
Министерство цифрового
развития, связи и массовых коммуникаций
Российской Федерации
Ордена Трудового Красного
Знамени
Федеральное государственное
образовательное бюджетное учреждение
высшего профессионального образования
Московский технический
университет связи и информатики
Кафедра Мультимедийных
сетей и услуг связи
Лабораторная работа №13
по теме: «Исследования
циклических свойств»
Выполнили: Пантелеева К.А.
Самарина А.В.
Назаренко С.С.
Группа: БСТ1904
Москва, 2021
Оглавление
Цель
работы 3
Лабораторное
задание 3
Контрольные
вопросы 3
Вывод 7
Цель работы
1. Изучить обнаруживающие и исправляющие
свойства циклических кодов.
2. Познакомиться с принципом построения
кодирующих и декодирующих устройств
циклических кодов.
Лабораторное задание
-
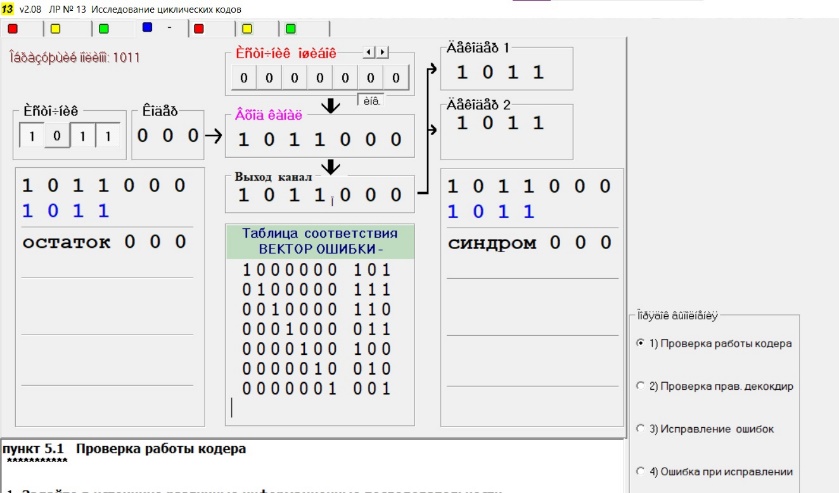
Проверить работу кодера.
-
Проверить правильность декодирования
при отсутствии ошибок – рисунки ниже
и также распечатка 1.

3. Исследовать способность кода исправлять
ошибки – распечатка 2.
4. Проверить факт ошибочного декодирования
в режиме исправления ошибок – распечатка
3.
5. Исследовать способность кода
обнаруживать ошибки – распечатка 4.
6. Проверить факт не обнаружения ошибок
кодом – распечатка 5.
7. Распечатайте таблицу с разрешенными
кодовыми комбинациями и таблицу с
расстояниями Хемминга для разрешенных
комбинаций – распечатка 6.
Контрольные вопросы
-
Поясните понятия: блочные, непрерывные,
разделимые, неразделимые, итеративные,
линейные, циклические коды?
Блочные – заменяют каждый блок из
$m$ символов более длинным блоком из $n$
символов, которые после передачи подлежат
декодированию.
Непрерывные – коды, в которых
введение избыточных символов в кодируемую
последовательность информационных
символов осуществляется непрерывно,
без разделения ее на независимые блоки.
Разделимые – коды, кодовые комбинации
которых состоят из двух частей:
информационной и проверочной.
Неразделимые – коды, кодовые
комбинации которых нельзя разделить
на информационные и проверочные части.
Итеративные – эти коды характеризуются
наличием двух или более систем проверок
внутри каждой кодовой комбинации.
Линейные – типы блокового кода,
использующиеся в схемах определения и
коррекции ошибок.
Циклические – линейные, блочные
коды, обладающие свойством цикличности,
то есть каждая циклическая перестановка
кодового слова также является кодовым
словом.
-
Что такое расстояние Хемминга и
кодовое расстояние?
Расстояние Хемминга между двумя кодовыми
словами равно числу единиц в сумме этих
слов по модулю 2, т.е. количеству разрядов,
в которых различаются эти два кодовых
слова.
Кодовое расстояние d, определяемое как
наименьшее расстояние Хемминга между
всеми возможными парами кодовых слов,
в линейном коде равно минимальному весу
ненулевого кодового слова.
-
Определение и основные свойства
циклического кода.
Циклические – линейные, блочные
коды, обладающие свойством цикличности,
то есть каждая циклическая перестановка
кодового слова также является кодовым
словом.
Свойства:
1) циклический код обнаруживает все
одиночные ошибки, если образующий
полином содержит более одного члена.
Если G(x)=x+1, то код обнаруживает одиночные
ошибки и все нечетные;
2) циклический код с G(x)=(x+1)G(x) обнаруживает
все одиночные, двойные и тройные ошибки;
3) циклический код с образующим полиномом
G(x) степени r = n — k обнаруживает все
групповые ошибки длительностью в r
символов.
-
Какое правило кодирования циклическим
кодом принято в лабораторной работе?
Смещение и умножение полинома v(x)
на х по модулю (хn

1).
-
Какое правило декодирования принято
в декодере в режиме исправления ошибок?
Декодирование заключается в определении
номера искаженного разряда и его
автоматического исправления. А также
отделения информационных разрядов от
контрольных.
-
Какое правило декодирования принято
в декодере в режиме обнаружения ошибок?
Процедура декодирования циклического
кода с обнаружением ошибок, по аналогии
с процессом кодирования основана на
использовании свойства делимости без
остатка кодового многочлена Р(x)
циклического (n,m)-кода на порождающий
многочлен g(x).
-
Как связаны кратности гарантированно
исправляемых кодов ошибок t
и гарантированно обнаруживаемых кодом
ошибок σ с кодовым расстоянием
d?
Количество (кратность) гарантированно
обнаруживаемых (tобн) и гарантированно
исправляемых (tисп) кодом ошибок
зависит от степени различия разрешенных
кодовых комбинаций – которые оцениваются
кодовым расстоянием d.
Кодовое расстояние d связано с кратностью
t исправляемых ошибок по формуле: d>=2t+1
Кодовое расстояние d связано с кратностью
o обнаруживаемых ошибок по формуле:
d>=o+1
-
Какие векторы ошибок не могут быть
обнаружены линейным циклическим кодом?
Векторы ошибок, совпадающие с кодовыми
словами, не могут быть обнаружены
декодером циклического кода.
-
Сколько различных векторов ошибок
может быть исправлено, не исправлено,
обнаружено, не обнаружено кодом (7,4)?
Исправлено – 1, не исправлено – 15,
обнаружено – 2, не обнаружено – 15.
-
Как рассчитать вероятность необнаружения
ошибки при заданном канале?
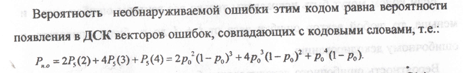
-
Как рассчитать вероятность ошибочного
декодирования при заданном канале?

-
Как по одной известной разрешенной
комбинации циклического кода определить
все остальные кодовые комбинации этого
кода?

![]()
-
Известна комбинация на входе кодера
v1 и выходе
декодера_2 v2. Как
определить вектор ошибки E?
(v1<>v2)?
Кодовая комбинация v на выходе кодера
может быть найдена как произведение
V=U×Gкан или можно вычислить проверочные
разряды кодовой комбинации через
образующий полином g(x). Потом сравнить
то, что должно было получиться с тем,
что получилось в итоге и найти вектор
ошибки.
-
Дана длина кодовой комбинации n,
вероятность ошибки в канале Рош. Как
определить вероятность появления в
кодовой комбинации ошибки кратностью
t?
C(t,n)*Pош^t
-
Как производится кодирование –
декодирование при использовании кода
с проверкой на четность (на нечетность)?
Берется число и остаток деления суммы
всех единиц числа на 2 дописывается
справа.
Вывод
В ходе лабораторной работе мы научились
различать виды кодов, исследовали
обнаруживающие и исправляющие свойства
циклических кодов и познакомилась с
принципом построения кодирующих и
декодирующих устройств циклических
кодов. На рисунке ниже можно увидеть
результаты тестирования лабораторной
работы.

Соседние файлы в предмете Информационные технологии
- #
- #
- #
- #
- #
Предложите, как улучшить StudyLib
(Для жалоб на нарушения авторских прав, используйте
другую форму
)
Ваш е-мэйл
Заполните, если хотите получить ответ
Оцените наш проект
1
2
3
4
5
Подборка по базе: Эссе о работе.docx, практика НИР отчет и дневник 2.docx, ПРИМЕР Отчет по практике ПМ 01.pdf, Титульник отчета по практике (1).docx, МБДОУ 24 Отчет.doc, Эргономичная поза при работе с компьютером.pptx, Комплектование,подготовка к работе пахотного агрегара.контроль к, ИЗ + Отчет о практике.pdf, Форма отчета по практике.docx, Общ отчет финал.doc
Нижегородский государственный технический университет
им. Р.Е. Алексеева
Кафедра «Электроника и сети ЭВМ»
Отчет по лабораторной работе №7
«Изучение линейных корректирующих кодов»
Выполнил:
Студент группы 17-ОСС
Мулина Е.М.
Проверил:
Семашко А.В.
г. Нижний Новгород
Цель работы: Исследование алгоритмов кодирования и декодирования сообщений с помощью линейных кодов и изучение способов их технической реализации.
Теоретическая часть.
Дискретный канал.

Рис.1. Схема система передачи данных.
В современной теории связи под каналом понимается среда распространения сигнала и совокупность технических средств, предназначенных для передачи информации, которые не могут быть изменены в рамках решаемой задачи. Если структура модулятора и демодулятора заданы, то каналом является та часть линии связи, которая на рис.1 обведена пунктиром. На вход такого канала подаются дискретные кодовые символы αА из некоторого алфавита А, объемом q, а с выхода снимаются символы βА, вообще говоря, не совпадающие с α. Такой канал называется дискретным.
Во всех реальных линиях связи дискретный канал содержит внутри себя непрерывный канал, на вход которого подаются сигналы S(t), а с выхода снимаются искаженные сигналы U(t). Свойства непрерывного канала и характеристики модулятора и демодулятора однозначно определяют все параметры дискретного канала. Иногда дискретный канал называют дискретным отображением непрерывного канала.
Искажения сигнала возникают в результате действия различных помех n(t), действующих в непрерывном канале.
При изучении передачи сообщений по дискретному каналу основной задачей является отыскание методов кодирования и декодирования, позволяющих наилучшим образом передавать информацию в рамках выбранного критерия оптимальности.
Помехоустойчивое кодирование.
Помехоустойчивое кодирование — процесс преобразования информации, предоставляющий возможность обнаружить и исправить ошибки, возникающие при передаче информации по каналам передачи данных.
Под ошибкой при этом понимают ситуацию, когда в результате действия помех и искажений в канале передачи данных приемник принимает неверное решение, отождествляя принятый сигнал не с фактически переданным символом, а с каким-либо другим.
Процесс помехоустойчивого кодирования заключается во введении избыточности, т. е. для передачи информации используется код, у которого используются не все возможные комбинации, а только некоторые из них. Такие коды называют избыточными или корректирующими.
Соответственно, процесс введения избыточности (преобразование информационных символов в кодовое слово) называется кодированием, а обратный процесс восстановления информации из кодового слова, возможно содержащего ошибки, — декодированием.
Основными параметрами, характеризующими корректирующие свойства кодов являются:
- избыточность кода;
- кодовое расстояние;
- кратность гарантированно обнаруживаемых ошибок;
- кратность гарантированно исправляемых ошибок.
Под избыточностью понимают число вводимых дополнительных разрядов
где n — число кодовых символов на выходе кодера, соответствующих k информационным символам на его входе.
Кодовое расстояние d или расстояние характеризует степень различия любых двух кодовых комбинаций. Оно выражается числом разрядов, в которых комбинации отличаются одна от другой.

Для помехоустойчивого кода наиболее важным является минимальное кодовое расстояние  — наименьшее кодовое расстояние из всех между всеми парами кодовых комбинаций.
— наименьшее кодовое расстояние из всех между всеми парами кодовых комбинаций.
В общем случае при необходимости обнаруживать ошибки кратности  минимальное кодовое расстояние должно быть, по крайней мере, на единицу
минимальное кодовое расстояние должно быть, по крайней мере, на единицу
больше , т. е. Соответственно, кратность гарантированно обнаруживаемых кодом ошибок равна
Соответственно, кратность гарантированно обнаруживаемых кодом ошибок равна

Кратность гарантированно исправляемых кодом ошибок вычисляется по формуле

Таким образом, код, имеющий минимальное кодовое расстояние  ,
,
позволяет гарантированно обнаружить  и менее ошибок и гарантированно
и менее ошибок и гарантированно
исправить t = 1 ошибку.
Коды коррекции ошибок.
Линейными или групповыми кодами коррекции ошибок называются методы реализации помехоустойчивого кодирования.
Линейные блочные коды позволяют представить информационные и кодовые слова в виде двоичных векторов, что позволяет описать процессы кодирования и декодирования с помощью аппарата линейной алгебры, с учетом того, что компонентами вводимых векторов и матриц являются символы «0» и «1». Операции над двоичными компонентами производятся при этом по правилам арифметики по модулю 2.
Множество 2k возможных двоичных информационных слов блокового (n,k)-кода взаимно однозначно отображается в множество 2k кодовых слов длиной n.
Рассмотрим механизм исправления и обнаружения ошибок в помехоустойчивом кодировании. Для этого удобно рассмотреть множество двоичных слов (векторов) длиной n в виде точек на плоскости (см. рис. 2).
На рис. 2 черными кругами показаны два кодовых слова  ,
, , отличающиеся друг от друга в двоичных символов. Вокруг них показаны области, содержащие слова длиной n, отличающиеся от этих кодовых слов не более чем в t позициях. Прочие кодовые слова показаны черными ромбами.
, отличающиеся друг от друга в двоичных символов. Вокруг них показаны области, содержащие слова длиной n, отличающиеся от этих кодовых слов не более чем в t позициях. Прочие кодовые слова показаны черными ромбами.

Рис.2. Общий принцип исправления и обнаружения ошибок.
В случае, если по каналу было передано кодовое слово , и оно пришло с искажениями, возможны три варианта декодирования с исправлением ошибки.
1. Было получено слово, попадающее в область вокруг вектора . Такое слово будет преобразовано декодером в слово и декодирование будет осуществлено верно.
- Если получено слово, не принадлежащее областям ни одного кодового слова, то оно не может быть декодировано и, следовательно, возникает ошибка декодирования.
3. Слово, попадающее в область вокруг , будет преобразовано декодером в .
Такая ошибка не может быть обнаружена.
В показанном на рис. 5.1 случае не все слова размерности n принадлежат областям декодирования. Таких кодов большинство. Коды, в которых непересекающиеся области декодирования охватывают все пространство слов размерности n, называются совершенными или плотноупакованными. При использовании совершенных кодов всегда возможна коррекция ошибок (не всегда правильная). Декодер такого кода не может определить ошибку декодирования. Он работает либо в режиме определения ошибок, либо в режиме исправления ошибок. Основными совершенными кодами являются коды Хэмминга и коды Голея.
Код Хэмминга можно построить для любого натурального числа r ≥ 3. Этот код будет обладать рядом свойств.
- n=2r-1
- k=2r-1-r
- r=n-k
- dmin=3, t=1
Кодирование линейных блочных кодов.
Поскольку между информационными и кодовыми словами существует взаимно однозначное соответствие, процесс кодирования может быть осуществлен с использованием таблицы соответствий, хранящейся в памяти кодера. Однако, для длинных кодов такой метод неприемлем, так как требует большой объем памяти для хранения таблицы.
Вместо этого вводится понятие так называемой порождающей матрицы G. Оно основано на том, что подпространство всех кодовых слов линейного блочного (n,k) —
кода имеет некоторый базис (v0,v1,…,vk-1 ), через который может быть выражено любое кодовое слово этого кода.
v=u0v0+u1v1+…+uk-1vk-1, (1)
где  .
.
Векторы базиса образуют порождающую матрицу G размера

Тогда уравнение (1) принимает вид
v=uG(2)
где u=(u0,u1, uk-1) — информационное слово.
Фактически, формула (36) описывает процедуру кодирования линейного блочного кода посредством образующей матрицы. Для пространства кодовых слов линейного (n,k)-кода существует дуальное ему пространство кода (n,n−k), порождаемое матрицей H размера (n−k)×n. Такая матрица получила название проверочной для кода (n,k) и обладает следующими свойствами
GHT=0 (3)
vHT=0
на основе которых реализована операция декодирования линейных блочных кодов.
Как правило рассматривают так называемые систематические или каноничные формы матриц G и H, использующиеся для процедуры систематического кодирования. На практике, любая порождающая матрица G линейного блочного (n,k)-кода может быть преобразована к систематическому виду посредством элементарных операций и перестановок столбцов матрицы.
Матрица G в систематической форме состоит из двух подматриц: единичной матрицы I размера k×k и проверочной подматрицы P размера k×(n−k) .

Соответственно, исходя из свойства (3), следует, что проверочная матрица H состоит из транспонированной проверочной матрицы и единичной матрицы размера  .
.

Декодирование линейных блочных кодов.
Как и в случае кодирования, декодирование линейных блочных кодов можно осуществлять посредством таблицы по принципу максимального правдоподобия. В этом случае производится последовательное поразрядное сравнение принятого на вход декодера слова со всеми возможными кодовыми словами. В результате будет выбрано кодовое слово, имеющее наименьшее число отличий от декодируемого. В случае несовершенных кодов возможен вариант, когда есть несколько кодовых слов, отличающихся от принятого в одинаковом числе разрядов. Соответственно, декодер
не может принять решение о верности одного из вариантов и выдает сигнал о невозможности декодирования. Недостатки такой схемы те же, что и в случае кодирования — необходим большой объем памяти для хранения всех кодовых слов в случае длинных кодов. Быстродействие для длинных кодов также значительно увеличивается.
В связи с этим используют механизм синдромного декодирования, основанный на использовании проверочной матрицы H.
Для понимания принципа декодирования рассмотрим как выражаются проверочные символы кодового слова через информационные на примере систематического кода Хэмминга (7,4).

Если в канале произошла ошибка, то для принятого вектора r хотя бы одно из равенств (4) выполняться не будет. Проверочные соотношения можно записать для принятого вектора в виде системы уравнений (4).

Соответственно, если хотя бы один из компонент вектора s = { ,
, ,
,  } не равен нулю, то в принятом слове есть ошибка.
} не равен нулю, то в принятом слове есть ошибка.
Уравнения (5) можно записать через проверочную матрицу H.

Вектор s принято называть синдромом. Таким образом, ошибка в принятом слове будет обнаружена, если хоть один компонент синдрома принятого слова не равен нулю. Для исправления ошибки используется тот факт, что каждый синдром соответствует своей позиции одиночной ошибки (мы говорим о кодах Хэмминга).
Расширенные коды Хэмминга.
Расширение кода Хэмминга заключается в дополнении кодового слова дополнительным двоичным разрядом так, чтобы оно содержало четное число единиц. Такое расширение дает ряд преимуществ.
- Длина кода увеличивается до n = 2r, что удобнее для хранения и передачи информации.
2. Минимальное расстояние = 4, следовательно  = 3.
= 3.
Также, дополнительный разряд позволяет использовать декодер в гибридном режиме обнаружения и коррекции ошибок.
Практическая часть.
Техническое задание: Написать программу для реализации кодирования и декодирования помехоустойчивым кодом Хемминга.
Исходные данные:
Порождающая матрица G:

Проверочная матрица H:

Текст для кодирования:
One of the most alarming forms of air pollution is acid rain. It results from the release into the atmosphere of sulphur and nitrogen oxides that react with water droplets and return to earth in the form of acid rain, mist or snow.
Acid rain is killing forests in Canada, the USA, and central and northern Europe. (Nearly every species of tree is affected.) It has acidified lakes and streams and they can’t support fish, wildlife, plants or insects. (In the USA 1 in 5 lakes suffer from this type of pollution).
Листинг программы.








Результаты работы программы.
Рис.3. Интерфейс программы.

Рис.4. Результаты кодирования.
Смоделируем действие шума в двоичном канале, изменив произвольным образом N символов:
Шифр до внесения изменений:
01000111 11111111
01101100 11100010
01101100 01011010
00101011 00000000
01101100 11111111
01101100 01101100
00101011 00000000
01110001 01000111
01101100 10001110
01101100 01011010
Шифр после внесения изменений:
01001111 11111111
01101100 11100010
11101100 01011010
00101011 00010000
01101100 11111111
01101000 01101100
00101011 00000000
01110001 11010111
01101100 10001110
01101101 01011010
Из рис.5 видно, что при декодировании по синдрому можно однозначно определить расположение единичной ошибки в пакете и сразу же исправить еѐ, и обнаружить наличие двойной, неисправимой ошибки.

Рис.5.
Рис.6. Результаты декодирования.
Вывод:
В ходе данной лабораторной работы мы изучили коды коррекции ошибок Хэмминга. Этот метод позволяет за счет избыточного кодирования шифровать информацию в двоичной системе перед её передачей через непрерывный канал, в котором сообщение может частично исказиться, так, чтобы ошибки, возникшие при передаче, не привели к потере информации или её неверной интерпретации.
Написанная программа реализует шифрование расширенным (8,4) — кодом Хэмминга с параметрами: число информационных символов k =4, избыточность r=4 , минимальное кодовое расстояние dmin = 3, кратность гарантированно исправляемых кодом ошибок tобн = 2, кратность обнаруживаемых кодом ошибок t=1. Результаты работы программы полностью подтверждают автокорректирующие и автоконтролирующие свойства кода Хэмминга.
Работа добавлена на сайт samzan.net: 2016-03-13
Поможем написать учебную работу
Если у вас возникли сложности с курсовой, контрольной, дипломной, рефератом, отчетом по практике, научно-исследовательской и любой другой работой — мы готовы помочь.

Предоплата всего
от 25%

Подписываем
договор
Федеральное агентство связи
МОСКОВСКИЙ ТЕХНИЧЕСКИЙ УНИВЕРСИТЕТ СВЯЗИ И ИНФОРМАТИКИ (МТУСИ)
Кафедра мультимедийных сетей и услуг связи
Лабораторная работа №13
Исследование свойств циклических кодов
Выполнила: Коровкина А.А.
Группа: СС1001
Проверил: Друзь В.В.
МОСКВА
2013
Цель работы:
1. Изучить основные принципы помехоустойчивого кодирования.
2. Изучить правила построения циклических кодов.
3. Исследовать обнаруживающие и исправляющие свойства циклических кодов.
4. Познакомится c принципом построения кодирующих и декодирующих устройств циклических кодов.
Кодер
Источник
Декодер_1
Исправление ошибки
Декодер_2
Обнаружение ошибки
Канал
Источник ошибки
Схема лабораторного макета
Индивидуальное задание:
Дан линейный код типа (7, 4) с образующим полиномом вида Х3+Х+1. Кодовое расстояние d=3
1) Найдем все кодовые слова заданного кода.
Образующий полином определяет кодовую последовательность:
V(x) = 1* x3+ 0*x2 +1*x + 1.
V(x)= 1 0 1 1
Допишем образующую комбинацию до кодового слова:
1 0 1 1 0 0 0
Циклическим сдвигом влево получим еще 6 кодовых слов:
0 1 1 0 0 0 1
1 1 0 0 0 1 0
1 0 0 0 1 0 1
0 0 0 1 0 1 1
0 0 1 0 1 1 0
0 1 0 1 1 0 0
Получили 7 кодовых слов. Поскольку k=4, число кодовых слов равно 2k=16, причем одно из них является комбинацией 0 0 0 0 0 0 0.
Сложением в разных комбинациях найденных кодовых слов по модулю 2 найдем остальные кодовые слова. Например:
1 0 1 1 0 0 0
(+)0 1 1 0 0 0 1
1 1 0 1 0 0 1
Таким образом, получим 16 кодовых слов.
0 0 0 0 0 0 0
1 1 1 1 1 1 1
0 1 1 0 0 0 1
1 1 0 0 0 1 0
1 0 0 0 1 0 1
0 0 0 1 0 1 1
0 0 1 0 1 1 0
0 1 0 1 1 0 0
1 0 1 1 0 0 0
0 1 0 0 1 1 1
1 0 0 1 1 1 0
0 0 1 1 1 0 1
0 1 1 1 0 1 0
1 1 1 0 1 0 0
1 1 0 1 0 0 1
1 0 1 0 0 1 1
2)Характеристики заданного кода в режиме исправления ошибок.
В режиме исправления ошибок декодер вычисляет остаток S(x) от деления принятой последовательности P(x) на g(x). Этот остаток называют синдромом. Принятый полином P(x) представляет собой сумму по модулю два переданного слова V(x) и вектора ошибок E(x):
P(x) = V(x) E(x)к.
Найдем синдромы ошибок.
d≥2t+1
2≥2t => t=1
Кратность ошибок не превышает единицу, значит декодер будет исправлять только одну ошибку в комбинации, значит вектор ошибки будет содержать 1 единицу. Исходя из этого, найдем вектора ошибки.
1 0 0 0 0 0 0
0 1 0 0 0 0 0
0 0 1 0 0 0 0
0 0 0 1 0 0 0
0 0 0 0 1 0 0
0 0 0 0 0 1 0
0 0 0 0 0 0 1
Рассчитаем синдромы ошибки. Для этого надо разделить комбинацию на выходе канала (суммированую с вектором ошибки) на образующий полином. Допустим, комбинация на входе канала 1 0 1 1 0 0 0, вектор ошибки 1 0 0 0 0 0 0. Комбинация на выходе канала- 0 0 1 1 0 0 0. Разделим на образующий полином 1 0 1 1.
0 0 1 1 0 0 0 | 1 0 1 1
(+) 1 0 1 1
1 1 1 0
(+) 1 0 1 1
1 0 1 <= Остаток и будет синдромом ошибки.
Аналогично найдем остальные синдромы.
1 0 0 0 0 0 0 1 0 1
0 1 0 0 0 0 0 1 1 1
0 0 1 0 0 0 0 1 1 0
0 0 0 1 0 0 0 0 1 1
0 0 0 0 1 0 0 1 0 0
0 0 0 0 0 1 0 0 1 0
0 0 0 0 0 0 1 0 0 1
Отметим, что один и тот же синдром может соответствовать 2k различным векторам ошибок. Положим, синдром S(x) соответствует вектору ошибок E1(x). Но и все векторы ошибок, равные сумме E1(x) V(x), где V(x) любое кодовое слово, будут давать тот же синдром.
Например: Вектор ошибки 0 0 0 0 1 0 1, с синдромом 1 0 1, таким же, как у вектора ошибки
1 0 0 0 0 0 0. При этом, в первом случае комбинация будет декодирована неправильно. Поэтому, поставив в соответствие синдрому S1(x) вектор ошибок E1(x), мы будем осуществлять правильное декодирование в случае, когда действительно вектор ошибок равен E1(x), во всех остальных 2k-1 случаях декодирование будет ошибочным.
Вероятность ошибочного декодирования будет равна вероятности Pn(>t) появления векторов ошибок веса t + 1 и больше в заданном канале. Для ДСК эта вероятность будет равна
- Характеристики кода в режиме обнаружения ошибок.
В режиме обнаружения ошибок, если принятая последовательность делится без остатка на g(x), делается вывод, что ошибки нет или она не обнаруживается. В противном случае комбинация бракуется.
d≥σ+1
3≥σ+1 => σ≤2
Кратность гарантированно обнаруживаемых ошибок σ≤2.
Слова любого линейного кода обладают свойством замкнутости по отношению к операции сложения, т.е. сумма двух и более кодовых слов тоже является кодовым словом.
Из этого свойства, видно, что векторы ошибок, совпадающие с кодовыми словами, не могут быть обнаружены декодером циклического кода.
Итак, векторы ошибок, которые нельзя обнаружить:
1 1 1 1 1 1 1
0 1 1 0 0 0 1
1 1 0 0 0 1 0
1 0 0 0 1 0 1
0 0 0 1 0 1 1
0 0 1 0 1 1 0
0 1 0 1 1 0 0
1 0 1 1 0 0 0
0 1 0 0 1 1 1
1 0 0 1 1 1 0
0 0 1 1 1 0 1
0 1 1 1 0 1 0
1 1 1 0 1 0 0
1 1 0 1 0 0 1
1 0 1 0 0 1 1
Найдем вероятность необнаруживаемой ошибки.
Имеем 7 векторов веса 4, 7 векторов веса 3 и 1 вектор веса 7.
5.2 Проверка правильности декодирования при отсутствии ошибок
5.3 Методика исследования способности кода исправлять ошибки
5.4 Методика проверки ошибочного декодирования в режиме исправления ошибок
5.5 Методика исследования способности кода обнаруживать ошибки
5.6 Методика проверки факта не обнаружения ошибки кодом
5.7. Таблица с разрешенными кодовыми комбинациями
Ответы на контрольные вопросы
Что такое расстояние Хемминга и кодовое расстояние ?
Расстояние Хемминга между двумя кодовыми словами равно числу единиц в сумме этих слов по модулю 2 , т.е. количеству разрядов, в которых различаются эти два кодовых слова. Например:
первое кодовое слово: 1000110,
второе кодовое слово: 0100010,
сумма по модулю два: 1100100 -> расстояние Хемминга равно 3.
Определение и основные свойства циклического кода?
Циклическим кодом называется такой линейный код, у которого при любом циклическом сдвиге какого-либо кодового слова получается другое кодовое слово.
Циклические коды относятся к классу линейных кодов и обладают всеми их свойствами. Дополнительным условием по отношению к циклическому линейному коду является условие замкнутости по отношению к операции циклического сдвига кодовых слов.
Поясните понятия: блочные, непрерывные, разделимые, неразделимые, итеративные, линейные, циклические коды ?
Линейные коды являются кодами блочными, регулярными. Для регулярных кодов задаются правила преобразования информационного слова длины k в кодовую последовательность длины n (n > k), а также правила декодирования. Наибольшее распространение получили линейные разделимые коды. Разделимым кодом называется код, в кодовых словах которого можно указать места информационных и проверочных символов.
Линейным кодом называют блочный (n, k) код, символы кодовых слов которого являются линейными комбинациями информационных символов.
ВыводыБыло проведено исследование циклических кодов с помощью электронной блок-схемы, содержащей кодер и декодер. Из полученных результатов можно сделать вывод, что блок-схема работает верно, имеет свойства обнаружения и исправления ошибок в линейных кодах.