
HTML Validator is a free online developer tool to validate HTML code against the W3C standards as known as HTML linter instantly. Supports partial HTML code validation.
You can either browse an HTML file, fetch HTML code from a URL, or paste HTML code manually, and then click the validate button. The results will be displayed accordingly when the process is done.
Basically, there are two types of result messages: warning and error
Warning — A suggestion to fix your HTML code. For instance, an HTML attribute that can be omitted.
Error — An error in your HTML code that’s against the W3C standards. You’re encouraged to fix it.
Each message comes with a line number and excerpt code indicating where a warning or an error is located.
Optionally, you can partially validate HTML code by enabling the fragment option so that the HTML code will be treated as part of an HTML document instead of a full one.
Loading…
Текст успешно скопирован!
Предварительная валидация
Онлайн HTML валидатор (HTML validator) является сервисом, который бесплатно анализирует html код web страниц на наличие ошибок. Валидатор HTML проводит верификацию согласно существующим стандартам. Большинство сайтов написаны с использованием языков разметки HTML5 или XHTML. Они должны содержать правильную разметку, которая обеспечит высокое качество веб-страниц, их быструю и полную индексацию. W3C валидатор HTML поможет вам найти отсутствующие или некорректные теги HTML в ваших документах. Валидация HTML является одним из основных факторов, влияющих на качество поисковой индексации в Яндекс и Google. W3C validator делает полный отчет по ошибкам в HTML коде. Он выполняет анализ сайта для оценки качества разметки в соответствии с действующими стандартами. Помогая вам проверить валидность кода HTML, выявить и исправить ошибки.
2018/06/10
Марат
55
0
html |
Иногда, бывает такое, что достаточно нехватки закрывающего тега либо наоборот лишний тег просочился, то ваша страница превращается в что-то непонятное и кривое!
Об оишибке синтаксиса в html
- Что такое Ошибка синтаксиса html
- Исключение ошибок синтаксиса на вашем сайте
- Как найти синтаксическую ошибку в коде html
- Бесплатный совет -> о синтаксических ошибках
Что такое Ошибка синтаксиса html
Предполагается, что синтаксис в html — это строгий синтаксис! Вообще, по идее браузер сам должен достроить дерево html(Честно признаюсь, что никогда не задумывался над всеми этими механизмами!), если не хватает какого-то из тегов! Но… кривизна все равно вылазит… знаю по собственному сайту! Как только вот прямо здесь я вставлю открывающийся тег -> div весь правый сайд бар улетит в футер… 
смайлы
Единственное и главное правило не создавать ошибки синтаксиса в html — писать правильный код!
Так…
Что же такое Ошибка синтаксиса html
Ошибка синтаксиса html — это нарушение правильной структуры каркаса html дерева, от которой визуальное представление сайта на мониторе выглядит не так, как оно задумывалось!
Исключение ошибок синтаксиса на вашем сайте
Для того, чтобы исключить появление ошибок синтаксиса на вашем сайте вам потребуется всего-то правильно сделать html + каркас сайта — да это звучит банально ничего умнее я не придумал, потому, что это азы! И без этого вы просто обречены каждый раз мучаться с ошибками синтаксиса в html!
Да я буду много сейчас говорить банальностей и эти банальности нужно делать, как ходить на работу, любить своих родителей и своих детей и т.д. можно продолжать до бесконечности!
Создавайте структуру сайта именно деревом, когда вложенный тег отодвигается на шаг вправо.
<div class=»div1″>
<div class=»div2″>
<div class=»div3″>
<div class=»div4″>
данные
</div>
</div>
</div>
</div>
Старайтесь делать код html простым(краткость сестра таланта), чтобы его можно было понять! Избегайте применять по поводу и без повода лишние теги!
Делайте ваш код html блоками, например блок menu -> блок futer
Добавляете описание в началу блока и и к концу блока:
<!— menu —>
здесь menu
<!— /menu —>
<!— futer —>
здесь futer
<!— /futer —>
Как найти синтаксическую ошибку в коде html
К сожалению, в html в отличии к примеру от php не указывается на какой строке ошибка! Но нам все равно от этого не легче и нам нужно
найти синтаксическую ошибку в коде html — как это сделать!?
Как я уже говорил, у вас должен быть html каркас создан по неким правилам, которые я немного озвучил выше!
Как раньше я искал синтаксическую ошибку в коде html!? Брал файл, в котором, есть основные блоки… удаляем блок меню… загружаем на сервер… смотрим пропала ошибка синтаксическая или нет… если пропала, то ошибка в блоке меню. Если нет, то меню возвращаем на место! Но и не забываем, что может быть сразу несколько ошибок…
Если в меню синтаксическая ошибка. не найдена идем в тело страницы… далее футер…и далее сайд бар… никто, ничего умнее еще не придумал…
Нашлась ошибка в блоке? … разбираем блок построчно! До тех пор, пока не найдем синтаксическую ошибку html!
Есть еще возможность проверять код в программах о которых вы знаете редакторы кода… Sublime + Notepad(не нравятся эти -> открываем поисковик ищем редактор кода…), открываем код html в этой программе и проверяем по тегам… если мы поставим мышку на один из тегов, то второй тег будет подсвечен аналогично, в sublime — это полоса снизу…
Нажмите, чтобы открыть в новом окне.

Бесплатный совет -> о синтаксических ошибках
Как я уже говорил и повторюсь! Делайте html код блоками!
Чем меньше тегов, тем лучше!
Длинный код, вас должен напрягать! Чем длиннее код, тем возможностей появления синтаксических ошибок и не только, возрастает!
Если у вас html и php перемешан и находится в разных файлах, то найти ошибку вообще будет сложно! Выделяйте html код в отдельный файл
Это… какие-то совсем простые советы, но я их говорю не просто так, а потому, что делаю это давно и у меня уже есть какие-то свои наработки и правила, которым я следую!
Выработайте свои правила и придерживайтесь их и у Вас больше никогда не будет синтаксических ошибок в html!
Не благодарите, но ссылкой можете поделиться!
COMMENTS+
BBcode
В этой статье мы рассмотрим, как с помощью сервиса Labrika обнаружить и исправить на сайте HTML-ошибки. Информация о таких ошибках будет полезна как для владельца веб-ресурса, который контролирует работу своего SEO-специалиста и хочет знать, какие нерешенные проблемы есть на сайте, так и для оптимизаторов, поскольку им нужно оперативно обнаружить и исправить все изъяны, мешающие продвижению ресурса.
HTML (от англ. HyperText Markup Language) — это язык гипертекстовой разметки, который применяется на каждой веб-странице в интернете и состоит из множества элементов (тегов). Как правило, ошибками в коде HTML являются незакрытые или дублированные элементы, неправильный порядок их расположения, неверные атрибуты или их отсутствие.
На примере ниже в коде страницы присутствует закрывающий тег ссылки </a> без открывающего тега <a>:

Для проверки валидности кода (то есть соответствия стандартам HTML) используются специальные инструменты. Они проверяют:
- Синтаксические ошибки: пропущенные символы, ошибки в написании тегов.
- Нарушения вложенности тэгов: незакрытые и неправильно закрытые теги. По правилам теги закрываются так же, как их открыли, только в обратном порядке.
- Соответствие кода указанному DTD (Document Type Definition): правильность названий тегов, вложенности, атрибутов. Наличие пользовательских тегов и атрибутов.
Как HTML-ошибки влияют на продвижение сайта?
Как отмечал представитель Google Джон Мюллер, валидность кода HTML не является прямым фактором ранжирования, однако критические ошибки в HTML мешают:
- сканированию сайта поисковыми ботами;
- определению структурированной разметки на странице;
- отображению на мобильных устройствах и кроссбраузерности.
В первую очередь наличие ошибок в коде HTML может привести к тому, что часть контента страницы не будет проиндексирована.
О том, что следует использовать действительный HTML, сказано в Рекомендациях Google для веб-мастеров. Среди авторитетных SEO-источников бытует мнение, что фильтр Google Panda может быть наложен на сайт за большое количество таких ошибок (отдельную статью об алгоритме Google Panda вы можете прочитать на нашем сайте).
Официальные источники Яндекса также сообщают, что подобного рода ошибки на сайте нежелательны, а верстка страниц должна соответствовать принятым стандартам.
Почему важно проверять наличие HTML-ошибок?
Ошибки в коде HTML могут быть критическими и несущественными, которые не ведут к серьезным потерям. Что касается критических, то одни из них отрицательно сказываются на функционировании сайта, а другие — на работе поисковых систем.
Современные браузеры автоматически исправляют 99% критических ошибок при загрузке сайта. Однако некоторые из них браузер исправить не может. Например, если тег <а> для создания ссылки не содержит адреса, то браузер не сможет определить, куда её направить. Или в теге <img> для размещения картинки не указан путь к ней, тогда браузер не сможет её подгрузить. Наличие таких ошибок в коде может привести к серьезным последствиям — например, не загрузятся фото товара или не будет работать корзина.
Поисковые системы также автоматически исправляют часть HTML-ошибок, но у них возникает следующая проблема: если браузеры в состоянии потратить несколько секунд на исправление ошибок, то у поисковых роботов нет такой возможности. Им приходится сканировать сотни миллиардов страниц ежемесячно, поэтому боты не могут тратить время на устранение всех ошибок. Некоторые из них поисковые системы игнорируют, а также могут не включать в индекс содержащие их страницы или проиндексировать только часть контента таких страниц.
Веб-мастера и пользователи просматривают сайты в браузере, где большая часть HTML-ошибок исправляется автоматически, и поэтому не придают им большого значения. Зачастую даже разработчики не исправляют элементарных грубых ошибок в разметке. Это приводит к тому, что критические для поисковых систем ошибки остаются на сайтах и могут стать причиной неправильной индексации страниц. В результате бюджеты на продвижение будут потрачены неэффективно, а источник проблемы так и остается неустановленным.
Как обнаружить HTML-ошибки с помощью сервиса Labrika
Labrika проверяет данные ошибки двумя способами:
- С помощью валидатора W3C, который проверяет наличие всех HTML-ошибок.
- С использованием валидатора Labrika «Критические ошибки HTML». Он устанавливает только те ошибки, которые могут повлиять на сбор данных поисковыми системами или привести к некорректному отображению сайта и нарушениям в его работе. определяет порядка 15 видов таких ошибок.
Отчет » Критические ошибки HTML» вы сможете найти в левом боковом меню в разделе «Технический аудит».
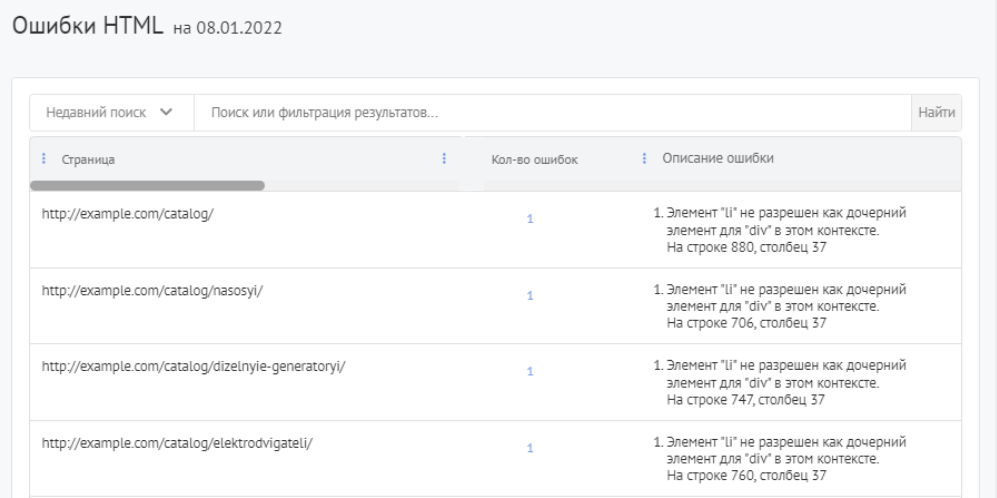
Актуальные данные в отчете вы сможете увидеть после запуска проверки сайта.
Отчет показывает:
- Страницы, которые содержат критические ошибки HTML.
- Количество и описание критических HTML-ошибок на данной странице.
При клике по их числу осуществляется переадресация на валидатор W3C, в котором вы сможете найти подробную информацию обо всех имеющихся в коде страницы ошибках.
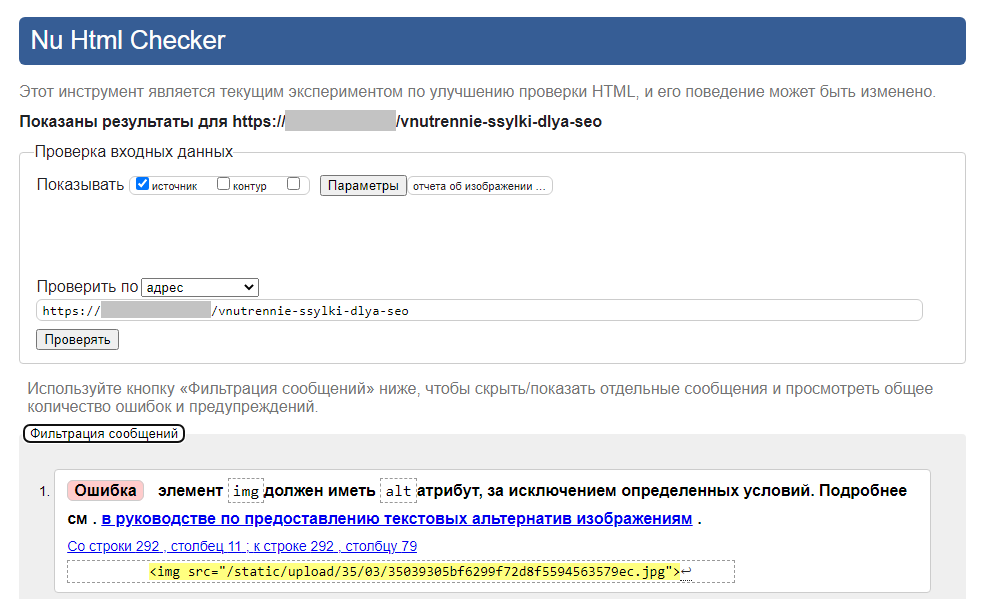
Как исправлять HTML-ошибки?
Критические HTML-ошибки необходимо исправлять в первую очередь, так как поисковые системы могут отреагировать на них отрицательно. Влияние прочих ошибок на продвижение в поиске не доказано.
Если для исправления ошибок требуется передать их список специалисту по верстке, с помощью кнопок в правой части страницы отчета вы можете скачать его данные в формате таблицы Excel или поделиться ссылкой на отчет по HTML-ошибкам с другими пользователями.

После нажатия на значок ссылки появится следующее всплывающее окно:
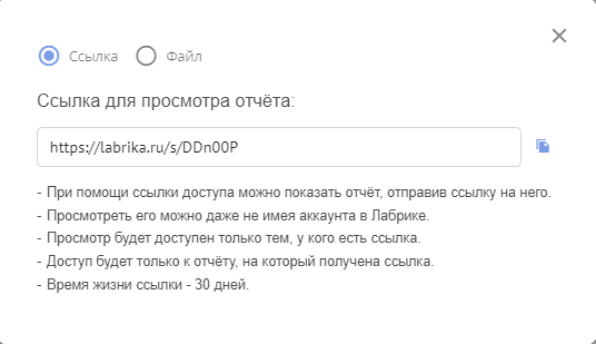
Кнопка, которая расположена справа от ссылки, позволяет скопировать её в буфер обмена. Отчет по ссылке будет доступен даже тем, кто не имеет аккаунта в Labrika.
Для ускорения работы по исправлению HTML-ошибок можно воспользоваться редакторами, которые автоматически создают закрывающие теги для документов HTML (например, Bluefish, Notepad++).
Validates HTML files for compliance against the W3C standards and performs linting to assess code quality against best practices.
Find missing or unbalanced HTML tags in your documents, stray characters, duplicate IDs, missing or invalid attributes and other recommendations.
Supports HTML5, SVG 1.1, MathML 3.0, ITS 2.0, RDFa Lite 1.1. Implementation is based on Validator.Nu.