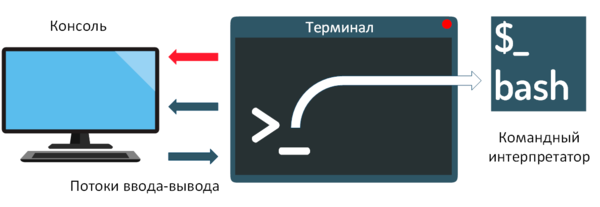
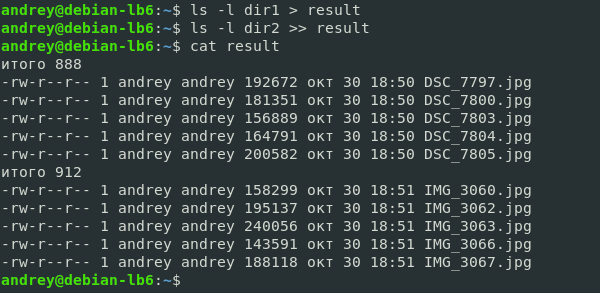
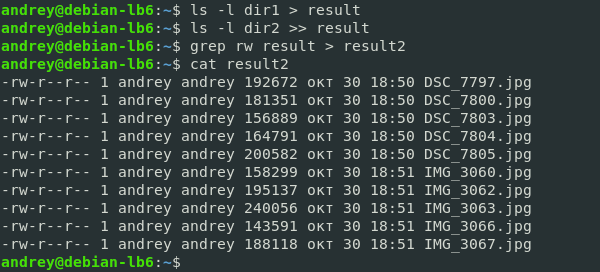
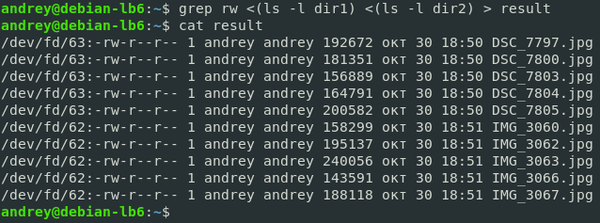
Часто возникает необходимость, чтобы скрипт командного интерпретатора Bash выводил результат своей работы. По умолчанию он отображает стандартный поток данных — окно терминала. Это удобно для обработки результатов небольшого объёма или, чтобы сразу увидеть необходимые данные.
В интерпретаторе можно делать вывод в файл Bash. Применяется это для отложенного анализа или сохранения массивного результата работы сценария. Чтобы сделать это, используется перенаправление потока вывода с помощью дескрипторов.
Стандартные дескрипторы вывода
В системе GNU/Linux каждый объект является файлом. Это правило работает также для процессов ввода/вывода. Каждый файловый объект в системе обозначается дескриптором файла — неотрицательным числом, однозначно определяющим открытые в сеансе файлы. Один процесс может открыть до девяти дескрипторов.
В командном интерпретаторе Bash первые три дескриптора зарезервированы для специального назначения:
| Дескриптор | Сокращение | Название |
|---|---|---|
| 0 | STDIN | Стандартный ввод |
| 1 | STDOUT | Стандартный вывод |
| 2 | STDERR | Стандартный вывод ошибок |
Их предназначение — обработка ввода/вывода в сценариях. По умолчанию стандартным потоком ввода является клавиатура, а вывода — терминал. Рассмотрим подробно последний.
1. Перенаправление стандартного потока вывода
Для того, чтобы перенаправить поток вывода с терминала в файл, используется знак «больше» (>).
#!/bin/bash
echo "Строка 1"
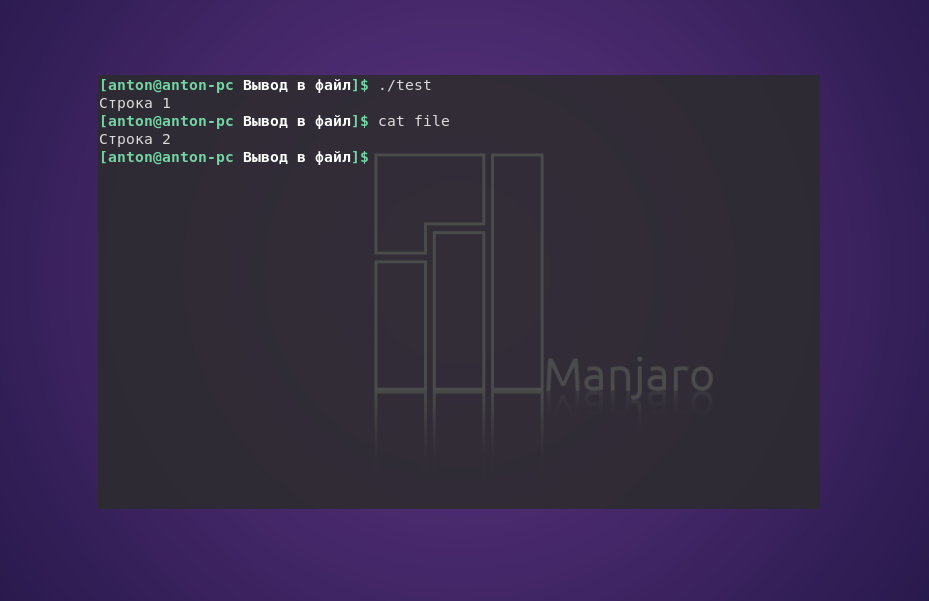
echo "Промежуточная строка" > file
echo "Строка 2" > file
Как результат, «Строка 1» выводится в терминале, а в файл file записывается только «Строка 2»:
Связано это с тем, что > перезаписывает файл новыми данными. Для того, чтобы дописать информацию в конец файла, используется два знака «больше» (>>).
#!/bin/bash
echo "Строка 1"
echo "Промежуточная строка" > file
echo "Строка 2" >> file
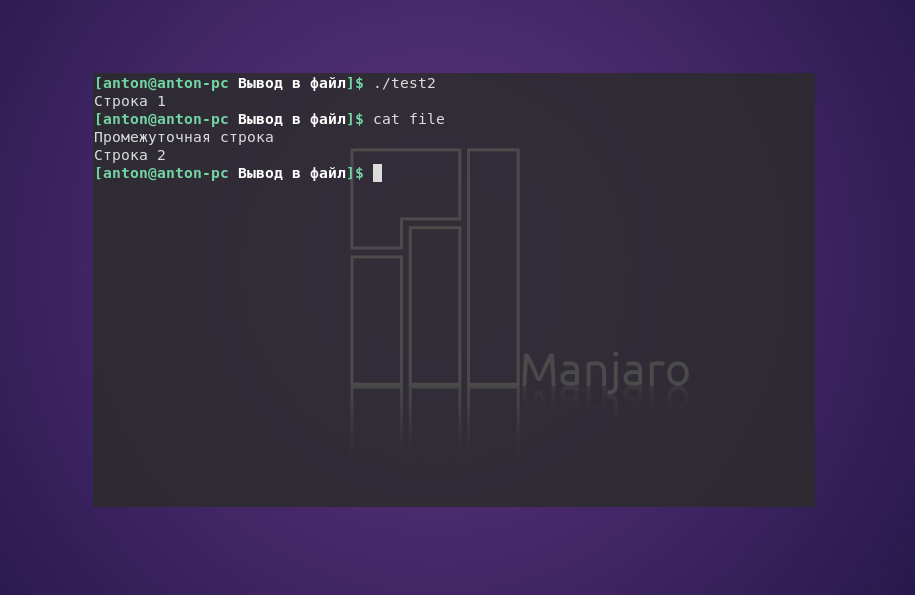
Здесь «Промежуточная строка» перезаписала предыдущее содержание file, а «Строка 2» дописалась в его конец.
Если во время использования перенаправления вывода интерпретатор обнаружит ошибку, то он не запишет сообщение о ней в файл.
#!/bin/bash
ls badfile > file2
echo "Строка 2" >> file2
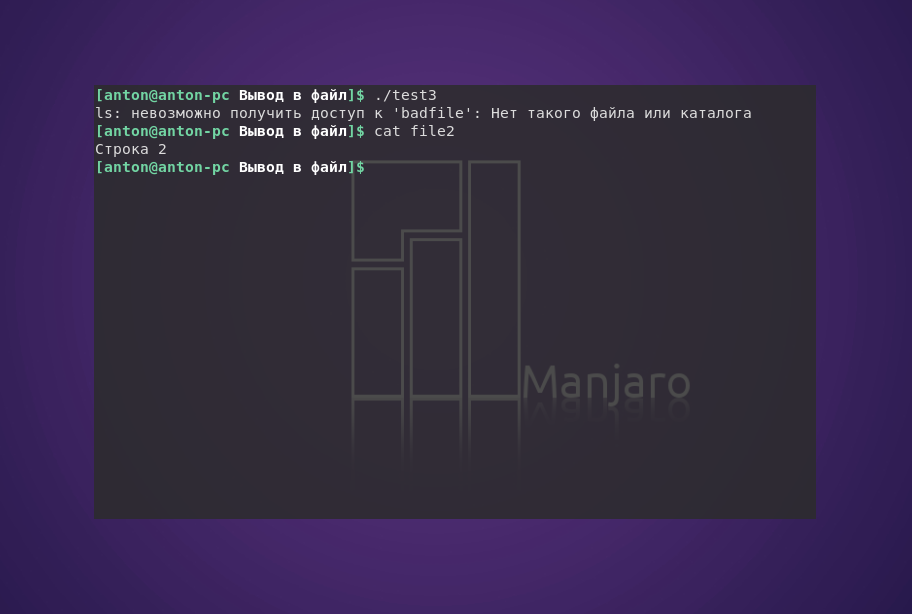
В данном случае ошибка была в том, что команда ls не смогла найти файл badfile, о чём Bash и сообщил. Но вывелось сообщение в терминал, а не записалось в файл. Всё потому, что использование перенаправления потоков указывает интерпретатору отделять мух от котлет ошибки от основной информации.
Это особенно полезно при выполнении сценариев в фоновом режиме, где приходится предусматривать вывод сообщений в журнал. Но так как ошибки в него писаться не будут, нужно отдельно перенаправлять поток ошибок для того, чтобы выполнить их вывод в файл Linux.
2. Перенаправление потока ошибок
В командном интерпретаторе для обработки сообщений об ошибках предназначен дескриптор STDERR, который работает с ошибками, сформированными как от работы интерпретатора, так и самим скриптом.
По умолчанию STDERR указывает в то же место, что и STDOUT, хотя для них и предназначены разные дескрипторы. Но, как было показано в примере, использование перенаправления заставляет Bash разделить эти потоки.
Чтобы выполнить перенаправление вывода в файл Linux для ошибок, следует перед знаком«больше» указать дескриптор 2.
#!/bin/bash
ls badfile 2> errors
echo "Строка 1" > file3
echo "Строка 2" >> file3
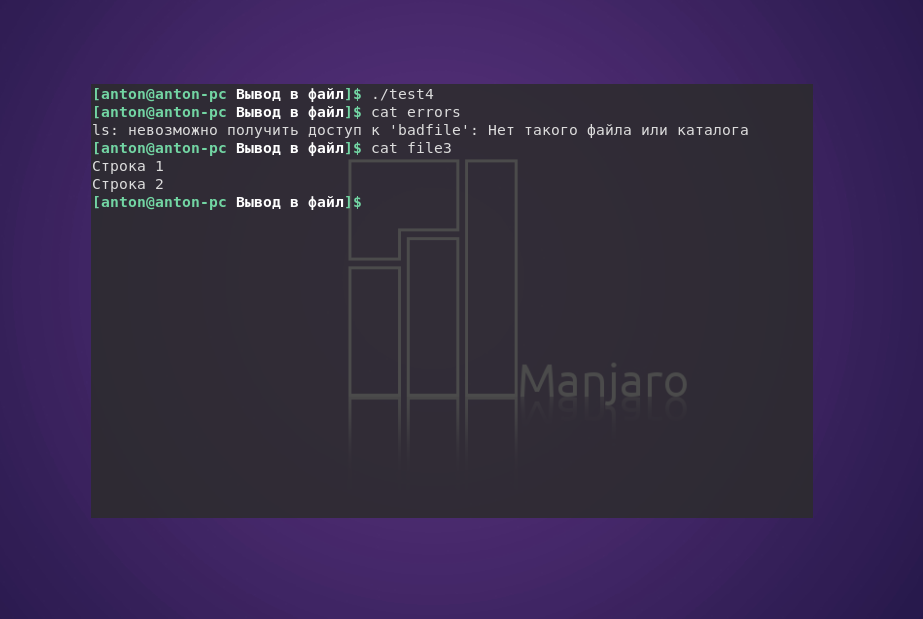
В результате работы скрипта создан файл errors, в который записана ошибка выполнения команды ls, а в file3 записаны предназначенные строки. Таким образом, выполнение сценария не сопровождается выводом информации в терминал.
Пример того, как одна команда возвращает и положительный результат, и ошибку:
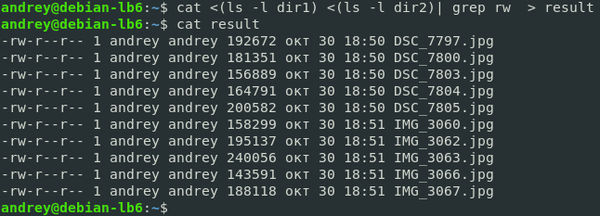
ls -lh test badtest 2> errors
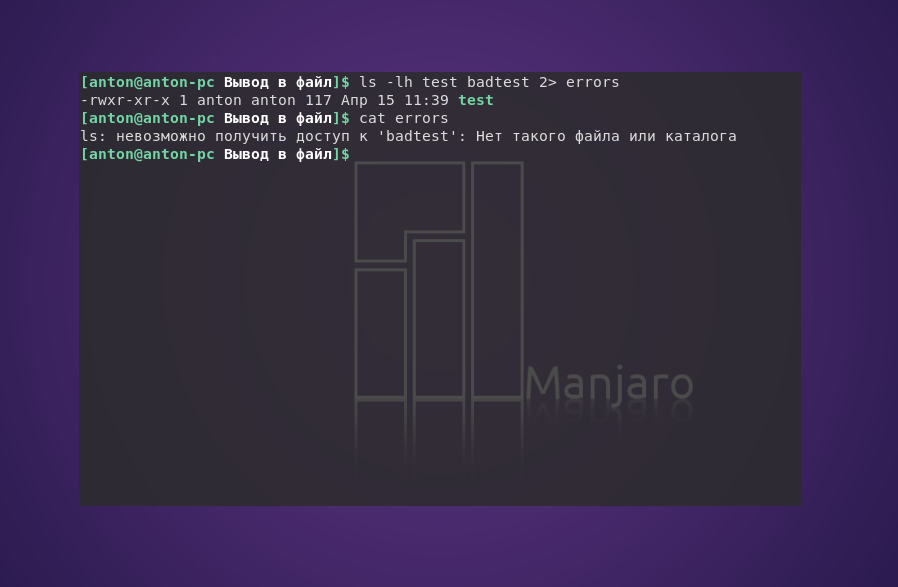
Команда ls попыталась показать наличие файлов test и badtest. Первый присутствовал в текущем каталоге, а второй — нет. Но сообщение об ошибке было записано в отдельный файл.
Если возникает необходимость выполнить вывод команды в файл Linux, включая её стандартный поток вывода и ошибки, стоит использовать два символа перенаправления, перед которыми стоит указывать необходимый дескриптор.
ls -lh test test2 badtest 2> errors 1> output

Результат успешного выполнения записан в файл output, а сообщение об ошибке — в errors.
По желанию можно выводить и ошибки, и обычные данные в один файл, используя &>.
ls -lh test badtest &> output
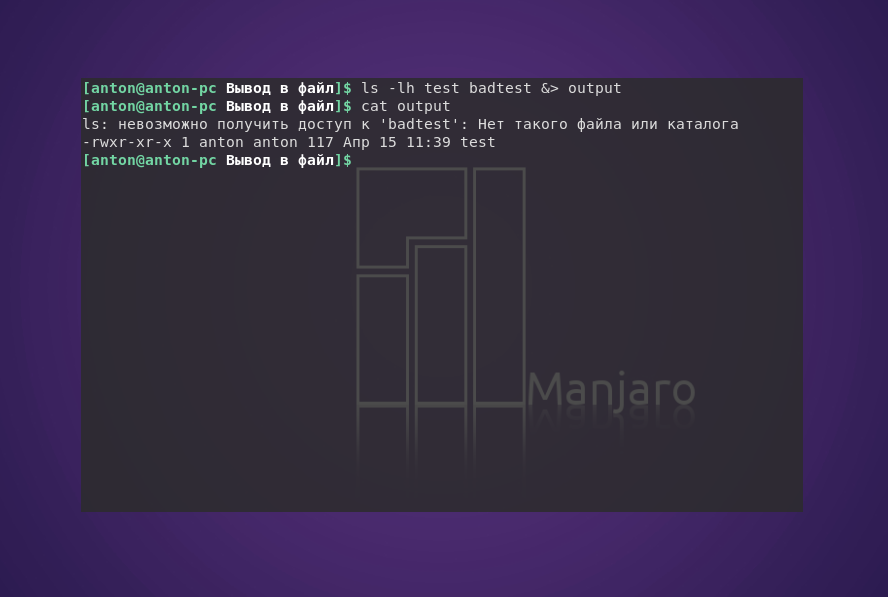
Обратите внимание, что Bash присваивает сообщениям об ошибке более высокий приоритет по сравнению с данными, поэтому в случае общего перенаправления ошибки всегда будут располагаться в начале.
Временные перенаправления в скриптах
Если есть необходимость в преднамеренном формировании ошибок в сценарии, можно каждую отдельную строку вывода перенаправлять в STDERR. Для этого достаточно воспользоваться символом перенаправления вывода, после которого нужно использовать & и номер дескриптора, чтобы перенаправить вывод в STDERR.
#!/bin/bash
echo "Это сообщение об ошибке" >&2
echo "Это нормальное сообщение"
При выполнении программы обычно нельзя будет обнаружить отличия:
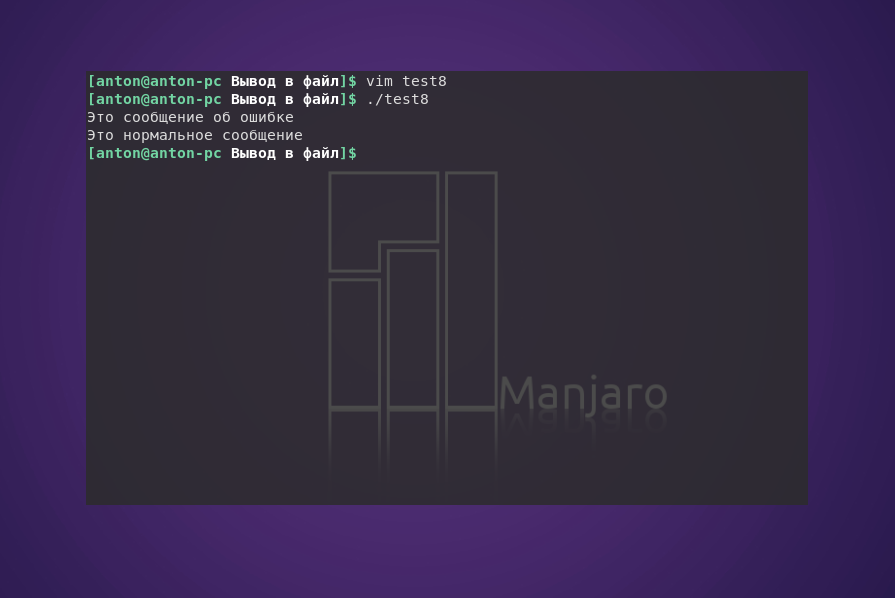
Вспомним, что GNU/Linux по умолчанию направляет вывод STDERR в STDOUT. Но если при выполнении скрипта будет перенаправлен поток ошибок, то Bash, как и полагается, разделит вывод.
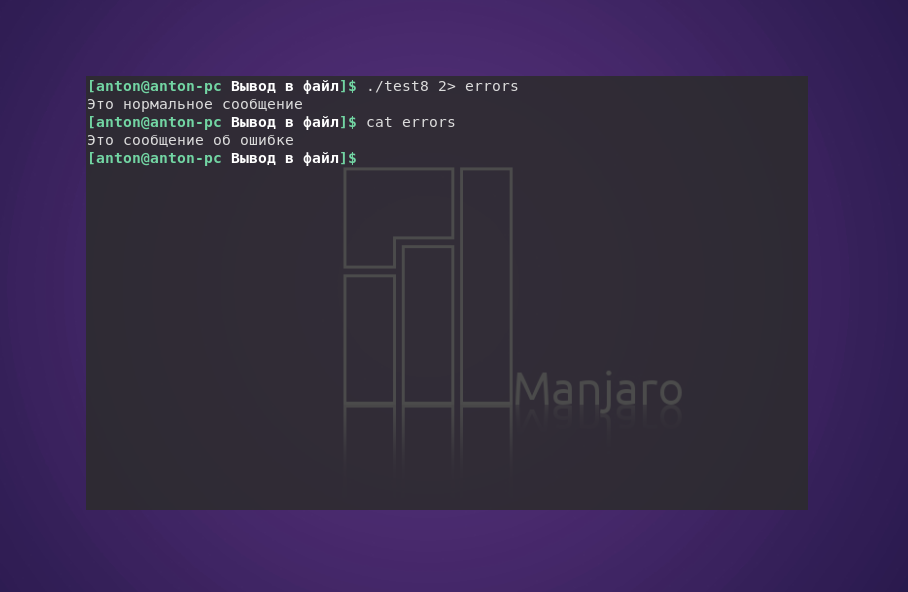
Этот метод хорошо подходит для создания собственных сообщений об ошибках в сценариях.
Постоянные перенаправления в скриптах
Если в сценарии необходимо перенаправить вывод в файл Linux для большого объёма данных, то указание способа вывода в каждой инструкции echo будет неудобным и трудоёмким занятием. Вместо этого можно указать, что в ходе выполнения данного скрипта должно осуществляться перенаправление конкретного дескриптора с помощью команды exec:
#!/bin/bash
exec 1> testout
echo "Это тест перенаправления всего вывода"
echo "из скрипта в другой файл"
echo "без использования временного перенаправления"
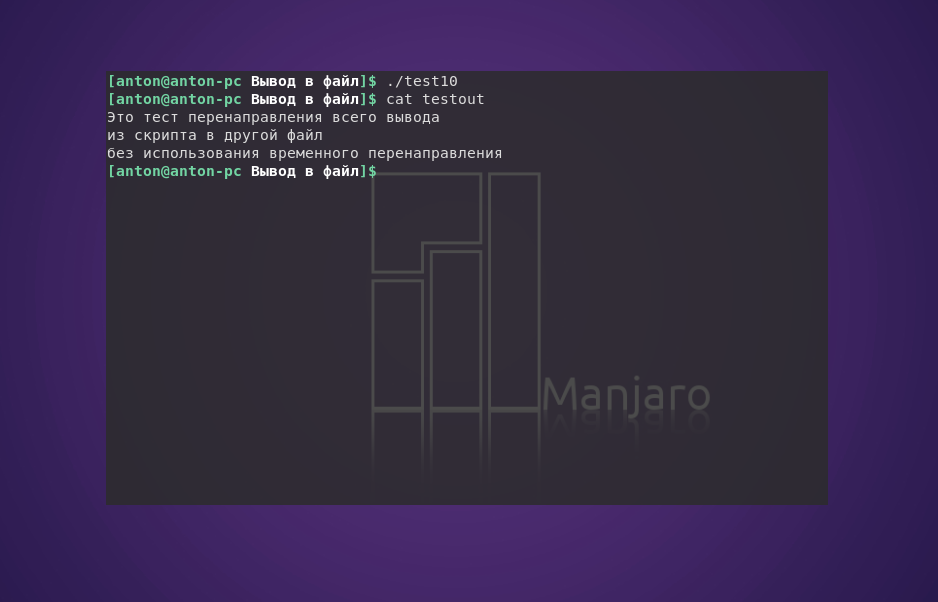
Вызов команды exec запускает новый командный интерпретатор и перенаправляет стандартный вывод в файл testout.
Также существует возможность перенаправлять вывод (в том числе и ошибок) в произвольном участке сценария:
#!/bin/bash
exec 2> testerror
echo "Это начально скрипта"
echo "И это первые две строки"
exec 1> testout
echo "Вывод сценария перенаправлен"
echo "из с терминала в другой файл"
echo "но эта строка записана в файл ошибок" >&2
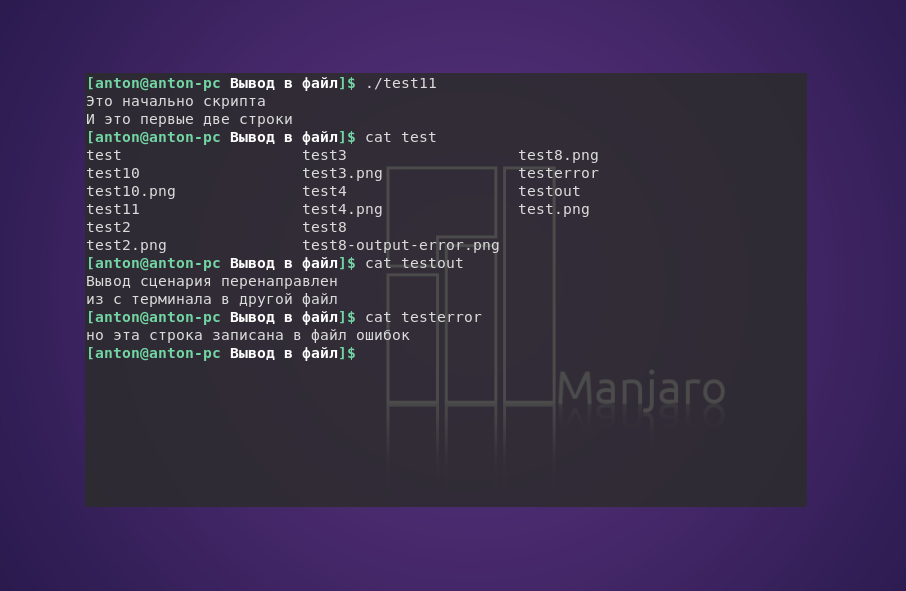
Такой метод часто применяется при необходимости перенаправить лишь часть вывода скрипта в другое место, например в журнал ошибок.
Выводы
Перенаправление в скриптах Bash, чтобы выполнить вывод в файл Bash, является хорошим средством ведения различных журналов, особенно в фоновом режиме.
Использование временного и постоянного перенаправлений в сценариях позволяет создавать собственные сообщения об ошибках для записи в отличное от STDOUT место.
Обнаружили ошибку в тексте? Сообщите мне об этом. Выделите текст с ошибкой и нажмите Ctrl+Enter.

Статья распространяется под лицензией Creative Commons ShareAlike 4.0 при копировании материала ссылка на источник обязательна .
Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
В прошлый раз, в третьей части этой серии материалов по bash-скриптам, мы говорили о параметрах командной строки и ключах. Наша сегодняшняя тема — ввод, вывод, и всё, что с этим связано.


Вы уже знакомы с двумя методами работы с тем, что выводят сценарии командной строки:
- Отображение выводимых данных на экране.
- Перенаправление вывода в файл.
Иногда что-то надо показать на экране, а что-то — записать в файл, поэтому нужно разобраться с тем, как в Linux обрабатывается ввод и вывод, а значит — научиться отправлять результаты работы сценариев туда, куда нужно. Начнём с разговора о стандартных дескрипторах файлов.
Стандартные дескрипторы файлов
Всё в Linux — это файлы, в том числе — ввод и вывод. Операционная система идентифицирует файлы с использованием дескрипторов.
Каждому процессу позволено иметь до девяти открытых дескрипторов файлов. Оболочка bash резервирует первые три дескриптора с идентификаторами 0, 1 и 2. Вот что они означают.
0,STDIN —стандартный поток ввода.1,STDOUT —стандартный поток вывода.2,STDERR —стандартный поток ошибок.
Эти три специальных дескриптора обрабатывают ввод и вывод данных в сценарии.
Вам нужно как следует разобраться в стандартных потоках. Их можно сравнить с фундаментом, на котором строится взаимодействие скриптов с внешним миром. Рассмотрим подробности о них.
STDIN
STDIN — это стандартный поток ввода оболочки. Для терминала стандартный ввод — это клавиатура. Когда в сценариях используют символ перенаправления ввода — <, Linux заменяет дескриптор файла стандартного ввода на тот, который указан в команде. Система читает файл и обрабатывает данные так, будто они введены с клавиатуры.
Многие команды bash принимают ввод из STDIN, если в командной строке не указан файл, из которого надо брать данные. Например, это справедливо для команды cat.
Когда вы вводите команду cat в командной строке, не задавая параметров, она принимает ввод из STDIN. После того, как вы вводите очередную строку, cat просто выводит её на экран.
STDOUT
STDOUT — стандартный поток вывода оболочки. По умолчанию это — экран. Большинство bash-команд выводят данные в STDOUT, что приводит к их появлению в консоли. Данные можно перенаправить в файл, присоединяя их к его содержимому, для этого служит команда >>.
Итак, у нас есть некий файл с данными, к которому мы можем добавить другие данные с помощью этой команды:
pwd >> myfile
То, что выведет pwd, будет добавлено к файлу myfile, при этом уже имеющиеся в нём данные никуда не денутся.
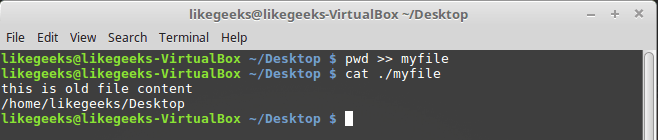
Перенаправление вывода команды в файл
Пока всё хорошо, но что если попытаться выполнить что-то вроде показанного ниже, обратившись к несуществующему файлу xfile, задумывая всё это для того, чтобы в файл myfile попало сообщение об ошибке.
ls –l xfile > myfileПосле выполнения этой команды мы увидим сообщения об ошибках на экране.

Попытка обращения к несуществующему файлу
При попытке обращения к несуществующему файлу генерируется ошибка, но оболочка не перенаправила сообщения об ошибках в файл, выведя их на экран. Но мы-то хотели, чтобы сообщения об ошибках попали в файл. Что делать? Ответ прост — воспользоваться третьим стандартным дескриптором.
STDERR
STDERR представляет собой стандартный поток ошибок оболочки. По умолчанию этот дескриптор указывает на то же самое, на что указывает STDOUT, именно поэтому при возникновении ошибки мы видим сообщение на экране.
Итак, предположим, что надо перенаправить сообщения об ошибках, скажем, в лог-файл, или куда-нибудь ещё, вместо того, чтобы выводить их на экран.
▍Перенаправление потока ошибок
Как вы уже знаете, дескриптор файла STDERR — 2. Мы можем перенаправить ошибки, разместив этот дескриптор перед командой перенаправления:
ls -l xfile 2>myfile
cat ./myfile
Сообщение об ошибке теперь попадёт в файл myfile.

Перенаправление сообщения об ошибке в файл
▍Перенаправление потоков ошибок и вывода
При написании сценариев командной строки может возникнуть ситуация, когда нужно организовать и перенаправление сообщений об ошибках, и перенаправление стандартного вывода. Для того, чтобы этого добиться, нужно использовать команды перенаправления для соответствующих дескрипторов с указанием файлов, куда должны попадать ошибки и стандартный вывод:
ls –l myfile xfile anotherfile 2> errorcontent 1> correctcontent
Перенаправление ошибок и стандартного вывода
Оболочка перенаправит то, что команда ls обычно отправляет в STDOUT, в файл correctcontent благодаря конструкции 1>. Сообщения об ошибках, которые попали бы в STDERR, оказываются в файле errorcontent из-за команды перенаправления 2>.
Если надо, и STDERR, и STDOUT можно перенаправить в один и тот же файл, воспользовавшись командой &>:
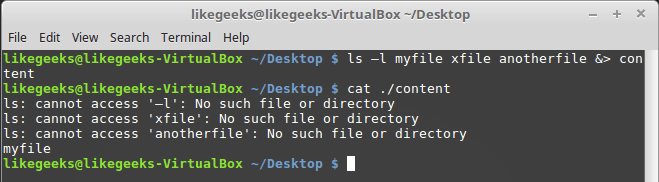
Перенаправление STDERR и STDOUT в один и тот же файл
После выполнения команды то, что предназначено для STDERR и STDOUT, оказывается в файле content.
Перенаправление вывода в скриптах
Существует два метода перенаправления вывода в сценариях командной строки:
- Временное перенаправление, или перенаправление вывода одной строки.
- Постоянное перенаправление, или перенаправление всего вывода в скрипте либо в какой-то его части.
▍Временное перенаправление вывода
В скрипте можно перенаправить вывод отдельной строки в STDERR. Для того, чтобы это сделать, достаточно использовать команду перенаправления, указав дескриптор STDERR, при этом перед номером дескриптора надо поставить символ амперсанда (&):
#!/bin/bash
echo "This is an error" >&2
echo "This is normal output"Если запустить скрипт, обе строки попадут на экран, так как, как вы уже знаете, по умолчанию ошибки выводятся туда же, куда и обычные данные.

Временное перенаправление
Запустим скрипт так, чтобы вывод STDERR попадал в файл.
./myscript 2> myfileКак видно, теперь обычный вывод делается в консоль, а сообщения об ошибках попадают в файл.
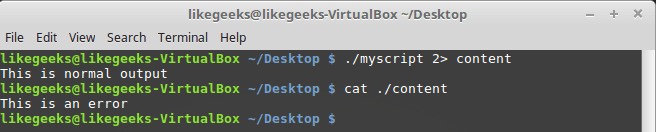
Сообщения об ошибках записываются в файл
▍Постоянное перенаправление вывода
Если в скрипте нужно перенаправлять много выводимых на экран данных, добавлять соответствующую команду к каждому вызову echo неудобно. Вместо этого можно задать перенаправление вывода в определённый дескриптор на время выполнения скрипта, воспользовавшись командой exec:
#!/bin/bash
exec 1>outfile
echo "This is a test of redirecting all output"
echo "from a shell script to another file."
echo "without having to redirect every line"Запустим скрипт.

Перенаправление всего вывода в файл
Если просмотреть файл, указанный в команде перенаправления вывода, окажется, что всё, что выводилось командами echo, попало в этот файл.
Команду exec можно использовать не только в начале скрипта, но и в других местах:
#!/bin/bash
exec 2>myerror
echo "This is the start of the script"
echo "now redirecting all output to another location"
exec 1>myfile
echo "This should go to the myfile file"
echo "and this should go to the myerror file" >&2Вот что получится после запуска скрипта и просмотра файлов, в которые мы перенаправляли вывод.
![]()
Перенаправление вывода в разные файлы
Сначала команда exec задаёт перенаправление вывода из STDERR в файл myerror. Затем вывод нескольких команд echo отправляется в STDOUT и выводится на экран. После этого команда exec задаёт отправку того, что попадает в STDOUT, в файл myfile, и, наконец, мы пользуемся командой перенаправления в STDERR в команде echo, что приводит к записи соответствующей строки в файл myerror.
Освоив это, вы сможете перенаправлять вывод туда, куда нужно. Теперь поговорим о перенаправлении ввода.
Перенаправление ввода в скриптах
Для перенаправления ввода можно воспользоваться той же методикой, которую мы применяли для перенаправления вывода. Например, команда exec позволяет сделать источником данных для STDIN какой-нибудь файл:
exec 0< myfile
Эта команда указывает оболочке на то, что источником вводимых данных должен стать файл myfile, а не обычный STDIN. Посмотрим на перенаправление ввода в действии:
#!/bin/bash
exec 0< testfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(( $count + 1 ))
doneВот что появится на экране после запуска скрипта.

Перенаправление ввода
В одном из предыдущих материалов вы узнали о том, как использовать команду read для чтения данных, вводимых пользователем с клавиатуры. Если перенаправить ввод, сделав источником данных файл, то команда read, при попытке прочитать данные из STDIN, будет читать их из файла, а не с клавиатуры.
Некоторые администраторы Linux используют этот подход для чтения и последующей обработки лог-файлов.
Создание собственного перенаправления вывода
Перенаправляя ввод и вывод в сценариях, вы не ограничены тремя стандартными дескрипторами файлов. Как уже говорилось, можно иметь до девяти открытых дескрипторов. Остальные шесть, с номерами от 3 до 8, можно использовать для перенаправления ввода или вывода. Любой из них можно назначить файлу и использовать в коде скрипта.
Назначить дескриптор для вывода данных можно, используя команду exec:
#!/bin/bash
exec 3>myfile
echo "This should display on the screen"
echo "and this should be stored in the file" >&3
echo "And this should be back on the screen"
После запуска скрипта часть вывода попадёт на экран, часть — в файл с дескриптором 3.
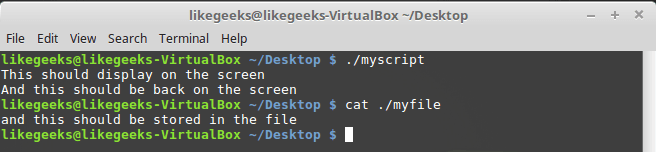
Перенаправление вывода, используя собственный дескриптор
Создание дескрипторов файлов для ввода данных
Перенаправить ввод в скрипте можно точно так же, как и вывод. Сохраните STDIN в другом дескрипторе, прежде чем перенаправлять ввод данных.
После окончания чтения файла можно восстановить STDIN и пользоваться им как обычно:
#!/bin/bash
exec 6<&0
exec 0< myfile
count=1
while read line
do
echo "Line #$count: $line"
count=$(( $count + 1 ))
done
exec 0<&6
read -p "Are you done now? " answer
case $answer in
y) echo "Goodbye";;
n) echo "Sorry, this is the end.";;
esacИспытаем сценарий.
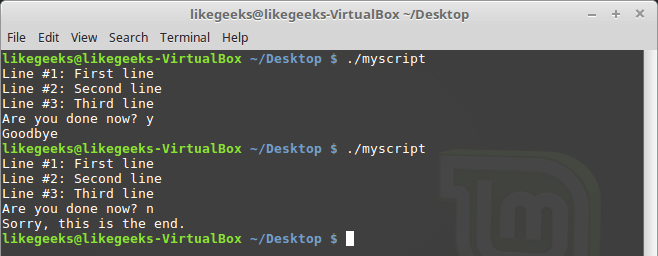
Перенаправление ввода
В этом примере дескриптор файла 6 использовался для хранения ссылки на STDIN. Затем было сделано перенаправление ввода, источником данных для STDIN стал файл. После этого входные данные для команды read поступали из перенаправленного STDIN, то есть из файла.
После чтения файла мы возвращаем STDIN в исходное состояние, перенаправляя его в дескриптор 6. Теперь, для того, чтобы проверить, что всё работает правильно, скрипт задаёт пользователю вопрос, ожидает ввода с клавиатуры и обрабатывает то, что введено.
Закрытие дескрипторов файлов
Оболочка автоматически закрывает дескрипторы файлов после завершения работы скрипта. Однако, в некоторых случаях нужно закрывать дескрипторы вручную, до того, как скрипт закончит работу. Для того, чтобы закрыть дескриптор, его нужно перенаправить в &-. Выглядит это так:
#!/bin/bash
exec 3> myfile
echo "This is a test line of data" >&3
exec 3>&-
echo "This won't work" >&3После исполнения скрипта мы получим сообщение об ошибке.

Попытка обращения к закрытому дескриптору файла
Всё дело в том, что мы попытались обратиться к несуществующему дескриптору.
Будьте внимательны, закрывая дескрипторы файлов в сценариях. Если вы отправляли данные в файл, потом закрыли дескриптор, потом — открыли снова, оболочка заменит существующий файл новым. То есть всё то, что было записано в этот файл ранее, будет утеряно.
Получение сведений об открытых дескрипторах
Для того, чтобы получить список всех открытых в Linux дескрипторов, можно воспользоваться командой lsof. Во многих дистрибутивах, вроде Fedora, утилита lsof находится в /usr/sbin. Эта команда весьма полезна, так как она выводит сведения о каждом дескрипторе, открытом в системе. Сюда входит и то, что открыли процессы, выполняемые в фоне, и то, что открыто пользователями, вошедшими в систему.
У этой команды есть множество ключей, рассмотрим самые важные.
-pПозволяет указатьIDпроцесса.-dПозволяет указать номер дескриптора, о котором надо получить сведения.
Для того, чтобы узнать PID текущего процесса, можно использовать специальную переменную окружения $$, в которую оболочка записывает текущий PID.
Ключ -a используется для выполнения операции логического И над результатами, возвращёнными благодаря использованию двух других ключей:
lsof -a -p $$ -d 0,1,2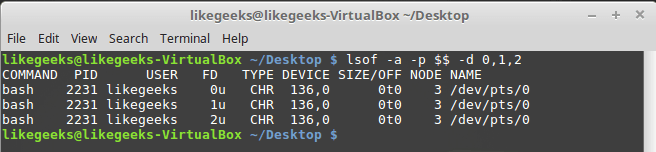
Вывод сведений об открытых дескрипторах
Тип файлов, связанных с STDIN, STDOUT и STDERR — CHR (character mode, символьный режим). Так как все они указывают на терминал, имя файла соответствует имени устройства, назначенного терминалу. Все три стандартных файла доступны и для чтения, и для записи.
Посмотрим на вызов команды lsof из скрипта, в котором открыты, в дополнение к стандартным, другие дескрипторы:
#!/bin/bash
exec 3> myfile1
exec 6> myfile2
exec 7< myfile3
lsof -a -p $$ -d 0,1,2,3,6,7Вот что получится, если этот скрипт запустить.
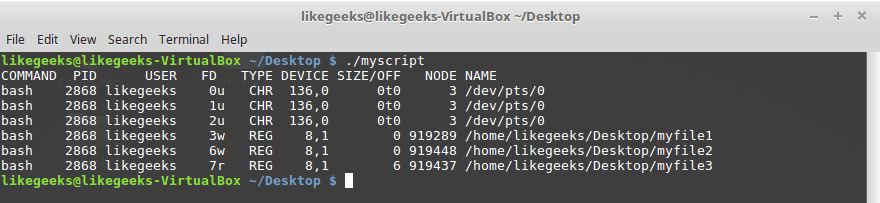
Просмотр дескрипторов файлов, открытых скриптом
Скрипт открыл два дескриптора для вывода (3 и 6) и один — для ввода (7). Тут же показаны и пути к файлам, использованных для настройки дескрипторов.
Подавление вывода
Иногда надо сделать так, чтобы команды в скрипте, который, например, может исполняться как фоновый процесс, ничего не выводили на экран. Для этого можно перенаправить вывод в /dev/null. Это — что-то вроде «чёрной дыры».
Вот, например, как подавить вывод сообщений об ошибках:
ls -al badfile anotherfile 2> /dev/nullТот же подход используется, если, например, надо очистить файл, не удаляя его:
cat /dev/null > myfileИтоги
Сегодня вы узнали о том, как в сценариях командной строки работают ввод и вывод. Теперь вы умеете обращаться с дескрипторами файлов, создавать, просматривать и закрывать их, знаете о перенаправлении потоков ввода, вывода и ошибок. Всё это очень важно в деле разработки bash-скриптов.
В следующий раз поговорим о сигналах Linux, о том, как обрабатывать их в сценариях, о запуске заданий по расписанию и о фоновых задачах.
Уважаемые читатели! В этом материале даны основы работы с потоками ввода, вывода и ошибок. Уверены, среди вас есть профессионалы, которые могут рассказать обо всём этом то, что приходит лишь с опытом. Если так — передаём слово вам.
Redirections from script himself
You could plan redirections from the script itself:
#!/bin/bash
exec 1>>logfile.txt
exec 2>&1
/bin/ls -ld /tmp /tnt
Running this will create/append logfile.txt, containing:
/bin/ls: cannot access '/tnt': No such file or directory
drwxrwxrwt 2 root root 4096 Apr 5 11:20 /tmp
Or
#!/bin/bash
exec 1>>logfile.txt
exec 2>>errfile.txt
/bin/ls -ld /tmp /tnt
While create or append standard output to logfile.txt and create or append errors output to errfile.txt.
Log to many different files
You could create two different logfiles, appending to one overall log and recreating another last log:
#!/bin/bash
if [ -e lastlog.txt ] ;then
mv -f lastlog.txt lastlog.old
fi
exec 1> >(tee -a overall.log /dev/tty >lastlog.txt)
exec 2>&1
ls -ld /tnt /tmp
Running this script will
- if
lastlog.txtalready exist, rename them tolastlog.old(overwritinglastlog.oldif they exist). - create a new
lastlog.txt. - append everything to
overall.log - output everything to the terminal.
Simple and combined logs
#!/bin/bash
[ -e lastlog.txt ] && mv -f lastlog.txt lastlog.old
[ -e lasterr.txt ] && mv -f lasterr.txt lasterr.old
exec 1> >(tee -a overall.log combined.log /dev/tty >lastlog.txt)
exec 2> >(tee -a overall.err combined.log /dev/tty >lasterr.txt)
ls -ld /tnt /tmp
So you have
lastlog.txtlast run log filelasterr.txtlast run error filelastlog.oldprevious run log filelasterr.oldprevious run error fileoverall.logappended overall log fileoverall.errappended overall error filecombined.logappended overall error and log combined file.- still output to the terminal
And for interactive session, use stdbuf:
stdbuf: Regarding Fonic’ comment and after some test, I have to agree: with tee, stdbuf is useless. But …
If you plan to use this in *interactive* shell, you must tell `tee` to not buffering his input/output:
# Source this to multi-log your session
[ -e lasterr.txt ] && mv -f lasterr.txt lasterr.old
[ -e lastlog.txt ] && mv -f lastlog.txt lastlog.old
exec 2> >(exec stdbuf -i0 -o0 tee -a overall.err combined.log /dev/tty >lasterr.txt)
exec 1> >(exec stdbuf -i0 -o0 tee -a overall.log combined.log /dev/tty >lastlog.txt)
Once sourced this, you could try:
ls -ld /tnt /tmp
More complex sample
From my 3 remarks about how to Convert Unix timestamp to a date string
I’ve used more complex command to parse and reassemble squid‘s log in real time: As each line begin by an UNIX EPOCH with milliseconds, I split the line on 1st dot, add @ symbol before EPOCH SECONDS to
pass them to date -f - +%F %T then reassemble date‘s output and the rest of line with a dot by using paste -d ..
exec {datesfd}<> <(:)
tail -f /var/log/squid/access.log |
tee >(
exec sed -u 's/^([0-9]+)..*/@1/'|
stdbuf -o0 date -f - +%F %T >&$datesfd
) |
sed -u 's/^[0-9]+.//' |
paste -d . /dev/fd/$datesfd -
With date, stdbuf was required…
Some explanations about exec and stdbuf commands:
-
Running
forksby using$(...)or<(...)is done by running subshell wich will execute binaries in another subshell (subsubshell). Theexeccommand tell shell that there are not further command in script to be run, so binary (stdbuf ... tee) will be executed as replacement process, at same level (no need to reserve more memory for running another sub-process).From
bash‘s man page (man -P'less +/^ *exec ' bash):exec [-cl] [-a name] [command [arguments]] If command is specified, it replaces the shell. No new process is created....This is not really needed, but reduce system footprint.
-
From
stdbuf‘s man page:NAME stdbuf - Run COMMAND, with modified buffering operations for its standard streams.This will tell system to use unbuffered I/O for
teecommand. So all outputs will be updated immediately, when some input are coming.
Введение
Стандартные потоки ввода и вывода в Linux являются одним из наиболее распространенных средств для обмена информацией процессов, а перенаправление >, >> и | является одной из самых популярных конструкций командного интерпретатора.
В данной статье мы ознакомимся с возможностями перенаправления потоков ввода/вывода, используемых при работе файлами и командами.
Требования
- Linux-система, например, Ubuntu 20.04
Потоки
Стандартный ввод при работе пользователя в терминале передается через клавиатуру.
Стандартный вывод и стандартная ошибка отображаются на дисплее терминала пользователя в виде текста.
Ввод и вывод распределяется между тремя стандартными потоками:
- stdin — стандартный ввод (клавиатура),
- stdout — стандартный вывод (экран),
- stderr — стандартная ошибка (вывод ошибок на экран).
Потоки также пронумерованы:
- stdin — 0,
- stdout — 1,
- stderr — 2.
Из стандартного ввода команда может только считывать данные, а два других потока могут использоваться только для записи. Данные выводятся на экран и считываются с клавиатуры, так как стандартные потоки по умолчанию ассоциированы с терминалом пользователя. Потоки можно подключать к чему угодно: к файлам, программам и даже устройствам. В командном интерпретаторе bash такая операция называется перенаправлением:
- < file — использовать файл как источник данных для стандартного потока ввода.
- > file — направить стандартный поток вывода в файл. Если файл не существует, он будет создан, если существует — перезаписан сверху.
- 2> file — направить стандартный поток ошибок в файл. Если файл не существует, он будет создан, если существует — перезаписан сверху.
- >>file — направить стандартный поток вывода в файл. Если файл не существует, он будет создан, если существует — данные будут дописаны к нему в конец.
- 2>>file — направить стандартный поток ошибок в файл. Если файл не существует, он будет создан, если существует — данные будут дописаны к нему в конец.
- &>file или >&file — направить стандартный поток вывода и стандартный поток ошибок в файл. Другая форма записи: >file 2>&1.
Стандартный ввод
Стандартный входной поток обычно переносит данные от пользователя к программе. Программы, которые предполагают стандартный ввод, обычно получают входные данные от устройства типа клавиатура. Стандартный ввод прекращается по достижении EOF (конец файла), который указывает на то, что данных для чтения больше нет.
EOF вводится нажатием сочетания клавиш Ctrl+D.
Рассмотрим работу со стандартным выводом на примере команды cat (от CONCATENATE, в переводе «связать» или «объединить что-то»).
Cat обычно используется для объединения содержимого двух файлов.
Cat отправляет полученные входные данные на дисплей терминала в качестве стандартного вывода и останавливается после того как получает EOF.
Пример
catВ открывшейся строке введите, например, 1 и нажмите клавишу Enter. На дисплей выводится 1. Введите a и нажмите клавишу Enter. На дисплей выводится a.
Дисплей терминала выглядит следующим образом:
test@111:~/stream$ cat
1
1
a
aДля завершения ввода данных следует нажать сочетание клавиш Ctrl + D.
Стандартный вывод
Стандартный вывод записывает данные, сгенерированные программой. Когда стандартный выходной поток не перенаправляется в какой-либо файл, он выводит текст на дисплей терминала.
При использовании без каких-либо дополнительных опций, команда echo выводит на экран любой аргумент, который передается ему в командной строке:
echo ПримерАргументом является то, что получено программой, в результате на дисплей терминала будет выведено:
ПримерПри выполнении echo без каких-либо аргументов, возвращается пустая строка.
Пример
Команда объединяет три файла: file1, file2 и file3 в один файл bigfile:
cat file1 file1 file1 > bigfileКоманда cat по очереди выводит содержимое файлов, перечисленных в качестве параметров на стандартный поток вывода. Стандартный поток вывода перенаправлен в файл bigfile.
Стандартная ошибка
Стандартная ошибка записывает ошибки, возникающие в ходе исполнения программы. Как и в случае стандартного вывода, по умолчанию этот поток выводится на терминал дисплея.
Пример
Рассмотрим пример стандартной ошибки с помощью команды ls, которая выводит список содержимого каталогов.
При запуске без аргументов ls выводит содержимое в пределах текущего каталога.
Введем команду ls с каталогом % в качестве аргумента:
ls %В результате должно выводиться содержимое соответствующей папки. Но так как каталога % не существует, на дисплей терминала будет выведен следующий текст стандартной ошибки:
ls: cannot access %: No such file or directoryПеренаправление потока
Linux включает в себя команды перенаправления для каждого потока.
Команды со знаками > или < означают перезапись существующего содержимого файла:
- > — стандартный вывод,
- < — стандартный ввод,
- 2> — стандартная ошибка.
Команды со знаками >> или << не перезаписывают существующее содержимое файла, а присоединяют данные к нему:
- >> — стандартный вывод,
- << — стандартный ввод,
- 2>> — стандартная ошибка.
Пример
В приведенном примере команда cat используется для записи в файл file1, который создается в результате цикла:
cat > file1
a
b
cДля завершения цикла нажмите сочетание клавиш Ctrl + D.
Если файла file1 не существует, то в текущем каталоге создается новый файл с таким именем.
Для просмотра содержимого файла file1 введите команду:
cat file1В результате на дисплей терминала должно быть выведено следующее:
a
b
cДля перезаписи содержимого файла введите следующее:
cat > file1
1
2
3Для завершения цикла нажмите сочетание клавиш Ctrl + D.
В результате на дисплей терминала должно быть выведено следующее:
1
2
3Предыдущего текста в текущем файле больше не существует, так как содержимое файла было переписано командой >.
Для добавления нового текста к уже существующему в файле с помощью двойных скобок >> выполните команду:
cat >> file1
a
b
cДля завершения цикла нажмите сочетание клавиш Ctrl + D.
Откройте file1 снова и в результате на дисплее монитора должно быть отражено следующее:
1
2
3
a
b
cКаналы
Каналы используются для перенаправления потока из одной программы в другую. Стандартный вывод данных после выполнения одной команды перенаправляется в другую через канал. Данные первой программы, которые получает вторая программа, не будут отображаться. На дисплей терминала будут выведены только отфильтрованные данные, возвращаемые второй командой.
Пример
Введите команду:
ls | lessВ результате каждый файл текущего каталога будет размещен на новой строке:
file1
file2
t1
t2Перенаправлять данные с помощью каналов можно как из одной команды в другую, так и из одного файла к другому, а перенаправление с помощью > и >> возможно только для перенаправления данных в файлах.
Пример
Для сохранения имен файлов, содержащих строку «LOG», используется следующая команда:
dir /catalog | find "LOG" > loglistВывод команды dir отсылается в команду-фильтр find. Имена файлов, содержащие строку «LOG», хранятся в файле loglist в виде списка (например, Config.log, Logdat.svd и Mylog.bat).
При использовании нескольких фильтров в одной команде рекомендуется разделять их с помощью знака канала |.
Фильтры
Фильтры представляют собой стандартные команды Linux, которые могут быть использованы без каналов:
- find — возвращает файлы с именами, которые соответствуют передаваемому аргументу.
- grep — возвращает только строки, содержащие (или не содержащие) заданное регулярное выражение.
- tee — перенаправляет стандартный ввод как стандартный вывод и один или несколько файлов.
- tr — находит и заменяет одну строку другой.
- wc — подсчитывает символы, линии и слова.
Как правило, все нижеприведенные команды работают как фильтры, если у них нет аргументов (опции могут быть):
- cat — считывает данные со стандартного потока ввода и передает их на стандартный поток вывода. Без опций работает как простой повторитель. С опциями может фильтровать пустые строки, нумеровать строки и делать другую подобную работу.
- head — показывает первые 10 строк (или другое заданное количество), считанных со стандартного потока ввода.
- tail — показывает последние 10 строк (или другое заданное количество), считанные со стандартного потока ввода. Важный частный случай tail -f, который в режиме слежения показывает концовку файла. Это используется, в частности, для просмотра файлов журнальных сообщений.
- cut — вырезает столбец (по символам или полям) из потока ввода и передает на поток вывода. В качестве разделителей полей могут использоваться любые символы.
- sort — сортирует данные в соответствии с какими-либо критериями, например, арифметически по второму столбцу.
- uniq — удаляет повторяющиеся строки. Или (с ключом -с) не просто удалить, а написать сколько таких строк было. Учитываются только подряд идущие одинаковые строки, поэтому часто данные сортируются перед тем как отправить их на вход программе.
- bc — вычисляет каждую отдельную строку потока и записывает вместо нее результат вычисления.
- hexdump — показывает шестнадцатеричное представление данных, поступающих на стандартный поток ввода.
- strings — выделяет и показывает в стандартном потоке (или файле) то, что напоминает строки. Всё что не похоже на строковые последовательности, игнорируется. Команда полезна в сочетании с grep для поиска интересующих строковых последовательностей в бинарных файлах.
- sed — обрабатывает текст в соответствии с заданным скриптом. Наиболее часто используется для замены текста в потоке: sed s/было/стало/g.
- awk — обрабатывает текст в соответствии с заданным скриптом. Как правило, используется для обработки текстовых таблиц, например, вывод ps aux и т.д.
- sh -s — текст, который передается на стандартный поток ввода sh -s. может интерпретироваться как последовательность команд shell. На выход передается результат их исполнения.
- ssh — средство удаленного доступа ssh, может работать как фильтр, который подхватывает данные, переданные ему на стандартный поток ввода, затем передает их на удаленный хост и подает на вход процессу программы, имя которой было передано ему в качестве аргумента. Результат выполнения программы (то есть то, что она выдала на стандартный поток вывода) передается со стандартного вывода ssh.
Если в качестве аргумента передается файл, команда-фильтр считывает данные из этого файла, а не со стандартного потока ввода (есть исключения, например, команда tr, обрабатывающая данные, поступающие исключительно через стандартный поток ввода).
Пример
Команда tee, как правило, используется для просмотра выводимого содержимого при одновременном сохранении его в файл.
wc ~/stream | tee file2Пример
Допускается перенаправление нескольких потоков в один файл:
ls -z >> file3 2>&1В результате сообщение о неверной опции «z» в команде ls будет записано в файл t2, поскольку stderr перенаправлен в файл.
Для просмотра содержимого файла file3 введите команду cat:
cat file3В результате на дисплее терминала отобразиться следующее:
ls: invalid option -- 'z'
Try 'ls --help' for more information.Заключение
Мы рассмотрели возможности работы с перенаправлениями потоков >, >> и |, использование которых позволяет лучше работать с bash-скриптами.
Перенаправление стандартного ввода и вывода позволяет пользователю управлять потоками данных в Linux. Этот может быть полезно к примеру в отлове ошибок, для автоматизации чего-либо, или, при работе в сфере безопасности может возникнуть необходимость сохранения результатов в файл.
Кроме того, перенаправление стандартного ввода и вывода может быть использовано в скриптах, как уже говорилось выше, для автоматизации выполнения задач. Например, можно написать скрипт, который будет перенаправлять вывод одной команды на вход другой команде.
Знание этого инструмента может быть очень полезным для системных администраторов, разработчиков и всех, кто работает с Linux.
Перенаправление стандартного вывода
Начнем с перенаправления стандартного вывода, когда команда выводит результат в терминал, это называется стандартным выводом (stdout). Для перенаправления стандартного вывода в файл используется символ “>”:
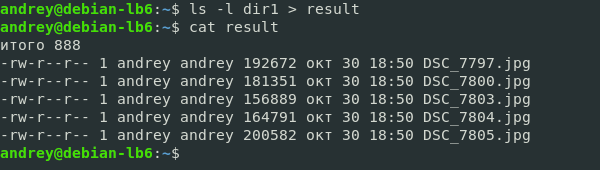
ls > output.logКоманда ls выводит список файлов и каталогов в текущей директории. При использовании символа > результат выполнения команды перенаправляется в файл output.log. Командой “cat” можно просмотреть содержимое файла:

Подробнее про команду ls читайте перейдя по этой ссылке. Стоит отметить, если файл output.log не существует, он будет создан.
Каждый раз при выполнении выше указанной команды, содержимое файла будет перезаписываться. Если мы хотим добавить вывод в конец файла, а не перезаписывать файл, мы можем использовать символ >> вместо >.
ls >> output.log
Перенаправление стандартного ввода
Когда команда принимает входные данные из терминала, это называется стандартным вводом (stdin). Для перенаправления стандартного ввода из файла используется символ “<“:
sort < output.logКоманда sort сортирует содержимое файла output.log. При использовании символа “<” входные данные для команды будут взяты из файла output.log и и отображены в терминал, что-то вроде того, что мы проделывали ранее командой cat:

Для перенаправления стандартного вывода и стандартного ввода одновременно можно воспользоваться символом |. Этот символ называется “конвейер”, о нем как-нибудь в следующий раз, сейчас его рассматривать не станем.
Перенаправление стандартного вывода и стандартного ввода
Мы можем использовать перенаправление стандартного ввода и вывода вместе. Это позволит к примеру получить данные из файла и записать результаты в другой файл. Это может быть полезно, когда есть необходимость обработать данные из одного файла и сохранить результаты в другом файле.
$ sort < ioutput.log > output_1.logЭта команда сортирует данные из файла output.log и записывает результат в файл output_1.log. На скриншоте ниже вы можете увидеть результат. С лева не обработанные данные, с права обработанные данные:

Перенаправление стандартного ввода и вывода – это мощный инструмент, который позволяет пользователю более тонко управлять потоками данных в Linux. Он может быть использован для автоматизации процессов, обработки больших объемов данных и многих других задач.
Заключение
Перенаправление стандартного ввода и вывода является одним из основных инструментов работы с командной строкой в Linux. Оно позволяет более гибко управлять потоками данных и повышать эффективность работы с системой.
Помимо символов > и < для перенаправления данных, существует еще несколько специальных файловых дескрипторов, которые могут быть использованы для перенаправления данных. Отчет одет от 0 далее 1 и 2 – Вывод (stderr) ошибок соответственно. Без указания дескриптора вывод ошибок получить не получится. Для примера укажем не существующий каталог “/etc/boot” и перенаправим вывод, скажем, в файл error.log:

Возможно, понадобится перенаправить вывод сразу из двух потоков в один файл. Существует два метода, мы рассмотрим лишь один, более современный и простой. Для перенаправления двух потоков в один файл используется оператор &, который также указывается перед знаком “>”:
ls /etc/boot /etc/alsa &> error.log
В данном примере, в файл error.log будет произведено перенаправление стандартного вывода и стандартного вывода ошибок:

А на этом сегодня все, если статья оказалась вам полезна, подписывайтесь на социальные сети журнала Cyber-X:
YouTube
ВКонтакте
Telegram
Дзен
По вопросам работы сайта, сотрудничества, а так же по иным возникшим вопросам пишите на E-Mail. Если вам нравится журнал и вы хотите отблагодарить за труды, вы можете перечислить донат на развитие проекта.
Введение
Одним из ключевых моментов философии UNIX было то, что все команды в командной строке (CLI) должны принимать текст в качестве ввода и выдавать текст в качестве вывода. Поскольку эта концепция была применена при разработке UNIX (и позже Linux), были разработаны команды для приема текста в качестве входных данных, выполнения какой-либо операции с текстом и последующего создания текста в качестве вывода. Команды, которые считывают текст в качестве входных данных, каким-либо образом изменяют этот текст, а затем создают текст в качестве выходных данных, иногда называют фильтрами.
Чтобы иметь возможность применять команды фильтрации и работать с текстовыми потоками, полезно понимать несколько форм перенаправления, которые можно использовать с большинством команд: конвейеры, стандартное перенаправление вывода, перенаправление вывода ошибок и перенаправление ввода.

Стандартный вывод
Когда команда выполняется без каких-либо ошибок, создаваемый вывод называется стандартным выводом, также называемым STDOUT. По умолчанию этот вывод будет отправлен на терминал, где выполняется команда.
Стандартный вывод можно перенаправить из команды, чтобы он перешел к файлу, а не к терминалу. Стандартное перенаправление вывода достигается выполнением команды с символом больше > и конечным файлом. Например, команда ls ~ выведет список файлов в домашнем каталоге. Чтобы сохранить список файлов в домашнем каталоге, вы должны направить вывод в текстовый файл.
timeweb@localhost:~$ ls ~ > /tmp/home.txtПосле чего содержимое файла home.txt будет иметь следующий вид:
timeweb@localhost:~$cat /tmp/home.txt
Desktop Documents Downloads Music Pictures Public Templates Videos
Перенаправление вывода с использованием одного символа больше > создаст новый файл или перезапишет содержимое существующего файла с тем же именем. Перенаправление стандартного вывода с двумя символами больше >> также создаст новый файл, если он не существует. Разница в том, что при использовании символов >> вывод команды будет добавлен в конец файла, если он уже существует. Например, чтобы добавить в конец файла вывод команды date, выполните следующее:
timeweb@localhost:~$ date >> /tmp/home.txt
timeweb@localhost:~$cat /tmp/home.txt
Desktop Documents Downloads Music Pictures Public Templates Videos Sun Jan 30 17:36:02 UTC 2022
Стандартная ошибка
Когда команда обнаруживает ошибку, она выдает вывод, известный как стандартная ошибка, также называемая stderr или STDERR. Как и стандартный вывод, стандартный вывод ошибок обычно отправляется на тот же терминал, где в данный момент выполняется команда. Число, связанное со стандартным дескриптором файла ошибок, равно 2.
Если вы попытаетесь выполнить команду ls /junk, то эта команда выдаст стандартные сообщения об ошибках, поскольку каталога /junk не существует.
timeweb@localhost:~$ ls /junk
ls: cannot access /junk: No such file or directoryПоскольку этот вывод переходит в стандартную ошибку, один только символ больше > не будет успешно перенаправлять его, и вывод команды все равно будет отправлен на терминал:
timeweb@localhost:~$ ls /junk > output
ls: cannot access /junk: No such file or directoryЧтобы перенаправить эти сообщения об ошибках, вы должны использовать правильный дескриптор файла, который для стандартной ошибки имеет номер 2. Выполните следующее, и ошибка будет перенаправлена в файл /tmp/ls.err:
timeweb@localhost:~$ ls /junk 2> /tmp/ls.errКак и при стандартном выводе, использование одного символа > для перенаправления либо создаст файл, если он не существует, либо уничтожит (перезапишет) содержимое существующего файла. Чтобы предотвратить стирание существующего файла при перенаправлении стандартной ошибки, вместо этого используйте двойные символы >> после числа 2 для добавления:
timeweb@localhost:~$ ls /junk 2>> /tmp/ls.errНекоторые команды будут выводить как stdout, так и stderr:
timeweb@localhost:~$ find /etc -name passwd
/etc/pam.d/passwd
/etc/passwd
find: '/etc/ssl/private': Permission deniedЭти два разных вывода можно перенаправить в два отдельных файла, используя следующий синтаксис:
timeweb@localhost:~$ find /etc -name passwd > /tmp/output.txt 2> /tmp/error.txtКоманду cat можно использовать для проверки успешности перенаправления выше:
timeweb@localhost:~$ cat /tmp/output.txt
/etc/pam.d/passwd
/etc/passwd
timeweb@localhost:~$ cat /tmp/error.txt
find: '/etc/ssl/private': Permission deniedИногда бесполезно отображать сообщения об ошибках в терминале или сохранять их в файле. Чтобы не сохранять эти сообщения об ошибках, используйте файл /dev/null.
Файл /dev/null похож на мусорное ведро, где все отправленное в него исчезает из системы; его иногда называют черной дырой. Любой тип вывода может быть перенаправлен в файл /dev/null; чаще всего пользователи перенаправляют стандартную ошибку в этот файл, а не в стандартный вывод.
Синтаксис использования файла /dev/null такой же, как и для перенаправления на обычный файл:
timeweb@localhost:~$ find /etc -name passw 2> /dev/null
/etc/pam.d/passwd
/etc/passwdЧто, если вы хотите, чтобы весь вывод (стандартная ошибка и стандартный вывод) отправлялся в один файл? Существует два метода перенаправления как стандартных ошибок, так и стандартных выходов:
timeweb@localhost:~$ ls > /tmp/ls.all 2>&1
timeweb@localhost:~$ ls &> /tmp/ls.all Обе предыдущие командные строки создадут файл с именем /tmp/ls.all, содержащий все стандартные выходные данные и стандартные ошибки. Первая команда перенаправляет стандартный вывод на /tmp/ls.all, а выражение 2>&1 означает «отправлять stderr туда, куда направляется stdout». Во втором примере выражение &> означает «перенаправить весь вывод».
Стандартный ввод
Стандартный ввод, также называемый stdin или STDIN, обычно поступает с клавиатуры, ввод осуществляется пользователем, выполняющим команду. Хотя большинство команд могут считывать ввод из файлов, некоторые ожидают, что пользователь введет их с помощью клавиатуры.
Одним из распространенных способов использования текстовых файлов в качестве стандартного ввода для команд является создание файлов сценариев. Скрипты представляют собой простые текстовые файлы, которые интерпретируются оболочкой при наличии соответствующих разрешений и начинаются с #!/bin/sh в первой строке, что указывает оболочке интерпретировать сценарий как стандартный ввод:
timeweb@localhost:~$ cat examplescriptfile.sh
#!/bin/sh
echo HelloWorldКогда файл скрипта вызывается в командной строке с использованием синтаксиса ./, оболочка выполнит все команды в файле скрипта и вернет результат в окно терминала или туда, куда указан вывод для отправки:
timeweb@localhost:~$ ./examplescriptfile.sh
HelloWorldВ некоторых случаях полезно перенаправить стандартный ввод, чтобы он поступал из файла, а не с клавиатуры. Хорошим примером того, когда желательно перенаправление ввода, является команда tr. Команда tr переводит символы, считывая данные со стандартного ввода; перевод одного набора символов в другой набор символов, а затем запись измененного текста в стандартный вывод.
Например, следующая команда tr будет принимать данные от пользователя (через клавиатуру), чтобы выполнить преобразование всех символов нижнего регистра в символы верхнего регистра. Выполните следующую команду, введите текст и нажмите Enter, чтобы увидеть перевод:
timeweb@localhost:~$ tr 'a-z' 'A-Z'
hello
HELLOКоманда tr не прекращает чтение из стандартного ввода, если только она не завершена. Это можно сделать, нажав комбинацию клавиш Ctrl+D.
Команда tr не принимает имя файла в качестве аргумента в командной строке. Чтобы выполнить перевод с использованием файла в качестве входных данных, используйте перенаправление ввода. Чтобы использовать перенаправление ввода, введите команду с ее параметрами и аргументами, за которыми следует символ меньше чем < и путь к файлу, который будет использоваться для ввода. Например:
timeweb@localhost:~$ cat Documents/animals.txt
1 retriever
2 badger
3 bat
4 wolf
5 eagle
timeweb@localhost:~$ tr 'a-z' 'A-Z' < Documents/animals.txt
1 RETRIEVER
2 BADGER
3 BAT
4 WOLF
5 EAGLEКонвейеры команд
Конвейеры команд часто используются для эффективного использования команд фильтрации. В командном конвейере выходные данные одной команды отправляются другой команде в качестве входных данных. В Linux и большинстве операционных систем вертикальная черта | используется между двумя командами для представления конвейера команд.
Например, представьте, что вывод команды history очень велик. Чтобы отправить этот вывод команде less, которая отображает одну страницу данных за раз, можно использовать следующий конвейер команд:
timeweb@localhost:~$ history | lessЕще лучше пример, взять вывод команды history и отфильтровать вывод с помощью команды grep. В следующем примере текст, выводимый командой history, перенаправляется в команду grep в качестве входных данных. Команда grep сопоставляет строки ls и отправляет вывод на стандартный вывод:
timeweb@localhost:~$ history | grep "ls"
1 ls ~ > /tmp/home.txt
5 ls l> /tmp/ls.txt
6 ls 1> /tmp/ls.txt
7 date 1>> /tmp/ls.txt
8 ls /junk
9 ls /junk > output
10 ls /junk 2> /tmp/ls.err
11 ls /junk 2>> /tmp/ls.err
14 ls > /tmp/ls.all 2>&1
15 ls &> /tmp/ls.all
16 ls /etc/au* >> /tmp/ls.all 2>&1
17 ls /etc/au* &>> /tmp.ls.all
20 history | grep "ls"Командные конвейеры становятся действительно мощными, когда объединяются в три или более команд. Например, просмотрите содержимое файла os.csv в каталоге Documents:
timeweb@localhost:~$ cat Documents/os.csv
1970,Unix,Richie
1987,Minix,Tanenbaum
1970,Unix,Thompson
1991,Linux,TorvaldsСледующая командная строка извлечет некоторые поля из файла os.csv с помощью команды cut, затем отсортирует эти строки с помощью команды sort и, наконец, удалит повторяющиеся строки с помощью команды uniq:
timeweb@localhost:~$ cut -f1 -d',' Documents/os.csv | sort -n | uniq
1970
1987
1991Команда tee
Администратор сервера работает как сантехник, используя «трубы» и иногда команду tee. Команда tee разбивает вывод команды на два потока: один направляется на стандартный вывод, который отображается в терминале, а другой — в файл.
Команда tee может быть очень полезна для создания журнала команды или сценария. Например, чтобы записать время выполнения процесса, начните с команды date и скопируйте вывод в файл timer.txt:
timeweb@localhost:~$ date | tee timer.txt
Mon Jan 1 02:21:24 UTC 2022Файл timer.txt теперь содержит копию даты, тот же вывод, что и в предыдущем примере:
timeweb@localhost:~$ cat timer.txt
Mon Jan 1 02:21:24 UTC 2022Чтобы добавить время в конец файла timer.txt, используйте параметр -a:
timeweb@localhost:~$ date | tee -a timer.txt
Mon Jan 1 02:28:43 UTC 2022Чтобы запустить несколько команд как одну команду, используйте точку с запятой; символ в качестве разделителя:
timeweb@localhost:~$ date | tee timer.txt; sleep 15; date | tee -a timer.txt
Mon Jan 1 02:35:47 UTC 2022
Mon Jan 1 02:36:02 UTC 2022Приведенная выше команда отобразит и запишет первый вывод команды date, сделает паузу на 15 секунд, затем отобразит и запишет вывод второй команды date. Файл timer.txt теперь содержит постоянный журнал среды выполнения.
Команда xargs
Опции и параметры команды обычно указываются в командной строке, как аргументы командной строки. В качестве альтернативы мы можем использовать команду xargs для сбора аргументов из другого источника ввода (например, файла или стандартного ввода), а затем передать эти аргументы команде. Команду xargs можно вызывать напрямую, и она примет любой ввод:
timeweb@localhost:~$ xargs
Hello
ThereЧтобы выйти из команды xargs, нажмите Ctrl+C.
По умолчанию команда xargs передает ввод команде echo, когда за ней явно не следует другая команда. После нажатия Ctrl+D команда xargs отправит ввод в команду echo:
Важно знать: Нажатие Ctrl+D после выхода из команды xargs с помощью Ctrl+C приведет к выходу из текущей оболочки. Чтобы отправить ввод команды xargs в команду echo без выхода из оболочки, нажмите Ctrl+D во время выполнения команды xargs.
Команда xargs наиболее полезна, когда она вызывается в канале. В следующем примере с помощью команды touch будут созданы четыре файла. Файлы будут называться 1a, 1b, 1c и 1d на основе вывода команды echo.
timeweb@localhost:~$ echo '1a 1b 1c 1d' | xargs touch
timeweb@localhost:~$ ls
1a 1c Desktop Downloads Pictures Templates timer.txt
1b 1d Documents Music Public VideosЗаключение
Мы рассмотрели перенаправление потоков ввода-вывода в Linux: стандартное перенаправление вывода, перенаправление вывода ошибок, перенаправление ввода и конвейеры. Понимание их возможностей упростит работу с bash-скриптами и позволит удобнее администрировать серверы cloud.timeweb.com с операционными системами семейства Linux.
Из статьи вы узнаете про стандартные потоки ввода и вывода, и перенаправление этих потоков в файл или от одного процесса другому.
Стандартные потоки ввода вывода
В этом курсе мы работает в терминале, вводим какие-то команды и иногда получаем какой-нибудь вывод. То есть консольные утилиты получают от нас какую-то информацию и могут выводить нам информацию на терминал.
Я уже писал о том, что в Linux всё считается файлом. Из этого следует, когда команда выводит результат своей работы, она пишет в какой-то файл. А когда получает данные, она читает какой-то файл.
По умолчанию, файл, из которого осуществляется чтение, называется стандартным потоком ввода, а в который осуществляется запись — стандартным потоком вывода.
Также существует стандартный поток ошибок — это файл, в который процесс записывает ошибки, если они возникают при работе.
В Linux стандартные потоки это виртуальные файлы и по умолчанию стандартные потоки вывода ассоциированы с экраном терминала пользователя. Поэтому вывод результата или ошибок поступает на экран терминала. А стандартный поток ввода связан с клавиатурой терминала, поэтому чтение данных происходит с клавиатуры.
| Название | Файловый дескриптор |
Связанное устройство |
Файл |
|---|---|---|---|
| stdin стандартный поток ввода |
0 | клавиатура терминала |
/dev/stdin |
| stdout стандартный поток вывода |
1 | экран терминала |
/dev/stdout |
| stderr стандартный поток ошибок |
2 | экран терминала |
/dev/stderr |
Вот как эти файлы увидеть:
alex@deb-11:~$ ls -l /dev/std* lrwxrwxrwx 1 root root 15 сен 9 10:57 /dev/stderr -> /proc/self/fd/2 lrwxrwxrwx 1 root root 15 сен 9 10:57 /dev/stdin -> /proc/self/fd/0 lrwxrwxrwx 1 root root 15 сен 9 10:57 /dev/stdout -> /proc/self/fd/1 alex@deb-11:~$ ls -l /proc/self/fd/[0,1,2] lrwx------ 1 alex alex 64 сен 12 14:28 /proc/self/fd/0 -> /dev/pts/0 lrwx------ 1 alex alex 64 сен 12 14:28 /proc/self/fd/1 -> /dev/pts/0 lrwx------ 1 alex alex 64 сен 12 14:28 /proc/self/fd/2 -> /dev/pts/0 alex@deb-11:~$ ls -l /dev/pts/0 crw--w---- 1 alex tty 136, 0 сен 12 14:28 /dev/pts/0
Из вывода мы можем понять что файлы потоков это символические ссылки, ведущие на номера файловых дескрипторов. А эти файловые дескрипторы ведут на одно и тоже устройство — /dev/pts/0. Это устройство называется псевдо-терминалом. Именно этому псевдо-терминалу (pts/0) подключен я по ssh:
alex@deb-11:~$ loginctl list-sessions
SESSION UID USER SEAT TTY
83 1000 alex pts/0
1 sessions listed.
alex@deb-11:~$ w
14:43:19 up 3 days, 3:45, 1 user, load average: 0,00, 0,00, 0,00
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
alex pts/0 172.28.80.14 10:46 0.00s 0.17s 0.00s w
И все эти потоки можно перенаправлять, например можно пустить:
- stdout не на терминал, а в файл;
- stdout от одного процесса на stdin другому;
- stdout в один файл, а stderr в в другой.
Про эти файлы можно почитать в официальном мануале здесь, или выполнив команду man stdin.
Перенаправление потоков stdout и stderr в файл
Перенаправление stdout в файл
Допустим мы запустили какую-то команду, которая выводит нам что-нибудь на экран терминала:
alex@deb-11:~$ id uid=1000(alex) gid=1000(alex) группы=1000(alex),24(cdrom),25(floppy),27(sudo),29(audio),30(dip),44(video),46(plugdev),109(netdev)
Мы можем перенаправить результат в файл с помощью символа «>«:
alex@deb-11:~$ id > id.txt alex@deb-11:~$ cat id.txt uid=1000(alex) gid=1000(alex) группы=1000(alex),24(cdrom),25(floppy),27(sudo),29(audio),30(dip),44(video),46(plugdev),109(netdev)
Как видим на терминале ничего показано не было, а всё записалось в файл. При этом, если бы файла не было то он создастся. А если бы файл был, то он пере-запишется, то есть все содержимое файла очищается и заменяется.
Если мы не хотим пере-записывать файл целиком, а хотим дописать в файл, то нужно использовать «>>«:
alex@deb-11:~$ id root >> id.txt alex@deb-11:~$ cat id.txt uid=1000(alex) gid=1000(alex) группы=1000(alex),24(cdrom),25(floppy),27(sudo),29(audio),30(dip),44(video),46(plugdev),109(netdev) uid=0(root) gid=0(root) группы=0(root)
Перенаправление stderr в файл
Если нам нужно перенаправить stderr в файл, то используется «2>«:
alex@deb-11:~$ touch test.txt alex@deb-11:~$ ls test.txt test2.txt ls: невозможно получить доступ к 'test2.txt': Нет такого файла или каталога test.txt alex@deb-11:~$ ls test.txt test2.txt 2> ls-error.txt test.txt alex@deb-11:~$ cat ls-error.txt ls: невозможно получить доступ к 'test2.txt': Нет такого файла или каталога
Как видим при таком перенаправлении stdout идет на терминал, а stderr в файл.
Тут как и с перенаправлением stdout:
- «2>» — перезапишет файл;
- «2>>» — допишет файл.
Перенаправление потоков stdout и stderr в файл одновременно
Вы можете простым образом перенаправить оба потока:
alex@deb-11:~$ ls test.txt test2.txt > ls-out.txt 2> ls-error.txt alex@deb-11:~$ cat ls-out.txt test.txt alex@deb-11:~$ cat ls-error.txt ls: невозможно получить доступ к 'test2.txt': Нет такого файла или каталога
А чтобы все перенаправить в один файл используется довольно интересная конструкция: > file 2>&1:
alex@deb-11:~$ ls test.txt test2.txt > ls-out.txt 2>&1 alex@deb-11:~$ cat ls-out.txt ls: невозможно получить доступ к 'test2.txt': Нет такого файла или каталога test.txt
То есть мы перенаправляем stdout в файл, а stderr в stdout, напомню что stdout имеет файловый дескриптор 1.
Есть такой файл в Linux — /dev/null, это как черная дыра, все что идет в /dev/null никуда не сохраняется. Во многих инструкциях можно найти примерно такую команду:
# команда > /dev/null 2>&1
Это делает процесс безмолвным, весь результат и все ошибки от выполнения подобной команды будут уходить в никуда.
Перенаправление stdout одного процесса на stdin другого
Допустим первая команда выводит какой-то результат, и нам нужно этот результат использовать как входные данные для следующей команды. В этом случае используется «|» (пайплайн (pipeline)).
Я очень долго путал stdin с параметрами команды, то есть я думал что:
alex@deb-11:~$ ls test.txt test.txt
Результат предыдущей команды «test.txt» пере-направится как параметр. То есть я думал что:
alex@deb-11:~$ ls test.txt | cat
будет равен:
alex@deb-11:~$ cat test.txt 1 2 3
Но на самом деле:
alex@deb-11:~$ ls test.txt | cat test.txt
Как же это работает на самом деле?
Pipeline заставляет cat читать не из файла а из stdout предыдущей команды. А первая команда пишет в stdout слово «test.txt«, вот и cat читает посимвольно слово «test.txt«.
Чтобы пайплайны работали, вторая команда должна уметь читать из stdin, а это умеют далеко не все утилиты. Но почти все утилиты, которые умеют читать данные из файла могут читать и из stdin. Как пример, могу привести следующие утилиты которые умеют принимать данные из stdin: cat, grep, less, tail, head, wc.
Вот еще один пример, найдем все файлы, в которых есть буква «l«:
alex@deb-11:~$ ls apache2_2.4.53-1~deb11u1_amd64.deb date.log ls-out.txt rootCA.srl site.key test.txt crash id.txt rootCA.crt site.crt sysadminium.cnf timer.sh crash.c ls-error.txt rootCA.key site.csr testfolder ulimit-t.sh alex@deb-11:~$ ls | grep l date.log ls-error.txt ls-out.txt rootCA.srl testfolder ulimit-t.sh
Итог
Мы узнали про стандартные потоки ввода и вывода: stdin, stdout, stderr. Научились перенаправить stdout и stderr в файл и перенаправлять stdout одной команды на stdin другой.
В статье все примеры были проведены на Debian 11, но всё точно также будет работать и в Ubuntu 22.04.
Сводка

Имя статьи
Объединение п перенаправление команд
Описание
Из статьи вы узнаете про стандартные потоки ввода и вывода, и перенаправление этих потоков в файл или от одного процесса другому
27 июля, 2016 12:04 пп
8 560 views
| Комментариев нет
Linux
Встроенные возможности перенаправления в Linux предоставляют вам широкий набор инструментов, используемых упрощения для всех видов задач. Умение управлять различными потоками ввода-вывода в значительно увеличит производительность, как при разработке сложного программного обеспечения, так и при управлении файлами с помощью командной строки.
Потоки ввода-вывода
Ввод и вывод в окружении Linux распределяется между тремя потоками:
- Стандартный ввод (standard input, stdin, поток номер 0)
- Стандартный вывод (standard output, stdout, номер 1)
- Стандартная ошибка, или поток диагностики (standard error, stderr, номер 2)
При взаимодействии пользователя с терминалом стандартный ввод передается через клавиатуру пользователя. Стандартный вывод и стандартная ошибка отображаются на терминале пользователя в виде текста. Все эти три потока называются стандартными потоками.
Стандартный ввод
Стандартный входной поток обычно передаёт данные от пользователя к программе. Программы, которые предполагают стандартный ввод, обычно получают входные данные от устройства (например, клавиатуры). Стандартный ввод прекращается по достижении EOF (end-of-file, конец файла). EOF указывает на то, что больше данных для чтения нет.
Чтобы увидеть, как работает стандартный ввод, запустите программу cat. Название этого инструмента означает «concatenate» (связать или объединить что-либо). Обычно этот инструмент используется для объединения содержимого двух файлов. При запуске без аргументов cat открывает командную строку и принимает содержание стандартного ввода.
cat
Теперь введите несколько цифр:
1
2
3
ctrl-d
Вводя цифру и нажимая enter, вы отправляете стандартный ввод запущенной программе cat, которая принимает эти данные. В свою очередь, программа cat отображает полученный ввод в стандартном выводе.
Пользователь может задать EOF, нажав ctrl-d, после чего программа cat остановится.
Стандартный вывод
Стандартный вывод записывает данные, сгенерированные программой. Если стандартный выходной поток не был перенаправлен, он выведет текст в терминал. Попробуйте запустить следующую команду для примера:
echo Sent to the terminal through standard output
Команда echo без дополнительных опций отображает на экране все аргументы, переданные ей в командной строке.
Теперь запустите echo без аргументов:
echo
Команда вернёт пустую строку.
Стандартная ошибка
Этот стандартный поток записывает ошибки, создаваемые программой, которая вышла из строя. Как и стандартный вывод, этот поток отправляет данные в терминал.
Рассмотрим пример потока ошибок команды ls. Команда ls отображает содержимое каталогов.
Без аргументов эта команда возвращает содержимое текущего каталога. Если указать в качестве аргумента ls имя каталога, команда вернёт его содержимое.
ls %
Поскольку каталога % не существует, команда вернёт стандартную ошибку:
ls: cannot access %: No such file or directory
Перенаправление потоков
Linux предоставляет специальные команды для перенаправления каждого потока. Эти команды записывают стандартный вывод в файл. Если вывод перенаправлен в несуществующий файл, команда создаст новый файл с таким именем и сохранит в него перенаправленный вывод.
Команды с одной угловой скобкой переписывают существующий контент целевого файла:
- > – стандартный вывод
- < – стандартный ввод
- 2> – стандартная ошибка
Команды с двойными угловыми скобками не переписывают содержимое целевого файла:
- >> – стандартный вывод
- << – стандартный ввод
- 2>> – стандартная ошибка
Рассмотрим следующий пример:
cat > write_to_me.txt
a
b
c
ctrl-d
В данном примере команда cat используется для записи выходных данных в файл.
Просмотрите содержимое write_to_me.txt:
cat write_to_me.txt
Команда должна вернуть:
a
b
c
Снова перенаправьте cat в файл write_to_me.txt и введите три цифры.
cat > write_to_me.txt
1
2
3
ctrl-d
Теперь проверьте содержимое файла.
cat write_to_me.txt
Команда должна вернуть:
1
2
3
Как видите, файл содержит только последние выходные данные, поскольку в команде, перенаправляющей выход, использовалась одна угловая скобка.
Теперь попробуйте запустить ту же команду с двумя угловыми скобками:
cat >> write_to_me.txt
a
b
c
ctrl-d
Откройте write_to_me.txt:
1
2
3
a
b
c
Команды с двойными угловыми скобками не перезаписывают существующий контент, а дополняют его.
Конвейеры
Конвейеры (pipes) перенаправляют потоки вывода одной команды на вход другой. При этом данные, передаваемые второй программе, не отображаются в терминале. На экране данные появятся только после обработки второй программой.
Конвейеры в Linux представлены вертикальной чертой.
*|*
Например:
ls | less
Такая команда передаст вывод ls (содержимое текущего каталога) программе less, которая отображает передаваемые ей данные построчно. Как правило, ls выводит содержимое каталогов подряд, не разбивая на строки. Если перенаправить вывод ls в less, то последняя команда разделит вывод на строки.
Как видите, конвейер может перенаправить вывод одной команды на вход другой, в отличие от > и >>, которые перенаправляют данные только в файлы.
Фильтры
Фильтры – это команды, которые могут изменить перенаправление и вывод конвейера.
Примечание: Фильтры также являются стандартными командами Linux, которые можно использовать и без конвейера.
- find – выполняет поиск файла по имени.
- grep – выполняет поиск текста по заданному шаблону.
- tee – перенаправляет стандартный ввод в стандартный вывод и один или несколько файлов.
- tr – поиск и замена строк.
- wc – подсчёт символов, строк и слов.
Примеры перенаправления ввода-вывода
Теперь, когда вы ознакомились с основными понятиями и механизмами перенаправления, рассмотрим несколько базовых примеров их использования.
команда > файл
Такой шаблон перенаправляет стандартный вывод команды в файл.
ls ~ > root_dir_contents.txt
Эта команда передает содержимое root каталога системы в качестве стандартного вывода и записывает вывод в файл root_dir_contents. Это удалит все предыдущее содержимое в файле, так как в команде использована одна угловая скобка.
команда > /dev/null
/dev/null – это специальный файл (так называемое «пустое устройство»), который используется для подавления стандартного потока вывода или диагностики, чтобы избежать нежелательного вывода в консоль. Все данные, попадающие в /dev/null, сбрасываются. Перенаправление в /dev/null обычно используется в сценариях оболочки.
ls > /dev/null
Такая команда сбрасывает стандартный выходной поток, возвращаемый командой ls, передав его в /dev/null.
команда 2 > файл
Этот шаблон перенаправляет стандартный поток ошибок команды в файл, перезаписывая его текущее содержимое.
mkdir '' 2> mkdir_log.txt
Эта команда перенаправит ошибку, вызванную неверным именем каталога, и запишет её в log.txt. Обратите внимание: ошибка по-прежнему отображается в терминале.
команда >> файл
Этот шаблон перенаправляет стандартный выход команды в файл, не переписывая текущего содержимого файла.
echo Written to a new file > data.txt
echo Appended to an existing file's contents >> data.txt
Эта пара команд сначала перенаправляет вводимый пользователем текст в новый файл, а затем вставляет его в существующий файл, не переписывая его содержимого.
команда 2>>файл
Этот шаблон перенаправляет стандартный поток ошибок команды в файл, не перезаписывая существующего содержимого файла. Он подходит для создания логов ошибок программы или сервиса, поскольку содержимое лога не будет постоянно обновляться.
find '' 2> stderr_log.txt
wc '' 2>> stderr_log.txt
Приведенная выше команда перенаправляет сообщение об ошибке, вызванное неверным аргументом find, в файл stderr_log.txt, а затем добавляет в него сообщение об ошибке, вызванной недействительным аргументом wc.
команда | команда
Этот шаблон перенаправляет стандартный выход первой команды на стандартный вход второй команды.
find /var lib | grep deb
Эта команда ищет в каталоге /var и его подкаталогах имена файлов и расширения deb и возвращает пути к файлам, выделяя шаблон поиска красным цветом.
команда | tee файл
Такой шаблон перенаправляет стандартный вывод команды в файл и переписывает его содержимое, а затем отображает перенаправленный выход в терминале. Если указанного файла не существует, он создает новый файл.
В данном шаблоне команда tee, как правило, используется для просмотра вывода программы и одновременного сохранения его в файл.
wc /etc/magic | tee magic_count.txt
Такая команда передаёт количество символов, строк и слов в файле magic (Linux использует его для определения типов файлов) команде tee, которая отправляет эти данные в терминал и в файл magic_count.txt.
команда | команда | команда >> файл
Этот шаблон перенаправляет стандартный вывод первой команды и фильтрует ее через следующие две команды, а затем добавляет окончательный результат в файл.
ls ~ | grep *tar | tr e E >> ls_log.txt
Такая команда отправляет вывод ls для каталога root команде grep. В свою очередь, grep ищет в полученных данных файлы tar. После этого результат grep передаётся команде tr, которая заменит все символы е символом Е. Полученный результат будет добавлен в файл ls_log.txt (если такого файла не существует, команда создаст его автоматически).
Заключение
Функции перенаправления ввода-вывода в Linux сначала кажутся слишком сложными. Однако работа с перенаправлением – один из важнейших навыков системного администратора.
Чтобы узнать больше о какой-либо команде, используйте:
man command | less
Например:
man tee | less
Такая команда вернёт полный список команд для tee.
Tags: Linux

Имя статьи
Объединение п перенаправление команд
Описание
Из статьи вы узнаете про стандартные потоки ввода и вывода, и перенаправление этих потоков в файл или от одного процесса другому