
Ошибки, возникающие при обследовании,
можно разделить на два основных типа:
ошибки в выборке и систематические
ошибки.
Ошибка в выборке — разность между
наблюдаемыми значениями количественного
признака и их долгосрочным средним
значением при повторении измерений.
Основой для ее рассмотрения была
концепция выборочного распределения
некоторой статистики, например выборочного
среднего, выборочной доли и тому
подобное. Само понятие выборочного
распределения неразрывно связано с
понятием ошибки в выборке. Названное
распределение существует благодаря
тому, что различные выборки, сформированные
в соответствии с принятым планом
исследования, дают разные оценки
параметра.
Статистика меняется от выборки к выборке
в силу того, что в каждом случае
выборочному отбору подвергается
лишь часть генеральной совокупности.
Соответственно можно определить ошибку
в выборке как разность между наблюдаемыми
значениями количественного признака
и их долгосрочным средним значением
при повторении измерений. Ошибка в
выборке может быть уменьшена путем
увеличения объема выборки.
Систематические
ошибки являются отражением ошибок иного
рода, которые могут возникать и не
при выборочных исследованиях.
Систематическая
ошибка
— ошибка исследования, не связанная с
выборкой. Она может быть вызвана
концептуальными или логическими
ошибками, неправильной интерпретацией
ответов, а также статистическими,
арифметическими, табуляционными,
кодовыми или отчетными ошибками.
Систематическая
ошибка подразделяется на: случайную
и неслучайную.
Случайные
ошибки
дают оценки, отличные от истинного
значения; они могут приводить к отклонениям
и в большую, и в меньшую сторону и имеют
при этом случайный характер.
Неслучайные
систематические ошибки имеют более
тяжкие последствия. Неслучайные
систематические ошибки
приводят
к односторонним отклонениям, Соответственно
для них характерна тенденция к смещению
выборочного значения относительно
параметра совокупности. Систематические
ошибки могут являться следствием
концептуальных или логических ошибок,
неправильной интерпретации ответов, а
также статистических, арифметических,
табуляционных, кодовых или отчетных
ошибок.
Один из авторов писал: «Перечень возможных
бед и напастей с увеличением наших
познаний только расширяется… Многолетняя
работа в определенной области, позволяет
приобрести известный методологический
опыт, который, к сожалению, практически
никогда не становится доступным другим.
Подлинной уверенности в правильности
выработанных подходов нет и быть не
может».
Недостатки
систематических ошибок:
—
не так часты, но и не настолько
подконтрольны, как ошибки в выборке.
При увеличении объема выборки ошибки
в выборке уменьшаются. Сказать то же
самое о систематических ошибках нельзя.
В этом случае они могут, как уменьшаться,
так и возрастать.
—
в систематических ошибках, как
направление, так и величина ошибки
могут оказаться совершенно непредсказуемыми,
в отличие от выборок, где ошибки в выборке
при использовании вероятностных методов
могут быть оценены. 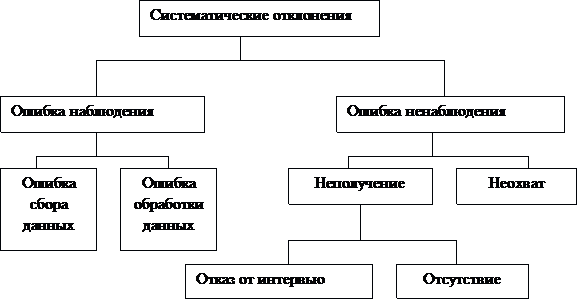
—
приводят к смещению выборочного
значения относительно параметра
совокупности. В
ряде случаев нельзя судить даже о том,
к чему именно приведут, к переоценке
или к недооценке параметра.
—
влияют на достоверность выборочных
оценок. Вызванное
ими смещение может увеличить ошибку
оценки определенных статистик до
такой степени, что оценка доверительного
интервала окажется ошибочной.
Например, одно из исследований, отражающие
финансовое положение потребителей,
направленное оценить уровень накоплений
потребителей, проведенное Иллинойским
университетом, служит наглядным
свидетельством сказанного. В ходе
этого исследования сравнивали полученные
от потребителей сведения об их
финансовых средствах и долгах с известной
информацией, отражающей финансовое
положение потребителей.
Например,
опытное обследование неожиданно
показало, что систематические ошибки
существуют не только в теории, оказалось,
что именно они являются основной
причиной замеченной тенденции к занижению
собранных показателей.
Эта
ошибка не просто присутствовала в данных
обследования, в ряде случаев роль
систематических ошибок была настолько
велика, что
определение
доверительных интервалов по известным
формулам статистики теряло всяческий
смысл. Следует отметить, что
при
увеличении объема выборки величина
этой ошибки только возрастала.
В
некоторых ситуациях даже самые изощренные
выборки не могут избавить от систематических
ошибок.
Особенно
критичными ошибки становятся при работе
с широкомасштабными, хорошо продуманными
вероятностными выборками, т.к. при
увеличении эффективности проектирования
выборки и уменьшении выборочной
дисперсии, эффект систематических
ошибок усиливается. В связи с тем, что
систематические отклонения практически
не зависят от объема выборки, то
сталкиваемся с парадоксальной ситуацией.
Чем эффективнее составлена выборка,
тем большую роль играют систематические
ошибки и тем меньшим смыслом обладают
вычисления по определению доверительного
интервала, в основе которых лежат
обычные формулы.
В
случае исследования, проведенного
Иллинойским университетом, можно было
определить систематическую ошибку,
т.к. в распоряжении исследователей
находились не только результаты опроса,
но и реальные данные, отражающие
финансовое положение потребителей.
Предположим, что подобных данных нет.
Исследователи могут предположить,
что полученные ими ответы не совсем
точны, но как они смогут определить хотя
бы направление вызванного такими
ошибками смещения? То ли респонденты
сознательно завышали уровень своих
сбережений, желая впечатлить
интервьюера, то ли занижали их, боясь,
что реальные цифры могут вызвать
повышенный интерес у сотрудников
Налогового управления. Предположим,
что сам факт неточности приведенных
сведений не вызывает у нас сомнений.
Возникает еще один вопрос: какова
величина этой «неточности»? Завышение
реальной суммы на 10 000 долларов или
ее занижение на 2000? Или наоборот?
Часто
проблема систематических ошибок
оказывается центральной. Два типа
систематических ошибок, отсутствие
ответов одних и некорректные ответы
других участников обследования, могут
обратить результаты исследования на
нет.
Например,
в результате специальных исследований,
проведенных Бюро переписей, выяснилось,
что такие систематические ошибки
могут в десять раз превышать ошибку
выборки. Помимо
прочего, оказалось, что систематическая
ошибка составляет большую часть ошибки
исследования, в то время как случайная
ошибка выборки сведена к минимуму.
Систематические
ошибки могут быть уменьшены, но
уменьшение их связано не столько с
увеличением объема выборки, сколько с
использованием специальных методов. А
для этого необходимо, прежде всего,
осознавать их причины.
На
рис. 6.1 представлены основные типы
систематических ошибок.
Систематические ошибки делятся на
два основных типа: ошибки, связанные с
неполучением данных (ошибки ненаблюдения),
и ошибки наблюдения.
Ошибки ненаблюдения возникают вследствие
невозможности получения данных от части
элементов обследуемой совокупности и
быть вызваны тем, что часть обследуемой
совокупности не была представлена в
выборке, или же элементы, отобранные
для включения в выборку, не представили
данных.
Ошибки наблюдений возникают вследствие
некорректной информации, полученной
от элементов выборки, они могут возникнуть
и на стадии обработки данных или
формулирования итогового вывода.
По ряду характеристик они представляют
еще более опасность, чем ошибки
ненаблюдения. В случае последних
ошибки этого вида обусловлены неполным
охватом или неполучением данных. О
существовании же ошибок наблюдения
можно и не подозревать.
Рис.
8.1. Виды систематических ошибок
Само
понятие ошибки наблюдения основывается
на предположении о том, что для
количественного признака или признаков
существует некоторое «истинное»
значение. Соответственно ошибка
наблюдения является разностью объявленного
и «истинного» значения. И естественно,
что определение ошибки наблюдения
создает трудности, т.к. при исследовании
задаются той самой величиной, определение
которой является целью исследования.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Two Types of Experimental Error
No matter how careful you are, there is always error in a measurement. Error is not a «mistake»—it’s part of the measuring process. In science, measurement error is called experimental error or observational error.
There are two broad classes of observational errors: random error and systematic error. Random error varies unpredictably from one measurement to another, while systematic error has the same value or proportion for every measurement. Random errors are unavoidable, but cluster around the true value. Systematic error can often be avoided by calibrating equipment, but if left uncorrected, can lead to measurements far from the true value.
Key Takeaways
- Random error causes one measurement to differ slightly from the next. It comes from unpredictable changes during an experiment.
- Systematic error always affects measurements the same amount or by the same proportion, provided that a reading is taken the same way each time. It is predictable.
- Random errors cannot be eliminated from an experiment, but most systematic errors can be reduced.
Random Error Example and Causes
If you take multiple measurements, the values cluster around the true value. Thus, random error primarily affects precision. Typically, random error affects the last significant digit of a measurement.
The main reasons for random error are limitations of instruments, environmental factors, and slight variations in procedure. For example:
- When weighing yourself on a scale, you position yourself slightly differently each time.
- When taking a volume reading in a flask, you may read the value from a different angle each time.
- Measuring the mass of a sample on an analytical balance may produce different values as air currents affect the balance or as water enters and leaves the specimen.
- Measuring your height is affected by minor posture changes.
- Measuring wind velocity depends on the height and time at which a measurement is taken. Multiple readings must be taken and averaged because gusts and changes in direction affect the value.
- Readings must be estimated when they fall between marks on a scale or when the thickness of a measurement marking is taken into account.
Because random error always occurs and cannot be predicted, it’s important to take multiple data points and average them to get a sense of the amount of variation and estimate the true value.
Systematic Error Example and Causes
Systematic error is predictable and either constant or else proportional to the measurement. Systematic errors primarily influence a measurement’s accuracy.
Typical causes of systematic error include observational error, imperfect instrument calibration, and environmental interference. For example:
- Forgetting to tare or zero a balance produces mass measurements that are always «off» by the same amount. An error caused by not setting an instrument to zero prior to its use is called an offset error.
- Not reading the meniscus at eye level for a volume measurement will always result in an inaccurate reading. The value will be consistently low or high, depending on whether the reading is taken from above or below the mark.
- Measuring length with a metal ruler will give a different result at a cold temperature than at a hot temperature, due to thermal expansion of the material.
- An improperly calibrated thermometer may give accurate readings within a certain temperature range, but become inaccurate at higher or lower temperatures.
- Measured distance is different using a new cloth measuring tape versus an older, stretched one. Proportional errors of this type are called scale factor errors.
- Drift occurs when successive readings become consistently lower or higher over time. Electronic equipment tends to be susceptible to drift. Many other instruments are affected by (usually positive) drift, as the device warms up.
Once its cause is identified, systematic error may be reduced to an extent. Systematic error can be minimized by routinely calibrating equipment, using controls in experiments, warming up instruments prior to taking readings, and comparing values against standards.
While random errors can be minimized by increasing sample size and averaging data, it’s harder to compensate for systematic error. The best way to avoid systematic error is to be familiar with the limitations of instruments and experienced with their correct use.
Key Takeaways: Random Error vs. Systematic Error
- The two main types of measurement error are random error and systematic error.
- Random error causes one measurement to differ slightly from the next. It comes from unpredictable changes during an experiment.
- Systematic error always affects measurements the same amount or by the same proportion, provided that a reading is taken the same way each time. It is predictable.
- Random errors cannot be eliminated from an experiment, but most systematic errors may be reduced.
Sources
- Bland, J. Martin, and Douglas G. Altman (1996). «Statistics Notes: Measurement Error.» BMJ 313.7059: 744.
- Cochran, W. G. (1968). «Errors of Measurement in Statistics». Technometrics. Taylor & Francis, Ltd. on behalf of American Statistical Association and American Society for Quality. 10: 637–666. doi:10.2307/1267450
- Dodge, Y. (2003). The Oxford Dictionary of Statistical Terms. OUP. ISBN 0-19-920613-9.
- Taylor, J. R. (1999). An Introduction to Error Analysis: The Study of Uncertainties in Physical Measurements. University Science Books. p. 94. ISBN 0-935702-75-X.

Содержание
- Как рассчитать систематическую ошибку?
- Постоянство и соразмерность
- Систематическая ошибка в химии
- Систематическая ошибка в физический
- Примеры eсистематическая ошибка
- Ссылки
В систематическая ошибка Это одна из составляющих ошибок эксперимента или наблюдений (ошибок измерения), которая влияет на точность результатов. Это также известно как детерминированная ошибка, поскольку в большинстве случаев ее можно обнаружить и устранить, не повторяя эксперименты.
Важной характеристикой систематической ошибки является постоянство ее относительной величины; то есть он не зависит от размера выборки или толщины данных. Например, предполагая, что его относительное значение составляет 0,2%, если измерения повторяются в тех же условиях, ошибка всегда будет оставаться 0,2%, пока не будет исправлена.

Как правило, систематическая ошибка возникает из-за неправильного обращения с приборами или из-за технической неисправности аналитика или ученого. Его легко обнаружить, если сравнить экспериментальные значения со стандартным или сертифицированным значением.
Примеры экспериментальной ошибки этого типа возникают, когда аналитические весы, термометры и спектрофотометры не откалиброваны; или в случаях, когда не выполняется хорошее чтение правил, верньеров, градуированных цилиндров или бюреток.
Как рассчитать систематическую ошибку?
Систематическая ошибка влияет на точность, в результате чего экспериментальные значения могут быть выше или ниже фактических результатов. Под реальным результатом или значением понимается результат, который был исчерпывающе проверен многими аналитиками и лабораториями и зарекомендовал себя в качестве эталона сравнения.
Таким образом, сравнивая экспериментальное значение с реальным, получается разница. Чем больше эта разница, тем больше абсолютное значение систематической ошибки.
Например, предположим, что в аквариуме насчитывается 105 рыб, но известно заранее или из других источников, что истинное число составляет 108. Таким образом, систематическая ошибка составляет 3 (108-105). Мы сталкиваемся с систематической ошибкой, если, повторяя подсчет рыб, мы снова и снова получаем 105 рыб.
Однако более важным, чем вычисление абсолютного значения этой ошибки, является определение ее относительного значения:
Относительная погрешность = (108-105) ÷ 108
= 0,0277
Если выражать в процентах, то получается 2,77%. То есть ошибка подсчета имеет вес 2,77% от истинного количества рыбы. Если в аквариуме теперь есть 1000 рыб, и он будет считать их с той же систематической ошибкой, то будет на 28 рыб меньше, чем ожидалось, а не на 3, как это происходит с меньшим аквариумом.
Постоянство и соразмерность
Систематическая ошибка обычно постоянная, аддитивная и пропорциональная. В приведенном выше примере ошибка 2,77% останется постоянной до тех пор, пока измерения будут повторяться в одних и тех же условиях, независимо от размера аквариума (уже соприкасающегося с аквариумом).
Также обратите внимание на пропорциональность систематической ошибки: чем больше размер выборки или толщина данных (или объем аквариума и количество рыб в нем), тем больше систематическая ошибка. Если в аквариуме теперь 3500 рыб, ошибка будет 97 рыб (3500 x 0,0277); абсолютная погрешность увеличивается, но ее относительное значение неизменно, постоянно.
Если число удвоить, на этот раз с 7000 рыб, то ошибка будет 194 рыбы. Таким образом, систематическая ошибка постоянна и пропорциональна.
Это не означает, что необходимо повторить подсчет рыбы: достаточно знать, что определенное количество соответствует 97,23% от общего количества рыбы (100–2,77%). Отсюда истинное количество рыбы можно рассчитать, умножив на коэффициент 100 / 97,23.
Например, если было подсчитано 5200 рыб, то фактическое количество было бы 5 348 рыб (5200 x 100 / 97,23).
Систематическая ошибка в химии
В химии систематические ошибки обычно возникают из-за неправильного взвешивания из-за некалиброванных весов или из-за неправильного считывания объемов стеклянных материалов. Хотя они могут показаться не такими, как это, они влияют на точность результатов, потому что чем их больше, тем больше их негативных эффектов.
Например, если весы плохо откалиброваны, и при определенном анализе необходимо провести несколько взвешиваний, то окончательный результат будет все дальше и дальше от ожидаемого; это будет более неточно. То же самое происходит, если анализ постоянно измеряет объемы бюреткой, показания которой неверны.
Помимо весов и стеклянных материалов, химики также могут ошибаться в обращении с термометрами и pH-метрами, в скорости перемешивания, во времени, необходимом для протекания реакции, в калибровке весов. спектрофотометры, если предполагается высокая чистота образца или реагента и т. д.
Другие систематические ошибки в химии могут быть связаны с изменением порядка добавления реагентов, нагревом реакционной смеси до температуры выше, чем рекомендованная методом, или неправильной перекристаллизацией продукта синтеза.
Систематическая ошибка в физический
В физических лабораториях систематические ошибки носят еще более технический характер: любое оборудование или инструмент без надлежащей калибровки, неправильное поданное напряжение, неправильное расположение зеркал или деталей в эксперименте, добавление слишком большого момента к объекту, который должен упасть. из-за эффекта гравитации, среди других экспериментов.
Обратите внимание на то, что есть систематические ошибки, которые происходят из инструментального несовершенства, а другие, скорее, операционного типа, являются результатом ошибки со стороны аналитика, ученого или отдельного человека, который выполняет какое-либо действие.
Примеры eсистематическая ошибка
Ниже будут упомянуты другие примеры систематических ошибок, которые не обязательно должны происходить в лаборатории или в научной сфере:
— Поместите булочки в нижнюю часть духовки, поджаривая их больше, чем хотелось бы.
-Плохая осанка при сидении
-Закройте горшок для мокко только из-за недостатка прочности
-Не очищайте пароварки кофемашин сразу после текстурирования или нагрева молока.
-Используйте чашки разных размеров, когда вы следуете или хотите повторить определенный рецепт
-Хотите дозировать солнечную радиацию в тенистые дни
— Выполняйте подтягивания на перекладине, подняв плечи к ушам.
-Играйте несколько песен на гитаре без предварительной настройки струн
-Жарить оладьи с недостаточным количеством масла в казане
-Проведите последующее объемное титрование без повторной стандартизации раствора титранта
Ссылки
- Дэй Р. и Андервуд А. (1986). Количественная аналитическая химия. (Пятое изд.). ПИРСОН Прентис Холл.
- Хельменстин, Энн Мари, доктор философии (11 февраля 2020 г.). Случайная ошибка vs. Систематическая ошибка. Получено с: thinkco.com
- Bodner Research Web. (н.д.). Ошибки. Получено с: chemed.chem.purdue.edu
- Elsevier B.V. (2020). Систематическая ошибка. ScienceDirect. Получено с: sciencedirect.com
- Сепульведа, Э. (2016). Систематические ошибки. Получено из Physics Online: fisicaenlinea.com
- Мария Ирма Гарсиа Ордас. (н.д.). Проблемы с ошибкой измерения. Автономный университет штата Идальго. Получено с: uaeh.edu.mx
- Википедия. (2020). Ошибка наблюдения. Получено с: en.wikipedia.org
- Джон Спейси. (2018, 18 июля). 7 видов систематической ошибки. Получено с: simplicable.com

- Разница между случайной ошибкой и систематической ошибкой
Разница между случайной ошибкой и систематической ошибкой
Ошибка определяется как разница между фактическим или истинным значением и измеренным значением. Измерение количества или стоимости основано на каком-то стандарте. Измерение любого количества осуществляется путем сравнения его с производным стандартом, который не является полностью точным. Чтобы понять ошибки в измерении, следует понимать два термина, которые определяют ошибку, и они являются истинным значением и измеренным значением. Истинное значение невозможно выяснить, оно может быть определено по среднему значению бесконечного числа. Измеренное значение определяется как оценочное значение истинного значения путем взятия нескольких измеренных значений. Ошибка не должна быть перепутана с ошибкой, ошибки можно избежать, но ошибки не избежать, но их можно минимизировать. Так что ошибка не является ошибкой его части измерительной обработки. Измерение — это разница между измеренным значением количества и его истинным значением. мы обсудим случайную ошибку и систематическую ошибку. Погрешности измерения делятся на два обширных класса ошибок.
- Случайная ошибка
- Систематическая ошибка
Случайная ошибка:
Случайная ошибка — это не что иное, как колебания в измерении, которые в основном наблюдаются путем проведения нескольких испытаний данного измерения. Как следует из названия, эта ошибка происходит совершенно случайно. Они непредсказуемы и не могут быть воспроизведены путем повторения эксперимента снова. Так что каждый раз это дает разные результаты. Случайная ошибка варьируется от наблюдения к другому. При случайной ошибке колебание может быть как отрицательным, так и положительным. Не всегда возможно определить источник случайной ошибки. Случайная ошибка происходит из-за фактора, который не может или не будет контролироваться. Случайная ошибка влияет на достоверность результатов. Некоторые из возможных источников или причин случайных ошибок перечислены ниже.
- Наблюдение: ошибка в суждении наблюдателя.
- Небольшие помехи: Небольшие помехи могут привести к ошибкам измерения, например
- Колеблющиеся условия: Некоторое изменение температуры во времени или в окружающей среде может привести к ошибке в измерении.
- Качество: Некоторое время, когда качество объекта, измерение которого должно быть выполнено, не определено должным образом, приводит к ошибке.
Ошибка может быть уменьшена, если взять число чтений, а затем найти среднее или среднее значение чтения.
Систематическая ошибка:
Систематическая ошибка — это когда одна и та же ошибка присутствует во всех показаниях. Систематическая ошибка предсказуема и обычно постоянна или пропорциональна истинному значению. Таким образом, систематическая ошибка повторяется каждый раз, и это приводит к ошибкам согласованности. Если мы повторим эксперимент, мы получим одну и ту же ошибку каждый раз. Систематические ошибки возникают из-за неправильной калибровки прибора. Систематическая ошибка влияет на точность результата. Систематическая ошибка также называется нулевой ошибкой, положительной или отрицательной ошибкой. Некоторые из возможных источников или причин систематической ошибки перечислены ниже.
- Инструментальная ошибка: оборудование, используемое для измерения объекта, может быть не совсем точным.
- Экологическая ошибка: ошибка возникает из-за изменений условий окружающей среды, таких как влажность, давление, температура и т. Д.
- Наблюдательная ошибка: ошибка в записи данных, также называемая человеческими ошибками. После выявления систематической ошибки она может быть в некоторой степени уменьшена. Систематическая ошибка может быть сведена к минимуму путем регулярной калибровки оборудования, использования элементов управления и сравнения значений со стандартным значением.
Сравнение между случайными ошибками и значением систематической ошибки (инфографика)
Ниже приведено 8 основных различий между случайной ошибкой и систематической ошибкой 
Ключевые различия между случайной ошибкой и систематической ошибкой
Давайте обсудим некоторые основные различия между случайной ошибкой и систематической ошибкой
- Случайная ошибка непредсказуема и возникает из-за неизвестных источников, тогда как систематическая ошибка является предсказуемой и возникает из-за дефекта прибора, который используется для измерения.
- Случайная ошибка возникает в обоих направлениях, тогда как систематическая ошибка возникает только в одном направлении.
- Случайная ошибка не может быть устранена, но большинство систематических ошибок может быть уменьшено.
- Случайная ошибка является уникальной и не имеет определенного типа, тогда как систематическая ошибка имеет 3 типа, как указано в таблице выше.
- Систематическую ошибку трудно обнаружить, это происходит из-за одних и тех же результатов каждый раз и не осознает, что проблема вообще существует, тогда как случайную ошибку легко обнаружить из-за разных результатов каждый раз.
Сравнительная таблица случайных ошибок и систематических ошибок
Ниже приведено 8 лучших сравнений между случайной ошибкой и систематической ошибкой.
| Основное сравнение между случайной ошибкой и систематической ошибкой | Случайная ошибка | Систематическая ошибка |
| Определение | Это происходит из-за неопределенных изменений в окружающей среде и колеблется каждый раз при измерении. | Это постоянная ошибка и остается неизменной для всех измерений. |
| Свести к минимуму | Путем многократного взятия показаний и расчета среднего или среднего из повторных показаний. | Сравнивая значение со стандартным значением и улучшая структуру оборудования. |
| Величина ошибки | Каждый раз дают другой результат, который меняется каждый раз. | Результат остается неизменным или постоянным каждый раз. |
| Направление ошибки | Это происходит в обоих направлениях. | Это происходит в том же направлении. |
|
Подтип ошибки |
Нет подтипов | Подтипы Инструмент, Среда и Систематическая Ошибка. |
| воспроизводимый | Невоспроизводимый. | Воспроизводимые. |
| Значение | Цена представляет собой сочетание стоимости. | Затраты снижаются, когда они сравниваются со стоимостью в стоимостном выражении. |
| Пример ошибки | Время реакции, погрешность измерения из-за недостаточной точности, погрешность параллакса (если каждый раз смотреть под случайным углом) | Ошибка шкалы, ошибка нуля, ошибка параллакса (если диск виден под тем же углом) |
Выводы
Таким образом, случайная ошибка в основном возникает из-за каких-либо возмущений в окружающей среде, таких как колебания или различия в давлении, температуре или из-за наблюдателя, который может принять неправильные показания, в то время как систематическая ошибка возникает из-за механической структуры прибора. Случайная ошибка не может быть предотвращена, в то время как систематическая ошибка может быть предотвращена. Полное устранение обеих ошибок невозможно. Основное различие между случайными ошибками и систематическими ошибками заключается в том, что случайная ошибка в основном приводит к колебаниям, тогда как систематические ошибки приводят к предсказуемому и последовательному результату. При работе с промышленными приборами важно, чтобы оператор тщательно следил за экспериментом, чтобы погрешность измерения могла быть уменьшена.
Рекомендуемые статьи
Это было руководство к разнице между случайной ошибкой и систематической ошибкой. Здесь мы также обсудим различия между случайной ошибкой и систематической ошибкой с помощью инфографики и сравнительной таблицы. Вы также можете взглянуть на следующие статьи, чтобы узнать больше.
- Экономический рост против экономического развития
- Бухгалтерский учет и финансовый менеджмент
- Покупка активов против покупки акций
- Ангел Инвестор против Венчурного Капитала
Если вы устраняете систематическую ошибку модели, то уже слишком поздно
Время на прочтение
7 мин
Количество просмотров 5.5K

Введение
Машинное обучение — это технологический прорыв, случающийся раз в поколение. Однако с ростом его популярности основной проблемой становятся систематические ошибки алгоритма. Если модели ML не обучаются на репрезентативных данных, у них могут развиться серьёзные систематические ошибки, оказывающие существенный вред недостаточно представленным группам и приводящие к созданию неэффективных продуктов. Мы изучили массив данных CoNLL-2003, являющийся стандартом для создания алгоритмов распознавания именованных сущностей в тексте, и выяснили, что в данных присутствует серьёзный перекос в сторону мужских имён. При помощи наших технологии мы смогли компенсировать эту систематическую ошибку:
- Мы обогатили данные, чтобы выявить сокрытые систематические ошибки
- Дополнили массив данных недостаточно представленными примерами, чтобы компенсировать гендерный перекос
Модель, обученная на нашем расширенном массиве данных CoNLL-2003, характеризуется снижением систематической ошибки и повышенной точностью, и это показывает, что систематическую ошибку можно устранить без каких-либо изменений в модели. Мы выложили в open source наши аннотации Named Entity Recognition для исходного массива данных CoNLL-2003, а также его улучшенную версию, скачать их можно здесь.
Систематическая ошибка алгоритма: слабое место ИИ
Сегодня тысячи инженеров и исследователей создают системы, самостоятельно обучающиеся тому, как достигать существенных прорывов — повышать безопасность на дорогах при помощи беспилотных автомобилей, лечить болезни оптимизированными ИИ процедурами, бороться с изменением климата при помощи управления энергопотреблением.
Однако сила самообучающихся систем является и их слабостью. Так как фундаментом всех процессов машинного обучения являются данные, обучение на несовершенных данных может привести к искажённым результатам.
ИИ-системы имеют большие полномочия, поэтому они могут наносить существенный ущерб. Недавние протесты против полицейской жестокости, приведшей к смертям Джорджа Флойда, Бреонны Тейлор, Филандо Кастиле, Сандры Блэнд и многих других, является важным напоминанием о систематическом неравенстве в нашем обществе, которое не должны усугублять ИИ-системы. Но нам известны многочисленные примеры (закрепляющие гендерные стереотипы результаты поиска картинок, дискриминация чёрных подсудимых в системах управления данными нарушителей и ошибочная идентификация цветных людей системами распознавания лиц), показывающие, что предстоит пройти долгий путь, прежде чем проблема систематических ошибок ИИ будет решена.
Распространённость ошибок вызвана лёгкостью их внесения. Например, они проникают в «золотые стандарты» моделей и массивов данных в open source, ставшие фундаментом огромного объёма работы в сфере ML. Массив данных для определения эмоционального настроя текста word2vec, используемый в построении моделей других языков, искажён по этнической принадлежности, а word embeddings — способ сопоставления слов и значений алгоритмом ML — содержит сильно искажённые допущения о занятиях, с которыми ассоциируются женщины.
Проблема (и, как минимум, часть её решения) лежит в данных. Чтобы проиллюстрировать это, мы провели эксперимент с одним из самых популярных массивов данных для построения систем распознавания именованных сущностей в тексте: CoNLL-2003.
Что такое «распознавание именованных сущностей»?
Распознавание именованных сущностей (Named-Entity Recognition, NER) — один из фундаментальных камней моделей естественных языков, без него были бы невозможны онлайн-поиск, извлечение информации и анализ эмоционального настроя текста.
Миссия нашей компании заключается в ускорении разработки ИИ. Естественный язык — одна из основных сфер наших интересов. Наш продукт Scale Text содержит NER, заключающееся в аннотировании текста согласно заданному списку меток. На практике, среди прочего, это может помочь крупным розничным сетям анализировать онлайн-обсуждение их продуктов.
Многие модели NER обучаются и подвергаются бенчмаркам на CoNLL-2003 — массиве данных из примерно 20 тысяч предложений новостных статей Reuters, аннотированных такими атрибутами, как «PERSON», «LOCATION» и «ORGANIZATION».
Нам захотелось изучить эти данные на наличие систематических ошибок. Для этого мы воспользовались своим конвейером разметки, чтобы категоризировать все имена в массиве данных, размечая их как мужские, женские или гендерно-нейтральные, исходя из традиционного использования имён.
При этом мы выявили существенную разницу. Мужские имена упоминались почти в пять раз чаще женских, и менее 2% имён были гендерно-нейтральными:

Это вызвано тем, что по социальным причинам новостные статьи в основном содержат мужские имена. Однако из-за этого модель NER, обученная на таких данных, лучше будет справляться с выбором мужских имён, чем женских. Например, поисковые движки используют модели NER для классификации имён в поисковых запросах, чтобы выдавать более точные результаты. Но если внедрить модель NER с перекосом, то поисковый движок хуже будет идентифицировать женские имена по сравнению с мужскими, и именно подобная малозаметная распространённая систематическая ошибка может проникнуть во многие системы реального мира.
Новый эксперимент по снижению систематической ошибки
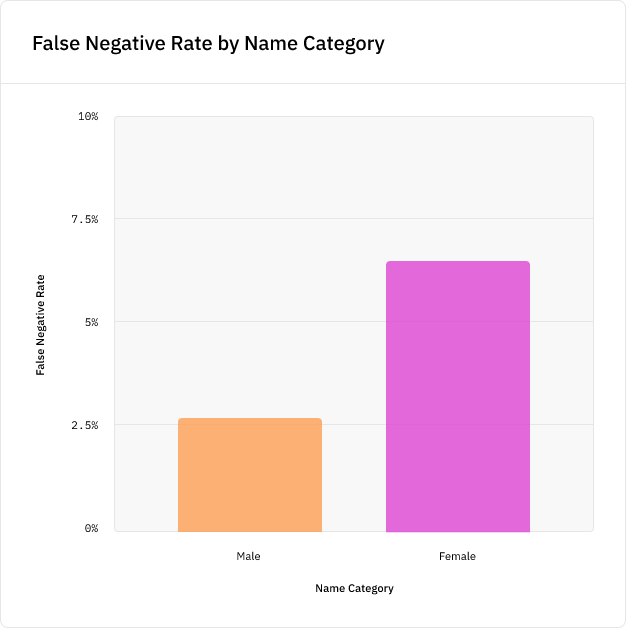
Чтобы проиллюстрировать это, мы обучили модель NER для изучения того, как этот гендерный перекос повлияет на её точность. Был создан алгоритм извлечения имён, выбирающий метки PERSON при помощи популярной NLP-библиотеки spaCy, и на подмножестве данных CoNLL была обучена модель. Затем мы протестировали модель на новых именах из тестовых данных, не присутствовавших в данных обучения, и обнаружили, что модель с вероятностью на 5% больше пропустит новое женское имя, чем новое мужское имя, а это серьёзное расхождение в точности:
Мы наблюдали схожие результаты, когда применили модель к шаблону «NAME is a person», подставив 100 самых популярных мужских и женских имён на каждый год переписи населения США. Результаты работы модели оказались значительно хуже для женских имён во все года переписи:
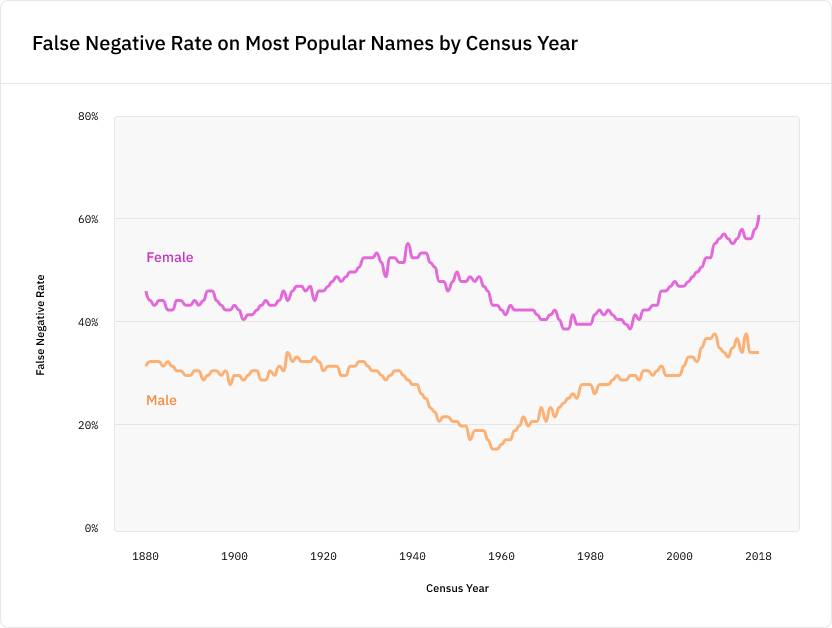
Критически важно то, что наличие перекоса в данных обучения приводит к смещению ошибок в сторону недостаточно представленных категорий. Эксперимент с переписями демонстрирует это и другим образом: точность модели существенно деградирует после 1997 года (точки отсечения статей Reuters в массиве данных CoNLL), потому что массив данных больше не является репрезентативным отображением популярности имён каждого последующего года.
Модели обучаются соответствовать трендам данных, на которых они обучены. Нельзя ожидать их хорошей точности в случаях, когда они видели лишь малое количество примеров.
Если вы исправляете систематическую ошибку модели, то уже слишком поздно
Как же это исправить?
Один из способов — попробовать устранить систематическую ошибку модели, например, выполнив постобработку модели или добавив целевую функцию для смягчения перекоса, оставив определение подробностей самой модели.
Но это не лучший подход по множеству причин:
- Справедливость — это очень сложная проблема, и мы не можем ждать, что алгоритм решит её сам. Исследование показало, что обучение алгоритма на одинаковый уровень точности для всех подмножеств населения не обеспечит справедливости и нанесёт вред обучению модели.
- Добавление новых целевых функций может навредить точности модели, приводя к негативному побочному эффекту. Вместо этого лучше обеспечить простоту алгоритма и сбалансированность данных, что повысит точность модели и позволит избежать негативных эффектов.
- Неразумно ожидать, что модель покажет хорошие результаты в случаях, примеров которых она видела очень мало. Наилучший способ обеспечения хороших результатов заключается в повышении разнообразия данных.
- Попытки устранения систематической ошибки при помощи инженерных техник — это дорогой и длительный процесс. Гораздо дешевле и проще изначально обучать модели на данных без перекосов, освободив ресурсы инженеров для работы над реализацией.
Данные — это лишь одна часть проблемы систематических ошибок. Однако эта часть фундаментальна и влияет на всё, что идёт после неё. Именно поэтому мы считаем, что данные содержат ключ к частичному решению, обеспечивая потенциальные систематические улучшения в исходных материалах. Если вы не размечаете критические классы (например, гендер или этническую принадлежность) явным образом, то невозможно сделать так, чтобы эти классы не были источником систематической ошибки.
Такая ситуация контринтуитивна. Кажется, что если нам нужно построить модель, не зависящую от чувствительных характеристик наподобие гендера, возраста или этнической принадлежности, то лучше исключить эти свойства из данных обучения, чтобы модель не могла их учитывать.
Однако принцип «справедливости, реализуемой через неведение» на самом деле усугубляет проблему. Модели ML превосходно справляются с выводом заключений из признаков, они не прекращают делать этого, если мы не разметили эти признаки явным образом. Систематические ошибки просто остаются невыявленными, из-за чего их сложнее устранить.
Единственный надёжный способ решения проблемы заключается в разметке большего количества данных, чтобы сбалансировать распределение имён. Мы использовали отдельную модель ML для идентификации предложений в корпусах Reuters и Brown, с большой вероятностью содержащих женские имена, а затем разметили эти предложения в нашем конвейере NER, чтобы дополнить CoNLL.
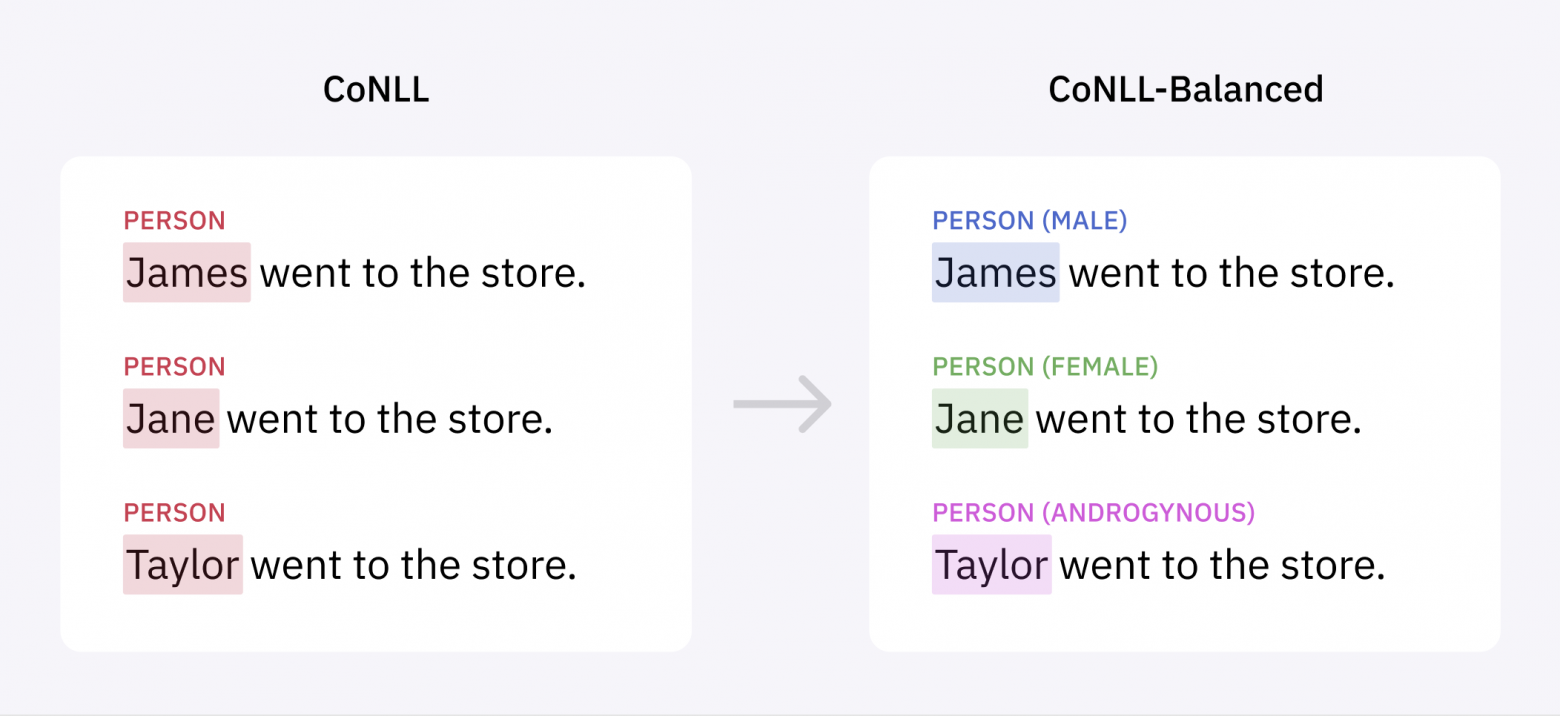
Получившийся массив данных, который мы назвали CoNLL-Balanced, содержит на 400 с лишним больше женских имён. После повторного обучения на нём модели NER мы обнаружили, что алгоритм больше не имеет систематической ошибки, приводящей к снижению показателей при распознавании женских имён:

Кроме того, модель улучшила показатели и при распознавании мужских имён.
Это стало впечатляющей демонстрацией важности данных. Благодаря устранению перекоса в исходном материале нам не пришлось вносить никаких изменений в нашу модель ML, что позволило сэкономить на времени разработки. И мы достигли этого без негативного влияния на точность модели; на самом деле, она даже слегка увеличилась.
Чтобы позволить сообществу разработчиков развивать нашу работу и устранять гендерный перекос в моделях, построенных на основе CoNLL-2003, мы выложили на наш веб-сайте дополненный массив данных в open source, в том числе и добавив гендерную информацию.
Сообщество разработчиков ИИ/ML имеет проблемы с культурными различиями, но мы испытываем умеренный оптимизм от этих результатов. Они намекают на то, что мы, возможно, сможем предложить техническое решение насущной социальной проблемы, если займёмся проблемой сразу же, выявим сокрытые систематические ошибки и улучшим точность модели для всех.
Сейчас мы изучаем, как этот подход можно применить к ещё одному критичному атрибуту — этнической принадлежности — чтобы придумать, как создать надёжную систему для устранения перекоса в массивах данных, распространяющегося и на другие охраняемые от дискриминации категории населения.
Кроме того, это показывает, почему наша компания уделяет так много внимания качеству данных. Если нельзя доказать, что данные точны, сбалансированы и лишены систематических ошибок, то нет гарантии того, что создаваемые на их основе модели будут безопасными и точными. А без этого мы не сможем создавать качественно новых ИИ-технологий, идущих на пользу всем людям.
Благодарности
Упоминаемый в этом посте массив данных CoNLL 2003 — это тестовый набор Reuters-21578, Distribution 1.0, доступный для скачивания на странице проекта исходного эксперимента 2003 года: https://www.clips.uantwerpen.be/conll2003/ner/.