удалении, перенаправляя пользователя на актуальную версию.
Преимущества редиректов в том, что они происходят автоматически и быстро. Их использование может быть полезно для SEO, когда нужно передать наработанный авторитет от исходной страницы к новой.
Но при настройке переадресаций нередко возникают такие проблемы, как:
- слишком длинная цепочка редиректов — чем больше в ней URL, тем позже отображается конечная страница;
- зацикленная (циклическая) переадресация, когда страница ссылается на себя или конечный URL содержит редирект на одно из предыдущих звеньев цепочки;
- в цепочке переадресаций есть неработающий, отдающий код ошибки URL;
- страниц с редиректами слишком много — это уменьшает краулинговый бюджет.
Как исправить
Проведите SEO-аудит сайта и найдите страницы со статусом 3ХХ. Если среди них есть цепочки редиректов, состоящие из трех и более URL, их нужно сократить до двух адресов — исходного и актуального. При выявлении зацикленных переадресаций необходимо откорректировать их последовательность. Страницы, имеющие статус ошибки 4ХХ или 5ХХ, нужно сделать доступными или удалить из цепочки.
Низкая скорость загрузки
Скорость отображения страниц — важный критерий удобства сайта, который поисковые системы учитывают при ранжировании. Если контент загружается слишком долго, пользователь может не дождаться и покинуть ресурс.
Google использует специальные показатели Core Web Vitals для оценки сайта, где о скорости говорят значения LCP (Largest Contentful Paint) и FID (First Input Delay). Рекомендуемая скорость загрузки основного контента (LCP) — до 2,5 секунд. Время отклика на взаимодействие с элементами страницы (FID) не должно превышать 0,1.
К распространённым факторам, негативно влияющим на скорость загрузки, относятся:
- объёмные по весу и размеру изображения;
- несжатый текстовый контент;
- большой вес HTML-кода и файлов, которые добавлены в него в виде ссылок.
Как исправить
Стремитесь к тому, чтобы вес HTML-страниц не превышал 2 МБ. Особое внимание стоит уделить изображениям сайта: выбирать правильное расширение файлов, сжимать их вес без потери качества с помощью специальных инструментов, уменьшать слишком крупные по размеру фотографии в графическом редакторе или через панель управления сайтом.
Также будет полезно настроить сжатие текстов. Благодаря заголовку Content-Encoding, сервер будет уменьшать размер передаваемых данных, и контент будет загружаться в браузере быстрее. Также полезно оптимизировать объем страницы, используя архивирование GZIP.
Не оптимизированы элементы JavaScript и CSS
Код JavaScript и CSS отвечает за внешний сайта. С помощью стилей CSS (Cascading Style Sheets) задают фон, размер и цвета блоков страницы, шрифты текста. Сценарии на языке JavaScript делают дизайн сайта динамичным.
Элементы CSS/JS важны для ресурса, но в то же время они увеличивают общий объём страниц. Файлы CSS, превышающие по размеру 150 KB, а JavaScript — 2 MB, могут негативно влиять на скорость загрузки.
Как исправить
Чтобы уменьшить размер и вес кода CSS и JavaScript, используют такие технологии, как сжатие, кэширование, минификация. SEO-аудит помогает определить, влияют ли CSS/JS-файлы на скорость сайта и какие методы оптимизации использованы.
Кэширование CSS/JS-элементов снижает нагрузку на сервер, поскольку в этом случае браузер загружает сохранённые в кэше копии контента и не воспроизводит страницы с нуля. Минификация кода, то есть удаление из него ненужных символов и комментариев, уменьшает исходный размер. Ещё один способ оптимизации таблиц стилей и скриптов — объединение нескольких файлов CSS и JavaScript в один.
Отсутствие мобильной оптимизации
Когда сайт подходит только для больших экранов и не оптимизирован для смартфонов, у посетителей возникают проблемы с его использованием. Это негативно отражается на поведенческих факторах и, как следствие, позициях при ранжировании.
Шрифт может оказаться слишком мелким для чтения. Если элементы интерфейса размещены слишком близко друг к другу, нажать на кнопку и ссылку проще только после увеличения фрагмента экрана. Нередко загруженная на смартфоне страница выходит за пределы экрана, и для просмотра контента приходится использовать нижнюю прокрутку.
О проблемах с настройками мобильной версии говорит отсутствие метатега viewport, отвечающего за адаптивность страницы под экраны разного формата, или его неправильное заполнение. Также о нестабильности элементов страницы во время загрузки информирует еще показатель производительности сайта Core Web Vitals — CLS (Cumulative Layout Shift). Его норма: 0,1.
Как исправить
В качестве альтернативы отдельной версии для мобильных устройств можно создать сайт с адаптивным дизайном. В этом случае его внешний вид, компоновка и величина блоков будет зависеть от размера экрана конкретного пользователя.
Обратите внимание, чтобы в HTML-коде страниц были метатеги viewport. При этом значение device-width не должно быть фиксированным, чтобы ширина страницы адаптировалась под размер ПК, планшета, смартфона.
Отсутствие alt-текста к изображениям
В HTML-коде страницы за визуальный контент отвечают теги <img>. Кроме ссылки на сам файл, тег может содержать альтернативный текст с описанием изображения и ключевыми словами.
Если атрибут alt — пустой, поисковику сложнее определить тематику фото. В итоге сайт не сможет привлекать дополнительный трафик из раздела «Картинки», где поисковая система отображает релевантные запросу изображения. Также текст alt отображается вместо фото, когда браузер не может его загрузить. Это особенно актуально для пользователей голосовыми помощниками и программами для чтения экрана.
Как исправить
Пропишите альтернативный текст к изображениям сайта. Это можно сделать после установки SEO-плагина к CMS, после чего в настройках к изображениям появятся специальные поля. Рекомендуем заполнить атрибут alt, используя несколько слов. Добавление ключевых фраз допустимо, но не стоит перегружать описание ими.
Заключение
Технические ошибки негативно влияют как на восприятие сайта пользователями, так и на позиции его страниц при ранжировании. Чтобы оптимизировать ресурс с учётом рекомендаций поисковых систем, нужно сначала провести SEO-аудит и определить внутренние проблемы. С этой задачей справляются платформы, выполняющие комплексный анализ сайта.
К частым проблемам оптимизации можно отнести:
- имя сайта с HTTP вместо безопасного расширения HTTPS;
- отсутствие или неправильное содержимое файлов robots.txt и sitemap.xml;
- медленная загрузка страниц;
- некорректное отображение сайта на смартфонах;
- большой вес файлов HTML, CSS, JS;
- дублированный контент;
- страницы с кодом ошибки 4ХХ, 5ХХ;
- неправильно настроенные редиректы;
- изображения без alt-текста.
Если вовремя находить и исправлять проблемы технической оптимизации сайта, это поможет в продвижении — его страницы будут занимать и сохранять высокие позиции при ранжировании.
Как проверить сайт на ошибки и их исправить
21.05.2018

Богдан Василенко
SEO-специалист SE Ranking
По каждому запросу поисковая система подбирает релевантные результаты — страницы, подходящие по тематике, и ранжирует их, отображая в виде списка. Согласно исследованиям, 99 % пользователей находят информацию, отвечающую запросу, уже на первой странице выдачи и не пролистывают дальше. И чем выше позиция сайта в топ-10, тем больше посетителей она привлекает.
Перед тем, как распределить ресурсы в определенном порядке, поисковики оценивают их по ряду параметров. Это позволяет улучшить выдачу для пользователя, предоставляя наиболее полезные, удобные и авторитетные варианты.
В чём заключается оптимизация сайта?
Оптимизация сайта или SEO (Search Engine Optimization) представляет собой комплекс действий, цель которых — улучшить качество ресурса и адаптировать его с учётом рекомендаций поисковых систем.
SEO помогает попасть содержимому сайта в индекс, улучшить позиции его страниц при ранжировании и увеличить органический, то есть бесплатный трафик. Техническая оптимизация сайта — это важный этап SEO, направленный на работу с его внутренней частью, которая обычно скрыта от пользователей, но доступна для поисковых роботов.
Страницы представляют собой HTML-документы, и их отображение на экране — это результат воспроизведения браузером HTML-кода, от которого зависит не только внешний вид сайта, но и его производительность. Серверные файлы и внутренние настройки ресурса могут влиять на его сканирование и индексацию поисковиком.
SEO включает анализ технических параметров сайта, выявление проблем и их устранение. Это помогает повысить позиции при ранжировании, обойти конкурентов, увеличить посещаемость и прибыль.
Как обнаружить проблемы SEO на сайте?
Процесс оптимизации стоит начать с SEO-аудита — анализа сайта по самым разным критериям. Есть инструменты, выполняющие оценку определенных показателей, например, статус страниц, скорость загрузки, адаптивность для мобильных устройств и так далее. Альтернативный вариант — аудит сайта на платформе для SEO-специалистов.
Один из примеров — сервис SE Ranking, объединяющий в себе разные аналитические инструменты. Результатом SEO-анализа будет комплексный отчёт. Для запуска анализа сайта онлайн нужно создать проект, указать в настройках домен своего ресурса, и перейти в раздел «Анализ сайта». Одна из вкладок — «Отчёт об ошибках», где отображаются выявленные проблемы оптимизации.
Все параметры сайта разделены на блоки: «Безопасность», «Дублирование контента», «Скорость загрузки» и другие. При нажатии на любую из проблем появится её описание и рекомендации по исправлению. После технической SEO оптимизации и внесения корректировок следует повторно запустить аудит сайта. Увидеть, были ли устранены ошибки, можно колонке «Исправленные».
Ошибки технической оптимизации и способы их устранения
Фрагменты кода страниц, внутренние файлы и настройки сайта могут негативно влиять на его эффективность. Давайте разберём частые проблемы SEO и узнаем, как их исправить.
Отсутствие протокола HTTPS
Расширение HTTPS (HyperText Transfer Protocol Secure), которое является частью доменного имени, — это более надежная альтернатива протоколу соединения HTTP. Оно обеспечивает шифрование и сохранность данных пользователей. Сегодня многие браузеры блокируют переход по ссылке, начинающейся на HTTP, и отображают предупреждение на экране.
Поисковые системы учитывают безопасность соединения при ранжировании, и если сайт использует версию HTTP, это будет минусом не только для посетителей, но и для его позиций в выдаче.
Как исправить
Чтобы перевести ресурс на HTTPS, необходимо приобрести специальный сертификат и затем своевременно продлевать срок его действия. Настроить автоматическое перенаправление с HTTP-версии (редирект) можно в файле конфигурации .htaccess.
После перехода на безопасный протокол будет полезно выполнить аудит сайта и убедиться, что всё сделано правильно, а также при необходимости заменить неактуальные URL с HTTP среди внутренних ссылок (смешанный контент).
У сайта нет файла robots.txt
Документ robots размещают в корневой папке сайта. Его содержимое доступно по ссылке website.com/robots.txt. Этот файл представляет собой инструкцию для поисковых систем, какое содержимое ресурса следует сканировать, а какое нет. К нему роботы обращаются в первую очередь и затем начинают обход сайта.
Ограничение сканирования файлов и папок особенно актуально для экономии краулингового бюджета — общего количества URL, которое может просканировать робот на данном сайте. Если инструкция для краулеров отсутствует или составлена неправильно, это может привести к проблемам с отображением страниц в выдаче.
Как исправить
Создайте текстовый документ с названием robots в корневой папке сайта и с помощью директив пропишите внутри рекомендации по сканированию содержимого страниц и каталогов. В файле могут быть указаны виды роботов (user-agent), для которых действуют правила; ограничивающие и разрешающие команды (disallow, allow), а также ссылка на карту сайта (sitemap).
Проблемы с файлом Sitemap.xml
Карта сайта — это файл, содержащий список всех URL ресурса, которые должен обойти поисковый робот. Наличие sitemap.xml не является обязательным условием, для попадания страниц в индекс, но во многих случаях файл помогает поисковику их обнаружить.
Обработка XML Sitemap может быть затруднительна, если ее размер превышает 50 МБ или 50000 URL. Другая проблема — присутствие в карте страниц, закрытых для индексации метатегом noindex. При использовании канонических ссылок на сайте, выделяющих их похожих страниц основную, в файле sitemap должны быть указаны только приоритетные для индексации URL.
Как исправить
Если в карте сайта очень много URL и её объем превышает лимит, разделите файл на несколько меньших по размеру. XML Sitemap можно создавать не только для страниц, но и для изображений или видео. В файле robots.txt укажите ссылки на все карты сайта.
В случае, когда SEO-аудит выявил противоречия, — страницы в карте сайта, имеющие запрет индексации noindex в коде, их необходимо устранить. Также проследите, чтобы в Sitemap были указаны только канонические URL.
Дубли контента
Один из важных факторов, влияющих на ранжирование, — уникальность контента. Недопустимо не только копирование текстов у конкурентов, но и дублирование их внутри своего сайта. Это проблема особенно актуальна для больших ресурсов, например, интернет-магазинов, где описания к товарам имеют минимальные отличия.
Причиной, почему дубли страниц попадают в индекс, может быть отсутствие или неправильная настройка «зеркала» — редиректа между именем сайта с www и без. В этом случае поисковая система индексирует две идентичные страницы, например, www.website.com и website.com.
Также к проблеме дублей приводит копирование контента внутри сайта без настройки канонических ссылок, определяющих приоритетную для индексации страницу из похожих.
Как исправить
Настройте www-редиректы и проверьте с помощью SEO-аудита, не осталось ли на сайте дублей. При создании страниц с минимальными отличиями используйте канонические ссылки, чтобы указать роботу, какие из них индексировать. Чтобы не ввести в заблуждение поисковые системы, неканоническая страница должна содержать тег rel=”canonical” только для одного URL.
Страницы, отдающие код ошибки
Перед тем, как отобразить страницу на экране, браузер отправляет запрос серверу. Если URL доступен, у него будет успешный статус HTTP-состояния — 200 ОК. При возникновении проблем, когда сервер не может выполнить задачу, страница возвращает код ошибки 4ХХ или 5ХХ. Это приводит к таким негативным последствиям для сайта, как:
- Ухудшение поведенческих факторов. Если вместо запрошенной страницы пользователь видит сообщение об ошибке, например, «Page Not Found» или «Internal Server Error», он не может получить нужную информацию или завершить целевое действие.
- Исключение контента из индекса. Когда роботу долго не удается просканировать страницу, она может быть удалена из индекса поисковой системы.
- Расход краулингового бюджета. Роботы делают попытку просканировать URL, независимо от его статуса. Если на сайте много страниц с ошибками, происходит бессмысленный расход краулингового лимита.
Как исправить
После анализа сайта найдите страницы в статусе 4ХХ и 5ХХ и установите, в чём причина ошибки. Если страница была удалена, поисковая система через время исключит её из индекса. Ускорить этот процесс поможет инструмент удаления URL. Чтобы своевременно находить проблемные страницы, периодически повторяйте поиск проблем на сайте.
Некорректная настройка редиректов
Редирект — это переадресация в браузере с запрошенного URL на другой. Обычно его настраивают при смене адреса страницы и её удалении, перенаправляя пользователя на актуальную версию.
Преимущества редиректов в том, что они происходят автоматически и быстро. Их использование может быть полезно для SEO, когда нужно передать наработанный авторитет от исходной страницы к новой.
Но при настройке переадресаций нередко возникают такие проблемы, как:
- слишком длинная цепочка редиректов — чем больше в ней URL, тем позже отображается конечная страница;
- зацикленная (циклическая) переадресация, когда страница ссылается на себя или конечный URL содержит редирект на одно из предыдущих звеньев цепочки;
- в цепочке переадресаций есть неработающий, отдающий код ошибки URL;
- страниц с редиректами слишком много — это уменьшает краулинговый бюджет.
Как исправить
Проведите SEO-аудит сайта и найдите страницы со статусом 3ХХ. Если среди них есть цепочки редиректов, состоящие из трех и более URL, их нужно сократить до двух адресов — исходного и актуального. При выявлении зацикленных переадресаций необходимо откорректировать их последовательность. Страницы, имеющие статус ошибки 4ХХ или 5ХХ, нужно сделать доступными или удалить из цепочки.
Низкая скорость загрузки
Скорость отображения страниц — важный критерий удобства сайта, который поисковые системы учитывают при ранжировании. Если контент загружается слишком долго, пользователь может не дождаться и покинуть ресурс.
Google использует специальные показатели Core Web Vitals для оценки сайта, где о скорости говорят значения LCP (Largest Contentful Paint) и FID (First Input Delay). Рекомендуемая скорость загрузки основного контента (LCP) — до 2,5 секунд. Время отклика на взаимодействие с элементами страницы (FID) не должно превышать 0,1.
К распространённым факторам, негативно влияющим на скорость загрузки, относятся:
- объёмные по весу и размеру изображения;
- несжатый текстовый контент;
- большой вес HTML-кода и файлов, которые добавлены в него в виде ссылок.
Как исправить
Стремитесь к тому, чтобы вес HTML-страниц не превышал 2 МБ. Особое внимание стоит уделить изображениям сайта: выбирать правильное расширение файлов, сжимать их вес без потери качества с помощью специальных инструментов, уменьшать слишком крупные по размеру фотографии в графическом редакторе или через панель управления сайтом.
Также будет полезно настроить сжатие текстов. Благодаря заголовку Content-Encoding, сервер будет уменьшать размер передаваемых данных, и контент будет загружаться в браузере быстрее. Также полезно оптимизировать объем страницы, используя архивирование GZIP.
Не оптимизированы элементы JavaScript и CSS
Код JavaScript и CSS отвечает за внешний сайта. С помощью стилей CSS (Cascading Style Sheets) задают фон, размер и цвета блоков страницы, шрифты текста. Сценарии на языке JavaScript делают дизайн сайта динамичным.
Элементы CSS/JS важны для ресурса, но в то же время они увеличивают общий объём страниц. Файлы CSS, превышающие по размеру 150 KB, а JavaScript — 2 MB, могут негативно влиять на скорость загрузки.
Как исправить
Чтобы уменьшить размер и вес кода CSS и JavaScript, используют такие технологии, как сжатие, кэширование, минификация. SEO-аудит помогает определить, влияют ли CSS/JS-файлы на скорость сайта и какие методы оптимизации использованы.
Кэширование CSS/JS-элементов снижает нагрузку на сервер, поскольку в этом случае браузер загружает сохранённые в кэше копии контента и не воспроизводит страницы с нуля. Минификация кода, то есть удаление из него ненужных символов и комментариев, уменьшает исходный размер. Ещё один способ оптимизации таблиц стилей и скриптов — объединение нескольких файлов CSS и JavaScript в один.
Отсутствие мобильной оптимизации
Когда сайт подходит только для больших экранов и не оптимизирован для смартфонов, у посетителей возникают проблемы с его использованием. Это негативно отражается на поведенческих факторах и, как следствие, позициях при ранжировании.
Шрифт может оказаться слишком мелким для чтения. Если элементы интерфейса размещены слишком близко друг к другу, нажать на кнопку и ссылку проще только после увеличения фрагмента экрана. Нередко загруженная на смартфоне страница выходит за пределы экрана, и для просмотра контента приходится использовать нижнюю прокрутку.
О проблемах с настройками мобильной версии говорит отсутствие метатега viewport, отвечающего за адаптивность страницы под экраны разного формата, или его неправильное заполнение. Также о нестабильности элементов страницы во время загрузки информирует еще показатель производительности сайта Core Web Vitals — CLS (Cumulative Layout Shift). Его норма: 0,1.
Как исправить
В качестве альтернативы отдельной версии для мобильных устройств можно создать сайт с адаптивным дизайном. В этом случае его внешний вид, компоновка и величина блоков будет зависеть от размера экрана конкретного пользователя.
Обратите внимание, чтобы в HTML-коде страниц были метатеги viewport. При этом значение device-width не должно быть фиксированным, чтобы ширина страницы адаптировалась под размер ПК, планшета, смартфона.
Отсутствие alt-текста к изображениям
В HTML-коде страницы за визуальный контент отвечают теги <img>. Кроме ссылки на сам файл, тег может содержать альтернативный текст с описанием изображения и ключевыми словами.
Если атрибут alt — пустой, поисковику сложнее определить тематику фото. В итоге сайт не сможет привлекать дополнительный трафик из раздела «Картинки», где поисковая система отображает релевантные запросу изображения. Также текст alt отображается вместо фото, когда браузер не может его загрузить. Это особенно актуально для пользователей голосовыми помощниками и программами для чтения экрана.
Как исправить
Пропишите альтернативный текст к изображениям сайта. Это можно сделать после установки SEO-плагина к CMS, после чего в настройках к изображениям появятся специальные поля. Рекомендуем заполнить атрибут alt, используя несколько слов. Добавление ключевых фраз допустимо, но не стоит перегружать описание ими.
Заключение
Технические ошибки негативно влияют как на восприятие сайта пользователями, так и на позиции его страниц при ранжировании. Чтобы оптимизировать ресурс с учётом рекомендаций поисковых систем, нужно сначала провести SEO-аудит и определить внутренние проблемы. С этой задачей справляются платформы, выполняющие комплексный анализ сайта.
К частым проблемам оптимизации можно отнести:
- имя сайта с HTTP вместо безопасного расширения HTTPS;
- отсутствие или неправильное содержимое файлов robots.txt и sitemap.xml;
- медленная загрузка страниц;
- некорректное отображение сайта на смартфонах;
- большой вес файлов HTML, CSS, JS;
- дублированный контент;
- страницы с кодом ошибки 4ХХ, 5ХХ;
- неправильно настроенные редиректы;
- изображения без alt-текста.
Если вовремя находить и исправлять проблемы технической оптимизации сайта, это поможет в продвижении — его страницы будут занимать и сохранять высокие позиции при ранжировании.










