
Обновлено: 12.06.2023
Для оценки качества прогноза принято использовать такие характеристики как надёжность, точность, достоверность, ошибки прогноза.
Под надёжностью прогнозных расчётов понимается мера неопределённости поведения объекта прогнозирования во времени.
Достоверность прогноза определяется вероятностью осуществления прогноза для заданного варианта или доверительного интервала.
Точность прогноза характеризует интервальный разброс прогнозных траекторий при фиксированном уровне достоверности.
Ошибки прогноза представляют собой меру отклонения прогнозных оценок от реальных значений состояния прогнозируемого объекта.
Рис. 8. Факторы, влияющие на качество прогноза.
Качество исходной информации, в свою очередь, определяется:
— точностью экономических измерений;
— отсутствием ошибок согласования (данные ошибки возникают в тех случаях, когда исходная информация для проведения прогнозных расчётов подготавливается различными специалистами, использующими разные методологические подходы).
Погрешности, связанные с выбором модели прогноза, возникают в результате упрощения, несовершенства теоретических построений или неадекватности моделей прогнозируемым социально-экономическим процессам. Иногда для прогнозирования процессов, протекающих в нашей стране, используются модели разработанные зарубежными специалистами и хорошо себя зарекомендовавшие для прогнозирования аналогичных процессов в других странах. Однако следует помнить о том, что данные модели могут быть неадекватны социально-экономическим процессам, происходящим в нашей стране и их использование может привести к серьезным ошибкам и просчетам.
Наиболее часто на практике для анализа адекватности модели прогноза исследуемым социально-экономическим процессам используются абсолютные показатели, позволяющие количественно определить величину ошибки моделирования в единицах измерения прогнозируемого объекта. К ним относятся:
— абсолютная ошибка, определяемая как разность между фактическим значением показателя и его расчётным значением ;
— средняя абсолютная ошибка ;
Следует отметить, что абсолютные показатели малопригодны для сравнения и анализа точности моделирования разнородных объектов, так как их значения существенно зависят от масштаба измерения исследуемых явлений. В этих случаях используются относительные показатели:
— средняя относительная ошибка .
Прогнозирование численности населения с помощью методов скользящей средней, наименьших квадратов и экспоненциального сглаживания. Построение графика потребления электроэнергии, определения сезонных колебаний и поквартальный прогноз объема потребления.
| Рубрика | Экономико-математическое моделирование |
| Вид | задача |
| Язык | русский |
| Дата добавления | 30.12.2010 |
| Размер файла | 58,3 K |
Студенты, аспиранты, молодые ученые, использующие базу знаний в своей учебе и работе, будут вам очень благодарны.
Государственное образовательное учреждение
Высшего профессионального образования
Уральский государственный экономический университет
По дисциплине Прогнозирование национальной экономики
Задание 1. Имеются данные размера ввода в действие общей площади жилых домов в городе за 1989-1999 гг., тыс. м 2
2. Постройте график фактического и расчетных показателей.
3. Рассчитайте ошибки полученных прогнозов при использовании каждого метода.
4. Сравните результаты.
Скользящая средняя (n = 3):
Ввод в действие общей площади жилых домов, тыс. м 2 . Уt
Скользящая средняя m
Расчет средней относительной ошибки |Уф — Ур| Уф * 100
Рис. 1 График фактических (чёрная линия) и расчетных (серая линия) показателей. (Составлено по таблице 1)
Прогноз на 2000 г.: У2000=806,7+(652-865)/3=735,7
Прогноз на 2001 г.: У2001=750,9+(735,7-652)/3=778,8 и т.д. (Таблица 1).
Средняя относительная ошибка: ?=42,6/9=4,7
Метод экспоненциального сглаживания:
Значение параметра сглаживания: 2/(n+1)=2/(11+1)=0,2=0,17
Начальное значение Uo двумя способами:
1 способ (средняя арифметическая): Uo = 16262/11 = 1478,4
2 способ (принимаем первое значение базы прогноза): Uo = 2360
Ввод в действие общей площади жилых домов, тыс. м 2 .
Экспоненциально взвешенная средняя Ut
Расчет средней относительной ошибки
Рис. 2 График фактических и расчетных показателей экспоненциально взвешенных средних 1 и 2 способ. (Составлено по таблице 2, 3)
Экспоненциально взвешенная средняя для каждого года:
U1989 = 2360*0,17+(1-0,17) * 1478,4=1628,272 1 способ
U1989 = 2360*0,17+(1-0,17) * 2360=2360 2 способ
(Остальное приведено в таблице до 2009 года с целью прогноза на 2007, 2008 годы)
Средняя относительная ошибка:
? = 442,945295/11 = 40,27% (1 способ)
? = 563,561351/11 = 51,23% (2 способ)
прогнозирование экспоненциальный сглаживание
Задание 2. Имеются данные потребления электроэнергии в городе за 2003-2006 гг., млн. кВт·ч
1. Постройте график исходных данных и определите наличие сезонных колебаний.
2. Постройте прогноз объема потребления электроэнергии в городе на 2007-2008 гг. с разбивкой по кварталам.
3. Рассчитайте ошибки прогноза.
I 1 = 102,5714108
I 2 = 134,6464502
I 3 = 90,91831558
I 4 = 73,11296966
Средняя относительная ошибка: 297,09/16=18,57%
потребления электроэнергии в городе., млн. кВт*ч Уф
потребления электроэнергии в городе., млн. кВт*ч
Подобные документы
Использование принципа дисконтирования информации в методах статистического прогнозирования. Общая формула расчета экспоненциальной средней. Определение значения параметра сглаживания. Ретроспективный прогноз и средняя квадратическая ошибка отклонений.
реферат [9,8 K], добавлен 16.12.2011
Сущность социально-экономического прогнозирования. Роль сахара в жизни человека. Математический аппарат, используемый при прогнозировании потребления. Регрессионный анализ. Методы наименьших квадратов и моментов. Оценка качества моделей прогнозирования.
курсовая работа [1,5 M], добавлен 26.11.2012
Сущность, содержание и цели экономического прогнозирования. Классификация и обзор базовых методов прогнозирования спроса. Основные показатели динамики экономических процессов. Моделирование сезонных колебаний при использовании фиктивных переменных.
дипломная работа [372,5 K], добавлен 29.11.2014
Основные задачи и принципы экстраполяционного прогнозирования, его методы и модели. Экономическое прогнозирование доходов ООО «Уфа-Аттракцион» с помощью экстраполяционных методов. Анализ особенностей применения метода экспоненциального сглаживания Хольта.
курсовая работа [1,7 M], добавлен 21.02.2015
Планирование деятельности предприятия по производству продуктов питания. Прогнозирование объема продаж продукции на заданный период времени, построение графика изменения, используя метод трехчленной скользящей средней; расчет доверительных интервалов.
контрольная работа [668,5 K], добавлен 02.01.2012
Порядок и особенности расчета прогнозных значений урожайности озимой пшеницы в Волгоградский области. Общая характеристика основных методов прогнозирования — аналитического выравнивания, экспоненциального сглаживания, скользящих средних и рядов Фурье.
контрольная работа [2,3 M], добавлен 11.07.2010
Построение поля корреляции, оценка тесноты связи с помощью показателей корреляции и детерминации, адекватности линейной модели. Статистическая надёжность нелинейных моделей по критерию Фишера. Модель сезонных колебаний и расчёт прогнозных значений.
практическая работа [145,7 K], добавлен 13.05.2014


В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.

- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:

Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Работая с научными публикациями, сталкиваюсь с различными показателями ошибок прогнозирования временных рядов. Среди всех встречающихся оценок ошибки прогнозирования стоит отметить две, которые в настоящее время, являются самыми популярными: MAE и MAPE. Пусть ошибка есть разность:
,
где Z(t) – фактическое значение временного ряда, а – прогнозное.
Тогда формулы для оценок ошибки прогнозирования временных рядов для N отчетов можно записать в следующем виде.
MAPE – средняя абсолютная ошибка в процентах

.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка

.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
Кроме указанных иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
MSE – среднеквадратичная ошибка

.
RMSE – квадратный корень из среднеквадратичной ошибки

.
ME – средняя ошибка

.
SD – стандартное отклонение
Связь точности и ошибки прогнозирования
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE
Величину точности оценивать не принято, говоря о прогнозировании всегда оценивают, то есть определяют значение именно ошибки прогноза, то есть величину MAPE и/или MAE. Однако нужно понимать, что если MAPE = 5%, то точность прогнозирования = 95%. Говоря о высокой точности, мы всегда говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности.
При этом величина MAPE является количественной оценкой именно ошибки, и эта величина нам ясно говорит и о точности прогнозирования, исходя из приведенной выше простой формулы. Таким образом, оценивая ошибку, мы всегда оцениваем точность прогнозирования.
Читайте также:
- Аппаратурные методы вольтамперометрии реферат
- Организация самостоятельной деятельности детей реферат
- Реферат шахматы увлекательная игра
- Реферат на тему праздники
- Реферат женщины и насилие
17 авг. 2022 г.
читать 2 мин
Одной из наиболее распространенных метрик, используемых для измерения точности прогнозирования модели, является MAPE , что означает среднюю абсолютную ошибку в процентах .
Формула для расчета MAPE выглядит следующим образом:
MAPE = (1/n) * Σ(|факт – прогноз| / |факт|) * 100
куда:
- Σ — причудливый символ, означающий «сумма».
- n – размер выборки
- фактический – фактическое значение данных
- прогноз – прогнозируемое значение данных
MAPE обычно используется, потому что его легко интерпретировать и легко объяснить. Например, значение MAPE, равное 11,5%, означает, что средняя разница между прогнозируемым значением и фактическим значением составляет 11,5%.
Чем ниже значение MAPE, тем лучше модель способна прогнозировать значения. Например, модель с MAPE 2% более точна, чем модель с MAPE 10%.
Как рассчитать MAPE в Excel
Чтобы рассчитать MAPE в Excel, мы можем выполнить следующие шаги:
Шаг 1: Введите фактические значения и прогнозируемые значения в два отдельных столбца.
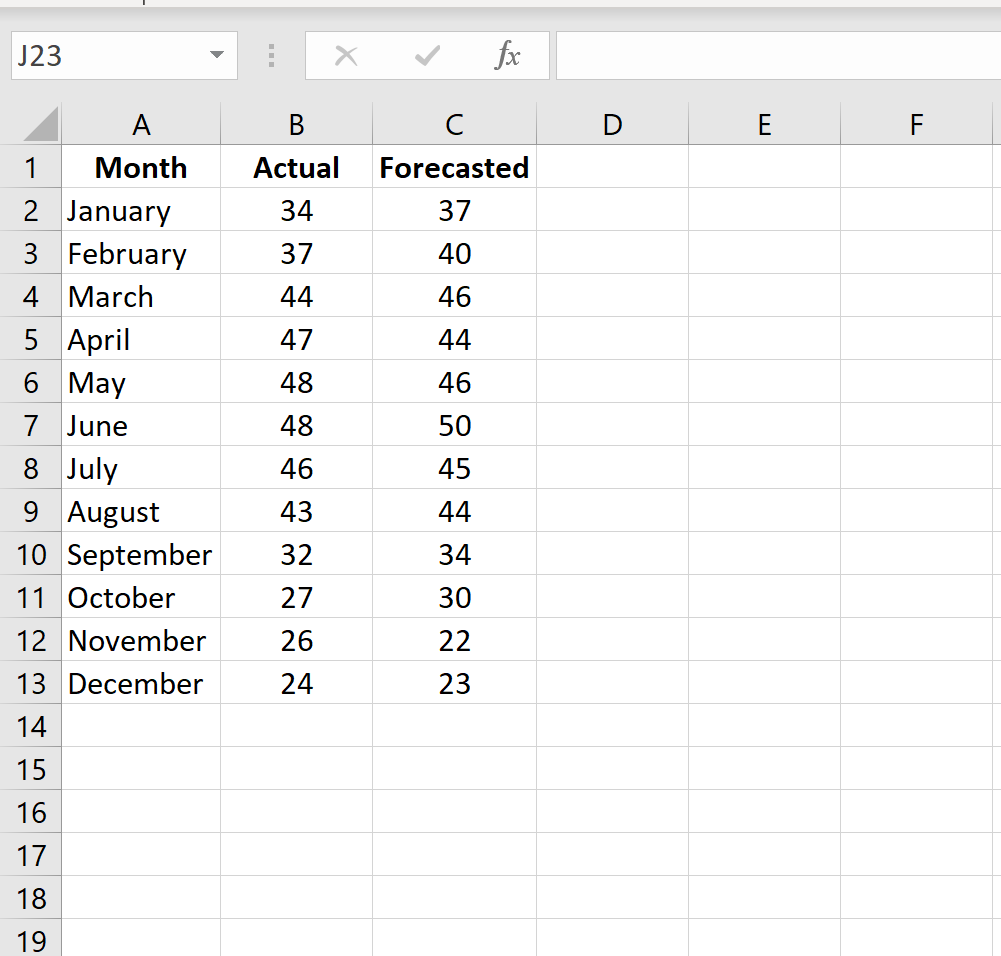
Шаг 2: Рассчитайте абсолютную процентную ошибку для каждой строки.
Напомним, что абсолютная процентная ошибка рассчитывается как: |фактический-прогноз| / |фактическое| * 100. Мы будем использовать эту формулу для расчета абсолютной процентной ошибки для каждой строки.
Столбец D отображает абсолютную процентную ошибку, а столбец E показывает формулу, которую мы использовали:
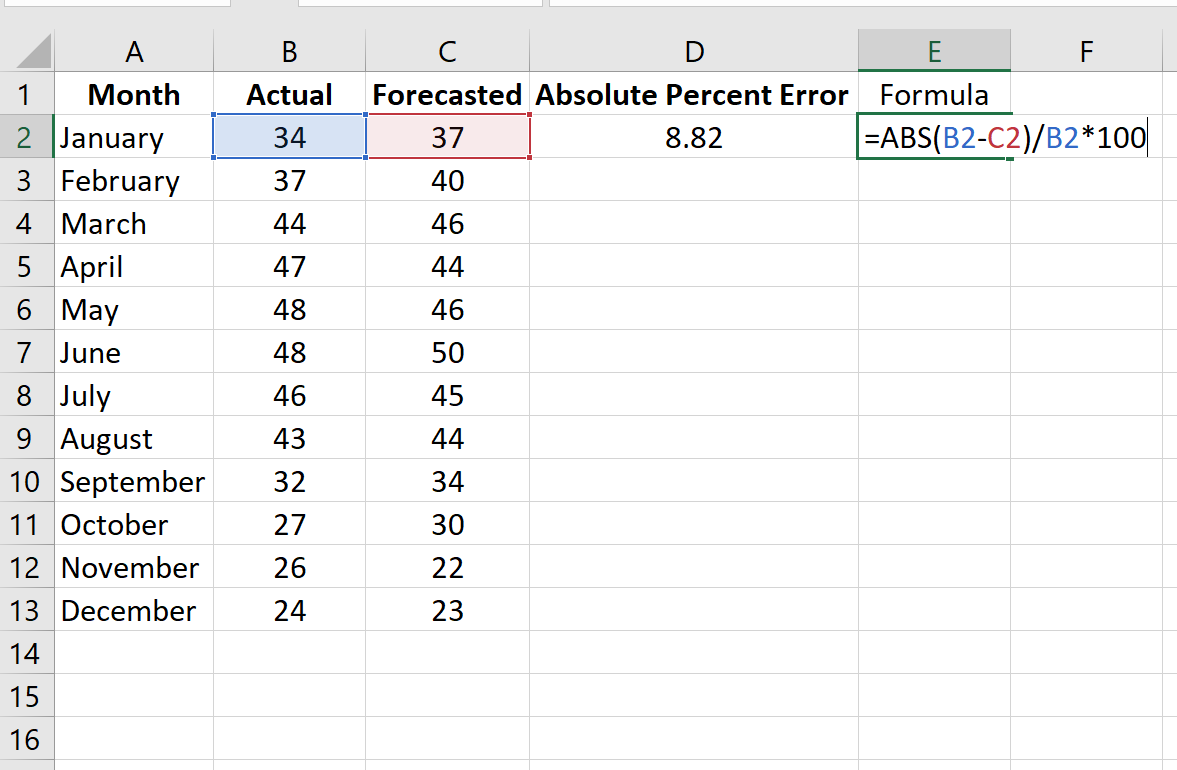
Повторим эту формулу для каждой строки:
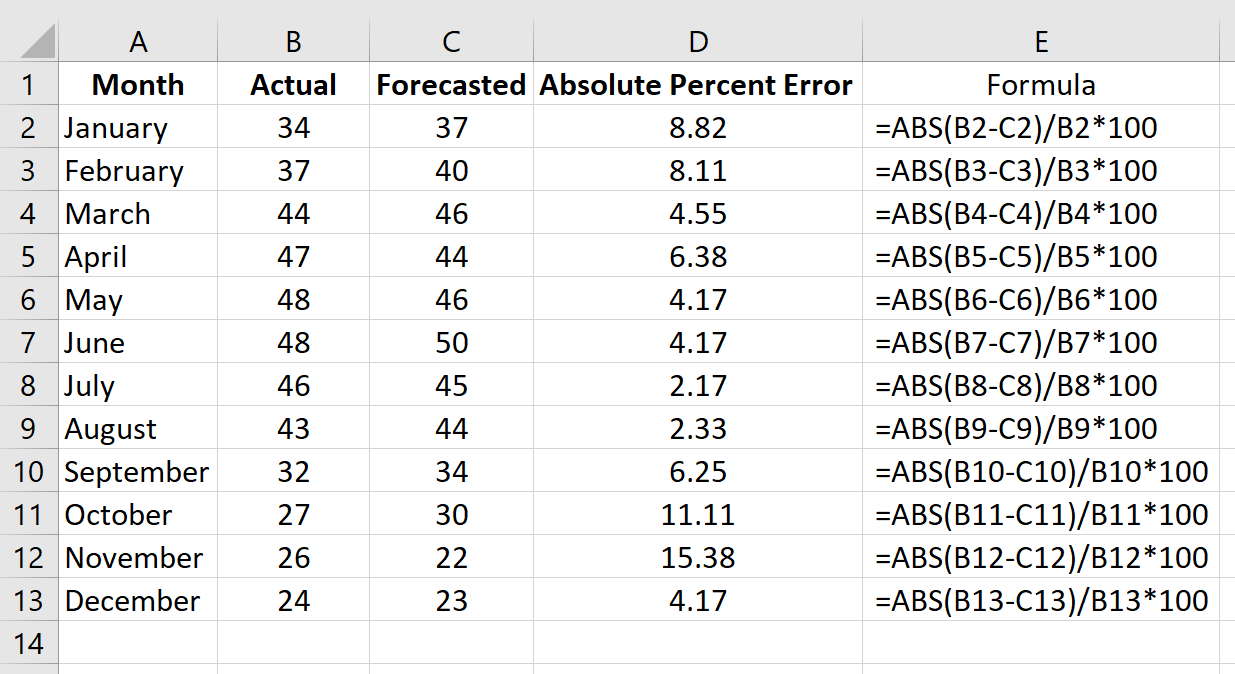
Шаг 3: Рассчитайте среднюю абсолютную ошибку в процентах.
Рассчитайте MAPE, просто найдя среднее значение в столбце D:
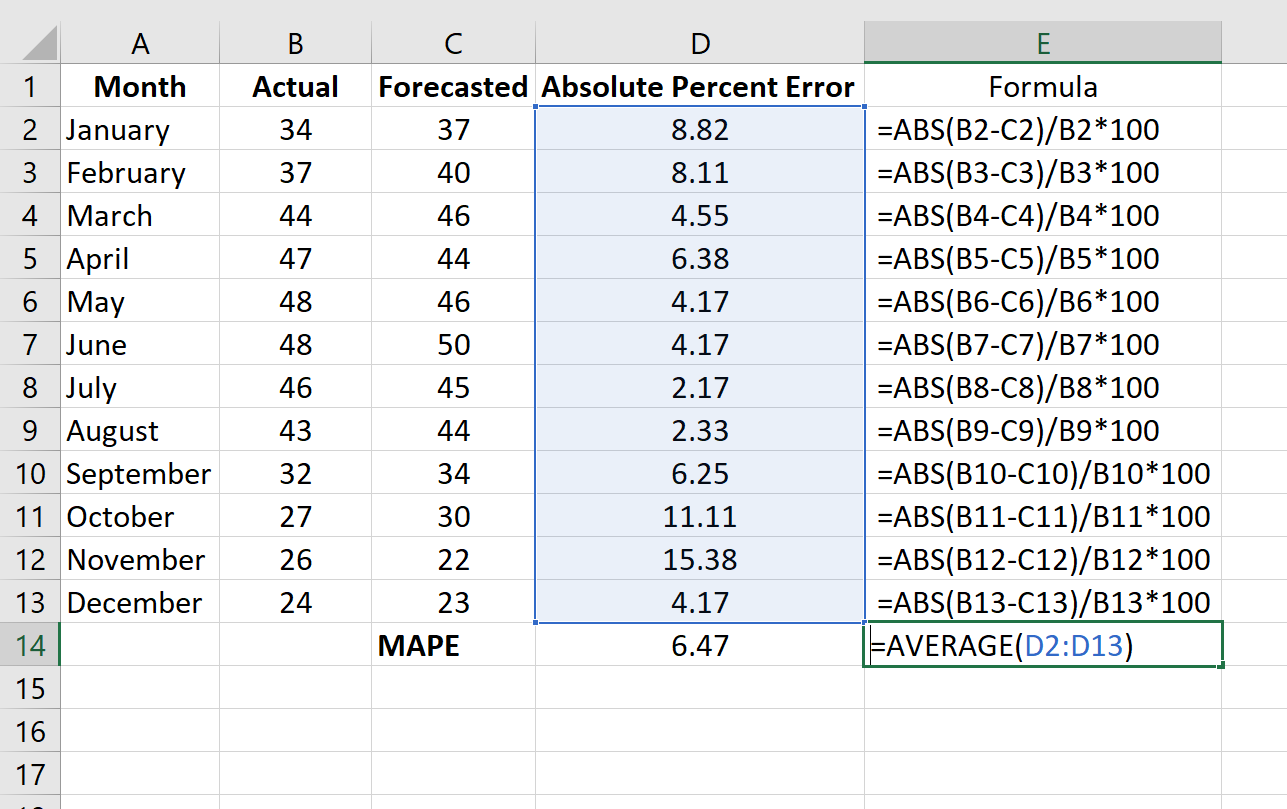
MAPE этой модели оказывается равным 6,47% .
Примечание по использованию MAPE
Хотя MAPE легко вычислить и легко интерпретировать, его использование имеет несколько потенциальных недостатков:
1. Поскольку формула для расчета абсолютной процентной ошибки |фактический-прогноз| / |фактическое| это означает, что он будет неопределенным, если какое-либо из фактических значений равно нулю.
2. MAPE не следует использовать с данными небольшого объема. Например, если фактический спрос на какой-либо товар равен 2, а прогноз равен 1, значение абсолютной процентной ошибки будет |2-1| / |2| = 50%, что создает впечатление, что ошибка прогноза довольно высока, несмотря на то, что прогноз отличается всего на одну единицу.
Другим распространенным способом измерения точности прогнозирования модели является MAD — среднее абсолютное отклонение. О том, как посчитать MAD в Excel, читайте здесь .
Дополнительные ресурсы
Что считается хорошей ценностью для MAPE?
Как рассчитать SMAPE в Excel
Как рассчитать MAE в Excel
Диагностика — это
исследование причин как отдельной,
индивидуальной ошибки, так и определенного
типа ошибок, допускаемых многими
учениками или даже большинством. В
процессе анализа ошибок и их причин
учитель опирается на признанные типологии
и использует свои, новые критерии. В
результате анализа строится методика
исправления и предупреждения ошибок,
прогнозируется дальнейшее обучение,
делаются определенные акценты в обучении,
выделяются приоритетные темы курса,
методы и приемы.
В диагностике
ошибок используются методы статистики,
накапливаются картотеки ошибок,
вычисляется частотность их по типам.
На основе анализа
и статистических обобщений установлено,
что в начальных классах самыми частотными
оказываются:
· Ошибки на
безударные гласные, преимущественно в
корне слова, на употребление звонких и
глухих согласных;
Ошибки на правописание
гласных и согласных в непроверяемых
словах (слабые позиции фонем);
· Ошибки от слабой
орфографической зоркости, от неумения
увидеть орфограмму.
Много ошибок на
жи, ши, ча, ща, чу, щу: у детей сильна
тенденция писать по произношению.
Нередки ошибки в написании безударных
падежных и личных окончаний имен
существительных, прилагательных и
глаголов, в слитном или раздельном
написании предлогов, приставок. Бывают
и такие случаи, когда статистика
показывает неожиданные «скачки»:
например, ошибки в употреблении заглавной
буквы.
Следующий этап
диагностики — выяснение причин массовых
ошибок. Так, в результате анализа
выясняется, что причины ошибок
квалифицируются так: первое место-
бедность или пассивность словаря,
мешающая быстро и правильно находить
проверочные слова; вторая — слабая
зоркость: ученик не видит орфограмму,
не слышит безударного гласного; третья
причина: ученик плохо разбирается в
морфемном составе слова, не обнаруживает
границ корня в слове.
У каждого типа
ошибок — свои причины, и очень важно,
чтобы сам ученик, допустивший ошибку,
понял ее причину. Это существенно
повышает осознание познавательного
процесса самим учеником.
2.4.3. Исправление и предупреждение ошибок
Согласно школьной
традиции, все допущенные учениками
ошибки должны быть исправлены. И не
только в тетради ученика, но и в его
сознании, в его памяти.
Наилучший способ
исправления — индивидуальная работа,
ибо сами ошибки носят личностный,
индивидуальный характер. Ученик и
учитель вместе проверяют написанное,
находят ошибку: учитель создает такую
ситуацию, в которой ученик сам находит
ошибку, определяет ее тип, анализирует
причины. Вместе они выясняют способы
проверки и исправления. К сожалению,
такая методика отнимает много времени.
Второй вариант:
учитель проверяет тетради, находит
ошибки, отмечает их, но сам исправляет
лишь в трудных случаях. В остальных —
ограничивается отметкой на полях
условными знаками, чтобы ученик сам
нашел и исправил ошибку. Операция
исправления завершается в индивидуальной
работе, помощь учителя — эпизодическая.
Известны приемы самостоятельного
письменного объяснения ошибки и ее
исправления. Оно завершается составлением
и записью предложения, в котором
употреблено слово, уже безошибочно
написанное.
Третий способ —
фронтальная проверка написанного общего
текста с устным комментированием всех
или выбранных (учителем) орфограмм. При
этом каждый ученик, прослушивая
комментарий, находит свои ошибки и
исправляет их при общем наблюдении
учителя. Метод удобен для такого класса,
где достигнут высокий уровень
самостоятельности и сознательности
учащихся.
Система исправления
ошибок предполагает ведение каждым
учеником (кроме безупречно пишущих)
своего личного учета ошибок в удобной
для него форме.
Для работы над
ошибками, свойственными большинство,
на одном из уроков выделяется фрагмент
продолжительностью в 20 минут на единую
тему: повторение грамматико-орфографической
темы, выполнение нескольких упражнений,
обсуждение конкретных ошибок, составление
примеров и задач самими учащимися и
т.п. Такой фрагмент урока проводится
обычно после контрольной работы или в
конце изучаемой темы по совокупности
накопившихся ошибок.
Уместны также
орфографические минутки в начале урока:
отчетливое проговаривание 5 — 10 слов, в
которых ранее многими допускались
ошибки. Практикуется также включение
таких слов в упражнения, выполняемые
устно или письменно на уроке. Также
ученику задаются вопросы по его прежним
ошибкам, когда он вызван отвечать к
столу учителя или к доске.
Полезна для
предупреждения ошибок работа с
орфографическим словарями, пользоваться
которыми учитель разрешает на всех
уроках; словари находятся в классе в
достаточном количестве.
Для слабых в
орфографии учащихся организуются
дополнительные групповые и индивидуальные
занятия во внеурочное время: письмо
дополнительных упражнений, диктантов,
повторение плохо усвоенных тем, приучение
детей к приемам самопроверки написанного.
К таким занятиям нередко привлекаются
хорошо успевающие дети.
Способы
предупредительной работы:
· На основе
диагностики допущенных ошибок выделение
«опасных» правил, слов, их сочетаний,
типов орфограмм;
· Соответствующие
акценты в процессе изучения курса:
усиление внимания к тем темам, вопросам,
которые труднее усваиваются;
· Отчетливое
выделение перечня трудных слов для
каждого класса, включение их в упражнения,
вывешивание плакатов с этими словами
и пр.;
· Поощрение тех
учащихся, которые сами преодолевают
свои ошибки;
· Одобрение каждого,
даже малого, успеха ученика, стремление
придать уверенности тем детям, которых
преследуют ошибки;
· Воспитание
орфографического оптимизма, создание
повышенной мотивации;
· Воспитание
уверенности учащихся в возможности
достижения высокого уровня грамотного
письма.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Ошибка прогнозирования: виды, формулы, примеры

Ошибка прогнозирования — это такая величина, которая показывает, как сильно прогнозное значение отклонилось от фактического. Она используется для расчета точности прогнозирования, что в свою очередь помогает нам оценивать как точно и корректно мы сформировали прогноз. В данной статье я расскажу про основные процентные «ошибки прогнозирования» с кратким описанием и формулой для расчета. А в конце статьи я приведу общий пример расчётов в Excel. Напомню, что в своих расчетах я в основном использую ошибку WAPE или MAD-Mean Ratio, о которой подробно я рассказал в статье про точность прогнозирования, здесь она также будет упомянута.
В каждой формуле буквой Ф обозначено фактическое значение, а буквой П — прогнозное. Каждая ошибка прогнозирования (кроме последней!), может использоваться для нахождения общей точности прогнозирования некоторого списка позиций, по типу того, что изображен ниже (либо для любого другого подобной детализации):
Алгоритм для нахождения любой из ошибок прогнозирования для такого списка примерно одинаковый: сначала находим ошибку прогнозирования по одной позиции, а затем рассчитываем общую. Итак, основные ошибки прогнозирования!
MPE — Mean Percent Error
MPE — средняя процентная ошибка прогнозирования. Основная проблема данной ошибки заключается в том, что в нестабильном числовом ряду с большими выбросами любое незначительное колебание факта или прогноза может значительно поменять показатель ошибки и, как следствие, точности прогнозирования. Помимо этого, ошибка является несимметричной: одинаковые отклонения в плюс и в минус по-разному влияют на показатель ошибки.

- Для каждой позиции рассчитывается ошибка прогноза (из факта вычитается прогноз) — Error
- Для каждой позиции рассчитывается процентная ошибка прогноза (ошибка прогноза делится на фактический показатель) — Percent Error
- Находится среднее арифметическое всех процентных ошибок прогноза (процентные ошибки суммируются и делятся на количество) — Mean Percent Error
MAPE — Mean Absolute Percent Error
MAPE — средняя абсолютная процентная ошибка прогнозирования. Основная проблема данной ошибки такая же, как и у MPE — нестабильность.

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта по модулю) — Absolute Error
- Для каждой позиции рассчитывается абсолютная процентная ошибка прогноза (абсолютная ошибка прогноза делится на фактический показатель) — Absolute Percent Error
- Находится среднее арифметическое всех абсолютных процентных ошибок прогноза (абсолютные процентные ошибки суммируются и делятся на количество) — Mean Absolute Percent Error
Вместо среднего арифметического всех абсолютных процентных ошибок прогноза можно использовать медиану числового ряда (MdAPE — Median Absolute Percent Error), она наиболее устойчива к выбросам.
WMAPE / MAD-Mean Ratio / WAPE — Weighted Absolute Percent Error
WAPE — взвешенная абсолютная процентная ошибка прогнозирования. Одна из «лучших ошибок» для расчета точности прогнозирования. Часто называется как MAD-Mean Ratio, то есть отношение MAD (Mean Absolute Deviation — среднее абсолютное отклонение/ошибка) к Mean (среднее арифметическое). После упрощения дроби получается искомая формула WAPE, которая очень проста в понимании:

- Для каждой позиции рассчитывается абсолютная ошибка прогноза (прогноз вычитается из факта, по модулю) — Absolute Error
- Находится сумма всех фактов по всем позициям (общий фактический объем)
- Сумма всех абсолютных ошибок делится на сумму всех фактов — WAPE
Данная ошибка прогнозирования является симметричной и наименее чувствительна к искажениям числового ряда.
Рекомендуется к использованию при расчете точности прогнозирования. Более подробно читать здесь.
RMSE (as %) / nRMSE — Root Mean Square Error
RMSE — среднеквадратичная ошибка прогнозирования. Примерно такая же проблема, как и в MPE и MAPE: так как каждое отклонение возводится в квадрат, любое небольшое отклонение может значительно повлиять на показатель ошибки. Стоит отметить, что существует также ошибка MSE, из которой RMSE как раз и получается путем извлечения корня. Но так как MSE дает расчетные единицы измерения в квадрате, то использовать данную ошибку будет немного неправильно.

- Для каждой позиции рассчитывается квадрат отклонений (разница между фактом и прогнозом, возведенная в квадрат) — Square Error
- Затем рассчитывается среднее арифметическое (сумма квадратов отклонений, деленное на количество) — MSE — Mean Square Error
- Извлекаем корень из полученного результат — RMSE
- Для перевода в процентную или в «нормализованную» среднеквадратичную ошибку необходимо:
- Разделить на разницу между максимальным и минимальным значением показателей
- Разделить на разницу между третьим и первым квартилем значений показателей
- Разделить на среднее арифметическое значений показателей (наиболее часто встречающийся вариант)
MASE — Mean Absolute Scaled Error
MASE — средняя абсолютная масштабированная ошибка прогнозирования. Согласно Википедии, является очень хорошим вариантом для расчета точности, так как сама ошибка не зависит от масштабов данных и является симметричной: то есть положительные и отрицательные отклонения от факта рассматриваются в равной степени.
Важно! Если предыдущие ошибки прогнозирования мы могли использовать для нахождения точности прогнозирования некого списка номенклатур, где каждой из которых соответствует фактическое и прогнозное значение (как было в примере в начале статьи), то данная ошибка для этого не предназначена: MASE используется для расчета точности прогнозирования одной единственной позиции, основываясь на предыдущих показателях факта и прогноза, и чем больше этих показателей, тем более точно мы сможем рассчитать показатель точности. Вероятно, из-за этого ошибка не получила широкого распространения.
Здесь данная формула представлена исключительно для ознакомления и не рекомендуется к использованию.
Суть формулы заключается в нахождении среднего арифметического всех масштабированных ошибок, что при упрощении даст нам следующую конечную формулу:

Также, хочу отметить, что существует ошибка RMMSE (Root Mean Square Scaled Error — Среднеквадратичная масштабированная ошибка), которая примерно похожа на MASE, с теми же преимуществами и недостатками.
Это основные ошибки прогнозирования, которые могут использоваться для расчета точности прогнозирования. Но не все! Их очень много и, возможно, чуть позже я добавлю еще немного информации о некоторых из них. А примеры расчетов уже описанных ошибок прогнозирования будут выложены через некоторое время, пока что я подготавливаю пример, ожидайте.
Об авторе

HeinzBr
Автор статей и создатель сайта SHTEM.RU
Анализировать опыт других — не стыдно. Напротив, это важно и необходимо в условиях растущей конкуренции. Улучшить свою деятельность, сравнивая себя с другими, — стратегия, которая работает. В статье расскажем, что такое бенчмарки, как определить ошибку и что она значит.
Бенчмаркинг как стратегия и опыт
Бенчмаркинг (от англ. «bench» — «уровень», «mark» — «отметка») — это способ анализа на основе «эталонных значений» (бенчмарков). Обычно это весь комплекс работ по оценке и сравнительному анализу.
Бенчмарки могут быть двух видов — средние и лучшие значения.
Первый вид: сравниваем себя с подобными
Бенчмарками выступает усредненная деятельность примерно таких же организаций или проектов. Ценность — понимание, где вы находитесь, каковы ваши результаты, по сравнению с другими подобными: много/мало; дорого/дешево; эффективно/нет; хорошо/плохо.
В качестве примера приведем американский сервис ImpactGenome, который проводит бенчмаркинг по затратам на достижение социального результата (cost per outcome).
Рассчитывается он так:

Такая усредненная оценка позволяют сравнить себя с другими, а донорам — выбирать наиболее эффективные программы.
Второй вид: ищем лучший опыт
Бенчмарки — это лучшие из лучших, образцы для подражания, эталон. Это может быть организация, которая является лидером в вашей сфере, вызывает восхищение, а, возможно, зависть. Не важно, в вашей сфере или в другом секторе, в России или в мире.
Соответственно, цель — найти такие бенчмарки под ваши задачи (организации, проекты, кампании, инициативы, практики, услуги, стратегии или процессы). Самого лучшего и прогрессивного в технологиях работы, фандрайзинге, оценке или коммуникациях. Изучить опыт победителя любого открытого конкурса в вашей сфере, взяв его годовой отчет — это и будет пример лучшего российского опыта. Такие бенчмарки — это кто-то успешный и опытный, обладающий гораздо большими ресурсами и готовностью к риску и инновациям, чем вы. Бенчмаркинг позволяет «подсматривать» успешные приемы работы и адаптировать их под свою деятельность; увидеть тренды — какие появляются новые идеи и услуги, а от чего начинают отказываться.
Зачем проводить бенчмаркинг, что он дает?
- Лучшее понимание вашей деятельности, сильных сторон и зон развития путем сравнения с другими
- Лучшее понимание внешнего контекста и «конкурентов»
- Поиск потенциальных партнеров и наставников
- Улучшение коммуникаций с партнерами
- Выявление готовых, работающих решений и прогноз ожидаемых результатов
- Поиск новых вдохновляющих идей и инноваций
- Выявление новых видов и направлений деятельности и услуг
- Способ минимизировать неудачи за счет анализа неудачного опыта бенчмарков
Хотим отметить, что бенчмарками пользуются и профессиональные управляющие, и начинающие инвесторы в связи с простотой, наглядностью и доступностью для анализа и отслеживания.
Бенчмарки и ошибка прогнозирования
Сравнительный анализ с помощью бенчмарков невозможен без примеров. Мы взяли интересные бенчмарки компании E2open — это одни из американских вендоров в сфере облачных технологий для прогнозирования и совместной работы над прогнозами. Компания является поставщиком бизнес-услуг облачного программного обеспечения по требованию для цепей поставок компьютерных, телекоммуникационных и электронных систем, компонентов и услуг.
Как мы уже сказали, бенчмарк — это эталонный показатель, который используется при сравнении величин в финансовой и иной среде. Это база для сопоставления различных индексов и величин, являющаяся основой многих аналитических коэффициентов. Только коэффициенты и оценки у всех разные, и это тоже очень важно.
Что же мы увидели у компании E2open? А увидели мы цифры, которые, честно говоря, начинают обескураживать. У них средняя ошибка получается равной 48%.
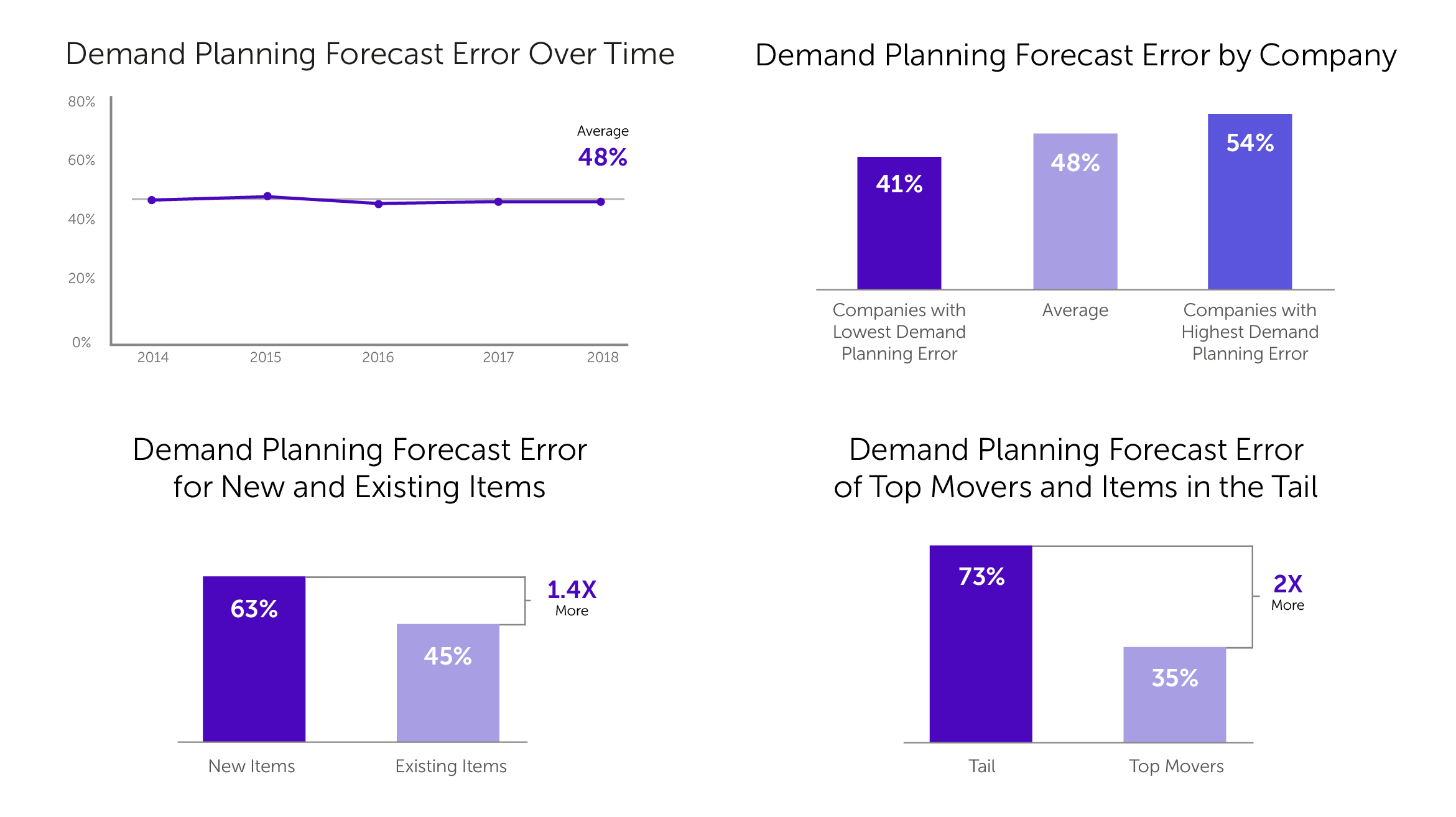
Также было проведено ранжирование по топ-компаниям, которые лучше прогнозируют, и компаниям-аутсайдерам. Что же в итоге? Компании, которые лучше прогнозируют, имеют результаты на 7 процентных пункта выше, а те, которые хуже, — на 6 процентных пунктов. То есть у лидеров (у топовых компаний, которые прогнозируют лучше всего), средняя ошибка (MAPE) — на уровне 41%. Такой результат удручает.
Когда мы рассказываем и показываем презентацию кому-то из наших потенциальных клиентов, многие говорят — «точнее, если мы будем монетку подбрасывать, чем такой прогноз». На самом деле, все не совсем так — естественно, важнее все равно прогнозировать.
Если начать углубляться в тематику, оказывается, что ошибка у E2open для новых позиций еще хуже почти в 1,5 раза. То есть действительно — прогнозировать новые позиции фирмам сложнее, о чем мы говорили в статье про выстраивание процесса прогнозирования спроса.
Дальше они пробуют разделить продажи на две группы: бестселлеры и «хвост». Так вот, в этом «хвосте» ошибка прогнозирования составляет целых 73%. Опять же вспоминаем, что MAPE там может быть достаточно крупно значимым, а бестселлеры у них должны прогнозироваться приблизительно в два раза лучше. И как такое ошибки могут вас не разочаровать?
Однако не спешите с выводами. Оказывается, это довольно частое явление.
Рассмотрим некие бенч-упражнения, которые мы, кстати, тоже выполняем:
- понимание структуры спроса;
- проведение некой предварительной очистки от факторов ошибок спроса;
- осуществление декомпозиции
Все эти процессы называются Demand Sensing («определение спроса»), и мы заметили, что данные упражнения дают значимый эффект. Причем этим должны заниматься прогнозисты, а не математики — а именно, работать над выявлением существенных факторов ошибок, а не осуществлять расчеты в Excel. Итак, вот некие результаты.
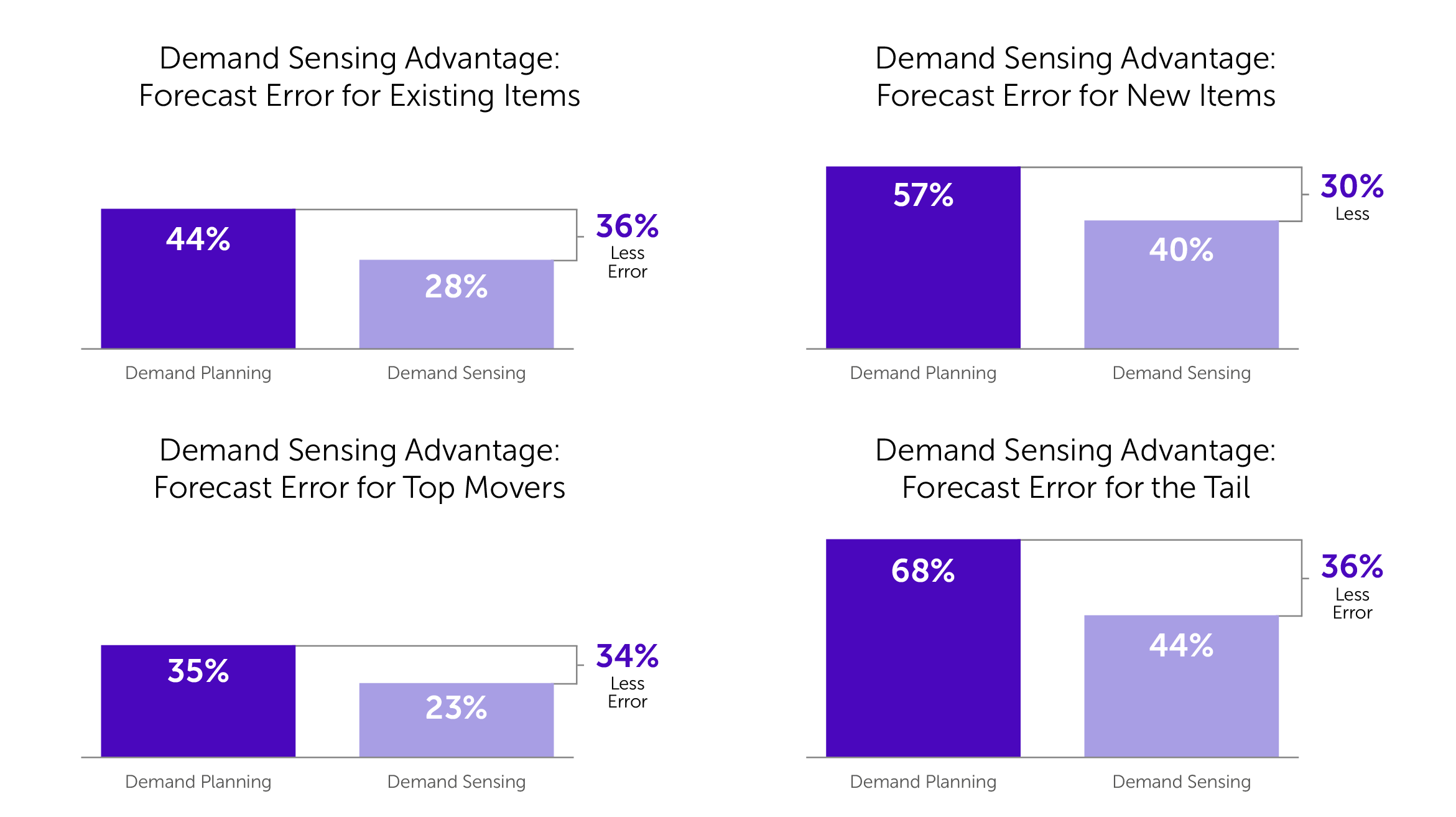
- Для позиции, которая имеет какой-то исторический спрос, эта ошибка уже становится приемлемой — 28%, что на 36 процентных пункта меньше, чем спрос, который спрогнозирован без использования Demand Sensing.
- Для новинок тоже существенно — ошибка уже 40%, точность 60а% (а не 50% на 50%).
- Для бестселлеров мы узнаем такой целевой показатель для всех прогнозов, по которым можно строить и на которые можно ориентироваться — они достигают ошибки 23%. То есть кто-то достигает ошибки 5%, кто-то — 30%, но плюс-минус выходит 23%.
- «Хвост», о котором мы говорили, то есть те позиции, которые плохо прогнозируются, которые составляют, на самом деле, по правилу Парето 80% вашего ассортимента, — дает ошибку 44%. Как ни старайся, но именно эта ошибка будет довольно велика — это неизбежно.
На самом деле, в нашей практике происходит следующим образом. Внедряя аналитические прогнозные решения, мы видим, что эффект для этой самой сложной группы («хвоста») — является всегда наиболее существенным для компании, так как он максимально разгружает людей, чтобы они смогли сфокусироваться на более значимых позициях спроса.
Хотим сделать такой нетривиальный вывод: прогноз — ничто, прогнозирование — всё.
Важно, чтобы вы понимали, главное — это соотношение ошибок для разного вида спроса и значимый эффект от вкладывания усилий в улучшение качества прогноза. Сам процесс для вас является очень эффективным, так как прогнозируя вы сможете дать объяснение максимально высоким ошибкам и понять их природу. Поэтому прогнозирование — это не какая-то автономная часть мероприятий, это часть экономики компании, которая ведет к улучшению ваших бизнес-результатов.
Почему для нас эта тема актуальна?
Команда Reshape Analytics может помочь Вам разобраться во всех хитросплетениях планирования и добиться максимально качественных данных для прогнозирования с помощью аналитических платформ и готовых решений: Loginom, NOVO BI, Optimacros, Alteryx, AnyLogistix и т. д.
Оставьте заявку на бесплатную консультацию, на которой мы подробно разберем задачи и особенности вашего проекта, ответим на все интересующие вопросы, а также подберем оптимальное решение для ваших задач.