
Классификация — одна из наиболее популярных технологий интеллектуального анализа данных. С необходимостью построения классификаторов рано или поздно сталкивается любой аналитик. Но даже построив модель, необходимо прежде всего убедиться в ее работоспособности. Для этого разработано большое количество мер качества. Наиболее популярные из них рассматриваются в данной статье.
Для классификационных моделей, как и для моделей регрессии, актуальна задача оценки их качества для определения работоспособности моделей и их сравнения. Однако решение этой задачи для моделей классификации вообще, и бинарной классификации в частности, сложнее, чем для регрессии. Связано это с тем, что целевая переменная (метка класса) является категориальным (дискретным) значением, и, следовательно, ошибка классификации не может быть выражена числовым значением.
Поэтому в основе оценки качества классификационных моделей лежит статистика результатов классификации обучающих примеров. С ее помощью вычисляются метрики качества — показатели, которые зависят от результатов классификации и не зависят от внутреннего состояния модели.
Среди наиболее популярных методов оценки качества классификаторов можно выделить следующие:
- Матрица ошибок (Сonfusion matrix).
- Меткость (Accuracy).
- Точность (Precision).
- Полнота (Recall).
- Специфичность (Specificity).
- F1-мера (F1-score).
- Метрика P4 .
- Площадь под ROC-кривой (Area under ROC-curve, AUC-ROC).
- Площадь под кривой полнота-точность (Area under precision-recall curve, AUC-PR).
- Коэффициент корреляции Мэтьюса (Matthews correlation coefficient, MCC).
- Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Матрица ошибок
Прежде чем переходить к описанию собственно метрик качества бинарных классификаторов, рассмотрим методику описания этих метрик в терминах ошибок классификации. Пусть заданы два класса y=left { 0,1 right } и алгоритм, предсказывающий принадлежность каждого объекта одному из классов. Эта задача анализа известна как бинарная классификация.
Приведем пример. Пусть в страховой компании используется аналитическая платформа для поддержки принятия решений о целесообразности страхования того или иного объекта. Если риск наступления страхового события выше определенного порога, то такие объекты страховать нецелесообразно. Именно выявление таких объектов и является целью анализа. Тогда для объектов, страхование которых целесообразно, система должна установить класс 0, а объектам, в страховании которых отказано, — класс 1.
Любой реальный классификатор совершает ошибки. В нашем случае таких ошибок может быть две:
- класс 0 распознается классификатором как класс 1, что можно интерпретировать как «ложную тревогу»;
- класс 1 распознается как класс 0, что можно трактовать как «пропуск цели».
Очевидно, что приведенные ошибки неравноценны по связанным с ними издержкам классификации. В случае «ложной тревоги» компания потеряет только потенциальную страховую премию, т.е. будет иметь место всего лишь упущенная выгода. В случае «пропуска цели» возможна потеря значительной суммы из-за наступления страхового случая. Поэтому важнее не допустить «пропуск цели», чем «ложную тревогу».
Иными словами, важнее правильно определить объект, нежелательный для страхования из-за высокого риска, чем ошибиться в распознавании желательного. Будем называть соответствующий исход классификации положительным (объект не подлежит страхованию y=1), а противоположный — отрицательным (объект подлежит страхованию y=0). Тогда возможны следующие исходы классификации:
- Объект, нежелательный для страхования, классифицирован как нежелательный, т.е. «положительный» класс распознан как положительный. Такой исход классификации (а также пример, для которого он получен) называют истинноположительным.
- Объект, желательный для страхования, распознан как желательный, т.е. «отрицательный» класс распознан как отрицательный. Такой исход классификации называют истинноотрицательными.
- Объект, желаемый для страхования, классифицирован как не желаемый, т.е. имела место ошибка, в результате которой отрицательный класс был распознан как положительный. Данный исход классификации называют ложноположительным, а ошибка классификации называется ошибкой I рода.
- Нежелательный объект распознан как желательный, т.е. имела место ошибка, в результате которой положительный класс был распознан как отрицательный. Такой исход классификации называется ложноотрицательным, а ошибка классификации — ошибкой II рода.
Таким образом, ошибка I рода, или ложноположительный исход классификации, имеет место, когда пример, с которым связано отрицательное событие распознан моделью как положительный. Ошибкой II рода, или ложноотрицательным исходом классификации, называют случай, когда пример, с которым связано положительное событие, распознан как отрицательный. Поясним это с помощью матрицы ошибок классификации, называемой также таблицей сопряженности:
| y=0 | y=1 | |
|---|---|---|
| widehat{y}=0 | Истинноположительный (True Positive — TP) | Ложноположительный (False Positive — FP) |
| widehat{y}=1 | Ложноотрицательный (False Negative — FN) | Истинноотрицательный (True Negative — TN) |
Здесь widehat{y} — отклик модели, а y — фактическое значение. Таким образом, ошибки классификации бывают двух видов: False Negative (FN) и False Positive (FP). В данном случае P означает, что классификатор определяет класс объекта как положительный, а N как — отрицательный. T значит, что класс предсказан правильно, соответственно, F — неправильно. Каждая строка в матрице ошибок представляет предсказанный класс, а каждый столбец — фактически наблюдаемый класс.
Идеальный классификатор, если бы он существовал, выдавал бы только истинноположительные и истинноотрицательные классификации, и его матрица ошибок содержала бы значения, отличные от нуля, только на главной диагонали.
Меткость
Представляет собой долю правильных классификаций модели:
ACC=frac{TP+TN}{TP+TN+FP+FN}.
Несложно увидеть, что сумма в знаменателе формулы представляет собой общее число классифицируемых примеров. Графически это можно интерпретировать следующим образом:
Рисунок 1. Меткость В английском языке этот термин обозначается как «accuracy», поэтому в интернете он часто упоминается как «аккуратность», хотя это слово и не передает смыслового значения данной величины. Несмотря на то, что эта мера хорошо интерпретируется, на практике она используется достаточно редко, поскольку плохо работает в случае дисбаланса классов в обучающей выборке. Поясним это на примере кредитного скоринга. Пусть требуется классифицировать заемщиков на добросовестных (не допустивших просрочку) и недобросовестных (допустивших просрочку). Целью является выявление недобросовестных заемщиков, поскольку связанные с ними издержки выше. Следовательно, классификация заемщика как недобросовестного является положительным событием, а как добросовестного — отрицательным. Выборка содержит 1000 добросовестных заемщиков, 900 из которых классификатор предсказал правильно (TN=900, FP=100), и 100 недобросовестных, 50 из которых классификатор также определил верно (TP=50, FN=50). Несложно вычислить, что: ACC=frac{50+900}{50+900+100+50}=0.866. Однако, если построить «наивную» модель, которая просто будет классифицировать всех клиентов, как добросовестных (на основании того, что таковых большинство), то меткость такой модели окажется: ACC=frac{0+1000}{0+1000+0+100}=0.909. Таким образом, оказалось, что меткость «бесполезной» модели, не имеющей предсказательной силы, выше, чем «рабочей» модели. Это противоречит здравому смыслу. Поэтому на практике стараются использовать альтернативные меры качества. Точность равна доле истинноположительных классификаций к общему числу положительных классификаций. Данная величина часто упоминается как positive predictive value (PPV) или положительное прогностическое значение: Pr=PPV=frac{TP}{TP+FP}. Поясним данное выражение с помощью рисунка: Рисунок 2. Точность Несложно увидеть, что попытка отнести все объекты к одному классу неизбежно приведет к росту FP и уменьшению значения точности. Полнота, известная еще как чувствительность или доля истинноположительных примеров (TPR — true positive rate), определяется как число истинноположительных классификаций относительно общего числа положительных наблюдений: Re=TPR=frac{TP}{TP+FN}. Таким образом, полноту можно рассматривать как способность классификатора обнаруживать определенный класс. Графически полноту можно проиллюстрировать с помощью рисунка: Рисунок 3. Полнота Точность и полноту для каждого класса легко определять с помощью матрицы ошибок. Точность равна отношению соответствующего диагонального элемента матрицы и суммы элементов всей строки класса, а полнота — отношению диагонального элемента матрицы и суммы элементов всего столбца класса. PPV_{c}=frac{A_{cc}}{sumlimits_{i=1}^{n}A_{ci}}, TPR_{c}=frac{A_{cc}}{sumlimits_{i=1}^{n}A_{ic}}, где c — класс, n — число элементов столбца (равно числу классов), i — номер элемента в столбце, A — элемент матрицы ошибок. Специфичность классификатора — это доля истинноотрицательных (True Negative Rate — TNR) классификаций в общем числе отрицательных классификаций: Sp=TNR=frac{TN}{TN+FP}. TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Поясним это с помощью рисунка. Рисунок 4. Специфичность Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1. Точность и полнота, в отличие от меткости, не зависят от соотношения классов и, следовательно, могут применяться в условиях несбалансированных выборок. На практике часто встречается задача поиска оптимального баланса между точностью и полнотой. Действительно, улучшая настройку модели на один класс, например, путем изменения дискриминационного порога, мы тем самым ухудшаем настройку на другой. Чем выше точность и полнота, тем лучше модель. Но на практике их максимальные значения одновременно недостижимы, поэтому приходится искать баланс между ними. Для этого используется метрика, объединяющая в себе информацию о точности и полноте. Она называется F1-мера и вычисляется следующим образом: F1=frac{2cdot PPVcdot TPR}{PPV+TPR}=frac{2cdot TP}{2cdot TP+FP+FN}. В данном выражении точность PPV и полнота TPR имеют одинаковый вес, поэтому при их уменьшении F1-мера сокращается пропорционально. Однако на практике чаще используется сбалансированная F1-мера, в которой точности и полноте присваиваются разные веса с целью найти оптимальный баланс между данными метриками. Для этого в формулу для F1-меры вводится дополнительный балансировочный параметр, обозначаемый β. Сбалансированная F1-мера вычисляется следующим образом: F1=frac{(1-beta ^{2})cdot PPVcdot TPR}{beta ^{2}cdot PPV+TPR}. Если параметр принимает значения из диапазона 0< beta < 1, то приоритет имеет точность, а если beta> 1, то полнота. Еще одним источником критики F1-меры является отсутствие симметрии. Это означает, что она может изменить свое значение при инверсии положительного и отрицательного классов. Метрика P_{4} была разработана как расширение F1-меры, обладающее симметрией относительно инверсии классов. Вычисляется по формуле: P_{4}=frac{4cdot TPcdot TN}{4cdot TPcdot TN+(TP+TN)cdot (FP+FN)}. Метрика P_{4} изменяется в диапазоне от 0 до 1. Чем ближе значение метрики к 1, тем лучше работает модель. Очевидно, что значение меры стремится к 0, если хотя бы один из множителей в числителе становится равным нулю, т.е. когда модель теряет способность правильно распознавать положительные или отрицательные примеры. ROC-кривая, или кривая рабочих характеристик приемника (Receiver Operating Characteristics curve), позволяет не только оценить качество работы классификатора, но и исследовать его поведение при различных значениях дискриминационного порога. Технология оценки качества моделей бинарной классификации с помощью ROC-кривых известна как ROC-анализ. Рассмотрим совместно TPR и TNR классификатора. TPR показывает, насколько хорошо модель классифицирует положительные примеры. Очевидно, что если все положительные примеры классифицированы правильно (т.е. число ложноотрицательных случаев равно 0), то TPR=1. TNR показывает, насколько хорошо модель классифицирует отрицательные примеры. Очевидно, что если все отрицательные примеры классифицированы правильно (т.е. число ложноположительных случаев равно 0), то TPR=1. Таким образом, по отдельности TPR и TNR характеризуют способность модели распознавать только один из классов. Но их совместное использование помогает создать метрику, которая позволяет выбирать значение дискриминационного порога, который оптимально балансирует модель между способностью распознавать положительные и отрицательные примеры. Именно эта задача и решается с помощью ROC-кривой. Действительно, если изменять дискриминационный порог от 0 до 1 и наносить по оси абсцисс точки 1−TNR, а по оси ординат TPR, то полученный график и будет ROC-кривой. Величину 1−TNR называют долей ложноположительных классификаций (false positive rate) или показателем ложной тревоги. Она вычисляется следующим образом: 1-TNR=FPR=frac{FP}{FP+TN}. При пороге, равном 1, все примеры будут классифицированы как отрицательные (FPR=1, TPR=1), а при пороге, равном 0, — как положительные (FPR=0, TPR=0). Поэтому ROC-кривая всегда идет от точки (0,0) до точки (1,1). Рисунок 5. ROC-кривая Несложно увидеть, что для идеальной модели ROC-кривая превращается в ломаную, проходящую через точки (0,0), (0,1) и (1,1). При этом площадь под ROC-кривой (AUC — Area Under Curve) окажется равной 1. Площадь под кривой выделена на рисунке светло-серым цветом. Точка (0,1) соответствует идеальному состоянию модели, в котором и TPR, и TNR одновременно равны 1. Т.е. модель одинаково хорошо «научилась» работать как с положительными, так и с отрицательными примерами при существующем в обучающей выборке балансе классов. Идеальная модель является скорее гипотетической и на практике, как правило, недостижима. Поэтому обычно приходится иметь дело с ROC-кривыми, которые не проходят через точку (0,1), а приближаются к ней на определенное расстояние. Соответственно и AUC−ROC оказывается меньше 1. Таким образом показатель AUC−ROC является удобной мерой качества классификатора относительно идеального. Принята следующая шкала оценки качества. Если AUC-ROC=0.5, то ROC-кривая превращается в линию, проходящую через точки (0,0) и (1,1), которая соответствует бесполезному классификатору, работающему как случайный предсказатель. Если AUC-ROC< 0.5, то получается модель, которая работает хуже случайного предсказателя и от ее использования следует отказаться. PR-кривые определяются аналогично ROC-кривым, но только по оси абсцисс у них откладываются значения полноты, а по оси ординат — точности. Точность и полнота — две наиболее важные метрики, на которые следует обращать внимание при оценке качества модели бинарной классификации в условиях несбалансированности классов. Они помогают увидеть, какая часть фактически положительных наблюдений была классифицирована правильно, и какие среди классифицированных как положительные, были истинноположительными. Если точность равна 1, то ложноположительные классификации отсутствуют. Но это ничего не говорит о том, были ли распознаны все положительные примеры. Если полнота равна 1, то все положительные объекты были распознаны правильно, а ложноотрицательные классификации отсутствуют. При этом ничего не говорится о том, сколько было допущено ложноположительных классификаций. Таким образом, точность и полнота не особенно полезны для оценки качества классификатора, если их использовать по отдельности. В задаче классификации оценка точности, равная 1 для класса C, означает, что каждый элемент, помеченный как принадлежащий классу C, действительно принадлежит к классу C, но ничего не говорит о количестве элементов из класса Обычно показатели точности и полноты не используются по отдельности. Вместо этого либо значения одной меры сравниваются с фиксированным уровнем другой (например, точность на уровне полноты 0.75), либо обе меры объединяются в один показатель. Примерами такой комбинации и является F1-мера — взвешенное гармоническое среднее точности и полноты. Еще одним способом комбинирования точности и полноты в задаче оценки качества классификации являются так называемые кривые полнота-точность, которые строятся в системе координат, где по оси абсцисс откладывается полнота, а по оси ординат — точность. Кривая точность-полнота показывает, как выбор порога влияет на точность классификатора, а также помогает выбрать лучшее значение дискриминационного порога для определенного баланса классов. Рисунок 6. Кривая точность-полнота Каждая точка PR-кривой представляет определенное значение дискриминационного порога, а ее расположение соответствует результирующей точности и полноте, когда этот порог выбран. Точка 1 на рисунке соответствует значению дискриминационного порога, равному 1, а точка 3 — значению порога 0. Точка 2 соответствует идеальному классификатору и совпадает с координатами (1,1), а точка 4 — оптимальному значению порога (точка кривой, наиболее близкая к идеальной точке (1,1)). Преимущества PR-кривой по сравнению с ROC: Аналогично ROC-кривой, площадь под PR-кривой (для отличия от ROC ее часто называют PR−AUC) отражает качество классификатора и позволяет сравнивать кривые, соответствующие различным балансам классов и значениям порога. Чем выше площадь, тем лучше работает модель. Пунктирная линия внизу графика соответствует бесполезному классификатору (no-skill model — модель без навыков, или базовая модель), уровень которой изменяется при изменении баланса классов. Такая модель будет присваивать рейтинг 0.5 для любого примера. На рисунке ниже представлена линия, соответствующая балансу классов, когда положительные примеры составляют 10% от обучающей выборки. Рисунок 7. Кривая точность-полнота при фиксированном балансе классов На рисунке точка 1 соответствует порогу 0.5, точка 2 соответствует порогу [0, 0.5). Для порогов (0.5, 1] точность не определена из-за деления на ноль. Можно увидеть, что точность здесь является константой, то есть PPV=0.1 (соответствует доле положительного класса), PR−AUC=0.1. Таким образом, полнота базовой модели лежит в диапазоне (0.5, 1] независимо от дисбаланса классов, а точность равна доле положительного класса в обучающей выборке. На следующем рисунке представлена PR-кривая для идеальной модели. На ней точка 1 соответствует порогу (0, 1], точка 2 соответствует порогу 0. Очевидно, что PR−AUC=1. Рисунок 8. Кривая точность-полнота для идеальной модели И, наконец, на рисунке ниже отображена PR-кривая (красная линия) для модели, которая работает хуже, чем базовая модель «без навыков» (синяя пунктирная линия). Она расположена ниже линии базовой модели. Рисунок 9. Кривая точность-полнота для модели хуже бесполезной Очевидный способ повысить качество «плохой» модели без каких-либо настроек — просто инвертировать классы (класс 0 изменить на класс 1). Это автоматически приведет к повышению точности по сравнению с базовой моделью. Обычно «плохая» PR-кривая классификатора указывает на то, что в обучающих данных присутствуют проблемы: они содержат шум или классы в них плохо выражены (модель не может выявить закономерность, в соответствии с которой один класс отличается от другого). В этом случае PR−AUC не превышает доли положительных примеров обучающей выборке. Возможен гибридный случай, когда «плохая» модель работает лучше, чем модель «без навыков», но для определенных пороговых значений. Коэффициент используется в качестве показателя качества бинарных классификаторов. Он учитывает истинные и ложные классификации и обычно рассматривается как сбалансированная мера, которую можно использовать даже в условиях сильного дисбаланса классов. MCC, по сути, коэффициент корреляции между фактическими и предсказанными моделью бинарными классификациями. Он изменяется в диапазоне от -1 до 1. MCC=1 указывает на идеальную классификацию, когда фактические и предсказанные классы совпадают для всех обучающих примеров (т.е. ложноположительные и ложноотрицательные классификации отсутствуют). Модель, для которой MCC=0, соответствует случайному предсказателю. MCC=−1 указывает на полное расхождение между фактом и предсказанием (т.е. вместо положительного класса модель всегда предсказывает отрицательный, и наоборот), следовательно, истинноположительные и истинноотрицательные классификации отсутствуют. Формула для расчета MCC имеет вид: MCC=frac{TPcdot TN-FPcdot FN}{sqrt{(TP+FP)(TP+FN)(TN+FP)(TN+FN)}}. Несложно увидеть, что если в этой формуле обнулить все ложные классификации, то MCC=1, что соответствует ранее сделанным заключениям. Если число истинных и ложных классификаций равны, то числитель формулы становится равным 0 и MCC=0. И, наконец, если число истинных классификаций равно нулю, то числитель становится отрицательным, и делает таковым результат формулы. Если какая-либо из четырех сумм в знаменателе равна нулю, знаменатель можно произвольно установить равным единице, это приводит к нулевому коэффициенту корреляции Мэтьюса. Функция потерь в задачах классификации показывает, какую «цену» придется заплатить за неточность предсказаний классификационной модели. Для логистической регрессии, решающей задачу бинарной классификации, она может быть вычислена следующим образом: Log Loss=-frac{1}{l}sumlimits_{i=1}^{l}(y_{i}cdot log(widehat{y_{i}})+(1-y_{i})cdot log(1-widehat{y_{i}})), где l — размер выборки, y_{i}=left { 0,1 right } — бинарная метка класса, заданная в примере, widehat{y_{i}} — предсказание модели. Несложно увидеть, что функция потерь получается путем суммирования логарифма потерь на каждом примере. Потери на каждом примере определяются следующим образом: если предсказанный класс совпадает с фактическим, то потери равны 0, в противном случае потери равны 1. Очевидно, чем больше будет неправильных классификаций, тем больше будет значение LogLoss и тем хуже будет модель. Таким образом, чтобы получить лучшую модель, нужно минимизировать функцию потерь. Преимуществом метрики LogLoss является устойчивость к выбросам и аномальным значениям в данных и простота вычисления. Недостатком — сложность интерпретации из-за нелинейного характера. Подведем итоги, кратко резюмируя преимущества и недостатки рассмотренных мер качества классификационных моделей. В статье рассмотрены наиболее общие меры оценки качества моделей бинарной классификации, отмечены их преимущества и недостатки. Однако в литературе авторы предлагают и другие подходы, которые показали хорошие результаты при решении конкретных задач и не претендующие на универсальность. Другие материалы по теме: Метрики качества линейных регрессионных моделей Отбор переменных в моделях линейной регрессии Репрезентативность выборочных данных
Точность

Полнота

Специфичность

F1-мера
Метрика P4
AUC-ROC

AUC
Оценка
0.9 — 1
Отличное
0.8 — 0.9
Очень хорошее
0.7 — 0.8
Хорошее
0.6 — 0.7
Удовлетворительное
0.5 — 0.7
Плохое
AUC-PR
C, которые не были правильно классифицированы. Тогда как полнота, равная 1, означает, что каждый элемент из класса C был помечен как принадлежащий к классу C, но ничего не говорит о том, сколько элементов из других классов были также неправильно классифицированы как принадлежащие к классу C.



Коэффициент корреляции Мэтьюса
Функция потерь логистической регрессии (Logistic loss function, Log Loss).
Сравнение метрик
Мера
Преимущества
Недостатки
Меткость
Хорошо интерпретируется.
Чувствительна к дисбалансу классов. Неадекватно отражает точность классификации.
Точность
Не чувствительна к дисбалансу классов.
Отражает качество классификации только для положительного класса.
Полнота
Не чувствительна к дисбалансу классов.
Не учитывает отрицательные классификации.
Специфичность
Просто вычисляется и интерпретируется.
Характеризует способность модели распознавать только один класс.
F1-мера
Позволяет найти баланс между точностью и полнотой.
Чувствительность к дисбалансу, отсутствие симметрии.
P4
Симметрична относительно инверсии классов.
Чувствительность к дисбалансу классов.
AUC-ROC
Наглядна, хорошо интерпретируется.
В условиях дисбаланса классов завышает качество модели. Не отражает изменения баланса классов.
AUC-PR
Наглядна, хорошо интерпретируется.
Не учитывает отрицательные классификации.
Коэффициент Мэтьюса
Более информативен, поскольку использует все типы результатов классификации.
Не может применяться, если один из множителей в знаменателе обращается в 0.
LogLoss
Устойчивость к выбросам в данных, простота вычисления.
Сложность интерпретации из-за нелинейного характера.
Методы классификации
Методы
классификации
– это совокупность приемов разделения
множества объектов, планомерный подход
к их разделению на подмножества.
В науке известны
три метода классификации объектов:
иерархический, фасетный, дескрипторный.
Эти методы различаются разной стратегией
применения классификационных признаков.
Рассмотрим
два основных метода классификации:
-
иерархический
-
фасетный
Иерархический
метод
характеризуется последовательным
делением заданного множества объектов
на подчиненные подмножества. То есть
все образуемые по этому методу
подразделения составляют единую систему
классификации распределяемого множества
со взаимосвязанными подразделениями,
единое целое, в котором все части
взаимосвязаны и определенным образом
соподчинены (рис. 1.5.).
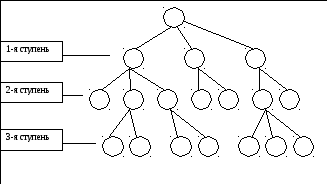
Рис.
1.5. Иерархический метод классификации.
Учитывая достаточно
жесткую процедуру построения структуры
классификации, необходимо на первом
этапе систематизации определить её
цель, то есть какими свойствами должны
обладать объединяемые в подмножества
объекты. Эти свойства в дальнейшем
принимаются за признаки классификации.
В основу деления
множества на подмножества по
основополагающему для данного этапа
признаку положена ступень классификации.
Ступень
классификации
– этап классификации при иерархическом
методе, в результате которого получается
совокупность классификационных
группировок.
Таким
образом, распределение множества
объектов на части (группы) только по
одному признаку называется классификационной
группировкой.
Иерархическая система классификации
всегда имеет несколько взаимоподчиненных
ступеней распределения и этим отличается
от простой группировки множества,
имеющей лишь одну ступень подразделения.
Количество
признаков и ступеней определяют глубину
классификации.
Глубина классификации теоретически
бесконечна, но на практике такая
классификация слишком громоздка и
запутана, многие низшие ступени дублируют
друг друга. Всё это затрудняет практическое
применение классификации. Поэтому на
практике глубина классификации обычно
не превышает 10. Признаками классификации
могут быть: химическая природа, состав,
структура, свойства, назначение и
применение, внешние признаки (размеры,
форма, цвет и др.). В зависимости от
характера выбранных признаков различают
естественные и вспомогательные
классификации.
Для
эффективного использования иерархического
метода классификации необходимо
выполнение следующих правил3:
-
Деление множества
следует начинать с наиболее общих
признаков. -
На каждой ступени
можно использовать только один признак,
имеющий принципиальное значение для
этого этапа. -
Разделение объектов
должно осуществляться последовательно
от большего к меньшему, от общего к
частному. -
Необходимо
установить оптимальное число признаков,
ступеней и глубину классификации.
Достоинствами
иерархического метода классификации
являются:
-
Простота построения;
-
Возможность
выделения общности и сходства признаков
объектов на одной и разных ступенях; -
Высокая
информационная насыщенность; -
Обзорность.
Недостатками
метода являются:
-
При большой глубине
– громоздкость; -
Высокие затраты
для применения; -
Трудность
применения за счет многоступенчатости
и большого числа взаимосвязанных
подмножеств. -
При небольшой
глубине – информационная недостаточность
и неполный охват объектов и признаков.
Анализируя
недостатки иерархического метода
классификации, можно предположить, что,
учитывая динамичное развитие науки,
производственных технологий, сложно
обозначит полное множество товаров и
признаки новых товаров, поэтому
представляется невозможным в качестве
модели построения товарной номенклатуры
выбрать только иерархический метод.
Вместе с тем элементы этого метода
применяются в низких уровнях детализации
ТН ВЭД ТС, обозначаемых дефисами: уровни
с большим количеством дефисов логически
подчинены уровням с меньшим количеством
дефисов.
Если
необходимо увеличить число признаков,
то применяют фасетный метод классификации.
Особенностью фасетного метода
классификации является то, что разные
признаки не связаны между собой.
Фасетный
метод классификации
– предусматривает параллельное
разделение множества объектов на
отдельные независимые одна от другой
группы или фасеты, по одному из признаков
в каждой.
Термин
этот произошёл от французского слова
facette
– грань отшлифованного камня.
Действительно, как каждая грань камня
существует независимо от других граней,
так и разные классификационные группировки
при фасетном методе независимы и не
подчиняются друг другу (рис.1.6). Благодаря
этому, фасетная система отличается
большой гибкостью, возможностью
ограничивать число признаков. Например
– это может быть назначение, или вид,
или состав исходного сырья. Использование
фасетного метода во многих случаях
облегчает составление классификаторов
и кодирование объектов классификации.
Специфичными
правилами фасетного метода являются:
-
Примерно одинаковая
значимость и независимость классификационных
признаков; -
Отсутствие общности
классификационных признаков; -
Возможность
дополнения количества признаков.
Достоинствами
этого метода классификации являются:
1.
Гибкость системы классификации;
2.
Удобство использования, так как в каждом
отдельном случае можно подразделять
множество товаров, ограничивая их
несколькими фасетами, представляющими
интерес в данном конкретном случае;
3.
Возможность ограничения количества
признаков без утраты достаточности
охвата объектов.
Рис.
1.6. Фасетный метод классификации.
Недостатками
фасетного метода классификации являются:
-
Невозможность
выделения общности и различий между
объектами в разных классификационных
группировках; -
Низкая информативность.
Итак, преимущества
одного метода классификации выступают
в качестве недостатков другого, то есть
методы дополняют друг друга. Знание
достоинств и недостатков различных
методов классификации позволяют их
рационально использовать с учетом их
целевого назначения. Часто оба метода
используют совместно. В этом случае
говорят о системе классификации.
Таким
образом, система
классификации
– это совокупность методов и правил
классификации, ее результатов. ТН ВЭД
ТС является одним из примеров совместного
применения системы классификации, в
которой на высоких уровнях детализации
применяется фасетный метод, а на низших
– иерархический.
В зависимости от
порядка образования классификационных
групп различают: десятичную, сотенную,
произвольную системы классификации.
При
десятичной и сотенной системах
классификации каждый высший класс
подразделяется соответственно на 10 и
100 последующих классов. При большом
количестве групп целесообразно применять
сотенную систему классификации. В ТН
ВЭД ТС применяется десятичная система,
то есть каждый разряд кода нумеруется
от 0 до 9.
Системы классификации
могут различать ступенчатостью, то есть
количеством классов. Существуют одно-,
двух-, трех- и более ступенчатые
классификации. При делении товаров
только на классы – применяют одноступенчатую
классификацию.
При четырехступенчатой
классификации могут использоваться
следующие градации: класс, подкласс,
группа, подгруппа.
Разработка системы
классификации сопровождается присвоением
каждому наименованию товаров
номенклатурного номера (или кода).
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Методом классификации называют совокупность приемов (способов) разделения множества объектов. Различают два метода классификации: иерархический и фасетный.
Иерархический метод классификации — последовательное деление заданного множества на подмножества так, что все подмножества составляют единую систему классификации распределяемого множества. Эта система фиксирует и сходство, и различие между объектами.
Как видно из приведенной схемы, иерархический метод классификации характеризуется тем, что исходное множество объектов последовательно разделяется на подмножества (классификационные группировки), а те в свою очередь — на подмножества, группы, виды и др. по основным признакам, описывающим эти объекты по принципу от общего к частному.
То есть каждая группировка в соответствии с выбранным признаком (основанием деления), делится на несколько других группировок, которые по другому признаку делятся еще на несколько подчиненных группировок. Так между классификационными группировками устанавливается отношение подчинения (иерархии).
Схема иерархической классификации

Построение иерархической классификации объектов происходит в следующей последовательности:
- определяется множество объектов, которое необходимо классифицировать (множество людей, предприятий, процессов и др.) для решения конкретных задач;
- выделяются основные признаки (свойства, характеристики, показатели, параметры и др.), по которым множество будет разделяться на подмножества;
- устанавливается оптимальное число признаков, ступеней и глубина классификации;
- выбирается порядок следования признаков — уровень деления и их количество.
Чаще всего классифицируют в следующей последовательности: класс — подкласс — группа — подгруппа — вид — подвид — разновидности.
Наиболее существенными и сложными вопросами, возникающими при построении иерархической классификации, считаются выбор системы признаков, используемых в качестве основания деления, и определение порядка их следования.
В основу иерархической классификации закладываются признаки, являющиеся необходимыми в решении задач, для которых она создается.
При этом последовательность признаков определяется от общего к частному, с учетом приоритетной вероятности обращений к разным уровням деления при решении конкретных задач.
Примером использования данного метода классификации является классификационная схема, используемая в Общероссийском классификаторе продукции по видам экономической деятельности (ОКПД 2).
Основные преимуществ иерархической классификации заключаются в ее логичности, последовательности и хорошей приспособленности для ручной обработки информации.
А ее недостаток — малая гибкость структуры, обусловленная фиксированностью признаков (оснований деления) и заранее установленным порядком их следования. Включение новых уровней деления по дополнительным признакам весьма затруднительно (если не предусмотрены резервные емкости).
Кроме того, иерархический метод не позволяет агрегировать объекты по необходимому для конкретных задач сочетанию признаков, что еще раз подтверждает его негибкость.
Фасетный метод классификации (фр. facette — грань отшлифованного камня) — параллельное разделение множества объектов по одному признаку на отдельные, независимые друг от друга подразделения — фасеты.
Схема классификации фасетным методом

На рис. каждый из фасетов характеризует одну из особенностей распределяемого множества потребительных свойств — социальных, функциональных, экономических и т. п.
Как видно из приведенной выше схемы, фасетный метод классификации характеризуется тем, что множество объектов разделяется на независимые подмножества (классификационные группировки), обладающие определенными заданными признаками, необходимыми для решения конкретных задач.
Последовательность действий при построении фасетной классификации практически такая же, как и при построении иерархической: определяется множество объектов, выделяются основные признаки и группы признаков этого множества и выбирается порядок следования групп признаков (фасетов) и признаков-характеристик.
Для вычленения из множества объектов конкретного подмножества, обладающего определенными признаками, нужно выделить основные признаки-характеристики, всесторонне характеризующие объект и обеспечивающие его идентификацию, сгруппировать их по принципу однородности в фасеты и присвоить им коды, определить фасетные формулы для образования подмножеств.
Особенность фасетного метода состоит в том, что подмножества формируются по принципу от частного к общему: на основе различных наборов конкретных характеристик объекта формируются конкретные подмножества.
Из сказанного следует, что особенностью фасетного метода является то, что разные признаки не связаны между собой.
Действительно, как каждая грань камня существует независимо от других граней, так и разные классификационные группировки при фасетном методе независимы и не подчиняются друг другу.
Благодаря этому фасетная система отличается большой гибкостью, возможностью ограничивать число признаков и группировок, что создает определенные удобства при использовании. Вместе с тем ее информационная емкость может быть увеличена путем выделения общих и частных классификационных группировок.
Примером фасетного метода классификации может служить классификация лекарственных средств по срокам годности. Количество признаков можно увеличивать многократно: по упаковке, по изготовителям и т. п.
Каждая разновидность методов классификации характеризуется определенными преимуществами и недостатками, знание которых позволяет рационально применять эти методы с учетом целевого назначения.
Преимущества и недостатки иерархического и фасетного методов классификации (по М.А. Николаевой)

Таким образом, преимущества одного метода классификации выступают в качестве недостатков другого, т. е. обе разновидности дополняют друг друга. Поэтому в ряде случаев их используют совместно. Здесь можно говорить о системе классификации как о совокупности методов и правил классификации.
Правила классификации предназначены для выбора разновидностей метода и признаков, по которым осуществляется деление множества на подмножества.
Важнейшим правилом для иерархического и фасетного методов является выбор разновидности метода классификации в зависимости от ее целевого назначения.
Правила классификации объектов при иерархическом методе:
- разделение множества объектов начинают с наиболее общих признаков;
- разделение множества на подмножества на каждом уровне производят только по одному признаку, имеющему принципиальное значение для этого этапа деления;
- получаемые в результате деления группировки на каждом уровне относят только к одной вышестоящей группировке и не пересекаются, т. е. не повторяются;
- разделение множества осуществляют без пропусков очередного или добавления промежуточного уровня деления;
- классификацию производят таким образом, чтобы сумма образованных подмножеств составляла делимое множество.
Правила классификации объектов при фасетном методе:
- признаки в различных фасетах не пересекаются, т. е. каждый признак отличается от другого по наименованию, значению и кодовому обозначению;
- из общего числа фасетов, характеризующих объекты, выбираются только те, которые необходимы для решения поставленных задач, и устанавливается их последовательность (фасетная формула).
Рассмотренные методы классификации широко используются в товароведении медицинских и фармацевтических товаров при делении множества товаров на системные категории: роды, классы, группы и т. п. Эти методы могут применяться как независимо друг от друга, так и совместно.
Методы классификации и кодирования товаров
На чтение 2 мин Просмотров 19.7к. Обновлено 01.05.2017
Содержание статьи
- Методы классификации и кодирования товаров
- Методы классификации: кодирование товаров
- Методы кодирования товаров
- Последовательный метод и параллельный метод
Методы классификации товаров и кодирования товаров — это основа для проведения товарной классификации.
Методы классификации и кодирования товаров
Существует всего три метода классификации:
- иерархический,
- фасетный
- и смешанный
Иерархический метод — это последовательное деление множества на подчиненные подмножества.
Иерархическая классификация распределяет товары от более общей характеристики к менее общей. Последующее звено конкретизирует предыдущее.
Иерархическая классификация — это:
- большая информационная емкость,
- легкость
- привычность применения.
Недостаток иерархической классификации — негибкая структура и фиксированный порядок ступеней распределения. В данной классификации нет возможности и резервной емкости для новых объектов и признаков.
Количество признаков — признак глубины классификации. Теоретически она может быть бесконечна, но если нужно увеличить число признаков, то применяют фасетный метод классификации.
Фасетный метод классификации – это параллельное разделение товаров на фасеты (группы, независимые друг от друга).
Особенность фасетной классификации — фасеты не подчиняются друг другу. Каждый фасет — характеристика одной стороны (характеристики) множества.
Преимущество этого вида классификации — гибкость структуры. Изменения любого фасета не влияют на множество.
Недостатки фасетной классификации:
- недостаточное использование емкости,
- нестандартное применение,
- сложность для ручной обработки информации.
В ряде случаев используют оба метода — смешанный тип классификации.
Методы классификации: кодирование товаров
Кодирование товара – это формирование и присвоение кода для группы товаров.
Код – это последовательность знаков для обозначения группы товаров.
Методы кодирования товаров
Существует четыре метода (или типа) кодирования товаров:
- последовательный
- серийно-порядковый;
- порядковый;
- параллельный;
.
Суть порядкового метода — образование и присвоение кода происходит из натуральных чисел.
Суть серийно-порядкового метода — образование и присвоение кода происходит из натуральных чисел. Но отдельные серии чисел закрепляют за определенными группами товаров.
Последовательный метод и параллельный метод
При последовательном методе — код формируют и присваивают группе товаров. При этом, используют последовательно расположенные подчиненные группы товаров (то есть, речь об иерархической классификации.
Суть параллельного метода — код формируют и присваивают на основе классификации фасетного типа.